JP2007207117A - Performance monitoring device, performance monitoring method and program - Google Patents
Performance monitoring device, performance monitoring method and program Download PDFInfo
- Publication number
- JP2007207117A JP2007207117A JP2006027622A JP2006027622A JP2007207117A JP 2007207117 A JP2007207117 A JP 2007207117A JP 2006027622 A JP2006027622 A JP 2006027622A JP 2006027622 A JP2006027622 A JP 2006027622A JP 2007207117 A JP2007207117 A JP 2007207117A
- Authority
- JP
- Japan
- Prior art keywords
- countermeasure
- information
- model
- state
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images










Landscapes
- Debugging And Monitoring (AREA)
- Computer And Data Communications (AREA)
- Stored Programmes (AREA)
Abstract
【課題】様々な形態で発生する事象に対して、最も的確な対策を選択・策定することを可能とする。
【解決手段】モニタ部101は、AC環境及び非AC環境の状態に係る状態情報を取得し、分析部103又はモデル診断部106は、取得された状態情報に基づいて、AC環境の装置の状態を判定する。シミュレーション部108は、その判定結果に対応する対策リストを参照し、対策リストに含まれる少なくとも一つの対策夫々によるシミュレーション処理を実行し、各対策の効果を評価する。
【選択図】図1It is possible to select and formulate the most appropriate countermeasure against an event that occurs in various forms.
A monitor unit 101 acquires state information related to states of an AC environment and a non-AC environment, and an analysis unit 103 or a model diagnosis unit 106 determines the state of an AC environment device based on the acquired state information. Determine. The simulation unit 108 refers to a countermeasure list corresponding to the determination result, executes a simulation process using at least one countermeasure included in the countermeasure list, and evaluates the effect of each countermeasure.
[Selection] Figure 1
Description
本発明は、例えば、対象となる外部装置の状態をコンピュータが管理する所謂自律型コンピューティングに適用可能な性能監視装置、性能監視方法及びプログラムに関するものである。 The present invention relates to a performance monitoring apparatus, a performance monitoring method, and a program applicable to so-called autonomous computing in which a computer manages the state of a target external device, for example.
人間によるコンピュータ管理の負荷を軽減するためにコンピュータが自ら管理する仕組み、所謂自律型コンピューティングが実現しつつある。自律型コンピューティングでは、コンピュータは所定の運用指針に基づいて、自律的に自己の障害を修復する(例えば、非特許文献1参照)。この自己管理は、以下のような手順を繰り返すことで実現されている。
(1)先ず、コンピュータシステムを監視してハードウェア、ソフトウェアの挙動をログデータとして集約
(2)集約したものを分析して状況を把握
(3)目的達成のための対策を立てる
(4)計画を実行・制御する
In order to reduce the burden of computer management by humans, so-called autonomous computing is being realized. In autonomous computing, a computer autonomously repairs its own failure based on a predetermined operation guideline (see, for example, Non-Patent Document 1). This self-management is realized by repeating the following procedure.
(1) First, monitor the computer system and aggregate hardware and software behavior as log data. (2) Analyze the aggregated data to understand the situation. (3) Establish measures to achieve the objective. (4) Plan Execute and control
例えば、CPUの利用率を監視し(1)、利用率が急激に高まったときに(2)、他のリソースに負荷分散するという対策を立て(3)、実際に一部の処理を他のマシンに振り分ける(4)という処理をコンピュータが自律的に実行する。 For example, the CPU usage rate is monitored (1), and when the usage rate suddenly increases (2), measures are taken to distribute the load to other resources (3). The computer autonomously executes the process (4) of distributing to machines.
ところで、今日提案されている自律型コンピューティングの技術では上記(1)〜(4)のサイクルで運用されるが、(3)のプランニングの処理は元々人間が設定した運用指針に沿うように仕向けられている。従って、自律型コンピューティングを実装する上で設計者は予想でき得る事象について様々な運用指針を用意しておく。コンピュータは当初設定した運用指針を守って動作し続けることができるかどうかを判断して必要なアクションを起こすようになっている。また、以後本文中の前記自律型コンピューティングを、非特許文献1中のオートノミック・コンピューティング(AC)と同義として説明する。
By the way, the autonomous computing technology proposed today is operated in the above cycles (1) to (4), but the planning process (3) is intended to follow the operation guidelines originally set by humans. It has been. Therefore, when implementing autonomous computing, designers prepare various operational guidelines for events that can be predicted. The computer decides whether it can continue to operate according to the operation guidelines set at the beginning, and takes necessary actions. Hereinafter, the autonomous computing in the text will be described as synonymous with autonomic computing (AC) in Non-Patent
しかしながら、コンピュータシステムでは日常的に発生しうる事象、例えば負荷が高まったりすることは想定しやすいが、システム構成が途中から変更されたり、人為的ミスによる障害など予想しがたい事象が発生することがある。また、現時点で問題が発生していなくとも、将来発生しうる問題の兆候が潜んでいることもある。そもそも、当初設定したポリシーが間違っているということも無いわけではない。 However, in a computer system, it is easy to assume an event that can occur on a daily basis, for example, an increase in load, but the system configuration is changed from the middle, or an unexpected event such as a failure due to human error occurs. There is. Even if no problem has occurred at this time, there may be signs of a problem that may occur in the future. In the first place, it is not without saying that the initially set policy is wrong.
このように、運用指針が適用しづらい事象が発生したり、現時点で異常が表れていないので通常の運用指針に基づいた運用が行われたり、本当は変更した方が良い運用指針が潜在したまま運用を続けると、間違えた運用指針に基づいてコンピュータが自律的制御を行ってしまうなど、オートノミック・コンピューティング本来の目的である"自律的に最適な処理を行うことで、人間が介在せずに変化に対応する"ことが達成できなくなってしまう。 In this way, an event that makes it difficult to apply the operation guideline occurs, or there is no abnormality at the moment, so operation based on the normal operation guideline is performed, or operation with a better operation guideline that is actually better changed is hidden. If you continue, the computer will perform autonomous control based on the wrong operation guidelines, such as "autonomous computing is the original purpose," autonomous optimal processing, changes without human intervention Will not be able to achieve that.
そこで、本発明の目的は、様々な形態で発生する、又は、将来発生しうる事象に対して、最も的確な対策を選択・策定することを可能とすることにある。 Therefore, an object of the present invention is to make it possible to select and formulate the most appropriate countermeasure against events that occur in various forms or may occur in the future.
本発明の性能監視装置は、少なくとも一つの外部装置と通信回線を介して接続される性能監視装置であって、前記外部装置の状態に係る状態情報を取得する取得手段と、前記取得手段により取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定手段と、前記判定手段による判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーション手段とを有することを特徴とする。
本発明の性能監視方法は、少なくとも一つの外部装置と通信回線を介して接続される性能監視装置による性能監視方法であって、前記外部装置の状態に係る状態情報を取得する取得ステップと、前記取得ステップにより取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定ステップと、前記判定ステップによる判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーションステップとを含むことを特徴とする。
本発明のプログラムは、前記性能監視方法をコンピュータに実行させることを特徴とする。
The performance monitoring device of the present invention is a performance monitoring device connected to at least one external device via a communication line, and obtains status information related to the status of the external device, and is obtained by the obtaining device The determination means for determining the state of the external device based on the state information, and the countermeasure list corresponding to the determination result by the determination means, and the at least one countermeasure information included in the countermeasure list And simulation means for executing a simulation process related to the state of the external device and evaluating the effect of the countermeasure indicated by each countermeasure information.
The performance monitoring method of the present invention is a performance monitoring method by a performance monitoring device connected to at least one external device via a communication line, and obtains status information related to the status of the external device; and At least one countermeasure included in the countermeasure list with reference to a determination step for determining the state of the external device based on the state information acquired in the acquisition step, and a countermeasure list corresponding to a determination result in the determination step A simulation step of executing a simulation process related to the state of the external device based on each piece of information and evaluating the effect of the countermeasure indicated by each countermeasure information.
The program according to the present invention causes a computer to execute the performance monitoring method.
本発明においては、外部装置の状態情報、又は後述する状態情報により作成したモデルに基づいて、外部装置の現在・将来の状態を分析・診断(判定)し、その判定結果に対応する対策リストに含まれる各対策によるシミュレーション処理を行って、対策リストに含まれる各対策情報に示される対策の効果を評価するように構成している。即ち、本発明は、外部装置が様々な事象の状態に陥っても、その状態に対応する対策リストによるシミュレーションを行って各対策の効果を評価することができる。
従って、本発明によれば、その評価結果に基づいて、様々な形態で発生する外部装置の事象に対して、最も的確な対策を選択・策定することが可能となる。
In the present invention, the current / future status of the external device is analyzed / diagnosed (determined) based on the status information of the external device or a model created by status information described later, and the countermeasure list corresponding to the determination result is displayed. A simulation process is performed by each countermeasure included, and the effect of the countermeasure shown in each countermeasure information included in the countermeasure list is evaluated. That is, according to the present invention, even if the external device falls into various event states, the effect of each measure can be evaluated by performing a simulation using a measure list corresponding to the state.
Therefore, according to the present invention, it is possible to select and formulate the most appropriate countermeasure against the event of the external device that occurs in various forms based on the evaluation result.
先ず、本発明の実施形態について説明する前に、以下の説明で用いる文言の定義を行う。
「ポリシー」とは、後述するオートノミック・コンピューティング環境(以下AC環境とする)の運用に関する指針である。ポリシーの一例としては、「CPU使用率が0〜10%であれば余剰である、CPU使用率が11〜80%であれば正常である、CPU使用率が81%以上であれば過負荷である」、「CPU使用率が過負荷の場合は、シミュレーションを実行して最適な結果を残した対策を選択する」、「システムの応答がない場合は、即座に再起動する」等が挙げられる。
「対策リスト」とは、AC環境内の装置に生じ得る各事象に紐つけられる対策の集合であり、事象と対策とはm:nで対応付けられている。なお、m=nであってもよく、m≠nであってもよい。対策リストの一例としては、「CPU使用率が閾値を超えている」という事象に対して「対策1.CPUを1つ追加、対策2.CPUを2つ追加、対策3.サーバ追加による負荷分散」で構成された対策リスト等が挙げられる。
「モデル」とは、AC環境及び後述する非AC環境から取得する監視データに基づいて、AC環境内の各装置について特徴を抽出したものである。その一例として、AC環境内におけるAPサーバからCPU使用率を示す監視データを取得した場合には、その線形近似式を求めることによってCPU使用率の時系列変化を表す以下のモデルが抽出できる。
f(t)=at+b
f(t):CPU使用率、t:時間、a,b:実値
First, before describing embodiments of the present invention, the terms used in the following description are defined.
The “policy” is a guideline regarding the operation of an autonomic computing environment (hereinafter referred to as an AC environment) described later. As an example of the policy, “If the CPU usage rate is 0 to 10%, it is surplus, normal if the CPU usage rate is 11 to 80%, overload if the CPU usage rate is 81% or more. Yes, “If the CPU usage rate is overloaded, run a simulation to select the countermeasure that left the best results”, “If there is no system response, restart immediately”, etc. .
The “countermeasure list” is a set of countermeasures associated with each event that can occur in the devices in the AC environment, and the event and the countermeasure are associated with each other by m: n. Note that m = n or m ≠ n. An example of the countermeasure list is “
The “model” is a characteristic extracted for each device in the AC environment based on monitoring data acquired from the AC environment and a non-AC environment described later. As an example, when monitoring data indicating the CPU usage rate is acquired from an AP server in the AC environment, the following model representing the time series change of the CPU usage rate can be extracted by obtaining the linear approximation formula.
f (t) = at + b
f (t): CPU usage rate, t: time, a, b: actual value
以下、本発明を適用した好適な実施形態を、添付図面を参照しながら詳細に説明する。 DESCRIPTION OF EXEMPLARY EMBODIMENTS Hereinafter, preferred embodiments to which the invention is applied will be described in detail with reference to the accompanying drawings.
図1は、本発明の実施形態に係るAC性能監視装置100の機能的な構成を示すブロック図である。図1に示すように、本実施形態に係るAC性能監視装置100は、サーバ類1001、ストレージ類1002及びネットワーク(NW)装置類1003等から構成される情報処理システムであるAC環境、及び、非AC環境とLAN(Local Area Network)等の通信回線で接続され、この通信回線を介して各装置の状態を監視することが可能である。
FIG. 1 is a block diagram showing a functional configuration of an AC
なお、AC環境とは、本実施形態におけるオートノミック・コンピューティングの技術を適用する環境であり、図1の例では、サーバ類1001、ストレージ類1002及びネットワーク装置類1003である。これに対し、非AC環境とは、本実施形態におけるオートノミック・コンピューティングの技術の適用外となる環境であり、この非AC環境から取得される監視データはAC環境に対するオートノミック・コンピューティングに利用することも可能である。
The AC environment is an environment to which the autonomic computing technology according to the present embodiment is applied. In the example of FIG. 1, the
また、上述したサーバ類1001とは、WebサーバやAPサーバ等の各種サーバのことであり、ストレージ類1002とは、DB等の情報を記録可能な装置類である。ネットワーク装置類1003とは、サーバ類1001及びストレージ類1002の各装置間を接続するLAN等の通信ネットワークである。
The
モニタ部101は、AC環境及び非AC環境の各装置の状態を示す以下の監視データを取得する。AC環境のWebサーバ、APサーバ及びDBサーバからは、監視データとして、メモリの使用量を示すデータ及びCPUの使用率を示すデータ等のリソース使用状況データ、AC環境の各装置の処理履歴を示すログデータ等を取得する。また、モニタ部101は、AC環境におけるWebサーバ、APサーバ及びDBサーバ間を接続する各通信回線(ネットワーク装置)からは、監視データとして、それらの通信回線で通信されるトランザクションのスループット、処理名等を示すトランザクションデータを取得する。モニタ部101は、取得した監視データを標準的なフォーマットに変換して後述するイベント情報蓄積部102に蓄積する。標準フォーマットへの変換は、必ずしも必要とはならないが、多種多様な情報を効率的に分析・診断(判定)するために行っている。以下では代表的な標準フォーマットであるCBE(Common Base Event)を用いた実施形態のみについて説明するが、処理を行う為の標準化に用いるフォーマットであればCBEに限定する必要が無い事は言うまでも無い。
The
さらに、モニタ部101は、非AC環境からも監視データを取得する。非AC環境の装置から取得する監視データとしては、例えば、AC環境に対してアクセスを行う非AC環境の装置を監視し、AC装置の各装置に対して行われるアクセス数を監視データとして取得したり、AC環境内の温度を計測する非AC環境内の装置である温度計から温度データを監視データとして取得することが挙げられる。その他にも、AC環境内の装置に対するアクセス数が急激増加することが予測される時期情報を非AC環境内の装置から監視データとして取得することもできる。以下では、AC環境から取得する監視データのみを用いたオートノミック・コンピューティングについて説明するが、これらの非AC環境から取得できる監視データを更に加味することによってより精度の高いオートノミック・コンピューティングを実現することが可能となる。
Furthermore, the
分析部103は、モニタ部101が変換したCBEデータに問題がないかを、知識情報蓄積部104から読み込んだポリシー1041に基づいて分析する。例えば、CBEデータによって示されるCPUの使用率が80%を越えている場合、ポリシー1041に基づいて、CPU使用率が過負荷な状態であるという事象が分析される。ポリシー1041の一例を上記の説明で挙げたが、例えば上記のようにCPU使用率に関して分析する場合、分析対象となるCBEデータが示す数値に一番近いポリシー、「CPUの使用率が閾値の80%を越えたら過負荷な状態である」旨のポリシー1041が知識情報蓄積部104から読み込まれる。
The
また例えば、分析対象となるCBEデータがメモリの使用量であり、CBEデータが90%を示す場合、この分析対象に一番近いデータに該当するポリシー「メモリに使用率が閾値の85%を越えるとメモリが過度に消費された状態にある」旨のポリシー1041が知識情報蓄積部104から読み込まれ、この場合CBEデータによって示されるメモリの使用率が85%を越えている為、メモリが過度に消費された状態であるという事象が分析される。
Further, for example, when the CBE data to be analyzed is the amount of memory used and the CBE data indicates 90%, the policy corresponding to the data closest to the analysis target “the usage rate in the memory exceeds 85% of the threshold value. "The memory is excessively consumed" is read from the knowledge
また例えば、分析対象となるCBEデータがスループットを示すトランザクションデータであり、CBEデータが120トランザクション/秒を示す場合、この分析対象に一番近いデータに該当するポリシー「スループットが100トランザクション/秒未満であればサービスレベルが所定の範囲に収まる、スループットが100トランザクション/秒以上であればサービスレベルが所定の範囲内に収まらない」旨のポリシー1041が読み込まれ、この場合CBEデータによって示されるスループットが100トランザクション/秒を越えている為、システムが過負荷な状態であるという事象が分析される。
Further, for example, when the CBE data to be analyzed is transaction data indicating throughput and the CBE data indicates 120 transactions / second, the policy “throughput is less than 100 transactions / second” corresponding to the data closest to the analysis target. If there is a service level within a predetermined range, a
イベント情報蓄積部102は、モニタ部101によって変換されたCBEデータを蓄積する。また、イベント情報蓄積部102は、蓄積したCBEデータに対して定期的に統計処理を行って蓄積するCBEデータ量を削減する。統計処理の例としては、一定期間中に蓄積したCBEデータの最大/最小値を求める方法や、一定期間中に蓄積したCBEデータの平均値を求める方法等が挙げられる。
The event
イベント情報蓄積部102に蓄積される情報としては、上述したリソース使用情報データ、ログデータ及びトランザクションデータ等の他、構成情報が蓄積される。構成情報とは、監視対象としたい情報処理システムの構成を示す情報(例えば、監視対象の情報処理システムは6台のWebサーバと2台のAPサーバと1台のDBサーバから構成される等)、情報処理システムを構成する各装置間がどのように接続され、そして、各装置間を接続するためのネットワークはどれほどの転送レートを持ったものであるかを示す情報、各装置内のハードウェア及びソフトウェアのスペックを示す情報等が含まれる。各ハードウェア及びソフトウェアのスペックとしては、単に購入時のスペックだけでなく、ファームウェアやソフトウェアのバージョン等も登録しておくとよい。なお、蓄積される構成情報は例えばオペレータ等によって入力される方法のみならず、ネットワークを介してAC性能監視装置100が取得して入力するようにしてもよい。
As information stored in the event
モデル抽出部105は、イベント情報蓄積部102に蓄積されたCBEデータに基づいて、該当するAC環境の装置のモデル1042を抽出する。例えば、モデル抽出部105はAC環境における或る装置のCPU使用率を示すCBEデータを逐次取得し、それを線形近似することによってCPU使用率の時系列変化を表すモデル1042を抽出することができる。
The
また、モデル抽出部105はAC環境における或る装置のスループットを示すCBEデータを逐次取得し、それを線形近似することによってスループットの時系列変化を表すモデル1042を抽出することができる。
Further, the
さらに、モデル抽出部105は、上記のように、CPU使用率及びスループットの時系列変化を線形近似したモデル1042を抽出した場合には、それらのモデル1042からCPU使用率とスループットとの相関関係を示すモデル1042を抽出することもできる。このようなモデル1042の抽出方法については後に詳述する。抽出した各モデル1042は、知識情報蓄積部104に蓄積する。
Further, when the
モデル診断部106は、知識情報蓄積部104に蓄積されるモデル1042と当該モデル1042に該当するポリシー1041とを参照し、ポリシー1041に基づいてモデル1042の診断を行う。
The
例えば、参照したモデル1042がCPU使用率の時系列変化を表すモデルであれば、当該モデル1042に該当するポリシー1041として、「CPU使用率が0〜10%であれば余剰である、CPU使用率が11〜80%であれば正常である、CPU使用率が81%以上であれば過負荷である」というポリシー1041が参照される。将来の或る時点における予測値が所定の閾値を越えると予測される場合には、CPU使用率に関して将来問題が生じる可能性があるという事象が診断される。
For example, if the referenced
図6を用いて問題の事象がモデル診断部106によって診断される例を具体的に説明する。CPU使用率の時系列変化を表すモデルがfa(x)=αx+βであり、そのモデルに紐付けられるポリシーが「CPU使用率が0〜10%であれば余剰である、CPU使用率が11〜80%であれば正常である、CPU使用率が81%以上であれば過負荷である」である場合、図6に示すように、1カ月後におけるCPU使用率fa(x)の値は80%を越えている。このような場合、モデル診断部106は、1カ月後にはCPU使用率が過負荷の為、問題が生じる可能性があると診断する。
An example in which a problem event is diagnosed by the
また、参照したモデル1042がスループットの時系列変化を表すモデルであれば、当該モデル1042に該当するポリシー1041として、「スループットが100トランザクション/秒以上であればサービスレベルが所定の範囲に収まる、スループットが100トランザクション/秒以上であればサービスレベルが所定の範囲内に収まらない」というポリシー1042が参照される。将来の或る時点における予測値が所定の閾値を越えると予測される場合には、スループットに関して将来問題が生じる可能性があるという事象が診断される。
Further, if the referenced
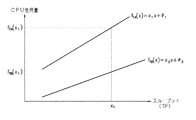
図7を用いて問題の事象がモデル診断部106によって診断される他の例を具体的に説明すると、処理A及び処理Bのスループットの時系列変化を表すモデルが夫々、fA(x)=α1x+β1、fB(x)=α2x+β2であり、それらのモデルに紐付けられるポリシーが「スループットが100トランザクション/秒未満であればサービスレベルが所定の範囲に収まる、スループットが100トランザクション/秒以上であればサービスレベルが所定の範囲内に収まらない」である場合、図7に示すように、1カ月後における処理AのスループットfA(x)の値は100トランザクション/秒を越えている。このような場合、モデル診断部106は、1カ月後には処理Aのスループットに問題が生じる可能性があると診断する。一方、1カ月後までの処理BのスループットfB(x)の値は100トランザクション/秒を下回っているため、1カ月後までに処理Bのスループットに問題が生じる可能性があると診断されない。
Referring to FIG. 7, another example in which a problem event is diagnosed by the
さらに、参照したモデル1042がCPU使用率とスループットとの相関関係を示すモデルであれば、当該モデル1042に該当するポリシー1041として、「CPU使用率とスループットとの相関関係が前後1日において誤差10%以内に収めるべきである」というポリシー1041が参照される。将来の或る時点におけるCPU使用率とスループットとの相関関係が所定の均衡を保てていないことが予測される場合には、それらの相関関係に将来問題が生じる可能性があるという事象が分析される。
Further, if the referenced
図8を用いて問題の事象がモデル診断部106によって診断される更に他の例を具体的に説明すると、処理aのCPU使用率とスループットとの相関関係を示すモデルが夫々、fTA(x)=ρ1x+θ1、fTB(x)=ρ2x+θ2であり、fTA(x)は2006/01/01のデータを、fTB(x)は2006/01/02のデータに基づいて作成したモデルである。それらのモデルに紐付けられるポリシーが「CPU使用率とスループットとの相関関係が前後1日において誤差10%以内に収めるべきである」である場合、図8に示すように、fTA(x1)とfTB(x1)の間に10%以上の誤差があれば、CPU使用率とスループットとのバランスが崩れてシステムが異常な状態にあると診断する。
A further example in which a problem event is diagnosed by the
計画部107は、分析部103によるCBEデータに対する分析の結果、問題があると分析された事象、又は、モデル診断部106により将来問題が生じる可能性があると診断された事象に紐付けられた対策リスト1043を知識情報蓄積部104から選択し、その対策リスト1043に含まれる各対策によるシミュレーション処理を後述のシミュレーション部108に対して依頼する。
The
例えば、対象となる事象が「1カ月後におけるCPU使用率が80%を越える」ような事象の場合、その事象に紐付けられる対策リスト1043の例として以下の(1)〜(6)に示すような対策リスト1043が挙げられる。
(1)CPUを1つ追加
(2)CPUを2つ追加
(3)サーバ追加による負荷分散(処理分散パターンA)
(4)サーバ追加による負荷分散(処理分散パターンB)
(5)サーバ追加による負荷分散(処理分散パターンC)
(6)サーバ追加による負荷分散(処理分散パターンD)
For example, when the target event is an event such that “the CPU usage rate after one month exceeds 80%”, the following (1) to (6) are shown as examples of the
(1) Add one CPU (2) Add two CPUs (3) Load distribution by adding servers (processing distribution pattern A)
(4) Load distribution by adding servers (processing distribution pattern B)
(5) Load distribution by adding servers (processing distribution pattern C)
(6) Load distribution by adding servers (processing distribution pattern D)
なお、図5(a)に示すように、処理分散パターンAとは、本来、2種類の処理Aと処理Bとを1つのサーバで処理していたが、そのサーバと追加したサーバとで処理Aと処理Bとを一つずつ分散させて処理させる処理分散パターンである。 As shown in FIG. 5 (a), the process distribution pattern A is originally a process in which two types of processes A and B are processed by one server, but the process is performed by the server and the added server. This is a processing distribution pattern in which A and processing B are distributed one by one.
処理分散パターンBとは、図5(b)に示すように、本来、2種類の処理Aと処理Bとを1つのサーバで処理していたが、そのサーバには同様に処理Aと処理Bとを実行させるとともに、追加サーバにも処理Aを実行させ、元々処理させていたサーバの処理Aに関する処理負担を軽減する処理分散パターンである。 As shown in FIG. 5B, the process distribution pattern B is originally a process where two types of processes A and B are processed by a single server. The processing distribution pattern reduces the processing burden on the processing A of the server that was originally processed by causing the additional server to execute processing A.
処理分散パターンCとは、図5(c)に示すように、本来、2種類の処理Aと処理Bとを1つのサーバで処理していたが、そのサーバには同様に処理Aと処理Bとを実行させるとともに、追加サーバにも処理Bを実行させ、元々処理させていたサーバの処理Bに関する処理負担を軽減する処理分散パターンである。 As shown in FIG. 5C, the process distribution pattern C originally has two types of processes A and B processed by a single server, but the servers A and B are similarly processed. And the additional server execute the process B to reduce the processing load related to the process B of the server that was originally processed.
処理分散パターンDとは、図5(d)に示すように、本来、2種類の処理Aと処理Bとを1つのサーバで処理していたが、そのサーバには同様に処理Aと処理Bとを実行させるとともに、追加サーバにも処理Aと処理Bとの両方を実行させ、元々処理させていたサーバの処理A及び処理Bに関する処理負担を軽減する処理分散パターンである。 As shown in FIG. 5 (d), the process distribution pattern D is originally a process where two types of processes A and B are processed by one server. The processing distribution pattern reduces the processing load related to processing A and processing B of the server that was originally processed by causing the additional server to execute both processing A and processing B.
シミュレーション部108は、計画部107によって選択された対策リスト1043を知識情報蓄積部104から参照し、その対策リスト1043によるシミュレーション処理を実行する。
The
なお、シミュレーション部108は、装置(又は、複数の装置から成るシステム)の構成変更の効果を定量化するためのシミュレータと呼ばれるツールによって構成することができる。シミュレータは、装置(又はシステム)構成や処理の特徴が入力されることによって性能値を予測することができる。ここで、装置(又はシステム)構成として入力される情報としては、例えば、サーバ数、CPU数等が挙げられる。処理の特徴として入力される情報としては、例えば、各処理のCPUにおける処理時間、各処理の発生頻度等が挙げられる。性能値として予測される情報としては、CPU使用率、各処理に対する応答時間等が挙げられる。これらの入力データは、知識情報蓄積部104から読み出したモデルに基づいて算出して得られる情報であるため、モデルをパラメータとしてシミュレータに与えてもよい。
The
例えば、対象となる事象が上述した「1カ月後におけるCPU使用率が80%を越える」ような事象の場合、上記の(1)〜(6)の対策を含む対策リスト1043についてシミュレーション処理が実行され、以下のように各対策を実施した際の効果が定量化される。
対策(1)の結果:CPU使用率85%
対策(2)の結果:CPU使用率なし(実現不可能な構成と判断されたため)
対策(3)の結果:CPU使用率40%
対策(4)の結果:CPU使用率55%
対策(5)の結果:CPU使用率55%
対策(6)の結果:CPU使用率65%
For example, when the target event is the above-mentioned event “the CPU usage rate after one month exceeds 80%”, the simulation process is executed for the
Result of measure (1): CPU usage rate 85%
Result of measure (2): No CPU usage rate (because it was determined that the configuration was not feasible)
Result of measure (3): CPU usage rate 40%
Result of measure (4): CPU usage rate 55%
Result of measure (5): CPU usage rate 55%
Result of measure (6): CPU usage rate 65%
また、対象となる事象が、例えば分析部103によって現在のCPU使用率が既に80%を越えていると分析されたような事象であれば、同じく、その事象に対応する対策リスト1043が参照され、シミュレーション処理によって当該対策リスト1043内の対策毎に効果が定量化されることになる。
Also, if the target event is an event that has been analyzed by the
計画部107は、当該事象に該当するポリシー1041を知識情報蓄積部104から参照し、シミュレーション部108によるシミュレーション処理の評価結果のうちポリシー1041を満たす結果を導いた対策を決定する。例えば、当該事象に該当するポリシー1041が「CPU使用率が過負荷の場合は、シミュレーションを実行して最適な結果を残した対策を選択する」というポリシー1041であれば、上記の例の場合、対策(3)が決定されることになる。計画部107は、このように対策を決定すると、例えば、対策(3)を1週間後に実行する等、対策の実行をスケジューリングする。
The
計画実行部109は、計画部107によって作成されたスケジュールに従って対策を実行する。
The
対策探索部110は、シミュレーション部108によるシミュレーション処理の全ての結果が、当該事象に該当するポリシー1041を満たさない場合、知識情報蓄積部104に蓄積される対策のうち当該事象に紐付けられていない対策を選択し、選択された対策によるシミュレーション処理をシミュレーション部108に対して依頼する。シミュレーション部108は、選択された対策を知識情報蓄積部104から参照し、各対策についてシミュレーション処理を実行し、各対策を実施した際の効果を定量化する。
If all the results of the simulation processing by the
対策探索部110は、このように当該事象に紐付けられていない対策に対するシミュレーション処理の結果のうち、上記ポリシー1041を満たす結果を導いた対策が存在する場合、知識情報蓄積部104内においてその対策を当該事象に紐付けられた対策リスト1043に追加させるとともに、上記ポリシー1041を満たす結果に対応する対策を計画部107に渡す。
In the case where there is a countermeasure that leads to a result satisfying the
このように対策探索部110によってポリシーを満たす対策が発見され、対策探索部110によって当該対策が渡された場合、計画部107は、同様に当該対策の実行をスケジューリングする。
In this way, when the
図2は、AC性能監視装置100のハードウェア構成を示すブロック図である。CPU201は、システムバスに接続される各デバイスやコントローラを統括的に制御する。ROM203又はHD207には、CPU201の制御プログラムであるBIOS(Basic Input/Output System)やオペレーティングシステムプログラムや、AC性能監視装置100が実行する例えば図3−1及び図3−2に示す処理のプログラム等が記憶されている。
FIG. 2 is a block diagram illustrating a hardware configuration of the AC
なお、図2の例では、ハードディスク(HD)207はAC性能監視装置100の内部に配置された構成としているが、他の実施形態としてHD207に相当する構成がAC性能監視装置外部に配置された構成としてもよい。また、本実施形態に係る例えば図3−1及び図3−2に示す処理を行なうためのプログラムは、フレキシブルディスク(FD)206やCD−ROM等、コンピュータ読み取り可能な記録媒体に記録され、それらの記録媒体から供給される構成としてもよいし、インターネット等の通信媒体を介して供給される構成としてもよい。
In the example of FIG. 2, the hard disk (HD) 207 is configured to be arranged inside the AC
RAM202は、CPU201の主メモリ、ワークエリア等として機能する。CPU201は、処理の実行に際して必要なプログラム等をRAM202にロードして、プログラムを実行することで各種動作を実現するものである。
The
ディスクコントローラ205は、HD207やFD206等の外部メモリへのアクセスを制御する。通信IFコントローラ204は、インターネットやLANと接続し、例えばTCP/IPによって外部との通信を制御するものである。
The
ディスプレイコントローラ208は、ディスプレイ209における画像表示を制御する。
The
KB(キーボード)コントローラ210は、キーボード(KB)211からの操作入力を受け付け、CPU201に対して送信する。なお、図示していないが、キーボード211の他に、マウス等のポインティングデバイスもユーザの操作手段として本実施形態に係るAC性能監視装置100に適用可能である。
The KB (keyboard)
モニタ部101、分析部103、モデル抽出部105、モデル診断部106、計画部107、シミュレーション部108、計画実行部107及び対策探索部110は、例えばHD207内に記憶され、必要に応じてRAM202にロードされるプログラム及びそれを実行するCPU201に相当する構成である。
The
また、知識情報蓄積部104及びイベント情報蓄積部102は、例えばHD207又はRAM202内の一部記憶領域に相当する構成である。なお、知識情報蓄積部104及びイベント情報蓄積部102は、AC性能監視装置100内部に備える構成の他、外部に備えた構成としてもよい。
The knowledge
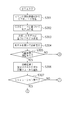
次に、本実施形態に係るAC性能監視装置100の動作を、図3−1、図3−2、図10及び図11のフローチャートを参照しながら説明する。
Next, the operation of the AC
先ず、図10を用いてモニタ部101による監視データの取得処理からイベント情報蓄積部102へのCBEデータの蓄積処理について説明する。図10において、モニタ部101は、AC環境及び非AC環境の各装置から監視データを取得し、取得した監視データをCBEデータに変換する(ステップS1001、S1002)。次に、モニタ部101は、当該CBEデータをイベント情報蓄積部102に蓄積させる(ステップS1003)。このようにモニタ部101は、ステップS1001〜ステップS1003の処理を繰り返し実行してCBEデータをイベント情報蓄積部102に対して蓄積していく。なお、イベント情報蓄積部102内では、例えば所定期間毎に、蓄積されるCBEデータの最大/最小値や平均値等を算出し、その値のみを保持するようにすることで蓄積するデータ量の削減が図られる。
First, a process for accumulating CBE data in the event
次に、図3−1及び図3−2を用いて、イベント情報蓄積部102に蓄積されたCBEデータに基づくモデルによってAC環境の診断処理を行い、診断結果に問題がある場合には対策を実行するまでの処理について説明する。図3−1において、モデル抽出部105は、AC環境及び非AC環境の各装置に対応するCBEデータをイベント情報蓄積部102から取得し、モデル1042を抽出する(ステップS301、S302)。
Next, using FIG. 3A and FIG. 3B, AC environment diagnosis processing is performed using a model based on the CBE data stored in the event
ここで、モデル1042の抽出方法を、図4を参照しながら具体的に説明する。
先ず、図4(a)において、前回モデル1042を抽出した時点(時間2)から所定時間が経過し、モデル抽出部105は、時間1及び時間2の監視データとともに、新たに時間3の監視データを今回取得する。ここで取得する監視データは、図4(a)に示すように、CPU使用率を示す監視データとスループットを示す監視データとであるものとする。
Here, a method of extracting the
First, in FIG. 4A, a predetermined time has elapsed from the time (time 2) when the
次に、モデル抽出部105は、時間に対するCPUの使用率の関係を表す座標系において、時間1〜時間3の監視データをプロットし、プロットした各監視データの線形近似式(fa(x)=αx+β)を求めることによって、CPU使用率の時系的変化を表すモデル1042を抽出する。モデル抽出部105は、抽出したモデル1042を知識情報蓄積部104に対して蓄積する。
Next, the
また、モデル抽出部105は、図4(b)に示すように、時間に対するスループットの関係を表す座標系において、処理A及び処理B夫々に関するスループットを示す時間1〜時間3の監視データをプロットし、処理Aと処理Bとの夫々について各監視データの線形近似式(fA(x)=α1x+β1、fB(x)=α2x+β2)を求めることによって、スループットの時系的変化を表すモデル1042を抽出する。モデル抽出部105は、抽出したモデル1042を知識情報蓄積部104に対して蓄積する。
Further, as shown in FIG. 4B, the
次に、モデル抽出部105は、これらの2つのモデル1042に対して相関分析及び多変量解析を行うことで、図4(c)に示すように、処理Aと処理Bとの夫々について、CPU使用率とスループットとの相関を表す線形近似式(fTA(x)=ρ1x+θ1、fTB(x)=ρ2x+θ2)を求め、CPU使用率とスループットとの相関を示すモデル1042を抽出する(ステップS303)。モデル抽出部105は、抽出したモデル1042を知識情報蓄積部104に対して蓄積する。
Next, the
続いて、モデル診断部106は、知識情報蓄積部104に蓄積される複数のモデル1042と各モデル1042に該当するポリシー1041を夫々参照し、各モデル1042に対して該当するポリシー1041に基づく診断を実行する(ステップS304)。例えば、CPU使用率の時系列変化を表すモデル1042に対しては、「CPU使用率が0〜10%であれば余剰である、CPU使用率が11〜80%であれば正常である、CPU使用率が81%以上であれば過負荷である」というポリシー1041が適用される。そして、今回抽出したモデル1042から将来のCPU使用率を予測することもできる。今回抽出したモデル1042の傾向でCPU使用率が増加していき、例えば1カ月後のCPU使用率が80%を越えることが予測される場合には、CPU使用率に将来(1カ月後)に問題が生じる可能性があると診断する。
Subsequently, the
また、例えば、スループットの時系列変化を表すモデル1042に対しては、「スループットが100トランザクション/秒以上であればサービスレベルが所定の範囲に収まる、スループットが100トランザクション/秒以上であればサービスレベルが所定の範囲内に収まらない」というポリシー1041が適用される。同じく今回抽出したモデル1042からスループットを予測することもできる。今回抽出したモデル1042の傾向でスループットが増加していき、例えば3週間後にスループットが100トランザクション/秒を越えることが予測される場合には、スループットに将来(3週間後)に問題が生じる可能性があると診断する。
Further, for example, for the
また、例えば、CPU使用率とスループットとの相関を表すモデル1042に対しては、「CPU使用率とスループットとの相関関係が前後1日において誤差10%以内に収めるべきである」というポリシー1041が適用される。このモデル1042からはCPU使用率に対するスループットの傾向を判定することができるため、例えば、上記ポリシー1401に基づきCPU使用率に対してスループットが1年前と比較して10%以上低い(又は、高い)と判定される場合には、問題があると診断される。
Further, for example, for the
なお、ここでは、CPU使用率の時系的変化を示すモデル1042とスループットの時系的変化を示すモデル1042とを抽出した後、CPU使用率とスループットとの相関を示すモデル1042を抽出する流れのみについて説明しているが、CPU使用率の時系列変化を示すモデル1042、スループットの時系的変化を示すモデル1042、CPU使用率とスループットとの相関を示すモデル1042の抽出処理は夫々独立して行なうことができる。つまり、本実施形態におけるモデル抽出処理は、図3−1に示す流れには限られず、それぞれのモデルの抽出処理は任意のタイミングで行なわれる。また、CPU使用率の時系列変化を示すモデル1042、スループットの時系的変化を示すモデル1042及びCPU使用率とスループットとの相関を示すモデル1042の全てを抽出せずに、そのうちの一部のモデルを抽出することもできる。即ち、CPU使用率とスループットとの相関を示すモデル1042は抽出せずにCPU使用率の時系列変化を示すモデル1042及びスループットの時系的変化を示すモデル1042の2つのモデルだけを抽出することもできるし、CPU使用率の時系列変化を示すモデル1042とスループットの時系的変化を示すモデル1042との何れか一方の1つのモデルのみを抽出することもできる。
Here, after extracting the
続いて、計画部107は、モデル診断部106によりモデル1042に問題があると診断された場合、知識情報蓄積部104においてその問題の事象に紐付けられる対策リスト1043を選択する(ステップS305/YES、S306)。例えば、対象となる事象が1カ月後におけるCPU使用率が80%を超過するという事象の場合、上述した(1)〜(6)の対策を含む対策リスト1043が選択されることになる。
Subsequently, when the
ここで、計画部107は、当該ポリシー1041に基づいてシミュレーション部108にシミュレーション処理を依頼するか否かを判断する(ステップS307)。例えば、当該ポリシー1041が「システムの応答がない場合は、即座に再起動する」である場合には、シミュレーション部108に対してシミュレーション処理を依頼せず、即座に対策の実行をスケジューリングする(ステップS307/NO、S312)。また、対象となる事象が緊急の対処を要するものであるとして予めポリシー1041において定められている場合には、その問題がある事象の内容と当該事象に紐付けられている対策リスト1043をユーザに対して報知してもよい。これによって、ユーザは報知された対策リスト1043のうちから所望の対策を選択し、対策の実行を行うことができる。
Here, the
一方、例えば、当該ポリシー1041が「CPU使用率が過負荷の場合は、シミュレーションを実行して最適な結果を残した対策を選択する」である場合、計画部107は、対策リスト1043に含まれる各対策のシミュレーション処理をシミュレーション部108に対して依頼する(ステップS307/YES、S308)。シミュレーション部108は、計画部107によって選択された対策リスト1043を参照し、その対策リスト1043に含まれる各対策のシミュレーション処理を実行する(ステップS309)。
On the other hand, for example, when the
続いて、計画部107は、当該事象に該当するポリシー1041を知識情報蓄積部104から参照し、シミュレーション部108によるシミュレーション処理の結果のうち、参照したポリシー1041を満たす結果を導いた対策が存在するか否かを判定する(ステップS310)。
Subsequently, the
ポリシー1041を満たす結果を導いた対策が一つのみ存在する場合、計画部107は、その対策の実行を決定し、当該対策の実行をスケジューリングする(ステップS310/YES、S311、S312)。また、ポリシー1041を満たす結果を導いた対策が複数存在する場合には、計画部107は、ポリシー1041「CPU使用率が過負荷の場合は、シミュレーションを実行して最適な結果を残した対策を選択する」に基づいてその複数の対策のうち最適な結果を導いた対策の実行を決定し、当該対策の実行をスケジューリングする(ステップS310/YES、S311、S312)。
When there is only one measure that has led to the result satisfying the
計画実行部109は、計画部107によって作成されたスケジュールに従って対策を実行する(ステップS313)。計画部107によって例えば「1カ月後に1つCPUを追加する」という対策のスケジュールが作成された場合、計画実行部109は、計画部107によって上記計画が作成された日から1カ月後に対象となるAC環境の装置に対してCPUを1つ追加するように制御する。
The
一方、シミュレーション部108によるシミュレーション処理の結果のうち、ポリシー1041を満たす結果を導いた対策が存在しないと判定された場合(当該事象に紐つけられる対策リスト1043にポリシー1041を満たす結果を導く対策が含まれない場合)、対策探索部110は、当該対策リスト1043以外の対策を知識情報蓄積部104から参照し、参照した対策に対するシミュレーション処理をシミュレーション処理部108に順次依頼する(ステップS310/NO、S314)。
On the other hand, when it is determined that there is no countermeasure that led to the result satisfying the
シミュレーション処理部108は、対策探索部110によって依頼された対策のシミュレーション処理を実行する(ステップS315)。
The
続いて、対策探索部110は、当該対策リスト1043以外の対策の全てについてのシミュレーション処理を依頼すると、シミュレーション部108による各対策に対するシミュレーション処理の結果と上記ポリシー1041とを照らし合わせ、ポリシー1041を満たす結果を導いた対策が存在するか否かを判断する(ステップS316/NO、S317)。なお、本実施形態では、対策探索部110は、知識情報蓄積部104内に蓄積される上記対策リスト以外の対策全てを探索する全探索手法を用いているが、他の実施形態として、上記対策リスト以外の対策をランダムに探索するランダム探索手法や一定のポリシー(条件)を満たす対策が発見された時点で探索を止める最適化方法論等を利用することもできる。
Subsequently, when the
ポリシー1041を満たす結果を導いた対策が一つのみ存在する場合、対策探索部110は、その対策の実行を決定し、当該対策の実行のスケジューリングを計画部107に対して依頼する(ステップS317/YES、S318)。また、ポリシー1041を満たす結果を導いた対策が複数存在する場合、対策探索部110は、その複数の対策のうち最適な結果を導いた対策の実行を決定し、当該探索の実行のスケジューリングを計画部107に対して依頼する(ステップS317/YES、S318)。一方、ポリシー1041を満たす結果を導いた対策が存在しない場合(ステップS317/NO)、ステップS301の処理に戻る。
When there is only one countermeasure that has led to the result satisfying the
続いて、対策探索部110は、計画部107に対してスケジューリングを依頼した対策を、当該事象の対策リスト1043に追加して紐つける(ステップS319)。このように対策探索部110によって今回探索された対策が対策リスト1043に追加される。従って、次回、同じ事象が分析部103によって分析、又は、モデル診断部106によって診断された場合、ステップS314〜ステップS319を行うことなく、今回探索された対策についてのシミュレーション処理を行うことが可能となる。
Subsequently, the
続いて、計画部107は、対策探索部110から依頼された対策の実行をスケジューリングする(ステップS312)。
Subsequently, the
計画実行部109は、計画部107によって作成されたスケジュールに従って対策を実行する(ステップS313)。
The
次に、図10及び図3−2を用いて、モニタ部101から直接得られるCBEデータを分析し、分析結果に問題がある場合には対策を実行するまでの処理について説明する。なお、図3−2は、上述したように、AC環境の診断処理を含む流れを説明する上でも用いている。以下に説明する分析処理を含む流れにおいても図3−2と同様の処理が行なわれるため、図3−2に該当する処理については適宜説明を省略する。
Next, with reference to FIG. 10 and FIG. 3-2, processing until CBE data obtained directly from the
図11において、分析部103は、モニタ部101からCBEデータを取得し、当該CBEデータに該当するポリシー1041を知識情報蓄積部104から参照し、参照したポリシー1041に基づいて当該CBEデータに問題がないかを分析する(ステップS1101、S1102)。上述したように、CBEデータがCPUの使用率を示すデータであって、且つ、「CPU使用率が0〜10%であれば余剰である、CPU使用率が11〜80%であれば正常である、CPU使用率が81%以上であれば過負荷である」というポリシー1041であれば、CBEデータにより示されるCPUの使用率が80%を越えていたらCBEデータに問題があると分析され、反対にCBEデータにより示されるCPUの使用率が80%未満である場合には、CBEデータには問題がないと分析される。
In FIG. 11, the
続いて、計画部107は、分析部103によりCBEデータに問題があると分析された場合、知識情報蓄積部104においてその問題の事象に紐付けられる対策リスト1043を選択する(ステップS1102/YES、S1103)。
Subsequently, when the
次に、計画部107は、当該ポリシー1041に基づいてシミュレーション部108にシミュレーション処理を依頼するか否かを判断する。例えば、当該ポリシー1041が「システムの応答がない場合は、即座に再起動する」である場合には、シミュレーション部108に対してシミュレーション処理を依頼せず、即座に対策の実行をスケジューリングする(ステップS1104/NO、S312)。また、対象となる事象が緊急の対処を要するものであるとして予めポリシー1041において定められている場合には、その問題がある事象の内容と当該事象に紐付けられている対策リスト1043をユーザに対して報知してもよい。これによって、ユーザは報知された対策リスト1043のうちから所望の対策を選択し、対策の実行を行なうことができる。なお、ステップS312以降の処理は、AC環境の診断処理を含む流れと同様であるため、説明を省略する。
Next, the
一方、例えば、当該ポリシー1041が「CPU使用率が過負荷の場合は、シミュレーションを実行して最適な結果を残した対策を選択する」である場合、計画部107は、対策リスト1043に含まれる各対策のシミュレーション処理をシミュレーション部108に対して依頼する(ステップS1104/YES、S308)。シミュレーション部108は、計画部107によって選択された対策リスト1043を参照し、その対策リスト1043に含まれる各対策のシミュレーション処理を実行する(ステップS309)。なお、ステップS310以降の処理は、AC環境の診断処理を含む流れと同様であるため、説明を省略する。
On the other hand, for example, when the
以上のように、本実施形態においては、監視データ(CBEデータ)に対応するポリシーから現在の問題の事象を分析(判定)し、又は、監視データ(CBEデータ)の履歴からモデルを抽出して当該モデルとそのモデルに対応するポリシーから現在・将来の問題の事象を診断(判定)し、上記判定結果に基づいてその事象に対応する対策リストによるシミュレーション処理を行って、各対策の効果を評価するようにしている。即ち、本実施形態は、AC環境内における各装置が様々な事象に陥った場合でも、その事象に対応する対策リストによるシミュレーション処理によって各対策の効果を評価することができる。 As described above, in this embodiment, the current problem event is analyzed (determined) from the policy corresponding to the monitoring data (CBE data), or the model is extracted from the history of the monitoring data (CBE data). Diagnose (determine) current and future problem events from the model and the policy corresponding to that model, and perform simulation processing using the countermeasure list corresponding to the event based on the above determination results to evaluate the effectiveness of each countermeasure Like to do. That is, according to the present embodiment, even when each device in the AC environment falls into various events, the effect of each countermeasure can be evaluated by simulation processing using a countermeasure list corresponding to the event.
従って、本実施形態によれば、各対策の効果に関する評価結果に基づいて、AC環境内における各装置の様々な事象に対して最も的確な対策を選択・策定することが可能である。 Therefore, according to the present embodiment, it is possible to select and formulate the most appropriate countermeasure for various events of each device in the AC environment based on the evaluation result regarding the effect of each countermeasure.
また、本実施形態では、計画部107が最適な効果を導いた対策の決定及び対策の実行のスケジューリングを行い、計画実行部109によってそのスケジューリングに従って対策を自動的に実行することが可能である。
Further, in the present embodiment, the
さらに、本実施形態では、仮に或る事象に対応する対策リストから最適な対策が発見できなかった場合でも、その他の対策を探索することによって、当該事象に適用する対策の幅を事前の対策リストから更に広げることが可能である。 Furthermore, in the present embodiment, even when an optimal countermeasure cannot be found from the countermeasure list corresponding to a certain event, the range of countermeasures to be applied to the event is determined in advance by searching for other countermeasures. It is possible to further expand from.
以上では、CPU使用率の時系列変化、スループットの時系列変化及びCPU使用率とスループットとの相関関係を表すモデルを抽出した場合について説明を行った。これら以外にも、例えば、図9に示すように、前後1日において処理Aのスループットと処理Bのスループットとの監視データを取得し、それらに基づいて処理Aのスループットと処理Bのスループットとの相関関係を表すモデルfTAB1(x)=ρAB1x+θAB1、fTAB2(x)=ρAB2x+θAB2を抽出して問題の事象を診断することも可能である。即ち、それらのモデルに紐付けられるポリシーが「処理Aのスループットと処理Bのスループットとの相関関係が前後1日において誤差10%以内に収めるべきである」である場合、図9に示すように、fTAB1(x1)とfTAB2(x1)の間に10%以上の誤差があれば、処理Aのスループットと処理Bのスループットとのバランスが崩れる可能性があると分析又は診断する。その後は同様に、この問題の事象に対応する対策リストによるシミュレーション処理が実行され、最適な結果を導いた対策が実行される。 In the above, the case where the model showing the time series change of the CPU usage rate, the time series change of the throughput, and the correlation between the CPU usage rate and the throughput has been described. In addition to these, for example, as shown in FIG. 9, monitoring data of the throughput of the process A and the throughput of the process B is acquired in the previous and next day, and the throughput of the process A and the throughput of the process B are obtained based on these data. It is also possible to extract a model f TAB1 (x) = ρ AB1 x + θ AB1 and f TAB2 (x) = ρ AB2 x + θ AB2 representing the correlation to diagnose a problem event. That is, when the policy associated with these models is “the correlation between the throughput of process A and the throughput of process B should be within 10% of error in the previous and next day”, as shown in FIG. , F TAB1 (x 1 ) and f TAB2 (x 1 ) are analyzed or diagnosed that there is a possibility that the balance between the throughput of process A and the throughput of process B may be lost if there is an error of 10% or more. Thereafter, similarly, a simulation process is executed using a countermeasure list corresponding to the event of this problem, and a countermeasure that has led to an optimum result is performed.
本発明は、以上に述べたモデル以外にもAC環境から取得し得る監視データに基づいて、種々のモデルを抽出できることは勿論である。また、同一の装置から得られた監視データだけでなく、異なる複数の装置から監視データを得て、装置間の監視データの相関関係を表すモデル等の抽出を行うことも可能である。 In the present invention, various models can be extracted based on monitoring data that can be acquired from the AC environment in addition to the models described above. In addition to monitoring data obtained from the same device, it is also possible to obtain monitoring data from a plurality of different devices and extract a model or the like representing the correlation of the monitoring data between the devices.
100:AC性能監視装置
101:モニタ部
102:イベント情報蓄積部
103:分析部
104:知識情報蓄積部
105:モデル抽出部
106:モデル診断部
107:計画部
108:シミュレーション部
109:計画実行部
110:対策探索部
1001:サーバ類
1002:ストレージ類
1003:ネットワーク装置類
1004:非AC環境
1041:ポリシー
1042:モデル
1043:対策リスト
100: AC performance monitoring device 101: Monitor unit 102: Event information storage unit 103: Analysis unit 104: Knowledge information storage unit 105: Model extraction unit 106: Model diagnosis unit 107: Planning unit 108: Simulation unit 109: Plan execution unit 110 : Countermeasure search unit 1001: Servers 1002: Storages 1003: Network devices 1004: Non-AC environment 1041: Policy 1042: Model 1043: Countermeasure list
Claims (8)
前記外部装置の状態に係る状態情報を取得する取得手段と、
前記取得手段により取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定手段と、
前記判定手段による判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーション手段とを有することを特徴とする性能監視装置。 A performance monitoring device connected to at least one external device via a communication line,
Obtaining means for obtaining state information relating to the state of the external device;
Determination means for determining the state of the external device based on the state information acquired by the acquisition means;
Referring to the countermeasure list corresponding to the determination result by the determination means, execute a simulation process related to the state of the external device by each of at least one countermeasure information included in the countermeasure list, and A performance monitoring apparatus comprising a simulation means for evaluating an effect.
前記記録媒体内に蓄積される前記状態情報の履歴に基づいて、前記外部装置の状態を表すモデル情報を抽出するモデル抽出手段とを更に有し、
前記判定手段は、前記モデル情報に基づいて前記外部装置の状態を判定することを特徴とする請求項1に記載の性能監視装置。 Storage means for storing the status information acquired by the acquisition means in an external or internal recording medium;
Model extraction means for extracting model information representing the state of the external device based on the history of the state information stored in the recording medium;
The performance monitoring apparatus according to claim 1, wherein the determination unit determines a state of the external device based on the model information.
前記シミュレーション手段は、前記他の対策情報による前記外部装置の状態に係るシミュレーション処理を実行し、前記他の対策情報により示される対策の効果を評価することを特徴とする請求項4に記載の性能監視装置。 When one measure information cannot be determined from the measure list based on the evaluation result by the measure determining unit, the measure determining unit further includes search means for searching for other measure information not included in the measure list,
5. The performance according to claim 4, wherein the simulation means executes a simulation process related to the state of the external device based on the other countermeasure information, and evaluates the effect of the countermeasure indicated by the other countermeasure information. Monitoring device.
前記外部装置の状態に係る状態情報を取得する取得ステップと、
前記取得ステップにより取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定ステップと、
前記判定ステップによる判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーションステップとを含むことを特徴とする性能監視方法。 A performance monitoring method by a performance monitoring device connected to at least one external device via a communication line,
An acquisition step of acquiring state information relating to the state of the external device;
A determination step of determining a state of the external device based on the state information acquired by the acquisition step;
Referring to the countermeasure list corresponding to the determination result of the determination step, execute a simulation process related to the state of the external device by each of at least one countermeasure information included in the countermeasure list, and the countermeasure list indicated by each countermeasure information And a simulation step for evaluating the effect.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006027622A JP4705484B2 (en) | 2006-02-03 | 2006-02-03 | Performance monitoring device, performance monitoring method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006027622A JP4705484B2 (en) | 2006-02-03 | 2006-02-03 | Performance monitoring device, performance monitoring method and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007207117A true JP2007207117A (en) | 2007-08-16 |
| JP4705484B2 JP4705484B2 (en) | 2011-06-22 |
Family
ID=38486511
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006027622A Active JP4705484B2 (en) | 2006-02-03 | 2006-02-03 | Performance monitoring device, performance monitoring method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4705484B2 (en) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010032701A1 (en) * | 2008-09-18 | 2010-03-25 | 日本電気株式会社 | Operation management device, operation management method, and operation management program |
| JP2010218000A (en) * | 2009-03-13 | 2010-09-30 | Nec Corp | System performance analysis device, system performance analysis method, and program |
| WO2011068015A1 (en) * | 2009-12-02 | 2011-06-09 | コニカミノルタホールディングス株式会社 | System building support method |
| US7975186B2 (en) | 2008-02-25 | 2011-07-05 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| US8225144B2 (en) | 2008-02-25 | 2012-07-17 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| WO2013141018A1 (en) * | 2012-03-21 | 2013-09-26 | 日本電気株式会社 | Device for supporting optimal system design |
| JP2018206245A (en) * | 2017-06-08 | 2018-12-27 | コニカミノルタ株式会社 | State prediction device, state prediction method and state prediction program |
| US11275044B2 (en) | 2018-08-31 | 2022-03-15 | Nuflare Technology, Inc. | Anomaly determination method and writing apparatus |
| CN114531333A (en) * | 2022-01-28 | 2022-05-24 | 新华三技术有限公司 | Method for managing operation and maintenance data, cloud platform and AC |
| CN115297035A (en) * | 2022-08-04 | 2022-11-04 | 杭州杰牌传动科技有限公司 | Intelligent operation and maintenance system with edge cloud cooperation |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08314751A (en) * | 1995-05-18 | 1996-11-29 | Hitachi Ltd | Disability countermeasure support method |
| JP2002268922A (en) * | 2001-03-09 | 2002-09-20 | Ntt Data Corp | Performance monitoring device of www site |
| JP2005099973A (en) * | 2003-09-24 | 2005-04-14 | Hitachi Ltd | Operation management system |
| JP2005346331A (en) * | 2004-06-02 | 2005-12-15 | Nec Corp | Failure recovery apparatus, method for restoring fault, manager apparatus, and program |
-
2006
- 2006-02-03 JP JP2006027622A patent/JP4705484B2/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08314751A (en) * | 1995-05-18 | 1996-11-29 | Hitachi Ltd | Disability countermeasure support method |
| JP2002268922A (en) * | 2001-03-09 | 2002-09-20 | Ntt Data Corp | Performance monitoring device of www site |
| JP2005099973A (en) * | 2003-09-24 | 2005-04-14 | Hitachi Ltd | Operation management system |
| JP2005346331A (en) * | 2004-06-02 | 2005-12-15 | Nec Corp | Failure recovery apparatus, method for restoring fault, manager apparatus, and program |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7975186B2 (en) | 2008-02-25 | 2011-07-05 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| US8621284B2 (en) | 2008-02-25 | 2013-12-31 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| US8225144B2 (en) | 2008-02-25 | 2012-07-17 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| JP5375829B2 (en) * | 2008-09-18 | 2013-12-25 | 日本電気株式会社 | Operation management apparatus, operation management method, and operation management program |
| WO2010032701A1 (en) * | 2008-09-18 | 2010-03-25 | 日本電気株式会社 | Operation management device, operation management method, and operation management program |
| US8700953B2 (en) | 2008-09-18 | 2014-04-15 | Nec Corporation | Operation management device, operation management method, and operation management program |
| JP2010218000A (en) * | 2009-03-13 | 2010-09-30 | Nec Corp | System performance analysis device, system performance analysis method, and program |
| WO2011068015A1 (en) * | 2009-12-02 | 2011-06-09 | コニカミノルタホールディングス株式会社 | System building support method |
| WO2013141018A1 (en) * | 2012-03-21 | 2013-09-26 | 日本電気株式会社 | Device for supporting optimal system design |
| JP2018206245A (en) * | 2017-06-08 | 2018-12-27 | コニカミノルタ株式会社 | State prediction device, state prediction method and state prediction program |
| US11275044B2 (en) | 2018-08-31 | 2022-03-15 | Nuflare Technology, Inc. | Anomaly determination method and writing apparatus |
| CN114531333A (en) * | 2022-01-28 | 2022-05-24 | 新华三技术有限公司 | Method for managing operation and maintenance data, cloud platform and AC |
| CN114531333B (en) * | 2022-01-28 | 2023-09-15 | 新华三技术有限公司 | Method for managing operation and maintenance data, cloud platform and AC |
| CN115297035A (en) * | 2022-08-04 | 2022-11-04 | 杭州杰牌传动科技有限公司 | Intelligent operation and maintenance system with edge cloud cooperation |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4705484B2 (en) | 2011-06-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4705484B2 (en) | Performance monitoring device, performance monitoring method and program | |
| US7702485B2 (en) | Method and apparatus for predicting remaining useful life for a computer system | |
| JP4980581B2 (en) | Performance monitoring device, performance monitoring method and program | |
| JP4756675B2 (en) | System, method and program for predicting computer resource capacity | |
| JP4859558B2 (en) | Computer system control method and computer system | |
| Urunuela et al. | Storm a simulation tool for real-time multiprocessor scheduling evaluation | |
| Soualhia et al. | Predicting scheduling failures in the cloud: A case study with google clusters and hadoop on amazon EMR | |
| Cheng et al. | Improving architecture-based self-adaptation through resource prediction | |
| JP6777142B2 (en) | System analyzer, system analysis method, and program | |
| GB2516357A (en) | Methods and apparatus for monitoring conditions prevailing in a distributed system | |
| JP2005099973A (en) | Operation management system | |
| CN111861012B (en) | A test task execution time prediction method and optimal execution node selection method | |
| JP7107991B2 (en) | Operation management device and operation management method | |
| US20140361978A1 (en) | Portable computer monitoring | |
| Foroni et al. | Moira: A goal-oriented incremental machine learning approach to dynamic resource cost estimation in distributed stream processing systems | |
| Sedaghatbaf et al. | A method for dependability evaluation of software architectures | |
| JP2006185055A (en) | Design support system and design support program for computer system | |
| Lewis et al. | Chaotic attractor prediction for server run-time energy consumption | |
| JP2008191849A (en) | Operation management apparatus, information processing apparatus, operation management apparatus control method, information processing apparatus control method, and program | |
| JP5443686B2 (en) | Information processing apparatus, information processing method, and program | |
| JP4881761B2 (en) | System resource monitoring method, monitoring apparatus, and program | |
| TWI781767B (en) | Prediction-based method for analyzing change impact on software components | |
| JP2009032052A (en) | Information processing apparatus, information processing method, and program | |
| Fedotova et al. | Upper bounds prediction of the execution time of programs running on arm cortex-a systems | |
| JP5349876B2 (en) | Information processing apparatus, information processing method, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090128 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100824 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100914 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101112 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110301 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110311 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4705484 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |