JP2007193697A - Information collection apparatus, information collection method and program - Google Patents
Information collection apparatus, information collection method and program Download PDFInfo
- Publication number
- JP2007193697A JP2007193697A JP2006013035A JP2006013035A JP2007193697A JP 2007193697 A JP2007193697 A JP 2007193697A JP 2006013035 A JP2006013035 A JP 2006013035A JP 2006013035 A JP2006013035 A JP 2006013035A JP 2007193697 A JP2007193697 A JP 2007193697A
- Authority
- JP
- Japan
- Prior art keywords
- metadata
- information
- field
- unit
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images









Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本発明は,掲示情報にメタデータを付与する情報収集装置,情報収集方法およびプログラムに関し,更に詳述すると,異義語あるいは同義語があったとしても,関連する特定の内容を検出でき,かつ,同じ分野の検索ユーザと情報を共有することが可能な情報収集装置,情報収集方法およびプログラムに関する。 The present invention relates to an information collection device, an information collection method, and a program for adding metadata to posted information. More specifically, even if there is a synonym or synonym, it is possible to detect related specific contents, and The present invention relates to an information collection apparatus, an information collection method, and a program capable of sharing information with search users in the same field.
コンピュータの通信網(通信ネットワーク)に代表されるインターネットでは,WWW(World Wide Web)システムを通じて,各コンピュータが,公開することを前提として生成された掲示情報(WebPage)を,その掲示情報に対応したブラウザを用いて閲覧することが可能である。 In the Internet typified by a computer communication network (communication network), the posting information (WebPage) generated on the assumption that each computer publishes through the WWW (World Wide Web) system corresponds to the posting information. It is possible to browse using a browser.
上記WWW上で所望する情報の検索を行う場合,全ての掲示情報の中から,ユーザに入力された特定のキーワードが含まれる掲示情報を抽出する全文検索技術が用いられる。ここでは掲示情報に含まれるキーワードの索引が予め作成されており,この索引を参照することによって大量の掲示情報を高速に検索することが可能となる。 When searching for desired information on the WWW, a full-text search technique is used that extracts posted information including a specific keyword input by the user from all posted information. Here, an index of keywords included in the posted information is created in advance, and a large amount of posted information can be searched at high speed by referring to the index.
しかし,様々な人が多様な視点で生成する掲示情報は,使用される用語に統一性がなく,同じ事が異なる用語(同義語)で表されたり,異なる事が同じ用語(異義語)で表されたり,「コンピューター」と「コンピュータ」といった長音の有無,片仮名平仮名英字を変えて(異表記)表したりして生成されることが多い。このような表記の違いによって,所望する掲示情報を適切に検索できない場合や,意図に反した掲示情報が抽出される場合が生じている。 However, in the posting information generated by various people from various viewpoints, the terms used are not uniform, and the same thing is expressed in different terms (synonyms) or different things are expressed in the same terms (synonyms). It is often generated by expressing or changing the presence or absence of long sounds such as “computer” and “computer”, or changing katakana hiragana / alphabet letters (notation). Due to such a difference in notation, there are cases where desired posting information cannot be properly searched or posting information that is not intended is extracted.
このような誤検索を避けるため,文献検索等の閉じたシステムにおいては,統制的なキーワードを付与して検索を実行することも検討されている。また,検索対象となる文書から自動的に全てのキーワード候補を抽出し,そのキーワードに従って,掲示情報から対応する文書を検索する技術も知られている。しかし,このような技術においても,異義語のような意図しない意味でキーワードが検索されたり,不要なキーワードで検索されたりして過大な検索結果が生じている。 In order to avoid such an erroneous search, in a closed system such as a literature search, it is also considered to execute a search by assigning a control keyword. A technique is also known in which all keyword candidates are automatically extracted from documents to be searched, and corresponding documents are searched from posted information according to the keywords. However, even in such a technique, an excessive search result is generated because a keyword is searched with an unintended meaning such as a synonym, or an unnecessary keyword is searched.
上記過大な検索結果の発生を回避する方法として,異義語に対して,どの意味での検索を望んでいるか逐次ユーザに確認し,また,キーワードの要否も確認してから文書の検索を行う技術が知られている(例えば,特許文献1)。また,ユーザが特定のシステムを用いて公開する掲示情報に対して,その掲示情報を特定する情報とキーワードとを関連付け,キーワードの検索結果を迅速に表示する技術も知られている(例えば,特許文献2)。
しかし,ユーザにキーワードの意味を問う技術では,キーワードの異義語に対する排他力は高いものの,確立された分別がなされていないので,そのキーワードの属性等を踏まえた自由度の高い検索を支援することができない。 However, although the technology that asks the user the meaning of a keyword has a high level of exclusivity against the keyword's synonyms, it has not been established, so it supports a search with a high degree of freedom based on the keyword's attributes. I can't.
また,掲示情報の特定情報とキーワードを関連付ける技術では,上述した異義語に対して意図しないリンクが生成され,所謂「誤爆」が生じる可能性がある。また,単一のキーワードによる指定であるため,検索結果が少なすぎる,もしくは多すぎる場合に,それを調整する機能も特に準備されていない。 Further, in the technology for associating the specific information of the posted information with the keyword, an unintended link is generated for the above-mentioned synonym and there is a possibility that a so-called “false explosion” may occur. In addition, since it is specified by a single keyword, there is no special function for adjusting the search results when there are too few or too many search results.
また,上記の技術は,同義語の場合に対しても,十分に対応し得るものではない。例えば,ユーザが検索時に「イベント」と入力した場合,「主催団体」,「入場料」,「参加資格」等というように色々な情報が結果として出力されが,実際の検索においては,このような検索結果はほとんど不要となる場合が多い。従って,同義語から検索する場合でも,検索結果として,ユーザのニーズに対応した情報のみが得られることが望まれている。 In addition, the above technique cannot sufficiently cope with the case of synonyms. For example, when the user inputs “event” at the time of search, various information such as “host organization”, “entrance fee”, “participation qualification”, and the like are output as a result. Search results are often unnecessary. Therefore, even when searching from synonyms, it is desired that only information corresponding to user needs is obtained as a search result.
本発明は,従来の検索システムが有する上記問題点に鑑みてなされたものであり,本発明の目的は,異義語等による意図しない検索結果の生成を回避し,掲示情報を容易かつ確実に検索可能な,新規かつ改良された情報収集装置,情報収集方法およびプログラムを提供することである。 The present invention has been made in view of the above-described problems of conventional search systems, and an object of the present invention is to avoid the generation of unintended search results by means of synonyms, etc., and to search posted information easily and reliably. To provide a new and improved information collecting apparatus, information collecting method and program.
上記課題を解決するために,本発明のある観点によれば,通信網に接続され,掲示情報に含まれる文書から自然言語解析により単語を抽出する単語抽出部と;オントロジ(ontology)に基づく語彙体系を保持する語彙体系保持部と;上記語彙体系に定義された関連付けに従い,キーワードと,該キーワードの属性値となるべき,上記単語抽出部で抽出された単語の候補とを出力する候補出力部と;上記キーワード,属性,上記候補からユーザが選択した単語を対にしたメタデータを生成するメタデータ生成部と;上記生成されたメタデータを保持するメタデータ保持部と;を備えることを特徴とする,情報収集装置が提供される。 In order to solve the above-described problems, according to an aspect of the present invention, a word extraction unit connected to a communication network and extracts a word from a document included in bulletin information by natural language analysis; a vocabulary based on ontology A lexical system holding unit that holds the system; a candidate output unit that outputs a keyword and a word candidate extracted by the word extraction unit that should be an attribute value of the keyword in accordance with the association defined in the vocabulary system A metadata generation unit that generates metadata in which a word selected by the user from the keyword, attribute, and candidate is paired; and a metadata holding unit that holds the generated metadata. An information collecting device is provided.
文書,単語,画像(静止画,動画)を含む掲示情報の検索精度を高めるため,本発明においては,公開されている掲示情報に,その掲示情報の記述内容を抽象的に表したメタデータを付与する。メタデータは,その掲示情報を表すキーワードだけでなく,キーワードに対する属性や属性値,その他の関連情報が付加されている。かかるメタデータによって掲示情報をより一層特徴付けることができ,検索対象の絞り込みが容易になる。 In order to improve the search accuracy of bulletin information including documents, words, and images (still images, moving images), in the present invention, metadata that abstractly describes the description content of the bulletin information is included in the public bulletin information. Give. Metadata includes not only a keyword representing the posting information but also an attribute, an attribute value, and other related information for the keyword. The posted information can be further characterized by such metadata, and the search target can be easily narrowed down.
また,メタデータの属性値を,キーワードと共に掲示情報から抽出することにより,ユーザが改めて属性値を手入力するという手間を省くことができ,自動的に抽出された単語の候補からユーザに属性値を選択させるという処理のみでメタデータを生成することが可能となる。 Also, by extracting the metadata attribute values from the posting information together with the keywords, it is possible to save the user from having to manually input the attribute values again. The metadata can be generated only by the process of selecting.
ユーザに所望の分野を選択させる分野選択部をさらに含み,上記語彙体系保持部は,分野毎に設けられた複数の語彙体系を含み,上記候補出力部は,上記分野選択部によりユーザが選択した分野の語彙体系に従い,属性値の候補を出力するとしてもよい。 A field selection unit that allows a user to select a desired field is further included. The lexical system holding unit includes a plurality of vocabulary systems provided for each field, and the candidate output unit is selected by the user by the field selection unit. Attribute value candidates may be output according to the vocabulary system of the field.
上記語彙体系は,分野やカテゴリ毎にその関連付けが相違する場合がある。このような場合,その分野毎の語彙体系を適用した方がより精度の高いメタデータを生成しうる。かかる構成では,メタデータを付与するユーザに所望の分野を選択させ,その分野の語彙体系を利用することによって,その分野に特化した語彙を抽出でき,検索に適したメタデータを生成することが可能となる。 The above vocabulary system may have different associations for each field or category. In such a case, more accurate metadata can be generated by applying a lexical system for each field. In such a configuration, the user who gives the metadata can select a desired field and use the vocabulary system of the field to extract vocabulary specialized for the field and generate metadata suitable for search. Is possible.
ユーザの当該情報収集装置への操作履歴からユーザの所望する分野を推定する所望分野推定部をさらに含み,上記語彙体系保持部は,分野毎に設けられた複数の語彙体系を含み,上記候補出力部は,上記推定された分野の語彙体系に従い,属性値の候補を出力するとしてもよい。 A desired field estimation unit for estimating a field desired by the user from an operation history of the user to the information collecting apparatus, and the vocabulary system holding unit includes a plurality of vocabulary systems provided for each field, and the candidate output The section may output candidate attribute values according to the estimated lexical system of the field.
かかる構成では,ユーザの当該情報収集装置への操作履歴を保持し,アクセス数の多い掲示情報の分野や指定される回数の多い分野から対象となる掲示情報の分野を推定し,その推定された分野の語彙体系を利用することによって,その分野に特化した語彙を抽出でき,検索に適したメタデータを生成することが可能となる。 In such a configuration, the user's operation history of the information collecting device is maintained, and the target posted information field is estimated from the field of the posted information having a large number of accesses or the field having the specified number of times, and the estimated By using the vocabulary system of a field, it is possible to extract vocabulary specialized for that field and generate metadata suitable for search.
上記単語抽出部により抽出された単語に基づいて,上記掲示情報が属する分野を推定する掲示分野推定部をさらに含み,上記語彙体系保持部は,分野毎に設けられた複数の語彙体系を含み,上記候補出力部は,上記推定された分野の語彙体系に従い,属性値の候補を出力するとしてもよい。 A posting field estimation unit for estimating a field to which the posting information belongs based on the word extracted by the word extraction unit; and the vocabulary system holding unit includes a plurality of vocabulary systems provided for each field, The candidate output unit may output attribute value candidates according to the estimated lexical system of the field.
かかる構成では,掲示情報から抽出された1または2以上の単語から当該掲示情報の分野を自動的に推定し,その推定された分野の語彙体系を利用することによって,その分野に特化した語彙を抽出でき,検索に適したメタデータを生成することが可能となる。 In such a configuration, a vocabulary specialized for a particular field is estimated by automatically estimating the field of the posted information from one or more words extracted from the bulletin information and using the vocabulary system of the estimated field. Can be extracted, and metadata suitable for search can be generated.
ユーザの所望するメタデータの条件を保持する条件保持部と;上記条件を満たすメタデータが,他のユーザによってメタデータ保持部に追加された場合,上記ユーザにその旨通知する追加通知部と;をさらに備えるとしてもよい。 A condition holding unit for holding metadata conditions desired by the user; and an additional notification unit for notifying the user when metadata satisfying the above conditions is added to the metadata holding unit by another user; May be further provided.
ユーザは,所望する分野,メタデータ,メタデータの条件式等を指定することによって,その指定した分野やメタデータが他のユーザによって追加(登録)された場合,その追加された旨,及び/又はその追加された情報自体を得ることができる。かかる構成により,各ユーザは,他のユーザからの情報提供を受けるため,また,他のユーザに情報を提供するため,率先して当該情報収集装置を利用することとなり,ひいては掲示情報のメタデータ付与化が促進される。 When the user adds (registers) the specified field or metadata by specifying the desired field, metadata, metadata conditional expression, etc., the fact that it has been added, and / or Alternatively, the added information itself can be obtained. With this configuration, each user takes the initiative to use the information collection device in order to receive information from other users and to provide information to other users. Granting is promoted.
上記情報収集装置は,複数の構成要素の集合体で表されるが,各構成要素や機能モジュールが単体の装置に属する場合に限られず,各構成要素が別体の装置として,または別体の装置に組み込まれて形成されるとしてもよい。 The above information collection device is represented by an aggregate of a plurality of components, but is not limited to the case where each component or functional module belongs to a single device, and each component is a separate device or a separate device. It may be formed by being incorporated in the apparatus.
上記課題を解決するために,本発明の別の観点によれば,掲示情報に含まれる文書から自然言語解析により単語を抽出する単語抽出ステップと;オントロジに基づく語彙体系に定義された関連付けに従い,キーワードと,該キーワードの属性値となるべき,上記単語抽出ステップにより抽出された単語の候補とを出力する候補出力ステップと;上記キーワード,属性,上記候補からユーザが選択した単語を対にしたメタデータを生成するメタデータ生成ステップと;上記生成されたメタデータを保持するメタデータ保持ステップと;を含むことを特徴とする,情報収集方法が提供される。 In order to solve the above-described problem, according to another aspect of the present invention, a word extraction step of extracting a word by a natural language analysis from a document included in posted information; according to an association defined in a vocabulary system based on an ontology, A candidate output step for outputting a keyword and a word candidate extracted by the word extraction step to be an attribute value of the keyword; a meta-data pairing the keyword, the attribute, and a word selected by the user from the candidate There is provided an information collecting method comprising: a metadata generating step for generating data; and a metadata holding step for holding the generated metadata.
また,コンピュータに,上記情報収集方法を遂行させるプログラムや,そのプログラムを記憶した記憶媒体も提供される。 Also provided are a program for causing a computer to perform the information collecting method and a storage medium storing the program.
上述した情報収集装置における従属項に対応する構成要素やその説明は,当該情報収集方法,プログラム,記憶媒体にも適用可能である。 The constituent elements corresponding to the dependent claims in the information collecting apparatus and the explanation thereof can be applied to the information collecting method, program, and storage medium.
以上説明したように本発明によれば,掲示情報に付与されたメタデータを検索対象にすることによって,異義語等による意図しない検索結果の生成を回避しつつ,掲示情報を容易かつ確実に検索することが可能となる。 As described above, according to the present invention, it is possible to search bulletin information easily and reliably while avoiding generation of an unintended search result by a synonym or the like by making metadata attached to the bulletin information a search target. It becomes possible to do.
また,人が読むことを前提としている掲示情報は,機械処理には向かないが,かかる掲示情報に,機械処理に対応したメタデータが付与されるので,メタデータを活用したアプリケーションのとの連携が容易になる。例えば,開催日等の情報を,メタデータを利用して取り出すことができるので,特定期間に開催されるイベントに関する情報のみをリストアップする等の処理が可能となる。 In addition, bulletin information that is assumed to be read by humans is not suitable for machine processing, but since metadata corresponding to machine processing is added to such bulletin information, it is linked with applications that use metadata. Becomes easier. For example, since information such as the date of an event can be extracted using metadata, it is possible to perform processing such as listing only information related to events held during a specific period.
以下に添付図面を参照しながら,本発明の好適な実施の形態について詳細に説明する。なお,本明細書及び図面において,実質的に同一の機能構成を有する構成要素については,同一の符号を付することにより重複説明を省略する。 Hereinafter, preferred embodiments of the present invention will be described in detail with reference to the accompanying drawings. In the present specification and drawings, components having substantially the same functional configuration are denoted by the same reference numerals, and redundant description is omitted.
現在,インターネット等の通信網に接続されたコンピュータを用いて,所望する掲示情報を検索することが可能である。しかし,Web(ウェブ)は開放されたシステムであるが故,単純なキーワードのみによる検索では対応する文書数が多すぎて適切な掲示情報を検出できない問題が想定される。 Currently, it is possible to search for desired posting information using a computer connected to a communication network such as the Internet. However, since the Web is an open system, there is a problem that it is impossible to detect appropriate posted information because there are too many corresponding documents in a search using only simple keywords.
掲示情報の検索精度を高めるため,掲示情報の文書全体に単一もしくは複数の統制的キーワードを付すことも考えられるが,本実施形態では,その掲示情報の記述内容を特徴付ける標準仕様として,メタデータを付与する。メタデータは,その掲示情報を特定するキーワードだけでなく,キーワードに対する属性や属性値,その他の関連情報が付加されている。かかるメタデータによって掲示情報をより一層特徴付けることができ,検索対象の絞り込みが容易になる。 In order to improve the search accuracy of the bulletin information, it may be possible to attach a single or plural control keywords to the entire bulletin information document. In this embodiment, metadata is used as a standard specification that characterizes the description content of the bulletin information. Is granted. Metadata includes not only a keyword specifying the posting information but also an attribute, an attribute value, and other related information for the keyword. The posted information can be further characterized by such metadata, and the search target can be easily narrowed down.
上記メタデータは,掲示情報を表すキーワードを主語とした場合の述語および目的語として生成され,ここでは,主語にあたる部分をキーワードのタイプ,述語にあたる部分を該タイプの任意の属性,目的語にあたる部分を該属性における任意の属性値としている。ここでは,このような[タイプ]−[属性]−[属性値]の関係をオントロジと言い,かかる定義に基づいて,具体的な[タイプ]に対する各[属性]や[属性値]を定めたものを語彙体系と言う。 The above metadata is generated as a predicate and object when the keyword representing the posted information is the subject. Here, the part corresponding to the subject is the type of the keyword, and the part corresponding to the predicate is the attribute corresponding to any attribute or object of the type. Is an arbitrary attribute value in the attribute. Here, this [type]-[attribute]-[attribute value] relationship is called ontology, and based on this definition, each [attribute] and [attribute value] for a specific [type] is defined. Things are called vocabulary systems.
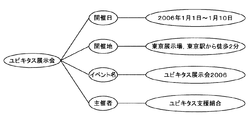
図1は,上述した語彙体系の一例を示した説明図である。かかる語彙体系は,階層によって表現され,例えば「イベント」100という[タイプ]に対して,その「イベント」100の[属性]である「開催日」110,「開催場所」112,「イベント名」114,「主催者」116等が定義付けられ,さらに各[属性]には,その[属性]における具体的な[属性値]である「日付,期間」120,「地名,場所表現」122,「タイトル表現」124,「人名,組織名」126等の各カテゴリが挙げられる。 FIG. 1 is an explanatory diagram showing an example of the vocabulary system described above. Such a vocabulary system is expressed by a hierarchy. For example, for “type” of “event” 100, “attribute” of “event” 100, “date of holding” 110, “place of holding” 112, “event name” 114, “organizer” 116 and the like are defined, and each [attribute] has a specific [attribute value] “date, period” 120, “place name, place expression” 122, Each category includes “title expression” 124, “person name, organization name” 126, and the like.
図2は,掲示情報中の文書の一例を示したテキスト図である。このような文書からメタデータを生成すると,語彙体系の「イベント」100−「開催日」110−「日付,期間」120の関連付けに従って,例えば,「ユビキタス展示会」−「開催日」−「2006年1月1日〜1月10日」をメタデータとして設定することができる。 FIG. 2 is a text diagram showing an example of the document in the posted information. When metadata is generated from such a document, for example, “Ubiquitous Exhibition” — “Date” — “2006” according to the association of “Event” 100— “Date” 110— “Date, Period” 120 of the vocabulary system. "January 1 to January 10" can be set as metadata.
図3は,図1に示した語彙体系に基づいて設定したメタデータの例を示した説明図である。ユーザは,掲示情報にこのようなメタデータを添付して,かかる掲示情報を表し,他のユーザによる検索を支援する。かかるメタデータは,図1の語彙体系と対応して生成され,上述したメタデータ「ユビキタス展示会」−「開催日」−「2006年1月1日〜1月10日」も含まれている。また,図3では,4つのメタデータを例に挙げているが,かかる数に限られず,あらゆる用語で構成された様々なメタデータを生成することができる。 FIG. 3 is an explanatory diagram showing an example of metadata set based on the vocabulary system shown in FIG. The user attaches such metadata to the bulletin information, represents the bulletin information, and supports searches by other users. Such metadata is generated corresponding to the vocabulary system of FIG. 1 and includes the above-mentioned metadata “Ubiquitous Exhibition”-“Date”-“January 1 to January 10, 2006”. . In FIG. 3, four metadata are given as an example. However, the number of metadata is not limited to this, and various metadata composed of all terms can be generated.
このようなメタデータは,通常,ユーザがその都度,手入力で設定していた。しかし,このような設定方法の下では,ユーザの負荷が過大になり,せっかくの上記システムが余り活用されないといった状況に陥ってしまう。従って,本実施形態では,メタデータとして定義される[属性値]を,キーワードと共に掲示情報から抽出することにより,ユーザが改めて[属性値]を手入力するという手間を省き,自動的に抽出された単語の候補からユーザに[属性値]を選択させるという処理のみでメタデータを生成している。 Such metadata is usually set manually by the user each time. However, under such a setting method, the load on the user becomes excessive and the above-mentioned system is not used much. Therefore, in this embodiment, the [attribute value] defined as metadata is extracted from the posting information together with the keyword, so that the user does not have to manually input the [attribute value] again and is automatically extracted. The metadata is generated only by the process of allowing the user to select [attribute value] from the candidate words.
(第1の実施形態:メタデータ付与支援装置)
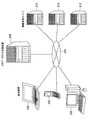
図4は,当該情報収集装置が利用される情報収集システムの概略を説明したブロック図である。かかる情報収集システムは,通信網200,情報資源サーバ210と,端末装置220と,情報収集装置としてのメタデータ付与支援装置230とを含んで構成される。当該情報収集システムにおいては,ユーザの検索処理を容易にする環境を提供することができ,さらにユーザ同士が情報を共有することが可能となる。以下では,この情報収集システム内の情報収集装置としてメタデータ付与装置230を挙げて説明しているが,メタデータの付与は勿論,さらに,情報収集等広い観点で当該メタデータ付与装置230を利用することが可能である。
(First embodiment: metadata assignment support apparatus)
FIG. 4 is a block diagram illustrating an outline of an information collection system in which the information collection apparatus is used. Such an information collection system includes a
上記通信網200は,例えば,インターネット,イントラネット,LAN(Local Area Network)等の双方向通信網であり,情報資源サーバ210,端末装置220,メタデータ付与支援装置230等に接続されている。
The
上記情報資源サーバ210は,1または2以上の掲示情報(WebPage)を有し,ユーザの閲覧要求に応じて,通信網200を介しその掲示情報を提供する。
The
上記端末装置220は,通常,個人ユーザにより管理され,通常のキーワードや,特定のメタデータによって所望する掲示情報を検索し,また,メタデータ付与支援装置230にアクセスして,情報資源サーバ210から提供される掲示情報にメタデータを付与する。
The
上記メタデータ付与支援装置230は,情報資源サーバ210,端末装置220,もしくはメタデータ付与支援装置230を操作するオペレータからのメタデータ付与請求に応じて,情報資源サーバ210から取得した掲示情報にメタデータを付与する。また,情報資源サーバ210,端末装置220からの掲示情報検索指令に応じて,保持しているメタデータを検索し,そのメタデータに関連付けられた掲示情報を情報資源サーバ210,端末装置220に伝達する。
The metadata
このように,上記メタデータ付与支援装置230を利用するユーザとしては,情報資源サーバ210,端末装置220,およびメタデータ付与支援装置230の使用者全てが対象となる。例えば,情報資源サーバ210の管理者であれば,当該掲示情報を多くの人に利用してもらうためメタデータを付与し,端末装置220の利用者であれば,同じ趣味を有する他の利用者に興味を深めるような掲示情報を教えるためにメタデータを付与し,メタデータ付与支援装置230のオペレータは,自己の検索エンジンをより多くの人に利用してもらうためにメタデータを付与する。
As described above, all users of the
また,電子機器メーカの技術者や相談窓口のオペレータが取り扱った,製品に関する問題点や解決策をメタデータに関連付け,その掲示情報を公開することによって,他のメーカの技術者や同様の問題を抱える使用者が当該問題点や解決策を参照し易くすることもできる。このようにして,技術者としては問題および解決策の共有を図ることができ,また,製品の使用者がその製品の使い方が分からなかったときも,オペレータを介さずに使用方法を検索することが可能となる。 In addition, by associating product problems and solutions handled by electronic equipment manufacturer engineers and consulting service operators with metadata and publishing the posted information, other manufacturers' engineers and similar problems can be identified. It is possible to make it easier for a user to refer to the problem or solution. In this way, engineers can share problems and solutions, and even when users of a product do not know how to use the product, they can search for usage without going through the operator. Is possible.
上記情報資源サーバ210と,端末装置220と,メタデータ付与支援装置230は,サーバ,パーソナルコンピュータ,PDA(Personal Digital Assistant),携帯電話,ゲーム機器等の電子機器によって構成されるとしてもよい。
The
次に,上記メタデータ付与支援装置230について詳細に説明する。
Next, the metadata
図5は,第1の実施形態におけるメタデータ付与支援装置230の概略的な機能を示した機能ブロック図である。かかるメタデータ付与支援装置230は,掲示情報取得部300と,辞書保持部302と,単語抽出部304と,語彙体系保持部306と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とを含んで構成される。
FIG. 5 is a functional block diagram showing a schematic function of the metadata
上記掲示情報取得部300は,通信網200を介してユーザが所望する掲示情報350を取得する。かかる掲示情報350は,HTML(Hyper Text Markup Language)等のマークアップ言語で形成され,メタデータを付与する対象となる。
The bulletin
上記辞書保持部302は,形態素や接辞,接続情報,文法情報,同義語等の単語認識に関する辞書352が保持されている。かかる辞書352によると,後述する単語抽出部304で抽出された単語の品詞やその単語の意味も検出することができる。例えば,「東京」を地名と判断したり,「3000円払う」の「3000円」を述語「払う」との関係から金額と判断したりすることが可能となる。
The
上記単語抽出部304は,辞書保持部302に保持されている辞書352を参照して,掲示情報350の文書を特定するのに不要なタグを削除し,掲示情報350に含まれる文書を自然言語解析(形態素解析やかかり受け等の構文解析)により名詞と動詞の関連付けがされた形態素に分解し,例えば,「てにをは」等の,それら単独では意味をなさない文字も除去し,掲示情報350を表す[タイプ]としてのキーワードと,該キーワードの[属性値](例えば,人名,地名等の固有名詞)を表しうる単語とを抽出する。
The
上記語彙体系保持部306は,オントロジに基づいて,キーワードの[タイプ],その[タイプ]がどのような[属性]をとり,該[属性]における[属性値]としてどのような語彙を取りうるかの具体的な値,およびその制約に関して定義する語彙体系354を保持する。
Based on the ontology, the lexical
語彙体系354は,例えば,W3CのRDF(Resource Description Framework)やOWL(Web Ontology Language)等の記述言語で表されるとしてもよい。さらに語彙体系354は,他のオントロジ記述言語によって表されるとしてもよいし,単に[タイプ]−[属性]−[属性値]をデータベース化した表であってもよい。語彙体系354の概略的な定義は,図1によって既に説明されているので,ここでは詳細な説明を省略する。
The
また,上記制約とは,[属性値]の取りうる範囲もしくは制限を示し,例えば,「従業員の年齢」という[属性]に対して,15歳以上という制限を表す。こうして,単語抽出部304が抽出した単語に「3歳」という表現があったとしても,この制約によって,[属性値]の対象から「3歳」を除外することが可能となる。このような制約は,その範囲を限定すればするほど[属性値]を絞ることができるが,意図する[属性値]を検出できなくなる可能性も生じてくる。
Further, the restriction indicates a range or restriction that can be taken by the [attribute value], for example, a restriction of 15 years or older with respect to the [attribute] called “employee age”. In this way, even if the word extracted by the
その他の例としては,「パソコンの価格」という[属性]に対して,「パソコン3000円引き」という文書から抽出した「3000円」は価格としての妥当性を満たしていないので上記制約により除外される。「パソコンの価格」の[属性値]としては単語に「円」,「¥」,「$」が含まれる単語が優先的に抽出され,適切な単語が発見されなかった場合,数値のみの単語も[属性値]の対象となる。 As another example, “3,000 yen” extracted from the document “personal computer discount of 3000 yen” is excluded because of the above restrictions because of the attribute “personal computer price”, which is extracted from the document “personal computer discount of 3000 yen”. The [Attribute value] of "PC price" is a word that contains only "yen", "\", and "$" in the word, and if a suitable word is not found, only a numerical value Are also subject to [Attribute Value].
上記候補出力部308は,キーワードの候補と,該キーワードの属性値となるべき,単語抽出部304で抽出された単語の候補と,をユーザの有する情報資源サーバ210や端末装置220のモニタ,もしくは当該メタデータ付与支援装置230のモニタ356に出力(表示)する。
The
ここでは,掲示情報を表す[タイプ]としてのキーワードも候補を挙げて出力しているが,[タイプ]を掲示情報自体とすることもできる。このように[タイプ]を掲示情報自体とした場合,キーワードの候補を抽出する必要がなくなり,その出力を省略することができる。 Here, the keyword as [type] representing the bulletin information is also output with candidates, but [type] may be the bulletin information itself. Thus, when [Type] is the bulletin information itself, it is not necessary to extract keyword candidates, and the output can be omitted.
また,キーワードの各[属性]に関連付けるべき[属性値]としては,単語抽出部304で実際に抽出された文字列を単に取り上げるとしてもよいし,[属性値]として取りうるカテゴリ別に表されるとしてもよい。例えば,図1に示した[属性]「開催地」に対しては,具体的な「地名」や,その開催地を間接的に表現する「場所表現」が[属性値]のカテゴリに相当する。従って,[属性値]は,「東京都千代田区…番地」という「地名」もしくは「東京駅八重洲口徒歩3分」等の「場所表現」を選択することができる。
In addition, as the [attribute value] to be associated with each [attribute] of the keyword, a character string actually extracted by the
また,上記[属性値]として,予め選択範囲が定義されている場合,例えば,[属性]「対戦球団」としてチーム数が制限されている場合,候補出力部308は,[属性値]としてそのチーム全てを出力するとしてもよい。
In addition, when the selection range is defined in advance as the [attribute value], for example, when the number of teams is limited as [attribute] “matching team”, the
また,その[属性]の階層概念(上位概念や下位概念)が辞書352に含まれている場合,辞書352に含まれる階層概念のリストを[属性値]として出力することもできる。例えば,特定メーカの「テレビ」という[属性値]が挙がった場合,さらにそのメーカの「テレビ」の製品名や製品番号が辞書352から読み出され,それをメタデータの[属性値]の候補とすることが可能である。
In addition, if the
また,上記候補となる[タイプ]や[属性値]に同義語がある場合,その単語と,その単語の代表元となる単語とを合わせて出力するとしてもよい。この代表元に関しては後から詳述する。 Further, when there is a synonym in the above-mentioned candidate [type] or [attribute value], the word and the word representing the word may be output together. This representative will be described in detail later.
候補出力部308は,[属性値]の候補を見つけることができなかった場合,逆に,抽出された各単語を,[属性]に関連付けることもできる。例えば,[属性]「パソコンの値段」の属性値候補がない場合,抽出された単語から「119,800」という数字を取り出し,これを「119,800円」と読み替えて,[属性]「パソコンの値段」の属性値とする。
If the
上記メタデータ生成部310は,候補出力部308が出力した候補からユーザが選択した単語を[属性値]として設定し,[タイプ]としての上記キーワードおよび[属性]と対にして,メタデータ360を生成する。かかるメタデータ360は,1つの掲示情報に複数付与されるとしてもよい。
The
ここで,[属性値]が他に同義語を有し,その他の同義語が代表的な用語(代表元),例えばJIS規格による用語であった場合,選択された[属性値]を代表元となる用語に置き換えた後,メタデータ360が生成されるとしてもよい。上記同義語は,例えば,同じ単語を漢字,片仮名,仮名,ローマ字表記で表されたものであったり,長音の有無の違いであったりする。即ち,「コンピューター」を代表元の「コンピュータ」に置き換えたり,「ウォッチ」を代表元の「時計」に置き換えたりする。
Here, when [attribute value] has another synonym and the other synonym is a representative term (representative), for example, a term according to JIS standard, the selected [attribute value] is represented by the representative The
また,後述するようにメタデータ360の付与される分野が特定されている場合において,抽出された[属性値]と代表元とが関連付けやすくなる場合がある。[属性値]として「CD」という単語が抽出された場合,例えば,「Compact Disc」や「Cash Dispenser」の略語として把握できるが,分野が音楽に限定されている場合,「CD」を「Compact Disc」と同義語であると判断することができ,分野が金融に限定されている場合,「CD」を「Cash Dispenser」と同義語であると判断することができる。
In addition, as described later, when the field to which the
上記メタデータ保持部312は,メタデータ生成部310によって生成されたメタデータ360を保持する。このように保持された1または2以上のメタデータは,検索エンジンに参照され,該当するメタデータが付された掲示情報が検索結果として表示される。また,上記メタデータは,他のアプリケーションの要求に応じて出力される。例えば,カレンダーを作成するアプリケーションからは,日付に関するメタデータのみが呼び出され,カレンダー上にメタデータに関するイベントがその対応する日に表示される。出力形式としては,上述したRDFやOWLが挙げられる。
The
また,辞書保持部302,語彙体系保持部306,メタデータ保持部312は,RAM,E2PROM,不揮発性RAM,フラッシュメモリ,カードメモリ,USBメモリ,HDD(Hard Disk Drive),その他の記憶媒体で構成され,辞書保持部302と語彙体系保持部306とメタデータ保持部312とが一体のHDDで構成されるとしてもよい。
The
また,掲示情報取得部300,単語抽出部304,候補出力部308,メタデータ生成部310等は,コンピュータ内におけるモジュールとして形成されるとしても良く,その場合,メタデータ付与支援装置230を構成する中央処理装置(CPU),プログラムが記憶されるメモリ,および各入出力回路によって各機能が遂行されるとしてもよい。
In addition, the bulletin
以上,説明したように,上述したメタデータ付与支援装置230によって,公開されている掲示情報350に,その掲示情報350の記述内容を特徴付けるメタデータ360を付与することができる。メタデータ360は,その掲示情報を表す[タイプ]としてのキーワードに[属性]や[属性値]が付されているので,掲示情報350をより一層特徴付けることができ,検索対象の絞り込みが容易になる。また,上記[属性値]は,掲示情報350自体から抽出しているので,ユーザに[属性値]を選択させるという簡単な処理のみでメタデータ360を生成することが可能となる。以下に,かかるメタデータ付与支援装置230を利用してメタデータを付与する方法を述べる。
As described above, the
(メタデータ付与支援方法)
図6は,第1の実施形態におけるメタデータ付与支援方法の処理の流れを示したフローチャートであり,以下,図5の構成と併せて処理の流れについて説明する。
(Metadata grant support method)
FIG. 6 is a flowchart showing the processing flow of the metadata assignment support method according to the first embodiment. Hereinafter, the processing flow will be described together with the configuration of FIG.
先ず,メタデータ付与支援装置230の掲示情報取得部300は,通信網200を介して,HTTPプロトコルにより掲示情報350を取得する(S400)。そして,単語抽出部304は,辞書352を用いて,文書を特定するのに不要なタグ等を削除し,掲示情報350に含まれる文書を形態素解析や構文解析により形態素に分解し,掲示情報350を表すキーワードと,該キーワードの[属性値](例えば,人名,地名等の固有名詞)と成りうる単語とを抽出する(S402)。
First, the bulletin
続いて,候補出力部308は,語彙体系354の関連付けに従い,単語抽出ステップ(S402)で抽出されたキーワードの候補と,該キーワードの属性値となるべき,単語抽出部304で抽出された単語の候補とをリスト化し,その候補リストをメニュー形式で表すWeb文書を作成する(S404)。そして,そのWeb文書をユーザの有する端末のモニタ,もしくは当該メタデータ付与支援装置230のモニタ356に出力(表示)する(S406)。このときの表示形式はメニュー形式に限定されず,様々な選択形式を適用することができる。
Subsequently, the
次に,メタデータ生成部310は,ユーザが選択した単語を[属性値]として設定し,上記キーワードおよび[属性]と対,即ち,[タイプ]−[属性]−[属性値]の組にして,メタデータ360を生成する(S408)。最後に,メタデータ保持部312は,メタデータ生成部310によって生成されたメタデータ360を他の端末装置220から参照できる形で保存する(S410)。
Next, the
また,コンピュータに,上述のメタデータ付与支援方法を遂行させるプログラムや,そのプログラムを記憶した記憶媒体も提供される。 Also provided are a program for causing a computer to perform the above-described metadata assignment support method, and a storage medium storing the program.
第1の実施形態におけるメタデータ付与支援装置およびメタデータ付与支援方法によると,メタデータ付与対象となる掲示情報の文書を解析し,単純な「キーワード」だけでなく,その[属性]および[属性値]をも提示し,適切な[属性値]をユーザに選択させることによって,キーワードもしくは掲示情報自体の意味が限定され,例え掲示情報が異義語を含む場合であっても,その掲示情報を検出することなく,より正確な検索が可能となる。 According to the metadata grant support apparatus and metadata grant support method in the first embodiment, a document of bulletin information to be given metadata is analyzed, and not only a simple “keyword” but also its [attribute] and [attribute] Value] and allowing the user to select an appropriate [attribute value] to limit the meaning of the keyword or the posted information itself, even if the posted information includes a synonym. A more accurate search is possible without detection.
また,掲示情報を検出する側においても,キーワードに付随して[属性]および[属性値]を指定することにより,キーワードが異義語を含んでいたとしても意図している掲示情報を検出することが容易となる。 Also, the posting information detection side can detect the intended posting information even if the keyword includes a synonym by specifying [attribute] and [attribute value] along with the keyword. Becomes easy.
例えば,ユーザが,東京展示場で開催されている「イベント」が何であるかを検索したい場合,単に「イベント」とキーワードを入力するだけでなく,「イベント」([タイプ])の[属性]として「開催地」を選択し,さらに[属性値]として「東京展示場」を入力する。すると,「イベント」−「開催地」−「東京展示場」のメタデータで検索が行われ,検索結果として「イベント」としての「ユビキタス展示会」を容易に得ることができる(図3参照)。 For example, if the user wants to search for what “events” are held at the Tokyo exhibition hall, he / she does not just enter “events” and keywords, but also “attributes” of “events” ([type]). Select “Venue” as “Enter”, and enter “Tokyo Exhibition Hall” as “Attribute Value”. Then, a search is performed with the metadata of “event” − “venue” − “Tokyo exhibition hall”, and “ubiquitous exhibition” as “event” can be easily obtained as a search result (see FIG. 3). .
また,ユーザが「今開催中のイベント」と文書で検索した場合,検索エンジンは,かかる文書を解析して「今」という単語から現在の日付「1月1日」を導出し,「開催日」([属性])の[属性値]に「1月1日」を含む「イベント」([タイプ])を検索する。その結果,「開催日」が「2006年1月1日〜1月10日」である「イベント」の「ユビキタス展示会」が得られることとなる(図3参照)。 In addition, when the user searches for a document “currently held event”, the search engine analyzes the document, derives the current date “January 1” from the word “now”, "(Attribute)" is searched for "event" ([type]) including "January 1" in [attribute value]. As a result, an “Ubiquitous Exhibition” of “Event” whose “Date” is “January 1 to January 10, 2006” is obtained (see FIG. 3).
(第2の実施形態:メタデータ付与支援装置)
第1の実施形態においては,辞書352や語彙体系354は,単一のものとして表されている。しかし,当該掲示情報が利用される分野によっては,同義語の範囲が異なったり,語彙の上位下位概念が異なったりする場合がある。例えば,「モデル」という単語は,製造メーカにおいて,模型,ひな形等の意味で利用されるが,ファッション業界では,ファッションモデルといった意味で利用されている。
(Second Embodiment: Metadata Assignment Support Device)
In the first embodiment, the
以下に示す第2の実施形態においては,掲示情報にメタデータを付与する際,付与目的に応じて分野を区別し,その分野毎の辞書352や語彙体系354を選択し,このような付与目的の観点から当該分野においては重要と考えられる単語を抽出することによって,より容易にかつより掲示情報に相応しいメタデータを生成することが可能となる。
In the second embodiment described below, when metadata is added to the posting information, the fields are distinguished according to the purpose of assignment, a
第2の実施形態における分野は,例えば,「スポーツ」,「料理」,「学業」といったカテゴリ,その中の「野球」,「サッカー」といった競技,また,「ビジネス」,「趣味」といった目的等,様々に区別され得る。 The fields in the second embodiment include, for example, categories such as “sports”, “cooking”, and “school”, competitions such as “baseball” and “soccer”, and purposes such as “business” and “hobby”. , Can be distinguished in various ways.
図7は,第2の実施形態におけるメタデータ付与支援装置500の概略的な機能を示した機能ブロック図である。かかるメタデータ付与支援装置500は,掲示情報取得部300と,分野選択部510と,辞書保持部302と,単語抽出部304と,語彙体系保持部306と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とを含んで構成される。
FIG. 7 is a functional block diagram showing a schematic function of the metadata
第1の実施形態における構成要素として既に述べた掲示情報取得部300と,単語抽出部304と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とは,実質的に機能が同一なので重複説明を省略し,ここでは,構成が相違する分野選択部510と,辞書保持部302と,語彙体系保持部306とを主に説明する。
The bulletin
上記分野選択部510は,掲示情報取得部300が取得した掲示情報に応じて,選択可能な分野を導出し,ユーザに所望の分野を選択させる。また,掲示情報を解析すること無しに,ユーザに特定の分野を入力させることもできる。
The
上記辞書保持部302は,形態素や接辞,接続情報,文法情報,同義語等の単語認識に関する分野毎の辞書352が複数保持され,単語抽出部304は,分野選択部510によって選択させた分野の辞書352を参照し,掲示情報350を表すキーワードと該キーワードの[属性値](例えば,人名,地名等の固有名詞)を表しうる単語とを抽出する。
The
上記語彙体系保持部306は,分野毎の語彙体系354を複数保持し,候補出力部308は,分野選択部510によって選択させた分野の語彙体系354に従って,キーワードと,キーワードの[属性値]となるべき,単語抽出部304で抽出された単語の候補とを出力(表示)する。
The lexical
上記語彙体系354は,分野やカテゴリ毎にその語彙の体系が相違する場合がある。このような場合,その分野毎の語彙体系を適用した方がより精度の高いメタデータ360を生成しうる。かかる構成では,メタデータ360を付与するユーザに所望の分野を選択させ,その分野の語彙体系354を利用することによって,その分野に特化した語彙を抽出でき,検索に適したメタデータ360を生成することが可能となる。
The
続いて,ユーザの所望する分野を,ユーザに選択させる代わりに,ユーザの操作履歴によって推定する構成を説明する。 Next, a configuration will be described in which the user's desired field is estimated based on the user's operation history instead of the user selecting.
図8は,第2の実施形態の他の例におけるメタデータ付与支援装置500の概略的な機能を示した機能ブロック図である。かかるメタデータ付与支援装置500は,掲示情報取得部300と,所望分野推定部520と,辞書保持部302と,単語抽出部304と,語彙体系保持部306と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とを含んで構成される。
FIG. 8 is a functional block diagram showing a schematic function of the metadata
第1の実施形態における構成要素として既に述べた掲示情報取得部300と,単語抽出部304と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とは,実質的に機能が同一なので重複説明を省略し,ここでは,構成が相違する所望分野推定部520と,辞書保持部302と,語彙体系保持部306とを主に説明する。
The bulletin
上記所望分野推定部520は,ユーザの当該メタデータ付与支援装置500への操作履歴,例えば,過去において参照した掲示情報の履歴,アクセス数の多い掲示情報の分野や指定される回数の多い分野からユーザの所望する分野を推定する。
The desired
上記辞書保持部302は,分野毎の辞書352が複数保持され,単語抽出部304は,所望分野推定部520によって推定させた分野の辞書352を参照し,掲示情報350を表すキーワードと該キーワードの[属性値](例えば,人名,地名等の固有名詞)を表しうる単語とを抽出する。
The
上記語彙体系保持部306は,分野毎の語彙体系354を複数保持し,候補出力部308は,所望分野推定部520によって推定させた分野の語彙体系354に従って,キーワードと,キーワードの[属性値]となるべき,単語抽出部304で抽出された単語の候補とを出力(表示)する。
The lexical
かかる構成では,ユーザの当該メタデータ付与支援装置500への操作履歴を保持し,アクセス数の多い掲示情報350の分野や指定される回数の多い分野を推定し,その推定された分野の語彙体系354を利用することによって,その分野に特化した語彙を抽出でき,検索に適したメタデータ360を生成することが可能となる。
In such a configuration, the user's operation history of the metadata
続いて,上記分野を,ユーザの操作履歴によって推定する代わりに,単語抽出部304により抽出された単語に基づいて,メタデータ付与支援装置500側で推定する構成を説明する。
Next, a description will be given of a configuration in which the above-mentioned field is estimated on the side of the metadata providing
図9は,第2の実施形態の他の例におけるメタデータ付与支援装置500の概略的な機能を示した機能ブロック図である。かかるメタデータ付与支援装置500は,掲示情報取得部300と,辞書保持部302と,単語抽出部304と,掲示分野推定部530と,語彙体系保持部306と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とを含んで構成される。
FIG. 9 is a functional block diagram showing a schematic function of the metadata
第1の実施形態における構成要素として既に述べた掲示情報取得部300と,辞書保持部302と,単語抽出部304と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とは,実質的に機能が同一なので重複説明を省略し,ここでは,構成が相違する掲示分野推定部530と,語彙体系保持部306とを主に説明する。
The bulletin
上記掲示分野推定部530は,単語抽出部304が抽出した単語に基づいて,掲示情報が属する分野を推定する。
The posting
上記語彙体系保持部306は,分野毎の語彙体系354を複数保持し,候補出力部308は,掲示分野推定部530によって推定させた分野の語彙体系354に従って,キーワードと,キーワードの[属性値]となるべき,単語抽出部304で抽出された単語の候補とを出力(表示)する。
The lexical
かかる構成では,掲示情報から抽出された1または2以上の単語から当該掲示情報の分野を自動的に推定し,その推定された分野の語彙体系354を利用することによって,その分野に特化した語彙を抽出でき,検索に適したメタデータ360を生成することが可能となる。
In such a configuration, the field of the posted information is automatically estimated from one or more words extracted from the posted information, and the
上記第2の実施形態によると,掲示情報を検索する上での分野を選択することにより,異義語による誤検出,所謂「誤爆」を削減することができ,不要な候補を検出することが少なくなるため,所望の掲示情報がより一層検出され易くなる。また,分野毎に同義語の定義や代表する単語が異なるため,掲示情報の原文では同一語句であってもメタデータの段階で異なる語句として表現され,さらに誤爆を回避することができる効果がある。 According to the second embodiment, by selecting a field for searching bulletin information, it is possible to reduce false detection by a synonym, so-called “misexplosion”, and to detect unnecessary candidates. Therefore, it becomes easier to detect desired bulletin information. Also, because synonym definitions and representative words are different for each field, even the same phrase in the original posted information is expressed as a different phrase at the metadata stage, and it is possible to avoid false explosions. .
(第3の実施形態:メタデータ付与支援装置)
第3の実施形態におけるメタデータ付与支援装置は,ユーザによるメタデータ360の付与にインセンティブを与えて,メタデータ360の付与の促進を図り,ひいてはメタデータ360が付与された掲示情報の数を増大させる。また,このような付与されたメタデータを用いることにより,プログラム等が自動的に情報の内容を解釈して何かしらの処理を行うことが可能な掲示情報が増大することも期待できる。
(Third Embodiment: Metadata Assignment Support Device)
The metadata grant support apparatus according to the third embodiment gives an incentive to the grant of
図10は,第3の実施形態におけるメタデータ付与支援装置600の概略的な機能を示した機能ブロック図である。かかるメタデータ付与支援装置600は,掲示情報取得部300と,辞書保持部302と,単語抽出部304と,語彙体系保持部306と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312と,条件保持部610と,追加通知部612とを含んで構成される。
FIG. 10 is a functional block diagram showing a schematic function of the metadata
第1の実施形態における構成要素として既に述べた掲示情報取得部300と,辞書保持部302と,単語抽出部304と,語彙体系保持部306と,候補出力部308と,メタデータ生成部310と,メタデータ保持部312とは,実質的に機能が同一なので重複説明を省略し,ここでは,構成が相違する条件保持部610と,追加通知部612とを主に説明する。
The bulletin
上記条件保持部610は,ユーザの所望する分野もしくはメタデータの条件を保持する。ユーザがメタデータ付与支援装置600に対して,特定のメタデータ,例えば「イベント」−「開催地」−「東京展示場」を,ユーザを特定するID等やユーザへの通知先と合わせて登録する。かかる登録は,メタデータを列挙して行われてもよいし,[タイプ]−[属性]のみ,[タイプ]のみ,分野のみによって行うとしても良く,[タイプ],[属性],[属性値]の上位概念,例えば,「スキー」および「スノーボード」を合わせて「ウィンタースポーツ」として行ってもよい。さらに,分野,[タイプ],[属性],[属性値]何れかの論理和や論理積をとって条件とすることも可能である。
The
また,ユーザが任意の掲示情報に対してメタデータを付与したとき,メタデータ付与支援装置600が自動的に付与されたメタデータを,メタデータの条件として条件保持部610に登録するとしてもよい。通常,ユーザは興味ある掲示情報に対してメタデータを付与する。上記の構成において,ユーザは,メタデータを付与すると同時に,興味あるメタデータを条件保持部610に登録することができる。
Further, when the user assigns metadata to arbitrary posted information, the metadata
上記追加通知部612は,条件保持部610に保持された条件を満たすメタデータが,他のユーザによってメタデータ保持部に追加された場合,上記登録されているユーザにその旨を通知する。例えば,上記の「イベント」−「開催地」−「東京展示場」のメタデータが,特定のユーザの条件として条件保持部610に登録されている場合に,他のユーザが同じメタデータを掲示情報に付与すると,その旨を,メタデータを登録しているユーザに通知し,ユーザの所望する掲示情報の登録があったことを伝達して,そのユーザに掲示情報の閲覧を勧める。かかる通知は,キーワードとその掲示情報を示すURL(Uniform Resource Locator)とを含むとしてもよい。
When the metadata that satisfies the condition held in the
以下に,かかるメタデータ付与支援装置600を利用してメタデータを付与する方法を述べる。
A method for assigning metadata using the metadata
(メタデータ付与支援方法)
図11は,第3の実施形態におけるメタデータ付与支援方法の処理の流れを示したフローチャートであり,以下,図10の構成と併せて処理の流れについて説明する。
(Metadata grant support method)
FIG. 11 is a flowchart showing the processing flow of the metadata assignment support method according to the third embodiment. The processing flow will be described below together with the configuration of FIG.
当該メタデータ付与支援方法の前提として,条件保持部610により,ユーザの所望する分野もしくはメタデータの条件が登録されているものとする。
As a premise of the metadata providing support method, it is assumed that the
先ず,メタデータ付与支援装置600の掲示情報取得部300は,通信網200を介して,HTTPプロトコルにより掲示情報350を取得する(S700)。そして,単語抽出部304は,文書を特定するのに不要なタグ等を削除し,掲示情報350に含まれる文書を形態素解析や構文解析により形態素に分解し,掲示情報350を特定するキーワードと,辞書352に定義された,該キーワードの[属性値](例えば,人名,地名等の固有名詞)を表しうる単語とを抽出する(S702)。
First, the posting
続いて,候補出力部308は,語彙体系354の関連付けに従い,単語抽出ステップ(S702)で抽出されたキーワードの候補と,該キーワードの属性値となるべき,単語抽出部304で抽出された単語の候補とをリスト化し,その候補リストをメニュー形式で表すWeb文書を作成する(S704)。そして,そのWeb文書をユーザの有する端末のモニタ,もしくは当該メタデータ付与支援装置230のモニタ356に出力(表示)する(S706)。このときの表示形式はメニュー形式に限定されず,様々な選択形式を適用することができる。
Subsequently, the
次に,メタデータ生成部310は,ユーザが選択した単語を[属性値]として設定し,上記キーワードおよび[属性]と対,即ち,[タイプ]−[属性]−[属性値]の組にして,メタデータ360を生成する(S708)。そして,メタデータ保持部312は,メタデータ生成部310によって生成されたメタデータ360を他の端末装置220から参照できる形で保存する(S710)。
Next, the
続いて,追加通知部612は,メタデータ生成部310によって生成されたメタデータを,条件保持部610に他のユーザが登録したメタデータの条件と比較する(S712)。この比較は,メタデータの条件に応じて行われ,単にメタデータが列挙されている場合は,そのメタデータとの完全一致を判断し,上位概念や論理計算を伴う場合はその演算も含んで判断される。上記比較した結果,同じメタデータが存在すれば,そのメタデータを登録しているユーザにその旨通知する(S714)。
Subsequently, the
また,コンピュータに,上述のメタデータ付与支援方法を遂行させるプログラムや,そのプログラムを記憶した記憶媒体も提供される。 Also provided are a program for causing a computer to perform the above-described metadata assignment support method, and a storage medium storing the program.
以上,説明したように,ユーザは,所望する分野やメタデータを指定(登録)することによって,その指定した分野やメタデータが他のユーザによって掲示情報に付与された場合,そのような掲示情報が追加された旨,及び/又はその追加された掲示情報自体を得ることができる。各ユーザは,自分の関心が高い分野について,他のユーザからの独自かつ新規に公表された情報の情報提供を受けるため,また,他のユーザに情報を提供するため,率先して当該メタデータ付与支援装置を利用することとなり,ひいては掲示情報のメタデータ付与化が促進される。このように多くの掲示情報にメタデータが付与されることで,システム全体の効用が増し,ユーザにとってより使いやすいシステムの構築がなされる。 As described above, when a user designates (registers) a desired field or metadata so that the designated field or metadata is added to the posted information by another user, such posted information Can be obtained and / or the added bulletin information itself. Each user takes the initiative to receive information about the fields that they are interested in in order to receive information provided by other users on their own and newly published information, and to provide information to other users. As a result, the use of the grant support device is promoted, so that the posting information can be given metadata. By adding metadata to such a large amount of bulletin information, the utility of the entire system is increased, and a system that is easier to use for the user is constructed.
以上,添付図面を参照しながら本発明の好適な実施形態について説明したが,本発明は係る例に限定されないことは言うまでもない。当業者であれば,特許請求の範囲に記載された範疇内において,各種の変更例または修正例に想到し得ることは明らかであり,それらについても当然に本発明の技術的範囲に属するものと了解される。 As mentioned above, although preferred embodiment of this invention was described referring an accompanying drawing, it cannot be overemphasized that this invention is not limited to the example which concerns. It will be apparent to those skilled in the art that various changes and modifications can be made within the scope of the claims, and these are naturally within the technical scope of the present invention. Understood.
例えば,上記実施形態においては,掲示情報の作成者とメタデータの付与者とを別人として表しているが,かかる場合に限られず,例えば,資源情報サーバとメタデータ付与支援装置とを一体に形成し,掲示情報を作成した時に併せてメタデータを付与することもできる。 For example, in the above-described embodiment, the creator of the posting information and the creator of the metadata are represented as different persons. However, the present invention is not limited to such a case. For example, the resource information server and the metadata providing support device are integrally formed. In addition, metadata can be added together with the posting information.
また,上記実施形態においては,メタデータを保持するメタデータ保持部をメタデータ付与支援装置内に設けているが,別体に設けるとしても良く,また,複数のメタデータDBを設けて,定期的にメタデータの同期をとるように構成することも可能である。 In the above embodiment, the metadata holding unit for holding the metadata is provided in the metadata assignment support apparatus. However, the metadata holding unit may be provided separately, and a plurality of metadata DBs may be provided for regular use. It is also possible to configure to synchronize metadata.
また,上記実施形態においては,単語抽出部において不要なタグを削除しているが,逆にこのタグを利用して,特定のタグ内にある単語を特定の条件で抽出するようにすることもできる。例えば,HTMLやXMLのヘッダタグを優先的にキーワードとして取り扱うことも可能である。 In the above embodiment, unnecessary tags are deleted in the word extraction unit. Conversely, it is also possible to extract words in a specific tag using a specific condition using this tag. it can. For example, it is possible to preferentially handle HTML or XML header tags as keywords.
また,上記実施形態においては,理解を容易にするため,インターネット上の掲示情報に限定して説明しているが,かかる場合に限られず,対応する文書が存在するWebサービスや,その他の電子的なドキュメントに適用することもできる。また,無体物でない例えば物品であっても,その物品を説明する文書および位置情報を利用するサービスで,必要な条件を満足する物品を検索するシステムにも適用可能である。 In the above embodiment, the description is limited to the posted information on the Internet in order to facilitate understanding. However, the present invention is not limited to this, and the Web service in which the corresponding document exists or other electronic information is described. It can also be applied to other documents. Further, even for an article that is not an intangible, for example, it can be applied to a system that searches for an article that satisfies a necessary condition with a service that uses a document and position information describing the article.
また,対象となる掲示情報は,日本語に限られず,本発明は,アルファベットやハングル等様々な言語に対応することができる。 Further, the target bulletin information is not limited to Japanese, and the present invention can deal with various languages such as alphabet and Korean.
さらに,上記実施形態においては,分野毎の複数の語彙体系を同階層に配しているが,分野を階層的に表すこともできる。例えば,「スポーツ」という分野の語彙体系の下の階層に「野球」の語彙体系を配置することが考えられる。このとき,状況に応じて,適用範囲を制限することも可能である。 Furthermore, in the above embodiment, a plurality of vocabulary systems for each field are arranged in the same hierarchy, but fields can also be represented hierarchically. For example, a vocabulary system of “baseball” may be arranged in a hierarchy below the vocabulary system of the field “sports”. At this time, it is possible to limit the application range according to the situation.
また,上記の実施形態においては,検索エンジンを例に挙げて各構成を説明したが,オントロジや語彙体系の考え方は他のアプリケーションにも適応可能であり,例えば,電子カレンダー,スケジューラ等のリンク付けにも使用することができる。例えば,イベント等の掲示情報に対するメタデータの[属性]として開催日等がある場合,カレンダーやスケジューラ等において,該当日に関連するイベントの情報を表示することにより,外部の情報と効率よく連携して,該情報を取り込むことができる。また,該メタデータを解釈し得る入出力機構をアプリケーション側に持たせることで,そのテーマや分野の属性を用い,興味ある分野のイベント情報だけを表示するアプリケーションを構成する等,様々な処理が容易に実行できる。 In the above embodiment, each configuration has been described by taking a search engine as an example. However, the concept of ontology and vocabulary can be applied to other applications, for example, a link such as an electronic calendar and a scheduler. Can also be used. For example, if there is a date etc. as metadata [attribute] for posted information such as events, the event information related to the relevant date is displayed in the calendar or scheduler, etc., so that it can be efficiently linked with external information. Thus, the information can be captured. In addition, by providing the application with an input / output mechanism that can interpret the metadata, various processes such as configuring an application that displays only the event information of the field of interest using the attributes of the theme and field. Easy to implement.
なお,本明細書のメタデータ付与支援方法における各工程は,必ずしもフローチャートとして記載された順序に沿って時系列に処理する必要はなく,並列的あるいは個別に実行される処理(例えば,並列処理あるいはオブジェクトによる処理)も含むとしてもよい。 Note that the steps in the metadata assignment support method of the present specification do not necessarily have to be processed in chronological order in the order described in the flowchart, but are performed in parallel or individually (for example, parallel processing or Object processing) may also be included.
230,500,600 メタデータ付与支援装置
304 単語抽出部
306 語彙体系保持部
308 候補出力部
310 メタデータ生成部
312 メタデータ保持部
354 語彙体系
510 分野選択部
520 所望分野推定部
530 掲示分野推定部
610 条件保持部
612 追加通知部
230, 500, 600 Metadata
Claims (7)
掲示情報に含まれる文書から自然言語解析により単語を抽出する単語抽出部と;
オントロジに基づく語彙体系を保持する語彙体系保持部と;
前記語彙体系に定義された関連付けに従い,キーワードと,該キーワードの属性値となるべき,前記単語抽出部で抽出された単語の候補とを出力する候補出力部と;
前記キーワード,属性,前記候補からユーザが選択した単語を対にしたメタデータを生成するメタデータ生成部と;
前記生成されたメタデータを保持するメタデータ保持部と;
を備えることを特徴とする,情報収集装置。 Connected to the communication network,
A word extraction unit for extracting words from a document included in the posted information by natural language analysis;
A vocabulary holding unit that holds an ontology-based vocabulary;
A candidate output unit that outputs a keyword and a word candidate extracted by the word extraction unit, which should be an attribute value of the keyword, according to the association defined in the vocabulary system;
A metadata generation unit that generates metadata paired with a word selected by the user from the keywords, attributes, and candidates;
A metadata holding unit for holding the generated metadata;
An information collecting apparatus comprising:
前記語彙体系保持部は,分野毎に設けられた複数の語彙体系を含み,
前記候補出力部は,前記分野選択部によりユーザが選択した分野の語彙体系に従い,属性値の候補を出力することを特徴とする,請求項1に記載の情報収集装置。 A field selection unit that allows the user to select a desired field;
The vocabulary system holding unit includes a plurality of vocabulary systems provided for each field,
The information collection device according to claim 1, wherein the candidate output unit outputs attribute value candidates according to a vocabulary system of a field selected by a user by the field selection unit.
前記語彙体系保持部は,分野毎に設けられた複数の語彙体系を含み,
前記候補出力部は,前記推定された分野の語彙体系に従い,属性値の候補を出力することを特徴とする,請求項1に記載の情報収集装置。 A desired field estimation unit for estimating a field desired by the user from an operation history of the user on the information collection device;
The vocabulary system holding unit includes a plurality of vocabulary systems provided for each field,
The information collection apparatus according to claim 1, wherein the candidate output unit outputs attribute value candidates according to a lexical system of the estimated field.
前記語彙体系保持部は,分野毎に設けられた複数の語彙体系を含み,
前記候補出力部は,前記推定された分野の語彙体系に従い,属性値の候補を出力することを特徴とする,請求項1に記載の情報収集装置。 A posting field estimation unit for estimating a field to which the posting information belongs based on the word extracted by the word extraction unit;
The vocabulary system holding unit includes a plurality of vocabulary systems provided for each field,
The information collection apparatus according to claim 1, wherein the candidate output unit outputs attribute value candidates according to a lexical system of the estimated field.
前記条件を満たすメタデータが,他のユーザによってメタデータ保持部に追加された場合,前記ユーザにその旨通知する追加通知部と;
をさらに備えることを特徴とする,請求項1〜4のいずれかに記載の情報収集装置。 A condition holding unit for holding metadata conditions desired by the user;
An additional notification unit for notifying the user when metadata satisfying the condition is added to the metadata holding unit by another user;
The information collection device according to claim 1, further comprising:
オントロジに基づく語彙体系に定義された関連付けに従い,キーワードと,該キーワードの属性値となるべき,前記単語抽出ステップにより抽出された単語の候補とを出力する候補出力ステップと;
前記キーワード,属性,前記候補からユーザが選択した単語を対にしたメタデータを生成するメタデータ生成ステップと;
前記生成されたメタデータを保持するメタデータ保持ステップと;
を含むことを特徴とする,情報収集方法。 A word extraction step of extracting words from the document included in the posted information by natural language analysis;
A candidate output step for outputting a keyword and a word candidate extracted by the word extraction step, which should be an attribute value of the keyword, in accordance with the association defined in the ontology-based vocabulary system;
A metadata generation step of generating metadata in which a word selected by the user from the keyword, attribute, and candidate is paired;
A metadata holding step for holding the generated metadata;
An information collection method characterized by including:
掲示情報に含まれる文書から自然言語解析により単語を抽出する単語抽出ステップと;
オントロジに基づく語彙体系に定義された関連付けに従い,キーワードと,該キーワードの属性値となるべき,前記単語抽出ステップにより抽出された単語の候補とを出力する候補出力ステップと;
前記キーワード,属性,前記候補からユーザが選択した単語を対にしたメタデータを生成するメタデータ生成ステップと;
前記生成されたメタデータを保持するメタデータ保持ステップと;
を実行させることを特徴とする,プログラム。 Computer
A word extraction step of extracting words from the document included in the posted information by natural language analysis;
A candidate output step for outputting a keyword and a word candidate extracted by the word extraction step, which should be an attribute value of the keyword, in accordance with the association defined in the ontology-based vocabulary system;
A metadata generation step of generating metadata in which a word selected by the user from the keyword, attribute, and candidate is paired;
A metadata holding step for holding the generated metadata;
A program characterized by running
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006013035A JP2007193697A (en) | 2006-01-20 | 2006-01-20 | Information collection apparatus, information collection method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006013035A JP2007193697A (en) | 2006-01-20 | 2006-01-20 | Information collection apparatus, information collection method and program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2007193697A true JP2007193697A (en) | 2007-08-02 |
Family
ID=38449335
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006013035A Pending JP2007193697A (en) | 2006-01-20 | 2006-01-20 | Information collection apparatus, information collection method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2007193697A (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007249907A (en) * | 2006-03-20 | 2007-09-27 | Nippon Hoso Kyokai <Nhk> | Knowledge metadata generation device and knowledge metadata generation program |
| JP2010026996A (en) * | 2008-07-24 | 2010-02-04 | Nippon Telegr & Teleph Corp <Ntt> | Tag attachment support method and its device, program, and recording medium |
| JP2010079812A (en) * | 2008-09-29 | 2010-04-08 | Oki Electric Ind Co Ltd | Apparatus and method for identifying location representation, and program |
| JP5315485B1 (en) * | 2012-06-27 | 2013-10-16 | 楽天株式会社 | Information processing apparatus, information processing method, and information processing program |
| JP5341276B1 (en) * | 2012-06-27 | 2013-11-13 | 楽天株式会社 | Information processing apparatus, information processing method, and information processing program |
| US10311867B2 (en) | 2015-03-20 | 2019-06-04 | Kabushiki Kaisha Toshiba | Tagging support apparatus and method |
| US11907239B2 (en) | 2019-12-27 | 2024-02-20 | Fujifilm Business Innovation Corp. | Information processing apparatus and non-transitory computer readable medium storing computer program |
-
2006
- 2006-01-20 JP JP2006013035A patent/JP2007193697A/en active Pending
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007249907A (en) * | 2006-03-20 | 2007-09-27 | Nippon Hoso Kyokai <Nhk> | Knowledge metadata generation device and knowledge metadata generation program |
| JP4709671B2 (en) * | 2006-03-20 | 2011-06-22 | 日本放送協会 | Knowledge metadata generation apparatus and knowledge metadata generation program |
| JP2010026996A (en) * | 2008-07-24 | 2010-02-04 | Nippon Telegr & Teleph Corp <Ntt> | Tag attachment support method and its device, program, and recording medium |
| JP2010079812A (en) * | 2008-09-29 | 2010-04-08 | Oki Electric Ind Co Ltd | Apparatus and method for identifying location representation, and program |
| JP5315485B1 (en) * | 2012-06-27 | 2013-10-16 | 楽天株式会社 | Information processing apparatus, information processing method, and information processing program |
| JP5341276B1 (en) * | 2012-06-27 | 2013-11-13 | 楽天株式会社 | Information processing apparatus, information processing method, and information processing program |
| WO2014002549A1 (en) * | 2012-06-27 | 2014-01-03 | 楽天株式会社 | Information processing device, information processing method, and information processing program |
| US10311867B2 (en) | 2015-03-20 | 2019-06-04 | Kabushiki Kaisha Toshiba | Tagging support apparatus and method |
| US11907239B2 (en) | 2019-12-27 | 2024-02-20 | Fujifilm Business Innovation Corp. | Information processing apparatus and non-transitory computer readable medium storing computer program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11023513B2 (en) | Method and apparatus for searching using an active ontology | |
| KR101506380B1 (en) | Infinite browse | |
| US10235681B2 (en) | Text extraction module for contextual analysis engine | |
| JP4365074B2 (en) | Document expansion system with user-definable personality | |
| US9990422B2 (en) | Contextual analysis engine | |
| US10430806B2 (en) | Input/output interface for contextual analysis engine | |
| US9846720B2 (en) | System and method for refining search results | |
| US8001135B2 (en) | Search support apparatus, computer program product, and search support system | |
| Hyvönen | Semantic portals for cultural heritage | |
| US10762140B2 (en) | Identifying content in a content management system relevant to content of a published electronic document | |
| JPH1166081A (en) | Profile acquisition system, information provision system, profile acquiring method and medium | |
| JP2007193697A (en) | Information collection apparatus, information collection method and program | |
| JP2007072646A (en) | Retrieval device, retrieval method, and program therefor | |
| Rodrigues et al. | Advanced applications of natural language processing for performing information extraction | |
| JP2011154739A (en) | Method and system for providing document search service | |
| Fauzi et al. | Image understanding and the web: a state-of-the-art review | |
| US8195458B2 (en) | Open class noun classification | |
| Tabarcea et al. | Framework for location-aware search engine | |
| KR20050045650A (en) | Information suppling system and method with info-box | |
| JP5187187B2 (en) | Experience information search system | |
| KR101124213B1 (en) | system of customized news-later service using ontology | |
| KR101628511B1 (en) | Search Engine Optimization and Server thereof | |
| JP7323484B2 (en) | Information processing device, information processing method, and program | |
| KR102625347B1 (en) | A method for extracting food menu nouns using parts of speech such as verbs and adjectives, a method for updating a food dictionary using the same, and a system for the same | |
| Veeraiah et al. | A novel approach for extraction and representation of main data from web pages to android application |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090303 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20090804 |