JP2005293582A - 複合語を構成する単語を割り出す装置及びコンピュータ化された方法 - Google Patents
複合語を構成する単語を割り出す装置及びコンピュータ化された方法 Download PDFInfo
- Publication number
- JP2005293582A JP2005293582A JP2005095536A JP2005095536A JP2005293582A JP 2005293582 A JP2005293582 A JP 2005293582A JP 2005095536 A JP2005095536 A JP 2005095536A JP 2005095536 A JP2005095536 A JP 2005095536A JP 2005293582 A JP2005293582 A JP 2005293582A
- Authority
- JP
- Japan
- Prior art keywords
- word
- documents
- compound
- constituent
- words
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/268—Morphological analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【解決手段】 構成単語は、複合語を構成する。構成単語が分割判断基準を満たすとき、構成単語はバラバラに用いることができる。バラバラの構成単語は、検索おいて、文書の集合体から関連する文書を検索するのに用いられる。
【選択図】 図3
Description
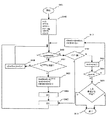
本システムの仕組みを説明するために、複合語内で分割判断基準を満たす構成単語を判断する具体例をいくつか紹介する。
第一の具体例において、検索はオランダ語の項目ti:「basketbalkampioenschappen」を含む。ここで、i=1である。英語訳は「basketball championships(バスケットボール選手権)」である。分割複合判断モジュール(202)は、文書の集合体から引き出したすべての名詞を含む単語リストを用いて複合語を構成するすべての構成名詞を見つけ出す。一例として図6の単語リストが用いられる。この単語リストの第1列は、文書の集合体において利用可能なすべての名詞をアルファベット順に含む。第2列は、各名詞について、文書の集合体の中でその名詞を含むすべての参照文書を含む。第3列は、文書の集合体の中でその名詞を含む文書の数を含む。単語リストの一実施形態として、最初の2列だけを含むものとしてもよい。第3列は、第2列から求めることができる。当業者には明らかなように、単語リストは、第3列などの追加的情報で拡張することも、或いは、動詞などの他の単語種類も含み、名詞は名詞インジケータで示すようにすることも可能である。当業者には図6から明らかなように、複合語ti(第1列)を含む文書数(第3列)は、この単語リストから求めることができる。
(「basketbal」AND「kampioenschappen」)
となる。ここで、例えば、
(「basketbal」AND「kampioenschappen」)OR「basketbalkampioenschappen」
も妥当である。
ここでは、オランド語の例を挙げて、複合語tiの構成単語がステップ303においてどのように見つけ出されるのかを説明する。この単語の英語訳は「course of life(人生航路)」である。
別の例を挙げる。
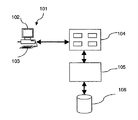
102 ディスプレイ
103 キーボード
104 検索エンジン・フロントエンド
105 検索エンジン
106 文書データベース
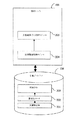
201 文書収集
202 意味ネットワーク
203 単語リスト
204 分割複合判断モジュール
205 文書検索・ランク付けモジュール
Claims (22)
- 文書の集合体と、
前記文書の集合体の中で複合語を含む文書の数を割り出す手段と、
前記文書の集合体の中で前記複合語を構成する構成単語を含む文書の数を割り出す手段とを有する複合語の構成単語を割り出す装置であって、
前記複合語を含む文書の数と前記複合語を構成する構成単語を含む文書の数との比を求める手段と、
前記比が閾値より小さいときに前記複合語を前記構成単語に分割する手段と、を有することを特徴とする装置。 - 請求項1記載の装置であって、
前記複合語中の結合形態素を検出する手段を更に有する、ことを特徴とする装置。 - 請求項1記載の装置であって、
前記文書の集合体から求めた単語リストと、
前記単語リストを用いることによって前記構成単語を見つける手段とを更に有する、ことを特徴とする装置。 - 請求項1記載の装置であって、
前記文書の集合体から求めた単語リストと、
前記単語リストから前記複合語を含む文書の数を求める手段とを更に有する、ことを特徴とする装置。 - 請求項1記載の装置であって、
前記文書の集合体から求めた単語リストと、
前記単語リストから前記複合語を構成する構成単語を含む文書の数を求める手段とを更に有する、ことを特徴とする装置。 - 請求項1記載の装置であって、
前記閾値は前記文書の集合体に依存する、ことを特徴とする装置。 - 請求項1記載の装置であって、
前記閾値は3である、ことを特徴とする装置。 - 請求項1乃至7のいずれか一項記載の装置であって、
前記複合語及び前記構成単語は、文法上、名詞に属する、ことを特徴とする装置。 - 請求項8記載の装置であって、
前記単語リストは、各単語の単数形及び複数形を含む、ことを特徴とする装置。 - 情報検索システムであって、
単語を含む検索項目を入力する手段と、
前記単語を分割する手段とを有し、
前記2つの手段は、
請求項1乃至9のいずれか一項記載の装置を組み込んでおり、
構成単語を伝達し、
本システムは、更に、前記伝達された構成単語を検索項目として検索を実行する手段を有する、ことを特徴とするシステム。 - 文書の集合体の中で複合語を含む文書の数を割り出す工程と、
前記文書の集合体の中で前記複合語を構成する構成単語を含む文書の数を割り出す工程とを有する複合語の構成単語を割り出すコンピュータ化された方法であって、
前記複合語を含む文書の数と前記複合語を構成する構成単語を含む文書の数との比を求める工程と、
前記比が閾値より小さいときに前記複合語を前記構成単語に分割する工程と、を有することを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
前記複合語中の結合形態素を検出する工程を更に有する、ことを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
単語リストを用いることによって前記構成単語を見つける工程を更に有する、ことを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
単語リストから前記複合語を含む文書の数を求める工程を更に有する、ことを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
単語リストから前記複合語を構成する構成単語を含む文書の数を求める工程を更に有する、ことを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
オペレータによって検索を入力する工程を更に有する、ことを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
前記閾値を前記文書の集合体に応じて選択する工程を更に有する、ことを特徴とする方法。 - 請求項11記載のコンピュータ化された方法であって、
前記閾値は3である、ことを特徴とする方法。 - 請求項11乃至18のいずれか一項記載のコンピュータ化された方法であって、
前記複合語及び前記構成単語は、文法上、名詞に属する、ことを特徴とする方法。 - 請求項19記載のコンピュータ化された方法であって、
前記単語リストは、各単語の単数形及び複数形を含む、ことを特徴とする方法。 - 情報を検索するコンピュータ化された方法であって、
単語を含む検索項目を入力する工程と、
前記単語を請求項11乃至20のいずれか一項記載の方法に従って分割する工程と、
構成単語を伝達する工程と、
前記伝達された構成単語を検索項目として検索を実行する工程とを有する、ことを特徴とする方法。 - コンピュータ上で実行されたときに請求項11記載のすべての工程を実行するコード手段を含むことを特徴とするコンピュータ・プログラム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP04075975 | 2004-03-31 | ||
| EP04075975.5 | 2004-03-31 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005293582A true JP2005293582A (ja) | 2005-10-20 |
| JP4754247B2 JP4754247B2 (ja) | 2011-08-24 |
Family
ID=34928127
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005095536A Expired - Fee Related JP4754247B2 (ja) | 2004-03-31 | 2005-03-29 | 複合語を構成する単語を割り出す装置及びコンピュータ化された方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7720847B2 (ja) |
| JP (1) | JP4754247B2 (ja) |
| CN (1) | CN1677402A (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013097395A (ja) * | 2011-10-27 | 2013-05-20 | Casio Comput Co Ltd | 情報処理装置及びプログラム |
| JP2013519949A (ja) * | 2010-02-12 | 2013-05-30 | グーグル・インコーポレーテッド | 複合語分割 |
| JP2016031572A (ja) * | 2014-07-28 | 2016-03-07 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 用語を適切な粒度で分割する方法、並びに、用語を適切な粒度で分割するためのコンピュータ及びそのコンピュータ・プログラム |
Families Citing this family (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7680333B2 (en) * | 2005-04-21 | 2010-03-16 | Microsoft Corporation | System and method for binary persistence format for a recognition result lattice |
| JP4720570B2 (ja) * | 2006-03-27 | 2011-07-13 | カシオ計算機株式会社 | 情報表示制御装置及び情報表示制御プログラム |
| US8086599B1 (en) * | 2006-10-24 | 2011-12-27 | Google Inc. | Method and apparatus for automatically identifying compunds |
| US8661029B1 (en) | 2006-11-02 | 2014-02-25 | Google Inc. | Modifying search result ranking based on implicit user feedback |
| CN100498790C (zh) * | 2007-02-06 | 2009-06-10 | 腾讯科技(深圳)有限公司 | 一种搜索方法和系统 |
| CN101261623A (zh) * | 2007-03-07 | 2008-09-10 | 国际商业机器公司 | 基于搜索的无词边界标记语言的分词方法以及装置 |
| US8938463B1 (en) | 2007-03-12 | 2015-01-20 | Google Inc. | Modifying search result ranking based on implicit user feedback and a model of presentation bias |
| US8694374B1 (en) | 2007-03-14 | 2014-04-08 | Google Inc. | Detecting click spam |
| US9092510B1 (en) | 2007-04-30 | 2015-07-28 | Google Inc. | Modifying search result ranking based on a temporal element of user feedback |
| US8694511B1 (en) | 2007-08-20 | 2014-04-08 | Google Inc. | Modifying search result ranking based on populations |
| US8046355B2 (en) | 2007-09-04 | 2011-10-25 | Google Inc. | Word decompounder |
| US8909655B1 (en) | 2007-10-11 | 2014-12-09 | Google Inc. | Time based ranking |
| US8396865B1 (en) | 2008-12-10 | 2013-03-12 | Google Inc. | Sharing search engine relevance data between corpora |
| US9009146B1 (en) * | 2009-04-08 | 2015-04-14 | Google Inc. | Ranking search results based on similar queries |
| KR20110006004A (ko) * | 2009-07-13 | 2011-01-20 | 삼성전자주식회사 | 결합인식단위 최적화 장치 및 그 방법 |
| US8447760B1 (en) | 2009-07-20 | 2013-05-21 | Google Inc. | Generating a related set of documents for an initial set of documents |
| US8498974B1 (en) | 2009-08-31 | 2013-07-30 | Google Inc. | Refining search results |
| US8972391B1 (en) | 2009-10-02 | 2015-03-03 | Google Inc. | Recent interest based relevance scoring |
| US8874555B1 (en) | 2009-11-20 | 2014-10-28 | Google Inc. | Modifying scoring data based on historical changes |
| US8615514B1 (en) | 2010-02-03 | 2013-12-24 | Google Inc. | Evaluating website properties by partitioning user feedback |
| US8924379B1 (en) | 2010-03-05 | 2014-12-30 | Google Inc. | Temporal-based score adjustments |
| US8959093B1 (en) | 2010-03-15 | 2015-02-17 | Google Inc. | Ranking search results based on anchors |
| US9623119B1 (en) | 2010-06-29 | 2017-04-18 | Google Inc. | Accentuating search results |
| US8832083B1 (en) | 2010-07-23 | 2014-09-09 | Google Inc. | Combining user feedback |
| CN102479191B (zh) * | 2010-11-22 | 2014-03-26 | 阿里巴巴集团控股有限公司 | 提供多粒度分词结果的方法及其装置 |
| US9002867B1 (en) | 2010-12-30 | 2015-04-07 | Google Inc. | Modifying ranking data based on document changes |
| JP5250709B1 (ja) * | 2012-03-12 | 2013-07-31 | 楽天株式会社 | 情報処理装置、情報処理方法、情報処理装置用プログラム、および、記録媒体 |
| CN103425691B (zh) | 2012-05-22 | 2016-12-14 | 阿里巴巴集团控股有限公司 | 一种搜索方法和系统 |
| US9104750B1 (en) | 2012-05-22 | 2015-08-11 | Google Inc. | Using concepts as contexts for query term substitutions |
| US20140025368A1 (en) * | 2012-07-18 | 2014-01-23 | International Business Machines Corporation | Fixing Broken Tagged Words |
| CN103870472B (zh) * | 2012-12-11 | 2018-07-10 | 百度国际科技(深圳)有限公司 | 一种复合词挖掘方法及装置 |
| US9183499B1 (en) | 2013-04-19 | 2015-11-10 | Google Inc. | Evaluating quality based on neighbor features |
| CN104679778B (zh) * | 2013-11-29 | 2019-03-26 | 腾讯科技(深圳)有限公司 | 一种搜索结果的生成方法及装置 |
| US10362060B2 (en) * | 2015-12-30 | 2019-07-23 | International Business Machines Corporation | Curtailing search engines from obtaining and controlling information |
| US10572586B2 (en) * | 2018-02-27 | 2020-02-25 | International Business Machines Corporation | Technique for automatically splitting words |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6373298A (ja) * | 1986-09-17 | 1988-04-02 | 富士通株式会社 | 文―音声変換装置に用いる複合語処理装置 |
| JPH07262191A (ja) * | 1994-03-24 | 1995-10-13 | Sony Corp | 単語分割方法、および音声合成装置 |
| JP2001249921A (ja) * | 2000-03-03 | 2001-09-14 | Nippon Telegr & Teleph Corp <Ntt> | 複合語解析方法、装置、および複合語解析プログラムを記録した記録媒体 |
| JP2002245062A (ja) * | 2001-02-14 | 2002-08-30 | Ricoh Co Ltd | 文書検索装置、文書検索方法、プログラムおよび記録媒体 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5867812A (en) | 1992-08-14 | 1999-02-02 | Fujitsu Limited | Registration apparatus for compound-word dictionary |
| US5778361A (en) * | 1995-09-29 | 1998-07-07 | Microsoft Corporation | Method and system for fast indexing and searching of text in compound-word languages |
| US6549897B1 (en) * | 1998-10-09 | 2003-04-15 | Microsoft Corporation | Method and system for calculating phrase-document importance |
| US6396699B1 (en) * | 2001-01-19 | 2002-05-28 | Lsi Logic Corporation | Heat sink with chip die EMC ground interconnect |
| US7610189B2 (en) | 2001-10-18 | 2009-10-27 | Nuance Communications, Inc. | Method and apparatus for efficient segmentation of compound words using probabilistic breakpoint traversal |
| US20040064447A1 (en) * | 2002-09-27 | 2004-04-01 | Simske Steven J. | System and method for management of synonymic searching |
| US7398269B2 (en) * | 2002-11-15 | 2008-07-08 | Justsystems Evans Research Inc. | Method and apparatus for document filtering using ensemble filters |
| US7421386B2 (en) * | 2003-10-23 | 2008-09-02 | Microsoft Corporation | Full-form lexicon with tagged data and methods of constructing and using the same |
-
2005
- 2005-03-29 JP JP2005095536A patent/JP4754247B2/ja not_active Expired - Fee Related
- 2005-03-30 US US11/092,653 patent/US7720847B2/en not_active Expired - Fee Related
- 2005-03-31 CN CNA2005100629781A patent/CN1677402A/zh active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6373298A (ja) * | 1986-09-17 | 1988-04-02 | 富士通株式会社 | 文―音声変換装置に用いる複合語処理装置 |
| JPH07262191A (ja) * | 1994-03-24 | 1995-10-13 | Sony Corp | 単語分割方法、および音声合成装置 |
| JP2001249921A (ja) * | 2000-03-03 | 2001-09-14 | Nippon Telegr & Teleph Corp <Ntt> | 複合語解析方法、装置、および複合語解析プログラムを記録した記録媒体 |
| JP2002245062A (ja) * | 2001-02-14 | 2002-08-30 | Ricoh Co Ltd | 文書検索装置、文書検索方法、プログラムおよび記録媒体 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013519949A (ja) * | 2010-02-12 | 2013-05-30 | グーグル・インコーポレーテッド | 複合語分割 |
| JP2013097395A (ja) * | 2011-10-27 | 2013-05-20 | Casio Comput Co Ltd | 情報処理装置及びプログラム |
| JP2016031572A (ja) * | 2014-07-28 | 2016-03-07 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 用語を適切な粒度で分割する方法、並びに、用語を適切な粒度で分割するためのコンピュータ及びそのコンピュータ・プログラム |
| US10198426B2 (en) | 2014-07-28 | 2019-02-05 | International Business Machines Corporation | Method, system, and computer program product for dividing a term with appropriate granularity |
Also Published As
| Publication number | Publication date |
|---|---|
| CN1677402A (zh) | 2005-10-05 |
| JP4754247B2 (ja) | 2011-08-24 |
| US7720847B2 (en) | 2010-05-18 |
| US20050222998A1 (en) | 2005-10-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4754247B2 (ja) | 複合語を構成する単語を割り出す装置及びコンピュータ化された方法 | |
| KR100451978B1 (ko) | 정보 검색 방법과 정보 검색 장치 | |
| CN110750704B (zh) | 一种查询自动补全的方法和装置 | |
| US20110295857A1 (en) | System and method for aligning and indexing multilingual documents | |
| JP2007323671A (ja) | 中国語テキストにおける単語分割 | |
| JP2010257488A (ja) | 対話形サーチクエリー改良のためのシステム及び方法 | |
| JP2005352888A (ja) | 表記揺れ対応辞書作成システム | |
| KR100396826B1 (ko) | 정보검색에서 질의어 처리를 위한 단어 클러스터 관리장치 및 그 방법 | |
| JP4426894B2 (ja) | 文書検索方法、文書検索プログラムおよびこれを実行する文書検索装置 | |
| JP2669601B2 (ja) | 情報検索方法及びシステム | |
| JP5718405B2 (ja) | 発話選択装置、方法、及びプログラム、対話装置及び方法 | |
| Pouliquen et al. | Automatic construction of multilingual name dictionaries | |
| JP5447368B2 (ja) | 新規事例生成装置、新規事例生成方法及び新規事例生成用プログラム | |
| JP2008152522A (ja) | データマイニングシステム、データマイニング方法及びデータ検索システム | |
| CN112949287A (zh) | 热词挖掘方法、系统、计算机设备和存储介质 | |
| JP2002032394A (ja) | 関連語情報作成装置、関連語提示装置、文書検索装置、関連語情報作成方法、関連語提示方法、文書検索方法および記憶媒体 | |
| Reddy et al. | An efficient approach for web document summarization by sentence ranking | |
| JP5491446B2 (ja) | 話題語獲得装置、方法、及びプログラム | |
| JP2009271819A (ja) | 文書検索システム、文書検索方法および文書検索プログラム | |
| JP4783563B2 (ja) | インデックス生成プログラム、検索プログラム、インデックス生成方法、検索方法、インデックス生成装置および検索装置 | |
| JP4389102B2 (ja) | 技術文献検索システム | |
| JP2970443B2 (ja) | 文書検索装置 | |
| KR20190009061A (ko) | 문자 상표 검색 시스템 및 검색 서비스 제공 방법 | |
| JPH07134720A (ja) | 文章作成システムにおける関連情報提示方法及び装置 | |
| JP4373478B2 (ja) | 文書検索装置及び文書検索方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080311 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100817 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101115 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110517 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110525 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140603 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |