JP2005157447A - 画像処理システム及び画像処理方法 - Google Patents
画像処理システム及び画像処理方法 Download PDFInfo
- Publication number
- JP2005157447A JP2005157447A JP2003390747A JP2003390747A JP2005157447A JP 2005157447 A JP2005157447 A JP 2005157447A JP 2003390747 A JP2003390747 A JP 2003390747A JP 2003390747 A JP2003390747 A JP 2003390747A JP 2005157447 A JP2005157447 A JP 2005157447A
- Authority
- JP
- Japan
- Prior art keywords
- image
- electronic file
- reading
- information
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



















Abstract
【課題】 再利用可能な状態にある電子ファイルに関する加筆原稿の登録を効果的に行うことができる画像処理システム及び画像処理方法を提供する。
【解決手段】 サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する。この際、原稿を読み取って取得したイメージ情報をその属性に応じて、文字コード化、ベクトルデータに変換、又は所定の画像形式に変換する。また、イメージ情報に対応する電子ファイルをサーバが保持する電子ファイルの中から検索し、その属性情報報に基づいて、変換により得られたデータへの置き換えが許可されているか禁止されているかを判定する。そして、許可されていると判定された場合、検索された電子ファイルを得られたデータに置き換える。
【選択図】 図3
【解決手段】 サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する。この際、原稿を読み取って取得したイメージ情報をその属性に応じて、文字コード化、ベクトルデータに変換、又は所定の画像形式に変換する。また、イメージ情報に対応する電子ファイルをサーバが保持する電子ファイルの中から検索し、その属性情報報に基づいて、変換により得られたデータへの置き換えが許可されているか禁止されているかを判定する。そして、許可されていると判定された場合、検索された電子ファイルを得られたデータに置き換える。
【選択図】 図3
Description
本発明は、複写機等の画像処理装置で読み取った画像データを既存の文書作成アプリケーションソフトで再利用可能なベクトルデータに変換する画像処理システム及び画像処理方法に関する。
近年、環境問題がクローズアップされている中で、オフィス等でのペーパーレス化が急速に進んでいる。そこで、従来からバインダー等で蓄積・保存された紙文書をスキャナで読み取って、ポータブルドキュメントフォーマット(以下、「PDF」と略す。)に変換し、画像記憶装置(データベース)に蓄積・保存する文書管理システムが構築されている。
一方、機能が拡張されたデジタル複合機(以下、「MFP」と略す。)には、画像を紙文書として印刷・出力する際に、当該画像が記憶されている画像記憶装置内のポインタ情報を紙文書の表紙或いは記載情報中に付加情報として記録しておくものがある。そして、当該画像が記録された紙文書を複写する場合には、表紙等に付加されているポインタ情報からオリジナルの画像が格納されている画像記憶装置内の格納場所を検出し、紙文書から読み取られた画像を再印刷に用いるのではなく、画像記憶装置内に記憶されているオリジナルの画像を編集や再印刷に直接用いることができる。これにより、紙文書として保存する必要がなく、紙文書から読み取られた画像を何度も再利用することによって生じる画質の劣化等の問題を防ぐことができる(例えば、特許文献1参照。)。
特開平10−143414号公報
しかしながら、画像として保存された紙文書はイメージデータのままでは再利用が困難であるため、それを再利用する際には、新たにアプリケーションソフトを用いて再度作成しなければならない。そのため、原稿を読み取った画像から再利用可能なテキストデータ等の電子データを生成するベクトル化技術を使用することで、比較的容易に再利用可能なデータを紙文書から生成できるようになる。
このようにして、紙文書から再利用可能な電子データが生成できるようになることにより、オフィスにおける会議等でも全員が同じデータを共有することが可能になった。しかし、オフィス等の会議等では、紙文書には容易に加筆できるために相変わらず紙文書が多用されている。ここで、上述した技術を用いて加筆した後の原稿をベクトルデータ化しようとする場合、元の原稿と類似した原稿が多数新たなベクトルデータとして生成されてしまう結果になるという問題が生じる。
このように、あるオリジナル原稿を元にして多数の加筆原稿が新たなベクトルデータとして登録された場合、どのデータがオリジナル原稿であって、どのデータが最新の加筆原稿であるのかを判別することが難しくなってしまう。また、どのような加筆文書が新たに登録されたのかを原作者が知ることができないという問題や、加筆文書の登録を禁止できないという問題も生じてしまう。
本発明は、このような事情を考慮してなされたものであり、再利用可能な状態にある電子ファイルに関する加筆原稿の登録を効果的に行うことができる画像処理システム及び画像処理方法を提供することを目的とする。
上記問題を解決するために、本発明は、サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理システムであって、
前記原稿を読み取ってイメージ情報を取得する読取手段と、
前記読取手段により得られたイメージ情報を文字コード化する文字処理手段と、
前記読取手段により得られたイメージ情報をベクトルデータに変換するベクトル化手段と、
前記読取手段により得られたイメージ情報を所定の画像形式に変換する画像変換手段と、
前記読取手段により得られたイメージ情報を、その属性に応じて前記文字処理手段、前記ベクトル化手段、前記画像変換手段の少なくともいずれかを用いて変換する変換手段と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索手段と、
前記検索手段で検索された電子ファイルの属性情報に基づいて、前記変換手段により得られたデータへの置き換えが許可されているか禁止されているかを判定する判定手段と、
前記判定手段によって前記変換手段により得たデータへの置き換えが許可されていると判定された場合、前記検索手段により検索された電子ファイルを、前記変換手段によって得られたデータに置き換える置換手段と
を備えることを特徴とする。
前記原稿を読み取ってイメージ情報を取得する読取手段と、
前記読取手段により得られたイメージ情報を文字コード化する文字処理手段と、
前記読取手段により得られたイメージ情報をベクトルデータに変換するベクトル化手段と、
前記読取手段により得られたイメージ情報を所定の画像形式に変換する画像変換手段と、
前記読取手段により得られたイメージ情報を、その属性に応じて前記文字処理手段、前記ベクトル化手段、前記画像変換手段の少なくともいずれかを用いて変換する変換手段と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索手段と、
前記検索手段で検索された電子ファイルの属性情報に基づいて、前記変換手段により得られたデータへの置き換えが許可されているか禁止されているかを判定する判定手段と、
前記判定手段によって前記変換手段により得たデータへの置き換えが許可されていると判定された場合、前記検索手段により検索された電子ファイルを、前記変換手段によって得られたデータに置き換える置換手段と
を備えることを特徴とする。
また、本発明は、サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理システムであって、
前記原稿を読み取ってイメージ情報を取得する読取手段と、
前記読取手段により得られたイメージ情報を文字コード化する文字処理手段と、
前記読取手段により得られたイメージ情報をベクトルデータに変換するベクトル化手段と、
前記読取手段により得られたイメージ情報を所定の画像形式に変換する画像変換手段と、
前記読取手段により得られたイメージ情報を、その属性に応じて前記文字処理手段、前記ベクトル化手段、前記画像変換手段の少なくともいずれかを用いて変換する変換手段と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索手段と、
前記検索手段により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出手段と、
前記検索手段で検索された電子ファイルの属性情報に基づいて、前記抽出手段で抽出された差分情報の追加が許可されているか禁止されているか判定する判定手段と、
前記判定手段により前記変換手段によって変換されたデータの追加が許可されていると判定された場合、前記検索手段により検索された電子ファイルに前記抽出手段で抽出された差分情報を前記変換手段により変換されたデータを追加する追加手段と
を備えることを特徴とする。
前記原稿を読み取ってイメージ情報を取得する読取手段と、
前記読取手段により得られたイメージ情報を文字コード化する文字処理手段と、
前記読取手段により得られたイメージ情報をベクトルデータに変換するベクトル化手段と、
前記読取手段により得られたイメージ情報を所定の画像形式に変換する画像変換手段と、
前記読取手段により得られたイメージ情報を、その属性に応じて前記文字処理手段、前記ベクトル化手段、前記画像変換手段の少なくともいずれかを用いて変換する変換手段と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索手段と、
前記検索手段により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出手段と、
前記検索手段で検索された電子ファイルの属性情報に基づいて、前記抽出手段で抽出された差分情報の追加が許可されているか禁止されているか判定する判定手段と、
前記判定手段により前記変換手段によって変換されたデータの追加が許可されていると判定された場合、前記検索手段により検索された電子ファイルに前記抽出手段で抽出された差分情報を前記変換手段により変換されたデータを追加する追加手段と
を備えることを特徴とする。
さらに、本発明は、サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理方法であって、
前記原稿を読み取ってイメージ情報を取得する読取工程と、
前記読取工程により得られたイメージ情報を文字コード化する文字処理工程と、
前記読取工程により得られたイメージ情報をベクトルデータに変換するベクトル化工程と、
前記読取工程により得られたイメージ情報を所定の画像形式に変換する画像変換工程と、
前記読取工程により得られたイメージ情報を、その属性に応じて前記文字処理工程、前記ベクトル化工程、前記画像変換工程の少なくともいずれかを用いて変換する変換工程と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索工程と、
前記検索工程で検索された電子ファイルの属性情報に基づいて、前記変換工程により得られたデータへの置き換えが許可されているか禁止されているかを判定する判定工程と、
前記判定工程によって前記変換工程により得たデータへの置き換えが許可されていると判定された場合、前記検索工程により検索された電子ファイルを、前記変換工程によって得られたデータに置き換える置換工程と
を有することを特徴とする。
前記原稿を読み取ってイメージ情報を取得する読取工程と、
前記読取工程により得られたイメージ情報を文字コード化する文字処理工程と、
前記読取工程により得られたイメージ情報をベクトルデータに変換するベクトル化工程と、
前記読取工程により得られたイメージ情報を所定の画像形式に変換する画像変換工程と、
前記読取工程により得られたイメージ情報を、その属性に応じて前記文字処理工程、前記ベクトル化工程、前記画像変換工程の少なくともいずれかを用いて変換する変換工程と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索工程と、
前記検索工程で検索された電子ファイルの属性情報に基づいて、前記変換工程により得られたデータへの置き換えが許可されているか禁止されているかを判定する判定工程と、
前記判定工程によって前記変換工程により得たデータへの置き換えが許可されていると判定された場合、前記検索工程により検索された電子ファイルを、前記変換工程によって得られたデータに置き換える置換工程と
を有することを特徴とする。
さらにまた、本発明は、サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理方法であって、
前記原稿を読み取ってイメージ情報を取得する読取工程と、
前記読取工程により得られたイメージ情報を文字コード化する文字処理工程と、
前記読取工程により得られたイメージ情報をベクトルデータに変換するベクトル化工程と、
前記読取工程により得られたイメージ情報を所定の画像形式に変換する画像変換工程と、
前記読取工程により得られたイメージ情報を、その属性に応じて前記文字処理工程、前記ベクトル化工程、前記画像変換工程の少なくともいずれかを用いて変換する変換工程と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索工程と、
前記検索工程により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出工程と、
前記検索工程で検索された電子ファイルの属性情報に基づいて、前記抽出工程で抽出された差分情報の追加が許可されているか禁止されているか判定する判定工程と、
前記判定工程により前記変換工程によって変換されたデータの追加が許可されていると判定された場合、前記検索工程により検索された電子ファイルに前記抽出工程で抽出された差分情報を前記変換工程により変換されたデータを追加する追加工程と
を有することを特徴とする。
前記原稿を読み取ってイメージ情報を取得する読取工程と、
前記読取工程により得られたイメージ情報を文字コード化する文字処理工程と、
前記読取工程により得られたイメージ情報をベクトルデータに変換するベクトル化工程と、
前記読取工程により得られたイメージ情報を所定の画像形式に変換する画像変換工程と、
前記読取工程により得られたイメージ情報を、その属性に応じて前記文字処理工程、前記ベクトル化工程、前記画像変換工程の少なくともいずれかを用いて変換する変換工程と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索工程と、
前記検索工程により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出工程と、
前記検索工程で検索された電子ファイルの属性情報に基づいて、前記抽出工程で抽出された差分情報の追加が許可されているか禁止されているか判定する判定工程と、
前記判定工程により前記変換工程によって変換されたデータの追加が許可されていると判定された場合、前記検索工程により検索された電子ファイルに前記抽出工程で抽出された差分情報を前記変換工程により変換されたデータを追加する追加工程と
を有することを特徴とする。
本発明によれば、再利用可能な状態にある電子ファイルに関する加筆原稿の登録を効果的に行うことができる。
以下、図面を参照して、本発明の実施形態について説明する。
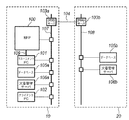
図1は、本発明の一実施形態に係る画像処理システムの構成を示すブロック図である。図1に示す画像処理システムは、オフィス10とオフィス20とをインターネット等のネットワーク104で接続された環境で実現される。
オフィス10内に構築されたLAN107には、MFP100と、MFP100を制御するマネージメントPC101と、クライアントPC102と、文書管理サーバ106aと、そのデータベース105a及びプロキシサーバ103aが接続されている。また、オフィス20内に構築されたLAN108には、文書管理サーバ106bと、そのデータベース105b及びプロキシサーバ103bが接続されている。尚、クライアントPC102は、外部記憶部、検索イメージ入力部及び検索結果出力部を備えている。また、LAN107及びオフィス20内のLAN108は、プロキシサーバ103a、103bを介してインターネット等のネットワーク104に接続されている。
MFP100は、本実施形態において紙文書を光学的に読み取って画像信号に変換する画像読み取り処理と、読み取った画像信号に対する画像処理の一部を担当し、画像信号はLAN109を用いてマネージメントPC101に入力する。尚、マネージメントPC101は、通常のPCでも実現可能であり、内部に画像記憶部、画像処理部、表示部及び入力部を備える。尚、マネージメントPC101は、その一部又は全部をMFP100と一体化して構成してもよい。
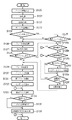
図2は、本発明の一実施形態に係るMFP100の構成を示すブロック図である。図2において、オートドキュメントフィーダ(以下、「ADF」と略す。)を含む画像読み取り部110は、束状或いは1枚の原稿画像を内部に備える光源で照射し、原稿反射像をレンズで固体撮像素子上に結像し、固体撮像素子からラスタ状の画像読み取り信号を例えば600dpiの密度のイメージ情報として得る。そして通常の複写機能を用いる場合は、この画像信号をデータ処理部115で記録信号へ画像処理し、複数毎複写の場合は記憶装置111に一旦1ページ分の記録データを保持した後、形成装置112に順次出力して紙上に画像を形成する。
一方、クライアントPC102から出力されるプリントデータは、LAN107からMFP100に入力され、ネットワークIF114を経てデータ処理装置115で記録可能なラスタデータに変換された後、形成装置112に出力して紙上に記録画像として形成される。
MFP100への操作者の指示は、MFP100に装備されているキー等の入力装置113、或いはマネージメントPC101のキーボードやマウス等からなる入力装置から行われ、これら一連の動作はデータ処理装置115内の制御部で制御される。
一方、操作入力の状態表示及び処理中の画像データの表示は、MFP100の表示装置116又は、マネージメントPC101、クライアントPC102のモニタ等で行われる。尚、記憶装置111は、マネージメントPC101からも制御され、MFP100とマネージメントPC101とのデータの授受及び制御は、ネットワークIF117及び直結したLAN109を用いて行われる。
[処理概要]
次に、本発明の一実施形態に係る画像処理システムによる画像処理全体の概要について説明する。
次に、本発明の一実施形態に係る画像処理システムによる画像処理全体の概要について説明する。
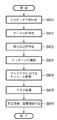
まず、MFP100の表示装置116上に、図20に示す画面を表示し、これから処理する原稿が初めて処理する新規原稿であるのか、既に登録されている原稿に加筆した原稿であるのか、又は加筆前の原稿をプリントするのかをユーザに指示させる。図20〜22は、本実施形態における画像処理システムのMFP100の表示装置116上に表示される指示画面例を示す図である。
ここで、図20における「新規登録」2001が選択された場合、表示装置116上には図21に示す画面が表示され、さらに詳細な設定をユーザに指示させる。図21に示す画面において「加筆登録許可」2101が選択された場合、加筆登録許可フラグをセットして、表示装置116は、「要パスワード」2102と「原本追跡」2103を表示する。そして、「要パスワード」2102が選択された場合は、パスワード要求フラグをセットする。一方、「原本追跡」2103が選択された場合は、原本追跡フラグをセットして、「メール通知」2104を表示する。そして、「メール通知」2104が選択された場合、メール通知フラグをセットして、アドレス入力欄を表示して、入力値をメール通知アドレスとして保持する。
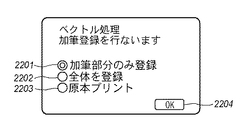
一方、図20における「加筆登録」2002が選択された場合、表示装置116上には図22に示す画面が表示され、さらに詳細な設定をユーザに指示させる。図22に示す画面において「加筆部分のみ登録」2201が選択された場合は、加筆部登録フラグをセットして、加筆部全体登録フラグをリセットする。また、「全体を登録」2202が選択された場合は、加筆部全体登録フラグをセットして、加筆部登録フラグをリセットする。さらに、「原本プリント」2203が選択された場合は、原本プリントフラグをセットする。
また、図20における「原本プリント」2003が選択された場合、原本プリントフラグをセットする。尚、上述した各フラグやアドレスは、後述するベクトル化情報に付加される。
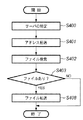
図3は、本発明の一実施形態に係る画像処理システムによる画像処理の手順について説明するためのフローチャートである。ユーザが、上述した手順でMFP100の操作部(UI)等を用いて各種設定を行った後、MFP100の画像読み取り部110を動作させて1枚の原稿をラスタ走査し、例えば、600dpi、8ビットの画像信号を得る(イメージ情報入力処理:ステップS120)。尚、当該画像信号は、データ処理装置115で前処理を施して記憶装置111に1ページ分の画像データとして保存する。
次に、マネージメントPC101のCPUにより、記憶装置111に格納された画像信号から、まず、文字/線画部分とハーフトーンの画像部分とに領域を分離する。そして、文字部分はさらに段落で塊として纏まっているブロック毎に、或いは、線で構成された表、図形に分離し各々セグメント化する。一方、ハーフトーンで表現される画像部分は、矩形に分離されたブロックの画像部分、背景部等のいわゆるブロック毎に独立したオブジェクトに分割する(BS処理:ステップS121)。
このとき、原稿画像中に付加情報として記録された2次元バーコード、或いはURLに該当するオブジェクトを検出して、URLはOCR処理(光学的文字認識処理)等で文字認識し、2次元バーコード又は当該オブジェクトを解読する(ステップS122)。
次いで、原稿のオリジナル電子ファイルが格納されている記憶装置内のポインタ情報を検出する(ステップS123)。尚、ポインタ情報を付加する手段としては、他に文字と文字の間隔に情報を埋め込む方法や、ハーフトーンの画像に埋め込む方法等の直接可視化されない電子透かしによる方法を用いた場合であってもよい。このように付加情報が電子透かしとして埋め込まれている場合は、ステップS123では透かし情報を検出して解読することとなる。
そして、ポインタ情報が検出されたか否かを判定し(ステップS124)、ポインタ情報が検出された場合(Yes)は、ポインタで示されたアドレスから原稿に対応する電子ファイルを検索することによって特定する(ステップS125)。電子ファイルは、図1においてクライアントPC101内のハードディスク内、或いはオフィス10、20のLAN107、108に接続された文書管理サーバ106a、106b内のデータベース105a、105b内、或いはMFP100自体が有する記憶装置111のいずれかに格納されている。そして、ステップS123で得られたアドレス情報に従って、これらの記憶装置内から検索される。
その結果、ステップS125で電子ファイルが見つからなかった場合(No)、又は、見つかったがPDFやtiffに代表されるようなイメージファイルであった場合(すなわち、既存の文書作成ソフトウェア等では再利用・再編集ができないイメージファイルの場合)は、ステップS126に分岐する。また、ステップS124で、ポインタ情報自体が存在しなかった場合(No)も、ステップS126に分岐する。
ステップS126は、いわゆる文書検索処理ルーチンである。まず、ステップS122で各文字ブロックに対して行ったOCRの結果から単語を抽出して、全文検索、或いは各オブジェクトの配列と各オブジェクトの属性からいわゆるレイアウト検索を行う。検索の結果、類似度の高い電子ファイルが見つかった場合は、そのサムネイル等を表示する(ステップS127)。また、検索された電子ファイルが複数存在する場合等の操作者の選択が必要な場合は、操作者の入力操作によってファイルの特定を行う。
尚、候補の電子ファイルが1つしかない場合、自動的にステップS128からステップS133に分岐して、格納アドレスを通知する。一方、ステップS126の検索処理で電子ファイルが見つからなかった場合、或いは、見つかったがPDFやtiffに代表されるいわゆるイメージファイルであった場合(ステップS128でNo)、ステップS129に分岐する。
上記ステップS125やステップS128で電子ファイルが見つかった場合(Yes)は、その電子ファイルをそのまま使用するか否かを前述した原本プリントフラグで判別する(ステップS128a)。そして、そのまま使用する場合(Yes)は、ステップS133に分岐する。一方、そのまま使用しない場合(No)は、電子ファイルの属性情報である加筆登録許可フラグを参照する(ステップS128b)。
その結果、加筆登録不可の場合(No)は、図24の画面を表示した上で、何も登録せずに終了する。一方、加筆登録可能の場合(Yes)は、パスワード要求フラグを参照し(ステップS128c)、必要な場合(Yes)は図23の画面を表示してパスワードを入力し(ステップS128d)、パスワードによる認証を行う。ここで認証方法については特に言及しないが、電子ファイルに付属するパスワードデータを使用したり、認証用のサーバに問い合わせたりして認証を行うものとする。従って、オリジナルの原稿へ加筆した加筆文書又はその加筆部分の登録可能者を、ベクトルデータへの変換可能なパスワードを知っているユーザのみに限定することができるので、オリジナルの電子ファイルに対する第三者による書き込みをした多数の類似する電子ファイルが作成されたり、第三者による不適切な書き込みをした類似する電子ファイルの作成等を防ぐことができる。図23、24及び図9は、本実施形態における画像処理システムのMFP100の表示装置116上に表示される画面例を示す図である。
一方、ステップS128cでパスワードが不要だったり、ステップS128dで認証に成功した場合は、加筆部全体登録フラグを参照し(ステップS128e)、イメージ情報全体を登録するのか加筆部分だけ登録するのかを判別する。その結果、加筆部分だけを登録する場合(No)には、画像処理を行って加筆部分のイメージ画像を抽出し(ステップS128f)、全体を登録する場合(Yes)は原稿全体のイメージ画像を使用してステップS129に進む。
ステップS129では、イメージデータからベクトルデータへの変換処理を行って、オリジナルの電子ファイルに近い、編集容易で容量の小さい電子ファイルに変換する。すなわち、ステップS122でOCR処理された文字ブロックに対して、文字のサイズ、スタイル及び字体等を認識し、原稿を走査して得られた文字に可視的に忠実なフォントデータに変換し、文字コード化する。一方、線や曲線で構成される線画、表、又は図形ブロック等に対してはアウトライン化、関数近似化(直線近似、曲線近似、図形近似等)を行う。さらに、画像ブロックに対しては、イメージデータとして個別のJPEGファイル等として処理する。
尚、これらのベクトル化処理は、各オブジェクト毎に行い、更に各オブジェクトのレイアウト情報を保存して、例えば、rtfやsvg等のアプリデータに変換し(ステップS130)、変換後のファイルを電子ファイルとして記憶装置111等に格納する(ステップS131)。
また、格納する際に加筆部全体登録フラグ又は加筆部登録フラグを参照し、加筆部全体登録フラグが立っていた場合は元の電子ファイルを今回読み取った原稿に基づく電子ファイルに置き換え、加筆部登録フラグが立っていた場合は加筆部を抽出してこの部分のみに基づくデータを原本の電子ファイルと関連付けて格納する。従って、既にベクトルデータに変換され電子ファイルとして再利用可能な状態にある原稿に加筆した加筆部分のみのベクトルデータを当該電子ファイルに対応付けて登録(保持)することが可能となる。さらに、格納後にメール通知フラグを参照し、メール通知が必要な場合には、図9に示す画面を表示した上で、電子ファイルの属性情報に含まれるメールアドレスに対して、原本の電子ファイルと関連付けて格納する旨の電子メールを送信する。従って、電子メールにより加筆文書が登録されたことが通知できるので、オリジナルの原稿の作者や管理者等が当該原稿の変更履歴等を確認することが可能になる。また、原本プリントが選択された場合は加筆前の原本の電子ファイルを取得することが可能となる。
ベクトル化された原稿画像は、以降同様の処理を行う際に直接電子ファイルとして検索することができるように、検索のためのインデックス情報を生成して(ステップS132)、検索用インデックスファイルに追加する。そして、格納アドレスを操作者(クライアント)に通知する(ステップS133)。
さらに、操作者が行おうとしている処理が記録であるか否かが判断され(ステップS134)、記録の場合(Yes)はステップS135に分岐して、ポインタ情報をイメージデータとしてファイルに付加する。
一方、検索処理で電子ファイルが特定できた場合も同様に、ステップS128からステップS129に分岐し、格納アドレスをクライアントに通知するとともに(ステップS133)、用紙等の媒体上に記録する場合は同様にポインタ情報を電子ファイルに付加する(ステップS135)。
尚、以上本実施例によって得られた電子ファイル自体を用いて、例えば文書の加工、蓄積、伝送、記録をステップS136で行うことが可能になる。
上述したような処理によって、イメージデータをそのままの形で取得するような場合に比べて、取得後の当該電子ファイルの再利用・再編集が可能になるだけでなく、情報量を削減することにより蓄積効率が高まり、伝送時間が短縮され、記録表示する際には高品位なデータとして非常に優位となるという効果が得られる。なお、加筆部全体登録フラグが立っていた場合、元の電子ファイルと置き換えず、元の電子ファイルを残しつつ新たに追加するようにしてもよい。
以下、各処理ブロックに対して詳細に説明する。まず、ステップS121で示すブロックセレクション(BS)処理について説明する。
[ブロックセレクション処理]
図4は、ブロックセレクション処理によって読み取った1枚のイメージデータを属性を判定し複数のブロックに分割する様子を示す図である。すなわち、ブロックセレクション処理とは、符号41に示すステップS121で読み取った一頁のイメージデータを、符号42に示すようにオブジェクト毎の塊として認識し、それぞれのブロックを文字(Text)、写真(Photo)、線(Line)、表(Table)等の属性に判定し、異なる属性を持つ領域(ブロック)に分割する処理である。
図4は、ブロックセレクション処理によって読み取った1枚のイメージデータを属性を判定し複数のブロックに分割する様子を示す図である。すなわち、ブロックセレクション処理とは、符号41に示すステップS121で読み取った一頁のイメージデータを、符号42に示すようにオブジェクト毎の塊として認識し、それぞれのブロックを文字(Text)、写真(Photo)、線(Line)、表(Table)等の属性に判定し、異なる属性を持つ領域(ブロック)に分割する処理である。
ブロックセレクション処理の一例を以下に説明する。
まず、入力画像を白黒に2値化して、輪郭線追跡を行って黒画素輪郭で囲まれる画素の塊を抽出する。そして、面積の大きい黒画素の塊については、内部にある白画素に対して同様に輪郭線追跡を行って白画素の塊を抽出する。さらに、一定面積以上の白画素の塊の内部からも再帰的に黒画素の塊を抽出する。尚、上記処理は、白地に黒字等で記載されている原稿の場合の処理であって、それ以外の場合は背景に相当する色を「白」、オブジェクトに相当する色を「黒」とすることにより同様に処理することができる。
このようにして得られた黒画素の塊を、大きさ及び形状等で分類し、異なる属性を持つ領域へ分類する。例えば、縦横比が1に近く、大きさが一定の範囲のものを文字相当の画素塊とし、さらに近接する文字が整列良くグループ化可能な部分を文字領域とする。また、扁平な画素塊を線領域、一定の大きさ以上でかつ四角系の白画素塊を整列よく内包する黒画素塊の占める範囲を表領域、不定形の画素塊が散在している領域を写真領域、それ以外の任意形状の画素塊を図画領域等とする。
図5は、ブロックセレクション処理で得られた各ブロックに対するブロック情報の一例について示す図である。図5に示されるブロック毎の情報は、後述するベクトル化、検索処理のための情報として用いられる。
[イメージデータからポインタ情報の検出]
まず、ステップS122で示す電子ファイルの格納位置を、読み取られたイメージデータから抽出するためのOCR/OMR処理について説明する。
まず、ステップS122で示す電子ファイルの格納位置を、読み取られたイメージデータから抽出するためのOCR/OMR処理について説明する。
図6は、原稿画像中に付加された2次元バーコード(QRコードシンボル)を復号してデータ文字列を出力する手順を説明するためのフローチャートである。図7は、2次元バーコードが付加された原稿310の一例を示す図である。
まず、データ処理装置115内のページメモリに格納された原稿310を読み取って得られたイメージデータを内部のCPUで走査して、前述したブロックセレクション処理の結果から所定の2次元バーコードシンボル311の位置を検出する。QRコードの位置検出パターンは、シンボルの4隅のうちの3隅に配置される同一の位置検出要素パターン311a〜311cから構成される (ステップS300)。
次に、位置検出パターンに隣接する形式情報を復元し、シンボルに適用されている誤り訂正レベル及びマスクパターンを得る(ステップS301)。さらに、シンボルの型番を決定した後(ステップS302)、形式情報で得られたマスクパターンを使って符号化領域ビットパターンをXOR演算することによってマスク処理を解除する(ステップS303)。
そして、モデルに対応する配置規則に従い、シンボルキャラクタを読み取り、メッセージのデータ及び誤り訂正コード語を復元する(ステップS304)。次いで、復元されたコード上に誤りがあるかどうかの検出を行う(ステップS305)。その結果、誤りが検出された場合(Yes)は当該誤りを訂正する(ステップS306)。そして、誤り訂正されたデータより、モード指示子及び文字数指示子に基づいて、データコード語をセグメントに分割する(ステップS307)。最後に、仕様モードに基づいてデータ文字を復号し、結果を出力する(ステップS308)。尚、ステップS305で誤りが検出されなかった場合(No)は、上記ステップS307に進む。
ここで、2次元バーコード内に組み込まれたデータは、対応する電子ファイルが格納されているサーバアドレス情報(ポインタ情報)を表しており、例えばファイルサーバ名及びサーバアドレスを示すIPアドレス、対応するURL等からなるパス情報で構成される。
本実施形態では上述したように、ポインタ情報が2次元バーコードを用いて付与された原稿310を例に挙げて説明したが、直接文字列でポインタ情報が記録される場合には、所定のルールに従った文字列のブロックを前述したブロックセレクション処理で検出し、当該ポインタ情報を示す文字列の各文字を文字認識することで、直接、オリジナルの電子ファイルが保存されているサーバのサーバアドレス情報を得ることが可能である。
また、図7の文書310の文字ブロック312や文字ブロック313の文字列に対して、隣接する文字と文字の間隔等に視認し難い程度の変調を加え、当該文字間隔を用いた透かし情報を埋め込むことでもポインタ情報を付与することができる。このような透かし情報は、後述する文字認識処理を行う際に各文字の間隔を検出することによって、ポインタ情報を得ることができる。また、自然画ブロック314の中に電子透かしとしてポインタ情報を付加することも可能である。
[ポインタ情報によるファイル検索]
次に、図3を用いて説明したステップS125、S128の処理で行われるポインタ情報からの電子ファイルが格納されているサーバの検索処理について詳細に説明する。図8は、検出されたポインタ情報から電子ファイルが格納されているサーバを検索する処理手順について説明するためのフローチャートである。
次に、図3を用いて説明したステップS125、S128の処理で行われるポインタ情報からの電子ファイルが格納されているサーバの検索処理について詳細に説明する。図8は、検出されたポインタ情報から電子ファイルが格納されているサーバを検索する処理手順について説明するためのフローチャートである。
まず、ポインタ情報に含まれるサーバアドレスに基づいて、当該電子ファイルが格納されているファイルサーバを特定する(ステップS400)。ここでファイルサーバとは、クライアントPC102や、データベース105a、bを内蔵する文書管理サーバ106a、106bや、記憶装置111を内蔵するMFP100自身を指す。また、アドレスとは、URLやサーバ名からなるパス情報である。
そして、ファイルサーバを特定した後、図3を用いて説明したステップS127におけるポインタ情報が示すサーバ(ファイルサーバ)内を検索するための準備をファイルサーバに対して要求する(ステップS401)。ファイルサーバは、ステップS126のファイル検索処理に従って、該当する電子ファイルを検索する(ステップS402)。そして、電子ファイルが存在するか否かを判定する(ステップS403)。
この結果、電子ファイルが存在しない場合(No)は、MFP100に対してその旨を通知して終了する。一方、電子ファイルが存在する場合(Yes)は、図3を用いて前述したように、該当する電子ファイルのアドレスを通知する(ステップS134)と共に、当該電子ファイルをユーザ(すなわち、MFP100)に対して転送する(ステップS408)。
[ファイル検索処理]
次に、図3のステップS126で示すファイル検索処理の詳細について図5及び図10を使用して説明する。ステップS126の処理は、前述したように、ステップS124で入力原稿(入力ファイル)にポインタ情報が存在しなかった場合、ポインタ情報は存在するが電子ファイルが見つからなかった場合、或いは電子ファイルがイメージファイルであった場合に行われる。
次に、図3のステップS126で示すファイル検索処理の詳細について図5及び図10を使用して説明する。ステップS126の処理は、前述したように、ステップS124で入力原稿(入力ファイル)にポインタ情報が存在しなかった場合、ポインタ情報は存在するが電子ファイルが見つからなかった場合、或いは電子ファイルがイメージファイルであった場合に行われる。
ここでは、ステップS122のOCR/OMR処理の結果、抽出された各ブロック及び入力ファイルが、図5に示す情報(ブロック情報、入力ファイル情報)を備えるものとする。本実施形態では、情報内容として、図5に示すように属性、座標位置、幅及び高さのサイズ、OCR情報の有無を用いる。
属性は、さらに、文字、線、写真、絵、表等に分類される。尚、図5では説明を簡単にするため、ブロックは座標Xの小さい順(例えば、X1<X2<X3<X4<X5<X6)に、ブロック1、ブロック2、ブロック3、ブロック4、ブロック5、ブロック6としている。また、ブロック総数は、入力ファイル中の全ブロック数であり、図5に示す例におけるブロック総数は6である。以下、これらの情報を使用して、データベース内から入力イメージファイルに類似した電子ファイルのレイアウト検索を行う手順について説明する。図10は、データベース内から入力イメージファイルに類似した電子ファイルのレイアウト検索を行う手順について説明するためのフローチャートである。尚、データベースファイルも、図5に示す情報と同様の情報を備えることを前提とする。図10のフローチャートの流れは、入力された原稿から読み取られた電子ファイルとデータベース中の電子ファイルを順次比較するものである。
まず、後述する類似率等の初期化を行って初期値を設定する(ステップS510)。次に、ブロック総数の比較を行い(ステップS511)、真の場合(Yes)は、さらにファイル内のブロックの情報を順次比較する(ステップS512)。すなわち、データベースのファイルのブロック数nが入力ファイルのブロック数Nの誤差ΔN範囲内かどうかを調べ、誤差範囲内であれば真(Yes)、範囲外であれば偽(No)とする。また、ステップS512では、入力ファイルとデータベースファイルのブロック属性を比較して一致すればステップS513以降の比較処理へ進み、不一致であればステップS521に進む。
ブロックの情報比較では、ステップS513、S515、S518において、それぞれ属性類似率、サイズ類似率、OCR類似率をそれぞれ算出し、ステップS522においてそれらに基づいて総合類似率を算出する。各類似率の算出方法については、公知の技術が用いれるので説明を省略する。
ステップS523においては、総合類似率が予め設定された閾値Thより高いかどうかを判定し、高い場合(Yes)は、その電子ファイルを類似候補として挙げて保存する(ステップS524)。尚、図中のN、W、Hは、入力ファイルのブロック総数、各ブロック幅、各ブロック高さ、ΔN、ΔW、ΔHは、入力ファイルのブロック情報を基準として誤差を考慮したものである。また、n、w、hは、データベースファイルのブロック総数、各ブロック幅、各ブロック高さとする。尚、ステップS514におけるサイズ比較時に、位置情報(X,Y)の比較等を行ってもよい。
以上、検索の結果、総合類似率が閾値Thより高いもので候補として保存されたデータベースファイルをサムネール等で表示する(ステップS127)。これにより、複数の中から操作者の選択が必要な場合は、操作者の入力操作よってファイルの特定を行う。
[ベクトル化処理]
ファイルサーバにオリジナルの電子ファイルが存在しない場合は、図4に示すイメージデータを各ブロック毎にベクトル化する。以下では、図3のベクトル化処理(ステップS129)について詳細に説明する。
ファイルサーバにオリジナルの電子ファイルが存在しない場合は、図4に示すイメージデータを各ブロック毎にベクトル化する。以下では、図3のベクトル化処理(ステップS129)について詳細に説明する。
《文字認識》
前述したように、本実施形態の文字認識処理では、文字単位で切り出された画像に対し、パターンマッチングの一手法を用いて認識を行い、対応する文字コードを得る。この認識処理は、文字画像から得られる特徴を数十次元の数値列に変換した観測特徴ベクトルと、あらかじめ字種毎に求められている辞書特徴ベクトルと比較し、最も距離の近い字種を認識結果とする処理である。尚、特徴ベクトルの抽出には種々の公知手法があり、例えば、文字をメッシュ状に分割し、各メッシュ内の文字線を方向別に線素としてカウントしたメッシュ数次元ベクトルを特徴とする方法を用いることができる。
前述したように、本実施形態の文字認識処理では、文字単位で切り出された画像に対し、パターンマッチングの一手法を用いて認識を行い、対応する文字コードを得る。この認識処理は、文字画像から得られる特徴を数十次元の数値列に変換した観測特徴ベクトルと、あらかじめ字種毎に求められている辞書特徴ベクトルと比較し、最も距離の近い字種を認識結果とする処理である。尚、特徴ベクトルの抽出には種々の公知手法があり、例えば、文字をメッシュ状に分割し、各メッシュ内の文字線を方向別に線素としてカウントしたメッシュ数次元ベクトルを特徴とする方法を用いることができる。
ブロックセレクション処理(ステップS121)で抽出された文字領域に対して文字認識を行う場合、まず該当領域に対して横書き、縦書きの判定を行い、各々対応する方向に行を切り出し、その後文字を切り出して文字画像を得る。横書き、縦書きの判定は、該当領域内で画素値に対する水平/垂直の射影を取り、水平射影の分散が大きい場合は横書き領域、垂直射影の分散が大きい場合は縦書き領域と判断すればよい。
また、文字列及び文字への分解は、横書きの場合は水平方向の射影を利用して行を切り出し、さらに切り出された行に対する垂直方向の射影から、文字を切り出す。一方、縦書きの文字領域に対しては、水平と垂直を逆にすればよい。尚、文字のサイズは切り出した大きさに基づいて検出することができる。
《フォント認識》
文字認識の際に用いられる字種数分の辞書特徴ベクトルを、文字形状種、すなわちフォント種に対して複数用意し、マッチングの際に文字コードとともにフォント種を出力することで、文字のフォントを認識することができる。
文字認識の際に用いられる字種数分の辞書特徴ベクトルを、文字形状種、すなわちフォント種に対して複数用意し、マッチングの際に文字コードとともにフォント種を出力することで、文字のフォントを認識することができる。
《文字のベクトル化》
前述した文字認識及びフォント認識によって得られた、文字コード及びフォント情報を用いて、アウトライン化処理によるアウトラインデータを用いて、文字部分の情報をベクトルデータに変換する。尚、元原稿がカラーの場合は、カラー画像から各文字の色を抽出してベクトルデータとともに記録する。以上の処理により、文字ブロックに属するイメージ情報をほぼ形状、大きさ、色が忠実なベクトルデータに変換することができる。
前述した文字認識及びフォント認識によって得られた、文字コード及びフォント情報を用いて、アウトライン化処理によるアウトラインデータを用いて、文字部分の情報をベクトルデータに変換する。尚、元原稿がカラーの場合は、カラー画像から各文字の色を抽出してベクトルデータとともに記録する。以上の処理により、文字ブロックに属するイメージ情報をほぼ形状、大きさ、色が忠実なベクトルデータに変換することができる。
《文字以外の部分のベクトル化》
ステップS121のブロックセレクション処理で、線画或いは線、表領域とされた領域を対象として、それぞれ抽出された画素塊の輪郭をベクトルデータに変換する。具体的には、輪郭を成す画素の点列を角とみなされる点で区切って、各区間を部分的な直線或いは曲線で近似する。ここで、「角」とは、曲率が極大となる点である。
ステップS121のブロックセレクション処理で、線画或いは線、表領域とされた領域を対象として、それぞれ抽出された画素塊の輪郭をベクトルデータに変換する。具体的には、輪郭を成す画素の点列を角とみなされる点で区切って、各区間を部分的な直線或いは曲線で近似する。ここで、「角」とは、曲率が極大となる点である。
図11は、曲率が極大となる点を説明するための図である。図11に示すように、任意点Piに対して左右k個の離れた点Pi-k〜Pi+kの間に弦を引いたとき、この弦とPiの距離が極大となる点として求められる。さらに、Pi-k〜Pi+k間の弦の長さ/弧の長さをRとし、Rの値が閾値以下である点を角とみなすことができる。角によって分割された後の各区間は、直線は点列に対する最小二乗法等を用いて、曲線は3次スプライン関数等を用いてベクトル化することができる。
また、対象が内輪郭を持つ場合、ブロックセレクション処理で抽出した白画素輪郭の点列を用いて、同様に部分的直線或いは曲線で近似する。
以上のように、輪郭の区分線近似を用いることによって、任意形状の図形のアウトラインをベクトル化することができる。尚、入力される原稿がカラーの場合は、カラー画像から図形の色を抽出してベクトルデータとともに記録する。
図12は、外輪郭が内輪郭又は別の外輪郭と近接している場合に太さを持った線として表現する例について説明するための図である。図12に示すように、ある区間で外輪郭が、内輪郭又は別の外輪郭が近接している場合、2つの輪郭線を一まとめにし、太さを持った線として表現することができる。具体的には、ある輪郭の各点Piから別輪郭上で最短距離となる点Qiまで線を引き、各距離PQiが平均的に一定長以下の場合、注目区間はPQi中点を点列として直線又は曲線で近似し、その太さはPQiの平均値とする。線や線の集合体である表罫線は、前記したような太さを持つ線の集合として、効率よくベクトル表現することができる。
尚、文字ブロックに対する文字認識処理を用いたベクトル化については前述したように、当該文字認識処理の結果、辞書からの距離が最も近い文字を認識結果として用いる。ここで、この距離が所定値以上の場合は、必ずしも本来の文字に一致するとは限らず、形状が類似する文字に誤認識するような場合が多い。従って、本発明では、このような文字に対しては上記したように、一般的な線画と同様に扱って当該文字をアウトライン化する。すなわち、従来は文字認識処理で誤認識を起こしていたような文字でも、誤った文字にベクトル化されることなく、可視的にイメージデータに忠実なアウトライン化によるベクトル化を行うことができる。また、写真と判定されたブロックに対しては、本発明ではベクトル化せずに、イメージデータのままとする。
《図形認識》
ここでは、上述したように任意形状の図形のアウトラインをベクトル化した後、これらのベクトル化された区分線を図形オブジェクト毎にグループ化する処理について説明する。
ここでは、上述したように任意形状の図形のアウトラインをベクトル化した後、これらのベクトル化された区分線を図形オブジェクト毎にグループ化する処理について説明する。
図13は、ベクトルデータを図形オブジェクト毎にグループ化するまでの処理手順を説明するためのフローチャートである。まず、各ベクトルデータの始点、終点を算出する(ステップS700)。次に、各ベクトルの始点、終点情報を用いて、図形要素を検出する(ステップS701)。ここで、図形要素の検出とは、区分線が構成している閉図形を検出することである。検出に際しては、閉形状を構成する各ベクトルはその両端にそれぞれ連結するベクトルを有しているという原理を応用して検出を行う。
次に、図形要素内に存在する他の図形要素又は区分線をグループ化し、一つの図形オブジェクトとする(ステップS702)。尚、図形要素内に他の図形要素又は区分線が存在しない場合は、図形要素を図形オブジェクトとする。
図14は、図形要素を検出する処理手順を説明するためのフローチャートである。まず、ベクトルデータから両端に連結していない不要なベクトルを除去し、閉図形構成ベクトルを抽出する(ステップS710)。次に、閉図形構成ベクトルの中から当該ベクトルの始点を開始点とし、時計回りに順にベクトルを追っていく。そして、開始点に戻るまで追跡を行い、通過したベクトルを全て一つの図形要素を構成する閉図形としてグループ化する(ステップS711)。尚、この際に、閉図形内部にある閉図形構成ベクトルも全てグループ化する。さらに、まだグループ化されていないベクトルの始点を開始点とし、同様の処理を繰り返す。最後に、ステップS710で除去された不要ベクトルのうち、ステップS711で閉図形としてグループ化されたベクトルに接合しているものを検出し、一つの図形要素としてグループ化する(ステップS712)。
以上の処理によって、図形ブロックを個別に再利用可能な個別の図形オブジェクトとして扱うことが可能になる。
[アプリデータへの変換処理]
図15は、一頁分のイメージデータをブロックセレクション処理(ステップS121)及びベクトル化処理(ステップS129)によって変換された結果として得られる中間データ形式のファイルのデータ構造を示す図である。図15に示すようなデータ形式は、ドキュメント・アナリシス・アウトプット・フォーマット(DAOF)と呼ばれる。すなわち、図15は、DAOFのデータ構造を示す図である。
図15は、一頁分のイメージデータをブロックセレクション処理(ステップS121)及びベクトル化処理(ステップS129)によって変換された結果として得られる中間データ形式のファイルのデータ構造を示す図である。図15に示すようなデータ形式は、ドキュメント・アナリシス・アウトプット・フォーマット(DAOF)と呼ばれる。すなわち、図15は、DAOFのデータ構造を示す図である。
図15において、791はHeader(ヘッダ)であり、処理対象の文書画像データに関する情報が保持される。792はレイアウト記述データ部であり、文書画像データ中のTEXT(文字)、TITLE(タイトル)、CAPTION(キャプション)、LINEART(線画)、PICTURE(自然画)、FRAME(枠)、TABLE(表)等の属性毎に認識された各ブロックの属性情報とその矩形アドレス情報を保持する。
793は文字認識記述データ部であり、TEXT、TITLE、CAPTION等のTEXTブロックを文字認識して得られる文字認識結果を保持する。794は表記述データ部であり、TABLEブロックの構造の詳細を格納する。795は画像記述データ部であり、PICTUREやLINEART等のブロックのイメージデータを文書画像データから切り出して保持する。
このようなDAOFは、中間データとしてのみならず、それ自体がファイル化されて保存される場合もあるが、このファイルの状態では、一般の文書作成アプリケーションで個々のオブジェクトを再利用・再編集等することはできない。そこで、次に、DAOFからアプリデータに変換する処理(ステップS132)について詳説する。
図16は、アプリデータへの変換処理全体の概略手順を説明するためのフローチャートである。まず、DAOFデータを入力する(ステップS800)。次いで、アプリデータの元となる文書構造ツリー生成を行う(ステップS802)。そして、生成した文書構造ツリーに基づいて、DAOF内の実データを流し込み、実際のアプリデータを生成する(ステップS804)。
図17は、文書構造ツリー生成処理(ステップS802)の詳細な処理手順を説明するためのフローチャートである。また、図18は、文書構造ツリーの概要を説明するための図である。尚、全体制御の基本ルールとして、処理の流れはミクロブロック(単一ブロック)からマクロブロック(ブロックの集合体)へ移行するものとする。また、以後の説明では、ブロックとは、ミクロブロック及びマクロブロック全体を指す。
まず、ブロック単位で縦方向の関連性を元に再グループ化する(ステップS802a)。尚、スタート直後はミクロブロック単位での判定となる。ここで、関連性とは、距離が近く、ブロック幅(横方向の場合は高さ)がほぼ同一であること等で定義することができる。また、距離、幅、高さ等の情報はDAOFを参照して抽出する。
図18において、(a)は実際のページ構成、(b)はその文書構造ツリーを示している。ステップS802aのグループ化の結果、T3、T4、T5が一つのグループV1として、T6、T7が一つのグループV2として、それぞれ同じ階層のグループとして生成される。
次に、縦方向のセパレータの有無をチェックする(ステップS802b)。セパレータは、例えば、物理的にはDAOF中でライン属性を持つオブジェクトである。また、論理的な意味としては、アプリ中で明示的にブロックを分割する要素である。ここでセパレータを検出した場合は、同じ階層で再分割する。
次いで、分割がこれ以上存在し得ないか否かをグループ長を利用して判定する(ステップS802c)。例えば、縦方向のグルーピング長がページ高さか否かを判定する。その結果、縦方向のグループ長がページ高さとなっている場合は(Yes)、文書構造ツリー生成は終了する。例えば、図18に示すような構造の場合は、セパレータもなく、グループ高さはページ高さではないので、Noと判定され、ステップS802dに進む。
ステップS802dでは、ブロック単位で横方向の関連性を元に再グループ化する。但し、この再グループ化においてもスタート直後の第一回目は、ミクロブロック単位で判定を行うことになる。また、関連性及びその判定情報の定義は、縦方向の場合と同じである。例えば、図18の構造の場合は、T1とT2でH1、V1とV2でH2が生成され、H1はT1、T2の一つ上、H2はV1、V2の1つ上の同じ階層のグループとして生成される。
次いで、横方向セパレータの有無をチェックする(ステップS802e)。図18では、S1があるので、これをツリーに登録し、H1、S1、H2という階層が生成される。そして、分割がこれ以上存在し得ないか否かをグループ長を利用して判定する(ステップS802f)。例えば、横方向のグルーピング長がページ幅か否かを判定する。その結果、横方向のグループ長がページ幅となっている場合(Yes)、文書構造ツリー生成は終了する。一方、ページ幅となっていない場合(No)は、ステップS802bに戻り、再度もう一段上の階層で、縦方向の関連性チェックから繰り返す。例えば、図18の構造の場合は、分割幅がページ幅になっているので、ここで終了し、最後にページ全体を表す最上位階層のV0が文書構造ツリーに付加される。
文書構造ツリーが完成した後、その情報に基づいて、ステップS804においてアプリデータの生成を行う。図18の構造の場合は、具体的に以下のようになる。
すなわち、H1は横方向に2つのブロックT1、T2があるので、2カラムとし、T1の内部情報(DAOFを参照した文字認識結果の文章や画像等)を出力後、カラムを変えて、T2の内部情報出力し、その後S1を出力する。また、H2は横方向に2つのブロックV1、V2があるので、2カラムとして出力し、V1はT3、T4、T5の順にその内部情報を出力し、その後カラムを変えて、V2のT6、T7の内部情報を出力する。以上により、アプリデータへの変換処理を行うことができる。
[ポインタ情報の付加]
次に、ステップS135で示されるポインタ情報付加処理について詳細に説明する。処理すべき文書が検索処理で特定された場合、或いはベクトル化によって元ファイルが再生できた場合において、該文書を記録処理する場合においては、紙への記録の際にポインタ情報を付与することで、この文書を用いて再度各種処理を行う場合に簡単に元ファイルデータを取得できる。
次に、ステップS135で示されるポインタ情報付加処理について詳細に説明する。処理すべき文書が検索処理で特定された場合、或いはベクトル化によって元ファイルが再生できた場合において、該文書を記録処理する場合においては、紙への記録の際にポインタ情報を付与することで、この文書を用いて再度各種処理を行う場合に簡単に元ファイルデータを取得できる。
図19は、ポインタ情報としてのデータ文字列を2次元バーコード(QRコードシンボル:JIS X0510)311を用いて符号化して画像中に付加する手順を説明するためのフローチャートである。
2次元バーコード内に組み込むデータは、対応するファイルが格納されるサーバーアドレス情報を表しており、例えばファイルサーバ名からなるパス情報で構成される。或いは、対応するサーバのURLや、対応するファイルが格納されているデータベース105a、b内或いはMFP100自体が有する記憶装置111を管理するためのID等で構成される。
まず、符号化する種種の異なる文字を識別するため、入力データ列を分析する。また、誤り検出及び誤り訂正レベルを選択し、入力データが収容できる最小型番を選択する(ステップS900)。次に、入力データ列を所定のビット列に変換し、必要に応じてデータのモード(数字、英数字、8ビットバイト、漢字等)を表す指示子や、終端パターンを付加する。さらに、所定のビットコード語に変換することによってデータの符号化を行う(ステップS901)。
この時、誤り訂正を行うため、コード語列を型番及び誤り訂正レベルに応じて所定のブロック数に分割し、各ブロック毎に誤り訂正コード語を生成し、データコード語列の後に付加する(ステップS902)。さらに、ステップS902で得られた各ブロックのデータコード語を接続し、各ブロックの誤り訂正コード語、また必要に応じて剰余コード語を接続して、メッセージの構築を行う(ステップS903)。
次に、マトリクスに位置検出パターン、分離パターン、タイミングパターン及び位置合わせパターン等とともにコード語モジュールを配置する(ステップS904)。さらに、シンボルの符号化領域に対して最適なマスクパターンを選択して、マスク処理パターンをステップS904で得られたモジュールにXOR演算により変換する(ステップS905)。最後に、ステップS905で得られたモジュールに形式情報及び型番情報を生成して、2次元コードシンボルを完成させる(ステップS906)。
上述したサーバアドレス情報の組み込まれた2次元バーコードは、例えば、クライアントPC102から電子ファイルをプリントデータとして形成装置112で紙上に記録画像として形成する場合に、データ処理装置115内で記録可能なラスタデータに変換された後にラスタデータ上の所定の個所に付加されて画像形成される。ここで、画像形成された紙を配布されたユーザは、画像読み取り部110で読み取ることにより、前述したステップS124においてポインタ情報からオリジナルの電子ファイルが格納されているサーバの場所を適切に検出することができる。
尚、同様の目的で付加情報を付与する手段は、本実施例で説明した2次元バーコードの他に、例えば、ポインタ情報を直接文字列で文書に付加する方法、文書内の文字列、特に文字と文字の間隔を変調して情報を埋め込む方法、文書中の中間調画像中に埋め込む方法等の一般に電子透かしと呼ばれる方法を適用してもよい。
上述したように本実施例によれば、原稿を読み取ったイメージデータからユーザが所望している(クライアント側で指定された)アプリケーションフォーマットの電子ファイルを効率良く取得することができる。
以上、実施形態例を詳述したが、本発明は、例えば、システム、装置、方法、プログラムもしくは記憶媒体等としての実施態様をとることが可能であり、具体的には、複数の機器から構成されるシステムに適用しても良いし、また、一つの機器からなる装置に適用しても良い。
尚、本発明は、前述した実施形態の機能を実現するソフトウェアのプログラム(実施形態では図に示すフローチャートに対応したプログラム)を、システムあるいは装置に直接あるいは遠隔から供給し、そのシステムあるいは装置のコンピュータが該供給されたプログラムコードを読み出して実行することによっても達成される場合を含む。
従って、本発明の機能処理をコンピュータで実現するために、該コンピュータにインストールされるプログラムコード自体も本発明を実現するものである。つまり、本発明は、本発明の機能処理を実現するためのコンピュータプログラム自体も含まれる。
その場合、プログラムの機能を有していれば、オブジェクトコード、インタプリタにより実行されるプログラム、OSに供給するスクリプトデータ等の形態であっても良い。
プログラムを供給するための記録媒体としては、例えば、フロッピー(登録商標)ディスク、ハードディスク、光ディスク、光磁気ディスク、MO、CD−ROM、CD−R、CD−RW、磁気テープ、不揮発性のメモリカード、ROM、DVD(DVD−ROM,DVD−R)などがある。
その他、プログラムの供給方法としては、クライアントコンピュータのブラウザを用いてインターネットのホームページに接続し、該ホームページから本発明のコンピュータプログラムそのもの、もしくは圧縮され自動インストール機能を含むファイルをハードディスク等の記録媒体にダウンロードすることによっても供給できる。また、本発明のプログラムを構成するプログラムコードを複数のファイルに分割し、それぞれのファイルを異なるホームページからダウンロードすることによっても実現可能である。つまり、本発明の機能処理をコンピュータで実現するためのプログラムファイルを複数のユーザに対してダウンロードさせるWWWサーバも、本発明に含まれるものである。
また、本発明のプログラムを暗号化してCD−ROM等の記憶媒体に格納してユーザに配布し、所定の条件をクリアしたユーザに対し、インターネットを介してホームページから暗号化を解く鍵情報をダウンロードさせ、その鍵情報を使用することにより暗号化されたプログラムを実行してコンピュータにインストールさせて実現することも可能である。
また、コンピュータが、読み出したプログラムを実行することによって、前述した実施形態の機能が実現される他、そのプログラムの指示に基づき、コンピュータ上で稼動しているOSなどが、実際の処理の一部または全部を行ない、その処理によっても前述した実施形態の機能が実現され得る。
さらに、記録媒体から読み出されたプログラムが、コンピュータに挿入された機能拡張ボードやコンピュータに接続された機能拡張ユニットに備わるメモリに書き込まれた後、そのプログラムの指示に基づき、その機能拡張ボードや機能拡張ユニットに備わるCPUなどが実際の処理の一部または全部を行ない、その処理によっても前述した実施形態の機能が実現される。
100 デジタル複合機(MFP)
101 マネージメントPC
102 クライアントPC
103a、103b プロキシサーバ
104 ネットワーク
105a、105b データベース
106a、106b 文書管理サーバ
107、108、109 LAN
110 画像読み取り部
111 記憶装置
112 形成装置
113 入力装置
114、117 ネットワークI/F
115 データ処理装置
116 表示装置
101 マネージメントPC
102 クライアントPC
103a、103b プロキシサーバ
104 ネットワーク
105a、105b データベース
106a、106b 文書管理サーバ
107、108、109 LAN
110 画像読み取り部
111 記憶装置
112 形成装置
113 入力装置
114、117 ネットワークI/F
115 データ処理装置
116 表示装置
Claims (15)
- サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理システムであって、
前記原稿を読み取ってイメージ情報を取得する読取手段と、
前記読取手段により得られたイメージ情報を文字コード化する文字処理手段と、
前記読取手段により得られたイメージ情報をベクトルデータに変換するベクトル化手段と、
前記読取手段により得られたイメージ情報を所定の画像形式に変換する画像変換手段と、
前記読取手段により得られたイメージ情報を、その属性に応じて前記文字処理手段、前記ベクトル化手段、前記画像変換手段の少なくともいずれかを用いて変換する変換手段と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索手段と、
前記検索手段で検索された電子ファイルの属性情報に基づいて、前記変換手段により得たデータへの置き換えが許可されているか禁止されているかを判定する判定手段と、
前記判定手段によって前記変換手段により得られたデータへの置き換えが許可されていると判定された場合、前記検索手段により検索された電子ファイルを、前記変換手段によって得られたデータに置き換える置換手段と
を備えることを特徴とする画像処理システム。 - 前記検索手段により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出手段と、
前記抽出手段で抽出された差分情報を前記変換手段に基づき変換したデータを、前記検索手段で検索した電子ファイルに追加登録する追加手段と
をさらに備えることを特徴とする請求項1に記載の画像処理システム。 - 前記追加手段は、前記抽出手段で抽出された差分情報を前記検索手段で検索された電子ファイルに対応付けることを特徴とする請求項2に記載の画像処理システム。
- 前記置換手段による置換、或いは前記追加手段への追加を行う際、パスワードの入力を要求する要求手段と、
入力されたパスワードを認証する認証手段とをさらに備え、
前記置換手段、或いは前記追加手段は、前記認証手段により前記パスワードが正しく認証された場合、前記変換手段に基づき変換したデータの置換、或いは追加を行う
ことを特徴とする請求項2又は3に記載の画像処理システム。 - 前記電子ファイルの属性情報に含まれるメールアドレスに基づいて、該メールアドレス宛てに、前記置換手段による置換、或いは前記追加手段による追加が行われたことを通知する通知手段をさらに備えることを特徴とする請求項2から4までのいずれか1項に記載の画像処理システム。
- 前記検索手段が、前記イメージ情報から前記原稿中に付加されている該原稿に対応する電子ファイルの格納場所を示す情報を認識することによって、該電子ファイルを検索することを特徴とする請求項1から5までのいずれか1項に記載の画像処理システム。
- 前記文字処理手段が、
前記原稿中の文字を文字認識処理する文字認識手段と、
前記文字認識処理の結果に基づいて前記文字をフォントデータに置き換えるフォント化手段と
を備えることを特徴とする請求項1から6までのいずれか1項に記載の画像処理システム。 - 前記変換手段が、前記イメージ情報を複数のオブジェクトに分割し、それぞれのオブジェクトを独立に処理することを特徴とする請求項1から7までのいずれか1項に記載の画像処理システム。
- 前記変換手段が、所定のソフトウェアアプリケーションで取り扱い可能なフォーマットに変換するフォーマット変換手段をさらに備えることを特徴とする請求項1から8までのいずれか1項に記載の画像処理システム。
- 前記変換手段で変換されたデータを所定の格納場所に格納する格納手段と、
前記変換手段で変換されたデータが格納された前記格納場所に関する情報を付加情報として生成する生成手段と、
前記付加情報を前記変換手段で変換されたデータに付加する付加手段と
をさらに備えることを特徴とする請求項1から9までのいずれか1項に記載の画像処理システム。 - 前記検索手段が、さらに、前記読取手段によって取得された前記原稿のイメージ情報中に所定情報が含まれている場合に限り前記電子ファイルを検索することを特徴とする請求項1から10までのいずれか1項に記載の画像処理システム。
- 前記検索手段が、さらに、前記追加手段による差分情報の追加後に当該差分情報の追加前の電子ファイルを検索を行うことを特徴とする請求項2から11までのいずれか1項に記載の画像処理システム。
- サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理システムであって、
前記原稿を読み取ってイメージ情報を取得する読取手段と、
前記読取手段により得られたイメージ情報を文字コード化する文字処理手段と、
前記読取手段により得られたイメージ情報をベクトルデータに変換するベクトル化手段と、
前記読取手段により得られたイメージ情報を所定の画像形式に変換する画像変換手段と、
前記読取手段により得られたイメージ情報を、その属性に応じて前記文字処理手段、前記ベクトル化手段、前記画像変換手段の少なくともいずれかを用いて変換する変換手段と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索手段と、
前記検索手段により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出手段と、
前記検索手段で検索された電子ファイルの属性情報に基づいて、前記抽出手段で抽出された差分情報の追加が許可されているか禁止されているか判定する判定手段と、
前記判定手段により前記変換手段によって変換されたデータの追加が許可されていると判定された場合、前記検索手段により検索された電子ファイルに前記抽出手段で抽出された差分情報を前記変換手段により変換されたデータを追加する追加手段と
を備えることを特徴とする画像処理システム。 - サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理方法であって、
前記原稿を読み取ってイメージ情報を取得する読取工程と、
前記読取工程により得られたイメージ情報を文字コード化する文字処理工程と、
前記読取工程により得られたイメージ情報をベクトルデータに変換するベクトル化工程と、
前記読取工程により得られたイメージ情報を所定の画像形式に変換する画像変換工程と、
前記読取工程により得られたイメージ情報を、その属性に応じて前記文字処理工程、前記ベクトル化工程、前記画像変換工程の少なくともいずれかを用いて変換する変換工程と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索工程と、
前記検索工程で検索された電子ファイルの属性情報に基づいて、前記変換工程により得たデータへの置き換えが許可されているか禁止されているかを判定する判定工程と、
前記判定工程によって前記変換工程により得られたデータへの置き換えが許可されていると判定された場合、前記検索工程により検索された電子ファイルを、前記変換工程によって得られたデータに置き換える置換工程と
を有することを特徴とする画像処理方法。 - サーバが保持する電子ファイルの中から指定された原稿に対応する電子ファイルを検索し、検索された電子ファイルを取得して出力する画像処理方法であって、
前記原稿を読み取ってイメージ情報を取得する読取工程と、
前記読取工程により得られたイメージ情報を文字コード化する文字処理工程と、
前記読取工程により得られたイメージ情報をベクトルデータに変換するベクトル化工程と、
前記読取工程により得られたイメージ情報を所定の画像形式に変換する画像変換工程と、
前記読取工程により得られたイメージ情報を、その属性に応じて前記文字処理工程、前記ベクトル化工程、前記画像変換工程の少なくともいずれかを用いて変換する変換工程と、
前記イメージ情報に対応する電子ファイルを前記サーバが保持する電子ファイルの中から検索する検索工程と、
前記検索工程により電子ファイルが検索できた場合、該電子ファイルと前記イメージ情報との差分情報を抽出する抽出工程と、
前記検索工程で検索された電子ファイルの属性情報に基づいて、前記抽出工程で抽出された差分情報の追加が許可されているか禁止されているか判定する判定工程と、
前記判定工程により前記変換工程によって変換されたデータの追加が許可されていると判定された場合、前記検索工程により検索された電子ファイルに前記抽出工程で抽出された差分情報を前記変換工程により変換されたデータを追加する追加工程と
を有することを特徴とする画像処理方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003390747A JP2005157447A (ja) | 2003-11-20 | 2003-11-20 | 画像処理システム及び画像処理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003390747A JP2005157447A (ja) | 2003-11-20 | 2003-11-20 | 画像処理システム及び画像処理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005157447A true JP2005157447A (ja) | 2005-06-16 |
| JP2005157447A5 JP2005157447A5 (ja) | 2007-01-18 |
Family
ID=34718026
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003390747A Pending JP2005157447A (ja) | 2003-11-20 | 2003-11-20 | 画像処理システム及び画像処理方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2005157447A (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007213321A (ja) * | 2006-02-09 | 2007-08-23 | Canon Inc | 情報処理装置、情報処理装置の制御方法、及びプログラム |
| JP2008077204A (ja) * | 2006-09-19 | 2008-04-03 | Konica Minolta Business Technologies Inc | 情報処理装置及び利用者の固有情報の登録方法 |
-
2003
- 2003-11-20 JP JP2003390747A patent/JP2005157447A/ja active Pending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007213321A (ja) * | 2006-02-09 | 2007-08-23 | Canon Inc | 情報処理装置、情報処理装置の制御方法、及びプログラム |
| JP2008077204A (ja) * | 2006-09-19 | 2008-04-03 | Konica Minolta Business Technologies Inc | 情報処理装置及び利用者の固有情報の登録方法 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4266784B2 (ja) | 画像処理システム及び画像処理方法 | |
| US7640269B2 (en) | Image processing system and image processing method | |
| US7542605B2 (en) | Image processing apparatus, control method therefor, and program | |
| JP4251629B2 (ja) | 画像処理システム及び情報処理装置、並びに制御方法及びコンピュータプログラム及びコンピュータ可読記憶媒体 | |
| US7681121B2 (en) | Image processing apparatus, control method therefor, and program | |
| JP4393161B2 (ja) | 画像処理装置及び画像処理方法 | |
| JP3997198B2 (ja) | 画像処理システム及び画像処理方法 | |
| JP3862694B2 (ja) | 画像処理装置及びその制御方法、プログラム | |
| JP4502385B2 (ja) | 画像処理装置およびその制御方法 | |
| JP2005159517A (ja) | 画像処理装置及びその制御方法、プログラム | |
| JP2008109394A (ja) | 画像処理装置及びその方法、プログラム | |
| JP4338189B2 (ja) | 画像処理システム及び画像処理方法 | |
| JP2006025129A (ja) | 画像処理システム及び画像処理方法 | |
| JP2007129557A (ja) | 画像処理システム | |
| CN100501728C (zh) | 图像处理方法、系统、程序、程序存储介质以及信息处理设备 | |
| JP2005149097A (ja) | 画像処理システム及び画像処理方法 | |
| JP4185858B2 (ja) | 画像処理装置及びその制御方法、プログラム | |
| JP2006134042A (ja) | 画像処理システム | |
| JP2005157447A (ja) | 画像処理システム及び画像処理方法 | |
| JP2005157905A (ja) | 画像処理装置、画像処理方法およびプログラム | |
| JP2006146486A (ja) | 画像処理装置 | |
| JP2005149098A (ja) | 画像処理システム及び画像処理装置並びに画像処理方法 | |
| JP2005208872A (ja) | 画像処理システム | |
| JP2005165674A (ja) | 画像処理装置、画像処理方法、及びコンピュータプログラム | |
| JP2006195886A (ja) | 画像処理システム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061117 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061117 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080623 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20081205 |