JP2004234582A - Dictionary construction method, system, and screen - Google Patents
Dictionary construction method, system, and screen Download PDFInfo
- Publication number
- JP2004234582A JP2004234582A JP2003025359A JP2003025359A JP2004234582A JP 2004234582 A JP2004234582 A JP 2004234582A JP 2003025359 A JP2003025359 A JP 2003025359A JP 2003025359 A JP2003025359 A JP 2003025359A JP 2004234582 A JP2004234582 A JP 2004234582A
- Authority
- JP
- Japan
- Prior art keywords
- term
- search
- data
- dictionary
- edited
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images




Abstract
Description
【0001】
【発明の属する技術分野】
本発明は辞書を構築する辞書構築方法,辞書構築システム,画面装置に関する。
【0002】
【従来の技術】
インターネットやドキュメント管理システムにおいて、情報ソースとなるドキュメントやデータファイル等のコンテンツの量が膨大になってくると、ユーザが必要とする情報を入手するための手間も一般に多くなる。そこで、少ない手間で必要な情報を入手するために、ユーザが利用したい情報の分野毎の専門用語、および、その上位概念や下位概念,別名,類義語等の用語間の関係をあらかじめコンピュータが理解可能なように辞書データベース化しておき、この辞書データベースを情報の検索や抽出,分類に利用している。
【0003】
しかしながら、上記のような専門用語の辞書データベースを構築する作業は、従来、その分野の有識者により人手で行われ、その作業工数も語数に応じてかなり多いという課題があった。具体的には、一般的な辞書構築方法としては、専門分野のドキュメントを入力として、これを自動的に用語に切り出す処理(形態素解析処理)を行って得られた用語集合に対して、人手で不要用語除去や分類作業を行っていた。
【0004】
これらの人手作業を低減するために、特開平11−296549号公報では概念情報の辞書編集のためのユーザインタフェースについて記載されており、特に関連度を用いて関連する概念情報の候補を一覧する方法が記載されている。
【0005】
【特許文献1】
特開平11−296549号公報
【0006】
【発明が解決しようとする課題】
従来技術では、特定分野のドキュメント、あるいはドキュメント群を入力として形態素解析を行い、得られた用語集合を用語間の関連度合い等を利用して分類、あるいは分類候補を提示している。
【0007】
しかしながら、入力を特定分野のドキュメントとすることにより、以下の課題がある。
【0008】
まず、ドキュメントは用語の集合体であることから、専門用語を抽出する処理として形態素解析処理を用いる必要があるが、これにより一般にノイズ(不要用語)除去の手間が発生し、ドキュメントの規模に応じて増大する傾向にある。このノイズ除去にドキュメント中の用語出現頻度等のパラメータが使われる場合があるが、出現頻度が極端に多い、あるいは少ないことと、専門用語である可能性との関連性は一概に言えない。
【0009】
また、用語の出現頻度等で一律に傾向を把握することはできても、古い用語と最新の用語を区別することはできず、用語の鮮度維持という観点では従来技術は利用できない。
【0010】
そこで、本発明の目的は、辞書構築工数を低減する辞書構築方法,システム及び画面を提供することである。
【0011】
【課題を解決するための手段】
本発明の一つの特徴は、辞書を構築する方法において、検索履歴情報から抽出された検索キーワード又は検索属性情報から、辞書を構築することである。
【0012】
なお、本発明のその他の特徴は本願特許請求の範囲に記載のとおりである。
【0013】
【発明の実施の形態】
以下、図面を用いて本発明の実施の形態を説明する。
【0014】
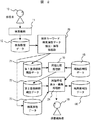
第1の実施例は、検索者10(ユーザ)が検索機能を利用した際の検索履歴データを利用して、用語辞書の構築支援を行う例であり、図1はその一例である。
【0015】
本実施例における検索機能とは、ファイルシステム,ドキュメント管理システム,メールシステム,インターネット等の検索エンジン等において、ユーザが必要とするファイル内の情報をキーワードを入力することで検索する機能を意味する。
【0016】
ここで「ファイル」とは、ワードプロセッサやエディタ等で作成されたドキュメントデータやHTML(Hyper Text Markup Language),XML(eXtensibleMarkup Language )等のインターネットにおける標準的なドキュメントデータ,ソフトウェアを記述するプログラムデータ,形状データ,解析データ,画像データ,動画データ等、データの1単位を意味する。
【0017】
また、検索キーワードはキーボード入力,音声入力等、最終的に単語として電子化できるものを意味する。
【0018】
まず、ユーザ検索者10が検索機能11を用いて自由に検索を行う。具体的には、ユーザがインターネットの検索エンジンを使用することである。これにより、検索履歴データ12が得られる。なお、検索者10が検索機能11を用いて検索する回数が多いほど、検索履歴データ12の量が多く、より充実した辞書を構築することが可能である。
【0019】
そこで、この検索履歴データ12から、検索キーワード抽出・保存処理部13は、検索キーワードを抽出し、その結果を第1登録候補用語データ14としてデータベースに格納する。次に、用語比較処理部16は、すでに専門用語辞書が存在する場合は、これを編集前用語データ15として、第1登録候補用語データ14と用語の文字列パタンマッチングを行い、編集前用語データ15に存在しない登録候補用語を抽出し、その結果を第2登録候補用語データ17としてデータベースに格納する。
【0020】
また、初回利用で編集前用語データ15が存在しない場合は、基本となる用語分類データを作成して、編集前用語データ15としてもよい。
【0021】
これにより、古い用語と最新の用語を区別することが可能となり、用語の鮮度維持をすることができる。
【0022】
次に、用語構成表示・編集処理部18では、最初に編集前用語データ15を読み込み、次に、辞書編集者19の指定する絞り込み条件に従って、第2登録候補用語データ17を読み込む。
【0023】
ここで登録候補用語の絞り込み方法の例としては、
[表記] [意味]
X* :先頭にXがつく用語すべて
X??? :Xの後に任意の3文字が続く
等の正規表現を利用して文字列マッチングを行う方法がある。
【0024】
また、用語構成表示とは、文字列の用語データは一般に上位語,下位語等の分類階層を持つことから、ツリー形式で画面上に表示することを意味する。
【0025】
以降、辞書編集者の操作により、画面上で、第2登録候補用語データから選択された用語を、ツリー形式で表示された編集前用語データ15の中の最適なノード(用語)の下に追加することで、用語編集を実行する。
【0026】
最後に、編集終了後は、編集結果を編集後用語データ100としてデータベースに保存する。
【0027】
なお、上記の説明では編集前用語データ15と編集後用語データ100は区別したが、一つのデータとして、編集後に上書きしてもよい。
【0028】
以上の実施の形態より、検索履歴情報から作業工数を少なくて、用語鮮度の高い辞書を構築することが可能となる。
【0029】
第2の実施例は、第1の実施例に、さらに検索属性データを利用して、辞書編集効率の向上をねらった例であり、図2はその一例である。
【0030】
検索機能11によって出力された検索履歴データ12から、検索キーワード,検索属性データ抽出・保存処理部20は、検索キーワード、および検索属性データを抽出し、その結果を、検索キーワードは第1登録候補用語データ21として、検索属性データは23としてデータベースに格納する。この際、21と23のデータ間は用語ID等で関連付けておく。
【0031】
ここで検索属性データとは、検索者が検索機能を利用して検索した際の日時,ヒット数等、1回の検索操作に関する情報である。また、検索者を特定できるデータ、たとえば、使用マシンのID(IPアドレス等)や、システムへのログイン情報から得られるユーザ情報も検索属性データに含まれる。
【0032】
用語構成表示・編集処理部24では、最初に編集前用語データ15を読み込み、次に、辞書編集者19の指定する絞り込み条件に従って、第2登録候補用語データ22を読み込む。
【0033】
ここで登録候補用語の絞り込みとしては、第一の実施例の正規表現を絞り込み条件とする方法の他に、検索日時,検索者,検索ヒット率等の検索属性データ
23を用いて絞り込み条件とする。検索条件の例としては以下の通り。
検索日時:2000年1月1日〜2001年12月31日
検索者:山田太郎
検索ヒット数:10件未満(または以上)
また、システムのユーザ管理情報からユーザの組織情報が得られる場合は、上記の検索者の部分に会社・部・課等の組織情報を指定してもよい。これにより、たとえば「A会社」向け,「B設計部」向けといった専門辞書の構築が容易になる。また、検索ヒット数を絞り込み条件として用いることにより、まだ、あまり一般的に使われない用語、あるいは逆に、すでに一般的に使われている用語をある程度絞り込める。また、検索ヒット数0件の場合は、検索キーワードが正しくない可能性が高いと判断してもよい。
【0034】
第3の実施例は、第2の実施例における第1登録候補用語データ21,第2登録候補用語データ22,検索属性データ23のデータ構造の一例であり、図3はその一例である。
【0035】
テーブル30は第2の実施例における第1登録候補用語データ21,第2登録候補用語データ22のデータ構造で、登録候補用語ID31と登録候補用語32を一つの行として対応付ける。
【0036】
さらにテーブル33は第2の実施例における検索属性データ23のデータ構造で、登録候補用語ID34と検索日時35,検索者36、等の検索属性データを一つの行として対応付ける。ここでは検索者36を識別するために、マシンの
IPアドレスを利用している。
【0037】
このようなデータ構造にすることによって、新たな検索属性項目の追加が容易になる。
【0038】
第4の実施例は、第2の実施例における検索機能利用時、および辞書構築時の処理の流れを示し、図4はその一例である。
【0039】
検索機能利用時は、処理40のように、検索者10が検索機能を利用して情報を検索した履歴を検索履歴データ12として保存する。
【0040】
一方、辞書構築時には、最初に、処理41のように、検索履歴データ12から検索キーワード,検索属性データを抽出し、検索キーワードを第1登録候補用語データ21,検索属性データ23として保存する。
【0041】
次に、処理42のように、編集前用語データ15と第1登録候補用語データ
21を比較して、編集前用語データ15に存在しない登録候補用語を抽出し、第2登録候補用語データ22として保存する。
【0042】
さらに、辞書編集時には、処理43のように、第2登録候補用語データ22と編集前用語データ15を読み込んで表示し、辞書編集者19がその表示を受け付けて、指示を行うことにより用語の編集が行われる。編集後、処理44のように、編集結果を編集後用語データ100として保存する。
【0043】
第5の実施例は、第1,第2の実施例における辞書編集画面の例を示し、図5はその一例である。
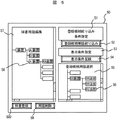
【0044】
画面50は、編集前用語データ15をツリー表示・編集するエリア57(画面左側)と、登録候補用語を選択するエリア(画面右側)に分かれる。
【0045】
登録候補用語絞り込み条件指定エリア51では、第1の実施例で示した用語の正規表現による絞り込み条件や、第2の実施例で示した検索属性データによる絞り込み条件を入力する。絞り込み条件入力後、登録候補用語絞り込みボタン52をマウス等のポインティングデバイスでクリックすることにより、登録候補絞り込み処理が実行される。
【0046】
次に、表示条件指定エリア53では、上記で絞り込まれた用語の表示順序等、表示条件を指定する。表示条件としては、単純な用語一覧表示で降順,昇順の他、文字列パタンマッチングにより階層化して表示する方法等がある。表示条件入力後、表示条件反映ボタン54をマウス等のポインティングデバイスでクリックすることにより、表示反映処理が実行され、登録候補用語選択エリア55に結果が表示される。
【0047】
登録候補用語選択エリア55で、辞書編集者が辞書に登録したい用語56をマウス等のポインティングデバイスで選択し、これを辞書用語編集エリア57の該当すると思われる用語58のところにドラッグ&ドロップする。その結果、辞書用語編集エリア57のドロップ先の用語58の下位階層に、用語56が追加される。
【0048】
なお、辞書用語編集エリア57内でも用語の移動がドラッグ&ドロップで任意に行え、不要な用語があれば、用語選択後、用語削除ボタン59をマウス等のポインティングデバイスでクリックすることにより、削除可能である。
【0049】
最終的に辞書編集作業が終了した時点で、辞書登録ボタン500をマウス等のポインティングデバイスでクリックすることにより、編集後用語データとして保存される。
【0050】
これにより、辞書登録用語を登録する際に、編集前用語データ15(既存の辞書)の用語と関連付けて辞書登録用語を登録することが可能となる。
【0051】
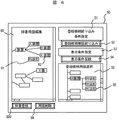
第6の実施例は、第5の実施例における辞書用語編集エリアの別の画面例を示し、図6はその一例である。
【0052】
登録候補用語選択エリア55で、辞書編集者が辞書に登録したい用語56をマウス等のポインティングデバイスで選択すると、その用語56が辞書用語編集エリア60の中央部に表示される。
【0053】
同時に、用語56と編集前用語データの各用語との文字列パタンマッチングにより、文字列一致度を算出する。たとえば、登録候補用語が「XXZ装置」の場合、「X装置」との文字列一致度の例としては、
一致文字検出方向:後方
位置が一致した文字数:a=2文字
それ以外に一致した文字:b=1文字
(文字列一致度)=w1×a+w2×b
ここで、w1,w2は重み(0以上の数値)で、一般に、w1>w2とする。辞書用語編集エリア60の中央部からの距離は、例として、
(距離)=1/(文字列一致度)
のように、文字列一致度の逆数を用いる方法がある。
【0054】
以上の方法により辞書用語編集エリア60で各用語の配置位置を決定すると、用語61に類似する用語が中央部近くに、類似しない用語が遠くに表示される。
【0055】
辞書編集者は用語61の近くに表示されている用語の中から該当すると思われる用語62のところにドラッグ&ドロップする。その結果、辞書用語編集エリアのドロップ先の用語62の下位階層に、用語61が追加される。
【0056】
これにより、辞書登録用語を登録する際に、編集前用語データ15(既存の辞書)に含まれる一致度の高い用語と関連付けて辞書登録用語を登録することが可能となる。
【0057】
第7の実施例は、本発明を辞書構築サービスに適用した場合のシステム構成例であり、図7はその一例である。
【0058】
検索サービスを行うための検索エンジン用サーバ72は、インターネット等のネットワーク74を介して、情報ソース73から検索用のインデックスを生成しておく。また、情報検索者76は検索用クライアント75を通じて、ネットワーク74を介して検索エンジン用サーバ72にアクセスする。ここで、システム管理者70は管理用クライアント71を通じて検索エンジン用サーバ72を管理している。
【0059】
辞書構築サービスを受ける者は、同じ組織に属する情報検索者76の検索履歴データ78を、辞書構築サービス提供者79に提供することを許可する。
【0060】
辞書構築サービス提供者79は検索履歴データ78、および利用者データ77を、本発明ですでに述べた辞書構築支援システム700に取り込み、専門用語辞書を構築する。
【0061】
サービス料金は、最終成果物である辞書の語数や情報検索者76の人数等でランク分けして設定してもよい。
【0062】
これにより、顧客に対して、円滑な辞書構築サービスを行うことが可能となる。
【0063】
以上により、様々な実施の形態について説明したが、これを実現する装置は、専用の装置として構成することも可能であるが、図8に例示するように、キーボード81と、前述したようなデータや処理プログラムを入力する入力手段,入力されたデータやプログラムをデータベースとして蓄積する記憶部,演算部などを備えたコンピュータ本体82と、ディスプレイ83で構成される汎用のコンピュータシステムとその上で稼働する処理プログラムによって実現することが可能である。
【0064】
このような汎用のコンピュータシステムに処理プログラムを付加して実現するときには、処理プログラムは図9に例示するような磁気ディスク91や図10に例示するようなCD−ROM101などのメディアに記録して配送,保管,実装され、コンピュータ本体82に設けた磁気ディスク読み取り装置やCD−ROM読み取り装置によって読み取って該コンピュータ本体82内に取り込まれる。通信ネットワークを通じて配送される処理プログラムを入力手段によって取り込んで実現する場合には、取り込んだ処理プログラムを磁気ディスク等のメディアに記憶させて保存することにより、繰り返し使用できるようにする。
【0065】
【発明の効果】
本発明によれば、辞書構築工数を低減する辞書構築方法,システム及び画面を提供できる。
【図面の簡単な説明】
【図1】本発明の実施例において、ユーザが検索機能を利用した際の検索履歴データを利用して、用語辞書の構築支援を実現するための機能ブロック図の一例である。
【図2】図1において、検索属性データを利用して、辞書編集効率の向上を実現する機能ブロック図の一例である。
【図3】図1,図2におけるデータベースのデータ構造図の一例である。
【図4】図2における検索機能利用時、および辞書構築時の処理の流れを表すフロー図の一例である。
【図5】第1,第2の実施例における辞書編集画面の一例である。
【図6】図5における辞書用語編集エリアの別画面の一例である。
【図7】本発明を辞書構築サービスに適用した場合のシステム構成例である。
【図8】コンピュータシステムの一例。
【図9】磁気ディスクの一例。
【図10】CD−ROMの一例。
【符号の説明】
10,36…検索者、11…検索機能、12,78…検索履歴データ、13…検索キーワード抽出・保存処理部、14,21…第1登録候補用語データ、15…編集前用語データ、16…用語比較処理部、17,22…第2登録候補用語データ、18,24…用語構成表示・編集処理部、19…辞書編集者、20…検索キーワード,検索属性データ抽出・保存処理部、23…検索属性データ、30,33…テーブル、31,34…登録候補用語ID、32,56,61…登録候補用語、35…検索日時、40…図1,図2の検索時の処理ステップ、41,42,43,44…辞書構築時の処理ステップ、50…画面、51…登録候補用語絞り込み条件指定エリア、52…登録候補用語絞り込みボタン、53…表示条件指定エリア、54…表示条件反映ボタン、55…登録候補用語選択エリア、57,60…辞書用語編集エリア、58,62…登録先用語(親)、59…用語削除ボタン、70…システム管理者、71…管理用クライアント、72…検索エンジン用サーバ、73…情報ソース、74…ネットワーク、75…検索用クライアント、76…情報検索者、77…利用者データ、79…辞書構築サービス提供者、81…キーボード、82…コンピュータ本体、83…ディスプレイ、91…磁気ディスク、100…編集後用語データ、101…CD−ROM、500…辞書登録ボタン、700…辞書構築支援システム。[0001]
TECHNICAL FIELD OF THE INVENTION
The present invention relates to a dictionary construction method for constructing a dictionary, a dictionary construction system, and a screen device.
[0002]
[Prior art]
In the Internet and document management systems, when the amount of contents such as documents and data files serving as information sources becomes enormous, the labor required for users to obtain necessary information generally increases. Therefore, in order to obtain necessary information with a small amount of time, the computer can understand in advance the technical terms for each field of information that the user wants to use and the relationships between terms such as superordinate and subordinate concepts, aliases, and synonyms. A dictionary database is prepared in this way, and this dictionary database is used for searching, extracting, and classifying information.
[0003]
However, the task of constructing a dictionary database of technical terms as described above has conventionally been performed manually by experts in the field, and there has been a problem that the number of work steps is considerably large depending on the number of words. Specifically, as a general dictionary construction method, a term set obtained by inputting a document in a specialized field and automatically extracting the term into words (morphological analysis process) is manually input. Unnecessary terms were removed and classified.
[0004]
In order to reduce these manual operations, Japanese Patent Application Laid-Open No. H11-296549 describes a user interface for editing a dictionary of concept information, and in particular, a method of listing related concept information candidates using a degree of association. Is described.
[0005]
[Patent Document 1]
JP-A-11-296549 [0006]
[Problems to be solved by the invention]
In the related art, a morphological analysis is performed by using a document in a specific field or a document group as an input, and the obtained term set is classified using the degree of association between terms or the like, or a classification candidate is presented.
[0007]
However, when the input is a document in a specific field, there are the following problems.
[0008]
First, since a document is a set of terms, it is necessary to use morphological analysis as a process for extracting technical terms. However, this generally requires time and effort to remove noise (unnecessary terms), and depends on the size of the document. Tend to increase. A parameter such as a term appearance frequency in a document may be used for this noise removal. However, the relationship between an extremely high or low appearance frequency and the possibility of a technical term cannot be generally described.
[0009]
Further, even if the tendency can be uniformly grasped based on the frequency of appearance of the term, the old term cannot be distinguished from the latest term, and the conventional technology cannot be used from the viewpoint of maintaining the freshness of the term.
[0010]
Therefore, an object of the present invention is to provide a dictionary construction method, system, and screen for reducing the number of dictionary construction steps.
[0011]
[Means for Solving the Problems]
One feature of the present invention is that in a method for constructing a dictionary, the dictionary is constructed from search keywords or search attribute information extracted from search history information.
[0012]
The other features of the present invention are as described in the claims of the present application.
[0013]
BEST MODE FOR CARRYING OUT THE INVENTION
Hereinafter, embodiments of the present invention will be described with reference to the drawings.
[0014]
The first embodiment is an example in which the searcher 10 (user) uses the search history data at the time of using the search function to support the construction of a term dictionary, and FIG. 1 shows an example thereof.
[0015]
The search function in the present embodiment means a function of searching for information in a file required by a user by inputting a keyword in a search engine such as a file system, a document management system, a mail system, and the Internet.
[0016]
Here, "file" refers to document data created by a word processor or an editor or the like, standard document data on the Internet such as HTML (Hyper Text Markup Language), XML (extensible Markup Language), program data describing software, and program data. One unit of data, such as data, analysis data, image data, and moving image data.
[0017]
The search keyword means a keyword that can be finally digitized as a word, such as a keyboard input or a voice input.
[0018]
First, the user searcher 10 freely searches using the search function 11. Specifically, the user uses an Internet search engine. Thereby, the
[0019]
Therefore, the search keyword extraction /
[0020]
If the
[0021]
This makes it possible to distinguish between the old term and the latest term, and maintain the freshness of the term.
[0022]
Next, the term configuration display /
[0023]
Here, as an example of a method for narrowing the registration candidate terms,
[Notation] [Meaning]
X *: All terms preceded by X are X? ? ? : There is a method of performing character string matching using a regular expression such as X followed by any three characters.
[0024]
The term composition display means that character string term data is generally displayed on a screen in a tree format because it has a classification hierarchy of upper words, lower words, and the like.
[0025]
Thereafter, the term selected from the second registration candidate term data is added below the optimal node (term) in the
[0026]
Finally, after the editing is completed, the edited result is stored in the database as the
[0027]
In the above description, the
[0028]
According to the above-described embodiment, it is possible to construct a dictionary with high term freshness while reducing the number of work steps from the search history information.
[0029]
The second embodiment is an example in which the search attribute data is further used to improve the dictionary editing efficiency in the first embodiment, and FIG. 2 shows an example thereof.
[0030]
From the
[0031]
Here, the search attribute data is information on one search operation, such as the date and time and the number of hits when a searcher performs a search using the search function. The search attribute data also includes data that can identify the searcher, for example, the ID (IP address or the like) of the machine used and user information obtained from login information to the system.
[0032]
The term configuration display /
[0033]
Here, in order to narrow down the registration candidate terms, in addition to the method of using the regular expression of the first embodiment as a narrowing condition, the narrowing condition is set using
Search date and time: January 1, 2000-December 31, 2001 Searcher: Taro Yamada Search hits: Less than 10 (or more)
When the organization information of the user can be obtained from the user management information of the system, organization information of a company, department, section, or the like may be specified in the searcher. This facilitates the construction of specialized dictionaries for, for example, “Company A” and “B Design Department”. In addition, by using the number of search hits as a narrowing condition, terms that are not commonly used yet, or conversely, terms that are already generally used can be narrowed down to some extent. When the number of search hits is 0, it may be determined that there is a high possibility that the search keyword is incorrect.
[0034]
The third embodiment is an example of the data structure of the first registration
[0035]
The table 30 is a data structure of the first registration
[0036]
Further, the table 33 has the data structure of the
[0037]
With such a data structure, it is easy to add a new search attribute item.
[0038]
The fourth embodiment shows the flow of processing when using the search function and constructing a dictionary in the second embodiment, and FIG. 4 shows an example thereof.
[0039]
When the search function is used, the history in which the
[0040]
On the other hand, when constructing a dictionary, first, as in
[0041]
Next, as in a
[0042]
Further, at the time of editing the dictionary, the second registration
[0043]
The fifth embodiment shows an example of the dictionary editing screen in the first and second embodiments, and FIG. 5 shows an example thereof.
[0044]
The
[0045]
In the registration candidate term narrowing
[0046]
Next, in the display
[0047]
In the registration candidate
[0048]
In the dictionary
[0049]
When the dictionary editing operation is finally completed, the
[0050]
Thereby, when registering the dictionary registration terms, it becomes possible to register the dictionary registration terms in association with the terms in the pre-editing term data 15 (existing dictionary).
[0051]
The sixth embodiment shows another example of the dictionary term editing area screen in the fifth embodiment, and FIG. 6 shows an example thereof.
[0052]
In the registration candidate
[0053]
At the same time, the degree of character string matching is calculated by character string pattern matching between the
Matched character detection direction: Number of characters whose back position matched: a = 2 characters Other characters matched: b = 1 character (character string matching degree) = w1 × a + w2 × b
Here, w1 and w2 are weights (numerical values of 0 or more), and generally, w1> w2. The distance from the center of the dictionary
(Distance) = 1 / (character string matching degree)
, There is a method using the reciprocal of the character string matching degree.
[0054]
When the arrangement position of each term is determined in the dictionary
[0055]
The dictionary editor drags and drops the
[0056]
Thereby, when registering the dictionary registration terms, it becomes possible to register the dictionary registration terms in association with the terms having a high degree of matching included in the pre-editing term data 15 (existing dictionary).
[0057]
The seventh embodiment is an example of a system configuration when the present invention is applied to a dictionary construction service, and FIG. 7 is an example of the system.
[0058]
The
[0059]
The person who receives the dictionary construction service permits the
[0060]
The dictionary
[0061]
The service fee may be set by ranking according to the number of words in the dictionary as the final product, the number of
[0062]
This makes it possible to provide a smooth dictionary construction service to the customer.
[0063]
As described above, various embodiments have been described. A device for realizing this may be configured as a dedicated device. However, as illustrated in FIG. And a general-purpose computer system including a storage unit for storing input data and programs as a database, an operation unit, and the like, and a
[0064]
When the processing program is added to such a general-purpose computer system and realized, the processing program is recorded on a medium such as the
[0065]
【The invention's effect】
ADVANTAGE OF THE INVENTION According to this invention, the dictionary construction method, system, and screen which reduce the dictionary construction man-hour can be provided.
[Brief description of the drawings]
FIG. 1 is an example of a functional block diagram for implementing a term dictionary construction support using search history data when a user uses a search function in an embodiment of the present invention.
FIG. 2 is an example of a functional block diagram for realizing improvement in dictionary editing efficiency using search attribute data in FIG.
FIG. 3 is an example of a data structure diagram of a database in FIGS. 1 and 2;
FIG. 4 is an example of a flowchart showing a processing flow when a search function is used and a dictionary is constructed in FIG. 2;
FIG. 5 is an example of a dictionary editing screen in the first and second embodiments.
6 is an example of another screen of the dictionary term editing area in FIG. 5;
FIG. 7 is a system configuration example when the present invention is applied to a dictionary construction service.
FIG. 8 is an example of a computer system.
FIG. 9 is an example of a magnetic disk.
FIG. 10 shows an example of a CD-ROM.
[Explanation of symbols]
10, 36 ... searcher, 11 ... search function, 12, 78 ... search history data, 13 ... search keyword extraction and storage processing unit, 14, 21 ... first registration candidate term data, 15 ... term data before editing, 16 ... Term comparison processing unit, 17, 22: second registration candidate term data, 18, 24: Term configuration display / edit processing unit, 19: dictionary editor, 20: search keyword, search attribute data extraction / storage processing unit, 23 ... Search attribute data, 30, 33 ... table, 31, 34 ... registration candidate term ID, 32, 56, 61 ... registration candidate term, 35 ... search date and time, 40 ... processing steps at the time of search in Figs. 42, 43, 44: processing steps for dictionary construction, 50: screen, 51: registration candidate term narrowing condition designation area, 52: registration candidate term narrowing button, 53: display condition designation area, 54: display Item reflection button, 55: registration candidate term selection area, 57, 60: dictionary term editing area, 58, 62: registration destination term (parent), 59: term deletion button, 70: system administrator, 71: management client, 72 search server, 73 information source, 74 network, 75 search client, 76 information searcher, 77 user data, 79 dictionary service provider, 81 keyboard, 82
Claims (14)
検索履歴情報から抽出された検索キーワード又は検索属性情報から、辞書を構築する辞書構築方法。In the method of building a dictionary,
A dictionary construction method for constructing a dictionary from search keywords or search attribute information extracted from search history information.
前記検索履歴情報を入力とし、第1の検索用語を抽出し、第1登録候補用語データに保存する処理と、
編集前用語データと前記第1登録候補用語データとを比較し、前記編集前用語データに含まれていない第2の検索用語を前記第1登録候補用語データから抽出し、第2登録候補用語データとして保存する処理と、
前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける処理と、
関連づけられた前記第2の検索用語を前記編集後用語データとして追加する処理とを有することを特徴とする辞書構築方法。In claim 1,
Inputting the search history information, extracting a first search term, and storing the first search term in the first registration candidate term data;
Comparing the pre-edited term data with the first registered candidate term data, extracting a second search term that is not included in the pre-edited term data from the first registered candidate term data, Processing to save as
Associating the second search term with a term included in the pre-edited term data;
Adding the associated second search term as the edited term data.
前記編集前用語データを階層的に表示する処理を有することを特徴とする辞書構築方法。In claim 2,
A dictionary construction method comprising a process of displaying the pre-edit term data hierarchically.
前記編集前用語データと前記編集後用語データは、同一のデータであることを特徴とする辞書構築方法。In claim 2,
A dictionary construction method, wherein the pre-edit term data and the post-edit term data are the same data.
前記第2の検索用語の中から登録候補の登録候補用語を選択する処理と、
前記登録候補用語を前記編集前用語データから検索し、類似度の高い用語順に提示する処理とを有することを特徴とする辞書構築方法。The process of associating the second search term with a term included in the pre-edited term data according to claim 2,
A process of selecting a registration candidate term of a registration candidate from the second search terms;
Searching the registered candidate terms from the pre-edited term data and presenting them in the order of terms having the highest similarity.
前記第2の検索用語の中から選択された登録候補用語を表示領域の中心部に配置して表示し、前記選択された登録候補用語と、前記編集前用語データに含まれる各用語との一致度を算出し、一致度の大きいものほど前記中心部に近く、一致度の小さいものほど前記中心部から遠い位置に、前記編集前用語データに含まれる各用語を表示する処理を有することを特徴とする辞書構築方法。The process of associating the second search term with a term included in the pre-edited term data according to claim 2,
A registration candidate term selected from the second search terms is arranged and displayed at the center of the display area, and a match between the selected registration candidate term and each term included in the pre-edit term data is displayed. Calculating a degree, and displaying each term included in the pre-editing term data at a position closer to the center as the degree of matching is higher and closer to the center as the degree of matching is lower. Dictionary construction method.
前記第2の検索用語の絞り込みを行うために、絞り込み条件を入力する処理と、
前記絞り込み条件を満足する第3の検索用語を検索し、提示する処理と、
前記第3の検索用語から登録候補用語を選択する処理とを有することを特徴とする辞書構築方法。The process of associating the second search term with a term included in the pre-edited term data according to claim 2,
A process of inputting a narrowing condition in order to narrow down the second search term;
Searching for and presenting a third search term that satisfies the narrowing condition;
Selecting a registration candidate term from the third search term.
検索属性データ又は正規表現を利用して登録候補用語の絞り込み条件を入力する処理と、
前記絞り込み条件を満足する第3の検索用語を検索し、提示する処理と、
前記第3の検索用語から登録候補用語を選択する処理とを有することを特徴とする辞書構築処理。The processing for narrowing down the second search term according to claim 8 is:
A process of inputting a condition for narrowing registration candidate terms using search attribute data or a regular expression;
Searching for and presenting a third search term that satisfies the narrowing condition;
Selecting a registration candidate term from the third search term.
絞り込まれた前記登録候補用語を表示する部分とを有する画面装置。In order to narrow the registration candidate terms from the search history data, a part for inputting conditions for narrowing the registration candidate terms,
A screen displaying the narrowed registration candidate terms.
前記登録候補用語を表示する表示条件を入力する部分とを有する画面装置。In claim 12,
A screen for inputting display conditions for displaying the registration candidate terms.
編集前用語データと前記第1登録候補用語データとを比較し、前記編集前用語データに含まれていない第2の検索用語を前記第1登録候補用語データから抽出し、第2登録候補用語データに保存する装置と、
前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける装置と、
関連づけられた前記第2の用語を前記編集後用語データに追加する装置とを有することを特徴とする辞書構築システム。An apparatus that receives search history information as input, extracts a first search term, and stores the first search term in first registered candidate term data;
Comparing the pre-edited term data with the first registered candidate term data, extracting a second search term that is not included in the pre-edited term data from the first registered candidate term data, A device for storing in
An apparatus for associating the second search term with a term included in the pre-edited term data,
A device for adding the associated second term to the edited term data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003025359A JP2004234582A (en) | 2003-02-03 | 2003-02-03 | Dictionary construction method, system, and screen |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003025359A JP2004234582A (en) | 2003-02-03 | 2003-02-03 | Dictionary construction method, system, and screen |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2004234582A true JP2004234582A (en) | 2004-08-19 |
Family
ID=32953661
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003025359A Withdrawn JP2004234582A (en) | 2003-02-03 | 2003-02-03 | Dictionary construction method, system, and screen |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2004234582A (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008090802A (en) * | 2006-10-05 | 2008-04-17 | Pioneer Electronic Corp | Information processing apparatus, information processing method and program |
| JP2010009262A (en) * | 2008-06-26 | 2010-01-14 | Yahoo Japan Corp | Information management device, information management method, and program for determining event unique to user |
| JP2010277415A (en) * | 2009-05-29 | 2010-12-09 | Nippon Telegr & Teleph Corp <Ntt> | Keyword extraction method, keyword extraction apparatus, and keyword extraction program |
| JP2012190254A (en) * | 2011-03-10 | 2012-10-04 | Fujitsu Ltd | Commodity information registration program, commodity information registration method, and commodity information registration device |
| KR20210120584A (en) * | 2020-03-27 | 2021-10-07 | 구주원 | Method and system for recording job history using terminology dictionary |
-
2003
- 2003-02-03 JP JP2003025359A patent/JP2004234582A/en not_active Withdrawn
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008090802A (en) * | 2006-10-05 | 2008-04-17 | Pioneer Electronic Corp | Information processing apparatus, information processing method and program |
| JP2010009262A (en) * | 2008-06-26 | 2010-01-14 | Yahoo Japan Corp | Information management device, information management method, and program for determining event unique to user |
| JP2010277415A (en) * | 2009-05-29 | 2010-12-09 | Nippon Telegr & Teleph Corp <Ntt> | Keyword extraction method, keyword extraction apparatus, and keyword extraction program |
| JP2012190254A (en) * | 2011-03-10 | 2012-10-04 | Fujitsu Ltd | Commodity information registration program, commodity information registration method, and commodity information registration device |
| KR20210120584A (en) * | 2020-03-27 | 2021-10-07 | 구주원 | Method and system for recording job history using terminology dictionary |
| KR102576985B1 (en) * | 2020-03-27 | 2023-09-11 | 구주원 | Method and system for recording job history using terminology dictionary |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3870666B2 (en) | Document retrieval method and apparatus, and recording medium recording the processing program | |
| KR100544514B1 (en) | Method and system for determining relation between search terms in the internet search system | |
| US20050223042A1 (en) | Method and apparatus for information mining and filtering | |
| JP2001134575A (en) | Method and system for detecting frequently appearing pattern | |
| JPH08153121A (en) | Method and device for document information classification | |
| US20040015485A1 (en) | Method and apparatus for improved internet searching | |
| JP2004220215A (en) | Operation guide and support system and operation guide and support method using computer | |
| JP2003173280A (en) | Apparatus, method and program for generating database | |
| JP5221664B2 (en) | Information map management system and information map management method | |
| JP2000285134A (en) | Method and device for managing document and storage medium | |
| CN107291951B (en) | Data processing method, device, storage medium and processor | |
| JP4469432B2 (en) | INTERNET INFORMATION PROCESSING DEVICE, INTERNET INFORMATION PROCESSING METHOD, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING PROGRAM FOR CAUSING COMPUTER TO EXECUTE THE METHOD | |
| JP2004192355A (en) | Informational searching method, its device and computer program for information search | |
| JP2004234582A (en) | Dictionary construction method, system, and screen | |
| JP2008027134A (en) | Document management device, document management method, and program of executing document management method | |
| JP4189387B2 (en) | Knowledge search system, knowledge search method and program | |
| JPH09223150A (en) | Information classification processing method | |
| JP3429225B2 (en) | Storage medium storing data search program | |
| JP2004046870A (en) | Information unit group operation device | |
| JPH1145252A (en) | Information retrieval device and computer readable recording medium for recording program for having computer function as the same device | |
| JPH117452A (en) | Method and device for collecting information through network and recording medium recording program for executing the method | |
| JP2000231569A (en) | Internet information retrieving device, internet information retrieving method and computer readable recording medium with program making computer execute method recorded therein | |
| JP4426893B2 (en) | Document search method, document search program, and document search apparatus for executing the same | |
| JP2002049638A (en) | Document information retrieval device, method, document information retrieval program and computer readable recording medium storing document information retrieval program | |
| KR101078907B1 (en) | System for valuation a document |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7421 Effective date: 20060420 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060822 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20060927 |