ES2955962T3 - Método y sistema que utiliza una diferencia de correlación a largo plazo entre los canales izquierdo y derecho para mezcla descendente en el dominio del tiempo de una señal de sonido estéreo en canales primarios y secundarios - Google Patents
Método y sistema que utiliza una diferencia de correlación a largo plazo entre los canales izquierdo y derecho para mezcla descendente en el dominio del tiempo de una señal de sonido estéreo en canales primarios y secundarios Download PDFInfo
- Publication number
- ES2955962T3 ES2955962T3 ES16847684T ES16847684T ES2955962T3 ES 2955962 T3 ES2955962 T3 ES 2955962T3 ES 16847684 T ES16847684 T ES 16847684T ES 16847684 T ES16847684 T ES 16847684T ES 2955962 T3 ES2955962 T3 ES 2955962T3
- Authority
- ES
- Spain
- Prior art keywords
- channel
- factor
- channels
- long
- time domain
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 95
- 230000007774 longterm Effects 0.000 title claims abstract description 82
- 230000005236 sound signal Effects 0.000 title claims abstract description 36
- 238000002156 mixing Methods 0.000 claims abstract description 14
- 238000004519 manufacturing process Methods 0.000 claims abstract description 4
- 238000012937 correction Methods 0.000 claims description 10
- 230000006870 function Effects 0.000 claims description 9
- 230000000694 effects Effects 0.000 claims description 8
- 230000004044 response Effects 0.000 claims description 4
- 230000003247 decreasing effect Effects 0.000 claims 3
- 230000007423 decrease Effects 0.000 claims 2
- 238000009499 grossing Methods 0.000 claims 1
- 108091006146 Channels Proteins 0.000 description 412
- 238000010586 diagram Methods 0.000 description 29
- 238000004458 analytical method Methods 0.000 description 26
- 238000004891 communication Methods 0.000 description 15
- 230000000875 corresponding effect Effects 0.000 description 12
- 238000010606 normalization Methods 0.000 description 12
- 230000003595 spectral effect Effects 0.000 description 12
- 238000012545 processing Methods 0.000 description 11
- 238000001514 detection method Methods 0.000 description 9
- 238000013139 quantization Methods 0.000 description 9
- 238000004364 calculation method Methods 0.000 description 8
- 238000006243 chemical reaction Methods 0.000 description 8
- 206010011878 Deafness Diseases 0.000 description 7
- 230000008901 benefit Effects 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 7
- 230000000670 limiting effect Effects 0.000 description 6
- 238000013459 approach Methods 0.000 description 5
- 238000005070 sampling Methods 0.000 description 5
- 230000006978 adaptation Effects 0.000 description 4
- 230000002596 correlated effect Effects 0.000 description 4
- 238000001914 filtration Methods 0.000 description 4
- 238000001228 spectrum Methods 0.000 description 4
- 239000013598 vector Substances 0.000 description 4
- 238000010219 correlation analysis Methods 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 210000005069 ears Anatomy 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 238000004091 panning Methods 0.000 description 3
- 238000007781 pre-processing Methods 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 230000002123 temporal effect Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 230000002452 interceptive effect Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000011524 similarity measure Methods 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 238000005303 weighing Methods 0.000 description 2
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000003466 anti-cipated effect Effects 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000005562 fading Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/09—Long term prediction, i.e. removing periodical redundancies, e.g. by using adaptive codebook or pitch predictor
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/12—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters the excitation function being a code excitation, e.g. in code excited linear prediction [CELP] vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/26—Pre-filtering or post-filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/06—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being correlation coefficients
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/21—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being power information
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S1/00—Two-channel systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S1/00—Two-channel systems
- H04S1/007—Two-channel systems in which the audio signals are in digital form
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/002—Dynamic bit allocation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/24—Variable rate codecs, e.g. for generating different qualities using a scalable representation such as hierarchical encoding or layered encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/01—Multi-channel, i.e. more than two input channels, sound reproduction with two speakers wherein the multi-channel information is substantially preserved
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/03—Aspects of down-mixing multi-channel audio to configurations with lower numbers of playback channels, e.g. 7.1 -> 5.1
Abstract
Un método y sistema de codificación de señal de sonido estéreo para mezclar en el dominio del tiempo los canales derecho e izquierdo de una señal de sonido estéreo de entrada en canales primarios y secundarios, determina las correlaciones normalizadas del canal izquierdo y el canal derecho en relación con una versión de señal monofónica del sonido. Una diferencia de correlación a largo plazo se determina sobre la base de la correlación normalizada del canal izquierdo y la correlación normalizada del canal derecho. La diferencia de correlación a largo plazo se convierte en un factor β, y los canales izquierdo y derecho se mezclan para producir los canales primario y secundario usando el factor β, en donde el factor β determina las contribuciones respectivas de los canales izquierdo y derecho tras la producción del canales primarios y secundarios. (Traducción automática con Google Translate, sin valor legal)
Description
DESCRIPCIÓN
Método y sistema que utiliza una diferencia de correlación a largo plazo entre los canales izquierdo y derecho para mezcla descendente en el dominio del tiempo de una señal de sonido estéreo en canales primarios y secundarios
Campo técnico
La presente divulgación se refiere a codificación de sonido estéreo, en particular, pero no exclusivamente, codificación de habla y/o audio estéreo capaz de producir una buena calidad estéreo en una escena de audio compleja a una baja tasa de bits y un retardo bajo.
Antecedentes
Históricamente, la telefonía conversacional se ha implementado con teléfonos que tenían un solo transductor para emitir sonido solo a uno de los oídos del usuario. En la última década, los usuarios han comenzado a utilizar su teléfono portátil junto con unos auriculares para recibir el sonido en sus dos oídos, principalmente para escuchar música pero, a veces, también para escuchar el habla. Sin embargo, cuando se utiliza un teléfono portátil para transmitir y recibir habla conversacional, el contenido sigue siendo monofónico pero se presenta a los dos oídos del usuario cuando se utilizan auriculares.
Con el estándar de codificación de habla 3GPP más reciente, como se describe en la referencia [1], se ha mejorado significativamente la calidad del sonido codificado, por ejemplo habla y/o audio que se transmite y recibe a través de un teléfono portátil. El siguiente paso natural es transmitir información estéreo de manera que el receptor se acerque lo más posible a una escena de audio de la vida real capturada en el otro extremo del enlace de comunicación.
En códecs de audio, por ejemplo como se describe en la referencia [2], normalmente se usa la transmisión de información estéreo.
Para los códecs de habla conversacionales, la señal monofónica es la norma. Cuando se transmite una señal estereofónica, a menudo es necesario duplicar la tasa de bits, ya que tanto el canal izquierdo como el derecho están codificados mediante un códec monofónico. Esto funciona bien en la mayoría de los escenarios, pero presenta los inconvenientes de duplicar la tasa de bits y no aprovechar ninguna redundancia potencial entre los dos canales (canales izquierdo y derecho). Además, para mantener la tasa de bits general en un nivel razonable, se utiliza una tasa de bits muy baja para cada canal, lo que afecta la calidad general del sonido.
Una posible alternativa es utilizar el llamado estéreo paramétrico como se describe en la referencia [6]. El estéreo paramétrico envía información tal como la diferencia de tiempo interaural (ITD) o las diferencias de intensidad interaural (IID), por ejemplo. Esta última información se envía por banda de frecuencia y, a baja tasa de bits, el presupuesto de bits asociado a la transmisión estéreo no es lo suficientemente alto como para permitir que estos parámetros funcionen eficientemente.
La transmisión de un factor de panorámica podría ayudar a crear un efecto estéreo básico a una baja tasa de bits, pero dicha técnica no hace nada para preservar el ambiente y presenta limitaciones inherentes. Una adaptación demasiado rápida del factor de panorámica resulta molesta para el oyente, mientras que una adaptación demasiado lenta del factor de panorámica no refleja la posición real de los altavoces, lo que dificulta la obtención de una buena calidad en caso de que los hablantes interfieran o cuando las fluctuaciones del ruido de fondo es importante. Actualmente, codificar habla conversacional estéreo con una calidad decente para todas las escenas de audio posibles requiere una tasa de bits mínima de alrededor de 24 kb/s para señales de banda ancha (WB); por debajo de esa tasa de bits, la calidad del habla comienza a verse afectada. Como otra alternativa para proporcionar un dispositivo de codificación estéreo, el documento EP 2405424 sugiere que los coeficientes de relación de energía de los canales izquierdo y derecho se pueden utilizar como coeficientes de panorámica. Sin embargo, el documento EP 2405424 es incapaz de superar las deficiencias y desventajas relacionadas con un factor de panorámica como se analizó anteriormente.
Con la globalización cada vez mayor de la fuerza laboral y la división de los equipos de trabajo en todo el mundo, existe la necesidad de mejorar las comunicaciones. Por ejemplo, los participantes de una teleconferencia pueden estar en ubicaciones diferentes y distantes. Algunos participantes podrían estar en sus coches, otros podrían estar en una gran sala anecoica o incluso en su sala de estar. De hecho, todos los participantes desean sentir que están teniendo una discusión cara a cara. Implementar habla estéreo, más generalmente sonido estéreo, en dispositivos portátiles sería un gran paso en esta dirección.
Resumen
El objeto de la invención se resuelve mediante el tema de las reivindicaciones independientes. Las realizaciones preferidas están definidas por las reivindicaciones dependientes.
Los anteriores y otros objetos, ventajas y características del método y sistema para mezcla descendente en el dominio del tiempo los canales derecho e izquierdo de una señal de sonido estéreo de entrada en canales primarios y
secundarios se harán más evidentes al leer la siguiente descripción no restrictiva de realizaciones ilustrativas de los mismos, dado a modo de ejemplo sólo con referencia a los dibujos adjuntos.
Breve descripción de los dibujos
En los dibujos adjuntos:
La figura 1 es un diagrama de bloques esquemático de un sistema de comunicación y procesamiento de sonido estéreo que representa un posible contexto de implementación del método y sistema de codificación de sonido estéreo como se divulga en la siguiente descripción;
La figura 2 es un diagrama de bloques que ilustra simultáneamente un método y un sistema de codificación de sonido estéreo de acuerdo con un primer modelo, presentado como un diseño estéreo integrado;
La figura 3 es un diagrama de bloques que ilustra simultáneamente un método y un sistema de codificación de sonido estéreo de acuerdo con un segundo modelo, presentado como un modelo incrustado;
La figura 4 es un diagrama de bloques que muestra simultáneamente suboperaciones de una operación de mezcla descendente en el dominio del tiempo del método de codificación de sonido estéreo de las figuras 2 y 3, y módulos de un mezclador de canales del sistema de codificación de sonido estéreo de las figuras 2 y 3;
La figura 5 es un gráfico que muestra cómo se asigna una diferencia de correlación linealizada a largo plazo a un factor p y a un factor £ de normalización de energía;
La figura 6 es un gráfico de curvas múltiples que muestra la diferencia entre usar un esquema pca/klt sobre un cuadro completo y utilizando una función de mapeo "coseno";
La figura 7 es un gráfico de curvas múltiples que muestra un canal primario, un canal secundario y los espectros de estos canales primarios y secundarios resultantes de aplicar una mezcla descendente en el dominio del tiempo a una muestra estéreo que se ha grabado en una pequeña sala ecoica utilizando una configuración de micrófonos binaurales con ruido de oficina de fondo;
La figura 8 es un diagrama de bloques que ilustra simultáneamente un método y sistema de codificación de sonido estéreo, con una posible implementación de optimización de la codificación de los canales primario Y y secundario X de la señal de sonido estéreo;
La figura 9 es un diagrama de bloques que ilustra una operación de análisis de coherencia de filtro LP y el correspondiente analizador de coherencia de filtro LP del método y sistema de codificación de sonido estéreo de la figura 8;
La figura 10 es un diagrama de bloques que ilustra simultáneamente un método de decodificación de sonido estéreo y un sistema de decodificación de sonido estéreo;
La figura 11 es un diagrama de bloques que ilustra características adicionales del método y sistema de decodificación de sonido estéreo de la figura 10;
La figura 12 es un diagrama de bloques simplificado de una configuración de ejemplo de componentes de hardware que forman el sistema de codificación de sonido estéreo y el decodificador de sonido estéreo de la presente divulgación;
La figura 13 es un diagrama de bloques que ilustra simultáneamente otras realizaciones de suboperaciones de la operación de mezcla descendente en el dominio del tiempo del método de codificación de sonido estéreo de las figuras 2 y 3, y módulos del mezclador de canales del sistema de codificación de sonido estéreo de las figuras 2 y 3, utilizando un factor de preadaptación para mejorar la estabilidad de la imagen estéreo;
La figura 14 es un diagrama de bloques que ilustra simultáneamente operaciones de una corrección de retardo temporal y módulos de un corrector de retardo temporal;
La figura 15 es un diagrama de bloques que ilustra simultáneamente un método y sistema de codificación de sonido estéreo alternativo;
La figura 16 es un diagrama de bloques que ilustra simultáneamente suboperaciones de un análisis de coherencia de tono y módulos de un analizador de coherencia de tono;
La figura 17 es un diagrama de bloques que ilustra simultáneamente un método y un sistema de codificación estéreo que utiliza mezcla descendente en el dominio del tiempo con capacidad de operar en el dominio del tiempo y en el dominio de la frecuencia; y
La figura 18 es un diagrama de bloques que ilustra simultáneamente otro método y sistema de codificación estéreo que utiliza mezcla descendente en el dominio del tiempo con capacidad de operar en el dominio del tiempo y en el dominio de la frecuencia.
Descripción detallada
La presente divulgación se refiere a la producción y transmisión, con una baja tasa de bits y un retardo bajo, de una representación realista de contenido de sonido estéreo, por ejemplo contenido de habla y/o audio, desde, en particular, pero no exclusivamente, una escena de audio compleja. Una escena de audio compleja incluye situaciones en las que (a) la correlación entre las señales de sonido grabadas por los micrófonos es baja, (b) hay una fluctuación importante del ruido de fondo y/o (c) está presente un hablante que interfiere. Ejemplos de escenas de audio complejas comprenden una gran sala de conferencias anecoica con una configuración de micrófonos A/B, una pequeña sala ecoica con micrófonos binaurales y una pequeña sala ecoica con una configuración de micrófonos mono/laterales. Todas estas configuraciones de sala podrían incluir ruidos de fondo fluctuantes y/o hablantes que interfieren.
Los códecs de sonido estéreo conocidos, tales como 3GPP AMR-WB+ como se describe en la referencia [7], son ineficientes para codificar sonido que no se aproxima al modelo monofónico, especialmente a baja tasa de bits. Ciertos casos son particularmente difíciles de codificar utilizando técnicas estéreo existentes. Tales casos incluyen:
LAAB (Gran sala anecoica con configuración de micrófonos A/B);
SEBI (Pequeña sala ecoica con configuración de micrófonos binaurales); y
SEMS (Pequeña sala ecoica con configuración de micrófonos mono/laterales).
Agregar un ruido de fondo fluctuante y/o hablar con interferencias hace que estas señales de sonido sean aún más difíciles de codificar a una baja tasa de bits utilizando técnicas estéreo dedicadas, tal como el estéreo paramétrico. Una alternativa para codificar dichas señales es utilizar dos canales monofónicos, duplicando así la tasa de bits y el ancho de banda de la red que se utiliza.
El último estándar de habla conversacional 3GPP EVS proporciona un rango de tasa de bits de 7.2 kb/s a 96 kb/s para operación de banda ancha (WB) y de 9.6 kb/s a 96 kb/s para operación de banda súper ancha (SWB). Esto significa que las tres tasas de bits dual mono más bajas usando EVS son 14.4, 16.0 y 19.2 kb/s para operación WB y 19.2, 26.3 y 32.8 kb/s para operación SWB. Aunque la calidad del habla del 3GPP AMR-WB implementado, como se describe en la referencia [3], mejora con respecto a su códec predecesor, la calidad del habla codificada a 7.2 kb/s en un entorno ruidoso está lejos de ser transparente y, por lo tanto, se puede anticipar que la calidad de habla del mono dual a 14.4 kb/s también sería limitada. A dichas bajas tasas de bits, el uso de la tasa de bits se maximiza de manera que se obtenga la mejor calidad de habla posible con la mayor frecuencia posible. Con el método y sistema de codificación de sonido estéreo como se divulga en la siguiente descripción, la tasa de bits total mínima para contenido de habla estéreo conversacional, incluso en el caso de escenas de audio complejas, debe ser de aproximadamente 13 kb/s para WB y 15.0 kb/s para SWB. Con tasas de bits inferiores a las utilizadas en un enfoque mono dual, la calidad y la inteligibilidad del habla estéreo mejoran enormemente para escenas de audio complejas.
La figura 1 es un diagrama de bloques esquemático de un sistema 100 de comunicación y procesamiento de sonido estéreo que representa un posible contexto de implementación del método y sistema de codificación de sonido estéreo como se divulga en la siguiente descripción.
El sistema 100 de comunicación y procesamiento de sonido estéreo de la figura 1 soporta la transmisión de una señal de sonido estéreo a través de un enlace 101 de comunicación. El enlace 101 de comunicación puede comprender, por ejemplo, un alambre o un enlace de fibra óptica. Alternativamente, el enlace 101 de comunicación puede comprender al menos en parte un enlace de radiofrecuencia. El enlace de radiofrecuencia a menudo soporta múltiples comunicaciones simultáneas que requieren recursos de ancho de banda compartidos, tales como los que se pueden encontrar en la telefonía celular. Aunque no se muestra, el enlace 101 de comunicación puede ser reemplazado por un dispositivo de almacenamiento en una implementación de dispositivo único del sistema 100 de procesamiento y comunicación que graba y almacena la señal de sonido estéreo codificada para su posterior reproducción.
Todavía con referencia a la figura 1, por ejemplo, un par de micrófonos 102 y 122 producen los canales izquierdo 103 y derecho 123 de una señal de sonido estéreo analógica original detectada, por ejemplo, en una escena de audio compleja. Como se indica en la descripción anterior, la señal de sonido puede comprender, en particular, pero no exclusivamente, habla y/o audio. Los micrófonos 102 y 122 pueden disponerse de acuerdo con una configuración A/B, binaural o mono/lateral.
Los canales izquierdo 103 y derecho 123 de la señal de sonido analógica original se suministran a un convertidor 104 analógico a digital (A/D) para convertirlos en los canales izquierdo 105 y derecho 125 de una señal de sonido estéreo digital original. Los canales izquierdo 105 y derecho 125 de la señal de sonido estéreo digital original también pueden grabarse y suministrarse desde un dispositivo de almacenamiento (no mostrado).
Un codificador 106 de sonido estéreo codifica los canales izquierdo 105 y derecho 125 de la señal de sonido estéreo digital produciendo así un conjunto de parámetros de codificación que se multiplexan en forma de un flujo 107 de bits suministrado a un codificador 108 de corrección de errores opcional. El codificador 108 de corrección de errores opcional, cuando está presente, añade redundancia a la representación binaria de los parámetros de codificación en el flujo 107 de bits antes de transmitir el flujo 111 de bits resultante a través del enlace 101 de comunicación.
En el lado del receptor, un decodificador 109 de corrección de errores opcional utiliza la información redundante mencionada anteriormente en el flujo 111 de bits digital recibido para detectar y corregir errores que pueden haber ocurrido durante la transmisión a través del enlace 101 de comunicación, produciendo un flujo 112 de bits con parámetros de codificación recibidos. Un decodificador 110 de sonido estéreo convierte los parámetros de codificación recibidos en el flujo 112 de bits para crear canales izquierdo 113 y derecho 133 sintetizados de la señal de sonido estéreo digital. Los canales izquierdo 113 y derecho 133 de la señal de sonido estéreo digital reconstruida en el decodificador 110 de sonido estéreo se convierten en canales izquierdo 114 y derecho 134 sintetizados de la señal de sonido estéreo analógico en un convertidor 115 digital a analógico (D/A).
Los canales sintetizados izquierdo 114 y derecho 134 de la señal de sonido estéreo analógica se reproducen respectivamente en un par de unidades 116 y 136 de altavoz. Alternativamente, los canales izquierdo 113 y derecho 133 de la señal de sonido estéreo digital procedente del decodificador 110 de sonido estéreo también pueden suministrarse y grabarse en un dispositivo de almacenamiento (no mostrado).
Los canales izquierdo 105 y derecho 125 de la señal de sonido estéreo digital original de la figura 1 corresponden a los canales izquierdo L y derecho R de las figuras 2, 3, 4, 8, 9, 13, 14, 15, 17 y 18. Además, el codificador 106 de sonido estéreo de la figura 1 corresponde al sistema de codificación de sonido estéreo de las figuras 2, 3, 8, 15, 17 y 18.
El método y sistema de codificación de sonido estéreo según la presente divulgación son dobles; se proporcionan el primer y segundo modelo.
La figura 2 es un diagrama de bloques que ilustra simultáneamente el método y el sistema de codificación de sonido estéreo de acuerdo con el primer modelo, presentado como un diseño estéreo integrado con base en el núcleo EVS.
Con referencia a la figura 2, el método de codificación de sonido estéreo de acuerdo con el primer modelo comprende una operación 201 de mezcla descendente en el dominio del tiempo, una operación 202 de codificación de canal primario, una operación 203 de codificación de canal secundario y una operación 204 de multiplexación.
Para realizar la operación 201 de mezcla descendente en el dominio del tiempo, un mezclador 251 de canales mezcla los dos canales estéreo de entrada (canal derecho R y canal izquierdo L) para producir un canal primario Y y un canal secundario X.
Para llevar a cabo la operación 203 de codificación de canal secundario, un codificador 253 de canal secundario selecciona y usa un número mínimo de bits (tasa de bits mínima) para codificar el canal secundario X usando uno de los modos de codificación como se define en la siguiente descripción y producir un correspondiente flujo 206 de bits codificado de canal secundario. El presupuesto de bits asociado puede cambiar en cada cuadro según el contenido del cuadro.
Para implementar la operación 202 de codificación de canal primario, se usa un codificador 252 de canal primario. El codificador 253 de canal secundario envía señales al codificador 252 de canal primario el número de bits 208 usados en el cuadro actual para codificar el canal secundario X. Se puede usar cualquier tipo adecuado de codificador como codificador 252 de canal primario. Como ejemplo no limitativo, el codificador 252 de canal primario puede ser un codificador de tipo CELP En esta realización ilustrativa, el codificador tipo CELP de canal primario es una versión modificada del codificador EVS heredado, donde el codificador EVS se modifica para presentar una mayor escalabilidad de tasa de bits para permitir una asignación flexible de tasa de bits entre los canales primario y secundario. De esta manera, el codificador EVS modificado podrá utilizar todos los bits que no se utilizan para codificar el canal secundario X para codificar, con una tasa de bits correspondiente, el canal primario Y y producir un flujo 205 de bits codificado del canal primario correspondiente.
Un multiplexor 254 concatena el flujo 205 de bits del canal primario y el flujo 206 de bits del canal secundario para formar un flujo 207 de bits multiplexado, para completar la operación 204 de multiplexación.
En el primer modelo, el número de bits y la tasa de bits correspondiente (en el flujo 206 de bits) usados para codificar el canal secundario X es menor que el número de bits y la tasa de bits correspondiente (en el flujo 205 de bits) usados para codificar el canal primario Y. Esto puede verse como dos (2) canales de tasa de bits variable en donde la suma de las tasas de bits de los dos canales X y Y representa una tasa de bits total constante. Este enfoque puede tener diferentes ideas con mayor o menor énfasis en el canal primario Y De acuerdo con un primer ejemplo, cuando se pone un énfasis máximo en el canal primario Y, el presupuesto de bits del canal secundario X se fuerza agresivamente al mínimo. De acuerdo con un segundo ejemplo, si se pone menos énfasis en el canal primario Y, entonces el presupuesto de bits para el canal secundario X puede hacerse más constante, lo que significa que la tasa de bits promedio del canal secundario X es ligeramente mayor en comparación con el primer ejemplo.
Se recuerda que los canales derecho R e izquierdo L de la señal de sonido estéreo digital de entrada se procesan mediante cuadros sucesivos de una duración determinada que puede corresponder a la duración de los cuadros utilizados en el procesamiento EVS. Cada cuadro comprende un número de muestras de los canales derecho R e izquierdo L dependiendo de la duración dada del cuadro y la tasa de muestreo que se utiliza.
La figura 3 es un diagrama de bloques que ilustra simultáneamente el método y el sistema de codificación de sonido estéreo de acuerdo con el segundo modelo, presentado como un modelo incrustado.
Con referencia a la figura 3, el método de codificación de sonido estéreo de acuerdo con el segundo modelo comprende una operación 301 de mezcla descendente en el dominio del tiempo, una operación 302 de codificación de canal primario, una operación 303 de codificación de canal secundario y una operación 304 de multiplexación.
Para completar la operación 301 de mezcla descendente en el dominio del tiempo, un mezclador 351 de canales mezcla los dos canales de entrada derecho R e izquierdo L para formar un canal primario Y y un canal secundario X.
En la operación 302 de codificación de canal primario, un codificador 352 de canal primario codifica el canal primario Y para producir un flujo 305 de bits codificado de canal primario. Nuevamente, se puede utilizar cualquier tipo adecuado de codificador como codificador 352 de canal primario. Como ejemplo no limitativo, el codificador 352 de canal primario puede ser un codificador de tipo CELP. En esta realización ilustrativa, el codificador 352 de canal primario usa un estándar de codificación de habla tal como el modo de codificación mono EVS heredado o el modo de codificación AMR-WB-IO, por ejemplo, lo que significa que la porción monofónica del flujo 305 de bits sería interoperable con el EVS heredado, el AMR-WB-IO o el decodificador AMR-WB heredado cuando la tasa de bits sea compatible con dicho decodificador. Dependiendo del modo de codificación que se seleccione, es posible que se requiera algún ajuste del canal primario Y para el procesamiento a través del codificador 352 de canal primario.
En la operación 303 de codificación de canal secundario, un codificador 353 de canal secundario codifica el canal secundario X a una tasa de bits inferior usando uno de los modos de codificación como se define en la siguiente descripción. El codificador 353 de canal secundario produce un flujo 306 de bits codificado de canal secundario.
Para realizar la operación 304 de multiplexación, un multiplexor 354 concatena el flujo 305 de bits codificado del canal primario con el flujo 306 de bits codificado del canal secundario para formar un flujo 307 de bits multiplexado. Esto se denomina modelo incrustado, porque el flujo 306 de bits codificado del canal secundario asociado al estéreo se agrega en la parte de arriba de un flujo 305 de bits interoperable. El flujo 306 de bits del canal secundario se puede separar del flujo 307 de bits estéreo multiplexado (flujos 305 y 306 de bits concatenados) en cualquier momento dando como resultado un flujo de bits decodificable por un códec heredado como se describe en este documento anteriormente, mientras que un usuario de una versión más reciente del códec aún podrá disfrutar de la decodificación estéreo completa.
De hecho, los modelos primero y segundo descritos anteriormente son muy parecidos entre sí. La principal diferencia entre los dos modelos es la posibilidad de utilizar una asignación dinámica de bits entre los dos canales Y y X en el primer modelo, mientras que la asignación de bits es más limitada en el segundo modelo debido a consideraciones de interoperabilidad.
En la siguiente descripción se dan ejemplos de implementación y enfoques utilizados para lograr los modelos primero y segundo descritos anteriormente.
1) Mezcla descendente en el dominio del tiempo
Como se expresa en la descripción anterior, los modelos estéreo conocidos que funcionan a una baja tasa de bits tienen dificultades con la codificación de habla que no se aproxima al modelo monofónico. Los enfoques tradicionales realizan una mezcla descendente en el dominio de la frecuencia, por banda de frecuencia, utilizando, por ejemplo, una correlación por banda de frecuencia asociada con un análisis de componentes principales (pca) utilizando, por ejemplo, una transformación de Karhunen-Loéve (klt), para obtener dos vectores, como se describe en las referencias [4] y [5]. Uno de estos dos vectores incorpora todo el contenido altamente correlacionado mientras que el otro vector define todo el contenido que no está muy correlacionado. El método más conocido para codificar habla a tasas de bits bajas utiliza un códec en el dominio del tiempo, tal como un códec CELP (predicción lineal excitada por código), en el que las soluciones conocidas en el dominio de la frecuencia no son directamente aplicables. Por esa razón, si bien la idea detrás del pca/klt por banda de frecuencia es interesante que, cuando el contenido es habla, el canal primario Y necesita volverse a convertir al dominio del tiempo y, después de dicha conversión, su contenido ya no parece habla tradicional, especialmente en el caso de las configuraciones descritas anteriormente que utilizan un modelo específico del habla tal como CELP. Esto tiene el efecto de reducir el rendimiento del códec de habla. Además, a una baja tasa de bits, la entrada de un códec de habla debe ser lo más cercana posible a las expectativas del modelo interior del códec.
Partiendo de la idea de que una entrada de un códec de habla de baja tasa de bits debería estar lo más cerca posible de la señal de habla esperada, se ha desarrollado una primera técnica. La primera técnica se basa en una evolución del esquema tradicional pca/klt. Mientras que el esquema tradicional calcula el pca/klt por banda de frecuencia, la primera técnica lo calcula en todo el cuadro, directamente en el dominio del tiempo. Esto funciona adecuadamente
durante segmentos de habla activa, siempre que no haya ruido de fondo ni interferencias del hablante. El esquema pca/klt determina qué canal (canal izquierdo L o derecho R) contiene la información más útil, y este canal se envía al codificador del canal principal. Desafortunadamente, el esquema pca/klt con base en cuadros no es confiable en presencia de ruido de fondo o cuando dos o más personas están hablando entre sí. El principio del esquema pca/klt implica la selección de un canal (R o L) de entrada u otro, lo que a menudo conduce a cambios drásticos en el contenido del canal principal a codificar. Al menos por las razones anteriores, la primera técnica no es suficientemente fiable y, en consecuencia, en este documento se presenta una segunda técnica para superar las deficiencias de la primera técnica y permitir una transición más suave entre los canales de entrada. Esta segunda técnica se describirá a continuación con referencia a las figuras 4-9.
Con referencia a la figura 4, la operación de mezcla 201/301 descendente en el dominio del tiempo (figuras 2 y 3) comprende las siguientes suboperaciones: una suboperación 401 de análisis de energía, una suboperación 402 de análisis de tendencias de energía, una suboperación 403 de análisis de correlación normalizada de los canales L y R, una suboperación 404 de cálculo de diferencia de correlación a largo plazo (LT), una suboperación 405 de conversión de diferencia de correlación a largo plazo y cuantificación del factor p y una suboperación 406 de mezcla descendente en el dominio del tiempo.
Teniendo en cuenta la idea de que la entrada de un códec de sonido de baja tasa de bits (tal como habla y/o audio) debe ser lo más homogénea posible, la suboperación 401 de análisis de energía se realiza en el mezclador 252/351 de canales mediante un analizador 451 de energía para determinar primero, por cuadro, la energía rms (media cuadrática) de cada canal R y L de entrada usando las relaciones (1):

donde las subindicaciones L y R representan los canales izquierdo y derecho respectivamente, L(i) significa muestra i de canal L, R(i) representa la muestra i del canal R, N corresponde al número de muestras por cuadro, y t representa un cuadro actual.
El analizador 451 de energía utiliza entonces los valores rms de las relaciones (1) para determinar los valores rms a largo plazo rms para cada canal usando relaciones (2):

donde t representa el cuadro actual y t i el cuadro anterior.
Para realizar la suboperación 402 de análisis de tendencias de energía, un analizador 452 de tendencias de energía del mezclador 251/351 de canales utiliza los valores rms a largo plazo rms para determinar la tendencia de la energía en cada canal L y R rms_dt usando relaciones (3):

La tendencia de los valores rms a largo plazo se utilizan como información que muestra si los eventos temporales capturados por los micrófonos se están desvaneciendo o si están cambiando de canal. Los valores rms a largo plazo y su tendencia también se utilizan para determinar una velocidad de convergencia a de una diferencia de correlación a largo plazo como se describirá más adelante.
Para realizar la suboperación 403 de análisis de correlación normalizada de los canales L y R, un analizador 453 de correlación normalizada L y R calcula una correlación Gl|r para cada uno de los canales izquierdo L y derecho R normalizados frente a una versión de señal monofónica m(i) del sonido, tal como habla y/o audio, en el cuadro t usando relaciones (4):
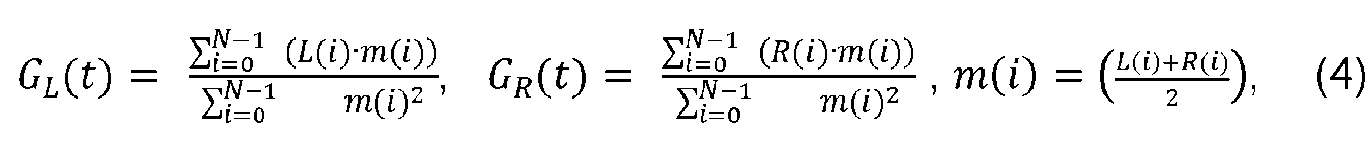
donde N , como ya se mencionó, corresponde al número de muestras en un cuadro, y t representa el cuadro actual. En la realización actual, todas las correlaciones normalizadas y los valores rms determinados por las relaciones 1 a 4 se calculan en el dominio del tiempo, para todo el cuadro. En otra configuración posible, estos valores se pueden calcular en el dominio de la frecuencia. Por ejemplo, las técnicas descritas en este documento, que están adaptadas a señales de sonido que tienen características de habla, pueden ser parte de un cuadro más amplio que puede conmutar entre un método de codificación de audio estéreo genérico en el dominio de frecuencia y el método descrito en la presente divulgación. En este caso, calcular las correlaciones normalizadas y los valores rms en el dominio de la frecuencia pueden presentar alguna ventaja en términos de complejidad o reutilización del código.
Para calcular la diferencia de correlación a largo plazo (LT) en la suboperación 404, una calculadora 454 calcula para cada canal L y R en el cuadro actual correlaciones normalizadas suavizadas usando relaciones (5):

donde a es la velocidad de convergencia mencionada anteriormente. Finalmente, la calculadora 454 determina la diferencia ^ lr de correlación a largo plazo (LT)usando la relación (6):

En una realización de ejemplo, la velocidad de convergencia a puede tener un valor de 0.8 o 0.5 dependiendo de las energías a largo plazo calculadas en las relaciones (2) y la tendencia de las energías a largo plazo calculadas en las relaciones (3). Por ejemplo, la velocidad de convergencia a puede tener un valor de 0.8 cuando las energías a largo plazo de los canales izquierdo L y derecho R evolucionan en la misma dirección, una diferencia entre la diferencia g lr de correlación a largo plazo en el cuadro t y la diferencia g lr de correlación a largo plazo en el cuadro t-i es bajo (por debajo de 0.31 para esta realización de ejemplo), y al menos uno de los valores rms a largo plazo de los canales izquierdo L y derecho R está por encima de un cierto umbral (2000 en esta realización de ejemplo). Estos casos significan que ambos canales L y R están evolucionando suavemente, no hay cambios rápidos de energía de un canal al otro y al menos un canal contiene un nivel significativo de energía. De lo contrario, cuando las energías a largo plazo de los canales derecho R e izquierdo L evolucionan en diferentes direcciones, cuando la diferencia entre las diferencias de correlación a largo plazo es alta, o cuando los dos canales derecho R e izquierdo L tienen energías bajas, entonces a se establecerá en 0.5 para aumentar la velocidad de adaptación de la diferencia ^ lr de correlación a largo plazo.
Para llevar a cabo la suboperación 405 de conversión y cuantificación, una vez que la diferencia ^ lr de correlación a largo plazo se ha estimado adecuadamente en la calculadora 454, el convertidor y cuantificador 455 convierte esta diferencia en un factor p que se cuantifica y se suministra a (a) el codificador 252 de canal primario (figura 2), (b) el codificador 253/353 de canal secundario (figuras 2 y 3), y (c) el multiplexor 254/354 (figuras 2 y 3) para transmisión a un decodificador dentro del flujo 207/307 de bits multiplexado a través de un enlace de comunicación tal como 101 de la figura 1.
El factor p representa dos aspectos de la entrada estéreo combinados en un parámetro. Primero, el factor p representa una proporción o contribución de cada uno de los canales derecho R e izquierdo L que se combinan para crear el canal primario Y y, en segundo lugar, también puede representar un factor de escala de energía para aplicar al canal primario Y para obtener un canal primario que está cerca en el dominio de la energía de cómo se vería una versión de señal monofónica del sonido. Por lo tanto, en el caso de una estructura incrustada, permite decodificar el canal primario Y solo sin necesidad de recibir el flujo 306 de bits secundario que transporta los parámetros estéreo. Este parámetro de energía también se puede utilizar para reescalar la energía del canal secundario X antes de codificarlo, de modo que la energía global del canal secundario X esté más cerca del rango de energía óptimo del codificador del canal secundario. Como se muestra en la figura 2, la información de energía intrínsecamente presente en el factor p También se puede utilizar para mejorar la asignación de bits entre los canales primario y secundario.
El factor p cuantificado puede transmitirse al decodificador utilizando un índice. Dado que el factor p puede representar tanto (a) contribuciones respectivas de los canales izquierdo y derecho al canal primario como (b) un factor de escala de energía para aplicar al canal primario para obtener una versión de señal monofónica del sonido o una información de correlación/energía que ayude a asignar más eficientemente los bits entre el canal primario Y y el canal secundario X, el índice transmitido al decodificador transmite dos elementos de información distintos con el mismo número de bits.
Para obtener un mapeo entre la diferencia Gid t) de correlación a largo plazo y el factor p, en esta realización de ejemplo, el convertidor y cuantificador 455 primero limita la diferencia de correlación a largo plazo entre -1.5 y
de correlación a largo plazo entre -1.5 y
1.5 y luego linealiza esta diferencia de correlación a largo plazo entre 0 y 2 para obtener una diferencia de correlación a largo plazo linealizada temporal como lo muestra la relación (7):
de correlación a largo plazo linealizada temporal como lo muestra la relación (7):
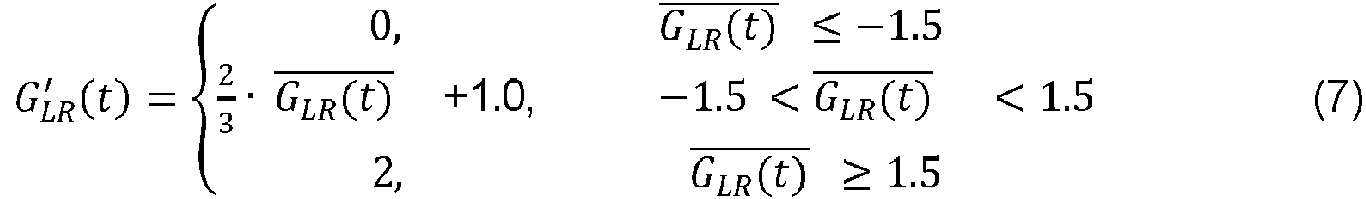
En una implementación alternativa, se puede decidir utilizar sólo una parte del espacio lleno con la diferencia G u lUr (.0 de correlación linealizada a largo plazo, limitando aún más sus valores entre, por ejemplo, 0.4 y 0.6. Esta limitación adicional tendría el efecto de reducir la localización de la imagen estéreo, pero también ahorraría algunos bits de cuantificación. Dependiendo del diseño elegido, se puede considerar esta opción.
Después de la linealización, el convertidor y cuantificador 455 realiza un mapeo de la diferencia de correlación
linealizada a largo plazo en el dominio "coseno" usando la relación (8):
en el dominio "coseno" usando la relación (8):

Para realizar la suboperación 406 de mezcla descendente en el dominio del tiempo, un mezclador 456 descendente en el dominio del tiempo produce el canal primario Y y el canal secundario X como una mezcla de los canales derecho R e izquierdo L usando las relaciones (9) y (10):

donde i = 0,...,N-1 es el índice de muestra en el soporte y t es el índice del cuadro.
La figura 13 es un diagrama de bloques que muestra simultáneamente otras realizaciones de suboperaciones de la operación 201/301 de mezcla descendente en el dominio del tiempo del método de codificación de sonido estéreo de las figuras 2 y 3, y módulos del mezclador 251/351 de canales del sistema de codificación de sonido estéreo de las figuras 2 y 3, utilizando un factor de preadaptación para mejorar la estabilidad de la imagen estéreo. En una implementación alternativa como se representa en la figura 13, la operación 201/301 de mezcla descendente en el dominio del tiempo comprende las siguientes suboperaciones: una suboperación 1301 de análisis de energía, una suboperación 1302 de análisis de tendencias de energía, una suboperación 1303 de análisis de correlación normalizada de los canales L y R, una suboperación 1304 de cálculo de factor de preadaptación, una operación 1305 de aplicar el factor de preadaptación a correlaciones normalizadas, una suboperación 1306 de cálculo de diferencia de correlación a largo plazo (LT), una suboperación 1307 de conversión y cuantificación de ganancia de factor p, y una suboperación 1308 de mezcla descendente en el dominio del tiempo.
Las suboperaciones 1301, 1302 y 1303 se realizan respectivamente mediante un analizador 1351 de energía, un analizador 1352 de tendencias de energía y un analizador 1353 de correlación normalizada L y R, sustancialmente de la misma manera como se explica en la descripción anterior en relación con las suboperaciones 401, 402 y 403, y analizadores 451,452 y 453 de la figura 4.
Para realizar la suboperación 1305, el mezclador 251/351 de canales comprende una calculadora 1355 para aplicar el factor ar de preadaptación directamente a las correlaciones Glr) (Gl ( í) y GR(t)) a partir de las relaciones (4) de manera que su evolución se suaviza en función de la energía y las características de ambos canales. Si la energía de la señal es baja o si tiene algunas características sordas, entonces la evolución de la ganancia de correlación puede ser más lenta.
Para llevar a cabo la suboperación 1304 de cálculo del factor de preadaptación, el mezclador 251/351 de canales comprende una calculadora 1354 del factor de preadaptación, suministrada con (a) los valores de energía de los canales izquierdo y derecho a largo plazo de las relaciones (2) de la analizador 1351 de energía, (b) clasificación de cuadros de cuadros anteriores y (c) información de actividad de voz de los cuadros anteriores. La calculadora 1354 del factor de preadaptación calcula el factor ar de preadaptación, que puede linealizarse entre 0.1 y 1 dependiendo de los valores rmsLR mínimos a largo plazo rms de los canales izquierdo y derecho del analizador 1351, usando la relación (6a):

En una realización, coeficiente Ma puede tener el valor de 0.0009 y el coeficiente Ba el valor de 0.16. En una variante, el factor ar de preadaptación puede forzarse a 0.15, por ejemplo, si una clasificación previa de los dos canales R y L es indicativa de características sordas y de una señal activa. También se puede utilizar un indicador de suspensión de detección de actividad de voz (VAD) para determinar que una parte anterior del contenido de un cuadro era un segmento activo.
La operación 1305 de aplicar el factor ar de preadaptación a las correlaciones normalizadas Gl|r (Gl(í) y Gr( í) de las relaciones (4)) de los canales izquierdo L y derecho R es distinta de la operación 404 de la figura 4. En lugar de calcular correlaciones normalizadas suavizadas a largo plazo (LT), aplicándolas a las correlaciones normalizadas Gl|r (Gl(0 y Gr(0) un factor (1-a), siendo a la velocidad de convergencia definida anteriormente (relaciones (5)), la calculadora 1355 aplica el factor ar de preadaptación directamente a las correlaciones normalizadas Gl|r (Gl(Ó y Gr ( í)) de los canales izquierdo L y derecho R usando la relación (11b):

La calculadora 1355 genera ganancias tL|R de correlación adaptadas que se proporcionan a una calculadora de diferencias 1356 de correlación a largo plazo (LT). La operación de mezcla 201/301 descendente en el dominio del tiempo (figuras 2 y 3) comprende, en la implementación de la figura 13, una diferencia de correlación a largo plazo (LT) que calcula la suboperación 1306, una diferencia de correlación a largo plazo con la suboperación 1307 de conversión y cuantificación del factor p y una suboperación 1358 de mezcla descendente en el dominio del tiempo similar a las suboperaciones 404, 405 y 406, respectivamente, de la figura 4.
La operación de mezcla 201/301 descendente en el dominio del tiempo (figuras 2 y 3) comprende, en la implementación de la figura 13, una diferencia de correlación a largo plazo (LT) que calcula la suboperación 1306, una diferencia de correlación a largo plazo con la suboperación 1307 de conversión y cuantificación del factor p y una suboperación 1358 de mezcla descendente en el dominio del tiempo similar a las suboperaciones 404, 405 y 406, respectivamente, de la figura 4.
Las suboperaciones 1306, 1307 y 1308 se realizan respectivamente mediante una calculadora 1356, un convertidor y cuantificador 1357 y un mezclador 1358 descendente en el dominio del tiempo, sustancialmente de la misma manera que se explica en la descripción anterior en relación con las suboperaciones 404, 405 y 406, y la calculadora 454, el convertidor y cuantificador 455 y el mezclador 456 descendente en el dominio del tiempo.
La figura 5 muestra cómo la diferencia de correlación linealizada a largo plazo se asigna al factor p y el
se asigna al factor p y el
escalamiento energético. Se puede observar que para una diferencia de correlación linealizada a largo plazo

de 1.0, lo que significa que las energías/correlaciones de los canales derecho R e izquierdo L son casi las mismas, el factor p es igual a 0.5 y un factor £ de normalización (reescalado) de energía es 1.0. En esta situación, el contenido del canal primario Y es básicamente una mezcla mono y el canal secundario X forma un canal lateral. El cálculo del factor £ de normalización (reescalado) de energía se describe a continuación.
Por otro lado, si la diferencia de correlación linealizada a largo plazo es igual a 2, lo que significa que la mayor parte de la energía está en el canal izquierdo L, entonces el factor p es 1 y el factor de normalización (reescalado) de energía es 0.5, lo que indica que el canal primario Y contiene básicamente el canal izquierdo L en una implementación de diseño incrustado o una representación reducida del canal izquierdo L en una implementación de diseño integrado. En este caso, el canal secundario X contiene el canal derecho R. En las realizaciones de ejemplo, el convertidor y cuantificador 455 o 1357 cuantifica el factor p utilizando 31 posibles entradas de cuantificación. La versión cuantificada del factor p se representa usando un índice de 5 bits y, como se describió anteriormente en este documento, se suministra al multiplexor para su integración en el flujo 207/307 de bits multiplexado, y se transmite al decodificador a través del enlace de comunicación.
es igual a 2, lo que significa que la mayor parte de la energía está en el canal izquierdo L, entonces el factor p es 1 y el factor de normalización (reescalado) de energía es 0.5, lo que indica que el canal primario Y contiene básicamente el canal izquierdo L en una implementación de diseño incrustado o una representación reducida del canal izquierdo L en una implementación de diseño integrado. En este caso, el canal secundario X contiene el canal derecho R. En las realizaciones de ejemplo, el convertidor y cuantificador 455 o 1357 cuantifica el factor p utilizando 31 posibles entradas de cuantificación. La versión cuantificada del factor p se representa usando un índice de 5 bits y, como se describió anteriormente en este documento, se suministra al multiplexor para su integración en el flujo 207/307 de bits multiplexado, y se transmite al decodificador a través del enlace de comunicación.
En una realización, el factor p también puede usarse como indicador tanto para el codificador 252/352 de canal primario como para el codificador 253/353 de canal secundario para determinar la asignación de tasa de bits. Por ejemplo, si el factor p está cerca de 0.5, lo que significa que las dos (2) energías/correlación del canal de entrada con el mono están cercanas entre sí, se asignarían más bits al canal secundario X y menos bits al canal primario Y, excepto si el contenido de ambos canales es bastante similar, entonces el contenido del canal secundario tendrá muy poca energía y probablemente se considerará inactivo, lo que permitirá que muy pocos bits lo codifiquen. Por otro lado, si el factor p está más cerca de 0 o 1, entonces la asignación de tasa de bits favorecerá al canal primario Y
La figura 6 muestra la diferencia entre usar el esquema pca/klt mencionado anteriormente sobre todo el cuadro (dos curvas de arriba de la figura 6) frente a usar la función "coseno" desarrollada en la relación (8) para calcular el factor p (curva de abajo de la figura 6). Por naturaleza el esquema pca/klt tiende a buscar un mínimo o un máximo. Esto funciona bien en el caso de habla activa, como se muestra en la curva central de la figura 6, pero no funciona muy bien para habla con ruido de fondo, ya que tiende a conmutar continuamente de 0 a 1, como se muestra en la curva media de la figura 6. La conmutación demasiado frecuente a las extremidades, 0 y 1, provoca muchos artefactos al codificar a una baja tasa de bits. Una posible solución habría sido suavizar las decisiones del esquema pca/klt, pero esto habría impactado negativamente en la detección de ráfagas de habla y sus ubicaciones correctas, mientras que la función "coseno" de la relación (8) es más eficiente a este respecto.
La figura 7 muestra el canal primario Y, el canal secundario X y los espectros de estos canales primario Y y secundario X resultantes de aplicar una mezcla descendente en el dominio del tiempo a una muestra estéreo que se ha grabado en una pequeña sala ecoica usando una configuración de micrófonos binaurales con ruido de oficina de fondo. Después de la operación de mezcla descendente en el dominio del tiempo, se puede ver que ambos canales todavía tienen formas de espectro similares y el canal secundario X todavía tiene un contenido temporal similar al habla, lo que permite usar un modelo basado en habla para codificar el canal secundario X.
La mezcla descendente en el dominio del tiempo presentada en la descripción anterior puede mostrar algunos problemas en el caso especial de los canales derecho R e izquierdo L que están invertidos en fase. La suma de los canales derecho R e izquierdo L para obtener una señal monofónica daría como resultado que los canales derecho R e izquierdo L se cancelaran entre sí. Para resolver este posible problema, en una realización, el mezclador 251/351 de canales compara la energía de la señal monofónica con la energía de los canales derecho R e izquierdo L. La
energía de la señal monofónica debe ser al menos mayor que la energía de uno de los canales derecho R e izquierdo L. De lo contrario, en esta realización, el modelo de mezcla descendente en el dominio del tiempo entra en el caso especial de fase invertida. En presencia de este caso especial, el factor p se fuerza a 1 y el canal secundario X se codifica forzosamente usando el modo genérico o sordo, evitando así el modo de codificación inactivo y asegurando la codificación adecuada del canal secundario X. Este caso especial, donde no se aplica ningún cambio de escala de energía, se señala al decodificador utilizando la última combinación de bits (valor de índice) disponible para la transmisión del factor p (básicamente desde p se cuantifica utilizando 5 bits y se utilizan 31 entradas (niveles de cuantificación) para la cuantificación como se describió anteriormente, la 32a combinación de bits posible (valor de entrada o índice) se utiliza para señalar este caso especial).
En una implementación alternativa, se puede poner más énfasis en la detección de señales que son subóptimas para las técnicas de codificación y mezcla descendente descritas anteriormente, tal como en casos de señales fuera de fases o casi fuera de fases. Una vez que se detectan estas señales, las técnicas de codificación subyacentes pueden adaptarse si es necesario.
Normalmente, para la mezcla descendente en el dominio del tiempo como se describe en este documento, cuando los canales izquierdo L y derecho R de una señal estéreo de entrada están fuera de fases, puede ocurrir alguna cancelación durante el proceso de mezcla descendente, lo que podría conducir a una calidad subóptima. En los ejemplos anteriores, la detección de estas señales es sencilla y la estrategia de codificación comprende codificar ambos canales por separado. Pero a veces, con señales especiales, tal como señales que están fuera de fases, puede ser más eficiente realizar una mezcla descendente similar a mono/lateral (3= 0.5), donde se pone mayor énfasis en el canal lateral. Dado que algún tratamiento especial de estas señales puede resultar beneficioso, la detección de dichas señales debe realizarse con cuidado. Además, la transición desde el modelo de mezcla descendente en el dominio del tiempo normal como se describe en la descripción anterior y el modelo de mezcla descendente en el dominio del tiempo que trata con estas señales especiales puede activarse en una región de muy baja energía o en regiones donde el tono de ambos canales no es estable, de modo que la conmutación entre los dos modelos tiene un efecto subjetivo mínimo.
La corrección de retardo temporal (TDC) (véase el corrector 1750 de retardo temporal en las figuras 17 y 18) entre los canales L y R, o una técnica similar a la que se describe en la referencia [8], se puede realizar antes de ingresar al módulo 201/301,251/351 de mezcla descendente. En tal realización, el factor p puede terminar teniendo un significado diferente del que se ha descrito anteriormente. Para este tipo de implementación, con la condición de que la corrección del retardo temporal funcione como se esperaba, el factor p puede acercarse a 0.5, lo que significa que la configuración de la mezcla descendente en el dominio del tiempo está próxima a una configuración mono/lateral. Con el funcionamiento adecuado de la corrección de retardo temporal (TDC), el lateral puede contener una señal que incluye una cantidad menor de información importante. En ese caso, la tasa de bits del canal secundario X puede ser mínima cuando el factor p es cercano a 0.5. Por otro lado, si el factor p está cerca de 0 o 1, esto significa que la corrección de retardo temporal (TDC) puede no superar adecuadamente la situación de desalineación del retardo y es probable que el contenido del canal secundario X sea más complejo, por lo que necesita una tasa de bits más alta. Para ambos tipos de implementación, el factor p y por asociación el factor £ de normalización (reescalado) de energía, pueden usarse para mejorar la asignación de bits entre el canal primario Y y el canal secundario X.
La figura 14 es un diagrama de bloques que muestra operaciones simultáneas de una detección de señal fuera de fase y módulos de un detector 1450 de señal fuera de fase que forma parte de la operación 201/301 de mezcla descendente y el mezclador 251/351 de canales. Las operaciones de detección de señal fuera de fase incluyen, como se muestra en la figura 14, una operación 1401 de detección de señal fuera de fase, una operación 1402 de detección de posición de conmutación y una operación 1403 de selección de mezclador de canal, para elegir entre la operación 201/301 de mezcla descendente de dominio el del tiempo y una operación 1404 de mezcla descendente de dominio de tiempo específico fuera de fase. Estas operaciones se realizan respectivamente mediante un detector 1451 de señal fuera de fase, un detector 1452 de posición de conmutación, un selector 1453 de mezclador de canal, el mezclador 251/351 de canal descendente de dominio de tiempo descrito anteriormente y un mezclador 1454 de canal descendente de dominio de tiempo específico fuera de fase.
La detección 1401 de señal fuera de fase se basa en una correlación de bucle abierto entre los canales primario y secundario en cuadros anteriores. Para este fin, el detector 1451 calcula en los cuadros anteriores una diferencia de energía Sm(t) entre una señal lateral s(i) y una señal mono m(/) usando las relaciones (12a) y (12b):

Luego, el detector 1451 calcula el lado a largo plazo de la diferencia de energía mono usando la relación (12c):
usando la relación (12c):

donde t indica el cuadro actual, t-1 el cuadro anterior, y donde el contenido inactivo puede derivarse del indicador de suspensión del detector de actividad de voz (VAD) o de un contador de suspensión de VAD.
Además del lado a largo plazo de la diferencia monoenergética ( , la correlación máxima del último tono en bucle abierto Cf|l de cada canal Y y X, como se define en la cláusula 5.1.10 de la referencia [1], también se tiene en cuenta para decidir cuándo el modelo actual se considera subóptimo. Cp(M) representa la correlación máxima de bucle abierto de tono del canal primario Y en un cuadro anterior y Cs(M), la correlación máxima del bucle de tono abierto del canal secundario X en el cuadro anterior. Un indicador Fsub de suboptimidad es calculado por el detector 1452 de posición de conmutación de acuerdo con los siguientes criterios:
( , la correlación máxima del último tono en bucle abierto Cf|l de cada canal Y y X, como se define en la cláusula 5.1.10 de la referencia [1], también se tiene en cuenta para decidir cuándo el modelo actual se considera subóptimo. Cp(M) representa la correlación máxima de bucle abierto de tono del canal primario Y en un cuadro anterior y Cs(M), la correlación máxima del bucle de tono abierto del canal secundario X en el cuadro anterior. Un indicador Fsub de suboptimidad es calculado por el detector 1452 de posición de conmutación de acuerdo con los siguientes criterios:
Si el lado a largo plazo de la diferencia monoenergética está por encima de un cierto umbral, por ejemplo cuand
está por encima de un cierto umbral, por ejemplo cuand  si ambas correlaciones máximas de bucle abierto de tono C p ^ y Cs(M) están entre 0.85 y 0.92, lo que significa que las señales tienen una buena correlación, pero no están tan correlacionadas como lo estaría una señal de voz, el indicador Fsub de suboptimidad se establece en 1, lo que indica una condición fuera de fase entre los canales izquierdo L y derecho R.
si ambas correlaciones máximas de bucle abierto de tono C p ^ y Cs(M) están entre 0.85 y 0.92, lo que significa que las señales tienen una buena correlación, pero no están tan correlacionadas como lo estaría una señal de voz, el indicador Fsub de suboptimidad se establece en 1, lo que indica una condición fuera de fase entre los canales izquierdo L y derecho R.
De lo contrario, el indicador Fsub de suboptimidad se establece en 0, lo que indica que no hay ninguna condición fuera de fase entre los canales izquierdo L y derecho R.
Para agregar cierta estabilidad en la decisión del indicador de suboptimidad, el detector 1452 de posición de conmutación implementa un criterio con respecto al contorno de tono de cada canal Y y X. El detector 1452 de posición de conmutación determina que el mezclador 1454 de canales se usará para codificar las señales subóptimas cuando, en la realización de ejemplo, al menos tres (3) instancias consecutivas del indicador Fsub de suboptimidad se establecen en 1 y la estabilidad de tono del último cuadro de uno del canal primario, ppC(t-1}, o del canal secundario, Psc(t-1), es mayor que 64. La estabilidad del tono consiste en la suma de las diferencias absolutas de los tres tonos en bucle abierto p0|1|2 como se define en 5.1.10 de la referencia [1], calculado por el detector 1452 de posición de conmutación usando la relación (12d):

El detector 1452 de posición de conmutación proporciona la decisión al selector 1453 del mezclador de canales que, a su vez, selecciona el mezclador 251/351 de canales o el mezclador 1454 de canales en consecuencia. El selector 1453 del mezclador de canales implementa una histéresis tal que, cuando se selecciona el mezclador 1454 de canales, esta decisión se mantiene hasta que se cumplan las siguientes condiciones: un número de cuadros consecutivos, por ejemplo 20 cuadros, se consideran óptimos, la estabilidad del tono del último cuadro de uno de los canales primario Ppc(f-i) o secundario pSc(t-i) es mayor que un número predeterminado, por ejemplo 64, y el lado a largo plazo de la diferencia de energía mono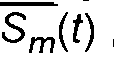 es menor o igual a 0.
es menor o igual a 0.
2) Codificación dinámica entre canales primarios y secundarios.
La figura 8 es un diagrama de bloques que ilustra simultáneamente el método y el sistema de codificación de sonido estéreo, con una posible implementación de optimización de la codificación de los canales primario Y y secundario X de la señal de sonido estéreo, tal como habla o audio.
Con referencia a la figura 8, el método de codificación de sonido estéreo comprende una operación 801 de preprocesamiento de baja complejidad implementada por un preprocesador 851 de baja complejidad, una operación 802 de clasificación de señales implementada por un clasificador 852 de señales, una operación 803 de decisión implementada por un módulo 853 de decisión, una operación 804 de codificación genérica solo de modelo de cuatro (4) subcuadros implementada por un módulo 854 de codificación solo genérica de modelo de cuatro (4) subcuadros, una operación 805 de codificación de modelo de dos (2) subcuadros implementada por un módulo 855 de codificación de modelo de dos (2) subcuadros, y una operación 806 de análisis de coherencia de filtro LP implementada por un analizador 856 de coherencia de filtro LP
Después de que el mezclador 351 de canales haya realizado la mezcla 301 descendente en el dominio del tiempo, en el caso del modelo incrustado, se codifica el canal primario Y (operación 302 de codificación de canal primario) (a) utilizando como codificador 352 de canal primario un codificador heredado tal como el codificador EVS heredado o cualquier otro codificador de sonido heredado adecuado (debe tenerse en cuenta que, como se menciona en la descripción anterior, se puede utilizar cualquier tipo adecuado de codificador como codificador 352 de canal primario). En el caso de una estructura integrada, se utiliza un códec de habla dedicado como codificador 252 de canal primario.
El codificador 252 de habla dedicado puede ser un codificador basado en una tasa de bits variable (VBR), por ejemplo una versión modificada del codificador EVS heredado, que se ha modificado para tener una mayor escalabilidad de la tasa de bits que permite el manejo de una tasa de bits variable por nivel de cuadro (de nuevo debe tenerse en cuenta que, como se menciona en la descripción anterior, se puede utilizar cualquier tipo adecuado de codificador como codificador 252 de canal primario). Esto permite que la cantidad mínima de bits utilizados para codificar el canal secundario X varíe en cada cuadro y se adapte a las características de la señal de sonido a codificar. Al final, la firma del canal secundario X será lo más homogénea posible.
La codificación del canal secundario X, es decir, la energía/correlación inferior con la entrada mono, está optimizada para utilizar una tasa de bits mínima, en particular, pero no exclusivamente, para contenido similar al habla. Para ese propósito, la codificación del canal secundario puede aprovechar parámetros que ya están codificados en el canal primario Y, tales como los coeficientes de filtro lP (LPC) y/o el retraso 807 de tono. Específicamente, se decidirá, como se describe más adelante, si los parámetros calculados durante la codificación del canal primario están lo suficientemente cerca de los parámetros correspondientes calculados durante la codificación del canal secundario para ser reutilizados durante la codificación del canal secundario.
En primer lugar, la operación 801 de preprocesamiento de baja complejidad se aplica al canal secundario X usando el preprocesador 851 de baja complejidad, en donde se calculan un filtro LP, una detección de actividad de voz (VAD) y un tono de bucle abierto en respuesta al canal secundario X. Estos últimos cálculos pueden implementarse, por ejemplo, mediante los realizados en el codificador heredado EVS y descritos respectivamente en las cláusulas 5.1.9, 5.1.12 y 5.1.10 de la referencia [1]. Dado que, como se menciona en la descripción anterior, se puede utilizar cualquier tipo adecuado de codificador como codificador 252/352 de canal primario, los cálculos anteriores se pueden implementar mediante los realizados en dicho codificador de canal primario.
Luego, las características de la señal del canal secundario X son analizadas por el clasificador 852 de señales para clasificar el canal secundario X como sordo, genérico o inactivo usando técnicas similares a las de la función de clasificación de señales EVS, cláusula 5.1.13 de la misma referencia [1]. Estas operaciones son conocidas por los expertos en la técnica y se pueden extraer del estándar 3GPP TS 26.445, v.12.0.0 por simplicidad, pero también se pueden usar implementaciones alternativas.
a. Reutilización de los coeficientes del filtro LP del canal primario
Una parte importante del consumo de tasa de bits reside en la cuantificación de los coeficientes del filtro LP (LPC). A una baja tasa de bits, la cuantificación completa de los coeficientes del filtro LP puede ocupar hasta casi el 25% del presupuesto de bits. Dado que el canal secundario X suele tener un contenido de frecuencia cercano al canal primario Y, pero con el nivel de energía más bajo, vale la pena verificar si sería posible reutilizar los coeficientes del filtro LP del canal primario Y Para hacerlo, como se muestra en la figura 8, se ha desarrollado una operación 806 de análisis de coherencia del filtro LP implementada por un analizador 856 de coherencia del filtro LP, en la que se calculan y comparan algunos parámetros para validar la posibilidad de reutilizar o no los coeficientes 807 del filtro LP (LPC) del canal primario Y
La figura 9 es un diagrama de bloques que ilustra la operación 806 de análisis de coherencia del filtro LP y el analizador 856 de coherencia del filtro LP correspondiente del método y sistema de codificación de sonido estéreo de la figura 8.
La operación 806 de análisis de coherencia del filtro LP y el analizador 856 de coherencia del filtro LP correspondiente del método y sistema de codificación de sonido estéreo de la figura 8 comprenden, como se ilustra en la figura 9, una suboperación 903 de análisis de filtro LP (predicción lineal) de canal primario implementada por una analizador 953 de filtro LP, una suboperación 904 de pesaje implementada por un filtro 954 de ponderación, una suboperación 912 de análisis de filtro LP de canal secundario implementada por un analizador 962 de filtro LP, una suboperación 901 de pesaje implementada por un filtro 951 de ponderación, una suboperación 902 de análisis de distancia euclidiana implementada por un analizador 952 de distancia euclidiana, una suboperación 913 de filtrado residual implementada por un filtro 963 residual, una suboperación 914 de cálculo de energía residual implementada por una calculadora 964 de energía de residual, una suboperación 915 de resta implementada por un restador 965, una suboperación 910 de cálculo de energía de sonido (tal como habla y/o audio) implementada por una calculadora 960 de energía, una operación 906 de filtrado residual de canal secundario implementada por un filtro 956 residual de canal secundario, una suboperación 907 de cálculo de energía residual implementada por una calculadora 957 de energía de residual, una suboperación 908 de resta implementada por un restador 958, una suboperación 911 de cálculo de relación de ganancia implementada por una calculadora de relación de ganancia, una suboperación 916 de comparación implementada por un comparador 966, una suboperación 917 de comparación implementada por un comparador 967, una suboperación 918 de decisión de uso de filtro LP de canal secundario implementada por un módulo 968 de decisión, y una suboperación 919 de decisión de reutilización de filtro LP de canal primario implementada por un módulo 969 de decisión.
Con referencia a la figura 9, el analizador 953 de filtro LP realiza un análisis de filtro LP en el canal primario Y mientras que el analizador 962 de filtro LP realiza un análisis de filtro LP en el canal secundario X. El análisis de filtro LP realizado en cada uno de los canales primario Y y secundario X es similar al análisis descrito en la cláusula 5.1.9 de la referencia [1].
Entonces, los coeficientes Ay del filtro LP desde el analizador 953 de filtro LP se suministran al filtro 956 residual para un primer filtrado residual, ry, del canal secundario X. De la misma manera, los coeficientes Ax óptimos del filtro LP desde el analizador 962 de filtro LP se suministran al filtro 963 residual para un segundo filtrado residual, rx, del canal secundario X. El filtrado residual con cualquiera de los coeficientes de filtro, Ay o Ax, se realiza usando la relación (11):

donde, en este ejemplo, sx representa el canal secundario, el orden del filtro LP es 16 y N es el número de muestras en el cuadro (tamaño del cuadro), que generalmente es 256, lo que corresponde a una duración de cuadro de 20 ms a una tasa de muestreo de 12.8 kHz.
La calculadora 910 calcula la energía Ex de la señal de sonido en el canal secundario X usando la relación (14):

y la calculadora 957 calcula la energía Ery del residual del filtro 956 residual usando la relación (15):

El restador 958 resta la energía residual de la calculadora 957 de la energía del sonido de la calculadora 960 para producir una ganancia de predicción Gy.
De la misma manera, la calculadora 964 calcula la energía Erx del residual del filtro 963 residual usando la relación (16):

y el restador 965 resta esta energía residual de la energía del sonido de la calculadora 960 para producir una ganancia de predicción Gx.
La calculadora 961 calcula la relación de ganancia Gy/Gx. El comparador 966 compara la relación de ganancia Gy/Gx a un umbral t, que es 0.92 en la realización de ejemplo. Si la relación Gy/Gx es menor que el umbral t, el resultado de la comparación se transmite al módulo 968 de decisión que fuerza el uso de los coeficientes de filtro LP del canal secundario para codificar el canal secundario X.
El analizador 952 de distancia euclidiana realiza una medida de similitud de filtro LP, tal como la distancia euclidiana entre los pares espectrales de líneas lspy calculada por el analizador 953 de filtro LP en respuesta al canal primario Y y los pares espectrales de línea lspx calculado por el analizador 962 de filtro LP en respuesta al canal secundario X. Como saben los expertos en la técnica, los pares espectrales de líneas lspy y lspx representan los coeficientes del filtro LP en un dominio de cuantificación. El analizador 952 utiliza la relación (17) para determinar la distancia euclidiana dist:

donde M representa el orden del filtro, y lspy y lspx representan respectivamente los pares espectrales de líneas calculados para los canales primario Y y secundario X.
Antes de calcular la distancia euclidiana en el analizador 952, es posible ponderar ambos conjuntos de pares espectrales de líneas lspy y lspx mediante factores de ponderación respectivos, de modo que se ponga más o menos énfasis en determinadas porciones del espectro. También se pueden utilizar otras representaciones del filtro LP para calcular la medida de similitud del filtro LP.
Una vez que la distancia euclidiana dist se conoce, se compara con un umbral a en el comparador 967. En la realización de ejemplo, el umbral a tiene un valor de 0.08. Cuando el comparador 966 determina que la relación Gy/Gx es igual o mayor que el umbral t y el comparador 967 determina que la distancia euclidiana dist es igual o mayor que el umbral a, el resultado de las comparaciones se transmite al módulo 968 de decisión que fuerza el uso de los coeficientes del filtro LP del canal secundario para codificar el canal secundario X. Cuando el comparador 966 determina que la relación Gy/Gx es igual o mayor que el umbral t y el comparador 967 determina que la distancia euclidiana dist es menor que el umbral a, el resultado de estas comparaciones se transmite al módulo 969 de decisión que fuerza la reutilización de los coeficientes del filtro LP del canal primario para codificar el canal secundario X. En el último caso, los coeficientes del filtro LP del canal primario se reutilizan como parte de la codificación de canal secundario.
Se pueden realizar algunas pruebas adicionales para limitar la reutilización de los coeficientes del filtro LP del canal primario para codificar el canal secundario X en casos particulares, por ejemplo en el caso del modo de codificación sorda, donde la señal es lo suficientemente fácil de codificar como para que todavía haya tasa de bits disponible para codificar también los coeficientes del filtro LP. También es posible forzar la reutilización de los coeficientes del filtro LP del canal primario cuando ya se obtiene una ganancia residual muy baja con los coeficientes del filtro LP del canal secundario o cuando el canal secundario X tiene un nivel de energía muy bajo. Finalmente, las variables t, a, el nivel de ganancia residual o el nivel de energía muy bajo al que se puede forzar la reutilización de los coeficientes del filtro LP se pueden adaptar en función del presupuesto de bits disponible y/o en función del tipo de contenido. Por ejemplo, si el contenido del canal secundario se considera inactivo, incluso si la energía es alta, se puede decidir reutilizar los coeficientes del filtro LP del canal primario.
b. Codificación de baja tasa de bits del canal secundario
Dado que los canales primario Y y secundario X pueden ser una mezcla de los canales de entrada derecho R e izquierdo L, esto implica que, incluso si el contenido de energía del canal secundario X es bajo en comparación con el contenido de energía del canal primario Y, se puede percibir un artefacto de codificación una vez que se realiza la mezcla ascendente de los canales. Para limitar este posible artefacto, la firma de codificación del canal secundario X se mantiene lo más constante posible para limitar cualquier variación de energía no deseada. Como se muestra en la figura 7, el contenido del canal secundario X tiene características similares al contenido del canal primario Y y por esa razón se ha desarrollado un modelo de codificación similar al habla de tasa de bits muy baja.
Volviendo a la figura 8, el analizador 856 de coherencia del filtro LP envía al módulo 853 de decisión la decisión de reutilizar los coeficientes del filtro LP del canal primario del módulo 969 de decisión o la decisión de usar los coeficientes del filtro LP del canal secundario del módulo 968 de decisión. El módulo de decisión 803 decide entonces no cuantificar los coeficientes del filtro LP del canal secundario cuando se reutilizan los coeficientes del filtro LP del canal primario y cuantificar los coeficientes del filtro LP del canal secundario cuando la decisión es usar los coeficientes del filtro LP del canal secundario. En el último caso, los coeficientes del filtro LP del canal secundario cuantificados se envían al multiplexor 254/354 para su inclusión en el flujo 207/307 de bits multiplexado.
En la operación 804 de codificación única genérica del modelo de cuatro (4) subcuadros y en el módulo 854 de codificación única genérica del modelo de cuatro subcuadros correspondientes, para mantener la tasa de bits lo más baja posible, se realiza una búsqueda ACELP como se describe en la cláusula 5.2.3.1 de la referencia [1] se usa sólo cuando los coeficientes del filtro LP del canal primario Y se pueden reutilizar, cuando el canal secundario X está clasificado como genérico por el clasificador 852 de señal, y cuando la energía de los canales derecho R e izquierdo L de entrada está cerca del centro, lo que significa que las energías de los canales derecho R e izquierdo L están cerca entre sí. Los parámetros de codificación encontrados durante la búsqueda ACELP en el módulo 854 de codificación genérico único del modelo de cuatro (4) subcuadros se usan luego para construir el flujo 206/306 de bits del canal secundario y se envían al multiplexor 254/354 para su inclusión en el flujo 207/307 de bits multiplexado.
De lo contrario, en la operación 805 de codificación del modelo de dos (2) subcuadros y el correspondiente módulo de codificación del modelo de dos (2) subcuadros 855, se usa un modelo de media banda para codificar el canal secundario X con contenido genérico cuando los coeficientes del filtro LP del canal primario Y no se pueden reutilizar. Para el contenido inactivo y sordo, sólo se codifica la forma del espectro.
En el módulo 855 de codificación, la codificación de contenido inactivo comprende (a) codificación de ganancia de banda espectral en el dominio de la frecuencia más relleno de ruido y (b) codificación de los coeficientes del filtro LP del canal secundario cuando sea necesario, como se describe respectivamente en (a) las cláusulas 5.2.3.5.7 y 5.2.3.5.11 y (b) cláusula 5.2.2.1 de la referencia [1]. El contenido inactivo se puede codificar a una tasa de bits tan baja como 1.5 kb/s.
En el módulo 855 de codificación, la codificación sorda del canal secundario X es similar a la codificación inactiva del canal secundario X, con la excepción de que la codificación sorda utiliza un número adicional de bits para la cuantificación de los coeficientes de filtro LP del canal secundario que están codificados para el secundario sordo.
El modelo de codificación genérica de media banda se construye de manera similar a ACELP como se describe en la cláusula 5.2.3.1 de la referencia [1], pero se utiliza sólo con dos (2) subcuadros por cuadro. Por lo tanto, para hacerlo, el residual como se describe en la cláusula 5.2.3.1.1 de la referencia [1], la memoria del libro de códigos adaptativo como se describe en la cláusula 5.2.3.1.4 de la referencia [1] y el canal secundario de entrada son primero muestreado descendentemente por un factor 2. Los coeficientes del filtro LP también se modifican para representar el dominio de muestreo descendente en lugar de la tasa de muestreo de 12.8 kHz utilizando una técnica como la descrita en la cláusula 5.4.4.2 de la referencia [1].
Después de la búsqueda ACELP, se realiza una extensión del ancho de banda en el dominio de la frecuencia de la excitación. La extensión del ancho de banda primero replica las energías de la banda espectral inferior en la banda superior. Para replicar las energías de las bandas espectrales, la energía de las primeras nueve (9) bandas espectrales, Gbd(i), se encuentran como se describe en la cláusula 5.2.3.5.7 de la referencia [1] y las últimas bandas se llenan como se muestra en la relación (18):

Entonces, el contenido de alta frecuencia del vector de excitación representado en el dominio Fd(k) de la frecuencia como se describe en la cláusula 5.2.3.5.9 de la referencia [1] se completa utilizando el contenido de frecuencia de la banda inferior utilizando la relación (19):

donde el tono se desplaza, Pb, se basa en un múltiplo de la información de tono como se describe en la cláusula 5.2.3.1.4.1 de la referencia [1] y se convierte en un desplazamiento de contenedores de frecuencia como se muestra en la relación (20):

donde representa un promedio de la información de tono decodificada por subcuadro, Fs es la tasa de muestreo interna, 12.8 kHz en esta realización de ejemplo, y Fr es la resolución de frecuencia.
Los parámetros de codificación encontrados durante la codificación inactiva de baja tasa, la codificación sorda de baja tasa o la codificación genérica de media banda realizada en el módulo 855 de codificación de modelo de dos (2) subcuadros se usan luego para construir el flujo 206/306 de bits del canal secundario enviado a el multiplexor 254/354 para su inclusión en el flujo 207/307 de bits multiplexado.
c. Implementación alternativa de la codificación de baja tasa de bits del canal secundario
La codificación del canal secundario X se puede conseguir de forma diferente, con el mismo objetivo de utilizar un número mínimo de bits logrando al mismo tiempo la mejor calidad posible y manteniendo una firma constante. La codificación del canal secundario X puede ser accionada en parte por el presupuesto de bits disponible, independientemente de la posible reutilización de los coeficientes del filtro LP y la información de tono. Además, la codificación del modelo de dos (2) subcuadros (operación 805) puede ser de media banda o de banda completa. En esta implementación alternativa de la codificación de baja tasa de bits del canal secundario, los coeficientes del filtro LP y/o la información de tono del canal primario se pueden reutilizar y la codificación del modelo de dos (2) subcuadros se puede elegir con base en el presupuesto de bits disponible para codificar el canal secundario X. Además, la codificación del modelo de 2 subcuadros que se presenta a continuación se ha creado duplicando la longitud del subcuadro en lugar de reducir o aumentar el muestreo de sus parámetros de entrada/salida.
La figura 15 es un diagrama de bloques que ilustra simultáneamente un método de codificación de sonido estéreo alternativo y un sistema de codificación de sonido estéreo alternativo. El método y sistema de codificación de sonido estéreo de la figura 15 incluyen varias de las operaciones y módulos del método y sistema de la figura 8, identificados usando los mismos numerales de referencia y cuya descripción no se repite en este documento por brevedad. Además, el método de codificación de sonido estéreo de la figura 15 comprende una operación 1501 de preprocesamiento aplicada al canal primario Y antes de su codificación en la operación 202/302, una operación 1502 de análisis de coherencia de tono, una operación 1504 de decisión sorda/inactiva, una operación 1505 de decisión de codificación sorda/inactiva, y una operación 1506 de decisión de modelo de 2/4 subcuadros.
Las suboperaciones 1501, 1502, 1503, 1504, 1505 y 1506 se realizan respectivamente mediante un preprocesador 1551 similar al preprocesador 851 de baja complejidad, un analizador 1552 de coherencia de tono, un estimador 1553 de asignación de bits, un módulo 1554 de decisión sorda/inactiva, un módulo 1555 de decisión de codificación sorda/inactiva y un módulo 1556 de decisión de modelo de 2/4 subcuadros.
Para realizar la operación 1502 de análisis de coherencia de tono, el analizador 1552 de coherencia de tono es suministrado por los preprocesadores 851 y 1551 con tonos de bucle abierto de los canales primario Y y secundario, respectivamente tono OLpri y tono OLsec. El analizador 1552 de coherencia de tono de la figura 15 se muestra con mayor detalle en la figura 16, que es un diagrama de bloques que ilustra simultáneamente suboperaciones de la operación 1502 de análisis de coherencia de tono y módulos del analizador 1552 de coherencia de tono.
La operación 1502 de análisis de coherencia de tono realiza una evaluación de la similitud de los tonos de bucle abierto entre el canal primario Y y el canal secundario X para decidir en qué circunstancias el tono de bucle abierto primario puede reutilizarse en la codificación del canal secundario X. Con este fin, la operación 1502 de análisis de coherencia de tono comprende una suboperación 1601 de suma de tonos de bucle abierto de canal primario realizada por un sumador 1651de tonos de bucle abierto de canal primario, y una suboperación de suma de tonos de bucle abierto de
canal secundario 1602 realizada por un sumador 1652 de tonos de bucle abierto canal secundario. La suma del sumador 1652 se resta (suboperación 1603) de la suma del sumador 1651 usando un restador 1653. El resultado de la resta de la suboperación 1603 proporciona una coherencia de tono estéreo. Como ejemplo no limitativo, las sumas en las suboperaciones 1601 y 1602 se basan en tres (3) tonos de bucle abierto consecutivos anteriores disponibles para cada canal Y y X. Los tonos de bucle abierto se pueden calcular, por ejemplo, como se define en la cláusula 5.1.10 de la referencia [1]. La coherencia del tono estéreo Spc se calcula en las suboperaciones 1601, 1602 y 1603 usando la relación (21):

donde pp^o representan los tonos de bucle abierto de los canales primario Y y secundario X e i representa la posición de los tonos de bucle abierto.
Cuando la coherencia de tono estéreo está por debajo de un umbral A predeterminado, se puede permitir la reutilización de la información de tono del canal primario Y dependiendo de un presupuesto de bits disponible para codificar el canal secundario X. Además, dependiendo del presupuesto de bits disponible, Es posible limitar la reutilización de la información de tono para señales que tienen una característica de voz tanto para el canal Y primario como para el canal X secundario.
Con este fin, la operación 1502 de análisis de coherencia de tono comprende una suboperación 1604 de decisión realizada por un módulo 1654 de decisión que considera el presupuesto de bits disponible y las características de la señal de sonido (indicadas, por ejemplo, por los modos de codificación de canal primario y secundario). Cuando el módulo 1654 de decisión detecta que el presupuesto de bits disponible es suficiente o las señales de sonido para los canales primario Y y secundario X no tienen característica de voz, la decisión es codificar la información de tono relacionada con el canal secundario X (1605).
Cuando el módulo 1654 de decisión detecta que el presupuesto de bits disponible es bajo con el propósito de codificar la información de tono del canal secundario X o las señales de sonido para los canales primario Y y secundario X tienen una característica de voz, el módulo de decisión compara la coherencia de tono estéreo Spc al umbral A. Cuando el presupuesto de bits es bajo, el umbral A se establece en un valor mayor en comparación con el caso en el que el presupuesto de bits es más importante (suficiente para codificar la información de tono del canal secundario X). Cuando el valor absoluto de la coherencia del tono estéreo Spc es menor o igual que el umbral A, el módulo 1654 decide reutilizar la información de tono del canal primario Y para codificar el canal secundario X (1607). Cuando el valor de la coherencia del tono estéreo Spc es mayor que el umbral A, el módulo 1654 decide codificar la información de tono del canal secundario X (1605).
Garantizar que los canales tengan características de voz aumenta la probabilidad de una evolución suave del tono, lo que reduce el riesgo de agregar artefactos al reutilizar el tono del canal principal. Como ejemplo no limitativo, cuando el presupuesto de bits estéreo está por debajo de 14 kb/s y la coherencia del tono estéreo Spc está por debajo o igual a 6 (A = 6), la información de tono primario se puede reutilizar en la codificación del canal secundario X. De acuerdo con otro ejemplo no limitativo, si el presupuesto de bits estéreo está por encima de 14 kb/s y por debajo 26 kb/s, entonces tanto el canal primario Y como el secundario X se consideran sonoros y la coherencia del tono estéreo Spc se compara con un umbral inferior A = 3, lo que conduce a una menor tasa de reutilización de la información de tono del canal primario Y a una tasa de bits de 22 kb/s.
Volviendo a la figura 15, el estimador 1553 de asignación de bits se suministra con el factor p desde el mezclador 251/351 de canales, con la decisión de reutilizar los coeficientes de filtro LP del canal primario o de usar y codificar los coeficientes de filtro LP del canal secundario del analizador 856 de coherencia de filtro LP, y con la información de tono determinada por el analizador 1552 de coherencia de tono. Dependiendo de los requisitos de codificación de canal primario y secundario, el estimador 1553 de asignación de bits proporciona un presupuesto de bits para codificar el canal primario Y al codificador 252/352 de canal primario y un presupuesto de bits para codificar el canal secundario X al módulo 1556 de decisión. En una posible implementación, para todo el contenido que no esté inactivo, se asigna una fracción de la tasa de bits total al canal secundario. Luego, la tasa de bits del canal secundario se incrementará en una cantidad que está relacionada con un factor £ de normalización (reescalamiento) de energía descrito anteriormente como:

donde Bx representa la tasa de bits asignada al canal X, Bt secundario representa la tasa de bits estéreo total disponible, Bm representa la tasa de bits mínima asignada al canal secundario y suele ser alrededor del 20% de la tasa de bits estéreo total. Finalmente, £ representa el factor de normalización de energía descrito anteriormente. Por lo tanto, la tasa de bits asignada al canal primario corresponde a la diferencia entre la tasa de bits estéreo total y la tasa de bits estéreo del canal secundario. En una implementación alternativa, la asignación de tasa de bits del canal secundario se puede describir como:

donde otra vez Bx representa la tasa de bits asignada al canal secundario X, Bt representa la tasa de bits estéreo total disponible y Bm representa la tasa de bits mínima asignada al canal secundario. Finalmente, £dx representa un índice transmitido del factor de normalización de energía. Por lo tanto, la tasa de bits asignada al canal primario corresponde a la diferencia entre la tasa de bits estéreo total y la tasa de bits del canal secundario. En todos los casos, para contenido inactivo, la tasa de bits del canal secundario se establece en la tasa de bits mínima necesaria para codificar la forma espectral del canal secundario, dando una tasa de bits generalmente cercana a 2 kb/s.
Mientras tanto, el clasificador 852 de señales proporciona una clasificación de señales del canal secundario X al módulo 1554 de decisión. Si el módulo 1554 de decisión determina que la señal de sonido está inactiva o sorda, el módulo 1555 de codificación sorda/inactiva proporciona la forma espectral del canal secundario X al multiplexor 254/354. Alternativamente, el módulo 1554 de decisión informa al módulo 1556 de decisión cuando la señal de sonido no está inactiva ni sorda. Para tales señales de sonido, usando el presupuesto de bits para codificar el canal secundario X, el módulo 1556 de decisión determina si hay un número suficiente de bits disponibles para codificar el canal secundario X usando el modelo de cuatro (4) subcuadros de codificación genérica única del módulo 854; de lo contrario, el módulo 1556 de decisión selecciona codificar el canal secundario X usando el módulo 855 de codificación de modelo de dos (2) subcuadros. Para elegir el módulo de codificación exclusivo genérico del modelo de cuatro subcuadros, el presupuesto de bits disponible para el canal secundario debe ser lo suficientemente alto como para asignar al menos 40 bits a los libros de códigos algebraicos, una vez que todo lo demás esté cuantificado o reutilizado, incluido el coeficiente LP y la información de tono y ganancias.
Como se entenderá a partir de la descripción anterior, en las cuatro (4) subcuadros del modelo de operación 804 de codificación única genérica y las cuatro (4) subcuadros correspondientes del modelo de codificación única genérica del módulo 854, para mantener la tasa de bits lo más baja posible. Se utiliza una búsqueda ACELP como se describe en la cláusula 5.2.3.1 de la referencia [1]. En el modelo de cuatro (4) subcuadros de codificación genérica únicamente, la información de tono se puede reutilizar del canal primario o no. Los parámetros de codificación encontrados durante la búsqueda ACELP en el módulo 854 de codificación genérico único del modelo de cuatro (4) subcuadros se usan luego para construir el flujo 206/306 de bits del canal secundario y se envían al multiplexor 254/354 para su inclusión en el flujo 207/307 de bits multiplexado.
En la operación 805 alternativa de codificación del modelo de dos (2) subcuadros y el correspondiente módulo 855 alternativo de codificación del modelo de dos (2) subcuadros, el modelo de codificación genérico se construye de manera similar a ACELP como se describe en la cláusula 5.2.3.1 de la referencia [1], pero se utiliza con sólo dos (2) subcuadros por cuadro. Por lo tanto, para hacerlo, la longitud de los subcuadros se incrementa de 64 muestras a 128 muestras, manteniendo aún la tasa de muestreo interna en 12.8 kHz. Si el analizador 1552 de coherencia de tono ha determinado reutilizar la información de tono del canal primario Y para codificar el canal secundario X, entonces el promedio de los tonos de las dos primeras subcuadros del canal primario Y se calcula y se utiliza como estimación del tono para la primera mitad del cuadro del canal secundario X. De manera similar, el promedio de los tonos de las dos últimas subcuadros del canal primario Y se calcula y se usa para la segunda mitad del cuadro del canal secundario X. Cuando se reutiliza desde el canal primario Y, los coeficientes del filtro LP se interpolan y la interpolación de los coeficientes del filtro LP como se describe en la cláusula 5.2.2.1 de la referencia [1] se modifica para adaptarse a un esquema de dos (2) subcuadros reemplazando el primer y tercer factor de interpolación con el segundo y cuarto factor de interpolación.
En la realización de la figura 15, el proceso para decidir entre las cuatro (4) subcuadros y el esquema de codificación de dos (2) subcuadros está accionado por el presupuesto de bits disponible para codificar el canal secundario X. Como se mencionó anteriormente, el presupuesto de bits del canal secundario X se deriva de diferentes elementos tales como el presupuesto total de bits disponible, el factor p o el factor £ de normalización de energía, la presencia o no de un módulo de corrección de retardo temporal (TDC), la posibilidad o no de reutilizar los coeficientes LP del filtro y/o la información de tono del canal primario Y
La tasa de bits mínima absoluta utilizada por el modelo de codificación de dos (2) subcuadros del canal secundario X cuando tanto los coeficientes del filtro LP como la información de tono se reutilizan del canal primario Y es de alrededor de 2 kb/s para una señal genérica, mientras que es de alrededor de 3.6 kb/s para el esquema de codificación de cuatro (4) subcuadros. Para un codificador tipo ACELP, que utiliza un modelo de codificación de dos (2) o cuatro (4) subcuadros, una gran parte de la calidad proviene del número de bits que se pueden asignar a la búsqueda del libro de códigos algebraicos (ACB) como se define en cláusula 5.2.3.1.5 de la referencia [1].
Luego, para maximizar la calidad, la idea es comparar el presupuesto de bits disponible tanto para la búsqueda del libro de códigos algebraicos (ACB) de cuatro (4) subcuadros como para la búsqueda del libro de códigos algebraicos (ACB) de dos (2) subcuadros, después de eso se tiene en cuenta todo lo que se codificará. Por ejemplo, si, para un cuadro específico, hay 4 kb/s (80 bits por cuadro de 20 ms) disponibles para codificar el canal secundario X y el coeficiente del filtro LP se puede reutilizar mientras se necesita transmitir la información de tono. Luego se quita de
los 80 bits, la cantidad mínima de bits para codificar la señalización del canal secundario, la información de tono del canal secundario, las ganancias y el libro de códigos algebraico tanto para los dos (2) subcuadros como para los cuatro (4) subcuadros, para obtenga el presupuesto de bits disponible para codificar el libro de códigos algebraicos. Por ejemplo, se elige el modelo de codificación de cuatro (4) subcuadros si hay al menos 40 bits disponibles para codificar el libro de códigos algebraico de cuatro (4) subcuadros; de lo contrario, se utiliza el esquema de dos (2) subcuadros.
3) Aproximación de la señal mono de un flujo de bits parcial
Como se describió en la descripción anterior, la mezcla descendente en el dominio del tiempo es compatible con mono, lo que significa que en el caso de una estructura incrustada, donde el canal primario Y está codificado con un códec heredado (se debe tener en cuenta que, como se menciona en la descripción anterior, se puede utilizar cualquier tipo adecuado de codificador como codificador 252/352 de canal primario) y los bits estéreo se añaden al flujo de bits del canal primario, los bits estéreo podrían eliminarse y un decodificador heredado podría crear una síntesis que sea subjetivamente cercano a una hipotética monosíntesis. Para hacerlo, se necesita una normalización de energía simple en el lado del codificador, antes de codificar el canal primario Y. Al reescalar la energía del canal primario Y a un valor suficientemente cercano a la energía de una versión de señal monofónica del sonido, la decodificación del canal primario Y con un decodificador heredado puede ser similar a la decodificación mediante el decodificador heredado de la versión de señal monofónica del sonido. La función de normalización de energía está directamente enlazada con la diferencia de correlación linealizada a largo plazo  se calcula usando la relación (7) y se calcula usando la relación (22):
se calcula usando la relación (7) y se calcula usando la relación (22):

El nivel de normalización se muestra en la figura 5. En la práctica, en lugar de utilizar la relación (22), se utiliza una tabla de consulta que relaciona los valores e de normalización con cada valor posible del factor p (31 valores en esta realización de ejemplo). Incluso si este paso adicional no es necesario al codificar una señal de sonido estéreo, por ejemplo habla y/o audio, con el modelo integrado, esto puede resultar útil al decodificar sólo la señal mono sin decodificar los bits estéreo.
4) Decodificación estéreo y mezcla ascendente
La figura 10 es un diagrama de bloques que ilustra simultáneamente un método de decodificación de sonido estéreo y un sistema de decodificación de sonido estéreo. La figura 11 es un diagrama de bloques que ilustra características adicionales del método de decodificación de sonido estéreo y del sistema de decodificación de sonido estéreo de la figura 10.
El método de decodificación de sonido estéreo de las figuras 10 y 11 comprende una operación 1007 de demultiplexación implementada por un demultiplexor 1057, una operación 1004 de decodificación de canal primario implementada por un decodificador 1054 de canal primario, una operación 1005 de decodificación de canal secundario implementada por un decodificador 1055 de canal secundario, y una operación 1006 de mezcla ascendente en el dominio del tiempo implementada por un mezclador 1056 ascendente de canal en el dominio del tiempo. La operación 1005 de decodificación de canal secundario comprende, como se muestra en la figura 11, una operación 1101 de decisión implementada por un módulo 1151 de decisión, una operación 1102 de decodificación genérica de cuatro (4) subcuadros implementada por un decodificador 1152 genérico de cuatro (4) subcuadros, y una operación 1103 de decodificación genérica/sorda/inactiva de dos (2) subcuadros implementada por un decodificador 1153 genérico/sordo/inactivo de dos (2) subcuadros.
En el sistema de decodificación de sonido estéreo, se recibe un flujo 1001 de bits desde un codificador. El demultiplexor 1057 recibe el flujo 1001 de bits y extrae del mismo los parámetros de codificación del canal primario Y (flujo 1002 de bits), los parámetros de codificación del canal secundario X (flujo 1003 de bits), y el factor p suministrado al decodificador 1054 de canal primario, al decodificador 1055 de canal secundario y al mezclador 1056 ascendente de canal. Como se mencionó anteriormente, el factor p se usa como indicador tanto para el codificador 252/352 de canal primario como para el codificador 253/353 de canal secundario para determinar la asignación de tasa de bits, por lo tanto, el decodificador 1054 de canal primario y el decodificador 1055 de canal secundario están ambos reutilizando el factor p para decodificar el flujo de bits correctamente.
Los parámetros de codificación del canal primario corresponden al modelo de codificación ACELP a la tasa de bits recibida y podrían estar relacionados con un codificador EVS heredado o modificado (debe tenerse en cuenta aquí que, como se menciona en la descripción anterior, cualquier tipo adecuado de codificador puede usarse como codificador 252 de canal primario). El decodificador 1054 de canal primario se suministra con el flujo 1002 de bits para decodificar los parámetros de codificación del canal primario (modoi de códec, f3, LPCi, tonoi, índicesi de libro de códigos fijos y ganancias1 como se muestra en la figura 11) usando un método similar a la referencia [1] para producir un canal primario decodificado Y'.
Los parámetros de codificación del canal secundario usados por el decodificador 1055 del canal secundario corresponden al modelo usado para codificar el segundo canal X y pueden comprender:
(a) El modelo de codificación genérico con reutilización de los coeficientes del filtro LP (LPC1) y/u otros parámetros de codificación (tal como, por ejemplo, el retraso de tono del tono1) del canal primario Y. El decodificador 1152 genérico de cuatro (4) subcuadros (figura 11) del decodificador 1055 de canal secundario se suministra con los coeficientes de filtro LP (LPC1) y/u otros parámetros de codificación (tal como, por ejemplo, el retraso de tono del tono1) desde el canal primario Y del decodificador 1054 y/o con el flujo 1003 de bits (3, tono2, índices2 de libro de códigos fijos y ganancias2 como se muestra en la figura 11) y utiliza un método inverso al del módulo 854 de codificación (figura 8) para producir el canal secundario decodificado X'.
(b) Otros modelos de codificación pueden o no reutilizar los coeficientes del filtro LP (LPC1) y/u otros parámetros de codificación (tal como, por ejemplo, el retraso de tono del tono1) del canal primario Y, incluido el modelo de codificación genérico de media banda, el modelo de codificación sorda de baja tasa y el modelo de codificación inactiva de baja tasa. Como ejemplo, el modelo de codificación inactiva puede reutilizar los coeficientes de filtro LP del canal primario LPC1. Los dos (2) subcuadros del decodificador 1153 genérico/sordo/inactivo (figura 11) del decodificador 1055 de canal secundario se suministran con los coeficientes de filtro LP (LPC1) y/u otros parámetros de codificación (tal como, por ejemplo, el retraso de tono del tono1) desde el canal primario Y y/o con los parámetros de codificación del canal secundario del flujo 1003 de bits (modo2 códec, 3 , LPC2, tono2, índices2de libro de códigos fijos y ganancias2 como se muestra en la figura 11) y utiliza métodos inversos a los del módulo 855 de codificación (figura 8) para producir el canal secundario decodificado X'.
Los parámetros de codificación recibidos correspondientes al canal secundario X (flujo 1003 de bits) contienen información (modo2 códec) relacionado con el modelo de codificación que se utiliza. El módulo 1151 de decisión utiliza esta información (modo2 códec) para determinar e indicar al decodificador 1152 genérico de cuatro (4) subcuadros y al decodificador 1153 genérico/sordo/inactivo de dos (2) subcuadros qué modelo de codificación se va a utilizar. En el caso de una estructura incrustada, el factor p se usa para recuperar el índice de escalamiento de energía que se almacena en una tabla de búsqueda (no mostrada) en el lado del decodificador y se usa para reescalar el canal primario Y' antes de realizar la operación 1006 de mezcla ascendente en el dominio del tiempo. Finalmente el factor p se suministra al mezclador 1056 ascendente de canal y se utiliza para mezclar ascendentemente los canales primario Y' y secundario X' decodificados. La operación 1006 de mezcla ascendente en el dominio del tiempo se realiza como la inversa de las relaciones (9) y (10) de mezcla descendente para obtener los canales derecho R' e izquierdo L' decodificados, utilizando las relaciones (23) y (24):
donde n=0,...,N-1 es el índice de la muestra en el cuadro y t es el índice del cuadro.
5) Integración de la codificación en el dominio del tiempo y en el dominio de la frecuencia.
Para aplicaciones de la presente técnica en las que se utiliza un modo de codificación en el dominio de la frecuencia, también se contempla realizar la mezcla descendente de tiempo en el dominio de la frecuencia para ahorrar algo de complejidad o simplificar el flujo de datos. En tales casos, se aplica el mismo factor de mezcla a todos los coeficientes espectrales para mantener las ventajas de la mezcla descendente en el dominio del tiempo. Puede observarse que esto supone una desviación de la aplicación de coeficientes espectrales por banda de frecuencia, como en el caso de la mayoría de las aplicaciones de mezcla descendente en el dominio de la frecuencia. El mezclador 456 descendente puede adaptarse para calcular las relaciones (25.1) y (25.2):

donde FR(k) representa un coeficiente de frecuencia k del canal derecho R y, de manera similar, Fi(k) representa un coeficiente de frecuencia k del canal izquierdo L. Los canales primario Y y secundario X se calculan aplicando una transformada de frecuencia inversa para obtener la representación del tiempo de las señales mezcladas descendentes.
Las figuras 17 y 18 muestran posibles implementaciones de un método y sistema de codificación estéreo en el dominio del tiempo que utiliza una mezcla descendente en el dominio de la frecuencia capaz de conmutar entre codificación en el dominio del tiempo y en el dominio de la frecuencia de los canales primario Y y secundario X.
Una primera variante de tal método y sistema se muestra en la figura 17, que es un diagrama de bloques que ilustra simultáneamente un método y sistema de codificación estéreo que utiliza conmutación descendente en el dominio del tiempo con capacidad de operar en el dominio del tiempo y en el dominio de la frecuencia.
En la figura 17, el método y sistema de codificación estéreo incluye muchas operaciones y módulos descritos anteriormente con referencia a figuras anteriores e identificados con los mismos numerales de referencia. Un módulo 1751 de decisión (operación 1701 de decisión) determina si los canales izquierdo L' y derecho R' del corrector 1750 de retardo temporal deben codificarse en el dominio del tiempo o en el dominio de la frecuencia. Si se selecciona la codificación en el dominio del tiempo, el método y sistema de codificación estéreo de la figura 17 funcionan sustancialmente de la misma manera que el método y sistema de codificación estéreo de las figuras anteriores, por ejemplo y sin limitación como en la realización de la figura 15.
Si el módulo 1751 de decisión selecciona la codificación de frecuencia, un convertidor 1752 de tiempo a frecuencia (operación 1702 de conversión de tiempo a frecuencia) convierte los canales izquierdo L' y derecho R' al dominio de la frecuencia. Un mezclador 1753 descendente de dominio de frecuencia (operación 1703 de mezclado descendente de dominio de frecuencia) genera canales de dominio de frecuencia primario Y y secundario X. El canal primario en el dominio de la frecuencia se convierte de nuevo al dominio del tiempo mediante un convertidor 1754 de frecuencia a tiempo (operación 1704 de conversión de frecuencia a tiempo) y el canal primario Y del dominio del tiempo resultante se aplica al codificador 252/352 de canal primario. El canal secundario X en el dominio de frecuencia del mezclador 1753 descendente en el dominio de frecuencia se procesa a través de un codificador 1755 paramétrico y/o residual convencional (operación 1705 de codificación paramétrica y/o residual).
La figura 18 es un diagrama de bloques que ilustra simultáneamente otro método y sistema de codificación estéreo que utiliza mezcla descendente en el dominio de la frecuencia con capacidad de operar en el dominio del tiempo y en el dominio de la frecuencia. En la figura 18, el método y sistema de codificación estéreo son similares al método y sistema de codificación estéreo de la figura 17 y sólo se describirán las nuevas operaciones y módulos.
Un analizador 1851 de dominio de tiempo (operación 1801 de análisis de dominio de tiempo) reemplaza al mezclador 251/351 de canales de dominio de tiempo descrito anteriormente (operación 201/301 de mezcla descendente de dominio de tiempo). El analizador 1851 de dominio de tiempo incluye la mayoría de los módulos de la figura 4, pero sin el mezclador 456 descendente de dominio de tiempo. Por lo tanto, su función es en gran parte proporcionar un cálculo del factor p. Este factor p se suministra al preprocesador 851 y a los convertidores 1852 y 1853 de dominio de frecuencia a tiempo (operaciones 1802 y 1803 de conversión de dominio de frecuencia a tiempo) que convierten respectivamente al dominio de tiempo los canales secundario X y primario Y del dominio de frecuencia recibidos del mezclador 1753 descendente de dominio de frecuencia para codificación en el dominio de tiempo. La salida del convertidor 1852 es, por lo tanto, un canal secundario X en el dominio del tiempo que se proporciona al preprocesador 851, mientras que la salida del convertidor 1852 es un canal primario Y en el dominio del tiempo que se proporciona tanto al preprocesador 1551 como al codificador 252/352.
6) Ejemplo de configuración de hardware
La figura 12 es un diagrama de bloques simplificado de una configuración de ejemplo de componentes de hardware que forman cada uno de los sistemas de codificación de sonido estéreo y sistemas de decodificación de sonido estéreo descritos anteriormente.
Cada uno de los sistemas de codificación de sonido estéreo y sistema de decodificación de sonido estéreo se puede implementar como parte de un terminal móvil, como parte de un reproductor multimedia portátil o en cualquier dispositivo similar. Cada uno de los sistemas de codificación de sonido estéreo y sistemas de decodificación de sonido estéreo (identificados como 1200 en la figura 12) comprende una entrada 1202, una salida 1204, un procesador 1206 y una memoria 1208.
La entrada 1202 está configurada para recibir los canales izquierdo L y derecho R de la señal de sonido estéreo de entrada en forma digital o analógica en el caso del sistema de codificación de sonido estéreo, o el flujo 1001 de bits en el caso del sistema de decodificación de sonido estéreo. La salida 1204 está configurada para suministrar el flujo 207/307 de bits multiplexado en el caso del sistema de codificación de sonido estéreo o el canal izquierdo L' decodificado y el canal derecho R' en el caso del sistema de decodificación de sonido estéreo. La entrada 1202 y la salida 1204 pueden implementarse en un módulo común, por ejemplo, un dispositivo de entrada/salida en serie.
El procesador 1206 está conectado operativamente a la entrada 1202, a la salida 1204 y a la memoria 1208. El procesador 1206 se realiza como uno o más procesadores para ejecutar instrucciones de código en soporte de las funciones de los diversos módulos de cada uno de los sistemas de codificación de sonido estéreo como se muestra en las figuras 2, 3, 4, 8, 9, 13, 14, 15, 16, 17 y 18 y el sistema de decodificación de sonido estéreo como se muestra en las figuras 10 y 11.
La memoria 1208 puede comprender una memoria no transitoria para almacenar instrucciones de código ejecutables por el procesador 1206, específicamente, una memoria legible por el procesador que comprende instrucciones no transitorias que, cuando se ejecutan, hacen que un procesador implemente las operaciones y módulos del método y sistema de codificación de sonido estéreo y el método y sistema de decodificación de sonido estéreo como se describe
en la presente divulgación. La memoria 1208 también puede comprender una memoria de acceso aleatorio o memorias intermedias para almacenar datos de procesamiento intermedio de las diversas funciones realizadas por el procesador 1206.
Los expertos en la técnica se darán cuenta de que la descripción del método y sistema de codificación de sonido estéreo y del método y sistema de decodificación de sonido estéreo son sólo ilustrativos y no pretenden ser de ningún modo limitantes. Otras realizaciones se les ocurrirán fácilmente a aquellas personas con conocimientos habituales en la técnica que tengan el beneficio de la presente divulgación. Además, el método y sistema de codificación de sonido estéreo y el método y sistema de decodificación de sonido estéreo divulgados se pueden personalizar para ofrecer soluciones valiosas a las necesidades y problemas existentes de codificación y decodificación de sonido estéreo.
En aras de la claridad, no se muestran y describen todas las características rutinarias de las implementaciones del método y sistema de codificación de sonido estéreo y del método y sistema de decodificación de sonido estéreo. Por supuesto, se apreciará que en el desarrollo de cualquier implementación real del método y sistema de codificación de sonido estéreo y del método y sistema de decodificación de sonido estéreo, es posible que sea necesario tomar numerosas decisiones específicas de implementación para lograr los objetivos específicos del desarrollador, tal como el cumplimiento de las restricciones relacionadas con aplicaciones, sistemas, redes y negocios, y que estos objetivos específicos variarán de una implementación a otra y de un desarrollador a otro. Además, se apreciará que un esfuerzo de desarrollo podría ser complejo y llevar mucho tiempo, pero, no obstante, sería una tarea de ingeniería rutinaria para aquellos con experiencia ordinaria en el campo del procesamiento de sonido que tengan el beneficio de la presente divulgación.
Según la presente divulgación, los módulos, operaciones de procesamiento y/o estructuras de datos descritos en este documento pueden implementarse utilizando diversos tipos de sistemas operativos, plataformas informáticas, dispositivos de red, programas informáticos y/o máquinas de uso general. Además, los expertos en la técnica reconocerán que también se pueden utilizar dispositivos de naturaleza menos general, tales como dispositivos cableados, arreglos de puertas programables en campo (FPGA), circuitos integrados de aplicación específica (ASIC) o similares. Cuando un procesador, ordenador o máquina implementa un método que comprende una serie de operaciones y suboperaciones y esas operaciones y suboperaciones pueden almacenarse como una serie de instrucciones de código no transitorias legibles por el procesador, ordenador o máquina, podrán almacenarse en un medio tangible y/o no transitorio.
Los módulos del método y sistema de codificación de sonido estéreo y el método y decodificador de decodificación de sonido estéreo como se describe en este documento pueden comprender software, firmware, hardware o cualquier combinación de software, firmware o hardware adecuado para los fines descritos en este documento.
En el método de codificación de sonido estéreo y el método de decodificación de sonido estéreo como se describe en este documento, las diversas operaciones y suboperaciones pueden realizarse en diversas órdenes y algunas de las operaciones y suboperaciones pueden ser opcionales.
Aunque la presente divulgación se ha descrito anteriormente a modo de realizaciones ilustrativas no restrictivas de la misma, estas realizaciones pueden modificarse a voluntad dentro del alcance de las reivindicaciones adjuntas.
Referencias
En la presente especificación se hace referencia a las siguientes referencias.
[1] 3GPP TS 26.445, v.12.0.0, "Codec for Enhanced Voice Services (EVS); Detailed Algorithmic Description", septiembre de 2014.
[2] M. Neuendorf, M. Multrus, N. Rettelbach, G. Fuchs, J. Robillard, J. Lecompte, S. Wilde, S. Bayer, S. Disch, C. Helmrich, R. Lefevbre, P Gournay, et al., "The ISO/MPEG Unified Speech and Audio Coding Standard - Consistent High Quality for All Content Types and at All Bit Rates", J. Audio Eng. Soc., vol. 61, núm. 12, páginas 956-977, diciembre de 2013.
[3] B. Bessette, R. Salaml, R. Lefebvre, M. Jelinek, J. Rotola-Pukkila, J. Vainio, H. Mikkola y K. Jarvinen, "The
Adaptive Multi-Rate Wideband Speech Codec (AMR-WB)," Special Issue of IEEE Trans. Speech and Audio Proc., Vol.
10, pp.620-636, noviembre de 2 O02.
[4] RG van der Waal y RNJ Veldhuis, "Subband coding of stereophonic digital audio signals", Proc. IEEE ICASSP, vol.
5, págs. 3601-3604, abril de 1991
[5] Dai Yang, Hongmei Ai, Chris Kyriakakis y C.-C. Jay Kuo, High-Fidelity Multichannel Audio Coding With Karhunen-Loéve Transform", IEEE Trans. Speech and Audio Proc., Vol. 11, No.4, pp.365-379, julio de 2003.
[6] J. Breebaart, S. van de Par, A. Kohlrausch y E. Schuijers, "Parametric Coding of Stereo Audio", revista EURASIP Journal on Applied Signal Processing, Issue 9, pp. 1305-1322, 2005
[7] 3GPP TS 26.290 V9.0.0, "Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec; Transcoding functions (Release 9)", septiembre de 2009.
[8] Jonathan A. Gibbs, "Apparatus and method for encoding a multi-channel audio signal", US 8577045 B2
Claims (22)
1. Un método implementado en un sistema de codificación de señal de sonido estéreo para mezcla descendente en el dominio del tiempo los canales derecho e izquierdo de una señal de sonido estéreo de entrada en canales primarios y secundarios, que comprende:
determinar una correlación normalizada del canal izquierdo en relación con una versión de señal monofónica del sonido y una correlación normalizada del canal derecho en relación con la versión de señal monofónica del sonido; determinar una diferencia de correlación a largo plazo basándose en la correlación normalizada del canal izquierdo y la correlación normalizada del canal derecho;
convertir la diferencia de correlación a largo plazo en un factor p; y
mezclar los canales izquierdo y derecho para producir los canales primario y secundario usando el factor p, en donde el factor P determina las contribuciones respectivas de los canales izquierdo y derecho tras la producción de los canales primario y secundario.
2. Un método de mezcla descendente en el dominio del tiempo como se define en la reivindicación 1, que comprende: determinar una energía de cada uno de los canales izquierdo y derecho;
determinar un valor de energía a largo plazo del canal izquierdo usando la energía del canal izquierdo y un valor de energía a largo plazo del canal derecho usando la energía del canal derecho; y
determinar una tendencia de la energía en el canal izquierdo usando el valor de energía a largo plazo del canal izquierdo y una tendencia de la energía en el canal derecho usando el valor de energía a largo plazo del canal derecho.
3. Un método de mezcla descendente en el dominio del tiempo como se define en la reivindicación 2, en donde determinar la diferencia de correlación a largo plazo comprende:
suavizar las correlaciones normalizadas de los canales izquierdo y derecho utilizando una velocidad de convergencia de la diferencia de correlación a largo plazo determinada utilizando las tendencias de las energías en los canales izquierdo y derecho; y
utilizar las correlaciones normalizadas suavizadas para determinar la diferencia de correlación a largo plazo.
4. Un método de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 1 a 3, en donde convertir la diferencia de correlación a largo plazo en un factor P comprende: linealizar la diferencia de correlación a largo plazo; y
mapear la diferencia de correlación linealizada a largo plazo en una función dada para producir el factor p.
5. Un método de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 1 a 4, en donde mezclar los canales izquierdo y derecho comprende usar las siguientes relaciones para producir el canal primario y el canal secundario a partir del canal izquierdo y el canal derecho:

donde Y(i) representa el canal primario, X(i) representa el canal secundario, L(i) representa el canal izquierdo, R(i) representa el canal derecho, y fi(t) representa el factor p.
6. Un método de mezcla descendente en el dominio del tiempo según se define en una cualquiera de las reivindicaciones 1 a 5, en donde el factor P representa (a) las contribuciones respectivas de los canales izquierdo y derecho al canal primario y (b) un factor de escala de energía para aplicar al canal primario para obtener una versión de señal monofónica del sonido.
7. Un método de mezcla descendente en el dominio del tiempo según se define en una cualquiera de las reivindicaciones 1 a 6, que comprende:
cuantificar el factor p y transmitir el factor p cuantificado a un decodificador; y
detectar un caso especial en donde los canales derecho e izquierdo están invertidos en fase,
donde cuantificar el factor p comprende representar el factor p con un índice transmitido al decodificador, y en donde un valor dado del índice se utiliza para señalar el caso especial de inversión de fase de los canales derecho e izquierdo.
8. Un método de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 1 a 6, que comprende cuantificar el factor p y transmitir el factor p cuantificado a un decodificador, en donde:
el factor p cuantificado se transmite al decodificador mediante un índice; y
el factor p representa tanto (a) las respectivas contribuciones de los canales izquierdo y derecho al canal primario como (b) un factor de escala de energía para aplicar al canal primario para obtener una versión de señal monofónica del sonido, mediante el cual el índice transmitido al decodificador transmite dos elementos de información distintos con el mismo número de bits.
9. Un método de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 1 a 8, que comprende aumentar o disminuir el énfasis en el canal secundario para la mezcla descendente en el dominio del tiempo en relación con el valor del factor p, en donde, cuando no se utiliza la corrección en el dominio del tiempo (TDC), el énfasis en el canal secundario aumenta cuando el factor p es cercano a 0.5 y el énfasis en el canal secundario disminuye cuando el factor p está cerca de 1.0 o 0.0.
10. Un método de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 1 a 8, que comprende aumentar o disminuir el énfasis en el canal secundario para la mezcla descendente en el dominio del tiempo en relación con el valor del factor p, en donde, cuando se utiliza la corrección en el dominio del tiempo (TDC), el énfasis en el canal secundario disminuye cuando el factor p es cercano a 0.5 y el énfasis en el canal secundario aumenta cuando el factor p está cerca de 1.0 o 0.0.
11. Un método de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 1, 2 y 4 a 8, que comprende aplicar un factor de preadaptación directamente a las correlaciones normalizadas de los canales izquierdo y derecho antes de determinar la diferencia de correlación a largo plazo, en donde el factor de preadaptación se calcula en respuesta a (a) valores de energía de los canales izquierdo y derecho a largo plazo, (b) una clasificación de cuadros de cuadros anteriores, y (c) información de actividad de voz de los cuadros anteriores.
12. Un sistema para mezcla descendente en el dominio del tiempo de los canales derecho e izquierdo de una señal de sonido estéreo de entrada en canales primarios y secundarios, que comprende:
un analizador de correlación normalizada para determinar una correlación normalizada del canal izquierdo en relación con una versión de señal monofónica del sonido y una correlación normalizada del canal derecho en relación con la versión de señal monofónica del sonido;
una calculadora de una diferencia de correlación a largo plazo sobre la base de la correlación normalizada del canal izquierdo y la correlación normalizada del canal derecho;
un convertidor de la diferencia de correlación a largo plazo en un factor p; y
un mezclador de los canales izquierdo y derecho para producir los canales primario y secundario usando el factor p, en donde el factor p determina las contribuciones respectivas de los canales izquierdo y derecho tras la producción de los canales primario y secundario.
13. Un sistema de mezcla descendente en el dominio del tiempo como se define en la reivindicación 12, que comprende:
un analizador de energía para determinar (a) una energía de cada uno de los canales izquierdo y derecho, y (b) un valor de energía a largo plazo del canal izquierdo usando la energía del canal izquierdo y un valor de energía a largo plazo del canal derecho utilizando la energía del canal derecho; y
un analizador de tendencias de energía para determinar una tendencia de la energía en el canal izquierdo usando el valor de energía a largo plazo del canal izquierdo y una tendencia de la energía en el canal derecho usando el valor de energía a largo plazo del canal derecho.
14. Un sistema de mezcla descendente en el dominio del tiempo como se define en la reivindicación 13, en donde la calculadora de la diferencia de correlación a largo plazo:
suaviza las correlaciones normalizadas de los canales izquierdo y derecho usando una velocidad de convergencia de la diferencia de correlación a largo plazo determinada usando las tendencias de las energías en los canales izquierdo y derecho; y
utiliza las correlaciones normalizadas suavizadas para determinar la diferencia de correlación a largo plazo.
15. Un sistema de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 12 a 14, en donde el convertidor de la diferencia de correlación a largo plazo en un factor p:
linealiza la diferencia de correlación a largo plazo; y
mapea la diferencia de correlación linealizada a largo plazo en una función dada para producir el factor p.
16. Un sistema de mezcla descendente en el dominio del tiempo según una cualquiera de las reivindicaciones 12 a 15, en donde el mezclador utiliza las siguientes relaciones para producir el canal primario y el canal secundario a partir del canal izquierdo y el canal derecho:

donde Y(i) representa el canal primario, X(i) representa el canal secundario, L(i) representa el canal izquierdo, R(i) representa el canal derecho, y fi(t) representa el factor p.
17. Un sistema de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 12 a 16, en donde el factor p representa (a) las contribuciones respectivas de los canales izquierdo y derecho al canal primario y (b) un factor de escala de energía para aplicar al canal primario para obtener una versión de señal monofónica del sonido.
18. Un sistema de mezcla descendente en el dominio del tiempo según se define en una cualquiera de las reivindicaciones 12 a 17, que comprende:
un cuantificador del factor p, en donde el factor p cuantificado se transmite a un decodificador; y
un detector de un caso especial en el que los canales derecho e izquierdo están invertidos en fase, en donde el cuantificador del factor p representa el factor p con un índice transmitido al decodificador, y en donde un valor dado del índice se utiliza para señalar el caso especial de inversión de fase de los canales derecho e izquierdo.
19. Un sistema de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 12 a 17, que comprende un cuantificador del factor p, en donde el factor p cuantificado se transmite a un decodificador usando un índice, y en donde el factor p representa tanto (a) las respectivas contribuciones de los canales izquierdo y derecho al canal primario como (b) un factor de escala de energía para aplicar al canal primario para obtener una versión de señal monofónica del sonido, mediante el cual el índice transmitido al decodificador transmite dos elementos de información distintos con el mismo número de bits.
20. Un sistema de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 12 a 19, que comprende medios para aumentar o disminuir el énfasis en el canal secundario para la mezcla descendente en el dominio del tiempo en relación con el valor del factor p.
21. Un sistema de mezcla descendente en el dominio del tiempo como se define en una cualquiera de las reivindicaciones 12, 13 y 15 a 19, que comprende una calculadora del factor de preadaptación para aplicar un factor de preadaptación directamente a las correlaciones normalizadas de los canales izquierdo y derecho antes de determinar la diferencia de correlación a largo plazo.
22. Una memoria legible por el procesador que comprende instrucciones no transitorias que, cuando se ejecutan, hacen que un procesador implemente las operaciones del método según una cualquiera de las reivindicaciones 1 a 11.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562232589P | 2015-09-25 | 2015-09-25 | |
| US201662362360P | 2016-07-14 | 2016-07-14 | |
| PCT/CA2016/051106 WO2017049397A1 (en) | 2015-09-25 | 2016-09-22 | Method and system using a long-term correlation difference between left and right channels for time domain down mixing a stereo sound signal into primary and secondary channels |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2955962T3 true ES2955962T3 (es) | 2023-12-11 |
Family
ID=58385516
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16847684T Active ES2955962T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema que utiliza una diferencia de correlación a largo plazo entre los canales izquierdo y derecho para mezcla descendente en el dominio del tiempo de una señal de sonido estéreo en canales primarios y secundarios |
| ES16847686T Active ES2904275T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema de decodificación de los canales izquierdo y derecho de una señal sonora estéreo |
| ES16847683T Active ES2949991T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema para la mezcla en el dominio del tiempo de una señal de sonido estéreo en canales primario y secundario mediante el uso de la detección de un estado de desfase de los canales izquierdo y derecho |
| ES16847685T Active ES2809677T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema para codificar una señal de sonido estéreo utilizando parámetros de codificación de un canal primario para codificar un canal secundario |
Family Applications After (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16847686T Active ES2904275T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema de decodificación de los canales izquierdo y derecho de una señal sonora estéreo |
| ES16847683T Active ES2949991T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema para la mezcla en el dominio del tiempo de una señal de sonido estéreo en canales primario y secundario mediante el uso de la detección de un estado de desfase de los canales izquierdo y derecho |
| ES16847685T Active ES2809677T3 (es) | 2015-09-25 | 2016-09-22 | Método y sistema para codificar una señal de sonido estéreo utilizando parámetros de codificación de un canal primario para codificar un canal secundario |
Country Status (17)
| Country | Link |
|---|---|
| US (8) | US10319385B2 (es) |
| EP (8) | EP3961623A1 (es) |
| JP (6) | JP6887995B2 (es) |
| KR (3) | KR102636396B1 (es) |
| CN (4) | CN108352162B (es) |
| AU (1) | AU2016325879B2 (es) |
| CA (5) | CA2997296C (es) |
| DK (1) | DK3353779T3 (es) |
| ES (4) | ES2955962T3 (es) |
| HK (4) | HK1253570A1 (es) |
| MX (4) | MX2018003703A (es) |
| MY (2) | MY188370A (es) |
| PL (1) | PL3353779T3 (es) |
| PT (1) | PT3353779T (es) |
| RU (6) | RU2763374C2 (es) |
| WO (5) | WO2017049398A1 (es) |
| ZA (2) | ZA201801675B (es) |
Families Citing this family (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102636396B1 (ko) | 2015-09-25 | 2024-02-15 | 보이세지 코포레이션 | 스테레오 사운드 신호를 1차 및 2차 채널로 시간 영역 다운 믹싱하기 위해 좌측 및 우측 채널들간의 장기 상관 차이를 이용하는 방법 및 시스템 |
| CN107742521B (zh) * | 2016-08-10 | 2021-08-13 | 华为技术有限公司 | 多声道信号的编码方法和编码器 |
| CN108140393B (zh) * | 2016-09-28 | 2023-10-20 | 华为技术有限公司 | 一种处理多声道音频信号的方法、装置和系统 |
| BR112019009424A2 (pt) | 2016-11-08 | 2019-07-30 | Fraunhofer Ges Forschung | mixador de redução, método para mixagem de redução de pelo menos dois canais, codificador multicanal, método para codificar um sinal multicanal, sistema e método de processamento de áudio |
| CN108269577B (zh) * | 2016-12-30 | 2019-10-22 | 华为技术有限公司 | 立体声编码方法及立体声编码器 |
| WO2018189414A1 (en) * | 2017-04-10 | 2018-10-18 | Nokia Technologies Oy | Audio coding |
| EP3396670B1 (en) * | 2017-04-28 | 2020-11-25 | Nxp B.V. | Speech signal processing |
| US10224045B2 (en) | 2017-05-11 | 2019-03-05 | Qualcomm Incorporated | Stereo parameters for stereo decoding |
| CN109300480B (zh) | 2017-07-25 | 2020-10-16 | 华为技术有限公司 | 立体声信号的编解码方法和编解码装置 |
| CN114898761A (zh) * | 2017-08-10 | 2022-08-12 | 华为技术有限公司 | 立体声信号编解码方法及装置 |
| CN113782039A (zh) * | 2017-08-10 | 2021-12-10 | 华为技术有限公司 | 时域立体声编解码方法和相关产品 |
| CN109389984B (zh) * | 2017-08-10 | 2021-09-14 | 华为技术有限公司 | 时域立体声编解码方法和相关产品 |
| CN117133297A (zh) * | 2017-08-10 | 2023-11-28 | 华为技术有限公司 | 时域立体声参数的编码方法和相关产品 |
| CN109427338B (zh) | 2017-08-23 | 2021-03-30 | 华为技术有限公司 | 立体声信号的编码方法和编码装置 |
| CN109427337B (zh) * | 2017-08-23 | 2021-03-30 | 华为技术有限公司 | 立体声信号编码时重建信号的方法和装置 |
| US10891960B2 (en) * | 2017-09-11 | 2021-01-12 | Qualcomm Incorproated | Temporal offset estimation |
| WO2019056108A1 (en) * | 2017-09-20 | 2019-03-28 | Voiceage Corporation | METHOD AND DEVICE FOR EFFICIENT DISTRIBUTION OF A BINARY BUDGET IN A CELP CODEC |
| CN109859766B (zh) * | 2017-11-30 | 2021-08-20 | 华为技术有限公司 | 音频编解码方法和相关产品 |
| CN110556118B (zh) | 2018-05-31 | 2022-05-10 | 华为技术有限公司 | 立体声信号的编码方法和装置 |
| CN114708874A (zh) | 2018-05-31 | 2022-07-05 | 华为技术有限公司 | 立体声信号的编码方法和装置 |
| CN110556119B (zh) * | 2018-05-31 | 2022-02-18 | 华为技术有限公司 | 一种下混信号的计算方法及装置 |
| CN110728986B (zh) * | 2018-06-29 | 2022-10-18 | 华为技术有限公司 | 立体声信号的编码方法、解码方法、编码装置和解码装置 |
| CN115132214A (zh) * | 2018-06-29 | 2022-09-30 | 华为技术有限公司 | 立体声信号的编码、解码方法、编码装置和解码装置 |
| US11031024B2 (en) * | 2019-03-14 | 2021-06-08 | Boomcloud 360, Inc. | Spatially aware multiband compression system with priority |
| EP3719799A1 (en) * | 2019-04-04 | 2020-10-07 | FRAUNHOFER-GESELLSCHAFT zur Förderung der angewandten Forschung e.V. | A multi-channel audio encoder, decoder, methods and computer program for switching between a parametric multi-channel operation and an individual channel operation |
| CN111988726A (zh) * | 2019-05-06 | 2020-11-24 | 深圳市三诺数字科技有限公司 | 一种立体声合成单声道的方法和系统 |
| CN112233682A (zh) * | 2019-06-29 | 2021-01-15 | 华为技术有限公司 | 一种立体声编码方法、立体声解码方法和装置 |
| CN112151045A (zh) * | 2019-06-29 | 2020-12-29 | 华为技术有限公司 | 一种立体声编码方法、立体声解码方法和装置 |
| AU2020320270A1 (en) * | 2019-08-01 | 2022-03-24 | Dolby Laboratories Licensing Corporation | Encoding and decoding IVAS bitstreams |
| CN110534120B (zh) * | 2019-08-31 | 2021-10-01 | 深圳市友恺通信技术有限公司 | 一种移动网络环境下的环绕声误码修复方法 |
| CN110809225B (zh) * | 2019-09-30 | 2021-11-23 | 歌尔股份有限公司 | 一种应用于立体声系统的自动校准喇叭的方法 |
| US10856082B1 (en) * | 2019-10-09 | 2020-12-01 | Echowell Electronic Co., Ltd. | Audio system with sound-field-type nature sound effect |
| WO2021181473A1 (ja) * | 2020-03-09 | 2021-09-16 | 日本電信電話株式会社 | 音信号符号化方法、音信号復号方法、音信号符号化装置、音信号復号装置、プログラム及び記録媒体 |
| WO2021181746A1 (ja) * | 2020-03-09 | 2021-09-16 | 日本電信電話株式会社 | 音信号ダウンミックス方法、音信号符号化方法、音信号ダウンミックス装置、音信号符号化装置、プログラム及び記録媒体 |
| EP4120250A4 (en) | 2020-03-09 | 2024-03-27 | Nippon Telegraph & Telephone | SOUND SIGNAL REDUCING MIXING METHOD, SOUND SIGNAL CODING METHOD, SOUND SIGNAL REDUCING MIXING DEVICE, SOUND SIGNAL CODING DEVICE, PROGRAM AND RECORDING MEDIUM |
| CN115244619A (zh) | 2020-03-09 | 2022-10-25 | 日本电信电话株式会社 | 声音信号编码方法、声音信号解码方法、声音信号编码装置、声音信号解码装置、程序以及记录介质 |
| CN113571073A (zh) * | 2020-04-28 | 2021-10-29 | 华为技术有限公司 | 一种线性预测编码参数的编码方法和编码装置 |
| CN111599381A (zh) * | 2020-05-29 | 2020-08-28 | 广州繁星互娱信息科技有限公司 | 音频数据处理方法、装置、设备及计算机存储介质 |
| EP4243015A4 (en) * | 2021-01-27 | 2024-04-17 | Samsung Electronics Co Ltd | AUDIO PROCESSING APPARATUS AND METHOD |
Family Cites Families (66)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH01231523A (ja) * | 1988-03-11 | 1989-09-14 | Fujitsu Ltd | ステレオ信号符号化装置 |
| JPH02124597A (ja) * | 1988-11-02 | 1990-05-11 | Yamaha Corp | 複数チャンネルの信号圧縮方法 |
| US6330533B2 (en) * | 1998-08-24 | 2001-12-11 | Conexant Systems, Inc. | Speech encoder adaptively applying pitch preprocessing with warping of target signal |
| SE519552C2 (sv) * | 1998-09-30 | 2003-03-11 | Ericsson Telefon Ab L M | Flerkanalig signalkodning och -avkodning |
| EP1054575A3 (en) * | 1999-05-17 | 2002-09-18 | Bose Corporation | Directional decoding |
| US6397175B1 (en) * | 1999-07-19 | 2002-05-28 | Qualcomm Incorporated | Method and apparatus for subsampling phase spectrum information |
| SE519976C2 (sv) * | 2000-09-15 | 2003-05-06 | Ericsson Telefon Ab L M | Kodning och avkodning av signaler från flera kanaler |
| SE519981C2 (sv) | 2000-09-15 | 2003-05-06 | Ericsson Telefon Ab L M | Kodning och avkodning av signaler från flera kanaler |
| CN100508026C (zh) * | 2002-04-10 | 2009-07-01 | 皇家飞利浦电子股份有限公司 | 立体声信号编码 |
| JP2004325633A (ja) * | 2003-04-23 | 2004-11-18 | Matsushita Electric Ind Co Ltd | 信号符号化方法、信号符号化プログラム及びその記録媒体 |
| SE527670C2 (sv) * | 2003-12-19 | 2006-05-09 | Ericsson Telefon Ab L M | Naturtrogenhetsoptimerad kodning med variabel ramlängd |
| JP2005202248A (ja) * | 2004-01-16 | 2005-07-28 | Fujitsu Ltd | オーディオ符号化装置およびオーディオ符号化装置のフレーム領域割り当て回路 |
| DE102004009954B4 (de) * | 2004-03-01 | 2005-12-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum Verarbeiten eines Multikanalsignals |
| US7668712B2 (en) * | 2004-03-31 | 2010-02-23 | Microsoft Corporation | Audio encoding and decoding with intra frames and adaptive forward error correction |
| SE0400998D0 (sv) | 2004-04-16 | 2004-04-16 | Cooding Technologies Sweden Ab | Method for representing multi-channel audio signals |
| US7283634B2 (en) | 2004-08-31 | 2007-10-16 | Dts, Inc. | Method of mixing audio channels using correlated outputs |
| US7630902B2 (en) * | 2004-09-17 | 2009-12-08 | Digital Rise Technology Co., Ltd. | Apparatus and methods for digital audio coding using codebook application ranges |
| CN101027718A (zh) * | 2004-09-28 | 2007-08-29 | 松下电器产业株式会社 | 可扩展性编码装置以及可扩展性编码方法 |
| BRPI0516658A (pt) * | 2004-11-30 | 2008-09-16 | Matsushita Electric Ind Co Ltd | aparelho de codificação de estéreo, aparelho de decodificação de estéreo e seus métodos |
| EP1691348A1 (en) * | 2005-02-14 | 2006-08-16 | Ecole Polytechnique Federale De Lausanne | Parametric joint-coding of audio sources |
| US7573912B2 (en) * | 2005-02-22 | 2009-08-11 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschunng E.V. | Near-transparent or transparent multi-channel encoder/decoder scheme |
| US9626973B2 (en) | 2005-02-23 | 2017-04-18 | Telefonaktiebolaget L M Ericsson (Publ) | Adaptive bit allocation for multi-channel audio encoding |
| ATE521143T1 (de) * | 2005-02-23 | 2011-09-15 | Ericsson Telefon Ab L M | Adaptive bitzuweisung für die mehrkanal- audiokodierung |
| US7751572B2 (en) * | 2005-04-15 | 2010-07-06 | Dolby International Ab | Adaptive residual audio coding |
| RU2007143418A (ru) * | 2005-05-25 | 2009-05-27 | Конинклейке Филипс Электроникс Н.В. (Nl) | Кодирование с предсказанием многоканального сигнала |
| US8227369B2 (en) | 2005-05-25 | 2012-07-24 | Celanese International Corp. | Layered composition and processes for preparing and using the composition |
| KR100841332B1 (ko) * | 2005-07-29 | 2008-06-25 | 엘지전자 주식회사 | 분할 정보를 시그널링 하는 방법 |
| WO2007026763A1 (ja) * | 2005-08-31 | 2007-03-08 | Matsushita Electric Industrial Co., Ltd. | ステレオ符号化装置、ステレオ復号装置、及びステレオ符号化方法 |
| US7974713B2 (en) * | 2005-10-12 | 2011-07-05 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Temporal and spatial shaping of multi-channel audio signals |
| US20080255859A1 (en) * | 2005-10-20 | 2008-10-16 | Lg Electronics, Inc. | Method for Encoding and Decoding Multi-Channel Audio Signal and Apparatus Thereof |
| KR100888474B1 (ko) | 2005-11-21 | 2009-03-12 | 삼성전자주식회사 | 멀티채널 오디오 신호의 부호화/복호화 장치 및 방법 |
| JP2007183528A (ja) * | 2005-12-06 | 2007-07-19 | Fujitsu Ltd | 符号化装置、符号化方法、および符号化プログラム |
| EP1989920B1 (en) * | 2006-02-21 | 2010-01-20 | Koninklijke Philips Electronics N.V. | Audio encoding and decoding |
| WO2007111568A2 (en) * | 2006-03-28 | 2007-10-04 | Telefonaktiebolaget L M Ericsson (Publ) | Method and arrangement for a decoder for multi-channel surround sound |
| MY145497A (en) | 2006-10-16 | 2012-02-29 | Dolby Sweden Ab | Enhanced coding and parameter representation of multichannel downmixed object coding |
| JPWO2008132826A1 (ja) * | 2007-04-20 | 2010-07-22 | パナソニック株式会社 | ステレオ音声符号化装置およびステレオ音声符号化方法 |
| US8046214B2 (en) * | 2007-06-22 | 2011-10-25 | Microsoft Corporation | Low complexity decoder for complex transform coding of multi-channel sound |
| GB2453117B (en) | 2007-09-25 | 2012-05-23 | Motorola Mobility Inc | Apparatus and method for encoding a multi channel audio signal |
| BRPI0816557B1 (pt) * | 2007-10-17 | 2020-02-18 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Codificação de áudio usando upmix |
| KR101505831B1 (ko) * | 2007-10-30 | 2015-03-26 | 삼성전자주식회사 | 멀티 채널 신호의 부호화/복호화 방법 및 장치 |
| US8103005B2 (en) * | 2008-02-04 | 2012-01-24 | Creative Technology Ltd | Primary-ambient decomposition of stereo audio signals using a complex similarity index |
| WO2009122757A1 (ja) | 2008-04-04 | 2009-10-08 | パナソニック株式会社 | ステレオ信号変換装置、ステレオ信号逆変換装置およびこれらの方法 |
| BRPI0914056B1 (pt) | 2008-10-08 | 2019-07-02 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Esquema de codificação/decodificação de áudio comutado multi-resolução |
| EP2381439B1 (en) * | 2009-01-22 | 2017-11-08 | III Holdings 12, LLC | Stereo acoustic signal encoding apparatus, stereo acoustic signal decoding apparatus, and methods for the same |
| EP2395504B1 (en) * | 2009-02-13 | 2013-09-18 | Huawei Technologies Co., Ltd. | Stereo encoding method and apparatus |
| WO2010097748A1 (en) | 2009-02-27 | 2010-09-02 | Koninklijke Philips Electronics N.V. | Parametric stereo encoding and decoding |
| CN101826326B (zh) * | 2009-03-04 | 2012-04-04 | 华为技术有限公司 | 一种立体声编码方法、装置和编码器 |
| MX2011009660A (es) * | 2009-03-17 | 2011-09-30 | Dolby Int Ab | Codificacion estereo avanzada basada en una combinacion de codificacion izquierda/derecha o media/lateral seleccionable de manera adaptable y de codificacion estereo parametrica. |
| US8666752B2 (en) | 2009-03-18 | 2014-03-04 | Samsung Electronics Co., Ltd. | Apparatus and method for encoding and decoding multi-channel signal |
| CN102884574B (zh) * | 2009-10-20 | 2015-10-14 | 弗兰霍菲尔运输应用研究公司 | 音频信号编码器、音频信号解码器、使用混迭抵消来将音频信号编码或解码的方法 |
| KR101710113B1 (ko) * | 2009-10-23 | 2017-02-27 | 삼성전자주식회사 | 위상 정보와 잔여 신호를 이용한 부호화/복호화 장치 및 방법 |
| EP2323130A1 (en) * | 2009-11-12 | 2011-05-18 | Koninklijke Philips Electronics N.V. | Parametric encoding and decoding |
| CN102884570B (zh) * | 2010-04-09 | 2015-06-17 | 杜比国际公司 | 基于mdct的复数预测立体声编码 |
| US8463414B2 (en) * | 2010-08-09 | 2013-06-11 | Motorola Mobility Llc | Method and apparatus for estimating a parameter for low bit rate stereo transmission |
| FR2966634A1 (fr) * | 2010-10-22 | 2012-04-27 | France Telecom | Codage/decodage parametrique stereo ameliore pour les canaux en opposition de phase |
| MX351750B (es) * | 2010-10-25 | 2017-09-29 | Voiceage Corp | Codificación de señales de audio genéricas a baja tasa de bits y a retardo bajo. |
| EP2633520B1 (en) * | 2010-11-03 | 2015-09-02 | Huawei Technologies Co., Ltd. | Parametric encoder for encoding a multi-channel audio signal |
| KR101621287B1 (ko) * | 2012-04-05 | 2016-05-16 | 후아웨이 테크놀러지 컴퍼니 리미티드 | 다채널 오디오 신호 및 다채널 오디오 인코더를 위한 인코딩 파라미터를 결정하는 방법 |
| JP5977434B2 (ja) | 2012-04-05 | 2016-08-24 | ホアウェイ・テクノロジーズ・カンパニー・リミテッド | パラメトリック空間オーディオ符号化および復号化のための方法、パラメトリック空間オーディオ符号器およびパラメトリック空間オーディオ復号器 |
| US9516446B2 (en) * | 2012-07-20 | 2016-12-06 | Qualcomm Incorporated | Scalable downmix design for object-based surround codec with cluster analysis by synthesis |
| JP6046274B2 (ja) * | 2013-02-14 | 2016-12-14 | ドルビー ラボラトリーズ ライセンシング コーポレイション | 上方混合されたオーディオ信号のチャネル間コヒーレンスの制御方法 |
| TWI634547B (zh) * | 2013-09-12 | 2018-09-01 | 瑞典商杜比國際公司 | 在包含至少四音訊聲道的多聲道音訊系統中之解碼方法、解碼裝置、編碼方法以及編碼裝置以及包含電腦可讀取的媒體之電腦程式產品 |
| TWI557724B (zh) * | 2013-09-27 | 2016-11-11 | 杜比實驗室特許公司 | 用於將 n 聲道音頻節目編碼之方法、用於恢復 n 聲道音頻節目的 m 個聲道之方法、被配置成將 n 聲道音頻節目編碼之音頻編碼器及被配置成執行 n 聲道音頻節目的恢復之解碼器 |
| KR101627661B1 (ko) * | 2013-12-23 | 2016-06-07 | 주식회사 윌러스표준기술연구소 | 오디오 신호 처리 방법, 이를 위한 파라메터화 장치 및 오디오 신호 처리 장치 |
| CN106463125B (zh) * | 2014-04-25 | 2020-09-15 | 杜比实验室特许公司 | 基于空间元数据的音频分割 |
| KR102636396B1 (ko) | 2015-09-25 | 2024-02-15 | 보이세지 코포레이션 | 스테레오 사운드 신호를 1차 및 2차 채널로 시간 영역 다운 믹싱하기 위해 좌측 및 우측 채널들간의 장기 상관 차이를 이용하는 방법 및 시스템 |
-
2016
- 2016-09-22 KR KR1020187008427A patent/KR102636396B1/ko active IP Right Grant
- 2016-09-22 RU RU2020124137A patent/RU2763374C2/ru active
- 2016-09-22 PT PT168476851T patent/PT3353779T/pt unknown
- 2016-09-22 US US15/761,858 patent/US10319385B2/en active Active
- 2016-09-22 WO PCT/CA2016/051107 patent/WO2017049398A1/en active Application Filing
- 2016-09-22 MY MYPI2018700870A patent/MY188370A/en unknown
- 2016-09-22 CN CN201680062546.7A patent/CN108352162B/zh active Active
- 2016-09-22 MX MX2018003703A patent/MX2018003703A/es unknown
- 2016-09-22 CA CA2997296A patent/CA2997296C/en active Active
- 2016-09-22 EP EP21201478.1A patent/EP3961623A1/en active Pending
- 2016-09-22 RU RU2020125468A patent/RU2765565C2/ru active
- 2016-09-22 KR KR1020187008428A patent/KR20180056662A/ko active IP Right Grant
- 2016-09-22 JP JP2018515517A patent/JP6887995B2/ja active Active
- 2016-09-22 RU RU2020126655A patent/RU2764287C1/ru active
- 2016-09-22 MX MX2021006677A patent/MX2021006677A/es unknown
- 2016-09-22 AU AU2016325879A patent/AU2016325879B2/en not_active Expired - Fee Related
- 2016-09-22 CA CA2997331A patent/CA2997331C/en active Active
- 2016-09-22 JP JP2018515504A patent/JP6804528B2/ja active Active
- 2016-09-22 EP EP16847687.7A patent/EP3353784A4/en active Pending
- 2016-09-22 WO PCT/CA2016/051105 patent/WO2017049396A1/en active Application Filing
- 2016-09-22 CN CN201680062619.2A patent/CN108352163B/zh active Active
- 2016-09-22 PL PL16847685T patent/PL3353779T3/pl unknown
- 2016-09-22 WO PCT/CA2016/051106 patent/WO2017049397A1/en active Application Filing
- 2016-09-22 CA CA2997513A patent/CA2997513A1/en active Pending
- 2016-09-22 RU RU2018114901A patent/RU2730548C2/ru active
- 2016-09-22 CN CN202310177584.9A patent/CN116343802A/zh active Pending
- 2016-09-22 US US15/761,883 patent/US10839813B2/en active Active
- 2016-09-22 MX MX2018003242A patent/MX2018003242A/es unknown
- 2016-09-22 ES ES16847684T patent/ES2955962T3/es active Active
- 2016-09-22 EP EP16847685.1A patent/EP3353779B1/en active Active
- 2016-09-22 US US15/761,900 patent/US10339940B2/en active Active
- 2016-09-22 EP EP16847683.6A patent/EP3353777B8/en active Active
- 2016-09-22 US US15/761,895 patent/US10522157B2/en active Active
- 2016-09-22 RU RU2018114899A patent/RU2729603C2/ru active
- 2016-09-22 JP JP2018515518A patent/JP6976934B2/ja active Active
- 2016-09-22 CA CA2997332A patent/CA2997332A1/en active Pending
- 2016-09-22 WO PCT/CA2016/051108 patent/WO2017049399A1/en active Application Filing
- 2016-09-22 ES ES16847686T patent/ES2904275T3/es active Active
- 2016-09-22 US US15/761,868 patent/US10325606B2/en active Active
- 2016-09-22 WO PCT/CA2016/051109 patent/WO2017049400A1/en active Application Filing
- 2016-09-22 EP EP20170546.4A patent/EP3699909A1/en active Pending
- 2016-09-22 DK DK16847685.1T patent/DK3353779T3/da active
- 2016-09-22 KR KR1020187008429A patent/KR102636424B1/ko active IP Right Grant
- 2016-09-22 CA CA2997334A patent/CA2997334A1/en active Pending
- 2016-09-22 MY MYPI2018700869A patent/MY186661A/en unknown
- 2016-09-22 CN CN201680062618.8A patent/CN108352164B/zh active Active
- 2016-09-22 EP EP16847684.4A patent/EP3353778B1/en active Active
- 2016-09-22 ES ES16847683T patent/ES2949991T3/es active Active
- 2016-09-22 MX MX2021005090A patent/MX2021005090A/es unknown
- 2016-09-22 EP EP23172915.3A patent/EP4235659A3/en active Pending
- 2016-09-22 EP EP16847686.9A patent/EP3353780B1/en active Active
- 2016-09-22 ES ES16847685T patent/ES2809677T3/es active Active
- 2016-09-22 RU RU2018114898A patent/RU2728535C2/ru active
-
2018
- 2018-03-12 ZA ZA2018/01675A patent/ZA201801675B/en unknown
- 2018-10-08 HK HK18112775.6A patent/HK1253570A1/zh unknown
- 2018-10-08 HK HK18112774.7A patent/HK1253569A1/zh unknown
-
2019
- 2019-01-03 HK HK19100048.1A patent/HK1257684A1/zh unknown
- 2019-02-01 HK HK19101883.7A patent/HK1259477A1/zh unknown
- 2019-03-29 US US16/369,086 patent/US11056121B2/en active Active
- 2019-03-29 US US16/369,156 patent/US10573327B2/en active Active
- 2019-04-11 US US16/381,706 patent/US10984806B2/en active Active
-
2020
- 2020-06-11 ZA ZA2020/03500A patent/ZA202003500B/en unknown
- 2020-12-01 JP JP2020199441A patent/JP7140817B2/ja active Active
-
2021
- 2021-05-19 JP JP2021084635A patent/JP7124170B2/ja active Active
- 2021-11-09 JP JP2021182560A patent/JP7244609B2/ja active Active
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2955962T3 (es) | Método y sistema que utiliza una diferencia de correlación a largo plazo entre los canales izquierdo y derecho para mezcla descendente en el dominio del tiempo de una señal de sonido estéreo en canales primarios y secundarios | |
| US20210027794A1 (en) | Method and system for decoding left and right channels of a stereo sound signal |