ES2859906T3 - Proteínas de unión similares a anticuerpos con regiones variables duales con una orientación de entrecruzamiento de la región de unión - Google Patents
Proteínas de unión similares a anticuerpos con regiones variables duales con una orientación de entrecruzamiento de la región de unión Download PDFInfo
- Publication number
- ES2859906T3 ES2859906T3 ES16205057T ES16205057T ES2859906T3 ES 2859906 T3 ES2859906 T3 ES 2859906T3 ES 16205057 T ES16205057 T ES 16205057T ES 16205057 T ES16205057 T ES 16205057T ES 2859906 T3 ES2859906 T3 ES 2859906T3
- Authority
- ES
- Spain
- Prior art keywords
- antibody
- immunoglobulin
- variable domain
- heavy chain
- light chain
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 0 CCC=C[C@](*)C(C(C)CCCCCCCCCCCN)C=C Chemical compound CCC=C[C@](*)C(C(C)CCCCCCCCCCCN)C=C 0.000 description 4
- DRWXNEGHNYZBMA-UHFFFAOYSA-N CCCC(CCC)C(F)(F)F Chemical compound CCCC(CCC)C(F)(F)F DRWXNEGHNYZBMA-UHFFFAOYSA-N 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/241—Tumor Necrosis Factors
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/244—Interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/244—Interleukins [IL]
- C07K16/245—IL-1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/244—Interleukins [IL]
- C07K16/247—IL-4
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/461—Igs containing Ig-regions, -domains or -residues form different species
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/522—CH1 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/53—Hinge
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/624—Disulfide-stabilized antibody (dsFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/626—Diabody or triabody
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/64—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a combination of variable region and constant region components
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/66—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a swap of domains, e.g. CH3-CH2, VH-CL or VL-CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2318/00—Antibody mimetics or scaffolds
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Oncology (AREA)
- Animal Behavior & Ethology (AREA)
- Engineering & Computer Science (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
Una proteína de unión similar a anticuerpo que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno capaces de unirse específicamente a una o más dianas antigénicas, en donde dos cadenas polipeptídicas tienen una estructura representada por la fórmula: VL1-L1-VL2-L2-CL [I] y dos cadenas polipéptídicas tienen una estructura representada por la fórmula: VH2-L3-VH1-L4-CH1-Fc [II] en donde: VL1 es un primer dominio variable de cadena ligera de inmunoglobulina; VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina; VH1 es un primer dominio variable de cadena pesada de inmunoglobulina; VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina; CL es un dominio constante de la cadena ligera de inmunoglobulina; CH1 es el dominio constante de la cadena pesada CH1 de inmunoglobulina; Fc es la región de bisagra de inmunoglobulina y CH2, CH3 son los dominios constantes de la cadena pesada de inmunoglobulina; y L1, L2, L3 y L4 son enlazadores de aminoácidos; en donde la longitud de L4 es al menos dos veces la longitud de L2; y la longitud de L3 es al menos dos veces la longitud de L1; y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de VL1 y VH1 y para el emparejamiento de VL2 y VH2, y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
Description
DESCRIPCIÓN
Proteínas de unión similares a anticuerpos con regiones variables duales con una orientación de entrecruzamiento de la región de unión
CAMPO DE LA INVENCIÓN
La invención se refiere a proteínas de unión similares a anticuerpos que comprenden cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, en el que cada uno de los pares de polipéptidos que forman la proteína de unión similar a anticuerpo posee dominios variables doble que tienen una orientación de entrecruzamiento. La invención se refiere también a métodos para preparar tales proteínas de unión similares a antígeno.
ANTECEDENTES DE LA INVENCIÓN
Anticuerpos IgG que se producen de forma natural son bivalentes y monoespecíficos. Los anticuerpos biespecíficos que tienen especificidades de unión para dos antígenos diferentes se pueden producir utilizando tecnologías recombinantes y se prevé que tengan amplias aplicaciones clínicas. Es bien sabido que las moléculas completas de anticuerpos IgG son moléculas en forma de Y que comprenden cuatro cadenas polipeptídicas: dos cadenas pesadas y dos cadenas ligeras. Cada una de las cadenas ligeras se compone de dos dominios, el dominio N-terminal, conocido como el dominio (o región) variable o Vl y el dominio C-terminal, conocido como el dominio constante (o Cl) (dominio kappa constante (Ck) o lambda constante (CA)). Cada una de las cadenas pesadas consiste en cuatro o cinco dominios, dependiendo de la clase del anticuerpo. El dominio N-terminal es conocido como el dominio (o región) variable (o Vh), que es seguido por el primer dominio constante (o Cm), la región de bisagra, y después el segundo y tercer dominios constantes (o Ch2 y Cm). En un anticuerpo ensamblado, los dominios Vl y Vh se asocien para formar un sitio de unión al antígeno. También los dominios Cl y Ch1 se asocian juntos para mantener una cadena pesada asociada con una cadena ligera. Los dos heterodímeros de cadena ligera-pesada se asocian entre sí mediante la interacción de los dominios Ch2 y Ch3 y la interacción entre las regiones de bisagra en las dos cadenas pesadas.
Se sabe que la digestión proteolítica de un anticuerpo puede conducir a la producción de fragmentos de anticuerpos (Fab y Fab2). Tales fragmentos del anticuerpo entero pueden exhibir actividad de unión a antígeno. Los fragmentos de anticuerpos también se pueden producir de forma recombinante. Se pueden obtener Fragmentos Fv, que consisten solamente en los dominios variables de las cadenas pesadas y ligeras asociadas entre sí. Estos fragmentos Fv son monovalentes para la unión de antígeno. Los fragmentos más pequeños tales como dominios individuales variables (anticuerpos de dominio o dABs Ward et al., 1989, Nature 341 (6242): 544-46), regiones determinantes de la complementariedad o CDR individuales (Williams et al., 1989, Proc Natl. Acad Sci. U.S.A. 86 (14): 5537-41) también han demostrado conservar las características de unión del anticuerpo parental, aunque la mayoría de los anticuerpos que se producen de forma natural generalmente necesitan tanto una Vh como una Vl para conservar una potencia unión completa.
Construcciones de fragmento de cadena sencilla (scFv) comprenden un dominio Vh y un dominio Vl de un anticuerpo contenido en una única cadena de polipéptido, en donde los dominios están separados por un enlazador flexible de una longitud suficiente (más de 12 residuos aminoácidos), que fuerza una interacción intramolecular, lo que permite un auto-ensamblaje de los dos dominios en un sitio de unión a epítopo funcional (Bird et al., 1988, Science 242 (4877): 423-26). Estas pequeñas proteínas (PM ~ 25.000 Da) generalmente conservan la especificidad y afinidad por su antígeno en un solo polipéptido y pueden proporcionar un bloque de construcción conveniente para moléculas más grandes, específicas de antígeno.
Una ventaja de utilizar fragmentos de anticuerpos en lugar de anticuerpos enteros en diagnóstico y terapia se encuentra en su tamaño más pequeño. Son probablemente menos inmunogénicos que los anticuerpos enteros y más capaces de penetrar en los tejidos. Una desventaja asociada con el uso de tales fragmentos es que tienen solamente un sitio de unión a antígeno, lo que conduce a una avidez reducida. Además, debido a su pequeño tamaño, que se borra muy rápido a partir del suero y, por lo tanto, muestran una semi-vida corta.
Ha sido de interés producir anticuerpos biespecíficos (BsAbs) que combinan los sitios de unión a antígeno de dos anticuerpos dentro de una sola molécula y que, por lo tanto, serían capaces de unirse a dos antígenos diferentes simultáneamente. Además de las aplicaciones con fines de diagnóstico, tales moléculas allanan el camino para nuevas aplicaciones terapéuticas, p. ej., mediante la reorientación de sistemas efectores potentes a las zonas enfermas (en donde las células cancerosas a menudo desarrollan mecanismos para suprimir respuestas inmunes normales desencadenadas por anticuerpos monoclonales tal como la citotoxicidad celular dependiente de anticuerpos (ADCC) o la citotoxicidad dependiente del complemento (CDC)), o mediante el aumento de las actividades neutralizantes o estimulantes de los anticuerpos. Este potencial fue reconocido desde el principio, dando lugar a una serie de enfoques para la obtención de dichos anticuerpos biespecíficos. Intentos iniciales para acoplar las especificidades de unión de dos anticuerpos completos contra diferentes antígenos diana con fines terapéuticos utilizaban moléculas de heteroconjugados fusionadas químicamente (Staerz et al., 1985, Nature 314 (6012): 628
Los anticuerpos biespecíficos se hicieron originalmente mediante la fusión de dos hibridomas, cada uno capaz de producir una inmunoglobulina diferente (Milstein et al., 1983, Nature 305 (5934): 537-40), pero la complejidad de las especies (hasta diez especies diferentes) producidas en cultivo celular hicieron la purificación difícil y costosa. George et al., 1997, THE ANTIBODIES 4: 99-141 (Capra et al., comp., Harwood Academic Publishers)). Utilizando este formato, un anticuerpo IgG2a de ratón y un anticuerpo IgG2b de rata se produjeron juntos en la misma célula (p. ej., ya sea como una fusión cuadroma de dos hibridomas, o en células CHO modificadas por ingeniería). Debido a que las cadenas ligeras de cada uno de los anticuerpos se asocian preferentemente con las cadenas pesadas de sus especies afines, se ensamblan tres especies principales de anticuerpo: los dos anticuerpos parentales, y un heterodímero de los dos anticuerpos comprenden un par de cadenas pesada/ligera de cada uno, asociándose a través sus porciones Fc. El heterodímero deseado puede purificarse a partir de esta mezcla debido a que sus propiedades de unión a la Proteína A son diferentes de las de los anticuerpos parentales: IgG2b de rata no se une a la Proteína A, mientras que la IgG2a de ratón sí lo hace. En consecuencia, el heterodímero ratón-rata se une a Proteína A, pero eluye a un pH más alto que el homodímero de IgG2a de ratón, y esto hace posible la purificación selectiva del heterodímero biespecífico (Lindhofer et al., 1995, J. Immunol 155 (1): 219-25). El heterodímero biespecífico resultante es totalmente no humano, por lo tanto es altamente inmunogénico, lo que podría tener efectos secundarios perjudiciales (p. ej., reacciones "HAMA" o "HARA") y/o neutralizan la terapéutica. Quedaba una necesidad de biespecíficos modificados por ingeniería con propiedades superiores que se puedan producir fácilmente en un alto rendimiento del cultivo de células de mamífero.
A pesar de los prometedores resultados obtenidos utilizando heteroconjugados o anticuerpos biespecíficos producidos a partir de la fusión de células como se cita anteriormente, varios factores les hacen poco prácticos para aplicaciones terapéuticas a gran escala. Tales factores incluyen: la rápida eliminación de los heteroconjugados in vivo, las técnicas intensivas de laboratorio requeridas para la generación de cualquier tipo de molécula, la necesidad de una purificación extensiva de heteroconjugados lejos de los homoconjugados o anticuerpos monoespecíficos, y los bajos rendimientos obtenidos en general.
La ingeniería genética ha sido utilizada con frecuencia cada vez mayor para diseñar, modificar y producir anticuerpos o derivados de anticuerpo con un conjunto deseado de propiedades de unión y funciones efectoras. Se ha desarrollado una diversidad de métodos recombinantes para la producción eficiente de BsAbs, tanto como fragmentos de anticuerpos (Carter et al., 1995, J. Hematother4(5):463-70; Pluckthun et al., 1997, Immunotechnology 3(2): 83-105; Todorovska et al., 2001, J. Immunol Methods 248(1-2): 47-66) y los formatos de IgG de longitud completa (Carter, 2001, J. Immunol Methods 248(1-2): 7-15).
La combinación de dos scFv diferentes resulta en formatos de BsAb con masa molecular mínima, denominado sc-BsAbs o Ta-scFv (Mack et al., 1995, Proc Natl Acad. Sci. U.S.A. 92(15): 7021-25; Mallender et al., 1994, J. Biol. Chem. 269(1): 199-206). BsAbs se han construido fusionando genéticamente dos scFvs a una funcionalidad de dimerización tal como una cremallera de leucina (Kostelny et al., 1992, J. Immunol. 148 (5): 1547-53;. de Kruif et al., 1996, J. Biol. Chem. 271(13): 7630-34).
Los diacuerpos son pequeños fragmentos de anticuerpos bivalentes y biespecíficos. Los fragmentos comprenden un Vh conectado a un Vl en la misma cadena de polipéptido, mediante el uso de un enlazador que es demasiado corto (menos de 12 residuos aminoácidos) para permitir el emparejamiento entre los dos dominios en la misma cadena. Los dominios son forzados a emparejarse de manera intermolecular con los dominios complementarios de otra cadena y crear dos sitios de unión a antígeno. Estos fragmentos de anticuerpos diméricos, o "diacuerpos", son bivalentes y biespecíficos (Holliger et al, 1993, Proc. Natl. Acad. Sci. U.S.A. 90 (14):.6444-48). Los diacuerpos son de un tamaño similar a un fragmento Fab. Cadenas de polipéptidos de dominios Vh y Vl se unieron con un enlazador de entre 3 y 12 residuos de aminoácidos forman predominantemente dímeros (diacuerpos), mientras que con un enlazador de entre 0 y 2 residuos aminoácido predominan trímeros (triacuerpos) y tetrámeros (tetracuerpos). Además de la longitud del enlazador, el patrón exacto de oligomerización parece depender de la composición, así como de la orientación de los dominios variables (Hudson et al., 1999, J. Immunol Methods 231(1-2): 177-89). La predictibilidad de la estructura final de las moléculas de diacuerpo es muy pobre.
Aunque sc-BsAb y construcciones basadas en diacuerpos exhiben un interesante potencial clínico, se demostró que tales moléculas asociadas de forma no covalente no son suficientemente estables en condiciones fisiológicas. La estabilidad global de un fragmento scFv depende de la estabilidad intrínseca de los dominios Vl y Vh, así como de la estabilidad de la interfaz del dominio. Una estabilidad insuficiente de la interfaz Vl y Vh de fragmentos scFv a menudo ha sido sugerida como una causa principal de la inactivación irreversible de scFv, ya que la apertura transitoria de la interfaz, que fuese permitida por el enlazador peptídico, expone parches hidrofóbicos que favorecen la agregación y, por lo tanto, inestabilidad y un pobre rendimiento de la producción. Worn et al., 2001, J. Mol. Biol.
305(5): 989-1010).
Un método alternativo de fabricación de proteínas de unión a antígeno bivalentes biespecíficas a partir de dominios Vh y Vl se describe en la Patente de EE.UU. N° 5.989.830. Configuraciones de doble cabeza y Fv dual de este tipo se obtienen mediante la expresión de un vector bicistrónico, que codifica dos cadenas polipeptídicas. En la configuración de Fv Dual, los dominios variables de dos anticuerpos diferentes se expresan en una orientación en tándem en dos cadenas separadas (una cadena pesada y una cadena ligera), en donde una cadena polipeptídica tiene dos veces un Vh en serie separados por un enlazador peptídico (Vm-enlazador-VH2) y la otra cadena
polipeptídica consiste en dominios Vl complementarios conectados en serie por un enlazador peptídico (Vlienlazador-VL2). En la configuración de doble cabeza de entrecruzamiento, los dominios variables de dos anticuerpos diferentes se expresan en una orientación en tándem en dos cadenas polipeptídicas separadas (una cadena pesada y una cadena ligera), en donde una cadena polipeptídica tiene dos veces un Vh en serie separado por un enlazador peptídico (VH1-enlazador-VH2) y la otra cadena polipeptídica consiste en dominios Vl complementarios conectados en serie por un enlazador peptídico en la orientación opuesta (VL2-enlazador-VL1). El modelado molecular de las construcciones sugirió que el tamaño del enlazador fuese lo suficientemente grande para abarcar 30-40 Á (15-20 residuos aminoácidos).
El aumento de la valencia de un anticuerpo es de interés, ya que mejora la afinidad funcional de ese anticuerpo debido al efecto de avidez. Complejos de proteínas polivalentes (PPC) con una valencia incrementada se describen en la Publicación de la Solicitud de Patente de EE.UU. N° 2005/0003403 A1. Los PPCs comprenden dos cadenas de polipéptidos, en general dispuestas lateralmente entre sí. Cada una de las cadenas de polipéptidos comprende típicamente tres o cuatro "regiones v", que comprenden secuencias de aminoácidos capaces de formar un sitio de unión al antígeno cuando se combina con una región v correspondiente en la cadena polipeptídica opuesta. Se pueden utilizar hasta aproximadamente seis "regiones v" en cada una de las cadenas polipeptídicas. Las regiones v de cada una de las cadenas polipeptídicas están conectadas linealmente entre sí y pueden estar conectados por regiones de enlace intercaladas. Cuando se disponen en forma del PPC, las regiones v de cada una de las cadenas polipeptídicas forman sitios individuales de unión al antígeno. El complejo puede contener una o varias especificidades de unión.
Una estrategia fue propuesto por Carter et al. (Ridgway et al., 1996, Protein Eng. 9(7): 617-21; Carter, 2011, J. Immunol. Methods 248 (1-2): 7-15) para producir un heterodímero Fc utilizando un conjunto de mutaciones de "botón-en-ojal" en el dominio Ch3 de Fc. Estas mutaciones conducen a la alteración de la complementariedad del empaquetamiento de residuos entre la interfaz del dominio Ch3 dentro del núcleo hidrofóbico conservado estructuralmente, de modo que se favorece la formación del heterodímero en comparación con homodímeros, lo cual logra una buena expresión del heterodímero a partir del cultivo de células de mamífero. Aunque la estrategia condujo a un mayor rendimiento de heterodímeros, los homodímeros no fueron suprimidos por completo (Merchant et al., 1998, Nat. Biotechnol. 16(7): 677-81.
Gunasekaran et al. exploró la viabilidad de conservar la integridad del núcleo hidrofóbico mientras se impulsa la formación de heterodímero Fc cambiando la complementariedad de carga en la interfaz de dominio Ch3 (Gunasekaran et al., 2010, J. Biol. Chem. 285(25): 19637-46). Aprovechando el mecanismo de dirección electrostática, estas construcciones mostraron una promoción eficiente de la formación de heterodímeros Fc con una mínima contaminación de homodímeros a través de la mutación de dos pares de residuos cargados situados periféricamente. En contraste con el diseño de botón-en-ojal, los homodímeros fueron suprimidos de manera uniforme debido a la naturaleza del mecanismo de repulsión electrostática, pero no se evitaron totalmente.
Davis et al, describen un enfoque de ingeniería de anticuerpos para convertir homodímeros Fc en heterodímeros por interdigitación de segmentos de la cadena p de dominios Ch3 de IgG e IgA humanos, sin la introducción de enlaces disulfuro entre cadenas extra (Davis et al., 2010, Protein Eng. Des. Sel. 23 (4):195-202). La expresión de proteínas de fusión SEEDbody (Sb) por células de mamífero proporciona heterodímeros Sb con un alto rendimiento que se purifican fácilmente para eliminar subproductos secundarios.
La Publicación de Solicitud de Patente de EE.UU. N° US 2010/331527 A1 describe un anticuerpo biespecífico basado en la heterodimerización del dominio Ch3, la introducción en una cadena pesada de las mutaciones H95R e Y96F dentro del dominio Ch3. Estas sustituciones de aminoácidos se originan en el dominio Ch3 del subtipo IgG3 y se heterodimerizará con una cadena principal de IgG 1. Una cadena ligera común propensa a emparejarse con cada una de las cadenas pesadas es un requisito previo para todos los formatos basados en la heterodimerización a través del dominio Ch3. Por lo tanto, se produce un total de tres tipos de anticuerpos: 50% tiene una cadena principal de IgG1 pura, un tercio tiene una cadena principal H95R e Y96F mutada pura, y un tercio tiene dos cadenas pesadas diferentes (biespecíficas). El heterodímero deseado puede purificarse a partir de esta mezcla, debido a que sus propiedades de unión a Proteína A son diferentes de las de los anticuerpos parentales: los dominios Ch3 derivados de IgG3 no se unen a Proteína A, mientras que la IgG1 sí lo hace. En consecuencia, el heterodímero se une a Proteína A, pero se eluye a un pH más alto que el homodímero de IgG1 pura, y esto hace posible la purificación selectiva del heterodímero biespecífico.
La Patente de EE.UU. N° 7.612.181 describe un anticuerpo biespecífico IgG Dual-Dominio Variable (DVD-IgG) que se basa en el formato de Fv Dual descrito en la Patente de EE.UU. N° 5.989.830. Un formato biespecífico similar se describió también en la Publicación de la Solicitud de Patente de EE.UU. N° 2010/0226923 A1. La adición de dominios constantes a respectivas cadenas de la Fv Dual (Ch1-Fc a la cadena pesada y el dominio constante kappa o lambda de la cadena ligera) dio lugar a anticuerpos biespecíficos funcionales sin necesidad de modificaciones adicionales (es decir, la adición obvia de dominios constantes para mejorar la estabilidad). Algunos de los anticuerpos expresados en el formato DVD-Ig/TBTI muestran un efecto de posición en la segunda posición (o más interna) de unión al antígeno (Fv2). Dependiendo de la secuencia y la naturaleza del antígeno reconocido por la posición Fv2, este dominio de anticuerpo muestra una afinidad reducida a su antígeno (es decir, la pérdida de tasa de enlace en comparación con el anticuerpo parental). Una posible explicación para esta observación es que el
enlazador entre Vli y Vl2 sobresale en la región CDR de Fv2, haciendo que Fv2 sea algo inaccesible para los antígenos más grandes.
La segunda configuración de un fragmento de anticuerpo biespecífico descrita en la Patente de EE.UU. N°.
5.989.830 es la doble cabeza de entrecruzamiento (CODH), que tiene la siguiente orientación de los dominios variables expresadas en dos cadenas:
VLi-enlazador-VL2 , para la cadena ligera, y
VH2-enlazador-VHi, para la cadena pesada
La patente ‘830 describe que un fragmento de anticuerpo biespecífico de doble cabeza de entrecruzamiento (construcción GOSA.E) conserva una actividad de unión mayor que un Fv Dual (véase la página 20, líneas 20-50 de la patente ‘830) y describe, además, que este formato se ve menos impactado por los enlazadores que se utilizan entre los dominios variables (véanse las páginas 20-21 de la patente ‘830).
SUMARIO DE LA INVENCIÓN
La invención proporciona una proteína de unión similar a anticuerpo que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno capaces de unirse específicamente a una o más dianas antigénicas, en donde dos cadenas polipeptídicas tienen una estructura representada por la fórmula:
Vli-Li -Vl2-L2-Cl [I]
y dos cadenas polipéptídicas tienen una estructura representada por la fórmula:
Vh2-Ls-Vhi-L4-Chi-Fc [II]
en donde:
Vli es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vhi es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Chi es el dominio constante de la cadena pesada Chi de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina;
Li, L2 , L3 y L4 son enlazadores de aminoácidos; en donde
la longitud de L4 es al menos dos veces la longitud de L2 ; y
la longitud de L3 es al menos dos veces la longitud de Li;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vli y Vhi y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
La invención también proporciona una proteína de unión similar a anticuerpo que comprende dos cadenas polipeptídicas que forman dos sitios de unión a antígeno capaces de unirse específicamente a una o más dianas antigénicas, en donde una primera cadena polipeptídica tiene una estructura representada por la fórmula:
Vli-Li -Vl2-L2-Cl [I]
y una segunda cadena polipeptídica tiene una estructura representada por la fórmula:
VH2-L3-VH1-L4-CH1 [II]
en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vhi es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina;
L1, L2 , L3 y L4 son enlazadores de aminoácidos; en donde
la longitud de L4 es al menos dos veces la longitud de L2 ; y
la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2, y los primero y segundo polipéptidos forman un par de cadena ligera-cadena pesada de entrecruzamiento.
La invención proporciona además un método de producir una proteína de unión similar a anticuerpo, que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, que comprende
(a) identificar un primer dominio variable del anticuerpo que se une a un primer antígeno diana y un segundo dominio variable de anticuerpo que une a un segundo antígeno diana, conteniendo cada uno un Vl y un Vh;
(b) asignar la cadena ligera en forma de una cadena de molde;
(c) asignar el Vl del primer dominio variable del anticuerpo o el segundo dominio variable del anticuerpo como Vl1 ;
(d) asignar un Vl2, un Vh1 y un Vh2 de acuerdo con las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
Vh2-L3-Vh1-L4-Ch1-Fc [II]
(e) determinar longitudes máxima y mínima para L1, L2 , L3 y L4 ;
(f) generar las estructuras de polipéptidos de fórmulas I y II;
(g) seleccionar estructuras de polipéptidos de fórmulas I y II que se unen al primer antígeno diana y al segundo antígeno diana cuando se combinan para formar la proteína de unión similar a anticuerpo; en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
La invención proporciona además un método de producir una proteína de unión similar a anticuerpo, que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, que comprende
(a) identificar un primer dominio variable del anticuerpo que se une a un primer antígeno diana y un segundo dominio variable de anticuerpo que une a un segundo antígeno diana, conteniendo cada uno un Vl y un Vh;
(b) asignar la cadena ligera en forma de una cadena de molde;
(c) asignar el Vl del primer dominio variable del anticuerpo o el segundo dominio variable del anticuerpo como Vl1 ;
(d) asignar un Vl2, un Vh1 y un Vh2 de acuerdo con las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1 [II]
(e) determinar longitudes máxima y mínima para L1, L2 , L3 y L4 ;
(f) generar las estructuras de polipéptidos de fórmulas I y II;
(g) seleccionar estructuras de polipéptidos de fórmulas I y II que se unen al primer antígeno diana y al segundo antígeno diana cuando se combinan para formar la proteína de unión similar a anticuerpo; en donde:
VL1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2, y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
Otros aspectos de la invención resultarán evidentes a partir de la siguiente descripción más detallada y las reivindicaciones.
BREVE DESCRIPCIÓN DE LOS DIBUJOS
Figura 1. Representación esquemática de los dominios Fv1 y Fv2 de unión a antígeno dentro de la configuración de la región V dual y disposición de sus respectivos enlazadores peptídicos Ll y Lh en el formato TBTI.
Figura 2. Diagrama esquemático (2D) de los dominios de unión a antígeno Fv1 (anti-IL4) y Fv2 (anti-IL13) dentro de la configuración dual variable de entrecruzamiento (CODV) y la disposición de sus respectivos enlazadores peptídicos.
Figura 3. Representación esquemática de Fv de anti-IL4 y Fab de anti-IL13 que muestra una posible disposición espacial obtenida por acoplamiento proteína-proteína de Fv de anti-IL4 y el Fv de anti-IL13.
Figura 4. Evaluación de la capacidad de unión tetravalente y biespecífica de la proteína CODV en un ensayo de BIACORE mediante la inyección de los dos antígenos de forma secuencial o simultánea a través de un chip revestido con proteína DVD-Ig. La señal máxima observada por inyección secuencial se puede obtener por co inyección de ambos antígenos, lo que demuestra la saturación de todos los sitios de unión.
Figura 5. Diagrama esquemático (2D) de los dominios de unión a antígeno dentro de la configuración CODV y la disposición de sus respectivos enlazadores peptídicos Ll (L1 y L2) y Lh (L3 y L4). En el panel A, la cadena ligera se
mantiene en una alineación "lineal o de molde", mientras que la cadena pesada está en la configuración de "entrecruzamiento". En el panel B, la cadena pesada se mantiene en una alineación "lineal o de molde" y la cadena ligera está en la configuración de "entrecruzamiento".
Figura 6. Representación esquemática del diseño CODV-Ig en función de si la cadena ligera o la cadena pesada se utiliza como "molde".
Figura 7. Comparación de moléculas TBTI/DVD-Ig o CODV-Ig que incorporan secuencias de anti-IL13 y anti-IL4. Figura 8. Comparación de formatos CODV-Fab y B-Fab en un ensayo citotóxico utilizando células NALM-6.
DESCRIPCION DETALLADA DE LA INVENCION
La invención proporciona proteínas de unión similares a anticuerpos tal como se ha descrito anteriormente en el Sumario de la Invención. La invención también proporciona métodos para preparar tales proteínas de unión similares a antígeno.
El modelado por ordenador predijo que el diseño de entrecruzamiento de doble cabeza (CODH) de la Patente de EE.UU. N° 5.989.830 produciría un complejo en el que los dos sitios de unión miran en la dirección opuesta, sin las restricciones sugeridas para la configuración Dual-Fv de la Patente de EE.UU. N° 7.612.181. En particular, el modelado por ordenador indicó que la longitud de los enlazadores de aminoácidos entre los dominios variables no era crítica para el diseño CODH, pero era importante para permitir el acceso completo a los dos sitios de unión a antígeno en el diseño de Dual Fv. Al igual que con el formato DVD-Ig/TBTI, se prepararon construcciones de proteínas de unión similares a anticuerpos en las que dominios constantes se fijaron a la configuración CODH para formar proteínas de unión similares a anticuerpos que comprenden cuatro cadenas de polipéptidos que forman cuatro sitios de unión a antígeno, en donde cada uno de los pares de polipéptidos que forman una proteína de unión similar a anticuerpo posee dominios duales variables que tienen una orientación de entrecruzamiento (es decir, CODH-Ig). Se espera que las moléculas de CODH-Ig posean una estabilidad significativamente mejorada en comparación con las moléculas de CODH (dado que DVD-Ig/TBTI poseía una estabilidad mejorada frente a moléculas Dual Fv).
Con el fin de probar la hipótesis anterior, se preparó una molécula de CODH-Ig utilizando las secuencias de anticuerpos el anti-IL4 y anti-IL13 descritas en la Publicación de la Solicitud de Patente de EE.UU. N° 2010/0226923 A1. La molécula de CODH-Ig difería de la molécula de CODH del documento US 2010/0226923 con respecto a las longitudes de enlazadores de aminoácidos que separan los dominios variables en las respectivas cadenas de polipéptidos. Las moléculas de CODH-Ig se expresaron en células después de la transfección transitoria y se purificaron por cromatografía de Proteína A. Aunque sus perfiles de cromatografía de exclusión por tamaño (SEC) mostraron niveles de agregación de 5-10%, ninguna de las moléculas de CODH-Ig era funcional, y por lo tanto ninguna de las moléculas de CODH-Ig era capaz de unirse a todos sus antígenos diana. La falta de actividad de unión al antígeno puede haber sido debida a una dimerización perturbado de las regiones Fv de las cadenas pesadas y ligeras debido a las inadecuadas longitudes del enlazador comprometiendo la formación correcta del paratopo. Como resultado, se desarrolló un protocolo para identificar enlazadores de aminoácidos adecuados para la inserción entre los dos dominios variables y el segundo dominio variable y el dominio constante tanto en las cadenas polipeptídicas pesada y ligera de una proteína de unión similar a anticuerpo. Este protocolo se basó en el acoplamiento proteína-proteína de homología y modelos experimentales de las regiones FvIL4 y FvIL13, respectivamente, la inclusión del dominio Fc1 el modelo y la construcción de enlazadores apropiados entre las regiones FvIL4 y FvIL13 y entre las regiones de Fv y Fc1 constantes.
Metodologías de ADN recombinante estándares se utilizan para construir los polinucleótidos que codifican los polipéptidos que forman las proteínas de unión similares a anticuerpos de la invención, incorporan estos polinucleótidos en vectores de expresión recombinantes e introducen dichos vectores en células huésped. Véase, p. ej., Sambrook et al., 2001 MOLECULAR CLONING: A LABORATORY MANUAL (Cold Spring Harbor Laboratory Press, 3a ed.). Reacciones enzimáticas y técnicas de purificación se pueden realizar de acuerdo con las especificaciones del fabricante, tal como comúnmente se logra en la técnica, o tal como se describe en esta memoria. A menos que se proporcionan definiciones específicas, la nomenclatura utilizada en relación con, y los procedimientos y técnicas de laboratorio de química analítica, química orgánica sintética y química médica y farmacéutica descritas en esta memoria son aquellos bien conocidos y comúnmente utilizados en la técnica. De manera similar, se pueden utilizar técnicas convencionales para síntesis químicas, análisis químicos, preparación farmacéutica, formulación, suministro y tratamiento de los pacientes.
1. Definiciones Generales
Tal como se utiliza de acuerdo con la presente descripción, se entenderá que los siguientes términos y expresiones, a menos que se indique otra cosa, tienen los siguientes significados. A menos que sea requerido por el contexto, los términos en singular incluirán plurales y los términos en plural incluirán el singular.
El término "polinucleótido", tal como se utiliza en esta memoria, se refiere a polímeros de ácidos nucleicos de cadena sencilla o de doble cadena de al menos 10 nucleótidos de longitud. En ciertas realizaciones, los nucleótidos
que comprenden el polinucleótido pueden ser ribonucleótidos o desoxirribonucleótidos o una forma modificada de cualquier tipo de nucleótido. Tales modificaciones incluyen modificaciones de bases tales como bromuridina, modificaciones de ribosa tales como arabinósido y 2',3'-didesoxirribosa, y modificaciones de enlaces internucleótidos tales como fosforotioato, fosforoditioato, fosforoselenoato, fosforodiselenoato, fosforoanilotioato, fosforaniladato y fosforoamidato. El término "polinucleótido" incluye específicamente formas de cadena sencilla y de doble cadena de ADN.
Un "polinucleótido aislado" es un polinucleótido de origen genómico, ADNc o sintético o alguna combinación de los mismos que, en virtud de su origen, el polinucleótido aislado: (1) no está asociado con todo o una parte de un polinucleótido en el que el polinucleótido aislado se encuentra en la naturaleza, (2) está unido a un polinucleótido al que no está unido en la naturaleza, o (3) no se produce en la naturaleza como parte de una secuencia mayor.
Un "polipéptido aislado" es uno que: (1) está libre de al menos algunos otros polipéptidos con los que normalmente se encuentra, (2) está esencialmente libre de otros polipéptidos de la misma fuente, p. ej., de la misma especie, (3) se expresa por una célula de una especie diferente, (4) se ha separado de al menos aproximadamente 50 por ciento de polinucleótidos, lípidos, hidratos de carbono u otros materiales con los que está asociado en la naturaleza, (5) no está asociado (por interacción covalente o no covalente) con porciones de un polipéptido con el que el "polipéptido aislado" se asocia en la naturaleza, (6) está asociado operativamente (por interacción covalente o no covalente) con un polipéptido con el que no está asociado en la naturaleza, o (7) no se produce en la naturaleza. Un polipéptido aislado de este tipo puede ser codificado por ADN genómico, ADNc, ARNm u otro ARN, de origen sintético, o cualquier combinación de los mismos. Preferiblemente, el polipéptido aislado está sustancialmente libre de polipéptidos u otros contaminantes que se encuentran en su entorno natural que interferirían con su uso (terapéutico, de diagnóstico, profiláctico, de investigación o de otro tipo).
La expresión "anticuerpo humano", tal como se utiliza en esta memoria, incluye anticuerpos que tienen regiones variables y constantes que corresponden esencialmente a secuencias de inmunoglobulina de la línea germinal humana. En algunas realizaciones, los anticuerpos humanos se producen en mamíferos no humanos, incluyendo, pero no limitados a, roedores tales como ratones y ratas, y lagomorfos tales como conejos. En otras realizaciones, los anticuerpos humanos se producen en células de hibridoma. Aún en otras realizaciones, los anticuerpos humanos se producen de forma recombinante.
Anticuerpos que se producen de forma natural comprenden típicamente un tetrámero. Cada uno de tales tetrámeros se compone típicamente de dos pares idénticos de cadenas polipeptídicas, teniendo cada uno de los pares una cadena "ligera" de longitud completa (que tiene típicamente un peso molecular de aproximadamente 25 kDa) y una cadena "pesada" de longitud completa (que tiene típicamente un peso molecular de aproximadamente 50-70 kDa). Las expresiones "cadena pesada" y "cadena ligera", tal como se utilizan en esta memoria, se refieren a cualquier polipéptido de inmunoglobulina que tenga suficiente secuencia de dominio variable para conferir especificidad para un antígeno diana. La porción amino-terminal de cada una de las cadenas ligera y pesada incluye típicamente un dominio variable de aproximadamente 100 a 110 o más aminoácidos que típicamente es responsable del reconocimiento del antígeno. La porción carboxi-terminal de cada una de las cadenas define típicamente un dominio constante responsable de la función efectora. Así, en un anticuerpo que se produce de forma natural, un polipéptido de inmunoglobulina de cadena pesada de longitud completa incluye un dominio variable (Vh) y tres dominios constantes (Ch1, Ch2 y Cm), en el que el dominio Vh está en el extremo amino del polipéptido y el dominio Ch3 está en el extremo carboxilo, y un polipéptido de inmunoglobulina de cadena ligera de longitud completa incluye un dominio variable (Vl) y un dominio constante (Cl), en donde el dominio Vl está en el extremo amino del polipéptido y el dominio Cl está en el extremo carboxilo.
Las cadenas ligeras humanas se clasifican típicamente como cadenas ligeras kappa y lambda, y las cadenas pesadas humanas se clasifican típicamente como mu, delta, gamma, alfa o épsilon, y definen el isotipo del anticuerpo tal como IgM, IgD, IgG, IgA e IgE, respectivamente. IgG tiene varias subclases, incluyendo, pero no limitadas a IgG1, IgG2, IgG3 e IgG4. IgM tiene subclases, incluyendo, pero no limitadas a IgM1 e IgM2. IgA se subdivide de manera similar en subclases, incluyendo, pero no limitadas a IgA1 e IgA2. Dentro de las cadenas ligeras y pesadas de longitud completa, los dominios variables y constantes están típicamente unidos por una región "J" de aproximadamente 12 o más aminoácidos, incluyendo la cadena pesada también una región "D" de aproximadamente 10 aminoácidos más. Véase, p. ej., FUNDAMENTAL IMMUNOLOGY (Paul, W., comp., Raven Press, 2a ed., 1989). Las regiones variables de cada par de cadena ligera/pesada forman típicamente un sitio de unión a antígeno. Los dominios variables de anticuerpos que se producen de forma natural exhiben típicamente la misma estructura general de regiones marco relativamente conservadas (FR) unidas por tres regiones hipervariables, también denominadas regiones determinantes de complementariedad o CDRs. Las CDRs de las dos cadenas de cada uno de los pares están alineadas normalmente por las regiones marco, que pueden permitir la unión a un epítopo específico. Desde el extremo amino al extremo carboxilo, ambos dominios variables de cadena ligera y pesada normalmente comprenden los dominios FR1, CDR1, FR2, CDR2, FR3, CDR3 y FR4.
La expresión "Fc nativa", tal como se utiliza en esta memoria, se refiere a una molécula que comprende la secuencia de un fragmento de no unión al antígeno que resulta de la digestión de un anticuerpo o producido por otros medios, ya sea en forma monomérica o multimérica, y puede contener la región de bisagra. La fuente de inmunoglobulina original del Fc nativo es preferiblemente de origen humano y puede ser cualquiera de las inmunoglobulinas, aunque
se prefieren IgG1 e IgG2. Moléculas de Fc nativo se componen de polipéptidos monoméricos que pueden estar enlazados en formas diméricas o multiméricas mediante enlaces covalentes (es decir, enlaces disulfuro) y asociación no covalente. El número de enlaces disulfuro intermoleculares entre subunidades monoméricas de moléculas de Fc nativo oscila entre 1 y 4 dependiendo de la clase (p. ej., IgG, IgA e IgE) o subclase (p. ej., IgG1, IgG2, IgG3, IgA1 e IgGA2). Un ejemplo de un Fc nativo es un dímero unido por disulfuro resultante de la digestión con papaína de una IgG. La expresión "Fc nativo", tal como se utiliza en esta memoria, es genérica para las formas monoméricas, diméricas y multiméricas.
La expresión "variante de Fc", tal como se utiliza en esta memoria, se refiere a una molécula o secuencia que se modifica a partir de un Fc nativo, pero que comprende todavía un sitio de unión para el receptor de salvamento, FcRn (receptor Fc neonatal). Variantes Fc a modo de ejemplo, y su interacción con el receptor de salvamento, son conocidas en la técnica. Así, la expresión "variante de Fc" puede comprender una molécula o secuencia que se humaniza a partir de un Fc nativo no humano. Además de ello, un Fc nativo comprende regiones que pueden separarse porque proporcionan características estructurales o actividad biológica que no son necesarias para las proteínas de unión similares a anticuerpos de la invención. Así, la expresión "variante de Fc" comprende una molécula o secuencia que carece de uno o más sitios o residuos Fc nativos, o en el que uno o más sitios o residuos Fc ha de ser modificado, que afectan o están implicados en: (1) la formación de un enlace disulfuro, (2) la incompatibilidad con una célula huésped seleccionada, (3) la heterogeneidad N-terminal tras de la expresión en una célula huésped seleccionada, (4) glicosilación, (5) interacción con el complemento, (6) la unión a un receptor Fc distinto de un receptor de salvamento o (7) citotoxicidad celular dependiente de anticuerpos (ADCC).
La expresión "dominio Fc", tal como se utiliza en esta memoria, abarca Fc nativos y variantes de Fc y secuencias tal como se define anteriormente. Al igual que con las variantes de Fc y moléculas de Fc nativas, la expresión "dominio de Fc" incluye moléculas en forma monomérica o multimérica, ya sean digeridas a partir del anticuerpo entero o producidos por otros medios.
La expresión "proteína de unión similar a anticuerpo", tal como se utiliza en esta memoria, se refiere a una molécula que no se produce de forma natural (o recombinante) que se une específicamente a al menos un antígeno diana, y que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión de antígeno, en donde dos cadenas polipeptídicas tienen una estructura representada por la fórmula:
VL1-L1-VL2-L2-CL [I]
y dos cadenas polipéptídicas tienen una estructura representada por la fórmula:
Vh2-L3-Vh1-L4-Ch1-Fc [II]
en donde:
VL1 es un primer dominio variable de cadena ligera de inmunoglobulina;
VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
VH1 es un primer dominio variable de cadena pesada de inmunoglobulina;
VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
CL es un dominio constante de la cadena ligera de inmunoglobulina;
CH1 es el dominio constante de la cadena pesada CH1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina;
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
y en donde los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento. La expresión “proteína de unión similar a anticuerpo”, tal como se utiliza en esta memoria, se refiere también a una molécula que se produce de forma no natural (o recombinante) que se une específicamente a al menos un antígeno diana y que comprende dos cadenas polipeptídicas que forman dos sitios de unión a antígeno, en donde una primera cadena polipeptídica tiene una estructura representada por la fórmula:
VL1-L1-VL2-L2-CL [I]
y una segunda cadena polipéptídica tiene una estructura representada por la fórmula:
VH2-L3-VH1-L4-CH1 [II]
en donde:
Vli es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina;
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
y en donde los primero y segundo polipéptidos forman un par de cadena ligera-cadena pesada de entrecruzamiento. Una molécula “recombinante” es una que ha sido preparada, expresada, creada o aislada por medios recombinantes.
Una realización de la invención proporciona proteínas de unión similares a anticuerpos tal como se define en el Sumario de la Invención que tienen especificidad biológica e inmunológica para entre uno y cuatro antígenos diana. Otra realización de la invención proporciona moléculas de ácido nucleico que comprenden secuencias de nucleótidos que codifican cadenas polipeptídicas que forman estas proteínas de unión similares a anticuerpos. Otra realización de la invención proporciona vectores de expresión que comprenden moléculas de ácido nucleico, que comprenden secuencias de nucleótidos que codifican cadenas polipeptídicas que forman tales proteínas de unión similares a anticuerpos. Aún otra realización de la invención proporciona células huésped que expresan tales proteínas de unión similares a anticuerpos (es decir, que comprenden moléculas o vectores de ácidos nucleicos que codifican cadenas de polipéptidos que forman tales proteínas de unión similares a anticuerpos).
La expresión "capacidad de permuta", tal como se utiliza en esta memoria, se refiere a la capacidad de intercambio de dominios variables dentro del formato CODV y con retención de plegado y afinidad de unión final. "Capacidad de permuta completa" se refiere a la capacidad de permutar el orden de los dos dominios Vh1 y Vh2 y, por lo tanto, el orden de los dominios Vl1 y Vl2 , en un CODV-Ig (es decir, para invertir el orden) o CODV-Fab,. al tiempo que se mantiene la plena funcionalidad de la proteína de unión similar a anticuerpo, como se evidencia por la retención de la afinidad de unión. Además, hay que señalar que las designaciones Vh y Vl dentro de un CODV-Ig o CODV-Fab particular se refieren sólo a la ubicación del dominio de una cadena de proteína particular en el formato final. Por ejemplo, Vh1 y Vh2 podrían derivarse de los dominios Vl1 y Vl2 en los anticuerpos parentales y se colocan en las posiciones Vh1 y Vh2 en la proteína de unión similar a anticuerpo. Del mismo modo, Vl1 y Vl2 se podrían derivar de los dominios Vh1 y Vh2 en los anticuerpos parentales y se colocan en las posiciones Vh1 y Vh2 en la proteína de unión similar a anticuerpo. Por lo tanto, las designaciones Vh y Vl se refieren a la ubicación actual y no a la ubicación original en un anticuerpo parental. Los dominios Vh y Vl son, por lo tanto, "permutables".
Una proteína de unión similar a anticuerpo "aislada" es una que ha sido identificada y separada y/o recuperada de un componente de su entorno natural. Los componentes contaminantes de su entorno natural son materiales que interferirían con los usos diagnósticos o terapéuticos para la proteína de unión similar a anticuerpo, y pueden incluir enzimas, hormonas y otros solutos proteicos o no proteicos. En realizaciones preferidas, la proteína de unión similar a anticuerpo se purificará: (1) hasta más del 95% en peso de anticuerpo según se determina por el método de Lowry, y más preferiblemente más de 99% en peso, (2) hasta un grado suficiente para obtener al menos 15 residuos de secuencia de aminoácidos N-terminal o interna mediante el uso de un secuenciador de copa giratoria, o (3) hasta homogeneidad mediante SDS-PAGE en condiciones reductoras o no reductoras utilizando azul de Coomassie o, preferiblemente, tinción de plata. Proteínas de unión similares a anticuerpos aisladas incluyen la proteína de unión similar a anticuerpo in situ dentro de células recombinantes, ya que al menos un componente del entorno natural de la proteína de unión similar a anticuerpo no estará presente.
Las expresiones "sustancialmente puro" o "sustancialmente purificado", tal como se utiliza en esta memoria, se refieren a un compuesto o especie que es la especie predominante presente (es decir, sobre una base molar es más abundante que cualquier otra especie individual en la composición). En algunas realizaciones, una fracción sustancialmente purificada es una composición en la que la especie comprende al menos aproximadamente 50% (sobre una base molar) de todas las especies macromoleculares presentes. En otras realizaciones, una composición sustancialmente pura comprenderá más de aproximadamente 80%, 85%, 90%, 95% o 99% de todas las especies macromolares presentes en la composición. En aún otras realizaciones, la especie se purifica hasta una homogeneidad esencial (especies contaminantes no pueden detectarse en la composición mediante métodos de detección convencionales) en donde la composición consiste esencialmente en una única especie macromolecular. El término "antígeno" o la expresión "antígeno diana", tal como se utiliza en esta memoria, se refiere a una molécula o una porción de una molécula que es capaz de unirse por una proteína de unión similar a anticuerpo y, además, es capaz de ser utilizada en un animal para producir anticuerpos capaces de unirse a un epítopo de ese antígeno. Un antígeno diana puede tener uno o más epítopos. Con respecto a cada uno de los antígenos diana reconocidos por una proteína de unión similar a anticuerpo, la proteína de unión similar a anticuerpo es capaz de competir con un
anticuerpo intacto que reconoce el antígeno diana. Una proteína de unión similar a anticuerpo "bivalente", que no sea una proteína de unión similar a anticuerpo "multiespecífica" o "multifuncional", se entiende que comprende sitios de unión a antígeno que tienen especificidad antigénica idéntica.
Un anticuerpo biespecífico o bifuncional es típicamente un anticuerpo híbrido artificial que tiene dos pares de cadena pesada/cadena ligera diferentes y dos sitios de unión o epítopos diferentes. Anticuerpos biespecíficos pueden producirse mediante una diversidad de métodos incluyendo, pero no limitados a la fusión de hibridomas o enlace de fragmentos F(ab').
Un fragmento F(ab) incluye típicamente una cadena ligera y los dominios Vh y Ch1 de una cadena pesada, en donde la porción Vh-Ch1 de la cadena pesada del fragmento F(ab) no puede formar un enlace disulfuro con otro polipéptido de cadena pesada . Tal como se utiliza en esta memoria, un fragmento F(ab) también puede incluir una cadena ligera que contiene dos dominios variables separados por un enlazador de aminoácidos y una cadena pesada que contiene dos dominios variables separadas por un enlazador de aminoácido y un dominio Ch1.
Un fragmento F(ab') incluye típicamente una cadena ligera y una porción de una cadena pesada que contiene más de la región constante (entre los dominios Ch1 y Ch2), de manera que se puede formar un enlace disulfuro intercadena entre dos cadenas pesadas para formar una molécula F(ab')2.
Las frases "propiedad biológica", "característica biológica" y el término "actividad" en referencia a una proteína de unión similar a anticuerpo de la invención se utilizan de manera indistinta en esta memoria e incluyen, pero no se limitan a, afinidad por y especificidad para el epítopo, la capacidad de antagonizar la actividad de la diana antigénica (o polipéptido fijado como objetivo), la estabilidad in vivo de la proteína de unión similar a anticuerpo y las propiedades inmunogénicas de la proteína de unión similar a anticuerpo. Otras propiedades biológicas identificables o características de una proteína de unión similar a anticuerpo incluyen, por ejemplo, reactividad cruzada, (es decir, con homólogos no humanos de la diana antigénica, o con otras dianas antigénicas o tejidos, generalmente), y capacidad de preservar los altos niveles de expresión de proteínas en células de mamíferos. Las propiedades o características mencionadas anteriormente pueden observarse o medirse utilizando técnicas reconocidas en la técnica, incluyendo, pero no limitadas a ELISA, ELISA competitivo, análisis de resonancia de plasmones de superficie, ensayos de neutralización in vitro e in vivo y la inmunohistoquímica con secciones de tejido de diferentes fuentes, incluyendo seres humanos, primates o cualquier otra fuente según se necesite.
La expresión "fragmento de inmunoglobulina inmunológicamente funcional", tal como se utiliza en esta memoria, se refiere a un fragmento de polipéptido que contiene al menos las CDRs de las cadenas pesada o ligera de inmunoglobulina de las que se deriva el fragmento de polipéptido. Un fragmento de inmunoglobulina inmunológicamente funcional es capaz de unirse a un antígeno diana.
Una proteína de unión similar a anticuerpo "neutralizante", tal como se utiliza en esta memoria, se refiere a una molécula que es capaz de bloquear o reducir sustancialmente una función efectora de un antígeno diana al que se une. Tal como se utiliza en esta memoria, "reducir sustancialmente" significa al menos aproximadamente 60%, preferiblemente al menos aproximadamente 70%, más preferiblemente al menos aproximadamente 75%, incluso más preferiblemente al menos aproximadamente 80%, aún más preferiblemente al menos aproximadamente 85%, más preferiblemente al menos una reducción de aproximadamente 90% de una función efectora del antígeno diana.
El término "epítopo" incluye cualquier determinante, preferiblemente un determinante polipeptídico, capaz de unirse específicamente a una inmunoglobulina o receptor de células T. En ciertas realizaciones, los determinantes epítopos incluyen agrupaciones superficiales químicamente activas de moléculas tales como aminoácidos, cadenas laterales de azúcares, grupos fosforilo o grupos sulfonilo y, en ciertas realizaciones, pueden tener características estructurales tridimensionales específicas y/o características de carga específicas. Un epítopo es una región de un antígeno que está unida por un anticuerpo o proteína de unión similar a anticuerpo. En ciertas realizaciones, se dice que una proteína de unión similar a anticuerpo se une específicamente a un antígeno cuando reconoce preferencialmente su antígeno diana en una mezcla compleja de proteínas y/o macromoléculas. En realizaciones preferidas, se dice que una proteína de unión similar a anticuerpo se une específicamente a un antígeno cuando la constante de disociación de equilibrio es < 10-8 M, más preferiblemente cuando la constante de disociación de equilibrio es < 10-9 M, y más preferiblemente cuando la constante de disociación es < 10-10 M.
La constante de disociación (Kd) de una proteína de unión similar a anticuerpo puede determinarse, por ejemplo, mediante resonancia de plasmones de superficie. En general, el análisis de resonancia de plasmones de superficie mide en tiempo real las interacciones entre la unión del ligando (un antígeno diana en una matriz de biosensor) y analito (una proteína de unión similar a anticuerpo en disolución) mediante resonancia de plasmones de superficie (SPR) utilizando el sistema BIAcore (Pharmacia Biosensor; Piscataway, NJ). El análisis de plasmones de superficie también se puede realizar mediante la inmovilización del analito (proteína de unión similar a anticuerpo en una matriz de biosensor) y la presentación del ligando (antígeno diana). El término "Kd", tal como se utiliza en esta memoria, se refiere a la constante de disociación de la interacción entre una proteína de unión similar a anticuerpo particular y un antígeno diana.
La expresión “se une específicamente", tal como se utiliza en esta memoria, se refiere a la capacidad de una proteína similar a anticuerpo o un fragmento de unión a antígeno del mismo de unirse a un antígeno que contiene un epítopo con una Kd de al menos aproximadamente 1 x 10-6 M, 1 x 10-7 M, 1 x 10-8 M, 1 x 10-9 M, 1 x 10-10 M, 1 x 10-11 M, 1 x 10-12 M, o más, y/o para unirse a un epítopo con una afinidad que es al menos dos veces mayor que su afinidad por un antígeno no específico.
El término "enlazador", tal como se utiliza en esta memoria, se refiere a uno o más residuos aminoácidos insertados entre dominios de inmunoglobulina para proporcionar suficiente movilidad para los dominios de las cadenas ligeras y pesadas para doblar en cruz inmunoglobulinas de región variable duales. Un enlazador se inserta en la transición entre los dominios variables o entre los dominios variables y constantes, respectivamente, a nivel de secuencia. La transición entre dominios puede ser identificada, debido a que el tamaño aproximado de los dominios de inmunoglobulina se conoce bien. La ubicación exacta de una transición de dominio se puede determinar mediante la localización de tramos de péptidos que no forman elementos estructurales secundarios tales como láminas beta o hélices alfa tal como se demuestra por los datos experimentales o como puede ser asumido por técnicas de modelado o de predicción de estructura secundaria. Los enlazadores descritos en esta memoria se denominan L1, que se encuentra en la cadena ligera entre los dominios Vl1 y Vl2 N-terminales ; L2 , que también está en la cadena ligera, se encuentra entre los dominios Vl2 y Cl C-terminal. Los enlazadores de cadena pesada se conocen como L3 , que se encuentra entre los dominios Vh2 y Vh1 N-terminales; y L4, que se encuentra entre los dominios Vh1 y Ch1-Fc Los enlazadores L1, L2 , L3 y L4 son independientes, pero pueden, en algunos casos, tener la misma secuencia y/o longitud.
El término "vector", tal como se utiliza en esta memoria, se refiere a cualquier molécula (p. ej., ácido nucleico, plásmido, o virus) que se utiliza para transferir información de codificación a una célula huésped. El término "vector" incluye una molécula de ácido nucleico que es capaz de transportar otro ácido nucleico al que está unido. Un tipo de vector es un "plásmido", que se refiere a una molécula de ADN de doble cadena circular, en la que pueden insertarse segmentos adicionales de ADN. Otro tipo de vector es un vector viral, en el que segmentos de ADN adicionales se pueden insertar en el genoma viral. Ciertos vectores son capaces de replicación autónoma en una célula huésped en la que se introducen (p. ej., vectores bacterianos que tienen un origen bacteriano de replicación y vectores episomales de mamífero). Otros vectores (p. ej., vectores no episomales de mamíferos) pueden integrarse en el genoma de una célula huésped tras la introducción en la célula huésped y, con ello, se replican junto con el genoma del huésped. Además, ciertos vectores son capaces de dirigir la expresión de genes a los que están enlazados operativamente. Tales vectores se denominan en esta memoria "vectores de expresión recombinante" (o simplemente, "vectores de expresión"). En general, los vectores de expresión de utilidad en técnicas de ADN recombinante están a menudo en forma de plásmidos. Los términos "plásmido" y "vector" pueden utilizarse indistintamente en esta memoria, dado que un plásmido es la forma más comúnmente utilizada de vector. Sin embargo, la invención pretende incluir otras formas de vectores de expresión, tales como vectores virales (p. ej., retrovirus de replicación defectuosa, adenovirus y virus adeno-asociados), que sirven para funciones equivalentes.
La expresión "enlazado operativamente" se utiliza en esta memoria para referirse a una disposición de secuencias flanqueantes en la que las secuencias flanqueantes así descritas se configuran o ensamblan con el fin de realizar su función habitual. Por lo tanto, una secuencia flanqueante unida operativamente a una secuencia codificante puede ser capaz de efectuar la replicación, transcripción y/o traducción de la secuencia codificante. Por ejemplo, una secuencia codificante está unida operativamente a un promotor cuando el promotor es capaz de dirigir la transcripción de esa secuencia de codificación. Una secuencia flanqueante no necesita ser contigua a la secuencia codificante, siempre que funcione correctamente. Así, por ejemplo, secuencias intermedias, no traducidas aunque transcritas, pueden estar presentes entre una secuencia de promotor y la secuencia codificante y la secuencia promotora todavía puede considerarse "operativamente unida" a la secuencia codificante.
La frase "célula huésped recombinante" (o "célula huésped"), tal como se utiliza en esta memoria, se refiere a una célula en la que se ha introducido un vector de expresión recombinante. Una célula huésped o una célula huésped recombinante pretende referirse no sólo a la célula objeto particular, sino también a la progenie de dicha célula. Debido a que pueden producirse ciertas modificaciones en generaciones sucesivas debido a mutación o influencias ambientales, tal progenie puede, de hecho, no ser idéntica a la célula parental, pero este tipo de células todavía están incluidas dentro del alcance de la expresión "célula huésped" tal como se utiliza en esta memoria. Una amplia variedad de sistemas de expresión de célula huésped se puede utilizar para expresar las proteínas de unión similares a anticuerpo de la invención, incluyendo sistemas de expresión en bacterias, levaduras, baculovirus y mamíferos (así como los sistemas de expresión de presentación de fagos). Un ejemplo de un vector de expresión bacteriano adecuado es pUC19. Para expresar una proteína de unión similar a anticuerpo de forma recombinante, una célula huésped se transforma o transfecta con uno o más vectores de expresión recombinantes que portan fragmentos de ADN que codifican las cadenas de polipéptidos de la proteína de unión similar a anticuerpo, de manera que las cadenas polipeptídicas se expresan en la célula huésped y , preferiblemente, se secretan en el medio en el que se cultivan las células huésped, medio del cual se puede recuperar la proteína de unión similar a anticuerpo.
El término "transformación" tal como se utiliza en esta memoria, se refiere a un cambio en las características genéticas de una célula, y una célula ha sido transformada cuando ha sido modificada para contener un nuevo ADN. Por ejemplo, una célula se transforma cuando se modifica genéticamente a partir de su estado nativo. Después de la
transformación, el ADN transformante puede recombinarse con el de la célula mediante la integración física en un cromosoma de la célula, o puede ser mantenido transitoriamente como un elemento episomal sin ser replicado, o puede replicarse independientemente como un plásmido. Se considera que una célula que ha sido transformada de forma estable cuando el ADN se replica con la división de la célula. El término "transfección", tal como se utiliza en esta memoria, se refiere a la captación de ADN extraño o exógeno por parte de una célula, y una célula ha sido "transfectada" cuando el ADN exógeno ha sido introducido dentro de la membrana celular. Un cierto número de técnicas de transfección son bien conocidas en la técnica. Tales técnicas se pueden utilizar para introducir una o más moléculas de ADN exógeno en células huésped adecuadas.
La expresión "que se produce de forma natural", tal como se utiliza en esta memoria y se aplica a un objeto, se refiere al hecho de que el objeto puede encontrarse en la naturaleza y no ha sido manipulado por el hombre. Por ejemplo, un polinucleótido o polipéptido que está presente en un organismo (incluyendo virus) que puede aislarse de una fuente en la naturaleza y que no ha sido modificado intencionadamente por el hombre es que se produce de forma natural. Del mismo modo, " que no se produce de forma natural", tal como se utiliza en esta memoria, se refiere a un objeto que no se encuentra en la naturaleza o que ha sido modificado estructuralmente o sintetizado por el hombre.
Tal como se utiliza en esta memoria, los veinte aminoácidos convencionales y sus abreviaturas siguen el uso convencional. Estereoisómeros (p. ej., D-aminoácidos) de los veinte aminoácidos convencionales; aminoácidos no naturales tales como aminoácidos a,a-disustituidos, N-alquil- aminoácidos, ácido láctico y otros aminoácidos no convencionales también pueden ser componentes adecuados para las cadenas polipeptídicas de proteínas de unión similares a anticuerpo de la invención. Ejemplos de aminoácidos no convencionales incluyen: 4-hidroxiprolina, y-carboxiglutamato, e-N,N, N-trimetillisina, s-N-acetillisina, O-fosfoserina, N-acetilserina, N-formilmetionina, 3-metilhistidina, 5-hidroxilisina, c-N-metilarginina, y otros aminoácidos e iminoácidos similares (p. ej., 4-hidroxiprolina). En la notación de polipéptidos utilizada en esta memoria, la dirección de la izquierda es la dirección amino-terminal y la dirección de la derecha es la dirección carboxi-terminal, de acuerdo con el uso y la convención estándares.
Residuos que se producen de forma natural pueden dividirse en clases basadas en propiedades de cadena lateral común:
(1) hidrofóbicos: Met, Ala, Val, Leu, Ile, Phe, Trp, Tyr, Pro;
(2) hidrofílicos polares: Arg, Asn, Asp, Gln, Glu, His, Lys, Ser, Thr;
(3) alifáticos: Ala, Gly, Ile, Leu, Val, Pro;
(4) hidrofóbicos alifáticos: Ala, Ile, Leu, Val, Pro;
(5) hidrofílicos neutros: Cys, Ser, Thr, Asn, Gln;
(6) de carácter ácido: Asp, Glu;
(7) de carácter básico: His, Lys, Arg;
(8) residuos que influyen en la orientación de la cadena: Gly, Pro;
(9) aromáticos: His, Trp, Tyr, Phe; y
(10) hidrofóbicos aromáticos: Phe, Trp, Tyr.
Sustituciones de aminoácidos conservativas pueden implicar el intercambio de un miembro de una de estas clases con otro miembro de la misma clase. Sustituciones conservadoras de aminoácidos pueden abarcar residuos aminoácidos que no se producen de forma natural, que se incorporan típicamente mediante síntesis peptídica química en lugar de mediante síntesis en sistemas biológicos. Estos incluyen peptidomiméticos y otras formas revertidas o invertidas de restos de aminoácidos. Las sustituciones no conservativas pueden implicar el intercambio de un miembro de una de estas clases por un miembro de otra clase.
Un experto en la técnica será capaz de determinar variantes adecuadas de las cadenas polipeptídicas de las proteínas de unión similares a anticuerpos de la invención utilizando técnicas bien conocidas. Por ejemplo, un experto en la técnica puede identificar zonas adecuadas de una cadena polipeptídica que se pueden cambiar sin destruir la actividad, fijando como objetivo regiones que no se cree que sean importantes para la actividad. Alternativamente, un experto en la técnica puede identificar residuos y porciones de las moléculas que se conservan entre polipéptidos similares. Además, incluso zonas que pueden ser importantes para la actividad biológica o para la estructura pueden ser objeto de sustituciones conservativas de aminoácidos sin destruir la actividad biológica o sin afectar adversamente la estructura del polipéptido.
El término "paciente", tal como se utiliza en esta memoria, incluye sujetos humanos y animales.
Un "trastorno" es cualquier condición que se beneficiaría del tratamiento utilizando las proteínas de unión similares a anticuerpos de la invención. "Trastorno" y "afección" se utilizan indistintamente en esta memoria e incluyen trastornos o enfermedades crónicas y agudas, incluyendo aquellas afecciones patológicas que predisponen a un paciente al trastorno en cuestión.
Los términos "tratamiento" o "tratar", tal como se utilizan en esta memoria, se refieren tanto al tratamiento terapéutico como a medidas profilácticas o preventivas. Los que están en necesidad de tratamiento incluyen aquellos que tienen el trastorno, así como aquellos propensos a tener el trastorno o aquellos en los que el trastorno debe prevenirse.
Las expresiones "composición farmacéutica" o "composición terapéutica", tal como se utiliza en esta memoria, se refieren a un compuesto o composición capaz de inducir un efecto terapéutico deseado cuando se administra apropiadamente a un paciente.
La expresión "soporte farmacéuticamente aceptable" o "soporte fisiológicamente aceptable" tal como se utiliza en esta memoria, se refiere a uno o más materiales de formulación adecuados para llevar a cabo o mejorar la administración de una proteína de unión similar a anticuerpo.
Las expresiones "cantidad eficaz" y "cantidad terapéuticamente eficaz", cuando se utilizan en referencia a una composición farmacéutica que comprende una o más proteínas de unión a anticuerpos se refieren a una cantidad o dosis suficiente para producir un resultado terapéutico deseado. Más específicamente, una cantidad terapéuticamente eficaz es una cantidad de una proteína de unión similar a anticuerpo suficiente para inhibir, durante algún periodo de tiempo, uno o más de los procesos patológicos clínicamente definidos asociados con la afección a tratar. La cantidad eficaz puede variar dependiendo de la proteína de unión similar a anticuerpo específico que se utiliza, y también depende de una diversidad de factores y condiciones relacionadas con el paciente a tratar y la gravedad del trastorno. Por ejemplo, si la proteína de unión similar a anticuerpo se ha de administrar in vivo, factores tales como la edad, el peso y la salud del paciente, así como las curvas de dosis-respuesta y los datos de toxicidad obtenidos en el trabajo preclínico con animales estaría entre esos factores considerados. La determinación de una cantidad eficaz o cantidad terapéuticamente eficaz de una composición farmacéutica dada está dentro de la capacidad de los expertos en la técnica.
Una realización de la invención proporciona una composición farmacéutica que comprende un soporte farmacéuticamente aceptable y una cantidad terapéuticamente eficaz de una proteína de unión similar a anticuerpo tal como se define en las reivindicaciones adjuntas.
2. Proteínas de unión similares a anticuerpos
En una realización de la invención, las proteínas de unión similares a anticuerpos comprenden cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno capaces de unirse específicamente a una o más dianas antigénicas, en donde dos cadenas polipeptídicas tienen una estructura representada por la fórmula:
VL1-L1-VL2-L2-CL [I]
y dos cadenas polipéptídicas tienen una estructura representada por la fórmula:
Vh2-L3-Vh1-L4-Ch1-Fc [II]
en donde
VL1 es un primer dominio variable de cadena ligera de inmunoglobulina;
VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
VH1 es un primer dominio variable de cadena pesada de inmunoglobulina;
VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
CL es un dominio constante de la cadena ligera de inmunoglobulina;
CH1 es el dominio constante de la cadena pesada CH1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina;
L1, L2 , L3 y L4 son enlazadores de aminoácidos; en donde
la longitud de L4 es al menos dos veces la longitud de L2 ; y
la longitud de L3 es al menos dos veces la longitud de L1 ;
y los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vli y Vhi y para el emparejamiento de Vl2 y Vh2 , y en donde los polipéptidos de fórmula I y los polipéptidos de fórmula II forman una pareja de cadena ligera-cadena pesada de entrecruzamiento.
En otra realización de la invención, las proteínas de unión similares a anticuerpos comprenden dos cadenas polipeptídicas que forman dos sitios de unión a antígeno capaces de unirse específicamente a una o más dianas antigénicas, en donde una primera cadena polipeptídica tiene una estructura representada por la fórmula:
Vl1-L1-Vl2-L2-Cl [I]
y una segunda cadena polipéptídica tiene una estructura representada por la fórmula:
Vh2-Ls-Vhi-L4-Chi [II]
en donde:
Vli es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vhi es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Chi es el dominio constante de la cadena pesada Chi de inmunoglobulina;
Li , L2 , L3 y L4 son enlazadores de aminoácidos; en donde
la longitud de L4 es al menos dos veces la longitud de L2 ; y
la longitud de L3 es al menos dos veces la longitud de Li ;
y los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vli y Vhi y para el emparejamiento de Vl2 y Vh2 , y en donde los primer y segundo polipéptidos forman una pareja de cadena ligera-cadena pesada de entrecruzamiento.
Las proteínas de unión similares a anticuerpos de la invención se pueden preparar utilizando los dominios o secuencias obtenidos o derivados de cualquier anticuerpo humano o no humano, incluyendo, por ejemplo, anticuerpos humanos, murinos o humanizados.
En algunas proteínas de unión similares a anticuerpos de la invención, Li es de 1 a 3 residuos aminoácidos de longitud, L2 es de 1 a 4 residuos aminoácidos de longitud, L3 es de 2 a 15 residuos aminoácidos de longitud y L4 es de 2 a 15 residuos aminoácidos de longitud. En otras proteínas de unión similares a anticuerpos, Li es de 1 a 2 residuos aminoácidos de longitud, L2 es de 1 a 2 residuos aminoácidos de longitud, L3 es de 4 a 12 residuos aminoácidos de longitud y L4 es de 2 a 12 residuos aminoácidos de longitud. En una proteína de unión similar a anticuerpo preferida, Li es de 1 residuo aminoácido de longitud, L2 es de 2 residuos aminoácidos de longitud, L3 es de 7 residuos aminoácidos de longitud y L4 es de 5 residuos aminoácidos de longitud.
En algunas proteínas de unión similares a anticuerpos de la invención, Li puede ser igual a cero. Sin embargo, en proteínas de unión similares a anticuerpos, en donde Li es igual a cero, el enlazador de transición correspondiente entre la región variable y la región constante o entre los dominios variables duales en la otra cadena pueden no ser cero. En algunas realizaciones, Li es igual a cero y L3 es 2 o más residuos aminoácidos.
En algunas proteínas de unión similares a anticuerpos de la invención, al menos uno de los enlazadores seleccionados del grupo que consiste en Li , L2 , L3 y L4 contienen al menos un residuo cisteína.
Ejemplos de enlazadores adecuados incluyen un solo residuo glicina (Gly); un péptido diglicina (Gly-Gly); un tripéptido (Gly-Gly-Gly); un péptido con cuatro residuos glicina (Gly-Gly-Gly-Gly; SEQ ID NO: 25); un péptido con cinco residuos glicina (Gly-Gly-Gly-Gly-Gly; SEQ ID NO: 26); un péptido con seis residuos glicina (Gly-Gly-Gly-Gly-Gly-Gly; SEQ ID NO: 27); un péptido con siete residuos glicina (G ly-Gly-G ly-G ly-Gly-G ly-G ly; SeQ iD nO: 28); un péptido con ocho residuos glicina (G ly-G ly-Gly-G ly-G ly-Gly-G ly-G ly; SEQ ID NO: 29). Se pueden utilizar otras combinaciones de residuos aminoácidos tal como el péptido Gly-Gly-Gly-Gly-Ser (SEQ ID NO: 30) y el péptido Gly-Gly-Gly-Gly-Ser-Gly-Gly-Gly-Gly- Ser (SEQ ID NO: 31). Otros enlazadores adecuados incluyen un solo residuo Ser y Val; el dipéptido Arg-Thr, Gln-Pro, Ser-Ser, Thr-Lys y Ser-Leu; Thr-Lys-Gly-Pro-Ser (SEQ ID NO: 52), Thr-Val-Ala-Ala-Pro (SEQ ID NO: 53), Gln-Pro-Lys-Ala-Ala (SEQ ID NO: 54), Gln-Arg-Ile-Glu-Gly (SEQ ID NO: 55); Ala-Ser-Thr-Lys-Gly-Pro-Ser (SEQ ID NO: 48), Arg-Thr-Val-Ala-Ala-Pro-Ser (SEQ ID NO: 49), Gly-Gln-Pro-Lys- Ala-Ala-Pro (SEQ iD NO: 50) y His-Ile-Asp-Ser-Pro-Asn-Lys (SEQ ID NO: 51). Los ejemplos enumerados anteriormente no están destinados a limitar el alcance de la invención de modo alguno, y enlazadores que comprenden los aminoácidos
seleccionados al azar, seleccionados de entre el grupo que consiste en valina, leucina, isoleucina, serina, treonina, lisina, arginina, histidina, aspartato, glutamato, asparagina, glutamina, glicina y prolina han demostrado ser adecuados en las proteínas de unión similares a anticuerpos de la invención (véase el Ejemplo 12).
La identidad y la secuencia de residuos aminoácidos en el enlazador pueden variar en función del tipo de elemento estructural secundario necesario para alcanzar en el enlazador. Por ejemplo, glicina, serina y alanina son los mejores para enlazadores que tienen la máxima flexibilidad. Una cierta combinación de glicina, prolina, treonina y serina es útil si es necesario un enlazador más rígido y extendido. Cualquier residuo aminoácido puede ser considerado como un enlazador en combinación con otros residuos aminoácidos para la construcción de enlazadores peptídicos más grandes según sea necesario dependiendo de las propiedades deseadas.
En algunas proteínas de unión similares a anticuerpos de la invención, Vl1 comprende la secuencia de aminoácidos de SEQ ID NO: 1; Vl2 comprende la secuencia de aminoácidos de SEQ ID NO: 3; Vh1 comprende la secuencia de aminoácidos de SEQ ID NO: 2; y Vh2 comprende la secuencia de aminoácidos de SEQ ID NO: 4.
En algunas realizaciones de la invención, la proteína de unión similar a anticuerpo es capaz de unirse específicamente a una o más dianas antigénicas. En realizaciones preferidas de la invención, la proteína de unión similar a anticuerpo es capaz de unirse específicamente a al menos una diana antigénica seleccionada del grupo que consiste en B7.1, B7.2, BAFF, BlyS, C3, C5, CCL11 (eotaxina), CCL15 (MIP-1 d), CCL17 (TARC), CCL19 (MIP-3b), CCL2 (MCP-1), CCL20 (MIP-3a), CCL21 (MIP-2), SLC, CCL24 (MPIF-2/eotaxina-2), CCL25 (TECK), CCL26 (eotaxina-3), CCL3 (MIP-1a), CCL4 (MIP-lb), CCL5 (RANTES), CCL7 (MCP-3), CCL8 (mcp-2), CD3, CD19, CD20, CD24, CD40, CD40L, CD80, CD86, CDH1 (E-cadherina), quitinasa, CSF1 (M-CSF), CSF2 (GM-CSF), CSF3 (GCSF), CTLA4, CX3CL1 (SCYD1), CXCL12 (SDF1), CXCL13, EGFR, FCER1A, FCER2, HER2, IGF1R, IL-1, IL-12, IL13, IL415, IL17, IL18, IL1A, IL1B, IL1F10, IL1 p, IL2, IL4, IL6, IL7, IL8, IL9, IL12/23, IL22, IL23, IL25, IL27, IL35, ITGB4 (b 4 integrina), LEP (leptina), MHC de clase II, TLR2, TLR4, TLR5, TNF, TNF-a, TNFSF4 (ligando OX40), TNFSF5 (ligando CD40), receptores de tipo Toll, TREM1, TSLP, TWEAK, XCR1 (GPR5/CCXCR1), DNGR-1 (CLEC91) y HMGB1. En otras realizaciones de la invención, la proteína de unión similar a anticuerpo es capaz de inhibir la función de una o más de las dianas antigénicas.
En algunas realizaciones de la invención, la proteína de unión similar a anticuerpo biespecífica es capaz de unir dos dianas o epítopos de antígenos diferentes. En una realización preferida de la invención, la proteína de unión similar a anticuerpo es biespecífica y cada par de cadena pesada-cadena ligera es capaz de unir dos dianas o epítopos antigénicos diferentes. En una realización más preferida, la proteína de unión similar a anticuerpo es capaz de unir dos dianas antigénicas diferentes que se seleccionan del grupo que consiste en IL4 e IL13, IGF1R y HER2, IGF1R y EGFR, EGFR y HER2, BK e IL13, PDL-1 y CTLA-4, CTLA4 y MHC clase II, IL-12 e IL-18, IL-1 a e IL-1 p, TNF e IL12/23, TNF e IL-12p40, TNFa e IL-1 p, TNFa e IL- 23, e IL17 e IL23. En una realización incluso más preferida, la proteína de unión a anticuerpo es capaz de unir las dianas antigénicas IL-4 e IL13.
En algunas realizaciones de la invención, la proteína de unión similar a anticuerpo se une específicamente a IL-4 con una tasa de enlace de 2.97 E 07 y una tasa de desenlace de 3,30 E-04, y se une específicamente a IL-13 con una tasa de enlace de 1,39 E 06 y una tasa de desenlace de 1,63 E-04. En otras realizaciones de la invención, la proteína de unión a anticuerpo se une específicamente a IL-4 con una tasa de enlace de 3,16 E 07 y una tasa de desenlace de 2,89 E-04 y se une específicamente a I L-13 con una tasa de enlace de 1,20 E 06 y una tasa de desenlace de 1,12 E-04.
En una realización de la invención, una proteína de unión similar a anticuerpo, que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, se prepara
(a) identificando un primer dominio variable del anticuerpo que se une a un primer antígeno diana y un segundo dominio variable del anticuerpo que se une a un segundo antígeno diana, conteniendo cada uno un Vl y un Vh;
(b) asignando la cadena ligera en forma de una cadena de molde;
(c) asignando el Vl del primer dominio variable del anticuerpo o el segundo dominio variable del anticuerpo como Vl1 ;
(d) asignando un Vl2, un Vh1 y un Vh2 de acuerdo con las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1-Fc [II]
(e) determinando longitudes máxima y mínima para L1, L2 , L3 y L4 ;
(f) generando las estructuras de polipéptidos de fórmulas I y II;
(g) seleccionando estructuras de polipéptidos de fórmulas I y II que se unen al primer antígeno diana y al segundo antígeno diana cuando se combinan para formar la proteína de unión similar a anticuerpo;
en donde:
Vli es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman una pareja de cadena ligera-cadena pesada de entrecruzamiento.
En otra realización de la invención, una proteína de unión similar a anticuerpo, que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, se prepara
(a) identificando un primer dominio variable del anticuerpo que se une a un primer antígeno diana y un segundo dominio variable del anticuerpo que se une a un segundo antígeno diana, conteniendo cada uno un Vl y un Vh;
(b) asignando la cadena ligera en forma de una cadena de molde;
(c) asignando el Vl del primer dominio variable del anticuerpo o el segundo dominio variable del anticuerpo como Vl1 ;
(d) asignando un Vl2, un Vh1 y un Vh2 de acuerdo con las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1 [II]
(e) determinando longitudes máxima y mínima para L1, L2 , L3 y L4 ;
(f) generando las estructuras de polipéptidos de fórmulas I y II;
(g) seleccionando estructuras de polipéptidos de fórmulas I y II que se unen al primer antígeno diana y al segundo antígeno diana cuando se combinan para formar la proteína de unión similar a anticuerpo; en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
y en donde los polipéptidos de fórmula I y los polipéptidos de fórmula II forman una pareja de cadena ligera-cadena pesada de entrecruzamiento.
En otras realizaciones de la invención, se prepara una proteína de unión similar a anticuerpo en la que el primer dominio variable de anticuerpo y el segundo dominio variable de anticuerpo son idénticos.
Una realización de la invención proporciona un método para producir una proteína de unión similar a anticuerpo, que comprende expresar en una célula una o más moléculas de ácido nucleico que codifican polipéptidos que tienen estructuras representadas por las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1-Fc [II]
en donde:
VL1 es un primer dominio variable de cadena ligera de inmunoglobulina;
VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
VH1 es un primer dominio variable de cadena pesada de inmunoglobulina;
VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
CL es un dominio constante de la cadena ligera de inmunoglobulina;
CH1 es el dominio constante de la cadena pesada CH1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2, y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman una pareja de cadena ligera-cadena pesada de entrecruzamiento.
Otra realización de la invención proporciona un método para producir una proteína de unión similar a anticuerpo, que comprende expresar en una célula una o más moléculas de ácido nucleico que codifican polipéptidos que tienen estructuras representadas por las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1 [II]
en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
CL es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2, y el polipéptido de fórmula I y el polipéptido de fórmula II forman una pareja de cadena ligera-cadena pesada de entrecruzamiento.
3. Usos de las proteínas de unión similares a anticuerpos
Las proteínas de unión similares a anticuerpos de la invención se pueden emplear en cualquier procedimiento de ensayo conocido tales como ensayos de unión competitiva, ensayos de sándwich directos e indirectos, y ensayos de inmunoprecipitación para la detección y cuantificación de uno o más antígenos diana. Las proteínas de unión similares a anticuerpos se unirán al uno o más antígenos diana con una afinidad que es apropiada para emplear el método de ensayo.
Para aplicaciones de diagnóstico, en ciertas realizaciones, las proteínas de unión similares a anticuerpos se pueden marcar con un resto detectable. El resto detectable puede ser uno cualquiera que sea capaz de producir, directa o indirectamente, una señal detectable. Por ejemplo, el resto detectable puede ser un radioisótopo tal como 3H, 14C, 32P, 35S, 125I, 99Tc, 111In, o 67Ga; un compuesto fluorescente o quimioluminiscente tal como isotiocianato de fluoresceína, rodamina o luciferina; o una enzima tal como fosfatasa alcalina, p-galactosidasa o peroxidasa de rábano picante.
Las proteínas de unión similares a anticuerpos de la invención también son útiles para la formación in vivo de imágenes. Una proteína de unión similar a anticuerpo marcada con un resto detectable se puede administrar a un animal, preferiblemente en el torrente sanguíneo, y se ensaya la presencia y localización del anticuerpo marcado en el huésped. La proteína de unión similar a anticuerpo puede marcarse con cualquier resto que sea detectable en un animal, ya sea por resonancia magnética nuclear, radiología u otro medio de detección conocido en la técnica. La invención también se refiere a un kit que comprende una proteína de unión similar a anticuerpo de la invención y otros reactivos útiles para detectar niveles de antígeno diana en muestras biológicas. Estos reactivos pueden incluir un marcador detectable, suero de bloqueo, muestras de control positivas y negativas y reactivos de detección.
4. Composiciones Terapéuticas de Proteínas de Unión Similares a Anticuerpos y administración de las mismas
Composiciones terapéuticas o farmacéuticas que comprenden las proteínas de unión similares a anticuerpos de la invención están dentro del alcance de la invención. Tales composiciones terapéuticas o farmacéuticas pueden comprender una cantidad terapéuticamente eficaz de una proteína de unión similar a anticuerpo, o conjugado de proteína-fármaco de unión similar a anticuerpo, en mezcla con un agente de formulación farmacéutica o fisiológicamente aceptable seleccionado para la idoneidad con el modo de administración.
Materiales de formulación aceptables son preferiblemente no tóxicos para los receptores a las dosis y concentraciones empleadas.
La composición farmacéutica puede contener materiales de formulación para modificar, mantener o preservar, por ejemplo, el pH, la osmolaridad, viscosidad, claridad, el color, la isotonicidad, el olor, la esterilidad, estabilidad, velocidad de disolución o liberación, la adsorción o la penetración de la composición. Materiales de formulación adecuados incluyen, pero no se limitan a aminoácidos (tales como glicina, glutamina, asparagina, arginina o lisina), antimicrobianos, antioxidantes (tales como ácido ascórbico, sulfito sódico o hidrógeno-sulfito de sodio), tampones (tales como borato, bicarbonato, Tris-HCl, citratos, fosfatos u otros ácidos orgánicos), agentes conferidores de consistencia (tales como manitol o glicina), agentes quelantes (tales como ácido etilendiaminotetraacético (EDTA)), agentes formadores de complejos (tales como cafeína, polivinilpirrolidona, beta-ciclodextrina o hidroxipropil-betaciclodextrina), cargas, monosacáridos, disacáridos y otros hidratos de carbono (tales como glucosa, manosa, o dextrinas), proteínas (tales como albúmina de suero, gelatina o inmunoglobulinas), colorantes, aromatizantes y agentes diluyentes, agentes emulsionantes, polímeros hidrofílicos (tales como polivinilpirrolidona), polipéptidos de bajo peso molecular, iones conjugados formadores de sales (tales como sodio), conservantes (tales como cloruro de benzalconio, ácido benzoico, ácido salicílico, timerosal, alcohol fenetílico, metilparabeno, propilparabeno, clorhexidina, ácido sórbico o peróxido de hidrógeno), disolventes (tales como glicerol, propilenglicol o polietilenglicol), azúcar-alcoholes (tales como manitol o sorbitol), agentes de suspensión, tensioactivos o agentes humectantes (tales como pluronics; PEG; ésteres de sorbitán; polisorbatos tales como polisorbato 20 o polisorbato 80; tritón; trometamina; lecitina; colesterol o tiloxapal), agentes mejoradores de la estabilidad (tales como sacarosa o sorbitol), agentes potenciadores de la tonicidad (tales como haluros de metales alcalinos - preferiblemente cloruro de sodio o potasio - o manitol sorbitol), vehículos de administración, diluyentes, excipientes y/o adyuvantes farmacéuticos (véase, p. ej., REMINGTON'S PHARMACEUTICAL SCIENCES (18a ed., A.R. Gennaro, comp., Mack Publishing Company 1990), y ediciones posteriores del mismo).
La composición farmacéutica óptima será determinada por un experto en la técnica dependiendo, por ejemplo, de la ruta de administración pretendida, el formato de suministro y la dosis deseada. Tales composiciones pueden influir en el estado físico, la estabilidad, velocidad de liberación in vivo y la tasa de aclaramiento in vivo de la proteína de unión similar a anticuerpo.
El vehículo o soporte primario en una composición farmacéutica puede ser acuoso o no acuoso por naturaleza. Por ejemplo, un vehículo o soporte adecuado para inyección puede ser agua, solución salina fisiológica o líquido cefalorraquídeo artificial, posiblemente complementado con otros materiales comunes en composiciones para la administración parenteral. Solución salina tamponada neutra o solución salina mezclada con albúmina de suero son vehículos a modo de ejemplo adicionales. Otras composiciones farmacéuticas a modo de ejemplo comprenden
tampón Tris de aproximadamente pH 7,0-8,5, o tampón acetato de aproximadamente pH 4,0-5,5, que puede incluir además sorbitol o un sustituto adecuado. En una realización de la invención, las composiciones de proteínas de unión similares a anticuerpos se pueden preparar para el almacenamiento mezclando la composición seleccionada que tiene el grado deseado de pureza con agentes de formulación opcionales en forma de una torta liofilizada o una disolución acuosa. Además, la proteína de unión similar a anticuerpo puede formularse como un liofilizado utilizando excipientes apropiados tales como sacarosa.
Las composiciones farmacéuticas de la invención se pueden seleccionar para la administración parenteral. Alternativamente, las composiciones pueden seleccionarse para inhalación o para el suministro a través del tracto digestivo tal como por vía oral. La preparación de tales composiciones farmacéuticamente aceptables está dentro de la experiencia de la técnica.
Los componentes de la formulación están presentes en concentraciones que son aceptables para el sitio de administración. Por ejemplo, se utilizan tampones para mantener la composición a pH fisiológico o a un pH ligeramente inferior, típicamente dentro de un intervalo de pH de aproximadamente 5 a aproximadamente 8.
Cuando se contempla la administración parenteral, las composiciones terapéuticas para uso en esta invención pueden estar en forma de una disolución apirógena, parenteralmente aceptable, acuosa que comprende la proteína de unión similar a anticuerpo deseada en un vehículo farmacéuticamente aceptable. Un vehículo particularmente adecuado para inyección parenteral es agua destilada estéril en la que una proteína de unión a anticuerpo se formula como una disolución estéril, isotónica, apropiadamente preservada. Aún otra preparación puede implicar la formulación de la molécula deseada con un agente tal como microesferas inyectables, partículas bioerosionables, compuestos poliméricos (tales como ácido poliláctico o ácido poliglicólico), perlas o liposomas, que proporciona la liberación controlada o sostenida del producto que puede ser suministrado a través de una inyección de depósito. También se puede utilizar ácido hialurónico, y esto puede tener el efecto de fomentar la duración sostenida en la circulación. Otros medios adecuados para la introducción de la molécula deseada incluyen dispositivos de administración de fármacos implantables.
En una realización, una composición farmacéutica se puede formular para inhalación. Por ejemplo, una proteína de unión similar a anticuerpo se puede formular como un polvo seco para inhalación. Disoluciones de inhalación de proteína de unión similares a anticuerpos también se pueden formular con un propulsor para la administración en aerosol. Aún en otra realización, las disoluciones se pueden nebulizar.
También se contempla que ciertas formulaciones se puedan administrar por vía oral. En una realización de la invención, las proteínas de unión similares a anticuerpos que se administran de esta manera se pueden formular con o sin los soportes habitualmente utilizados en la composición de formas de dosificación sólidas tales como comprimidos y cápsulas. Por ejemplo, una cápsula puede diseñarse para liberar la porción activa de la formulación en el punto en el tracto gastrointestinal cuando la biodisponibilidad es maximizada y la degradación pre-sistémica se minimiza. Pueden incluirse agentes adicionales para facilitar la absorción de la proteína de unión similar a anticuerpo. Pueden emplearse también diluyentes, aromatizantes, ceras de bajo punto de fusión, aceites vegetales, lubricantes, agentes de suspensión, agentes disgregantes de comprimidos y aglutinantes.
Otra composición farmacéutica puede implicar una cantidad eficaz de proteínas de unión similares a anticuerpo en una mezcla con excipientes no tóxicos que son adecuados para la fabricación de comprimidos. Disolviendo los comprimidos en agua estéril, u otro vehículo apropiado, las disoluciones se pueden preparar en forma de dosis unitaria. Excipientes adecuados incluyen, pero no se limitan a diluyentes inertes tales como carbonato de calcio, carbonato o bicarbonato de sodio, lactosa o fosfato de calcio; o agentes de unión tales como almidón, gelatina o acacia; o agentes tales como estearato de magnesio, ácido esteárico o talco lubricante.
Composiciones farmacéuticas adicionales de la invención resultarán evidentes para los expertos en la técnica, incluyendo formulaciones que implican proteínas de unión similares a anticuerpos en formulaciones de suministro sostenida o controlada. Las técnicas para formular una diversidad de otros medios de suministro sostenido o controlado tales como soportes de liposomas, micropartículas bio-erosionables o perlas porosas e inyecciones de depósito, también son conocidas por los expertos en la técnica. Ejemplos adicionales de preparaciones de liberación sostenida incluyen matrices poliméricas semipermeables en forma de artículos conformados, p. ej., películas o microcápsulas. Matrices de liberación sostenida pueden incluir poliésteres, hidrogeles, polilactidas, copolímeros de ácido L-glutámico y gamma etil-L-glutamato, poli(2-hidroxietilmetacrilato), etileno-acetato de vinilo o ácido poli-D(-)-3-hidroxibutírico. Las composiciones de liberación sostenida también pueden incluir liposomas, que se pueden preparar por cualquiera de varios métodos conocidos en la técnica.
Las composiciones farmacéuticas de la invención a utilizar para la administración in vivo típicamente deben ser estériles. Esto se puede lograr mediante filtración a través de membranas de filtración estériles. En los casos en los que la composición se liofiliza, la esterilización utilizando este método puede llevarse a cabo ya sea antes de, o después de la liofilización y reconstitución. La composición para administración parenteral se puede almacenar en forma liofilizada o en una disolución. Además, las composiciones parenterales generalmente se colocan en un recipiente que tiene una lumbrera de acceso estéril, por ejemplo, una bolsa o vial de disolución intravenosa que tiene un tapón perforable por una aguja de inyección hipodérmica.
Una vez que se ha formulado la composición farmacéutica, se puede almacenar en viales estériles en forma de una disolución, suspensión, gel, emulsión, sólido, o como un polvo deshidratado o liofilizado. Tales formulaciones se pueden almacenar ya sea en una forma lista para usar o en una forma (p. ej., liofilizada) que requiere la reconstitución antes de la administración.
La invención también abarca kits para producir una unidad de administración de dosis única. Cada uno de los kits puede contener tanto un primer recipiente que tiene una proteína seca como un segundo recipiente que tiene una formulación acuosa. También se incluyen dentro del alcance de esta invención kits que contienen jeringas precargadas de una y múltiples cámaras (p. ej., jeringas de líquido y liso-jeringas).
La cantidad eficaz de una composición farmacéutica de proteína de unión similar a anticuerpo a emplearse terapéuticamente dependerá, por ejemplo, del contexto y los objetivos terapéuticos. Un experto en la técnica apreciará que los niveles de dosificación apropiados para el tratamiento variarán, por lo tanto, dependiendo, en parte, de la molécula suministrada, de la indicación para la que se utiliza la proteína de unión similar a anticuerpo, la vía de administración y el tamaño (peso corporal, superficie corporal o tamaño del órgano) y condición (edad y salud general) del paciente. De acuerdo con ello, el médico puede titular la dosificación y modificar la vía de administración para obtener el efecto terapéutico óptimo. Una dosis típica puede oscilar entre aproximadamente 0,1 pg/kg y hasta aproximadamente 100 mg/kg o más, dependiendo de los factores mencionados anteriormente. En otras realizaciones, la dosificación puede variar desde 0,1 pg/kg hasta aproximadamente 100 mg/kg; o 1 pg/kg hasta aproximadamente 100 mg/kg; o 5 pg/kg, 10 pg/kg, 15 pg/kg, 20 pg/kg, 25 pg/kg, 30 pg/kg, 35 pg/kg, 40 pg/kg, 45 pg/kg, 50 pg/kg, 55 pg/kg, 60 pg/kg, 65 pg/kg, 70 pg/kg, 75 pg/kg hasta aproximadamente 100 mg/kg.
La frecuencia de dosificación dependerá de los parámetros farmacocinéticos de la proteína de unión similar a anticuerpo en la formulación que se esté utilizando. Típicamente, un médico administrará la composición hasta que se alcance una dosis que consiga el efecto deseado. Por lo tanto, la composición puede administrarse como una dosis única, como dos o más dosis (que pueden o no contener la misma cantidad de la molécula deseada) a lo largo del tiempo, o como una infusión continua a través de un dispositivo de implantación o catéter. El refinamiento adicional de la dosificación apropiada se realiza rutinariamente por los expertos ordinarios en la técnica y está dentro del ámbito de las tareas realizadas rutinariamente por ellos. Las dosificaciones apropiadas pueden determinarse a través del uso de datos de dosis-respuesta apropiados.
La vía de administración de la composición farmacéutica está de acuerdo con métodos conocidos, p. ej., por vía oral; a través de inyección por vía intravenosa, intraperitoneal, intracerebral (intraparenquimatosa), intracerebroventricular, intramuscular, intraocular, intraarterial, intraportal o intralesional; por sistemas de liberación sostenida; o mediante dispositivos de implantación. En los casos en los que se desee, las composiciones se pueden administrar por inyección de bolo o continuamente mediante infusión, o mediante un dispositivo de implantación. La composición también se puede administrar localmente a través de implantación de una membrana, esponja, u otro material apropiado sobre el que la molécula deseada se ha absorbido o encapsulado. En los casos en los que se utilice un dispositivo de implantación, el dispositivo puede ser implantado en cualquier tejido u órgano adecuado, y el suministro de la molécula deseada puede ser mediante difusión, bolo de liberación en el tiempo o una administración continua.
5. Ejemplos
Los Ejemplos se recogen únicamente con fines explicativos, y no deben interpretarse como limitantes del alcance de la invención de modo alguno.
Ejemplo 1. Diseño y Modificación por Ingeniería de Proteínas de Unión similares a Anticuerpo de la Región Variable Dual de Entrecruzamiento Biespecíficos
La región variable dual de entrecruzamiento en un formato Fv fue descrita en la Patente de EE.UU. N° 5,989,830 y fue aludida como una configuración de doble cabeza de entrecruzamiento (CODH). El modelado molecular predijo que los resultados del diseño de doble cabeza de entrecruzamiento (CODH) en un complejo con los dos sitios de unión que miran en direcciones opuestas, sin las restricciones sugeridas para la configuración de Fv Dual. El formato CODH Fv se examinó para determinar si se podría convertir en moléculas similares a anticuerpos completas por adición de un dominio Cl en la cadena ligera y una región Fc en la cadena pesada. Una conversión similar fue un éxito para los correspondientes dominios variables duales (DVD-Ig) y TBTI tal como se describe en la Patente de EE.UU. N° 7.612.181 y la Publicación Internacional N° WO 2009/052081. La disposición de las regiones variables en el formato CODH se muestra en las estructuras que figuran a continuación, que indican la orientación de amino a carboxilo de las cadenas peptídicas:
(a) cadena ligera: NH2-VL1-Enlazador-VL2-COOH
(b) cadena pesada: NH2-VH2-Enlazador-Vm-COOH
La disposición amino a carboxilo-terminal de las regiones variables en (a) y (b) anteriores se pueden distinguir de la disposición en la configuración de Fv-Dual mostrada en (c) y (d) que figuran a continuación:
(c) cadena ligera: NH2-Vu-Enlazador-VL2-COOH
(d) cadena pesada: NH2-Vm-Enlazador-VH2-COOH
La principal diferencia a destacar es la colocación distinta de las correspondientes regiones variables de cadena ligera y de cadena pesada (Vh1/Vl1 y VH2/VL2) con respecto entre sí en las dos configuraciones de la región variable duales. Los correspondientes dominios Vl1 y Vh1 estaban ambos en el extremo N de las cadenas ligeras y pesadas en la configuración de la región variable dual. En contraste, en la configuración de entrecruzamiento, la mitad de un par de una región variable de anticuerpo se separó espacialmente dentro de la cadena de proteína en la configuración de entrecruzamiento. En la configuración de entrecruzamiento, el dominio Vl1 sería en el extremo N-terminal de la cadena ligera de la proteína, pero el emparejamiento del dominio Vh1 está en el extremo C de la cadena pesada de configuración de entrecruzamiento. La relación espacial entre Vl1 y Vh1 encontrada en la configuración de la región variable dual es la disposición que se encuentra en los anticuerpos naturales.
Una desventaja potencial de la configuración de Fv dual es que el enlazador Ll que separa las dos regiones variables sobresale en el sitio de unión al antígeno del dominio Fv2 (véase la Figura 1). Esta protuberancia puede interferir con la unión del antígeno y resultar en una accesibilidad perturbada del Antígeno 2 a Fv2. Esta accesibilidad perturbada o interferencia puede impedir la unión a antígenos. Además, esta interferencia podría ser más pronunciada cuando el tamaño del antígeno 2 es mayor. De hecho, se ha documentado en la Patente de EE.UU. N° 7.612.181 que la afinidad de unión y la capacidad de neutralización de una molécula de DVD-Ig depende de qué especificidad para antígeno esté presente en el extremo N o el extremo C. Véase la Patente de EE.UU.N2 7.612.181, Ejemplo 2.
Por lo tanto, para crear proteínas de unión similares a anticuerpos más estables que no estén sujetas a la pérdida de afinidad de antígeno en comparación con el anticuerpo parental, se diseñaron y construyeron moléculas de la región variable dual de entrecruzamiento que tienen un dominio Cl en la cadena ligera y una región Fc en la cadena pesada. Los polipéptidos que forman estas proteínas similares a anticuerpos tienen las estructuras mostradas más adelante, en que se indica la orientación amino a carboxilo terminal de las cadenas polipeptídicas:
(e) cadena ligera: NH2-VL1-Enlazador-VL2-CL-COOH
(f) cadena pesada: NH2-VH2-Enlazador-Vm-Cm-Fc-COOH
Para evaluar si este diseño de proteína similar a anticuerpo biespecífica podría unirse a dos antígenos diferentes, se utilizaron dos regiones variables previamente generadas y humanizadas de anticuerpos específicos para IL-4 (anti-IL4 parental humanizado) e IL13 (anti-IL13 parental humanizado) para construir moléculas similares a anticuerpos biespecíficas mostradas en la Tabla 1. La secuenciación de los anticuerpos de ratón y el proceso de humanización se han descrito en la Publicación Internacional N° WO 2009/052081 (TBTI). En síntesis, las secuencias de aminoácidos de las cadenas pesadas y ligeras variables del clon B-B13 de anti-IL13 murina y el clon 8D4-8 de anti-IL4 murina se determinaron mediante secuenciación de aminoácidos. Las secuencias murinas fueron humanizadas y luego se volvieron a traducir en secuencias de nucleótidos tal como se describe en el Ejemplo 5 de la Publicación Internacional N° WO 2009/052081. Las secuencias Vh y Vl anti-IL4 parentales humanizadas y Vh y Vl anti-IL13 parentales humanizadas se combinaron y se dispusieron tal como se muestra en la Tabla 1. Los códigos abreviados en la columna uno de la Tabla 1 fueron creados para simplificar la discusión de estas proteínas de unión similares a anticuerpos. Las proteínas de unión similares a anticuerpos difieren en el tamaño del enlazador insertado entre las dos regiones variables tal como se muestra en la Tabla 1. Las moléculas de ADN que codifican los polipéptidos mostrados en la Tabla 1 fueron generadas a partir de los anticuerpos anti-IL-4 y anti-IL13 parentales retrotraducidos. Los dominios Ch1, Cl y Fc se obtuvieron de IGHG1 (GenBank N° de Acceso 569F4) e IGKC (GenBank N° de Acceso Q502W4).
Tabla 1. Inmunoglobulinas de Doble Cabeza de Entrecruzamiento


Las combinaciones de proteínas mostradas en la Tabla 2 se expresaron mediante transfección transitoria y se purificaron por cromatografía de Proteína A. En cada caso, la cromatografía de exclusión por tamaño reveló menos de 12% de agregación, teniendo la mayoría menos de 7% de agregación; pero se encontró que ninguna de las inmunoglobulinas de doble cabeza de entrecruzamiento exhibía capacidad alguna de unirse a IL-4 o IL-13. Sin embargo, no se pudo detectar ninguna unión similar a anticuerpo, y las razones de esta falta de actividad no se pudo establecer. Se predijo anteriormente que esta disposición podría mostrar una estabilidad superior a lo largo del los anticuerpos de dominio de la región variable dual descritos en la Patente de EE.UU. N° 7.612.181 y la Publicación Internacional N2 WO 2009/052081.
Tabla 2. Unión de CODH-Ig a IL4 e IL13


* ND significa ninguna detectada
Ejemplo 2. Diseño de Proteínas CODV-Ig mediante Modelado Molecular
Para obtener proteínas similares a anticuerpos completamente funcionales utilizando la configuración de doble cabeza de entrecruzamiento que son modificables a la incorporación de los dominios Fc y Cl1, se desarrolló un protocolo de modelado molecular para la inclusión y la evaluación de diferentes enlazadores entre los dominios constante y variable y entre los dominios variables de las cadenas tanto pesadas como ligeras. La cuestión era si la adición de enlazadores únicos entre cada interfaz de dominio constante/variable y entre las dos interfaces de dominio variable/variable en las cadenas tanto pesadas como ligeras permitiría que se produjera un plegamiento adecuado de la proteína y produjera moléculas similares a anticuerpos funcionales en la configuración de la región variable dual de entrecruzamiento (véase la Figura 2). En otras palabras, se evaluaron un total de cuatro enlazadores independientes y únicos (véase la Figura 2). Este protocolo de modelado molecular se basó en el acoplamiento proteína-proteína de modelos de homología y modelos experimentales de las regiones Fvil4 y Fvil13, respectivamente, en combinación con enlazadores apropiados entre las regiones Fvil4 y Fvil13 y entre las regiones Fv y constante o Fc.
A los enlazadores independientes se les asignaron nombres únicos como sigue: L1 se refiere al enlazador entre Vl N-terminal y Vl C-terminal en la cadena ligera; L2 se refiere al enlazador entre Vl C-terminal y Cl en la cadena ligera; L3 se refiere al enlazador entre Vh N-terminal y el Vh C-terminal en la cadena pesada; L4 se refiere al enlazador entre el Vh C-terminal y Ch1 (y Fc) en la cadena pesada. Cabe señalar que las designaciones Vh y Vl se refieren sólo a la ubicación del dominio en una cadena de proteína particular en el formato final. Por ejemplo, Vh1 y Vh2 podrían derivarse de dominios Vl1 y Vl2 en los anticuerpos parentales y se colocan en las posiciones Vh1 y Vh2 en una CODV-Ig. Del mismo modo, Vl1 y Vl2 se podrían derivar de dominios Vh1 y Vh2 en los anticuerpos parentales y se colocan en las posiciones Vh1 y Vh2 en una CODV-Ig. Por lo tanto, las designaciones Vh y Vl se refieren a la ubicación actual y no a la ubicación original en un anticuerpo parental.
En más detalle, se construyó un modelo de homología de Fv il4 en entradas AP 1YLD (cadena ligera) y 1IQW (cadena pesada). El dímero Fvil4 se recompuso en una estructura cristalina interna del complejo IL13 / anti-IL13 FabiL13 y se optimizó. Con el fin de obtener una estimación del volumen requerido por IL4 cuando se une a Fvil4, la estructura cristalina de IL4 (1RCB.pdb) fue acoplada al modelo de homología de Fvil4. A continuación, se generaron veintidós modelos putativos del complejo que merecían una mayor consideración.
Paralelamente, el modelo de homología de Fvil4 se acopló a Fvil13 extraído de una estructura cristalina interna del complejo IL13/FabiL13. Se encontró que una solución superior permitía la construcción de enlazadores relativamente cortos, al tiempo que no muestran interferencia estérica para la unión al antígeno y la colocación de los dominios constantes como fue el caso para las inmunoglobulinas de la región variable dual (véase la Figura 3). En esta disposición Fvil4 (Vl1) se colocó en el extremo N de la cadena ligera, seguido de Fvil13 (Vl2) y Fc (Cl1) en el extremo C de la cadena ligera. En la cadena pesada, Fvil13 (Vh2) se colocó en posición N-terminal, seguido de Fvil4 (Vh1) y las regiones constantes (Ch1 - Ch2 - Cm).
Tal como se muestra en la Tabla 3, los modelos de la cadena ligera sugirieron que el enlazador L1 entre los dominios Vl1 y Vl2 y el enlazador L2 entre los dominios Vl2 y Cl1 debería ser entre uno a tres y cero a dos residuos glicina de longitud, respectivamente. Modelos de la cadena pesada sugirieron que el enlazador L3 entre los dominios Vh2 y Vh1 y el enlazador L4 entre los dominios Vmy Ch1 debe ser entre dos y seis y cuatro a siete residuos glicina de longitud, respectivamente (véase la Tabla 3 y la Figura 2). En este ejemplo, la glicina se utilizó como un aminoácido prototípico para los enlazadores, pero otros residuos de aminoácidos también pueden servir como enlazadores. La estabilidad estructural de los modelos propuestos se verificó mediante la optimización de las conformaciones de los enlazadores, la minimización y los cálculos de dinámica molecular. La combinación sistemática entre cuatro construcciones de cadena ligera y seis construcciones de cadena pesada resultó en 24 posibles proteínas de unión similares a anticuerpos anti-IL-4 y anti-IL13 biespecíficas de región variable dual de entrecruzamiento (véase la Tabla 4).
Tabla 3. Longitudes de Enlazador Propuestas

Tabla 4. CODV-Ig para Expresión


*Se diseñó un código corto para representar las estructuras asociadas. Los códigos que comienzan con HC representan la cadena pesada adyacente, y los códigos que comienzan con LC representan la cadena ligera adyacente.
En la Tabla 4, no se incluye el prefijo "anti", sino que pretende dar a entender que significa que IL13 se refiere a anti-IL13 e IL4 se refiere a anti-IL4.
Ejemplo 3. Generación de Plásmidos de Expresión de CODV-Ig
Moléculas de ácido nucleico que codifican las cadenas pesadas y ligeras variables de las seis cadenas pesadas y cuatro cadenas ligeras descritas en la Tabla 4 fueron generadas por síntesis de genes en Geneart (Regensburg, Alemania). Los dominios de cadena ligera variable se fusionaron a la cadena ligera constante (IGKC, GenBank N° de Acceso Q502W4) por digestión con las endonucleasas de restricción ApaLI y BsiWI y, posteriormente, se ligaron en los sitios ApaLI/BsiWI del vector de expresión episomal pFF, un análogo del vector pTT descrito por Durocher et al., (2002, Nucl. Acids Res. 30(2): E9), creando el plásmido de expresión en mamíferos para la expresión de las cadenas ligeras.
Los dominios de cadena pesada variable se fusionaron a la variante "Ted" de la cadena humana pesada constante (IGHG1, GenBank N° de Acceso 569F4) o, alternativamente, a un dominio Ch1 marcado con 6x His de IGHG1 constante humana con el fin de crear un Fab biespecífico. A continuación, el dominio Vh se digirió con las endonucleasas de restricción ApaLI y Apal y después se fusionó al IGHG1 o al dominio Ch1 marcado con 6x His, respectivamente, por ligadura en los sitios ApaLI/Apal del vector de expresión episomal pFF, creando los plásmidos de expresión de mamífero para la expresión de las cadenas pesadas (IgG1 o Fab, respectivamente).
Ejemplo 4. Expresión de CODV-Ig
Los plásmidos de expresión que codifican las cadenas pesadas y ligeras de las construcciones correspondientes se propagaron en células DH5a de E. coli. Los plásmidos utilizados para la transfección se prepararon a partir de E. coli utilizando el kit EndoFree Plasmid Mega de Qiagen.
Células HEK 293-FS que crecen en Medio Freestyle (Invitrogen) fueron transfectadas con plásmidos LC y HC indicados que codifican las cadenas pesadas y las cadenas ligeras mostradas en la Tabla 4 utilizando reactivo de transfección 293fectin (Invitrogen) tal como se describe por el fabricante. Después de 7 días, las células se separaron por centrifugación y el sobrenadante se pasó por un filtro de 0,22 pm para separar partículas.
Construcciones de CODV-IgG1 se purificaron por cromatografía de afinidad en columnas de Proteína A (Columnas HP de Proteína A HiTrap, GE Life Sciences). Después de la elución de la columna con tampón acetato 100 mM y NaCl 100 mM, pH 3,5, las construcciones de CODV-IgG1 se desalaron utilizando Columnas de Desalinización HiPrep 26/10, formuladas en PBS a una concentración de 1 mg/mL y se filtraron utilizando una membrana de 0,22 pm.
Construcciones biespecíficas de CODV Fab se purificaron mediante IMAC en columnas HiTrap IMAC HP (GE Life Sciences). Después de la elución de la columna con un gradiente lineal (tampón de elución: fosfato de sodio 20 mM, NaCl 0,5 M, imidazol 50-500 mM, pH 7,4), la proteína que contiene fracciones se agrupó y se desaló utilizando Columnas de Desalinización HiPrep 26/10, se formuló en PBS a una concentración de 1 mg/mL y se filtró utilizando una membrana de 0,22 pm.
La concentración de proteína se determinó por medición de la absorbancia a 280 nm. Cada uno de los lotes se analizó mediante SDS-PAGE en condiciones reductoras y no reductoras para determinar la pureza y el peso molecular de cada subunidad y del monómero.
Una placa Nunc F96-MaxiSorp-Inmuno se recubrió con IgG anti-humana de cabra (específica para Fc) [NatuTec A80-104A]. El anticuerpo se diluyó a 10 pg/ml en tampón de recubrimiento de carbonato (carbonato de sodio50 mM, pH 9,6) y se dispensó a 50 pL por pocillo. La placa se selló con cinta adhesiva y se almacenó durante la noche a 4°C. La placa se lavó tres veces con tampón Wash (PBS, pH 7,4 y Tween 20 al 0,1%). 150 pL de disolución de bloqueo (BSA / PBS al 1%) se dispensó en cada pocillo para cubrir la placa. Después de 1 hora a temperatura ambiente, la placa se lavó tres veces con tampón Wash. Se añadieron 100 pL de muestra o patrones (en un intervalo de 1500 ng/ml a 120 ng/ml) y se dejó reposar durante 1 hora a temperatura ambiente. La placa se lavó tres veces con tampón Wash. Se añadieron 100 pL de conjugado de IgG-FC anti-humano de cabra - HRP [NatuTec A80-104P-60] diluido en la relación 1:10.000 utilizando disolución de incubación (BSA al 0,1%, PBS, pH 7,4, y Tween 20 al 0,05%). Después de 1 hora de incubación a temperatura ambiente, la placa se lavó tres veces con tampón Wash.
100 pL de sustrato ABTS (comprimido de 10 mg de ABTS (Pierce 34026) en Na2HPO40,1 M, disolución de ácido cítrico 0,05 M, pH 5,0). La adición de 10 pL de H2O2 al 30%/ 10 ml de tampón Sustrato antes de su uso) se dispensó
a cada uno de los pocilios, y se dejó que el color se desarrollara. Después de que el color se hubiese desarrollado (aproximadamente 10 a 15 minutos), se añadieron 50 pL de disolución de SDS al 1% para detener la reacción. La placa se leyó a A405.
Ejemplo 5. Caracterización de Variantes de CODV-Ig
Para determinar si las cadenas pesadas y ligeras de proteína similar a anticuerpo CODV-Ig se apareaban y plegaban correctamente, se midió el nivel de agregación mediante cromatografía de exclusión por tamaño analítica (SEC). La SEC analítica se realizó en parejas ensambladas utilizando un explorador AKTA 10 (GE Healthcare) equipado con una columna de TSKgel G3000SWXL (7,8 mm x 30 cm) y la columna de seguridad de TSKgel SWXL (Tosoh Bioscience). El análisis se realizó a 1 ml/min utilizando NaCl 250 mM, fosfato de Na100 mM, pH 6,7, con detección a 280 nm. 30 pL de muestra de proteína (a 0,5-1 mg/ml) se aplicaron a la columna. Para la estimación del tamaño molecular, la columna se calibró utilizando una mezcla estándar de filtración en gel (MWGF-1000, Sigma Aldrich). La evaluación de los datos se realizó utilizando el software UNICORN v5.11.
La Tabla 5 muestra los resultados de la primera serie de 24 diferentes moléculas de CODV-Ig hechas utilizando las combinaciones de la región variable de anti-IL4 y anti-IL13 que se describen en la Tabla 4. Los códigos asignados en la Tabla 4 representan las estructuras adyacentes que se muestran en la Tabla 4. Para los pares de cadena ligera y cadenas pesadas en donde se producía proteína, los niveles de agregación se midieron utilizando SEC. Los resultados se muestran en la Tabla 5, en donde LC4 (L1 = 1; L2 = 2) tuvo más éxito en el apareamiento con las seis cadenas pesadas. LC4 corresponde a la estructura de IL-4 Vl-(Gly) -IL13 Vl-(Gly2)-CL1 con el enlazador L1 igual a 1, en donde un único residuo aminoácido separa los dos dominios Vl de la cadena ligera de la región variable dual. Además, LC4 tenía L2 igual a 2, que contenía un enlazador dipéptido Gly-Gly entre el Vl central y el Ch1 C-terminal.
Tabla 5. Niveles de Agregación Entre Pares de Cadenas Pesadas y Ligeras

*ND indica que no se produjo proteína
En los casos en los que se produjeron moléculas de CODV-Ig, se llevó a cabo un experimento BIACORE de una sola concentración a concentraciones de IL-4 e IL-13 intermedias para verificar la unión a antígenos diana. Moléculas similares a anticuerpos CODV-Ig correspondientes a las combinaciones LC4:HC4 y LC4:HC6 descritas en la Tabla 4 fueron elegidos para la evaluación de un análisis cinético completo utilizando la resonancia de plasmones de superficie.
Tal como se representa en la Tabla 5, la mayoría de las moléculas de CODV-Ig no se podían producir en absoluto o sólo en forma de agregados (hasta 90%). Las combinaciones de cadena pesada/ cadena ligera que dan lugar a niveles de agregación aceptables (5-10%) después de una etapa de cromatografía fueron los combinados con la cadena ligera de IL-4 VL-(Gly)-IL13 VL-(Gly2)-CL1. La cadena ligera fue la cadena más meticulosa dentro de estas variantes de CODV-Ig y sirvió como plataforma para aceptar diferentes cadenas pesadas con diferentes composiciones de enlazador.
1. Análisis cinético
Se seleccionaron dos pares de cadenas pesadas y ligeras para el análisis cinético completo. IL13 e IL4 humanas recombinantes se adquirieron de Chemicon (EE.UU.). La caracterización cinética de los anticuerpos purificados se llevó a cabo utilizando la tecnología de resonancia de plasmones de superficie en un BIACORE 3000 (GE Healthcare). Un ensayo de captura utilizando un anticuerpo específico para especies (p. ej., MAB 1302 específico para Fc humano, Chemicon) se utilizó para la captura y la orientación de los anticuerpos investigados. El anticuerpo de captura se inmovilizó a través de grupos amina primaria (11.000 RU) en un chip CM5 de calidad para investigación (GE Life Sciences) utilizando procedimientos estándares. El anticuerpo analizado fue capturado a un caudal de 10 pL/min con un valor de RU ajustado que resultaría en la unión de analito máxima de 30 RU. Las cinéticas de unión se midieron frente a IL4 e IL13 humanas recombinantes en un intervalo de concentraciones entre 0 y 25 nM en HBS EP (HEPES 10 mM, pH 7.4, NaCl 150 mM, EDTA 3 mM y tensioactivo P20 al 0,005%) a un caudal de 30 pl/min. Las superficies de chips se regeneraron con glicina 10 mM, pH 2,5. Los parámetros cinéticos se
analizaron y se calcularon en el paquete de programas v4.1 de BIAevaluation utilizando una celda de flujo sin anticuerpo capturado como referencia.
La Tabla 6 muestra la comparación de la cinética de los anticuerpos BB13 (anti-IL13) y 8D4 (anti-IL-4) parentales (expresados como IgGs) con los dominios respectivos dentro del formato CODV-Ig (Tabla 4, Códigos de LC4:HC4 y LC4:HC6). Tal como se muestra en la Tabla 6, las construcciones de CODV-Ig no exhibían propiedades de unión reducidas frente a los antígenos correspondientes, en comparación con los anticuerpos anti-IL13 y anti-IL4 parentales. La pérdida en la tasa de enlace observada en el formato DVD-Ig/TBTI utilizando las mismas secuencias de Fv no se produjo con la configuración CODV-Ig. Los sitios de unión que miran en dirección opuesta deben permitir la unión de grandes antígenos o el puenteo de células diferentes con una configuración similar a anticuerpo biespecífica, y también sería adecuado para una selección más amplia de anticuerpos parentales. Una ventaja adicional de la CODV-Ig era que no hay residuos de enlazador que sobresalgan en el sitio de unión al antígeno y que reduzcan la accesibilidad del antígeno.
Tabla 6. Análisis Cinético de LC4:HC4 y LC4:HC6

2. o-inyecci n de IL4 e IL13 para la Demostraci n de la Uni n de Antgeno Aditivo por DV-Ig
Para investigar la unión aditiva de los dos antígenos, se aplicó un método de co-inyección con asistente en el que se inyectó inmediatamente un antígeno seguido por el otro antígeno después de un tiempo de retraso (IL4, después IL13, y viceversa). El nivel de unión resultante se puede comparar con el que se consigue con una mezcla 1: 1 de los dos antígenos en la misma concentración. Con el fin de demostrar la unión aditiva de ambos antígenos IL4 y IL13 por las moléculas de CODV-Ig, se llevó a cabo un experimento BIACORE con una combinación CODV-Ig [HC4:LC4] por co-inyección de ambos antígenos en tres ciclos de análisis separados (véase la Figura 4). La co-inyección se realizó con IL4 3,125 nM/IL13 25 nM (y viceversa) y con una mezcla 1:1 de IL43,125 nM e IL13 25 nM. Una co inyección de tampón HBS-EP se hizo como una referencia. En un punto de 800 segundos, se logró un nivel de unión idéntico de 63 RU después de la inyección de la mezcla de antígenos o de la co-inyección de los antígenos, independientemente de la secuencia de co-inyección. Cuando la proteína CODV-Ig había sido saturada por el primer antígeno (IL4), se inyectó el segundo antígeno (IL13) y se observó una segunda señal de unión. Esta observación se reprodujo cuando se invirtió la secuencia de la inyección del antígeno. Esto demuestra la unión aditiva y la no inhibición de la unión de ambos antígenos por la CODV-Ig. Por lo tanto, la construcción CODV-Ig fue capaz de unir ambos antígenos simultáneamente (es decir, exhiben biespecificidad) saturando todos los sitios de unión (es decir, exhiben tetravalencia).
Ejemplo 6. Tolerancia de las Longitudes de Enlazador para CODV-Ig
La tolerancia para los enlazadores de diferentes longitudes se evaluó mediante la construcción de moléculas de CODV-Ig que tienen diferentes combinaciones de longitudes de enlazador para L1, L2 en la cadena ligera y para L3 y L4 en la cadena pesada. Construcciones de CODV-Ig se generaron con enlazadores de la cadena pesada L3 y L4 que varían entre 1 y 8 residuos para L3 y 0 ó 1 residuo para L4. La cadena pesada contenía anti-IL4 como el dominio de unión N-terminal y anti-IL13 como el dominio de unión C-terminal, seguido de Ch1-Fc. Los enlazadores de la cadena ligera L1 y L2 se variaron de 3 a 12 residuos para L1 y de 3 a 14 residuos para L2. La cadena ligera contenía anti-IL13 como el dominio de unión N-terminal y anti-IL4 como el dominio de unión C-terminal seguido de Cl1.
1. Caracterización de Variantes CODV-Ig
La determinación del nivel de agregación se realizó por cromatografía de exclusión por tamaño analítica (SEC). La SEC analítica se realizó utilizando un explorador ÁKTA 10 (GE Healthcare) equipado con una columna TSKgel G3000SWXL (7,8 mm x 30 cm) y una columna de seguridad TSKgel SWXL (Tosoh Bioscience). El análisis se realizó a 1 ml/min utilizando NaCl 250 mM, fosfato de Na 100 mM, pH 6,7, con detección a 280 nm. 30 pL de muestra de
proteína (a 0,5-1 mg/ml) se aplicó en la columna. Para la estimación del tamaño molecular, la columna se calibró utilizando una mezcla estándar de filtración en gel (MWGF-1000, SIGMA Aldrich). La evaluación de los datos se realizó utilizando el software UNICORN v5.11.
IL13 e IL4 humanas recombinantes se adquirieron de Chemicon (EE.UU.). TNF-a humano recombinante se adquirió de Sigma Aldrich (H8916-10 gg), IL-1 p humana recombinante (201-LB/CF), IL-23 humana recombinante (1290-IL/CF), EGFR humana recombinante (344 ER) y HER2 humana recombinante (1129-ER-50) se adquirieron de R&D Systems.
El análisis de unión cinética por Biacore se realizó como sigue. Se utilizó la tecnología de resonancia de plasmones de superficie en un Biacore 3000 (GE Healthcare) para la caracterización cinética detallada de los anticuerpos purificados. Un ensayo de captura utilizando un anticuerpo específico para la especie (p. ej., MAB 1302 específico para Fc humano, Chemicon) se utilizó para la captura y la orientación de los anticuerpos investigados. Para la determinación de las cinéticas de unión de IL4 e IL13, se capturaron los correspondientes CODV Fabs como en el Ejemplo 10, Tabla 12 utilizando el kit de captura de Fab anti-humano (GE Healthcare). El anticuerpo de captura se inmovilizó a través de grupos amina primaria (11000 RU) en un chip CM5 de calidad para investigación (GE Life Sciences) utilizando procedimientos estándares. El anticuerpo analizado fue capturado a un caudal de 10 pL/min con un valor ajustado RU que resultaría en la unión de analito máxima de 30 RU. Las cinéticas de unión se midieron frente a IL4 humana recombinante e IL13 en un intervalo de concentraciones entre 0 y 25 nM en HBS EP (HEPES 10 mM pH 7,4, NaCl 150 mM, EDTA 3 mM, tensioactivo P20 al 0,005%) a un caudal de 30 pL/min. Las superficies de los chips se regeneraron con glicina 10 mM pH 2,5. Los parámetros cinéticos se analizaron y se calcularon en el paquete de programas v4.1 de BIAevaluation utilizando una celda de flujo sin anticuerpo capturado como referencia.
Las afinidades de unión de CODV-Ig, CODV-Fab y TBTI frente a EGFR y HER2 se midieron utilizando un sistema de matriz de interacción de proteínas Proteon XPR36 (Biorad). Los antígenos fueron inmovilizadas por acoplamiento de amina reactiva en chips sensores GLC (BioRad). Series de dilución de las variantes de anticuerpos biespecíficos en tampón PBSET (Biorad) se analizaron en paralelo en un modo de cinética de un solo disparo con doble referencia. Los datos se analizaron utilizando el Software Proteon Manager v3.0 (Biorad) con el modelo de Langmuir 1:1 con transferencia de masa modelo o modelo de analito bivalente.
La Tabla 7 resume los resultados para el rendimiento, la agregación (tal como se mide por cromatografía de exclusión por tamaño) y la afinidad de unión para CODV-Ig que tienen diferentes combinaciones de tamaños de los enlazadores. Los resultados revelaron que las moléculas de Ig-CODV, en las que L2 fue cero en general no podían ser producidos, o en los casos en los que se produjo la proteína, había un alto nivel de agregación (véanse Lotes con N°s de ID 101, 102, 106-111 y 132-137 en la Tabla 7). Por lo tanto, en contraposición con la predicción de modelado molecular del Ejemplo 2, en que L2 igual a cero estaba dentro del intervalo aceptable, estos resultados indican que la transición Vl2-Cl (o L2) requiere un enlazador de al menos un residuo (véase la Tabla 7).
Tabla 7. Optimización de los Tamaños de Enlazador para CODV-Ig

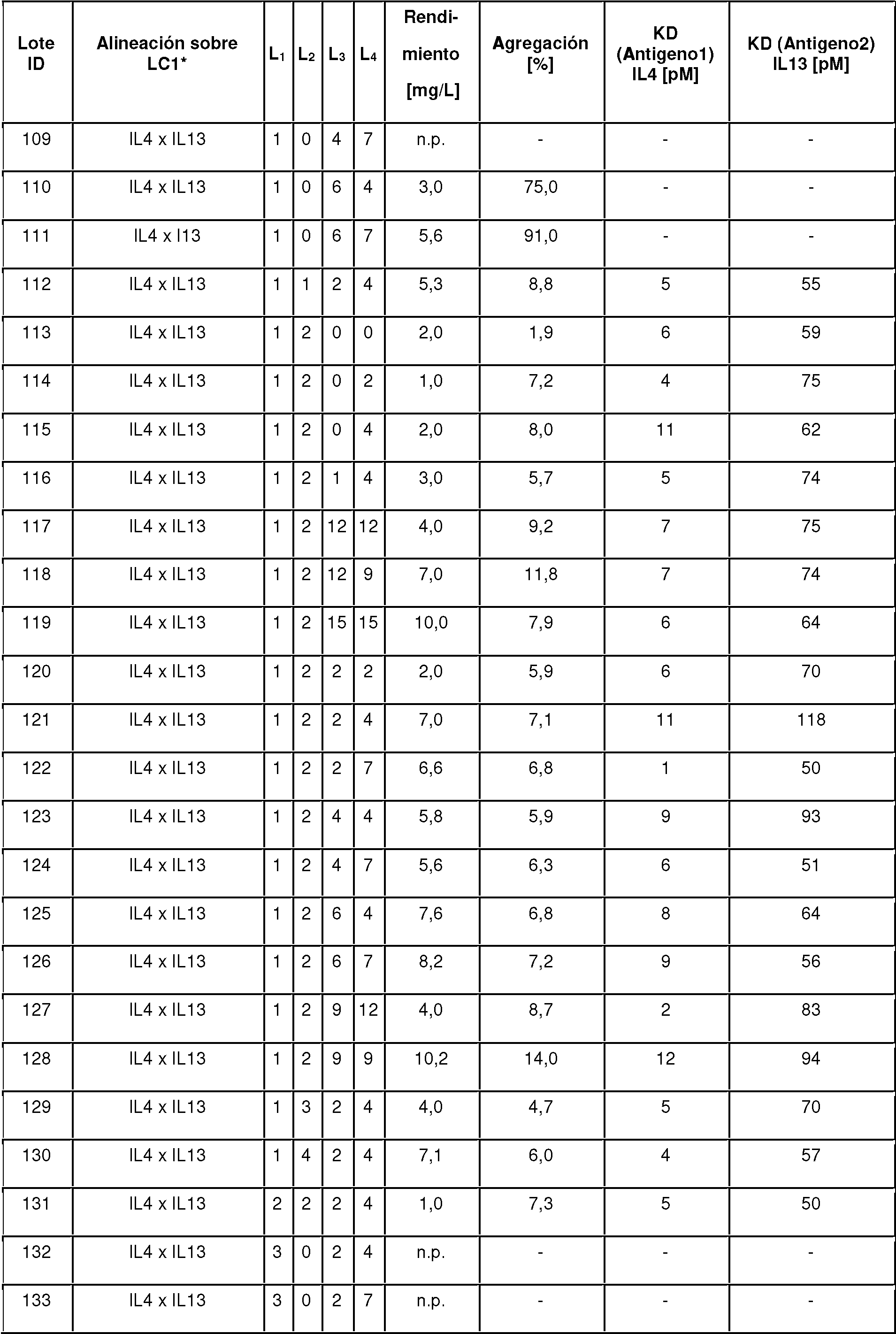

* La alineación en la cadena pesada debe ser IL13Vh-L3-IL4Vh-L4-Chi-Fc 1 n.p. significa que la construcción no se pudo producir.
Además, se encontró que las longitudes de enlazador CODV-lg descritas anteriormente eran más sensibles a los aumentos en 1 residuo aminoácido que aumentos en 2 residuos aminoácidos. Por ejemplo, mientras que los Lotes de N°s de ID 103 y 104 difieren en 1 residuo aminoácido en L2 , el Lote de N° de ID 103 muestra 6 veces más agregación y el Lote de N° de ID 104 muestra menos agregación y dos veces el rendimiento. En contraposición, los Lotes de N°s de ID de lote No. 104 y 105, que se diferencian por dos residuos en L2 exhibían perfiles similares con respecto al rendimiento, la agregación y la unión.
Ejemplo 7. Cadena Pesada como la Cadena de Molde para CODV-Ig
En los ejemplos 1 a 5, los tamaños de enlazadores cortos óptimos en la cadena ligera sugirieron que la cadena ligera servía como un molde al permanecer en una disposición lineal y que se requerían enlazadores más grandes en la cadena pesada con el fin de que la cadena pesada se plegara correctamente en la configuración de entrecruzamiento para adaptarse a la cadena ligera del molde (véase la Figura 5, Panel A). Seguidamente se evaluó si los enlazadores cortos colocados específicamente en la cadena pesada para mantener una disposición de revestimiento en la cadena pesada hicieron que la cadena pesada fuese la cadena "molde", y si el patrón se repetiría y serían necesarios enlazadores más grandes para permitir que la cadena no molde se plegara correctamente y alojara ahora la cadena pesada del molde (véase la Figura 5, Panel B).
La Figura 6 ilustra estos principios de diseño CODV-lg sobre la base de tener a la cadena ligera o a la cadena pesada como "molde". Para evaluar el carácter genérico de este concepto, se generaron construcciones CODV-lg con enlazadores de cadena pesada L3 y L4 que varía entre 1 y 8 residuos para L3 y 0 ó 1 residuos para L4. La cadena pesada contenía anti-lL4 como el dominio de unión N-terminal y anti-lL13 como el dominio de unión C-terminal seguido de Ch1-Fc. Los enlazadores de la cadena ligera L1 y L2 se variaron de 3 a 12 residuos para L1 y de 3 a 14 residuos para L2. La cadena ligera contenía anti-lL13 como el dominio de unión N-terminal y anti-lL4 como el dominio de unión C-terminal seguido de Cl1.
La Tabla 8 resume los resultados para el rendimiento, la agregación (tal como se mide por cromatografía de exclusión por tamaño) y la afinidad de unión para CODV-lg que tienen diferentes combinaciones de tamaños de los enlazadores y en donde la cadena pesada se mantiene en una disposición lineal como la cadena de molde y se permite que la cadena ligera se pliegue en una configuración de entrecruzamiento. Los resultados revelaron que no podían producirse las moléculas de CODV-lg en las que L4 era generalmente cero, o en los casos en los que se produjo la proteína, había un alto nivel de agregación (similar a las moléculas en las que L2 era igual a cero) (véanse los Lotes de N2s de ID 207-209, 211 -212, 219-224, 231 -236, 243-252 y 263-266 en la Tabla 8). Una excepción era el Lote de N° de ID 210, en el que L1 era 7, L2 era 5, L3 era 2 y L4 era cero. Esta disposición produjo una cantidad
suficiente de proteína y tenía un nivel aceptable de la agregación y de unión, lo que sugirió que alguna combinación de los tamaños de enlazador se pudo encontrar para compensar un enlazador de longitud cero en L4 en algunas circunstancias.
Tabla 8. Optimización de los Tamaños de Enlazador con Cadena Pesada como Molde



* La alineación en la cadena ligera debe ser IL13Vl-Li -IL4 Vl-L2-Cli
Los resultados de las Tablas 7 y 8 demuestran claramente que se requieren enlazadores entre los dominios variables y constantes para permitir un plegamiento óptimo. Sólo en raras disposiciones se toleró un enlazador igual a cero (véanse los Lotes de N°s de ID 103 a 105, en donde Li (LC) era cero, y el Lote N° 210, en que L4 era cero). Sin embargo, en cada caso, el enlazador de transición correspondiente entre la región variable y la región constante en la otra cadena podría no ser cero.
Los resultados anteriores indicaron que las combinaciones de Li = 7, L2 = 5, L3 = 1 y L4 = 2 eran un buen punto de partida para la optimización de un nuevo CODV-Ig en el que la cadena pesada es el molde. Los intervalos en la Tabla 9 demostraron ser intervalos razonables para la modificación por ingeniería con éxito un nuevo CODV-Ig a partir de dos anticuerpos parentales.
Tabla 9. Intervalos de Tamaños de Enlazador para cada LC o HC como Molde

Ejemplo 8. Aplicabilidad Universal de Formato CODV-Ig
Para evaluar la idoneidad del formato CODV-Ig para la ingeniería de nuevas proteínas de unión similares a anticuerpos de las regiones variables de numerosos anticuerpos humanos y humanizados existentes que tienen especificidad para el receptor del factor de crecimiento similar a la insulina 1 (IGF1 R(1)), un segundo receptor del factor de crecimiento similar a la insulina 1 (IGF1R(2)), receptor 2 de factor de crecimiento epidérmico humano (HER2), receptor del factor de crecimiento epidérmico (EGFR), factor de necrosis tumoral - alfa (TNFa), interleuquinas 12 y 23 (IL-12/23) e interleuquina 1beta (IL-1 p) se incorporaron en el formato CODV-Ig (véase la Tabla 10).
Tabla 10. Códigos Descriptivos para Cadenas Pesadas y Ligeras utilizados en CODV-Ig Biespecífico


* Se diseñó un código corto para representar las estructuras asociadas. Los códigos que comienzan con HC representan la cadena pesada adyacente, y los códigos que comienzan con LC representan las cadenas ligeras adyacentes
Las regiones variables de anticuerpos de anticuerpos humanos y humanizados conocidos se utilizaron para ensayar la aplicabilidad universal del formato CODV-Ig en el diseño de proteínas de unión similares a anticuerpos biespecíficas. Además, se examinó la posibilidad de efectos posicionales con respecto a la colocación de ciertas regiones variables de anticuerpo N-terminal o C-terminal en cualquiera de la cadena pesada o la cadena ligera. Basado en el diseño de moléculas de CODV-Ig que tienen una composición de enlazador L1 = 7, L2 = 5, L3 = 1 y L4 = 2, se introdujeron diferentes secuencias de anticuerpos en el formato CODV-Ig.
Las actividades de anticuerpos biespecíficos o derivados contra IL1p y TNFa se determinaron utilizando células informadoras HEK-Blue TNFa/IL1p disponibles comercialmente (InvivoGen). Para determinar las actividades de anticuerpos contra TNFa e IL1 p, las citoquinas se pre-incubaron durante 1 hora con diferentes concentraciones de los anticuerpos y se añaden a 50.000 células HEK Blue TNFa/IL1p. La inducción mediada por citoquinas de SEAP se midió después de 24 horas en el sobrenadante del cultivo con el ensayo QUANTI-Blue (InvivoGen).
Tal como se muestra en la Tabla 11, todas las construcciones mostraron un buen a excelente rendimiento de proteínas y niveles aceptables de agregación (véase, en particular, Lotes de N°s de ID 301 y 302 en la Tabla 11). La afinidad medida para cada dominio variable de anticuerpo estaba dentro de la afinidad publicada o esperada. En los casos en que se evaluó la afinidad, no se detectaron efectos posicionales. En resumen, tal como se muestra en las siguientes tablas, no se observaron efectos posicionales con ninguno de los dominios variables de anticuerpos utilizados o con el uso de estos dominios en cualquier cadena de anticuerpo.
Tabla 11. Uso Universal de Formato CODV-Ig para Proteínas de Unión similares a Anticuerpos Biespecíficas

*n.m.= no medibles por Biacore
1 - La cadena pesada y las cadenas ligeras correspondientes a los códigos pueden encontrarse en la Tabla 10. Ejemplo 9. Retención de la Afinidad de Anticuerpos Parentales en Formato CODV-Ig
Las secuencias de anticuerpos idénticas para anti-IL4 y anti-IL13 se incorporaron en los formatos TBTI/DVD-Ig o CODV-Ig para una comparación directa de estas configuraciones, el posicionamiento de los enlazadores y las afinidades de las moléculas resultantes. Como se muestra en la Figura 7, la afinidad de los parentales de cada uno de los anticuerpos se mantuvo en el formato CODV. Tal como se muestra en el panel superior de la Figura 7, cuando las regiones variables se colocaron en el formato TBTI/DVD-Ig, un descenso en la afinidad del anticuerpo IL4 colocado en la posición interior de Fv2 se manifestó como una reducción de la tasa en enlace de la unión del anticuerpo al antígeno. En contraposición, no hubo pérdida en la afinidad para el formato CODV-Ig, en comparación con los anticuerpos parentales (véase la Figura 7, Panel inferior).
Ejemplo 10. Adaptabilidad de CODV-Ig al Formato de Fab
Se evalúo seguidamente la capacidad del formato CODV-Ig de proporcionar fragmentos tales como fragmentos Fab. Dos cadenas pesadas variables diferentes se fusionaron entre sí a través del enlazador L3 y fueron alargadas en posición C-terminal por el enlazador L4. Este complejo Vh se fusionó entonces al dominio Ch1 de IGHG1 (GenBank N° de Acceso Q569F4) que alberga en posición C-terminal las cinco secuencias de aminoácidos DKTHT (SEQ ID NO: 60) de la región de bisagra seguidas de seis residuos histidina. Dos cadenas ligeras variables diferentes se fusionaron entre sí en una configuración de entrecruzamiento a la cadena pesada correspondiente a través del enlazador L1 y fueron extendidas en posición C-terminal por el enlazador L2 y posteriormente fueron fusionadas a la cadena kappa constante (IGKC, GenBank N° de Acceso Q502W4).
Los fragmentos Fab se expresaron mediante transfección transitoria tal como se ha descrito anteriormente. Siete días después de la transfección, las células se separaron por centrifugación, se añadió Tris-HCl 1M al 10% v/v, pH 8,0 y el sobrenadante se hizo pasar por un filtro de 0,22 gm para separar las partículas. Las proteínas Fab fueron capturadas utilizando columnas de alto rendimiento Histrap (GE Healthcare) y fueron eluidas a través de gradiente de imidazol. Las fracciones que contienen proteínas se reunieron y se desalaron utilizando columnas PD-10 o
Sephadex. Disoluciones de proteínas concentradas y filtradas en condiciones estériles (0,22 pm) se ajustaron a 1 mg/ml y se mantuvieron a 4°C hasta su uso.
Se observaron ventajas inmediatas debido a que las moléculas de tipo Fab en una orientación CODV no mostraron tendencia a agregarse y conservaron las afinidades de los anticuerpos parentales (véase la Tabla 12). Construcciones de proteínas de unión de los Lotes de N°s de ID. 401-421 compararon directamente proteínas similares a anticuerpos en las que las regiones variables de anticuerpos se dispusieron como en moléculas CODV-Ig con la cadena pesada como molde (401,402, 406, y 407), fragmentos similares a Fab CODV (402, 408, 413, 418 y 421), moléculas de cuatro dominios similares a anticuerpos en formato TBTI/DVD-Ig (404, 409, 414 y 419) y CODV-Ig sin enlazadores (405, 410, 415 y 420). Tal como se muestra en la Tabla 12, los resultados de esta comparación indicaron que hay más probabilidades de haber una pérdida en la afinidad en comparación con los anticuerpos parentales cuando la región variable se incorpora en un formato TBTI o DVD-Ig. Por el contrario, tanto el formato CODV-Ig como el formato CODV-Ig similares a Fab eran más capaces de mantener las afinidades de los parentales. Los resultados confirmaron, además, que moléculas de Ig-CODV requieren enlazadores entre las regiones variables y entre las regiones variables y los dominios constantes (véase la Tabla 12).
Tabla 12. Uso del Formato CODV-Ig para Fragmentos similares a Fab


Ejemplo 11. Sustitución de los Dominios Variables dentro de CODV-Ig y CODV-Fab
Para caracterizar el formato CODV en un enfoque de acoplamiento de células T, se generaron proteínas de unión similares a CODV Fab biespecíficas (CODV-Fab) que tienen un sitio de de unión TCR (CD3epsilon) y un sitio de unión a CD19 y se compararon con un Fab biespecífico derivado del formato TBTI/DVD-Ig (B-Fab). Para investigar la importancia de la orientación de los sitios de unión (TCR x CD19 frente a CD19 x TCR), se evaluaron ambas orientaciones para cada una de las proteínas de unión.
Las proteínas de unión se caracterizaron en un ensayo citotóxico utilizando células NALM-6 (que expresan CD 19) como células diana y células T primarias humanas como células efectoras. Células CD3 positivas se aislaron de PBMCs humanas recién preparadas. Las células efectoras y diana se mezclaron en una proporción de 10:1 y se incubaron durante 20 horas con las concentraciones indicadas de las proteínas de unión biespecíficas (véase la Figura 8). Se determinaron las células diana apoptóticas en un ensayo basado en FACS utilizando tinción con 7-aminoactinomicina.
El formato B-Fab en la configuración CD3-CD19 (1060) demostró ser activo para inducir la citotoxicidad mediada por células T hacia células NALM-6 con una CE50 de 3,7 ng/ml. Se observó una actividad similarmente alta para el CD19-CD3 CODV-Fab (1109) con una EC50 de 3,2 ng/ml (véase la Figura 8).
Una permuta de la configuración de la molécula de B-Fab (Fab del formato TBTI/DVD-Ig) a una orientación CD19-CD3 resultó en una pérdida significativa de la actividad (véasela Figura 8). La molécula de B-Fab permutada no mostró actividad a concentraciones que eran máximas para ambas orientaciones de CODV-Ig Fab y la otra orientación de B-Fab. Para los CODV-Ig Fabs y una orientación de B-Fab, se observó una respuesta máxima (que
oscila entre 1 y 100 ng/ml). Para la orientación CD19-CD3 de B-Fab, incluso a la concentración máxima (30 gg/ml), no se alcanzó la respuesta óptima citotóxica. En contraste nítido, un cambio en la orientación de los dominios en el CODV-Fab hacia CD3-CD19 (1108) dio como resultado una molécula con actividad significativa en este ensayo (véase la Figura 8). Aunque la permuta del dominio en el CODV-Fab también redujo la inducción de la citotoxicidad mediada por células T (aumento de EC50 en un factor de ~ 100), este efecto fue mucho menos pronunciado que el que se vio en el formato B-Fab y la molécula fue capaz de inducir citotoxicidad hasta el nivel máximo. Los datos eran representativos y se obtuvieron a partir de tres experimentos independientes.
Ejemplo 12. Influencia de la Identidad de la Secuencia de Aminoácidos en Enlazadores de CODV-Ig
La construcción optimizada correspondiente al Lote ID 204 (véase el Ejemplo 7 y la Tabla 8) fue elegida para investigar la influencia de la composición de enlazador en los enlazadores L1 a L4. Las longitudes de enlazador se ajustaron a 7, 5, 1 y 2 residuos de longitud para L1, L2 , L3 y L4, respectivamente (véase la Tabla 13). Las secuencias de ensayo se derivaron de enlazadores que se producen de forma natural en las transiciones entre los dominios Vh y Ch1 de anticuerpos naturales o entre los dominios Fv y Cl de anticuerpo de cadenas ligeras kappa o lambda. Las secuencias candidatas eran ASTKGPS (SEQ ID NO: 48), que se deriva de la transición de los dominios Vh y Ch1, RTVAAPS (SEQ ID NO: 49) y GQPKAAp (SEQ ID NO: 50), que se derivaron de las transiciones de los dominios Fv y Cl de cadenas ligeras kappa y lambda, respectivamente. Además, se generó una construcción con una composición arbitraria de enlazador para demostrar que potencialmente se puede utilizar cualquier secuencia en los enlazadores L1 a L4. Esta composición de enlazador se obtuvo mediante la distribución al azar de los aminoácidos valina, leucina, isoleucina, serina, treonina, lisina, arginina, histidina, aspartato, glutamato, asparagina, glutamina, glicina y prolina en las 15 posiciones de los cuatro enlazadores. Los aminoácidos aromáticos fenilalanina, tirosina y triptófano, así como los aminoácidos metionina y cisteína fueron excluidos deliberadamente para evitar potenciales aumentos en la agregación.
Un modelo tridimensional de la construcción para el Lote ID No. 204 fue generado para asegurar la idoneidad o refinar las opciones de composición de enlazador. Por lo tanto, serina fue elegido para el enlazador L3 , ya que se observan residuos cargados positiva y negativamente en las inmediaciones del modelo tridimensional. Los residuos en el enlazador L4 fueron seleccionados para que fuesen compatibles con la exposición a disolventes de estas posiciones tal como se sugiere por el modelo. Del mismo modo, no se anticiparon o pronosticaron problemas para las composiciones de enlazador de L1 y L2. Se construyeron modelos tridimensionales de las propuestas seleccionadas para la composición de enlazador.
Tal como se muestra en la Tabla 12, la composición de enlazador puede tener una influencia drástica en el rendimiento. Las secuencias que se derivaron de la cadena lambda en L1 (comparando los Lotes de N°s de ID 505 a 507 con Lotes de N°s de ID 501 a 503) eran los generadores de proteínas más productivos (hasta 8 veces mayor). De hecho, los enlazadores basados en la generación aleatoria también producen buenos rendimientos, tal como se muestra en la Tabla 13, Lote de N° de ID 508. Por lo tanto, la composición de enlazador debe ser un parámetro considerado durante la optimización de CODV-Ig.
Tabla 13. Efecto de la Composición del Enlazador sobre CODV-Ig


Las actividades de anticuerpos biespecíficos o derivados contra citoquinas IL4 e IL13 se determinaron en células informadoras HEK-Blue IL-4/IL-13 disponibles comercialmente (InvivoGen). Las células HEK-Blue IL-4/IL-13 están diseñadas para controlar la activación de la vía STAT6 por IL-4 o IL13. La estimulación de las células con cualquiera de las citoquinas resulta en la producción del gen informador fosfatasa alcalina secretada embrionaria (SEAP), que puede medirse en el sobrenadante del cultivo con el ensayo QUANTI-Blue. Para testar las actividades de anticuerpos contra IL4 o IL13, las citoquinas se pre-incubaron durante 1 hora con diferentes concentraciones de los anticuerpos y se añadieron a 50.000 células HEK-Blue IL-4/IL-13. La inducción de SEAP mediada por citoquinas se midió después de 24 horas de incubación en el sobrenadante de cultivo de células con el ensayo QUANTI-Blue (InvivoGen).
Ejemplo 13. Introducción de Cisteínas en Enlazadores de CODV-Ig
Los datos publicados sugieren que la estabilidad de los anticuerpos y proteínas derivadas de anticuerpos se puede aumentar mediante la introducción de puentes disulfuro no naturales (véase Wozniak-Knopp et al., 2012, "Stabilisation of the Fc Fragment of Human IgG1 by Engineered Intradomain Disulfide Bonds," PLoS ONE 7(1): e30083). Para examinar si el fragmento Fc equivalente derivado de un anticuerpo IgG1 humano y modificado por ingeniería genética en una molécula de CODV-Ig se puede estabilizar por la introducción de puentes disulfuro inter e intra-cadena, las posiciones de Fc equivalentes de la construcción de CODV-Ig Lote de N° de ID 204 (del Ejemplo 7) se mutaron a residuos cisteína, y las proteínas mutantes se produjeron en exceso, se purificaron y se caracterizaron (véase la Tabla 14).
Tal como se muestra en la Tabla 14, cada una de las moléculas de CODV-Ig mutadas que contienen residuos cisteína adicionales tenían temperaturas de fusión que eran la misma que la temperatura de fusión para la construcción de CODV-Ig Lote de N° de ID 204.
Además, dos cisteínas simultáneas se introdujeron en las posiciones Kabat 100 para la cadena ligera y 44 para la cadena pesada en cada uno de los dominios variables tal como se describe en Brinkmann et al., 1993, Proc. Natl. Acad. Sci. U.S.A. 90: 7538-42. Estas posiciones han demostrado estar conservadas estructuralmente dentro de los pliegues de anticuerpos y, por lo tanto, son tolerables de la sustitución de cisteínas sin interferir en la integridad de los dominios individuales.
Tal como se muestra en la Tabla 15, construcciones de CODV y CODV-Ig en las que se introdujeron residuos cisteína en las posiciones Kabat 100 para la cadena ligera y 44 para la cadena pesada en cada uno de los dominios variables tenían temperaturas de fusión más altas que las construcciones de CODV y CODV-Ig, en las que los residuos cisteína no se introdujeron en estas posiciones (véase, p. ej., Lote de N°s de ID 704 y 706 y Lote de N°s de ID 713 y 714).
1. Mediciones de Termoestabilidad de Variantes de CODV y TBTI
Los puntos de fusión (Tm) de variantes de CODV y TBTI se determinaron utilizando fluorimetría de exploración diferencial (DSF). Las muestras se diluyeron en tampón D-PBS (Invitrogen) a una concentración final de 0,2 pg/pl y
se añadieron a 2 |jl de una disolución concentrada 40x de colorante SYPRO-Orange (Invitrogen) en D-PBS en placas de 96 pocillos con semi-faldón blancas. Todas las mediciones se realizaron por duplicado utilizando un instrumento de PCR en tiempo real MyiQ2 (Biorad). Los valores de Tm fueron extraídos de la primera derivada negativa de las curvas de fusión utilizando el Software iQ5 v2.1.
A continuación, se examinó el efecto de introducir residuos cisteína directamente en los enlazadores o dentro de la región variable. En este ejemplo, el Lote de N° de ID 204 (del Ejemplo 7 y la Tabla 8 ) se utilizó como proteína de unión CODV-Ig modelo, y la cisteína fue sustituida por glicina en L i, L3 , o la región variable sobre la base del modelo tridimensional. Tal como se muestra en la Tabla 16 que figura más adelante, los resultados indican cómo la introducción de pares de cisteína afectaría al rendimiento y a la agregación. Las mutaciones previstas fueron modeladas para comprobar si los enlaces disulfuro se formaron correctamente y la geometría correcta se mantuvo para los enlazadores y su entorno en los modelos. No obstante, el Lote de N° de ID 808 mostró un buen rendimiento y poca agregación, lo que sugiere que se podría formar un puente cisteína adecuada.
Tabla 14. Efecto de la Estabilización del Puente Disulfuro sobre CODV-Ig

Tabla 15. Efecto de la Estabilización del Puente Disulfuro sobre CODV-Ig

Tabla 16A. Efecto de la Estabilización del Puente Disulfuro sobre CODV-Ig


Tabla 16B. Efecto de la Estabilización del Puente Disulfuro sobre CODV-Ig

Claims (16)
1. Una proteína de unión similar a anticuerpo que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno capaces de unirse específicamente a una o más dianas antigénicas, en donde dos cadenas polipeptídicas tienen una estructura representada por la fórmula:
VL1-L1-VL2-L2-CL [I]
y dos cadenas polipéptídicas tienen una estructura representada por la fórmula:
Vh2-L3-Vh1-L4-Ch1-Fc [II]
en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
VH1 es un primer dominio variable de cadena pesada de inmunoglobulina;
VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
CL es un dominio constante de la cadena ligera de inmunoglobulina;
CH1 es el dominio constante de la cadena pesada CH1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y CH2, CH3 son los dominios constantes de la cadena pesada de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos; en donde
la longitud de L4 es al menos dos veces la longitud de L2 ; y
la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
2. Una proteína de unión similar a anticuerpo que comprende dos cadenas polipeptídicas que forman dos sitios de unión a antígeno capaz de unirse específicamente a al menos una diana antigénica, en donde una primera cadena polipeptídica tiene una estructura representada por la fórmula:
VL1-L1-VL2-L2-CL [I]
y una segunda cadena polipéptídica tiene una estructura representada por la fórmula:
VH2-L3-VH1-L4-CH1 [II]
en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos; en donde
la longitud de L4 es al menos dos veces la longitud de L2 ; y
la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2, y los primero y segundo polipéptidos forman un par de cadena ligera-cadena pesada de entrecruzamiento.
3. La proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1-2, en donde las una o más dianas antigénicas se selecciona del grupo que consiste en B7.1, B7.2, BAFF, BlyS, C3, C5, CCL11 (eotaxina), CCL15 (MIP-ld), CCL17 (TARC), CCL19 (MIP-3b), CCL2 (MCP-1), CCL20 (MIP-3a), CCL21 (MIP-2), SLC, CCL24 (MPIF-2/eotaxina-2), CCL25 (TECK), CCL26 (eotaxina-3), CCL3 (MIP-la), CCL4 (MIP-lb), CCL5 (RANTES), CCL7 (MCP-3), CCL8 (mcp-2), CD3, CD19, CD20, CD24, CD40, CD40L, CD80, CD86, CDH1 (E-cadherina), quitinasa, CSF1 (M-CSF), CSF2 (GM-CSF), CSF3 (GCSF), CTLA4, CX3CL1 (SCYD1), CXCL12 (SDF1), CXCL13, EGFR, FCER1A, FCER2, HER2, IGF1R, IL-1, IL-12, IL13, IL15, IL17, IL18, IL1A, IL1B, IL1F10, IL1 p, IL2, IL4, IL6, IL7, IL8, IL9, IL12/23, IL22, IL23, IL25, IL27, IL35, ITGB4 (b 4 integrina), LEP (leptina), MHC clase II, TLR2, TLR4, TLR5, TNF, TNFa, TNFSF4 (ligando OX40), TNFSF5 (ligando CD40), receptores similares a Toll, TREM1, TSLP, TWEAK, XCR1 (GPR5/CCXCR1), DNGR-1(CLEC91) y HMGB1.
4. La proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1-3, en donde la proteína de unión es biespecífica y es capaz de unirse a dos dianas antigénicas diferentes, preferiblemente IL-4 e IL-13.
5. La proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1-4, en donde las dos dianas antigénicas diferentes se seleccionan del grupo que consiste en IL4 e IL13, IGF1R y HER2, IGF1R y EGFR, EGFR y HER2, BK e IL13, PDL-1 y CTLA-4, CTLA4 y MHC clase II, IL-12 e IL-18, IL-1 a e IL-1 p, TNFa e IL12/23, TNFa e IL-12p40, TNFa e IL1 p, TNFa e IL-23, e IL17 e IL23.
6. La proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1-5, en donde la proteína de unión es capaz de inhibir la función de una o más de las dianas antigénicas.
7. La proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1 -6, en donde al menos uno de los enlazadores seleccionados del grupo que consiste en L1, L2 , L3 y L4 contiene al menos un residuo cisteína.
8. Una molécula de ácido nucleico aislada que comprende una secuencia de nucleótidos que codifica la proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1 -7.
9. Un vector de expresión que comprende la molécula de ácido nucleico de la reivindicación 8.
10. Una célula huésped aislada que comprende la molécula de ácido nucleico de la reivindicación 8 o el vector de expresión de la reivindicación 9, en donde la célula huésped es preferiblemente una célula de mamífero o una célula de insecto.
11. Una composición farmacéutica que comprende un soporte farmacéuticamente aceptable y una cantidad terapéuticamente eficaz de la proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1-7.
12. Un método para producir una proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 1, y 3 a 7, que comprende expresar en una célula una o más moléculas de ácido nucleico que codifican polipéptidos que tienen estructuras representadas por las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
Vh2-Ls-Vh1-L4-Ch1-Fc [II]
en donde:
VL1 es un primer dominio variable de cadena ligera de inmunoglobulina;
VL2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
VH1 es un primer dominio variable de cadena pesada de inmunoglobulina;
VH2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
CL es un dominio constante de la cadena ligera de inmunoglobulina;
CH1 es el dominio constante de la cadena pesada CH1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y CH2 , CH3 son los dominios constantes de la cadena pesada de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vli y Vhi y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
13. Un método para producir una proteína de unión similar a anticuerpo de una cualquiera de las reivindicaciones 2 a 7, que comprende expresar en una célula una o más moléculas de ácido nucleico que codifican polipéptidos que tienen estructuras representadas por las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1 [II]
en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2 , y el polipéptido de fórmula I y el polipéptido de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
14. Un método de producir una proteína de unión similar a anticuerpo, que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, que comprende:
(a) identificar un primer dominio variable del anticuerpo que se une a un primer antígeno diana y un segundo dominio variable de anticuerpo que une a un segundo antígeno diana, conteniendo cada uno un Vl y un Vh;
(b) asignar la cadena ligera en forma de una cadena de molde;
(c) asignar el Vl del primer dominio variable del anticuerpo o el segundo dominio variable del anticuerpo como Vl1 ;
(d) asignar un Vl2, un Vh1 y un Vh2 de acuerdo con las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
Vh2-L3-Vh1-L4-Ch1-Fc [II]
(e) determinar longitudes máxima y mínima para L1, L2 , L3 y L4 ;
(f) generar las estructuras de polipéptidos de fórmulas I y II;
(g) seleccionar estructuras de polipéptidos de fórmulas I y II que se unen al primer antígeno diana y al segundo antígeno diana cuando se combinan para formar la proteína de unión similar a anticuerpo;
en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Chi es el dominio constante de la cadena pesada Ch1 de inmunoglobulina;
Fc es la región de bisagra de inmunoglobulina y Ch2 , Ch3 son los dominios constantes de la cadena pesada de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
15. Un método de producir una proteína de unión similar a anticuerpo, que comprende cuatro cadenas polipeptídicas que forman cuatro sitios de unión a antígeno, que comprende:
(a) identificar un primer dominio variable del anticuerpo que se une a un primer antígeno diana y un segundo dominio variable de anticuerpo que une a un segundo antígeno diana, conteniendo cada uno un Vl y un Vh;
(b) asignar la cadena ligera en forma de una cadena de molde;
(c) asignar el Vl del primer dominio variable del anticuerpo o el segundo dominio variable del anticuerpo como Vl1 ;
(d) asignar un Vl2, un Vh1 y un Vh2 de acuerdo con las fórmulas [I] y [II] que figuran a continuación:
VL1-L1-VL2-L2-CL [I]
VH2-L3-VH1-L4-CH1 [II]
(e) determinar longitudes máxima y mínima para L1, L2 , L3 y L4 ;
(f) generar las estructuras de polipéptidos de fórmulas I y II;
(g) seleccionar estructuras de polipéptidos de fórmulas I y II que se unen al primer antígeno diana y al segundo antígeno diana cuando se combinan para formar la proteína de unión similar a anticuerpo; en donde:
Vl1 es un primer dominio variable de cadena ligera de inmunoglobulina;
Vl2 es un segundo dominio variable de cadena ligera de inmunoglobulina;
Vh1 es un primer dominio variable de cadena pesada de inmunoglobulina;
Vh2 es un segundo dominio variable de cadena pesada de inmunoglobulina;
Cl es un dominio constante de la cadena ligera de inmunoglobulina;
Ch1 es el dominio constante de la cadena pesada Ch1 de inmunoglobulina; y
L1, L2 , L3 y L4 son enlazadores de aminoácidos;
en donde la longitud de L4 es al menos dos veces la longitud de L2 ; y
en donde la longitud de L3 es al menos dos veces la longitud de L1 ;
y en donde los enlazadores proporcionan suficiente movilidad para el emparejamiento de Vl1 y Vh1 y para el emparejamiento de Vl2 y Vh2 , y los polipéptidos de fórmula I y los polipéptidos de fórmula II forman un par de cadena ligera-cadena pesada de entrecruzamiento.
16. El método de la reivindicación 14 o 15, en donde el primer dominio variable de anticuerpo y el segundo dominio variable de anticuerpo son idénticos.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201161468276P | 2011-03-28 | 2011-03-28 | |
| FR1160311 | 2011-11-14 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2859906T3 true ES2859906T3 (es) | 2021-10-04 |
Family
ID=65657124
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16205057T Active ES2859906T3 (es) | 2011-03-28 | 2012-03-28 | Proteínas de unión similares a anticuerpos con regiones variables duales con una orientación de entrecruzamiento de la región de unión |
Country Status (10)
| Country | Link |
|---|---|
| KR (1) | KR102240802B1 (es) |
| CL (1) | CL2013002763A1 (es) |
| ES (1) | ES2859906T3 (es) |
| HR (1) | HRP20210240T1 (es) |
| HU (1) | HUE053139T2 (es) |
| IL (3) | IL249369B (es) |
| LT (1) | LT3199547T (es) |
| MX (2) | MX366923B (es) |
| PH (1) | PH12018501305A1 (es) |
| PT (1) | PT3199547T (es) |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5989830A (en) | 1995-10-16 | 1999-11-23 | Unilever Patent Holdings Bv | Bifunctional or bivalent antibody fragment analogue |
| CN101821288A (zh) * | 2007-06-21 | 2010-09-01 | 宏观基因有限公司 | 共价双抗体及其用途 |
| EP2050764A1 (en) | 2007-10-15 | 2009-04-22 | sanofi-aventis | Novel polyvalent bispecific antibody format and uses thereof |
| TW201109438A (en) * | 2009-07-29 | 2011-03-16 | Abbott Lab | Dual variable domain immunoglobulins and uses thereof |
-
2012
- 2012-03-28 ES ES16205057T patent/ES2859906T3/es active Active
- 2012-03-28 LT LTEP16205057.9T patent/LT3199547T/lt unknown
- 2012-03-28 HU HUE16205057A patent/HUE053139T2/hu unknown
- 2012-03-28 PT PT162050579T patent/PT3199547T/pt unknown
- 2012-03-28 MX MX2016000274A patent/MX366923B/es unknown
- 2012-03-28 KR KR1020197012135A patent/KR102240802B1/ko active IP Right Grant
-
2013
- 2013-09-26 CL CL2013002763A patent/CL2013002763A1/es unknown
- 2013-09-27 MX MX2019009016A patent/MX2019009016A/es unknown
-
2016
- 2016-12-04 IL IL24936916A patent/IL249369B/en active IP Right Grant
-
2018
- 2018-06-19 PH PH12018501305A patent/PH12018501305A1/en unknown
-
2020
- 2020-05-24 IL IL274870A patent/IL274870B2/en unknown
- 2020-05-24 IL IL274876A patent/IL274876A/en unknown
-
2021
- 2021-02-11 HR HRP20210240TT patent/HRP20210240T1/hr unknown
Also Published As
| Publication number | Publication date |
|---|---|
| IL274870A (en) | 2020-07-30 |
| HUE053139T2 (hu) | 2021-06-28 |
| IL249369B (en) | 2019-11-28 |
| IL249369A0 (en) | 2017-02-28 |
| PT3199547T (pt) | 2021-02-02 |
| HRP20210240T1 (hr) | 2021-04-02 |
| PH12018501305A1 (en) | 2020-01-27 |
| MX2019009016A (es) | 2019-09-10 |
| IL274876A (en) | 2020-07-30 |
| IL274870B1 (en) | 2023-01-01 |
| RU2019122155A (ru) | 2020-03-16 |
| LT3199547T (lt) | 2021-02-25 |
| KR20190049902A (ko) | 2019-05-09 |
| IL274870B2 (en) | 2023-05-01 |
| KR102240802B1 (ko) | 2021-04-16 |
| MX366923B (es) | 2019-07-31 |
| CL2013002763A1 (es) | 2014-03-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7003101B2 (ja) | 交差結合領域の配向性を有する二重可変領域抗体様結合タンパク質 | |
| ES2859906T3 (es) | Proteínas de unión similares a anticuerpos con regiones variables duales con una orientación de entrecruzamiento de la región de unión | |
| RU2823693C2 (ru) | Антитело-подобные связывающие белки с двойными вариабельными областями, имеющие ориентацию связывающих областей крест-накрест | |
| NZ616174B2 (en) | Dual variable region antibody-like binding proteins having cross-over binding region orientation |