EP1016072B1 - Procede et dispositif de debruitage d'un signal de parole numerique - Google Patents
Procede et dispositif de debruitage d'un signal de parole numerique Download PDFInfo
- Publication number
- EP1016072B1 EP1016072B1 EP98943999A EP98943999A EP1016072B1 EP 1016072 B1 EP1016072 B1 EP 1016072B1 EP 98943999 A EP98943999 A EP 98943999A EP 98943999 A EP98943999 A EP 98943999A EP 1016072 B1 EP1016072 B1 EP 1016072B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- signal
- speech signal
- noise
- frame
- spectral
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 238000000034 method Methods 0.000 title claims description 49
- 230000003595 spectral effect Effects 0.000 claims description 81
- 230000000873 masking effect Effects 0.000 claims description 28
- 230000006870 function Effects 0.000 claims description 22
- 230000001143 conditioned effect Effects 0.000 claims description 18
- 238000004458 analytical method Methods 0.000 claims description 14
- 238000012545 processing Methods 0.000 claims description 14
- 238000005070 sampling Methods 0.000 claims description 12
- 230000001755 vocal effect Effects 0.000 claims description 8
- 230000008447 perception Effects 0.000 claims description 6
- 230000007423 decrease Effects 0.000 claims description 4
- 230000003247 decreasing effect Effects 0.000 claims description 2
- 230000000717 retained effect Effects 0.000 claims 2
- 230000001419 dependent effect Effects 0.000 claims 1
- 230000007774 longterm Effects 0.000 description 19
- 230000000694 effects Effects 0.000 description 15
- 230000004044 response Effects 0.000 description 14
- 238000001514 detection method Methods 0.000 description 10
- 238000001228 spectrum Methods 0.000 description 9
- 238000004364 calculation method Methods 0.000 description 8
- 238000004891 communication Methods 0.000 description 8
- 230000008569 process Effects 0.000 description 7
- 230000003750 conditioning effect Effects 0.000 description 6
- 230000008859 change Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 238000004422 calculation algorithm Methods 0.000 description 4
- 238000012937 correction Methods 0.000 description 4
- 238000012935 Averaging Methods 0.000 description 3
- 238000011084 recovery Methods 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 230000000630 rising effect Effects 0.000 description 3
- 239000000523 sample Substances 0.000 description 3
- 230000007480 spreading Effects 0.000 description 3
- 238000000528 statistical test Methods 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 210000000721 basilar membrane Anatomy 0.000 description 2
- 238000000354 decomposition reaction Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000002964 excitative effect Effects 0.000 description 2
- 230000005534 acoustic noise Effects 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000001427 coherent effect Effects 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 230000002542 deteriorative effect Effects 0.000 description 1
- 230000000916 dilatatory effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 210000004704 glottis Anatomy 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L21/0232—Processing in the frequency domain
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0264—Noise filtering characterised by the type of parameter measurement, e.g. correlation techniques, zero crossing techniques or predictive techniques
Definitions
- the present invention relates to techniques digital denoising of speech signals. She relates more particularly to denoising by nonlinear spectral subtraction.
- This technique allows acceptable denoising to be obtained for strongly voiced signals, but completely distorts the speech signal. Faced with relatively coherent noise, such as that caused by the contact of car tires or the clicking of an engine, the noise may be more easily predictable as the unvoiced speech signal. We then tend to project the speech signal into part of the noise vector space.
- the method does disregards the speech signal, especially unvoiced speech areas where predictability is scaled down.
- predict the speech signal from of a reduced set of parameters does not allow taking counts all the intrinsic richness of speech. We understands here the limits of techniques based only on mathematical considerations forgetting the special character of speech.
- a main object of the present invention is to propose a new denoising technique that takes take into account the characteristics of speech perception through the human ear, allowing denoising effective without deteriorating speech perception.
- a method as set out in claim 1 and a device as set out in claim 19 are provided.
- the second subtracted quantity can in particular be limited to the fraction of the estimate increased by the corresponding spectral component of the noise which exceeds the masking curve. This way of proceeding is based on the observation that it is enough to denoise the frequencies of audible noise. Conversely, there is no point in eliminating noise that is masked by speech.
- the overestimation of the spectral envelope of the noise is generally desirable so that the estimate increased thus obtained is robust to sudden variations noise.
- this overestimation has usually the downside of distorting the speech signal when it becomes too large. This has the effect to affect the voiced character of the speech signal in removing some of its predictability.
- This disadvantage is very inconvenient in the conditions of the telephony, because it is during the voicing areas that the speech signal is then the most energetic.
- the invention allows greatly reduce this drawback.
- the denoising system shown in FIG. 1 processes a digital speech signal s.
- the signal frame is transformed in the frequency domain by a module 11 applying a conventional fast Fourier transform (TFR) algorithm to calculate the module of the signal spectrum.
- TFR fast Fourier transform
- the frequency resolution available at the output of the fast Fourier transform is not used, but a lower resolution, determined by a number I of frequency bands covering the band [0 , F e / 2] of the signal.
- a module 12 calculates the respective averages of the spectral components S n, f of the speech signal in bands, for example by a uniform weighting such that:
- This averaging reduces the fluctuations between the bands by averaging the noise contributions in these bands, which will decrease the variance of the estimator of noise. In addition, this averaging allows a large reduction of the complexity of the system.
- the averaged spectral components S n, i are addressed to a voice activity detection module 15 and to a noise estimation module 16. These two modules 15, 16 operate jointly, in the sense that degrees of vocal activity ⁇ n, i measured for the different bands by the module 15 are used by the module 16 to estimate the long-term energy of the noise in the different bands, while these long-term estimates B and n, i are used by module 15 to carry out a priori denoising of the speech signal in the different bands to determine the degrees of vocal activity ⁇ n, i .
- modules 15 and 16 can correspond to the flowcharts represented in the figures 2 and 3.
- the module 15 proceeds a priori to denoising the speech signal in the different bands i for the signal frame n.
- This a priori denoising is carried out according to a conventional process of non-linear spectral subtraction from noise estimates obtained during one or more previous frames.
- ⁇ 1 and ⁇ 2 are delays expressed in number of frames ( ⁇ 1 ⁇ 1, ⁇ 2 ⁇ 0), and ⁇ '/ n, i is a noise overestimation coefficient whose determination will be explained later.
- the spectral components pp n, i are calculated according to: where ⁇ p i is a floor coefficient close to 0, conventionally used to prevent the spectrum of the denoised signal from taking negative or too low values which would cause musical noise.
- Steps 17 to 20 therefore essentially consist in subtracting from the spectrum of the signal an estimate, increased by the coefficient ⁇ ' n - ⁇ 1, i , from the spectrum of noise estimated a priori.
- the module 15 calculates, for each band i (0 ⁇ i ⁇ I), a quantity ⁇ E n, i representing the short-term variation of the energy of the noise-suppressed signal in the band i, as well as long-term value E n, i of the energy of the denoised signal in band i.
- step 25 the quantity ⁇ E n, i is compared with a threshold ⁇ 1. If the threshold ⁇ 1 is not reached, the counter b i is incremented by one unit in step 26.
- step 27 the long-term estimator ba i is compared to the value of the smoothed energy E n, i . If ba i ⁇ E n, i , the estimator ba i is taken equal to the smoothed value E n, i in step 28, and the counter b i is reset to zero.
- the quantity ⁇ i which is taken equal to the ratio ba i / E n, i (step 36), is then equal to 1.
- step 27 shows that ba i ⁇ E n, i
- the counter b i is compared with a limit value bmax in step 29. If b i > bmax, the signal is considered to be too stationary to support vocal activity.
- Bm represents an update coefficient between 0.90 and 1. Its value differs depending on the state of a voice activity detection automaton (steps 30 to 32). This state ⁇ n-1 is that determined during the processing of the previous frame.
- the coefficient Bm takes a value Bmp very close to 1 so that the noise estimator is very slightly updated in the presence of speech. Otherwise, the coefficient Bm takes a lower value Bms, to allow a more significant update of the noise estimator in silence phase.
- the difference ba i -bi i between the long-term estimator and the internal noise estimator is compared to a threshold ⁇ 2. If the threshold ⁇ 2 is not reached, the long-term estimator ba i is updated with the value of the internal estimator bi i in step 35. Otherwise, the long-term estimator ba i remains unchanged . This avoids that sudden variations due to a speech signal lead to an update of the noise estimator.
- the module 15 After having obtained the quantities ⁇ i , the module 15 proceeds to the voice activity decisions in step 37.
- the module 15 first updates the state of the detection automaton according to the quantity ⁇ 0 calculated for l of the signal band.
- the new state ⁇ n of the automaton depends on the previous state ⁇ n-1 and on ⁇ 0 , as shown in Figure 4.
- the module 15 also calculates the degrees of vocal activity ⁇ n, i in each band i ⁇ 1.
- This function has for example the appearance shown in FIG. 5.
- Module 16 calculates the band noise estimates, which will be used in the denoising process, using the successive values of the components S n, i and the degrees of voice activity ⁇ n, i . This corresponds to steps 40 to 42 of FIG. 3.
- step 40 it is determined whether the voice activity detection machine has just gone from the rising state to the speaking state. If so, the last two estimates B and n -1, i and B and n -2, i Previously calculated for each band i ⁇ 1 are corrected according to the value of the previous estimate B and n -3, i .
- step 42 the module 16 updates the noise estimates per band according to the formulas: where ⁇ B denotes a forgetting factor such as 0 ⁇ B ⁇ 1.
- Formula (6) shows how the degree of non-binary vocal activity ⁇ n, i is taken into account.
- the long-term noise estimates B and n, i are overestimated, by a module 45 (FIG. 1), before proceeding to denoising by nonlinear spectral subtraction.
- Module 45 calculates the overestimation coefficient ⁇ '/ n, i previously mentioned, as well as an increased estimate B and ' / n, i which essentially corresponds to ⁇ '/ n, i . B and n, i .
- the organization of the overestimation module 45 is shown in FIG. 6.
- the enhanced estimate B and '/ n, i is obtained by combining the long-term estimate B and n, i and a measure ⁇ B max / n, i the variability of the noise component in band i around its long-term estimate.
- this combination is essentially a simple sum made by an adder 46. It could also be a weighted sum.
- the measure ⁇ B max / n, i of the noise variability reflects the variance of the noise estimator. It is obtained as a function of the values of S n, i and of B and n, i calculated for a certain number of previous frames on which the speech channel does not present any vocal activity in the band i. It is a function of deviations S nk, i - B nk, i calculated for a number K of frames of silence (nk ⁇ n). In the example shown, this function is simply the maximum (block 50).
- the degree of voice activity ⁇ n, i is compared to a threshold (block 51) to decide whether the difference S or - B or , calculated in 52-53, may or may not be loaded into a queue 54 of K locations organized in first-in-first-out (FIFO) mode. If ⁇ n, i does not exceed the threshold (which can be equal to 0 if the function g () has the form of FIG. 5), the FIFO 54 is not supplied, while it is in the opposite case. The maximum value contained in FIFO 54 is then provided as a measure of variability ⁇ B max / n, i .
- the measure of variability ⁇ B max / n, i can, as a variant, be obtained as a function of the values S n, f (and not S n, i ) and B and n, i .
- FIFO 54 does not contain S nk, i - B nk, i for each of the bands i, but rather
- the enhanced estimator B and '/ n, i provides excellent robustness to the musical noises of the denoising process.
- a first phase of the spectral subtraction is carried out by the module 55 shown in FIG. 1.
- This phase provides, with the resolution of the bands i (1 i i I I), the frequency response H 1 / n, i of first denoising filter, as a function of the components S n, i and B and n, i and the overestimation coefficients ⁇ '/ n, i .
- the coefficient ⁇ 1 / i represents, like the coefficient ⁇ p i of formula (3), a floor conventionally used to avoid negative or too low values of the denoised signal.
- the overestimation coefficient ⁇ ' n, i could be replaced in formula (7) by another coefficient equal to a function of ⁇ ' n, i and an estimate of the signal-to-noise ratio (for example S n, i / B and n, i ), this function decreasing according to the estimated value of the signal-to-noise ratio.
- This function is then equal to ⁇ ' n, i for the lowest values of the signal-to-noise ratio. Indeed, when the signal is very noisy, it is a priori not useful to reduce the overestimation factor.
- this function decreases to zero for the highest values of the signal / noise ratio. This protects the most energetic areas of the spectrum, where the speech signal is most significant, the amount subtracted from the signal then tending towards zero.
- This strategy can be refined by applying it selectively to frequency harmonics pitch of the speech signal when it has voice activity.
- a second denoising phase is carried out by a module 56 for protecting harmonics.
- the module 57 can apply any known method of analysis of the speech signal of the frame to determine the period T p , expressed as an integer or fractional number of samples, for example a linear prediction method.
- the protection provided by the module 56 may consist in carrying out, for each frequency f belonging to a band i:
- H 2 / n, f 1
- the quantity subtracted from the component S n, f will be zero.
- the floor coefficients ⁇ 2 / i express the fact that certain harmonics of the tone frequency f p can be masked by noise, so that n protecting them is useless.
- This protection strategy is preferably applied for each of the frequencies closest to the harmonics of f p , that is to say for any arbitrary integer.
- condition (9) the difference between the ⁇ -th harmonic of the real tonal frequency is its estimate ⁇ ⁇ f p (condition (9)) can go up to ⁇ ⁇ ⁇ ⁇ f p / 2.
- this difference can be greater than the spectral half-resolution ⁇ f / 2 of the Fourier transform.
- the corrected frequency response H 2 / n, f can be equal to 1 as indicated above, which corresponds to the subtraction of a zero quantity in the context of spectral subtraction, that is to say ie full protection of the frequency in question. More generally, this corrected frequency response H 2 / n, f could be taken equal to a value between 1 and H 1 / n, f depending on the degree of protection desired, which corresponds to the subtraction of an amount less than which would be subtracted if the frequency in question was not protected.
- S 2 / n, f H 2 n, f .
- S n, f H 2 n, f .
- This signal S 2 / n, f is supplied to a module 60 which calculates, for each frame n, a masking curve by applying a psychoacoustic model of auditory perception by the human ear.
- the masking phenomenon is a principle known from functioning of the human ear. When two frequencies are heard simultaneously, it is possible that one of the two is no longer audible. We say then that it is hidden.
- the masking curve is seen as the convolution of the spectral spreading function of the basilar membrane in the bark domain with the excitatory signal, constituted in the present application by the signal S 2 / n, f .
- the spectral spreading function can be modeled as shown in Figure 7.
- R q depends on the more or less voiced character of the signal.
- ⁇ designates a degree of voicing of the speech signal, varying between zero (no voicing) and 1 (strongly voiced signal).
- the denoising system also includes a module 62 which corrects the frequency response of the denoising filter, as a function of the masking curve M n, q calculated by the module 60 and of the increased estimates B and '/ n, i calculated by the module 45.
- Module 62 decides the level of denoising which must really be reached.
- the new response H 3 / n, f for a frequency f belonging to the band i defined by the module 12 and to the bark band q, thus depends on the relative difference between the increased estimate B and '/ n, i of the corresponding spectral component of the noise and the masking curve M n, q , as follows:
- the quantity subtracted from a spectral component S n, f , in the process of spectral subtraction having the frequency response H 3 / n, f is substantially equal to the minimum between on the one hand the quantity subtracted from this spectral component in the spectral subtraction process having the frequency response H 2 / n, f , and on the other hand the fraction of the increased estimate B and '/ n, i of the corresponding spectral component of the noise which, if if necessary, exceeds the masking curve M n, q .
- FIG. 8 illustrates the principle of the correction applied by the module 62. It schematically shows an example of masking curve M n, q calculated on the basis of the spectral components S 2 / n, f of the noise-suppressed signal, as well as the estimation plus B and '/ n, i of the noise spectrum.
- the quantity finally subtracted from the components S n, f will be that represented by the hatched areas, that is to say limited to the fraction of the increased estimate B and '/ n, i of the spectral components of the noise which exceeds the curve masking.
- This subtraction is carried out by multiplying the frequency response H 3 / n, f of the denoising filter by the spectral components S n, f of the speech signal (multiplier 64).
- TFRI inverse fast Fourier transform
- FIG. 9 shows a preferred embodiment of a denoising system implementing the invention.
- This system comprises a certain number of elements similar to corresponding elements of the system of FIG. 1, for which the same reference numbers have been used.
- modules 10, 11, 12, 15, 16, 45 and 55 provide in particular the quantities S n, i , B and n, i , ⁇ '/ n, i,, B and ' / n, i and H 1 / n, f to perform selective denoising.
- the frequency resolution of the fast Fourier transform 11 is a limitation of the system of FIG. 1.
- the frequency causing protection by the module 56 is not necessarily the precise tonal frequency f p , but the frequency closest to it in the discrete spectrum. In some cases, it is then possible to protect harmonics relatively far from that of the tone frequency.
- the system of FIG. 9 overcomes this drawback thanks to an appropriate conditioning of the speech signal.
- the sampling frequency of the signal is modified so that the period 1 / f p covers exactly an integer number of sample times of the conditioned signal.
- This size N is usually a power of 2 for putting implementation of the TFR. It is 256 in the example considered.
- This choice is made by a module 70 according to the value of the delay T p supplied by the harmonic analysis module 57.
- the module 70 provides the ratio K between the sampling frequencies to three frequency change modules 71, 72, 73 .
- the module 71 is used to transform the values S n, i , B and n, i , ⁇ '/ n, i,, B and ' / n, i and H 1 / n, f , relating to the bands i defined by the module 12, in the scale of modified frequencies (sampling frequency f e ). This transformation consists simply in dilating the bands i in the factor K. The values thus transformed are supplied to the module 56 for protecting harmonics.
- the module 72 performs the oversampling of the frame of N samples provided by the windowing module 10.
- the conditioned signal frame supplied by the module 72 includes KN samples at the frequency f e . These samples are sent to a module 75 which calculates their Fourier transform.
- the two blocks therefore have an overlap of (2-K) ⁇ 100%.
- the autocorrelations A (k) are calculated by a module 76, for example according to the formula:
- a module 77 then calculates the normalized entropy H, and supplies it to module 60 for the calculation of the masking curve (see SA McClellan et al: “Spectral Entropy: an Alternative Indicator for Rate Allocation?”, Proc. ICASSP'94 , pages 201-204):
- the normalized entropy H constitutes a measurement of voicing very robust to noise and variations in the tonal frequency.
- the correction module 62 operates in the same way as that of the system in FIG. 1, taking into account the overestimated noise B and '/ n, i rescaled by the frequency change module 71. It provides the response in frequency H 3 / n, f of the final denoising filter, which is multiplied by the spectral components S n, f of the signal conditioned by the multiplier 64. The components S 3 / n, f which result therefrom are brought back into the time domain by the TFRI 65 module. At the output of this TFRI 65, a module 80 combines, for each frame, the two signal blocks resulting from the processing of the two overlapping blocks delivered by the TFR 75. This combination can consist of a weighted sum Hamming of samples, to form a denoised conditioned signal frame of KN samples.
- the management module 82 controls the windowing module 10 so that the overlap between the current frame and the next one corresponds to NM. This recovery of NM samples will be required in the recovery sum carried out by the module 66 during the processing of the next frame.
- the tone frequency is estimated in an average way on the frame.
- the tonal frequency can vary some little over this period. It is possible to take into account these variations in the context of the present invention, in conditioning the signal so as to obtain artificially a constant tone frequency in the frame.
- the analysis module 57 harmonic provides the time intervals between the consecutive breaks in speech signal due to closures of the glottis of the intervening speaker for the duration of the frame.
- Usable methods to detect such micro-ruptures are well known in the area of harmonic signal analysis lyrics.
- the principle of these methods is to perform a statistical test between two models, one in the short term and the other in the long term. Both models are adaptive linear prediction models.
- the value of this statistical test w m is the cumulative sum of the posterior likelihood ratio of two distributions, corrected by the Kullback divergence. For a distribution of residuals having a Gaussian statistic, this value w m is given by: where e 0 / m and ⁇ 2/0 represent the residue calculated at the time of the sample m of the frame and the variance of the long-term model, e 1 / m and ⁇ 2/1 likewise representing the residue and the variance of the short term model. The closer the two models are, the more the value w m of the statistical test is close to 0. On the other hand, when the two models are distant from each other, this value w m becomes negative, which indicates a break R of the signal.
- FIG. 10 thus shows a possible example of evolution of the value w m , showing the breaks R of the speech signal.
- FIG. 11 shows the means used to calculate the conditioning of the signal in the latter case.
- the harmonic analysis module 57 is produced so as to implement the above analysis method, and to provide the intervals t r relative to the signal frame produced by the module 10.
- These oversampling reports K r are supplied to the frequency change modules 72 and 73, so that the interpolations are carried out with the sampling ratio K r over the corresponding time interval t r .
- the largest T p of the time intervals t r supplied by the module 57 for a frame is selected by the module 70 (block 91 in FIG. 11) to obtain a torque p, ⁇ as indicated in table I.
- This embodiment of the invention also involves an adaptation of the window management module 82.
- the number M of samples of the denoised signal to be saved on the current frame here corresponds to an integer number of consecutive time intervals t r between two glottal breaks (see FIG. 10). This arrangement avoids the problems of phase discontinuity between frames, while taking into account the possible variations of the time intervals t r on a frame.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Description
- on calcule des composantes spectrales du signal de parole sur chaque trame ;
- on calcule pour chaque trame des estimations majorées de composantes spectrales du bruit compris dans le signal de parole ;
- on effectue une soustraction spectrale comportant au moins une première étape de soustraction
- le calcul d'une courbe de masquage en appliquant un modèle de perception auditive à partir des composantes spectrales du premier signal débruité ;
- la comparaison des estimations majorées des composantes spectrales du bruit pour la trame à la courbe de masquage calculée ; et
- une seconde étape de soustraction dans laquelle on soustrait respectivement, de chaque composante spectrale du signal de parole sur la trame, une seconde quantité dépendant de paramètres incluant un écart entre l'estimation majorée de la composante spectrale correspondante du bruit et la courbe de masquage calculée.
- la figure 1 est un schéma synoptique d'un système de débruitage mettant en oeuvre la présente invention ;
- les figures 2 et 3 sont des organigrammes de procédures utilisées par un détecteur d'activité vocale du système de la figure 1 ;
- la figure 4 est un diagramme représentant les états d'un automate de détection d'activité vocale ;
- la figure 5 est un graphique illustrant les variations d'un degré d'activité vocale ;
- la figure 6 est un schéma synoptique d'un module de surestimation du bruit du système de la figure 1 ;
- la figure 7 est un graphique illustrant le calcul d'une courbe de masquage ;
- la figure 8 est un graphique illustrant l'exploitation des courbes de masquage dans le système de la figure 1 ;
- la figure 9 est un schéma synoptique d'un autre svstème de débruitage mettant en oeuvre la présente invention ;
- la figure 10 est un graphique illustrant une méthode d'analyse harmonique utilisable dans un procédé selon l'invention ; et
- la figure 11 montre partiellement une variante du schéma synoptique de la figure 9.









| 500 Hz < fp < 1000 Hz | 8 < Tp < 16 | p = 16 | α = 16 |
| 250 Hz < fp < 500 Hz | 16 < Tp < 32 | p = 32 | α = 8 |
| 125 Hz < fp < 250 Hz | 32 < Tp < 64 | p = 64 | α = 4 |
| 62,5 Hz < fp < 125 Hz | 64 < Tp < 123 | p = 128 | α = 2 |
| 31,25 Hz < fp < 62,5 Hz | 128 < Tp < 256 | p = 256 | α = 1 |



Claims (19)
- Procédé de débruitage d'un signal de parole numérique (s) traité par trames successives, dans lequel :caractérisé en ce que la soustraction spectrale comporte en outre les étapes suivantes :on calcule des composantes spectrales (Sn,f, Sn,i) du signal de parole sur chaque trame ;on calcule pour chaque trame des estimations majorées (B and ' / n,i) de composantes spectrales du bruit compris dans le signal de parole ;on effectue une soustraction spectrale comportant au moins une première étape de soustraction dans laquelle on soustrait respectivement, de chaque composante spectrale (Sn,f) du signal de parole sur la trame, une première quantité dépendant de paramètres incluant l'estimation majorée (B and ' / n,i) de la composante spectrale correspondante du bruit pour ladite trame, de manière à obtenir des composantes spectrales (S 2 / n,f) d'un premier signal débruité,le calcul d'une courbe de masquage (Mn,q) en appliquant un modèle de perception auditive à partir des composantes spectrales (S 2 / n,f) du premier signal débruité ;la comparaison des estimations majorées (B and ' / n,i) des composantes spectrales du bruit pour la trame à la courbe de masquage calculée (Mn,q) ; etune seconde étape de soustraction dans laquelle on soustrait respectivement, de chaque composante spectrale (Sn,f) du signal de parole sur la trame, une seconde quantité dépendant de paramètres incluant un écart entre l'estimation majorée de la composante spectrale correspondante du bruit et la courbe de masquage calculée.
- Procédé selon la revendication 1, dans lequel ladite seconde quantité relative à une composante spectrale (Sn,f) du signal de parole sur la trame est sensiblement égale au minimum entre la première quantité correspondante et la fraction de l'estimation majorée (B and ' / n,i) de la composante spectrale correspondante du bruit qui dépasse la courbe de masquage (Mn,q).
- Procédé selon la revendication 1 ou 2, dans lequel on effectue une analyse harmonique du signal de parole pour estimer une fréquence tonale (fp) du signal de parole sur chaque trame où il présente une activité vocale.
- Procédé selon la revendication 3, dans lequel les paramètres dont dépendent les premières quantités soustraites incluent la fréquence tonale estimée (fp).
- Procédé selon la revendication 4, dans lequel la première quantité soustraite d'une composante spectrale donnée (Sn,f) du signal de parole est plus faible si ladite composante spectrale correspond à la fréquence la plus proche d'un multiple entier de la fréquence tonale estimée (fp) que si ladite composante spectrale ne correspond pas à la fréquence la plus proche d'un multiple entier de la fréquence tonale estimée.
- Procédé selon la revendication 4 ou 5, dans lequel les quantités respectivement soustraites des composantes spectrales (Sn,f) du signal de parole correspondant aux fréquences les plus proches des multiples entiers de la fréquence tonale estimée (fp) sont sensiblement nulles.
- Procédé selon l'une quelconque des revendications 3 à 6, dans lequel, après avoir estimé la fréquence tonale (fp) du signal de parole sur une trame, on conditionne le signal de parole de la trame en le suréchantillonnant à une fréquence de suréchantillonnage (fe) multiple de la fréquence tonale estimée, et on calcule les composantes spectrales (Sn,f) du signal de parole sur la trame sur la base du signal conditionné (s') pour leur soustraire lesdites quantités.
- Procédé selon la revendication 7, dans lequel on calcule des composantes spectrales (Sn,f) du signal de parole en distribuant le signal conditionné (s') par blocs de N échantillons soumis a une transformation dans le domaine fréquentiel, et dans lequel le rapport (p) entre la fréquence de suréchantillonnage (fe) et la fréquence tonale estimée est un diviseur du nombre N.
- Procédé selon la revendication 7 ou 8, dans lequel on estime un degré de voisement (χ) du signal de parole sur la trame à partir d'un calcul de l'entropie (H) de l'autocorrelation des composantes spectrales calculées sur la base du signal conditionné.
- Procédé selon la revendication 9, dans lequel lesdites composantes spectrales (S 2 / n,f) dont on calcule l'autocorrelation (H) sont celles calculées sur la base du signal conditionné (s') après soustraction desdites premières quantités.
- Procédé selon la revendication 9 ou 10, dans lequel le degré de voisement (χ) est mesuré à partir une entropie normalisée H de la forme :où N est le nombre d'échantillons utilisés pour calculer les composantes spectrales (Sn,f) sur la base du signal conditionné (s'), et A(k) est l'autocorrelation normalisée définie par :
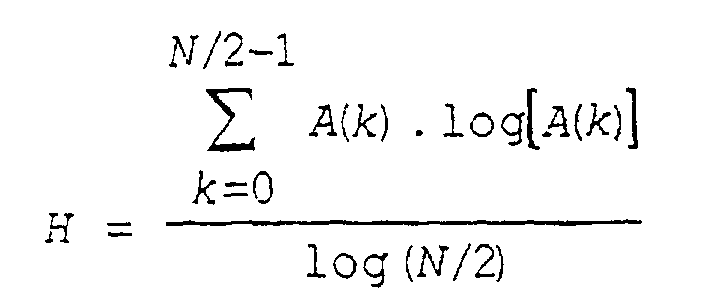 S 2 / n,f désignant la composante spectrale de rang f calculée sur la base du signal conditionné.
S 2 / n,f désignant la composante spectrale de rang f calculée sur la base du signal conditionné.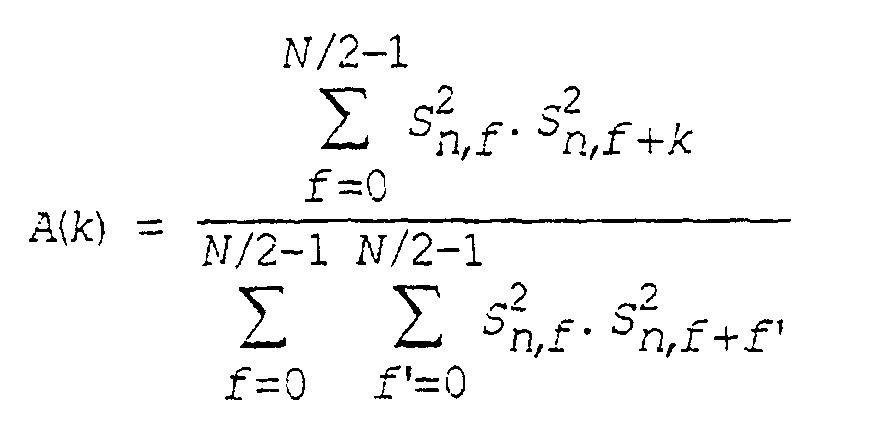
- Procédé selon la revendication 11, dans lequel le calcul de la courbe de masquage (Mn,q) fait intervenir le degré de voisement (χ) mesuré par l'entropie normalisée H.
- Procédé selon l'une quelconque des revendications 3 à 12, dans lequel, après le traitement de chaque trame, on conserve, parmi les échantillons du signal de parole débruité fournis par ce traitement, un nombre d'échantillons (M) égal à un multiple entier de fois le rapport (Tp) entre la fréquence d'échantillonnage (Fe) et la fréquence tonale estimée (fp).
- Procédé selon l'une quelconque des revendications 3 à 12, dans lequel l'estimation de la fréquence tonale du signal de parole sur une trame comporte les étapes suivantes :on estime des intervalles de temps (tr) entre deux ruptures consécutives (R) du signal attribuables à des fermetures de la glotte du locuteur intervenant pendant la durée de la trame, la fréquence tonale estimée étant inversement proportionnelle auxdits intervalles de temps ;on interpole le signal de parole dans lesdits intervalles de temps, afin que le signal conditionné (s') résultant de cette interpolation présente un intervalle de temps constant entre deux ruptures consécutives.
- Procédé selon la revendication 14, àans lequel, après le traitement de chaque trame, on conserve, parmi les échantillons du signal de parole débruité fournis par ce traitement, un nombre d'échantillons (M) correspondant à un nombre entier d'intervalles de temps estimés (tr).
- Procédé selon l'une quelconque des revendications précédentes, dans lequel on estime dans le domaine spectral des valeurs d'un rapport signal-sur-bruit que présente le signal de parole (s) sur chaque trame, et dans lequel les paramètres dont dépendent les premières quantités soustraites incluent les valeurs estimées du rapport signal-sur-bruit, la première quantité soustraite de chaque composante spectrale (Sn,f) du signal de parole sur la trame étant une fonction décroissante de la valeur estimée correspondante du rapport signal-sur-bruit.
- Procédé selon la revendication 16, dans lequel ladite fonction décroít vers zéro pour les valeurs les plus élevées du rapport signal-sur-bruit.
- Procédé selon l'une quelconque des revendications précédentes, dans lequel on applique au résultat de la soustraction spectrale une transformation vers le domaine temporel pour construire un signal de parole débruité (s3).
- Dispositif de débruitage d'un signal de parole, comprenant des moyens de traitement adaptés pour mettre en oeuvre un procédé selon l'une quelconque des revendications précédentes.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9711643A FR2768547B1 (fr) | 1997-09-18 | 1997-09-18 | Procede de debruitage d'un signal de parole numerique |
| FR9711643 | 1997-09-18 | ||
| PCT/FR1998/001980 WO1999014738A1 (fr) | 1997-09-18 | 1998-09-16 | Procede de debruitage d'un signal de parole numerique |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP1016072A1 EP1016072A1 (fr) | 2000-07-05 |
| EP1016072B1 true EP1016072B1 (fr) | 2002-01-16 |
Family
ID=9511230
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP98943999A Expired - Lifetime EP1016072B1 (fr) | 1997-09-18 | 1998-09-16 | Procede et dispositif de debruitage d'un signal de parole numerique |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US6477489B1 (fr) |
| EP (1) | EP1016072B1 (fr) |
| AU (1) | AU9168998A (fr) |
| CA (1) | CA2304571A1 (fr) |
| DE (1) | DE69803203T2 (fr) |
| FR (1) | FR2768547B1 (fr) |
| WO (1) | WO1999014738A1 (fr) |
Families Citing this family (44)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6510408B1 (en) * | 1997-07-01 | 2003-01-21 | Patran Aps | Method of noise reduction in speech signals and an apparatus for performing the method |
| US6549586B2 (en) | 1999-04-12 | 2003-04-15 | Telefonaktiebolaget L M Ericsson | System and method for dual microphone signal noise reduction using spectral subtraction |
| US6717991B1 (en) | 1998-05-27 | 2004-04-06 | Telefonaktiebolaget Lm Ericsson (Publ) | System and method for dual microphone signal noise reduction using spectral subtraction |
| FR2797343B1 (fr) * | 1999-08-04 | 2001-10-05 | Matra Nortel Communications | Procede et dispositif de detection d'activite vocale |
| JP3454206B2 (ja) * | 1999-11-10 | 2003-10-06 | 三菱電機株式会社 | 雑音抑圧装置及び雑音抑圧方法 |
| US6804640B1 (en) * | 2000-02-29 | 2004-10-12 | Nuance Communications | Signal noise reduction using magnitude-domain spectral subtraction |
| US6766292B1 (en) * | 2000-03-28 | 2004-07-20 | Tellabs Operations, Inc. | Relative noise ratio weighting techniques for adaptive noise cancellation |
| JP2002221988A (ja) * | 2001-01-25 | 2002-08-09 | Toshiba Corp | 音声信号の雑音抑圧方法と装置及び音声認識装置 |
| WO2001047335A2 (fr) * | 2001-04-11 | 2001-07-05 | Phonak Ag | Procede pour eliminer des composantes de signaux parasites dans un signal d'entree d'un systeme auditif, mise en oeuvre dudit procede et appareil auditif |
| US6985709B2 (en) * | 2001-06-22 | 2006-01-10 | Intel Corporation | Noise dependent filter |
| DE10150519B4 (de) | 2001-10-12 | 2014-01-09 | Hewlett-Packard Development Co., L.P. | Verfahren und Anordnung zur Sprachverarbeitung |
| US7103539B2 (en) * | 2001-11-08 | 2006-09-05 | Global Ip Sound Europe Ab | Enhanced coded speech |
| US20040078199A1 (en) * | 2002-08-20 | 2004-04-22 | Hanoh Kremer | Method for auditory based noise reduction and an apparatus for auditory based noise reduction |
| US7398204B2 (en) * | 2002-08-27 | 2008-07-08 | Her Majesty In Right Of Canada As Represented By The Minister Of Industry | Bit rate reduction in audio encoders by exploiting inharmonicity effects and auditory temporal masking |
| US20060100861A1 (en) * | 2002-10-14 | 2006-05-11 | Koninkijkle Phillips Electronics N.V | Signal filtering |
| CN1890711B (zh) * | 2003-10-10 | 2011-01-19 | 新加坡科技研究局 | 将数字信号编码成可扩缩比特流的方法和对可扩缩比特流解码的方法 |
| US7725314B2 (en) * | 2004-02-16 | 2010-05-25 | Microsoft Corporation | Method and apparatus for constructing a speech filter using estimates of clean speech and noise |
| US7729908B2 (en) * | 2005-03-04 | 2010-06-01 | Panasonic Corporation | Joint signal and model based noise matching noise robustness method for automatic speech recognition |
| US20060206320A1 (en) * | 2005-03-14 | 2006-09-14 | Li Qi P | Apparatus and method for noise reduction and speech enhancement with microphones and loudspeakers |
| CN101091209B (zh) * | 2005-09-02 | 2010-06-09 | 日本电气株式会社 | 抑制噪声的方法及装置 |
| US8126706B2 (en) * | 2005-12-09 | 2012-02-28 | Acoustic Technologies, Inc. | Music detector for echo cancellation and noise reduction |
| JP4592623B2 (ja) * | 2006-03-14 | 2010-12-01 | 富士通株式会社 | 通信システム |
| US8949120B1 (en) | 2006-05-25 | 2015-02-03 | Audience, Inc. | Adaptive noise cancelation |
| JP4757158B2 (ja) * | 2006-09-20 | 2011-08-24 | 富士通株式会社 | 音信号処理方法、音信号処理装置及びコンピュータプログラム |
| US20080162119A1 (en) * | 2007-01-03 | 2008-07-03 | Lenhardt Martin L | Discourse Non-Speech Sound Identification and Elimination |
| JP5530720B2 (ja) | 2007-02-26 | 2014-06-25 | ドルビー ラボラトリーズ ライセンシング コーポレイション | エンターテイメントオーディオにおける音声強調方法、装置、およびコンピュータ読取り可能な記録媒体 |
| KR101163411B1 (ko) * | 2007-03-19 | 2012-07-12 | 돌비 레버러토리즈 라이쎈싱 코오포레이션 | 지각 모델을 사용한 스피치 개선 |
| EP2191466B1 (fr) * | 2007-09-12 | 2013-05-22 | Dolby Laboratories Licensing Corporation | Amélioration de la qualité de la parole avec clarification de la voix |
| CN101802909B (zh) * | 2007-09-12 | 2013-07-10 | 杜比实验室特许公司 | 通过噪声水平估计调整进行的语音增强 |
| WO2009038136A1 (fr) * | 2007-09-19 | 2009-03-26 | Nec Corporation | Dispositif de suppression de bruit, son procédé et programme |
| JP5056654B2 (ja) * | 2008-07-29 | 2012-10-24 | 株式会社Jvcケンウッド | 雑音抑制装置、及び雑音抑制方法 |
| US20110257978A1 (en) * | 2009-10-23 | 2011-10-20 | Brainlike, Inc. | Time Series Filtering, Data Reduction and Voice Recognition in Communication Device |
| US9838784B2 (en) | 2009-12-02 | 2017-12-05 | Knowles Electronics, Llc | Directional audio capture |
| US8423357B2 (en) * | 2010-06-18 | 2013-04-16 | Alon Konchitsky | System and method for biometric acoustic noise reduction |
| US9640194B1 (en) | 2012-10-04 | 2017-05-02 | Knowles Electronics, Llc | Noise suppression for speech processing based on machine-learning mask estimation |
| US9536540B2 (en) * | 2013-07-19 | 2017-01-03 | Knowles Electronics, Llc | Speech signal separation and synthesis based on auditory scene analysis and speech modeling |
| CN103824562B (zh) * | 2014-02-10 | 2016-08-17 | 太原理工大学 | 基于心理声学模型的语音后置感知滤波器 |
| DE102014009689A1 (de) * | 2014-06-30 | 2015-12-31 | Airbus Operations Gmbh | Intelligentes Soundsystem/-modul zur Kabinenkommunikation |
| DE112015003945T5 (de) | 2014-08-28 | 2017-05-11 | Knowles Electronics, Llc | Mehrquellen-Rauschunterdrückung |
| CN107112025A (zh) | 2014-09-12 | 2017-08-29 | 美商楼氏电子有限公司 | 用于恢复语音分量的系统和方法 |
| CN105869652B (zh) * | 2015-01-21 | 2020-02-18 | 北京大学深圳研究院 | 心理声学模型计算方法和装置 |
| US9820042B1 (en) | 2016-05-02 | 2017-11-14 | Knowles Electronics, Llc | Stereo separation and directional suppression with omni-directional microphones |
| CN110168640B (zh) * | 2017-01-23 | 2021-08-03 | 华为技术有限公司 | 用于增强信号中需要分量的装置和方法 |
| US11017798B2 (en) * | 2017-12-29 | 2021-05-25 | Harman Becker Automotive Systems Gmbh | Dynamic noise suppression and operations for noisy speech signals |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH03117919A (ja) * | 1989-09-30 | 1991-05-20 | Sony Corp | ディジタル信号符号化装置 |
| AU633673B2 (en) | 1990-01-18 | 1993-02-04 | Matsushita Electric Industrial Co., Ltd. | Signal processing device |
| EP0459362B1 (fr) | 1990-05-28 | 1997-01-08 | Matsushita Electric Industrial Co., Ltd. | Processeur de signal de parole |
| US5450522A (en) * | 1991-08-19 | 1995-09-12 | U S West Advanced Technologies, Inc. | Auditory model for parametrization of speech |
| US5469087A (en) | 1992-06-25 | 1995-11-21 | Noise Cancellation Technologies, Inc. | Control system using harmonic filters |
| US5400409A (en) * | 1992-12-23 | 1995-03-21 | Daimler-Benz Ag | Noise-reduction method for noise-affected voice channels |
| ES2137355T3 (es) * | 1993-02-12 | 1999-12-16 | British Telecomm | Reduccion de ruido. |
| US5623577A (en) * | 1993-07-16 | 1997-04-22 | Dolby Laboratories Licensing Corporation | Computationally efficient adaptive bit allocation for encoding method and apparatus with allowance for decoder spectral distortions |
| JP3131542B2 (ja) * | 1993-11-25 | 2001-02-05 | シャープ株式会社 | 符号化復号化装置 |
| US5555190A (en) | 1995-07-12 | 1996-09-10 | Micro Motion, Inc. | Method and apparatus for adaptive line enhancement in Coriolis mass flow meter measurement |
| FR2739736B1 (fr) * | 1995-10-05 | 1997-12-05 | Jean Laroche | Procede de reduction des pre-echos ou post-echos affectant des enregistrements audio |
| FI100840B (fi) * | 1995-12-12 | 1998-02-27 | Nokia Mobile Phones Ltd | Kohinanvaimennin ja menetelmä taustakohinan vaimentamiseksi kohinaises ta puheesta sekä matkaviestin |
| US6144937A (en) * | 1997-07-23 | 2000-11-07 | Texas Instruments Incorporated | Noise suppression of speech by signal processing including applying a transform to time domain input sequences of digital signals representing audio information |
-
1997
- 1997-09-18 FR FR9711643A patent/FR2768547B1/fr not_active Expired - Fee Related
-
1998
- 1998-09-16 US US09/509,145 patent/US6477489B1/en not_active Expired - Fee Related
- 1998-09-16 EP EP98943999A patent/EP1016072B1/fr not_active Expired - Lifetime
- 1998-09-16 WO PCT/FR1998/001980 patent/WO1999014738A1/fr active IP Right Grant
- 1998-09-16 CA CA002304571A patent/CA2304571A1/fr not_active Abandoned
- 1998-09-16 DE DE69803203T patent/DE69803203T2/de not_active Expired - Fee Related
- 1998-09-16 AU AU91689/98A patent/AU9168998A/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| AU9168998A (en) | 1999-04-05 |
| DE69803203T2 (de) | 2002-08-29 |
| FR2768547B1 (fr) | 1999-11-19 |
| WO1999014738A1 (fr) | 1999-03-25 |
| EP1016072A1 (fr) | 2000-07-05 |
| CA2304571A1 (fr) | 1999-03-25 |
| DE69803203D1 (de) | 2002-02-21 |
| US6477489B1 (en) | 2002-11-05 |
| FR2768547A1 (fr) | 1999-03-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1016072B1 (fr) | Procede et dispositif de debruitage d'un signal de parole numerique | |
| EP2002428B1 (fr) | Procede de discrimination et d'attenuation fiabilisees des echos d'un signal numerique dans un decodeur et dispositif correspondant | |
| EP1789956B1 (fr) | Procede de traitement d'un signal sonore bruite et dispositif pour la mise en oeuvre du procede | |
| EP1356461B1 (fr) | Procede et dispositif de reduction de bruit | |
| EP1320087B1 (fr) | Synthèse d'un signal d'excitation utilisé dans un générateur de bruit de confort | |
| EP1016071B1 (fr) | Procede et dispositif de detection d'activite vocale | |
| EP1395981B1 (fr) | Dispositif et procede de traitement d'un signal audio. | |
| EP1016073B1 (fr) | Procede et dispositif de debruitage d'un signal de parole numerique | |
| EP0490740A1 (fr) | Procédé et dispositif pour l'évaluation de la périodicité et du voisement du signal de parole dans les vocodeurs à très bas débit. | |
| JP2003280696A (ja) | 音声強調装置及び音声強調方法 | |
| EP1021805B1 (fr) | Procede et disposition de conditionnement d'un signal de parole numerique | |
| EP1429316B1 (fr) | Procédé et système de correction multi-références des déformations spectrales de la voix introduites par un réseau de communication | |
| EP3192073B1 (fr) | Discrimination et atténuation de pré-échos dans un signal audionumérique | |
| EP2515300B1 (fr) | Procédé et système de réduction du bruit | |
| FR2888704A1 (fr) | ||
| EP4287648A1 (fr) | Dispositif électronique et procédé de traitement, appareil acoustique et programme d'ordinateur associés | |
| FR2885462A1 (fr) | Procede d'attenuation des pre-et post-echos d'un signal numerique audio et dispositif correspondant |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| 17P | Request for examination filed |
Effective date: 20000316 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): DE FR GB |
|
| 17Q | First examination report despatched |
Effective date: 20001004 |
|
| RIC1 | Information provided on ipc code assigned before grant |
Free format text: 7G 10L 21/02 A |
|
| RTI1 | Title (correction) |
Free format text: METHOD AND APPARATUS FOR SUPPRESSING NOISE IN A DIGITAL SPEECH SIGNAL |
|
| RIC1 | Information provided on ipc code assigned before grant |
Free format text: 7G 10L 21/02 A |
|
| RTI1 | Title (correction) |
Free format text: METHOD AND APPARATUS FOR SUPPRESSING NOISE IN A DIGITAL SPEECH SIGNAL |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: IF02 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): DE FR GB |
|
| REF | Corresponds to: |
Ref document number: 69803203 Country of ref document: DE Date of ref document: 20020221 |
|
| GBT | Gb: translation of ep patent filed (gb section 77(6)(a)/1977) |
Effective date: 20020407 |
|
| RAP2 | Party data changed (patent owner data changed or rights of a patent transferred) |
Owner name: NORTEL NETWORKS FRANCE |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: CD Ref country code: FR Ref legal event code: CA |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20031127 Year of fee payment: 6 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20050401 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20050817 Year of fee payment: 8 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20050902 Year of fee payment: 8 |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 20060916 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: ST Effective date: 20070531 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060916 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20061002 |