-
HINTERGRUND DER ERFINDUNG
-
1. Gebiet der Erfindung
-
Die vorliegende Erfindung bezieht sich auf eine Vorrichtung, die Spracherkennung verwendet, um verschiedene Texte wie ein Dokument zu suchen.
-
2. Beschreibung des Standes der Technik
-
Die
US 2004/0254795 A1 beschreibt ein Sprachmodell zur Spracherkennung anhand einer Textdatenbank, wobei eine Offline-Modellierung zum Einsatz kommt. Ein Transcript wird online durch Ausführung eines Spracherkennungsprozesses erzeugt, wobei ein akustisches Modell und ein Sprachmodell zum Einsatz kommen, wenn ein Benutzer eine Suchanfrage stellt.
-
Die
US 5,832,428 beschreibt ein Verfahren zum Erzeugen eines Sprachmodelles für eine ausdrucksbasierte Suche in einem Spracherkennungssystem sowie eine Vorrichtung zum Erzeugen und/oder Suchen auf Basis des Sprachmodells. Das Verfahren beinhaltet den Schritt eines Trennens einer Mehrzahl von Ausdrücken in eine Mehrzahl von Worten in ein Präfix-Wort, ein Körperwort und ein Suffix-Wort.
-
Die
JP 2003-271629 A beschreibt ein Verfahren, bei dem, wenn ein Benutzer A eine Sprachsuchanfrage B ausgibt, ein Stimmerkennungsteil die Anfrage B des Nutzers A, die ein unbekanntes Wort beinhaltet, unter Verwendung eines Wörterbuches, eines akustischen Modells und eines Sprachmodells schreibt und ein Wort, das phonologisch äquivalent oder ähnlich dem erfassten, unbekannten Wort ist, aus Indexwörtern einer aufgefundenen Textsammlung unter automatischer Ergänzung auffindet.
-
Als eine Technik zum Suchen verschiedener Texte wie eines Dokuments durch Verwendung einer Sprache ist ein Verfahren zur Verwendung einer Diktatspracherkennung, um eine Sprache in einen Text umzuwandeln für die Durchführung einer Volltextsuche bei einem Text, üblich. Gemäß diesem Verfahren ist jedoch die Anzahl von erkennbaren Wörtern auf mehrere Tausend oder mehrere Zehntausend begrenzt. Daher ist es erforderlich, wenn ein Dokument, das Wörter enthält, die außerhalb des Bereichs der erkennbaren Wörter sind, durch eine Suche zu finden ist, die Anwesenheit von unbekannten Wörtern in Betracht zu ziehen.
-
Um das vorbeschriebene Problem zu bewältigen, offenbart die
Japanische Patentanmeldungs-Offenlegungsschrift Nr. 2003-271629 die folgende Technik. In einem durch eine Suche zu findenden Dokument werden nur die oberen K Wörter, die die am häufigsten erscheinenden Wörter sind, als Wörter erkannt, während die anderen Wörter in Einheiten von Silben erkannt werden. Dann wird eine Volltextsuche durchgeführt durch Verwendung der herausgezogenen Wörter als den Ergebnissen der Erkennung, um vorbereitend ein Dokument auszuwählen. Danach wird der als eine Silbenkette erkannte Teil als ein Wort geschätzt, um ein endgültiges Ergebnis der Suche zu erhalten.
-
Bei dem vorbeschriebenen Stand der Technik wird eine Volltextsuche durchgeführt durch Verwendung der Wörter als Indexwörter für die Teile, die als in einer Eingangssprache enthaltene Wörter erkannt wurden. Daher wird, wenn irgendeiner der als die Wörter erkannten Teile fälschlicherweise erkannt wird, die Suchgenauigkeit nachteilig verringert. Selbst wenn beispielsweise eine Sprache gleich ”wakayamanonachiotaki” ist und das Ergebnis der Erkennung vollständig als Wörter ”okayama no machi otaku” erhalten wird, kann ein Dokument enthaltend ”wakayamanonachiotaki” durch die Suche nicht gefunden werden.
-
ZUSAMMENFASSUNG DER ERFINDUNG
-
Die vorliegende Erfindung wurde gemacht, um das vorbeschriebene Problem zu lösen, und sie hat die Aufgabe, eine Suche zu ermöglichen, solange wie eine Sprache akustisch ähnlich dem Ergebnis der Spracherkennung ist, selbst wenn eine Buchstabendarstellung der Sprache und die des Ergebnisses der Spracherkennung nicht einander identisch sind.
-
Die vorliegende Erfindung hat eine andere Aufgabe des Vorsehens einer Technik zum Verhindern, dass eine Erkennungsrate herabgesetzt wird, selbst bei einem ein unbekanntes Wort enthaltenden Dokument.
-
Die vorliegende Erfindung hat eine weitere Aufgabe des Vorsehens einer Technik zum Reduzieren einer unvollständigen Suche, selbst wenn die Sprache kurz ist und nur wenige Schlüssel für die Suche liefert.
-
Eine Sprachsuchvorrichtung gemäß der vorliegenden Erfindung enthält:
eine Lerndaten-Teilungsvorrichtung zum Teilen von einer Suche zu unterziehenden Textdaten wie eines Dokuments in vorbestimmte linguistische Einheiten und zum Ausgeben eines Ergebnisses der Teilung;
eine Sprachmodell-Erzeugungsvorrichtung zum Erzeugen eines Sprachmodells für Spracherkennung auf der Grundlage des Ergebnisses der Teilung;
eine Textwörterbuch-Erzeugungsvorrichtung zum Teilen der der Suche zu unterziehenden Textdaten wie des Dokuments in Einheiten, wobei jede kleiner ist als die in der Lerndaten-Teilungsvorrichtung, um ein Textsuch-Wörterbuch zu erzeugen;
eine Spracherkennungsvorrichtung zur Verwendung des Sprachmodells, um eine Eingangssprache zu erkennen und ein Ergebnis der Spracherkennung als einen Text auszugeben;
eine Anpassungseinheiten-Umwandlungsvorrichtung zum Teilen des Ergebnisses der Spracherkennung in dieselben Teilungseinheiten wie diejenigen in der Textwörterbuch-Erzeugungsvorrichtung und zum Ausgeben eines Ergebnisses der Teilung; und
eine Textsuchvorrichtung zum Empfangen eines Ausgangssignals von der Anpassungseinheiten-Umwandlungsvorrichtung als ein Eingangssignal, um eine Textsuche durchzuführen unter Verwendung des Textsuch-Wörterbuchs.
-
Gemäß der vorliegenden Erfindung wird unter Bezugnahme auf das Sprachmodell, das durch Teilen der Textdaten in linguistische Einheiten erhalten wurde, und ein akustisches Modell, das durch Formen von Sprachmerkmalen erhalten wurde, eine Spracherkennung für eine Eingangssprache durchgeführt, um eine phonemische Darstellung auszugeben. Die Anpassungseinheiten-Umwandlungsvorrichtung teilt die phonemische Darstellung in dieselben Einheiten wie diejenigen des Textsuch-Wörterbuchs, wobei jede der Einheiten kleiner als die des Sprachmodells ist. Die Textsuchvorrichtung verwendet das Ergebnis der Teilung, um eine Suche in dem Textsuch-Wörterbuch durchzuführen. Als eine Folge hat die vorliegende Erfindung die Wirkung, dass es möglich ist, eine gewünschte Einrichtung durch die Suche zu finden, selbst wenn ein Teil einer Wortreihe entsprechend dem Ergebnis der Erkennung falsch erkannt ist.
-
KURZBESCHREIBUNG DER ZEICHNUNGEN
-
In den begleitenden Zeichnungen:
-
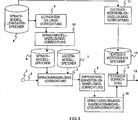
1 ist ein Blockschaltbild, das eine Konfiguration eines ersten Ausführungsbeispiels einer Sprachsuchvorrichtung gemäß der vorliegenden Erfindung illustriert;
-
2 ist eine erläuternde Ansicht eines beispielhaften Inhalts eines Sprachmodell-Datenspeichers;
-
3 ist eine erläuternde Ansicht eines beispielhaften Inhalts eines Textsuch-Wörterbuchs;
-
4 ist eine erläuternde Ansicht eines beispielhaften Inhalts einer Gewichtsfaktortabelle bei einem zweiten Ausführungsbeispiel;
-
5 ist ein Flussdiagramm für die Erzeugung eines Sprachmodells gemäß dem zweiten Ausführungsbeispiel;
-
6 ist ein Blockschaltbild, das eine Konfiguration eines dritten Ausführungsbeispiels illustriert;
-
7 ist ein Flussdiagramm für die Erzeugung des Sprachmodells gemäß dem dritten Ausführungsbeispiel;
-
8 ist ein Blockschaltbild, das eine Konfiguration eines vierten Ausführungsbeispiels illustriert;
-
9 ist eine erläuternde Ansicht eines beispielhaften Inhalts einer Spracherkennungs-Kandidatenanzahltabelle bei dem vierten Ausführungsbeispiel; und
-
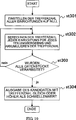
10 ist ein Flussdiagramm einer Textsuche durch die Textsuchvorrichtung gemäß dem vierten Ausführungsbeispiel.
-
DETAILLIERTE BESCHREIBUNG DER BEVORZUGTEN AUSFÜHRUNGSBEISPIELE
-
Erstes Ausführungsbeispiel
-
1 ist ein Blockschaltbild, das eine Konfiguration eines ersten Ausführungsbeispiels einer Sprachsuchvorrichtung gemäß der vorliegenden Erfindung illustriert.
-
In 1 enthält die Sprachsuchvorrichtung einen Spracheingangsanschluss 1, eine Eingangssprache 2, eine Spracherkennungsvorrichtung 3, eine Anpassungseinheiten-Umwandlungsvorrichtung 4 zum Umwandeln einer Anpassungseinheit, die für das Ergebnis einer Spracherkennung verwendet wird, in eine andere Einheit, eine Textsuchvorrichtung 5, einen Sprachmodellspeicher 6, einen Audiomodellspeicher 7, einen Sprachmodell-Lerndatenspeicher 8, eine Lerndaten-Teilungsvorrichtung 9, eine Sprachmodell-Erzeugungsvorrichtung 10, eine Textsuchwörterbuch-Erzeugungsvorrichtung 11, einen Textsuch-Wörterbuchspeicher 12 und ein Suchergebnis 13. Der Audiomodellspeicher 7 speichert ein Audiomodell, das durch Formen von Sprachmerkmalen erhalten wurde. Bei diesem Ausführungsbeispiel ist das Audiomodell beispielsweise ein HMM (Verstecktes Markov-Modell).
-
Bei diesem ersten Ausführungsbeispiel wird der folgende Fall als ein Beispiel beschrieben. Ein Name von jeder von Einrichtungen und touristischen Punkten in Japan (nachfolgend werden die Einrichtungen und die touristischen Punkte insgesamt aus Gründen der Einfachheit als Einrichtungen bezeichnet) wird als ein Textdokument betrachtet, das aus mehreren Wörtern zusammengesetzt ist. Der Name der Einrichtung wird durch eine Suche unter Verwendung einer Spracherkennung gefunden. Die Suche des Einrichtungsnamens, die nicht innerhalb des Rahmens von Spracherkennung allgemeiner Wörter durchgeführt wird, sondern innerhalb des Rahmens einer Textsuche, ist dahingehend vorteilhaft, dass selbst eine teilweise Übereinstimmung ermöglicht, einen Einrichtungsnamen durch die Suche zu finden, selbst wenn ein Benutzer den durch die Suche zu findenden Einrichtungsnamen nicht genau kennt.
-
Die Arbeitsweise der Sprachsuchvorrichtung gemäß diesem ersten Ausführungsbeispiel wird nun beschrieben. Vor der Spracherkennung und einer Suche werden vorher ein Sprachmodell und ein Textsuch-Wörterbuch erzeugt, um in dem Sprachmodellspeicher 6 bzw. dem Textsuch-Wörterbuchspeicher 12 gespeichert zu werden.
-
Zuerst wird ein Verfahren des Erzeugens des Sprachmodells beschrieben. Eine ID-Nummer, eine Kana/chinesische Zeichendarstellung und eine phonemische Darstellung von jeder der der Suche zu unterziehenden Einrichtungen werden in dem Sprachmodell-Lerndatenspeicher 6 vorgespeichert. Ein beispielhafter Inhalt des Sprachmodell-Lerndatenspeichers 8 ist in 2 gezeigt.
-
Die Lerndaten-Teilungsvorrichtung 9 empfängt Eingangssignale für die Zeichendarstellung und die phonemische Darstellung jeder Einrichtung, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert sind, um eine morphologische Analyse zur Teilung einer Zeichenreihe beispielsweise in Wörter durchzuführen.
-
Beispielsweise wird, wenn die Zeichendarstellung gleich ”wakayamanonachiotaki” ist und die phonemische Darstellung gleich ”wakayamanonaciootaki” ist, die Zeichenreihe geteilt als ”(wakayama)/(no)/(naci)/(ootaki)”. Die Klammern ”()” zeigen an, dass die Zeichenreihe in den Klammern die phonemische Darstellung ist. Das Zeichen ”/” zeigt die Position der Teilung an und ist nicht in den Lerndaten des Sprachmodells enthalten.
-
Die Lerndaten-Teilungsvorrichtung 9 führt die vorbeschriebene Verarbeitung für alle Einrichtungsnamen durch, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert sind, und gibt dann die Ergebnisse der Teilung zu der Sprachmodell-Erzeugungsvorrichtung 10 aus.
-
Die Sprachmodell-Erzeugungsvorrichtung 10 empfängt die Eingangssignale für die Ergebnisse der Teilung für alle Einrichtungen, um das Sprachmodell zu erzeugen, und speichert das erzeugte Sprachmodell in dem Sprachmodellspeicher 6. Das Sprachmodell ist bei diesem ersten Ausführungsbeispiel beispielsweise ein Trigram-Modell.
-
Als Nächstes wird ein Verfahren der Erzeugung des Textsuch-Wörterbuchs beschrieben. Die Textsuchwörterbuch-Erzeugungsvorrichtung 11 empfängt die Eingangssignale für die phonemische Darstellung und die ID-Nummer von jeder der Einrichtungen, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert sind, um die phonemische Darstellung zu teilen. Eine Einheit der Teilung in der Textsuchwörterbuch-Erzeugungsvorrichtung 11 ist kleiner als das Wort entsprechend der Einheit der Teilung in der Lerndaten-Teilungsvorrichtung 9. Die Einheit der Teilung ist beispielsweise bei diesem ersten Ausführungsbeispiel eine Silbe. Für die Einrichtung mit der ID-Nummer 1, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert ist, ist die phonemische Darstellung ”wakayamanonaciootaki”, und das Ergebnis der Teilung wird erhalten als ”wa/ka/ya/ma/no/na/ci/o/o/ta/ki”.
-
Die Textsuchwörterbuch-Erzeugungsvorrichtung 11 führt die vorbeschriebene Verarbeitung für alle Einrichtungsnamen durch, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert sind. Dann wird jede der Silben als ein Indexwort verwendet, um beispielsweise eine invertierte Datei zu erzeugen. Die erzeugte invertierte Datei wird als das Textsuch-Wörterbuch in dem Textsuch-Wörterbuchspeicher gespeichert. 3 illustriert ein Beispiel für das von den Einrichtungen mit den ID-Nummern 1 und 2 erzeugte Textsuch-Wörterbuch.
-
Als Nächstes werden der Spracherkennungs- und der Suchvorgang beschrieben.
-
Bei Empfang des Eingangssignals der Sprache 2 von dem Spracheingangsanschluss 1 verwendet die Spracherkennungsvorrichtung 3 das in dem Sprachmodellspeicher 6 gespeicherte Sprachmodell und das in dem akustischen Modellspeicher 7 gespeicherte akustische Modell, um die Spracherkennung durchzuführen. Als ein Ergebnis der Spracherkennung gibt die Spracherkennungsvorrichtung die phonemische Darstellung der Wortreihe aus.
-
Wenn beispielsweise eine Sprache als die Eingangssprache gleich ”wakayamanonachiotaki” ist und das Ergebnis der Erkennung gleich ”okayama/no/machi/otaku” ist, gibt die Spracherkennungsvorrichtung 3 ”okayama/no/maci/ootaku” entsprechend der phonemischen Darstellung des Ergebnisses der Erkennung aus.
-
Bei Empfang eines Eingangssignals der phonemischen Darstellung teilt die Anpassungseinheiten-Umwandlungsvorrichtung 4 die phonemische Darstellung in Einheiten, die kleiner als das Wort sind, und gibt das Ergebnis der Teilung aus. Die Einheit der Teilung ist dieselbe wie die in der Textsuchwörterbuch-Erzeugungsvorrichtung 11 verwendete. Insbesondere ist, wie vorstehend beschrieben ist, da die Einheit der Teilung in der Textsuchwörterbuch-Erzeugungsvorrichtung 11 bei diesem Ausführungsbeispiel die Silbe ist, die Einheit der Teilung in der Anpassungseinheiten-Umwandlungsvorrichtung 4 ebenfalls die Silbe. Daher gibt bei diesem ersten Ausführungsbeispiel die Anpassungseinheiten-Umwandlungsvorrichtung 4 ”o/ka/ya/ma/no/ma/ci/o/o/ta/ku aus.
-
Als Nächstes empfangt die Textsuchvorrichtung 5 das Ergebnis der Teilung als ein Eingangssignal und bezieht sich auf die in dem Textsuch-Wörterbuchspeicher 12 gespeicherte invertierte Datei aufeinander folgend von der ersten Silbe des Ergebnisses der Teilung. Dann addiert die Textsuchvorrichtung 5 eins zu einem Treffer der Einrichtung enthaltend die interessierende Silbe in dem Ergebnis der Teilung. Die Textsuchvorrichtung 5 führt die vorbeschriebene Verarbeitung von der ersten Silbe bis zu der letzten Silbe des Ergebnisses der Teilung durch. Dann gibt die Textsuchvorrichtung 5 die Einrichtung mit einem Trefferwert aus, der gleich einem oder höher als ein vorbestimmter Schwellenwert S ist, als ein Ergebnis der Suche. Der Schwellenwert S ist beispielsweise das 0,8-fache der Anzahl von Silben, die in dem Ergebnis der Erkennung enthalten sind. Insbesondere wird bei dem vorliegenden Ausführungsbeispiel ein Wert, der durch Multiplizieren von elf entsprechend der Anzahl von eingegebenen Silben mit 0,8 erhalten wird, d. h., 11·0,8 = 8,8 als der Schwellenwert S verwendet.
-
Als ein Ergebnis stimmt die eingegebene Silbenreihe ”o/ka/ya/ma/no/ma/ci/o/o/ta/ku” mit der Silbenreihe ”wa/ka/ya/ma/no/na/ci/o/o/ta/ki” entsprechend einer korrekten Sprache ”wakayamanonachiataki” mit Ausnahme der letzten Silbe ”ku” überein. Daher kann der Einrichtungsname ”wakayamanonachiotaki” mit zehn als einer Trefferzahl als das Ergebnis der Suche ausgegeben werden.
-
Wie vorstehend beschrieben ist, teilt gemäß der vorliegenden Erfindung die Anpassungseinheiten-Umwandlungsvorrichtung 4 die phonemische Darstellung in Einheiten, von denen jede kleiner als die für die Spracherkennung verwendete ist, und die Textsuchvorrichtung 5 verwendet das Ergebnis der Teilung, um die Textsuche durchzuführen. Daher hat die vorliegende Erfindung die Wirkung, dass es möglich ist, eine gewünschte Einrichtung durch die Suche zu finden, selbst wenn ein Teil der als das Ergebnis der Erkennung erhaltenen Wortreihe falsch erkannt ist.
-
Zweites Ausführungsbeispiel
-
Bei dem zweiten Ausführungsbeispiel wird die Arbeitsweise der Lerndaten-Teilungsvorrichtung 9 und der Sprachmodell-Erzeugungsvorrichtung 10 wie folgt modifiziert.
-
Die Lerndaten-Teilungsvorrichtung 3 empfängt die Zeichendarstellung und die phonemische Darstellung von jeder der in dem Sprachmodell-Lerndatenspeicher 8 gespeicherten Einrichtungen als Eingangssignale, um eine morphologische Analyse zur Teilung der Zeichenreihe in Wörter durchzuführen. In diesem Fall werden nur die oberen K Wörter, die die am häufigsten erscheinenden Wörter sind, als Wörter gelassen, während jedes der anderen Wörter weiter in eine Reihe von Silben geteilt wird.
-
Obgleich die Wörter, die ungeteilt bleiben sollen, auf der Grundlage einer Häufigkeit des Erscheinens bei diesem zweiten Ausführungsbeispiel ausgewählt werden, kann eine andere beliebige Bezugsgröße verwendet werden, um die Wörter auszuwählen, die ungeteilt bleiben sollen.
-
Ein Ausgangssignal der Sprachmodell-Erzeugungsvorrichtung 10 wird mit einer Kennmarke versehen, die anzeigt, ob die Einheit der Teilung der phonemischen Darstellung das Wort oder die Silbe ist. Die Erscheinungshäufigkeit K ist eine vorbestimmte Konstante, beispielsweise ist K = 500.
-
Wenn beispielsweise drei Wörter, d. h. ”wakayama”, ”no” und ”taki” in der Zeichendarstellung ”wakayamanonachiotaki” der in dem in 2 illustrierten Sprachmodell-Lerndatenspeicher 8 gespeicherten Einrichtung in den Wörtern enthalten sind, die die oberen K Erscheinungshäufigkeiten haben, wird das Ergebnis der Teilung erhalten als ”wakayama[w]/no[w]/na[s]/ci[s]/o[s]/o[s]/taki[w]”, welches dann ausgegeben wird. In diesem Fall ist [] eine Kennmarke, die anzeigt, ob das Ergebnis der Teilung als das Wort oder die Silbe erhalten ist, wobei [w] anzeigt, dass das Ergebnis der Teilung als das Wort erhalten ist, und [s] anzeigt, dass das Ergebnis der Teilung als die Silbe erhalten ist. Wenn andererseits die Wörter, die in einer Zeichendarstellung ”tokyonochiyodakuyakusyo” enthalten sind, alle in den Wörtern mit den oberen K Erscheinungshäufigkeiten enthalten sind, wird das Ergebnis der Teilung erhalten als ”tookjoo[w]/no[w]/ciyoda[w]/kuyakusjo[w]”.
-
Die Lerndaten-Teilungsvorrichtung 9 führt die vorbeschriebene Verarbeitung für alle Einrichtungsnamen durch, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert sind, und gibt dann die Ergebnisse der Teilung zu der Sprachmodell-Erzeugungsvorrichtung 10 aus.
-
Die Sprachmodell-Erzeugungsvorrichtung 10 empfängt den Eingang der Ergebnisse der Teilung, um das Sprachmodell zu erzeugen. In diesem Fall jedoch lernt die Sprachmodell-Erzeugungsvorrichtung 10 die Lerndaten von jeder der Einrichtungen, während die Lerndaten in der folgenden Weise gewichtet werden.
-
Ein Vorgang der Erzeugung des Sprachmodells durch die Sprachmodell-Erzeugungsvorrichtung 10 ist in 5 illustriert. Bei Empfang des Eingangs des Ergebnisses der Teilung von der Lerndaten-Teilungsvorrichtung 9 berechnet die Sprachmodell-Erzeugungsvorrichtung 10 eine Rate von Silben (nachfolgend als eine Silbenrate bezeichnet) Rs in dem Ergebnis der Teilung gemäß der folgenden Formel (1) (ST101). Rs = Ns/N (1) worin N die Anzahl von Silben in dem Ergebnis der Teilung ist und N eine Gesamtzahl von Wörtern und Silben, die durch die Teilung erhalten wurden, ist. Beispielsweise sind in ”wakayama[w]/no[w]/na[s]/ci[s]/o[s]/o[s]/taki[w]” NS gleich 4 und N gleich 7. Daher wird Rs = 4/7 = 0,57 erhalten. In dem Fall von ”tookjoo[w]/no[w]/ciyoda[w]/kuyakusjo[w]” ist Ns gleich 0 und N gleich 4. Daher wird Rs = 0/4 = 0 erhalten.
-
Als Nächstes wird unter Bezugnahme auf eine Gewichtsfaktortabelle, die die Beziehungen zwischen den Silbenraten Rs und den in der Sprachmodell-Erzeugungsvorrichtung 10 gespeicherten Gewichtsfaktoren beschreibt, ein Gewichtsfaktor w für jede Einrichtung bestimmt (ST102). Ein Beispiel für die Gewichtsfaktortabelle ist in 4 illustriert.
-
Da Rs = 4/7 = 0,57 für ”wakayama[w]/no[w]/na[s]/ci[s]/o[s]/o[s]/taki[w]” erhalten wird, wird der Gewichtsfaktor w als 4 bestimmt. Dann betrachtet die Sprachmodell-Erzeugungsvorrichtung 10 die Einrichtung als viermal erschienen. Insbesondere vervierfacht die Sprachmodell-Erzeugungsvorrichtung 10 eine Verkettungsfrequenz zwischen Wörtern und Silben, die von der Einrichtung erhalten wurden (ST103).
-
Andererseits wird, da Rs = 0 für ”tookjoo[w]/no[w]/ciyoda[w]/kuyakusjo[w]” erhalten wird, der Gewichtsfaktor als 1 erhalten. Daher verbleibt eine Verkettungsfrequenz zwischen Wort und Silben, die von dieser Einrichtung erhalten wurden, als eins.
-
Die Sprachmodell-Erzeugungsvorrichtung 10 führt die vorbeschriebene Verarbeitung für alle Einrichtungen durch, die in dem Sprachmodell-Lerndatenspeicher 8 gespeichert sind, um eine Verkettungsfrequenz zwischen Wörtern und Silben für die Erzeugung des Sprachmodells zu akkumulieren (ST105). Das Sprachmodell ist beispielsweise ein Trigram-Modell. Da der restliche Vorgang derselbe wie der bei dem ersten Ausführungsbeispiel ist, wird die Beschreibung hiervon hier weggelassen.
-
Im Stand der Technik hat die Einrichtung mit dem großenteils durch Silben dargestellten Teilungsergebnis eine geringe linguistische Wahrscheinlichkeit, die von dem Sprachmodell berechnet wird, und hat daher die Tendenz zu einer verringerten Erkennungsrate. Durch Erzeugen des Sprachmodells in der vorbeschriebenen Weise gemäß diesem Ausführungsbeispiel wird jedoch die Erscheinungshäufigkeit für die Einrichtung mit dem Ergebnis der Teilung, das groß dargestellt ist, groß eingestellt, wenn das Sprachmodell erzeugt wird. Als ein Ergebnis kann die linguistische Wahrscheinlichkeit erhöht werden, um ein Absinken der Erkennungsrate zu vermeiden.
-
Drittes Ausführungsbeispiel
-
Dieses dritte Ausführungsbeispiel wird erhalten durch Hinzufügen eines Sprachmodell-Zwischenspeichers 14 und eines Sprachdaten-Teilungsergebnisspeichers 15 zu dem vorbeschriebenen zweiten Ausführungsbeispiel. 6 illustriert eine beispielhafte Konfiguration des dritten Ausführungsbeispiels. Weiterhin wird die Arbeitsweise der Sprachmodell-Erzeugungsvorrichtung 10 wie folgt modifiziert.
-
Die Arbeitsweise der Sprachmodell-Erzeugungsvorrichtung 10 ist in 7 illustriert. Die Sprachmodell-Erzeugungsvorrichtung 10 empfängt dasselbe Eingangssignal wie bei dem zweiten Ausführungsbeispiel von der Lerndaten-Teilungsvorrichtung 9. Dann setzt die Sprachmodell-Erzeugungsvorrichtung 10 zuerst alle addierten Gewichte für die Verkettungsfrequenzen zwischen Wärtern und Silben in den Daten der jeweiligen Einrichtungen auf 1, um das Sprachmodell zu erzeugen. Die Sprachmodell-Erzeugungsvorrichtung 10 speichert das erzeugte Sprachmodell als ein Zwischensprachmodell in dem Zwischensprachmodellspeicher 14. Das Zwischensprachmodell ist das Trigram bei diesem dritten Ausführungsbeispiel. Die Ergebnisse der Teilung der Eingangsdaten für alle Einrichtungen werden in dem Lerndaten-Teilungsergebnisspeicher 15 gespeichert (ST201).
-
Als Nächstes wird das Ergebnis der Teilung für jede der Einrichtungen, das in dem Lerndaten-Teilungsergebnisspeicher 15 gespeichert ist, für jede Einrichtung i aufgenommen. Dann verwendet die Sprachmodell-Erzeugungsvorrichtung 10 das in dem Zwischensprachmodellspeicher 14 gespeicherte Zwischensprachmodell, um eine linguistische Wahrscheinlichkeit P(i) gemäß der folgenden Formel (2) zu berechnen (ST202). P(i) = Πj=l,Jp(wj|wj-2, wj-1) (2) worin p(wj|wj-2, Wj-1) eine Trigram-Wahrscheinlichkeit für eine Teilungseinheitsreihe w1-2, wj-1 und wj ist, und J die Anzahl von Malen der Teilung der Einrichtung i ist. Dann wird ein Gewichtsfaktor w(i) für die Einrichtung i durch die folgende Formel (3) erhalten (ST203). w(i) = f((Σi=J,NP(i))/P(i)) (3) worin N eine Gesamtzahl von der Suche zu unterziehenden Einrichtungen ist, und f(x) eine Funktion zum Mildern einer Veränderung von x ist. Beispielsweise wird für f(x) f(x) = x1/4 (4) verwendet.
-
Wie aus der vorstehenden Formel (3) ersichtlich ist, hat der Gewichtsfaktor w(i) einen größeren Wert für die Einrichtung mit der kleineren linguistischen Wahrscheinlichkeit P(i) in dem Zwischensprachmodell.
-
Die Sprachmodell-Erzeugungsvorrichtung 10 betrachtet die Einrichtung so, als ob sie die Anzahl von Malen erschienen ist, die gleich dem erhaltenen Gewichtsfaktor w(i) ist. Insbesondere wird die Verkettungshäufigkeit zwischen Wörtern und Silben, die von der Einrichtung erhalten wurde, mit w(i) multipliziert, um die Verkettungshäufigkeit zu akkumulieren (ST204).
-
Die Sprachmodell-Erzeugungsvorrichtung 10 führt die vorbeschriebene Verarbeitung für alle Ergebnisse der Teilung der jeweiligen Einrichtungen, die in dem Lerndaten-Teilungsergebnisspeicher 15 gespeichert sind, durch, um zu bestimmen, ob ein nicht verarbeitetes Ergebnis der Teilung für irgendeine der Einrichtungen besteht oder nicht (ST205). Dann wird die Verkettungshäufigkeit zwischen Wörtern oder Silben akkumuliert, um das Sprachmodell zu erzeugen. Das erzeugte Sprachmodell wird in dem Sprachmodellspeicher 6 gespeichert (ST206). Das Sprachmodell ist beispielsweise das Trigram-Modell. Da der restliche Vorgang derselbe ist wie bei dem zweiten Ausführungsbeispiel, wird die Beschreibung hiervon hier weggelassen.
-
Im Stand der Technik hat die Einrichtung, deren Ergebnis der Teilung groß in Silben dargestellt ist, eine niedrige linguistische Wahrscheinlichkeit, die durch das Sprachmodell berechnet ist, und hat daher die Tendenz, eine verringerte Erkennungsrate zu haben. Gemäß diesem dritten Ausführungsbeispiel ist jedoch die Erscheinungshäufigkeit bei der Erzeugung des Sprachmodells für die Einrichtung mit einer geringen linguistischen Wahrscheinlichkeit in dem Zwischensprachmodell groß eingestellt, wenn das Sprachmodell erzeugt wird. Als eine Folge kann die linguistische Wahrscheinlichkeit erhöht werden, um zu verhindern, dass die Erkennungsrate absinkt.
-
Viertes Ausführungsbeispiel
-
Das vierte Ausführungsbeispiel wird erhalten durch Hinzufügen einer Spracherkennungs-Kandidatenanzahl-Steuervorrichtung 16 jeweils zu dem ersten bis dritten Ausführungsbeispiel, und weiterhin durch Modifizieren der Arbeitsweise der Spracherkennungsvorrichtung 3, der Anpassungseinheiten-Umwandlungsvorrichtung 4 und der Textsuchvorrichtung 5 in der nachfolgend beschriebenen Weise. Eine beispielhafte Konfiguration des vierten Ausführungsbeispiels ist in 8 illustriert.
-
Bei diesem vierten Ausführungsbeispiel wird der Fall beschrieben, in welchem die Spracherkennungs-Kandidatenanzahl-Steuervorrichtung 16 zu der Erfindung des ersten Ausführungsbeispiels hinzugefügt ist. Vor der Spracherkennung werden das Sprachmodell und das Textsuch-Wörterbuch in derselben Weise wie bei dem ersten Ausführungsbeispiel erzeugt.
-
Der Spracherkennungs- und der Suchvorgang werden beschrieben. Bei Empfang des Eingangs der Sprache 2 von dem Spracheingangsanschluss 1 verwendet die Spracherkennungsvorrichtung 3 das in dem Sprachmodellspeicher 6 gespeicherte Sprachmodell und das in dem Akustikmodellspeicher 7 gespeicherte Akustikmodell, um die Spracherkennung durchzuführen. Dann gibt die Spracherkennungsvorrichtung 3 die phonemische Darstellung der Wortreihe als ein Ergebnis der Spracherkennung aus. Als das Ergebnis der Spracherkennung bei diesem vierten Ausführungsbeispiel werden jedoch die oberen L Kandidaten der phonemischen Darstellungen in absteigender Reihenfolge der Erkennungstreffer ausgegeben. in diesem Fall ist L eine Konstante gleich oder größer als 2 und bei diesem Ausführungsbeispiel gleich 3. Wenn beispielsweise eine Sprache ”oze” gegeben wird und das erstrangige Ergebnis der Erkennung gleich ”tone” ist, das zweitrangige Ergebnis gleich ”oze” ist und das drittrangige Ergebnis gleich ”tobe” ist, werden die phonemischen Darstellungen entsprechend dem erst- bis drittrangigen Ergebnis der Erkennung, ”tone”, ”oze” und ”tobe” aufeinander folgend ausgegeben.
-
Die Anpassungseinheiten-Umwandlungsvorrichtung 4 empfängt die phonemischen Darstellungen entsprechend den L Ergebnissen der Spracherkennung, um jede der als die Ergebnisse der Spracherkennung erhaltenen phonemischen Darstellungen in die Einheiten zu teilen, von denen jede kleiner als das Wort ist, in derselben Weise wie bei dem ersten Ausführungsbeispiel. Dann gibt die Anpassungseinheiten-Umwandlungsvorrichtung 4 das erhaltene Ergebnis der Teilung aus. Wie bei dem ersten Ausführungsbeispiel ist die Einheit der Teilung bei diesem vierten Ausführungsbeispiel dieselbe.
-
Die Arbeitsweise der Anpassungseinheiten-Umwandlungsvorrichtung 4 unterscheidet sich von der bei dem ersten Ausführungsbeispiel dadurch, dass die Anpassungseinheiten-Umwandlungsvorrichtung 4 L Eingangssignale in absteigender Reihenfolge der Erkennungstreffer empfängt und L Ergebnisse der Teilung in derselben Reihenfolge ausgibt. Bei diesem Ausführungsbeispiel gibt die Anpassungseinheiten-Umwandlungsvorrichtung 4 ”to/ne”, ”o/ze” und ”to/be” in dieser Reihenfolge aus.
-
Die Spracherkennungs-Kandidatenanzahl-Steuervorrichtung 16 empfängt die L Ergebnisse der Teilung als Eingangssignale und bezieht sich auf die Anzahl von Silben von ”to/ne” entsprechend dem Silbenteilungsergebnis des erstrangigen Kandidaten und eine Spracherkennungs-Kandidatenanzahltabelle, die in der Spracherkennungs-Kandidatenanzahl-Steuervorrichtung 16 gespeichert ist, um die Anzahl von zu der Textsuchvorrichtung auszugebenden Kandidaten zu steuern.
-
Der Inhalt der Spracherkennungs-Kandidatenanzahltabelle ist in 9 illustriert. Die Anzahl von auszugebenden Kandidaten ist vorher als größer eingestellt, wenn die Anzahl von Silben in dem Silbenteilungsergebnis des erstrangigen Kandidaten kleiner wird. Da die Anzahl von Silben in dem Silbenteilungsergebnis des erstrangigen Kandidaten bei diesem Ausführungsbeispiel gleich 2 ist, wird die Anzahl von auszugebenden Kandidaten mit Bezug auf die Spracherkennungs-Kandidatenanzahltabelle als 3 bestimmt.
-
Als Nächstes empfängt die Textsuchvorrichtung 5 die drei Ergebnisse der Teilung als Eingangssignale. Dann wird unter Bezugnahme auf die invertierte Datei, die als das in dem Textsuch-Wörterbuchspeicher 12 gespeicherte Textsuch-Wörterbuch dient, ein Vorgang des Addierens von 1 zu dem Treffer der Einrichtung enthaltend die interessierende Silbe für die erste Silbe bis zu der letzten Silbe für jedes der drei Ergebnisse der Teilung aufeinander folgend durchgeführt. Dann gibt die Textsuchvorrichtung 5 die Einrichtung mit der Trefferzahl gleich dem oder höher als der vorbestimmte Schwellenwert S als ein Ergebnis der Suche aus. Der Schwellenwert S ist auf einen Wert gesetzt, der das 0,8-fache der Anzahl von Silben in dem erstrangigen Erkennungsergebnis ist. Insbesondere wird, da die Anzahl von eingegebenen Silben bei diesem Ausführungsbeispiel gleich 2 ist, der Schwellenwert S als 2·0,8 = 1,6 erhalten. Indem die Suche auf diese Weise durchgeführt wird, enthält das zweitrangige Erkennungsergebnis ”o/ze” bei diesem vierten Ausführungsbeispiel. Daher hat ”oze” entsprechend dem richtigen Wort zwei als eine Suchtrefferzahl und kann als ein Suchergebniskandidat ausgegeben werden.
-
Ein spezifischer Verarbeitungsinhalt wird mit Bezug auf 10 entsprechend einem Flussdiagramm eines Arbeitsvorgangs der Textsuchvorrichtung 5 beschrieben. Zuerst werden als anfängliche Verarbeitung Trefferzahlen für alle Einrichtungen auf 0 gesetzt (ST301). Als Nächstes führt die Textsuchvorrichtung 5 für das erste der drei Ergebnisse der Teilung unter Bezugnahme auf die invertierte Datei den Vorgang des Addierens von 1 zu der Trefferzahl der die interessierende Silbe enthaltenden Einrichtung aufeinander folgend für die erste Silbe bis zur letzten Silbe des Ergebnisses der Teilung durch (ST302).
-
Als Nächstes bestimmt die Textsuchvorrichtung 5, ob noch ein weiteres Ergebnis der Teilung, das einzugeben ist, vorhanden ist oder nicht (ST303). Wenn eines vorhanden ist, wird dieselbe Verarbeitung für das nächste Ergebnis der Teilung als ein Eingangssignal durchgeführt. Dann akkumuliert die Textsuchvorrichtung eine Trefferzahl für jede der Einrichtungen (ST302). Andererseits wird, wenn kein weiteres Ergebnis der Teilung einzugeben ist, die Trefferakkumulationsverarbeitung beendet. Dann wird der Kandidat mit der Trefferzahl, die gleich dem oder höher als der Schwellenwert ist, als ein Ergebnis der Suche ausgegeben (ST304).
-
Wie vorstehend beschrieben ist, steuert die Spracherkennungs-Kandidatenzahl-Steuervorrichtung 16 die Anzahl von Kandidaten, die in die Textsuchvorrichtung eingegeben werden, derart, dass sie größer ist, wenn die Anzahl von Silben in dem Ergebnis der Spracherkennung kleiner wird. Daher werden, wenn das Ergebnis der Erkennung eine kleine Anzahl von Silben hat und daher eine geringe Möglichkeit besteht, dass der durch falsche Erkennung erhaltene Kandidat korrekte Silben enthalten kann, selbst niederrangige Kandidaten, die als die Ergebnisse der Erkennung erhalten werden, der Suche unterzogen. Auf diese Weise hat die vorliegende Erfindung die Wirkung der Herabsetzung der Möglichkeit des Versagens beim Finden einer gewünschten Einrichtung aufgrund einer unvollständigen Suche.
-
Die vorliegende Erfindung ist verfügbar für ein System, das eine Sprache verwendet, um eine Suche bei Textdaten enthaltend eine große Anzahl von Wörtern durchzuführen, und sie ist insbesondere beispielsweise auf ein Fahrzeugnavigationssystem anwendbar.