CN1591415A - 机器翻译装置以及机器翻译计算机程序 - Google Patents
机器翻译装置以及机器翻译计算机程序 Download PDFInfo
- Publication number
- CN1591415A CN1591415A CNA2004100749435A CN200410074943A CN1591415A CN 1591415 A CN1591415 A CN 1591415A CN A2004100749435 A CNA2004100749435 A CN A2004100749435A CN 200410074943 A CN200410074943 A CN 200410074943A CN 1591415 A CN1591415 A CN 1591415A
- Authority
- CN
- China
- Prior art keywords
- sentence
- language
- translation
- translations
- mark
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000013519 translation Methods 0.000 title claims abstract description 314
- 238000004590 computer program Methods 0.000 title claims description 4
- 230000014616 translation Effects 0.000 claims abstract description 309
- 238000000034 method Methods 0.000 claims abstract description 75
- 238000004364 calculation method Methods 0.000 claims abstract description 63
- 238000012217 deletion Methods 0.000 claims description 11
- 230000037430 deletion Effects 0.000 claims description 11
- 238000003780 insertion Methods 0.000 claims description 11
- 230000037431 insertion Effects 0.000 claims description 11
- 230000009471 action Effects 0.000 claims description 2
- 239000000203 mixture Substances 0.000 claims 26
- 239000000284 extract Substances 0.000 claims 6
- 230000008878 coupling Effects 0.000 claims 4
- 238000010168 coupling process Methods 0.000 claims 4
- 238000005859 coupling reaction Methods 0.000 claims 4
- 238000006073 displacement reaction Methods 0.000 claims 2
- 230000008676 import Effects 0.000 claims 2
- 238000000605 extraction Methods 0.000 abstract description 3
- 238000001514 detection method Methods 0.000 description 18
- 238000010586 diagram Methods 0.000 description 9
- 238000012937 correction Methods 0.000 description 7
- 238000009795 derivation Methods 0.000 description 7
- 230000009194 climbing Effects 0.000 description 6
- 238000011156 evaluation Methods 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 238000004422 calculation algorithm Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000000844 transformation Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000012804 iterative process Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000010845 search algorithm Methods 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/42—Data-driven translation
- G06F40/45—Example-based machine translation; Alignment
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Abstract
本发明提供一种机器翻译方法,采用包含由第1种语言的句子和第2种语言的句子构成对译的对译文集,将第1种语言的输入文翻译为第2种语言的句子,其包括以下步骤:接收第1种语言的输入文,从对译文集之中,摘录出和输入文最类似的、和第1种语言的句子成对的第2种语言的句子的步骤;对于摘录出的第2种语言的句子,应用多个变形之中的任意的变形,计算由变形得到的句子的类似度的步骤;选择由变形得到的句子之中的、规定数目的、类似度高的句子的步骤;直到类似度没有改善为止,对于选择步骤中选择的句子的各个,重复摘录步骤、计算步骤以及选择步骤的步骤;当重复步骤结束时,将剩余的第2种语言的句子之中,具有最大类似度的句子作为对输入文的译文输出的步骤。
Description
技术领域
本发明涉及一种机器翻译装置,特别是在发挥范例翻译的优点的同时能进行高精度的翻译的统计机器翻译装置。
背景技术
在统计性的翻译中,将某一种语言的句子(J)翻译为其它语言的句子(E)的问题,作为最大化以下附带条件的概率的问题被定型化。
对于此公式,通过适用贝叶斯定理得到下面的公式。
其中,P(J)与
的计算无关。因此,能得到下面的公式。
右边的第1项P(E)被称为语言模型,表示句子E的类似度。第2项的P(J|E)被称为翻译模型,表示从句子E生成句子J的概率。
在这样的思考方式下,由单词排列(单词的对应)这样的概念提出了所谓使第1种语言的句子(称为信道目标文)映射为第2种语言的句子(称为信道源文)的翻译模型。此翻译模型在法语和英语、德语和英语等相互间类似的语言之间获得了成功。
但是,此翻译模型例如应用在日语和英语等相互间差异很大的语言时没有取得成果。这样的结果是因为在构造相互不同的语言间进行映射时,频繁地进行单词的插入和删除,各单词的派生很多以及词语的对应很复杂等的原因,带来了搜索空间庞大这样的问题而产生的。因为搜索变复杂,所以如果采用根据束搜索(beam search)的解码算法,那么在多数的情况下只能得到局部的解。
基于单词排列(alignment)的统计的机器翻译采用单词排列A这样的考虑方法表示2种语言的对应。此时,允许1个单词和多个单词相对应。所谓单词排列A是指将信道目标文的各个单词和信道源文的哪个单词相对应,采用信道源文的单词指标进行表示的排列。在此排列中,和信道源文的单词的对应采用赋予信道源文的单词的指标表示,这些指标根据信道目标文的单词的顺序排列。
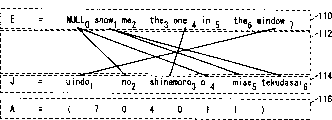
图7表示英语(E)以及日语(J)句子之间的单词排列的例A。参照图7,将第2种语言(此处为英语E)的句子110的1~7的各个单词,和第1种语言(此处为日语J)的句子114的各个单词1~6对应。对应由连接信道源文110的各个单词和信道目标文114的单词的连线群112表示。例如,由信道源文110的单词[show1]生成信道目标文114的两个单词[mise5](让看)以及[tekudasai6](请)。另外信道目标文114的两个单词[no2](的)以及[o4](を)和信道源文110的哪个单词都没有对应,假设信道源文110的开始部分为[null0](空),作为与此对应的单词。这样的话此时的排列A为[7,0,4,0,1,1]。
作为单词排列如果假设为这样的映射,翻译模型P(J|E)能进一步写成以下这样。
右边的项P(J|E)被进一步分解为、4个要素,由此4个要素构成将信道源文E变换为具有排列A的信道目标文J的以往技术的顺序。此4个要素如下。
(1)根据派生模式,对于信道源文的各单词决定能生成几个翻译词。有由一个单词可以生成两个翻译词的情况,也有一个翻译词都不能生成的情况。
(2)根据NULL生成模式,在信道源文的适当位置插入NULL。
(3)通过查找词汇模型,进行对生成的各单词的翻译。
(4)通过参照变形模型,对翻译的各单词进行排列变换。为了保存有关句子的限制条件,此时的位置由刚才的单词排列决定。
这样,基于单词排列这样的思考方式得到翻译模型。
另一方面,提出了最初生成按照信道目标文的顺序排列的、由最初信道目标文的各单词翻译为信道源文的语言的句子,对于此文字应用各种运算子生成多个译文的方法。(Ulrich Germann,Michael Jahr,Kevin Knight,Daniel Marcu,Kenji Yamada:“机器翻译的快速解码以及优化解码”(2001)ACL2001会议录,图卢兹,法国)。在此提出的方法中,在这样生成的译文之中,求出类似度最高的句子作为翻译文选择出来。
基于单词排列的统计翻译模型是对于作为例如法语和英语等相互类似的语言的两种语言设计的。另一方面,日语和英语相互之间具有极其不同的构造。因此,日语和英语相互翻译的情况下,图7所示那样的单词排列就变得非常复杂。此复杂度反映了语言的构造的差异。例如对于英语采用SVO的句型,而通常日语采用SOV这样的句型。还有,从图7所示的例子中也可以看出,非常频繁地产生插入和删除。例如对于图7所示的[the3]以及[the6],在日语中不存在对应的形态要素。也就是说,对于这样的词当从日语翻译为英语时,必须进行插入。同样,对于日语的no2以及o4也必须进行删除。
由于这样的排列复杂以及词语的插入和删除频繁地进行,如果对每个单词进行束搜索,会产生计算量增大这样的问题。为了能在一定的时间内得出结果,就必须进行某些形式的修改。但是,通常的搜索算法中,如果这样在限定的空间中进行搜索的话,不可避免的会产生搜索误差。我们承认翻译的质量和由翻译模型指定的类似度之间存在某种程度的相关性,但由束搜索得到更高的质量是困难的。
另外在Germann等的方法中,存在着在搜索中得到局部的最适当的解很多这样的问题,不能稳定得到高精度的解。
发明内容
本发明的目的在于提供一种采用统计机器翻译的机器翻译方法及其装置,与语言的组合无关,而可以得到高品质的翻译。
本发明的另一目的在于提供一种采用统计机器翻译的机器翻译方法及其装置,其与语言的组合无关,而可以在一定程度的时间内得到高品质的翻译。
本发明的又一目的在于提供一种采用统计机器翻译的机器翻译方法及其装置,其与语言的组合无关,而可以稳定得到高品质的翻译。
有关本发明第1方面的机器翻译方法,其采用包含多个由第1种语言的句子和第2种语言的句子构成对译的对译文集,将第1种语言输入文翻译为第2种语言的句子,包括以下步骤:摘录步骤,接收第1种语言输入文,从对译文集之中,摘录出和输入文之间具有规定关系的、和第1种语言的句子成对的第2种语言的句子;计算步骤,对于摘录出的第2种语言的句子,应用预先决定的多个变形之中的任意变形,计算由变形得到的句子的类似度;选择步骤,从由变形得到的句子中,选择具有满足规定条件的类似度的句子;重复步骤,直到预先决定的结束条件成立为止,对于选择步骤选择的句子的每一个,重复摘录步骤、计算步骤以及选择步骤;和输出步骤,在重复步骤结束时剩余的第2种语言的句子之中,具有满足预先决定的选择条件的类似度的句子作为对输入文的译文并输出。
对于输入文,从对译文集之中摘录出规定的关系成立的、和第1种语言成对的第2种语言的句子。对此第2种语言的句子进行种种的变形,重复从得到的句子中选择具有满足规定的条件的类似度的句子,将最终满足选择条件的句子作为对于输入文的译文输出。因为在对译文集之中的对译文是两种语言之间相互较好的对译文,所以摘录出的第2种语言的句子和输入文的理想的译文相类似的可能性很高。重复这样摘录出的第2种语言的句子的种种变形,从得到的句子中基于类似度选择的译文,成为输入文的理想的译文的可能性很高。因为考虑最初摘录出的句子与理想的译文接近,所以在重复的过程中限于局部的最适当解的危险性很低。
优选,摘录步骤包括读取步骤,其接收第1种语言的输入文,从对译文集之中,读取当表示和输入文的类似度的规定分数满足预先决定的条件的、和第1种语言的句子成对的第2种语言的句子。
优选,读取步骤包括:分数计算步骤,其接收第1种语言的输入文,对于对译文集之中所包含的第1种语言的句子的每一个,计算和输入文之间的分数;确定步骤,其确定在分数计算步骤中算出的分数最大的1个或者多个的第1种语言的句子;和句子读出步骤,其将确定步骤中决定的1个或者多个第1种语言的句子和分别与其成对的1个或者多个第2种语言的句子从对译文集之中读出。
每当摘录出第2种语言的句子时,确定表示和输入文的类似度的分数最大的1个或者多个第1种语言的句子,将这些句子和与其分别对应的第2种语言的句子从对译文集之中读出。以读出的第2种语言的句子为种子,进行变形以及类似度计算的循环,将得到的句子中满足规定的条件的句子作为输入文的译文。得到的第2种语言的句子对于输入文来讲,和理想的译文类似的可能性高,最终得到的译文相对于输入文来讲成为理想的译文的可能性增高。
分数计算步骤也可以包括:类似尺度计算步骤,其在输入文和对译文集之中所包含的第1种语言的各个之间,将对译文集之中所包含的第1种语言的句子作为文本,对输入文采用定义的文本频率计算规定的类似尺度;编辑距离计算步骤,其计算输入文、与包含在对译文集之中的第1种语言的各个之间的编辑距离;和分数算出步骤,其基于在类似尺度计算步骤中算出的类似尺度以及在编辑距离计算步骤中算出的编辑距离,计算分数。
优选,类似尺度计算步骤包括tf/idf标准Ptf/idf计算步骤,在对译文集之中所包含的第1种语言的各句子和输入文之间,按照下面的公式计算tf/idf标准Ptf/idf,
式中,J0表示输入文,J0,i表示输入文J0的第i个单词,df(J0,i)表示对于单词J0,i的文本频率,Jk表示第k个第1种语言的句子(1≤k≤N),N表示对译文集之中的全部对译文数目。
进一步,编辑距离计算步骤包括:进行输入文J0和第1种语言的句子Jk之间的DP匹配,即动态编程匹配,计算编辑距离dis(Jk,J0)的步骤,编辑距离dis(Jk,J0)由以下公式决定,
dis(Jk,J0)=I(Jk,J0)+D(Jk,J0)+S(Jk,J0)
式中,k是1≤k≤N的整数,I(Jk,J0)、D(Jk,J0)以及S(Jk,J0)分别为将句子J0变换为句子Jk时,必要的词语的插入、删除以及置换的数量。
分数算出步骤包括:分数求出步骤,其对第1种语言的句子Jk,基于在类似尺度计算步骤中算出的tf/idf标准Ptf/idf以及在编辑距离计算步骤算出的编辑距离dis(Jk,J0),求出由下面公式所定义的分数,
式中,α为调整参数;对译文选择步骤,其从在分数求出步骤中求得的分数较大的对译文中,作为初始备用,依次选择预先决定个数的对译文。
机器翻译方法也可以进一步包括:判定步骤,其判断在读取步骤中读出的第1种语言的句子中是否存在分数为1的句子;和译文输出步骤,其对在判定步骤中判断为存在分数为1的第1种语言的句子一事进行应答,将该分数为1的第1种语言的句子作为对于输入文的译文输出。
分数为1是指在对译文集之中存在和输入文一致的第1种语言的句子。即通过将此和第1种语言的句子成对的第2种语言的句子作为对于输入文的译文进行选择,能够得到很好的译文。
重复步骤也可以包括:直到看不出选择步骤所选择的句子的类似度改善为止,对于选择步骤中选择的句子的各个,重复摘录步骤、计算步骤以及选择步骤的步骤。
优选,输出步骤包括:在重复步骤结束时剩余的第2种语言的句子之中,具有最大的类似度的句子作为对于输入文的译文输出的步骤。
这样,通过将具有最大类似度的句子作为对于输入文的译文输出,对于输入文来说,作为译文得到最接近于理想的译文的可能性增高。
有关本发明第2方面的记录介质,记录了让计算机动作的机器翻译计算机程序,在计算机执行该程序时将实施以下机器翻译方法,机器翻译方法采用包含多个由第1种语言的句子和第2种语言的句子构成对译的对译文集,将第1种语言输入文翻译为第2种语言,包括以下步骤:摘录步骤,接收第1种语言输入文,从对译文集之中,摘录出和输入文之间具有规定关系的、和第1种语言的句子成对的第2种语言的句子;计算步骤,对于摘录出的第2种语言的句子,应用预先决定的多个变形之中的任意变形,计算由变形得到的句子的类似度;选择步骤,从由变形得到的句子中,选择具有满足规定条件的类似度的句子;重复步骤,直到预先决定的结束条件成立为止,对于选择步骤选择的句子的每一个,重复摘录步骤、计算步骤以及选择步骤;和输出步骤,在重复步骤结束时剩余的第2种语言的句子之中,具有满足预先决定的选择条件的类似度的句子作为对输入文的译文并输出。
通过使该记录介质中存储的程序在计算机中执行,能够在计算机中执行上述机器翻译方法。
通过结合附图进行以下的发明的详细说明,就会清楚本发明的目的、特征、方面以及效果。
附图说明
图1表示有关本发明一实施例的机器翻译系统的功能框图。
图2表示图1所示的初始备用选择部32的更详细的功能框图。
图3表示图1所示的备用修正部36的更详细的功能框图。
图4表示图3所示的排列搜索部74的处理的详细过程的示意图。
图5表示实现有关本发明一实施例的机器翻译系统的计算机的外观图。
图6表示图5所示的计算机的框图。
图7表示单词排列一例的图。
具体实施方式
作为并非象束搜索(beam search)那样对每个单词都进行翻译的系统的机器翻译系统,存在基于范例的系统(范例翻译)。范例翻译是基于对译文集的翻译方式的一种。在对译文集之中,保存了多个由第1种语言的句子和第2种语言译文构成的对译文。如果输入了第1种语言的输入文,在对译文集之中找出和输入文类似的第1种语言的句子,基于找出的第1种语言的句子的译文(第2种语言的句子)生成输出文。
本实施例的机器翻译系统是基于组合了此范例翻译系统和统计机器翻译系统的新框架的系统。
(构成)
图1表示有关本实施例的机器翻译系统20的框图。参照图1,此机器翻译系统20包括:包含多个由第1种语言(将此作为语言J)句子和第2种语言(将此作为语言E)句子构成的对译文的对译文集34;接收第1种语言的输入文30,为了从对译文集34中选择和输入文30相似的规定数量(例如5个)的第1种语言的句子的初始备用选择部32。
机器翻译系统20进一步包括:在统计机器翻译中通常使用的、第2种语言的语言模型(P(E))38以及翻译模型40(P(J|E));对于由初始备用选择部32选择的多个第1种语言的句子的每一个,如后述那样在搜索的同时进行第2种语言译文的修正,将采用语言模型38以及翻译模型40算出的类似度最高的译文作为对输入文30进行翻译的结果得到的输出文42输出的备选修正部36。
图2表示初始备用选择部32的详细框图。参照图2,初始备用选择部32包括tf/idf计算部50,其参照对译文集34,计算作为表示输入文30和对译文集34的第1种语言的句子的各个之间的类似程度的类似尺度的tf/idf标准Ptf/idf。tf/idf标准Ptf/idf是将对译文集34的第1种语言的各句子作为一个文本,利用在信息检索算法中一般采用的被称为文本频率的概念由下面的公式定义的尺度。
式中,J0表示输入文,J0,i表示输入文J0的第i个单词,df(J0,i)表示对于输入文J0的第i个单词J0,i的文本频率,N表示对译文集之中的全部对译文数目。所谓文本频率df(J0,i)是指输入文J0中的第i个单词J0,i出现的文本(本实施例中指句子)的数目。
初始备用选择部32进一步包括:编辑距离计算部52,其对于在对译文集34中包含的各对译文(Jk,Ek)的第1种语言的句子Jk,进行和输入文J0之间的DP(Dynamic Programing:动态编程)匹配,计算编辑距离dis(Jk,J0);和分数计算部54,其基于由tf/idf计算部50算出的tf/idf标准Ptf/idf以及由编辑距离计算部52算出的编辑距离,根据后述的公式计算各句子的分数。
由编辑距离计算部52算出的编辑距离dis(Jk,J0)由以下的公式表示。
dis(Jk,J0)=I(Jk,J0)+D(Jk,J0)+S(Jk,J0)
式中,k是1≤k≤N的整数,I(Jk,J0)、D(Jk,J0)以及S(Jk,J0)分别为从句子J0变换为句子Jk为止时的插入/删除/置换的次数。
由分数计算部54算出的分数Score由以下的公式表示。
式中,α为调整参数,在本实施例中α为0.2。
参照图2,初始备用选择部32进一步包含基于由分数计算部54算出的分数score,选择分数大的规定个数(本实施例中为5个)的对译文,作为备选对译文58输出,提供给图1所示的备选修正部36的对译文选择部56。
图3表示图1所示的备选修正部36的详细框图。参照图3,备选修正部36包含:接收由初始备用选择部32输出的备选对译文58中所包含的各初始备选对译文(Jk,Ek),对于各个初始备选对译文,使用语言模型和翻译模型,计算第1种语言输入文和第2种语言的句子之间类似度最高的维特比排列的维特比排列部70。由维特比排列部70计算对于输入文J0和各个备选对译文(Jk,Ek)之中由第2种语言的句子Ek构成的新的备选对译文(J0,Ek)的初始排列Ak,表示排列结束的备选对译文(J0,Ak,Ek)。
备选修正部36进一步包含:一致检测部72,由维特比排列部70判断排列Ak算出的排列完毕的各备选对译文(J0,Ak,Ek)之中是否有分数为1的备选对译文,如果一致就将第1值,如果不一致就将第2值分别作为一致检测信号73输出,同时如果存在分数为1的备选对译文时,将此备选对译文75排列同时输出;和排列搜索部74,当一致检测部72没有检测出一致时,对于来自维特比排列部70的排列完毕的备选对译文(J0,Ak,Ek)进行以下所述的排列Ak以及译文Ek的修正,最终作为对于输入文30的译文,将表示最高类似度的对译文77和其排列同时输出。排列搜索部74在此搜索时,如后述那样使用语言模型38以及翻译模型40。另外一致检测部72当检测出一致时,由排列搜索部74停止排列搜索,使其不执行。
备选修正部36进一步包含译文选择部76,对一致检测部72输出的一致信号73进行应答,一致检测信号73根据第1值或者第2值选择一致检测部72的输出对译文75或者排列搜索部74的输出对译文77之中的任何一个,作为输出文42输出。
图4表示排列搜索部74进行的修正备选文的搜索和登山法的概略。参照图4,排列搜索部74包含操作适用部81A、81B、…,对于来自维特比排列部70的备选对译文58中所包含的排列完毕的对译文80A~80N,通过应用表示单词的移动/删除/置换等操作之一,修正排列,生成多个新的备选对译文群82A、82B、…。排列搜索部74进一步包含选择处理部84A、84B、…,对于这样得到的备选对译文群82A、82B、…的各个中包含的排列修正后的对译文的各个,采用语言模型38以及翻译模型40算出类似度,从各备选对译文中类似度最高的对译文开始,按照顺序保留规定的个数(本实施例中为5个)将其它的备选对译文删除,为了从备选对译文群82A、82B、…中生成新的备选对译文群86A、…、86N的根据类似度。
排列搜索部74的操作适用部81A、81B、…,例如对于备选对译文群86A中所包含的备选对译文88A、…、88N也进行上述的动作生成新的备选对译文90A、…、90N。然后根据类似度的选择处理部84A、84B、…对于这些备选对译文群94A、…、94N也采用语言模型38以及翻译模型40,将具有最高类似度的备选对译文96A、…、96N保留下来,生成新的备选对译文群94A、…、94N。
这样,排列搜索部74将最初的备选对译文58中所包含的备选对译文80A、…、80N作为种子(seed),将对译文的排列不断地应用操作,生成新的备选对译文。排列搜索部74按照根据类似度的选择部84A、84B、…进行备选对译文的选择时,对于备选对译文,当判断计算的类似度不能得到改善的时刻将上述的重复处理中止(登山法)。
这样,排列搜索部74进行对译文的排列的搜索、修正,根据登山法将在搜索处理中求出的备选对译文和排列之中类似度最高的翻译文作为输出文42输出。
操作适用部81A、81B、…对于排列完毕的对译(J0,Ak,Ek)进行的操作和Germann等所记载的几乎相同,如以下。
(1)单词的翻译
对单词J0,j将排列的输出的单词EA,j变换为单词e。如果单词e是NULL,单词J0,j被配列为NULL,Aj=0。如果单词EA,j的派生为0,此单词EA,j被删除。单词e通过反向利用词汇模型计算,从单词备选中选择。
(2)单词的翻译以及插入
进行单词的翻译,在适当的位置插入派生为0的一连串的单词。派生为0的一连串的单词的备选,是对于学习文集从维特比排列中选择的。
(3)单词的翻译以及排列
排列中的第j个单词Ej移动到第i个,将第i个单词Ei修正为单词e。
(4)排列的移动
此操作不是进行输出单词顺序的变更,而是通过排列A的移动以及交换只对排列进行修正。
(5)段的交换
译文E之中,没有重复的部分相互交换。即将从第i0个单词开始到第i1个单词组成的段和从第i2个单词开始到第i3个(其中,i1<i2)单词组成的段进行交换。
(6)单词(群)的删除
从译文E中将派生为0的单词序列删除。
(7)单词的组合
当译文Ei以及Ei′中所包含的单词的派生任何一个都为1以上时,将此两个单词组合。
此7种操作之中,除去(3)、(4)剩下的5种和由Germann等提出的几乎相同。(3)和(4)的操作是在本实施例中新追加的。最初由维特比排列部70执行的维特比排列中,将第1种语言的句子之中没有和第2种语言的句子相对应的译文的单词和NULL相对应,或者通过提高派生将其排列到不适当的单词中。通过操作(3)单词的翻译以及排列,采用词汇模型能找出每个适当的单词的翻译,此排列是强制地移动到其它的单词处。同样地,操作(4)排列的移动是通过将已经存在的排列进行移动得到同样的效果。
(动作)
机器翻译系统20是采用以下这样的动作。在对译文集34中预先包含由第1种语言的句子和第2种语言的译文构成的多个对译文。另外语言模型38以及翻译模型40通过某些方法预先准备。
参照图1,输入文30输入到初始备用选择部32中。参照图2,初始备用选择部32的tf/idf计算部50计算输入文30和对译文集34之中全部的对译文中的第1种语言的句子之间的tf/idf标准Ptf/idf。编辑距离计算部52同样地计算输入文30和全部的对译文集34中的第1种语言的句子Jk之间的编辑距离dis(Jk,J0)。
分数计算部54利用由tf/idf计算部50算出的tf/idf标准Ptf/idf以及由编辑距离计算部52算出的编辑距离dis(Jk,J0),根据下式计算上述的分数score。
对译文选择部56选择对译文集34中所包含的对译文之中分数score高的规定个数的对译文,作为备选对译文58提供给图3的维特比排列部70。
参照图3,维特比排列部70将作为输入文J0提供的备选对译文58中所包含的对译文(Jk,Ek)的各个之中的第2种语言的句子Ek计算维特比排列Ak,将结果以(J0,Ak,Ek)的形式提供给一致检测部72以及排列搜索检测部74。
一致检测部7判断来自维特比排列部70的对译文之中是否有分数score=1的对译文。即一致检测部72判断备选对译文之中第1语言的句子是否有和输入文一致的,当存在一致的对译文时,一致检测部72将一致检测信号73的值作为第1值,此外的情况下,一致检测部72将一致检测信号73的值作为第2值。当存在一致对译文的情况下,一致检测部72还将此对译文作为对译文75提供给译文选择部76。
排列搜索部74将由维特比排列部70提供的排列完毕的备选对译文(J0,Ak,Ek)作为最初的种子,参照语言模型38以及翻译模型40进行上述搜索,根据登山法进行直到得到类似度最高的译文为止的搜索。搜索的过程中,排列搜索部74对于全部的排列完毕的备选对译文,采用可能的全部的操作生成新的备选对译文(和排列)。排列搜索部74进一步只留下这样生成的备选对译文(和排列)之中满足规定条件的备选对译文(从类似度最高的开始,规定个数的对译文),删除其它的对译文。排列搜索部74进一步将剩余的备选对译文作为种子重复同样的处理。然后,对于生成的备选对译文直到计算的类似度没有改善为止,结束其路径的搜索(登山法)。
这样,在对于全部的路径的搜索结束的时刻,将具有最高类似度的对译文作为最终的输出。排列搜索部74将此对译文77提供给译文选择部76。译文选择部76当一致检测部73为第1值时,将作为一致检测部72的输出的对译文75,其它的情况下将作为排列搜索部74的输出的对译文77,分别选择并作为输出文42输出。
(评价)
进行了对关于上述的实施例的系统的翻译精度的评价。作为文集,采用了申请人准备的旅行会话用的文集。此文集包含日语、英语、韩国语以及中文的对译文。文集的统计信息在下面的表中表示。
表1
| 中文 | 英语 | 日语 | 韩国语 | |
| 句子数 | 167,163 | |||
| 词语数 | 956,732 | 980,790 | 1,148,428 | 1,269,888 |
| 词汇大小 | 16,411 | 15,641 | 21,896 | 13,395 |
| 单音数 | 5,207 | 5,547 | 9,220 | 4,191 |
| 3元语法复杂度 | 45.33 | 35.35 | 24.06 | 20.34 |
将文集全体分为3部分。即将152,169的句子用于翻译模型以及语言模型的学习中,将4,849的句子用于文本,剩余的10,148用于参数调整。作为参数有学习时的重复的结束标准以及解码的参数调整等的参数。
作为语言模型进行了4种语言的3元语法(Tri-gram)语言模型的学习,如上面的表中所示,由复杂度(perplexity)尺度进行评价。对于4种语言的组合的全部,关于双向翻译进行了全部的12种的翻译模型的学习。
下表中表示采用有关本实施例的系统在上述的4种语言间进行翻译得到的结果。表中所使用的省略语的意思如下。
<WER>表示Word-error-rate(单词错误率)。这是反映了与标准的模范翻译相比较时的编辑距离(插入/删除/置换)。
<PER>表示位置独立(Position-independent)的WER。这是除了位置的问题,只反映了关于插入和删除的编辑距离。
<BLEU>表示BLUE分数。这是表示翻译结果的n—克之中,在成为标准的模范翻译中找出的比率。上述的WER以及PER不同,BLUE分数越高翻译的质量越高。
<SE>表示主观的评价。分为A~D(A:非常完美、B:基本没有问题、C:还可以、D:不合理)的4个等级,由说此母语的人进行的评价。此评价由说母语的人评价为A的比例(A)、评价为A或者B的比例(A+B)、评价为A、B或者C的比例(A+B+C)表示。在本实验中,上述4种语言之中,对于英语之外的3种语言翻译为英语,以及日语以外的3种语言翻译为日语,作为日语—英语之间的翻译结果进行了评价。在此表中,细体表示根据采用束搜索的机器翻译装置的翻译结果,粗体表示根据有关本实施例的机器翻译装置的翻译结果。
表2
| WER[%] | PER[%] | BLEU[%] | 主観的評価(SE)[%] | |||
| A | A+B | A+B+C | ||||
| C-EC-JC-K | 45.0 34.335.7 25.538.4 29.1 | 39.8 30.331.3 22.634.2 26.2 | 43.6 56.756.9 67.856.1 65.0 | 48.4 65.050.8 69.0- - | 65.9 76.959.4 74.3- - | 71.4 81.066.9 80.2- - |
| E-CE-JE-K | 45.0 38.034.2 29.038.7 35.6 | 39.7 33.430.5 26.134.3 31.6 | 42.1 51.959.2 65.757.3 61.5 | - -55.8 65.1- - | - -62.4 71.6- - | - -70.2 77.8- - |
| J-CJ-EJ-K | 46.8 33.042.9 35.027.7 20.8 | 38.9 27.837.4 30.325.4 19.2 | 39.7 57.147.6 57.467.2 73.5 | - -50.8 63.7- - | - -65.7 74.5- - | - -70.2 77.6- - |
| K-CK-EK-J | 41.9 32.945.1 36.426.8 20.8 | 34.4 27.638.5 32.124.6 19.3 | 45.1 55.544.3 56.864.3 70.8 | - -49.2 61.656.5 69.2 | - -65.7 72.966.5 77.5 | - -72.2 78.478.4 84.7 |
从此表中能够明白,根据本实施例的机器翻译装置的翻译结果,对于全部的语言的组合,对于翻译为任何一种语言都得到比由束搜索方式的翻译装置更好的结果。此差异是非常大的,根据本实施例的机器翻译装置的性能和采用束搜索的装置相比是非常高的,这点已经明确了。另外根据本实施例的翻译结果是安定的,限于局部的最适解的情况很少。其原因被认为作为最初的解,检索出和输入文最接近的,以此作为出发点通过进行和上述的登山法组合的搜索,在较大的范围内找出接近于最合适的翻译结果的可能性高。
根据初始备用选择部32的初始备用的选择中,如果能够根据某种标准找出和输入文30接近的第1种语言的句子的对译文,也可以采用和本实施例中采用的初始备用选择部32不同的构成的装置。另外,也存在在对译文集34中找不到以句子为单位的输入文相对应的翻译文的情况。在这样的以句子为单位的检索不能实现的情况下,采用比输入句子更小的单位,例如分割为词组或者节等,以分割后的单位通过检索对译文集34找出和其相对应的译文,通过组合译文生成初始备选也可以。
进一步,代替由初始备用选择部32的初始备用的选择,采用根据其它的某一种翻译方式的翻译装置翻译输入文,将其作为初始备选也可以。例如,作为这样的翻译装置采用范例翻译装置,将范例翻译的结果作为初始备选也可以。此时,范例翻译中所使用的文集可以是和对译文集34同样的,也可以是完全不同的文集。
另外,在上述实施例中,排列搜索部74的登山法中,采用了和幅度优先搜索同样的算法。但是本发明并非仅限定于这样的实施例,采用深度优先的算法在理论上也是可行的。
(由计算机实现)
另外有关本实施例的机器翻译装置也能够通过计算机硬件、在该计算机硬件上动作的程序以及该计算机的存储装置中存储的对译文集、翻译模型以及语言模型实现。特别是,图4所示的由排列搜索部74进行的搜索通过采用循环编程能够更有效地执行。
根据上述的实施例的说明,这样的程序如果是该行业的一般技术人员,应该能够更容易地实现。
图5表示实现此机器翻译装置的计算机系统330的外观。图6是表示计算机系统330的内部构成。
参照图5,此计算机系统330包括:具有FD(软盘)驱动器352以及CD-ROM(光盘读取专用存储器)驱动器350的计算机340、键盘346、鼠标348和监视器342。
参照图6,计算机340除了FD驱动器352以及CD-ROM驱动器350之外,还包括:CPU(中央处理器)356;连接CPU356、FD驱动器352以及CD-ROM驱动器350的总线366;存储引导程序等的读取专用存储器(ROM)358;与总线366相连、存储程序命令、系统程序以及计算数据等的随机存取存储器(RAM)360。计算机系统330进一步包括打印机344。
在此处虽然未画出,计算机340也可以进一步包括连接局域网(LAN)的网卡。
计算机系统330中,为了执行机器翻译装置的动作的计算机程序是存储在插入CD-ROM驱动器350或者FD驱动器352中的CD-ROM362或者FD364中,进一步传送到硬盘354。另外,程序通过图中未画出的网络向计算机340发送,存储在硬盘354中也可以。程序执行时下载到RAM360中。也可以从CD-ROM362、FD364或者通过网络直接将程序下载到RAM360中。
此程序包含计算机340执行作为此实施例的机器翻译装置的动作的多个命令。执行此方法所必要的几个基本功能由在计算机上动作的操作系统(OS)或者第三方的程序、或者由计算机340中所安装的各种工具包的模块提供。也就是说,此程序并非必须包括实现此实施例的系统以及方法所必要的全部功能。此程序的命令之中,只需包括为了能得到所期望的结果,以控制的方法通过读出适当的功能或者“工具”,实现上述的机器翻译装置的命令即可。因为计算机系统330的动作是周知的,此处不重复叙述。
此次展示的实施例只是示例,本发明并非仅限定于上述实施例。本发明的范围是在参考发明的详细说明的记述的基础上,包括由权利要求书的各个权利要求所提到的、和其中所述具有相同的意思以及范围内全部的变更。
Claims (26)
1、一种机器翻译方法,其采用包含多个由第1种语言的句子和第2种语言的句子构成对译的对译文集,将所述第1种语言输入文翻译为所述第2种语言的句子,其特征在于,包括以下步骤:
摘录步骤,接收所述第1种语言输入文,从所述对译文集之中,摘录出和所述输入文之间具有规定关系的、和第1种语言的句子成对的所述第2种语言的句子;
计算步骤,对于所述摘录出的所述第2种语言的句子,应用预先决定的多个变形之中的任意变形,计算由变形得到的句子的类似度;
选择步骤,从由所述变形得到的句子中,选择具有满足规定条件的类似度的句子;
重复步骤,直到预先决定的结束条件成立为止,对于所述选择步骤选择的句子的每一个,重复所述摘录步骤、所述计算步骤以及所述选择步骤;和
输出步骤,在所述重复步骤结束时剩余的所述第2种语言的句子之中,具有满足预先决定的选择条件的类似度的句子作为对所述输入文的译文并输出。
2、根据权利要求1所述的机器翻译方法,其特征在于,所述摘录步骤包括读取步骤,其接收所述第1种语言的输入文,从所述对译文集之中,读取当表示和所述输入文的类似度的规定分数满足预先决定的条件的、和所述第1种语言的句子成对的所述第2种语言的句子。
3、根据权利要求2所述的机器翻译方法,其特征在于,所述读取步骤包括:
分数计算步骤,其接收所述第1种语言的输入文,对于所述对译文集之中所包含的所述第1种语言的句子的每一个,计算和所述输入文之间的所述分数;
确定步骤,其确定在所述分数计算步骤中算出的分数最大的1个或者多个的所述第1种语言的句子;和
句子读出步骤,其将所述确定步骤中决定的所述1个或者多个第1种语言的句子和分别与其成对的1个或者多个所述第2种语言的句子从所述对译文集之中读出。
4、根据权利要求3所述的机器翻译方法,其特征在于,所述分数计算步骤包括:
类似尺度计算步骤,其在所述输入文和所述对译文集之中所包含的所述第1种语言的各个之间,将所述对译文集之中所包含的所述第1种语言的句子作为文本,对所述输入文采用定义的文本频率计算规定的类似尺度;
编辑距离计算步骤,其计算所述输入文、与包含在所述对译文集之中的所述第1种语言的各个之间的编辑距离;和
分数算出步骤,其基于在所述类似尺度计算步骤中算出的类似尺度以及在所述编辑距离计算步骤中算出的编辑距离,计算所述分数。
5、根据权利要求4所述的机器翻译方法,其特征在于,所述类似尺度计算步骤包括tf/idf标准Ptf/idf计算步骤,在所述对译文集之中所包含的所述第1种语言的各句子和所述输入文之间,按照下面的公式计算tf/idf标准Ptf/idf,
式中,J0表示输入文,J0,i表示输入文J0的第i个单词,df(J0,i)表示对于单词J0,i的文本频率,Jk表示第k个所述第1种语言的句子,1≤k≤N,N表示对译文集之中的全部对译文数目。
6、根据权利要求5所述的机器翻译方法,其特征在于,所述编辑距离计算步骤包括:进行输入文J0和所述第1种语言的句子Jk之间的DP匹配,即动态编程匹配,计算编辑距离dis(Jk,J0)的步骤,编辑距离dis(Jk,J0)由以下公式决定,
dis(Jk,J0)=I(Jk,J0)+D(Jk,J0)+S(Jk,J0)式中,k是1≤k≤N的整数,I(Jk,J0)、D(Jk,J0)以及S(Jk,J0)分别为将句子J0变换为句子Jk时,必要的词语的插入、删除以及置换的数量。
7、根据权利要求6所述的机器翻译方法,其特征在于,所述分数算出步骤包括:
分数求出步骤,其对所述第1种语言的句子Jk,基于在所述类似尺度计算步骤中算出的tf/idf标准Ptf/idf以及在所述编辑距离计算步骤算出的编辑距离dis(Jk,J0),求出由下面公式所定义的分数,
式中,α为调整参数;
对译文选择步骤,其从在所述分数求出步骤中求得的分数较大的对译文中,作为所述初始备用,依次选择预先决定个数的对译文。
8、根据权利要求7所述的机器翻译方法,其特征在于,进一步包括:
判定步骤,其判断在所述读取步骤中读出的所述第1种语言的句子中是否存在所述分数为1的句子;和
译文输出步骤,其对在所述判定步骤中判断为存在分数为1的所述第1种语言的句子一事进行应答,将该分数为1的所述第1种语言的句子作为对于所述输入文的译文输出。
9、根据权利要求7所述的机器翻译方法,其特征在于,进一步包括:
对在所述判定步骤中判断存在分数为1的所述第2种语言的句子一事进行应答,对所述计算步骤,所述选择步骤,所述重复步骤以及所述输出步骤的执行进行抑制的步骤。
10、根据权利要求1所述的机器翻译方法,其特征在于,所述选择步骤包括:
在由所述变形得到的句子中,选择规定个数的类似度最高的句子的步骤。
11、根据权利要求1所述的机器翻译方法,其特征在于,所述重复步骤包括:
直到看不出所述选择步骤所选择的句子的类似度改善为止,对于所述选择步骤中选择的句子的各个,重复所述摘录步骤、所述计算步骤以及所述选择步骤的步骤。
12、根据权利要求1所述的机器翻译方法,其特征在于,所述输出步骤包括:
在所述重复步骤结束时剩余的所述第2种语言的句子之中,具有最大的类似度的句子作为对于所述输入文的译文输出的步骤。
13、根据权利要求1所述的机器翻译方法,其特征在于,
所述机器翻译方法与所述第2种语言的语言模型、以及由所述第2种语言向所述第1种语言的翻译模型连接并使用,
所述计算步骤包括:对于摘录出的所述第2种语言的句子,应用所述预先决定的多个变形之中的任意变形,采用所述语言模型以及所述翻译模型计算由变形得到的句子的类似度的步骤。
14、一种记录介质,记录了让计算机动作的机器翻译计算机程序,在计算机执行该程序时将实施以下机器翻译方法,所述机器翻译方法采用包含多个由第1种语言的句子和第2种语言的句子构成对译的对译文集,将所述第1种语言输入文翻译为所述第2种语言,其特征在于,包括以下步骤:
摘录步骤,接收所述第1种语言输入文,从所述对译文集之中,摘录出和所述输入文之间具有规定关系的、和第1种语言的句子成对的所述第2种语言的句子;
计算步骤,对于所述摘录出的所述第2种语言的句子,应用预先决定的多个变形之中的任意变形,计算由变形得到的句子的类似度;
选择步骤,从由所述变形得到的句子中,选择具有满足规定条件的类似度的句子;
重复步骤,直到预先决定的结束条件成立为止,对于所述选择步骤选择的句子的每一个,重复所述摘录步骤、所述计算步骤以及所述选择步骤;和
输出步骤,在所述重复步骤结束时剩余的所述第2种语言的句子之中,具有满足预先决定的选择条件的类似度的句子作为对所述输入文的译文并输出。
15、根据权利要求14所述的记录介质,其特征在于,所述摘录步骤包括读取步骤,其接收所述第1种语言的输入文,从所述对译文集之中,读取当表示和所述输入文的类似度的规定分数满足预先决定的条件的、和所述第1种语言的句子成对的所述第2种语言的句子。
16、根据权利要求15所述的记录介质,其特征在于,所述读取步骤包括:
分数计算步骤,其接收所述第1种语言的输入文,对于所述对译文集之中所包含的所述第1种语言的句子的每一个,计算和所述输入文之间的所述分数;
确定步骤,其确定在所述分数计算步骤中算出的分数最大的1个或者多个的所述第1种语言的句子;和
句子读出步骤,其将所述确定步骤中决定的所述1个或者多个第1种语言的句子和分别与其成对的1个或者多个所述第2种语言的句子从所述对译文集之中读出。
17、根据权利要求16所述的记录介质,其特征在于,所述分数计算步骤包括:
类似尺度计算步骤,其在所述输入文和所述对译文集之中所包含的所述第1种语言的各个之间,将所述对译文集之中所包含的所述第1种语言的句子作为文本,对所述输入文采用定义的文本频率计算规定的类似尺度;
编辑距离计算步骤,其计算所述输入文、与包含在所述对译文集之中的所述第1种语言的各个之间的编辑距离;和
分数算出步骤,其基于在所述类似尺度计算步骤中算出的类似尺度以及在所述编辑距离计算步骤中算出的编辑距离,计算所述分数。
18、根据权利要求17所述的记录介质,其特征在于,所述类似尺度计算步骤包括tf/idf标准Ptf/idf计算步骤,在所述对译文集之中所包含的所述第1种语言的各句子和所述输入文之间,按照下面的公式计算tf/idf标准Ptf/idf,
式中,J0表示输入文,J0,i表示输入文J0的第i个单词,df(J0,i)表示对于单词J0,i的文本频率,Jk表示第k个所述第1种语言的句子,1≤k≤N,N表示对译文集之中的全部对译文数目。
19、根据权利要求14所述的记录介质,其特征在于,所述编辑距离计算步骤包括:进行输入文J0和所述第1种语言的句子Jk之间的DP匹配,即动态编程匹配,计算编辑距离dis(Jk,J0)的步骤,编辑距离dis(Jk,J0)由以下公式决定,
dis(Jk,J0)=I(Jk,J0)+D(Jk,J0)+S(Jk,J0)式中,k是1≤k≤N的整数,I(Jk,J0)、D(Jk,J0)以及S(Jk,J0)分别为将句子J0变换为句子Jk时,必要的词语的插入、删除以及置换的数量。
20、根据权利要求19所述的记录介质,其特征在于,所述分数算出步骤包括:
分数求出步骤,其对所述第1种语言的句子Jk,基于在所述类似尺度计算步骤中算出的tf/idf标准Ptf/idf以及在所述编辑距离计算步骤算出的编辑距离dis(Jk,J0),求出由下面公式所定义的分数,

式中,α为调整参数;
对译文选择步骤,其从在所述分数求出步骤中求得的分数较大的对译文中,作为所述初始备用,依次选择预先决定个数的对译文。
21、根据权利要求20所述的记录介质,其特征在于,所述机器翻译方法进一步包括:
判定步骤,其判断在所述读取步骤中读出的所述第1种语言的句子中是否存在所述分数为1的句子;和
译文输出步骤,其对在所述判定步骤中判断为存在分数为1的所述第1种语言的句子一事进行应答,将该分数为1的所述第1种语言的句子作为对于所述输入文的译文输出。
22、根据权利要求21所述的记录介质,其特征在于,所述机器翻译方法进一步包括:
对在所述判定步骤中判断存在分数为1的所述第2种语言的句子一事进行应答,对所述计算步骤,所述选择步骤,所述重复步骤以及所述输出步骤的执行进行抑制的步骤。
23、根据权利要求14所述的记录介质,其特征在于,所述选择步骤包括:
在由所述变形得到的句子中,选择规定个数的类似度最高的句子的步骤。
24、根据权利要求14所述的记录介质,其特征在于,所述重复步骤包括:
直到看不出所述选择步骤所选择的句子的类似度改善为止,对于所述选择步骤中选择的句子的各个,重复所述摘录步骤、所述计算步骤以及所述选择步骤的步骤。
25、根据权利要求14所述的记录介质,其特征在于,所述输出步骤包括:
在所述重复步骤结束时剩余的所述第2种语言的句子之中,具有最大的类似度的句子作为对于所述输入文的译文输出的步骤。
26、根据权利要求14所述的记录介质,其特征在于,
所述机器翻译方法与所述第2种语言的语言模型、以及由所述第2种语言向所述第1种语言的翻译模型连接并使用,
所述计算步骤包括:对于摘录出的所述第2种语言的句子,应用所述预先决定的多个变形之中的任意变形,采用所述语言模型以及所述翻译模型计算由变形得到的句子的类似度的步骤。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003308409 | 2003-09-01 | ||
| JP2003308409 | 2003-09-01 | ||
| JP2004151965A JP2005100335A (ja) | 2003-09-01 | 2004-05-21 | 機械翻訳装置、機械翻訳コンピュータプログラム及びコンピュータ |
| JP2004151965 | 2004-05-21 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN1591415A true CN1591415A (zh) | 2005-03-09 |
Family
ID=34220787
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNA2004100749435A Pending CN1591415A (zh) | 2003-09-01 | 2004-09-01 | 机器翻译装置以及机器翻译计算机程序 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7925493B2 (zh) |
| JP (1) | JP2005100335A (zh) |
| CN (1) | CN1591415A (zh) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101707873B (zh) * | 2007-03-26 | 2013-07-03 | 谷歌公司 | 机器翻译中的大语言模型 |
| CN103782291A (zh) * | 2011-07-26 | 2014-05-07 | 国际商业机器公司 | 定制自然语言处理引擎 |
| WO2014114140A1 (zh) * | 2013-01-25 | 2014-07-31 | 哈尔滨工业大学 | 一种用于统计机器翻译的参数调整方法 |
| CN105094358A (zh) * | 2014-05-20 | 2015-11-25 | 富士通株式会社 | 信息处理装置和通过外码输入目标语言文字的方法 |
| CN105593845A (zh) * | 2013-10-02 | 2016-05-18 | 系统翻译国际有限公司 | 基于自学排列的排列语料库的生成装置及其方法、使用排列语料库的破坏性表达语素分析装置及其语素分析方法 |
| CN106062736A (zh) * | 2014-03-07 | 2016-10-26 | 国立研究开发法人情报通信研究机构 | 词语对齐分数算出装置、词语对齐装置、以及计算机程序 |
| CN109977426A (zh) * | 2017-12-27 | 2019-07-05 | 北京搜狗科技发展有限公司 | 一种翻译模型的训练方法、装置以及机器可读介质 |
| CN110543642A (zh) * | 2019-08-20 | 2019-12-06 | 语联网(武汉)信息技术有限公司 | 基于机器翻译引擎的翻译方法及装置 |
Families Citing this family (53)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060116865A1 (en) | 1999-09-17 | 2006-06-01 | Www.Uniscape.Com | E-services translation utilizing machine translation and translation memory |
| US7904595B2 (en) | 2001-01-18 | 2011-03-08 | Sdl International America Incorporated | Globalization management system and method therefor |
| WO2003038663A2 (en) * | 2001-10-29 | 2003-05-08 | British Telecommunications Public Limited Company | Machine translation |
| US7584092B2 (en) * | 2004-11-15 | 2009-09-01 | Microsoft Corporation | Unsupervised learning of paraphrase/translation alternations and selective application thereof |
| US7983896B2 (en) | 2004-03-05 | 2011-07-19 | SDL Language Technology | In-context exact (ICE) matching |
| US7552046B2 (en) * | 2004-11-15 | 2009-06-23 | Microsoft Corporation | Unsupervised learning of paraphrase/translation alternations and selective application thereof |
| US7546235B2 (en) * | 2004-11-15 | 2009-06-09 | Microsoft Corporation | Unsupervised learning of paraphrase/translation alternations and selective application thereof |
| US20070010989A1 (en) * | 2005-07-07 | 2007-01-11 | International Business Machines Corporation | Decoding procedure for statistical machine translation |
| JP3983794B2 (ja) | 2005-07-13 | 2007-09-26 | 松下電器産業株式会社 | 対話支援装置 |
| US7908132B2 (en) * | 2005-09-29 | 2011-03-15 | Microsoft Corporation | Writing assistance using machine translation techniques |
| US10319252B2 (en) | 2005-11-09 | 2019-06-11 | Sdl Inc. | Language capability assessment and training apparatus and techniques |
| BRPI0706404B1 (pt) | 2006-02-17 | 2019-08-27 | Google Inc | acesso escalável, de codificação e adaptável de modelos distribuídos |
| US8898052B2 (en) * | 2006-05-22 | 2014-11-25 | Facebook, Inc. | Systems and methods for training statistical speech translation systems from speech utilizing a universal speech recognizer |
| US7865352B2 (en) * | 2006-06-02 | 2011-01-04 | Microsoft Corporation | Generating grammatical elements in natural language sentences |
| US8209163B2 (en) * | 2006-06-02 | 2012-06-26 | Microsoft Corporation | Grammatical element generation in machine translation |
| WO2008019509A1 (en) * | 2006-08-18 | 2008-02-21 | National Research Council Of Canada | Means and method for training a statistical machine translation system |
| US20080120092A1 (en) * | 2006-11-20 | 2008-05-22 | Microsoft Corporation | Phrase pair extraction for statistical machine translation |
| US8000955B2 (en) * | 2006-12-20 | 2011-08-16 | Microsoft Corporation | Generating Chinese language banners |
| US7895030B2 (en) * | 2007-03-16 | 2011-02-22 | International Business Machines Corporation | Visualization method for machine translation |
| US8180624B2 (en) * | 2007-09-05 | 2012-05-15 | Microsoft Corporation | Fast beam-search decoding for phrasal statistical machine translation |
| US8046211B2 (en) | 2007-10-23 | 2011-10-25 | Microsoft Corporation | Technologies for statistical machine translation based on generated reordering knowledge |
| US20090326916A1 (en) * | 2008-06-27 | 2009-12-31 | Microsoft Corporation | Unsupervised chinese word segmentation for statistical machine translation |
| US8326599B2 (en) * | 2009-04-21 | 2012-12-04 | Xerox Corporation | Bi-phrase filtering for statistical machine translation |
| US8185373B1 (en) * | 2009-05-05 | 2012-05-22 | The United States Of America As Represented By The Director, National Security Agency, The | Method of assessing language translation and interpretation |
| WO2011016078A1 (ja) * | 2009-08-04 | 2011-02-10 | 株式会社 東芝 | 機械翻訳装置および翻訳プログラム |
| US10417646B2 (en) | 2010-03-09 | 2019-09-17 | Sdl Inc. | Predicting the cost associated with translating textual content |
| US20120143593A1 (en) * | 2010-12-07 | 2012-06-07 | Microsoft Corporation | Fuzzy matching and scoring based on direct alignment |
| US9547626B2 (en) | 2011-01-29 | 2017-01-17 | Sdl Plc | Systems, methods, and media for managing ambient adaptability of web applications and web services |
| US10657540B2 (en) | 2011-01-29 | 2020-05-19 | Sdl Netherlands B.V. | Systems, methods, and media for web content management |
| US20120209590A1 (en) * | 2011-02-16 | 2012-08-16 | International Business Machines Corporation | Translated sentence quality estimation |
| JP5666937B2 (ja) * | 2011-02-16 | 2015-02-12 | 株式会社東芝 | 機械翻訳装置、機械翻訳方法および機械翻訳プログラム |
| US10580015B2 (en) | 2011-02-25 | 2020-03-03 | Sdl Netherlands B.V. | Systems, methods, and media for executing and optimizing online marketing initiatives |
| US10140320B2 (en) | 2011-02-28 | 2018-11-27 | Sdl Inc. | Systems, methods, and media for generating analytical data |
| US9984054B2 (en) | 2011-08-24 | 2018-05-29 | Sdl Inc. | Web interface including the review and manipulation of a web document and utilizing permission based control |
| US9646001B2 (en) * | 2011-09-19 | 2017-05-09 | Nuance Communications, Inc. | Machine translation (MT) based spoken dialog systems customer/machine dialog |
| US9218339B2 (en) * | 2011-11-29 | 2015-12-22 | Educational Testing Service | Computer-implemented systems and methods for content scoring of spoken responses |
| US9098494B2 (en) * | 2012-05-10 | 2015-08-04 | Microsoft Technology Licensing, Llc | Building multi-language processes from existing single-language processes |
| US9773270B2 (en) | 2012-05-11 | 2017-09-26 | Fredhopper B.V. | Method and system for recommending products based on a ranking cocktail |
| US10261994B2 (en) | 2012-05-25 | 2019-04-16 | Sdl Inc. | Method and system for automatic management of reputation of translators |
| US11386186B2 (en) | 2012-09-14 | 2022-07-12 | Sdl Netherlands B.V. | External content library connector systems and methods |
| US10452740B2 (en) | 2012-09-14 | 2019-10-22 | Sdl Netherlands B.V. | External content libraries |
| US11308528B2 (en) | 2012-09-14 | 2022-04-19 | Sdl Netherlands B.V. | Blueprinting of multimedia assets |
| US9916306B2 (en) | 2012-10-19 | 2018-03-13 | Sdl Inc. | Statistical linguistic analysis of source content |
| US20160132491A1 (en) * | 2013-06-17 | 2016-05-12 | National Institute Of Information And Communications Technology | Bilingual phrase learning apparatus, statistical machine translation apparatus, bilingual phrase learning method, and storage medium |
| US9778929B2 (en) | 2015-05-29 | 2017-10-03 | Microsoft Technology Licensing, Llc | Automated efficient translation context delivery |
| US10114817B2 (en) * | 2015-06-01 | 2018-10-30 | Microsoft Technology Licensing, Llc | Data mining multilingual and contextual cognates from user profiles |
| US10614167B2 (en) | 2015-10-30 | 2020-04-07 | Sdl Plc | Translation review workflow systems and methods |
| US9747281B2 (en) | 2015-12-07 | 2017-08-29 | Linkedin Corporation | Generating multi-language social network user profiles by translation |
| US10318640B2 (en) * | 2016-06-24 | 2019-06-11 | Facebook, Inc. | Identifying risky translations |
| US10635863B2 (en) | 2017-10-30 | 2020-04-28 | Sdl Inc. | Fragment recall and adaptive automated translation |
| US10817676B2 (en) | 2017-12-27 | 2020-10-27 | Sdl Inc. | Intelligent routing services and systems |
| JP7107059B2 (ja) * | 2018-07-24 | 2022-07-27 | 日本電信電話株式会社 | 文生成装置、モデル学習装置、文生成方法、モデル学習方法、及びプログラム |
| US11256867B2 (en) | 2018-10-09 | 2022-02-22 | Sdl Inc. | Systems and methods of machine learning for digital assets and message creation |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5369574A (en) | 1990-08-01 | 1994-11-29 | Canon Kabushiki Kaisha | Sentence generating system |
| US5477451A (en) | 1991-07-25 | 1995-12-19 | International Business Machines Corp. | Method and system for natural language translation |
| DE69837979T2 (de) * | 1997-06-27 | 2008-03-06 | International Business Machines Corp. | System zum Extrahieren einer mehrsprachigen Terminologie |
| WO2001086489A2 (en) | 2000-05-11 | 2001-11-15 | University Of Southern California | Discourse parsing and summarization |
| US7295962B2 (en) * | 2001-05-11 | 2007-11-13 | University Of Southern California | Statistical memory-based translation system |
| WO2002093417A1 (en) * | 2001-05-17 | 2002-11-21 | University Of Southern California | Statistical method for building a translation memory |
| JP2003006193A (ja) | 2001-06-20 | 2003-01-10 | Atr Onsei Gengo Tsushin Kenkyusho:Kk | 機械翻訳装置および方法 |
| US20030110023A1 (en) | 2001-12-07 | 2003-06-12 | Srinivas Bangalore | Systems and methods for translating languages |
| AU2003228288A1 (en) * | 2002-03-04 | 2003-09-22 | University Of Southern California | Sentence generator |
| US7624005B2 (en) * | 2002-03-28 | 2009-11-24 | University Of Southern California | Statistical machine translation |
| US7353165B2 (en) * | 2002-06-28 | 2008-04-01 | Microsoft Corporation | Example based machine translation system |
| US7349839B2 (en) * | 2002-08-27 | 2008-03-25 | Microsoft Corporation | Method and apparatus for aligning bilingual corpora |
| US7249012B2 (en) * | 2002-11-20 | 2007-07-24 | Microsoft Corporation | Statistical method and apparatus for learning translation relationships among phrases |
| US7319949B2 (en) * | 2003-05-27 | 2008-01-15 | Microsoft Corporation | Unilingual translator |
-
2004
- 2004-05-21 JP JP2004151965A patent/JP2005100335A/ja active Pending
- 2004-08-13 US US10/917,420 patent/US7925493B2/en active Active
- 2004-09-01 CN CNA2004100749435A patent/CN1591415A/zh active Pending
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101707873B (zh) * | 2007-03-26 | 2013-07-03 | 谷歌公司 | 机器翻译中的大语言模型 |
| CN103782291A (zh) * | 2011-07-26 | 2014-05-07 | 国际商业机器公司 | 定制自然语言处理引擎 |
| CN103782291B (zh) * | 2011-07-26 | 2017-06-23 | 国际商业机器公司 | 定制自然语言处理引擎 |
| WO2014114140A1 (zh) * | 2013-01-25 | 2014-07-31 | 哈尔滨工业大学 | 一种用于统计机器翻译的参数调整方法 |
| CN105593845A (zh) * | 2013-10-02 | 2016-05-18 | 系统翻译国际有限公司 | 基于自学排列的排列语料库的生成装置及其方法、使用排列语料库的破坏性表达语素分析装置及其语素分析方法 |
| CN105593845B (zh) * | 2013-10-02 | 2018-04-17 | 系统翻译国际有限公司 | 基于自学排列的排列语料库的生成装置及其方法、使用排列语料库的破坏性表达语素分析装置及其语素分析方法 |
| US10282413B2 (en) | 2013-10-02 | 2019-05-07 | Systran International Co., Ltd. | Device for generating aligned corpus based on unsupervised-learning alignment, method thereof, device for analyzing destructive expression morpheme using aligned corpus, and method for analyzing morpheme thereof |
| CN106062736A (zh) * | 2014-03-07 | 2016-10-26 | 国立研究开发法人情报通信研究机构 | 词语对齐分数算出装置、词语对齐装置、以及计算机程序 |
| CN106062736B (zh) * | 2014-03-07 | 2019-04-05 | 国立研究开发法人情报通信研究机构 | 词语对齐分数算出装置、词语对齐装置、以及存储介质 |
| CN105094358A (zh) * | 2014-05-20 | 2015-11-25 | 富士通株式会社 | 信息处理装置和通过外码输入目标语言文字的方法 |
| CN109977426A (zh) * | 2017-12-27 | 2019-07-05 | 北京搜狗科技发展有限公司 | 一种翻译模型的训练方法、装置以及机器可读介质 |
| CN110543642A (zh) * | 2019-08-20 | 2019-12-06 | 语联网(武汉)信息技术有限公司 | 基于机器翻译引擎的翻译方法及装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| US7925493B2 (en) | 2011-04-12 |
| JP2005100335A (ja) | 2005-04-14 |
| US20050049851A1 (en) | 2005-03-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1591415A (zh) | 机器翻译装置以及机器翻译计算机程序 | |
| US7505894B2 (en) | Order model for dependency structure | |
| CN1145872C (zh) | 手写汉字自动分割和识别方法以及使用该方法的系统 | |
| CN1595398A (zh) | 选择改良多个候补译文所生成的最优译文的机器翻译系统 | |
| Och | Minimum error rate training in statistical machine translation | |
| CA2480398C (en) | Phrase-based joint probability model for statistical machine translation | |
| Och et al. | A systematic comparison of various statistical alignment models | |
| CN1475907A (zh) | 基于例子的机器翻译系统 | |
| CN1471029A (zh) | 自动检测文件中搭配错误的系统和方法 | |
| CN1465018A (zh) | 机器翻译技术 | |
| JP2005100335A6 (ja) | 機械翻訳装置、機械翻訳コンピュータプログラム及びコンピュータ | |
| US20080109209A1 (en) | Semi-supervised training for statistical word alignment | |
| CN1542649A (zh) | 自然语言生成系统中用于句子实现中排序的成分结构的语言信息统计模型 | |
| CN1625739A (zh) | 内容转换方法和装置 | |
| CN1945562A (zh) | 训练音译模型、切分统计模型以及自动音译的方法和装置 | |
| CN1352774A (zh) | 用于中文的标记和命名实体识别的系统 | |
| CN101055588A (zh) | 获取限制词信息的方法、优化输出的方法和输入法系统 | |
| CN1771494A (zh) | 包括无分隔符的块的文本的自动分块 | |
| EP1657651B1 (en) | Extracting treelet translation pairs | |
| CN101075230A (zh) | 一种基于语块的中文机构名翻译方法及装置 | |
| CN1102779C (zh) | 中文简繁体字文件转换装置 | |
| CN1158621C (zh) | 信息处理装置、信息处理方法 | |
| Federico et al. | A word-to-phrase statistical translation model | |
| Hoang | Improving statistical machine translation with linguistic information | |
| CN1717680A (zh) | 文本分析的系统和方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C12 | Rejection of a patent application after its publication | ||
| RJ01 | Rejection of invention patent application after publication |