CN114675545B - 一种基于强化学习的高超声速飞行器再入协同制导方法 - Google Patents
一种基于强化学习的高超声速飞行器再入协同制导方法 Download PDFInfo
- Publication number
- CN114675545B CN114675545B CN202210577852.1A CN202210577852A CN114675545B CN 114675545 B CN114675545 B CN 114675545B CN 202210577852 A CN202210577852 A CN 202210577852A CN 114675545 B CN114675545 B CN 114675545B
- Authority
- CN
- China
- Prior art keywords
- angle
- aircraft
- guidance
- reentry
- hypersonic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B13/00—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion
- G05B13/02—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric
- G05B13/04—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric involving the use of models or simulators
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T90/00—Enabling technologies or technologies with a potential or indirect contribution to GHG emissions mitigation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Automation & Control Theory (AREA)
- Manipulator (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明公开了一种基于强化学习的高超声速飞行器再入协同制导方法,具体涉及一种基于强化学习的高超声速飞行器再入协同制导方法。建立高超声速再入动力学模型以及多约束再入模型;设计攻角剖面和高度能量剖面,获得攻角和倾侧角的解析解;根据DQN算法对倾侧角符号智能决策,扩展其动作空间,考虑时间协同和落角协同设计阶梯状混合奖励函数;离线训练倾侧角智能决策模型,给定协同时间和协同落角在线获得制导指令,得到了一种基于智强化学习的高超声速飞行器再入协同制导方法,有效的克服了飞行器制导策略中,倾侧角符号翻转频繁,满足了时间协同和落角协同,仿真实验验证了本发明能够很好的考虑时间和落角协同下进行多高超声速飞行器制导。
Description
技术领域
本发明涉及高超声速飞行器再入协同制导技术领域,尤其是涉及一种基于强化学习的高超声速飞行器再入协同制导方法。
背景技术
高超声速飞行器再入协同制导是近年来高超声速飞行器研究的核心和重点之一,采用多个高超声速飞行器同时实现时间协同和落角协同仍是多国未解决的难题。
高超声速飞行器本生具有强耦合、强非线性、强不确定性的特点,单枚飞行器的轨迹优化与制导已十分困难,可想而知,多枚高超声速飞行器轨迹优化与制导问题的复杂度必然是急剧增加的,再加上时间协同的约束,多高超飞行器时间协同的再入机动制导问题研究具有一定的挑战性。除此之外,不同再入任务对终端约束也不同,一些新型任务同时对落角有一定要求,因此,以时间和角度协同为性能指标,完成多高超声速飞行器再入协同制导问题研究,能够极大地提升高超声速飞行器的生存能力,对于高超声速飞行器实际应用具有重要意义。高超声速飞行器再入机动飞行中,飞行高度和马赫数跨度范围大、飞行环境复杂、气动特性变化剧烈、飞行约束条件多,对高超声速飞行器精确制导系统提出了较高的要求,多枚高超协同完成任务,问题的复杂度急剧提升,传统针对单枚高超的制导算法,难以直接应用到再入协同制导方法设计中,因此如何设计具备飞行时间可控能力的再入制导方法是一个领域内研究的热点。
再入飞行器制导方法主要有标称轨迹制导方法和预测校正制导方法两大类。标称轨迹制导方法依赖事先规划好的再入轨迹,难以满足未来对升力式再入飞行器自主性要求。预测校正法随着弹载计算机计算能力的提高,采用数值方法预测轨迹逐渐成为主流。随着人工智能的高速发展,采用强化学习改进预测校正法,提高制导能力成为更多学者的选择。
发明内容
本发明的目的是提供一种基于强化学习的高超声速飞行器再入协同制导方法,有效的克服了飞行器制导策略中,倾侧角符号翻转频繁,满足了时间协同和落角协同,仿真实验验证了本发明能够很好的考虑时间和落角协同下进行多高超声速飞行器制导。
为实现上述目的,本发明提供了一种基于强化学习的高超声速飞行器再入协同制导方法,包括以下步骤:
S1、基于地心直角坐标系,建立高超声速滑翔飞行器再入动力学模型;
S2、结合高超声速飞行器再入动力学模型,考虑端点约束、常规路径约束,建立多约束条件下高超声速滑翔飞行器再入制导问题的模型;
S3、基于步骤S2的制导模型,纵向制导设计攻角剖面和高度能量剖面,快速计算攻角指令,解析推导倾侧角幅值;
S4、横向制导采用强化学习思想设计倾侧角符号决策机制,同时考虑落角和时间协同设计混合奖励函数;
S5、获得倾侧角指令后,进行约束的强化管理,利用路径约束和倾侧角上下限约束对倾侧角指令进行限值,最后得到能够满足时间角度协同的再入制导指令;
S6、设计基于强化学习的高超声速飞行器再入协同制导方法。
优选的,所述步骤S1中基于地心直角坐标系中建立高超声速滑翔飞行器再入机动制导动力学模型为:



式中, 是飞行器的地心距,
是飞行器的地心距, 是飞行器的地球相对速度,
是飞行器的地球相对速度, 与
与 分别是飞行器的航向角与航迹角,飞行器所处的经度
分别是飞行器的航向角与航迹角,飞行器所处的经度 纬度
纬度 是判断飞行器路径约束的主要因素,
是判断飞行器路径约束的主要因素, 和
和 是飞行器的质量和当前地心距的重力加速度,飞行器的侧滑角
是飞行器的质量和当前地心距的重力加速度,飞行器的侧滑角 与攻角
与攻角 分别控制飞行器制导策略中的横向、纵向制导剖面,
分别控制飞行器制导策略中的横向、纵向制导剖面, 与
与 是飞行器在飞行过程中的气动阻力与升力,其中
是飞行器在飞行过程中的气动阻力与升力,其中 是飞行器当前高度的空气密度,
是飞行器当前高度的空气密度, 是飞行器的参考横截面积,
是飞行器的参考横截面积, 与
与 分别是与飞行器攻角有关的空气动力学参数,该模型中,侧滑角
分别是与飞行器攻角有关的空气动力学参数,该模型中,侧滑角 与攻角
与攻角 是控制量。
是控制量。
优选的,所述步骤S2中考虑端点约束、常规路径约束,建立多约束条件下高超声速滑翔飞行器再入制导问题的模型:
多约束问题考虑端点约束和常规路径约束:
令 为飞行器状态矩阵,
为飞行器状态矩阵, 为较小的常值矩阵,端点约束描述为
为较小的常值矩阵,端点约束描述为 ,式中,
,式中, 代表终端时刻算法得到的状态量,
代表终端时刻算法得到的状态量, 代表终端时刻的目标状态量,
代表终端时刻的目标状态量, 越小,飞行器轨迹优化目标终点状态越接近任务的预定状态,轨迹优化的效果越好;
越小,飞行器轨迹优化目标终点状态越接近任务的预定状态,轨迹优化的效果越好;
常规路径约束包括热流率约束、过载约束和动压约束,其数学模型分别为:

其中, 分别是热流率、过载与动压在飞行器飞行过程中的最大值,热流率常数
分别是热流率、过载与动压在飞行器飞行过程中的最大值,热流率常数 ;
;
最终得到的模型多约束条件下高超声速飞行器再入协同制导问题描述,模型如下:


需要满足的约束:


优选的,所述步骤S3中纵向制导设计攻角剖面和高度能量剖面,快速计算攻角指令,解析推导倾侧角幅值:
设计攻角剖面如下:

其中, 是最大攻角,
是最大攻角, 是最大升阻比攻角,
是最大升阻比攻角, 和
和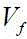 分别是起始和终止速度,
分别是起始和终止速度, 和
和 是根据攻角剖面给定的两个参数;
是根据攻角剖面给定的两个参数;
能量 定义为:
定义为:

将步骤S1中动力学模型转换为:


设计高度能量剖面如下:

其中, 是五个待设计的系数,
是五个待设计的系数, 是无量纲能量,表示为:
是无量纲能量,表示为:

其中, 和
和 为再入和终端能量;
为再入和终端能量;
考虑再入运动方程,得高度-能量的一阶、二阶关系如下:

假设 不变,得阻力对能量的一阶导数:
不变,得阻力对能量的一阶导数:

则地心距对能量的二阶导数可得:

最终攻角和倾侧角可解析为:

其中, 。
。
优选的,所述步骤S4中横向制导采用强化学习思想设计倾侧角符号决策机制,同时考虑落角和时间协同设计混合奖励函数:
由于高超声速飞行器横向制导问题是一个典型的状态空间连续、动作空间离散的最优控制问题,选择强化学习中的DQN网络进行倾侧角符号智能决策问题研究;
采用两个深度神经网络(DNN)结构,一个为当前主网络,用来根据当前状态 和采取的动作
和采取的动作 估计
估计 值即
值即 ,
, 为当前主网络的参数;一个为目标网络,根据目标状态
为当前主网络的参数;一个为目标网络,根据目标状态 和历史参数
和历史参数 ,计算目标状态-动作的
,计算目标状态-动作的 值即
值即 ,
, 为当前时刻的奖励值,
为当前时刻的奖励值, 为折扣因子,规定每运行
为折扣因子,规定每运行 步,使用主网络中的参数代替目标网络中的参数,即
步,使用主网络中的参数代替目标网络中的参数,即 ;
;
倾侧角符号为“+”或“-”或“0”,动作空间记作: ,三个动作对应的实际意义分别为:1表示维持上一制导周期倾侧角符号不变;-1表示倾侧角符号反转即与上一制导周期符号相反;0表示倾侧角值为零,在实际的轨迹中体现为无横向机动,采用Epsilon-greedy策略进行动作选择,即有概率为
,三个动作对应的实际意义分别为:1表示维持上一制导周期倾侧角符号不变;-1表示倾侧角符号反转即与上一制导周期符号相反;0表示倾侧角值为零,在实际的轨迹中体现为无横向机动,采用Epsilon-greedy策略进行动作选择,即有概率为 时,从动作空间中随机选择动作;当有概率
时,从动作空间中随机选择动作;当有概率 时,从动作空间中选择
时,从动作空间中选择 值最大的动作;
值最大的动作;
根据 值的Bellman方程形式,在神经网络训练中,定义当前主网络估计
值的Bellman方程形式,在神经网络训练中,定义当前主网络估计 值与目标
值与目标 值的均方差为损失函数,即:
值的均方差为损失函数,即:

在迭代过程中,采用梯度下降法更新参数 ;
;
每次动作执行后会转移到下一个状态,并且获得一个奖励值,因此每次动作执行后将四元组 ,放入经验池,当需要对网络进行训练时,随机从经验池采集小批量的四元组进行训练,进而加快训练速度;
,放入经验池,当需要对网络进行训练时,随机从经验池采集小批量的四元组进行训练,进而加快训练速度;
对于多个高超声速再入飞行器,在可行时间域内选取飞行时间 ,到达目标时刻视线角
,到达目标时刻视线角 ,则可设计阶梯状混合奖励函数为:
,则可设计阶梯状混合奖励函数为:

式中, 为奖励函数;
为奖励函数; 、
、 、
、 分别为期望的飞行航程、飞行时间、落角;
分别为期望的飞行航程、飞行时间、落角; 、
、 、
、 分别为实际的飞行航程、飞行时间、终端时刻落角。
分别为实际的飞行航程、飞行时间、终端时刻落角。
优选的,所述步骤S5中获得倾侧角指令后,进行约束的强化管理,利用路径约束和倾侧角上下限约束对倾侧角指令进行限值,最后得到能够满足时间角度协同的再入制导指令,其中协同制导步骤如下:
步骤一、离线学习时,考察动作空间扩展后奖励函数的变化及倾侧角翻转次数的变化,与传统的二值决策动作空间的训练结果进行比较;
步骤二、值网络训练的过程中,经验池中随机选取小批量四元组进行经验回放,确保选取数组的独立性,加快收敛;
步骤三、将离线训练环节生成的倾侧角符号决策方案应用到实际任务中去,在线求解满足时间和角度协同的制导指令。
作为一种模型转换方法,步骤S3中将能量引入动力学模型。利用横纵向解耦的特性,纵向制导设计攻角剖面和高度能量剖面,用能量约束速度,再将其带入动力学模型求解,构造了高度能量剖面;在阻力不变的假设下,快速计算攻角指令,解析推导了倾侧角幅值,提高计算速度和效率。
作为一种深度学习方法,步骤S4中设计倾侧角符合决策机制。采用两个深度神经网络,一个作为目标网络,一个作为值网络,迭代训练参数更符合应用需求。将倾侧角符号进行扩展,减少不必要翻转行为。同时考虑到达时间和落角,将奖励函数设计为梯度函数,更好满足了实际应用需求。
作为一种制导策略,步骤S5针对步骤S4中倾侧角符号决策进行离线训练,与传统二值决策动作空间进行比较,减少了不必要的翻转次数。值网络训练的过程中,经验池中随机选取小批量四元组进行经验回放,确保选取数组的独立性,加快收敛。离线训练的倾侧角符号决策行为在线求解,满足实际应用。
因此,本发明采用上述一种基于强化学习的高超声速飞行器再入协同制导方法,具备以下有益效果:
(1)通过纵向制导设计攻角剖面和高度能量剖面,快速计算攻角指令,解析推导倾侧角幅值,满足终端约束并减小了计算压力;
(2)通过利用强化学习的方法,拓展了传统倾侧角二值决策空间,减少了翻转次数,克服了传统二值决策易于超出边界区域的缺陷,阶梯状的混合奖励函数同时考虑了落角和时间协同,有效提高任务实现效能;
(3)通过离线训练好的倾侧角符号决策机制,并能在线协同时间和落角后在线求解,为高超声速飞行器协同制导律研究提供科学思路,仿真实验表明了本发明提出方法的有效性。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明一种基于强化学习的高超声速飞行器再入协同制导方法实施例的流程图;
图2是基于强化学习的多飞行器协同任务的倾侧角-时间曲线;
图3是基于强化学习的多飞行器协同任务的经度-纬度曲线。
具体实施方式
为了使本发明的目的、技术方案及优点更加清晰,下面结合附图、仿真实验对本发明进一步说明。
实施例
本发明提供了一种基于强化学习的高超声速飞行器再入协同制导方法,包括以下步骤:
首先建立多约束下的高超声速飞行器再入机动制导的动力学模型:


其中,端点约束模型建立如下:

常规路径约束为:

模型中, 是飞行器的地心距,
是飞行器的地心距, 是飞行器的地球相对速度,
是飞行器的地球相对速度, 与
与 分别是飞行器的航向角与航迹角,飞行器所处的经度
分别是飞行器的航向角与航迹角,飞行器所处的经度 纬度
纬度 是判断飞行器路径约束的主要因素,
是判断飞行器路径约束的主要因素, 和
和 是飞行器的质量和当前地心距的重力加速度,
是飞行器的质量和当前地心距的重力加速度, 是飞行器当前高度的空气密度,
是飞行器当前高度的空气密度, 是飞行器的参考横截面积,
是飞行器的参考横截面积, 与
与 分别是与飞行器攻角有关的空气动力学参数;
分别是与飞行器攻角有关的空气动力学参数; 为飞行器状态矩阵,
为飞行器状态矩阵, 为较小的常值矩阵;
为较小的常值矩阵; 分别是热流率、过载与动压在飞行器飞行过程中的最大值;
分别是热流率、过载与动压在飞行器飞行过程中的最大值; 是终点的经纬度坐标。
是终点的经纬度坐标。
其次设计攻角剖面如下:

其中, 是最大攻角,
是最大攻角, 是最大升阻比攻角,
是最大升阻比攻角, 和
和 分别是起始和终止速度,
分别是起始和终止速度, 和
和 是根据攻角剖面给定的两个参数。
是根据攻角剖面给定的两个参数。
将能量引入动力学模型:


设计高度能量剖面如下:

其中, 是五个待设计的系数,
是五个待设计的系数, 是无量纲能量,可表示为:
是无量纲能量,可表示为:

其中, 和
和 为再入和终端能量。
为再入和终端能量。
考虑再入运动方程,可得高度-能量的一阶、二阶关系如下:

假设 不变,可得阻力对能量的一阶导数:
不变,可得阻力对能量的一阶导数:

则地心距对能量的二阶导数可得:

最终攻角和倾侧角可解析为:

其中, 。
。
再其次,横向制导采用强化学习思想设计倾侧角符号决策机制,同时考虑落角和时间协同设计混合奖励函数。采用两个深度神经网络(DNN)结构,一个为当前主网络,用来根据当前状态 和采取的动作
和采取的动作 估计
估计 值即
值即 ,
, 为当前主网络的参数;一个为目标网络,根据目标状态
为当前主网络的参数;一个为目标网络,根据目标状态 和历史参数
和历史参数 ,计算目标状态-动作的
,计算目标状态-动作的 值即
值即 ,
, 为当前时刻的奖励值,
为当前时刻的奖励值, 为折扣因子。规定每运行
为折扣因子。规定每运行 步,使用主网络中的参数代替目标网络中的参数,即
步,使用主网络中的参数代替目标网络中的参数,即 。倾侧角符号为“+”或“-”或“0”,动作空间记作:
。倾侧角符号为“+”或“-”或“0”,动作空间记作: 。三个动作对应的实际意义分别为:1表示维持上一制导周期倾侧角符号不变;-1表示倾侧角符号反转即与上一制导周期符号相反;0表示倾侧角值为零,在实际的轨迹中体现为无横向机动。采用Epsilon-greedy策略进行动作选择,即有概率为
。三个动作对应的实际意义分别为:1表示维持上一制导周期倾侧角符号不变;-1表示倾侧角符号反转即与上一制导周期符号相反;0表示倾侧角值为零,在实际的轨迹中体现为无横向机动。采用Epsilon-greedy策略进行动作选择,即有概率为 时,从动作空间中随机选择动作;当有概率
时,从动作空间中随机选择动作;当有概率 时,从动作空间中选择
时,从动作空间中选择 值最大的动作。根据
值最大的动作。根据 值的Bellman方程形式,在神经网络训练中,定义当前主网络估计
值的Bellman方程形式,在神经网络训练中,定义当前主网络估计 值与目标
值与目标 值的均方差为损失函数,即:
值的均方差为损失函数,即:

在迭代过程中,采用梯度下降法更新参数 。每次动作执行后会转移到下一个状态,并且获得一个奖励值,因此每次动作执行后将四元组
。每次动作执行后会转移到下一个状态,并且获得一个奖励值,因此每次动作执行后将四元组 ,放入经验池。当需要对网络进行训练时,随机从经验池采集小批量的四元组进行训练,进而加快训练速度。
,放入经验池。当需要对网络进行训练时,随机从经验池采集小批量的四元组进行训练,进而加快训练速度。
对于多个高超声速再入飞行器,在可行时间域内选取飞行时间 ,到达目标时刻视线角
,到达目标时刻视线角 ,则可设计阶梯状混合奖励函数为:
,则可设计阶梯状混合奖励函数为:

式中, 为奖励函数;
为奖励函数; 、
、 、
、 分别为期望的飞行航程、飞行时间、落角;
分别为期望的飞行航程、飞行时间、落角; 、
、 、
、 分别为实际的飞行航程、飞行时间、终端时刻落角。
分别为实际的飞行航程、飞行时间、终端时刻落角。
最后,获得倾侧角指令后,进行约束的强化管理,利用路径约束和倾侧角上下限约束对倾侧角指令进行限值,最后得到能够满足时间角度协同的再入制导指令。离线学习时,考察动作空间扩展后奖励函数的变化及倾侧角翻转次数的变化,与传统的二值决策动作空间的训练结果进行比较;值网络训练的过程中,经验池中随机选取小批量四元组进行经验回放,确保选取数组的独立性,加快收敛;值网络训练的过程中,经验池中随机选取小批量四元组进行经验回放,确保选取数组的独立性,加快收敛。
下面对仿真实验进行介绍。
以3个高超声速飞行器从起始点相同时间、相同落角精确到达目标为目标任务,进行仿真实验。
步骤一、采用通用的CAV-H高超声速飞行器模型进行实验。CAV-H参数如表1。
步骤二、采用DQN算法离线训练横向倾侧角符号决策机制,DQN网络参数设置如表2。
步骤三、在训练好的智能体基础上,改变初始发射点与期望时间、期望落角约束,进行三枚高超声速飞行器再入协同制导任务,多飞行器再入初始条件设置如表3。
表1 CAV-H参数

表2 DQN网络参数设置

表3 多飞行器再入初始条件、目标设置

根据仿真实验,可知,本发明所提出的一种基于强化学习的高超声速飞行器再入协同制导方法能够达到预期的制导效果。
因此,本发明采用上述一种基于强化学习的高超声速飞行器再入协同制导方法,有效的克服了飞行器制导策略中,倾侧角符号翻转频繁,满足了时间协同和落角协同,仿真实验验证了本发明能够很好的考虑时间和落角协同下进行多高超声速飞行器制导。
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。
Claims (5)
1.一种基于强化学习的高超声速飞行器再入协同制导方法,其特征在于包括以下步骤:
S1、基于地心直角坐标系,建立高超声速滑翔飞行器再入动力学模型;
S2、结合高超声速飞行器再入动力学模型,考虑端点约束、常规路径约束,建立多约束条件下高超声速滑翔飞行器再入制导问题的模型;
S3、基于步骤S2的制导模型,纵向制导设计攻角剖面和高度能量剖面,快速计算攻角指令,解析推导倾侧角幅值;
S4、横向制导采用强化学习思想设计倾侧角符号决策机制,同时考虑落角和时间协同设计混合奖励函数;由于高超声速飞行器横向制导问题是一个典型的状态空间连续、动作空间离散的最优控制问题,选择强化学习中的DQN网络进行倾侧角符号智能决策问题研究;
采用两个深度神经网络(DNN)结构,一个为当前主网络,用来根据当前状态 和采取的动作
和采取的动作 估计
估计 值即
值即 ,
, 为当前主网络的参数;一个为目标网络,根据目标状态
为当前主网络的参数;一个为目标网络,根据目标状态 和历史参数
和历史参数 ,计算目标状态-动作的
,计算目标状态-动作的 值即
值即 ,
, 为当前时刻的奖励值,
为当前时刻的奖励值, 为折扣因子,规定每运行
为折扣因子,规定每运行 步,使用主网络中的参数代替目标网络中的参数,即
步,使用主网络中的参数代替目标网络中的参数,即 ;
;
倾侧角符号为“+”或“-”或“0”,动作空间记作: ,三个动作对应的实际意义分别为:1表示维持上一制导周期倾侧角符号不变;-1表示倾侧角符号反转即与上一制导周期符号相反;0表示倾侧角值为零,在实际的轨迹中体现为无横向机动,采用Epsilon-greedy策略进行动作选择,即有概率为
,三个动作对应的实际意义分别为:1表示维持上一制导周期倾侧角符号不变;-1表示倾侧角符号反转即与上一制导周期符号相反;0表示倾侧角值为零,在实际的轨迹中体现为无横向机动,采用Epsilon-greedy策略进行动作选择,即有概率为 时,从动作空间中随机选择动作;当有概率
时,从动作空间中随机选择动作;当有概率 时,从动作空间中选择
时,从动作空间中选择 值最大的动作;
值最大的动作;
根据 值的Bellman方程形式,在神经网络训练中,定义当前主网络估计
值的Bellman方程形式,在神经网络训练中,定义当前主网络估计 值与目标
值与目标 值的均方差为损失函数,即:
值的均方差为损失函数,即:

在迭代过程中,采用梯度下降法更新参数 ;
;
每次动作执行后会转移到下一个状态,并且获得一个奖励值,因此每次动作执行后将四元组 ,放入经验池,当需要对网络进行训练时,随机从经验池采集小批量的四元组进行训练,进而加快训练速度;
,放入经验池,当需要对网络进行训练时,随机从经验池采集小批量的四元组进行训练,进而加快训练速度;
对于多个高超声速再入飞行器,在可行时间域内选取飞行时间 ,到达目标时刻视线角
,到达目标时刻视线角 ,则可设计阶梯状混合奖励函数为:
,则可设计阶梯状混合奖励函数为:

式中, 为奖励函数;
为奖励函数; 、
、 、
、 分别为期望的飞行航程、飞行时间、落角;
分别为期望的飞行航程、飞行时间、落角; 、
、 、
、 分别为实际的飞行航程、飞行时间、终端时刻落角;
分别为实际的飞行航程、飞行时间、终端时刻落角;
S5、获得倾侧角指令后,进行约束的强化管理,利用路径约束和倾侧角上下限约束对倾侧角指令进行限值,最后得到能够满足时间角度协同的再入制导指令;
S6、设计基于强化学习的高超声速飞行器再入协同制导方法。
2.根据权利要求1所述的一种基于强化学习的高超声速飞行器再入协同制导方法,其特征在于,所述步骤S1中基于地心直角坐标系中建立高超声速滑翔飞行器再入机动制导动力学模型为:






式中, 是飞行器的地心距,
是飞行器的地心距, 是飞行器的地球相对速度,
是飞行器的地球相对速度, 与
与 分别是飞行器的航向角与航迹角,飞行器所处的经度
分别是飞行器的航向角与航迹角,飞行器所处的经度 纬度
纬度 是判断飞行器路径约束的主要因素,
是判断飞行器路径约束的主要因素, 和
和 是飞行器的质量和当前地心距的重力加速度,飞行器的侧滑角
是飞行器的质量和当前地心距的重力加速度,飞行器的侧滑角 与攻角
与攻角 分别控制飞行器制导策略中的横向、纵向制导剖面,
分别控制飞行器制导策略中的横向、纵向制导剖面, 与
与 是飞行器在飞行过程中的气动阻力与升力,其中
是飞行器在飞行过程中的气动阻力与升力,其中 是飞行器当前高度的空气密度,
是飞行器当前高度的空气密度, 是飞行器的参考横截面积,
是飞行器的参考横截面积, 与
与 分别是与飞行器攻角有关的空气动力学参数,该模型中,侧滑角
分别是与飞行器攻角有关的空气动力学参数,该模型中,侧滑角 与攻角
与攻角 是控制量。
是控制量。
3.根据权利要求1所述的一种基于强化学习的高超声速飞行器再入协同制导方法,其特征在于,所述步骤S2中考虑端点约束、常规路径约束,建立多约束条件下高超声速滑翔飞行器再入制导问题的模型:
多约束问题考虑端点约束和常规路径约束:
令 为飞行器状态矩阵,
为飞行器状态矩阵, 为较小的常值矩阵,端点约束描述为
为较小的常值矩阵,端点约束描述为 ,式中,
,式中, 代表终端时刻算法得到的状态量,
代表终端时刻算法得到的状态量, 代表终端时刻的目标状态量,
代表终端时刻的目标状态量, 越小,飞行器轨迹优化目标终点状态越接近任务的预定状态,轨迹优化的效果越好;
越小,飞行器轨迹优化目标终点状态越接近任务的预定状态,轨迹优化的效果越好;
常规路径约束包括热流率约束、过载约束和动压约束,其数学模型分别为:



其中, 分别是热流率、过载与动压在飞行器飞行过程中的最大值,热流率常数
分别是热流率、过载与动压在飞行器飞行过程中的最大值,热流率常数 ;
;
最终得到的模型多约束条件下高超声速飞行器再入协同制导问题描述,模型如下:

需要满足的约束:




4.根据权利要求1所述的一种基于强化学习的高超声速飞行器再入协同制导方法,其特征在于,所述步骤S3中纵向制导设计攻角剖面和高度能量剖面,快速计算攻角指令,解析推导倾侧角幅值:
设计攻角剖面如下:

其中, 是最大攻角,
是最大攻角, 是最大升阻比攻角,
是最大升阻比攻角, 和
和 分别是起始和终止速度,
分别是起始和终止速度, 和
和 是根据攻角剖面给定的两个参数;
是根据攻角剖面给定的两个参数;
能量 定义为:
定义为:

将步骤S1中动力学模型转换为:





设计高度能量剖面如下:

其中, 是五个待设计的系数,
是五个待设计的系数, 是无量纲能量,表示为:
是无量纲能量,表示为:

其中, 和
和 为再入和终端能量;
为再入和终端能量;
考虑再入运动方程,得高度-能量的一阶、二阶关系如下:

假设 不变,得阻力对能量的一阶导数:
不变,得阻力对能量的一阶导数:

则地心距对能量的二阶导数可得:

最终攻角和倾侧角可解析为:


其中, 。
。
5.根据权利要求1所述的一种基于强化学习的高超声速飞行器再入协同制导方法,其特征在于,所述步骤S5中获得倾侧角指令后,进行约束的强化管理,利用路径约束和倾侧角上下限约束对倾侧角指令进行限值,最后得到能够满足时间角度协同的再入制导指令,其中协同制导步骤如下:
步骤一、离线学习时,考察动作空间扩展后奖励函数的变化及倾侧角翻转次数的变化,与传统的二值决策动作空间的训练结果进行比较;
步骤二、值网络训练的过程中,经验池中随机选取小批量四元组进行经验回放,确保选取数组的独立性,加快收敛;
步骤三、将离线训练环节生成的倾侧角符号决策方案应用到实际任务中去,在线求解满足时间和角度协同的制导指令。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210577852.1A CN114675545B (zh) | 2022-05-26 | 2022-05-26 | 一种基于强化学习的高超声速飞行器再入协同制导方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210577852.1A CN114675545B (zh) | 2022-05-26 | 2022-05-26 | 一种基于强化学习的高超声速飞行器再入协同制导方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114675545A CN114675545A (zh) | 2022-06-28 |
| CN114675545B true CN114675545B (zh) | 2022-08-23 |
Family
ID=82079348
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210577852.1A Active CN114675545B (zh) | 2022-05-26 | 2022-05-26 | 一种基于强化学习的高超声速飞行器再入协同制导方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114675545B (zh) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115079565B (zh) * | 2022-08-23 | 2022-10-25 | 中国人民解放军国防科技大学 | 变系数的带落角约束制导方法、装置和飞行器 |
| CN115357051B (zh) * | 2022-10-18 | 2023-02-03 | 北京理工大学 | 变形与机动一体化的规避与突防方法 |
| CN115981149B (zh) * | 2022-12-09 | 2024-01-09 | 中国矿业大学 | 基于安全强化学习的高超声速飞行器最优控制方法 |
| CN115951585B (zh) * | 2023-03-08 | 2023-06-02 | 中南大学 | 基于深度神经网络的高超声速飞行器再入制导方法 |
| CN116430900B (zh) * | 2023-05-04 | 2023-12-05 | 四川大学 | 基于深度强化学习的高超声速弹头的博弈轨迹规划方法 |
| CN117130277B (zh) * | 2023-09-13 | 2024-05-10 | 中国矿业大学 | 基于安全强化学习的高超声速飞行器零和博弈方法 |
| CN117518836B (zh) * | 2024-01-04 | 2024-04-09 | 中南大学 | 变体飞行器鲁棒深度强化学习制导控制一体化方法 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2629166A1 (en) * | 2012-02-17 | 2013-08-21 | The Boeing Company | An unmanned aerial vehicle harvesting energy in updraft |
| CN111006693A (zh) * | 2019-12-12 | 2020-04-14 | 中国人民解放军陆军工程大学 | 智能飞行器航迹规划系统及其方法 |
| CN111306989A (zh) * | 2020-03-12 | 2020-06-19 | 北京航空航天大学 | 一种基于平稳滑翔弹道解析解的高超声速再入制导方法 |
| CN111881518A (zh) * | 2020-07-30 | 2020-11-03 | 中国人民解放军火箭军工程大学 | 一种智能的高超声速飞行器再入机动制导方法及系统 |
| CN112256061A (zh) * | 2020-10-30 | 2021-01-22 | 北京航空航天大学 | 复杂环境及任务约束下的高超声速飞行器再入制导方法 |
| CN113377121A (zh) * | 2020-07-02 | 2021-09-10 | 北京航空航天大学 | 一种基于深度强化学习的飞行器智能抗扰动控制方法 |
| CN114253296A (zh) * | 2021-12-22 | 2022-03-29 | 中国人民解放军国防科技大学 | 高超声速飞行器机载轨迹规划方法、装置、飞行器及介质 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113031642B (zh) * | 2021-05-24 | 2021-08-10 | 北京航空航天大学 | 动态禁飞区约束的高超声速飞行器轨迹规划方法和系统 |
-
2022
- 2022-05-26 CN CN202210577852.1A patent/CN114675545B/zh active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2629166A1 (en) * | 2012-02-17 | 2013-08-21 | The Boeing Company | An unmanned aerial vehicle harvesting energy in updraft |
| CN111006693A (zh) * | 2019-12-12 | 2020-04-14 | 中国人民解放军陆军工程大学 | 智能飞行器航迹规划系统及其方法 |
| CN111306989A (zh) * | 2020-03-12 | 2020-06-19 | 北京航空航天大学 | 一种基于平稳滑翔弹道解析解的高超声速再入制导方法 |
| CN113377121A (zh) * | 2020-07-02 | 2021-09-10 | 北京航空航天大学 | 一种基于深度强化学习的飞行器智能抗扰动控制方法 |
| CN111881518A (zh) * | 2020-07-30 | 2020-11-03 | 中国人民解放军火箭军工程大学 | 一种智能的高超声速飞行器再入机动制导方法及系统 |
| CN112256061A (zh) * | 2020-10-30 | 2021-01-22 | 北京航空航天大学 | 复杂环境及任务约束下的高超声速飞行器再入制导方法 |
| CN114253296A (zh) * | 2021-12-22 | 2022-03-29 | 中国人民解放军国防科技大学 | 高超声速飞行器机载轨迹规划方法、装置、飞行器及介质 |
Non-Patent Citations (1)
| Title |
|---|
| 多路径约束下的高超声速滑翔飞行器再入制导;王子瑶等;《导弹与航天运载技术》;20200702(第3期);论文第62-67页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114675545A (zh) | 2022-06-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114675545B (zh) | 一种基于强化学习的高超声速飞行器再入协同制导方法 | |
| CN112162564B (zh) | 基于模仿学习和强化学习算法的无人机飞行控制方法 | |
| CN111351488A (zh) | 飞行器智能轨迹重构再入制导方法 | |
| CN109871032A (zh) | 一种基于模型预测控制的多无人机编队协同控制方法 | |
| CN105953800B (zh) | 一种无人飞行器航迹规划栅格空间划分方法 | |
| CN110347181B (zh) | 基于能耗的无人机分布式编队控制方法 | |
| CN111813146B (zh) | 基于bp神经网络预测航程的再入预测-校正制导方法 | |
| CN102866635B (zh) | 基于等价模型的高超声速飞行器离散神经网络自适应控制方法 | |
| CN104850009A (zh) | 一种基于捕食逃逸鸽群优化的多无人飞行器编队协调控制方法 | |
| CN105911867A (zh) | 基于nsga-ii算法的船舶推力分配方法 | |
| CN111553118B (zh) | 基于强化学习的多维连续型优化变量全局优化方法 | |
| CN103971160A (zh) | 基于复杂网络的粒子群优化方法 | |
| CN110958625B (zh) | 一种基于移动边缘智能的实时多模态语言分析系统和方法 | |
| CN114967713B (zh) | 基于强化学习的水下航行器浮力离散变化下的控制方法 | |
| Zhang et al. | A multi-objective path planning method for the wave glider in the complex marine environment | |
| CN113625569A (zh) | 一种基于深度强化学习和规则驱动的小型无人机防控混合决策方法及系统 | |
| CN114089776B (zh) | 一种基于深度强化学习的无人机避障方法 | |
| CN115755598A (zh) | 一种智能航天器集群分布式模型预测路径规划方法 | |
| CN114637327A (zh) | 基于深度策略性梯度强化学习的在线轨迹生成制导方法 | |
| CN114637312A (zh) | 一种基于智能变形决策的无人机节能飞行控制方法及系统 | |
| CN112001120B (zh) | 一种基于强化学习的航天器对多拦截器自主规避机动方法 | |
| CN106569503A (zh) | 一种基于触发式预测控制的飞行器控制方法 | |
| Li et al. | A warm-started trajectory planner for fixed-wing unmanned aerial vehicle formation | |
| CN114943168B (zh) | 一种水上浮桥组合方法及系统 | |
| CN115289917B (zh) | 基于深度学习的火箭子级着陆实时最优制导方法及系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |