CN112840396A - 用于处理用户话语的电子装置及其控制方法 - Google Patents
用于处理用户话语的电子装置及其控制方法 Download PDFInfo
- Publication number
- CN112840396A CN112840396A CN201980065264.6A CN201980065264A CN112840396A CN 112840396 A CN112840396 A CN 112840396A CN 201980065264 A CN201980065264 A CN 201980065264A CN 112840396 A CN112840396 A CN 112840396A
- Authority
- CN
- China
- Prior art keywords
- response
- module
- model
- wake
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 39
- 238000012545 processing Methods 0.000 title claims abstract description 32
- 230000004044 response Effects 0.000 claims abstract description 308
- 230000008569 process Effects 0.000 abstract description 9
- 230000009471 action Effects 0.000 description 51
- 238000004891 communication Methods 0.000 description 47
- 230000006870 function Effects 0.000 description 41
- 239000002775 capsule Substances 0.000 description 36
- 238000012549 training Methods 0.000 description 35
- 238000004422 calculation algorithm Methods 0.000 description 20
- 238000010586 diagram Methods 0.000 description 17
- 230000008859 change Effects 0.000 description 15
- 238000013528 artificial neural network Methods 0.000 description 8
- 230000015572 biosynthetic process Effects 0.000 description 6
- 238000004590 computer program Methods 0.000 description 6
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 6
- 239000010931 gold Substances 0.000 description 6
- 229910052737 gold Inorganic materials 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 238000013473 artificial intelligence Methods 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 241001122315 Polites Species 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 238000000691 measurement method Methods 0.000 description 4
- 230000003044 adaptive effect Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 230000008571 general function Effects 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000003058 natural language processing Methods 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- MQJKPEGWNLWLTK-UHFFFAOYSA-N Dapsone Chemical compound C1=CC(N)=CC=C1S(=O)(=O)C1=CC=C(N)C=C1 MQJKPEGWNLWLTK-UHFFFAOYSA-N 0.000 description 1
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000010267 cellular communication Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 239000004020 conductor Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000000446 fuel Substances 0.000 description 1
- 230000007274 generation of a signal involved in cell-cell signaling Effects 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 235000012054 meals Nutrition 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 230000024159 perception of rate of movement Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 238000007670 refining Methods 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
- 230000002618 waking effect Effects 0.000 description 1
Images




















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G06F40/35—Discourse or dialogue representation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/04—Segmentation; Word boundary detection
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1815—Semantic context, e.g. disambiguation of the recognition hypotheses based on word meaning
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/183—Speech classification or search using natural language modelling using context dependencies, e.g. language models
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L2015/088—Word spotting
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/225—Feedback of the input speech
Abstract
提供了一种用于处理语音输入的方法及系统。该系统包括麦克风、扬声器、处理器和存储器。在第一操作中,处理器接收包括第一唤醒关键字的第一语音输入,基于第一语音输入选择第一响应模型,在第一语音输入之后接收第二语音输入,使用NLU模块处理第二语音输入,以及基于处理后的第二语音输入生成第一响应。在第二操作中,处理器接收包括不同于第一唤醒关键字的第二唤醒关键字的第三语音输入,基于第三语音输入选择第二响应模型,在第三语音输入之后接收第四语音输入,使用NLU模块处理第四语音输入,以及基于处理后的第四语音输入生成第二响应。
Description
技术领域
本公开涉及一种用于处理用户话语的技术。
背景技术
除了使用现有技术的键盘或鼠标的输入方案之外,电子装置最近还支持各种输入方案,例如语音输入等。例如,诸如智能电话或平板个人计算机(PC)之类的电子装置可以识别在执行语音识别服务的状态下输入的用户语音,并且可以执行与语音输入相对应的动作或者可以提供找到的结果。
如今,语音识别服务正基于用于处理自然语言的技术而发展。处理自然语言的技术是指掌握用户话语意图并向用户提供与意图相匹配的结果的技术。
发明内容
技术问题
当用户终端识别出包括在接收到的语音输入中的唤醒关键词时,用户终端可以将终端的语音识别服务的状态改变为用于处理一般语音输入的启用状态。用户可以将用户期望的词语设置为唤醒关键词。因此,唤醒关键词可以是用户经由语音输入来控制用户终端的起点,并且还可以包括与用户相关联的偏好信息。然而,由于硬件的限制,识别用户设置的唤醒关键词的含义,然后使用所识别的信息来提供个性化服务对用户终端来说是很难的。
本公开的方面在于至少解决上述问题和/或缺点,并至少提供下述优点。因此,本公开的一方面在于提供一种集成智能系统,其使用用户设置的唤醒关键词为用户提供个性化语音响应服务。
问题的解决方案
根据本公开的一方面,提供了一种系统。所述系统包括:麦克风;扬声器;至少一个处理器,所述至少一个处理器可操作地连接到所述麦克风和所述扬声器;以及存储器,所述存储器可操作地连接到所述至少一个处理器。所述存储器可以被配置为存储自然语言理解(NLU)模块、第一响应模型和第二响应模型,并且存储指令,所述指令在被执行时使所述至少一个处理器:在第一操作中,经由麦克风接收包括用于调用基于语音的智能助手服务的第一唤醒关键词的第一语音输入,基于第一语音输入选择第一响应模型,在第一语音输入之后,经由麦克风接收第二语音输入,使用NLU模块来处理第二语音输入,以及基于处理后的第二语音输入生成第一响应,以及在第二操作中,经由麦克风接收第三语音输入,该语音输入包括不同于第一唤醒关键词的第二唤醒关键词,基于第三语音输入选择第二响应模型,在第三语音输入之后,经由麦克风接收第四语音输入,使用NLU模块来处理第四语音输入,以及基于处理后的第四语音输入生成第二响应。可以使用第一响应模型来生成第一响应。可以使用第二响应模型来生成第二响应。
根据本公开的另一方面,提供了一种系统。所述系统包括:麦克风;扬声器;至少一个处理器,所述至少一个处理器可操作地连接到麦克风和扬声器;以及存储器,所述存储器可操作地连接到所述至少一个处理器。存储器可以被配置为存储自动语音识别(ASR)模块、自然语言理解(NLU)模块和多个响应模型,并存储指令,该指令在被执行时使至少一个处理器经由麦克风接收第一语音输入,使用ASR模块从第一语音输入提取第一文本数据,并至少部分地基于所提取的第一文本数据选择响应模型中的至少一个。
根据本公开的另一方面,提供了一种处理语音输入的方法。所述方法包括:接收第一语音输入;使用自动语音识别(ASR模块)从第一语音输入提取第一文本数据;以及至少部分地基于所提取的第一文本数据选择多个响应模型中的至少一个。
发明的有益效果
根据说明书中公开的各种实施例,集成智能系统可以基于能够由用户设置的唤醒关键词来选择响应模型以使用所选择的响应模型来生成语音响应,并且因此可以向用户提供使用个性化语音助手服务(或基于语音的智能助手服务)设置唤醒关键词。因此,可以增加语音助手服务的可用性以及用户体验,诸如直接与人类交谈和用户对用户终端的所有权。
此外,可以提供通过本公开直接或间接理解的各种效果。
附图说明
图1是示出根据本公开的实施例的集成智能系统的框图;
图2是示出根据本公开的各种实施例的概念与动作之间的关系信息被存储在数据库中的形式的图;
图3是示出根据本公开的实施例的显示处理通过智能应用(app)接收到的语音输入的屏幕的用户终端的视图;
图4a是示出根据本公开的实施例的集成智能系统的配置的框图;
图4b是示出根据本公开的实施例的集成智能系统的操作的流程图;
图5a是示出根据本公开的实施例的集成智能系统注册唤醒关键词的方法的流程图;
图5b是示出根据本公开的实施例的集成智能系统的操作的流程图;
图6a和图6b是示出根据本公开的各种实施例的用户终端注册唤醒关键词的屏幕的视图;
图7是示出根据本公开的实施例的集成智能系统设置响应模型的方法的流程图;
图8是示出根据本公开的实施例的集成智能系统设置用户终端的初始响应模型的方法的视图;
图9a和图9b是示出根据本公开的各种实施例的集成智能系统设置用户终端的初始响应模型的方法的视图;
图10a和图10b是示出根据本公开的各种实施例的在集成智能系统中设置响应模型的方法的视图;
图11是示出根据本公开的实施例的智能服务器确定响应模型的方法的流程图;
图12是示出根据本公开的实施例的集成智能系统提供对语音输入的响应的方法的流程图;
图13是示出根据本公开的实施例的智能服务器的文本到语音(TTS)模块的操作的视图;
图14a和图14b是示出根据本公开的各种实施例的集成智能系统根据所选择的响应模型来提供服务的视图;以及
图15是示出根据本公开的实施例的在网络环境1500中的电子设备1501的框图。
在所有附图中,应注意,相同的附图标记用于表示相同或相似的元件、特征和结构。
具体实施方式
提供以下参考附图的描述以帮助全面理解由权利要求及其等同形式所限定的本公开的各种实施例。它包括各种具体细节以帮助理解,但是这些具体细节仅被认为是示例性的。因此,本领域一般技术人员将认识到,在不脱离本公开的范围和精神的情况下,可以对本文所述的各种实施方式进行各种改变和修改。另外,为了清楚和简洁起见,可以省略对公知功能和构造的描述。
在以下描述和权利要求中使用的术语和词语不限于书面含义,而是仅由发明人用来使对本公开的清楚和一致的理解成为可能。因此,对于本领域技术人员而言显而易见的是,提供对本公开的各种实施例的以下描述仅是出于说明的目的,而不是出于限制由所附权利要求及其等同形式所限定的本公开的目的。
应当理解,单数形式的“一”、“一个”和“该”包括复数对象,除非上下文另有明确规定。因此,例如,对“部件表面”的引用包括对一个或更多个这样的表面的引用。
图1是示出根据本公开的实施例的集成智能系统的框图。
参考图1,根据实施例的集成智能系统可以包括用户终端100、智能服务器200和服务服务器300。
根据实施例的用户终端100可以是能够连接到互联网的终端设备(或电子装置),并且可以是例如移动电话、智能电话、个人数字助理(PDA)、笔记本电脑、电视(TV)、白色家用电器、可穿戴设备、头戴式显示器(HMD)或智能扬声器。
根据所示的实施例,用户终端100可以包括通信接口110、麦克风120、扬声器130、显示器140、存储器150或处理器160。列出的组件可以可操作地或电气地相互连接。
根据实施例的通信接口110可以被配置为向外部设备发送数据或从外部设备接收数据。根据实施例的麦克风120可以接收声音(例如,用户话语)以将声音转换为电信号。根据实施例,扬声器130可以输出电信号作为声音(例如,语音)。根据实施例,显示器140可以被配置为显示图像或视频。根据实施例,显示器140还可以显示正在运行的应用(或应用程序)的图形用户界面(GUI)。
根据实施例,存储器150可以存储客户端模块151、软件开发套件(SDK)153和多个应用155。客户端模块151和SDK 153可以构成框架(或解决方案程序)以执行通用功能。此外,客户端模块151或SDK 153可以构成用于处理语音输入的框架。
根据实施例,存储器150中的多个应用155可以是用于执行指定功能的程序。根据实施例,多个应用155可以包括第一应用155_1和第二应用155_2。根据实施例,多个应用155中的每一个可以包括用于执行指定功能的多个动作。例如,这些应用可以包括警报应用、消息应用和/或调度应用。根据实施例,多个应用155可以由处理器160执行以顺序地执行多个动作的至少一部分。
根据实施例,处理器160可以控制用户终端100的整体操作。例如,处理器160可以电连接到通信接口110、麦克风120、扬声器130和显示器140以执行指定的操作。
根据实施例,处理器160还可以执行存储在存储器150中的程序以执行指定的功能。例如,处理器160可以执行客户端模块151或SDK 153中的至少一个,以执行用于处理语音输入的以下动作。处理器160可以经由SDK 153控制多个应用155的动作。被描述为客户端模块151或SDK 153的动作的以下动作可以是由处理器160执行的动作。
根据实施例,客户端模块151可以接收语音输入。例如,客户端模块151可以接收与经由麦克风120检测到的用户话语相对应的语音信号。客户端模块151可以将接收到的语音输入发送到智能服务器200。客户端模块151可以将用户终端100的状态信息与接收到的语音输入一起发送到智能服务器200。例如,状态信息可以是应用的执行状态信息。
根据实施例,客户端模块151可以接收与接收到的语音输入相对应的结果。例如,当智能服务器200能够计算与接收到的语音输入相对应的结果时,客户端模块151可以接收与接收到的语音输入相对应的结果。客户端模块151可以在显示器140中显示接收到的结果。
根据实施例,客户端模块151可以接收与接收到的语音输入相对应的计划。客户端模块151可以在显示器140中显示依据该计划执行应用的多个动作的结果。例如,客户端模块151可以在显示器中顺序地显示多个动作的执行结果。对于另一个示例,用户终端100可以在显示器上仅显示执行多个动作的结果的一部分(例如,最后动作的结果)。
根据实施例,客户端模块151可以从智能服务器200接收用于获取计算与语音输入相对应的结果所需的信息的请求。根据实施例,客户端模块151可以响应于请求将必需的信息发送到智能服务器200。
根据实施例,客户端模块151可以将关于依据计划执行多个动作的结果的信息发送到智能服务器200。智能服务器200可以使用结果信息来确定接收到的语音输入被正确地处理了。
根据实施例,客户端模块151可以包括语音识别模块。根据实施例,客户端模块151可以经由语音识别模块来识别语音输入以执行受限功能。例如,客户端模块151可以经由指定的输入(例如,唤醒!)来启动智能应用,该智能应用处理用于执行有机动作(organicaction)的语音输入。
根据实施例,智能服务器200可以通过通信网络从用户终端100接收与用户的语音输入相关联的信息。根据实施例,智能服务器200可以将与接收到的语音输入相关联的数据改变为文本数据。根据实施例,智能服务器200可以基于文本数据生成用于执行与用户语音输入相对应的任务的计划。
根据实施例,该计划可以由人工智能(AI)系统生成。AI系统可以是基于规则的系统,也可以是基于神经网络的系统(例如,前馈神经网络(FNN)或递归神经网络(RNN))。或者,AI系统可以是上述系统的组合,也可以是不同于上述系统的AI系统。根据实施例,该计划可以从一组预定义的计划中选择或者可以响应于用户请求而实时地生成。例如,AI系统可以选择多个预定义计划中的至少一个计划。
根据实施例,智能服务器200可以将根据生成的计划的结果发送到用户终端100,或者可以将生成的计划发送到用户终端100。根据实施例,用户终端100可以在显示器上显示根据计划的结果。根据实施例,用户终端100可以在显示器上显示根据计划执行动作的结果。
根据实施例的智能服务器200可以包括前端210、自然语言平台220、胶囊数据库(DB)230、执行引擎240、端用户界面(UI)250、管理平台260、大数据平台270或分析平台280。
根据实施例,前端210可以接收从用户终端100接收的语音输入。前端210可以发送与语音输入相对应的响应。
根据实施例,自然语言平台220可以包括自动语音识别(ASR)模块221、自然语言理解(NLU)模块223、计划器模块225、自然语言生成器(NLG)模块227和文本到语音模块(TTS)模块229。
根据实施例,ASR模块221可以将从用户终端100接收的语音输入转换为文本数据。根据实施例,NLU模块223可以使用语音输入的文本数据来掌握用户的意图。例如,NLU模块223可以通过执行语法分析或语义分析来掌握用户的意图。根据实施例,NLU模块223可以通过使用诸如语素或短语之类的语言特征(例如,句法元素)来掌握从语音输入中提取的词语的含义,并且可以通过将所掌握的词语的含义与意图相匹配来确定用户的意图。
根据实施例,计划器模块225可以通过使用由NLU模块223确定的意图和参数来生成计划。根据实施例,计划器模块225可以基于确定的意图来确定执行任务所需的多个域。计划器模块225可以确定包括在基于意图而确定的多个域中的每一个域中的多个动作。根据实施例,计划器模块225可以确定执行所确定的多个动作所需的参数或通过执行多个动作而输出的结果值。参数和结果值可以定义为指定形式(或类)的概念。如此,该计划可以包括由用户的意图确定的多个动作和多个概念。计划器模块225可以逐步地(或分层地)确定多个动作和多个概念之间的关系。例如,计划器模块225可以基于多个概念来确定基于用户的意图而确定的多个动作的执行顺序。换句话说,计划器模块225可以基于执行多个动作所需的参数和通过执行多个动作而输出的结果来确定多个动作的执行顺序。如此,计划器模块225可以生成包括多个动作和多个概念之间的关系的信息(例如,本体)的计划。计划器模块225可以使用存储在存储概念和动作之间的一组关系的胶囊DB 230中的信息来生成计划。
根据实施例,NLG模块227可以将指定的信息改变为文本形式的信息。改变为文本形式的信息可以是自然语言话语的形式。根据实施例的TTS模块229可以将文本形式的信息改变为语音形式的信息。
根据实施例,自然语言平台220的全部或部分功能可以在用户终端100中实现。
胶囊DB 230可以存储关于动作与对应于多个域的多个概念之间的关系的信息。根据实施例,胶囊可以包括计划中包括的多个动作对象(或动作信息)和概念对象(或概念信息)。根据实施例,胶囊DB 230可以以概念动作网络(CAN)的形式存储多个胶囊。根据实施例,多个胶囊可以被存储在胶囊DB 230中包括的功能注册表中。胶囊DB 230可以包括策略注册表,该策略注册表存储确定与语音输入相对应的计划所需的策略信息。策略信息可以包括用于当存在与语音输入相对应的多个计划时确定单个计划的参考信息。根据实施例,胶囊DB 230可以包括追踪注册表,该追踪注册表存储用于在指定的上下文中向用户建议追踪动作的追踪动作的信息。例如,追踪动作可以包括追踪话语。根据实施例,胶囊DB 230可以包括布局注册表,用于存储经由用户终端100输出的信息的布局信息。根据实施例,胶囊DB 230可以包括词汇注册表,该词汇注册表存储在胶囊信息中包括的词汇信息。根据实施例,胶囊DB 230可以包括对话注册表,该对话注册表存储关于与用户的对话(或交互)的信息。
胶囊DB 230可以经由开发者工具更新所存储的对象。例如,开发者工具可以包括用于更新动作对象或概念对象的功能编辑器。开发者工具可以包括用于更新词汇表的词汇表编辑器。开发者工具可以包括策略编辑器,该策略编辑器生成并注册用于确定计划的策略。开发者工具可以包括对话框编辑器,该对话框编辑器创建与用户的对话框。开发者工具可以包括能够启用追踪目标并编辑追踪话语以提供提示的追踪编辑器。可以基于当前设置的目标、用户的偏好或环境条件来确定追踪目标。根据实施例,胶囊DB 230可以在用户终端100中实现。
根据实施例,执行引擎240可以使用所生成的计划来计算结果。端用户界面250可以将计算出的结果发送到用户终端100。因此,用户终端100可以接收结果并且可以向用户提供接收到的结果。根据实施例,管理平台260可以管理由智能服务器200使用的信息。根据实施例,大数据平台270可以收集用户的数据。根据实施例,分析平台280可以管理智能服务器200的服务质量(QoS)。例如,分析平台280可以管理智能服务器200的部件和处理速度(或效率)。
根据实施例,服务服务器300可以向用户终端100提供指定的服务,例如CP服务A301、CP服务B 302、CP服务C 303等(例如,点餐、酒店预订服务)。根据实施例,服务服务器300可以是由第三方操作的服务器。根据实施例,服务服务器300可以向智能服务器200提供用于生成与接收到的语音输入相对应的计划的信息。所提供的信息可以存储在胶囊DB 230中。此外,服务服务器300可以根据计划向智能服务器200提供结果信息。
在上述集成智能系统中,用户终端100可以响应于用户输入向用户提供各种智能服务。用户输入可以包括例如通过物理按钮的输入、触摸输入或语音输入。
根据实施例,用户终端100可以经由存储在其中的智能应用(或语音识别应用)来提供语音识别服务。在这种情况下,例如,用户终端100可以识别经由麦克风接收的用户话语或语音输入,并且可以向用户提供与所识别的语音输入相对应的服务。
根据实施例,用户终端100可以基于接收到的语音输入,排他地或者与智能服务器和/或服务服务器一起执行指定的动作。例如,用户终端100可以执行与接收到的语音输入相对应的应用,并且可以经由所执行的应用来执行指定动作。
根据实施例,当用户终端100与智能服务器200和/或服务服务器一起提供服务时,用户终端可以使用麦克风120检测用户话语,并且可以生成与检测到的用户话语相对应的信号(或语音数据)。用户终端可以使用通信接口110将语音数据发送到智能服务器200。
根据实施例,智能服务器200可以生成用于执行与语音输入相对应的任务的计划或依据该计划执行动作的结果,作为对从用户终端100接收的语音输入的响应。例如,该计划可以包括用于执行与用户的语音输入相对应的任务的多个动作以及与该多个动作相关联的多个概念。该概念可以定义要被输入以执行多个动作的参数或通过执行多个动作而输出的结果值。该计划可以包括多个动作和多个概念之间的关系信息。
根据实施例,用户终端100可以使用通信接口110来接收响应。用户终端100可以使用扬声器130将在用户终端100中生成的语音信号输出到外部,或者可以使用显示器140将在用户终端100中生成的图像输出到外部。
图2是示出根据本公开的各种实施例的概念与动作之间的关系信息被存储在数据库中的形式的图。
参考图2,智能服务器200的胶囊数据库(例如,胶囊DB 230)可以以概念动作网络(CAN)400的形式存储胶囊。胶囊数据库可以以CAN形式存储用于处理与语音输入相对应的任务的动作和该动作所需的参数。
胶囊数据库可以存储分别与多个域(例如,应用)相对应的多个胶囊(例如,胶囊A401和胶囊B 404)。根据实施例,单个胶囊(例如,胶囊A 401)可以对应于一个域(例如,位置(地理位置)或应用)。此外,单个胶囊可以对应于用于执行与胶囊相关联的域的功能的至少一个服务提供商(例如,CP1 402、CP 2 403、CP 3 406或CP 4 405)。根据实施例,单个胶囊可以包括至少一个或更多个动作410和用于执行指定功能的至少一个或更多个概念420。
自然语言平台220可以使用存储在胶囊数据库中的胶囊来生成用于执行与接收到的语音输入相对应的任务的计划。例如,自然语言平台的计划器模块225可以使用存储在胶囊数据库中的胶囊来生成计划。例如,可以使用胶囊A 401的动作4011、4013、概念4012和4014以及胶囊B 404的动作4041和概念4042来生成计划407。
图3是示出根据本公开的实施例的用户终端通过智能应用处理接收到的语音输入的屏幕的图。
参考图3,用户终端100可以执行智能应用以通过智能服务器200处理用户输入。
根据实施例,在屏幕310中,当识别指定的语音输入(例如,唤醒!)或接收经由硬件键(例如,专用硬件键)的输入时,用户终端100可以启动用于处理语音输入的智能应用。例如,用户终端100可以在执行调度应用的状态下启动智能应用。根据实施例,用户终端100可以在显示器140中显示与智能应用相对应的对象(例如,图标)311。根据实施例,用户终端100可以接收由用户话语输入的语音输入。例如,用户终端100可以接收语音输入,该语音输入是“让我知道本周的行程!”。根据实施例,用户终端100可以在显示器中显示智能应用的用户界面(UI)313(例如,输入窗口),该用户界面显示接收到的语音输入的文本数据。
根据实施例,在屏幕320中,用户终端100可以在显示器中显示与接收到的语音输入相对应的结果。例如,用户终端100可以接收与接收到的用户输入相对应的计划,并且可以依据计划在显示器中显示“本周的时间表”。
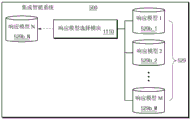
图4a是示出根据本公开的实施例的集成智能系统500的配置的框图。
参考图4a,集成智能系统500可以包括用户终端510和智能服务器520。用户终端510和智能服务器520可以类似于图1的用户终端100和智能服务器200。
根据实施例,用户终端510可以包括存储器511(例如,图1的存储器150)、子处理器513和主处理器515(例如,图1的处理器160)。根据实施例,用户终端510的配置可以不限于此,并且还可以包括图1的用户终端100的配置。
根据实施例,存储器511可以存储唤醒关键词识别模块511a、客户端模块511b、唤醒关键词训练模块511c、主题选择模块511d和唤醒关键词识别模型数据库(DB)511e。唤醒关键词识别模块511a、客户端模块511b、唤醒关键词训练模块511c和主题选择模块511d可以是用于执行通用功能的框架。根据实施例,唤醒关键词识别模块511a、客户端模块511b、唤醒关键词训练模块511c和主题选择模块511d可以由处理器(例如,子处理器513和主处理器515)执行,然后可以实现其功能。根据实施例,唤醒关键词识别模块511a、客户端模块511b、唤醒关键词训练模块511c和主题选择模块511d不仅可以用软件实现,而且可以用硬件实现。
根据实施例,包括由唤醒关键词识别模块511a识别的唤醒关键词的用户话语可以是用于呼叫语音识别服务(或基于语音的智能助手服务)的唤醒话语。例如,包括唤醒关键词的语音输入可以是用于将一般语音输入的状态改变为能够处理一般语音输入的状态的语音输入。例如,一般语音输入可以是用于执行指定功能(例如,消息的发送/接收)的语音输入。
根据实施例,存储器511可以包括至少一个存储器。例如,存储器511可以包括用于存储唤醒关键词识别模型DB 511e的单独的存储器。换句话说,存储器511可以包括:第一存储器,其存储用于控制处理器(例如,子处理器513和主处理器515)的操作的指令;以及第二存储器,其存储唤醒关键词识别模型DB 511e。例如,第一存储器可以存储唤醒关键词识别模块511a、客户端模块511b、唤醒关键词训练模块511c和主题选择模块511d。根据实施例,第二存储器可以是与第一存储器物理上分离的存储器。在启用由用户终端510提供的语音识别服务或基于语音的智能助手服务之前的状态下,第二存储器可以被子处理器513访问。例如,子处理器513可以读出存储在第二存储器中的信息(例如,唤醒关键词识别模型信息),以识别用于启用由用户终端510提供的语音识别服务或基于语音的智能助手服务的语音输入。作为另一示例,存储器511可以包括一个存储器,该存储器存储唤醒关键词识别模块511a、客户端模块511b、唤醒关键词训练模块511c、主题选择模块511d和唤醒关键词识别模块DB 511e。换句话说,存储器511可以不单独包括用于唤醒关键词识别模型DB 511e的存储器。
根据实施例,子处理器513可以控制用户终端510的一部分操作。换句话说,子处理器513可以限制性地控制用户终端510。例如,子处理器513可以识别指定的词语(或唤醒关键词)以启用主处理器515。换句话说,用户终端510的状态可以从子处理器513仅执行部分操作(例如,保持系统引导状态)的停用状态(或待机状态或睡眠状态)改变为用于执行提供多个服务(例如,消息服务或电话服务)的操作的启用状态。根据实施例,子处理器513可以是消耗低功率的处理器。
根据实施例,子处理器513可以通过执行唤醒关键词识别模块511a来执行识别唤醒关键词的操作。被描述为唤醒关键词识别模块511a的操作的以下操作可以是通过子处理器513执行的操作。
根据实施例,唤醒关键词识别模块511a可以识别限制数量的词语。例如,唤醒关键词识别模块511a可以识别用于启用主处理器515的唤醒关键词。根据实施例,唤醒关键词识别模块511a可以使用唤醒关键词识别模型。唤醒关键词识别模型可以包括识别唤醒关键词所必需的信息。例如,当基于隐马尔可夫模型(HMM)算法执行语音识别功能时,唤醒关键词识别模型可以包括状态初始概率、状态转变概率、观察概率等。作为另一示例,当基于神经网络算法执行语音识别功能时,唤醒关键词识别模块可以包括神经网络模型信息,例如层、节点的类型和结构、每个节点的权重、网络连接信息、非线性启用函数等。根据实施例,当通过唤醒关键词识别模块511a识别唤醒关键词时,子处理器513可以启用主处理器515。
根据实施例,唤醒关键词识别模块511a可以测量多个语音输入之间的相似性,以确定多个语音输入是否彼此相同。例如,唤醒关键词识别模块511a可以提取多个语音输入的特征向量,并且可以测量使用动态时间规整(DTW)提取的特征向量之间的相似性。对于另一示例,当基于HMM模型算法执行语音识别功能时,唤醒关键词识别模块511a可以使用向前-向后概率来测量多个语音输入之间的相似性。对于另一示例,当基于神经网络算法执行唤醒关键词识别模块511a时,唤醒关键词识别模块511a可以使用通过音素识别器测量的音素水平来测量多个语音输入之间的相似性。根据实施例,当所测量的相似性不小于指定值时,唤醒关键词识别模块511a可以确定多个语音输入彼此相同。根据实施例,唤醒关键词识别模块511a可以判定用于训练唤醒关键词的多个语音输入是否包括相同的词语。根据实施例,唤醒关键词识别模块511a用于训练唤醒关键词的操作可以由主处理器515执行。
根据实施例,主处理器515可以执行客户端模块511b以执行用于处理语音输入的操作。语音输入可以是用于命令执行指定任务的用户输入。被描述为客户端模块511b的操作的以下操作可以是通过主处理器515执行的操作。
根据实施例,客户端模块511b可以将用于执行指定任务的语音输入发送到智能服务器520。根据实施例,客户端模块511b可以通过智能服务器520接收与语音输入相对应的计划。该计划可以包括用于执行指定的任务的操作信息。根据实施例,客户端模块511b可以依据接收到的计划来执行应用的操作以执行指定的任务,从而可以向用户提供结果。
根据实施例,当客户端模块511b接收到用于注册唤醒关键词的语音输入时,客户端模块511b可以将语音输入发送到智能服务器520。例如,客户端模块511b可以通过通信接口(例如,图1的通信接口110)将语音输入发送到智能服务器520。根据实施例,客户端模块511b可以从智能服务器520接收确定语音输入是否包括指定的词语的结果。例如,客户端模块511b可以通过通信接口接收所确定的结果。根据实施例,客户端模块511b可以基于所确定的结果来确定唤醒关键词是否能够被注册。因此,当接收到的语音输入能够被注册为唤醒关键词时,客户端模块511b可以通过唤醒关键词训练模块511c注册基于接收到的语音输入的注册唤醒关键词。
根据实施例,主处理器515可以执行唤醒关键词训练模块511c以执行注册(或生成)唤醒关键词的操作。用户可以注册用户想要的词语,作为启用主处理器515的唤醒关键词。被描述为唤醒关键词训练模块511c的操作的以下操作可以是通过执行主处理器515进行的操作。
根据实施例,唤醒关键词训练模块511c可以执行用于注册唤醒关键词的唤醒关键词识别训练。唤醒关键词训练模块511c可以基于接收到的语音输入来重复地执行唤醒关键词识别训练。例如,当基于HMM算法执行语音识别功能时,唤醒关键词训练模块511c可以通过使用期望最大化(EM)算法执行模型训练或通过使用最大似然线性回归(MLLR)和最大后验估计(MAP)执行自适应训练来生成唤醒关键词识别模型。对于另一示例,当基于神经网络算法执行语音识别功能时,唤醒关键词训练模块511c可以使用前馈传播算法或后向传播算法来执行模型训练,或者可以使用线性变换来执行自适应训练。根据实施例,唤醒关键词训练模块511c可以确定在通过唤醒关键词识别模块511a重复接收到的语音输入中是否包括相同的唤醒关键词。因此,可以基于包括相同的唤醒关键词的语音输入来执行唤醒关键词识别训练。根据实施例,唤醒关键词训练模块511c可以通过唤醒关键词识别训练来生成唤醒关键词识别模型。
根据实施例,主题选择模块511d可以向用户提供用于选择响应模型(例如,语音响应模型或响应主题模型)的列表。例如,该列表可以包括至少一个响应模型。根据实施例,智能服务器520可以选择列表中包括的至少一个响应模型。例如,智能服务器520可以基于唤醒关键词来确定至少一个响应模型。对于另一示例,智能服务器520可以基于用户信息来选择至少一个响应模型。根据实施例,主题选择模块511d可以接收用户输入以选择列表中包括的至少一个响应模型中的至少一个。根据实施例,当主题选择模块511d通过唤醒关键词训练模块511c训练对唤醒关键词的识别时,主题选择模块511d可以提供列表并且可以接收用户输入以选择列表中包括的至少一个响应模型。根据实施例,客户端模块511b可以将接收到的用户输入发送到智能服务器520。
根据实施例,智能服务器520可以依据接收到的用户输入来选择响应模型,并且可以使用所选择的响应模型来生成与用户输入(例如,语音输入)相对应的响应。例如,智能服务器520可以依据所选择的响应模型来生成与指定形式的用户输入相对应的响应。或者,用户终端510可以通过用户的选择来向用户提供格式(或主题)的响应。
根据实施例,主题选择模块511d可以与唤醒关键词训练模块511c集成为单个模块。换句话说,主题选择模块511d和唤醒关键词训练模块511c可以用单个硬件模块或软件模块来实现。
根据实施例,可以将所生成的唤醒关键词识别模型存储在唤醒关键词识别模型DB511e中。根据实施例,唤醒关键词识别模块511a可以使用存储在唤醒关键词识别模型DB511e中的唤醒关键词识别模型信息来识别唤醒关键词。
根据实施例,智能服务器520可以包括自动语音识别(ASR)模块521(例如,图1的ASR模块221)、自然语言理解(NLU)模块522(例如,图1的NLU模块223)、计划器模块523(例如,图1的计划器模块225)、自然语言响应生成器模块524、图像响应生成器模块525、第一文本到语音(TTS)模块526、对话管理模块527、唤醒关键词细化模块528、唤醒名称数据库(DB)529a和响应模型数据库(DB)529b。根据实施例,智能服务器520的配置可以不限于此,并且还可以包括图1的智能服务器520的配置。智能服务器520的配置可以是存储在存储器中的程序,或者可以是数据库。
根据实施例,ASR模块521可以将语音输入改变为文本数据。根据实施例,ASR模块521可以使用诸如隐马尔可夫模型(HMM)算法、加权有限状态变换器(wFST)算法、神经网络算法等算法来实现。例如,ASR模块521可以通过使用距离测量方法将指定的词语与语音输入进行比较,将语音输入改变为文本数据。例如,距离测量方法可以包括诸如Levenshtein距离、Jaro-Winkler距离等的测量方法。对于另一个示例,距离测量方法可以包括在从字素到音素(G2P)转换为发音之后测量音素级别的文本之间的距离的方法。
根据实施例,ASR模块521可以包括大词汇量连续语音识别(LVCSR)。因此,ASR模块521可以使用比用户终端510的唤醒关键词识别模块511a更复杂的计算过程,并且可以识别很多词语。
根据实施例,NLU模块522可以使用从ASR模块521发送的文本数据来确定与语音输入相对应的意图和参数。
根据实施例,计划器模块523可以基于由NLU模块522确定的意图和参数来生成与语音输入相对应的计划。该计划可以包括用于执行与语音输入相对应的任务的操作信息。根据实施例,计划器模块523可以逐步安排用于执行任务的操作,并且可以确定为执行所安排的操作而输入的参数或者定义通过执行输出的结果值的概念,从而可以生成计划。
根据实施例,自然语言响应生成器模块524可以生成要提供给用户的自然语言信息、所确定的意图和参数。例如,自然语言信息不仅可以包括视觉信息(例如,图像信息),而且还包括听觉信息(例如,声音信息)。根据实施例,听觉信息可以是通过语音输出给用户的信息。可以根据指定的模板来生成与要与语音一起提供的听觉信息相对应的文本。例如,指定的模板可以与文本提供的形式相关联。此外,可以通过NLG模块(例如,图1的NLG模块227)生成复杂文本。根据实施例,自然语言响应生成器模块524可以使用多个模板中的一个模板来生成自然语言信息。根据实施例,自然语言响应生成器模块524可以使用唤醒名称来生成要提供给用户的信息。例如,自然语言响应生成器模块524可以生成包括唤醒名称的文本。例如,可以通过细化唤醒关键词来生成唤醒名称。唤醒名称可以存储在唤醒名称DB 529a中。
根据实施例,图像响应生成器模块525可以基于所确定的意图和参数来生成图像信息。例如,图像信息可以是通过自然语言响应生成器模块524生成的自然语言信息以外的信息,并且可以包括图像信息和与该图像信息相对应的声音信息。根据实施例,可以依据指定的模板来生成图像信息。例如,指定的模板可以包括图像对象的位置信息、颜色信息、形状信息等。根据实施例,图像响应生成器模块525可以使用多个模板中的一个模板来生成图像信息。
根据实施例,TTS模块526可以将由自然语言响应生成器模块524生成的自然语言信息转换为语音信号。TTS模块526可以依据算法以各种形式实现。例如,TTS模块526可以以单元结合形式实现。例如,以单元结合形式实现的TTS模块526可以包括大的单元语音数据库。大单元语音数据库可以存储TTS模型,通过该TTS模型来标记通过多个人记录的语音信号。根据实施例,TTS模块526可以使用TTS模型将自然语言信息转换为语音信号。根据另一个实施例,TTS模块526可以通过调整语音元素将自然语言信息转换为语音信号。例如,TTS模块526可以通过调整音调、语速、语调等将自然语言信息转换为语音信号。音元素的调整可以在自然语言信息被转换为语音信号时进行调整(例如,参数TTS方法),或者可以在自然语言信息被转换为语音信号后进行调整(例如,后处理方法)。
根据实施例,对话管理模块527可以管理与用户的对话流。例如,对话管理模块527可以确定对基于与用户对话期间的上下文接收到的语音输入的响应。根据实施例,对话管理模块527可以使用对话管理模型来确定对语音输入的响应。例如,对话管理模型可以确定响应。
根据实施例,唤醒关键词细化模块528可以细化注册的唤醒关键词以生成用户终端510的唤醒名称。根据实施例,智能服务器520可以使用唤醒名称来生成与语音输入相对应的响应。换句话说,智能服务器520可以向用户终端510提供包括唤醒名称的响应。例如,唤醒名称可以用作提供与用户的语音输入相对应的响应的语音助手的名称。根据实施例,唤醒关键词细化模块528可以将生成的唤醒名称存储在唤醒名称DB 529a中。
根据实施例,智能服务器520可以选择用于提供与用户输入相对应的响应的响应模型。根据实施例,智能服务器520可以基于唤醒关键词来选择响应模型。例如,智能服务器520可以通过ASR模块521获得与唤醒关键词相对应的文本数据,并且可以基于所获得的文本数据来选择响应模型。根据另一实施例,智能服务器520可以基于用户信息来选择响应模型。例如,用户信息可以包括性别、年龄、居住地区和用户终端使用信息中的至少一个。
根据实施例,智能服务器520可以使用所选择的响应模型来生成与接收到的语音输入相对应的响应。例如,智能服务器520可以根据所选择的响应模型生成与该形式的接收到的语音输入相对应的响应。根据实施例,可以基于所选择的语音输入模型来设置用于生成智能服务器520的响应的配置。例如,自然语言响应生成器模块524和图像响应生成器模块525可以被设置为通过使用与所选择的语音输入模型相对应的模板来生成提供给用户的信息(例如,自然语言信息和图像信息)。对于另一个示例,TTS模块526可以使用与所选择的语音输入模型相对应的TTS模型将自然语言转换为语音信号。对话管理模块527可以使用与所选择的语音输入模型相对应的对话管理模型来确定响应。
根据实施例,响应模型DB 529b可以存储TTS模型的信息。例如,TTS模型的信息可以存储模板信息,TTS模型信息和对话管理模型信息。因此,智能服务器520可以使用存储在响应模型DB 529b中的TTS模型的信息来生成与接收到的语音输入相对应的响应。根据实施例,响应模型DB 529b可以存储多个TTS模型的信息。智能服务器520可以基于注册的唤醒关键词来确定多个TTS模型中的一个TTS模型。根据实施例,用户终端510可以注册多个唤醒关键词。智能服务器520可以使用与所识别的唤醒关键词相对应的TTS模型来生成响应。
根据实施例,智能服务器520可以生成用于从用户接收指定语音输入的指南信息。例如,智能服务器520可以生成用于接收语音输入的指南信息,以进行唤醒关键词训练。此外,当接收到包括不适当的词语的语音输入时,智能服务器520可以生成用于接收不同语音输入的指南信息。根据实施例,智能服务器520可以将所生成的指南信息发送到用户终端510。用户终端510可以输出指南信息。
图4b是示出根据本公开的实施例的集成智能系统500的操作的流程图530。
根据实施例,集成智能系统500的智能服务器520可以使用不同的响应模型来提供对不同的唤醒关键词的响应。
参考图4b,根据实施例的智能服务器520可以执行包括操作531至操作535的第一操作。
在操作531中,智能服务器520可以接收包括第一唤醒关键词的第一语音输入。第一唤醒关键词可以调用智能助手服务。可以经由麦克风来接收第一语音输入。
在操作532中,智能服务器520可以基于第一语音输入来选择第一响应模型。
在操作533中,智能服务器520可以接收第二语音输入。可以经由麦克风来接收第二语音输入。可以在第一语音输入之后接收第二语音输入。第二语音输入可以是用于计算第一结果的语音输入。
在操作534中,智能服务器520可以处理第二语音输入。可以使用NLU模块522来处理第二语音输入。
在操作535中,智能服务器520可以基于处理后的第二语音输入来生成第一响应。可以使用第一响应模型来生成第一响应。
此外,根据实施例的智能服务器520可以执行包括操作536至操作540的第二操作。
在操作536中,智能服务器520可以接收第三语音输入,该第三语音输入包括与第一唤醒关键词不同的第二唤醒关键词。可以经由麦克风来接收第三语音输入。
在操作537中,智能服务器520可以基于第三语音输入来选择第二响应模型。
在操作538中,智能服务器520可以接收第四语音输入。可以在第三语音输入之后接收第四语音输入。可以经由麦克风接收第四语音输入。
在操作539中,智能服务器520可以处理第四语音输入。可以使用NLU模块522来处理第四语音输入。
在操作540中,智能服务器520可以基于处理后的第四语音输入来生成第二响应。可以使用第二响应模型来生成第二响应。
图5a是示出根据本公开实施例的集成智能系统500注册唤醒关键词的方法的流程图600。
参考图5a,用户终端(例如,图4a的用户终端510)可以通过智能服务器(例如,图4a的智能服务器520)确定语音输入中是否包括不适当的词语,并且可以注册唤醒关键词。
在操作610中,用户终端可以接收用于注册唤醒关键词的第一语音输入。例如,用户终端可以接收“盖乐世(galaxy)”。根据实施例,用户终端可以将接收到的第一语音输入发送到智能服务器。
根据实施例,在操作620中,智能服务器可以识别接收到的第一语音输入。例如,智能服务器可以通过ASR模块(例如,图4a的ASR模块521)将第一语音输入转换为文本数据(例如,galaxy)以识别第一语音输入。
根据实施例,在操作630中,用户终端可以请求用于唤醒关键词识别训练的附加话语。例如,用户终端可以经由扬声器或显示器输出用于接收与第一语音输入(例如,galaxy)相同的第二语音输入的第一指南信息(例如,请再次说“galaxy”)。例如,可以使用第一语音输入来生成第一指南信息。根据实施例,用户终端可以从智能服务器接收第一指南信息。智能服务器可以使用从用户终端接收的第一语音输入来生成第一指南信息。
根据实施例,在操作640中,用户终端可以接收包括与第一语音输入相同的信息的第二语音输入。例如,用户终端可以再次接收“galaxy”。
根据实施例,在操作650中,用户终端可以基于第一语音输入和第二语音输入来生成用于识别唤醒关键词的唤醒关键词识别模型。例如,可以使用基于HMM算法或神经网络算法或自适应训练算法中的至少一个的模型训练来生成关键词识别模型。根据实施例,用户终端可以通过将所生成的唤醒关键词识别模型存储在存储器中来注册唤醒关键词。
根据实施例,在操作640中,用户终端可以多次(例如,N次)接收包括与第一语音输入相同的信息的语音输入。根据实施例,在操作650中,用户终端可以基于多个语音输入来生成唤醒关键词识别模型。因此,用户终端可以生成能够准确地识别唤醒关键词的唤醒关键词识别模型。
因此,当在待机状态下接收到包括注册的唤醒关键词的语音输入时,用户终端可以识别该唤醒关键词,并且可以将语音识别服务(或基于语音的智能助手服务)的状态改变为启用状态。
图5b是示出根据本公开的实施例的集成智能系统500的操作的流程图660。
参考图5b,在操作661中,智能服务器520可以使用ASR模块521从第一语音输入中提取第一文本数据。在操作610中,可以使用麦克风来接收第一语音输入。
在操作662中,智能服务器520可以至少部分地基于所提取的第一文本数据向用户提供包括响应模型中的至少一个的列表。
在操作663中,智能服务器520可以接收用户输入以选择响应模型列表中的至少一个响应模型。
在操作664中,智能服务器520可以依据接收到的用户输入来选择至少一个响应模型。
图6a和图6b是示出根据本公开的各种实施例的用户终端注册唤醒关键词的屏幕的视图。
参考图6a和图6b,用户终端510可以经由显示器(例如,图1的显示器140)输出用于注册唤醒关键词的用户界面(UI)。
根据实施例,在屏幕710中,用户终端510可以输出用于开始注册唤醒关键词的UI。用户终端510可以在UI上显示用于注册唤醒关键词的用户话语的指南信息711。根据实施例,用户终端510可以通过对象(例如,虚拟按钮713)接收用户输入以开始注册唤醒关键词。
根据实施例,在屏幕720中,在执行图5a的操作610的步骤中,用户终端510可以接收用于接收第一语音输入以注册唤醒关键词的UI。用户终端510可以在UI上显示用于接收第一语音输入的第一指南信息721和用于显示唤醒关键词注册步骤的指示符723。指示符723可以指示接收第一语音输入的步骤。根据实施例,用户终端510可以接收第一语音输入。例如,用户终端510可以接收“Hi Bixby!”。根据实施例,用户终端510可以通过智能服务器(例如,图4a的智能服务器520)来确定第一语音输入是否包括指定的词语。
根据实施例,在屏幕730中,在执行图5a的操作630的步骤中,用户终端510可以输出用于接收第二语音输入的UI,该第二语音输入包括与第一语音输入相同的词语。用户终端510可以在UI上显示用于接收第二语音输入的第二指南信息731和指示接收第二语音输入的步骤的指示符733。例如,第二指南信息731可以包括与第一语音输入相对应的文本数据(例如,Hi Bixby)。根据实施例,用户终端510可以接收第二语音输入。例如,用户终端510可以再次接收“Hi Bixby!”。
根据实施例,在屏幕740中,在执行图5a的操作650的步骤中,用户终端510可以输出指示执行唤醒关键词识别训练的过程的UI。用户终端510可以在UI上显示指示用户终端510正在训练中的第三指南信息741和指示训练步骤的指示符743。根据实施例,用户终端510可以基于第一语音输入和第二语音输入来注册唤醒关键词。例如,用户终端510可以基于第一语音输入和第二语音输入来生成唤醒关键词识别模型。用户终端510可以将所生成的唤醒关键词识别模型存储在存储器(例如,图4a的存储器511)中。
根据实施例,在屏幕750中,用户终端510可以输出指示注册唤醒关键词的结果的UI。用户终端510可以在UI上显示第三指南信息751,该第三指南信息751包括注册唤醒关键词的结果和用于执行指定功能的语音输入的图示753。根据实施例,用户终端510可以通过对象(例如,虚拟按钮755)接收用户输入以完成唤醒关键词的注册。
因此,当识别出注册的唤醒关键词时,用户终端可以将语音识别服务(或基于语音的智能助手服务)的状态从待机状态改变为启用状态。
图7是示出根据本公开的实施例的集成智能系统设置响应模型的方法的流程图800。
参考图7,集成智能系统(例如,图4a的集成智能系统500)可以基于所注册的唤醒关键词来确定响应模型。
根据实施例,在操作811中,类似于图5a的操作610,用户终端510可以接收第一语音输入。例如,用户终端510可以接收“金秘书”。根据实施例,在操作813中,用户终端510可以将接收到的第一语音输入发送到智能服务器520。
根据实施例,在操作821中,类似于图5a的操作620,智能服务器520可以对第一语音输入执行语音识别。例如,智能服务器520可以将第一语音输入改变为作为文本数据的“金秘书”。根据实施例,在操作823中,智能服务器520可以将识别出的结果发送到用户终端510。例如,识别出的结果可以包括与第一语音输入相对应的文本数据(例如,“金秘书”)。
根据实施例,在操作831中,类似于图5a的操作630,用户终端510可以向用户请求附加话语。例如,用户终端510可以输出“请说出金秘书三次”。根据实施例,在操作833中,类似于图5a的操作640,用户终端510可以接收与第一语音输入相同的第二语音输入。此外,用户终端510可以接收多个语音输入,每个语音输入与第一语音输入相同。根据实施例,在操作835中,类似于图5a的操作650,用户终端510可以基于第一语音输入和第二语音输入来生成语音识别模型。换句话说,用户终端510可以训练语音识别模型。例如,用户终端510可以生成与“金秘书”相对应的语音识别模型。
根据实施例,在操作841至操作845中,当用户终端510训练语音识别模型时,智能服务器520可以选择响应模型。根据实施例,在操作841中,智能服务器520可以基于识别出的唤醒关键词来选择响应模型。例如,智能服务器520可以选择与“金秘书”的含义类似的响应模型(例如,细心礼貌的助手的响应模型、运动健谈的女友的响应模型、热心温柔的男友的响应模型等)。根据实施例,在操作843中,智能服务器520可以生成关于推荐模型(或推荐响应模型)的信息。例如,推荐模型信息可以包括推荐模型列表。该列表可以包括所选择的至少一个响应模型。根据实施例,在操作845中,智能服务器520可以将所生成的推荐模型信息发送到用户终端510。
根据实施例,在操作851中,用户终端510可以接收用户输入以选择响应模型。例如,用户终端510可以接收用户输入,以在包括在推荐模型列表中的至少一个响应模型中选择至少一个语音响应(例如,谨慎礼貌的助手的响应)。根据实施例,在操作853中,用户终端510可以通过用户输入将选择信息发送到智能服务器520。
根据实施例,在操作860中,智能服务器520可以设置与选择信息相对应的响应模型。例如,可以将智能服务器520设置为使用与选择信息相对应的响应模型来生成响应。因此,智能服务器520可以使用设置的语音响应模型生成与接收到的语音输入相对应的响应。
图8是示出根据本公开的实施例的集成智能系统设置用户终端的初始响应模型的方法的视图。
参考图8,集成智能系统(例如,图4a的集成智能系统500)可以使用用户终端510的开箱即用体验(OOBE)下的用户信息来输出用于设置响应模型的指南信息。
根据实施例,用户终端510可以输出指南信息,以便使用关于已登录的用户的信息910来设置响应模型。例如,用户终端510可以通过基于用户信息确定的UI 920向用户提供用于指导响应模型的文本信息921。此外,用户终端510可以向用户提供用于指导响应模型的语音信息。可以基于用户信息来确定用于指导设置响应模型的UI 920的颜色(例如,亮色)、文本信息921的书写风格(例如,友好的书写风格)、语音信息的音调(例如,友好的音调)。根据实施例,用户信息不仅可以包括用户的个人信息,而且可以包括用户偏好信息。例如,用户信息可以包括性别(例如,女性)、年龄(例如,青少年)、位置(例如,学校和房屋)、常用应用(例如,YouTube或Facebook)、事件历史(例如,期中考试)和搜索数据(例如,V-app)。
图9a和图9b是示出根据本公开的各种实施例的集成智能系统设置用户终端的初始响应模型的方法的视图。
参考图9a,集成智能系统(例如,图4a的集成智能系统500)可以接收用于在用户终端510的OOBE处设置唤醒关键词的用户输入。
根据实施例,用户终端510可以在显示器上显示用于输入唤醒关键词的用户界面(UI)1010。可以基于用户信息来确定在显示器上显示的UI 1010的颜色(例如,亮色)。根据实施例,用户终端510可以通过在显示器上显示的UI 1010接收用户输入1011以输入唤醒关键词。例如,可以通过直接输入文本数据(例如,我的叔叔)来接收用户输入1011。根据实施例,所输入的文本数据可以原样用作唤醒名称。
根据实施例,智能服务器(例如,图4a的智能服务器520)可以基于接收到的用户输入1011来选择响应模型。此外,智能服务器可以使用用户信息和用户输入1011来选择响应模型。根据实施例,智能服务器可以使用所选择的响应模型来提供响应。根据实施例,用户终端510可以基于所选择的响应模型在显示器上显示用户界面(UI)1020。用户终端510可以显示用于指导通过UI 1020选择的响应模型的文本信息1021。UI 1010的颜色(例如,深色)、文本信息1021的书写风格(例如,正式书写风格)、语音信息的音调(例如,正式音调)可以根据所选择的响应模型来确定。
参考图9b,集成智能系统可以接收用户输入以在用户终端510的OOBE处选择响应模型。
根据实施例,用户终端510可以在显示器上显示用于输入唤醒关键词的UI 1010。根据实施例,用户终端510可以通过显示器上显示的UI 1010来接收用户输入1011以输入唤醒关键词。
根据实施例,智能服务器可以将包括至少一个响应模型的列表发送到用户终端510,以便基于接收到的用户输入1011来选择至少一个响应模型。根据实施例,用户终端510可以在显示器上显示的用户界面(UI)1030上显示用于接收用户输入以选择响应模型的列表1031。根据实施例,用户终端510可以通过显示器上显示的列表1031接收用户输入1031a以选择响应模型。根据实施例,用户终端510可以将接收到的用户输入1031a发送到智能服务器。
根据实施例,智能服务器可以依据接收到的用户输入1031a来设置响应模型。根据实施例,智能服务器可以使用设置的响应模型来提供响应。根据实施例,用户终端510可以基于所选择的响应模型在显示器上显示UI 1020。
图10a和图10b是示出根据本公开的各种实施例的在集成智能系统中设置响应模型的方法的视图。
参考图10a,可以在集成智能系统(例如,图4a的集成智能系统500)中设置基于唤醒关键词选择的响应模型529b_N。
根据实施例,响应模型选择模块1110可以用智能服务器(例如,图4a的智能服务器520)的多个组件中的至少一部分来实现。换句话说,响应模型选择模块1110的功能可以通过智能服务器的多个组件中的至少一部分来实现。
根据实施例,响应模型选择模块1110可以基于唤醒关键词来选择响应模型529b_N。例如,响应模型选择模块1110可以基于唤醒关键词选择多个响应模型529b_1到529b_M(在图10a中累积地示为529,包括529b_2)中的至少一个响应模型529b_N。例如,多个响应模型529b_1到529b_M可以被存储在响应模型DB 529b中。将参考图11详细描述基于唤醒关键词来选择响应模型529b_N的方法。
根据实施例,响应模型选择模块1110可以在集成智能系统500中设置所选择的响应模型529b_N。因此,集成智能系统500可以使用所设置的响应模型529b_N来生成与接收到的用户输入相对应的响应。
参考图10b,所选择的响应模型529b_N可以包括用于集成智能系统500中包括的每个组件的模型。
根据实施例,响应模型529b_N可以包括用于智能服务器中包括的每个组件的模型。例如,响应模型529b_N可以包括计划器模型529b_N1、自然语言响应生成器模型529b_N3、图像响应生成器模型529b_N5、TTS模型529b_N7或对话管理模型529b_N9中的至少一个或更多个。
根据实施例,当智能服务器的计划器模块523生成计划时,可以使用计划器模型529b_N1。例如,可以基于接收到的语音输入的意图来生成计划。该计划可以包括由用户终端100执行的多个动作。根据实施例,计划器模块523可以依据计划器模型529b_N1来生成计划。例如,计划器模块523可以依据计划器模型529b_N1来生成用于执行指定的应用或用于执行指定的功能的计划。换句话说,计划器模块523可以根据所选择的响应模型529b_N的计划器模型529b_N1来生成用于针对相同意图执行不同应用或针对相同意图执行不同功能的计划。根据实施例,计划器模型529b_N1可以包括关于指定的应用或功能的信息。
根据实施例,当智能服务器520的自然语言响应生成器模块524生成包括自然语言信息的响应时,可以使用自然语言响应生成器模型529b_N3。例如,可以基于接收到的语音输入的意图来生成响应。根据实施例,自然语言响应生成器模块524可以依据自然语言响应生成器模型529b_N3以指定的形式生成响应。例如,自然语言响应生成器模块524可以根据自然语言响应生成器模型529b_N3来生成包括要在屏幕上显示的符号(例如,表情符号)或自然语言响应(文本)的响应。换句话说,自然语言响应生成器模块524可以根据所选择的响应模型529b_N的自然语言响应生成器模型529b_N3来生成包括针对相同意图的不同符号和/或文本的自然语言响应。根据实施例,自然语言响应生成器模型529b_N3可以包括用于生成特定响应的规则。例如,该规则可以包括要包括在屏幕中的自然语言响应(例如,图像和/或文本)。要包括在屏幕中的自然语言响应可以包括指示表情的符号表达规则。根据实施例,可以依据用户使用的模式来设置规则。例如,用户使用的模式可以包括免视模式、免提模式和屏幕模式。根据实施例,多个规则可以对应于一个响应(或响应标识(ID))。
表1

如表1所示,NLG模块227可以具有至少一个响应ID。例如,NLG模块227可以具有星巴克(Starbucks)10和星巴克11的响应ID。相应的自然语言生成版本、评论主题、多个对话显示和/或与话语(说话)相关联的其他规则可以分配给每个ID。例如,当评论主题是“Borong-yi”时,可以分配对话显示或与聊天、半敬语标题、推荐功能和/或表情符号相关联的话语规则。
表2


如表2所示,当每个响应ID的评论主题改变时,可以分配多个对话显示和/或与话语(说话)相关联的其他规则。例如,当评论主题是“我的叔叔”时,对话显示或话语规则可以分配给相同情况下的坚定的和简短的表达和/或简洁的表达。根据实施例,当智能服务器520的图像响应生成器模块525生成包括图像信息的响应时,可以使用图像响应生成器模型529b_N5。例如,可以基于接收到的语音输入的意图来生成响应。根据实施例,图像响应生成器模块525可以根据图像响应生成器模型529b_N5以指定的形式生成响应。例如,图像响应生成器模块525可以根据图像响应生成器模型529b_N5来选择内容或者可以生成指定窗口的类型和颜色的响应。换句话说,图像响应生成器模块525可以根据所选择的响应模型529b_N的图像响应生成器模型529b_N5针对同一意图选择不同的内容,或者可以针对相同意图生成不同窗口的类型和颜色的响应。根据实施例,图像响应生成器模型529b_N5可以包括内容选择规则或关于窗口的默认类型和颜色的信息。
当生成对用户命令的响应时,可以选择或使用图像响应生成器模型529b_N5中包括的窗口的类型和颜色。另外,当在用户输入唤醒关键词之后输入用户命令之前显示指示待机状态的屏幕时,图像响应生成器模型529b_N5中包括的窗口的默认类型和/或颜色可以用作用于显示待机屏幕的信息。
根据实施例,当智能服务器520的TTS模块526将由自然语言响应生成器模块524生成的自然语言信息转换为语音信号时,可以使用TTS模型529b_N7。根据实施例,TTS模块526可以根据TTS模型529b_N7将自然语言信息转换成指定形式的语音信号。例如,TTS模块526可以根据TTS模型529b_N7中包括的每个合成单元(例如,音素、双音、三音等)的波形和参数(例如,音调、频谱、频带噪声、语速、语调变化)将自然语言信息转换为语音信号。换句话说,TTS模块526可以根据所选择的TTS模型529b_N7中包括的每个合成单元的波形和参数将相同的自然语言信息转换为不同的语音信号。根据实施例,TTS模型529b_N7可以包括关于每个合成单元和参数的多个波形的信息。例如,TTS模型529b_N7可以根据要合成的语音的特征,使用每个合成单元的多个波形和语音DB中包括的参数集(例如,用于合成信号的参数集)。
根据实施例,当智能服务器520的对话管理模块527管理对话流时,可以使用对话管理模型529b_N9。根据实施例,对话管理模块527可以根据对话管理模型529b_N9来管理对话流。例如,对话管理模块527可以根据对话管理模型529b_N9的指定上下文来确定响应。换句话说,对话管理模块527可以根据所选择的响应模型529b_N的对话管理模型529b_N9来确定对应于相同用户输入的不同响应。根据实施例,对话管理模型529b_N9可以包括关于指定上下文的信息。
在实施例中,可以使用响应模型529b_N中包括的计划器模型529b_N1、自然语言响应生成器模型529b_N3、图像响应生成器模型529b_N5、TTS模型529b_N7和/或对话管理模型529b_N9来确定响应主题。仅包括在响应模型529b_N中的模型的一部分可以用于确定主题。例如,其余模型可以照原样使用;例如,仅TTS模型529b_N7可以根据主题进行不同的应用。因此,集成智能系统500可以使用包括在所选择的响应模型529b_N中的模型来生成与用户输入相对应的响应。
图11是示出根据本公开的实施例的智能服务器确定响应模型的方法的流程图1200。
参考图11,智能服务器(例如,图4a的智能服务器520)可以基于唤醒关键词来确定响应模型。
根据实施例,在操作1210中,智能服务器(例如,图4a的ASR模块521)可以将包括唤醒关键词的语音输入转换为文本数据。例如,语音输入可以是用于注册唤醒关键词的用户输入。根据实施例,智能服务器520可以使用转换后的文本数据来注册唤醒关键词。
在实施例中,如图9b的用户输入1011所示,用户可以用文本输入唤醒关键词。当用文本输入唤醒关键词时,可以在不进行单独更改的情况下完成用户输入,并且在这种情况下,可以省略操作1210。
根据实施例,在操作1220中,智能服务器(例如,图4a的唤醒关键词细化模块528)可以细化所注册的唤醒关键词以生成用户终端510的唤醒名称。例如,唤醒名称可以用作与用户输入相对应的响应。例如,当输入的唤醒关键词被输入为“Hi Borong-yi”时,唤醒关键词细化模块可以移除被确定为感叹词的“Hi”,然后可以将“Borong-yi”设置为唤醒名称。
根据实施例,在操作1230中,智能服务器可以分析唤醒名称的含义。根据实施例,在操作1230a中,智能服务器可以分析唤醒名称的语素。换句话说,智能服务器可以使用语言特征来分析唤醒名称。根据实施例,在操作1230b中,智能服务器可以使用唤醒名称的语素来执行语义类别标签。例如,可以使用各种算法来执行语义类别标签,这些算法包括统计方法(例如,Ciaramita及其他人,“WordNet中未知名词的超感知标签”,EMNLP 2003)、基于规则的方法(例如,Curran及其他人,“使用语义相似性对未知名词进行超感知标签”,ACL2005)等。
根据实施例,在操作1240中,智能服务器可以计算所分析的唤醒名称的含义与响应模型的主题之间的语义距离。例如,智能服务器可以使用冗余标签的数量、语义网络的距离等来计算所分析的唤醒名称的含义与响应模型的主题之间的语义距离。例如,响应模型的主题可以包括语义类别标签。在下文中,表3示出了为响应模型的主题设置的语义类别标签(例如,15个含义)。
表3

根据实施例,在操作1250中,智能服务器可以选择与唤醒名称的语义距离很近的响应模型。根据实施例,智能服务器可以向用户提供包括多个响应模型的列表。例如,智能服务器可以向用户提供包括响应模型的列表,该列表的语义距离不大于指定值。对于另一个示例,智能服务器可以基于语义距离接近的顺序向用户提供包括直到指定等级的响应模型的列表。根据实施例,智能服务器可以接收用户输入以选择包括在列表中的多个响应模型中的至少一个。根据实施例,智能服务器可以根据用户输入来选择响应模型。
因此,智能服务器可以在集成智能系统500中设置所选择的响应模型。
例如,智能服务器可以向用户提供包括响应模型的列表,该列表的语义距离不小于指定值。对于另一个示例,智能服务器可以向用户提供包括上述指定的响应模型的列表。智能服务器可以接收用户输入以通过该列表选择至少一个响应模型。智能服务器可以选择与接收到的用户输入相对应的响应模型。
图12是示出根据本公开的实施例的集成智能系统500提供对语音输入的响应的方法的流程图1300。
参考图12,可以基于唤醒关键词在集成智能系统500中设置所选择的响应模型。当接收到包括唤醒关键词的语音输入时,集成智能系统500的用户终端510可以启用由用户终端510提供的语音识别服务或基于语音的智能助手服务。
根据实施例,在操作1311中,用户终端510的子处理器513可以接收包括唤醒关键词的语音输入。例如,用户终端510可以接收包括“金秘书”的语音输入。
根据实施例,在操作1313中,子处理器513可以识别包括在语音输入中的唤醒关键词。根据实施例,子处理器513可以将启用请求发送到用户终端510的主处理器515。此外,子处理器513可以将关于唤醒关键词的信息与启用请求一起发送。
根据实施例,在操作1321中,主处理器515可以再次识别包括唤醒关键词的语音输入。主处理器515再次识别语音输入的操作可以被选择性地应用。因为与子处理器513相比,主处理器515进行了大量计算,所以主处理器515可以准确地识别唤醒关键词。因此,用户终端510可以准确地识别用户的启用命令。根据实施例,在操作1323中,主处理器515可以将唤醒关键词信息发送到智能服务器520。
根据实施例,在操作1331中,智能服务器520可以从用户终端510接收关于唤醒关键词的信息,并且可以设置与接收到的唤醒关键词相对应的响应模型。
根据实施例,可以将操作1331替换为使用在设置先前的唤醒关键词的操作期间确定的响应模型的操作,而不使用由用户终端510发送的唤醒关键词信息。在这种情况下,由于不需要用户终端510发送的唤醒关键词信息,因此可以省略操作1323。根据实施例,在操作1341中,主处理器515可以待机接收包括用于执行指定功能的指令的语音输入。根据实施例,在操作1343中,主处理器515可以接收包括指令的用户输入。例如,主处理器515可以接收说“让我知道今天首尔的天气”的语音输入。根据实施例,在操作1345中,主处理器515可以将接收到的语音输入发送到智能服务器520。
根据实施例,在操作1351中,智能服务器520可以从用户终端510识别用于执行指定功能的语音输入,并且可以将识别出的结果发送到用户终端510。根据实施例,智能服务器520可以将语音输入转换为文本数据。例如,智能服务器520可以将“让我知道今天的首尔天气!”转换为文本数据。用户终端510可以向用户提供所识别的文本数据。
根据实施例,在操作1353中,智能服务器520可以使用所设置的响应模型来生成与接收到的语音输入相对应的响应。根据实施例,智能服务器520可以基于转换后的文本数据来确定意图和参数。例如,智能服务器520可以确定用于获得天气信息的意图(例如,意图=__WEATHER_MESSAGE_)以及包括日期(例如,param.weather.date=“2018.2.28”)或位置(例如,param.weather.location=“首尔”)。根据实施例,智能服务器520可以基于所确定的意图和所确定的参数来生成计划。例如,智能服务器250可以使用所设置的响应模型来生成计划。智能服务器520可以根据所生成的计划来生成结果。根据实施例,智能服务器520可以使用所设置的响应模型来生成包括所生成的结果的响应。例如,智能服务器520可以生成自然语言响应,说“金秘书告诉您天气。今天的天气是将在下午晚些时候下雨。”并且可以通过图4的TTS模块526将所生成的自然语言响应转换为语音信号(例如,冷静的人的语音)。以生成响应。根据实施例,在操作1355中,智能服务器520可以将所生成的响应发送到用户终端510。
根据实施例,在操作1361中,用户终端510的主处理器515可以输出接收到的响应。
图13是示出根据本公开的实施例的智能服务器的TTS模块的操作的视图。
参考图13,智能服务器(例如,图4a的智能服务器520)的TTS模块526可以使用各种算法来生成语音信号。TTS模块526可以使用单元选择合成算法来生成语音信号。
根据实施例,TTS模块526可以包括自然语言处理单元526_1和数字信号处理单元526_3。根据实施例,自然语言处理单元526_1可以基于文本数据确定合成所需的单元和属性。根据实施例,数字信号处理单元526_3可以基于所确定的属性来生成语音信号。数字信号处理单元526_3可以包括数字信号生成单元526_3a和语音数据库(DB)526_3b。根据实施例,数字信号生成单元526_3a可以改变合成语音信号所需的参数。例如,数字信号生成单元526_3a可以改变音调、语速(例如,语音长度)和语调(例如,频谱信息)中的至少一个。根据实施例,语音DB 526_3b可以存储从多个扬声器收集的语音数据库。在下文中,表4示出了存储在语音DB 526_3b中的语音信息。
表4

根据实施例,TTS模块526可以根据所选择的响应模型来改变合成语音信号所需的参数。例如,当执行时域音调同步交叠和相加(TD-PSOLA)操作时,TTS模块526的数字信号处理单元526_3可以改变合成语音信号所需的参数。根据实施例,TTS模块526可以根据改变的参数来生成语音信号。例如,数字信号处理单元526_3可以使用存储在语音DB 526_3b中的语音信息,根据改变后的参数来生成语音信号。
图14a和图14b是示出根据本公开的各种实施例的集成智能系统根据所选择的响应模型来提供服务的视图。
参考图14a和图14b,集成智能系统(例如,图4a的集成智能系统500)可以提供与根据所选择的语音模型接收到的语音输入相对应的响应。
根据实施例,集成智能系统500可以基于唤醒关键词来设置指定的响应模型。根据实施例,集成智能系统500可以存储关于多个响应模型的信息。根据实施例,响应模型的信息可以包括生成响应所需的信息。例如,响应模型的信息可以包括关于在生成响应消息时所应用的规则的信息,例如是否使用表情符号、句子长度、是否使用敬语、表达方式、是否使用流行语、TTS特征、推荐功能、专用功能等。下面的表3说明了有关基于“我的叔叔”的唤醒关键词所选择的礼貌响应模型(例如,助手响应模型)和基于“Borong-yi”的唤醒关键词所选择的角色响应模型(例如,可爱响应模型)的消息生成信息。
表5

根据实施例,TTS特征信息可以包括合成语音信号所需的参数信息。例如,TTS特征信息可以包括关于播放速度(例如,速度:+5)、音调(例如,音调偏差:-5)、频谱调整等的信息。
根据实施例,集成智能系统500可以提供使用基于唤醒关键词选择的响应模型生成的响应。
根据实施例,用户终端510可以在显示器上显示使用选择的响应模型的信息生成的响应。例如,用户终端510可以向用户提供基于“我的叔叔”的唤醒关键词确定的礼貌主题的响应。用户终端510可以通过包括深色背景屏幕的用户界面(UI)1410向用户提供包括简短和正式表达的响应1411(例如,当期望的菜单正确时,请按下支付按钮!)。对于另一个示例,用户终端510可以向用户提供基于“Borong-yi”的唤醒关键词确定的角色主题的响应。用户终端510可以通过包括亮色背景屏幕的用户界面(UI)1420向用户提供包括冗长而机智的表达的响应1421(例如,您喜欢吗?我会记得最近点过的饮料~)。
根据实施例,集成智能系统500可以基于所选择的响应模型来提供指定的服务。
根据实施例,集成智能系统500可以基于选择的响应模型来提供指定语音输入的结果(或响应)。例如,当将“我的叔叔”设置为唤醒关键词时,集成智能系统500可以响应于用户输入“我很无聊!”来提供包括“电影和节目信息”的结果。用户终端510可以通过包括深色背景屏幕的UI 1430来提供包括“电影和节目信息”的结果1431。例如,当将“Borong-yi”设置为唤醒关键词时,响应于用户输入“我很无聊!”,集成智能系统500可以提供包括“卡通或游戏信息”的结果。用户终端510可以通过包括亮色背景屏幕的用户界面(UI)1440来提供包括“卡通或游戏信息”的结果1441。
参考本公开的图1、图2、图3、图4a、图4b、图5a、图5b、图6a、图6b、图7、图8、图9a、图9b、图10a、图10b、图11、图12和图13而描述的集成智能系统500可以基于用户能够设置的唤醒关键词来选择响应模型,可以使用所选择的响应模型来生成语音响应,因此可以提供个性化语音助手服务。因此,可以增加语音助手服务的可用性以及诸如与人类交谈以及用户对用户终端的所有权之类的用户体验。
图15是示出根据本发明实施例的网络环境1500中的电子装置1501的框图。
参考图15,网络环境1500中的电子装置1501可经由第一网络1598(例如,短距离无线通信网络)与电子装置1502进行通信,或者经由第二网络1599(例如,长距离无线通信网络)与电子装置1504或服务器1508进行通信。根据实施例,电子装置1501可经由服务器1508与电子装置1504进行通信。根据实施例,电子装置1501可包括处理器1520、存储器1530、输入装置1550、声音输出装置1555、显示装置1560、音频模块1570、传感器模块1576、接口1577、触觉模块1579、相机模块1580、电力管理模块1588、电池1589、通信模块1590、用户识别模块(SIM)1596或天线模块1597。在一些实施例中,可从电子装置1501中省略所述部件中的至少一个(例如,显示装置1560或相机模块1580),或者可将一个或更多个其它部件添加到电子装置1501中。在一些实施例中,可将所述部件中的一些部件实现为单个集成电路。例如,可将传感器模块1576(例如,指纹传感器、虹膜传感器、或照度传感器)实现为嵌入在显示装置1560(例如,显示器)中。
处理器1520可运行例如软件(例如,程序1540)来控制电子装置1501的与处理器1520连接的至少一个其它部件(例如,硬件部件或软件部件),并可执行各种数据处理或计算。根据实施例,作为所述数据处理或计算的至少部分,处理器1520可将从另一部件(例如,传感器模块1576或通信模块1590)接收到的命令或数据加载到易失性存储器1532中,对存储在易失性存储器1532中的命令或数据进行处理,并将结果数据存储在非易失性存储器1534中。根据实施例,处理器1520可包括主处理器1521(例如,中央处理器(CPU)或应用处理器(AP))以及与主处理器1521在操作上独立的或者相结合的辅助处理器1523(例如,图形处理单元(GPU)、图像信号处理器(ISP)、传感器中枢处理器或通信处理器(CP))。另外地或者可选择地,辅助处理器1523可被适配为比主处理器1521耗电更少,或者被适配为具体用于指定的功能。可将辅助处理器1523实现为与主处理器1521分离,或者实现为主处理器1521的部分。
在主处理器1521处于未激活(例如,睡眠)状态时,辅助处理器1523可控制与电子装置1501(而非主处理器1521)的部件之中的至少一个部件(例如,显示装置1560、传感器模块1576或通信模块1590)相关的功能或状态中的至少一些,或者在主处理器1521处于启用状态(例如,运行应用)时,辅助处理器1523可与主处理器1521一起来控制与电子装置1501的部件之中的至少一个部件(例如,显示装置1560、传感器模块1576或通信模块1590)相关的功能或状态中的至少一些。根据实施例,可将辅助处理器1523(例如,图像信号处理器或通信处理器)实现为在功能上与辅助处理器1523相关的另一部件(例如,相机模块1580或通信模块1590)的部分。
存储器1530可存储由电子装置1501的至少一个部件(例如,处理器1520或传感器模块1576)使用的各种数据。所述各种数据可包括例如软件(例如,程序1540)以及针对与其相关的命令的输入数据或输出数据。存储器1530可包括易失性存储器1532或非易失性存储器1534。
可将程序1540作为软件存储在存储器1530中,并且程序1540可包括例如操作系统(OS)1542、中间件1544或应用1546。
输入装置1550可从电子装置1501的外部(例如,用户)接收将由电子装置1501的其它部件(例如,处理器1520)使用的命令或数据。输入装置1550可包括例如麦克风、鼠标、键盘或数字笔(例如,手写笔)。
声音输出装置1555可将声音信号输出到电子装置1501的外部。声音输出装置1555可包括例如扬声器或接收器。扬声器可用于诸如播放多媒体或播放唱片的通用目的,接收器可用于呼入呼叫。根据实施例,可将接收器实现为与扬声器分离,或实现为扬声器的部分。
显示装置1560可向电子装置1501的外部(例如,用户)视觉地提供信息。显示装置1560可包括例如显示器、全息装置或投影仪以及用于控制显示器、全息装置和投影仪中的相应一个的控制电路。根据实施例,显示装置1560可包括被适配为检测触摸的触摸电路或被适配为测量由触摸引起的力的强度的传感器电路(例如,压力传感器)。
音频模块1570可将声音转换为电信号,反之亦可。根据实施例,音频模块1570可经由输入装置1550获得声音,或者经由声音输出装置1555或与电子装置1501直接(例如,有线地)连接或无线连接的外部电子装置(例如,电子装置1502)的耳机输出声音。
传感器模块1576可检测电子装置1501的操作状态(例如,功率或温度)或电子装置1501外部的环境状态(例如,用户的状态),然后产生与检测到的状态相应的电信号或数据值。根据实施例,传感器模块1576可包括例如手势传感器、陀螺仪传感器、大气压力传感器、磁性传感器、加速度传感器、握持传感器、接近传感器、颜色传感器、红外(IR)传感器、生物特征传感器、温度传感器、湿度传感器或照度传感器。
接口1577可支持将用来使电子装置1501与外部电子装置(例如,电子装置1502)直接(例如,有线地)或无线连接的一个或更多个特定协议。根据实施例,接口1577可包括例如高清晰度多媒体接口(HDMI)、通用串行总线(USB)接口、安全数字(SD)卡接口或音频接口。
连接端1578可包括连接器,其中,电子装置1501可经由所述连接器与外部电子装置(例如,电子装置1502)物理连接。根据实施例,连接端1578可包括例如HDMI连接器、USB连接器、SD卡连接器或音频连接器(例如,耳机连接器)。
触觉模块1579可将电信号转换为可被用户经由他的触觉或动觉识别的机械刺激(例如,振动或运动)或电刺激。根据实施例,触觉模块1579可包括例如电机、压电元件或电刺激器。
相机模块1580可捕获静止图像或运动图像。根据实施例,相机模块1580可包括一个或更多个透镜、图像传感器、图像信号处理器或闪光灯。
电力管理模块1588可管理对电子装置1501的供电。根据实施例,可将电力管理模块1588实现为例如电力管理集成电路(PMIC)的至少部分。
电池1589可对电子装置1501的至少一个部件供电。根据实施例,电池1589可包括例如不可再充电的原电池、可再充电的蓄电池、或燃料电池。
通信模块1590可支持在电子装置1501与外部电子装置(例如,电子装置1502、电子装置1504或服务器1508)之间建立直接(例如,有线)通信信道或无线通信信道,并经由建立的通信信道执行通信。通信模块1590可包括能够与处理器1520(例如,应用处理器(AP))独立操作的一个或更多个通信处理器,并支持直接(例如,有线)通信或无线通信。根据实施例,通信模块1590可包括无线通信模块1592(例如,蜂窝通信模块、短距离无线通信模块或全球导航卫星系统(GNSS)通信模块)或有线通信模块1594(例如,局域网(LAN)通信模块或电力线通信(PLC)模块)。这些通信模块中的相应一个可经由第一网络1598(例如,短距离通信网络,诸如蓝牙、无线保真(Wi-Fi)直连或红外数据协会(IrDA))或第二网络1599(例如,长距离通信网络,诸如蜂窝网络、互联网、或计算机网络(例如,LAN或广域网(WAN)))与外部电子装置进行通信。可将这些各种类型的通信模块实现为单个部件(例如,单个芯片),或可将这些各种类型的通信模块实现为彼此分离的多个部件(例如,多个芯片)。无线通信模块1592可使用存储在用户识别模块1596中的用户信息(例如,国际移动用户识别码(IMSI))识别并验证通信网络(诸如第一网络1598或第二网络1599)中的电子装置1501。
天线模块1597可将信号或电力发送到电子装置1501的外部(例如,外部电子装置)或者从电子装置1501的外部(例如,外部电子装置)接收信号或电力。根据实施例,天线模块1597可包括天线,所述天线包括辐射元件,所述辐射元件由形成在基底(例如,PCB)中或形成在基底上的导电材料或导电图案构成。根据实施例,天线模块1597可包括多个天线。在这种情况下,可由例如通信模块1590(例如,无线通信模块1592)从所述多个天线中选择适合于在通信网络(诸如第一网络1598或第二网络1599)中使用的通信方案的至少一个天线。随后可经由所选择的至少一个天线在通信模块1590和外部电子装置之间发送或接收信号或电力。根据实施例,除了辐射元件之外的另外的组件(例如,射频集成电路(RFIC))可附加地形成为天线模块1597的一部分。
上述部件中的至少一些可经由外设间通信方案(例如,总线、通用输入输出(GPIO)、串行外设接口(SPI)或移动工业处理器接口(MIPI))相互连接并在它们之间通信地传送信号(例如,命令或数据)。
根据实施例,可经由与第二网络1599连接的服务器1508在电子装置1501和外部电子装置1504之间发送或接收命令或数据。电子装置1502和电子装置1504中的每一个可以是与电子装置1501相同类型的装置,或者是与电子装置1501不同类型的装置。根据实施例,将在电子装置1501运行的全部操作或一些操作可在外部电子装置1502、外部电子装置1504或服务器1508中的一个或更多个运行。例如,如果电子装置1501应该自动执行功能或服务或者应该响应于来自用户或另一装置的请求执行功能或服务,则电子装置1501可请求所述一个或更多个外部电子装置执行所述功能或服务中的至少部分,而不是运行所述功能或服务,或者电子装置1501除了运行所述功能或服务以外,还可请求所述一个或更多个外部电子装置执行所述功能或服务中的至少部分。接收到所述请求的所述一个或更多个外部电子装置可执行所述功能或服务中的所请求的所述至少部分,或者执行与所述请求相关的另外功能或另外服务,并将执行的结果传送到电子装置1501。电子装置1501可在对所述结果进行进一步处理的情况下或者在不对所述结果进行进一步处理的情况下将所述结果提供作为对所述请求的至少部分答复。为此,可使用例如云计算技术、分布式计算技术或客户机-服务器计算技术。
根据各种实施例的电子装置可以是各种类型的电子装置之一。电子装置可包括例如便携式通信装置(例如,智能电话)、计算机装置、便携式多媒体装置、便携式医疗装置、相机、可穿戴装置或家用电器。根据本公开的实施例,电子装置不限于以上所述的那些电子装置。
应该理解的是,本公开的各种实施例以及其中使用的术语并不意图将在此阐述的技术特征限制于具体实施例,而是包括针对相应实施例的各种改变、等同形式或替换形式。对于附图的描述,相似的参考标号可用来指代相似或相关的元件。将理解的是,与术语相应的单数形式的名词可包括一个或更多个事物,除非相关上下文另有明确指示。如这里所使用的,诸如“A或B”、“A和B中的至少一个”、“A或B中的至少一个”、“A、B或C”、“A、B和C中的至少一个”以及“A、B或C中的至少一个”的短语中的每一个短语可包括在与所述多个短语中的相应一个短语中一起列举出的项的任意一项或所有可能组合。如这里所使用的,诸如“第1”和“第2”或者“第一”和“第二”的术语可用于将相应部件与另一部件进行简单区分,并且不在其它方面(例如,重要性或顺序)限制所述部件。将理解的是,在使用了术语“可操作地”或“通信地”的情况下或者在不使用术语“可操作地”或“通信地”的情况下,如果一元件(例如,第一元件)被称为“与另一元件(例如,第二元件)结合”、“结合到另一元件(例如,第二元件)”、“与另一元件(例如,第二元件)连接”或“连接到另一元件(例如,第二元件)”,则意味着所述一元件可与所述另一元件直接(例如,有线地)连接、与所述另一元件无线连接、或经由第三元件与所述另一元件连接。
如这里所使用的,术语“模块”可包括以硬件、软件或固件实现的单元,并可与其他术语(例如,“逻辑”、“逻辑块”、“部分”或“电路”)可互换地使用。模块可以是被适配为执行一个或更多个功能的单个集成部件或者是该单个集成部件的最小单元或部分。例如,根据实施例,可以以专用集成电路(ASIC)的形式来实现模块。
可将在此阐述的各种实施例实现为包括存储在存储介质(例如,内部存储器1536或外部存储器1538)中的可由机器(例如,电子装置1501)读取的一个或更多个指令的软件(例如,程序1540)。例如,在处理器的控制下,所述机器(例如,电子装置1501)的处理器(例如,处理器1520)可在使用或无需使用一个或更多个其它部件的情况下调用存储在存储介质中的所述一个或更多个指令中的至少一个指令并运行所述至少一个指令。这使得所述机器能够操作用于根据所调用的至少一个指令执行至少一个功能。所述一个或更多个指令可包括由编译器产生的代码或能够由解释器运行的代码。可以以非暂时性存储介质的形式来提供机器可读存储介质。其中,术语“非暂时性”仅意味着所述存储介质是有形装置,并且不包括信号(例如,电磁波),但是该术语并不在数据被半永久性地存储在存储介质中与数据被临时存储在存储介质中之间进行区分。
根据实施例,可在计算机程序产品中包括和提供根据本公开的各种实施例的方法。计算机程序产品可作为产品在销售者和购买者之间进行交易。可以以机器可读存储介质(例如,紧凑盘只读存储器(CD-ROM))的形式来发布计算机程序产品,或者可经由应用商店(例如,Play StoreTM)在线发布(例如,下载或上传)计算机程序产品,或者可直接在两个用户装置(例如,智能电话)之间分发(例如,下载或上传)计算机程序产品。如果是在线发布的,则计算机程序产品中的至少部分可以是临时产生的,或者可将计算机程序产品中的至少部分至少临时存储在机器可读存储介质(诸如制造商的服务器、应用商店的服务器或转发服务器的存储器)中。
根据各种实施例,上述部件中的每个部件(例如,模块或程序)可包括单个实体或多个实体。根据各种实施例,可省略上述部件中的一个或更多个部件,或者可添加一个或更多个其它部件。可选择地或者另外地,可将多个部件(例如,模块或程序)集成为单个部件。在这种情况下,根据各种实施例,该集成部件可仍旧按照与所述多个部件中的相应一个部件在集成之前执行一个或更多个功能相同或相似的方式,执行所述多个部件中的每一个部件的所述一个或更多个功能。根据各种实施例,由模块、程序或另一部件所执行的操作可顺序地、并行地、重复地或以启发式方式来执行,或者所述操作中的一个或更多个操作可按照不同的顺序来运行或被省略,或者可添加一个或更多个其它操作。
虽然本公开已参考其各种实施例进行了展示和描述,但本领域技术人员应理解,在不脱离所附权利要求及其等效物所界定的本发明的精神和范围的情况下,可以对其形式和细节进行各种更改。
Claims (15)
1.一种系统,所述系统包括:
麦克风;
扬声器;
至少一个处理器,所述至少一个处理器可操作地连接到所述麦克风和所述扬声器;以及
存储器,所述存储器可操作地连接到所述至少一个处理器,
其中,所述存储器被配置为存储自然语言理解(NLU)模块、第一响应模型和第二响应模型,并且存储指令,所述指令在被执行时使所述至少一个处理器:
在第一操作中,
经由所述麦克风,接收包括用于调用基于语音的智能助手服务的第一唤醒关键词的第一语音输入,
基于所述第一语音输入,选择所述第一响应模型,
在所述第一语音输入之后,经由所述麦克风接收第二语音输入,
使用所述NLU模块来处理所述第二语音输入,以及
基于处理后的第二语音输入生成第一响应,该第一响应是使用所述第一响应模型生成的,并且
在第二操作中,
经由所述麦克风,接收包括与所述第一唤醒关键词不同的第二唤醒关键词的第三语音输入,
基于所述第三语音输入,选择所述第二响应模型,
在所述第三语音输入之后,经由所述麦克风接收第四语音输入,
使用所述NLU模块来处理所述第四语音输入,以及
基于处理后的第四语音输入生成第二响应,该第二响应是使用所述第二响应模型生成的。
2.根据权利要求1所述的系统,
其中,所述第一响应模型包括第一自然语言响应生成器模型和第一文本到语音(TTS)模型,以及
其中,所述第二响应模型包括与所述第一自然语言响应生成器模型不同的第二自然语言响应生成器模型和与所述第一TTS模型不同的第二TTS模型。
3.根据权利要求1所述的系统,所述系统还包括:
用户终端;以及
服务器,
其中,所述用户终端包括所述麦克风,以及
其中,所述服务器包括所述至少一个存储器和所述至少一个处理器。
4.根据权利要求3所述的系统,
其中,所述用户终端接收所述第一语音输入至所述第四语音输入,并向用户提供所述第一响应和所述第二响应,以及
其中,所述服务器基于所述第一语音输入和所述第三语音输入选择第一语音输入模型和第二语音输入模型,并生成所述第一响应和所述第二响应。
5.一种系统,所述系统包括:
麦克风;
扬声器;
至少一个处理器,所述至少一个处理器可操作地连接到所述麦克风和所述扬声器;以及
存储器,所述存储器可操作地连接到所述至少一个处理器,
其中,所述存储器被配置为:
存储自动语音识别(ASR)模块、自然语言理解(NLU)模块和多个响应模型,以及
存储指令,所述指令在被执行时使所述至少一个处理器:
经由所述麦克风接收第一语音输入,
利用所述ASR模块从所述第一语音输入中提取第一文本数据,以及
至少部分地基于所提取的第一文本数据来选择响应模型中的至少一个。
6.根据权利要求5所述的系统,其中,所述指令使所述至少一个处理器:
至少部分地基于所提取的第一文本数据向用户提供包括所述响应模型中的至少一个的列表;
接收用户输入以选择所述列表中的至少一个响应模型;以及
依据接收到的用户输入选择所述至少一个响应模型。
7.根据权利要求5所述的系统,
其中,所述指令使所述至少一个处理器生成语音识别模型,所述语音识别模型用于至少部分地基于所述第一语音输入来识别唤醒关键词,并且
其中,所述唤醒关键词用于调用基于语音的智能助手服务。
8.根据权利要求7所述的系统,其中,所述指令使所述至少一个处理器:
在接收到所述第一语音输入之后,经由所述麦克风接收第二语音输入;以及
至少部分地基于所述第一语音输入和所述第二语音输入来生成所述语音识别模型。
9.根据权利要求5所述的系统,其中,所述指令使所述至少一个处理器:
计算指示提取出的第一文本数据与所述多个响应模型之间的关系的值;以及
从所述多个响应模型中选择至少一个响应模型,其计算出的值不小于指定值。
10.根据权利要求5所述的系统,其中,所述指令使所述至少一个处理器执行以下操作:
基于代替所提取的第一文本数据的用户信息选择至少一个响应模型。
11.根据权利要求10所述的系统,其中,所述用户信息包括性别、年龄、居住地区或用户终端使用信息中的至少一个。
12.根据权利要求5所述的系统,其中,所述指令使所述至少一个处理器:
经由所述麦克风接收第二用户语音输入,
使用所述NLU模块处理所述第二语音输入,以及
基于处理后的第二语音输入生成第一响应,并且
其中,所述第一响应使用所选择的至少一个响应模型。
13.根据权利要求5所述的系统,其中,所述多个响应模型中的每一个包括文本到语音(TTS)模块。
14.一种处理语音输入的方法,所述方法包括:
接收第一语音输入;
使用自动语音识别(ASR)模块从所述第一语音输入中提取第一文本数据;以及
至少部分地基于所提取的第一文本数据来选择多个响应模型中的至少一个。
15.根据权利要求14所述的方法,还包括:
至少部分地基于所述第一语音输入,生成用于识别唤醒关键词的语音识别模型,
其中,所述唤醒关键词用于调用基于语音的智能助手服务。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2018-0143885 | 2018-11-20 | ||
| KR1020180143885A KR20200059054A (ko) | 2018-11-20 | 2018-11-20 | 사용자 발화를 처리하는 전자 장치, 및 그 전자 장치의 제어 방법 |
| PCT/KR2019/012387 WO2020105856A1 (en) | 2018-11-20 | 2019-09-24 | Electronic apparatus for processing user utterance and controlling method thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112840396A true CN112840396A (zh) | 2021-05-25 |
Family
ID=70726698
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980065264.6A Pending CN112840396A (zh) | 2018-11-20 | 2019-09-24 | 用于处理用户话语的电子装置及其控制方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11455989B2 (zh) |
| EP (1) | EP3824462B1 (zh) |
| KR (1) | KR20200059054A (zh) |
| CN (1) | CN112840396A (zh) |
| WO (1) | WO2020105856A1 (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110085222A (zh) * | 2013-08-05 | 2019-08-02 | 三星电子株式会社 | 用于支持语音对话服务的交互装置和方法 |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108600911B (zh) | 2018-03-30 | 2021-05-18 | 联想(北京)有限公司 | 一种输出方法及电子设备 |
| CN114365143A (zh) * | 2019-09-04 | 2022-04-15 | 布莱恩科技有限责任公司 | 用于在计算机屏幕上显示的实时变形界面 |
| WO2021146661A2 (en) * | 2020-01-17 | 2021-07-22 | Syntiant | Systems and methods for generating wake signals from known users |
| JP7359008B2 (ja) * | 2020-01-31 | 2023-10-11 | 富士フイルムビジネスイノベーション株式会社 | 情報処理装置及び情報処理プログラム |
| CN111640426A (zh) * | 2020-06-10 | 2020-09-08 | 北京百度网讯科技有限公司 | 用于输出信息的方法和装置 |
| EP4174850A4 (en) | 2020-09-09 | 2023-12-06 | Samsung Electronics Co., Ltd. | ELECTRONIC VOICE RECOGNITION DEVICE AND CONTROL METHOD THEREFOR |
| KR20220034488A (ko) * | 2020-09-11 | 2022-03-18 | 삼성전자주식회사 | 전자 장치 및 이의 제어 방법 |
| CN112291438B (zh) * | 2020-10-23 | 2021-10-01 | 北京蓦然认知科技有限公司 | 一种控制通话的方法及语音助手 |
| KR20220159170A (ko) * | 2021-05-25 | 2022-12-02 | 삼성전자주식회사 | 전자 장치 및 전자 장치의 동작 방법 |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140278443A1 (en) * | 2012-10-30 | 2014-09-18 | Motorola Mobility Llc | Voice Control User Interface with Progressive Command Engagement |
| US20150379993A1 (en) * | 2014-06-30 | 2015-12-31 | Samsung Electronics Co., Ltd. | Method of providing voice command and electronic device supporting the same |
| US20160267913A1 (en) * | 2015-03-13 | 2016-09-15 | Samsung Electronics Co., Ltd. | Speech recognition system and speech recognition method thereof |
| CN106940998A (zh) * | 2015-12-31 | 2017-07-11 | 阿里巴巴集团控股有限公司 | 一种设定操作的执行方法及装置 |
| US20170206900A1 (en) * | 2016-01-20 | 2017-07-20 | Samsung Electronics Co., Ltd. | Electronic device and voice command processing method thereof |
| CN107450879A (zh) * | 2016-05-30 | 2017-12-08 | 中兴通讯股份有限公司 | 终端操作方法及装置 |
| US20180108343A1 (en) * | 2016-10-14 | 2018-04-19 | Soundhound, Inc. | Virtual assistant configured by selection of wake-up phrase |
| US20180286401A1 (en) * | 2017-03-28 | 2018-10-04 | Samsung Electronics Co., Ltd. | Method for operating speech recognition service, electronic device and system supporting the same |
| CN108766446A (zh) * | 2018-04-18 | 2018-11-06 | 上海问之信息科技有限公司 | 声纹识别方法、装置、存储介质及音箱 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101393023B1 (ko) | 2007-03-29 | 2014-05-12 | 엘지전자 주식회사 | 이동통신단말기 및 그 음성인식 사용자 인터페이스 방법 |
| KR101160071B1 (ko) * | 2009-12-01 | 2012-06-26 | (주)에이치씨아이랩 | 다중인식 음성 인터페이스장치 및 그 방법 |
| US8924219B1 (en) * | 2011-09-30 | 2014-12-30 | Google Inc. | Multi hotword robust continuous voice command detection in mobile devices |
| US9142215B2 (en) * | 2012-06-15 | 2015-09-22 | Cypress Semiconductor Corporation | Power-efficient voice activation |
| US10381001B2 (en) * | 2012-10-30 | 2019-08-13 | Google Technology Holdings LLC | Voice control user interface during low-power mode |
| US20150302856A1 (en) * | 2014-04-17 | 2015-10-22 | Qualcomm Incorporated | Method and apparatus for performing function by speech input |
| US9508262B2 (en) * | 2015-03-26 | 2016-11-29 | Honeywell International Inc. | Systems and methods for voice enabled traffic prioritization |
| TWI525532B (zh) | 2015-03-30 | 2016-03-11 | Yu-Wei Chen | Set the name of the person to wake up the name for voice manipulation |
| CN105741838B (zh) * | 2016-01-20 | 2019-10-15 | 百度在线网络技术(北京)有限公司 | 语音唤醒方法及装置 |
| US10444934B2 (en) | 2016-03-18 | 2019-10-15 | Audioeye, Inc. | Modular systems and methods for selectively enabling cloud-based assistive technologies |
| CN106653022B (zh) * | 2016-12-29 | 2020-06-23 | 百度在线网络技术(北京)有限公司 | 基于人工智能的语音唤醒方法和装置 |
| US10885899B2 (en) * | 2018-10-09 | 2021-01-05 | Motorola Mobility Llc | Retraining voice model for trigger phrase using training data collected during usage |
-
2018
- 2018-11-20 KR KR1020180143885A patent/KR20200059054A/ko active Search and Examination
-
2019
- 2019-09-24 EP EP19887714.4A patent/EP3824462B1/en active Active
- 2019-09-24 US US16/580,622 patent/US11455989B2/en active Active
- 2019-09-24 WO PCT/KR2019/012387 patent/WO2020105856A1/en unknown
- 2019-09-24 CN CN201980065264.6A patent/CN112840396A/zh active Pending
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140278443A1 (en) * | 2012-10-30 | 2014-09-18 | Motorola Mobility Llc | Voice Control User Interface with Progressive Command Engagement |
| US20150379993A1 (en) * | 2014-06-30 | 2015-12-31 | Samsung Electronics Co., Ltd. | Method of providing voice command and electronic device supporting the same |
| US20160267913A1 (en) * | 2015-03-13 | 2016-09-15 | Samsung Electronics Co., Ltd. | Speech recognition system and speech recognition method thereof |
| CN106940998A (zh) * | 2015-12-31 | 2017-07-11 | 阿里巴巴集团控股有限公司 | 一种设定操作的执行方法及装置 |
| US20170206900A1 (en) * | 2016-01-20 | 2017-07-20 | Samsung Electronics Co., Ltd. | Electronic device and voice command processing method thereof |
| CN107450879A (zh) * | 2016-05-30 | 2017-12-08 | 中兴通讯股份有限公司 | 终端操作方法及装置 |
| US20180108343A1 (en) * | 2016-10-14 | 2018-04-19 | Soundhound, Inc. | Virtual assistant configured by selection of wake-up phrase |
| US20180286401A1 (en) * | 2017-03-28 | 2018-10-04 | Samsung Electronics Co., Ltd. | Method for operating speech recognition service, electronic device and system supporting the same |
| CN108766446A (zh) * | 2018-04-18 | 2018-11-06 | 上海问之信息科技有限公司 | 声纹识别方法、装置、存储介质及音箱 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110085222A (zh) * | 2013-08-05 | 2019-08-02 | 三星电子株式会社 | 用于支持语音对话服务的交互装置和方法 |
| CN110085222B (zh) * | 2013-08-05 | 2023-01-10 | 三星电子株式会社 | 用于支持语音对话服务的交互装置和方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US11455989B2 (en) | 2022-09-27 |
| EP3824462B1 (en) | 2024-03-13 |
| EP3824462C0 (en) | 2024-03-13 |
| EP3824462A1 (en) | 2021-05-26 |
| EP3824462A4 (en) | 2021-11-17 |
| US20200160863A1 (en) | 2020-05-21 |
| KR20200059054A (ko) | 2020-05-28 |
| WO2020105856A1 (en) | 2020-05-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11455989B2 (en) | Electronic apparatus for processing user utterance and controlling method thereof | |
| US10777193B2 (en) | System and device for selecting speech recognition model | |
| US20210335360A1 (en) | Electronic apparatus for processing user utterance and controlling method thereof | |
| US11120792B2 (en) | System for processing user utterance and controlling method thereof | |
| KR102545666B1 (ko) | 페르소나에 기반하여 문장을 제공하는 방법 및 이를 지원하는 전자 장치 | |
| US11151995B2 (en) | Electronic device for mapping an invoke word to a sequence of inputs for generating a personalized command | |
| EP4220628A1 (en) | Electronic device for supporting service for artificial intelligent agent that talks with user | |
| US20200125603A1 (en) | Electronic device and system which provides service based on voice recognition | |
| KR102426411B1 (ko) | 사용자 발화을 처리하는 전자 장치 및 시스템 | |
| CN113678119A (zh) | 用于生成自然语言响应的电子装置及其方法 | |
| US20220301542A1 (en) | Electronic device and personalized text-to-speech model generation method of the electronic device | |
| US20220130377A1 (en) | Electronic device and method for performing voice recognition thereof | |
| US11670294B2 (en) | Method of generating wakeup model and electronic device therefor | |
| US20240071363A1 (en) | Electronic device and method of controlling text-to-speech (tts) rate | |
| KR20200101103A (ko) | 사용자 입력을 처리하는 전자 장치 및 방법 | |
| US11961505B2 (en) | Electronic device and method for identifying language level of target | |
| US20230245647A1 (en) | Electronic device and method for creating customized language model | |
| US20240119960A1 (en) | Electronic device and method of recognizing voice | |
| US20230186031A1 (en) | Electronic device for providing voice recognition service using user data and operating method thereof | |
| US20230145198A1 (en) | Method for outputting text in artificial intelligence virtual assistant service and electronic device for supporting the same | |
| US20220189463A1 (en) | Electronic device and operation method thereof | |
| KR20240020137A (ko) | 전자 장치 및 음성 인식 방법 | |
| CN116635933A (zh) | 包括个性化文本到语音模块的电子装置及其控制方法 | |
| KR20240045927A (ko) | 음성인식 장치 및 음성인식 장치의 동작방법 | |
| KR20240026811A (ko) | 사용자 발화를 분석하기 위한 방법 및 이를 지원하는 전자 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |