CN112105721A - 内皮细胞因子及其方法 - Google Patents
内皮细胞因子及其方法 Download PDFInfo
- Publication number
- CN112105721A CN112105721A CN201980020598.1A CN201980020598A CN112105721A CN 112105721 A CN112105721 A CN 112105721A CN 201980020598 A CN201980020598 A CN 201980020598A CN 112105721 A CN112105721 A CN 112105721A
- Authority
- CN
- China
- Prior art keywords
- niche
- endothelial
- cell
- cells
- family
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 230000003511 endothelial effect Effects 0.000 title claims abstract description 150
- 238000000034 method Methods 0.000 title claims abstract description 147
- 108090000695 Cytokines Proteins 0.000 title description 2
- 102000004127 Cytokines Human genes 0.000 title description 2
- 210000004027 cell Anatomy 0.000 claims abstract description 201
- 102000040945 Transcription factor Human genes 0.000 claims abstract description 156
- 108091023040 Transcription factor Proteins 0.000 claims abstract description 156
- 210000002889 endothelial cell Anatomy 0.000 claims abstract description 99
- 239000013598 vector Substances 0.000 claims abstract description 86
- 239000000203 mixture Substances 0.000 claims abstract description 60
- 229940088597 hormone Drugs 0.000 claims abstract description 20
- 239000005556 hormone Substances 0.000 claims abstract description 20
- 108090000623 proteins and genes Proteins 0.000 claims description 164
- 101000813735 Homo sapiens ETS translocation variant 2 Proteins 0.000 claims description 92
- 102100039579 ETS translocation variant 2 Human genes 0.000 claims description 87
- 101000642523 Homo sapiens Transcription factor SOX-7 Proteins 0.000 claims description 80
- 102100036730 Transcription factor SOX-7 Human genes 0.000 claims description 80
- 101001105486 Homo sapiens Proteasome subunit alpha type-7 Proteins 0.000 claims description 79
- 102100021201 Proteasome subunit alpha type-7 Human genes 0.000 claims description 79
- 102100035178 Retinoic acid receptor RXR-alpha Human genes 0.000 claims description 72
- 101000876829 Homo sapiens Protein C-ets-1 Proteins 0.000 claims description 70
- 101001093899 Homo sapiens Retinoic acid receptor RXR-alpha Proteins 0.000 claims description 70
- 102100035251 Protein C-ets-1 Human genes 0.000 claims description 68
- PZNPLUBHRSSFHT-RRHRGVEJSA-N 1-hexadecanoyl-2-octadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[C@@H](COP([O-])(=O)OCC[N+](C)(C)C)COC(=O)CCCCCCCCCCCCCCC PZNPLUBHRSSFHT-RRHRGVEJSA-N 0.000 claims description 66
- 108020005497 Nuclear hormone receptor Proteins 0.000 claims description 65
- 150000007523 nucleic acids Chemical group 0.000 claims description 62
- 102000007399 Nuclear hormone receptor Human genes 0.000 claims description 61
- 210000001185 bone marrow Anatomy 0.000 claims description 40
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 31
- 230000002792 vascular Effects 0.000 claims description 31
- 241000282414 Homo sapiens Species 0.000 claims description 30
- 230000011132 hemopoiesis Effects 0.000 claims description 27
- 108091008640 NR2F Proteins 0.000 claims description 17
- 238000012258 culturing Methods 0.000 claims description 13
- 238000000338 in vitro Methods 0.000 claims description 13
- 239000003153 chemical reaction reagent Substances 0.000 claims description 12
- 102100030334 Friend leukemia integration 1 transcription factor Human genes 0.000 claims description 11
- 101001062996 Homo sapiens Friend leukemia integration 1 transcription factor Proteins 0.000 claims description 11
- 239000003937 drug carrier Substances 0.000 claims description 11
- BSFODEXXVBBYOC-UHFFFAOYSA-N 8-[4-(dimethylamino)butan-2-ylamino]quinolin-6-ol Chemical compound C1=CN=C2C(NC(CCN(C)C)C)=CC(O)=CC2=C1 BSFODEXXVBBYOC-UHFFFAOYSA-N 0.000 claims description 8
- 238000003501 co-culture Methods 0.000 claims description 8
- 101150109675 LGMN gene Proteins 0.000 claims description 5
- 239000003814 drug Substances 0.000 claims description 5
- 230000012010 growth Effects 0.000 claims description 5
- 238000002513 implantation Methods 0.000 claims description 5
- 101000652326 Homo sapiens Transcription factor SOX-18 Proteins 0.000 claims description 4
- 102100030249 Transcription factor SOX-18 Human genes 0.000 claims description 4
- 230000002708 enhancing effect Effects 0.000 claims description 4
- 210000000245 forearm Anatomy 0.000 claims description 4
- 239000000725 suspension Substances 0.000 claims description 4
- 101150071246 Hexb gene Proteins 0.000 claims description 3
- 101000893493 Homo sapiens Protein flightless-1 homolog Proteins 0.000 claims description 3
- 229940124597 therapeutic agent Drugs 0.000 claims description 3
- 101150105613 tll1 gene Proteins 0.000 claims description 3
- -1 kits Substances 0.000 abstract description 123
- 238000005516 engineering process Methods 0.000 abstract description 7
- 230000014509 gene expression Effects 0.000 description 146
- 239000005090 green fluorescent protein Substances 0.000 description 100
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 92
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 92
- 206010028537 myelofibrosis Diseases 0.000 description 67
- 102100028226 COUP transcription factor 2 Human genes 0.000 description 64
- 241000252212 Danio rerio Species 0.000 description 64
- 101000860860 Homo sapiens COUP transcription factor 2 Proteins 0.000 description 59
- 210000002257 embryonic structure Anatomy 0.000 description 58
- 108090000765 processed proteins & peptides Proteins 0.000 description 56
- 229920001184 polypeptide Polymers 0.000 description 53
- 102000004196 processed proteins & peptides Human genes 0.000 description 53
- 102000004169 proteins and genes Human genes 0.000 description 51
- 235000018102 proteins Nutrition 0.000 description 49
- 238000011282 treatment Methods 0.000 description 46
- 208000014767 Myeloproliferative disease Diseases 0.000 description 36
- 102000039446 nucleic acids Human genes 0.000 description 35
- 108020004707 nucleic acids Proteins 0.000 description 35
- 239000000523 sample Substances 0.000 description 35
- 108020004414 DNA Proteins 0.000 description 34
- 230000003394 haemopoietic effect Effects 0.000 description 31
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 27
- 201000007224 Myeloproliferative neoplasm Diseases 0.000 description 26
- 235000001014 amino acid Nutrition 0.000 description 25
- 150000001413 amino acids Chemical class 0.000 description 25
- 208000024891 symptom Diseases 0.000 description 24
- 101150015020 Nr2f2 gene Proteins 0.000 description 23
- 239000003623 enhancer Substances 0.000 description 22
- 239000007924 injection Substances 0.000 description 22
- 238000002347 injection Methods 0.000 description 22
- 230000002829 reductive effect Effects 0.000 description 22
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 21
- 101150031329 Ets1 gene Proteins 0.000 description 21
- 108700019146 Transgenes Proteins 0.000 description 20
- 238000003556 assay Methods 0.000 description 20
- 230000005014 ectopic expression Effects 0.000 description 20
- 230000027455 binding Effects 0.000 description 19
- 210000001519 tissue Anatomy 0.000 description 19
- 201000010099 disease Diseases 0.000 description 18
- 230000001105 regulatory effect Effects 0.000 description 18
- 238000006467 substitution reaction Methods 0.000 description 18
- 238000003559 RNA-seq method Methods 0.000 description 17
- 239000008280 blood Substances 0.000 description 15
- 239000003795 chemical substances by application Substances 0.000 description 15
- 210000000130 stem cell Anatomy 0.000 description 15
- 210000004369 blood Anatomy 0.000 description 14
- 230000000694 effects Effects 0.000 description 14
- 238000013518 transcription Methods 0.000 description 14
- 230000035897 transcription Effects 0.000 description 14
- 230000009261 transgenic effect Effects 0.000 description 14
- 241000269370 Xenopus <genus> Species 0.000 description 13
- 230000006870 function Effects 0.000 description 13
- 239000003550 marker Substances 0.000 description 13
- 239000000306 component Substances 0.000 description 12
- 230000000670 limiting effect Effects 0.000 description 12
- 239000013612 plasmid Substances 0.000 description 12
- 108010077544 Chromatin Proteins 0.000 description 11
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 11
- 241000699666 Mus <mouse, genus> Species 0.000 description 11
- 125000003275 alpha amino acid group Chemical group 0.000 description 11
- 210000003483 chromatin Anatomy 0.000 description 11
- 238000011161 development Methods 0.000 description 11
- 230000018109 developmental process Effects 0.000 description 11
- 239000012634 fragment Substances 0.000 description 11
- 238000001727 in vivo Methods 0.000 description 11
- 210000004185 liver Anatomy 0.000 description 11
- 239000000463 material Substances 0.000 description 11
- 230000035772 mutation Effects 0.000 description 11
- 230000002018 overexpression Effects 0.000 description 11
- 239000000126 substance Substances 0.000 description 11
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 10
- 241000124008 Mammalia Species 0.000 description 10
- 239000013604 expression vector Substances 0.000 description 10
- 230000001605 fetal effect Effects 0.000 description 10
- 108020004017 nuclear receptors Proteins 0.000 description 10
- 239000002773 nucleotide Substances 0.000 description 10
- 125000003729 nucleotide group Chemical group 0.000 description 10
- 101100540419 Danio rerio kdrl gene Proteins 0.000 description 9
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 241000282412 Homo Species 0.000 description 9
- 241001465754 Metazoa Species 0.000 description 9
- 238000004458 analytical method Methods 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 9
- 230000007423 decrease Effects 0.000 description 9
- 208000035475 disorder Diseases 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 9
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 9
- 210000003734 kidney Anatomy 0.000 description 9
- 239000008194 pharmaceutical composition Substances 0.000 description 9
- 239000000047 product Substances 0.000 description 9
- 230000010076 replication Effects 0.000 description 9
- 241000894007 species Species 0.000 description 9
- 210000002536 stromal cell Anatomy 0.000 description 9
- 230000001225 therapeutic effect Effects 0.000 description 9
- 238000002054 transplantation Methods 0.000 description 9
- 238000011144 upstream manufacturing Methods 0.000 description 9
- 108020004705 Codon Proteins 0.000 description 8
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 8
- 108010038912 Retinoid X Receptors Proteins 0.000 description 8
- 102000034527 Retinoid X Receptors Human genes 0.000 description 8
- 101100043972 Xenopus laevis sox18-b gene Proteins 0.000 description 8
- 238000003384 imaging method Methods 0.000 description 8
- 230000004807 localization Effects 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 101100310650 Mus musculus Sox18 gene Proteins 0.000 description 7
- 241000699670 Mus sp. Species 0.000 description 7
- 238000010171 animal model Methods 0.000 description 7
- 238000010367 cloning Methods 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- 210000000056 organ Anatomy 0.000 description 7
- 102000005962 receptors Human genes 0.000 description 7
- 108020003175 receptors Proteins 0.000 description 7
- 239000013603 viral vector Substances 0.000 description 7
- UHOVQNZJYSORNB-UHFFFAOYSA-N Benzene Chemical compound C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 description 6
- 108010020650 COUP Transcription Factor II Proteins 0.000 description 6
- 108091026890 Coding region Proteins 0.000 description 6
- 102000053602 DNA Human genes 0.000 description 6
- 102000040848 ETS family Human genes 0.000 description 6
- 108091071901 ETS family Proteins 0.000 description 6
- 101100043062 Mus musculus Sox7 gene Proteins 0.000 description 6
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 6
- 206010041660 Splenomegaly Diseases 0.000 description 6
- 101100043971 Xenopus laevis sox18-a gene Proteins 0.000 description 6
- 210000000601 blood cell Anatomy 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 229960004679 doxorubicin Drugs 0.000 description 6
- 230000006698 induction Effects 0.000 description 6
- 239000006201 parenteral dosage form Substances 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 238000003325 tomography Methods 0.000 description 6
- 238000013519 translation Methods 0.000 description 6
- 241000251468 Actinopterygii Species 0.000 description 5
- 101100202236 Danio rerio rxraa gene Proteins 0.000 description 5
- 208000002193 Pain Diseases 0.000 description 5
- 241000700159 Rattus Species 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 210000001772 blood platelet Anatomy 0.000 description 5
- 150000001875 compounds Chemical class 0.000 description 5
- 230000004069 differentiation Effects 0.000 description 5
- 235000019688 fish Nutrition 0.000 description 5
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 5
- 230000013632 homeostatic process Effects 0.000 description 5
- 238000007901 in situ hybridization Methods 0.000 description 5
- 230000005764 inhibitory process Effects 0.000 description 5
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 5
- 230000009467 reduction Effects 0.000 description 5
- 230000003612 virological effect Effects 0.000 description 5
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Natural products C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 description 4
- 230000004568 DNA-binding Effects 0.000 description 4
- 102100039578 ETS translocation variant 4 Human genes 0.000 description 4
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 4
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 4
- 101000813747 Homo sapiens ETS translocation variant 4 Proteins 0.000 description 4
- 206010061218 Inflammation Diseases 0.000 description 4
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 4
- 108091008747 NR2F3 Proteins 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- 102100034018 SAM pointed domain-containing Ets transcription factor Human genes 0.000 description 4
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 4
- 230000004913 activation Effects 0.000 description 4
- 239000004480 active ingredient Substances 0.000 description 4
- 239000003242 anti bacterial agent Substances 0.000 description 4
- 229940088710 antibiotic agent Drugs 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 230000017531 blood circulation Effects 0.000 description 4
- 210000004204 blood vessel Anatomy 0.000 description 4
- 229960004630 chlorambucil Drugs 0.000 description 4
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 4
- 230000004087 circulation Effects 0.000 description 4
- 238000003745 diagnosis Methods 0.000 description 4
- 210000002969 egg yolk Anatomy 0.000 description 4
- 235000008191 folinic acid Nutrition 0.000 description 4
- 239000011672 folinic acid Substances 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- 230000004054 inflammatory process Effects 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 229960001691 leucovorin Drugs 0.000 description 4
- 210000001161 mammalian embryo Anatomy 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 229960000485 methotrexate Drugs 0.000 description 4
- 229960001756 oxaliplatin Drugs 0.000 description 4
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 230000007115 recruitment Effects 0.000 description 4
- 230000008672 reprogramming Effects 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 101150108218 sox7 gene Proteins 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 230000002103 transcriptional effect Effects 0.000 description 4
- 238000011269 treatment regimen Methods 0.000 description 4
- 210000005166 vasculature Anatomy 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- 101710188750 COUP transcription factor 2 Proteins 0.000 description 3
- 108010092160 Dactinomycin Proteins 0.000 description 3
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 3
- MPJKWIXIYCLVCU-UHFFFAOYSA-N Folinic acid Natural products NC1=NC2=C(N(C=O)C(CNc3ccc(cc3)C(=O)NC(CCC(=O)O)CC(=O)O)CN2)C(=O)N1 MPJKWIXIYCLVCU-UHFFFAOYSA-N 0.000 description 3
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 3
- 208000032843 Hemorrhage Diseases 0.000 description 3
- 101000711466 Homo sapiens SAM pointed domain-containing Ets transcription factor Proteins 0.000 description 3
- 229930012538 Paclitaxel Natural products 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- 241000288906 Primates Species 0.000 description 3
- KDCGOANMDULRCW-UHFFFAOYSA-N Purine Natural products N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 3
- 108700032475 Sex-Determining Region Y Proteins 0.000 description 3
- 102100022978 Sex-determining region Y protein Human genes 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 3
- 229930183665 actinomycin Natural products 0.000 description 3
- 239000012190 activator Substances 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- BBDAGFIXKZCXAH-CCXZUQQUSA-N ancitabine Chemical compound N=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 BBDAGFIXKZCXAH-CCXZUQQUSA-N 0.000 description 3
- 229950000242 ancitabine Drugs 0.000 description 3
- 208000007502 anemia Diseases 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- 230000033228 biological regulation Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 208000034158 bleeding Diseases 0.000 description 3
- 230000000740 bleeding effect Effects 0.000 description 3
- 210000000988 bone and bone Anatomy 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 230000001684 chronic effect Effects 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 239000002552 dosage form Substances 0.000 description 3
- FSIRXIHZBIXHKT-MHTVFEQDSA-N edatrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CC(CC)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FSIRXIHZBIXHKT-MHTVFEQDSA-N 0.000 description 3
- 229950006700 edatrexate Drugs 0.000 description 3
- 235000019441 ethanol Nutrition 0.000 description 3
- 229960002949 fluorouracil Drugs 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 102000048856 human ETV2 Human genes 0.000 description 3
- 210000005260 human cell Anatomy 0.000 description 3
- 229960001101 ifosfamide Drugs 0.000 description 3
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 3
- 230000010354 integration Effects 0.000 description 3
- 229960004768 irinotecan Drugs 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 210000002540 macrophage Anatomy 0.000 description 3
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 3
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 229960001592 paclitaxel Drugs 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 230000005855 radiation Effects 0.000 description 3
- 238000001959 radiotherapy Methods 0.000 description 3
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- HXCHCVDVKSCDHU-PJKCJEBCSA-N s-[(2r,3s,4s,6s)-6-[[(2r,3s,4s,5r,6r)-5-[(2s,4s,5s)-5-(ethylamino)-4-methoxyoxan-2-yl]oxy-4-hydroxy-6-[[(2s,5z,9r,13e)-9-hydroxy-12-(methoxycarbonylamino)-13-[2-(methyltrisulfanyl)ethylidene]-11-oxo-2-bicyclo[7.3.1]trideca-1(12),5-dien-3,7-diynyl]oxy]-2-m Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-PJKCJEBCSA-N 0.000 description 3
- 230000009870 specific binding Effects 0.000 description 3
- 210000000952 spleen Anatomy 0.000 description 3
- 150000003431 steroids Chemical class 0.000 description 3
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 3
- 238000002560 therapeutic procedure Methods 0.000 description 3
- 230000001052 transient effect Effects 0.000 description 3
- 229940072040 tricaine Drugs 0.000 description 3
- FQZJYWMRQDKBQN-UHFFFAOYSA-N tricaine methanesulfonate Chemical compound CS([O-])(=O)=O.CCOC(=O)C1=CC=CC([NH3+])=C1 FQZJYWMRQDKBQN-UHFFFAOYSA-N 0.000 description 3
- 210000003462 vein Anatomy 0.000 description 3
- CGMTUJFWROPELF-YPAAEMCBSA-N (3E,5S)-5-[(2S)-butan-2-yl]-3-(1-hydroxyethylidene)pyrrolidine-2,4-dione Chemical compound CC[C@H](C)[C@@H]1NC(=O)\C(=C(/C)O)C1=O CGMTUJFWROPELF-YPAAEMCBSA-N 0.000 description 2
- XRBSKUSTLXISAB-XVVDYKMHSA-N (5r,6r,7r,8r)-8-hydroxy-7-(hydroxymethyl)-5-(3,4,5-trimethoxyphenyl)-5,6,7,8-tetrahydrobenzo[f][1,3]benzodioxole-6-carboxylic acid Chemical compound COC1=C(OC)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@H](O)[C@@H](CO)[C@@H]2C(O)=O)=C1 XRBSKUSTLXISAB-XVVDYKMHSA-N 0.000 description 2
- RCFNNLSZHVHCEK-IMHLAKCZSA-N (7s,9s)-7-(4-amino-6-methyloxan-2-yl)oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound [Cl-].O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)C1CC([NH3+])CC(C)O1 RCFNNLSZHVHCEK-IMHLAKCZSA-N 0.000 description 2
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 2
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 2
- FONKWHRXTPJODV-DNQXCXABSA-N 1,3-bis[2-[(8s)-8-(chloromethyl)-4-hydroxy-1-methyl-7,8-dihydro-3h-pyrrolo[3,2-e]indole-6-carbonyl]-1h-indol-5-yl]urea Chemical compound C1([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C4=CC(O)=C5NC=C(C5=C4[C@H](CCl)C3)C)=C2C=C(O)C2=C1C(C)=CN2 FONKWHRXTPJODV-DNQXCXABSA-N 0.000 description 2
- AZQWKYJCGOJGHM-UHFFFAOYSA-N 1,4-benzoquinone Chemical compound O=C1C=CC(=O)C=C1 AZQWKYJCGOJGHM-UHFFFAOYSA-N 0.000 description 2
- BTOTXLJHDSNXMW-POYBYMJQSA-N 2,3-dideoxyuridine Chemical compound O1[C@H](CO)CC[C@@H]1N1C(=O)NC(=O)C=C1 BTOTXLJHDSNXMW-POYBYMJQSA-N 0.000 description 2
- LGZKGOGODCLQHG-CYBMUJFWSA-N 5-[(2r)-2-hydroxy-2-(3,4,5-trimethoxyphenyl)ethyl]-2-methoxyphenol Chemical compound C1=C(O)C(OC)=CC=C1C[C@@H](O)C1=CC(OC)=C(OC)C(OC)=C1 LGZKGOGODCLQHG-CYBMUJFWSA-N 0.000 description 2
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- CEIZFXOZIQNICU-UHFFFAOYSA-N Alternaria alternata Crofton-weed toxin Natural products CCC(C)C1NC(=O)C(C(C)=O)=C1O CEIZFXOZIQNICU-UHFFFAOYSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000271566 Aves Species 0.000 description 2
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 2
- 241000283726 Bison Species 0.000 description 2
- 206010006002 Bone pain Diseases 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 244000056139 Brassica cretica Species 0.000 description 2
- 235000003351 Brassica cretica Nutrition 0.000 description 2
- 235000003343 Brassica rupestris Nutrition 0.000 description 2
- MBABCNBNDNGODA-LTGLSHGVSA-N Bullatacin Natural products O=C1C(C[C@H](O)CCCCCCCCCC[C@@H](O)[C@@H]2O[C@@H]([C@@H]3O[C@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)=C[C@H](C)O1 MBABCNBNDNGODA-LTGLSHGVSA-N 0.000 description 2
- 108010065376 COUP Transcription Factor I Proteins 0.000 description 2
- 102100028228 COUP transcription factor 1 Human genes 0.000 description 2
- 101100227322 Caenorhabditis elegans fli-1 gene Proteins 0.000 description 2
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 2
- 241000282421 Canidae Species 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- AOCCBINRVIKJHY-UHFFFAOYSA-N Carmofur Chemical compound CCCCCCNC(=O)N1C=C(F)C(=O)NC1=O AOCCBINRVIKJHY-UHFFFAOYSA-N 0.000 description 2
- MKQWTWSXVILIKJ-LXGUWJNJSA-N Chlorozotocin Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](C=O)NC(=O)N(N=O)CCCl MKQWTWSXVILIKJ-LXGUWJNJSA-N 0.000 description 2
- 108010060434 Co-Repressor Proteins Proteins 0.000 description 2
- 102000008169 Co-Repressor Proteins Human genes 0.000 description 2
- 102000002664 Core Binding Factor Alpha 2 Subunit Human genes 0.000 description 2
- 108010043471 Core Binding Factor Alpha 2 Subunit Proteins 0.000 description 2
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 102100023794 ETS domain-containing protein Elk-3 Human genes 0.000 description 2
- 102100023792 ETS domain-containing protein Elk-4 Human genes 0.000 description 2
- 102100035078 ETS-related transcription factor Elf-2 Human genes 0.000 description 2
- 102100035079 ETS-related transcription factor Elf-3 Human genes 0.000 description 2
- 102100039244 ETS-related transcription factor Elf-5 Human genes 0.000 description 2
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 2
- SAMRUMKYXPVKPA-VFKOLLTISA-N Enocitabine Chemical compound O=C1N=C(NC(=O)CCCCCCCCCCCCCCCCCCCCC)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 SAMRUMKYXPVKPA-VFKOLLTISA-N 0.000 description 2
- OBMLHUPNRURLOK-XGRAFVIBSA-N Epitiostanol Chemical compound C1[C@@H]2S[C@@H]2C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 OBMLHUPNRURLOK-XGRAFVIBSA-N 0.000 description 2
- 208000032027 Essential Thrombocythemia Diseases 0.000 description 2
- JOYRKODLDBILNP-UHFFFAOYSA-N Ethyl urethane Chemical compound CCOC(N)=O JOYRKODLDBILNP-UHFFFAOYSA-N 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 101000609762 Gallus gallus Ovalbumin Proteins 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 101001048716 Homo sapiens ETS domain-containing protein Elk-4 Proteins 0.000 description 2
- 101000877377 Homo sapiens ETS-related transcription factor Elf-2 Proteins 0.000 description 2
- 101000877379 Homo sapiens ETS-related transcription factor Elf-3 Proteins 0.000 description 2
- 101001092930 Homo sapiens Prosaposin Proteins 0.000 description 2
- 101001057127 Homo sapiens Transcription factor ETV7 Proteins 0.000 description 2
- 206010021079 Hypopnoea Diseases 0.000 description 2
- MPBVHIBUJCELCL-UHFFFAOYSA-N Ibandronate Chemical compound CCCCCN(C)CCC(O)(P(O)(O)=O)P(O)(O)=O MPBVHIBUJCELCL-UHFFFAOYSA-N 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- 239000002136 L01XE07 - Lapatinib Substances 0.000 description 2
- 108010052014 Liberase Proteins 0.000 description 2
- 241000282553 Macaca Species 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 101100281205 Mus musculus Fli1 gene Proteins 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- KGTDRFCXGRULNK-UHFFFAOYSA-N Nogalamycin Natural products COC1C(OC)(C)C(OC)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=C4C5(C)OC(C(C(C5O)N(C)C)O)OC4=C3C3=O)=C3C=C2C(C(=O)OC)C(C)(O)C1 KGTDRFCXGRULNK-UHFFFAOYSA-N 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 235000019483 Peanut oil Nutrition 0.000 description 2
- 108090000029 Peroxisome Proliferator-Activated Receptors Proteins 0.000 description 2
- 102000003728 Peroxisome Proliferator-Activated Receptors Human genes 0.000 description 2
- KMSKQZKKOZQFFG-HSUXVGOQSA-N Pirarubicin Chemical compound O([C@H]1[C@@H](N)C[C@@H](O[C@H]1C)O[C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1CCCCO1 KMSKQZKKOZQFFG-HSUXVGOQSA-N 0.000 description 2
- HFVNWDWLWUCIHC-GUPDPFMOSA-N Prednimustine Chemical compound O=C([C@@]1(O)CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)[C@@H](O)C[C@@]21C)COC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 HFVNWDWLWUCIHC-GUPDPFMOSA-N 0.000 description 2
- 101710204015 Protein C-ets-1 Proteins 0.000 description 2
- 108010018070 Proto-Oncogene Proteins c-ets Proteins 0.000 description 2
- 102000004053 Proto-Oncogene Proteins c-ets Human genes 0.000 description 2
- 101710172556 Retinoic acid receptor RXR-alpha Proteins 0.000 description 2
- 108010066463 Retinoid X Receptor alpha Proteins 0.000 description 2
- 239000008156 Ringer's lactate solution Substances 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- CGMTUJFWROPELF-UHFFFAOYSA-N Tenuazonic acid Natural products CCC(C)C1NC(=O)C(=C(C)/O)C1=O CGMTUJFWROPELF-UHFFFAOYSA-N 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- 102100027263 Transcription factor ETV7 Human genes 0.000 description 2
- 102100027654 Transcription factor PU.1 Human genes 0.000 description 2
- 101710176385 Transcription factor SOX-18 Proteins 0.000 description 2
- 101710198024 Transcription factor Sox-7 Proteins 0.000 description 2
- 102100029983 Transcriptional regulator ERG Human genes 0.000 description 2
- 102100033444 Tyrosine-protein kinase JAK2 Human genes 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 229930188522 aclacinomycin Natural products 0.000 description 2
- USZYSDMBJDPRIF-SVEJIMAYSA-N aclacinomycin A Chemical compound O([C@H]1[C@@H](O)C[C@@H](O[C@H]1C)O[C@H]1[C@H](C[C@@H](O[C@H]1C)O[C@H]1C[C@]([C@@H](C2=CC=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C21)C(=O)OC)(O)CC)N(C)C)[C@H]1CCC(=O)[C@H](C)O1 USZYSDMBJDPRIF-SVEJIMAYSA-N 0.000 description 2
- 229960004176 aclarubicin Drugs 0.000 description 2
- 208000017733 acquired polycythemia vera Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- BYRVKDUQDLJUBX-JJCDCTGGSA-N adozelesin Chemical compound C1=CC=C2OC(C(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C[C@H]4C[C@]44C5=C(C(C=C43)=O)NC=C5C)=CC2=C1 BYRVKDUQDLJUBX-JJCDCTGGSA-N 0.000 description 2
- 229950004955 adozelesin Drugs 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- FPIPGXGPPPQFEQ-OVSJKPMPSA-N all-trans-retinol Chemical compound OC\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C FPIPGXGPPPQFEQ-OVSJKPMPSA-N 0.000 description 2
- 229960000473 altretamine Drugs 0.000 description 2
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 2
- 229960003437 aminoglutethimide Drugs 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 229960001220 amsacrine Drugs 0.000 description 2
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 2
- 238000000137 annealing Methods 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- SESFRYSPDFLNCH-UHFFFAOYSA-N benzyl benzoate Chemical compound C=1C=CC=CC=1C(=O)OCC1=CC=CC=C1 SESFRYSPDFLNCH-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 239000000090 biomarker Substances 0.000 description 2
- QKSKPIVNLNLAAV-UHFFFAOYSA-N bis(2-chloroethyl) sulfide Chemical compound ClCCSCCCl QKSKPIVNLNLAAV-UHFFFAOYSA-N 0.000 description 2
- 229950006844 bizelesin Drugs 0.000 description 2
- 238000004820 blood count Methods 0.000 description 2
- 238000010322 bone marrow transplantation Methods 0.000 description 2
- MBABCNBNDNGODA-LUVUIASKSA-N bullatacin Chemical compound O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-LUVUIASKSA-N 0.000 description 2
- 229930195731 calicheamicin Natural products 0.000 description 2
- 229940127093 camptothecin Drugs 0.000 description 2
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 2
- 229960004562 carboplatin Drugs 0.000 description 2
- 229960003261 carmofur Drugs 0.000 description 2
- 230000004663 cell proliferation Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 229960001480 chlorozotocin Drugs 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 238000002648 combination therapy Methods 0.000 description 2
- LGZKGOGODCLQHG-UHFFFAOYSA-N combretastatin Natural products C1=C(O)C(OC)=CC=C1CC(O)C1=CC(OC)=C(OC)C(OC)=C1 LGZKGOGODCLQHG-UHFFFAOYSA-N 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 235000005687 corn oil Nutrition 0.000 description 2
- 239000002285 corn oil Substances 0.000 description 2
- 235000012343 cottonseed oil Nutrition 0.000 description 2
- 239000002385 cottonseed oil Substances 0.000 description 2
- PSNOPSMXOBPNNV-VVCTWANISA-N cryptophycin 1 Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H]2[C@H](O2)C=2C=CC=CC=2)C/C=C/C(=O)N1 PSNOPSMXOBPNNV-VVCTWANISA-N 0.000 description 2
- PSNOPSMXOBPNNV-UHFFFAOYSA-N cryptophycin-327 Natural products C1=C(Cl)C(OC)=CC=C1CC1C(=O)NCC(C)C(=O)OC(CC(C)C)C(=O)OC(C(C)C2C(O2)C=2C=CC=CC=2)CC=CC(=O)N1 PSNOPSMXOBPNNV-UHFFFAOYSA-N 0.000 description 2
- 229960004397 cyclophosphamide Drugs 0.000 description 2
- 238000002716 delivery method Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 238000002224 dissection Methods 0.000 description 2
- 230000005593 dissociations Effects 0.000 description 2
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 2
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 2
- 229930188854 dolastatin Natural products 0.000 description 2
- ZWAOHEXOSAUJHY-ZIYNGMLESA-N doxifluridine Chemical compound O[C@@H]1[C@H](O)[C@@H](C)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ZWAOHEXOSAUJHY-ZIYNGMLESA-N 0.000 description 2
- 229950005454 doxifluridine Drugs 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 238000002337 electrophoretic mobility shift assay Methods 0.000 description 2
- XOPYFXBZMVTEJF-UHFFFAOYSA-N eleutherobin Natural products C1=CC2(OC)OC1(C)C(OC(=O)C=CC=1N=CN(C)C=1)CC(C(=CCC1C(C)C)C)C1C=C2COC1OCC(O)C(O)C1OC(C)=O XOPYFXBZMVTEJF-UHFFFAOYSA-N 0.000 description 2
- XOPYFXBZMVTEJF-PDACKIITSA-N eleutherobin Chemical compound C(/[C@H]1[C@H](C(=CC[C@@H]1C(C)C)C)C[C@@H]([C@@]1(C)O[C@@]2(C=C1)OC)OC(=O)\C=C\C=1N=CN(C)C=1)=C2\CO[C@@H]1OC[C@@H](O)[C@@H](O)[C@@H]1OC(C)=O XOPYFXBZMVTEJF-PDACKIITSA-N 0.000 description 2
- 230000013020 embryo development Effects 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- JOZGNYDSEBIJDH-UHFFFAOYSA-N eniluracil Chemical compound O=C1NC=C(C#C)C(=O)N1 JOZGNYDSEBIJDH-UHFFFAOYSA-N 0.000 description 2
- 229950010213 eniluracil Drugs 0.000 description 2
- 229950011487 enocitabine Drugs 0.000 description 2
- 238000010201 enrichment analysis Methods 0.000 description 2
- 229930013356 epothilone Natural products 0.000 description 2
- 150000003883 epothilone derivatives Chemical class 0.000 description 2
- 210000003743 erythrocyte Anatomy 0.000 description 2
- ITSGNOIFAJAQHJ-BMFNZSJVSA-N esorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)C[C@H](C)O1 ITSGNOIFAJAQHJ-BMFNZSJVSA-N 0.000 description 2
- 229950002017 esorubicin Drugs 0.000 description 2
- 229960001842 estramustine Drugs 0.000 description 2
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 2
- 102000015694 estrogen receptors Human genes 0.000 description 2
- 108010038795 estrogen receptors Proteins 0.000 description 2
- MMXKVMNBHPAILY-UHFFFAOYSA-N ethyl laurate Chemical compound CCCCCCCCCCCC(=O)OCC MMXKVMNBHPAILY-UHFFFAOYSA-N 0.000 description 2
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 2
- 229940093471 ethyl oleate Drugs 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 238000010195 expression analysis Methods 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- CHPZKNULDCNCBW-UHFFFAOYSA-N gallium nitrate Chemical compound [Ga+3].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O CHPZKNULDCNCBW-UHFFFAOYSA-N 0.000 description 2
- 229960005277 gemcitabine Drugs 0.000 description 2
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- 210000002360 granulocyte-macrophage progenitor cell Anatomy 0.000 description 2
- 201000005787 hematologic cancer Diseases 0.000 description 2
- 208000014951 hematologic disease Diseases 0.000 description 2
- 230000002489 hematologic effect Effects 0.000 description 2
- 210000000777 hematopoietic system Anatomy 0.000 description 2
- 208000018706 hematopoietic system disease Diseases 0.000 description 2
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 229940015872 ibandronate Drugs 0.000 description 2
- 230000001771 impaired effect Effects 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 239000003317 industrial substance Substances 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 239000006193 liquid solution Substances 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 229960003538 lonidamine Drugs 0.000 description 2
- WDRYRZXSPDWGEB-UHFFFAOYSA-N lonidamine Chemical compound C12=CC=CC=C2C(C(=O)O)=NN1CC1=CC=C(Cl)C=C1Cl WDRYRZXSPDWGEB-UHFFFAOYSA-N 0.000 description 2
- YROQEQPFUCPDCP-UHFFFAOYSA-N losoxantrone Chemical compound OCCNCCN1N=C2C3=CC=CC(O)=C3C(=O)C3=C2C1=CC=C3NCCNCCO YROQEQPFUCPDCP-UHFFFAOYSA-N 0.000 description 2
- 229950008745 losoxantrone Drugs 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- 229920000609 methyl cellulose Polymers 0.000 description 2
- 239000001923 methylcellulose Substances 0.000 description 2
- 235000010981 methylcellulose Nutrition 0.000 description 2
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- FOYWNSCCNCUEPU-UHFFFAOYSA-N mopidamol Chemical compound C12=NC(N(CCO)CCO)=NC=C2N=C(N(CCO)CCO)N=C1N1CCCCC1 FOYWNSCCNCUEPU-UHFFFAOYSA-N 0.000 description 2
- 229950010718 mopidamol Drugs 0.000 description 2
- BQJCRHHNABKAKU-KBQPJGBKSA-N morphine Chemical compound O([C@H]1[C@H](C=C[C@H]23)O)C4=C5[C@@]12CCN(C)[C@@H]3CC5=CC=C4O BQJCRHHNABKAKU-KBQPJGBKSA-N 0.000 description 2
- 235000010460 mustard Nutrition 0.000 description 2
- 229960000951 mycophenolic acid Drugs 0.000 description 2
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 2
- 239000002105 nanoparticle Substances 0.000 description 2
- 229960001420 nimustine Drugs 0.000 description 2
- VFEDRRNHLBGPNN-UHFFFAOYSA-N nimustine Chemical compound CC1=NC=C(CNC(=O)N(CCCl)N=O)C(N)=N1 VFEDRRNHLBGPNN-UHFFFAOYSA-N 0.000 description 2
- KGTDRFCXGRULNK-JYOBTZKQSA-N nogalamycin Chemical compound CO[C@@H]1[C@@](OC)(C)[C@@H](OC)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=C4[C@@]5(C)O[C@H]([C@H]([C@@H]([C@H]5O)N(C)C)O)OC4=C3C3=O)=C3C=C2[C@@H](C(=O)OC)[C@@](C)(O)C1 KGTDRFCXGRULNK-JYOBTZKQSA-N 0.000 description 2
- 229950009266 nogalamycin Drugs 0.000 description 2
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 102000027419 nuclear receptor subfamilies Human genes 0.000 description 2
- 108091008607 nuclear receptor subfamilies Proteins 0.000 description 2
- 102000027507 nuclear receptors type II Human genes 0.000 description 2
- 108091008686 nuclear receptors type II Proteins 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 239000000312 peanut oil Substances 0.000 description 2
- 229960002340 pentostatin Drugs 0.000 description 2
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 230000037081 physical activity Effects 0.000 description 2
- 229960001221 pirarubicin Drugs 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 208000037244 polycythemia vera Diseases 0.000 description 2
- 239000008389 polyethoxylated castor oil Substances 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 210000003240 portal vein Anatomy 0.000 description 2
- 229960004694 prednimustine Drugs 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 208000003476 primary myelofibrosis Diseases 0.000 description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 2
- 229960000624 procarbazine Drugs 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- VYXXMAGSIYIYGD-NWAYQTQBSA-N propan-2-yl 2-[[[(2R)-1-(6-aminopurin-9-yl)propan-2-yl]oxymethyl-(pyrimidine-4-carbonylamino)phosphoryl]amino]-2-methylpropanoate Chemical compound CC(C)OC(=O)C(C)(C)NP(=O)(CO[C@H](C)Cn1cnc2c(N)ncnc12)NC(=O)c1ccncn1 VYXXMAGSIYIYGD-NWAYQTQBSA-N 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000014493 regulation of gene expression Effects 0.000 description 2
- 102000003702 retinoic acid receptors Human genes 0.000 description 2
- 108090000064 retinoic acid receptors Proteins 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- 238000003757 reverse transcription PCR Methods 0.000 description 2
- MBABCNBNDNGODA-WPZDJQSSSA-N rolliniastatin 1 Natural products O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@H]1[C@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-WPZDJQSSSA-N 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 239000008159 sesame oil Substances 0.000 description 2
- 235000011803 sesame oil Nutrition 0.000 description 2
- 230000020509 sex determination Effects 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 210000000278 spinal cord Anatomy 0.000 description 2
- 238000010186 staining Methods 0.000 description 2
- 230000008093 supporting effect Effects 0.000 description 2
- 230000003319 supportive effect Effects 0.000 description 2
- 238000001356 surgical procedure Methods 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 231100001274 therapeutic index Toxicity 0.000 description 2
- 229960001196 thiotepa Drugs 0.000 description 2
- 238000002287 time-lapse microscopy Methods 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 229960005294 triamcinolone Drugs 0.000 description 2
- GFNANZIMVAIWHM-OBYCQNJPSA-N triamcinolone Chemical compound O=C1C=C[C@]2(C)[C@@]3(F)[C@@H](O)C[C@](C)([C@@]([C@H](O)C4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 GFNANZIMVAIWHM-OBYCQNJPSA-N 0.000 description 2
- 229960001670 trilostane Drugs 0.000 description 2
- KVJXBPDAXMEYOA-CXANFOAXSA-N trilostane Chemical compound OC1=C(C#N)C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@@]32O[C@@H]31 KVJXBPDAXMEYOA-CXANFOAXSA-N 0.000 description 2
- 230000007306 turnover Effects 0.000 description 2
- 229960001055 uracil mustard Drugs 0.000 description 2
- 210000005167 vascular cell Anatomy 0.000 description 2
- 210000003556 vascular endothelial cell Anatomy 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- 238000012800 visualization Methods 0.000 description 2
- 108700033799 zebrafish Sox7 Proteins 0.000 description 2
- 229960000641 zorubicin Drugs 0.000 description 2
- FBTUMDXHSRTGRV-ALTNURHMSA-N zorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(\C)=N\NC(=O)C=1C=CC=CC=1)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 FBTUMDXHSRTGRV-ALTNURHMSA-N 0.000 description 2
- NNJPGOLRFBJNIW-HNNXBMFYSA-N (-)-demecolcine Chemical compound C1=C(OC)C(=O)C=C2[C@@H](NC)CCC3=CC(OC)=C(OC)C(OC)=C3C2=C1 NNJPGOLRFBJNIW-HNNXBMFYSA-N 0.000 description 1
- LNAZSHAWQACDHT-XIYTZBAFSA-N (2r,3r,4s,5r,6s)-4,5-dimethoxy-2-(methoxymethyl)-3-[(2s,3r,4s,5r,6r)-3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6r)-4,5,6-trimethoxy-2-(methoxymethyl)oxan-3-yl]oxyoxane Chemical compound CO[C@@H]1[C@@H](OC)[C@H](OC)[C@@H](COC)O[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@H]2[C@@H]([C@@H](OC)[C@H](OC)O[C@@H]2COC)OC)O[C@@H]1COC LNAZSHAWQACDHT-XIYTZBAFSA-N 0.000 description 1
- YXTKHLHCVFUPPT-YYFJYKOTSA-N (2s)-2-[[4-[(2-amino-5-formyl-4-oxo-1,6,7,8-tetrahydropteridin-6-yl)methylamino]benzoyl]amino]pentanedioic acid;(1r,2r)-1,2-dimethanidylcyclohexane;5-fluoro-1h-pyrimidine-2,4-dione;oxalic acid;platinum(2+) Chemical compound [Pt+2].OC(=O)C(O)=O.[CH2-][C@@H]1CCCC[C@H]1[CH2-].FC1=CNC(=O)NC1=O.C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 YXTKHLHCVFUPPT-YYFJYKOTSA-N 0.000 description 1
- FLWWDYNPWOSLEO-HQVZTVAUSA-N (2s)-2-[[4-[1-(2-amino-4-oxo-1h-pteridin-6-yl)ethyl-methylamino]benzoyl]amino]pentanedioic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1C(C)N(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FLWWDYNPWOSLEO-HQVZTVAUSA-N 0.000 description 1
- TVIRNGFXQVMMGB-OFWIHYRESA-N (3s,6r,10r,13e,16s)-16-[(2r,3r,4s)-4-chloro-3-hydroxy-4-phenylbutan-2-yl]-10-[(3-chloro-4-methoxyphenyl)methyl]-6-methyl-3-(2-methylpropyl)-1,4-dioxa-8,11-diazacyclohexadec-13-ene-2,5,9,12-tetrone Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H](O)[C@@H](Cl)C=2C=CC=CC=2)C/C=C/C(=O)N1 TVIRNGFXQVMMGB-OFWIHYRESA-N 0.000 description 1
- XRBSKUSTLXISAB-UHFFFAOYSA-N (7R,7'R,8R,8'R)-form-Podophyllic acid Natural products COC1=C(OC)C(OC)=CC(C2C3=CC=4OCOC=4C=C3C(O)C(CO)C2C(O)=O)=C1 XRBSKUSTLXISAB-UHFFFAOYSA-N 0.000 description 1
- AESVUZLWRXEGEX-DKCAWCKPSA-N (7S,9R)-7-[(2S,4R,5R,6R)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7H-tetracene-5,12-dione iron(3+) Chemical compound [Fe+3].COc1cccc2C(=O)c3c(O)c4C[C@@](O)(C[C@H](O[C@@H]5C[C@@H](N)[C@@H](O)[C@@H](C)O5)c4c(O)c3C(=O)c12)C(=O)CO AESVUZLWRXEGEX-DKCAWCKPSA-N 0.000 description 1
- JXVAMODRWBNUSF-KZQKBALLSA-N (7s,9r,10r)-7-[(2r,4s,5s,6s)-5-[[(2s,4as,5as,7s,9s,9ar,10ar)-2,9-dimethyl-3-oxo-4,4a,5a,6,7,9,9a,10a-octahydrodipyrano[4,2-a:4',3'-e][1,4]dioxin-7-yl]oxy]-4-(dimethylamino)-6-methyloxan-2-yl]oxy-10-[(2s,4s,5s,6s)-4-(dimethylamino)-5-hydroxy-6-methyloxan-2 Chemical compound O([C@@H]1C2=C(O)C=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C2[C@@H](O[C@@H]2O[C@@H](C)[C@@H](O[C@@H]3O[C@@H](C)[C@H]4O[C@@H]5O[C@@H](C)C(=O)C[C@@H]5O[C@H]4C3)[C@H](C2)N(C)C)C[C@]1(O)CC)[C@H]1C[C@H](N(C)C)[C@H](O)[C@H](C)O1 JXVAMODRWBNUSF-KZQKBALLSA-N 0.000 description 1
- INAUWOVKEZHHDM-PEDBPRJASA-N (7s,9s)-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-7-[(2r,4s,5s,6s)-5-hydroxy-6-methyl-4-morpholin-4-yloxan-2-yl]oxy-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound Cl.N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1 INAUWOVKEZHHDM-PEDBPRJASA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 description 1
- HCUOEKSZWPGJIM-IYNMRSRQSA-N (e,2z)-2-hydroxyimino-6-methoxy-4-methyl-5-nitrohex-3-enamide Chemical compound COCC([N+]([O-])=O)\C(C)=C\C(=N\O)\C(N)=O HCUOEKSZWPGJIM-IYNMRSRQSA-N 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- FPIPGXGPPPQFEQ-UHFFFAOYSA-N 13-cis retinol Natural products OCC=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C FPIPGXGPPPQFEQ-UHFFFAOYSA-N 0.000 description 1
- QCXJFISCRQIYID-IAEPZHFASA-N 2-amino-1-n-[(3s,6s,7r,10s,16s)-3-[(2s)-butan-2-yl]-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-10-propan-2-yl-8-oxa-1,4,11,14-tetrazabicyclo[14.3.0]nonadecan-6-yl]-4,6-dimethyl-3-oxo-9-n-[(3s,6s,7r,10s,16s)-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-3,10-di(propa Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N=C2C(C(=O)N[C@@H]3C(=O)N[C@H](C(N4CCC[C@H]4C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]3C)=O)[C@@H](C)CC)=C(N)C(=O)C(C)=C2O2)C2=C(C)C=C1 QCXJFISCRQIYID-IAEPZHFASA-N 0.000 description 1
- ALHXTYGCVYTWIY-UHFFFAOYSA-N 2-amino-3,7-dihydropurine-6-thione Chemical compound N1C(N)=NC(=S)C2=C1N=CN2.N1C(N)=NC(=S)C2=C1N=CN2 ALHXTYGCVYTWIY-UHFFFAOYSA-N 0.000 description 1
- CTRPRMNBTVRDFH-UHFFFAOYSA-N 2-n-methyl-1,3,5-triazine-2,4,6-triamine Chemical compound CNC1=NC(N)=NC(N)=N1 CTRPRMNBTVRDFH-UHFFFAOYSA-N 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- YIMDLWDNDGKDTJ-QLKYHASDSA-N 3'-deamino-3'-(3-cyanomorpholin-4-yl)doxorubicin Chemical compound N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1C#N YIMDLWDNDGKDTJ-QLKYHASDSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- PWMYMKOUNYTVQN-UHFFFAOYSA-N 3-(8,8-diethyl-2-aza-8-germaspiro[4.5]decan-2-yl)-n,n-dimethylpropan-1-amine Chemical compound C1C[Ge](CC)(CC)CCC11CN(CCCN(C)C)CC1 PWMYMKOUNYTVQN-UHFFFAOYSA-N 0.000 description 1
- 108020004021 3-ketosteroid receptors Proteins 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 1
- HIQIXEFWDLTDED-UHFFFAOYSA-N 4-hydroxy-1-piperidin-4-ylpyrrolidin-2-one Chemical compound O=C1CC(O)CN1C1CCNCC1 HIQIXEFWDLTDED-UHFFFAOYSA-N 0.000 description 1
- 108020003589 5' Untranslated Regions Proteins 0.000 description 1
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 description 1
- WYXSYVWAUAUWLD-SHUUEZRQSA-N 6-azauridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=N1 WYXSYVWAUAUWLD-SHUUEZRQSA-N 0.000 description 1
- FVFVNNKYKYZTJU-UHFFFAOYSA-N 6-chloro-1,3,5-triazine-2,4-diamine Chemical group NC1=NC(N)=NC(Cl)=N1 FVFVNNKYKYZTJU-UHFFFAOYSA-N 0.000 description 1
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 1
- SHGAZHPCJJPHSC-ZVCIMWCZSA-N 9-cis-retinoic acid Chemical compound OC(=O)/C=C(\C)/C=C/C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-ZVCIMWCZSA-N 0.000 description 1
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 1
- HPLNQCPCUACXLM-PGUFJCEWSA-N ABT-737 Chemical compound C([C@@H](CCN(C)C)NC=1C(=CC(=CC=1)S(=O)(=O)NC(=O)C=1C=CC(=CC=1)N1CCN(CC=2C(=CC=CC=2)C=2C=CC(Cl)=CC=2)CC1)[N+]([O-])=O)SC1=CC=CC=C1 HPLNQCPCUACXLM-PGUFJCEWSA-N 0.000 description 1
- 102100038776 ADP-ribosylation factor-related protein 1 Human genes 0.000 description 1
- 101710165611 ADP-ribosylation factor-related protein 1 Proteins 0.000 description 1
- 208000004998 Abdominal Pain Diseases 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 206010000830 Acute leukaemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- 102100030379 Acyl-coenzyme A synthetase ACSM2A, mitochondrial Human genes 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 101710101449 Alpha-centractin Proteins 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 101100004644 Arabidopsis thaliana BAT1 gene Proteins 0.000 description 1
- 101100065582 Arabidopsis thaliana ERF071 gene Proteins 0.000 description 1
- 208000006820 Arthralgia Diseases 0.000 description 1
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 1
- 241000282672 Ateles sp. Species 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 241000713840 Avian erythroblastosis virus Species 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 208000008035 Back Pain Diseases 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 206010065553 Bone marrow failure Diseases 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 102000013014 COUP Transcription Factor I Human genes 0.000 description 1
- 102000008523 COUP Transcription Factor II Human genes 0.000 description 1
- 108091033409 CRISPR Proteins 0.000 description 1
- 238000010354 CRISPR gene editing Methods 0.000 description 1
- 101100257372 Caenorhabditis elegans sox-3 gene Proteins 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 1
- SHHKQEUPHAENFK-UHFFFAOYSA-N Carboquone Chemical compound O=C1C(C)=C(N2CC2)C(=O)C(C(COC(N)=O)OC)=C1N1CC1 SHHKQEUPHAENFK-UHFFFAOYSA-N 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 102000004172 Cathepsin L Human genes 0.000 description 1
- 108090000624 Cathepsin L Proteins 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 108091006146 Channels Proteins 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 1
- 241000222511 Coprinus Species 0.000 description 1
- 229920002261 Corn starch Polymers 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 229930188224 Cryptophycin Natural products 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000004594 DNA Polymerase I Human genes 0.000 description 1
- 108010017826 DNA Polymerase I Proteins 0.000 description 1
- 239000003298 DNA probe Substances 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- NNJPGOLRFBJNIW-UHFFFAOYSA-N Demecolcine Natural products C1=C(OC)C(=O)C=C2C(NC)CCC3=CC(OC)=C(OC)C(OC)=C3C2=C1 NNJPGOLRFBJNIW-UHFFFAOYSA-N 0.000 description 1
- AUGQEEXBDZWUJY-ZLJUKNTDSA-N Diacetoxyscirpenol Chemical compound C([C@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@@H]1C=C(C)CC[C@@]13COC(=O)C)O2 AUGQEEXBDZWUJY-ZLJUKNTDSA-N 0.000 description 1
- AUGQEEXBDZWUJY-UHFFFAOYSA-N Diacetoxyscirpenol Natural products CC(=O)OCC12CCC(C)=CC1OC1C(O)C(OC(C)=O)C2(C)C11CO1 AUGQEEXBDZWUJY-UHFFFAOYSA-N 0.000 description 1
- SHIBSTMRCDJXLN-UHFFFAOYSA-N Digoxigenin Natural products C1CC(C2C(C3(C)CCC(O)CC3CC2)CC2O)(O)C2(C)C1C1=CC(=O)OC1 SHIBSTMRCDJXLN-UHFFFAOYSA-N 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 241000271559 Dromaiidae Species 0.000 description 1
- 229930193152 Dynemicin Natural products 0.000 description 1
- 108010065372 Dynorphins Proteins 0.000 description 1
- 108010024212 E-Selectin Proteins 0.000 description 1
- 102100032057 ETS domain-containing protein Elk-1 Human genes 0.000 description 1
- 102100039563 ETS translocation variant 1 Human genes 0.000 description 1
- 101710179955 ETS translocation variant 2 Proteins 0.000 description 1
- 102100039562 ETS translocation variant 3 Human genes 0.000 description 1
- 102100039577 ETS translocation variant 5 Human genes 0.000 description 1
- 102100035075 ETS-related transcription factor Elf-1 Human genes 0.000 description 1
- 102100031780 Endonuclease Human genes 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 108010049140 Endorphins Proteins 0.000 description 1
- 102000009025 Endorphins Human genes 0.000 description 1
- 108010092674 Enkephalins Proteins 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 101000823089 Equus caballus Alpha-1-antiproteinase 1 Proteins 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 229930189413 Esperamicin Natural products 0.000 description 1
- 239000001856 Ethyl cellulose Substances 0.000 description 1
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 1
- 101000914063 Eucalyptus globulus Leafy/floricaula homolog FL1 Proteins 0.000 description 1
- 244000239659 Eucalyptus pulverulenta Species 0.000 description 1
- 208000006168 Ewing Sarcoma Diseases 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 206010073306 Exposure to radiation Diseases 0.000 description 1
- 108091092566 Extrachromosomal DNA Proteins 0.000 description 1
- 241000282324 Felis Species 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- 108700037539 Friend leukemia integration 1 transcription factor Proteins 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108010061414 Hepatocyte Nuclear Factor 1-beta Proteins 0.000 description 1
- 102000006752 Hepatocyte Nuclear Factor 4 Human genes 0.000 description 1
- 102100022123 Hepatocyte nuclear factor 1-beta Human genes 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 102000010029 Homer Scaffolding Proteins Human genes 0.000 description 1
- 108010077223 Homer Scaffolding Proteins Proteins 0.000 description 1
- 101100054737 Homo sapiens ACSM2A gene Proteins 0.000 description 1
- 101000884714 Homo sapiens Beta-defensin 4A Proteins 0.000 description 1
- 101000860854 Homo sapiens COUP transcription factor 1 Proteins 0.000 description 1
- 101100011489 Homo sapiens ELF5 gene Proteins 0.000 description 1
- 101001048720 Homo sapiens ETS domain-containing protein Elk-3 Proteins 0.000 description 1
- 101000813729 Homo sapiens ETS translocation variant 1 Proteins 0.000 description 1
- 101000813726 Homo sapiens ETS translocation variant 3 Proteins 0.000 description 1
- 101000813745 Homo sapiens ETS translocation variant 5 Proteins 0.000 description 1
- 101000877395 Homo sapiens ETS-related transcription factor Elf-1 Proteins 0.000 description 1
- 101000813141 Homo sapiens ETS-related transcription factor Elf-5 Proteins 0.000 description 1
- 101100012008 Homo sapiens ETV2 gene Proteins 0.000 description 1
- 101001109700 Homo sapiens Nuclear receptor subfamily 4 group A member 1 Proteins 0.000 description 1
- 101001109698 Homo sapiens Nuclear receptor subfamily 4 group A member 2 Proteins 0.000 description 1
- 101000640876 Homo sapiens Retinoic acid receptor RXR-beta Proteins 0.000 description 1
- 101000640882 Homo sapiens Retinoic acid receptor RXR-gamma Proteins 0.000 description 1
- 101000617130 Homo sapiens Stromal cell-derived factor 1 Proteins 0.000 description 1
- 101000597183 Homo sapiens Telomere length regulation protein TEL2 homolog Proteins 0.000 description 1
- 101000881764 Homo sapiens Transcription elongation factor 1 homolog Proteins 0.000 description 1
- 101000813738 Homo sapiens Transcription factor ETV6 Proteins 0.000 description 1
- 101000651211 Homo sapiens Transcription factor PU.1 Proteins 0.000 description 1
- 101000652332 Homo sapiens Transcription factor SOX-1 Proteins 0.000 description 1
- 101000825086 Homo sapiens Transcription factor SOX-11 Proteins 0.000 description 1
- 101000825079 Homo sapiens Transcription factor SOX-13 Proteins 0.000 description 1
- 101000825060 Homo sapiens Transcription factor SOX-14 Proteins 0.000 description 1
- 101000652324 Homo sapiens Transcription factor SOX-17 Proteins 0.000 description 1
- 101000687905 Homo sapiens Transcription factor SOX-2 Proteins 0.000 description 1
- 101000642514 Homo sapiens Transcription factor SOX-4 Proteins 0.000 description 1
- 101000642512 Homo sapiens Transcription factor SOX-5 Proteins 0.000 description 1
- 101000642517 Homo sapiens Transcription factor SOX-6 Proteins 0.000 description 1
- 101000642528 Homo sapiens Transcription factor SOX-8 Proteins 0.000 description 1
- 101000711846 Homo sapiens Transcription factor SOX-9 Proteins 0.000 description 1
- 101000825182 Homo sapiens Transcription factor Spi-B Proteins 0.000 description 1
- 101000825161 Homo sapiens Transcription factor Spi-C Proteins 0.000 description 1
- 101000997832 Homo sapiens Tyrosine-protein kinase JAK2 Proteins 0.000 description 1
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 description 1
- 206010020772 Hypertension Diseases 0.000 description 1
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- 102100027303 Interferon-induced protein with tetratricopeptide repeats 2 Human genes 0.000 description 1
- 101710166698 Interferon-induced protein with tetratricopeptide repeats 2 Proteins 0.000 description 1
- UETNIIAIRMUTSM-UHFFFAOYSA-N Jacareubin Natural products CC1(C)OC2=CC3Oc4c(O)c(O)ccc4C(=O)C3C(=C2C=C1)O UETNIIAIRMUTSM-UHFFFAOYSA-N 0.000 description 1
- 108010019437 Janus Kinase 2 Proteins 0.000 description 1
- 229940122245 Janus kinase inhibitor Drugs 0.000 description 1
- 101000978704 Kluyveromyces lactis (strain ATCC 8585 / CBS 2359 / DSM 70799 / NBRC 1267 / NRRL Y-1140 / WM37) Mating-type protein A1 Proteins 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 1
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 229920001491 Lentinan Polymers 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- 241000270322 Lepidosauria Species 0.000 description 1
- URLZCHNOLZSCCA-VABKMULXSA-N Leu-enkephalin Chemical class C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CNC(=O)CNC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=CC=C1 URLZCHNOLZSCCA-VABKMULXSA-N 0.000 description 1
- 206010024291 Leukaemias acute myeloid Diseases 0.000 description 1
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 241000282560 Macaca mulatta Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- VJRAUFKOOPNFIQ-UHFFFAOYSA-N Marcellomycin Natural products C12=C(O)C=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C=C2C(C(=O)OC)C(CC)(O)CC1OC(OC1C)CC(N(C)C)C1OC(OC1C)CC(O)C1OC1CC(O)C(O)C(C)O1 VJRAUFKOOPNFIQ-UHFFFAOYSA-N 0.000 description 1
- 241000283923 Marmota monax Species 0.000 description 1
- 229930126263 Maytansine Natural products 0.000 description 1
- FQISKWAFAHGMGT-SGJOWKDISA-M Methylprednisolone sodium succinate Chemical compound [Na+].C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)COC(=O)CCC([O-])=O)CC[C@H]21 FQISKWAFAHGMGT-SGJOWKDISA-M 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 101100509424 Mus musculus Itsn1 gene Proteins 0.000 description 1
- 101100509428 Mus musculus Itsn2 gene Proteins 0.000 description 1
- 101100384870 Mus musculus Nr2f2 gene Proteins 0.000 description 1
- 101100149887 Mus musculus Sox10 gene Proteins 0.000 description 1
- 101100366231 Mus musculus Sox12 gene Proteins 0.000 description 1
- 101100310645 Mus musculus Sox15 gene Proteins 0.000 description 1
- 101100257376 Mus musculus Sox3 gene Proteins 0.000 description 1
- 101000635833 Mus musculus Tissue factor Proteins 0.000 description 1
- 241000282339 Mustela Species 0.000 description 1
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- WNYOPINACXXCOV-BCAICVSZSA-N N-[(4S,7R,11S,17S,20R,24S)-2,4,12,15,17,25-hexamethyl-11,24-bis[(2R)-3-methylbutan-2-yl]-27-methylsulfanyl-3,6,10,13,16,19,23,26-octaoxo-20-(quinoxaline-2-carbonylamino)-9,22-dioxa-28-thia-2,5,12,15,18,25-hexazabicyclo[12.12.3]nonacosan-7-yl]quinoxaline-2-carboxamide Chemical compound CSC1SCC2N(C)C(=O)[C@H](C)NC(=O)[C@@H](COC(=O)[C@H]([C@H](C)C(C)C)N(C)C(=O)C1N(C)C(=O)[C@H](C)NC(=O)[C@@H](COC(=O)[C@H]([C@H](C)C(C)C)N(C)C2=O)NC(=O)c1cnc2ccccc2n1)NC(=O)c1cnc2ccccc2n1 WNYOPINACXXCOV-BCAICVSZSA-N 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- 102000034570 NR1 subfamily Human genes 0.000 description 1
- 108020001305 NR1 subfamily Proteins 0.000 description 1
- 102000038100 NR2 subfamily Human genes 0.000 description 1
- 108020002076 NR2 subfamily Proteins 0.000 description 1
- 108020002144 NR4 subfamily Proteins 0.000 description 1
- 108020002397 NR6 subfamily Proteins 0.000 description 1
- 108091061960 Naked DNA Proteins 0.000 description 1
- CMWTZPSULFXXJA-UHFFFAOYSA-N Naproxen Natural products C1=C(C(C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-UHFFFAOYSA-N 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 208000033755 Neutrophilic Chronic Leukemia Diseases 0.000 description 1
- SYNHCENRCUAUNM-UHFFFAOYSA-N Nitrogen mustard N-oxide hydrochloride Chemical compound Cl.ClCC[N+]([O-])(C)CCCl SYNHCENRCUAUNM-UHFFFAOYSA-N 0.000 description 1
- 102100022679 Nuclear receptor subfamily 4 group A member 1 Human genes 0.000 description 1
- 102100022676 Nuclear receptor subfamily 4 group A member 2 Human genes 0.000 description 1
- 102100022670 Nuclear receptor subfamily 6 group A member 1 Human genes 0.000 description 1
- 101710093927 Nuclear receptor subfamily 6 group A member 1 Proteins 0.000 description 1
- 229930187135 Olivomycin Natural products 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- BRUQQQPBMZOVGD-XFKAJCMBSA-N Oxycodone Chemical compound O=C([C@@H]1O2)CC[C@@]3(O)[C@H]4CC5=CC=C(OC)C2=C5[C@@]13CCN4C BRUQQQPBMZOVGD-XFKAJCMBSA-N 0.000 description 1
- TUVCWJQQGGETHL-UHFFFAOYSA-N PI-103 Chemical compound OC1=CC=CC(C=2N=C3C4=CC=CN=C4OC3=C(N3CCOCC3)N=2)=C1 TUVCWJQQGGETHL-UHFFFAOYSA-N 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- VREZDOWOLGNDPW-ALTGWBOUSA-N Pancratistatin Chemical compound C1=C2[C@H]3[C@@H](O)[C@H](O)[C@@H](O)[C@@H](O)[C@@H]3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-ALTGWBOUSA-N 0.000 description 1
- VREZDOWOLGNDPW-MYVCAWNPSA-N Pancratistatin Natural products O=C1N[C@H]2[C@H](O)[C@H](O)[C@H](O)[C@H](O)[C@@H]2c2c1c(O)c1OCOc1c2 VREZDOWOLGNDPW-MYVCAWNPSA-N 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 101710163352 Potassium voltage-gated channel subfamily H member 4 Proteins 0.000 description 1
- 101710163348 Potassium voltage-gated channel subfamily H member 8 Proteins 0.000 description 1
- 102100026534 Procathepsin L Human genes 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 102100024924 Protein kinase C alpha type Human genes 0.000 description 1
- 101710109947 Protein kinase C alpha type Proteins 0.000 description 1
- 108010080989 Proto-Oncogene Protein c-fli-1 Proteins 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108091008680 RAR-related orphan receptors Proteins 0.000 description 1
- AHHFEZNOXOZZQA-ZEBDFXRSSA-N Ranimustine Chemical compound CO[C@H]1O[C@H](CNC(=O)N(CCCl)N=O)[C@@H](O)[C@H](O)[C@H]1O AHHFEZNOXOZZQA-ZEBDFXRSSA-N 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- 102100034253 Retinoic acid receptor RXR-beta Human genes 0.000 description 1
- OWPCHSCAPHNHAV-UHFFFAOYSA-N Rhizoxin Natural products C1C(O)C2(C)OC2C=CC(C)C(OC(=O)C2)CC2CC2OC2C(=O)OC1C(C)C(OC)C(C)=CC=CC(C)=CC1=COC(C)=N1 OWPCHSCAPHNHAV-UHFFFAOYSA-N 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 235000019485 Safflower oil Nutrition 0.000 description 1
- 241000277331 Salmonidae Species 0.000 description 1
- 208000034189 Sclerosis Diseases 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 241000270295 Serpentes Species 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 239000004141 Sodium laurylsulphate Substances 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 1
- 241000271567 Struthioniformes Species 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- BXFOFFBJRFZBQZ-QYWOHJEZSA-N T-2 toxin Chemical compound C([C@@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@H]1[C@]3(COC(C)=O)C[C@@H](C(=C1)C)OC(=O)CC(C)C)O2 BXFOFFBJRFZBQZ-QYWOHJEZSA-N 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 description 1
- 101150001671 Tfec gene Proteins 0.000 description 1
- 229920001615 Tragacanth Polymers 0.000 description 1
- 230000010632 Transcription Factor Activity Effects 0.000 description 1
- 102100039580 Transcription factor ETV6 Human genes 0.000 description 1
- 102100030248 Transcription factor SOX-1 Human genes 0.000 description 1
- 102100022415 Transcription factor SOX-11 Human genes 0.000 description 1
- 102100022435 Transcription factor SOX-13 Human genes 0.000 description 1
- 102100022431 Transcription factor SOX-14 Human genes 0.000 description 1
- 102100030243 Transcription factor SOX-17 Human genes 0.000 description 1
- 102100024270 Transcription factor SOX-2 Human genes 0.000 description 1
- 102100036693 Transcription factor SOX-4 Human genes 0.000 description 1
- 102100036692 Transcription factor SOX-5 Human genes 0.000 description 1
- 102100036694 Transcription factor SOX-6 Human genes 0.000 description 1
- 102100036731 Transcription factor SOX-8 Human genes 0.000 description 1
- 102100034204 Transcription factor SOX-9 Human genes 0.000 description 1
- 102100022281 Transcription factor Spi-B Human genes 0.000 description 1
- 102100022285 Transcription factor Spi-C Human genes 0.000 description 1
- UMILHIMHKXVDGH-UHFFFAOYSA-N Triethylene glycol diglycidyl ether Chemical compound C1OC1COCCOCCOCCOCC1CO1 UMILHIMHKXVDGH-UHFFFAOYSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- FYAMXEPQQLNQDM-UHFFFAOYSA-N Tris(1-aziridinyl)phosphine oxide Chemical compound C1CN1P(N1CC1)(=O)N1CC1 FYAMXEPQQLNQDM-UHFFFAOYSA-N 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 1
- 102000016549 Vascular Endothelial Growth Factor Receptor-2 Human genes 0.000 description 1
- 208000032594 Vascular Remodeling Diseases 0.000 description 1
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 108700005077 Viral Genes Proteins 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 241000269368 Xenopus laevis Species 0.000 description 1
- 241000269457 Xenopus tropicalis Species 0.000 description 1
- 210000002593 Y chromosome Anatomy 0.000 description 1
- PVNFMCBFDPTNQI-UIBOPQHZSA-N [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] acetate [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] 3-methylbutanoate [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] 2-methylpropanoate [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] propanoate Chemical compound CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(C)=O)[C@]2(C)OC2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2.CCC(=O)O[C@H]1CC(=O)N(C)c2cc(C\C(C)=C\C=C\[C@@H](OC)[C@@]3(O)C[C@H](OC(=O)N3)[C@@H](C)C3O[C@@]13C)cc(OC)c2Cl.CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(=O)C(C)C)[C@]2(C)OC2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2.CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(=O)CC(C)C)[C@]2(C)OC2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2 PVNFMCBFDPTNQI-UIBOPQHZSA-N 0.000 description 1
- SPJCRMJCFSJKDE-ZWBUGVOYSA-N [(3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthren-3-yl] 2-[4-[bis(2-chloroethyl)amino]phenyl]acetate Chemical compound O([C@@H]1CC2=CC[C@H]3[C@@H]4CC[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@H](C)CCCC(C)C)C(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 SPJCRMJCFSJKDE-ZWBUGVOYSA-N 0.000 description 1
- IFJUINDAXYAPTO-UUBSBJJBSA-N [(8r,9s,13s,14s,17s)-17-[2-[4-[4-[bis(2-chloroethyl)amino]phenyl]butanoyloxy]acetyl]oxy-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-3-yl] benzoate Chemical compound C([C@@H]1[C@@H](C2=CC=3)CC[C@]4([C@H]1CC[C@@H]4OC(=O)COC(=O)CCCC=1C=CC(=CC=1)N(CCCl)CCCl)C)CC2=CC=3OC(=O)C1=CC=CC=C1 IFJUINDAXYAPTO-UUBSBJJBSA-N 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- USDJGQLNFPZEON-UHFFFAOYSA-N [[4,6-bis(hydroxymethylamino)-1,3,5-triazin-2-yl]amino]methanol Chemical compound OCNC1=NC(NCO)=NC(NCO)=N1 USDJGQLNFPZEON-UHFFFAOYSA-N 0.000 description 1
- 230000003187 abdominal effect Effects 0.000 description 1
- 238000005299 abrasion Methods 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 229960001138 acetylsalicylic acid Drugs 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 235000010443 alginic acid Nutrition 0.000 description 1
- 239000000783 alginic acid Substances 0.000 description 1
- 229920000615 alginic acid Polymers 0.000 description 1
- 229960001126 alginic acid Drugs 0.000 description 1
- 150000004781 alginic acids Chemical class 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229960001445 alitretinoin Drugs 0.000 description 1
- 229940045714 alkyl sulfonate alkylating agent Drugs 0.000 description 1
- 150000008052 alkyl sulfonates Chemical class 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 125000000539 amino acid group Chemical class 0.000 description 1
- 229960002749 aminolevulinic acid Drugs 0.000 description 1
- 229960003896 aminopterin Drugs 0.000 description 1
- 229960003022 amoxicillin Drugs 0.000 description 1
- LSQZJLSUYDQPKJ-NJBDSQKTSA-N amoxicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=C(O)C=C1 LSQZJLSUYDQPKJ-NJBDSQKTSA-N 0.000 description 1
- 229940035676 analgesics Drugs 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000000730 antalgic agent Substances 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 210000000709 aorta Anatomy 0.000 description 1
- 238000003782 apoptosis assay Methods 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- 239000008135 aqueous vehicle Substances 0.000 description 1
- 150000008209 arabinosides Chemical class 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 230000010455 autoregulation Effects 0.000 description 1
- 229960002756 azacitidine Drugs 0.000 description 1
- 229950011321 azaserine Drugs 0.000 description 1
- 150000001541 aziridines Chemical class 0.000 description 1
- 229940125717 barbiturate Drugs 0.000 description 1
- 229940092705 beclomethasone Drugs 0.000 description 1
- NBMKJKDGKREAPL-DVTGEIKXSA-N beclomethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(Cl)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O NBMKJKDGKREAPL-DVTGEIKXSA-N 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000003542 behavioural effect Effects 0.000 description 1
- 229960002903 benzyl benzoate Drugs 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 229960002537 betamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-DVTGEIKXSA-N betamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-DVTGEIKXSA-N 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 238000002306 biochemical method Methods 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 229920001222 biopolymer Polymers 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 229950008548 bisantrene Drugs 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 238000009534 blood test Methods 0.000 description 1
- 208000015322 bone marrow disease Diseases 0.000 description 1
- 229960001467 bortezomib Drugs 0.000 description 1
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 description 1
- 229960005520 bryostatin Drugs 0.000 description 1
- MJQUEDHRCUIRLF-TVIXENOKSA-N bryostatin 1 Chemical compound C([C@@H]1CC(/[C@@H]([C@@](C(C)(C)/C=C/2)(O)O1)OC(=O)/C=C/C=C/CCC)=C\C(=O)OC)[C@H]([C@@H](C)O)OC(=O)C[C@H](O)C[C@@H](O1)C[C@H](OC(C)=O)C(C)(C)[C@]1(O)C[C@@H]1C\C(=C\C(=O)OC)C[C@H]\2O1 MJQUEDHRCUIRLF-TVIXENOKSA-N 0.000 description 1
- MUIWQCKLQMOUAT-AKUNNTHJSA-N bryostatin 20 Natural products COC(=O)C=C1C[C@@]2(C)C[C@]3(O)O[C@](C)(C[C@@H](O)CC(=O)O[C@](C)(C[C@@]4(C)O[C@](O)(CC5=CC(=O)O[C@]45C)C(C)(C)C=C[C@@](C)(C1)O2)[C@@H](C)O)C[C@H](OC(=O)C(C)(C)C)C3(C)C MUIWQCKLQMOUAT-AKUNNTHJSA-N 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 239000004067 bulking agent Substances 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 108700002839 cactinomycin Proteins 0.000 description 1
- 229950009908 cactinomycin Drugs 0.000 description 1
- BPKIGYQJPYCAOW-FFJTTWKXSA-I calcium;potassium;disodium;(2s)-2-hydroxypropanoate;dichloride;dihydroxide;hydrate Chemical compound O.[OH-].[OH-].[Na+].[Na+].[Cl-].[Cl-].[K+].[Ca+2].C[C@H](O)C([O-])=O BPKIGYQJPYCAOW-FFJTTWKXSA-I 0.000 description 1
- BMLSTPRTEKLIPM-UHFFFAOYSA-I calcium;potassium;disodium;hydrogen carbonate;dichloride;dihydroxide;hydrate Chemical compound O.[OH-].[OH-].[Na+].[Na+].[Cl-].[Cl-].[K+].[Ca+2].OC([O-])=O BMLSTPRTEKLIPM-UHFFFAOYSA-I 0.000 description 1
- IVFYLRMMHVYGJH-PVPPCFLZSA-N calusterone Chemical compound C1C[C@]2(C)[C@](O)(C)CC[C@H]2[C@@H]2[C@@H](C)CC3=CC(=O)CC[C@]3(C)[C@H]21 IVFYLRMMHVYGJH-PVPPCFLZSA-N 0.000 description 1
- 229950009823 calusterone Drugs 0.000 description 1
- 229940088954 camptosar Drugs 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 235000011089 carbon dioxide Nutrition 0.000 description 1
- 229960002115 carboquone Drugs 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- XREUEWVEMYWFFA-CSKJXFQVSA-N carminomycin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XREUEWVEMYWFFA-CSKJXFQVSA-N 0.000 description 1
- XREUEWVEMYWFFA-UHFFFAOYSA-N carminomycin I Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XREUEWVEMYWFFA-UHFFFAOYSA-N 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 229950001725 carubicin Drugs 0.000 description 1
- BBZDXMBRAFTCAA-AREMUKBSSA-N carzelesin Chemical compound C1=2NC=C(C)C=2C([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)C3=CC4=CC=C(C=C4O3)N(CC)CC)=C2C=C1OC(=O)NC1=CC=CC=C1 BBZDXMBRAFTCAA-AREMUKBSSA-N 0.000 description 1
- 229950007509 carzelesin Drugs 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 241001233037 catfish Species 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 239000002771 cell marker Substances 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000033077 cellular process Effects 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 230000002925 chemical effect Effects 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- CYDMQBQPVICBEU-UHFFFAOYSA-N chlorotetracycline Natural products C1=CC(Cl)=C2C(O)(C)C3CC4C(N(C)C)C(O)=C(C(N)=O)C(=O)C4(O)C(O)=C3C(=O)C2=C1O CYDMQBQPVICBEU-UHFFFAOYSA-N 0.000 description 1
- 229960004475 chlortetracycline Drugs 0.000 description 1
- CYDMQBQPVICBEU-XRNKAMNCSA-N chlortetracycline Chemical compound C1=CC(Cl)=C2[C@](O)(C)[C@H]3C[C@H]4[C@H](N(C)C)C(O)=C(C(N)=O)C(=O)[C@@]4(O)C(O)=C3C(=O)C2=C1O CYDMQBQPVICBEU-XRNKAMNCSA-N 0.000 description 1
- 235000019365 chlortetracycline Nutrition 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- ZYVSOIYQKUDENJ-WKSBCEQHSA-N chromomycin A3 Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@@H]1OC(C)=O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@@H](O)[C@H](O[C@@H]3O[C@@H](C)[C@H](OC(C)=O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@@H]1C[C@@H](O)[C@@H](OC)[C@@H](C)O1 ZYVSOIYQKUDENJ-WKSBCEQHSA-N 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000021668 chronic eosinophilic leukemia Diseases 0.000 description 1
- 208000024207 chronic leukemia Diseases 0.000 description 1
- 201000010903 chronic neutrophilic leukemia Diseases 0.000 description 1
- 101150111834 cht gene Proteins 0.000 description 1
- 229960004912 cilastatin Drugs 0.000 description 1
- DHSUYTOATWAVLW-WFVMDLQDSA-N cilastatin Chemical compound CC1(C)C[C@@H]1C(=O)N\C(=C/CCCCSC[C@H](N)C(O)=O)C(O)=O DHSUYTOATWAVLW-WFVMDLQDSA-N 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- AGOYDEPGAOXOCK-KCBOHYOISA-N clarithromycin Chemical compound O([C@@H]1[C@@H](C)C(=O)O[C@@H]([C@@]([C@H](O)[C@@H](C)C(=O)[C@H](C)C[C@](C)([C@H](O[C@H]2[C@@H]([C@H](C[C@@H](C)O2)N(C)C)O)[C@H]1C)OC)(C)O)CC)[C@H]1C[C@@](C)(OC)[C@@H](O)[C@H](C)O1 AGOYDEPGAOXOCK-KCBOHYOISA-N 0.000 description 1
- 229960002626 clarithromycin Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- ACSIXWWBWUQEHA-UHFFFAOYSA-N clodronic acid Chemical compound OP(O)(=O)C(Cl)(Cl)P(O)(O)=O ACSIXWWBWUQEHA-UHFFFAOYSA-N 0.000 description 1
- 229960002286 clodronic acid Drugs 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 229940110456 cocoa butter Drugs 0.000 description 1
- 235000019868 cocoa butter Nutrition 0.000 description 1
- 229960001338 colchicine Drugs 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000004624 confocal microscopy Methods 0.000 description 1
- 210000002808 connective tissue Anatomy 0.000 description 1
- 108091036078 conserved sequence Proteins 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 239000008358 core component Substances 0.000 description 1
- 239000008120 corn starch Substances 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 229960001334 corticosteroids Drugs 0.000 description 1
- 239000006071 cream Substances 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 108010006226 cryptophycin Proteins 0.000 description 1
- 108010089438 cryptophycin 1 Proteins 0.000 description 1
- 108010090203 cryptophycin 8 Proteins 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000007850 degeneration Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 229960005052 demecolcine Drugs 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 1
- 239000008356 dextrose and sodium chloride injection Substances 0.000 description 1
- 230000009274 differential gene expression Effects 0.000 description 1
- 238000001152 differential interference contrast microscopy Methods 0.000 description 1
- QONQRTHLHBTMGP-UHFFFAOYSA-N digitoxigenin Natural products CC12CCC(C3(CCC(O)CC3CC3)C)C3C11OC1CC2C1=CC(=O)OC1 QONQRTHLHBTMGP-UHFFFAOYSA-N 0.000 description 1
- SHIBSTMRCDJXLN-KCZCNTNESA-N digoxigenin Chemical compound C1([C@@H]2[C@@]3([C@@](CC2)(O)[C@H]2[C@@H]([C@@]4(C)CC[C@H](O)C[C@H]4CC2)C[C@H]3O)C)=CC(=O)OC1 SHIBSTMRCDJXLN-KCZCNTNESA-N 0.000 description 1
- 239000001177 diphosphate Substances 0.000 description 1
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical class [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 1
- 235000011180 diphosphates Nutrition 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229940017825 dromostanolone Drugs 0.000 description 1
- NOTIQUSPUUHHEH-UXOVVSIBSA-N dromostanolone propionate Chemical compound C([C@@H]1CC2)C(=O)[C@H](C)C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H](OC(=O)CC)[C@@]2(C)CC1 NOTIQUSPUUHHEH-UXOVVSIBSA-N 0.000 description 1
- 229960005501 duocarmycin Drugs 0.000 description 1
- 229930184221 duocarmycin Natural products 0.000 description 1
- JMNJYGMAUMANNW-FIXZTSJVSA-N dynorphin a Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)CNC(=O)CNC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=CC=C1 JMNJYGMAUMANNW-FIXZTSJVSA-N 0.000 description 1
- 230000002500 effect on skin Effects 0.000 description 1
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 description 1
- 238000010291 electrical method Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 1
- 210000002615 epidermis Anatomy 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 229950002973 epitiostanol Drugs 0.000 description 1
- 229960001433 erlotinib Drugs 0.000 description 1
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 108020004067 estrogen-related receptors Proteins 0.000 description 1
- 235000019325 ethyl cellulose Nutrition 0.000 description 1
- 229920001249 ethyl cellulose Polymers 0.000 description 1
- 229960005237 etoglucid Drugs 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 230000005713 exacerbation Effects 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 230000004720 fertilization Effects 0.000 description 1
- 210000004700 fetal blood Anatomy 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 101150029652 fli-1 gene Proteins 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 229960000961 floxuridine Drugs 0.000 description 1
- ODKNJVUHOIMIIZ-RRKCRQDMSA-N floxuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ODKNJVUHOIMIIZ-RRKCRQDMSA-N 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- 108010021843 fluorescent protein 583 Proteins 0.000 description 1
- 239000006260 foam Substances 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 229960004783 fotemustine Drugs 0.000 description 1
- YAKWPXVTIGTRJH-UHFFFAOYSA-N fotemustine Chemical compound CCOP(=O)(OCC)C(C)NC(=O)N(CCCl)N=O YAKWPXVTIGTRJH-UHFFFAOYSA-N 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 231100000221 frame shift mutation induction Toxicity 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 239000012595 freezing medium Substances 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 229940044658 gallium nitrate Drugs 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000001879 gelation Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 238000011331 genomic analysis Methods 0.000 description 1
- 229910052732 germanium Inorganic materials 0.000 description 1
- GNPVGFCGXDBREM-UHFFFAOYSA-N germanium atom Chemical compound [Ge] GNPVGFCGXDBREM-UHFFFAOYSA-N 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 208000035474 group of disease Diseases 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 108091008634 hepatocyte nuclear factors 4 Proteins 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 102000051882 human ETS1 Human genes 0.000 description 1
- 102000050757 human FLI1 Human genes 0.000 description 1
- 102000048816 human NR2F2 Human genes 0.000 description 1
- 102000046668 human RXRA Human genes 0.000 description 1
- 102000048688 human SOX18 Human genes 0.000 description 1
- 102000052241 human SOX7 Human genes 0.000 description 1
- 239000003906 humectant Substances 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- 229960001330 hydroxycarbamide Drugs 0.000 description 1
- 229960001680 ibuprofen Drugs 0.000 description 1
- 229940099279 idamycin Drugs 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 208000026278 immune system disease Diseases 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- DBIGHPPNXATHOF-UHFFFAOYSA-N improsulfan Chemical compound CS(=O)(=O)OCCCNCCCOS(C)(=O)=O DBIGHPPNXATHOF-UHFFFAOYSA-N 0.000 description 1
- 229950008097 improsulfan Drugs 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000012750 in vivo screening Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 238000011221 initial treatment Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 230000007794 irritation Effects 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 229940074928 isopropyl myristate Drugs 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 229960004891 lapatinib Drugs 0.000 description 1
- 229960000681 leflunomide Drugs 0.000 description 1
- VHOGYURTWQBHIL-UHFFFAOYSA-N leflunomide Chemical compound O1N=CC(C(=O)NC=2C=CC(=CC=2)C(F)(F)F)=C1C VHOGYURTWQBHIL-UHFFFAOYSA-N 0.000 description 1
- 229940115286 lentinan Drugs 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 229960004194 lidocaine Drugs 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000010859 live-cell imaging Methods 0.000 description 1
- 108091008780 liver X receptor-like Proteins 0.000 description 1
- 102000027528 liver X receptor-like Human genes 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 230000001926 lymphatic effect Effects 0.000 description 1
- 210000003738 lymphoid progenitor cell Anatomy 0.000 description 1
- 230000001320 lysogenic effect Effects 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- VTHJTEIRLNZDEV-UHFFFAOYSA-L magnesium dihydroxide Chemical compound [OH-].[OH-].[Mg+2] VTHJTEIRLNZDEV-UHFFFAOYSA-L 0.000 description 1
- 239000000347 magnesium hydroxide Substances 0.000 description 1
- 229910001862 magnesium hydroxide Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- 229960002868 mechlorethamine hydrochloride Drugs 0.000 description 1
- QZIQJVCYUQZDIR-UHFFFAOYSA-N mechlorethamine hydrochloride Chemical compound Cl.ClCCN(C)CCCl QZIQJVCYUQZDIR-UHFFFAOYSA-N 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 210000000135 megakaryocyte-erythroid progenitor cell Anatomy 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- VJRAUFKOOPNFIQ-TVEKBUMESA-N methyl (1r,2r,4s)-4-[(2r,4s,5s,6s)-5-[(2s,4s,5s,6s)-5-[(2s,4s,5s,6s)-4,5-dihydroxy-6-methyloxan-2-yl]oxy-4-hydroxy-6-methyloxan-2-yl]oxy-4-(dimethylamino)-6-methyloxan-2-yl]oxy-2-ethyl-2,5,7,10-tetrahydroxy-6,11-dioxo-3,4-dihydro-1h-tetracene-1-carboxylat Chemical compound O([C@H]1[C@@H](O)C[C@@H](O[C@H]1C)O[C@H]1[C@H](C[C@@H](O[C@H]1C)O[C@H]1C[C@]([C@@H](C2=CC=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C(O)=C21)C(=O)OC)(O)CC)N(C)C)[C@H]1C[C@H](O)[C@H](O)[C@H](C)O1 VJRAUFKOOPNFIQ-TVEKBUMESA-N 0.000 description 1
- 229960004584 methylprednisolone Drugs 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 229960005485 mitobronitol Drugs 0.000 description 1
- 229960003539 mitoguazone Drugs 0.000 description 1
- MXWHMTNPTTVWDM-NXOFHUPFSA-N mitoguazone Chemical compound NC(N)=N\N=C(/C)\C=N\N=C(N)N MXWHMTNPTTVWDM-NXOFHUPFSA-N 0.000 description 1
- VFKZTMPDYBFSTM-GUCUJZIJSA-N mitolactol Chemical compound BrC[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-GUCUJZIJSA-N 0.000 description 1
- 229950010913 mitolactol Drugs 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 230000011278 mitosis Effects 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 239000006082 mold release agent Substances 0.000 description 1
- 230000003990 molecular pathway Effects 0.000 description 1
- 229960005181 morphine Drugs 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- RTGDFNSFWBGLEC-SYZQJQIISA-N mycophenolate mofetil Chemical compound COC1=C(C)C=2COC(=O)C=2C(O)=C1C\C=C(/C)CCC(=O)OCCN1CCOCC1 RTGDFNSFWBGLEC-SYZQJQIISA-N 0.000 description 1
- 229960004866 mycophenolate mofetil Drugs 0.000 description 1
- 210000003643 myeloid progenitor cell Anatomy 0.000 description 1
- NJSMWLQOCQIOPE-OCHFTUDZSA-N n-[(e)-[10-[(e)-(4,5-dihydro-1h-imidazol-2-ylhydrazinylidene)methyl]anthracen-9-yl]methylideneamino]-4,5-dihydro-1h-imidazol-2-amine Chemical compound N1CCN=C1N\N=C\C(C1=CC=CC=C11)=C(C=CC=C2)C2=C1\C=N\NC1=NCCN1 NJSMWLQOCQIOPE-OCHFTUDZSA-N 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- 229960002009 naproxen Drugs 0.000 description 1
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical compound C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 description 1
- 230000037125 natural defense Effects 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 229940086322 navelbine Drugs 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000007472 neurodevelopment Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 230000036565 night sweats Effects 0.000 description 1
- 206010029410 night sweats Diseases 0.000 description 1
- YMVWGSQGCWCDGW-UHFFFAOYSA-N nitracrine Chemical compound C1=CC([N+]([O-])=O)=C2C(NCCCN(C)C)=C(C=CC=C3)C3=NC2=C1 YMVWGSQGCWCDGW-UHFFFAOYSA-N 0.000 description 1
- 229950008607 nitracrine Drugs 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 239000000041 non-steroidal anti-inflammatory agent Substances 0.000 description 1
- 239000002687 nonaqueous vehicle Substances 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002674 ointment Substances 0.000 description 1
- 238000006384 oligomerization reaction Methods 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- CZDBNBLGZNWKMC-MWQNXGTOSA-N olivomycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1)O[C@H]1O[C@@H](C)[C@H](O)[C@@H](OC2O[C@@H](C)[C@H](O)[C@@H](O)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@H](O)[C@H](OC)[C@H](C)O1 CZDBNBLGZNWKMC-MWQNXGTOSA-N 0.000 description 1
- 229950005848 olivomycin Drugs 0.000 description 1
- 238000001543 one-way ANOVA Methods 0.000 description 1
- 230000005868 ontogenesis Effects 0.000 description 1
- 229940005483 opioid analgesics Drugs 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 229960002085 oxycodone Drugs 0.000 description 1
- LSQZJLSUYDQPKJ-UHFFFAOYSA-N p-Hydroxyampicillin Natural products O=C1N2C(C(O)=O)C(C)(C)SC2C1NC(=O)C(N)C1=CC=C(O)C=C1 LSQZJLSUYDQPKJ-UHFFFAOYSA-N 0.000 description 1
- 238000002638 palliative care Methods 0.000 description 1
- VREZDOWOLGNDPW-UHFFFAOYSA-N pancratistatine Natural products C1=C2C3C(O)C(O)C(O)C(O)C3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-UHFFFAOYSA-N 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000010412 perfusion Effects 0.000 description 1
- 230000010399 physical interaction Effects 0.000 description 1
- 229960000952 pipobroman Drugs 0.000 description 1
- NJBFOOCLYDNZJN-UHFFFAOYSA-N pipobroman Chemical compound BrCCC(=O)N1CCN(C(=O)CCBr)CC1 NJBFOOCLYDNZJN-UHFFFAOYSA-N 0.000 description 1
- NUKCGLDCWQXYOQ-UHFFFAOYSA-N piposulfan Chemical compound CS(=O)(=O)OCCC(=O)N1CCN(C(=O)CCOS(C)(=O)=O)CC1 NUKCGLDCWQXYOQ-UHFFFAOYSA-N 0.000 description 1
- 229950001100 piposulfan Drugs 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 150000003057 platinum Chemical class 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 229920000729 poly(L-lysine) polymer Polymers 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 150000004804 polysaccharides Chemical class 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 208000007232 portal hypertension Diseases 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 229920001592 potato starch Polymers 0.000 description 1
- 230000003334 potential effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 229960005205 prednisolone Drugs 0.000 description 1
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 description 1
- 229960004618 prednisone Drugs 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000005522 programmed cell death Effects 0.000 description 1
- 239000002325 prokinetic agent Substances 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 108010008359 protein kinase C lambda Proteins 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 230000020978 protein processing Effects 0.000 description 1
- 230000004850 protein–protein interaction Effects 0.000 description 1
- 108010008929 proto-oncogene protein Spi-1 Proteins 0.000 description 1
- WOLQREOUPKZMEX-UHFFFAOYSA-N pteroyltriglutamic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(=O)NC(CCC(=O)NC(CCC(O)=O)C(O)=O)C(O)=O)C(O)=O)C=C1 WOLQREOUPKZMEX-UHFFFAOYSA-N 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 125000000561 purinyl group Chemical group N1=C(N=C2N=CNC2=C1)* 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 229930183794 quinomycin Natural products 0.000 description 1
- 108700038839 quinomycin Proteins 0.000 description 1
- 239000002516 radical scavenger Substances 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 229960002185 ranimustine Drugs 0.000 description 1
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 1
- BMKDZUISNHGIBY-UHFFFAOYSA-N razoxane Chemical compound C1C(=O)NC(=O)CN1C(C)CN1CC(=O)NC(=O)C1 BMKDZUISNHGIBY-UHFFFAOYSA-N 0.000 description 1
- 229960000460 razoxane Drugs 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022983 regulation of cell cycle Effects 0.000 description 1
- 230000009703 regulation of cell differentiation Effects 0.000 description 1
- 238000001403 relative X-ray reflectometry Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 150000004492 retinoid derivatives Chemical class 0.000 description 1
- 229960003471 retinol Drugs 0.000 description 1
- 235000020944 retinol Nutrition 0.000 description 1
- 239000011607 retinol Substances 0.000 description 1
- OWPCHSCAPHNHAV-LMONGJCWSA-N rhizoxin Chemical compound C/C([C@H](OC)[C@@H](C)[C@@H]1C[C@H](O)[C@]2(C)O[C@@H]2/C=C/[C@@H](C)[C@]2([H])OC(=O)C[C@@](C2)(C[C@@H]2O[C@H]2C(=O)O1)[H])=C\C=C\C(\C)=C\C1=COC(C)=N1 OWPCHSCAPHNHAV-LMONGJCWSA-N 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 229950004892 rodorubicin Drugs 0.000 description 1
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 description 1
- 235000005713 safflower oil Nutrition 0.000 description 1
- 239000003813 safflower oil Substances 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 229930182947 sarcodictyin Natural products 0.000 description 1
- 230000037390 scarring Effects 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000009097 single-agent therapy Methods 0.000 description 1
- 229960002930 sirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 1
- 210000003625 skull Anatomy 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000008354 sodium chloride injection Substances 0.000 description 1
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 229950006315 spirogermanium Drugs 0.000 description 1
- ICXJVZHDZFXYQC-UHFFFAOYSA-N spongistatin 1 Natural products OC1C(O2)(O)CC(O)C(C)C2CCCC=CC(O2)CC(O)CC2(O2)CC(OC)CC2CC(=O)C(C)C(OC(C)=O)C(C)C(=C)CC(O2)CC(C)(O)CC2(O2)CC(OC(C)=O)CC2CC(=O)OC2C(O)C(CC(=C)CC(O)C=CC(Cl)=C)OC1C2C ICXJVZHDZFXYQC-UHFFFAOYSA-N 0.000 description 1
- 238000012289 standard assay Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 210000000603 stem cell niche Anatomy 0.000 description 1
- 239000008223 sterile water Substances 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- NCEXYHBECQHGNR-QZQOTICOSA-N sulfasalazine Chemical compound C1=C(O)C(C(=O)O)=CC(\N=N\C=2C=CC(=CC=2)S(=O)(=O)NC=2N=CC=CC=2)=C1 NCEXYHBECQHGNR-QZQOTICOSA-N 0.000 description 1
- NCEXYHBECQHGNR-UHFFFAOYSA-N sulfasalazine Natural products C1=C(O)C(C(=O)O)=CC(N=NC=2C=CC(=CC=2)S(=O)(=O)NC=2N=CC=CC=2)=C1 NCEXYHBECQHGNR-UHFFFAOYSA-N 0.000 description 1
- 229960001940 sulfasalazine Drugs 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 230000035900 sweating Effects 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 229960004964 temozolomide Drugs 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 229960005353 testolactone Drugs 0.000 description 1
- BPEWUONYVDABNZ-DZBHQSCQSA-N testolactone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(OC(=O)CC4)[C@@H]4[C@@H]3CCC2=C1 BPEWUONYVDABNZ-DZBHQSCQSA-N 0.000 description 1
- 206010043554 thrombocytopenia Diseases 0.000 description 1
- 239000005495 thyroid hormone Substances 0.000 description 1
- 229940036555 thyroid hormone Drugs 0.000 description 1
- 102000004217 thyroid hormone receptors Human genes 0.000 description 1
- 108090000721 thyroid hormone receptors Proteins 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000006276 transfer reaction Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- IUCJMVBFZDHPDX-UHFFFAOYSA-N tretamine Chemical compound C1CN1C1=NC(N2CC2)=NC(N2CC2)=N1 IUCJMVBFZDHPDX-UHFFFAOYSA-N 0.000 description 1
- 229950001353 tretamine Drugs 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- 229960004560 triaziquone Drugs 0.000 description 1
- PXSOHRWMIRDKMP-UHFFFAOYSA-N triaziquone Chemical compound O=C1C(N2CC2)=C(N2CC2)C(=O)C=C1N1CC1 PXSOHRWMIRDKMP-UHFFFAOYSA-N 0.000 description 1
- 229930013292 trichothecene Natural products 0.000 description 1
- 150000003327 trichothecene derivatives Chemical class 0.000 description 1
- NOYPYLRCIDNJJB-UHFFFAOYSA-N trimetrexate Chemical compound COC1=C(OC)C(OC)=CC(NCC=2C(=C3C(N)=NC(N)=NC3=CC=2)C)=C1 NOYPYLRCIDNJJB-UHFFFAOYSA-N 0.000 description 1
- 229960001099 trimetrexate Drugs 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 229960000875 trofosfamide Drugs 0.000 description 1
- UMKFEPPTGMDVMI-UHFFFAOYSA-N trofosfamide Chemical compound ClCCN(CCCl)P1(=O)OCCCN1CCCl UMKFEPPTGMDVMI-UHFFFAOYSA-N 0.000 description 1
- HDZZVAMISRMYHH-LITAXDCLSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@@H](CO)[C@H](O)[C@H]1O HDZZVAMISRMYHH-LITAXDCLSA-N 0.000 description 1
- 229940094060 tykerb Drugs 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- SPDZFJLQFWSJGA-UHFFFAOYSA-N uredepa Chemical compound C1CN1P(=O)(NC(=O)OCC)N1CC1 SPDZFJLQFWSJGA-UHFFFAOYSA-N 0.000 description 1
- 229950006929 uredepa Drugs 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- GBABOYUKABKIAF-IELIFDKJSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-IELIFDKJSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- CILBMBUYJCWATM-PYGJLNRPSA-N vinorelbine ditartrate Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O.OC(=O)[C@H](O)[C@@H](O)C(O)=O.C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC CILBMBUYJCWATM-PYGJLNRPSA-N 0.000 description 1
- 239000000277 virosome Substances 0.000 description 1
- 108091008781 vitamin D receptor-like Proteins 0.000 description 1
- 102000027529 vitamin D receptor-like Human genes 0.000 description 1
- 229960000237 vorinostat Drugs 0.000 description 1
- WAEXFXRVDQXREF-UHFFFAOYSA-N vorinostat Chemical compound ONC(=O)CCCCCCC(=O)NC1=CC=CC=C1 WAEXFXRVDQXREF-UHFFFAOYSA-N 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 239000008136 water-miscible vehicle Substances 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 108700028382 zebrafish Etv2 Proteins 0.000 description 1
- 108700033804 zebrafish Sox18 Proteins 0.000 description 1
- 108700024526 zebrafish sox32 Proteins 0.000 description 1
Images




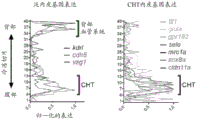





























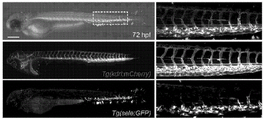









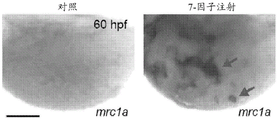








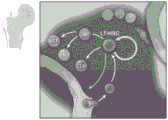









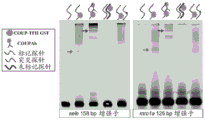









Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/069—Vascular Endothelial cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0647—Haematopoietic stem cells; Uncommitted or multipotent progenitors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/28—Bone marrow; Haematopoietic stem cells; Mesenchymal stem cells of any origin, e.g. adipose-derived stem cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/44—Vessels; Vascular smooth muscle cells; Endothelial cells; Endothelial progenitor cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/10—Cells modified by introduction of foreign genetic material
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/30—Hormones
- C12N2501/38—Hormones with nuclear receptors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/60—Transcription factors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/60—Transcription factors
- C12N2501/602—Sox-2
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2502/00—Coculture with; Conditioned medium produced by
- C12N2502/11—Coculture with; Conditioned medium produced by blood or immune system cells
- C12N2502/1171—Haematopoietic stem cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2502/00—Coculture with; Conditioned medium produced by
- C12N2502/28—Vascular endothelial cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Chemical & Material Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Cell Biology (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Developmental Biology & Embryology (AREA)
- Immunology (AREA)
- Vascular Medicine (AREA)
- Hematology (AREA)
- Veterinary Medicine (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Medicinal Chemistry (AREA)
- Virology (AREA)
- Pharmacology & Pharmacy (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
本文所述的技术涉及产生内皮龛细胞的组合物和方法。本文所述技术的实施方案包括与产生或工程化内皮龛细胞相关的组合物、试剂盒、载体和方法。一方面包括产生/工程化内皮龛细胞的方法,其包括在内皮细胞中表达一种或多种转录因子,其中所述一种或多种转录因子来自Ets家族、Sox家族和/或核激素(NHR)家族。
Description
相关申请的交叉引用
本申请根据35 U.S.C§119(e)要求2018年3月23日提交的美国临时申请第62/647,433号的优先权,其内容以其整体并入本文中。
政府支持
本发明是在国立卫生研究院授予的资助号DK111790和HL048801 下,由政府支持作出的。政府享有本发明的某些权利。
序列表
本申请包含通过EFS-Web以ASCII格式提交的序列表,并且以其整体在此并入。在2019年3月22日创建的所述ASCII副本被命名为 701039-091810-seq_ST25.txt,大小为32536字节。
技术领域
本文所述的技术涉及产生内皮龛细胞的组合物和方法。
背景
造血干细胞和祖细胞(HSPC)是移植后能够重建整个血液系统的罕见细胞群。作为骨髓移植物的功能单位,这些细胞为许多血液和免疫疾病提供了有效性治疗。不幸的是,移植对于许多个体,特别是那些缺乏免疫匹配供体的个体,不是可行的治疗选择。血液学研究的长期目标是在体外培养和扩增用于移植和/或遗传修饰的HSPC。尽管脐带血来源的 HSPC在体外扩增方面有一定程度的适应性,但在没有龛信号的情况下维持和诱导成体来源的HSPC的自我更新已被证明是具有挑战性的。
在试图概述体内支持HSPC的微环境或“龛”的方面,针对体外扩增的策略具有与支持细胞共培养的HSPC。在成体的骨髓中,认为多种细胞类型均包括HSPC龛,其中主要的贡献因子是内皮细胞(EC)和血管周间充质基质细胞。骨髓中不同内皮细胞亚型可差异调节HSPC稳态。动脉EC(AEC)的渗透性较低并且被认为促进HSPC静止,而血窦EC(SEC) 是渗漏的并且支持HSPC的分化和动员。此外,在骨髓抑制后的造血恢复期间,EC在多谱系造血的龛再造和重建中起关键作用。在胚胎发育期间和在诱导诸如肝脏、脾和头骨的组织中的髓外造血的应激条件下, HSPC也可被支持在骨髓外。如在骨髓中一样,认为EC在这些组织中作为HSPC龛的关键核心成分发挥作用。
研究人员集中于这样的体外培养物的开发,其中HSPC可以在实验室中与支持用于随后在移植中使用的HSPC的维持或扩增的其它细胞类型一起生长。然而,迄今为止,这些体外培养物仅仅是适度成功的。
概述
在斑马鱼胚胎的血管HSPC龛的研究中,研究了在内源性龛内皮细胞中正常表达的转录因子(来自Ets、Sox和核激素家族)的组合。当这些相同转录因子的人直系同源物被异位表达时,在斑马鱼胚胎中产生异位血管龛,HSPC被募集和维持在该异位血管龛处。
作为将这些发现转化成临床应用的步骤,转录因子(其最初在斑马鱼研究中鉴定)可以在人内皮细胞中表达,以将这些细胞重新编程成HSPC 龛样身份。这些龛内皮细胞可用于与HSPC共培养,以扩大HSPC数量或延长培养时间,用于随后的移植。
例如,已知结合Ets、Sox和核激素基序的转录因子可以在龛内皮细胞中表达。在Ets家族中,这些因子包括etv2、fli1a和Ets1;其中相应的人因子是ETV2、FLI1和ETS1。在Sox家族中,这些转录因子包括sox18 和sox7;其中相应的人因子是SOX7和SOX18。在核激素家族中,这些转录因子包括rxraa和nr2f2;其中相应的人因子是RXRA和NR2R2。
本发明提供了制备合成的龛内皮细胞以刺激血液干细胞的方法。转录因子包括Ets家族:etv2、fli1a、ets1;SOX家族:sox18、sox7和核激素家族:rxraa、nr2f2以及相应的人因子:ETV2、FLI1、ETS1、SOX7、 SOX18、RXRA和NR2F2。
所述方法包括在内皮细胞(例如人)中表达转录因子以将这些细胞重新编程为HSPC龛样身份。
在另一个实施方案中,为了扩大HSPC数量或延长培养时间,将龛内皮细胞用于与HSPC共培养,以随后用于移植。
一个方面提供了产生/工程化内皮龛细胞的方法,其包括在内皮细胞中表达一种或多种转录因子,其中所述一种或多种转录因子来自Ets家族、Sox家族和/或核激素受体家族。
另一方面提供了工程化的内皮龛细胞,其包含编码一种或多种转录因子的一种或多种外源核酸序列,其中所述一种或多种转录因子来自Ets 家族、Sox家族和/或核激素家族。
另一方面提供了包含本文所述的工程化内皮龛的组合物。
另一方面提供了培养HSPC的方法,所述方法包括在存在工程化的内皮龛细胞群的情况下培养HSPC。
另一方面提供了治疗受试者的方法,所述方法包括将包含HSPC和工程化的内皮龛细胞群的组合物移植到受试者中。
另一方面提供了增强HSPC植入的方法,所述方法包括向有需要的受试者施用包含HSPC和工程化的内皮龛细胞群的组合物。
另一方面提供了包含工程化的内皮龛细胞和HSPC的共培养物。
另一方面提供了用于培养HSPC的试剂盒,所述试剂盒包含:工程化的内皮龛细胞群,试剂及其使用说明书。
另一方面提供了用于产生工程化的内皮龛细胞的试剂盒,其包含载体及其使用说明书,所述载体包含编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列。
另一方面提供了产生异位血管龛的方法,所述方法包括将工程化的内皮龛细胞施用于有需要的受试者的靶位点。
另一方面提供了用于髓外造血的方法,所述方法包括将工程化龛内皮细胞移植到受试者中骨髓外的位置(例如,前臂)处,从而产生合成龛。
另一方面提供了载体,其包含与启动子可操作地连接的编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列。
附图的简要说明
图1A-图1E是显示胎儿HSPC龛中内皮表达特征的一系列图像和图。 (图1A)示意图说明斑马鱼胚胎的造血组织(顶部)和用于在CHT上进行 RNA断层摄影术(tomo-seq)的切片策略(底部;显示了携带HSPC标志物 cd41:GFP和runx1:mCherry的双转基因胚胎)。(图1B)示意横截面和(图 1B续)分层聚类热图揭示基因表达的簇,其对应于沿斑马鱼尾背腹轴的不同组织。(图1C)示意图描述了使用kdr1:GFP转基因胚胎和FACS从整个胚胎中分离EC以通过RNA-seq分析的策略。(图1D)显示了泛内皮表达基因(左)和CHT EC富集的基因(右)的各个tomo-seq表达痕迹。(图1E) 图像显示了通过Tomo-seq和组织特异性RNA-seq鉴定的泛内皮基因 kdr1(顶部)和CHT EC富集的基因的整体原位杂交(WISH)。箭头指向背部血管系统中的表达,楔形符号指向CHT中的表达。除非另有说明,否则比例尺表示250μm。
图2A-图2C是显示内皮龛特异性顺式调节元件的一系列图像和图。 (图2A)图像和示意图描述了从mrc1a:GFP,kdr1:mCherry双阳性胚胎中分离的四个细胞群,用于ATAC-seq分析。(图2B)基因痕迹显示在 mCherry+;GFP+CHT EC级分中唯一开放的染色质区域(方框和箭头)。(图 2C)图像显示了注射了对应于图2B中方框区域的CHT EC增强子-GFP报告基因构建体的胚胎。楔形符号指向CHT EC中的GFP表达。除非另有说明,否则比例尺表示250μm。
图3A-图3F是显示Ets、Sox和NHR结合位点是龛EC中选择性表达所必需的一系列图像和图。(图3A)基因痕迹显示在双阳性CHT EC级分中唯一开放,而在其它三个细胞群中则不是的mrc1a上游的染色质区域(方框和下面的箭头)。条形表示用于产生mrc1a:GFP报告基因转基因的 125bp的增强子序列和1.3kb的序列的位置。(图3B)图像显示在注射了与最小启动子和GFP连接的125bp的增强子序列的F0胚胎中的瞬时GFP 表达。(图3C)图像显示同时注射kdr1:mCherry和mrc1a 125bp:GFP质粒的F0胚胎。(图3D)图像显示表达稳定整合了mrc1a 125bp:GFP转基因的胚胎。(图3E)显示了125bp mrc1a增强子的野生型序列(参见例如SEQ ID NO:12),其注释突出了Ets、Sox和NHR结合基序。示意图描述了增强子-报告基因构建体,其中每一类基序或控制区被突变靶向。X表示靶位点的位置。mp-GFP:与GFP融合的小鼠β-珠蛋白最小启动子。(图3F) 图报道了在注射野生型序列或mrc1a 125bp(顶部)或sele158bp(底部)增强子的突变变体后,在CHT EC中具有GFP表达的胚胎的频率。将数据归一化至每个实验的相应野生型对照(对于mrc1a 125bp增强子为 44%(155/356)和对于sele158bp增强子为23%(176/775))。平均值+/-平均值的标准误差(s.e.m.),单向ANOVA;**P<0.01,***P<0.001。除非另有说明,否则比例尺表示250μm。
图4A-图4F是显示所定义的因子的过表达诱导CHT外的异位血管基因表达的一系列图像和图。(图4A)示意图描述了在转录因子过表达实验中使用的策略。(图4B)图像显示了用对照DNA(左)或来自Ets、Sox和 NHR家族的7种转录因子(FLI1、ETV2、ETS1、SOX7、SOX18、Nr2f2 和RXRA)的集合(右)注射,然后通过针对mrc1a(顶部)或sele(底部)的 WISH染色的胚胎。箭头表示异位表达的区域,楔形符号指向图4A-4E 的所有图中的正常表达结构域。(图4C)图像显示注射有对照DNA或7- 因子集合的mrc1a:GFP;kdr1:mCherry双转基因胚胎。(图4D)注射含有 ETV2、SOX7和Nr2f2的3-因子集合导致mrc1a:GFP的异位表达(箭头)。 (图4E)图像显示对照胚胎(顶部)中,或注射含有ETV2、SOX7和Nr2f2(中部)或ETS1、SOX7和Nr2f2(底部)的3-因子集合后的针对mrc1a的WISH。 (图4F)图报道了在转录因子过表达后显示异位mrc1a表达的注射胚胎的百分比的定量。卡方检验;**P<0.01,***P<0.001。在图4B和图4E中比例尺表示250μm,在图4C和图4D中比例尺表示100μm。
图5A-5E是显示HSPC定位于异位龛内皮基因表达区域的一系列图像和图。(图5A)图像显示了定位于CHT外,位于注射了ETV2、SOX7 和Nr2f2的集合(顶部)或ETS1、SOX7和Nr2f2的集合(底部)的胚胎中背部异位mrc1a:GFP表达区域内的runx1:mCherry+HSPC。右边示出了每个通道的具有灰度级图像的插图放大图。箭头指向异位表达或定位,而楔形符号指向图5A-5E的所有图中的正常表达或定位。(图5B)针对runx1 的WISH显示HSPC在对照(顶部)和3因子注射的胚胎(底部)中的定位。(图5C)异位表达mrc1a:GFP的EC与cxcl12a:DsRed2+基质细胞相关,类似于CHT中的EC。星号表示cxcl12a:DsRed2的脊索表达。(图5D)延时系列示出了runx1:mCherry+HSPC最初到达CHT并且随后分裂。时间表示为hh:mm。(图5E)来自与图5D中不同的胚胎的延时系列显示 runx1:mCherry+HSPC分裂并迁移到循环中。在图5A-图5C中比例尺表示100μm,在图5D-图5E中比例尺表示30μm。
图6A-图6B是显示HSPC龛中保守的内皮表达特征的一系列图像和图。(图6A)热图显示29种CHT EC基因在包含成年斑马鱼肾骨髓的不同细胞群中的表达。光谱标度显示0(低)至1(高)的归一化表达。(图6B)热图显示来自不同发育阶段和出生后向成年期转变的小鼠不同器官的EC 中CHT EC基因的直系同源物的表达。箭头表示在各自发育阶段的造血组织。黑色括号表示在E14-17阶段的胎儿肝脏EC中,然后以后在成体骨髓中富集的基因。光谱标度报告z-分数。BM:骨髓。
图7A-7B是显示RNA断层摄影术和龛特异性内皮基因表达的一系列图像和图。(图7A)图显示各组织特异性基因的tomo-seq表达痕迹。在万维网的zfin.org上可获得显示35种CHT富集的基因的整体原位杂交 (WISH)的图像。(图7B)WISH证实了使用tomo-seq和组织特异性RNA-seq 的组合鉴定的CHT EC基因的CHT富集的表达(楔形符号)。除非另有说明,否则比例尺表示250μm。
图8A-图8E是显示GFP报告基因转基因选择性标记HSPC龛中的 EC的一系列图像和图。(图8A)图像显示携带泛内皮标志物kdr1:mCherry 和mrc1a:GFP转基因(其在CHT EC中选择性表达)的双转基因胚胎。方框区域的放大图显示在右边。(图8B)图像显示runx1:mCherry+HSPC与CHT 龛内的mrc1a:GFP+EC直接相互作用(箭头)。中间图显示了方框区域的放大图。另外的放大图(底部)显示了mrc1a:GFP+EC口袋中的HSPC。(图8C) cxcl12a:DsRed2+基质细胞与CHT中的mrc1a:GFP+EC密切相关。(图8D) 图像显示携带泛内皮标志物kdr1:mCherry和sele:GFP转基因(其在CHT EC中选择性表达)的双转基因胚胎。方框区域的放大图显示在右边。(图 8E)图像显示runx1:mCherry+HSPC与CHT龛内的sele:GFP+EC直接相互作用(箭头)。方框区域的放大图显示在右边。在图8A和图8D中比例尺表示250μm,在图8B、图8C和图8E中比例尺表示100μm。
图9A-图9C是显示泛内皮调节元件和全基因组基序富集分析的一系列图像和图。(图9A)基因痕迹显示了在mCherry+GFP+(CHT EC)和 mCherry+GFP-(非CHT EC)群体中都开放的染色质区域(方框和直箭头)。 (图9B)图像显示了注射了对应于图9A中方框区域的泛内皮增强子-GFP 报告基因构建体的胚胎。箭头指向非CHT EC中的GFP表达,楔形符号指向CHT EC中的表达。(图9C)图像显示了在CHT EC区(顶部)或泛内皮区(底部)内最富集的转录因子结合基序。除非另有说明,否则比例尺表示 250μm。
图10A-10E是显示CHT内皮顺式调节元件的一系列图像和图。(图 10A)图报道了注射mrc1A 125bp:GFP和kdr1:mCherry质粒的F0胚胎中内皮表达的解剖学位置。(图10B)基因痕迹显示了在双阳性CHT EC级分中唯一开放,而其它三个细胞群则不是的sele上游的染色质区域(方框和下面的箭头)。条形表示用于产生sele:GFP报告基因转基因的158bp的增强子序列和5.3kb序列的位置。(图10C)图像显示sele 158bp:GFP构建体的瞬时F0(顶部)和稳定的F2表达(底部)。(图10D)显示了158bp的sele增强子的野生型序列(参见例如,SEQ IDNO:13),注释突出了Ets、Sox和 NHR结合基序(顶部)。示意图描述了序列变体,其中每一类基序或控制区通过突变靶向。X表示靶位点的位置。mp-GFP:与GFP融合的小鼠β- 珠蛋白最小启动子。(图10E)图像显示了用重组Nr2f2-GST进行的电泳迁移率变动测定,所述重组Nr2f2-GST与跨越125bp的mrc1a(左两个凝胶) 或158bp的sele(右凝胶)增强子序列中存在的NHR基序的DNA序列一起孵育。箭头指向DNA:蛋白质结合,而楔形符号指向超迁移的DNA:蛋白质复合物。标记的DNA:蛋白质复合物被未标记的野生型探针超越(泳道4)而不被其中NHR基序被突变破坏的探针超越(带有星号的箭头)。除非另有说明,否则比例尺表示250μm。
图11A-11C是显示转录因子过表达诱导异位CHT内皮细胞程序的一系列图像和图。(图11A)图像显示针对对照(左)和注射7-因子的胚胎(右) 中的卵黄球上的mrc1a的WISH。箭头指向异位表达,楔形符号指向图11A-11C的所有图中的正常表达结构域。(图11B)图像显示了mrc1a:GFP 和kdr1:mCherry转基因在注射7-因子的胚胎的卵黄延伸部上的异位表达。方框区域的放大图显示在底部。(图11C)图像显示针对对照胚胎(左)和注射了ETV2、SOX7和Nr2f2的组合的胚胎(右)中的sele、gpr182和lgmn 的WISH。图11A-11C中的比例尺表示100μm。
图12A-图12D是显示CHT龛内皮基因表达通过转录因子过表达而被异位诱导的一系列图像和图。(图12A-12B)单独注射ETV2诱导内源性 mrc1a基因(图12A)和mrc1a:GFP转基因(图12B)的异位表达。箭头指向异位表达,黑色楔形符号指向图12A-12D中所有图的正常表达结构域。(图 12C)单独注射人ETV2诱导斑马鱼转录因子,包括sox7、sox18、fli1a和etv2的异位表达。(图12D)注射含有ETS1、SOX7和Nr2f2的3-因子集合导致mrc1a:GFP的异位表达。在图12A和图12C中比例尺表示250μm,在图12B和图12D中比例尺表示50μm。
图13A-13B是显示成体肾EC中龛内皮转基因表达的一系列图像和图。(图13A)图像显示了从kdrl:mCherry,mrc1a:GFP双转基因成年斑马鱼的肾脏解剖的血管系统的片段(白色箭头)。(图13B)图像显示通过分离自sele:GFP转基因鱼的成体肾的连续切片。切片用H&E(左)和针对GFP 的抗体(右)染色。黑色箭头指向GFP+血管内皮细胞。在图13A中比例尺表示50μm,在图13B中比例尺表示100μm。
图14是显示造血干细胞自我更新和分化的示意图。LT-HSC表示长期造血干细胞。CMP表示常见的骨髓祖细胞。MEP表示巨核细胞-红系祖细胞。GMP表示粒细胞-巨噬细胞祖细胞。CLP表示常见的淋巴祖细胞。
图15A-图15B是显示体内HSPC的龛定殖的可视化的一系列图像。图15A显示了背主动脉和尾部造血组织的可视化。图15B显示了被5个内皮细胞包围并附着于基质细胞的HSPC。
图16是显示使用RNA断层摄影术(tomo-seq)检测HSPC龛中基因表达的一系列图像。
图17是显示Tomo-seq+内皮RNA-seq如何鉴定龛内皮细胞内选择性富集的约20种基因的一系列图像和图。
图18是显示sele和mrc1a启动子-GFP融合物标记HSPC龛中的内皮细胞的一系列图像。
图19是显示靠近原始20种基因的特定ATAC-seq峰可以驱动龛内皮细胞中的表达的一系列图像。19种克隆的ATAC-seq峰中的13种可以驱动CHT内皮细胞中的GFP表达(当与最小启动子连接时)。
图20是显示龛内皮细胞的开放染色质中最富集的TF结合基序的图像。使用HOMER对6,710种独特的ATAC-seq峰进行基序富集分析。
图21是显示Ets、Sox和NHR位点对于158bp的sele增强子的龛表达是必需的一系列图像和图(参见例如SEQ ID NO:14)。
图22是显示Ets、Sox和NHR基序对于125bp的mrc1a增强子的龛表达是必需的一系列图像和图(参见例如SEQ ID NO:15)。
图23是显示小鼠TF可以在体外结合斑马鱼序列的一系列图像。破坏增强子:GFP表达的相同突变消除TF结合。
图24是显示已知结合Ets、Sox和NH基序的转录因子在龛内皮细胞中表达的图像。
图25是显示龛内皮细胞的重新编程的一系列图像。
图26是显示3-TF集合注射导致异位龛内皮基因表达的一系列图像和图。
图27A-图27C是显示异位血管补片可募集runx1+HSPC的一系列图像。
图28是显示HSPC龛内皮特征也在成体骨髓中的一系列图像和热图。
图29是显示在哺乳动物胎儿肝脏和骨髓中发现的类似的龛内皮特征的热图。
图30是显示HSPC龛的RNA断层摄影术产生以下数据的图:约20 种基因在HSPC龛内皮细胞中选择性富集;仅3种TF的异位表达可诱导龛内皮基因表达并募集HSPC;Ets、Sox和核激素基序是龛内皮细胞中表达所必需的。
详细描述
本文所述技术的实施方案包括与产生或工程化内皮龛细胞相关的组合物、试剂盒、载体和方法。一个方面包括产生/工程化内皮龛细胞的方法,包括在内皮细胞中表达一种或多种转录因子,其中所述一种或多种转录因子来自Ets家族、Sox家族和/或核激素受体(NHR)家族。
在一些实施方案中,至少一种转录因子选自Ets家族。在一些实施方案中,至少一种转录因子选自Sox家族。在一些实施方案中,至少一种转录因子选自NHR家族。
在一些实施方案中,至少一种转录因子选自Ets家族,并且至少一种转录因子选自Sox家族。在一些实施方案中,至少一种转录因子选自Ets 家族,并且至少一种转录因子选自NHR家族。在一些实施方案中,至少一种转录因子选自Sox家族,并且至少一种转录因子选自NHR家族。
在一些实施方案中,至少一种转录因子选自Ets家族,至少一种转录因子选自Sox家族,并且至少一种转录因子选自NHR家族。在一些实施方案中,至少一种转录因子选自Ets家族,至少一种转录因子选自Sox 家族,或至少一种转录因子选自NHR家族。
Ets家族
在任一方面的一些实施方案中,内皮龛细胞表达来自ETS家族的转录因子。ETS(E26转化特异性或E-26)家族是最大的转录因子家族之一,并且是动物特有的。ETS家族被分成12个亚家族:1)ELF(例如,ELF1、 ELF2/NERF、ELF4/MEF);2)ELG(例如,GABPα、ELG);3)ERG(例如, ERG、FL1、FEV);4)ERF(例如,ERF/PE2、ETV3/PE1);5)ESE(例如, ELF3/ESE1/ESX、ELF5/ESE2、ESE3/EHF);6)ETS(例如,ETS1、ETS、 POINTED);7)PDEF(例如,SPDEF/PDEF/PSE);8)PEA3(例如, ETV4/PEA3/E1AF、ETV5/ERM、ETV1/ER81);9)ERF71(例如, ETV2/ER71);10)SPI(例如,SPI1/PU.1、SPIB、SPIC);11)TCF(例如, ELK1、ELK4/SAP1、ELK3/NET/SAP2、LIN);12)TEL(例如,ETV6/TEL、 ETV7/TEL2、YAN)。
所有的ETS家族成员通过高度保守的DNA结合结构域,即ETS结构域来鉴定,所述ETS结构域是能够结合具有中心GGA(A/T)DNA序列的DNA位点的翼状螺旋-转角-螺旋结构。Ets家族的DNA基序也可以包含中心TTCCT序列(例如,在与第一基序互补的DNA链上)。除了DNA 结合功能,证据表明ETS结构域也参与蛋白质-蛋白质相互作用。
ETS家族存在于整个体内,并且参与多种功能,包括细胞分化、细胞周期控制、细胞迁移、细胞增殖、细胞凋亡(程序性细胞死亡)和血管生成的调节。
与内皮龛细胞相关的人Ets家族成员的非限制性实例包括ETV2、 FLI1和ETS1。斑马鱼中的相应因子包括etv2、fli1和ets1。
ETV2在本文中也可称为ETS变体2、ETS易位变体2、Ets相关蛋白71、Ets变体基因2、ETSRP71或ER71。
朋友白血病整合1转录因子(FLI1),也称为转录因子ERGB,是在人体中由FLI1基因编码的蛋白质。FLI1在本文中也可称为Fli-1原癌基因、 ETS转录因子、朋友白血病整合1转录因子、朋友白血病病毒整合1、转录因子ERGB、尤因肉瘤断点区、原癌基因Fli-1、BDPLT21、EWSR2或 SIC-1。
ETS1或蛋白C-ets-1是在人体中由ETS1基因编码的蛋白质。该基因编码的蛋白质属于ETS转录因子家族。ETS1在本文中也可被称为ETS 原癌基因1转录因子、禽类成红细胞增多症病毒E26(V-ETS)癌基因同源物-1、V-Ets禽类成红细胞增多症病毒E26癌基因同源物1、蛋白C-Ets-1、 EWSR2、P54、V-Ets禽类成红细胞增多症病毒E2癌基因同源物1、Ets 蛋白、C-Ets-1或ETS-1。
在任一方面的一些实施方案中,产生或工程化表达选自ETV2、FLI1 和ETS1的Ets家族成员的细胞。
在一些实施方案中,Ets基因或蛋白可以是ETV2或相应的斑马鱼 etv2。在一些实施方案中,Ets基因或蛋白可以是FLI1或相应的斑马鱼fli1。在一些实施方案中,Ets基因或蛋白可以是ETS1或相应的斑马鱼ets1。
在一些实施方案中,Ets基因或蛋白可以是ETV2和FLI1或相应的斑马鱼因子。在一些实施方案中,Ets基因或蛋白可以是ETV2和ETS1 或相应的斑马鱼因子。在一些实施方案中,Ets基因或蛋白可以是ETS1 和FLI1或相应的斑马鱼因子。在一些实施方案中,Ets基因或蛋白可以是ETV2、FLI1和ETS1或相应的斑马鱼因子。在一些实施方案中,Ets 基因或蛋白可以是ETV2、FLI1或ETS1或相应的斑马鱼因子。
本文所述多肽的氨基酸序列已针对不同物种如人,小鼠,大鼠和斑马鱼分配了NCBI登录号。具体而言,人ETV2(例如SEQ ID NO:1),人FLI1(例如SEQ ID NO:2)和人ETS1(例如SEQ ID NO:3)的氨基酸序列的非限制性实例的NCBI登录号包括在本文中。
SEQ ID NO:1(智人ETV2,NCBI登录号AAI40747,342个氨基酸 (aa):
MDLWNWDEASPQEVPPGNKLAGLEGAKLGFCFPDLALQGDTPT ATAETCWKGTSSSLASFPQLDWGSALLHPEVPWGAEPDSQALPWSGD WTDMACTAWDSWSGASQTLGPAPLGPIPAAGSEGAAGQNCVPVAGE ATSWSRAQAAGSNTSWDCSVGPDGDTYWGSGLGGEPRTDCTISWGG PAGPDCTTSWNPGLHAGGTTSLKRYQSSALTVCSEPSPQSDRASLARC PKTNHRGPIQLWQFLLELLHDGARSSCIRWTGNSREFQLCDPKEVARL WGERKPGMNYEKLSRGLRYYYYRRDIVRKSGGRKYTYRFGGRVPSL AYPDCAGGGRGAETQ
SEQ ID NO:2(智人FLI1,NCBI登录号AAH10115.1,452aa):
MDGTIKEALSVVSDDQSLFDSAYGAAAHLPKADMTASGSPDYG QPHKINPLPPQQEWINQPVRVNVKREYDHMNGSRESPVDCSVSKCSK LVGGGESNPMNYNSYMDEKNGPPPPNMTTNERRVIVPADPTLWTQEH VRQWLEWAIKEYSLMEIDTSFFQNMDGKELMNKEDFLRATTLYNTEV LLSHLSYLRESSLLAYNTTSHTDQSSRLSVKEDPSYDSVRRGAWGNNN MNSGLNKSPPLGGAQTISKNTEQRPQPDPYQILGPTSSRLANPGSGQIQ LWQFLLELLSDSANASCITWEGTNGEFKMTDPDEVARRWGERKSKPN MNYDKLSRALRYYDKNIMTKVHGKRYAYKFDFHGIAQALQPHPTESS MYKYYYYPSDISYMPSYHAHQQKVNFVPPHPSSMPVTSSSFFGAASQYWTSPTGGIYPNPNVPRHPNTHVPSHLGSYY
SEQ ID NO:3(智人ETS1,NCBI登录号CAG47050.1,441aa):
MKAAVDLKPTLTIIKTEKVDLELFPSPDMECADVPLLTPSSKEMM SQALKATFSGFTKEQQRLGIPKDPRQWTETHVRDWVMWAVNEFSLK GVDFQKFCMNGAALCALGKDCFLELAPDFVGDILWEHLEILQKEDVK PYQVNGVNPAYPESSRYTSDYFISYGIEHAQCVPPSEFSEPSFITESYQT LHPISSEELLSLKYENDYPSVILRDPLQTDTLQNDYFAIKQEVVTPDNM CMGRTSRGKLGGQDSFESIESYDSCDRLTQSWSSQSSFNSLQRVPSYD SFDSEDYPAALPNHKPKGTFKDYVRDRADLNKDKPVIPAAALAGYTG SGPIQLRQFLLLTDKSCQSFISWTGDGWEFKLSDPDEVARRWGKRKNK PKMNYEKLSRGLRYYDKNIIHKTAGKRYVYRFVCDLQSLLGYTPEEL HAMLDVKPDADE
在一些实施方案中,ETV2氨基酸或DNA序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更多相同。在一些实施方案中,FLI1氨基酸或DNA序列与天然或参考序列可以至少90%、至少 91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更多相同。在一些实施方案中,ETS氨基酸或DNA 序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更多相同。
SOX家族
SOX基因编码与DNA中的小沟结合的转录因子家族,并且属于以称为HMG-盒(对于高迁移率组)的同源序列为特征的基因超家族。该 HMG盒是在真核生物物种中高度保守的DNA结合结构域。已经在昆虫,线虫,两栖动物,爬行动物,鸟类和一系列哺乳动物中鉴定了同源物。
Sox基因被定义为含有参与性别决定的基因(称为SRY)的HMG盒,其位于Y染色体上(Sox代表Sry相关的HMG盒)。在人和小鼠中存在20 种SOX基因。根据HMG结构域和其它结构基序内的同源性以及根据功能测定将该家族分成亚组。在人体中,SOX组的成员包括:1)SoxA(例如, SRY);2)SoxB1(例如,SOX1、SOX2、SOX3);3)SoxB2(例如,SOX14、 SOX21);4)SoxC(例如,SOX4、SOX11、SOX12);5)SoxD(例如,SOX5、 SOX6、SOX13);6)SoxE(例如,SOX8、SOX9、SOX10);7)SoxF(例如, SOX7、SOX17、SOX18);8)SoxG(例如,SOX15);9)SoxH(例如,SOX30)。
发育上重要的Sox家族没有单一的功能,并且许多成员具有调节发育的几个不同方面的能力。虽然许多Sox基因参与性别决定,但一些基因在诸如神经元发育的过程中也是重要的。Sox蛋白与序列WWCAAW 和类似序列(W=A或T)结合。Sox家族的DNA基序也可以包含中心 ATTGT序列(例如,在与第一基序互补的DNA链上)。
与内皮龛细胞相关的人Sox家族成员的非限制性实例包括SOX18和 SOX7。斑马鱼或爪蟾中的相应因子包括sox18和sox7。
SOX18在本文中也可称为SRY-Box18、SRY(性别决定区Y)-Box18、转录因子SOX-18、SRY-Box18、HLTRS或HLTS。
SOX7在本文中也可称为SRY-Box7、SRY(性别决定区Y)-Box7、转录因子SOX-7或SRY-Box7。
在任一方面的一些实施方案中,产生或工程化表达选自SOX18和 SOX7的Sox家族成员的细胞。在一些实施方案中,Sox基因或蛋白可以是SOX18或相应的斑马鱼sox18或爪蟾SOX18。在一些实施方案中,Ets 基因或蛋白可以是SOX7或相应的斑马鱼sox7。在一些实施方案中,Sox 基因或蛋白可以是SOX18和SOX7或相应的斑马鱼或爪蟾因子。在一些实施方案中,Sox基因或蛋白可以是SOX18或SOX7或相应的斑马鱼或爪蟾因子。
本文所述多肽的氨基酸序列已针对不同物种如人,小鼠,大鼠和斑马鱼分配了NCBI登录号。特别地,人SOX18(例如SEQ ID NO:4),人 SOX7(例如SEQ ID NO:5)和爪蟾SOX18(例如SEQ ID NO:8)的氨基酸序列的非限制性实例的NCBI登录号包括在本文中。
SEQ ID NO:4(智人SOX18,NCBI登录号BAA94874.1,384aa):
MQRSPPGYGAQDDPPARRDCAWAPGHGAAADTRGLAAGPAALA APAPAPASPPSPQRSPPRSPEPGRYGLSPAGRGERQAADESRIRRPMNA FMVWAKDERKRLAQQNPDLHNAVLSKMLGKAWKELNAAEKRPFVE EAERLRVQHLRDHPNYKYRPRRKKQARKARRLEPGLLLPGLAPPQPP PEPFPAASGSARAFRELPPLGAEFDGLPTPERSPLDGLEPGEAAFFPPPA APEDCALRPFRAPYAPTELSRDPGGCYGAPLALRTAPPAAPLAGLYYG TLGTPGPYPGPLPPEAPPLEPLGPAADLWADVDLTEFDQYLNCSRTRPD APGLPYHVALAKLGPRAMSCPEESSLISALSDASVYSACISG
SEQ ID NO:5(智人SOX7,NCBI登录号,CAC84226.1,388aa):
MASLLGAYPWPEGLECPALDAELSDGQSPPAVPRPPGDKGSESRI RRPMNAFMVWAKDERKRLAVQNPDLHNAELSKMLGKSWKALTLSQ KRPYVDEAERLRLQHMQDYPNYKYRPRRKKQAKRLCKRVDPGFLLS SLSRDQNALPEKRSGSRGALGEKEDRGEYSPGTALPSLRGCYHEGPAG GGGGGTPSSVDTYPYGLPTPPEMSPLDVLEPEQTFFSSPCQEEHGHPR RIPHLPGHPYSPEYSPEYAPSPLHCSHPLGSLALGQSPGVSMMSPVPGC PPSPAYSPYSPATYHPLHSNLQAHLGQLSPPPEHPGFDALDQLSQVELL GDMDRNEFDQYLNTPGHPDSATGAMALSGHVPVSQVTPTGPTETSLI SVLADATYYNSYSVS
SEQ ID NO:8(热带爪蟾(Xenopus tropicalis)SOX18,NCI登录号: AAI67402.1,362aa):
MHRPEPSYCREEPTPCQGVNSTWVPPADTVPETSPTPSSPPAPDSP TPSPQPGYGYSPCEEKPGDPRIRRPMNAFMVWAKDERKRLAQQNPDL HNAVLSKMLGQSWKNLSSAEKRPFVEEAERLRVQHLQDHPNYKYRP RRKKQAKKLKRVDPSPLLRNEGYRGQAMANLSHFRDLHPLGGSGDL ESYGLPTPEMSPLDVVEPSEPAFFPPHMREEADPGPFRTYQHGVDFGQ EKTLREISLPYSSSPSHMGGFLRTPTASAFYNPHGGSPACTPLGQLSPPP EAPALEAMDHLGPAELWGDFDRNEFDQYLNMSRTQGPGYPFPMSKL GAPRTIPCEESSLISALSDASTAMYYTPCITG
在一些实施方案中,SOX7氨基酸或DNA序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更多相同。在一些实施方案中,SOX18氨基酸或DNA序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少 97%、至少98%、至少99%或更多相同。
NHR家族
核激素受体(NHR)家族,也称为核受体,是在负责感应类固醇和甲状腺激素以及某些其它分子的细胞内发现的一类蛋白质。作为响应,这些受体与其它蛋白质一起调节特定基因的表达,从而控制生物体的发育,体内平衡和代谢。核受体将它们与其它类型的受体区分开的独特性质是它们直接与基因组DNA相互作用并控制基因组DNA的表达的能力。因此,核受体在胚胎发育和成体体内平衡中起关键作用。NHR家族成员的 DNA基序的非限制性实例包括RRGGTCA,其中R表示嘌呤(例如A或 G)。
在人体中已经鉴定出至少48种核受体,分类为以下亚家族:1)甲状腺激素受体样(例如,甲状腺激素受体、视黄酸受体、过氧化物酶体增殖物激活受体、Rev-Erba、RAR相关孤儿受体、肝X受体样、维生素D受体样、具有两个DNA结合结构域的NR(RORA);2)类视黄醇X受体样(例如肝细胞核因子-4、类视黄醇X受体、睾丸受体、TLX、PNR、COUP、 EAR、RXRA、NR2F2);3)雌激素受体样(例如,雌激素受体、雌激素相关受体、3-酮基类固醇受体);4)神经生长因子IB样(例如NGFIB、NURR1、 NOR1);5)类固醇因子样(例如,SF1、LRH1);6)生殖细胞核因子样(例如 GCNF);7)杂核受体(例如,DX、SHP1)。
与内皮龛细胞相关的人NHR家族成员的非限制性实例包括RXRA 和NR2F2。斑马鱼中的相应因子包括rxraa和nr2f2。
RXRA是属于RXR转录因子组的核受体。RXRA在本文中也可称为类视黄醇X受体α、核受体亚家族2组B成员1、视黄酸受体RXR-α、 NR2B1、类视黄醇X核受体α或类视黄醇X受体α。
类视黄醇X受体(RXR)是由9-顺式视黄酸和9-顺式-13,14-二氢-视黄酸(其可能是主要的内源性哺乳动物RXR选择性激动剂)激活的一种核受体。存在分别由RXRA、RXRB、RXRG基因编码的三种视黄醇X受体(RXR):RXR-α、RXR-β和RXR-γ。RXR与包括CAR、FXR、LXR、PPAR、PXR、RAR、TR和VDR的亚家族1核受体异二聚化。与其它II型核受体一样,在不存在配体的情况下,RXR异二聚体结合与共阻遏蛋白复合的激素应答元件。激动剂配体与RXR的结合导致共阻遏物的解离和共激活蛋白的募集,其继而促进下游靶基因转录成mRNA和最终的蛋白质。
NR2F2是属于COUP转录因子组的核受体。NR2F2在本文中也可称为核受体亚家族2组F成员2、载脂蛋白A-I调节蛋白1、COUP转录因子II、COUP转录因子2、TFCOUP2、ARP-1、ARP1、鸡卵清蛋白上游启动子转录因子2、鸡卵清蛋白上游启动子转录因子I、核受体亚家族2 组F成员2、ADP-核糖基化因子相关蛋白1、载脂蛋白AI调节蛋白1、 COUP-TF II、COUPTFII、COUP-TF2、COUPTF2、COUPTFB、CHTD4、 NF-E3或SVP40。
鸡卵清蛋白上游启动子转录因子(COUP-TFs)蛋白是细胞内转录因子的核受体家族的成员。有两种COUP-TFs变体,分别标记为由NR2F1和 NR2F2基因编码的COUP-TFI和COUP-TFII。COUP-TFs在生物体的发育中起关键作用。
在任一方面的一些实施方案中,产生或工程化表达选自RXRA和 NR2F2的NHR家族成员的细胞。在一些实施方案中,NHR基因或蛋白可以是RXRA或相应的斑马鱼rxraa。在一些实施方案中,NHR基因或蛋白可以是NR2F2或相应的斑马鱼nr2f2。在一些实施方案中,NHR基因或蛋白可以是RXRA和NR2F2或相应的斑马鱼因子。在一些实施方案中,NHR基因或蛋白可以是RXRA或NR2F2或相应的斑马鱼因子。
本文所述多肽的氨基酸序列已针对不同物种如人,小鼠,大鼠和斑马鱼分配了NCBI登录号。具体而言,人RXRA(例如SEQ ID NO:6),人 NR2F2(例如SEQ ID NO:7)和斑马鱼Nr2f2(例如SEQ ID NO:9)的氨基酸序列的非限制性实例的NCBI登录号包括在本文中。
SEQ ID NO:6(智人RXRA同种型A,NCBI登录号J1.1,462aa):
MDTKHFLPLDFSTQVNSSLTSPTGRGSMAAPSLHPSLGPGIGSPGQ LHSPISTLSSPINGMGPPFSVISSPMGPHSMSVPTTPTLGFSTGSPQLSSP MNPVSSSEDIKPPLGLNGVLKVPAHPSGNMASFTKHICAICGDRSSGK HYGVYSCCKEGCKGFFKRT.VRKDLTYTCRDNKDCLIDKRQRNRCQY CRYQKCLAMGMKREAVQEERQRGKDRNENEVESTSSANEDMPVERI LEAELAVEPKTETYVEANMGLNPSSPNPVTNICQAADKQLFTLVEWA KRIPHFSELPLDDQVILLRAGWNELLIASFSHRSIAVKDGIL.LATGLHV HRNSAHSAGVGAIFDRVLTELVSKMRDMQMDKTELGCLRAIVLFNPD SKGLSNPAEVEALREKVYASLEAYCKHKYPEQPGRFAKLLLRLPALRSI GLKCLEHLFFFKLIGDTPIDTFLMEMLEAPHQMT
SEQ ID NO:7(智人NR2F2同种型A,NCBI登录号F1.1,414aa):
MAMVVSTWRDPQDEVPGSQGSQASQAPPVPGPPPGAPHTPQTPG QGGPASTPAQTAAGGQGGPGGPGSDKQQQQQQQHIECVVCGDKSSG KHYGQFTCEGCKSFFKRSVRRNLSYTCRANRNCPIDQHHRNQCQYCR LKKCLKVGMRREAVQRG.RMPPTQPTHGQFALTNGDPLNCHSYLSGYI SLRAEPYPTSRFGSQCMQPNNMGNICELAARMLFSAVEWARNIPFFPD LQITDQVALLRLTWSELFVLNAAQCSMPLHVAPLLAAAGLHASPMSA DRVAFMDHIRIFQEQVEKLKALHVDSAEYSCLKAIVLFTSDACGLSDV AHVESLQEKSQCALEEYVRSQYPNQPTRFGKLLLRLPSLRTVSSSVIEQ LFFVRLVGKTPIETLIRDMLLSGSSFNWPYMAIQ
SEQ ID NO:9(斑马鱼Nr2f2;NCBI登录号:AAI62484.1;428aa):
MAMVVWRGSQDDVAETHGTLSSQTQGGLSLPTPQPGQLGLTAS QVAPPTPQTPVQGPPNNNNNTQSTPTNQTTQSQSEKQQPQHIECVVCG DKSSGKHYGQFTCEGCKSFKRSVRRNLTYTCRANRNCPIDQHHRNQC QYCRLKKCLKVGMRREVSLFTAAVQRGRMPPTQPHHGQFALTNGDPL HCHSYLSGYISLLLRAEPYPTSRYGSQCMQPNNIMGNICELAARMLFS AVEWARNIPFFPDLQITDQVALLRLTWSELFVLNAAQCSMPLHVAPLL AAAGLHASPMSADRVVAFMDHIRIFQEQVEKLKALHVDSAEYSCLKA IVLFTSDACGLSDVAHVESLQEKSQCALEEYVRSQYPNQPTRFGKLLL RLPSLRTVSSSVIEQLFFVRLVGKTPIETLIRDMLLSGSSFNWPYMSIQ
在一些实施方案中,RXRA氨基酸或DNA序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更多相同。在一些实施方案中,NR2F2氨基酸或DNA序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少 97%、至少98%、至少99%或更多相同。
在一些实施方案中,转录因子可以选自ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA和NR2F2或相应的斑马鱼或爪蟾因子。在一些实施方案中,转录因子可以是ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或 NR2F2或相应的斑马鱼或爪蟾因子。在一些实施方案中,转录因子可以是ETV2、FLI1、ETS1、SOX18、SOX7、RXRA和NR2F2或相应的斑马鱼或爪蟾因子。
在一些实施方案中,转录因子可以是ETV2、SOX7和NR2F2或相应的斑马鱼或爪蟾因子。在一些实施方案中,转录因子可以是ETS1、 SOX7和NR2F2或相应的斑马鱼或爪蟾因子。在一些实施方案中,转录因子可以是单独的ETV2或相应的斑马鱼或爪蟾因子。
在一些实施方案中,转录因子可以是选自ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA和NR2F2或相应的斑马鱼或爪蟾因子的至少1种因子、至少2种因子、至少3种因子、至少4种因子、至少5种因子、至少6 种因子或至少7种因子。
在一些实施方案中,转录因子可以是ETV2和选自FLI1、ETS1、 SOX18、SOX7、RXRA和NR2F2或相应的斑马鱼或爪蟾因子的至少1 种因子。在一些实施方案中,转录因子可以是ETS1和选自ETV2、FLI1、 SOX18、SOX7、RXRA和NR2F2或相应的斑马鱼或爪蟾因子的至少1 种因子。
造血系统发育
造血系统,包括细胞群和分子途径的发育,在鱼和哺乳动物之间是高度保守的。HSPC起源于主动脉-生殖腺-中肾(AGM)区,然后迁移至暂时性胎儿龛,哺乳动物的胎儿肝脏或称为尾部造血组织(CHT)的鱼尾的血管丛。HSPC在迁移至成体龛——哺乳动物的骨髓或鱼的肾骨髓之前在这些发育位点中驻留和扩增数天。
CHT主要由间充质基质细胞包围的低流动性血窦组成。HSPC最初通过位于血管丛内并直接与cxcl12a+基质细胞相互作用而定居CHT龛。在特征性血管重构步骤中,内皮细胞(EC)重新组织形成围绕HSPC的支持口袋,其与基质细胞和可能的其它细胞类型一起形成干细胞的龛(围绕 HSPC的内皮细胞在本文中可称为内皮龛细胞)。在哺乳动物和斑马鱼中,特定的信号传导分子,粘附蛋白和转录因子已经参与介导龛中的干细胞和EC之间的通讯和物理相互作用。总的来说,这些研究表明,在造血器官的血管龛内的EC表达龛特异性基因程序。然而,迄今为止,还没有进行对指定HSPC龛中EC的龛身份的转录回路的全面研究。理解这种调节指导了新的策略以提高骨髓移植治疗的功效和可用性。
内皮龛细胞
如本文所述,内皮龛细胞是为HSPC分化提供指导龛的内皮细胞。内皮龛细胞通常存在于骨髓中。然而,如本文所述,特异性转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA、NR2F2)的外源表达可导致在非骨髓组织中发现内皮龛细胞,从而提供髓外造血。
在任一方面的一些实施方案中,内皮龛细胞包括表达一种或多种选自以下的基因的细胞:sele、exoc312a、snx8a、cltca、aqp7、ap1b1、 lgmn、prcp、cldn11a、lyve1b、adra1d、hya12a、hya12b、tll1、i113ra2、 glu1a、hexb、slc16a9a和sepp1a。在一些实施方案中,内皮细胞是人的。
在任一方面的一些实施方案中,产生或工程化表达转录因子的内皮龛细胞,所述转录因子包括人转录因子ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA或NR2F2中的至少一种。在一些实施方案中,转录因子包括来自Ets家族的至少一种转录因子、来自Sox家族的至少一种转录因子和来自核激素受体家族的至少一种转录因子。在一些实施方案中,转录因子包括ETV2、FLI1、ETS1、SOX18、SOX7、RXRA和NR2F2。
在任一方面的一些实施方案中,转录因子由至少一种载体表达。在一些实施方案中,载体包含编码一种或多种转录因子的一种或多种外源核酸序列。在一些实施方案中,将外源核酸序列掺入内皮细胞的基因组中。作为非限制性实例,可以使用病毒载体(例如,AAV、慢病毒)或CRISPR 技术将外源核酸序列掺入基因组中。
一个方面提供了包含工程化的内皮龛细胞的组合物,所述工程化的内皮龛细胞包含编码一种或多种转录因子的一种或多种外源核酸序列,其中所述一种或多种转录因子来自Ets家族,Sox家族和/或核激素家族。在任一方面的一些实施方案中,所述组合物可以包含工程化的内皮龛细胞。在一些实施方案中,所述组合物是治疗剂,或者所述组合物还包含药学上可接受的载体。在一些实施方案中,所述组合物还包含培养皿、 3D细胞系统或悬浮系统。在一些实施方案中,所述组合物包含支架。
另一方面提供了培养HSPC的方法,所述方法包括在存在工程化的内皮龛细胞群的情况下培养HSPC。在任一方面的一些实施方案中,所述方法在体外进行。在一些实施方案中,工程化的内皮龛细胞分泌影响 HSPC细胞生长和/或扩增的因子(例如生长因子)。
在一些实施方案中,在存在工程化的内皮龛细胞的情况下培养的 HSPC可以比在不存在这样的工程化的内皮龛细胞的情况下培养的HSPC 多培养至少3天。在一些实施方案中,在存在工程化的内皮龛细胞的情况下培养的HSPC可以在不存在这样的工程化的内皮龛细胞的情况下培养的HSPC多培养至少1天、至少2天、至少3天、至少4天、至少5 天、至少6天、至少7天、至少8天、至少9天、至少10天、至少11 天、至少12天、至少13天或至少长14天。
在一些实施方案中,细胞在生物相容性支架上培养。生物相容性支架的非限制性实例包括:水凝胶,生物聚合物,或具有在准备移植中体外培养细胞的能力的另一种生物材料。在一些实施方案中,相比不与工程化的内皮龛细胞一起培养的基本上相似的HSPC在施用于受试者时的植入相比,在存在工程化内皮细胞的情况下培养的HSPC具有增加的植入。本文所用的“植入”是指移植的HSPC开始生长并产生健康血细胞的过程。植入是从HSPC移植物中恢复的关键里程碑。
另一方面提供了治疗受试者的方法,所述方法包括将包含工程化的内皮龛细胞群的组合物移植到受试者中。作为非限制性实例,所述方法可用于治疗骨髓纤维化或其中内源性骨髓龛受损的其它造血疾病,其非限制性实例在本文中公开。在一些实施方案中,所述方法可包括将包含 HSPC群体的组合物移植到受试者中。在一些实施方案中,所述方法可包括将包含HSPC群体和工程化的内皮龛细胞的组合物移植到受试者中。
另一方面提供了增强HSPC植入的方法,所述方法包括将包含HSPC 和工程化的内皮龛细胞群的组合物施用于有需要的受试者。在任一方面的一些实施方案中,所述HSPC的植入与在不存在工程化的内皮龛细胞的情况下基本上相似的HSPC的植入相比增加至少10%。在任一方面的一些实施方案中,所述HSPC的植入与在不存在工程化的内皮龛细胞的情况下基本上相似的HSPC的植入相比增加至少1%、至少2%、至少3%、至少4%、至少5%、至少6%、至少7%、至少8%、至少9%、至少10%、至少15%、至少20%、至少25%、至少30%、至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少100%。
另一方面提供了包含工程化的内皮龛细胞和HSPC的共培养物。在任一方面的一些实施方案中,内皮细胞通过本文所述的方法制备。
另一方面提供了产生异位血管龛的方法,所述方法包括:将工程化的内皮龛细胞施用于有需要的受试者的靶位点。如本文所用,“异位血管龛”是指内皮龛细胞的非典型位点。例如,可以在骨髓外发现血管龛。包含产生的或工程化的内皮龛细胞的异位血管龛可以在体内的任何地方。异位血管龛可以在注射了HSPC,产生的或工程化的内皮龛细胞,和/或其相关转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或 NR2F2)的位置发现。
另一方面提供了用于髓外造血的方法,所述方法包括将工程化龛内皮细胞移植到受试者中骨髓外的位置(例如,前臂)处,从而产生合成龛。如本文所用,“髓外造血”是指在骨髓外器官中发生的造血。在任一方面的一些实施方案中,内皮细胞通过本文所述的方法制备。
骨髓纤维化
在任一方面的一些实施方案中,产生的或工程化的内皮龛细胞或其相关转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或 NR2F2)可用于治疗骨髓纤维化。
骨髓纤维化是一种罕见类型的慢性白血病。骨髓纤维化属于称为骨髓增生性病症的一组疾病,通常为慢性形式。慢性骨髓增生性病症是一组生长缓慢的血癌,其中骨髓产生过多异常红细胞、白细胞或血小板,它们会在血液中积聚。慢性骨髓增生性肿瘤的非限制性实例包括:慢性骨髓性白血病、真性红细胞增多症、原发性骨髓纤维化(也称为慢性特发性骨髓纤维化)、原发性血小板增多症、慢性嗜中性粒细胞性白血病和慢性嗜酸性粒细胞性白血病。
骨髓纤维化是严重的骨髓病症,其破坏身体正常的血细胞产生。其结果是骨髓中广泛的瘢痕,导致严重的贫血,虚弱,乏力且常常脾脏增大。许多患有骨髓纤维化的受试者或患者逐渐恶化,并且一些受试者或患者可能最终发展成更严重形式的白血病。骨髓纤维化可在血液干细胞 (例如HSPC)发生遗传突变时发生。已经在患有骨髓纤维化的人中鉴定了几种特定的基因突变。最常见的是Janus激酶2(JAK2)基因。
尽管骨髓纤维化的原因通常未知,但已知某些因素会增加风险。年龄增加可能与骨髓纤维化的发展有关。骨髓纤维化可影响任何人,但其在50岁以上的人中最常被诊断。患有另一血细胞病症的患者处于发展成骨髓纤维化的较高风险中。一小部分患有骨髓纤维化的人发展为原发性血小板增多症或真性红细胞增多症的并发症的病症。暴露于某些化学品可增加骨髓纤维化的风险。骨髓纤维化与暴露于工业化学品如甲苯和苯有关。暴露于辐射可增加骨髓纤维化的风险。暴露于高水平辐射的人(例如原子弹攻击的存活者)具有增加的骨髓纤维化风险。接受称为Thorotrast 的放射性造影材料(使用到二十世纪五十年代)的一些人已经发展成了骨髓纤维化。
骨髓纤维化可导致多种并发症。骨髓纤维化的并发症可包括流入患者肝脏的血液的压力增加。通常,来自脾脏的血流通过称为门静脉的大血管进入肝脏。来自增大的脾脏的血流可导致门静脉中的高血压(例如,门静脉高血压)。这又可以迫使过量的血液进入胃和食道中的较小的静脉,潜在地导致这些静脉破裂和出血。疼痛可以是骨髓纤维化的另一种并发症。严重增大的脾脏可引起腹痛和背痛。骨髓纤维化可导致身体其它区域的生长。骨髓纤维化可与出血并发症有关。随着疾病的发展,血小板计数趋于下降到正常以下(血小板减少症),并且血小板功能受损。血小板数量不足会导致容易出血。骨髓纤维化也可与疼痛的骨和关节有关。骨髓纤维化可导致骨髓硬化和在骨周围发现的结缔组织的炎症。这可能导致骨和关节痛痛。骨髓纤维化也可与急性白血病的发展有关。一些患有骨髓纤维化的患者发展成急性骨髓性白血病,其是一种快速发展的血液和骨髓癌症。
骨髓移植是目前唯一批准的用于骨髓纤维化的治疗。另外的治疗只能改善骨髓纤维化的症状(例如,贫血、增大的脾脏)。卢索替尼(一种JAK 抑制剂,其靶向在骨髓纤维化的大多数情况中发现的基因突变)可用于减轻增大的脾脏的症状。
治疗方法
如本文所述,在骨髓纤维化和/或患有骨髓纤维化的受试者中,功能性造血水平可以降低。如本文所用,“功能性造血”是指产生正常水平和比例的血细胞(例如,红细胞、白细胞、血小板)的造血作用。在任一方面的一些实施方案中,在骨髓纤维化或骨髓增生性病症和/或患有骨髓纤维化或骨髓增生性病症的受试者中,造血水平可以降低。因此,在任何实施方案的一个方面中,本文描述了治疗有需要的受试者中的骨髓纤维化或骨髓增生性病症的方法,所述方法包括向受试者施用HSPC、工程化内皮细胞和/或转录因子(例如,ETV2、FLI1、ETS1、 SOX18、SOX7、RXRA或NR2F2),所述受试者被确定为相对于参考具有降低的功能性造血水平。在任何实施方案的一个方面,本文描述了治疗有需要的受试者中的骨髓纤维化或骨髓增生性病症的方法,所述方法包括:a)确定从受试者获得的样品中的功能性造血水平;和b) 如果功能性造血水平相对于参考降低,则向受试者施用HSPC、工程化内皮细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、 RXRA或NR2F2)。
在任一方面的一些实施方案中,所述方法包括向先前确定为相对于参考具有降低的功能性造血水平的受试者施用HSPC、工程化内皮细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)。在任一方面的一些实施方案中,本文描述了治疗有需要的受试者中的骨髓纤维化或骨髓增生性病症的方法,所述方法包括:a) 首先确定从受试者获得的样品中的功能性造血水平;和b)如果功能性造血水平相对于参考降低,则向受试者施用HSPC、工程化内皮细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)。
在任何实施方案的一个方面,本文描述了治疗有需要的受试者中的骨髓纤维化或骨髓增生性病症的方法,所述方法包括:a)确定所述受试者是否具有降低的造血水平;和b)如果功能性造血水平相对于参考降低,则向受试者施用HSPC、工程化内皮细胞和/或转录因子(例如, ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2)。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括i)从受试者获得或已经获得样品,和ii)对从受试者获得的样品进行或已经进行测定以确定/测量受试者中的造血水平。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括对从受试者获得的样品进行或已经进行测定以确定/ 测量受试者中的造血水平。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括对从受试者获得的样品指示或请求测定以确定/测量受试者中的造血水平。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括接收对从受试者获得的样品的测定结果以确定/测量受试者中的功能性造血水平。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括接收报告、结果或将受试者鉴定为具有降低的功能性造血水平的受试者的其他手段。
在任何实施方案的一个方面,本文描述了治疗有需要的受试者的骨髓纤维化或骨髓增生性病症的方法,所述方法包括:a)确定所述受试者是否具有降低的功能性造血水平;和b)如果功能性造血水平相对于参考降低,则指导或引导向受试者施用HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括i)从受试者获得或已经获得样品,和ii)对从受试者获得的样品进行或已经进行测定以确定/测量受试者中的功能性造血水平。在任一方面的一些实施方案中,确定受试者是否具有降低的功能性造血水平的步骤可以包括对从受试者获得的样品进行或已经进行了测定以确定/测量受试者中的功能性造血水平。在任一方面的一些实施方案中,确定受试者是否具有功能水平的功能性造血的步骤可以包括对从受试者获得的样品进行指示或请求测定以确定 /测量受试者中的功能性造血水平。在任一方面的一些实施方案中,指导或引导向受试者施用特定治疗的步骤可以包括提供测定结果的报告。在任一方面的一些实施方案中,指导或引导向受试者施用特定治疗的步骤可以包括提供测定结果和/或鉴于测定结果的治疗建议的报告。
施用
在一些实施方案中,本文所述的方法涉及治疗患有或被诊断为患有骨髓纤维化或骨髓增生性病症的受试者。患有骨髓纤维化或骨髓增生性病症的受试者可由医师使用当前的诊断骨髓纤维化或骨髓增生性病症的方法来鉴定。骨髓纤维化或骨髓增生性病症的症状和/或并发症 (其表征这些病症并有助于诊断)是本领域熟知的,并且包括但不限于贫血、脾肿大(即增大和疼痛的脾脏)、乏力、呼吸弱或呼吸不足、左侧肋骨下方的疼痛或充盈、容易擦伤、容易出血、睡眠期间过度出汗(盗汗)、发烧和/或骨痛。可有助于骨髓纤维化或骨髓增生性病症的诊断的测试包括但不限于血液测试(例如,全血计数)或骨髓活组织检查。骨髓纤维化或骨髓增生性病症也可通过物理检查,成像测试或遗传测试来检测。骨髓纤维化或骨髓增生性病症的家族史,或暴露于骨髓纤维化或骨髓增生性病症的风险因子(例如工业化学品,辐射)也可有助于确定受试者是否可能患有骨髓纤维化或骨髓增生性病症或进行骨髓纤维化或骨髓增生性病症的诊断。
本文所述的组合物和方法可施用于患有或诊断为患有骨髓纤维化或骨髓增生性疾病的受试者。在一些实施方案中,本文所述的方法包括向受试者施用有效量的本文所述的组合物,例如HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或 NR2F2),以减轻骨髓纤维化或骨髓增生性病症的症状。如本文所用,“减轻骨髓纤维化或骨髓增生性病症的症状”是改善与骨髓纤维化或骨髓增生性病症相关的任何病症或症状。与等同的未处理对照相比,通过任何标准技术测量,这种减轻为至少5%、10%、20%、40%、50%、60%、80%、 90%、95%、99%或更多。用于将本文所述的组合物施用于受试者的各种方式是本领域技术人员已知的。这些方法可以包括但不限于口服施用、肠胃外施用、静脉内施用、肌内施用、皮下施用、透皮施用、气道(气溶胶)施用、肺部施用、皮肤施用、局部施用、注射施用或肿瘤内施用。施用可以是局部的或全身的。
本文所用的术语“有效量”是指减轻疾病或病症的至少一种或多种症状所需的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、 ETS1、SOX18、SOX7、RXRA或NR2F2)的量,并且涉及提供所需效果的足够量的药物组合物。因此,术语“治疗有效量”是指在向典型受试者施用时,足以提供特定的抗骨髓纤维化或抗骨髓增生性病症效果的 HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、 SOX18、SOX7、RXRA或NR2F2)的量。本文所用的在各种上下文中的有效量还包括足以延迟疾病的症状发展、改变疾病症状的进程(例如但不限于减缓疾病的症状的进展)或逆转疾病的症状的量。因此,指定确切的“有效量”通常是不可行的。然而,对于任何给定的情况,合适的“有效量”可以由本领域技术人员仅使用常规实验来确定。
有效量、毒性和治疗功效可通过细胞培养物或实验动物中的标准药学程序来确定,例如用于确定LD50(群体的50%致死的剂量)和ED50(群体的50%治疗有效的剂量)的标准药学程序。剂量可以根据使用的剂型和使用的施用途径而变化。毒性和治疗效果之间的剂量比是治疗指数,并且可以表示为比率LD50/ED50。显示出大治疗指数的组合物和方法是优选的。治疗有效剂量可最初由细胞培养物测定估计。此外,可以在动物模型中配制剂量以实现循环血浆浓度范围,其包括在细胞培养物中或在适当的动物模型中测定的IC50(即,实现症状的半数最大抑制的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA或NR2F2)的浓度)。血浆中的水平可以例如通过高效液相色谱来测量。可以通过合适的生物测定来监测任何特定剂量的效果。剂量可以由医师确定,并且根据需要调节以适合观察到的治疗效果。
在一些实施方案中,本文所述的技术涉及药物组合物,其包含本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、 ETS1、SOX18、SOX7、RXRA或NR2F2),以及任选的药学上可接受的载体。在一些实施方案中,药物组合物的活性成分包含本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA或NR2F2)。在一些实施方案中,药物组合物的活性成分基本上由本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如, ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2)组成。在一些实施方案中,药物组合物的活性成分由本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)组成。
药学上可接受的载体和稀释剂包括盐水、水性缓冲溶液、溶剂和/或分散介质。这种载体和稀释剂的使用是本领域熟知的。可用作药学上可接受的载体的材料的一些非限制性实例包括:(1)糖,例如乳糖、葡萄糖和蔗糖;(2)淀粉,例如玉米淀粉和马铃薯淀粉;(3)纤维素及其衍生物,例如羧甲基纤维素钠、甲基纤维素、乙基纤维素、微晶纤维素和乙酸纤维素;(4)粉末状黄蓍胶;(5)麦芽;(6)明胶;(7)润滑剂,例如硬脂酸镁、十二烷基硫酸钠和滑石;(8)赋形剂,例如可可脂和栓剂蜡;(9)油,例如花生油、棉籽油、红花油、芝麻油、橄榄油、玉米油和大豆油;(10)二醇,例如丙二醇;(11)多元醇,例如甘油、山梨糖醇、甘露糖醇和聚乙二醇 (PEG);(12)酯,例如油酸乙酯和月桂酸乙酯;(13)琼脂;(14)缓冲剂,例如氢氧化镁和氢氧化铝;(15)藻酸;(16)无热原水;(17)等渗盐水;(18) 林格氏溶液;(19)乙基酒精;(20)pH缓冲溶液;(21)聚酯、聚碳酸酯和/ 或聚酸酐;(22)填充剂,例如多肽和氨基酸;(23)血清组分,例如血清白蛋白、HDL和LDL;(22)C2-C12醇类,例如乙醇;以及(23)药物制剂中所用的其他无毒的相容物质。湿润剂、着色剂、脱模剂、包衣剂、甜味剂、调味剂、芳香剂、防腐剂和抗氧化剂也可以存在于制剂中。术语如“赋形剂”、“载体”、“药学上可接受的载体”等在本文中可互换使用。在一些实施方案中,载体抑制本文所述的活性剂(例如HSPC、工程化的内皮龛细胞和/或转录因子(例如ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或 NR2F2))的降解。
在一些实施方案中,包含本文所述的HSPC、工程化的内皮龛细胞和 /或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2) 的药物组合物可以是肠胃外剂型。由于肠胃外剂型的施用通常绕过患者的针对污染物的天然防御,因此肠胃外剂型优选是无菌的或能够在施用至患者之前进行灭菌。肠胃外剂型的实例包括但不限于准备注射的溶液、准备溶解或悬浮在药学上可接受的注射用媒介物中的干燥产品、准备注射的悬浮液和乳液。此外,可以制备用于施用于患者的控释肠胃外剂型,包括但不限于 -类型剂型和剂量倾卸。
-类型剂型和剂量倾卸。
所公开的可用于提供HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2)的肠胃外剂型的合适媒介物为本领域技术人员所熟知。实例包括但不限于:无菌水; USP注射用水;盐水溶液;葡萄糖溶液;水性媒介物,例如但不限于氯化钠注射液、林格氏注射液、右旋糖注射液、右旋糖和氯化钠注射液以及乳酸化林格氏注射液;水混溶性媒介物,例如但不限于乙醇、聚乙二醇和丙二醇;和非水性媒介物,例如但不限于玉米油,棉籽油,花生油,芝麻油,油酸乙酯,肉豆蔻酸异丙酯和苯甲酸苄酯。
在任一方面的一些实施方案中,本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)作为单一疗法施用,例如,不向受试者施用用于骨髓纤维化或骨髓增生性病症的另一治疗。
在任一方面的一些实施方案中,本文所述的方法还可包括向受试者施用第二药剂和/或治疗,例如作为联合疗法的一部分。第二药剂和/或治疗的非限制性实例可包括放射疗法、手术、吉西他滨、西司他丁、紫杉醇、卡铂、硼替佐米、AMG479、伏立诺他、利妥昔单抗、替莫唑胺、雷帕霉素、ABT-737、PI-103;烷化剂,诸如噻替派和 环磷酰胺;烷基磺酸盐,诸如白消安、英丙舒凡(improsulfan)和哌泊舒凡 (piposulfan);氮丙啶,诸如苯多巴(benzodopa)、卡巴醌(carboquone)、美妥替哌(meturedopa)和乌瑞替哌(uredopa);乙撑亚胺(ethylenimine)和甲基蜜胺(methylamelamine),包括六甲蜜胺(altretamine)、三亚乙基蜜胺(triethylenemelamine)、三亚乙基磷酰胺(triethylenephosphoramide)、三亚乙基硫代磷酰胺(triethylenethiophosphoramide)和三羟甲蜜胺(trimethylolomelamine);多聚乙酰(acetogenin)(尤其是布拉它辛(bullatacin) 和bullatacinone);喜树碱(camptothecin)(包括合成的类似物拓扑替康 (topotecan));苔藓抑素(bryostatin);callystatin;CC-1065(包括其阿多来新 (adozelesin)、卡折来新(carzelesin)和比折来新(bizelesin)合成的类似物);念珠藻素(cryptophycin)(尤其是念珠藻素1和念珠藻素8);尾海兔素 (dolastatin);duocarmycin(包括合成的类似物KW-2189和CB1-TM1);五加素(eleutherobin);水鬼蕉碱(pancratistatin);sarcodictyin;spongistatin;氮芥,诸如苯丁酸氮芥(chlorambucil)、萘氮芥(chlornaphazine)、胆磷酰胺 (cholophosphamide)、雌莫司汀(estramustine)、异环磷酰胺(ifosfamide)、二氯甲基二乙胺、盐酸甲氧氮芥(mechlorethamine oxide hydrochloride)、美法仑、新氮芥(novembiehin)、苯芥胆甾醇(phenesterine)、泼尼莫司汀 (prednimustine)、曲磷胺(trofosfamide)、尿嘧啶氮芥(uracil mustard);硝基脲,诸如卡莫司汀、氯脲菌素(chlorozotocin)、福莫司汀、洛莫司汀、尼莫斯汀(nimustine)和雷莫司汀(ranimnustine);抗生素,诸如烯二炔抗生素 (例如,加利车霉素(calicheamicin),尤其是加利车霉素γ1I和加利车霉素ωI1(参见例如,Agnew,Chem.Intl.Ed.Engl.,33:183-186(1994));达内霉素(dynemicin),包括达内霉素A;二磷酸盐诸如氯膦酸盐;埃斯培拉霉素(esperamicin);以及新抑癌蛋白生色团和相关的色蛋白烯二炔抗生素生色团)、阿克拉霉素(aclacinomysin)、放线菌素(actinomycin)、安曲霉素 (authramycin)、重氮丝氨酸、博莱霉素、放线菌素(cactinomycin)、卡柔比星(carabicin)、洋红霉素(caminomycin)、嗜癌菌素(carzinophilin)、色霉素 (chromomycinis)、更生霉素、柔红霉素、地托比星(detorubicin)、6-重氮基-5-氧亚基-l-正亮氨酸、
环磷酰胺;烷基磺酸盐,诸如白消安、英丙舒凡(improsulfan)和哌泊舒凡 (piposulfan);氮丙啶,诸如苯多巴(benzodopa)、卡巴醌(carboquone)、美妥替哌(meturedopa)和乌瑞替哌(uredopa);乙撑亚胺(ethylenimine)和甲基蜜胺(methylamelamine),包括六甲蜜胺(altretamine)、三亚乙基蜜胺(triethylenemelamine)、三亚乙基磷酰胺(triethylenephosphoramide)、三亚乙基硫代磷酰胺(triethylenethiophosphoramide)和三羟甲蜜胺(trimethylolomelamine);多聚乙酰(acetogenin)(尤其是布拉它辛(bullatacin) 和bullatacinone);喜树碱(camptothecin)(包括合成的类似物拓扑替康 (topotecan));苔藓抑素(bryostatin);callystatin;CC-1065(包括其阿多来新 (adozelesin)、卡折来新(carzelesin)和比折来新(bizelesin)合成的类似物);念珠藻素(cryptophycin)(尤其是念珠藻素1和念珠藻素8);尾海兔素 (dolastatin);duocarmycin(包括合成的类似物KW-2189和CB1-TM1);五加素(eleutherobin);水鬼蕉碱(pancratistatin);sarcodictyin;spongistatin;氮芥,诸如苯丁酸氮芥(chlorambucil)、萘氮芥(chlornaphazine)、胆磷酰胺 (cholophosphamide)、雌莫司汀(estramustine)、异环磷酰胺(ifosfamide)、二氯甲基二乙胺、盐酸甲氧氮芥(mechlorethamine oxide hydrochloride)、美法仑、新氮芥(novembiehin)、苯芥胆甾醇(phenesterine)、泼尼莫司汀 (prednimustine)、曲磷胺(trofosfamide)、尿嘧啶氮芥(uracil mustard);硝基脲,诸如卡莫司汀、氯脲菌素(chlorozotocin)、福莫司汀、洛莫司汀、尼莫斯汀(nimustine)和雷莫司汀(ranimnustine);抗生素,诸如烯二炔抗生素 (例如,加利车霉素(calicheamicin),尤其是加利车霉素γ1I和加利车霉素ωI1(参见例如,Agnew,Chem.Intl.Ed.Engl.,33:183-186(1994));达内霉素(dynemicin),包括达内霉素A;二磷酸盐诸如氯膦酸盐;埃斯培拉霉素(esperamicin);以及新抑癌蛋白生色团和相关的色蛋白烯二炔抗生素生色团)、阿克拉霉素(aclacinomysin)、放线菌素(actinomycin)、安曲霉素 (authramycin)、重氮丝氨酸、博莱霉素、放线菌素(cactinomycin)、卡柔比星(carabicin)、洋红霉素(caminomycin)、嗜癌菌素(carzinophilin)、色霉素 (chromomycinis)、更生霉素、柔红霉素、地托比星(detorubicin)、6-重氮基-5-氧亚基-l-正亮氨酸、 多柔比星(doxorubicin)(包括吗啉代-多柔比星、氰基吗啉代-多柔比星、2-吡咯啉-多柔比星、脱氧多柔比星(deoxydoxorubicin))、表阿霉素、依索比星(esorubicin)、伊达霉素(idambicin)、麻西罗霉素(marcellomycin)、丝裂霉素诸如丝裂霉素C、霉酚酸(mycophenolic acid)、诺加霉素(nogalamycin)、橄榄霉素、培洛霉素 (peplomycin)、泊非霉素(potfiromycin)、嘌呤霉素、奎拉霉素(quelamycin)、罗多比星(rodorubicin)、链黑菌素、链脲佐菌素、杀结核菌素、乌苯美司 (ubenimex)、净司他丁(zinostatin)、佐柔比星(zorubicin);抗代谢物,诸如甲氨蝶呤和5-氟尿嘧啶(5-FU);叶酸类似物,诸如二甲叶酸(denopterin)、甲氨蝶呤、蝶罗呤(pteropterin)、三甲曲沙(trimetrexate);嘌呤类似物,诸如氟达拉滨、6-巯基嘌呤、硫咪嘌呤(thiamiprine)、硫鸟嘌呤;嘧啶类似物,诸如安西他滨(ancitabine)、阿扎胞苷(ancitabine)、6-氮杂尿苷、卡莫氟(carmofur)、阿糖胞苷、双脱氧尿苷(dideoxyuridine)、去氧氟尿苷 (doxifluridine)、依诺他滨(enocitabine)、氟尿苷;雄激素,诸如卡鲁睾酮 (calusterone)、屈他雄酮(dromostanolone)丙酸酯、环硫雄醇(epitiostanol)、美雄烷(mepitiostane)、睾内酯;抗肾上腺,诸如氨鲁米特(aminoglutethimide)、米托坦和曲洛司坦(trilostane);叶酸补充剂,诸如亚叶酸(frolinicacid);醋葡醛内酯(aceglatone);醛磷酰胺糖苷 (aldophosphamideglycoside);氨基乙酰丙酸;恩尿嘧啶(eniluracil);安吖啶(amsacrine);阿莫司汀(bestrabucil);比生群(bisantrene);依达曲沙 (edatraxate);地磷酰胺(defofamine);秋水仙胺(demecolcine);地吖醌 (diaziquone);elfornithine;依利醋铵(elliptiniumacetate);埃博霉素 (epothilone);依托格鲁(etoglucid);硝酸镓;羟基脲;香菇多糖;氯尼达明 (lonidamine);美坦生类(maytansinods)诸如美登素(maytansine)和美登木素(ansamitocin);米托胍腙(mitoguazone);米托蒽醌(mitoxantrone);莫哌达醇(mopidamol);硝氨丙吖啶(nitracrine);喷司他丁(pentostatin);蛋氨氮芥 (phenamet);吡柔比星(pirarubicin);洛索蒽醌(losoxantrone);鬼臼酸 (podophyllinic acid);2-乙酰肼(2-ethylhydrazide);甲基苄肼(procarbazine);
多柔比星(doxorubicin)(包括吗啉代-多柔比星、氰基吗啉代-多柔比星、2-吡咯啉-多柔比星、脱氧多柔比星(deoxydoxorubicin))、表阿霉素、依索比星(esorubicin)、伊达霉素(idambicin)、麻西罗霉素(marcellomycin)、丝裂霉素诸如丝裂霉素C、霉酚酸(mycophenolic acid)、诺加霉素(nogalamycin)、橄榄霉素、培洛霉素 (peplomycin)、泊非霉素(potfiromycin)、嘌呤霉素、奎拉霉素(quelamycin)、罗多比星(rodorubicin)、链黑菌素、链脲佐菌素、杀结核菌素、乌苯美司 (ubenimex)、净司他丁(zinostatin)、佐柔比星(zorubicin);抗代谢物,诸如甲氨蝶呤和5-氟尿嘧啶(5-FU);叶酸类似物,诸如二甲叶酸(denopterin)、甲氨蝶呤、蝶罗呤(pteropterin)、三甲曲沙(trimetrexate);嘌呤类似物,诸如氟达拉滨、6-巯基嘌呤、硫咪嘌呤(thiamiprine)、硫鸟嘌呤;嘧啶类似物,诸如安西他滨(ancitabine)、阿扎胞苷(ancitabine)、6-氮杂尿苷、卡莫氟(carmofur)、阿糖胞苷、双脱氧尿苷(dideoxyuridine)、去氧氟尿苷 (doxifluridine)、依诺他滨(enocitabine)、氟尿苷;雄激素,诸如卡鲁睾酮 (calusterone)、屈他雄酮(dromostanolone)丙酸酯、环硫雄醇(epitiostanol)、美雄烷(mepitiostane)、睾内酯;抗肾上腺,诸如氨鲁米特(aminoglutethimide)、米托坦和曲洛司坦(trilostane);叶酸补充剂,诸如亚叶酸(frolinicacid);醋葡醛内酯(aceglatone);醛磷酰胺糖苷 (aldophosphamideglycoside);氨基乙酰丙酸;恩尿嘧啶(eniluracil);安吖啶(amsacrine);阿莫司汀(bestrabucil);比生群(bisantrene);依达曲沙 (edatraxate);地磷酰胺(defofamine);秋水仙胺(demecolcine);地吖醌 (diaziquone);elfornithine;依利醋铵(elliptiniumacetate);埃博霉素 (epothilone);依托格鲁(etoglucid);硝酸镓;羟基脲;香菇多糖;氯尼达明 (lonidamine);美坦生类(maytansinods)诸如美登素(maytansine)和美登木素(ansamitocin);米托胍腙(mitoguazone);米托蒽醌(mitoxantrone);莫哌达醇(mopidamol);硝氨丙吖啶(nitracrine);喷司他丁(pentostatin);蛋氨氮芥 (phenamet);吡柔比星(pirarubicin);洛索蒽醌(losoxantrone);鬼臼酸 (podophyllinic acid);2-乙酰肼(2-ethylhydrazide);甲基苄肼(procarbazine); 多糖复合物(JHS NaturalProducts,Eugene,Oreg.);雷佐生 (razoxane);利索新(rhizoxin);西佐夫兰(sizofuran);螺旋锗(spirogermanium);细交链孢菌酮酸(tenuazonic acid);三亚胺醌(triaziquone);2,2',2”-三氯三乙胺;单端孢霉烯类(尤其是T-2毒素、疣孢菌素A、杆孢菌素A和蛇形菌素(anguidine);氨基甲酸乙酯(urethan);长春地辛;氮烯咪胺;甘露醇氮芥;二溴甘露醇;二溴卫矛醇;哌泊溴烷(pipobroman);gacytosine;阿拉伯糖苷(“Ara-C”);环磷酰胺;噻替派;紫杉烷类(taxoids),例如,
多糖复合物(JHS NaturalProducts,Eugene,Oreg.);雷佐生 (razoxane);利索新(rhizoxin);西佐夫兰(sizofuran);螺旋锗(spirogermanium);细交链孢菌酮酸(tenuazonic acid);三亚胺醌(triaziquone);2,2',2”-三氯三乙胺;单端孢霉烯类(尤其是T-2毒素、疣孢菌素A、杆孢菌素A和蛇形菌素(anguidine);氨基甲酸乙酯(urethan);长春地辛;氮烯咪胺;甘露醇氮芥;二溴甘露醇;二溴卫矛醇;哌泊溴烷(pipobroman);gacytosine;阿拉伯糖苷(“Ara-C”);环磷酰胺;噻替派;紫杉烷类(taxoids),例如, 紫杉醇(Bristol-Myers SquibbOncology, Princeton,N.J.)、
紫杉醇(Bristol-Myers SquibbOncology, Princeton,N.J.)、 克列莫佛(Cremophor)无、白蛋白-工程化的紫杉醇纳米颗粒制剂(American Pharmaceutical Partners,Schaumberg,Ill.) 和
克列莫佛(Cremophor)无、白蛋白-工程化的紫杉醇纳米颗粒制剂(American Pharmaceutical Partners,Schaumberg,Ill.) 和 多烯紫杉醇(doxetaxel)(Rhone-Poulenc Rorer,Antony, France);苯丁酸氮芥;
多烯紫杉醇(doxetaxel)(Rhone-Poulenc Rorer,Antony, France);苯丁酸氮芥; 吉西他滨;6-硫鸟嘌呤(6-thioguanine);巯基嘌呤;甲氨蝶呤;铂类似物,诸如顺铂、奥沙利铂和卡铂;长春碱;铂;依托泊苷(VP-16);异环磷酰胺;米托蒽醌;长春新碱; NAVELBINE.RTM.长春瑞滨;诺肖林(novantrone);替尼泊苷;依达曲沙(edatrexate);正定霉素(daunomycin);氨基蝶呤;希罗达(xeloda);伊班膦酸盐(ibandronate);伊立替康(irinotecan)(Camptosar,CPT-11)(包括伊立替康与5-FU和亚叶酸(leucovorin)的治疗方案);拓扑异构酶抑制剂 RFS2000;二氟甲基鸟氨酸(DMFO);类视黄醇类物质诸如维甲酸;卡培他滨;康普瑞汀(combretastatin);亚叶酸(LV);奥沙利铂(oxaliplatin),包括奥沙利铂治疗方案(FOLFOX);拉帕替尼(lapatinib)(Tykerb.RTM.);降低细胞增殖的PKC-α、Raf、H-Ras、EGFR(例如,埃罗替尼
吉西他滨;6-硫鸟嘌呤(6-thioguanine);巯基嘌呤;甲氨蝶呤;铂类似物,诸如顺铂、奥沙利铂和卡铂;长春碱;铂;依托泊苷(VP-16);异环磷酰胺;米托蒽醌;长春新碱; NAVELBINE.RTM.长春瑞滨;诺肖林(novantrone);替尼泊苷;依达曲沙(edatrexate);正定霉素(daunomycin);氨基蝶呤;希罗达(xeloda);伊班膦酸盐(ibandronate);伊立替康(irinotecan)(Camptosar,CPT-11)(包括伊立替康与5-FU和亚叶酸(leucovorin)的治疗方案);拓扑异构酶抑制剂 RFS2000;二氟甲基鸟氨酸(DMFO);类视黄醇类物质诸如维甲酸;卡培他滨;康普瑞汀(combretastatin);亚叶酸(LV);奥沙利铂(oxaliplatin),包括奥沙利铂治疗方案(FOLFOX);拉帕替尼(lapatinib)(Tykerb.RTM.);降低细胞增殖的PKC-α、Raf、H-Ras、EGFR(例如,埃罗替尼 ) 和VEGF-A的抑制剂以及上述任何的药学上可接受的盐、酸或衍生物。
) 和VEGF-A的抑制剂以及上述任何的药学上可接受的盐、酸或衍生物。
此外,治疗方法还可包括使用辐射或放射疗法。此外,治疗方法还可包括使用手术治疗。
本文所述的方法还可包括向受试者施用第二药剂和/或治疗,例如作为联合疗法的一部分。作为非限制性实例,如果受试者要根据本文所述的方法治疗疼痛或炎症,则还可向受试者施用已知对患有疼痛或炎症的受试者有益的第二药剂和/或治疗。在一些实施方案中,第二药剂是抗炎剂。此类药剂和/或治疗的实例包括但不限于非甾体抗炎药(NSAID,例如阿司匹林、布洛芬或萘普生);皮质类固醇,包括糖皮质激素(例如皮质醇、泼尼松、泼尼松龙、甲基泼尼松龙、地塞米松、倍他米松、曲安西龙和倍氯米松);甲氨蝶呤;柳氮磺吡啶;来氟米特;抗TNF药物;环磷酰胺;促消退药物;霉酚酸酯;或阿片类(例如内啡肽、脑啡肽和强啡肽)、类固醇、止痛剂、巴比妥酸盐、羟考酮、吗啡、利多卡因等。
在某些实施方案中,可向患者施用一次本文所述的包含HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、 RXRA或NR2F2)的组合物的有效剂量。在某些实施方案中,可以将有效剂量的包含HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、 FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2)的组合物重复施用于患者。对于全身性施用,可以向受试者施用治疗量的包含HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、 RXRA或NR2F2)的组合物,例如0.1mg/kg、0.5mg/kg、1.0mg/kg、2.0mg/kg、 2.5mg/kg、5mg/kg、10mg/kg、15mg/kg、20mg/kg、25mg/kg、30mg/kg、 40mg/kg、50mg/kg或更多。
在一些实施方案中,在初始治疗方案之后,可以较不频繁施用治疗。例如,在每两周治疗三个月后,可以每月重复治疗一次,持续六个月或一年或更长时间。根据本文所述的方法的治疗可以将病况的标志物或症状(例如HSPC、工程化的内皮龛细胞和/或转录因子(例如ETV2、FLI1、 ETS1、SOX18、SOX7、RXRA或NR2F2))的水平降低至少10%、至少 15%、至少20%、至少25%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%或至少90%或更多。
本文所述的组合物的剂量可以由医师确定,并且根据需要调节以适合观察到的治疗效果。就治疗的持续时间和频率而言,技术性临床医生通常监测受试者以确定治疗何时提供治疗益处,并确定是增加或减少剂量、增加或减少施用频率、停止治疗、恢复治疗,还是对治疗方案进行其它改变。给药方案可以根据多种临床因素从一周一次变化到每日,所述临床因素例如受试者对HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2)的敏感性。激活的所需剂量或量可以一次施用或分成亚剂量,例如2-4个亚剂量,并在一段时间内施用,例如在一天内以适当的间隔或其它适当的时间表施用。在一些实施方案中,施用可以是慢性的,例如,在数周或数月内每日一次或多次剂量和/或治疗。给药和/或治疗方案的实例是在1周、2周、 3周、4周、1个月、2个月、3个月、4个月、5个月或6个月或更长的时间内每日、每日两次、每日三次或每日四次或更多次施用。包含HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA或NR2F2)的组合物可以在一段时间内施用,例如在5分钟、10分钟、15分钟、20分钟或25分钟的时间内施用。
根据本文所述的方法,用于施用HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2) 的剂量范围取决于例如其形式、其效力和本文所述的病况的症状、标志物或指标期望被降低的程度。例如,骨髓纤维化或骨髓增生性病症期望被减轻,功能性造血期望被减轻的程度。剂量不应大到引起不利的副作用,例如过度的造血或过度的髓外造血。通常,剂量将随患者的年龄,状况和性别而变化,并且可以由本领域技术人员确定。在任何并发症的情况下,剂量也可以由单独的医师调节。
HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、 SOX18、SOX7、RXRA或NR2F2)在例如治疗本文所述的病况或诱导如本文所述的应答(例如功能性造血)中的功效可由技术性临床医生确定。然而,如果本文所述的病况的一种或多种体征或症状以有益的方式改变,其它临床上接受的症状得到改善,或甚至得到减轻,或在根据本文所述的方法治疗后诱导期望的反应例如至少10%,则治疗被认为是如本文所用的术语“有效治疗”。功效可例如通过测量根据本文所述的方法治疗的病况的标志物、指标、症状和/或发病率或任何其它合适的可测量参数(例如血细胞计数)来评估。功效还可以通过个体没有恶化来测量,如通过住院治疗或需要医学干预(即,疾病的进展停止)所评估的。测量这些指标的方法是本领域技术人员已知的和/或本文描述的。治疗包括对个体或动物 (一些非限制性实例包括人或动物)中的疾病的任何治疗,并且包括:(1) 抑制疾病,例如预防症状(例如疼痛或炎症)的恶化;或(2)减轻疾病的严重程度,例如引起症状的消退。用于治疗疾病的有效量是指当向有需要的受试者施用时足以导致该疾病的有效治疗(如本文所定义的该术语)的量。药剂的功效可通过评估病况的物理指标或期望的反应来确定。通过测量这些参数中的任一个或参数的任意组合来监测施用和/或治疗的功效完全在本领域技术人员的能力范围内的。可以在本文所述的病况(例如治疗骨髓纤维化或骨髓增生性病症)的动物模型中评估功效。当使用实验动物模型时,当观察到标志物的统计学显著变化时,证明了治疗的功效。
试剂盒
本文所述的一个方面提供了用于培养HSPC的试剂盒,所述试剂盒包含:工程化的内皮龛细胞群、试剂及其使用说明书。另一方面提供了用于产生工程化的内皮龛细胞的试剂盒,其包含:包含编码Ets家族、Sox 家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列的载体及其使用说明书。本文描述了可包含在本文所述的一种或多种试剂盒中的试剂盒组分。
在一些实施方案中,所述试剂盒包含有效量的用于培养HSPC和/或内皮龛细胞的试剂。如本领域技术人员将理解的,试剂可以冻干形式或浓缩形式提供,其可以在与培养的细胞一起使用之前稀释。优选的制剂包括对细胞无毒和/或不影响生长速率或活力等的那些制剂,可以以等分试样或单位剂量提供试剂。
在一些实施方案中,所述试剂盒还包含载体,所述载体包含在启动子控制下的编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的基因的核酸。
在一些实施方案中,本文所述的组分可以作为试剂盒单独或以任何组合提供。试剂盒包含本文所述的组分,例如包含HSPC、工程化的内皮龛细胞和/或转录因子(例如ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)的组合物,包含载体的组合物,所述载体包含例如在启动子控制下的Ets家族、Sox家族或核激素家族的一种或多种转录因子的基因,如说明书全文中所描述的。此外,所述试剂盒任选地包含信息材料。试剂盒还可以包含培养皿和/或用于包被培养皿的基质,例如层粘连蛋白、纤连蛋白、聚-L-赖氨酸或甲基纤维素。
在一些实施方案中,试剂盒中的组合物可以提供在防水或气密容器中,其在一些实施方案中基本上不含试剂盒的其它组分。例如,HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、 SOX7、RXRA或NR2F2)组合物可以在一个以上的容器中提供,例如,其可以提供在具有用于预定数量的实验,例如1、2、3或更多次的足够试剂的容器中。本文所述的一种或多种组分可以以任何形式提供,例如液体、干燥或冻干形式。优选本文所述的组分是基本上是纯的和/或无菌的。当本文所述的组分以液体溶液提供时,液体溶液优选为水溶液,优选无菌水溶液。
信息材料可以是描述性的,指导性的,销售的或与本文所述的方法有关的其它材料。试剂盒的信息材料不限于其形式。在一个实施方案中,信息材料可包括关于内皮龛细胞和/或HSPC的产生、浓度、期满日期、批次或生产地点信息等的信息。在一个实施方案中,信息材料涉及使用或施用试剂盒的组分的方法。
试剂盒可以包含用于检测HSPC分化和/或内皮龛细胞分化的标志物的组分。此外,试剂盒可以包含一种或多种能结合细胞标志物的抗体,或用于RT-PCR或PCR反应(例如半定量或定量RT-PCR或PCR反应)的引物。这种组分可用于评估成熟标志物的活化或内皮龛细胞和/或HSPC 的未成熟细胞标志物的丧失。如果检测试剂是抗体,则其可以以干燥制剂(例如冻干)或溶液的形式提供。抗体或其它检测试剂可以连接到用于检测的标记物,例如放射性、荧光(例如GFP)或比色标记物。如果检测试剂是引物,则其可以干制剂形式提供,例如冻干,或者以溶液形式提供。
试剂盒通常这样提供,其各种元件包括在一个包装中,例如基于纤维的,例如纸板的,或聚合物的,例如泡沫塑料盒。外壳可以被构造成保持内部和外部之间的温差,例如,它可以提供绝缘特性以将试剂保持在预选温度下一段预选的时间。
载体
在一些实施方案中,本文所述的一种或多种因子在重组表达载体或质粒中表达。如本文所用,术语“载体”是指适于将转基因转移到宿主细胞中的多核苷酸序列。术语“载体”包括质粒、小染色体、噬菌体、裸DNA等。参见例如,美国专利号4,980,285;5,631,150;5,707,828; 5,759,828;5,888,783和5,919,670,以及Sambrook等人,Molecular Cloning: ALaboratory Manual,第2版,Cold Spring Harbor Press(1989)。一种类型的载体是“质粒”,它是指环状双链DNA环,其中连接了另外的DNA片段。另一种类型的载体是病毒载体,其中另外的DNA片段连接到病毒基因组中。某些载体能够在导入它们的宿主细胞中自主复制(例如,具有细菌复制起点的细菌载体和游离型哺乳动物载体)。此外,某些载体能够指导与其可操作地连接的基因的表达。这种载体在本文中被称为“表达载体”。通常,在重组DNA技术中有用的表达载体通常是质粒的形式。在本说明书中,“质粒”和“载体”可互换使用,因为质粒是最常用的载体形式。然而,本发明旨在包括具有等同功能的这些其它形式的表达载体,例如病毒载体(例如复制缺陷型逆转录病毒、腺病毒和腺相关病毒)。
克隆载体是能够在宿主细胞的基因组中自主复制或整合的载体,其特征还在于一个或多个内切核酸酶限制性位点,在该位点可以以可确定的方式切割载体,并且可以将所需DNA序列连接到其中,使得新的重组载体保持其在宿主细胞中复制的能力。在质粒的情况下,随着质粒在宿主细胞如宿主细菌内拷贝数的增加,所需序列的复制可以发生许多次,或在宿主通过有丝分裂繁殖之前每个宿主只发生一次所需序列的复制,所需序列的复制可以发生许多次。在噬菌体的情况下,复制可以在裂解期主动发生或在溶原期被动发生。
表达载体是可以通过限制和连接将所需DNA序列插入其中,从而使其与调节序列可操作地连接,并且可以作为RNA转录物表达的载体。载体还可以含有一个或多个标志物序列,其适用于鉴定已经转化或转染了载体的细胞或尚未转化或转染了载体的细胞。标志物包括,例如,编码增加或降低对抗生素或其它化合物的抗性或敏感性的蛋白质的基因,编码其活性通过本领域已知的标准测定可检测的酶(例如,β-半乳糖苷酶、荧光素酶或碱性磷酸酶)的基因,和可见地影响转化或转染的细胞、宿主、集落或斑块的表型的基因(例如,绿色荧光蛋白)。在某些实施方案中,本文所用的载体能够自主复制和表达存在于DNA片段中与其可操作地连接的结构基因产物。
如本文所用,当编码序列和调节序列以这样的方式共价连接以使编码序列的表达或转录处于调节序列的影响或控制之下时,所述编码序列和调节序列被称为“可操作地”连接。如果需要将编码序列翻译成功能蛋白,则如果5'调节序列中的启动子的诱导导致编码序列的转录并且如果两个DNA序列之间的连接性质(1)不导致移码突变的引入,(2)不干扰启动子区指导编码序列转录的能力,或(3)不干扰相应的RNA转录物翻译成蛋白质的能力,则认为两个DNA序列是可操作地连接的。因此,如果启动子区能够实现DNA序列的转录,使得所得到的转录物可以翻译成所需的蛋白质或多肽,则启动子区与编码序列将是可操作连接的。
当编码本文所述的任何因子/多肽的核酸分子在细胞中表达时,各种转录控制序列(例如,启动子/增强子序列)可用于指导其表达。启动子可以是天然启动子,即基因在其内源性环境中的启动子,其提供基因表达的正常调节。在一些实施方案中,启动子可以是组成型的,即,启动子是不受调节的,允许其相关基因的连续转录。也可使用多种条件启动子,例如由分子存在或不存在控制的启动子。
基因表达所需的调节序列的精确性质可在物种或细胞类型之间变化,但通常可视需要分别包括涉及转录和翻译起始的5'非转录序列和5' 非翻译序列,如TATA盒,加帽序列,CAAT序列等。具体地,这种5' 非转录调节序列将包括启动子区,其包括用于转录控制可操作连接的基因的启动子序列。调节序列还可以根据需要包括增强子序列或上游激活子序列。本发明的载体可以任选地包括5'前导序列或信号序列。适当载体的选择和设计在本领域技术人员的能力和判断范围内。
含有用于表达的所有必需元件的表达载体是市售的并且是本领域技术人员已知的。参见例如,Sambrook等人,Molecular Cloning:A Laboratory Manual,第2版,ColdSpring Harbor Laboratory Press,1989。通过将异源 DNA(RNA)引入细胞中对细胞进行基因工程改造。将该异源DNA(RNA) 置于转录元件的可操作控制下,以允许异源DNA在宿主细胞中表达。
在一些实施方案中,载体是pME Gateway载体(InvitrogenTM)。在一些实施方案中,载体是p5EGatewayTM载体。在一些其它实施方案中,载体是pGEX2TKTM载体。在一些其它实施方案中,载体是TOPO-TATM载体。
在没有限制的情况下,本文所述的基因可以包含在一个载体或单独的载体中。例如,来自Ets家族的至少一种基因(例如,ETV2、FLI1、ETS1) 和来自SOX家族的至少一种基因(例如,SOX18、SOX7)以及来自NHR 家族的至少一种基因(例如,RXRA、NR2F2)可以包含在同一个载体中。
在一些实施方案中,来自Ets家族的至少一种基因(例如,ETV2、FLI1、 ETS1)和来自SOX家族的至少一种基因(例如,SOX18、SOX7)可以包含在第一载体中,并且来自NHR家族的至少一种基因(例如,RXRA、NR2F2) 可以包含在第二载体中。
在一些实施方案中,来自NHR家族的至少一种基因(例如,RXRA、 NR2F2)和来自SOX家族的至少一种基因(例如,SOX18、SOX7)可以包含在第一载体中,并且来自Ets家族的至少一种基因(例如,ETV2、FLI1、 ETS1)可以包含在第二载体中。
在一些实施方案中,来自Ets家族的至少一种基因(例如,ETV2、FLI1、 ETS1)和来自NHR家族的至少一种基因(例如,RXRA、NR2F2)可以包含在第一载体中,并且来自SOX家族的至少一种基因(例如,SOX18、SOX7) 可以包含在第二载体中。
在一些实施方案中,来自Ets家族的至少一种基因(例如,ETV2、FLI1、 ETS1)可以包含在第一载体中,来自SOX家族的至少一种基因(例如, SOX18、SOX7)可以包含在第二载体中,并且来自NHR家族的至少一种基因(例如,RXRA、NR2F2)可以包含在第三载体中。
在一些实施方案中,可操作地连接于基因的启动子可以是斑马鱼ubi 启动子。
在一些实施方案中,一种或多种重组表达的基因可以整合到细胞的基因组中。
可以使用本领域标准的方法和技术将编码所要求保护的本发明的酶的核酸分子引入一个或多个细胞。例如,核酸分子可以通过标准方案引入,例如转化,包括化学转化和电穿孔,转导,颗粒轰击等。表达编码所要求保护的本发明的酶的核酸分子也可以通过将核酸分子整合到基因组中来实现。
定义
为方便起见,下文提供了在说明书,实施例和所附权利要求书中使用的一些术语和短语的含义。除非另有说明,或者从上下文中暗示,以下术语和短语包括以下提供的含义。提供这些定义是为了帮助描述特定的实施方案,而不是意图限制所要求保护的发明,因为本发明的范围仅由权利要求书限定。除非另有定义,否则本文使用的所有技术和科学术语具有与本发明所属领域的技术人员通常理解的相同的含义。如果本领域中术语的使用与其在本文提供的定义之间存在明显的差异,则以说明书内提供的定义为准。
为方便起见,本文在说明书,实施例和所附权利要求书中使用的某些术语汇集于此。
术语“减少”、“降低”、“减轻”或“抑制”在本文中都用于表示统计学上显著量的降低。在一些实施方案中,“减轻”、“降低”或“减少”或“抑制”通常是指与参考水平(例如不存在给定的治疗或药剂)相比降低至少10%,并且可以包括例如降低至少约10%、至少约20%、至少约25%、至少约30%、至少约35%、至少约40%、至少约45%、至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%、至少约98%、至少约99%或更多。如本文所用,“降低”或“抑制”不包括与参考水平相比的完全抑制或降低。“完全抑制”是与参考水平相比100%的抑制。对于没有给定病症的个体,可以优选地将降低降至在正常范围内所接受的水平。
术语“增加的”、“增加”、“增强”或“激活”在本文中都用于表示统计学上显著量的增加。在一些实施方案中,术语“增加的”、“增加”、“增强”或“激活”可以意指与参考水平相比增加至少10%,例如与参考水平相比增加至少约20%、或至少约30%、或至少约40%、或至少约50%、或至少约60%、或至少约70%、或至少约80%、或至少约90%、或增加至多并包括100%,或与参考水平相比10-100%的任何增加,或与参考水平相比至少约2倍、或至少约3倍、或至少约4倍、或至少约5 倍或至少约10倍的增加,或与参考水平相比2倍至10倍或更多倍的任何增加。在标志物或症状的上下文中,“增加”是这种水平的统计学上显著的增加。
如本文所用,“受试者”是指人或动物。通常,动物是脊椎动物,例如灵长类动物、啮齿类动物、家畜或狩猎动物。灵长类动物包括黑猩猩、猕猴、蜘蛛猴和猕猴,例如恒河猴。啮齿类动物包括小鼠、大鼠、土拨鼠、雪貂、兔和仓鼠。家畜和狩猎动物包括牛、马、猪、鹿、北美野牛(bison)、水牛、猫科动物,例如家猫,犬科动物,例如狗、狐、狼,禽类,例如鸡、鸸鹋、鸵鸟和鱼,例如鳟鱼、鲶鱼和鲑鱼。在一些实施方案中,受试者是哺乳动物,例如灵长类动物,例如人。术语“个体”、“患者”和“受试者”在本文中可互换使用。
优选地,受试者是哺乳动物。哺乳动物可以是人、非人灵长类动物、小鼠、大鼠、狗、猫、马或牛,但不限于这些实例。除人以外的哺乳动物可有利地用作代表骨髓纤维化或骨髓增生性病症的动物模型的受试者。受试者可以是男性或女性。
受试者可以是这样的受试者,其先前已经被诊断或鉴定罹患或患有需要治疗的病况(例如骨髓纤维化或骨髓增生性病症)或与这种病况相关的一种或多种并发症,并且任选地已经经历骨髓纤维化或骨髓增生性病症或与骨髓纤维化或骨髓增生性病症相关的一种或多种并发症的治疗。或者,受试者也可以是这样的受试者,其先前未被诊断患有骨髓纤维化或骨髓增生性病症或与骨髓纤维化或骨髓增生性病症相关的一种或多种并发症。例如,受试者可以是表现出骨髓纤维化或骨髓增生性病症或与骨髓纤维化或骨髓增生性病症相关的一种或多种并发症的一种或多种风险因子的受试者或未表现出风险因子的受试者。
治疗特定病况的“有需要的受试者”可以是患有该病况,被诊断为患有该病症,或处于发展该病症的风险中的受试者。
本文所用的术语“蛋白质”和“多肽”在本文中可互换使用,指通过相邻残基的α-氨基和羧基之间的肽键相互连接的一系列氨基酸残基。术语“蛋白质”和“多肽”是指氨基酸的聚合物,包括修饰的氨基酸(例如,磷酸化的、糖化的、糖基化的等)和氨基酸类似物,而不管其大小或功能。“蛋白质”和“多肽”常用于指相对大的多肽,而术语“肽”常用于指小的多肽,但这些术语在本领域中的使用重叠。当涉及基因产物及其片段时,术语“蛋白质”和“多肽”在本文中可互换使用。因此,示例性多肽或蛋白质包括基因产物,天然存在的蛋白质,同源物,直系同源物,旁系同源物,片段及前述的其它等同物,变体,片段和类似物。
在本文所述的各实施方案中,还考虑了涵盖所描述的任何特定多肽的变体(天然存在的或其它的)、等位基因、同源物、保守修饰的变体和/ 或保守取代变体。对于氨基酸序列,本领域技术人员将认识到,对核酸,肽,多肽或蛋白质序列的改变所编码的序列中的单个氨基酸或小百分比的氨基酸的单独取代,缺失或添加,如果所述改变导致氨基酸被化学上相似的氨基酸取代并保留所需的多肽活性,则是“保守修饰的变体”。这种保守修饰的变体是除了与本公开内容一致的多态性变体,种间同源物和等位基因之外的并且不排除它们。
给定的氨基酸可以被具有类似物理化学特征的残基替代,例如,一个脂族残基替代另一个脂族残基(例如,Ile、Val、Leu或Ala替代另一个脂族残基),或者一个极性残基替代另一个极性残基(例如,在Lys和Arg 之间;Glu和Asp之间;或Gln和Asn之间)。其它这样的保守取代,例如具有相似疏水特征的整个区域的取代是众所周知的。可以在本文所述的任何一种测定中测试包含保守氨基酸取代的多肽,以证实保留了天然或参考多肽的所需的活性,例如转录因子活性和特异性。
氨基酸可以根据其侧链性质的相似性分组(在A.L.Lehninger, Biochemistry,第2版,pp.73-75,Worth Publishers,New York(1975)中):(1) 非极性的:Ala(A)、Val(V)、Leu(L)、Ile(I)、Pro(P)、Phe(F)、Trp(W)、 Met(M);(2)不带电荷的极性的:Gly(G)、Ser(S)、Thr(T)、Cys(C)、Tyr (Y)、Asn(N)、Gln(Q);(3)酸性的:Asp(D)、Glu(E);(4)碱性的:Lys(K)、Arg(R)、His(H)。或者,天然存在的残基可基于共同的侧链性质分组: (1)疏水性的:正亮氨酸、Met、Ala、Val、Leu、Ile;(2)中性亲水性的: Cys、Ser、Thr、Asn、Gln;(3)酸性的:Asp、Glu;(4)碱性的:His、Lys、 Arg;(5)影响链取向的残基:Gly、Pro;(6)芳香族的:Trp、Tyr、Phe。非保守性取代将需要将这些类别中的一个的成员替换为另一个类别。具体的保守取代包括,例如Ala替换成Gly或Ser;Arg替换成Lys;Asn 替换成Gln或His;Asp替换成Glu;Cys变成Ser;Gln替换成Asn;Glu 替换成Asp;Gly替换成Ala或Pro;His替换成Asn或Gln;Ile替换成 Leu或Val;Leu替换成Ile或Val;Lys替换成Arg、Gln或Glu;Met替换成Leu、Tyr或Ile;Phe替换成Met、Leu或Tyr;Ser替换成Thr;Thr 变成Ser;Trp替换成Tyr;Tyr替换成Trp;和/或Phe替换成Val、Ile或 Leu。
在一些实施方案中,本文所述的多肽(或编码这些多肽的核酸)可以是本文所述的氨基酸序列之一的功能性片段。如本文所用,“功能性片段”是根据下文所述的测定保留野生型参考多肽活性的至少50%的肽的片段或区段。功能性片段可包含本文公开的序列的保守性取代。
在一些实施方案中,本文所述的多肽可以是本文所述序列的变体。在一些实施方案中,变体是保守修饰的变体。保守取代变体可以通过例如天然核苷酸序列的突变获得。本文所用的“变体”是与天然或参考多肽基本同源的多肽,但由于一个或多个缺失,插入或取代,其具有不同于天然或参考多肽的氨基酸序列。编码变体多肽的DNA序列包括与天然或参考DNA序列相比包含核苷酸的一个或多个添加,缺失或取代,但编码保留活性的变体蛋白或其片段的序列。多种基于PCR的位点特异性诱变方法是本领域已知的,并且可以由本领域技术人员应用。
变体氨基酸或DNA序列与天然或参考序列可以至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更多相同。天然和突变序列之间的同源性程度(同一性百分比)可以例如通过使用在万维网上通常用于该目的的免费使用的计算机程序(例如具有默认设置的BLASTp或BLASTn)比较两个序列来确定。
天然氨基酸序列的改变可以通过本领域技术人员已知的多种技术中的任一种来完成。突变可以例如通过合成含有突变序列的寡核苷酸在特定位点引入,该特定位点的侧翼是能够与天然序列的片段连接的限制性位点。连接后,得到的重建序列编码具有所需氨基酸插入,取代或缺失的类似物。或者,可采用寡核苷酸指导的位点特异性诱变方法来提供改变的核苷酸序列,其具有根据所需的取代,缺失或插入而改变的特定密码子。用于进行这种改变的技术是非常成熟的,并且包括例如以下公开的那些:Walder等人(Gene 42:133,1986);Bauer等人(Gene 37:73,1985); Craik(BioTechniques,1985年1月,12-19);Smith等人(Genetic Engineering: Principles and Methods,Plenum Press,1981);和美国专利号4,518,584和 4,737,462,其通过引用全文并入本文中。任何不参与维持多肽的适当构象的半胱氨酸残基也可以被取代,通常用丝氨酸取代,以改善分子的氧化稳定性并防止异常交联。相反,可以将半胱氨酸键添加到多肽中以改善其稳定性或促进寡聚化。
本文所用的术语“核酸”或“核酸序列”是指掺入核糖核酸,脱氧核糖核酸或其类似物的单元的任何分子,优选聚合物分子。核酸可以是单链或双链的。单链核酸可以是变性双链DNA的一条核酸链。或者,它可以是并非源自任何双链DNA的单链核酸。在一个方面,核酸可以是DNA。在另一方面,核酸可以是RNA。合适的DNA可包括例如基因组DNA或 cDNA。合适的RNA可包括例如mRNA。
术语“表达”是指参与产生RNA和蛋白质,并且适当时,分泌蛋白质的细胞过程,在适当的情况下包括但不限于例如转录,转录物加工,翻译和蛋白质折叠,修饰和加工。表达可以指从本发明的一个或多个核酸片段衍生的有义(mRNA)或反义RNA的转录和稳定积累和/或mRNA翻译成多肽。
在一些实施方案中,本文所述的生物标志物、靶标或基因/多肽的表达是组织特异性的。在一些实施方案中,本文所述的标志物、靶标或基因/多肽的表达是全局的。在一些实施方案中,本文所述的标志物、靶标或基因/多肽的表达是全身性的。
“表达产物”包括从基因转录的RNA,和通过翻译从基因转录的 mRNA获得的多肽。术语“基因”是指当与适当的调节序列可操作地连接时,在体外或体内被转录(DNA)成RNA的核酸序列。基因可以包括或可以不包括编码区之前和之后的区域,例如5'非翻译(5'UTR)或“前导”序列和3'UTR或“尾随”序列,以及各编码区段(外显子)之间的插入序列(内含子)。
在本发明的上下文中,“标志物”是指表达产物,例如核酸或多肽,其与取自对照受试者(例如健康受试者)的相当样品相比,差异性存在于取自患有骨髓纤维化或骨髓增生性病症的受试者的样品中。术语“生物标志物”与术语“标志物”互换使用。
在一些实施方案中,本文所述的方法涉及测量,检测或测定至少一种标志物的水平。如本文所用,术语“检测”或“测量”是指观察来自例如探针、标记物或靶分子的信号以指示样品中分析物的存在。可以使用本领域已知的用于检测特定标记部分的任何方法进行检测。示例性的检测方法包括但不限于光谱学方法、荧光方法、光化学方法、生物化学方法、免疫化学方法、电方法、光学方法或化学方法。在任一方面的一些实施方案中,测量可以是定量观察。
在任一方面的一些实施方案中,可以工程化如本文所述的多肽,核酸或细胞。如本文所用,“工程化”是指已经由人的手操纵的方面。例如,当多肽的至少一个方面,例如它的序列,已经被人的手操纵以不同于它在自然界中存在的方面时,多肽被认为是“工程化的”。如通常的实践和本领域技术人员所理解的,工程化细胞的后代通常仍然被称为“工程化的”,即使实际的操作是在先前的实体上进行的。
在任一方面的一些实施方案中,本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA 或NR2F2)是外源性的。在任一方面的一些实施方案中,本文所述的 HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、 SOX18、SOX7、RXRA或NR2F2)是异位的。在任一方面的一些实施方案中,本文所述的HSPC、工程化的内皮龛细胞和/或转录因子(例如,ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2)不是内源性的。
术语“外源性”是指存在于细胞中而不是其天然来源的物质。当在本文中使用时,术语“外源性”可以指通过涉及人手的过程引入生物系统(例如细胞或生物体)的核酸(例如编码多肽的核酸)或多肽,在所述生物系统中通常不会存在所述核酸或多肽,并且人们希望将所述核酸或多肽引入所述细胞或生物体。或者,“外源性”可指通过涉及人手的过程引入生物系统(例如细胞或生物体)的核酸或多肽,在所述生物系统中存在相对较低量的所述核酸或多肽,并且人们希望增加细胞或生物体中的所述核酸或多肽的量,例如,以产生异位表达或水平。相反,术语“内源性”是指生物系统或细胞天然的物质。如本文所用,“异位”是指在不寻常的位置和/ 或以不寻常的量存在的物质。异位物质可以是通常在给定的细胞中存在的,但是数量低得多和/或在不同的时间存在的物质。异位也包括在给定细胞中在其天然环境下不天然存在或表达的物质,例如多肽或核酸。
在一些实施方案中,载体包含编码本文所述多肽(例如ETV2、FLI1、 ETS1、SOX18、SOX7、RXRA或NR2F2多肽)的核酸。在本文所述的一些方面,编码本文所述的给定多肽或其任何模块的核酸序列与载体可操作地连接。本文所用的术语“载体”是指设计用于递送至宿主细胞或用于在不同宿主细胞之间转移的核酸构建体。本文所用的载体可以是病毒或非病毒的。术语“载体”包括当与适当的控制元件结合时能够复制并且能够将基因序列转移到细胞中的任何遗传元件。载体可以包括但不限于克隆载体、表达载体、质粒、噬菌体、转座子、粘粒、染色体、病毒、病毒体等。
在任一方面的一些实施方案中,载体是重组的,例如,其包含源自至少两种不同来源的序列。在任一方面的一些实施方案中,载体包含源自至少两种不同物种的序列。在任一方面的一些实施方案中,载体包含源自至少两种不同基因的序列,例如,其包含融合蛋白或编码表达产物的核酸,其与至少一种非天然的(例如,异源的)遗传控制元件(例如,启动子、抑制子、激活子、增强子、应答元件等)可操作地连接。
在任一方面的一些实施方案中,本文所述的载体或核酸是密码子优化的,例如,核酸序列的天然或野生型序列已经被改变或工程化以包括替代密码子,使得改变或工程化的核酸编码与天然/野生型序列相同的多肽表达产物,但是将在期望的表达系统中以改进的效率被转录和/或翻译。在任一方面的一些实施方案中,表达系统是天然/野生型序列来源以外的生物体(或从这样的生物体获得的细胞)。在任一方面的一些实施方案中,本文所述的载体和/或核酸序列经密码子优化以在哺乳动物或哺乳动物细胞(例如小鼠,鼠细胞或人细胞)中表达。在任一方面的一些实施方案中,本文所述的载体和/或核酸序列经密码子优化以在人细胞中表达。在任一方面的一些实施方案中,本文所述的载体和/或核酸序列经密码子优化以在酵母或酵母细胞中表达。在任一方面的一些实施方案中,本文所述的载体和/或核酸序列经密码子优化以在细菌细胞中表达。在任一方面的一些实施方案中,本文所述的载体和/或核酸序列经密码子优化以在大肠杆菌细胞中表达。
如本文所用,术语“表达载体”是指指导RNA或多肽从与载体上的转录调节序列连接的序列中表达的载体。表达的序列通常但不一定是细胞异源的。表达载体可以包含另外的元件,例如,表达载体可以具有两套复制系统,从而允许其在两种生物体中维持,例如在人细胞中表达和在原核宿主中克隆和扩增。
如本文所用,术语“病毒载体”是指核酸载体构建体,其包括病毒来源的至少一个元件并具有包装成病毒载体颗粒的能力。病毒载体可以含有编码本文所述多肽的核酸来代替非必需病毒基因。载体和/或颗粒可用于在体外或体内将任何核酸转移到细胞中的目的。多种形式的病毒载体是本领域已知的。
应当理解,在一些实施方案中,本文所述的载体可以与其它合适的组合物和疗法组合。在一些实施方案中,载体是游离型的。合适的游离型载体的使用提供了以高拷贝数染色体外DNA维持受试者中感兴趣的核苷酸从而消除染色体整合的潜在影响的方法。
如本文所用,术语“治疗(treat)”、“治疗(treatment)”、“治疗(treating)”或“改善”是指治疗性治疗,其中目的是逆转、减轻、改善、抑制、减缓或停止与疾病或病症(例如骨髓纤维化或骨髓增生性病症)相关的病况的进展或严重程度。术语“治疗”包括减少或减轻与骨髓纤维化或骨髓增生性病症相关的病况、疾病或病症的至少一种副作用或症状。如果一种或多种症状或临床标志物减少,治疗通常是“有效的”。或者,如果疾病的进展降低或停止,治疗是“有效的”。也就是说,“治疗”不仅包括症状或标志物的改善,而且包括与没有治疗时预期的症状相比,症状的停止或至少减缓、进展或恶化。有益的或期望的临床结果包括但不限于减轻一种或多种症状,减少疾病程度,稳定(即不恶化)疾病状态,延迟或减缓疾病进展,改善或减轻疾病状态,缓解(不论是部分或全部)和/或降低死亡率,无论是可检测的还是不可检测的。术语疾病的“治疗”还包括减轻疾病的症状或副作用(包括姑息治疗)。
如本文所用,术语“药物组合物”是指与药学上可接受的载体(例如制药工业中常用的载体)组合的活性剂。本文所用的短语“药学上可接受的”是指在合理的医学判断范围内适合用于与人类和动物的组织接触而没有过度的毒性、刺激、过敏反应或其它问题或并发症,与合理的益处/风险比相称的那些化合物、材料、组合物和/或剂型。在任一方面的一些实施方案中,药学上可接受的载体可以是除水以外的载体。在任一方面的一些实施方案中,药学上可接受的载体可以是乳膏、乳液、凝胶、脂质体、纳米颗粒和/或软膏。在任一方面的一些实施方案中,药学上可接受的载体可以是人工的或工程化的载体,例如,在自然界中不会发现活性成分存在的载体。
如本文所用,术语“施用”是指通过导致药剂在所需部位至少部分递送的方法或途径将如本文公开的化合物置于受试者中。包含本文公开的化合物的药物组合物可以通过任何适当的途径施用,其导致受试者的有效治疗。在一些实施方案中,施用包括人体物理活动,例如注射、摄取动作、敷用动作和/或递送装置或机器的操作。这种活动可以由例如医学专业人员和/或所治疗的受试者来执行。
如本文所用,“接触”是指用于递送或暴露药剂至至少一个细胞的任何合适的方式。示例性的递送方法包括但不限于直接递送至细胞培养基、灌注、注射或本领域技术人员熟知的其它递送方法。在一些实施方案中,接触包括人体物理活动,例如注射;分配、混合和/或倾析的动作;和/ 或递送装置或机器的操作。
术语“统计学上显著的”或“显著地”是指统计学上的显著性,并且通常是指两个标准偏差(2SD)或更大的差异。
除了在操作实施例中,或者在另外指出的情况下,本文使用的表示成分或反应条件的量的所有数字应当理解为在所有情况下由术语“约”修饰。当与百分比一起使用时,术语“约”可以意指±1%。
如本文所用,术语“包含”意指除了所呈现的所限定的要素之外,还可存在其它要素。“包含”的使用表示包括而不是限制。
术语“由……组成”是指如本文所述的组合物、方法和其各自的组分,其排除了在实施方案的那个描述中未陈述的任何要素。
如本文所用,术语“基本上由……组成”是指给定实施方案所需的那些要素。该术语允许存在不会实质上影响本发明的该实施方案的基本、新颖的或功能性的特性的其它元件。
如本文所用,术语“对应于”是指在第一多肽或核酸中的列举位置处的氨基酸或核苷酸,或相当于第二多肽或核酸中的列举氨基酸或核苷酸的氨基酸或核苷酸。等同的列举的氨基酸或核苷酸可以通过使用本领域已知的同源程度程序(例如BLAST)对候选序列进行比对来确定。
如本文所用,术语“特异性结合”是指两个分子、化合物、细胞和/或颗粒之间的化学相互作用,其中第一实体以比其与非靶标的第三实体结合更高的特异性和亲和力与第二靶标实体结合。在一些实施方案中,特异性结合可指第一实体对第二靶标实体的亲和力是其对第三非靶标实体的亲和力的至少10倍、至少50倍、至少100倍、至少500倍、至少1000 倍或更高。特异于给定靶标的试剂是在所利用的测定条件下对该靶标表现出特异性结合的试剂。
单数术语“一个”、“一种”和“所述”包括复数对象,除非上下文另外清楚地指示。类似地,词语“或”旨在包括“和”,除非上下文另外清楚地指示。尽管与本文所述的方法和材料类似或等同的方法和材料可用于本公开的实践或测试,但合适的方法和材料描述如下。缩写“例如(e.g.)”衍生自拉丁文例如(exempli gratia),并且在本文中用于表示非限制性实例。因此,缩写“例如(e.g.)”与术语“例如(for example)”同义。
本文所公开的本发明的可选要素或实施方案的分组不应被解释为限制。每个组成员可以单独提及和要求保护,或者以与该组的其它成员或本文中出现的其它要素的任何组合提及和要求保护。为了方便和/或可专利性的原因,组的一个或多个成员可以被包括在组中或从组中删除。当任何这样的包括或删除发生时,本说明书在本文中被认为包含如此修改的组,从而实现所附权利要求书中使用的所有马库什组的书面描述。
除非在本文中另外定义,结合本申请使用的科学和技术术语应具有本公开所属领域的技术人员通常理解的含义。应当理解,本发明不限于本文所述的特定方法、方案和试剂等,因此可以变化。本文所用的术语仅用于描述特定实施方案的目的,且不旨在限制本发明的范围,本发明的范围仅由权利要求书限定。免疫学和分子生物学中常见术语的定义可见于The Merck Manual of Diagnosis and Therapy,第20版,由Merck Sharp&Dohme Corp.出版,2018(ISBN 0911910190,978-0911910421); Robert S.Porter等人(编辑),TheEncyclopedia of Molecular Cell Biology and Molecular Medicine,由BlackwellScience Ltd.出版,1999-2012(ISBN 9783527600908);和Robert A.Meyers(编辑),Molecular Biology and Biotechnology:a Comprehensive Desk Reference,由VCHPublishers,Inc. 出版,1995(ISBN 1-56081-569-8);Immunology by Werner Luttmann,由 Elsevier出版,2006;Janeway's Immunobiology,Kenneth Murphy,Allan Mowat,CaseyWeaver(编辑),W.W.Norton&Company,2016(ISBN 0815345054,978-0815345053);Lewin'sGenes XI,由Jones&Bartlett Publishers出版,2014(ISBN-1449659055);MichaelRichard Green and Joseph Sambrook,Molecular Cloning:A Laboratory Manual,第4版,Cold Spring Harbor Laboratory Press,Cold Spring Harbor,N.Y.,USA(2012)(ISBN 1936113414);Davis等人,Basic Methods in Molecular Biology, ElsevierScience Publishing,Inc.,New York,USA(2012)(ISBN 044460149X);LaboratoryMethods in Enzymology:DNA,Jon Lorsch(编辑) Elsevier,2013(ISBN 0124199542);Current Protocols in Molecular Biology (CPMB),Frederick M.Ausubel(编辑),JohnWiley and Sons,2014(ISBN 047150338X,9780471503385),Current Protocols inProtein Science(CPPS), John E.Coligan(编辑),John Wiley and Sons,Inc.,2005;以及Current Protocols in Immunology(CPI)(John E.Coligan,ADA M Kruisbeek,David HMargulies,Ethan M Shevach,Warren Strobe,(编辑)John Wiley and Sons, Inc.,2003(ISBN 0471142735,9780471142737),其内容均通过引用整体并入本文。
本文定义的其它术语在在本发明的各个方面的描述中。
在整个本申请中引用的所有专利和其它出版物;包括参考文献,公布的专利,公开的专利申请和共同未决的专利申请;通过引用明确地并入本文,用于描述和公开例如在这些出版物中描述的可能与本文描述的技术结合使用的方法的目的。提供这些出版物仅用于它们的公开在本申请的申请日之前。在这一点上,不应将任何东西解释为承认本发明人不具有借助于先前发明或出于任何其它原因而先于这样的公开的权利。关于这些文件的内容的日期或表示的所有声明都是基于申请人可获得的信息,并且不构成对这些文件的日期或内容的正确性的任何认可。
本公开的实施方案的描述并非旨在穷举或将本公开限制于所公开的精确形式。虽然本文出于说明目的描述了本公开的具体实施方案和实施例,但是如相关领域的技术人员将认识到的,在本公开的范围内,各种等同的修改是可能的。例如,虽然方法步骤或功能以给定的顺序呈现,但是替换实施方案可以以不同的顺序执行功能,或者可以基本上同时执行功能。本文提供的本公开的教导视情况可适用于其它程序或方法。本文所述的各种实施方案可经组合以提供其它实施方案。如果需要,可以修改本公开的方面,以采用上述参考文献和申请的组成,功能和概念来提供本公开的其它实施方案。此外,由于生物功能等同的考虑,可以在蛋白质结构上进行一些改变,而不会在种类或量上影响生物或化学作用。根据详细描述,可以对本公开进行这些和其它改变。所有这些修改都旨在包括在所附权利要求书的范围内。
任何前述实施方案的特定要素可以被组合或替代成其它实施方案中的要素。此外,虽然已经在这些实施方案的上下文中描述了与本公开的某些实施方案相关联的优点,但是其他实施方案也可以呈现这些优点,并且不是所有实施方案都必须呈现落入本公开的范围内的这些优点。
本文所述的技术通过以下实施例进一步说明,这些实施例决不应被解释为进一步的限制。
本文描述的技术的一些实施方案可以根据以下编号的段落中的任一个来限定:
1.产生/工程化内皮龛细胞的方法,其包括在内皮细胞中表达一种或多种转录因子,其中所述一种或多种转录因子来自Ets家族,Sox家族和 /或核激素受体家族。
2.如上述段落中任一段所述的方法,其中所述内皮龛细胞表达一种或多种基因,所述基因包括:sele、exoc312a、snx8a、cltca、aqp7、ap1b1、 lgmn、prcp、cldn11a、lyve1b、adra1d、hya12a、hya12b、tll1、i113ra2、 glu1a、hexb、slc16a9a或sepp1a。
3.如上述段落中任一段所述的方法,其中所述内皮细胞是人的。
4.如上述段落中任一段所述的方法,其中所述转录因子包括人转录因子ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2中的至少一种。
5.如上述段落中任一段所述的方法,其中所述转录因子包括来自Ets 家族的至少一种转录因子、来自Sox家族的至少一种转录因子和来自核激素受体家族的至少一种转录因子。
6.如上述段落中任一段所述的方法,其中所述转录因子包括ETV2、 FLI1、ETS1、SOX18、SOX7、RXRA和NR2F2。
7.如上述段落中任一段所述的方法,其中所述转录因子由至少一种载体表达。
8.如上述段落中任一段所述的方法,其中所述载体包含编码所述一种或多种转录因子的外源核酸序列。
9.如上述段落中任一段所述的方法,其中将所述外源核酸序列掺入所述内皮细胞的基因组中。
10.工程化的内皮龛细胞,其包含编码一种或多种转录因子的一种或多种外源核酸序列,其中所述一种或多种转录因子来自Ets家族、Sox家族和/或核激素家族。
11.组合物,其包含段落10的工程化的内皮龛细胞。
12.如上述段落中任一段所述的组合物,其中所述组合物是治疗剂,或者所述组合物还包含药学上可接受的载体。
13.如上述段落中任一段所述的组合物,其中所述组合物还包含培养皿、3D细胞系统或悬浮系统。
14.如上述段落中任一段所述的组合物,其中所述组合物包含支架。
15.培养HSPC的方法,所述方法包括在存在工程化的内皮龛细胞群的情况下培养HSPC。
16.如上述段落中任一段所述的方法,其中所述方法在体外进行。
17.如上述段落中任一段所述的方法,其中所述工程化内皮细胞分泌影响HSPC细胞生长和/或扩增的因子。
18.如上述段落中任一段所述的方法,其中在存在所述工程化的内皮龛细胞的情况下培养的所述HSPC可比在不存在所述工程化的内皮龛细胞的情况下培养的HSPC多培养至少3天(例如,至少4天、至少5天、至少6天、至少7天)。
19.如上述段落中任一段所述的方法,其中所述细胞在生物相容性支架上培养。
20.如上述段落中任一段所述的方法,其中相比不与工程化的内皮龛细胞一起培养的基本上相似的HSPC在施用于受试者时的植入相比,在存在工程化内皮细胞的情况下培养的HSPC具有增加的植入。
21.治疗受试者的方法,所述方法包括将包含HSPC和工程化的内皮龛细胞群的组合物移植到所述受试者中。
22.增强HSPC植入的方法,所述方法包括向有需要的受试者施用包含HSPC和工程化的内皮龛细胞群的组合物。
23.如上述段落中任一段所述的方法,其中所述HSPC的植入与不存在工程化的内皮龛细胞的情况下的基本相似的HSPC的植入相比增加至少10%。
24.共培养物,其包含工程化的内皮龛细胞和HSPC。
25.如段落24所述的共培养物,其中所述内皮细胞通过上述段落中任一段所述的方法制备。
26.用于培养HSPC的试剂盒,所述试剂盒包含:工程化的内皮龛细胞群、试剂及其使用说明书。
27.用于产生工程化的内皮龛细胞的试剂盒,其包含载体及其使用说明书,所述载体包含编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列。
28.产生异位血管龛的方法,所述方法包括将工程化的内皮龛细胞施用于有需要的受试者的靶位点。
29.用于髓外造血的方法,所述方法包括将工程化龛内皮细胞移植到受试者中骨髓外的位置(例如,前臂)处,从而产生合成龛。
30.如上述段落中任一段所述的方法,其中所述内皮细胞通过上述段落所述方法的任一种制备。
31.载体,其包含与启动子可操作地连接的编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列。
实施例
实施例1
体内血管血液干细胞龛的转录因子诱导
造血龛是由不同细胞类型(包括与造血干细胞和祖细胞(HSPC)直接相互作用以促进干细胞功能的特化血管内皮细胞)组成的支持性体内微环境。决定龛内皮细胞及其促造血活性的分子因子在很大程度上仍然未知。使用多维基因表达分析和染色质可及性测定,本文定义的是HSPC龛中血窦内皮细胞独特的保守基因表达特征和顺式调节景观。使用增强子诱变和转录因子过表达,阐明了涉及Ets、Sox和核激素受体家族成员的转录编码,其足以诱导募集HSPC并支持其体内稳态的异位龛内皮细胞。总之,这些研究对于为血液干细胞产生更有效的合成血管龛或在治疗环境中调节龛具有重要的意义。
结果
胎儿HSPC龛特有的内皮基因表达特征
来自不同器官的EC表达不同的基因,但是这是否受器官特异性转录程序调节仍然了解很少。为了研究CHT龛中基因表达的调控,在受精后 72小时(hpf)的斑马鱼尾上进行RNA断层摄影术(tomo-seq)(参见例如图 1A)。这种tomo-seq分析揭示了沿着尾部的背腹轴对应于特定组织(包括脊髓,脊索,肌肉和表皮)以及特定的血液和免疫细胞群的基因表达簇(参见例如,图1B,图7A,图7B)。总之,144种基因在跨越CHT的几个冷冻切片中显示出富集的表达(参见例如表3)。使用整体原位杂交 (WISH),确认这些基因中的35种的CHT表达(参见例如表3;在zfin.org 的万维网上可获得的图像)。为了确认144种基因中的任何一种是否均由 EC表达,用泛内皮转基因kdr1:GFP和荧光激活细胞分选(FACS)分离用于大批和单细胞RNA-seq的EC(参见例如,图1C)。此外,这些基因与巨噬细胞和嗜中性粒细胞RNA-seq数据集互相参照(参见例如,Theodore 等人,Distinct Roles for MatrixMetalloproteinases 2 and 9 in Embryonic Hematopoietic Stem Cell Emergence,Migration,and Niche Colonization. Stem cell reports 8,1226-1241,2017)。鉴定了在CHT EC中选择性富集的 29种基因(参见例如表1)。与泛内皮基因相反,这些CHT内皮基因的 tomo-seq表达痕迹缺少对应于背部血管系统中表达的强峰(参见例如,图1D)。对于29种基因中的25种,通过WISH证实了CHT EC富集的表达 (参见例如,图1E,图7A,图7B和表1)。
为了选择性地分离CHT EC,设计了标记这些细胞的转基因系。将 1.3或5.3kb的上游调节序列克隆到两个CHT内皮基因mrc1a和sele中,以产生GFP报告基因转基因,然后将其与泛内皮标志物kdr1:mCherry杂交。对于mrc1a:GFP和sele:GFP转基因,在CHT的静脉窦中观察到最高水平的表达,而在卵黄延伸部上方的后主静脉中和头部的少量血管中检测到低水平的GFP表达(参见例如,图8A-图8E)。尽管在外尾鳍的间充质细胞中也观察到GFP表达,但是这些细胞是异位转基因表达的频繁位点,并不代表这些基因的内源性表达。值得注意的是,在直接与HSPC 相互作用的血窦EC中观察到稳健的GFP表达,证实了mrc1a:GFP和sele:GFP转基因标记了HSPC龛中的EC(参见例如,图8A-图8E)。这些 GFP+EC与cxcl12a:dsRed2+基质细胞密切相关并且被观察到形成围绕 HSPC的口袋——CHT龛中EC的细胞行为特征(参见例如图8A-图8E)。
内皮龛特异性顺式调节元件
为了研究CHT EC中龛特异性基因表达的转录控制,解离双阳性 mrc1a:GFP/kdrl:mCherry胚胎并使用FACS分离4个不同的群用于 RNA-seq和ATAC-seq分析:GFP+/mCherry+(CHT EC)、GFP-/mCherry+ (CHT以外的EC)、GFP+/mCherry-(尾鳍中的间充质细胞)和GFP-/mCherry- (胚胎的阴性剩余部分;参见例如,参见图2A)。通过比较四个群的染色质可及性的区域,在CHT EC中鉴定出6,848个唯一开放的区域。29种 CHT EC基因中,29种中的26种具有在100kb的转录起始位点内的 ATAC-seq元件,这仅在CHT EC中发现(参见例如图2B,表1)。为了测试这些区域是否可能是组织特异性增强子,克隆15个元件的序列,然后将其与最小启动子和GFP融合,然后注射到斑马鱼胚胎中。15个构建体中的12个显示在60-72hpf的CHT EC中富集的GFP表达(参见例如,图 2C,表2)。作为对照,克隆染色质区域,基于与先前注释的血管特异性基因的接近性以及它们在CHT和非CHT EC级分中的可及性,预测它们含有泛内皮调节元件(参见例如,图9A-图9C,表2)。先前已显示许多这些区域含有内皮增强子(参见例如Quillien等人,Robust Identification of Developmentally ActiveEndothelial Enhancers in Zebrafish Using FANS-Assisted ATAC-Seq.Cell reports20,709-720,2017)。对于6个泛内皮区域中的6个,在不限于CHT的整个胚胎中观察到EC中的嵌合GFP表达(参见例如,图9A-图9C)。因此,斑马鱼系统能够在体内快速验证通过ATAC-seq分析预测的龛特异性内皮增强子。
用于龛内皮表达的转录因子结合位点
为了鉴定可能结合CHT EC增强子的转录因子,对CHT EC中唯一可及的染色质的6,848个区域进行基序富集分析。这种分析揭示了Ets、 Sox(具体为SoxF因子)和核激素受体(具体为NR2F2/RORA/RXRA因子,下文缩写为NHR)结合基序在6,848个区域中富集最多(参见例如,图9A- 图9C)。相比之下,在富含Ets位点的基因组中存在4,522个泛内皮元件 (即,在CHT和非CHT EC中均可及的染色质区域),但不存在SoxF或 NHR结合基序(参见例如,图9A-图9C)。值得注意的是,在体内报告基因测定中驱动GFP表达的12个CHT-EC元件都具有Ets、SoxF和NHR 位点,而不驱动GFP表达的3个CHT-EC元件中的1个和6个泛内皮区域中的3个缺少NHR结合位点(参见例如表2)。
为了确定足以驱动CHT EC表达的最小序列,克隆了mrc1a上游的 125个碱基对(bp)序列和sele上游的158bp序列;这些序列已经包括我们的原始转基因,并对应于这些区域中最强的ATAC-seq信号(参见例如,图3A,图10A-10E)。当与最小启动子连接时,这些元件在注射的胚胎的 44%(125bp的mrc1a序列;356个中的155个)和23%(158bp的sele序列;775个中的176个)中驱动CHT EC中的GFP表达(参见例如,图3B,图 10A-10E)。与注射kdrl:mCherry构建体(其中在整个胚胎的EC中观察到嵌合表达)相比,mrc1a和sele增强子-GFP构建体的表达限于CHT EC(参见例如,图3C,图10A-10E)。此外,当使用这些短构建体建立稳定的转基因系时,GFP在CHT EC中特异性表达(参见例如,图3D,图10A-10E)。哺乳动物Mrc1主要由巨噬细胞和静脉窦EC表达。斑马鱼具有两种同源基因mrc1a和mrc1b。最近对mrc1a的研究报道了当启动子与内含子增强子(显示出与用mrc1b的保守性)连接时,在巨噬细胞和EC中均表达(参见例如Jung等人,Development of the larval lymphatic system inzebrafish. Development 144,2070-2081,2017)。相比之下,125bp的增强子元件在 CHTEC中特异性地驱动表达,说明增强子中的特异性。
125bp的mrc1A和158bp的sele调节序列都含有Ets、SoxF和NHR 基序(参见例如,图3E,图10A-10E)。为了测试这些转录因子结合位点对于表达是否是必需的,产生了这样的变体,其中每一类基序通过突变破坏。在每种情况下,Ets、SoxF或NHR基序的破坏导致CHT EC中GFP 表达的显著降低或完全丧失(参见例如图3F)。在对照构建体(其中突变靶向Ets、SoxF和NHR基序之间的插入序列)中,GFP表达未被扰乱(参见例如,图3F)。斑马鱼中动脉-静脉指定的研究已经表明NHR Nr2f2,也称为COUP-TFII,促进静脉内皮细胞命运(参见例如,Aranguren等人, Transcription factor COUP-TFII is indispensable for venous andlymphatic development in zebrafish and Xenopus laevis.Biochemical andbiophysical research communications 410,121-126,2011)。为了测试Nr2f2是否能够直接结合增强子序列,进行体外凝胶电泳迁移率变动测定。鼠NR2F2-GST 蛋白与来自125bpmrc1a或158bp sele斑马鱼增强子的标记探针的孵育产生DNA:蛋白质复合物,其在添加NR2F2抗体时超迁移,并且可以被未标记的竞争探针超越(参见例如,图10A-图10E)。然而,其中NHR基序突变的未标记探针不能超越野生型探针,证明了NR2F2以序列特异性方式结合这些NHR基序。
确定的因子诱导龛内皮表达
为了确定哪些转录因子在CHT EC中表达并且可能在体内结合Ets、 Sox和NHR基序,检查来自CHT EC的RNA-seq数据。最高表达的因子是fli1a、etv2、ets1、sox18、sox7、nr2f2和rxraa(参见例如表4)。为了测试这七种因子是否可以诱导CHT外的龛内皮基因表达,产生了构建体,其中每种转录因子的直系同源物在泛素(ubi)启动子的控制下(参见例如,图4A)。然后将七种ubi驱动的因子的集合注射到单细胞期的斑马鱼胚胎中,通过WISH在60-72hpf时检测mrc1a和sele表达。令人惊奇的是,这些胚胎中的17%(69个中的12个)在CHT外,躯干和尾的背部内以及卵黄上具有mrc1a表达的异位血管补片(vascular patch)(参见例如,图4B,图11A-11C)。对照注射的胚胎没有显示异位表达(56个中的0个)。用针对sele的WISH,或者当将因子注射到mrc1a:GFP/kdr1:mCherry双转基因胚胎中时获得了类似的结果(参见例如,图4B-图4C,图11A-图11C)。在这些区域中,异位表达mrc1a的血管通常大于它们的正常对应物,并且具有类似于CHT的血窦样形态(参见例如图4C)。使用DIC显微术,通过这些区域的血流容易显现(数据未示出)。这些数据表明少量转录因子足以异位诱导龛内皮基因程序。
对125bp mrc1a和158bp sele增强子的该突变分析表明,表达需要来自Ets、Sox和NHR家族中每一种的因子,这导致了三种因子(每个家族一种因子)的组合是否足以诱导龛内皮基因表达的实验。ETV2是将早期中胚层祖细胞指定为血管细胞命运所必需的先驱因子。ETV2在非血管细胞中的强制表达诱导向早期内皮细胞命运的重新编程,所述早期内皮细胞命运可产生许多类型的血管系统。先前在斑马鱼中的工作已经显示了 SoxF因子(sox7和sox18)和nr2f2在动脉-静脉指定期间的重要性(参见例如Swift等人,SoxF factors andNotch regulate nr2f2 gene expression during venous differentiation inzebrafish.Developmental biology 390,116-125, 2014)。这些因子中的三种—ETV2、SOX7和Nr2f2—的组合可以足以诱导异位龛内皮基因表达。与此相一致,当注射这三种因子时,观察到显著的异位mrc1a表达(参见例如,图4D-图4F)。3种因子产生的异位血管的频率高于7种因子的集合,提示因子浓度具有功能意义。注射的胚胎类似地显示了sele、gpr182和lgmn的异位表达,表明3种因子的集合诱导了龛内皮程序(参见例如,图11A-11C)。
为了评价各转录因子的贡献,单独注射每种因子,并对mrc1a进行 WISH。单独注射SOX7或Nr2f2的胚胎显示最小的异位表达(参见例如图 4F)。单独注射ETV2导致mrc1a的异位表达,尽管其频率低于与SOX7 和Nr2f2联合注射ETV2时的频率,这表明另外的因子增加了异位诱导(参见例如,图4F,图12-图12D)。单独注射ETV2诱导内源性斑马鱼sox7 基因以及sox18、fli1a和etv2的异位表达,证明人ETV2可诱导若干斑马鱼内皮基因程序,包括动脉,静脉和龛内皮基因(参见例如图12-图12D)。因为内源性ets1和nr2f2在CHT外广泛表达(例如在脊髓区域),所以难以观察它们是否类似地由ETV2过表达诱导(参见例如图12-图12D)。ETS1具有与峰中富含的共有ETS基序结合的能力,并且在龛EC中以可观的水平表达。与ETV2相反,单独过表达ETS1不会导致广泛的血管诱导或异位mrc1a表达(参见例如图4F)。然而,注射ETS1、SOX7和Nr2f2 导致mrc1a的显著异位表达,说明这些转录因子的组合活性(参见例如,图4E,图4F,图12-图12D)。值得注意的是,编码七种起始转录因子中的每一种的斑马鱼基因具有与其相关的染色质区域,所述染色质区域在 CHT EC级分中是唯一可及的并含有Ets、SoxF和NHR位点(参见例如表 5),表明这些因子以类似于在重新编程期间建立的自动调节环调节彼此。因此,三种因子组合(包括ETV2或ETS1与Sox和NHR因子)的过表达模拟这些因子在72hpf时的龛EC中的内源性表达,并驱动龛内皮基因程序的稳健指定。
异位血管区募集HSPC
接下来询问异位CHT EC基因表达的区域是否能够募集和支持 HSPC。将ETV2、SOX7和Nr2f2集合注射到mrc1a:GFP/runx1:mCherry 双阳性转基因胚胎中,并检查runx1:mCherry+HSPC的定位。令人惊奇的是,在具有mrc1a:GFP的异位血管补片的22个胚胎的12个中,观察到 HSPC定位于这些区域(参见例如图5A)。相比之下,27个对照胚胎中的 0个具有异位定位的HSPC。通过runx1WISH和在注射ETS1、SOX7和 Nr2f2组合的胚胎中观察到runx1+HSPC的类似异位定位(参见例如,图 5A,5B)。
为了评估这些异位区域是否为HSPC提供支持环境,使用高分辨率活细胞共聚焦显微镜来更密切地检查HSPC行为和与这些位点处的EC的相互作用。该分析显示HSPC与异位位点内的mrc1a:GFP+EC直接相关,并且可以在管腔内和血管外间隙中发现它们。异位mrc1a:GFP+EC通常与 cxcl12a:DsRed2+基质细胞相关,并形成围绕HSPC的口袋,类似于在CHT 中观察到的(参见例如,图5A,图5C)。值得注意的是,使用延时显微镜 (time-lapsemicroscopy),在这些位点处观察到HSPC的初始募集,驻留和分裂(参见例如,图5D)。当HSPC分裂时,子细胞迁移离开异位位点并进入循环,推测移动到随后的龛(参见例如图5E)。总之,这些数据表明,通过驱动龛内皮基因程序的三种因子的重新编程产生能够募集和维持HSPC的功能性异位龛。
HSPC龛中的保守内皮细胞特征
为了确定在成体斑马鱼龛中是否存在类似的内皮表达特征,检查 mrc1a:GFP和sele:GFP转基因,发现两个品系在肾骨髓的EC中都具有 GFP表达(参见例如,图13A,图13B)。此外,检查斑马鱼肾骨髓的单细胞RNA-seq数据集(参见例如Tang等人,Dissectinghematopoietic and renal cell heterogeneity in adult zebrafish at single-cellresolution using RNA sequencing.The Journal of experimental medicine 214,2875-2887,2017)。该分析发现29种CHT EC基因中的23种在肾骨髓的血管EC中被强烈富集(参见例如图6A)。为了确定这种促造血血管龛特征在哺乳动物中是否是保守的,探查了RNA-seq数据集,其包括来自五个发育阶段(E11-13、 E14-15、E16-17、P2-P4和成体)的小鼠的多个器官(包括心脏、肾脏、肝脏、肺和骨髓)的EC的基因表达。29种CHT EC基因中的21种基因的直系同源物,相对于其在来自处于相同发育阶段的非造血器官的EC中的表达而在哺乳动物造血器官——胎儿肝脏和/或成体骨髓—的EC中富集(参见例如图6B)。值得注意的是,表达模式的子集反映了HSPC个体发育的时间动态,显示在E14-17阶段的胎儿肝脏EC中的稳健表达,然后显示在成体骨髓EC中升高的表达,伴随着预期的肝脏EC表达的降低(P2-P4 和成体;参见例如图6B)。为了确定与斑马鱼中揭示的转录程序相似的转录程序是否可以控制小鼠中的这些基因,使用相同的RNA-seq数据集检测来自Ets、Sox和NHR家族的转录因子的表达。在胎儿肝脏EC(E14-17) 和成体骨髓EC中,最高表达的因子是Ets1、SOX18和Nr2f2(参见例如表5)。总之,这些数据表明保守的转录程序调节胎儿和成体HSPC龛中 EC的促造血龛身份。
讨论
这些数据支持一种模型,其中由来自Ets、SoxF和NHR家族的因子组成的转录程序指定血管龛EC维持和扩增血液干细胞的身份和独特能力。这是在多个发育阶段和物种间的造血龛的保守特征。本文鉴定的龛内皮表达特征包括具有已知龛功能的基因(例如,粘附受体E-选择蛋白和半胱氨酸蛋白酶组织蛋白酶L,其已经与骨髓中的CXCL12周转相关)。此外,有许多基因先前不与HSPC龛相关,包括具有与胞吞作用和细胞内摄取相关的清道夫功能或活性的几种基因,包括mrc1a、stab1/2、dab2、 ap1b1、pxk和snx8。这些分子可以调节龛中的配体和受体周转,或者可以从龛微环境中清除潜在的有害物质,例如废物,修饰的蛋白质,或病毒,细菌或真菌相关物质。CHT EC与淋巴EC共有基因表达,包括与它们的共有起源一致的基因如lyve1b。在小鼠骨髓的最近研究中,检测了 SEC和AEC之间的差异基因表达。本文公开的龛EC特征与骨髓的静脉 SEC对齐。尽管AEC也可支持造血,但本文的工作说明SEC足以指导血管龛形成和促进干细胞扩增。在应激期间发生的髓外造血可以包括这种SEC龛程序的局部诱导。其它转录因子已经显示出驱动维持造血细胞 (包括tfec和klf6a)的CHT基因表达,尽管这些因子没有观察到富集的结合基序。似乎它们的靶标在CHT的不同细胞中,或者这些因子在我们的程序的下游起作用以指定组织特异性血管龛的不同群体。
用联体小鼠进行的实验表明,龛的大小决定了HSPC的数量(参见例如Chen等人,Mobilization as a preparative regimen for hematopoietic stem celltransplantation.Blood 107,3764-3771,2006)。功能性异位龛,称为小骨,已被用于在移植到小鼠中时组装骨髓等同物,并且很可能的是SEC 存在于这些结构中。总之,这些研究和本文提出的工作支持通过在体内新的安全港位置产生异位血管龛来增加体内HSPC数目的方法。该方法为内源性骨髓龛受损的疾病(例如骨髓纤维化)的新治疗奠定了基础。在更广泛的水平上,本工作推进了对设计血液干细胞的稳态和再生的血管龛的基本理解,这可以指导新的治疗策略来培养和扩增用于移植的HSPC。
方法
动物模型
野生型AB、casper或casper-EKK以及转基因系cd41:EGFP、 runx1:mCherry[runx1+23:NLS-mCherry]、kdrl(flk1):GFP[kdrl:GRCFP]、 kdrl:mCherry[kdrl:Hsa.hras-mCherry]和cxcl12a(sdf1a):DsRed2用于本研究。备选基因名称列在圆括号中,完整转基因名称列在方括号中。
基因组分析
对于RNA断层摄影术(tomo-seq),72hpf的胚胎用过量三卡因进行安乐死,并用解剖刀手工解剖含有CHT的尾部分。将组织定向在低温模具的最佳切割温度(OCT)组织冷冻介质中,其中腹侧面向模具的底部。在干冰上快速冷冻后,使用低温恒温器沿着背腹轴收集40个单独的8μm厚的冷冻切片。使用TRIzolTM从单独的冷冻切片提取RNA,然后在用于文库制备和测序的汇集之前在逆转录步骤期间条形码化(参见例如,Junker等人,Genome-wide RNATomography in the zebrafish embryo.Cell 159, 662-675,2014)。对于单细胞和大批RNA-seq,使用LiberaseTM解离kdrl: GFP胚胎,并通过FACS分离GFP+细胞。对于大批RNA-seq,使用TRIzolTM和GenEluteLPATM载体分离总RNA。使用RibomeanTM和SMARTer UniversalLow Input RNA KitTM从50ng总RNA/样品制备文库作为输入。对于单细胞测序,包封约2,000个细胞,并制备文库用于测序。对于ATAC-seq,使用LiberaseTM离解胚胎,并且通过FACS分离最少12,000 个细胞(最大50,000个)。随后裂解细胞,并在转位反应中孵育分离的细胞核。使用Illumina HiSeq2500TM进行所有测序。对于RNA-seq,通过 FastQCTM和CutadaptTM进行质量控制以去除适配子序列和低质量区域。使用TophatTM2.0.1158将高质量读数与斑马鱼基因组的UCSC构建 danRer7比对,而没有新的剪接形式调用。使用CufflinksTM2.2.159计算转录物丰度和差异表达。使用FPKM值来归一化和定量每种转录物。对于 ATAC-seq,使用Bowtie2TM(2.2.1版)按以下参数将读数与斑马鱼基因组的 UCSC构建danRer7比对:--末端至末端、-N0-、-L20。使用MACS2TM(2.1.0 版)峰发现算法按以下参数鉴定ATAC-seq峰的区域: -nomodel—Shift-100—extsize200。富集0.05的初始q值阈值用于峰调用,更严格的14的q值用于鉴定在不同样品之间不同的峰。使用HOMERTM进行全基因组基序富集分析,并且使用ConsiteTM进行基序注释。成体肾骨髓的基因表达分析在万维网上以mopath.shinyapps.10/zebrafishBlood/可获得。
整体原位杂交(WISH)
使用标准方案进行原位杂交。随后将胚胎转移到甘油中进行评分和成像。通过使用cDNA或质粒(对于来自其它物种的转录因子)模板进行PCR扩增,然后用地高辛连接的核苷酸进行逆转录,产生原位探针。本文所用的所有WISH探针的引物序列提供于表7中。通过Tomo-seq鉴定的35种CHT富集的基因的WISH图像可以在万维网上以zfin.org的找到。
转基因和增强子-GFP报告基因测定
建立转基因系。对于mrc1a:GFP和sele:GFP转基因,分别PCR扩增出基因组DNA的转录起始位点上游的1.3kb和5.3kb的序列,然后通过 TOPO-TATM克隆到p5E GatewayTM载体中,然后将其与GFP和聚A尾重组,所有都在Tol2位点侧。对于125bp的mrc1a和158bp的sele增强子, PCR扩增出基因组DNA的元件,通过TOPO-TATM克隆到p5E GatewayTM载体中,然后与融合到具有聚A尾的GFP的小鼠β-珠蛋白最小启动子重组,所有都在Tol2位点侧。在单细胞期用Tol2RNA注射胚胎,为每个构建体建立至少两个显示相似表达的独立品系:(Tg(mrc1a(1.3kb):GFP); Tg(sele(5.3kb):GFP);Tg(mrc1a(125bp):GFP)和Tg(sele(158bp):GFP)。CHT EC和泛EC ATAC-seq元件类似地使用基因组DNA通过PCR扩增,然后与β-珠蛋白最小启动子和GFP融合。125bp mrc1a和158bp sele的突变变体是通过退火重叠的寡聚物,随后进行T4 DNA聚合酶反应以产生平末端产物而产生的,随后将其克隆到p5E GatewayTM载体中(之后使用与 ATAC-seq元件相同的工作流程用Klenow片段加A-尾)。转录因子结合基序通过改变核心结合位点中的核苷酸而被破坏,嘌呤变成嘧啶,反之亦然。注射的F0胚胎在60-72hpf时评分。对照组和实验组在评分前是盲的,所有实验进行至少三次,利用独立的离合器。如果在至少10%的F0注射的胚胎中观察到GFP表达,则CHT EC或泛-EC表达中的GFP表达被评分为显著的。评分为阴性的胚胎或者没有GFP表达,或者在肌肉细胞中仅具有稀疏的异位表达。用于扩增mrc1a和sele调控元件以及15CHT EC 和6泛-ECATAC-seq元件的引物的序列在表7中提供。表8中提供了用于产生增强子变体的重叠寡聚物的序列。所有构建体的保真度通过在注射前进行测序来确认。
转录因子过表达研究
对于转录因子过表达研究,将人(FLI1、ETV2、ETS1、SOX7和 RXRA),爪蟾(Sox18)或斑马鱼(Nr2f2)基因的开放阅读框克隆到PME Gateway载体(InvitrogenTM)中,然后与斑马鱼ubi启动子和聚A尾重组。所有都在Tol2位点侧。所有构建体的保真度通过在注射前进行测序来确认。在单细胞期用ubi驱动的转录因子(1nl的25ng/μl总DNA,加上Tol2 RNA)的集合注射胚胎,然后在24-72hpf时筛选异位龛内皮基因表达或异位HSPC定位。对于对照和单因子注射,使用空的Tol2 GatewayTM目的载体作为注射混合物中的填充DNA。使用物种特异性原位探针通过 WISH证实转录因子的表达。异位表达被评分为基因表达的正常结构域外的血管染色或血管GFP表达。对照和实验样品在评分之是盲的,并且所有实验进行至少三次,利用独立的离合器。
显微镜和图像分析
使用安装在倒置Nikon Eclipse TiTM显微镜上的Yokogawa CSU-X1TM旋转盘进行延时显微镜检查,该倒置Nikon Eclipse TiTM显微镜配备了双 Andor iXonTM EMCCD相机和气候控制(维持在28.5℃)的机动化x-y载物台,以促进多个样本同时的拼接和成像。使用配备了Nikon DS-Ri2TM相机的Nikon SMZ18TM立体显微镜进行注射的增强子-GFP构建体的筛查和 WISH胚胎的成像。使用NIS-ElementsTM获取所有图像并使用ImarisTM或AdobePhotoshopTM软件处理。安装胚胎用于成像。简言之,将样本安装在玻璃底6孔板的0.8%LMP琼脂糖和三卡因(0.16mg/ml)中,并用含有三卡因(0.16mg/ml)的E3培养基覆盖。
流式细胞术、肾骨髓解剖、解离和组织学
为FACS准备胚胎。简言之,将胚胎用刀片在冷PBS中切碎,然后在LiberaseTM中在37℃下孵育20分钟,然后通过40μm筛孔过滤器过滤解离的细胞并转移至2%FBS。使用FACSAriaTM机器进行FACS。使用转基因阳性和阴性对照胚胎设置门,并且使用SYTOX BlueTM作为活的/死的染剂。对于ATAC-seq实验,每个样品收集至少12,000(最大50,000)个细胞,并且对于RNA-seq实验,每个样品收集至少10,000(最大300,000) 个细胞。通过手工解剖从成年斑马鱼中收集肾骨髓,然后固定在4%PFA 中(用于组织学)或通过轻轻吸取分离(用于活细胞成像)。对于组织学,在切片之前将肾骨髓包埋在石蜡中;备选切片用H&E或用针对GFP的抗体染色。将小鼠EC群分选为Cd45-Pdpn-Cd31+细胞。
电泳迁移率变动测定
将Nr2f2片段克隆到pGEX2TKTM载体中以产生GST标记的Nr2f2,并通过测序来验证保真度。将pGEX2TK-Nr2f2蛋白质粒转化到大肠杆菌 BL21感受态细胞中。表达和纯化蛋白质,并针对BSA定量纯化蛋白质。进行EMSA。通过退火100pmol的有义和反义寡核苷酸产生探针,并且在每个反应中使用1-2pmol的探针。表9中提供了所有引物和探针序列。在4℃下,在20%甘油、20mM Tris(pH8.0),10mM KCl,1mM DTT, 12.5ng聚dI/C,6.25pmol随机单链寡核苷酸、BSA和上述指定量的探针中进行凝胶转移反应。将涉及Nr2f2蛋白的样品加载到6%凝胶上以解析蛋白-DNA复合物。在与冷竞争剂的反应中,在反应中包括20x未标记的探针。抗-NR2F2抗体(R&D BiosystemsTM;cat#PP-H7147-00)与Nr2f2蛋白的量相同以获得超迁移。
本文报道的哺乳动物基因组数据的GEO登录号是GSE100910。将本文报道的斑马鱼基因组数据提交至NCBITM Gene Expression Omnibus。
实时成像可通过异位龛内皮基因表达区域显示血液循环。在72hpf 显示可见血细胞循环通过在72hpf的胚胎中异位表达mrc1a:GFP的背躯干中的血管区域,所述胚胎在单细胞期注射了7种转录因子的集合。
实时成像可显示HSPC初始募集到异位龛内皮表达区域。最初可以看到runx1+HSPC存在于72hpf的胚胎中异位表达mrc1a:GFP(参见例如图 5D箭头)的背血管中,所述胚胎在单细胞期注射了ETV2、SOX7和Nr2f2 的集合。黑箭头指向CHT中的HSPC定位。延时的持续时间为6.5小时;时间间隔为2分钟。时间序列在图5D中示出。
实时成像可显示HSPC的增殖和从异位龛内皮基因表达的区域的外流。runx1+HSPC可定位于72hpf的胚胎中异位表达mrc1a:GFP(参见例如图5E箭头)的血管中,所述胚胎在单细胞期注射了ETV2、SOX7和Nr2f2 的集合。HSPC数次分裂并迁移到循环中。黑箭头指向CHT中的HSPC 定位。延时的持续时间为2.6小时;时间间隔为2分钟。时间序列在图 5E中示出。
表1:CHT EC富集的基因

表2:预测的增强子元件的体内筛查

表1显示了由tomo-seq和组织特异性RNA-seq鉴定的CHT EC基因。星号(*)表示基因在TSS的100kb内;一些基因与多个元件相关。十字 表示通过WISH没有观察到表达。双十字
表示通过WISH没有观察到表达。双十字 表示WISH未被尝试,但是在万维网可获得的zfin.org上报道了CHT表达。双S(§)表示WISH未被尝试。
表示WISH未被尝试,但是在万维网可获得的zfin.org上报道了CHT表达。双S(§)表示WISH未被尝试。
表2显示了与最小启动子和GFP融合并注射到单细胞阶段斑马鱼胚胎中的CHT EC-特异性和泛-ECATAC-seq元件。星号(*)表示MACS2峰的坐标。十字 表示CHT EC元件在CHTEC中的表达以及泛-EC元件在整个胚胎的血管中的表达。双十字
表示CHT EC元件在CHTEC中的表达以及泛-EC元件在整个胚胎的血管中的表达。双十字 表示缺乏NHR基序。
表示缺乏NHR基序。
表3:通过Tomo-seq鉴定的CHT富集的基因




表3中的星号(*)表示通过WISH没有观察到CHT表达。表3中的匕首符号 表示WISH未被尝试。
表示WISH未被尝试。
表4:CHT EC中的转录因子表达

表4显示了Ets、Sox和NHR转录因子家族的高表达成员在CHT ECS 中的FPHM表达值。表4中的星号(*)表示在TSS的100kb内;一些基因与多个元件相关。
表5:小鼠造血龛中的转录因子表达


表6:用于WISH探针合成的引物


表6中的星号(*)表示T3序列CATTAACCCTCATAAAGGGAA(SEQ ID NO:10)被添加到每条正向引物的5'末端。表6中的匕首符号 表示T7 序列TAATACGACTCACTATAGGG(SEQ IDNO:11)被添加到每条反向引物的5'末端。
表示T7 序列TAATACGACTCACTATAGGG(SEQ IDNO:11)被添加到每条反向引物的5'末端。
表7:用于克隆启动子和增强子元件的引物

表8:125bp mrc1a和158bp sele增强子元件的突变变体的序列和引物

在表8中,小写字母表示用于破坏转录因子结合基序的碱基对改变。
表9:用于克隆和EMSA探针合成的引物

表9显示用于将小鼠Nr2f2克隆到pGEX2TK载体中的引物和来自斑马鱼mrc1a和sele增强子的DNA探针。
Claims (31)
1.产生/工程化内皮龛细胞的方法,其包括在内皮细胞中表达一种或多种转录因子,其中所述一种或多种转录因子来自Ets家族,Sox家族和/或核激素受体家族。
2.如权利要求1所述的方法,其中所述内皮龛细胞表达一种或多种基因,所述基因包括:sele、exoc312a、snx8a、cltca、aqp7、ap1b1、lgmn、prcp、cldn11a、lyve1b、adra1d、hya12a、hya12b、tll1、i113ra2、glu1a、hexb、slc16a9a或sepp1a。
3.如权利要求1所述的方法,其中所述内皮细胞是人的。
4.如上述权利要求中任一项所述的方法,其中所述转录因子包括人转录因子ETV2、FLI1、ETS1、SOX18、SOX7、RXRA或NR2F2中的至少一种。
5.如权利要求1所述的方法,其中所述转录因子包括来自Ets家族的至少一种转录因子、来自Sox家族的至少一种转录因子和来自核激素受体家族的至少一种转录因子。
6.如权利要求1所述的方法,其中所述转录因子包括ETV2、FLI1、ETS1、SOX18、SOX7、RXRA和NR2F2。
7.如权利要求1所述的方法,其中所述转录因子由至少一种载体表达。
8.如权利要求1所述的方法,其中所述载体包含编码所述一种或多种转录因子的外源核酸序列。
9.如权利要求1所述的方法,其中将所述外源核酸序列掺入所述内皮细胞的基因组中。
10.工程化的内皮龛细胞,其包含编码一种或多种转录因子的一种或多种外源核酸序列,其中所述一种或多种转录因子来自Ets家族、Sox家族和/或核激素家族。
11.组合物,其包含权利要求10所述的工程化的内皮龛细胞。
12.如权利要求11所述的组合物,其中所述组合物是治疗剂,或者所述组合物还包含药学上可接受的载体。
13.如权利要求11所述的组合物,其中所述组合物还包含培养皿、3D细胞系统或悬浮系统。
14.如权利要求11所述的组合物,其中所述组合物包含支架。
15.培养HSPC的方法,所述方法包括在存在工程化的内皮龛细胞群的情况下培养HSPC。
16.如权利要求15所述的方法,其中所述方法在体外进行。
17.如权利要求15所述的方法,其中所述工程化的内皮细胞分泌影响HSPC细胞生长和/或扩增的因子。
18.如权利要求15所述的方法,其中在存在所述工程化的内皮龛细胞的情况下培养的所述HSPC可比在不存在所述工程化的内皮龛细胞的情况下培养的HSPC多培养至少3天(例如,至少4天、至少5天、至少6天、至少7天)。
19.如权利要求15所述的方法,其中所述细胞在生物相容性支架上培养。
20.如权利要求15所述的方法,其中相比不与工程化的内皮龛细胞一起培养的基本上相似的HSPC在施用于受试者时的植入相比,在存在工程化的内皮细胞的情况下培养的HSPC具有增加的植入。
21.治疗受试者的方法,所述方法包括将包含HSPC和工程化的内皮龛细胞群的组合物移植到所述受试者中。
22.增强HSPC植入的方法,所述方法包括向有需要的受试者施用包含HSPC和工程化的内皮龛细胞群的组合物。
23.如权利要求22所述的方法,其中所述HSPC的植入与不存在工程化的内皮龛细胞的情况下的基本相似的HSPC的植入相比增加至少10%。
24.共培养物,其包含工程化的内皮龛细胞和HSPC。
25.如权利要求24所述的共培养物,其中所述内皮细胞通过权利要求1-9所述的方法制备。
26.用于培养HSPC的试剂盒,所述试剂盒包含:工程化的内皮龛细胞群、试剂及其使用说明书。
27.用于产生工程化的内皮龛细胞的试剂盒,其包含载体及其使用说明书,所述载体包含编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列。
28.产生异位血管龛的方法,所述方法包括将工程化的内皮龛细胞施用于有需要的受试者的靶位点。
29.用于髓外造血的方法,所述方法包括将工程化的龛内皮细胞移植到受试者中骨髓外的位置(例如,前臂)处,从而产生合成龛。
30.如权利要求29所述的方法,其中所述内皮细胞通过上述权利要求所述方法的任一种制备。
31.载体,其包含与启动子可操作地连接的编码Ets家族、Sox家族或核激素家族的一种或多种转录因子的一种或多种外源核酸序列。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862647433P | 2018-03-23 | 2018-03-23 | |
| US62/647,433 | 2018-03-23 | ||
| PCT/US2019/023637 WO2019183508A1 (en) | 2018-03-23 | 2019-03-22 | Endothelial cell factors and methods thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112105721A true CN112105721A (zh) | 2020-12-18 |
Family
ID=67987596
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980020598.1A Pending CN112105721A (zh) | 2018-03-23 | 2019-03-22 | 内皮细胞因子及其方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20210079343A1 (zh) |
| EP (1) | EP3768282A4 (zh) |
| JP (1) | JP7455067B2 (zh) |
| CN (1) | CN112105721A (zh) |
| CA (1) | CA3094837A1 (zh) |
| WO (1) | WO2019183508A1 (zh) |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050227352A1 (en) * | 2004-04-09 | 2005-10-13 | Stowers Institute For Medical Research | Use of BMP (BAM) signaling to control stem cell fate determination |
| US20120207744A1 (en) * | 2009-03-19 | 2012-08-16 | Mendlein John D | Reprogramming compositions and methods of using the same |
| US20130243736A1 (en) * | 2012-01-27 | 2013-09-19 | Sapporo Medical University | Replacement of bone marrow niche cells for treatment of various diseases |
| US20140162366A1 (en) * | 2012-08-31 | 2014-06-12 | Salk Institute For Biological Studies | Generation of vascular progenitor cells |
| WO2016201133A2 (en) * | 2015-06-09 | 2016-12-15 | The Regents Of The University Of California | Hematopoietic cells and methods of using and generating the same |
| WO2017015245A1 (en) * | 2015-07-20 | 2017-01-26 | Angiocrine Bioscience, Inc. | Methods and compositions for stem cell transplantation |
| CN107249607A (zh) * | 2014-12-19 | 2017-10-13 | 安吉克莱茵生物科学有限公司 | 包括工程化内皮细胞的生物相容性植入物 |
| US20180010124A1 (en) * | 2012-10-22 | 2018-01-11 | Wisconsin Alumni Research Foundation | Induction of Hemogenic Endothelium from Pluripotent Stem Cells by Forced Expression of Transcription Factors |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7807464B2 (en) * | 2005-05-24 | 2010-10-05 | Whitehead Institute For Biomedical Research | Methods for expansion and analysis of cultured hematopoietic stem cells |
| US20100136026A1 (en) * | 2007-09-26 | 2010-06-03 | Kerr William G | Ship Inhibition to Direct Hematopoietic Stem Cells and Induce Extramedullary Hematopoiesis |
| GB201212111D0 (en) * | 2012-07-06 | 2012-08-22 | Gmbh | Vascular bed-specific endothelial cells |
| CN105051184B (zh) * | 2013-01-15 | 2018-08-10 | 康奈尔大学 | 通过给定的因子将人内皮细胞重编程为造血多系祖细胞 |
| KR20180053646A (ko) * | 2015-07-20 | 2018-05-23 | 앤지오크린 바이오사이언스 인코포레이티드 | Ets 전사 인자를 발현하는 조작된 내피 세포 |
-
2019
- 2019-03-22 US US17/040,421 patent/US20210079343A1/en active Pending
- 2019-03-22 CA CA3094837A patent/CA3094837A1/en active Pending
- 2019-03-22 CN CN201980020598.1A patent/CN112105721A/zh active Pending
- 2019-03-22 JP JP2020550792A patent/JP7455067B2/ja active Active
- 2019-03-22 EP EP19772190.5A patent/EP3768282A4/en active Pending
- 2019-03-22 WO PCT/US2019/023637 patent/WO2019183508A1/en active Application Filing
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050227352A1 (en) * | 2004-04-09 | 2005-10-13 | Stowers Institute For Medical Research | Use of BMP (BAM) signaling to control stem cell fate determination |
| US20120207744A1 (en) * | 2009-03-19 | 2012-08-16 | Mendlein John D | Reprogramming compositions and methods of using the same |
| US20130243736A1 (en) * | 2012-01-27 | 2013-09-19 | Sapporo Medical University | Replacement of bone marrow niche cells for treatment of various diseases |
| US20140162366A1 (en) * | 2012-08-31 | 2014-06-12 | Salk Institute For Biological Studies | Generation of vascular progenitor cells |
| US20180010124A1 (en) * | 2012-10-22 | 2018-01-11 | Wisconsin Alumni Research Foundation | Induction of Hemogenic Endothelium from Pluripotent Stem Cells by Forced Expression of Transcription Factors |
| CN107249607A (zh) * | 2014-12-19 | 2017-10-13 | 安吉克莱茵生物科学有限公司 | 包括工程化内皮细胞的生物相容性植入物 |
| WO2016201133A2 (en) * | 2015-06-09 | 2016-12-15 | The Regents Of The University Of California | Hematopoietic cells and methods of using and generating the same |
| WO2017015245A1 (en) * | 2015-07-20 | 2017-01-26 | Angiocrine Bioscience, Inc. | Methods and compositions for stem cell transplantation |
Non-Patent Citations (7)
| Title |
|---|
| HAGEDORN, ELLIOTT J.等: "Defining the Transcriptional Code That Specifies Sinusoidal Endothelial Cells in the HSPC Niche", 《BLOOD》, vol. 130, pages 1 - 2 * |
| MAESTRE, INÉS FERNÁNDEZ: "Elucidating the Transcriptional Program Specifying Endothelial Cells in the Zebrafish Blood Stem Cell Niche", MASTER THESIS OF UNIVERSITY OF APPLIED SCIENCES TECHNIKUM WIEN, pages 1 - 132 * |
| PARK C等: "Transcriptional regulation of endothelial cell and vascular development", 《CIRC RES》, vol. 112, no. 10, pages 1380 - 1400, XP055547751, DOI: 10.1161/CIRCRESAHA.113.301078 * |
| PERLIN, J.R.等: "Blood on the tracks: hematopoietic stem cell-endothelial cell interactions in homing and engraftment", 《J MOL MED》, vol. 95, pages 809 - 819, XP036279062, DOI: 10.1007/s00109-017-1559-8 * |
| YOU LR等: "Suppression of Notch signalling by the COUP-TFII transcription factor regulates vein identity", 《NATURE》, vol. 435, no. 7038, pages 98 - 104 * |
| 张开滋等: "《骨髓纤维化中西医结合治疗》", vol. 2014, 湖南科学技术出版社, pages: 781 - 785 * |
| 杜华等: "骨髓微环境对造血干细胞命运的调控", 《中国组织工程研究》, vol. 19, no. 14, pages 2283 - 2290 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021518143A (ja) | 2021-08-02 |
| WO2019183508A1 (en) | 2019-09-26 |
| JP7455067B2 (ja) | 2024-03-25 |
| EP3768282A4 (en) | 2021-12-08 |
| EP3768282A1 (en) | 2021-01-27 |
| US20210079343A1 (en) | 2021-03-18 |
| CA3094837A1 (en) | 2019-09-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Grove et al. | YAP/TAZ initiate and maintain Schwann cell myelination | |
| Wamsley et al. | Rbfox1 mediates cell-type-specific splicing in cortical interneurons | |
| El-Naggar et al. | Translational activation of HIF1α by YB-1 promotes sarcoma metastasis | |
| Dulauroy et al. | Lineage tracing and genetic ablation of ADAM12+ perivascular cells identify a major source of profibrotic cells during acute tissue injury | |
| Aimé et al. | Trib3 is elevated in Parkinson's disease and mediates death in Parkinson's disease models | |
| DK2081586T3 (en) | RSPONDINES AS MODULATORS OF ANGIOGENESE AND VASCULOGENESES | |
| Willems et al. | Regeneration in the pituitary after cell-ablation injury: time-related aspects and molecular analysis | |
| EP2841067A2 (en) | A drug screening platform for rett syndrome | |
| US20210008070A1 (en) | Targeting minimal residual disease in cancer with cd36 antagonists | |
| US20210010089A1 (en) | Tumor minimal residual disease stratification | |
| US20210008047A1 (en) | Targeting minimal residual disease in cancer with rxr antagonists | |
| Nabokina et al. | Regulation of basal promoter activity of the human thiamine pyrophosphate transporter SLC44A4 in human intestinal epithelial cells | |
| JP7325466B2 (ja) | 再生医療のためのベクターおよび方法 | |
| US20170218036A1 (en) | Innate immune system modification for anticancer therapy | |
| JP2023522903A (ja) | 方法および組成物 | |
| CN112105721A (zh) | 内皮细胞因子及其方法 | |
| US20220062234A1 (en) | Novel drug-controlled systems and uses thereof | |
| JP2022543589A (ja) | Klf誘導心筋再生 | |
| US20240034765A1 (en) | Scg2 neuropeptides and uses thereof | |
| Swadi | Characterisation of Potential Therapeutic Molecules for Neuroblastoma Using Chick Chorioallantoic Membrane Xenograft Model | |
| Al Reza | The Role of Forkhead Box F1 Transcription Factor in Mesenchymal-Epithelial Signaling During Lung Development | |
| Harris | The function of NFIX during developmental and adult neurogenesis | |
| Peek | Cellular and molecular mechanisms of Akirin2 function in maturing neurons | |
| Lopez Delgado | Meis Transcription Factor in Axial Development | |
| Distasio | Novel Regulators of Neural Crest and Neural Progenitor Survival |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |