CN109313548B - 用于执行simd收集和复制操作的方法和设备 - Google Patents
用于执行simd收集和复制操作的方法和设备 Download PDFInfo
- Publication number
- CN109313548B CN109313548B CN201780035161.6A CN201780035161A CN109313548B CN 109313548 B CN109313548 B CN 109313548B CN 201780035161 A CN201780035161 A CN 201780035161A CN 109313548 B CN109313548 B CN 109313548B
- Authority
- CN
- China
- Prior art keywords
- memory
- processor
- data elements
- source addresses
- addresses
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 33
- 230000010076 replication Effects 0.000 title description 7
- 239000013598 vector Substances 0.000 claims description 40
- 230000001419 dependent effect Effects 0.000 claims description 10
- 238000003860 storage Methods 0.000 claims description 8
- 230000004044 response Effects 0.000 claims 3
- 238000012546 transfer Methods 0.000 abstract description 4
- 238000012545 processing Methods 0.000 description 12
- 230000007246 mechanism Effects 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 238000004891 communication Methods 0.000 description 4
- 230000008901 benefit Effects 0.000 description 3
- 230000006870 function Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000012432 intermediate storage Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3004—Arrangements for executing specific machine instructions to perform operations on memory
- G06F9/30043—LOAD or STORE instructions; Clear instruction
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/061—Improving I/O performance
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0655—Vertical data movement, i.e. input-output transfer; data movement between one or more hosts and one or more storage devices
- G06F3/0656—Data buffering arrangements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/0671—In-line storage system
- G06F3/0673—Single storage device
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3004—Arrangements for executing specific machine instructions to perform operations on memory
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/3017—Runtime instruction translation, e.g. macros
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3824—Operand accessing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3877—Concurrent instruction execution, e.g. pipeline or look ahead using a slave processor, e.g. coprocessor
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Mathematical Physics (AREA)
- Advance Control (AREA)
- Memory System (AREA)
- Executing Machine-Instructions (AREA)
- Image Processing (AREA)
- Display Devices Of Pinball Game Machines (AREA)
Abstract
系统和方法涉及高效存储器操作。运用定位于存储器内或非常接近于存储器的收集结果缓冲器实施单指令多数据SIMD收集操作,以在存储器中从多个正交位置接收或收集多个数据元素,且一旦所述收集结果缓冲器完成,那么将所述所收集数据传送到处理器寄存器。通过执行用于将来自多个正交源地址的多个数据元素复制到所述存储器内的对应多个目标地址而不在中间复制到处理器寄存器的两个或更多个指令来执行SIMD复制操作。因此,在未由所述处理器引导的情况下在背景模式下执行所述存储器操作。
Description
技术领域
所公开方面是针对处理器指令和其高效实施方案。更具体地,示范性方面涉及多个数据元素的高效存储器指令,例如与存储器复制、散射、收集和其组合相关的指令。
背景技术
单指令多数据(single instruction multiple data,SIMD)指令可用于采用数据并行性的处理系统。当在例如数据向量的两个或多于两个数据元素上进行相同或共同任务时存在数据并行性。可通过使用单条SIMD指令而不是使用多条指令对两个或多于两个数据元素并行地进行共同任务,所述单条SIMD指令限定有待对对应多个SIMD通道中的多个数据元素进行的相同指令。SIMD指令可用于多种操作,例如算术运算、数据移动操作、存储器操作等。关于存储器操作,“散射”和“收集”是用于将数据元素从一个位置复制到另一位置的熟知操作。数据元素可位于存储器(例如,主存储器或硬盘驱动器)中且操作中规定的寄存器可位于处理器或芯片上系统(SoC)上。
常规加载指令可用于将数据元素从存储器位置读取到例如位于处理器中的标量目标寄存器中,而另一方面“收集”指令用以将多个数据元素加载到例如位于处理器中的向量目标寄存器中。多个数据元素中的每一个可具有独立或正交的源地址(其可在存储器中是非相连的),这使收集指令的SIMD实施具有挑战性。一些实施方案可通过多个加载指令实行收集指令以将每一数据元素串行加载到其在向量目标寄存器中的相应位置中,直到向量目标寄存器完成为止。然而,以此方式进行串行化会产生不良性能且每一组件加载指令可具有可变时延,这取决于每一数据元素的来源(例如,一些源地址可能在高速缓冲存储器中命中,而其它源地址可能不会;不同源地址可具有不同数据依赖性等)。如果实施组件加载指令以按顺序更新向量目标寄存器,那么可能无法使用乱序处理机制在软件中流水化处理更新或隐藏大部分此可变时延。对于在向量目标寄存器的乱序更新是可能的情况下的实施,可能引起附加寄存器(例如,用于临时存储)、用于个别更新的每一数据元素的跟踪机制,以及其它相关软件和/或硬件支持。因此,收集操作的常规实施可能是低效的且涉及较长时延和额外硬件。
散射操作可被视为上文所描述的收集操作的对应部分,其中来自例如位于处理器中的源向量寄存器的数据元素可存储于可以是非相连的多个目标存储器位置中。一些代码序列或程序可能涉及多个数据元素要从独立或正交源位置(在存储器中可能是非相连的)读取并复制或写入独立或正交目标位置(在存储器中也可能是非相连的)的操作。此类操作可被视为对多个数据元素的多个复制操作。因此,期望对此类操作使用SIMD处理以实施从存储器中的正交源位置到正交目标位置的多个数据元素的SIMD复制行为。
虽然理论上可以通过将多个数据元素从存储器中的多个源位置SIMD收集到位于处理器中的收集目标向量寄存器中且接着执行从收集目标向量寄存器到存储器中多个目标位置的数据元素的SIMD分散来实现此功能性,但是此功能性的实施可能是不实际或不可行的。这是因为等待收集目标向量寄存器完成引入了SIMD收集操作的常规实施的上述低效。如果在允许发生SIMD散射之前要在不等待首先完成收集目标向量寄存器的情况下实施SIMD复制,那么SIMD聚集的组件负载与SIMD分散操作的组件存储之间的同步也是具有挑战性的。此外,在SIMD散射之后实施SIMD收集以执行SIMD复制可能涉及使用处理器中的聚集目标向量寄存器作为中间着陆点从存储器中的源位置传输大量数据元素,且接着返回到存储器中的目标位置。可以理解,在存储器和处理器之间来回传输的这种大数据增加了SIMD复制的功耗和时延。
因此,需要上述存储器操作的改进的实施方案以利用SIMD处理的益处,同时避免常规实施方案的前述缺点。
发明内容
本发明的示范性实施例涉及用于高效存储器操作的系统和方法。运用定位于存储器内或非常接近于存储器的收集结果缓冲器实施单指令多数据(SIMD)收集操作,以在存储器中从多个正交位置接收或收集多个数据元素,且一旦所述收集结果缓冲器完成,那么将所述所收集数据传送到处理器寄存器。通过执行用于将来自多个正交源地址的多个数据元素复制到所述存储器内的对应多个目标地址而不在中间复制到处理器寄存器的两个或更多个指令来执行SIMD复制操作。因此,在未由所述处理器引导的情况下在背景模式下执行所述存储器操作。
举例来说,示范性方面是针对一种执行存储器操作的方法,所述方法包括:通过处理器提供存储器的两个或更多个源地址;将来自所述存储器中的两个或更多个源地址的两个或更多个数据元素复制到收集结果缓冲器;以及使用单指令多数据(SIMD)加载操作来将所述两个或更多个数据元素从所述收集结果缓冲器加载到所述处理器中的向量寄存器。
另一示范性方面是针对一种执行存储器操作的方法,所述方法包括:通过处理器提供存储器的两个或更多个源地址和和对应两个或更多个目标地址;以及执行用于将来自所述两个或更多个源地址的两个或更多个数据元素复制到所述存储器内的对应两个或更多个目标地址的两个或更多个指令,而不在中间复制到处理器中的寄存器。
另一示范性方面是针对一种设备,其包括:处理器,其经配置以提供存储器的两个或更多个源地址;收集结果缓冲器,其经配置以接收从所述存储器中的所述两个或更多个源地址复制的两个或更多个数据元素;以及逻辑,其经配置以基于由所述处理器执行的单指令多数据(SIMD)加载操作而将来自所述收集结果缓冲器的所述两个或更多个数据元素加载到所述处理器中的向量寄存器。
又一示范性方面是针对一种设备,其包括:处理器,其经配置以提供存储器的两个或更多个源地址和和对应两个或更多个目标地址;以及逻辑,其经配置以将来自所述两个或更多个源地址的两个或更多个数据元素复制到所述存储器内的对应两个或更多个目标地址,而不在中间复制到处理器中的寄存器。
附图说明
呈现附图以协助描述本发明的实施例,且提供所述图式仅仅是为了说明实施例而非对其加以限制。
图1说明根据本公开的示范性方面配置的处理系统。
图2到3说明根据本公开的示范性方面的与示范性存储器操作相关的过程。
图4说明其中可有利地利用本公开的方面的示范性计算装置400。
具体实施方式
在以下针对于本发明的具体实施例的描述和相关图式中公开本发明的方面。可在不脱离本发明的范围的情况下设计替代性实施例。另外,将不会详细描述或将省略本发明的众所周知的元件以免混淆本发明的相关细节。
词语“例示性”在本文中用于意指“充当实例、例子或说明”。在本文中被描述为“示范性”的任何实施例未必被理解为比其它实施例优选或有利。同样,术语“本发明的实施例”并非要求本发明的所有实施例包含所论述的特征、优点或操作模式。
本文中所使用的术语仅仅是出于描述特定实施例的目的,且并不意图限制本发明的实施例。如本文中所使用,除非上下文另外明确指示,否则单数形式“一”和“所述”既定还包括复数形式。应进一步理解,术语“包括”和/或“包含”在本文中使用时指定所陈述特征、整数、步骤、操作、元件和/或组件的存在,但并不排除一或多个其它特征、整数、步骤、操作、元件、组件和/或其群组的存在或添加。
另外,依据待由例如计算装置的元件执行的动作序列来描述许多实施例。应认识到,本文中所描述的各种动作可由具体电路(例如,专用集成电路(application specificintegrated circuit,ASIC)),由正由一或多个处理器执行的程序指令或由两者的组合来执行。此外,本文中所描述的这些动作序列可被视为全部在任何形式的计算机可读存储媒体内体现,在所述计算机可读存储媒体中存储有对应的计算机指令集,所述计算机指令在执行时将致使相关联的处理器执行本文中所描述的功能性。因此,本发明的各个方面可以许多不同形式来体现,预期所有形式属于所要求主题的范围内。另外,对于本文中所描述的实施例中的每一个来说,任何此类实施例的对应形式可在本文中被描述为例如“经配置以(执行所描述的动作)的逻辑”。
在本公开的示范性方面中,可通过将操作分裂成两个子操作来实施SIMD收集操作:将多个数据元素(例如,来自存储器中的可非相连的非相依或正交位置)收集到收集结果缓冲器的第一子操作;和将从收集结果缓冲器加载到例如定位于处理器中的SIMD寄存器的第二子操作。示范性SIMD收集操作可由软件实施方案(例如,编译程序)分离成两个子操作,且可流水化处理所述子操作以最小化时延(例如,针对第一子操作使用软件流水化处理机构,来以乱序方式将多个数据元素收集到收集结果缓冲器中)。收集结果缓冲器可定位于存储器内或接近存储器,且区别于定位于处理器中的常规收集目标向量寄存器。因此,对于收集结果缓冲器,不需要每元素跟踪机构。此外,第二子操作可将来自收集结果缓冲器的多个数据元素加载到可适应所述多个数据元素的目标寄存器(例如,定位于处理器中)中。数据元素可个别地可从目标寄存器存取,并可基于收集结果缓冲器中的次序而定序,此简化从收集结果缓冲器到目标寄存器的多个数据元素的加载操作(例如,加载操作可相似于多个数据元素的纯量加载,而非指定多个数据元素中的每一个的位置的向量加载)。因此,在示范性方面中,通过使用定位于存储器中的收集结果缓冲器,可有效地将来自正交源位置的多个数据元素收集到处理器中的目标寄存器中。
在本公开的另一示范性方面中,可将来自存储器中的正交源位置的数据元素有效率地复制到存储器中的正交目标位置上。举例来说,可使用收集操作与散射操作的组合来实施SIMD复制操作,其中可在存储器内有效地执行所述组合。在这方面,执行存储器内的SIMD复制意图传达执行所述操作而不使用定位于处理器中的寄存器(例如定位于处理器中的常规收集目标向量寄存器)以进行中间存储。举例来说,执行存储器内的收集操作与散射操作的组合可涉及使用网络或非常接近于存储器而定位的定序器,同时避免在存储器与处理器之间传送数据元素。具有多个数据元素的按元件寻址的示范性SIMD复制指令可指定待从其复制多个数据元素的收集地址或源地址的列表和待向其写入多个数据元素的散射地址或目标地址的对应列表。从这些列表,可以非相依或正交方式执行多个复制操作,以将来自其相应源地址的多个数据元素中的每一个复制到其相应目标地址。在示范性方面中,可允许多个复制操作中的每一个完成而不需要不断地完成中间向量(例如,收集向量),因此允许多个复制操作的宽松的存储器定序和乱序完成。
参考图1,将描述根据上述示范性方面配置的示范性处理系统100。如所展示,处理系统100可包含可经配置以实施执行流水化处理的处理器102。在一些方面中,处理器102的执行流水化处理可支持向量指令,且更具体地说,SIMD处理。已在处理器102中说明两个寄存器103a和103b以便于描述示范性方面。这些寄存器103a到103b可属于寄存器组(未展示),且在一些方面中,这些寄存器可以是向量寄存器。因此,对于下文论述的实例状况,寄存器103a可以是源寄存器且寄存器103b可以是向量寄存器。举例来说,可在常规散射操作中指定源向量寄存器103a的数据元素。可在如下文所描述的示范性SIMD收集操作中使用目标向量寄存器103b。
对于示范性SIMD操作,事务输入缓冲器106可从处理器102接收指令,其具有总线104上的源运算数和目标运算数的地址。总线104上的源地址和目标地址可对应于示范性SIMD收集操作(例如,对应于目标向量寄存器103b)或先前描述的示范性SIMD复制操作,且在下文参考图2和3进一步加以解释。为了传送是否可从处理器102接收到更多指令(或相关运算数)或在队列完整的情况下通过解除确证可用性105,事务输入缓冲器106可实施列队列队机构以根据确证展示为可用性105的信号而对反馈进行队列和传送。
在事务输入缓冲器106中列队的指令可在总线108上传送到事务定序器110。在示范性方面中,事务定序器110可经配置以基于操作和可调整设定而串行化或并行化来自总线108的指令。对于存储器操作,可将源地址和/或目标地址提供给总线112上的存储器114(连同相应控制)。总线112展示为二通总线,在其上可传回来自存储器114的数据(数据的方向的控制可指示数据传送是来自存储器114还是通往存储器114)。在各种替代性实施方案中,单独的导线可用于一起展示为总线112的地址、控制和数据总线。
处理系统100还可包含处理元件,例如展示为相连存储器存取120和记分板122的块。在实例中,如果SIMD指令涉及收集来自相连存储器位置的数据元素,那么可将SIMD指令执行为常规向量运算以将来自相连存储器位置的数据加载到处理器102中的向量寄存器(例如,寄存器103b)中,可针对示范性事务定序器110避免此情况。记分板122可与事务输入缓冲器106类似地起作用,并因而可实施列队机构。在记分板122接收来自存储器114的数据以进行例如SIMD加载或来自相连存储器位置的SIMD收集的常规向量运算的一个方面中,可通过事务定序器110将多个数据元素提供到记分板122,且一旦目标向量完成,那么可例如将目标向量提供给处理器102以在处理器102的向量寄存器103b中更新。已说明例如相连存储器存取120和记分板122等常规元件的操作以传送其与示范性块、事务输入缓冲器106和事务定序器110交互操作以进行存储器操作的能力。
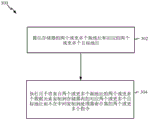
结合参考图1到2,现将解释与示范性SIMD收集操作相关的过程200。如框202中所展示,处理器102可例如基于收集指令或两个或更多个加载指令而提供两个或更多个源地址。编译程序或其它软件可识别SIMD收集操作,并在一些方面中将其分解成示范性SIMD收集操作的组件加载指令。两个或更多个源地址可正交或非相依,并可涉及存储器114内的非相连位置。分量加载指令可指定处理器102的应将来自两个或更多个源地址的两个或更多个数据元素收集到其中的相连寄存器或目标向量寄存器(例如,寄存器103b)。
在框204中,处理器102可通过向事务输入缓冲器106发送两个或更多个源地址并从所述事务输入缓冲器将所述源地址发送到汇流排104和108上的定序器110来实施示范性SIMD收集操作。交易定序器110可并行或串行地提供将来自两个或更多个源地址的两个或更多个数据元素复制到存储器114中示范性地展示的收集结果缓冲器(例如,GRB 115)的两个或更多个指令。收集结果缓冲器115可以是存储器114内实施的循环缓冲器。在一些方面中,收集结果缓冲器115可定位于存储器114外部(例如,比接近处理器102更接近存储器114)且与存储器114通信。在一些方面中,收集结果缓冲器115可以是任何其它适当的存储结构且不一定是循环缓冲器。两个或更多个数据元素的两个或更多个复制操作可涉及两个或更多个不同时延。另外,可在未由处理器102引导的情况下在背景下,例如在交易定序器110的引导下执行两个或更多个数据元素到收集结果缓冲器115的两个或更多个复制操作。因此,当正在背景下执行复制操作时,处理器102可执行其它操作(例如,利用未明确展示的一或多个执行单元)。
一旦收集结果缓冲器115完成,如框206中所展示,那么可发布将来自收集结果缓冲器115的数据元素加载到处理器102中的向量寄存器,例如寄存器103b。加载可对应于用以将来自收集结果缓冲器115内的存储器位置的两个或更多个数据元素加载到向量寄存器103b中的SIMD加载。还可利用记分板122以跟踪已执行多少复制操作以确定收集结果缓冲器115在发出加载指令之前是否完成。在一些方法中,可执行一或多个同步指令(例如,通过软件控制)以确保收集结果缓冲器115在将来自收集结果缓冲器115的数据元素负载到处理器102中的向量寄存器103b中之前完成。以此方式,可对处理器102隐藏到收集结果缓冲器115的复制操作的时延,且可以精确定时具有加载指令以避免延迟。
结合参考图1和3,将解释与示范性SIMD复制操作相关的过程300。过程300的SIMD复制操作可实现与常规SIMD收集操作后跟着常规SIMD散射操作等效的结果。但是,相比于以常规方式实施SIMD收集操作后跟着SIMD散射操作,可在示范性方面中以更少的复杂度和时延实施示范性SIMD复制操作。
举例来说,参考框302,处理器102可提供存储器114的两个或更多个源地址和对应两个或更多个目标地址。两个或更多个源地址和/或两个或更多个目标地址可正交或非相依且非相连。举例来说,编译程序可将指令或代码的常规收集到散射序列分解成用于向处理器102供应源地址和目标地址的分量指令。再次,处理器102可向事务输入缓冲器106提供两个或更多个源地址和对应两个或更多个目标地址。事务输入缓冲器106可向事务定序器110供应两个或更多个源地址和对应(如参考上文的图2的过程200所解释)。事务定序器110可向存储器114供应在框304中执行以下操作的指令。
在框304中,可执行用于将来自两个或更多个源地址的两个或更多个数据元素复制到存储器内的对应两个或更多个目标地址而不在中间复制到处理器102中的处理器寄存器的两个或更多个指令。举例来说,可利用例如事务定序器110等网络元件,而不在执行两个或更多个复制指令期间向处理器102传送数据。因此,将来自两个或更多个源地址的两个或更多个数据元素复制到存储器内的对应两个或更多个目标地址(例如,存储器到存储器复制操作)可包含在未由处理器102引导的情况下在背景模式下执行SIMD复制指令。以此方式,可避免形成中间收集向量结果,且在一些状况下,完成收集向量可以从不在执行两个或更多个复制指令的过程中完全形成。一旦完成对两个或更多个复制指令的执行,那么事务定序器110可向记分板122和/或处理器102通知两个或更多个存储器到存储器复制操作的状态完成。
参考图4,展示根据示范性方面的计算装置400的特定说明性方面的框图。计算装置400包含处理器102,所述处理器可经配置以支持并实施分别根据图2到3的过程200和300的示范性存储器操作的执行。图4中,已特别标识图1的处理器102(包括寄存器103a到103b)、事务输入缓冲器106、事务定序器110和存储器114(包括收集结果缓冲器115),而已为清楚起见而在此描述中省略图1的剩余细节。尽管未展示,但一或多个高速缓存器或其它存储器结构还可包含于计算装置400中。
图4还展示耦合到处理器102和显示器428的显示器控制器426。图4还展示可以基于计算装置400的特定实施方案,例如用于无线通信,而是任选块的若干组件。因此,编码解码器(coder/decoder,CODEC)434(例如,音频和/或语音CODEC)可以是任选的且在存在时耦合到处理器102,且任选块扬声器436和麦克风438可耦合到CODEC 434。无线控制器440(其可包含调制解调器)也可以是任选的且耦合到无线天线442。在特定方面中,处理器402、显示器控制器426、存储器432、CODEC 434和无线控制器440包含于系统级封装或系统单芯片装置422中。
在特定方面中,输入装置430和电源444耦合到芯片上系统装置422。此外,在特定方面中,如图4中所说明,显示器428、输入装置430、扬声器436、麦克风438、无线天线442和电源444在芯片上系统装置422外部。然而,显示器428、输入装置430、扬声器436、麦克风438、无线天线442和电源444中的每一个可耦合到芯片上系统装置422的组件,例如接口或控制器。
应注意,虽然图4描绘无线通信装置,但是处理器102和存储器114也可集成到机顶盒、音乐播放器、视频播放器、娱乐单元、导航装置、个人数字助理(personal digitalassistant,PDA)、固定位置数据单元、通信装置、服务器或计算机中。此外,无线装置400的至少一或多个示范性方面可集成于至少一个半导体晶粒中。
所属领域的技术人员将了解,可使用多种不同技术和技艺中的任一个来表示信息和信号。举例来说,可通过电压、电流、电磁波、磁场或磁粒子、光场或光粒子或其任何组合来表示在整个上文描述中可能参考的数据、指令、命令、信息、信号、位、符号和码片。
另外,所属领域的技术人员将了解,结合本文中所公开的实施例而描述的各种说明性逻辑块、模块、电路和算法步骤可实施为电子硬件、计算机软件或两者的组合。为清晰地说明硬件与软件的此可互换性,上文已大体就其功能性描述了各种说明性组件、块、模块、电路和步骤。此功能性实施为硬件还是软件取决于特定应用和强加于总体系统的设计约束。熟练的技术人员可针对每一特定应用而以不同方式来实施所描述功能性,但这样的实施决策不应被解释为会引起脱离本发明的范围。
结合本文中所公开的实施例所描述的方法、序列和/或算法可直接以硬件、以由处理器执行的软件模块或以两者的组合来体现。软件模块可驻留于RAM存储器、快闪存储器、ROM存储器、EPROM存储器、EEPROM存储器、寄存器、硬盘、可装卸盘、CD-ROM,或此项技术中已知的任一其它形式的存储媒体中。示范性存储媒体耦合到处理器,使得处理器可从存储媒体读取信息且将信息写入到存储媒体。在替代方案中,存储媒体可以与处理器成一体式。
相应地,本发明的实施例可包含实施用于用于例如散射和收集等高效存储器复制操作的方法的计算机可读媒体。因此,本发明不限于所说明实例,且用于执行本文中所描述的功能性的任何装置包含于本发明的实施例中。
虽然前面的公开内容展示本发明的说明性实施例,但应注意,可在不脱离如由所附权利要求书定义的本发明的范围的情况下,在其中作出各种改变和修改。无需以任何特定次序来执行根据本文中所描述的本发明的实施例的方法权利要求项的功能、步骤和/或动作。此外,虽然可以单数形式描述或要求本发明的元件,但除非明确陈述限于单数形式,否则也涵盖复数形式。
Claims (23)
1.一种执行存储器操作的方法,所述方法包括:
通过处理器向事务输入缓冲器提供存储器的两个或更多个源地址;
由所述事务输入缓冲器向事务定序器提供所述两个或更多个源地址;
由所述事务定序器提供用于将来自所述两个或更多个源地址的两个或更多个数据元素复制到收集结果缓冲器中的指令;
响应于所述指令,将来自所述存储器中的所述两个或更多个源地址的所述两个或更多个数据元素复制到所述收集结果缓冲器;以及
使用单指令多数据SIMD加载操作来将所述两个或更多个数据元素从所述收集结果缓冲器加载到所述处理器中的向量寄存器。
2.根据权利要求1所述的方法,其中所述收集结果缓冲器定位于所述存储器中或非常接近于所述存储器。
3.根据权利要求1所述的方法,其中所述收集结果缓冲器是循环缓冲器。
4.根据权利要求1所述的方法,其中所述两个或更多个源地址在所述存储器中正交或非相依且非相连。
5.根据权利要求1所述的方法,其包括将所述两个或更多个数据元素乱序复制到所述收集结果缓冲器。
6.根据权利要求5所述的方法,其中将所述两个或更多个数据元素乱序复制到所述收集结果缓冲器涉及两个或更多个不同时延。
7.根据权利要求5所述的方法,其包括在未由所述处理器引导的情况下在背景模式下将所述两个或更多个数据元素乱序复制到所述收集结果缓冲器。
8.根据权利要求5所述的方法,其包括跟踪所述收集结果缓冲器并在所述收集结果缓冲器完成之后加载来自所述收集结果缓冲器的所述两个或更多个数据元素。
9.一种执行存储器操作的方法,所述方法包括:
通过处理器向事务输入缓冲器提供存储器的两个或更多个源地址和对应两个或更多个目标地址;
由所述向事务输入缓冲器向事务定序器提供所述两个或更多个源地址和所述对应两个或更多个目标地址;以及
执行由所述事务定序器提供的、用于将来自所述两个或更多个源地址的两个或更多个数据元素复制到所述存储器内的对应两个或更多个目标地址的两个或更多个指令,而不在中间复制到所述处理器中的寄存器。
10.根据权利要求9所述的方法,其中所述两个或更多个源地址正交或非相依且非相连。
11.根据权利要求9所述的方法,其中所述两个或更多个目标地址在所述存储器中正交或非相依且非相连。
12.根据权利要求9所述的方法,其中将来自所述两个或更多个源地址的两个或更多个数据元素复制到所述存储器内的对应两个或更多个目标地址包括执行单指令多数据SIMD复制指令。
13.根据权利要求12所述的方法,其包括在未由所述处理器引导的情况下在背景模式下执行所述SIMD复制指令。
14.一种用于执行存储器操作的设备,其包括:
处理器,其经配置以提供存储器的两个或更多个源地址;
事务输入缓冲器,其经配置以从所述处理器接收所述两个或更多个源地址;
事务定序器,其经配置以从所述事务输入缓冲器接收所述两个或更多个源地址,并且提供用于复制来自所述两个或更多个源地址的两个或更多个数据元素的指令;
收集结果缓冲器,其经配置以响应于所述指令,接收从所述存储器中的所述两个或更多个源地址复制的所述两个或更多个数据元素;以及
逻辑,其经配置以基于由所述处理器执行的单指令多数据SIMD加载操作而将来自所述收集结果缓冲器的所述两个或更多个数据元素加载到所述处理器中的向量寄存器。
15.根据权利要求14所述的设备,其中所述收集结果缓冲器定位于所述存储器中或非常接近于所述存储器。
16.根据权利要求14所述的设备,其中所述收集结果缓冲器是经配置以乱序接收所述两个或更多个数据元素的循环缓冲器或存储结构。
17.根据权利要求14所述的设备,其中所述两个或更多个源地址在所述存储器中正交或非相依且非相连。
18.根据权利要求14所述的设备,其中在未由所述处理器引导的情况下在背景模式下将所述两个或更多个数据元素乱序复制到所述收集结果缓冲器。
19.根据权利要求14所述的设备,其中所述逻辑包括经配置以跟踪所述收集结果缓冲器并在所述收集结果缓冲器完成时产生向量完成信号的事务定序器。
20.一种用于执行存储器操作的设备,其包括:
处理器,其经配置以提供存储器的两个或更多个源地址和和对应两个或更多个目标地址;
事务输入缓冲器,其经配置以从所述处理器接收所述两个或更多个源地址;
事务定序器,其经配置以从所述事务输入缓冲器接收所述两个或更多个源地址,并且提供用于复制来自所述两个或更多个源地址的两个或更多个数据元素的指令;以及
逻辑,其经配置以响应于所述指令,将来自所述两个或更多个源地址的所述两个或更多个数据元素复制到所述存储器内的对应两个或更多个目标地址,而不在中间复制到所述处理器中的寄存器。
21.根据权利要求20所述的设备,其中所述两个或更多个源地址正交或非相依且非相连。
22.根据权利要求20所述的设备,其中所述两个或更多个目标地址在所述存储器中正交或非相依且非相连。
23.根据权利要求20所述的设备,其包括经配置以在未由所述处理器引导的情况下在背景模式下将来自所述两个或更多个源地址的所述两个或更多个数据元素复制到对应两个或更多个目标地址的逻辑。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/192,992 US20170371657A1 (en) | 2016-06-24 | 2016-06-24 | Scatter to gather operation |
| US15/192,992 | 2016-06-24 | ||
| PCT/US2017/036041 WO2017222798A1 (en) | 2016-06-24 | 2017-06-06 | Method and apparatus for performing simd gather and copy operations |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109313548A CN109313548A (zh) | 2019-02-05 |
| CN109313548B true CN109313548B (zh) | 2023-05-26 |
Family
ID=59054330
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201780035161.6A Active CN109313548B (zh) | 2016-06-24 | 2017-06-06 | 用于执行simd收集和复制操作的方法和设备 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US20170371657A1 (zh) |
| EP (1) | EP3475808B1 (zh) |
| JP (1) | JP7134100B2 (zh) |
| KR (1) | KR102507275B1 (zh) |
| CN (1) | CN109313548B (zh) |
| BR (1) | BR112018076270A8 (zh) |
| ES (1) | ES2869865T3 (zh) |
| SG (1) | SG11201810051VA (zh) |
| WO (1) | WO2017222798A1 (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10795678B2 (en) * | 2018-04-21 | 2020-10-06 | Microsoft Technology Licensing, Llc | Matrix vector multiplier with a vector register file comprising a multi-port memory |
| US10782918B2 (en) * | 2018-09-06 | 2020-09-22 | Advanced Micro Devices, Inc. | Near-memory data-dependent gather and packing |
| KR20210112949A (ko) | 2020-03-06 | 2021-09-15 | 삼성전자주식회사 | 데이터 버스, 그것의 데이터 처리 방법 및 데이터 처리 장치 |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5887183A (en) * | 1995-01-04 | 1999-03-23 | International Business Machines Corporation | Method and system in a data processing system for loading and storing vectors in a plurality of modes |
| US6513107B1 (en) * | 1999-08-17 | 2003-01-28 | Nec Electronics, Inc. | Vector transfer system generating address error exception when vector to be transferred does not start and end on same memory page |
| WO2007071606A2 (en) * | 2005-12-22 | 2007-06-28 | International Business Machines Corporation | Cache injection using semi-synchronous memory copy operation |
| JP2007172609A (ja) * | 2005-12-22 | 2007-07-05 | Internatl Business Mach Corp <Ibm> | 効率的かつ柔軟なメモリ・コピー動作 |
| WO2010088129A1 (en) * | 2009-01-30 | 2010-08-05 | Mips Technologies, Inc. | System and method for improving memory transfer |
| CN102124443A (zh) * | 2008-08-15 | 2011-07-13 | 飞思卡尔半导体公司 | 在单指令多数据(simd)数据处理器中提供扩展寻址模式 |
| CN104303142A (zh) * | 2012-06-02 | 2015-01-21 | 英特尔公司 | 使用索引阵列和有限状态机的分散 |
| CN104937539A (zh) * | 2012-11-28 | 2015-09-23 | 英特尔公司 | 用于提供推入缓冲器复制和存储功能的指令和逻辑 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5761706A (en) * | 1994-11-01 | 1998-06-02 | Cray Research, Inc. | Stream buffers for high-performance computer memory system |
| US8432409B1 (en) * | 2005-12-23 | 2013-04-30 | Globalfoundries Inc. | Strided block transfer instruction |
| US20120060016A1 (en) * | 2010-09-07 | 2012-03-08 | International Business Machines Corporation | Vector Loads from Scattered Memory Locations |
| US8635431B2 (en) * | 2010-12-08 | 2014-01-21 | International Business Machines Corporation | Vector gather buffer for multiple address vector loads |
| US8972697B2 (en) * | 2012-06-02 | 2015-03-03 | Intel Corporation | Gather using index array and finite state machine |
| US10049061B2 (en) * | 2012-11-12 | 2018-08-14 | International Business Machines Corporation | Active memory device gather, scatter, and filter |
-
2016
- 2016-06-24 US US15/192,992 patent/US20170371657A1/en active Pending
-
2017
- 2017-06-06 BR BR112018076270A patent/BR112018076270A8/pt unknown
- 2017-06-06 SG SG11201810051VA patent/SG11201810051VA/en unknown
- 2017-06-06 CN CN201780035161.6A patent/CN109313548B/zh active Active
- 2017-06-06 WO PCT/US2017/036041 patent/WO2017222798A1/en unknown
- 2017-06-06 JP JP2018566347A patent/JP7134100B2/ja active Active
- 2017-06-06 KR KR1020187036298A patent/KR102507275B1/ko active IP Right Grant
- 2017-06-06 ES ES17729733T patent/ES2869865T3/es active Active
- 2017-06-06 EP EP17729733.0A patent/EP3475808B1/en active Active
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5887183A (en) * | 1995-01-04 | 1999-03-23 | International Business Machines Corporation | Method and system in a data processing system for loading and storing vectors in a plurality of modes |
| US6513107B1 (en) * | 1999-08-17 | 2003-01-28 | Nec Electronics, Inc. | Vector transfer system generating address error exception when vector to be transferred does not start and end on same memory page |
| WO2007071606A2 (en) * | 2005-12-22 | 2007-06-28 | International Business Machines Corporation | Cache injection using semi-synchronous memory copy operation |
| JP2007172609A (ja) * | 2005-12-22 | 2007-07-05 | Internatl Business Mach Corp <Ibm> | 効率的かつ柔軟なメモリ・コピー動作 |
| CN102124443A (zh) * | 2008-08-15 | 2011-07-13 | 飞思卡尔半导体公司 | 在单指令多数据(simd)数据处理器中提供扩展寻址模式 |
| WO2010088129A1 (en) * | 2009-01-30 | 2010-08-05 | Mips Technologies, Inc. | System and method for improving memory transfer |
| CN104303142A (zh) * | 2012-06-02 | 2015-01-21 | 英特尔公司 | 使用索引阵列和有限状态机的分散 |
| CN104937539A (zh) * | 2012-11-28 | 2015-09-23 | 英特尔公司 | 用于提供推入缓冲器复制和存储功能的指令和逻辑 |
Also Published As
| Publication number | Publication date |
|---|---|
| BR112018076270A2 (pt) | 2019-03-26 |
| KR20190020672A (ko) | 2019-03-04 |
| US20170371657A1 (en) | 2017-12-28 |
| SG11201810051VA (en) | 2019-01-30 |
| JP2019525294A (ja) | 2019-09-05 |
| ES2869865T3 (es) | 2021-10-26 |
| EP3475808B1 (en) | 2021-04-14 |
| EP3475808A1 (en) | 2019-05-01 |
| CN109313548A (zh) | 2019-02-05 |
| WO2017222798A1 (en) | 2017-12-28 |
| KR102507275B1 (ko) | 2023-03-06 |
| BR112018076270A8 (pt) | 2023-01-31 |
| JP7134100B2 (ja) | 2022-09-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10552163B2 (en) | Method and apparatus for efficient scheduling for asymmetrical execution units | |
| US9678758B2 (en) | Coprocessor for out-of-order loads | |
| JP5758515B2 (ja) | バイパスマルチプルインスタンス化テーブルを用いた移動除去のためのシステム及び方法 | |
| TW201702866A (zh) | 用戶等級分叉及會合處理器、方法、系統及指令 | |
| KR20100003309A (ko) | 파이프라인 프로세서에서 조건 명령 실행을 촉진시키기 위해 로컬 조건 코드 레지스터를 이용하기 위한 방법 및 장치 | |
| KR102524565B1 (ko) | 로드 스토어 유닛들을 바이패싱하여 스토어 및 로드 추적 | |
| CN109313548B (zh) | 用于执行simd收集和复制操作的方法和设备 | |
| US20140047218A1 (en) | Multi-stage register renaming using dependency removal | |
| US10942745B2 (en) | Fast multi-width instruction issue in parallel slice processor | |
| JP2009099097A (ja) | データ処理装置 | |
| US11023242B2 (en) | Method and apparatus for asynchronous scheduling | |
| US7047397B2 (en) | Method and apparatus to execute an instruction with a semi-fast operation in a staggered ALU | |
| CN111295641A (zh) | 使用宽度减小vliw处理器的vliw指令处理的系统和方法 | |
| US11093246B2 (en) | Banked slice-target register file for wide dataflow execution in a microprocessor | |
| WO2014202825A1 (en) | Microprocessor apparatus | |
| TW201915715A (zh) | 使用亂序指令選取器選擇按序指令選取 | |
| CN109564510B (zh) | 用于在地址生成时间分配加载和存储队列的系统和方法 | |
| US11609764B2 (en) | Inserting a proxy read instruction in an instruction pipeline in a processor | |
| US11157276B2 (en) | Thread-based organization of slice target register file entry in a microprocessor to permit writing scalar or vector data to portions of a single register file entry | |
| US10983799B1 (en) | Selection of instructions to issue in a processor | |
| US20140075140A1 (en) | Selective control for commit lines for shadowing data in storage elements |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 1260879 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant |