CN107693797B - Peptide oligonucleotide conjugates - Google Patents
Peptide oligonucleotide conjugates Download PDFInfo
- Publication number
- CN107693797B CN107693797B CN201710707423.0A CN201710707423A CN107693797B CN 107693797 B CN107693797 B CN 107693797B CN 201710707423 A CN201710707423 A CN 201710707423A CN 107693797 B CN107693797 B CN 107693797B
- Authority
- CN
- China
- Prior art keywords
- group
- conjugate
- carrier peptide
- oligomer
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images
























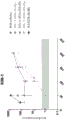


Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
- A61K47/645—Polycationic or polyanionic oligopeptides, polypeptides or polyamino acids, e.g. polylysine, polyarginine, polyglutamic acid or peptide TAT
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7105—Natural ribonucleic acids, i.e. containing only riboses attached to adenine, guanine, cytosine or uracil and having 3'-5' phosphodiester links
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/30—Macromolecular organic or inorganic compounds, e.g. inorganic polyphosphates
- A61K47/42—Proteins; Polypeptides; Degradation products thereof; Derivatives thereof, e.g. albumin, gelatin or zein
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
- A61K47/645—Polycationic or polyanionic oligopeptides, polypeptides or polyamino acids, e.g. polylysine, polyarginine, polyglutamic acid or peptide TAT
- A61K47/6455—Polycationic oligopeptides, polypeptides or polyamino acids, e.g. for complexing nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
- A61P21/04—Drugs for disorders of the muscular or neuromuscular system for myasthenia gravis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
- A61P31/16—Antivirals for RNA viruses for influenza or rhinoviruses
Abstract
Oligonucleotide analogs conjugated to carrier peptides are provided. The compounds of the present disclosure are useful in the treatment of various diseases, for example, diseases in which inhibition of protein expression or correction of aberrant mRNA splice products can produce a beneficial therapeutic effect.
Description
Cross Reference to Related Applications
This application claims the benefit of united states patent application No. 13/101942, filed 5/2011 and united states patent application No. 13/107528, filed 5/13/2011 in accordance with chapter 35, 120 of the united states code, which are all incorporated herein by reference.
Background
Technical Field
The present invention relates generally to oligonucleotide compounds (oligomers) useful as antisense compounds, and more particularly to oligomer compounds that bind to cell-penetrating peptides, and the use of such oligomer compounds in antisense applications.
Description of the related Art
The practical utility of many drugs with potentially useful biological activities is often hindered by the difficulty of delivering such drugs to their targets. It is often necessary to deliver a compound to be delivered into a cell out of an extracellular environment containing a large amount of water and then penetrate the lipophilic cell membrane to enter the cell. Unless a substance is actively transported by a particular transport mechanism, many molecules, especially macromolecules, are either too lipophilic to actually dissolve, or too hydrophilic to penetrate the membrane.
Fragments of the HIV Tat protein consisting of amino acid residues 49-57(Tat 49-57, having the sequence RKKRRQRRR) are used to deliver biologically active peptides and proteins into cells (e.g.Barsum et al, 1994, PCT Pubn. No. WO 94/04686). Tat (49-60) was used to facilitate the delivery of phosphorothioate oligonucleotides (Astriab-Fisher, Sergueev et al 2000; Astriab-Fisher, Sergueev et al 2002). Reverse Tat or rTat (57-49) (RRRQRRKKR) was reported to have improved utility for delivering fluorescein into cells compared to Tat (49-57) (Wender, Mitchell et al.2000; Rothbard, Kreider et al.2002). Other arginine-rich transport polymers are also disclosed by Rothbard and Wender (PCT publication No. WO 01/62297; U.S. Pat. No. 6306993; U.S. patent application publication No. 2003/0032593).
Oligonucleotides are a potentially useful class of pharmaceutical compounds, the delivery of which is often a barrier to therapeutic use. In this regard, morpholino oligomers with attached phosphorodiamidates (PMOs; see, e.g., Summerton and Weller,1997) have been found to be more promising than charged oligonucleotide analogs such as phosphorothioates. PMOs are water-soluble, uncharged or substantially uncharged antisense molecules that inhibit gene expression by preventing the binding or progression of splicing or translation machinery elements. PMOs have also been shown to inhibit or prevent viral replication (Stein, Skilling et al 2001; McCaffrey, Meuse et al 2003). They are highly resistant to enzymatic digestion (Hudziak, Barofsky et al 1996). PMOs exhibit high antisense specificity and efficacy in cell-free and cell culture models in vitro (Stein, Foster et al 1997; Summerton and Weller 1997), and in vivo in zebrafish, frog and sea urchin embryos (Heasman, Kofren et al 2000; Nasevivicus and Ekker 2000), as well as in adult animal models such as rat, mouse, rabbit, dog and pig (see, e.g., Arora and Iversen 2000; Qin, Taylor et al 2000; Iversen 2001; Kipshidze, Keane et al 2001; Devi 2002; Devi, Oldenkamp et al 2002; Kipshidze, Kim et al 2002; Ricker, Mata et al 2002).
Antisense PMO Oligomers have also been shown to be taken up into cells with more consistent effectiveness and less non-specific effects in vivo than other widely used Antisense oligonucleotides (see, e.g., p.iversen, "phospho amide morphologies", in Antisense Drug Technology, s.t. crook, ed., Marcel Dekker, inc., New York, 2001). Binding of PMOs to arginine-rich peptides has been shown to increase their cellular uptake (see, e.g., U.S. patent No. 7468418); however, the toxicity of the conjugates slowed their development as viable drug candidates.
Despite the significant advances that have been made, there remains a need in the art for oligonucleotide conjugates with improved antisense or antigene performance. Such enhanced antisense or antigene properties include: low toxicity, strong affinity for DNA and RNA without compromising sequence selectivity; improved pharmacokinetics and tissue distribution; improved cell delivery and reliable and controllable distribution in vivo.
Summary of The Invention
The compounds of the present invention can solve these problems and provide improvements over existing antisense molecules in the art. The present inventors have solved the toxicity problems associated with other peptide oligomer conjugates by linking the cell-penetrating peptide to a substantially uncharged nucleic acid analog by a glycine or proline amino acid. In addition, modification of the intersubunit linkages and/or binding of the terminal moieties to the 5 'and/or 3' ends of the oligonucleotide analogs, e.g., morpholino oligonucleotides, can also improve the performance of the conjugates. For example, in certain embodiments, the conjugates of the present disclosure have reduced toxicity and/or improved cell delivery, potency, and/or tissue distribution, and/or can be delivered to a target organ more efficiently than other oligonucleotide analogs. These superior properties may result in favorable therapeutic indices, reduced clinical dosages, and lower cost of goods.
Thus, in one embodiment, the present disclosure provides a conjugate comprising:
(a) a carrier peptide comprising amino acid subunits; and
(b) a nucleic acid analog comprising a substantially uncharged backbone and a sequence of homing bases for sequence-specific binding to a target nucleic acid;
wherein:
two or more of the amino acid subunits are positively charged amino acids, the carrier peptide comprises glycine (G) or proline (P) at the carboxy terminus of the carrier peptide, and the carrier peptide is covalently linked to the nucleic acid analog. Also provided are compositions comprising the above conjugates and a pharmaceutically acceptable carrier.
In another embodiment, the present disclosure provides a method of inhibiting the production of a protein comprising exposing a nucleic acid encoding the protein to a conjugate of the present disclosure.
Another aspect of the disclosure includes a method of facilitating transport of a nucleic acid analog into a cell, the method comprising binding the carrier peptide of claim 1 to a nucleic acid analog, and wherein transport of the nucleic acid analog into the cell is facilitated relative to a non-conjugated form of the nucleic acid analog.
In another embodiment, the present disclosure is directed to a method of treating a disease in a subject comprising administering to the subject a pharmaceutically effective amount of the disclosed conjugate. Also provided are methods of making the conjugates, methods of their use, and carrier peptides useful for binding to nucleic acid analogs.
These and other aspects of the invention will become apparent by reference to the following detailed description. For this purpose, various references are set forth herein which describe in more detail certain background information, procedures, compounds and/or compositions, and each of which is incorporated herein by reference in its entirety.
Drawings
Figure 1A shows an exemplary morpholino oligomer structure comprising a phosphodiamide linkage.
FIG. 1B shows morpholino oligomers conjugated to the 5' end of the carrier peptide.
Figure 1C shows morpholino oligomers conjugated to the 3' end of the carrier peptide.
Fig. 1D-G show repeat subunit fragments of exemplary morpholino oligonucleotides, designated 1D through 1G.
FIG. 2 depicts exemplary intersubunit linkages to morpholino-T moieties.
FIG. 3 is a reaction scheme showing preparation of linker arms for solid phase synthesis.
FIG. 4 shows the preparation of a solid support (support) for oligomer synthesis.
Figures 5A, 5B and 5C show exon skipping data for exemplary conjugates compared to known conjugates in mouse quadriceps, septum and heart, respectively.
Fig. 6A, 6B, and 6C are alternative representations of exon skipping data for exemplary conjugates compared to known conjugates in mouse quadriceps, septum, and heart, respectively.
Fig. 7A and 7B depict Blood Urea Nitrogen (BUN) levels and survival, respectively, in mice treated with different peptide-oligomer conjugates.
Fig. 8A and 8B show Kidney Injury Marker (KIM) data and clusterin (Clu) data, respectively, for mice treated with different peptide-oligomer conjugates.
Figures 9A, 9B, 9C, and 9D are graphs comparing exon skipping, BUN levels,% survival, and KIM levels, respectively, in mice treated with exemplary conjugates compared to known conjugates.
Figure 10 shows KIM data for mice treated with different conjugates.
Figure 11 shows the results of BUN analysis of mice treated with different conjugates.
FIG. 12 is a graph showing the concentration of different oligomers in mouse kidney tissue.
Detailed Description
I.Definition of
In the following description, certain specific details are set forth in order to provide a thorough understanding of the various embodiments. However, it will be understood by those skilled in the art that the present invention may be practiced without these details. In other instances, well-known structures have not been shown or described in detail to avoid unnecessarily obscuring the description of the embodiments. Throughout this specification and the claims which follow, unless the context requires otherwise, the word "comprise" and variations such as "comprises" and "comprising", will be interpreted in an open, inclusive sense, i.e. in an inclusive sense. Moreover, the headings provided herein are for convenience only and do not interpret the scope or meaning of the claimed invention.
Reference throughout this specification to "one embodiment" or "an embodiment" means that a particular feature, structure, or characteristic described in connection with the embodiment is included in at least one embodiment. Thus, the appearances of the phrases "in one embodiment" or "in an embodiment" in various places throughout this specification are not necessarily all referring to the same embodiment. Furthermore, the particular features, structures, or characteristics may be combined in any suitable manner in one or more embodiments. In addition, as used in this specification and the appended claims, the singular forms "a," "an," and "the" include plural referents unless the context clearly dictates otherwise. It should also be noted that the term "or" is generally employed in its sense including "and/or" unless the context clearly dictates otherwise.
As used herein, the following terms have the following meanings, unless otherwise indicated:
"amino" refers to-NH2And (4) a base.
"cyano" or "nitrile" refers to the group-CN.
"Hydroxy (Hydroxy)" or "Hydroxy (hydroxyyl)" refers to an-OH group.
"imino" refers to the NH substituent.
"guanidino" refers to — NHC (═ NH) NH2And (4) a substituent.
"amidino" refers to-C (═ NH) NH2And (4) a substituent.
"Nitro" means-NO2And (4) a base.
"oxo" refers to an ═ O substituent.
"thio" refers to ═ S substituents.
"cholate" refers to the following structure:

"deoxycholate" refers to the following structure:

"alkyl" refers to a straight or branched hydrocarbon chain radical which is saturated or unsaturated (i.e., contains one or more double and/or triple bonds), has from 1 to 30 carbon atoms, and which is attached to the remainder of the molecule by a single bond. Including alkyl groups containing any number of carbon atoms from 1 to 30. Alkyl groups containing up to 30 carbon atoms are referred to as C1-C30Alkyl, likewise, for example, alkyl containing up to 12 carbon atoms is C1-C12An alkyl group. Similarly represent alkyl groups (and other moieties as defined herein) containing other numbers of carbon atoms. Alkyl groups include, but are not limited to, C1-C30Alkyl radical, C1-C20Alkyl radical, C1-C15Alkyl radical, C1-C10Alkyl radical, C1-C8Alkyl radical, C1-C6Alkyl radical, C1-C4Alkyl radical, C1-C3Alkyl radical, C1-C2Alkyl radical, C2-C8Alkyl radical, C3-C8Alkyl and C4-C8An alkyl group. Representative alkyl groups include, but are not limited to, methyl, ethyl, n-propyl, 1-methylethyl (isopropyl), n-butyl, isobutyl, sec-butyl, n-pentyl, 1-dimethylethyl (tert-butyl), 3-methylhexyl, 2-methylhexyl, vinyl, prop-1-enyl, but-1-enyl, pent-1, 4-dienyl, ethynyl, propynyl, but-2-ynyl, but-3-ynyl, pentynyl, hexynyl, and the like. Unless otherwise specifically stated in the specification, an alkyl group may be optionally substituted as described below.
"alkylene" or "alkylene chain" refers to a moleculeThe remainder of (a) is attached to a linear or branched divalent hydrocarbon chain on the radical. The alkylene group can be saturated or unsaturated (i.e., contain one or more double and/or triple bonds). Representative alkylene groups include, but are not limited to, C1-C12Alkylene radical, C1-C8Alkylene radical, C1-C6Alkylene radical, C1-C4Alkylene radical, C1-C3Alkylene radical, C1-C2Alkylene radical, C1An alkylene group. Representative alkylene groups include, but are not limited to, methylene, ethylene, propylene, n-butylene, vinylene, propenylene, n-butenyl, propynylene, n-butynylene, and the like. The alkylene chain is connected to the rest of the molecule by a single or double bond and to the group by a single or double bond. The point of attachment of the alkylene chain to the remainder of the molecule and to the group may be through one or any two carbons in the chain. Unless otherwise specifically stated in the present specification, the alkylene chain may be optionally substituted as described below.
"alkoxy" refers to the formula-ORaWherein R isaIs alkyl as defined. Unless otherwise specifically stated in the specification, an alkoxy group may be optionally substituted as described below.
"alkoxyalkyl" refers to the formula-RbORaWherein R isaIs alkyl as defined, and wherein R isbIs alkylene as defined. Unless otherwise specifically stated in the specification, an alkoxyalkyl group may be optionally substituted as described below.
"alkylcarbonyl" refers to the formula-C (═ O) RaWherein R isaIs an alkyl group as defined above. Unless otherwise specifically stated in the specification, an alkylcarbonyl group may be optionally substituted as described below.
"alkoxycarbonyl" refers to a group of formula-C (═ O) ORaWherein R isaIs alkyl as defined. Unless otherwise specifically stated in the specification, an alkoxycarbonyl group may be optionally substituted as described below.
By "alkylamino" is meantIs of the formula-NHRaRadical or-NRaRaWherein each R isaAre each independently an alkyl group as defined above. Unless otherwise specifically stated in the specification, alkylamino may be optionally substituted as described below.
"amido" refers to the formula-n (h) C (═ O) RaWherein R isaIs an alkyl or aryl group as defined herein. Unless otherwise explicitly stated in the specification, the amide group may be optionally substituted as described below.
"Amidinylalkyl" means a compound of the formula-Rb-C(=NH)NH2Wherein R isbIs alkylene as defined above. Unless otherwise specifically stated in the specification, an amidinoalkyl group may be optionally substituted as described below.
"Amidinoalkylcarbonyl" means a compound of the formula-C (═ O) Rb-C(=NH)NH2Wherein R isbIs alkylene as defined above. Unless otherwise specifically stated in the specification, amidinoalkylcarbonyl groups may be optionally substituted as described below.
"aminoalkyl" refers to the formula-Rb-NRaRaWherein R isbIs alkylene as defined above, and each RaAre each independently hydrogen or alkyl.
"Thioalkyl" refers to the formula-SRaWherein R isaIs an alkyl group as defined above. Unless otherwise specifically stated in the specification, a thioalkyl group may be optionally substituted.
"aryl" refers to a group from a hydrocarbon ring system containing hydrogen, 6 to 30 carbon atoms, and at least 1 aromatic ring. Aryl groups may be monocyclic, bicyclic, tricyclic or tetracyclic ring systems, which may include fused or bridged ring systems. Aryl groups include, but are not limited to, aryl groups from the following hydrocarbon ring systems: aceanthrylene, acenaphthylene, acephenanthrylene, anthracene, azulene (az. mu. ene), benzene, chrysene (chrysene), fluoranthene, fluorene, asymmetric indacene (as-indacene), symmetric indacene (s-indacene), indane, indene, naphthalene, phenalene (phenalene), phenanthrene, pleiadene, pyrene and triphenylene. Unless otherwise explicitly stated in the specification, the term "aryl" or the prefix "aryl" (as in "aralkyl") is intended to include optionally substituted aryl groups.
"aralkyl" refers to the formula-Rb-RcWherein R isbIs an alkylene chain as defined above, and RcIs one or more aryl groups as defined above, e.g., benzyl, diphenylmethyl, trityl, and the like. Unless otherwise specifically stated in the specification, an aralkyl group may be optionally substituted.
"Arylcarbonyl" refers to the formula-C (═ O) RcWherein R iscIs one or more aryl groups as defined above, for example, phenyl. Unless stated otherwise specifically in the specification, an arylcarbonyl group may be optionally substituted.
"Aryloxycarbonyl" refers to a compound of formula-C (═ O) ORcWherein R iscIs one or more aryl groups as defined above, for example, phenyl. Unless otherwise specifically stated in the specification, an aryloxycarbonyl group may be optionally substituted.
"Arylcarbonyl" refers to the formula-C (═ O) Rb-RcWherein R isbIs an alkylene chain as defined above, and RcIs one or more aryl groups as defined above, for example, phenyl. Unless otherwise specifically stated in the specification, an aralkylcarbonyl group may be optionally substituted.
"Aryloxycarbonyl" refers to the radical-C (═ O) ORb-RcWherein R isbIs an alkylene chain as defined above, and RcIs one or more aryl groups as defined above, for example, phenyl. Unless otherwise specifically stated in the specification, an aralkoxycarbonyl group may be optionally substituted.
"aryloxy" refers to the formula-ORcWherein R iscIs one or more aryl groups as defined above, for example, phenyl. Unless stated otherwise specifically in the specification, an arylcarbonyl group may be optionally substituted.
"cycloalkyl" refers to a stable, non-aromatic, monocyclic or polycyclic, carbocyclic ring which may include fused or bridged ring systems, saturated or unsaturated, and attached to the remainder of the molecule by a single bond. Representative cycloalkyl groups include, but are not limited to, cycloalkanes having 3 to 15 carbon atoms and 3 to 8 carbon atoms. Monocyclic cycloalkyl groups include, for example, cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, cycloheptyl, and cyclooctyl. Polycyclic groups include, for example, adamantyl, norbornyl, decahydronaphthyl, and 7, 7-dimethyl-bicyclo [2.2.1] heptanyl. Unless stated otherwise specifically in the specification, cycloalkyl groups may be optionally substituted.
"cycloalkylalkyl" refers to the formula-RbRdWherein R isbIs an alkylene chain as defined above, and RdIs cycloalkyl as defined above. Unless stated otherwise specifically in the specification, cycloalkylalkyl groups may be optionally substituted.
"Cycloalkylcarbonyl" refers to the formula-C (═ O) RdWherein R isdIs cycloalkyl as defined above. Unless stated otherwise specifically in the specification, a cycloalkylcarbonyl group may be optionally substituted.
"Cycloalkyloxycarbonyl" refers to the formula-C (═ O) ORdWherein R isdIs cycloalkyl as defined above. Unless otherwise specifically stated in the specification, a cycloalkoxycarbonyl group may be optionally substituted.
"fused" refers to any cyclic structure described herein that is fused to an existing cyclic structure. When the fused ring is a heterocyclyl or heteroaryl ring, any carbon atom that is part of the fused heterocyclyl or heteroaryl ring in its existing cyclic structure may be substituted with a nitrogen atom.
"guanidinoalkyl" means a compound of the formula-Rb-NHC(=NH)NH2Wherein R isbIs alkylene as defined above. Unless otherwise specifically stated in the specification, a guanidinoalkyl group may be optionally substituted as described below.
"guanidinoalkylcarbonyl" means a compound of formula-C (═ O) Rb-NHC(=NH)NH2Wherein R isbIs alkylene as defined above. Unless otherwise specifically stated in the specification, a guanidinoalkylcarbonyl group may optionally be taken as described belowAnd (4) generation.
"halo" or "halogen" refers to bromo, chloro, fluoro or iodo.
"haloalkyl" refers to an alkyl group as defined above substituted with one or more halo groups as defined above, e.g., trifluoromethyl, difluoromethyl, fluoromethyl, trichloromethyl, 2,2, 2-trifluoroethyl, 1, 2-difluoroethyl, 3-bromo-2-fluoropropyl, 1, 2-dibromoethyl, and the like. Unless otherwise specifically stated in the specification, haloalkyl may be optionally substituted.
"perhalo" or "perfluoro" refers to a moiety in which each hydrogen atom is replaced by a halogen atom or a fluorine atom, respectively.
"heterocyclyl", "heterocycle" or "heterocyclic ring" refers to a stable 3-to 24-membered non-aromatic cyclic group containing 2 to 23 carbon atoms and 1 to 8 heteroatoms selected from: nitrogen, oxygen, phosphorus and sulfur. Unless otherwise specifically stated in the specification, a heterocyclyl group may be a monocyclic, bicyclic, tricyclic or tetracyclic ring system, which may contain fused or bridged ring systems; and the nitrogen, carbon or sulfur atoms in the heterocyclic group may be optionally oxidized; the nitrogen atoms may optionally be quaternized; and the heterocyclic group may be partially or fully saturated. Examples of such heterocyclyl groups include, but are not limited to, dioxolanyl (dioxolanyl), thienyl [1,3] dithianyl, decahydroisoquinolinyl, imidazolinyl, imidazolidinyl, isothiazolidinyl (isothiazolidinyl), isoxazolidinyl, morpholinyl, octahydroindolyl, octahydroisoindolyl, 2-oxopiperazinyl, 2-oxopiperidinyl, 2-oxopyrrolidinyl, oxazolidinyl, piperidinyl, piperazinyl, 4-piperidinonyl, pyrrolidinyl, pyrazolidinyl, quinolinyl, thiazolidinyl, tetrahydrofuranyl, trithianyl, tetrahydropyranyl, thiomorpholinyl (thiomorpholinyl), 1-oxo-thiomorpholinyl, 1-dioxo-thiomorpholinyl, 12-crown-4, 15-crown-5, 18-crown-6, 21-crown-7, 21-crown-4, 15-crown-5, 18-crown-6, 21-crown-7, and, Aza-18-crown-6, diaza-18-crown-6, aza-21-crown-7, and diaza-21-crown-7. Unless otherwise specifically stated in the specification, heterocyclic groups may be optionally substituted.
"heteroaryl" refers to a5 to 14 membered ring system group containing hydrogen atoms, 1 to 13 carbon atoms, 1 to 6 heteroatoms selected from nitrogen, oxygen, phosphorus and sulfur, and at least 1 aromatic ring. For the purposes of the present invention, heteroaryl groups may be monocyclic, bicyclic, tricyclic or tetracyclic ring systems, which may contain fused or bridged ring systems; and the nitrogen, carbon or sulfur atoms in the heteroaryl group may be optionally oxidized; the nitrogen atoms may optionally be quaternized. Examples include, but are not limited to, azepinyl, acridinyl, benzimidazolyl, benzothiazolyl, benzindolyl, benzodioxolyl (benzodioxolyl), benzofuranyl, benzoxazolyl, benzothiazolyl, benzothiadiazole, benzo [ b ] [1,4] dioxepanyl (benzob ] [1,4] dioxepinyl), 1, 4-benzodioxoyl (1, 4-benzodioxolyl), benzonaphthofuranyl, benzoxazolyl, benzodioxolyl (benzodioxolyl), benzoxadinyl (benzodioxolyl), benzopyranyl, benzopyranonyl, benzofuranyl, benzothiophenyl (benzothiophenyl), benzotriazolyl, benzo [4,6] imidazo [1,2-a ] pyridinyl, carbazolyl, cinnolinyl (cinnolinyl), dibenzofuranyl, dibenzothiophenyl, Furyl, furanonyl, isothiazolyl, imidazolyl, indazolyl, indolyl, indazolyl, isoindolyl, indolinyl, isoindolinyl, isoquinolinyl, indolizinyl, isoxazolyl, naphthyridinyl, oxadiazolyl (oxadiazolyl), 2-oxazepinyl, oxazolyl, oxiranyl, 1-oxidopyridyl, 1-phenyl-1H-pyrrolyl, phenazinyl, phenothiazinyl, phenoxazinyl, phthalazinyl, pteridinyl, purinyl, pyrrolyl, pyrazolyl, pyridyl, pyrazinyl, pyrimidinyl, pyridazinyl, quinazolinyl, quinoxalyl, quinolyl, quinolinyl, isoquinolyl, tetrahydroquinolyl, thiazolyl, thiadiazole, triazolyl, tetrazolyl, indolinyl, isoindolinyl, oxidoyl, oxazepinyl, oxazidinyl, 1-oxidopyridyl, 1-oxadiazinyl, 1-phenyl-1H-pyrrolyl, phenazinyl, pheno, Triazinyl and thiophenyl (i.e., thienyl). Unless expressly stated otherwise in the specification, heteroaryl groups may be optionally substituted.
All of the above groups may be substituted or unsubstituted. The term "taking" as used hereinBy substituted is meant that any of the above groups (i.e., alkyl, alkylene, alkoxy, alkoxyalkyl, alkylcarbonyl, alkoxycarbonyl, alkylamino, amido, amidinoalkyl, amidinoalkylcarbonyl, aminoalkyl, aryl, aralkyl, arylcarbonyl, aryloxycarbonyl, aralkoxycarbonyl, aryloxy, cycloalkyl, cycloalkylalkyl, cycloalkylcarbonyl, cycloalkylalkylcarbonyl, cycloalkoxycarbonyl, guanidinoalkyl, guanidinoalkylcarbonyl, haloalkyl, heterocyclyl, and/or heteroaryl) can be further functionalized wherein at least 1 hydrogen atom is substituted with a bond to a substituent other than a hydrogen atom. Unless explicitly stated in the specification, a substituent may include one or more substituents selected from the group consisting of: oxo (oxo), -CO2H. Nitrile, nitro, -CONH2Hydroxyl, thio (oxy), alkyl, alkylene, alkoxy, alkoxyalkyl, alkylcarbonyl, alkoxycarbonyl, aryl, aralkyl, arylcarbonyl, aryloxycarbonyl, aralkylcarbonyl, aralkoxycarbonyl, aryloxy, cycloalkyl, cycloalkylalkyl, cycloalkylcarbonyl, cycloalkylalkylcarbonyl, cycloalkoxycarbonyl, heterocyclyl, heteroaryl, dialkylamine, arylamine, alkylarylamine, diarylamine, N-oxide, imide, and enamine; silicon atom-containing groups, such as trialkylsilyl, dialkylarylsilyl, alkyldiarylsilyl, triarylsilyl, perfluoroalkyl, or perfluoroalkoxy groups, for example trifluoromethyl or trifluoromethoxy groups. "substituted" also refers to any of the above groups in which one or more hydrogen atoms are substituted with higher order bonds (e.g., double or triple bonds) attached to oxygen such as in oxo, carbonyl, carboxyl, and ester groups, and heteroatoms such as nitrogen in imine, oxime, hydrazone, and nitrile groups. For example, "substituted" includes any of the above groups in which one or more hydrogen atoms are replaced with: -NRgC(=O)NRgRh、-NRgC(=O)ORh、-NRgSO2Rh、-OC(=O)NRgRh、-ORg、-SRg、-SORg、-SO2Rg、-OSO2Rg、-SO2ORg、=NSO2Rgand-SO2NRgRh. "substituted" also refers to any of the above groups in which one or more hydrogen atoms are replaced with: -C (═ O) Rg、-C(=O)ORg、-CH2SO2Rg、-CH2SO2NRgRh、-SH、-SRgor-SSRg. In the foregoing radicals, RgAnd RhAre the same or different and independently are: hydrogen, alkyl, alkoxy, alkylamino, thioalkyl, aryl, aralkyl, cycloalkyl, cycloalkylalkyl, haloalkyl, heterocyclyl, N-heterocyclyl, heterocyclylalkyl, heteroaryl, N-heteroaryl and/or heteroarylalkyl. In addition, each of the foregoing substituents may also be optionally substituted with one or more of the substituents described above. Further, any of the above groups may be substituted to contain one or more internal oxygen or sulfur atoms. For example, an alkyl group may be substituted with one or more internal oxygen atoms to form an ether group or a polyether group. Similarly, an alkyl group may be substituted with one or more internal sulfur atoms to form a thioether, disulfide, or the like. The amido moiety may be substituted with up to 2 halogen atoms, while the other above groups may be substituted with one or more halogen atoms. Any of the above groups may also be substituted with amino, monoalkylamino, guanidino or amidino (amidino). Optional substituents for any of the above groups also include aryl phosphoryl, e.g., -RaP(Ar)3Wherein R isaIs alkylene, and ArIs an aryl moiety, such as phenyl.
The terms "antisense oligomer" or "antisense compound" are used interchangeably and refer to sequences of subunits each having bases carried on backbone subunits consisting of ribose or other pentose or morpholino groups, and wherein the backbone groups are linked by intersubunit linkages that allow the bases in the compound to hybridize by Watson-Crick base pairing to a target sequence in a nucleic acid (typically RNA) to form a nucleic acid: an oligomer within the target sequence hybridizes to both strands. The oligomer may form a sequence that is exactly or approximately complementary to the target sequence. Such antisense oligomers are designed to prevent or inhibit translation of an mRNA containing the target sequence, and may be said to "point" to the sequence with which they hybridize.
"morpholino oligomer" or "PMO" refers to a polymeric molecule having a backbone supporting bases capable of hydrogen bonding to a typical polynucleotide, wherein the polymer lacks pentose backbone moieties, and more specifically, the backbone is a ribose backbone linked by phosphodiester bonds (which are typically the phosphodiester bonds of nucleotides and nucleosides, but contain a ring nitrogen bound by the ring nitrogen). Exemplary "morpholino" oligomers comprise morpholino subunit structures linked together by (thio) phosphoramidate or (thio) phosphodiamide bonds, which bind a morpholino nitrogen of one subunit to a 5' exocyclic carbon of an adjacent subunit, each subunit comprising a purine or pyrimidine base-pairing moiety that can efficiently bind to a base in a polynucleotide by base-specific hydrogen bonding. Morpholino oligomers (including antisense oligomers) are described in detail, for example, in PCT publications No. 5698685, No. 5217866, No. 5142047, No. 5034506, No. 5166315, No. 5185444, No. 5521063, No. 5506337, and pending U.S. patent applications 12/271036, 12/271040 and No. WO/2009/064471, all of which are incorporated herein by reference in their entirety. Representative PMOs include PMOs in which the intersubunit linkage is a junction (A1).
"PMO +" refers to diamide morpholino oligomers of phosphoric acid diamides that have been previously described comprising any number of (1-piperazine) phosphinoyloxy ((1-piperazino) phosphinoyleneoxy), (1- (4- (ω -guanidino-alkanolyl)) -piperazine) phosphinoyloxy linkages (A2 and A3) (see, e.g., PCT publication WO/2008/036127, which is incorporated herein by reference in its entirety).
"PMO-X" refers to a phosphodiamide morpholino oligomer comprising at least 1 (B) linkage or at least one disclosed end modification disclosed herein.
The "phosphoramide" group comprises phosphorus having 3 attached oxygen atoms and 1 attached nitrogen atom, while the "phosphodiamide" group (see, e.g., fig. 1D-E) comprises phosphorus having 2 attached oxygen atoms and 2 attached nitrogen atoms. In the uncharged or modified intersubunit linkages of the oligomers described herein and in pending U.S. patent applications No. 61/349783 and No. 11/801885, 1 nitrogen is always flanked (pendant to) by the backbone chain. In the phosphodiamide linkage, the second nitrogen is typically a ring nitrogen in a morpholino ring structure.
A "thiophosphoramidate" or "thiophosphordiamide ester" linkage is a phosphoramidate or phosphodiamide ester linkage, respectively, in which 1 oxygen atom, typically the oxygen pendant to the backbone, is substituted with sulfur.
"intersubunit linkage" refers to a linkage that links 2 morpholino subunits, e.g., structure (I).
As used herein, "charged," "uncharged," "cationic," and "anionic" refer to the predominant state of a chemical moiety at approximately neutral pH, e.g., about 6 to 8. For example, this term may refer to the predominant state of the chemical moiety at physiological pH, i.e., about 7.4.
"lower alkyl" refers to an alkyl group of 1 to 6 carbon atoms, such as exemplified by methyl, ethyl, n-butyl, isobutyl, tert-butyl, isopentyl, n-pentyl, and isopentyl. In certain embodiments, "lower alkyl" has 1 to 4 carbon atoms. In other embodiments, "lower alkyl" has 1 to 2 carbon atoms; i.e. methyl or ethyl. Similarly, "lower alkenyl" refers to alkenyl of 2 to 6, preferably 3 or 4 carbon atoms, as exemplified by propenyl and butenyl.
A "non-interfering" substituent is a substituent that does not adversely affect the ability of the antisense oligomer as described herein to bind to its intended target. Such substituents include small and/or relatively non-polar groups such as methyl, ethyl, methoxy, ethoxy, or fluoro groups.
If the oligomer has a T at physiological conditions of greater than 37 deg.C, greater than 45 deg.C, preferably at least 50 deg.C, and usually 60 deg.C to 80 deg.C or highermWhen hybridized to a target, the oligonucleotide or antisense oligomer "specifically hybridizes" to the target polynucleotide. The term "T" of an oligomerm"is the temperature at which 50% of the oligomer hybridizes to a complementary polynucleotide. T ismIn normal saline under standard conditionsMeasured as described, for example, in Miyada et al, Methods enzymol.154:94-107 (1987). Such hybridization can occur with antisense oligomers that are "approximately" or "substantially" complementary, as well as being precisely complementary, to the target sequence.
Polynucleotides are described as "complementary" to each other when hybridization occurs between two single-stranded polynucleotides in an antiparallel configuration. Complementarity (the degree to which 1 polynucleotide is complementary to another polynucleotide) can be quantified based on the proportion of bases in the opposing strands that are expected to form hydrogen bonds with each other according to commonly accepted base pairing rules.
A first sequence is an "antisense sequence" to a second sequence if the polynucleotide has a sequence that specifically binds to or specifically hybridizes under physiological conditions to the sequence of a second polynucleotide.
The term "targeting sequence" is a sequence in an oligonucleotide analog that is complementary (otherwise, meaning substantially complementary) to a target sequence in an RNA genome. The entire sequence of the analog compound or only a portion thereof may be complementary to the target sequence. For example, in analogs with 20 bases, only 12-14 are likely targeting sequences. Typically, the targeting sequence consists of contiguous bases in an analog, but may alternatively consist of non-contiguous sequences, i.e., when these non-contiguous sequences are brought together, e.g., from the other end of the analog, the sequence that spans the target sequence is made up.
The "backbone" (e.g., uncharged oligonucleotide analogs) of an oligonucleotide analog refers to a structure that supports a base-pairing moiety; for example, for morpholino oligomers, as described herein, a "backbone" comprises morpholino ring structures linked by intersubunit linkages (e.g., phosphorus-containing linkages). "substantially uncharged backbone" refers to a backbone of an oligonucleotide analog in which less than 50% of the intersubunit linkages are charged at near neutral pH. For example, a substantially uncharged backbone can comprise less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or even 0% intersubunit linkages, which are charged at near neutral pH. In some embodiments, the substantially uncharged backbone comprises at most 1 charged (at physiological pH) intersubunit linkage per 4 uncharged (at physiological pH) linkages, at most 1 linkage per 8 linkages, or at most 1 uncharged linkage per 16 linkages. In some embodiments, a nucleic acid analog described herein is fully uncharged.
When hybridization occurs in an antiparallel configuration, the targeting and targeting sequences are described as "complementary" to one another. The targeting sequence may have "approximate" or "substantial" complementarity to the target sequence and still function for the purposes of the presently described methods, i.e., still be "complementary". Preferably, the oligonucleotide analogue compounds employed in the presently described methods have at most 1 mismatch per 10 nucleotides, and preferably at most 1 mismatch out of 20, with the target sequence. Alternatively, the antisense oligomer used has at least 80%, at least 90% sequence homology, or at least 95% sequence homology with the exemplary targeting sequence as specified herein. For complementary binding to an RNA target, and as described below, the guanine base can be complementary to a cytosine or uracil RNA base.
"hybrid double-stranded" refers to the double-stranded form between an oligonucleotide analog and a complementary portion of a target RNA. "nuclease-resistant hybrid duplex" refers to a hybrid duplex formed by binding an antisense oligomer to its complementary target such that the hybrid duplex is substantially resistant to in vivo degradation by intracellular and extracellular nucleases, such as rnase H, wherein the nucleases are capable of cleaving double-stranded RNA/RNA or RNA/DNA complexes.
An agent is "actively taken up" by mammalian cells when it is able to enter the cell by a mechanism other than passive diffusion across the cell membrane. The agent can be transported, for example, by "active transport," which refers to transport of the agent across a mammalian cell membrane by, for example, an ATP-dependent transport mechanism, or by "facilitated transport," which refers to transport of an antisense agent across a cell membrane by a transport mechanism that requires binding of the agent to a transport protein that will subsequently facilitate transport of the bound agent across the membrane.
The term "modulating expression" and/or "antisense activity" refers to the ability of an antisense oligomer to increase or more generally decrease the expression of a given protein by interfering with the expression or translation of RNA. In the case of reduced protein expression, antisense oligomers may directly prevent the expression of a given gene, or promote accelerated breakdown of RNA transcribed from that gene. Morpholino oligomers as described herein are believed to act through the former (steric repression) mechanism. Preferred antisense targets for sterically hindered oligos include the ATG initiation codon region, the splice site, the region immediately adjacent to the splice site, and the 5' -untranslated region of the mRNA, although other regions have been successfully targeted using morpholino oligos.
"amino acid subunit" is typically an α -amino acid residue (-CO-CHR-NH-); but may also be beta-or other amino acid residues (e.g., -CO-CH)2CHR-NH-), wherein R is an amino acid side chain.
The term "naturally occurring amino acid" refers to an amino acid that is present in a protein found in nature. The term "unnatural amino acid" refers to those amino acids that are not found in proteins found in nature; examples include beta-alanine (beta-Ala) and 6-aminocaproic acid (Ahx).
An "effective amount" or "therapeutically effective amount" refers to the amount of antisense oligomer administered to a mammalian subject, whether as a single dose or as part of a series of doses, which is effective to produce a desired therapeutic effect, typically by inhibiting translation of a selected target nucleic acid sequence.
"treatment" of an individual (e.g., a mammal, such as a human) or cell is any type of intervention used in an attempt to alter the natural course of the individual or cell. Treatment includes, but is not limited to, administration of a pharmaceutical composition and can be performed as a prophylaxis, or after a pathological event or contact with a pathogenic agent.
II.Carrier peptide
A.Properties of the Carrier peptide
As described above, the present disclosure relates to conjugates of carrier peptides and nucleic acid analogs. The carrier peptide is generally effective to increase cellular penetration of the nucleic acid analog. Furthermore, applicants have surprisingly found that inclusion of a glycine (G) or proline (P) subunit between the nucleic acid analog and the remainder of the carrier peptide (e.g., at the carboxy-or amino-terminus of the carrier peptide) can reduce the toxicity of the conjugate while maintaining or improving efficacy relative to conjugates having different linkages between the carrier peptide and the nucleic acid analog. Thus, the conjugates of the present disclosure have a better therapeutic window and are more promising drug candidates than other peptide-oligomer conjugates.
In addition to reduced toxicity, the presence of glycine or proline subunits between the nucleic acid analog and the carrier peptide is believed to provide additional advantages. For example, glycine is inexpensive and can be readily conjugated to nucleic acid analogs (or optional linker arms) without any possibility of racemization. Similarly, proline is readily bound without racemization and also provides a carrier peptide that is not a helix former. The hydrophobicity of proline may also confer certain advantages with respect to the interaction of the carrier peptide with the cellular lipid bilayer, and carrier peptides comprising multiple prolines (e.g., in certain embodiments) may be resistant to G-quadruplex formation. Finally, in certain embodiments, when the proline moiety is adjacent to an arginine subunit, the proline moiety confers metabolization to the conjugate because the arginine-proline amide bond cannot be cleaved by conventional endopeptidase enzymes.
As described above, conjugates comprising a carrier peptide linked to a nucleic acid analog via a glycine or proline subunit have lower toxicity and similar efficacy compared to other known conjugates. Experiments performed in support of the present application showed that the toxicity of the nephrotoxicity marker using the conjugates of the present disclosure was much lower compared to other conjugates (see, e.g., Kidney Injury Marker (KIM) and Blood Urea Nitrogen (BUN) data described in example 30). While not wishing to be bound by theory, the inventors believe that the reduced toxicity of the conjugates of the disclosure may involve the absence of unnatural amino acids such as aminocaproic acid or β -alanine in the peptide portion (e.g., carboxy terminus) attached to the nucleic acid analog. Because these unnatural amino acids are not cleaved in vivo, it is believed that the toxic concentrations of the uncleaved peptide can accumulate and cause toxic effects.
The glycine or proline moiety may be located at the amino terminus or the carboxy terminus of the carrier peptide, and in some cases, the carrier peptide may be linked directly to the nucleic acid analog through a glycine or proline subunit, or the carrier peptide may be linked to the nucleic acid analog through an optional linker arm.
In one embodiment, the present disclosure relates to a conjugate comprising:
(a) a carrier peptide comprising amino acid subunits; and
(b) a nucleic acid analog comprising a substantially uncharged backbone and a homing base sequence for sequence-specific binding to a target nucleic acid;
wherein:
the two or more amino acid subunits are positively charged amino acids, the carrier peptide comprises a glycine (G) or proline (P) subunit at the carboxy terminus of the carrier peptide, and the carrier peptide is covalently linked to a nucleic acid analog. In some embodiments, no more than 7 contiguous amino acid subunits are arginines, e.g., 6 or fewer contiguous amino acid subunits are arginines. In some embodiments, the carrier peptide comprises a glycine subunit at the carboxy terminus. In other embodiments, the carrier peptide comprises a proline subunit at the carboxy terminus. In still other embodiments, the carrier peptide comprises a single glycine or proline at the carboxy terminus (i.e., does not comprise glycine or proline dimers or trimers, etc. at the carboxy terminus).
In certain embodiments, the carrier peptide, when bound to an antisense oligomer having a substantially uncharged backbone, is effective to promote binding of the antisense oligomer to its target sequence relative to an unconjugated version of the antisense oligomer, as demonstrated by:
(i) when the antisense oligomer is bound to its target sequence effective to prevent translation initiation codon of the encoded protein, expression of the encoded protein is reduced relative to that provided by the unconjugated oligomer, or
(ii) When the antisense oligomer binds to its target sequence effective to prevent aberrant splicing sites in the precursor mRNA that encodes the protein when correctly spliced, expression of the encoded protein is increased relative to that provided by the unconjugated oligomer. Assays suitable for measuring these effects are described further below. In one embodiment, conjugation of the peptide provides this activity in a cell-free translation assay, as described herein. In some embodiments, the activity is increased by at least 2 fold, at least 5 fold, or at least 10 fold.
Alternatively or additionally, the carrier peptide may be effective to facilitate transport of the nucleic acid analog into the cell relative to the unconjugated form of the analog. In certain embodiments, transport is increased at least 2-fold, at least 5-fold, or at least 10-fold.
In other embodiments, the carrier peptide is effective to reduce the toxicity (i.e., increase the maximum tolerated dose) of the conjugate relative to a conjugate comprising the carrier peptide lacking a terminal glycine or proline subunit. In certain embodiments, toxicity is reduced by at least 2 fold, at least 5 fold, or at least 10 fold.
An additional advantage of the peptide trafficking moiety is its ability to be expected to stabilize the double strand between the antisense oligomer and its target nucleic acid sequence. While not wishing to be bound by theory, this ability to stabilize the duplex may result from electrostatic interactions between the positively charged transport moiety and the negatively charged nucleic acid.
The length of the carrier peptide is not particularly limited and varies in different embodiments. In some embodiments, the carrier peptide comprises 4 to 40 amino acid subunits. In other embodiments, the carrier peptide comprises 6 to 30, 6 to 20, 8 to 25, or 10 to 20 amino acid subunits. In some embodiments, the carrier peptide is linear, while in other embodiments it is branched.
In some embodiments, the carrier peptide is enriched in a positively charged amino acid subunit, such as an arginine subunit. A carrier peptide is "rich" in positively charged amino acids if at least 10% of the amino acid subunits are positively charged. For example, in some embodiments, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, or at least 90% of the amino acid subunits are positively charged. In even other embodiments, all amino acid subunits other than the glycine or proline subunits are positively charged. In other embodiments, all of the positively charged amino acid subunits are arginines.
In other embodiments, the number of positively charged amino acid subunits in the carrier peptide is from 1 to 20, such as from 1 to 10 or from 1 to 6. In certain embodiments, the number of positively charged amino acids in the carrier peptide is 1,2,3, 4,5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20.
The positively charged amino acid can be a naturally occurring, non-naturally occurring, synthetic, modified, or analog of a naturally occurring amino acid. For example, modified amino acids with a net positive charge can be specifically designed for use in the present invention, as described in more detail below. Many different types of modifications to amino acids are well known in the art. In certain embodiments, the positively charged amino acid is histidine (H), lysine (K), or arginine (R). In other embodiments, the carrier peptide comprises only natural amino acid subunits (i.e., does not comprise unnatural amino acids). In other embodiments, the terminal amino acid may be capped, e.g., with an acetyl, benzoyl, or stearoyl moiety, e.g., at the N-terminus.
H. Any number, combination, and/or sequence of K and/or R can be present in the carrier peptide. In some embodiments, all amino acid subunits except the carboxy terminal glycine or proline are positively charged amino acids. In other embodiments, at least 1 of the positively charged amino acids is arginine. For example, in some embodiments, all positively charged amino acids are arginine, and in even other embodiments, the carrier peptide consists of arginine and a carboxy-terminal glycine or proline. In still other embodiments, the carrier peptide comprises no more than 7 consecutive arginines, e.g., no more than 6 consecutive arginines.
Other types of positively charged amino acids are also contemplated. For example, in certain embodiments, at least 1 of the positively charged amino acids is an arginine analog. For example, the arginine analog may be a peptide comprising RaN=C(NH2)RbCationic alpha-amino acids of side chain structure, wherein RaIs H or Rc;RbIs Rc、NH2NHR or N (R)c)2Wherein R iscIs lower alkyl or lower alkenyl, and optionally contains oxygen or nitrogen, or RaAnd RbMay together form a ring; and wherein the side chain is through RaOr RbLinked to an amino acid. The carrier peptide may comprise any number of these arginine analogs.
The positively charged amino acids may occur in any sequence within the carrier peptide. For example, in some embodiments, the positively charged amino acids can be alternating or consecutive. For example, the carrier peptide may comprise the sequence (R)d)mWherein R isdIndependently at each occurrence, is a positively charged amino acid, and m is an integer from 2 to 12, 2 to 10, 2 to 8, or 2 to 6. For example, in certain embodiments, RdIs arginine and the carrier peptide comprises a sequence selected from: (R)4、(R)5、(R)6、(R)7And (R)8Or is selected from: (R)4、(R)5、(R)6And (R)7For example, in certain embodiments, the carrier peptide comprises the sequence (R)6E.g. (R)6G or (R)6P。
In other embodiments, the carrier peptide consists of the sequence (R)d)mAnd carboxy terminal glycine or proline, wherein RdIndependently at each occurrence, is a positively charged amino acid, and m is an integer from 2 to 12, 2 to 10, 2 to 8, or 2 to 6. In certain embodiments, RdAt each occurrence is independently arginine, histidine or lysine. For example, in certain embodiments, RdIs arginine and the carrier peptide consists of a sequence selected from: (R)4、(R)5、(R)6、(R)7And (R)8And carboxy terminal glycine or proline. For example, in a particular embodiment, the carrier peptide consists of the sequence (R)6G or (R)6P is formed.
In some other embodiments, the carrier peptide may comprise one or more hydrophobic amino acid subunits comprising a substituted or unsubstituted alkyl, alkenyl, alkynyl, aryl, or aralkyl side chain, wherein the alkyl, alkenyl, and alkynyl side chains contain up to 1 heteroatom per 6 carbon atoms. In some embodiments, the hydrophobic amino acid is phenylalanine (F). For example, the carrier peptide may comprise two or more consecutive hydrophobic amino acids such as phenylalanine (F), for example 2 consecutive phenylalanine moieties. The hydrophobic amino acids may be located at any point in the carrier peptide sequence.
In other embodiments, the carrier peptide comprises the sequence [ (R)dYbRd)x(RdRdYb)y]zOr [ (R)dRdYb)y(RdYbRd)x]zWherein R isdIndependently at each occurrence a positively charged amino acid, x and Y independently at each occurrence 0 or 1, provided that x + Y is 1 or 2, z is 1,2,3, 4,5 or 6, and Y isbComprises the following steps:
-C(O)-(CHRe)n-NH-
(Yb)
wherein n is 2 to 7, and each ReIndependently at each occurrence is hydrogen or methyl. In some of these embodiments, RdAt each occurrence is independently arginine, histidine or lysine. In other embodiments, each R isdAre all arginine. In other embodiments, n is 5, and YbIs an aminocaproic acid moiety. In other embodiments, n is 2, and YbIs a beta-alanine moiety. In other embodiments, ReIs hydrogen.
In certain of the foregoing embodiments, x is 1, y is 0, and the carrier peptide comprises the sequence (R)dYbRd)z. In other embodiments, n is 5, and YbIs an aminocaproic acid moiety. In other embodiments, n is 2, and YbIs a beta-alanine moiety. In still other embodiments, ReIs hydrogen.
Further in other embodiments of the foregoing, x is 0, y is 1, and the carrier peptide comprises the sequence (R)dRdYb)z. In other embodiments, n is 5, and YbIs an aminocaproic acid moiety. In other embodiments, n is 2, and YbIs a beta-alanine moiety. In still other embodiments, ReIs hydrogen.
In other embodiments, the carrier peptide comprises the sequence (R)dYb)pWherein R isdAnd YbAs defined above, and p is an integer from 2 to 8. In other embodiments, each R isdAre all arginine. In other embodiments, n is 5, and YbIs an aminocaproic acid moiety. In other embodiments, n is 2, and YbIs a beta-alanine moiety. In still other embodiments, ReIs hydrogen.
In other embodiments, the carrier peptide comprises the sequence ILFQY. The peptide may comprise the ILFQY sequence in addition to any other sequence disclosed herein. For example, the carrier peptide may comprise ILFQY and [ (R)dYbRd)x(RdRdYb)y]z、[(RdRdYb)y(RdYbRd)x]z、(RdYb)pOr combinations thereof, wherein RdX, Y and YbAs defined above. The [ (R)dYbRd)x(RdRdYb)y]z、[(RdRdYb)y(RdYbRd)x]zOr (R)dYb)pThe sequence may be amino-terminal, carboxy-terminal, or both to the ILFQY sequence. In certain embodiments, x is 1, y is 0, and the carrier peptide comprises (R) linked to the ILFQY sequence by an optional Z linker armdYbRd)z。
In other related embodiments, the vectorThe peptide comprises the sequence ILFQ, IWFQ or ILIQ. Other embodiments include carrier peptides comprising the sequence PPMWS, PPMWT, PPMFS, or PPMYS. In addition to any other sequence described herein, e.g., in addition to the sequence [ (R)dYbRd)x(RdRdYb)y]z、[(RdRdYb)y(RdYbRd)x]zOr (R)dYb)pThe carrier peptide may also comprise these sequences, wherein RdX, Y and YbAs defined above.
Some embodiments of the carrier peptide include modifications to naturally occurring amino acid subunits, e.g., amino terminal or carboxy terminal amino acid subunits may be modified. Such modifications include capping of free amino groups or free carboxyl groups with hydrophobic groups. For example, the amino terminus can be capped with an acetyl, benzoyl or stearyl moiety. For example, any of the peptide sequences in table 1 may have such modifications, even if not explicitly described in the table. In these embodiments, the amino terminus of the carrier peptide may be as described below:

in still other embodiments, the carrier comprises at least 1 of alanine, aspartic acid, cysteine, glutamine, glycine, histidine, lysine, methionine, serine, or threonine.
In some embodiments disclosed herein, the carrier peptide consists of the annotated sequence and a carboxy-terminal glycine or proline subunit.
In some embodiments, the carrier peptide does not consist of (amino-terminal to carboxy-terminal) the following sequence: r6G、R7G、R8G、R5GR4G、R5F2R4G、Tat-G、rTat-G、(RXR2G2)2Or (RXR)3X)2G. In other embodiments, the carrier peptide isFrom R8G、R9G or R9F2G is used for preparing the composition. In still other embodiments, the carrier peptide does not consist of the sequence: Tat-G, rTat-G, R9F2G、R5F2R4、R4G、R5G、R6G、R7G、R8G、R9G、(RXR)4G、(RXR)5G、(RXRRBR)2G、(RAR)4F2Or (RGR)4F2. In other embodiments, the carrier peptide is not a "transmembrane peptide Penetratin" or "R6Pen' composition.
In another aspect, the present disclosure provides a peptide-nucleic acid analog conjugate comprising:
nucleic acid analogs having substantially uncharged backbone and targeting base sequences, and
a peptide covalently linked to a nucleic acid analog comprising a carboxy-terminal glycine or proline subunit and consisting of 8 to 16 additional other subunits selected from the group consisting of: rdSubunits, Y subunits, and optionally Z subunits, comprising at least 8RdA subunit, at least 2Y subunits and at most 3Z subunits, wherein>50% of the subunits are RdA subunit, and wherein:
(a) each RdThe subunits all independently represent arginine or an arginine analogue comprising RaN=C(NH2)RbCationic alpha-amino acids of side chain structure, wherein RaIs H or Rc;RbIs Rc、NH2NHR or N (R)c)2Wherein R iscIs lower alkyl or lower alkenyl, and optionally contains oxygen or nitrogen, or RaAnd RbMay together form a ring; and wherein the side chain is through RaOr Rb(ii) attachment to an amino acid;
(b) at least 2Y subunits being YaOr YbWherein:
(i) each YaAre each independently a neutral α -amino acid subunit having a side chain independently selected from the group consisting of: substituted or unsubstitutedAlkyl, alkenyl, alkynyl, aryl and aralkyl, wherein the side chain, when selected from substituted alkyl, alkenyl and alkynyl groups, contains up to 1 heteroatom per 2, preferably per 4, and more preferably per 6 carbon atoms, and wherein the subunits are continuous or flanking the linker arm portion, and
(ii)Ybcomprises the following steps:
-C(O)-(CHRe)n-NH-
(Yb)
wherein n is 2 to 7, and each ReIndependently at each occurrence is hydrogen or methyl; and is
(c) Z represents an amino acid subunit selected from: alanine, aspartic acid, cysteine, glutamine, glycine, histidine, lysine, methionine, serine, threonine, and amino acids having side chains that are 1-carbon or 2-carbon homologs of naturally occurring side chains, excluding side chains that are negatively charged at physiological pH (e.g., carboxylate side chains). In some embodiments, the side chain is neutral. In other embodiments, the Z side chain is a side chain of a naturally occurring amino acid. In some embodiments the optional Z subunit is selected from: alanine, glycine, methionine, serine and threonine. The carrier peptide may comprise 0, 1,2, or 3Z subunits, and in some embodiments comprises up to 2Z subunits.
In selected embodiments, the carrier peptide is of type YaIs continuous or flanked by cysteine subunits. In some embodiments, 2YaThe subunits are contiguous. In other embodiments, YaThe side chains of the subunits include those of naturally occurring amino acids and 1-or 2-carbon homologs thereof, excluding those charged at physiological pH. Other possible side chains are those of naturally occurring amino acids. In further embodiments, the side chain is an aryl or aralkyl side chain; for example, each YaMay be independently selected from: phenylalanine, tyrosine, tryptophan, leucine, isoleucine and valine.
In selected embodiments, each YaAre all independently selected from phenylalanine and tyrosine(ii) a In other embodiments, each Y isaAre all phenylalanine. This includes, for example, conjugates consisting of an arginine subunit, a phenylalanine subunit, a glycine or proline subunit, an optional linker moiety, and a nucleic acid analog. One such conjugate includes a conjugate having the formula Arg9Phe2aa, wherein aa is glycine or proline.
The aforementioned carrier peptide may further comprise ILFQY, ILFQ, IWFQ, or ILIQ. Other embodiments include the aforementioned carrier peptides comprising the sequence PPMWS, PPMWT, PPMFS, or PPMYS.
The peptide-oligomer conjugates of the invention are more effective than unconjugated oligomers in different functions, including: inhibiting the expression of a target mRNA in a protein expression system, including a cell-free translation system; inhibiting splicing of target pre-mRNA; and inhibiting viral replication by targeting cis-acting elements that control viral nucleic acid replication or mRNA transcription.
Conjugates of other pharmacological agents (i.e., not nucleic acid analogs) and carrier peptides are also included within the scope of the invention. In particular, some embodiments provide conjugates comprising:
(a) a carrier peptide comprising amino acid subunits; and
(b) a pharmacological agent;
wherein:
the two or more amino acid subunits are positively charged amino acids, the carrier peptide comprises a glycine (G) or proline (P) subunit at the carboxy terminus of the carrier peptide, and the carrier peptide is covalently linked to a pharmacological agent. The carrier peptide in these embodiments can be any carrier peptide described herein. Methods of delivering pharmacological agents by conjugating them to carrier peptides are also provided.
The pharmacological agent to be delivered may be a bioactive agent, such as a therapeutic or diagnostic agent, although it may be a compound for detection, such as a fluorescent compound. The bioactive agent comprises a drug selected from the group consisting of: biomolecules, such as peptides, proteins, carbohydrates or nucleic acids, especially antisense oligonucleotides, or "small molecule" organic or inorganic compounds. "Small molecule" compounds may be more broadly defined as organic, inorganic or organometallic compounds that are not biomolecules as described above. Typically, such compounds have a molecular weight of less than 1000, or, in one embodiment, less than 500.
In one embodiment, the pharmacological agent to be delivered does not include a single amino acid, dipeptide, or tripeptide. In another embodiment, it does not include short oligopeptides; i.e., oligopeptides having fewer than 6 amino acid subunits. In other embodiments, it does not include longer oligopeptides; i.e., oligopeptides having 7 to 20 amino acid subunits. In still other embodiments, it does not include oligopeptides or proteins having greater than 20 amino acid subunits.
The carrier peptide may be effective to facilitate transport of the pharmacological agent into a cell relative to the unconjugated form and/or the pharmacological agent having less toxicity, relative to the pharmacological agent conjugated to a corresponding peptide lacking a glycine or proline subunit. In some embodiments, transport is provided at least 2 fold, at least 5 fold, or at least 10 fold. In other embodiments, toxicity is reduced (i.e., maximum tolerated dose is reduced) by at least 2-fold, at least 5-fold, or at least 10-fold.
B.Peptide linker arm
The carrier peptide can be linked to the agent (e.g., nucleic acid analog, pharmacological agent, etc.) to be delivered by one of skill in the art using a variety of methods. In some embodiments, the carrier peptide is directly linked to the nucleic acid analog without the use of an intermediate linking arm. In this regard, the formation of an amide bond between the terminal amino acid on the nucleic acid analog and the free amine of the free carboxyl group may be useful for forming the conjugate. In certain embodiments, the carboxy-terminal glycine or proline subunit is directly linked to the 3 'end of the nucleic acid analog, e.g., the carrier peptide can be linked by forming an amide bond between the carboxy-terminal glycine or proline moiety and the 3' morpholino ring nitrogen (see, e.g., fig. 1C).
In some embodiments, the nucleic acid analog is conjugated to the carrier peptide via a linker moiety selected from the group consisting of: y isaOr YbSubunits, cysteine subunits, and uncharged non-amino acid linker moieties. In other embodiments, the nucleic acid analog is directly linked to the carrier peptide via a glycine or proline moiety located at the 5 'or 3' terminus of the nucleic acid analog. In some embodiments, the carrier peptide is directly linked to the 3 'end of the nucleic acid analog through a glycine or proline subunit, for example, directly to the 3' morpholino nitrogen through an amide bond.
In other embodiments, the conjugate comprises a linking moiety between terminal glycine or proline subunits. In some of these embodiments, the linker arm is up to 18 atoms in length, comprising a linkage (bonds) selected from the group consisting of: alkyl, hydroxy, alkoxy, alkylamino, amide, ester, carbonyl, carbamate, phosphodiamide, phosphoamide, thiophosphonic acid, and phosphodiester. In certain embodiments, the linker arm comprises a phosphodiamide and a piperazine. For example, in some embodiments, the linker arm has the following structure (XXIX):

wherein R is24Is absent, H or C1-C6An alkyl group. In certain embodiments, R24Absent, and in other embodiments, structure (XXIX) links the 5' end of a nucleic acid analog (e.g., morpholino oligomer) to a carrier peptide (see, e.g., fig. 1B).
In some embodiments, RdThe side chain moieties of the subunits are independently selected from: guanidino (HN ═ C (NH)2) NH-), amidino group (HN ═ C (NH)2)C<) 2-aminodihydropyrimidyl, 2-aminotetrahydropyrimidinyl, 2-aminopyridinyl and 2-aminopyrimidinyl.
If desired, multiple carrier peptides can be linked to a single compound; alternatively, multiple compounds may be combined onto a single transporter. The linker arm between the carrier peptide and the nucleic acid analog may also be composed of natural or unnatural amino acids (e.g., 6-aminocaproic acid or β -alanine). The linker arm may also comprise a direct bond between the carboxy terminus of the transport peptide and the amino or hydroxyl group of the nucleic acid analog (e.g., at the 3 'morpholino nitrogen or 5' OH) formed by condensation facilitated by, for example, carbodiimide.
In general, the linker arm may include any non-reactive moiety that does not interfere with the transport or function of the conjugate. The linker may be selected from linkers that are not cleavable under the normal conditions of use, e.g., containing ether, thioether, amide or urethane linkages. In other embodiments, it may be desirable to include a linkage between an in vivo cleavable carrier peptide and a compound (e.g., an oligonucleotide analog, a pharmacological agent, etc.). Linkages that are cleavable in vivo are known in the art and include, for example, carboxylates (which are enzymatically hydrolyzed) and disulfides (which are cleaved in the presence of glutathione). Photolytically cleavable linkages, such as o-nitrophenyl ether, may also be cleaved in vivo by the application of radiation of an appropriate wavelength. Exemplary heterobifunctional linkers further containing a cleavable disulfide group include N-hydroxysuccinimide 3- [ (4-azidophenyl) dithio ] propionate and other materials described in Vanin, E.F. and Ji, T.H., Biochemistry 20:6754-6760 (1981).
C.Exemplary Carrier peptides
A table of exemplary vector peptide sequences and oligonucleotide sequences is provided in table 1 below. In some embodiments, the present disclosure provides a peptide oligomer conjugate, wherein the peptide comprises or consists of any one of the peptide sequences in table 1. In another embodiment, the nucleic acid analog comprises or consists of any of the oligonucleotide sequences in table 1. In still other embodiments, the present disclosure provides peptide oligomer conjugates, wherein the peptide comprises or consists of any one of the peptide sequences in table 1 and the nucleic acid analog comprises or consists of any of the oligonucleotide sequences in table 1. In other embodiments, the disclosure provides peptides comprising or consisting of any one of the sequences in table 1.
TABLE 1 exemplary vector peptide and oligonucleotide sequences
















aa ═ glycine or proline; b ═ β -alanine; x ═ 6-aminocaproic acid; tg ═ unmodified amino terminus, or amino terminus capped with acetyl, benzoyl or stearoyl (i.e., acetylamide, benzoylamide or stearoylamide), and YbComprises the following steps:
-C(O)-(CHRe)n-NH-
wherein n is 2 to 7 and each ReIndependently at each occurrence is hydrogen or methyl. For simplicity, not all sequences are annotated with a terminal tg group; however, each of the above sequences may comprise an unmodified amino terminus or an amino terminus capped with an acetyl, benzoyl or stearoyl group.
III.Antisense oligomer
The nucleic acid analogs included in the conjugates of the invention are substantially uncharged synthetic oligomers capable of base-specific binding to a polynucleotide target sequence, e.g., antisense oligonucleotide analogs. Such analogs include, for example, methylphosphonate, peptide nucleic acids, substantially uncharged N3'→ P5' phosphoramidate, and morpholino oligomers.
The nucleic acid analog base sequence provided by the base pairing groups supported by the analog backbone can be any sequence in which the supported base pairing groups include standard or modified A, T, C, G and U bases, or non-standard creatinine (I) and 7-deaza-G bases.
In some embodiments, the nucleic acid analog is a morpholino oligomer, i.e., an oligonucleotide analog consisting of a morpholino subunit structure of the form shown in figure 1, wherein: (i) the structures are linked together by phosphorus-containing linkages (1 to 3 atoms in length, preferably 2 atoms in length) binding morpholino nitrogens of 1 subunit to 5' exocyclic carbons of adjacent subunits, and (ii) Pi and Pj are purine or pyrimidine base-pairing moieties that can be effectively bound to bases in a polynucleotide by base-specific hydrogen bonding. The purine or pyrimidine base-pairing moiety is typically adenine, cytosine, guanine, uracil or thymine. The synthesis, structural and binding characteristics of morpholino oligomers are further described below and are described in detail in U.S. patents No. 5698685, No. 5217866, No. 5142047, No. 5034506, No. 5166315, No. 5521063 and No. 5506337, all of which are incorporated herein by reference in their entirety.
Desirable chemical properties of morpholino-based oligomers include having a high TmComplementary base target nucleic acids of (a) include the ability of selective hybridization of target RNA, even oligomers as short as 8-14 bases, the ability to actively transport into mammalian cells, and oligomers: the ability of RNA hybrid duplexes to resist rnase degradation.
In a preferred embodiment, the morpholino oligomer is about 8-40 subunits in length. More typically, the oligomer is about 8-20, about 8-16, about 10-30, or about 12-25 subunits in length. For some applications, such as antibacterial agents, short oligomers, e.g. of about 8-12 subunits in length, may be particularly advantageous, especially when attached to a peptide transporter as disclosed herein.
A.Oligomers with modified intersubunit linkages
One embodiment of the present disclosure relates to peptide-oligomer conjugates comprising a nucleic acid analog comprising a modified intersubunit linkage (e.g., a morpholino oligomer). In some embodiments, the conjugates have a higher affinity for DNA and RNA than the affinity of the corresponding unmodified oligomers, and exhibit improved cell delivery, potency, and/or tissue distribution properties compared to oligomers with other intersubunit linkages. In one embodiment, the conjugate comprises one or more intersubunit linkages of type (a) as defined below. In other embodiments, the conjugate comprises at least 1 type (B) intersubunit linkage as defined below. In still other embodiments, the conjugate comprises an intersubunit linkage of type (a) and type (B). In still other embodiments, the conjugate comprises a morpholino oligomer as described in more detail below. The structural features and properties of the different linkage types and oligomers are described in more detail in the discussion below.
1.Connection (A)
Applicants have discovered that by preparing oligomers with different intersubunit linkages, improvements in antisense activity, biodistribution, and/or other desired properties can be optimized. For example, the oligomer may optionally comprise one or more type (a) intersubunit linkages, and in certain embodiments, the oligomer comprises at least 1 type (a) linkage, e.g., each linkage may be of type (a). In some other embodiments, each type (a) linkage has the same structure. (A) Type connections may include those disclosed in commonly owned U.S. patent No. 7943762, which is hereby incorporated by reference in its entirety. Linkage (a) has the following structure (I) or a salt or isomer of that structure, wherein 3 'and 5' indicate the points of attachment of the morpholino ring (i.e., structure (I) discussed below) to the 3 'and 5' ends, respectively:

wherein:
w is independently at each occurrence S or O;
x is independently at each occurrence-N (CH)3)2、-NR1R2、-OR3Or

Y is independently at each occurrence O or-NR2,
R1Independently at each occurrence is hydrogen or methyl;
R2each occurrence is independently hydrogen or-LNR4R5R7;
R3Each occurrence is independently hydrogen or C1-C6An alkyl group;
R4independently at each occurrence, is hydrogen, methyl, -C (═ NH) NH2、-Z-L-NHC(=NH)NH2Or- [ C (═ O) CHR' NH]mH, wherein Z is-C (═ O) -or a direct bond, R' is the side chain of a naturally occurring amino acid or a 1-or 2-carbon homolog thereof, and m is 1 to 6;
R5independently at each occurrence is hydrogen, methyl, or an electron pair;
R6independently at each occurrence is hydrogen or methyl;
R7independently at each occurrence hydrogen, C1-C6Alkyl or C1-C6An alkoxyalkyl group; and is
L is an optional linker arm up to 18 atoms in length comprising an alkyl, alkoxy, or alkylamino group, or a combination thereof.
In some examples, the oligomer comprises at least 1 linkage of type (a). In some other embodiments, the oligomer comprises at least 2 consecutive linkages of form (a). In other embodiments, at least 5% of the linkages in the oligomer are in (a) form; for example, in some embodiments, 5% to 95%, 10% to 90%, 10% to 50%, or 10% to 35% of the linkages may be of linkage (a) type. In some particular embodiments, at least 1 linkage of type (A) is-N (CH)3)2. In other embodiments, each linkage of type (A) is-N (CH)3)2And even inIn other embodiments, each linkage in the oligomer is-N (CH)3)2. In other embodiments, at least 1 linkage of type (a) is piperazin-1-yl, such as unsubstituted piperazin-1-yl (e.g., a2 or A3). In other embodiments, each linkage of type (a) is piperazin-1-yl, e.g., unsubstituted piperazin-1-yl.
In some embodiments, W is independently at each occurrence S or O, and in certain embodiments, W is O.
In some embodiments, X is independently at each occurrence-N (CH)3)2、-NR1R2、-OR3. In some embodiments, X is-N (CH)3)2. In other aspects, X is-NR1R2And in other examples, X is-OR3。
In some embodiments, R1Independently at each occurrence is hydrogen or methyl. In some embodiments, R1Is hydrogen. In other embodiments, X is methyl.
In some embodiments, R2At each occurrence is hydrogen. In other embodiments, R2At each occurrence is-LNR4R5R7. In some embodiments, R3Each occurrence is independently hydrogen or C1-C6An alkyl group. In other embodiments, R3Is methyl. In other embodiments, R3Is ethyl. In some other embodiments, R3Is n-propyl or isopropyl. In some other embodiments, R3Is C4An alkyl group. In other embodiments, R3Is C5An alkyl group. In some embodiments, R3Is C6An alkyl group.
In certain embodiments, R4At each occurrence is independently hydrogen. In other embodiments, R4Is methyl. In still other embodiments, R4is-C (═ NH) NH2And in other embodiments, R4is-Z-L-NHC (═ NH) NH2. In still other embodiments, R4Is- [ C (═ O) CHR' NH]mH. In one embodiment, Z is-C (═ O) -, and in another embodiment, Z is a direct bond. R' is the side chain of a naturally occurring amino acid. In some embodiments, R' is a 1-carbon or 2-carbon homolog of the side chain of a naturally occurring amino acid.
m is an integer of 1 to 6. m may be 1. m may be 2. m may be 3. m may be 4. m may be 5. m may be 6.
In some embodiments, R5Independently at each occurrence is hydrogen, methyl, or an electron pair. In some embodiments, R5Is hydrogen. In other embodiments, R5Is methyl. In other embodiments, R5Is an electron pair.
In some embodiments, R6Independently at each occurrence is hydrogen or methyl. In some embodiments, R6Is hydrogen. In other embodiments, R6Is methyl.
In other embodiments, R7Independently at each occurrence hydrogen, C1-C6Alkyl or C2-C6An alkoxyalkyl group. In some embodiments, R7Is hydrogen. In other embodiments, R7Is C1-C6An alkyl group. In still other embodiments, R7Is C2-C6An alkoxyalkyl group. In some embodiments, R7Is methyl. In other embodiments, R7Is ethyl. In still other embodiments, R7Is n-propyl or isopropyl. In some other embodiments, R7Is C4An alkyl group. In some embodiments, R7Is C5An alkyl group. In some embodiments, R7Is C6An alkyl group. In still other embodiments, R7Is C2An alkoxyalkyl group. In some other embodiments, R7Is C3An alkoxyalkyl group. In still other embodiments, R7Is C4An alkoxyalkyl group. In some embodiments, R7Is C5An alkoxyalkyl group. In other embodiments, R7Is C6An alkoxyalkyl group.
As mentioned above, the linker arm group L contains in its backbone a linkage selected from: alkyl (e.g. -CH)2-CH2-), alkoxy (e.g., -C-O-C-), and alkylamino (e.g., -CH)2-NH-), provided that the terminal atom of L (e.g., the atom adjacent to the carbonyl group or nitrogen) is a carbon atom. Although branched linkages (e.g. -CH) are possible2-CHCH3-, but the linker arm is typically unbranched. In one embodiment, the linker arm is a hydrocarbon linker arm. Such linker arms may have the structure (CH)2)n-, where n is 1 to 12, preferably 2 to 8, and more preferably 2 to 6.
Oligomers having any number of type (a) linkages are provided. In some embodiments, the oligomer is free of type (a) linkages. In certain embodiments, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, or 90% of the linkages are linkages (a). In selected embodiments, 10% to 80%, 20% to 60%, 20% to 50%, 20% to 40%, or 20% to 35% of the linkages are linkages (a). In other embodiments, each linkage is of type (a).
2.Connection (B)
In some embodiments, the oligomer comprises at least 1 linkage of type (B). For example, the oligomer may comprise 1,2,3, 4,5, 6, or more linkages of type (B). (B) The type linkages may be contiguous or may be interspersed throughout the oligomer. (B) Type I linkages have the following structure (I):

or a salt or isomer of the structure, wherein:
w is independently at each occurrence S or O;
x is independently at each occurrence-NR8R9OR-OR3(ii) a And is
Each occurrence of YIndependently is O or-NR10,
R3Each occurrence is independently hydrogen or C1-C6An alkyl group;
R8each occurrence is independently hydrogen or C2-C12An alkyl group;
R9independently at each occurrence hydrogen, C1-C12Alkyl radical, C1-C12Aralkyl or aryl;
R10independently at each occurrence hydrogen, C1-C12Alkyl or-LNR4R5R7;
Wherein R is8And R9May combine to form a 5-to 18-membered monocyclic or bicyclic heterocycle, or R8、R9Or R3Can be reacted with R10Combine to form a 5-7 membered heterocyclic ring, and wherein when X is 4-piperazinyl, X has the following structure (III):

wherein:
R11independently at each occurrence is C2-C12Alkyl radical, C1-C12Aminoalkyl radical, C1-C12Alkylcarbonyl, aryl, heteroaryl or heterocyclyl;
r is independently at each occurrence an electron pair, hydrogen or C1-C12An alkyl group; and is
R12Independently at each occurrence hydrogen, C1-C12Alkyl radical, C1-C12Aminoalkyl radical, -NH2、-CONH2、-NR13R14、-NR13R14R15、C1-C12Alkylcarbonyl, oxo (oxo), -CN, trifluoromethyl, amido, amidino, amidinoalkyl, amidinoalkylcarbonylguanidino, guanidinoalkyl, guanidinoalkylcarbonyl, cholate, deoxycholate, aryl, heteroaryl, heterocycle, -SR13Or C1-C12Alkoxy radical, wherein R13、R14And R15Independently at each occurrence is C1-C12An alkyl group.
In some examples, the oligomer comprises 1 linkage of type (B). In some other embodiments, the oligomer comprises 2 linkages of type (B). In some other embodiments, the oligomer comprises 3 linkages of type (B). In some other embodiments, the oligomer comprises 4 linkages of type (B). In still other embodiments, the type (B) linkages are contiguous (i.e., the type (B) linkages are adjacent to each other). In other embodiments, at least 5% of the linkages in the oligomer are of type (B); for example, in some embodiments, 5% to 95%, 10% to 90%, 10% to 50%, or 10% to 35% of the linkages can be (B) -type linkages.
In other embodiments, R3Each occurrence is independently hydrogen or C1-C6An alkyl group. In other embodiments, R3May be a methyl group. In some embodiments, R3May be an ethyl group. In some other embodiments, R3It may be n-propyl or isopropyl. In other embodiments, R3Can be C4An alkyl group. In some embodiments, R3Can be C5An alkyl group. In some embodiments, R3Can be C6An alkyl group.
In some embodiments, R8Each occurrence is independently hydrogen or C2-C12An alkyl group. In some embodiments, R8Is hydrogen. In other embodiments, R8Is ethyl. In some other embodiments, R8Is n-propyl or isopropyl. In some embodiments, R8Is C4An alkyl group. In other embodiments, R8Is C5An alkyl group. In other embodiments, R8Is C6An alkyl group. In some embodiments, R8Is C7An alkyl group. In other embodiments, R8Is C8An alkyl group. In other embodiments, R8Is C9An alkyl group. In other embodimentsIn the scheme, R8Is C10An alkyl group. In some other embodiments, R8Is C11An alkyl group. In other embodiments, R8Is C12An alkyl group. In some other embodiments, R8Is C2-C12Alkyl radical, and said C2-C12Alkyl groups contain one or more double bonds (e.g., alkenes), triple bonds (e.g., alkynes), or both. In some embodiments, R8Is unsubstituted C2-C12An alkyl group.
In some embodiments, R9Independently at each occurrence hydrogen, C1-C12Alkyl radical, C1-C12Aralkyl or aryl. In some embodiments, R9Is hydrogen. In other embodiments, R9Is C1-C12An alkyl group. In other embodiments, R9Is methyl. In other embodiments, R9Is ethyl. In some other embodiments, R9Is n-propyl or isopropyl. In some embodiments, R9Is C4An alkyl group. In some embodiments, R9Is C5An alkyl group. In other embodiments, R9Is C6An alkyl group. In some other embodiments, R9Is C7An alkyl group. In some embodiments, R9Is C8An alkyl group. In some embodiments, R9Is C9An alkyl group. In some other embodiments, R9Is C10An alkyl group. In some other embodiments, R9Is C11An alkyl group. In other embodiments, R9Is C12An alkyl group.
In some other embodiments, R9Is C1-C12An aralkyl group. For example, in some embodiments, R9Is benzyl, and the benzyl may be optionally substituted on the phenyl ring or the benzyl carbon. In this connection, substituents include alkyl and alkoxy groups, for example methyl or methoxy. In some embodiments, the benzyl group is substituted with a methyl group at the benzyl carbon. For example, in some embodimentsIn the scheme, R9Having the following structure (XIV):

in other embodiments, R9Is an aryl group. For example, in some embodiments, R9Is phenyl, and the phenyl may be optionally substituted. In this connection, substituents include alkyl and alkoxy groups, for example methyl or methoxy. In other embodiments, R9Is phenyl, and the phenyl group contains a crown ether moiety, such as a 12-18 membered crown ether. In one embodiment, the crown ether is 18-membered and may further comprise additional phenyl moieties. For example, in one embodiment, R9Having one of the following structures (XV or XVI):

in some embodiments, R10Independently at each occurrence hydrogen, C1-C12Alkyl or LNR4R5R7Wherein R is4、R5And R7As defined above for connection (a). In other embodiments, R10Is hydrogen. In other embodiments, R10Is C1-C12Alkyl, and in other embodiments, R10is-LNR4R5R7. In some embodiments, R10Is methyl. In other embodiments, R10Is ethyl. In some embodiments, R10Is C3An alkyl group. In some embodiments, R10Is C4An alkyl group. In other embodiments, R10Is C5An alkyl group. In some other embodiments, R10Is C6An alkyl group. In other embodiments, R10Is C7An alkyl group. In other embodiments, R10Is C8An alkyl group. In some embodiments, R10Is C9An alkyl group. In other embodiments, R10Is C10An alkyl group. In other embodiments, R10Is C11An alkyl group. In some other embodiments, R10Is C12An alkyl group.
In some embodiments, R8And R9Combine to form a 5-18 membered monocyclic or bicyclic heterocycle. In some embodiments, the heterocycle is a5 or 6 membered monocyclic heterocycle. For example, in some embodiments, linkage (B) has the following structure (IV):

wherein Z represents a5 or 6 membered monocyclic heterocycle.
In other embodiments, the heterocycle is bicyclic, e.g., a 12-membered bicyclic heterocycle. The heterocycle may be piperazinyl. The heterocycle may be morpholino. The heterocycle may be piperidinyl. The heterocyclic ring may be decahydroisoquinoline. Representative heterocycles include the following:

in some embodiments, R11Independently at each occurrence is C2-C12Alkyl radical, C1-C12Aminoalkyl, aryl, heteroaryl, or heterocyclyl.
In some embodiments, R11Is C2-C12An alkyl group. In some embodiments, R11Is ethyl. In other embodiments, R11Is C3An alkyl group. In other embodiments, R11Is isopropyl. In some other embodiments, R11Is C4An alkyl group. In other embodiments, R11Is C5An alkyl group. In some embodiments, R11Is C6An alkyl group. In other embodiments, R11Is C7An alkyl group. In some embodiments, R11Is C8An alkyl group. In other embodiments, R11Is C9An alkyl group. In other embodiments, R11Is C10An alkyl group. In some other embodiments, R11Is C11An alkyl group. In some embodiments, R11Is C12An alkyl group.
In other embodiments, R11Is C1-C12An aminoalkyl group. In some embodiments, R11Is a methylamino group. In some embodiments, R11Is an ethylamino group. In other embodiments, R11Is C3An aminoalkyl group. In other embodiments, R11Is C4An aminoalkyl group. In some other embodiments, R11Is C5An aminoalkyl group. In other embodiments, R11Is C6An aminoalkyl group. In other embodiments, R11Is C7An aminoalkyl group. In some embodiments, R11Is C8An aminoalkyl group. In other embodiments, R11Is C9An aminoalkyl group. In other embodiments, R11Is C10An aminoalkyl group. In some other embodiments, R11Is C11An aminoalkyl group. In other embodiments, R11Is C12An aminoalkyl group.
In other embodiments, R11Is C1-C12An alkylcarbonyl group. In other embodiments, R11Is C1An alkylcarbonyl group. In other embodiments, R11Is C2An alkylcarbonyl group. In some embodiments, R11Is C3An alkylcarbonyl group. In other embodiments, R11Is C4An alkylcarbonyl group. In some embodiments, R11Is C5An alkylcarbonyl group. In some other embodiments, R11Is C6An alkylcarbonyl group. In other embodiments, R11Is C7An alkylcarbonyl group. In other embodiments, R11Is C8An alkylcarbonyl group. In some embodiments, R11Is C9An alkylcarbonyl group. In other embodimentsIn, R11Is C10An alkylcarbonyl group. In some other embodiments, R11Is C11An alkylcarbonyl group. In some embodiments, R11Is C12An alkylcarbonyl group. In other embodiments, R11is-C (═ O) (CH)2)nCO2H, wherein n is 1 to 6. For example, in some embodiments, n is 1. In other embodiments, n is 2. In other embodiments, n is 3. In some other embodiments, n is 4. In other embodiments, n is 5. In other embodiments, n is 6.
In other embodiments, R11Is an aryl group. For example, in some embodiments, R11Is phenyl. In some embodiments, phenyl is substituted, for example with nitro.
In other embodiments, R11Is heteroaryl. For example, in some embodiments, R11Is a pyridyl group. In other embodiments, R11Is a pyrimidinyl group.
In other embodiments, R11Is a heterocyclic group. For example, in some embodiments, R11Is piperidinyl, for example piperidin-4-yl.
In some embodiments, R11Is ethyl, isopropyl, piperidinyl, pyrimidinyl, cholate, deoxycholate or-C (═ O) (CH)2)nCO2H, wherein n is 1 to 6.
In some embodiments, R is an electron pair. In other embodiments, R is hydrogen, and in other embodiments, R is C1-C12An alkyl group. In some embodiments, R is methyl. In some embodiments, R is ethyl. In other embodiments, R is C3An alkyl group. In other embodiments, R is isopropyl. In some other embodiments, R is C4An alkyl group. In other embodiments, R is C5An alkyl group. In some embodiments, R is C6An alkyl group. In other embodiments, R is C7An alkyl group. In other embodiments, R is C8An alkyl group. In other embodiments, R isC9An alkyl group. In some embodiments, R is C10An alkyl group. In other embodiments, R is C11An alkyl group. In some embodiments, R is C12An alkyl group.
In some embodiments, R12Independently at each occurrence hydrogen, C1-C12Alkyl radical, C1-C12Aminoalkyl radical, -NH2、-CONH2、-NR13R14、-NR13R14R15Oxo (oxo), -CN, trifluoromethyl, amido, amidino, amidinoalkyl, amidinoalkylcarbonylguanidino, guanidinoalkyl, guanidinoalkylcarbonyl, cholate, deoxycholate, aryl, heteroaryl, heterocycle, -SR13Or C1-C12Alkoxy radical, wherein R13、R14And R15Independently at each occurrence is C1-C12An alkyl group.
In some embodiments, R12Is hydrogen. In some embodiments, R12Is C1-C12An alkyl group. In some embodiments, R12Is C1-C12An aminoalkyl group. In some embodiments, R12is-NH2. In some embodiments, R12is-CONH2. In some embodiments, R12is-NR13R14. In some embodiments, R12is-NR13R14R15. In some embodiments, R12Is C1-C12An alkylcarbonyl group. In some embodiments, R12Is oxo. In some embodiments, R12is-CN. In some embodiments, R12Is trifluoromethyl. In some embodiments, R12Is an amide group. In some embodiments, R12Is an amidino group. In some embodiments, R12Is an amidinoalkyl group. In some embodiments, R12Is amidinoalkylcarbonyl. In some embodiments, R12Is guanidino, for example monomethylguanidino or dimethylguanidino. In some embodiments, R12Is guanidinoalkyl. In some embodiments, R12Is amidinoalkylcarbonyl. In some embodiments, R12Is cholate. In some embodiments, R12Is deoxycholate. In some embodiments, R12Is an aryl group. In some embodiments, R12Is heteroaryl. In some embodiments, R12Is a heterocyclic ring. In some embodiments, R12is-SR13. In some embodiments, R12Is C1-C12An alkoxy group. In some embodiments, R12Is dimethylamino.
In other embodiments, R12Is methyl. In other embodiments, R12Is ethyl. In some embodiments, R12Is C3An alkyl group. In some embodiments, R12Is isopropyl. In some embodiments, R12Is C4An alkyl group. In other embodiments, R12Is C5An alkyl group. In other embodiments, R12Is C6An alkyl group. In some other embodiments, R12Is C7An alkyl group. In some embodiments, R12Is C8An alkyl group. In other embodiments, R12Is C9An alkyl group. In some embodiments, R12Is C10An alkyl group. In other embodiments, R12Is C11An alkyl group. In other embodiments, R12Is C12An alkyl group. In other embodiments, the alkyl moiety is substituted with one or more oxygen atoms to form an ether moiety, such as a methoxymethyl moiety.
In some embodiments, R12Is a methylamino group. In other embodiments, R12Is an ethylamino group. In other embodiments, R12Is C3An aminoalkyl group. In some embodiments, R12Is C4An aminoalkyl group. In other embodiments, R12Is C5An aminoalkyl group. In some other embodiments, R12Is C6An aminoalkyl group. In some embodiments, R12Is C7An aminoalkyl group. In some embodiments, R12Is C8An aminoalkyl group. In other embodiments, R12Is C9An aminoalkyl group. In some other embodiments, R12Is C10An aminoalkyl group. In other embodiments, R12Is C11An aminoalkyl group. In other embodiments, R12Is C12An aminoalkyl group. In some embodiments, the aminoalkyl is a dimethylaminoalkyl.
In other embodiments, R12Is acetyl. In some other embodiments, R12Is C2An alkylcarbonyl group. In some embodiments, R12Is C3An alkylcarbonyl group. In other embodiments, R12Is C4An alkylcarbonyl group. In some embodiments, R12Is C5An alkylcarbonyl group. In other embodiments, R12Is C6An alkylcarbonyl group. In some other embodiments, R12Is C7An alkylcarbonyl group. In some embodiments, R12Is C8An alkylcarbonyl group. In other embodiments, R12Is C9An alkylcarbonyl group. In some other embodiments, R12Is C10An alkylcarbonyl group. In some embodiments, R12Is C11An alkylcarbonyl group. In other embodiments, R12Is C12An alkylcarbonyl group. The alkylcarbonyl group is substituted with a carboxyl moiety, for example the alkylcarbonyl group is substituted to form a succinic acid moiety (i.e., a 3-carboxyalkylcarbonyl group). In other embodiments, the alkylcarbonyl group is substituted with a terminal-SH group.
In some embodiments, R12Is an amide group. In some embodiments, the amide group comprises an alkyl moiety that is further substituted, for example with-SH, carbamate, or a combination thereof. In other embodiments, the amide group is substituted with an aryl moiety, such as phenyl. In certain embodiments, R12May have the following structure (IX):

wherein R is16Independently at each occurrence hydrogen, C1-C12Alkyl radical, C1-C12Alkoxy, -CN, aryl or heteroaryl.
In some embodiments, R12Is methoxy. In other embodiments, R12Is ethoxy. In other embodiments, R12Is C3An alkoxy group. In some embodiments, R12Is C4An alkoxy group. In some embodiments, R12Is C5An alkoxy group. In some other embodiments, R12Is C6An alkoxy group. In other embodiments, R12Is C7An alkoxy group. In some other embodiments, R12Is C8An alkoxy group. In some embodiments, R12Is C9An alkoxy group. In other embodiments, R12Is C10An alkoxy group. In some embodiments, R12Is C11An alkoxy group. In other embodiments, R12Is C12An alkoxy group.
In certain embodiments, R12Is pyrrolidinyl, such as pyrrolidin-1-yl. In other embodiments, R12Is piperidinyl, for example piperidin-1-yl or piperidin-4-yl. In other embodiments, R12Is morpholino, e.g. morpholin-4-yl. In other embodiments, R12Is phenyl, and in even other embodiments, the phenyl is substituted, for example, with nitro. In other embodiments, R12Is a pyrimidinyl radical, for example pyrimidin-2-yl.
In other embodiments, R13、R14And R15Independently at each occurrence is C1-C12An alkyl group. In some embodiments, R13、R14Or R15Is methyl. In other embodiments, R13、R14Or R15Is ethyl. In other embodiments, R13、R14Or R15Is C3An alkyl group. At itIn other embodiments, R13、R14Or R15Is isopropyl. In other embodiments, R13、R14Or R15Is C4An alkyl group. In some embodiments, R13、R14Or R15Is C5An alkyl group. In some other embodiments, R13、R14Or R15Is C6An alkyl group. In other embodiments, R13、R14Or R15Is a C7 alkyl group. In other embodiments, R13、R14Or R15Is C8An alkyl group. In other embodiments, R13、R14Or R15Is C9An alkyl group. In some embodiments, R13、R14Or R15Is C10An alkyl group. In some embodiments, R13、R14Or R15Is C11An alkyl group. In other embodiments, R13、R14Or R15Is C12An alkyl group.
As noted above, in some embodiments, R12Is an amide group substituted with an aryl moiety. In this connection, R16May be the same or different for each occurrence of (a). In certain of these embodiments, R16Is hydrogen. In other embodiments, R16is-CN. In other embodiments, R16Is heteroaryl, for example tetrazolyl. In certain other embodiments, R16Is methoxy. In other embodiments, R16Is an aryl group, and the aryl group may be optionally substituted. In this regard, optional substituents include: c1-C12Alkyl radical, C1-C12Alkoxy groups such as methoxy; a trifluoromethoxy group; halo, such as chloro; and a trifluoromethyl group.
In other embodiments, R16Is methyl. In other embodiments, R16Is ethyl. In some embodiments, R16Is C3An alkyl group. In some other embodiments, R16Is isopropyl. In other embodiments, R16Is C4An alkyl group. In other embodiments, R16Is C5An alkyl group. In other embodiments, R16Is C6An alkyl group. In some other embodiments, R16Is C7An alkyl group. In some embodiments, R16Is C8An alkyl group. In other embodiments, R16Is C9An alkyl group. In some other embodiments, R16Is C10An alkyl group. In other embodiments, R16Is C11An alkyl group. In some other embodiments, R16Is C12An alkyl group.
In some embodiments, R16Is methoxy. In some embodiments, R16Is ethoxy. In other embodiments, R16Is C3An alkoxy group. In some other embodiments, R16Is C4An alkoxy group. In other embodiments, R16Is C5An alkoxy group. In some other embodiments, R16Is C6An alkoxy group. In other embodiments, R16Is C7An alkoxy group. In some other embodiments, R16Is C8An alkoxy group. In other embodiments, R16Is C9An alkoxy group. In some other embodiments, R16Is C10An alkoxy group. In some embodiments, R16Is C11An alkoxy group. In some other embodiments, R16Is C12An alkoxy group.
In some other embodiments, R8And R9Combine to form a 12-to 18-membered crown ether. For example, in some embodiments, the crown ether is 18-membered, and in other embodiments, the crown ether is 15-membered. In certain embodiments, R8And R9Combine to form a heterocycle having one of the following structures (X) or (XI):

in some embodiments, R8、R9Or R3And R10Combine to form a 5-7 membered heterocyclic ring. For example, in some embodiments, R3And R10Combine to form a 5-7 membered heterocyclic ring. In some embodiments, the heterocycle is 5-membered. In other embodiments, the heterocycle is 6 membered. In other embodiments, the heterocycle is 7-membered. In some embodiments, the heterocycle may be represented by the following structure (XII):

wherein Z' represents a 5-7 membered heterocyclic ring. In certain embodiments of structure (XI), R12At each occurrence is hydrogen. For example, the linkage (B) may have one of the following structures (B1), (B2), or (B3):

in certain other embodiments, R12Is C1-C12An alkylcarbonyl group or an amido group, which is further substituted with an arylphosphoryl moiety, such as a triphenylphosphoryl moiety. Examples of the connection having this structure include B56 and B55.
In certain embodiments, linkage (B) is free of any of structures a1-a 5. Table 2 shows representative linkages of (a) type and (B).
TABLE 2 representative intersubunit linkages













In the sequences and discussion that follows, the names of the above connections are often used. For example, comprising PMOapnThe linked bases are described asapnB, wherein B is a base. Other connections may be similarly named. In addition, abbreviated names may be used, for example, the above abbreviated names in parentheses (e.g.,ab, meansapnB) In that respect Other easily recognizable abbreviations may also be used.
B.Oligomers with modified end groups
In addition to the carrier peptide, the conjugate may also comprise an oligomer containing a modified terminal group. Applicants have discovered that modification of the 3 'and/or 5' end of the oligomer with various chemical moieties provides the conjugate with advantageous therapeutic properties (e.g., improved cell delivery, potency, and/or tissue distribution, etc.). In various embodiments, the modified terminal group comprises a hydrophobic moiety, while in other embodiments, the modified terminal group comprises a hydrophilic moiety. The modified end group may or may not have a linkage as described above. For example, in some embodiments, the oligomer that is bound to the carrier peptide comprises one or more modified terminal groups and a type (a) linkage, e.g., where X is-N (CH)3)2The connection of (2). In other embodiments, the oligomer comprises one or more modified terminal groups and a type (B) linkage, for example a linkage wherein X is 4-aminopiperidin-1-yl (i.e., APN). In still other embodiments, the oligomer comprises one or more modified terminal groups and a mixture of linkages (a) and (B). For example, the oligomer can comprise one or more modified terminal groups (e.g., trityl or triphenylacetyl) and wherein X is-N (CH)3)2And wherein X is 4-aminopiperidin-1-yl. Other combinations of modified end groups and modified linkages also provide advantageous therapeutic properties to the oligomers.
In one embodiment, the oligomer comprising a terminal modification has the following structure (XVII):

or a salt or isomer of that structure, wherein X, W and Y are as defined above for any of linkages (A) and (B), and:
R17independently at each occurrence is absent, hydrogen or C1-C6An alkyl group;
R18and R19Independently at each occurrence, absent, hydrogen, carrier peptide, natural or unnatural amino acid, C2-C30Alkylcarbonyl, -C (═ O) OR21Or R20;
R20At each occurrence is independently guanidino, heterocyclyl, C1-C30Alkyl radical, C3-C8A cycloalkyl group; c6-C30Aryl radical, C7-C30Aralkyl radical, C3-C30Alkylcarbonyl group, C3-C8Cycloalkyl carbonyl group, C3-C8Cycloalkylalkylcarbonyl, C7-C30Aryl carbonyl group, C7-C30Aralkyl carbonyl group, C2-C30Alkoxycarbonyl group, C3-C8Cycloalkoxycarbonyl radical, C7-C30Aryloxycarbonyl group, C8-C30Arylalkoxycarbonyl or-P (═ O) (R)22)2;
Pi is independently at each occurrence a base-pairing moiety;
L1is an optional linker arm up to 18 atoms in length comprising a linkage selected from the group consisting of: alkyl, hydroxy, alkoxy, alkylamino, amide, ester, disulfide, carbonyl, carbamate, phosphodiamide, phosphoamide, phosphorothioate, piperazine, and phosphodiester; and is
x is an integer of 0 or more; and wherein R18Or R19At least 1 of which is R20(ii) a And is
Wherein R is18Or R19At least 1 of which is R20And provided that R is17And R18Neither is present.
Oligomers with modified end groups may compriseAny number of linkages of type (A) and type (B). For example, the oligomer may comprise only type (a) linkages. For example, X in each connection may be-N (CH)3)2. Alternatively, the oligomer may comprise only linkage (B). In certain embodiments, the oligomer comprises a mixture of linkages (a) and (B), e.g., 1 to 4 linkages of type (B), and the remainder of the linkages are of type (a). In this regard, linkages include, but are not limited to, type (B) linkages wherein X is aminopiperidinyl and type (a) linkages wherein X is dimethylamino.
In some embodiments, R17Is absent. In some embodiments, R17Is hydrogen. In some embodiments, R17Is C1-C6An alkyl group. In some embodiments, R17Is methyl. In other embodiments, R17Is ethyl. In some embodiments, R17Is C3An alkyl group. In some other embodiments, R17Is isopropyl. In other embodiments, R17Is C4An alkyl group. In still other embodiments, R17Is C5An alkyl group. In some other embodiments, R17Is C6An alkyl group.
In other embodiments, R18Is absent. In some embodiments, R18Is hydrogen. In some embodiments, R18Is a carrier peptide. In some embodiments, R18Natural or unnatural amino acids, such as trimethylglycine. In some embodiments, R18Is R20。
In other embodiments, R19Is absent. In some embodiments, R19Is hydrogen. In some embodiments, R19Is a carrier peptide. In some embodiments, R19Natural or unnatural amino acids, such as trimethylglycine. In some embodiments, R19is-C (═ O) OR17E.g. R19May have the following structure:

in other embodiments, R18Or R19Is C2-C30Alkylcarbonyl, e.g. -C (═ O) (CH)2)nCO2H, wherein n is 1 to 6, e.g. 2. In other examples, R18Or R19Is acetyl.
In some embodiments, R20At each occurrence is independently guanidino, heterocyclyl, C1-C30Alkyl radical, C3-C8A cycloalkyl group; c6-C30Aryl radical, C7-C30Aralkyl radical, C3-C30Alkylcarbonyl group, C3-C8Cycloalkyl carbonyl group, C3-C8Cycloalkylalkylcarbonyl, C6-C30Aryl carbonyl group, C7-C30Aralkyl carbonyl group, C2-C30Alkoxycarbonyl group, C3-C8Cycloalkoxycarbonyl radical, C7-C30Aryloxycarbonyl group, C8-C30Arylalkoxycarbonyl, -C (═ O) OR21or-P (═ O) (R)22)2Wherein R is21Is C containing one or more oxygen or hydroxyl moieties or combinations thereof1-C30Alkyl, and each R22Are all C6-C12An aryloxy group.
In certain other embodiments, R19is-C (═ O) OR21And R is18Is hydrogen, guanidino, heterocyclic radical, C1-C30Alkyl radical, C3-C8A cycloalkyl group; c6-C30Aryl radical, C3-C30Alkylcarbonyl group, C3-C8Alkylcarbonyl group, C3-C8Cycloalkylalkylcarbonyl, C7-C30Aryl carbonyl group, C7-C30Aralkyl carbonyl group, C2-C30Alkoxycarbonyl group, C3-C8Cycloalkoxycarbonyl radical, C7-C30Aryloxycarbonyl group, C8-C30Arylalkoxycarbonyl or-P (═ O) (R)22)2Each of whichR22Are all C6-C12An aryloxy group.
In other embodiments, R20At each occurrence is independently guanidino, heterocyclyl, C1-C30Alkyl radical, C3-C8A cycloalkyl group; c6-C30Aryl radical, C3-C30Alkylcarbonyl group, C3-C8Cycloalkyl carbonyl group, C3-C8Cycloalkylalkylcarbonyl, C7-C30Aryl carbonyl group, C7-C30Aralkyl carbonyl group, C2-C30Alkoxycarbonyl group, C3-C8Cycloalkoxycarbonyl radical, C7-C30Aryloxycarbonyl group, C8-C30Arylalkoxycarbonyl or-P (═ O) (R)22)2. And in other examples, R20At each occurrence is independently guanidino, heterocyclyl, C1-C30Alkyl radical, C3-C8A cycloalkyl group; c6-C30Aryl radical, C7-C30Aralkyl radical, C3-C8Cycloalkyl carbonyl group, C3-C8Cycloalkylalkylcarbonyl, C7-C30Aryl carbonyl group, C7-C30Aralkyl carbonyl group, C2-C30Alkoxycarbonyl group, C3-C8Cycloalkoxycarbonyl radical, C7-C30Aryloxycarbonyl group, C8-C30Arylalkoxycarbonyl or-P (═ O) (R)22)2。
In some embodiments, R20Is guanidino, for example monomethylguanidino or dimethylguanidino. In other embodiments, R20Is a heterocyclic group. For example, in some embodiments, R20Is piperidin-4-yl. In some embodiments, the piperidin-4-yl group is substituted with a trityl or Boc group. In other embodiments, R20Is C3-C8A cycloalkyl group. In other embodiments, R20Is C6-C30And (4) an aryl group.
In some embodiments, R20Is C7-C30An arylcarbonyl group. For example, inIn some embodiments, R20Has the following structure (XVIII):

wherein R is23Independently at each occurrence is hydrogen, halo, C1-C30Alkyl radical, C1-C30Alkoxy radical, C1-C30Alkoxycarbonyl group, C7-C30Aralkyl, aryl, heteroaryl, heterocyclyl or heterocycloalkyl, and wherein 1R23May be reacted with another R23Combine to form a heterocyclyl ring. In some embodiments, at least 1R23Is hydrogen, e.g., in some embodiments, each R23Are both hydrogen. In other embodiments, at least 1R23Is C1-C30Alkoxy, e.g., in some embodiments, each R23Are both methoxy groups. In other embodiments, at least 1R23Is heteroaryl, e.g., in some embodiments, at least 1R23Having one of the following structures (XVIIIa) or (XVIIb):

in other embodiments, 1R23With another R23Combine to form a heterocyclyl ring. For example, in one embodiment, R20Is 5-carboxyfluorescein.
In other embodiments, R20Is C7-C30An aralkyl carbonyl group. For example, in various embodiments, R20Having one of the following structures (XIX), (XX) or (XXI):

wherein R is23Independently at each occurrence is hydrogen, halo, C1-C30Alkyl radical, C1-C30Alkoxy radical, C1-C30Alkoxycarbonyl group, C7-C30Aralkyl, aryl, heteroaryl, heterocyclyl or heterocycloalkyl, wherein 1R23May be reacted with another R23Combine to form a heterocyclyl ring, X is-OH or halo, and m is an integer from 0 to 6. In some particular embodiments, m is 0. In other embodiments, m is 1, and in other embodiments, m is 2. In other embodiments, at least 1R23Is hydrogen, e.g., in some embodiments, each R23Are both hydrogen. In some embodiments, X is hydrogen. In other embodiments, X is-OH. In other embodiments, X is Cl. In other embodiments, at least 1R23Is C1-C30Alkoxy groups, such as methoxy.
In still other embodiments, R20Is C7-C30Aralkyl, such as trityl. In other embodiments, R20Is methoxy trityl. In some embodiments, R20Having the following structure (XXII):

wherein R is23Independently at each occurrence is hydrogen, halo, C1-C30Alkyl radical, C1-C30Alkoxy radical, C1-C30Alkoxycarbonyl group, C7-C30Aralkyl, aryl, heteroaryl, heterocyclyl or heterocycloalkyl, and wherein 1R23May be reacted with another R23Combine to form a heterocyclyl ring. For example, in some embodiments, each R is23Are both hydrogen. In other embodiments, at least 1R23Is C1-C30Alkoxy groups, such as methoxy.
In other embodiments, R20Is C7-C30Aralkyl, and R20Having the following structure (XXIII):

in some embodiments, at least 1R23Is a halogen group, such as a chlorine group. In some other embodiments, 1R23Is a chloro group at the para position.
In other embodiments, R20Is C1-C30An alkyl group. For example, in some embodiments, R20Is C4-C20Alkyl groups, and optionally one or more double bonds. For example, in some embodiments, R20Is C containing a triple bond, e.g. a terminal triple bond4-10An alkyl group. In some embodiments, R20Is hexyn-6-yl. In some embodiments, R20Having one of the following structures (XXIV), (XXV), (XXVI), or (XXVII):

in still other embodiments, R20Is C3-C30Alkylcarbonyl radicals, e.g. C3-C10An alkylcarbonyl group. In some embodiments, R20is-C (═ O) (CH)2)pSH or-C (═ O) (CH)2)pSShet, wherein p is an integer from 1 to 6 and Het is heteroaryl. For example, p may be 1, or p may be 2. In other examples, Het is pyridinyl, such as pyridin-2-yl. In other embodiments, C3-C30The alkylcarbonyl group is substituted with other oligomers, e.g., in some embodiments, the oligomer comprises a C at the 3' position3-C30An alkylcarbonyl group that links the oligomer to the 3' position of another oligomer. Such terminal modifications are included within the scope of the present disclosure.
In other embodiments, R20Is C further substituted by an aryl phosphoryl moiety3-C30Alkylcarbonyl, for example triphenylphosphoryl. Such R20Radical (I)Examples of (a) include structure 33 in table 3.
In other examples, R20Is C3-C8Cycloalkyl-carbonyl radicals, e.g. C5-C7An alkylcarbonyl group. In these embodiments, R20Having the following structure (XXVIII):

wherein R is23Independently at each occurrence is hydrogen, halo, C1-C30Alkyl radical, C1-C30Alkoxy radical, C1-C30Alkoxycarbonyl group, C7-C30Aralkyl, aryl, heteroaryl, heterocyclyl or heterocycloalkyl, and wherein 1R23May be reacted with another R23Combine to form a heterocyclyl ring. In some embodiments, R23Is a heterocyclylalkyl group, for example in some embodiments. R23Has the following structure:

in some other embodiments, R20Is C3-C8A cycloalkylalkylcarbonyl group. In other embodiments, R20Is C2-C30An alkoxycarbonyl group. In other embodiments, R20Is C3-C8A cycloalkoxycarbonyl group. In other embodiments, R20Is C7-C30An aryloxycarbonyl group. In other embodiments, R20Is C8-C30An arylalkoxycarbonyl group. In other embodiments, R20is-P (═ O) (R)22)2Wherein each R is22Are all C6-C12Aryloxy, e.g. in some embodiments, R20Has the following structure (C24):

in other embodiments, R20Containing one or more halogen atoms. For example, in some embodiments, R20Including any of the above R20A partial perfluorinated analog. In other embodiments, R20Is p-trifluoromethylphenyl, trifluoromethyltrityl, perfluoropentyl or pentafluorophenyl.
In some embodiments, the 3 'end comprises a modification, and in other embodiments, the 5' end comprises a modification. In other embodiments, both the 3 'and 5' ends comprise a modification. Thus, in some embodiments, R18Is absent, and R19Is R20. In other embodiments, R19Is absent, and R18Is R20. In still other embodiments, R18And R19Each is R20。
In some embodiments, the oligomer further comprises a cell-penetrating peptide in addition to the 3 'or 5' modification. Thus, in some embodiments, R19Is a cell-penetrating peptide, and R18Is R20. In other embodiments, R18Is a cell-penetrating peptide, and R19Is R20. In a further embodiment of the foregoing scheme, the cell-penetrating peptide is an arginine-rich peptide.
In some embodiments, the 5' end group (i.e., R) may be present or absent19) Linker arm L to oligomer1. The linker arm can comprise any number of functional groups and lengths, provided that the linker arm retains its ability to attach the 5' end group to the oligomer, and provided that the linker arm does not interfere with the ability of the oligomer to bind to the target sequence in a sequence-specific manner. In one embodiment, L comprises a phosphodiamide and piperazine linkage. For example, in some embodiments, L has the following structure (XXIX):

wherein R is24Is absent, hydrogen or C1-C6An alkyl group. In some embodiments, R24Is absent. In some embodiments, R24Is hydrogen. In some embodiments, R24Is C1-C6An alkyl group. In some embodiments, R24Is methyl. In other embodiments, R24Is ethyl. In still other embodiments, R24Is C3An alkyl group. In some other embodiments, R24Is isopropyl. In other embodiments, R24Is C4An alkyl group. In some embodiments, R24Is C5An alkyl group. In other embodiments, R24Is C6An alkyl group.
In still other embodiments, R20Is C3-C30Alkylcarbonyl, and R20Having the following structure (XXX):

wherein R is25Is hydrogen or-SR26Wherein R is26Is hydrogen, C1-C30Alkyl, heterocyclyl, aryl or heteroaryl, and q is an integer from 0 to 6.
In any of the other embodiments above, R23Independently at each occurrence is hydrogen, halo, C1-C30Alkyl radical, C1-C30Alkoxy, aryl, heteroaryl, heterocyclyl or heterocycloalkyl.
In some other embodiments, only the 3' end of the oligomer is bound to 1 or more of the groups described above. In some other embodiments, only the 5' end of the oligomer is bound to 1 or more of the groups described above. In other embodiments, both the 3 'and 5' ends comprise 1 or more of the groups described above. The terminal groups may be selected from any 1 of the groups described above or any particular group set forth in table 3.
TABLE 3 representative end groups






C. Properties of the conjugates
As described above, the present disclosure relates to conjugates (i.e., oligomers) of carrier peptides and oligonucleotide analogs. The oligomer can comprise various modifications that confer a desired property (e.g., increased antisense activity) to the oligomer. In certain embodiments, the oligomer comprises a scaffold comprising a sequence of morpholino loops bound by an intersubunit linkage joining the 3 'end of 1 morpholino loop to the 5' end of an adjacent morpholino loop, wherein each morpholino loop is bound to a base-pairing moiety such that the oligomer can bind to a target nucleic acid in a sequence-specific manner. The morpholino ring structure can have the following structure (i):

wherein Pi is independently at each occurrence a base-pairing moiety.
Each morpholino loop structure supports a base-pairing moiety (Pi) to form a base-pairing moiety sequence that is typically designed to hybridize to a selected antisense target in a cell or in a subject being treated. The base-pairing moiety may be a purine or pyrimidine found in natural DNA or RNA (A, G, C, T or U) or analogues, such as hypoxanthine (the base component of nucleoside inosine) or 5-methylcytosine. Analog bases that confer increased binding affinity to the oligomer may also be utilized. In this regard, exemplary analogs include C5-propynyl modified pyrimidines, 9- (aminoethoxy) phenoxazines (G-haircard), and the like.
As described above, in accordance with one aspect of the invention, the oligomer can be modified to include one or more (B) linkages, e.g., up to about 1 (B) linkage per 2-5 uncharged linkages, typically 3-5 (B) linkages per 10 uncharged linkages. Certain embodiments further comprise one or more type (B) linkages. In some embodiments, an optimal increase in antisense activity is seen if up to about half of the backbone linkages are of type (B). With a small number, e.g. 10-20%, of (B) connections, some, but not the largest, increase is usually seen.
In one embodiment, the type (a) and type (B) linkages are interspersed along the backbone. In some embodiments, the oligomer does not have a strictly alternating pattern of (a) and (B) linkages along its entire length. In addition to the carrier peptide, the oligomer may optionally comprise 5 'and/or 3' modifications as described above.
Also contemplated are oligomers having a plurality of (A) junction blocks and (B) junction blocks; for example, a plurality (B) of connection blocks may be located on the side of a central (a) connection block, or vice versa. In one embodiment, the oligomer has 5', 3' ends and a central region of approximately equal length, and the percentage of (B) or (a) linkages of the central region is greater than about 50%, or greater than about 70%. Oligomers for antisense applications typically range in length from about 10 to about 40 subunits, more preferably from about 15 to 25 subunits. For example, an oligomer of the invention having 19-20 subunits (of a length useful for antisense oligomers) may desirably have 2 to 7, e.g., 4 to 6 or 3 to 5, (B) linkages, and the remainder (a) linkages. Oligomers having 14-15 subunits may desirably have 2 to 5, e.g., 3 or 4, (B) linkages, and the remaining (a) linkages.
Morpholino subunits can also be linked by non-phosphorus-based intersubunit linkages, as described further below.
Other oligonucleotide analogue linkages, which are uncharged when in the unmodified state but which may also have pendant amino substituents, may also be used. For example, the 5' nitrogen atom on the morpholino ring can be used in sulfonamide linkage (or urea linkage, where phosphorus is substituted with carbon or sulfur, respectively).
In some embodiments of antisense applications, the oligomer may be 100% complementary to the nucleic acid target sequence, or it may contain mismatches, e.g., to accommodate variants, provided that the hybrid duplex formed between the oligomer and the nucleic acid target sequence is sufficiently stable to withstand the effects of cellular nucleases and other modes of degradation that may occur in vivo. Mismatches, if present, make the end regions of the hybrid duplex less likely to be unstable than the middle region. The number of mismatches allowed depends on the length of the oligo, the percentage of G: C base pairs in the duplex, and the position in the duplex where the mismatch occurs, according to well-known principles of duplex stability. Although such antisense oligomers are not necessarily 100% complementary to the nucleic acid target sequence, they can still efficiently and stably and specifically bind to the target sequence such that the biological activity of the nucleic acid target, e.g., expression of the encoded protein, is modulated.
The stability of the duplex formed between the oligo and the target sequence is binding TmAnd the sensitivity of the duplex to enzymatic cleavage. The T of antisense compounds with respect to complementary sequence RNA can be measured by conventional methodsmMethods as described in Hames et al, Nucleic Acid Hybridization, IRL Press,1985, pp.107-108, or as described in Miyada c.g. and Wallace r.b.,1987, Oligonucleotide Hybridization techniques, Methods enzyme. vol.154pp.94-107.
In some embodiments, each antisense oligomer is a single antisense oligomerHaving binding T for complementary sequence RNAmGreater than body temperature, or in other embodiments, greater than 50 ℃. In other embodiments, TmIs 60-80 deg.C or more. The T of an oligomeric compound with respect to complementary RNA-based hybridization can be increased by increasing the ratio of C: G paired bases in the duplex, and/or by increasing the length of the hybridized duplex (in base pairs), according to well-known principlesm. At the same time, it may be advantageous to limit the size of the oligomers in order to optimize cellular uptake. For this reason, T is higher than that for obtainingmCompounds that require values greater than 20 bases are generally preferred, as are compounds that exhibit a high Tm (50 ℃ or greater) at 20 bases or less in length. For some applications, longer oligomers, e.g., longer than 20 bases, may have certain advantages. For example, in certain embodiments, longer oligomers are particularly useful for exon skipping or splicing regulation.
The targeting sequence bases can be normal DNA bases or analogs thereof, e.g., uracil and creatinine capable of Watson-Crick base pairing with the target sequence RNA bases.
When the target nucleotide is a uracil residue, the oligomer may also incorporate a guanine base in place of adenine. This is useful when the target sequence varies between different virus species and the variation of any given nucleotide residue is cytosine or uracil. By using guanine at the site of variation in the targeting oligomer, the well-known ability of guanine to base pair with uracil (referred to as C/U: G base pairing) can be exploited. By incorporating guanines at these positions, a single oligo can effectively target a wide range of RNA target variability.
Compounds (e.g., oligomers, intersubunit linkages, terminal groups) can exist in different isomeric forms, such as structural isomers (e.g., tautomers). With respect to stereoisomers, the compounds may have chiral centers and may occur as racemates, enantiomerically enriched mixtures, individual enantiomers, mixtures or diastereomers or as individual diastereomers. All such isomeric forms are included in the present invention, including mixtures thereof. The compounds may also have axial chirality, which may lead to the formation of atropisomers. In addition, some forms of the compounds may exist as polymorphs and as such are included in the present invention. In addition, some compounds may also form solvates with water or other organic solvents. Such solvates are likewise included within the scope of the present invention.
The oligomers described herein can be used in methods of inhibiting protein production or viral replication. Thus, in one embodiment, nucleic acids encoding such proteins are exposed to an oligomer as disclosed herein. In a further embodiment of the foregoing, the antisense oligomer comprises a5 'or 3' modified end group or a combination thereof, as disclosed herein, and the base-pairing moiety B forms a sequence that can effectively hybridize to a nucleic acid moiety at a position effective to inhibit protein production. In one embodiment, the location is the ATG start codon region of the mRNA, the splice site of the pre-mRNA, or a viral target sequence as described below.
In one embodiment, the oligomer has a Tm for binding to a target sequence that is greater than about 50 ℃ and which is taken up by mammalian cells or bacterial cells. In another embodiment, the oligomer may be conjugated to a transport moiety, such as an arginine-rich peptide, as described herein, to facilitate such uptake. In another embodiment, the terminal modifications described herein can function as a transport moiety to facilitate uptake by mammalian and/or bacterial cells.
The preparation and performance of morpholino oligomers are described in more detail below and in U.S. patent No. 5185444 and WO/2009/064471, each of which is incorporated herein by reference in its entirety.
D.Formulation and administration of conjugates
The present disclosure also provides for the formulation and delivery of the disclosed conjugates. Thus, in one embodiment, the present disclosure relates to a composition comprising a peptide-oligomer conjugate as disclosed herein and a pharmaceutically acceptable carrier.
Efficient delivery of the conjugate to the target nucleic acid is an important aspect of treatment. Routes of antisense oligomer delivery include, but are not limited to, various systemic routes, including oral and parenteral routes, e.g., intravenous, subcutaneous, intraperitoneal, and intramuscular, as well as inhalation, transdermal, and topical delivery. Suitable routes can be determined by those skilled in the art, which are appropriate for the condition of the subject receiving treatment. For example, a suitable route of delivery of antisense oligomers in the treatment of cutaneous viral infections is topical delivery, while delivery of antisense oligomers for the treatment of viral respiratory infections is by inhalation. Oligomers can also be delivered directly to the site of viral infection or into the bloodstream.
The conjugate may be administered in any physiologically and/or pharmaceutically acceptable convenient carrier. Such compositions may include any of a variety of standard pharmaceutically acceptable carriers employed by those of ordinary skill in the art. Examples include, but are not limited to, saline, Phosphate Buffered Saline (PBS), water, aqueous ethanol, emulsions such as oil/water emulsions or triglyceride emulsions, tablets, and capsules. The choice of a suitable physiologically acceptable carrier will vary depending on the mode of administration selected.
The compounds of the invention (e.g., conjugates) can generally be used as the free acid or free base. Alternatively, the compounds of the present invention may be used in the form of acid or base addition salts. Acid addition salts of the free amino compounds of the present invention can be prepared by methods well known in the art and can be formed from organic and inorganic acids. Suitable organic acids include maleic acid, fumaric acid, benzoic acid, ascorbic acid, succinic acid, methanesulfonic acid, acetic acid, trifluoroacetic acid, oxalic acid, propionic acid, tartaric acid, salicylic acid, citric acid, gluconic acid, lactic acid, mandelic acid, cinnamic acid, aspartic acid, stearic acid, palmitic acid, glycolic acid, glutamic acid, and benzenesulfonic acid. Suitable inorganic acids include hydrochloric acid, hydrobromic acid, sulfuric acid, phosphoric acid and nitric acid. Base addition salts include those formed from carboxylate anions and include salts formed from organic and inorganic cations such as those selected from the group consisting of alkali and alkaline earth metals (e.g., lithium, sodium, potassium, magnesium, barium, and calcium) and ammonium ions and substituted derivatives thereof (e.g., benzhydrylammonium, benzylammonium, 2-hydroxyethylammonium, and the like). Thus, the term "pharmaceutically acceptable salt" of structure (I) is intended to include any and all acceptable salt forms.
In addition, prodrugs are also included in the context of the present invention. Prodrugs are any covalently bonded carriers that release the compound of structure (I) in vivo when such prodrugs are administered to a patient. Prodrugs are typically prepared by modifying functional groups in a manner such that the modification can be cleaved, either by routine manipulation or in vivo, to yield the parent compound. Prodrugs include, for example, compounds of the present invention wherein a hydroxy, amino, or sulfhydryl group is bound to any group that is cleavable when administered to a patient, thereby forming the hydroxy, amino, or sulfhydryl group. Thus, representative examples of prodrugs include, but are not limited to, acetate, formate and benzoate derivatives of ethanol and amino functional groups of compounds of structure (I). Also, in the case of carboxylic acid (-COOH), esters such as methyl ester, ethyl ester, and the like may be employed.
In some cases, liposomes can be used to facilitate uptake of antisense oligonucleotides into cells. (see, e.g., Williams, S.A., Leukemia 10(12): 1980-. The antisense oligomer may also be administered using a hydrogel as a carrier, for example, as described in WO 93/01286. Alternatively, the oligonucleotide may be administered in the form of microspheres or microparticles. (see, e.g., Wu, G.Y.and Wu, C.H., J.biol.chem.262:4429-4432, 1987). Alternatively, the use of gas-filled microbubbles complexed with antisense oligomers may increase delivery to the target tissue, as described in U.S. patent No. 6245747. Sustained release compositions may also be used. These may comprise a semipermeable polymeric matrix in the form of shaped particles, such as films or microcapsules.
In one embodiment, antisense inhibition is effective in treating viral infection in a host animal by contacting a virally infected cell with an antisense agent effective to inhibit replication of the particular virus. Antisense agents in suitable pharmaceutical carriers can be administered to a mammalian subject, such as a human or livestock infected with a given virus. It is expected that antisense oligonucleotides may prevent the growth of RNA viruses in a host. The RNA virus can be reduced in number, or eliminated with little or no deleterious effect on the normal growth or development of the host.
In one aspect of the method, the subject is a human subject, e.g., a patient diagnosed with a local or systemic viral infection. The condition of the patient may also indicate prophylactic administration of the antisense oligomer of the invention, for example in a situation wherein the patient (1) is immunocompromised; (2) is a person who is burnt; (3) having an indwelling catheter; or (4) will undergo or have just undergone surgery. In a preferred embodiment, the oligomer is a phosphodiamide morpholino oligomer contained within a pharmaceutically acceptable carrier and delivered orally. In another preferred embodiment, the oligomer is a phosphodiamide morpholino oligomer contained within a pharmaceutically acceptable carrier and delivered intravenously (i.v.).
In another application of the method, the subject is a livestock animal, e.g., a chicken, turkey, pig, cow, or goat, etc., and the treatment is prophylactic or therapeutic. The invention also includes livestock and poultry food compositions comprising a food grain supplemented with a subtherapeutic amount of an antiviral antisense compound of the type described above. Also contemplated is a method of feeding livestock and poultry with a food grain supplemented with a subtherapeutic level of an antiviral oligonucleotide composition, wherein the improvement is supplementing the food grain with a subtherapeutic amount of an antiviral oligonucleotide composition as described above.
In one embodiment, the conjugate is administered in an amount and manner effective to cause a peak blood concentration of at least 200 and 400nM of antisense oligomer. One or more doses of antisense oligomer are typically administered at intervals, i.e., over a period of about 1 to 2 weeks. A preferred dose for oral administration is about 1-1000mg of oligomer per 70 kg. In some cases, a dose of greater than 1000mg of oligomer per patient may be necessary. For i.v. administration, a preferred dose is about 0.5-1000mg of oligomer per 70 kg. The conjugate may be administered at short intervals, e.g., daily for two weeks or less. However, in some cases, the conjugate is administered intermittently over a longer period of time. Antibiotics or other treatments may be administered after administration, or concurrently with administration. The treatment regimen (dose, frequency, route, etc.) may be adjusted as indicated by the results of the immunoassay based on the subject receiving the treatment, other biochemical tests, and physiological examinations.
Depending on the duration, dose, frequency and route of administration, as well as the condition of the subject being treated, the effective in vivo treatment regimen using the conjugates of the invention may vary (i.e., prophylactic administration versus administration in response to a local or systemic infection). Thus, such in vivo treatments often require monitoring by detection of infection by the particular type of virus being treated and corresponding adjustment of the dosage or treatment regimen in order to achieve a preferred therapeutic result. For example, treatment can be monitored by general indicators of disease and/or infection, such as Complete Blood Count (CBC), nucleic acid detection methods, immunodiagnostic tests, detection of viral cultures, or detection of hybrid duplexes.
The efficacy of in vivo administration of an antiviral conjugate of the invention that inhibits or eliminates the growth of one or more types of RNA viruses can be determined from a biological sample (tissue, blood, urine, etc.) taken from the subject before, during, and after administration of the antisense oligomer. The analysis of such samples includes: (1) monitoring the presence or absence of hybrid double strands formed with the target and non-target sequences using procedures known to those skilled in the art, such as electrophoretic gel mobility analysis; (2) monitoring the amount of viral protein production as measured by standard techniques such as ELISA or Western blotting, or (3) measuring the effect on viral titer, e.g., by the method of Spearman-Karber. (see, e.g., Pari, G.S.et al, antibodies.Agents and Chemotherapy 39(5): 1157. sup. 1161, 1995; Anderson, K.P.et al, antibodies.Agents and Chemotherapy 40(9): 2004. sup. 2011,1996, Cottral, G.E. (ed) in: Manual of Standard Methods for dimensional Microbiology, pp.60-93,1978).
E.Preparation of conjugates
The preparation of morpholino subunits, modified intersubunit linkages, and oligomers containing the same can be as described in examples and U.S. patent nos. 5185444 and 7943762, which are hereby incorporated by reference in their entirety. Morpholino subunits can be prepared according to the following general reaction scheme I.

With respect to reaction scheme 1, wherein B represents a base-pairing moiety and PG represents a protecting group, morpholino subunits can be prepared from the corresponding ribonucleoside (1) as shown above. The morpholino subunit (2) may optionally be protected by reaction with a suitable protecting group precursor, for example trityl chloride. The 3' protecting group is typically removed during solid state oligomer synthesis, as described in more detail below. The base-pairing moiety can be suitably protected for solid phase oligomer synthesis. Suitable protecting groups for adenine and cytosine include benzoyl, for guanine include phenylacetyl, and for hypoxanthine (I) include pivaloyloxymethyl. Pivaloyloxymethyl group may be introduced at the N1 position of the hypoxanthine heterocyclic base. Although an unprotected hypoxanthine subunit can be used, the yield in the activation reaction is much higher when the base is protected. Other suitable protecting groups include those disclosed in co-pending U.S. application No. 12/271040, which is hereby incorporated by reference in its entirety.
Reaction of 3 with activated phosphorus compound 4 produces a morpholino substituent having the desired linking moiety (5). The compounds of structure 4 can be prepared using any number of methods known to those skilled in the art. Such compounds can be prepared, for example, by reacting the corresponding amine with phosphorus oxychloride. In this regard, the amine starting materials may be prepared using any method known in the art, such as those described in the examples and U.S. patent No. 7943762. Although the above scheme describes the preparation of type (B) linkages (e.g., X is-NR)8R9) The preparation of form (A) may be carried out in a similar mannerAnd (e.g., X is dimethylamine).
The compound of structure 5 can be used in solid phase automated oligomer synthesis to produce oligomers comprising intersubunit linkages. Such methods are well known in the art. Briefly, the compound of structure 5 can be modified at the 5' end to include a linker arm on the solid support. For example, L can be introduced by including L1And/or R19The linker arm of (a) links compound 5 to the solid support. Exemplary methods are set forth in fig. 3 and 4. In this manner, the oligomer may comprise a 5' -terminal modification after completion of oligomer synthesis and cleavage of the oligomer from the solid support. Once supported, the protecting group (e.g., trityl) of 5 can be removed and the free amine can react with the activated phosphorous moiety of the second compound of structure 5. This sequence is repeated until an oligomer of the desired length is obtained. If a5 'modification is desired, the 5' terminal protecting group at the terminus can be removed or retained. Any number of methods can be used to remove the oligomer from the solid support, such as treatment with bases to cleave the linkage to the solid support.
Peptide oligomer conjugates can be prepared by combining the desired peptide (prepared according to standard peptide synthesis methods known in the art) with an oligomer comprising free NH (e.g., 3' NH of a morpholino oligomer) in the presence of a suitable activator (e.g., HATU). The conjugate can be purified using a variety of techniques known in the art, such as SCX chromatography.
The preparation of modified morpholino subunits and peptide oligomer conjugates is described in more detail in the examples. Peptide oligomer conjugates containing any number of modified linkages can be prepared using the methods described herein, methods known in the art, and/or the methods described herein by reference. Also described in the examples are overall modifications of PMO + morpholino oligomers prepared as previously described (see, e.g., PCT publication WO 2008036127).
F.Antisense Activity of oligomers
The present disclosure also provides methods of inhibiting protein production, comprising exposing a nucleic acid encoding a protein to a peptide-oligomer conjugate as disclosed herein. Thus, in one embodiment, nucleic acids encoding such proteins are exposed to a conjugate, as disclosed herein, in which the sequence formed by the base-pairing moiety Pi effectively hybridizes to the portion of the nucleic acid at a location effective to inhibit production of the protein. The oligomer may target, for example, the ATG start codon region of mRNA, the splice site of a precursor mRNA, or a viral target sequence as described below.
In another embodiment, the present disclosure provides a method of increasing the antisense activity of a peptide oligomer conjugate comprising an oligonucleotide analog having a morpholino subunit sequence bound by an intersubunit linkage, supporting a base-pairing moiety, the method comprising binding a carrier peptide as described herein to an oligonucleotide.
In some embodiments, the increase in antisense activity can be demonstrated by:
(i) when the binding of the antisense oligomer to its target sequence is effective to prevent the translation initiation codon of the encoded protein, the expression of the encoded protein is reduced relative to that provided by the corresponding unmodified oligomer, or
(ii) Expression of the encoded protein is increased relative to that provided by the corresponding unmodified oligomer, when binding of the antisense oligomer to its target sequence is effective to prevent the occurrence of aberrant splicing sites in the precursor mRNA encoding the protein when correctly spliced. Assays suitable for measuring these effects are described further below. In one embodiment, the modification provides for this activity in a cell-free translation assay, a splice-corrected translation assay in cell culture, or a splice correction obtained from a functional animal model system as described herein. In one embodiment, the activity is increased by at least 2 fold, at least 5 fold, or at least 10 fold.
Various exemplary uses of the conjugates of the invention are described below, including antiviral uses, treatment of neuromuscular diseases, bacterial infections, inflammation, and polycystic kidney disease. This description is not intended to limit the invention in any way, but serves to illustrate the range of human and animal disease conditions that can be treated using the conjugates described herein.
G.Exemplary therapeutic uses of the conjugates
Oligomers that bind to the carrier peptide contain good efficacy and low toxicity, resulting in a better therapeutic window than that obtained with other oligomers or peptide-oligomer conjugates. The following description provides examples of exemplary, but non-limiting, therapeutic uses of the conjugates.
1.Stem-loop secondary structures of targeted ssRNA viruses
An exemplary class of antisense antiviral compounds are morpholino oligomers as described herein having 12-40 subunit sequences and a targeting sequence complementary to a region of interest in stem-loop secondary structure within 40 bases of the 5' end of the target viral sense RNA strand. (see, e.g., PCT publication No. WO/2006/033933 or U.S. application publications Nos. 20060269911 and 20050096291, which are incorporated herein by reference in their entirety).
The method comprises the following steps: first, a viral target sequence, a region within 40 bases of the 5' end of the infectious viral sense strand, is determined, wherein the virus has a sequence that forms an internal stem-loop secondary structure. A morpholino oligomer having a targeting sequence of at least 12 subunits complementary to a region of the viral genome capable of forming an internal double stranded structure is then constructed by stepwise solid phase synthesis, wherein the oligomer is capable of forming a hybrid double stranded structure with the viral target sequence consisting of a viral sense strand and an oligonucleotide compound and is characterized by a dissociation Tm of at least 45 ℃ and disruption of such stem-loop structure. The oligomer is bound to a carrier peptide as described herein.
By means of a computer program which is able to perform secondary structure prediction based on searching for the smallest free energy state of an input RNA sequence, the target sequence can be identified by analyzing the 5 '-end sequence, e.g. the 5' -end 40 bases.
In a related aspect, the conjugates can be used in a method of inhibiting replication of an infectious RNA virus having a single-stranded, positive-sense genome and one virus selected from the group consisting of: flaviviridae, picornaviridae (Picornoviridae), caliciviridae, togaviridae, arteriviridae, coronaviridae, astroviridae or hepadnaviridae. The method comprises administering to an infected host cell a virus inhibitory amount of a conjugate as described herein having a targeting sequence of at least 12 subunits complementary to a region within 40 bases of the 5' -terminus of the positive strand viral genome capable of forming an internal stem-loop secondary structure. When administered to a host cell, the conjugate can effectively form a hybrid double-stranded structure that (i) consists of the viral sense strand and the oligonucleotide compound, and (ii) is characterized by a dissociated Tm of at least 45 ℃ and disruption of such stem-loop secondary structure. The conjugate can be administered to a mammalian subject infected with or at risk of viral infection.
Exemplary targeting sequences targeting the terminal stem-loop structures of dengue virus and Japanese encephalitis virus are set forth below as SEQ ID NOs:1 and 2, respectively.
Other exemplary targeting sequences that target the terminal stem-loop structure of ssRNA viruses can also be found in U.S. application No. 11/801885 and PCT publication WO/2008/036127, which are incorporated herein by reference.
2.First open reading frame of targeted ssRNA virus
A second class of exemplary conjugates are those for inhibiting the growth of picornaviruses, caliciviruses, togaviruses, coronaviruses, and viruses of the flaviviridae family, wherein the viruses have a single-stranded, sense genome of less than 12kb and a first open reading frame encoding a polyprotein containing multiple functional proteins. In particular embodiments, the virus is an RNA virus from the family coronaviridae or a west nile virus, yellow fever virus or dengue virus from the family flaviviridae. The inhibitory conjugates comprise an antisense oligomer described herein having a targeting base sequence that is substantially complementary to a viral target sequence spanning the AUG start site of the first open reading frame of the viral genome. In one embodiment of the method, the conjugate is administered to a mammalian subject infected with a virus. See, for example, PCT publication No. WO/2005/007805 and U.S. application publication No. 2003224353, which are incorporated herein by reference.
Preferred target sequences are regions spanning the AUG start site of the first open reading frame (ORF1) of the viral genome. The first ORF typically encodes a polyprotein containing nonstructural proteins such as polymerases, helicases, and proteases. By "spanning the AUG initiation site" is meant that the target sequence comprises at least 3 bases on one side of the AUG initiation site and at least 2 bases on the other side (at least 8 bases in total). Preferably, it comprises at least 4 bases on each side of the start site (at least 11 bases in total).
More generally, preferred target sites include conserved targets between multiple viral isolates. Other advantageous sites include IRES (internal ribosome entry site), transactivator binding sites and sites for initiation of replication. By targeting host cell genes encoding viral entry and host response to viral presence, complex and large viral genomes that can provide multiple redundant genes can be effectively targeted.
Various viral genomic sequences are available from well known sources such as the NCBI Genbank database. The AUG start site of ORF1 can also be identified in the gene database or a reference based thereon, or can be found by searching for the sequence of the AUG codon within the region of the expected ORF1 start site.
Exemplary target sequences for the general gene organization of each of the 4 virus families, and for selected members (genera, species or strains) subsequently obtained within each family, are given below.
3.Targeting influenza viruses
A third class of exemplary conjugates is used to inhibit the growth of orthomyxoviridae viruses and to treat viral infections. In one embodiment, a host cell is contacted with a conjugate as described herein, e.g., a conjugate comprising a base sequence effective to hybridize to a target region selected from the group consisting of: 1) 25 bases at the 5 'or 3' end of the negative sense viral RNA fragment; 2) the terminal 25 bases of the 5 'or 3' end of the sense cRNA; 3) 45 bases around the AUG start site of influenza mRNAs; and 4) 50 bases around the splice donor or acceptor site of the influenza mRNAs undergoing alternative splicing. (see, e.g., PCT publication No. WO/2006/047683; U.S. application publication No. 20070004661; and PCT application Nos. 2010/056613 and 12/945081, which are incorporated herein by reference).
In this regard, exemplary conjugates include conjugates comprising an oligomer comprising SEQ ID NO 3.
TABLE 4 influenza targeting sequences comprising modified intersubunit linkages or terminal groups

**3' -benzhydryl;*+ linkage is trimethylglycine acylated at the PMO + linkage; PMOm represents a T base with a methyl group at the 3-nitrogen position.
The conjugates are particularly useful for treating influenza virus infections in mammals. The conjugate can be administered to a mammalian subject infected with or at risk of infection by an influenza virus.
4.Targeted picornaviridae viruses
The fourth class of exemplary conjugates is used to inhibit the growth of viruses of the picornaviridae family and to treat viral infections. The conjugates are particularly useful for treating enterovirus and/or rhinovirus infections in mammals. In this embodiment, the conjugate comprises a morpholino oligomer having the sequence 12-40 subunits comprising at least 12 subunits having a targeting sequence complementary to a region associated with a viral RNA sequence within one of two 32 conserved nucleotide regions of the 5' untranslated region of the virus. (see, for example, PCT publications WO/2007/030576 and WO/2007/030691, or co-pending and commonly owned U.S. application Nos. 11/518058 and 11/517757, which are incorporated herein by reference). Exemplary targeting sequences are set forth below as SEQ NO 6.
5.Targeting flaviviridae viruses
A fifth class of exemplary conjugates is used to inhibit replication of flavivirus in animal cells. An exemplary conjugate of this type comprises a morpholino oligomer that is 8-40 nucleotide bases in length and has a sequence of at least 8 bases complementary to a region of the viral plus-strand RNA genome that comprises at least a portion of the 5' -circularized sequence (5' -CS) or the 3' -CS sequence of plus-strand viras (flaviviral) RNA. A highly preferred target is 3' -CS, and an exemplary targeting sequence for dengue virus is set forth below as SEQ ID NO 7. (see, for example, PCT publication No. (WO/2005/030800) or pending and commonly owned U.S. application No. 10/913996, which is incorporated herein by reference).
6.Targeted norovirus (Nidovirus) family viruses
A sixth class of exemplary conjugates is used to inhibit norovirus replication in cells of a virus-infected animal. Exemplary conjugates of this class comprise morpholino oligomers comprising 8-25 nucleotide bases and having sequences that disrupt base pairing between Transcription Regulatory Sequences (TRSs) within the 5 'leader and 3' subgenomic regions of the plus strand viral genome (see, e.g., PCT publication No. WO/2005/065268 or U.S. application publication No. 20070037763, which are incorporated herein by reference).
7.Targeted Filoviruses (Filoviruses)
In another embodiment, one or more conjugates as described herein can be used in a method of inhibiting replication of an ebola or marburg virus in a host cell by contacting the cell with a conjugate as described herein, e.g., a conjugate having a targeting base sequence that is complementary to a target sequence consisting of at least 12 consecutive bases within the AUG initiation site region of a positive strand mRNA, as described in further detail below.
The filovirus genome is a single-stranded RNA of about 19000 bases that is non-segmented and in the antisense orientation. The genome encodes 7 proteins from monocistronic mRNAs complementary to vrnas.
The target sequence is a positive-stranded (sense) RNA sequence spanning or located just downstream (within 25 bases) or upstream (within 100 bases) of the AUG initiation codon of a selected Epovirus protein or the 3' end of a negative-stranded viral RNA. Preferred protein targets are the viral polymerase subunits VP35 and VP24, although L, the nucleoprotein NP and VP30 are also contemplated. Of these, early proteins are favored, for example, VP35 is favored over late-expressed L polymerase.
In another embodiment, one or more conjugates as described herein can be used in a method of inhibiting replication of an ebola or marburg virus in a host cell by contacting the cell with a conjugate as described herein having a targeting base sequence that is complementary to a target sequence consisting of at least 12 consecutive bases within the AUG initiation site region of a filovirus mRNA sequence positive strand mRNA. (see, for example, PCT publication No. WO/2006/050414 or U.S. patent nos. 7524829 and 7507196, and successive applications of U.S. application nos. 12/402455, 12/402461, 12/402464, and 12/853180, which are incorporated herein by reference).
8.Targeted arenaviruses
In another embodiment, the conjugates as described herein may be used in a method of inhibiting viral infection in a mammalian cell by a species in the arenaviridae family. In one aspect, the conjugates can be used to treat a mammalian subject infected with a virus. (see, e.g., PCT publication No. WO/2007/103529 or U.S. Pat. No. 7582615, which are incorporated herein by reference).
Table 5 is an exemplary list of target viruses targeted by the conjugates of the invention, organized by their old world or new world arenavirus classifications.
TABLE 5 target arenaviruses

The genome of arenaviruses consists of two single-stranded RNA fragments designated S (small) and L (large). In the virion, the molar ratio of S-stretch to L-stretch RNA is approximately 2: 1. The full S segment RNA sequences of several arenaviruses have been determined and range from 3366-3535 nucleotides. The full L-segment RNA sequence of several arenaviruses was also determined and ranged from 7102 to 7279 nucleotides. The 3' terminal sequences of the S and L RNA fragments were identical in 17 of the last 19 nucleotides. These terminal sequences are conserved in all known arenaviruses. The 5 '-end 19 or 20 nucleotides of the head end of each genomic RNA are perfectly complementary to each corresponding 3' end. Due to this complementarity, the 3 'and 5' ends are thought to base pair and form panhandle structures (panhandle structures).
Replication of infectious virions or viral rna (vrna) to form viral complementary rna (vcrna) strands of an antigene occurs within infected cells. Both vRNA and vcRNA encode complementary mRNAs; thus, arenaviruses are classified as ambisense RNA viruses, rather than negative-sense or positive-sense RNA viruses. The ambisense orientation of the viral genes is located in the L and S segments. The NP and polymerase genes are located at the 3' ends of the S and L vRNA fragments, respectively, and are encoded in conventional antisense (i.e., they are expressed by transcription of vRNA or genome complementary mRNAs). The genes located at the 5' end of the S and L vRNA fragments, GPC and Z respectively, were encoded as mRNA, but there was no evidence that they were translated directly from genomic vRNA. These genes are not expressed by transcription of genome-sense mRNAs from full-length complementary copies of antigenomic (i.e., vcRNA), genomic vRNA that function as replication intermediates.
An exemplary targeting sequence for an arenaviridae virus is set forth below as SEQ ID NO 8.
9.Targeted respiratory syncytial virus
Respiratory Syncytial Virus (RSV) is the most important respiratory pathogen in young children. RSV causes lower respiratory tract disorders such as bronchiolitis and pneumonia in children younger than 1 year of age, often requiring hospitalization. Children with cardiopulmonary and premature children are particularly susceptible to the serious illness caused by this infection. RSV infection is also an important disease of the elderly and high-risk adults, and it is the second most commonly established cause of viral pneumonia in the elderly (Falsey, Hennessey et al 2005). The world health organization estimates that RSV worldwide causes 6400 million clinical infections and 16 million deaths per year. No vaccine is currently available to prevent RSV infection. Although significant advances have been made in our understanding of RSV biology, epidemiology, pathophysiology, and host immune response over the past decades, there remains considerable debate regarding the optimal management of RSV infected infants. Ribavirin (Ribavirin) is the only antiviral drug approved for the treatment of RSV infections, but its use is limited to high-risk or critically ill infants. The use of ribavirin is limited by its cost, variable efficacy and tendency to produce antiviral effects (Marquardt 1995; Prince 2001). The current need for other effective anti-RSV agents is well known.
Peptide-bound pmo (ppmo) is known to be effective in inhibiting RSV both in tissue culture and in vivo animal model systems (Lai, Stein et al 2008). Two antisense PPMOs designed to target sequences comprising the 5' -terminal region and the translation start site region of RSV L mRNA were tested for anti-RSV activity in cultures of two human airway cell lines. One of them (RSV-AUG-2; SEQ ID NO 10), reduced>2.0log10The virus titer of (a). BALB/c mice treated intranasally (i.n.) with RSV-AUG-2PPMO prior to RSV vaccination produced 1.2log in lung tissue on day 5 post-infection (p.i.)10Reduction in viral titers and relief of pulmonary inflammation at 7 th post-infection. These data indicate that RSV-AUG-2 provides potent anti-RSV activity, and is worthy of further investigation as a candidate for potential therapeutic applications (Lai, Stein et al.2008). Despite the success of RSV-AUG-2PPMO as described above, it is appropriate to use conjugates as disclosed herein to address the toxicity issues associated with previous peptide conjugates. Thus, in another embodiment of the invention, one or more conjugates as described herein can be used in a method of inhibiting replication of RSV in a host cell by contacting the cell with a conjugate as described herein, e.g., a conjugate having a homing base sequence complementary to a target sequence consisting of at least 12 consecutive bases within the AUG start site region of mRNA from RSV, as described in further detail below.
The L gene of RSV encodes a key component of the viral RNA-dependent RNA polymerase complex. Antisense PPMO designed in the form of RSV-AUG-2PPMO for sequences spanning the AUG translation start site codon of the RSV L gene mRNA is complementary to a sequence from the "gene start" sequence (GS) present at the 5' end of the L mRNA to 13 nucleotides into the coding sequence. Thus, the preferred L gene targeting sequence is complementary to any 12 consecutive bases extending 40 bases in the 3 'direction from the 5' end of the L gene mRNA or into the L gene 22 bases encoding the sequence shown as SEQ ID NO 9 in Table 6 below. Exemplary RSV L gene targeting sequences are set forth below in Table 6 as SEQ ID NOs: 10-14. Any of the intersubunit modifications of the invention described herein can be incorporated into oligomers to provide increased antisense activity, increased intracellular delivery, and/or tissue specificity to increase therapeutic activity. Exemplary oligomer sequences containing the intersubunit linkages of the invention are listed in table 6 below.
TABLE 6 RSV targeting and targeting sequences

10.Neuromuscular diseases
In another embodiment, therapeutic conjugates are provided for treating a disease condition associated with a neuromuscular disease in a mammalian subject. Antisense oligomers (e.g., SEQ ID NO:16) have been shown to be active against Duchenne Muscular Dystrophy (DMD) in an MDX mouse model. Exemplary oligomer sequences incorporating linkages used in some embodiments are listed in table 7 below. In some embodiments, the conjugate comprises an oligomer selected from the group consisting of:
(a) human myostatin targeting antisense oligomer having a base sequence complementary to at least 12 consecutive bases within a target region of a human myostatin mRNA identified by SEQ ID NO:18, for use in treating muscle wasting disorders, as previously described (see, e.g., U.S. patent application No. 12/493140, which is incorporated herein by reference; and PCT publication WO 2006/086667). Exemplary mouse targeting sequences are set forth as SEQ ID NOs: 19-20; and
(b) antisense oligomers capable of producing exon skipping in a DMD protein (dystrophin) such as a PMO having a sequence selected from SEQ ID NOs:22-35 to restore partial activity of dystrophin, for use in the treatment of DMD, as previously described (see, e.g., PCT publication nos. WO/2010/048586 and WO/2006/000057 or US patent publication No. US09/061960, all of which are incorporated herein by reference).
Several other neuromuscular diseases can be treated using the modified linkages and terminal groups of the present invention. Exemplary compounds for treating Spinal Muscular Atrophy (SMA) and myotonic Dystrophy (DM) are discussed below.
SMA is an autosomal recessive disease caused by chronic loss of a-motoneurons in the spinal cord and can affect children and adults. Reduced expression of motor neuron Survival (SMN) is responsible for the disease (Hua, Sahashi et al 2010). The mutation causing SMA is in the SMN1 gene, but a parallel homologous gene, SMN2, if expressed from a selectively spliced form lacking exon 7(δ 7SMN2), can allow survival by compensating for the loss of SMN 1. Antisense compounds targeting intron 6, exon 7, and intron 7 have all been shown to induce varying degrees of exon 7 incorporation (inclusion). Antisense compounds targeting intron 7 are preferred (see, e.g., WO/2010/148249, WO/2010/120820, WO/2007/002390 PCT publication and 7838657 U.S. patent). Exemplary antisense sequences that target SMN2 pre-mRNA and induce increased exon 7 inclusion are listed below as SEQ ID NOs: 36-38. Selected modifications to these oligomer sequences using the modified linkages and terminal groups described herein are expected to have improved performance over what is known in the art. Furthermore, any oligomer targeting intron 7 of the SMN2 gene and incorporating features of the invention is expected to have the potential to induce exon 7 inclusion and provide therapeutic effects to SMA patients. Myotonic dystrophy type 1(DM1) and type 2(DM2) are major genetic diseases caused by neuromuscular degeneration due to toxic RNA expression. DM1 and DM2 are associated with long polycug and polycugs repeats within the 3' -UTR and intron 1 regions of Dystrophic Myotonic Protein Kinase (DMPK) and zinc finger protein 9(ZNF9), respectively (see, e.g., WO 2008/036406). While normal individuals have up to 30 CTG repeats, DM1 patients carry a greater number of repeats ranging from 50 to several thousand. The severity and age of onset of the disease are related to the number of repeats. Adult onset patients show mild symptoms and have less than 100 repeats, juvenile onset DM1 patients carry up to 500 repeats, and congenital conditions typically have about 1000 CTG repeats. The increased transcripts containing CUG repeats form secondary structures, accumulate in the nucleus in the form of nuclear foci (nuclear foci), and sequester RNA-binding proteins (RNA-BP). Several RNA-BPs are implicated in this disease, including the Blind muscle-like (MBNL) protein and the CUG binding protein (CUGBP). MBNL proteins are homologous to the photoreceptor and drosophila blindus muscle (Mbl) proteins that are essential for muscle differentiation. MBNL and cubbp were identified as antagonistic splice modulators affecting transcripts in DM1, such as cardiac troponin t (ctnt), Insulin Receptor (IR), and muscle-specific chloride channel (ClC-1).
It is known in the art that antisense oligonucleotides targeting increased repeats of the DMPK gene can replace RNA-BP sequestration and reverse myotonic symptoms in animal models of DM1 (WO 2008/036406). Oligomers comprising the features of the present invention are expected to provide increased activity and therapeutic potential for DM1 and DM2 patients. Exemplary sequences targeting the above-described polycug and polycccug repeats are set forth below as SEQ ID NOs:39-55, and are further described in U.S. application No. 13/101942, which is incorporated herein in its entirety.
Other embodiments of the invention for treating neuromuscular disorders are contemplated, including oligomers designed to treat other DNA repeat instability genetic diseases. These diseases include Huntington's disease, spinocerebellar ataxia (spino-cerebellar ataxia), X-chromosome associated spinal and bulbar muscular atrophy, and spinocerebellar ataxia type 10(SCA10), as described in WO 2008/018795.
TABLE 7M 23D sequences comprising modified intersubunit linkages and/or 3 'and/or 5' terminal groups (SEQ ID NO:15)





*Dimerized means that the oligomer is dimerized by a linkage connecting the 3' ends of the two monomers. For example, the connection may be a-COCH2CH2-S-CH(CONH2)CH2-CO-NHCH2CH2CO-or any other suitable linkage. EG3 refers to the triethylene glycol tail (see, e.g., conjugates in examples 30 and 31).
11.Antibacterial applications
In another embodiment, the invention includes a conjugate comprising an antimicrobial antisense oligomer for use in treating a bacterial infection in a mammalian host. In some embodiments, the oligomer comprises a targeting sequence of 10-20 bases and at least 10 consecutive bases, wherein the consecutive bases are complementary to a target region of the mRNA of the acyl carrier protein (acpP), gyrA a subunit (gyrA), ftsZ, ribosomal protein S10(rpsJ), leuD, mgtC, pirG, pcaA, and cma1 genes of an infectious bacterium, wherein the target region contains the bacterial mRNA or a translation initiation codon of a sequence located within 20 bases upstream (i.e., 5 ') or downstream (i.e., 3') of the translation initiation codon, and wherein the oligomer ligates to the mRNA to form a hybrid duplex, thereby inhibiting replication of the bacterium.
12.Modulation of nuclear hormone receptors
In another embodiment, the invention relates to compositions and methods for modulating the expression of Nuclear Hormone Receptors (NHRs) from the Nuclear Hormone Receptor Superfamily (NHRSF), primarily by controlling or altering the splicing of precursor mRNAs encoding the receptors. Examples of specific NHRs include: glucocorticoid Receptor (GR), Progesterone Receptor (PR), and Androgen Receptor (AR). In certain embodiments, the conjugates described herein can cause increased expression of the ligand-independent or other selected form of the receptor, and decreased expression of their inactive forms.
Embodiments of the invention include conjugates comprising an oligomer, e.g., an oligomer complementary to the exon or intron sequence of a selected NHR, wherein the exon or intron includes the "ligand-binding exon" and/or adjacent intron of NHRSF pre-mRNA, in addition to other NHR domains described herein. The term "ligand-binding exon" refers to an exon that is present in a wild-type mRNA, but is removed from a primary transcript ("pre-mRNA") to produce a ligand-independent form of the mRNA. In certain embodiments, complementarity may be based on sequences in the pre-mRNA sequence that span the splice site, including, but not limited to, complementarity based on sequences that span an exon-intron junction. In other embodiments, complementarity may be based solely on sequences of introns. In other embodiments, complementarity may be based solely on the sequence of the exons. (see, e.g., U.S. application No. 13/046356, which is incorporated herein by reference).
NHR modulators are useful for treating NHR-related diseases, including diseases associated with the expression products of genes whose transcription is stimulated or inhibited by NHRs. For example, modulators of NHRs that inhibit AP-1 and/or NF- κ B may be useful for the treatment of inflammatory and immune diseases and conditions such as: osteoarthritis, rheumatoid arthritis, multiple sclerosis, asthma, inflammatory bowel disease, transplant rejection, and graft-versus-host disease, as well as other types described herein and known in the art. Antagonistic transactivation compounds are useful for the treatment of metabolic disorders associated with increased glucocorticoid levels, such as diabetes, osteoporosis, and glaucoma, among others. In addition, compounds that promote (agonize) transactivation may be useful in the treatment of metabolic disorders associated with glucocorticoid insufficiency, such as Addison's disease and other diseases.
Embodiments of the invention include methods of modulating activity or expression of NHR in a cell comprising contacting the cell with a conjugate comprising a carrier protein and an antisense oligomer consisting of morpholino subunits linked by a phosphorus-containing intersubunit linkage linking a morpholino nitrogen of one subunit to a phosphorus-containing exocyclic carbon of an adjacent subunit, wherein the oligonucleotide comprises 10-40 bases and a targeting sequence of at least 10 contiguous bases complementary to the target sequence, wherein the target sequence is a precursor mRNA transcript of NHR, thereby modulating the activity or expression of NHR. In certain embodiments, the oligomer can alter the splicing of the precursor mRNA transcript and increase expression of a variant of the NHR. In some embodiments, the oligomer induces complete or partial exon skipping of one or more exons of the pre-mRNA transcript. In certain embodiments, the one or more exons encode at least a portion of the ligand-binding domain of NHR, and the variant is a ligand-independent form of NHR. In certain embodiments, the one or more exons encode at least a portion of a transactivation domain of a NHR, and the variant has reduced transcriptional activation activity. In certain embodiments, the one or more exons encode at least a portion of the DNA-binding domain of a NHR. In certain embodiments, the one or more exons encode at least a portion of the N-terminal activation domain of a NHR. In certain embodiments, the one or more exons encode at least a portion of the carboxy-terminal domain of a NHR. In particular embodiments, the variant binds to NF-KB, AP-l, or both and reduces transcription of one or more of their pro-inflammatory target genes.
In certain embodiments, the oligomer promotes transactivation transcriptional activity of (agonife) NHR. In other embodiments, the oligomer antagonizes the transactivating transcriptional activity of NHR. In certain embodiments, the oligomer promotes the trans-inhibitory activity of NHR. In other embodiments, the oligomer antagonizes the trans inhibitory activity of NHR. In particular embodiments, the oligomer antagonizes the transactivating transcriptional activity of NHR and promotes the trans inhibitory activity of NHR. (see, e.g., U.S. application No. 61/313652, which is incorporated herein by reference).
Examples
All chemicals were obtained from Sigma-Aldrich-Fluka unless otherwise stated. Benzoyl adenosine, benzoyl cytidine and phenylacetyl guanosine were obtained from Carbosynth Limited, uk.
The synthesis of PMO, PMO +, PPMO, and PMO containing other linkage modifications as described herein, are accomplished using methods known in the art and described in pending U.S. application nos. 12/271036 and 12/271040 and PCT publication No. WO/2009/064471, which are hereby incorporated by reference in their entirety.
PMOs with 3' trityl modifications were synthesized essentially as described in PCT publication WO/2009/064471, except that the detritylation step was omitted.
Example 1
4- (2,2, 2-trifluoroacetamido) piperidine-1-carboxylic acid tert-butyl ester

Ethyl trifluoroacetate (35.6mL, 0.300mol) was added dropwise with stirring to a suspension of tert-butyl 4-aminopiperidine-1-carboxylate (48.7g, 0.243mol) and DIPEA (130mL, 0.749mol) in DCM (250 mL). After 20 hours, the solution was washed with citric acid solution (200mL x3, 10% w/v aqueous solution) and sodium bicarbonate solution (200mL x3, concentrated aqueous solution), dried (MgSO)4) And filtered through silica (24 g). The silica was washed with DCM and the combined eluent fractions were concentrated (100mL) and used directly in the next step. C12H19F3N2O3Calculated APCI/MS of 296.1, found M/z 294.9 (M-1).
Example 2
2,2, 2-trifluoro-N- (piperidin-4-yl) acetamide hydrochloride

Will dissolve in 1A solution of 4-dioxane (4M) in hydrogen chloride (250mL, 1.0mol) was added dropwise to a stirred solution of the title compound of example 1 in DCM (100 mL). Stirring was continued for 6 hours, then the suspension was filtered and the solid was washed with diethyl ether (500mL) to provide the title compound (54.2g, 96% yield) as a white solid. C7H11F3N2O has an APCI/MS calculated of 196.1 and an M/z found of 196.9(M + 1).
Example 3
(4- (2,2, 2-trifluoroacetamido) piperidin-1-yl) dichlorophosphoric acid

Phosphorus oxychloride (23.9mL, 0.256mol) and DIPEA (121.7mL, 0.699mol) were added dropwise to a cooled (ice bath/water bath) suspension of the title compound of example 2 (54.2g, 0.233mol) in DCM (250mL) and stirred. After 15 minutes, the cooling bath was removed and the mixture was stirred continuously to allow it to warm to ambient temperature. After 1 hour, the mixture was partially concentrated (100mL), the suspension was filtered and the solid was washed with diethyl ether to provide the title compound (43.8g, 60% yield) as a white solid. The eluent was partially concentrated (100mL), the resulting suspension was filtered and the solid was washed with diethyl ether to afford the other title compound (6.5g, 9% yield). 1- (4-nitrophenyl) piperazine derivative C17H22ClF3N5O4Calculated ESI/MS for P is 483.1, found M/z is 482.1 (M-1).
Example 4
((2S,6S) -6- ((R) -5-methyl-2, 6-dioxo-1, 2,3, 6-tetrahydropyridin-3-yl) -4-tritylmorpholin-2-yl) methyl (4- (2,2, 2-trifluoroacetamido) piperidin-1-yl) chlorophosphonate

Mo (Tr) T # (22.6g, 46.7mmol), 2, 6-Lu spindle (21.7 mL, 187mmol) and 4- (dimethylamino) were mixed over 10 minutesA solution of pyridine (1.14g, 9.33mmol) in DCM (100mL) was added dropwise to a stirred and cooled (ice/water bath) solution of the title compound of example 3 (29.2g, 93.3mmol) in DCM (100 mL). The cold bath was allowed to warm to ambient temperature. After 15 hours, the solution was washed with citric acid solution (200mL x3, 10% w/v aqueous solution) and dried (MgSO4) Concentrated and the crude oil loaded directly onto the column. Concentration chromatography [ SiO2Column (120g), hexane/EtOAc eluent (gradient 1:1 to 0:1), repeat x3]Fraction (fraction) to provide the title compound (27.2g, 77% yield) as a white solid. 1- (4-nitrophenyl) piperazine derivative C46H50F3N8O8The calculated ESI/MS for P was 930.3, found M/z 929.5 (M-1).
Example 5
((2S,6R) -6- (6-benzamido-9H-purin-9-yl) -4-tritylmorpholin-2-yl) methyl (4- (2,2, 2-trifluoroacetamido) piperidin-1-yl) chlorophosphonate

The title compound was synthesized in analogy to the procedure described in example 4 to provide the title compound (15.4g, 66% yield) as a white solid. 1- (4-nitrophenyl) piperazine derivative C53H53F3N11O7The calculated ESI/MS for P was 1043.4, found M/z 1042.5 (M-1).
Example 6
(R) -methyl (1-phenylethyl) aminophosphoryl dichloride

A solution of 2, 6-lutidine (7.06mL, 60.6mmol) and (R) - (+) -N, a-dimethylbenzylamine (3.73g, 27.6mmol) in DCM was added dropwise with stirring to a cooled (ice/water bath) solution of phosphorus oxychloride (2.83mL, 30.3mmol) in DCM (30 mL). After 5 minutes, the cooling bath was removed and the reaction was allowed to mixThe material was warmed to ambient temperature. After 1 hour, the reaction solution was washed with citric acid solution (50mL x3, 10% w/v aqueous solution) and dried (MgSO)4) By SiO2Filtered and concentrated to provide the title compound (3.80g) as a white foam. 1- (4-nitrophenyl) piperazine derivative C19H25N4O4The calculated ESI/MS for P was 404.2, and the measured M/z was 403.1 (M-1).
Example 7
(S) -methyl (1-phenylethyl) aminophosphoryl dichloride

The title compound was synthesized in analogy to the procedure described in example 6 to provide the title compound (3.95g) as a white foam. C of 1- (4-nitrophenyl) piperazine derivative19H25N4O4The calculated ESI/MS for P was 404.2, and the measured M/z was 403.1 (M-1).
Example 8
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methyl ((R) -1-phenylethyl) chloroaminophosphate

The title compound was synthesized in analogy to the procedure described in example 4 to provide the title compound phosphoramido chloride (4.46g, 28% yield) as a white solid. C38H40ClN4O5The calculated ESI/MS for P was 698.2, found M/z 697.3 (M-1).
Example 9
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methyl ((S) -1-phenylethyl) chloroaminophosphate

The title compound was synthesized in analogy to the procedure described in example 4 to provide the title compound phosphoramido chloride (4.65g, 23% yield) as a white solid. C38H40ClN4O5The calculated ESI/MS for P was 698.2, found M/z 697.3 (M-1).
Example 10
(4- (pyrrolidin-1-yl) piperidin-1-yl) phosphoryl dichloride hydrochloride

A solution of 2, 6-lutidine (19.4mL, 167mmol) and 4- (1-pyrrolidinyl) -piperidine (8.58g, 55.6mmol) in DCM (30mL) was added to a cooled (ice bath/water bath) solution of phosphorus oxychloride (5.70mL, 55.6mmol) in DCM (30mL) and stirred for 1 h. The suspension was filtered and the solid was washed with excess diethyl ether to afford the title pyrrolidine (17.7g, 91% yield) as a white solid. 1- (4-nitrophenyl) piperazine derivative C19H30N5O4The calculated ESI/MS for P was 423.2, found M/z 422.2 (M-1).
Example 11
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methyl (4- (pyrrolidin-1-yl) piperidin-1-yl) chlorophosphonate hydrochloride

A solution of Mo (Tr) T # (24.5g, 50.6mmol), 2, 6-lutidine (17.7mL, 152mmol), and 1-methylimidazole (0.401mL, 5.06mmol) in DCM (100mL) was added dropwise over 10 minutes to a stirred and cooled (ice/water bath) solution of dichlorophosphoramide ester 8(17.7g, 50.6mmol) in DCM (100 mL). The cold bath was allowed to warm to ambient temperature while the suspension was stirred. After 6 hours, the suspension is poured into diethyl etherOver ether (1L), stirred for 15 min, filtered and the resulting solid washed with additional ether to afford a white solid (45.4 g). By chromatography [ SiO ]2Column (120g), DCM/MeOH eluent (gradient 1:0 to 6:4)]The crude product was purified and the combined fractions were poured onto diethyl ether (2.5L), stirred for 15 minutes, filtered and the resulting solid washed with additional ether to provide the title compound (23.1g, 60% yield) as a white solid. 1- (4-nitrophenyl) piperazine derivative C48H57N8O7The calculated ESI/MS for P was 888.4, found M/z 887.6 (M-1).
Example 12
3- (tert-butyldisulfonyl) -2- (isobutoxycarbonylamino) propionic acid

Will dissolve in H2K of O (20mL)2CO3(16.5g, 119.5mmol) was added to the solution in CH3CN (40mL) in S-tert-butylmercapto-L-cysteine (10g, 47.8 mmol). After stirring for 15 min, isobutyl chloroformate (9.4mL, 72mmol) was slowly injected. The reaction was allowed to proceed for 3 hours. The white solid was filtered through Celite filter aid; the filtrate was concentrated to remove CH3And (C) CN. The residue was dissolved in ethyl acetate (200mL), washed with 1N HCl (40mL X3), brine (40X1), and Na2SO4And (5) drying. Chromatography (5% MeOH/DCM) gave the expected product (2).
Example 13
4- (3- (tert-Butyldisulfonyl) -2- (isobutoxycarbonylamino) propionamido) piperidine-1-carboxylic acid tert-butyl ester

HATU (8.58g, 22.6mmol) was added to an acid (compound 2 from example 12, 6.98g, 22.6mmol) dissolved in DMF (50 ml). After 30 min, Hunig's base (4.71ml, 27.1mmol) and 1-Boc-4-aminopiperidine (5.43g, 27.1mmol) were added to the mixture. At room temperatureThe reaction was continued for another 3 hours with stirring. DMF was removed under high vacuum and the crude residue was dissolved in EtAc (300ml) with H2O (50ml X3) wash. ISCO purification (5% MeOH/DCM) afforded the final product (3).
Example 14
3- (tert-Butyldisulfonyl) -1-oxo-1- (piperidin-4-ylamino) propan-2-ylcarbamic acid isobutyl ester

30ml of 4M HCl/dioxane were added to compound 3(7.085g, 18.12mmol) prepared in example 13. The reaction was complete after 2 hours at room temperature. The HCl salt (4) was used in the next step without further purification.
Example 15
3- (tert-Butyldisulfonyl) -1- (1- (dichlorophosphoryl) piperidin-4-ylamino) -1-oxoprop-2-ylcarbamic acid isobutyl ester

POCl was reacted at-78 ℃ under argon atmosphere3(1.69ml, 18.12mmol) was slowly injected into a solution of Compound 4 prepared in example 15 (7.746g, 18.12mmol) in DCM (200ml) followed by the addition of Et3N (7.58ml, 54.36 mmol). The reaction was stirred at room temperature for 5 hours and concentrated to remove excess base and solvent. After ISCO purification (50% EtAc/hexanes) the product (5) was obtained as a white solid.
Example 16
3- (tert-Butyldisulfonyl) -1- (1- (chloro (((2S, 6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methoxy) phosphoryl) piperidin-4-ylamino) -1-oxopropan-2-ylcarbamic acid isobutyl ester

Lutidine (1.92ml, 16.47mmol) and DMAP (669mg, 5.5mmol) were added to 1- ((2R, 6S) -6- (hydroxymethyl) -4-tritylmorpholin-2-yl) -5-methylpyrimidine-2, 4(1H, 3H) -dione (mot) (5.576g, 10.98mmol) dissolved in DCM (100ml) at 0 ℃ followed by 4(6.13g, 12.08 mmol). The reaction was left to stir at room temperature for 18 hours. After ISCO purification (50% EtAc/hexanes) the expected product (6) was obtained.
Example 17
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methylhexyl (methyl) chloroaminophosphate

In N2A solution of N-antelope methylamine (4.85ml, 32mmol) in DCM (80ml) was cooled to-78 ℃. A solution of phosphoryl chloride (2.98ml, 32mmol) in DCM (10ml) was added slowly followed by the slow addition of Et3N (4.46ml, 32mmol) in DCM (10 ml). The reaction was allowed to proceed with continued stirring to warm to room temperature overnight. After ISCO purification (20% EtAc/hexanes) the desired product (1) was obtained as clear oil.
Lutidine (3.68ml, 31.6mmol) and DMAP (642mg, 5.27mmol) were added to mot (Tr) (5.10g, 10.54mmol) dissolved in DCM (100ml) at 0 deg.C followed by 1(4.89g, 21.08 mmol). The reaction was left to stir at room temperature for 18 hours. ISCO purification (50% EtOAc/hexanes) gave the desired product (2).
Example 18
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methyldodecyl (methyl) chloroaminophosphate

The title compound was prepared according to the general procedures described in example 6 and example 8.
Example 19
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methylmorpholino phosphorochloridate

The title compound was prepared according to the general procedures described in example 6 and example 8.
Example 20
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methyl (S) -2- (methoxymethyl) pyrrolidin-1-yl chlorophosphate

The title compound was prepared according to the general procedures described in example 6 and example 8.
Example 21
((2S,6R) -6- (5-methyl-2, 4-dioxo-3, 4-dihydropyrimidin-1 (2H) -yl) -4-tritylmorpholin-2-yl) methyl 4- (3, 4, 5-trimethoxybenzamido) piperidin-1-yl chlorophosphate

Hunig base (1.74ml, 10mmol) was added to 1-Boc-4-piperidine (1g, 5mmol) dissolved in DCM (20ml) followed by 3,4, 5-trimethoxybenzoyl chloride (1.38g, 6 mmol). The reaction was allowed to proceed at room temperature for 3 hours and concentrated to remove the solvent and excess base. The residue was dissolved in EtAc (100ml) and washed with 0.05N HCl (3X 15ml), saturated NaHCO3(2X 15ml) Wash with Na2SO4And (5) drying. ISCO purification (5% MeOH/DCM) afforded the product (1).
15ml of 4N HCl/dioxane were added to 7 and the reaction was terminated after 4 hours. 8 was obtained as a white solid.
In N2A solution of 8(1.23g, 4.18mmol) in DCM (20ml) was cooled to-78 ℃. A solution of phosphoryl chloride (0.39ml, 4.18mmol) in DCM (2ml) was added slowly followed by Et slowly3N (0.583ml, 4.18mmol) in DCM (2 ml). The reaction was allowed to proceed with continued stirring to warm to room temperature overnight. After ISCO purification (50% EtAc/hexanes) the expected product (9) was obtained.
Lutidine (0.93ml, 8mmol) and DMAP (49mg, 0.4mmol) were added to a solution of 0 ℃ mot (Tr) (1.933g, 4.0mmol) in DCM (20ml) followed by 9(1.647g, 4 mmol). The reaction was left to stir at room temperature for 18 hours. After ISCO purification (50% EtAc/hexanes) the expected product (10) was obtained.
Example 22
Synthesis of a peptide containing subunit (CPCyclophosphamide of T)

moT subunits (25g) were suspended in DCM (175ml) and NMI (N-methylimidazole, 5.94g, 1.4eq.) was added to give a clear solution. P-toluenesulfonyl chloride was added to the reaction mixture and the progress of the reaction was monitored by TLC until completion (about 2 hours). Aqueous treatment was accomplished by washing with 0.5M citric acid buffer (pH 5) and then brine. The organic layer was separated and washed with Na2SO4And (5) drying. The solvent was removed on a rotary evaporator to give the crude product, which was used in the next step without further purification.
moT tosylate salt prepared above was mixed with propanolamine (1g/10 ml). The reaction mixture was then placed in an oven at 45 ℃ overnight and subsequently diluted with DCM (10 ml). Aqueous treatment was accomplished by washing with 0.5M citric acid buffer (pH 5) and then brine. The organic layer was separated and washed with Na2SO4And (5) drying. The solvent was removed by rotary evaporator to give crude product. The crude product was analyzed and determined by NMR and HPLC and was used as next step without further purification.
The crude product was dissolved in DCM (2.5ml DCM/g, 1eq.) and mixed with DIEA (3 eq.). Cooling with dry ice-acetoneThe solution was added dropwise with POCl3(1.5 eq.). The resulting mixture was stirred at room temperature overnight. Aqueous treatment was accomplished by washing with 0.5M citric acid buffer (pH 5) and then brine. The organic layer was separated and washed with Na2SO4And (5) drying. The solvent was removed with a rotary evaporator to give the crude product as a yellowish solid. The crude product was purified by silica gel chromatography (1 to 5 ratio crude product/silica, gradient DCM to 50% EA/DCM) and the eluted fractions were combined according to TLC analysis. The solvent was removed to give the desired product as a mixture of diastereomers. The purified product was analyzed by HPLC (NPP quenching) and NMR (H-1 and P-31).
The diastereomeric mixtures were separated according to the following procedure. The mixture (2.6g) was dissolved in DCM. The sample was loaded on a RediSepRf column (80g normal phase, manufactured by Teledyne Isco) and eluted with 10% EA/DCM to 50% EA/DCM for 20 min. The eluted fractions were collected and analyzed by TLC. The eluted fractions were combined according to TLC analysis and the solvent was removed at room temperature using a rotary evaporator. The diastereomer ratio of the combined fractions was determined by P-31NMR and NPP-TFA analysis. If desired, the above procedure was repeated until the diastereomer ratio reached 97%.
Example 23
Total cholic acid modification of PMO +

Succinimide-activated cholic acid derivatives were prepared according to the following procedure. Cholic acid (12g, 29.4mmol), N-hydroxysuccinimide (4.0g, 34.8mmol), EDCI (5.6g, 29.3mmol) and DMAP (1g, 8.2mmol) were charged to a round-bottomed flask. DCM (400ml) and THF (40ml) were added to dissolve. The reaction mixture was stirred at room temperature overnight. Water (400ml) was then added to the reaction mixture, the organic layer was separated and washed with water (2X 400ml) and then saturated NaHCO3(300ml) and brine (300 ml). Followed by application of Na2SO4The organic layer was dried. The solvent was removed with a rotary evaporator to give a white solid. The crude product was dissolved in chloroform (100ml) and precipitatedHeptane (1000 ml). The solid was collected by filtration, analyzed by HPLC and NMR, and used without purification.
The appropriate amount of PMO + (20mg, 2.8. mu. mol) was weighed into a vial (4ml) and dissolved in DMSO (500. mu.l). The activated cholate (13mg, 25 μmol) was added to the reaction mixture at a ratio of 2 equivalents of active ester per modification site, followed by stirring at room temperature overnight. The progress of the reaction was determined by MALDI and HPLC (C-18 or SAX).
After the reaction was complete (as determined by disappearance of the starting PMO +), 1ml of concentrated ammonia was added to the reaction mixture once the reaction was complete. The reaction vial was then placed in an oven (45 ℃) overnight (18 hours), then cooled to room temperature and diluted with 1% ammonia (10ml) in water. The sample was loaded onto a SPE column (2cm) and the vial was rinsed with 1% ammonia solution (2X 2 ml). The SPE column was washed with 1% ammonia in water (3X 6ml) and the product was eluted with 45% acetonitrile in 1% aqueous ammonia (6 ml). Elution fractions containing oligomers were identified by UV densitometry. The product was isolated by lyophilization. Purity and identity were determined by MALDI and HPLC (C-18 and/or SAX).
The same procedure applies to deoxycholic acid activation and binding to PMO+The above.
Example 24
Total guanidation of PMO +
An appropriate amount of PMO + (25mg, 2.8. mu. mol) was weighed into a vial (6 ml). 1H-pyrazole-1-carboxamidine chloride (15mg, 102. mu. mol) and potassium carbonate (20mg, 0.15mmol) were added to the vial. Water (500. mu.l) was added and the reaction mixture was stirred at room temperature overnight (about 18 hours). Completion of the reaction was confirmed by MALDI.
Once complete, the reaction was diluted with 1% ammonia in water (10ml) and loaded onto an SPE cartridge (2 cm). The vial was rinsed with 1% ammonia solution (2X 2ml) and the SPE cartridge was washed with 1% ammonia in water (3X 6 ml). The product was eluted with 45% acetonitrile in 1% aqueous ammonia (6 ml). Elution fractions containing oligomers were identified by UV densitometry. The product was isolated by lyophilization. Purity and identity were determined by MALDI and HPLC (C-18 and/or SAX).
Example 25
Total thioacetyl modification of PMO + (M23D)

The appropriate amount of PMO + (20mg, 2.3. mu. mol) was weighed into a vial (4ml) and dissolved in DMSO (500. mu.l). N-Succinimidyl-S-acetylthioacetate (SATA) (7mg, 28. mu. mol) was added to the reaction mixture and allowed to stir at room temperature overnight. The progress of the reaction was monitored by MALDI and HPLC.
Once complete, 1% ammonia dissolved in water was added to the reaction mixture and stirred at room temperature for 2 hours. The solution was loaded onto a SPE cartridge (2 cm). The vial was rinsed with 1% ammonia solution (2X 2ml) and the SPE cartridge was washed with 1% ammonia in water (3X 6 ml). The product was eluted with 45% acetonitrile in 1% aqueous ammonia (6 ml). Elution fractions containing oligomers were identified by UV densitometry. The product was isolated by lyophilization. Purity and identity were determined by MALDI and HPLC (C-18 and/or SAX).
Example 26
Total succinic acid modification of PMO +

The appropriate amount of PMO + (32mg, 3.7. mu. mol) was weighed into a vial (4ml) and dissolved in DMSO (500. mu.l). N-Ethylmorpholino (12mg, 100. mu. mol) and succinic anhydride (10mg, 100. mu. mol) were added to the reaction mixture and allowed to stir at room temperature overnight. The progress of the reaction was monitored by MALDI and HPLC.
Once complete, 1% ammonia dissolved in water was added to the reaction mixture and stirred at room temperature for 2 hours. The solution was loaded onto a SPE cartridge (2 cm). The vial was rinsed with 1% ammonia solution (2X 2ml) and the SPE cartridge was washed with 1% ammonia in water (3X 6 ml). The product was eluted with 45% acetonitrile in 1% aqueous ammonia (6 ml). Elution fractions containing oligomers were identified by UV densitometry. The product was isolated by lyophilization. Purity and identity were determined by MALDI and HPLC (C-18 and/or SAX).
The above procedure is also applicable to the glutaric acid (glutaric anhydride) and tetramethylene glutaric acid (tetramethylene glutaric anhydride) modification of PMO +.

Example 27
Preparation of oligonucleotide analogs comprising modified terminal groups
Farnesyl bromide (1.75. mu.l, 6.452. mu. mol) and diisopropylethylamine (2.24. mu.L, 12.9. mu. mol) were added to a DMSO (300. mu.L) solution containing the 25-mer PMO (27.7mg, 3.226. mu. mol) at the free 3' end. The reaction mixture was stirred at room temperature for 5 hours. With 10mL of 1% aqueous NH4The crude reaction mixture was diluted with OH and then loaded onto a 2mL Amberchrome CG300M column. The column was then rinsed with 3 column volumes of water and the product eluted with 6mL1:1 of acetonitrile and water (v/v). The solution was then lyophilized to give the title compound as a white solid.
Example 28
Preparation of morpholino oligomers
Preparation of trityl piperazine phenyl carbamate 35 (see fig. 3): a solution of potassium carbonate (3.2eq) in water (4mL/g potassium carbonate) was added to a cooled suspension of Compound 11 in dichloromethane (6mL/g 11). A solution of phenyl chloroformate (1.03eq) in methylene chloride (2g/g phenyl chloroformate) was slowly added to the mixture of the two phases. The reaction mixture was warmed to 20 ℃. Once the reaction was complete (1-2 hours), the different layers were separated. The organic layer was washed with water and dried over anhydrous potassium carbonate. The product 35 was isolated from acetonitrile by crystallization. The yield was 80%.
Preparation of carbamate ethanol (carbamate alcohol) 36: sodium hydride (1.2eq) was suspended in 1-methyl-2-pyrrolidone (32mL/g sodium hydride). Triethylene glycol (10.0eq) and compound 35(1.0eq) were added to the suspension. The resulting slurry was heated to 95 ℃. Once the reaction was complete (1-2 hours), the mixture was cooled to 20 ℃. 30% methylene chloride/methyl tert-butyl ether (v: v) and water were added to the mixture. The product containing the organic layer was washed successively with an aqueous NaOH solution, an aqueous succinic acid solution and a saturated aqueous sodium chloride solution. Product 36 was isolated by crystallization from dichloromethane/methyl tert-butyl ether/heptane. The yield was 90%.
Preparation of tail acid 37: succinic anhydride (2.0eq) and DMAP (0.5eq) were added to a solution of compound 36 in tetrahydrofuran (7mL/g 36). The mixture was heated to 50 ℃. Once the reaction was complete (5 hours), the mixture was cooled to 20 ℃ and NaHCO was used3The aqueous solution was adjusted to pH 8.5. Methyl tertiary-butyl ether was added and the product was extracted into the aqueous layer. Dichloromethane was added and the mixture was adjusted to pH 3 with aqueous citric acid. The product containing the organic layer was washed with a mixture of citrate buffer at pH 3 and saturated aqueous sodium chloride solution. This dichloromethane solution of 37 was used directly without isolation in the preparation of compound 38.
38 preparation: n-hydroxy-5-norbornene-2, 3-dicarboxylic acid imide (HONB) (1.02eq), 4-Dimethylaminopyridine (DMAP) (0.34eq) were added to the solution of compound 37 followed by 1- (3-dimethylaminopropyl) -N' -ethylcarbodiimide hydrochloride (EDC) (1.1 eq). The mixture was heated to 55 ℃. Once the reaction was complete (4-5 hours), the mixture was cooled to 20 ℃ and washed with 1:1 of 0.2M citric acid/brine and brine in sequence. The dichloromethane solution was solvent exchanged for acetone and subsequently for N, N-dimethylformamide and the product was isolated by precipitation from acetone/N, N-dimethylformamide to a saturated aqueous sodium chloride solution. The crude product was reslurried several times in water to remove residual N, N-dimethylformamide and salts. The yield of preparation 38 from compound 36 was 70%. Introduction of the activated "tail" onto the disulfide-anchored resin was performed in NMP by a procedure for incorporation of the subunit during solid phase synthesis.
Preparation of solid support (support) for synthesis of morpholino oligomers: the procedure was carried out in silanized jacketed peptide tubing (custom made by Chemglass Inc. of New Jersey, USA) with coarse porosity (40-60 μm) glass frit, overhead stirrer and 3-pass Teflon plug valve to allow N2Bubbling up through the frit or vacuum extraction. Temperature control was achieved in the reaction vessel by circulating a water bath.
The resin treatment/washing step in the following procedure consists of two basic operations: resin fluidization and solvent/solution extraction. For resin fluidization, place stopcock in place to allow N2Flows up through the frit, adds the designated resin treatment/washing liquid to the reactor and allows it to penetrate and completely wet the resin. Mixing was then started and the resin slurry was mixed for the indicated time. For solvent/solution extraction, mixing and N were stopped2Flow and turn on the vacuum pump, then place the stopcock valve in the appropriate position to allow the resin treatment/wash to drain to the waste tank (waste). All resin treatment/wash volumes were 15mL/g resin unless otherwise stated.
1-methyl-2-pyrrolidone (NMP; 20ml/g resin) was added to an aminomethyl polystyrene resin (100-200 mesh; -1.0 mmol/g N) in a silanized jacketed peptide tube2A substituent; 75g, 1eq, Polymer Labs, UK, part #1464-X799) and allow the resin to expand for 1-2 hours with stirring. After evacuation of the expansion solvent, the resin was washed with dichloromethane (2X 1-2 min), 5% diisopropylethylamine dissolved in 25% isopropanol/dichloromethane (2X 3-4 min) and dichloromethane (2X 1-2 min). After the final wash was drained, the resin was fluidized with a solution of the disulfide anchor 34 dissolved in 1-methyl-2-pyrrolidone (0.17M; 15mL/g resin,. about.2.5 eq), and the resin/reagent mixture was heated at 45 ℃ for 60 hours. Upon completion of the reaction, the heating was stopped and the anchoring solution was drained, followed by washing the resin with 1-methyl-2-pyrrolidone (4x 3-4 min) and dichloromethane (6x 1-2 min). The resin was treated with a solution of 10% (v/v) diethylpyrocarbonate in dichloromethane (16 mL/g; 2X 5-6 min) followed by washing with dichloromethane (6X 1-2 min). In N2The resin 39 (see fig. 4) was dried under flow for 1-3 hours and then dried under vacuum to constant weight (+ -2%). Yield: 110-150% of the initial resin weight.
Load measurement of aminomethyl polystyrene-disulfide resin: the loading of the resin (number of potentially available reaction sites) is determined by spectrometric analysis of the number of triphenylmethyl groups (trityl groups) per gram of resin.
A known weight of dry resin (25. + -.3 mg) was transferred to a silanized 25mL volumetric flask and 2% (v/v) trifluoroacetic acid in 5mL of dichloromethane was added. The contents were mixed by gentle rotation and then allowed to stand for 30 minutes. The volume was diluted to 25mL with an additional 2% (v/v) trifluoroacetic acid in dichloromethane and the contents mixed thoroughly. Using a positive displacement pipette, 1 part of the trityl containing solution (500. mu.L) was transferred to a10 mL volumetric flask and the volume was diluted to 10mL with methanesulfonic acid.
The trityl cation content of the final solution was measured by UV absorbance at 431.7nm and the resin loading was calculated as trityl per gram of resin (. mu. mol/g) using the appropriate volume, dilution, extinction coefficient (. epsilon.: 41. mu. mol-1cm-1) and resin weight. The analysis was performed in triplicate and the average load was calculated.
The resin loading procedure in this example will provide a resin with a loading of about 500. mu. mol/g. If the disulfide anchor incorporation step is carried out at room temperature for 24 hours, a loading of 300-400. mu. mol/g can be obtained.
Tail loading: the tail can be introduced into the molecule using the same setup and volume as for the preparation of the aminomethyl polystyrene-disulfide resin. For the coupling step, a solution of 38(0.2M) dissolved in NMP containing 4-ethylmorpholine (NEM, 0.4M) was used instead of a disulfide anchor solution. After 2 hours at 45 deg.C, the resin 39 was washed twice with 5% diisopropylethylamine dissolved in 25% isopropanol/dichloromethane and once with DCM. A solution of benzoic anhydride (0.4M) and NEM (0.4M) was added to the resin. After 25 minutes, the reactor jacket was cooled to room temperature and the resin was washed twice with 5% diisopropylethylamine dissolved in 25% isopropanol/dichloromethane and 8 times with DCM. The resin 40 is filtered and dried under high vacuum. The loading of the resin 40 is defined as the loading of the initial aminomethylpolystyrene-disulfide resin 39 used in the tail loading.
Solid-phase synthesis: morpholino oligomers were prepared on a Gilson AMS-422 automated peptide synthesizer in a 2mL Gilson polypropylene reaction column (Part # 3980270). When they were on the synthesizer, an aluminum block with water flow channels was placed around the column. AMS-422 will add the reagents/wash solutions alternately, hold for the indicated time, and evacuate the column using vacuum.
For oligomers up to about 25 subunits in length, a loaded aminomethyl polystyrene-disulfide resin having about 500. mu. mol/g resin is preferred. For larger oligomers, aminomethylpolystyrene-disulfide resin with a loading of 300-400. mu. mol/g resin is preferred. If a molecule with a 5' -tail is desired, the same loading guidance is used to select the resin that has been loaded with a tail.
The following reagent solutions were prepared:
detritylation solution: 10% cyanoacetic acid (w/v) in 4:1 dichloromethane/acetonitrile; neutralizing the solution: 5% diisopropylethylamine dissolved in 3:1 dichloromethane/isopropanol; coupling solution: the desired base and ligation type of 0.18M (or 0.24M oligomers grown longer than 20 subunits) activated morpholino subunit and 0.4M N-ethylmorpholine, dissolved in 1, 3-dimethylimidazolidinone. Dichloromethane (DCM) was used as a transitional wash separating washes of different solvent solutions.
On the synthesizer, the block was set to 42 ℃, 2mL of 1-methyl-2-pyrrolidone was added to each column containing 30mg of aminomethyl polystyrene-disulfide resin (or tail resin), and allowed to stand at room temperature for 30 minutes. After washing 2 times with 2mL of dichloromethane, the following synthesis cycle was employed:


the sequence of individual oligos is programmed into the synthesizer so that each column receives the appropriate coupling solution (A, C, G, T, I) in the appropriate sequence. When the oligo in the column was completely incorporated into its final subunit, the column was removed from the block and a final cycle was performed manually with a coupling solution consisting of 4-methoxytriphenylmethyl chloride containing 0.89M 4-ethylmorpholine (0.32M in DMI).
Cleavage and removal of base and backbone protecting groups from the resin: after methoxytritylation, the resin was washed 8 times with 2mL 1-methyl-2-pyrrolidone. 1mL of a cleavage solution consisting of 0.1M 1, 4-Dithiothreitol (DTT) and 0.73M triethylamine in 1-methyl-2-pyrrolidone was added, the column was covered with a cap, and allowed to stand at room temperature for 30 minutes. After that time, the solution was flowed into a 12mL Wheaton bottle. The greatly shrunk resin was washed twice with 300. mu.L of the cutting solution. 4.0mL of concentrated aqueous ammonia (stored at-20 ℃) was added to the solution, the vial was securely capped (with a Teflon threaded screw cap), and the mixture was rotated to mix the solutions. The vial was placed in a 45 ℃ oven for 16-24 hours to effect cleavage of the base and backbone protecting groups.
Initial oligomer isolation: the vial-filled aminolysis solution was removed from the oven and allowed to cool to room temperature. The solution was diluted with 20mL of 0.28% ammonia and passed through a 2.5X10cm column containing Macroprep HQ resin (BioRad). A salt gradient (A: 0.28% ammonia, B: 1M sodium chloride in 0.28% ammonia; 0-100% B, 60 min) was used to elute the peak containing the methoxytrityl group. The combined fractions are combined and further processed according to the desired product.
Demethoxy tritylation of morpholino oligomers: with 1M H3PO4The pooled fractions from Macroprep purification were treated to lower the pH to 2.5. After initial mixing, the samples were allowed to stand at room temperature for 4 minutes, at which time they were neutralized to pH 10-11 with 2.8% ammonia/water. The product was purified by Solid Phase Extraction (SPE).
Amberchrome CG-300M (Rohm and Haas; Philadelphia, PA) (3mL) was loaded onto a 20mL sieve column (BioRad Econo-Pac column (732-1011)) and the resin was washed with 3mL of: 0.28% NH4OH/80% acetonitrile; 0.5M NaOH/20% ethanol; water; 50mM H3PO480% acetonitrile; water; 0.5 NaOH/20% ethanol; water; 0.28% NH4OH。
The solution from the demethoxytritylation was loaded onto the column and the resin was washed 3 times with 3-6ml of 0.28% ammonia. A Wheaton bottle (12mL) was placed under the column and the product eluted by washing twice with 2mL of 45% acetonitrile in 0.28% aqueous ammonia. The solution was frozen in dry ice and the vial was placed in a freeze-dryer to produce a fluffy white powder. The samples were dissolved in water, filtered through a 0.22 micron filter (Pall Life Sciences, Acrodisc 25mm syringe filter, with 0.2 micron HT Tuffryn membrane) using a syringe, and the Optical Density (OD) was measured on a UV spectrophotometer to determine the OD units presented by the oligomers, and the samples were dispensed for analysis. The solution was then returned to Wheaton bottles for lyophilization.
Analysis of morpholino oligomers: MALDI-TOF mass spectrometry was used to determine the composition of the fractions under purification and to provide a demonstration of the identity (molecular weight) of the oligomers. Samples were run as a substrate after dilution with a solution of 3, 5-dimethoxy-4-hydroxycinnamic acid (sinapic acid), 3,4, 5-Trihydroxyacetophenone (THAP) or alpha-cyano-4-hydroxycinnamic acid (HCCA).
25mM pH 5 sodium acetate, 25% acetonitrile (buffer A) and 25mM pH 5 sodium acetate, 25% acetonitrile, 1.5M potassium chloride (buffer B) (gradient 10-100% B, 15 min) or 25mM KH were used2PO425% acetonitrile, pH 3.5 (buffer A) and 25mM KH2PO4Cation exchange (SCX) HPLC was performed with 25% acetonitrile, pH 3.5, 1.5M potassium chloride (buffer B) (gradient 0-35% B, 15 min) on a Dionex ProPac SCX-10, 4x250mm column (Dionex Corporation; Sunnyvale, CA). The former system was used for positively charged oligomers without peptide attachment, while the latter was used for peptide conjugates.
Purification of morpholino oligomers by cation exchange chromatography: the sample was dissolved in 20mM sodium acetate, pH 4.5 (buffer a) and applied to a column of Source 30 cation exchange resin (GE Healthcare) and eluted with a gradient of 0.5M sodium chloride in 20mM sodium acetate and 40% acetonitrile, pH 4.5 (buffer B). The combined fractions containing the product were neutralized with concentrated aqueous ammonia and applied to an Amberchrome SPE column. The product was eluted, frozen and lyophilized as above.
Example 29
Preparation of exemplary conjugates
Preparation of the peptide sequence AcR according to standard peptide Synthesis procedures known in the art6G. Diisopropylethylamine (36. mu.L, 5eq) was added to PMO (NG-05-0225, 3 '-H: M23D: 5' -EG3, sequence for binding to exon 23 of mdx mice, 350mg, 1eq), AcR in DMSO (3mL) at room temperature6G (142mg, 2eq), HATU (31mg, 2 eq). After 1 hour, the reaction was started and chromatographed by SCX (elution with a gradient: A: dissolved in 25% acetonitrile/H)220mM NaH for O2PO4pH7.0; b, dissolving in 25% acetonitrile/H2O1.5M guanidine HCl and 20mM NaH2PO4Ph7.0) purifying the desired peptide-oligomer conjugate. The combined fractions were subjected to solid phase extraction (1M NaCl followed by water elution). The conjugate was obtained as a white powder after lyophilization (257mg, 65.5% yield).
Example 30
Treatment of MDX mice with exemplary conjugates of the invention
MDX mice are a well-established and well-characterized animal model of Duchenne Muscular Dystrophy (DMD) that contains a mutation in exon 23 of the dystrophin gene. The M23D antisense sequence (SEQ ID NO:15) is known to induce exon 23 skipping and repair of functional dystrophin expression. One dose (50mg/kg) was administered to MDX mice by tail vein injection with one of the following conjugates:
1. 5’-EG3-M23D-BX(RXRRBR)2(AVI5225);
2. 5’-EG3-M23D-G(R)5(NG-11-0045);
3. 5’-EG3-M23D-G(R)6(NG-11-0009);
4. 5’-EG3-M23D-G(R)7(NG-11-0010); or
5. 5’-EG3-M23D-G(R)8(NG-11-0216)
Wherein M23D is a morpholino oligonucleotide having sequence GGCCAAACCTCGGCTTACCTGAAAT, and "EG 3" refers to the structure:

it is attached to the 5' end of the oligomer via a piperazine linker arm (i.e., structure XXIX).
One week after injection, MDX mice were sacrificed and RNA was extracted from different muscle tissues. The relative abundance of dystrophin mRNA containing exon 23 and mRNA lacking exon 23 due to antisense-induced exon skipping was determined by End-point PCR. Percent exon 23 reads skip is a measure of antisense activity in vivo. Fig. 5 and 6 show results from quadriceps (QC, fig. 5A and 6A), diaphragm (DT, fig. 5B and 6B) and heart (HT, fig. 5C and 6C), respectively, 1 week after treatment. Dose responses were similar between AVI-5225 and other conjugates. In the arginine series, R6The G peptide has the highest efficacy in the quadriceps and septum, and is similar to the efficacy of other arginine series peptides in the heart.
Example 31
BUN levels and survival in mice treated with exemplary conjugates
Mice were treated with the conjugates described in example 30 and KIM-1 levels, BUN levels and survival determined according to the general procedures described in example 32 below and known in the art. Surprisingly, figure 7A shows that all glycine-linked conjugates have significantly lower BUN levels than the XB-linked conjugate (AVI-5225). In addition, mice treated with glycine-linked conjugate survived longer at higher doses than the XB-linked conjugate (fig. 7B), where R8The G conjugate was least resistant to arginine polymers. With R6All mice treated with the G conjugate (NG-11-0009) survived at doses up to 400mg/kg (data not shown).
The level of KIM-1 (FIG. 8A) and clusterin (FIG. 8B) was significantly lower in mice treated with the glycine-linked conjugate than in mice treated with AVI-5225. This data indicates that the conjugates of the invention have lower toxicity than previous conjugates and that the efficacy of the conjugates is not diminished as shown in example 30 above. Thus, the conjugates of the invention have a better therapeutic window than other known conjugates and are potentially better drug candidates.
Example 32
Toxicology of exemplary conjugates
The toxicology of 4 exemplary conjugates of the invention was tested in mice. The conjugates are as follows:
1. 5’-EG3-M23D-BX(RXRRBR)2(AVI5225);
2. 5’-EG3-M23D-G(RXRRBR)2(NG-11-0654);
3. 5’-EG3-M23D-BX(R)6(NG-11-0634); and
4. 5’-EG3-M23D-G(R)6(NG-11-0009)
wherein M23D is a morpholino oligonucleotide having sequence GGCCAAACCTCGGCTTACCTGAAAT, and "EG 3" refers to the structure:

it is attached to the 5' end of the oligomer via a piperazine linker arm (i.e., structure XXIX).
Animals were kept at a density of up to 3 animals per cage in clean polycarbonate micro-isolation cages with certified and irradiated contact bedding. The cage complies with the standards set forth in the animal welfare act (including all amendments) and the instructions for the Care and Use of Laboratory Animals published in 2010 by the National Academy Press of Washington (Guide for the Care and Use of Laboratory Animals, National Academy Press, Washington, d.c., 2010).
Animals were randomly assigned to treatment groups based on cage weights specified in the following table. The group assignments are specified in the study record.
TABLE 8 toxicological study design

The day of dose administration in the study was designated as study day 1. The conjugate was administered as a bolus (5 seconds) of slow push via the tail vein. All animals were dosed for 2 days. Doses were given in groups 1-8 on the first day and in groups 9-16 on the second day. The Treatment Groups (TG)13-16 were dosed as per the above table. The results from these TGs did not affect the progression of other TGs. The first 2 TG doses of each conjugate were given as per the table above. If all animals in the 100mg/kg group died, the remaining TG of that test item would then be left un-dosed and the study discontinued. If at least 1 animal in the 100mg/kg group survived 2 hours after dose administration, a 150mg/kg group dose was subsequently administered. If all animals in the 150mg/kg group died, the remaining TG of that test item would then be left un-dosed and the study discontinued. If at least 1 animal in the 150mg/kg group survived 2 hours after dose administration, then the 200mg/kg group dose was administered subsequently.
Animals were observed once daily for moribund and mortality. Humanely will show signs of distress, especially euthanasia of any animal whose death is imminent, according to the Numira Biosciences standard operating procedures. Body weights were recorded on the day of arrival, on the day of dosing, and on the day of necropsy. Detailed clinical observations were made and recorded at 0 min, 15 min and 2 hours post dose administration to assess the tolerability of injections.
Blood samples (maximum volume, about 1mL) were obtained from all animals by cardiac puncture 3 days after dose administration prior to necropsy. Blood samples were collected in red-topped Microtainer tubes and maintained at room temperature for at least 30 minutes but not longer than 60 minutes prior to centrifugation. The samples were centrifuged at about 1500-.
Animals that are unlikely to survive to the next scheduled observation are weighed and euthanized. Animals found to have died are weighed and the time of death is estimated as closely as possible. Blood and tissue samples were not collected.
On day 3 (2 days after dosing), all animals were humanely euthanized with carbon dioxide. Euthanasia was performed according to the accepted guidelines for euthanasia at month 6 of the american veterinary association (AVMA).
Local gross necropsy included examination and recording of the test cases. All external surfaces and orifices were evaluated. All abnormalities observed during the tissue acquisition were fully described and recorded. No other tissue was collected.
Left and right kidneys were collected. Tissues were collected within 15 minutes or less of euthanasia. All instruments and tools used are changed between processing groups. All tissues were snap frozen as soon as possible after harvest and stored at < -70 ℃.
Renal injury marker data were obtained as follows. RNA from mouse kidney Tissue was purified using the Quick gene Mini80Tissue Kit SII (Fuji Film). Briefly, approximately 40mg of tissue was added to 0.5ml lysis buffer (5 μ l 2-mercaptoethanol in 0.5ml lysis buffer) in a magnaLyser Green Bead vial (Roche) and homogenized using MagNA Lyser (Roche) with 2 series 3x 3800RPM and 3 series 1x 6500 RPM. The samples were cooled on ice for 3-4 minutes between each low speed series and between each high speed run. 400x g the homogenate was centrifuged for 5 minutes at room temperature. The homogenate was immediately processed for RNA purification according to the Quick gene Mini80 protocol. The samples were subjected to upper column DNA digestion using dnase i (qiagen) for 5 minutes. Total RNA was quantified using a NanoDrop 2000 spectrophotometer (Thermo Scientific).
qRT-PCR was performed using the Applied Biosystems reagent (one-step RT-PCR) and a previously designed primer/probe set (ACTB, GAPDH, KIM-1, clusterin-FAM reporter).
| Reagent | Company(s) | Commodity catalog number |
| One-step PCR kit | Applied Biosystems | 4309169 |
| GAPDH mouse primer/probe series | Applied Biosystems | 4352932E |
| KIM-1 mouse primer/probe series | Applied Biosystems | Mm00506686_m1 |
Each reaction contained the following ingredients (30 μ l total):

the qRT one-step procedure was run as follows:
1.48 ℃ for 30 minutes
2.95 ℃ for 10 minutes
3.95 ℃ for 15 seconds
4.60 ℃ for 1 minute
5. Repeating steps 3-4 for 39 times for a total of 40 cycles
Samples were run in triplicate wells and their average value used for further analysis. Analysis was performed using the Δ Δ Ct method. Briefly, experiment Δ Ct [ Ct (target) -Ct (reference) ] -control Δ Ct [ Ct (target) -Ct (reference) ] ═ Δ Δ Ct. Calculated fold change range: 2^ - (Δ Δ Ct + SD) to 2^ - (Δ Δ Ct-SD). Control-vehicle treated group of animals (pooled), target-KIM-1; reference to GAPDH; sqrt [ (SD target ^2) + (SD reference ^2) ].
The results of the KIM data are shown in fig. 10. Containing beltConjugates of carrier peptides with terminal glycines have low KIM concentrations, where R6The G peptide had the lowest KIM concentration. Both the terminal G and the presence of the unnatural amino acid (aminocaproic acid) appear to play a role in the toxicity of the conjugate.
Frozen serum samples were sent to IDEXX laboratories (West sacrmento, CA) on dry ice for processing. Serum dilutions were performed according to IDEXX standard procedures (SOPs) if necessary. Blood chemistry results were analyzed. Blood urea nitrogen levels are shown in figure 11. Again, the G-linked conjugates have low BUN levels, and both the terminal G and the overall peptide sequence appear to play a role in the toxicological profile of the conjugate.
Kidney tissue (approximately 150mg) was accurately weighed in a 2mL screw cap vial partially filled with ceramic beads. 5 parts by volume of tissue PE LB buffer (G Biosciences) containing 10U/mL proteinase K (Sigma) were added to 1 part of the tissue. The samples were homogenized with Roche MagnaLyser (4X 40 sec @7000rpm with cooling between runs) and incubated at 40 ℃ for 30 min. When required, the homogenate was diluted with BSAsal (3mg/mL BSA +20mM NaCl) to reduce the high sample concentration to the calibrated range.
Calibration samples were prepared by spiking a 3mg/mL BSA solution in 20mM NaCl with a known amount of the appropriate analytical reference standard. Duplicate series of 8 samples were prepared for each sample. μ m LOQ of 40 μ g/mL and LLOQ of 0.065536 μ g/mL. An internal standard (NG-07-0775) was added to all samples except some of the blank samples designated as double white (no drug, no internal standard). Samples were extracted by vortexing 100 μ L aliquots and 3 volumes of methanol.
After centrifugation (15 min, 14,000rpm), the supernatant was transferred to a new tube and dried in Speedvac. The dried samples were reconstituted with the appropriate amount of FDNA (5'd FAM-ATTTCAGGTAAGCCGAGGTTTGGCC 3') in [10mM Tris pH 8.0+1mM EDTA +100mM NaCl ] -acetonitrile (75-25).
Samples were analyzed on a Dionex m timate 3000HPLC using anion exchange chromatography (Dionex DNAPac 4x250mm column). The injection volume was 5 μ L. The mobile phase consisted of 20% acetonitrile and 80% water containing 25mM Tris pH 8.0 and increasing NaCl concentration gradient. The flow rate was 1 mL/min and the run time was 10 minutes per sample. Fluorescence detectors were set at EX 494nm and EM 520 nm. Peak identification is based on retention time. The peak height ratio (analyte: internal standard) was used for quantification. A calibration curve was calculated based on the average response coefficients of duplicate calibration samples (one run at the start of the batch and the other at the end of the batch). A linear curve fitted with a 1/x weighting factor is used. Blank samples (calibration samples without reference compound added) and double white samples (without internal standard added) were used to ensure assay specificity and no migration.
Figure 12 shows that kidney concentrations were similar in the conjugates tested.
The above data indicate that the conjugates of the invention have similar efficacy and improved toxicity compared to other conjugates. FIGS. 9A-D outline about R6These results for the G conjugate (NG-11-0009).
Other embodiments may be provided in combination with the different embodiments described above. All U.S. patents, U.S. patent application publications, U.S. patent applications, foreign patents, foreign patent applications and non-patent publications referred to in this specification and/or listed in the application data sheet, are incorporated herein by reference, in their entirety. Aspects of the embodiments can be modified, if necessary, to employ concepts of the various patents, applications and publications to provide yet further embodiments. These and other changes can be made to the embodiments in light of the above detailed description. In general, in the following claims, the terms used should not be construed to limit the claims to the specific embodiments disclosed in the specification and the claims, but should be construed to include all possible embodiments along with the full scope of equivalents to which such claims are entitled. Accordingly, the claims are not limited by the disclosure.








































































































































































































Claims (28)
1. A conjugate, comprising:
(a) a carrier peptide comprising amino acid subunits, the carrier peptide comprising a glycine (G) or proline (P) subunit located at the carboxy terminus of the carrier peptide;
(b) a nucleic acid analog comprising a substantially uncharged backbone and a sequence of targeting bases for sequence specific binding to a target nucleic acid; and
(c) a covalent linkage between the nucleic acid analog and the carrier peptide, the covalent linkage comprising an amide linked to a carboxy-terminal glycine or proline and optionally a linker arm group;
wherein:
two or more of the amino acid subunits are positively charged amino acids and no more than 7 consecutive amino acid subunits are arginines.
2. The conjugate of claim 1, wherein the carrier peptide comprises a glycine at the carboxy terminus.
3. The conjugate of claim 1, wherein the carrier peptide comprises a proline at the carboxy terminus.
4. The conjugate of claim 1, wherein the carrier peptide comprises 4 to 40 amino acid subunits.
5. The conjugate of claim 1, wherein the carrier peptide comprises 6 to 20 amino acid subunits.
6. The conjugate of claim 1, wherein the positively charged amino acid is histidine (H), lysine (K), arginine (R), or a combination thereof.
7. The conjugate of claim 1, wherein at least 1 of the positively charged amino acids is arginine.
8. The conjugate of claim 1, wherein the carrier peptide is selected from the group consisting of SEQ ID NOS: 60. 69, 70, 89-121, 125, 130-.
9. The conjugate of claim 1, wherein the carrier peptide is selected from the group consisting of SEQ ID NOS: 130. 157-.
10. The conjugate of claim 1, wherein the carrier peptide is SEQ ID NO: 159.
11. the conjugate of claim 1, wherein the carrier peptide is of a formula selected from:



wherein:
y is an integer from 4 to 7; and is
R is selected from H, acetyl, benzoyl and stearoyl.
12. The conjugate of claim 11, wherein the carrier peptide is of the formula:

13. The conjugate of claim 1, wherein the conjugate is selected from the group consisting of:

or a pharmaceutically acceptable salt of any of the above, wherein:
z is an integer of 0 or more;
r is selected from H, acetyl, benzoyl and stearoyl;
R1selected from the group consisting of H, acetyl, benzoyl and stearoyl;
R2selected from the group consisting of H, acetyl, benzoyl, stearoyl, trityl, and 4-methoxytrityl;
x, at each occurrence, is independently selected from: wherein R is3Selected from H, methyl and electron pair;
wherein R is3Selected from H, methyl and electron pair;
each Pi is a purine or pyrimidine base-pairing moiety which together form a targeting base sequence; and is
The carrier peptide is selected from SEQ ID NOS: 60. 69, 70, 89-121, 125, 130-,
wherein Xaa is carboxyl-terminal glycine or proline.
14. The conjugate of claim 13, wherein the carrier peptide is selected from the group consisting of SEQ ID NOS: 130. 157-.
15. The conjugate of claim 14, wherein the carrier peptide is SEQ ID NO: 159.
16. the conjugate of claim 1, wherein the conjugate is selected from the group consisting of:

and

or a pharmaceutically acceptable salt of any of the above, wherein:
x is an integer of 0 or more;
r is selected from H, acetyl, benzoyl and stearoyl;
R1selected from the group consisting of H, acetyl, benzoyl and stearoyl;
R2selected from the group consisting of H, acetyl, benzoyl, stearoyl, trityl, and 4-methoxytrityl;
each Pi is a purine or pyrimidine base-pairing moiety which together form a targeting base sequence; and is
The carrier peptide is selected from SEQ ID NOS: 60. 69, 70, 89-121, 125, 130-,
wherein Xaa is carboxyl-terminal glycine or proline.
17. The conjugate of claim 16, wherein the carrier peptide is selected from the group consisting of SEQ ID NOS: 130. 157-.
18. The conjugate of claim 17, wherein the carrier peptide is SEQ ID NO: 159.
19. the conjugate of claim 16, wherein each Pi is independently selected from adenine, cytosine, guanine, uracil, thymine, and inosine.
20. A composition comprising the conjugate of claim 1 and a pharmaceutically acceptable carrier.
21. Use of a pharmaceutically effective amount of the conjugate of claim 1 in the manufacture of a medicament for treating a disease in a subject.
22. Use of the conjugate of claim 1 in the preparation of a medicament for facilitating transport of a nucleic acid analog into a cell, wherein transport of the nucleic acid analog into the cell is enhanced relative to the unconjugated form of the nucleic acid analog.
23. A compound selected from:





or a pharmaceutically acceptable salt of any of the above, wherein:
x is an integer of 0 or more;
y is an integer from 4 to 9;
z is 6 or 9;
r is selected from H, acetyl, benzoyl and stearoyl;
R1selected from the group consisting of H, acetyl, benzoyl and stearoyl;
R2selected from the group consisting of H, acetyl, benzoyl, stearoyl, trityl, and 4-methoxytrityl; and is
Each Pi is a purine or pyrimidine base-pairing moiety which together form a targeting base sequence.
24. The compound of claim 23, wherein each Pi is independently selected from adenine, cytosine, guanine, uracil, thymine, and inosine.
25. The compound of claim 24, wherein the compound is:

or a pharmaceutically acceptable salt thereof.
26. The compound of claim 25, wherein R is H.
27. The compound of claim 25, wherein R is acetyl.
28. The compound of claim 25, wherein each Pi is independently selected from adenine, cytosine, guanine, uracil, thymine, and inosine.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/101,942 | 2011-05-05 | ||
| US13/101,942 US20110269665A1 (en) | 2009-06-26 | 2011-05-05 | Compound and method for treating myotonic dystrophy |
| US13/107,528 US9238042B2 (en) | 2010-05-13 | 2011-05-13 | Antisense modulation of interleukins 17 and 23 signaling |
| US13/107,528 | 2011-05-13 | ||
| CN201180071918.XA CN103619356B (en) | 2011-05-05 | 2011-11-17 | Peptide oligonucleotide conjugates |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201180071918.XA Division CN103619356B (en) | 2011-05-05 | 2011-11-17 | Peptide oligonucleotide conjugates |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107693797A CN107693797A (en) | 2018-02-16 |
| CN107693797B true CN107693797B (en) | 2021-05-11 |
Family
ID=45218873
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201180071918.XA Active CN103619356B (en) | 2011-05-05 | 2011-11-17 | Peptide oligonucleotide conjugates |
| CN201710707423.0A Active CN107693797B (en) | 2011-05-05 | 2011-11-17 | Peptide oligonucleotide conjugates |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201180071918.XA Active CN103619356B (en) | 2011-05-05 | 2011-11-17 | Peptide oligonucleotide conjugates |
Country Status (8)
| Country | Link |
|---|---|
| EP (1) | EP2704749A1 (en) |
| JP (6) | JP6478632B2 (en) |
| KR (3) | KR102339196B1 (en) |
| CN (2) | CN103619356B (en) |
| AU (5) | AU2011367230B2 (en) |
| CA (2) | CA2834128A1 (en) |
| IL (2) | IL273838B (en) |
| WO (1) | WO2012150960A1 (en) |
Families Citing this family (85)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| PL1766010T3 (en) | 2004-06-28 | 2011-07-29 | Univ Western Australia | Antisense oligonucleotides for inducing exon skipping and methods of use thereof |
| AU2006213686A1 (en) | 2005-02-09 | 2006-08-17 | Avi Bio Pharma, Inc. | Antisense composition and method for treating muscle atrophy |
| WO2008018795A1 (en) | 2006-08-11 | 2008-02-14 | Prosensa Technologies B.V. | Methods and means for treating dna repeat instability associated genetic disorders |
| US20100016215A1 (en) | 2007-06-29 | 2010-01-21 | Avi Biopharma, Inc. | Compound and method for treating myotonic dystrophy |
| WO2009054725A2 (en) | 2007-10-26 | 2009-04-30 | Academisch Ziekenhuis Leiden | Means and methods for counteracting muscle disorders |
| EP2119783A1 (en) | 2008-05-14 | 2009-11-18 | Prosensa Technologies B.V. | Method for efficient exon (44) skipping in Duchenne Muscular Dystrophy and associated means |
| LT3133160T (en) | 2008-10-24 | 2019-04-10 | Sarepta Therapeutics, Inc. | Exon skipping compositions for dmd |
| CA2780563A1 (en) | 2009-11-12 | 2011-05-19 | The University Of Western Australia | Antisense molecules and methods for treating pathologies |
| TWI541024B (en) | 2010-09-01 | 2016-07-11 | 日本新藥股份有限公司 | Antisense nucleic acid |
| US20130085139A1 (en) | 2011-10-04 | 2013-04-04 | Royal Holloway And Bedford New College | Oligomers |
| CN111808135A (en) | 2011-11-18 | 2020-10-23 | 萨勒普塔医疗公司 | Functionally modified oligonucleotides and subunits thereof |
| CA2857664A1 (en) | 2011-11-30 | 2013-06-06 | Sarepta Therapeutics, Inc. | Antisense oligonucleotides targeting within the smn2 pre-mrna for use ininduced exon inclusion in spinal muscle atrophy |
| WO2013082548A1 (en) | 2011-11-30 | 2013-06-06 | Sarepta Therapeutics, Inc. | Oligonucleotides for treating expanded repeat diseases |
| PT2788487T (en) | 2011-12-08 | 2018-07-03 | Sarepta Therapeutics Inc | Oligonucleotide analogues targeting human lmna |
| EP2806900B1 (en) | 2012-01-27 | 2021-12-15 | BioMarin Technologies B.V. | Rna modulating oligonucleotides with improved characteristics for the treatment of duchenne and becker muscular dystrophy |
| BR112014026285B1 (en) | 2012-04-23 | 2021-08-31 | Biomarin Technologies B.V | RNA MODULATOR OLIGONUCLEOTIDES WITH IMPROVED CHARACTERISTICS FOR THE TREATMENT OF NEUROMUSCULAR DISORDERS |
| EP2935584A1 (en) | 2012-12-20 | 2015-10-28 | Sarepta Therapeutics, Inc. | Improved exon skipping compositions for treating muscular dystrophy |
| WO2014113540A1 (en) | 2013-01-16 | 2014-07-24 | Iowa State University Research Foundation, Inc. | A deep intronic target for splicing correction on spinal muscular atrophy gene |
| SI2970964T1 (en) | 2013-03-14 | 2019-05-31 | Sarepta Therapeutics, Inc. | Exon skipping compositions for treating muscular dystrophy |
| EA035882B1 (en) * | 2013-03-14 | 2020-08-27 | Сарепта Терапьютикс, Инк. | Antisense oligonucleotides inducing exon skipping for treating muscular dystrophy |
| CN105307723A (en) | 2013-03-15 | 2016-02-03 | 萨勒普塔医疗公司 | Improved compositions for treating muscular dystrophy |
| CN105228999B (en) * | 2013-05-24 | 2021-03-02 | 味之素株式会社 | Process for preparing morpholino oligonucleotides |
| KR102275504B1 (en) * | 2013-09-05 | 2021-07-09 | 사렙타 쎄러퓨틱스, 인코퍼레이티드 | Antisense-induced exon2 inclusion in acid alpha-glucosidase |
| EA030615B1 (en) | 2013-12-24 | 2018-08-31 | Сентисс Фарма Прайвет Лимитед | Topical brimonidine tartrate ophthalmic solution |
| TWI672314B (en) * | 2014-03-12 | 2019-09-21 | Nippon Shinyaku Co., Ltd. | Antisense mucleic acid |
| KR101661277B1 (en) * | 2014-03-17 | 2016-09-30 | 제주광어주식회사 | Single point nucleotide changed Live Attenuated Viral Hemorrhagic Septicemia Virus |
| EP3620178A3 (en) | 2014-05-16 | 2020-07-22 | Oregon State University | Antisense antibacterial compounds and methods |
| CA2948568A1 (en) | 2014-05-19 | 2015-11-26 | David Greenberg | Antisense antibacterial compounds and methods |
| US11293024B2 (en) | 2014-12-31 | 2022-04-05 | Board Of Regents, The University Of Texas System | Antisense antibacterial compounds and methods |
| WO2016138534A2 (en) * | 2015-02-27 | 2016-09-01 | Sarepta Therapeutics, Inc. | Antisense-induced exon2 inclusion in acid alpha-glucosidase |
| MA41795A (en) * | 2015-03-18 | 2018-01-23 | Sarepta Therapeutics Inc | EXCLUSION OF AN EXON INDUCED BY ANTISENSE COMPOUNDS IN MYOSTATIN |
| MX2017014806A (en) * | 2015-05-19 | 2018-05-11 | Sarepta Therapeutics Inc | Peptide oligonucleotide conjugates. |
| WO2016196670A1 (en) | 2015-06-01 | 2016-12-08 | Sarepta Therapeutics, Inc. | Antisense-induced exon exclusion in type vii collagen |
| WO2016196897A1 (en) | 2015-06-04 | 2016-12-08 | Sarepta Therapeutics, Inc. | Methods and compounds for treatment of lymphocyte-related diseases and conditions |
| EP4039690A1 (en) * | 2015-08-05 | 2022-08-10 | Eisai R&D Management Co., Ltd. | A substantially diastereomerically pure phosphoramidochloridate, a method and a pharmaceutical composition |
| CA2996164A1 (en) * | 2015-08-28 | 2017-03-09 | Sarepta Therapeutics, Inc. | Modified antisense oligomers for exon inclusion in spinal muscular atrophy |
| US10858395B2 (en) * | 2015-09-10 | 2020-12-08 | Iucf-Hyu (Industry-University Cooperation Foundation Hanyang University) | Skin-penetrating peptide and method for using same |
| WO2017062835A2 (en) | 2015-10-09 | 2017-04-13 | Sarepta Therapeutics, Inc. | Compositions and methods for treating duchenne muscular dystrophy and related disorders |
| GB2545898B (en) * | 2015-12-21 | 2019-10-09 | Sutura Therapeutics Ltd | Improved drug delivery by conjugating oligonucleotides to stitched/stapled peptides |
| US11142764B2 (en) | 2015-12-23 | 2021-10-12 | Board Of Regents, The University Of Texas System | Antisense antibacterial compounds and methods |
| AU2016379399B2 (en) | 2015-12-23 | 2022-12-08 | Board Of Regents, The University Of Texas System | Antisense antibacterial compounds and methods |
| CN109414511B (en) | 2016-04-18 | 2023-05-23 | 萨勒普塔医疗公司 | Antisense oligomers for treating diseases associated with acid alpha-glucosidase genes and methods of use thereof |
| SG11201809468XA (en) * | 2016-04-29 | 2018-11-29 | Sarepta Therapeutics Inc | Oligonucleotide analogues targeting human lmna |
| CA3024153A1 (en) * | 2016-06-30 | 2017-11-30 | Sarepta Therapeutics, Inc. | Processes for preparing phosphorodiamidate morpholino oligomers |
| TW201811807A (en) * | 2016-06-30 | 2018-04-01 | 美商薩羅塔治療公司 | Exon skipping oligomers for muscular dystrophy |
| US11382981B2 (en) * | 2016-12-19 | 2022-07-12 | Sarepta Therapeutics, Inc. | Exon skipping oligomer conjugates for muscular dystrophy |
| AU2017382773A1 (en) * | 2016-12-19 | 2019-08-01 | Sarepta Therapeutics, Inc. | Exon skipping oligomer conjugates for muscular dystrophy |
| RS63610B1 (en) * | 2016-12-19 | 2022-10-31 | Sarepta Therapeutics Inc | Exon skipping oligomer conjugates for muscular dystrophy |
| TW201919682A (en) | 2017-08-08 | 2019-06-01 | 西班牙商阿爾米雷爾有限公司 | Novel compounds activating the Nrf2 pathway |
| EA201991450A1 (en) * | 2017-09-22 | 2019-12-30 | Сарепта Терапьютикс, Инк. | OLIGOMER CONJUGATES FOR EXONISM SKIP IN MUSCULAR DYSTROPHY |
| JP7441455B2 (en) | 2017-09-22 | 2024-03-01 | ザ リージェンツ オブ ザ ユニバーシティ オブ コロラド,ア ボディー コーポレイト | Thiomorpholino oligonucleotides for the treatment of muscular dystrophy |
| EP3687519A1 (en) | 2017-09-28 | 2020-08-05 | Sarepta Therapeutics, Inc. | Combination therapies for treating muscular dystrophy |
| US20200248178A1 (en) | 2017-09-28 | 2020-08-06 | Sarepta Therapeutics, Inc. | Combination therapies for treating muscular dystrophy |
| JP2020536058A (en) | 2017-09-28 | 2020-12-10 | サレプタ セラピューティクス, インコーポレイテッド | Combination therapy to treat muscular dystrophy |
| JP7320500B2 (en) * | 2017-10-17 | 2023-08-03 | サレプタ セラピューティクス, インコーポレイテッド | Cell-penetrating peptides for antisense delivery |
| JP7394753B2 (en) | 2017-10-18 | 2023-12-08 | サレプタ セラピューティクス, インコーポレイテッド | antisense oligomer compounds |
| JP2021521794A (en) * | 2018-04-26 | 2021-08-30 | サレプタ セラピューティクス, インコーポレイテッド | Exon skipping oligomers and oligomeric conjugates for muscular dystrophy |
| US20220251551A1 (en) * | 2018-06-13 | 2022-08-11 | Sarepta Therapeutics, Inc. | Exon skipping oligomers for muscular dystrophy |
| EP3806868A4 (en) | 2018-06-13 | 2022-06-22 | Sarepta Therapeutics, Inc. | Exon skipping oligomers for muscular dystrophy |
| TW202020153A (en) | 2018-07-27 | 2020-06-01 | 美商薩羅塔治療公司 | Exon skipping oligomers for muscular dystrophy |
| EP3829597A4 (en) * | 2018-07-30 | 2022-05-18 | Sarepta Therapeutics, Inc. | Trimeric peptides for antisense delivery |
| GB201812980D0 (en) * | 2018-08-09 | 2018-09-26 | Univ Oxford Innovation Ltd | Cell-penetrating peptides |
| CN113453723A (en) * | 2018-12-07 | 2021-09-28 | 牛津大学科技创新有限公司 | Joint |
| MX2021006737A (en) | 2018-12-13 | 2021-09-23 | Sarepta Therapeutics Inc | Exon skipping oligomer conjugates for muscular dystrophy. |
| GB201821269D0 (en) | 2018-12-28 | 2019-02-13 | Nippon Shinyaku Co Ltd | Myostatin signal inhibitor |
| JP2022528725A (en) | 2019-04-18 | 2022-06-15 | サレプタ セラピューティクス, インコーポレイテッド | Composition for treating muscular dystrophy |
| CN110724180B (en) * | 2019-10-17 | 2021-08-20 | 山东大学 | Polypeptide for inhibiting angiogenesis and application thereof |
| EP4083208A4 (en) | 2019-12-26 | 2024-01-03 | Nippon Shinyaku Co Ltd | Antisense nucleic acid that induces skipping of exon 50 |
| US20230203098A1 (en) | 2020-02-22 | 2023-06-29 | Jcr Pharmaceuticals Co., Ltd. | Human transferrin receptor binding peptide |
| JPWO2021172498A1 (en) | 2020-02-28 | 2021-09-02 | ||
| US20220064638A1 (en) | 2020-02-28 | 2022-03-03 | Ionis Pharmaceuticals, Inc. | Compounds and methods for modulating smn2 |
| WO2022061216A1 (en) * | 2020-09-21 | 2022-03-24 | Icahn School Of Medicine At Mount Sinai | Archaea l30 proteins as universal influenza virus therapeutics |
| EP4267191A1 (en) | 2020-12-23 | 2023-11-01 | Sarepta Therapeutics, Inc. | Compositions comprising exon skipping oligonucleotide conjugates for treating muscular dystrophy |
| WO2022171972A1 (en) * | 2021-02-12 | 2022-08-18 | Oxford University Innovation Limited | Cell-penetrating peptide conjugates and methods of their use |
| KR20240004609A (en) | 2021-04-30 | 2024-01-11 | 사렙타 쎄러퓨틱스 인코퍼레이티드 | Treatment Methods for Muscular Dystrophy |
| BR112023027298A2 (en) | 2021-06-23 | 2024-03-12 | Nat Center Neurology & Psychiatry | COMBINATION OF ANTISENSE OLIGOMERS |
| WO2023282344A1 (en) | 2021-07-08 | 2023-01-12 | 日本新薬株式会社 | Nephrotoxicity reducing agent |
| IL310001A (en) | 2021-07-08 | 2024-03-01 | Nippon Shinyaku Co Ltd | Precipitation suppressing agent |
| AU2022306820A1 (en) | 2021-07-08 | 2024-01-04 | Nippon Shinyaku Co., Ltd. | Nephrotoxicity reducing agent |
| WO2023026994A1 (en) | 2021-08-21 | 2023-03-02 | 武田薬品工業株式会社 | Human transferrin receptor binding peptide-drug conjugate |
| IL311025A (en) | 2021-08-24 | 2024-04-01 | Peptidream Inc | Human transferrin receptor-binding antibody-peptide conjugate |
| WO2023055774A1 (en) | 2021-09-30 | 2023-04-06 | Sarepta Therapeutics, Inc. | Antisense oligonucleotides having one or more abasic units |
| WO2023070086A1 (en) | 2021-10-22 | 2023-04-27 | Sarepta Therapeutics, Inc. | Morpholino oligomers for treatment of peripheral myelin protein 22 related diseases |
| WO2023178230A1 (en) | 2022-03-17 | 2023-09-21 | Sarepta Therapeutics, Inc. | Phosphorodiamidate morpholino oligomer conjugates |
| WO2024064237A2 (en) | 2022-09-21 | 2024-03-28 | Sarepta Therapeutics, Inc. | Dmd antisense oligonucleotide-mediated exon skipping efficiency |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009005793A2 (en) * | 2007-06-29 | 2009-01-08 | Avi Biopharma, Inc. | Tissue specific peptide conjugates and methods |
Family Cites Families (46)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5166315A (en) | 1989-12-20 | 1992-11-24 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5521063A (en) | 1985-03-15 | 1996-05-28 | Antivirals Inc. | Polynucleotide reagent containing chiral subunits and methods of use |
| JP3022967B2 (en) | 1985-03-15 | 2000-03-21 | アンチバイラルズ インコーポレイテッド | Stereoregular polynucleotide binding polymer |
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| US5185444A (en) | 1985-03-15 | 1993-02-09 | Anti-Gene Deveopment Group | Uncharged morpolino-based polymers having phosphorous containing chiral intersubunit linkages |
| US5506337A (en) | 1985-03-15 | 1996-04-09 | Antivirals Inc. | Morpholino-subunit combinatorial library and method |
| US5217866A (en) | 1985-03-15 | 1993-06-08 | Anti-Gene Development Group | Polynucleotide assay reagent and method |
| AU659482B2 (en) | 1991-06-28 | 1995-05-18 | Massachusetts Institute Of Technology | Localized oligonucleotide therapy |
| EP0656950B1 (en) | 1992-08-21 | 1998-11-04 | Biogen, Inc. | Tat-derived transport polypeptides |
| JPH0915828A (en) | 1995-07-03 | 1997-01-17 | Fuji Photo Film Co Ltd | Paper cutter for photographic processing system |
| US6245747B1 (en) | 1996-03-12 | 2001-06-12 | The Board Of Regents Of The University Of Nebraska | Targeted site specific antisense oligodeoxynucleotide delivery method |
| GB2341390B (en) | 1997-05-21 | 2000-11-08 | Univ Leland Stanford Junior | Composition and method for enhancing transport across biological membranes |
| AU741546B2 (en) * | 1997-07-24 | 2001-12-06 | Perseptive Biosystems, Inc. | Conjugates of transporter peptides and nucleic acid analogs, and their use |
| DE19933492B4 (en) * | 1999-07-16 | 2008-01-10 | Deutsches Krebsforschungszentrum Stiftung des öffentlichen Rechts | Conjugate for the mediation of a cell-, compartment- or membrane-specific transport of active substances, process for its preparation and its use |
| US20020009491A1 (en) | 2000-02-14 | 2002-01-24 | Rothbard Jonathan B. | Compositions and methods for enhancing drug delivery across biological membranes and tissues |
| JP2005508832A (en) | 2001-02-16 | 2005-04-07 | セルゲイト, インコーポレイテッド | Transporter with arginine part at intervals |
| US20030224353A1 (en) | 2001-10-16 | 2003-12-04 | Stein David A. | Antisense antiviral agent and method for treating ssRNA viral infection |
| ES2500921T3 (en) | 2003-04-29 | 2014-10-01 | Sarepta Therapeutics, Inc. | Compositions to enhance the transport and antisense efficacy of nucleic acid analogs in cells |
| CA2533218C (en) | 2003-08-05 | 2014-11-18 | Avi Biopharma, Inc. | Oligonucleotide analog and method for treating flavivirus infections |
| US20050171044A1 (en) | 2003-12-24 | 2005-08-04 | Stein David A. | Oligonucleotide compound and method for treating nidovirus infections |
| JP2007536253A (en) * | 2004-05-04 | 2007-12-13 | ナステック・ファーマシューティカル・カンパニー・インコーポレーテッド | Compositions and methods for enhancing delivery of nucleic acids into cells and modifying expression of target genes in cells |
| US20050288246A1 (en) * | 2004-05-24 | 2005-12-29 | Iversen Patrick L | Peptide conjugated, inosine-substituted antisense oligomer compound and method |
| PL1766010T3 (en) | 2004-06-28 | 2011-07-29 | Univ Western Australia | Antisense oligonucleotides for inducing exon skipping and methods of use thereof |
| US8129352B2 (en) | 2004-09-16 | 2012-03-06 | Avi Biopharma, Inc. | Antisense antiviral compound and method for treating ssRNA viral infection |
| US8357664B2 (en) | 2004-10-26 | 2013-01-22 | Avi Biopharma, Inc. | Antisense antiviral compound and method for treating influenza viral infection |
| US7524829B2 (en) | 2004-11-01 | 2009-04-28 | Avi Biopharma, Inc. | Antisense antiviral compounds and methods for treating a filovirus infection |
| US7838657B2 (en) | 2004-12-03 | 2010-11-23 | University Of Massachusetts | Spinal muscular atrophy (SMA) treatment via targeting of SMN2 splice site inhibitory sequences |
| AU2006213686A1 (en) | 2005-02-09 | 2006-08-17 | Avi Bio Pharma, Inc. | Antisense composition and method for treating muscle atrophy |
| LT3308788T (en) | 2005-06-23 | 2018-12-10 | Biogen Ma Inc. | Compositions and methods for modulation of smn2 splicing |
| WO2007030691A2 (en) | 2005-09-08 | 2007-03-15 | Avi Biopharma, Inc. | Antisense antiviral compound and method for treating picornavirus infection |
| EP1937278B1 (en) | 2005-09-08 | 2012-07-25 | AVI BioPharma, Inc. | Antisense antiviral compound and method for treating picornavirus infection |
| CA2644262C (en) | 2006-03-07 | 2016-01-05 | Avi Biopharma, Inc. | Antisense antiviral compound and method for treating arenavirus infection |
| DK2735568T3 (en) | 2006-05-10 | 2017-11-13 | Sarepta Therapeutics Inc | OLIGONUCLEOTIDE ANALYSIS WITH CATIONIC BINDINGS BETWEEN SUB-UNITS |
| WO2008018795A1 (en) | 2006-08-11 | 2008-02-14 | Prosensa Technologies B.V. | Methods and means for treating dna repeat instability associated genetic disorders |
| JP5926475B2 (en) | 2006-09-21 | 2016-05-25 | ユニバーシティー オブ ロチェスター | Compositions and methods for protein replacement therapy for myotonic dystrophy |
| EP2070919B1 (en) | 2006-11-24 | 2012-10-10 | Hykes Laboratories LLC | Spiroquinone compound and pharmaceutical composition |
| WO2009005783A1 (en) * | 2007-06-28 | 2009-01-08 | Blanchette Rockefeller Neurosciences Institute | Peptides, compositions and methods for reducing beta-amyloid-mediated apoptosis |
| US20100016215A1 (en) * | 2007-06-29 | 2010-01-21 | Avi Biopharma, Inc. | Compound and method for treating myotonic dystrophy |
| WO2009064471A1 (en) | 2007-11-15 | 2009-05-22 | Avi Biopharma, Inc. | Method of synthesis of morpholino oligomers |
| CA2709635A1 (en) * | 2007-12-20 | 2009-07-02 | Angiochem Inc. | Polypeptide-nucleic acid conjugates and uses thereof |
| US20110130346A1 (en) * | 2008-05-30 | 2011-06-02 | Isis Innovation Limited | Peptide conjugates for delvery of biologically active compounds |
| LT3133160T (en) | 2008-10-24 | 2019-04-10 | Sarepta Therapeutics, Inc. | Exon skipping compositions for dmd |
| WO2010072228A1 (en) * | 2008-12-22 | 2010-07-01 | Xigen S.A. | Novel transporter constructs and transporter cargo conjugate molecules |
| WO2010120820A1 (en) | 2009-04-13 | 2010-10-21 | Isis Pharmaceuticals, Inc. | Compositions and methods for modulation of smn2 splicing |
| CN102665731A (en) | 2009-06-17 | 2012-09-12 | Isis制药公司 | Compositions and methods for modulation of SMN2 splicing in a subject |
| CA3090304A1 (en) * | 2010-05-13 | 2011-11-17 | Sarepta Therapeutics, Inc. | Antisense modulation of interleukins 17 and 23 signaling |
-
2011
- 2011-11-17 JP JP2014509281A patent/JP6478632B2/en active Active
- 2011-11-17 IL IL273838A patent/IL273838B/en unknown
- 2011-11-17 AU AU2011367230A patent/AU2011367230B2/en active Active
- 2011-11-17 KR KR1020217007616A patent/KR102339196B1/en active IP Right Grant
- 2011-11-17 KR KR1020197019623A patent/KR102229650B1/en active IP Right Grant
- 2011-11-17 KR KR1020137032241A patent/KR102183273B1/en active IP Right Grant
- 2011-11-17 CN CN201180071918.XA patent/CN103619356B/en active Active
- 2011-11-17 WO PCT/US2011/061282 patent/WO2012150960A1/en active Application Filing
- 2011-11-17 EP EP11793913.2A patent/EP2704749A1/en active Pending
- 2011-11-17 CA CA2834128A patent/CA2834128A1/en active Pending
- 2011-11-17 CN CN201710707423.0A patent/CN107693797B/en active Active
- 2011-11-17 CA CA3092114A patent/CA3092114A1/en active Pending
-
2013
- 2013-11-04 IL IL229227A patent/IL229227B/en active IP Right Grant
-
2016
- 2016-08-01 JP JP2016151179A patent/JP2016185991A/en active Pending
-
2017
- 2017-07-18 AU AU2017206179A patent/AU2017206179A1/en not_active Abandoned
-
2018
- 2018-06-06 JP JP2018108772A patent/JP2018135396A/en not_active Withdrawn
-
2019
- 2019-07-09 AU AU2019204913A patent/AU2019204913A1/en not_active Abandoned
-
2020
- 2020-04-09 JP JP2020070566A patent/JP6884250B2/en active Active
-
2021
- 2021-04-13 AU AU2021202224A patent/AU2021202224A1/en not_active Abandoned
- 2021-05-11 JP JP2021080358A patent/JP2021113232A/en active Pending
-
2023
- 2023-05-18 AU AU2023203112A patent/AU2023203112A1/en active Pending
-
2024
- 2024-02-02 JP JP2024014898A patent/JP2024032974A/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009005793A2 (en) * | 2007-06-29 | 2009-01-08 | Avi Biopharma, Inc. | Tissue specific peptide conjugates and methods |
Non-Patent Citations (1)
| Title |
|---|
| "Construction of a novel chimera consisting of a chelator-containing Tat peptide conjugated to a morpholino antisense oligomer for technetium-99m labeling and accelerating cellular kinetics";Yu-Min Zhang et al.;《Nuclear Medicine and Biology》;20060228;第33卷(第2期);第263-269页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019204913A1 (en) | 2019-07-25 |
| CA2834128A1 (en) | 2012-11-08 |
| CN107693797A (en) | 2018-02-16 |
| JP2018135396A (en) | 2018-08-30 |
| JP2024032974A (en) | 2024-03-12 |
| WO2012150960A1 (en) | 2012-11-08 |
| AU2011367230A1 (en) | 2013-12-05 |
| IL229227B (en) | 2020-07-30 |
| CN103619356B (en) | 2017-09-12 |
| KR20140028058A (en) | 2014-03-07 |
| JP2016185991A (en) | 2016-10-27 |
| KR102183273B1 (en) | 2020-11-27 |
| CN103619356A (en) | 2014-03-05 |
| KR20190084351A (en) | 2019-07-16 |
| KR102339196B1 (en) | 2021-12-15 |
| KR20210032545A (en) | 2021-03-24 |
| IL273838B (en) | 2022-09-01 |
| IL229227A0 (en) | 2014-01-30 |
| IL273838A (en) | 2020-05-31 |
| AU2023203112A1 (en) | 2023-06-08 |
| KR102229650B1 (en) | 2021-03-19 |
| JP2014515762A (en) | 2014-07-03 |
| AU2011367230B2 (en) | 2017-08-10 |
| AU2021202224A1 (en) | 2021-05-06 |
| JP6884250B2 (en) | 2021-06-09 |
| EP2704749A1 (en) | 2014-03-12 |
| JP2020111607A (en) | 2020-07-27 |
| JP2021113232A (en) | 2021-08-05 |
| AU2017206179A1 (en) | 2017-08-03 |
| JP6478632B2 (en) | 2019-03-06 |
| CA3092114A1 (en) | 2012-11-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107693797B (en) | Peptide oligonucleotide conjugates | |
| US11732259B2 (en) | Peptide oligonucleotide conjugates | |
| JP6634424B2 (en) | Oligonucleotide analogs with modified intersubunit linkages and / or end groups |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 1250922 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant |