CN103003303A - 改进的抗-血清白蛋白结合变体 - Google Patents
改进的抗-血清白蛋白结合变体 Download PDFInfo
- Publication number
- CN103003303A CN103003303A CN2011800351661A CN201180035166A CN103003303A CN 103003303 A CN103003303 A CN 103003303A CN 2011800351661 A CN2011800351661 A CN 2011800351661A CN 201180035166 A CN201180035166 A CN 201180035166A CN 103003303 A CN103003303 A CN 103003303A
- Authority
- CN
- China
- Prior art keywords
- dom7h
- variant
- seq
- variable domains
- single variable
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 102000009027 Albumins Human genes 0.000 title claims abstract description 25
- 108010088751 Albumins Proteins 0.000 title claims abstract description 25
- 230000027455 binding Effects 0.000 title claims description 65
- 230000001976 improved effect Effects 0.000 title abstract description 41
- 108060003951 Immunoglobulin Proteins 0.000 claims abstract description 62
- 102000018358 immunoglobulin Human genes 0.000 claims abstract description 62
- 239000003814 drug Substances 0.000 claims abstract description 44
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 24
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 24
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 24
- 239000000203 mixture Substances 0.000 claims abstract description 10
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 54
- 230000004927 fusion Effects 0.000 claims description 52
- 239000002773 nucleotide Substances 0.000 claims description 49
- 125000003729 nucleotide group Chemical group 0.000 claims description 48
- 230000009870 specific binding Effects 0.000 claims description 46
- 230000008859 change Effects 0.000 claims description 45
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 41
- 239000000427 antigen Substances 0.000 claims description 30
- 102000036639 antigens Human genes 0.000 claims description 30
- 108091007433 antigens Proteins 0.000 claims description 30
- 238000000034 method Methods 0.000 claims description 26
- 241000282553 Macaca Species 0.000 claims description 25
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 24
- 229920001184 polypeptide Polymers 0.000 claims description 22
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 22
- 238000010494 dissociation reaction Methods 0.000 claims description 20
- 230000005593 dissociations Effects 0.000 claims description 12
- 201000010099 disease Diseases 0.000 claims description 11
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 11
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 claims description 4
- 229940079593 drug Drugs 0.000 abstract description 10
- 239000013598 vector Substances 0.000 abstract description 6
- 239000003446 ligand Substances 0.000 abstract description 4
- 102000008100 Human Serum Albumin Human genes 0.000 description 50
- 108091006905 Human Serum Albumin Proteins 0.000 description 50
- 102000007562 Serum Albumin Human genes 0.000 description 47
- 108010071390 Serum Albumin Proteins 0.000 description 47
- 235000001014 amino acid Nutrition 0.000 description 34
- 229940024606 amino acid Drugs 0.000 description 33
- 150000001413 amino acids Chemical class 0.000 description 32
- 210000004027 cell Anatomy 0.000 description 26
- 210000002966 serum Anatomy 0.000 description 22
- 241000700159 Rattus Species 0.000 description 21
- 108090000623 proteins and genes Proteins 0.000 description 20
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 19
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 18
- 230000009466 transformation Effects 0.000 description 18
- 101000959820 Homo sapiens Interferon alpha-1/13 Proteins 0.000 description 17
- 102100040019 Interferon alpha-1/13 Human genes 0.000 description 17
- 239000000047 product Substances 0.000 description 17
- 241000699666 Mus <mouse, genus> Species 0.000 description 16
- 230000009824 affinity maturation Effects 0.000 description 15
- 230000014509 gene expression Effects 0.000 description 15
- 102000004169 proteins and genes Human genes 0.000 description 14
- 239000000178 monomer Substances 0.000 description 13
- 108010011459 Exenatide Proteins 0.000 description 12
- JUFFVKRROAPVBI-PVOYSMBESA-N chembl1210015 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N[C@H]1[C@@H]([C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO[C@]3(O[C@@H](C[C@H](O)[C@H](O)CO)[C@H](NC(C)=O)[C@@H](O)C3)C(O)=O)O2)O)[C@@H](CO)O1)NC(C)=O)C(=O)NCC(=O)NCC(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 JUFFVKRROAPVBI-PVOYSMBESA-N 0.000 description 12
- 230000009977 dual effect Effects 0.000 description 12
- 229960001519 exenatide Drugs 0.000 description 12
- 235000018102 proteins Nutrition 0.000 description 12
- 241000894007 species Species 0.000 description 12
- 108020004414 DNA Proteins 0.000 description 11
- 239000012634 fragment Substances 0.000 description 11
- 238000012360 testing method Methods 0.000 description 11
- -1 Met Chemical compound 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 10
- 241000894006 Bacteria Species 0.000 description 9
- 239000004471 Glycine Substances 0.000 description 9
- 150000001875 compounds Chemical class 0.000 description 9
- 239000000463 material Substances 0.000 description 9
- 150000005829 chemical entities Chemical class 0.000 description 8
- 230000002349 favourable effect Effects 0.000 description 8
- 238000000569 multi-angle light scattering Methods 0.000 description 8
- 230000035772 mutation Effects 0.000 description 8
- 239000003153 chemical reaction reagent Substances 0.000 description 7
- 230000001684 chronic effect Effects 0.000 description 7
- 229920000642 polymer Polymers 0.000 description 7
- 239000000243 solution Substances 0.000 description 7
- 230000001154 acute effect Effects 0.000 description 6
- 230000029087 digestion Effects 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- 239000011347 resin Substances 0.000 description 6
- 229920005989 resin Polymers 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- 108020004705 Codon Proteins 0.000 description 5
- 102000004127 Cytokines Human genes 0.000 description 5
- 108090000695 Cytokines Proteins 0.000 description 5
- 102000004190 Enzymes Human genes 0.000 description 5
- 108090000790 Enzymes Proteins 0.000 description 5
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 5
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 5
- 239000007983 Tris buffer Substances 0.000 description 5
- 102000018594 Tumour necrosis factor Human genes 0.000 description 5
- 108050007852 Tumour necrosis factor Proteins 0.000 description 5
- 239000005557 antagonist Substances 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 239000012228 culture supernatant Substances 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 239000013604 expression vector Substances 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 230000009467 reduction Effects 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 5
- 229920001817 Agar Polymers 0.000 description 4
- 102100036845 C-C motif chemokine 22 Human genes 0.000 description 4
- 101710121366 Disintegrin and metalloproteinase domain-containing protein 11 Proteins 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- 102100040018 Interferon alpha-2 Human genes 0.000 description 4
- 108010079944 Interferon-alpha2b Proteins 0.000 description 4
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 241000699670 Mus sp. Species 0.000 description 4
- 239000008272 agar Substances 0.000 description 4
- 239000003795 chemical substances by application Substances 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 230000037029 cross reaction Effects 0.000 description 4
- 238000002474 experimental method Methods 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 125000000896 monocarboxylic acid group Chemical group 0.000 description 4
- 229920001223 polyethylene glycol Polymers 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 3
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 3
- 239000004475 Arginine Substances 0.000 description 3
- 102100036850 C-C motif chemokine 23 Human genes 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 102100037362 Fibronectin Human genes 0.000 description 3
- 108010067306 Fibronectins Proteins 0.000 description 3
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 101000713081 Homo sapiens C-C motif chemokine 23 Proteins 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- 206010067268 Post procedural infection Diseases 0.000 description 3
- 101100108055 Rattus norvegicus Acsm3 gene Proteins 0.000 description 3
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 3
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 3
- 108091008605 VEGF receptors Proteins 0.000 description 3
- 102000009484 Vascular Endothelial Growth Factor Receptors Human genes 0.000 description 3
- 229930003756 Vitamin B7 Natural products 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 238000000246 agarose gel electrophoresis Methods 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 239000000539 dimer Substances 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 239000005556 hormone Substances 0.000 description 3
- 229940088597 hormone Drugs 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 230000000968 intestinal effect Effects 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 230000002045 lasting effect Effects 0.000 description 3
- 150000002632 lipids Chemical class 0.000 description 3
- 239000008176 lyophilized powder Substances 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 238000006386 neutralization reaction Methods 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 230000000630 rising effect Effects 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 3
- 239000003053 toxin Substances 0.000 description 3
- 231100000765 toxin Toxicity 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 230000001131 transforming effect Effects 0.000 description 3
- 239000011735 vitamin B7 Substances 0.000 description 3
- 235000011912 vitamin B7 Nutrition 0.000 description 3
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 2
- 102100023995 Beta-nerve growth factor Human genes 0.000 description 2
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 2
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 2
- 102000008203 CTLA-4 Antigen Human genes 0.000 description 2
- 229940045513 CTLA4 antagonist Drugs 0.000 description 2
- 241000282832 Camelidae Species 0.000 description 2
- 241000282836 Camelus dromedarius Species 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 102000019034 Chemokines Human genes 0.000 description 2
- 108010012236 Chemokines Proteins 0.000 description 2
- RZXLPPRPEOUENN-UHFFFAOYSA-N Chlorfenson Chemical compound C1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=C(Cl)C=C1 RZXLPPRPEOUENN-UHFFFAOYSA-N 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 108010088406 Glucagon-Like Peptides Proteins 0.000 description 2
- 102400000322 Glucagon-like peptide 1 Human genes 0.000 description 2
- 101800000224 Glucagon-like peptide 1 Proteins 0.000 description 2
- 102100034221 Growth-regulated alpha protein Human genes 0.000 description 2
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 2
- 206010018873 Haemoconcentration Diseases 0.000 description 2
- 241000590002 Helicobacter pylori Species 0.000 description 2
- 101000616810 Homo sapiens MAL-like protein Proteins 0.000 description 2
- 101000740205 Homo sapiens Sal-like protein 1 Proteins 0.000 description 2
- 101000617130 Homo sapiens Stromal cell-derived factor 1 Proteins 0.000 description 2
- 102100037850 Interferon gamma Human genes 0.000 description 2
- 108010074328 Interferon-gamma Proteins 0.000 description 2
- 108090001007 Interleukin-8 Proteins 0.000 description 2
- 102000004890 Interleukin-8 Human genes 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- 241000282852 Lama guanicoe Species 0.000 description 2
- 102100021832 MAL-like protein Human genes 0.000 description 2
- 241000282560 Macaca mulatta Species 0.000 description 2
- 102100027998 Macrophage metalloelastase Human genes 0.000 description 2
- 101710187853 Macrophage metalloelastase Proteins 0.000 description 2
- 101710151805 Mitochondrial intermediate peptidase 1 Proteins 0.000 description 2
- 101100288142 Mus musculus Klkb1 gene Proteins 0.000 description 2
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 2
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 241000009328 Perro Species 0.000 description 2
- 101710098940 Pro-epidermal growth factor Proteins 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 102100037204 Sal-like protein 1 Human genes 0.000 description 2
- 102000013275 Somatomedins Human genes 0.000 description 2
- 241000288726 Soricidae Species 0.000 description 2
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 2
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 2
- 239000005864 Sulphur Substances 0.000 description 2
- 241000282898 Sus scrofa Species 0.000 description 2
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- 239000006035 Tryptophane Substances 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 2
- 101150117115 V gene Proteins 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- RTYJTGSCYUUYAL-YCAHSCEMSA-L carbenicillin disodium Chemical compound [Na+].[Na+].N([C@H]1[C@H]2SC([C@@H](N2C1=O)C([O-])=O)(C)C)C(=O)C(C([O-])=O)C1=CC=CC=C1 RTYJTGSCYUUYAL-YCAHSCEMSA-L 0.000 description 2
- 239000002131 composite material Substances 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- LEVWYRKDKASIDU-IMJSIDKUSA-N cystine group Chemical group C([C@@H](C(=O)O)N)SSC[C@@H](C(=O)O)N LEVWYRKDKASIDU-IMJSIDKUSA-N 0.000 description 2
- 102000003675 cytokine receptors Human genes 0.000 description 2
- 108010057085 cytokine receptors Proteins 0.000 description 2
- 238000013016 damping Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 231100000284 endotoxic Toxicity 0.000 description 2
- 230000002346 endotoxic effect Effects 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 210000003979 eosinophil Anatomy 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 238000005755 formation reaction Methods 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 229940037467 helicobacter pylori Drugs 0.000 description 2
- MGXWVYUBJRZYPE-YUGYIWNOSA-N incretin Chemical class C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)[C@@H](C)O)[C@@H](C)CC)C1=CC=C(O)C=C1 MGXWVYUBJRZYPE-YUGYIWNOSA-N 0.000 description 2
- 239000000859 incretin Substances 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 108010019677 lymphotactin Proteins 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- 238000009629 microbiological culture Methods 0.000 description 2
- 210000001616 monocyte Anatomy 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 238000005192 partition Methods 0.000 description 2
- 230000001717 pathogenic effect Effects 0.000 description 2
- 210000004896 polypeptide structure Anatomy 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- GCYXWQUSHADNBF-AAEALURTSA-N preproglucagon 78-108 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 GCYXWQUSHADNBF-AAEALURTSA-N 0.000 description 2
- 230000001681 protective effect Effects 0.000 description 2
- 238000004088 simulation Methods 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 229960004799 tryptophan Drugs 0.000 description 2
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 2
- 102100024341 10 kDa heat shock protein, mitochondrial Human genes 0.000 description 1
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 1
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 1
- 102100038222 60 kDa heat shock protein, mitochondrial Human genes 0.000 description 1
- 102100027401 A disintegrin and metalloproteinase with thrombospondin motifs 3 Human genes 0.000 description 1
- 108091005664 ADAMTS4 Proteins 0.000 description 1
- 208000030090 Acute Disease Diseases 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 101710153593 Albumin A Proteins 0.000 description 1
- KHOITXIGCFIULA-UHFFFAOYSA-N Alophen Chemical compound C1=CC(OC(=O)C)=CC=C1C(C=1N=CC=CC=1)C1=CC=C(OC(C)=O)C=C1 KHOITXIGCFIULA-UHFFFAOYSA-N 0.000 description 1
- 108010025628 Apolipoproteins E Proteins 0.000 description 1
- 102000013918 Apolipoproteins E Human genes 0.000 description 1
- 101000716807 Arabidopsis thaliana Protein SCO1 homolog 1, mitochondrial Proteins 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 108010081589 Becaplermin Proteins 0.000 description 1
- 101710129634 Beta-nerve growth factor Proteins 0.000 description 1
- 101001069913 Bos taurus Growth-regulated protein homolog beta Proteins 0.000 description 1
- 101001069912 Bos taurus Growth-regulated protein homolog gamma Proteins 0.000 description 1
- 108090000715 Brain-derived neurotrophic factor Proteins 0.000 description 1
- 102000004219 Brain-derived neurotrophic factor Human genes 0.000 description 1
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 1
- 101710149870 C-C chemokine receptor type 5 Proteins 0.000 description 1
- 102100023702 C-C motif chemokine 13 Human genes 0.000 description 1
- 101710112613 C-C motif chemokine 13 Proteins 0.000 description 1
- 102100023698 C-C motif chemokine 17 Human genes 0.000 description 1
- 102100023701 C-C motif chemokine 18 Human genes 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 102100036846 C-C motif chemokine 21 Human genes 0.000 description 1
- 102100032367 C-C motif chemokine 5 Human genes 0.000 description 1
- 102100032366 C-C motif chemokine 7 Human genes 0.000 description 1
- 101710155834 C-C motif chemokine 7 Proteins 0.000 description 1
- 102100034871 C-C motif chemokine 8 Human genes 0.000 description 1
- 101710155833 C-C motif chemokine 8 Proteins 0.000 description 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 1
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 description 1
- 102100039398 C-X-C motif chemokine 2 Human genes 0.000 description 1
- 102100036189 C-X-C motif chemokine 3 Human genes 0.000 description 1
- 102100036150 C-X-C motif chemokine 5 Human genes 0.000 description 1
- 102100036153 C-X-C motif chemokine 6 Human genes 0.000 description 1
- 101710085504 C-X-C motif chemokine 6 Proteins 0.000 description 1
- 102100032528 C-type lectin domain family 11 member A Human genes 0.000 description 1
- 101150093802 CXCL1 gene Proteins 0.000 description 1
- 101100123850 Caenorhabditis elegans her-1 gene Proteins 0.000 description 1
- 101100314454 Caenorhabditis elegans tra-1 gene Proteins 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 102000004039 Caspase-9 Human genes 0.000 description 1
- 108090000566 Caspase-9 Proteins 0.000 description 1
- 108010059013 Chaperonin 10 Proteins 0.000 description 1
- 108010058432 Chaperonin 60 Proteins 0.000 description 1
- 108010082155 Chemokine CCL18 Proteins 0.000 description 1
- 108010055166 Chemokine CCL5 Proteins 0.000 description 1
- 108010078239 Chemokine CX3CL1 Proteins 0.000 description 1
- 208000017667 Chronic Disease Diseases 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 108010014258 Elastin Proteins 0.000 description 1
- 102000016942 Elastin Human genes 0.000 description 1
- 244000070010 Erythrina variegata Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 1
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 102100028412 Fibroblast growth factor 10 Human genes 0.000 description 1
- 108090001047 Fibroblast growth factor 10 Proteins 0.000 description 1
- 102100035290 Fibroblast growth factor 13 Human genes 0.000 description 1
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 1
- 108090000385 Fibroblast growth factor 7 Proteins 0.000 description 1
- 102100020715 Fms-related tyrosine kinase 3 ligand protein Human genes 0.000 description 1
- 101710162577 Fms-related tyrosine kinase 3 ligand protein Proteins 0.000 description 1
- 102000013818 Fractalkine Human genes 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 101150099798 GSK1 gene Proteins 0.000 description 1
- 101710115997 Gamma-tubulin complex component 2 Proteins 0.000 description 1
- 241000251152 Ginglymostoma cirratum Species 0.000 description 1
- 102000034615 Glial cell line-derived neurotrophic factor Human genes 0.000 description 1
- 108091010837 Glial cell line-derived neurotrophic factor Proteins 0.000 description 1
- 101800004266 Glucagon-like peptide 1(7-37) Proteins 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 1
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 102100036683 Growth arrest-specific protein 1 Human genes 0.000 description 1
- 241000711549 Hepacivirus C Species 0.000 description 1
- 101000600756 Homo sapiens 3-phosphoinositide-dependent protein kinase 1 Proteins 0.000 description 1
- 101000978362 Homo sapiens C-C motif chemokine 17 Proteins 0.000 description 1
- 101000897480 Homo sapiens C-C motif chemokine 2 Proteins 0.000 description 1
- 101000713085 Homo sapiens C-C motif chemokine 21 Proteins 0.000 description 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 1
- 101000947193 Homo sapiens C-X-C motif chemokine 3 Proteins 0.000 description 1
- 101000947186 Homo sapiens C-X-C motif chemokine 5 Proteins 0.000 description 1
- 101000942297 Homo sapiens C-type lectin domain family 11 member A Proteins 0.000 description 1
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 1
- 101000914321 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 7 Proteins 0.000 description 1
- 101001072723 Homo sapiens Growth arrest-specific protein 1 Proteins 0.000 description 1
- 101001069921 Homo sapiens Growth-regulated alpha protein Proteins 0.000 description 1
- 101000960954 Homo sapiens Interleukin-18 Proteins 0.000 description 1
- 101000958041 Homo sapiens Musculin Proteins 0.000 description 1
- 101000973997 Homo sapiens Nucleosome assembly protein 1-like 4 Proteins 0.000 description 1
- 101000947178 Homo sapiens Platelet basic protein Proteins 0.000 description 1
- 101000617725 Homo sapiens Pregnancy-specific beta-1-glycoprotein 2 Proteins 0.000 description 1
- 101001076715 Homo sapiens RNA-binding protein 39 Proteins 0.000 description 1
- 101000851030 Homo sapiens Vascular endothelial growth factor receptor 3 Proteins 0.000 description 1
- 101001117146 Homo sapiens [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 1, mitochondrial Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 description 1
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 description 1
- 102000048143 Insulin-Like Growth Factor II Human genes 0.000 description 1
- 102100020881 Interleukin-1 alpha Human genes 0.000 description 1
- 102000003777 Interleukin-1 beta Human genes 0.000 description 1
- 108090000193 Interleukin-1 beta Proteins 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 108090000177 Interleukin-11 Proteins 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 101800003050 Interleukin-16 Proteins 0.000 description 1
- 108050003558 Interleukin-17 Proteins 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 102000003810 Interleukin-18 Human genes 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- 102100039898 Interleukin-18 Human genes 0.000 description 1
- 108010082786 Interleukin-1alpha Proteins 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 102000000588 Interleukin-2 Human genes 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 102000000646 Interleukin-3 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 102000000743 Interleukin-5 Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 102000004889 Interleukin-6 Human genes 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 102000000704 Interleukin-7 Human genes 0.000 description 1
- 108010002335 Interleukin-9 Proteins 0.000 description 1
- 102000000585 Interleukin-9 Human genes 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 102000000853 LDL receptors Human genes 0.000 description 1
- 108010001831 LDL receptors Proteins 0.000 description 1
- 108010092277 Leptin Proteins 0.000 description 1
- 102000016267 Leptin Human genes 0.000 description 1
- 108090000581 Leukemia inhibitory factor Proteins 0.000 description 1
- 102000019298 Lipocalin Human genes 0.000 description 1
- 108050006654 Lipocalin Proteins 0.000 description 1
- 102000004083 Lymphotoxin-alpha Human genes 0.000 description 1
- 108090000542 Lymphotoxin-alpha Proteins 0.000 description 1
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100028123 Macrophage colony-stimulating factor 1 Human genes 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 101710085938 Matrix protein Proteins 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 101710127721 Membrane protein Proteins 0.000 description 1
- 102100039364 Metalloproteinase inhibitor 1 Human genes 0.000 description 1
- 241000282341 Mustela putorius furo Species 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 108010025020 Nerve Growth Factor Proteins 0.000 description 1
- 108090000742 Neurotrophin 3 Proteins 0.000 description 1
- 102100029268 Neurotrophin-3 Human genes 0.000 description 1
- 102000003683 Neurotrophin-4 Human genes 0.000 description 1
- 108090000099 Neurotrophin-4 Proteins 0.000 description 1
- 102100021584 Neurturin Human genes 0.000 description 1
- 108010015406 Neurturin Proteins 0.000 description 1
- 108091008606 PDGF receptors Proteins 0.000 description 1
- 241001504519 Papio ursinus Species 0.000 description 1
- 102100036154 Platelet basic protein Human genes 0.000 description 1
- 102100030304 Platelet factor 4 Human genes 0.000 description 1
- 108090000778 Platelet factor 4 Proteins 0.000 description 1
- 102000011653 Platelet-Derived Growth Factor Receptors Human genes 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 102100022019 Pregnancy-specific beta-1-glycoprotein 2 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102220513579 Pulmonary surfactant-associated protein D_S12P_mutation Human genes 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 102100023361 SAP domain-containing ribonucleoprotein Human genes 0.000 description 1
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 102100027188 Thyroid peroxidase Human genes 0.000 description 1
- 101710113649 Thyroid peroxidase Proteins 0.000 description 1
- 102100030859 Tissue factor Human genes 0.000 description 1
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 1
- 108050003222 Transferrin receptor protein 1 Proteins 0.000 description 1
- 102000002070 Transferrins Human genes 0.000 description 1
- 108010015865 Transferrins Proteins 0.000 description 1
- 102400001320 Transforming growth factor alpha Human genes 0.000 description 1
- 101800004564 Transforming growth factor alpha Proteins 0.000 description 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 1
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 1
- 102100033179 Vascular endothelial growth factor receptor 3 Human genes 0.000 description 1
- 241001416177 Vicugna pacos Species 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 102100024148 [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 1, mitochondrial Human genes 0.000 description 1
- 238000011481 absorbance measurement Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 238000003314 affinity selection Methods 0.000 description 1
- 230000008484 agonism Effects 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 description 1
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 description 1
- 229940024142 alpha 1-antitrypsin Drugs 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 108010026054 apolipoprotein SAA Proteins 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 238000002306 biochemical method Methods 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- OWMVSZAMULFTJU-UHFFFAOYSA-N bis-tris Chemical compound OCCN(CCO)C(CO)(CO)CO OWMVSZAMULFTJU-UHFFFAOYSA-N 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 108010041776 cardiotrophin 1 Proteins 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 230000007541 cellular toxicity Effects 0.000 description 1
- 238000001311 chemical methods and process Methods 0.000 description 1
- 238000000978 circular dichroism spectroscopy Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 238000010612 desalination reaction Methods 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 238000011143 downstream manufacturing Methods 0.000 description 1
- 238000001647 drug administration Methods 0.000 description 1
- 229920002549 elastin Polymers 0.000 description 1
- 230000005611 electricity Effects 0.000 description 1
- 239000002532 enzyme inhibitor Substances 0.000 description 1
- 230000003203 everyday effect Effects 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 239000003877 glucagon like peptide 1 receptor agonist Substances 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 201000010284 hepatitis E Diseases 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 102000046949 human MSC Human genes 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000008863 intramolecular interaction Effects 0.000 description 1
- 150000002505 iron Chemical class 0.000 description 1
- 230000002427 irreversible effect Effects 0.000 description 1
- 238000002356 laser light scattering Methods 0.000 description 1
- NRYBAZVQPHGZNS-ZSOCWYAHSA-N leptin Chemical compound O=C([C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)CCSC)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CS)C(O)=O NRYBAZVQPHGZNS-ZSOCWYAHSA-N 0.000 description 1
- 229940039781 leptin Drugs 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 241001515942 marmosets Species 0.000 description 1
- AEUKDPKXTPNBNY-XEYRWQBLSA-N mcp 2 Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)C1=CC=CC=C1 AEUKDPKXTPNBNY-XEYRWQBLSA-N 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 210000003643 myeloid progenitor cell Anatomy 0.000 description 1
- 229940053128 nerve growth factor Drugs 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000008194 pharmaceutical composition Substances 0.000 description 1
- 108010017843 platelet-derived growth factor A Proteins 0.000 description 1
- 108010000685 platelet-derived growth factor AB Proteins 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000009465 prokaryotic expression Effects 0.000 description 1
- 230000012743 protein tagging Effects 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000007789 sealing Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- IBKZNJXGCYVTBZ-IDBHZBAZSA-M sodium;1-[3-[2-[5-[(3as,4s,6ar)-2-oxo-1,3,3a,4,6,6a-hexahydrothieno[3,4-d]imidazol-4-yl]pentanoylamino]ethyldisulfanyl]propanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCSSCCNC(=O)CCCC[C@H]1[C@H]2NC(=O)N[C@H]2CS1 IBKZNJXGCYVTBZ-IDBHZBAZSA-M 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 238000002076 thermal analysis method Methods 0.000 description 1
- 231100000820 toxicity test Toxicity 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000032895 transmembrane transport Effects 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
Images


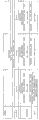
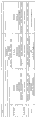


Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6843—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2878—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/76—Albumins
- C07K14/765—Serum albumin, e.g. HSA
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/31—Fusion polypeptide fusions, other than Fc, for prolonged plasma life, e.g. albumin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
Abstract
本发明涉及抗-血清白蛋白免疫球蛋白单可变结构域DOM7h-11的改进的变体,以及包含这种变体的配体和药物缀合物、组合物、核酸、载体和宿主。
Description
本发明涉及抗-血清白蛋白免疫球蛋白单一可变结构域DOM7h-11的改进的变体,以及包含这种变体的配体和药物缀合物、组合物、核酸、载体和宿主。
发明背景
WO04003019和WO2008/096158公开了具有治疗有用的半衰期的抗-血清白蛋白(SA)结合部分,如抗-SA免疫球蛋白单一可变结构域(dAbs)。这些文献公开了单体抗-SA dAbs以及包含这种dAbs的多特异性配体,例如,包括抗-SA dAb和特异性结合目标抗原如TNFR1的dAb的配体。公开了特异性结合来自多于一个物种的血清白蛋白的结合部分,例如人/小鼠交叉反应的抗-SA dAbs。
WO05118642和WO2006/059106公开了为了增加药物的半衰期而将抗-SA结合部分,如抗-SA免疫球蛋白单一可变结构域,缀合或结合至药物的概念。其公开并例举了蛋白、肽和新的化学实体(NCE)药物。WO2006/059106公开了使用这种概念以增加促胰岛素释放试剂(insulintropic
agents),例如,肠降血糖素激素如胰高血糖素样肽(GLP)-1的半衰期。还可参考Holt等, “Anti-Serum albumin domain antibodies for extending the
half-lives of short lived drugs”, Protein
Engineering, Design & Selection, vol 21, no 5, pp283-288, 2008。WO2008/096158公开了一种很好的抗-SA
dAb,DOM7h-11。期望提供作为DOM7h-11的变体并特异性结合血清白蛋白,优选来自人和非人物种的白蛋白的改进的dAbs,这将在疾病的动物模型中以及对于人的治疗和/或诊断提供实用性。还期望在相对温和和高亲和力的抗-SA结合部分(dAbs)之间提供选择。这种部分可以连接至药物,根据设想的最终应用选择抗-SA结合部分。根据抗-SA结合部分的选择,这允许更好地定制药物以治疗和/或预防慢性或急性适应症。还期望提供是单体或者在溶液中基本上如此的抗-SA dAbs。以拮抗受体为目的,当抗-SA dAb被连接到特异性结合细胞表面受体如TNFR1的结合部分例如dAb时,这是特别有利的。抗-SA dAb的单体状态在减少受体交联的机会中是有用的,因为可以结合并交联细胞表面上的受体(例如,TNFR1)的多聚体形成的可能性更小,从而增加了受体激动和有害的受体信号传递的可能性。
PCT/EP2010/052008和PCT/EP2010/052007公开了许多改进的dAbs,其公开内容被引用并入。
还期望提供具有改进稳定性的改进的dAbs。这对于允许dAb具有合适的稳定性特征或储存时间是有利的。具体而言,期望提供具有暴露于升高的温度后耐受解折叠(unfolding)的改进的能力,即改进的热稳定性,的dAbs。还期望提供当形式为构建体如多特异性配体或者当缀合于蛋白、肽或NCE时具有改进的稳定性的dAbs。
发明概述
本发明的方面解决了这些问题。
为了这个目的,本发明人惊讶地发现,可以对DOM7h-11系的免疫球蛋白单一可变结构域分子进行突变,得到由相对于母体DOM7h-11分子的改进的热稳定性所测定的分子的改进的稳定性。
在一个方面中,提供了DOM7h-11(DOM7h-11如图1中所示)的抗-血清白蛋白(SA)免疫球蛋白单一可变结构域变体,所述变体具有至少54℃的Tm。在另一个方面中,提供了DOM7h-11(DOM7h-11如图1中所示)的抗-血清白蛋白(SA)免疫球蛋白单一可变结构域变体,所述变体具有高于54℃的Tm。转化中点(Tm)为其中50%蛋白是在其天然构象并且其它50%是变性的温度。合适地,通过差示扫描量热法测定所述Tm。
在一个实施方案中,与DOM7h-11相比,所述变体在22、42或91位(根据Kabat编号)中任何位置包含至少一个突变。合适地,抗-SA免疫球蛋白单一可变结构域变体是DOM7h-11-15(DOM7h-11-15如图1(SEQ ID NO:7)中所示)的变体,与DOM7h-11-15相比,在22、42或91位(根据Kabat编号)中任何位置包含至少一个突变。在一个实施方案中,变体包含选自下列的至少一个突变:
22位 = Ser、Phe、Thr、Ala或Cys;
42位= Glu或Asp;
91位= Thr或Ser;
在其它实施方案中,提供了抗-SA免疫球蛋白单一可变结构域变体,其中22位是Ser或Phe;抗-SA免疫球蛋白单一可变结构域变体,其中42位是Glu和91位是Thr;抗-SA免疫球蛋白单一可变结构域变体,其中91位是Thr;抗-SA免疫球蛋白单一可变结构域变体,其中22位是Phe。在一个实施方案中,108位是Trp。
进一步的实施方案提供了变体,所述变体包含与选自DOM7h-11-56 (SEQ ID NO:412)、DOM7h-11-68 (SEQ
ID NO:416)、DOM7h-11-79
(SEQ ID NO:418)和DOM7h-11-80
(SEQ ID NO:419)的单一可变结构域的氨基酸序列相同的氨基酸序列(或者所述变体具有与选择的氨基酸序列的氨基酸序列至少95、96、97、98或99%相同的氨基酸)或者与选择的氨基酸序列相比具有最多达4个改变的氨基酸序列。
尤其地,已经发现,针对DOM7h-11的FW3(57-88位,根据Kabat编号)和CDR3区(89-97位,根据Kabat编号)的突变赋予改进的稳定性。因此,在另一个实施方案中,提供了与本发明的一个方面一致的抗-SA免疫球蛋白单一可变结构域变体,其中,与DOM7h-11相比,所述变体在FW3区中(57-88位,根据Kabat编号)或在CDR3区中(89-97位,根据Kabat编号)包含至少一个突变。
进一步的实施方案提供了抗-SA免疫球蛋白单一可变结构域,其中所述变体是DOM7h-11-15(DOM7h-11-15如图1中所示)的变体,与DOM7h-11-15相比,所述变体在FW3区中(57-88位,根据Kabat编号)或在CDR3区中(89-97位,根据Kabat编号)包含至少一个突变。合适地,所述变体在77、83、93或95位(根据Kabat编号)中任何位置包含至少一个突变。
在一个实施方案中,变体包含选自下列的至少一个突变:
77位 = Asn、Gln
83位= Val、Ile、Met、Leu、Phe、Ala或正亮氨酸。
93位= Val、Ile、Met、Leu、Phe、Ala或正亮氨酸。
95位= His、Asn、Gln、Lys或Arg。
在另一个实施方案中,本发明的抗-SA免疫球蛋白单一可变结构域在106或108位(根据Kabat编号)还包括突变。合适地,106位是Asn或Gln。合适地,108位是Trp、Tyr或Phe。
在进一步的实施方案中,提供了抗-SA免疫球蛋白单一可变结构域变体,其中77位是Asn;抗-SA单一可变结构域,其中83位是Val;抗-SA单一可变结构域,其中95位是His;抗-SA单一可变结构域,其中95位是His;抗-SA单一可变结构域,其中93位是Val。
在更进一步的实施方案中,提供了变体,所述变体包含与选自DOM7h-11-57 (SEQ ID NO:413)、DOM7h-11-65 (SEQ
ID NO:414)或DOM7h-11-67
(SEQ ID NO:415)的单一可变结构域的氨基酸序列相同的氨基酸序列(或者所述变体具有与选择的氨基酸序列的氨基酸序列至少95、96、97、98或99%相同的氨基酸)或者与选择的氨基酸序列相比具有最多达4个改变的氨基酸序列,条件是所述变体的氨基酸序列在FW3或CDR3区中具有至少一个突变。
在进一步的实施方案中,提供了变体,所述变体包含与选自DOM7h-11-69 (SEQ ID NO:417)、DOM 7h-11-90
(SEQ ID NO:420)、DOM
7h-11-86 (SEQ ID NO:421)、DOM 7h-11-87 (SEQ ID NO:422)或DOM 7h-11-88 (SEQ ID NO:423)的单一可变结构域的氨基酸序列相同的氨基酸序列(或者所述变体具有与选择的氨基酸序列的氨基酸序列至少95、96、97、98或99%相同的氨基酸序列)。
合适地,变体具有至少57℃的Tm。在另一个实施方案中,变体具有高于57℃的Tm。
在一个实施方案中,本发明的任何实施方案的变体与DOM7h-11相比具有增加的Tm值。在另一个实施方案中,所述变体与DOM7h-11-15相比具有增加的Tm值。在另一个实施方案中,提供了包含上面列出的任何突变的任何组合的变体。合适地,根据本文所述的方法通过DSC测定Tm。
合适地,本发明的变体包含结合位点,所述结合位点以约0.1-约10000
nM、任选地约1-约6000
nM的解离常数(KD)(由表面等离子体共振所测定)特异性结合人SA。任何前述权利要求的变体,其中所述变体包含结合位点,所述结合位点以约1.5 x
10-4-约0.1sec-1、任选地约3 x 10-4-约0.1sec-1的解离速率常数(Kd)(由表面等离子体共振所测定)特异性结合人SA。任何前述权利要求的变体,其中所述变体包含结合位点,所述结合位点以约2 x
106-约1 x 104 M-1sec-1、任选地约1 x 106-约2 x
104 M-1sec-1的结合速率常数(on-rate
constant, Ka)(由表面等离子体共振所测定)特异性结合人SA。
有利地,本发明的变体与来自许多不同物种的血清白蛋白如,例如,猴例如猕猴、臭鼩属(鼩鼱科)、狨猴、雪貂、大鼠、小鼠、猪和狗SA交叉反应。
因此,在一个实施方案中,本发明的变体包含结合位点,所述结合位点以约0.1-约10000 nM、任选地约1-约6000 nM的解离常数(KD)(由表面等离子体共振所测定)特异性结合猕猴SA。任何前述权利要求的变体,其中所述变体包含结合位点,所述结合位点以约1.5 x 10-4-约0.1sec-1、任选地约3 x
10-4-约0.1sec-1的解离速率常数(Kd)(由表面等离子体共振所测定)特异性结合猕猴SA。任何前述权利要求的变体,其中所述变体包含结合位点,所述结合位点以约2 x
106-约1 x 104 M-1sec-1、任选地约1 x 106-约5 x
103M-1sec-1的结合速率常数(on-rate
constant, Ka)(由表面等离子体共振所测定)特异性结合猕猴SA。在另一个方面,提供了多特异性配体,其包含本发明的抗-SA变体和特异性结合除SA以外的目标抗原的结合部分。本文列举了合适的目标抗原。在一个实施方案中,特异性结合目标抗原的结合部分可以是另一种单一结构域免疫球蛋白分子。在另一个实施方案中,特异性结合目标抗原的结合部分可以是单克隆抗体。例如在WO2009/068649中描述了用于制造双特异性分子,如mAbdAb分子的合适的形式和方法。
本发明的一个方面提供了融合产物,例如,与肽或NCE(新的化学实体)药物的融合蛋白或融合体,包括融合或缀合(对于NCE)于上面所述的任何变体的多肽、蛋白、肽或NCE药物。在另一个方面,提供了融合蛋白、多肽融合体或缀合物,其包括融合于本发明的抗-血清白蛋白dAb变体的多肽或肽药物,任选地,其中选择的变体是DOM7h-11-56
(SEQ ID NO:412)、DOM7h-11-57
(SEQ ID NO:413)、DOM7h-11-65
(SEQ ID NO:414)、DOM7h-11-67
(SEQ ID NO:415)、DOM7h-11-68
(SEQ ID NO:416)、DOM7h-11-69
(SEQ ID NO:417)、DOM7h-11-79
(SEQ ID NO:418)、DOM7h-11-80
(SEQ ID NO:419)、DOM
7h-11-90 (SEQ ID NO:420)、DOM 7h-11-86 (SEQ ID NO:421)、DOM 7h-11-87 (SEQ ID NO:422)或DOM 7h-11-88 (SEQ ID NO:423)。合适地,这种融合蛋白在变体和药物之间包含接头(例如,包括氨基酸序列TVA的接头,任选TVAAPS(SEQ ID NO:437))。
在一个实施方案中,提供了多肽融合体或缀合物,其包含本文所述的抗-血清白蛋白dAb和肠降血糖素或促胰岛素试剂,例如,毒蜥外泌肽-4、GLP-1(7-37)、GLP-1(6-36)或WO06/059106中公开的任何肠降血糖素或促胰岛素试剂,本文所述的这些试剂明确地在本文被引用并入用于包含在本发明和下面的权利要求中。
在另一个方面,提供了本发明的抗-SA变体单一可变结构域,其中所述可变结构域缀合于药物(任选地NCE药物),任选地,其中选择的变体是DOM7h-11-56 (SEQ ID NO:412)、DOM7h-11-57 (SEQ ID NO:413)、DOM7h-11-65 (SEQ ID NO:414)、DOM7h-11-67 (SEQ ID NO:415)、DOM7h-11-68 (SEQ ID NO:416)、DOM7h-11-69 (SEQ ID NO:417)、DOM7h-11-79 (SEQ ID NO:418)、DOM7h-11-80 (SEQ ID NO:419)、DOM 7h-11-90 (SEQ ID NO:420)、DOM 7h-11-86 (SEQ ID NO:421)、DOM 7h-11-87 (SEQ ID NO:422)或DOM 7h-11-88 (SEQ ID NO:423)。
在另一个方面,提供了组合物,所述组合物包含前述任一权利要求的变体、融合蛋白或配体和药学上可接受的稀释剂、载体、赋形剂或媒介。
在进一步的方面,提供了核酸,所述核酸包含编码本发明的变体或者本发明的多特异性配体或融合蛋白的核苷酸序列。合适地,提供了包含DOM7h-11变体的核苷酸序列的核酸,所述核苷酸序列选自核苷酸序列DOM7h-11-56 (SEQ ID NO:425)、DOM7h-11-57 (SEQ
ID NO:426)、DOM7h-11-65
(SEQ ID NO:427)、DOM7h-11-67
(SEQ ID NO:428)、DOM7h-11-68
(SEQ ID NO:429)、DOM7h-11-69
(SEQ ID NO:430)、DOM7h-11-79
(SEQ ID NO:431)、DOM7h-11-80
(SEQ ID NO:432)、DOM
7h-11-90 (SEQ ID NO:433)、DOM 7h-11-86 (SEQ ID NO:434)、DOM 7h-11-87 (SEQ ID NO:435)或DOM 7h-11-88 (SEQ ID NO:436)或者与所述选择的序列至少80%相同的核苷酸序列。
另一个方面提供了包含本发明的核酸的载体。进一步的方面提供了包含本发明的载体的分离的宿主细胞。
在进一步的方面,提供了在患者中治疗或预防疾病或病症的方法,包括将至少一个剂量的本发明的任何方面或实施方案的变体施用于所述患者。
附图简要说明
图1:对于DOM7h-11变体dAbs的氨基酸序列比对。在特定位置的“.”表示在DOM7h-11中在该位置发现的相同的氨基酸。通过下划线和粗体文字显示CDRs(第一组下划线的序列是CDR1,第二组下划线的序列是CDR2,第三组下划线的序列是CDR3)。
图2:DOM7h-11变体的动力学参数。KD单位 = nM;Kd单位 = sec-1;Ka单位 = M-1
sec-1。符号A e-B意味着A x 10-B,Ce D意味着C x 10D。显示了在各个物种中的总体动力学范围,这由下面的实施例所支持。还提供了用于特定的治疗设置(急性或慢性适应症、状况或疾病和用于慢性和急性设置中的“中间的”)的任选范围。高亲和力dAbs和包含这些的产品可用于慢性设置。中等亲和力dAbs和包含这些的产品可用于中间的设置。低亲和力dAbs和包含这些的产品可用于急性设置。在这方面的亲和力是对于血清白蛋白的亲和力。列出了抗-血清dAbs和融合蛋白的各种例子,这些支持公开的范围。许多例子在人和一种或多种非人动物(例如,在人和猕猴和/或小鼠中)具有有利的动力学。根据本发明所述,这取决于待治疗性处理的设置(例如,慢性的或急性的),可以定制dAb或包含其的产品的选择。
图3:对于DOM7h-11-15变体dAbs的氨基酸(A)和核酸(B)序列比对。在特定位置的“.”表示在DOM7h-11-15中在该位置发现的相同的氨基酸。
发明的详细说明
在本说明书中,关于实施方案,已经以撰写清晰、简明的说明书的方式描述了本发明。希望并且应当理解的是,在不偏离本发明的情况下,实施方案可以多种方式组合或分开。
除非另有定义,本文所用的所有技术和科学术语与本领域(例如,在细胞培养、分子遗传学、核酸化学、杂交技术和生物化学中)普通技术人员通常理解的具有相同含义。对于分子的、遗传的和生物化学的方法(通常见Sambrook等, Molecular
Cloning:A Laboratory Manual,二版. (1989) Cold Spring Harbor Laboratory Press, Cold Spring
Harbor, N.Y.和Ausubel等,
Short Protocols in Molecular Biology (1999) 四版,
John Wiley & Sons, Inc.其在本文被引用并入)和化学方法,使用标准的技术。
本文所用的术语“肿瘤坏死因子受体1(TNFR1)的拮抗剂”或“抗-TNFR1拮抗剂”或类似物是指结合TNFR1并可以抑制TNFR1的(即,一种或多种)功能的试剂(例如,分子、化合物)。例如,TNFR1的拮抗剂可以抑制TNFα与TNFR1的结合和/或抑制通过TNFR1介导的信号转导。因此,可以用TNFR1的拮抗剂抑制TNFR1介导的过程和细胞应答(例如,在标准的L929细胞毒性试验中的TNFα诱导的细胞死亡)。
“患者”是任何动物,例如,哺乳动物,例如,非人灵长类(如狒狒、恒河猴或猕猴)、小鼠、人、兔、大鼠、狗、猫或猪。在一个实施方案中,患者是人。
本文所用的“肽”是指通过肽键连接在一起的约2至约50个氨基酸。
本文所用的“多肽”是指通过肽键连接在一起的至少约50个氨基酸。多肽通常包括三级结构并折叠成功能结构域。
本文所用的抗体是指IgG、IgM、IgA、IgD或IgE或片段(如Fab、Fab’、F(ab’)2、Fv、二硫连接的Fv、scFv、封闭构象的多特异性抗体、二硫连接的scFv、双抗体),无论其是否源自任何天然产生抗体的物种,还是通过重组DNA技术生成;无论其是否从血清、B-细胞、杂交瘤、转染瘤酵母或细菌分离。
本文所用的“抗体形式”是指任何合适的多肽结构,其中可以并入一个或多个抗体可变结构域从而在结构上赋予对于抗原的结合特异性。各种合适的抗体形式是本领域已知的,如,嵌合抗体、人源化抗体、人抗体、单链抗体、双特异性抗体、抗体重链、抗体轻链、抗体重链和/或轻链的同源二聚体和异源二聚体,上述任何的抗原结合片段(例如,Fv片段(例如,单链Fv(scFv)、二硫键合的Fv)、Fab片段、Fab'片段、F(ab’)2片段)、单一抗体可变结构域(例如,dAb、VH、VHH、VL)和上述任何的修饰版本(例如,通过聚乙二醇或其它合适的聚合物或人源化的VHH的共价连接而修饰)。
短语“免疫球蛋白单一可变结构域”是指不依赖于不同的V区或结构域地特异性结合抗原或表位的抗体可变结构域(VH、VHH、VL)。免疫球蛋白单一可变结构域可以与其它可变区或可变结构域以一定形式(例如,同源或异源多聚体)存在,其中其它区或结构域对于通过单一免疫球蛋白可变结构域的抗原结合是不需要的(即,其中免疫球蛋白单一可变结构域不依赖于额外可变结构域地结合抗原)。“结构域抗体”或“dAb”与本文所用的术语“免疫球蛋白单一可变结构域”是相同的。“单一免疫球蛋白可变结构域”与本文所用的术语“免疫球蛋白单一可变结构域”是相同的。“单一抗体可变结构域”或“抗体单一可变结构域”与本文所用的术语“免疫球蛋白单一可变结构域”是相同的。在一个实施方案中,免疫球蛋白单一可变结构域是人抗体可变结构域,但还包括来自其它物种的单一抗体可变结构域,如啮齿类(例如,在WO 00/29004中公开的,其内容在本文被完整地引用并入)、铰口鲨和骆驼科VHH dAbs。骆驼科VHH是免疫球蛋白单一可变结构域多肽,其来源于某些物种,包括骆驼、美洲驼、羊驼、单峰骆驼和原驼(guanaco),其产生天然没有轻链的重链抗体。VHH可以是人源化的。
“结构域”是指折叠的蛋白结构,其具有不依赖于于该蛋白剩余部分的三级结构。通常,结构域负责蛋白的离散的功能特性,在许多情况下,可以在不丧失蛋白和/或结构域的剩余部分的功能的情况下被增加、去除或转移到其他蛋白。“单一抗体可变结构域”是折叠的多肽结构域,其包含抗体可变结构域的特征序列。因此,它包括完整的抗体可变结构域和修饰的可变结构域(例如,其中有一个或多个环(loop)被不是抗体可变结构域特征的序列所替代),或者被截短或包含N末端或C末端延伸的抗体可变结构域,以及至少保留全长结构域的结合活性和特异性的可变结构域的折叠片段。
“系”是指源自相同的“母体”克隆的一系列免疫球蛋白单一可变结构域。例如,可以通过多样化(diversification)、位点定向诱变,易错或掺杂的文库(error prone or doped libraries)的产生从母体或初始的免疫球蛋白单一可变结构域产生包括许多变体克隆的系。合适地,在亲和力成熟的过程中产生结合分子。在本发明中,提到的“DOM7h-11”是PCT/EP2010/052008和PCT/EP2010/052007中所述的抗-SA免疫球蛋白单一可变结构域。如本文所述,DOM7h-11-15是源自DOM7h-11母体克隆的DOM7h-11系之一。
在本申请中,术语“防止(prevention)”和“防止(preventing)”涉及在疾病或状况的诱导之前施用保护性组合物。“治疗(Treatment)”和“治疗(treating)”涉及在疾病或状况症状变得明显之后施用保护性组合物。“抑制(Suppression)”或“抑制(suppressing)”是指在诱导事件之后,但是在疾病或状况的临床显现之前施用组合物。
本文所用的术语“剂量”是指一次所有的(单位剂量)或在确定的时间间隔两次或更多次施用中施用于受试者的配体的量。例如,剂量可以是指在一天(24小时)(每天剂量)、两天、一周、两周、三周或一个或更多个月期间施用(例如,通过单次施用,或通过两次或更多次施用)于受试者的配体(例如,包含结合目标抗原的免疫球蛋白单一可变结构域的配体)的量。剂量间的间隔可以是任何所需量的时间。当涉及剂量时,术语“药学上有效的”是指足以提供所需效果的足够量的配体、结构域或药学活性剂。根据个体的年龄和总体状况、具体的药物或药学活性剂等,“有效的”量在受试者与受试者之间不同。因此,对于所有患者不可能总是指定确切的“有效的”量。然而,本领域普通技术人员用常规实验可以确定在任何个体情况下的适当的“有效的”剂量。
用于配体(例如,单一可变结构域、融合蛋白或多特异性配体)半衰期的药代动力学分析和测定的方法是本领域技术人员熟悉的。详情可见Kenneth, A 等:Chemical Stability of Pharmaceuticals:A Handbook for Pharmacists和Peters 等 , Pharmacokinetc analysis:A Practical Approach (1996)。也可参见 “Pharmacokinetics”, M
Gibaldi & D Perron, published by Marcel Dekker, 2nd Rev. ex
edition (1982),其描述了药代动力学参数,如t α和t β半衰期和曲线下面积(AUC)。任选地,本文引用的所有药代动力学参数和数值可以被理解为在人中的数值。任选地,本文引用的所有药代动力学参数和数值可以被理解为在小鼠或大鼠或猕猴中的数值。
可以从配体的血清浓度针对时间的曲线确定半衰期(t½ α和t½ β)和AUC。可以使用,例如,WinNonlin分析软件包,例如版本5.1(从Pharsight Corp.,
Mountain View, CA94040, USA获得)来模拟曲线。当使用二室模型(two-compartment modeling)时,在第一阶段(α阶段),配体经历在患者中的主要分布,以及一些清除。第二阶段(β阶段)是当配体已经分布并且血清浓度正在减少(因为配体从患者中被清除)的阶段。t α半衰期是第一阶段的半衰期,t β半衰期是第二阶段的半衰期。因此,在一个实施方案中,在本发明的上下文中,可变结构域、融合蛋白或配体具有15分钟或更长(或约该数值)的范围的tα半衰期。在一个实施方案中,范围的下端是(或约)30分钟、45分钟、1小时、2小时、3小时、4小时、5小时、6小时、7小时、10小时、11小时或12小时。此外,或另外,本发明的可变结构域、融合蛋白或配体具有最多达并包括12小时(或约12小时)的范围中的tα半衰期。在一个实施方案中,范围的上端是(或约)11、10、9、8、7、6或5小时。合适的范围的例子是(或约)1-6小时、2-5小时或3-4小时。
在一个实施方案中,本发明提供了本发明的可变结构域、融合蛋白或配体,其具有2.5小时或更长(或约该数值)的范围的tβ半衰期。在一个实施方案中,范围的下端是(或约)3小时、4小时、5小时、6小时、7小时、10小时、11小时或12小时。此外,或另外,tβ半衰期是(或约)最多达并包括21或25天。在一个实施方案中,范围的上端是(或约)12小时、24小时、2天、3天、5天、10天、15天、19天、20天、21天或22天。例如,本发明的可变结构域、融合蛋白或配体具有12-60小时(或约12-60小时)的范围的tβ半衰期。在进一步的实施方案中,它将在12-48小时(或约12-48小时)的范围内。在仍进一步的实施方案中,它将在12-26小时(或约12-26小时)的范围内。
作为使用二室模型的替代方案,本领域技术人员熟悉非房室模型(non-compartmental modeling)的使用,其可以用于确定终末半衰期(在这个方面,本文所用的术语“终末半衰期”是指用非房室模型确定的终末半衰期)。可以使用,例如,WinNonlin分析软件包,例如版本5.1(从Pharsight Corp., Mountain View, CA94040, USA获得)来以这种方式模拟曲线。在这种情况下,在一个实施方案中,单一可变结构域、融合蛋白或配体具有至少(或至少约)8小时、10小时、12小时、15小时、28小时、20小时、1天、2天、3天、7天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天或25天的终末半衰期。在一个实施方案中,这种范围的上端是(或约)24小时、48小时、60小时或72小时或120小时。例如,终末半衰期是(或约)8小时-60小时,或8小时-48小时或12小时-120小时,例如,在人中。
上述标准的此外或另外,本发明的可变结构域、融合蛋白或配体具有1 mg.min/ml或更高(或约该数值)的范围的AUC数值(曲线下面积)。在一个实施方案中,范围的下端是(或约)5、10、15、20、30、100、200或300 mg.min/ml。此外或另外,本发明的可变结构域、融合蛋白或配体具有最高达600 mg.min/ml(或约该数值)的范围的AUC。在一个实施方案中,范围的上端是(或约)500、400、300、200、150、100、75或50 mg.min/ml。有利地,可变结构域、融合蛋白或配体具有选自如下的范围中(或约该范围中)的AUC:15-150 mg.min/ml、15-100
mg.min/ml、15-75 mg.min/ml和15-50mg.min/ml。
“表面等离子体共振”:可以使用竞争试验确定特异性抗原或表位如人血清白蛋白是否与另一种抗原或表位如猕猴血清白蛋白竞争结合本文所述的血清白蛋白结合配体如特异性dAb。可以使用类似的竞争试验确定第一配体如dAb是否与第二配体如dAb竞争结合目标抗原或表位。本文所用的术语“竞争”是指能够在任何程度上干扰两种或多种分子之间的特异性结合相互作用的物质,如分子、化合物,优选蛋白。短语“没有竞争性地抑制”是指物质,如分子、化合物,优选蛋白不以任何可测量的或显著的程度干扰两种或更多种分子之间的特异性结合相互作用。两种或更多种分子之间的特异性结合相互作用优选包括单一可变结构域和其同源伴侣或目标之间的特异性结合相互作用。干扰或竞争分子可以是另一种单一可变结构域,或者它可以是结构上和/或功能上与同源伴侣或目标相似的分子。
术语“结合部分”是指不依赖于不同表位或抗原结合结构域地特异性结合抗原或表位的结构域。结合部分可以是结构域抗体(dAb)或者可以是结合除天然配体(在本发明的情况下,该部分结合血清白蛋白)以外的配体的结构域,该结构域是非免疫球蛋白支架,例如选自如下的支架的衍生物:CTLA-4、脂质运载蛋白、SpA、adnectin、affibody、avimer、GroEl、转铁蛋白、GroES和纤连蛋白。见WO2008/096158,其公开了蛋白支架的例子和用于从所有组成成分中选择抗原或表位特异性结合结构域的方法(见实施例17-25)。WO2008/096158的这些特定公开内容由于在本文中明确描述并用于和本发明共同使用而在本文中被清楚地引用并入,可以设想这种公开的任何部分可以并入本发明的一个或多个权利要求中)。
在一个方面,本发明提供了DOM7h-11的抗-血清白蛋白(SA)免疫球蛋白单一可变结构域变体,其中与DOM7h-11相比,该变体在22、42或91位(根据Kabat编号)包含至少一个突变。在一个实施方案中,与DOM7h-11-15相比,该变体在22、42或91位(根据Kabat编号)包含至少一个突变。合适地,与DOM7h-11或DOM7h-11-15的氨基酸序列相比,本发明的变体具有1、2、3或最多达8个改变。
在另一个方面,本发明提供了DOM7h-11的抗-血清白蛋白(SA)免疫球蛋白单一可变结构域变体,其中与DOM7h-11相比,该变体在框架区3(FW3)(氨基酸57-88)或互补决定区3(CDR3)(氨基酸89-97)包含至少一个突变,其中与DOM7h-11的氨基酸序列相比,该变体具有1、2、3或最多达8个改变。在一个实施方案中,与DOM7h11-15相比,该变体在这些位置包含至少一个突变。
在一个实施方案中,在这些位置中的任何位置的突变是如本文实施例部分所例举的对残基的突变。在另一个实施方案中,突变针是例举的残基的保守的氨基酸取代。
保守的氨基酸取代是本领域技术人员公知的,由下表所例举:

保守的氨基酸取代还可以涉及非天然存在的氨基酸残基,如可以通过化学肽合成引入的肽模拟物和氨基酸部分的其它颠倒或反转的形式。
热稳定性或热动力学稳定性是当暴露于升高的温度之后物质/蛋白耐受可逆(不可逆)解折叠的质量。
可以用差示扫描量热法(DSC)进行热稳定性/热动力学稳定性的测量。DSC是热分析技术,其中将升高样品和参照的温度所需的能量或热量的量的差异测量为温度的函数。它可以用来研究范围广泛的蛋白的热转换,可用于确定熔解温度以及热动力学参数。简而言之,以180度C/hr的恒定速率(常规在PBS中为1mg/mL)和与测定的热变性相关的可检测的热容量变化加热蛋白。测定转化中点(Tm),其被描述为其中50%蛋白是在其天然构象并且其它50%是变性的温度。这里,当检查的大部分蛋白没有完全再折叠时,DSC确定表观转化中点(appTm)。Tm或appTm越高,分子越稳定。软件包如OriginR v7.0383 (Origin Lab)可用于产生Tm值。
在本发明的一个实施方案中,改进的热稳定性意味着与母体分子相比增加的或更高的Tm。合适地,母体分子是DOM7h-11或DOM7h-11-15。合适地,“改进的”热稳定性意味着比母体分子的Tm值更高的Tm值。合适地,“改进的热稳定性”是指至少54℃或至少55℃。在一个实施方案中,“改进的热稳定性”是指至少57℃。在另一个实施方案中,“改进的热稳定性”是指高于55℃或高于57℃。合适地,如本文所述用DSC测定Tm。
免疫球蛋白单一可变结构域中的改进的热稳定性是期望的,因为它提供了免疫球蛋白单一可变结构域或蛋白的增强的稳定性。重要的是,增强的热稳定性给出了可开发的蛋白的可能性的量度,使得包含该改进的免疫球蛋白单一可变结构域的产品具有整个生产过程中的良好的稳定性和/或合适的稳定性/储存时间。改进的热稳定性和用于测定它的示例性方法如圆二色谱学描述于,例如,van
der Sloot等.Protein Engineering, Design and
Selection, 2004, vol.17, no. 9, p.673-680和Demarest等. J. Mol. Biol. 2004, 335, 41-48。
对于改进的或更高的热稳定性的分子基础可以是比非热稳定或热稳定性更低的变体中发现的更高特定数量的分子内氢键和离子相互作用。
显示具有改进的热稳定性的免疫球蛋白单一可变结构域也可以,作为直接结果,给予来自宿主细胞表达系统的更高的初始表达产量。这是因为,改进的热稳定性可以是由于它们的更高数量的分子内相互作用引起的,这可以进而导致翻译或跨膜转运期间更低水平的错误折叠和/或更快的折叠动力学。
此外,具有改进的热稳定性的蛋白如免疫球蛋白单一可变结构域可以显示更好的整体可展性(developability),因为当与具有更低热稳定性的免疫球蛋白单一可变结构域相比时,该蛋白更可能对下游过程如增高的温度和压力以及极端pH和盐条件更耐受。
在一个实施方案中,本发明的免疫球蛋白单一可变结构域可用于产生双或多-特异性组合物或融合多肽。因此,本发明的免疫球蛋白单一可变结构域可用于更大的构建体中。合适的构建体包括抗-SA免疫球蛋白单一可变结构域(dAb)和单克隆抗体、NCE、蛋白或多肽等之间的融合蛋白。因此,本发明的抗-SA免疫球蛋白单一可变结构域可用于构建多特异性分子,例如,双特异性分子如dAb-dAb(即,两个连接的免疫球蛋白单一可变结构域,其中,一个是抗-SA dAb)、mAb-dAb或多肽-dAb构建体。在这些构建体中,抗-SA dAb(AlbudAbTM)组分通过结合血清白蛋白(SA)而提供半衰期延长。例如在WO2009/068649中描述了合适的mAb-dAbs和用于产生这些构建体的方法。
选择具有增强的、改进的或增加的热稳定性的抗-SA免疫球蛋白单一可变结构域作为用于被制备为融合蛋白的分子的起点是期望的,因为一旦单一分子被连接成双特异性构建体,它们可能失去热稳定性特性。因此,以具有更高的热稳定性的部分开始将使任何热稳定性的损失被纳入考虑,以至于在产生双(或多)特异性构建体之后,保持总的有用的热稳定性。
在一个实施方案中,变体包括以下的动力学特征的一种或多种:-
(a)变体包含结合位点,所述结合位点以(或约)0.1-(或约)10000 nM、任选地(或约)1-(或约)6000 nM的解离常数(KD)(由表面等离子体共振所测定)特异性结合人SA;
(b)变体包含结合位点,所述结合位点以(或约) 1.5 x 10-4-(或约)
0.1sec-1、任选地(或约) 3 x 10-4-(或约)
0.1sec-1的解离速率常数(Kd)(由表面等离子体共振所测定)特异性结合人SA;
(c)变体包含结合位点,所述结合位点以(或约) 2 x 106-(或约) 1 x
104 M-1sec-1、任选地(或约) 1 x 106-(或约) 2 x
104 M-1sec-1的结合速率常数(Ka)(由表面等离子体共振所测定)特异性结合人SA;
(d)变体包含结合位点,所述结合位点以(或约)0.1-(或约)10000 nM、任选地(或约)1-(或约)6000 nM的解离常数(KD)(由表面等离子体共振所测定)特异性结合猕猴SA;
(e)前述任一项权利要求的变体,其中该变体包含结合位点,所述结合位点以(或约) 1.5 x 10-4-(或约)
0.1sec-1、任选地(或约) 3 x 10-4-(或约)
0.1sec-1的解离速率常数(Kd)(由表面等离子体共振所测定)特异性结合猕猴SA;
(f)前述任一项权利要求的变体,其中该变体包含结合位点,所述结合位点以(或约) 2 x 106-(或约) 1 x
104 M-1sec-1、任选地(或约) 1 x 106-(或约) 5 x
103 M-1sec-1的结合速率常数(Ka)(由表面等离子体共振所测定)特异性结合猕猴SA;
(g)变体包含结合位点,所述结合位点以(或约) 1-(或约)10000 nM、任选地(或约)20-(或约)6000 nM的解离常数(KD)(由表面等离子体共振所测定)特异性结合大鼠SA;
(h)变体包含结合位点,所述结合位点以(或约) 2 x 10-3-(或约) 0.15sec-1、任选地(或约) 9 x 10-3-(或约) 0.14sec-1的解离速率常数(Kd)(由表面等离子体共振所测定)特异性结合大鼠SA;
(i)变体包含结合位点,所述结合位点以(或约) 2 x 106-(或约) 1 x
104 M-1sec-1、任选地(或约) 1 x 106-(或约) 3 x
104 M-1sec-1的结合速率常数(Ka)(由表面等离子体共振所测定)特异性结合大鼠SA;
(j)变体包含结合位点,所述结合位点以(或约) 1-(或约)10000 nM的解离常数(KD)(由表面等离子体共振所测定)特异性结合小鼠SA;
(k)变体包含结合位点,所述结合位点以(或约) 2 x 10-3-(或约)
0.15sec-1的解离速率常数(Kd)(由表面等离子体共振所测定)特异性结合小鼠SA;和/或
(l)变体包含结合位点,所述结合位点以(或约) 2 x 106-(或约) 1 x
104 M-1sec-1、任选地(或约) 2 x 106-(或约) 1.5
x 104 M-1sec-1的结合速率常数(Ka)(由表面等离子体共振所测定)特异性结合小鼠SA。
任选地,该变体具有
I:根据(a)和(d) 所述的KD,根据(b)和(e) 所述的Kd,根据(c)和(f) 所述的Ka;或
II:根据(a) 和(g) 所述的KD,根据(b)和(h) 所述的Kd,根据(c)和(i) 所述的Ka;或
III:根据(a) 和(j) 所述的KD,根据(b)和(k) 所述的Kd,根据(c)和(l) 所述的Ka;或
IV:根据I和II所述的动力学;或
V:根据I和III所述的动力学;或
VI:根据I, II和III所述的动力学。
本发明还提供了包含本发明的前述任一方面或实施方案的变体的配体。例如,配体可以是双特异性配体(对于双特异性配体的例子见WO04003019)。在一个方面,本发明提供了多特异性配体,其包含本发明的前述任一方面或实施方案的抗-SA变体和特异性结合除SA以外的目标抗原的结合部分。结合部分可以是特异性结合目标的任何结合部分,例如,该部分是抗体、抗体片段、scFv、Fab、dAb或包含非免疫球蛋白蛋白支架的结合部分。WO2008/096158中详细公开了这种部分(见实施例17-25,其公开内容通过引用并入本文)。非免疫球蛋白支架的例子是CTLA-4、lipocallin、葡萄球菌蛋白A(spA)、Affibody™、Avimers™、adnectins、GroEL和纤连蛋白。
在一个实施方案中,在抗-目标结合部分和抗-SA单一变体之间提供了接头,该接头包含氨基酸序列AST,任选ASTSGPS。WO2007085814(通过引用并入本文)和WO2008/096158(见135页12行至140页14行的段落,其公开内容和所有的接头序列如同在本文中明确描述并用于和本发明共同使用而被清楚地引用并入本文,可以设想这种公开的任何部分可以并入本文的一项或多项权利要求中)描述了其它接头。
在多特异性配体的一个实施方案中,目标抗原可以是天然存在的或合成的多肽、蛋白或核酸,或其部分。在这方面,本发明的配体可以结合目标抗原,并作为拮抗剂或激动剂(例如,EPO受体激动剂)起作用。本领域技术人员将理解,选择是大量且变化的。它们可以是例如,人或动物蛋白、细胞因子、细胞因子受体(其中细胞因子受体包括细胞因子的受体)、酶、酶或DNA结合蛋白的辅因子。合适的细胞因子和生长因子包括,但优选不限于:ApoE、Apo-SAA、BDNF、心肌营养素-1、EGF、EGF受体、ENA-78、嗜酸性细胞活化趋化因子、嗜酸性细胞活化趋化因子-2、Exodus-2、EpoR、FGF-酸性的、FGF-碱性的、成纤维细胞生长因子-10、FLT3配体、分形趋化因子(Fractalkine,CX3C)、GDNF、G-CSF、GM-CSF、GF-β1、胰岛素、IFN-γ、IGF-I、IGF-II、IL-1α、IL-1β、IL-2、IL-3、IL-4、IL-5、IL-6、IL-7、IL-8 (72 a.a.)、IL-8 (77 a.a.)、IL-9、IL-10、IL-11、IL-12、IL-13、IL-15、IL-16、IL-17、IL-18 (IGIF)、抑制素α、抑制素β、IP-10、角质细胞生长因子-2
(KGF-2)、KGF、瘦素、LIF、淋巴细胞趋化因子、苗勒氏管抑制物质、单核细胞集落抑制因子、单核细胞引诱蛋白、M-CSF、MDC (67 a.a.)、MDC
(69 a.a.)、MCP-1 (MCAF)、MCP-2、MCP-3、MCP-4、MDC (67 a.a.)、MDC (69 a.a.)、MIG、MIP-1α、MIP-1β、MIP-3α、MIP-3β、MIP-4、髓样祖细胞抑制因子-1 (MPIF-1)、NAP-2、神经秩蛋白(Neurturin)、神经生长因子、β-NGF、NT-3、NT-4、抑癌蛋白M、PDGF-AA、PDGF-AB、PDGF-BB、PF-4、RANTES、SDF1α、SDF1β、SCF、SCGF、干细胞因子(SCF)、TARC、TGF-α、TGF-β、TGF-β2、TGF-β3、肿瘤坏死因子(TNF)、TNF-α、TNF-β、TNF受体I、TNF受体II、TNIL-1、TPO、VEGF、VEGF受体1、VEGF受体2、VEGF受体3、GCP-2、GRO/MGSA、GRO-β、GRO-γ、HCC1、1-309、HER 1、HER 2、HER 3和HER 4、CD4、人趋化因子受体CXCR4或CCR5、来自丙型肝炎病毒的3型非结构蛋白、TNF-α、IgE、IFN-γ、MMP-12、CEA、幽门螺旋菌、TB、流感、戊型肝炎、MMP-12、在某些细胞上过表达的内化受体,如表皮生长因子受体(EGFR)、肿瘤细胞上的ErBb2受体、内化性细胞受体、LDL受体、FGF2受体、转铁蛋白受体、PDGF受体、VEGF受体、PsmAr、细胞外基质蛋白、弹性蛋白、纤连蛋白、层粘连蛋白、α1-抗胰蛋白酶、组织因子蛋白酶抑制剂、PDK1、GSK1、Bad、半胱天冬酶-9、Forkhead、幽门螺杆菌的抗原、结核分枝杆菌的抗原和流感病毒的抗原。可以理解的是,这份列表绝非详尽无遗的。
在一个实施方案中,多特异性配体包括本发明的抗-SA dAb变体和抗-TNFR1结合部分,例如,抗-TNFR1 dAb。任选地,配体仅仅具有一个抗-TNFR1结合部分(例如,dAb)以减少受体交联的机会。
在一个实施方案中,抗-TNFR1结合部分是WO2008149148中公开的DOM1h-131-206(在该PCT申请中公开了其氨基酸序列和其核苷酸序列,该氨基酸序列和核苷酸序列如同在本文中明确描述并用于和本发明共同使用而被清楚地通过引用并入本文中,可以设想这种公开的任何部分可以并入本发明的一项或多项权利要求中)。
在一个实施方案中,抗-TNFR1结合部分或dAb是共同尚未授权的申请PCT/EP2010/05200中公开的任何这种部分或dAb,其公开的内容通过引用并入本文。在一个实施方案中,抗-TNFR1结合部分包括与DOM1h-574-156、DOM1h-574-72、DOM1h-574-109、DOM1h-574-138、DOM1h-574-162或DOM1h-574-180的氨基酸序列或表3中公开的任何抗-TNFR1 dAb的氨基酸序列至少95%相同的氨基酸序列。
在一个实施方案中,本发明的配体是包含直接或间接地融合于一种或多种多肽的本发明的变体的融合蛋白。例如,融合蛋白可以是WO2005/118642(其公开内容通过引用并入本文)中公开的“药物融合体”,其包括本发明的变体和在该PCT申请中定义的多肽药物。
本文所用的“药物”是指可以施用于个体以通过结合和/或改变的个体中的生物目标分子的功能而产生有益的、治疗的或诊断作用的任何化合物(例如,有机小分子、核酸、多肽)。目标分子可以是由个体的基因组编码的内源性目标分子(例如,由个体的基因组编码的酶、受体、生长因子、细胞因子)或由病原体的基因组编码的外源性目标分子(例如,由病毒、细菌、真菌、线虫或其它病原体的基因组编码的酶)。WO2005/118642和WO2006/059106中公开了用于在包含本发明的抗-SA
dAb 变体的融合蛋白和缀合物中使用的合适的药物(其完整公开内容通过引用并入本文,包括特定药物的完整列表,如同该列表在本文中清楚地描述,可以设想这种并入为包括进本文的权利要求中提供了特定药物的公开内容)。例如,该药物可以是胰高血糖素样肽1(GLP-1)或变体,干扰素α2b或变体或毒蜥外泌肽-4或变体。
在一个实施方案中,本发明提供了WO2005/118642和WO2006/059106中定义并公开的药物缀合物,其中该缀合物包括本发明的变体。在一个例子中,将药物共价连接于变体(例如,将变体和药物表示为单一多肽的部分)。另外,在一个例子中,将药物与变体非共价键合或结合。药物可以直接或间接地共价或非共价地键合于变体(例如,通过合适的接头和/或互补结合伴侣的非共价结合(例如,生物素和亲和素))。当采用互补结合伴侣时,结合伴侣之一可以直接或者通过合适的接头部分共价键合于药物,互补结合伴侣可以直接或者通过合适的接头部分共价键合于变体。当药物是多肽或肽时,药物组合物可以是融合蛋白,其中多肽或肽、药物和多肽结合部分是连续的多肽链的离散部分(部分)。如本文所述,多肽结合部分和多肽药物部分可以通过肽键彼此直接键合,或者通过合适的氨基酸或肽或多肽接头连接。
包含特异性结合血清白蛋白的本发明的一个单一可变结构域(单体)变体或多于一个单一可变结构域(本文所定义的多聚体、融合蛋白、缀合物和双特异性配体)的配体可以进一步包括一种或更多种实体,该实体选自但优选不限于标记、标签、额外的单一可变结构域、dAb、抗体、抗体片段、标记物和药物。这些实体中的一个或多个可以位于包括单一可变结构域的配体的COOH 末端或N末端或N末端和COOH 末端,(免疫球蛋白或非免疫球蛋白单一可变结构域)。这些实体中的一个或多个可以位于配体的特异性结合血清白蛋白的单一可变结构域的COOH 末端或N末端或N末端和COOH 末端,所述配体包含一个单一可变结构域(单体)或多于一个单一可变结构域(本文定义的多聚体、融合蛋白、缀合物和双特异性配体)。可以位于这些末端中的一个或两个的标签的非限制性例子包括HA、his或myc标签。可以将这些实体,包括一个或多个标签、标记和药物,连接于包含一个单一可变结构域(单体)或多于一个单一可变结构域(本文定义的多聚体、融合蛋白、缀合物和双特异性配体)的配体,所述结构域如上所述或者直接或者通过接头结合血清白蛋白。
本发明的一个方面提供了融合产物,例如,与肽的融合蛋白或融合体或与NCE(新的化学实体)药物的缀合物,包括融合或缀合(对于NCE)于根据本发明上面所述的任何变体的多肽药物。
本发明提供了组合物,该组合物包含本发明的任一方面的变体、融合蛋白或缀合物或配体和药学上可接受的稀释剂、载体、赋形剂或媒介。
本文还包括编码包含本文所述的变体、融合蛋白、缀合物或配体中任一种,例如,包含本发明的一个单一可变结构域(单体)变体或多于一个单一可变结构域(例如,本文定义的多聚体、融合蛋白、缀合物和双特异性配体)变体的配体,所述变体特异性结合血清白蛋白,或者同时特异性结合人血清白蛋白和至少一种非-人血清白蛋白或其功能上活性的片段。本文还包括载体和/或表达载体,包含该载体的宿主细胞,例如,用载体转化的植物或动物细胞和/或细胞系,表达和/或生产一种或多种变体、融合蛋白或配体或由所述载体编码的其片段的方法,所述变体、融合蛋白或配体包含一个单一可变结构域(单体)变体或多于一个单一可变结构域变体(本文定义的多聚体、融合蛋白、缀合物和双特异性配体)的配体,所述变体特异性结合血清白蛋白,其在一些情况下包括培养宿主细胞以便表达一种或多种变体、融合蛋白或配体或其片段,任选地从宿主细胞培养基中回收包含一个单一可变结构域(单体)或多于一个单一可变结构域(本文定义的多聚体、融合蛋白、缀合物和双特异性配体)的配体,所述结构域特异性结合血清白蛋白。还包括将本文所述的配体与血清白蛋白,包括血清白蛋白和/或非人血清白蛋白和/或除血清白蛋白以外的一种或多种目标接触以及将本文所述的变体、融合蛋白或配体体内和/或体外施用于个体宿主动物或细胞的方法,其中所述目标包括生物学活性分子,包括动物蛋白,如上面列举的细胞因子,包括其中接触是在体外的方法。优选地,施用本文所述的配体,该配体包括针对血清白蛋白和/或非人血清白蛋白的一个单一的可变结构域(免疫球蛋白或非免疫球蛋白)和针对除血清白蛋白以外的一个或多个目标的一个或多个结构域,将增加抗-目标配体的半衰期,包括Tβ和/或终末半衰期。本文考虑了编码变体、融合蛋白或包含配体的单个结构域或其片段(包括其功能片段)的核酸。本文考虑了编码核酸分子的载体,包括但优选不限于表达载体,以及包含一种或多种这些表达载体的来自细胞系或生物的宿主细胞。本文还考虑了产生任何变体、融合蛋白或配体,包括但优选不限于任何上述核酸、载体和宿主细胞,的方法。
本发明的一个方面提供了包含编码本发明的变体或或本发明的多特异性配体或本发明的融合蛋白的核苷酸序列的核酸。
本发明的一个方面提供了包括选自DOM7h-11-56、DOM7h-11-57、DOM7h-11-65、DOM7h-11-67、DOM7h-11-68、DOM7h-11-69、DOM7h-11-79和DOM7h-11-80的DOM7h-11变体的核苷酸序列或者与所述选择的序列至少70、75、80、85、90、95、96、97、98或99%相同的核苷酸序列的核酸。
本发明的一个方面提供了包含本发明的核酸的载体。本发明的一个方面提供了包含载体的分离的宿主细胞。
对于文库载体系统、单一可变结构域的组合、双特异性配体的表征、双特异性配体的结构、用于构建双特异性配体的支架、抗-血清白蛋白dAb和多特异性配体和半衰期增加的配体的用途以及包含抗-血清白蛋白dAbs的组合物和制剂的详情可以参考WO2008/096158。通过引用并入这些公开内容以提供对于和本发明的使用,包括对于本发明的变体、配体、融合蛋白、缀合物、核酸、载体、宿主和组合物,的指导。
虽然本发明的描述提到DOM7h-11变体,但是可以理解的是,可以设想类似地突变为其它抗-SA免疫球蛋白单一可变结构域系。
序列
表
1
:
DOM7h-11
变体
dAbs
的氨基酸序列


表
2
:
DOM7h-11
变体
dAbs
的核苷酸序列


表
3
:抗
-TNFR1 dAbs
的氨基酸序列












表
4
:抗
-TNFR1 dAbs
的核苷酸序列

























表
5
:抗
-
血清白蛋白
dAb (DOM7h)
融合体
(在大鼠研究中使用的):-
DOM7h-14/毒蜥外泌肽-4融合体
DMS号 7138
氨基酸序列 (SEQ ID NO:307)
核苷酸序列(SEQ ID NO:308)

DOM7h-14-10/毒蜥外泌肽-4融合体 DMS号 7139
氨基酸序列 (SEQ ID NO:309)

核苷酸序列(SEQ ID NO:310)

DOM7h-14-18/毒蜥外泌肽-4融合体 DMS号 7140
氨基酸序列 (SEQ ID NO:311)

核苷酸序列(SEQ ID NO:312)

DOM7h-14-19/毒蜥外泌肽-4融合体 DMS号 7141
氨基酸序列 (SEQ ID NO:313)

核苷酸序列(SEQ ID NO:314)

DOM7h-11/毒蜥外泌肽-4融合体
DMS号 7142
氨基酸序列 (SEQ ID NO:315)

核苷酸序列(SEQ ID NO:316)

DOM7h-11-12/毒蜥外泌肽-4融合体 DMS号 7147
氨基酸序列 (SEQ ID NO:317)

核苷酸序列(SEQ ID NO:318)

DOM7h-11-15/毒蜥外泌肽-4融合体 DMS号 7143
氨基酸序列 (SEQ ID NO:319)
核苷酸序列(SEQ ID NO:320)

DOM7h14-10/ G4SC-NCE融合体
编码DOM7h14-10/G4SC的氨基酸序列(SEQ ID NO:321)

可以,例如用马来酰亚胺连接,将C-末端半胱氨酸连接于新的化学实体(药物化学化合物,NCE)。
编码DOM7h14-10/G4SC的核苷酸序列(SEQ
ID NO:322)

DOM7h14-10/TVAAPSC融合体
氨基酸序列 (SEQ ID NO:323)

可以,例如用马来酰亚胺连接,将C-末端半胱氨酸连接于新的化学实体(药物化学化合物,NCE)。
核苷酸序列(SEQ ID NO:324)

(在小鼠研究中使用的):-
DOM7h-11/DOM1m-21-23融合体
DMS号 5515
氨基酸序列 (SEQ ID NO:325)

加myc标签序列的氨基酸和核苷酸 (SEQ
ID NO:326)

核苷酸序列(SEQ ID NO:327)

加myc标签序列的核苷酸(SEQ
ID NO:328)

DOM7h-11-12/DOM1m-21-23融合体
DMS号 5516
氨基酸序列 (SEQ ID NO:329)

加myc标签序列的氨基酸和核苷酸(SEQ
ID NO:330)

核苷酸序列(SEQ ID NO:331)

加myc标签序列的核苷酸 (SEQ
ID NO:332)

DOM7h-11-15/DOM1m-21-23融合体
DMS号 5517
氨基酸序列 (SEQ ID NO:333)

加myc标签序列的氨基酸和核苷酸(SEQ
ID NO:334)
核苷酸序列(SEQ ID NO:335)

加myc标签序列的核苷酸(SEQ
ID NO:336)

当myc-标签的分子在这个表中表示时,这是在实施例中的PK研究中使用的版本。当没有给出myc-标签的序列时,没有用myc-标签的材料进行实施例中的PK研究,即该研究是用所示的没有标签的构建体进行的。
实施例
实验部分的所有编号是根据Kabat(Kabat, E.A. National Institutes of Health (US)
& Columbia University.Sequences of proteins of immunological interest, edn
5 (US Dept. Of Health and Human Services Public Health Service, National
Institutes of Health, Bethesda, MD, 1991))。
描述了DOM7h-11变体的来历。
实施例
1
:
Vk
亲和力成熟
选择:
从Sigma获得HSA(人血清白蛋白)和RSA(大鼠血清白蛋白)抗原(基本上无脂肪酸,〜99%(琼脂糖凝胶电泳),冻干粉目录号分别为A3782和A6414)
通过使用EZ Link Sulfo-NHS-SS-Biotin (Pierce,
Cat.No.21331)制备上述两种抗原的生物素化产物。通过使样品两次通过PD10脱盐柱随后在4℃针对1000x过量体积的PBS过夜透析而去除游离的生物素试剂。通过质谱测试获得的产物,观察到每分子有1-2个生物素。
亲和力成熟文库:
用DOM7h-11和DOM7h-14母体dAbs产生二者易错的CDR文库(对于DOM7h-11和DOM7h-14的序列见WO2008/096158)。在pDOM4载体中产生CDR文库,在pDOM33载体中产生易错的文库(以允许用于在用或不用蛋白酶处理的情况下选择)。载体pDOM4,是Fd噬菌体载体的衍生物,其中用酵母糖脂锚定的表面蛋白(GAS)信号肽替代基因III信号肽序列。它在前导序列和基因III之间还包含c-myc标签,该标签与后面的基因III同框。该前导序列既在噬菌体展示载体中,也在其它原核表达载体中功能良好,可以普遍使用。pDOM33是pDOM4载体的修饰的版本,其中已经去除c-myc标签,这使得dAb-噬菌体融合体耐受蛋白酶胰蛋白酶。这允许在噬菌体选择中使用胰蛋白酶以选择对蛋白酶更稳定的dAbs(见WO2008149143)。
对于易错的成熟文库,使用GeneMorph® II随机突变试剂盒(随机的,独特的突变试剂盒,Stratagene),通过PCR扩增编码待成熟的dAb的质粒DNA。用Sal I和Not I消化产物,并与切割的噬菌体载体pDOM33用于连接反应中。对于CDR文库,用包含NNK或NNS密码子的简并寡核苷酸进行PCR反应以使待亲和力成熟的dAb中的所需位置多元化。然后用装配PCR来产生完整长度的多元化的插入物。用Sal I和Not I消化插入物,并与用于诱变多个残基的pDOM4和用于诱变单个残基的pDOM5用于连接反应中。pDOM5载体是基于pUC119的表达载体,其中蛋白表达由LacZ启动子驱动。GAS1前导序列(见WO 2005/093074)确保分离的可溶性dAbs分泌到大肠杆菌的周质和培养上清液。将dAbs以SalI/NotI克隆进该载体中,该载体在dAb的C-末端附加myc标签。使用SalI和Not I的该方案导致在N-末端包括ST氨基酸序列。
然后通过任一方法产生的连接产物用于通过电穿孔转化大肠杆菌菌株TB1,转化的细胞铺于包含15
µg/ml四环素的2xTY琼脂上,产生>5×107个克隆的文库大小。
易错文库具有下列平均突变率和大小:DOM7h-11 (2.5个突变/dAb), 大小:6.1 x 108,DOM7h-14 (2.9个突变/dAb)
,大小:5.4 x 108。
每个CDR文库具有4种氨基酸多样性。对于CDRs 1和3中的每一个,产生两个文库,对于CDR2,产生一个文库。每个文库内多样性的位置如下(基于VK dummy DPK9序列的氨基酸):
实施例
2
:选择策略:
1)采用三种噬菌体选择策略用于Vκ
AlbudAb™ (抗-血清白蛋白dAb)亲和力成熟:仅针对HSA的选择:
进行了三轮针对HSA的选择。在所有轮次中选择易错文库和每个CDR文库作为单个的合并物。针对以1mg/ml被动地包被至免疫管上的HSA进行第一轮选择。针对100nM HSA进行第2轮,针对10nM (CDR选择)或20或100nM (易错选择)HSA进行第3轮,两轮都是可溶性的选择,随后作为可溶性的选择,用易错文库针对1.5 nM HSA进行第四轮选择。用0.1M甘氨酸pH2.0洗脱易错文库,随后用1M Tris pH 8.0中和,用1mg/ml胰蛋白酶洗脱CDR文库,随后感染进对数期的TG1细胞。将每种选择的第三轮亚克隆进pDOM5用于筛选。可溶性选择使用生物素化的HSA。
2)针对HSA的胰蛋白酶选择:
为了选择具有与母体克隆相比增加的蛋白酶耐受性并具有可能改进的生物物理特性,在噬菌体选择中使用胰蛋白酶(见WO2008149143)。针对HSA进行了四轮选择。在没有胰蛋白酶的情况下针对以1mg/ml被动地包被的HSA进行易错文库的第一轮选择;在37℃在20µg/ml胰蛋白酶存在的情况下针对以1mg/ml被动地包被的HSA进行第二轮选择1小时;在37℃在20µg/ml或100 μg/ml胰蛋白酶存在的情况下使用生物素化的HSA针对100 nM HSA通过可溶性选择进行第三轮选择1小时。在37℃在100 μg/ml胰蛋白酶存在的情况下使用生物素化的HSA针对100nM HSA通过可溶性选择进行最后一轮选择1小时。
3)针对HSA(第1轮)和RSA(第2-4轮)的交叉选择:
针对1mg/ml被动地包被的HSA或1 μM HSA进行第一轮选择(可溶性选择),随后针对生物素化的RSA进行进一步的三轮的可溶性选择,其中所述生物素化的RSA的浓度对于第1轮为1 μM,对于第2轮为100nm,对于第3轮为20nM, 10nM或1nM。
筛选策略和亲和力测定:
在每种情况下,在使用QIAfilter midiprep试剂盒(Qiagen)从适当轮的选择制备噬菌体DNA的合并物之后,使用限制性酶Sal1和Not1消化DNA,将富集的V基因连接进pDOM5可溶性表达载体的对应位点,其产物表达具有myc标签的dAb(见PCT/EP2008/067789)。连接的DNA用于电转化大肠杆菌HB 2151细胞,然后所述细胞在包含抗生素羧苄青霉素的琼脂平板上生长过夜。个别评价产生的菌落的抗原结合。在每种情况下,通过BIAcore™(表面等离子体共振)测试至少96个克隆与HSA、CSA(猕猴血清白蛋白)、MSA(小鼠血清清蛋白)和RSA的结合。从Sigma获得MSA抗原(基本上无脂肪酸,~99%(琼脂糖凝胶电泳),冻干粉末目录号A3559),使用prometic蓝色树脂(Amersham)从猕猴血清白蛋白纯化CSA。在96孔板中ONEX培养基(Novagen)中的细菌培养37℃过夜产生可溶性dAb片段。离心包含可溶性dAb的培养上清液并通过BIAcore分析与高密度HSA、CSA、MSA和RSA CM5芯片的结合。通过解离速率筛选发现结合所有这些物种的血清白蛋白的克隆。对克隆进行测序以揭示独特的dAb序列。选择的克隆与母体的最小同一性(在氨基酸水平上)为97.2% (DOM7h-11-3:97.2%,
DOM7h-11-12:98.2%, DOM7h11-15:96.3%, DOM7h-11-18:98.2%,
DOM7h-11-19:97.2%)。
选择的克隆与母体的最小同一性(在氨基酸水平上)为96.3% (DOM7h-14-10:96.3%,
DOM7h-14-18:96.3%, DOM7h-14-19:98.2%, DOM7h-14-28:99.1%,
DOM7h-14-36:97.2%)。
在30℃持续48hrs以250rpm在2.5L摇瓶中Onex培养基中将独特的dAbs表达为细菌上清液。通过吸附至蛋白L琼脂糖,然后用10mM甘氨酸pH2.0洗脱而从培养基中纯化dAbs。使用三个浓度(1μM, 500nM和50nM)的纯化的蛋白通过BIAcore验证与HSA、CSA、MSA和RSA的结合。为了确定AlbudAbs与每种血清白蛋白的结合亲和力(KD);以5000nM至39nM (5000nM,
2500nM, 1250nM, 625nM, 312nM, 156nM, 78nM, 39nM)的白蛋白浓度范围通过BIAcore分析纯化的dAbs。
表
6



*:括号内的值源自第二次独立的SPR实验。
所有源自DOM7h-14的变体与小鼠、大鼠、人和猕猴血清白蛋白交叉反应。相比于母体,DOM7h-14-10具有与大鼠、猕猴和人血清白蛋白的改进的亲和力。DOM7h-14-28具有与RSA的改进的亲和力。DOM7h-14-36具有与RSA、CSA和MSA的改进的亲和力。
DOM7h-11-3具有与CSA和HSA的改进的亲和力。DOM7h-11-12具有与RSA、MSA和HSA的改进的亲和力。DOM7h-11-15具有与RSA、MSA、CSA和HSA的改进的亲和力。DOM7h-11-18和DOM7h-11-19具有与RSA、MSA和HSA的改进的亲和力。
实施例
3
:关键
DOM7h-11
系克隆的来源:
DOM7h-11-3:来自使用CDR2文库(Y49, A50, A51, S53), 第3轮输出10nM HSA的针对HSA进行的亲和力成熟。
DOM7h-11-12:来自用100ug/ml胰蛋白酶使用易错文库, 第3轮输出(100nM, HSA)的针对HSA进行的亲和力成熟。
DOM7h-11-15:来自用CDR2文库(Y49, A50, A51,
S53)(以1nM RSA的第3轮选择)的第1轮针对HSA ,随后额外3轮针对RSA 的选择进行的交叉选择。
DOM7h-11-18来自用易错文库(在20nM RSA的第3轮输出)的第1轮针对HSA ,随后额外3轮针对RSA 的选择进行的交叉选择。
DOM7h-11-19来自用易错文库(在5nM RSA的第3轮输出)的第1轮针对HSA ,随后额外3轮针对RSA 的选择进行的交叉选择。
表7:CDR序列(根据Kabat;参考文献如上)

实施例
4
:关键
DOM7h-14
系克隆的来源:
DOM7h-14-19:来自用100ug/ml胰蛋白酶使用易错文库, 第3轮输出(100nM, HSA)的针对HSA进行的亲和力成熟。
DOM7h-14-10,
DOM7h-14-18, DOM7h-14-28, DOM7h-14-36:来自使用CDR3文库(Y92, Y93, T94, N96), 第3轮输出的针对HSA进行的亲和力成熟。
表
8
:
CDR
序列
(
根据
Kabat
;参考文献如上
)

实施例 5 :表达和生物物理表征:
在30℃持续48hrs以250rpm在Onex培养基中培养后测定2.5L摇瓶中常规的细菌表达水平。通过SEC MALLS和DSC测定生物物理特征。
SEC
MALLS(使用多角度激光光散射的大小排阻色谱)是一种用于表征溶液中的大分子的非侵入性的技术。简而言之,通过大小排阻色谱法(柱:来自TOSOH Biosciences的TSK3000;来自Pharmacia的S200)根据蛋白的水动力学特征分离蛋白(浓度为缓冲液Dulbecco’s PBS中的1mg/mL,0.5 ml/min。分离后,使用多角度激光光散射(MALLS)检测仪测定蛋白对散射光的倾向。将蛋白通过检测仪的同时散射光的强度测定为角度的函数。这种测定结果连同使用折射率(RI)检测仪测定的蛋白浓度允许使用适当的方程(分析软件Astra
v.5.3.4.12的积分部分)计算摩尔质量。
DSC(差示扫描量热法): 简而言之,以180 ℃/hr的恒定速率加热蛋白(在PBS中的1mg/mL),可检测的热变化与测定的热变性相关。测定转化中点(appTm),其被描述为其中50%蛋白是在其天然构象并且其它50%是变性的温度。在这里,DSC测定表观转化中点(appTm),因为检查的大部分蛋白没有完全再折叠。Tm越高,分子越稳定。通过非-2-状态方程分析解折叠曲线。使用的软件包是OriginR v7.0383。
表
9
*在一个其它试验中,通过SEC MALLS主要看到单体,尽管低于95%
观察到表9中所有克隆在大肠杆菌的表达水平为15-119mg/L。
对于DOM7h-14和DOM7h-11变体,在亲和力成熟过程中维持有利的生物物理参数(如SEC
MALLs所测定的在溶液中为单体,如DSC所测定的>55℃的appTm)和表达水平。单体状态是有利的,因为它避免了二聚化以及产物可以与目标如细胞表面受体交联的风险。
实施例
6
:测定大鼠、小鼠和猕猴中的血清半衰期
将AlbudAbs DOM7h-14-10、DOM7h-14-18、DOM7h-14-19、DOM7h-11、DOM7h11-12和DOM7h-11-15克隆进pDOM5载体。对于每种AlbudAbTM,20-50mg量在大肠杆菌中表达,并使用蛋白L亲和树脂从细菌培养物上清液纯化,用100mM甘氨酸pH2洗脱。将蛋白浓缩至高于1mg/ml,缓冲液交换至PBS并使用Q离心柱(Vivascience)去除内毒素。对于大鼠药代动力学(PK)分析,使用每种化合物3只大鼠,以2.5mg/kg单次i.v注射而给药AlbudAbs。在0.16, 1, 4, 12, 24, 48, 72, 120, 168hrs采集血清样品。根据下述方法通过抗-myc ELISA分析血清水平。
对于小鼠PK,以每个剂量组(3个受试者) 2.5mg/kg作为单次i.v注射而给药DOM7h-11、DOM7h11-12和DOM7h-11-15,在10mins;1h;8h;24h;48h;72h;96h采集血清样品。根据下述方法通过抗-myc ELISA分析血清水平。
对于猕猴PK,以2.5mg/kg将DOM7h-14-10和DOM7h-11-15作为单次i.v注射而给药于每个剂量组的3只雌性猕猴,在0.083, 0.25, 0.5, 1, 2, 4, 8, 24, 48, 96, 144, 192, 288,
336, 504hrs采集血清样品。根据下述方法通过抗-myc ELISA分析血清水平。
抗-myc ELISA方法
通过抗-myc ELISA测定血清中AlbudAb浓度。简而言之,将山羊抗-myc多克隆抗体(1:500;Abcam,产品目录号ab9132)过夜包被至Nunc 96-孔Maxisorp板上并用5% BSA/PBS + 1%
tween封闭。在已知浓度的标准品旁边加入一定稀释度范围的血清样品。然后使用兔多克隆抗-Vk(1:1000;内部试剂,使用前合并血液并用蛋白A纯化)以及随后的抗-兔IgG HRP抗体(1:10,000;Sigma,目录号A2074)检测结合的myc-标签的AlbudAb。在测定的每个阶段之间用3×PBS+0.1%Tween20以及随后的3×PBS洗涤板。最后一次洗涤后加入TMB(SureBlue TMB 1-单组分微孔过氧化物酶底物,KPL,目录号52-00-00),并允许显色。用1M HCl终止该反应,然后使用在450nm处的吸光度测定信号。
从原始的ELISA数据,通过针对考虑稀释因子的标准曲线内插而确立未知样品的浓度。从重复值确定来自每个时间点的平均浓度结果,并输入WinNonlin分析软件包(例如,版本5.1(从Pharsight Corp., Mountain View, CA94040, USA获得)。使用非房室模型拟合数据,其中通过软件评价PK参数以给出终末半衰期。选择给药信息和时间点以反映每个PK曲线的终末阶段。
表
10
:单
AlbudAbTM
PK

* 历史数据。
使用非房室模型拟合源自大鼠、小鼠和猕猴研究的药代动力学参数。关键词:AUC:从外推至无穷远的给药时间的曲线下面积;CL:清除;t1/2:期间血液浓度减半的时间;Vz:基于终末阶段的分配容量。
DOM7h-11
12和DOM7h-11-15在大鼠和小鼠中具有与母体相比改进的AUC和t1/2。DOM7h-11-15在猕猴中也具有与母体相比改进的AUC和t1/2。这种AUC/t1/2的改进与对血清白蛋白改进的体外KD相关。
实施例
7
:
AlbudAbTM
IFN
融合体
克隆和表达
和单一AlbudAbs一样,将亲和力成熟的Vk
AlbudAbs连接至干扰素α 2b(IFNα2b)以确定作为融合蛋白是否维持AlbudAb的有用的PK。
干扰素α
2b
氨基酸序列:

干扰素α 2b核苷酸序列:

IFNa2b通过TVAAPS接头区域连接至AlbudAb(见WO2007085814)。通过SOE-PCR克隆构建体(根据Horton等 .Gene, 77, p61 (1989) 的方法的单一重叠延伸)。分别使用在TVAAPS接头区域具有~15碱基对重叠的引物进行AlbudAb和IFN序列的PCR扩增。使用如下引物:-

分别纯化片段,随后在SOE(单一重叠延伸PCR延伸)反应中仅使用侧翼的引物进行组装。

使用限制性酶BamHⅠ和HindⅢ消化组装的PCR产物,将基因连接进哺乳动物表达载体pDOM50的对应位点,所述载体是具有用于帮助表达进细胞培养基的N-末端的V-J2-C小鼠IgG分泌前导序列的pTT5衍生物。
前导序列(氨基酸):

前导序列(核苷酸):

使用QIAfilter megaprep(Qiagen)制备质粒DNA。用293-Fectin将1μg DNA/ml转染进HEK293E细胞,并在无血清培养基中生长。蛋白在培养基中表达5天,使用蛋白L亲和树脂从培养物上清液纯化,并用100mM甘氨酸pH2洗脱。将蛋白浓缩至高于1mg/ml,缓冲液交换至PBS并使用Q离心柱(Vivascience)去除内毒素。
亲和力测定和生物物理表征:
为了确定AlbudAb-IFNα2b融合蛋白与每种血清白蛋白的结合亲和力(KD);以在HBS-EP BIAcore 缓冲液中5000nM至39nM (5000nM, 2500nM, 1250nM, 625nM, 312nM, 156nM, 78nM,
39nM)的融合蛋白浓度范围通过对白蛋白的BIAcore (由伯胺偶联固定化到CM5芯片上;BIACORE)分析纯化的融合蛋白。
表
12
:对
SA
的亲和力

当IFNα2b连接至AlbudAb变体时,在所有情况下,AlbudAb与血清白蛋白的结合亲和力降低。相比于母体,DOM7h-14-10和DOM7-11-15在物种间保留了与血清白蛋白的改进的结合亲和力。相比于母体,DOM7h-11-12也显示在物种间与血清白蛋白的改进的结合亲和力。
表
13
:生物物理表征:
对于单AlbudAbs如上所述通过SEC
MALLS和DSC进行生物物理表征。

M/D表示通过SEC MALLS检测的单体/二聚体平衡
观察到表13中所有克隆在HEK293中的表达为17.5-54mg/L。
对于IFNα2b-DOM7h-14和IFNα2b-DOM7h-11变体,在亲和力成熟期间保持有利的生物物理参数和表达水平。
AlbudAb-IFN
α
2b
融合体的
PK
测定
具有myc标签的AlbudAbs
IFNα2b融合体DMS7321
(IFNα2b-DOM7h-14) DMS7322 (IFNα2b-DOM7h-14-10) DMS7323 (IFNα2b-DOM7h-14-18), DMS7324 (IFNα2b-DOM7h-14-19), DMS7325 (IFNα2b-DOM7h-11), DMS7326 (IFNα2b-DOM7h-11-12),
DMS7327 (IFNα2b-DOM7h-11-15)以20-50mg量在HEK293细胞中表达并使用蛋白L亲和树脂从培养物上清液纯化,用100mM甘氨酸pH2洗脱。将蛋白浓缩至高于1mg/ml,缓冲液交换至Dulbecco’s PBS并使用Q离心柱(Vivascience)去除内毒素。
对于大鼠PK,使用每种化合物3只大鼠,以2.0mg/kg单次i.v注射而给药AlbudAbs。在0.16, 1, 4, 8,
24, 48, 72, 120, 168hrs采集血清样品。根据制造商的说明书(GE
Healthcare,目录号RPN5960)通过EASY
ELISA分析血清水平。
对于小鼠PK,以每个剂量组(3个受试者) 2.0mg/kg作为单次i.v注射而给药所有具有myc 标签的DMS7322
(IFN2b-DOM7h-14-10) DMS7325 (IFN2b-DOM7h-11), DMS7326 (IFN2b-DOM7h-11-12),
DMS7327 (IFN2b-DOM7h-11-15),在10mins;1h;8h;24h;48h;72h;96h采集血清样品。根据制造商的说明书(GE Healthcare,目录号RPN5960)通过EASY ELISA分析血清水平。
表
14
:

使用非房室模型拟合源自大鼠和小鼠研究的药代动力学参数。关键词:AUC:从外推至无穷远的给药时间的曲线下面积;CL:清除;t1/2:期间血液浓度减半的时间;Vz:基于终末阶段的分配容量。
在大鼠和小鼠中测试IFNα2b–AlbudAbs。对于所有IFNα2b-DOM7h-11变体融合蛋白,在大鼠和小鼠中,t1/2都相比于母体改进。t1/2的改进与对血清白蛋白改进的体外KD相关。对于IFNα2b-DOM7h-14-10变体,在大鼠中与血清白蛋白的体外KD的改进也与t1/2的改进相关。
与单一AlbudAb相比,所有IFNα2b-AlbudAb融合蛋白表现出与RSA 的结合的5-10倍降低。与DOM7h-11系列(仅5倍降低)相比,对于DOM7h-14系列,这种效果更显著(即10倍)。
实施例8:与蛋白、肽和NCE的进一步的AlbudAb融合体。
测试与其它化学实体,即结构域抗体(dAbs)、肽和NCE融合的各种AlbudAbs。结果如表15中所示。
表
15
:

关键词:DOM1m-21-23是抗-TNFR1
dAb,毒蜥外泌肽-4是39个氨基酸长的肽(GLP-1激动剂)。NCE、NCE-GGGGSC和NCE-TVAAPSC如下所述。
以前,描述了利用与白蛋白结合dAb (AlbudAb)的基因融合体来延长抗-TNFR1
dAbs的体内PK半衰期(见,例如,WO04003019,WO2006038027,WO2008149148)。参见这些PCT申请中的方案。在上面的表格中,DOM1m-21-23是抗-小鼠TNFR1 dAb。
为了产生毒蜥外泌肽-4的或与结合血清白蛋白的DOM7h-14(或其它AlbudAb)的基因融合体,将毒蜥外泌肽-4-接头-AlbudAb序列克隆进PTT-5载体(从CNRC, Canada获得)。在每种情况下,毒蜥外泌肽-4在构建体的5'末端,dAb在3'末端。接头是(G4S)3接头。使用碱裂解法在大肠杆菌中制备无内毒素的DNA(使用无内毒素的质粒Giga试剂盒,从Qiagen CA获得),并用于转染HEK293E细胞(从CNRC, Canada获得)。使用333ul 293fectin (Invitrogen)和250ug DNA/烧瓶转染进250ml/烧瓶中1.75x106细胞/ml的HEK293E细胞,在30℃表达5天。通过离心收获上清液,通过在蛋白L上亲和纯化而纯化。蛋白分批结合至树脂,包装在柱上,并用10倍柱体积的PBS洗涤。用50ml 0.1M甘氨酸pH2洗脱蛋白,并用Tris pH8中和。在SDS-PAGE凝胶上鉴别预期大小的蛋白。
NCE
Albudab融合体:
测试了新的化学实体(NCE)AlbudAb融合体。合成具有PEG接头(PEG 4接头(即马来酰亚胺之前的4个PEG分子)和用于缀合至AlbudAb的马来酰亚胺基团的NCE,小分子ADAMTS-4抑制剂。NCE缀合至AlbudAb是通过氨基酸位置R108C处的工程化的胱氨酸残基,或者通过在AlbudAb的末端工程化的5个氨基酸(GGGGSC)或6个氨基酸(TVAAPSC)间隔子之后的胱氨酸残基。简而言之,用TCEP
(Pierce, 目录号77720)还原AlbudAb,用PD10柱(GE healthcare)脱盐至25mM Bis-Tris, 5mM EDTA, 10% (v/v)甘油pH6.5中。将5倍摩尔过量的马来酰亚胺活化的NCE加入DMSO中至不超过10%(V/V)最终浓度。将反应在室温孵育过夜,充分地透析至20mM Tris pH7.4中。
PEG接头:
序列:

核苷酸:

参见表5的序列DOM7h-14-10/TVAAPSC和DOM7h-14-10/GGGGSC (即,DOM7h-14-10/G4SC)。
当融合至化学实体时,如BIAcore 所测定的,NCE-AlbudAbs
DOM7h-14-10 GGGGSC和DOM7h14-10
TVAAPSC表现出与RSA 的体外亲和力(KD)的5-10倍的降低。对于这些分子还没有获得PK数据。
dAb-Albudab融合:与未融合的AlbudAb相比,当融合至治疗性结构域抗体(DOM1m-21-23)时,具有与RSA的最高亲和力的2 DOM7h-11
AlbudAbs经历与RSA的亲和力的2倍降低。当融合时,DOM7h-11克隆显示的微摩尔KD为2.8uM,当未融合时为~5uM。
毒蜥外泌肽 4-AlbudAb融合:除了DOM7h-14-10(其仅显示出结合的4倍降低)以外,AlbudAbs融合至肽对与RSA的结合能力的影响为约10倍。然而,该影响对于DOM7h-14系列(除了DOM7h-14-10)比似乎对于DOM7h-11系列的影响更显著。
对于所有上述数据,融合体的T1/2随着与物种的SA的改进的亲和力而增加。
通常,当AlbudAb-药物融合体显示出对于血清白蛋白结合的0.1nM-10mM的亲和力范围(KD)时,Albudab-治疗剂被分类为治疗上适用的(对于疾病、状况或适应症的治疗和/或预防)。
AlbudAbs和AlbudAb融合体(蛋白-AlbudAbs例如IFNa2b-DOM7h-14-10;肽-AlbudAbs例如毒蜥外泌肽-4-DOM7h-14-10;dAb-AlbudAbs例如DOM1m21-23-DOM7h11-15;NCE-AlbudAb例如ADAMTS-4-DOM7h-14-10)的治疗范围如下所述:显示了用于慢性或急性的状况、疾病或适应症的治疗的亲和力(KD)范围。还显示了标记为“中间的”亲和力范围。在此范围内的AlbudAbs和融合体具有对于慢性或急性的疾病、状况或适应症的实用性。在这种方式中,可以根据待解决的疾病、状况或适应症定制或选择AlbudAb或融合体对于血清白蛋白的亲和力。如上所述,本发明提供了AlbudAbs,其亲和力允许每种AlbudAb被归类为“高亲和力”、“中等亲和力”或“低亲和力”,从而帮助本领域技术人员根据手头的治疗选择本发明的适当的AlbudAb。参见图2。
实施例9:DOM7h-11-15S12P序列
DOM7h-11-15S12P的氨基酸序列

本发明的一个方面提供了包含DOM7h-11-15S12P的核苷酸序列或与所述选择的序列至少80%相同的核苷酸序列的核酸。使用下列核酸序列产生DOM7h-11-15S12P(带下划线的C表示产生12位的脯氨酸的变化(相对于编码DOM7h-11-15的核酸)): -
在PCR中通过使用DOM7h-11-15作为模板构建DOM7h-11-15S12P,其中使用引物来引入S12P突变。引物序列是:-


本发明的另一个方面提供了包含SEQ ID NO:389的核苷酸序列或与所述选择的序列至少80%相同的核苷酸序列的核酸。在一个实施方案中,包含接头区域和C-末端序列的载体编码并表达DOM7h-11-15S12P,所述C-末端序列编码蛋白或肽药物或单一可变结构域或其它抗体片段以制备串联(in-line)蛋白融合产物。在一个实施方案中,接头包含氨基酸序列TVA,例如,TVAAPS。本发明的其它方面是包含核酸的载体;和包含该载体的分离的宿主细胞。本发明还提供了在患者中治疗或预防疾病或病症的方法,包括将至少一个剂量的DOM7h-11-15S12P施用于所述患者。
实施例
10
:
DOM
7h-11-15
变体
i) Vk 亲和力成熟
选择:
如实施例1中所述获得HSA(人血清白蛋白)和RSA(大鼠血清白蛋白)抗原和生物素化的产物。
亲和力成熟文库:
用DOM7h-11-15母体dAb(参见SEQ ID NO:2)作为模板产生既易错又掺杂的文库,所述DOM7h-11-15母体dAb在108位具有被突变至色氨酸的精氨酸(DOM7h-11-15 R108W (DOM7h-11-55)),从而允许使用胰蛋白酶用于噬菌体筛选。在pDOM33载体中生成文库。
对于掺杂的CDR文库,用包含偏移的简并密码子的掺杂的寡核苷酸进行初始PCR反应以使dAb中的所需位置多元化。例如,Balint和Larrick, Gene, 137, 109-118 (1993)中描述了掺杂文库的生成。设计引物以便从每个简并密码子仅改变前两个核苷酸,使得母体的核苷酸在85%的情况下存在,所有其它可能的核苷酸在5%的情况下存在。每个CDR针对六个密码子同时突变,密码子中每个核苷酸与母体的核苷酸不同的概率为15%。然后用装配PCR来产生完整长度的多元化的插入物。用Sal I和Not I消化插入物,并与pDOM33用于连接反应中。然后文库的连接产物用于通过电穿孔转化大肠杆菌菌株TB1,转化的细胞铺于包含15
µg/ml四环素的2xTY琼脂上。
有三个掺杂的文库,每个CDR一个,突变率和文库大小如下:
CDR1文库- 每个dAb
1.6个氨基酸突变,文库大小为1.4x 108
CDR2文库- 每个dAb
1.7个氨基酸突变,文库大小为2x 108
CDR2文库- 每个dAb 2个氨基酸突变,文库大小为1.1x 108。
ii)
选择策略:
针对HSA的选择
进行了两轮针对HSA的选择。在所有轮次中选择每个CDR文库作为单个的合并物。在溶液中针对10nM浓度的生物素化的HSA进行了两轮选择。用0.1M甘氨酸pH2.0洗脱文库,随后用1M Tris pH 8.0中和,随后感染进对数期的TG1细胞。将每种选择的第二轮亚克隆进pDOM5用于筛选。
交叉选择 在溶液中进行了两轮针对生物素化的HSA的选择。第一轮针对10nM浓度的HSA进行,第二轮针对100nM浓度的RSA进行。在所有轮次中选择每个CDR文库作为单个的合并物。用0.1M甘氨酸pH2.0洗脱文库,随后用1M Tris pH 8.0中和,随后感染进对数期的TG1细胞。将每种选择的第二轮亚克隆进pDOM5用于筛选。
ii)
筛选策略和亲和力测定
在每种情况下,在使用QIAfilter midiprep试剂盒(Qiagen)从适当轮的选择制备噬菌体DNA的合并物之后,使用限制性酶Sal1和Not1消化DNA,将富集的V基因连接进可溶性表达载体pDOM5的对应位点,其表达具有myc标签的dAb(见PCT/EP2008/067789)。连接的DNA用于转化化学感受态的大肠杆菌HB 2151细胞,然后其在包含抗生素羧苄青霉素的琼脂平板上生长过夜。个别评价产生的菌落的抗原结合。对于每种选择输出,通过BIAcore™(表面等离子体共振)测试93个克隆与HSA和RSA的结合。在96孔板中ONEX培养基(Novagen)中的细菌培养37℃过夜产生可溶性dAb片段。离心包含可溶性dAb的培养上清液并通过BIAcore分析与高密度HSA和RSA CM5芯片的结合。对通过解离速率筛选发现与母体克隆相比相等地或更好地结合这两种物种的血清白蛋白的克隆进行测序,揭示独特的dAb序列。
在30℃持续48hrs以250rpm在0.5L摇瓶中Onex培养基中将独特的dAbs表达为细菌上清液。通过吸附至蛋白L流线(streamline),然后用0.1M甘氨酸pH2.0洗脱而从培养基中纯化dAbs。
为了确定AlbudAbs与人、大鼠、小鼠和猕猴血清白蛋白的结合亲和力(KD);以500nM至3.9nM (500nM,
250nM, 125nM, 31.25nM, 15.625nM, 7.8125nM, 3.90625nM)的白蛋白浓度范围通过BIAcore分析纯化的dAbs。
从Sigma获得MSA抗原(基本上无脂肪酸,~99%(琼脂糖凝胶电泳),冻干粉末目录号A3559),使用prometic蓝色树脂(Amersham)从猕猴血清白蛋白纯化CSA。关键克隆与所有测试的血清白蛋白种类的亲和力如表16中所示。
在这些测定中,myc-标签的分子用于PK研究中。
表
16 A-D


所有DOM7h-11-15变体与大鼠、人、猕猴和小鼠血清白蛋白交叉反应。(解离常数(KD);解离速率常数(Kd);结合速率常数(Ka))。
iv) 表达和生物物理表征:
如上述实施例5中所述进行细菌表达和通过SECMALLS和DSC的测定。
表17。

T/D和D/M分别表示通过SEC-MALLS检测的三聚体和二聚体或二聚体和单体之间的平衡。
表2中所示的所有DOM7h-11-15变体具有有利的生物物理参数(如SEC MALLs所测定的在溶液中为单体,如DSC所测定的>55℃的appTm)并且亲和力成熟过程中主要维持表达水平。热稳定性是有利的,因为与具有低Tm的Albudab相比时,它可以改进具有更高熔解温度的与AlbudAb融合的药物的储存时间。
v)
最热稳定的克隆的
CDR3
和框架
3
序列
最热稳定的AlbudAbs的特性的本质差异(>57℃的appTm)是由于当与母体克隆DOM7h-11-15相比时这些克隆的CDR 3或框架3中的单个氨基酸突变(由于聚合酶误差的突变)导致的。包含有利突变的框架3或CDR3的序列如表18和19中所示。区分热稳定的AlbudAbs与母体的氨基酸以粗体显示。
DOM7h-11-15的母体和所有热稳定的变体(>55℃的Tm)的完整氨基酸和核苷酸序列列于序列部分(序列1-18)。大多数克隆的108位精氨酸被突变为色氨酸,这么做是为了帮助如果需要时胰蛋白酶驱动的选择(将胰蛋白酶识别位点敲除)。还包括DOM7h-11-67中106位的异亮氨酸突变为天冬酰胺。
衍生其它克隆(见DOM 7h-11-87,
DOM 7h-11-90, DOM 7h-11-86),其中108位被回复突变至精氨酸(W108R)和,任选地,106位被回复突变至异亮氨酸。下面列出了这些克隆的序列。
下表总结了与SA的结合:


显示生物物理特性的表格

表
18
区分热稳定的AlbudAbs与母体的氨基酸以粗体显示。所有编号根据Kabat。

。
表
19

鉴别的针对
DOM 7h-11-15
的突变如下:

DOM7h-11-15变体的序列
氨基酸序列



核苷酸序列



序列表格



Claims (42)
1.DOM7h-11(DOM7h-11如图1(SEQ ID NO:438)中所示)的抗-血清白蛋白(SA)免疫球蛋白单一可变结构域变体,所述变体具有至少54℃的Tm。
2.权利要求1要求保护的抗-SA免疫球蛋白,其中所述变体与DOM7h-11相比在22、42或91位(根据Kabat编号)中任何位置包含至少一个突变。
3.权利要求2要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中所述变体是DOM7h-11-15(DOM7h-11-15如图1(SEQ ID NO:2)中所示)的变体,与DOM7h-11-15相比在22、42或91位(根据Kabat编号)中任何位置包含至少一个突变。
4.权利要求1-3中任一项的变体,其中所述变体包含选自下列的至少一个突变:
22位 = Ser、Phe、Thr、Ala或Cys;
42位 = Glu或Asp;
91位= Thr 或Ser。
5.权利要求4要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中22位是Ser或Phe。
6.权利要求4要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中42位是Glu,91位是Thr。
7.权利要求4要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中91位是Thr。
8.权利要求4要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中22位是Phe。
9.权利要求1或2的变体,其中所述变体包含与选自DOM7h-11-56 (SEQ ID NO:412)、DOM7h-11-68 (SEQ ID NO:416)、DOM7h-11-79 (SEQ ID NO:418)和DOM7h-11-80 (SEQ ID NO:419)的单一可变结构域的氨基酸序列相同或者与所述选择的氨基酸序列相比具有最多达4个改变的氨基酸序列。
10.权利要求4要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中,与DOM7h-11相比,所述变体在FW3区中(57-88位,根据Kabat编号)或在CDR3区中(89-97位,根据Kabat编号)包含至少一个突变。
11.权利要求7要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中所述变体是DOM7h-11-15(DOM7h-11-15如图1中所示)的变体,与DOM7h-11-15相比,在FW3区中(57-88位,根据Kabat编号)或在CDR3区中(89-97位,根据Kabat编号)包含至少一个突变。
12.权利要求7或8要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中所述变体在77、83、93或95位(根据Kabat编号)中任何位置包含至少一个突变。
13.权利要求7-9中任一项的变体,其中所述变体包含选自下列的至少一个突变:
77位 = Asn、Gln
83位 = Val、Ile、Met、Leu、Phe、Ala或正亮氨酸
93位 = Val、Ile、Met、Leu、Phe、Ala或正亮氨酸
95位 = His、Asn、Gln、Lys或Arg。
14.前述任一权利要求要求保护的抗-SA免疫球蛋白单一可变结构域变体,在106或108位(根据Kabat编号)进一步包括突变。
15.权利要求14要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中106位是Asn或Gln。
16.权利要求14要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中108位是Trp、Tyr或Phe。
17.前述任一权利要求要求保护的抗-SA免疫球蛋白单一可变结构域变体,其中77位是Asn。
18.前述任一权利要求要求保护的抗-SA单一可变结构域,其中83位是Val。
19.前述任一权利要求要求保护的抗-SA单一可变结构域,其中95位是His。
20.前述任一权利要求要求保护的抗-SA单一可变结构域,其中95位是His。
21.前述任一权利要求要求保护的抗-SA单一可变结构域,其中93位是Val。
22.权利要求1的变体,其中所述变体包含与选自DOM7h-11-57 (SEQ ID NO:413)、DOM7h-11-65 (SEQ ID NO:414)、DOM7h-11-67 (SEQ ID NO:415)和DOM7h-11-69 (SEQ ID NO:417)的单一可变结构域的氨基酸序列相同或者与所述选择的氨基酸序列相比具有最多达4个改变的氨基酸序列,条件是所述变体的氨基酸序列具有如权利要求1-12中任一项所定义的FW3或CDR3区中的至少一个突变。
23.权利要求10-21中任一项要求保护的变体,所述变体具有至少57℃的Tm。
24.前述任一权利要求要求保护的变体,其中所述变体与DOM7h-11相比具有增加的Tm值。
25.前述任一权利要求要求保护的变体,其中所述变体与DOM7h-11-15相比具有增加的Tm值。
26.前述任一权利要求要求保护的变体,包括权利要求4和13中列出的任何突变的任何组合。
27.前述任一权利要求的变体,其中所述变体包含结合位点,如表面等离子体共振所测定的,所述结合位点以约0.1-约10000 nM、任选地约1-约6000 nM的解离常数(KD)特异性结合人SA。
28. 前述任一权利要求的变体,其中所述变体包含结合位点,如表面等离子体共振所测定的,所述结合位点以约1.5 x 10-4-约0.1sec-1、任选地约3 x 10-4-约0.1sec-1的解离速率常数(Kd)特异性结合人SA。
29. 前述任一权利要求的变体,其中所述变体包含结合位点,如表面等离子体共振所测定的,所述结合位点以约2 x 106-约1 x 104 M-1sec-1、任选地约1 x 106-约2 x 104 M-1sec-1的结合速率常数(Ka)特异性结合人SA。
30.前述任一权利要求的变体,其中所述变体包含结合位点,如表面等离子体共振所测定的,所述结合位点以约0.1-约10000 nM、任选地约1-约6000 nM的解离常数(KD)特异性结合猕猴SA。
31. 前述任一权利要求的变体,其中变体包含结合位点,如表面等离子体共振所测定的,所述结合位点以约1.5 x 10-4-约0.1sec-1、任选地约3 x 10-4-约0.1sec-1的解离速率常数(Kd)特异性结合猕猴SA。
32.前述任一权利要求的变体,其中变体包含结合位点,如表面等离子体共振所测定的,所述结合位点以约2 x 106-约1 x 104 M-1sec-1、任选地约1 x 106-约5 x 103M-1sec-1的结合速率常数(Ka)特异性结合猕猴SA。
33.多特异性配体,包含前述任一权利要求的抗-SA变体和特异性结合除SA以外的目标抗原的结合部分。
34.权利要求1-17中任一项要求保护的抗-SA变体单一可变结构域,其中所述可变结构域缀合于药物(任选地NCE药物),任选地其中所述选择的变体是DOM7h-11-56
(SEQ ID NO:412)、DOM7h-11-57
(SEQ ID NO:413)、DOM7h-11-65
(SEQ ID NO:414)、DOM7h-11-67
(SEQ ID NO:415)、DOM7h-11-68
(SEQ ID NO:416)、DOM7h-11-69
(SEQ ID NO:417)、DOM7h-11-79
(SEQ ID NO:418)、DOM7h-11-80
(SEQ ID NO:419)、DOM7h-11-90
(SEQ ID NO:420)、DOM7h-11-86
(SEQ ID NO:421)、DOM7h-11-87
(SEQ ID NO:422)或DOM7h-11-88
(SEQ ID NO:423)。
35.融合蛋白,包括融合至权利要求1-17中任一项的变体的多肽或肽药物,其中所述选择的变体是DOM7h-11-56
(SEQ ID NO:412)、DOM7h-11-57
(SEQ ID NO:413)、DOM7h-11-65
(SEQ ID NO:414)、DOM7h-11-67 (SEQ
ID NO:415)、DOM7h-11-68
(SEQ ID NO:416)、DOM7h-11-69
(SEQ ID NO:417)、DOM7h-11-79
(SEQ ID NO:418)、DOM7h-11-80
(SEQ ID NO:419)、DOM7h-11-90
(SEQ ID NO:420)、DOM7h-11-86
(SEQ ID NO:421)、DOM7h-11-87
(SEQ ID NO:422)或DOM7h-11-88
(SEQ ID NO:423)。
36.权利要求20的融合蛋白,其中所述融合蛋白在所述变体和药物之间包含接头(例如,包括氨基酸序列TVA,任选TVAAPS的接头)。
37.组合物,包含前述任一权利要求所述的变体、融合蛋白或配体和药学上可接受的稀释剂、载体、赋形剂或媒介。
38.核酸,包括编码权利要求1-17中任一项的变体或权利要求18的多特异性配体或权利要求20或21的融合蛋白的核苷酸序列。
39.核酸,包括选自如下的DOM7h-11变体的核苷酸序列:DOM7h-11-56 (SEQ ID NO:425)、DOM7h-11-57 (SEQ ID NO:426)、DOM7h-11-65 (SEQ ID NO:427)、DOM7h-11-67 (SEQ ID NO:428)、DOM7h-11-68 (SEQ ID NO:429)、DOM7h-11-69 (SEQ ID NO:430)、DOM7h-11-79 (SEQ ID NO:431)、 DOM7h-11-80 (SEQ ID NO:432)、DOM7h-11-90 (SEQ ID NO:433)、DOM7h-11-86 (SEQ ID NO:434)、DOM7h-11-87 (SEQ ID NO:435)或DOM7h-11-88 (SEQ ID NO:436)的核苷酸序列或者与所述选择的序列至少80%相同的核苷酸序列。
40.载体,包括权利要求23、24或25的核酸。
41.分离的宿主细胞,包含权利要求26的载体。
42.在患者中治疗或预防疾病或病症的方法,包括将至少一个剂量的权利要求1-22中任一项的变体施用于所述患者。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US34651910P | 2010-05-20 | 2010-05-20 | |
| US61/346,519 | 2010-05-20 | ||
| PCT/EP2011/058298 WO2011144751A1 (en) | 2010-05-20 | 2011-05-20 | Improved anti-serum albumin binding variants |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN103003303A true CN103003303A (zh) | 2013-03-27 |
Family
ID=44352234
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2011800351661A Pending CN103003303A (zh) | 2010-05-20 | 2011-05-20 | 改进的抗-血清白蛋白结合变体 |
Country Status (13)
| Country | Link |
|---|---|
| US (2) | US9040668B2 (zh) |
| EP (1) | EP2571900A1 (zh) |
| JP (1) | JP2013529080A (zh) |
| KR (1) | KR20130109977A (zh) |
| CN (1) | CN103003303A (zh) |
| AU (1) | AU2011254559B2 (zh) |
| BR (1) | BR112012029280A2 (zh) |
| CA (1) | CA2799633A1 (zh) |
| EA (1) | EA201291009A1 (zh) |
| IL (1) | IL222802A0 (zh) |
| MX (1) | MX2012013406A (zh) |
| SG (1) | SG185437A1 (zh) |
| WO (1) | WO2011144751A1 (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108290943A (zh) * | 2015-11-13 | 2018-07-17 | 埃博灵克斯股份有限公司 | 改进的血清白蛋白结合免疫球蛋白可变结构域 |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| UA116217C2 (uk) | 2012-10-09 | 2018-02-26 | Санофі | Пептидна сполука як подвійний агоніст рецепторів glp1-1 та глюкагону |
| AU2013366691A1 (en) | 2012-12-21 | 2015-07-09 | Sanofi | Exendin-4 derivatives |
| TW201609799A (zh) | 2013-12-13 | 2016-03-16 | 賽諾菲公司 | 雙重glp-1/gip受體促效劑 |
| EP3080150B1 (en) | 2013-12-13 | 2018-08-01 | Sanofi | Exendin-4 peptide analogues as dual glp-1/gip receptor agonists |
| TW201609797A (zh) | 2013-12-13 | 2016-03-16 | 賽諾菲公司 | 雙重glp-1/升糖素受體促效劑 |
| TW201609796A (zh) | 2013-12-13 | 2016-03-16 | 賽諾菲公司 | 非醯化之艾塞那肽-4(exendin-4)胜肽類似物 |
| TW201625669A (zh) | 2014-04-07 | 2016-07-16 | 賽諾菲公司 | 衍生自艾塞那肽-4(Exendin-4)之肽類雙重GLP-1/升糖素受體促效劑 |
| TW201625670A (zh) | 2014-04-07 | 2016-07-16 | 賽諾菲公司 | 衍生自exendin-4之雙重glp-1/升糖素受體促效劑 |
| TW201625668A (zh) | 2014-04-07 | 2016-07-16 | 賽諾菲公司 | 作為胜肽性雙重glp-1/昇糖素受體激動劑之艾塞那肽-4衍生物 |
| US9932381B2 (en) | 2014-06-18 | 2018-04-03 | Sanofi | Exendin-4 derivatives as selective glucagon receptor agonists |
| AR105319A1 (es) | 2015-06-05 | 2017-09-27 | Sanofi Sa | Profármacos que comprenden un conjugado agonista dual de glp-1 / glucagón conector ácido hialurónico |
| TW201706291A (zh) | 2015-07-10 | 2017-02-16 | 賽諾菲公司 | 作為選擇性肽雙重glp-1/升糖素受體促效劑之新毒蜥外泌肽(exendin-4)衍生物 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010094723A2 (en) * | 2009-02-19 | 2010-08-26 | Glaxo Group Limited | Improved anti-serum albumin binding variants |
| WO2011039096A1 (en) * | 2009-09-30 | 2011-04-07 | Glaxo Group Limited | Drug fusions and conjugates with extended half life |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL127127A0 (en) | 1998-11-18 | 1999-09-22 | Peptor Ltd | Small functional units of antibody heavy chain variable regions |
| US9321832B2 (en) * | 2002-06-28 | 2016-04-26 | Domantis Limited | Ligand |
| US20060002935A1 (en) | 2002-06-28 | 2006-01-05 | Domantis Limited | Tumor Necrosis Factor Receptor 1 antagonists and methods of use therefor |
| JP2006512895A (ja) | 2002-06-28 | 2006-04-20 | ドマンティス リミテッド | リガンド |
| PL1737962T3 (pl) | 2004-03-24 | 2011-02-28 | Domantis Ltd | Uniwersalny lider GAS1 |
| US8921528B2 (en) | 2004-06-01 | 2014-12-30 | Domantis Limited | Bispecific fusion antibodies with enhanced serum half-life |
| NZ555464A (en) | 2004-12-02 | 2010-03-26 | Domantis Ltd | Bispecific domain antibodies targeting serum albumin and glp-1 or pyy |
| EP1976991A1 (en) | 2006-01-24 | 2008-10-08 | Domantis Limited | Fusion proteins that contain natural junctions |
| WO2008149147A2 (en) * | 2007-06-06 | 2008-12-11 | Domantis Limited | Polypeptides, antibody variable domains and antagonists |
| EA200901494A1 (ru) * | 2007-06-06 | 2010-06-30 | Домантис Лимитед | Способы селекции протеазоустойчивых полипептидов |
| GB0724331D0 (en) | 2007-12-13 | 2008-01-23 | Domantis Ltd | Compositions for pulmonary delivery |
| CA2706419A1 (en) | 2007-11-30 | 2009-06-04 | Glaxo Group Limited | Antigen-binding constructs binding il-13 |
| MX2011008799A (es) * | 2009-02-19 | 2011-09-27 | Glaxo Group Ltd | Polipeptidos, dominios variables de anticuerpos, y antagonistas anti-tnfr1 mejorados. |
| CN105061593B (zh) * | 2009-02-19 | 2018-08-03 | 葛兰素集团有限公司 | 改良的抗血清清蛋白结合变体 |
| BRPI1013588A2 (pt) | 2009-03-27 | 2016-04-19 | Glaxo Group Ltd | composição |
| WO2011006914A2 (en) * | 2009-07-16 | 2011-01-20 | Glaxo Group Limited | Antagonists, uses & methods for partially inhibiting tnfr1 |
-
2011
- 2011-05-20 EA EA201291009A patent/EA201291009A1/ru unknown
- 2011-05-20 SG SG2012081683A patent/SG185437A1/en unknown
- 2011-05-20 CA CA2799633A patent/CA2799633A1/en not_active Abandoned
- 2011-05-20 CN CN2011800351661A patent/CN103003303A/zh active Pending
- 2011-05-20 EP EP11720310A patent/EP2571900A1/en not_active Withdrawn
- 2011-05-20 BR BR112012029280A patent/BR112012029280A2/pt not_active IP Right Cessation
- 2011-05-20 WO PCT/EP2011/058298 patent/WO2011144751A1/en active Application Filing
- 2011-05-20 KR KR1020127033268A patent/KR20130109977A/ko not_active Application Discontinuation
- 2011-05-20 JP JP2013510643A patent/JP2013529080A/ja active Pending
- 2011-05-20 MX MX2012013406A patent/MX2012013406A/es not_active Application Discontinuation
- 2011-05-20 AU AU2011254559A patent/AU2011254559B2/en not_active Ceased
- 2011-05-20 US US13/698,794 patent/US9040668B2/en not_active Expired - Fee Related
-
2012
- 2012-11-01 IL IL222802A patent/IL222802A0/en unknown
-
2015
- 2015-04-21 US US14/691,913 patent/US20150284454A1/en not_active Abandoned
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010094723A2 (en) * | 2009-02-19 | 2010-08-26 | Glaxo Group Limited | Improved anti-serum albumin binding variants |
| WO2011039096A1 (en) * | 2009-09-30 | 2011-04-07 | Glaxo Group Limited | Drug fusions and conjugates with extended half life |
Non-Patent Citations (1)
| Title |
|---|
| HOLT等: "Anti-serum albumin domain antibodies for extending the half-lives of short lived drugs", 《PROTEIN ENGINEERING,DESIGN AND SELECTION》, vol. 21, no. 5, 31 December 2008 (2008-12-31), pages 283 - 288 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108290943A (zh) * | 2015-11-13 | 2018-07-17 | 埃博灵克斯股份有限公司 | 改进的血清白蛋白结合免疫球蛋白可变结构域 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20130109977A (ko) | 2013-10-08 |
| US20150284454A1 (en) | 2015-10-08 |
| CA2799633A1 (en) | 2011-11-24 |
| IL222802A0 (en) | 2012-12-31 |
| EA201291009A1 (ru) | 2013-05-30 |
| MX2012013406A (es) | 2012-12-10 |
| AU2011254559A1 (en) | 2013-01-17 |
| AU2011254559B2 (en) | 2014-09-04 |
| SG185437A1 (en) | 2012-12-28 |
| BR112012029280A2 (pt) | 2016-11-29 |
| EP2571900A1 (en) | 2013-03-27 |
| US9040668B2 (en) | 2015-05-26 |
| WO2011144751A1 (en) | 2011-11-24 |
| JP2013529080A (ja) | 2013-07-18 |
| US20130129746A1 (en) | 2013-05-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103003303A (zh) | 改进的抗-血清白蛋白结合变体 | |
| CN102405232B (zh) | 改良的抗血清清蛋白结合变体 | |
| US8679496B2 (en) | Anti-serum albumin single variable domains | |
| US10696738B2 (en) | Anti-serum albumin binding variants | |
| JP2013538566A (ja) | 改良された抗血清アルブミン結合変異体 | |
| JP2016027801A (ja) | 改良された抗血清アルブミン結合変異体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C02 | Deemed withdrawal of patent application after publication (patent law 2001) | ||
| WD01 | Invention patent application deemed withdrawn after publication |
Application publication date: 20130327 |