WO2025041222A1 - Appareil de mise en correspondance d'images, procédé de mise en correspondance d'images, appareil d'entraînement, procédé d'entraînement et support non transitoire lisible par ordinateur - Google Patents
Appareil de mise en correspondance d'images, procédé de mise en correspondance d'images, appareil d'entraînement, procédé d'entraînement et support non transitoire lisible par ordinateur Download PDFInfo
- Publication number
- WO2025041222A1 WO2025041222A1 PCT/JP2023/029987 JP2023029987W WO2025041222A1 WO 2025041222 A1 WO2025041222 A1 WO 2025041222A1 JP 2023029987 W JP2023029987 W JP 2023029987W WO 2025041222 A1 WO2025041222 A1 WO 2025041222A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- view image
- resolution
- image
- feature value
- target image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4053—Scaling of whole images or parts thereof, e.g. expanding or contracting based on super-resolution, i.e. the output image resolution being higher than the sensor resolution
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/74—Image or video pattern matching; Proximity measures in feature spaces
- G06V10/761—Proximity, similarity or dissimilarity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/10—Terrestrial scenes
- G06V20/176—Urban or other man-made structures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10032—Satellite or aerial image; Remote sensing
Definitions
- the present disclosure generally relates to an image matching apparatus, an image matching method, a training apparatus, a training method, and a non-transitory computer-readable medium.
- NPL1 discloses a system comprising a set of CNNs (Convolutional Neural Networks) to match a ground-view image against an aerial-view image.
- CNNs Convolutional Neural Networks
- one of the CNNs acquires a set of a ground-view image and orientation maps that indicate orientations (azimuth and altitude) for each location captured on the ground-view image, and extracts features therefrom.
- the other one acquires a set of an aerial-view image and orientation maps that indicate orientations (azimuth and range) for each location captured on the aerial-view image, and extracts features therefrom.
- the system determines whether the ground-view image matches the aerial-view image based on the extracted features.
- NPL1 Liu Liu and Hongdong Li, "Lending Orientation to Neural Networks for Cross-view Geo-localization", [online], March 29, 2019, [retrieved on 2021-09-24], retrieved from ⁇ arXiv, https://arxiv.org/pdf/1903.12351>
- NPL1 does not mention resolution of images.
- An objective of the present disclosure is to provide a novel technique to determine whether or not a ground-view image and an aerial-view image match each other.
- the present disclosure provides an image matching apparatus comprising at least one memory that is configured to store instructions and at least one processor that is configured to execute the instructions to: acquire a first-view image and a second-view image; compute a feature value of the first-view image; compute a feature value of the second-view image; and determine whether the first-view image and the second-view image match each other based on the feature value of the first-view image and the feature value of the second-view image.
- the computation of the feature value of the first-view image includes: enhancing a resolution of the first-view image to generate a resolution-enhanced first-view image; and computing a feature value of the resolution-enhanced first-view image as the feature value of the first-view image.
- the first-view image and the second-view image are respectively a ground-view image and an aerial-view image, or the first-view image and the second-view image are respectively an aerial-view image and a ground-view image.
- the present disclosure further provides an image matching method that is performed by a computer.
- the image matching method comprises: acquiring a first-view image and a second-view image; computing a feature value of the first-view image; computing a feature value of the second-view image; and determining whether the first-view image and the second-view image match each other based on the feature value of the first-view image and the feature value of the second-view image.
- the computation of the feature value of the first-view image includes: enhancing a resolution of the first-view image to generate a resolution-enhanced first-view image; and computing a feature value of the resolution-enhanced first-view image as the feature value of the first-view image.
- the first-view image and the second-view image are respectively a ground-view image and an aerial-view image, or the first-view image and the second-view image are respectively an aerial-view image and a ground-view image.
- the present disclosure further provides a non-transitory computer-readable medium storing a program that cause a computer to execute: acquiring a first-view image and a second-view image; computing a feature value of the first-view image; computing a feature value of the second-view image; and determining whether the first-view image and the second-view image match each other based on the feature value of the first-view image and the feature value of the second-view image.
- the computation of the feature value of the first-view image includes: enhancing a resolution of the first-view image to generate a resolution-enhanced first-view image; and computing a feature value of the resolution-enhanced first-view image as the feature value of the first-view image.
- the first-view image and the second-view image are respectively a ground-view image and an aerial-view image, or the first-view image and the second-view image are respectively an aerial-view image and a ground-view image.
- the present disclosure further provides a training apparatus comprising at least one memory that is configured to store instructions and at least one processor that is configured to execute the instructions to: acquire a target image; and perform training of one or more models.
- the training of the one or more models includes: reducing a resolution of the acquired target image to generate a resolution-reduced target image; inputting the resolution-reduced target image into a resolution enhancing model to generate a resolution-reenhanced target image; computing a loss using the acquired target image and the resolution-reenhanced target image; and updating the resolution enhancing model based on the loss.
- the target image is a ground-view image or an aerial-view image.
- the present disclosure further provides a training method that is performed by a computer.
- the training method comprises: acquiring a target image; and performing training of one or more models.
- the training of the one or more models includes: reducing a resolution of the acquired target image to generate a resolution-reduced target image; inputting the resolution-reduced target image into a resolution enhancing model to generate a resolution-reenhanced target image; computing a loss using the acquired target image and the resolution-reenhanced target image; and updating the resolution enhancing model based on the loss.
- the target image is a ground-view image or an aerial-view image.
- the present disclosure further provides a non-transitory computer-readable medium storing a program that causes a computer to execute: acquiring a target image; and performing training of one or more models.
- the training of the one or more models includes: reducing a resolution of the acquired target image to generate a resolution-reduced target image; inputting the resolution-reduced target image into a resolution enhancing model to generate a resolution-reenhanced target image; computing a loss using the acquired target image and the resolution-reenhanced target image; and updating the resolution enhancing model based on the loss.
- the target image is a ground-view image or an aerial-view image.
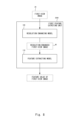
- Fig. 1 illustrates an overview of an image matching apparatus.
- Fig. 2 illustrates an example of the ground-view image and the aerial-view image.
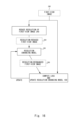
- Fig. 3 illustrates an overview of the image matching apparatus that handles the second-view image with the resolution of the first level.
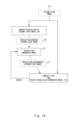
- Fig. 4 is a block diagram showing an example of the functional configuration of the image matching apparatus
- Fig. 5 is a block diagram illustrating an example of the hardware configuration of a computer 1000 realizing the image matching apparatus.
- Fig. 6 is a flowchart illustrating an example flow of processing performed by the image matching apparatus.
- Fig. 7 illustrates a geo-localization system that includes the image matching apparatus.
- Fig. 8 illustrates an example structure of the first feature extracting unit.
- Fig. 1 illustrates an overview of an image matching apparatus.
- Fig. 2 illustrates an example of the ground-view image and the aerial-view image.
- Fig. 3 illustrates an overview of the image matching apparatus that handles the second-view image with the resolution of the
- FIG. 9 illustrates a first example of a structure of the second feature extracting unit.
- Fig. 10 illustrates a second example of a structure of the second feature extracting unit.
- Fig. 11 is a diagram illustrating an example of functional configuration of the training apparatus.
- Fig. 12 is a flowchart illustrating an example flow of processing performed by the training apparatus.
- Fig. 13 illustrates a first example way of training the first feature extracting unit.
- Fig. 14 illustrates an image matching apparatus that handles the first-view image with the resolution of the second level and the second-view image with the resolution of the second level.
- Fig. 15 illustrates an additional training performed on the feature extracting model.
- Fig. 16 illustrates an example way of training the resolution enhancing model separately from the feature extracting model.
- Fig. 17 illustrates a first example way of training the second feature extracting unit.
- Fig. 18 illustrates an additional training performed on the feature extracting model.
- Fig. 19 illustrates an example way of training the
- predetermined information e.g., a predetermined value or a predetermined threshold
- a storage device to which a computer using that information has access unless otherwise described.
- FIG. 1 illustrates an overview of an image matching apparatus 2000.
- the image matching apparatus 2000 functions as a discriminator that performs matching between a ground-view image and an aerial-view image (so-called ground-to-aerial cross-view matching).
- Fig. 2 illustrates an example of the ground-view image 10 and the aerial-view image 15.
- the ground-view image 10 is a digital image that includes a ground view of a place, e.g., an RGB or gray-scale image of ground scenery.
- the ground-view image is generated by a ground camera that is held by a pedestrian or installed in a car.
- the ground-view image may be panoramic (having 360-degree field of view), or may have limited (less than 360-degree) field of view.
- the aerial-view image 15 is a digital image that includes a top view of a place, e.g., an RGB or gray-scale image of aerial scenery.
- the aerial-view image is generated by an aerial camera installed in a drone, an air plane, or a satellite.
- the image matching apparatus 2000 acquires a first-view image 20 and a second-view image 30.
- One of them is a ground-view image 10 and the other one of them is an aerial-view image 15.
- the image matching apparatus 2000 is configured to acquire a ground-view image 10 as the first-view image 20
- the image matching apparatus 2000 is configured to acquire an aerial-view image 15 as the second-view image 30.
- the image matching apparatus 2000 is configured to acquire an aerial-view image 15 as the first-view image 20
- the image matching apparatus 2000 is configured to acquire a ground-view image 10 as the second-view image 30.
- the image matching apparatus 2000 is used under a situation where the first-view image 20 has a resolution of a first level while the second-view image 30 has a resolution of a first level or a second level.
- the first level of resolution may include only a specific image resolution or may include image resolutions within a specific rage. The same applies to the second level of resolution.
- the first level and the second level of resolution are defined so that the resolution of the second level is higher than the resolution of the first level.
- the resolution is quantified so that the higher a resolution of an image is, the smaller a value representing the resolution of the image is.
- An example of this case is a case where a unit of "cm/pixel" is used to represent the resolution of the image.
- the first level and the second level of resolution are respectively defined by specific real numbers r1 and r2, the numbers r1 and r2 satisfy a condition of "r1>r2".
- the first level of resolution is defined as "50cm/pixel” while the second level of resolution is defined as "25cm/pixel”.
- the ranges R1 and R2 satisfy a condition of "the supremum of the rage R2 is less than the infimum of the rage R1".
- the first level of resolution is defined as a rage of (45[cm/pixel], 55[cm/pixel]) while the second level of resolution is defined as a range of (20[cm/pixel], 30[cm/pixel]).
- the levels of the resolution of first-view image and the levels of the resolution of second-view image may be defined separately from each other. It means that the first level of the resolution of first-view image is not necessarily equivalent to the first level of the resolution of second-view image. Similarly, the second level of the resolution of first-view image is not necessarily equivalent to the second level of the resolution of second-view image.
- the image matching apparatus 2000 Since the resolution of the first-view image 20 is of the first level, the image matching apparatus 2000 performs resolution enhancement on the first-view image 20 to increase the level of the resolution of the first-view image 20 to the second level.
- a first-view image that is obtained as a result of the resolution enhancement is called "resolution-enhanced first-view image 40".
- the image matching apparatus 2000 computes a feature value of the resolution-enhanced first-view image 40 as the feature value of the first-view image 20.
- the image matching apparatus 2000 does not perform resolution enhancement on the second-view image 30 when the resolution of the second-view image 30 is of the second level. In this case, the image matching apparatus 2000 computes the feature value of the second-view image 30 directly therefrom. Fig. 1 illustrates this case.
- the image matching apparatus 2000 performs resolution enhancement on the second-view image 30 to increase the level of the resolution of the second-view image 30 to the second level.
- Fig. 3 illustrates an overview of the image matching apparatus 2000 that handles the second-view image 30 with the resolution of the first level.
- a second-view image that is obtained as a result of the resolution enhancement is called "resolution-enhanced second-view image 50".
- the image matching apparatus 2000 computes a feature value of the resolution-enhanced second-view image 50 as the feature value of the second-view image 30.
- the image matching apparatus 2000 acquires the first-view image 20 and the second-view image 30, and determine whether the first-view image 20 and the second-view image 30 match each other by comparing their feature values.
- the first-view image 20 is converted into the resolution-enhanced first-view image 40 by performing resolution enhancement on the first-view image 20.
- the feature value of the resolution-enhanced first-view image 40 is used as the feature value of the first-view image 20.
- the image matching apparatus 2000 Since the image matching apparatus 2000 has a mechanism of enhancing the resolution of the first-view image 20 before computing the feature value thereof, the image matching apparatus 2000 can handle first-view images whose resolution is not high enough to determine whether the first-view image matches the second-view image 30. Furthermore, in the case where the image matching apparatus 2000 has a mechanism of enhancing the resolution of the second-view image 30 before computing the feature value thereof, the image matching apparatus 2000 can handle second-view images whose resolution is not sufficiently high.
- the image matching apparatus 2000 is useful in various situations.
- One of such the situations is a situation in which it is difficult to make it sure to acquire a first-view image with high resolution.
- the first-view image 20 is a ground-view image provided by a user.
- the user may use her/his smartphone to take a picture around her/him, and that picture may be provided as the first-view image 20.
- the resolution of the first-view image 20 depends on the performance of the smartphone.
- the image matching apparatus 2000 can determine whether the first-view image 20 and the second-view image 30 match each other even in this case.
- Fig. 4 is a block diagram showing an example of the functional configuration of the image matching apparatus 2000.
- the image matching apparatus 2000 includes an acquiring unit 2020, a first feature extracting unit 2040, a second feature extracting unit 2060, and a determining unit 2080.
- the acquiring unit 2020 acquires the first-view image 20 and the second-view image 30.
- the first feature extracting unit 2040 computes the feature value of the first-view image 20. Specifically, the first feature extracting unit 2040 enhances the resolution of the first-view image 20 to generate the resolution-enhanced first-view image 40. Then, the first feature extracting unit 2040 computes the feature value of the resolution-enhanced first-view image 40 as the feature value of the first-view image 20.
- the second feature extracting unit 2060 computes the feature value of the second-view image 30.
- the determining unit 2080 determines whether the first-view image 20 and the second-view image 30 match each other based on the feature value of the first-view image 20 and the feature value of the second-view image 30.
- the second feature extracting unit 2060 is configured to enhance the resolution of the second-view image 30 to generate the resolution-enhanced second-view image 50.
- the second feature extracting unit 2060 is also configured to compute the feature value of the resolution-enhanced second-view image 50 as the second-view image 30.
- the image matching apparatus 2000 may be realized by one or more computers.
- Each of the one or more computers may be a special-purpose computer manufactured for implementing the image matching apparatus 2000, or may be a general-purpose computer like a personal computer (PC), a server machine, or a mobile device.
- PC personal computer
- server machine a server machine
- mobile device a mobile device
- the image matching apparatus 2000 may be realized by installing an application in the one or more computers.
- the application is implemented with a program that causes the one or more computers to function as the image matching apparatus 2000.
- the program is an implementation of the functional units of the image matching apparatus 2000.
- Fig. 5 is a block diagram illustrating an example of the hardware configuration of a computer 1000 realizing the image matching apparatus 2000.
- the computer 1000 includes a bus 1020, a processor 1040, a memory 1060, a storage device 1080, an input/output (I/O) interface 1100, and a network interface 1120.
- I/O input/output
- the bus 1020 is a data transmission channel in order for the processor 1040, the memory 1060, the storage device 1080, and the I/O interface 1100, and the network interface 1120 to mutually transmit and receive data.
- the processor 1040 is a processer, such as a CPU (Central Processing Unit), GPU (Graphics Processing Unit), FPGA (Field-Programmable Gate Array), or DSP (Digital Signal Processor).
- the memory 1060 is a primary memory component, such as a RAM (Random Access Memory) or a ROM (Read Only Memory).
- the storage device 1080 is a secondary memory component, such as a hard disk, an SSD (Solid State Drive), or a memory card.
- the I/O interface 1100 is an interface between the computer 1000 and peripheral devices, such as a keyboard, mouse, or display device.
- the network interface 1120 is an interface between the computer 1000 and a network.
- the network may be a LAN (Local Area Network) or a WAN (Wide Area Network).
- the storage device 1080 may store the program mentioned above.
- the processor 1040 reads the program from the storage device 1080, and executes the program to realize each functional unit of the image matching apparatus 2000.
- the hardware configuration of the computer 1000 is not restricted to that shown in Fig. 5.
- the image matching apparatus 2000 may be realized by plural computers. In this case, those computers may be connected with each other through the network.
- Fig. 6 is a flowchart illustrating an example flow of processing performed by the image matching apparatus 2000.
- the acquiring unit 2020 acquires the first-view image 20 and the second-view image 30 (S102).
- the first feature extracting unit 2040 computes the feature value of the first-view image 20 (S104).
- the second feature extracting unit 2060 computes the feature value of the second-view image 30 (S106).
- the determining unit 2080 determines whether the first-view image 20 and the second-view image 30 match each other based on the feature value of the first-view image 20 and the feature value of the second-view image 30 (S108).
- a flow of processing performed by the image matching apparatus 2000 is not limited to that illustrated by Fig. 6.
- the computation of the feature value of the first-view image 20 (i.e., Step S104) and the computation of the feature value of the second-view image 30 (i.e., Step S106) may be performed in parallel with each other or in an order opposite to the order illustrated by Fig. 6.
- the image matching apparatus 2000 can be used as a part of a system (hereinafter, a geo-localization system) that performs image geo-localization.
- Image geo-localization is a technique to determine the place at which an input image is captured.
- the geo-localization system 500 may be implemented by one or more arbitrary computers such as ones depicted by Fig. 5. It is noted that the geo-localization system is merely an example of the application of the image matching apparatus 2000, and the application of the image matching apparatus 2000 is not restricted to being used in the geo-localization system.
- Fig. 7 illustrates a geo-localization system 500 that includes the image matching apparatus 2000.
- the geo-localization system 500 includes the image matching apparatus 2000 and the location database 600.
- the location database 600 includes a plurality of aerial-view images to each of which location information is attached.
- An example of the location information may be GPS (Global Positioning System) coordinates of the place captured on the center of the corresponding aerial-view image.
- the geo-localization system 500 receives a query that includes a ground-view image from a client (e.g., user terminal). Then, the geo-localization system 500 searches the location database 600 for the aerial-view image that matches the ground-view image in the received query, thereby determining the place at which the ground-view image is captured. Specifically, until the aerial-view image that matches the ground-view image in the query is detected, the geo-localization system 500 repeatedly executes: acquiring one of the aerial-view images from the location database 600; inputting the ground-view image acquired from the query and the aerial-view acquired from the location database 600 into the image matching apparatus 2000; and determining whether the output of the image matching apparatus 2000 indicates that the ground-view image and the aerial-view image match each other.
- a client e.g., user terminal
- the geo-localization system 500 searches the location database 600 for the aerial-view image that matches the ground-view image in the received query, thereby determining the place at which the ground-view image is captured. Specifically, until the
- the image matching apparatus 2000 may be configured to handle the ground-view image and the aerial-view image as the first-view image 20 and the second-view image 30, respectively, or may be configured to handle the ground-view image and the aerial-view image as the second-view image 30 and the first-view image 20, respectively.
- the geo-localization system 500 can find the aerial-view image that includes the place at which the ground-view image is captured. Since the detected aerial-view image is associated with the location information such as the GPS coordinates, the geo-localization system 500 can determine that where the ground-view image is captured is the place that is indicated by the location information associated with the aerial-view image that matches the ground-view image.
- the ground-view image and the aerial-view image are used in an opposite way in the geo-localization system 500.
- the location database 600 stores a plurality of ground-view images to each of which the location information is attached.
- the geo-localization system 500 receives a query including an aerial-view image, and searches the location database 600 for the ground-view image that matches the aerial-view image in the query, thereby determining the location of the place that is captured on the aerial-view image.
- the acquiring unit 2020 acquires the first-view image 20 and the second-view image 30 (S102). There are various ways to acquire those data. In some implementations, the acquiring unit 2020 may receive the first-view image 20, the second-view image 30, or both sent from another computer. In other implementations, the acquiring unit 2020 may retrieve the first-view image 20, the second-view image 30, or both from a storage device to which the acquiring unit 2020 has access.
- the first-view image 20 and the second-view image 30 may be acquired in the manner same as each other or may be acquired in different manners from each other.
- the acquiring unit 2020 receives the first-view image 20 from another computer while the acquiring unit 2020 retrieves the second-view image 30 from a storage device, or vice versa.
- the first feature extracting unit 2040 computes the feature value of the first-view image 20 (S104). As described above, resolution enhancement is performed on the first-view image 20 to generate the resolution-enhanced first-view image 40. Then, the first feature extracting unit 2040 computes a feature value of the resolution-enhanced first-view image 40 as the feature value of the first-view image 20.
- Fig. 8 illustrates an example structure of the first feature extracting unit 2040.
- the first feature extracting unit 2040 may include two machine learning-based models (e.g., neural networks) called "resolution enhancing model 100" and "feature extracting model 110".
- the resolution enhancing model 100 is configured to take an image as input, and output another image whose size is the same as the input image.
- the resolution enhancing model 100 is pre-trained to, in response to a first-view image with a resolution of the first level being input thereinto, enhance the resolution of the input first-view image to the second level and thereby generate a first-view image with a resolution of the second level. How to train the resolution enhancing model 100 will be explained later.
- the feature extracting model 110 is configured to take an image as input, and output a value (e.g., vector or tensor) that is computed based on the input image.
- a value e.g., vector or tensor
- the feature extracting model 110 is pre-trained to, in response to a first-view image with a resolution of the second level being input thereinto, compute a feature value of that input image. How to train the first feature extracting model 110 will be explained later.
- the first feature extracting unit 2040 inputs the first-view image 20 acquired by the acquiring unit 2020 into the resolution enhancing model 100.
- the resolution enhancing model 100 outputs the resolution-enhanced first-view image 40.
- the resolution-enhanced first-view image 40 is fed into the feature extracting model 110.
- the feature extracting model 110 outputs the feature value of the resolution-enhanced first-view image 40.
- the feature value of the resolution-enhanced first-view image 40 is handled as the feature value of the first-view image 20 by the determining unit 2080.
- the second feature extracting unit 2060 computes the feature value of the second-view image 30 (S106).
- Fig. 9 illustrates a first example of a structure of the second feature extracting unit 2060. In the example illustrated by Fig. 9, it is assumed that the second-view image 30 has a resolution of the second level. Thus, the second feature extracting unit 2060 does not have a function of enhancing the second-view image 30.
- the second feature extracting model 2060 may include a machine learning-based model (e.g., neural network) called "feature extracting model 120".
- the feature extracting model 120 is configured to take an image as input, and output a value (e.g., vector or tensor) that is computed based on the input image.
- a value e.g., vector or tensor
- the feature extracting model 120 is pre-trained to, in response to a second-view image with a resolution of the second level being input thereinto, compute a feature value of that input image. How to train the second feature extracting model 120 will be explained later.
- the second feature extracting unit 2060 inputs the second-view image 30 acquired by the acquiring unit 2020 into the feature extracting model 120, thereby acquiring the feature value of the second-view image 30 that is output by the feature extracting model 120.
- the second feature extraction unit 2060 further includes a function of enhancing a resolution of the second-view image 30 to the second level to generate the resolution-enhanced second-view image 50.
- Fig. 10 illustrates a second example of a structure of the second feature extracting unit 2060. In the example illustrated by Fig. 10, it is assumed that the second-view image 30 has a resolution of the first level.
- the second feature extracting unit 2060 includes a resolution enhancing model 130 as well as the feature extracting model 120.
- the resolution enhancing model 130 is configured to take an image as input, and output another image whose size is the same as the input image.
- the resolution enhancing model 130 is pre-trained to, in response to a second-view image with a resolution of the first level being input thereinto, enhance the resolution of the input second-view image to the second level and thereby generate a second-view image with a resolution of the second level. How to train the resolution enhancing model 130 will be explained later.
- the second feature extracting unit 2060 inputs the second-view image 30 acquired by the acquiring unit 2020 into the resolution enhancing model 130.
- the resolution enhancing model 130 outputs the resolution-enhanced second-view image 50.
- the resolution-enhanced second-view image 50 is fed into the feature extracting model 120.
- the feature extracting model 120 outputs the feature value of the resolution-enhanced second-view image 50.
- the feature value of the resolution-enhanced second-view image 50 is handled as the feature value of the second-view image 30 by the determining unit 2080.
- the determining unit 2080 determines whether the first-view image 20 and the second-view image 30 match each other (S108). Specifically, the determining unit 2080 performs the determination by comparing the feature value of the first-view image 20 and the feature value of the second-view image 30.
- the determining unit 2080 may compute a similarity score, which represents a degree of similarity between the feature value of the first-view image 20 and the feature value of the second-view image 30.
- a similarity score represents a degree of similarity between the feature value of the first-view image 20 and the feature value of the second-view image 30.
- the similarity score may be computed as one of various types of distance (e.g., L2 distance), correlation, cosine similarity, or neural network (NN) based similarity between the feature value of the first-view image 20 and the feature value of the second-view image 30.
- the NN based similarity is the degree of similarity computed by a neural network that is trained to compute the degree of similarity between two input data (in this disclosure, the feature value of the first-view image 20 and the feature value of the second-view image 30).
- the determining unit 2080 determines whether the first-view image 20 and the second-view image 30 match each other based on the similarity score computed for them.
- the similarity score is assumed to become larger as the degree of similarity between the feature values becomes higher.
- the similarity score may be defined as a reciprocal of the value computed for the compared feature values.
- the determining unit 2080 may determine whether the similarity score is equal to or less than a predefined threshold. If the similarity score is equal to or less than the predefined threshold, the determining unit 2080 determines that the first-view image 20 and the second-view image 30 match each other. On the other hand, if the similarity score is larger than the predefined threshold, the determining unit 2080 determines that the first-view image 20 and the second-view image 30 do not match each other.
- the image matching apparatus 2000 may output information (hereinafter, output information) related to a result of the determination.
- the output information may indicate whether the first-view image 20 and the second-view image 30 match each other.
- the output information may further include the location information that indicates the location at which the queried image is captured.
- the queried image is either the first-view image 20 or the second-view image 30. In other words, the queried image is either the ground-view image or the aerial-view image.
- the image matching apparatus 2000 may put the output information into a storage device.
- the image matching apparatus 2000 may output the output information to a display device so that the display device displays the contents of the output information.
- the image matching apparatus 2000 may output the output information to another computer, such as one included in the geo-localization system 500 shown in Fig. 7.
- machine learning-based models may be used to compute the feature value of the first-view image 20 and the feature value of the second-view image 30. Those models are trained in advance of being used by the image matching apparatus. Hereinafter, an apparatus that performs training of those models are called "training apparatus”.
- Fig. 11 is a diagram illustrating an example of functional configuration of the training apparatus 3000.
- the training apparatus 3000 includes an acquiring unit 3020, a computing unit 3040, and an updating unit 3060.
- the acquiring unit 3020 acquires a training data.
- the computing unit 3020 applies the training data to a model to be trained, and computes a loss based on data output by the model.
- the updating unit 3060 updates the model based on the loss.
- trainable parameters may include weights assigned to edges and biases.
- the training apparatus 3000 may have hardware configuration similar to the hardware configuration of the image matching apparatus 2000.
- the hardware configuration of the training apparatus 3000 may be illustrated by Fig. 5.
- the storage device of the training apparatus 3000 includes a program that implements the functions of the training apparatus 3000.
- Fig. 12 is a flowchart illustrating an example flow of processing performed by the training apparatus 3000.
- the acquiring unit 3020 acquires the training data (S202).
- the computing unit 3040 inputs the training data to the model to be trained (S204).
- the computing unit 3040 computes a loss based on data output by the model (S206).
- the updating unit 3060 updates the model based on the loss (S208).
- example ways of training the models will be described. Specifically, example ways of training the models in the first feature extracting unit 2040 will be described first. Then, example ways of training the models in the second feature extracting unit 2060 will be described.
- the first feature extracting unit 2040 may include the resolution enhancing model 100 and the feature extracting model 110.
- Fig. 13 illustrates a first example way of training the first feature extracting unit 2040.
- the acquiring unit 3020 acquires a first-view image 150 as a training data.
- the first-view image 150 is a first-view image with the resolution of the second level.
- the computing unit 3040 preforms resolution reduction on the first-view image 150 to generate a resolution-reduced first-view image 160, which is a first-view image with the resolution of the first level. For example, the computing unit 3040 performs down-sampling on the first-view image 150 and resizes the obtained image to the size same as the first-view image 150. By doing so, the computing unit 3040 can obtain, as the resolution-reduced first-view image 160, a first-view image whose size is the same as the first-view image 150 and whose resolution is lower than the first-view image 150.
- the computing unit 3040 inputs the resolution-reduced first-view image 160 into the resolution enhancing model 100, thereby obtaining a resolution-reenhanced first-view image 170.
- the resolution-reenhanced first-view image 170 is supposed to be equivalent to the first-view image 150 when the resolution enhancing model 100 is already trained sufficiently.
- the resolution-reenhanced first-view image 170 is fed into the feature extracting model 110.
- a feature value of the resolution-reenhanced first-view image 170 is output by the feature extracting model 110.
- the computing unit 3040 also computes a feature value of the first-view image 150. Specifically, the computing unit 3040 inputs the first-view image 150 into a pre-trained feature extracting model 180, which is a machine learning-based model that is trained in advance to compute a feature value of a first-view image with the resolution of the second level.
- a pre-trained feature extracting model 180 which is a machine learning-based model that is trained in advance to compute a feature value of a first-view image with the resolution of the second level.
- the feature value of the resolution-reenhanced first-view image 170 and the feature value of the first-view image 150 are supposed to be equivalent to each other when the resolution enhancing model 100 and the feature extracting model 110 are already trained sufficiently.
- the training apparatus 3000 computes a loss that represents a degree of difference between the feature value of the first-view image 150 and the feature value of the resolution-reenhanced first-view image 170.
- the updating unit 3060 uses the computed loss to update the resolution enhancing model 100 and the feature extracting model 110. Specifically, the updating unit 3060 updates trainable parameters of the resolution enhancing model 100 and trainable parameters of the feature extracting model 110 based on the loss.
- the training apparatus 3000 that performs the training depicted by Fig. 13, it is possible to train the resolution enhancing model 100 so that the resolution enhancing model 100 can accurately enhance the resolution of a first-view image from the first level to the second level.
- the pre-trained feature extracting model 180 is trained in advance.
- the pre-trained feature extracting model 180 is trained to be used a part of another image matching apparatus, which is configured to take a first-view image with the resolution of the second level and a second-view image with the resolution of the second level, and to determine whether the acquired first-view image and the acquired second-view image match each other.
- Fig. 14 illustrates an image matching apparatus 400 that handles the first-view image with the resolution of the second level and the second-view image with the resolution of the second level.
- the image matching apparatus 400 acquires a first-view image 410 and a second-view image 420, whose resolutions are of the second level.
- the image matching apparatus 400 has a feature extracting model 430 and a feature extracting model 440.
- the feature extracting model 430 takes the first-view image 410 as input, and computes a feature value of the first-view image 410.
- the feature extracting model 440 takes the second-view image 420 as input, and computes a feature value of the second-view image 420.
- the image matching apparatus 400 determines whether the first-view image 410 and the second-view image 420 match each other by comparing their feature values.
- What the feature extracting model 430 performs is to compute a feature value of the first-view image whose resolution is of the second level, and this is the same as what the pre-trained feature extracting model 180 performs.
- the feature extracting model 430 may be employed in the training apparatus 3000 to be used as the pre-trained feature extracting model 180.
- the training apparatus 3000 may further perform additional training on the feature extracting model 110.
- Fig. 15 illustrates an additional training performed on the feature extracting model 110.
- the acquiring unit 3020 acquires a first-view image 200 and a second-view image 210 as training data.
- the first-view image 200 is a first-view image with the resolution of the first level while the second-view image 210 is a second-view image with the resolution of the second level.
- the computing unit 3040 inputs the first-view image 200 into the resolution enhancing model 100 that has been trained in the way depicted by Fig. 13, thereby obtaining a resolution-enhanced first-view image 220. Then, the resolution-enhanced first-view image 220 is fed into the feature extracting model 110 that has been trained in the way depicted by Fig. 13. As a result, a feature value of the resolution-enhanced first-view image 220 is obtained.
- the computing unit 3040 inputs the second-view image 210 into a pre-trained feature extracting model 230, thereby obtaining a feature value of the second-view image 210.
- the feature extracting model 440 depicted by Fig. 14 can be used as the pre-trained feature extracting model 230.
- the computing unit 3040 computes a loss that represents a degree of difference between the feature value of the first-view image 200 and the feature value of the second-view image 210, and update the feature extracting model 110 based on the loss. It is noted that the feature extracting model 110 may be trained so that the loss becomes smaller when the first-view image 200 and the second-view image 210 are supposed to match each other. On the other hand, the feature extracting model 110 may be trained so that the loss becomes larger when the first-view image 200 and the second-view image 210 are supposed not to match each other.
- the training apparatus 3000 may use, as training data, a set of the first-view image 200, a positive example of the second-view image 210, and a negative example of the second-view image 210.
- the positive example of the second-view image 210 is a second-view image 210 that is supposed to match the first-view image 200.
- the negative example of the second-view image 210 is a second-view image 210 that is supposed not to match the first-view image 200.
- the training apparatus 3000 may compute a triplet loss based on the feature value of the first-view image 200, the feature value of the positive example of the second-view image 210, and the feature value of the negative example of the second-view image 210, and update the feature extracting model 110 based on the triplet loss.
- the feature extracting model 110 it is possible to train the feature extracting model 110 so that the feature extracting model 110 can accurately compute the feature value of the first-view image from the viewpoint of matching between the first-view image and the second-view image.
- the resolution enhancing model 100 may be trained separately from the feature extracting model 110.
- Fig. 16 illustrates an example way of training the resolution enhancing model 100 separately from the feature extracting model 110.
- the acquiring unit 3020 acquires a first-view image 240 as a training data.
- the first-view image 240 is a first-view image with the resolution of the second level.
- the computing unit 3040 preforms resolution reduction on the first-view image 240 to generate a resolution-reduced first-view image 250, which is a first-view image with the resolution of the first level.
- the computing unit 3040 inputs the resolution-reduced first-view image 250 into the resolution enhancing model 100, thereby obtaining a resolution-reenhanced first-view image 260.
- the resolution-reenhanced first-view image 260 is supposed to be equivalent to the first-view image 240 when the resolution enhancing model 100 is already trained sufficiently.
- the computing unit 3040 computes a loss that represents a degree of difference between the first-view image 240 and the resolution-reenhanced first-view image 260, and updates the resolution enhancing model 100 based on the loss.
- the second feature extracting unit 2060 may include the feature extracting model 120 and not include the resolution enhancing model 130.
- the feature extracting model 440 depicted by Fig. 14 may be used as the feature extracting model 120.
- the second feature extracting unit 2060 may include the resolution enhancing model 130 and the feature extracting model 120.
- the second extracting model 2060 may be trained in the same manner as the manner of training the first feature extracting unit 2040.
- Fig. 17 illustrates a first example way of training the second feature extracting unit 2060.
- the acquiring unit 3020 acquires a second-view image 270 as a training data.
- the second-view image 270 is a second-view image with the resolution of the second level.
- the computing unit 3040 preforms resolution reduction on the second-view image 270 to generate a resolution-reduced second-view image 280, which is a second-view image with the resolution of the first level.
- the computing unit 3040 inputs the resolution-reduced second-view image 280 into the resolution enhancing model 130, thereby obtaining a resolution-reenhanced second-view image 290.
- the resolution-reenhanced second-view image 290 is fed into the feature extracting model 120.
- a feature value of the resolution-reenhanced second-view image 290 is output by the feature extracting model 120.
- the computing unit 3040 also computes a feature value of the second-view image 270. Specifically, the computing unit 3040 inputs the second-view image 270 into a pre-trained feature extracting model 300, which is a machine learning-based model that is trained in advance to compute a feature value of a second-view image with the resolution of the second level.
- the feature extracting model 340 depicted by Fig. 14 may be used as the pre-trained feature extracting model 300.
- the feature value of the resolution-reenhanced first-view image 170 and the feature value of the first-view image 150 are supposed to be equivalent to each other when the resolution enhancing model 130 and the feature extracting model 120 are already trained sufficiently.
- the computing unit 3040 computes a loss that represents a degree of difference between the feature value of the second-view image 270 and the feature value of the resolution-reenhanced second-view image 290.
- the updating unit 3060 uses the computed loss to update the resolution enhancing model 130 and the feature extracting model 120. Specifically, the updating unit 3060 updates trainable parameters of the resolution enhancing model 130 and trainable parameters of the feature extracting model 120 based on the loss.
- the training apparatus 3000 that performs the training depicted by Fig. 17, it is possible to train the resolution enhancing model 130 so that the resolution enhancing model 130 can accurately enhance the resolution of a second-view image from the first level to the second level.
- the training apparatus 3000 may further perform additional training on the feature extracting model 120.
- Fig. 18 illustrates an additional training performed on the feature extracting model 120.
- the acquiring unit 3020 acquires a first-view image 310 and a second-view image 320 as training data.
- the first-view image 310 is a first-view image with the resolution of the second level while the second-view image 320 is a second-view image with the resolution of the first level.
- the computing unit 3040 inputs the second-view image 320 into the resolution enhancing model 130 that has been trained in the way depicted by Fig. 17, thereby obtaining a resolution-enhanced second-view image 330. Then, the resolution-enhanced second-view image 330 is fed into the feature extracting model 120 that has been trained in the way depicted by Fig. 17. As a result, a feature value of the resolution-enhanced second-view image 330 is obtained.
- the computing unit 3040 inputs the first-view image 310 into a pre-trained feature extracting model 340, thereby obtaining a feature value of the first-view image 310.
- the feature extracting model 430 depicted by Fig. 14 can be used as the pre-trained feature extracting model 340.
- the computing unit 3040 computes a loss that represents a degree of difference between the feature value of the first-view image 310 and the feature value of the second-view image 320, and update the feature extracting model 120 based on the loss. It is noted that the feature extracting model 120 may be trained so that the loss becomes smaller when the first-view image 310 and the second-view image 320 are supposed to match each other. On the other hand, the feature extracting model 120 may be trained so that the loss becomes larger when the first-view image 310 and the second-view image 320 are supposed not to match each other.
- the training apparatus 3000 may use, as training data, a set of the first-view image 310, a positive example of the second-view image 320, and a negative example of the second-view image 320.
- the positive example of the second-view image 320 is a second-view image 320 that is supposed to match the first-view image 310.
- the negative example of the second-view image 320 is a second-view image 320 that is supposed not to match the first-view image 310.
- the training apparatus 3000 may compute a triplet loss based on the feature value of the first-view image 310, the feature value of the positive example of the second-view image 320, and the feature value of the negative example of the second-view image 320, and update the feature extracting model 120 based on the triplet loss.
- the feature extracting model 120 it is possible to train the feature extracting model 120 so that the feature extracting model 120 can accurately compute the feature value of the second-view image from the viewpoint of matching between the first-view image and the second-view image.
- the resolution enhancing model 130 may be trained separately from the feature extracting model 120.
- Fig. 19 illustrates an example way of training the resolution enhancing model 130 separately from the feature extracting model 120.
- the acquiring unit 3020 acquires a second-view image 350 as a training data.
- the second-view image 350 is a second-view image with the resolution of the second level.
- the computing unit 3040 preforms resolution reduction on the second-view image 350 to generate a resolution-reduced second-view image 360, which is a second-view image with the resolution of the first level.
- the computing unit 3040 inputs the resolution-reduced second-view image 360 into the resolution enhancing model 130, thereby obtaining a resolution-reenhanced second-view image 370.
- the resolution-reenhanced second-view image 370 is supposed to be equivalent to the second-view image 350 when the resolution enhancing model 130 is already trained sufficiently.
- the computing unit 3040 computes a loss that represents a degree of difference between the second-view image 350 and the resolution-reenhanced second-view image 370, and updates the resolution enhancing model 130 based on the loss.
- Non-transitory computer readable media include any type of tangible storage media.
- Examples of non-transitory computer readable media include magnetic storage media (such as floppy disks, magnetic tapes, hard disk drives, etc.), optical magnetic storage media (e.g., magneto-optical disks), CD-ROM (compact disc read only memory), CD-R (compact disc recordable), CD-R/W (compact disc rewritable), and semiconductor memories (such as mask ROM, PROM (programmable ROM), EPROM (erasable PROM), flash ROM, RAM (random access memory), etc.).
- magnetic storage media such as floppy disks, magnetic tapes, hard disk drives, etc.
- optical magnetic storage media e.g., magneto-optical disks
- CD-ROM compact disc read only memory
- CD-R compact disc recordable
- CD-R/W compact disc rewritable
- semiconductor memories such as mask ROM, PROM (programmable ROM), EPROM (erasable PROM), flash
- the program may be provided to a computer using any type of transitory computer readable media.
- Examples of transitory computer readable media include electric signals, optical signals, and electromagnetic waves.
- Transitory computer readable media can provide the program to a computer via a wired communication line (e.g., electric wires, and optical fibers) or a wireless communication line.
- An image matching apparatus comprising: at least one memory that is configured to store instructions; and at least one processor that is configured to execute the instructions to: acquire a first-view image and a second-view image; compute a feature value of the first-view image; compute a feature value of the second-view image; and determine whether the first-view image and the second-view image match each other based on the feature value of the first-view image and the feature value of the second-view image, wherein the computation of the feature value of the first-view image includes: enhancing a resolution of the first-view image to generate a resolution-enhanced first-view image; and computing a feature value of the resolution-enhanced first-view image as the feature value of the first-view image, wherein the first-view image and the second-view image are respectively a ground-view image and an aerial-view image, or
- An image matching method performed by a computer, comprising: acquiring a first-view image and a second-view image; computing a feature value of the first-view image; computing a feature value of the second-view image; and determining whether the first-view image and the second-view image match each other based on the feature value of the first-view image and the feature value of the second-view image, wherein the computation of the feature value of the first-view image includes: enhancing a resolution of the first-view image to generate a resolution-enhanced first-view image; and computing a feature value of the resolution-enhanced first-view image as the feature value of the first-view image, wherein the first-view image and the second-view image are respectively a ground-view image and an aerial-view image, or the first-view image and the second-view image are respectively an aerial-view image and a ground-view image.
- a non-transitory computer-readable medium storing a program that cause a computer to execute: acquiring a first-view image and a second-view image; computing a feature value of the first-view image; computing a feature value of the second-view image; and determining whether the first-view image and the second-view image match each other based on the feature value of the first-view image and the feature value of the second-view image, wherein the computation of the feature value of the first-view image includes: enhancing a resolution of the first-view image to generate a resolution-enhanced first-view image; and computing a feature value of the resolution-enhanced first-view image as the feature value of the first-view image, wherein the first-view image and the second-view image are respectively a ground-view image and an aerial-view image, or the first-view image and the second-view image are respectively an aerial-view image and a ground-view image.
- a training apparatus comprising: at least one memory that is configured to store instructions; and at least one processor that is configured to execute the instructions to: acquire a target image; and perform training of one or more models, wherein the training of the one or more models includes: reducing a resolution of the acquired target image to generate a resolution-reduced target image; inputting the resolution-reduced target image into a resolution enhancing model to generate a resolution-reenhanced target image; computing a loss using the acquired target image and the resolution-reenhanced target image; and updating the resolution enhancing model based on the loss, wherein the target image is a ground-view image or an aerial-view image.
- the training apparatus includes: down-sampling the acquired target image; and increase a size of an image that is acquired by the down-sampling to a size of the acquired target image, thereby generating the resolution-reduced target image.
- the training apparatus comprising according to supplementary note 7 or 8, wherein the loss is computed so as to represent a degree of difference between the acquired target image and the resolution-reenhanced target image.
- the training apparatus comprising according to supplementary note 7 or 8, wherein the training of the one or more models further includes: inputting the resolution-reenhanced target image into a feature extracting model to compute a feature value of the resolution-reenhanced target image; computing a feature value of the acquired target image; computing the loss that represents a degree of difference between the feature value of the acquired target image and the feature value of the resolution-reenhanced target image; and updating the resolution-reenhanced target image and the feature extracting model based on the loss.
- a training method performed by a computer comprising: acquiring a target image; and performing training of one or more models, wherein the training of the one or more models includes: reducing a resolution of the acquired target image to generate a resolution-reduced target image; inputting the resolution-reduced target image into a resolution enhancing model to generate a resolution-reenhanced target image; computing a loss using the acquired target image and the resolution-reenhanced target image; and updating the resolution enhancing model based on the loss, wherein the target image is a ground-view image or an aerial-view image.
- the training method comprising according to supplementary note 11 or 12, wherein the training of the one or more models further includes: inputting the resolution-reenhanced target image into a feature extracting model to compute a feature value of the resolution-reenhanced target image; computing a feature value of the acquired target image; computing the loss that represents a degree of difference between the feature value of the acquired target image and the feature value of the resolution-reenhanced target image; and updating the resolution-reenhanced target image and the feature extracting model based on the loss.
- a non-transitory computer-readable medium storing a program that causes a computer to execute: acquiring a target image; and performing training of one or more models, wherein the training of the one or more models includes: reducing a resolution of the acquired target image to generate a resolution-reduced target image; inputting the resolution-reduced target image into a resolution enhancing model to generate a resolution-reenhanced target image; computing a loss using the acquired target image and the resolution-reenhanced target image; and updating the resolution enhancing model based on the loss, wherein the target image is a ground-view image or an aerial-view image.
- the medium according to supplementary note 15 wherein the reduction of the resolution of the acquired target image includes: down-sampling the acquired target image; and increase a size of an image that is acquired by the down-sampling to a size of the acquired target image, thereby generating the resolution-reduced target image.
- the loss is computed so as to represent a degree of difference between the acquired target image and the resolution-reenhanced target image.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
Un appareil de mise en correspondance d'images est conçu pour : acquérir une image d'une première vue et une image d'une seconde vue ; calculer une valeur caractéristique de l'image de la première vue ; calculer une valeur caractéristique de l'image de la seconde vue ; et déterminer si l'image de la première vue et l'image de la seconde vue correspondent l'une à l'autre sur la base de la valeur caractéristique de l'image de la première vue et de la valeur caractéristique de l'image de la seconde vue. Le calcul de la valeur caractéristique de l'image de la première vue consiste à : améliorer la résolution de l'image de la première vue pour générer une image de la première vue à résolution améliorée ; et calculer une valeur caractéristique de l'image de la première vue à résolution améliorée en tant que valeur caractéristique de l'image de la première vue. L'image de la première vue et l'image de la seconde vue sont respectivement une image vue du sol et une image en vue aérienne, ou l'image de la première vue et l'image de la seconde vue sont respectivement une image en vue aérienne et une image vue du sol.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2023/029987 WO2025041222A1 (fr) | 2023-08-21 | 2023-08-21 | Appareil de mise en correspondance d'images, procédé de mise en correspondance d'images, appareil d'entraînement, procédé d'entraînement et support non transitoire lisible par ordinateur |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2023/029987 WO2025041222A1 (fr) | 2023-08-21 | 2023-08-21 | Appareil de mise en correspondance d'images, procédé de mise en correspondance d'images, appareil d'entraînement, procédé d'entraînement et support non transitoire lisible par ordinateur |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025041222A1 true WO2025041222A1 (fr) | 2025-02-27 |
Family
ID=94731692
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/029987 Pending WO2025041222A1 (fr) | 2023-08-21 | 2023-08-21 | Appareil de mise en correspondance d'images, procédé de mise en correspondance d'images, appareil d'entraînement, procédé d'entraînement et support non transitoire lisible par ordinateur |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2025041222A1 (fr) |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005215883A (ja) * | 2004-01-28 | 2005-08-11 | Sony Corp | 画像照合装置、プログラム、および画像照合方法 |
| WO2016019484A1 (fr) * | 2014-08-08 | 2016-02-11 | Xiaoou Tang | Appareil et procédé pour fournir une super-résolution d'une image à basse résolution |
| WO2019230665A1 (fr) * | 2018-06-01 | 2019-12-05 | 日本電信電話株式会社 | Dispositif d'apprentissage, dispositif de recherche, procédé et programme |
| WO2021256091A1 (fr) * | 2020-06-15 | 2021-12-23 | ソニーグループ株式会社 | Dispositif et procédé de traitement d'informations, et programme |
| WO2022044104A1 (fr) * | 2020-08-25 | 2022-03-03 | Nec Corporation | Appareil de mise en correspondance d'images, procédé de commande et support de stockage non transitoire lisible par ordinateur |
| CN114663965B (zh) * | 2022-05-24 | 2022-10-21 | 之江实验室 | 一种基于双阶段交替学习的人证比对方法和装置 |
| WO2022243671A1 (fr) * | 2021-05-18 | 2022-11-24 | Calipsa Limited | Apprentissage par transfert par mise à l'échelle inférieure et mise à l'échelle supérieure |
-
2023
- 2023-08-21 WO PCT/JP2023/029987 patent/WO2025041222A1/fr active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005215883A (ja) * | 2004-01-28 | 2005-08-11 | Sony Corp | 画像照合装置、プログラム、および画像照合方法 |
| WO2016019484A1 (fr) * | 2014-08-08 | 2016-02-11 | Xiaoou Tang | Appareil et procédé pour fournir une super-résolution d'une image à basse résolution |
| WO2019230665A1 (fr) * | 2018-06-01 | 2019-12-05 | 日本電信電話株式会社 | Dispositif d'apprentissage, dispositif de recherche, procédé et programme |
| WO2021256091A1 (fr) * | 2020-06-15 | 2021-12-23 | ソニーグループ株式会社 | Dispositif et procédé de traitement d'informations, et programme |
| WO2022044104A1 (fr) * | 2020-08-25 | 2022-03-03 | Nec Corporation | Appareil de mise en correspondance d'images, procédé de commande et support de stockage non transitoire lisible par ordinateur |
| WO2022243671A1 (fr) * | 2021-05-18 | 2022-11-24 | Calipsa Limited | Apprentissage par transfert par mise à l'échelle inférieure et mise à l'échelle supérieure |
| CN114663965B (zh) * | 2022-05-24 | 2022-10-21 | 之江实验室 | 一种基于双阶段交替学习的人证比对方法和装置 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN116188893B (zh) | 基于bev的图像检测模型训练及目标检测方法和装置 | |
| US20200334287A1 (en) | Image retrieval method, image retrieval apparatus, image retrieval device and medium | |
| JP5833507B2 (ja) | 画像処理装置 | |
| CN111814821A (zh) | 深度学习模型的建立方法、样本处理方法及装置 | |
| US12499658B2 (en) | Training apparatus, control method, and non-transitory computer-readable storage medium | |
| US12374079B2 (en) | Image matching apparatus, control method, and non-transitory computer-readable storage medium | |
| CN118674785A (zh) | 方向未对齐条件下的跨视角图像地理定位方法及装置 | |
| US10430459B2 (en) | Server and method for providing city street search service | |
| US20240338927A1 (en) | Image matching apparatus, control method, and non-transitory computer-readable storage medium | |
| JP7716313B2 (ja) | 情報処理方法、プログラム及び情報処理装置 | |
| WO2022034678A1 (fr) | Appareil d'augmentation d'image, procédé de commande, et support de stockage non transitoire lisible par ordinateur | |
| WO2025041222A1 (fr) | Appareil de mise en correspondance d'images, procédé de mise en correspondance d'images, appareil d'entraînement, procédé d'entraînement et support non transitoire lisible par ordinateur | |
| WO2022201545A1 (fr) | Appareil de mise en correspondance d'images, procédé de commande et support de stockage non transitoire lisible par ordinateur | |
| US20250139939A1 (en) | Image matching apparatus, image matching method, and non-transitory computer-readable storage medium | |
| WO2023132040A1 (fr) | Appareil de localisation d'action, procédé de commande et support de stockage lisible par ordinateur non transitoire | |
| US12536680B2 (en) | Training apparatus, control method, and non-transitory computer-readable storage medium | |
| WO2025142231A1 (fr) | Appareil d'entraînement, procédé d'entraînement et support lisible par ordinateur non transitoire | |
| WO2024042669A1 (fr) | Appareil d'entraînement, procédé d'entraînement et support de stockage lisible par ordinateur non transitoire | |
| WO2026048594A1 (fr) | Appareil d'entraînement, procédé d'entraînement, appareil de mise en correspondance de données, procédé de mise en correspondance de données et support de stockage | |
| CN113535996B (zh) | 一种基于航拍图像的道路图像数据集制备方法及装置 | |
| CN119648610A (zh) | 一种图像质量评估方法、装置、可读存储介质及终端设备 | |
| CN121117250A (zh) | 车辆定位方法、装置、终端、存储介质及车辆 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23949683 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |