WO2024127986A1 - 音声処理システム、音声処理方法、及びプログラム - Google Patents
音声処理システム、音声処理方法、及びプログラム Download PDFInfo
- Publication number
- WO2024127986A1 WO2024127986A1 PCT/JP2023/042673 JP2023042673W WO2024127986A1 WO 2024127986 A1 WO2024127986 A1 WO 2024127986A1 JP 2023042673 W JP2023042673 W JP 2023042673W WO 2024127986 A1 WO2024127986 A1 WO 2024127986A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- audio signal
- voice
- audio
- condition
- processor
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/06—Decision making techniques; Pattern matching strategies
- G10L17/14—Use of phonemic categorisation or speech recognition prior to speaker recognition or verification
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0264—Noise filtering characterised by the type of parameter measurement, e.g. correlation techniques, zero crossing techniques or predictive techniques
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers
- H04R3/02—Circuits for transducers for preventing acoustic reaction, i.e. acoustic oscillatory feedback
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
Definitions
- This disclosure relates to an audio processing system for processing audio emitted by a speaker.
- Patent Document 1 discloses a voice communication terminal.
- This voice communication terminal is a device that controls the audio output of at least one of multiple terminals participating in a multipoint voice communication system, and has a voice placement unit and a party management unit.
- the voice placement unit sets the sound source placement when audio from other terminals is output.
- the party management unit detects a speaker and his/her partner from among the multiple terminals, and detects a conversation group based on the detected combination of speaker and party.
- the voice placement unit changes the sound source placement settings in response to changes in the detected conversation group.
- This disclosure provides a voice processing system etc. that does not impair the comfort of conversation even in an environment where multiple users are present at the same location.
- the audio processing system includes a first input interface, a second input interface, and a signal processing circuit.
- the first input interface acquires a first audio signal via a communication line.
- the second input interface acquires a second audio signal based on audio picked up by a microphone.
- the signal processing circuit outputs an output audio signal based on the first audio signal and the second audio signal to a speaker.
- the signal processing circuit includes in the output audio signal a signal in which components corresponding to the first audio signal are reduced.
- a first voice signal is acquired via a communication line.
- a second voice signal based on a voice picked up by a microphone is acquired.
- a signal in which the components corresponding to the first voice signal are reduced is included in an output voice signal and output to a speaker.
- a program according to one aspect of the present disclosure causes one or more processors to execute the audio processing method.
- the voice processing system and the like disclosed herein has the advantage that the comfort of conversation is less likely to be compromised even in an environment where both offline and online conversations are mixed.
- FIG. 1 is a diagram illustrating a problem in communication using a conference system.
- FIG. 2 is a block diagram showing an example of an overall configuration including a voice processing system according to an embodiment.
- FIG. 3 is a diagram illustrating a first determination operation for determining the clarity of the second audio signal.
- FIG. 4 is an explanatory diagram of the second determination operation for determining the clarity of the second audio signal.
- FIG. 5 is a flowchart showing an example of the operation of the voice processing system according to the embodiment.
- FIG. 6 is a flowchart showing an example of calculation of parameters necessary for determining the clarity of the second audio signal.
- FIG. 7 is a flowchart showing an example of calculation of parameters necessary for determining speech identity.
- FIG. 8 is a diagram illustrating an outline of an operation example of the voice processing system according to the embodiment.
- FIG. 9 is a diagram illustrating advantages of the voice processing system according to the embodiment.
- FIG. 1 is an explanatory diagram of the problem of communication using a conference system.
- the conference system 100 is a server provided by the conference system via the above-mentioned MCU or a Web conference service.
- two users U1 and U2 at the first location A1, a user U3 at the second location A2, and a user U4 at the third location A3 are holding an online conference using the conference system 100.
- Each of the users U1 to U4 can hear the voices of the other users by outputting the voice based on the voice signal transmitted via the conference system 100 from the speaker.
- the user U1 says "Hello”
- the other users U2, U3, and U4 can hear the voice of the user U1 saying "Hello” by outputting the voice based on the voice signal transmitted via the conference system 100 from the speaker.
- the user at that location will hear both the direct voice from the other users at that location and the voice via the conference system 100, which makes it difficult for them to hear the voices made by the other users.
- the voice from the other users at that location via the conference system 100 reaches the user's ears with a delay from the direct voice from the other users. This causes a problem that at the time when a user is about to hear the direct voice from another user and make a statement, the voice from the other users via the conference system 100 reaches the user's ears, disrupting the user's speech and making it difficult for the user to speak.
- there is a problem that the comfort of conversation is easily compromised.
- each figure is a schematic diagram and is not necessarily a precise illustration.
- the same reference numerals are used for substantially the same configurations, and duplicate explanations may be omitted or simplified.
- Fig. 2 is a block diagram showing an overall configuration including a voice processing system according to an embodiment.
- the voice processing system 1 is a system for outputting a voice based on a voice signal from a speaker 3 when the voice signal is acquired from outside.
- the voice processing system 1 is realized by a voice communication device 4.
- the voice communication device 4 can communicate with the conference system 100 via a network such as the Internet.
- the voice communication device 4 may also communicate with the conference system 100 via a LAN (Local Area Network).
- LAN Local Area Network
- the voice communication device 4 is a device worn on the user's head or neck, and can be divided into a closed type voice communication device, an open type voice communication device, and a voice communication device switchable between the closed type and the open type.
- the closed type voice communication device is a device that covers the user's ear hole (eardrum), and includes, for example, an earphone type headset or a headphone type headset.
- the open type voice communication device is a device that does not cover the user's ear hole, and includes, for example, a neck speaker or a goggle type wearable device for XR.
- the voice communication device switchable between the closed type and the open type is a device that can switch between a function that covers the user's ear hole and a function that does not cover the user's ear hole, and includes, for example, an earphone type headset or a headphone type headset that can be switched by opening and closing a plate of the housing part.
- the voice communication device 4 may be configured such that the main body part that performs voice processing, etc. and the headset part including the microphone and speaker are integrated, or each of them may be configured separately.
- the voice processing system 1 can be applied to any of a closed type voice communication device, an open type voice communication device, and a voice communication device that can be switched between a closed type and an open type.
- the voice communication device 4 will be described as a closed type voice communication device.
- the conference system 100 is, for example, a conference system via an MCU, or a server provided by a Web conference service.
- the conference system 100 receives an audio signal output from a voice communication device 4 worn by a user, the conference system 100 performs an appropriate correction process on the received audio signal, and then transmits the corrected audio signal to one or more voice communication devices 4 worn by one or more other users.
- the correction process may include, for example, a noise suppression process for reducing noise contained in the received audio signal.
- the correction process may also include, for example, a frequency correction process for emphasizing the human audible frequency range in the received audio signal. Note that the conference system 100 does not have to perform a correction process on the received audio signal.
- the voice communication device 4 includes a microphone 2, a first input interface (hereinafter, referred to as "first input I/F (Interface)") 10, a second input interface (hereinafter, referred to as "second input I/F”) 11, a processor 12, a memory 13, and a speaker 3.
- first input I/F Interface
- second input I/F second input interface
- the microphone 2 is a sound collection device that acquires sound around the voice communication device 4 and outputs a second sound signal Sig2 based on the acquired sound.
- the microphone 2 is a condenser microphone, a dynamic microphone, a MEMS (Micro Electro Mechanical Systems) microphone, or the like, but is not limited thereto.
- the microphone may be omnidirectional or directional.
- the speaker 3 outputs audio based on the output audio signal Sig3 output from the processor 12.
- the speaker 3 is a speaker that emits sound waves toward the ear canal of a user wearing the voice communication device 4, but may also be, for example, a bone conduction speaker.
- the first input I/F 10 is, for example, a wireless communication interface, and receives the first audio signal Sig1 transmitted from the conference system 100 by communicating with the conference system 100 via a network based on a wireless communication standard such as Wi-Fi (registered trademark). In other words, the first input I/F 10 acquires the first audio signal Sig1 via a communication line.
- the first audio signal Sig1 is an audio signal that is mainly based on the audio uttered by another user.
- the first input I/F 10 outputs the acquired first audio signal Sig1 to the processor 12.
- the second input I/F 11 is an interface that receives the second audio signal Sig2 output from the microphone 2. In other words, the second input I/F 11 acquires the second audio signal Sig2 based on the sound picked up by the microphone 2. The second input I/F 11 outputs the acquired second audio signal Sig2 to the processor 12.
- the processor 12 is, for example, a CPU (Central Processing Unit) or a DSP (Digital Signal Processor).
- the processor 12 performs information processing to output to the speaker 3 an output audio signal Sig3 based on a first audio signal Sig1 acquired by the first input I/F 10 and a second audio signal Sig2 acquired by the second input I/F 11.
- the above-mentioned information processing is realized by the processor 12 executing a computer program stored in the memory 13.
- the processor 12 is an example of a signal processing circuit of the audio processing system 1.
- the processor 12 includes, as functional components, a clarity calculation unit 121, a clarity judgment unit 122, a first feature calculation unit 123, a second feature calculation unit 124, a speech identity judgment unit 125, an output voice judgment unit 126, an output voice control unit 127, an external sound capture switching unit 128, and an ANC (Active Noise Cancelling) control unit 129.
- a clarity calculation unit 121 a clarity judgment unit 122, a first feature calculation unit 123, a second feature calculation unit 124, a speech identity judgment unit 125, an output voice judgment unit 126, an output voice control unit 127, an external sound capture switching unit 128, and an ANC (Active Noise Cancelling) control unit 129.
- ANC Active Noise Cancelling
- the clarity calculation unit 121 calculates the feature amount of the second audio signal Sig2 used when the clarity judgment unit 122 judges whether the second audio signal Sig2 is clear or not.
- the second audio signal Sig2 being clear means that the SNR (Signal to Noise Ratio) of the frequency band (hereinafter referred to as the "audio band") corresponding to human voice in the second audio signal Sig2 is higher than a threshold value and the characteristics of the human voice are clear.
- the second audio signal Sig2 being clear means that when a person listens to the audio based on the second audio signal Sig2 output from the speaker 3, the person can understand the content.
- the clarity calculation unit 121 calculates the SNR and the spectral envelope of the second audio signal Sig2 as the feature of the second audio signal Sig2. Specifically, the clarity calculation unit 121 performs appropriate signal processing on the second audio signal Sig2 to calculate the spectral contrast of the second audio signal Sig2, and calculates the SNR of the voice band in the second audio signal Sig2 based on the calculated spectral contrast. The clarity calculation unit 121 also calculates the MFCC (Mel-Frequency Cepstral Coefficient) of the second audio signal Sig2.
- MFCC Mel-Frequency Cepstral Coefficient
- the MFCC is a cepstrum coefficient used as a feature in voice recognition, etc., and is obtained by converting the power spectrum compressed using a Mel filter bank into a logarithmic power spectrum and applying an inverse discrete cosine transform to the logarithmic power spectrum.
- the MFCC corresponds to the spectral envelope.
- the clarity judgment unit 122 judges whether or not the second audio signal Sig2 satisfies the second condition that the second audio signal Sig2 is clear, using the feature amount of the second audio signal Sig2 calculated by the clarity calculation unit 121.
- the judgment operation by the clarity judgment unit 122 will be described in detail in [2-3. Clarity judgment] below.
- the first feature calculation unit 123 calculates the feature of the first audio signal Sig1, which is used when the speech identity determination unit 125 determines whether the first audio signal Sig1 and the second audio signal Sig2 are both audio signals based on the voice of the same person.
- the first feature calculation unit 123 calculates the fundamental frequency of the first audio signal Sig1 and the spectral envelope of the first audio signal Sig1 as the feature of the first audio signal Sig1.
- the first feature calculation unit 123 calculates the cepstrum of the first audio signal Sig1 and calculates the fundamental frequency of the first audio signal Sig1 from the calculated cepstrum.
- the cepstrum is obtained by applying a Fourier transform to calculate the power spectrum of the first audio signal Sig1, converting the calculated power spectrum into a logarithmic power spectrum, and further applying a Fourier transform to the logarithmic power spectrum.
- the first feature calculation unit 123 also calculates the MFCC of the first audio signal Sig1 to calculate the spectral envelope. In addition, the first feature calculation unit 123 calculates the timing at which a vowel appears in the first audio signal Sig1 from the calculated spectral envelope.
- the second feature calculation unit 124 calculates the feature of the second audio signal Sig2, which is used when the speech identity determination unit 125 determines whether the first audio signal Sig1 and the second audio signal Sig2 are audio signals based on the voice of the same person.
- the second feature calculation unit 124 calculates the fundamental frequency of the second audio signal Sig2 and the spectral envelope of the second audio signal Sig2 as the feature of the second audio signal Sig2.
- the second feature calculation unit 124 calculates the cepstrum of the second audio signal Sig2 and calculates the fundamental frequency of the second audio signal Sig2 from the calculated cepstrum.
- the second feature calculation unit 124 also calculates the spectral envelope by calculating the MFCC of the second audio signal Sig2.
- the second feature calculation unit 124 also calculates the timing at which a vowel appears in the second audio signal Sig2 from the calculated spectral envelope.
- the spectral envelope of the second audio signal Sig2 needs to be calculated by only one of the clarity calculation unit 121 and the second feature calculation unit 124.
- the spectral envelope of the second audio signal Sig2 is described as being calculated by the second feature calculation unit 124. Therefore, the clarity calculation unit 121 does not need to calculate the spectral envelope of the second audio signal Sig2.
- the spectral envelope of the second audio signal Sig2 is calculated by only one of the clarity calculation unit 121 and the second feature calculation unit 124, the calculated spectral envelope is shared with the other one.
- the speech identity determination unit 125 uses the feature of the first speech signal Sig1 calculated by the first feature calculation unit 123 and the feature of the second speech signal Sig2 calculated by the second feature calculation unit 124 to determine whether or not the first condition is satisfied, that the first speech signal Sig1 and the second speech signal Sig2 both contain speech signals based on the speech of the same person. In the embodiment, the speech identity determination unit 125 determines that the first condition is satisfied if (i) the fundamental frequency of the first speech signal Sig1 and the fundamental frequency of the second speech signal Sig2 are the same, and (ii) the timing and type of vowels appearing in the first speech signal Sig1 and the timing and type of vowels appearing in the second speech signal Sig2 are the same. On the other hand, the speech identity determination unit 125 determines that the first condition is not satisfied if at least one of the above (i) and (ii) is not satisfied.
- the timing at which a vowel appears in each audio signal can be detected from the spectral envelope of each audio signal.
- the first audio signal Sig1 is acquired by the first input I/F 10 with a delay compared to the second audio signal Sig2, since it passes through a communication line. For this reason, the speech identity determination unit 125 makes a determination regarding (ii) taking the above-mentioned delay into account.
- the processor 12 determines whether or not the first condition is satisfied based on the correlation between the components corresponding to vowels in the first audio signal Sig1 and the components corresponding to vowels in the second audio signal Sig2. Specifically, the speech identity determination unit 125 (i) calculates the difference between the fundamental frequency of the first audio signal Sig1 and the fundamental frequency of the second audio signal Sig2, and determines that the first condition is satisfied if the calculated difference is equal to or less than a threshold, and (ii) calculates the difference between the time at which a vowel appears in the first audio signal Sig1 and the time at which a vowel appears in the second audio signal Sig2, and determines that the first condition is satisfied if the calculated difference is equal to or less than a threshold, and the type of vowel that appears in the first audio signal Sig1 is the same as the type of vowel that appears in the second audio signal Sig2.
- the speech identity determination unit 125 may determine whether or not a pattern in which vowels appear consecutively in the first speech signal Sig1 is the same as a pattern in which vowels appear consecutively in the second speech signal Sig2. In this case, the speech identity determination unit 125 does not need to take the above-mentioned delay into consideration.
- a method can be considered in which, based on the similarity between the waveforms of the first audio signal Sig1 and the second audio signal Sig2, it is determined that if the waveform similarity is equal to or greater than a threshold, the first condition is met, and if the waveform similarity is less than the threshold, the first condition is not met.
- the "waveform” here refers to the waveform of the signal amplitude, that is, the waveform of the sound pressure level.
- the first audio signal Sig1 is an audio signal that has been corrected in the conference system 100, and therefore the waveforms of the first audio signal Sig1 and the second audio signal Sig2 differ. For this reason, the speech identity determination unit 125 determines whether or not the first condition is met using a method other than the method based on the waveform similarity, as described above.
- the speech identity determination unit 125 may determine whether or not the first condition is satisfied based on the similarity of the waveforms. For example, the speech identity determination unit 125 may determine whether or not the first condition is satisfied based on whether the change in the sound pressure level of the first audio signal Sig1 and the change in the sound pressure level of the second audio signal Sig2 generally match, in other words, based on the correlation between the amplitude envelope of the first audio signal Sig1 and the amplitude envelope of the second audio signal Sig2.
- the output voice determination unit 126 determines whether the situation is the first situation or the second situation based on the determination result of whether the second condition is satisfied by the clarity determination unit 122 and the determination result of whether the first condition is satisfied by the speech identity determination unit 125.
- the first situation is a situation in which the distance between the user and other users is relatively short and the user can easily directly hear the voices uttered by other users.
- the second situation is a situation other than the first situation.
- the second situation includes, for example, a situation in which the distance between the user and other users is relatively long and the user has difficulty directly hearing the voices uttered by other users.
- the output voice determination unit 126 determines that the situation is the first situation when both the first condition and the second condition are satisfied. On the other hand, the output voice determination unit 126 determines that the situation is the second situation when at least one of the first condition and the second condition is not satisfied.
- the output audio control unit 127 controls the audio signal to be included in the output audio signal Sig3 based on the judgment result of the output audio judgment unit 126. Specifically, when the output audio judgment unit 126 judges that the first situation is present, the output audio control unit 127 controls the volume of the audio based on the first audio signal Sig1 output from the speaker 3 to be lowered.
- "lowering the volume of the audio based on the first audio signal Sig1” refers to making the volume of the audio based on the first audio signal Sig1 lower than the volume of the audio based on the first audio signal Sig1 in the second situation (in other words, the default volume).
- the output audio control unit 127 controls the external sound capture switching unit 128 to turn on the external sound capture function, and controls the ANC control unit 129 to turn off the noise cancellation function.
- the processor 12 turns on the external sound capture function, that is, includes the second audio signal Sig2 in the output audio signal Sig3.
- the second audio signal Sig2 included in the output audio signal Sig3 may be a signal that has been processed by audio processing such as noise reduction processing or equalizing processing.
- the output sound control unit 127 controls the volume of the sound based on the first sound signal Sig1 output from the speaker 3 to the default volume.
- the output sound control unit 127 controls the external sound capture switching unit 128 to turn off the external sound capture function, and controls the ANC control unit 129 to turn on the noise cancellation function.
- the processor 12 includes the first audio signal Sig1 in the output audio signal Sig3 and turns off the external sound capture function, that is, does not include the second audio signal Sig2 in the output audio signal Sig3.
- the first audio signal Sig1 included in the output audio signal Sig3 may be a signal that has been processed by audio processing such as noise reduction processing or equalizing processing.
- Memory 13 is a storage device that stores computer programs executed by processor 12 and information necessary to realize various functions. Memory 13 is realized, for example, by a semiconductor memory. Note that memory 13 may be realized as an internal memory of processor 12, rather than an external memory of processor 12.
- FIG. 3 is an explanatory diagram of the first judgment operation for judging the clarity of the second audio signal Sig2.
- FIG. 3 shows the spectral contrast of the second audio signal Sig2.
- the vertical axis shows the frequency band of the second audio signal Sig2
- the horizontal axis shows time (in seconds).
- light and dark represent high and low SNR, with lighter representing a higher SNR and darker representing a lower SNR.
- the clarity determination unit 122 compares the SNR of the voice band in the second audio signal Sig2 with a threshold value in the voice section (the section surrounded by a rectangular frame in FIG. 3, for example, a section of a few tenths of a second). Then, in the first determination operation, the clarity determination unit 122 determines that the second audio signal Sig2 is clear if the SNR is higher than the threshold value, and determines that the second audio signal Sig2 is not clear if the SNR is lower than the threshold value.
- a threshold value in the voice section the section surrounded by a rectangular frame in FIG. 3, for example, a section of a few tenths of a second.
- the SNR of the voice band in the audio signal can be calculated, for example, as a representative value of the SNR of each frequency band included in the voice band of the audio signal.
- the representative value is, for example, the average value, median value, maximum value, or mode value.
- the SNR of the voice band in the audio signal can also be calculated, for example, as the ratio between the representative value of the SNR of each frequency band included in the voice band and the representative value of the SNR of each frequency band other than the voice band. In the latter case, even if the user's surroundings are relatively noisy due to, for example, a loud operating ventilation fan, and the SNR is relatively high in all frequency bands, the clarity determination unit 122 can easily determine whether the second audio signal Sig2 is clear or not.
- FIG. 3 shows that in the voice section enclosed in a rectangular frame, the SNR of the voice band in the second voice signal Sig2 (the band indicated by the arrow in (a) in FIG. 3) is lower than the threshold value. Therefore, in the example shown in (a) in FIG. 3, the clarity judgment unit 122 judges that the second voice signal Sig2 is not clear in the first judgment operation.
- FIG. 3(b) shows that in the voice section enclosed in the rectangular frame, the SNR of the voice band in the second voice signal Sig2 (the band indicated by the arrow in FIG. 3(b)) is higher than the threshold value. Therefore, in the example shown in FIG. 3(b), the clarity determination unit 122 determines that the second voice signal Sig2 is clear in the first determination operation.
- FIG. 4 is an explanatory diagram of the second judgment operation for judging the clarity of the second audio signal Sig2.
- FIG. 4 shows the spectrum of the second audio signal Sig2 in the above-mentioned audio section.
- the vertical axis shows the amplitude value of the second audio signal Sig2
- the horizontal axis shows the frequency of the second audio signal Sig2.
- the solid line L1 shows the spectral envelope
- the dashed line shows the tendency of the spectral envelope.
- the clarity determination unit 122 calculates the kurtosis of the spectral envelope in each of the first frequency band B1, the second frequency band B2, and the third frequency band B3 in the speech section, and compares the calculated kurtosis with a threshold value. In the second determination operation, the clarity determination unit 122 determines that the second audio signal Sig2 is clear if the kurtosis is higher than the threshold value in any of the frequency bands B1, B2, and B3, and determines that the second audio signal Sig2 is not clear if the kurtosis is lower than the threshold value in at least one frequency band.
- the first frequency band B1 is a frequency band corresponding to the first formant of a vowel in human speech.
- the second frequency band B2 is a frequency band corresponding to the second formant of a vowel in human speech.
- the third frequency band B3 is a frequency band corresponding to the second and subsequent formants of a vowel in human speech.
- each of the frequency bands B1 to B3 is a frequency band that corresponds to the formants of vowels in Japanese. Therefore, when determining whether the second speech signal Sig2 is clear for a language other than Japanese, such as English, the clarity determination unit 122 can calculate the kurtosis of the spectral envelope in each of one or more frequency bands that correspond to the formants of vowels in that language, and compare the calculated kurtosis with a threshold value.
- Kurtosis is an index that expresses the sharpness of the probability density function or frequency distribution of a random variable. The higher the kurtosis, the sharper the peak and the longer, thicker the tails of the distribution compared to a normal distribution (in other words, the sharper the change around the peak of the spectral envelope), and the lower the kurtosis, the rounder the peak and the shorter, thinner the tails of the distribution compared to a normal distribution (in other words, the more gradual the change in the spectral envelope).
- the clarity judgment unit 122 judges that the characteristics of vowels in human voice are prominent, that is, the human voice is clear enough that the vowels can be heard.
- Both (a) and (b) of FIG. 4 show the case where a person utters the vowel "o" during a speech section.
- (a) of FIG. 4 shows that the spectral envelope is gentle in each of the frequency bands B1 to B3, as shown by the solid line L1 and the dashed dotted line, that is, the kurtosis is lower than the threshold value in each of the frequency bands B1 to B3.
- the clarity judgment unit 122 judges that the second speech signal Sig2 is not clear in the second judgment operation.
- FIG. 4(b) As shown by the solid line and the dashed-dotted line, peaks appear in the spectral envelope in each of the frequency bands B1 to B3, and the changes around the peaks are steep; in other words, the kurtosis is higher than the threshold in each of the frequency bands B1 to B3. For this reason, in the example shown in FIG. 4(b), the clarity determination unit 122 determines that the second audio signal Sig2 is clear in the second determination operation.
- the processor 12 determines whether or not the second condition is met based on at least the components corresponding to vowels in the second audio signal Sig2.
- the clarity judgment unit 122 executes both the first judgment operation and the second judgment operation, but is not limited to this, and may, for example, judge whether the second condition is satisfied by only the second judgment operation. However, considering the influence of background noise such as reverberation in a space, the clarity judgment unit 122 can more accurately judge the clarity of the second audio signal Sig2 by executing both the first judgment operation and the second judgment operation.
- FIG. 5 shows the operation of the voice processing system 1 according to the embodiment. 1 is a flowchart illustrating an example.
- the processor 12 stores the acquired second audio signal Sig2 in a buffer.
- the "second audio signal Sig2" corresponds to the second audio signal Sig2 stored in the buffer.
- the processor 12 calculates and updates the delay time (S103). Specifically, the processor 12 calculates the delay time by calculating the difference between the time when the first input I/F 10 acquires the first audio signal Sig1 and the time when the second input I/F 11 acquires the second audio signal Sig2, and updates the previous delay time to the calculated delay time. Note that if the calculated delay time is the same as the previous delay time, the processor 12 does not update it.
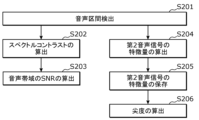
- Step S105 the processor 12 calculates parameters necessary for determining the clarity of the second audio signal Sig2 based on the second audio signal Sig2 (S105). Step S105 will be described in detail below with reference to FIG. 6.
- FIG. 6 is a flowchart showing an example of calculation of parameters necessary for determining the clarity of the second audio signal Sig2.
- the processor 12 detects the voice section of the second audio signal Sig2 (S201). For example, the processor 12 detects the voice section starting from a point when a predetermined time has elapsed from the start of the second audio signal Sig2.
- the voice section is, for example, a section of a few tenths of a second.
- the processor 12 calculates the kurtosis of the spectral envelope of the second speech signal Sig2 in the detected speech section (S206). Specifically, the processor 12 calculates the kurtosis of the spectral envelope in each of the first frequency band B1, the second frequency band B2, and the third frequency band B3 in the detected speech section.
- the processor 12 judges the clarity of the second audio signal Sig2 (S106). Specifically, the processor 12 executes a first judgment operation in which the SNR of the audio band of the second audio signal Sig2 is compared with a threshold value in the detected audio section. The processor 12 also executes a second judgment operation in which the kurtosis of the spectral envelope of each of the frequency bands B1 to B3 is compared with a threshold value in the detected audio section. If the processor 12 judges that the second audio signal Sig2 is clear in both the first judgment operation and the second judgment operation, the processor 12 judges that the second audio signal Sig2 is clear, that is, that the second condition is satisfied.
- the processor 12 judges that the second audio signal Sig2 is not clear in at least one of the first judgment operation and the second judgment operation, the processor 12 judges that the second audio signal Sig2 is not clear, that is, that the second condition is not satisfied.
- Step S107 will be described in detail below with reference to FIG. 7.
- FIG. 7 is a flowchart showing an example of calculation of parameters necessary for determining speech identity.
- the processor 12 detects a voice section of the first audio signal Sig1 (S301). For example, the processor 12 detects a voice section starting from a point when a predetermined time has elapsed from the start of the first audio signal Sig1. The detected voice section is the same section as the voice section of the second audio signal Sig2.
- the processor 12 reads the features of the second audio signal Sig2 stored in the memory 13 (S302).
- the processor 12 also calculates the features of the first audio signal Sig1 in the detected audio section (S303), either in parallel with step S302 or before or after step S302.
- the processor 12 calculates the fundamental frequency of the first audio signal Sig1 and the spectral envelope of the first audio signal Sig1 as the features of the first audio signal Sig1.
- the processor 12 determines whether the speech is identical (S108). Specifically, if (i) the fundamental frequency of the first audio signal Sig1 is the same as the fundamental frequency of the second audio signal Sig2, and (ii) the timing at which a vowel appears in the first audio signal Sig1 is the same as the timing at which a vowel appears in the second audio signal Sig2, the processor 12 determines that the speakers are the same, that is, that the first condition is satisfied. On the other hand, if at least one of (i) and (ii) above is not satisfied, the processor 12 determines that the speakers are not the same, that is, that the first condition is not satisfied. Note that here, the processor 12 determines that the two comparison targets are the same if the difference between the two comparison targets is equal to or less than a threshold value.
- both the first and second conditions are satisfied, so the processor 12 determines that the first situation is present and reduces the volume of the voice (i.e., the communication voice) based on the first audio signal Sig1 output from the speaker 3 (S109).
- the processor 12 also turns off the noise cancellation function (S110) and turns on the external sound capture function (S111). Note that the order in which steps S109 to S111 are executed is not limited to this order.
- the processor 12 determines that the second situation exists. Then, the processor 12 sets the volume of the communication voice to the default volume (S112). The processor 12 also turns on the noise cancellation function (S113) and turns off the external sound capture function (S114). Note that the order in which steps S112 to S114 are executed is not limited to this order.
- Steps S112 to S114 are also executed when the second input I/F 11 has not acquired the second audio signal Sig2 (S101: No) or when the first input I/F 10 has not acquired the first audio signal Sig1 (S102: No).
- the processor 12 repeats the above series of processes until the call ends (S115: No). On the other hand, when the call ends (S115: Yes), the processor 12 ends its operation.
- FIG. 8 is an explanatory diagram of an overview of an example of the operation of the voice processing system 1 according to the embodiment.
- FIG. 8 shows a series of operations of the voice communication device 4 (voice processing system 1) worn by user U1 when two users U1 and U2 are present at the same location.
- the microphone 2 converts the voice into a second voice signal Sig2, and the second input I/F 11 acquires the second voice signal Sig2.
- the processor 12 detects a voice section, and calculates the fundamental frequency and MFCC (spectral envelope) of the second voice signal Sig2, which are the feature quantities of the second voice signal Sig2, in the detected voice section.
- the processor 12 also stores the calculated fundamental frequency and MFCC of the second voice signal Sig2 in the memory 13.
- the voice V2 uttered by the other user U2 is also transmitted to the conference system 100 as the first voice signal Sig1.
- the processor 12 calculates the SNR of the voice band of the second audio signal Sig2 in the detected voice section and the kurtosis of the spectral envelope. The processor 12 then uses the calculated SNR of the voice band and the kurtosis of the spectral envelope of the second audio signal Sig2 to determine whether the second audio signal Sig2 is clear, i.e., whether it satisfies the second condition.
- the processor 12 detects the voice section of the first audio signal Sig1 and calculates the fundamental frequency and MFCC (spectral envelope) of the first audio signal Sig1, which are the feature quantities of the first audio signal Sig1, in the detected voice section.
- the processor 12 then reads the fundamental frequency and MFCC of the second audio signal Sig2 from the memory 13 and compares them with the fundamental frequency and MFCC of the first audio signal Sig1 to determine whether the speakers are the same, i.e., whether the first condition is satisfied.
- the processor 12 When both the first and second conditions are satisfied, that is, when it is determined that the first situation exists, the processor 12 lowers the volume of the communication voice (voice based on the first audio signal Sig1) output from the speaker 3, or does not play the communication voice from the speaker 3, as shown in (d) of FIG. 8.
- the processor 12 also turns off the noise cancellation function and turns on the external sound capture function. This allows the user U1 to mainly hear the direct and clear voice from the other user U2, without hearing much of the voice V2 emitted by the other user U2 via the conference system 100.
- the processor 12 when at least one of the first and second conditions is not satisfied, that is, when it is determined that the second situation exists, the processor 12 outputs the communication voice (voice based on the first voice signal Sig1) from the speaker 3, as shown in (e) of FIG. 8.
- the processor 12 also turns on the noise cancellation function and turns off the external sound capture function. This allows the user U1 to mainly hear the voice V2 emitted by the other user U2 via the conference system 100, without hearing much of the direct voice from the other user U2 and unclear voice.
- Fig. 9 is an explanatory diagram of the advantages of the speech processing system 1 according to the embodiment.
- Fig. 9 shows that two users U1 and U2 at a first location A1, a user U3 at a second location A2, and a user U4 at a third location A3 are holding an online conference using a conference system 100.
- FIG. 9 shows a situation where two users U1 and U2 at a first location A1 are located relatively close to each other, and user U1 can easily directly hear the voice V2 saying "Hello" spoken by the other user U2.
- the voice communication device 4 worn by user U1 determines that both the first and second conditions are satisfied, i.e., that the first situation is being met, and includes in the output voice signal Sig3 a signal in which the components corresponding to the first voice signal Sig1 have been reduced.
- the voice processing system 1 does not include the first voice signal Sig1 in the output voice signal Sig3, i.e., does not play voice based on the first voice signal Sig1 from the speaker 3.
- the voice processing system 1 has the advantage that the comfort of conversation is less likely to be compromised even in an environment where multiple users exist at the same location.
- the voice processing system 1 determines that the user is in the first situation, it turns on the external sound capture function, i.e., includes the second voice signal Sig2 in the output voice signal Sig3.
- This has the advantage that by capturing the voices around the user U1, it becomes easier to hear the direct voice of the other user U2.
- FIG. 9 shows a situation where two users U1 and U2 at the first location A1 are located relatively far away from each other, making it difficult for user U1 to directly hear the voice V2 saying "hello" uttered by the other user U2.
- the voice communication device 4 (voice processing system 1) worn by user U1 determines that at least the second condition is not satisfied, i.e., that the situation is the second situation, and includes the first voice signal Sig1 in the output voice signal Sig3, and does not include the second voice signal Sig2 in the output voice signal Sig3.
- the voice processing system 1 has the advantage that the comfort of conversation is less likely to be compromised even in an environment where multiple users exist at the same location.
- the voice processing system 1 determines that the second situation exists, it turns on the noise cancellation function, that is, it includes in the output voice signal Sig3 a voice signal that is in the opposite phase to the second voice signal Sig2.
- This has the advantage that by removing the noise around the user U1, including the direct voice from the other user U2, the user U1 can more easily hear the voice from the other user U2 via the conference system 100 (communication line).
- the voice processing system 1 determines that neither the first nor second condition is met, i.e., that the second situation exists. In this case, the speaker 3 outputs voices from the other users U2 to U4 via the conference system 100. In such a case, the conversation between the users U1 to U4 temporarily stops, so the advantages of the voice processing system 1 are not hindered.
- User U1 who employs the voice processing system 1 only needs to be able to enjoy the above advantages in at least a situation in which the users U1 to U4 speak alternately.
- the processor 12 may not include the external sound capture switching unit 128 and the ANC control unit 129. In this case, the voice processing system 1 may not execute steps S110, S111, S113, and S114 in the flowchart shown in FIG. 5. More specifically, when the voice communication device 4 is an open-type voice communication device, the processor 12 may include the external sound capture switching unit 128 and the ANC control unit 129, but it is not necessary to include them. Note that even when the voice communication device 4 is an open-type voice communication device, the processor 12 may include the ANC control unit 129. In this case, the voice processing system 1 may not execute steps S111 and S114 in the flowchart shown in FIG. 5.
- the processor 12 when the voice communication device 4 is a closed-type voice communication device, it is preferable that the processor 12 includes the external sound capture switching unit 128, but for example, if some external sound leaks out, the processor 12 may not include the external sound capture switching unit 128. Furthermore, if the voice communication device 4 is a closed type voice communication device, it is preferable that the processor 12 is provided with an ANC control unit 129, but if external sound is reduced to a certain extent by blocking the user's ear holes, the processor 12 does not need to be provided with an ANC control unit 129.
- the output sound control unit 127, the external sound capture switching unit 128, and the ANC control unit 129 are always controlled, but they do not need to be controlled for a certain period of time. More specifically, the sound processing system 1 does not need to execute steps S112 to S114 and S109 to S111 in the flowchart shown in FIG. 5 for a certain period of time (e.g., several milliseconds). In this case, the output sound control unit 127, the external sound capture switching unit 128, and the ANC control unit 129 may be controlled at regular intervals to prevent them from being controlled frequently. The time for controlling the output sound control unit 127, the time for controlling the external sound capture switching unit 128, and the time for controlling the ANC control unit 129 do not need to be the same.
- the voice processing system 1 is realized by a single device (voice call device 4), but it may be realized by multiple devices.
- the functional components of the voice processing system 1 may be distributed in any way among the multiple devices.
- the voice processing system 1 may be realized by a server including a first input I/F 10, a second input I/F 11, and a processor 12.
- the voice processing system 1 can acquire the second audio signal Sig2 from the microphone 2 and output audio based on the output audio signal Sig3 from the speaker 3 by communicating with a device including the microphone 2 and speaker 3.
- the method of communication between the devices in the above embodiment is not particularly limited.
- a relay device (not shown) may be interposed between the two devices.
- the order of the processes described in the above embodiment is just an example.
- the order of multiple processes may be changed, and multiple processes may be executed in parallel.
- a process executed by a specific processing unit may be executed by another processing unit.
- part of the digital signal processing described in the above embodiment may be realized by analog signal processing.
- each component may be realized by executing a software program suitable for each component.
- Each component may be realized by a program execution unit such as a CPU or processor reading and executing a software program recorded on a recording medium such as a hard disk or semiconductor memory.
- each component may be realized by hardware.
- each component may be a circuit (or an integrated circuit). These circuits may form a single circuit as a whole, or each may be a separate circuit. Furthermore, each of these circuits may be a general-purpose circuit, or a dedicated circuit.
- the general or specific aspects of the present disclosure may be realized as a system, an apparatus, a method, an integrated circuit, a computer program, or a computer-readable recording medium such as a CD-ROM. Also, they may be realized as any combination of a system, an apparatus, a method, an integrated circuit, a computer program, and a recording medium.
- the present disclosure may be implemented as a voice processing method executed by a computer, or may be realized as a program for causing a computer to execute such a voice processing method.
- the present disclosure may be realized as a non-transitory computer-readable recording medium on which such a program is recorded.
- the program here includes an application program for causing a general-purpose information terminal to function as the voice processing system of the above-mentioned embodiment.
- this disclosure also includes forms obtained by applying various modifications to each embodiment that a person skilled in the art may conceive, or forms realized by arbitrarily combining the components and functions of each embodiment within the scope of the spirit of this disclosure.
- the voice processing system 1 includes the first input I/F 10, the second input I/F 11, and the processor 12.
- the processor 12 is an example of a signal processing circuit.
- the first input I/F 10 acquires the first voice signal Sig1 via a communication line.
- the second input I/F 11 acquires the second voice signal Sig2 based on the voice picked up by the microphone 2.
- the processor 12 outputs an output voice signal Sig3 based on the first voice signal Sig1 and the second voice signal Sig2 to the speaker 3.
- the processor 12 includes a signal in which the component corresponding to the first voice signal Sig1 is reduced in the output voice signal Sig3.
- the processor 12 in the first aspect, if at least one of the first condition and the second condition is not satisfied, the processor 12 includes the first audio signal Sig1 in the output audio signal Sig3 and does not include the second audio signal Sig2 in the output audio signal Sig3.
- the processor 12 determines whether the first condition is satisfied based on the correlation between the component corresponding to the vowel in the first voice signal Sig1 and the component corresponding to the vowel in the second voice signal Sig2.
- the processor 12 determines whether or not the second condition is satisfied based on the component corresponding to the vowel in the second voice signal Sig2.
- the processor 12 includes the second voice signal Sig2 in the output voice signal Sig3 when both the first condition and the second condition are satisfied.
- the processor 12 further includes an audio signal in the opposite phase to the second audio signal Sig2 in the output audio signal Sig3.
- a first audio signal Sig1 is acquired via a communication line (S102: Yes)
- a second audio signal Sig2 based on audio picked up by the microphone 2 is acquired (S101: Yes)
- both the first condition that the first audio signal Sig1 and the second audio signal Sig2 both contain audio signals based on audio produced by the same person and the second condition that the second audio signal Sig2 is clear are satisfied (S106: Yes, S108: Yes)
- a signal in which the components corresponding to the first audio signal Sig1 have been reduced is included in the output audio signal Sig3 and output to the speaker 3 (S109).
- the program according to the eighth aspect also causes one or more processors to execute the audio processing method according to the seventh aspect.
- the voice processing system disclosed herein can be applied to systems that process voice emitted by speakers.
- Audio processing system 10 First input I/F 11 Second input I/F REFERENCE SIG NUMBER 12 Processor 121 Clarity calculation unit 122 Clarity judgment unit 123 First feature calculation unit 124 Second feature calculation unit 125 Speech identity judgment unit 126 Output voice judgment unit 127 Output voice control unit 128 External sound capture switching unit 129 ANC control unit 13 Memory 2 Microphone 3 Speaker 100 Conference system Sig1 First voice signal Sig2 Second voice signal Sig3 Output voice signal V1, V2 Voice
Landscapes
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Signal Processing (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Otolaryngology (AREA)
- General Health & Medical Sciences (AREA)
- Business, Economics & Management (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Game Theory and Decision Science (AREA)
- Telephonic Communication Services (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024564262A JPWO2024127986A1 (https=) | 2022-12-12 | 2023-11-29 | |
| CN202380083798.8A CN120303954A (zh) | 2022-12-12 | 2023-11-29 | 语音处理系统、语音处理方法以及程序 |
| EP23903277.4A EP4637182A4 (en) | 2022-12-12 | 2023-11-29 | SPEECH PROCESSING SYSTEM, METHOD AND PROGRAM |
| US19/220,858 US20250285633A1 (en) | 2022-12-12 | 2025-05-28 | Audio processing system, audio processing method, and recording medium |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022-198122 | 2022-12-12 | ||
| JP2022198122 | 2022-12-12 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US19/220,858 Continuation US20250285633A1 (en) | 2022-12-12 | 2025-05-28 | Audio processing system, audio processing method, and recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024127986A1 true WO2024127986A1 (ja) | 2024-06-20 |
Family
ID=91485676
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/042673 Ceased WO2024127986A1 (ja) | 2022-12-12 | 2023-11-29 | 音声処理システム、音声処理方法、及びプログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250285633A1 (https=) |
| EP (1) | EP4637182A4 (https=) |
| JP (1) | JPWO2024127986A1 (https=) |
| CN (1) | CN120303954A (https=) |
| WO (1) | WO2024127986A1 (https=) |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006023758A (ja) * | 2005-08-08 | 2006-01-26 | Yamaha Corp | 発音評価装置 |
| JP2012108587A (ja) | 2010-11-15 | 2012-06-07 | Panasonic Corp | 音声コミュニケーション装置および音声コミュニケーション方法 |
| JP2017028351A (ja) * | 2015-07-15 | 2017-02-02 | 富士通株式会社 | ヘッドセット |
| JP2017045180A (ja) * | 2015-08-25 | 2017-03-02 | 富士ゼロックス株式会社 | プログラム |
| JP2019140517A (ja) * | 2018-02-09 | 2019-08-22 | 富士ゼロックス株式会社 | 情報処理装置及びプログラム |
| JP2021140065A (ja) * | 2020-03-06 | 2021-09-16 | 株式会社バンダイナムコエンターテインメント | 処理システム、音響システム及びプログラム |
| WO2022118671A1 (ja) * | 2020-12-04 | 2022-06-09 | ソニーグループ株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP2022138245A (ja) * | 2021-03-10 | 2022-09-26 | シャープ株式会社 | 音声処理システム及び音声処理方法 |
| JP2022142038A (ja) * | 2021-03-16 | 2022-09-30 | 株式会社コトバデザイン | プログラム、方法、情報処理装置、及びシステム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB201414352D0 (en) * | 2014-08-13 | 2014-09-24 | Microsoft Corp | Reversed echo canceller |
| EP3594802A1 (en) * | 2018-07-09 | 2020-01-15 | Koninklijke Philips N.V. | Audio apparatus, audio distribution system and method of operation therefor |
-
2023
- 2023-11-29 WO PCT/JP2023/042673 patent/WO2024127986A1/ja not_active Ceased
- 2023-11-29 CN CN202380083798.8A patent/CN120303954A/zh active Pending
- 2023-11-29 EP EP23903277.4A patent/EP4637182A4/en active Pending
- 2023-11-29 JP JP2024564262A patent/JPWO2024127986A1/ja active Pending
-
2025
- 2025-05-28 US US19/220,858 patent/US20250285633A1/en active Pending
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006023758A (ja) * | 2005-08-08 | 2006-01-26 | Yamaha Corp | 発音評価装置 |
| JP2012108587A (ja) | 2010-11-15 | 2012-06-07 | Panasonic Corp | 音声コミュニケーション装置および音声コミュニケーション方法 |
| JP2017028351A (ja) * | 2015-07-15 | 2017-02-02 | 富士通株式会社 | ヘッドセット |
| JP2017045180A (ja) * | 2015-08-25 | 2017-03-02 | 富士ゼロックス株式会社 | プログラム |
| JP2019140517A (ja) * | 2018-02-09 | 2019-08-22 | 富士ゼロックス株式会社 | 情報処理装置及びプログラム |
| JP2021140065A (ja) * | 2020-03-06 | 2021-09-16 | 株式会社バンダイナムコエンターテインメント | 処理システム、音響システム及びプログラム |
| WO2022118671A1 (ja) * | 2020-12-04 | 2022-06-09 | ソニーグループ株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP2022138245A (ja) * | 2021-03-10 | 2022-09-26 | シャープ株式会社 | 音声処理システム及び音声処理方法 |
| JP2022142038A (ja) * | 2021-03-16 | 2022-09-30 | 株式会社コトバデザイン | プログラム、方法、情報処理装置、及びシステム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4637182A1 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN120303954A (zh) | 2025-07-11 |
| EP4637182A4 (en) | 2026-04-08 |
| JPWO2024127986A1 (https=) | 2024-06-20 |
| EP4637182A1 (en) | 2025-10-22 |
| US20250285633A1 (en) | 2025-09-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111464905A (zh) | 基于智能穿戴设备的听力增强方法、系统和穿戴设备 | |
| US20250024209A1 (en) | Hearing aid determining talkers of interest | |
| US12520080B2 (en) | Audio processing based on target signal-to-noise ratio | |
| JP2012231468A (ja) | 特に「ハンズフリー」電話システム向けの近接音声信号を雑音除去するための手段を有するマイクロホンとイヤホンの組合せ型のオーディオ・ヘッドセット | |
| US9654855B2 (en) | Self-voice occlusion mitigation in headsets | |
| US11265661B1 (en) | Hearing aid comprising a record and replay function | |
| US10204637B2 (en) | Noise reduction methodology for wearable devices employing multitude of sensors | |
| CN111683319A (zh) | 一种通话拾音降噪方法及耳机、存储介质 | |
| US10547956B2 (en) | Method of operating a hearing aid, and hearing aid | |
| JP7532748B2 (ja) | 音響装置および音響処理方法 | |
| CN115398934B (zh) | 再现音频信号时主动抑制闭塞效应的方法、装置、耳机及计算机程序 | |
| WO2024205944A1 (en) | Audio processing based on target signal-to-noise ratio | |
| US20250372119A1 (en) | Capturing and processing audio signals | |
| CN116112839A (zh) | 无线耳机的切换控制方法、系统及无线耳机 | |
| JP7740337B2 (ja) | 音声処理装置及び音声処理方法 | |
| US12520087B2 (en) | Hearing aid comprising an adaptive notification unit | |
| WO2024127986A1 (ja) | 音声処理システム、音声処理方法、及びプログラム | |
| Kąkol et al. | A study on signal processing methods applied to hearing aids | |
| JP7641548B2 (ja) | マイクロホン装置、及び、マイクロホン装置を備えた通話装置 | |
| CN118870277A (zh) | 具有主动降噪的助听方法、头戴式设备和计算机程序产品 | |
| CN119400147A (zh) | 基于侧音的降噪方法、主动降噪耳机和存储介质 | |
| Moore | Hearing Aids: What Works Well and What Can Be Improved | |
| CN121056802A (zh) | 用于运行听力设备的方法 | |
| CN115580678A (zh) | 一种数据处理方法、装置和设备 | |
| JP2025023586A (ja) | マイクロホン装置、及び、マイクロホン装置を備えた通話装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23903277 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024564262 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202380083798.8 Country of ref document: CN |
|
| WWP | Wipo information: published in national office |
Ref document number: 202380083798.8 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023903277 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2023903277 Country of ref document: EP Effective date: 20250714 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2023903277 Country of ref document: EP |