WO2023286340A1 - 情報処理装置および情報処理方法 - Google Patents
情報処理装置および情報処理方法 Download PDFInfo
- Publication number
- WO2023286340A1 WO2023286340A1 PCT/JP2022/010202 JP2022010202W WO2023286340A1 WO 2023286340 A1 WO2023286340 A1 WO 2023286340A1 JP 2022010202 W JP2022010202 W JP 2022010202W WO 2023286340 A1 WO2023286340 A1 WO 2023286340A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- notation
- information processing
- unit
- notations
- variation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/53—Processing of non-Latin text
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/247—Thesauruses; Synonyms
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/274—Converting codes to words; Guess-ahead of partial word inputs
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Definitions
- the present disclosure relates to an information processing device and an information processing method.
- the notation that indicates a single entity varies depending on the character type used by each country. Among them, Japanese is known as a language that is tolerant of notation, and various notation variations are likely to occur. For this reason, even if a user such as an application developer who wants to acquire and utilize notational data indicating a certain entity obtains notational data that is considered applicable from among a wide variety of sources, for example, via the Internet, the necessary notationalization will not be possible. It is not easy to determine precisely whether
- the present disclosure proposes an information processing apparatus and an information processing method that can easily determine notation variations and structure notation data regardless of differences in notation character types and language areas.
- an information processing apparatus when arbitrary two notations to be determined as to whether they are in a spelling variation relationship with each other are input, convert the two notations into A conversion unit that converts into a linguistic unified space representation, and a conversion result by the conversion unit are input, and based on the feature amount related to the spelling variation included in the conversion result, the spelling variation relationship between the two spellings is determined. and a determination unit.
- FIG. 2 is an explanatory diagram (part 1) regarding definitions of terms according to the embodiment of the present disclosure
- FIG. 2 is an explanatory diagram (part 2) regarding definitions of terms according to the embodiment of the present disclosure
- FIG. 3 is an explanatory diagram (part 3) regarding definitions of terms according to the embodiment of the present disclosure
- 1 is a schematic explanatory diagram of an information processing method according to an embodiment of the present disclosure
- FIG. 1 is a block diagram showing a configuration example of an information processing device according to an embodiment of the present disclosure
- FIG. FIG. 10 is a schematic explanatory diagram of a notation variation determination model
- FIG. 4 is a block diagram showing a configuration example of a spelling variation determination model; It is a figure which shows the feature-value which a notation variation determination part uses.
- FIG. 2 is an explanatory diagram (part 1) relating to notation variations of subwords;
- FIG. 11 is an explanatory diagram (part 2) relating to notation variations of subwords;
- FIG. 13 is an explanatory diagram (part 3) regarding spelling variations of subwords;
- FIG. 11 is an explanatory diagram (part 4) regarding spelling variations of subwords;
- FIG. 4 is an explanatory diagram of grouping of notation;
- FIG. 10 is a diagram showing an example of a GUI screen when two entities exist for the same notation;
- FIG. 10 is a diagram showing an example of a GUI screen when two entities exist for the same notation;
- FIG. 10 is a diagram showing an example of a GUI screen when two entities exist for the same notation;
- FIG. 10 is a diagram showing an example of a GUI screen
- FIG. 10 is a diagram showing an example of a UI that allows the threshold to be arbitrarily increased or decreased;
- FIG. 10 is a diagram showing an example of explicitly extracting and displaying a specific notation;
- FIG. 11 is a diagram (part 1) showing an example of editing processing;
- FIG. 12 is a diagram (part 2) showing an example of editing processing;
- FIG. 13 is a diagram (part 3) showing an example of editing processing;
- FIG. 14 is a diagram (part 4) showing an example of editing processing;
- FIG. 12 is a diagram (No. 5) showing an example of editing processing;
- 4 is a flowchart showing a processing procedure executed by an information processing device;
- 1 is a hardware configuration diagram showing an example of a computer that implements functions of an information processing apparatus;
- FIG. 11 is a hardware configuration diagram showing an example of a computer that implements functions of an information processing apparatus;
- FIG. 11 is a hardware configuration diagram showing an example of a computer that implements functions of an information processing apparatus
- FIG. 1 is an explanatory diagram (part 1) regarding definitions of terms according to an embodiment of the present disclosure.
- FIG. 2 is an explanatory diagram (part 2) regarding definitions of terms according to the embodiment of the present disclosure.
- FIG. 3 is an explanatory diagram (part 3) regarding definitions of terms according to the embodiment of the present disclosure.
- FIG. 4 is a schematic explanatory diagram of the information processing method according to the embodiment of the present disclosure.
- notation refers to a list of characters, in other words a string of characters.
- “notation” includes various character types such as kanji, katakana, hiragana, the alphabet, and symbols.
- the “notation” is "Mt. Fuji”, “Michael Jackson”, “Taro Tanaka”, “Beat it”, and the like.
- entity refers to one thing or thing as a concept. As shown in FIG. 2, for example, notations such as “Michael Jackson”, “Michael Jackson”, “MJ”, and “King of Pop” refer to the “entity” of the singer “Michael Jackson”.
- notation variations refer to different notations that refer to the same entity.
- notations such as “Michael Jackson”, “Michael Jackson”, “MJ”, and “King of Pop” shown in FIG.
- notation variation can be broadly classified into two types: “linguistic” notation variation and “notation-specific” notation variation. Embodiments of the present disclosure are primarily targeted at “linguistic” notational variations.
- "Linguistic” spelling variation is a phenomenon that occurs commonly in all specific writings such as katakana, regardless of information unique to the writing (for example, semantic). As shown in Fig. 3, For example, variations due to close pronunciation, typos, abbreviations, and the like.
- notation-specific fluctuations are notation fluctuation events that occur due to the information in the notation itself, such as nicknames, aliases, translations, etc., as shown in Fig. 3.
- Google registered trademark
- Bing registered trademark
- the two notations when arbitrary two notations to be determined as to whether or not there is a relationship of spelling variation with each other are input, the two notations are transformed into a linguistic unified spatial expression.
- the conversion result is used as an input, and the relationship between the two notation variations is determined based on the feature amount related to the notation variation included in the conversion result.
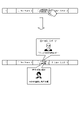
- a GUI (Graphical User Interface) screen as shown in FIG. 4 is provided to the user.
- Such a GUI screen has an input field 51 and an output field 52, as shown in FIG.
- the input field 51 accepts input from the user of a list of spellings that the user wishes to organize about spelling variations (hereinafter referred to as a "wrong list" as appropriate).
- the notation list may be an enumeration of notations for a single entity, or may be an enumeration of notations for a plurality of entities.
- the notation data structured with respect to the notation variation is automatically displayed in the output field 52.
- the information processing method first normalizes the input notation list.
- the normalization referred to here is, for example, the unification of lowercase and uppercase characters, the unification of half-width and full-width characters, and the like.
- notation pairs two notation pairs (hereinafter referred to as "notation pairs") are sequentially created from the notation list. ) is performed.
- each row indicated by a dashed rectangle corresponds to one group, and shows an example in which notations are classified for each character type for each notation type. Details of the structuring process will be described later with reference to FIG. 5 and subsequent drawings.
- notation data structured in this way can be edited manually or automatically, such as correcting or deleting as appropriate. Details of the editing process will be described later with reference to FIG. 17 and subsequent drawings.
- the structured or appropriately modified notation data may be reflected in the notation database 11d (see FIG. 5) or output in an appropriate format.
- Such a mechanism can be implemented so that it operates as a software library. Therefore, for example, it can be incorporated into suitable software as a portable library, or it can be used as a Web API provided by a cloud server. In that case, for example, it is possible to receive structured notation data as an output with a notation list and an arbitrary URL (Uniform Resource Locator) as input.
- a software library for example, it can be incorporated into suitable software as a portable library, or it can be used as a Web API provided by a cloud server. In that case, for example, it is possible to receive structured notation data as an output with a notation list and an arbitrary URL (Uniform Resource Locator) as input.
- URL Uniform Resource Locator
- the two notations are combined into a unified linguistic space.
- the conversion result is used as an input, and the notation variation relationship between the two notation variations is determined based on the feature amount related to the notation variation included in the conversion result.
- FIG. 5 is a diagram showing a configuration example of the information processing device 10 according to the embodiment of the present disclosure. Also, FIG. 6 is a schematic explanatory diagram of the spelling variation determination model 11b. FIG. 7 is a block diagram showing a configuration example of the spelling variation determination model 11b.
- FIGS. 5 to 7 show only the constituent elements necessary for describing the features of the embodiments of the present disclosure, and omit the description of general constituent elements.
- each component illustrated in FIGS. 5 to 7 is functionally conceptual and does not necessarily need to be physically configured as illustrated.
- the specific form of distribution/integration of each block is not limited to the one shown in the figure. It is possible to integrate and configure.
- the information processing device 10 is a computer used by a user who wants to acquire structured notation data about spelling variations.
- the information processing device 10 is realized by, for example, a PC (Personal Computer) such as a desktop type or notebook type, a mobile terminal such as a smartphone, a tablet terminal, a PDA (Personal Digital Assistant), a server, a workstation, or the like. be.
- a PC Personal Computer
- PDA Personal Digital Assistant
- the information processing device 10 includes a storage section 11 and a control section 12 .
- the operation unit 3 and the display unit 5 are connected by wire or wirelessly.
- the operation unit 3 is an operation device that receives operations from the user.
- the operation unit 3 is implemented by, for example, a mouse and a keyboard.
- the display unit 5 is a display device that displays the GUI screen described above with reference to FIG. 4 to the user.
- the display unit 5 is realized by a display or the like. Note that the operation unit 3 and the display unit 5 may be provided integrally by a touch panel display or the like.
- the storage unit 11 is implemented, for example, by a semiconductor memory device such as RAM (Random Access Memory), ROM (Read Only Memory), flash memory, or a storage device such as a hard disk or optical disk.
- a semiconductor memory device such as RAM (Random Access Memory), ROM (Read Only Memory), flash memory, or a storage device such as a hard disk or optical disk.
- the storage unit 11 stores a notation list 11a, a notation variation determination model 11b, structured notation data 11c, and a notation database 11d.
- the notation list 11a is a notation list to be entered in the input field 51 described above.
- the spelling variation determination model 11b is used in the structuring process executed by the structuring processing unit 12b, which will be described later. In the structuring process, the spelling variation determination process for determining the spelling variation relationship for each spelling pair described above is recursively repeated.
- the spelling variation determination model 11b is a model for judging the spelling variation relationship for each spelling pair.
- the spelling variation determination model 11b when the spelling variation determination model 11b receives input of two spellings of a first spelling and a second spelling, it determines whether these two spellings have a spelling variation relationship. Acts as a function that outputs an indicative Boolean value and/or score.
- the structured notation data 11c is notation data structured by the structuring processing unit 12b.
- the notation database 11d is a database in which notation data that is structured or appropriately modified by the user is stored.
- the control unit 12 is a controller. For example, various programs (not shown) stored in the storage unit 11 are executed by a CPU (Central Processing Unit), MPU (Micro Processing Unit), etc., using RAM as a work area. It is realized by being Also, the control unit 12 can be realized by an integrated circuit such as an ASIC (Application Specific Integrated Circuit) or an FPGA (Field Programmable Gate Array).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- the control unit 12 has an acquisition unit 12a, a structuring processing unit 12b, a display control unit 12c, and an editing processing unit 12d, and implements or executes the information processing functions and actions described below.
- the acquisition unit 12a acquires the input content of the user via the operation unit 3. When the user performs an operation of inputting a notation list in the input field 51, the acquisition unit 12a acquires the input notation list and stores it as the notation list 11a.
- the acquisition unit 12a acquires the input editing content and notifies it to the editing processing unit 12d.
- the structuring processing unit 12b executes a structuring process for structuring the spelling variation on the spelling list 11a. Specifically, in the structuring process, the structuring process unit 12b first normalizes the notation list 11a.
- the structuring processing unit 12b can divide the notation into a plurality of tokens. For example, if the notation is "Michael Joseph Jackson", there are three tokens “Michael”, “Joseph”, and “Jackson”. Also, for example, if the notation is "Taro Tanaka", the two tokens are “Tanaka” and "Taro”.
- the structuring processing unit 12b divides the first notation and the second notation into tokens, changes the order of one notation, and uses the notation variation determination model 11b to determine the notation variation for each of the other notation and each token. judge.
- the spelling variation determination model 11b includes a conversion unit 11ba and a spelling variation determination unit 11bb.
- the conversion unit 11ba converts the first notation and the second notation into a linguistic unified spatial representation.
- the conversion unit 11ba uses, for example, a series conversion model learned in advance.
- the conversion unit 11ba unifies the notation into the katakana space.
- conversion may be performed to a unified space representation using another character type, or conversion to an embedding space (latent space) representation by deep learning may be performed.
- the first notation and the second notation are each extended to N-best.
- the conversion unit 11ba converts from Latin to katakana
- the appropriate top N characters are used as the conversion result.
- N ⁇ N comparison is necessary, but if a sufficiently high score is observed on the way, the calculation may be stopped there. , N ⁇ N, a weighted average of the N-best ranks may be calculated.
- the spelling variation determination unit 11bb receives the list of unified spatial representations of the first notation and the second notation as input, and calculates the probability of spelling variation determination.
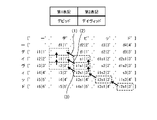
- the spelling variation determination unit 11bb uses, for example, the feature values shown in FIG. FIG. 8 is a diagram showing feature amounts used by the spelling variation determination unit 11bb.
- the feature amounts include “edit distance”, “first notation length”, “second notation length”, “subword notation variation cost”, and “subword notation variation count”. , “difference in character string length”, “common number of characters in unified space”, “common number of characters in Latin space”, and the like.
- sub-word spelling variation refers to taking statistics of diffs of the first and second notations when spelling variation data is available in advance and using them as feature quantities. This point will be described later with reference to FIGS. 9 to 12.
- the "number of common characters in the unified space” is “2" when comparing, for example, “Thomas” and “Maiko” because the two characters “-” and “ma” are common.
- “the number of common characters in the Latin space” is the number of common characters when, for example, both "Thomas” and “Maiko” are represented by the first character of the Roman alphabet notation, such as "T-MS” and “MIK-”. Therefore, "-” and "M” are common, resulting in "2".
- characters alphabet, katakana
- character positions may be treated as feature quantities.
- the spelling variation determination unit 11bb uses these feature amounts to perform binary determination using a rule-based, decision-tree-based, deep-learning-based, or other method. If there is a score, you may output the score.
- a threshold value is required for binary determination, and the threshold value may be adjusted according to false positives by drawing an ROC (Receiver Operating Characteristic) curve. Alternatively, the user may independently set the threshold without determining the threshold.
- the katakana spelling variation patterns of overseas personal names are statistically analyzed without depending on language information, and "diff We decided to conduct an analysis using
- diff means not only the difference between the two notations, but also the substitution (s), insertion (i), and deletion (d) that occurred when converting one notation to the other. It focuses on the editing occurrence point that indicates the character position. By compiling statistics of such "diff" based on edit distance, patterns of katakana spelling variation can be analyzed statistically.
- Such an edit pass is called a diff pattern. More specifically, when following the reverse order of FIG. 9, as shown in FIG. 10, the diff pattern from the cell in the lower right corner to the cell where the edit distance is 0 is (1) to (3) It can be read that there are three that pass through each.
- the statistics of insertion, deletion, and replacement patterns can be calculated. For example, in the case of deleting (or inserting) one character, the number of times the character "i" is deleted (or inserted) is known. Also, in the case of two characters, by looking at the surrounding words of the edited portion, it can be known how many conversions such as debi to dei occur. By using this method, it is possible to automatically obtain statistics such as the number of V ⁇ B replacements without using language knowledge.
- each diff pattern including one character before, one character after, and one character before and after the edited location, not limited to the edited location.
- 1 may be added to each instance of a combination of personal names corresponding to each diff pattern and included in the statistic of the diff pattern. Also, the data may be aggregated by country.
- the spelling variation determination model 11b using this pre-obtained dictionary of diff patterns, a search is made to see if a diff pattern appears in the spelling pair to be checked this time. is set so that its feature value is large.
- the number of appearances of the diff pattern may be used as it is, or it may be normalized to a value such as the number of occurrences (percentage) of the total number of replacement occurrences of one character and then adopted as a feature amount. good.
- FIG. 13 is an explanatory diagram of grouping of notations.
- the grouping of notations is performed through the algorithm shown in FIG. First, the input notation list is sorted. Note that any sorting method may be used as long as it maintains the consistency of the results.
- the first notation A after sorting is adopted as the first group. Then, the remaining notations B to H and the notation variations are determined. Next, for the notations C to F newly added to the group, the remaining notations B, D, G, and H are similarly checked for notation variation.
- the notations may be further classified by notation type.
- the notation is structured by classifying the character types.
- documents but also topics may be extracted based on the media (video, audio, etc.) in which the person appears, using image recognition, voice recognition, scene recognition, etc. of the media. .
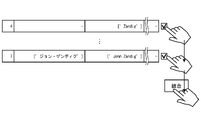
- FIG. 14 shows an example of a GUI screen when there are two entities for the notation "Taro Tanaka".
- FIG. 14 is a diagram showing an example of a GUI screen when two entities exist for the same notation.
- the display control unit 12c which will be described later, indicates that the notation "Taro Tanaka” can be selected on the GUI screen described above. As specified, such notation is displayed in output column 52 .
- the display control unit 12c searches for an appropriate medium, and selects topics related to the notation and the two entities corresponding to the notation. display. Thereby, even if different entities are associated with the same notation, the user can confirm each entity.
- the threshold for a specific notation may be increased or decreased instead of the entire notation list. For example, by setting a low threshold for spelling variations for representative spellings of an entity and a high threshold for minor spellings other than representative spellings, it is possible to find many spellings related to representative spellings. It can also be used for full-text searches and the like.
- FIG. 15 is a diagram showing an example of a UI that allows such thresholds to be arbitrarily increased or decreased.
- FIG. 15 shows an example of a UI in which the default thresholds for the entire spelling list and the thresholds for the specific spellings "Michael Jackson" and "King of Pop" can be customized accordingly.
- FIG. 16 is a diagram showing an example of explicitly extracting and displaying a specific notation.
- FIG. 16 clearly displays the notational variation relationship in the form of a threshold or N-best score for notational variations specified for a specific notation of "Michael Jackson" and the top three notations of such scores. shows an example of
- the appropriateness (“OK” button), inappropriateness (“NG” button), and determination not possible (“NG” button) of each notation can be specified.
- a UI component that enables the addition of a label or the like (“input field”) may be arranged.
- the structuring processing unit 12b After executing the structuring process, stores the structured notation data as structured notation data 11c.
- the display control unit 12c generates a GUI screen to be displayed on the display unit 5 and causes the display unit 5 to display it. In addition, the display control unit 12c appropriately generates display content to be displayed in the output field 52 based on the structured notation data 11c, and causes the display unit 5 to display the display content.
- the display control unit 12c causes the display unit 5 to display the GUI screen shown in FIG. Further, for example, the display control unit 12c causes the display unit 5 to display the display contents shown in FIGS.
- the display control unit 12c displays the GUI screen so that the user can appropriately edit each line and each notation displayed on the GUI screen.
- the editing processing unit 12d executes an editing process of editing the structured notation data 11c based on the user's editing content acquired via the operation unit 3 by the acquiring unit 12a.
- an example of editing processing will be described.
- 17 to 21 are diagrams (part 1) to (part 5) showing an example of editing processing.
- the display control unit 12c for example, when a user's touch operation or a designation operation using a mouse, a keyboard, or the like is added to each notation displayed in the output column 52 of the GUI screen, the A GUI screen is displayed so that the notation can be directly edited. Then, when the notation is directly edited, the editing processing unit 12d reflects the edited content in the structured notation data 11c.
- the structured notation data may contain an error, and in that case, the user can directly edit and correct it, for example, as shown in FIG. It should be noted that this function may be used by, for example, the technical provider side of the embodiment of the present disclosure, or may be used by the client side that receives the technical provision, regardless of the user.
- the edited content can be saved as new learning data, with the erroneous portions as negative examples and the corrected portions as positive examples.
- the re-learning at this time may be fine-tuning using a database on the client side, or may be re-learning by returning examples to the technical provider side and adding them to the original learning data.
- the notation may be extended by inverse conversion such as katakana ⁇ Latin ⁇ katakana, and data may be generated (augmented) as examples where mistakes are likely to occur.
- the display control unit 12c displays, on the GUI screen, a check box that enables the user to specify, for example, each line displayed in the output column 52, and deletes the specified line.
- a possible "delete” button is displayed on the GUI screen. Then, when the check box is specified and the "delete” button is pressed, the edit processing unit 12d reflects the edited content of deleting the corresponding line in the structured notation data 11c.
- the display control unit 12c controls, for example, when the user performs a touch operation or a designation operation using a mouse, a keyboard, or the like on an unmarked portion of the output column 52, the display control unit 12c A GUI screen is displayed so that a portion can be selected.
- the display control unit 12c also displays an "external document acquisition" button on the GUI screen. Then, when such a part is selected and the "external document acquisition” button is pressed, the editing processing unit 12d acquires the notation corresponding to the corresponding part from, for example, a cloud server, and stores it in the structured notation data 11c. To reflect. Then, the display control unit 12c displays the notation reflected in the structured notation data 11c on the GUI screen.
- FIG. 19 shows an example in which an external document is imported and structured notation data is updated, instead of direct manual editing.
- a technique such as morphological analysis is used to extract the notation of each person's name.
- the entire table may be used as a query to determine whether there is a relationship of notation variation in any part of the table.
- the display control unit 12c displays the above-described check boxes so that a plurality of lines displayed in the output column 52 can be designated, and the designated lines can be integrated. Integrate” button is displayed on the GUI screen. Then, when multiple lines are designated by the check boxes and the "Integrate” button is pressed, the editing processing unit 12d adds the edited content for integrating the corresponding multiple lines into one group to the structured notation data 11c. To reflect.
- FIG. 20 shows an example of integration, that is, merging, one group may be divided into multiple groups. Also, simultaneous editing or multiple editing by a plurality of users may be performed.
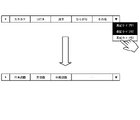
- the display control unit 12c displays a GUI screen so that the notation type displayed in the output column 52 can be changed using a drop-down list. Then, when the notation type is changed by such a drop-down list, the editing processing unit 12d reflects it in the structured notation data 11c so that the notation data corresponding to the changed notation type is obtained. Then, the display control unit 12c displays the notation data reflected in the structured notation data 11c on the GUI screen.
- Fig. 21 shows an example in which the notation type is changed from the character type to the language area.
- the linguistic domain is determined using the character type of the notation, a dictionary, or the like.
- Other notation types such as character string length and popularity (for example, the number of times the query is hit by web search or full-text search of documents) can be considered.
- the type of notation to be used may be defined by the user's own program. In that case, a group-by-group notation is given to the program, and any program can distinguish between notation types. Do nothing and pass through.
- FIG. 22 is a flow chart showing a processing procedure executed by the information processing apparatus 10. As shown in FIG. In the description using FIG. 22, the notation variation determination process using the notation variation determination model 11b included in the structuring process executed by the structuring processing unit 12b will be mainly described.
- the conversion unit 11ba determines whether or not any two notations to be determined as to whether or not there is a relationship of spelling variation with each other have been input (step S101).
- the conversion unit 11ba expands the two notations to N-best and converts them into linguistic unified space (for example, katakana space) expression (step S102 ).
- the spelling variation determination unit 11bb determines the spelling variation relationship between the two spellings based on the feature amount related to the spelling variation included in the conversion result (step S103).
- the spelling variation determination unit 11bb outputs one or both of the Boolean value and the score, which are the determination result of the spelling variation relationship, and repeats the processing from step S101.
- step S101, No the conversion unit 11ba repeats the processing from step S101.
- the notation database 11d that is finally generated by the information processing apparatus 10 can be used as a dictionary of notation data structured with respect to notation variation, and can also be used as a dictionary of notation data, for example, any notation input when inputting an IME (Input Method Editor). can be used as a conversion candidate dictionary for IME (Input Method Editor).
- the notation data of the group to which the one notation belongs can be used as a search query dictionary as a search query.
- the user designates only one notation, even a search by a search query having a relation of notation variation with that notation is automatically performed, so that the matching rate of search can be improved.
- search engine services provided by Google (registered trademark), Bing (registered trademark), etc., even if you search with a notation that includes typos, etc. It can be said that it is a kind of notation variation detection system.
- the embodiment of the present disclosure it is possible to determine the spelling variation relationship directly from the spelling pair.
- the notation variation is determined, and the notation data is structured based on this. be able to.
- the conversion unit 11ba converts the two notations into a linguistic unified spatial expression. It is possible to extract secret words.
- the information processing apparatus 10 may be configured as an information processing system including, for example, a server and one or more terminal devices.
- each terminal device will use each terminal device to input a notation list via a GUI screen provided by the server, or receive structured notation data.
- the server performs structuring processing based on the notation list input from each terminal device, and returns the result to each terminal device.
- a plurality of terminal devices may share a GUI screen and jointly generate and edit structured notation data corresponding to one notation list.
- each component of each illustrated device is functionally conceptual and does not necessarily need to be physically configured as illustrated.
- the specific form of distribution and integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed and integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
- FIG. 23 is a hardware configuration diagram showing an example of a computer 1000 that implements the functions of the information processing apparatus 10.
- Computer 1000 has CPU 1100 , RAM 1200 , ROM 1300 , storage 1400 , communication interface 1500 and input/output interface 1600 .
- Each part of computer 1000 is connected by bus 1050 .
- the CPU 1100 operates based on programs stored in the ROM 1300 or storage 1400, and controls each section. For example, CPU 1100 expands programs stored in ROM 1300 or storage 1400 into RAM 1200 and executes processes corresponding to various programs.
- the ROM 1300 stores a boot program such as BIOS (Basic Input Output System) executed by the CPU 1100 when the computer 1000 is started, and programs dependent on the hardware of the computer 1000.
- BIOS Basic Input Output System
- the storage 1400 is a computer-readable recording medium that non-temporarily records programs executed by the CPU 1100 and data used by such programs.
- the storage 1400 is a recording medium that records an information processing program according to the present disclosure, which is an example of the program data 1450 .
- a communication interface 1500 is an interface for connecting the computer 1000 to an external network 1550 .
- CPU 1100 receives data from another device or transmits data generated by CPU 1100 to another device via communication interface 1500 .
- the input/output interface 1600 is an interface for connecting the input/output device 1650 and the computer 1000 .
- CPU 1100 can receive data from an input device such as a keyboard or mouse via input/output interface 1600 .
- the CPU 1100 can transmit data to an output device such as a display, speaker, or printer via the input/output interface 1600 .
- the input/output interface 1600 may function as a media interface for reading a program or the like recorded on a predetermined recording medium.
- Media include, for example, optical recording media such as DVD (Digital Versatile Disc) and PD (Phase change rewritable disk), magneto-optical recording media such as MO (Magneto-Optical disk), tape media, magnetic recording media, semiconductor memories, etc. is.
- the CPU 1100 of the computer 1000 implements the functions of the control unit 12 by executing the information processing program loaded on the RAM 1200.
- the storage 1400 stores an information processing program according to the present disclosure and data in the storage unit 11 .
- CPU 1100 reads and executes program data 1450 from storage 1400 , as another example, these programs may be acquired from another device via external network 1550 .
- the information processing apparatus 10 when arbitrary two notations to be determined as to whether or not there is a relationship of spelling variation with each other are input, the two notations into a linguistic unified space representation, and the conversion result of the conversion unit 11ba is input, and the notational variation relationship between the two notations is determined based on the feature amount related to the notational variation included in the conversion result. and a notation deviation determination unit 11bb (corresponding to an example of a “determination unit”).
- a notation deviation determination unit 11bb (corresponding to an example of a “determination unit”).
- the present technology can also take the following configuration.
- a conversion unit that, when arbitrary two notations to be determined as to whether or not they have a relationship of spelling variation with each other are input, converts the two notations into a unified linguistic spatial expression; a determination unit that receives a conversion result from the conversion unit and determines the relationship between the two spelling variations based on a feature amount related to the spelling variation included in the conversion result; An information processing device.
- the conversion unit After extending the two notations to N-best, respectively, converting to the unified space representation, The information processing device according to (1) above.
- the conversion unit transforming the two notations into the unified spatial representation of script types; The information processing apparatus according to (1) or (2).
- the conversion unit transforming the two notations into the unified spatial representation, which is an embedded spatial representation by deep learning;
- the information processing apparatus according to (1), (2) or (3).
- the determination unit is Determining the notation variation relationship based on the feature amount including at least the two notation edit distances, the lengths of each, and the difference between the lengths.
- the information processing apparatus according to any one of (1) to (4) above.
- the determination unit is Determining the notation variation relationship based on the feature amount that further includes a statistic related to an edit path that can be traced in reverse order so that the edit distance is 0;
- the information processing device according to (5) above.
- the determination unit is Determining the spelling variation relationship based on the feature amount including the statistic calculated based on the two existing spelling examples collected in advance;
- the information processing device according to (6) above.
- an acquisition unit that acquires a notation list that is an enumeration of arbitrary notations; a structuring processing unit that recursively repeats determination by the determining unit using the two notations extracted from the notation list as input, thereby generating notation data in which the notation list is structured for each group with respect to notation variation;
- the information processing apparatus according to any one of (1) to (7), further comprising: (9)
- the structuring processing unit further includes: generating the notation data for each notation type including at least character type;
- the information processing device according to (8) above.
- (10) a display unit; a display control unit that causes the display unit to display the notation data generated by the structuring processing unit;
- the information processing apparatus according to (8) or (9), further comprising: (11) The display control unit causing the display unit to display the notation data so that the same notation pointing to different entities exists in the notation data so that the same notation can be separated according to the entity; The information processing device according to (10) above. (12) The display control unit causing the display unit to display the notation data so that the same notation can be separated by topic based on the context of each of the entities; The information processing device according to (11) above. (13) The display control unit extracting the topics based on the media for each of the entities; The information processing device according to (12) above.
- the structuring processing unit generating the notation data so that, when one notation is specified as a search query, the notation data of the group to which the one notation belongs can be collectively used as the search query;
- the information processing apparatus according to any one of (8) to (13) above.
- arbitrary two notations to be determined as to whether or not they have a relationship of spelling variation with each other are input, converting the two notations into a linguistic unified spatial expression; Determining the notation variation relationship between the two notations based on a feature amount related to the notation variation included in the conversion result, using the conversion result in the conversion as an input;
- a method of processing information comprising:
- operation unit 5 display unit 10 information processing device 11 storage unit 11a notation list 11b notation variation determination model 11ba conversion unit 11bb notation variation determination unit 11c structured notation data 11d notation database 12 control unit 12a acquisition unit 12b structuring processing unit 12c Display control unit 12d Edit processing unit 51 Input field 52 Output field
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/575,904 US20240320448A1 (en) | 2021-07-14 | 2022-03-09 | Information processing apparatus and information processing method |
| JP2023535113A JPWO2023286340A1 (https=) | 2021-07-14 | 2022-03-09 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021116296 | 2021-07-14 | ||
| JP2021-116296 | 2021-07-14 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023286340A1 true WO2023286340A1 (ja) | 2023-01-19 |
Family
ID=84919228
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/010202 Ceased WO2023286340A1 (ja) | 2021-07-14 | 2022-03-09 | 情報処理装置および情報処理方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240320448A1 (https=) |
| JP (1) | JPWO2023286340A1 (https=) |
| WO (1) | WO2023286340A1 (https=) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006053866A (ja) * | 2004-08-16 | 2006-02-23 | Advanced Telecommunication Research Institute International | カタカナ文字列の表記ゆれの検出方法 |
| JP2012256197A (ja) * | 2011-06-08 | 2012-12-27 | Toshiba Corp | 表記ゆれ検出装置及び表記ゆれ検出プログラム |
| JP2020154668A (ja) * | 2019-03-20 | 2020-09-24 | 株式会社Screenホールディングス | 同義語判定方法、同義語判定プログラム、および、同義語判定装置 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005352888A (ja) * | 2004-06-11 | 2005-12-22 | Hitachi Ltd | 表記揺れ対応辞書作成システム |
| US11113175B1 (en) * | 2018-05-31 | 2021-09-07 | The Ultimate Software Group, Inc. | System for discovering semantic relationships in computer programs |
-
2022
- 2022-03-09 WO PCT/JP2022/010202 patent/WO2023286340A1/ja not_active Ceased
- 2022-03-09 US US18/575,904 patent/US20240320448A1/en active Pending
- 2022-03-09 JP JP2023535113A patent/JPWO2023286340A1/ja not_active Abandoned
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006053866A (ja) * | 2004-08-16 | 2006-02-23 | Advanced Telecommunication Research Institute International | カタカナ文字列の表記ゆれの検出方法 |
| JP2012256197A (ja) * | 2011-06-08 | 2012-12-27 | Toshiba Corp | 表記ゆれ検出装置及び表記ゆれ検出プログラム |
| JP2020154668A (ja) * | 2019-03-20 | 2020-09-24 | 株式会社Screenホールディングス | 同義語判定方法、同義語判定プログラム、および、同義語判定装置 |
Non-Patent Citations (1)
| Title |
|---|
| MASUYAMA TAKESHI, HIROSHI NAKAGAWA : "Automatic Acquisition of Different Katakana Notation Using Web Data ", PROCEEDINGS OF THE 11TH ANNUAL MEETING OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, JP, 1 January 2005 (2005-01-01) - 18 March 2005 (2005-03-18), JP, pages 412 - 415, XP093023938 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2023286340A1 (https=) | 2023-01-19 |
| US20240320448A1 (en) | 2024-09-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Kestemont et al. | Cross-genre authorship verification using unmasking | |
| JP5241828B2 (ja) | 辞書の単語及び熟語の判定 | |
| CN100419733C (zh) | 解决方案数据编辑处理及自动概括处理装置和方法 | |
| Linhares Pontes et al. | Impact of OCR quality on named entity linking | |
| US9645987B2 (en) | Topic extraction and video association | |
| Balasubramanian et al. | A multimodal approach for extracting content descriptive metadata from lecture videos | |
| Mac Kim et al. | Finding names in trove: named entity recognition for Australian historical newspapers | |
| KR102753536B1 (ko) | 인공지능 학습 모델을 이용한 저자 식별 시스템 및 그 방법 | |
| CN112988784B (zh) | 数据查询方法、查询语句生成方法及其装置 | |
| CN114692655B (zh) | 翻译系统及文本翻译、下载、质量检查和编辑方法 | |
| CN112989010A (zh) | 数据查询方法、数据查询装置和电子设备 | |
| JP2006072744A (ja) | 文書処理装置、その制御方法、プログラム、及び記憶媒体 | |
| Mihret et al. | Sentiment analysis model for opinionated awngi text | |
| US12493641B2 (en) | Automatic document classification | |
| KR101105798B1 (ko) | 키워드 정련 장치 및 방법과 그를 위한 컨텐츠 검색 시스템 및 그 방법 | |
| Wojciechowska et al. | Deep dive into the Language of International Relations: NLP-based Analysis of UNESCO’s Summary Records | |
| WO2023286340A1 (ja) | 情報処理装置および情報処理方法 | |
| US11880392B2 (en) | Systems and methods for associating data with a non-material concept | |
| CN112989011B (zh) | 数据查询方法、数据查询装置和电子设备 | |
| Zinvandi et al. | Persian web document retrieval corpus | |
| KR102856336B1 (ko) | 온라인 동영상 자동 요약 및 텍스트 컨텐츠 생성방법 | |
| CA3168741C (en) | Systems and methods for associating data with a non-material concept | |
| Hast et al. | Making large collections of handwritten material easily accessible and searchable | |
| Vieira et al. | A distantly supervised approach for recognizing product mentions in user-generated content | |
| JP2025174732A (ja) | 情報処理方法およびコンピュータプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22841690 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023535113 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18575904 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22841690 Country of ref document: EP Kind code of ref document: A1 |