WO2023275983A1 - 仮想化システム障害分離装置及び仮想化システム障害分離方法 - Google Patents
仮想化システム障害分離装置及び仮想化システム障害分離方法 Download PDFInfo
- Publication number
- WO2023275983A1 WO2023275983A1 PCT/JP2021/024527 JP2021024527W WO2023275983A1 WO 2023275983 A1 WO2023275983 A1 WO 2023275983A1 JP 2021024527 W JP2021024527 W JP 2021024527W WO 2023275983 A1 WO2023275983 A1 WO 2023275983A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- container
- unit
- management unit
- cluster
- containers
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operations
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1415—Saving, restoring, recovering or retrying at system level
- G06F11/142—Reconfiguring to eliminate the error
- G06F11/1423—Reconfiguring to eliminate the error by reconfiguration of paths
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operations
- G06F11/1479—Generic software techniques for error detection or fault masking
- G06F11/1482—Generic software techniques for error detection or fault masking using middleware or operating system [OS] functionalities
- G06F11/1484—Generic software techniques for error detection or fault masking using middleware or operating system [OS] functionalities involving virtual machines
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0706—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment
- G06F11/0712—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment in a virtual computing platform, e.g. logically partitioned systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operations
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1415—Saving, restoring, recovering or retrying at system level
- G06F11/1443—Transmit or communication errors
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2201/00—Indexing scheme relating to error detection, to error correction, and to monitoring
- G06F2201/815—Virtual
Definitions
- the present invention relates to a virtualization system failure isolation device and a virtualization system failure isolation method for realizing failure detection and failure recovery of containers and applications running on containers in a computing infrastructure based on virtual machines and containers.
- the virtual machine mentioned above is a computer that realizes the same functions as a physical computer with software.
- a container is a virtualization technology created by packaging an application in an environment called a "container" and running on a container engine.
- anomaly detection and failure recovery of containers and applications running on containers are realized mainly by Liveness/Readiness Probe functions (also called probe functions) of kubernetes, which will be described later. ing.
- Kubernetes is container virtualization software that creates and clusters containers such as Docker, and is open source software.
- the Liveness Probe function performs control such as restarting the container, and the Readiness Probe function performs control such as whether or not the container accepts requests.
- restoration work etc. are performed by human power based on the alert issued for the failure in the virtualization system.
- the failure monitoring cycle can only be set to a predetermined slow cycle such as 1 second. For this reason, there is a problem that, when failure recovery is required as quickly as possible, it cannot be recovered faster than recovery by the failure recovery function of Kubernetes in the default state.
- the present invention has been made in view of such circumstances, and the object of the present invention is to restore a failure that occurs in a virtualization system faster than recovery by the failure recovery function of container virtualization software.
- the virtualization system fault isolation device of the present invention provides a computational resource cluster that is virtually created on a physical machine by container virtualization software, and clusters and arranges the virtualized containers. and a cluster management unit that is virtually created and manages control related to the arrangement and operation of the clustered containers, and is associated with each of a plurality of containers, and sets a traffic distribution ratio to each container.
- a deployment instruction unit that performs a process of arranging an endpoint setting unit, which is the end point of communication data to be transferred, in association with a container;
- An anomaly detection unit that detects an anomaly in a container, and an anomaly that is created externally and transmits to the cluster management unit a change command for setting the allocation ratio to the abnormal container detected by the anomaly detection unit to 0%.
- a recovery handling unit wherein the cluster management unit sets the distribution ratio of the endpoint setting unit associated with the abnormal container to 0% according to the change command.
- a failure occurring in a virtualization system can be recovered faster than recovery by the failure recovery function of container virtualization software.
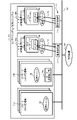
- FIG. 1 is a block diagram showing the configuration of a virtualization system fault isolation device according to an embodiment of the present invention
- FIG. FIG. 10 is a block diagram for explaining the first container abnormality detection processing by the Pod of the virtualization system fault isolation device of the present embodiment
- FIG. 12 is a block diagram for explaining second anomaly detection processing by a routing table provided for each worker node of the virtualization system fault isolation device of this embodiment
- FIG. 11 is a block diagram for explaining third anomaly detection processing by monitoring daemons of virtual switches provided for each worker node of the virtualization system fault isolation device of the present embodiment
- FIG. 12 is a block diagram for explaining fourth anomaly detection processing by monitoring daemons of container runtime provided for each worker node of the virtualization system fault isolation device of the present embodiment
- FIG. 10 is a block diagram for explaining the first container abnormality detection processing by the Pod of the virtualization system fault isolation device of the present embodiment
- FIG. 12 is a block diagram for explaining second anomaly detection processing by a routing table provided for each worker
- FIG. 14 is a block diagram for explaining fifth anomaly detection processing by monitoring each worker node of the virtualization system fault isolation device of the present embodiment
- FIG. 11 is a block diagram for explaining sixth anomaly detection processing by monitoring a DB externally attached to a cluster of a container system of the virtualization system fault isolation device of the present embodiment
- FIG. 13 is a block diagram showing a configuration when the endpoint setting unit and the Pod are deployed as a 1:1 configuration by the failure handling deployment instruction unit in the virtualization system failure isolation device of the present embodiment
- FIG. 4 is a block diagram for explaining the first anomaly handling process of the virtualization system fault isolation device of the present embodiment
- It is a flow chart for explaining the operation of the first abnormality handling process.
- FIG. 11 is a block diagram for explaining second anomaly handling processing of the virtualization system fault isolation device of the present embodiment
- 1 is a hardware configuration diagram showing an example of a computer that implements the functions of a virtualization system fault isolation device according to this embodiment
- FIG. 1 is a block diagram showing the configuration of a virtualization system fault isolation device according to an embodiment of the present invention.
- a virtualization system failure isolation device (also referred to as a failure isolation device) 10 shown in FIG. 1 stops or deletes a failed container in a container system 20 described later to isolate it, and restores the isolated container.
- the fault isolation device 10 comprises a cluster management section 14 , a computing resource cluster 15 , an anomaly detection section 17 , an anomaly recovery handling section 18 , and a failure handling deployment instruction section 19 .
- a cluster 12 is configured by the cluster management unit 14 and the computational resource cluster 15 . Outside the cluster 12, an anomaly detection unit 17, an anomaly recovery handling unit 18, and a failure handling deployment instruction unit 19 are provided.
- the failure handling deployment instruction unit 19 constitutes the deployment instruction unit described in the claims.
- the computational resource cluster 15 is configured with a plurality of applications 15a and 15b.
- the applications 15a and 15b are, in other words, Pods as management units of aggregates of one or more containers.
- a Pod is the smallest unit of an application that can be executed on Kubernetes (container virtualization software). That is, the applications 15a and 15b as pods create containers and cluster them, and the clusters are operated on the container engine.
- the computing resource cluster 15 is virtually created on a physical machine by container virtualization software, and clusters and arranges the virtually created containers.
- the container system 20 is a virtualization system composed of one or more clusters 12. When there are two clusters 12 , each cluster 12 is configured with a cluster manager 14 and a computational resource cluster 15 .
- the cluster management unit 14 manages the placement and operation of the virtually created and clustered containers.
- the cluster management unit 14 includes a communication allocation unit 14a, a computational resource operation unit 14b, a computational resource management unit 14c, a container configuration reception unit 14d, a container arrangement destination determination unit 14e, and a container management unit 14f. configured as follows.
- the fault handling deployment instruction unit (also referred to as the deployment instruction unit) 19 connects the endpoint (end point) setting units 14j and 14k and the Pods 15a and 15b shown in FIG. Performs the process of deploying (arranging) as a configuration of .
- the endpoint setting units 14j and 14k are associated with each of the plurality of Pods 15a and 15b, set the distribution ratio (%) of traffic to each of the Pods 15a and 15b, and serve as the end point of communication data.
- the distribution ratio is called a weight value (%).
- the anomaly detection unit 17 shown in FIG. 1 detects anomalies in Pods (applications) 15a and 15b, which are one or more containers in the container system 20.
- the error recovery handling unit 18 changes the weight value of the deployment instruction unit 19 associated with the Pod (for example, Pod 15a) in which the error is detected by the error detection unit 17 to 0%, and issues a change command for disconnecting the error Pod 15a. to the communication distribution unit 14a. Further, when restoring the disconnected Pod 15a, the abnormality restoration handling unit 18 transmits a restoration command for gradually increasing the traffic to the Pod 15a to be restored to a predetermined traffic value to the communication distribution unit 14a. .
- the communication distribution unit 14a shown in FIG. 1 is a router, and distributes the change command or recovery command from the failure recovery response unit 18 to the corresponding units 14b to 14f and notifies them.
- the communication distribution unit 14a sets a weight value (%) indicating a traffic distribution ratio set for each of the endpoint setting units 14j and 14k (to be described later) below the transmission destination endpoint setting units 14j and 14k (to be described later). ) to distribute traffic. It should be noted that the weight value corresponds to the distribution ratio described in the claims.
- the container configuration reception unit (also referred to as reception unit) 14d receives configuration information for deploying containers to the computational resource cluster 15 from an external server or the like.
- the container placement destination determination unit (also referred to as placement destination determination unit) 14e determines which container to place on which worker node (computation resource cluster 15) based on the configuration information received by the reception unit 14d.
- the container management unit 14f checks whether the container is operating normally.
- the computational resource management unit 14c grasps and manages whether the worker node is operable, the usage amount of computational resources of the server that constitutes the worker node, the remaining amount of CPU (Central Processing Unit), and the like.
- the computational resource operation unit 14b performs an operation of allocating a predetermined amount of computational resources such as a certain amount of CPU to a certain container, in other words, an operation of allocating storage capacity, CPU time, memory capacity usable by the container, and the like. conduct.
- FIG. 1 various abnormality detection processes (first to sixth abnormality detection processes) related to containers of the container system 20 by the abnormality detection unit 17 of the fault isolation device 10 will be described with reference to FIGS. 2 to 7.
- FIG. 1 various abnormality detection processes (first to sixth abnormality detection processes) related to containers of the container system 20 by the abnormality detection unit 17 of the fault isolation device 10 will be described with reference to FIGS. 2 to 7.
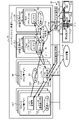
- FIG. 2 is a block diagram for explaining the first container abnormality detection processing by the Pods (applications) 15a and 15b of the virtualization system fault isolation apparatus 10 of this embodiment.
- each Pod 15a, 15b constitutes one or more containers.
- a master node 14J, an infrastructure node 14K, and worker nodes 15J and 15K are configured by virtual machines in the container system 20, and are connected by a virtual switch ⁇ OVS (Open vSwitch) ⁇ 30. It's like The master node 14J and the infrastructure node 14K correspond to the cluster management unit 14 (FIG. 1), and the worker nodes 15J and 15K correspond to the computational resource cluster 15 (FIG. 1).
- OVS Open vSwitch
- the master node 14J and the worker node 15J constitute the first cluster 12, and the infrastructure node 14K and the worker node 15K constitute the second cluster 12. Assume that the container system 20 is composed of these clusters 12 .
- An anomaly detection unit 17 is arranged outside the container system 20 in the same manner as in the configuration of FIG. In FIG. 2, a total of two abnormality detection units 17 are shown for each of the worker nodes 15J and 15K, but the number may be one.
- the master node 14J, the infrastructure node 14K, the worker nodes 15J and 15K, and the anomaly detector 17 are connected to the opposite device 24 via the network 22.
- FIG. The opposing device 24 is a communication device such as an external server that transmits request signals and the like to the container system 20 .
- the anomaly detection unit 17 transmits a predetermined command (for example, "sudo crictl ps") to the Pods 15a and 15b of the worker nodes 15J and 15K by polling indicated by the two-way arrows Y1 and Y2, and the Pods 15a and 15b reply according to the command. It judges whether it is normal or abnormal according to the received response result. In this actual polling test, the average round-trip time was 0.06 seconds when polling was performed 10 times.
- a predetermined command for example, "sudo crictl ps”
- the anomaly detection unit 17 makes an anomaly judgment by reading a character string indicating normality or anomaly described in the command response results returned from the Pods 15a and 15b by polling.
- the character string "Running” indicates that the operation of the container (Pods 15a, 15b) is normal, and character strings other than “Running” indicate that it is abnormal. Therefore, the abnormality detection unit 17 determines that the operation of the container (Pods 15a, 15b) is normal when "Running" is described in the command response result, and determines that it is abnormal when a character string other than "Running” is described. do.
- FIG. 3 is a block diagram for explaining the second anomaly detection processing by the routing table 15c provided for each of the worker nodes 15J and 15K of the virtualization system fault isolation device 10 of this embodiment.
- a routing table (also referred to as a table) 15c manages destination containers of packets transmitted from the opposite device 24 to the Pods 15a and 15b of the worker nodes 15J and 15K via the network 22, using route information indicating the destination. ing. If the destination management of this table 15c is not correct, the packet will not reach the appropriate container. For this reason, the abnormality detection unit 17 detects whether the transmission destination management of the table 15c is normal or abnormal.
- routing table 15c consists of a pair of tables “iptables" and “nftables”.
- the abnormality detection unit 17 transmits a predetermined command to each table 15c of the worker nodes 15J and 15K by polling indicated by the two-way arrows Y3 and Y4, and determines whether it is normal based on the response results returned from each table 15c in response to the command. Determine if there is an abnormality.
- the predetermined command above is a pair of "sudo iptables -L
- ” is notified to "iptables” of the table 15c, and the command “sudo nft list ruleset” is notified to "nftables”.
- each of the “iptables” and “nftables” tables sends a response to the command to the anomaly detection unit 17 .
- the abnormality detection unit 17 determines that the command response result sent back from each table 15c is normal if the route information of the transmission destination is described, and that it is abnormal if nothing is described. .
- FIG. 4 is a block diagram for explaining the third abnormality detection processing by monitoring the daemon of the virtual switch 30 provided for each of the worker nodes 15J and 15K of the virtualization system fault isolation device 10 of this embodiment. be.
- the daemon of the virtual switch 30 is also called an OVS daemon.
- a daemon is a program that manages the destination of packets in the virtual switch 30.
- the abnormality detection unit 17 monitors the OVS daemon, and detects that the packet is normal if the packet is properly transmitted, and that it is abnormal if the packet is not transmitted properly.
- the abnormality detection unit 17 sends a predetermined command (for example, “ps aux
- a predetermined command for example, “ps aux
- the abnormality detection unit 17 determines that the command response result returned from each virtual switch 30 is normal if, for example, "db.sock process" related to the destination is described. judged to be abnormal.
- FIG. 5 is a block diagram for explaining the fourth anomaly detection processing by monitoring the daemon of the container runtime 15d provided for each of the worker nodes 15J and 15K of the virtualization system fault isolation device 10 of this embodiment.
- the daemon of the container runtime 15d is also called a crio daemon.
- crio is an open-source, community-driven container engine used in containerized virtualization technology.
- the container runtime 15d is responsible for starting the containers of the Pods 15a and 15b, so by monitoring the container runtime 15d, it is possible to detect whether the containers are starting normally. Therefore, the abnormality detection unit 17 monitors the crio daemon, and detects that the container is normal if the container has started, and that it is abnormal if the container has not started.
- the anomaly detection unit 17 transmits a predetermined command (for example, "systemctl status crio
- a predetermined command for example, "systemctl status crio
- the anomaly detection unit 17 judges an anomaly as normal if “active (running)”, which indicates the running state of the crio daemon, is described in the command response result returned from each virtual switch 30. (running)” is determined to be abnormal.
- FIG. 6 is a block diagram for explaining the fifth anomaly detection processing by monitoring each of the worker nodes 15J and 15K of the virtualization system fault isolation device 10 of this embodiment.
- the worker nodes 15J and 15K are created by virtualization technology (virtual machine) using the physical machine 32.
- the anomaly detector 17 exists on the physical machine 32 outside the virtual machine. If the virtual machine is running, the anomaly detector 17 detects that the container is normal. is detected as abnormal.
- the abnormality detection unit 17 transmits a predetermined command (for example, "sudo virsh list") to each of the worker nodes 15J and 15K by polling indicated by the round-trip arrows Y9 and Y10, and each worker node 15J and 15K replies in response to the command. It judges whether it is normal or abnormal according to the received response result.
- a predetermined command for example, "sudo virsh list”
- the abnormality detection unit 17 determines that the abnormality is normal if "running" indicating the activation state of the target worker node 15J or 15K is described in the command response result returned from each worker node 15J or 15K. If the description is anything other than "running", it is determined to be abnormal.
- FIG. 7 is for explaining the sixth anomaly detection processing by monitoring DBs (Data Bases) 26a and 26b externally attached to the cluster 12 of the container system 20 of the virtualization system fault isolation device 10 of this embodiment. is a block diagram of.
- DBs Data Bases
- DBs also referred to as external DBs
- the abnormality detection unit 17 is also connected to the worker nodes 15J and 15K via the network 22 .
- the abnormality detection unit 17 transmits predetermined commands to the external DBs 26a and 26b via the network 22 by polling indicated by the two-way arrows Y11 and Y12, and according to the response results returned from the external DBs 26a and 26b in response to the commands, Determine normal or abnormal.
- the commands in this case depend on the types of the external DBs 26a and 26b.
- the response results include the results related to responses and life-and-death monitoring, and the results related to exceeding the upper limit on the number of connections.
- the response/life-and-death monitoring monitors whether the external DBs 26a and 26b are operating normally. In other words, the abnormality detection unit 17 determines that there is an abnormality if the response result indicates that the external DBs 26a and 26b have not started normally.
- “Exceeding the upper limit of the number of connections” indicates that the number of containers to which the external DBs 26a and 26b are connected exceeds a predetermined threshold. That is, if the response result indicates that the number of connected containers of the external DBs 26a and 26b exceeds the threshold, the abnormality detection unit 17 determines that there is an abnormality.
- the polling round-trip time depends on the types of the external DBs 26a and 26b.
- the endpoint setting units 14j and 14k are endpoints that receive service information related to the communication indicated by the arrow Y20 from the opposite device 24 via the router 14a, and are accessible by the pods 15a and 15b.
- the service information from the opposite device 24 is sent from the router 14a to the containers of the Pods 15a and 15b via the endpoint setting units 14j and 14k.
- a weight value (%) indicating a traffic distribution ratio is set for each of the endpoint setting units 14j and 14k.
- the router 14a Based on the weight values, the router 14a distributes the traffic to the destination endpoint setting units 14j and 14k as indicated by arrows Y16 and Y17. For example, assume that the weight value of the endpoint setting unit 14j is set to 30% and the weight value of the endpoint setting unit 14k is set to 70%. In this case, 30% of the data transmitted from the router 14a is distributed to the endpoint setting section 14j in the direction indicated by the arrow Y16, and 70% is distributed to the endpoint setting section 14k in the direction indicated by the arrow Y17.
- FIG. 9 is a block diagram for explaining the first anomaly handling process of the virtualization system fault isolation device 10 of this embodiment.
- Anomaly detection requiring the first anomaly handling process is any one of the first to fifth anomaly detections.
- the abnormality recovery handling unit 18 sets the traffic distribution ratio to the abnormal Pod 15a to 0% as indicated by the arrow Y21. to the router 14a of the master node 14J.
- the router 14a sets the weight value of the endpoint setting unit 14j associated with the abnormal Pod 15a of the worker node 15J to 0%, thereby performing processing (see x mark) to isolate the abnormal Pod 15a. .
- the router 14a performs processing to set the weight value of the endpoint setting unit 14k associated with the Pod 15a of the worker node 15K to 100%, as indicated by an arrow Y23, if necessary.
- the abnormal Pod 15a is separated, so that the transmission data from the router 14a of the infrastructure node 14K is not transmitted in the direction indicated by the arrow Y16, and all of the transmission data (100%) is transferred to the direction indicated by the arrow Y17. It is distributed to and transmitted to the endpoint setting unit 14k in the indicated direction.
- the master node 14J starts the standby state of the disconnected abnormal Pod 15a to be restored after the abnormality is resolved. Thereafter, the failure recovery handling unit 18 transmits a recovery command to the router 14a of the master node 14J to gradually increase the traffic to the Pod 15a that has been started up to a predetermined traffic value and recover the traffic.
- the router 14a In response to the restoration change command, the router 14a gradually increases the weight value of the endpoint setting unit 14j associated with the launched Pod 15a to a predetermined traffic value, as indicated by arrow Y22. By this processing, the weight value is set to a predetermined value (eg, 50%), and restoration of the Pod 15a is completed.
- a predetermined value eg, 50%
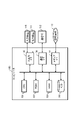
- FIG. 1 the endpoint setting units 14j and 14k and the Pods (one or a plurality of containers) 15a and 15b are deployed in a 1:1 configuration by the failure-handling deploy instruction unit 19.
- FIG. A precondition is that a weight value (%) indicating a predetermined traffic distribution ratio is set to, for example, 50% for each of the endpoint setting units 14j and 14k.
- the abnormality detection unit 17 shown in FIG. 9 detects an abnormality in the Pod 15a (container) of the worker node 15J.
- step S3 the router 14a that received the change command changes the weight value of the endpoint setting unit 14j associated with the abnormal Pod 15a of the worker node 15J from 50% to 0%, as indicated by arrow Y22.
- the abnormal Pod 15a is separated (see the x mark).
- the router 14a changes the weight value of the other endpoint setting unit 14k associated with the Pod 15a of the worker node 15K from 50% to 100%, as indicated by an arrow Y23.
- step S4 all data (100%) transmitted from the router 14a of the infrastructure node 14K to the Pods 15a of the worker nodes 15J and 15K will be transmitted through the endpoint setting unit 14k as indicated by an arrow Y17. is sent to the normal Pod 15a.
- the abnormality recovery handling unit 18 issues a recovery command to gradually increase the traffic to the launched Pod 15a to a predetermined traffic value, for example, 10%, 30%, and 50%. , to the router 14a of the master node 14J.
- step S6 in response to the recovery command, the router 14a sets the weight values of the endpoint setting unit 14j associated with the recovery target Pod 15a of the worker node 15J to 10%, 30%, Gradually increase to 50% and a predetermined traffic value and restore.
- FIG. 11 is a block diagram for explaining the second anomaly handling process of the virtualization system fault isolation device 10 of this embodiment. Anomaly detection requiring the second anomaly handling process is the sixth anomaly detection.
- an external endpoint setting unit 16 associated so as to be shared by the Pods 15a and 15b of each of the worker nodes 15J and 15K is provided.
- the external endpoint setting unit 16 has a configuration in which the external DBs 26a and 26b of endpoints (end points) are associated in a 1:n manner. These association configurations are performed by the deployment instruction unit 19 .
- the external endpoint setting unit 16 receives the data indicated by the arrow Y31 or the arrow Y32 from the Pods 15a and 15b of the worker nodes 15J and 15K, distributes and transmits the data to the plurality of external DBs 26a and 26b as indicated by the arrows Y33 and Y34. do. Also, the external endpoint setting unit 16 is set with a distribution ratio (%) for distributing the traffic at the time of transmission, and transmits data to the external DBs 26a and 26b with traffic according to the distribution ratio.
- the container management unit 14f deletes the endpoint of the abnormal external DB 26a from the external endpoint setting unit 16. This deletion suppresses communication of a Pod that communicates with the deleted endpoint (for example, Pod 15a of worker node 15J).
- the anomaly recovery handling unit 18 determines which external endpoint setting unit 16 possesses the detected IP (Internet Protocol) address of the external DB 26a. recognize.
- IP Internet Protocol
- the failure recovery handling unit 18 makes an inquiry to the container management unit 14f as indicated by the two-way arrow Y24, and receives from the container management unit 14f an external endpoint setting unit having the IP address of the abnormal external DB 26a. Get 16 pieces of information.
- the failure recovery handling unit 18 transmits a command to the router 14a of the master node 14J to set the traffic allocation ratio to the external DB 26a for the IP address set in the external endpoint setting unit 16 obtained above to 0%. .
- the router 14a receives the command and notifies it to the container management section 14f.
- the container management unit 14f changes the traffic distribution ratio to the abnormal external DB 26a set in the external endpoint setting unit 16 to 0%. As a result, the abnormal external DB 26a is cut off (see x mark).
- the virtualization system fault isolation device 10 is implemented by a computer 100 configured as shown in FIG. 12, for example.
- the computer 100 includes a CPU (Central Processing Unit) 101, a ROM (Read Only Memory) 102, a RAM (Random Access Memory) 103, a HDD (Hard Disk Drive) 104, an input/output I/F (Interface) 105, and a communication I/F 106. , and a media I/F 107 .
- the CPU 101 operates based on programs stored in the ROM 102 or HDD 104, and controls each functional unit.
- the ROM 102 stores a boot program executed by the CPU 101 when the computer 100 is started, a program related to the hardware of the computer 100, and the like.
- the CPU 101 controls an output device 111 such as a printer or display and an input device 110 such as a mouse or keyboard via the input/output I/F 105 .
- the CPU 101 acquires data from the input device 110 or outputs generated data to the output device 111 via the input/output I/F 105 .
- the HDD 104 stores programs executed by the CPU 101 and data used by the programs.
- Communication I/F 106 receives data from another device (not shown) via communication network 112 and outputs the data to CPU 101, and also transmits data generated by CPU 101 to another device via communication network 112. .
- the media I/F 107 reads programs or data stored in the recording medium 113 and outputs them to the CPU 101 via the RAM 103 .
- the CPU 101 loads a program related to target processing from the recording medium 113 onto the RAM 103 via the media I/F 107, and executes the loaded program.
- the recording medium 113 is an optical recording medium such as a DVD (Digital Versatile Disc) or a PD (Phase change rewritable Disk), a magneto-optical recording medium such as an MO (Magneto Optical disk), a magnetic recording medium, a conductor memory tape medium, a semiconductor memory, or the like. is.
- the CPU 101 of the computer 100 performs the functions of the virtualization system fault isolation device 10 by executing the program loaded on the RAM 103. Realize. Data in the RAM 103 is also stored in the HDD 104 .
- the CPU 101 reads a program related to target processing from the recording medium 113 and executes it. In addition, the CPU 101 may read a program related to target processing from another device via the communication network 112 .
- the fault isolation device 10 is virtually created by container virtualization software on a physical machine, and is virtually created with a computational resource cluster 15 that clusters and arranges the virtually created containers, and a cluster management unit 14 that manages control related to arrangement and operation of clustered containers.
- the fault isolation device 10 associates endpoint setting units 14j and 14k, which are associated with each of a plurality of containers and serve as end points of communication data in which the distribution ratio of traffic to each container is set, with each container. It includes a deploy instruction unit 19 that performs placement processing, and an anomaly detection unit 17 that is created outside the virtually created computational resource cluster 15 and cluster management unit 14 and detects an anomaly in a container.
- the fault isolation device 10 is created externally, and the fault recovery handling unit 18 sends to the cluster management unit 14 a change command for setting the allocation ratio to the faulty container detected by the fault detection unit 17 to 0%.
- the cluster management unit 14 described above is configured to set the distribution ratio of the endpoint setting unit (for example, the endpoint setting unit 14j) associated with the abnormal container to 0% in response to the change command.
- the traffic of abnormal container communication via the endpoint setting units 14j and 14k with a distribution ratio of 0% is 0. Therefore, the abnormal container can be separated from the normal container. Since the anomaly detection unit 17 and the anomaly recovery handling unit 18 are not involved in the container virtualization software, the recovery can be performed faster than the recovery by the container failure recovery function of the container virtualization software.
- the fault monitoring cycle can only be set to a predetermined cycle, but in the present invention, container faults are detected regardless of the monitoring cycle. to stop the abnormal container. Therefore, it is possible to recover faster than recovery by the failure recovery function.
- the abnormal recovery handling unit 18 sends a restoration command to the cluster management unit 14 to gradually increase the traffic to the container to be restored to a predetermined traffic value.
- the cluster management unit 14 is configured to gradually increase the distribution ratio of the endpoint setting units 14j and 14k associated with the container to be restored to a predetermined traffic value in response to the restoration command.
- the traffic distribution ratio of the endpoint setting units 14j and 14k associated with the abnormal container is gradually increased to a predetermined traffic value. Therefore, it is possible to reduce the risk of a failure caused by a sudden increase in traffic when the container is restored.
- the recovery command is sent by the failure recovery handling unit 18, which is not involved in the container virtualization software, and the failure container is recovered, the recovery can be performed faster than recovery by the container failure recovery function of the container virtualization software.
- the fault isolation device 10 is virtually created by container virtualization software on a physical machine, and is virtually created with a computational resource cluster 15 that clusters and arranges the virtually created containers, and a cluster management unit 14 that manages control related to arrangement and operation of clustered containers.
- the fault isolation device 10 is connected to the outside of the computing resource cluster 15 via a network, and is associated with a plurality of external DBs 26a and 26b storing data related to containers, and a plurality of containers of the computing resource cluster 15. and an external endpoint setting unit 16 in which a traffic distribution ratio is set when data from a container is distributed to the plurality of external DBs 26a and 26b and transmitted. .
- the fault isolation device 10 associates endpoint setting units 14j and 14k, which are associated with each of a plurality of containers and serve as end points of communication data in which the distribution ratio of traffic to each container is set, with each container. It comprises a deploy instruction unit 19 that performs placement processing, and an anomaly detection unit 17 that is created outside the virtually created computational resource cluster 15 and cluster management unit 14 and that detects anomalies in the external DBs 26a and 26b. Further, an abnormality recovery handling unit 18 is provided which transmits to the cluster management unit 14 a change command created externally and for setting the distribution ratio to the abnormality DB 16a detected by the abnormality detection unit 17 to 0%.
- the abnormality recovery handling unit 18 cluster-manages the information of the external endpoint setting unit 16 having the IP address of the detected abnormal external DB 26a.
- a command is sent to the cluster management unit 14 to set the allocation ratio set in the external endpoint setting unit 16 of the acquired information to 0%.
- the cluster management unit 14 is configured to change the traffic distribution ratio to the abnormal external DB 26a to 0% according to the command.
- the communication traffic to the abnormal external DB 26a outside the computational resource cluster 15 via the external endpoint setting unit 16 with a distribution ratio of 0% is 0. Therefore, the abnormal external DBs 26a and 26b outside the computational resource cluster 15 can be separated.
- a computational resource cluster that is virtually created on a physical machine by container virtualization software and that clusters and arranges the virtually created containers, and the virtually created and clustered containers
- a cluster management unit that manages control related to the placement and operation of a container, and an endpoint setting unit that is associated with each of a plurality of containers and serves as the end point of communication data in which the distribution ratio of traffic to each container is set.
- the virtualization system failure isolation device is characterized in that, according to a command, the distribution ratio of the endpoint setting unit associated with the abnormal container is set to 0%.
- the traffic of abnormal container communication via the endpoint setting unit with a distribution ratio of 0% is 0. Therefore, the abnormal container can be separated from the normal container. Since the anomaly detection part and the anomaly recovery handling part are not involved in the container virtualization software, the recovery can be performed faster than the recovery by the container failure recovery function of the container virtualization software.
- the fault monitoring cycle can only be set to a predetermined cycle, but in the present invention, container faults are detected regardless of the monitoring cycle. to stop the abnormal container. Therefore, it is possible to recover faster than recovery by the failure recovery function.
- the abnormal recovery handling unit transmits to the cluster management unit a restoration command for gradually increasing the traffic to the container to be restored to a predetermined traffic value, and the cluster management unit , the virtualization system according to the above (1), wherein, according to the restoration command, the distribution ratio of the endpoint setting unit associated with the container to be restored is gradually increased to the predetermined traffic value. It is a fault isolation device.
- the traffic distribution ratio of the endpoint setting unit associated with the abnormal container is gradually increased to a predetermined traffic value. Therefore, it is possible to reduce the risk of a failure caused by a sudden increase in traffic when the container is restored.
- the recovery command is sent by the failure recovery handling unit that is not involved in the container virtualization software to recover the failed container, recovery can be performed faster than recovery by the container failure recovery function of the container virtualization software.
- a computational resource cluster that is virtually created on a physical machine by container virtualization software and that clusters and arranges the virtually created containers; and the virtually created and clustered containers a plurality of DBs (Data Bases) connected to the outside of the computational resource cluster via a network and storing data related to the containers; and the computational resource cluster External endpoint setting associated with a plurality of containers of and associated with the plurality of DBs, and in which a traffic distribution ratio is set when data from the container is distributed to the plurality of DBs and transmitted an anomaly detection unit created outside the virtually created computational resource cluster and the cluster management unit to detect an anomaly in the DB; and an anomaly detected by the anomaly detection unit created outside the an error recovery handling unit for transmitting a change command for setting the allocation ratio to the DB to 0% to the cluster management unit, wherein the error recovery handling unit detects an error in the DB by the error detection unit; information of the external endpoint setting unit having the IP (Internet Protocol) address of the detected anomaly DB is obtained from the cluster management unit
- the communication traffic to the anomaly DB external to the computational resource cluster via the external endpoint setting unit with a distribution ratio of 0% is 0. Therefore, the abnormal DB outside the computational resource cluster can be separated.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Quality & Reliability (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/571,435 US20240289227A1 (en) | 2021-06-29 | 2021-06-29 | Virtualized system fault isolation device and virtualized system fault isolation method |
| JP2023531189A JP7632632B2 (ja) | 2021-06-29 | 2021-06-29 | 仮想化システム障害分離装置及び仮想化システム障害分離方法 |
| PCT/JP2021/024527 WO2023275983A1 (ja) | 2021-06-29 | 2021-06-29 | 仮想化システム障害分離装置及び仮想化システム障害分離方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/024527 WO2023275983A1 (ja) | 2021-06-29 | 2021-06-29 | 仮想化システム障害分離装置及び仮想化システム障害分離方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023275983A1 true WO2023275983A1 (ja) | 2023-01-05 |
Family
ID=84689786
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/024527 Ceased WO2023275983A1 (ja) | 2021-06-29 | 2021-06-29 | 仮想化システム障害分離装置及び仮想化システム障害分離方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240289227A1 (https=) |
| JP (1) | JP7632632B2 (https=) |
| WO (1) | WO2023275983A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120762379A (zh) * | 2025-07-11 | 2025-10-10 | 深圳华诚包装科技股份有限公司 | 基于智能控制的自动化包装生产线优化方法及其系统 |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12149600B2 (en) * | 2021-12-15 | 2024-11-19 | Red Hat, Inc. | Differentiating controllers and reconcilers for software operators in a distributed computing environment |
| US12306980B2 (en) * | 2023-08-21 | 2025-05-20 | Bank Of America Corporation | Network operating system deployment to remote hardware for network extensibility |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111414229A (zh) * | 2020-03-09 | 2020-07-14 | 网宿科技股份有限公司 | 一种应用容器异常处理方法及装置 |
| WO2020184362A1 (ja) * | 2019-03-08 | 2020-09-17 | ラトナ株式会社 | コンテナオーケストレーション技術を利用したセンサ情報処理システム |
| JP2021027398A (ja) * | 2019-07-31 | 2021-02-22 | 日本電気株式会社 | コンテナデーモン、情報処理装置、コンテナ型仮想化システム、パケット振り分け方法及びプログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9535794B2 (en) * | 2013-07-26 | 2017-01-03 | Globalfoundries Inc. | Monitoring hierarchical container-based software systems |
| US10732995B2 (en) * | 2018-02-27 | 2020-08-04 | Portworx, Inc. | Distributed job manager for stateful microservices |
-
2021
- 2021-06-29 WO PCT/JP2021/024527 patent/WO2023275983A1/ja not_active Ceased
- 2021-06-29 US US18/571,435 patent/US20240289227A1/en not_active Abandoned
- 2021-06-29 JP JP2023531189A patent/JP7632632B2/ja active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020184362A1 (ja) * | 2019-03-08 | 2020-09-17 | ラトナ株式会社 | コンテナオーケストレーション技術を利用したセンサ情報処理システム |
| JP2021027398A (ja) * | 2019-07-31 | 2021-02-22 | 日本電気株式会社 | コンテナデーモン、情報処理装置、コンテナ型仮想化システム、パケット振り分け方法及びプログラム |
| CN111414229A (zh) * | 2020-03-09 | 2020-07-14 | 网宿科技股份有限公司 | 一种应用容器异常处理方法及装置 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120762379A (zh) * | 2025-07-11 | 2025-10-10 | 深圳华诚包装科技股份有限公司 | 基于智能控制的自动化包装生产线优化方法及其系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7632632B2 (ja) | 2025-02-19 |
| JPWO2023275983A1 (https=) | 2023-01-05 |
| US20240289227A1 (en) | 2024-08-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10860311B2 (en) | Method and apparatus for drift management in clustered environments | |
| US8910172B2 (en) | Application resource switchover systems and methods | |
| CN102597962B (zh) | 用于虚拟计算环境中的故障管理的方法和系统 | |
| CN108270726B (zh) | 应用实例部署方法及装置 | |
| JP6089884B2 (ja) | 情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 | |
| JP5298764B2 (ja) | 仮想システム制御プログラム、方法及び装置 | |
| JP7632632B2 (ja) | 仮想化システム障害分離装置及び仮想化システム障害分離方法 | |
| US11119872B1 (en) | Log management for a multi-node data processing system | |
| US9223606B1 (en) | Automatically configuring and maintaining cluster level high availability of a virtual machine running an application according to an application level specified service level agreement | |
| US8990608B1 (en) | Failover of applications between isolated user space instances on a single instance of an operating system | |
| WO2014076838A1 (ja) | 仮想マシン同期システム | |
| CN103718535A (zh) | 硬件故障的缓解 | |
| US20110099273A1 (en) | Monitoring apparatus, monitoring method, and a computer-readable recording medium storing a monitoring program | |
| US11762741B2 (en) | Storage system, storage node virtual machine restore method, and recording medium | |
| US12596567B2 (en) | High availability control plane node for container-based clusters | |
| KR102153622B1 (ko) | 결함 처리를 위한 확장 가능한 네트워크 연결 저장 장치 및 방법 | |
| US10367711B2 (en) | Protecting virtual computing instances from network failures | |
| WO2020032169A1 (ja) | 障害復旧制御方法、通信装置、通信システム、及びプログラム | |
| JP2018055481A (ja) | ログ監視装置、ログ監視方法及びログ監視プログラム | |
| JP6555721B2 (ja) | 障害復旧システム及び方法 | |
| JP7694659B2 (ja) | 仮想化システム障害分離装置及び仮想化システム障害分離方法 | |
| US20230289203A1 (en) | Server maintenance control device, server maintenance system, server maintenance control method, and program | |
| JP7632633B2 (ja) | 仮想化システム復旧装置及び仮想化システム復旧方法 | |
| Kitamura et al. | Development of a Server Management System Incorporating a Peer-to-Peer Method for Constructing a High-availability Server System | |
| US9405605B1 (en) | Correction of dependency issues in network-based service remedial workflows |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21948292 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023531189 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18571435 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21948292 Country of ref document: EP Kind code of ref document: A1 |