WO2023233633A1 - 情報処理プログラム、情報処理方法および情報処理装置 - Google Patents
情報処理プログラム、情報処理方法および情報処理装置 Download PDFInfo
- Publication number
- WO2023233633A1 WO2023233633A1 PCT/JP2022/022525 JP2022022525W WO2023233633A1 WO 2023233633 A1 WO2023233633 A1 WO 2023233633A1 JP 2022022525 W JP2022022525 W JP 2022022525W WO 2023233633 A1 WO2023233633 A1 WO 2023233633A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sentence
- vector
- learning model
- machine learning
- information processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/268—Morphological analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/42—Data-driven translation
- G06F40/44—Statistical methods, e.g. probability models
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
Definitions
- the present invention relates to information processing programs and the like.
- the correct sentence ⁇ The function is the characteristic'' and the incorrectly input sentence ⁇ The yesterday is the characteristic'' are sentences with greatly different meanings, and the vectors of each sentence are also significantly different.
- a learning model is trained using a dataset of pairs of input errors and their corrected sentences from the correction history, and the trained learning model is used to select target sentences.
- the above-mentioned conventional technology is a technology that fills in blank spaces in which some words in a sentence are masked, and although the accuracy of filling in blank spaces in a sentence consisting of multiple words is high, There are few descriptions of improving the accuracy of sentences that fill in the blanks in sentences that are composed of sentences, and there are no descriptions of sentences that include input errors. Further, in the conventional technology, although input errors such as typos and omissions can be corrected, input errors due to erroneous conversion cannot be correctly corrected in many cases.
- the present invention provides an information processing program, an information processing method, and an information processing apparatus that are capable of estimating a sentence to fill in a blank in a sentence composed of a plurality of sentences and detecting a sentence containing an input error.
- the purpose is to provide
- the computer executes the following process.
- the computer calculates vectors for each of a plurality of consecutive sentences that have a relationship with the preceding and following sentences. By sequentially inputting multiple sentence vectors into a machine learning model and training it, a computer can calculate the sentence vector of the sentence input next to a certain sentence when inputting a sentence vector to the machine learning model. Generate a machine learning model to predict.
- the computer calculates a vector for the first sentence and a vector for the second sentence following the first sentence.
- the computer calculates a vector of a sentence predicted to follow the first sentence by inputting the vector of the first sentence into the machine learning model, and determines whether the vector of the second sentence is appropriate.
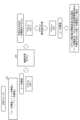
- FIG. 1 is a diagram for explaining learning phase processing of the information processing apparatus according to the present embodiment.
- FIG. 2 is a diagram for explaining analysis phase processing of the information processing apparatus according to the present embodiment.
- FIG. 3 is a functional block diagram showing the configuration of the information processing device according to this embodiment.
- FIG. 4 is a diagram showing an example of the data structure of a word vector dictionary.
- FIG. 5A is a diagram (1) for explaining the process of calculating a sentence vector.
- FIG. 5B is a diagram (2) for explaining the process of calculating a sentence vector.
- FIG. 6 is a diagram for explaining the process of generating a transposed sentence index.
- FIG. 7 is a flowchart showing the processing procedure of the learning phase of the information processing apparatus according to the present embodiment.
- FIG. 7 is a flowchart showing the processing procedure of the learning phase of the information processing apparatus according to the present embodiment.
- FIG. 8 is a flowchart showing the processing procedure of the analysis phase of the information processing apparatus according to this embodiment.
- FIG. 9 is a diagram (1) for explaining other processing of the information processing device.
- FIG. 10 is a diagram (2) for explaining other processing of the information processing device.
- FIG. 11 is a diagram illustrating an example of the hardware configuration of a computer that implements the same functions as the information processing device of the embodiment.
- FIG. 1 is a diagram for explaining learning phase processing of the information processing apparatus according to the present embodiment.
- the information processing device executes learning of the machine learning model 50 using a plurality of sentences included in the teacher data 141 (trains the machine learning model 50).
- the machine learning model 50 is a NN (Neural Network) such as BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding), Next Sentence Prediction, Transformers, etc.
- the sentences included in the teacher data 141 include multiple sentences.
- the plurality of sentences have a predetermined relationship with the sentences before and after them.
- Each sentence is a sentence set in advance based on induction, deductive syllogism, or the like.
- the sentence 10a includes, in order from the beginning, the sentence ⁇ Birds lay eggs.'', the sentence ⁇ Penguins are birds.'', ..., and the sentences ⁇ Therefore, penguins lay eggs.''.
- Sentence 10b includes, in order from the beginning, the sentences ⁇ Birds are born from eggs.'', the sentences ⁇ Pigeons are a member of the bird family.'', ..., and the sentences ⁇ Therefore, pigeons are born from eggs.''
- the information processing device calculates sentence vectors for each sentence included in sentences 10a, 10b, and other sentences. For example, the information processing device performs morphological analysis on a sentence, divides it into words, and calculates a sentence vector by integrating the vectors of each word.
- the information processing device repeatedly performs the process of inputting vectors to the machine learning model 50 in order from the vector of the first sentence included in the text. For example, the information processing device inputs sentence vectors to the machine learning model 50 in the order of sentence vectors "SV1-1", “SV1-2”, . . . , "SV1-3". The information processing device inputs sentence vectors to the machine learning model 50 in the order of sentence vectors "SV2-1", “SV2-2", . . . , "SV2-3".
- a machine learning model 50 in which an information processing device predicts a sentence vector of a second sentence following the first sentence when a sentence vector of a certain first sentence is input by executing the process of the learning phase described above. is generated.
- FIG. 2 is a diagram for explaining the analysis phase processing of the information processing apparatus according to the present embodiment.
- the information processing device uses the trained machine learning model 50 to calculate sentence vectors included in the sentence to be processed, and detects inappropriate sentences based on cosine similarity or the like.
- Sentence 20 is composed of, in order from the beginning, the sentence ⁇ Birds lay eggs.'', the sentence ⁇ Penguins take pictures.'', ..., and the sentences ⁇ Therefore, penguins lay eggs.''
- the sentence "Penguin is a photo.” is a sentence containing an input error of the homophone "Tori" of the word "Bird” in contrast to the correct sentence "Penguin is a bird.” included in the sentence 10a of the teacher data 141.
- the information processing device calculates the sentence vector “SV1-1” of the sentence “Birds lay eggs.” and inputs the calculated sentence vector “SV1-1” into the machine learning model 50. Predict the sentence vector for the next sentence. In the example shown in FIG. 2, the machine learning model 50 predicts "SV1-2" as the sentence vector of the next sentence after the sentence "Birds lay eggs.”
- the information processing device calculates the sentence vector “SV3” of the sentence “Penguin is photographed” which is a sentence included in the sentence 20 and is the next sentence after the sentence “Birds lay eggs.”
- the information processing device uses the sentence vector "SV1-2" of the next sentence predicted by the machine learning model 50 and the sentence "SV1-2" included in the sentence 20, which is the next sentence after the sentence "Birds lay eggs.”
- the cosine similarity with the sentence vector "SV3" of "Penguin is a photo” is calculated.
- the information processing device determines that the sentence "Penguins are birds.”, which is the sentence included in sentence 10a and follows the sentence "Birds lay eggs.”, is correct when the cosine similarity is less than the threshold (hereinafter referred to as It is determined that the sentence is correct.
- the information processing device determines that the sentence ⁇ The penguin is photographing'', which is the sentence included in sentence 20 and follows the sentence ⁇ Birds lay eggs.'', is an input error when the cosine similarity is less than the threshold. It is determined that the sentence is inappropriate.
- the information processing device sequentially inputs the vectors of each sentence of the sentences included in the teacher data 141 to the machine learning model 50, so that when the sentence vector of a certain first sentence is input, A machine learning model 50 is generated that predicts the sentence vector of the second sentence following the first sentence.
- the information processing device inputs the sentence vector of the sentence to be processed into the generated machine learning model, predicts the sentence vector of the next sentence, and based on the predicted sentence vector, extracts the sentence from the sentence to be processed. Detect sentences with input errors. That is, it is possible to detect sentences that include input errors and have inappropriate sentence vectors from each sentence included in the text to be processed.
- the information processing device determines that the sentence "Penguin is a photo" is a sentence with an inappropriate sentence vector
- the information processing device uses the sentence vector SV1-2 predicted by the machine learning model 50. Then, the correct sentence vector "Penguin is a bird.” may be searched from a DB (Data Base) or the like, and output as a correct correction candidate to the display device (hereinafter referred to as optimization).
- DB Data Base
- the information processing device uses another machine learning model that has learned the order of vectors in word units to include the words ⁇ penguin'' and ⁇ ha'' that make up the sentence ⁇ Penguin is a photo'' in which the incorrect sentence vector was detected. , "Tori.” may be calculated, and input errors of the deviated word “Tori.” may be corrected.
- FIG. 3 is a functional block diagram showing the configuration of the information processing apparatus according to this embodiment.
- the information processing device 100 includes a communication section 110, an input section 120, a display section 130, a storage section 140, and a control section 150.
- the communication unit 110 is connected to an external device or the like by wire or wirelessly, and transmits and receives information to and from the external device.
- the communication unit 110 is realized by a NIC (Network Interface Card) or the like.
- the communication unit 110 may be connected to a network (not shown).
- the input unit 120 is an input device that inputs various information to the information processing device 100.
- the input unit 120 corresponds to a keyboard, a mouse, a touch panel, etc.
- the user may operate the input unit 120 to input text data and the like.
- the display unit 130 is a display device that displays information output from the control unit 150.
- the display unit 130 corresponds to a liquid crystal display, an organic EL (Electro Luminescence) display, a touch panel, etc. For example, a sentence with an input error is displayed on the display unit 130.
- the storage unit 140 includes a machine learning model 50, teacher data 141, and a word vector dictionary 142.
- the storage unit 140 is realized by, for example, a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory, or a storage device such as a hard disk or an optical disk.
- a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory
- a storage device such as a hard disk or an optical disk.
- the machine learning model 50 is a NN such as BERT, Next Sentence Prediction, Transformers, etc. described in FIG. 1.
- the teacher data 141 is the teacher data 141 described in FIG.
- the sentences included in the teacher data 141 include a plurality of sentences.
- the plurality of sentences have a predetermined relationship with the sentences before and after them.
- Each sentence is a sentence set in advance based on induction, deductive syllogism, or the like.
- the word vector dictionary 142 is a table that defines codes and word vectors assigned to words.
- FIG. 4 is a diagram showing an example of the data structure of a word vector dictionary. As shown in FIG. 4, this word vector dictionary 142 has codes, words, and word vectors (1) to (7).
- the code is a code assigned to a word.
- a word is a word included in a character string.
- Word vectors (1) to (7) are vectors assigned to words.
- the DB 143 has various texts.
- a sentence contains multiple sentences, and each sentence contains multiple words.
- the DB 143 may have sentences included in the teacher data 141.
- the sentence transposed index 144 associates sentence vectors with position pointers.
- the position pointer indicates the position in the DB 143 where the sentence corresponding to the sentence vector exists.
- the control unit 150 includes a preprocessing unit 151, a learning unit 152, and an analysis unit 153.
- the control unit 150 is realized by, for example, a CPU (Central Processing Unit) or an MPU (Micro Processing Unit). Further, the control unit 150 may be executed by an integrated circuit such as an ASIC (Application Specific Integrated Circuit) or an FPGA (Field Programmable Gate Array).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- the preprocessing unit 151 performs various preprocessing. For example, the preprocessing unit 151 obtains an unprocessed sentence from the DB 143 and calculates a sentence vector of the sentence. The preprocessing unit 151 sets the relationship between the calculated sentence vector and the sentence position pointer corresponding to the sentence vector in the sentence transposition index 144.
- 5A and 5B are diagrams for explaining the process of calculating a sentence vector.
- the preprocessing unit 151 performs morphological analysis on the sentence "Horses like carrots.” to decompose it into a plurality of words. Each decomposed word is marked with a " ⁇ (space)".
- sentence 1 "Horses like carrots.” can be changed to "uma ⁇ ", “ha ⁇ ”, “carrot ⁇ ”, “ga ⁇ ”, “like ⁇ ”, “desu ⁇ ", “. ⁇ ” To divide.
- the preprocessing unit 151 identifies the code corresponding to each word by comparing each divided word with the word vector dictionary 45, and replaces the code with the word.
- the words “horse ⁇ ”, “ha ⁇ ”, “carrot ⁇ ”, “ga ⁇ ”, “suki ⁇ ”, “desu ⁇ ”, “. ⁇ ” are respectively "C1", “C2”, Replaced with "C3", “C4", “C5", “C6”, and "C7".
- the preprocessing unit 151 identifies word vectors (1) to (7) assigned to the code based on the word vector dictionary 45 and each code. For example, word vectors (1) to (7) with code “C1” are assumed to be wv1-1 to wv1-7. The word vectors (1) to (7) with code “C2” are wv2-1 to wv2-7. Word vectors (1) to (7) with code “C3” are assumed to be wv3-1 to wv3-7.
- the word vectors (1) to (7) with code “C4” are wv4-1 to wv4-7.
- Word vectors (1) to (7) with code “C5” are assumed to be wv5-1 to wv5-7.
- Word vectors (1) to (7) with code “C6” are assumed to be wv6-1 to wv6-7.
- Word vectors (1) to (7) with code “C7” are assumed to be wv7-1 to wv7-7.
- the preprocessing unit 151 calculates the sentence vector SV1 of the sentence by integrating word vectors for each element. For example, the preprocessing unit 151 calculates the first component "SV1-1" of the sentence vector SV1 by integrating the word vectors (1) from wv1-1 to wv7-1. The preprocessing unit 151 calculates the second component "SV1-2" of the sentence vector SV1 by integrating the word vectors (2) from wv1-2 to wv7-2. The third component "SV1-3" of the sentence vector SV1 is calculated by integrating wv1-3 to wv7-3, which are each word vector (3).
- the preprocessing unit 151 calculates the fourth component "SV1-4" of the sentence vector SV1 by integrating wv1-4 to wv7-4, which are each word vector (4).
- the preprocessing unit 151 calculates the fifth component "SV1-5" of the sentence vector SV1 by integrating wv1-5 to wv7-5, which are each word vector (5).
- the preprocessing unit 151 calculates the sixth component "SV1-6" of the sentence vector SV1 by integrating the word vectors (6) from wv1-6 to wv7-6.
- the preprocessing unit 151 calculates the seventh component "SV1-7" of the sentence vector SV1 by integrating wv1-7 to wv7-7, which are each word vector (7).
- the preprocessing unit 151 calculates a sentence vector for each sentence by repeatedly performing the above process for each sentence of other sentences included in the DB 143.
- the preprocessing unit 151 generates a sentence transposed index 144 by associating the calculated sentence vector of each sentence with the position pointer of the DB 143.
- the preprocessing unit 151 may generate the sentence transposed index 144 having a data structure as shown in FIG.
- FIG. 6 is a diagram for explaining the process of generating a transposed sentence index.
- the preprocessing unit 151 may associate a sentence vector, a plurality of record pointers, and a plurality of position pointers, and may associate each record pointer and position pointer with each sentence in the DB 143. .
- the learning unit 152 is a machine that predicts the sentence vector of the second sentence following the first sentence when the sentence vector of a certain first sentence is input by executing the process of the learning phase explained in FIG. A learning model 50 is generated.
- the learning unit 152 executes learning of the machine learning model 50 by calculating sentence vectors of each sentence included in the sentences of the teacher data 141 and sequentially inputting the calculated sentence vectors to the machine learning model 50.
- Other processing by the learning unit 152 is similar to the processing described with reference to FIG.
- the process by which the learning unit 152 calculates a sentence vector of a sentence is similar to the process by which the preprocessing unit 151 calculates a sentence vector of a sentence.
- the analysis unit 153 detects sentences with inappropriate sentence vectors from the sentences included in the text to be processed by executing the processing of the analysis phase described in FIG. 2.
- the analysis unit 153 calculates the sentence vector of the sentence included in the text 20.
- the analysis unit 153 identifies sentences included in the sentence 20 based on the period “.” included in the sentence 20.
- the process by which the analysis unit 153 calculates a sentence vector of a sentence is similar to the process by which the preprocessing unit 151 calculates a sentence vector of a sentence.
- the analysis unit 153 inputs the sentence vector SVn into the trained machine learning model 50 and predicts the sentence vector SVn+1' of the n+1st sentence from the beginning of the sentence 20.
- the analysis unit 153 calculates the cosine similarity between the sentence vector SVn+1' predicted using the machine learning model 50 and the sentence vector SVn+1.
- the analysis unit 153 determines that the n+1st sentence from the beginning is the correct sentence. On the other hand, if the cosine similarity between the sentence vector SVn+1' and the sentence vector SVn+1 is greater than or equal to the threshold, the analysis unit 153 determines that the n+1st sentence from the beginning is an inappropriate sentence for the sentence vector.
- the analysis unit 153 determines that the sentence vector is an invalid sentence, the analysis unit 153 compares the sentence vector SVn+1' and the sentence transposed index 144 to identify the position pointer of the sentence corresponding to the sentence vector SVn+1'. . The analysis unit 153 searches the DB 143 for a sentence corresponding to the sentence vector SVn+1' based on the position pointer. The analysis unit 153 causes the display unit 130 to display the incorrect sentence in the sentence vector in association with the retrieved sentence.
- the analysis unit 153 compares the incorrect sentence in the sentence vector with the searched sentence word by word, detects words with input errors from the incorrect sentences in the sentence vector, and displays the detected words. Good too.
- FIG. 7 is a flowchart showing the processing procedure of the learning phase of the information processing apparatus according to the present embodiment.
- the learning unit 152 of the information processing device 100 selects unselected sentences from the teacher data 141 (step S101).
- the learning unit 152 calculates the sentence vector of each sentence included in the selected sentence, and generates a sentence transposed index that associates the sentence vector with the DB record and the sentence position (step S102).
- the learning unit 152 performs learning by sequentially inputting sentence vectors of the first sentence included in the selected sentence to the machine learning model 50 (step S103).
- step S104 If learning is to be continued (step S104, Yes), the learning unit 152 moves to step S101. On the other hand, if learning is not to be continued (step S104, No), the learning unit 152 ends the learning phase process.
- FIG. 8 is a flowchart showing the processing procedure of the analysis phase of the information processing device according to this embodiment.
- the analysis unit 153 of the information processing device 100 receives input of a text to be processed (step S201).
- the analysis unit 153 calculates a sentence vector for each sentence included in the input sentence (step S202).
- the analysis unit 153 sets n to an initial value (step S203).
- the analysis unit 153 inputs the sentence vector SVn of the n-th sentence among the multiple sentences included in the text to the machine learning model 50, and predicts the sentence vector SVn+1' of the n+1-th sentence (step S204).
- the analysis unit 153 calculates the cosine similarity between the sentence vector SVn+1 of the n+1-th sentence among the multiple sentences included in the sentence and the sentence vector SVn+1' of the predicted sentence (step S205).
- step S206 If the cosine similarity is greater than or equal to the threshold (step S206, Yes), the analysis unit 153 moves to step S210.
- the analysis unit 153 detects the (n+1)th sentence as a sentence with an inappropriate sentence vector (step S207).
- the analysis unit 153 detects a sentence corresponding to the sentence vector SVn+1' from the DB 143 based on the predicted sentence vector SVn+1' and the sentence transposed index 144 (step S208).
- the analysis unit 153 displays the sentences with inappropriate sentence vectors and the sentences detected from the DB 143 on the display unit 130 (step S209).
- step S210 If n is greater than or equal to L (step S210, Yes), the analysis unit 153 ends the process. L is the number of sentences included in the text to be processed. If n is not greater than or equal to L (step S210, No), the analysis unit 153 updates n with a value obtained by adding 1 to n (step S211), and proceeds to step S204.
- the information processing device 100 sequentially inputs the vectors of each sentence of the sentences included in the teacher data 141 to the machine learning model 50, so that when the sentence vector of a certain first sentence is input, A machine learning model 50 is generated that predicts the sentence vector of the second sentence.
- the information processing device 100 inputs the sentence vector of the sentence to be processed into the generated machine learning model 50, predicts the sentence vector of the next sentence, and based on the predicted sentence vector, calculates the sentence vector of the sentence to be processed. Detect sentences with invalid sentence vectors. In addition, it is possible to correct words that have been input incorrectly from the incorrect sentence.
- the information processing device 100 calculates the sentence vector based on the cosine similarity between the sentence vector of the next sentence predicted by the machine learning model 50 and the sentence vector of the sentence next to the sentence included in the processing target sentence. Detect inappropriate sentences and correct input errors. This makes it possible to detect inappropriate sentences in sentence vectors and correct input errors, etc., while reducing calculation costs.
- the information processing device 100 trains the machine learning model by sequentially inputting vectors of a plurality of sentences whose arrangement order is determined based on an induction method or a deductive method to a machine learning model. This makes it possible to predict the next sentence after the target sentence based on induction or deduction.
- the information processing device 100 searches for a corrected sentence based on the vector predicted by the machine learning model 50. With this, it is possible to notify the corrected sentence.
- processing content of the information processing device 100 described above is an example, and the information processing device 100 may perform other processing. Below, other processing of the information processing device 100 will be explained.
- FIGS. 9 and 10 are diagrams for explaining other processing of the information processing device.
- the information processing device 100 described above had the machine learning model 50 learn the order of sentence vectors based on a syllogism, but instead of a sentence vector, it is a sequence of proteins, and a plurality of amino acids corresponding to words.
- the order of vectors of protein primary structure composed of sequences may be learned.
- the continuous amino acid sequence of a protein will be referred to as a "basic structure” and the primary structure of a protein will be referred to as a "primary structure.”
- FIG. 9 will be explained.
- the information processing device 100 executes learning of the machine learning model 50 using the plurality of protein sequences 20a and 20b included in the teacher data 241.
- the sequence 20a includes primary structures “ ⁇ primary structure”, “ ⁇ primary structure”, . . . , “ ⁇ primary structure”.
- the array 20b includes primary structures “ ⁇ primary structure”, “ ⁇ primary structure”, . . . , “ ⁇ primary structure”.
- the information processing device 100 identifies vectors of each primary structure using a vector dictionary of protein basic structures that associates basic structures with vectors.
- the vector of the primary structure " ⁇ primary structure” consisting of multiple basic structures is “V20-1”
- the vector of the primary structure " ⁇ primary structure” is “V20-2”
- the vector of the primary structure " ⁇ primary structure” is Let the vector be "V20-3”.
- the vector of the primary structure “ ⁇ primary structure” be "V21-2”
- the vector of the primary structure " ⁇ primary structure” be "V21-3”.
- the vector of each primary structure is calculated based on the vector of each basic structure of the plurality of basic structures that constitute the primary structure.
- the information processing device 100 repeatedly performs the process of inputting vectors to the machine learning model 50 in order from the first primary structure vector included in the protein sequence. For example, the information processing device inputs vectors to the machine learning model 50 in the order of vectors "V20-1", “V20-2”, . . . , “V20-3". The information processing device inputs the vectors to the machine learning model 50 in the order of vectors "V21-1", “V21-2”, . . . , "V21-3".
- the information processing device 100 executes the above-described learning phase process to generate a machine learning model 50 that predicts a vector of a primary structure next to a certain primary structure when a vector of a certain primary structure is input. Ru.
- sequence 25 the sequence of the protein to be processed is designated as sequence 25.
- the array 25 includes primary structures " ⁇ primary structure”, “ ⁇ primary structure”, . . . , " ⁇ primary structure” in order from the beginning.
- the information processing device 100 calculates the vector “V20-1” of the primary structure “ ⁇ primary structure” and inputs the calculated vector “V20-1” to the machine learning model 50 to obtain the primary structure “ ⁇ primary structure”. ” to predict the next primary structure vector.
- the machine learning model 50 predicts "V20-2" as the vector of the primary structure next to the primary structure " ⁇ primary structure”.
- the information processing device 100 calculates the vector "V22" of the " ⁇ primary structure” which is a primary structure included in the array 25 and is the next to the primary structure " ⁇ primary structure”.
- the information processing device 100 uses the vector “V20-2” of the next primary structure predicted by the machine learning model 50 and the primary structure “ ⁇ ” next to the basic structure “ ⁇ primary structure” included in the array 25.
- the cosine similarity of the vector “V22” of the “primary structure” is calculated.
- the information processing device determines that the “ ⁇ primary structure” included in the array 25, which follows the primary structure “ ⁇ primary structure”, is the correct primary structure. On the other hand, if the cosine similarity is less than the threshold, the information processing device determines that the " ⁇ primary structure” that is included in the array 25 and that follows the primary structure " ⁇ primary structure” is an inappropriate primary structure. It is determined that mutations in the basic structure included in the primary structure " ⁇ primary structure” are optimized.
- a primary structure having an inappropriate primary structure vector is detected from a plurality of primary structures included in a protein sequence, and mutation etc. It is possible to optimize a certain basic structure. This makes it possible to detect protein primary structures that have mutations (typical examples being SNPs) that occur in receptors that are composed of multiple protein primary structures. Furthermore, by machine learning the primary structures of many proteins that make up the receptor and the primary structures of single or multiple proteins that bind to the receptor in the binding order, we can predict the protein primary structure vector of the ligand that binds to the receptor. can do. This makes it possible to support the improvement of ligands with new protein primary structure vectors that are similar to ligands already commercialized as biopharmaceuticals, have excellent medicinal efficacy, and suppress side reactions.
- FIG. 11 is a diagram illustrating an example of the hardware configuration of a computer that implements the same functions as the information processing device of the embodiment.
- the computer 300 includes a CPU 301 that executes various calculation processes, an input device 302 that accepts data input from the user, and a display 303.
- the computer 300 also includes a communication device 304 and an interface device 305 that exchange data with an external device or the like via a wired or wireless network.
- the computer 300 also includes a RAM 306 that temporarily stores various information and a hard disk device 307. Each device 301 to 307 is then connected to a bus 308.
- the hard disk device 307 has a preprocessing program 307a, a learning program 307b, and an analysis program 307c. Further, the CPU 301 reads each program 307a to 307c and expands it into the RAM 306.
- the preprocessing program 307a functions as a preprocessing process 306a.
- the learning program 307b functions as a learning process 306b.
- the analysis program 307c functions as an analysis process 306c.
- the processing of the preprocessing process 306a corresponds to the processing of the preprocessing section 151.
- the processing of the learning process 306b corresponds to the processing of the learning section 152.
- the processing of the analysis process 306c corresponds to the processing of the analysis unit 153.
- each of the programs 307a to 307c does not necessarily need to be stored in the hard disk device 307 from the beginning.
- each program is stored in a "portable physical medium" such as a flexible disk (FD), CD-ROM, DVD, magneto-optical disk, or IC card that is inserted into the computer 300. Then, the computer 300 may read and execute each program 307a to 307c.
- Machine learning model 100 Information processing device 110 Communication unit 120 Input unit 130 Display unit 140 Storage unit 141 Teacher data 142 Word vector dictionary 143 DB 144 Sentence transposition index 150 Control unit 151 Preprocessing unit 152 Learning unit 153 Analysis unit
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Probability & Statistics with Applications (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/022525 WO2023233633A1 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
| CN202280096573.1A CN119301599A (zh) | 2022-06-02 | 2022-06-02 | 信息处理程序、信息处理方法以及信息处理装置 |
| JP2024524117A JP7806894B2 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
| EP22944914.5A EP4535224A4 (en) | 2022-06-02 | 2022-06-02 | INFORMATION PROCESSING PROGRAM, INFORMATION PROCESSING METHOD, AND INFORMATION PROCESSING DEVICE |
| AU2022461080A AU2022461080A1 (en) | 2022-06-02 | 2022-06-02 | Information processing program, information processing method, and information processing device |
| US18/957,134 US20250086387A1 (en) | 2022-06-02 | 2024-11-22 | Recording medium storing information processing program, information processing method, and information processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/022525 WO2023233633A1 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/957,134 Continuation US20250086387A1 (en) | 2022-06-02 | 2024-11-22 | Recording medium storing information processing program, information processing method, and information processing apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023233633A1 true WO2023233633A1 (ja) | 2023-12-07 |
Family
ID=89026185
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/022525 Ceased WO2023233633A1 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20250086387A1 (https=) |
| EP (1) | EP4535224A4 (https=) |
| JP (1) | JP7806894B2 (https=) |
| CN (1) | CN119301599A (https=) |
| AU (1) | AU2022461080A1 (https=) |
| WO (1) | WO2023233633A1 (https=) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019016140A (ja) * | 2017-07-06 | 2019-01-31 | 株式会社朝日新聞社 | 校正支援装置、校正支援方法及び校正支援プログラム |
| JP2019101993A (ja) | 2017-12-07 | 2019-06-24 | 富士通株式会社 | 特定プログラム、特定方法および情報処理装置 |
| CN111539199A (zh) * | 2020-04-17 | 2020-08-14 | 中移(杭州)信息技术有限公司 | 文本的纠错方法、装置、终端、及存储介质 |
| JP2021089696A (ja) * | 2019-12-06 | 2021-06-10 | アイビーリサーチ株式会社 | 入力支援装置、入力支援システム及びプログラム |
| WO2021124490A1 (ja) * | 2019-12-18 | 2021-06-24 | 富士通株式会社 | 情報処理プログラム、情報処理方法および情報処理装置 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102329738B1 (ko) * | 2019-10-30 | 2021-11-19 | 연세대학교 산학협력단 | 토픽 기반의 일관성 모델링을 통한 문장 순서 재구성 방법 및 장치 |
| CN111428470B (zh) * | 2020-03-23 | 2022-04-22 | 北京世纪好未来教育科技有限公司 | 文本连贯性判定及其模型训练方法、电子设备及可读介质 |
| CN112256840A (zh) * | 2020-11-12 | 2021-01-22 | 北京亚鸿世纪科技发展有限公司 | 改进迁移学习模型进行工业互联网发现并提取信息的装置 |
-
2022
- 2022-06-02 EP EP22944914.5A patent/EP4535224A4/en active Pending
- 2022-06-02 CN CN202280096573.1A patent/CN119301599A/zh active Pending
- 2022-06-02 WO PCT/JP2022/022525 patent/WO2023233633A1/ja not_active Ceased
- 2022-06-02 AU AU2022461080A patent/AU2022461080A1/en active Pending
- 2022-06-02 JP JP2024524117A patent/JP7806894B2/ja active Active
-
2024
- 2024-11-22 US US18/957,134 patent/US20250086387A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019016140A (ja) * | 2017-07-06 | 2019-01-31 | 株式会社朝日新聞社 | 校正支援装置、校正支援方法及び校正支援プログラム |
| JP2019101993A (ja) | 2017-12-07 | 2019-06-24 | 富士通株式会社 | 特定プログラム、特定方法および情報処理装置 |
| JP2021089696A (ja) * | 2019-12-06 | 2021-06-10 | アイビーリサーチ株式会社 | 入力支援装置、入力支援システム及びプログラム |
| WO2021124490A1 (ja) * | 2019-12-18 | 2021-06-24 | 富士通株式会社 | 情報処理プログラム、情報処理方法および情報処理装置 |
| CN111539199A (zh) * | 2020-04-17 | 2020-08-14 | 中移(杭州)信息技术有限公司 | 文本的纠错方法、装置、终端、及存储介质 |
Non-Patent Citations (3)
| Title |
|---|
| KAZUHIRO MIKI ET AL.: "Department of Information Technology Faculty of Engineering", OKAYAMA UNIVERSITY, article "Answering English Fill-in-the-blank Questions Using BERT" |
| See also references of EP4535224A4 |
| TANAKA YU ET AL.: "Department of Intelligence Science and Technology", March 2020, KYOTO UNIVERSITY GRADUATE SCHOOL, article "Building Japanese Input Error Dataset Using Wikipedias Revision History" |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2022461080A1 (en) | 2024-11-28 |
| EP4535224A1 (en) | 2025-04-09 |
| US20250086387A1 (en) | 2025-03-13 |
| CN119301599A (zh) | 2025-01-10 |
| JPWO2023233633A1 (https=) | 2023-12-07 |
| JP7806894B2 (ja) | 2026-01-27 |
| EP4535224A4 (en) | 2025-07-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Senior et al. | Protein structure prediction using multiple deep neural networks in the 13th Critical Assessment of Protein Structure Prediction (CASP13) | |
| US10311146B2 (en) | Machine translation method for performing translation between languages | |
| AU2018217281B2 (en) | Using deep learning techniques to determine the contextual reading order in a form document | |
| Iyer et al. | Learning a neural semantic parser from user feedback | |
| CN106649288B (zh) | 基于人工智能的翻译方法和装置 | |
| US11157686B2 (en) | Text sequence segmentation method, apparatus and device, and storage medium thereof | |
| US11003993B1 (en) | Training recurrent neural networks to generate sequences | |
| US10445654B2 (en) | Learning parameters in a feed forward probabilistic graphical model | |
| CN111046659B (zh) | 上下文信息生成方法、上下文信息生成装置及计算机可读记录介质 | |
| US20170103337A1 (en) | System and method to discover meaningful paths from linked open data | |
| CN110929524A (zh) | 数据筛选方法、装置、设备及计算机可读存储介质 | |
| Rei et al. | Auxiliary objectives for neural error detection models | |
| US11615294B2 (en) | Method and apparatus based on position relation-based skip-gram model and storage medium | |
| JP2021096807A (ja) | 機械翻訳モデルトレーニング方法、装置、プログラム及び記録媒体 | |
| CN111191441A (zh) | 文本纠错方法、装置及存储介质 | |
| CN111858947B (zh) | 自动知识图谱嵌入方法和系统 | |
| JP2020046792A (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| JP7806894B2 (ja) | 情報処理プログラム、情報処理方法および情報処理装置 | |
| JP7194759B2 (ja) | 翻訳用データ生成システム | |
| US12573377B2 (en) | Stable output streaming speech translation system | |
| CN115936010B (zh) | 文本缩写数据处理方法、装置 | |
| JP2020140674A (ja) | 回答選択装置及びプログラム | |
| Kondofersky et al. | TREVOR HASTIE, ROBERT TIBSHIRANI, and MARTIN WAINWRIGHT. Statistical learning with sparsity: The lasso and generalizations. Boca Raton: CRC press | |
| US11537794B2 (en) | Learning device, learning method, computer program product, and information processing system | |
| Mishra et al. | SIG |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22944914 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2024524117 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: AU2022461080 Country of ref document: AU |
|
| ENP | Entry into the national phase |
Ref document number: 2022461080 Country of ref document: AU Date of ref document: 20220602 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280096573.1 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022944914 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022944914 Country of ref document: EP Effective date: 20250102 |
|
| WWP | Wipo information: published in national office |
Ref document number: 202280096573.1 Country of ref document: CN |
|
| WWP | Wipo information: published in national office |
Ref document number: 2022944914 Country of ref document: EP |