WO2023233633A1 - 情報処理プログラム、情報処理方法および情報処理装置 - Google Patents
情報処理プログラム、情報処理方法および情報処理装置 Download PDFInfo
- Publication number
- WO2023233633A1 WO2023233633A1 PCT/JP2022/022525 JP2022022525W WO2023233633A1 WO 2023233633 A1 WO2023233633 A1 WO 2023233633A1 JP 2022022525 W JP2022022525 W JP 2022022525W WO 2023233633 A1 WO2023233633 A1 WO 2023233633A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sentence
- vector
- learning model
- machine learning
- information processing
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 94
- 238000003672 processing method Methods 0.000 title claims description 8
- 239000013598 vector Substances 0.000 claims abstract description 252
- 238000010801 machine learning Methods 0.000 claims abstract description 76
- 238000012549 training Methods 0.000 claims abstract description 9
- 238000000034 method Methods 0.000 claims description 61
- 238000012545 processing Methods 0.000 claims description 34
- 230000006698 induction Effects 0.000 claims description 10
- 238000004458 analytical method Methods 0.000 description 39
- 238000007781 pre-processing Methods 0.000 description 26
- 238000010586 diagram Methods 0.000 description 18
- 235000013601 eggs Nutrition 0.000 description 16
- 102000004169 proteins and genes Human genes 0.000 description 15
- 108090000623 proteins and genes Proteins 0.000 description 15
- 241000272194 Ciconiiformes Species 0.000 description 12
- 241000271566 Aves Species 0.000 description 9
- 230000006870 function Effects 0.000 description 7
- 238000004891 communication Methods 0.000 description 6
- 244000000626 Daucus carota Species 0.000 description 5
- 235000002767 Daucus carota Nutrition 0.000 description 5
- 238000013528 artificial neural network Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 241000272201 Columbiformes Species 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 238000005401 electroluminescence Methods 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 230000017105 transposition Effects 0.000 description 2
- 125000003275 alpha amino acid group Chemical group 0.000 description 1
- 150000001413 amino acids Chemical class 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000007086 side reaction Methods 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/42—Data-driven translation
- G06F40/44—Statistical methods, e.g. probability models
Definitions
- the present invention relates to information processing programs and the like.
- the correct sentence ⁇ The function is the characteristic'' and the incorrectly input sentence ⁇ The yesterday is the characteristic'' are sentences with greatly different meanings, and the vectors of each sentence are also significantly different.
- a learning model is trained using a dataset of pairs of input errors and their corrected sentences from the correction history, and the trained learning model is used to select target sentences.
- the above-mentioned conventional technology is a technology that fills in blank spaces in which some words in a sentence are masked, and although the accuracy of filling in blank spaces in a sentence consisting of multiple words is high, There are few descriptions of improving the accuracy of sentences that fill in the blanks in sentences that are composed of sentences, and there are no descriptions of sentences that include input errors. Further, in the conventional technology, although input errors such as typos and omissions can be corrected, input errors due to erroneous conversion cannot be correctly corrected in many cases.
- the present invention provides an information processing program, an information processing method, and an information processing apparatus that are capable of estimating a sentence to fill in a blank in a sentence composed of a plurality of sentences and detecting a sentence containing an input error.
- the purpose is to provide
- the computer executes the following process.
- the computer calculates vectors for each of a plurality of consecutive sentences that have a relationship with the preceding and following sentences. By sequentially inputting multiple sentence vectors into a machine learning model and training it, a computer can calculate the sentence vector of the sentence input next to a certain sentence when inputting a sentence vector to the machine learning model. Generate a machine learning model to predict.
- the computer calculates a vector for the first sentence and a vector for the second sentence following the first sentence.
- the computer calculates a vector of a sentence predicted to follow the first sentence by inputting the vector of the first sentence into the machine learning model, and determines whether the vector of the second sentence is appropriate.
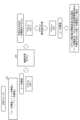
- FIG. 1 is a diagram for explaining learning phase processing of the information processing apparatus according to the present embodiment.
- FIG. 2 is a diagram for explaining analysis phase processing of the information processing apparatus according to the present embodiment.
- FIG. 3 is a functional block diagram showing the configuration of the information processing device according to this embodiment.
- FIG. 4 is a diagram showing an example of the data structure of a word vector dictionary.
- FIG. 5A is a diagram (1) for explaining the process of calculating a sentence vector.
- FIG. 5B is a diagram (2) for explaining the process of calculating a sentence vector.
- FIG. 6 is a diagram for explaining the process of generating a transposed sentence index.
- FIG. 7 is a flowchart showing the processing procedure of the learning phase of the information processing apparatus according to the present embodiment.
- FIG. 7 is a flowchart showing the processing procedure of the learning phase of the information processing apparatus according to the present embodiment.
- FIG. 8 is a flowchart showing the processing procedure of the analysis phase of the information processing apparatus according to this embodiment.
- FIG. 9 is a diagram (1) for explaining other processing of the information processing device.
- FIG. 10 is a diagram (2) for explaining other processing of the information processing device.
- FIG. 11 is a diagram illustrating an example of the hardware configuration of a computer that implements the same functions as the information processing device of the embodiment.
- FIG. 1 is a diagram for explaining learning phase processing of the information processing apparatus according to the present embodiment.
- the information processing device executes learning of the machine learning model 50 using a plurality of sentences included in the teacher data 141 (trains the machine learning model 50).
- the machine learning model 50 is a NN (Neural Network) such as BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding), Next Sentence Prediction, Transformers, etc.
- the sentences included in the teacher data 141 include multiple sentences.
- the plurality of sentences have a predetermined relationship with the sentences before and after them.
- Each sentence is a sentence set in advance based on induction, deductive syllogism, or the like.
- the sentence 10a includes, in order from the beginning, the sentence ⁇ Birds lay eggs.'', the sentence ⁇ Penguins are birds.'', ..., and the sentences ⁇ Therefore, penguins lay eggs.''.
- Sentence 10b includes, in order from the beginning, the sentences ⁇ Birds are born from eggs.'', the sentences ⁇ Pigeons are a member of the bird family.'', ..., and the sentences ⁇ Therefore, pigeons are born from eggs.''
- the information processing device calculates sentence vectors for each sentence included in sentences 10a, 10b, and other sentences. For example, the information processing device performs morphological analysis on a sentence, divides it into words, and calculates a sentence vector by integrating the vectors of each word.
- the information processing device repeatedly performs the process of inputting vectors to the machine learning model 50 in order from the vector of the first sentence included in the text. For example, the information processing device inputs sentence vectors to the machine learning model 50 in the order of sentence vectors "SV1-1", “SV1-2”, . . . , "SV1-3". The information processing device inputs sentence vectors to the machine learning model 50 in the order of sentence vectors "SV2-1", “SV2-2", . . . , "SV2-3".
- a machine learning model 50 in which an information processing device predicts a sentence vector of a second sentence following the first sentence when a sentence vector of a certain first sentence is input by executing the process of the learning phase described above. is generated.
- FIG. 2 is a diagram for explaining the analysis phase processing of the information processing apparatus according to the present embodiment.
- the information processing device uses the trained machine learning model 50 to calculate sentence vectors included in the sentence to be processed, and detects inappropriate sentences based on cosine similarity or the like.
- Sentence 20 is composed of, in order from the beginning, the sentence ⁇ Birds lay eggs.'', the sentence ⁇ Penguins take pictures.'', ..., and the sentences ⁇ Therefore, penguins lay eggs.''
- the sentence "Penguin is a photo.” is a sentence containing an input error of the homophone "Tori" of the word "Bird” in contrast to the correct sentence "Penguin is a bird.” included in the sentence 10a of the teacher data 141.
- the information processing device calculates the sentence vector “SV1-1” of the sentence “Birds lay eggs.” and inputs the calculated sentence vector “SV1-1” into the machine learning model 50. Predict the sentence vector for the next sentence. In the example shown in FIG. 2, the machine learning model 50 predicts "SV1-2" as the sentence vector of the next sentence after the sentence "Birds lay eggs.”
- the information processing device calculates the sentence vector “SV3” of the sentence “Penguin is photographed” which is a sentence included in the sentence 20 and is the next sentence after the sentence “Birds lay eggs.”
- the information processing device uses the sentence vector "SV1-2" of the next sentence predicted by the machine learning model 50 and the sentence "SV1-2" included in the sentence 20, which is the next sentence after the sentence "Birds lay eggs.”
- the cosine similarity with the sentence vector "SV3" of "Penguin is a photo” is calculated.
- the information processing device determines that the sentence "Penguins are birds.”, which is the sentence included in sentence 10a and follows the sentence "Birds lay eggs.”, is correct when the cosine similarity is less than the threshold (hereinafter referred to as It is determined that the sentence is correct.
- the information processing device determines that the sentence ⁇ The penguin is photographing'', which is the sentence included in sentence 20 and follows the sentence ⁇ Birds lay eggs.'', is an input error when the cosine similarity is less than the threshold. It is determined that the sentence is inappropriate.
- the information processing device sequentially inputs the vectors of each sentence of the sentences included in the teacher data 141 to the machine learning model 50, so that when the sentence vector of a certain first sentence is input, A machine learning model 50 is generated that predicts the sentence vector of the second sentence following the first sentence.
- the information processing device inputs the sentence vector of the sentence to be processed into the generated machine learning model, predicts the sentence vector of the next sentence, and based on the predicted sentence vector, extracts the sentence from the sentence to be processed. Detect sentences with input errors. That is, it is possible to detect sentences that include input errors and have inappropriate sentence vectors from each sentence included in the text to be processed.
- the information processing device determines that the sentence "Penguin is a photo" is a sentence with an inappropriate sentence vector
- the information processing device uses the sentence vector SV1-2 predicted by the machine learning model 50. Then, the correct sentence vector "Penguin is a bird.” may be searched from a DB (Data Base) or the like, and output as a correct correction candidate to the display device (hereinafter referred to as optimization).
- DB Data Base
- the information processing device uses another machine learning model that has learned the order of vectors in word units to include the words ⁇ penguin'' and ⁇ ha'' that make up the sentence ⁇ Penguin is a photo'' in which the incorrect sentence vector was detected. , "Tori.” may be calculated, and input errors of the deviated word “Tori.” may be corrected.
- FIG. 3 is a functional block diagram showing the configuration of the information processing apparatus according to this embodiment.
- the information processing device 100 includes a communication section 110, an input section 120, a display section 130, a storage section 140, and a control section 150.
- the communication unit 110 is connected to an external device or the like by wire or wirelessly, and transmits and receives information to and from the external device.
- the communication unit 110 is realized by a NIC (Network Interface Card) or the like.
- the communication unit 110 may be connected to a network (not shown).
- the input unit 120 is an input device that inputs various information to the information processing device 100.
- the input unit 120 corresponds to a keyboard, a mouse, a touch panel, etc.
- the user may operate the input unit 120 to input text data and the like.
- the display unit 130 is a display device that displays information output from the control unit 150.
- the display unit 130 corresponds to a liquid crystal display, an organic EL (Electro Luminescence) display, a touch panel, etc. For example, a sentence with an input error is displayed on the display unit 130.
- the storage unit 140 includes a machine learning model 50, teacher data 141, and a word vector dictionary 142.
- the storage unit 140 is realized by, for example, a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory, or a storage device such as a hard disk or an optical disk.
- a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory
- a storage device such as a hard disk or an optical disk.
- the machine learning model 50 is a NN such as BERT, Next Sentence Prediction, Transformers, etc. described in FIG. 1.
- the teacher data 141 is the teacher data 141 described in FIG.
- the sentences included in the teacher data 141 include a plurality of sentences.
- the plurality of sentences have a predetermined relationship with the sentences before and after them.
- Each sentence is a sentence set in advance based on induction, deductive syllogism, or the like.
- the word vector dictionary 142 is a table that defines codes and word vectors assigned to words.
- FIG. 4 is a diagram showing an example of the data structure of a word vector dictionary. As shown in FIG. 4, this word vector dictionary 142 has codes, words, and word vectors (1) to (7).
- the code is a code assigned to a word.
- a word is a word included in a character string.
- Word vectors (1) to (7) are vectors assigned to words.
- the DB 143 has various texts.
- a sentence contains multiple sentences, and each sentence contains multiple words.
- the DB 143 may have sentences included in the teacher data 141.
- the sentence transposed index 144 associates sentence vectors with position pointers.
- the position pointer indicates the position in the DB 143 where the sentence corresponding to the sentence vector exists.
- the control unit 150 includes a preprocessing unit 151, a learning unit 152, and an analysis unit 153.
- the control unit 150 is realized by, for example, a CPU (Central Processing Unit) or an MPU (Micro Processing Unit). Further, the control unit 150 may be executed by an integrated circuit such as an ASIC (Application Specific Integrated Circuit) or an FPGA (Field Programmable Gate Array).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- the preprocessing unit 151 performs various preprocessing. For example, the preprocessing unit 151 obtains an unprocessed sentence from the DB 143 and calculates a sentence vector of the sentence. The preprocessing unit 151 sets the relationship between the calculated sentence vector and the sentence position pointer corresponding to the sentence vector in the sentence transposition index 144.
- 5A and 5B are diagrams for explaining the process of calculating a sentence vector.
- the preprocessing unit 151 performs morphological analysis on the sentence "Horses like carrots.” to decompose it into a plurality of words. Each decomposed word is marked with a " ⁇ (space)".
- sentence 1 "Horses like carrots.” can be changed to "uma ⁇ ", “ha ⁇ ”, “carrot ⁇ ”, “ga ⁇ ”, “like ⁇ ”, “desu ⁇ ", “. ⁇ ” To divide.
- the preprocessing unit 151 identifies the code corresponding to each word by comparing each divided word with the word vector dictionary 45, and replaces the code with the word.
- the words “horse ⁇ ”, “ha ⁇ ”, “carrot ⁇ ”, “ga ⁇ ”, “suki ⁇ ”, “desu ⁇ ”, “. ⁇ ” are respectively "C1", “C2”, Replaced with "C3", “C4", “C5", “C6”, and "C7".
- the preprocessing unit 151 identifies word vectors (1) to (7) assigned to the code based on the word vector dictionary 45 and each code. For example, word vectors (1) to (7) with code “C1” are assumed to be wv1-1 to wv1-7. The word vectors (1) to (7) with code “C2” are wv2-1 to wv2-7. Word vectors (1) to (7) with code “C3” are assumed to be wv3-1 to wv3-7.
- the word vectors (1) to (7) with code “C4” are wv4-1 to wv4-7.
- Word vectors (1) to (7) with code “C5” are assumed to be wv5-1 to wv5-7.
- Word vectors (1) to (7) with code “C6” are assumed to be wv6-1 to wv6-7.
- Word vectors (1) to (7) with code “C7” are assumed to be wv7-1 to wv7-7.
- the preprocessing unit 151 calculates the sentence vector SV1 of the sentence by integrating word vectors for each element. For example, the preprocessing unit 151 calculates the first component "SV1-1" of the sentence vector SV1 by integrating the word vectors (1) from wv1-1 to wv7-1. The preprocessing unit 151 calculates the second component "SV1-2" of the sentence vector SV1 by integrating the word vectors (2) from wv1-2 to wv7-2. The third component "SV1-3" of the sentence vector SV1 is calculated by integrating wv1-3 to wv7-3, which are each word vector (3).
- the preprocessing unit 151 calculates the fourth component "SV1-4" of the sentence vector SV1 by integrating wv1-4 to wv7-4, which are each word vector (4).
- the preprocessing unit 151 calculates the fifth component "SV1-5" of the sentence vector SV1 by integrating wv1-5 to wv7-5, which are each word vector (5).
- the preprocessing unit 151 calculates the sixth component "SV1-6" of the sentence vector SV1 by integrating the word vectors (6) from wv1-6 to wv7-6.
- the preprocessing unit 151 calculates the seventh component "SV1-7" of the sentence vector SV1 by integrating wv1-7 to wv7-7, which are each word vector (7).
- the preprocessing unit 151 calculates a sentence vector for each sentence by repeatedly performing the above process for each sentence of other sentences included in the DB 143.
- the preprocessing unit 151 generates a sentence transposed index 144 by associating the calculated sentence vector of each sentence with the position pointer of the DB 143.
- the preprocessing unit 151 may generate the sentence transposed index 144 having a data structure as shown in FIG.
- FIG. 6 is a diagram for explaining the process of generating a transposed sentence index.
- the preprocessing unit 151 may associate a sentence vector, a plurality of record pointers, and a plurality of position pointers, and may associate each record pointer and position pointer with each sentence in the DB 143. .
- the learning unit 152 is a machine that predicts the sentence vector of the second sentence following the first sentence when the sentence vector of a certain first sentence is input by executing the process of the learning phase explained in FIG. A learning model 50 is generated.
- the learning unit 152 executes learning of the machine learning model 50 by calculating sentence vectors of each sentence included in the sentences of the teacher data 141 and sequentially inputting the calculated sentence vectors to the machine learning model 50.
- Other processing by the learning unit 152 is similar to the processing described with reference to FIG.
- the process by which the learning unit 152 calculates a sentence vector of a sentence is similar to the process by which the preprocessing unit 151 calculates a sentence vector of a sentence.
- the analysis unit 153 detects sentences with inappropriate sentence vectors from the sentences included in the text to be processed by executing the processing of the analysis phase described in FIG. 2.
- the analysis unit 153 calculates the sentence vector of the sentence included in the text 20.
- the analysis unit 153 identifies sentences included in the sentence 20 based on the period “.” included in the sentence 20.
- the process by which the analysis unit 153 calculates a sentence vector of a sentence is similar to the process by which the preprocessing unit 151 calculates a sentence vector of a sentence.
- the analysis unit 153 inputs the sentence vector SVn into the trained machine learning model 50 and predicts the sentence vector SVn+1' of the n+1st sentence from the beginning of the sentence 20.
- the analysis unit 153 calculates the cosine similarity between the sentence vector SVn+1' predicted using the machine learning model 50 and the sentence vector SVn+1.
- the analysis unit 153 determines that the n+1st sentence from the beginning is the correct sentence. On the other hand, if the cosine similarity between the sentence vector SVn+1' and the sentence vector SVn+1 is greater than or equal to the threshold, the analysis unit 153 determines that the n+1st sentence from the beginning is an inappropriate sentence for the sentence vector.
- the analysis unit 153 determines that the sentence vector is an invalid sentence, the analysis unit 153 compares the sentence vector SVn+1' and the sentence transposed index 144 to identify the position pointer of the sentence corresponding to the sentence vector SVn+1'. . The analysis unit 153 searches the DB 143 for a sentence corresponding to the sentence vector SVn+1' based on the position pointer. The analysis unit 153 causes the display unit 130 to display the incorrect sentence in the sentence vector in association with the retrieved sentence.
- the analysis unit 153 compares the incorrect sentence in the sentence vector with the searched sentence word by word, detects words with input errors from the incorrect sentences in the sentence vector, and displays the detected words. Good too.
- FIG. 7 is a flowchart showing the processing procedure of the learning phase of the information processing apparatus according to the present embodiment.
- the learning unit 152 of the information processing device 100 selects unselected sentences from the teacher data 141 (step S101).
- the learning unit 152 calculates the sentence vector of each sentence included in the selected sentence, and generates a sentence transposed index that associates the sentence vector with the DB record and the sentence position (step S102).
- the learning unit 152 performs learning by sequentially inputting sentence vectors of the first sentence included in the selected sentence to the machine learning model 50 (step S103).
- step S104 If learning is to be continued (step S104, Yes), the learning unit 152 moves to step S101. On the other hand, if learning is not to be continued (step S104, No), the learning unit 152 ends the learning phase process.
- FIG. 8 is a flowchart showing the processing procedure of the analysis phase of the information processing device according to this embodiment.
- the analysis unit 153 of the information processing device 100 receives input of a text to be processed (step S201).
- the analysis unit 153 calculates a sentence vector for each sentence included in the input sentence (step S202).
- the analysis unit 153 sets n to an initial value (step S203).
- the analysis unit 153 inputs the sentence vector SVn of the n-th sentence among the multiple sentences included in the text to the machine learning model 50, and predicts the sentence vector SVn+1' of the n+1-th sentence (step S204).
- the analysis unit 153 calculates the cosine similarity between the sentence vector SVn+1 of the n+1-th sentence among the multiple sentences included in the sentence and the sentence vector SVn+1' of the predicted sentence (step S205).
- step S206 If the cosine similarity is greater than or equal to the threshold (step S206, Yes), the analysis unit 153 moves to step S210.
- the analysis unit 153 detects the (n+1)th sentence as a sentence with an inappropriate sentence vector (step S207).
- the analysis unit 153 detects a sentence corresponding to the sentence vector SVn+1' from the DB 143 based on the predicted sentence vector SVn+1' and the sentence transposed index 144 (step S208).
- the analysis unit 153 displays the sentences with inappropriate sentence vectors and the sentences detected from the DB 143 on the display unit 130 (step S209).
- step S210 If n is greater than or equal to L (step S210, Yes), the analysis unit 153 ends the process. L is the number of sentences included in the text to be processed. If n is not greater than or equal to L (step S210, No), the analysis unit 153 updates n with a value obtained by adding 1 to n (step S211), and proceeds to step S204.
- the information processing device 100 sequentially inputs the vectors of each sentence of the sentences included in the teacher data 141 to the machine learning model 50, so that when the sentence vector of a certain first sentence is input, A machine learning model 50 is generated that predicts the sentence vector of the second sentence.
- the information processing device 100 inputs the sentence vector of the sentence to be processed into the generated machine learning model 50, predicts the sentence vector of the next sentence, and based on the predicted sentence vector, calculates the sentence vector of the sentence to be processed. Detect sentences with invalid sentence vectors. In addition, it is possible to correct words that have been input incorrectly from the incorrect sentence.
- the information processing device 100 calculates the sentence vector based on the cosine similarity between the sentence vector of the next sentence predicted by the machine learning model 50 and the sentence vector of the sentence next to the sentence included in the processing target sentence. Detect inappropriate sentences and correct input errors. This makes it possible to detect inappropriate sentences in sentence vectors and correct input errors, etc., while reducing calculation costs.
- the information processing device 100 trains the machine learning model by sequentially inputting vectors of a plurality of sentences whose arrangement order is determined based on an induction method or a deductive method to a machine learning model. This makes it possible to predict the next sentence after the target sentence based on induction or deduction.
- the information processing device 100 searches for a corrected sentence based on the vector predicted by the machine learning model 50. With this, it is possible to notify the corrected sentence.
- processing content of the information processing device 100 described above is an example, and the information processing device 100 may perform other processing. Below, other processing of the information processing device 100 will be explained.
- FIGS. 9 and 10 are diagrams for explaining other processing of the information processing device.
- the information processing device 100 described above had the machine learning model 50 learn the order of sentence vectors based on a syllogism, but instead of a sentence vector, it is a sequence of proteins, and a plurality of amino acids corresponding to words.
- the order of vectors of protein primary structure composed of sequences may be learned.
- the continuous amino acid sequence of a protein will be referred to as a "basic structure” and the primary structure of a protein will be referred to as a "primary structure.”
- FIG. 9 will be explained.
- the information processing device 100 executes learning of the machine learning model 50 using the plurality of protein sequences 20a and 20b included in the teacher data 241.
- the sequence 20a includes primary structures “ ⁇ primary structure”, “ ⁇ primary structure”, . . . , “ ⁇ primary structure”.
- the array 20b includes primary structures “ ⁇ primary structure”, “ ⁇ primary structure”, . . . , “ ⁇ primary structure”.
- the information processing device 100 identifies vectors of each primary structure using a vector dictionary of protein basic structures that associates basic structures with vectors.
- the vector of the primary structure " ⁇ primary structure” consisting of multiple basic structures is “V20-1”
- the vector of the primary structure " ⁇ primary structure” is “V20-2”
- the vector of the primary structure " ⁇ primary structure” is Let the vector be "V20-3”.
- the vector of the primary structure “ ⁇ primary structure” be "V21-2”
- the vector of the primary structure " ⁇ primary structure” be "V21-3”.
- the vector of each primary structure is calculated based on the vector of each basic structure of the plurality of basic structures that constitute the primary structure.
- the information processing device 100 repeatedly performs the process of inputting vectors to the machine learning model 50 in order from the first primary structure vector included in the protein sequence. For example, the information processing device inputs vectors to the machine learning model 50 in the order of vectors "V20-1", “V20-2”, . . . , “V20-3". The information processing device inputs the vectors to the machine learning model 50 in the order of vectors "V21-1", “V21-2”, . . . , "V21-3".
- the information processing device 100 executes the above-described learning phase process to generate a machine learning model 50 that predicts a vector of a primary structure next to a certain primary structure when a vector of a certain primary structure is input. Ru.
- sequence 25 the sequence of the protein to be processed is designated as sequence 25.
- the array 25 includes primary structures " ⁇ primary structure”, “ ⁇ primary structure”, . . . , " ⁇ primary structure” in order from the beginning.
- the information processing device 100 calculates the vector “V20-1” of the primary structure “ ⁇ primary structure” and inputs the calculated vector “V20-1” to the machine learning model 50 to obtain the primary structure “ ⁇ primary structure”. ” to predict the next primary structure vector.
- the machine learning model 50 predicts "V20-2" as the vector of the primary structure next to the primary structure " ⁇ primary structure”.
- the information processing device 100 calculates the vector "V22" of the " ⁇ primary structure” which is a primary structure included in the array 25 and is the next to the primary structure " ⁇ primary structure”.
- the information processing device 100 uses the vector “V20-2” of the next primary structure predicted by the machine learning model 50 and the primary structure “ ⁇ ” next to the basic structure “ ⁇ primary structure” included in the array 25.
- the cosine similarity of the vector “V22” of the “primary structure” is calculated.
- the information processing device determines that the “ ⁇ primary structure” included in the array 25, which follows the primary structure “ ⁇ primary structure”, is the correct primary structure. On the other hand, if the cosine similarity is less than the threshold, the information processing device determines that the " ⁇ primary structure” that is included in the array 25 and that follows the primary structure " ⁇ primary structure” is an inappropriate primary structure. It is determined that mutations in the basic structure included in the primary structure " ⁇ primary structure” are optimized.
- a primary structure having an inappropriate primary structure vector is detected from a plurality of primary structures included in a protein sequence, and mutation etc. It is possible to optimize a certain basic structure. This makes it possible to detect protein primary structures that have mutations (typical examples being SNPs) that occur in receptors that are composed of multiple protein primary structures. Furthermore, by machine learning the primary structures of many proteins that make up the receptor and the primary structures of single or multiple proteins that bind to the receptor in the binding order, we can predict the protein primary structure vector of the ligand that binds to the receptor. can do. This makes it possible to support the improvement of ligands with new protein primary structure vectors that are similar to ligands already commercialized as biopharmaceuticals, have excellent medicinal efficacy, and suppress side reactions.
- FIG. 11 is a diagram illustrating an example of the hardware configuration of a computer that implements the same functions as the information processing device of the embodiment.
- the computer 300 includes a CPU 301 that executes various calculation processes, an input device 302 that accepts data input from the user, and a display 303.
- the computer 300 also includes a communication device 304 and an interface device 305 that exchange data with an external device or the like via a wired or wireless network.
- the computer 300 also includes a RAM 306 that temporarily stores various information and a hard disk device 307. Each device 301 to 307 is then connected to a bus 308.
- the hard disk device 307 has a preprocessing program 307a, a learning program 307b, and an analysis program 307c. Further, the CPU 301 reads each program 307a to 307c and expands it into the RAM 306.
- the preprocessing program 307a functions as a preprocessing process 306a.
- the learning program 307b functions as a learning process 306b.
- the analysis program 307c functions as an analysis process 306c.
- the processing of the preprocessing process 306a corresponds to the processing of the preprocessing section 151.
- the processing of the learning process 306b corresponds to the processing of the learning section 152.
- the processing of the analysis process 306c corresponds to the processing of the analysis unit 153.
- each of the programs 307a to 307c does not necessarily need to be stored in the hard disk device 307 from the beginning.
- each program is stored in a "portable physical medium" such as a flexible disk (FD), CD-ROM, DVD, magneto-optical disk, or IC card that is inserted into the computer 300. Then, the computer 300 may read and execute each program 307a to 307c.
- Machine learning model 100 Information processing device 110 Communication unit 120 Input unit 130 Display unit 140 Storage unit 141 Teacher data 142 Word vector dictionary 143 DB 144 Sentence transposition index 150 Control unit 151 Preprocessing unit 152 Learning unit 153 Analysis unit
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
Abstract
情報処理装置は、連続する複数の文であって、前後の文に関係性を有する複数の文のベクトルをそれぞれ算出する。情報処理装置は、複数の文のベクトルを順番に機械学習モデルに入力して訓練することで、機械学習モデルにある文のベクトルを入力した際に、ある文の次に入力される文の文ベクトルを予測する機械学習モデルを生成する。情報処理装置は、第1文のベクトルと、第1文に続く第2文のベクトルとを算出する。情報処理装置は、第1文のベクトルを機械学習モデルに入力することで第1文に続くと予測される文のベクトルを算出し、第2文のベクトルが適正であるか否かを判定する。
Description
本発明は、情報処理プログラム等に関する。
近年、文のベクトルを算出し、算出したベクトルを利用して、他言語への翻訳、データベースの検索等の各種処理を実行するサービスが提供されている。しかし、ユーザに指定される文自体に入力誤り等が存在すると、文のベクトルを精度よく算出することができず、翻訳、検索等の処理に誤りが生じる場合がある。
たとえば、適正な文「その機能が特徴である」と、入力誤りの文「その昨日が特徴である」とは、相互に大きく意味の異なる文となり、各文のベクトルも大きく異なる。
文の入力誤りを修正する従来技術として、修正履歴から、入力誤りと、その修正文とのペアのデータセットを用いて、学習モデルを訓練しておき、訓練した学習モデルに対象となる文を入力することで、対象となる文の入力誤りを修正する従来技術がある。
三木一弘、他"BERTを用いた英文空所補充問題の一解法"岡山大学工学部情報系学科、DEIM2020 G2-4 (day1 p47)
田中佑、他"Wikipediaの修正履歴を用いた日本語入力誤りデータセットの構築"京都大学 大学院情報学科研究科、言語処理学会、第26回年次大会、発表論文集、2020年3月
しかしながら、上述した従来技術では、文章の一部の単語などがマスクされた空所補充する技術であり、複数の単語で構成される文の空所を補充する単語の精度は高いものの、複数の文で構成される文章の空所を補充する文に関する高精度化の記述は少なく、かつ、入力誤りを含む文を検出するものではなかった。また、従来技術では、誤字、脱字等の入力誤りを修正できるものの、誤変換の入力誤りを正しく修正できないケースが多かった。
1つの側面では、本発明は、複数の文で構成される文章の空所を補充する文の推定や、入力誤りを含む文を検出することができる情報処理プログラム、情報処理方法および情報処理装置を提供することを目的とする。
第1の案では、コンピュータに次の処理を実行させる。コンピュータは、連続する複数の文であって、前後の文に関係性を有する複数の文のベクトルをそれぞれ算出する。コンピュータは、複数の文のベクトルを順番に機械学習モデルに入力して訓練することで、機械学習モデルにある文のベクトルを入力した際に、ある文の次に入力される文の文ベクトルを予測する機械学習モデルを生成する。コンピュータは、第1文のベクトルと、第1文に続く第2文のベクトルとを算出する。コンピュータは、第1文のベクトルを前記機械学習モデルに入力することで第1文に続くと予測される文のベクトルを算出し、第2文のベクトルが適正であるか否かを判定する。
複数の文で構成される文章の空所を補充する文の推定や、入力誤りを含む文を検出することができる。
以下に、本願の開示する情報処理プログラム、情報処理方法および情報処理装置の実施例を図面に基づいて詳細に説明する。なお、この実施例によりこの発明が限定されるものではない。
本実施例に係る情報処理装置の処理について説明する。情報処理装置は、学習フェーズの処理を実行した後に、分析フェーズの処理を実行する。図1は、本実施例に係る情報処理装置の学習フェーズの処理を説明するための図である。
学習フェーズにおいて、情報処理装置は、教師データ141に含まれる複数の文章を用いて、機械学習モデル50の学習を実行する(機械学習モデル50を訓練する)。機械学習モデル50は、BERT(Pre-training of Deep Bidirectional Transformers for Language Understanding)、Next Sentence Prediction、Transformers等のNN(Neural Network)である。
教師データ141に含まれる文章には、複数の文が含まれる。複数の文は、前後の文に所定の関係性を有する。各文は、帰納法や演繹法の三段論法等に基づいて予め設定された文である。
たとえば、文章10aには、先頭から順に、文「鳥は卵を産む。」、文「ペンギンは鳥。」、・・・、文「だから、ペンギンは卵を産む。」が含まれる。文章10bには、先頭から順に、文「鳥は卵から生まれる。」、文「鳩は鳥の仲間である。」、・・・、文「従って、鳩は卵から生まれる。」が含まれる。
情報処理装置は、文章10a,10b、その他の文章に含まれる各文の文ベクトルを算出する。たとえば、情報処理装置は、文に対して形態素解析を実行して単語に分割し、各単語のベクトルを積算することで、文ベクトルを算出する。
文章10aの文「鳥は卵を産む。」の文ベクトルを「SV1-1」とする。文「ペンギンは鳥」の文ベクトルを「SV1-2」とする。文「だから、ペンギンは卵を産む。」の文ベクトルを「SV1-3」とする。
文章10bの文「鳥は卵から生まれる。」の文ベクトルを「SV2-1」とする。文「鳩は鳥の仲間である。」の文ベクトルを「SV2-2」とする。文「従って、鳩は卵から生まれる。」の文ベクトルを「SV2-3」とする。
情報処理装置は、文章に含まれる先頭の文のベクトルから順番に、機械学習モデル50に入力する処理を繰り返し実行する。たとえば、情報処理装置は、文ベクトル「SV1-1」、「SV1-2」、・・・、「SV1-3」の順に、機械学習モデル50に文ベクトルを入力する。情報処理装置は、文ベクトル「SV2-1」、「SV2-2」、・・・、「SV2-3」の順に、機械学習モデル50に文ベクトルを入力する。
情報処理装置が、上記の学習フェーズの処理を実行することで、ある第1文の文ベクトルが入力された場合に、第1文の次の第2文の文ベクトルを予測する機械学習モデル50が生成される。
図2は、本実施例に係る情報処理装置の分析フェーズの処理を説明するための図である。分析フェーズにおいて、情報処理装置は、訓練済みの機械学習モデル50を用いて、処理対象の文章に含まれる文ベクトルを算出し、コサイン類似度などにより、不適正な文を検出する。
図2の説明では、入力誤り等を含む処理対象の文章を文章20とする。文章20には、先頭から順に、文「鳥は卵を産む。」、文「ペンギンは撮り。」、・・・、文「だから、ペンギンは卵を産む。」により構成される。文「ペンギンは撮り。」は、教師データ141の文章10aに含まれる正しい文「ペンギンは鳥。」に対して、単語「鳥」の同音異義語「撮り」の入力誤りを含む文である。
情報処理装置は、文「鳥は卵を産む。」の文ベクトル「SV1-1」を算出し、算出した文ベクトル「SV1-1」を、機械学習モデル50に入力することで、文「鳥は卵を産む。」の次の文の文ベクトルを予測する。図2に示す例では、機械学習モデル50によって、文「鳥は卵を産む。」の次の文の文ベクトルとして、「SV1-2」が予測されている。
情報処理装置は、文章20に含まれる文であって、文「鳥は卵を産む。」の次の文「ペンギンは撮り」の文ベクトル「SV3」を算出する。
情報処理装置は、機械学習モデル50によって予測された次の文の文ベクトル「SV1-2」と、文章20に含まれる文であって、文「鳥は卵を産む。」の次の文「ペンギンは撮り」の文ベクトル「SV3」とのコサイン類似度を算出する。
情報処理装置は、文章10aに含まれる文であって、文「鳥は卵を産む。」の次の文「ペンギンは鳥。」は、コサイン類似度が閾値未満の場合として、正しい(以下、適正な、と表記する)文であると判定する。一方、情報処理装置は、文章20に含まれる文であって、文「鳥は卵を産む。」の次の文「ペンギンは撮り。」は、コサイン類似度が閾値未満の場合として、入力誤り等を含む不適正な文であると判定する。
上記のように、情報処理装置は、教師データ141に含まれる文章の各文のベクトルを順番に機械学習モデル50に入力することで、ある第1文の文ベクトルが入力された場合に、第1文の次の第2文の文ベクトルを予測する機械学習モデル50を生成する。情報処理装置は、生成した機械学習モデルに、処理対象の文章の文の文ベクトルを入力し、次の文の文ベクトルを予測し、予測した文ベクトルを基にして、処理対象の文章から、入力誤りのある文を検出する。すなわち、処理対象の文章に含まれる各文から、入力誤り等を含み、不適正な文ベクトルを持つ文を検出することができる。
なお、情報処理装置は、図2の処理において、文「ペンギンは撮り」が不適正な文ベクトルの文であると判定した場合に、機械学習モデル50によって予測された文ベクトルSV1-2を基にして、適正な文ベクトルの文「ペンギンは鳥。」をDB(Data Base)などから検索して、正しい修正候補として表示装置に出力(以下、適正化と表記する)してもよい。
更に、情報処理装置は、単語単位のベクトルの順番を学習した他の機械学習モデルに、不適正な文ベクトルを検出した文「ペンギンは撮り」を構成する複数の単語「ペンギン」、「は」、「撮り。」の各単語ベクトルを算出し、乖離した単語「撮り。」の入力誤り等を適正化してもよい。
次に、図1及び図2で説明した処理を実行する情報処理装置の構成例について説明する。図3は、本実施例に係る情報処理装置の構成を示す機能ブロック図である。図3に示すように、情報処理装置100は、通信部110、入力部120、表示部130、記憶部140、制御部150を有する。
通信部110は、有線又は無線で外部装置等に接続され、外部装置等との間で情報の送受信を行う。たとえば、通信部110は、NIC(Network Interface Card)等によって実現される。通信部110は、図示しないネットワークに接続されていてもよい。
入力部120は、各種の情報を、情報処理装置100に入力する入力装置である。入力部120は、キーボードやマウス、タッチパネル等に対応する。たとえば、ユーザは、入力部120を操作して、文章のデータ等を入力してもよい。
表示部130は、制御部150から出力される情報を表示する表示装置である。表示部130は、液晶ディスプレイ、有機EL(Electro Luminescence)ディスプレイ、タッチパネル等に対応する。たとえば、入力誤りのある文が、表示部130に表示される。
記憶部140は、機械学習モデル50、教師データ141、単語ベクトル辞書142を有する。記憶部140は、たとえば、RAM(Random Access Memory)、フラッシュメモリ(Flash Memory)等の半導体メモリ素子、または、ハードディスク、光ディスク等の記憶装置によって実現される。
機械学習モデル50は、図1で説明したBERT、Next Sentence Prediction、Transformers等のNN等である。
教師データ141は、図1で説明した教師データ141である。教師データ141に含まれる文章には、複数の文が含まれる。複数の文は、前後の文に所定の関係性を有する。各文は、帰納法や演繹法の三段論法等に基づいて予め設定された文である。
単語ベクトル辞書142は、単語に割り当てられた符号、単語ベクトルを定義するテーブルである。図4は、単語ベクトル辞書のデータ構造の一例を示す図である。図4に示すように、この単語ベクトル辞書142は、符号、単語、単語ベクトル(1)~(7)を有する。符号は、単語に割り当てられる符号(Code)である。単語は、文字列に含まれる単語である。単語ベクトル(1)~(7)は、単語に割り当てられたベクトルである。単語ベクトルの第n成分を単語ベクトル(n)と表記する(n=1~7)。
DB143は、様々な文章を有する。文章には複数の文が含まれ、各文には複数の単語が含まれる。DB143は、教師データ141に含まれる文章を有していてもよい。
文転置インデックス144は、文ベクトルと、位置ポインタとを対応付ける。位置ポインタは、文ベクトルに対応する文が存在するDB143の位置を示す。
図3の説明に戻る。制御部150は、前処理部151と、学習部152と、分析部153とを有する。制御部150は、たとえば、CPU(Central Processing Unit)やMPU(Micro Processing Unit)により実現される。また、制御部150は、例えばASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)等の集積回路により実行されてもよい。
前処理部151は、各種の前処理を実行する。たとえば、前処理部151は、DB143から未処理に文を取得し、文の文ベクトルを算出する。前処理部151は、算出した文ベクトルと、文ベクトルに対応する文の位置ポインタとの関係を、文転置インデックス144に設定する。
前処理部151が、文の文ベクトルを算出する処理の一例について説明する。図5A及び図5Bは、文ベクトルを算出する処理を説明するための図である。ここでは、文「馬は人参が好きです。」の文ベクトルを算出する場合について説明する。前処理部151は、文「馬は人参が好きです。」に対して、形態素解析を実行することで、複数の単語に分解する。分解した各単語には、「△(スペース)」を付与する。たとえば、文1「馬は人参が好きです。」は、「馬△」、「は△」、「人参△」、「が△」、「好き△」、「です△」、「。△」に分割する。
前処理部151は、分割した各単語と、単語ベクトル辞書45とを比較することで、各単語に対応する符号を特定し、単語と置き換える。たとえば、各単語「馬△」、「は△」、「人参△」、「が△」、「好き△」、「です△」、「。△」は、それぞれ、「C1」、「C2」、「C3」、「C4」、「C5」、「C6」、「C7」に置き換えられる。
図5Bの説明に移行する。前処理部151は、単語ベクトル辞書45と、各符号とを基にして、符号に割り当てられた単語ベクトル(1)~(7)を特定する。たとえば、符号「C1」の単語ベクトル(1)~(7)は、wv1-1~1-7とする。符号「C2」の単語ベクトル(1)~(7)は、wv2-1~2-7とする。符号「C3」の単語ベクトル(1)~(7)は、wv3-1~3-7とする。
符号「C4」の単語ベクトル(1)~(7)は、wv4-1~4-7とする。符号「C5」の単語ベクトル(1)~(7)は、wv5-1~5-7とする。符号「C6」の単語ベクトル(1)~(7)は、wv6-1~6-7とする。符号「C7」の単語ベクトル(1)~(7)は、wv7-1~7-7とする。
前処理部151は、要素毎に単語ベクトルを積算することで、文の文ベクトルSV1を算出する。たとえば、前処理部151は、各単語ベクトル(1)となるwv1-1~7-1を積算することで、文ベクトルSV1の第1成分「SV1-1」を算出する。前処理部151は、各単語ベクトル(2)となるwv1-2~7-2を積算することで、文ベクトルSV1の第2成分「SV1-2」を算出する。各単語ベクトル(3)となるwv1-3~7-3を積算することで、文ベクトルSV1の第3成分「SV1-3」を算出する。
前処理部151は、各単語ベクトル(4)となるwv1-4~7-4を積算することで、文ベクトルSV1の第4成分「SV1-4」を算出する。前処理部151は、各単語ベクトル(5)となるwv1-5~7-5を積算することで、文ベクトルSV1の第5成分「SV1-5」を算出する。前処理部151は、各単語ベクトル(6)となるwv1-6~7-6を積算することで、文ベクトルSV1の第6成分「SV1-6」を算出する。前処理部151は、各単語ベクトル(7)となるwv1-7~7-7を積算することで、文ベクトルSV1の第7成分「SV1-7」を算出する。
前処理部151は、DB143に含まれる他の文章の各文についても、上記処理を繰り返し実行することで、各文の文ベクトルを算出する。
前処理部151は、算出した各文の文ベクトルと、DB143の位置ポインタとを対応付けることで、文転置インデックス144を生成する。なお、前処理部151は、図6に示すようなデータ構造の文転置インデックス144を生成してもよい。図6は、文転置インデックスを生成する処理を説明するための図である。図6に示すように、前処理部151は、文ベクトルと、複数のレコードポインタと、複数の位置ポインタとを対応付け、各レコードポインタ、位置ポインタを、DB143の各文に対応付けてもよい。
図3の説明に戻る。学習部152は、図1で説明した学習フェーズの処理を実行することで、ある第1文の文ベクトルが入力された場合に、第1文の次の第2文の文ベクトルを予測する機械学習モデル50を生成する。
たとえば、学習部152は、教師データ141の文章に含まれる各文の文ベクトルを算出し、算出した文ベクトルを順番に機械学習モデル50に入力することで、機械学習モデル50の学習を実行する。学習部152のその他の処理は、図1で説明した処理と同様である。学習部152が、文の文ベクトルを算出する処理は、前処理部151が文の文ベクトルを算出する処理と同様である。
分析部153は、図2で説明した分析フェーズの処理を実行することで、処理対象の文章に含まれる文から、文ベクトルが不適正な文を検出する。
たとえば、分析部153は、処理対象の文章20を受け付けた場合に、文章20に含まれる文の文ベクトルを算出する。分析部153は、文章20に含まれる句点「。」を基にして、文章20に含まれる文を特定する。分析部153が、文の文ベクトルを算出する処理は、前処理部151が文の文ベクトルを算出する処理と同様である。文章20の先頭からn番目の文の文ベクトル「SVn」と表記する(n=0~M)。
分析部153は、文ベクトルSVnを、訓練済みの機械学習モデル50に入力して、文章20の先頭からn+1番目の文の文ベクトルSVn+1’を予測する。分析部153は、機械学習モデル50を用いて予測した文ベクトルSVn+1’と、文のベクトルSVn+1とのコサイン類似度を算出する。
分析部153は、文ベクトルSVn+1’と、文ベクトルSVn+1とのコサイン類似度が閾値以上の場合には、先頭からn+1番目の文が適正な文であると判定する。一方、分析部153は、文ベクトルSVn+1’と、文ベクトルSVn+1とのコサイン類似度が閾値以上の場合には、先頭からn+1番目の文が、文ベクトルの不適正な文であると判定する。
分析部153は、文ベクトルの不適正な文であると判定した場合に、文ベクトルSVn+1’と、文転置インデックス144とを比較して、文ベクトルSVn+1’に対応する文の位置ポインタを特定する。分析部153は、位置ポインタを基にして、文ベクトルSVn+1’に対応する文を、DB143から検索する。分析部153は、文ベクトルの不適正な文と、検索した文とを対応付けて、表示部130に表示させる。
分析部153は、文ベクトルの不適正な文と、検索した文とを単語単位に比較して、文ベクトルの不適正な文から、入力誤りの単語を検出し、検出した単語を表示させてもよい。
次に、本実施例に係る情報処理装置100の処理手順の一例について説明する。図7は、本実施例に係る情報処理装置の学習フェーズの処理手順を示すフローチャートである。図7に示すように、情報処理装置100の学習部152は、教師データ141から、未選択の文章を選択する(ステップS101)。
学習部152は、選択した文章に含まれる各文の文ベクトルをそれぞれ算出し、文ベクトルとDBのレコードと文の位置とを対応付けた文転置インデックスを生成する(ステップS102)。学習部152は、選択した文章に含まれる先頭の文の文ベクトルから順に、機械学習モデル50に入力することで、学習を実行する(ステップS103)。
学習部152は、学習を継続する場合には(ステップS104,Yes)、ステップS101に移行する。一方、学習部152は、学習を継続しない場合には(ステップS104,No)、学習フェーズの処理を終了する。
図8は、本実施例に係る情報処理装置の分析フェーズの処理手順を示すフローチャートである。図8に示すように、情報処理装置100の分析部153は、処理対象の文章の入力を受け付ける(ステップS201)。
分析部153は、入力された文章に含まれる各文の文ベクトルをそれぞれ算出する(ステップS202)。分析部153は、nを初期値に設定する(ステップS203)。
分析部153は、文章に含まれる複数の文のうち、n番目の文の文ベクトルSVnを機械学習モデル50に入力し、n+1番目の文の文ベクトルSVn+1’を予測する(ステップS204)。
分析部153は、文章に含まれる複数の文のうち、n+1番目の文の文ベクトルSVn+1と、予測した文の文ベクトルSVn+1’とのコサイン類似度を算出する(ステップS205)。
分析部153は、コサイン類似度が閾値以上である場合には(ステップS206,Yes)、ステップS210に移行する。
一方、分析部153は、コサイン類似度が閾値以上でない場合には(ステップS206,No)、n+1番目の文を、文ベクトルが不適正な文として検出する(ステップS207)。分析部153は、予測した文ベクトルSVn+1’と、文転置インデックス144とを基にして、文ベクトルSVn+1’に対応する文をDB143から検出する(ステップS208)。
分析部153は、文ベクトルが不適正な文と、DB143から検出した文とを、表示部130に表示する(ステップS209)。
ステップS210以降の処理について説明する。分析部153は、nがL以上である場合には(ステップS210,Yes)、処理を終了する。Lは、処理対象の文章に含まれる文の数である。分析部153は、nがL以上でない場合には(ステップS210,No)、nに1を加算した値によって、nを更新し(ステップS211)、ステップS204に移行する。
次に、本実施例に係る情報処理装置100の効果について説明する。情報処理装置100は、教師データ141に含まれる文章の各文のベクトルを順番に機械学習モデル50に入力することで、ある第1文の文ベクトルが入力された場合に、第1文の次の第2文の文ベクトルを予測する機械学習モデル50を生成する。情報処理装置100は、生成した機械学習モデル50に、処理対象の文章の文の文ベクトルを入力し、次の文の文ベクトルを予測し、予測した文ベクトルを基にして、処理対象の文章から、不適正な文ベクトルを持つ文を検出する。また、その不適正な文から入力誤り等の単語を適正化することができる。
情報処理装置100は、機械学習モデル50によって予測された次の文の文ベクトルと、処理対象の文章に含まれる文の次の文の文ベクトルとのコサイン類似度を基にして、文ベクトルの不適正な文を検出し、入力誤り等を適正化する。これによって、計算コストを抑えて、文ベクトルの不適正な文を検出し、入力誤り等を適正化することができる。
情報処理装置100は、帰納法または演繹法に基づいて並び順が決定された複数の文のベクトルを順番に機械学習モデルに入力して訓練する。これによって、帰納法または演繹法に基づいた対象文の次の文を予測することができる。
情報処理装置100は、修正対象の文であると判定された場合に、機械学習モデル50に予測されたベクトルを基にして、修正後の文を検索する。これによって、修正後の文を通知することができる。
なお、上述した情報処理装置100の処理内容は一例であり、情報処理装置100は、その他の処理を実行してもよい。以下では、情報処理装置100のその他の処理について説明する。
図9及び図10は、情報処理装置のその他の処理を説明するための図である。上記の情報処理装置100は、機械学習モデル50に、三段論法に基づく文のベクトルの順番を学習させていたが、文のベクトルの代わりに、タンパク質の配列であり、単語に相当する複数のアミノ酸配列で構成されるタンパク質一次構造のベクトルの順番を学習させてもよい。以下の説明では、タンパク質の連続アミノ酸配列を「基本構造」と、タンパク質一次構造を「一次構造」と表記する。
図9について説明する。学習フェーズにおいて、情報処理装置100は、教師データ241に含まれる複数のタンパク質の配列20a,20bを用いて、機械学習モデル50の学習を実行する。
たとえば、配列20aには、一次構造「α一次構造」、「β一次構造」、・・・、「γ一次構造」が含まれる。配列20bには、一次構造「Δ一次構造」、「ε一次構造」、・・・、「ζ一次構造」が含まれる。
情報処理装置100は、基本構造と、ベクトルとを対応付けたタンパク質の基本構造のベクトル辞書を用いて、各一次構造のベクトルを特定する。たとえば、複数の基本構造で構成される一次構造「α一次構造」のベクトルを「V20-1」、一次構造「β一次構造」のベクトルを「V20-2」、一次構造「γ一次構造」のベクトルを「V20-3」とする。一次構造「Δ一次構造」のベクトルを「V21-1」、一次構造「ε一次構造」のベクトルを「V21-2」、一次構造「ζ一次構造」のベクトルを「V21-3」とする。各一次構造のベクトルは、その一次構造を構成する複数の基本構造の各基本構造のベクトルをもとに算出される。
情報処理装置100は、タンパク質の配列に含まれる先頭の一次構造のベクトルから順番に、機械学習モデル50に入力する処理を繰り返し実行する。たとえば、情報処理装置は、ベクトル「V20-1」、「V20-2」、・・・、「V20-3」の順に、機械学習モデル50にベクトルを入力する。情報処理装置は、ベクトル「V21-1」、「V21-2」、・・・、「V21-3」の順に、機械学習モデル50にベクトルを入力する。
情報処理装置100が、上記の学習フェーズの処理を実行することで、ある一次構造のベクトルが入力された場合に、ある一次構造の次の一次構造のベクトルを予測する機械学習モデル50が生成される。
図10について説明する。分析フェーズにおいて、処理対象のタンパク質の配列を、配列25とする。配列25には、先頭から順に、一次構造「α一次構造」、「η一次構造」、・・・、「γ一次構造」が含まれる。
情報処理装置100は、一次構造「α一次構造」のベクトル「V20-1」を算出し、算出したベクトル「V20-1」を、機械学習モデル50に入力することで、一次構造「α一次構造」の次の一次構造のベクトルを予測する。図10に示す例では、機械学習モデル50によって、一次構造「α一次構造」の次の一次構造のベクトルとして、「V20-2」が予測されている。
情報処理装置100は、配列25に含まれる一次構造であって、一次構造「α一次構造」の次の「η一次構造」のベクトル「V22」を算出する。
情報処理装置100は、機械学習モデル50によって予測された次の一次構造のベクトル「V20-2」と、配列25に含まれる一次構造であって、基本構造「α一次構造」の次の「η一次構造」のベクトル「V22」とのコサイン類似度を算出する。
情報処理装置は、コサイン類似度が閾値以上の場合、配列25に含まれる一次構造であって、一次構造「α一次構造」の次の「η一次構造」が正しい一次構造であると判定する。一方、情報処理装置は、コサイン類似度が閾値未満の場合、配列25に含まれる一次構造であって、一次構造「α一次構造」の次の「η一次構造」を不適正な一次構造であると判定し、一次構造「η一次構造」に含まれる基本構造の突然変異等を適正化する。
図9及び図10に示した処理を、情報処理装置100が実行することで、タンパク質の配列に含まれる複数の一次構造から、不適正な一次構造ベクトルを持つ一次構造を検出し、突然変異等のある基本構造を適正化することができる。これにより、複数のタンパク質一次構造で構成される受容体に発生した突然変異等(SNPsが代表例である)を持つタンパク質一次構造を検出することができる。さらに、受容体を構成する多数のタンパク質一次構造と、受容体に結合する単一または複数のタンパク質一次構造を結合順に機械学習することで、受容体に結合するリガンドのタンパク質一次構造のベクトルを予測することができる。これにより、既に、バイオ医薬品として製品化されたリガンドと類似し、優れた薬効を持ち、副反応が抑制された、新しいタンパク質一次構造のベクトルを持つリガンドの改良を支援することができる。
次に、上記実施例に示した情報処理装置100と同様の機能を実現するコンピュータのハードウェア構成の一例について説明する。図11は、実施例の情報処理装置と同様の機能を実現するコンピュータのハードウェア構成の一例を示す図である。
図11に示すように、コンピュータ300は、各種演算処理を実行するCPU301と、ユーザからのデータの入力を受け付ける入力装置302と、ディスプレイ303とを有する。また、コンピュータ300は、有線または無線ネットワークを介して、外部装置等との間でデータの授受を行う通信装置304と、インタフェース装置305とを有する。また、コンピュータ300は、各種情報を一時記憶するRAM306と、ハードディスク装置307とを有する。そして、各装置301~307は、バス308に接続される。
ハードディスク装置307は、前処理プログラム307a、学習プログラム307b、分析プログラム307cを有する。また、CPU301は、各プログラム307a~307cを読み出してRAM306に展開する。
前処理プログラム307aは、前処理プロセス306aとして機能する。学習プログラム307bは、学習プロセス306bとして機能する。分析プログラム307cは、分析プロセス306cとして機能する。
前処理プロセス306aの処理は、前処理部151の処理に対応する。学習プロセス306bの処理は、学習部152の処理に対応する。分析プロセス306cの処理は、分析部153の処理に対応する。
なお、各プログラム307a~307cについては、必ずしも最初からハードディスク装置307に記憶させておかなくても良い。例えば、コンピュータ300に挿入されるフレキシブルディスク(FD)、CD-ROM、DVD、光磁気ディスク、ICカードなどの「可搬用の物理媒体」に各プログラムを記憶させておく。そして、コンピュータ300が各プログラム307a~307cを読み出して実行するようにしてもよい。
50 機械学習モデル
100 情報処理装置
110 通信部
120 入力部
130 表示部
140 記憶部
141 教師データ
142 単語ベクトル辞書
143 DB
144 文転置インデックス
150 制御部
151 前処理部
152 学習部
153 分析部
100 情報処理装置
110 通信部
120 入力部
130 表示部
140 記憶部
141 教師データ
142 単語ベクトル辞書
143 DB
144 文転置インデックス
150 制御部
151 前処理部
152 学習部
153 分析部
Claims (12)
- 連続する複数の文であって、前後の文に関係性を有する前記複数の文のベクトルをそれぞれ算出し、
前記複数の文のベクトルを順番に機械学習モデルに入力して訓練することで、前記機械学習モデルにある文のベクトルを入力した際に、前記ある文の次に入力される文の文ベクトルを予測する前記機械学習モデルを生成し、
第1文のベクトルと、前記第1文に続く第2文のベクトルとを算出し、
前記第1文のベクトルを前記機械学習モデルに入力することで前記第1文に続くと予測される文のベクトルを算出し、前記第2文のベクトルが適正であるか否かを判定する
処理をコンピュータに実行させることを特徴とする情報処理プログラム。 - 前記判定する処理は、前記第1文のベクトルを、前記機械学習モデルに入力することで予測されるベクトルと、前記第2文のベクトルとのコサイン類似度を基にして、前記第2文のベクトルが適正であるか否かを判定することを特徴とする請求項1に記載の情報処理プログラム。
- 前記連続する複数の文は、帰納法または演繹法に基づいて並び順が決定された複数の文であり、前記機械学習モデルを生成する処理は、帰納法または演繹法に基づいて並び順が決定された複数の文のベクトルを順番に機械学習モデルに入力して訓練することを特徴とする請求項2に記載の情報処理プログラム。
- 前記第2文のベクトルが不適正であると判定された場合に、前記第1文のベクトルを前記機械学習モデルに入力することで前記第1文に続くと予測される文のベクトルを算出し、算出したベクトルと類似した文を検索し適正な文の候補として提示するために、算出した前記第1文に続くと予測される文のベクトルを基にして、適正な文を推薦する処理を更にコンピュータに実行させることを特徴とする請求項1に記載の情報処理プログラム。
- 連続する複数の文であって、前後の文に関係性を有する前記複数の文のベクトルをそれぞれ算出し、
前記複数の文のベクトルを順番に機械学習モデルに入力して訓練することで、前記機械学習モデルにある文のベクトルを入力した際に、前記ある文の次に入力される文の文ベクトルを予測する前記機械学習モデルを生成し、
第1文のベクトルと、前記第1文に続く第2文のベクトルとを算出し、
前記第1文のベクトルを前記機械学習モデルに入力することで前記第1文に続くと予測される文のベクトルを算出し、前記第2文のベクトルが適正であるか否かを判定する
処理をコンピュータが実行することを特徴とする情報処理方法。 - 前記判定する処理は、前記第1文のベクトルを、前記機械学習モデルに入力することで予測されるベクトルと、前記第2文のベクトルとのコサイン類似度を基にして、前記第2文のベクトルが適正であるか否かを判定することを特徴とする請求項5に記載の情報処理方法。
- 前記連続する複数の文は、帰納法または演繹法に基づいて並び順が決定された複数の文であり、前記機械学習モデルを生成する処理は、帰納法または演繹法に基づいて並び順が決定された複数の文のベクトルを順番に機械学習モデルに入力して訓練することを特徴とする請求項6に記載の情報処理方法。
- 前記第2文のベクトルが不適正であると判定された場合に、前記第1文のベクトルを前記機械学習モデルに入力することで前記第1文に続くと予測される文のベクトルを算出し、算出したベクトルと類似した文を検索し適正な文の候補として提示するために、算出した前記第1文に続くと予測される文のベクトルを基にして、適正な文を推薦する処理を更にコンピュータに実行させることを特徴とする請求項6に記載の情報処理方法。
- 連続する複数の文であって、前後の文に関係性を有する前記複数の文のベクトルをそれぞれ算出し、
前記複数の文のベクトルを順番に機械学習モデルに入力して訓練することで、前記機械学習モデルにある文のベクトルを入力した際に、前記ある文の次に入力される文の文ベクトルを予測する前記機械学習モデルを生成し、
第1文のベクトルと、前記第1文に続く第2文のベクトルとを算出し、
前記第1文のベクトルを前記機械学習モデルに入力することで前記第1文に続くと予測される文のベクトルを算出し、前記第2文のベクトルが適正であるか否かを判定する
処理を実行する制御部を有することを特徴とする情報処理装置。 - 前記制御部が実行する前記判定する処理は、前記第1文のベクトルを、前記機械学習モデルに入力することで予測されるベクトルと、前記第2文のベクトルとのコサイン類似度を基にして、前記第2文のベクトルが適正であるか否かを判定することを特徴とする請求項9に記載の情報処理装置。
- 前記連続する複数の文は、帰納法または演繹法に基づいて並び順が決定された複数の文であり、前記制御部が実行する前記機械学習モデルを生成する処理は、帰納法または演繹法に基づいて並び順が決定された複数の文のベクトルを順番に機械学習モデルに入力して訓練することを特徴とする請求項10に記載の情報処理装置。
- 前記制御部は、前記第2文のベクトルが不適正であると判定された場合に、前記第1文のベクトルを前記機械学習モデルに入力することで前記第1文に続くと予測される文のベクトルを算出し、算出したベクトルと類似した文を検索し適正な文の候補として提示するために、算出した前記第1文に続くと予測される文のベクトルを基にして、適正な文を推薦する処理を更にコンピュータに実行させることを特徴とする請求項9に記載の情報処理装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/022525 WO2023233633A1 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/022525 WO2023233633A1 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023233633A1 true WO2023233633A1 (ja) | 2023-12-07 |
Family
ID=89026185
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/022525 WO2023233633A1 (ja) | 2022-06-02 | 2022-06-02 | 情報処理プログラム、情報処理方法および情報処理装置 |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2023233633A1 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019016140A (ja) * | 2017-07-06 | 2019-01-31 | 株式会社朝日新聞社 | 校正支援装置、校正支援方法及び校正支援プログラム |
| CN111539199A (zh) * | 2020-04-17 | 2020-08-14 | 中移(杭州)信息技术有限公司 | 文本的纠错方法、装置、终端、及存储介质 |
| JP2021089696A (ja) * | 2019-12-06 | 2021-06-10 | アイビーリサーチ株式会社 | 入力支援装置、入力支援システム及びプログラム |
| WO2021124490A1 (ja) * | 2019-12-18 | 2021-06-24 | 富士通株式会社 | 情報処理プログラム、情報処理方法および情報処理装置 |
-
2022
- 2022-06-02 WO PCT/JP2022/022525 patent/WO2023233633A1/ja unknown
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019016140A (ja) * | 2017-07-06 | 2019-01-31 | 株式会社朝日新聞社 | 校正支援装置、校正支援方法及び校正支援プログラム |
| JP2021089696A (ja) * | 2019-12-06 | 2021-06-10 | アイビーリサーチ株式会社 | 入力支援装置、入力支援システム及びプログラム |
| WO2021124490A1 (ja) * | 2019-12-18 | 2021-06-24 | 富士通株式会社 | 情報処理プログラム、情報処理方法および情報処理装置 |
| CN111539199A (zh) * | 2020-04-17 | 2020-08-14 | 中移(杭州)信息技术有限公司 | 文本的纠错方法、装置、终端、及存储介质 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Senior et al. | Protein structure prediction using multiple deep neural networks in the 13th Critical Assessment of Protein Structure Prediction (CASP13) | |
| US10311146B2 (en) | Machine translation method for performing translation between languages | |
| Iyer et al. | Learning a neural semantic parser from user feedback | |
| Alvarez-Melis et al. | A causal framework for explaining the predictions of black-box sequence-to-sequence models | |
| Rei | Semi-supervised multitask learning for sequence labeling | |
| CN106649288B (zh) | 基于人工智能的翻译方法和装置 | |
| AU2018217281B2 (en) | Using deep learning techniques to determine the contextual reading order in a form document | |
| Rei et al. | Compositional sequence labeling models for error detection in learner writing | |
| US11157686B2 (en) | Text sequence segmentation method, apparatus and device, and storage medium thereof | |
| US11954594B1 (en) | Training recurrent neural networks to generate sequences | |
| US20210182733A1 (en) | Training method and device for machine translation model and storage medium | |
| Kaneko et al. | Grammatical error detection using error-and grammaticality-specific word embeddings | |
| Rei et al. | Auxiliary objectives for neural error detection models | |
| CN110929524A (zh) | 数据筛选方法、装置、设备及计算机可读存储介质 | |
| Fu et al. | Chinese grammatical error diagnosis using statistical and prior knowledge driven features with probabilistic ensemble enhancement | |
| CN110807335A (zh) | 基于机器学习的翻译方法、装置、设备及存储介质 | |
| CN111046659A (zh) | 上下文信息生成方法、上下文信息生成装置及计算机可读记录介质 | |
| CN109558570A (zh) | 句生成方法和设备 | |
| CN111191441A (zh) | 文本纠错方法、装置及存储介质 | |
| US11615294B2 (en) | Method and apparatus based on position relation-based skip-gram model and storage medium | |
| Solyman et al. | Optimizing the impact of data augmentation for low-resource grammatical error correction | |
| Sagara et al. | Unsupervised lexical acquisition of relative spatial concepts using spoken user utterances | |
| JP2022141191A (ja) | 機械学習プログラム、機械学習方法および翻訳装置 | |
| JP7194759B2 (ja) | 翻訳用データ生成システム | |
| WO2023233633A1 (ja) | 情報処理プログラム、情報処理方法および情報処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22944914 Country of ref document: EP Kind code of ref document: A1 |