WO2023166573A1 - 学習装置、制御装置、学習方法及び記憶媒体 - Google Patents
学習装置、制御装置、学習方法及び記憶媒体 Download PDFInfo
- Publication number
- WO2023166573A1 WO2023166573A1 PCT/JP2022/008699 JP2022008699W WO2023166573A1 WO 2023166573 A1 WO2023166573 A1 WO 2023166573A1 JP 2022008699 W JP2022008699 W JP 2022008699W WO 2023166573 A1 WO2023166573 A1 WO 2023166573A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- parameter
- meta
- value
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B25—HAND TOOLS; PORTABLE POWER-DRIVEN TOOLS; MANIPULATORS
- B25J—MANIPULATORS; CHAMBERS PROVIDED WITH MANIPULATION DEVICES
- B25J13/00—Controls for manipulators
Definitions
- the present invention relates to a learning device, a control device, a learning method and a storage medium.
- a system has been proposed in which robot control is performed by providing skills that modularize the robot's movements when controlling the robot necessary to execute a task.
- robot skills that can be selected according to the task are defined as a tuple. is disclosed.
- the robot can be made to perform a plurality of skills with a single model. In this way, when learning meta-parameter values of a learning model, if it is possible to determine whether or not to continue learning, it is expected that unnecessary learning can be omitted and learning can be performed efficiently.
- An example of the purpose of this disclosure is to provide a learning device, a control device, a learning method, and a recording medium that can solve the above problems.
- the learning device performs learning of values of metaparameters indicating the probability distribution in a learning model in which parameter values follow the probability distribution to training data indicating inputs and outputs in the learning model.
- generalization error evaluation means for calculating an evaluation value indicating an evaluation of the generalization error of the learning model; and whether or not to continue learning the value of the metaparameter based on the evaluation value.
- learning continuation determination means for determining.
- control device includes control means for controlling the robot according to the shape of the grasped object so that the robot grasps grasped objects having different shapes.
- a learning method comprises: a computer performing learning of values of metaparameters indicating the probability distribution in a learning model in which parameter values follow a probability distribution; Based on the training data, calculating an evaluation value indicating an evaluation of the generalization error of the learning model, and determining whether or not to continue learning the value of the metaparameter based on the evaluation value.
- the recording medium indicates to a computer learning of meta-parameter values indicating the probability distribution in a learning model in which parameter values follow a probability distribution, and inputs and outputs in the learning model. Based on the training data, calculating an evaluation value indicating an evaluation of the generalization error of the learning model, and determining whether or not to continue learning the value of the metaparameter based on the evaluation value.
- FIG. 4 is a diagram showing an example of known task parameters according to the first embodiment
- FIG. FIG. 4 is a diagram showing an example of unknown task parameters according to the first embodiment
- FIG. 1 is a diagram illustrating an example of a hardware configuration of a learning device according to a first embodiment
- FIG. 3 is a diagram showing an example of the hardware configuration of a robot controller according to the first embodiment
- FIG. 1 is a diagram showing a robot that grips an object and an object to be gripped in real space according to the first embodiment
- FIG. 7 is a diagram representing the state shown in FIG. 6 in an abstract space
- FIG. 4 is a diagram showing an example of the configuration of a control system regarding skill execution according to the first embodiment
- FIG. 3 is a diagram showing an example of a functional configuration of a learning device regarding update of a skill database according to the first embodiment
- FIG. It is a figure which shows the example of a structure of the skill learning part which concerns on 1st embodiment. It is a figure which shows the example of input-output of the data in the skill learning part which concerns on 1st embodiment.
- FIG. 7 is a diagram showing an example of update processing of a skill database by the learning device according to the first embodiment; It is a figure which shows the example of input-output of the data in the skill learning part which concerns on 2nd embodiment.
- FIG. 10 is a diagram showing an example of update processing of a skill database by the learning device according to the second embodiment; It is a figure which shows the example of a structure of the skill learning part which concerns on 3rd embodiment.
- FIG. 10 is a diagram showing an example of data input/output in a skill learning unit according to the third embodiment
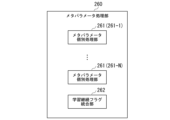
- FIG. 13 is a diagram showing an example of the configuration of a meta-parameter processing unit according to the third embodiment
- FIG. 10 is a diagram showing an example of data input/output in a meta-parameter processing unit according to the third embodiment
- FIG. 10 is a diagram showing a first example of the configuration of a meta-parameter individual processing unit according to the third embodiment;
- FIG. 20 is a diagram showing an example of data input/output in the meta-parameter individual processing unit shown in FIG. 19;
- FIG. 12 is a diagram showing a second example of the configuration of the meta-parameter individual processing unit according to the third embodiment;
- FIG. 22 is a diagram showing an example of data input/output in the meta-parameter individual processing unit shown in FIG. 21;
- FIG. 11 is a diagram showing an example of update processing of a skill database by the learning device according to the third embodiment;
- FIG. 11 is a diagram showing an example of processing for calculating a meta-parameter value of a predictor by a meta-parameter processing unit according to the third embodiment;
- FIG. 12 is a diagram showing a first example of processing in which the meta-parameter individual processing unit according to the third embodiment calculates a meta-parameter value for each predictor and determines whether or not learning of the meta-parameter value should be continued;
- FIG. 10 is a diagram showing a second example of processing in which the meta-parameter individual processing unit according to the third embodiment calculates a meta-parameter value for each predictor and determines whether learning of the meta-parameter value should be continued.
- FIG. 13 is a diagram showing an example of the configuration of a learning device according to the fourth embodiment; FIG. It is a figure which shows the example of a structure of the control apparatus which concerns on 5th embodiment.
- FIG. 20 is a diagram showing an example of a procedure of processing in a learning method according to the sixth embodiment;
- FIG. 1 is a diagram showing an example of the configuration of a control system according to the first embodiment.
- the control system 100 includes a learning device 1 , a storage device 2 , a robot controller 3 , a measuring device 4 and a robot 5 .
- the learning device 1 performs data communication with the storage device 2 via a communication network or by direct wireless or wired communication.
- the robot controller 3 performs data communication with the storage device 2, the measuring device 4, and the robot 5 via a communication network or direct wireless or wired communication.
- the learning device 1 learns the motion of the robot 5 to perform a given task by machine learning such as self-supervised learning (SSL). In addition, the learning device 1 learns a set of states in which an action to be learned can be executed.
- machine learning such as self-supervised learning (SSL).
- SSL self-supervised learning
- the object from which the learning device 1 learns the motion is not limited to a specific object, and various control objects that can be controlled and whose control can be learned can be used.
- the motion of the controlled object such as the robot 5 is not limited to one that accompanies a change in position.
- the acquisition of sensor measurement data by the robot 5 using a sensor may be set as one of the actions of the robot 5 . The same applies to the following embodiments.
- the state here is the state of the target system including the robot 5 and the operating environment of the robot 5 .
- the robot 5 and the operating environment of the robot 5 are collectively referred to as a target system or simply a system.
- a task handles an object, such as a task of grasping an object, the object of the task is also included in the target system.
- the state of the target system is called a system state or simply a state.
- the system state at the time of task completion determined for a task is also called the target state of the task or simply the target state. Reaching the goal state of a task is also referred to as accomplishing or succeeding in the task. If the task is accomplished by executing the skill, the state at the end of the skill execution corresponds to the target state.
- the system state at the start of a task is also called the initial state of that task.
- the learning device 1 learns about skills in which specific actions of the robot 5 are modularized for each action. In the embodiment, it is assumed that one task can be accomplished by executing one skill, and the case where the learning device 1 learns the skill so that the task can be accomplished will be described as an example. do.
- the robot controller 3 may combine multiple skills to execute the task. For example, the robot controller 3 may divide a given task into subtasks corresponding to skills, combine the skills for performing each subtask, and plan the execution of the given task.
- the learning device 1 also learns a set of states in which the skill can be executed in learning about the skill.
- the learning device 1 registers information about learned skills in a skill database stored in the storage device 2 .
- Information registered in the skill database is also called a skill tuple.
- the skill tuple contains various pieces of information necessary to perform the operations we want to modularize.
- the learning device 1 generates skill tuples based on detailed system model information, low-level controller information, and target parameter information stored in the storage device 2 .
- the storage device 2 stores information that the learning device 1 and the robot controller 3 refer to.
- the storage device 2 stores, for example, detailed system model information, low-level controller information, target parameter information, and a skill database.
- the storage device 2 may be an external storage device such as a hard disk connected to or built into the learning device 1 or the robot controller 3, or may be a storage medium such as a flash memory. 3 may be a server device or the like that performs data communication. Further, the storage device 2 may be composed of a plurality of storage devices, and each of the storage units described above may be held in a distributed manner.
- the detailed system model information is information representing a model of the target system in real space.
- a model of the target system in real space is also called a detailed system model.
- a "detailed" system model is used to distinguish from an "abstract" system model in which the detailed system model is abstracted.
- the detailed system model information may be expressed in differential or difference equations representing the detailed system model.
- the detailed system model may be configured as a simulator that imitates the motion of the robot 5 .
- the low-level controller information is information about the low-level controller that generates inputs for controlling the actual motion of the robot 5 based on the parameter values output by the high-level controller. For example, when the high-level controller generates a trajectory for the robot 5, the low-level controller may generate a control input that follows the movement of the robot 5 according to the trajectory. For example, the low-level controller may control the robot 5 through PID (Proportional Integral Differential) servo control based on the parameters output by the high-level controller.
- PID Proportional Integral Differential
- the target parameter information is provided for each skill learned by the learning device 1, and includes, for example, initial state information, target state/known task parameter information, unknown task parameter information, execution time information, and general constraint information. .
- the variable parts of the task are called task parameters.
- known task parameters those represented by numerical values are referred to as known task parameters.
- known task parameters include the size of an object to be grasped in the task, such as the size of a grasped object when the task is a task of grasping an object, and the trajectory of the robot 5 for executing the task. can be, but are not limited to:
- Known task parameters can also be treated as parameters in skills.
- Known task parameters are examples of skill parameters.
- FIG. 2 is a diagram showing an example of known task parameters.
- FIG. 2 shows an example in which the robot 5 performs a task of gripping a cylindrical object.
- the radius and height of the target cylinder are examples of known task parameters.
- unknown task parameters include the shape of an object to be grasped when the task is a task to grasp an object, the shape of an object in the task, and the skill required to execute the task.
- the types of motions of the robot 5 for the purpose can include, but are not limited to.
- FIG. 3 is a diagram showing an example of unknown task parameters.
- FIG. 3 shows an example in which the robot 5 performs a task of gripping objects of various shapes.
- the shape of the object corresponds to an example of an unknown parameter.
- the target state is expressed numerically.
- the target state may be expressed as the coordinates of the object being within a predetermined range.
- the initial state information is information indicating a set of states in which the target skill can be executed.
- the state at the start of skill execution is also referred to as the initial state of the skill, or simply the initial state.
- a set of initial states is also called an initial state set. Denote the initial state by x s or x si .
- "i" is a positive integer representing an identification number that identifies the initial state.
- the time of the initial state is set to 0, and the initial state is represented by x0 .
- the goal state/known task parameter information is a combination of the possible values of the goal state, which is a state that can be reached by executing the target skill, and the possible values of the known task parameters, which are treated as explicit parameters in the target skill. is information indicating a set of For example, in the case of a skill in which the robot 5 grips an object, information regarding stable gripping conditions such as Form Closure, Force Closure, etc., may be included as possible values of the target state.
- the combination of the goal state and the known task parameter value is called the goal state/known task parameter value and is denoted by ⁇ g or ⁇ gi .
- "i" is a positive integer representing an identification number identifying the target state/known task parameter value.
- a task with either or both different target states and known task parameter values can be executed with one skill. can be done.
- the learning device 1 when the learning device 1 performs processing related to skill learning using a predictor (Predictor), a target state and known task parameter values are input to the predictor, and an output corresponding to the target state and known task parameter values value can be obtained.
- the predictor is constructed using a learning model (model in machine learning), for example a neural network or a Gaussian Process (GP).
- the goal state/known task parameter information may be configured as a set of possible values for the goal state.
- the target state/known task parameter value ⁇ g may indicate the target state.
- the unknown task parameter information is information about unknown task parameters.
- the unknown task parameter information may indicate the probability distribution of data related to unknown parameters.
- information about each unknown task parameter may be indicated by unknown task parameter information. Note that, in the first embodiment and the second embodiment, correspondence to target state/known task parameter information will be described. In the first embodiment and the second embodiment, values corresponding to unknown task parameters may be indicated as fixed values.
- Control system 100 treats two tasks as the same task if the unknown task parameter values for the two tasks are the same, and treats the two tasks as separate tasks if the unknown task parameter values are different.
- a task may be denoted by ⁇ or ⁇ j .
- the above "j" can also be regarded as a positive integer representing an identification number that identifies a task.
- the execution time information is information regarding the time limit for skill execution.
- the execution time information may indicate the execution time of the skill (the time required to execute the skill), the permissible condition value of the time from the start to the end of skill execution, or both.
- the general constraint information is information indicating general constraint conditions such as restrictions on the movable range of the robot 5, speed restrictions, and input restrictions.
- the skill database is a database of skill tuples prepared for each skill.
- a skill tuple consists of information about a high-level controller for executing the target skill, information about a low-level controller for executing the target skill, and a state (initial state in the skill) in which the target skill can be executed. ) and information about the set of target state/known task parameter value combinations.
- a set of states and target states/known task parameter values in which the target skill can be executed is also called an executable state set.
- the executable state set may be defined in an abstract space that abstracts the actual space.
- the executable state set is expressed using, for example, a Gaussian Process Regression (GPR), a level set function estimated by a level set estimation (LSE), or an approximation function of a level set function. be able to.
- GPR Gaussian Process Regression
- LSE level set estimation
- an approximation function of a level set function able to.
- whether the set of executable states contains a state and goal state/known task parameter value combination is determined by the value of a Gaussian process regression for that state and goal state/known task parameter value combination (e.g. , mean value) or the value of the approximation function for the combination of the certain state and target state/known task parameter values satisfies the constraints for judging feasibility.
- a level set function is used as a function representing an executable state set will be described as an example, but the present invention is not limited to this.
- the robot controller 3 formulates a motion plan for the robot 5 based on the measurement signal supplied by the measuring device 4, the skill database, and the like.
- the robot controller 3 generates a control command (control input) for causing the robot 5 to execute a planned action, and supplies the control command to the robot 5 .
- the robot controller 3 converts the task to be executed by the robot 5 into a sequence of tasks that the robot 5 can accept for each time step. Then, the robot controller 3 controls the robot 5 based on the control command corresponding to the generated sequence execution command.
- a control command corresponds to a control input output by a low-level controller.
- the measuring device 4 is, for example, one or more sensors such as a camera, a range sensor, a sonar, or a combination thereof that detect the state in the work space where the task by the robot 5 is executed.
- the measurement device 4 supplies the generated measurement signal to the robot controller 3 .
- the measurement device 4 may be a self-propelled or flying sensor (including a drone) that moves within the work space.
- the measuring device 4 may also include sensors provided on the robot 5 and sensors provided on other objects in the work space.
- the measurement device 4 may also include a sensor that detects sound within the work space. In this way, the measuring device 4 may include various sensors that detect conditions within the work space, and may include sensors provided at arbitrary locations.
- the robot 5 performs work related to designated tasks based on control commands supplied from the robot controller 3 .
- the robot 5 is, for example, a robot that operates in various factories such as an assembly factory and a food factory, or a physical distribution site.
- the robot 5 may be a vertical articulated robot, a horizontal articulated robot, or any other type of robot.
- the robot 5 may supply a status signal to the robot controller 3 indicating the status of the robot 5 .
- This state signal may be an output signal of a sensor that detects the state (position, angle, etc.) of the entire robot 5 or a specific part such as a joint, or a signal indicating the progress of the operation of the robot 5. .
- control system 100 shown in FIG. 1 is an example, and various modifications may be made to the configuration.
- the robot controller 3 and the robot 5 may be configured integrally.
- at least any two of the learning device 1, the storage device 2, and the robot controller 3 may be integrated.
- the control target of the control system 100 is not limited to robots.
- the control system 100 can control various control targets whose control can be learned by the learning device 1 .
- FIG. 4 is a diagram showing an example of the hardware configuration of the learning device 1. As shown in FIG.
- the learning device 1 includes a processor 11, a memory 12, and an interface 13 as hardware. Processor 11 , memory 12 and interface 13 are connected via data bus 10 .
- the processor 11 functions as a controller (arithmetic device) that controls the entire learning device 1 by executing programs stored in the memory 12 .
- the processor 11 is, for example, a CPU (Central Processing Unit), a GPU (Graphics Processing Unit), or a TPU (Tensor Processing Unit).
- Processor 11 may be composed of a plurality of processors.
- the processor 11 corresponds to an example of a computer.
- the memory 12 is composed of various volatile and nonvolatile memories such as RAM (Random Access Memory), ROM (Read Only Memory), and flash memory.
- the memory 12 also stores a program for executing the processing that the learning device 1 executes. Note that part of the information stored in the memory 12 may be stored in one or more external storage devices (for example, the storage device 2) that can communicate with the learning device 1. It may be stored by a medium.
- the interface 13 is an interface for electrically connecting the learning device 1 and other devices. These interfaces may be wireless interfaces such as network adapters for wirelessly transmitting and receiving data to and from other devices, or hardware interfaces for connecting to other devices via cables or the like. For example, the interface 13 performs an interface operation with an input device such as a touch panel, button, keyboard, voice input device that receives user input (external input), a display device such as a display or a projector, a sound output device such as a speaker, and the like.
- an input device such as a touch panel, button, keyboard, voice input device that receives user input (external input)
- a display device such as a display or a projector
- a sound output device such as a speaker, and the like.
- the hardware configuration of the learning device 1 is not limited to the configuration shown in FIG.
- the learning device 1 may incorporate at least one of a display device, an input device, and a sound output device.
- the learning device 1 may be configured to include the storage device 2 .
- FIG. 5 is a diagram showing an example of the hardware configuration of the robot controller 3. As shown in FIG.
- the robot controller 3 includes a processor 31, a memory 32, and an interface 33 as hardware. Processor 31 , memory 32 and interface 33 are connected via data bus 30 .
- the processor 31 functions as a controller (arithmetic device) that performs overall control of the robot controller 3 by executing programs stored in the memory 32 .
- the processor 31 is, for example, a processor such as a CPU, GPU, or TPU.
- the processor 31 may be composed of multiple processors.
- the memory 32 is composed of various volatile memories and non-volatile memories such as RAM, ROM, and flash memory.
- the memory 32 also stores a program for executing the process executed by the robot controller 3 .
- Part of the information stored in the memory 32 may be stored in one or a plurality of external storage devices (for example, the storage device 2) that can communicate with the robot controller 3. It may be stored by a medium.
- the interface 33 is an interface for electrically connecting the robot controller 3 and other devices. These interfaces may be wireless interfaces such as network adapters for wirelessly transmitting and receiving data to and from other devices, or hardware interfaces for connecting to other devices via cables or the like.
- the hardware configuration of the robot controller 3 is not limited to the configuration shown in FIG.
- the robot controller 3 may incorporate at least one of a display device, an input device, and a sound output device.
- the robot controller 3 may be configured to include the storage device 2 .
- the robot controller 3 formulates a motion plan for the robot 5 in the abstract space based on the skill tuple. Therefore, the abstract space targeted in the motion planning of the robot 5 will be described.
- FIG. 6 is a diagram showing a robot (manipulator) 5 that grips an object and a grip target object 6 in real space.
- FIG. 7 is a diagram representing the state shown in FIG. 6 in an abstract space.
- the shape of the end effector of the robot 5, the geometric shape of the object to be gripped 6, the gripping position/orientation of the robot 5, and the shape of the object to be gripped 6 are: Strict calculations are required in consideration of object characteristics and the like.
- the robot controller 3 formulates a motion plan in an abstract space in which the state of each object such as the robot 5 and the graspable object 6 is abstractly (simplifiedly) represented. In the example of FIG.
- an abstract model 5x corresponding to the end effector of the robot 5, an abstract model 6x corresponding to the gripping target object 6, and a gripping operation executable region (dashed line) of the gripping target object 6 by the robot 5 See box 60) is defined.
- the set of executable states is indicated as a set of combinations of initial states and target states/known task parameter values that allow the skill to be executed.
- a set of combinations of initial states and target states/known task parameter values in which the gripping skill can be executed is exemplified as a gripping action executable region 60 framed by a dashed line.
- the state of the robot in the abstract space is abstractly expressed as the state of the end effector.
- the state of each object corresponding to the operation target object or the environmental object is also represented abstractly, for example, in a coordinate system based on a reference object such as a workbench.
- the robot controller 3 in this embodiment uses skills to formulate a motion plan in an abstract space that abstracts the actual system. As a result, even in multi-stage tasks, the calculation cost required for motion planning is suitably suppressed.
- the robot controller 3 formulates a motion plan for executing a skill for performing a grip in a grippable region (dashed-line frame 60) defined in the abstract space, and based on the formulated motion plan, the robot controller 3 5 control commands are generated.
- a state x' is represented as a vector (abstract state vector).
- the abstract state vector includes a vector representing the state of the object to be manipulated (for example, position, orientation, speed, etc.), a vector representing the state of the end effector of the operable robot 5, and an environment vector. Contains a vector representing the state of the object.
- the state x' is defined as a state vector abstractly representing the state of some elements in the real system.
- the goal state/known task parameter value in the real space may be denoted as “ ⁇ g ”
- the goal state/known task parameter value in the abstract space as “ ⁇ g ′” to distinguish between them.
- FIG. 8 is a diagram showing an example of the configuration of a control system for skill execution.
- the processor 31 of the robot controller 3 functionally includes a motion planner 34 , a high-level controller 35 and a low-level controller 36 .
- the system 50 corresponds to a real system (a real system including the robot 5).
- the high-level controller 35 is also called a high-level controller and is denoted by ⁇ H .
- the high-level control section 35 corresponds to an example of control means.
- the low-level controller 36 is also referred to as a low-level controller and is denoted by ⁇ L .
- the robot controller 3 corresponds to an example of a control device that controls the robot 5 .
- a speech balloon representing a diagram (see FIG. 7) exemplifying an abstract space targeted by the motion planning unit 34 is displayed in association with the motion planning unit 34, and is associated with the system 50.
- a balloon showing an example of a real system (see FIG. 6) is displayed in association with the system 50 .
- balloons representing information about the set of skill executable states are displayed in association with the high-level control section 35 .
- the motion planning unit 34 formulates a motion plan for the robot 5 based on the state x' in the abstract system and the skill database.
- the motion planning unit 34 expresses the target state by, for example, a logical expression based on temporal logic.
- the motion planning unit 34 may express the logical formula using arbitrary temporal logic such as linear temporal logic, MTL (Metric Temporal Logic), STL (Signal Temporal Logic).
- the operation planning unit 34 converts the generated logical expression into a sequence (operation sequence) for each time step. This action sequence includes, for example, information about the skill used at each time step.
- the high-level control section 35 recognizes the skill to be executed for each time step based on the motion sequence generated by the motion planning section 34 . Then, the high-level control unit 35 inputs the parameter " ⁇ ”.
- the high-level control unit 35 determines that the combination of the state "x 0 '" in the abstract space at the start of execution of the skill to be executed and the goal state/known task parameter value is the executable state set " ⁇ 0 '" of the skill. , the control parameter ⁇ is generated as shown in the following equation (1).
- the state at the start of skill execution is also referred to as the initial state.
- the initial state is indicated by, for example, a state in an abstract space.
- an approximation function of the level set function that can determine whether or not the skill belongs to the executable state set ⁇ 0 ′ is defined as “ ⁇ ”
- the robot controller 3 determines that the state x 0 ′ belongs to the executable state set ⁇ 0 ′ can be determined by determining whether expression (2) is satisfied.
- Equation (2) can also be said to represent a constraint that determines the feasibility of a skill from a certain state.
- the approximation function “ ⁇ ” can be said to be a model that can evaluate whether the goal state can be reached under known task parameter values from some initial state x 0 ′.
- the approximation function ⁇ is obtained by learning by the learning device 1 as will be described later.
- a goal state set which is a set of goal states in the abstract space after execution of the target skill, is denoted as " ⁇ ' d ", and the execution time of the target skill is denoted as "T”. Also, the state at the time when T time has passed from the start of skill execution is assumed to be "x'(T)".
- Expression (3) can be realized by executing the skill using the low-level control unit 36 .
- the low-level control unit 36 Based on the control parameter ⁇ generated by the high-level control unit 35, the current state x in the actual system obtained from the system 50, and the target state/known task parameter value ⁇ g , the low-level control unit 36 inputs "u ”.
- the low-level control unit 36 generates the input u as a control command as shown in Equation (4) based on the low-level controller " ⁇ L " included in the skill tuple.
- the low-level controller ⁇ L is not limited to the form of the above formula, and controllers having various forms may be used.
- the low-level control unit 36 recognizes the state of the robot 5 and the environment using any state recognition technology based on the measurement signal (which may include the signal from the robot 5) output by the measuring device 4, etc., as the state x. get.
- the system 50 is represented by the state equation shown in Equation (5) using a function "f" having arguments of the input u to the robot 5 and the state x.
- the operator “ ⁇ ” represents differentiation with respect to time or difference with respect to time.
- FIG. 9 is a diagram showing an example of the functional configuration of the learning device 1 regarding update of the skill database.
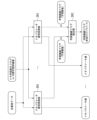
- the processor 11 of the learning device 1 functionally includes an abstract system model setting unit 14 , a skill learning unit 15 , and a skill tuple generation unit 16 .
- FIG. 9 shows an example of data exchanged for each block, the present invention is not limited to this. The same applies to other figures.
- the abstract system model setting unit 14 sets an abstract system model based on the detailed system model information.
- This abstract system model is a simplified model of the detailed system model specified by the detailed system model information.
- the detailed system model is a model corresponding to system 50 in FIG.
- the abstract system model is a model having as a state an abstract state vector x' constructed based on the state x in the detailed system model.
- the action planner 34 formulates an action plan using the abstract system model.
- the abstract system model setting unit 14 calculates an abstract system model from the detailed system model, for example, based on an algorithm stored in advance in the storage device 2 or the like.
- information about the abstract system model may be stored in advance in the storage device 2 or the like.
- the abstract system model setting unit 14 may acquire information about the abstract system model from the storage device 2 or the like.
- the abstract system model setting unit 14 supplies information about the set abstract system model to the skill learning unit 15 and skill tuple generation unit 16 .
- the skill learning unit 15 controls skill execution based on the abstract system model set by the abstract system model setting unit 14, detailed system model information, low-level controller information, and target parameter information stored in the storage device 2. study.
- the skill learning unit 15 learns the value of the control parameter ⁇ of the low-level controller ⁇ L output by the high-level controller ⁇ H .
- the skill learning unit 15 learns the level set function, and acquires training data for learning the control parameter ⁇ , for example, using an evaluation function that evaluates the prediction accuracy of the level set function.
- the skill tuple generation unit 16 generates information about the executable state set ⁇ 0 ′ learned by the skill learning unit 15, information about the high-level controller ⁇ H , and information about the abstract system model set by the abstract system model setting unit 14. , a set (tuple) containing low-level controller information and target parameter information is generated as a skill tuple. Then, the skill tuple generation unit 16 registers the generated skill tuple in the skill database. Data in the skill database is used by the robot controller 3 to control the robot 5 .
- Each component of the abstract system model setting unit 14, the skill learning unit 15, and the skill tuple generating unit 16 can be realized, for example, by the processor 11 executing a program. Further, each component may be realized by recording necessary programs in an arbitrary nonvolatile storage medium and installing them as necessary. Note that at least part of each of these components may be realized by any combination of hardware, firmware, and software, without being limited to being implemented by program software. Also, at least part of each of these components may be implemented using a user-programmable integrated circuit, such as an FPGA (Field-Programmable Gate Array) or a microcontroller. In this case, this integrated circuit may be used to implement a program composed of the above components.
- FPGA Field-Programmable Gate Array
- each component may be composed of an ASSP (Application Specific Standard Produce), an ASIC (Application Specific Integrated Circuit), or a quantum computer control chip.
- ASSP Application Specific Standard Produce
- ASIC Application Specific Integrated Circuit
- quantum computer control chip a quantum computer control chip.
- each component may be realized by various hardware. The above also applies to other embodiments described later.
- each of these components may be implemented by cooperation of a plurality of computers using, for example, cloud computing technology.
- FIG. 10 is a diagram showing an example of the configuration of the skill learning unit 15 according to the first embodiment.
- the skill learning section 15 functionally includes a search point set setting section 210 , a data acquisition section 220 , a prediction accuracy evaluation function learning section 230 , and a high-level controller learning section 240 .
- the search point set setting unit 210 includes a search point set initialization unit 211 and a next search point set setting unit 212 .
- the data acquisition section 220 includes a system model setting section 221 , a problem setting calculation section 222 and a data update section 223 .
- the prediction accuracy evaluation function learning unit 230 includes a level set function learning unit 231 , a prediction accuracy evaluation function setting unit 232 and an evaluation unit 233 .
- the skill learning unit 15 generates training data for learning the high-level controller ⁇ H , and uses the generated training data to train the high-level controller ⁇ H . . Also, the skill learning unit 15 learns a level set function.
- the search point set setting unit 210 prepares a plurality of combinations of the initial state xs and the target state/known task parameter value ⁇ g as task setting candidates to be learned by the high-level controller ⁇ H .
- the search point set setting unit 210 selects, from among the plurality of prepared candidates, a task setting for acquiring training data for learning control of the robot 5 by the robot controller 3 .
- the search point set setting unit 210 corresponds to an example of search point setting means.
- the search point set initialization unit 211 sets a set of task setting candidates for learning of the high-level controller ⁇ H and the level set function. Specifically, the search point set initialization unit 211 sets a set whose elements are combinations of the initial state x s and the target state/known task parameter value ⁇ g .
- a set of task setting candidates to be learned by the high-level controller ⁇ H which is set by the search point set initialization unit 211, is called a search point set and is represented by X ⁇ search .
- a candidate for task setting is also called a search point.
- a search point can be represented as (x s , ⁇ g ). Once the search point (x s , ⁇ g ) is determined, the task setting is determined, and the motion of the robot 5 is determined. It can be said that the search point (x s , ⁇ g ) indicates the motion of the robot 5 for each task.
- the next search point set setting unit 212 extracts a subset from the search point set X ⁇ search .
- Each element of the subset extracted by the next search point set setting unit 212 is treated as a task setting to be learned by the high-level controller ⁇ H .
- a subset extracted from the search point set X ⁇ search by the next search point set setting unit 212 is called a search point subset and is represented by X ⁇ check .
- Elements of the search point subset X ⁇ check are represented by X ⁇ or X ⁇ i .
- "i" is a positive integer representing an identification number that identifies an element of the search point subset.
- the elements of the search point subset X ⁇ check are also referred to as selected search points, or simply search points.
- the data acquisition unit 220 acquires training data for learning the high-level controller ⁇ H for each element X 1 - of the search point subset X 1 -check set by the next search point set setting part 212.
- the system model setting unit 221 sets a system model and the like for setting an optimum control problem for each search point X 1 ⁇ .
- the problem setting calculation unit 222 sets a solution search problem indicating task execution by the robot 5 based on the settings made by the system model setting unit 221 .
- the solution search problem here is a problem of finding a solution that satisfies the given constraints.
- the problem setting calculation unit 222 sets an optimal control problem including constraints such as constraints related to tasks and constraints related to the motion of the robot, and an evaluation function of reachability to the target state.
- the optimum control problem is a problem of obtaining a control input that maximizes the evaluation indicated by the evaluation function value, and can be regarded as an optimization problem.
- a function indicating that the smaller the evaluation function value is, the higher the evaluation is is used as the evaluation function for the optimum control problem.
- a solution that minimizes the evaluation function value such as the minimum value of the evaluation function
- the learning device 1 may use, as the evaluation function for the optimal control problem, a function indicating that the larger the function value, the higher the evaluation.
- the problem setting calculation unit 222 solves the set optimum control problem and calculates the output value of the high-level controller ⁇ H and the evaluation function value in the case of the output value so that the evaluation function value becomes as small as possible.
- the evaluation function value calculated by the problem setting calculation unit 222 corresponds to an example of information indicating the evaluation of whether or not the action indicated by the search point X 1 ⁇ can be executed.
- the problem setting calculation unit 222 corresponds to an example of calculation means.
- the data updating unit 223 includes the data obtained by solving the optimal control problem by the problem setting calculation unit 222 in the training data of the high-level controller ⁇ H and the training data of the level set function. Update data.
- the training data for the high-level controller ⁇ H referred to here is training data for learning of the high-level controller ⁇ H .
- the level set function training data is the training data for level set function learning.
- the parameter value ⁇ * to be output by the high-level controller ⁇ H obtained by solving the optimal control problem can be used as training data for learning the high-level controller ⁇ H .
- skill feasibility information indicated by the solution of the optimal control problem can be used in the training data for the level set function.
- These training data also include search points X to j , respectively.
- the training data for the high-level controller ⁇ H can be said to be the training data for learning the control of the robot 5 performed by the robot controller 3 using the high-level controller ⁇ H .
- the data update unit 223 corresponds to an example of data acquisition means.
- a set representing the training data of the high-level controller ⁇ H handled by the data updating unit 223 is called an acquired data set and is denoted by D opt .
- the prediction accuracy evaluation function learning unit 230 uses the acquired data set D opt to learn the level set function and the prediction accuracy evaluation function, and determines whether or not it is necessary to continue learning the level set function.
- the level set function is a function that indicates the set of executable states, which is the set of states and goal state/known task parameter value combinations in which the goal state is reachable.
- the prediction accuracy evaluation function is a function that indicates an evaluation of the estimation accuracy of the state and target state/known task parameter value combination that can reach the target state by the level set function.
- the training of the level set function is used for the training data of the high-level controller ⁇ H calculated by the problem setting calculation unit 222 for the search points X selected as targets for obtaining the training data of the high-level controller ⁇ H. It is done using the data obtained from It is considered that there is a positive correlation between the number of training data acquired by the data updating unit 223 and the estimation accuracy of the level set function.
- the prediction accuracy evaluation function can also be said to be a function that indicates an evaluation of the acquisition status of training data.
- the level set function learning unit 231 learns the level set function using the acquired data set D opt . For example, the level set function learning unit 231 determines whether or not the target state can be reached based on the evaluation function value calculated by the problem setting calculation unit 222 for each element of the acquired data set Dopt . Then, the level set function learning unit 231 uses, as training data, a combination of whether or not the target state can be reached, the initial state x s indicated by the element, and the target state/known task parameter value ⁇ g , and learns the level set function. do the learning.
- the level set function learning unit 231 corresponds to an example of level set function learning means.
- the prediction accuracy evaluation function setting section 232 learns a prediction accuracy evaluation function for the level set function learned by the level set function learning section 231 . For example, the prediction accuracy evaluation function setting unit 232 determines, based on the distribution of the search points X for which the level set function is to be learned, in the space of the candidates for the search points X , the part where the number of the search points X is large. A prediction accuracy evaluation function may be learned so that a space or a subspace with a high density is highly evaluated.
- the prediction accuracy evaluation function setting unit 232 corresponds to an example of prediction accuracy evaluation function setting means.
- a prediction accuracy evaluation function is represented by J g ⁇ or J g ⁇ j .
- "j" here is a positive integer representing an identification number that identifies a task.
- control system 100 treats two tasks as separate tasks when the unknown task parameter values are different.
- the evaluation unit 233 uses the prediction accuracy evaluation function to determine whether or not to continue acquisition of training data for the high-level controller ⁇ H .
- the evaluation unit 233 corresponds to an example of evaluation means. Whether or not to continue acquiring training data for the high-level controller ⁇ H can be regarded as whether or not to continue learning the level set function.
- a flag indicating the determination result of the evaluation unit 233 is also referred to as a learning continuation flag.
- the high-level controller learning unit 240 learns the high-level controller ⁇ H using the acquired data set D opt when the evaluation unit 233 determines that acquisition of training data for the high-level controller ⁇ H is not necessary. For example, the high-level controller learning unit 240 uses an element of the acquired data set D opt that indicates that the evaluation function value can reach the target state, and performs high-level control of the state indicated by that element. The high-level controller .pi.H is trained so that the input to the .pi.H will output the output value indicated by that element.
- the method of learning the high-level controller ⁇ H by the high-level controller learning section 240 is not limited to a specific method.
- FIG. 11 is a diagram showing an example of data input/output in the skill learning unit 15 according to the first embodiment.
- the search point set initialization unit 211 uses the target parameter information stored in the storage device 2 to set the search point set X 1 search .
- the search point set initialization unit 211 sets all possible combinations of the initial state x si and the target state/known task parameter value ⁇ g as elements of the search point set X ⁇ search . It may be set.
- the setting of the search point set X 1 -search by the search point set initializing unit 211 corresponds to the initial setting of the search point set X 1 -search .
- the search point set X ⁇ search is updated by the next search point set setting unit 212 .
- the next search point set setting unit 212 extracts a search point subset X 1 -check from the search point set X 1 -search. Specifically, the next search point set setting unit 212 reads one or more elements from the search point set X 1 -search , and sets the read elements as elements of the search point subset X 1 -check . Then, the next search point set setting unit 212 deletes the elements whose read elements are set in the search point subset X 1 -check from the elements of the search point set X 1 -search .
- the next search point set setting unit 212 uses the obtained prediction accuracy evaluation function to set search point subsets X 1 to check .
- the next search point set setting unit 212 selects, among the elements of the search point set X to search , the elements whose prediction accuracy evaluation function values indicate that the estimation accuracy of the level set function is lower than a predetermined condition as search points. Set as an element of the subset X to check .
- the method for determining whether the estimation accuracy here is lower than a predetermined condition is not limited to a specific method. For example, when indicating that the larger the prediction accuracy evaluation function value is, the lower the accuracy is, the lower the estimation accuracy than the predetermined condition may be that the prediction accuracy evaluation function value is greater than a predetermined threshold. but not limited to this.
- the system model setting unit 221 performs various settings for setting the optimum control problem for each element of the search point subsets X 1 to check. For example, the system model setting unit 221 performs low-level A controller ⁇ l , a system model, constraints on parameters of the system model, and an evaluation function of reachability to a target state are set.
- the system model here is a model of the target system, such as a motion model of the target system.
- Constraints on system model parameters are, for example, constraints on the values that parameters of the system model can take, such as constraints on the specifications of devices included in the target system and physical constraints.
- the system model and the constraints on the parameters of the system model are used as part of the constraints in the optimal control problem handled by the problem setting calculator 222 .
- the system model setting unit 221 includes the set low-level controller ⁇ l , the system model, the parameters of the system model, the evaluation function of the reachability to the target state, the search points X to i , the execution time T, etc. Information about the time limit for skill execution is output to the problem setting calculation unit 222 .
- the problem setting calculator 222 sets an optimum control problem for each of the search points X 1 to i based on the information from the system model setting unit 221, and searches for a solution to the set optimum control problem.
- the optimum control problem is, for example, a problem of finding a control input that minimizes the evaluation function value.
- the optimal control problem here is a problem of finding a control input that minimizes the value of the evaluation function under constraints such as the operating environment when an initial state and evaluation function are given. .
- the problem setting calculator 222 sets the evaluation function of the reachability to the target state as the evaluation function in the optimum control problem, and sets other various settings as the constraint conditions in the optimum control problem.
- the problem setting calculation unit 222 obtains an output value of the high-level controller ⁇ H that makes the evaluation function value as small as possible under the constraint conditions of the optimum control problem.
- the problem setting calculation unit 222 calculates a combination of the search points X to i , the output value ⁇ * i of the high-level controller ⁇ H that minimizes the evaluation function value, and the evaluation function value g * i at that time ( X ⁇ i , g * i , ⁇ * i ) to the data updating unit 223 .
- the problem setting calculation unit 222 may use an evaluation function g such that the state x' is the target state when the formula (6) holds as the evaluation function for the optimum control problem.
- x d ' represents the target state set. If the mapping from the state x of the detailed system model to the state x' of the abstract system model is represented by ⁇ , the formulas (7) to (8) are obtained.
- Equation (9) Minimizing the value of the evaluation function g in the optimal control problem is represented by Equation (9).
- T represents the time required to perform the skill.
- g( ⁇ (x(T)), ⁇ g ) represents the evaluation function value according to the state x(T) at the end of the skill. If this evaluation function value becomes 0 or less, it can be determined that the target state can be reached by executing the skill.
- ⁇ represents the output of the high level controller ⁇ H .
- Equation (9) represents obtaining the output ⁇ of the high-level controller ⁇ H that minimizes the value of the evaluation function g.
- Equation (10) A system model for the optimal control problem can be expressed as in Equation (10).
- Equation (12) The inequality constraint in the optimal control problem can be expressed as shown in Equation (12).
- Equation (13) is a function representing a constraint, and is set based on target parameter information, for example.
- the state at time 0 is the initial state, which is represented by Equation (13).
- Equation (14) The fact that ⁇ is the mapping from the state x of the detailed system model to the state x' of the abstract system model can be expressed as Equation (14).
- the problem setting calculation unit 222 is a high-level controller that minimizes the value of the evaluation function g as shown in Equation (9) under the constraints of Equations (10) to (14), for example. and the value g* of the evaluation function g at that time.
- Equation (9) the value of the evaluation function g as shown in Equation (9) under the constraints of Equations (10) to (14), for example.
- g* the value of the evaluation function g at that time.
- equation (6) if g * ⁇ 0, it can be determined that the target state can be reached by executing the skill with the output of the high-level controller set to ⁇ * from the initial state at this time. can.
- the problem setting calculator 222 calculates the obtained minimum value g * of the evaluation function and the output ⁇ * of the high-level controller at that time together with the initial state x s and the target state/known task parameter value ⁇ g . , to the data updating unit 223 .
- the problem setting calculator 222 may output to the data updater 223, in addition to or instead of the output ⁇ * of the high-level controller, information indicating that the target state can be reached.
- the data updating unit 223 includes this data in the training data used for learning the high-level controller ⁇ H by the high-level controller learning unit 240 .
- the method by which the problem setting calculation unit 222 solves the optimal control problem is not limited to a specific method.
- the problem setting calculator 222 may use a known algorithm as a solution search algorithm for the optimal control problem, or a known algorithm as a iteration search problem for the optimization problem.
- the problem setting calculation unit 222 may perform motion learning, such as reinforcement learning, in a motion simulation of the robot 5 so that the evaluation function value becomes as small as possible.
- the problem setting calculation unit 222 uses an arbitrary optimal control algorithm such as the Direct Collocation method and Differential Dynamic Programming (DDP). can be used to solve the optimal control problem.
- DDP Differential Dynamic Programming
- the problem setting calculation unit 222 uses a black-box optimization method such as Path Integral Control or a model-free optimal control method. can solve the optimal control problem.
- the problem setting calculator 222 obtains the control parameter ⁇ according to the problem of minimizing the evaluation function g based on the function c representing the constraint.
- generating a skill means learning a skill for a task different from the task for which the skill has already been learned.
- different tasks are tasks with different unknown task parameter values.
- the execution time information of the target parameter information shall include information designating the upper limit "T max " (T ⁇ T max ) of the execution time T of the skill. Also, it is assumed that the general constraint information of the target parameter information includes information representing a constraint expression regarding the state x, the input u, and the contact force F, as shown in Equation (16).
- this constraint formula includes the upper limit of contact force F “F max ” (F ⁇ F max ), the limit of movable range (or speed) “x max ” (
- the low-level controller ⁇ L is, for example, a PID-based servo controller.
- the input u is expressed as in Equation (17), for example.
- the target trajectory x rd is represented, for example, by Equation (18).
- control parameters by the output ⁇ of the high-level controller ⁇ H are the coefficients of the target trajectory polynomial and the PID control gain, and are expressed as in equation (19).
- the problem setting calculator 222 solves the optimum control problem and calculates the optimum value ( ⁇ * ) of the control parameter ( ⁇ ) shown in Equation (19).
- the data updating unit 223 updates the acquired data set D opt so that ( X i , g * i , ⁇ * i ) output from the problem setting calculation unit 222 is included in the acquired data set D opt .
- the level set function learning unit 231 learns the level set function based on the acquired data set D opt as described above.
- the level set function learning section 231 outputs the obtained level set function to the prediction accuracy evaluation function setting section 232 .
- the level set function learning unit 231 compares the evaluation function value indicated in the acquisition data set D opt with a predetermined threshold to determine whether the initial state indicated in the acquisition data set D opt can reach the target state. .
- the level set function learning unit 231 determines whether the target state can be reached based on whether the evaluation function value g * is 0 or less.
- the level-set function learning unit 231 learns the level-set function using, as training data, a combination of the state shown in the acquired data set Dopt , the target state, and the determination result of whether or not the target state can be reached. conduct.
- Equation (20) the function that outputs the optimal value g * of the evaluation function g for the initial state x 0 ' in the abstract state and the target state/known task parameter value ⁇ g is denoted by g * (x 0 ', ⁇ g ). .
- the target skill's executable state set ⁇ 0 ′ is expressed as in Equation (20).
- the level set function learning unit 231 calculates the executable state set Learn a level set function that represents ⁇ 0 '. For example, the level-set function learning unit 231 calculates a level-set function using a level-set estimation method, which is an estimation method using Gaussian process regression based on the concept of Bayesian optimization. We denote this level set function by g GP .
- this level set function g GP may be defined using the mean value function of the Gaussian process obtained through the level set estimation method, or may be defined as a combination of the mean value function and the variance function.
- the method by which the level set function learning unit 231 learns the function indicating the set of executable states is not limited to a specific method.
- the level-set function learning unit 231 may obtain the level-set function using Truncated Variance Reduction (TruVaR), which is an estimation method using Gaussian process regression, like the level-set estimation method.
- TruVaR Truncated Variance Reduction
- the level set function may be any model that evaluates the initial states that can be reached with respect to the desired state.
- the level set function and the output value ⁇ * of the high-level controller ⁇ H are determined based on a set of the initial state x 0 ', the target state/known task parameter value ⁇ g ', and the evaluation function value g * . It can also be said that By determining the level set function, it is possible to evaluate the reachable state and the known task parameter values, so that it is possible to determine the control parameters capable of achieving the desired state of the system.
- the output value ⁇ * of the high-level controller ⁇ H corresponds to an example of the control parameter.
- a control device such as a robot may use a level set function to determine whether or not a desired state can be reached from an initial state under given known task parameter values. Then, when the control device determines that the object is reachable, the control object such as the robot may be controlled using control parameters according to the initial state.
- the level set function learning unit 231 may learn a level set function simplified by polynomial approximation or the like.
- the level set function in this case is represented by g ⁇ .
- the level-set function learning unit 231 may learn a level-set approximation function g ⁇ that satisfies Equation (21).
- the prediction accuracy evaluation function setting unit 232 sets a prediction accuracy evaluation function that indicates the evaluation of the level set function learned by the level set function learning unit 231. Prediction accuracy evaluation function setting section 232 outputs the obtained prediction accuracy evaluation function to evaluation section 233 .
- the prediction accuracy evaluation function setting unit 232 learns, as a prediction accuracy evaluation function, a function that indicates the evaluation of the distribution of the search point X for which the level set function is learned, in the space of the candidates for the search point X. You may make it
- the space of candidates for the search point X 1 ⁇ here is a space constituted by values that the search point X ⁇ can take.
- the prediction accuracy evaluation function setting unit 232 may use the space formed by the domain of the search points X 1 to as the candidate spaces for the search points X 1 to .
- the space of candidates for the search point X 1 ⁇ may be the initial value of the search point set X ⁇ search .
- a prediction accuracy evaluation function a function that takes a candidate for search point X ⁇ as an argument and outputs an evaluation value for the reachability to the target state indicated by the level set function for that candidate for search point X ⁇ as a function value. may be used. Then, the prediction accuracy evaluation function setting unit 232 indicates a higher evaluation as the number of learned search points X within a predetermined distance from the candidate for the search point X input as an argument of the prediction accuracy evaluation function increases. Thus, the prediction accuracy evaluation function value may be calculated. Alternatively, as described in the third embodiment, when the variance of the level set function value is obtained, the prediction accuracy evaluation function setting unit 232 sets the prediction accuracy evaluation function so that the smaller the variance of the level set function value, the higher the evaluation.
- a function may be set.
- the method by which the prediction accuracy evaluation function setting unit 232 learns the prediction accuracy evaluation function is not limited to a specific method.
- the level set function g GP and the level set function ⁇ will be collectively referred to as the level set function ⁇ if there is no particular need to distinguish them.
- the evaluation unit 233 uses the prediction accuracy evaluation function to determine whether it is necessary to continue acquisition of training data for the high-level controller ⁇ H .
- the evaluation unit 233 sets the determination result to the learning continuation flag. For example, the evaluation unit 233 may calculate the lowest value of the prediction accuracy evaluation function in the space of candidates for search points X 1 to .
- the lowest value of the prediction accuracy evaluation function referred to here is the value with the lowest evaluation. Then, when the lowest value of the prediction accuracy evaluation function is evaluated lower than a predetermined threshold value, the evaluation unit 233 may determine that acquisition of training data needs to be continued. On the other hand, when the lowest value of the prediction accuracy evaluation function is evaluated as high as a predetermined threshold value or more, the evaluation unit 233 may determine that continuation of acquisition of training data is unnecessary.
- the evaluation unit 233 samples the prediction accuracy evaluation function values in the candidate space of the search point X ⁇ , and based on the value with the lowest evaluation among the obtained prediction accuracy evaluation function values, the acquisition of training data. You may make it determine the necessity of a continuation.
- the method by which the evaluation unit 233 determines whether or not to continue acquisition of training data for the high-level controller ⁇ H is not limited to a specific method.
- the evaluation unit 233 may determine whether or not to continue acquiring training data based on a predetermined learning condition in addition to the value of the prediction accuracy evaluation function.
- Various conditions can be used as the learning conditions here. For example, when the number of training data acquisitions reaches a predetermined number or more, the evaluation unit 233 determines that it is unnecessary to continue acquiring training data even if the evaluation indicated by the prediction accuracy evaluation function does not reach the predetermined evaluation. You may make it
- the high-level controller learning unit 240 uses the acquired data set Dopt to obtain the high-level controller ⁇ H . study. Specifically, the high-level controller learning unit 240 sets the high-level controller ⁇ H to the initial state x 0 included in the elements of the acquired data set D opt that can reach the target state. ' and the target state/known task parameter value ⁇ g ', the high-level controller ⁇ H is trained so as to output the output value ⁇ * included in that element.
- the model used by the high-level controller learning unit 240 to learn the high-level controller ⁇ H can be various models, such as neural network, Gaussian process regression, or support vector regression. Regression) may be used, but is not limited to these.
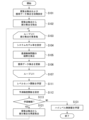
- FIG. 12 is a diagram showing an example of skill database update processing by the learning device 1 according to the first embodiment.
- the learning device 1 executes the processing of FIG. 12 for each skill to be generated.
- Step S101 The search point set initialization unit 211 initializes the search point set X 1 search and the acquired data set D opt .
- the search point set initialization unit 211 determines the initial state x s included in the initial state information of the target parameter information and the target state/known task parameter value ⁇ g included in the target state/known task parameter information.
- a search point set X 1 search is generated by using each arbitrary combination as an element of the search point set X 1 search .
- the search point set initialization unit 211 also sets the value of the acquired data set D opt to an empty set. After step S101, the process proceeds to step S102.
- Step S102 The next search point set setting unit 212 extracts a subset from the search point set X ⁇ search . Specifically, the next search point set setting unit 212 sets a subset of the search point set X 1 -search as the search point subset X 1 -check . Then, the next search point set setting unit 212 excludes each element of the set search point subset X 1 -check from the search point set X 1 -search . As in Equation (22), the search point subset X ⁇ check has as elements a combination of the initial state x si and the target state/known task parameter value ⁇ gi .
- Equation (23) The process by which the next search point set setting unit 212 excludes each element of the set subset X 1 ⁇ check from the search point set X 1 ⁇ search can be expressed as in Equation (23).
- step S102 indicates to exclude a subset from the set.
- Step S103 The learning device 1 starts a loop L11 that performs processing for each search point X 1 - that is an element of the subset X 1 - check of the search point set.
- loop L11 the number of iterations of the loop is represented by "i".
- search points X 1 ⁇ to be processed in the loop L11 are also referred to as target search points X 1 ⁇ i .
- step S104 the process proceeds to step S104.
- Step S104 The system model setting unit 221 performs various settings for setting the optimum control problem based on the target search points X 1 to i .
- the system model setting unit 221 sets the low-level controller ⁇ l , the system model, the constraint conditions regarding the parameters of the system model, and the evaluation function of the reachability to the target state.
- the process proceeds to step S105.
- Step S105 The problem setting calculator 222 sets the optimum control problem based on the setting by the system model setting unit 221 in step S104. Then, the problem setting calculation unit 222 solves the set optimum control problem, and uses the output ⁇ * of the high-level controller that makes the evaluation function value as small as possible and the value g * of the evaluation function g at that time as solutions. get. After step S105, the process proceeds to step S106.
- the data update unit 223 updates the acquired data set D opt . Specifically, the data updating unit 223 updates the i-th element X ⁇ i of the subset X ⁇ check of the search point set, the determination result g * i as to whether or not the task was successful, and the obtained control parameter Add the combination (X ⁇ i , g * i , ⁇ * i ) with ⁇ * i as an element of the acquisition data set Dopt .
- the processing by which the data updating unit 223 updates the acquired data set D opt is represented by equation (24).
- step S106 the process proceeds to step S107.
- Step S107 The learning device 1 performs termination processing of the loop L11. Specifically, the learning device 1 determines whether or not the processing of the loop L11 has been performed for all the elements of the subset X to check of the search point set. If it is determined that there is an element that has not yet been subjected to the processing of loop L11, the learning device 1 continues to perform the processing of loop L11 on the element that has not been subjected to the processing of loop L11. In this case, the process returns to step S103. On the other hand, when it is determined that the processing of loop L11 has been performed for all the elements of subsets X to check of the search point set, learning device 1 terminates loop L11. In this case, the process proceeds to step S111.
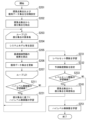
- Step S111 The level-set function learning unit 231 learns the level-set function g ⁇ based on the acquired data set Dopt . After step S111, the process proceeds to step S112.
- Step S112 The prediction accuracy evaluation function setting unit 232 sets the prediction accuracy evaluation function J g ⁇ based on the level set function g ⁇ . After step S112, the process proceeds to step S110.
- Step S113 The evaluation unit 233 determines whether or not learning of the level set function ⁇ should be continued based on the prediction accuracy evaluation function J g .
- the evaluation unit 233 may determine whether or not learning of the level set function ⁇ should be continued based on a predetermined learning condition in addition to the prediction accuracy evaluation function J g . If the evaluation unit 233 determines that learning of the level set function ⁇ needs to be continued (step S113: YES), the process proceeds to step S121. On the other hand, when the evaluation unit 233 determines that it is unnecessary to continue learning the level set function ⁇ (step S113: NO), the process proceeds to step S131.
- Step S121 Based on the prediction accuracy evaluation function J g , the next search point set setting unit 212 again extracts the subset X 1 -check from the search point set X 1 -search . Specifically, the next search point set setting unit 212 sets a subset X 1 -check of the search point set X 1 -search based on the prediction accuracy evaluation function J g . Then, the next search point set setting unit 212 excludes each element of the set subset X 1 -check from the search point set X 1 -search. After step S121, the process returns to step S103.
- Step S131 The high-level controller learning unit 240 learns the high-level controller ⁇ H using the acquired data set D opt . After step S131, the learning device 1 ends the processing of FIG.
- the search point set setting unit 210 selects the search point X, which is the target of acquisition of training data for learning control of the robot 5, among the search points (x s , ⁇ g ) indicating the motion of the robot 5.
- the problem setting calculation unit 222 is a high-level controller that controls the robot 5 with respect to information indicating whether or not the action indicated by the selected search point X is executable or not, and the action indicated by the selected search point X Calculate the output value that ⁇ H should output.
- the data updating unit 223 updates the selected search point X ⁇ , the information indicating whether or not the action indicated by the selected search point X ⁇ can be executed, and the action indicated by the selected search point X ⁇ at a high level.
- training data for learning the control of the robot 5 by the high-level controller ⁇ H is acquired.
- the evaluation unit 233 determines whether or not to continue acquiring the training data based on the evaluation of the acquisition status of the training data.
- the learning device 1 it is possible to determine whether or not to continue control learning for the robot 5, and to eliminate unnecessary learning, so that learning can be performed efficiently.
- the level set function learning unit 231 receives the input of the search point (x s , ⁇ g ) and outputs an estimated value of whether or not the action indicated by the search point (x s , ⁇ g ) can be executed.
- the learning of g ⁇ is performed based on the evaluation result of whether or not the action indicated by the search point (x s , ⁇ g ) can be executed by the problem setting calculation unit 222 .
- the prediction accuracy evaluation function setting unit 232 receives the input of the search point (x s , ⁇ g ), and outputs the evaluation value of the estimation accuracy of the level set function g ⁇ for the search point (x s , ⁇ g ). Set the accuracy evaluation function J g ⁇ .
- the evaluation unit 233 determines whether or not to continue acquiring the training data based on the prediction accuracy evaluation function J g ⁇ .
- the learning device 1 it is possible to determine whether to continue acquiring training data using the level set function g ⁇ .
- the level set function ⁇ is used for skill selection when the robot controller 3 controls the robot 5 .
- the work required only for determining whether to continue acquisition of training data is relatively small. It can be carried out.
- the search point set setting unit 210 sets search points (x s , ⁇ g ) that indicate that the evaluation value by the prediction accuracy evaluation function J g ⁇ indicates that the estimation accuracy of the level set function g ⁇ is lower than a predetermined condition. , are selected as targets for acquisition of training data for controlling the robot 5 .
- the learning device 1 can acquire training data indicating the input/output for which the accuracy of the output of the high-level controller ⁇ H is considered to be low, and the learning of the high-level controller ⁇ H can be efficiently performed. can be done.
- the search point (x s , ⁇ g ) includes known task parameters, which are parameter values of the skill in which the motion of the controlled object is modularized.
- learning device 1 differences in the motions of the robot 5 that can be expressed by parameter values are represented by skill parameter values, and control learning can be performed so that the same skill is applied to different motions. .
- the search point (x s , ⁇ g ) is the initial state of the robot 5 and its operating environment at the start of the skill, the known parameter values of the skill, and the target state of the robot 5 and its operating environment at the end of the skill. Composed of combinations.
- the learning device 1 can learn the high-level controller ⁇ H in the abstract space, and learn control corresponding to both the high-level controller ⁇ H and the low-level controller ⁇ L in the real space. It is possible to learn more efficiently than when performing
- the robot controller 3 also includes a high-level controller ⁇ H obtained by learning using the training data acquired by the learning device 1 . According to the robot controller 3, when the robot controller 3 learns, it is possible to determine whether or not it is necessary to continue learning the control of the robot 5, and it is possible to eliminate useless learning, so that learning can be performed efficiently. It can be carried out.
- the robot controller 3 also includes a high-level controller ⁇ H that controls the robot 5 according to the size of the object to be gripped so that the robot 5 can grip objects of different sizes. According to the robot controller 3, it is expected that the robot 5 can be controlled with high precision according to the size of the object to be grasped.
- the high-level controller learning unit 240 may learn the high-level controller ⁇ H and feed back the learning result. This point will be described in the second embodiment.
- the configuration of the control system 100 in the second embodiment is the same as in the first embodiment.
- the second embodiment will also be described using the configuration of the control system 100 shown in FIGS. 1 to 10.
- FIG. 13 is a diagram showing an example of data input/output in the skill learning unit 15 according to the second embodiment.
- the high-level controller learning unit 240 learns the high-level controller when the data acquisition unit 220 acquires data, and the high-level controller ⁇ * H obtained by learning is applied to the data acquisition unit. 220.
- Outputting the high-level controller can be performed by outputting parameter setting values of predictors, such as neural networks or Gaussian processes, which constitute the high-level controller, for example.
- the data input/output shown in FIG. 13 is the same as the data input/output in the first embodiment described with reference to FIG.
- FIG. 14 is a diagram showing an example of update processing of the skill database by the learning device 1 according to the second embodiment.
- the learning device 1 executes the processing of FIG. 14 for each skill to be generated.
- Steps S201 to S204 in FIG. 14 are the same as steps S101 to S104 in FIG.
- a loop from steps S203 to S207 in FIG. 14 is denoted as loop L21.
- Step S205 As described in step S105, the problem setting calculation unit 222 sets the optimum control problem, solves the set optimum control problem, and outputs the output of the high-level controller ⁇ H so that the evaluation function value becomes as small as possible. , and the evaluation function value at that time is obtained.
- step S205 if there is a high-level controller ⁇ H , the problem setting calculator 222 obtains the output of the high-level controller ⁇ H so as not to deviate from the output value of the high-level controller ⁇ H .
- the problem setting calculation unit 222 uses the error norm term between the obtained output value of the high-level controller ⁇ H and the output value of the high-level controller ⁇ H obtained in the optimal control problem as It may be included in the evaluation function. Then, the problem setting calculation unit 222 may obtain the solution of the optimum control problem so that the evaluation function value becomes as small as possible. As a result, the problem setting calculation unit 222 minimizes the value of the original evaluation function and makes the output value of the high-level controller ⁇ H closer to the obtained output value of the high-level controller ⁇ H . solution can be found.
- Steps S206 and S207 are the same as steps S106 and S107 in FIG.
- step S207 when the learning device 1 ends the loop L21, the process proceeds to step S211.
- the high-level controller learning unit 240 determines whether or not it is necessary to continue learning the high-level controller ⁇ H . For example, the high-level controller learning unit 240 sets the difference between the output of the high-level controller ⁇ H obtained by solving the optimal control problem in step S205 and the output obtained using the high-level controller ⁇ H to a predetermined value. If it is smaller than the condition, it may be determined that there is no need to continue the learning of the high-level controller ⁇ H .
- step S211 when the high-level controller learning unit 240 determines that learning of the high-level controller ⁇ H needs to be continued (step S211: YES), the process proceeds to step S221. On the other hand, if the high-level controller learning unit 240 determines that it is not necessary to continue learning the high-level controller ⁇ H (step S211: NO), the process proceeds to step S231.
- Step S221 The high-level controller learning unit 240 learns the high-level controller ⁇ H using the acquired data set D opt .
- the method by which the high-level controller learning unit 240 learns the high-level controller in step S221 is the same as in step S131 of FIG. Step S221 is different from step S131 in that the acquired data set D opt is in the process of being generated. After step S221, the process returns to step S203.
- Steps S231 to S233 are the same as steps S111 to S113 in FIG.
- step S233 when the evaluation unit 233 determines that learning of the level set function ⁇ needs to be continued (step S233: YES), the process proceeds to step S241.
- step S233: NO when the evaluation unit 233 determines that it is unnecessary to continue learning the level set function ⁇ (step S233: NO), the process proceeds to step S251.
- Step S241 is the same as step S121 in FIG. After step S241, the process returns to step S203.
- Step S251 is the same as step 131 in FIG. After step S251, the learning device 1 ends the processing of FIG.
- the learning device 1 learns skills corresponding to differences in tasks that are difficult to express using parameter values. Specifically, in addition to learning in the case of the first embodiment, the learning device 1 learns the meta-parameter values of each of the predictors that make up the level set function and the predictors that make up the high-level controller. conduct. When the learning device 1 acquires training data for a new task and learns a skill for executing the task, the learning device 1 uses the already acquired training data so that the prediction accuracy of these predictors is as high as possible. is used to learn and set meta-parameter values in advance. The learning device 1 may perform learning according to the third embodiment in addition to learning according to the second embodiment. That is, it is also possible to combine the second embodiment and the third embodiment.
- FIG. 15 is a diagram showing an example of the configuration of the skill learning unit 15 according to the third embodiment.
- the skill learning unit 15 includes a search task setting unit 250 and a meta-parameter processing unit 260 in addition to the units shown in FIG.
- the configuration of the control system in the third embodiment is the same as in the case of the first embodiment.
- the third embodiment will also be described using the configuration of the control system 100 shown in FIGS. 1 to 9.
- the search task setting unit 250 sets a task to be learned by the learning device 1 .
- a task to be learned by the learning apparatus 1, which is set by the search task setting unit 250, is also referred to as a search task.
- the search task setting unit 250 assumes a probability distribution T that the task to be generated follows, and sets the search task based on the assumed probability distribution T.
- FIG. The method by which the search task setting unit 250 assumes the probability distribution T that the generated task follows is not limited to a specific method. For example, the probability distribution T may be set in advance, but it is not limited to this.
- the meta-parameter processing unit 260 learns the meta-parameter values of the predictors that make up the level set function and the predictors that make up the high-level controller ⁇ H , and applies the learned meta-parameter values to these predictors. set to
- the predictor that configures the level set function and the predictor that configures the high-level controller ⁇ H are learning models such as Bayesian neural networks or Gaussian processes in which parameter values are set according to probability distributions. A predictor is used.
- the meta-parameter processing unit 260 learns and sets the probability distributions to which these parameter values follow as meta-parameter values.
- the meta-parameter processing unit 260 also evaluates the prediction accuracy of the predictor for which meta-parameters are set, and determines whether to continue learning meta-parameter values based on the evaluation result.
- FIG. 16 is a diagram showing an example of data input/output in the skill learning unit 15 according to the third embodiment. 15, also in the configuration shown in FIG. 16, the skill learning unit 15 includes a search task setting unit 250 and a meta-parameter processing unit 260 in addition to the units shown in FIG.
- the search task setting unit 250 receives input of task parameter information and sets a search task.
- the task parameter information includes information on the probability distribution T of the task to be generated.
- the task parameter information may be information indicating the probability distribution T of the task to be generated, and the search task setting section 250 may set the search task according to this probability distribution T.
- the search task setting unit 250 repeats the search task setting while the learning continuation flag for the unknown task parameter indicates the continuation of learning.
- the learning continuation flag for unknown task parameters is a flag indicating whether or not to continue learning the meta-parameter values of the predictor. While the learning continuation flag for the unknown task parameter indicates the continuation of learning, the search task setting unit 250 sets the next search task each time the learning device 1 finishes learning the search task.
- the learning continuation flag set by the evaluation unit 233 is also referred to as a learning continuation flag for known task parameters in order to distinguish it from the learning continuation flag for unknown task parameters. Also, for data for each task, " ⁇ j " or "j" may be written to indicate that the data is for each task.
- the learning device 1 performs learning according to the first embodiment for the task ⁇ j set as the search task.
- the search point set initialization unit 211 sets the search point set X 1 search according to the search task.
- the system model setting unit 221 performs various settings for setting the optimum control problem according to the search task.
- the meta-parameter processing unit 260 uses the entire acquired data set D_optall to perform the above-described meta-parameter value learning and to determine whether to continue meta-parameter value learning.
- the total acquired data set D optall is a combination of all the acquired data sets D opt,j acquired by the data updating unit 223 .
- the data updating unit 223 sets the initial value of all acquired data sets D_optall to 0, and every time an acquired data set D_opt ,j is generated, the generated acquired data set D_opt ,j is It may be linked to the data set D_optall .
- the process of joining the acquired data set D opt,j to the total acquired data set D optall can be expressed as Equation (25).
- the meta-parameter values learned by the meta-parameter processing unit 260 are set in the predictors that make up the level set aggregate and the predictors that make up the high-level controller. Further, as described above, while the unknown task parameter learning continuation flag set by the meta-parameter processing unit 260 indicates the continuation of learning, the search task setting unit 250 sets the , set the next search task.
- FIG. 17 is a diagram showing an example of the configuration of the meta-parameter processing unit 260.
- the metaparameter processing unit 260 includes a metaparameter individual processing unit 261 and a learning continuation flag integration unit 262 .
- the meta-parameter processing unit 260 includes a meta-parameter individual processing unit 261 for each predictor to be learned.
- the level-set function and the high-level controller ⁇ H are constructed using predictors to learn meta-parameter values.
- the meta-parameter processor 260 includes two meta-parameter individual processors 261 .
- the number of meta-parameter individual processing units 261 included in the meta-parameter processing unit 260 is not limited to two.
- the meta-parameter processing unit 260 may include a meta-parameter individual processing unit 261 for each target of meta-parameter value learning that is configured using a predictor.
- meta-parameter individual processing unit 261-1 When distinguishing the individual meta-parameter processing units 261, they are denoted as the meta-parameter individual processing unit 261-1, the meta-parameter individual processing unit 261-2, . . . , the meta-parameter individual processing unit 261-N.
- N is a positive integer indicating the number of meta-parameter individual processors 261 included in the meta-parameter processor 260 .
- the meta-parameter individual processing unit 261 learns meta-parameter values of predictors. When there are multiple meta-parameters of the predictor, the meta-parameter individual processing unit 261 learns the value for each meta-parameter. For example, when each predictor is configured using a Bayesian neural network and has a weighting factor for each node and a bias for each node as parameters, the probability distributions followed by each of these parameters correspond to meta-parameters. The meta-parameter individual processing unit 261 learns the value for each of these meta-parameters.
- the meta-parameter individual processing unit 261 sets the value of the learning continuation flag for each predictor, which indicates whether learning of the meta-parameter value is necessary or not for the target predictor.
- a learning continuation flag for each predictor is also referred to as an individual learning continuation flag.
- the learning continuation flag integration unit 262 integrates the values of the individual learning continuation flags and sets the value of the learning continuation flag for the unknown task parameter.
- the learning continuation flag integration unit 262 corresponds to an example of learning continuation determination integration means.
- FIG. 18 is a diagram showing an example of data input/output in the meta-parameter processing unit 260.
- the individual meta-parameter processing unit 261 is provided for each predictor targeted by the meta-parameter processing unit 260 .
- the meta-parameter individual processing unit 261 receives the input of all acquired data D optall and the meta-learning execution flag or the internal learning evaluation value, and outputs the value of the meta-parameter targeted by the meta-parameter individual processing unit 261, It also sets the value of the individual learning continuation flag.
- the meta-learning execution flag is a flag indicating whether or not to learn meta-parameter values. For example, when a predetermined number or more of data of each task (elements of the set) are accumulated in the total acquired data set D_optall , the data update unit 223 sets the value of the meta-learning execution flag to indicate that the meta-parameter value is to be learned. It may be set to the indicated value. Further, the meta-parameter processing unit 260 may set the value of the meta-learning execution flag to a value indicating that meta-parameter value learning is not to be performed when completing the meta-parameter value learning.
- the internal learning evaluation value is a value that indicates the prediction accuracy evaluation of the predictor.
- the individual meta-parameter processing unit 261 may calculate the generalization error of the meta-parameters.
- the meta-parameter processing unit 260 may calculate an internal learning evaluation value indicating a comprehensive evaluation of all predictors whose meta-parameter values are learned based on the generalization error of the meta-parameters. .
- the learning continuation flag integration unit 262 integrates the values of the individual learning continuation flags and sets the value of the learning continuation flag for the unknown task parameter. For example, when the value of one or more individual learning continuation flags indicates that learning continuation is necessary, the learning continuation flag integration unit 262 sets the value of the learning continuation flag for the unknown task parameter to set to a value indicating that Further, when the values of all the individual learning continuation flags indicate that learning continuation is unnecessary, the learning continuation flag integration unit 262 sets the value of the learning continuation flag for the unknown task parameter to indicate that learning continuation is unnecessary. set to a value that indicates
- FIG. 19 is a diagram showing a first example of the configuration of the meta-parameter individual processing unit 261.
- the meta-parameter individual processing unit 261 includes a training data extraction unit 271 , a meta-parameter learning unit 272 , a generalization error evaluation unit 273 , and a learning continuation determination unit 274 .
- the training data extraction unit 271 extracts training data for learning meta-parameter values from the total acquisition data set Doptall .
- the meta-parameter learning unit 272 learns meta-parameter values using the training data extracted by the training data extraction unit 271 .
- the generalization error evaluation unit 273 calculates an evaluation value for the generalization error of the predictor when using the metaparameter values learned by the metaparameter learning unit 272 .
- the learning continuation determination unit 274 determines whether or not to continue learning metaparameter values based on the evaluation value calculated by the generalization error evaluation unit 273 .
- FIG. 20 is a diagram showing an example of data input/output in the meta-parameter individual processing unit 261 shown in FIG.
- the training data extracting unit 271 extracts training data for learning meta-parameter values from the entire acquired data set Doptall when the value of the meta-learning execution flag indicates that learning of meta-parameter values is to be performed.
- the training data extraction unit 271 repeats the extraction of training data until the value of the meta-learning execution flag becomes a value indicating the determination result that continuation of learning is unnecessary.
- the training data extraction unit 271 corresponds to an example of training data extraction means.
- the meta-parameter learning unit 272 When the value of the meta-learning execution flag indicates that the meta-parameter value is to be learned, the meta-parameter learning unit 272 performs training data for meta-parameter value learning, learning parameter information, and predictor information. , to learn meta-parameter values. Training data for learning metaparameter values includes a combination of input values in the learning model and the correct output value of the learning model given the input values.
- the meta-parameter learning unit 272 corresponds to an example of meta-parameter learning means.
- Predictor information is information about predictors having meta-parameters to be learned.
- predictor information may include information about functions that represent the predictor.
- the learning parameter information is information related to metaparameters to be learned.
- the learning parameter information may include information indicating the number of metaparameters possessed by the learning target predictor.
- the predictor whose metaparameter value is to be learned is represented by a function f as shown in Equation (26).
- Equation (27) The probability distribution p(y
- S) by the data S of this parameter ⁇ is obtained.
- S) is not limited to a specific method.
- the learning device 1 may obtain the probability distribution p( ⁇
- P( ⁇ ) represents the prior distribution of the values of the parameter ⁇ .
- the meta-parameter learning unit 272 learns this prior distribution P( ⁇ ) as a meta-parameter value.
- ⁇ is a parameter called temperature parameter.
- the value of the temperature parameter ⁇ is preset, for example.
- l(S, f(x, ⁇ )) indicates a loss function l based on the difference between the output of the predictor and the correct value of the output based on correct data S shown as training data.
- "E” represents expected value. Specifically, “E ⁇ ⁇ P ( ⁇ ) [exp (- ⁇ l (S, f (x, ⁇ )))]” is “exp (- ⁇ l(S, f(x, ⁇ )))”.
- the meta-parameter learning unit 272 learns meta-parameter values so that, for example, the expected value of the loss function represented by Equation (30) is minimized.
- Equation (30) represents a loss function l similar to “l(S, f(x, ⁇ )))” in equation (29).
- the function f indicating the predictor is denoted as "f ⁇ ,P " to indicate the parameter ⁇ and the probability distribution P, which is a meta-parameter.
- E stands for expected value. Specifically, “E S ⁇ D [l(S, f ⁇ , P )]” represents the expected value of the loss function l when the correct data S follows the probability distribution D. "E D ⁇ ⁇ [E S ⁇ D [l (S, f ⁇ , P )]]” is the expected value "E D ⁇ ⁇ [E S ⁇ D [l (S, f ⁇ , P )]]”.
- the meta-parameter learning unit 272 obtains the probability distribution Q(P) of the probability distribution P( ⁇ ) as the meta-parameter based on Equation (31).
- P(P) represents the prior distribution of the probability distribution P( ⁇ ), which is a meta parameter.
- ⁇ is a parameter called temperature parameter.
- the value of ⁇ is preset, for example.
- N ⁇ is a positive integer representing the number of tasks.
- E stands for expected value.
- E ⁇ ⁇ P( ⁇ ) is the expected value of the value in parentheses ([...]) when the value of the parameter ⁇ follows the probability distribution P( ⁇ ).
- E P ⁇ P represents the expected value of the value in parentheses ([...]) when the probability distribution P( ⁇ ) follows the probability distribution P(P).
- the generalization error evaluation unit 273 calculates the evaluation value of the generalization error of the predictor when the above probability distributions P( ⁇ ) and Q(P) are used. For example, the generalization error evaluation unit 273 calculates the evaluation value of the generalization error L(Q,T) given by Equation (32).
- Equation (32) E P ⁇ Q [E D ⁇ T [E S ⁇ D [l(S, f ⁇ , P )]]]” is such that the probability distribution P( ⁇ ) is Represents the expected value of the expected value “E D ⁇ T [E S ⁇ D [l(S, f ⁇ , P )]]” shown in Equation (30) when following the distribution Q(P).
- the generalization error evaluation unit 273 calculates, for example, the value of the right side of Equation (33) (the right side of the inequality shown in Equation (33)) as the evaluation value of generalization error L(Q, T).
- Equation (33) is a function determined according to the type of loss function l(S, f ⁇ , f ).
- the right side of Equation (33) indicates the upper bound of the generalization error L(Q,T).
- the right side of Equation (33) is also written as L ⁇ (Q,T).
- the learning continuation determination unit 274 sets the value of the individual learning continuation flag based on the generalization error evaluation value L ⁇ (Q, T) calculated by the generalization error evaluation unit 273 .
- the learning continuation determination unit 274 may calculate the value of the individual learning continuation flag I based on Equation (34).
- the value “0” of the individual learning continuation flag I indicates that learning of meta parameter values does not need to be continued.
- the value “1” of the individual learning continuation flag I indicates that learning of meta parameter values needs to be continued.
- ⁇ is a constant indicating a predetermined threshold.
- the evaluation value L ⁇ (Q, T) of the generalization error indicates a smaller value as the evaluation is higher. Therefore, when the value of the evaluation value L ⁇ (Q, T) is equal to or less than the threshold value ⁇ , the learning continuation determination unit 274 determines that it is not necessary to continue learning the metaparameter values. On the other hand, when the value of the evaluation value L ⁇ (Q,T) is greater than the threshold value ⁇ , the learning continuation determination unit 274 determines that learning of metaparameter values needs to be continued.
- the learning continuation determination unit 274 may determine whether or not it is necessary to continue learning the meta-parameter values based on the information regarding the conditions for continuing learning.
- FIG. 20 shows an example in which the learning continuation determination unit 274 acquires error threshold information and continuation condition information as information regarding conditions for continuation of learning.
- the error threshold information is a determination threshold for the generalization error evaluation value L ⁇ (Q, T), like the threshold ⁇ described above.
- the continuation condition information is information indicating a determination method other than the determination based on the evaluation value L ⁇ (Q,T) of the generalization error. For example, when the number of iterations of meta parameter value learning reaches a predetermined number, even if the generalization error evaluation value L ⁇ (Q,T) is greater than the threshold ⁇ , the learning continuation determination unit 274 It may be determined that there is no need to continue learning the parameter values.
- the method by which the learning continuation determination unit 274 determines whether or not it is necessary to continue learning metaparameter values is not limited to a specific method.
- the information related to the conditions for continuing learning, which is used by the learning continuation determination unit 274, can be various information according to the method by which the learning continuation determination unit 274 determines whether learning of meta parameter values needs to be continued.
- FIG. 21 is a diagram showing a second example of the configuration of the meta-parameter individual processing unit 261.
- the meta-parameter individual processing unit 261 includes a meta-learning execution determination unit 281 in addition to the units shown in FIG.
- the meta-learning execution determination unit 281 sets a meta-learning execution flag.
- FIG. 22 is a diagram showing an example of data input/output in the meta-parameter individual processing unit 261 shown in FIG.
- the meta-learning execution determination unit 281 sets the value of the meta-learning execution flag based on the internal learning evaluation value.
- the meta-learning execution determination unit 281 sets the value of the meta-learning execution flag to indicate that the meta-parameter value is to be learned. set to a value.
- the meta-learning execution determination unit 281 sets the value of the meta-learning execution flag to indicate that meta-parameter value learning is not performed. set to the value shown.
- the meta-learning execution determination unit 281 corresponds to an example of meta-learning execution determination means. In this manner, the value of the meta-learning execution flag may be set inside the learning continuation determination unit 274 .
- FIG. 23 is a diagram showing an example of skill database update processing by the learning device 1 according to the third embodiment.
- the learning device 1 performs the processing of FIG. 23 when training data for a plurality of skills is acquired.
- Step S301 The data updating unit 223 performs initial setting of the total acquisition data set D_optall . Specifically, the data updating unit 223 sets the value of the all acquired data set D_optall to an empty set. After step S301, the process proceeds to step S302.
- Step S302 The search task setting unit 250 sets search tasks. For example, the search task setting unit 250 may select the unknown task parameter value ⁇ j to set the task ⁇ j associated with the unknown task parameter value ⁇ j as the search task. After step S302, the process proceeds to step S303.
- Steps S303 to S313 in FIG. 23 are the same as steps S101 to S113 in FIG.
- a loop from steps S305 to S309 in FIG. 23 is denoted as loop L31.
- step S313 when the high-level controller learning unit 240 determines that learning of the high-level controller ⁇ H needs to be continued (step S313: YES), the process proceeds to step S321. On the other hand, when the high-level controller learning unit 240 determines that it is not necessary to continue learning the high-level controller ⁇ H (step S313: NO), the process proceeds to step S331.
- Step S321 in FIG. 23 is the same as step S121 in FIG. After step S321, the process returns to step S305.
- Step S331 in FIG. 23 is the same as step S131 in FIG. After step S331, the process proceeds to step S332.
- Step S332 The data update unit 223 updates the total acquired data set D_optall . As described above, the data updating unit 223 combines the generated acquired data set D opt,j with the total acquired data set D optall . After step S332, the process proceeds to step S333.
- Step S333 The meta-parameter processing unit 260 calculates meta-parameter values of the predictor. After step S333, the process proceeds to step S334.
- Step S334 The meta-parameter processing unit 260 determines whether or not it is necessary to continue learning meta-parameter values. When the meta-parameter processing unit 260 determines that learning continuation is necessary (step S334: YES), the process proceeds to step S341. On the other hand, if the meta-parameter processing unit 260 determines that continuation of learning is unnecessary (step S334: NO), the learning device 1 ends the processing of FIG.
- Step S341 The search task setting unit 250 updates the search task. Specifically, the search task setting unit 250 sets any of the tasks that have not yet been set as search tasks as search tasks. After step S341, the process returns to step S303.
- FIG. 24 is a diagram showing an example of processing for the meta-parameter processing unit 260 to calculate the meta-parameter value of the predictor.
- the meta-parameter processing unit 260 performs the processing of FIG. 24 in step S333 of FIG.
- Step S401 The meta-parameter individual processing unit 261 calculates a meta-parameter value for each predictor. Further, the meta-parameter individual processing unit 261 determines whether or not learning of meta-parameter values should be continued for each predictor. The meta-parameter individual processing unit 261 may execute the process of step S401 for each predictor in parallel. Alternatively, the meta-parameter individual processing unit 261 may sequentially execute the process of step S401 for each predictor. After the process of step S401 is completed for all predictors to be processed, the process proceeds to step S402.
- Step S402 The learning continuation flag integration unit 262 determines whether or not to continue learning the metaparameter values for all of the plurality of predictors based on the determination result of whether or not to continue learning the metaparameter values for each predictor. After step S402, the meta-parameter processing unit 260 terminates the processing of FIG.
- FIG. 25 is a diagram showing a first example of a process in which the meta-parameter individual processing unit 261 calculates a meta-parameter value for each predictor and determines whether learning of the meta-parameter value should be continued. Meta-parameter individual processing unit 261 In step S401 of FIG. 24, the processing of FIG. 25 is performed for each predictor.
- Step S411 The training data extraction unit 271 extracts training data for learning meta-parameter values from the total acquisition data set Doptall. After step S411, the process proceeds to step S412.
- Step S412 The meta-parameter learning unit 272 learns the meta-parameter values of the predictor to be processed. After step S412, the process proceeds to step S413.
- Step S413 The generalization error evaluation unit 273 calculates the evaluation value of the generalization error when using the meta-parameter values obtained by learning. After step S413, the process proceeds to step S414.
- Step S414 The learning continuation determination unit 274 determines whether or not parameter value learning needs to be continued based on the evaluation value of the generalization error. After step S414, the meta-parameter individual processing unit 261 terminates the processing of FIG.
- FIG. 26 is a diagram showing a second example of processing by the meta-parameter individual processing unit 261 to calculate the meta-parameter value for each predictor and determine whether learning of the meta-parameter value should be continued.
- Meta-parameter individual processor 261 In step S401 of FIG. 24, the process of FIG. 26 is performed instead of the process of FIG. 25 for each predictor.
- Step S421 The meta-learning execution determination unit 281 sets the value of the meta-learning execution flag based on the internal learning evaluation value. After step S421, the process proceeds to step S422.
- Steps S422 to S425 in FIG. 26 are the same as steps S411 to S414 in FIG. After step S425, the meta-parameter individual processing unit 261 terminates the processing in FIG.
- step S302 the search task setting unit 250 selects, for example, the shape of the target object for learning the grasping motion as an unknown task parameter.
- the search task setting unit 250 may sample the unknown task parameters according to the probability distribution T.
- the search task setting unit 250 may set unknown task parameters using an algorithm for stochastically selecting unknown task parameters. The same applies to step S341.
- the search point set initialization unit 211 defines a state variable x representing the position, orientation, etc. of the robot 5 and the gripped object, and defines the state of the robot 5 and the gripped object before execution of the gripping motion as the initial state x Set as si .
- the search point set initialization unit 211 sets the target state/known task parameter ⁇ gi including the target state of the robot 5 and the gripped object after execution of the gripping motion and the size (scale) of the gripped object.
- the search point set initialization unit 211 sets the set (x si , ⁇ gi ) of the initial state x si and the target state/known task parameter ⁇ gi to the elements of the search point set X to search,j. .
- step S306 the system model setting unit 221 extracts the search points X ⁇ i that are elements of the search point subset X ⁇ check , and based on the target state/known task parameter ⁇ gi and the set task ⁇ j , We set up the system model (dynamics), the constraints in the system model, and the low-level controller ⁇ L .
- the constraint conditions include, but are not limited to, the motion area of the robot 5, the upper limit of the input in the specifications of the robot 5, and the constraint conditions for collision avoidance.
- system model setting unit 221 sets the initial state x si from the search points X ⁇ i and the x fi included in the target state/known task parameter ⁇ gi . Also, the system model setting unit 221 sets an evaluation function g for the optimum control problem based on these values. The system model setting unit 221 may set the evaluation function g shown in Equation (35).
- ⁇ g is a tolerance parameter that indicates the tolerance of the magnitude of the error.
- the prediction accuracy evaluation function setting unit 232 may set the prediction accuracy evaluation function J g ⁇ i shown in Equation (36) for a predictor configured using a Bayesian neural network.
- ⁇ g ⁇ j (X ⁇ ) denotes the predicted mean value.
- ⁇ g ⁇ j 2 (X ⁇ ) denotes the prediction variance.
- ⁇ is a coefficient by which the prediction variance is multiplied, and can be interpreted as a parameter that sets a confidence region (confidence interval).
- the prediction accuracy evaluation function setting unit 232 may set a function for calculating the entropy of the level set function g ⁇ i as the prediction accuracy evaluation function Jg ⁇ i .
- the evaluation unit 233 calculates the prediction variance ⁇ g ⁇ j 2 ( X ) for each element X ⁇ of the search point set X ⁇ search,j, and calculates ⁇ g ⁇ j 2 ( It may be determined that learning does not need to be continued when X ⁇ ) ⁇ .
- ⁇ ⁇ is the prediction variance threshold.
- ⁇ ⁇ is also called the variance threshold parameter.
- the element (x si , ⁇ gi ) of the search point set X ⁇ search,j is expressed as X ⁇ .
- the meta-parameter learning unit 272 learns meta-parameter values indicating the probability distribution in the learning model in which the parameter values follow the probability distribution, based on the training data indicating the input and output in the learning model.
- the generalization error evaluation unit 273 calculates an evaluation value indicating an evaluation of the generalization error of the learning model.
- the learning continuation determination unit 274 determines whether or not to continue learning the value of the metaparameter based on the evaluation value indicating the evaluation of the generalization error of the learning model. According to the learning device 1, when learning the meta-parameter values of the learning model, it is possible to determine whether or not to continue learning, and it is possible to eliminate unnecessary learning, so that learning can be performed efficiently. can be done.
- the training data extraction unit 271 repeats selection of training data to be used for learning from the training data for learning the value of the meta parameter until it is determined that continuation of learning is unnecessary. According to the learning device 1, when learning the meta-parameter values of the learning model, it is possible to determine whether or not to continue learning, and it is possible to eliminate unnecessary learning, so that learning can be performed efficiently. can be done.
- the meta-learning execution determination unit 281 determines whether or not to learn the value of the meta-parameter based on the evaluation value indicating the evaluation of the generalization error of the learning model.
- the training data extraction unit 271 selects training data when the meta-learning execution determination unit 281 determines that the value of the meta-parameter is to be learned. According to the learning device 1, when learning the meta-parameter values of the learning model, it is possible to determine whether or not to continue learning based on the evaluation of the generalization error of the learning model, thereby eliminating unnecessary learning. Learning can be done efficiently in that it can be done.
- the learning continuation flag integration unit 262 determines whether or not learning continuation of the meta-parameter value is necessary for all of the plurality of learning models based on the determination results of the plurality of learning continuation determining means corresponding to the plurality of learning models. According to the learning device 1, it is possible to determine whether or not to continue learning metaparameter values for a plurality of learning models, and to eliminate useless learning, so that learning can be performed efficiently.
- one of the learning models is configured as a high-level controller ⁇ H that controls the robot 5 to execute a task in which the motion of the robot 5 is modularized, and the skill parameter values are included in the input values for the learning model.
- the meta-parameter learning unit 272 learns meta-parameter values using training data for a plurality of skills. According to the learning device 1, a plurality of tasks can be executed by the high-level controller ⁇ H based on one learning model, corresponding to differences in tasks by learning meta-parameter values.
- the robot controller 3 also includes a high-level controller ⁇ H that has been learned by the learning device 1 . According to the robot controller 3, a plurality of tasks can be executed by the high-level controller ⁇ H based on one learning model, corresponding to different tasks by setting meta-parameter values.
- the robot controller 3 also includes a high-level controller ⁇ H that controls the robot 5 according to the shape of the gripping target so that the robot 5 grips gripping targets having different shapes. According to the robot controller 3, it is expected that the robot 5 can be controlled with high accuracy according to the shape of the object to be grasped.
- FIG. 27 is a diagram showing an example of the configuration of a learning device according to the fourth embodiment.
- learning device 610 includes metaparameter learning section 611 , generalization error evaluation section 612 , and learning continuation determination section 613 .
- the meta-parameter learning unit 611 learns meta-parameter values indicating the probability distribution in the learning model in which the parameter values follow the probability distribution, based on training data indicating inputs and outputs in the learning model.
- the generalization error evaluation unit 612 calculates an evaluation value indicating an evaluation of the generalization error of the learning model.
- the learning continuation determination unit 613 determines whether or not to continue learning the value of the metaparameter based on the evaluation value indicating the evaluation of the generalization error of the learning model.
- the meta-parameter learning unit 611 corresponds to an example of meta-parameter learning means.
- the generalization error evaluation unit 612 corresponds to an example of generalization error evaluation means.
- the learning continuation determination unit 613 corresponds to an example of learning continuation determination means. According to the learning device 610, when learning the meta-parameter values of the learning model, it is possible to determine whether or not to continue learning, and it is possible to eliminate unnecessary learning, so that learning can be performed efficiently. can be done.
- FIG. 28 is a diagram showing an example of the configuration of a control device according to the fifth embodiment.
- the control device 620 includes a control section 621 .
- the control unit 621 controls the robot according to the shape of the gripping target so that the robot grips gripping targets having different shapes.
- the control device 620 is expected to be able to control the robot with high precision according to the shape of the object to be grasped.
- FIG. 29 is a diagram showing an example of processing in the learning method according to the sixth embodiment.
- the learning method shown in FIG. 29 includes learning metaparameters (step S611), evaluating generalization error (step S612), and determining whether to continue learning (step S613). .
- step S611 the computer learns the values of the meta-parameters indicating the probability distribution in the learning model in which the values of the parameters follow the probability distribution to the training data indicating the input and output in the pre-learning model.
- step S612 the computer calculates an evaluation value indicating an evaluation of the generalization error of the learning model.
- step S613 the computer determines whether or not to continue learning the metaparameter value based on the evaluation value indicating the evaluation of the generalization error of the learning model. According to the learning method shown in FIG. 29, when learning the meta-parameter values of the learning model, it is possible to determine whether or not to continue learning, and it is possible to eliminate unnecessary learning, which makes learning efficient. can be done.
- a program for executing all or part of the processing performed by the learning device 1, the robot controller 3, the learning device 610, and the control device 620 is recorded on a computer-readable recording medium and recorded on this recording medium. Each part may be processed by loading the program into a computer system and executing it.
- the "computer system” referred to here includes hardware such as an OS and peripheral devices.
- “computer-readable recording medium” refers to portable media such as flexible discs, magneto-optical discs, ROM (Read Only Memory), CD-ROM (Compact Disc Read Only Memory), hard disks built into computer systems It refers to a storage device such as Further, the program may be for realizing part of the functions described above, or may be capable of realizing the functions described above in combination with a program already recorded in the computer system.
- the present invention may be applied to a learning device, a control device, a learning method, and a recording medium.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Mechanical Engineering (AREA)
- Robotics (AREA)
- Manipulator (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024504055A JP7806879B2 (ja) | 2022-03-01 | 2022-03-01 | 学習装置、制御装置、学習方法及びプログラム |
| US18/841,436 US20250165860A1 (en) | 2022-03-01 | 2022-03-01 | Learning device, control device, learning method, and storage medium |
| PCT/JP2022/008699 WO2023166573A1 (ja) | 2022-03-01 | 2022-03-01 | 学習装置、制御装置、学習方法及び記憶媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/008699 WO2023166573A1 (ja) | 2022-03-01 | 2022-03-01 | 学習装置、制御装置、学習方法及び記憶媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023166573A1 true WO2023166573A1 (ja) | 2023-09-07 |
Family
ID=87883189
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/008699 Ceased WO2023166573A1 (ja) | 2022-03-01 | 2022-03-01 | 学習装置、制御装置、学習方法及び記憶媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20250165860A1 (https=) |
| JP (1) | JP7806879B2 (https=) |
| WO (1) | WO2023166573A1 (https=) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025057366A1 (ja) * | 2023-09-14 | 2025-03-20 | 日本電気株式会社 | 推定装置、推定方法および記録媒体 |
| WO2025182034A1 (ja) * | 2024-02-29 | 2025-09-04 | 日本電気株式会社 | 処理装置、処理システム、処理方法、および記録媒体 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012024882A (ja) * | 2010-07-23 | 2012-02-09 | Seiko Epson Corp | ロボットの駆動装置、ロボットの駆動方法、およびロボット |
| US8756175B1 (en) * | 2012-02-22 | 2014-06-17 | Google Inc. | Robust and fast model fitting by adaptive sampling |
| JP2020522394A (ja) * | 2017-05-29 | 2020-07-30 | フランカ エミカ ゲーエムベーハーFRANKA EMIKA GmbH | 多関節ロボットのアクチュエータを制御するシステムおよび方法 |
| WO2020201516A1 (en) * | 2019-04-04 | 2020-10-08 | Koninklijke Philips N.V. | Identifying boundaries of lesions within image data |
-
2022
- 2022-03-01 JP JP2024504055A patent/JP7806879B2/ja active Active
- 2022-03-01 WO PCT/JP2022/008699 patent/WO2023166573A1/ja not_active Ceased
- 2022-03-01 US US18/841,436 patent/US20250165860A1/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012024882A (ja) * | 2010-07-23 | 2012-02-09 | Seiko Epson Corp | ロボットの駆動装置、ロボットの駆動方法、およびロボット |
| US8756175B1 (en) * | 2012-02-22 | 2014-06-17 | Google Inc. | Robust and fast model fitting by adaptive sampling |
| JP2020522394A (ja) * | 2017-05-29 | 2020-07-30 | フランカ エミカ ゲーエムベーハーFRANKA EMIKA GmbH | 多関節ロボットのアクチュエータを制御するシステムおよび方法 |
| WO2020201516A1 (en) * | 2019-04-04 | 2020-10-08 | Koninklijke Philips N.V. | Identifying boundaries of lesions within image data |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025057366A1 (ja) * | 2023-09-14 | 2025-03-20 | 日本電気株式会社 | 推定装置、推定方法および記録媒体 |
| WO2025182034A1 (ja) * | 2024-02-29 | 2025-09-04 | 日本電気株式会社 | 処理装置、処理システム、処理方法、および記録媒体 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7806879B2 (ja) | 2026-01-27 |
| US20250165860A1 (en) | 2025-05-22 |
| JPWO2023166573A1 (https=) | 2023-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113677485B (zh) | 使用基于元模仿学习和元强化学习的元学习的用于新任务的机器人控制策略的高效自适应 | |
| Chatzilygeroudis et al. | A survey on policy search algorithms for learning robot controllers in a handful of trials | |
| CN110119844B (zh) | 引入情绪调控机制的机器人运动决策方法、系统、装置 | |
| JP4169063B2 (ja) | データ処理装置、データ処理方法、及びプログラム | |
| Peters et al. | Reinforcement learning by reward-weighted regression for operational space control | |
| Osa et al. | Guiding trajectory optimization by demonstrated distributions | |
| JP4803212B2 (ja) | データ処理装置、データ処理方法、及びプログラム | |
| CN112045675A (zh) | 机器人设备控制器、机器人设备布置和用于控制机器人设备的方法 | |
| CN112292239B (zh) | 用于计算机辅助地确定用于适宜操作技术系统的调节参数的方法和设备 | |
| JP4201012B2 (ja) | データ処理装置、データ処理方法、およびプログラム | |
| CN114529010A (zh) | 一种机器人自主学习方法、装置、设备及存储介质 | |
| WO2023166573A1 (ja) | 学習装置、制御装置、学習方法及び記憶媒体 | |
| CN112016611B (zh) | 生成器网络和策略生成网络的训练方法、装置和电子设备 | |
| Cursi et al. | Task accuracy enhancement for a surgical macro-micro manipulator with probabilistic neural networks and uncertainty minimization | |
| CN112016678A (zh) | 用于增强学习的策略生成网络的训练方法、装置和电子设备 | |
| Rottmann et al. | Adaptive autonomous control using online value iteration with gaussian processes | |
| JP7647862B2 (ja) | 学習装置、学習方法及びプログラム | |
| JP7736159B2 (ja) | 学習装置、制御装置、学習方法及びプログラム | |
| CN120428566A (zh) | 全局轨迹策略强化学习方法及机器人控制系统 | |
| Amirshirzad et al. | Context-based echo state networks with prediction confidence for human-robot shared control | |
| Blinov et al. | Deep q-learning algorithm for solving inverse kinematics of four-link manipulator | |
| WO2024180656A1 (ja) | 学習装置、制御装置、制御システム、学習方法および記憶媒体 | |
| Liu et al. | Research on motion planning of seven degree of freedom manipulator based on DDPG | |
| CN117260701A (zh) | 训练机器学习模型以实现控制规则的方法 | |
| Caamaño et al. | Introducing synaptic delays in the NEAT algorithm to improve modelling in cognitive robotics |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22929721 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18841436 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2024504055 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22929721 Country of ref document: EP Kind code of ref document: A1 |
|
| WWP | Wipo information: published in national office |
Ref document number: 18841436 Country of ref document: US |