WO2023100339A1 - 学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、学習済モデル、および推定装置 - Google Patents
学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、学習済モデル、および推定装置 Download PDFInfo
- Publication number
- WO2023100339A1 WO2023100339A1 PCT/JP2021/044400 JP2021044400W WO2023100339A1 WO 2023100339 A1 WO2023100339 A1 WO 2023100339A1 JP 2021044400 W JP2021044400 W JP 2021044400W WO 2023100339 A1 WO2023100339 A1 WO 2023100339A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- trained model
- calculating
- parameters
- learning rate
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
Definitions
- the present invention relates to a trained model generation system, a trained model generation method, an information processing device, a program, a trained model, and an estimation device.
- gradient descent is known as a method (optimizer) for obtaining parameters such as neural network weights in machine learning using neural networks.
- SGD Spochastic Gradient Descent
- Momentum SGD Momentum SGD
- Adagrad Adaptive Gradient Algorithm
- RMSprop Root Mean Square Propagation
- Adam Adaptive Moment estimation
- Adagrad the sum of squared gradients in each parameter direction is stored in the cache.
- the learning rate By dividing the learning rate by the square root of the cache, it is possible to set a high learning rate for rare features.
- the cache grows as the number of epochs increases, the learning rate approaches zero. Therefore, in subsequent learning, there is a problem that the learning rate in that axis direction becomes small.
- RMSprop uses an exponential moving average of slope information.
- the exponential moving average since the past information decays exponentially, the gradient information of the extremely distant past is removed, and the most recent gradient information is more reflected.
- Adam makes large updates to rare information like Adagrad, and very distant past gradient information like RMSprop. It is possible to remove it.
- the learning rate and parameter update amount are exponential moving averages that monotonically decrease.
- the correction coefficient becomes an extremely large value and diverges.
- the present disclosure has been made in view of such circumstances, and provides a trained model generation system, a trained model generation method, an information processing device, a program, a trained model, and a system capable of escaping from a stagnant state of learning. Provide an estimator.
- the present disclosure has been made to solve the problems described above, and one aspect of the present disclosure is a trained model generation system that generates a trained model, comprising: an estimation unit that estimates learning data; and an optimizer unit for calculating a plurality of parameters constituting a trained model based on the loss gradients, wherein the optimizer unit calculates the plurality of As a formula for calculating the learning rate when calculating the parameters of the epoch
- the trained model generation system uses a formula including a first factor that increases the effect of increasing the learning rate when the learning stagnates as the number progresses.
- Another aspect of the present disclosure is the above-described trained model generation system, wherein the first factor has the effect of suppressing the learning rate as the absolute value of the gradient increases, and the number of epochs advances, the effect of suppressing the learning rate increases.
- Another aspect of the present disclosure is the above-described trained model generation system, wherein the formula for calculating the learning rate is, at the beginning of learning, according to the cumulative update amount of each of the plurality of parameters by learning containing a second factor with a maximum value of 1, which slows down the learning rate, and does not include said second factor after the beginning of said learning.
- another aspect of the present disclosure is the above-described trained model generation system, wherein the second factor has an absolute value smaller than 1 when the cumulative update amount is smaller than a threshold; When greater than the threshold, it monotonically decreases.
- Another aspect of the present disclosure is a trained model generation method for generating a trained model, comprising: a first step of estimating learning data; a second step of calculating a gradient; and a third step of calculating a plurality of parameters constituting a trained model based on the gradient of the loss, wherein the plurality of parameters are calculated in the third step
- a formula for calculating the learning rate at the time of calculation it is a first factor that has the effect of increasing the learning rate by increasing the absolute value when learning stagnates, and the number of epochs advances.
- the learned model generation method uses an equation including a first factor that increases the effect of increasing the learning rate when the learning stagnates as much as .
- another aspect of the present disclosure includes an optimizer unit that calculates a plurality of parameters constituting a trained model based on a gradient of loss calculated for an estimation result for learning data, wherein the optimizer unit includes the plurality of As a formula for calculating the learning rate when calculating the parameters of the epoch
- the information processing apparatus uses a formula including a first factor that increases the effect of increasing the learning rate when the learning stagnates as the number progresses.
- another aspect of the present disclosure is a program for causing a computer to function as an optimizer unit that calculates a plurality of parameters that make up a trained model based on the gradient of loss calculated for the estimation result for learning data.
- the optimizer unit as an expression for calculating the learning rate when calculating the plurality of parameters, the absolute value becomes larger than 1 when learning stagnates, so that the effect of increasing the learning rate can be obtained.
- the program uses a formula including a first factor that increases the effect of increasing the learning rate when the learning stagnates as the number of epochs progresses.
- another aspect of the present disclosure is a trained model generated by calculating a plurality of parameters constituting the trained model based on the gradient of the loss calculated for the estimation result for the learning data, As a formula for calculating the learning rate when calculating the plurality of parameters, a first factor that has an absolute value greater than 1 when learning stagnates, thereby obtaining the effect of increasing the learning rate. , a trained model using a formula including a first factor that increases the effect of increasing the learning rate when the learning stagnates as the number of epochs progresses.
- another aspect of the present disclosure is a trained model generated by calculating a plurality of parameters constituting the trained model based on the gradient of the loss calculated for the estimation result for the learning data, As a formula for calculating the learning rate when calculating the plurality of parameters, a first factor that has an absolute value greater than 1 when learning stagnates, thereby obtaining the effect of increasing the learning rate. , using a trained model using a formula containing a first factor that increases the effect of increasing the learning rate when the learning stagnates as the number of epochs progresses, It is an estimating device for estimating input information.
- FIG. 1 is a schematic block diagram showing the configuration of a trained model generation and registration system 10 according to an embodiment of the present disclosure
- FIG. 2 is a schematic block diagram showing the configuration of a trained model generation device 200 according to the same embodiment
- FIG. 4 is a flowchart for explaining the operation of the trained model generation device 200 according to the embodiment
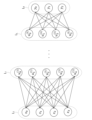
- 4 is a schematic diagram showing an example of a neural network included in an estimating unit 210 according to the same embodiment
- FIG. It is the graph which plotted the example of the learning rate according to the amount of accumulation update in the same embodiment.
- It is a schematic diagram which shows the Example of the optimizer part 230 in the same embodiment
- 3 is a schematic block diagram showing the configuration of a monitoring camera device 300 according to the same embodiment
- FIG. 1 is a schematic block diagram showing the configuration of a trained model generation and registration system 10 according to an embodiment of the present disclosure
- FIG. 2 is a schematic block diagram showing the configuration of a trained model generation device 200 according to the same embodiment
- FIG. 4 is
- FIG. 1 is a schematic block diagram showing the configuration of a trained model generation and registration system 10 according to this embodiment.
- the trained model generation and registration system 10 generates a trained model by performing supervised learning, and registers the trained model thus generated in the surveillance camera device 300 .
- the trained model generation and registration system 10 in this embodiment uses the gradient method according to the present disclosure to adaptively determine the learning rate when generating trained models. Details of the gradient method according to the present disclosure are provided below.
- a neural network is used to perform supervised learning, but the method of generating a trained model using the gradient method according to the present disclosure is not limited to this.
- Machine learning may use machine learning other than neural networks, such as regression analysis, to perform learning methods other than supervised learning, such as unsupervised learning or reinforcement learning.
- the learned model generation and registration system includes a learning data DB 100, a learned model generation device 200, and a monitoring camera device 300.
- the learning data DB 100 stores images that serve as learning data for machine learning.
- the surveillance camera device 300 has a learned model for each time zone and location, so the learning data DB 100 stores images as learning data for each time zone and location.
- the learning data DB 100 may separately store daytime images captured during the daytime and nighttime images captured during the nighttime. Further, as an example for each location, the learning data DB 100 may separately store an image of an entrance and an image of a parking lot.
- the learned model generation device 200 generates a learned model by performing machine learning using the images stored in the learning data DB 100. For example, the trained model generation device 200 learns daytime images to generate a daytime trained model, and learns nighttime images to generate a nighttime trained model. Also, the trained model generation device 200 learns images of entrances and exits to generate a trained model for entrances, and learns images of parking lots to generate a trained model for parking lots.
- the monitoring camera device 300 stores the learned models generated by the trained model generation device 200 for each time zone and each place. These learned models may be stored in a memory or the like incorporated in the surveillance camera device 300 when the surveillance camera device 300 is manufactured. Alternatively, monitoring camera device 300 may acquire the learned model from a server storing the learned model via a network such as the Internet. The monitoring camera device 300 detects an object in the captured image using the stored learned model for each time zone and each place. In addition, the monitoring camera device 300 notifies the user of the monitoring camera device 300 of the detected object.
- FIG. 2 is a schematic block diagram showing the configuration of the trained model generation device 200 according to this embodiment.
- the trained model generation device 200 includes an estimation section 210 , a loss gradient calculation section 220 and an optimizer section 230 .
- the trained model generation device 200 (trained model generation system) may be composed of a plurality of devices, or may be composed of a single device.
- each of the estimation unit 210, the loss gradient calculation unit 220, and the optimizer unit 230 may be one information processing device.
- the estimation unit 210 has a neural network and estimates an object included in the image read from the learning data DB 100 .
- the loss gradient calculation unit 220 calculates a loss gradient for the estimation result calculated by the estimation unit 210 .
- the loss represents the magnitude of the difference between the estimated result and the ideal value such as the correct answer.
- the estimation result for an image is (0.3, 0.2, 0.1, 0.9)
- the correct answer for that image is (0.0, 0.0, 0.0, 1.0 )
- the loss may be Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Root Mean Square Logarithmic Error (RMSLE).
- the loss gradient calculator 220 calculates the gradient of loss for each direction of a plurality of parameters of the neural network of the estimator 210 .
- the gradient of the loss in the direction of the parameter x i is the loss Loss (x i +h) when the value of the parameter x i is x i + h and the loss Loss (x i ⁇ h) is approximately obtained by dividing the difference by 2h ((Loss (x i + h) - (Loss (x i - h)) / 2h).
- the optimizer unit 230 is calculated by the loss gradient calculation unit 220
- a plurality of parameters of the neural network of the estimator 210 are calculated based on the slope of the loss, which constitutes a trained model.
- FIG. 3 is a flowchart explaining the operation of the trained model generation device 200 according to this embodiment.
- the estimation unit 210 sets initial values of parameters of the neural network (step S1).
- the estimation unit 210 acquires learning data from the learning data DB 100 (step S2). For example, when generating a trained model for daytime, an image in daytime is acquired.
- the estimation unit 210 estimates the selected learning data (step S3). This estimation is performed using a neural network provided in the estimation unit 210 . Also, this estimation is an estimation of an object included in the learning data image.
- the loss gradient calculator 220 calculates the gradient of loss for the estimation result of the estimator 210 (step S4).
- the optimizer unit 230 performs optimization to calculate the parameters of the neural network based on the loss gradient calculated by the loss gradient calculation unit 220 (step S5). This optimization is performed by solving an optimization problem that seeks combinations of parameter values that minimize loss. In solving this optimization problem, we use the gradient method according to the present disclosure. Details of the gradient method according to the present disclosure are provided below.
- the optimizer unit 230 determines whether or not the termination condition for generating the learned model is satisfied (step S6). Any conditions such as the number of iterations, loss convergence, or the like may be used as termination conditions. When it is determined that the termination condition is satisfied (step S6-Yes), the optimizer unit 230 terminates this learned model generation processing and sets the model made up of the parameters at this time as a learned model.
- step S6 When it is determined in step S6 that the termination condition is not satisfied (step S6-No), the optimizer unit 230 updates the parameters of the neural network of the estimation unit 210 to the parameters optimized in step S5 (step S7). .
- the estimation unit 210 determines whether or not to change the learning data (step S8). For example, when the processing of steps S3 to S7 is performed on the same learning data a predetermined number of times or more, the estimating unit 210 determines to change the learning data. You may decide not to change. Alternatively, the estimating unit 210 may determine that the learning data should be changed if the loss does not decrease even after repeating the processing from steps S3 to S7, and otherwise determine that the learning data should not be changed.
- step S8 when it is determined to change the learning data (step S8-Yes), the process proceeds to step S2, and when it is determined not to change the learning data (step S8-No), the process proceeds to step S3.
- the determination of the termination condition in step S6 is performed after step S5, but the present invention is not limited to this.
- step S6 may be performed after step S2 or after step S3.
- the trained model generation device 200 generates a trained model by repeatedly performing estimation on learning data, calculation of the gradient of loss, and optimization of parameters.
- the number of iterations is also called the number of epochs.
- the number of learning data acquired in step S2 may be one, or may be plural.
- FIG. 4 is a schematic diagram showing an example of a neural network included in the estimation unit 210 according to this embodiment.
- the example of FIG. 4 comprises an input layer LI , L intermediate layers L 1 , L 2 , . . . , LL and an output layer LO .
- the input layer L I consists of four nodes x 0 , x 1 , x 2 , x 3 .
- Each pixel value of the learning data image may be input to each of the nodes x 0 , x 1 , x 2 , and x 3 of the input layer LI .
- values after preprocessing such as outline extraction and brightness adjustment are applied to the learning data image, they are input to each of the nodes x 0 , x 1 , x 2 and x 3 of the input layer LI . good.
- L hidden layers L 1 , L 2 , . (m) consists of n-1 .
- the first hidden layer L 1 is composed of five nodes u (1) 0 , u (1) 1 , u (1) 2 , u (1) 3 and u (1) 4 .
- L-th hidden layer L L consists of four nodes u (L) 0 , u (L) 1 , u (L) 2 , u (L) 3 .
- the output layer L O consists of three nodes y 0 , y 1 , y 2 .
- Each value of nodes y 0 , y 1 , and y 2 in the output layer LO is a value representing the estimation result of the estimation unit 210, and represents, for example, the probability that the object corresponding to that node is included.
- a value input to a node in a certain layer is determined by the value of the node in the previous layer, as expressed by Equation (1).
- Equation 1 w (l) i,j are weights and b (l) i are biases. These weights w (l) i,j and bias b (l) i are parameters of the neural network and are determined by the optimizer section 230 .
- f() is an activation function.
- the activation function in this embodiment may be, for example, a sigmoid function, a normalized linear function, or any other function as long as it is used as an activation function for a neural network.
- the optimizer unit 230 optimizes the parameters of the neural network of the estimating unit 210 using Equation (2) each time step S5 of FIG. 3 is processed.
- x is an optimizing parameter, ie, one of weight w (l) i,j and bias b (l) i, which are parameters of the neural network. That is, the optimizer unit 230 performs the processing of Equation (2) on each of the weights w (l) i,j and the biases b (l) i .
- ⁇ 1, ⁇ 2, and ⁇ 3 are values greater than 0 and less than 1, and are predetermined constants. These values may be set by the operator of the trained model generation device 200.
- dx is the x-direction gradient of the loss calculated by the loss gradient calculator 220 . That is, when x is the weight w (l) i,j , dx is the gradient in the direction of the weight w (l) i,j . When x is the bias b (l) i , dx is the gradient in the direction of the bias b (l) i . t is the number of epochs. at is the learning rate. a0 is the initial value of the learning rate. The value of a0 may be set by the operator of the trained model generation device 200. FIG. eps is a predetermined very small constant that prevents the denominator from becoming zero.
- log is the common logarithm.
- FIG. 5 is a graph plotting an example of update values according to the cumulative update amount in this embodiment.
- the horizontal axis is the cumulative update amount (cache in formula (2))
- the vertical axis is the updated value of parameter X (-at*mt/(sqrt(vt)+eps) in formula (2)).
- the updated values are prominent at the three circled locations.
- the absolute value of m which is the exponential moving average of the gradient dx
- the absolute value of the first factor which is the reciprocal of m raised to the tth power
- the learning rate increases, so that when the gradient dx suddenly takes a value away from 0 due to learning data with a different tendency, it is possible to suppress the update value of the parameter X from becoming small. can be done.
- the value of t increases as the number of epochs progresses.
- the t power effect increases the absolute value of this first factor as the number of epochs advances. Therefore, the first factor increases the effect of increasing the learning rate when learning stagnates as the number of epochs progresses.
- the first factor has the effect of increasing the learning rate by having an absolute value greater than 1 when learning stagnates. Furthermore, since the reciprocal of m is raised to the power of t, the first factor has a greater effect of increasing the learning rate when learning stagnates as the number of epochs progresses. Thereby, it is possible to escape from the stagnant state of learning.
- the absolute value of m which is the exponential moving average of the gradient dx
- the first factor has a smaller absolute value as the absolute value of the gradient dx increases, and the effect of suppressing the learning rate is obtained.
- the absolute value of m exceeds 1
- the effect of suppressing the learning rate by the first factor increases as the number of epochs progresses.
- the learning rate is suppressed even if the gradient dx continuously assumes a large value when the number of epochs advances, that is, when learning advances. Therefore, it is possible to avoid greatly deviating from the learning result up to that point, that is, destroying the learning information up to that point.
- the learning rate in the section T1 in which the cumulative update amount is small is smaller than the learning rate in the sections T2 and T3. This is because the factor (1/cache) ⁇ log This is the effect of (
- the value of this second factor is a small value such as 0.0001 when cache is 0.01, for example. Note that the value of the second factor becomes the maximum value of 1 when the cache is 1, and then monotonically decreases.
- the gradient may be large, for example, when the initial values of the parameters deviate significantly from the optimal values. Then, due to the large gradient, the update amount of the parameter becomes large, and the learning may diverge. However, if the learning rate is reduced in the section T1 in which the cumulative update amount is small, the learning rate in the initial stage of learning can be reduced because the cumulative update amount is small at the beginning of learning. When the learning rate is small, it is possible to prevent divergence of learning due to an increase in parameter update amount due to a large gradient.
- the value of the second factor is 1 or less until the cumulative update amount reaches the threshold value of 1.
- the cumulative update amount becomes 1.
- the value of the second factor monotonically decreases, so the update value also decreases except for the circled protrusions. As a result, it is possible to prevent the learning from diverging from the previous learning and continuing to oscillate.
- the formula for calculating the learning rate at includes the first factor but does not include the second factor.
- the learning rate is suppressed by the first factor even if the gradient dx continuously takes a large value. Therefore, it is possible to avoid greatly deviating from the learning result up to that point, that is, destroying the learning information up to that point.
- FIG. 6 is a schematic diagram showing an example of the optimizer unit 230 in this embodiment.
- the number of parameters is assumed to be only two, wi and wj , for the sake of simplicity of explanation, but the number of parameters is of course not limited to this.
- FIG. 6 is a graph plotting loss against combinations of values of parameters wi and wj .
- the horizontal plane consists of axes with parameters wi and wj .
- the vertical direction is the axis of loss.
- the initial values of the parameters wi and wj are the circles in FIG. 6, that is, the places with large gradients. It is This causes the values of the parameters w i and w j to change smoothly down the gradient without diverging. After that, when the values of the parameters w i and w j enter the extreme values indicated by the first flag, learning stalls. However, due to the effect of the first factor, the values of parameters w i and w j are updated to bounce. Likewise when the values of the parameters w i and w j subsequently enter the extreme values indicated by the second flag. The values of the parameters w i and w j can then reach the extreme values indicated by flag number 3 in FIG. 6 where the loss is minimal.
- FIG. 7 is a schematic block diagram showing the configuration of the monitoring camera device 300 according to this embodiment.
- the monitoring camera device 300 includes an image input unit 301, a feature extraction unit 302, a trained model primary storage unit 303, an object recognition unit 304, an anomaly detection unit 305, a recognition result display unit 306, a recognition result warning unit 307, and a high precision locator 308. , a clock 309 , a learning information exchange unit 310 , a place-based learning DB 311 , and a time-based learning DB 312 .
- the monitoring camera device 300 may be one device, or may be composed of a plurality of devices.
- the feature extraction unit 302 and the trained model primary storage unit 303 may constitute an estimation device.
- the image input unit 301 includes an imaging device and an optical system for forming an image of a subject on the imaging surface of the imaging device.
- the image input unit 301 converts the image of the subject imaged on the imaging surface into an electric signal.
- the feature extraction unit 302 uses a neural network to estimate an object included in the video of the subject converted into the electrical signal.
- a trained model primary storage unit 303 stores a trained model, which is a parameter of the neural network of the feature extraction unit 302 .
- the object recognition unit 304 recognizes objects included in the video from the estimation result of the feature extraction unit 302.
- the anomaly detection unit 305 determines whether the object recognized by the object recognition unit 304 is an anomaly that should issue a warning.
- the recognition result display unit 306 displays the name of the object recognized by the object recognition unit 304 on the screen and notifies the operator.
- the recognition result warning unit 307 issues a warning by voice and notifies the operator. At this time, the recognition result warning unit 307 may change the sound to be emitted according to the content of the abnormality.
- the high-precision locator 308 detects the position where the surveillance camera device 300 is installed by GPS (Global Positioning System) or the like.
- a clock 309 notifies the current time.
- the learning information exchange unit 310 acquires a learned model corresponding to the position detected by the high-accuracy locator 308 or the current time notified by the clock 309 from the location-based learning DB 311 or the time-based learning DB.
- the learning information exchange unit 310 stores the acquired trained model in the trained model primary storage unit 303 via the feature extraction unit 302 .
- the location-specific learning DB 311 stores the learned model generated by the trained model generation device 200 for each location.
- the hourly learning DB 312 stores the learned model generated by the trained model generation device 200 by time.
- the location-based learning DB 311 and the time-based learning DB 312 may be used by a plurality of surveillance camera devices 300 .
- a plurality of surveillance camera devices 300 may access the same location-based learning DB 311 and time-based learning DB 312 via a network.
- the surveillance camera device 300 may include the learning data DB 100 and the learned model generation device 200 .
- the learning data stored in the learning data DB 100 may be video data output by the video input unit 301 .
- the optimizer unit 230 may also include extremal regression, such as by a Hessian matrix. That is, the optimizer The unit 230 may calculate the learning rate at in the same manner as in Equation (2). Furthermore, when calculating the learning rate at, the optimizer section 230 may multiply other factors or add other terms in addition to the first factor and the second factor.
- a program for realizing the functions of the trained model generation device 200 or the monitoring camera device 300 in FIG. 1 is recorded in a computer-readable recording medium, and the program recorded in this recording medium is read into the computer system.
- the learned model generating device 200 or the monitoring camera device 300 may be realized by executing the above.
- the "computer system” here includes an OS or hardware such as peripheral devices.
- “computer-readable recording medium” refers to portable media such as flexible discs, magneto-optical discs, ROMs, CD-ROMs, and DVDs, and storage devices such as hard disks and SSDs built into computer systems.
- “computer-readable recording medium” refers to a program that dynamically retains a program for a short period of time, like a communication line when transmitting a program via a network such as the Internet or a communication line such as a telephone line. It also includes those that retain programs for a certain period of time, such as volatile memory inside a computer system that serves as a server or client in that case. Further, the program may be for realizing part of the functions described above, or may be capable of realizing the functions described above in combination with a program already recorded in the computer system.
- each functional block of the learned model generation device 200 in FIG. 1 or the monitoring camera device 300 in FIG. is not limited to LSI, and may be realized by a dedicated circuit or a general-purpose processor. It can be either hybrid or monolithic. Some of the functions may be implemented by hardware and some may be implemented by software. In addition, when a technology such as integration circuit that replaces LSI appears due to progress in semiconductor technology, it is also possible to use an integrated circuit based on this technology.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Mathematical Physics (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21930596.8A EP4443344A4 (en) | 2021-12-03 | 2021-12-03 | TRAINED MODEL GENERATION SYSTEM, TRAINED MODEL GENERATION METHOD, INFORMATION PROCESSING DEVICE, PROGRAM, TRAINED MODEL, AND ESTIMATION DEVICE |
| KR1020227034545A KR20230084423A (ko) | 2021-12-03 | 2021-12-03 | 학습된 모델 생성 시스템, 학습된 모델 생성 방법, 정보 처리 장치, 기록 매체, 학습된 모델, 및 추정 장치 |
| CN202180022559.2A CN116569187A (zh) | 2021-12-03 | 2021-12-03 | 已学习模型生成系统、已学习模型生成方法、信息处理装置、程序、已学习模型以及推测装置 |
| PCT/JP2021/044400 WO2023100339A1 (ja) | 2021-12-03 | 2021-12-03 | 学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、学習済モデル、および推定装置 |
| JP2022527676A JP7413528B2 (ja) | 2021-12-03 | 2021-12-03 | 学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、および推定装置 |
| US17/802,413 US20240249178A1 (en) | 2021-12-03 | 2021-12-03 | Trained model generation system, trained model generation method, information processing device, non-transitory computer-readable storage medium, trained model, and estimation device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/044400 WO2023100339A1 (ja) | 2021-12-03 | 2021-12-03 | 学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、学習済モデル、および推定装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023100339A1 true WO2023100339A1 (ja) | 2023-06-08 |
Family
ID=86611771
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/044400 Ceased WO2023100339A1 (ja) | 2021-12-03 | 2021-12-03 | 学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、学習済モデル、および推定装置 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20240249178A1 (https=) |
| EP (1) | EP4443344A4 (https=) |
| JP (1) | JP7413528B2 (https=) |
| KR (1) | KR20230084423A (https=) |
| CN (1) | CN116569187A (https=) |
| WO (1) | WO2023100339A1 (https=) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12579822B2 (en) * | 2023-06-06 | 2026-03-17 | GM Global Technology Operations LLC | Vehicle display system for nighttime driving |
| CN119445238B (zh) * | 2024-10-31 | 2025-09-26 | 北京理工大学 | 一种基于深度学习串联优化器的图像分类方法 |
| CN120067586B (zh) * | 2025-02-10 | 2025-11-21 | 广东工业大学 | 一种用于处理机电设备故障诊断数据的方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0756880A (ja) * | 1993-08-19 | 1995-03-03 | Chubu Denki Kk | 神経系学習装置 |
| JP2001056802A (ja) * | 1999-08-19 | 2001-02-27 | Oki Electric Ind Co Ltd | ニューラルネットワークの学習方法 |
| US6269351B1 (en) * | 1999-03-31 | 2001-07-31 | Dryken Technologies, Inc. | Method and system for training an artificial neural network |
| WO2017183587A1 (ja) | 2016-04-18 | 2017-10-26 | 日本電信電話株式会社 | 学習装置、学習方法および学習プログラム |
| US20200401893A1 (en) * | 2018-12-04 | 2020-12-24 | Google Llc | Controlled Adaptive Optimization |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7181585B2 (ja) * | 2018-10-18 | 2022-12-01 | 国立大学法人神戸大学 | 学習システム、学習方法、およびプログラム |
| CN114930350A (zh) * | 2020-01-10 | 2022-08-19 | 富士通株式会社 | 神经网络系统、神经网络的学习方法以及神经网络的学习程序 |
| JP7436830B2 (ja) * | 2020-04-06 | 2024-02-22 | 富士通株式会社 | 学習プログラム、学習方法、および学習装置 |
| US12399501B2 (en) * | 2020-12-10 | 2025-08-26 | AI Incorporated | Method of lightweight simultaneous localization and mapping performed on a real-time computing and battery operated wheeled device |
-
2021
- 2021-12-03 JP JP2022527676A patent/JP7413528B2/ja active Active
- 2021-12-03 CN CN202180022559.2A patent/CN116569187A/zh active Pending
- 2021-12-03 WO PCT/JP2021/044400 patent/WO2023100339A1/ja not_active Ceased
- 2021-12-03 EP EP21930596.8A patent/EP4443344A4/en active Pending
- 2021-12-03 KR KR1020227034545A patent/KR20230084423A/ko active Pending
- 2021-12-03 US US17/802,413 patent/US20240249178A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0756880A (ja) * | 1993-08-19 | 1995-03-03 | Chubu Denki Kk | 神経系学習装置 |
| US6269351B1 (en) * | 1999-03-31 | 2001-07-31 | Dryken Technologies, Inc. | Method and system for training an artificial neural network |
| JP2001056802A (ja) * | 1999-08-19 | 2001-02-27 | Oki Electric Ind Co Ltd | ニューラルネットワークの学習方法 |
| WO2017183587A1 (ja) | 2016-04-18 | 2017-10-26 | 日本電信電話株式会社 | 学習装置、学習方法および学習プログラム |
| US20200401893A1 (en) * | 2018-12-04 | 2020-12-24 | Google Llc | Controlled Adaptive Optimization |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4443344A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7413528B2 (ja) | 2024-01-15 |
| EP4443344A1 (en) | 2024-10-09 |
| EP4443344A4 (en) | 2025-02-12 |
| JPWO2023100339A1 (https=) | 2023-06-08 |
| US20240249178A1 (en) | 2024-07-25 |
| CN116569187A (zh) | 2023-08-08 |
| KR20230084423A (ko) | 2023-06-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7413528B2 (ja) | 学習済モデル生成システム、学習済モデル生成方法、情報処理装置、プログラム、および推定装置 | |
| US12544913B2 (en) | Domain adaptation using simulation to simulation transfer | |
| JP6610278B2 (ja) | 機械学習装置、機械学習方法及び機械学習プログラム | |
| US9047566B2 (en) | Quadratic regularization for neural network with skip-layer connections | |
| CN114926701B (zh) | 一种模型训练方法、目标检测方法、以及相关设备 | |
| JP2019528502A (ja) | パターン認識に適用可能なモデルを最適化するための方法および装置ならびに端末デバイス | |
| JP7742001B1 (ja) | 異常管理装置、および異常管理方法 | |
| CN112183283A (zh) | 一种基于图像的年龄估计方法、装置、设备及存储介质 | |
| CN110728358A (zh) | 基于神经网络的数据处理方法和装置 | |
| CN113469204A (zh) | 数据处理方法、装置、设备和计算机存储介质 | |
| CN117493884B (zh) | 面向复杂场景的强化学习决策方法及装置 | |
| JP5791555B2 (ja) | 状態追跡装置、方法、及びプログラム | |
| CN118876073B (zh) | 基于分布式鲁棒元强化学习的机器人运动控制方法 | |
| CN119807892A (zh) | 车辆控制策略生成模型训练方法、设备、介质及程序产品 | |
| HK40090079A (zh) | 已学习模型生成系统、已学习模型生成方法、信息处理装置、程序、已学习模型以及推测装置 | |
| CN114676797B (zh) | 一种模型精度的计算方法、装置和计算机可读存储介质 | |
| US20220237116A1 (en) | Method for Obtaining a Computational Result | |
| CN118333112A (zh) | 神经网络量化参数生成方法、装置、集成电路和计算设备 | |
| CN116152648A (zh) | 基于马尔科夫决策过程的水下声呐小目标检测方法 | |
| CN115909432B (zh) | 网络训练方法及装置、网络优化方法及数据处理方法 | |
| KR102622438B1 (ko) | 옵티컬 플로우 추정 방법 및 이를 이용하는 객체 검출 방법 | |
| CN116403045B (zh) | 一种基于深度学习的样本生成方法、存储介质及电子设备 | |
| JP2021189553A (ja) | 訓練装置、モデル生成方法及びプログラム | |
| CN119625640B (zh) | 一种基于密度自适应计数网络的人群分析方法 | |
| JP5746078B2 (ja) | 時間的再現確率推定装置、状態追跡装置、方法、及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022527676 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202180022559.2 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 17802413 Country of ref document: US |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21930596 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2021930596 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021930596 Country of ref document: EP Effective date: 20240703 |