WO2023073837A1 - データ修正プログラム、装置、及び方法 - Google Patents
データ修正プログラム、装置、及び方法 Download PDFInfo
- Publication number
- WO2023073837A1 WO2023073837A1 PCT/JP2021/039692 JP2021039692W WO2023073837A1 WO 2023073837 A1 WO2023073837 A1 WO 2023073837A1 JP 2021039692 W JP2021039692 W JP 2021039692W WO 2023073837 A1 WO2023073837 A1 WO 2023073837A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- value
- hot
- component
- machine learning
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- the technology disclosed relates to a data correction program, a data correction device, and a data correction method.
- the value of a specific attribute contained in the training data used to train the machine learning model may be biased, and the judgment result of the machine learning model may be discriminatory.
- the judgment result of the machine learning model may be discriminatory. For example, by using training data with attribute values such as a person's gender, age, hometown, etc. as explanatory variables and the result of the person's pass/fail for hiring, tests, etc.
- attribute values such as a person's gender, age, hometown, etc.
- the machine learning model trained using the training data will: They make discriminatory predictions that make judgments against women.
- DIR Dispose Impact Remover
- DIR is intended to be modified for so-called numerical feature values, attributes whose variables are numerical values that have superiority or inferiority such as magnitude. Therefore, there is a problem that DIR cannot be applied to the modification of so-called categorical variables, attributes whose variables have a limited number of numerical values or categories.
- the disclosed technology aims to remove factors that bias machine learning models toward discriminatory predictions from data containing categorical variables.
- the disclosed technology generates a second plurality of data in which the first type categorical variable included in each of the first plurality of data is changed to a one-hot expression. Further, the technology disclosed herein uses a first component of a one-hot expression of the first type categorical variable included in each of the second plurality of data as an objective variable, and the Parts other than the One-hot expression of the first type categorical variable are used as explanatory variables. In the disclosed technology, a machine learning model generated based on training data including the objective variable and the explanatory variable is added to the second plurality of data except for the One-hot representation of the first type categorical variable enter the part.
- the disclosed technique ranks each of the second plurality of data based on the inference result of the machine learning model in that case. Then, the disclosed technology generates a third plurality of data by correcting the bias of each attribute of the first type categorical variable in the second plurality of data based on the result of the ranking process. do.
- FIG. 4 is a diagram for explaining problems in applying DIR to a data set containing categorical variables; It is a figure for demonstrating calculation of certainty.
- FIG. 4 is a diagram for explaining rank setting; It is a figure which shows an example of the combination of the value of the component of correction
- FIG. 10 is a diagram for explaining correction of inconsistency in one-hot representation;
- FIG. 10 is a diagram for explaining correction of inconsistency in one-hot representation;
- 1 is a block diagram showing a schematic configuration of a computer functioning as a data correction device;
- FIG. 6 is a flowchart showing an example of data correction processing;
- a data set containing multiple data is input to the data correction device 10 .
- the data correction device 10 corrects factors that bias the discriminatory prediction of the machine learning model (hereinafter also simply referred to as "bias") contained in the input data set, and the corrected data set Output.
- the data set is an example of the "first plurality of data” of the technology disclosed herein
- the corrected data set is an example of the "third plurality of data” of the technology disclosed herein.
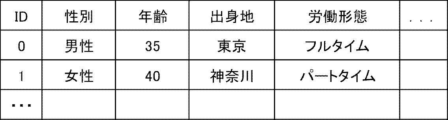
- FIG. 2 shows an example of a data set.
- each row (each record) is one piece of data, and each piece of data is given an "ID" that is identification information of the data.
- ID identification information of the data.
- each piece of data has values (variables) for attributes such as “sex”, “age”, “hometown”, and “work type” as feature quantities.
- the value of the attribute “age” is a numerical feature quantity.
- each of the attributes “gender”, “hometown”, and “work type” is a categorical variable.
- DIR modifies numerical features and cannot be applied to categorical variables. Therefore, the following two methods are conceivable as simple methods of applying DIR to a data set containing categorical variables.
- the first is a method of correcting only the numerical feature values without modifying the categorical variables.
- the second method is to apply DIR while excluding categorical variable sequences from the data set and leaving only numerical feature quantity sequences.
- the first method cannot completely remove the bias from the data set because the bias remains latent in the categorical variables.
- useful information for prediction by the machine learning model will be missing from the dataset, and the accuracy of the machine learning model trained using that dataset may be greatly reduced. be.
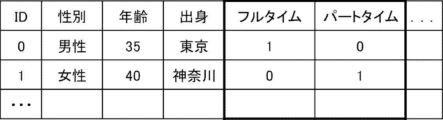
- One-hot representation is a representation in which one of a plurality of components has a value of 1 and the other components have a value of 0.
- One-hot representation converts a single-column categorical variable into multiple columns of numerical features.
- FIG. 3 shows an example in which the categorical variable "labor type" in the example of FIG. 2 is converted into a one-hot expression.
- the categorical variable ⁇ work style'' which includes the categories ⁇ full-time'' and ⁇ part-time,'' has multiple components (columns) of ⁇ full-time'' and ⁇ part-time,'' as shown in the bold frame in Figure 3.
- each component is a numerical feature amount.
- the DIR algorithm uses numerical features, which are the values of attributes other than protected attributes, for each group based on the values of attributes that are subject to protection from discriminatory treatment, such as gender and nationality (hereinafter referred to as “protected attributes”). Generate rankings based on quantity values. Then, the DIR algorithm corrects the value of the numerical feature amount other than the protection attribute to the median value of the values of the numerical feature amount belonging to the same rank.
- the possible values are 0 or 1 only. There will only be 2 ranks with 1 rank. Therefore, the median value of the numerical feature values belonging to the rank of 0 is 0, and the median value of the numerical feature values belonging to the rank of 1 is 1. Since the values do not change before and after the correction, the bias is not removed.
- the protected attribute is "sex”
- the numerical feature value to be corrected is the one-hot representation of the categorical variable "work style”.
- One of the components of expression is “full-time”.
- An information processing device that executes DIR, as indicated by A in FIG. Extract the value of each "full time”.
- the information processing device extracts the value of "full-time” for each data included in the group of data whose value of the attribute "gender” is "female” (hereinafter also referred to as "female group”).
- the information processing device acquires a non-overlapping set of values extracted from each group. In this case, the information processing device obtains a set (0, 1) for any group.
- the information processing device sets the size of the set obtained from each group, that is, the number of values included in the set, to the smaller one as the size of the ranking.
- the size of the ranking is also 2, because the size of the set of all groups is 2.
- the information processing device ranks the values included in the obtained set according to the magnitude of the values. For example, as indicated by B in FIG. 4, the information processing device sets rank 1 to the value "1" and rank 2 to the value "0" for the men's group. The information processing device also sets rank 1 to the value "1" and sets rank 2 to the value "0" for the women's group. Note that if the size of the set is larger than the size of the ranking, the same rank may be set for two or more values.
- the information processing device collects data having the value set for that rank as the “full time” value for each rank from each group, and the data within the same rank has Calculate the median "full-time” value. Then, as indicated by D in FIG. 4, the information processing apparatus corrects the value of "full time” of each data to the median value calculated for the rank to which the data belongs.
- the median value is also "1"
- all the values of "full time” belonging to rank 2 are "0”
- the median value is also "0". Therefore, the above method does not remove the bias either, since the values are unchanged before and after the modification.
- the data correction device 10 when creating a ranking of data based on the value of the component to be corrected for each group, the data having the same value as the value of the component to be corrected are further ranked. , to create a ranking.
- the functional configuration of the data correction device 10 according to this embodiment will be described in detail below.
- the data correction device 10 functionally includes a conversion unit 12, a ranking unit 14, and a correction unit 16, as shown in FIG.
- the conversion unit 12 converts the categorical variables to be corrected contained in each of the data contained in the data set into a one-hot representation, and generates a post-conversion data set.
- the categorical variable to be corrected is an example of the "first type categorical variable" of the technology disclosed herein
- the post-transformation data set is an example of the "second plurality of data" of the technology disclosed herein.
- the conversion unit 12 converts the value of the categorical variable of the attribute "work style" into a one-hot expression, A post-transformation data set as shown in FIG. 3 is generated. Each row (each record) of the post-conversion data set shown in FIG. 3 corresponds to one piece of post-conversion data.
- the ranking unit 14 calculates a proxy value for ranking the value of each component of the one-hot expression of the categorical variable to be corrected.
- the proxy value may be, for example, a degree of certainty that indicates the likelihood of the value of each component of the one-hot expression with respect to the portion other than the one-hot expression of the categorical variable to be corrected in the transformed data.
- the ranking unit 14 determines each component of the one-hot representation of the categorical variable to be corrected contained in each of the post-transformation data contained in the post-transformation data set (example in FIG. Then, the shaded columns “component 1” and “component 2”) are used as objective variables.
- the ranking unit 14 uses the parts other than the categorical variables to be corrected (“attribute 1” to “attribute 6” in the example of FIG. 5) in the converted data as explanatory variables.
- the ranking unit 14 generates a machine learning model based on the training data consisting of the objective variables and explanatory variables.
- the ranking unit 14 may perform machine learning of the machine learning model using all of the training data.
- the ranking unit 14 performs machine learning of the machine learning model using part of the training data (eg, 4/5 of the whole), and the remaining part of the training data (eg, 1/5 of the whole) may be used to cross-validate the generated machine learning model.
- the ranking unit 14 inputs a portion other than the One-hot expression of the categorical variable to be corrected out of the converted data to the generated machine learning model, that is, the explanatory variable portion of the training data, and as the inference result of the machine learning model, each Obtain the confidence for each component of the transformed data.
- the certainty factor of each component is a value between 0.0 and 1.0, and the sum of the certainty factors of each component for each post-transformation data is 1.0.
- the ranking unit 14 ranks each piece of post-conversion data based on the degree of certainty that is the inference result of the machine learning model. Specifically, the ranking unit 14 arranges the post-conversion data in the order of the value of the component of the one-hot expression of the categorical variable to be corrected for each value of the protection attribute. Furthermore, the ranking unit 14 arranges the post-transformation data having the same value of the correction target component in descending order of certainty and sets a rank.
- the protection attribute is an example of the "first attribute" of technology disclosed herein.
- the ranking unit 14 accepts designation of protection attributes. For example, if the received protection attribute specification is the attribute “gender”, the ranking unit 14 selects, for each of the male group and the female group, the converted data whose correction target component value is “1” and the correction target The converted data whose value of the component of is "0" is extracted. For each group, the ranking unit 14 arranges the post-transformation data in which the value of the correction target component is “1” in descending order of certainty. Similarly, for each group, the ranking unit 14 arranges the post-transformation data in which the value of the correction target component is “0” in descending order of certainty.
- the ranking unit 14 ranks the post-transformation data in which the value of the component to be corrected is "1", which is arranged in descending order of certainty, followed by the converted data in which the value of the component to be corrected, which is arranged in descending order of certainty, is " 0” after conversion data is concatenated.
- the post-transformation data are arranged in order of values of the components to be corrected and in descending order of certainty for each group.
- the ranking unit 14 acquires a non-overlapping set of combinations of the values of the components to be corrected and the degrees of certainty, and ranks the size of the set, that is, the number of combinations included in the set, whichever is smaller. Size. Then, the ranking unit 14 ranks the post-conversion data arranged in the order of values of the components to be corrected and in order of the degree of certainty according to the size of the ranking. For example, for two pieces of transformed data in which one component of the One-hot expression of a categorical variable has the same value “1”, the certainty for that component is 0.998 for one transformed data and 0.998 for the other transformed data Assume that the data is 0.940. In this case, the former post-conversion data is set to a higher rank.
- the correction unit 16 Based on the results of the ranking process by the ranking unit 14, the correction unit 16 generates a post-correction data set by correcting the bias of each attribute of the categorical variables to be corrected in the post-conversion data set. Specifically, the correction unit 16 converts the value of the component to be corrected of the converted data having the same rank set by the ranking unit 14 to the value of the component to be corrected in the set of the converted data having the same rank. Corrected to the median.
- FIG. 7 shows an example of the combination of the value of the component to be corrected and the degree of certainty for each rank, and the median value of the rank. Even if the value of the component to be corrected is the same, the rank differs depending on the degree of certainty. , rank 453).
- the correction unit 16 may set the predetermined value of 1 or 0 as the median value, that is, the corrected value.
- the correction unit 16 corrects the one-hot representation of the categorical variable to be corrected after changing the component value to the median so as to maintain consistency.
- the correction unit 16 leaves the value of any one of the multiple "1”s as "1” and corrects the values of the other components to "0". do.
- the correction unit 16 may leave the value of the component with the highest degree of certainty as "1".
- the values of component 1 and component 2 are "1". to "0" (bold frame in FIG. 8).
- the one-hot value that is, "1" may not exist in the one-hot expression of the categorical variable to be corrected.
- the correction unit 16 corrects the value of any one component to "1" based on the certainty of each component.
- the modifying unit 16 may modify the value of the component with the highest degree of certainty to "1".
- all of the values of component 1, component 2, and component 3 are "0", so the correction unit 16 changes the value of component 1, which has the highest degree of certainty, from "0" to "1". Correct (bold frame part in FIG. 9).
- the correction unit 16 also performs correction to maintain the consistency of the One-hot representation as described above, and then outputs the corrected data set.
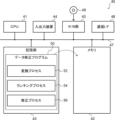
- the data correction device 10 may be realized, for example, by the computer 40 shown in FIG.
- the computer 40 includes a CPU (Central Processing Unit) 41 , a memory 42 as a temporary storage area, and a non-volatile storage section 43 .
- the computer 40 also includes an input/output device 44 such as an input unit and a display unit, and an R/W (Read/Write) unit 45 that controls reading and writing of data to and from a non-temporary storage medium 49 .
- the computer 40 also has a communication I/F (Interface) 46 connected to a network such as the Internet.
- the CPU 41 , memory 42 , storage unit 43 , input/output device 44 , R/W unit 45 and communication I/F 46 are connected to each other via bus 47 .
- the storage unit 43 may be implemented by a HDD (Hard Disk Drive), SSD (Solid State Drive), flash memory, or the like.
- a data correction program 50 for causing the computer 40 to function as the data correction device 10 is stored in the storage unit 43 as a storage medium.
- the data modification program 50 has a transformation process 52 , a ranking process 54 and a modification process 56 .
- the CPU 41 reads out the data correction program 50 from the storage unit 43, develops it in the memory 42, and sequentially executes the processes of the data correction program 50.
- the CPU 41 operates as the conversion unit 12 shown in FIG. 1 by executing the conversion process 52 . Further, the CPU 41 operates as the ranking section 14 shown in FIG. 1 by executing the ranking process 54 . Further, the CPU 41 operates as the correction unit 16 shown in FIG. 1 by executing the correction process 56 .
- the computer 40 executing the data correction program 50 functions as the data correction device 10.
- FIG. Note that the CPU 41 that executes the program is hardware.
- the function realized by the data correction program 50 can also be realized by, for example, a semiconductor integrated circuit, more specifically an ASIC (Application Specific Integrated Circuit) or the like.
- the data correction process is an example of the data correction method of technology disclosed herein.
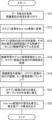
- the conversion unit 12 acquires the data set input to the data correction device 10. Also, the ranking unit 14 receives designation of the protection attribute from the user.
- the conversion unit 12 converts the categorical variables to be corrected included in the acquired data set into one-hot representation, and generates a post-conversion data set.
- the categorical variable to be corrected may be a categorical variable specified by the user, or all categorical variables included in the data set may be sequentially set as categorical variables to be corrected.
- step S14 the ranking unit 14 performs training using each component of the one-hot expression of the categorical variable to be corrected included in the post-transformation data set as the objective variable and attributes other than the categorical variable to be corrected as explanatory variables. Generate data.
- the ranking unit 14 is a machine learning model for estimating the degree of certainty indicating the likelihood of the value of each component of the one-hot expression with respect to the portion other than the one-hot expression of the categorical variable to be corrected, based on the generated training data. to generate
- step S16 the ranking unit 14 inputs the explanatory variable part of the generated training data to the generated machine learning model. Then, the ranking unit 14 acquires, as a machine learning model estimation result, the certainty factor for each component of the one-hot representation of the categorical variable to be corrected in each post-transformation data.
- step S18 the ranking unit 14 arranges the post-conversion data in the order of values of the components of the one-hot expression of the categorical variable to be corrected for each value of the protection attribute received in step S10. Furthermore, the ranking unit 14 arranges the post-transformation data having the same value of the correction target component in descending order of certainty and sets a rank.
- step S20 the correction unit 16 converts the value of the component to be corrected in the converted data to the median of the values of the component to be corrected in the set of converted data having the same rank set in step S18. to be corrected.
- step S22 the correction unit 16 corrects the post-transformation data in which the one-hot expression of the categorical variable to be corrected has a plurality of "1"s or does not have a "1" inconsistent. Based on the certainty, the value of any one component is corrected to be "1". Then, the correction unit 16 outputs the corrected data set, and the data correction processing ends.
- the data correction device generates a post-conversion data set in which the categorical variables to be corrected included in the data set are changed to the one-hot representation.
- the data correction device uses each component of the one-hot expression of the categorical variable to be corrected included in the converted data set as the objective variable, and the attribute other than the categorical variable to be corrected as the explanatory variable. Generate machine learning models. Then, the data correction device ranks each of the converted data based on the inference result of the machine learning model when the part other than the one-hot expression of the categorical variable to be corrected is input from the converted data set. do.
- the data correction device corrects the bias in the value of each component of the categorical variable to be corrected due to the difference in the value of the protected attribute in the converted data set based on the result of the ranking process. Generate and output a dataset. This can remove factors that bias machine learning models toward discriminatory predictions from data containing categorical variables. Further, by generating a machine learning model using the corrected data set generated by the data correction device according to the present embodiment as training data, discriminatory prediction by the machine learning model can be suppressed.
- the data correction program is pre-stored (installed) in the storage unit, but the present invention is not limited to this.
- the program according to the disclosed technology can also be provided in a form stored in non-temporary storage media such as CD-ROMs, DVD-ROMs, and USB memories.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Complex Calculations (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/039692 WO2023073837A1 (ja) | 2021-10-27 | 2021-10-27 | データ修正プログラム、装置、及び方法 |
| JP2023555957A JP7582506B2 (ja) | 2021-10-27 | 2021-10-27 | データ修正プログラム、装置、及び方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/039692 WO2023073837A1 (ja) | 2021-10-27 | 2021-10-27 | データ修正プログラム、装置、及び方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023073837A1 true WO2023073837A1 (ja) | 2023-05-04 |
Family
ID=86159238
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/039692 Ceased WO2023073837A1 (ja) | 2021-10-27 | 2021-10-27 | データ修正プログラム、装置、及び方法 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7582506B2 (https=) |
| WO (1) | WO2023073837A1 (https=) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019234802A1 (en) * | 2018-06-04 | 2019-12-12 | Nec Corporation | Information processing apparatus, method, and program |
| JP2020154828A (ja) * | 2019-03-20 | 2020-09-24 | 富士通株式会社 | データ補完プログラム、データ補完方法及びデータ補完装置 |
| JP2021152838A (ja) * | 2020-03-25 | 2021-09-30 | 株式会社日立製作所 | 情報処理システムおよび情報処理プログラム |
-
2021
- 2021-10-27 WO PCT/JP2021/039692 patent/WO2023073837A1/ja not_active Ceased
- 2021-10-27 JP JP2023555957A patent/JP7582506B2/ja active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019234802A1 (en) * | 2018-06-04 | 2019-12-12 | Nec Corporation | Information processing apparatus, method, and program |
| JP2020154828A (ja) * | 2019-03-20 | 2020-09-24 | 富士通株式会社 | データ補完プログラム、データ補完方法及びデータ補完装置 |
| JP2021152838A (ja) * | 2020-03-25 | 2021-09-30 | 株式会社日立製作所 | 情報処理システムおよび情報処理プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7582506B2 (ja) | 2024-11-13 |
| JPWO2023073837A1 (https=) | 2023-05-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6421421B2 (ja) | 注釈情報付与プログラム及び情報処理装置 | |
| JP6414363B2 (ja) | 予測システム、方法およびプログラム | |
| JP7409513B2 (ja) | 機械学習データ生成プログラム、機械学習データ生成方法および機械学習データ生成装置 | |
| CN110503531A (zh) | 时序感知的动态社交场景推荐方法 | |
| JP7139932B2 (ja) | 需要予測方法、需要予測プログラムおよび需要予測装置 | |
| US11379772B2 (en) | Systems and methods for analyzing computer input to provide suggested next action for automation | |
| JP6311851B2 (ja) | 共クラスタリングシステム、方法およびプログラム | |
| JP5795743B2 (ja) | 適応的重み付けを用いた様々な文書間類似度計算方法に基づいた文書比較方法および文書比較システム | |
| EP3382609A1 (en) | Risk assessment method, risk assessment program, and information processing device | |
| CN117891811B (zh) | 一种客户数据采集分析方法、装置及云服务器 | |
| JP2020119101A (ja) | テンソル生成プログラム、テンソル生成方法およびテンソル生成装置 | |
| JP7510789B2 (ja) | 映像区間重要度算出モデル学習装置およびそのプログラム、ならびに、要約映像生成装置およびそのプログラム | |
| JP7613607B2 (ja) | ベイズ最適化装置、ベイズ最適化方法、およびベイズ最適化プログラム | |
| KR102813612B1 (ko) | 신경망 구조 설계를 위한 프루닝 방법 및 이를 위한 컴퓨팅 장치 | |
| JP2024034276A (ja) | 生成プログラム、装置、及び方法 | |
| WO2023073837A1 (ja) | データ修正プログラム、装置、及び方法 | |
| JP2007323315A (ja) | 協調フィルタリング方法、協調フィルタリング装置、および協調フィルタリングプログラムならびにそのプログラムを記録した記録媒体 | |
| CN116187403A (zh) | 存储介质、模型简化装置和模型简化方法 | |
| JP7345744B2 (ja) | データ処理装置 | |
| WO2022239245A1 (ja) | 学習方法、推論方法、学習装置、推論装置、及びプログラム | |
| JP2023544560A (ja) | 文字認識における制約条件を強制するためのシステムおよび方法 | |
| WO2021166231A1 (ja) | シナリオ生成装置、シナリオ生成方法、及びコンピュータ読み取り可能な記録媒体 | |
| JP7705622B2 (ja) | データ変換プログラム、装置、及び方法 | |
| WO2021234916A1 (ja) | 分析装置、分析方法および分析プログラム | |
| CN116932898B (zh) | 新闻推荐方法、装置、存储介质及计算机设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21962385 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023555957 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21962385 Country of ref document: EP Kind code of ref document: A1 |