WO2023073813A1 - 画像処理システム - Google Patents
画像処理システム Download PDFInfo
- Publication number
- WO2023073813A1 WO2023073813A1 PCT/JP2021/039520 JP2021039520W WO2023073813A1 WO 2023073813 A1 WO2023073813 A1 WO 2023073813A1 JP 2021039520 W JP2021039520 W JP 2021039520W WO 2023073813 A1 WO2023073813 A1 WO 2023073813A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- inference
- feature
- task
- component
- tasks
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
Definitions
- the present invention relates to an image processing system, an image processing method, and a recording medium.
- Multi-task learning can reduce learning and estimation time, which increases in proportion to the number of tasks. Multi-task learning has become one of the effective methods for applications such as human image analysis that require information obtained from multiple tasks.
- Patent Document 1 An example of multitask learning is described in Patent Document 1.
- a DNN extracts a feature quantity x L common to a plurality of tasks from an image showing a person's face.
- the DNN extracts a feature quantity unique to the task of identifying facial expressions from the feature quantity x L and outputs an estimation result y c . It extracts the feature quantity unique to the task of estimating the position of the nose and outputs the estimation result y r .
- a feature amount common to all tasks is extracted from an image, a task-specific feature amount is extracted from this common feature amount, and an estimation result of each task is estimated. It is configured. Therefore, there is a problem that a feature amount unique to a certain task cannot be used for estimating other tasks.
- An object of the present invention is to provide an image processing system that solves the above-mentioned problem, that is, the problem that task-specific feature amounts cannot be used mutually among a plurality of tasks.
- An image processing system includes: including a learning unit that generates a trained model that performs a plurality of different inference tasks from the image;
- the trained model is a first component that extracts a first feature common to the plurality of inference tasks from the image; a second component that is provided corresponding to the inference task and extracts a second feature unique to the corresponding inference task from the first feature; a third component that combines the second features extracted for each inference task to generate a third feature; a fourth component that is provided corresponding to the inference task and outputs an inference result of the corresponding inference task from the third feature quantity; is configured to include
- An image processing system includes: Using the trained model, including an inference unit that outputs inference results of a plurality of inference tasks that differ from each other from the image,
- the trained model is a first component that extracts a first feature common to the plurality of inference tasks from the image; a second component that is provided corresponding to the inference task and extracts a second feature unique to the corresponding inference task from the first feature; a third component that combines the second features extracted for each inference task to generate a third feature; a fourth component that is provided corresponding to the inference task and outputs an inference result of the corresponding inference task from the third feature quantity; is configured to include
- An image processing method comprises: Generate a trained model that performs multiple different inference tasks from images,
- the trained model includes: extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; For each inference task, the inference result of the inference task corresponding to the third feature is output.
- An image processing method comprises: Estimate and output inference results of multiple inference tasks that are different from each other from images using the trained model, In the estimation, in the trained model, extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; For each inference task, the inference result of the inference task corresponding to the third feature is output.
- a computer-readable recording medium comprises: A program for causing a computer to generate a trained model that performs a plurality of different inference tasks from an image,
- the trained model includes: extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; outputting an inference result of the inference task corresponding to the third feature quantity for each inference task; Configured to record programs.
- a computer-readable recording medium comprises: A program for causing a computer to perform a process of estimating and outputting inference results of a plurality of different inference tasks from images using a trained model, In the estimation, in the trained model, extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; outputting an inference result of the inference task corresponding to the third feature quantity for each inference task; Configured to record programs.
- the present invention can mutually utilize task-specific feature amounts among multiple tasks. Therefore, in each of a plurality of tasks, it is possible to perform learning and estimation in consideration of feature amounts specific to the task and feature amounts specific to other tasks.
- FIG. 1 is a block diagram of an image processing device according to a first embodiment of the present invention
- FIG. 4 is a flow chart showing an example of operation in a learning phase in the image processing device according to the first embodiment of the present invention
- 4 is a flow chart showing an example of an operation in an estimation phase in the image processing device according to the first embodiment of the present invention
- 1 is a configuration diagram showing an example of a model used in the first embodiment of the present invention
- FIG. FIG. 3 is a configuration diagram showing an example of a model component CM3 used in the first embodiment of the present invention
- FIG. 4 is a configuration diagram showing another example of a model component CM3 used in the first embodiment of the present invention. It is a figure which shows an example of the list
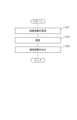
- FIG. 1 is a block diagram of an image processing apparatus 10 according to the first embodiment of the invention.
- the image processing device 10 is configured to perform a plurality of different inference tasks from images.
- an image processing apparatus 10 includes a camera I/F (interface) section 11, a communication I/F section 12, an operation input section 13, a screen display section 14, a storage section 15, and an arithmetic processing section 16. consists of
- the camera I/F section 11 is connected to the image server 17 by wire or wirelessly, and is configured to transmit and receive data between the image server 17 and the arithmetic processing section 16 .
- the image server 17 is connected to the camera 18 by wire or wirelessly, and is configured to store a plurality of images captured by the camera 18 at different shooting times for a certain period of time in the past.
- the camera 18 may be, for example, a color camera or black-and-white camera equipped with a CCD (Charge-Coupled Device) image sensor or a CMOS (Complementary MOS) image sensor having a pixel capacity of several million pixels.
- the camera 18 may be a camera installed on the street or indoors where many people come and go for the purpose of crime prevention and monitoring.
- the camera 18 may be a camera that is mounted on a moving object such as a car and that photographs the same or different photographing areas while moving.
- the number of cameras 18 is not limited to one, and may be a plurality of cameras that capture different imaging regions from different locations.
- the communication I/F unit 12 is composed of a data communication circuit, and is configured to perform data communication with an external device (not shown) by wire or wirelessly.
- the operation input unit 13 is composed of an operation input device such as a keyboard and a mouse, and is configured to detect an operator's operation and output it to the arithmetic processing unit 16 .
- the screen display unit 14 is composed of a screen display device such as an LCD (Liquid Crystal Display), and is configured to display various information on the screen according to instructions from the arithmetic processing unit 16 .
- the storage unit 15 is composed of a storage device such as a hard disk or memory, and is configured to store processing information and programs 151 necessary for various processes in the arithmetic processing unit 16 .
- the program 151 is a program that realizes various processing units by being read and executed by the arithmetic processing unit 16, and can be read from an external device or recording medium (not shown) via a data input/output function such as the communication I/F unit 12. It is read in advance and stored in the storage unit 15 .
- Main processing information stored in the storage unit 15 includes image information 152 , model 153 , and estimation result information 154 .
- the image information 152 is a frame image of the camera 18 acquired from the image server 17 through the camera I/F section 11.
- the model 153 is a machine learning model that simultaneously learns and estimates a plurality of different inference tasks from the frame images of the camera 18.
- the model 153 may be configured using, for example, a DCNN (Deep Convolutional Neural Network).
- the model 153 is trained with parameters to perform three inference tasks: object detection, pose estimation, and semantic segmentation estimation.
- a model whose parameters have been learned is called a trained model to distinguish it from a pre-learning model.
- Object detection detects classes and object positions in images.
- the result of object detection includes a class name, an estimated reliability of the class, and a bounding box (hereinafter referred to as a rectangle) representing the object position.
- a class to be detected may be, for example, a person. However, the class to be detected is not limited to persons, and may be animals or objects.
- Pose estimation estimates the skeleton information of a person in an image.
- Human skeleton information includes information representing the positions of joints that form the human body. Joints may include not only joints such as neck and shoulders, but also facial parts such as eyes and nose.
- the results of pose estimation include joint names (joint IDs), joint positions, and joint reliability.
- Semantic segmentation estimation estimates the class of each pixel in an image.
- the result of semantic segmentation estimation contains the class of each pixel.
- the class to be estimated is the same as the class detected in object detection.
- the estimation result information 154 is information representing the result estimated from the image using the trained model 153 .
- the estimation result information 154 includes object detection results, pose estimation results, and semantic segmentation estimation results.
- the arithmetic processing unit 16 has one or more processors such as an MPU and its peripheral circuits, and reads the program 151 from the storage unit 15 and executes it to cooperate with the hardware and the program 151 to perform various processing units. is configured to achieve Main processing units realized by the arithmetic processing unit 16 include an acquisition unit 161 , a learning unit 162 , and an estimation unit 163 .
- the acquisition unit 161 acquires frame images constituting a moving image captured by the camera 18 or down-sampled frame images from the image server 17 through the camera I/F unit 11 , and stores them in the storage unit 15 as image information 152 .
- the learning unit 162 is configured to make the model 153 learn the above three inference tasks at the same time using the training data. That is, the learning unit 162 generates the trained model 153 that performs the above three inference tasks from the image.
- the learning unit 21 causes the model 153 to extract the first feature amount common to the three inference tasks from the image, and then extracts the corresponding inference task from the first feature amount for each inference task. to extract a second feature quantity unique to each inference task, then combine the second feature quantity extracted for each inference task to generate a third feature quantity, and then for each inference task, to generate a third feature quantity. output the inference result of the corresponding inference task from the feature values of
- the estimation unit 163 is configured to use the trained model 153 to estimate and output the inference results of the above three inference tasks from the images.
- the estimating unit 31 first causes the trained model 153 to extract the first feature amount common to the three inference tasks from the image, and then extracts the first feature amount from the first feature amount for each inference task.
- a second feature quantity unique to the corresponding inference task is extracted, then the second feature quantity extracted for each inference task is combined to generate a third feature quantity, and then for each inference task to output the inference result of the inference task corresponding to the third feature quantity.
- the phases of the image processing apparatus 10 are roughly divided into a learning phase and an estimation phase.
- the learning phase is a phase in which the model 153 undergoes machine learning.
- the estimation phase is a phase in which the trained model 153 is used to estimate and output the inference results of the above three inference tasks from the images.
- FIG. 2 is a flow chart showing an example of the operation of the learning phase.
- the acquisition unit 161 first acquires a frame image captured by the camera 18 from the image server 17 through the camera I/F unit 11, and stores it in the storage unit 15 as image information 152 (step S1). .
- the learning unit 162 creates training data used for machine learning of the model 153 (step S2).
- the learning unit 162 machine-learns the model 153 using the training data, the input as the image, and the output as the estimation results of the three inference tasks, to generate the trained model 153 (step S3).
- FIG. 3 is a flow chart showing an example of the operation of the estimation phase.
- the acquisition unit 161 acquires a frame image captured by the camera 18 from the image server 17 through the camera I/F unit 110, and stores it in the storage unit 15 as image information 152 (step S11). .
- the estimation unit 163 uses the trained model 153 to simultaneously estimate the estimation results of the three inference tasks from the frame images included in the image information 152 (step S12).
- the estimation unit 163 displays the estimation results of the estimated three inference tasks on the screen display unit 14 and/or transmits them to an external device through the communication I/F unit 12 (step S13).
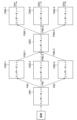
- FIG. 4 is a configuration diagram showing an example of a multitasking model that can be used as the model 153.
- the model 153 of this example is composed of eight component CMs, and the whole is one multi-layered neural network.
- the component CM1 is provided on the lower layer side of the multi-layer neural network, and is configured to input an image and extract a low-order feature quantity FM1 common to all tasks.
- Component CM1 is also called backbone.
- the feature quantity FM1 extracted by the component CM1 is also called a low-order feature map.
- Component CM1 may comprise one or more convolutional layers.
- the component CM1 may use VGG-16, which is a component of SSD (Single Shot MultiBox Detector).
- component CM1 may use VGG-19, which is a component of OpenPose, for example.
- component CM1 may use, for example, an encoder that is a component of SegNet.
- the component CM1 may use a backbone of a model other than SSD, OpenPose or SegNet, for example.
- the component CM2-1 is configured to receive the feature quantity FM1 from the component CM1 and extract a higher-order feature quantity FM2-1 specific to the object detection task.
- Component CM2-1 may be configured to include one or more convolutional layers.
- component CM2-1 may use the extra convolutional layers (Extra Feature Layers) that are part of the SSD.
- the component CM2-1 is not limited to the above, and may use a convolutional layer for extracting high-order feature quantities specific to the object detection task in object detection models other than SSD.
- the component CM2-2 is configured to receive the feature quantity FM1 from the component CM1 and extract a higher-order feature quantity FM2-2 specific to the pose estimation task.
- Component CM2-2 may be configured with one or more convolutional layers.
- the component CM2-2 includes a convolutional layer that generates a Part Confidence Map that represents the positions of keypoints, a convolutional layer that generates Part Affinity Fields that represents the degree of association between keypoints, which are components of OpenPose, and a convolutional layer that generates A layer that concatenates the obtained Part Confidence Map, Part Affinity Fields, and the feature quantity FM1 of the extraction source (the feature map obtained by this combination is hereinafter referred to as the OpenPose feature map) may be used.
- the component CM2-2 is not limited to the above, and may use a convolutional layer for extracting high-order feature quantities specific to the pose estimation task in pose estimation models other than OpenPose.
- the component CM2-3 is configured to receive the feature quantity FM1 from the component CM1 and extract a higher-order feature quantity FM2-3 specific to the semantic segmentation estimation task.
- Components CM2-3 may be configured with one or more convolutional layers.
- components CM2-3 may use decoders that are components of SegNet.
- the components CM2-3 are not limited to the above, and may use convolutional layers for extracting higher-order features unique to the semantic segmentation estimation task in semantic segmentation estimation models other than SegNet.
- Component CM3 receives feature quantities FM2-1, FM2-2, and FM2-3 from components CM2-1, CM2-2, and CM-2-3, and converts these three feature quantities FM2-1, FM2-2, and FM2 -3 to generate feature amounts FM3-1, FM3-2, and FM3-3 obtained by concatenating.
- FIG. 5 is a configuration diagram showing an example of the component CM3.
- the component CM3 in this example includes a resizing section CM3-1, a connecting section CM3-2, and a resizing section CM3-3.
- the resizing unit CM3-1 is configured to match the sizes of the feature quantities FM2-1, FM2-2, and FM2-3 so that they can be combined.
- the resizing unit CM3-1 uses any one of the three feature amounts as a reference feature amount, and changes the size of the remaining two feature amounts according to the size of the reference feature amount.
- the feature amounts FM2-1, FM2-2, and FM2-3 have sizes of 38 ⁇ 38, 70 ⁇ 70, and 240 ⁇ 320, respectively, and the reference feature amount is the feature amount FM2-1.
- the resizing unit CM3-1 generates and outputs a feature quantity FM2-2' obtained by changing the size of the feature quantity FM2-2 from 70 ⁇ 70 to 38 ⁇ 38.
- the resizing unit CM3-1 generates and outputs a feature quantity FM2-3' obtained by changing the size of the feature quantity FM2-3 from 240 ⁇ 320 to 38 ⁇ 38. Further, the resizing unit CM3-1 does not change the size of the feature quantity FM2-1, and outputs the feature quantity FM2-1 itself as the feature quantity FM2-1'.
- the combining unit CM3-2 receives the feature amounts FM2-1', FM2-2', and FM2-3' from the resizing unit CM3-1, generates and outputs a feature amount FM3 obtained by combining these.
- the combining unit CM3-2 inputs feature amounts FM2-1′, FM2-2′, and FM2-3′ each having a size of 38 ⁇ 38, and generates a feature amount FM3 having a size of 38 ⁇ 38 ⁇ 3. Generate and output. In this way, the number of channels (number of dimensions) is increased by combining feature amounts.
- the resizing unit CM3-3 receives the feature amount FM3 from the combining unit CM3-2, generates and outputs feature amounts FM3-1, FM3-2, and FM3-3 changed in size according to each task. For example, assume that the input sizes of the components CM4-1, CM4-2, and CM4-3 are 38 ⁇ 38 ⁇ 3, 70 ⁇ 70 ⁇ 3, and 240 ⁇ 320 ⁇ 3, respectively. In this case, the resizing unit CM3-3 generates a feature amount FM3-2 by changing the size of the feature amount FM3 from 38 ⁇ 38 ⁇ 3 to 70 ⁇ 70 ⁇ 3, and outputs it to the component CM4-2.
- the resizing unit CM3-3 generates a feature amount FM3-3 by changing the size of the feature amount FM3 from 38 ⁇ 38 ⁇ 3 to 240 ⁇ 320 ⁇ 3, and outputs it to the component CM4-3. Further, the resizing unit CM3-3 outputs the feature amount FM3 itself having a size of 38 ⁇ 38 ⁇ 3 as the feature amount FM3-1 to the component CM4-1.
- FIG. 6 is a configuration diagram showing another example of the component CM3.
- the component CM3 in this example is configured including three sub-components CM3A, CM3B and CM3C.
- the subcomponent CM3A is configured to generate and output the feature quantity FM3-1 for the component CM4-1 of the object detection task from the feature quantities FM2-1, FM2-2, and FM2-3.
- the sub-component CM3A generates and outputs feature amounts FM2-2' and FM2-3' obtained by changing the size of the feature amounts FM2-2 and FM2-3 according to the size of the feature amount FM2-1.
- a combining unit CM3A-2 for generating and outputting a feature quantity FM3-1 obtained by combining the three feature quantities FM2-1, FM2-2', and FM2-3' It is configured.
- the sizes of feature amounts FM2-1, FM2-2, and FM2-3 are set to 38 ⁇ 38, 70 ⁇ 70, and 240 ⁇ 320, respectively, and the input size of component CM4-1 is set to 38 ⁇ 38 ⁇ 3.
- the resizing unit CM3A-1 changes the size of the feature quantity FM2-2 from 70 ⁇ 70 to 38 ⁇ 38 to generate and output the feature quantity FM2-2′, and changes the size of the feature quantity FM2-3 to 240 ⁇ 38 ⁇ 38.
- a feature quantity FM2-3′ changed from ⁇ 320 to 38 ⁇ 38 is generated and output.
- the combiner CM3A-2 combines feature quantities FM2-1, FM2-2′ and FM2-3′ of the same size of 38 ⁇ 38 to generate a feature quantity FM3-1 of size 38 ⁇ 38 ⁇ 3. Output. This makes it possible to suppress deterioration of the feature amount FM2-1 due to the combination.
- the subcomponent CM3B is configured to generate and output a feature quantity FM3-2 for the component CM4-2 of the pose estimation task from the feature quantities FM2-1, FM2-2, and FM2-3.
- the subcomponent CM3B generates and outputs feature quantities FM2-1′ and FM2-3′ obtained by changing the sizes of the feature quantities FM2-1 and FM2-3 according to the size of the feature quantity FM2-2.
- a combining unit CM3B-2 that generates and outputs a feature quantity FM3-2 obtained by combining three feature quantities FM2-1′, FM2-2, and FM2-3′. It is configured.
- the sizes of feature amounts FM2-1, FM2-2, and FM2-3 are set to 38 ⁇ 38, 70 ⁇ 70, and 240 ⁇ 320, respectively, and the input size of component CM4-2 is set to 70 ⁇ 70 ⁇ 3.
- the resizing unit CM3B-1 changes the size of the feature quantity FM2-1 from 38 ⁇ 38 to 70 ⁇ 70 to generate and output the feature quantity FM2-1′, and changes the size of the feature quantity FM2-3 to 240 ⁇ 70 ⁇ 70.
- a feature amount FM2-3′ changed from 320 ⁇ 70 ⁇ 70 is generated and output.
- the combiner CM3B-2 combines feature quantities FM2-1′, FM2-2 FM2-3′ of the same size of 70 ⁇ 70 to generate a feature quantity FM3-2 of size 70 ⁇ 70 ⁇ 3. Output. This makes it possible to suppress deterioration of the feature amount FM2-2 due to the combination.
- the subcomponent CM3C is configured to generate and output a feature quantity FM3-3 for the component CM4-3 of the semantic segmentation estimation task from the feature quantities FM2-1, FM2-2, and FM2-3.
- the subcomponent CM3C generates and outputs feature quantities FM2-1′ and FM2-2′ obtained by changing the size of the feature quantities FM2-1 and FM2-2 in accordance with the size of the feature quantity FM2-3.
- a combining unit CM3C-2 for generating and outputting a feature quantity FM3-3 obtained by combining the three feature quantities FM2-1′, FM2-2′, and FM2-3. It is configured.
- the sizes of feature amounts FM2-1, FM2-2, and FM2-3 are set to 38 ⁇ 38, 70 ⁇ 70, and 240 ⁇ 320, respectively, and the input size of component CM4-3 is set to 240 ⁇ 320 ⁇ 3.
- the resizing unit CM3C-1 changes the size of the feature quantity FM2-1 from 38 ⁇ 38 to 240 ⁇ 240 to generate and output the feature quantity FM2-1′, and changes the size of the feature quantity FM2-2 to 70 ⁇ 70.
- a feature quantity FM2-2′ changed from ⁇ 70 to 240 ⁇ 320 is generated and output.
- the combiner CM3C-2 combines feature quantities FM2-1′, FM2-2′ and FM2-3 of the same size of 240 ⁇ 320 to generate a feature quantity FM3-3 of size 240 ⁇ 320 ⁇ 3. Output. This makes it possible to suppress deterioration of the feature quantity FM2-3 due to the combination.
- the component CM4-1 is configured to receive the feature amount FM3-1 from the component CM3, estimate the object detection task estimation result ER1 from the feature amount FM3-1, and output the estimation result ER1.
- the feature quantity FM3-1 includes not only the high-order feature quantity FM2-1 specific to the object detection task, but also the high-order feature quantity FM2-2 specific to the pose estimation task and the high-order feature quantity specific to semantic segmentation estimation. Quantities FM2-3. Therefore, the component CM4-1 is capable of learning and estimating considering these three high-order feature quantities.
- Component CM4-1 may use, for example, an output layer (Detections: 8732 per Class, Non-Maximum Suppression) leading to a special convolutional layer that constitutes an SSD.
- the component CM4-1 may set the weight that determines the priority of the high-order feature amount FM2-1 unique to the object detection task to be greater than the weight that determines the priority of the other second feature amounts. .
- the component CM4-1 assigns a weight of 0.5 to determine the priority of the high-order feature quantity FM2-1 unique to the object detection task, and a weight of 0.5 to determine the priority of the other second feature quantities. 25 may be used.
- the component CM4-1 performs 1 ⁇ 1 convolution (Channel-Wise Convolution) on the input feature quantity FM3-1 so that the number of dimensions of the high-order feature quantity is reduced to, for example, 38 ⁇ 38 It may be reduced from x3 to 38x38x1.
- the network part of the existing model such as SSD, which estimates and outputs the estimation result from the high-order feature amount, can be used as it is.
- the component CM4-2 is configured to receive the feature quantity FM3-2 from the component CM3, estimate the pose estimation task estimation result ER2 from the feature quantity FM3-2, and output the estimated result ER2.
- the feature quantity FM3-2 includes not only the high-order feature quantity FM2-2 specific to the pose estimation task, but also the high-order feature quantity FM2-1 specific to the object detection task and the high-order feature quantity specific to semantic segmentation estimation. Quantities FM2-3 are included. Therefore, the component CM4-2 is capable of learning and estimating considering these three higher-order feature quantities.
- the component CM4-2 may use, for example, a network part that estimates a pose estimation result from an OpenPose feature map, which is a component of OpenPose.
- the component CM4-2 may set the weight that determines the priority of the high-order feature quantity FM2-2 unique to the pose estimation task to be greater than the weight that determines the priority of the other second feature quantity. .
- the component CM4-2 assigns a weight of 0.5 to determine the priority of the high-order feature quantity FM2-2 unique to the pose estimation task, and a weight of 0.5 to determine the priority of the other second feature quantities. 25 may be used.
- the component CM4-2 performs 1 ⁇ 1 convolution (Channel-Wise Convolution) on the input feature quantity FM3-2, so that the number of dimensions of the high-order feature quantity is reduced to, for example, 70 ⁇ 70 It may be reduced from x3 to 70x70x1.
- the network part of the existing model such as OpenPose, which estimates and outputs the estimation result from the high-order feature amount, can be used as it is.
- the component CM4-3 is configured to receive the feature quantity FM3-3 from the component CM3, estimate the estimation result ER3 of the semantic segmentation estimation task from the feature quantity FM3-3, and output the estimated result ER3.
- the feature quantity FM3-3 includes not only the high-order feature quantity FM2-3 specific to the semantic segmentation estimation task, but also the high-order feature quantity FM2-1 specific to the object detection task and the high-order feature quantity specific to pose estimation.
- the quantity FM2-2 is included. Therefore, the component CM4-3 is capable of learning and estimating considering these three higher-order feature quantities.
- the component CM4-3 may use, for example, a softmax layer, which is a component of SegNet.
- the component CM4-3 sets the weight that determines the priority of the high-order feature quantity FM2-3 unique to the semantic segmentation estimation task to be greater than the weight that determines the priority of the other second feature quantity. good. For example, the component CM4-3 assigns a weight of 0.5 to determine the priority of the high-order feature quantity FM2-3 unique to the semantic segmentation estimation task, and a weight of 0 to determine the priority of the other second feature quantities. .25.
- the high-order feature quantity FM2 unique to the semantic segmentation estimation task -3 importance can be increased.
- the component CM4-3 performs 1 ⁇ 1 convolution (Channel-Wise Convolution) on the input feature quantity FM3-3, so that the number of dimensions of the high-order feature quantity is reduced to, for example, 240 ⁇ 320 It may be reduced from x3 to 240 x 320 x 1.
- the network part of the existing model such as SegNet, which estimates and outputs the estimation result from the high-order feature amount, can be used as it is.
- FIG. 7 shows an example of a list of training data used for machine learning of the model 153.
- a total of n training data are registered in this list.
- Each piece of training data consists of an ID that uniquely identifies the training data, an image, an object detection label, a pose estimation label, and a semantic segmentation estimation label.
- a frame image captured by the camera 18 is set in the image item.
- the object detection label item the presence or absence of a label, and if the label is present, a class such as a person present in the image, which is label information, and its position information (rectangle information) are set.
- the pose estimation label item the presence or absence of a label, and if there is a label, the joint name (joint ID) of the joint present in the image and its position information are set.
- the semantic segmentation estimation label item whether or not there is a label and, if there is a label, the class of each pixel of the image are set. In this way, in the training data group, all of the three label items (object detection label, pose estimation label, and semantic segmentation estimation label) have label information set, and some label items Only the label information may be included.
- the training data as described above may be created, for example, through interactive processing with the user.
- the learning unit 162 displays the image of the camera 18 acquired by the acquisition unit 161 on the screen display unit 14 and receives label information of the image from the user through the operation input unit 13 . Then, the learning unit 162 creates a set of the displayed image and the received label information as one piece of training data.
- the learning unit 162 creates a necessary and sufficient number of training data by a similar method.
- the method of creating training data is not limited to the above.
- FIG. 8 is a flowchart showing an example of the learning process of the learning unit 162.
- FIG. 8 the model 153 having the configuration shown in FIG. 4 is used as the model to be learned.
- the learning process of this example does not learn the entire model 153 at once, but learns while gradually expanding the network portion to be learned. This enables stable learning. Specifically, it passes through the following four learning stages.
- the learning unit 162 learns only the components CM2-1 and CM4-1, which are deep-layer network parts related to object detection. At this time, the component CM-1 that is the backbone, the components CM2-2 and CM4-2 that are deep layer network parts related to pose estimation, and the components CM2-3 that are deep layer network parts related to semantic segmentation estimation and The parameters of CM4-3 are fixed.
- the learning unit 162 learns only the components CM2-1, CM2-2, CM4-1, and CM4-2, which are deep layer network parts related to object detection and pose estimation.
- the parameters of the component CM-1, which is the backbone, and the components CM2-3 and CM4-3, which are deep-layer network portions related to semantic segmentation estimation, are fixed.
- the learning unit 162 builds the components CM2-1, CM2-2, CM2-3, CM4-1 which are the deep layer network parts involved in all inference tasks, namely object detection, pose estimation and semantic segmentation estimation. , CM4-2, and CM4-3.
- the parameters of the component CM-1, which is the backbone are fixed.
- the learning unit 162 prepares the entire model, namely, the component CM-1 which is the backbone, and the components CM2-1, CM2-2, CM2 which are deep layer network parts related to object detection, pose estimation and semantic segmentation estimation. -3, CM4-1, CM4-2, and CM4-3.
- the learning unit 162 creates a training data group to be used in each learning stage from the training data group used for machine learning of the model 153 (step S21).
- the learning unit 162 selects the training data group to be used in the learning stage 3 and the training data group to be used in the learning stage 4 from the training data list shown in FIG. create.
- Learning stage 3 and learning stage 4 require training data in which label information is set for all three label items (object detection label, pose estimation label, and semantic segmentation estimation label). Therefore, the learning unit 162 creates a training data group used in the learning stage 3 and a training data group used in the learning stage 4 by extracting training data satisfying such conditions from the list.
- step S21 the learning unit 162 creates a training data group to be used in the learning stage 2 from the remaining training data groups in the list.
- learning stage 2 training data in which label information is set in the items of object detection label and pose estimation label (whether or not semantic segmentation estimation label information is present) is required. Therefore, the learning unit 162 creates a training data group to be used in the learning stage 2 by extracting training data satisfying such conditions from the list.
- the learning unit 162 creates a training data group to be used in the learning stage 1 from the remaining training data groups in the list.
- training data in which label information is set in the item of object detection label presence or absence of pose estimation label information and semantic segmentation estimation label information is irrelevant
- the learning unit 162 creates a training data group to be used in the learning stage 1 by extracting training data satisfying such conditions from the list.
- the learning unit 162 performs learning at each stage in the order of learning stage 1, learning stage 2, learning stage 3, and learning stage 4 until a predetermined termination condition is satisfied (steps S22 to S25).
- the error between the inference result of the inference task obtained as the output of the model 153 when the image included in the training data is input to the model 153 and the label information included in the training data is calculated as a loss given in advance. Calculate using a function.
- a loss function exists for each of the object detection task, pose estimation task, and semantic segmentation estimation task. Let L1 be the loss function for the object detection task, L2 be the loss function for the pose estimation task, and L3 be the loss function for the semantic segmentation estimation task.
- the parameters of the components CM2-1 and CM4-1 of the model 153 are learned so as to minimize the loss calculated by the loss function L1.
- the components CM2-1 of the model 153 so as to minimize the sum (for example, weighted sum) of the loss calculated by the loss function L1, the loss calculated by the loss function L2, and the loss calculated by the loss function L3, Learn the parameters of CM2-2, CM2-3, CM4-1, CM4-2 and CM4-3.
- Each learning may use, for example, gradient descent and error backpropagation.
- the learning method applicable to the present invention is not limited to the above examples.
- the following learning method may be used. That is, first, only the components CM2-1 and CM4-1 related to object detection are learned (the parameters of the other components CM1, CM2-2, CM2-3, CM4-2 and CM4-3 are fixed). Next, only the components CM2-2 and CM4-2 related to pose estimation are learned (the parameters of the other components CM1, CM2-1, CM2-3, CM4-1 and CM4-3 are fixed).
- CM2-3 and CM4-3 related to semantic segmentation estimation are learned (the parameters of the other components CM1, CM2-1, CM2-3, CM4-1 and CM4-3 are fixed).
- CM2-1 to CM2-3 and CM3-1 to CM3-3 related to all inference tasks are learned (the parameters of the component CM1 are fixed.
- the components CM1, CM2-3 of the entire model are learned. 1 to CM2-3 and CM4-1 to CM4-3.
- the image processing apparatus 10 it is possible to mutually use task-specific high-order feature amounts among a plurality of tasks. Therefore, in each of a plurality of tasks, it is possible to perform learning and estimation in consideration of the task-specific high-order feature amount and other task-specific high-order feature amounts.
- model 153 was configured to perform semantic segmentation estimation.
- model 153 may be configured to perform instant semantic segmentation estimation instead of semantic segmentation estimation. In this case, for example, between the component CM3 and the component CM4-3 of the multitasking model 153 shown in FIG. It may be configured to estimate the class on a pixel-by-pixel basis for each individual class rectangle.
- model 153 was configured to perform three inference tasks: object detection, pose estimation, and semantic segmentation estimation.
- model 153 may be configured to perform only any two inference tasks of object detection, pose estimation, and semantic segmentation estimation.
- the inference tasks performed by the model 153 are not limited to object detection, pose estimation, and semantic segmentation estimation, and may be tasks other than these.
- FIG. 9 is a block diagram of an image processing system 20 according to a second embodiment of the invention.
- the image processing system 20 comprises a learning section 21 and a trained model 22 .
- the learning unit 21 is configured to generate a trained model 22 that performs a plurality of different inference tasks from images.
- the learning unit 21 can be configured, for example, in the same manner as the learning unit 162 in FIG. 1, but is not limited thereto.
- the trained model 22 includes a first component for extracting a first feature quantity common to the plurality of inference tasks from the image, and a trained model 22 provided corresponding to the inference task and corresponding to the first feature quantity. a second component that extracts a second feature quantity unique to an inference task; a third component that combines the second feature quantity extracted for each inference task to generate a third feature quantity; and a fourth component that is provided corresponding to the inference task and outputs an inference result of the corresponding inference task from the third feature quantity.
- the image processing system 20 configured as described above operates as follows. That is, the learning unit 21 generates a trained model 22 that performs a plurality of different inference tasks from the image. In the above generation, the learning unit 21 causes the trained model 22 to extract a first feature amount common to a plurality of inference tasks from the image, and then, for each inference task, performs corresponding inference from the first feature amount. A second feature quantity unique to the task is extracted, then the second feature quantity extracted for each inference task is combined to generate a third feature quantity, and then a third feature quantity is generated for each inference task. Output the inference result of the inference task corresponding to the feature amount of 3.
- the image processing system 20 configured and operated as described above, it is possible to mutually use task-specific feature amounts among a plurality of inference tasks.
- the reason is that the image processing system 20 combines the second feature amounts extracted for each inference task to generate the third feature amount, and outputs the inference result of the corresponding inference task from the third feature amount. This is because it is configured to Therefore, in each of a plurality of inference tasks, it is possible to perform learning and estimation in consideration of the task-specific feature amount and other task-specific feature amounts.
- FIG. 10 is a block diagram of an image processing system 30 according to the third embodiment of the invention.
- the image processing system 30 includes an estimator 31 and a trained model 32 .
- the estimation unit 31 is configured to use the trained model 32 to output inference results of a plurality of different inference tasks from the image.
- the estimating unit 31 can be configured, for example, in the same manner as the estimating unit 163 in FIG. 1, but is not limited to this.
- the trained model 32 includes a first component for extracting a first feature common to the plurality of inference tasks from the image, and a trained model 32 provided corresponding to the inference task and corresponding to the first feature. a second component that extracts a second feature quantity unique to an inference task; a third component that combines the second feature quantity extracted for each inference task to generate a third feature quantity; and a fourth component that is provided corresponding to the inference task and outputs an inference result of the corresponding inference task from the third feature quantity.
- the image processing system 30 configured as described above operates as follows. That is, the estimating unit 31 uses the trained model 32 to estimate and output the inference results of a plurality of different inference tasks from the images. In the above estimation, the estimating unit 31 first causes the trained model 32 to extract the first feature amount common to a plurality of inference tasks from the image, and then, for each inference task, extracts the first feature amount from the corresponding Extract a second feature quantity unique to the inference task to be performed, then combine the second feature quantity extracted for each inference task to generate a third feature quantity, and then generate a third feature quantity for each inference task , output the inference result of the inference task corresponding to the third feature quantity.
- the image processing system 30 configured and operated as described above, it is possible to mutually use task-specific feature amounts among a plurality of inference tasks.
- the reason is that the image processing system 30 combines the second feature amounts extracted for each inference task to generate the third feature amount, and outputs the inference result of the corresponding inference task from the third feature amount. This is because it is configured to Therefore, in each of a plurality of inference tasks, it is possible to perform learning and estimation in consideration of the task-specific feature amount and other task-specific feature amounts.
- the present invention can be used in general fields where multiple inference tasks such as object detection, pose estimation, and semantic segmentation estimation are performed from images such as camera images.
- [Appendix 1] including a learning unit that generates a trained model that performs a plurality of different inference tasks from the image;
- the trained model is a first component that extracts a first feature common to the plurality of inference tasks from the image; a second component that is provided corresponding to the inference task and extracts a second feature unique to the corresponding inference task from the first feature; a third component that combines the second features extracted for each inference task to generate a third feature; a fourth component that is provided corresponding to the inference task and outputs an inference result of the corresponding inference task from the third feature quantity; image processing system including [Appendix 2]
- the third component uses one of the plurality of second feature amounts as a reference feature amount, and adjusts the size of the second feature amount other than the reference feature amount to match the size of the reference feature amount.
- the third component includes a subcomponent corresponding to the inference task, wherein the subcomponent uses the second feature amount of the corresponding inference task as a reference feature amount, and uses the second feature amount of the corresponding inference task as a reference feature amount. 2 is changed in accordance with the size of the reference feature quantity, and the second feature quantity other than the corresponding inference task after the size change is combined with the reference feature quantity to obtain the second feature quantity.
- the image processing system according to Appendix 1.
- the learning unit learns the trained model in a plurality of learning stages, The plurality of learning stages includes at least: Any one of the plurality of inference tasks is set as a learning target task, and parameters of the second component, the third component, and the first component related to inference tasks other than the learning target task are fixed. a first learning stage of learning parameters of the second component and the third component of the task to be learned; a second learning stage of fixing the parameters of the first component and learning the parameters of the second and third components for all the inference tasks; 4.
- the image processing system according to any one of Appendices 1 to 3.
- a fourth component provided corresponding to the inference task is a priority of the second feature amount of the corresponding inference task among the plurality of second feature amounts constituting the third feature amount.
- the weight that determines the is larger than the weight that determines the priority of the other second feature quantity, 5.
- a fourth component provided corresponding to the inference task reduces the number of dimensions of the third feature amount by performing 1 ⁇ 1 convolution on the input third feature amount. , 6.
- the plurality of inference tasks includes an object detection task, a pose estimation task, a semantic segmentation estimation task; 7.
- the trained model is a first component that extracts a first feature common to the plurality of inference tasks from the image; a second component that is provided corresponding to the inference task and extracts a second feature unique to the corresponding inference task from the first feature; a third component that combines the second features extracted for each inference task to generate a third feature; a fourth component that is provided corresponding to the inference task and outputs an inference result of the corresponding inference task from the third feature quantity; image processing system including [Appendix 10] Generate a trained model that performs multiple different inference tasks from images, In the generation, the trained model includes: extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third
- [Appendix 11] Estimate and output inference results of multiple inference tasks that are different from each other from images using the trained model, In the estimation, in the trained model, extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; outputting an inference result of the inference task corresponding to the third feature quantity for each inference task; Image processing method.
- Appendix 12 A program for causing a computer to generate a trained model that performs a plurality of different inference tasks from an image,
- the trained model includes: extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; outputting an inference result of the inference task corresponding to the third feature quantity for each inference task;
- a computer-readable recording medium that records a program.
- Appendix 13 A program for causing a computer to perform a process of estimating and outputting inference results of a plurality of different inference tasks from images using a trained model, In the estimation, in the trained model, extracting a first feature common to the plurality of inference tasks from the image; extracting a second feature unique to the corresponding inference task from the first feature for each inference task; combining the second features extracted for each inference task to generate a third feature; outputting an inference result of the inference task corresponding to the third feature quantity for each inference task; A computer-readable recording medium that records a program.
- image processing device 11 camera I/F unit 12 communication I/F unit 13 operation input unit 14 screen display unit 15 storage unit 16 arithmetic processing unit 17 image server 18 camera 151 program 152 image information 153 model 154 estimation result information 161 acquisition unit 162 learning unit 163 estimating unit
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Multimedia (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Image Analysis (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023555935A JP7683723B2 (ja) | 2021-10-26 | 2021-10-26 | 画像処理システム |
| US18/698,418 US20240428551A1 (en) | 2021-10-26 | 2021-10-26 | Image processing system |
| PCT/JP2021/039520 WO2023073813A1 (ja) | 2021-10-26 | 2021-10-26 | 画像処理システム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/039520 WO2023073813A1 (ja) | 2021-10-26 | 2021-10-26 | 画像処理システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023073813A1 true WO2023073813A1 (ja) | 2023-05-04 |
Family
ID=86159261
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/039520 Ceased WO2023073813A1 (ja) | 2021-10-26 | 2021-10-26 | 画像処理システム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240428551A1 (https=) |
| JP (1) | JP7683723B2 (https=) |
| WO (1) | WO2023073813A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3193358A1 (en) * | 2022-08-02 | 2023-01-05 | Mitsubishi Electric Corporation | Inference device, inference method, and non-transitory computer-readable medium |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021021978A (ja) * | 2019-07-24 | 2021-02-18 | 富士ゼロックス株式会社 | 情報処理装置及びプログラム |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7166784B2 (ja) | 2018-04-26 | 2022-11-08 | キヤノン株式会社 | 情報処理装置、情報処理方法及びプログラム |
-
2021
- 2021-10-26 US US18/698,418 patent/US20240428551A1/en active Pending
- 2021-10-26 WO PCT/JP2021/039520 patent/WO2023073813A1/ja not_active Ceased
- 2021-10-26 JP JP2023555935A patent/JP7683723B2/ja active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021021978A (ja) * | 2019-07-24 | 2021-02-18 | 富士ゼロックス株式会社 | 情報処理装置及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7683723B2 (ja) | 2025-05-27 |
| JPWO2023073813A1 (https=) | 2023-05-04 |
| US20240428551A1 (en) | 2024-12-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10911775B1 (en) | System and method for vision-based joint action and pose motion forecasting | |
| CN108898579B (zh) | 一种图像清晰度识别方法、装置和存储介质 | |
| US10832069B2 (en) | Living body detection method, electronic device and computer readable medium | |
| US9576607B2 (en) | Techniques for creating a composite image | |
| WO2020192483A1 (zh) | 图像显示方法和设备 | |
| JP2020057111A (ja) | 表情判定システム、プログラム及び表情判定方法 | |
| CN111325051A (zh) | 一种基于人脸图像roi选取的人脸识别方法及装置 | |
| CN108875900A (zh) | 视频图像处理方法和装置、神经网络训练方法、存储介质 | |
| WO2023023160A1 (en) | Depth information reconstruction from multi-view stereo (mvs) images | |
| JPWO2020194378A1 (ja) | 画像処理システム、画像処理装置、画像処理方法、及び画像処理プログラム | |
| CN118158516A (zh) | 一种智能照相方法及系统 | |
| WO2020217425A1 (ja) | 教師データ生成装置 | |
| JP7683723B2 (ja) | 画像処理システム | |
| CN115509351B (zh) | 一种感官联动情景式数码相框交互方法与系统 | |
| EP3543902B1 (en) | Image processing apparatus and method and storage medium storing instructions | |
| WO2023229591A1 (en) | Real scene super-resolution with raw images for mobile devices | |
| WO2023229589A1 (en) | Real-time video super-resolution for mobile devices | |
| CN103155002A (zh) | 用于在图像中识别虚拟视觉信息的方法和装置 | |
| US12244931B2 (en) | Information processing device to set photographing device, information processing device to retrieve photographing recipe, information processing method, and non-transitory computer readable medium | |
| CN114170506B (zh) | 一种面向机器人的基于场景图的视觉场景理解系统及方法 | |
| CN110909579A (zh) | 一种视频图像处理方法、装置、电子设备及存储介质 | |
| CN119096265A (zh) | 使用轻量级深度学习模型的实时设备上远距离姿势识别 | |
| CN114299411B (zh) | 一种数据处理方法以及计算机设备 | |
| US20240257498A1 (en) | Electronic apparatus for classifying object region and background region and operating method of the electronic apparatus | |
| US20250124612A1 (en) | Information processing apparatus, information processing method, and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21962362 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18698418 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2023555935 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21962362 Country of ref document: EP Kind code of ref document: A1 |