WO2023027041A1 - 部位特異的ヌクレアーゼ - Google Patents
部位特異的ヌクレアーゼ Download PDFInfo
- Publication number
- WO2023027041A1 WO2023027041A1 PCT/JP2022/031615 JP2022031615W WO2023027041A1 WO 2023027041 A1 WO2023027041 A1 WO 2023027041A1 JP 2022031615 W JP2022031615 W JP 2022031615W WO 2023027041 A1 WO2023027041 A1 WO 2023027041A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- amino acid
- mad7
- protein
- acid sequence
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/09—Fusion polypeptide containing a localisation/targetting motif containing a nuclear localisation signal
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPR]
Definitions
- the present invention relates to site-specific nucleases and the like.
- RNA double-strand breaks at arbitrary sites on the genome of cells.
- mutation such as random deletion or addition of DNA occurs during repair by non-homologous end joining at the cut end, and the gene is knocked out due to frameshift etc.
- Non-Patent Document 1 attempts to improve genome editing efficiency by linking a nuclear localization signal to the Cas12a protein.
- the objective of the present invention is to provide a genome editing technology with higher genome editing efficiency.
- the present inventors found that any one of the proteins 1 to 3 of the present invention, which will be described later, can solve the above problems.
- the present inventor has completed the present invention as a result of further research based on this finding. That is, the present invention includes the following aspects.
- Section 1 A protein comprising the amino acid sequence b1 of the MAD7 protein, wherein the amino acid sequence b1 is a mutated sequence of the amino acid sequence shown in SEQ ID NO: 6, and contains the K169R mutation in the amino acid sequence shown in SEQ ID NO: 6. .
- Section 2 wherein the amino acid sequence b1 further comprises at least one mutation selected from the group consisting of S469R and H1025K in the amino acid sequence shown in SEQ ID NO:6.
- a protein according to item 1 or 2 comprising a MAD7 domain comprising said amino acid sequence b1 of the MAD7 protein and a linking sequence b2 of multiple nuclear localization signal sequences.
- Item 4 Item 3, wherein the linking sequence b2 is located on the C-terminal side of the amino acid sequence b1 in the MAD7 domain.
- Item 5 (a) a 5′ ⁇ 3′ exonuclease domain comprising amino acid sequence a1 and nuclear localization signal sequence a2 of the 5′ ⁇ 3′ exonuclease, and (b) said amino acid sequence b1 and multiple nuclear localizations of the MAD7 protein.
- Item 5. A protein according to Item 3 or 4, comprising a MAD7 domain containing a linking sequence b2 of a signal sequence.
- Item 6 Item 5, wherein the 5' ⁇ 3' exonuclease domain is located on the N-terminal side of the MAD7 domain.
- Item 7 Item 5 or 6, wherein the nuclear localization signal sequence a2 is located on the N-terminal side of the amino acid sequence a1 in the 5' ⁇ 3' exonuclease domain.
- Item 8 The protein according to any one of items 5 to 7, wherein the nuclear localization signal sequence a2, the amino acid sequence a1, the amino acid sequence b1, and the linking sequence b2 are arranged in this order from the N-terminal side.
- the amino acid sequence b1 is a variant sequence of the amino acid sequence shown in SEQ ID NO: 6, and A24E, I180K, A290R, S469K, S469R, K535R, N583K, N583R, K590R, I646K in the amino acid sequence shown in SEQ ID NO: 6, Item 9.
- Item 10 wherein the mutation is at least one mutation selected from the group consisting of N583K, N583R, Y832K, Y832R, H1025K, H1025R, and C1219N.
- Item 11 (a) a 5′ ⁇ 3′ exonuclease domain comprising amino acid sequence a1 and nuclear localization signal sequence a2 of the 5′ ⁇ 3′ exonuclease, and (b) said amino acid sequence b1 and multiple nuclear localizations of the MAD7 protein.
- a protein comprising a MAD7 domain containing a linking sequence b2 of the activation signal sequence.
- a protein comprising an amino acid sequence b1, wherein the amino acid sequence b1 is a mutant sequence of the amino acid sequence shown in SEQ ID NO: 6, and A24E, K169R, I180K, A290R, S469K in the amino acid sequence shown in SEQ ID NO: 6,
- a protein comprising at least one mutation selected from the group consisting of S469R, K535R, N583K, N583R, K590R, I646K, I646R, T714K, T714R, N827D, Y832K, Y832R, K970R, H1025K, H1025R, S1175A, and C1219N.
- Item 13 (ai) a 5′ ⁇ 3′ exonuclease domain comprising the amino acid sequence a1 of the 5′ ⁇ 3′ exonuclease and a nuclear localization signal sequence a2, and (bi) a MAD7 domain comprising the amino acid sequence b1 of the MAD7 protein, protein.
- Item 14 A polynucleotide comprising a coding sequence for the protein according to any one of Items 1 to 13.
- Item 15 (aii) an expression cassette of a protein comprising a 5′ ⁇ 3′ exonuclease domain comprising the amino acid sequence a1 of the 5′ ⁇ 3′ exonuclease and a nuclear localization signal sequence a2, and (bii) the amino acid sequences b1 and b1 of the MAD7 protein; A polynucleotide comprising an expression cassette for a protein comprising a MAD7 domain comprising a linking sequence b2 of multiple nuclear localization signal sequences.
- Item 16 A cell comprising the polynucleotide according to Item 14 or 15.
- composition for genome editing comprising at least one selected from the group consisting of the protein according to any one of Items 1 to 13 and the polynucleotide according to Item 14 or 15.
- Item 18 A genome editing method comprising introducing at least one selected from the group consisting of the protein according to any one of items 1 to 13 and the polynucleotide according to items 14 or 15 into a cell or non-human organism.
- a genome-edited cell comprising introducing at least one selected from the group consisting of the protein according to any one of Items 1 to 13 and the polynucleotide according to Item 14 or 15 into the cell or non-human organism. Or a method for producing a non-human organism.
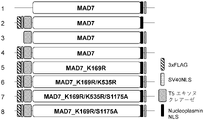
- FIG. 1 shows the structure of an effector expression vector used in Test Example 1-1.
- Test Example 1-1 shows the Fluc/Rluc values when using each effector expression vector.
- Reporter only indicates the case where no effector expression vector is used, and others indicate the case where the effector expression vector (the name and structure correspond to FIG. 2) is used.
- the upper graph (-target) shows the case of using pALTER-pSSA (a vector without the target sequence of the guide RNA) as a reporter vector
- the lower graph (+target) shows the case of using pALTER-pSSA-NbPDS ( A vector having a guide RNA target sequence) is used.
- the dark gray and light gray columns represent the results of independent tests.
- Test Example 1-2 shows the Fluc/Rluc values when using each effector expression vector. In the horizontal axis, "Reporter only” indicates the case where the effector expression vector is not used, "No mutation” indicates the case where MAD7 was not mutated (when pALTER-MAD7-2xNLS was used), and others are MAD7. shows the mutations introduced in .
- Test Example 1-3 shows the Fluc/Rluc values when using each effector expression vector.
- Reporter only indicates the case where the effector expression vector is not used
- No mutation indicates the case where MAD7 was not mutated (when pALTER-MAD7-2xNLS was used)
- others are MAD7. shows the mutations introduced in .
- Each column represents the mean of three independently performed tests. Description of the left/right graphs is the same as in FIG.
- FIG. 1 shows the structure of an effector expression vector used in Test Example 1-4.
- Test Example 1-4 shows the Fluc/Rluc values when using each effector expression vector.
- identity refers to the degree of amino acid sequence matching between two or more comparable amino acid sequences. Therefore, the higher the identity or similarity between two amino acid sequences, the higher the identity or similarity between those sequences.
- the level of amino acid sequence identity is determined, for example, using the sequence analysis tool FASTA, using default parameters. or Algorithm BLAST by Karlin S, Altschul SF. "Applications and statistics for multiple high-scoring segments in molecular sequences.” Proc Natl Acad Sci USA. 90:5873-7 (1993)). A program called blastp and a program called tblastn based on such a BLAST algorithm have been developed.
- conservative substitution means that an amino acid residue is replaced with an amino acid residue having a similar side chain.
- substitutions between amino acid residues having basic side chains such as lysine, arginine, and histidine correspond to conservative substitutions.
- amino acid residues with acidic side chains such as aspartic acid and glutamic acid
- amino acid residues with uncharged polar side chains such as asparagine, glutamine, serine, threonine, tyrosine and cysteine
- Amino acid residues with nonpolar side chains such as proline, phenylalanine, methionine, and tryptophan
- amino acid residues with branched chains such as valine, isoleucine, and leucine
- amino acid residues with aromatic side chains such as tyrosine, phenylalanine, and tryptophan.
- substitutions also correspond to conservative substitutions.
- coding sequence is a base sequence that encodes an amino acid sequence of a protein, and is not particularly limited as long as it is.
- an amino acid mutation in a specific amino acid sequence is defined as "one-letter code for amino acid before mutation + amino acid number counted from N-terminal amino acid + one-letter code for amino acid after mutation" in the specific amino acid sequence ( Mutation name).
- the mutation name "K169R” in the amino acid sequence shown in SEQ ID NO: 6 is the 169th amino acid counting from the N-terminal amino acid in the amino acid sequence shown in SEQ ID NO: 6 to arginine (R) from lysine (K) shows a mutation of
- the respective mutation names of the multiple mutations provided may be written together, separated by slashes.
- the mutation designation "K169R/K535R” in the amino acid sequence shown in SEQ ID NO: 6 indicates that both K169R and K535R mutations are present.
- domain refers to a region that constitutes part of a protein and consists of a continuous amino acid sequence.
- the protein present invention provides (a) a 5′ ⁇ 3′ exonuclease domain comprising the 5′ ⁇ 3′ exonuclease amino acid sequence a1 and a nuclear localization signal sequence a2, and (b) the MAD7 protein A protein (also referred to herein as "Protein 1 of the invention") comprising a MAD7 domain comprising an amino acid sequence b1 and a linking sequence b2 of multiple nuclear localization signal sequences.
- the MAD7 protein A protein also referred to herein as "Protein 1 of the invention
- the protein 1 of the present invention contains a 5' ⁇ 3' exonuclease domain and a MAD7 domain.
- the 5' ⁇ 3' exonuclease domain is a domain containing the 5' ⁇ 3' exonuclease amino acid sequence a1 and the nuclear localization signal sequence a2.
- the amino acid sequence a1 is the amino acid sequence of a 5' ⁇ 3' exonuclease, and is not particularly limited in this respect.
- the 5' ⁇ 3' exonuclease is not particularly limited as long as it is a protein having 5' ⁇ 3' exonuclease activity, that is, the activity of sequentially cleaving nucleic acid (DNA) from the 5' end.
- Nuclease specifically, for example, amino acid sequence: SEQ ID NO: 64
- Betaproteobacteria bacterium-derived 5′ ⁇ 3′ exonuclease specifically, for example, Genbank ID: NDC03965.1, amino acid sequence: SEQ ID NO: 66
- Pelagibacterales bacterium-derived 5′ ⁇ 3′ exonuclease specifically, , e.g. Genbank ID: MBL6840569.1, amino acid sequence: SEQ ID NO: 67
- Agrobacterium fabrum-derived 5′ ⁇ 3′ exonuclease (specifically, for example, Genbank ID: WP_144623114.1, amino acid sequence: SEQ ID NO: 69), Bacteriophage Eos-derived 5′ ⁇ 3′ exonuclease (specifically, , e.g. Genbank ID: QGH45232.1, amino acid sequence: SEQ ID NO: 70), 5' to 3' exonuclease from Providencia phage vB_PreS_PR1 (e.g., e.g.
- Genbank ID: YP_009599164.1 amino acid sequence: SEQ ID NO: 71) , a 5′ ⁇ 3′ exonuclease from Pantoea phage vB_PagS_AAS21 (specifically, for example, Genbank ID: QCW23761.1, amino acid sequence: SEQ ID NO: 72), a 5′ ⁇ 3′ exonuclease from Klebsiella phage vB_KaS-Veronica ( Specifically, for example, Genbank ID: CAD5240202.1, amino acid sequence: SEQ ID NO: 73), 5' ⁇ 3' exonuclease derived from Proteus phage PM135 (specifically, for example, Genbank ID: YP_009 620590.1, amino acid sequence: SEQ ID NO: 74), 5′ ⁇ 3′ exonuclease from Pectobacterium phage My1 (specifically, for example, Genbank ID: YP_006906376.1,
- the 5' ⁇ 3' exonuclease may have amino acid sequence mutations (eg, substitutions, deletions, insertions, additions, etc.) as long as its activity is not significantly impaired.
- the 5′ ⁇ 3′ exonuclease has an amino acid sequence that is, for example, 70% or more, preferably 80% or more, more preferably 90% or more, even more preferably 95% of the amino acid sequence of the wild-type 5′ ⁇ 3′ exonuclease. It may be a protein consisting of an amino acid sequence having an identity of 97% or more, particularly preferably 99% or more, and having the activity thereof.
- the above "activity" can be evaluated in vitro or in vivo according to or according to known methods.
- the amino acid sequence a1 preferably includes amino acid sequences having 70% or more identity with the amino acid sequences shown in SEQ ID NOs: 64-79.
- the nuclear localization signal sequence a2 is an amino acid sequence of a nuclear localization signal, and is not particularly limited in this respect.
- a nuclear localization signal is an amino acid sequence capable of targeting a protein of interest to the nucleus; in other words, a nuclear localization signal labels a protein of interest for nuclear import.
- Targeting to the nucleus is enabled, for example, by the binding of nuclear localization signals to their receptors known as importins (karyopherins).
- Nuclear transport of proteins generally begins with the formation of a ternary complex of importin- ⁇ , importin- ⁇ 1, and a cargo (such as a polypeptide), and importin- ⁇ 1 transports the complex into the nuclear pore complex by docking it into the nuclear pore complex.
- nuclear localization signals may comprise one or more short sequences (eg, 2-10, 3-8, 4-6 residues) of positively charged amino acids (eg, lysine, arginine, etc.). , or consist of them.
- Various amino acid sequences are known as nuclear localization signals.
- Nuclear localization signals include, for example, classical NLS (cNLS), which contain a contiguous sequence of one (unary) or two (binode) basic amino acids.
- Unamed nuclear localization signal sequences typically consist of helix-breaking residues (eg, proline, glycine, etc.), basic residues (eg, 2 to 10, 3 to 8, 4 to 6 residues). ) (or consensus sequence K(K/R)X(K/R) (X is an arbitrary amino acid)).
- a bimodal nuclear localization signal sequence typically comprises a sequence consisting of basic residues (eg, 2-10, 3-8, 4-6 residues), a linker sequence, a sequence consisting of basic residues (eg, 2 to 10, 3 to 8, 4 to 6 residues) (or consensus sequence R/K(X) 10-12 KRXK (X is an arbitrary amino acid)).
- a specific example of the unarted nuclear localization signal sequence is the SV40 nuclear localization signal sequence (amino acid sequence: SEQ ID NO: 10).
- a specific example of the binode nuclear localization signal sequence is the nucleoplasmin nuclear localization signal (amino acid sequence: SEQ ID NO: 12).
- the nuclear localization signal sequence may have amino acid sequence mutations (eg, substitutions, deletions, insertions, additions, etc.) as long as its activity is not significantly impaired. From this point of view, the nuclear localization signal sequence is, for example, 70% or more, preferably 80% or more, more preferably 90% or more, even more preferably 95% or more, and even more It may be a sequence consisting of an amino acid sequence having an identity of preferably 97% or more, particularly preferably 99% or more, and having the activity.
- the above "activity" can be evaluated in vitro or in vivo according to or according to known methods.
- the nuclear localization signal sequence a2 is preferably a unamed nuclear localization signal sequence.
- the nuclear localization signal sequence a2 may consist of only one nuclear localization signal sequence, or a plurality of (for example, 2 to 6, 2 to 5, 2 to 4, 2 to 3) identical or It may be a sequence formed by connecting different nuclear localization signal sequences. In the latter case, the nuclear localization signal sequences may be directly linked without intervening other amino acid sequences, or linked with other amino acid sequences (for example, 1-50, 1-30, 1-20, 1- They may be linked via an amino acid sequence of about 10 or 1 to 5 residues (eg, linker sequence). In one aspect of the present invention, the nuclear localization signal sequence a2 preferably consists of only one nuclear localization signal sequence.
- the mode of linkage between the amino acid sequence a1 and the nuclear localization signal sequence a2 is not particularly limited, and may be directly linked without intervening another amino acid sequence. (for example, an amino acid sequence of about 1 to 50, 1 to 30, 1 to 20, 1 to 10, or 1 to 5 residues (eg, linker sequence)).
- the positional relationship between the amino acid sequence a1 and the nuclear localization signal sequence a2 in the 5′ ⁇ 3′ exonuclease domain is not particularly limited, and the nuclear localization signal sequence a2 is arranged on the N-terminal side of the amino acid sequence a1.
- Embodiments and embodiments in which the nuclear localization signal sequence a2 is located on the C-terminal side of the amino acid sequence a1 are all encompassed.
- the nuclear localization signal sequence a2 is preferably arranged on the N-terminal side of the amino acid sequence a1.
- the nuclear localization signal sequence a2 is located N-terminal to the amino acid sequence a1 when the 5′ ⁇ 3′ exonuclease domain is located N-terminal to the MAD7 domain.
- the nuclear localization signal sequence a2 is arranged on the C-terminal side of the amino acid sequence a1. is preferred.
- the MAD7 domain is a domain containing the amino acid sequence b1 of the MAD7 protein and the linking sequence b2 of multiple nuclear localization signal sequences.
- the amino acid sequence b1 is the amino acid sequence of the MAD7 protein and is not particularly limited in this respect.
- the MAD7 protein is a Cas12a protein from Eubacterium rectale.
- the MAD7 protein can be used in the CRISPR/Cas system, for example, it can bind to a target site of genomic DNA in a complex with a guide RNA and cleave the target site.
- Information on the amino acid sequence of the MAD7 protein and its coding sequence can be easily obtained on various databases such as NCBI.
- a representative amino acid sequence of the MAD7 protein includes the amino acid sequence shown in SEQ ID NO:6.
- the MAD7 protein may have amino acid sequence mutations (eg, substitutions, deletions, insertions, additions, etc.) as long as its activity is not significantly impaired.
- the MAD7 protein is, for example, 70% or more, preferably 80% or more, more preferably 90% or more, still more preferably 95% or more, and even more preferably 97% or more of the amino acid sequence shown in SEQ ID NO: 6 , Particularly preferably, it may be a protein consisting of an amino acid sequence having an identity of 99% or more and having the activity.
- the above "activity" can be evaluated in vitro or in vivo according to or according to known methods.
- the amino acid sequence b1 preferably includes an amino acid sequence having 70% or more identity with the amino acid sequence shown in SEQ ID NO:6.
- the amino acid sequence b1 is a mutant sequence of the amino acid sequence shown in SEQ ID NO: 6, and A24E, K169R, I180K, A290R, S469K, S469R, K535R, N583K, N583R, K590R, I646K, I646R, T714K, T714R, N827D, Y832K, Y832R, K970R, H1025K, H1025R, S1175A, and C1219N. This can further improve genome editing efficiency.
- the mutation can be at least one mutation selected from the group consisting of K169R, N583K, N583R, Y832K, Y832R, H1025K, H1025R, and C1219N. In a further preferred embodiment, the mutation can be the K169R mutation.
- K169R/S469R, K169R/N583K, K169R/N583R, K169R/Y832K, K169R/Y832R, K169R/H1025R, and K169R/H1025K are preferred as combinations of two mutations.
- K169R/N583K/H1025R K169R/N583K/H1025K
- K169R/N583R/H1025R K169R/N583R/H1025K
- K169R/N583R/H1025K K169R/N583K/Y832K
- K169R/N583K/Y832R K1819K/NK5169K/NK183K/NK183K/N583K/I646R ⁇ K169R/N583K/S469R ⁇ K169R/N583K/N827D ⁇ K169R/N583R/Y832K ⁇ K169R/N583R/Y832R ⁇ K169R/N583R/C1219N ⁇ K169R/N583R/I646R ⁇ K169R/N583R/S469R ⁇ K169R/N583R /N827D, K169R/H1025R/C1219N, K169
- the amino acid sequence b1 is a mutated sequence of the amino acid sequence shown in SEQ ID NO: 6, and is shown in SEQ ID NO: 6. It preferably contains the K169R mutation in the amino acid sequence, and more preferably further contains at least one mutation selected from the group consisting of S469R and H1025K in addition to the K169R mutation.
- an amino acid sequence (amino acid sequence b1') of a Cas protein other than the MAD7 protein can be employed instead of the amino acid sequence b1.
- the Cas protein is not particularly limited as long as it is used in the CRISPR/Cas system.
- various Cas proteins that can bind to a target site of genomic DNA in a complex with a guide RNA and cleave the target site can be used. can do.
- Cas proteins derived from various organisms are known. Cas9 protein from N. meningitidis, Cas9 protein from T. denticola, Cas protein from S. solfataricus (type I-A), Cas protein from H. walsbyi (type I-B), Cas protein from Microcystis aeruginosa protein (I-D type), E. coli-derived Cas protein (I-E type), E.
- Cas9 protein is preferred, and Cas9 protein endogenously possessed by bacteria belonging to the genus Streptococcus is more preferred. Amino acid sequences of various Cas proteins and information on their coding sequences can be easily obtained on various databases such as NCBI.
- the Cas protein may be a wild-type double-strand truncated Cas protein or a nickase-type Cas protein.
- Double-strand truncated Cas proteins usually contain a domain involved in cleaving the target strand (HNH domain) and a domain involved in cleaving the non-target strand (RuvC domain).
- HNH domain a domain involved in cleaving the target strand
- RuvC domain a domain involved in cleaving the non-target strand
- the cleavage activity is impaired (for example, the cleavage activity is reduced to 1/2, 1/5, 1/10, 1/100, 1/1000 or less) mutations.
- Such mutations include, for example, when the double-strand truncated Cas protein is a Cas9 protein derived from S. pyogenes, for example, mutation of the 10th amino acid (aspartic acid) from the N-terminus to alanine (D10A: RuvCI domain mutation), N-terminal amino acid 840 (histidine) to alanine (H840A: HNH domain mutation), N-terminal amino acid 863 (asparagine) to alanine (N863A: HNH domain), N-terminal amino acid 762 (glutamic acid) to alanine (E762A: mutation in RuvCII domain), N-terminal amino acid 986 (aspartic acid) to alanine (D986A) : mutation in the RuvCIII domain) and the like.
- D10A RuvCI domain mutation
- N-terminal amino acid 840 histidine
- H840A HNH domain mutation
- N-terminal amino acid 863
- a Cas protein may have amino acid sequence mutations (eg, substitutions, deletions, insertions, additions, etc.) as long as they do not impair its activity. From this point of view, the Cas protein is, for example, 85% or more, preferably 90% or more of the amino acid sequence of the wild-type double-strand truncated Cas protein or the nickase-type Cas protein based on the wild-type double-strand truncated Cas protein.
- the target site may be a protein having a cleaving activity.
- the Cas protein is one or more (for example, 2 to 100, preferably 2 to 50, more preferably 2 to 20, still more preferably 2 to 10, even more preferably 2 to 5, particularly preferably 2) amino acids are substituted or deleted , added, or inserted (preferably conservatively substituted) amino acid sequence, and its activity (the activity of binding to a target site of genomic DNA in a complex with a guide RNA and cleaving the target site) may be a protein having The above "activity" can be evaluated in vitro or in vivo according to or according to known methods.
- the ligation sequence b2 is a sequence formed by ligating a plurality of (for example, 2 to 6, 2 to 5, 2 to 4, 2 to 3, 2) identical or different nuclear localization signal sequences. not.
- the description of the “nuclear localization signal” in the 5′ ⁇ 3′ exonuclease domain is incorporated.
- the nuclear localization signal sequences may be directly linked without intervening other amino acid sequences, or other amino acid sequences (eg, 1 to 50, 1 to 30, 1 to 20, 1 They may be linked via an amino acid sequence of about 10 or 1 to 5 residues (eg, linker sequence).
- Linking sequence b2 preferably comprises both a unimated nuclear localization signal sequence and a bi-node nuclear localization signal sequence, wherein at least one un-melted nuclear localization signal sequence and one bi-node nuclear localization signal sequence.
- a combination with a nuclear localization signal sequence is more preferable (specifically, for example, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, SEQ ID NO: 97, SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100).
- the bi-node nuclear localization signal sequence is located on the N-terminal side of the unimated nuclear localization signal sequence. is preferably arranged.
- the bi-node nuclear localization signal sequence is arranged closer to the amino acid sequence b1, and the amino acid sequence Arrangement of the unnoded nuclear localization signal sequence farther from b1 (that is, from the N-terminal side, the amino acid sequence b1, the binode nuclear localization signal sequence, the unmelted nuclear localization signal Arranged in the order of the sequence, or arranged in the order from the N-terminal side: a single-node nuclear localization signal sequence, a double-node nuclear localization signal sequence, and the amino acid sequence b1).
- the mode of linkage between the amino acid sequence b1 and the linking sequence b2 is not particularly limited, and may be linked directly without intervening another amino acid sequence, or may be linked directly with other amino acid sequences (e.g. They may be linked via an amino acid sequence of about 30, 1 to 20, 1 to 10, or 1 to 5 residues (eg, linker sequence).
- the positional relationship between the amino acid sequence b1 and the linking sequence b2 in the MAD7 domain is not particularly limited. Any arranged aspect is encompassed.
- the linking sequence b2 is preferably arranged on the C-terminal side of the amino acid sequence b1.
- the connecting sequence b2 when the 5′ ⁇ 3′ exonuclease domain is arranged on the N-terminal side of the MAD7 domain, the connecting sequence b2 is preferably arranged on the C-terminal side of the amino acid sequence b1, On the other hand, when the 5' ⁇ 3' exonuclease domain is arranged on the C-terminal side of the MAD7 domain, the connecting sequence b2 is preferably arranged on the N-terminal side of the amino acid sequence b1.
- the ligation mode between the 5' ⁇ 3' exonuclease domain and the MAD7 domain is not particularly limited. (eg, an amino acid sequence of about 1 to 50, 1 to 30, 1 to 20, 1 to 10, or 1 to 5 residues (eg, linker sequence)).
- the arrangement relationship between the 5' ⁇ 3' exonuclease domain and the MAD7 domain in the protein 1 of the present invention is not particularly limited, and the 5' ⁇ 3' exonuclease domain is arranged on the N-terminal side of the MAD7 domain. Any embodiment in which the ' ⁇ 3' exonuclease domain is located C-terminal to said MAD7 domain is encompassed. In one aspect of the invention, it is preferred that the 5′ ⁇ 3′ exonuclease domain is positioned N-terminal to the MAD7 domain.
- the nuclear localization signal sequence a2 the amino acid sequence a1, the amino acid sequence b1, and the linking sequence b2 are arranged in this order from the N-terminal side.
- a protein comprising an amino acid sequence b1, wherein the amino acid sequence b1 is a mutant sequence of the amino acid sequence shown in SEQ ID NO: 6 , and A24E, K169R, I180K, A290R, S469K, S469R, K535R, N583K, N583R, K590R, I646K, I646R, T714K, T714R, N827D, Y832K, Y832R, K970R, H1025K, in the amino acid sequence shown in SEQ ID NO: 6 , S1175A, and C1219N (also referred to herein as “protein 2 of the present invention”).
- proteins 1 and 2 of the present invention as an aspect different from the proteins 1 and 2 of the present invention, (ai) 5' ⁇ 3' exonuclease amino acid sequence a1 and nuclear localization signal sequence a2 5 A protein (also referred to herein as "Protein 3 of the invention") comprising a ' ⁇ 3' exonuclease domain and (bi) a MAD7 domain comprising the amino acid sequence b1 of the MAD7 protein.
- proteins 1 to 3 of the present invention may be collectively referred to as "proteins of the present invention”.
- each configuration of protein 1 of the present invention can be incorporated independently as a configuration of proteins 2 and 3 of the present invention.
- the amino acid sequence b1 is a mutated sequence of the amino acid sequence shown in SEQ ID NO: 6 from the viewpoint of genome editing efficiency (especially genome editing efficiency in plant cells), and It preferably contains the K169R mutation in the amino acid sequence represented by number 6, and more preferably further contains at least one mutation selected from the group consisting of S469R and H1025K in addition to the K169R mutation.
- the MAD7 domain comprises the amino acid sequence b1 of the MAD7 protein and a linking sequence b2 of multiple nuclear localization signal sequences.
- the protein of the present invention contains amino acid sequences other than the 5′ ⁇ 3′ exonuclease domain and MAD7 domain, such as proteins or peptides such as protein tags, fluorescent proteins, and luminescent proteins, as long as the genome editing efficiency is not significantly impaired. It may be added.
- protein tags include His tag, FLAG tag, Halo tag, MBP tag, HA tag, Myc tag, V5 tag, PA tag, Sun tag and the like.
- the protein of the present invention may be chemically modified as long as the efficiency of genome editing is not significantly impaired.
- the protein of the present invention may have a carboxyl group (--COOH), carboxylate ( --COO- ), amide (--CONH 2 ) or ester (--COOR) at the C-terminus.
- R in the ester includes, for example, C 1-6 alkyl groups such as methyl, ethyl, n-propyl, isopropyl and n-butyl; C 3-8 cycloalkyl groups such as cyclopentyl and cyclohexyl; C 6-12 aryl groups such as , ⁇ -naphthyl; phenyl-C 1-2 alkyl groups such as benzyl, phenethyl; C 7- such as ⁇ -naphthyl-C 1-2 alkyl groups such as ⁇ -naphthylmethyl 14 Aralkyl group; pivaloyloxymethyl group and the like are used.
- C 1-6 alkyl groups such as methyl, ethyl, n-propyl, isopropyl and n-butyl
- C 3-8 cycloalkyl groups such as cyclopentyl and cyclohexyl
- carboxyl groups (or carboxylates) other than the C-terminus may be amidated or esterified.
- ester in this case, for example, the above-described C-terminal ester or the like is used.
- the amino group of the amino acid residue at the N-terminus is protected with a protective group (for example, a formyl group, a C 1-6 acyl group such as a C 1-6 alkanoyl such as an acetyl group, etc.).
- a protective group for example, a formyl group, a C 1-6 acyl group such as a C 1-6 alkanoyl such as an acetyl group, etc.
- the protein of the present invention may be in the form of salts with acids or bases.
- Salts are not particularly limited, and both acid salts and basic salts can be employed.
- acid salts include mineral salts such as hydrochloride, hydrobromide, sulfate, nitrate, and phosphate; acetate, propionate, tartrate, fumarate, maleate, apple organic acid salts such as acid salts, citrates, methanesulfonates, and paratoluenesulfonates; and amino acid salts such as aspartates and glutamates.
- Examples of basic salts include alkali metal salts such as sodium salts and potassium salts; and alkaline earth metal salts such as calcium salts and magnesium salts.
- the protein of the present invention may be in the form of a solvate.
- the solvent is not particularly limited, and examples thereof include water, ethanol, glycerol, acetic acid and the like.
- the protein of the present invention can be easily produced according to known genetic engineering techniques. For example, it can be produced using PCR, restriction enzyme cleavage, DNA ligation technology, in vitro transcription/translation technology, recombinant protein preparation technology, and the like.
- a recombinant protein production technique for example, not only a method of employing cultured cells but also a method of employing plants such as tobacco as a host can be mentioned.
- polynucleotide of the present invention comprising a coding sequence of the protein of the present invention (in the present specification, may be referred to as a "polynucleotide of the present invention"), a polynucleotide of the present invention, cells (in this specification, sometimes referred to as “cells of the present invention”). These are described below.
- the coding sequence of the protein of the present invention is not particularly limited as long as it is a polynucleotide consisting of a base sequence encoding the protein of the present invention.
- the polynucleotide of the present invention contains an expression cassette for the protein of the present invention.
- the expression cassette of the protein of the present invention is not particularly limited as long as it is a polynucleotide capable of expressing the protein of the present invention in cells.
- a typical example of an expression cassette for a protein of the invention includes a promoter and a polynucleotide comprising a coding sequence for a protein of the invention placed under the control of the promoter.
- the promoter contained in the expression cassette of the protein of the present invention is not particularly limited and can be appropriately selected according to the target cell.
- various pol II promoters can be used.
- pol II promoters include, but are not limited to, CMV promoter, EF1 promoter, SV40 promoter, MSCV promoter and the like.
- promoters include, for example, RPS5A promoter, UBQ promoter, CaMV35S promoter, NOS promoter, CmYLCV promoter, tryptophan promoters such as trc and tac, lac promoter, T7 promoter, T5 promoter, T3 promoter, SP6 promoter, arabinose-inducible promoter, cold shock promoters, tetracycline-inducible promoters, and the like.
- the expression cassette of the protein of the present invention may optionally contain other elements (e.g., multiple cloning site (MCS), origin of replication, enhancer sequence, repressor sequence, insulator sequence, terminator sequence, reporter protein (e.g., fluorescent proteins, etc.) coding sequences, drug resistance gene coding sequences, guide RNA expression cassettes, etc.).
- MCS multiple cloning site
- the polynucleotide of the present invention can be in the form of a vector.
- a suitable vector is selected depending on the purpose of use (cloning, expression of protein) and in consideration of the type of host cell.
- E. coli host vectors include M13 phage or variants thereof, ⁇ phage or variants thereof, pBR322 or variants thereof (pB325, pAT153, pUC8, etc.), and yeast hosts include pYepSec1, pMFa, pYES2. , pPIC3.5K and the like, pAc, pVL and the like for insect cell hosts, and pcDNA, pCDM8, pMT2PC and the like for mammalian cell hosts.
- retrovirus lentivirus, adenovirus, adeno-associated virus, herpes virus, Sendai virus, tobacco mosaic virus, cucumber mosaic virus, African cassava mosaic virus, latent apple globular virus, barley mottled leaf mosaic virus, Bean pod mottle virus, Beet curly top virus, Brome mosaic virus, Cabbage leaf curl virus, Cotton leaf crumple virus, Cymbidium mosaic virus, Grape A virus, Pea early browning virus, Poplar mosaic virus, Potato X virus, Rice tungro bacilliform virus, Viral vectors such as satellite tobacco mosaic virus, Tobacco curly shoot virus, tobacco stem virus, and Bean yellow dwarf virus can be exemplified.
- the present invention provides, in one aspect thereof, (aii) an expression cassette of a protein comprising a 5′ ⁇ 3′ exonuclease domain comprising a 5′ ⁇ 3′ exonuclease amino acid sequence a1 and a nuclear localization signal sequence a2, and ( bii) A polynucleotide comprising an expression cassette of a protein comprising a MAD7 domain comprising the amino acid sequence b1 of the MAD7 protein and a linking sequence b2 of multiple nuclear localization signal sequences.
- the polynucleotide is also included in the "polynucleotide of the present invention". Each configuration in the polynucleotide is the same as described above.
- the polynucleotide can be a polynucleotide containing both the expression cassette (aii) and the expression cassette (bii) in the same molecule, or a polynucleotide containing the expression cassette (aii) and a molecule different from this. It can be in combination with a polynucleotide containing an expression cassette (bii).
- the cell of the present invention is not particularly limited as long as it contains the polynucleotide of the present invention.
- Cells include, for example, Escherichia coli K12 and other Escherichia coli, Bacillus subtilis MI114 and other Bacillus bacteria, Saccharomyces cerevisiae AH22 and other yeasts, Spodoptera frugiperda-derived Sf cell lines or Trichoplusia ni-derived HighFive cell lines, and olfactory neurons.
- Examples include insect cells, animal cells such as COS7 cells, and plant cells.
- Animal cells are preferably cultured cells derived from mammals, specifically COS7 cells, CHO cells, HEK293 cells, HEK293FT cells, Hela cells, PC12 cells, N1E-115 cells, SH-SY5Y cells and the like. be done.
- compositions, Kit, Genome Editing Method, Production Method The polynucleotide of the present invention and the protein of the present invention can be used as a composition for genome editing or as a kit for genome editing. Moreover, it is possible to provide a genome editing method and a method for producing a genome editor (cell or organism) using the polynucleotide of the present invention.
- the genome editing composition is not particularly limited as long as it contains at least one selected from the group consisting of the protein of the present invention and the polynucleotide of the present invention, and if necessary further contains other components. good too.
- other components include, but are not limited to, bases, carriers, solvents, dispersants, emulsifiers, buffers, stabilizers, excipients, binders, disintegrants, lubricants, and thickeners. agents, moisturizing agents, coloring agents, fragrances, chelating agents, and the like.
- the genome-editing composition may optionally contain a polynucleotide containing a guide RNA expression cassette. It may also contain a donor polynucleotide, if desired.
- the genome editing kit is not particularly limited as long as it contains at least one selected from the group consisting of the protein of the present invention and the polynucleotide of the present invention, and if necessary, a nucleic acid introduction reagent, a buffer solution, etc. , other materials, reagents, instruments, etc. necessary for carrying out the genome editing method of the present invention may be included as appropriate.
- the genome editing kit may contain a polynucleotide containing a guide RNA expression cassette, if necessary. It may also contain a donor polynucleotide, if desired.
- Genome editing methods and methods for producing genome editors include introducing at least one selected from the group consisting of the proteins of the present invention and the polynucleotides of the present invention into cells or organisms.
- Cells and organisms targeted for genome editing are not particularly limited as long as they are cells and organisms that can be genome-edited by the CRISPR/Cas system.
- Target cells for genome editing include cells derived from various tissues or with various properties, such as blood cells, hematopoietic stem cells/progenitor cells, gametes (sperm, eggs), fertilized eggs, fibroblasts, epithelial cells, vascular endothelial cells, and nerve cells. , hepatocytes, keratinocytes, muscle cells, epidermal cells, endocrine cells, ES cells, iPS cells, tissue stem cells, cancer cells, leaf cells, pollen, shoot apical cells and the like.
- Organisms targeted for genome editing include, for example, mammals such as humans, monkeys, mice, rats, dogs, cats, and rabbits; amphibians such as Xenopus; fish animals such as zebrafish, killifish, tiger puffer; and chordates such as sea squirts.
- amphibians such as Xenopus
- fish animals such as zebrafish, killifish, tiger puffer
- chordates such as sea squirts.
- Arthropods such as fruit flies and silkworms
- Fungi such as yeast and Neurospora
- organisms to be genome-edited include plants.
- plants include bryophytes, pteridophytes, gymnosperms, angiosperm magnolias, monocotyledons, true dicotyledons (roses I, roses II, chrysanthemums I, chrysanthemums II and their outgroups).
- plants include eggplants such as tomatoes, green peppers, peppers, eggplants, tobacco, and torvum; gourds such as cucumbers, pumpkins, melons and watermelons; vegetables such as cabbages, broccoli, Chinese cabbage, and mustard greens; Raw and spicy vegetables such as celery, parsley, lettuce; Green onions such as green onions, onions and garlic; Other fruit vegetables such as strawberries; , Potatoes such as Chinese yam; Cereals such as rice, corn, wheat, sorghum, barley, rye, chamomile, and buckwheat; Beans such as soybean, adzuki bean, mung bean, cowpea, kidney bean, groundnut, pea, broad bean; Asparagus, spinach , Japanese honeywort and other soft vegetables; Eustoma, stock, carnation, chrysanthemum, and other flowering plants; Bentgrass, Korai shiba, and other lawns; Oilseed crops, such as
- the method of introduction is not particularly limited, and can be appropriately selected according to the type of target cell or organism and the type of material to be introduced (nucleic acid, protein, etc.).
- Methods of introduction include, for example, microinjection, electroporation, DEAE-dextran treatment, lipofection, nanoparticle-mediated transfection, virus-mediated nucleic acid delivery, and the like.
- methods of introduction include, for example, Agrobacterium methods such as floral dip method and floral spray method; particle gun method; virus-mediated nucleic acid delivery and the like.
- genome editing occurs in the target cell or target organism, so by collecting this cell or organism, it is possible to obtain a genome-edited cell or organism.
- Preparation example 1 Vector Construction Unless otherwise specified, the following reagents and contract services were used for vector cloning. PCR amplification was performed using PrimeSTAR Max (Takara Bio Inc.). NucleoSpin Gel and PCR Cleanup (Macharei Nagel) were used for purification of PCR products. For the Golden Gate method, NEB Golden Gate Assembly Kit (BsaI-HF v2) (New England Biolab Japan Co., Ltd.) was used. The NEB PCR Cloning Kit (New England Biolab Japan Co., Ltd.) was used for cloning the insert into the pMiniT2.0 vector.
- 2xGeneArt Enzyme Mix (Thermo Fisher Scientific Co., Ltd.) was used for assembly (seamless cloning) between DNA fragments (vector and insert) having homologous sequences at their ends. Sequence analysis (Sanger method) and preparation of oligonucleotides (primers) were outsourced to Eurofins Genomics.
- Preparation example 1-1 Preparation of Reporter Vector
- a reporter vector used in the SSA assay (assay for measuring genome editing efficiency) of Test Example 1 described later was prepared. A schematic of the assay is shown in FIG.
- the reporter gene in the reporter vector is a gene that expresses a protein that does not have reporter activity (inactive reporter gene). annealed through the cell and transformed into a gene that expresses a protein with reporter activity (activation reporter gene). Therefore, genome editing efficiency can be measured by measuring the activity of the reporter protein expressed from the active reporter gene.
- the cloning site of pGL4-SSA was modified to contain two BpiI sites. In addition, it was designated to add a restriction enzyme BsaI site to both ends of the DNA fragment.
- the pUC57-pSSA vector into which the above DNA fragment was integrated was contracted (artificial synthesis) to GenScript Japan Co., Ltd. and obtained.
- the target sequence was a sequence derived from the Nicotiana benthamiana PDS gene.
- oligonucleotides containing the target sequence derived from the Nicotiana benthamiana PDS gene and oligonucleotides containing sequences complementary to the above target sequences were provided.
- two oligonucleotides containing this target sequence are annealed, treated with restriction enzyme BpiI (Thermo Fisher Scientific Co., Ltd.) and ligated to insert the annealed oligonucleotides into the synthetic vector, pUC57- A pSSA-NbPDS vector was obtained.
- the target sequence is located at the position indicated by " ⁇ " in FIG.
- the pALTER-MAX vector (Promega Corporation) as a vector for gene expression in mammalian cells, modify the multicloning site using the seamless cloning method so that it can be cloned with the restriction enzyme BsaI, and create the pALTER-MAX-GG vector. Obtained. Then, using the Golden Gate cloning method, the reporter gene portion [pSSA-NbPDS] of the pUC57-pSSA-NbPDS vector was inserted into the pALTER-MAX-GG vector to generate the luciferase reporter vector pALTER-pSSA-NbPDS containing the target sequence. It was constructed. At the same time, pUC57-pSSA containing no target sequence was used as a negative control for genome editing detection to construct a luciferase reporter vector pALTER-pSSA containing no target sequence.
- Reporter vector Entry vector pUC57-pSSA ⁇ pUC57-pSSA-NbPDS ⁇ pALTER-MAX-GG Mammalian cell expression vector ⁇ pALTER-pSSA-NbPDS • pALTER - pSSA.
- Preparation example 1-2 Preparation of guide RNA expression vector
- a DNA fragment containing a human U6 promoter sequence, a direct repeat sequence, a sequence derived from Nicotiana benthamiana PDS gene as a spacer, and a poly-T sequence is incorporated.
- the pEXA2J2-hU6-crRNA-NbPDS vector was contracted (artificially synthesized) to Eurofins Genomics and obtained.
- the direct repeat sequence portion was modified by a seamless cloning method to obtain two types of crRNA expression vectors (pEXA2J2-hU6-crRNAqa2-NbPDS and pEXA2J2-hU6-crRNAqa2GT-NbPDS).
- pEXA2J2-hU6-crRNAqa2-NbPDS vector was prepared using the above synthetic vector as a base plasmid, and pEXA2J2-hU6-crRNAqa2GT-NbPDS was obtained using this as a base plasmid.
- PCR was first performed using a mutation-introducing primer and a base plasmid, and after digestion of the template DNA in the reaction solution, the PCR product was column-purified.
- the purified PCR product was mixed with 2xGeneArt Enzyme Mix in equal volume and allowed to stand at room temperature for 30 minutes. Subsequently, using the total amount of the reaction solution obtained above and competent cells (TOP10: Thermo Fisher Scientific Co., Ltd.), E. coli was transformed by a conventional heat shock method. Thereafter, plasmids were extracted from the transformed Escherichia coli using Wizard Plus SV Minipreps DNA Purification Systems (Promega Corporation), and the base sequences were confirmed by sequence analysis (Sanger method).
- the primer sequences used to modify the direct repeat sequence portion and the vector names after modification are as follows.
- Preparation example 1-3 Preparation of effector expression vector (MAD7 gene expression vector) 3xFLAG epitope tag (nucleotide sequence: SEQ ID NO: 7, amino acid sequence: SEQ ID NO: 8) and SV40 nuclear localization signal (nucleotide sequence: SEQ ID NO: 9, amino acid sequence: SEQ ID NO: 10) (spacer (6 base length, 2 amino acid residues) between 3xFLAG and SV40 NLS, SV40 A spacer (24 nucleotides long, 8 amino acid residues) is placed between NLS and MAD7, and a nucleoplasmin nuclear localization signal at the C-terminus (immediately above the stop codon) (nucleotide sequence: SEQ ID NO: 11, amino acid sequence: SEQ ID NO: 12) ) was obtained by entrusting production (artificial synthesis) to Eurofins Genomics KK.
- effector expression vector MAD7 gene expression vector
- 3xFLAG epitope tag amino acid sequence:
- the pMT-3xFLAG-NLS-MAD7-NLS vector was created by adding restriction enzyme BsaI sites to both ends of the coding region and cloning it into the pMiniT2.0 vector (New England Biolab Japan Co., Ltd.). Obtained.
- the gene portion [3xFLAG-NLS-MAD7-NLS] of the pMT-3xFLAG-NLS-MAD7-NLS vector was inserted into the pALTER-MAX-GG vector using the Golden Gate cloning method for gene expression in mammalian cells. , pALTER-3xFLAG-NLS-MAD7-NLS was constructed.
- Preparation example 1-4 Preparation of Effector Expression Vector (MAD7 Expression Vector with Modified Nuclear Localization Signal (NLS) Arrangement)
- a pMT-MAD7-NLS vector lacking the localization signal and a pMT-NLS-MAD7-NLS vector lacking only the 3xFLAG epitope tag were constructed. Deletion was performed by PCR using a deletion introduction primer and the pMT-3xFLAG-NLS-MAD7-NLS vector as a base plasmid in the same manner as the mutation introduction method described in Preparation Example 1-2.
- the primer sequences used for the deletion and the name of the vector after introduction of the deletion are shown in the "Prepared vector" column below.
- nucleoplasmin nuclear localization signal (nucleotide sequence: SEQ ID NO: 11, amino acid sequence: SEQ ID NO: 12), linker (6 base length, 2 amino acid residues), 3xHA epitope tag (nucleotide sequence: SEQ ID NO: 13, amino acid Sequence: SEQ ID NO: 14), linker (6 base length, 2 amino acid residues), and SV40 nuclear localization signal (nucleotide sequence: SEQ ID NO: 9, amino acid sequence: SEQ ID NO: 10) are fused in this order.
- pEXK4J2_2xNLS vector into which is incorporated was contracted (artificially synthesized) to Eurofins Genomics, Inc. and obtained.
- DNA fragment (insert) obtained by PCR-amplifying the region containing two NLSs from this artificially synthesized vector, one nucleoplasmin nuclear localization in the C-terminal region of the MAD7 gene on the pMT-MAD7-NLS vector was detected.
- the pMT-MAD7-2xNLS vector was obtained by replacing the DNA sequence encoding the mutagenesis signal. More specifically, two DNA fragments (vector and insert) having homologous sequences at their ends were separately prepared by PCR amplification, and constructed by seamless assembly between the homologous sequences.
- pALTER vector effector expression vector
- Entry vector pMT-MAD7-NLS primer sequences used for preparation: SEQ ID NOs: 15 and 16
- pMT-NLS-MAD7-NLS sequences of primers used for preparation: SEQ ID NOs: 17 and 18
- pMT-MAD7-2xNLS Mammalian cell expression vector pALTER-MAD7-NLS ⁇ pALTER-NLS-MAD7-NLS ⁇ pALTER-MAD7-2xNLS.
- Preparation example 1-5 Preparation of effector expression vector (MAD7 expression vector introduced with amino acid mutation)
- MAD7 expression vector introduced with amino acid mutation For introduction of amino acid mutations of K169R, K535R, and S1175A of MAD7 (amino acid sequence: SEQ ID NO: 6), pMT-3xFLAG-NLS was used as a mutation introduction primer and a base plasmid.
- pMT-3xFLAG-NLS was used as a mutation introduction primer and a base plasmid.
- the procedure was carried out in the same manner as described in Preparation Example 1-2 to obtain the pMT-3xFLAG-NLS-MAD7-NLS-[mutation name] vector.
- Preparation example 1-6 Preparation of effector expression vector (MAD7 expression vector into which multiple amino acid mutations have been introduced)
- the pMT-MAD7-2xNLS-K169R vector was used as a mutation introduction primer and a base plasmid, and the method described in Preparation Example 1-2. was carried out in the same manner as above to prepare the pMT-MAD7-2xNLS-[mutation name] vector.
- the primer sequences used for mutagenesis and the name of the vector after mutagenesis are shown in the "Prepared vector" column below.
- Insertion into the pALTER-MAX-GG vector for gene expression in mammalian cells was carried out in the same manner as described in Preparation Example 1-3.
- Preparation example 1-7 Preparation of Effector Expression Vector (MAD7 Expression Vector with T5 Exonuclease Fused to the N-Terminal Side) D15 gene encoding phage-derived T5 exonuclease (nucleotide sequence: SEQ ID NO: 63, amino acid sequence: SEQ ID NO: 64) and XTEN peptide
- a pEXK4J2_T5 vector in which the DNA sequence encoding the linker is integrated in this order without the initiation codon (ATG) was contracted to Eurofins Genomics (artificial synthesis) and obtained.
- a DNA fragment (insert) obtained by PCR-amplifying the D15 gene and the XTEN linker region from this synthetic vector is directly below the SV40 nuclear localization signal on the pMT-3xFLAG-NLS-MAD7-NLS vector and at the start of the pMT-MAD7-2xNLS vector.
- pMT-3xFLAG-NLS-T5-MAD7-NLS vector (between 3xFLAG and NLS: spacer (6 nucleotides, 2 amino acid residues), between NLS and T5: spacer (24 nucleotides length, 8 amino acid residues), between T5 and MAD7: XTEN linker (48 base length, 16 amino acid residues)) and pMT-T5-MAD7-2xNLS vector (between T5 and MAD7: XTEN linker (48 base length, 16 amino acid residues)) 16 amino acid residues)) were obtained, respectively.
- the [3xFLAG-NLS-T5-] portion of the pMT-3xFLAG-NLS-T5-MAD7-NLS vector is amplified by PCR and inserted directly below the start codon of the pMT-MAD7-2xNLS vector to produce pMT-3xFLAG-NLS. - obtained the T5-MAD7-2xNLS vector. More specifically, two DNA fragments (vector and insert) having homologous sequences at their ends were separately prepared by PCR amplification, and seamlessly assembled between the homologous sequences.
- Preparation example 1-8 Preparation of effector expression vector (amino acid mutant MAD7 expression vector containing two NLS at the C-terminus and T5 exonuclease fused at the N-terminus) Based on pMT-3xFLAG-NLS-MAD7-NLS-K169R vector As a material plasmid, mutation was introduced in the same manner as described in Preparation Example 1-5 to obtain pMT-3xFLAG-NLS-MAD7-NLS-K169R/K535R.
- the [3xFLAG-NLS-T5-] portion of the pMT-3xFLAG-NLS-T5-MAD7-NLS vector was amplified by PCR, pMT-MAD7-2xNLS-K169R, pMT-MAD7-2xNLS-K169R/K535R, pMT-MAD7- pMT-3xFLAG-NLS-T5-MAD7-2xNLS-K169R, pMT-3xFLAG-NLS-T5-MAD7 by inserting directly below the initiation codon of the 2xNLS-K169R/S1175A and pMT-MAD7-2xNLS-K169R/K535R/S1175A vectors -2xNLS-K169R/K535R, pMT-3xFLAG-NLS-T5-MAD7-2xNLS-K169R/S1175A and pMT-3xFLAG-NLS-T5-MAD7-2xNLS
- the effector expression vector was constructed as follows. pKIR described in a previous report (Tsutsui et al. (2016) pKAMA-ITACHI Vectors for Highly Efficient CRISPR/Cas9-Mediated Gene Knockout in Arabidopsis thaliana, Plant and Cell Physiology, Vol.58 (Issue 1), pp.46-56) An artificially synthesized BeYDV-derived sequence was inserted between the Left Border and Right Border of the vector (binary) by a seamless cloning method. BeYDV-derived MP and CP were deleted, and sequences encoding Replicase proteins, long intergenic region (LIR) and small intergenic region (SIR) were used.
- LIR long intergenic region
- SIR small intergenic region
- the inserted MAD7 protein expression cassette is, in order from the 5' end side, (1) Cestrum yellow leaf curling virus (CmYLCV) promoter (SEQ ID NO: 80), (2) the dMac3 sequence (SEQ ID NO:81), (3) the following MAD7 protein coding sequence, a. MAD7-2xNLS b. MAD7-2xNLS-K169R c. MAD7-2xNLS-N583R d. MAD7-2xNLS-K169R/S469R e. MAD7-2xNLS-K169R/N583R f. MAD7-2xNLS-K169R/Y832K g.
- CmYLCV Cestrum yellow leaf curling virus
- MAD7-2xNLS-K169R/H1025K (4) the 35S terminator of cauliflower mosaic virus (SEQ ID NO: 82); (5) Nicotiana benthamiana ACT3 (ACTIN3) (NbACT3) terminator (SEQ ID NO: 83); (6) the Rb7 scaffold/matrix attachment region (MAR) of Nicotiana tabacum (SEQ ID NO: 84); is arranged in the DNA.
- the inserted guide RNA expression cassette is, in order from the 5' end side, (7) the 35S promoter of cauliflower mosaic virus (SEQ ID NO: 85), (8) hammerhead (HH) ribozyme (SEQ ID NO: 86) (9) Direct repeat sequence (SEQ ID NO: 87) (10) a sequence derived from Nicotiana benthamiana XT1 gene as a spacer (SEQ ID NO: 88), (11) hepatitis delta virus (HDV) ribozyme (SEQ ID NO: 89) (12) Nos terminator (SEQ ID NO:90) is arranged in the DNA.
- the insertion method is as follows.
- the Golden Gate method which is a partial modification of the method of Lampropoulos et al. (2013), was used.
- the cassette containing the above sequence was inserted between the BeYDV-derived LIR and SIR sequences by performing the Golden Gate reaction using the NEB Golden Gate Assembly Kit. Reaction conditions were carried out according to the recommended protocol of the above kit.
- Test example 1 Single-Strand Annealing (SSA) Assay An SSA assay was performed to measure the genome editing efficiency when using each effector expression vector. The outline of the assay is as described in FIG. 1 and Preparation Example 1-1. A specific method is shown below.
- SSA Single-Strand Annealing
- HEK293T cells were cultured in 10 cm dishes prior to transfection .
- HEK293T cells were cultured in Dulbecco's modified Eagle's medium (high glucose type DMEM: Fujifilm Wako Pure Chemical Industries, Ltd.) supplemented with 10% fetal bovine serum (FBS: BioCera), 100 units/mL penicillin, and 100 ⁇ g/mL streptomycin. , at 37 °C and 5% CO2 atmosphere.
- Dulbecco's modified Eagle's medium high glucose type DMEM: Fujifilm Wako Pure Chemical Industries, Ltd.
- FBS fetal bovine serum
- plasmids used for transfection were extracted using the PureYield Plasmid Miniprep System (Promega Corporation) according to standard protocols. 100 ng of reporter vector for genome editing efficiency measurement, 50 ng of Rluc expression vector (pRL-CMV: Promega Corporation) for transfection efficiency correction, 250 ng of effector (genome editing tool) expression vector, 100 ng of guide RNA expression vector, total amount of 5.5 Adjusted to be ⁇ L.
- DMEM fetal bovine serum
- HilyMAX Diojindo Laboratories
- 10 ⁇ L of DMEM were mixed, and the mixture was added to 5.5 ⁇ L of plasmid DNA sample and incubated for 15 minutes at room temperature.
- 100 ⁇ L of cell suspension was added to the plasmid+DMEM+HilyMAX mixture and transferred to a 96-well plate for culture (AGC Techno Glass Co., Ltd.). After culturing for 24 hours at 37°C under 5% CO 2 atmosphere, a dual luciferase assay was performed.
- Dual-Luciferase Assay A dual-luciferase assay was performed using the Dual-Glo Luciferase Assay System (Promega Corporation). 24 hours after transfection, the medium in each well was replaced with 40 ⁇ L of 1 ⁇ PBS( ⁇ ). 40 ⁇ L of Dual-Glo luciferase reagent was added to each well and mixed well. After allowing to stand at room temperature for 10 minutes, the entire amount was transferred to a 96-well lumino plate (PerkinElmer Japan Co., Ltd.). Luminescence by firefly luciferase for Fluc gene expression was measured with a plate reader (PerkinElmer Japan, Nivo multimode plate reader).
- the Stop&Glo substrate was diluted 100-fold with Dual-Glo Stop&Glo buffer. 40 ⁇ L of the diluted solution was added to each well. At least 10 minutes at room temperature, then luminescence by Renilla luciferase for Rluc gene expression was measured.
- Test example 1-1 As an effector expression vector, the effector expression vectors obtained in Preparation Examples 1-3 and 1-4 were used, and pEXA2J2-hU6-crRNAqa2-NbPDS was used as a guide RNA expression vector to test (Test Example 1 -1).
- FIG. 2 shows the structure of the effector expression vector used, and
- FIG. 3 shows the results when using each effector expression vector. Both assays showed the highest activity values when pALTER-MAD7-2xNLS was used.
- Test example 1-2 Using the effector expression vector (pMT-MAD7-2xNLS-[mutation name]) obtained in Preparation Example 1-5 as the effector expression vector, and pEXA2J2-hU6-crRNAqa2GT-NbPDS as the guide RNA expression vector. tested (Test Example 1-2).
- FIG. 4 shows the results when using each effector expression vector.
- the activity value increased the most when the K169R amino acid mutation was introduced (both the first and second assays were 2.3-fold compared to no mutation).
- introduction of the H1025R amino acid mutation showed the second highest increase in activity value (2-fold in the first and 1.9-fold in the second).
- mutations that increased the activity value by 1.5-fold or more in both assays were as follows: N583K, N583R, Y832R, H1025K, and C1219N.
- Test example 1-3 Using the effector expression vector (pMT-MAD7-2xNLS-[mutation name]) obtained in Preparation Example 1-6 as the effector expression vector, and pEXA2J2-hU6-crRNAqa2GT-NbPDS as the guide RNA expression vector. tested (Test Example 1-3).
- FIG. 5 shows the results when each effector expression vector was used. When the K169R amino acid mutation was introduced, an approximately two-fold increase in the activity value was observed as compared to the case without the mutation.
- Test example 1-4 As an effector expression vector, the effector expression vectors obtained in Preparation Examples 1-7 and 1-8 were used, and pEXA2J2-hU6-crRNAqa2GT-NbPDS was used as a guide RNA expression vector to test (Test Example 1 -Four).
- FIG. 6 shows the structure of the effector expression vector used
- FIG. 7 shows the results when using each effector expression vector.
- MAD7 MAD7-2xNLS
- which has two NLSs (binode + uninode) added to the C-terminus showed an increase in activity when 3xFLAG + SV40 NLS-attached T5 exonuclease was fused to the N-terminus. observed.
- a further increase in the activity value was observed when single and multiple mutations were introduced into the MAD7 protein portion.
- Test example 2 Agroinfiltration Assay Using Tobacco Using the effector expression vector of Preparation Example 2, a genome editing test was performed in plants, and the efficiency was compared. Specifically, it was carried out as follows.
- induction buffer 10 mM MES, 100 ⁇ M acetosyringone, pH 5.5 with Na
- Nicotiana benthamiana seeds were sterilized with a hyter, spread on a seeding medium, left to stand at 4°C in the dark for 4 days, and then incubated at 25°C with a 16-hour light/8-hour dark cycle (16L8D). It was grown in a chamber for 1 week.
- the seedlings are planted in a mixture of Hana-chan culture soil (Hanagokoro) and vermiculite at a ratio of 1:1, grown at 26°C-30°C, 16L8D, and infiltrated for 2-3 weeks after transplanting.
- used for Infiltration was performed from the underside of the leaf using a 1 mL syringe. After inoculation, the plants were moistened so as not to dry out, and grown in an environment of 26-30°C and 16L8D.
- Mutation detection by CAPS cleaved amplified polymorphic sequence 7 days after inoculation, cut out the inoculated site using a punch with a diameter of 8 mm, crush with multi-bead shocker MB2200 (YASUI KIKAI), and use automated nucleic acid extractor Maxwell (Promega). was used to extract total DNA.
- the DNA region containing the target sequence was amplified by PCR using KOD Fx Neo (TOYOBO). After column purification (MACHEREY-NAGEL), the PCR product was treated with EcoRI (NEB), and the presence or absence of mutation introduction was detected with a microchip electrophoresis device for DNA/RNA analysis MultiNA (SHIMADZU). Genome editing can be judged to have occurred when an uncleaved band is generated. The ratio (%) of the uncleaved band when (uncleaved band + cleaved band) was taken as 100% was calculated as the genome editing efficiency.
- Figure 8 shows the results when using each effector expression vector. An approximately 2.3-fold increase in editing efficiency was observed when the K169R amino acid mutation was introduced, compared to the case without the mutation. Similarly, when the N583R amino acid mutation was introduced, an approximately two-fold increase in editing efficiency was observed as compared to the case without the mutation. By introducing a combination of amino acid mutations of S469R and H1025K in addition to K169R, a further increase in editing efficiency (about 3.7-fold to about 4-fold compared to the case without mutation) was observed. No uncleaved band was observed in wild type without effector expression vector.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Medicinal Chemistry (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Crystallography & Structural Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gastroenterology & Hepatology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Peptides Or Proteins (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023543913A JPWO2023027041A1 (https=) | 2021-08-23 | 2022-08-22 | |
| US18/685,710 US20240352436A1 (en) | 2021-08-23 | 2022-08-22 | Site-specific nuclease |
| EP22861329.5A EP4394037A4 (en) | 2021-08-23 | 2022-08-22 | SITE-SPECIFIC NUCLEASE |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021-135502 | 2021-08-23 | ||
| JP2021135502 | 2021-08-23 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023027041A1 true WO2023027041A1 (ja) | 2023-03-02 |
Family
ID=85323220
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/031615 Ceased WO2023027041A1 (ja) | 2021-08-23 | 2022-08-22 | 部位特異的ヌクレアーゼ |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240352436A1 (https=) |
| EP (1) | EP4394037A4 (https=) |
| JP (1) | JPWO2023027041A1 (https=) |
| WO (1) | WO2023027041A1 (https=) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024226940A1 (en) * | 2023-04-28 | 2024-10-31 | Integrated Dna Technologies, Inc. | Eubacterium rectale cas12a mutants |
| WO2025038872A1 (en) * | 2023-08-15 | 2025-02-20 | Bio-Techne Corporation | Compositions and methods related to crispr-associated enzymes |
| US12264342B2 (en) | 2019-02-22 | 2025-04-01 | Integrated Dna Technologies, Inc. | Lachnospiraceae bacterium ND2006 CAS12A mutant genes and polypeptides encoded by same |
| US12435324B2 (en) | 2020-05-01 | 2025-10-07 | Integrated Dna Technologies, Inc. | Lachnospiraceae sp. Cas12a mutants with enhanced cleavage activity at non-canonical TTTT protospacer adjacent motifs |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119264278B (zh) * | 2024-12-09 | 2025-04-11 | 中国水产科学研究院南海水产研究所 | 一种用于斑节对虾基因编辑的融合蛋白PmMAD7-NLS及其应用 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019504649A (ja) * | 2016-02-15 | 2019-02-21 | ベンソン ヒル バイオシステムズ,インコーポレイティド | ゲノムを改変するための組成物及び方法 |
| WO2020086475A1 (en) | 2018-10-22 | 2020-04-30 | Inscripta, Inc. | Engineered enzymes |
| WO2021074191A1 (en) * | 2019-10-14 | 2021-04-22 | KWS SAAT SE & Co. KGaA | Mad7 nuclease in plants and expanding its pam recognition capability |
| WO2021257716A2 (en) | 2020-06-16 | 2021-12-23 | Bio-Techne Corporation | Engineered mad7 directed endonuclease |
| JP7113415B1 (ja) | 2022-01-28 | 2022-08-05 | 株式会社セツロテック | 変異型mad7タンパク質 |
-
2022
- 2022-08-22 US US18/685,710 patent/US20240352436A1/en active Pending
- 2022-08-22 WO PCT/JP2022/031615 patent/WO2023027041A1/ja not_active Ceased
- 2022-08-22 EP EP22861329.5A patent/EP4394037A4/en active Pending
- 2022-08-22 JP JP2023543913A patent/JPWO2023027041A1/ja active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019504649A (ja) * | 2016-02-15 | 2019-02-21 | ベンソン ヒル バイオシステムズ,インコーポレイティド | ゲノムを改変するための組成物及び方法 |
| WO2020086475A1 (en) | 2018-10-22 | 2020-04-30 | Inscripta, Inc. | Engineered enzymes |
| WO2021074191A1 (en) * | 2019-10-14 | 2021-04-22 | KWS SAAT SE & Co. KGaA | Mad7 nuclease in plants and expanding its pam recognition capability |
| WO2021257716A2 (en) | 2020-06-16 | 2021-12-23 | Bio-Techne Corporation | Engineered mad7 directed endonuclease |
| JP7113415B1 (ja) | 2022-01-28 | 2022-08-05 | 株式会社セツロテック | 変異型mad7タンパク質 |
Non-Patent Citations (5)
| Title |
|---|
| KARLIN SALTSCHUL SF: "Applications and statistics for multiple high-scoring segments in molecular sequences", PROC NATL ACAD SCI USA, vol. 90, 1993, pages 5873 - 7, XP001030852, DOI: 10.1073/pnas.90.12.5873 |
| KARLIN SALTSCHUL SF: "Methods for assessing the statistical significance of molecular sequence features by using general scoring schemes", PROC NATL ACAD SCI USA, vol. 87, 1990, pages 2264 - 2268, XP001030853, DOI: 10.1073/pnas.87.6.2264 |
| LIU PLUK KSHIN M ET AL.: "Enhanced Cas12a editing in mammalian cells and zebrafish.", NUCLEIC ACIDS RES., vol. 47, no. 8, 2019, pages 4169 - 4180, XP055889954, DOI: 10.1093/nar/gkz184 |
| See also references of EP4394037A4 |
| TSUTSUI ET AL.: "pKAMA-ITACHI Vectors for Highly Efficient CRISPR/Cas9-Mediated Gene Knockout in Arabidopsis thaliana", PLANT AND CELL PHYSIOLOGY, vol. 58, 2016, pages 46 - 56, XP055603134, DOI: 10.1093/pcp/pcw191 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12264342B2 (en) | 2019-02-22 | 2025-04-01 | Integrated Dna Technologies, Inc. | Lachnospiraceae bacterium ND2006 CAS12A mutant genes and polypeptides encoded by same |
| US12435324B2 (en) | 2020-05-01 | 2025-10-07 | Integrated Dna Technologies, Inc. | Lachnospiraceae sp. Cas12a mutants with enhanced cleavage activity at non-canonical TTTT protospacer adjacent motifs |
| WO2024226940A1 (en) * | 2023-04-28 | 2024-10-31 | Integrated Dna Technologies, Inc. | Eubacterium rectale cas12a mutants |
| WO2025038872A1 (en) * | 2023-08-15 | 2025-02-20 | Bio-Techne Corporation | Compositions and methods related to crispr-associated enzymes |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2023027041A1 (https=) | 2023-03-02 |
| EP4394037A4 (en) | 2026-01-28 |
| US20240352436A1 (en) | 2024-10-24 |
| EP4394037A1 (en) | 2024-07-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2023027041A1 (ja) | 部位特異的ヌクレアーゼ | |
| US20210062170A1 (en) | Site-specific enzymes and methods of use | |
| CN116334037A (zh) | 新型Cas酶和系统以及应用 | |
| CN116004573B (zh) | 编辑活性提高的Cas蛋白及其应用 | |
| AU2020232850A1 (en) | RNA-guided DNA integration using Tn7-like transposons | |
| CN114507654B (zh) | Cas酶和系统以及应用 | |
| WO2023227028A1 (zh) | 新型Cas效应蛋白、基因编辑系统及用途 | |
| CN114410609A (zh) | 一种活性提高的Cas蛋白以及应用 | |
| CN118726314A (zh) | 新型的crispr酶和系统以及应用 | |
| CN116555225B (zh) | 活性改善的Cas蛋白及其应用 | |
| CN114686456B (zh) | 基于双分子脱氨酶互补的碱基编辑系统及其应用 | |
| WO2023143150A1 (zh) | 新型Cas酶和系统以及应用 | |
| WO2024008145A1 (zh) | Cas酶及其应用 | |
| CN117050971A (zh) | Cas突变蛋白及其应用 | |
| WO2024041299A1 (zh) | 突变的CRISPR-Cas蛋白及其应用 | |
| WO2023143342A1 (zh) | Cas酶和系统以及应用 | |
| WO2024040874A1 (zh) | 突变的Cas12j蛋白及其应用 | |
| CN115725533A (zh) | 一种获得抗草甘膦水稻的方法及其所用双碱基融合编辑系统 | |
| CN119410609B (zh) | 一种突变的Cas蛋白及其应用 | |
| Lacroix et al. | Extracellular VirB5 enhances T-DNA transfer from Agrobacterium to the host plant | |
| CN117821424B (zh) | 一种优化的IscB蛋白及其应用 | |
| CN117625578B (zh) | Crispr酶和系统及应用 | |
| WO2023231456A1 (zh) | 一种优化的Cas蛋白及其应用 | |
| WO2023173682A1 (zh) | 一种优化的Cas蛋白及其应用 | |
| US20240051999A1 (en) | Methods for targeted protein degradation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22861329 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023543913 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18685710 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022861329 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022861329 Country of ref document: EP Effective date: 20240325 |