WO2023022206A1 - 音声合成装置、音声合成方法及び音声合成プログラム - Google Patents
音声合成装置、音声合成方法及び音声合成プログラム Download PDFInfo
- Publication number
- WO2023022206A1 WO2023022206A1 PCT/JP2022/031276 JP2022031276W WO2023022206A1 WO 2023022206 A1 WO2023022206 A1 WO 2023022206A1 JP 2022031276 W JP2022031276 W JP 2022031276W WO 2023022206 A1 WO2023022206 A1 WO 2023022206A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- speech
- book
- utterance
- acquisition unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
Definitions
- the present disclosure relates to a speech synthesizer, a speech synthesis method, and a speech synthesis program.
- a book containing images is a picture book.
- the above prior art has a difference in naturalness such as intonation. The reason for this difference is that the above prior art generates synthesized speech from linguistic information such as reading and accent obtained from the text of the picture book.
- a narrator When a narrator reads a picture book, not only the linguistic information, but also the visual information obtained from the illustrations (e.g. description of the characters and background), the emotions of the characters inferred from the long-term context, etc. , using various information to speak.
- the present disclosure proposes a speech synthesizer, a speech synthesis method, and a speech synthesis program capable of reading a book containing images with natural synthesized speech.
- a speech synthesizer includes: utterance information about an utterance target that is text included in a first book; image information about an image included in the first book; an acquisition unit that acquires data; and a speech synthesis model for reading out a second book containing text associated with the image based on the speech information, the image information, and the audio data acquired by the acquisition unit. and a generator.
- a speech synthesizer can read a book containing images with natural synthesized speech.
- FIG. 1 is a block diagram of an example environment for speech synthesis.
- FIG. 2 shows an example structure of a speech synthesis model according to this disclosure.
- FIG. 3A shows an overview of speech synthesis processing according to the present disclosure.
- FIG. 3B shows an overview of speech synthesis processing according to the present disclosure.
- FIG. 3C shows an overview of speech synthesis processing according to the present disclosure.
- FIG. 3D shows an overview of speech synthesis processing according to the present disclosure.
- FIG. 4 is a block diagram of an example configuration of a speech synthesizer according to the present disclosure.
- FIG. 5 shows an example of speech information according to the present disclosure.
- FIG. 6 shows an example of book information according to the present disclosure.
- FIG. 7 illustrates an example of training a speech synthesis model according to this disclosure.
- FIG. 8 illustrates an example of speech synthesis according to this disclosure.
- FIG. 9 is a flowchart illustrating an example of processing for generating a speech synthesis model.
- FIG. 10 shows an
- FIG. 1 is a block diagram of Environment 1, which is an example of an environment for speech synthesis. As shown in FIG. 1, the environment 1 includes a speech synthesizer 100, a network 200, and a user device 300. FIG.
- the speech synthesizer 100 is a device that performs one or more speech synthesis processes.
- the one or more speech synthesis processes include processes for generating a speech synthesis model and processes for generating synthesized speech using the generated speech synthesis model. An outline of speech synthesis processing according to the present disclosure will be described in the next section.
- the speech synthesizer 100 is a data processing device such as a server.
- An example configuration of the speech synthesizer 100 will be described in Section 4.
- the network 200 is, for example, a LAN (Local Area Network), a WAN (Wide Area Network), or the Internet.
- Network 200 connects speech synthesizer 100 and user device 300 .
- the user device 300 is a data processing device such as a client device.
- the user device 300 provides the speech synthesis device 100 with training data for the speech synthesis model. After that, the generated speech synthesis model is provided from the speech synthesizer 100 to the user device 300 .
- the data related to the book is provided to the speech synthesizer 100 .
- synthesized speech reading a book is provided from the speech synthesizer 100 to the user device 300 .
- FIG. 2 shows a model structure 10, which is an example of the model structure of the speech synthesis model according to the present disclosure.
- a speech synthesis model according to the present disclosure is implemented, for example, by a neural network.
- Model structure 10 is shown as a neural network structure for speech synthesis according to the present disclosure.
- Neural networks have traditionally been used to implement speech synthesis models.
- a neural network for conventional speech synthesis has one input, which is a language vector obtained from text information contained in a book (see Non-Patent Document 2 above).
- model structure 10 in FIG. 2 has two inputs.
- the input layer 11 and the visual information extraction layer 12 are the major differences between the conventional neural network structure for speech synthesis and the neural network structure for speech synthesis according to the present disclosure.
- the first input of the model structure 10 is the language vector, similar to the neural network structure for conventional speech synthesis.
- language vectors are obtained by vectorizing speech information extracted from the picture book 13 .
- the utterance information is information on the object of utterance.
- the object of speech in the picture book 13 is sentences included in the picture book 13 .
- the second input of the model structure 10 is a visual feature vector, which is not found in conventional neural network structures for speech synthesis.
- the visual feature vector is obtained by vectorizing the illustration image information 14 extracted from the picture book 13 .
- the illustration image information 14 is information of an illustration image.
- the image of the illustration in the picture book 13 is a picture included in the picture book 13 .
- the output of the visual information extraction layer 12 is input to, for example, the decoder layer (solid arrow).
- the output of the visual information extraction layer 12 may be input to the encoder layer (dashed arrow), depending on the implementation of the neural network.
- FIG. 3A, 3B, 3C and 3D collectively show an overview 20 of speech synthesis processing according to the present disclosure.
- Overview 20 includes eight steps.
- step S1 the speech synthesizer 100 in FIG.
- step S2 the speech synthesizer 100 generates speech data 23 from the speech signal 22.
- Audio data 23 includes audio parameters (eg, fundamental frequency) and spectral parameters (eg, mel-spectrogram) of audio signal 22 .
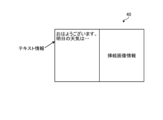
- step S3 the speech synthesizer 100 extracts the utterance information 24 from the picture book 21.
- a certain page of picture book 21 includes the sentence "Good morning.” Therefore, the utterance information 24 includes the character string "Good morning.”
- step S4 the speech synthesizer 100 extracts the illustration image information 25 from the picture book 21.
- the page containing the text above contains a picture of the sun. Therefore, the illustration image information 25 includes an image of the sun.
- step S5 the speech synthesizer 100 vectorizes the utterance information 24 and the illustration image information 25.
- FIG. In the example of FIG. 3C, speech synthesizer 100 converts speech information 24 into language vector 26 .
- the speech synthesizer 100 also converts the illustration image information 25 into a visual feature vector 27 .
- step S6 the speech synthesizer 100 learns a neural network for speech synthesis.
- the speech synthesizer 100 uses the language vector 26 and the visual feature vector 27 obtained in step S5 as input learning data. Also, the speech synthesizer 100 uses the speech data 23 obtained in step S2 as output of learning data. As a result, speech synthesizer 100 generates speech synthesis model 28 .
- step S7 the speech synthesizer 100 generates a language vector 26a and a visual feature vector 27a from the picture book 21a that is the object of speech synthesis.
- the picture book 21 a is an unknown picture book different from the picture book 21 .
- step S8 the speech synthesizer 100 generates synthesized speech for reading out the picture book 21a.
- the speech synthesizer 100 inputs the language vector 26a and the visual feature vector 27a to the speech synthesis model 28, and obtains the speech feature quantity. Then, the speech synthesizer 100 generates synthesized speech by generating a speech waveform from the speech feature amount.
- the speech synthesizer 100 utilizes the illustration image information 25 in speech synthesis of books such as picture books.
- Conventional speech synthesis technology uses linguistic information such as pronunciation and accent as input to a neural network for speech synthesis.
- the speech synthesizer 100 also utilizes visual information obtained from books such as picture books as input for a neural network for speech synthesis. Therefore, the speech synthesizing device 100 can generate synthetic speech in consideration of information included in the illustration.
- FIG. 4 is a block diagram of the speech synthesizer 100, which is an example of the configuration of the speech synthesizer according to the present disclosure.
- speech synthesizer 100 includes communication section 110 , control section 120 and storage section 130 .
- Speech synthesizer 100 may include an input unit (eg, keyboard, mouse) that receives input from an administrator of speech synthesizer 100 .
- the speech synthesizer 100 may also include an output unit (for example, a liquid crystal display, an organic EL (Electro Luminescence) display) that displays information to the administrator of the speech synthesizer 100 .
- an output unit for example, a liquid crystal display, an organic EL (Electro Luminescence) display
- the communication unit 110 is implemented by, for example, a NIC (Network Interface Card). Communication unit 110 is connected to network 200 by wire or wirelessly. The communication unit 110 can transmit and receive information to and from the user device 300 via the network 200 .
- NIC Network Interface Card
- the control unit 120 is a controller.
- the control unit 120 uses a RAM (Random Access Memory) as a work area, and includes one or more processors (e.g., CPU (Central Processing Unit), It is implemented by an MPU (Micro Processing Unit).
- processors e.g., CPU (Central Processing Unit)
- MPU Micro Processing Unit
- the control unit 120 may be implemented by an integrated circuit such as an ASIC (Application Specific Integrated Circuit), an FPGA (Field Programmable Gate Array), or a GPGPU (General Purpose Graphic Processing Unit).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- GPGPU General Purpose Graphic Processing Unit
- the control unit 120 includes a voice data acquisition unit 121, an utterance information acquisition unit 122, a book information acquisition unit 123, a vector representation acquisition unit 124, a visual feature extraction unit 125, a model learning unit 126, and a voice synthesis unit. 127 is included.
- One or more processors of speech synthesizer 100 may implement each control unit by executing instructions stored in one or more memories of speech synthesizer 100 .
- the data processing performed by each controller is an example, and each controller (e.g., model learner) may perform the data processing described in relation to other controllers (e.g., model learner). .
- the voice data acquisition unit 121, the speech information acquisition unit 122, and the book information acquisition unit 123 are multiple examples of the "acquisition unit”.
- the vector representation acquisition unit 124 is an example of a “first conversion unit”.
- the visual feature extraction unit 125 is an example of a “second conversion unit”.
- the model learning unit 126 is an example of a “generating unit”.
- the voice data acquisition unit 121 acquires voice data corresponding to an utterance target in the book.
- An utterance target is a text contained in a book. Examples of books include picture books and picture-story shows.
- the target of speech is text contained in a specific page of a book. This text is associated with the image contained on this particular page.
- Speech data includes pre-recorded speech for use in training the speech synthesis model.
- the voice data holds voice including utterances of a narrator reading text included in book information (that is, text included in a book) to be described later.
- Audio data is obtained by performing signal processing on the audio signal emitted by the narrator.
- Speech data holds speech parameters (eg, pitch parameters such as fundamental frequency) and spectral parameters (eg, mel-spectrogram, cepstrum, mel-cepstrum).
- the voice data acquisition unit 121 can receive voice data from the user device 300.
- the voice data acquisition unit 121 can store the received voice data in the storage unit 130 .
- the voice data acquisition unit 121 can acquire voice data from the storage unit 130 .
- the utterance information acquisition unit 122 acquires utterance information regarding an utterance target.
- the utterance information corresponds to voice data acquired by the voice data acquisition unit 121 .
- the utterance information includes text information included in book information, which will be described later. Text information shows the text contained in this book.
- the utterance information may include information indicating the accent of the utterance target, the part of speech, the start time of the phoneme, or the end time of the phoneme.
- the utterance information includes pronunciation information given to each utterance in the audio data. This utterance information is attached to each utterance in the audio data acquired by the audio data acquisition unit 121 .
- the utterance information can include at least text information included in book information, which will be described later.
- the utterance information added to the audio data may include information other than text information.
- the utterance information may include accent information (accent type, accent phrase length), part of speech information, start time of each phoneme or end time of each phoneme (phoneme segmentation information). The start time and end time are elapsed times when the start point of each utterance is 0 [seconds].
- FIG. 5 shows speech information 30, which is an example of speech information according to the present disclosure.
- the utterance information 30 includes a character string "good morning”. Also, an illustration number included in the book information, which will be described later, is assigned to each utterance.
- the utterance "o”, the utterance "o”, the utterance "ha”, the utterance “yo” and the utterance "u” correspond to the illustration number "1". Each utterance is associated with a corresponding illustration number.
- the illustration number is included in the book information, which will be described later, and represents the correspondence between the utterance information and the illustration.
- a unique identifier such as a number, is assigned to each illustration.
- the speech information acquisition unit 122 can receive speech information from the user device 300 .
- the speech information acquisition unit 122 can store the received speech information in the storage unit 130 .
- the speech information acquisition unit 122 can acquire speech information from the storage unit 130 .
- the book information acquisition unit 123 acquires various information related to books.
- the book information includes text included in the book. Further, the book information includes image information regarding images included in the book.
- FIG. 6 shows book information 40, which is an example of book information according to the present disclosure. As shown in FIG. 5, it contains text information and pictorial image information. This text information can be the information needed to create the audio data mentioned above.
- the text information indicates, for example, a character string to be spoken in a picture book or a picture-story show.
- the illustration image information includes an illustration image corresponding to the text information.
- the book information acquisition unit 123 can receive book information from the user device 300 .
- the book information acquisition unit 123 can store the received book information in the storage unit 130 .
- the book information acquisition unit 123 can acquire book information from the storage unit 130 .
- the vector expression acquisition unit 124 converts the utterance information into a language vector indicating linguistic information of the utterance target.
- the vector expression acquisition unit 124 acquires language vectors by converting the speech information into expressions (numerical expressions) that can be used by the model learning unit 126, which will be described later.
- one-hot expressions are used to convert speech information into language vectors.
- the number of dimensions of the one-hot expression vector is the number N of characters included in the speech information.
- the value of the dimension corresponding to the input character is '1', and the value of the dimension not corresponding to the input character is '0'.
- the one-hot expression vector corresponds to the character "a”.
- a vector of one-hot representations may correspond to the character "i" when the value in the second dimension is "1" and the values in the other dimensions are "0".
- the vector expression acquisition unit 124 converts the phonemes and accents into numerical vectors in the same manner as in Non-Patent Document 1 above. If characters are used as speech information, the vector representation acquisition unit 124 applies text analysis to the speech information. The vector representation acquirer 124 can use phoneme and accent information obtained from text analysis. Therefore, the vector expression acquisition unit 124 can convert phonemes and accents into numerical vectors in the same manner as in Non-Patent Document 1 above.
- the visual feature extraction unit 125 can extract visual features from the illustration image information included in the book information.
- the visual feature extraction unit 125 converts the image information into a visual feature vector indicating the visual features of the images included in the book.
- the visual feature extraction unit 125 acquires a visual feature vector by converting illustration image information included in the book information into a vector representation that can be used by the model learning unit 126, which will be described later.
- the visual feature extraction unit 125 outputs a visual feature vector that is used as input for a neural network for speech synthesis from the illustration image information.
- a neural network for image identification which is pre-trained from a large amount of image data, is used to convert illustration image information into visual feature vectors.
- the visual feature extraction unit 125 executes forward propagation processing from the illustration image information input to the neural network ("Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-Excitation Networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.”).
- the visual feature extraction unit 125 finally acquires the information of the output layer and outputs this information of the output layer as a visual feature vector.
- the output visual feature information vector may be information other than the information of the output layer.
- the visual feature extraction unit 125 may use the output of any intermediate layer (bottleneck layer) as the visual feature information vector. By using such a pre-learned neural network for image identification, the visual feature extraction unit 125 can acquire vectors reflecting information such as characters and backgrounds included in the illustration image information. .
- model learning unit 126 performs voice synthesis based on the utterance information acquired by the utterance information acquisition unit 122, the image information acquired by the book information acquisition unit 123, and the voice data acquired by the voice data acquisition unit 121. Generate a model. To generate the speech synthesis model, the model learner 126 uses training data including speech data associated with language vectors and visual feature vectors.
- FIG. 7 shows training 50, which is an example of training a speech synthesis model according to the present disclosure.
- the model learning unit 126 learns a speech synthesis model (for example, a neural network for speech synthesis) using the audio data, the utterance information, and the illustration image information included in the book information.
- Training 50 shows the flow of various data used to train the speech synthesis model.
- the model learning unit 126 uses the speech data, the language vector acquired by the vector expression acquisition unit 124, and the visual feature vector acquired by the visual feature extraction unit 125 to obtain the language vector and train a neural network for speech synthesis that estimates speech parameters from visual feature vectors.
- the model learning unit 126 can use a learning algorithm similar to that of Non-Patent Document 2 above.
- the model learning unit 126 can use various neural network structures.
- the model learning unit 126 includes not only normal MLP (Multilayer Perceptron), but also neural networks such as RNN (Recurrent Neural Network), RNN-LSTM (Long Short Term Memory), CNN (Convolutional Neural Network), Transformers, Combinations of these neural networks can be used.
- MLP Multilayer Perceptron
- RNN Recurrent Neural Network
- RNN-LSTM Long Short Term Memory
- CNN Convolutional Neural Network
- Transformers Combinations of these neural networks can be used.
- model learning unit 126 can store the generated speech synthesis model in the storage unit 130.
- the model learning unit 126 uses visual feature vectors acquired by the visual feature extraction unit 125 in addition to language vectors used in conventional neural networks for speech synthesis.
- a visual information vector is obtained from illustration image information extracted from a book such as a picture book.
- the model learning unit 126 learns a neural network for speech synthesis in consideration of the character's appearance, expression, or background information (for example, scenery, weather, etc.) included in the illustration image information. can be done.
- the speech synthesis model generated by the model learning unit 126 enables generation of synthetic speech with natural intonation.
- speech synthesis unit 127 uses the speech synthesis model generated by the model learning unit 126 to generate synthesized speech.
- the speech synthesis unit 127 acquires a speech synthesis model from the storage unit 130. Also, the speech synthesis unit 127 acquires language vectors and visual feature vectors from an unknown book. Then, the speech synthesizing unit 127 inputs the acquired language vector and visual feature vector to the speech synthesis model and acquires the speech feature quantity. The speech synthesizing unit 127 generates synthesized speech by generating a speech waveform from the acquired speech feature quantity.
- FIG. 8 shows speech synthesis 60, which is an example of speech synthesis according to the present disclosure.
- the speech synthesizing unit 127 generates synthetic speech from the text contained in the picture book or picture-story show that is the object of speech synthesis and the illustration image information corresponding to this picture book or picture-story show.
- the difference between the speech synthesis 60 and the algorithm of Non-Patent Document 2 is that the speech synthesis unit 127 uses a visual feature vector, which is information other than the language vector, for the input of the speech synthesis model.
- a visual feature vector is obtained from the visual feature extractor 125 .
- Speech synthesis 60 shows the flow of various data used to generate synthesized speech.
- the speech synthesis unit 127 applies text analysis to the input text to obtain information corresponding to speech information.
- the vector expression acquisition unit 124 converts the acquired utterance information into language vectors.
- the visual feature extraction unit 125 converts the illustration image information corresponding to the input text into a visual feature vector.
- the speech synthesis unit 127 inputs the language vector and the visual feature vector to the speech synthesis model generated by the model learning unit 126 . Then, the speech feature amount is output by forward propagation.
- the speech synthesizing unit 127 acquires synthesized speech by generating a speech waveform from the speech feature quantity.
- the speech synthesis unit 127 may use the MLPG (Maximum Likelihood Generation) algorithm to obtain a speech parameter sequence smoothed in the time direction (“Mashiko et al., “Dynamic Feature Speech Synthesis based on HMM using ", IEICE Theory, vol.J79-D-II, no.12, pp.2184-2190, Dec. 1996”).
- MLPG Maximum Likelihood Generation
- the speech synthesis unit 127 may use a technique of generating speech waveforms by signal processing (see Imai et al., "Mel Logarithmic Spectrum Approximation (MLSA) Filter for Speech Synthesis", The Transactions of the Institute of Electronics, Information and Communication Engineers A Vol.J66-A No.2 pp.122-129, Feb. 1983.”).
- the speech synthesis unit 127 may use a method of generating speech waveforms using a neural network ("Oord, Aaron van den, et al. "WAVENET: A GENERATIVE MODEL FOR RAW AUDIO.” arXiv preprint arXiv:1609.03499 (2016)”).
- Storage unit 130 is implemented by, for example, a semiconductor memory device such as a RAM or flash memory, or a storage device such as a hard disk or optical disk.
- Storage unit 130 includes audio data 131 , utterance information 132 , book information 133 and speech synthesis model 134 .
- the audio data 131 is, for example, audio data acquired by the audio data acquisition unit 121 .
- the speech information 132 is, for example, speech information acquired by the speech information acquisition unit 122 .
- the book information 133 is book information acquired by the book information acquisition unit 123 .
- the speech synthesis model 134 is, for example, a speech synthesis model generated by the model learning unit 126 .
- Examples of speech synthesis processing include processing for generating a speech synthesis model. Processing for generating a speech synthesis model is performed by the speech synthesis device 100 in FIG. 1, for example.
- FIG. 9 is a flowchart showing processing P100, which is an example of processing for generating a speech synthesis model.
- the speech information acquisition unit 122 of the speech synthesizer 100 acquires text included in a book (step S101).
- the book information acquisition unit 123 of the speech synthesizer 100 acquires an image included in the book and associated with the acquired text (step S102).
- the speech data acquisition unit 121 of the speech synthesizer 100 acquires a speech signal corresponding to the text acquired by the speech information acquisition unit 122 (step S103).
- the model learning unit 126 of the speech synthesizer 100 associates with the image based on the text acquired by the speech information acquisition unit 122, the image acquired by the book information acquisition unit 123, and the audio signal of the audio data acquisition unit 121.
- a model for converting the obtained text into a speech signal is generated (step S104).
- the generated model can transform the text associated with the image into audio features.
- the speech synthesizing unit 127 of the speech synthesizing device 100 can convert the generated speech feature quantity into a speech signal.
- the speech synthesizer 100 utilizes not only the linguistic information obtained from the text when a book such as a picture book is read, but also the visual information obtained from the illustrations in the book. As a result, the speech synthesizer 100 can generate synthetic speech that naturally reads a book such as a picture book.
- the illustrated components of the device conceptually indicate the functions of the device. Components are not necessarily physically arranged as shown in the drawings. In other words, the specific form of the distributed or integrated apparatus is not limited to the form of the system and apparatus shown in the figures. All or part of the devices may be functionally or physically distributed or integrated according to various loads and usage conditions.
- FIG. 10 is a diagram showing a computer 1000 as an example of the hardware configuration of a computer.
- the systems and methods described herein may be implemented, for example, by computer 1000 shown in FIG.
- FIG. 10 shows an example of a computer in which the speech synthesizer 100 is implemented by executing a program.
- the computer 1000 has a memory 1010 and a CPU 1020, for example.
- Computer 1000 also has hard disk drive interface 1030 , disk drive interface 1040 , serial port interface 1050 , video adapter 1060 and network interface 1070 . These units are connected by a bus 1080 .
- the memory 1010 includes a ROM (Read Only Memory) 1011 and a RAM 1012.
- the ROM 1011 stores a boot program such as BIOS (Basic Input Output System).
- Hard disk drive interface 1030 is connected to hard disk drive 1090 .
- a disk drive interface 1040 is connected to the disk drive 1100 .
- a removable storage medium such as a magnetic disk or optical disk is inserted into the disk drive 1100 .
- Serial port interface 1050 is connected to mouse 1110 and keyboard 1120, for example.
- Video adapter 1060 is connected to display 1130, for example.
- the hard disk drive 1090 stores, for example, an OS 1091, application programs 1092, program modules 1093, and program data 1094. That is, a program that defines each process of the speech synthesizer 100 is implemented as a program module 1093 in which code executable by the computer 1000 is described. Program modules 1093 are stored, for example, on hard disk drive 1090 .
- the hard disk drive 1090 stores a program module 1093 for executing processing similar to the functional configuration of the speech synthesizer 100 .
- the hard disk drive 1090 may be replaced by an SSD (Solid State Drive).
- the hard disk drive 1090 can store a speech synthesis program for speech synthesis processing. Also, the speech synthesis program can be created as a program product. The program product, when executed, performs one or more methods, such as those described above.
- the setting data used in the processing of the above-described embodiment is stored as program data 1094 in the memory 1010 or the hard disk drive 1090, for example. Then, the CPU 1020 reads out the program module 1093 and the program data 1094 stored in the memory 1010 and the hard disk drive 1090 to the RAM 1012 as necessary and executes them.
- the program modules 1093 and program data 1094 are not limited to being stored in the hard disk drive 1090, but may be stored in a removable storage medium, for example, and read by the CPU 1020 via the disk drive 1100 or the like. Alternatively, program modules 1093 and program data 1094 may be stored in other computers connected through a network (LAN, WAN, etc.). Program modules 1093 and program data 1094 may then be read by CPU 1020 through network interface 1070 from other computers.
- the speech synthesis device 100 includes the speech data acquisition unit 121, the utterance information acquisition unit 122, the book information acquisition unit 123, and the model learning unit 126.
- the utterance information acquisition unit 122 acquires utterance information related to an utterance target that is text included in the first book
- the book information acquisition unit 123 acquires images related to images included in the first book.
- the voice data acquisition unit 121 acquires voice data corresponding to the utterance target.
- the model learning unit 126 uses the utterance information acquired by the utterance information acquisition unit 122, the image information acquired by the book information acquisition unit 123, and the voice data acquired by the voice data acquisition unit 121. generates a text-to-speech model for reading a second book containing text associated with the image.
- the book information acquisition unit 123 acquires, as image information, information about an image included in a specific page of the first book and associated with text included in the specific page.
- the audio data acquisition unit 121 acquires, as audio data, audio data for reading out text included in a specific page of the first book and associated with an image included in the specific page. do.
- the utterance information acquisition unit 122 acquires utterance information indicating at least one of the accent of the utterance target, the part of speech, the start time of the phoneme, and the end time of the phoneme.
- the speech synthesizer 100 includes the vector representation acquisition unit 124 and the visual feature extraction unit 125.
- the vector representation acquirer 124 converts the speech information into a language vector representing the linguistic information of the speech target.
- visual feature extractor 125 converts the image information into a visual feature vector that indicates the visual features of the images included in the first book.
- model learner 126 generates a speech synthesis model using training data including speech data associated with language vectors and visual feature vectors.
- a communication module, a control module, and a storage module can be read as a communication unit, a control unit, and a storage unit, respectively.
- each control unit (for example, model learner) in the control unit 120 can also be read as a model learning unit.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Electrically Operated Instructional Devices (AREA)
- Processing Or Creating Images (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/683,786 US20240347039A1 (en) | 2021-08-18 | 2022-08-18 | Speech synthesis apparatus, speech synthesis method, and speech synthesis program |
| JP2023542446A JP7603948B2 (ja) | 2021-08-18 | 2022-08-18 | 音声合成装置、音声合成方法及び音声合成プログラム |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021133713 | 2021-08-18 | ||
| JP2021-133713 | 2021-08-18 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023022206A1 true WO2023022206A1 (ja) | 2023-02-23 |
Family
ID=85240853
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/031276 Ceased WO2023022206A1 (ja) | 2021-08-18 | 2022-08-18 | 音声合成装置、音声合成方法及び音声合成プログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240347039A1 (https=) |
| JP (1) | JP7603948B2 (https=) |
| WO (1) | WO2023022206A1 (https=) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240203418A1 (en) * | 2022-12-20 | 2024-06-20 | Jpmorgan Chase Bank, N.A. | Method and system for automatically visualizing a transcript |
| US12548589B1 (en) | 2025-09-24 | 2026-02-10 | CNTXT FZCo | Systems and methods for generating audio descriptions |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003044072A (ja) * | 2001-07-30 | 2003-02-14 | Seiko Epson Corp | 音声読み上げ設定装置、音声読み上げ装置、音声読み上げ設定方法、音声読み上げ設定プログラム及び記録媒体 |
| JP2005249880A (ja) * | 2004-03-01 | 2005-09-15 | Xing Inc | 携帯式通信端末によるディジタル絵本システム |
| JP2005321706A (ja) * | 2004-05-11 | 2005-11-17 | Nippon Telegr & Teleph Corp <Ntt> | 電子書籍の再生方法及びその装置 |
| WO2020235696A1 (ko) * | 2019-05-17 | 2020-11-26 | 엘지전자 주식회사 | 스타일을 고려하여 텍스트와 음성을 상호 변환하는 인공 지능 장치 및 그 방법 |
| JP2021099454A (ja) * | 2019-12-23 | 2021-07-01 | 株式会社 ディー・エヌ・エー | 音声合成装置、音声合成プログラム及び音声合成方法 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080070199A1 (en) * | 2006-08-28 | 2008-03-20 | Sommer Sandra R | Coloring book composed of digital images converted to black and white outlines |
| WO2016103652A1 (ja) * | 2014-12-24 | 2016-06-30 | 日本電気株式会社 | 音声処理装置、音声処理方法、および記録媒体 |
| US20180133900A1 (en) * | 2016-11-15 | 2018-05-17 | JIBO, Inc. | Embodied dialog and embodied speech authoring tools for use with an expressive social robot |
| CN108885614B (zh) * | 2017-02-06 | 2020-12-15 | 华为技术有限公司 | 一种文本和语音信息的处理方法以及终端 |
| US10607595B2 (en) * | 2017-08-07 | 2020-03-31 | Lenovo (Singapore) Pte. Ltd. | Generating audio rendering from textual content based on character models |
| US10540445B2 (en) * | 2017-11-03 | 2020-01-21 | International Business Machines Corporation | Intelligent integration of graphical elements into context for screen reader applications |
| US11226673B2 (en) * | 2018-01-26 | 2022-01-18 | Institute Of Software Chinese Academy Of Sciences | Affective interaction systems, devices, and methods based on affective computing user interface |
| KR20210011844A (ko) * | 2019-07-23 | 2021-02-02 | 삼성전자주식회사 | 전자 장치 및 그 제어 방법 |
| US11270684B2 (en) * | 2019-09-11 | 2022-03-08 | Artificial Intelligence Foundation, Inc. | Generation of speech with a prosodic characteristic |
| CN110717498A (zh) * | 2019-09-16 | 2020-01-21 | 腾讯科技(深圳)有限公司 | 图像描述生成方法、装置及电子设备 |
| US20220269870A1 (en) * | 2021-02-18 | 2022-08-25 | Meta Platforms, Inc. | Readout of Communication Content Comprising Non-Latin or Non-Parsable Content Items for Assistant Systems |
| JP2024516664A (ja) * | 2021-04-27 | 2024-04-16 | フラウンホッファー-ゲゼルシャフト ツァ フェルダールング デァ アンゲヴァンテン フォアシュンク エー.ファオ | デコーダ |
-
2022
- 2022-08-18 JP JP2023542446A patent/JP7603948B2/ja active Active
- 2022-08-18 WO PCT/JP2022/031276 patent/WO2023022206A1/ja not_active Ceased
- 2022-08-18 US US18/683,786 patent/US20240347039A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003044072A (ja) * | 2001-07-30 | 2003-02-14 | Seiko Epson Corp | 音声読み上げ設定装置、音声読み上げ装置、音声読み上げ設定方法、音声読み上げ設定プログラム及び記録媒体 |
| JP2005249880A (ja) * | 2004-03-01 | 2005-09-15 | Xing Inc | 携帯式通信端末によるディジタル絵本システム |
| JP2005321706A (ja) * | 2004-05-11 | 2005-11-17 | Nippon Telegr & Teleph Corp <Ntt> | 電子書籍の再生方法及びその装置 |
| WO2020235696A1 (ko) * | 2019-05-17 | 2020-11-26 | 엘지전자 주식회사 | 스타일을 고려하여 텍스트와 음성을 상호 변환하는 인공 지능 장치 및 그 방법 |
| JP2021099454A (ja) * | 2019-12-23 | 2021-07-01 | 株式会社 ディー・エヌ・エー | 音声合成装置、音声合成プログラム及び音声合成方法 |
Non-Patent Citations (1)
| Title |
|---|
| HYAKUTAKE, KYOTA ET AL.: "An experimental study of designing context labels for infant-directed storytelling speech synthesis", IEICE TECHNICAL REPORT, vol. 115, no. 523, 29 February 2016 (2016-02-29), pages 255 - 260, XP009543533, ISSN: 0913-5685 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7603948B2 (ja) | 2024-12-23 |
| US20240347039A1 (en) | 2024-10-17 |
| JPWO2023022206A1 (https=) | 2023-02-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7745022B2 (ja) | 非発話テキストおよび音声合成を使う音声認識 | |
| JP7500020B2 (ja) | 多言語テキスト音声合成方法 | |
| JP7280386B2 (ja) | 多言語音声合成およびクロスランゲージボイスクローニング | |
| US20250078808A1 (en) | Two-Level Text-To-Speech Systems Using Synthetic Training Data | |
| JP7228998B2 (ja) | 音声合成装置及びプログラム | |
| JP7753567B2 (ja) | 音声認識モデルを訓練するための非並列音声変換の使用 | |
| KR20230133362A (ko) | 다양하고 자연스러운 텍스트 스피치 변환 샘플들 생성 | |
| JP7257593B2 (ja) | 区別可能な言語音を生成するための音声合成のトレーニング | |
| CN111954903A (zh) | 多说话者神经文本到语音合成 | |
| CN112599113B (zh) | 方言语音合成方法、装置、电子设备和可读存储介质 | |
| Oh et al. | Diffprosody: Diffusion-based latent prosody generation for expressive speech synthesis with prosody conditional adversarial training | |
| JP7603948B2 (ja) | 音声合成装置、音声合成方法及び音声合成プログラム | |
| CN120153418A (zh) | 用于文本转语音的大规模多语言语音-文本联合半监督学习 | |
| CN114373445B (zh) | 语音生成方法、装置、电子设备及存储介质 | |
| CN121753095A (zh) | 利用对已发现的数据进行零监督来扩展多语言语音合成 | |
| De et al. | Making social platforms accessible: Emotion-aware speech generation with integrated text analysis | |
| KR102418465B1 (ko) | 동화 낭독 서비스를 제공하는 서버, 방법 및 컴퓨터 프로그램 | |
| KR20220004272A (ko) | 음성 감정 인식 및 합성의 반복 학습 방법 및 장치 | |
| WO2022039636A1 (ru) | Способ синтеза речи с передачей достоверного интонирования клонируемого образца | |
| JP7357518B2 (ja) | 音声合成装置及びプログラム | |
| JP6475572B2 (ja) | 発話リズム変換装置、方法及びプログラム | |
| Hamad et al. | Arabic text-to-speech synthesizer | |
| JP6748607B2 (ja) | 音声合成学習装置、音声合成装置、これらの方法及びプログラム | |
| JP7605229B2 (ja) | 話者埋め込み装置、話者埋め込み方法、および、話者埋め込みプログラム | |
| Behr | Fine-Grained Prosody Control in Neural TTS Systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22858523 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023542446 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18683786 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22858523 Country of ref document: EP Kind code of ref document: A1 |