WO2022269885A1 - Learning data collection device, learning data collection method, and learning data collection program - Google Patents
Learning data collection device, learning data collection method, and learning data collection program Download PDFInfo
- Publication number
- WO2022269885A1 WO2022269885A1 PCT/JP2021/024066 JP2021024066W WO2022269885A1 WO 2022269885 A1 WO2022269885 A1 WO 2022269885A1 JP 2021024066 W JP2021024066 W JP 2021024066W WO 2022269885 A1 WO2022269885 A1 WO 2022269885A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- new data
- new
- existing
- learning
- Prior art date
Links
- 238000013480 data collection Methods 0.000 title claims abstract description 51
- 238000000034 method Methods 0.000 title claims description 15
- 238000013500 data storage Methods 0.000 claims description 73
- 238000010801 machine learning Methods 0.000 claims description 32
- 238000013528 artificial neural network Methods 0.000 claims description 22
- 230000006870 function Effects 0.000 claims description 4
- 230000014759 maintenance of location Effects 0.000 abstract 2
- 230000000717 retained effect Effects 0.000 abstract 1
- 238000004364 calculation method Methods 0.000 description 11
- 230000015654 memory Effects 0.000 description 11
- 239000013598 vector Substances 0.000 description 11
- 238000010586 diagram Methods 0.000 description 7
- 238000012545 processing Methods 0.000 description 7
- 238000013434 data augmentation Methods 0.000 description 6
- 239000007787 solid Substances 0.000 description 2
- 101100421903 Arabidopsis thaliana SOT10 gene Proteins 0.000 description 1
- 101100421909 Arabidopsis thaliana SOT16 gene Proteins 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000002040 relaxant effect Effects 0.000 description 1
- 238000012827 research and development Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000012549 training Methods 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- This disclosure relates to learning data collection technology.
- Patent Literature 1 discloses a learning data collection system for collecting learning data used for image recognition. The system of Patent Document 1 determines whether it is appropriate to use newly captured image data as learning data based on various determination criteria, and if the captured image is not appropriate as learning data, it is determined that it is not appropriate. The determination result is reported to the photographer.
- Patent Document 1 there is a problem that a large amount of new data similar to existing data can be collected as learning data.
- the present disclosure was made to solve such problems, and aims to provide a learning data collection technique that does not collect new data similar to existing data as learning data.
- a learning data collection device acquires new data newly acquired through a sensor and two existing data already stored in a data storage device, and stores the new data or the new data
- a data storage determination unit that determines whether or not to store related data as learning data using the two existing data.
- the learning data collection device According to the learning data collection device according to the embodiment of the present disclosure, it is possible not to collect new data similar to existing data as learning data.
- FIG. 1 is a diagram showing a configuration example of a learning data collection device according to Embodiments 1 and 2;
- FIG. FIG. 4 is a diagram illustrating a hardware configuration example of a data storage determination unit of the learning data collection device;
- FIG. 4 is a diagram illustrating a hardware configuration example of a data storage determination unit of the learning data collection device;
- 4 is a flow chart showing the operation of the learning data collection device according to Embodiment 1;
- 4 is a diagram for explaining the operation of the learning data collection device according to Embodiment 1;
- FIG. 9 is a flow chart showing the operation of the learning data collection device according to Embodiment 2;
- FIG. 12 is a diagram for explaining the operation of the learning data collection device according to Embodiment 2;
- FIG. 12 is a diagram for explaining the operation of the learning data collection device according to Embodiment 2;
- FIG. 13 is a diagram showing a configuration example of a learning data collection device according to Embodiment 3;
- new data similar to existing data means that when new data is represented by linear interpolation of two existing data, new data is represented by linear interpolation of two existing data. is within a predetermined distance from or when the hidden layer output obtained by inputting new data to the neural network is within a predetermined distance from the linear interpolation of the hidden layer output obtained by inputting two existing data to the neural network.
- similar includes not only cases where new data has a fixed relationship with two existing data, but also cases where the new data's hidden layer output has a fixed relationship with two existing data's hidden layer outputs. included in some cases.
- Embodiment 1 A configuration of a learning data collection device according to Embodiment 1 of the present disclosure will be described with reference to FIGS. 1 to 4.
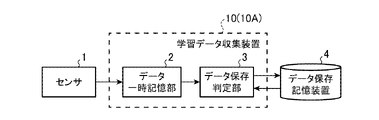
- FIG. 1 the learning data collection device 10 is electrically connected to the sensor 1 and the data storage device 4, and the learning data collection device 10, the sensor 1 and the data storage device 4 are used for learning data collection. configure the system;
- the learning data collection device 10 includes a data temporary storage section 2 and a data storage determination section 3 .
- the data temporary storage unit 2 may be provided outside the learning data collection device 10 .
- the learning data collection device 10 receives data acquired by the sensor 1 from the sensor 1 and exchanges data with the data storage device 4 .
- the sensor 1 is a device that can acquire some data, such as a sensor that acquires data related to physical quantities such as vibration, voltage, current, temperature, or humidity, a camera that acquires images, and a microphone that acquires sound.
- the sensor 1 may be any device as long as the acquired data can be used for AI or machine learning.
- Data acquired by the sensor 1 is converted into digital data by the sensor 1 or an AD converter (not shown) and supplied to the data temporary storage unit 2 .
- the data temporary storage unit 2 is a device for temporarily holding data, and temporarily holds data supplied from the sensor 1 .
- the data temporary storage unit 2 is implemented by a storage device such as a memory, HDD (Hard Disk Drive), or SSD (Solid State Drive).
- the data storage determination unit 3 is a functional unit that determines whether or not to store the data acquired from the data temporary storage unit 2 in the data storage device 4 .
- the hardware configuration of the data save determination unit 3 will be described with reference to FIGS. 2A and 2B.
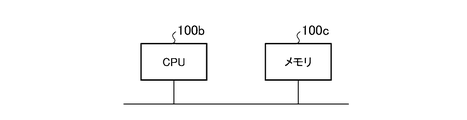
- the data storage determination unit 3 is implemented by a processing circuit 100a.
- the processing circuit 100a is, for example, a single circuit, a composite circuit, a programmed processor, a parallel programmed processor, an ASIC (Application Specific Integrated Circuit), an FPGA (Field-Programmable Gate Array), or a combination thereof.
- the data storage determination unit 3 is realized by a CPU (Central Processing Unit) 100b and a memory 100c.
- the function of the data storage determination unit 3 (data storage determination function) is realized by reading out and executing the program stored in the memory 100c by the CPU 100b.
- Programs may be implemented as software, firmware, or a combination of software and firmware.
- Examples of the memory 100c include non-volatile or volatile semiconductors such as RAM (Random Access Memory), ROM (Read Only Memory), flash memory, EPROM (Erasable Programmable Read Only Memory), and EEPROM (Electrically-EPROM). Memory, magnetic disk, flexible disk, optical disk, compact disk, mini disk, DVD are included.
- the data storage storage device 4 is a storage device that stores data.
- the data storage storage device 4 stores the data determined to be stored by the data storage determination unit 3 .
- the data saving memory device 4 supplies data to be used for deciding whether to save data to the data saving determination unit 3 .
- Examples of the data storage device 4 include storage media such as HDDs (Hard Disk Drives), SSDs (Solid State Drives), memories, or memory cards.
- the data storage determination unit 3 uses the new data d held in the data temporary storage unit 2 and the two existing data e1 and e2 stored in the data storage storage device 4 to generate the new data d should be saved.
- data handled by AI or machine learning can be represented by a vector, and in the present disclosure, data is assumed to be an n-dimensional vector represented by two or more dimensions.
- the new data d can be linearly interpolated with the two existing data e1 and e2, it is determined that the new data d is not important and should not be saved. Details of the determination method will be described with reference to FIGS. 3 and 4. FIG. It is assumed that some existing data are stored in the data storage device 4 at the start of the operation of this system.
- step ST1 the data storage determination unit 3 acquires from the data temporary storage unit 2 new data d acquired by the sensor 1 and held in the data temporary storage unit 2 as digital data.
- the data storage determination unit 3 repeats the selection loop of step ST2.
- the selection loop of step ST2 two pairs of data e1 and e2 are selected from the set of existing data stored in the data storage device 4.
- FIG. The end condition of the loop is whether the loop has been repeated a preset number of times, or whether the loop has been repeated until all the existing data pairs e1 and e2 have been selected.
- the loop may be terminated immediately after it is determined that linear interpolation is possible. In this case, the calculation time can be reduced by the part that the loop is terminated halfway.
- step ST3 the data storage determination unit 3 selects a pair of existing data e1 and e2. In step ST3, different pairs of e1 and e2 are selected each time, and once selected pairs are not selected repeatedly.
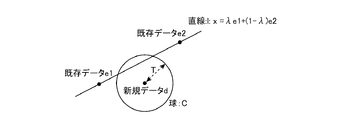
- step ST4 the data storage determination unit 3 calculates whether the new data d can be linearly interpolated with the existing data e1 and e2.
- the new data d When the new data d is linearly interpolable with the existing data e1 and e2, the new data d exists as a point on the line l, while when it is not linearly interpolable, the new data d does not exist on the line l.
- This equation is an n-dimensional linear equation, and it can be easily calculated whether a solution ⁇ exists. For example, it is sufficient to solve each of n linear equations and determine whether or not all of the obtained n solutions ⁇ agree with each other.
- step ST5 the data storage determination unit 3 determines whether it is determined that at least one line-type interpolation is possible for the new data d based on the calculation result in step ST4. If it is not determined even once that the new data d can be linearly interpolated in step ST4 (No in step ST5), the data storage determining unit 3 determines to store the new data d, and stores the new data d as data. It is saved in the save storage device 4 (step ST6).
- step ST4 when it is determined at least once in step ST4 that the new data d can be linearly interpolated (Yes in step ST5), the new data d is considered to be similar to the existing data e1 or e2.
- the data storage determination unit 3 determines not to store the new data d (step ST7).
- the data storage determination unit 3 does not simply determine that the new data d is not to be stored. It may be determined to save the information specifying e2 and the parameters for restoring the new data d as learning data. Both the information specifying the existing data e1 and e2 and the parameters for restoring the new data d are data related to the new data d. Examples of information identifying the existing data e1 and e2 include numbers or codes identifying the existing data e1 and e2. Examples of parameters for reconstructing the new data d include the value of ⁇ used when determining that the new data d can be linearly interpolated with the existing data e1 and e2. The data storage determination unit 3 stores the information and parameters in the data storage device 4 (step ST7).
- new data d similar to existing data e1 or e2 is not acquired as learning data.
- the learning data collection device 10 collects information specifying the existing data e1 and e2 used when it was determined that the new data d can be linearly interpolated, a parameter ⁇ for restoring the new data d, and to save.
- the capacity of a storage device for holding learning data can be reduced.
- AI or machine learning trained on the saved data can acquire its recognition or regression with high accuracy because it selects valid data for learning.
- the smaller the amount of learning data the smaller the calculation time or amount of calculation required for learning AI or machine learning. can do. By reducing the amount of calculation, it is possible to reduce the cost of the equipment that performs learning.
- mixup which is a data augmentation method proposed in the following reference, may be used.
- Mixup is a data augmentation method that uses linear interpolation of arbitrary pairs in learning data as learning data, and can learn to interpolate new data d that is rejected without being saved in this embodiment, and AI Or it can improve the accuracy of machine learning.
- Reference 1 H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: beyond empirical risk minimization,” arXiv:1710.09412, 2017.
- Embodiment 2 the data storage determination unit 3 uses linear interpolation of existing data to determine whether or not to store new data d. Therefore, the effect of reducing the amount of learning data to be saved may be limited. In the present embodiment, less data is stored by relaxing the conditions for determination by the data storage determination unit 3 compared to linear interpolation, thereby further reducing the amount of learning data to be stored.
- the configuration of the learning data collection device 10A according to the second embodiment is the same as that of the learning data collection device 10 of the first embodiment.
- the processing content (determination method) by the data storage determination unit 3 is different from that of the first embodiment.
- the processing contents of the data storage determination unit 3 in the case of the second embodiment will be described with reference to FIG. In FIG. 5, steps ST1, ST2, ST3, ST6 and ST7 are the same as in the first embodiment.
- Embodiment 2 differs from Embodiment 1 in that the processing contents in steps ST4A and ST5A differ from steps ST4 and ST5 in embodiment 1, respectively. These differences are described below.
- step ST4A the data storage determination unit 3 calculates whether or not the new data d exists within a distance T from the straight line l indicating linear interpolation of the existing data e1 and e2.
- T is a threshold, which is appropriately set for the data for judging whether or not to save using the learning data collection device 10A. If T is increased, the amount of training data can be reduced more, but if it is increased more than necessary, there is a possibility that important data will be discarded without being saved.
- Determination of whether the straight line l and the sphere C intersect can be realized as follows.
- An n-dimensional sphere C with radius T ( distance T) centered at point d can be expressed as
- the following two-dimensional simultaneous equation x ⁇ e1+(1- ⁇ )e2 with x and ⁇ as variables (1)
- 2 T 2 (2) has a real solution if the sphere C and the line l intersect, and does not have a real solution if they do not intersect.
- Equation (3) becomes an equation for ⁇ that does not include x.
- the following formula (4) is obtained.
- 2 T 2 (4)
- Equation (5) represents the inner product of vectors. Equation (5) is a quadratic equation of ⁇ , and all coefficients are scalar values.
- Whether or not a quadratic equation has a real number solution can be determined by calculating the sign of the discriminant of the quadratic equation. If the discriminant is positive or zero, there is a real solution, and if it is negative, there is no real solution.
- a
- b 2(e1-e2) ⁇ (e2-d) (7)
- c
- the conditions for saving data can be relaxed compared to the first embodiment, and the amount of data to be saved can be reduced.
- mixup which is a data augmentation method proposed in Reference 1, may be used when performing learning later.
- Mixup is a data augmentation method that uses linear interpolation of any pair in the learning data as learning data, and can learn to interpolate the new data d that is rejected without saving in the present embodiment, AI or It can improve the accuracy of machine learning.
- Embodiment 3. ⁇ Configuration>
- the data storage determination unit 3 performed determination using the data d, e1, and e2. It is thought that there are few things that can be represented by linear interpolation of existing data. Moreover, when the conditions are relaxed as in the second embodiment, it is necessary to increase the distance T as the threshold value in order to reduce the amount of stored data, and the possibility of discarding important data increases. end up
- Embodiment 3 instead of using the data d, e1 and e2, the data storage determination unit 3 inputs the data d, e1 and e2 to the trained neural network, and outputs these data to the intermediate layer. A similar determination is made using the value.
- the configuration of a system including the learning data collection device 20 according to Embodiment 3 is shown in FIG.
- the system shown in FIG. 8 is the same as the system shown in FIG. It differs from the system shown in FIG. 1 in that the model 5 is provided.
- the data storage determination unit 3 of the learning data collection device 20 is configured to exchange data with the trained machine learning model 5 .
- the trained machine learning model 5 is a storage device that holds a neural network trained and prepared in advance. This neural network is trained in advance with learning data collected by the learning data collecting device 20 or another means. This neural network is held in a state in which inference operations are possible, and the trained machine learning model 5 supplies the neural network for the data storage determination unit 3 .
- the data storage determination unit 3 inputs the new data d and the existing data e1 and e2 to the neural network provided from the trained machine learning model 5, and learns the respective intermediate layer outputs d', e'1 and e'2. obtained from the machine learning model 5.
- the data storage determination unit 3 uses the intermediate layer outputs d′, e′1 and e′2 instead of the data d, e1 and e2 to obtain the data shown in FIG. 3 of the first embodiment or FIG. 5 of the second embodiment. It is determined whether to save the new data d or data related to the new data d according to the determination method of .
- the data storage determination unit 3 determines that the intermediate layer output d′ is represented by linear interpolation of the intermediate layer outputs e′1 and e′2. Calculate if If the intermediate layer output d' is not represented by linear interpolation of the intermediate layer outputs e'1 and e'2, the data storage determination unit 3, in the step corresponding to step ST6 in FIG. may be determined to be stored, or instead of determining to store the new data d, it may be determined to store the intermediate layer output d', which is data related to the new data d.
- the data storage determination unit 3 determines that the new data d should be stored in the step corresponding to step ST7 in FIG. You can judge. Further, in a step corresponding to step ST7 in FIG. may be determined to be stored.
- the data storage determination unit 3 determines that the intermediate layer output d' is linearly interpolated between the intermediate layer outputs e'1 and e'2. Calculate if it exists within the distance T. If the intermediate layer output d' does not exist within the distance T from the linear interpolation of the intermediate layer outputs e'1 and e'2, the data storage determination unit 3 performs the same operation as in step ST6 in the step corresponding to step ST6 in FIG. Alternatively, it may be determined to store the intermediate layer output d', which is data related to the new data d, instead of storing the new data d.
- the data storage determination unit 3 stores the new data d in the step corresponding to step ST7 in FIG. It may be determined not to save.
- the data storage determination unit 3 stores information specifying the existing data e1 and e2, which are data related to the new data d, and parameters for restoring the new data d. may be determined to be stored.
- the number of dimensions of d', e'1 and e'2 obtained in the hidden layer output can be made smaller than the number of dimensions of data d, e1 and e2, and the new data can be
- the possibility that existing data can be represented by linear interpolation or the possibility that new data exists within the distance T increases, and the amount of learning data to be stored can be reduced compared to the first and second embodiments.
- the intermediate layer output d' which is data related to the new data
- the number of dimensions of the data to be saved can be suppressed, and the amount of data to be saved can be reduced. be able to.
- the intermediate layer output of the neural network is a value in which the feature amount of the input data is appropriately extracted, and it is possible to determine whether the data should be saved more appropriately.
- the accuracy of AI or machine learning learned with the learning data obtained in the present embodiment can be improved.
- mixup which is a data augmentation method proposed in Reference 1, may be used when performing learning later.
- Mixup is a data augmentation method that uses linear interpolation of any pair in the learning data as learning data, and can learn to interpolate the new data d that is rejected without saving in the present embodiment, AI or It can improve the accuracy of machine learning.
- the learning data collection technology of the present disclosure can be used as a device for collecting learning data for use in AI or machine learning.
- 1 sensor 1 sensor, 2 data temporary storage unit, 3 data storage determination unit, 4 data storage storage device, 5 learned machine learning model, 10 learning data collection device, 10A learning data collection device, 20 learning data collection device, 100a processing circuit, 100b CPU, 100c memory.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Complex Calculations (AREA)
- Testing Or Calibration Of Command Recording Devices (AREA)
Abstract
This learning data collection device is provided with a data retention determination unit (3) that acquires new data newly acquired via a sensor and two existing data items already retained in a data retention storage device and that determines whether or not to retain, as learning data, the new data or data concerning the new data, by using the two existing data items.
Description
本開示は、学習データ収集技術に関する。
This disclosure relates to learning data collection technology.
従来、AIまたは機械学習で用いるための学習データの収集を効果的に行うための研究開発がなされている。一例として、特許文献1には、画像認識に利用される学習データを収集するための学習データ収集システムが開示されている。特許文献1のシステムは、新規に撮影した画像データを様々な判定基準に基づいて学習データとして用いるのが適切か否かを判定し、撮影画像が学習データとして適切でない場合には適切でない旨の判定結果を撮影者に対して報知する。
Conventionally, research and development has been conducted to effectively collect learning data for use in AI or machine learning. As an example, Patent Literature 1 discloses a learning data collection system for collecting learning data used for image recognition. The system of Patent Document 1 determines whether it is appropriate to use newly captured image data as learning data based on various determination criteria, and if the captured image is not appropriate as learning data, it is determined that it is not appropriate. The determination result is reported to the photographer.
特許文献1を含む従来技術によれば、既存データと類似するような新規データが学習データとして大量に収集されうるという課題がある。
According to the conventional technology including Patent Document 1, there is a problem that a large amount of new data similar to existing data can be collected as learning data.
本開示は、このような課題を解決するためになされたものであり、既存データと類似する新規データを学習データとして収集しない学習データ収集技術を提供することを目的とする。
The present disclosure was made to solve such problems, and aims to provide a learning data collection technique that does not collect new data similar to existing data as learning data.
本開示の実施形態による学習データ収集装置は、センサを介して新たに取得された新規データおよびデータ保存記憶装置に既に保存されている2つの既存データを取得し、前記新規データまたは前記新規データに関連するデータを学習データとして保存するか否かを前記2つの既存データを用いて判定するデータ保存判定部を備える。
A learning data collection device according to an embodiment of the present disclosure acquires new data newly acquired through a sensor and two existing data already stored in a data storage device, and stores the new data or the new data A data storage determination unit that determines whether or not to store related data as learning data using the two existing data.
本開示の実施形態による学習データ収集装置によれば、既存データと類似する新規データを学習データとして収集しないようにすることができる。
According to the learning data collection device according to the embodiment of the present disclosure, it is possible not to collect new data similar to existing data as learning data.
以下、添付の図面を参照して、本開示における種々の実施形態について詳細に説明する。なお、図面において同一または類似の符号を付された構成要素は、同一または類似の構成または機能を有するものであり、そのような構成要素についての重複する説明は省略する。また、上述の「既存データと類似する新規データ」という文言における「類似」との用語は、新規データが2つの既存データの線形補間で表される場合、新規データが2つの既存データの線形補間から所定の距離以内に存在する場合、新規データをニューラルネットワークへ入力して得られた中間層出力が2つの既存データをニューラルネットワークへ入力して得られた中間層出力の線形補間で表される場合、または新規データをニューラルネットワークへ入力して得られた中間層出力が2つの既存データをニューラルネットワークへ入力して得られた中間層出力の線形補間から所定の距離以内に存在する場合を含む用語である。すなわち、その「類似」との用語には、新規データが2つの既存データと一定の関係にある場合だけでなく、新規データの中間層出力が2つの既存データの中間層出力と一定の関係にある場合も含まれる。
Various embodiments of the present disclosure will be described in detail below with reference to the accompanying drawings. Components denoted by the same or similar reference numerals in the drawings have the same or similar configurations or functions, and duplicate descriptions of such components will be omitted. In addition, the term "similar" in the above-mentioned phrase "new data similar to existing data" means that when new data is represented by linear interpolation of two existing data, new data is represented by linear interpolation of two existing data. is within a predetermined distance from or when the hidden layer output obtained by inputting new data to the neural network is within a predetermined distance from the linear interpolation of the hidden layer output obtained by inputting two existing data to the neural network. terminology. That is, the term "similar" includes not only cases where new data has a fixed relationship with two existing data, but also cases where the new data's hidden layer output has a fixed relationship with two existing data's hidden layer outputs. included in some cases.
実施の形態1.
<構成>
図1から図4を参照して、本開示の実施の形態1に係る学習データ収集装置の構成について説明する。図1に示されているように、学習データ収集装置10は、センサ1およびデータ保存記憶装置4に電気的に接続され、学習データ収集装置10、センサ1およびデータ保存記憶装置4は学習データ収集システムを構成する。一例として、学習データ収集装置10は、データ一時記憶部2およびデータ保存判定部3を備える。別の例として、データ一時記憶部2は、学習データ収集装置10の外部に設けられていてもよい。学習データ収集装置10は、センサ1が取得したデータをセンサ1から受け付け、データ保存記憶装置4との間でデータを授受する。 Embodiment 1.
<Configuration>
A configuration of a learning data collection device according to Embodiment 1 of the present disclosure will be described with reference to FIGS. 1 to 4. FIG. As shown in FIG. 1, the learningdata collection device 10 is electrically connected to the sensor 1 and the data storage device 4, and the learning data collection device 10, the sensor 1 and the data storage device 4 are used for learning data collection. configure the system; As an example, the learning data collection device 10 includes a data temporary storage section 2 and a data storage determination section 3 . As another example, the data temporary storage unit 2 may be provided outside the learning data collection device 10 . The learning data collection device 10 receives data acquired by the sensor 1 from the sensor 1 and exchanges data with the data storage device 4 .
<構成>
図1から図4を参照して、本開示の実施の形態1に係る学習データ収集装置の構成について説明する。図1に示されているように、学習データ収集装置10は、センサ1およびデータ保存記憶装置4に電気的に接続され、学習データ収集装置10、センサ1およびデータ保存記憶装置4は学習データ収集システムを構成する。一例として、学習データ収集装置10は、データ一時記憶部2およびデータ保存判定部3を備える。別の例として、データ一時記憶部2は、学習データ収集装置10の外部に設けられていてもよい。学習データ収集装置10は、センサ1が取得したデータをセンサ1から受け付け、データ保存記憶装置4との間でデータを授受する。 Embodiment 1.
<Configuration>
A configuration of a learning data collection device according to Embodiment 1 of the present disclosure will be described with reference to FIGS. 1 to 4. FIG. As shown in FIG. 1, the learning
(センサ)
センサ1は、振動、電圧、電流、温度、または湿度などの物理量に係るデータを取得するセンサ、画像を取得するカメラ、音声を取得するマイクロフォンなど、何らかのデータを取得できるデバイスである。取得されるデータをAIまたは機械学習の学習に使用可能であれば、センサ1はどのようなデバイスであってもよい。センサ1により取得されたデータは、センサ1または不図示のAD変換器によりデジタルデータに変換されてデータ一時記憶部2へ供給される。 (sensor)
The sensor 1 is a device that can acquire some data, such as a sensor that acquires data related to physical quantities such as vibration, voltage, current, temperature, or humidity, a camera that acquires images, and a microphone that acquires sound. The sensor 1 may be any device as long as the acquired data can be used for AI or machine learning. Data acquired by the sensor 1 is converted into digital data by the sensor 1 or an AD converter (not shown) and supplied to the datatemporary storage unit 2 .
センサ1は、振動、電圧、電流、温度、または湿度などの物理量に係るデータを取得するセンサ、画像を取得するカメラ、音声を取得するマイクロフォンなど、何らかのデータを取得できるデバイスである。取得されるデータをAIまたは機械学習の学習に使用可能であれば、センサ1はどのようなデバイスであってもよい。センサ1により取得されたデータは、センサ1または不図示のAD変換器によりデジタルデータに変換されてデータ一時記憶部2へ供給される。 (sensor)
The sensor 1 is a device that can acquire some data, such as a sensor that acquires data related to physical quantities such as vibration, voltage, current, temperature, or humidity, a camera that acquires images, and a microphone that acquires sound. The sensor 1 may be any device as long as the acquired data can be used for AI or machine learning. Data acquired by the sensor 1 is converted into digital data by the sensor 1 or an AD converter (not shown) and supplied to the data
(データ一時記憶部)
データ一時記憶部2は一時的にデータを保持するためのデバイスであり、センサ1から供給されたデータを一時的に保持する。データ一時記憶部2は、例えば、メモリ、HDD(Hard Disk Drive)、またはSSD(Solid State Drive)などの記憶デバイスにより実現される。 (Temporary data storage unit)
The datatemporary storage unit 2 is a device for temporarily holding data, and temporarily holds data supplied from the sensor 1 . The data temporary storage unit 2 is implemented by a storage device such as a memory, HDD (Hard Disk Drive), or SSD (Solid State Drive).
データ一時記憶部2は一時的にデータを保持するためのデバイスであり、センサ1から供給されたデータを一時的に保持する。データ一時記憶部2は、例えば、メモリ、HDD(Hard Disk Drive)、またはSSD(Solid State Drive)などの記憶デバイスにより実現される。 (Temporary data storage unit)
The data
(データ保存判定部)
データ保存判定部3は、データ一時記憶部2から取得したデータを、データ保存記憶装置4に記憶するか否かを判定する機能部である。ここで、図2Aおよび図2Bを参照して、データ保存判定部3のハードウェア構成について説明する。一例として、図2Aに示されているように、データ保存判定部3は処理回路100aにより実現される。処理回路100aは、例えば、単一回路、複合回路、プログラム化したプロセッサ、並列プログラム化したプロセッサ、ASIC(Application Specific Integrated Circuit)、FPGA(Field-Programmable Gate Array)、又は、これらの組合せである。 (Data storage judgment part)
The datastorage determination unit 3 is a functional unit that determines whether or not to store the data acquired from the data temporary storage unit 2 in the data storage device 4 . Here, the hardware configuration of the data save determination unit 3 will be described with reference to FIGS. 2A and 2B. As an example, as shown in FIG. 2A, the data storage determination unit 3 is implemented by a processing circuit 100a. The processing circuit 100a is, for example, a single circuit, a composite circuit, a programmed processor, a parallel programmed processor, an ASIC (Application Specific Integrated Circuit), an FPGA (Field-Programmable Gate Array), or a combination thereof.
データ保存判定部3は、データ一時記憶部2から取得したデータを、データ保存記憶装置4に記憶するか否かを判定する機能部である。ここで、図2Aおよび図2Bを参照して、データ保存判定部3のハードウェア構成について説明する。一例として、図2Aに示されているように、データ保存判定部3は処理回路100aにより実現される。処理回路100aは、例えば、単一回路、複合回路、プログラム化したプロセッサ、並列プログラム化したプロセッサ、ASIC(Application Specific Integrated Circuit)、FPGA(Field-Programmable Gate Array)、又は、これらの組合せである。 (Data storage judgment part)
The data
別の例として、図2Bに示されているように、データ保存判定部3は、CPU(Central Processing Unit)100bと、メモリ100cとにより実現される。メモリ100cに格納されたプログラムがCPU100bに読み出されて実行されることにより、データ保存判定部3の機能(データ保存判定機能)が実現される。プログラムは、ソフトウェア、ファームウェア又はソフトウェアとファームウェアとの組合せとして実現される。メモリ100cの例には、例えば、RAM(Random Access Memory)、ROM(Read Only Memory)、フラッシュメモリ、EPROM(Erasable Programmable Read Only Memory)、EEPROM(Electrically-EPROM)などの不揮発性又は揮発性の半導体メモリ、磁気ディスク、フレキシブルディスク、光ディスク、コンパクトディスク、ミニディスク、DVDが含まれる。
As another example, as shown in FIG. 2B, the data storage determination unit 3 is realized by a CPU (Central Processing Unit) 100b and a memory 100c. The function of the data storage determination unit 3 (data storage determination function) is realized by reading out and executing the program stored in the memory 100c by the CPU 100b. Programs may be implemented as software, firmware, or a combination of software and firmware. Examples of the memory 100c include non-volatile or volatile semiconductors such as RAM (Random Access Memory), ROM (Read Only Memory), flash memory, EPROM (Erasable Programmable Read Only Memory), and EEPROM (Electrically-EPROM). Memory, magnetic disk, flexible disk, optical disk, compact disk, mini disk, DVD are included.
(データ保存記憶装置)
データ保存記憶装置4は、データを記憶するストレージデバイスである。データ保存記憶装置4は、データ保存判定部3により保存すると判定されたデータを保存する。また、データ保存記憶装置4は、データの保存の判定に使用するためのデータをデータ保存判定部3に供給する。データ保存記憶装置4の例には、HDD(Hard Disk Drive)、SSD(Solid State Drive)、メモリ、またはメモリカードなどの保存媒体が含まれる。 (data storage storage device)
The data storage storage device 4 is a storage device that stores data. The data storage storage device 4 stores the data determined to be stored by the datastorage determination unit 3 . In addition, the data saving memory device 4 supplies data to be used for deciding whether to save data to the data saving determination unit 3 . Examples of the data storage device 4 include storage media such as HDDs (Hard Disk Drives), SSDs (Solid State Drives), memories, or memory cards.
データ保存記憶装置4は、データを記憶するストレージデバイスである。データ保存記憶装置4は、データ保存判定部3により保存すると判定されたデータを保存する。また、データ保存記憶装置4は、データの保存の判定に使用するためのデータをデータ保存判定部3に供給する。データ保存記憶装置4の例には、HDD(Hard Disk Drive)、SSD(Solid State Drive)、メモリ、またはメモリカードなどの保存媒体が含まれる。 (data storage storage device)
The data storage storage device 4 is a storage device that stores data. The data storage storage device 4 stores the data determined to be stored by the data
<動作>
次に、学習データ収集装置10のデータ保存判定部3の動作について説明する。端的には、データ保存判定部3は、データ一時記憶部2に保持された新規データdと、データ保存記憶装置4に保存されている2つの既存のデータe1およびe2を用いて、新規データdを保存すべきか否か判定する。一般的にAIまたは機械学習で扱うデータはベクトルで表すことができ、本開示ではデータを2以上の複数次元で表されたn次元ベクトルとする。本実施の形態では、新規データdが2つの既存のデータe1およびe2で線形補間可能であれば、新規データdは重要でないものとして、保存しないと判定する。判定方法の詳細について、図3および図4を参照して説明する。なお、本システムの動作の開始時点において、いくつかの既存データがデータ保存記憶装置4に保存されているものとする。 <Action>
Next, the operation of the datastorage determination unit 3 of the learning data collection device 10 will be described. Briefly, the data storage determination unit 3 uses the new data d held in the data temporary storage unit 2 and the two existing data e1 and e2 stored in the data storage storage device 4 to generate the new data d should be saved. Generally, data handled by AI or machine learning can be represented by a vector, and in the present disclosure, data is assumed to be an n-dimensional vector represented by two or more dimensions. In this embodiment, if the new data d can be linearly interpolated with the two existing data e1 and e2, it is determined that the new data d is not important and should not be saved. Details of the determination method will be described with reference to FIGS. 3 and 4. FIG. It is assumed that some existing data are stored in the data storage device 4 at the start of the operation of this system.
次に、学習データ収集装置10のデータ保存判定部3の動作について説明する。端的には、データ保存判定部3は、データ一時記憶部2に保持された新規データdと、データ保存記憶装置4に保存されている2つの既存のデータe1およびe2を用いて、新規データdを保存すべきか否か判定する。一般的にAIまたは機械学習で扱うデータはベクトルで表すことができ、本開示ではデータを2以上の複数次元で表されたn次元ベクトルとする。本実施の形態では、新規データdが2つの既存のデータe1およびe2で線形補間可能であれば、新規データdは重要でないものとして、保存しないと判定する。判定方法の詳細について、図3および図4を参照して説明する。なお、本システムの動作の開始時点において、いくつかの既存データがデータ保存記憶装置4に保存されているものとする。 <Action>
Next, the operation of the data
まず、ステップST1において、データ保存判定部3は、センサ1により取得されてデータ一時記憶部2にデジタルデータとして保持されている新規データdをデータ一時記憶部2から取得する。
First, in step ST1, the data storage determination unit 3 acquires from the data temporary storage unit 2 new data d acquired by the sensor 1 and held in the data temporary storage unit 2 as digital data.
引き続き、データ保存判定部3は、ステップST2の選択ループを繰り返す。ステップST2の選択ループにおいて、データ保存記憶装置4に保存されている既存のデータの集合から、2つのデータe1およびe2のペアが選択される。ループの終了条件は、予め設定した回数繰り返しを実行したか、既存データのペアe1およびe2を全て選択するまで繰り返したかなどとする。または、以下で説明するステップST4で線形補間可能であるかを計算した結果、線形補間可能であると判定された後にただちにループを終了してもよい。この場合、ループを途中で終了した分だけ計算時間を削減できる。
Subsequently, the data storage determination unit 3 repeats the selection loop of step ST2. In the selection loop of step ST2, two pairs of data e1 and e2 are selected from the set of existing data stored in the data storage device 4. FIG. The end condition of the loop is whether the loop has been repeated a preset number of times, or whether the loop has been repeated until all the existing data pairs e1 and e2 have been selected. Alternatively, as a result of calculating whether or not linear interpolation is possible in step ST4 described below, the loop may be terminated immediately after it is determined that linear interpolation is possible. In this case, the calculation time can be reduced by the part that the loop is terminated halfway.
ステップST3において、データ保存判定部3は、既存のデータe1およびe2のペアを選択する。ステップST3では、毎回異なるe1およびe2のペアを選択し、一度選択されたペアは繰り返して選択されない。
In step ST3, the data storage determination unit 3 selects a pair of existing data e1 and e2. In step ST3, different pairs of e1 and e2 are selected each time, and once selected pairs are not selected repeatedly.
ステップST4において、データ保存判定部3は、新規データdが既存データe1およびe2で線形補間可能であるか計算する。データe1とe2の線形補間xはスカラー値のパラメータλを用いてx=λe1+(1-λ)e2と表すことができる。図4に示すように、線形補間x=λe1+(1-λ)e2は、n次元空間内の点xが取りうる直線lを表した式とみることができる。新規データdが既存データe1およびe2で線形補間可能であるとき、新規データdは直線l上の点として存在し、一方で線形補間可能でないときには、新規データdは直線l上に存在しない。
In step ST4, the data storage determination unit 3 calculates whether the new data d can be linearly interpolated with the existing data e1 and e2. A linear interpolation x of data e1 and e2 can be expressed as x=λe1+(1−λ)e2 using a scalar value parameter λ. As shown in FIG. 4, linear interpolation x=λe1+(1−λ)e2 can be regarded as an equation representing a straight line 1 that can be taken by a point x in an n-dimensional space. When the new data d is linearly interpolable with the existing data e1 and e2, the new data d exists as a point on the line l, while when it is not linearly interpolable, the new data d does not exist on the line l.
直線l上に新規データdが存在するかを計算するには、λの方程式d=λe1+(1-λ)e2に解があるかを判定すればよい。この方程式はn元1次方程式であり、解λが存在するかは簡単に計算することができる。例えば、n個の1次方程式をそれぞれ解き、得られたn個の解λが全て一致するかを判定すればよい。
To calculate whether new data d exists on straight line l, it is sufficient to determine whether the equation d=λe1+(1−λ)e2 of λ has a solution. This equation is an n-dimensional linear equation, and it can be easily calculated whether a solution λ exists. For example, it is sufficient to solve each of n linear equations and determine whether or not all of the obtained n solutions λ agree with each other.
なお、機械学習において教師有り学習を行う場合、データだけでなくデータに対応するラベルを学習に用いる。本実施の形態では、ラベルも含めて線形補間可能であるかを計算してもよい。上述した新規データd、既存のデータe1およびe2の各ラベルをm次元ベクトルyd、y1、y2とし、n+m次元のベクトルd’=(d,yd)、e’1=(e1,y1)およびe’2=(e2,y2)を上述のd、e1およびe2の代わりに用いて、ベクトルd’がベクトルe’1およびe’2により線形補間可能であるかを計算すればよい。ただし、例えばベクトルd’=(d,yd)は、ベクトルdのn個の要素とベクトルydのm個の要素から構成されるn+m個の要素のn+m次元を表すこととする。
In addition, when performing supervised learning in machine learning, not only the data but also the labels corresponding to the data are used for learning. In this embodiment, it may be calculated whether or not linear interpolation is possible, including labels. Let m-dimensional vectors yd, y1, and y2 be the respective labels of the new data d and the existing data e1 and e2 described above, and n+m-dimensional vectors d′=(d, yd), e′1=(e1, y1) and e '2=(e2, y2) can be used in place of d, e1 and e2 above to calculate if vector d' is linearly interpolable by vectors e'1 and e'2. However, for example, vector d'=(d, yd) represents n+m dimension of n+m elements composed of n elements of vector d and m elements of vector yd.
ステップST5において、データ保存判定部3は、ステップST4での計算結果に基づいて、新規データdが少なくとも1回線形補間可能であると判定されたかを判定する。ステップST4で新規データdが線形補間可能であると1回も判定されなかった場合(ステップST5においてNo)、データ保存判定部3は、新規データdを保存すると判定して、新規データdをデータ保存記憶装置4に保存する(ステップST6)。
In step ST5, the data storage determination unit 3 determines whether it is determined that at least one line-type interpolation is possible for the new data d based on the calculation result in step ST4. If it is not determined even once that the new data d can be linearly interpolated in step ST4 (No in step ST5), the data storage determining unit 3 determines to store the new data d, and stores the new data d as data. It is saved in the save storage device 4 (step ST6).
一方、少なくとも1回、ステップST4で新規データdが線形補間可能であると判定された場合(ステップST5においてYes)、新規データdは既存データe1またはe2に類似するデータであると考えられるので、データ保存判定部3は、新規データdを保存しないと判定する(ステップST7)。
On the other hand, when it is determined at least once in step ST4 that the new data d can be linearly interpolated (Yes in step ST5), the new data d is considered to be similar to the existing data e1 or e2. The data storage determination unit 3 determines not to store the new data d (step ST7).
ステップST7において、データ保存判定部3は、単純に新規データdを保存しないと判定するのでなく、ステップST4で新規データdが線形補間可能であると判定された際に用いられた既存データe1およびe2を特定する情報と、新規データdを復元するためのパラメータとを学習データとして保存すると判定してもよい。なお、既存データe1およびe2を特定する情報と、新規データdを復元するためのパラメータは、いずれも新規データdに関連するデータである。既存データe1およびe2を特定する情報の例には、既存データe1およびe2を特定する番号または符号が含まれる。新規データdを復元するためのパラメータの例には、新規データdを既存データe1およびe2で線形補間可能であると判定した際に用いられたλの値が含まれる。データ保存判定部3は、これらの情報とパラメータとをデータ保存記憶装置4に保存する(ステップST7)。
In step ST7, the data storage determination unit 3 does not simply determine that the new data d is not to be stored. It may be determined to save the information specifying e2 and the parameters for restoring the new data d as learning data. Both the information specifying the existing data e1 and e2 and the parameters for restoring the new data d are data related to the new data d. Examples of information identifying the existing data e1 and e2 include numbers or codes identifying the existing data e1 and e2. Examples of parameters for reconstructing the new data d include the value of λ used when determining that the new data d can be linearly interpolated with the existing data e1 and e2. The data storage determination unit 3 stores the information and parameters in the data storage device 4 (step ST7).
このように既存データe1およびe2を特定する情報と新規データdを復元するためのパラメータとを保存することにより、後に学習する際において、既存データを特定する情報から既存データe1およびe2とを抽出し、抽出された既存データe1およびe2と保存されたパラメータとを用いて、保存されずに棄却された新規データdをd=λe1+(1-λ)e2として完全に復元することができる。したがって、既存データe1およびe2を特定する情報と新規データdを復元するためのパラメータλとを保存する場合、単純に新規データdを保存しないとする場合に比べて、学習データ全体の情報量の欠損を回避できるため、AIまたは機械学習の精度を高くすることができる。
By storing the information specifying the existing data e1 and e2 and the parameters for restoring the new data d in this way, the existing data e1 and e2 can be extracted from the information specifying the existing data in subsequent learning. Then, using the extracted existing data e1 and e2 and the saved parameters, the discarded new data d can be completely restored as d=λe1+(1−λ)e2. Therefore, when storing the information specifying the existing data e1 and e2 and the parameter λ for restoring the new data d, the amount of information of the entire learning data is reduced compared to the case of simply not storing the new data d. Since loss can be avoided, the accuracy of AI or machine learning can be improved.
一般に、学習するデータは量だけでなく質も重要であり、同じようなデータが大量にあって似たようなデータを学習したとしても、必ずしもAIまたは機械学習が高精度になるとは限らない。例えば、画像認識であれば、認識させたい対象を様々な角度から撮影した画像を取得することが効果的である。しかしながら、従来技術によれば、類似のデータが大量に収集されるという問題があった。
In general, not only the quantity but also the quality of the data to be learned is important, and even if there is a large amount of similar data and learning similar data, AI or machine learning will not necessarily be highly accurate. For example, in the case of image recognition, it is effective to obtain images of an object to be recognized which are photographed from various angles. However, according to the prior art, there is a problem that a large amount of similar data is collected.
これに対し、以上で説明した本開示の学習データ収集装置10によれば、既存のデータe1またはe2と類似する新規データdは学習データとして取得されない。選択的に、学習データ収集装置10は、新規データdが線形補間可能であると判定された際に用いられた既存データe1およびe2を特定する情報と新規データdを復元するためのパラメータλとを保存する。センサ1で取得したデータの中からAIまたは機械学習の学習に有効なデータを選択して保存することで、学習データを保持するための記憶装置の容量を削減することができる。学習に有効なデータを選択しているので、保存されたデータを学習したAIまたは機械学習は、その認識または回帰を高い精度で獲得することができる。さらに、AIまたは機械学習の学習に必要な計算時間または演算量は学習データ量が少ないほど小さくできるため、学習データ収集装置10により保存された学習データを学習する際の計算時間または演算量を削減することができる。演算量を削減することで、学習を行う機器の低コスト化も実現できる。
On the other hand, according to the learning data collection device 10 of the present disclosure described above, new data d similar to existing data e1 or e2 is not acquired as learning data. Optionally, the learning data collection device 10 collects information specifying the existing data e1 and e2 used when it was determined that the new data d can be linearly interpolated, a parameter λ for restoring the new data d, and to save. By selecting and storing data effective for learning AI or machine learning from the data acquired by the sensor 1, the capacity of a storage device for holding learning data can be reduced. AI or machine learning trained on the saved data can acquire its recognition or regression with high accuracy because it selects valid data for learning. Furthermore, the smaller the amount of learning data, the smaller the calculation time or amount of calculation required for learning AI or machine learning. can do. By reducing the amount of calculation, it is possible to reduce the cost of the equipment that performs learning.
また、後に学習を行う際において、次の参考文献で提案されているデータ拡張手法であるmixupを用いてもよい。Mixupは学習データ内の任意のペアの線形補間を学習データとして用いるデータ拡張手法であり、本実施の形態で保存されずに棄却された新規データdを補間するように学習することができ、AIまたは機械学習の精度を向上することができる。
(参考文献1)H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: beyond empirical risk minimization,” arXiv:1710.09412, 2017. Also, when performing learning later, mixup, which is a data augmentation method proposed in the following reference, may be used. Mixup is a data augmentation method that uses linear interpolation of arbitrary pairs in learning data as learning data, and can learn to interpolate new data d that is rejected without being saved in this embodiment, and AI Or it can improve the accuracy of machine learning.
(Reference 1) H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: beyond empirical risk minimization,” arXiv:1710.09412, 2017.
(参考文献1)H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: beyond empirical risk minimization,” arXiv:1710.09412, 2017. Also, when performing learning later, mixup, which is a data augmentation method proposed in the following reference, may be used. Mixup is a data augmentation method that uses linear interpolation of arbitrary pairs in learning data as learning data, and can learn to interpolate new data d that is rejected without being saved in this embodiment, and AI Or it can improve the accuracy of machine learning.
(Reference 1) H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: beyond empirical risk minimization,” arXiv:1710.09412, 2017.
実施の形態2.
実施の形態1では、データ保存判定部3による新規データdを保存するか否かの判定において既存データによる線形補間を用いたが、新規データdが既存データの線形補間となる可能性は必ずしも大きいとは限らないので、保存する学習データ量の削減効果が限定的になる可能性がある。本実施の形態では、データ保存判定部3による判定において線形補間よりも条件を緩和することにより、より少ないデータが保存されるようにし、これにより保存する学習データ量をより削減できるようにする。Embodiment 2.
In Embodiment 1, the datastorage determination unit 3 uses linear interpolation of existing data to determine whether or not to store new data d. Therefore, the effect of reducing the amount of learning data to be saved may be limited. In the present embodiment, less data is stored by relaxing the conditions for determination by the data storage determination unit 3 compared to linear interpolation, thereby further reducing the amount of learning data to be stored.
実施の形態1では、データ保存判定部3による新規データdを保存するか否かの判定において既存データによる線形補間を用いたが、新規データdが既存データの線形補間となる可能性は必ずしも大きいとは限らないので、保存する学習データ量の削減効果が限定的になる可能性がある。本実施の形態では、データ保存判定部3による判定において線形補間よりも条件を緩和することにより、より少ないデータが保存されるようにし、これにより保存する学習データ量をより削減できるようにする。
In Embodiment 1, the data
実施の形態2による学習データ収集装置10Aの構成は実施の形態1の学習データ収集装置10と同様である。実施の形態2による学習データ収集装置10Aによれば、データ保存判定部3による処理内容(判定方法)が実施の形態1のそれと異なる。実施の形態2の場合のデータ保存判定部3の処理内容について、図5を参照して説明する。図5において、ステップST1、ST2、ST3、ST6およびST7は、実施の形態1の場合と同様である。実施の形態2では、ステップST4AおよびST5Aにおける処理内容が、実施の形態1におけるステップST4およびST5とそれぞれ異なる点で、実施の形態2は実施の形態1と異なる。これらの相違点について、以下にて説明する。
The configuration of the learning data collection device 10A according to the second embodiment is the same as that of the learning data collection device 10 of the first embodiment. According to the learning data collection device 10A according to the second embodiment, the processing content (determination method) by the data storage determination unit 3 is different from that of the first embodiment. The processing contents of the data storage determination unit 3 in the case of the second embodiment will be described with reference to FIG. In FIG. 5, steps ST1, ST2, ST3, ST6 and ST7 are the same as in the first embodiment. Embodiment 2 differs from Embodiment 1 in that the processing contents in steps ST4A and ST5A differ from steps ST4 and ST5 in embodiment 1, respectively. These differences are described below.
ステップST4Aにおいて、データ保存判定部3は、新規データdが既存データe1およびe2の線形補間を示す直線lと距離T以内に存在するかを計算する。Tはしきい値であり、学習データ収集装置10Aを用いて保存の肯否を判定するデータに対して適切に設定する。Tを大きくすると、より多くの学習データ量を削減できるが、必要以上に大きくしすぎると保存されないで棄却されるデータの中に重要なものが含まれる可能性がある。
In step ST4A, the data storage determination unit 3 calculates whether or not the new data d exists within a distance T from the straight line l indicating linear interpolation of the existing data e1 and e2. T is a threshold, which is appropriately set for the data for judging whether or not to save using the learning data collection device 10A. If T is increased, the amount of training data can be reduced more, but if it is increased more than necessary, there is a possibility that important data will be discarded without being saved.
実施の形態1で説明したように、既存データe1およびe2の線形補間はn次元空間内の直線l:x=λe1+(1-λ)e2で表すことができる。実施の形態2では、新規データを表す点dを中心とした距離Tの半径のn次元球Cが直線lと交差するか否かを判定する。図6のように直線lと球Cが交差すれば、新規データdが既存データe1およびe2の線形補間と距離T以内に存在し、図7のように交差しなければ新規データdは既存データe1およびe2の線形補間と距離Tよりも離れて存在することとなる。
As described in Embodiment 1, linear interpolation of existing data e1 and e2 can be represented by a straight line l: x=λe1+(1−λ)e2 in n-dimensional space. In the second embodiment, it is determined whether or not an n-dimensional sphere C with a radius of a distance T centered at a point d representing new data intersects the straight line l. If the straight line l and the sphere C intersect as shown in FIG. 6, the new data d exists within the distance T from the linear interpolation of the existing data e1 and e2. It exists farther than the linear interpolation of e1 and e2 and the distance T.
直線lと球Cが交差するかの判定は次のように実現できる。点dを中心とした半径T(距離T)のn次元球Cは|x-d|2=T2と表すことができ、直線lは上述のようにx=λe1+(1-λ)e2で表される。xとλを変数とした次の2元連立方程式
x=λe1+(1-λ)e2 (1)
|x-d|2=T2 (2)
は、球Cと直線lが交差する場合は実数解をもち、交差しない場合は実数解をもたない。 Determination of whether the straight line l and the sphere C intersect can be realized as follows. An n-dimensional sphere C with radius T ( distance T) centered at point d can be expressed as |x − d| expressed. The following two-dimensional simultaneous equation x=λe1+(1-λ)e2 with x and λ as variables (1)
|xd| 2 =T 2 (2)
has a real solution if the sphere C and the line l intersect, and does not have a real solution if they do not intersect.
x=λe1+(1-λ)e2 (1)
|x-d|2=T2 (2)
は、球Cと直線lが交差する場合は実数解をもち、交差しない場合は実数解をもたない。 Determination of whether the straight line l and the sphere C intersect can be realized as follows. An n-dimensional sphere C with radius T ( distance T) centered at point d can be expressed as |x − d| expressed. The following two-dimensional simultaneous equation x=λe1+(1-λ)e2 with x and λ as variables (1)
|xd| 2 =T 2 (2)
has a real solution if the sphere C and the line l intersect, and does not have a real solution if they do not intersect.
式(1)を式(2)に代入すると、次の式(3)が得られる。
|λe1+(1-λ)e2-d|2=T2 (3) Substituting equation (1) into equation (2) yields the following equation (3).
|λe1+(1-λ)e2-d| 2 =T 2 (3)
|λe1+(1-λ)e2-d|2=T2 (3) Substituting equation (1) into equation (2) yields the following equation (3).
|λe1+(1-λ)e2-d| 2 =T 2 (3)
式(3)は、xを含まない、λの方程式となる。この式(3)を整理すると、次の式(4)が得られる。
|(e1-e2)λ+(e2-d)|2=T2 (4) Equation (3) becomes an equation for λ that does not include x. By rearranging this formula (3), the following formula (4) is obtained.
|(e1-e2)λ+(e2-d)| 2 =T 2 (4)
|(e1-e2)λ+(e2-d)|2=T2 (4) Equation (3) becomes an equation for λ that does not include x. By rearranging this formula (3), the following formula (4) is obtained.
|(e1-e2)λ+(e2-d)| 2 =T 2 (4)
式(4)を更に整理すると、次の式(5)が得られる。
|(e1-e2)|2λ2+2(e1-e2)・(e2-d)λ+(|(e2-d)|2-T2)=0 (5) Further arranging the equation (4) yields the following equation (5).
|(e1-e2)| 2 λ 2 +2(e1-e2)・(e2-d)λ+(|(e2-d)| 2 -T 2 )=0 (5)
|(e1-e2)|2λ2+2(e1-e2)・(e2-d)λ+(|(e2-d)|2-T2)=0 (5) Further arranging the equation (4) yields the following equation (5).
|(e1-e2)| 2 λ 2 +2(e1-e2)・(e2-d)λ+(|(e2-d)| 2 -T 2 )=0 (5)
式(5)の第2項目における記号“・”はベクトルの内積を表す。式(5)はλの2次方程式であり、係数は全てスカラー値になっている。
The symbol "·" in the second item of Equation (5) represents the inner product of vectors. Equation (5) is a quadratic equation of λ, and all coefficients are scalar values.
2次方程式が実数解を持つか否かは、2次方程式の判別式の符号を計算して判定すればよい。判別式が正または0であれば実数解が存在し、負であれば実数解は存在しない。判別式Dは2次方程式の係数a、b、およびcを用いてD=b2-4acと表すことができ、式(5)の場合の係数a、b、およびcは具体的には次の式(6)~(8)のとおりである。
a=|(e1-e2)|2 (6)
b=2(e1-e2)・(e2-d) (7)
c=|(e2-d)|2-T2 (8)
D≧0であれば、球Cと直線lは交差し、D<0なら球Cと直線lは交差しない。 Whether or not a quadratic equation has a real number solution can be determined by calculating the sign of the discriminant of the quadratic equation. If the discriminant is positive or zero, there is a real solution, and if it is negative, there is no real solution. The discriminant D can be expressed as D=b 2 −4ac using the coefficients a, b, and c of the quadratic equation, and the coefficients a, b, and c in the case of equation (5) are specifically (6) to (8).
a=|(e1-e2)| 2 (6)
b=2(e1-e2)・(e2-d) (7)
c=|(e2 - d)| 2 -T2 (8)
If D≧0, the sphere C and the line l intersect, and if D<0, the sphere C and the line l do not intersect.
a=|(e1-e2)|2 (6)
b=2(e1-e2)・(e2-d) (7)
c=|(e2-d)|2-T2 (8)
D≧0であれば、球Cと直線lは交差し、D<0なら球Cと直線lは交差しない。 Whether or not a quadratic equation has a real number solution can be determined by calculating the sign of the discriminant of the quadratic equation. If the discriminant is positive or zero, there is a real solution, and if it is negative, there is no real solution. The discriminant D can be expressed as D=b 2 −4ac using the coefficients a, b, and c of the quadratic equation, and the coefficients a, b, and c in the case of equation (5) are specifically (6) to (8).
a=|(e1-e2)| 2 (6)
b=2(e1-e2)・(e2-d) (7)
c=|(e2 - d)| 2 -T2 (8)
If D≧0, the sphere C and the line l intersect, and if D<0, the sphere C and the line l do not intersect.
なお、実施の形態1で説明したように、ラベルを含めたn+m次元のベクトルd’=(d,yd)、e’1=(e1,y1)およびe’2=(e2,y2)を、上述のd、e1およびe2の代わりにそれぞれ用いてもよい。
As described in Embodiment 1, n+m-dimensional vectors d'=(d, yd), e'1=(e1, y1) and e'2=(e2, y2) including labels are may be used in place of d, e1 and e2 above, respectively.
以上のようにすれば、実施の形態1と比べてデータを保存する条件を緩和することができ、保存するデータ量を削減することができる。
By doing so, the conditions for saving data can be relaxed compared to the first embodiment, and the amount of data to be saved can be reduced.
以上のように、センサ1で取得したデータの中からAIまたは機械学習の学習に有効なデータを選択して保存することで、学習データを保持するための記憶装置の容量を削減することができる。学習に有効なデータを選択しているので、保存されたデータを学習したAIまたは機械学習は、その認識または回帰を高い精度で獲得することができる。さらに、AIまたは機械学習の学習に必要な計算時間や演算量は学習データ量が少ないほど小さくできるため、学習データ収集装置10Aにより保存された学習データを学習する際の計算時間や演算量を削減することができる。演算量を削減することで、学習を行う機器の低コスト化も実現できる。
As described above, by selecting and saving data effective for learning AI or machine learning from the data acquired by the sensor 1, it is possible to reduce the capacity of the storage device for holding the learning data. . AI or machine learning trained on the saved data can acquire its recognition or regression with high accuracy because it selects valid data for learning. Furthermore, the smaller the amount of learning data, the smaller the calculation time and amount of calculation required for learning AI or machine learning. can do. By reducing the amount of calculation, it is possible to reduce the cost of the equipment that performs learning.
また、後に学習を行う際において、参考文献1で提案されているデータ拡張手法であるmixupを用いてもよい。Mixupは学習データ内の任意のペアの線形補間を学習データとして用いるデータ拡張手法であり、本実施の形態で保存せず棄却された新規データdを補間するように学習することができ、AIまたは機械学習の精度を向上することができる。
In addition, mixup, which is a data augmentation method proposed in Reference 1, may be used when performing learning later. Mixup is a data augmentation method that uses linear interpolation of any pair in the learning data as learning data, and can learn to interpolate the new data d that is rejected without saving in the present embodiment, AI or It can improve the accuracy of machine learning.
実施の形態3.
<構成>
実施の形態1と実施の形態2では、データ保存判定部3はデータd、e1およびe2を用いて判定を行ったが、収集するデータが画像のように次元が大きい場合には、新規データが既存データの線形補間で表せることが少ないと考えられる。また、実施の形態2のように条件を緩和した場合、保存データ量を削減するためにはしきい値としての距離Tを大きくする必要があり、重要なデータを棄却してしまう可能性が高まってしまう。Embodiment 3.
<Configuration>
InEmbodiments 1 and 2, the data storage determination unit 3 performed determination using the data d, e1, and e2. It is thought that there are few things that can be represented by linear interpolation of existing data. Moreover, when the conditions are relaxed as in the second embodiment, it is necessary to increase the distance T as the threshold value in order to reduce the amount of stored data, and the possibility of discarding important data increases. end up
<構成>
実施の形態1と実施の形態2では、データ保存判定部3はデータd、e1およびe2を用いて判定を行ったが、収集するデータが画像のように次元が大きい場合には、新規データが既存データの線形補間で表せることが少ないと考えられる。また、実施の形態2のように条件を緩和した場合、保存データ量を削減するためにはしきい値としての距離Tを大きくする必要があり、重要なデータを棄却してしまう可能性が高まってしまう。
<Configuration>
In
そこで実施の形態3では、データ保存判定部3は、データd、e1およびe2を用いることに代えて、データd、e1およびe2を学習済みニューラルネットワークに入力し、これらのデータの中間層出力の値を用いて同様の判定を行う。
Therefore, in Embodiment 3, instead of using the data d, e1 and e2, the data storage determination unit 3 inputs the data d, e1 and e2 to the trained neural network, and outputs these data to the intermediate layer. A similar determination is made using the value.
実施の形態3による学習データ収集装置20を含むシステムの構成を図8に示す。図8に示されたシステムは、センサ1、データ一時記憶部2、データ保存判定部3、データ保存記憶装置4を備える点で図1に示されたシステムと同様であるが、学習済み機械学習モデル5を備える点で図1に示されたシステムと異なる。学習データ収集装置20のデータ保存判定部3は、学習済み機械学習モデル5との間でデータの授受を行うように構成されている。学習済み機械学習モデル5は、予め学習し用意されたニューラルネットワークが保持された記憶装置である。このニューラルネットワークは、学習データ収集装置20または別の手段で収集した学習データで予め学習されているものとする。このニューラルネットワークは推論動作が可能な状態で保持されており、学習済み機械学習モデル5はデータ保存判定部3のためにニューラルネットワークを供給する。
The configuration of a system including the learning data collection device 20 according to Embodiment 3 is shown in FIG. The system shown in FIG. 8 is the same as the system shown in FIG. It differs from the system shown in FIG. 1 in that the model 5 is provided. The data storage determination unit 3 of the learning data collection device 20 is configured to exchange data with the trained machine learning model 5 . The trained machine learning model 5 is a storage device that holds a neural network trained and prepared in advance. This neural network is trained in advance with learning data collected by the learning data collecting device 20 or another means. This neural network is held in a state in which inference operations are possible, and the trained machine learning model 5 supplies the neural network for the data storage determination unit 3 .
データ保存判定部3は、学習済み機械学習モデル5から提供されたニューラルネットワークに新規データd、既存データe1およびe2を入力し、それぞれの中間層出力d’、e’1およびe’2を学習済み機械学習モデル5から取得する。
The data storage determination unit 3 inputs the new data d and the existing data e1 and e2 to the neural network provided from the trained machine learning model 5, and learns the respective intermediate layer outputs d', e'1 and e'2. obtained from the machine learning model 5.
その後、データ保存判定部3は、データd、e1およびe2の代わりに中間層出力d’、e’1およびe’2を用いて、実施の形態1の図3または実施の形態2の図5の判定方法に準じて新規データdまたは新規データdに関連するデータを保存するか判定する。
After that, the data storage determination unit 3 uses the intermediate layer outputs d′, e′1 and e′2 instead of the data d, e1 and e2 to obtain the data shown in FIG. 3 of the first embodiment or FIG. 5 of the second embodiment. It is determined whether to save the new data d or data related to the new data d according to the determination method of .
実施の形態1の図3の判定方法に準じる場合、ステップST4に対応するステップでは、データ保存判定部3は、中間層出力d’が中間層出力e’1およびe’2の線形補間で表されるかを計算する。中間層出力d’が中間層出力e’1およびe’2の線形補間で表されない場合、データ保存判定部3は、図3のステップST6に対応するステップにおいて、ステップST6と同様に新規データdを保存すると判定してもよいし、新規データdを保存するとの判定に代えて新規データdに関連するデータである中間層出力d’を保存すると判定してもよい。中間層出力d’が中間層出力e’1およびe’2の線形補間で表される場合、データ保存判定部3は、図3のステップST7に対応するステップにおいて、新規データdを保存しないと判定してもよい。また、データ保存判定部3は、図3のステップST7に対応するステップにおいて、新規データdに関連するデータである、既存データe1およびe2を特定する情報と新規データdを復元するためのパラメータとを保存すると判定してもよい。
In the case of conforming to the determination method of FIG. 3 of Embodiment 1, in the step corresponding to step ST4, the data storage determination unit 3 determines that the intermediate layer output d′ is represented by linear interpolation of the intermediate layer outputs e′1 and e′2. Calculate if If the intermediate layer output d' is not represented by linear interpolation of the intermediate layer outputs e'1 and e'2, the data storage determination unit 3, in the step corresponding to step ST6 in FIG. may be determined to be stored, or instead of determining to store the new data d, it may be determined to store the intermediate layer output d', which is data related to the new data d. When the intermediate layer output d' is represented by linear interpolation of the intermediate layer outputs e'1 and e'2, the data storage determination unit 3 determines that the new data d should be stored in the step corresponding to step ST7 in FIG. You can judge. Further, in a step corresponding to step ST7 in FIG. may be determined to be stored.
実施の形態2に係る図5の判定方法に準じる場合、ステップST4Aに相当するステップでは、データ保存判定部3は、中間層出力d’が中間層出力e’1およびe’2の線形補間と距離T以内に存在するかを計算する。中間層出力d’が中間層出力e’1およびe’2の線形補間と距離T以内に存在しない場合、データ保存判定部3は、図5のステップST6に対応するステップにおいて、ステップST6と同様に新規データdを保存すると判定してもよいし、新規データdを保存するとの判定に代えて新規データdに関連するデータである中間層出力d’を保存すると判定してもよい。中間層出力d’が中間層出力e’1およびe’2の線形補間と距離T以内に存在する場合、データ保存判定部3は、図5のステップST7に対応するステップにおいて、新規データdを保存しないと判定してもよい。また、データ保存判定部3は、図5のステップST7に対応するステップにおいて、新規データdに関連するデータである、既存データe1およびe2を特定する情報と新規データdを復元するためのパラメータとを保存すると判定してもよい。
5 according to the second embodiment, in a step corresponding to step ST4A, the data storage determination unit 3 determines that the intermediate layer output d' is linearly interpolated between the intermediate layer outputs e'1 and e'2. Calculate if it exists within the distance T. If the intermediate layer output d' does not exist within the distance T from the linear interpolation of the intermediate layer outputs e'1 and e'2, the data storage determination unit 3 performs the same operation as in step ST6 in the step corresponding to step ST6 in FIG. Alternatively, it may be determined to store the intermediate layer output d', which is data related to the new data d, instead of storing the new data d. If the intermediate layer output d' exists within the distance T from the linear interpolation of the intermediate layer outputs e'1 and e'2, the data storage determination unit 3 stores the new data d in the step corresponding to step ST7 in FIG. It may be determined not to save. In a step corresponding to step ST7 in FIG. 5, the data storage determination unit 3 stores information specifying the existing data e1 and e2, which are data related to the new data d, and parameters for restoring the new data d. may be determined to be stored.
ニューラルネットワークを適切に設計することにより、データd、e1およびe2の次元数よりも中間層出力で得られるd’、e’1およびe’2の次元数を小さくすることができ、新規データを既存データの線形補間で表せる可能性または新規データが距離T以内に存在する可能性が高まり、保存する学習データ量を実施の形態1や実施の形態2よりも削減することができる。
By appropriately designing the neural network, the number of dimensions of d', e'1 and e'2 obtained in the hidden layer output can be made smaller than the number of dimensions of data d, e1 and e2, and the new data can be The possibility that existing data can be represented by linear interpolation or the possibility that new data exists within the distance T increases, and the amount of learning data to be stored can be reduced compared to the first and second embodiments.
さらには、新規データdに代えて新規データに関連するデータである中間層出力d’を学習データとして保存すれば、保存するデータの次元数を抑制することができ、保存するデータ量を削減することができる。
Furthermore, if the intermediate layer output d', which is data related to the new data, is saved as learning data instead of the new data d, the number of dimensions of the data to be saved can be suppressed, and the amount of data to be saved can be reduced. be able to.
また、ニューラルネットワークの中間層出力は、入力データの特徴量が適切に抽出された値である可能性が高く、より適切にデータ保存すべきか否かの判定ができる。その結果、本実施の形態で得られた学習データで学習したAIまたは機械学習の精度を高めることができる。
In addition, there is a high possibility that the intermediate layer output of the neural network is a value in which the feature amount of the input data is appropriately extracted, and it is possible to determine whether the data should be saved more appropriately. As a result, the accuracy of AI or machine learning learned with the learning data obtained in the present embodiment can be improved.
以上のように、センサ1で取得したデータの中からAIまたは機械学習の学習に有効なデータを選択して保存することで、学習データを保持するための記憶装置の容量を削減することができる。学習に有効なデータを選択しているので、保存されたデータを学習したAIまたは機械学習は、その認識または回帰を高い精度で獲得することができる。さらに、AIまたは機械学習の学習に必要な計算時間や演算量は学習データ量が少ないほど小さくできるため、学習データ収集装置20により保存された学習データを学習する際の計算時間や演算量を削減することができる。演算量を削減することで、学習を行う機器の低コスト化も実現できる。
As described above, by selecting and saving data effective for learning AI or machine learning from the data acquired by the sensor 1, it is possible to reduce the capacity of the storage device for holding the learning data. . AI or machine learning trained on the saved data can acquire its recognition or regression with high accuracy because it selects valid data for learning. Furthermore, the smaller the amount of learning data, the smaller the calculation time and amount of calculation required for learning AI or machine learning. can do. By reducing the amount of calculation, it is possible to reduce the cost of the equipment that performs learning.
また、後に学習を行う際において、参考文献1で提案されているデータ拡張手法であるmixupを用いてもよい。Mixupは学習データ内の任意のペアの線形補間を学習データとして用いるデータ拡張手法であり、本実施の形態で保存せず棄却された新規データdを補間するように学習することができ、AIまたは機械学習の精度を向上することができる。
In addition, mixup, which is a data augmentation method proposed in Reference 1, may be used when performing learning later. Mixup is a data augmentation method that uses linear interpolation of any pair in the learning data as learning data, and can learn to interpolate the new data d that is rejected without saving in the present embodiment, AI or It can improve the accuracy of machine learning.
なお、実施形態を組み合わせたり、各実施形態を適宜、変形、省略したりすることが可能である。
It should be noted that the embodiments can be combined, and each embodiment can be modified or omitted as appropriate.
本開示の学習データ収集技術は、AIまたは機械学習で用いるための学習データを収集するための装置として用いることができる。
The learning data collection technology of the present disclosure can be used as a device for collecting learning data for use in AI or machine learning.
1 センサ、2 データ一時記憶部、3 データ保存判定部、4 データ保存記憶装置、5 学習済み機械学習モデル、10 学習データ収集装置、10A 学習データ収集装置、20 学習データ収集装置、100a 処理回路、100b CPU、100c メモリ。
1 sensor, 2 data temporary storage unit, 3 data storage determination unit, 4 data storage storage device, 5 learned machine learning model, 10 learning data collection device, 10A learning data collection device, 20 learning data collection device, 100a processing circuit, 100b CPU, 100c memory.
Claims (13)
- センサを介して新たに取得された新規データおよびデータ保存記憶装置に既に保存されている2つの既存データを取得し、前記新規データまたは前記新規データに関連するデータを学習データとして保存するか否かを前記2つの既存データを用いて判定するデータ保存判定部、
を備える、学習データ収集装置。 Whether to acquire new data newly acquired through a sensor and two existing data already stored in a data storage device, and store the new data or data related to the new data as learning data A data storage determination unit that determines using the two existing data,
A learning data collection device. - 前記データ保存判定部は、前記新規データを前記2つの既存データの線形補間で表せるかを計算し、前記新規データを前記2つの既存データの線形補間で表せる場合、前記新規データを保存しないと判定する、
請求項1に記載の学習データ収集装置。 The data storage determination unit calculates whether the new data can be represented by linear interpolation of the two existing data, and determines not to store the new data if the new data can be represented by linear interpolation of the two existing data. do,
The learning data collection device according to claim 1. - 前記データ保存判定部は、前記新規データを前記2つの既存データの線形補間で表せるかを計算し、前記新規データを前記2つの既存データの線形補間で表せる場合、前記新規データを復元するためのパラメータと前記2つの既存データを特定する情報とを前記新規データに関連するデータとして保存すると判定する、
請求項1または2に記載の学習データ収集装置。 The data storage determination unit calculates whether the new data can be expressed by linear interpolation of the two existing data, and if the new data can be expressed by linear interpolation of the two existing data, a method for restoring the new data. determining to store parameters and information identifying the two existing data as data associated with the new data;
The learning data collection device according to claim 1 or 2. - 前記データ保存判定部は、前記新規データが前記2つの既存データの線形補間からある距離以内に存在するかを計算し、前記新規データが前記距離以内に存在する場合、前記新規データを保存しないと判定する、
請求項1に記載の学習データ収集装置。 The data storage determination unit calculates whether the new data exists within a certain distance from the linear interpolation of the two existing data, and if the new data exists within the distance, the new data is not stored. judge,
The learning data collection device according to claim 1. - 前記データ保存判定部は、前記新規データが前記2つの既存データの線形補間からある距離以内に存在するかを計算し、前記新規データが前記距離以内に存在する場合、前記新規データを復元するためのパラメータと前記2つの既存データを特定する情報とを前記新規データに関連するデータとして保存すると判定する、
請求項1または4に記載の学習データ収集装置。 The data storage determination unit calculates whether the new data exists within a certain distance from the linear interpolation of the two existing data, and restores the new data if the new data exists within the distance. and information identifying the two existing data are stored as data associated with the new data;
The learning data collection device according to claim 1 or 4. - 前記データ保存判定部は、ニューラルネットワークで構成された学習済み機械学習モデルを参照して前記新規データおよび前記2つの既存データを前記ニューラルネットワークに入力して中間層出力を取得し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間で表せるかを計算し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間で表せる場合、前記新規データを保存しないと判定する、
請求項1に記載の学習データ収集装置。 The data storage determination unit refers to a trained machine learning model configured by a neural network, inputs the new data and the two existing data to the neural network, acquires an intermediate layer output, and stores the new data. calculating whether the hidden layer output can be represented by a linear interpolation of the hidden layer outputs of the two existing data, and if the hidden layer output of the new data can be represented by a linear interpolation of the hidden layer outputs of the two existing data, the new data; determine not to save the
The learning data collection device according to claim 1. - 前記データ保存判定部は、ニューラルネットワークで構成された学習済み機械学習モデルを参照して前記新規データおよび前記2つの既存データを前記ニューラルネットワークに入力して中間層出力を取得し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間で表せるかを計算し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間で表せる場合、前記新規データを復元するためのパラメータと前記2つの既存データを特定する情報とを前記新規データに関連するデータとして保存すると判定する、
請求項1または6に記載の学習データ収集装置。 The data storage determination unit refers to a trained machine learning model configured by a neural network, inputs the new data and the two existing data to the neural network, acquires an intermediate layer output, and stores the new data. calculating whether the hidden layer output can be represented by a linear interpolation of the hidden layer outputs of the two existing data, and if the hidden layer output of the new data can be represented by a linear interpolation of the hidden layer outputs of the two existing data, the new data; and information identifying the two existing data are stored as data associated with the new data;
The learning data collection device according to claim 1 or 6. - 前記データ保存判定部は、ニューラルネットワークで構成された学習済み機械学習モデルを参照して前記新規データおよび前記2つの既存データを前記ニューラルネットワークに入力して中間層出力を取得し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間からある距離以内に存在するかを計算し、前記新規データの中間層出力が前記距離以内に存在する場合、前記新規データを保存しないと判定する、
請求項1に記載の学習データ収集装置。 The data storage determination unit refers to a trained machine learning model configured by a neural network, inputs the new data and the two existing data to the neural network, acquires an intermediate layer output, and stores the new data. calculating if the hidden layer output is within a distance from a linear interpolation of the two existing data hidden layer outputs, and if the new data hidden layer output is within the distance, do not store the new data. determine that
The learning data collection device according to claim 1. - 前記データ保存判定部は、ニューラルネットワークで構成された学習済み機械学習モデルを参照して前記新規データおよび前記2つの既存データを前記ニューラルネットワークに入力して中間層出力を取得し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間からある距離以内に存在するかを計算し、前記新規データの中間層出力が前記距離以内に存在する場合、前記新規データを復元するためのパラメータと前記2つの既存データを特定する情報とを前記新規データに関連するデータとして保存すると判定する、
請求項1または8に記載の学習データ収集装置。 The data storage determination unit refers to a trained machine learning model configured by a neural network, inputs the new data and the two existing data to the neural network, acquires an intermediate layer output, and stores the new data. calculating if the hidden layer output is within a distance from a linear interpolation of the two existing data hidden layer outputs, and if the new data hidden layer output is within the distance, reconstructing the new data. determining to store parameters for and information identifying the two existing data as data associated with the new data;
The learning data collection device according to claim 1 or 8. - 前記データ保存判定部は、ニューラルネットワークで構成された学習済み機械学習モデルを参照して前記新規データおよび前記2つの既存データを前記ニューラルネットワークに入力して中間層出力を取得し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間で表せるかを計算し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間で表せない場合、前記新規データの中間層出力を前記新規データに関連するデータとして保存すると判定する、
請求項1に記載の学習データ収集装置。 The data storage determination unit refers to a trained machine learning model configured by a neural network, inputs the new data and the two existing data to the neural network, acquires an intermediate layer output, and stores the new data. calculating whether the hidden layer output can be represented by a linear interpolation of the hidden layer outputs of the two existing data, and if the hidden layer output of the new data cannot be represented by a linear interpolation of the hidden layer outputs of the two existing data, the new determining to store a hidden layer output of data as data associated with the new data;
The learning data collection device according to claim 1. - 前記データ保存判定部は、ニューラルネットワークで構成された学習済み機械学習モデルを参照して前記新規データおよび前記2つの既存データを前記ニューラルネットワークに入力して中間層出力を取得し、前記新規データの中間層出力が前記2つの既存データの中間層出力の線形補間からある距離以内に存在するかを計算し、前記新規データの中間層出力が前記距離以内に存在しない場合、前記新規データの中間層出力を前記新規データに関連するデータとして保存すると判定する、
請求項1に記載の学習データ収集装置。 The data storage determination unit refers to a trained machine learning model configured by a neural network, inputs the new data and the two existing data to the neural network, acquires an intermediate layer output, and stores the new data. calculating if the hidden layer output is within a distance from a linear interpolation of the two existing data hidden layer outputs, and if the new data hidden layer output is not within the distance, then the new data hidden layer output determining to store output as data associated with the new data;
The learning data collection device according to claim 1. - データ保存判定部を備える学習データ収集装置による学習データ収集方法であって、
前記データ保存判定部が、センサを介して新たに取得された新規データおよびデータ保存記憶装置に既に保存されている2つの既存データを取得し、前記新規データまたは前記新規データに関連するデータを学習データとして保存するか否かを前記2つの既存データを用いて判定するステップ、
を備える、学習データ収集方法。 A learning data collection method using a learning data collection device comprising a data storage determination unit,
The data storage determination unit acquires new data newly acquired through a sensor and two existing data already stored in a data storage device, and learns the new data or data related to the new data. Determining whether to save as data using the two existing data;
A learning data collection method comprising: - センサを介して新たに取得された新規データおよびデータ保存記憶装置に既に保存されている2つの既存データを取得し、前記新規データまたは前記新規データに関連するデータを学習データとして保存するか否かを前記2つの既存データを用いて判定するデータ保存判定機能、
をコンピュータに実行させる学習データ収集プログラム。 Whether to acquire new data newly acquired through a sensor and two existing data already stored in a data storage device, and store the new data or data related to the new data as learning data A data storage determination function that determines using the two existing data,
A learning data collection program that causes a computer to execute
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/024066 WO2022269885A1 (en) | 2021-06-25 | 2021-06-25 | Learning data collection device, learning data collection method, and learning data collection program |
| JP2023529390A JP7415082B2 (en) | 2021-06-25 | 2021-06-25 | Learning data collection device, learning data collection method, and learning data collection program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/024066 WO2022269885A1 (en) | 2021-06-25 | 2021-06-25 | Learning data collection device, learning data collection method, and learning data collection program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022269885A1 true WO2022269885A1 (en) | 2022-12-29 |
Family
ID=84544440
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/024066 WO2022269885A1 (en) | 2021-06-25 | 2021-06-25 | Learning data collection device, learning data collection method, and learning data collection program |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7415082B2 (en) |
| WO (1) | WO2022269885A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025109662A1 (en) * | 2023-11-20 | 2025-05-30 | 日本電信電話株式会社 | Reinforcement learning device, reinforcement learning method, and reinforcement learning program |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0738745A (en) * | 1993-06-25 | 1995-02-07 | Sharp Corp | Image forming device setting picture quality by neural network |
| JPH08329196A (en) * | 1995-05-31 | 1996-12-13 | Sanyo Electric Co Ltd | Character recognition device and learning method therefor |
| JP2020166397A (en) * | 2019-03-28 | 2020-10-08 | パナソニックIpマネジメント株式会社 | Image processing equipment, image processing methods, and programs |
| JP2021096511A (en) * | 2019-12-13 | 2021-06-24 | 富士通株式会社 | Learning data generation method, learning data generation program, and information processing device |
-
2021
- 2021-06-25 JP JP2023529390A patent/JP7415082B2/en active Active
- 2021-06-25 WO PCT/JP2021/024066 patent/WO2022269885A1/en active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0738745A (en) * | 1993-06-25 | 1995-02-07 | Sharp Corp | Image forming device setting picture quality by neural network |
| JPH08329196A (en) * | 1995-05-31 | 1996-12-13 | Sanyo Electric Co Ltd | Character recognition device and learning method therefor |
| JP2020166397A (en) * | 2019-03-28 | 2020-10-08 | パナソニックIpマネジメント株式会社 | Image processing equipment, image processing methods, and programs |
| JP2021096511A (en) * | 2019-12-13 | 2021-06-24 | 富士通株式会社 | Learning data generation method, learning data generation program, and information processing device |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025109662A1 (en) * | 2023-11-20 | 2025-05-30 | 日本電信電話株式会社 | Reinforcement learning device, reinforcement learning method, and reinforcement learning program |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022269885A1 (en) | 2022-12-29 |
| JP7415082B2 (en) | 2024-01-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107545889B (en) | Model optimization method and device suitable for pattern recognition and terminal equipment | |
| CN110383299B (en) | Memory enhanced generation time model | |
| JP6943291B2 (en) | Learning device, learning method, and program | |
| CN110210513A (en) | Data classification method, device and terminal device | |
| CN112001488A (en) | Training generative antagonistic networks | |
| CN111582105A (en) | Unsupervised point cloud feature learning method and unsupervised point cloud feature learning device based on local global bidirectional reasoning | |
| CN111524118A (en) | Transformer operating state detection method, device, computer equipment and storage medium | |
| US20220108153A1 (en) | Bayesian context aggregation for neural processes | |
| Spera et al. | Egocentric shopping cart localization | |
| CN116434303A (en) | Facial expression capturing method, device and medium based on multi-scale feature fusion | |
| WO2022269885A1 (en) | Learning data collection device, learning data collection method, and learning data collection program | |
| JP5776694B2 (en) | Learning apparatus, learning system, learning method, and learning program for object identification | |
| CN111788582B (en) | Electronic apparatus and control method thereof | |
| Liu et al. | Lidarnas: Unifying and searching neural architectures for 3d point clouds | |
| CN118313445A (en) | A federated incremental learning method and system based on constrained gradient updating | |
| CN112712094B (en) | Model training method, device, equipment and storage medium | |
| CN118865433A (en) | A pedestrian target detection model training method, device and equipment | |
| Qin et al. | Evolving domain generalization via latent structure-aware sequential autoencoder | |
| CN115775214A (en) | A method and system for point cloud completion based on multi-stage fractal combination | |
| KR20220073652A (en) | Method and apparatus for anomaly detection by reward-based retraining of GAN | |
| EP4446944A1 (en) | Efficient active learning | |
| US12045153B1 (en) | Apparatus and method of hot-swapping a component of a component unit in a cluster | |
| CN118664607B (en) | A method and system for predicting motion trajectory of an upper limb rehabilitation robot | |
| US20240203105A1 (en) | Methods, Systems, and Computer Systems for Training a Machine-Learning Model, Generating a Training Corpus, and Using a Machine-Learning Model for Use in a Scientific or Surgical Imaging System | |
| Jodogne et al. | Approximate policy iteration for closed-loop learning of visual tasks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21947170 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2023529390 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21947170 Country of ref document: EP Kind code of ref document: A1 |