WO2022230038A1 - 学習装置、学習方法および学習プログラム - Google Patents
学習装置、学習方法および学習プログラム Download PDFInfo
- Publication number
- WO2022230038A1 WO2022230038A1 PCT/JP2021/016728 JP2021016728W WO2022230038A1 WO 2022230038 A1 WO2022230038 A1 WO 2022230038A1 JP 2021016728 W JP2021016728 W JP 2021016728W WO 2022230038 A1 WO2022230038 A1 WO 2022230038A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- function
- parameter
- trajectory data
- distribution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/092—Reinforcement learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/004—Artificial life, i.e. computing arrangements simulating life
- G06N3/006—Artificial life, i.e. computing arrangements simulating life based on simulated virtual individual or collective life forms, e.g. social simulations or particle swarm optimisation [PSO]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
Definitions
- the present invention relates to a learning device, a learning method, and a learning program that perform inverse reinforcement learning.
- Reinforcement learning is known as one of the machine learning methods. Reinforcement learning is a method of learning actions that maximize value through trial and error of various actions. Reinforcement learning sets a reward function for evaluating this value, and searches for actions that maximize this reward function. However, setting the reward function is generally difficult.
- Inverse Reinforcement Learning is known as a method to facilitate the setting of this reward function.
- inverse reinforcement learning the decision-making history data of experts is used to repeat optimization using an objective function (reward function) and update of the parameters of the objective function (reward function). Generate an objective function (reward function) that reflects
- Non-Patent Document 1 describes maximum entropy inverse reinforcement learning (ME-IRL: Maximum Entropy-IRL), which is one type of inverse reinforcement learning.
- ME-IRL uses the maximum entropy principle to specify the trajectory distribution and learn the reward function by approximating the true distribution (ie maximum likelihood estimation). This solves the ambiguity that there are multiple objective functions (reward functions) that reproduce the trajectory (behavior history) of the expert.
- Non-Patent Document 2 describes a method of learning constraints based on the method of maximum entropy inverse reinforcement learning. In the method described in Non-Patent Document 2, parameters indicating constraint conditions are learned on the premise that the objective function is known.
- Non-Patent Document 3 also describes a method of learning constraints.
- constraints are learned from data indicating human behavior using Lagrangian undetermined multipliers.
- an objective function (reward function) in the Markov decision process is calculated from data (hereinafter sometimes referred to as demonstration data) indicating human behavior such as an expert.
- demonstration data data indicating human behavior
- the constraint conditions regarding the action of the expert must be given in advance.
- Non-Patent Document 2 Although it is possible to learn constraint conditions from the demonstration data of experts by the method described in Non-Patent Document 2, there is the problem that the objective function (reward function) must be given in advance as a known one. There is Furthermore, in the method described in Non-Patent Document 2, it is necessary to prepare in advance a plurality of candidates for constraint conditions whose parameters are not changed. There is also a problem.
- Non-Patent Document 3 by using the learning method described in Non-Patent Document 3, it is possible to estimate the objective function (reward function) and constraint conditions from the demonstration data of experts.
- learning is performed on the assumption that all demonstration data are mathematically optimal solutions. Therefore, the trajectory data indicating the decision-making history including human actions and information indicating the state from which the action was performed (hereinafter sometimes referred to as state information) may contain noise.
- state information the trajectory data indicating the decision-making history including human actions and information indicating the state from which the action was performed
- the present invention provides a learning device, a learning method, and a learning program capable of simultaneously learning an appropriate reward function and constraint conditions when performing inverse reinforcement learning using trajectory data representing human decision-making history. intended to
- a learning device includes input means for receiving input of trajectory data indicating a subject's decision-making history, learning means for executing inverse reinforcement learning using the trajectory data, a reward function derived by inverse reinforcement learning, and output means for outputting the constraint, and the learning means executes inverse reinforcement learning based on the distribution of the trajectory data calculated using a differentiable function indicating the distribution of the constraint.
- a learning method receives input of trajectory data indicating a subject's decision-making history, executes inverse reinforcement learning using the trajectory data, outputs a reward function and constraints derived by inverse reinforcement learning,
- the inverse reinforcement learning is characterized by executing inverse reinforcement learning based on the distribution of trajectory data calculated using a differentiable function indicating the distribution of the constraint.
- a learning program comprises an input process for accepting input of trajectory data indicating a subject's decision-making history, a learning process for executing inverse reinforcement learning using the trajectory data, and a learning process derived by inverse reinforcement learning.
- output processing for outputting the reward function and the constraint, and in the learning processing, inverse reinforcement learning is performed based on the distribution of the trajectory data calculated using the differentiable function indicating the distribution of the constraint.
- FIG. 1 is a block diagram showing a configuration example of an embodiment of a learning device according to the present invention
- FIG. 4 is a flowchart showing an operation example of the learning device
- 1 is a block diagram showing a configuration example of an embodiment of a robot control system
- FIG. 1 is a block diagram showing an outline of a learning device according to this embodiment
- FIG. 1 is a schematic block diagram showing a configuration of a computer according to at least one embodiment
- FIG. 1 is a block diagram showing a configuration example of one embodiment of a learning device according to the present invention.
- the learning device 100 of the present embodiment uses machine learning to indicate a decision-making history that includes the actions of a target person (expert) and information indicating the state that led to the action (that is, state information). It is a device that performs inverse reinforcement learning for estimating a reward function from trajectory data, and is a device that specifically performs information processing based on the behavioral characteristics of a subject (expert). In the following description, trajectory data indicating decision-making history may be simply referred to as trajectory data or demonstration data.
- the learning device 100 includes a storage section 10 , an input section 20 , a learning section 70 and an output section 60 .
- the storage unit 10 stores information necessary for the learning device 100 to perform various processes.
- the storage unit 10 may store trajectory data of the subject's decision-making history received by the input unit 20, which will be described later.
- the storage unit 10 may also store a probability model used by the learning unit 70, which will be described later.
- the storage unit 10 is realized by, for example, a magnetic disk or the like.
- the input unit 20 accepts input of information necessary for the learning device 100 to perform various processes. Specifically, the input unit 20 receives input of trajectory data and a probability model that assumes the distribution of the trajectory data.
- trajectory data (demonstration data) will be further explained. Inverse reinforcement learning is performed using trajectory data.
- the trajectory data indicates the decision-making history including the behavior of the target person (expert) and the state information on which the behavior is based.
- Various data can be used as trajectory data.
- the trajectory data includes a history of actions performed in the target environment in the past (history of which action was performed in which state). This action is preferably performed by an expert who is familiar with handling the target environment. However, this action is not necessarily limited to being performed by an expert.
- the trajectory data may represent the history of actions taken in the past in an environment other than the target environment (hereinafter referred to as the target environment).
- This environment is preferably an environment similar to the target environment.
- the target environment is equipment such as a power generation device, and the action is control of the equipment.
- the history of actions performed by similar equipment that has already been in operation it is conceivable to use the history of actions performed by similar equipment that has already been in operation.
- trajectory data may be other than the history of actions actually performed in a certain state.
- trajectory data may be generated manually.
- the trajectory data may be randomly generated data. That is, trajectory data may be generated by associating each state in the target environment with an action that is randomly selected from possible actions.
- the details of the probability model used by the learning device 100 of this embodiment will be described below.
- the learning device 100 of the present embodiment employs the maximum entropy principle used in maximum entropy inverse reinforcement learning, which enables appropriate estimation of a reward function (objective function) from demonstration data even if data varies.
- the input unit 20 receives an input of a probability model that hypothesizes the distribution of demonstration data derived by the maximum entropy principle based on a reward function and constraints.
- the reward function f ⁇ (x) is represented by the parameter ⁇ to be estimated
- the constraint g cm (x) ⁇ 0 is represented by the parameter c m to be estimated.
- the parameter ⁇ may be referred to as the first parameter
- the parameter cm may be referred to as the second parameter.
- the probability model is defined such that the data distribution p(x) of the trajectory data (hereinafter simply referred to as data distribution) includes both parameters (the first parameter and the second parameter), and the model parameters It reduces to the problem of estimating ⁇ and cm as .
- Equation 1 A probability model that hypothesizes a data distribution derived from the maximum entropy principle based on a reward function and constraints can be specifically defined as shown in Equation 1 below.
- x is a feature vector
- c is a constraint parameter
- m is the number of constraints.
- the first function is a function based on the reward function of the (probability) distribution of the trajectory, and has the property that the larger the value of the reward function, the larger the probability value.
- the first function is the same as the function representing the assumed distribution in maximum entropy inverse reinforcement learning described in Non-Patent Document 1.
- the second function is a function that approaches 1 as each constraint is satisfied and approaches 0 as each constraint is not satisfied. It is sometimes written as a differentiable function.). More specifically, as exemplified in Equation 1 above, the second function has a function g cm (x) that takes a non-negative value when each of the constraints 1 to m is satisfied. It is defined by the total power ⁇ of ⁇ . ⁇ is a continuous function that transforms the value of the argument from 0 to 1, such as a sigmoid function or a softmax function.
- ⁇ is a sigmoid function
- the argument of the function is y
- Z( ⁇ , c) is a normalization constant such that the sum (integration) of the entire distribution becomes 1.
- the parameter expression of the first function and the parameter expression of the second function are determined in advance by the designer or the like.
- the constraint g cm (x) ⁇ 0 included in the second function is determined according to the problem to which the learning result (reward function etc.) according to the present invention is applied.
- two specific examples are given to explain aspects of the constraint.
- Each vector element of a variable vector (feature vector) x to be optimized in a mixed integer programming problem is composed of a continuous variable or an integer variable.
- This optimization target variable vector x corresponds to the feature amount in inverse reinforcement learning and also matches the state.
- a m is a matrix (coefficient vector)
- b m is a vector (scalar quantity).
- Mixed integer programming problems include linear programming problems and integer programming problems. Therefore, the learning result according to the present invention can be applied to lower problem classes such as "traveling salesman problem”, “work scheduling problem”, and "knapsack problem”.
- the learning result according to the present invention is applied to image recognition and robot control.
- the constraint g cm (x) for the state variable x which is different from the feature quantity, cannot generally be represented by the linear form of x. So in this case, the parameters of g cm (x) may be manually preset based on domain knowledge or represented by a neural network.
- x When expressing g cm (x) by a neural network, x corresponds to the input vector of the neural network, the parameter c m to the set of hyperparameters in the neural network, and the output of the network to g cm (x).
- the number of constraints is generally not limited to one. So we do not define a separate neural network for each g cm (x) for different m, e.g. x is the input vector of the neural network, the output of the network is [g c1 (x), g c2 (x), . , g cM (x)] may be defined.
- a function ⁇ (for example, a sigmoid function) that converts the output from the neural network to a value of 0 to 1 is applied, so even if these constraint conditions g cm (x) are used, the The output values of the two functions are 0-1.
- the learning unit 70 includes a probability model calculation unit 30, an update unit 40, and a convergence determination unit 50.
- the learning unit 70 of the present embodiment executes inverse reinforcement learning using the trajectory data described above. The operation of each configuration will be described below.
- the probabilistic model calculator 30 calculates the gradient of the logarithmic likelihood based on the probabilistic model and the trajectory data (demonstration data).
- the method of calculating the gradient of the log-likelihood is the same as the maximum entropy inverse reinforcement learning described in Non-Patent Document 1, except that there are two types of parameters (first parameter ⁇ and second parameter c m ). is. Specifically, the optimal parameters ⁇ * and cm * are given by Equation 2 below. Note that N is the number of trajectory data (demonstration data).
- the probabilistic model calculation unit 30 calculates the log-likelihood gradient ⁇ L( ⁇ , c m ) using Equation 3 exemplified below.
- the update unit 40 updates the reward function and constraint conditions so as to maximize the logarithmic likelihood calculated by the probability model calculation unit 30.
- the updating unit 40 has a reward function updating unit 41 and a constraint condition updating unit 42 .
- the first function representing the distribution based on the reward function is expressed using the first parameter ⁇
- the constraint condition is expressed using the second parameter cm . Therefore, the reward function updating unit 41 updates the first parameter ⁇ so as to maximize the logarithmic likelihood. Also, the constraint updating unit 42 updates the second parameter c m so as to maximize the logarithmic likelihood.
- the reward function updating unit 41 updates the first parameter ⁇ as shown in Equation 4 exemplified below
- the constraint condition updating unit 42 Update the second parameter cm as shown in Equation 5 exemplified below.
- the method by which the reward function updating unit 41 updates the first parameter ⁇ so as to maximize the logarithmic likelihood is the same as the maximum entropy inverse reinforcement learning described in Non-Patent Document 1.
- the constraint updating unit 42 updates the first parameter ⁇ by the reward function updating unit 41, and also updates the parameter of the constraint (the second parameter cm ). That is, the probabilistic model calculator 30 and the updater 40 of the present embodiment perform inverse reinforcement learning based on the distribution of trajectory data calculated using a differentiable function that indicates the distribution of constraints. Therefore, it becomes possible to learn a suitable reward function and constraints at the same time.
- the convergence determination unit 50 determines whether or not the parameters of the reward function and the constraint conditions have converged. Specifically, the convergence determination unit 50 determines that the gradient of the logarithmic likelihood (more specifically, ⁇ ⁇ L( ⁇ , cm ) and ⁇ cm L( ⁇ , cm )) is equal to or less than a predetermined threshold. , it is determined that the parameters of the reward function and the constraint have converged.
- the probability model calculation unit 30 updates the probability model with the updated parameters (the first parameter ⁇ and the second parameter c m ), and the updated probability Compute the log-likelihood gradient based on the model and the demonstration data. Then, the updating unit 40 updates the reward function and the constraint so as to maximize the logarithmic likelihood calculated by the probability model calculating unit 30.
- the output unit 60 outputs the reward function and constraint conditions derived by inverse reinforcement learning. More specifically, when it is determined that the parameters have converged, the output unit 60 outputs the reward function and the constraint condition represented by the updated parameters.
- the input unit 20, the learning unit 70 (more specifically, the probability model calculation unit 30, the update unit 40 (more specifically, the reward function update unit 41 and the constraint condition update unit 42), and the convergence determination unit 50) and the output unit 60 are computer processors (e.g., CPU (Central Processing Unit), GPU (Graphics Processing Unit)) that operate according to a program (learning program), FPGA (Field-Programmable Gate Array), quantum processor (quantum computer control chip)).
- CPU Central Processing Unit
- GPU Graphics Processing Unit
- FPGA Field-Programmable Gate Array
- quantum processor quantum computer control chip
- the program is stored in the storage unit 10 included in the learning device 100, the processor reads the program, and according to the program, the input unit 20, the learning unit 70 (more specifically, the probability model calculation unit 30, the update It may operate as the unit 40 (more specifically, the reward function update unit 41 and the constraint condition update unit 42 , the convergence determination unit 50 ) and the output unit 60 .
- the functions of the learning device 100 may be provided in a SaaS (Software as a Service) format.
- the input unit 20, the learning unit 70 (more specifically, the probability model calculation unit 30, the update unit 40 (more specifically, the reward function update unit 41 and the constraint condition update unit 42), the convergence The determination unit 50) and the output unit 60 may each be realized by dedicated hardware. Also, part or all of each component of each device may be implemented by general-purpose or dedicated circuitry, processors, etc., or combinations thereof. These may be composed of a single chip, or may be composed of multiple chips connected via a bus. A part or all of each component of each device may be implemented by a combination of the above-described circuits and the like and programs.
- the plurality of information processing devices, circuits, etc. may be centrally arranged or distributed. may be placed.
- the information processing device, circuits, and the like may be implemented as a form in which each is connected via a communication network, such as a client-server system, a cloud computing system, or the like.
- FIG. 2 is a flowchart showing an operation example of the learning device 100 of this embodiment.
- the input unit 20 receives input of trajectory data (that is, trajectory/decision-making history data of an expert) and a probability model (step S11).
- the probability model calculator 30 calculates the gradient of the logarithmic likelihood based on the probability model and the trajectory data (step S12).
- the reward function updating unit 41 updates the parameters of the reward function so as to maximize the logarithmic likelihood (step S13)
- the constraint updating unit 42 updates the parameters of the constraint so as to maximize the logarithmic likelihood. is updated (step S14).
- the convergence determination unit 50 determines whether or not the parameters of the reward function and the constraint conditions have converged (step S15). If it is determined that the parameters have not converged (No in step S15), the processes after step S12 are repeated using the updated parameters. On the other hand, when it is determined that the parameters have converged (Yes in step S15), the output unit 60 outputs the reward function and constraint conditions derived by inverse reinforcement learning (step S16).
- the input unit 20 receives input of trajectory data
- the learning unit 70 performs inverse reinforcement learning using the trajectory data
- the output unit 60 performs inverse reinforcement learning. Output the reward function and constraints.
- the learning unit 70 performs inverse reinforcement learning based on the distribution of the trajectory data calculated using the differentiable function indicating the distribution of the constraint.
- the input unit 20 receives input of the trajectory data and the probability model, and the probability model calculation unit 30 calculates the gradient of the logarithmic likelihood based on the probability model and the trajectory data. Then, the updating unit 40 updates the reward function and the constraint so as to maximize the logarithmic likelihood.
- the stochastic model includes a first function representing a distribution based on a reward function expressed using a first parameter ⁇ and a distribution based on a constraint condition expressed using a second parameter c m
- the update unit 40 updates the first parameter and the second parameter so as to maximize the logarithmic likelihood.
- the stochastic model calculator 30 and the updater 40 learn the objective function and the constraint at the same time, that is, estimate the reward function from the trajectory data and automatically estimate the constraint. Therefore, the expert's actions and decisions can be formulated as an optimization problem, which makes it possible to reproduce the expert's behavior.
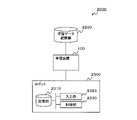
- FIG. 3 is a block diagram showing a configuration example of an embodiment of the robot control system.
- a robot control system 2000 illustrated in FIG. 3 includes a learning device 100 , a learning data storage unit 2200 and a robot 2300 .
- the learning device 100 illustrated in FIG. 3 is the same as the learning device 100 in the above embodiment.
- the learning device 100 stores the reward function and constraint conditions created as a result of learning in the storage unit 2310 of the robot 2300, which will be described later.
- the learning data storage unit 2200 stores learning data that the learning device 100 uses for learning.
- the learning data storage unit 2200 may store trajectory data (demonstration data), for example.
- a robot 2300 is a device that operates based on a reward function. It should be noted that the robots here are not limited to devices shaped like humans or animals, and include devices that perform automatic work (automatic operation, automatic control, etc.). Robot 2300 includes a storage unit 2310 , an input unit 2320 and a control unit 2330 .
- the storage unit 2310 stores the reward function and constraint conditions learned by the learning device 100 .
- the input unit 2320 accepts input of data indicating the state when the robot is operated.
- the control unit 2330 determines the action to be performed by the robot 2300 based on the received data (indicating the state), the reward function stored in the storage unit 2310, and the constraint conditions.
- the method by which the control unit 2330 determines the control action based on the reward function and the constraint is widely known, and detailed description thereof will be omitted here.
- a device that performs automatic work such as the robot 2300, can be controlled based on a reward function that reflects the intention of the expert.
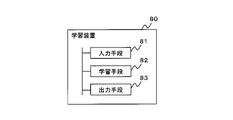
- FIG. 4 is a block diagram showing an overview of the learning device according to this embodiment.
- the learning device 80 (for example, the learning device 100) according to the present embodiment includes input means 81 (for example, the input unit 20) that receives input of trajectory data (for example, demonstration data) indicating the decision-making history of the subject, and trajectory data and an output means 83 (e.g., output unit 60) for outputting the reward function and constraint conditions derived by the inverse reinforcement learning.
- trajectory data for example, demonstration data
- output means 83 e.g., output unit 60
- the learning means 82 executes inverse reinforcement learning based on the distribution of trajectory data calculated using a differentiable function that indicates the distribution of the constraint.
- the input means 81 uses a probability model (for example, , p(x)), the learning means 82 (for example, the probability model calculation unit 30 and the update unit 40) calculates the gradient of the logarithmic likelihood based on the probability model and the trajectory data, and the logarithm
- the reward function and constraints may be updated to maximize likelihood.
- the stochastic model is represented using a first function showing a distribution based on a reward function represented using a first parameter (e.g., ⁇ ) and a second parameter (e.g., cm ). is defined by the product of a second function representing a distribution based on the constraint condition (for example, Equation 1), and the learning means 82 updates the first parameter and the second parameter so as to maximize the logarithmic likelihood You may
- the learning device 80 may include determination means (for example, the convergence determination unit 50) for determining whether or not the first parameter and the second parameter have converged. Then, if it is not determined that convergence has occurred, the learning means 82 calculates the gradient of the logarithmic likelihood based on the probability model defined by the updated first and second parameters and the trajectory data. and update the first and second parameters to maximize the log-likelihood.
- determination means for example, the convergence determination unit 50
- the second function may be defined as a continuous function differentiable by the second parameter, which approaches 1 as each constraint is satisfied and approaches 0 as each constraint is not satisfied.
- the probability model may be defined as a function that takes a higher probability value as the value of the reward function increases, and takes a higher probability value as the constraint conditions are satisfied.
- the second function may be defined by the multiplication of sigmoid functions whose arguments are constraints that indicate non-negative values when each constraint is satisfied.
- FIG. 5 is a schematic block diagram showing the configuration of a computer according to at least one embodiment.
- a computer 1000 comprises a processor 1001 , a main storage device 1002 , an auxiliary storage device 1003 and an interface 1004 .
- the learning device 80 described above is implemented in the computer 1000 .
- the operation of each processing unit described above is stored in the auxiliary storage device 1003 in the form of a program (learning program).
- the processor 1001 reads out the program from the auxiliary storage device 1003, develops it in the main storage device 1002, and executes the above processing according to the program.
- the secondary storage device 1003 is an example of a non-transitory tangible medium.
- Other examples of non-transitory tangible media include magnetic disks, magneto-optical disks, CD-ROMs (Compact Disc Read-only memory), DVD-ROMs (Read-only memory), connected via interface 1004, A semiconductor memory and the like are included.
- the computer 1000 receiving the distribution may develop the program in the main storage device 1002 and execute the above process.
- the program may be for realizing part of the functions described above.
- the program may be a so-called difference file (difference program) that implements the above-described functions in combination with another program already stored in the auxiliary storage device 1003 .
- the input means accepts an input of a stochastic model that assumes a distribution of trajectory data derived by the maximum entropy principle based on a reward function and constraints, learning means calculates a gradient of the log likelihood based on the probability model and the trajectory data, and updates the reward function and the constraint so as to maximize the log likelihood;
- the probability model includes a first function representing a distribution based on the reward function represented using a first parameter, and a second function representing a distribution based on the constraint condition represented using a second parameter. defined by the product with the function,
- the learning device according to supplementary note 2, wherein the learning means updates the first parameter and the second parameter so as to maximize the logarithmic likelihood.
- Appendix 3 comprising determination means for determining whether the first parameter and the second parameter have converged,
- the learning means calculates the gradient of the logarithmic likelihood based on the trajectory data and the probability model defined by the updated first parameter and the second parameter when it is not determined that convergence has occurred, and
- the learning device according to appendix 2, wherein the first parameter and the second parameter are updated to maximize the log-likelihood.
- the second function is defined as a continuous function differentiable by the second parameter, which approaches 1 as each constraint is satisfied and approaches 0 as each constraint is not satisfied. 3.
- the learning device according to any one of Supplementary Notes 3 to 3.
- the stochastic model is defined as a function that takes a larger probability value as the value of the reward function increases, and takes a larger probability value as the constraint conditions are satisfied Any one of Appendixes 1 to 4 The learning device according to .
- Appendix 6 The second function is defined as the sum of sigmoid functions whose arguments are constraints that indicate non-negative values when each constraint is satisfied. Any one of Appendices 1 to 5 A learning device as described.
- Appendix 8 Accepting an input of a stochastic model that assumes a distribution of trajectory data derived by the maximum entropy principle based on a reward function and constraints,
- the stochastic model comprises a first function representing a distribution based on the reward function represented using a first parameter, and a second function representing a distribution based on the constraint condition represented using a second parameter. defined by the product with the function, calculating a log-likelihood gradient based on the probabilistic model and trajectory data; 8.
- a program storage medium for storing a learning program for executing the inverse reinforcement learning based on the distribution of the trajectory data calculated using a differentiable function indicating the distribution of the constraint in the learning process.
- the probability model includes a first function representing a distribution based on the reward function represented using a first parameter, and a second function representing a distribution based on the constraint condition represented using a second parameter. defined by the product with the function, 10.
- Appendix 12 to the computer, In input processing, accept input of a stochastic model that assumes a distribution of trajectory data derived by the maximum entropy principle based on a reward function and constraints, In the learning process, based on the probability model and the trajectory data, calculate the gradient of the logarithmic likelihood, update the reward function and the constraint condition so as to maximize the logarithmic likelihood,
- the probability model includes a first function representing a distribution based on the reward function represented using a first parameter, and a second function representing a distribution based on the constraint condition represented using a second parameter. defined by the product with the function, 12.
- the learning program according to appendix 11, wherein in the learning process, the first parameter and the second parameter are updated so as to maximize the logarithmic likelihood.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Probability & Statistics with Applications (AREA)
- Algebra (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Manipulator (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023516888A JP7529145B2 (ja) | 2021-04-27 | 2021-04-27 | 学習装置、学習方法および学習プログラム |
| PCT/JP2021/016728 WO2022230038A1 (ja) | 2021-04-27 | 2021-04-27 | 学習装置、学習方法および学習プログラム |
| US18/287,132 US20240202504A1 (en) | 2021-04-27 | 2021-04-27 | Learning device, learning method, and learning program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/016728 WO2022230038A1 (ja) | 2021-04-27 | 2021-04-27 | 学習装置、学習方法および学習プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022230038A1 true WO2022230038A1 (ja) | 2022-11-03 |
Family
ID=83846769
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/016728 Ceased WO2022230038A1 (ja) | 2021-04-27 | 2021-04-27 | 学習装置、学習方法および学習プログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240202504A1 (https=) |
| JP (1) | JP7529145B2 (https=) |
| WO (1) | WO2022230038A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120217907A (zh) * | 2025-05-28 | 2025-06-27 | 集美大学 | 一种基于航行意图感知的无人艇避碰决策方法 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230401262A1 (en) * | 2022-06-10 | 2023-12-14 | Multiverse Computing Sl | Quantum-inspired method and system for clustering of data |
| CN119388413B (zh) * | 2024-08-30 | 2025-12-26 | 北京长木谷医疗科技股份有限公司 | 基于具身智能的手术机器人控制逆强化学习方法及装置 |
| CN119328776B (zh) * | 2024-12-20 | 2025-07-01 | 江苏骠马电力科技有限公司 | 一种基于变电站仿生操作机器人视觉定位引导方法 |
| CN121094343B (zh) * | 2025-11-11 | 2026-04-14 | 江西五十铃汽车有限公司 | 新能源汽车动力系统的跨技术路线协同决策方法及系统 |
-
2021
- 2021-04-27 US US18/287,132 patent/US20240202504A1/en active Pending
- 2021-04-27 JP JP2023516888A patent/JP7529145B2/ja active Active
- 2021-04-27 WO PCT/JP2021/016728 patent/WO2022230038A1/ja not_active Ceased
Non-Patent Citations (3)
| Title |
|---|
| DEXTER R.R. SCOBEE; S. SHANKAR SASTRY: "Maximum Likelihood Constraint Inference for Inverse Reinforcement Learning", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 12 September 2019 (2019-09-12), 201 Olin Library Cornell University Ithaca, NY 14853 , XP081482066 * |
| GLEN CHOU; DMITRY BERENSON; NECMIYE OZAY: "Learning Constraints from Demonstrations", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 17 December 2018 (2018-12-17), 201 Olin Library Cornell University Ithaca, NY 14853 , XP080994019 * |
| MASUYAMA, GAKUTO ET AL.: "Estimating reward function considering learners' preference by inverse reinforcement learning", THE 32ND ANNUAL CONFERENCE OF THE ROBOTICS SOCIETY OF JAPAN (RSJ); FUKUOKA, JAPAN; SEPTEMBER 4-6, 2014, vol. 32, 2014, pages 1 - 3, XP009541072 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120217907A (zh) * | 2025-05-28 | 2025-06-27 | 集美大学 | 一种基于航行意图感知的无人艇避碰决策方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022230038A1 (https=) | 2022-11-03 |
| JP7529145B2 (ja) | 2024-08-06 |
| US20240202504A1 (en) | 2024-06-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7529145B2 (ja) | 学習装置、学習方法および学習プログラム | |
| KR102170105B1 (ko) | 신경 네트워크 구조의 생성 방법 및 장치, 전자 기기, 저장 매체 | |
| Le et al. | Batch policy learning under constraints | |
| AU2020202542B2 (en) | Transforming attributes for training automated modeling systems | |
| Walsh et al. | Exploring compact reinforcement-learning representations with linear regression | |
| CN110276442A (zh) | 一种神经网络架构的搜索方法及装置 | |
| US20170364825A1 (en) | Adaptive augmented decision engine | |
| US20220343180A1 (en) | Learning device, learning method, and learning program | |
| CN111475848A (zh) | 保障边缘计算数据隐私的全局和局部低噪声训练方法 | |
| CN115151917A (zh) | 经由批量归一化统计的域泛化 | |
| CN112990958A (zh) | 数据处理方法、装置、存储介质及计算机设备 | |
| CN118760100B (zh) | 一种大规模模糊柔性作业车间调度方法及相关设备 | |
| CN112016611B (zh) | 生成器网络和策略生成网络的训练方法、装置和电子设备 | |
| Kolahdoozi et al. | A novel quantum inspired algorithm for sparse fuzzy cognitive maps learning: M. Kolahdoozi et al. | |
| Sanches et al. | Short quantum circuits in reinforcement learning policies for the vehicle routing problem | |
| US20210264307A1 (en) | Learning device, information processing system, learning method, and learning program | |
| El-Laham et al. | Policy gradient importance sampling for Bayesian inference | |
| WO2019220653A1 (ja) | 因果関係推定装置、因果関係推定方法および因果関係推定プログラム | |
| CN120540820B (zh) | 多智能体协同方法、装置、电子设备及存储介质 | |
| Ghorbel et al. | Smart adaptive run parameterization (SArP): enhancement of user manual selection of running parameters in fluid dynamic simulations using bio-inspired and machine-learning techniques: H. Ghorbel et al. | |
| WO2021064931A1 (ja) | ナレッジトレース装置、方法、および、プログラム | |
| JP7464115B2 (ja) | 学習装置、学習方法および学習プログラム | |
| WO2022137520A1 (ja) | 学習装置、学習方法および学習プログラム | |
| US20220405599A1 (en) | Automated design of architectures of artificial neural networks | |
| JP7420236B2 (ja) | 学習装置、学習方法および学習プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21939200 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023516888 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18287132 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21939200 Country of ref document: EP Kind code of ref document: A1 |