WO2022215559A1 - ハイブリッドモデル作成方法、ハイブリッドモデル作成装置、及び、プログラム - Google Patents
ハイブリッドモデル作成方法、ハイブリッドモデル作成装置、及び、プログラム Download PDFInfo
- Publication number
- WO2022215559A1 WO2022215559A1 PCT/JP2022/014692 JP2022014692W WO2022215559A1 WO 2022215559 A1 WO2022215559 A1 WO 2022215559A1 JP 2022014692 W JP2022014692 W JP 2022014692W WO 2022215559 A1 WO2022215559 A1 WO 2022215559A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- models
- hybrid model
- model
- hybrid
- candidates
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 83
- 238000010801 machine learning Methods 0.000 claims abstract description 79
- 238000011176 pooling Methods 0.000 claims abstract description 5
- 238000012795 verification Methods 0.000 claims description 72
- 238000012545 processing Methods 0.000 claims description 65
- 230000002950 deficient Effects 0.000 claims description 49
- 230000006870 function Effects 0.000 claims description 27
- 238000007689 inspection Methods 0.000 claims description 22
- 238000009826 distribution Methods 0.000 claims description 13
- 238000010200 validation analysis Methods 0.000 claims description 9
- 230000007423 decrease Effects 0.000 claims description 2
- 238000010586 diagram Methods 0.000 description 33
- 238000007477 logistic regression Methods 0.000 description 28
- 238000004590 computer program Methods 0.000 description 13
- 230000008569 process Effects 0.000 description 13
- 230000000875 corresponding effect Effects 0.000 description 12
- 230000002596 correlated effect Effects 0.000 description 7
- 230000007717 exclusion Effects 0.000 description 7
- 239000011159 matrix material Substances 0.000 description 6
- 238000004364 calculation method Methods 0.000 description 4
- 239000013598 vector Substances 0.000 description 4
- 239000000470 constituent Substances 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000010397 one-hybrid screening Methods 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000007637 random forest analysis Methods 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- -1 standards Substances 0.000 description 1
- 238000012706 support-vector machine Methods 0.000 description 1
- 238000012549 training Methods 0.000 description 1
Images




















Classifications
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B19/00—Programme-control systems
- G05B19/02—Programme-control systems electric
- G05B19/418—Total factory control, i.e. centrally controlling a plurality of machines, e.g. direct or distributed numerical control [DNC], flexible manufacturing systems [FMS], integrated manufacturing systems [IMS] or computer integrated manufacturing [CIM]
- G05B19/41875—Total factory control, i.e. centrally controlling a plurality of machines, e.g. direct or distributed numerical control [DNC], flexible manufacturing systems [FMS], integrated manufacturing systems [IMS] or computer integrated manufacturing [CIM] characterised by quality surveillance of production
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B13/00—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion
- G05B13/02—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric
- G05B13/0265—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric the criterion being a learning criterion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B2219/00—Program-control systems
- G05B2219/30—Nc systems
- G05B2219/32—Operator till task planning
- G05B2219/32368—Quality control
Definitions
- the present disclosure relates to a hybrid model creation method, a hybrid model creation device, and a program.
- Patent Literature 1 discloses obtaining a final judgment result by integrating the results obtained by using all of the multiple models possessed by the device.
- Patent Document 1 uses all of the multiple models that the device has, so there is a problem that redundant models that are not complementary to other models are used in combination.
- the present disclosure has been made in view of the circumstances described above, and aims to provide a hybrid model creation method and the like capable of creating a hybrid model with higher accuracy.
- a hybrid model creation method pools a plurality of models for estimating categories of input data, and at least one of the plurality of models is a machine learning By selecting and combining two or more models from a plurality of pooled models, a plurality of hybrid model candidates for determining the category are created, and the plurality of hybrid model candidates are compared. , one of the plurality of hybrid model candidates is selected as the hybrid model.
- FIG. 1 is a block diagram showing the functional configuration of the hybrid model creation device according to the embodiment.
- FIG. 2 is a diagram for conceptually explaining the processing when the hybrid model creation method according to the embodiment is executed.
- FIG. 3 is a flow chart showing an outline of the operation of the hybrid model creation device according to the embodiment.
- FIG. 4 is a flowchart illustrating an example of detailed processing of step S1 according to the first embodiment.
- FIG. 5 is a flowchart illustrating an example of detailed processing of step S1 according to the second embodiment.
- FIG. 6 is a flowchart illustrating an example of detailed processing of step S3 according to the third embodiment.
- FIG. 7A is a diagram for explaining the accuracy of a hybrid model candidate when three highly correlated models are combined according to the third embodiment.
- FIG. 7A is a diagram for explaining the accuracy of a hybrid model candidate when three highly correlated models are combined according to the third embodiment.
- FIG. 7B is a diagram for explaining the accuracy of a hybrid model candidate when three weakly correlated models are combined according to the third embodiment.
- FIG. 8 is a diagram for conceptually explaining an example of the details of the hybrid model candidate creation process according to the fourth embodiment.
- FIG. 9 is a flowchart illustrating an example of processing of the hybrid model creation device according to the fourth embodiment.
- FIG. 10 is a flowchart illustrating an example of detailed processing of step S3 according to the fifth embodiment.
- FIG. 11 is a diagram conceptually showing an example of a hybrid model candidate created by combining model 1 and model 2 according to the sixth embodiment.
- FIG. 12 is a flowchart illustrating an example of detailed processing of step S3 according to the sixth embodiment.
- FIG. 13 is a diagram conceptually showing the outputs of the models 1 and 2 according to the seventh embodiment and the convex hull of the distribution of the outputs corresponding to the defective product image.
- FIG. 14 is a diagram conceptually showing an example of a hybrid model candidate created from the outputs of models 1 and 2 in which the output corresponding to the defective product image excluding the vertices of the convex hull shown in FIG. 13 is removed.
- FIG. 15 is a flowchart illustrating an example of detailed processing of step S3 according to the seventh embodiment.
- FIG. 16 is a diagram conceptually showing outputs and exclusion regions of models 1 and 2 according to the seventh embodiment.
- FIG. 17 is a diagram conceptually showing an example of a hybrid model candidate created from outputs of models 1 and 2 from which outputs corresponding to defective product images included in the exclusion area shown in FIG. 16 are removed.
- FIG. 18 is a diagram for explaining a method of calculating a FAR curve for model 1 according to the eighth embodiment.
- FIG. 19 is a diagram illustrating an example of a FAR table of model 1 according to the eighth embodiment.
- FIG. 20 is a diagram conceptually showing first FAR values of two models and second FAR values of hybrid model candidates created by combining the two models according to the eighth embodiment.
- FIG. 21 is a diagram showing an example of a hybrid model creation method according to another embodiment.
- FIG. 22 is a diagram showing another example of a hybrid model creation method according to another embodiment.
- FIG. 23A is a diagram showing an example of a confusion matrix table according to another embodiment.
- FIG. 23B is a diagram showing an example of a confusion matrix table according to another embodiment.
- FIG. 1 is a block diagram showing the functional configuration of a hybrid model creation device 10 according to this embodiment.
- FIG. 2 is a diagram for conceptually explaining the processing when the hybrid model creation method according to the present embodiment is executed.
- the hybrid model creation device 10 is implemented by a computer or the like, and is a device that can create a hybrid model with higher accuracy using a plurality of models.
- the hybrid model generation device 10 includes a model pool section 11, a model selection section 12, a hybrid model candidate generation section 13, a hybrid model selection section 14, a determination threshold value and a determination unit 15 .
- the determination threshold determination unit 15 may be provided in a device other than the hybrid model generation device 10 .
- the model pool unit 11 is composed of a HDD (Hard Disk Drive), a memory, or the like, and pools (stores) a plurality of models for estimating the category of input data.
- the model pool unit 11 pools a plurality of pre-created models 11a such as model 1, model 2, model 3 and model 4, as shown in FIG.
- at least one model of the plurality of models 11a is a machine-learned model.
- Each of the multiple models 11a can also be referred to as an AI model.
- input data is an inspection image of a manufactured product.
- At least one model among the plurality of models 11a is an AI model learned by deep learning.
- the plurality of models 11a may include AI models whose feature values are designed manually. For example, each of the plurality of models 11a receives an inspection image of a manufactured product as an input, estimates the probability that the manufactured product shown in the inspection image is defective, and outputs the estimated probability. Note that each of the plurality of models 11a may output a binary estimation result indicating whether or not the manufactured product shown in the inspection image is defective.
- Model selection unit 12 A model selection unit 12 selects two or more models from a plurality of models pooled in the model pool unit 11 .
- the model selection unit 12 selects two or more models after excluding a predetermined model from the plurality of models pooled in the model pool unit 11 .
- the model selection unit 12 selects two or more models after excluding model 4 as a predetermined model from among model 1, model 2, model 3, and model 4, for example. Processing 12a is performed.
- the model selection unit 12 may select two or more models after excluding a predetermined model from the plurality of models pooled in the model pool unit 11, or may select two or more models. Of the plurality of models, two or more models may be selected after excluding a predetermined model.
- the predetermined model may be, for example, a model with low estimation accuracy or a model with strong correlation with other models.
- the details of the method for excluding such a predetermined model will be explained in Examples 1 and 2 to be described later, so explanations thereof will be omitted here.
- the hybrid model candidate creation unit 13 creates a plurality of hybrid model candidates for category determination by combining two or more models selected by the model selection unit 12 .
- the hybrid model candidate creation unit 13 creates a plurality of hybrid model candidates by combining two or more models selected by the model selection unit 12 so as not to include a combination of models having a correlation stronger than a threshold.
- Hybrid model candidates may be combined by simply connecting (cascading) two or more models selected by the model selection unit 12, or may be combined using logistic regression or the like as described later.
- the hybrid model candidate creation unit 13 performs hybrid model candidate creation processing 13a for creating hybrid model candidates by combining the models 1, 2, and 3 selected by the model selection unit 12. More specifically, the hybrid model candidate creating unit 13 creates a hybrid model candidate 1 that combines model 1 and model 2, for example, and a hybrid model candidate 2 that combines model 2 and model 3, for example. Further, the hybrid model candidate creating unit 13 creates a hybrid model candidate 3 that combines the model 1 and the model 3, for example, and a hybrid model candidate 4 that combines the model 1, the model 2, and the model 3, for example.
- the category to be determined is whether the manufactured product shown in the inspection image is a non-defective product or a defective product.
- the hybrid model candidate 3 determines whether the manufactured product shown in the inspection image is a non-defective product or a defective product.
- the hybrid model candidates 1 to 3 may output determination results obtained by determining (estimating) whether or not the manufactured product shown in the inspection image is defective by probability.
- the hybrid model candidate creation unit 13 compares the created hybrid model candidates.
- the hybrid model candidate creation unit 13 performs comparison processing for comparing the created hybrid model candidates 1 to 4.
- a method for comparing the hybrid model candidates 1 to 4 for example, a method of comparing the accuracy of the determination result of each of the hybrid model candidates 1 to 4, and a method of comparing each of the two or more models that can be calculated from the respective determination results.
- a method of comparing degrees of importance also referred to as degrees of contribution
- degrees of contribution can be used.
- Hybrid model selection unit 14 A hybrid model selection unit 14 selects one of the plurality of hybrid model candidates as a hybrid model based on the comparison results of the plurality of hybrid model candidates.
- the hybrid model selection unit 14 performs a hybrid model selection process 14a for selecting one of the hybrid model candidates 1 to 4 as the hybrid model from the comparison result of the hybrid model candidates 1 to 4.
- the hybrid model candidate having the highest accuracy among the accuracy of the determination result or the combination of the models having the highest importance is selected as the hybrid model. is selected as
- the determination threshold determination unit 15 adjusts the sensitivity of the hybrid model selected by the hybrid model selection unit 14 using, for example, a verification data set such as an inspection image of a manufactured product, and determines an allowable excess for suppressing erroneous determination. Determine the detection rate threshold.
- the determination threshold determination unit 15 receives a verification data set such as an inspection image of a manufactured product, for example, and obtains a determination result obtained by determining whether the manufactured product is a non-defective product or a defective product.
- the determination threshold determination unit 15 generates a confusion matrix from the acquired determination results, and determines an allowable overdetection rate threshold (determination threshold) for suppressing erroneous determination.
- the Cascading Model shown in the determination threshold determination process 15a shown in FIG. 2 means the hybrid model selected by the hybrid model selection unit 14, and the determination threshold is optimized.
- FIG. 3 is a flow chart showing an overview of the operation of the hybrid model creation device 10 according to this embodiment.
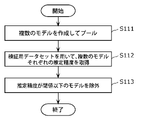
- the hybrid model creation device 10 pools a plurality of models for estimating the category of input data (S1).
- at least one model of the plurality of models is a machine-learned model.
- each of the plurality of models receives an inspection image of a manufactured product as an input, estimates the probability that the manufactured product reflected in the inspection image is defective, and outputs the estimated probability.
- the hybrid model creation device 10 selects two or more models from a plurality of pooled models (S2).
- the hybrid model generating apparatus 10 selects two or more models from a plurality of pooled models, excluding some (predetermined models).
- the hybrid model creation device 10 creates multiple hybrid model candidates for category determination by combining the two or more models selected in step S2 (S3).
- the hybrid model generating device 10 may combine two or more models selected in step S2 by sequentially cascading them, or may combine them using logistic regression.
- the hybrid model creation device 10 compares the multiple hybrid model candidates created in step S3 (S4).
- the hybrid model generation device 10 compares the accuracy of the determination result of each of the hybrid model candidates, for example, and compares two or more models that can be calculated from the determination results of each of the hybrid model candidates. You can compare the importance of
- step S5 determines whether all hybrid model candidates have been compared (S5). If all the hybrid model candidates have not been compared (No in S5), the process returns to step S4.
- step S5 if all hybrid model candidates have been compared (Yes in S5), one of the plurality of hybrid model candidates is selected as the hybrid model (S6).
- the hybrid model generating apparatus 10 selects a hybrid model candidate consisting of a combination of models with the highest accuracy or highest importance among the judgment results of each of the hybrid model candidates as the hybrid model. be able to.
- a plurality of hybrid model candidates are created without using all of the pooled models, and a plurality of hybrid model candidates are created using, for example, determination accuracy. Compare model candidates.
- the hybrid model candidate with the highest accuracy among the determination results can be selected as the hybrid model.
- a hybrid model with higher accuracy can be created using a plurality of models.
- a model with low estimation accuracy may be excluded as a predetermined model from the plurality of pooled models. That is, among a plurality of pooled models, models with low estimation accuracy may be excluded from the hybrid model candidates.
- the estimation accuracy is not limited to the accuracy rate, but also the precision rate, the recall rate, the F value calculated by the harmonic average of the precision rate and the recall rate, the AUC (Area Under Curve) of the ROC (Receiver Operating Characteristic) curve, and the accuracy rate. Any combination of at least one of the rates may be used.
- FIG. 4 is a flowchart showing an example of detailed processing of step S1 according to the first embodiment.
- step S1 the hybrid model creation device 10 first pools a plurality of models for estimating the category of input data (S111).
- the hybrid model creation device 10 acquires the estimation accuracy of each of the multiple models using the verification data set (S112). More specifically, before selecting two or more models, the model selection unit 12 inputs a plurality of verification data sets to each of the plurality of models pooled in the model pool unit 11 to select categories. By estimating, the estimation accuracy of each of the plurality of models is obtained.
- the estimation accuracy of each of the pooled models may be calculated using all of the verification datasets prepared in advance, but this is not the only option.
- a verification data set with different estimation results depending on the model may be used. For example, when the pooled models are model 1, model 2, model 3 and model 4, the estimation result of model 1 and the estimation results of model 2, model 3 and model 4 are different validation data sets Use
- the hybrid model creation device 10 excludes models whose estimation accuracy is equal to or less than the threshold (S113). More specifically, the model selection unit 12 excludes models whose estimation accuracy is equal to or less than a threshold from the plurality of models pooled in the model pool unit 11 . Then, the model selection unit 12 selects two or more models from a plurality of models from which the models below the threshold are excluded. Note that the threshold is set in advance by the user.
- the model selection unit 12 Exclude model 4 from models 1-4 that are present. Then, the model selection unit 12 selects two or more models from the model 1, the model 2, and the model 3 pooled in the model pool unit 11.
- the hybrid model creation device 10 can exclude models whose estimation accuracy is equal to or less than the threshold from the hybrid model candidates among the plurality of pooled models.
- a model having a strong correlation with all other models may be excluded from the pooled models as a predetermined model. That is, among a plurality of pooled models, a model that has a strong correlation with all other models may be excluded from the hybrid model candidates. A specific example of this case will be described below as a second embodiment.
- FIG. 5 is a flowchart showing an example of detailed processing of step S1 according to the second embodiment.
- step S1 first, the hybrid model creation device 10 pools a plurality of models for estimating the category of input data (S121).
- the hybrid model creation device 10 uses the verification data set to obtain estimation results for each of the multiple models (S122). More specifically, before selecting two or more models, the model selection unit 12 inputs a plurality of verification data sets to each of the plurality of models pooled in the model pool unit 11 to select categories. By estimating, the estimation result of each of the plurality of models is acquired.
- the estimation result may be the final output result of the model or an intermediate quantity of the model.
- the estimation result is the intermediate or final layer output result of the deep-learned model.
- the hybrid model creation device 10 uses the estimation results obtained in step S122 to calculate the correlations of all of the pooled models (S123). More specifically, the model selection unit 12 calculates the correlation between two models for all of the models pooled in the model pool unit 11 .
- c j be the estimation result of the j-th (j is a natural number) model for the verification data set.
- cj,i be the estimation result for the i-th (i is a natural number) verification data in the verification data set. It is also assumed that the estimation result is the final output result of the model or a scalar intermediate quantity.
- Equation 1 is an equation for calculating the matching rate (Jcacard coefficient) of the estimation result, and can be used when the estimation result is a binary value of 0 or 1.
- Equation 1 ⁇ is Kronecker's ⁇ .
- (Formula 2) to (Formula 4) can be used not only when the estimation result is binary but also when it is a continuous value.
- (Formula 2) is a formula for calculating the covariance, and E[X] indicates the average of X.
- V[X] in (Formula 3) indicates the variance of X.
- (Formula 3) is a formula for calculating a correlation coefficient
- (Formula 4) is a formula for calculating a cosine similarity
- c j is a vector created by arranging c j and k with respect to i. .
- the correlation between the j-th model and the k-th model can be calculated by using (Equation 5) or (Equation 6) to calculate the intermediate degree of similarity sim i for each verification data.
- fj,i is an intermediate quantity of a vector consisting of multiple values.
- a statistic such as the median value or the average value represented by (Equation 7) is calculated. This allows the calculated correlations to be compared even if the estimation result is an intermediate quantity of vectors.
- the hybrid model creation device 10 excludes models whose correlations with all other models are stronger than a threshold (S124). More specifically, the model selection unit 12 excludes a model whose average or median correlation coefficient with all other models is stronger than a threshold from among the models pooled in the model pool unit 11. do. Then, the model selection unit 12 selects two or more models from a plurality of models from which the models below the threshold are excluded. Note that the threshold is set in advance by the user.
- the model selection unit 12 selects the model Model 4 is excluded from models 1 to 4 pooled in pool unit 11 . Then, the model selection unit 12 selects two or more models from the model 1, the model 2, and the model 3 pooled in the model pool unit 11.
- the hybrid model creation device 10 can exclude from the hybrid model candidates those models that have stronger correlations than the threshold with all other models among the pooled models.
- step S1 shown in FIG. 3 a model having a strong correlation with all other models is excluded from a plurality of pooled models as a predetermined model.
- the present invention is not limited to this.
- step 3 shown in FIG. 3 a hybrid model candidate may be created by not including a combination of models with a strong correlation. A specific example of this case will be described below as a third embodiment.
- FIG. 6 is a flowchart showing an example of detailed processing of step S3 according to the third embodiment.
- the hybrid model creation device 10 uses the verification data set to acquire the estimation results of each of the multiple models (S311). More specifically, before creating a plurality of hybrid model candidates, the hybrid model candidate creating unit 13 inputs a plurality of verification data sets to each of the plurality of models pooled in the model pooling unit 11 to classify them into categories. is obtained by estimating the estimation result of each of the plurality of models. In addition, the hybrid model candidate creation unit 13 inputs a plurality of verification data sets to each of the plurality of models selected by the model selection unit 12 to estimate the category, thereby obtaining estimation results for each of the plurality of models. You may Here, the estimation result may be the final output result of the model or the intermediate quantity of the model, as described in the second embodiment. For example, in a deep-learned model, the estimation result is the intermediate or final layer output result of the deep-learned model.
- the hybrid model creation device 10 uses the estimation results obtained in step S311 to calculate the correlations of all of the pooled or selected models (S312). More specifically, the hybrid model candidate creation unit 13 calculates the correlation between two models for all of the multiple models pooled in the model pool unit 11 or selected by the model selection unit 12 . Since the method of calculating the correlation has been described in the second embodiment, the description thereof will be omitted here.
- the hybrid model creation device 10 selects two or more models from the pooled models so as not to include a combination of two models having a correlation stronger than a threshold (S313). More specifically, the hybrid model candidate creation unit 13 combines the two or more models selected by the model selection unit 12 so as not to include a combination of two models having a correlation stronger than a threshold, so that the hybrid model candidate creation unit 13 Create multiple model candidates.
- the hybrid model creation device 10 can create hybrid model candidates by combining weakly correlated models from a plurality of selected models.
- FIG. 7A is a diagram for explaining the accuracy of a hybrid model candidate when combining three models with a strong correlation according to the third embodiment.
- FIG. 7B is a diagram for explaining the accuracy of a hybrid model candidate when three weakly correlated models are combined according to the third embodiment.
- the hybrid model candidate shown in FIGS. 7A and 7B combines the estimated results of the three models using logistic regression or the like. In order to simplify the explanation, it is assumed that the hybrid model candidates in FIGS. 7A and 7B output the majority of the estimation results of the three models.
- FIG. 7A shows binary estimation results and determinations when 10 verification data out of the verification data set are used for each of models 1, 2, and 3, which have strong correlations, and a hybrid model candidate. The results and the true values of 10 validation data are shown.
- the accuracies (estimated accuracies) of model 1, model 2 and model 3 are 80%, 70% and 80%, and the hybrid model combining model 1, model 2 and model 3
- the candidate accuracy (determination accuracy) is 80%.
- FIG. 7B shows binary estimation results and determinations when using 10 validation data out of the validation data set for each of models 1, 2, and 3 with weak correlations, and a hybrid model candidate. The results and the true values of 10 validation data are shown.
- the accuracies (estimated accuracies) of model 1, model 2 and model 3 are 80%, 60% and 50%, and the hybrid model candidate combining model 1, model 2 and model 3
- the accuracy (determination accuracy) of is 90%.
- the hybrid model creation device 10 can create hybrid model candidates by combining models with weak correlations. Since the hybrid model creation device 10 can select one hybrid model from such hybrid model candidates, it is possible to create a hybrid model with higher accuracy.
- Example 4 In a fourth embodiment, a specific example of generating hybrid model candidates using logistic regression or the like will be described.
- the hybrid model candidate creation unit 13 creates multiple hybrid model candidates for category determination by combining two or more models selected by the model selection unit 12 using logistic regression or the like. Although the maximum number of models to be combined is set in advance, it may be set each time a hybrid model candidate is created.
- the hybrid model candidate creating unit 13 creates each of the plurality of hybrid model candidates as a machine learning model.
- the machine learning model is input with two or more output results obtained by inputting a verification data set into each of two or more models selected to configure the hybrid model candidate and estimating the category. , is a model for outputting the judgment result of judging the category of the verification data set.
- the hybrid model candidate creation unit 13 compares the judgment results output to the plurality of created hybrid model candidates. More specifically, the hybrid model candidate creation unit 13 compares the determination results output after performing machine learning on the plurality of created hybrid model candidates.
- FIG. 8 is a diagram for conceptually explaining an example of the details of the hybrid model candidate creation process 13a according to the fourth embodiment.
- the hybrid model candidate creation process 13a shown in FIG. 8 is an example of details of the hybrid model candidate creation process 13a shown in FIG.
- the hybrid model candidate creation unit 13 performs hybrid model candidate creation processing 13a for creating hybrid model candidates by combining the models 1, 2, and 3 selected by the model selection unit 12. More specifically, the hybrid model candidate creating unit 13 creates machine learning models 1 & 2 (hybrid model candidate 1) by combining the model 1 and the model 2 using logistic regression, for example. Further, the hybrid model candidate creating unit 13 creates machine learning models 2 & 3 (hybrid model candidate 2) by combining the model 2 and the model 3 using logistic regression, for example. Further, the hybrid model candidate creating unit 13 creates machine learning models 1 & 3 (hybrid model candidate 3) by combining the model 1 and the model 3 using logistic regression, for example. In the example shown in FIG. 8, the maximum number of models to be combined is two, and machine learning models are created by combining them in a round-robin manner.
- the hybrid model candidate creation unit 13 uses the verification data set to learn the machine learning models 1 & 2, the machine learning models 2 & 3, and the machine learning models 1 & 3, and then the output result (determination result) obtained. to get The hybrid model candidate creation unit 13 performs comparison processing for comparing the output results of the machine learning models 1&2, the machine learning models 2&3, and the machine learning models 1&3.
- the hybrid model candidate creating unit 13 ranks the results of the comparison processing, for example, in descending order of accuracy. In the example shown in FIG. 8, the ranking is in the order of machine learning models 2&3, machine learning models 1&3, and machine learning models 1&2.
- a machine learning model obtained by combining using logistic regression can be expressed using a logistic function (sigmoid function) as shown in (Formula 8) below. Although two models are combined in (Equation 8), the same applies when three or more models are combined.
- function S b ( ⁇ 0 + ⁇ 1 x 1 + ⁇ 2 x 2 ) is a sigmoid function with outputs from 0 to 1, ⁇ 0 is a constant, ⁇ 1 and ⁇ 2 are x 1 and x2 coefficients. Also, x 1 and x 2 denote the outputs of the two models.
- x 1 and x 2 correspond to outputs (estimation results) obtained after learning two models, respectively, and are expressed by probabilities.
- the output of the function S b ( ⁇ 0 + ⁇ 1 x 1 + ⁇ 2 x 2 ) is the output (judgment result) obtained after learning the coefficient using the verification data set for the machine learning model that combines the two models. and is expressed with a probability of 0 to 1.
- machine learning models 1 & 2 which are obtained by combining using logistic regression, use the output of model 1 and the output of model 2 as inputs, and make a decision by applying a logistic function whose coefficients are learned using a verification data set. It is a hybrid model candidate that outputs results.
- machine learning models 2 & 3 which are obtained by combining using logistic regression, use the output of model 2 and the output of model 3 as inputs and apply a logistic function that has learned coefficients using the verification data set. It is a hybrid model candidate that outputs the determination result.
- Machine learning models 1 & 3 which are obtained by combining using logistic regression, use the output of model 1 and the output of model 3 as inputs, and apply the logistic function whose coefficients are learned using the verification data set to obtain the judgment result. It is a hybrid model candidate to be output.
- the method of combining multiple models is not limited to the method using logistic regression. If machine learning can be performed using the output (estimation results) obtained after training multiple models as input, it is possible to appropriately select machine learning methods such as support vector machines, random forests, gradient boosting methods, and neural networks.
- FIG. 9 is a flowchart showing an example of processing of the hybrid model creation device 10 according to the fourth embodiment. Note that steps S1, S2, S5, and S6 shown in FIG. 9 are the same as steps S1, S2, S5, and S6 described with reference to FIG. 3, and description thereof will be omitted.
- step S321 the hybrid model creation device 10 acquires estimation results for each of the multiple models using the verification data set. More specifically, the hybrid model candidate creation unit 13 inputs a plurality of verification data sets to each of a plurality of models pooled in the model pool unit 11 or selected by the model selection unit 12, and selects categories. By estimating, the estimation result of each of the plurality of models is acquired. The estimation result may be the final output result of the model, or an intermediate quantity of the model, as described above. It should be noted that step S321 may be executed before step S2 when obtaining estimation results for each of a plurality of models pooled in the model pool unit 11 .
- the hybrid model creation device 10 creates a plurality of hybrid model candidates by combining two or more models selected in step S2 as machine learning models (S322).
- each of the plurality of hybrid model candidates is a machine learning model that outputs the judgment result of judging the category of the verification data set by inputting the estimation results output from two or more models selected as a combination.
- This machine learning model is typically a model obtained by combining two or more models selected as a combination using logistic regression.
- the machine learning model is created by the hybrid model candidate creating unit 13 according to the user's instruction.
- the hybrid model creation device 10 compares the determination results output to each of the plurality of hybrid model candidates created in step S322 (S41). More specifically, the hybrid model candidate creation unit 13 inputs, for example, a verification data set to each of the hybrid model candidates, and compares the accuracy of the output judgment results.
- the hybrid model candidate creation unit 13 may compare the importance of two or more configured models that can be calculated from the determination results of each of the hybrid model candidates. More specifically, when comparing a plurality of hybrid model candidates, the hybrid model candidate creation unit 13 selects the candidate hybrid model selected for constructing the hybrid model candidate based on the determination results output to each of the plurality of hybrid model candidates. The respective importance of two or more models may be calculated. Then, the hybrid model candidate creation unit 13 may perform the comparison processing in step S41 by notifying the models with the calculated importance levels below a preset threshold value.
- the hybrid model candidate creation unit 13 may make the above notification to the hybrid model selection unit 14, or may make the above notification by displaying on a display or the like the models with importance levels below the threshold. good too.
- the hybrid model selection unit 14 selects one of the plurality of hybrid model candidates as a hybrid model, excluding hybrid model candidates having a model with a degree of importance below a preset threshold. can be selected.
- the output of the function S b ( ⁇ 0 + ⁇ 1 x 1 + ⁇ 2 x 2 ) is the machine learning model that combines the two models, and the coefficients using the validation data set. This is an output (judgment result) obtained after learning.
- the coefficient ⁇ 1 indicates the importance of the model that outputs x 1 in this machine learning model
- the coefficient ⁇ 2 indicates the importance of the model that outputs x 2 in this machine learning model. That is, the coefficient ⁇ i indicates the importance of model i that outputs x i in a machine learning model that combines a plurality of models.
- the model i has an influence (contribution) on the decision result in the machine learning model ) is small, it can be analyzed.
- the coefficient ⁇ i is a negative value
- the model i may cause overfitting of the machine learning model. This is because it is considered that the judgment result of the machine learning model and each of the plurality of models constituting the machine learning model should have a positive correlation.
- a machine learning model that combines multiple models learns the coefficients using the verification dataset, and by analyzing the coefficients, it is possible to analyze the importance of each of the multiple combined models.
- the model is a model that constitutes a machine learning model. i should not be used.
- Example 5 processing speed is taken into consideration when creating hybrid model candidates by machine learning using logistic regression. A specific example thereof will be described below.
- the hybrid model candidate creating unit 13 receives a verification data set and selects a category of the verification data set. Measure (acquire) the processing time required for estimation.
- the verification data set contains X pieces of sample data.
- the hybrid model candidate creation unit 13 calculates the average processing time, which is the processing time per piece of sample data, for each of the plurality of models from the measured processing time.
- the hybrid model candidate creation unit 13 creates a plurality of hybrid model candidates only from among the two or more models selected by the model selection unit 12, with only the combination that satisfies the execution time requirement for the total average processing time. do. Note that the method of creating a hybrid model candidate by machine learning using logistic regression is as described in Example 4, so description thereof will be omitted here.
- the hybrid model candidate creating unit 13 receives a verification data set and selects a category of the verification data set. Get the processing time required for estimation.
- the verification data set contains X pieces of sample data.
- the hybrid model candidate creation unit 13 calculates the average processing time, which is the processing time per piece of sample data, for each of the plurality of models from the acquired processing time.
- the hybrid model candidate creating unit 13 defines the value of the average processing time of each of the multiple models with respect to the sum of the average processing times of all of the multiple models as the hardware cost.
- the hardware cost Cm can be defined as in (Equation 9) below.
- c m avg(processing speed of model)/sum(processing speed of avg_all_models) (Formula 9)
- the hybrid model candidate creation unit 13 adds the hardware cost of each of the two or more models selected to form the hybrid model candidate to the loss function of the machine learning model of each of the plurality of hybrid model candidates. Add a weighted regularization term.
- the regularization term that takes into account the hardware cost is, for example, a regularization term such as Lasso (L1 norm or L1 regularization) multiplied by the parameter ⁇ and the hardware cost C m ⁇ ⁇ C m ⁇ L1 regularization term can be expressed as
- the parameter ⁇ is a hyperparameter that can change the weight of the hardware cost. Details will be described later.
- the hybrid model candidate creation unit 13 adds a regularization term that takes into account the hardware cost, and then executes logistic regression machine learning. As a result, it is possible to reduce the coefficient (weight) of a model that contributes little to the hybrid model candidate despite the high calculation cost, so that the model that contributes little to the hybrid model candidate can be excluded.
- the logistic regression loss function E(w) is expressed as (Equation 10).
- learning is performed so as to obtain a combination of weights (coefficients) that minimizes the loss function E(w).
- Equation 11 a loss function E ′ (w) obtained by adding an L1 regularization term to the loss function E(w), for example, is expressed as (Equation 11).
- Equation 11 the parameter ⁇ is a hyperparameter.
- explanatory variables are the output values of each model. Therefore, using the hardware cost Cm of the corresponding model, the loss function E ′ (w) with the hardware cost added can be expressed as in (Equation 12).
- the L1 regularization term As the regularization term has been described, but the L2 regularization term may be used. Also in this case, a loss function can be similarly defined in consideration of the hardware cost Cm . Note that the L1 regularization term can be expected to have the effect of not only reducing the value of the weight (coefficient) but also making it zero. Therefore, the L1 regularization term is better than the L2 regularization term for the purpose of creating hybrid model candidates by excluding models with long processing times.
- FIG. 10 is a flowchart showing an example of detailed processing of step S3 according to the fifth embodiment. 10 corresponds to another example of the processing of steps S321 and S322 shown in FIG.
- step S3 the hybrid model creation device 10 uses the verification data set to obtain the processing time and estimation results for each of the multiple models (S331). More specifically, the hybrid model candidate creation unit 13 inputs a plurality of verification data sets to each of the plurality of models selected by the model selection unit 12 to estimate the category. The hybrid model candidate creation unit 13 calculates the processing time and the estimation result required from inputting the verification data set to estimating the category of the verification data set for each of the plurality of models selected by the model selection unit 12. get.
- the estimation result may be the final output result of the model, or an intermediate quantity of the model, as described above. Note that the processing time and estimation result may be obtained from each of a plurality of models pooled in the model pool unit 11 . In this case, step S331 may be performed before step S2.
- the hybrid model generation device 10 defines the value of the time required for each of the plurality of models with respect to the sum of all the processing times of the plurality of models as the hardware cost. (S332).
- the processing time used to define the hardware cost is the average processing time.
- the hybrid model creation device 10 creates a plurality of hybrid model candidates by combining two or more models selected in step S2 as machine learning models.
- the hybrid model creation device 10 adds a regularization term that takes into consideration the hardware cost to the loss function of each of the plurality of hybrid model candidates during machine learning (S333). More specifically, the loss function of each of the plurality of hybrid model candidates is regularized by adding (multiplying) the hardware cost of each of the two or more models selected to construct the hybrid model candidate. term is added.
- the hybrid model candidate creation unit 13 Before comparing a plurality of hybrid model candidates in subsequent step S4, the hybrid model candidate creation unit 13 performs coefficient analysis from the output (determination result) obtained after learning using the verification data set. As a result, the hybrid model candidate creation unit 13 can exclude hybrid model candidates including models requiring a long processing time. Therefore, in the subsequent step S4, the hybrid model candidate creation unit 13 may perform comparison processing of a plurality of hybrid model candidates after excluding hybrid model candidates including models requiring a long processing time.
- Example 6 A hybrid model candidate is created and machine-learned as a machine learning model that takes as input the estimation results output from two or more models selected as a combination and outputs the judgment result of judging the category of the verification data set. .
- the estimation results output from two or more models reliably indicate NG, and the true value (label) is also NG. is excluded and machine learning is performed.
- FIG. 11 is a diagram conceptually showing an example of a hybrid model candidate created by combining model 1 and model 2 according to the sixth embodiment.
- the hybrid model candidate shown in FIG. 11 is a logistic regression model (boundary) created by machine learning.
- the vertical axis is the output value that is output (estimated) when the verification data set is input to model 2, and is expressed in terms of probability.
- the horizontal axis is the output value that is output (estimated) when the verification data set is input to model 1, and is expressed in terms of probability.
- the sample data included in the verification data set is an inspection image of a manufactured product
- the black circles are inspection images in which the true value of the sample data is a non-defective product, and are called non-defective product images.
- a white circle is an inspection image in which the true value of the sample data is a defective product, and is called a defective product image.
- the output of the defective product image with large output values (probability) for both model 1 and model 2 (referred to as the output showing clear NG) is machine-learned so as to become the logistic regression model (boundary) shown in FIG. In some cases, it can be seen that the importance is relatively low.
- the output in the area surrounded by the circle is the output indicating a clear NG.
- the number of clear NGs contained in the circled area is large. For this reason, when creating a hybrid model candidate by machine learning using the output of model 1 and model 2 as shown in FIG. 11 and the true value (label) of the verification data set, It is strongly affected by such an output that clearly shows NG, and there is a possibility that the boundary shown in FIG. 11 cannot be obtained.
- machine learning is performed by excluding the output that clearly shows NG, which is the output in the area surrounded by the circle.
- the hybrid model candidate creation unit 13 inputs a verification data set to each of the two or more models selected to configure the hybrid model candidate, and causes the category to be estimated. output values that are higher than the threshold value and are estimated to be defective are excluded from the output values of .
- the hybrid model candidate creation unit 13 uses as inputs a plurality of output values from which output values higher than the threshold are excluded, and uses the true values of the verification data set corresponding to the plurality of output values. Create multiple hybrid model candidates by performing machine learning.
- FIG. 12 is a flowchart showing an example of detailed processing of step S3 according to the sixth embodiment. 12 corresponds to another example of the processing of steps S321 and S322 shown in FIG.
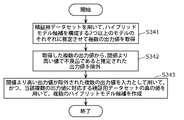
- step S3 the hybrid model creation device 10 obtains a plurality of output values by estimating each of the two or more models that constitute the hybrid model candidate using the verification data set (S341).
- the hybrid model creation device 10 excludes output values that are higher than a threshold value and are estimated to be defective from the plurality of output values acquired in step S341 (S342).
- an output value that is higher than the threshold value and is estimated to be a defective product is an output value that clearly indicates NG as described with reference to FIG. 11 .
- the hybrid model generating apparatus 10 uses as inputs a plurality of output values from which output values higher than the threshold are excluded in step S342, and the true values of the verification data set corresponding to the plurality of output values.
- a plurality of hybrid model candidates are created by performing machine learning using (S342).
- the hybrid model creation device 10 can create a plurality of hybrid model candidates with high determination accuracy by performing machine learning while excluding outputs included in areas where clear NGs are gathered.
- Example 7 In the sixth embodiment, a case has been described in which machine learning is performed by excluding outputs included in a region where clear NGs are gathered among the outputs of two or more models constituting a hybrid model candidate, but the present invention is not limited to this.
- a method using a convex hull will be described as another method of excluding outputs clearly indicating NG.
- the convex hull means the smallest convex polygon (convex polyhedron) that includes all given points.
- FIG. 13 is a diagram conceptually showing the outputs of the models 1 and 2 according to the seventh embodiment and the convex hull of the output distribution corresponding to the defective product image.
- FIG. 14 is a diagram conceptually showing an example of a hybrid model candidate created from the outputs of models 1 and 2, in which outputs corresponding to defective product images excluding the vertices of the convex hull shown in FIG. 13 are removed. .
- FIG. 14(a) conceptually shows the outputs of model 1 and model 2 from which outputs indicating NG other than the vertices of the convex hull shown in FIG. 13 are removed.
- an example of a logistic regression model (boundary) as a hybrid model candidate created by machine learning from the outputs of model 1 and model 2 shown in (a) of FIG. 14 is conceptually shown. It is shown.
- the hybrid model candidate creation unit 13 inputs a verification data set to each of the two or more models selected to configure the hybrid model candidate, and causes the category to be estimated. Among the output values of , the convex hull is calculated when the output values estimated to be defective are plotted. Next, the hybrid model candidate creation unit 13 excludes the output values included in the convex hull except for the vertices of the convex hull from the plurality of output values. Then, the hybrid model candidate creation unit 13 inputs and uses a plurality of output values obtained by excluding the output values included in the convex hull except for the vertices of the convex hull, and uses the plurality of output values for verification corresponding to the plurality of output values. Create multiple hybrid model candidates by performing machine learning using the true values of the dataset.
- miss-miss determination 0.
- FIG. 15 is a flowchart showing an example of detailed processing of step S3 according to the seventh embodiment. 15 corresponds to another example of the processing of steps S321 and S322 shown in FIG.
- step S3 the hybrid model creation device 10 obtains a plurality of output values by estimating each of the two or more models that constitute the hybrid model candidate using the verification data set (S351).
- the hybrid model creation device 10 calculates a convex hull when plotting the output values estimated to be defective among the plurality of output values acquired in step S351 (S352).
- the hybrid model creation device 10 excludes the output values included in the convex hull excluding the vertices of the convex hull from the plurality of output values acquired in step S351 (S353).
- the hybrid model generating apparatus 10 uses as input a plurality of output values obtained by excluding the output values included in the convex hull excluding the vertices of the convex hull, and verifies data corresponding to the plurality of output values.
- Machine learning is performed using the set of true values to create a plurality of hybrid model candidates (S354).
- the hybrid model creation device 10 creates a plurality of hybrid model candidates with high judgment accuracy such that the oversight (oversight judgment) is 0. can do.
- the number of models (number of dimensions) selected to construct a hybrid model candidate is large, such as 10 or more, the number of vertices of the convex hull becomes enormous, and the calculation cost of the convex hull increases. becomes large, the method using the convex hull may not be adopted.
- FIG. 16 is a diagram conceptually showing outputs and exclusion regions of models 1 and 2 according to the seventh embodiment.
- FIG. 17 is a diagram conceptually showing an example of a hybrid model candidate created from outputs of models 1 and 2 from which outputs corresponding to defective product images included in the exclusion area shown in FIG. 16 are removed.
- (a) of FIG. 17 conceptually shows the outputs of the model 1 and the model 2 from which the output indicating NG included in the exclusion area shown in FIG. 16 is removed.
- FIG. 17(b) shows an example of a conceptual logistic regression model (boundary) as a hybrid model candidate created by machine learning from the outputs of model 1 and model 2 shown in FIG. 17(a). It is shown.
- the output value (probability) indicating NG is large, and the output indicating definite NG where the true value is also NG gathers. It can be calculated as an exclusion area. Such a calculation method can be used as an approximate method for calculating the convex hull. Then, machine learning may be performed by excluding outputs that clearly indicate NG in the exclusion area.
- Example 8 As a comparison method for comparing a plurality of hybrid model candidates, there is a method for comparing the judgment results of each of the hybrid model candidates.
- the results of machine learning decisions are usually output as probabilities.
- the probability output as the determination result does not represent the actual probability of the category indicated as the determination result. That is, for example, even if the determination result of determining whether or not the manufactured product shown in the inspection image input as sample data is defective is 0.9, the probability that the manufactured product is defective is 90. %, and it is known that there is a difference between the actual probability and the judgment result.
- the miss rate of the hybrid model candidate is used as the judgment result output by each of the plurality of hybrid model candidates.
- FAR tables of a plurality of models selected to create a hybrid model candidate are calculated and used as parameters for adjusting the overlook rate of the hybrid model candidate.
- FIG. 18 is a diagram for explaining a method of calculating the FAR curve for the model 1 according to the eighth embodiment.
- FIG. 19 is a diagram illustrating an example of a FAR table of model 1 according to the eighth embodiment.
- Model 1 is one of multiple models selected to create a hybrid model candidate.
- FAR is an abbreviation for False Acceptance Rate, which is the probability of erroneously determining NG as OK.
- the FAR value is called a miss rate.
- FA is an abbreviation for False Accept, which means to erroneously determine NG as OK.
- FA is referred to as miss or miss determination.
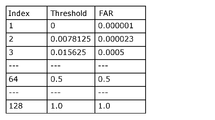
- the FAR table is a table of miss rates (FAR values) when the threshold is varied with a predetermined step size.
- the hybrid model candidate creation unit 13 creates a FAR table for each of the multiple models selected to create the hybrid model candidate using the verification data set during machine learning.
- the output value and frequency obtained by inputting the verification data set into model 1 and estimating the category are obtained.
- the distribution of output values (probabilities) indicating defective products shown in FIG. A FAR curve shown in (b) can be obtained. Note that the area ratio when the area of the entire distribution is 1 corresponds to the overlook rate (FAR value).
- the oversight rate (FAR value) is obtained by obtaining the oversight rate (FAR value) at a predetermined step size in the distribution of output values (probabilities) indicating defective products shown in (a) of FIG. can.
- the step size is set to 0.0078125, and the FAR values from 0 to 1 are described for the index assigned to each step size.
- the hybrid model candidate creation unit 13 inputs a plurality of data indicating defective products in the verification data set for each of the plurality of selected models, and outputs the output value obtained by estimating the category.
- a FAR table can be created from the distribution.
- the hybrid model candidate creation unit 13 can obtain the miss rate by varying the threshold value in the distribution of the acquired output values, and thus can create the FAR table, which is a table of the miss rate.
- the hybrid model candidate creation unit 13 inputs the data samples included in the verification data set to each of the two or more models selected to form the hybrid model candidate, and causes the category to be estimated. Get results.
- the hybrid model candidate creation unit 13 compares the acquired estimation result (output value) with a FAR table created in advance to obtain a first FAR value of each of the two or more models for the data sample. Get the 1FAR value.
- the probability that an inspection image is defective can be estimated (adjusted) based on the distribution of output values (probabilities) indicating defective products when the FAR table is created.
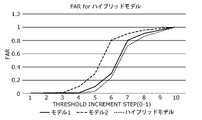
- the hybrid model candidate creation unit 13 multiplies the first FAR values of each of the two or more acquired models. Thereby, the hybrid model candidate creation unit 13 can acquire the second FAR value, which is the FAR value of the hybrid model candidate combined with the two or more models.
- FIG. 20 is a diagram conceptually showing the first FAR values of each of the two models according to Example 8 and the second FAR values of the hybrid model candidate created by combining the two models. As shown in FIG. 20, by multiplying the respective first FAR values of two or more models, a second FAR value that is improved over the respective first FAR values of the two or more models can be obtained.
- the FAR distributions of the multiple models that make up the hybrid model candidate are independent. Therefore, by the law of probability for independent events, the first FAR value of each of the two or more models can be multiplied to obtain the second FAR value of the hybrid model candidate combined with the two or more models.
- the method of calculating the correlation coefficient is as follows. That is, first, the hybrid model candidate creation unit 13 inputs a plurality of verification data sets for each of a plurality of models selected to create a plurality of hybrid model candidates, and causes the categories to be estimated, thereby estimating the plurality of models. Get the estimation results for each of the models in . Next, the hybrid model candidate creation unit 13 may calculate correlation coefficients of all combinations of two models out of the plurality of models using the obtained estimation result. As a result, the hybrid model candidate creation unit 13 multiplies the first FAR values of the two or more acquired models, and further multiplies by a coefficient that decreases as the correlation coefficient increases, thereby obtaining the corrected second FAR value. value can be obtained.
- the hybrid model candidate creation unit 13 determines that the data sample is non-defective.
- the hybrid model candidate creation unit 13 can acquire this determination result as the determination result when the hybrid model candidate is caused to input the data sample.
- the hybrid model candidate creation unit 13 can acquire the determination result adjusted using the second FAR value and the preset threshold value as the determination result when data samples are input to a plurality of hybrid model candidates. Then, the hybrid model candidate creation unit 13 can compare a plurality of hybrid model candidates using the adjusted determination result.
- the FAR threshold should be determined in advance based on what degree of miss rate the user using the hybrid model can tolerate.
- Model 1 and model 2 are a plurality of models constituting hybrid model candidates.
- the second FAR value can be obtained as a value obtained by multiplying them. If the second FAR value is smaller than the FAR threshold value of 1/1,000,000, the sample data can be judged as NG (indicating a defective product), and if it is larger, it can be judged as OK (indicating a non-defective product).
- the hybrid model creation apparatus 10 and the hybrid model creation method according to the present disclosure can create a hybrid model that does not use all of a plurality of models prepared and pooled in advance.
- the hybrid model creation device 10 and the hybrid model creation method according to the present disclosure can create hybrid model candidates excluding models that have high calculation costs and do not contribute much. can be created in
- the hybrid model creation device 10 and the hybrid model creation method according to the present disclosure can create hybrid model candidates by excluding models that do not contribute to accuracy improvement using the importance, so that hybrid models can be created lightly and effectively. .
- the hybrid model creation device 10 and the like according to the present disclosure have been described above based on the embodiment and each example, the present disclosure is not limited to these embodiments and the like. As long as it does not deviate from the gist of the present disclosure, various modifications that a person skilled in the art can think of are applied to the embodiments and each example, and other modifications constructed by combining some components of the embodiments and each example Forms are also included within the scope of this disclosure.
- the hybrid model creation device 10 creates hybrid model candidates by combining a plurality of models selected from a plurality of pooled models using logistic regression or the like, and compares them. Although one hybrid model was selected in , it is not limited to this. Combine multiple models selected from multiple pooled models, create hybrid model candidates that perform estimation processing with logical formulas in the order of combination, and select one hybrid model by comparing accuracy You may
- FIG. 21 is a diagram showing an example of a hybrid model creation method according to another embodiment.
- FIG. 21 shows a hybrid model creation method when model 1, model 2, and model 3 are selected from a plurality of pooled models.
- three different models connected by arrows are combined in this order to create a hybrid model candidate.
- the hybrid model candidates are compared with accuracies obtained by ORing or ANDing the accuracies of Model 1, Model 2, and Model 3 in the order in which they were combined.
- the example shown in FIG. 21 indicates that the hybrid model candidate combining the order of model 3-model 1-model 2 has the highest accuracy of 93%, and thus is selected as the hybrid model.
- FIG. 22 is a diagram showing another example of a hybrid model creation method according to another embodiment.
- model 1, model 2 and model 3 are selected from a plurality of pooled models
- a hybrid model candidate is created by combining at least two of model 1, model 2 and model 3. It shows how to do it.
- the hybrid model candidate in which model 2 and model 1 are combined in this order has the highest accuracy of 93%, so it is selected as the hybrid model.
- the determination threshold determination unit 15 that configures the hybrid model generation device 10 determines the determination threshold using the confusion matrix. may be used to determine the determination threshold in the following two steps.
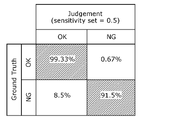
- FIGS. 23A and 23B are diagrams showing examples of tables of confusion matrices according to other embodiments.
- the judgment threshold determination unit 15 acquires the judgment result (binary prediction value of OK or NG) of the hybrid model selected by the hybrid model selection unit 14 using the verification data set.
- the determination threshold determination unit 15 sets the threshold to 0.5, and creates a confusion matrix table shown in FIG. 23A, for example, from combinations of determination results and true values (binary values of OK or NG).
- step 2 the desired accuracy, such as an overdetection rate of 0.86%, is input, and the above judgment result (binary prediction value of OK or NG) is converted to the true value (OK or NG). ) to create a confusion matrix table shown in FIG. 23B.
- the threshold of 0.42 shown in FIG. 23B can be selected as the optimal threshold (decision threshold).
- Some of the components that make up the hybrid model creation device 10 may be a computer system made up of a microprocessor, ROM, RAM, hard disk unit, display unit, keyboard, mouse, and the like.
- a computer program is stored in the RAM or hard disk unit. The function is achieved by the microprocessor operating according to the computer program.
- the computer program is constructed by combining a plurality of instruction codes indicating instructions to the computer in order to achieve a predetermined function.
- a system LSI is an ultra-multifunctional LSI manufactured by integrating multiple components on a single chip. Specifically, it is a computer system that includes a microprocessor, ROM, RAM, etc. . A computer program is stored in the RAM. The system LSI achieves its functions by the microprocessor operating according to the computer program.
- Some of the components that make up the hybrid model creation device 10 may be made up of an IC card or a single module that can be attached to and detached from each device.
- the IC card or module is a computer system composed of a microprocessor, ROM, RAM and the like.
- the IC card or the module may include the super multifunctional LSI.
- the IC card or the module achieves its function by the microprocessor operating according to the computer program. This IC card or this module may have tamper resistance.
- some of the components that make up the above-described hybrid model creation device 10 include a computer-readable recording medium for the computer program or the digital signal, such as a flexible disk, hard disk, CD-ROM, MO , DVD, DVD-ROM, DVD-RAM, BD (Blu-ray (registered trademark) Disc), semiconductor memory, or the like. Moreover, it may be the digital signal recorded on these recording media.
- a computer-readable recording medium for the computer program or the digital signal such as a flexible disk, hard disk, CD-ROM, MO , DVD, DVD-ROM, DVD-RAM, BD (Blu-ray (registered trademark) Disc), semiconductor memory, or the like.
- BD Blu-ray (registered trademark) Disc
- some of the components that make up the above-described hybrid model creation apparatus 10 transmit the computer program or the digital signal via an electric communication line, a wireless or wired communication line, a network represented by the Internet, data broadcasting, or the like. may be transmitted as
- the present disclosure may be the method shown above. Moreover, it may be a computer program for realizing these methods by a computer, or it may be a digital signal composed of the computer program.
- the present disclosure may also be a computer system comprising a microprocessor and memory, the memory storing the computer program, and the microprocessor operating according to the computer program. .
- the present disclosure can be used for a method, a hybrid model method, a hybrid model creation apparatus, a program, and the like for creating a hybrid model that combines machine learning models for performing non-defective product determination in an inspection process.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Automation & Control Theory (AREA)
- Medical Informatics (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Manufacturing & Machinery (AREA)
- Quality & Reliability (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
まず、本実施の形態に係るハイブリッドモデル作成装置及びハイブリッドモデル作成方法の概要について説明する。
以下、本実施の形態に係るハイブリッドモデル作成装置10の構成等の概要について説明する。
モデルプール部11は、HDD(Hard Disk Drive)またはメモリ等で構成され、入力されるデータのカテゴリを推定する複数のモデルをプール(記憶)している。本実施の形態では、モデルプール部11は、図2に示すように、例えばモデル1、モデル2、モデル3及びモデル4などの予め作成された複数のモデル11aをプールしている。ここで、複数のモデル11aの少なくとも一つのモデルは、機械学習されたモデルである。複数のモデル11aのそれぞれは、AIモデルとも称することができる。本実施の形態では、入力されるデータは、製造品の検査画像であるとして説明する。複数のモデル11aのうちの少なくとも1つのモデルは、深層学習により学習されたAIモデルである。複数のモデル11aには、人手により特徴量が設計されたAIモデルが含まれていてもよい。例えば、複数のモデル11aのそれぞれは、製造品の検査画像を入力とし、検査画像に映る製造品が不良である確率を推定して出力する。なお、複数のモデル11aのそれぞれは、検査画像に映る製造品が不良であるか否かの2値の推定結果を出力してもよい。
モデル選択部12は、モデルプール部11にプールされている複数のモデルから2つ以上のモデルを選択する。本実施の形態では、モデル選択部12は、モデルプール部11にプールされている複数のモデルのうち所定のモデルを除外した上で2つ以上のモデルを選択する。図2に示す例では、モデル選択部12は、例えばモデル1、モデル2、モデル3及びモデル4のうち、モデル4を所定のモデルとして除外した上で、2つ以上のモデルを選択するモデル選択処理12aを行う。モデル選択部12は、モデルプール部11にプールされている複数のモデルから所定のモデルを除外してから、2つ以上のモデルを選択してもよいし、モデルプール部11にプールされている複数のモデルのうち、2つ以上のモデルを所定のモデルを除外した上で選択してもよい。また、所定のモデルは、例えば推定精度の低いモデルであってもよいし、他のモデルとの相関が強いモデルであってもよい。このような所定のモデルを除外する方法等の詳細は、後述する実施例1及び実施例2で説明するのでここでの説明は省略する。
ハイブリッドモデル候補作成部13は、モデル選択部12により選択された2つ以上のモデルを組み合わせることで、カテゴリを判定するハイブリッドモデル候補を複数作成する。なお、ハイブリッドモデル候補作成部13は、閾値より強い相関があるモデルの組み合わせを含めないように、モデル選択部12により選択された2つ以上のモデルを組み合わせることで、ハイブリッドモデル候補を複数作成してもよい。ハイブリッドモデル候補は、モデル選択部12により選択された2つ以上のモデルを単純に連結(カスケード)することで組み合わせてもよいし、後述するようにロジスティック回帰などを用いて組み合わせてもよい。
ハイブリッドモデル選択部14は、複数のハイブリッドモデル候補の比較結果に基づき、複数のハイブリッドモデル候補のうちの1つをハイブリッドモデルとして選択する。
判定閾値決定部15は、例えば製造品の検査画像などの検証用データセットを用いて、ハイブリッドモデル選択部14により選択されたハイブリッドモデルの感度を調整し、誤判定を抑制するために許容できる過検出率の閾値を決定する。判定閾値決定部15は、例えば製造品の検査画像などの検証用データセットを入力して当該製造品が良品または不良品であるかを判定させた判定結果を取得する。判定閾値決定部15は、取得した判定結果から混同行列を生成し、誤判定を抑制するために許容できる過検出率の閾値(判定閾値)を決定する。なお、図2に示す判定閾値決定処理15aにおいて示されるCascading Modelは、ハイブリッドモデル選択部14により選択されたハイブリッドモデルを意味し、判定閾値が最適化されている。
以上のように構成されたハイブリッドモデル作成装置10の動作概要について以下説明する。
図3に示すステップS1において、プールされている複数のモデルから、推定精度の低いモデルを所定のモデルとして除いてもよい。すなわち、プールされている複数のモデルのうち、推定精度の低いモデルをハイブリッドモデル候補から除外してもよい。以下、この場合の具体例を実施例1として説明する。なお、推定精度は、正解率に限らず、適合率、再現率、適合率及び再現率の調和平均により算出されるF値、ROC(Receiver Operating Characteristic)曲線のAUC(Area Under Curve)並びに、正解率のうちの少なくとも一の組み合わせであればよい。
図3に示すステップS1において、プールされている複数のモデルから、他のすべてのモデルとの相関が強いモデルを所定のモデルとして除いてもよい。すなわち、プールされている複数のモデルのうち、他のすべてのモデルとの相関が強いモデルをハイブリッドモデル候補から除外してもよい。以下、この場合の具体例を実施例2として説明する。







実施例2では、図3に示すステップS1において、プールされている複数のモデルから、他のすべてのモデルとの相関が強いモデルを所定のモデルとして除いた場合について説明したが、これに限らない。図3に示すステップ3において、相関の強いモデルの組み合わせを含めないようにしてハイブリッドモデル候補を作成してもよい。以下、この場合の具体例を実施例3として説明する。
実施例4では、ロジスティック回帰などを用いてハイブリッドモデル候補を作成する場合の具体例について説明する。

複数のモデルには計算コストが高いモデルが含まれている場合がある。このような場合、計算コストが高いモデルが組み合わされて作成されたハイブリッドモデル候補は、使用するハードウェアの要件または実行時間の要件を満たせない可能性がある。なお、実行時間が要件内であっても処理速度は速い方がよいと考えられる。
cm=avg(modelの処理速度)/sum(avg_all_modelsの処理速度) (式9)



ハイブリッドモデル候補は、組み合わせとして選ばれた2つ以上のモデルから出力された推定結果を入力として、検証用データセットのカテゴリを判定した判定結果を出力させる機械学習モデルとして作成され、機械学習される。実施例6では、機械学習モデルを機械学習する際に、2つ以上のモデルから出力された推定結果が確実にNGを示しかつ、真の値(ラベル)もNGである明確なNGを示す出力を、除外して機械学習される場合について説明する。
実施例6では、ハイブリッドモデル候補を構成する2つ以上のモデルのそれぞれの出力のうち明確なNGが集まる領域に含まれる出力を除外して機械学習する場合について説明したが、これに限らない。実施例7では、明確なNGを示す出力を除外する別の方法として、凸包を用いる方法について説明する。なお、凸包とは、与えられた点をすべて包含する最小の凸多角形(凸多面体)のことを意味する。
複数のハイブリッドモデル候補を比較する比較方法として、ハイブリッドモデル候補のそれぞれの判定結果を比較する方法がある。
(1)上記の実施の形態では、ハイブリッドモデル作成装置10は、プールされている複数のモデルから選択した複数のモデルを、ロジスティック回帰などを用いて組み合わせたハイブリッドモデル候補を作成し、比較することで1つのハイブリッドモデルを選択したが、これに限らない。プールされている複数のモデルから選択した複数のモデルを組み合わせされて、組み合わせた順番に論理式で推定処理を行わせるハイブリッドモデル候補を作成して、精度を比較することで1つのハイブリッドモデルを選択してもよい。
11 モデルプール部
11a モデル
12 モデル選択部
12a モデル選択処理
13 ハイブリッドモデル候補作成部
13a ハイブリッドモデル候補作成処理
14 ハイブリッドモデル選択部
14a ハイブリッドモデル選択処理
15 判定閾値決定部
15a 判定閾値決定処理
Claims (16)
- 入力されるデータのカテゴリを推定する複数のモデルをプールし、
前記複数のモデルの少なくとも一つのモデルは、機械学習されたモデルであり、
プールされている複数のモデルから2つ以上のモデルを選択して組み合わせることで、前記カテゴリを判定するハイブリッドモデル候補を複数作成し、
複数の前記ハイブリッドモデル候補を比較することで、前記複数のハイブリッドモデル候補のうちの1つをハイブリッドモデルとして選択する、
ハイブリッドモデル作成方法。 - 前記入力されるデータは、製造品の検査画像であり、
判定されるカテゴリは、前記製造品が良品または不良品であるかである、
請求項1に記載のハイブリッドモデル作成方法。 - 前記複数のハイブリッドモデル候補を作成する際、
当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれに検証用データセットを入力してカテゴリを推定させることで得た複数の出力値から、閾値より高い値で不良品であると推定された出力値を除外し、
前記閾値より高い出力値が除外された前記複数の出力値を入力として用いて、かつ、前記複数の出力値に対応する検証用データセットの真の値を用いて機械学習を行うことで、前記複数のハイブリッドモデル候補を作成する、
請求項2に記載のハイブリッドモデル作成方法。 - 前記複数のハイブリッドモデル候補を作成する際、
当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれに複数の検証用データセットを入力してカテゴリを推定させることで得た複数の出力値のうち、不良品であると推定された出力値をプロットしたときの凸包を算出し、
前記複数の出力値から、前記凸包の頂点を除き前記凸包に含まれる出力値を除外し、
前記凸包の頂点を除き前記凸包に含まれる出力値が除外された前記複数の出力値を入力して用いて、かつ、前記複数の出力値に対応する検証用データセットの真の値を用いて機械学習を行うことで、前記複数のハイブリッドモデル候補を作成する、
請求項2に記載のハイブリッドモデル作成方法。 - 前記2つ以上のモデルを選択する前に、プールされている複数のモデルそれぞれに、複数の検証用データセットを入力してカテゴリを推定させることでプールされている前記複数のモデルそれぞれの推定精度を取得し、
前記推定精度が閾値以下のモデルを、プールされている前記複数のモデルの中から除外し、
前記閾値以下のモデルが除外された前記複数のモデルから、前記2つ以上のモデルを選択する、
請求項1~4のいずれか1項に記載のハイブリッドモデル作成方法。 - 前記2つ以上のモデルを選択する前に、プールされている複数のモデルそれぞれに、複数の検証用データセットを入力してカテゴリを推定させることでプールされている前記複数のモデルそれぞれの推定結果を取得し、
前記推定結果を用いて、プールされている前記複数のモデルのすべての相関を算出し、
他のすべてのモデルとの相関が閾値より強いモデルをプールされている前記複数のモデルの中から除外し、
前記閾値より強いモデルが除外された後において前記複数のモデルから、前記2つ以上のモデルを選択する、
請求項1~4のいずれか1項に記載のハイブリッドモデル作成方法。 - 前記ハイブリッドモデル候補を複数作成する前に、プールされているまたは選択された複数のモデルそれぞれに、複数の検証用データセットを入力してカテゴリを推定させることで当該複数のモデルそれぞれの推定結果を取得し、
前記推定結果を用いて、当該複数のモデルのすべての相関を算出し、
前記ハイブリッドモデル候補を複数作成する際に、閾値より強い相関がある2つのモデルの組み合わせを含めないように、選択された前記2つ以上のモデルを組み合わせることで、前記ハイブリッドモデル候補を複数作成する、
請求項1~4のいずれか1項に記載のハイブリッドモデル作成方法。 - 深層学習されたモデルでは、前記推定結果は、前記深層学習されたモデルの中間層または最終層の出力結果である、
請求項6または7に記載のハイブリッドモデル作成方法。 - 前記複数のハイブリッドモデル候補それぞれは、当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれに複数の検証用データセットを入力してカテゴリを推定させることで得た2つ以上の出力結果を入力として、前記複数の検証用データセットのカテゴリを判定した判定結果を出力させる機械学習モデルであり、
前記複数のハイブリッドモデル候補に出力させた判定結果を比較することで、前記複数のハイブリッドモデル候補のうちの1つをハイブリッドモデルとして選択する、
請求項1~8のいずれか1項に記載のハイブリッドモデル作成方法。 - 前記複数のハイブリッドモデル候補を比較する際、
前記複数のハイブリッドモデル候補それぞれに出力させた判定結果から、当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれの重要度を算出し、
算出された重要度のうち予め設定されていた閾値を下回った重要度のモデルを通知する、
請求項9に記載のハイブリッドモデル作成方法。 - 前記複数のハイブリッドモデル候補を比較する際、
前記複数のハイブリッドモデル候補それぞれに出力された判定結果から、当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれの重要度を算出し、
前記ハイブリッドモデルとして選択する際、
算出された重要度のうち予め設定されていた閾値を下回った重要度のモデルを有するハイブリッドモデル候補を除いた前記複数のハイブリッドモデル候補のうちの1つを、ハイブリッドモデルとして選択する、
請求項9に記載のハイブリッドモデル作成方法。 - さらに、前記複数のハイブリッドモデル候補を作成するために選択された複数のモデルのそれぞれにおいて、検証用データセットが入力されて前記検証用データセットのカテゴリを推定するまでに要した処理時間を取得し、
取得した前記処理時間に基づき、前記複数のモデルのすべての前記処理時間の和に対する前記複数のモデルのそれぞれの当該処理時間の値をハードウェアコストと定義し、
前記複数のハイブリッドモデル候補を作成する際、
前記複数のハイブリッドモデル候補それぞれの機械学習モデルの損失関数に、当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれのハードウェアコストを加味した正則化項を追加する、
請求項9~11のいずれか1項に記載のハイブリッドモデル作成方法。 - さらに、前記複数のハイブリッドモデル候補を作成するために選択された複数のモデルのそれぞれにおいて、前記入力されるデータとして、検証用データセットのうち不良品を示す複数のデータを入力してカテゴリを推定させることで得た出力値の分布に基づいて、閾値を変動させたときの見逃し率の表であるFAR表を作成し、
前記複数のハイブリッドモデル候補を比較する際、
当該ハイブリッドモデル候補を構成するために選択された前記2つ以上のモデルのそれぞれに、検証用データセットに含まれるデータサンプルを入力してカテゴリを推定させることで得た出力値と、前記FAR表とを照合することで、前記データサンプルに対する前記2つ以上のモデルのそれぞれの第1FAR値を取得し、
取得した前記2つ以上のモデルのそれぞれの第1FAR値を乗算することで、前記ハイブリッドモデル候補の第2FAR値を取得し、
前記第2FAR値が事前に設定された閾値より小さい場合に、前記データサンプルが良品であるとの判定結果を、複数のハイブリッドモデル候補それぞれに出力させた判定結果として取得して、比較する、
請求項2に記載のハイブリッドモデル作成方法。 - さらに、前記複数のハイブリッドモデル候補を作成するために選択された複数のモデルのそれぞれにおいて、複数の検証用データセットを入力してカテゴリを推定させることで前記選択された複数のモデルそれぞれの推定結果を取得し、
前記推定結果を用いて、前記選択された複数のモデルのうち2つのモデルの組み合わせすべての相関係数を算出し、
前記第2FAR値を取得する際、
取得した前記2つ以上のモデルのそれぞれの第1FAR値を乗算して、さらに、前記相関係数が大きいほど小さくなる係数を乗算することで、前記第2FAR値を取得する、
請求項13に記載のハイブリッドモデル作成方法。 - 入力されるデータのカテゴリを推定する複数のモデルをプールするモデルプール部と、
前記複数のモデルの少なくとも一つのモデルは、機械学習されたモデルであり、プールされている複数のモデルから2つ以上のモデルを選択するモデル選択部と、
選択された前記2つ以上のモデルを組み合わせることで、前記カテゴリを判定するハイブリッドモデル候補を複数作成し、複数の前記ハイブリッドモデル候補を比較するハイブリッドモデル候補作成部と、
前記複数のハイブリッドモデル候補のうちの1つをハイブリッドモデルとして選択するハイブリッド選択部とを備える、
ハイブリッドモデル作成装置。 - 入力されるデータのカテゴリを推定する複数のモデルをプールし、
前記複数のモデルの少なくとも一つのモデルは、機械学習されたモデルであり、
プールされている複数のモデルから2つ以上のモデルを選択して組み合わせることで、前記カテゴリを判定するハイブリッドモデル候補を複数作成し、
複数の前記ハイブリッドモデル候補を比較することで、前記複数のハイブリッドモデル候補のうちの1つをハイブリッドモデルとして選択することを、
コンピュータに実行させるプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023512942A JPWO2022215559A1 (ja) | 2021-04-05 | 2022-03-25 | |
| US18/283,411 US20240160196A1 (en) | 2021-04-05 | 2022-03-25 | Hybrid model creation method, hybrid model creation device, and recording medium |
| CN202280019081.2A CN116917910A (zh) | 2021-04-05 | 2022-03-25 | 混合模型制作方法、混合模型制作装置以及程序 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163171016P | 2021-04-05 | 2021-04-05 | |
| US63/171,016 | 2021-04-05 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022215559A1 true WO2022215559A1 (ja) | 2022-10-13 |
Family
ID=83545406
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/014692 WO2022215559A1 (ja) | 2021-04-05 | 2022-03-25 | ハイブリッドモデル作成方法、ハイブリッドモデル作成装置、及び、プログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240160196A1 (ja) |
| JP (1) | JPWO2022215559A1 (ja) |
| CN (1) | CN116917910A (ja) |
| WO (1) | WO2022215559A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116822253A (zh) * | 2023-08-29 | 2023-09-29 | 山东省计算中心(国家超级计算济南中心) | 适用于masnum海浪模式的混合精度实现方法及系统 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019015654A (ja) * | 2017-07-10 | 2019-01-31 | ファナック株式会社 | 機械学習装置、検査装置及び機械学習方法 |
| CN112085205A (zh) * | 2019-06-14 | 2020-12-15 | 第四范式(北京)技术有限公司 | 用于自动训练机器学习模型的方法和系统 |
| JP6801149B1 (ja) * | 2020-01-20 | 2020-12-16 | 楽天株式会社 | 情報処理装置、情報処理方法およびプログラム |
| KR102211852B1 (ko) * | 2020-03-20 | 2021-02-03 | 주식회사 루닛 | 데이터의 특징점을 취합하여 기계 학습하는 방법 및 장치 |
| US20210081725A1 (en) * | 2018-08-07 | 2021-03-18 | Advanced New Technologies Co., Ltd. | Method, apparatus, server, and user terminal for constructing data processing model |
-
2022
- 2022-03-25 WO PCT/JP2022/014692 patent/WO2022215559A1/ja active Application Filing
- 2022-03-25 US US18/283,411 patent/US20240160196A1/en active Pending
- 2022-03-25 CN CN202280019081.2A patent/CN116917910A/zh active Pending
- 2022-03-25 JP JP2023512942A patent/JPWO2022215559A1/ja active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019015654A (ja) * | 2017-07-10 | 2019-01-31 | ファナック株式会社 | 機械学習装置、検査装置及び機械学習方法 |
| US20210081725A1 (en) * | 2018-08-07 | 2021-03-18 | Advanced New Technologies Co., Ltd. | Method, apparatus, server, and user terminal for constructing data processing model |
| CN112085205A (zh) * | 2019-06-14 | 2020-12-15 | 第四范式(北京)技术有限公司 | 用于自动训练机器学习模型的方法和系统 |
| JP6801149B1 (ja) * | 2020-01-20 | 2020-12-16 | 楽天株式会社 | 情報処理装置、情報処理方法およびプログラム |
| KR102211852B1 (ko) * | 2020-03-20 | 2021-02-03 | 주식회사 루닛 | 데이터의 특징점을 취합하여 기계 학습하는 방법 및 장치 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116822253A (zh) * | 2023-08-29 | 2023-09-29 | 山东省计算中心(国家超级计算济南中心) | 适用于masnum海浪模式的混合精度实现方法及系统 |
| CN116822253B (zh) * | 2023-08-29 | 2023-12-08 | 山东省计算中心(国家超级计算济南中心) | 适用于masnum海浪模式的混合精度实现方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240160196A1 (en) | 2024-05-16 |
| CN116917910A (zh) | 2023-10-20 |
| JPWO2022215559A1 (ja) | 2022-10-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US6636862B2 (en) | Method and system for the dynamic analysis of data | |
| US20190087737A1 (en) | Anomaly detection and automated analysis in systems based on fully masked weighted directed | |
| JP4627674B2 (ja) | データ処理方法及びプログラム | |
| Liquet et al. | Bayesian variable selection regression of multivariate responses for group data | |
| US20110029469A1 (en) | Information processing apparatus, information processing method and program | |
| US10394631B2 (en) | Anomaly detection and automated analysis using weighted directed graphs | |
| JP7028322B2 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| US20190311258A1 (en) | Data dependent model initialization | |
| CN111834010A (zh) | 一种基于属性约简和XGBoost的COVID-19检测假阴性识别方法 | |
| US20200334557A1 (en) | Chained influence scores for improving synthetic data generation | |
| US11748600B2 (en) | Quantization parameter optimization method and quantization parameter optimization device | |
| WO2022215559A1 (ja) | ハイブリッドモデル作成方法、ハイブリッドモデル作成装置、及び、プログラム | |
| WO2007020466A2 (en) | Data classification apparatus and method | |
| CN114169460A (zh) | 样本筛选方法、装置、计算机设备和存储介质 | |
| US20210248293A1 (en) | Optimization device and optimization method | |
| CN112801231A (zh) | 用于业务对象分类的决策模型训练方法和装置 | |
| CN114830137A (zh) | 用于生成预测模型的方法和系统 | |
| US20230214668A1 (en) | Hyperparameter adjustment device, non-transitory recording medium in which hyperparameter adjustment program is recorded, and hyperparameter adjustment program | |
| CN111026661B (zh) | 一种软件易用性全面测试方法及系统 | |
| CN114386580A (zh) | 决策模型训练、决策方法、装置、电子设备及存储介质 | |
| Mbaluka et al. | Application of principal component analysis and hierarchical regression model on Kenya macroeconomic indicators | |
| de Almeida et al. | Multiple objective particle swarm for classification-rule discovery | |
| US20230206054A1 (en) | Expedited Assessment and Ranking of Model Quality in Machine Learning | |
| US20220237459A1 (en) | Generation method, computer-readable recording medium storing generation program, and information processing apparatus | |
| US20220215272A1 (en) | Deterioration detection method, computer-readable recording medium storing deterioration detection program, and information processing apparatus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22784544 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2023512942 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280019081.2 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18283411 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22784544 Country of ref document: EP Kind code of ref document: A1 |