WO2022195819A1 - 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法および記録媒体 - Google Patents
特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法および記録媒体 Download PDFInfo
- Publication number
- WO2022195819A1 WO2022195819A1 PCT/JP2021/011192 JP2021011192W WO2022195819A1 WO 2022195819 A1 WO2022195819 A1 WO 2022195819A1 JP 2021011192 W JP2021011192 W JP 2021011192W WO 2022195819 A1 WO2022195819 A1 WO 2022195819A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- feature amount
- feature
- conversion
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/18—Eye characteristics, e.g. of the iris
- G06V40/193—Preprocessing; Feature extraction
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/7715—Feature extraction, e.g. by transforming the feature space, e.g. multi-dimensional scaling [MDS]; Mappings, e.g. subspace methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/776—Validation; Performance evaluation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/18—Eye characteristics, e.g. of the iris
- G06V40/197—Matching; Classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4053—Scaling of whole images or parts thereof, e.g. expanding or contracting based on super-resolution, i.e. the output image resolution being higher than the sensor resolution
Definitions
- This disclosure relates to a feature conversion learning device, an authentication device, a feature conversion learning method, an authentication method, and a recording medium.
- Super-Resolution A technique for converting an image into an image with higher resolution than the original image is called Super-Resolution (see, for example, Patent Document 1).
- An example of the purpose of this disclosure is to provide a feature conversion learning device, an authentication device, a feature conversion learning method, an authentication method, and a recording medium that can solve the above problems.
- a feature conversion learning device includes image acquisition means for acquiring a first image, and reducing the first image to a second image having a resolution lower than that of the first image.
- image reduction means for enlarging the second image to a third image having the same resolution as the first image; a first feature amount that is a feature amount of the first image;
- Feature quantity extraction means for extracting a second feature quantity which is a feature quantity;
- Feature quantity conversion means for converting the second feature quantity into a third feature quantity; and Comparison between the first feature quantity and the third feature quantity.
- learning control means for causing the feature quantity conversion means to learn a feature quantity conversion method based on the result.
- an authentication device includes authentication target image acquisition means for acquiring an authentication target image, image enlargement means for enlarging the authentication target image, and a feature amount of the enlarged image of the authentication target image. is extracted by the same method as the feature extraction method for a comparison image having a resolution higher than that of the authentication target image, a feature after conversion from the feature of the learning image, and the learning image Based on the learning result of the feature amount conversion method using a loss function whose value decreases as the difference from the feature amount of the degraded image that is enlarged after being reduced is smaller, the feature amount of the enlarged image of the authentication target image and feature quantity comparison means for comparing the feature quantity after conversion by the feature quantity conversion means with the feature quantity of the comparison image.
- a feature conversion learning method includes acquiring a first image, and reducing the first image to a second image having a resolution lower than that of the first image. , enlarging the second image to a third image having the same resolution as that of the first image; extracting a feature quantity; converting the second feature quantity to a third feature quantity; and learning a feature quantity conversion method for converting into three feature quantities.
- an authentication method includes acquiring an authentication target image, enlarging the authentication target image, and calculating a feature amount of the enlarged image of the authentication target image as the authentication target image.
- the feature amount after conversion from the feature amount of the learning image, and the deterioration that is enlarged after the learning image is reduced converting the feature quantity of an enlarged image of the authentication target image based on the learning result of the feature quantity conversion method using a loss function whose value decreases as the difference from the feature quantity of the image decreases; Comparing the feature amount after conversion from the feature amount of the enlarged image of the image with the feature amount of the comparison image.
- the recording medium instructs the computer to acquire a first image and reduce the first image to a second image having a lower resolution than the first image. , enlarging the second image to a third image having the same resolution as that of the first image; extracting a feature quantity; converting the second feature quantity to a third feature quantity; It is a recording medium for recording a program for executing learning of a feature amount conversion method for converting into three feature amounts.
- a recording medium acquires an authentication target image, enlarges the authentication target image, and converts the feature amount of the enlarged image of the authentication target image into the authentication target image.
- the feature amount after conversion from the feature amount of the learning image, and the deterioration that is enlarged after the learning image is reduced converting the feature quantity of an enlarged image of the authentication target image based on the learning result of the feature quantity conversion method using a loss function whose value decreases as the difference from the feature quantity of the image decreases;
- FIG. 10 is a diagram showing an example of a processing procedure for learning a feature quantity conversion unit by the feature quantity conversion learning device according to the second embodiment;
- FIG. 10 is a diagram showing an example of a processing procedure for calculating a loss by the feature conversion learning device according to the second embodiment;
- FIG. 11 is a diagram showing a configuration example of an attention block 302 according to a first modified example of the attention processing unit according to the third embodiment
- FIG. FIG. 14 is a diagram showing a configuration example of an attention processing unit 303 according to a second modification of the attention processing unit according to the third embodiment
- FIG. 13 is a diagram showing a configuration example of an attention processing unit 304 according to a second modification of the attention processing unit according to the third embodiment
- FIG. 14 is a diagram showing a configuration example of a feature quantity extraction unit according to a modification of the feature quantity extraction unit in the fourth embodiment
- FIG. 11 is a diagram showing a configuration example of an attention block 302 according to a first modified example of the attention processing unit according to the third embodiment
- FIG. 14 is a diagram showing a configuration example of an attention processing unit 303 according to a second modification of the attention processing unit according to the third embodiment
- FIG. 13 is a diagram showing a configuration example of an attention processing unit 304 according to a second modification of the attention processing unit according
- FIG. 11 is a diagram showing an example of a hierarchical structure of neural networks forming a feature amount extraction unit according to the fourth embodiment; It is a figure which shows the structural example of the authentication apparatus which concerns on 5th Embodiment.
- FIG. 21 is a diagram illustrating a configuration example of a feature conversion learning device according to a sixth embodiment;
- FIG. 21 is a diagram illustrating a configuration example of an authentication device according to a seventh embodiment;
- FIG. 21 is a diagram illustrating a configuration example of a feature conversion learning device according to an eighth embodiment;
- FIG. 21 is a diagram illustrating a configuration example of an authentication device according to a ninth embodiment;
- FIG. 14 is a diagram showing a configuration example of a feature conversion learning device according to a tenth embodiment;
- FIG. 22 is a diagram illustrating a configuration example of an authentication device according to an eleventh embodiment
- FIG. 22 is a diagram showing a configuration example of a feature conversion learning device according to a twelfth embodiment
- FIG. 22 is a diagram showing a configuration example of a feature conversion learning device according to a thirteenth embodiment
- FIG. 14 is a diagram showing a configuration example of an authentication device according to a fourteenth embodiment
- FIG. 16 is a flow chart showing an example of a processing procedure in a feature quantity conversion learning method according to the fifteenth embodiment
- FIG. FIG. 22 is a flow chart showing an example of a procedure of processing in an authentication method according to the sixteenth embodiment
- FIG. 1 is a schematic block diagram showing a configuration of a computer according to at least one embodiment
- FIG. 1 is a diagram showing a configuration example of an authentication device according to the first embodiment.
- the authentication apparatus 100 includes an authentication target image acquisition unit 101, a comparison image acquisition unit 102, an image enlargement unit 103, a feature amount extraction unit 104, a feature amount conversion unit 105, a feature amount and a comparison unit 106 .
- the authentication device 100 extracts the feature amount of the image and performs authentication using the extracted feature amount.
- a case in which the authentication device 100 performs iris authentication using a low-resolution image will be described below as an example.
- the authentication performed by authentication device 100 is not limited to iris authentication. It is assumed that the resolutions of two images are compared in a state where the sizes of the images are the same.
- the authentication target image acquisition unit 101 acquires a photographed image of the eyes of the authentication target, which is the authentication target image.
- the authentication target image acquisition unit 101 corresponds to an example of authentication target image acquisition means.
- the comparison image acquisition unit 102 acquires a comparison image to be compared with the authentication target image.
- a comparison image may be registered in the authentication device 100 in advance.
- the authentication target image has a lower resolution than the comparison image.
- the image to be authenticated may be an image of the eye portion of the image of the entire face of the person to be authenticated.
- the comparison image may be an image obtained by photographing only the eye portion for iris authentication. In this way, if iris authentication can be performed using the image of the eye part of the image of the entire face, it will be possible to perform both face authentication and iris authentication to improve authentication accuracy. .
- the image enlarger 103 enlarges the authentication target image, which is a low-resolution image.
- the image enlarging unit 103 corresponds to an example of image enlarging means.
- the enlarged authentication target image is also called an enlarged image of the authentication target image or simply an enlarged image.
- the feature quantity extraction unit 104 extracts the feature quantity of the authentication target image by the same method as the feature quantity extraction method for the comparison image.
- the feature quantity extraction unit 104 extracts the feature quantity of the enlarged authentication target image and the feature quantity of the comparison image.
- the feature quantity extraction unit 104 applies the same algorithm to the enlarged authentication target image and the comparison image to extract respective feature quantities.
- the authentication device 100 may include two identical feature quantity extraction units 104 .
- one feature amount extraction unit 104 may extract the feature amount of the enlarged authentication target image and the feature amount of the comparison image by, for example, time-division processing.
- the feature amount of the comparison image may be registered in the authentication device 100 in advance, such as the feature amount extraction unit 104 extracting the feature amount of the comparison image in advance.
- the feature amount extraction unit 104 corresponds to an example of feature amount extraction means.
- the feature quantity conversion unit 105 converts the feature quantity of the enlarged authentication target image.
- the feature quantity conversion unit 105 converts the feature quantity so as to reduce the difference between the feature quantity of the enlarged authentication target image and the high-resolution feature quantity.
- the feature amount conversion unit 105 corresponds to an example of feature amount conversion means.
- the conversion of the feature amount by the feature amount conversion unit 105 is also called feature super-resolution.
- the feature amount after conversion by the feature amount conversion unit 105 is also called a super-resolution feature amount.
- the feature amount conversion unit 105 converts the feature amount by learning using a loss function that decreases as the difference between the feature amount of the learning image and the feature amount of the degraded image that is enlarged after the learning image is reduced decreases. Learn how to convert.
- the feature amount comparison unit 106 compares the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the comparison image, and determines, for example, whether the person in the authentication target image and the person in the comparison image are the same person. It is determined whether or not there is
- the feature amount comparison unit 106 corresponds to an example of feature amount comparison means.
- FIG. 2 is a flowchart showing an example of a procedure for iris authentication performed by the authentication device 100 .
- the authentication target image acquisition unit 101 acquires an authentication target image (step S111).
- the image enlarging unit 103 interpolates the pixels of the authentication target image to enlarge the authentication target image so that the authentication target image, which is a low-resolution image, has the same resolution as the high-resolution image for comparison.
- An algorithm for enlarging an image by the image enlarging unit 103 is not limited to a specific algorithm.
- the image enlargement unit 103 may enlarge the image using a bicubic method or a bilinear method, but the invention is not limited to these.
- An image enlarged by the image enlarger 103 is also referred to as an enlarged image.
- the feature quantity extraction unit 104 extracts the feature quantity of the enlarged image (step S113).
- the feature amount extraction unit 104 may be a feature extractor that has been trained for authentication using high-resolution images, but is not limited to this.
- the feature quantity extraction unit 104 may be configured using a trained model by a deep neural network (DNN) such as VGG or ResNet (Residual Network).
- DNN deep neural network
- the feature quantity extraction unit 104 may output the feature quantity in the form of a one-dimensional vector.
- the feature amount extraction unit 104 may output the feature amount in the form of a two-dimensional or three-dimensional tensor that maintains the image information.
- the feature quantity conversion unit 105 converts the feature quantity of the enlarged image (step S114).
- a feature quantity conversion unit 105 converts the feature quantity of the enlarged image so that it can be compared with the feature quantity of the high-resolution image.
- the comparison image acquisition unit 102 acquires a comparison image (step S121). Then, the feature quantity extraction unit 104 extracts the feature quantity of the comparison image (step S122). As described above, the feature amount extraction unit 104 extracts the feature amount of the comparison image using the same algorithm as that used for extracting the feature amount of the enlarged image. Steps S111 to S114 and steps S121 to S122 may be executed in parallel. Alternatively, the processing from steps S121 to S122 may be performed in advance, and the authentication device 100 may store the feature amount of the comparison image.
- the feature quantity comparison unit 106 compares the feature quantity of the enlarged image and the feature quantity of the comparison image (step S131). For example, the feature quantity comparison unit 106 calculates the degree of similarity between the feature quantity of the enlarged image and the feature quantity of the comparison image. is the same person.
- the similarity calculation method used by the feature amount comparison unit 106 can be various methods that can calculate the similarity of vectors or tensors, and is not limited to a specific method. For example, the feature quantity comparison unit 106 may calculate the L2 distance or cosine similarity between the feature quantity of the enlarged image and the feature quantity of the comparison image.
- the authentication target image acquisition unit 101 acquires the authentication target image.
- the image enlarger 103 enlarges the authentication target image.
- the feature quantity extraction unit 104 extracts the feature quantity of the enlarged image of the authentication target image by the same method as the feature quantity extraction method for the comparison image having a resolution higher than that of the authentication target image.
- the feature amount conversion unit 105 performs authentication based on learning using a loss function that becomes smaller as the difference between the feature amount of the learning image and the feature amount of the degraded image that is enlarged after the learning image is reduced is smaller. Convert the feature amount of the enlarged image of the target image.
- the feature amount comparison unit 106 compares the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the comparison image.
- the authentication apparatus 100 by enlarging a low-resolution image to extract a feature amount and generating a super-resolution feature amount, the feature amount of the authentication target image, which is a low-resolution image, is compared with a high-resolution image. A feature quantity that can be compared with the feature quantity of the original image can be obtained. In this respect, the authentication device 100 can perform authentication even if the input image is a low-resolution image.
- the feature amount of the enlarged authentication target image is expected to approach the feature amount when the authentication target image is photographed at a higher resolution.
- the authentication device 100 is expected to perform authentication with high accuracy.
- iris authentication can be performed using a low-resolution image.
- authentication apparatus 100 can perform both face authentication and iris authentication using a single face image without requiring a high-resolution camera, and is expected to improve authentication accuracy.
- FIG. 3 is a diagram showing a configuration example of a feature conversion learning device according to the second embodiment.
- the feature conversion learning device 200 includes an image batch acquisition unit 201, an image reduction unit 202, an image enlargement unit 103, a feature extraction unit 104, a feature conversion unit 105, a loss function A calculation unit 203 and a learning control unit 208 are provided.
- the loss function calculator 203 includes a reconstruction loss calculator 204 , a feature determiner 205 , an adversarial loss calculator 206 , and a similarity loss calculator 207 . 3, the same reference numerals (103, 104, 105) are given to the parts having the same functions as those in FIG.
- the feature quantity conversion learning device 200 learns the feature quantity conversion unit 105 .
- the feature quantity conversion unit 105 after learning can be used in the authentication device 100 .
- a model having parameters to be adjusted by learning is called a machine learning model.
- a parameter of the machine learning model is called a machine learning model parameter, and a parameter value of the machine learning model is called a machine learning model parameter value.
- Tuning machine learning model parameter values corresponds to learning.
- a case in which the machine learning model of the feature quantity conversion unit 105 is configured using a neural network will be described below as an example. However, the configuration of the machine learning model of feature quantity conversion unit 105 is not limited to a specific one.
- the feature-value conversion learning apparatus 200 uses a loss function for learning is demonstrated as an example.
- the feature quantity conversion learning device 200 performs learning so that the loss function value becomes small.
- the feature conversion learning device 200 may perform learning using an evaluation function in which the higher the evaluation, the larger the function value. In this case, the feature quantity conversion learning device 200 performs learning so that the evaluation function value increases.
- the image batch acquisition unit 201 acquires a training data set used for learning of the feature quantity conversion unit 105 .
- the training data acquired by the image batch acquisition unit 201 includes a plurality of combinations of captured images of human eyes and class labels indicating correct classes in class classification of the images.
- a training data set is also simply referred to as training data.
- Each combination of one image and one class label in the training dataset is also referred to as a labeled image.
- images acquired by the image batch acquisition unit 201 are also referred to as high-resolution images.
- the image batch acquisition unit 201 corresponds to an example of image acquisition means.
- the high-resolution image acquired by the image batch acquisition unit 201 corresponds to an example of the first image.
- An image reduction unit 202 reduces the high-resolution image. Pixels are thinned out by image reduction performed by the image reduction unit 202, and the resolution becomes lower than that of the high-resolution image. An image that has been reduced by the image reduction unit 202 is referred to as a reduced image.
- the image reduction unit 202 may reduce the image by randomly determining the size or reduction ratio of the reduced image using random numbers.
- the image reduction unit 202 corresponds to an example of image reduction means.
- a reduced image corresponds to an example of the second image.
- the image enlargement unit 103 enlarges the image by the reduction ratio at which the image reduction unit 202 has reduced the image.
- the image enlarging unit 103 enlarges the reduced image by interpolating the pixels of the reduced image so that the enlarged image of the reduced image, which is a low-resolution image, has the same resolution as the high-resolution image.
- An image obtained by enlarging a reduced image by the image enlarging unit 103 is also called a degraded image.
- the image enlarging unit 103 corresponds to an example of image enlarging means.
- a degraded image corresponds to an example of the third image.
- the feature quantity extraction unit 104 extracts the feature quantity of the high-resolution image and the feature quantity of the degraded image using the same algorithm.
- the feature quantity extraction unit 104 corresponds to an example of feature quantity extraction means.
- the feature quantity conversion unit 105 converts the feature quantity of the degraded image.
- the feature quantity conversion unit 105 converts the feature quantity of the degraded image so as to approximate the feature quantity of the high-resolution image.
- the feature amount after conversion by the feature amount conversion unit 105 is also called a super-resolution feature amount.
- the feature quantity conversion unit 105 corresponds to an example of feature quantity conversion means.
- a loss function calculation unit 203 calculates a loss function for learning of the feature quantity conversion unit 105 .
- the loss function calculator 203 corresponds to an example of loss function calculator.
- a reconstruction loss calculator 204 calculates a reconstruction loss.
- the reconstruction loss is a loss whose value decreases as the similarity between the feature amount of the high-resolution image and the super-resolution feature amount as a vector or tensor increases.
- the reconstruction loss corresponds to an example of the index value of the similarity between the feature amount of the high-resolution image and the super-resolution feature amount of the loss function calculation unit 203 .
- a total loss function using reconstruction loss as one of variables corresponds to an example of a loss function in which the loss decreases as the feature amount of the high-resolution image and the super-resolution feature amount are similar.
- a feature discrimination unit 205 discriminates between the feature amount of the high-resolution image and the super-resolution feature amount. Specifically, the feature determination unit 205 receives input of the feature amount, and determines whether the input feature amount is the feature amount of the high-resolution image or the super-resolution feature amount.
- the feature discrimination unit 205 is also configured to be able to learn. For example, the machine learning model of the feature discrimination section 205 may be constructed using a neural network.
- the feature determination unit 205 corresponds to an example of feature determination means.
- the hostile loss calculation unit 206 calculates the loss for learning of the feature amount conversion unit 105 and the loss for learning of the feature determination unit 205 based on the determination result (determination result) of the feature determination unit 205 .
- a loss for learning of the feature quantity conversion unit 105 is also referred to as a loss of the feature quantity conversion unit 105 .
- the loss for learning of the feature discriminator 205 is also referred to as the loss of the feature discriminator 205 . Learning by the feature quantity conversion unit 105 and learning by the feature discrimination unit 205 are alternately performed in one batch of learning under the control of the learning control unit 208 .
- the adversarial loss calculation unit 206 calculates the adversarial loss.
- the hostile loss referred to here is a loss whose value decreases when the feature determination unit 205 erroneously determines that the super-resolution feature amount is the feature amount of the high-resolution image.
- the total loss function that uses the hostile loss as one of the variables is a loss function that reduces the loss when the feature determination unit 205 cannot distinguish between the feature amount converted by the feature amount conversion unit 105 and other feature amounts. corresponds to the example.
- the hostile loss calculation unit 206 calculates a loss that becomes small when the feature discrimination unit 205 correctly discriminates between the super-resolution feature quantity and the feature quantity of the high-resolution image. .
- the similarity loss calculation unit 207 calculates similarity loss.
- the similarity loss is a loss whose value decreases when the class of the classification result matches the correct class in class classification using the super-resolution feature amount.
- a total loss function that uses similarity loss as one of the variables corresponds to an example of a loss function that reduces loss when a class obtained by class classification based on super-resolution feature values matches a correct class.
- the learning control unit 208 uses the loss calculated by the loss function calculation unit 203 to update the machine learning model parameter values of the feature quantity conversion unit 105 and the feature discrimination unit 205 respectively.
- the learning control unit 208 corresponds to an example of learning control means.
- the learning control unit 208 uses the loss calculated by the loss function calculation unit 203 to adjust the machine learning model parameter values converted into feature amounts by the feature amount conversion unit 105 .
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on the loss function. Updating the machine learning model parameter values of the feature quantity conversion unit 105 corresponds to learning of the feature quantity conversion unit 105 . Updating the machine learning model parameter values of the feature determination unit 205 corresponds to learning of the feature determination unit 205 .
- FIG. 4 is a diagram showing an example of a processing procedure for the feature quantity conversion learning device 200 to learn the feature quantity conversion unit 105.
- the image batch acquisition unit 201 acquires a training data set including a plurality of combinations of high-resolution images captured by the human eye and class labels indicating correct classes of the high-resolution images (step S211). As described above, each combination of one high-resolution image and one class label included in the training data set is also referred to as a labeled image.
- the image batch acquisition unit 201 acquires batch data from the training data set (step S212). For example, the image batch acquisition unit 201 randomly selects a predetermined batch size of labeled images from the labeled images included in the training data set.
- the batch data acquired by the image batch acquisition unit 201 is also referred to as image batch data.
- the batch size of the image batch data acquired by the image batch acquisition unit 201 is not limited to a specific size.
- the image batch acquisition unit 201 may acquire a training data set including 128 labeled images, but is not limited to this.
- the feature conversion learning device 200 starts a loop L11 for processing each labeled image included in the image batch data (step S213).
- the feature conversion learning apparatus 200 may execute the processing of the loop L11 in parallel or sequentially.
- the image reduction unit 202 reduces the high-resolution image of the labeled image (step S221).
- the image reduction unit 202 may randomly determine the size of the reduced image and reduce the image.
- the image reduction unit 202 reduces the image by thinning out the pixels of the image. Therefore, the resolution of the image is reduced by the reduction of the image by the image reduction unit 202 .
- a reduced image corresponds to a low-resolution image.
- the image enlargement unit 103 enlarges the reduced image (step S222).
- An image obtained by enlarging a reduced image by the image enlarging unit 103 is also called a degraded image.
- the image enlargement unit 103 enlarges the reduced image by interpolating the pixels of the reduced image so that the degraded image has the same resolution as the high-resolution image.
- the feature quantity extraction unit 104 extracts the feature quantity of the degraded image (step S223).
- the feature quantity conversion unit 105 converts the feature quantity of the degraded image (step S224).
- the feature amount after conversion by the feature amount conversion unit 105 is also called a super-resolution feature amount.
- the feature quantity extraction unit 104 extracts the feature quantity of the high-resolution image of the labeled image (step S231). Steps S221 to S224 and step S231 may be executed in parallel.
- the feature quantity conversion learning device 200 performs termination processing of loop L11 (step S241). Specifically, the feature conversion learning apparatus 200 waits for completion of the processing of loop L11 for all labeled images included in the learning batch. When the feature conversion learning device 200 detects that the processing of loop L11 has been completed for all labeled images included in the learning batch, loop L11 ends.
- the feature quantity conversion learning device 200 calculates a loss for learning of the feature quantity conversion unit 105 (step S242).
- the feature conversion learning device 200 calculates one total loss function value based on the results of the loop L11 processing for all labeled images included in the image batch data.
- FIG. 5 is a diagram showing an example of a processing procedure for the feature conversion learning device 200 to calculate the loss.
- the feature conversion learning device 200 performs the process of FIG. 5 in step S242 of FIG.
- the feature determination unit 205 outputs a vector for determining (determining) whether the input feature amount is a super-resolution feature amount or a high-resolution image feature amount (step S251).
- the feature determination unit 205 may calculate the probability that the input feature amount is the feature amount of the high-resolution image, and output a vector containing the probability as an element. This probability takes a real value from 0 to 1. For example, the closer to 1, the higher the possibility that it is a feature quantity of a high-resolution image, and the closer to 0, the higher the possibility that it is a super-resolution feature quantity. As shown, the type of input image can be determined.
- the hostile loss calculation unit 206 calculates the loss using the vector output by the feature determination unit 205 (step S252).
- the feature amount conversion unit 105 and the feature discrimination unit 205 have a structure of a Generative Adversarial Network (GAN), and the adversarial loss calculation unit 206 calculates the adversarial loss using the vector output by the feature discrimination unit 205. do.
- the adversarial loss referred to here is a loss whose value decreases when the discriminator makes an erroneous determination.
- the hostile loss calculation unit 206 uses a loss function that reduces the hostile loss when the feature determination unit 205 erroneously determines the super-resolution feature amount as the feature amount of the high-resolution image, Compute adversarial losses.
- the learning control unit 208 adjusts the machine learning model parameter values of the feature amount conversion unit 105 so that the hostile loss calculated by the hostile loss calculation unit 206 becomes small.
- the feature quantity conversion unit 105 generates a super-resolution feature quantity so as to deceive the feature determination unit 205 .
- the feature amount transforming unit 105 may learn using the cross entropy loss so that the hostile loss calculating unit 206 outputs 1 when the super-resolution feature is input.
- the adversarial loss calculating unit 206 determines that the feature discriminating unit 205 correctly discriminates between the super-resolution feature amount and the feature amount of the high-resolution image. Calculate the loss using a loss function that reduces the loss when The learning control unit 208 adjusts the machine learning model parameter values of the feature determination unit 205 so that the loss calculated by the adversarial loss calculation unit 206 becomes small. Therefore, the feature discrimination unit 205 is adjusted so that the feature discrimination unit 205 can correctly discriminate between the super-resolution feature quantity and the feature quantity of the high-resolution image.
- the feature discrimination unit 205 may output the discrimination result as a real number having a value range from 0 to 1.
- the feature determination unit 205 may output the probability that the input feature amount is the feature amount of the high-resolution image.
- the hostile loss calculation unit 206 outputs 1 when the feature amount of the high-resolution image is input, and outputs 0 when the feature amount of the super-resolution image is input. (Binary Cross Entropy) may be used for calculation.
- the learning control unit 208 determines that the input to the feature discrimination unit 205 is the super-resolution feature amount. In this case, the machine learning model parameter value of the feature amount conversion unit 105 is adjusted so that the output of the feature determination unit 205 approaches 1. Thereby, the feature quantity conversion unit 105 generates a super-resolution feature quantity so as to deceive the feature determination unit 205 .
- the learning control unit 208 causes the output of the feature determination unit 205 to approach 0, and the input to the feature determination unit 205 is the feature amount of the high-resolution image.
- the machine learning model parameter value of the feature determination unit 205 is adjusted so that the output of the feature determination unit 205 approaches 1. That is, the feature determination unit 205 is adjusted so as to increase the possibility of correctly determining the super-resolution feature amount and the feature amount of the high-resolution image.
- the reconstruction loss calculation unit 204 calculates a reconstruction loss that decreases as the similarity between the super-resolution feature quantity and the feature quantity of the high-resolution image as a vector or tensor increases (step S261).
- the learning control unit 208 adjusts the machine learning model parameter values of the feature quantity conversion unit 105 so as to reduce the reconstruction loss. Thereby, the learning control unit 208 adjusts the machine learning model parameter values of the feature quantity conversion unit 105 so that the super-resolution feature quantity approaches the feature quantity of the high-resolution image.
- the index value calculated by the reconstruction loss calculation unit 204 and indicating the degree of similarity as a vector or tensor between the super-resolution feature quantity and the feature quantity of the high-resolution image is not limited to a specific one.
- the reconstruction loss calculation unit 204 may calculate the reconstruction loss such that the smaller the super-resolution feature quantity, the feature quantity of the high-resolution image, and the L2 distance, the smaller the reconstruction loss.
- the reconstruction loss calculator 204 may calculate the reconstruction loss using the L1 distance instead of the L2 distance.
- the similarity loss calculation unit 207 calculates similarity loss using class labels.
- the similarity loss calculated by the similarity loss calculation unit 207 can be various losses that decrease in value when the class classification result using the super-resolution feature value matches the correct answer, and is not limited to a specific one. .
- one learnable linear layer (linear layer) is added after the super-resolution feature amount output layer of the feature amount conversion unit 105, and the output of the linear layer is the same number of one-hot vectors as the number of classes ( One-hot Vector).
- the learning control unit 208 causes the linear layer to learn so that the linear layer performs class estimation based on the super-resolution feature amount.
- the one-hot vector output by the linear layer indicates the class of the estimation result.
- the similarity loss calculation unit 207 inputs each element of the one-hot vector output by the linear layer to the softmax function, and calculates the similarity loss by cross entropy using the class label. good too.
- similarity loss used by the similarity loss calculation unit 207 is not limited to a specific one.
- similarity loss calculator 207 may use L2 Softmax Loss, Cosine Loss, ArcFace, CosFace, SphereFace, or AdaCos as similarity loss.
- the similarity loss calculation unit 207 uses triplet loss, center loss, or contrastive loss as the similarity loss. etc. may be used.
- Steps S251 to S252, S261, and S271 may be executed in parallel.
- the loss function calculator 203 calculates a total loss function value based on the adversarial loss, reconstruction loss and similarity loss (step S261).
- the loss function calculation unit 203 decreases the loss function value as the value of the adversarial loss decreases, decreases the value of the reconstruction loss as the value of the reconstruction loss decreases, and decreases the loss function value as the value of the similarity loss decreases.
- a loss function value is calculated using the smaller loss function. For example, the loss function calculator 203 multiplies each loss by a coefficient to calculate the total loss function. The values of these coefficients are not particularly limited.
- the loss function calculation unit 203 may calculate the loss function value using only one or two of the adversarial loss, the reconstruction loss, and the similarity loss. Alternatively, the loss function calculation unit 203 may calculate the loss function value by another method without using any of the adversarial loss, reconstruction loss, and similarity loss. After step S261, the feature conversion learning device 200 ends the processing of FIG.
- the learning control unit 208 uses the error backpropagation method to calculate the parameter gradient of the neural network of the feature amount conversion unit 105 (step S243). Then, the learning control unit 208 uses the calculated gradient to update the parameter value of the feature amount conversion unit 105 (step S244). Updating the parameter values in step S244 corresponds to learning of the feature quantity conversion unit 105.
- the learning control unit 208 optimizes the parameter values so that the loss function value is minimized.
- Examples of the optimization method used by the learning control unit 208 include Stochastic Gradient Descent (SGD) and Adam, but are not limited to these.
- the feature conversion learning device 200 calculates a loss for learning of the feature discrimination unit 205 (step S245).
- the hostile loss calculation unit 206 uses the loss function to calculate the loss.
- the learning control unit 208 uses the error backpropagation method to calculate the gradient of the parameter of the neural network of the feature discrimination unit 205 (step S246). Then, the learning control unit 208 uses the calculated gradient to update the parameter values of the feature discrimination unit 205 (step S244). Updating the parameter values in step S244 corresponds to learning of the feature determination unit 205. FIG.
- the learning control unit 208 alternately optimizes the parameter values in the feature quantity conversion unit 105 and the feature determination unit 205 .
- the learning control unit 208 fixes the parameter values of the feature determination unit 205 when optimizing the parameter values of the feature amount conversion unit 105 . Further, the learning control unit 208 fixes the parameter values of the feature amount conversion unit 105 when optimizing the parameter values of the feature determination unit 205 .
- the learning control unit 208 determines whether or not the learning termination condition is satisfied (step S248).
- the end condition of learning here is not limited to a specific condition.
- the learning control unit 208 may determine that the end condition is met when the number of repetitions of the loop from steps S212 to S248 reaches a predetermined number.
- the learning control unit 208 or the loss function calculation unit 203 controls the super-resolution feature quantity based on the evaluation data obtained during the loop. You may make it calculate the collation accuracy by. Then, the learning control unit 208 may determine that the termination condition is met when the matching accuracy based on the super-resolution feature amount is equal to or higher than a predetermined accuracy.
- step S248 determines in step S248 that the termination condition is not satisfied (step S248: NO)
- the process returns to step S212.
- the feature quantity conversion learning device 200 continues to learn the feature quantity conversion section 105 and the feature determination section 205 .
- step S248: YES determines in step S248 that the end condition is satisfied (step S248: YES)
- the feature conversion learning device 200 ends the processing of FIG.
- the image batch acquisition unit 201 acquires high-resolution images.
- An image reduction unit 202 reduces the high-resolution image to a reduced image having a resolution lower than that of the high-resolution image.
- the image enlarger 103 enlarges the reduced image to a degraded image having the same resolution as the high resolution image.
- the feature quantity extraction unit 104 extracts the feature quantity of the high-resolution image and the feature quantity of the degraded image.
- a feature amount conversion unit 105 converts the feature amount of the degraded image to generate a super-resolution feature amount.
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on the result of comparison between the feature amount of the high-resolution image and the super-resolution feature amount.
- the learning of the feature quantity conversion method here means adjusting the machine learning model parameter values for converting the feature quantity.
- the feature quantity conversion unit 105 learns so that the feature quantity of the image obtained by enlarging the reduced image approaches the feature quantity of the high-resolution image. It is expected that the authentication device 100 using the learned feature quantity conversion unit 105 can perform authentication with relatively high accuracy even when receiving an input of a low-resolution image.
- the feature determination unit 205 receives an input of the feature amount of the high-resolution image or the super-resolution feature amount, and determines whether or not the input feature amount is the super-resolution feature amount.
- the loss function calculation unit 203 calculates the feature amount conversion unit based on the loss function that reduces the loss when the feature determination unit 205 cannot distinguish between the feature amount converted by the feature amount conversion unit 105 and other feature amounts. 105 is caused to learn the feature quantity conversion method.
- the feature amount conversion unit 105 determines the feature amount of the high-resolution image so that the feature determination unit 205 fails to distinguish between the feature amount of the high-resolution image and the super-resolution feature amount. It is expected to output a similar super-resolution feature quantity. As a result, it is expected that the authentication apparatus 100 using the learned feature quantity conversion unit 105 can perform authentication with relatively high accuracy even when receiving an input of a low-resolution image.
- the loss function calculation unit 203 calculates an index value of the degree of similarity between the feature amount of the high-resolution image and the super-resolution feature amount.
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on a loss function in which loss decreases as the feature amount of the high-resolution image and the super-resolution feature amount are similar.
- the feature amount conversion unit 105 is expected to output a super-resolution feature amount similar to the feature amount of the high-resolution image. As a result, it is expected that the authentication apparatus 100 using the learned feature quantity conversion unit 105 can perform authentication with relatively high accuracy even when receiving an input of a low-resolution image.
- the learning control unit 208 instructs the feature amount conversion unit 105 to learn the feature amount conversion method based on the loss function that reduces the loss when the class by class classification based on the super-resolution feature amount matches the correct class. to do
- the authentication device 100 using the learned feature quantity conversion unit 105 can perform authentication with relatively high accuracy even when receiving an input of a low-resolution image.
- the image reduction unit 202 generates a reduced image by reducing the high-resolution image to a size determined using random numbers.
- the feature quantity conversion unit 105 is expected to be able to output a super-resolution feature quantity close to the feature quantity of a high-resolution image for an enlarged image obtained by enlarging images of various resolutions. be done. As a result, it is expected that the authentication device 100 using the learned feature quantity conversion unit 105 can perform highly accurate authentication for input images of various resolutions.
- the third embodiment a configuration example of the feature amount extraction unit 104 shown in FIGS. 1 and 3 will be described. Although it is preferable that the authentication device 100 in FIG. 1 and the feature quantity conversion learning device 200 in FIG. may include the feature amount extraction unit according to the third embodiment.
- FIG. 6 is a diagram showing a configuration example of the feature quantity extraction unit 104 according to the third embodiment.
- the feature quantity extraction unit 104 includes an attention processing unit 301 .
- attention processing units 301 are connected in series.
- the attention processing unit 301 at the head receives input of image data, and the attention processing unit 301 at the end outputs feature amounts.
- the number of attention processing units 301 included in the feature amount extraction unit 104 may be one or more.
- Attention here means emphasizing a portion of an image or a feature quantity corresponding to it. It becomes easier for the emphasized feature amount to be reflected in the authentication result.
- the attention processing unit 301 may emphasize the feature amount corresponding to the iris portion among the feature amounts extracted from the eye image by the feature amount extraction unit 104 . It is expected that the authentication accuracy of the authentication apparatus 100 is improved by the attention processing unit 301 emphasizing the feature amount corresponding to the characteristic portion of the image in this way.
- the attention processing unit 301 corresponds to an example of attention processing means.
- the feature quantity extraction unit 104 in FIG. 6 corresponds to an example of the feature quantity extraction unit 104 in FIGS. 1 and 3 .
- the feature quantity extraction unit 104 extracts feature quantities from each of the high-resolution image and the enlarged low-resolution image. It is preferable to perform learning of the feature quantity extraction unit 104 in advance using high-resolution data.
- FIG. 6 shows an example in which the feature quantity extraction unit 104 is configured using a neural network, and each of the attention processing units 301 corresponds to a layer of the neural network. Attention processing may be performed in each layer of the neural network. Alternatively, attention processing may be performed only in some layers of the neural network. Alternatively, attention processing may be performed as pre-processing or post-processing for feature quantity extraction.
- FIG. 7 is a diagram showing a configuration example of the attention processing unit 301.
- the attention processing unit 301 includes two-dimensional convolution calculation units 311 a and 311 b, a function calculation unit 312 and a multiplication unit 313 .
- the two-dimensional convolution calculation units 311a and 311b are also collectively referred to as the two-dimensional convolution calculation unit 311.
- FIG. 1 is a diagram showing a configuration example of the attention processing unit 301.
- the attention processing unit 301 includes two-dimensional convolution calculation units 311 a and 311 b, a function calculation unit 312 and a multiplication unit 313 .
- the two-dimensional convolution calculation units 311a and 311b are also collectively referred to as the two-dimensional convolution calculation unit 311.
- a two-dimensional convolution operation unit 311 performs a convolution operation on data in the form of a two-dimensional matrix.
- the two-dimensional convolution calculation unit 311a performs a convolution calculation for feature quantity extraction.
- the two-dimensional convolution calculation unit 311b performs a convolution calculation as filtering for attention on the feature amount extracted by the two-dimensional convolution calculation unit 311a.
- the function calculation unit 312 applies a predetermined function to the output of the two-dimensional convolution calculation unit 311b. For example, the function calculation unit 312 replaces the value of each element of data in the form of a two-dimensional matrix representing the calculation result of the two-dimensional convolution calculation unit 311b with a value to which a softmax function is applied. Thereby, the function calculation unit 312 calculates a weighting factor for emphasizing the portion detected by the two-dimensional convolution calculation unit 311b from the output data of the two-dimensional convolution calculation unit 311a. Application of the function by the function calculation unit 312 also corresponds to calculation of the activation function of the neural network.
- the multiplication unit 313 multiplies the output of the two-dimensional convolution operation unit 311a and the output of the function calculation unit 312 for each element of data in the form of a two-dimensional matrix. As a result, the multiplication unit 313 weights the feature amount extracted by the two-dimensional convolution operation unit 311a with the weight coefficient calculated by the function calculation unit 312.
- FIG. The attention processing unit 301 may learn a method of detecting an attention target area. Specifically, the attention processing unit 301 may learn the filter of the two-dimensional convolution operation unit 311b so as to reduce the loss calculated by the learning control unit 208. FIG.
- FIG. 8 is a diagram showing a configuration example of the attention block 302 according to the first modification of the attention processing section 301.
- the feature amount extraction unit 104 shown in FIG. 6 may include an attention block 302 instead of the attention processing unit 301 .
- the attention block 302 includes a channel separating section 321 , an attention processing section 301 and a channel combining section 322 .
- Each attention processing section 301 receives data input from the channel separating section 321 and outputs data to the channel combining section 322 .
- the number of attention processing units 301 included in the attention block 302 may be one or more.
- the channel separation section 321 acquires input data to the attention block 302 as input data to the channel separation section 321 and outputs the input data or part of the data to each of the attention processing sections 301 .
- the processing performed by the channel separation unit 321 corresponds to processing for separating channels of the neural network into a plurality of blocks.
- the method by which the channel separation unit 321 generates data for each attention processing unit 301 from input data is not limited to a specific method.
- the channel separation unit 321 may output the input data as it is to each of the attention processing units 301 .
- the channel separation unit 321 divides the input data based on the position in the image, such as dividing the input data into data corresponding to the left, center, and right of the original image, and outputs each data to the attention processing unit 301.
- the channel separation unit 321 may divide the input data into a plurality of channels from the original number of channels based on the position in the channel, and output each data to the attention processing unit 301 .
- Each of the attention processing units 301 extracts a feature amount from the input data to the attention processing unit 301 itself, emphasizes a part of the extracted feature amount, and outputs it.
- the attention processing unit 301 of the attention block 302 the attention processing unit 301 in FIG. 7 can be used.
- the channel combining unit 322 combines the data output from each of the attention processing units 301 into one data.
- the method of combining data by the channel combining unit 322 can be various methods corresponding to the method of generating data for each attention processing unit 301 from one data by the channel separating unit 321 .
- the channel combining unit 322 converts the two-dimensional matrix format data output from each of the attention processing units 301 into You may make it put together to one data by averaging or totaling.
- the channel combining unit 322 arranges and combines the data from each of the attention processing units 301 according to the position in the image. You may make it collect to one data.
- the attention block 302 can perform feature quantity extraction by paying attention to each portion where there are many features for identifying an individual, such as the iris, eyelids, and eyebrows.
- Attention block 302 may emphasize some channels relative to the channels of the feature vector instead of image regions.
- FIG. 9 is a diagram showing a configuration example of the attention processing unit 303 according to the second modification of the attention processing unit 301. As shown in FIG. The attention block 302 shown in FIG. 8 may include an attention processing section 303 instead of the attention processing section 301 .
- the attention processing unit 303 includes an image reduction unit 331 , a linear calculation unit 332 , a function calculation unit 312 and a multiplication unit 313 .
- the two-dimensional convolution operation unit 311b of the attention processing unit 301 is replaced with an image reduction unit 331 and a linear operation unit 332 in the attention processing unit 303. That is, in the attention processing unit 303 , the two-dimensional convolution calculation unit 311 is divided into an image reduction unit 331 and a linear calculation unit 332 . Otherwise, the attention processing unit 303 is the same as the attention processing unit 301 .
- the image reduction unit 331 corresponding to the two-dimensional convolution operation unit 311a is referred to as the image reduction unit 331a
- the image reduction unit 331 corresponding to the two-dimensional convolution operation unit 311b is referred to as the image reduction unit. 331b.
- the linear operation unit 332 corresponding to the two-dimensional convolution operation unit 311a is referred to as a linear operation unit 332a
- the linear operation unit 332 corresponding to the two-dimensional convolution operation unit 311b is referred to as a linear operation unit. 332b.
- the image reduction unit 331 reduces the input image to a size of 1x1. That is, the image reduction unit 331 reduces a tensor having a size of channel C, height H, and width W to a tensor having a size of channel C, height 1, and width 1.
- the method by which the image reduction unit 331 reduces the image is not limited to a specific method. For example, the image reduction unit 331 may reduce the image using an averaging method, but the method is not limited to this.
- the linear calculator 332 performs linear calculation on the channel.
- the input tensor and output tensor of the linear calculator 332 each have a size of (C, 1, 1).
- the function calculator 312 applies the softmax function to the output of the linear calculator 332b to calculate the weight for emphasizing the channel.
- FIG. 10 is a diagram showing a configuration example of the attention processing unit 304 according to the third modification of the attention processing unit 301.
- the feature quantity extraction unit 104 shown in FIG. 6 may include an attention processing unit 304 instead of the attention processing unit 301 .
- the attention processing unit 304 includes a two-dimensional convolution calculation unit 311 a, a multiplication unit 313 and an attention map acquisition unit 341 .
- the two-dimensional convolution calculation unit 311 a is also called a two-dimensional convolution calculation unit 311 .
- the processing performed by the two-dimensional convolution calculation unit 311 a is the same as the two-dimensional convolution calculation unit 311 a of the attention processing unit 301 .
- the processing performed by the multiplication unit 313 is the same as the multiplication unit 313 of the attention processing unit 301 .
- the attention map acquisition unit 341 acquires an attention map.
- the attention map is data indicating a portion of the input data to the attention processing unit 304 that should be emphasized by the attention processing unit 304 .
- the attention map is, so to speak, correct data for attention and is included in the training data.
- the multiplication unit 313 weights the output from the two-dimensional convolution operation unit 311a using the attention map. Further, the attention processing unit 304 may learn not only the method of extracting the feature amount in the two-dimensional convolution operation unit 311a, but also the method of emphasizing the feature amount by attention. For example, the attention processing unit 304 multiplies the attention map input from the training data by the temperature coefficient S and then inputs the softmax function, and the multiplication unit 313 multiplies the result of the convolution operation unit 311 by the obtained function value You may do so. In this case, the temperature coefficient S may be a parameter adjusted by learning.
- the attention processing unit 301 performs weighting for emphasizing the feature amount corresponding to a specific portion of the image or channel from which the feature amount is to be extracted. As a result, it is expected that the authentication device 100 can perform authentication with relatively high accuracy by using the feature quantity in which the part where many features for identifying an individual are emphasized.
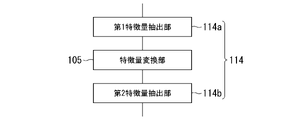
- FIG. 11 is a diagram showing a configuration example of the feature amount extraction unit 114 according to a modification of the feature amount extraction unit 104. As shown in FIG. Both or one of the authentication device 100 in FIG. 1 and the feature quantity conversion learning device 200 in FIG.
- the feature quantity extraction unit 114 includes a first feature quantity extraction unit 114a and a second feature quantity extraction unit 114b.
- the output of the first feature amount extraction unit 114a is input to the feature amount conversion unit 105, and the output of the feature amount conversion unit 105 is input to the second feature amount extraction unit 114b.
- the first feature quantity extraction unit 114a and the second feature quantity extraction unit 114b are each composed of partial networks obtained by dividing the neural network constituting the feature quantity extraction unit 104 into two between layers.
- FIG. 12 is a diagram showing an example of the hierarchical structure of the neural network that constitutes the feature quantity extraction unit 104.
- the feature quantity extraction unit 104 is configured using a neural network having multiple layers.
- the layers of the neural network forming the feature amount extraction unit 104 are grouped into a group of one or more layers from the front side and a group of one or more layers from the back side.
- the front side here is the side of the input layer.
- the back side is the side of the output layer.
- the first feature quantity extraction unit 114a is configured using a neural network corresponding to one or more layer groups from the front of these two groups.
- the second feature quantity extraction unit 114b is configured using a neural network corresponding to one or more layer groups from the rear of these two groups.
- the output of the first feature amount extraction unit 114 a corresponds to the intermediate feature amount in the feature amount extraction unit 104 .
- the output of the first feature amount extraction unit 114a when a low-resolution image is input as image data to the first feature amount extraction unit 114a is also referred to as a low-resolution intermediate feature amount.
- the feature amount conversion unit 105 receives input of the low-resolution intermediate feature amount and converts the input low-resolution intermediate feature amount.
- the output of the feature amount conversion unit 105 in this case is also referred to as a super-resolution intermediate feature amount.
- the second feature amount extraction unit 114b receives the input of the super-resolution intermediate feature amount and further extracts the feature amount.
- the output of the second feature amount extraction unit 114b corresponds to the super-resolution feature amount output by the feature amount conversion unit 105 with the configuration in FIG. 1 and the configuration in FIG.
- the feature amount conversion unit 105 may perform feature super-resolution using not only the feature amount output by the neural network that constitutes the feature amount extraction unit 104, but also the feature amount in the intermediate layer.
- VGG 16 consists of 13 convolutional layers and 3 fully connected layers. Among these layers, the feature amount conversion unit 105 performs feature super-resolution on the intermediate feature amount output from the second layer from the front side of the convolution layer, and the super-resolution intermediate feature amount output by the feature amount conversion unit 105 is performed. may be input to the third layer from the front side of the convolution layer.
- the feature amount conversion unit 105 performs feature super-resolution on the intermediate feature amount output from the fourth layer from the front of the convolution layers, and the super-resolution intermediate feature amount output by the feature amount conversion unit 105 is the convolution layer. Input may be made to the fifth layer from the front side.
- the feature amount conversion unit 105 performs feature amount conversion on the intermediate feature amount generated by the feature amount extraction unit.
- the authentication device 100 can obtain an effect between image super-resolution that super-resolutions an input image to the feature amount extractor and feature super-resolution that super-resolutions an output feature.
- the feature super-resolution is performed with an intermediate feature capable of maximizing the authentication performance at the desired magnification ratio. can do.
- feature super-resolution can be performed with even higher precision.
- FIG. 13 is a diagram showing a configuration example of an authentication device according to the fifth embodiment.
- the authentication device 411 includes an authentication target image acquisition unit 101, a comparison image acquisition unit 102, a feature amount extraction unit 104, a feature amount conversion unit 105, and a feature amount comparison unit 106. .
- the authentication device 100 in FIG. 1 and the authentication device 411 in FIG. 13 use different images for authentication.
- the authentication device 100 acquires a low-resolution image as an authentication target image and acquires a high-resolution image as a comparison image.
- the authentication device 411 acquires an image of the iris when wearing glasses as an image to be authenticated, and acquires an image of the iris with the naked eye having the same resolution as that of the image to be authenticated as a comparison image. Note that the resolutions of the authentication image and the comparison image need only be approximately the same, and need not be exactly the same.
- authentication device 411 does not have the image enlarging unit 103 that the authentication device 100 has.
- authentication target image acquisition section 101 outputs the authentication target image to be acquired to feature amount extraction section 104 . Otherwise, authentication device 411 is similar to authentication device 100 .
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the iris image of the naked eye.
- the feature quantity extraction unit 104 may extract the feature quantity of the comparison image at the time of authentication.
- authentication device 100 may store in advance the feature amount of the comparison image.
- the feature amount conversion unit 105 receives the input of the feature amount of the iris image when wearing the glasses, and performs Perform feature conversion.
- the machine learning parameter value of the feature amount conversion unit 105 decreases as the difference between the feature amount after conversion from the feature amount of the iris image when wearing glasses and the feature amount of the iris image with the naked eye decreases.
- the image of the iris when wearing glasses corresponds to an example of the first learning image
- the image of the iris with the naked eye corresponds to an example of the second learning image.
- the feature conversion learning device 412 according to the sixth embodiment performs this learning.
- the authentication target image acquisition unit 101 acquires the image of the iris when wearing the glasses as the authentication target image.
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the iris image of the naked eye.
- the feature amount conversion unit 105 converts the feature amount after conversion from the feature amount of the first learning image, which is the iris image when wearing glasses, and the feature amount of the second learning image, which is the iris image of the naked eye.
- the feature quantity of the authentication target image is converted based on the learning result of the feature quantity conversion method using a loss function whose value decreases as the difference decreases.
- the feature amount comparison unit 106 compares the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the comparison image.
- the authentication device 411 according to the fifth embodiment it is expected that the feature amount of the iris image when wearing glasses can be brought closer to the feature amount of the iris image with the naked eye.
- the authentication device 411 according to the fifth embodiment is expected to perform iris authentication with relatively high accuracy even when the person to be authenticated wears glasses.
- FIG. 14 is a diagram showing a configuration example of a feature conversion learning device according to the sixth embodiment.
- the feature quantity conversion learning device 412 of the sixth embodiment learns the feature quantity conversion unit 105 of the authentication device 411 of the fifth embodiment.
- the feature conversion learning device 412 includes an image batch acquisition unit 413, a feature extraction unit 104, a feature conversion unit 105, a loss function calculation unit 203, and a learning control unit 208.
- the loss function calculator 203 includes a reconstruction loss calculator 204 , a feature determiner 205 , an adversarial loss calculator 206 , and a similarity loss calculator 207 . 14, the same reference numerals (104, 105, 203-208) are given to the parts having the same functions as those in FIG. 3, and detailed description thereof will be omitted here.
- the images included in the training data differ between the feature quantity conversion learning device 200 in FIG. 3 and the feature quantity conversion learning device 412 in FIG.
- the image batch acquisition unit 201 of the feature conversion learning device 200 acquires training data including a plurality of combinations of high-resolution images and class labels indicating correct classes in class classification of the images.
- the image batch acquisition unit 413 of the feature quantity conversion learning device 412 determines that the combination of the iris image when wearing glasses and the iris image when the iris is viewed with the naked eye and the class label indicating the correct class in the class classification of these images is Get multiple training data.
- An image of the same person and having the same resolution is used as the iris image when wearing the glasses and the iris image when the iris is unaided.
- the image batch acquisition unit 413 corresponds to an example of an image acquisition unit.
- An image of the iris with the naked eye included in the training data corresponds to an example of the first image
- an image of the iris when the eyeglasses are worn corresponds to an example of the second image.
- the feature conversion learning device 412 does not include the image reduction unit 202 and the image enlargement unit 103 included in the feature conversion learning device 200 .
- the image batch acquisition unit 201 outputs the image of the iris when wearing glasses and the image of the iris with the naked eye to the feature amount extraction unit 104 .
- the feature amount extracting unit 104 extracts the feature amount of the iris image when the wearer is wearing glasses and the feature amount of the iris image when the eyeglasses are worn.
- the feature quantity of the image of the iris of the naked eye corresponds to an example of the first feature quantity.
- the feature amount of the image of the iris when the eyeglasses are worn corresponds to an example of the second feature amount.
- the feature amount conversion unit 105 receives the input of the feature amount of the iris image when wearing glasses, and converts the feature amount so that the difference from the feature amount of the iris image with the naked eye is reduced.
- the feature amount after conversion from the feature amount of the image of the iris when the eyeglasses are worn corresponds to an example of the third feature amount.
- a loss function calculation unit 203 calculates a loss based on the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the iris image to the naked eye.
- the learning control unit 208 updates the machine learning model parameter values of the feature quantity conversion unit 105 and the feature determination unit 205 based on the loss calculated by the loss function calculation unit 203 .
- the learning control unit 208 updates the machine learning model parameter values so that the difference between the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the iris image to the naked eye is reduced.
- the image batch acquisition unit 413 acquires the first image, which is the image of the iris with the naked eye, and the second image, which is the image of the iris when the eyeglasses are worn.
- the feature amount extraction unit 104 extracts a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the second image.
- a feature quantity conversion unit 105 converts the second feature quantity into a third feature quantity.
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on the result of comparison between the first feature amount and the third feature amount.
- the feature amount conversion unit 105 performs conversion to bring the feature amount of the iris image when wearing the glasses closer to the feature amount of the iris image with the naked eye. so that it can learn. It is expected that the authentication device 411 performs authentication using the feature amount conversion unit 105, so that iris authentication can be performed with relatively high accuracy even when the person to be authenticated wears glasses.
- FIG. 15 is a diagram showing a configuration example of an authentication device according to the seventh embodiment.
- the authentication device 411 includes an authentication target image acquisition unit 101, a comparison image acquisition unit 102, a feature amount extraction unit 104, a feature amount conversion unit 105, and a feature amount comparison unit 106. .
- the configuration of the authentication device 411 according to the seventh embodiment is the same as the configuration of the authentication device 411 according to the fifth embodiment. 15, portions having similar functions corresponding to those in FIG. 13 are given the same reference numerals (101, 102, 104, 105, 106, 411), and detailed description thereof is omitted here. do.
- the image used by the authentication device 411 for authentication differs from that in the fifth embodiment.
- the authentication device 411 of the fifth embodiment acquires an iris image when wearing glasses as an authentication target image, and acquires an iris image with the same resolution as the authentication target image with the naked eye as a comparison image.
- the authentication device 411 of the seventh embodiment acquires an iris image taken obliquely as an authentication target image, and uses an iris image taken from the front with the same resolution as the authentication target image as a comparison image. to get
- the feature quantity extraction unit 104 extracts the feature quantity of the authentication target image by the same method as the feature quantity extraction method for the comparison image, which is the iris image taken from the front.
- the feature quantity extraction unit 104 may extract the feature quantity of the comparison image at the time of authentication.
- authentication device 100 may store in advance the feature amount of the comparison image.
- the feature quantity conversion unit 105 receives input of the feature quantity of the iris image taken from an oblique direction, and the difference from the feature quantity of the iris image taken from the front is small.
- the feature quantity is transformed so that The machine-learning parameter value of the feature amount conversion unit 105 increases as the difference between the feature amount after conversion from the feature amount of the iris image photographed from an oblique direction and the feature amount of the iris image photographed from the front becomes smaller. is adjusted by learning with a loss function that reduces In this case, the iris image taken obliquely corresponds to an example of the first learning image, and the iris image taken from the front corresponds to an example of the second learning image.
- the feature conversion learning device 412 according to the eighth embodiment performs this learning.
- the authentication target image acquisition unit 101 acquires an iris image captured obliquely as the authentication target image.
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the iris image taken from the front.
- the feature amount conversion unit 105 converts the feature amount after conversion from the feature amount of the first learning image, which is an iris image photographed from an oblique direction, and the second learning image, which is an iris image photographed from the front.
- the feature quantity of the authentication target image is converted based on the learning result of the feature quantity conversion method using a loss function whose value decreases as the difference from the feature quantity decreases.
- the feature amount comparison unit 106 compares the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the comparison image.
- the authentication device 411 according to the seventh embodiment it is expected that the feature amount of an iris image taken obliquely can be brought closer to the feature amount of an iris image taken from the front.
- FIG. 16 is a diagram showing a configuration example of a feature conversion learning device according to the eighth embodiment.
- the feature quantity conversion learning device 412 of the eighth embodiment learns the feature quantity conversion unit 105 of the authentication device 411 of the seventh embodiment.
- the feature conversion learning device 412 includes an image batch acquisition unit 413, a feature extraction unit 104, a feature conversion unit 105, a loss function calculation unit 203, and a learning control unit 208.
- the loss function calculator 203 includes a reconstruction loss calculator 204 , a feature determiner 205 , an adversarial loss calculator 206 , and a similarity loss calculator 207 .
- the configuration of the feature quantity conversion learning device 412 according to the eighth embodiment is the same as the configuration of the feature quantity conversion learning device 412 according to the sixth embodiment. 16, the parts having the same functions as those in FIG. 14 are denoted by the same reference numerals (104, 105, 203-208, 312, 412, 413), and a detailed description thereof will be given here. omitted.
- images included in training data acquired by the feature conversion learning device 412 are different from those in the sixth embodiment.
- the image batch acquisition unit 413 of the feature quantity conversion learning device 412 combines an iris image when wearing glasses and an iris image with the naked eye, and a class label indicating the correct class in the class classification of these images. Get training data that contains multiple combinations.
- the image batch acquisition unit 413 of the feature conversion learning device 412 includes an iris image taken from the front and an iris image taken from an oblique direction, and class classification of these images.
- Acquire training data that includes a plurality of combinations with class labels that indicate correct classes. Images of the same person and having the same resolution are used as the iris image photographed from the front and the iris image photographed obliquely.
- the image batch acquisition unit 413 corresponds to an example of an image acquisition unit.
- An iris image taken from the front included in the training data corresponds to an example of the first image
- an iris image taken from an oblique direction corresponds to an example of the second image.
- the image batch acquisition unit 201 outputs an iris image captured obliquely and an iris image captured from the front to the feature amount extraction unit 104 .
- the feature quantity extraction unit 104 extracts the feature quantity of the iris image taken obliquely and the feature quantity of the iris image taken frontally.
- the feature amount of the iris image captured from the front corresponds to an example of the first feature amount.
- the feature quantity of an iris image captured obliquely corresponds to an example of the second feature quantity.
- the feature quantity conversion unit 105 receives the input of the feature quantity of the iris image photographed obliquely, and converts the feature quantity so that the difference from the feature quantity of the iris image photographed from the front is reduced. .
- the feature amount after conversion from the feature amount of the iris image photographed obliquely corresponds to an example of the third feature amount.
- a loss function calculation unit 203 calculates a loss based on the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the iris image photographed from the front.
- the learning control unit 208 updates the machine learning model parameter values of the feature quantity conversion unit 105 and the feature determination unit 205 based on the loss calculated by the loss function calculation unit 203 .
- the learning control unit 208 updates the machine learning model parameter values so that the difference between the feature amount after the conversion by the feature amount conversion unit 105 and the feature amount of the iris image photographed from the front is reduced.
- the image batch acquisition unit 413 acquires a first image that is an iris image taken from the front and a second image that is an iris image taken from an oblique direction.
- the feature amount extraction unit 104 extracts a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the second image.
- a feature quantity conversion unit 105 converts the second feature quantity into a third feature quantity.
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on the result of comparison between the first feature amount and the third feature amount.
- the feature amount conversion unit 105 converts the feature amount of the iris image photographed from an oblique angle into the feature amount of the iris image photographed from the front. It can be trained to do a transform that brings it closer. It is expected that the authentication device 411 performs authentication using the feature amount conversion unit 105, so that iris authentication can be performed with relatively high accuracy even when an iris image taken obliquely is used as the authentication target image. .
- FIG. 17 is a diagram showing a configuration example of an authentication device according to the ninth embodiment.
- the authentication device 411 includes an authentication target image acquisition unit 101, a comparison image acquisition unit 102, a feature amount extraction unit 104, a feature amount conversion unit 105, and a feature amount comparison unit 106. .
- the configuration of the authentication device 411 according to the ninth embodiment is the same as the configuration of the authentication device 411 according to the fifth embodiment. 17 having the same functions as those in FIG. 13 are denoted by the same reference numerals (101, 102, 104, 105, 106, 411), and detailed description thereof is omitted here. do.
- the image used by the authentication device 411 for authentication differs from that in the fifth embodiment.
- the authentication device 411 of the fifth embodiment acquires an iris image when wearing glasses as an authentication target image, and acquires an iris image with the same resolution as the authentication target image with the naked eye as a comparison image.
- the authentication device 411 of the ninth embodiment acquires an iris image captured with visible light as an authentication target image, and uses an image with the same resolution as the authentication target image as a comparison image and also uses a visible light such as near-infrared light. Acquire an image of the iris taken with light other than light.
- the wavelength of the image for authentication is not limited to visible light, and may be an image captured with other wavelengths such as ultraviolet light and near-infrared light.
- the number of channels representing the colors of the input image is not particularly limited.
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the iris image captured with light other than visible light. Extract with The feature quantity extraction unit 104 may extract the feature quantity of the comparison image at the time of authentication. Alternatively, authentication device 100 may store in advance the feature amount of the comparison image.
- the feature quantity conversion unit 105 receives the input of the feature quantity of the iris image captured with visible light, and receives the feature quantity of the iris image captured with light other than visible light. The feature quantity is transformed so that the difference between is small.
- the machine learning parameter value of the feature amount conversion unit 105 is the feature amount after conversion from the feature amount of the iris image captured with visible light and the feature amount of the iris image captured with light other than visible light. It is adjusted by learning using a loss function whose value decreases as the difference decreases.
- the iris image captured with visible light corresponds to an example of the first learning image
- the iris image captured with light other than visible light corresponds to an example of the second learning image.
- the feature conversion learning device 412 according to the tenth embodiment performs this learning.
- the authentication target image acquisition unit 101 acquires an iris image captured with visible light as an authentication target image.
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the iris image captured with light other than visible light.
- the feature amount conversion unit 105 converts the feature amount after conversion from the feature amount of the first learning image, which is the iris image captured with visible light, and the first learning image, which is the iris image captured with light other than visible light. 2. Convert the feature amount of the authentication target image based on the learning result of the feature amount conversion method using a loss function whose value decreases as the difference from the feature amount of the learning image decreases.
- the feature amount comparison unit 106 compares the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the comparison image.
- the authentication device 411 according to the ninth embodiment it is expected that the feature amount of an iris image captured with visible light can be brought closer to the feature amount of an iris image captured with light other than visible light. .
- the authentication device 411 according to the seventh embodiment even when the comparison image is captured with light other than visible light, the image captured with visible light is used to perform comparative iris authentication. High accuracy is expected.
- FIG. 18 is a diagram showing a configuration example of a feature conversion learning device according to the tenth embodiment.
- the feature quantity conversion learning device 412 of the tenth embodiment learns the feature quantity conversion unit 105 of the authentication device 411 of the ninth embodiment.
- the wavelength of the image for authentication is not limited to visible light, and may be an image captured with other wavelengths such as ultraviolet light and near-infrared light.
- the number of channels representing the colors of the input image is not particularly limited.
- the feature conversion learning device 412 includes an image batch acquisition unit 413, a feature extraction unit 104, a feature conversion unit 105, a loss function calculation unit 203, and a learning control unit 208.
- the loss function calculator 203 includes a reconstruction loss calculator 204 , a feature determiner 205 , an adversarial loss calculator 206 , and a similarity loss calculator 207 .
- the configuration of the feature conversion learning device 412 according to the tenth embodiment is the same as the configuration of the feature conversion learning device 412 according to the sixth embodiment. 18, the parts having the same functions as those in FIG. 14 are denoted by the same reference numerals (104, 105, 203-208, 312, 412, 413), and a detailed description thereof will be given here. omitted.
- the images included in the training data acquired by the feature conversion learning device 412 are different from those in the sixth embodiment.
- the image batch acquisition unit 413 of the feature quantity conversion learning device 412 combines an iris image when wearing glasses and an iris image with the naked eye, and a class label indicating the correct class in the class classification of these images. Get training data that contains multiple combinations.
- the image batch acquisition unit 413 of the feature conversion learning device 412 obtains an iris image captured with light other than visible light, an iris image captured with visible light, and Acquire training data that includes a plurality of combinations with class labels that indicate correct classes in image classification. Images of the same person and having the same resolution are used as the iris image captured with light other than visible light and the iris image captured with visible light.
- the image batch acquisition unit 413 corresponds to an example of an image acquisition unit.
- An iris image captured with light other than visible light included in the training data corresponds to an example of the first image
- an iris image captured with visible light corresponds to an example of the second image.
- the image batch acquisition unit 201 outputs an iris image captured with visible light and an iris image captured with light other than visible light to the feature amount extraction unit 104 .
- the feature quantity extraction unit 104 extracts the feature quantity of the iris image captured with visible light and the feature quantity of the iris image captured with light other than visible light.
- a feature amount of an iris image captured with light other than visible light corresponds to an example of the first feature amount.
- a feature amount of an iris image captured with visible light corresponds to an example of the second feature amount.
- the feature amount conversion unit 105 receives input of the feature amount of the iris image captured with visible light, and converts the feature amount so that the difference from the feature amount of the iris image captured with light other than visible light becomes small. Perform quantity conversions.
- the feature amount after conversion from the feature amount of the iris image captured with visible light corresponds to an example of the third feature amount.
- a loss function calculation unit 203 calculates a loss based on the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of an iris image captured with light other than visible light.
- the learning control unit 208 updates the machine learning model parameter values of the feature quantity conversion unit 105 and the feature determination unit 205 based on the loss calculated by the loss function calculation unit 203 .
- the learning control unit 208 adjusts the machine learning model parameter value so that the difference between the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the iris image captured with light other than visible light is small. to update.
- the image batch acquisition unit 413 acquires the first image, which is an iris image captured with light other than visible light, and the second image, which is an iris image captured with visible light.
- the feature amount extraction unit 104 extracts a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the second image.
- a feature quantity conversion unit 105 converts the second feature quantity into a third feature quantity.
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on the result of comparison between the first feature amount and the third feature amount.
- the feature amount of the iris image captured with visible light is converted to the feature amount of the iris image captured with light other than visible light for the feature amount conversion unit 105. Learning can be performed so as to perform conversion that approximates the feature amount of the image. Since the authentication device 411 performs authentication using the feature amount conversion unit 105, even when the comparison image is captured with light other than visible light, the image captured with visible light can be used for iris authentication. is expected to be performed with relatively high accuracy.
- FIG. 19 is a diagram showing a configuration example of an authentication device according to the eleventh embodiment.
- the authentication device 411 includes an authentication target image acquisition unit 101, a comparison image acquisition unit 102, a feature amount extraction unit 104, a feature amount conversion unit 105, and a feature amount comparison unit 106. .
- the configuration of the authentication device 411 according to the eleventh embodiment is the same as the configuration of the authentication device 411 according to the fifth embodiment. 19, the same reference numerals (101, 102, 104, 105, 106, 411) are attached to the parts having the same functions as those of FIG. 13, and detailed description thereof is omitted here. do.
- the image used for authentication by the authentication device 411 is different from that in the fifth embodiment.
- the authentication device 411 of the fifth embodiment acquires an iris image when wearing glasses as an authentication target image, and acquires an iris image with the same resolution as the authentication target image with the naked eye as a comparison image.
- the authentication device 411 of the eleventh embodiment acquires an out-of-focus iris image as an authentication target image, and uses an in-focus image with the same resolution as the authentication target image as a comparison image. Acquire an image of the iris Being in focus is also called a focus position. Out of focus is also called out of focus.
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the image of the iris in focus. do.
- the feature quantity extraction unit 104 may extract the feature quantity of the comparison image at the time of authentication.
- authentication device 100 may store in advance the feature amount of the comparison image.
- the feature quantity conversion unit 105 receives the input of the feature quantity of the out-of-focus iris image, and converts the feature quantity of the in-focus iris image into The feature quantity is transformed so that the difference between is small.
- the machine learning parameter value of the feature amount conversion unit 105 is the difference between the feature amount after conversion from the feature amount of the out-of-focus iris image and the feature amount of the in-focus iris image. It is adjusted by learning using a loss function whose value decreases as .
- the out-of-focus iris image corresponds to an example of the first learning image
- the focused iris image corresponds to an example of the second learning image.
- the feature conversion learning device 412 according to the twelfth embodiment performs this learning.
- the authentication target image acquisition unit 101 acquires the out-of-focus iris image as the authentication target image.
- the feature amount extraction unit 104 extracts the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is the image of the iris in focus.
- the feature amount conversion unit 105 converts the feature amount after conversion from the feature amount of the first learning image, which is an out-of-focus iris image, and the second learning image, which is an in-focus iris image.
- the feature quantity of the authentication target image is converted based on the learning result of the feature quantity conversion method using a loss function whose value decreases as the difference from the feature quantity of the learning image decreases.
- the feature amount comparison unit 106 compares the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the comparison image.
- the authentication device 411 according to the eleventh embodiment it is expected that the feature amount of the out-of-focus iris image can be brought closer to the feature amount of the in-focus iris image. .
- the authentication device 411 according to the eleventh embodiment is expected to perform iris authentication with relatively high accuracy even when an image of an iris out of focus is used as an authentication target image.
- FIG. 20 is a diagram showing a configuration example of a feature conversion learning device according to the twelfth embodiment.
- the feature quantity conversion learning device 412 of the twelfth embodiment learns the feature quantity conversion unit 105 of the authentication device 411 of the eleventh embodiment.
- the feature conversion learning device 412 includes an image batch acquisition unit 413, a feature extraction unit 104, a feature conversion unit 105, a loss function calculation unit 203, and a learning control unit 208.
- the loss function calculator 203 includes a reconstruction loss calculator 204 , a feature determiner 205 , an adversarial loss calculator 206 , and a similarity loss calculator 207 .
- the configuration of the feature conversion learning device 412 according to the twelfth embodiment is the same as the configuration of the feature conversion learning device 412 according to the sixth embodiment. 20, portions having similar functions corresponding to those in FIG. 14 are denoted by the same reference numerals (104, 105, 203-208, 312, 412, 413), and a detailed description thereof will be given here. omitted.
- the images included in the training data acquired by the feature conversion learning device 412 are different from those in the sixth embodiment.
- the image batch acquisition unit 413 of the feature quantity conversion learning device 412 combines an iris image when wearing glasses and an iris image with the naked eye, and a class label indicating the correct class in the class classification of these images. Get training data that contains multiple combinations.
- the image batch acquisition unit 413 of the feature conversion learning device 412 obtains an iris image that is out of focus and an iris image that is in focus, and Acquire training data that includes multiple combinations with class labels that indicate correct classes in class classification. Images of the same person and having the same resolution are used as the out-of-focus iris image and the in-focus iris image.
- the image batch acquisition unit 413 corresponds to an example of an image acquisition unit.
- An in-focus iris image included in the training data corresponds to an example of the first image
- an out-of-focus iris image corresponds to an example of the second image.
- the image batch acquisition unit 201 outputs an out-of-focus iris image and an in-focus iris image to the feature quantity extraction unit 104, respectively.
- the feature quantity extraction unit 104 extracts a feature quantity of an iris image in which the image is out of focus and a feature quantity of an iris image in which the image is in focus.
- the feature amount of the iris image in which the image is in focus corresponds to an example of the first feature amount.
- a feature amount of an iris image in which the image is out of focus corresponds to an example of the second feature amount.
- the feature amount conversion unit 105 receives input of the feature amount of the out-of-focus iris image, and converts the feature amount so as to reduce the difference from the feature amount of the in-focus iris image. conversion.
- the feature amount after conversion from the feature amount of the iris image in which the image is out of focus corresponds to an example of the third feature amount.
- a loss function calculation unit 203 calculates a loss based on the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the in-focus iris image.
- the learning control unit 208 updates the machine learning model parameter values of the feature quantity conversion unit 105 and the feature determination unit 205 based on the loss calculated by the loss function calculation unit 203 .
- the learning control unit 208 updates the machine learning model parameter values so that the difference between the feature amount after conversion by the feature amount conversion unit 105 and the feature amount of the iris image in which the image is in focus is reduced. do.
- the image batch acquisition unit 413 acquires the first image, which is an in-focus iris image, and the second image, which is an out-of-focus iris image.
- the feature amount extraction unit 104 extracts a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the second image.
- a feature quantity conversion unit 105 converts the second feature quantity into a third feature quantity.
- the learning control unit 208 causes the feature amount conversion unit 105 to learn the feature amount conversion method based on the result of comparison between the first feature amount and the third feature amount.
- the feature amount of the out-of-focus iris image is converted to the feature amount of the in-focus iris image in the feature-value conversion unit 105 .
- Learning can be performed so as to perform a conversion that brings the feature amount closer to the value of .
- the authentication device 411 performs authentication using the feature amount conversion unit 105, so that iris authentication can be performed with relatively high accuracy even when a blurred image is used as the authentication target image. .
- FIG. 21 is a diagram showing a configuration example of a feature conversion learning device according to the thirteenth embodiment.
- the feature conversion learning device 610 includes an image acquisition unit 611, an image reduction unit 612, an image enlargement unit 613, a feature extraction unit 614, a feature conversion unit 615, and a learning control unit. 616.
- the image acquisition unit 611 acquires the first image.
- the image reduction unit 612 reduces the first image to a second image having a resolution lower than that of the first image.
- the image enlarger 613 enlarges the second image to a third image having the same resolution as the first image.
- the feature amount extraction unit 614 extracts a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the third image.
- a feature quantity conversion unit 615 converts the second feature quantity into a third feature quantity.
- the learning control unit 616 causes the feature amount conversion unit 615 to learn the feature amount conversion method based on the result of comparison between the first feature amount and the third feature amount.
- the image acquisition unit 611 corresponds to an example of image acquisition means.
- the image reduction unit 612 corresponds to an example of image reduction means.
- the image enlarging unit 613 corresponds to an example of image enlarging means.
- the feature amount extraction unit 614 corresponds to an example of feature amount extraction means.
- the feature amount conversion unit 615 corresponds to an example of feature amount conversion means.
- the learning control unit 616 corresponds to an example of learning control means.
- the feature quantity conversion unit 615 learns, so that the feature quantity conversion unit 615 can bring the feature quantity of the image obtained by enlarging the reduced image closer to the feature quantity of the high-resolution image. It is expected that an authentication device using the learned feature quantity conversion unit 615 can perform authentication with relatively high accuracy even when receiving an input of a low-resolution image.
- FIG. 22 is a diagram showing a configuration example of an authentication device according to the fourteenth embodiment.
- the authentication device 620 includes an authentication target image acquisition unit 621 , an image enlargement unit 622 , a feature amount extraction unit 623 , a feature amount conversion unit 624 , and a feature amount comparison unit 625 .
- the authentication target image acquisition unit 621 acquires the authentication target image.
- the image enlarger 622 enlarges the authentication target image.
- the feature quantity extraction unit 623 extracts the feature quantity of the enlarged image of the authentication target image by the same method as the feature quantity extraction method for the comparison image having a resolution higher than that of the authentication target image.
- the feature amount conversion unit 624 uses a loss function whose value decreases as the difference between the feature amount after conversion from the feature amount of the learning image and the feature amount of the degraded image that is enlarged after the reduction of the learning image is smaller. is used to convert the feature quantity of the enlarged image of the authentication target image based on the learning result of the feature quantity conversion method.
- the feature amount comparison unit 625 compares the feature amount after conversion by the feature amount conversion unit 624 with the feature amount of the comparison image.
- the authentication target image acquisition unit 621 corresponds to an example of authentication target image acquisition means.
- the image enlarging section 622 corresponds to an example of image enlarging means.
- the feature amount extraction unit 623 corresponds to an example of feature amount extraction means.
- the feature quantity conversion unit 624 corresponds to an example of feature quantity conversion means.
- the feature amount comparison unit 625 corresponds to an example of feature amount comparison means.
- the authentication device 620 by enlarging the low-resolution image, extracting the feature amount, and converting the extracted feature amount, the high-resolution image for comparison is obtained as the feature amount of the authentication target image, which is the low-resolution image. A feature quantity that can be compared with the feature quantity of an image can be obtained. In this respect, the authentication device 620 can perform authentication even if the input image is a low-resolution image.
- the feature amount of the enlarged authentication target image is expected to approach the feature amount when the authentication target image is photographed at a higher resolution.
- the authentication device 620 is expected to perform authentication with high accuracy.
- iris authentication can be performed using a low-resolution image.
- authentication device 620 can perform both face authentication and iris authentication using a single face image without requiring a high-resolution camera, and is expected to improve authentication accuracy.
- FIG. 23 is a flow chart showing an example of the procedure of the feature conversion learning method according to the fifteenth embodiment.
- the feature amount conversion learning method shown in FIG. 23 includes acquiring an image (step S611), reducing the image (step S612), enlarging the image (step S613), (Step S614), converting the feature amount (Step S615), and controlling learning (Step S616).
- step S611 the first image is obtained.
- step S612 reduces the first image to a second image having a lower resolution than the first image.
- step S613 involves enlarging the second image to a third image with the same resolution as the first image.
- step S614 the first feature amount, which is the feature amount of the first image, and the second feature amount, which is the feature amount of the third image, are extracted.
- step S615 the second feature amount is converted into the third feature amount.
- step S616 learning of a feature amount conversion method for converting the second feature amount into the third feature amount is performed based on the result of comparison between the first feature amount and the third feature amount.
- the feature amount of an image obtained by enlarging a reduced image can be brought closer to the feature amount of a high-resolution image by the feature amount conversion. .
- the authentication using the trained feature quantity conversion method it is expected that the authentication can be performed with relatively high accuracy even when the input of the low-resolution image is received.
- FIG. 24 is a flowchart showing an example of a procedure of processing in an authentication method according to the sixteenth embodiment.
- the authentication method shown in FIG. 24 includes acquiring an image to be authenticated (step S621), enlarging the image (step S622), extracting a feature amount (step S623), and converting the feature amount. (Step S624), and comparing the feature amount (Step S625).
- the authentication target image In acquiring the authentication target image (step S621), the authentication target image is acquired. In enlarging the image (step S622), the image to be authenticated is enlarged. In extracting the feature amount (step S623), the feature amount of the enlarged image of the authentication target image is extracted by the same method as the feature extraction method for the comparison image having a higher resolution than the authentication target image. In converting the feature amount (step S624), the smaller the difference between the feature amount after conversion from the feature amount of the learning image and the feature amount of the degraded image that is enlarged after the reduction of the learning image, the value The feature quantity of the enlarged image of the authentication target image is converted based on the learning result of the feature quantity conversion method using the loss function that reduces the . In the feature amount comparison (step S625), the feature amount after conversion from the feature amount of the enlarged image of the authentication target image is compared with the feature amount of the comparison image.
- the authentication method shown in FIG. 24 by enlarging the low-resolution image, extracting the feature amount, and converting the extracted feature amount, the high-resolution image is obtained as the feature amount of the authentication target image, which is the low-resolution image. A feature amount that can be compared with the feature amount of the comparison image can be obtained. According to the authentication method shown in FIG. 24, in this respect, authentication can be performed even if the input image is a low-resolution image.
- the feature amount of the enlarged authentication target image approaches the feature amount when the authentication target image is photographed at a higher resolution.
- it is expected that authentication can be performed with high accuracy.
- iris authentication can be performed using a low-resolution image.
- authentication apparatus 100 can perform both face authentication and iris authentication using a single face image without requiring a high-resolution camera, and is expected to improve authentication accuracy.
- the configuration of the authentication device 620 according to the seventeenth embodiment is the same as the configuration of the authentication device 620 according to the fourteenth embodiment.
- the authentication device 620 according to the seventeenth embodiment further includes a feature determination unit that receives input of the feature amount of the high-resolution image or the super-resolution feature amount and determines whether or not the input feature amount is the super-resolution feature amount. Prepare. With such a configuration, the feature discrimination unit outputs the feature quantity Let them learn how to convert.
- the configuration of the authentication device 620 according to the eighteenth embodiment is the same as the configuration of the authentication device 620 according to the fourteenth or seventeenth embodiment.
- the learning control unit 616 causes the feature amount conversion unit 615 to perform Learn the feature value conversion method.
- the configuration of the authentication device 620 according to the 19th embodiment is the same as the configuration of the authentication device 620 according to the 14th, 17th, or 18th embodiment.
- the learning control unit 616 performs feature conversion based on a loss function that reduces loss when the class by class classification based on the super-resolution feature quantity matches the correct class.
- the unit 615 is caused to learn the feature amount conversion method.
- the configuration of the authentication device 620 according to the twentieth embodiment is the same as the configuration of the authentication device 620 according to the fourteenth, seventeenth, eighteenth, or nineteenth embodiments.
- the image reduction unit 612 generates a reduced image by reducing the high-resolution image to a size determined using random numbers.
- FIG. 25 is a schematic block diagram showing the configuration of a computer according to at least one embodiment;
- a computer 700 includes a CPU (Central Processing Unit) 710 , a main storage device 720 , an auxiliary storage device 730 and an interface 740 .
- CPU Central Processing Unit
- any one or more of the authentication device 100, the feature conversion learning device 200, the authentication device 411, the feature conversion learning device 412, the feature conversion learning device 610, and the authentication device 620 or a part thereof is a computer. 700 may be implemented.
- the operation of each processing unit described above is stored in the auxiliary storage device 730 in the form of a program.
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 secures storage areas corresponding to the storage units described above in the main storage device 720 according to the program. Communication between each device and another device is performed by the interface 740 having a communication function and performing communication under the control of the CPU 710 .
- the authentication target image acquisition unit 101 When the authentication device 100 is implemented in the computer 700, the authentication target image acquisition unit 101, the comparison image acquisition unit 102, the image enlargement unit 103, the feature amount extraction unit 104, the feature amount conversion unit 105, and the feature amount comparison unit 106 is stored in the auxiliary storage device 730 in the form of a program.
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 reserves a storage area for the processing of the authentication device 100 in the main storage device 720 according to the program. Communication between authentication device 100 and another device is performed by interface 740 having a communication function and performing communication under the control of CPU 710 . Interaction between the authentication device 100 and the user is executed by the interface 740 having a display device and an input device, displaying various images under the control of the CPU 710, and accepting user operations.
- the image batch acquisition unit 201, the image reduction unit 202, the image enlargement unit 103, the feature extraction unit 104, the feature conversion unit 105, the loss function calculation unit 203, the learning Control unit 208 and the operation of each unit thereof are stored in auxiliary storage device 730 in the form of programs.
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 secures a storage area in the main storage device 720 for the processing of the feature conversion learning device 200 according to the program.
- Communication between the feature conversion learning device 200 and other devices is performed by the interface 740 having a communication function and performing communication under the control of the CPU 710 .
- Interaction between the feature conversion learning device 200 and the user is executed by the interface 740 having a display device and an input device, displaying various images under the control of the CPU 710, and accepting user operations.
- the operations of the authentication target image acquisition unit 101, the comparison image acquisition unit 102, the feature amount extraction unit 104, the feature amount conversion unit 105, and the feature amount comparison unit 106 are performed by a program.
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 reserves a storage area for the processing of the authentication device 411 in the main storage device 720 according to the program. Communication between the authentication device 411 and another device is performed by the interface 740 having a communication function and performing communication under the control of the CPU 710 . Interaction between the authentication device 411 and the user is executed by the interface 740 having a display device and an input device, displaying various images under the control of the CPU 710, and accepting user operations.
- the image batch acquisition unit 413 When the feature conversion learning device 412 is implemented in the computer 700, the image batch acquisition unit 413, the feature extraction unit 104, the feature conversion unit 105, the loss function calculation unit 203, the learning control unit 208, and their respective units
- the actions are stored in secondary storage device 730 in the form of programs.
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 secures a storage area in the main storage device 720 for the processing of the feature conversion learning device 412 according to the program.
- Communication between the feature conversion learning device 412 and other devices is performed by the interface 740 having a communication function and performing communication under the control of the CPU 710 .
- Interaction between the feature conversion learning device 412 and the user is executed by the interface 740 having a display device and an input device, displaying various images under the control of the CPU 710, and accepting user operations.
- the image acquisition unit 611, the image reduction unit 612, the image expansion unit 613, the feature extraction unit 614, the feature conversion unit 615, and the learning control unit 616 operate.
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 secures a storage area in the main storage device 720 for the processing of the feature conversion learning device 610 according to the program.
- Communication between the feature conversion learning device 610 and other devices is performed by the interface 740 having a communication function and performing communication under the control of the CPU 710 .
- Interaction between the feature conversion learning device 610 and the user is executed by the interface 740 having a display device and an input device, displaying various images under the control of the CPU 710, and accepting user operations.
- the operations of the authentication target image acquisition unit 621, the image enlargement unit 622, the feature amount extraction unit 623, the feature amount conversion unit 624, and the feature amount comparison unit 625 are implemented in the form of a program. is stored in the auxiliary storage device 730 at .
- the CPU 710 reads out the program from the auxiliary storage device 730, develops it in the main storage device 720, and executes the above processing according to the program.
- the CPU 710 reserves a storage area in the main storage device 720 for processing by the authentication device 620 according to the program. Communication between authentication device 620 and other devices is performed by interface 740 having a communication function and performing communication under the control of CPU 710 . Interaction between authentication device 620 and the user is executed by interface 740, which includes a display device and an input device, displays various images under the control of CPU 710, and accepts user operations.
- a program for executing all or part of the processing performed by the authentication device 100, the feature conversion learning device 200, the authentication device 411, the feature conversion learning device 412, the feature conversion learning device 610, and the authentication device 620. may be recorded in a computer-readable recording medium, and the program recorded in this recording medium may be read into a computer system and executed to perform the processing of each part.
- the "computer system” referred to here includes hardware such as an OS (Operating System) and peripheral devices.
- “computer-readable recording medium” refers to portable media such as flexible discs, magneto-optical discs, ROM (Read Only Memory), CD-ROM (Compact Disc Read Only Memory), hard disks built into computer systems It refers to a storage device such as Further, the program may be for realizing part of the functions described above, or may be capable of realizing the functions described above in combination with a program already recorded in the computer system.
- (Appendix 1) an image acquisition means for acquiring a first image; image reduction means for reducing the first image to a second image having a resolution lower than that of the first image; image enlarging means for enlarging the second image to a third image having the same resolution as the first image; a feature amount extracting means for extracting a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the third image; feature quantity conversion means for converting the second feature quantity into a third feature quantity; learning control means for causing the feature quantity conversion means to learn a feature quantity conversion method based on a comparison result between the first feature quantity and the third feature quantity;
- a feature conversion learning device comprising: (Appendix 2) Further comprising feature determination means for receiving input of the first feature amount or the third feature amount and determining whether or not the input feature amount is a feature amount converted by the feature amount conversion means, The learning control means controls the feature amount conversion means based on a loss function that reduces loss when the feature discrimination means cannot distinguish
- the feature conversion learning device To learn the feature transformation method, The feature conversion learning device according to appendix 1. (Appendix 3) The learning control means causes the feature amount conversion means to learn the feature amount conversion method based on a loss function in which the loss decreases as the first feature amount and the third feature amount are similar, The feature conversion learning device according to appendix 1 or appendix 2. (Appendix 4) The learning control means causes the feature quantity conversion means to learn a feature quantity conversion method based on a loss function that reduces loss when the class classified based on the third feature quantity matches the correct class. let The feature conversion learning device according to any one of Appendices 1 to 3. (Appendix 5) 5.
- the feature conversion learning device according to any one of appendices 1 to 4, wherein the image reduction means reduces the first image to a size determined using a random number to generate the second image.
- the feature quantity extraction means is 6.
- the feature conversion learning device according to any one of appendices 1 to 5, further comprising attention processing means for performing weighting for emphasizing a feature corresponding to a specific portion of an image from which feature is to be extracted.
- the feature amount conversion means performs feature amount conversion on the intermediate feature amount generated by the feature amount extraction means. 7.
- the feature conversion learning device according to any one of Appendices 1 to 6.
- authentication target image acquiring means for acquiring an authentication target image; image enlarging means for enlarging the authentication target image; a feature quantity extracting means for extracting a feature quantity of an enlarged image of the authentication target image by the same method as a feature quantity extraction method for a comparison image having a resolution higher than that of the authentication target image; A feature amount using a loss function whose value decreases as the difference between the feature amount after conversion from the feature amount of the learning image and the feature amount of the degraded image that is enlarged after the reduction of the learning image is smaller.
- a feature conversion learning device comprising: (Appendix 10) authentication target image acquiring means for acquiring an image of an iris when wearing eyeglasses as an authentication target image; a feature amount extraction means for extracting the
- a feature amount conversion means for converting the feature amount of the authentication target image based on the learning result of the feature amount conversion method using a loss function of feature quantity comparison means for comparing the feature quantity after conversion by the feature quantity conversion means with the feature quantity of the comparison image; authentication device.
- a feature conversion learning device comprising: (Appendix 12) authentication target image acquisition means for acquiring an image of an iris photographed obliquely as an authentication target image; feature quantity extraction means for extracting the feature quantity of the authentication target image by the same method as the feature quantity extraction method for the comparison image, which is an image of the iris photographed from the front; The smaller the difference between the feature amount after conversion from the feature amount of the first learning image, which is an image of
- a feature amount conversion means for converting the feature amount of the authentication target image based on the learning result of the feature amount conversion method using a loss function that reduces the feature quantity comparison means for comparing the feature quantity after conversion by the feature quantity conversion means with the feature quantity of the comparison image; authentication device.
- an image acquiring means for acquiring a first image that is an image of the iris captured with light other than visible light and a second image that is an image of the iris captured with visible light; a feature amount extracting means for extracting a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the second image; feature quantity conversion means for converting the second feature quantity into a third feature quantity; learning control means for causing the feature quantity conversion means to learn a feature quantity conversion method based on a comparison result between the first feature quantity and the third feature quantity;
- a feature conversion learning device comprising: (Appendix 14) authentication target image acquisition means for acquiring an image of an iris photographed with visible light as an authentication target image; a feature amount extracting means for extracting the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is an image of the iris photographed with light other than visible light; The feature amount after conversion from the feature amount of the first learning image, which is an image of the
- a feature quantity conversion means for converting the feature quantity of the authentication target image based on the learning result of the feature quantity conversion method using a loss function whose value decreases as the difference decreases; feature quantity comparison means for comparing the feature quantity after conversion by the feature quantity conversion means with the feature quantity of the comparison image; authentication device.
- a feature conversion learning device comprising: (Appendix 16) authentication target image acquisition means for acquiring an image of an iris taken out of focus as an authentication target image; a feature amount extraction means for extracting the feature amount of the authentication target image by the same method as the feature amount extraction method for the comparison image, which is an iris image taken in focus; The feature amount after conversion from the feature amount of the first learning image, which is an image of the iris out of focus, and
- a feature amount conversion means for converting the feature amount of the authentication target image based on the learning result of the feature amount conversion method using a loss function whose value decreases as the difference from the feature amount of is smaller; feature quantity comparison means for comparing the feature quantity after conversion by the feature quantity conversion means with the feature quantity of the comparison image; authentication device.
- (Appendix 17) obtaining a first image; reducing the first image to a second image having a lower resolution than the first image; enlarging the second image to a third image of the same resolution as the first image; Extracting a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the third image; converting the second feature into a third feature; learning a feature amount conversion method for converting the second feature amount into a third feature amount based on a comparison result between the first feature amount and the third feature amount; Feature transformation learning method including (Appendix 18) obtaining an image to be authenticated; enlarging the authentication target image; Extracting the feature quantity of the enlarged image of the authentication target image by the same method as the feature quantity extraction method for the comparison image having higher resolution than the authentication target image; A feature amount using a loss function whose value decreases as the difference between the feature amount after conversion from the feature amount of the learning image and the feature amount of the degraded image that is enlarged after the reduction of the
- Authentication methods including (Appendix 19) to the computer, obtaining a first image; reducing the first image to a second image having a lower resolution than the first image; enlarging the second image to a third image of the same resolution as the first image; Extracting a first feature amount that is the feature amount of the first image and a second feature amount that is the feature amount of the third image; converting the second feature into a third feature; learning a feature amount conversion method for converting the second feature amount into a third feature amount based on a comparison result between the first feature amount and the third feature amount;
- a recording medium that records a program for executing (Appendix 20) to the computer, obtaining an image to be authenticated; enlarging the authentication target image; Extracting the feature quantity of the enlarged image of the authentication
- a recording medium that records a program for executing
- This disclosure may be applied to a feature conversion learning device, an authentication device, a feature conversion learning method, an authentication method, and a recording medium.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Databases & Information Systems (AREA)
- Artificial Intelligence (AREA)
- Computing Systems (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Human Computer Interaction (AREA)
- Ophthalmology & Optometry (AREA)
- Image Analysis (AREA)
- Collating Specific Patterns (AREA)
- Image Processing (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/011192 WO2022195819A1 (ja) | 2021-03-18 | 2021-03-18 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法および記録媒体 |
| US17/636,074 US12142079B2 (en) | 2021-03-18 | 2021-03-18 | Feature conversion learning device, authentication device, feature conversion learning method, authentication method, and recording medium |
| JP2023506640A JP7614577B2 (ja) | 2021-03-18 | 2021-03-18 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法およびプログラム |
| JP2024219493A JP2025032332A (ja) | 2021-03-18 | 2024-12-13 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/011192 WO2022195819A1 (ja) | 2021-03-18 | 2021-03-18 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法および記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022195819A1 true WO2022195819A1 (ja) | 2022-09-22 |
Family
ID=83322038
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/011192 Ceased WO2022195819A1 (ja) | 2021-03-18 | 2021-03-18 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法および記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12142079B2 (https=) |
| JP (2) | JP7614577B2 (https=) |
| WO (1) | WO2022195819A1 (https=) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024185330A1 (ja) * | 2023-03-09 | 2024-09-12 | 日本電気株式会社 | 学習装置、指紋状態推定装置、学習方法、指紋状態推定方法、及び記録媒体 |
| WO2024195055A1 (ja) * | 2023-03-22 | 2024-09-26 | 日本電気株式会社 | 情報処理装置、情報処理方法、及び、記録媒体 |
| WO2025074546A1 (ja) * | 2023-10-04 | 2025-04-10 | 日本電気株式会社 | 情報処理システム、情報処理方法、プログラム |
| WO2025115057A1 (ja) * | 2023-11-27 | 2025-06-05 | 日本電気株式会社 | 情報処理システム、情報処理装置、情報処理方法及び記録媒体 |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7614577B2 (ja) * | 2021-03-18 | 2025-01-16 | 日本電気株式会社 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法およびプログラム |
| CN116188255A (zh) * | 2021-11-25 | 2023-05-30 | 北京字跳网络技术有限公司 | 基于gan网络的超分图像处理方法、装置、设备及介质 |
| US20250005365A1 (en) * | 2023-06-29 | 2025-01-02 | Microsoft Technology Licensing, Llc | Neural network inference based on table lookup |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004021491A (ja) * | 2002-06-14 | 2004-01-22 | Canon Inc | 生体パターン認証装置、生体パターン認証方法及びこの方法を記述したプログラム |
| JP2007036836A (ja) * | 2005-07-28 | 2007-02-08 | Canon Inc | 画像認証システム |
| JP2008299618A (ja) * | 2007-05-31 | 2008-12-11 | Toshiba Corp | 画像高品質化装置、方法およびプログラム |
| WO2016002068A1 (ja) * | 2014-07-04 | 2016-01-07 | 三菱電機株式会社 | 画像拡大装置、画像拡大方法、及び監視カメラ、並びにプログラム及び記録媒体 |
| JP2020144700A (ja) * | 2019-03-07 | 2020-09-10 | 株式会社日立製作所 | 画像診断装置、画像処理方法及びプログラム |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5121506B2 (ja) * | 2008-02-29 | 2013-01-16 | キヤノン株式会社 | 画像処理装置、画像処理方法、プログラム及び記憶媒体 |
| WO2009122760A1 (ja) * | 2008-04-04 | 2009-10-08 | 富士フイルム株式会社 | 画像処理装置、画像処理方法、およびコンピュータ読取可能な媒体 |
| JP2011118694A (ja) * | 2009-12-03 | 2011-06-16 | Sony Corp | 学習装置および方法、認識装置および方法、並びにプログラム |
| JP2013031163A (ja) | 2011-06-24 | 2013-02-07 | Panasonic Corp | 超解像処理装置及び超解像処理方法 |
| JP7167832B2 (ja) * | 2019-04-19 | 2022-11-09 | 日本電信電話株式会社 | 画像変換装置、画像変換モデル学習装置、方法、及びプログラム |
| JP7353825B2 (ja) * | 2019-06-27 | 2023-10-02 | キヤノン株式会社 | 画像処理装置及びその方法、画像入力装置、画像処理システム、プログラム |
| JP7614577B2 (ja) * | 2021-03-18 | 2025-01-16 | 日本電気株式会社 | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法およびプログラム |
-
2021
- 2021-03-18 JP JP2023506640A patent/JP7614577B2/ja active Active
- 2021-03-18 WO PCT/JP2021/011192 patent/WO2022195819A1/ja not_active Ceased
- 2021-03-18 US US17/636,074 patent/US12142079B2/en active Active
-
2024
- 2024-12-13 JP JP2024219493A patent/JP2025032332A/ja active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004021491A (ja) * | 2002-06-14 | 2004-01-22 | Canon Inc | 生体パターン認証装置、生体パターン認証方法及びこの方法を記述したプログラム |
| JP2007036836A (ja) * | 2005-07-28 | 2007-02-08 | Canon Inc | 画像認証システム |
| JP2008299618A (ja) * | 2007-05-31 | 2008-12-11 | Toshiba Corp | 画像高品質化装置、方法およびプログラム |
| WO2016002068A1 (ja) * | 2014-07-04 | 2016-01-07 | 三菱電機株式会社 | 画像拡大装置、画像拡大方法、及び監視カメラ、並びにプログラム及び記録媒体 |
| JP2020144700A (ja) * | 2019-03-07 | 2020-09-10 | 株式会社日立製作所 | 画像診断装置、画像処理方法及びプログラム |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024185330A1 (ja) * | 2023-03-09 | 2024-09-12 | 日本電気株式会社 | 学習装置、指紋状態推定装置、学習方法、指紋状態推定方法、及び記録媒体 |
| WO2024195055A1 (ja) * | 2023-03-22 | 2024-09-26 | 日本電気株式会社 | 情報処理装置、情報処理方法、及び、記録媒体 |
| WO2025074546A1 (ja) * | 2023-10-04 | 2025-04-10 | 日本電気株式会社 | 情報処理システム、情報処理方法、プログラム |
| WO2025115057A1 (ja) * | 2023-11-27 | 2025-06-05 | 日本電気株式会社 | 情報処理システム、情報処理装置、情報処理方法及び記録媒体 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7614577B2 (ja) | 2025-01-16 |
| US12142079B2 (en) | 2024-11-12 |
| US20230360440A1 (en) | 2023-11-09 |
| JP2025032332A (ja) | 2025-03-11 |
| JPWO2022195819A1 (https=) | 2022-09-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7614577B2 (ja) | 特徴量変換学習装置、認証装置、特徴量変換学習方法、認証方法およびプログラム | |
| KR102332088B1 (ko) | 세부 업샘플링 인코더-디코더 네트워크를 이용한 대장 내시경 이미지에서의 폴립 바운더리 인식을 통한 폴립 세그먼테이션 장치 및 그 방법 | |
| CN110188776A (zh) | 图像处理方法及装置、神经网络的训练方法、存储介质 | |
| Alruwaili et al. | Deep learning-based YOLO models for the detection of people with disabilities | |
| JP4619927B2 (ja) | 顔検出方法および装置並びにプログラム | |
| CN113822325A (zh) | 图像特征的监督学习方法、装置、设备及存储介质 | |
| CN111476806B (zh) | 图像处理方法、装置、计算机设备和存储介质 | |
| JP7294695B2 (ja) | 学習済モデルによるプログラム、情報記録媒体、分類装置、ならびに、分類方法 | |
| KR20210016587A (ko) | 입력 데이터 세트 쌍의 변위 맵을 생성하는 방법 및 장치 | |
| JP4708909B2 (ja) | デジタル画像の対象物検出方法および装置並びにプログラム | |
| JP2009211178A (ja) | 画像処理装置、画像処理方法、プログラム及び記憶媒体 | |
| JP2008517352A (ja) | 非接触光学手段および3d指紋認識方法 | |
| WO2004008391A1 (ja) | パターン特徴抽出方法及びその装置 | |
| CN113762117A (zh) | 一种图像处理模型的训练方法、图像处理模型及计算机设备 | |
| CN116912154B (zh) | 一种皮损检测网络的相关方法、装置、设备和存储介质 | |
| CN113393434A (zh) | 一种基于非对称双流网络架构的rgb-d显著性检测方法 | |
| CN114299218A (zh) | 一种基于手绘素描寻找真实人脸的系统 | |
| CN115797731A (zh) | 目标检测模型训练方法、检测方法、终端设备及存储介质 | |
| CN116503932B (zh) | 重点区域加权的眼周特征提取方法、系统及存储介质 | |
| JP7364959B2 (ja) | 被写体別特徴点分離装置、被写体別特徴点分離方法及びコンピュータプログラム | |
| CN114419741B (zh) | 活体检测方法、活体检测装置、电子设备以及存储介质 | |
| KR102656662B1 (ko) | 리셉티브 필드의 차이 정보를 활용한 딥러닝 기반 키포인트 검출 장치 및 방법 | |
| JP6202938B2 (ja) | 画像認識装置および画像認識方法 | |
| Labiadh et al. | Optimization of 2D and 3D facial recognition through the fusion of CBAM AlexNet and ResNeXt models: I. Labiadh et al. | |
| CN117830115A (zh) | 一种面向深度估计的单透镜计算成像系统设计方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21931566 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023506640 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21931566 Country of ref document: EP Kind code of ref document: A1 |