WO2022172442A1 - Flooding prediction program, flooding prediction device, and machine-learning method - Google Patents
Flooding prediction program, flooding prediction device, and machine-learning method Download PDFInfo
- Publication number
- WO2022172442A1 WO2022172442A1 PCT/JP2021/005495 JP2021005495W WO2022172442A1 WO 2022172442 A1 WO2022172442 A1 WO 2022172442A1 JP 2021005495 W JP2021005495 W JP 2021005495W WO 2022172442 A1 WO2022172442 A1 WO 2022172442A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- machine learning
- inundation
- resolution
- image
- prediction
- Prior art date
Links
- 238000010801 machine learning Methods 0.000 title claims abstract description 164
- 238000000034 method Methods 0.000 claims abstract description 30
- 238000012545 processing Methods 0.000 claims description 34
- 238000011156 evaluation Methods 0.000 claims description 12
- 238000012549 training Methods 0.000 description 56
- 230000010365 information processing Effects 0.000 description 53
- 238000004891 communication Methods 0.000 description 13
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 13
- 238000010586 diagram Methods 0.000 description 12
- 230000015654 memory Effects 0.000 description 9
- 238000005516 engineering process Methods 0.000 description 7
- 238000004088 simulation Methods 0.000 description 6
- 230000006870 function Effects 0.000 description 5
- 238000004364 calculation method Methods 0.000 description 4
- 238000013527 convolutional neural network Methods 0.000 description 4
- 238000001556 precipitation Methods 0.000 description 4
- 238000005070 sampling Methods 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 2
- 238000013178 mathematical model Methods 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 238000010200 validation analysis Methods 0.000 description 2
- 230000008094 contradictory effect Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 238000012876 topography Methods 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01W—METEOROLOGY
- G01W1/00—Meteorology
- G01W1/10—Devices for predicting weather conditions
-
- G—PHYSICS
- G08—SIGNALLING
- G08B—SIGNALLING OR CALLING SYSTEMS; ORDER TELEGRAPHS; ALARM SYSTEMS
- G08B31/00—Predictive alarm systems characterised by extrapolation or other computation using updated historic data
Definitions
- Embodiments of the present invention relate to inundation prediction technology.
- One aspect aims to reduce the computational cost of inundation prediction.
- the inundation prediction program causes a computer to execute acquisition processing, generation processing, and output processing.
- the acquisition process acquires observation information about the target area.
- the observation information is input to the first machine learning model to generate the first image showing the prediction result of the inundation situation in the target area, and the first image is applied to the second machine learning model.
- the input produces a second image with higher resolution than the first image.
- the second image is output as the inundation prediction result of the target area.
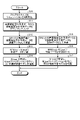
- FIG. 1 is an explanatory diagram illustrating an overview of inundation prediction (at the time of machine learning) according to the embodiment.
- FIG. 2 is an explanatory diagram for explaining downsampling and super-resolution.
- FIG. 3 is an explanatory diagram for explaining an outline of inundation prediction (at the time of prediction) according to the embodiment.
- FIG. 4 is a block diagram of a functional configuration example of the information processing apparatus according to the embodiment;
- FIG. 5 is a flowchart illustrating an operation example of the information processing apparatus according to the embodiment during machine learning.
- FIG. 6 is an explanatory diagram for explaining an overview of downsampling.
- 7 is a flowchart illustrating an operation example of the information processing apparatus according to the embodiment during machine learning;
- FIG. 8 is a flowchart illustrating an operation example of the information processing apparatus according to the embodiment during prediction.
- FIG. 9 is a block diagram showing an example of a computer configuration.
- machine learning is performed so that the prediction map is output as the correct answer for the observation information input. , to create a machine learning model. Then, at the time of prediction, by inputting actual observation information about the target area into the machine learning model, a prediction map is obtained from the output of the machine learning model.
- FIG. 1 is an explanatory diagram explaining an overview of inundation prediction (during machine learning) according to the embodiment.
- the information processing apparatus As shown in FIG. 1, in S1, the information processing apparatus according to the embodiment prepares a set of training data used for machine learning.
- the high-resolution inundation prediction data D2 is the correct answer corresponding to the observation information D1, which indicates the predicted value of the inundation situation at each point corresponding to each mesh (water level from the ground, underfloor inundation, presence of above-floor inundation, etc.) is a forecast map of Also, the pixel value of each pixel in the high-resolution inundation prediction data D2 corresponds to the prediction value of the inundation situation at each point in the target area.
- the method of obtaining high-resolution inundation prediction data D2 by an information processing device is not limited to obtaining by simulation from observation information D1.
- the information processing device may acquire high-resolution inundation prediction data D2 based on observed values (water level at each point, etc.) obtained by actual observation.
- the information processing device down-samples the prediction map in the high-resolution inundation prediction data D2 (S1b), thereby obtaining low-resolution inundation prediction data D3 having a resolution lower than that of the high-resolution inundation prediction data D2. .
- FIG. 2 is an explanatory diagram explaining downsampling and super-resolution.
- the information processing device obtains low-resolution inundation prediction data D3 of 50 m mesh by down-sampling the high-resolution prediction inundation data D2 of 5 m mesh.
- the information processing device prepares data sets of high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3 corresponding to observation information D1 from observation information D1 in various cases as training data.
- the information processing device uses the low-resolution inundation prediction data D3 and the high-resolution inundation prediction data D2 in the prepared training data to create a model in a known super-resolution technology using a CNN (Convolutional Neural Network) or the like.
- a second machine learning model M2 is generated (S3).
- the second machine learning model M2 is a CNN that provides a single image super-resolution method for obtaining a higher-resolution image by increasing the resolution (super-resolution) from one image. .
- the information processing device has a gradient such that the output from the second machine learning model M2 when the low-resolution inundation prediction data D3 is input to the second machine learning model M2 is the low-resolution inundation prediction data D3 that is correct.
- the parameters of the second machine learning model M2 are set using a known method such as the method or error backpropagation method.
- FIG. 3 is an explanatory diagram for explaining an overview of inundation prediction (at the time of prediction) according to the embodiment.
- the information processing apparatus of the embodiment collects information distributed from meteorological organizations and the like and measurement data from measurement devices, and generates observation information D10 regarding the target area. get.
- the information processing device inputs the obtained observation information D10 to the first machine learning model M1 to generate low-resolution inundation prediction data D11 indicating the prediction result (prediction map) of the inundation situation in the target area.
- the information processing device inputs the generated low-resolution inundation prediction data D11 to the second machine learning model M2 to generate high-resolution inundation prediction data D12 having a higher resolution than the low-resolution inundation prediction data D11.
- the information processing device obtains high-resolution inundation prediction data D12 by increasing the resolution (super-resolution) of the low-resolution inundation prediction data D11 using the second machine learning model M2.
- the information processing apparatus can obtain the high-resolution inundation prediction data D12, which is a prediction map of the inundation situation with high resolution (for example, 5m mesh).
- low-resolution inundation prediction data D11 which is a low-resolution prediction map with coarser resolution than high-resolution inundation prediction data D12, is obtained from the observation information D10 using the first machine learning model M1 (task B).
- the information processing apparatus of the embodiment obtains high-resolution inundation prediction data D12 by increasing the resolution of the low-resolution inundation prediction data D11 using the second machine learning model M2 (task C).
- task (B) performs machine learning on how flooding occurs from various observation information D10, the number of cases is about the same as task (A) (N_A ⁇ N_B). However, since the amount of data for each case used for machine learning is the low-resolution inundation prediction data D3 down-sampled from the high-resolution inundation prediction data D2, S_A>>S_B.
- Task (C) obtains high-resolution inundation prediction data D12 by increasing the resolution of low-resolution inundation prediction data D11, and differences in observation information D1 do not matter during machine learning.
- the predicted values (pixel values) of each point in the same target area are targeted for high resolution, so the number of cases is less (N_A>>N_C).
- FIG. 4 is a block diagram showing a functional configuration example of the information processing device according to the embodiment.
- the information processing apparatus 1 has a communication section 10 , a display section 11 , an operation section 12 , an input/output section 13 , a storage section 14 and a control section 15 .
- This information processing device 1 is an example of a flood prediction device, and for example, a PC (Personal Computer) can be applied.
- PC Personal Computer
- the communication unit 10 is realized by, for example, a NIC (Network Interface Card) or the like.
- the communication unit 10 is a communication interface that is wired or wirelessly connected to another information processing apparatus via a network (not shown) and controls information communication with the other information processing apparatus.
- the operation unit 12 is an input device that receives various operations from the user of the information processing device 1 .
- the operation unit 12 is realized by, for example, a keyboard, a mouse, etc. as an input device.
- the operation unit 12 outputs the operation input by the user to the control unit 15 as operation information.
- the operation unit 12 may be realized by a touch panel or the like as an input device, and the display device of the display unit 11 and the input device of the operation unit 12 may be integrated.
- the input/output unit 13 is, for example, a memory card R/W (Reader/Writer).
- the input/output unit 13 may read the observation information 141 or the like stored in the memory card and store it in the storage unit 14 instead of the observation information 141 or the like received by the communication unit 10 .
- the input/output unit 13 stores, for example, the prediction result output from the control unit 15 in a memory card.
- the memory card for example, an SD memory card or the like can be used.
- the storage unit 14 is realized by, for example, semiconductor memory devices such as RAM (Random Access Memory) and flash memory, and storage devices such as hard disks and optical disks.
- the storage unit 14 stores observation information 141, training data 142, prediction data 143, first machine learning model information 144, second machine learning model information 145, and the like.
- the observation information 141 is observation information about the target area obtained from a server or the like, and corresponds to the observation information D1 and D10 described above.
- the training data 142 is data used for machine learning of the first machine learning model M1 and the second machine learning model M2. Specifically, the training data 142 is a set of the observation information D1 described above, the high-resolution inundation prediction data D2 corresponding to the observation information D1, and the low-resolution inundation prediction data D3 for each case used for machine learning. be.
- the prediction data 143 is data indicating prediction results from the observation information D10. Specifically, the prediction data 143 is the low-resolution inundation prediction data D11 obtained by inputting the observation information D10 into the first machine learning model M1, and the low-resolution inundation prediction data D11 obtained by the second machine learning model M2. corresponds to the high-resolution inundation prediction data D12 obtained by inputting to .
- the first machine learning model information 144 is information related to the first machine learning model M1, and includes parameters and the like for constructing the first machine learning model M1 such as a neural network.
- the second machine learning model information 145 is information about the second machine learning model M2, and includes parameters and the like for constructing the second machine learning model M2 such as CNN.
- the control unit 15 is a processing unit that controls the operation of the information processing device 1 .
- the control unit 15 has an acquisition unit 151 , a training data generation unit 152 , a first machine learning unit 153 , a second machine learning unit 154 , an estimation unit 155 and an output unit 156 .
- the control unit 15 can be realized by a CPU (Central Processing Unit), an MPU (Micro Processing Unit), or the like.
- the control unit 15 can also be realized by hardwired logic such as ASIC (Application Specific Integrated Circuit) and FPGA (Field Programmable Gate Array).
- the acquisition unit 151 is a processing unit that acquires the observation information 141.
- the acquisition unit 151 acquires the observation information 141 by communicating via the communication unit 10 with a specific server that provides the observation information 141 regarding the target area.
- the acquisition unit 151 stores the acquired observation information 141 in the storage unit 14 .
- the training data creation unit 152 is a processing unit that creates the training data 142 used for machine learning of the first machine learning model M1 and the second machine learning model M2. Specifically, the training data creation unit 152 performs a simulation or the like from the observation information D1 (141) to obtain high-resolution inundation prediction data D2 corresponding to the observation information D1. Note that the training data creation unit 152 may obtain the high-resolution inundation prediction data D2 by directly applying the observation values included in the observation information D1.
- the training data creation unit 152 acquires low-resolution inundation prediction data D3 with a resolution lower than that of the high-resolution inundation prediction data D2 by down-sampling the prediction map in the high-resolution inundation prediction data D2.
- the training data creation unit 152 stores in the storage unit 14 training data 142 that is a set of the observation information D1 and the high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3 corresponding to the observation information D1.
- the training data creation unit 152 creates training data 142 for the number of cases by performing the above process for the number of cases used for machine learning.
- the parameters of the first machine learning model M1 are set to the first machine learning model information 144 , and stored in the storage unit 14 .
- the second machine learning unit 154 is a processing unit that generates a second machine learning model M2 based on the training data 142. Specifically, the second machine learning unit 154 reads the low resolution inundation prediction data D3 and the high resolution inundation prediction data D2 for each case included in the training data 142 . Next, the second machine learning unit 154 inputs the read low-resolution flood prediction data D3 to the second machine-learning model M2, and the high-resolution flood prediction that the output from the second machine-learning model M2 is correct. The parameters of the second machine learning model M2 are set (adjusted) so as to become the data D2.
- the second machine learning unit 154 performs the above processing on each of the predetermined number of cases prepared as the training data 142, and then converts the parameters of the second machine learning model M2 into the second machine learning model information 145. , and stored in the storage unit 14 .
- the estimation unit 155 is a processing unit that estimates high-resolution inundation prediction data D12, which is a prediction map of the flood situation in the target area, based on the observation information 141 (D10) of the target area. Specifically, the estimation unit 155 constructs the first machine learning model M1 based on the first machine learning model information 144 read from the storage unit 14 . Next, the estimation unit 155 generates low-resolution inundation prediction data D11 by inputting the observation information D10 to the first machine learning model M1. The estimation unit 155 stores the generated low-resolution inundation prediction data D ⁇ b>11 as prediction data 143 in the storage unit 14 .
- the estimation unit 155 constructs the second machine learning model M2 based on the second machine learning model information 145 read from the storage unit 14.
- the estimation unit 155 generates high-resolution flood prediction data D12 by inputting the low-resolution prediction flood data D11 to the second machine learning model M2.
- the estimation unit 155 stores the generated high-resolution inundation prediction data D ⁇ b>12 as prediction data 143 in the storage unit 14 .
- the output unit 156 is a processing unit that outputs the estimation result of the estimation unit 155 . Specifically, the output unit 156 reads the high-resolution inundation prediction data D12 included in the prediction data 143 from the storage unit 14, and based on the high-resolution inundation prediction data D12, predicts the inundation situation at each point in the target area. Generate a map display screen. Next, the output unit 156 outputs the data of the generated display screen to the display unit 11 to display the prediction map on the display device.
- FIG. 5 is a flowchart showing an operation example of the information processing apparatus 1 according to the embodiment during machine learning.
- the training data 142 is created by simulation based on the observation information D1.
- the training data creation unit 152 down-samples the N sets of high-resolution inundation prediction data D2 to acquire low-resolution inundation prediction data D3 from the high-resolution inundation prediction data D2 (S11).
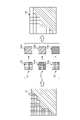
- FIG. 6 is an explanatory diagram explaining an outline of downsampling.
- the training data creation unit 152 acquires low-resolution inundation prediction data D3 from high-resolution inundation prediction data D2 by performing downsampling on a predetermined scale (for example, 5 m mesh ⁇ 50 m mesh). .
- the training data creation unit 152 samples pixels with the worst inundation prediction evaluation among the pixels included in the area. By doing so, the low-resolution inundation prediction data D3 is acquired.
- the good or bad inundation evaluation means the height of the water level from the ground, and the higher the water level, the worse the evaluation (the evaluation is worse for the inundation above the floor than for the inundation under the floor).
- the training data creation unit 152 prevents pixels with the worst inundation prediction evaluation from being removed by downsampling.
- the high-resolution inundation prediction data D2a of the specific region includes a right diagonal shaded portion (predicted value a) and a left diagonal shaded portion (predicted value b).
- the predicted value b has a lower evaluation than the predicted value a.
- the training data creation unit 152 samples the predicted value b with a poor evaluation. That is, the training data creation unit 152 down-samples the high-resolution flood prediction data D2a to the low-resolution flood prediction data D3a with the prediction value b for one pixel.
- the high-resolution inundation prediction data D2b of the specific area includes a right diagonal shaded portion (predicted value a) and a left diagonal shaded portion (predicted value b). Therefore, the training data generation unit 152 down-samples the high-resolution flood prediction data D2b to the low-resolution flood prediction data D3b in which the prediction value b is one pixel.
- the training data generation unit 152 down-samples the high-resolution flood prediction data D2c to the low-resolution flood prediction data D3c in which the prediction value a is one pixel.
- the training data creation unit 152 prepares N sets of observation information D1 and low-resolution inundation prediction data D3 as training data 142 (S12).
- the first machine learning unit 153 performs machine learning for the first machine learning model M1 using a set of the N_train observation information D1 and the low-resolution flood prediction data D3.
- the first machine learning unit 153 also validates the first machine learning model M1 after machine learning using a set of the N_test observation information D1 and the low-resolution inundation prediction data D3.
- the first machine learning unit 153 adopts the first machine learning model M1 whose prediction error is confirmed to be within a predetermined range by validation, and constructs the first machine learning model M1 (S14).
- the training data creation unit 152 prepares M sets of high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3 as training data 142 (S15).
- the second machine learning unit 154 performs machine learning of the second machine learning model M2 using a set of the M_train high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3. Also, the second machine learning unit 154 validates the second machine learning model M2 after machine learning with a set of the high-resolution inundation prediction data D2 of M_test and the low-resolution inundation prediction data D3. The second machine learning unit 154 adopts the second machine learning model M2 whose prediction error is confirmed to be within a predetermined range by validation, and constructs the second machine learning model M2 (S17).
- control unit 15 stores the first machine learning model information 144 and the second machine learning model information 145 regarding the constructed first machine learning model M1 and second machine learning model M2 in the storage unit 14. , and terminate the process.
- the processing of S13 and S14 by the first machine learning unit 153 and the processing of S16 and S17 by the second machine learning unit 154 may be performed in parallel.
- the training data creation unit 152 prepares N pieces of observation information D1 of various types (S10a).
- the observation information D1 also includes high-resolution inundation observation data (actually measured inundation situation map) corresponding to the high-resolution inundation prediction data D2.
- the training data creation unit 152 down-samples the low-resolution inundation observation data from the high-resolution inundation observation data for the N sets of observation information D1 (S11a).
- the training data generator 152 prepares N sets of observation information D1 and low-resolution inundation observation data as training data 142 (S12a).
- the first machine learning unit 153 performs the same processing as S13 and S14 described above based on the prepared training data 142 to build the first machine learning model M1.
- the training data creation unit 152 prepares M sets of high-resolution inundation observation data and low-resolution inundation observation data as training data 142 (S15a).
- the second machine learning unit 154 performs the same processing as S16 and S17 described above based on the prepared training data 142 to build the second machine learning model M2.
- FIG. 8 is a flowchart showing an operation example of the information processing apparatus 1 according to the embodiment during prediction.
- the acquisition unit 151 acquires observation information D10 at the time of disaster occurrence from a specific server or the like that provides observation information on the target area (S20).
- the estimation unit 155 constructs a second machine learning model M2 from the second machine learning model information 145.
- the estimating unit 155 acquires high-resolution inundation prediction data D12 by inputting the low-resolution inundation prediction data D11 acquired in S21 to the constructed second machine learning model M2 (S22).
- the output unit 156 outputs the high-resolution inundation prediction data D12 acquired in S22 to the display unit 11 (S23), and displays a prediction map based on the observation information D10 when a disaster occurs.
- the information processing device 1 acquires the observation information D10 regarding the target area.
- the information processing device 1 inputs the obtained observation information D10 to the first machine learning model M1 to generate a first image (low-resolution inundation prediction data D11) showing the prediction result of the inundation situation in the target area.
- the information processing device 1 inputs the first image to the second machine learning model M2 to generate a second image (high-resolution flood prediction data D12) having a resolution higher than that of the first image.
- the information processing device 1 outputs a second image generated as a flood prediction result for the target area.
- the information processing device 1 can perform highly accurate inundation prediction using a machine learning model at high resolution while suppressing an increase in the amount of memory and calculation required for processing. In this way, the information processing device 1 can assist in increasing the accuracy of flood prediction.
- the first image generated by the information processing device 1 is a map image showing the flooding situation at each point in the target area.
- the information processing apparatus 1 can obtain a higher-definition map image of the inundation situation at each point of the target area.
- the information processing device 1 can create a machine learning model that performs highly accurate inundation prediction at high resolution while suppressing increases in memory and computational complexity required for processing. In this way, the information processing device 1 can assist in increasing the accuracy of inundation prediction.
- a computer 200 includes a CPU 201 that executes various types of arithmetic processing, a GPU 201a that specializes in predetermined arithmetic processing such as image processing and machine learning processing, an input device 202 that receives data input, and a monitor 203. , and a speaker 204 .
- the computer 200 also has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting with various devices, and a communication device 207 for communicating with an external device by wire or wirelessly.
- the computer 200 also has a RAM 208 that temporarily stores various information, and a hard disk device 209 . Each unit ( 201 to 209 ) in computer 200 is connected to bus 210 .
Abstract
This flooding prediction program causes a computer to execute an acquisition process, a generation process, and an output process. The acquisition process acquires observation information pertaining to a target district. The generation process generates a first image representing a prediction result of a flooding situation in the target district by inputting the observation information to a first machine-learning model, and generates a second image of a higher resolution than the first image by inputting the first image to a second machine-learning model. The output process outputs the second image as the flooding prediction result of the target district.
Description
本発明の実施形態は、浸水予測技術に関する。
Embodiments of the present invention relate to inundation prediction technology.
従来、降水量や台風の状況などの観測情報から、その後に発生する浸水予測を行う技術が知られている。この浸水予測に関する従来技術としては、過去の雨量・水位データなどを機械学習させることで最適なパラメータを導き出す数理モデルを構築する。そして、構築した数理モデルを用いて、現在までの雨量・水位データや気象関連機関から各自治体へ配信される数時間先の気象(降雨予測)データなどをもとに今後の水位を精度よく予測する技術がある。また、都市内水域の面的な浸水状況をリアルタイム予測し、解析格子を定型5mおよび10mメッシュとした場合の評価結果を提示する従来技術がある。
Conventionally, there is a known technique for predicting subsequent inundation based on observational information such as precipitation and typhoon conditions. As a conventional technology related to this inundation prediction, we build a mathematical model that derives optimal parameters by machine learning past rainfall and water level data. Then, using the constructed mathematical model, future water levels can be accurately predicted based on rainfall and water level data up to the present, as well as weather (precipitation forecast) data several hours ahead delivered to each local government from meteorological organizations. there is a technology to In addition, there is a conventional technology that predicts in real time the planar inundation status of urban water areas and presents evaluation results when analysis grids are standard 5-m and 10-m meshes.
しかしながら、上記の従来技術では、機械学習モデルによる精度のよい浸水予測をメッシュ(解析格子)を細かくして面的に高解像度で行おうとすると、処理に要するデータ量が大きくなり、必要なメモリや計算量が多大なものとなるという問題がある。
However, with the conventional technology described above, when trying to perform highly accurate inundation prediction using a machine learning model with a finer mesh (analysis grid) and high resolution across the surface, the amount of data required for processing becomes large, and the required memory and memory are required. There is a problem that the amount of calculation becomes enormous.
1つの側面では、浸水予測の計算コストを低減することを目的とする。
One aspect aims to reduce the computational cost of inundation prediction.
1つの案では、浸水予測プログラムは、取得する処理と、生成する処理と、出力する処理とをコンピュータに実行させる。取得する処理は、対象地区に関する観測情報を取得する。生成する処理は、観測情報を第1の機械学習モデルに入力することによって、対象地区における浸水状況の予測結果を示す第1の画像を生成し、第1の画像を第2の機械学習モデルに入力することによって、第1の画像より解像度の高い第2の画像を生成する。出力する処理は、対象地区の浸水予測結果として第2の画像を出力する。
In one proposal, the inundation prediction program causes a computer to execute acquisition processing, generation processing, and output processing. The acquisition process acquires observation information about the target area. In the generating process, the observation information is input to the first machine learning model to generate the first image showing the prediction result of the inundation situation in the target area, and the first image is applied to the second machine learning model. The input produces a second image with higher resolution than the first image. In the outputting process, the second image is output as the inundation prediction result of the target area.
浸水予測の計算コストを低減できる。
The calculation cost of inundation prediction can be reduced.
以下、図面を参照して、実施形態にかかる浸水予測プログラム、浸水予測装置および機械学習方法を説明する。実施形態において同一の機能を有する構成には同一の符号を付し、重複する説明は省略する。なお、以下の実施形態で説明する浸水予測プログラム、浸水予測装置および機械学習方法は、一例を示すに過ぎず、実施形態を限定するものではない。また、以下の各実施形態は、矛盾しない範囲内で適宜組みあわせてもよい。
The inundation prediction program, inundation prediction device, and machine learning method according to the embodiment will be described below with reference to the drawings. Configurations having the same functions in the embodiments are denoted by the same reference numerals, and overlapping descriptions are omitted. Note that the inundation prediction program, the inundation prediction device, and the machine learning method described in the following embodiments are merely examples, and do not limit the embodiments. Moreover, each of the following embodiments may be appropriately combined within a non-contradictory range.
実施形態では、浸水予測の対象地区について、降水量、水位などの対象地区の浸水に関連する観測情報をもとに、機械学習モデルを用いて、各地点の浸水状況の予測値を示す予測地図を求める。なお、浸水予測の対象地区は、行政等で区切られた特定の地域(例えば市域、町域)などである。また、観測情報は、対象地区に関連する河川や海域の水位、流量、流入量、排出量、対象地区を含む地域一帯の降水量などである。
In this embodiment, a prediction map showing the predicted value of the inundation situation at each point using a machine learning model based on observational information related to inundation in the target area such as precipitation and water level. Ask for Note that the target area for inundation prediction is a specific area (for example, a city area, a town area) or the like that is demarcated by administration or the like. Observation information includes the water level, flow rate, inflow, and discharge of rivers and sea areas related to the target area, and the amount of precipitation in the area including the target area.
具体的には、実施形態では、対象地区に関する観測情報と、この観測情報に対応する予測地図とをもとに、観測情報の入力に対して予測地図を正解として出力するように機械学習を行い、機械学習モデルを作成する。そして、予測時には、対象地区に関する実際の観測情報を機械学習モデルに入力することで、機械学習モデルの出力より予測地図を得る。
Specifically, in the embodiment, based on observation information about the target area and a prediction map corresponding to this observation information, machine learning is performed so that the prediction map is output as the correct answer for the observation information input. , to create a machine learning model. Then, at the time of prediction, by inputting actual observation information about the target area into the machine learning model, a prediction map is obtained from the output of the machine learning model.
図1は、実施形態にかかる浸水予測の概要(機械学習時)を説明する説明図である。図1に示すように、S1では、実施形態にかかる情報処理装置は、機械学習に用いる訓練データのセットを準備する。
FIG. 1 is an explanatory diagram explaining an overview of inundation prediction (during machine learning) according to the embodiment. As shown in FIG. 1, in S1, the information processing apparatus according to the embodiment prepares a set of training data used for machine learning.
具体的には、S1において、情報処理装置は、対象地区に関する観測情報D1より、シミュレーションなどを行って(S1a)、メッシュを細かくして得られた面的に高解像度(例えば5mメッシュ)な予測地図である高解像度浸水予測データD2を取得する。
Specifically, in S1, the information processing device performs a simulation or the like (S1a) based on the observation information D1 regarding the target area, and obtains a planar high-resolution prediction (for example, a 5m mesh) obtained by making the mesh finer. Obtain high-resolution inundation prediction data D2, which is a map.
なお、高解像度浸水予測データD2は、各メッシュに対応する各地点の浸水状況(地面からの水位、床下浸水、床上浸水の有無など)の予測値が示された、観測情報D1に対応する正解の予測地図である。また、高解像度浸水予測データD2における各画素の画素値は、対象地区における各地点の浸水状況の予測値に対応する。
The high-resolution inundation prediction data D2 is the correct answer corresponding to the observation information D1, which indicates the predicted value of the inundation situation at each point corresponding to each mesh (water level from the ground, underfloor inundation, presence of above-floor inundation, etc.) is a forecast map of Also, the pixel value of each pixel in the high-resolution inundation prediction data D2 corresponds to the prediction value of the inundation situation at each point in the target area.
情報処理装置による高解像度浸水予測データD2の取得方法は、観測情報D1からのシミュレーションにより取得するものに限定するものではない。例えば、S1aにおいて、情報処理装置は、実際の観測により得られた観測値(各地点の水位など)をもとに高解像度浸水予測データD2を取得してもよい。
The method of obtaining high-resolution inundation prediction data D2 by an information processing device is not limited to obtaining by simulation from observation information D1. For example, in S1a, the information processing device may acquire high-resolution inundation prediction data D2 based on observed values (water level at each point, etc.) obtained by actual observation.
次いで、S1において、情報処理装置は、高解像度浸水予測データD2における予測地図についてダウンサンプリングを行うことで(S1b)、高解像度浸水予測データD2よりも低解像度な低解像度浸水予測データD3を取得する。
Next, in S1, the information processing device down-samples the prediction map in the high-resolution inundation prediction data D2 (S1b), thereby obtaining low-resolution inundation prediction data D3 having a resolution lower than that of the high-resolution inundation prediction data D2. .
図2は、ダウンサンプリングおよび超解像を説明する説明図である。図2に示すように、例えば、情報処理装置は、5mメッシュの高解像度浸水予測データD2についてダウンサンプリングすることで、50mメッシュの低解像度浸水予測データD3を得る。
FIG. 2 is an explanatory diagram explaining downsampling and super-resolution. As shown in FIG. 2, for example, the information processing device obtains low-resolution inundation prediction data D3 of 50 m mesh by down-sampling the high-resolution prediction inundation data D2 of 5 m mesh.
情報処理装置は、S1において、多様な事例における観測情報D1より、観測情報D1に対応する高解像度浸水予測データD2および低解像度浸水予測データD3のデータセットを訓練データとして準備する。
In S1, the information processing device prepares data sets of high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3 corresponding to observation information D1 from observation information D1 in various cases as training data.
次いで、情報処理装置は、準備した訓練データにおける観測情報D1と、低解像度浸水予測データD3とをもとにニューラルネットワークなどの回帰予測技術を用いた公知の機械学習を行うことで、第1の機械学習モデルM1を生成する(S2)。具体的には、情報処理装置は、観測情報D1を第1の機械学習モデルM1に入力した場合の第1の機械学習モデルM1からの出力が正解とする低解像度浸水予測データD3となるように、勾配法や誤差逆伝播法などの公知の手法を用いて第1の機械学習モデルM1のパラメータを設定する。
Next, the information processing device performs known machine learning using a regression prediction technique such as a neural network based on the observation information D1 in the prepared training data and the low-resolution inundation prediction data D3. A machine learning model M1 is generated (S2). Specifically, the information processing device is configured so that the output from the first machine learning model M1 when the observation information D1 is input to the first machine learning model M1 is the low-resolution inundation prediction data D3 that is the correct answer. , parameters of the first machine learning model M1 are set using known methods such as the gradient method and the error backpropagation method.
また、情報処理装置は、準備した訓練データにおける低解像度浸水予測データD3と、高解像度浸水予測データD2とをもとにCNN(Convolutional Neural Network)などを用いた公知の超解像技術におけるモデルの機械学習を行うことで、第2の機械学習モデルM2を生成する(S3)。具体的には、第2の機械学習モデルM2は、1枚の画像から高解像度化(超解像)することで解像度をより高くした画像を得る単画像超解像手法を提供するCNNである。情報処理装置は、低解像度浸水予測データD3を第2の機械学習モデルM2に入力した場合の第2の機械学習モデルM2からの出力が正解とする低解像度浸水予測データD3となるように、勾配法や誤差逆伝播法などの公知の手法を用いて第2の機械学習モデルM2のパラメータを設定する。
In addition, the information processing device uses the low-resolution inundation prediction data D3 and the high-resolution inundation prediction data D2 in the prepared training data to create a model in a known super-resolution technology using a CNN (Convolutional Neural Network) or the like. By performing machine learning, a second machine learning model M2 is generated (S3). Specifically, the second machine learning model M2 is a CNN that provides a single image super-resolution method for obtaining a higher-resolution image by increasing the resolution (super-resolution) from one image. . The information processing device has a gradient such that the output from the second machine learning model M2 when the low-resolution inundation prediction data D3 is input to the second machine learning model M2 is the low-resolution inundation prediction data D3 that is correct. The parameters of the second machine learning model M2 are set using a known method such as the method or error backpropagation method.
一般の超解像手法では、様々な画像(サブグリッドスケールの構造が異なる)を対象に高解像度化するので、多数の訓練データ(事例)を用いて機械学習を行うこととなる。これに対し、実施形態の超解像手法では、対象地区(サブグリッドスケール内の地形・建物形状が同じ)における各地点の予測値(画素値)が高解像度化の対象である。したがって、第2の機械学習モデルM2の生成においては、一般の超解像よりも少ない訓練データ(事例)で十分である。
In general super-resolution methods, various images (with different sub-grid scale structures) are targeted for high resolution, so machine learning is performed using a large number of training data (examples). On the other hand, in the super-resolution method of the embodiment, the predicted value (pixel value) of each point in the target area (same topography and building shape within the sub-grid scale) is the object of high resolution. Therefore, less training data (examples) than general super-resolution is sufficient for generating the second machine learning model M2.
図3は、実施形態にかかる浸水予測の概要(予測時)を説明する説明図である。図3に示すように、予測時(S4)おいて、実施形態の情報処理装置は、気象関連機関などから配信される情報や測定装置からの測定データを収集して対象地区に関する観測情報D10を取得する。
FIG. 3 is an explanatory diagram for explaining an overview of inundation prediction (at the time of prediction) according to the embodiment. As shown in FIG. 3, at the time of prediction (S4), the information processing apparatus of the embodiment collects information distributed from meteorological organizations and the like and measurement data from measurement devices, and generates observation information D10 regarding the target area. get.
次いで、情報処理装置は、取得した観測情報D10を第1の機械学習モデルM1に入力することにより、対象地区における浸水状況の予測結果(予測地図)を示す低解像度浸水予測データD11を生成する。
Next, the information processing device inputs the obtained observation information D10 to the first machine learning model M1 to generate low-resolution inundation prediction data D11 indicating the prediction result (prediction map) of the inundation situation in the target area.
次いで、情報処理装置は、生成した低解像度浸水予測データD11を第2の機械学習モデルM2に入力することにより、低解像度浸水予測データD11より解像度の高い高解像度浸水予測データD12を生成する。具体的には、図2に示すように、情報処理装置は、低解像度浸水予測データD11を第2の機械学習モデルM2により高解像度化(超解像)して高解像度浸水予測データD12を得る。これにより、情報処理装置は、面的に高解像度(例えば5mメッシュ)な浸水状況の予測地図である高解像度浸水予測データD12を得ることができる。
Next, the information processing device inputs the generated low-resolution inundation prediction data D11 to the second machine learning model M2 to generate high-resolution inundation prediction data D12 having a higher resolution than the low-resolution inundation prediction data D11. Specifically, as shown in FIG. 2, the information processing device obtains high-resolution inundation prediction data D12 by increasing the resolution (super-resolution) of the low-resolution inundation prediction data D11 using the second machine learning model M2. . As a result, the information processing apparatus can obtain the high-resolution inundation prediction data D12, which is a prediction map of the inundation situation with high resolution (for example, 5m mesh).
機械学習モデルにより観測情報D10から高解像度な予測地図である高解像度浸水予測データD12を直接求めようとすると(タスクA)、処理に要するデータ量が大きくなり、必要なメモリや計算量が多大なものとなる。この理由は、例えば、予測値をy、観測情報D10に含まれる観測値をxとすると、y=f(x)においてyがxに対して桁違いにデータの要素数が多いため、計算量が大きくなり、機械学習には膨大なデータ量を要するためである。
When attempting to directly obtain high-resolution inundation prediction data D12, which is a high-resolution prediction map, from observation information D10 using a machine learning model (Task A), the amount of data required for processing becomes large, requiring a large amount of memory and computation. become a thing. The reason for this is that, for example, if the predicted value is y and the observed value included in the observation information D10 is x, the number of data elements in y is orders of magnitude larger than that of x in y=f(x). becomes large, and machine learning requires a huge amount of data.
そこで、実施形態の情報処理装置では、第1の機械学習モデルM1により観測情報D10から高解像度浸水予測データD12よりも解像度の粗い低解像度な予測地図である低解像度浸水予測データD11を得る(タスクB)。次いで、実施形態の情報処理装置は、第2の機械学習モデルM2により低解像度浸水予測データD11を高解像度化して高解像度浸水予測データD12を得る(タスクC)。
Therefore, in the information processing apparatus of the embodiment, low-resolution inundation prediction data D11, which is a low-resolution prediction map with coarser resolution than high-resolution inundation prediction data D12, is obtained from the observation information D10 using the first machine learning model M1 (task B). Next, the information processing apparatus of the embodiment obtains high-resolution inundation prediction data D12 by increasing the resolution of the low-resolution inundation prediction data D11 using the second machine learning model M2 (task C).
一例として、観測情報D10から高解像度な予測地図である高解像度浸水予測データD12を直接求めようとするタスク(A)における機械学習時のデータ量(事例数)をN_Aとし、事例ごとのデータサイズをS_Aとする。また、観測情報D10から高解像度な予測地図である低解像度浸水予測データD11を求めようとするタスク(B)における機械学習時のデータ量(事例数)をN_Bとし、事例ごとのデータサイズをS_Bとする。また、低解像度浸水予測データD11から高解像度浸水予測データD12を求めようとするタスク(C)における機械学習時のデータ量(事例数)をN_Cとし、事例ごとのデータサイズをS_Cとする。
As an example, let N_A be the data volume (number of cases) during machine learning in task (A) to directly obtain high-resolution inundation prediction data D12, which is a high-resolution prediction map, from observation information D10, and the data size for each case be S_A. Also, let N_B be the data amount (number of cases) during machine learning in task (B) to obtain low-resolution inundation prediction data D11, which is a high-resolution prediction map, from observation information D10, and S_B be the data size for each case. and Let N_C be the data amount (the number of cases) during machine learning in task (C) for obtaining high-resolution prediction flood data D12 from low-resolution prediction flood data D11, and S_C be the data size for each case.
タスク(B)は、多様な観測情報D10からの浸水の起こり方を機械学習するため、事例数はタスク(A)と同程度(N_A≒N_B)となる。しかしながら、機械学習に用いる事例ごとのデータ量は、高解像度浸水予測データD2よりダウンサンプリングした低解像度浸水予測データD3であるため、S_A>>S_Bとなる。
Since task (B) performs machine learning on how flooding occurs from various observation information D10, the number of cases is about the same as task (A) (N_A ≒ N_B). However, since the amount of data for each case used for machine learning is the low-resolution inundation prediction data D3 down-sampled from the high-resolution inundation prediction data D2, S_A>>S_B.
タスク(C)は、低解像度浸水予測データD11を高解像度化した高解像度浸水予測データD12を求めるものであり、機械学習時には観測情報D1の違いは問題にならない。また、タスク(C)に関する機械学習では、同じ対象地区(サブグリッドスケール内の地形・建物形状が同じ)における各地点の予測値(画素値)が高解像度化の対象であるので、事例数は少なくてよい(N_A>>N_C)。
Task (C) obtains high-resolution inundation prediction data D12 by increasing the resolution of low-resolution inundation prediction data D11, and differences in observation information D1 do not matter during machine learning. In addition, in the machine learning related to task (C), the predicted values (pixel values) of each point in the same target area (same terrain and building shape within the sub-grid scale) are targeted for high resolution, so the number of cases is less (N_A>>N_C).
このため、タスク(B)+タスク(C)における機械学習時のデータサイズ(事例数×事例ごとのデータ量)と、タスク(A)における機械学習時のデータサイズとを比較すると次のとおりである。
N_A×S_A>>N_B×S_B+N_C×S_C For this reason, comparing the data size (number of cases x data amount for each case) during machine learning in task (B) + task (C) with the data size during machine learning in task (A) is as follows. be.
N_A*S_A>>N_B*S_B+N_C*S_C
N_A×S_A>>N_B×S_B+N_C×S_C For this reason, comparing the data size (number of cases x data amount for each case) during machine learning in task (B) + task (C) with the data size during machine learning in task (A) is as follows. be.
N_A*S_A>>N_B*S_B+N_C*S_C
すなわち、タスク(B)+タスク(C)の方が、タスク(A)よりもデータサイズが小さくなる。具体的には、100倍程度の差が出る場合がある。このため、実施形態の情報処理装置では、機械学習時におけるデータ量を抑え、計算量が大きくなることを抑止できる。
That is, task (B) + task (C) has a smaller data size than task (A). Specifically, a difference of about 100 times may occur. Therefore, in the information processing apparatus of the embodiment, it is possible to suppress the amount of data during machine learning and prevent the amount of calculation from increasing.
図4は、実施形態にかかる情報処理装置の機能構成例を示すブロック図である。図4に示すように、情報処理装置1は、通信部10、表示部11、操作部12、入出力部13、記憶部14および制御部15を有する。この情報処理装置1は、浸水予測装置の一例であり、例えばPC(Personal Computer)などを適用できる。
FIG. 4 is a block diagram showing a functional configuration example of the information processing device according to the embodiment. As shown in FIG. 4 , the information processing apparatus 1 has a communication section 10 , a display section 11 , an operation section 12 , an input/output section 13 , a storage section 14 and a control section 15 . This information processing device 1 is an example of a flood prediction device, and for example, a PC (Personal Computer) can be applied.
通信部10は、例えば、NIC(Network Interface Card)等によって実現される。通信部10は、図示しないネットワークを介して他の情報処理装置と有線または無線で接続され、他の情報処理装置との間で情報の通信を司る通信インタフェースである。
The communication unit 10 is realized by, for example, a NIC (Network Interface Card) or the like. The communication unit 10 is a communication interface that is wired or wirelessly connected to another information processing apparatus via a network (not shown) and controls information communication with the other information processing apparatus.
表示部11は、各種情報を表示するための表示デバイスである。表示部11は、例えば、表示デバイスとして液晶ディスプレイ等によって実現される。表示部11は、制御部15から入力された表示画面等の各種画面を表示する。
The display unit 11 is a display device for displaying various information. The display unit 11 is implemented by, for example, a liquid crystal display as a display device. The display unit 11 displays various screens such as a display screen input from the control unit 15 .
操作部12は、情報処理装置1のユーザから各種操作を受け付ける入力デバイスである。操作部12は、例えば、入力デバイスとして、キーボードやマウス等によって実現される。操作部12は、ユーザによって入力された操作を操作情報として制御部15に出力する。なお、操作部12は、入力デバイスとして、タッチパネル等によって実現されるようにしてもよく、表示部11の表示デバイスと、操作部12の入力デバイスとは、一体化されるようにしてもよい。
The operation unit 12 is an input device that receives various operations from the user of the information processing device 1 . The operation unit 12 is realized by, for example, a keyboard, a mouse, etc. as an input device. The operation unit 12 outputs the operation input by the user to the control unit 15 as operation information. The operation unit 12 may be realized by a touch panel or the like as an input device, and the display device of the display unit 11 and the input device of the operation unit 12 may be integrated.
入出力部13は、例えば、メモリカードR/W(Reader/Writer)である。入出力部13は、通信部10で受信する観測情報141等の代わりに、メモリカードに記憶された観測情報141等を読み出して記憶部14に格納するようにしてもよい。また、入出力部13は、例えば、制御部15から出力された予測結果をメモリカードに記憶する。なお、メモリカードとしては、例えばSDメモリカード等を用いることができる。
The input/output unit 13 is, for example, a memory card R/W (Reader/Writer). The input/output unit 13 may read the observation information 141 or the like stored in the memory card and store it in the storage unit 14 instead of the observation information 141 or the like received by the communication unit 10 . Also, the input/output unit 13 stores, for example, the prediction result output from the control unit 15 in a memory card. As the memory card, for example, an SD memory card or the like can be used.
記憶部14は、例えば、RAM(Random Access Memory)、フラッシュメモリ(Flash Memory)等の半導体メモリ素子、ハードディスクや光ディスク等の記憶装置によって実現される。記憶部14は、観測情報141、訓練データ142、予測データ143、第1の機械学習モデル情報144および第2の機械学習モデル情報145などを格納する。
The storage unit 14 is realized by, for example, semiconductor memory devices such as RAM (Random Access Memory) and flash memory, and storage devices such as hard disks and optical disks. The storage unit 14 stores observation information 141, training data 142, prediction data 143, first machine learning model information 144, second machine learning model information 145, and the like.
観測情報141は、サーバなどより取得した、対象地区に関する観測情報であり、前述した観測情報D1、D10に対応する。
The observation information 141 is observation information about the target area obtained from a server or the like, and corresponds to the observation information D1 and D10 described above.
訓練データ142は、第1の機械学習モデルM1および第2の機械学習モデルM2の機械学習に用いるデータである。具体的には、訓練データ142は、機械学習に用いる事例ごとに、前述した観測情報D1と、観測情報D1に対応する高解像度浸水予測データD2および低解像度浸水予測データD3をセットとしたデータである。
The training data 142 is data used for machine learning of the first machine learning model M1 and the second machine learning model M2. Specifically, the training data 142 is a set of the observation information D1 described above, the high-resolution inundation prediction data D2 corresponding to the observation information D1, and the low-resolution inundation prediction data D3 for each case used for machine learning. be.
予測データ143は、観測情報D10からの予測結果を示すデータである。具体的には、予測データ143は、観測情報D10を第1の機械学習モデルM1に入力することにより得られた低解像度浸水予測データD11、低解像度浸水予測データD11を第2の機械学習モデルM2に入力することにより得られた高解像度浸水予測データD12に対応する。
The prediction data 143 is data indicating prediction results from the observation information D10. Specifically, the prediction data 143 is the low-resolution inundation prediction data D11 obtained by inputting the observation information D10 into the first machine learning model M1, and the low-resolution inundation prediction data D11 obtained by the second machine learning model M2. corresponds to the high-resolution inundation prediction data D12 obtained by inputting to .
第1の機械学習モデル情報144は、第1の機械学習モデルM1に関する情報であり、ニューラルネットワークなどの第1の機械学習モデルM1を構築するためのパラメータ等である。第2の機械学習モデル情報145は、第2の機械学習モデルM2に関する情報であり、CNNなどの第2の機械学習モデルM2を構築するためのパラメータ等である。
The first machine learning model information 144 is information related to the first machine learning model M1, and includes parameters and the like for constructing the first machine learning model M1 such as a neural network. The second machine learning model information 145 is information about the second machine learning model M2, and includes parameters and the like for constructing the second machine learning model M2 such as CNN.
制御部15は、情報処理装置1の動作を統括する処理部である。制御部15は、取得部151、訓練データ作成部152、第1の機械学習部153、第2の機械学習部154、推定部155および出力部156を有する。制御部15は、CPU(Central Processing Unit)やMPU(Micro Processing Unit)などによって実現できる。また、制御部15は、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)などのハードワイヤードロジックによっても実現できる。
The control unit 15 is a processing unit that controls the operation of the information processing device 1 . The control unit 15 has an acquisition unit 151 , a training data generation unit 152 , a first machine learning unit 153 , a second machine learning unit 154 , an estimation unit 155 and an output unit 156 . The control unit 15 can be realized by a CPU (Central Processing Unit), an MPU (Micro Processing Unit), or the like. The control unit 15 can also be realized by hardwired logic such as ASIC (Application Specific Integrated Circuit) and FPGA (Field Programmable Gate Array).
取得部151は、観測情報141を取得する処理部である。例えば、取得部151は、対象地区に関する観測情報141を提供する特定のサーバとの通信部10を介した通信により観測情報141を取得する。取得部151は、取得した観測情報141を記憶部14に格納する。
The acquisition unit 151 is a processing unit that acquires the observation information 141. For example, the acquisition unit 151 acquires the observation information 141 by communicating via the communication unit 10 with a specific server that provides the observation information 141 regarding the target area. The acquisition unit 151 stores the acquired observation information 141 in the storage unit 14 .
訓練データ作成部152は、第1の機械学習モデルM1および第2の機械学習モデルM2の機械学習に用いる訓練データ142を作成する処理部である。具体的には、訓練データ作成部152は、観測情報D1(141)よりシミュレーションなどを行って、観測情報D1に対応する高解像度浸水予測データD2を得る。なお、訓練データ作成部152は、観測情報D1に含まれる観測値をそのまま適用して高解像度浸水予測データD2を得てもよい。
The training data creation unit 152 is a processing unit that creates the training data 142 used for machine learning of the first machine learning model M1 and the second machine learning model M2. Specifically, the training data creation unit 152 performs a simulation or the like from the observation information D1 (141) to obtain high-resolution inundation prediction data D2 corresponding to the observation information D1. Note that the training data creation unit 152 may obtain the high-resolution inundation prediction data D2 by directly applying the observation values included in the observation information D1.
次いで、訓練データ作成部152は、高解像度浸水予測データD2における予測地図についてダウンサンプリングを行うことで、高解像度浸水予測データD2よりも低解像度な低解像度浸水予測データD3を取得する。次いで、訓練データ作成部152は、観測情報D1と、この観測情報D1に対応する高解像度浸水予測データD2および低解像度浸水予測データD3とをセットとした訓練データ142を記憶部14に格納する。訓練データ作成部152は、上記の処理を機械学習に用いる事例数分行うことで、事例数分の訓練データ142を作成する。
Next, the training data creation unit 152 acquires low-resolution inundation prediction data D3 with a resolution lower than that of the high-resolution inundation prediction data D2 by down-sampling the prediction map in the high-resolution inundation prediction data D2. Next, the training data creation unit 152 stores in the storage unit 14 training data 142 that is a set of the observation information D1 and the high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3 corresponding to the observation information D1. The training data creation unit 152 creates training data 142 for the number of cases by performing the above process for the number of cases used for machine learning.
第1の機械学習部153は、訓練データ142をもとに第1の機械学習モデルM1を生成する処理部である。具体的には、第1の機械学習部153は、訓練データ142に含まれる事例ごとに、観測情報D1および低解像度浸水予測データD3を読み出す。次いで、第1の機械学習部153は、読み出した観測情報D1を第1の機械学習モデルM1に入力した場合の第1の機械学習モデルM1からの出力が正解とする低解像度浸水予測データD3となるように第1の機械学習モデルM1のパラメータを設定(調整)する。
The first machine learning unit 153 is a processing unit that generates the first machine learning model M1 based on the training data 142. Specifically, the first machine learning unit 153 reads the observation information D1 and the low-resolution inundation prediction data D3 for each case included in the training data 142 . Next, the first machine learning unit 153 inputs the read observation information D1 to the first machine learning model M1, and the low-resolution inundation prediction data D3 that the output from the first machine learning model M1 is correct. The parameters of the first machine learning model M1 are set (adjusted) so that
次いで、第1の機械学習部153は、訓練データ142として準備された所定数の各事例について上記の処理を行った後、第1の機械学習モデルM1のパラメータを第1の機械学習モデル情報144として記憶部14に格納する。
Next, after the first machine learning unit 153 performs the above processing on each of the predetermined number of cases prepared as the training data 142, the parameters of the first machine learning model M1 are set to the first machine learning model information 144 , and stored in the storage unit 14 .
第2の機械学習部154は、訓練データ142をもとに第2の機械学習モデルM2を生成する処理部である。具体的には、第2の機械学習部154は、訓練データ142に含まれる事例ごとに、低解像度浸水予測データD3および高解像度浸水予測データD2を読み出す。次いで、第2の機械学習部154は、読み出した低解像度浸水予測データD3を第2の機械学習モデルM2に入力した場合の第2の機械学習モデルM2からの出力が正解とする高解像度浸水予測データD2となるように第2の機械学習モデルM2のパラメータを設定(調整)する。
The second machine learning unit 154 is a processing unit that generates a second machine learning model M2 based on the training data 142. Specifically, the second machine learning unit 154 reads the low resolution inundation prediction data D3 and the high resolution inundation prediction data D2 for each case included in the training data 142 . Next, the second machine learning unit 154 inputs the read low-resolution flood prediction data D3 to the second machine-learning model M2, and the high-resolution flood prediction that the output from the second machine-learning model M2 is correct. The parameters of the second machine learning model M2 are set (adjusted) so as to become the data D2.
次いで、第2の機械学習部154は、訓練データ142として準備された所定数の各事例について上記の処理を行った後、第2の機械学習モデルM2のパラメータを第2の機械学習モデル情報145として記憶部14に格納する。
Next, the second machine learning unit 154 performs the above processing on each of the predetermined number of cases prepared as the training data 142, and then converts the parameters of the second machine learning model M2 into the second machine learning model information 145. , and stored in the storage unit 14 .
推定部155は、対象地区の観測情報141(D10)をもとに、対象地区における浸水状況の予測地図である高解像度浸水予測データD12を推定する処理部である。具体的には、推定部155は、記憶部14より読み出した第1の機械学習モデル情報144をもとに第1の機械学習モデルM1を構築する。次いで、推定部155は、観測情報D10を第1の機械学習モデルM1に入力することで低解像度浸水予測データD11を生成する。推定部155は、生成した低解像度浸水予測データD11を予測データ143として記憶部14に格納する。
The estimation unit 155 is a processing unit that estimates high-resolution inundation prediction data D12, which is a prediction map of the flood situation in the target area, based on the observation information 141 (D10) of the target area. Specifically, the estimation unit 155 constructs the first machine learning model M1 based on the first machine learning model information 144 read from the storage unit 14 . Next, the estimation unit 155 generates low-resolution inundation prediction data D11 by inputting the observation information D10 to the first machine learning model M1. The estimation unit 155 stores the generated low-resolution inundation prediction data D<b>11 as prediction data 143 in the storage unit 14 .
次いで、推定部155は、記憶部14より読み出した第2の機械学習モデル情報145をもとに第2の機械学習モデルM2を構築する。次いで、推定部155は、低解像度浸水予測データD11を第2の機械学習モデルM2に入力することで高解像度化した高解像度浸水予測データD12を生成する。推定部155は、生成した高解像度浸水予測データD12を予測データ143として記憶部14に格納する。
Next, the estimation unit 155 constructs the second machine learning model M2 based on the second machine learning model information 145 read from the storage unit 14. Next, the estimation unit 155 generates high-resolution flood prediction data D12 by inputting the low-resolution prediction flood data D11 to the second machine learning model M2. The estimation unit 155 stores the generated high-resolution inundation prediction data D<b>12 as prediction data 143 in the storage unit 14 .
出力部156は、推定部155の推定結果を出力する処理部である。具体的には、出力部156は、記憶部14より予測データ143に含まれる高解像度浸水予測データD12を読み出し、高解像度浸水予測データD12をもとに対象地区における各地点の浸水状況を示す予測地図の表示画面を生成する。次いで、出力部156は、生成した表示画面のデータを表示部11に出力し、予測地図を表示デバイスに表示させる。
The output unit 156 is a processing unit that outputs the estimation result of the estimation unit 155 . Specifically, the output unit 156 reads the high-resolution inundation prediction data D12 included in the prediction data 143 from the storage unit 14, and based on the high-resolution inundation prediction data D12, predicts the inundation situation at each point in the target area. Generate a map display screen. Next, the output unit 156 outputs the data of the generated display screen to the display unit 11 to display the prediction map on the display device.
なお、出力部156における出力先は、表示部11に限定しない。例えば、出力部156は、記憶部14より読み出した高解像度浸水予測データD12を入出力部13を介してメモリカードに出力してもよい。
The output destination of the output unit 156 is not limited to the display unit 11. For example, the output unit 156 may output the high resolution flood prediction data D12 read from the storage unit 14 to the memory card via the input/output unit 13 .
図5は、実施形態にかかる情報処理装置1の機械学習時の動作例を示すフローチャートである。なお、図5に示すフローチャートでは、観測情報D1をもとにしたシミュレーションにより訓練データ142を作成するものとする。
FIG. 5 is a flowchart showing an operation example of the information processing apparatus 1 according to the embodiment during machine learning. In the flowchart shown in FIG. 5, it is assumed that the training data 142 is created by simulation based on the observation information D1.
図5に示すように、処理が開始されると、訓練データ作成部152は、訓練データ142(D1)をもとに、さまざまなタイプ(例えば気象条件などを異ならせる)のシミュレーションをN回実施し(S10)、Nセットの高解像度浸水予測データD2を取得する。
As shown in FIG. 5, when the process is started, the training data creation unit 152 performs various types of simulations (for example, different weather conditions) N times based on the training data 142 (D1). (S10) to acquire N sets of high-resolution flood prediction data D2.
次いで、訓練データ作成部152は、Nセットの高解像度浸水予測データD2について、高解像度浸水予測データD2から低解像度浸水予測データD3をダウンサンプリングにより取得する(S11)。
Next, the training data creation unit 152 down-samples the N sets of high-resolution inundation prediction data D2 to acquire low-resolution inundation prediction data D3 from the high-resolution inundation prediction data D2 (S11).
図6は、ダウンサンプリングの概要を説明する説明図である。図6に示すように、訓練データ作成部152は、所定のスケール(例えば5mメッシュ→50mメッシュ)でのダウンサンプリングを行うことで、高解像度浸水予測データD2より低解像度浸水予測データD3を取得する。
FIG. 6 is an explanatory diagram explaining an outline of downsampling. As shown in FIG. 6, the training data creation unit 152 acquires low-resolution inundation prediction data D3 from high-resolution inundation prediction data D2 by performing downsampling on a predetermined scale (for example, 5 m mesh→50 m mesh). .
ここで、訓練データ作成部152は、高解像度浸水予測データD2の特定の領域に含まれる画素からダウンサンプリングする際に、その領域に含まれる画素の中で浸水予測の評価が最も悪い画素をサンプリングすることで、低解像度浸水予測データD3を取得する。ここでいう、浸水評価の良し悪しは、地面からの水位の高さを意味するものであり、水位が高いほど評価が悪い(床下浸水より床上浸水の方が評価が悪い)ものとする。これにより、訓練データ作成部152は、ダウンサンプリングによって浸水予測の評価が最も悪い画素が除かれることを抑止する。
Here, when down-sampling pixels included in a specific area of the high-resolution inundation prediction data D2, the training data creation unit 152 samples pixels with the worst inundation prediction evaluation among the pixels included in the area. By doing so, the low-resolution inundation prediction data D3 is acquired. Here, the good or bad inundation evaluation means the height of the water level from the ground, and the higher the water level, the worse the evaluation (the evaluation is worse for the inundation above the floor than for the inundation under the floor). As a result, the training data creation unit 152 prevents pixels with the worst inundation prediction evaluation from being removed by downsampling.
具体的には、ケースC1では、特定の領域の高解像度浸水予測データD2aにおいて、右斜めの網掛け部分(予測値a)と、左斜めの網掛け部分(予測値b)とが含まれており、予測値bの方がaより評価が悪いものとする。この場合、訓練データ作成部152は、評価が悪い予測値bをサンプリングする。すなわち、訓練データ作成部152は、高解像度浸水予測データD2aより予測値bを1画素分とする低解像度浸水予測データD3aにダウンサンプリングする。
Specifically, in case C1, the high-resolution inundation prediction data D2a of the specific region includes a right diagonal shaded portion (predicted value a) and a left diagonal shaded portion (predicted value b). , and the predicted value b has a lower evaluation than the predicted value a. In this case, the training data creation unit 152 samples the predicted value b with a poor evaluation. That is, the training data creation unit 152 down-samples the high-resolution flood prediction data D2a to the low-resolution flood prediction data D3a with the prediction value b for one pixel.
同様に、ケースC2では、特定の領域の高解像度浸水予測データD2bにおいて、右斜めの網掛け部分(予測値a)と、左斜めの網掛け部分(予測値b)とが含まれている。したがって、訓練データ作成部152は、高解像度浸水予測データD2bより予測値bを1画素分とする低解像度浸水予測データD3bにダウンサンプリングする。
Similarly, in case C2, the high-resolution inundation prediction data D2b of the specific area includes a right diagonal shaded portion (predicted value a) and a left diagonal shaded portion (predicted value b). Therefore, the training data generation unit 152 down-samples the high-resolution flood prediction data D2b to the low-resolution flood prediction data D3b in which the prediction value b is one pixel.
ケースC3では、特定の領域の高解像度浸水予測データD2cにおいて、右斜めの網掛け部分(予測値a)を含むが、左斜めの網掛け部分(予測値b)が含まれていない。したがって、訓練データ作成部152は、高解像度浸水予測データD2cより予測値aを1画素分とする低解像度浸水予測データD3cにダウンサンプリングする。
In case C3, the high-resolution inundation prediction data D2c of the specific region includes the diagonally right shaded portion (predicted value a), but does not include the diagonally left shaded portion (predicted value b). Therefore, the training data generation unit 152 down-samples the high-resolution flood prediction data D2c to the low-resolution flood prediction data D3c in which the prediction value a is one pixel.
次いで、訓練データ作成部152は、Nセットの観測情報D1と、低解像度浸水予測データD3を訓練データ142として準備する(S12)。次いで、第1の機械学習部153は、Nセットの訓練データ142をN=N_train+N_testに分割する(S13)。
Next, the training data creation unit 152 prepares N sets of observation information D1 and low-resolution inundation prediction data D3 as training data 142 (S12). Next, the first machine learning unit 153 divides the N sets of training data 142 into N=N_train+N_test (S13).
次いで、第1の機械学習部153は、N_trainの観測情報D1と、低解像度浸水予測データD3の組で第1の機械学習モデルM1の機械学習を行う。また、第1の機械学習部153は、N_testの観測情報D1と、低解像度浸水予測データD3の組で機械学習後の第1の機械学習モデルM1のバリデーション(検証)を行う。第1の機械学習部153は、バリデーションによって予測に含まれる誤差が所定範囲内と確認された第1の機械学習モデルM1を採用し、第1の機械学習モデルM1を構築する(S14)。
Next, the first machine learning unit 153 performs machine learning for the first machine learning model M1 using a set of the N_train observation information D1 and the low-resolution flood prediction data D3. The first machine learning unit 153 also validates the first machine learning model M1 after machine learning using a set of the N_test observation information D1 and the low-resolution inundation prediction data D3. The first machine learning unit 153 adopts the first machine learning model M1 whose prediction error is confirmed to be within a predetermined range by validation, and constructs the first machine learning model M1 (S14).
また、S11に次いで、訓練データ作成部152は、Mセットの高解像度浸水予測データD2と、低解像度浸水予測データD3を訓練データ142として準備する(S15)。次いで、第2の機械学習部154は、Mセットの訓練データ142をM=M_train+M_testに分割する(S16)。なお、セット数については、M<<Nである。
Further, following S11, the training data creation unit 152 prepares M sets of high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3 as training data 142 (S15). Next, the second machine learning unit 154 divides the M sets of training data 142 into M=M_train+M_test (S16). Note that the number of sets is M<<N.
次いで、第2の機械学習部154は、M_trainの高解像度浸水予測データD2と、低解像度浸水予測データD3の組で第2の機械学習モデルM2の機械学習を行う。また、第2の機械学習部154は、M_testの高解像度浸水予測データD2と、低解像度浸水予測データD3の組で機械学習後の第2の機械学習モデルM2のバリデーション(検証)を行う。第2の機械学習部154は、バリデーションによって予測に含まれる誤差が所定範囲内と確認された第2の機械学習モデルM2を採用し、第2の機械学習モデルM2を構築する(S17)。
Next, the second machine learning unit 154 performs machine learning of the second machine learning model M2 using a set of the M_train high-resolution inundation prediction data D2 and low-resolution inundation prediction data D3. Also, the second machine learning unit 154 validates the second machine learning model M2 after machine learning with a set of the high-resolution inundation prediction data D2 of M_test and the low-resolution inundation prediction data D3. The second machine learning unit 154 adopts the second machine learning model M2 whose prediction error is confirmed to be within a predetermined range by validation, and constructs the second machine learning model M2 (S17).
S14、S17に次いで、制御部15は、構築した第1の機械学習モデルM1および第2の機械学習モデルM2に関する第1の機械学習モデル情報144および第2の機械学習モデル情報145を記憶部14に格納し、処理を終了する。なお、第1の機械学習部153によるS13、S14の処理と、第2の機械学習部154によるS16、S17の処理は、並列に行ってもよい。
Following S14 and S17, the control unit 15 stores the first machine learning model information 144 and the second machine learning model information 145 regarding the constructed first machine learning model M1 and second machine learning model M2 in the storage unit 14. , and terminate the process. The processing of S13 and S14 by the first machine learning unit 153 and the processing of S16 and S17 by the second machine learning unit 154 may be performed in parallel.
図7は、実施形態にかかる情報処理装置1の機械学習時の動作例を示すフローチャートである。なお、図7に示すフローチャートでは、シミュレーションを行わず、観測情報D1に含まれる観測データを採用して訓練データ142を作成するものとする。
FIG. 7 is a flowchart showing an operation example of the information processing apparatus 1 according to the embodiment during machine learning. Note that in the flowchart shown in FIG. 7, the training data 142 is created by adopting the observation data included in the observation information D1 without performing a simulation.
図7に示すように、処理が開始されると、訓練データ作成部152は、さまざまなタイプの観測情報D1をN件準備する(S10a)。ここで、観測情報D1には、高解像度浸水予測データD2に対応する高解像度浸水観測データ(実測の浸水状況地図)も含まれているものとする。
As shown in FIG. 7, when the process is started, the training data creation unit 152 prepares N pieces of observation information D1 of various types (S10a). Here, it is assumed that the observation information D1 also includes high-resolution inundation observation data (actually measured inundation situation map) corresponding to the high-resolution inundation prediction data D2.
訓練データ作成部152は、Nセットの観測情報D1について、高解像度浸水観測データから低解像度浸水観測データをダウンサンプリングする(S11a)。次いで、訓練データ作成部152は、Nセットの観測情報D1と、低解像度浸水観測データを訓練データ142として準備する(S12a)。以後、第1の機械学習部153は、準備した訓練データ142をもとに、前述したS13、S14と同様に処理を行い、第1の機械学習モデルM1を構築する。
The training data creation unit 152 down-samples the low-resolution inundation observation data from the high-resolution inundation observation data for the N sets of observation information D1 (S11a). Next, the training data generator 152 prepares N sets of observation information D1 and low-resolution inundation observation data as training data 142 (S12a). After that, the first machine learning unit 153 performs the same processing as S13 and S14 described above based on the prepared training data 142 to build the first machine learning model M1.
また、S11aに次いで、訓練データ作成部152は、Mセットの高解像度浸水観測データと、低解像度浸水観測データを訓練データ142として準備する(S15a)。以後、第2の機械学習部154は、準備した訓練データ142をもとに、前述したS16、S17と同様に処理を行い、第2の機械学習モデルM2を構築する。
Further, following S11a, the training data creation unit 152 prepares M sets of high-resolution inundation observation data and low-resolution inundation observation data as training data 142 (S15a). After that, the second machine learning unit 154 performs the same processing as S16 and S17 described above based on the prepared training data 142 to build the second machine learning model M2.
図8は、実施形態にかかる情報処理装置1の予測時の動作例を示すフローチャートである。図8に示すように、処理が開始されると、取得部151は、対象地区に関する観測情報を提供する特定のサーバなどにより、災害発生時の観測情報D10を取得する(S20)。
FIG. 8 is a flowchart showing an operation example of the information processing apparatus 1 according to the embodiment during prediction. As shown in FIG. 8, when the process is started, the acquisition unit 151 acquires observation information D10 at the time of disaster occurrence from a specific server or the like that provides observation information on the target area (S20).
次いで、推定部155は、第1の機械学習モデル情報144より第1の機械学習モデルM1を構築する。次いで、推定部155は、取得した観測情報D10を構築した第1の機械学習モデルM1に入力することで低解像度浸水予測データD11を取得する(S21)。
Next, the estimation unit 155 constructs the first machine learning model M1 from the first machine learning model information 144. Next, the estimation unit 155 acquires low-resolution inundation prediction data D11 by inputting the acquired observation information D10 into the constructed first machine learning model M1 (S21).
次いで、推定部155は、第2の機械学習モデル情報145より第2の機械学習モデルM2を構築する。次いで、推定部155は、S21で取得した低解像度浸水予測データD11を構築した第2の機械学習モデルM2に入力することで高解像度浸水予測データD12を取得する(S22)。出力部156は、S22で取得した高解像度浸水予測データD12を表示部11に出力し(S23)、災害発生時の観測情報D10に基づく予測地図の表示を行う。
Next, the estimation unit 155 constructs a second machine learning model M2 from the second machine learning model information 145. Next, the estimating unit 155 acquires high-resolution inundation prediction data D12 by inputting the low-resolution inundation prediction data D11 acquired in S21 to the constructed second machine learning model M2 (S22). The output unit 156 outputs the high-resolution inundation prediction data D12 acquired in S22 to the display unit 11 (S23), and displays a prediction map based on the observation information D10 when a disaster occurs.
以上のように、情報処理装置1は、対象地区に関する観測情報D10を取得する。情報処理装置1は、取得した観測情報D10を第1の機械学習モデルM1に入力することによって、対象地区における浸水状況の予測結果を示す第1の画像(低解像度浸水予測データD11)を生成する。情報処理装置1は、第1の画像を第2の機械学習モデルM2に入力することによって、第1の画像より解像度の高い第2の画像(高解像度浸水予測データD12)を生成する。情報処理装置1は、対象地区の浸水予測結果として生成した第2の画像を出力する。
As described above, the information processing device 1 acquires the observation information D10 regarding the target area. The information processing device 1 inputs the obtained observation information D10 to the first machine learning model M1 to generate a first image (low-resolution inundation prediction data D11) showing the prediction result of the inundation situation in the target area. . The information processing device 1 inputs the first image to the second machine learning model M2 to generate a second image (high-resolution flood prediction data D12) having a resolution higher than that of the first image. The information processing device 1 outputs a second image generated as a flood prediction result for the target area.
これにより、情報処理装置1は、機械学習モデルを用いた精度のよい浸水予測を、処理に要するメモリや計算量の増加を抑えつつ、高解像度で行うことができる。このようにして、情報処理装置1は、浸水予測の高精度化を支援できる。
As a result, the information processing device 1 can perform highly accurate inundation prediction using a machine learning model at high resolution while suppressing an increase in the amount of memory and calculation required for processing. In this way, the information processing device 1 can assist in increasing the accuracy of flood prediction.
情報処理装置1が生成する第1の画像は、対象地区を俯瞰した各地点の浸水状況を示す地図画像である。これにより、情報処理装置1では、対象地区を俯瞰した各地点の浸水状況のより高精細な地図画像を得ることができる。
The first image generated by the information processing device 1 is a map image showing the flooding situation at each point in the target area. As a result, the information processing apparatus 1 can obtain a higher-definition map image of the inundation situation at each point of the target area.
また、情報処理装置1は、対象地区に関する観測情報D1と対応する浸水予測画像(高解像度浸水予測データD2)をダウンサンプリングする。情報処理装置1は、ダウンサンプリングされた浸水予測画像(低解像度浸水予測データD3)と観測情報D1に基づいて第1の機械学習モデルM1を生成する。情報処理装置1は、ダウンサンプリングされた浸水予測画像(低解像度浸水予測データD3)と、もとの浸水予測画像(高解像度浸水予測データD2)とに基づいて、第1の機械学習モデルM1の出力を入力とし、入力された画像を高解像度化した画像を出力する第2の機械学習モデルM2を生成する。
The information processing device 1 also down-samples the observation information D1 about the target area and the corresponding inundation prediction image (high-resolution inundation prediction data D2). The information processing device 1 generates a first machine learning model M1 based on the down-sampled inundation prediction image (low-resolution inundation prediction data D3) and the observation information D1. The information processing device 1 generates a first machine learning model M1 based on the downsampled inundation prediction image (low-resolution inundation prediction data D3) and the original inundation prediction image (high-resolution inundation prediction data D2). A second machine learning model M2 is generated that takes the output as an input and outputs an image obtained by increasing the resolution of the input image.
これにより、情報処理装置1は、処理に要するメモリや計算量の増加を抑えつつ、精度のよい浸水予測を高解像度で行う機械学習モデルを作成することができる。このようにして、情報処理装置1は、浸水予測の高精度化を支援できる。
As a result, the information processing device 1 can create a machine learning model that performs highly accurate inundation prediction at high resolution while suppressing increases in memory and computational complexity required for processing. In this way, the information processing device 1 can assist in increasing the accuracy of inundation prediction.
また、情報処理装置1は、浸水予測画像(高解像度浸水予測データD2)について、特定の領域に含まれる画素からダウンサンプリングする際に、その領域に含まれる画素の中で浸水予測の評価が最も悪い画素をサンプリングする。これにより、情報処理装置1では、ダウンサンプリングにより浸水予測の評価が最も悪い画素が除かれることを抑止できる。また、情報処理装置1は、このようにダウンサンプリングされた浸水予測画像(低解像度浸水予測データD3)を用いて第1の機械学習モデルM1を作成することで、第1の機械学習モデルM1を用いた浸水予測において評価が最も悪くなるようなワーストケースを的確に予測できるようになる。
Further, when down-sampling pixels included in a specific region of the predicted flood image (high-resolution predicted flood data D2), the information processing device 1 performs the most inundation prediction evaluation among pixels included in the region. Sample bad pixels. Thereby, in the information processing device 1, it is possible to prevent pixels with the worst inundation prediction evaluation from being removed by downsampling. In addition, the information processing device 1 creates the first machine learning model M1 using the downsampled inundation prediction image (low-resolution inundation prediction data D3) in this way, thereby obtaining the first machine learning model M1 as It becomes possible to accurately predict the worst case in which the evaluation is the worst in the inundation prediction used.
なお、図示した各装置の各構成要素は、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、情報処理装置1における機械学習に関する機能構成(例えば、訓練データ作成部152、第1の機械学習部153および第2の機械学習部154)と、予測に関する機能構成(例えば、推定部155および出力部156)とは、分離した構成であってもよく、それぞれが独立した装置構成で実現してもよい。
It should be noted that each component of each illustrated device does not necessarily need to be physically configured as illustrated. In other words, the specific form of distribution/integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed/integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured. For example, the functional configuration related to machine learning in the information processing device 1 (e.g., training data creation unit 152, first machine learning unit 153 and second machine learning unit 154) and the functional configuration related to prediction (e.g., estimating unit 155 and The output unit 156) may be a separate configuration, or may be realized by an independent device configuration.
また、情報処理装置1で行われる各種処理機能は、CPU(またはMPU、MCU(Micro Controller Unit)等のマイクロ・コンピュータ)あるいはGPU(Graphics Processing Unit)上で、その全部または任意の一部を実行するようにしてもよい。また、各種処理機能は、CPU(またはMPU、MCU等のマイクロ・コンピュータ)あるいはGPUで解析実行されるプログラム上、またはワイヤードロジックによるハードウエア上で、その全部または任意の一部を実行するようにしてもよいことは言うまでもない。また、情報処理装置1で行われる各種処理機能は、クラウドコンピューティングにより、複数のコンピュータが協働して実行してもよい。
In addition, the various processing functions performed by the information processing device 1 are executed in whole or in part on a CPU (or a microcomputer such as an MPU or MCU (Micro Controller Unit)) or a GPU (Graphics Processing Unit). You may make it Also, all or any part of the various processing functions should be executed on a program analyzed and executed by the CPU (or microcomputer such as MPU or MCU) or GPU, or on hardware based on wired logic. It goes without saying that Further, various processing functions performed by the information processing apparatus 1 may be performed in collaboration with a plurality of computers by cloud computing.
ところで、上記の実施形態で説明した各種の処理は、予め用意されたプログラムをコンピュータで実行することで実現できる。そこで、以下では、上記の実施形態と同様の機能を有するプログラムを実行するコンピュータ(ハードウエア)の一例を説明する。図9は、コンピュータ構成の一例を示すブロック図である。
By the way, the various processes described in the above embodiments can be realized by executing a prepared program on a computer. Therefore, an example of a computer (hardware) that executes a program having functions similar to those of the above embodiments will be described below. FIG. 9 is a block diagram showing an example of a computer configuration.
図9に示すように、コンピュータ200は、各種演算処理を実行するCPU201と、画像処理や機械学習処理等の所定の演算処理に特化したGPU201aと、データ入力を受け付ける入力装置202と、モニタ203と、スピーカ204とを有する。また、コンピュータ200は、記憶媒体からプログラム等を読み取る媒体読取装置205と、各種装置と接続するためのインタフェース装置206と、有線または無線により外部機器と通信接続するための通信装置207とを有する。また、コンピュータ200は、各種情報を一時記憶するRAM208と、ハードディスク装置209とを有する。また、コンピュータ200内の各部(201~209)は、バス210に接続される。
As shown in FIG. 9, a computer 200 includes a CPU 201 that executes various types of arithmetic processing, a GPU 201a that specializes in predetermined arithmetic processing such as image processing and machine learning processing, an input device 202 that receives data input, and a monitor 203. , and a speaker 204 . The computer 200 also has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting with various devices, and a communication device 207 for communicating with an external device by wire or wirelessly. The computer 200 also has a RAM 208 that temporarily stores various information, and a hard disk device 209 . Each unit ( 201 to 209 ) in computer 200 is connected to bus 210 .
ハードディスク装置209には、上記の実施形態で説明した制御部15における取得部151、訓練データ作成部152、第1の機械学習部153、第2の機械学習部154、推定部155および出力部156等における各種の処理を実行するためのプログラム211が記憶される。また、ハードディスク装置209には、プログラム211が参照する観測情報などの各種データ212が記憶される。入力装置202は、例えば、操作者から操作情報の入力を受け付ける。モニタ203は、例えば、操作者が操作する各種画面を表示する。インタフェース装置206は、例えば印刷装置等が接続される。通信装置207は、LAN(Local Area Network)等の通信ネットワークと接続され、通信ネットワークを介した外部機器との間で各種情報をやりとりする。
The hard disk device 209 includes the acquisition unit 151, the training data creation unit 152, the first machine learning unit 153, the second machine learning unit 154, the estimation unit 155, and the output unit 156 in the control unit 15 described in the above embodiment. A program 211 for executing various kinds of processing in, etc. is stored. The hard disk device 209 also stores various data 212 such as observation information that the program 211 refers to. The input device 202 receives input of operation information from an operator, for example. The monitor 203 displays, for example, various screens operated by the operator. The interface device 206 is connected with, for example, a printing device. The communication device 207 is connected to a communication network such as a LAN (Local Area Network), and exchanges various information with external devices via the communication network.
CPU201あるいはGPU201aは、ハードディスク装置209に記憶されたプログラム211を読み出して、RAM208に展開して実行することで、取得部151、訓練データ作成部152、第1の機械学習部153、第2の機械学習部154、推定部155および出力部156等に関する各種の処理を行う。なお、プログラム211は、ハードディスク装置209に記憶されていなくてもよい。例えば、コンピュータ200が読み取り可能な記憶媒体に記憶されたプログラム211を読み出して実行するようにしてもよい。コンピュータ200が読み取り可能な記憶媒体は、例えば、CD-ROMやDVDディスク、USB(Universal Serial Bus)メモリ等の可搬型記録媒体、フラッシュメモリ等の半導体メモリ、ハードディスクドライブ等が対応する。また、公衆回線、インターネット、LAN等に接続された装置にこのプログラム211を記憶させておき、コンピュータ200がこれらからプログラム211を読み出して実行するようにしてもよい。
The CPU 201 or the GPU 201a reads out the program 211 stored in the hard disk device 209, develops it in the RAM 208, and executes it to obtain the acquisition unit 151, the training data creation unit 152, the first machine learning unit 153, the second machine Various processes related to the learning unit 154, the estimation unit 155, the output unit 156, and the like are performed. Note that the program 211 does not have to be stored in the hard disk device 209 . For example, the computer 200 may read and execute the program 211 stored in a readable storage medium. Storage media readable by the computer 200 are, for example, portable recording media such as CD-ROMs, DVD discs, USB (Universal Serial Bus) memories, semiconductor memories such as flash memories, hard disk drives, and the like. Alternatively, the program 211 may be stored in a device connected to a public line, the Internet, a LAN, or the like, and the computer 200 may read the program 211 from these devices and execute it.
1…情報処理装置
10…通信部
11…表示部
12…操作部
13…入出力部
14…記憶部
15…制御部
141…観測情報
142…訓練データ
143…予測データ
144…第1の機械学習モデル情報
145…第2の機械学習モデル情報
151…取得部
152…訓練データ作成部
153…第1の機械学習部
154…第2の機械学習部
155…推定部
156…出力部
200…コンピュータ
201…CPU
201a…GPU
202…入力装置
203…モニタ
204…スピーカ
205…媒体読取装置
206…インタフェース装置
207…通信装置
208…RAM
209…ハードディスク装置
210…バス
211…プログラム
212…各種データ
C1~C3…ケース
D1、D10…観測情報
D2、D2a~D2c、D12…高解像度浸水予測データ
D3、D3a~D3c、D11…低解像度浸水予測データ
M1…第1の機械学習モデル
M2…第2の機械学習モデル
Reference Signs List 1 information processing device 10communication unit 11 display unit 12 operation unit 13 input/output unit 14 storage unit 15 control unit 141 observation information 142 training data 143 prediction data 144 first machine learning model Information 145 Second machine learning model information 151 Acquisition unit 152 Training data creation unit 153 First machine learning unit 154 Second machine learning unit 155 Estimation unit 156 Output unit 200 Computer 201 CPU
201a GPU
202... Input device 203...Monitor 204... Speaker 205... Medium reading device 206... Interface device 207... Communication device 208... RAM
209Hard disk device 210 Bus 211 Program 212 Various data C1-C3 Cases D1, D10 Observation information D2, D2a-D2c, D12 High-resolution inundation prediction data D3, D3a-D3c, D11 Low-resolution inundation prediction Data M1... First machine learning model M2... Second machine learning model
10…通信部
11…表示部
12…操作部
13…入出力部
14…記憶部
15…制御部
141…観測情報
142…訓練データ
143…予測データ
144…第1の機械学習モデル情報
145…第2の機械学習モデル情報
151…取得部
152…訓練データ作成部
153…第1の機械学習部
154…第2の機械学習部
155…推定部
156…出力部
200…コンピュータ
201…CPU
201a…GPU
202…入力装置
203…モニタ
204…スピーカ
205…媒体読取装置
206…インタフェース装置
207…通信装置
208…RAM
209…ハードディスク装置
210…バス
211…プログラム
212…各種データ
C1~C3…ケース
D1、D10…観測情報
D2、D2a~D2c、D12…高解像度浸水予測データ
D3、D3a~D3c、D11…低解像度浸水予測データ
M1…第1の機械学習モデル
M2…第2の機械学習モデル
Reference Signs List 1 information processing device 10
201a GPU
202... Input device 203...
209
Claims (6)
- 対象地区に関する観測情報を取得し、
前記観測情報を第1の機械学習モデルに入力することによって、前記対象地区における浸水状況の予測結果を示す第1の画像を生成し、
前記第1の画像を第2の機械学習モデルに入力することによって、前記第1の画像より解像度の高い第2の画像を生成し、
前記対象地区の浸水予測結果として前記第2の画像を出力する、
処理をコンピュータに実行させることを特徴とする浸水予測プログラム。 Acquire observation information about the target area,
By inputting the observation information into the first machine learning model, generating a first image showing a prediction result of the inundation situation in the target area,
generating a second image having a higher resolution than the first image by inputting the first image into a second machine learning model;
Outputting the second image as a result of inundation prediction for the target area;
An inundation prediction program characterized by causing a computer to execute processing. - 前記第1の画像は、前記対象地区を俯瞰した各地点の浸水状況を示す地図画像である、
ことを特徴とする請求項1に記載の浸水予測プログラム。 The first image is a map image showing the flood situation at each point overlooking the target area,
The inundation prediction program according to claim 1, characterized by: - 対象地区に関する観測情報を取得し、
前記観測情報を第1の機械学習モデルに入力することによって、前記対象地区における浸水状況の予測結果を示す第1の画像を生成し、
前記第1の画像を第2の機械学習モデルに入力することによって、前記第1の画像より解像度の高い第2の画像を生成し、
前記対象地区の浸水予測結果として前記第2の画像を出力する、
処理を実行する制御部を含むことを特徴とする浸水予測装置。 Acquire observation information about the target area,
By inputting the observation information into the first machine learning model, generating a first image showing a prediction result of the inundation situation in the target area,
generating a second image having a higher resolution than the first image by inputting the first image into a second machine learning model;
Outputting the second image as a result of inundation prediction for the target area;
A flood prediction device comprising a control unit that executes processing. - 前記第1の画像は、前記対象地区を俯瞰した各地点の浸水状況を示す地図画像である、
ことを特徴とする請求項3に記載の浸水予測装置。 The first image is a map image showing the flood situation at each point overlooking the target area,
The inundation prediction device according to claim 3, characterized by: - 対象地区に関する観測情報と対応する浸水予測画像をダウンサンプリングし、
ダウンサンプリングされた浸水予測画像と前記観測情報に基づいて第1の機械学習モデルを生成し、
前記ダウンサンプリングされた浸水予測画像と、前記浸水予測画像とに基づいて、前記第1の機械学習モデルの出力を入力とし、入力された画像を高解像度化した画像を出力する第2の機械学習モデルを生成する、
処理をコンピュータが実行することを特徴とする機械学習方法。 Downsample the observation information and the corresponding inundation prediction image for the target area,
generating a first machine learning model based on the downsampled predicted inundation image and the observation information;
Second machine learning for outputting an image obtained by increasing the resolution of the input image based on the downsampled predicted inundation image and the predicted inundation image, with the output of the first machine learning model as input. generate the model,
A machine learning method characterized in that processing is executed by a computer. - 前記ダウンサンプリングする処理は、前記浸水予測画像について、特定の領域に含まれる画素からダウンサンプリングする際に、当該領域に含まれる画素の中で浸水予測の評価が最も悪い画素をサンプリングする
ことを特徴とする請求項5に記載の機械学習方法。 In the downsampling process, when downsampling pixels included in a specific region of the predicted inundation image, pixels with the worst evaluation of inundation prediction among the pixels included in the region are sampled. The machine learning method according to claim 5, wherein
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/005495 WO2022172442A1 (en) | 2021-02-15 | 2021-02-15 | Flooding prediction program, flooding prediction device, and machine-learning method |
| JP2022581146A JPWO2022172442A1 (en) | 2021-02-15 | 2021-02-15 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/005495 WO2022172442A1 (en) | 2021-02-15 | 2021-02-15 | Flooding prediction program, flooding prediction device, and machine-learning method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022172442A1 true WO2022172442A1 (en) | 2022-08-18 |
Family
ID=82837531
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/005495 WO2022172442A1 (en) | 2021-02-15 | 2021-02-15 | Flooding prediction program, flooding prediction device, and machine-learning method |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2022172442A1 (en) |
| WO (1) | WO2022172442A1 (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008084243A (en) * | 2006-09-29 | 2008-04-10 | Hitachi Engineering & Services Co Ltd | Flood simulation device and program |
| CN111382716A (en) * | 2020-03-17 | 2020-07-07 | 上海眼控科技股份有限公司 | Weather prediction method and device of numerical mode, computer equipment and storage medium |
| JP6813865B1 (en) * | 2020-02-25 | 2021-01-13 | Arithmer株式会社 | Information processing method, program, information processing device and model generation method |
-
2021
- 2021-02-15 WO PCT/JP2021/005495 patent/WO2022172442A1/en active Application Filing
- 2021-02-15 JP JP2022581146A patent/JPWO2022172442A1/ja active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008084243A (en) * | 2006-09-29 | 2008-04-10 | Hitachi Engineering & Services Co Ltd | Flood simulation device and program |
| JP6813865B1 (en) * | 2020-02-25 | 2021-01-13 | Arithmer株式会社 | Information processing method, program, information processing device and model generation method |
| CN111382716A (en) * | 2020-03-17 | 2020-07-07 | 上海眼控科技股份有限公司 | Weather prediction method and device of numerical mode, computer equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022172442A1 (en) | 2022-08-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Lee et al. | CNN-based image recognition for topology optimization | |
| Heitzler et al. | GPU-accelerated rendering methods to visually analyze large-scale disaster simulation data | |
| Willis et al. | Systematic analysis of uncertainty in 2D flood inundation models | |
| JP4979322B2 (en) | Inundation simulation device and program | |
| Huang et al. | Machine learning-based optimal mesh generation in computational fluid dynamics | |
| Carreau et al. | A PCA spatial pattern based artificial neural network downscaling model for urban flood hazard assessment | |
| JP2010054266A (en) | System for predicting inundation | |
| Kyprioti et al. | Incorporation of sea level rise in storm surge surrogate modeling | |
| Loverdos et al. | Geometrical digital twins of masonry structures for documentation and structural assessment using machine learning | |
| Gupta et al. | Accelerated multiscale mechanics modeling in a deep learning framework | |
| McCarroll et al. | An XBeach derived parametric expression for headland bypassing | |
| WO2022107485A1 (en) | Structure inspection assistance device, structure inspection assistance method, and program | |
| WO2022172442A1 (en) | Flooding prediction program, flooding prediction device, and machine-learning method | |
| Tariq et al. | Structural health monitoring installation scheme using utility computing model | |
| WO2022070734A1 (en) | Structure inspection assistance device, structure inspection assistance method, and program | |
| Carreau et al. | A spatially adaptive multi-resolution generative algorithm: Application to simulating flood wave propagation | |
| Neumann et al. | Comparing the" bathtub method" with Mike 21 HD flow model for modelling storm surge inundation | |
| JPWO2018179376A1 (en) | Degradation prediction device, deterioration prediction method, and program | |
| Zhuang et al. | Prediction of Ventilation Performance in Urban Area with CFD Simulation and Conditional Generative Adversarial Networks | |
| WO2022209290A1 (en) | Structure state prediction device, method, and program | |
| Shin | Visualizing the Invisible–Wind Flow Animation in Digital Twin Based Environmental Impact Assessments | |
| WO2022209304A1 (en) | Monitoring design assistance device, monitoring design assistance method, and program | |
| JP7283574B2 (en) | SPATIAL DATA RESOLUTION METHOD, SPATIAL DATA RESOLUTION APPARATUS, AND PROGRAM | |
| Chen et al. | Subpixel Mapping algorithms based on block structural self-similarity learning | |
| JP7294383B2 (en) | Parameter estimation device, route-based population estimation device, parameter estimation method, route-based population estimation method and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21925692 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022581146 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21925692 Country of ref document: EP Kind code of ref document: A1 |