WO2022138960A1 - 診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラム - Google Patents
診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラム Download PDFInfo
- Publication number
- WO2022138960A1 WO2022138960A1 PCT/JP2021/048386 JP2021048386W WO2022138960A1 WO 2022138960 A1 WO2022138960 A1 WO 2022138960A1 JP 2021048386 W JP2021048386 W JP 2021048386W WO 2022138960 A1 WO2022138960 A1 WO 2022138960A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- dementia
- cropping
- derivation model
- image
- finding
- Prior art date
Links
- 238000003745 diagnosis Methods 0.000 title abstract description 12
- 238000011017 operating method Methods 0.000 title 1
- 238000009795 derivation Methods 0.000 claims abstract description 210
- 201000010099 disease Diseases 0.000 claims abstract description 44
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 44
- 210000000056 organ Anatomy 0.000 claims abstract description 20
- 206010012289 Dementia Diseases 0.000 claims description 203
- 210000003484 anatomy Anatomy 0.000 claims description 43
- 238000012545 processing Methods 0.000 claims description 36
- 210000004556 brain Anatomy 0.000 claims description 22
- 210000001320 hippocampus Anatomy 0.000 claims description 22
- 238000012360 testing method Methods 0.000 claims description 19
- 238000004458 analytical method Methods 0.000 claims description 15
- 210000003478 temporal lobe Anatomy 0.000 claims description 12
- 238000013527 convolutional neural network Methods 0.000 claims description 11
- 238000002224 dissection Methods 0.000 claims description 10
- 238000013528 artificial neural network Methods 0.000 claims description 6
- 238000012706 support-vector machine Methods 0.000 claims description 5
- 238000009534 blood test Methods 0.000 claims description 3
- 230000002068 genetic effect Effects 0.000 claims description 3
- 239000012530 fluid Substances 0.000 claims 1
- 239000000284 extract Substances 0.000 abstract description 11
- 230000013016 learning Effects 0.000 description 147
- 238000002595 magnetic resonance imaging Methods 0.000 description 82
- 238000000034 method Methods 0.000 description 75
- 230000006835 compression Effects 0.000 description 50
- 238000007906 compression Methods 0.000 description 50
- 230000008569 process Effects 0.000 description 37
- 238000003860 storage Methods 0.000 description 30
- 238000004364 calculation method Methods 0.000 description 25
- 238000010606 normalization Methods 0.000 description 25
- 238000000605 extraction Methods 0.000 description 19
- 210000001652 frontal lobe Anatomy 0.000 description 17
- 230000006870 function Effects 0.000 description 17
- 238000005259 measurement Methods 0.000 description 17
- 208000024827 Alzheimer disease Diseases 0.000 description 14
- 230000011218 segmentation Effects 0.000 description 14
- 238000011176 pooling Methods 0.000 description 13
- 208000010877 cognitive disease Diseases 0.000 description 12
- 208000027061 mild cognitive impairment Diseases 0.000 description 12
- 230000000971 hippocampal effect Effects 0.000 description 9
- 238000010801 machine learning Methods 0.000 description 8
- 238000009336 multiple cropping Methods 0.000 description 7
- 238000000513 principal component analysis Methods 0.000 description 7
- 101150037123 APOE gene Proteins 0.000 description 5
- 102000013455 Amyloid beta-Peptides Human genes 0.000 description 4
- 108010090849 Amyloid beta-Peptides Proteins 0.000 description 4
- 102000000989 Complement System Proteins Human genes 0.000 description 4
- 108010069112 Complement System Proteins Proteins 0.000 description 4
- 210000004727 amygdala Anatomy 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 230000003247 decreasing effect Effects 0.000 description 4
- 210000004072 lung Anatomy 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 102000013498 tau Proteins Human genes 0.000 description 4
- 108010026424 tau Proteins Proteins 0.000 description 4
- 102000007592 Apolipoproteins Human genes 0.000 description 3
- 108010071619 Apolipoproteins Proteins 0.000 description 3
- 206010003694 Atrophy Diseases 0.000 description 3
- 230000037444 atrophy Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 238000003062 neural network model Methods 0.000 description 3
- 210000000869 occipital lobe Anatomy 0.000 description 3
- 206010059245 Angiopathy Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000017531 blood circulation Effects 0.000 description 2
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 2
- 210000000038 chest Anatomy 0.000 description 2
- 238000002591 computed tomography Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- 238000002600 positron emission tomography Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 210000004885 white matter Anatomy 0.000 description 2
- 208000022099 Alzheimer disease 2 Diseases 0.000 description 1
- 108010025628 Apolipoproteins E Proteins 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 206010062767 Hypophysitis Diseases 0.000 description 1
- 208000029523 Interstitial Lung disease Diseases 0.000 description 1
- 208000009829 Lewy Body Disease Diseases 0.000 description 1
- 201000002832 Lewy body dementia Diseases 0.000 description 1
- 208000019693 Lung disease Diseases 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 108010071690 Prealbumin Proteins 0.000 description 1
- 102000009190 Transthyretin Human genes 0.000 description 1
- 201000004810 Vascular dementia Diseases 0.000 description 1
- 230000032683 aging Effects 0.000 description 1
- 230000003542 behavioural effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000011157 brain segmentation Effects 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 208000019425 cirrhosis of liver Diseases 0.000 description 1
- 230000019771 cognition Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 210000000877 corpus callosum Anatomy 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 210000000232 gallbladder Anatomy 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 210000003140 lateral ventricle Anatomy 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 208000019423 liver disease Diseases 0.000 description 1
- 230000005976 liver dysfunction Effects 0.000 description 1
- 210000000691 mamillary body Anatomy 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 210000001769 parahippocampal gyrus Anatomy 0.000 description 1
- 210000003635 pituitary gland Anatomy 0.000 description 1
- 230000002250 progressing effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000003325 tomography Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
Images

























Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B10/00—Other methods or instruments for diagnosis, e.g. instruments for taking a cell sample, for biopsy, for vaccination diagnosis; Sex determination; Ovulation-period determination; Throat striking implements
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/05—Detecting, measuring or recording for diagnosis by means of electric currents or magnetic fields; Measuring using microwaves or radio waves
- A61B5/055—Detecting, measuring or recording for diagnosis by means of electric currents or magnetic fields; Measuring using microwaves or radio waves involving electronic [EMR] or nuclear [NMR] magnetic resonance, e.g. magnetic resonance imaging
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/16—Devices for psychotechnics; Testing reaction times ; Devices for evaluating the psychological state
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H30/00—ICT specially adapted for the handling or processing of medical images
- G16H30/20—ICT specially adapted for the handling or processing of medical images for handling medical images, e.g. DICOM, HL7 or PACS
Definitions
- the technique of the present disclosure relates to a diagnostic support device, an operation method of the diagnostic support device, and an operation program of the diagnostic support device.
- a doctor In diagnosing a disease, for example, dementia represented by Alzheimer's disease, a doctor refers to a medical image such as a head MRI (Magnetic Resonance Imaging) image. For example, the doctor observes the degree of atrophy of the hippocampus, parahippocampal gyrus, amygdala, etc., the degree of angiopathy of the white matter, the presence or absence of decreased blood flow metabolism in the frontal lobe, temporal lobe, and occipital lobe, and makes findings of dementia. obtain.
- MRI Magnetic Resonance Imaging
- Patent No. 6438890 describes a diagnostic support device that derives the findings of dementia on a head MRI image by a machine learning model and provides it to a doctor.
- the diagnostic support device described in Japanese Patent No. 6438890 extracts a plurality of anatomical areas according to Brodmann's brain map and the like from the head MRI image, and calculates a Z value indicating the degree of atrophy of each anatomical area. .. Then, the calculated Z value of each anatomical area is input to the machine learning model, and the findings of dementia are output from the machine learning model.
- One embodiment according to the technique of the present disclosure provides a diagnostic support device, an operation method of the diagnostic support device, and an operation program of the diagnostic support device capable of obtaining more accurate findings of a disease.
- the diagnostic assist device of the present disclosure comprises a processor and a memory connected to or built into the processor, which acquires a medical image, extracts an anatomical area of an organ from the medical image, and has a different location and / or size.
- a plurality of cropping images are generated by cropping an area including at least a part of the dissection area, and the plurality of cropping images are converted into a feature quantity derivation model prepared corresponding to each of the plurality of cropping images.
- feature amount data corresponding to the cropping image is output from the feature amount derivation model
- feature amount data output for each of multiple cropping images is input to the disease finding derivation model
- diseases related to organs from the disease finding derivation model are output.
- the processor extracts a plurality of dissected areas and generates a plurality of cropping images for each of the plurality of dissected areas.
- the feature quantity derivation model preferably includes at least one of an autoencoder, a single-tasking convolutional neural network for class discrimination, and a multitasking convolutional neural network for class discrimination.
- the processor inputs one cropping image into a plurality of different feature quantity derivation models and outputs feature quantity data from each of the plurality of feature quantity derivation models.
- the disease finding derivation model is preferably constructed by any of the following methods: neural network, support vector machine, boosting, and linear discriminant analysis.
- the processor inputs disease-related information related to the disease into the disease finding derivation model in addition to the plurality of feature data.
- the organ is the brain and the disease is dementia.
- the dissecting area preferably comprises at least one of the hippocampus and the anterior temporal lobe.
- the disease-related information preferably includes at least one of the volume of the dissected area, the score of the dementia test, the test result of the genetic test, the test result of the cerebrospinal fluid test, and the test result of the blood test. ..
- the method of operating the diagnostic support device of the present disclosure is to acquire a medical image, extract an anatomical area of an organ from the medical image, and cover an area including at least a part of the anatomical area at different positions and / or sizes.
- Generating multiple cropping images by cropping inputting multiple cropping images into the feature quantity derivation model prepared for each of the multiple cropping images, and corresponding to the cropping image from the feature quantity derivation model. It includes outputting feature amount data, inputting feature amount data output for each of a plurality of cropped images into a disease finding derivation model, and outputting the findings of diseases related to organs from the disease finding derivation model.
- the actuation program of the diagnostic support device of the present disclosure is to acquire a medical image, extract an anatomical area of an organ from the medical image, and cover an area covering at least a part of the anatomical area at different positions and / or sizes.
- Generating multiple cropping images by cropping inputting multiple cropping images into the feature quantity derivation model prepared for each of the multiple cropping images, and corresponding to the cropping image from the feature quantity derivation model.
- Processing including output of feature amount data and input of feature amount data output for each of a plurality of cropped images to a disease finding derivation model and output of disease findings related to organs from the disease finding derivation model. Let the computer run.
- a diagnostic support device capable of obtaining more accurate findings of a disease, an operation method of the diagnostic support device, and an operation program of the diagnostic support device.
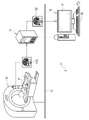
- the medical system 2 includes an MRI apparatus 10, a PACS (Picture Archiving and Communication System) server 11, and a diagnostic support apparatus 12.
- MRI apparatus 10 Magnetic Imaging apparatus
- PACS server 11 Picture Archiving and Communication System
- diagnostic support apparatus 12 are connected to a LAN (Local Area Network) 13 installed in a medical facility, and can communicate with each other via the LAN 13.
- LAN Local Area Network
- the MRI apparatus 10 photographs the head of patient P and outputs a head MRI image 15.
- the head MRI image 15 is voxel data representing the three-dimensional shape of the head of the patient P.
- FIG. 1 shows a head MRI image 15S of a sagittal cross section.
- the MRI apparatus 10 transmits the head MRI image 15 to the PACS server 11.
- the PACS server 11 stores and manages the head MRI image 15 from the MRI apparatus 10.
- the head MRI image 15 is an example of a "medical image" according to the technique of the present disclosure.
- the diagnostic support device 12 is, for example, a desktop personal computer, and includes a display 17 and an input device 18.
- the input device 18 is a keyboard, a mouse, a touch panel, a microphone, or the like.
- the doctor operates the input device 18 to send a delivery request for the head MRI image 15 of the patient P to the PACS server 11.
- the PACS server 11 searches for the head MRI image 15 of the patient P requested to be delivered and delivers it to the diagnosis support device 12.
- the diagnosis support device 12 displays the head MRI image 15 distributed from the PACS server 11 on the display 17. The doctor observes the brain of the patient P shown in the head MRI image 15 to make a diagnosis of dementia for the patient P.
- the brain is an example of an "organ” according to the technique of the present disclosure
- dementia is an example of a "disease” according to the technique of the present disclosure.
- FIG. 1 Although only one MRI device 10 and one diagnostic support device 12 are drawn in FIG. 1, a plurality of MRI device 10 and a plurality of diagnostic support devices 12 may be provided.
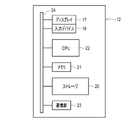
- the computer constituting the diagnostic support device 12 includes a storage 20, a memory 21, a CPU (Central Processing Unit) 22, and a communication unit 23 in addition to the display 17 and the input device 18 described above. I have. These are interconnected via a bus line 24.
- the CPU 22 is an example of a "processor" according to the technique of the present disclosure.
- the storage 20 is a hard disk drive built in the computer constituting the diagnostic support device 12 or connected via a cable or a network.
- the storage 20 is a disk array in which a plurality of hard disk drives are connected.
- the storage 20 stores control programs such as an operating system, various application programs, and various data associated with these programs.
- a solid state drive may be used instead of the hard disk drive.
- the memory 21 is a work memory for the CPU 22 to execute a process.
- the CPU 22 loads the program stored in the storage 20 into the memory 21 and executes the process according to the program. As a result, the CPU 22 controls each part of the computer in an integrated manner.
- the communication unit 23 controls the transmission of various information with an external device such as the PACS server 11.
- the memory 21 may be built in the CPU 22.
- the operation program 30 is stored in the storage 20 of the diagnostic support device 12.
- the operation program 30 is an application program for making the computer function as the diagnostic support device 12. That is, the operation program 30 is an example of the "operation program of the diagnostic support device" according to the technique of the present disclosure.
- a head MRI image 15 a standard head MRI image 35, a segmentation model 36, a cropping condition group 38 composed of a plurality of cropping conditions 37, and a feature quantity derivation including a plurality of feature quantity derivation models 39 are derived.
- the model group 40 and the dementia finding derivation model 41 are also stored.
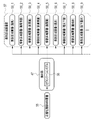
- the CPU 22 of the computer constituting the diagnostic support device 12 cooperates with the memory 21 and the like to read / write (hereinafter abbreviated as RW (Read Write)) control unit 45 and normalization unit. It functions as 46, an extraction unit 47, a cropping image generation unit 48, a feature amount derivation unit 49, a dementia finding derivation unit 50, and a display control unit 51.
- RW Read Write
- the RW control unit 45 controls the storage of various data in the storage 20 and the reading of various data in the storage 20.
- the RW control unit 45 receives the head MRI image 15 from the PACS server 11 and stores the received head MRI image 15 in the storage 20.
- the RW control unit 45 receives the head MRI image 15 from the PACS server 11 and stores the received head MRI image 15 in the storage 20.
- FIG. 3 only one head MRI image 15 is stored in the storage 20, but a plurality of head MRI images 15 may be stored in the storage 20.
- the RW control unit 45 reads out the head MRI image 15 of the patient P designated by the doctor for diagnosing dementia from the storage 20, and outputs the read head MRI image 15 to the normalization unit 46 and the display control unit 51. do.
- the RW control unit 45 has acquired the head MRI image 15 by reading the head MRI image 15 from the storage 20.
- the RW control unit 45 reads the standard head MRI image 35 from the storage 20, and outputs the read standard head MRI image 35 to the normalization unit 46.
- the RW control unit 45 reads the segmentation model 36 from the storage 20, and outputs the read segmentation model 36 to the extraction unit 47.
- the RW control unit 45 reads the cropping condition group 38 from the storage 20, and outputs the read cropping condition group 38 to the cropping image generation unit 48.
- the RW control unit 45 reads out the feature amount derivation model group 40 from the storage 20, and outputs the read feature amount derivation model group 40 to the feature amount derivation unit 49.
- the RW control unit 45 reads the dementia finding derivation model 41 from the storage 20 and outputs the read dementia finding derivation model 41 to the dementia finding derivation unit 50.
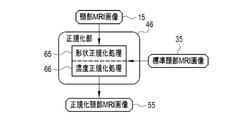
- the normalization unit 46 performs a normalization process to match the head MRI image 15 with the standard head MRI image 35, and sets the head MRI image 15 as the normalized head MRI image 55.
- the normalization unit 46 outputs the normalized head MRI image 55 to the extraction unit 47.
- the standard head MRI image 35 is a head MRI image showing the brain having a standard shape, size, and density (pixel value).
- the standard head MRI image 35 is, for example, an image generated by averaging the head MRI images 15 of a plurality of healthy subjects, or an image generated by computer graphics.
- the extraction unit 47 inputs the normalized head MRI image 55 into the segmentation model 36.
- the segmentation model 36 is a machine learning model that performs so-called semantic segmentation, in which a label representing each anatomical area of the brain such as the hippocampus, amygdala, and frontal lobe is given to each pixel of the brain reflected in the normalized head MRI image 55.
- the extraction unit 47 extracts an image (hereinafter referred to as an anatomical area image) 56 of a plurality of anatomical areas of the brain from the normalized head MRI image 55 based on the label given by the segmentation model 36.
- the extraction unit 47 outputs the dissection area image group 57 composed of the plurality of dissection area images 56 for each dissection area to the cropping image generation unit 48.
- the cropping image generation unit 48 generates a cropping image 58 by cropping an area including at least a part of the dissected area of the brain reflected in the dissected area image 56 according to the cropping condition 37.
- the region including at least a part of the dissected area of the brain may be a region including the entire hippocampus or a region including a part of the hippocampus, for example, when the dissected area is the hippocampus. May be good.
- the cropping image generation unit 48 outputs the cropping image group 59 composed of the generated plurality of cropping images 58 to the feature amount derivation unit 49.
- One feature quantity derivation model 39 is prepared for each cropping image 58 (see FIG. 8).
- the feature amount derivation unit 49 inputs the cropping image 58 into the corresponding feature amount derivation model 39.
- the aggregated feature amount ZA is output from the feature amount derivation model 39.
- the feature amount derivation unit 49 outputs the aggregated feature amount group ZAG composed of a plurality of aggregated feature amounts ZA corresponding to the plurality of cropping images 58 to the dementia finding derivation unit 50.
- the aggregated feature amount ZA is an example of "feature amount data" according to the technique of the present disclosure.
- the dementia finding derivation unit 50 inputs the aggregated feature group ZAG into the dementia finding derivation model 41. Then, the dementia finding information 60 representing the dementia finding is output from the dementia finding derivation model 41. The dementia finding derivation unit 50 outputs the dementia finding information 60 to the display control unit 51.
- the dementia finding derivation model 41 is an example of the "disease finding derivation model" according to the technique of the present disclosure.
- the display control unit 51 controls the display of various screens on the display 17. On the various screens, a first display screen 70 (see FIG. 10) for instructing analysis by the segmentation model 36, the feature quantity derivation model 39, and the dementia finding derivation model 41, and a second dementia finding information 60 are displayed. A display screen 75 (see FIG. 11) and the like are included.
- the normalization unit 46 performs shape normalization processing 65 and density normalization processing 66 as normalization processing on the head MRI image 15.
- the shape normalization process 65 extracts, for example, a landmark that serves as a reference for alignment from the head MRI image 15 and the standard head MRI image 35, and the landmark of the head MRI image 15 and the standard head MRI image 35. This is a process of moving, rotating, and / or scaling the head MRI image 15 in parallel with the standard head MRI image 35 so as to maximize the correlation with the landmark.
- the density normalization process 66 is, for example, a process of correcting the density histogram of the head MRI image 15 according to the density histogram of the standard head MRI image 35.
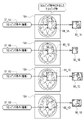
- the extraction unit 47 has, as the anatomical area image 56, the anatomical area image 56_1 of the hippocampus, the anatomical area image 56_2 around the hippocampus, the anatomical area image 56_3 of the frontal lobe, and the anatomical area image of the anterior temporal lobe.
- 56_4 anatomical area image 56_5 of the occipital lobe, anatomical area image 56_6 of the thorax, anatomical area image 56_7 of the lower part of the thorax, anatomical area image 56_8 of the tongue, anatomical area image 56_9 of the pituitary gland, and the like are extracted.
- the extraction unit 47 extracts an anatomical area image 56 of each anatomical area such as the mammillary body, corpus callosum, fornix, and lateral ventricle.
- the anatomical areas such as the hippocampus, frontal lobe, anterior temporal lobe, and amygdala are paired left and right.
- the anatomical area image 56 of each of the left and right anatomical areas is extracted from such a pair of left and right anatomical areas. For example, for the hippocampus, an anatomical area image 56_1 of the left hippocampus and an anatomical area image 56_1 of the right hippocampus are extracted.
- the dissected areas it is preferable to include at least one of the hippocampus and the anterior temporal lobe, and it is more preferable to include all of the hippocampus and the anterior temporal lobe.
- the anterior temporal lobe means the anterior part of the temporal lobe.
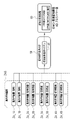
- the cropping image generation unit 48 has the hippocampal cropping images 58_1A, 58_1B, 58_1C, ... ⁇ ⁇ Generate. Similarly, the cropping image generation unit 48, according to the cropping conditions 37_2A, 37_2B, 37_2C, ... ⁇ ⁇ Generate. Further, the cropping image generation unit 48 generates frontal lobe cropping images 58_3A, 58_3B, 58_3C, ... From the frontal lobe anatomical area image 56_3 according to the frontal lobe cropping conditions 37_3A, 37_3B, 37_3C, ....
- the cropping image generation unit 48 obtains the anterior temporal lobe cropping images 58_4A, 58_4B, 58_4C, ... ⁇ Generate. In this way, the cropping image generation unit 48 generates a plurality of cropping images 58 for each of a plurality of anatomical areas of the brain such as the hippocampus, frontal lobe, and frontal lobe.
- FIG. 7 which shows an example of generating a hippocampal cropping image 58_1
- the cropping image generation unit 48 sets a cropping frame 68 corresponding to the cropping condition 37 in the dissected area image 56. Then, the cropping image 58 is generated by cropping the dissected area image 56 with the set cropping frame 68.
- a head MRI image 15A having an axial cross section is shown instead of the dissected area image 56.
- the cropping frame 68 is illustrated by a two-dimensional rectangle. However, in reality, the cropping frame 68 is a three-dimensional voxel.
- the cropping condition 37 is the coordinate information of the cropping frame 68, for example, the XYZ coordinates of the corner position and the center position of the cropping frame 68.
- the center position of the cropping frame 68 is set with respect to the center position of the dissected area.
- the feature amount derivation unit 49 inputs the hippocampal cropping images 58_1A, 58_1B, ... To the hippocampal feature amount derivation model 39_1A, 39_1B, ..., And derives the hippocampal feature amount.
- the hippocampal aggregate features ZA_1A, ZA_1B, ... Are output from the models 39_1A, 39_1B, ....
- the feature amount derivation unit 49 inputs the cropping images 58_2A, 58_2B, ... 58_3B, ... Are input to the frontal lobe feature quantity derivation models 39_3A, 39_3B, ..., And the frontal lobe cropping images 58_4A, 58_4B, ... Are input to the frontal lobe feature quantity derivation models 39_4A, 39_4B, ... ⁇ ⁇ Enter in. Then, the aggregated feature quantities ZA_2A, ZA_2B, ... The aggregated feature amounts ZA_3A, ZA_3B, ...
- the aggregated feature amounts ZA_4A, ZA_4B, ... Of the frontal lobe are output from the features derived models 39_4A, 39_4B, ... Of the frontal lobe.
- the plurality of cropping images 58 are input to the corresponding feature amount derivation model 39, whereby the plurality of aggregated feature amounts ZA for each cropping image 58 are output from each feature amount derivation model 39.
- the dementia finding derivation unit 50 inputs the aggregated feature group ZAG into the dementia finding derivation model 41. Then, from the dementia finding derivation model 41, as dementia finding information 60, the patient P with mild cognitive impairment (MCI; Mild Cognitive Impairment) remains mild cognitive impairment after 2 years, or Alzheimer's disease (AD) after 2 years. ; Proceed to Alzheimer's Disease), whichever is output.
- MCI Mild Cognitive Impairment
- AD Alzheimer's disease
- FIG. 10 shows an example of a first display screen 70 for instructing analysis by the segmentation model 36, the feature amount derivation model 39, and the dementia finding derivation model 41.
- the head MRI image 15 of the patient P diagnosing dementia is displayed.
- the head MRI image 15 is a head MRI image 15S having a sagittal cross section, a head MRI image 15A having an axial cross section, and a head MRI image 15C having a coronal cross section.
- a button group 71 for switching the display is provided at the lower part of each of the head MRI images 15S, 15A, and 15C.
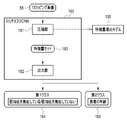
- the analysis button 72 is provided on the first display screen 70.
- the doctor selects the analysis button 72 when he / she wants to perform analysis by the segmentation model 36, the feature amount derivation model 39, and the dementia finding derivation model 41.
- the CPU 22 accepts the instruction for analysis by the segmentation model 36, the feature amount derivation model 39, and the dementia finding derivation model 41.
- FIG. 11 shows an example of a second display screen 75 displaying dementia finding information 60 obtained as a result of analysis by the segmentation model 36, the feature amount derivation model 39, and the dementia finding derivation model 41.
- a message 76 corresponding to the dementia finding information 60 is displayed.
- the dementia finding information 60 states that the patient P with mild cognitive impairment currently progresses to Alzheimer's disease two years later, and the message 76 states that "there is a risk of progressing to Alzheimer's disease two years later.”
- the displayed example is shown.
- the display control unit 51 turns off the display of the message 76 and returns the second display screen 75 to the first display screen 70.
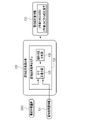
- the feature quantity derivation model 39 includes an autoencoder (hereinafter abbreviated as AE (Auto Encoder)) 80 and a single-task convolutional neural network (hereinafter, single-task CNN (Convolutional Neural)).
- AE Auto Encoder
- single-task CNN Convolutional Neural
- a model that combines (Newwork)) and 81) is used.
- the AE80 has a compression unit 82 and a restoration unit 83.
- the cropping image 58 is input to the compression unit 82.
- the compression unit 82 converts the cropping image 58 into the feature amount set 84.
- the feature amount set 84 is composed of a plurality of feature amounts Z1, Z2, ..., ZN. Note that N is the number of feature quantities, for example, tens to hundreds of thousands.
- the compression unit 82 passes the feature amount set 84 to the restoration unit 83.
- the restoration unit 83 generates the restoration image 85 of the cropping image 58 from the feature amount
- the single task CNN81 has a compression unit 82 and an output unit 86. That is, the compression unit 82 is shared by the AE80 and the single task CNN81.
- the compression unit 82 passes the feature amount set 84 to the output unit 86.
- the output unit 86 outputs one class 87 based on the feature amount set 84. In FIG. 12, the output unit 86 outputs the determination result that the patient P with mild cognitive impairment remains mild cognitive impairment after 2 years or progresses to Alzheimer's disease after 2 years as class 87. Further, the output unit 86 outputs an aggregated feature amount ZA that aggregates a plurality of feature amounts Z constituting the feature amount set 84.
- the compression unit 82 converts the cropping image 58 into the feature amount set 84 by performing a convolution operation as shown in FIG. 13 as an example.
- the compression unit 82 has a convolution layer 90 represented by “conv” (abbreviation for convolution).
- the convolution layer 90 applies, for example, a 3 ⁇ 3 filter 93 to the target data 92 having a plurality of elements 91 arranged in two dimensions. Then, the element value e of one of the elements 91 of interest and the element values a, b, c, d, f, g, h, and i of eight elements 91S adjacent to the element 91I of interest are convolved.
- the convolution layer 90 sequentially performs a convolution operation on each element 91 of the target data 92 while shifting the element of interest 91I by one element, and outputs the element value of the element 94 of the operation data 95.
- the operation data 95 having a plurality of elements 94 arranged in two dimensions can be obtained as in the target data 92.
- the target data 92 first input to the convolution layer 90 is the cropping image 58, and then the reduction calculation data 95S (see FIG. 15) described later is input to the convolution layer 90 as the target data 92.
- the element 94I corresponding to the element of interest 91I of the operation data 95 which is the result of the convolution operation for the element of interest 91I.
- One operation data 95 is output for one filter 93.
- the calculation data 95 is output for each filter 93. That is, as shown in FIG. 14 as an example, the arithmetic data 95 is generated for the number of filters 93 applied to the target data 92. Further, since the arithmetic data 95 has a plurality of elements 94 arranged in two dimensions, it has a width and a height. The number of arithmetic data 95 is called the number of channels.
- FIG. 14 illustrates the four-channel arithmetic data 95 output by applying the four filters 93 to the target data 92.
- the compression unit 82 has a pooling layer 100 represented by “pool (abbreviation of pooling)” in addition to the convolution layer 90.
- the pooling layer 100 obtains a local statistic of the element value of the element 94 of the operation data 95, and generates the reduced operation data 95S having the obtained statistic as the element value.
- the pooling layer 100 performs a maximum value pooling process for obtaining the maximum value of the element value in the block 101 of the 2 ⁇ 2 element as a local statistic. If the block 101 is processed while being shifted by one element in the width direction and the height direction, the reduction calculation data 95S is reduced to half the size of the original calculation data 95.
- the element values a, b, e, and b in the block 101A, the element values b, c, f, and g in the block 101B, and the element values c and d in the block 101C are shown.
- G, and h are exemplified when h is the maximum value, respectively. It should be noted that the mean value pooling process may be performed in which the mean value is obtained as a local statistic instead of the maximum value.
- the compression unit 82 outputs the final calculation data 95 by repeating the convolution process by the convolution layer 90 and the pooling process by the pooling layer 100 a plurality of times.
- the final calculated data 95 is the feature set 84, and the element value of each element 94 of the final calculated data 95 is the feature Z.
- the characteristic amount Z thus obtained represents the shape and texture characteristics of the dissected area, such as the degree of hippocampal atrophy, the degree of white matter angiopathy, and the presence or absence of decreased blood flow metabolism in the frontal lobe, frontal lobe, and occipital lobe. There is.
- each process is actually performed in three dimensions.
- the output unit 86 has a self-attention (hereinafter abbreviated as SA (Self-Attention)) mechanism layer 110, an overall average pooling (hereinafter abbreviated as GAP (Global Function Polling)) layer 111, and Fully coupled (hereinafter abbreviated as FC (Full Connected)) layer 112, softmax function (hereinafter abbreviated as SMF (SoftMax Function) layer 113, and principal component analysis (hereinafter abbreviated as PCA (Principal Component Analysis)) layer 114.
- SA Self-attention
- GAP Global Function Polling
- FC Fully coupled
- SMF SoftMax Function
- PCA Principal component analysis
- the SA mechanism layer 110 performs the convolution process shown in FIG. 13 on the feature amount set 84 while changing the coefficient of the filter 93 according to the element value of the element of interest 91I.
- the convolution process performed by the SA mechanism layer 110 is referred to as an SA convolution process.
- the SA mechanism layer 110 outputs the feature amount set 84 after the SA convolution process to the GAP layer 111.
- the GAP layer 111 is subjected to an overall average pooling treatment on the feature amount set 84 after the SA convolution treatment.
- the overall average pooling process is a process for obtaining the average value of the feature amount Z for each channel (see FIG. 14) of the feature amount set 84. For example, when the number of channels of the feature amount set 84 is 512, the average value of 512 feature amounts Z is obtained by the overall average pooling process.
- the GAP layer 111 outputs the average value of the obtained feature amount Z to the FC layer 112 and the PCA layer 114.
- the FC layer 112 converts the average value of the feature amount Z into a variable handled by the SMF of the SMF layer 113.
- the FC layer 112 has an input layer having as many units as the number of average values of the feature amount Z (that is, the number of channels of the feature amount set 84) and an output layer having as many units as the number of variables handled by the SMF.
- Each unit of the input layer and each unit of the output layer are fully connected to each other, and weights are set for each.
- An average value of the feature amount Z is input to each unit of the input layer.
- the sum of products of the average value of the feature amount Z and the weight set between each unit is the output value of each unit of the output layer.
- This output value is a variable handled by SMF.
- the FC layer 112 outputs the variables handled by the SMF to the SMF layer 113.
- the SMF layer 113 outputs the class 87 by applying the variable to the SMF.
- the PCA layer 114 performs PCA on the average value of the feature amount Z, and sets the average value of the plurality of feature amount Z as a smaller number of aggregate feature amount ZA. For example, the PCA layer 114 aggregates the average value of 512 feature quantities Z into one aggregated feature quantity ZA.
- the AE80 is learned by inputting a learning cropping image 58L in the learning phase.
- the AE80 outputs a learning restored image 85L to a learning cropping image 58L.
- the loss calculation of the AE80 using the loss function is performed.
- various coefficients of the AE80 coefficients of the filter 93, etc.
- the loss L1 the result of the loss calculation
- the above series of processes of inputting the learning cropping image 58L to the AE80, outputting the learning restoration image 85L from the AE80, loss calculation, update setting, and updating the AE80 are the learning cropping images. It is repeated while 58L is exchanged.
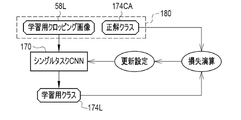
- the single task CNN81 is given the learning data 120 and is learned in the learning phase.
- the learning data 120 is a set of a learning cropping image 58L and a correct answer class 87CA corresponding to the learning cropping image 58L.
- Correct class 87CA indicates whether patient P with a learning cropping image 58L actually remained mild cognitive impairment after 2 years or progressed to Alzheimer's disease 2 years later.
- the learning cropping image 58L is input to the single task CNN81.
- the single task CNN81 outputs a learning class 87L for a learning cropping image 58L.
- the loss calculation of the single task CNN81 using the cross entropy function or the like is performed.
- various coefficients of the single task CNN 81 are updated according to the result of the loss calculation (hereinafter referred to as loss L2), and the single task CNN 81 is updated according to the update settings.
- the processing is repeated while the learning data 120 is exchanged.
- the update setting of the AE80 and the update setting of the single task CNN81 are performed based on the total loss L represented by the following equation (2).
- ⁇ is a weight.
- L L1 ⁇ ⁇ + L2 ⁇ (1- ⁇ ) ⁇ ⁇ ⁇ (2) That is, the total loss L is a weighted sum of the loss L1 of the AE80 and the loss L2 of the single task CNN81.
- 1 is set for the weight ⁇ in the initial stage of the learning phase.
- the weight ⁇ is gradually reduced from 1 as learning progresses, and eventually becomes a fixed value (0.8 in FIG. 18).
- the learning of the AE80 and the learning of the single task CNN81 are performed together with the intensity corresponding to the weight ⁇ .
- the weight given to the loss L1 is larger than the weight given to the loss L2.
- the weight given to the loss L1 is gradually decreased from the maximum value of 1, and the weight given to the loss L2 is gradually increased from the minimum value of 0, and both are set to fixed values.
- the restoration accuracy from the cropping image 58L for learning by AE80 to the restored image 85L for learning reaches a predetermined setting level, and the learning class for the correct answer class 87CA by single task CNN81. It ends when the prediction accuracy of 87L reaches a predetermined set level.
- the AE80 and the single-tasking CNN81 whose restoration accuracy and prediction accuracy have reached the set level are stored in the storage 20 and used as the feature amount derivation model 39.
- the dementia finding derivation model 41 is constructed by any one of a neural network, a support vector machine, and boosting.
- the dementia finding derivation model 41 is trained given the learning data 125.
- the learning data 125 is a set of the learning aggregated feature group ZAGL and the correct answer dementia finding information 60CA corresponding to the learning aggregated feature group ZAGL.
- the learning aggregate feature quantity group ZAGL is obtained by inputting the cropping image 58 of a certain head MRI image 15 into the feature quantity derivation model 39.
- the correct dementia finding information 60CA is the result of the doctor actually diagnosing the dementia findings on the head MRI image 15 obtained the learning aggregate feature group ZAGL.
- the learning aggregate feature group ZAGL is input to the dementia finding derivation model 41.
- the dementia finding derivation model 41 outputs learning dementia finding information 60L for the learning aggregate feature group ZAGL.
- the loss calculation of the dementia finding derivation model 41 using the loss function is performed.
- various coefficients of the dementia finding derivation model 41 are updated according to the result of the loss calculation, and the dementia finding derivation model 41 is updated according to the update setting.
- the update setting, and the above-mentioned series of processes for updating the dementia finding derivation model 41 are repeated while the learning data 125 is exchanged.
- the repetition of the above series of processes ends when the prediction accuracy of the learning dementia finding information 60L with respect to the correct dementia finding information 60CA reaches a predetermined set level.
- the dementia finding derivation model 41 whose prediction accuracy has reached a set level is stored in the storage 20 and used by the dementia finding derivation unit 50.
- the CPU 22 of the diagnostic support device 12 has a RW control unit 45, a normalization unit 46, an extraction unit 47, and a cropping image generation unit. It functions as 48, a feature amount derivation unit 49, a dementia finding derivation unit 50, and a display control unit 51.
- the RW control unit 45 reads out the corresponding head MRI image 15 and the standard head MRI image 35 from the storage 20 (step). ST100).
- the head MRI image 15 and the standard head MRI image 35 are output from the RW control unit 45 to the normalization unit 46.
- a normalization process for matching the head MRI image 15 with the standard head MRI image 35 is performed (step ST110). ).
- the head MRI image 15 becomes a normalized head MRI image 55.
- the normalized head MRI image 55 is output from the normalized unit 46 to the extraction unit 47.
- a plurality of anatomical area images 56 of the brain are extracted from the normalized head MRI image 55 using the segmentation model 36 (step ST120).
- the dissection area image group 57 composed of the plurality of dissection area images 56 is output from the extraction unit 47 to the cropping image generation unit 48.
- the cropping image generator 48 crops the area including at least a part of the dissected area of the dissected area image 56 at different positions and / or sizes according to the cropping condition 37. By doing so, a plurality of cropping images 58 are generated (step ST130).
- the cropping image group 59 composed of the plurality of cropping images 58 is output from the cropping image generation unit 48 to the feature amount derivation unit 49.
- a plurality of cropping images 58 are input to the feature amount derivation model 39 corresponding to each.
- a plurality of aggregated feature quantities ZA corresponding to the cropping image 58 are output from each feature quantity derivation model 39 (step ST140).
- the aggregated feature group ZAG composed of a plurality of aggregated feature quantities ZA corresponding to the number of cropping images 58 is output from the feature quantity derivation unit 49 to the dementia finding derivation unit 50.
- the aggregate feature group ZAG composed of a plurality of aggregate feature ZAs is input to the dementia findings derivation model 41.
- the dementia finding information 60 is output from the dementia finding derivation model 41 (step ST150).
- the dementia finding information 60 is output from the dementia finding derivation unit 50 to the display control unit 51.
- the second display screen 75 shown in FIG. 11 is displayed on the display 17 (step ST160).
- the doctor confirms the dementia finding information 60 through the message 76 on the second display screen 75.
- the CPU 22 of the diagnostic support device 12 includes a RW control unit 45, an extraction unit 47, a cropping image generation unit 48, a feature amount derivation unit 49, and a dementia finding derivation unit 50.
- the RW control unit 45 acquires the head MRI image 15 by reading the head MRI image 15 of the patient P who diagnoses dementia from the storage 20.
- the extraction unit 47 extracts an anatomical area image 56 of a plurality of anatomical areas of the brain from the normalized head MRI image 55.
- the cropping image generator 48 generates a plurality of cropped images 58 by cropping an area including at least a part of the anatomical area of the brain at different positions and / or sizes.
- the feature amount derivation unit 49 inputs a plurality of cropping images 58 into the feature amount derivation model 39 prepared corresponding to each of the plurality of cropping images 58, and aggregates the feature amount derivation model 39 to the cropping image 58.
- the feature amount ZA is output.
- the dementia finding derivation unit 50 inputs the aggregated feature group ZAG composed of a plurality of aggregated feature quantities ZA into the dementia finding derivation model 41, and outputs the dementia finding information 60 from the dementia finding derivation model 41. Therefore, the accuracy of predicting the findings of dementia can be improved as compared with the method described in Japanese Patent No. 6438890, and more accurate findings of dementia can be obtained.
- the extraction unit 47 extracts a plurality of dissected areas. Further, as shown in FIG. 6, the cropping image generation unit 48 generates a plurality of cropping images 58 for each of the plurality of dissected areas. Therefore, it is possible to obtain an aggregate feature amount ZA corresponding to a plurality of cropping images 58 for each of a plurality of dissected areas.
- the aggregated feature amount ZA thus obtained does not represent the limited features of the brain as in the Z value described in Japanese Patent No. 6438890, but represents the comprehensive features of the brain. Further, the aggregated feature amount ZA is not a value obtained statistically like the Z value described in Japanese Patent No. 6438890, but is obtained by inputting a cropping image 58 into the feature amount derivation model 39. Therefore, the accuracy of predicting the findings of dementia can be further improved.
- the brain is subdivided into a plurality of anatomical areas, a plurality of cropping images 58 are further generated from the plurality of anatomical areas, and an aggregate feature amount ZA is derived for each of the plurality of cropping images 58. ing. Then, the derived plurality of aggregated feature quantities ZA are input to one dementia finding derivation model 41. Therefore, it is possible to achieve the purpose of obtaining more accurate findings of dementia, which has been difficult in the past.
- the feature quantity derivation model 39 is a diversion of a model in which AE80 and single task CNN81 are combined.
- AE80 and single-tasking CNN81 are one of the frequently used neural network models in the field of machine learning and are generally very well known. Therefore, it can be diverted to the feature amount derivation model 39 relatively easily.
- a single task CNN81 that performs a main task such as output of class 87 and an AE80 that performs a subtask that is partially common to the single task CNN81 and is more general than the main task such as generation of a restored image 85 are used as a feature amount derivation model 39. .. Then, the AE80 and the single task CNN81 are learned at the same time. Therefore, as compared with the case where the AE80 and the single task CNN81 are separate, a more appropriate feature amount set 84 and the aggregated feature amount ZA can be output, and as a result, the prediction accuracy of the dementia finding information 60 can be improved. ..
- the update setting is performed based on the total loss L, which is the weighted sum of the loss L1 of the AE80 and the loss L2 of the single task CNN81. Therefore, by setting the weight ⁇ to an appropriate value, the AE80 can be intensively learned, the single-tasking CNN81 can be intensively learned, and the AE80 and the single-tasking CNN81 can be learned in a well-balanced manner.
- the weight given to the loss L1 is larger than the weight given to the loss L2. Therefore, the AE80 can always be focused on learning. If the AE80 is always focused on learning, the feature amount set 84 that more expresses the features of the shape and texture of the dissected area can be output from the compression unit 82, and as a result, the more plausible aggregate feature amount ZA can be output from the output unit. It can be output from 86.
- the weight given to the loss L1 is gradually decreased from the maximum value, and the weight given to the loss L2 is gradually increased from the minimum value, and when learning is performed a predetermined number of times, both are set as fixed values. Therefore, the AE80 can be learned more intensively in the initial stage of learning.
- the AE80 is responsible for the relatively simple subtask of generating the restored image 85. Therefore, if the AE80 is trained more intensively in the initial stage of learning, the feature amount set 84 that more expresses the characteristics of the shape and texture of the dissected area can be output from the compression unit 82 in the initial stage of learning. ..
- the dementia finding derivation model 41 is constructed by one of a neural network, a support vector machine, and a boosting method. Any of these neural networks, support vector machines, and boosting techniques are generally very well known. Therefore, the dementia finding derivation model 41 can be constructed relatively easily.
- this embodiment in which the organ is the brain, the disease is dementia, and the dementia finding information 60 is output, is a form that matches the current social problem.
- the hippocampus and anterior temporal lobe are anatomical areas with a particularly high correlation with dementia such as Alzheimer's disease. Therefore, even more accurate dementia findings can be obtained if the plurality of dissected areas contain at least one of the hippocampus and the anterior temporal lobe.
- the presentation mode of the dementia finding information 60 is not limited to the second display screen 75.
- the dementia finding information 60 may be printed out on a paper medium, or the dementia finding information 60 may be transmitted to a doctor's mobile terminal as an attachment file of an e-mail.
- dementia-related information 131 related to dementia is input to the dementia finding derivation model 132.
- the dementia finding derivation unit 130 of the present embodiment inputs dementia-related information 131 related to dementia into the dementia finding derivation model 132 in addition to the aggregated feature group ZAG. Then, the dementia finding information 133 is output from the dementia finding derivation model 132.
- the dementia-related information 131 is information on the patient P who makes a diagnosis of dementia.
- the dementia-related information 131 is an example of "disease-related information" according to the technique of the present disclosure.
- the dementia finding derivation model 132 has a quantile normalization unit 135 and a linear discriminant analysis unit 136.
- the aggregate feature group ZAG and the dementia-related information 131 are input to the quantile normalization unit 135.
- the quantile normalization unit 135 converts the plurality of aggregated feature quantities ZA constituting the aggregated feature quantity group ZAG and the parameters of the dementia-related information 131 into data according to a normal distribution in order to handle them in the same row.
- Quantile Normalization is performed.
- the linear discriminant analysis unit 136 performs linear discriminant analysis (Linear Discriminant Analysis) for each parameter of the aggregated feature amount ZA and the dementia-related information 131 after the division normalization process, and as a result, the dementia finding information 133 is obtained. Output.
- the dementia finding derivation model 132 is constructed by the method of linear discriminant analysis.
- the dementia finding information 133 similarly to the dementia finding information 60 of the first embodiment, the patient P with mild cognitive impairment currently remains mild cognitive impairment after 2 years, or progresses to Alzheimer's disease after 2 years. Is one of.
- the dementia-related information 131 includes, for example, the volume of the hippocampus.
- dementia-related information 131 includes Hasegawa-type dementia scale score, ApoE gene genotype, amyloid ⁇ measurement value, tau protein measurement value, apolipoprotein measurement value, complement protein measurement value, transsiletin measurement value, etc. including.
- the Hasegawa dementia scale score, ApoE gene genotype, amyloid ⁇ measurement value, tau protein measurement value, apolipoprotein measurement value, complement protein measurement value, transsiletin measurement value, etc. are obtained from the electronic chart system (not shown). Be quoted.
- the volume of the hippocampus is, for example, the total number of pixels of the anatomical area image 56_1 of the hippocampus.
- the hippocampal volume is an example of the "volume of the dissected area" according to the technique of the present disclosure.
- the volume of other dissected areas such as the amygdala may be included in the dementia-related information 131.
- the Hasegawa dementia scale score is an example of the "dementia test score" related to the technique of the present disclosure.
- the Mini-Mental State Examination (MMSE) score the Mini-Mental State Examination (MMSE) score, Rivermead Behavioral Memory Test (RBMT) score, and clinical cognition.
- MMSE Mini-Mental State Examination
- RBMT Rivermead Behavioral Memory Test
- Dementia evaluation scale CDR; Clinical Dementia Racing
- daily life activity ADL; Actives of Daily Living
- ADAS-Cog Alzheimer's Desiresex
- the genotype of the ApoE gene is a combination of two of the three ApoE genes ( ⁇ 2 and ⁇ 3, ⁇ 3 and ⁇ 4, etc.). For genotypes that do not have ⁇ 4 at all ( ⁇ 2 and ⁇ 3, ⁇ 3 and ⁇ 3, etc.), the risk of developing Alzheimer's disease for genotypes that have one or two ⁇ 4 ( ⁇ 2 and ⁇ 4, ⁇ 4 and ⁇ 4, etc.) is It is said to be about 3 to 12 times.
- the genotype of the ApoE gene is an example of the "test result of genetic test" according to the technique of the present disclosure.
- amyloid ⁇ measurement value and the tau protein measurement value are examples of the "test results of the cerebrospinal fluid test” according to the technique of the present disclosure. Further, the apolypoprotein measured value, the complement protein measured value, and the transthyretin measured value are examples of the "blood test test result" according to the technique of the present disclosure.
- the dementia finding derivation model 132 is trained given the learning data 140.
- the learning data 140 is a combination of the learning aggregate feature group ZAGL and the learning dementia-related information 131L, and the correct answer dementia finding information 133CA corresponding to the learning aggregate feature group ZAGL and the learning dementia-related information 131L.
- the learning aggregate feature quantity group ZAGL is obtained by inputting the cropping image 58 of a certain head MRI image 15 into the feature quantity derivation model 39.
- the learning dementia-related information 131L is information on the patient P to be photographed on the head MRI image 15 obtained the learning aggregate feature group ZAGL.
- the correct answer dementia finding information 133CA is the result of the doctor actually diagnosing the dementia findings on the head MRI image 15 obtained the learning aggregate feature group ZAGL, taking into account the learning dementia-related information 131L. ..
- the learning aggregate feature group ZAGL and the learning dementia-related information 131L are input to the dementia finding derivation model 132.
- the dementia finding derivation model 132 outputs learning dementia finding information 133L for learning aggregate feature group ZAGL and learning dementia-related information 131L.
- the loss calculation of the dementia finding derivation model 132 using the loss function is performed.
- various coefficients of the dementia finding derivation model 132 are updated according to the result of the loss calculation, and the dementia finding derivation model 132 is updated according to the update setting.
- the input of the learning aggregate feature quantity group ZAGL and the learning dementia-related information 131L into the dementia finding derivation model 132, and the learning dementia from the dementia finding derivation model 132 is repeatedly performed while the learning data 140 is exchanged.
- the repetition of the above series of processes ends when the prediction accuracy of the learning dementia finding information 133L with respect to the correct dementia finding information 133CA reaches a predetermined set level.
- the dementia finding derivation model 132 whose prediction accuracy has reached a set level is stored in the storage 20 and used by the dementia finding derivation unit 130.
- the dementia-related information 131 is input to the dementia finding derivation model 132.
- Dementia-related information 131 includes hippocampal volume, Hasegawa dementia scale score, ApoE gene genotype, amyloid ⁇ measurement value, tau protein measurement value, apolipoprotein measurement value, complement protein measurement value, and transsiletin measurement. Including values etc.
- Dementia-related information 131 which is powerful information useful for predicting dementia findings, is added, so the accuracy of predicting dementia findings is dramatically higher than when predicting dementia findings using only the aggregate feature group ZAG. Can be improved.
- the dementia-related information 131 may include the gender, age, medical history of patient P, or whether or not patient P has a relative who has developed dementia.
- the compression unit 151 of the AE150 is used as the feature amount derivation model 155.
- the AE150 has a compression unit 151 and a restoration unit 152, similarly to the AE80 of the first embodiment.
- the cropping image 58 is input to the compression unit 151.
- the compression unit 151 converts the cropping image 58 into the feature amount set 153.
- the compression unit 151 passes the feature amount set 153 to the restoration unit 152.
- the restoration unit 152 generates the restoration image 154 of the cropping image 58 from the feature amount set 153.
- the AE150 is trained by inputting a learning cropping image 58L in the learning phase before diverting the compression unit 151 to the feature quantity derivation model 155.
- the AE150 outputs a learning restored image 154L to a learning cropping image 58L.
- the loss calculation of the AE150 using the loss function is performed.
- various coefficients of the AE150 are updated according to the result of the loss calculation, and the AE150 is updated according to the update settings.
- the above series of processes of inputting the learning cropping image 58L to the AE150, outputting the learning restoration image 154L from the AE150, loss calculation, update setting, and updating the AE150 are the learning cropping images. It is repeated while 58L is exchanged. The repetition of the above series of processes ends when the restoration accuracy from the learning cropping image 58L to the learning restoration image 154L reaches a predetermined set level.
- the compression unit 151 of the AE 150 whose restoration accuracy has reached the set level in this way is stored in the storage 20 and used as the feature amount derivation model 155. Therefore, in the present embodiment, the feature amount set 153 output from the compression unit 151 is treated as "feature amount data" according to the technique of the present disclosure (see FIG. 26).
- the dementia finding derivation unit 160 of the present embodiment inputs the feature amount set group 161 into the dementia finding derivation model 162. Then, the dementia finding information 163 is output from the dementia finding derivation model 162.
- the feature amount set group 161 is composed of a plurality of feature amount sets 153 output from the feature amount derivation model 155 for each of the plurality of cropping images 58.
- the dementia finding information 163 has the same contents as the dementia finding information 60 of the first embodiment and the dementia finding information 133 of the second embodiment.
- the compression unit 151 of the AE150 is used as the feature amount derivation model 155.
- the AE150 is one of the neural network models frequently used in the field of machine learning, it can be diverted to the feature amount derivation model 155 relatively easily.
- the compression unit 171 of the single task CNN170 is used as the feature amount derivation model 175.
- the single task CNN 170 has a compression unit 171 and an output unit 172, similarly to the single task CNN 81 of the first embodiment.
- the cropping image 58 is input to the compression unit 171.
- the compression unit 171 converts the cropping image 58 into the feature amount set 173.
- the compression unit 171 passes the feature amount set 173 to the output unit 172.
- the output unit 172 outputs one class 174 based on the feature amount set 173. In FIG. 27, the output unit 172 outputs the determination result that dementia has developed or has not developed dementia as class 174.
- the single task CNN 170 is given learning data 180 and learned in the learning phase before the compression unit 171 is diverted to the feature quantity derivation model 175.
- the learning data 180 is a set of a learning cropping image 58L and a correct answer class 174CA corresponding to the learning cropping image 58L.
- the correct answer class 174CA is the result of the doctor actually determining whether or not dementia has developed with respect to the cropping image 58L for learning.
- the learning cropping image 58L is input to the single task CNN170.
- the single task CNN170 outputs a learning class 174L for a learning cropping image 58L.
- the loss calculation of the single task CNN170 is performed.
- various coefficients of the single task CNN 170 are updated according to the result of the loss calculation, and the single task CNN 170 is updated according to the update settings.
- the processing is repeated while the learning data 180 is exchanged.
- the repetition of the above series of processes ends when the prediction accuracy of the learning class 174L with respect to the correct answer class 174CA reaches a predetermined setting level.
- the compression unit 171 of the single task CNN 170 whose prediction accuracy has reached the set level in this way is stored in the storage 20 and used as the feature amount derivation model 175. Similar to the third embodiment, in the present embodiment as well, the feature amount set 173 output from the compression unit 171 is treated as "feature amount data" according to the technique of the present disclosure.
- the compression unit 171 of the single task CNN170 is used as the feature amount derivation model 175.
- the single-tasking CNN170 is also one of the neural network models frequently used in the field of machine learning, it can be diverted to the feature amount derivation model 175 relatively easily.
- the class 174 may be, for example, that the age of the patient P is less than 75 years old or is 75 years or older, or may be in the age group of the patient P such as 60s and 70s. There may be.
- the compression unit 181 of the multitasking class discrimination CNN (hereinafter, abbreviated as multitasking CNN) 180 is used as the feature amount derivation model 186.
- the multitasking CNN180 has a compression unit 181 and an output unit 182.
- the cropping image 58 is input to the compression unit 181.
- the compression unit 181 converts the cropping image 58 into the feature amount set 183.
- the compression unit 181 passes the feature amount set 183 to the output unit 182.
- the output unit 182 outputs two classes, the first class 184 and the second class 185, based on the feature amount set 183. In FIG. 29, the output unit 182 outputs the determination result that dementia has developed or has not developed dementia as the first class 184. Further, in FIG. 29, the output unit 182 outputs the age of the patient P as the second class 185.
- the multitasking CNN 180 is given learning data 190 and learned in the learning phase before the compression unit 181 is diverted to the feature quantity derivation model 186.
- the learning data 190 is a set of a learning cropping image 58L and a correct answer first class 184CA and a correct answer second class 185CA corresponding to the learning cropping image 58L.
- the correct answer first class 184CA is the result of the doctor actually determining whether or not dementia has developed with respect to the cropping image 58L for learning.
- the correct answer second class 185CA is the actual age of the patient P to be photographed on the head MRI image 15 obtained the cropping image 58L for learning.
- the learning cropping image 58L is input to the multitasking CNN180.
- the multitasking CNN180 outputs a learning first class 184L and a learning second class 185L to the learning cropping image 58L.
- the loss calculation of the multitasking CNN180 is performed.
- various coefficients of the multitasking CNN180 are updated according to the result of the loss calculation, and the multitasking CNN180 is updated according to the updating settings.
- the repetition of the above series of processes ends when the prediction accuracy of the learning first class 184L and the learning second class 185L for the correct answer first class 184CA and the correct answer second class 185CA reaches a predetermined setting level. Will be done.
- the compression unit 181 of the multitasking CNN180 whose prediction accuracy has reached the set level in this way is stored in the storage 20 and used as the feature amount derivation model 186. Similar to the third embodiment and the fourth embodiment, in the present embodiment as well, the feature amount set 183 output from the compression unit 181 is treated as "feature amount data" according to the technique of the present disclosure. ..
- the compression unit 181 of the multitasking CNN180 is used as the feature amount derivation model 186.
- the multitasking CNN180 performs a more complicated process of outputting a plurality of classes (first class 184 and second class 185) as compared with the AE80 and 150 or the singletasking CNN81 and 170. Therefore, the feature amount set 183 output from the compression unit 181 is likely to more comprehensively represent the features of the cropping image 58. Therefore, as a result, the accuracy of predicting the findings of dementia can be further improved.
- the first class 184 may be, for example, the degree of progression of dementia at five levels. Further, as the second class 185, the determination result of the age of the patient P may be used.
- the multitasking CNN180 may output three or more classes.
- the multitasking CNN180 of the present embodiment may be used instead of the singletasking CNN81.
- one cropping image 58 is input to a plurality of different feature quantity derivation models 201 to 204.
- the feature amount derivation unit 200 of the present embodiment inputs one cropping image 58 to the first feature amount derivation model 201, inputs it to the second feature amount derivation model 202, and inputs the cropping image 58 to the second feature amount derivation model 202.
- 3 Input to the feature quantity derivation model 203, and input to the fourth feature quantity derivation model 204.
- the feature quantity derivation unit 200 outputs the first feature quantity data 205 from the first feature quantity derivation model 201, outputs the second feature quantity data 206 from the second feature quantity derivation model 202, and derives the third feature quantity.
- the third feature amount data 207 is output from the model 203
- the fourth feature amount data 208 is output from the fourth feature amount derivation model 204.
- the first feature quantity derivation model 201 is a combination of the AE80 and the single task CNN81 of the first embodiment. Therefore, the first feature amount data 205 is the aggregate feature amount ZA.
- the second feature quantity derivation model 202 is a diversion of the compression unit 151 of the AE150 of the third embodiment. Therefore, the second feature amount data 206 is the feature amount set 153.
- the third feature quantity derivation model 203 is obtained by diverting the compression unit 171 of the single task CNN 170 of the fourth embodiment. Therefore, the third feature amount data 207 is the feature amount set 173.
- the fourth feature quantity derivation model 204 is obtained by diverting the compression unit 181 of the multitasking CNN180 of the fifth embodiment. Therefore, the fourth feature amount data 208 is the feature amount set 183.
- the feature quantity derivation unit 200 uses one cropping image 58 as the first feature quantity derivation model 201, the second feature quantity derivation model 202, the third feature quantity derivation model 203, and the third feature quantity derivation model 203. 4 Input to the feature quantity derivation model 204. Then, the first feature amount data 205, the second feature amount data 206, the third feature amount data 207, and the fourth feature amount data 208 are output from each model 201 to 204. Therefore, a wide variety of feature data can be obtained as compared with the case of using one type of feature derivation model. As a result, the accuracy of predicting the findings of dementia can be further improved.
- the plurality of different feature quantity derivation models may be, for example, a combination of the second feature quantity derivation model 202 diverted from the compression unit 151 of the AE150 and the third feature quantity derivation model 203 diverted from the compression unit 171 of the single task CNN 170. ..
- a combination of the third feature amount derivation model 203 diverted from the compression unit 171 of the single task CNN 170 and the fourth feature amount derivation model 204 diverted from the compression unit 181 of the multitask CNN 180 may be used.
- dementia finding information 215 it may be either normal (NC; Normal Control), mild cognitive impairment (MCI), or Alzheimer's disease (AD).
- NCI normal
- MCI mild cognitive impairment
- AD Alzheimer's disease
- the degree of progression of dementia one year after the patient P may be fast or slow.
- the type of dementia may be any of Alzheimer's disease, Lewy body dementia, and vascular dementia.
- the learning, the learning of the multitasking CNN180 shown in FIG. 30, and the like may be performed by the diagnostic support device 12, or may be performed by a device other than the diagnostic support device 12. Further, these learnings may be continuously performed after storing each model in the storage 20 of the diagnostic support device 12.
- the PACS server 11 may function as the diagnostic support device 12.
- the medical image is not limited to the illustrated head MRI image 15.
- PET Positron Emission Tomography
- SPECT Single Photon Emission Tomography
- CT Computed Tomography
- the organ is not limited to the illustrated brain, but may be the heart, lungs, liver, etc.
- the right lungs S1, S2, left lungs S1, S2 and the like are extracted as dissected areas.
- the liver the right lobe, left lobe, gallbladder, etc. are extracted as dissected areas.
- the disease is not limited to the exemplified dementia, and may be a diffuse lung disease such as heart disease or interstitial pneumonia, or a liver dysfunction such as liver cirrhosis.
- the RW control unit 45 for example, the RW control unit 45, the normalization unit 46, the extraction unit 47, the cropping image generation unit 48, the feature quantity derivation units 49 and 200, the dementia findings derivation unit 50, 130, and 160, and the display.
- the processing unit Processes
- various processors shown below can be used.
- the CPU 22 which is a general-purpose processor that executes software (operation program 30) and functions as various processing units, after manufacturing FPGA (Field Programmable Gate Array) and the like.
- Dedicated processor with a circuit configuration specially designed to execute specific processing such as programmable logic device (Programmable Logic Device: PLD), ASIC (Application Specific Integrated Circuit), which is a processor whose circuit configuration can be changed. Includes electrical circuits and the like.
- One processing unit may be composed of one of these various processors, or may be a combination of two or more processors of the same type or different types (for example, a combination of a plurality of FPGAs and / or a CPU). It may be configured in combination with FPGA). Further, a plurality of processing units may be configured by one processor.
- one processor is configured by a combination of one or more CPUs and software, as represented by a computer such as a client and a server.
- the processor functions as a plurality of processing units.
- SoC System On Chip
- SoC system On Chip
- the various processing units are configured by using one or more of the above-mentioned various processors as a hardware-like structure.
- an electric circuit in which circuit elements such as semiconductor elements are combined can be used.
- the techniques of the present disclosure can also be appropriately combined with the various embodiments described above and / or various modifications. Further, it is of course not limited to each of the above embodiments, and various configurations can be adopted as long as they do not deviate from the gist. Further, the technique of the present disclosure extends to a storage medium for storing the program non-temporarily in addition to the program.
- a and / or B is synonymous with "at least one of A and B". That is, “A and / or B” means that it may be A alone, B alone, or a combination of A and B. Further, in the present specification, when three or more matters are connected and expressed by "and / or", the same concept as “A and / or B" is applied.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Public Health (AREA)
- Physics & Mathematics (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Molecular Biology (AREA)
- Heart & Thoracic Surgery (AREA)
- Surgery (AREA)
- Pathology (AREA)
- Biomedical Technology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Biophysics (AREA)
- Radiology & Medical Imaging (AREA)
- Epidemiology (AREA)
- Primary Health Care (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- High Energy & Nuclear Physics (AREA)
- Child & Adolescent Psychology (AREA)
- Developmental Disabilities (AREA)
- Educational Technology (AREA)
- Hospice & Palliative Care (AREA)
- Psychiatry (AREA)
- Psychology (AREA)
- Social Psychology (AREA)
- Magnetic Resonance Imaging Apparatus (AREA)
- Measuring And Recording Apparatus For Diagnosis (AREA)
Abstract
プロセッサと、プロセッサに接続または内蔵されたメモリと、を備え、プロセッサは、医用画像を取得し、医用画像から臓器の解剖区域を抽出し、異なる位置および/またはサイズにて、解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成し、複数のクロッピング画像を、複数のクロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、特徴量導出モデルからクロッピング画像に対応する特徴量データを出力させ、複数のクロッピング画像毎に出力された特徴量データを疾病所見導出モデルに入力し、疾病所見導出モデルから臓器に関わる疾病の所見を出力させる、診断支援装置。
Description
本開示の技術は、診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラムに関する。
疾病、例えばアルツハイマー病に代表される認知症の診断において、医師は、頭部MRI(Magnetic Resonance Imaging)画像等の医用画像を参照する。医師は、例えば、海馬、海馬傍回、扁桃体等の萎縮の程度、白質の血管障害の程度、前頭葉、側頭葉、後頭葉の血流代謝低下の有無等を観察し、認知症の所見を得る。
特許第6483890号には、頭部MRI画像に対する認知症の所見を、機械学習モデルにより導出して医師に提供する診断支援装置が記載されている。特許第6483890号に記載の診断支援装置は、ブロードマンの脳地図等に応じた複数の解剖区域を頭部MRI画像から抽出し、各解剖区域の萎縮の程度を示すZ値を算出している。そして、算出した各解剖区域のZ値を機械学習モデルに入力し、機械学習モデルから認知症の所見を出力させている。
前述のように、認知症等の疾病の所見を得るためには、脳等の臓器の各解剖区域を、様々な視点で隈なく精査する必要がある。しかしながら特許第6483890号では、統計的に得られたただ1つのZ値という指標値だけを用いている。このため、こうした限定的な情報だけで得られる疾病の所見の予測精度には限界があった。
本開示の技術に係る1つの実施形態は、より的確な疾病の所見を得ることが可能な診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラムを提供する。
本開示の診断支援装置は、プロセッサと、プロセッサに接続または内蔵されたメモリと、を備え、プロセッサは、医用画像を取得し、医用画像から臓器の解剖区域を抽出し、異なる位置および/またはサイズにて、解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成し、複数のクロッピング画像を、複数のクロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、特徴量導出モデルからクロッピング画像に対応する特徴量データを出力させ、複数のクロッピング画像毎に出力された特徴量データを疾病所見導出モデルに入力し、疾病所見導出モデルから臓器に関わる疾病の所見を出力させる。
プロセッサは、解剖区域を複数抽出し、複数の解剖区域毎に複数のクロッピング画像を生成することが好ましい。
特徴量導出モデルは、オートエンコーダ、シングルタスクのクラス判別用畳み込みニューラルネットワーク、およびマルチタスクのクラス判別用畳み込みニューラルネットワークのうちの少なくともいずれか1つを含むことが好ましい。
プロセッサは、1つのクロッピング画像を、異なる複数の特徴量導出モデルに入力し、複数の特徴量導出モデルの各々から特徴量データを出力させることが好ましい。
疾病所見導出モデルは、ニューラルネットワーク、サポートベクターマシン、ブースティング、および線形判別分析のうちのいずれかの手法によって構築されることが好ましい。
プロセッサは、複数の特徴量データに加えて、疾病に関わる疾病関連情報を疾病所見導出モデルに入力することが好ましい。
臓器は脳であり、疾病は認知症であることが好ましい。この場合、複数の解剖区域は、海馬および前側頭葉のうちの少なくともいずれか1つを含むことが好ましい。また、疾病関連情報は、解剖区域の体積、認知症テストのスコア、遺伝子検査の検査結果、髄液検査の検査結果、および血液検査の検査結果のうちの少なくともいずれか1つを含むことが好ましい。
本開示の診断支援装置の作動方法は、医用画像を取得すること、医用画像から臓器の解剖区域を抽出すること、異なる位置および/またはサイズにて、解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成すること、複数のクロッピング画像を、複数のクロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、特徴量導出モデルからクロッピング画像に対応する特徴量データを出力させること、および、複数のクロッピング画像毎に出力された特徴量データを疾病所見導出モデルに入力し、疾病所見導出モデルから臓器に関わる疾病の所見を出力させること、を含む。
本開示の診断支援装置の作動プログラムは、医用画像を取得すること、医用画像から臓器の解剖区域を抽出すること、異なる位置および/またはサイズにて、解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成すること、複数のクロッピング画像を、複数のクロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、特徴量導出モデルからクロッピング画像に対応する特徴量データを出力させること、および、複数のクロッピング画像毎に出力された特徴量データを疾病所見導出モデルに入力し、疾病所見導出モデルから臓器に関わる疾病の所見を出力させること、を含む処理をコンピュータに実行させる。
本開示の技術によれば、より的確な疾病の所見を得ることが可能な診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラムを提供することができる。
[第1実施形態]
一例として図1に示すように、医療システム2は、MRI装置10、PACS(Picture Archiving and Communication System)サーバ11、および診断支援装置12を備える。これらMRI装置10、PACSサーバ11、および診断支援装置12は、医療施設内に敷設されたLAN(Local Area Network)13に接続されており、LAN13を介して相互に通信することが可能である。
一例として図1に示すように、医療システム2は、MRI装置10、PACS(Picture Archiving and Communication System)サーバ11、および診断支援装置12を備える。これらMRI装置10、PACSサーバ11、および診断支援装置12は、医療施設内に敷設されたLAN(Local Area Network)13に接続されており、LAN13を介して相互に通信することが可能である。
MRI装置10は、患者Pの頭部を撮影して頭部MRI画像15を出力する。頭部MRI画像15は、患者Pの頭部の3次元形状を表すボクセルデータである。図1においては、サジタル断面の頭部MRI画像15Sを示している。MRI装置10は、頭部MRI画像15をPACSサーバ11に送信する。PACSサーバ11は、MRI装置10からの頭部MRI画像15を記憶し、管理する。なお、頭部MRI画像15は、本開示の技術に係る「医用画像」の一例である。
診断支援装置12は、例えばデスクトップ型のパーソナルコンピュータであり、ディスプレイ17と入力デバイス18とを備える。入力デバイス18は、キーボード、マウス、タッチパネル、マイクロフォン等である。医師は、入力デバイス18を操作して、PACSサーバ11に対して患者Pの頭部MRI画像15の配信要求を送信する。PACSサーバ11は、配信要求された患者Pの頭部MRI画像15を検索して診断支援装置12に配信する。診断支援装置12は、PACSサーバ11から配信された頭部MRI画像15をディスプレイ17に表示する。医師は、頭部MRI画像15に写る患者Pの脳を観察して、患者Pに対する認知症の診断を行う。脳は、本開示の技術に係る「臓器」の一例であり、認知症は、本開示の技術に係る「疾病」の一例である。なお、図1では、MRI装置10および診断支援装置12はそれぞれ1台しか描かれていないが、MRI装置10および診断支援装置12はそれぞれ複数台あってもよい。
一例として図2に示すように、診断支援装置12を構成するコンピュータは、前述のディスプレイ17および入力デバイス18に加えて、ストレージ20、メモリ21、CPU(Central Processing Unit)22、および通信部23を備えている。これらはバスライン24を介して相互接続されている。なお、CPU22は、本開示の技術に係る「プロセッサ」の一例である。
ストレージ20は、診断支援装置12を構成するコンピュータに内蔵、またはケーブル、ネットワークを通じて接続されたハードディスクドライブである。もしくはストレージ20は、ハードディスクドライブを複数台連装したディスクアレイである。ストレージ20には、オペレーティングシステム等の制御プログラム、各種アプリケーションプログラム、およびこれらのプログラムに付随する各種データ等が記憶されている。なお、ハードディスクドライブに代えてソリッドステートドライブを用いてもよい。
メモリ21は、CPU22が処理を実行するためのワークメモリである。CPU22は、ストレージ20に記憶されたプログラムをメモリ21へロードして、プログラムにしたがった処理を実行する。これによりCPU22は、コンピュータの各部を統括的に制御する。通信部23は、PACSサーバ11等の外部装置との各種情報の伝送制御を行う。なお、メモリ21は、CPU22に内蔵されていてもよい。
一例として図3に示すように、診断支援装置12のストレージ20には、作動プログラム30が記憶されている。作動プログラム30は、コンピュータを診断支援装置12として機能させるためのアプリケーションプログラムである。すなわち、作動プログラム30は、本開示の技術に係る「診断支援装置の作動プログラム」の一例である。ストレージ20には、頭部MRI画像15、標準頭部MRI画像35、セグメンテーションモデル36、複数のクロッピング条件37で構成されるクロッピング条件群38、複数の特徴量導出モデル39で構成される特徴量導出モデル群40、および認知症所見導出モデル41も記憶される。
作動プログラム30が起動されると、診断支援装置12を構成するコンピュータのCPU22は、メモリ21等と協働して、リードライト(以下、RW(Read Write)と略す)制御部45、正規化部46、抽出部47、クロッピング画像生成部48、特徴量導出部49、認知症所見導出部50、および表示制御部51として機能する。
RW制御部45は、ストレージ20への各種データの記憶、およびストレージ20内の各種データの読み出しを制御する。例えばRW制御部45は、PACSサーバ11からの頭部MRI画像15を受け取り、受け取った頭部MRI画像15をストレージ20に記憶する。なお、図3では頭部MRI画像15は1つしかストレージ20に記憶されていないが、頭部MRI画像15はストレージ20に複数記憶されていてもよい。
RW制御部45は、認知症を診断するために医師が指定した患者Pの頭部MRI画像15をストレージ20から読み出し、読み出した頭部MRI画像15を正規化部46および表示制御部51に出力する。RW制御部45は、頭部MRI画像15をストレージ20から読み出すことで、頭部MRI画像15を取得していることになる。
また、RW制御部45は、標準頭部MRI画像35をストレージ20から読み出し、読み出した標準頭部MRI画像35を正規化部46に出力する。RW制御部45は、セグメンテーションモデル36をストレージ20から読み出し、読み出したセグメンテーションモデル36を抽出部47に出力する。RW制御部45は、クロッピング条件群38をストレージ20から読み出し、読み出したクロッピング条件群38をクロッピング画像生成部48に出力する。RW制御部45は、特徴量導出モデル群40をストレージ20から読み出し、読み出した特徴量導出モデル群40を特徴量導出部49に出力する。さらに、RW制御部45は、認知症所見導出モデル41をストレージ20から読み出し、読み出した認知症所見導出モデル41を認知症所見導出部50に出力する。
正規化部46は、頭部MRI画像15を標準頭部MRI画像35に合わせる正規化処理を行い、頭部MRI画像15を正規化頭部MRI画像55とする。正規化部46は、正規化頭部MRI画像55を抽出部47に出力する。
標準頭部MRI画像35は、標準的な形状、大きさ、および濃度(画素値)の脳が写った頭部MRI画像である。標準頭部MRI画像35は、例えば、複数の健常者の頭部MRI画像15を平均することで生成した画像、あるいは、コンピュータグラフィックスにより生成した画像である。
抽出部47は、正規化頭部MRI画像55をセグメンテーションモデル36に入力する。セグメンテーションモデル36は、正規化頭部MRI画像55に写る脳の画素毎に、海馬、扁桃体、前頭葉等の脳の各解剖区域を表すラベルを付与する、いわゆるセマンティックセグメンテーションを行う機械学習モデルである。抽出部47は、セグメンテーションモデル36が付与したラベルに基づいて、正規化頭部MRI画像55から、脳の複数の解剖区域の画像(以下、解剖区域画像という)56を抽出する。抽出部47は、複数の解剖区域毎の複数の解剖区域画像56で構成される解剖区域画像群57を、クロッピング画像生成部48に出力する。
クロッピング画像生成部48は、クロッピング条件37にしたがって、解剖区域画像56に写る脳の解剖区域の少なくとも一部を包含する領域をクロッピングすることで、クロッピング画像58を生成する。脳の解剖区域の少なくとも一部を包含する領域とは、例えば解剖区域が海馬であった場合、海馬の全体を包含する領域であってもよいし、海馬の一部を包含する領域であってもよい。
クロッピング条件37は、1つの解剖区域に対して複数個(例えば数個~数十個)用意されている。このため、クロッピング画像生成部48は、1つの解剖区域の解剖区域画像56から複数のクロッピング画像58を生成する。例えば解剖区域画像56の枚数が20枚で、各解剖区域に対して10個ずつクロッピング条件37が用意されていた場合、クロッピング画像生成部48は20×10=200枚のクロッピング画像58を生成する。クロッピング画像生成部48は、生成した複数のクロッピング画像58で構成されるクロッピング画像群59を、特徴量導出部49に出力する。
特徴量導出モデル39は、クロッピング画像58毎に1つずつ用意されている(図8参照)。特徴量導出部49は、クロッピング画像58を対応する特徴量導出モデル39に入力する。そして、特徴量導出モデル39から集約特徴量ZAを出力させる。特徴量導出部49は、複数のクロッピング画像58に対応する複数の集約特徴量ZAで構成される集約特徴量群ZAGを、認知症所見導出部50に出力する。なお、集約特徴量ZAは、本開示の技術に係る「特徴量データ」の一例である。
認知症所見導出部50は、集約特徴量群ZAGを認知症所見導出モデル41に入力する。そして、認知症所見導出モデル41から認知症の所見を表す認知症所見情報60を出力させる。認知症所見導出部50は、認知症所見情報60を表示制御部51に出力する。なお、認知症所見導出モデル41は、本開示の技術に係る「疾病所見導出モデル」の一例である。
表示制御部51は、ディスプレイ17への各種画面の表示を制御する。各種画面には、セグメンテーションモデル36、特徴量導出モデル39、および認知症所見導出モデル41による解析を指示するための第1表示画面70(図10参照)、認知症所見情報60を表示する第2表示画面75(図11参照)等が含まれる。
一例として図4に示すように、正規化部46は、頭部MRI画像15に対して、正規化処理として形状正規化処理65および濃度正規化処理66を行う。形状正規化処理65は、例えば、頭部MRI画像15および標準頭部MRI画像35から、位置合わせの基準となるランドマークを抽出し、頭部MRI画像15のランドマークと標準頭部MRI画像35のランドマークとの相関が最大となるよう、頭部MRI画像15を標準頭部MRI画像35に合わせて平行移動、回転、および/または拡大縮小する処理である。濃度正規化処理66は、例えば、頭部MRI画像15の濃度ヒストグラムを、標準頭部MRI画像35の濃度ヒストグラムに合わせて補正する処理である。
一例として図5に示すように、抽出部47は、解剖区域画像56として、海馬の解剖区域画像56_1、海馬傍回の解剖区域画像56_2、前頭葉の解剖区域画像56_3、前側頭葉の解剖区域画像56_4、後頭葉の解剖区域画像56_5、視床の解剖区域画像56_6、視床下部の解剖区域画像56_7、扁桃体の解剖区域画像56_8、脳下垂体の解剖区域画像56_9、・・・等を抽出する。これらの他にも、抽出部47は、乳頭体、脳梁、脳弓、側脳室等の各解剖区域の解剖区域画像56を抽出する。海馬、前頭葉、前側頭葉、扁桃体といった解剖区域は左右一対である。図では表現していないが、こうした左右一対の解剖区域は、左右それぞれの解剖区域の解剖区域画像56が抽出される。例えば海馬は、左海馬の解剖区域画像56_1と右海馬の解剖区域画像56_1が抽出される。なお、これらの解剖区域のうち、海馬および前側頭葉のうちの少なくともいずれか1つを含むことが好ましく、海馬および前側頭葉を全て含むことがより好ましい。前側頭葉とは、側頭葉の前部という意である。抽出部47によるセグメンテーションモデル36を用いた解剖区域の抽出は、例えば下記文献に記載の方法を用いる。
<Patrick McClure, etc., Knowing What You Know in Brain Segmentation Using Bayesian Deep Neural Networks, Front. Neuroinform., 17 October 2019.>
<Patrick McClure, etc., Knowing What You Know in Brain Segmentation Using Bayesian Deep Neural Networks, Front. Neuroinform., 17 October 2019.>
一例として図6に示すように、クロッピング画像生成部48は、海馬のクロッピング条件37_1A、37_1B、37_1C、・・・にしたがって、海馬の解剖区域画像56_1から海馬のクロッピング画像58_1A、58_1B、58_1C、・・・を生成する。同様に、クロッピング画像生成部48は、海馬傍回のクロッピング条件37_2A、37_2B、37_2C、・・・にしたがって、海馬傍回の解剖区域画像56_2から海馬傍回のクロッピング画像58_2A、58_2B、58_2C、・・・を生成する。また、クロッピング画像生成部48は、前頭葉のクロッピング条件37_3A、37_3B、37_3C、・・・にしたがって、前頭葉の解剖区域画像56_3から前頭葉のクロッピング画像58_3A、58_3B、58_3C、・・・を生成する。さらに、クロッピング画像生成部48は、前側頭葉のクロッピング条件37_4A、37_4B、37_4C、・・・にしたがって、前側頭葉の解剖区域画像56_4から前側頭葉のクロッピング画像58_4A、58_4B、58_4C、・・・を生成する。このように、クロッピング画像生成部48は、海馬、前頭葉、前側頭葉といった脳の複数の解剖区域毎に複数のクロッピング画像58を生成する。
海馬のクロッピング画像58_1を生成する様子を一例として示す図7において、クロッピング画像生成部48は、クロッピング条件37に対応したクロッピング枠68を解剖区域画像56に設定する。そして、設定したクロッピング枠68にて解剖区域画像56をクロッピングすることで、クロッピング画像58を生成する。図7においては、説明の便宜上、解剖区域画像56の代わりにアキシャル断面の頭部MRI画像15Aを図示している。また、クロッピング枠68を2次元の矩形で図示している。ただし実際は、クロッピング枠68は3次元のボクセルである。クロッピング条件37は、このクロッピング枠68の座標情報、例えば、クロッピング枠68の角位置および中心位置のXYZ座標である。クロッピング枠68の中心位置は、解剖区域の中心位置に対して設定される。
クロッピング条件37_1A、37_1B、37_1C、37_1D、・・・に対応するクロッピング枠68_1A、68_1B、68_1C、68_1D、・・・は、位置および/またはサイズがそれぞれ異なる。このため、クロッピング画像58_1A、58_1B、58_1C、58_1D、・・・も、クロッピングされた領域の位置および/またはサイズがそれぞれ異なる。例えばクロッピング画像58_1Aおよび58_1Bは、位置は一部重複するがサイズは異なる。また、例えばクロッピング画像58_1Aおよび58_1Dは、サイズは同じであるが位置が異なる。
一例として図8に示すように、特徴量導出部49は、海馬のクロッピング画像58_1A、58_1B、・・・を海馬の特徴量導出モデル39_1A、39_1B、・・・に入力し、海馬の特徴量導出モデル39_1A、39_1B、・・・から海馬の集約特徴量ZA_1A、ZA_1B、・・・を出力させる。
同様にして、特徴量導出部49は、海馬傍回のクロッピング画像58_2A、58_2B、・・・を海馬傍回の特徴量導出モデル39_2A、39_2B、・・・に入力し、前頭葉のクロッピング画像58_3A、58_3B、・・・を前頭葉の特徴量導出モデル39_3A、39_3B、・・・に入力し、前側頭葉のクロッピング画像58_4A、58_4B、・・・を前側頭葉の特徴量導出モデル39_4A、39_4B、・・・に入力する。そして、海馬傍回の特徴量導出モデル39_2A、39_2B、・・・から海馬傍回の集約特徴量ZA_2A、ZA_2B、・・・を出力させ、前頭葉の特徴量導出モデル39_3A、39_3B、・・・から前頭葉の集約特徴量ZA_3A、ZA_3B、・・・を出力させ、前側頭葉の特徴量導出モデル39_4A、39_4B、・・・から前側頭葉の集約特徴量ZA_4A、ZA_4B、・・・を出力させる。このように、複数のクロッピング画像58は、それぞれ対応する特徴量導出モデル39に入力され、これによりクロッピング画像58毎の複数の集約特徴量ZAが各特徴量導出モデル39から出力される。
一例として図9に示すように、認知症所見導出部50は、集約特徴量群ZAGを認知症所見導出モデル41に入力する。そして、認知症所見導出モデル41から、認知症所見情報60として、現在軽度認知障害(MCI;Mild Cognitive Impairment)の患者Pが2年後も軽度認知障害のまま、あるいは2年後にアルツハイマー病(AD;Alzheimer’s Disease)に進行する、のいずれかを出力させる。
図10に、セグメンテーションモデル36、特徴量導出モデル39、および認知症所見導出モデル41による解析を指示するための第1表示画面70の一例を示す。第1表示画面70には、認知症を診断する患者Pの頭部MRI画像15が表示される。頭部MRI画像15は、サジタル断面の頭部MRI画像15S、アキシャル断面の頭部MRI画像15A、およびコロナル断面の頭部MRI画像15Cである。これら各頭部MRI画像15S、15A、および15Cの下部には、表示を切り替えるためのボタン群71が設けられている。
第1表示画面70には、解析ボタン72が設けられている。医師は、セグメンテーションモデル36、特徴量導出モデル39、および認知症所見導出モデル41による解析を行いたい場合、解析ボタン72を選択する。これにより、セグメンテーションモデル36、特徴量導出モデル39、および認知症所見導出モデル41による解析の指示が、CPU22にて受け付けられる。
図11に、セグメンテーションモデル36、特徴量導出モデル39、および認知症所見導出モデル41による解析の結果得られた認知症所見情報60を表示する第2表示画面75の一例を示す。第2表示画面75には、認知症所見情報60に応じたメッセージ76が表示される。図11においては、認知症所見情報60が、現在軽度認知障害の患者Pが2年後にアルツハイマー病に進行するという内容で、メッセージ76として「2年後にアルツハイマー病に進行するおそれがあります。」が表示された例を示している。なお、表示制御部51は、確認ボタン77が選択された場合、メッセージ76の表示を消し、第2表示画面75を第1表示画面70に戻す。
一例として図12に示すように、特徴量導出モデル39には、オートエンコーダ(以下、AE(Auto Encoder)と略す)80とシングルタスクのクラス判別用畳み込みニューラルネットワーク(以下、シングルタスクCNN(Convolutional Neural Network)と略す)81を合わせたモデルが用いられる。AE80は、圧縮部82と復元部83とを有する。圧縮部82にはクロッピング画像58が入力される。圧縮部82は、クロッピング画像58を特徴量セット84に変換する。特徴量セット84は、複数の特徴量Z1、Z2、・・・、ZNで構成される。なお、Nは特徴量の個数であり、例えば数十個~数十万個である。圧縮部82は、特徴量セット84を復元部83に受け渡す。復元部83は、特徴量セット84からクロッピング画像58の復元画像85を生成する。
シングルタスクCNN81は、圧縮部82と出力部86とを有する。つまり、圧縮部82は、AE80とシングルタスクCNN81とで共用される。圧縮部82は、特徴量セット84を出力部86に受け渡す。出力部86は、特徴量セット84に基づいて、1つのクラス87を出力する。図12においては、出力部86は、現在軽度認知障害の患者Pが2年後も軽度認知障害のまま、あるいは2年後にアルツハイマー病に進行する、という判別結果をクラス87として出力する。また、出力部86は、特徴量セット84を構成する複数の特徴量Zを集約した集約特徴量ZAを出力する。
圧縮部82は、一例として図13に示すような畳み込み演算を行うことで、クロッピング画像58を特徴量セット84に変換する。具体的には、圧縮部82は、「conv(convolutionの略)」で表される畳み込み層90を有する。畳み込み層90は、2次元に配列された複数の要素91をもつ対象データ92に、例えば3×3のフィルタ93を適用する。そして、要素91のうちの1つの注目要素91Iの要素値eと、注目要素91Iに隣接する8個の要素91Sの要素値a、b、c、d、f、g、h、iを畳み込む。畳み込み層90は、注目要素91Iを1要素ずつずらしつつ、対象データ92の各要素91に対して畳み込み演算を順次行い、演算データ95の要素94の要素値を出力する。これにより、対象データ92と同様に、2次元に配列された複数の要素94を有する演算データ95が得られる。なお、最初に畳み込み層90に入力される対象データ92はクロッピング画像58であり、その後は後述する縮小演算データ95S(図15参照)が対象データ92として畳み込み層90に入力される。
フィルタ93の係数をr、s、t、u、v、w、x、y、zとした場合、注目要素91Iに対する畳み込み演算の結果である、演算データ95の注目要素91Iに対応する要素94Iの要素値kは、例えば下記の式(1)を計算することで得られる。
k=az+by+cx+dw+ev+fu+gt+hs+ir・・・(1)
k=az+by+cx+dw+ev+fu+gt+hs+ir・・・(1)
演算データ95は、1個のフィルタ93に対して1つ出力される。1つの対象データ92に対して複数種のフィルタ93が適用された場合は、フィルタ93毎に演算データ95が出力される。つまり、一例として図14に示すように、演算データ95は、対象データ92に適用されたフィルタ93の個数分生成される。また、演算データ95は、2次元に配列された複数の要素94を有するため、幅と高さをもつ。演算データ95の数はチャンネル数と呼ばれる。図14においては、対象データ92に4個のフィルタ93を適用して出力された4チャンネルの演算データ95を例示している。
一例として図15に示すように、圧縮部82は、畳み込み層90の他に、「pool(poolingの略)」で表されるプーリング層100を有する。プーリング層100は、演算データ95の要素94の要素値の局所的な統計量を求め、求めた統計量を要素値とする縮小演算データ95Sを生成する。ここでは、プーリング層100は、局所的な統計量として、2×2の要素のブロック101内における要素値の最大値を求める最大値プーリング処理を行っている。ブロック101を幅方向および高さ方向に1要素ずつずらしつつ処理を行えば、縮小演算データ95Sは、元の演算データ95の1/2のサイズに縮小される。図15においては、ブロック101A内における要素値a、b、e、fのうちのb、ブロック101B内における要素値b、c、f、gのうちのb、ブロック101C内における要素値c、d、g、hのうちのhがそれぞれ最大値であった場合を例示している。なお、最大値ではなく平均値を局所的な統計量として求める、平均値プーリング処理を行ってもよい。
圧縮部82は、畳み込み層90による畳み込み処理とプーリング層100によるプーリング処理とを複数回繰り返すことで、最終的な演算データ95を出力する。この最終的な演算データ95が、すなわち特徴量セット84であり、最終的な演算データ95の各要素94の要素値が、すなわち特徴量Zである。こうして得られた特徴量Zは、海馬の萎縮の程度、白質の血管障害の程度、前頭葉、前側頭葉、後頭葉の血流代謝低下の有無といった、解剖区域の形状およびテクスチャーの特徴を表している。なお、ここでは、説明を簡単化するため2次元としているが、実際には3次元で各処理が行われる。
一例として図16に示すように、出力部86は、自己注意(以下、SA(Self-Attention)と略す)機構層110、全体平均プーリング(以下、GAP(Global Average Pooling)と略す)層111、全結合(以下、FC(Fully Connected)と略す)層112、ソフトマックス関数(以下、SMF(SoftMax Functionと略す)層113、および主成分分析(以下、PCA(Principal Component Analysis)と略す)層114を有する。
SA機構層110は、特徴量セット84に対して、図13で示した畳み込み処理を、注目要素91Iの要素値に応じてフィルタ93の係数を変更しつつ行う。以下、このSA機構層110で行われる畳み込み処理を、SA畳み込み処理という。SA機構層110は、SA畳み込み処理後の特徴量セット84をGAP層111に出力する。
GAP層111は、SA畳み込み処理後の特徴量セット84に対して、全体平均プーリング処理を施す。全体平均プーリング処理は、特徴量セット84のチャンネル(図14参照)毎に、特徴量Zの平均値を求める処理である。例えば特徴量セット84のチャンネル数が512であった場合、全体平均プーリング処理によって512個の特徴量Zの平均値が求められる。GAP層111は、求めた特徴量Zの平均値をFC層112およびPCA層114に出力する。
FC層112は、特徴量Zの平均値をSMF層113のSMFで扱う変数に変換する。FC層112は、特徴量Zの平均値の個数分(つまり特徴量セット84のチャンネル数分)のユニットをもつ入力層と、SMFで扱う変数の個数分のユニットをもつ出力層とを有する。入力層の各ユニットと出力層の各ユニットは、互いに全結合されていて、それぞれに重みが設定されている。入力層の各ユニットには、特徴量Zの平均値が入力される。特徴量Zの平均値と、各ユニット間に設定された重みとの積和が、出力層の各ユニットの出力値となる。この出力値がSMFで扱う変数である。FC層112は、SMFで扱う変数をSMF層113に出力する。SMF層113は、変数をSMFに適用することでクラス87を出力する。
PCA層114は、特徴量Zの平均値に対してPCAを行い、複数個の特徴量Zの平均値を、それよりも少ない個数の集約特徴量ZAとする。例えばPCA層114は、512個の特徴量Zの平均値を1個の集約特徴量ZAに集約する。
一例として図17に示すように、AE80は、学習フェーズにおいて、学習用クロッピング画像58Lが入力されて学習される。AE80は、学習用クロッピング画像58Lに対して学習用復元画像85Lを出力する。これら学習用クロッピング画像58Lおよび学習用復元画像85Lに基づいて、損失関数を用いたAE80の損失演算がなされる。そして、損失演算の結果(以下、損失L1と表記する)に応じてAE80の各種係数(フィルタ93の係数等)の更新設定がなされ、更新設定にしたがってAE80が更新される。
AE80の学習フェーズにおいては、学習用クロッピング画像58LのAE80への入力、AE80からの学習用復元画像85Lの出力、損失演算、更新設定、およびAE80の更新の上記一連の処理が、学習用クロッピング画像58Lが交換されつつ繰り返し行われる。
シングルタスクCNN81は、学習フェーズにおいて、学習データ120を与えられて学習される。学習データ120は、学習用クロッピング画像58Lと、学習用クロッピング画像58Lに対応する正解クラス87CAとの組である。正解クラス87CAは、学習用クロッピング画像58Lの患者Pが、実際に2年後も軽度認知障害のままか、あるいは2年後にアルツハイマー病に進行したかを示す。
学習フェーズにおいて、シングルタスクCNN81には、学習用クロッピング画像58Lが入力される。シングルタスクCNN81は、学習用クロッピング画像58Lに対して学習用クラス87Lを出力する。この学習用クラス87Lおよび正解クラス87CAに基づいて、クロスエントロピー関数等を用いたシングルタスクCNN81の損失演算がなされる。そして、損失演算の結果(以下、損失L2と表記する)に応じてシングルタスクCNN81の各種係数の更新設定がなされ、更新設定にしたがってシングルタスクCNN81が更新される。
シングルタスクCNN81の学習フェーズにおいては、学習用クロッピング画像58LのシングルタスクCNN81への入力、シングルタスクCNN81からの学習用クラス87Lの出力、損失演算、更新設定、およびシングルタスクCNN81の更新の上記一連の処理が、学習データ120が交換されつつ繰り返し行われる。
AE80の更新設定およびシングルタスクCNN81の更新設定は、下記の式(2)に示す総合損失Lに基づいて行われる。なお、αは重みである。
L=L1×α+L2×(1-α)・・・(2)
すなわち、総合損失Lは、AE80の損失L1とシングルタスクCNN81の損失L2との重み付き和である。
L=L1×α+L2×(1-α)・・・(2)
すなわち、総合損失Lは、AE80の損失L1とシングルタスクCNN81の損失L2との重み付き和である。
一例として図18に示すように、学習フェーズの初期段階においては、重みαには1が設定される。重みαを1とした場合、総合損失L=L1となる。したがってこの場合はAE80の学習のみが行われ、シングルタスクCNN81の学習は行われない。
重みαは、学習が進むにつれて1から漸減され、やがて固定値(図18においては0.8)となる。この場合、AE80の学習とシングルタスクCNN81の学習が、重みαに応じた強度でともに行われる。このように、損失L1に与えられる重みは、損失L2に与えられる重みよりも大きい。また、損失L1に与えられる重みは最高値の1から漸減され、かつ損失L2に与えられる重みは最低値の0から漸増され、さらに両者は固定値とされる。
AE80およびシングルタスクCNN81の学習は、AE80による学習用クロッピング画像58Lから学習用復元画像85Lへの復元精度が、予め定められた設定レベルまで達し、かつ、シングルタスクCNN81による正解クラス87CAに対する学習用クラス87Lの予測精度が、予め定められた設定レベルまで達した場合に終了される。こうして復元精度および予測精度が設定レベルまで達したAE80およびシングルタスクCNN81が、ストレージ20に記憶されて特徴量導出モデル39として用いられる。
認知症所見導出モデル41の学習フェーズにおける処理の概要の一例を示す図19において、認知症所見導出モデル41は、ニューラルネットワーク、サポートベクターマシン、ブースティングのうちのいずれかの手法によって構築される。学習フェーズにおいて、認知症所見導出モデル41は、学習データ125を与えられて学習される。学習データ125は、学習用集約特徴量群ZAGLと、学習用集約特徴量群ZAGLに対応する正解認知症所見情報60CAとの組である。学習用集約特徴量群ZAGLは、ある頭部MRI画像15のクロッピング画像58を特徴量導出モデル39に入力して得られたものである。正解認知症所見情報60CAは、学習用集約特徴量群ZAGLを得た頭部MRI画像15に対する認知症の所見を、医師が実際に診断した結果である。
学習フェーズにおいて、認知症所見導出モデル41には、学習用集約特徴量群ZAGLが入力される。認知症所見導出モデル41は、学習用集約特徴量群ZAGLに対して学習用認知症所見情報60Lを出力する。この学習用認知症所見情報60Lおよび正解認知症所見情報60CAに基づいて、損失関数を用いた認知症所見導出モデル41の損失演算がなされる。そして、損失演算の結果に応じて認知症所見導出モデル41の各種係数の更新設定がなされ、更新設定にしたがって認知症所見導出モデル41が更新される。
認知症所見導出モデル41の学習フェーズにおいては、学習用集約特徴量群ZAGLの認知症所見導出モデル41への入力、認知症所見導出モデル41からの学習用認知症所見情報60Lの出力、損失演算、更新設定、および認知症所見導出モデル41の更新の上記一連の処理が、学習データ125が交換されつつ繰り返し行われる。上記一連の処理の繰り返しは、正解認知症所見情報60CAに対する学習用認知症所見情報60Lの予測精度が、予め定められた設定レベルまで達した場合に終了される。こうして予測精度が設定レベルまで達した認知症所見導出モデル41が、ストレージ20に記憶されて認知症所見導出部50で用いられる。
次に、上記構成による作用について、図20のフローチャートを参照して説明する。まず、診断支援装置12において作動プログラム30が起動されると、図3で示したように、診断支援装置12のCPU22は、RW制御部45、正規化部46、抽出部47、クロッピング画像生成部48、特徴量導出部49、認知症所見導出部50、および表示制御部51として機能される。
図10で示した第1表示画面70において、解析ボタン72が選択された場合、RW制御部45により、ストレージ20から対応する頭部MRI画像15、および標準頭部MRI画像35が読み出される(ステップST100)。頭部MRI画像15および標準頭部MRI画像35は、RW制御部45から正規化部46に出力される。
図4で示したように、正規化部46において、頭部MRI画像15を標準頭部MRI画像35に合わせる正規化処理(形状正規化処理65および濃度正規化処理66)が行われる(ステップST110)。これにより頭部MRI画像15が正規化頭部MRI画像55とされる。正規化頭部MRI画像55は、正規化部46から抽出部47に出力される。
図5で示したように、抽出部47において、セグメンテーションモデル36を用いて、正規化頭部MRI画像55から脳の複数の解剖区域画像56が抽出される(ステップST120)。複数の解剖区域画像56で構成される解剖区域画像群57は、抽出部47からクロッピング画像生成部48に出力される。
図6および図7で示したように、クロッピング画像生成部48によって、クロッピング条件37にしたがって、異なる位置および/またはサイズにて、解剖区域画像56の解剖区域の少なくとも一部を包含する領域がクロッピングされることで、複数のクロッピング画像58が生成される(ステップST130)。複数のクロッピング画像58で構成されるクロッピング画像群59は、クロッピング画像生成部48から特徴量導出部49に出力される。
図8で示したように、特徴量導出部49では、複数のクロッピング画像58が、各々に対応する特徴量導出モデル39に入力される。これによりそれぞれの特徴量導出モデル39からクロッピング画像58に対応する複数の集約特徴量ZAが出力される(ステップST140)。クロッピング画像58の枚数分の複数の集約特徴量ZAで構成される集約特徴量群ZAGは、特徴量導出部49から認知症所見導出部50に出力される。
図9で示したように、認知症所見導出部50では、複数の集約特徴量ZAで構成される集約特徴量群ZAGが認知症所見導出モデル41に入力される。これにより認知症所見導出モデル41から認知症所見情報60が出力される(ステップST150)。認知症所見情報60は、認知症所見導出部50から表示制御部51に出力される。
表示制御部51の制御の下、図11で示した第2表示画面75がディスプレイ17に表示される(ステップST160)。医師は、第2表示画面75のメッセージ76を通じて、認知症所見情報60を確認する。
以上説明したように、診断支援装置12のCPU22は、RW制御部45と、抽出部47と、クロッピング画像生成部48と、特徴量導出部49と、認知症所見導出部50とを備える。RW制御部45は、認知症の診断を行う患者Pの頭部MRI画像15をストレージ20から読み出すことで、頭部MRI画像15を取得する。抽出部47は、正規化頭部MRI画像55から脳の複数の解剖区域の解剖区域画像56を抽出する。クロッピング画像生成部48は、異なる位置および/またはサイズにて、脳の解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像58を生成する。特徴量導出部49は、複数のクロッピング画像58を、複数のクロッピング画像58の各々に対応して用意された特徴量導出モデル39に入力し、特徴量導出モデル39からクロッピング画像58に対応する集約特徴量ZAを出力させる。認知症所見導出部50は、複数の集約特徴量ZAで構成される集約特徴量群ZAGを認知症所見導出モデル41に入力し、認知症所見導出モデル41から認知症所見情報60を出力させる。したがって、特許第6483890号に記載の方法と比べて認知症の所見の予測精度を高めることができ、より的確な認知症の所見を得ることが可能となる。
図5で示したように、抽出部47は解剖区域を複数抽出する。また、図6で示したように、クロッピング画像生成部48は、複数の解剖区域毎に複数のクロッピング画像58を生成する。このため複数の解剖区域毎の複数のクロッピング画像58に対応する集約特徴量ZAを得ることができる。こうして得られた集約特徴量ZAは、特許第6483890号に記載のZ値のように脳の限定的な特徴を表すものではなく、脳の網羅的な特徴を表すものである。また、集約特徴量ZAは、特許第6483890号に記載のZ値のように統計的に得られた値ではなく、特徴量導出モデル39にクロッピング画像58を入力して得られたものである。したがって、さらに認知症の所見の予測精度を高めることができる。
認知症は、癌等の他の疾病と比べて、肉眼でも認識できるような特異的な病変が画像に現れにくい。また、認知症は、脳全体にその影響が及び、局所的ではない。こうした背景があるため、従来は頭部MRI画像15等の医用画像から機械学習モデルを用いて的確な認知症の所見を得ることが困難であった。しかし、本開示の技術によれば、脳を複数の解剖区域に細かく分けて、さらに複数の解剖区域から複数のクロッピング画像58を生成し、複数のクロッピング画像58についてそれぞれ集約特徴量ZAを導出している。そして、導出した複数の集約特徴量ZAを1つの認知症所見導出モデル41に入力している。このため、従来困難であった、より的確な認知症の所見を得るという目的を達成することができる。
図12で示したように、特徴量導出モデル39は、AE80およびシングルタスクCNN81を合わせたモデルを転用したものである。AE80およびシングルタスクCNN81は、機械学習の分野において頻繁に用いられるニューラルネットワークモデルの1つで、一般的に非常によく知られている。このため、比較的容易に特徴量導出モデル39に転用することができる。
クラス87の出力といったメインタスクを行うシングルタスクCNN81と、シングルタスクCNN81と一部共通し、復元画像85の生成といったメインタスクよりも汎用的なサブタスクを行うAE80とを、特徴量導出モデル39として用いる。そして、AE80とシングルタスクCNN81とを同時に学習させる。このため、AE80とシングルタスクCNN81が別々の場合と比べて、より適切な特徴量セット84および集約特徴量ZAを出力することができ、結果として認知症所見情報60の予測精度を高めることができる。
学習フェーズにおいては、AE80の損失L1とシングルタスクCNN81の損失L2との重み付き和である総合損失Lに基づいて更新設定を行う。このため、重みαを適値に設定することで、AE80を重点的に学習させたり、シングルタスクCNN81を重点的に学習させたり、AE80およびシングルタスクCNN81をバランスよく学習させたりすることができる。
損失L1に与えられる重みは、損失L2に与えられる重みよりも大きい。このため、AE80を常に重点的に学習させることができる。AE80を常に重点的に学習させれば、解剖区域の形状およびテクスチャーの特徴をより表した特徴量セット84を圧縮部82から出力させることができ、結果としてより尤もらしい集約特徴量ZAを出力部86から出力させることができる。
また、損失L1に与えられる重みを最高値から漸減し、かつ損失L2に与えられる重みを最低値から漸増して、学習が所定回数行われたら両者を固定値とする。このため、学習の初期段階にAE80をより重点的に学習させることができる。AE80は、復元画像85の生成という比較的簡単なサブタスクを担う。したがって、学習の初期段階にAE80をより重点的に学習させれば、解剖区域の形状およびテクスチャーの特徴をより表した特徴量セット84を、学習の初期段階において圧縮部82から出力させることができる。
図19で示したように、認知症所見導出モデル41は、ニューラルネットワーク、サポートベクターマシン、およびブースティングのうちのいずれかの手法によって構築される。これらニューラルネットワーク、サポートベクターマシン、およびブースティングのいずれの手法も、一般的に非常によく知られている。このため、比較的容易に認知症所見導出モデル41を構築することができる。
認知症は、昨今の高齢化社会の到来とともに社会問題化している。このため、臓器を脳とし、疾病を認知症として、認知症所見情報60を出力する本実施形態は、現状の社会問題にマッチした形態であるといえる。
海馬および前側頭葉は、アルツハイマー病をはじめとする認知症との相関が特に高い解剖区域である。このため、複数の解剖区域に、海馬および前側頭葉のうちの少なくともいずれか1つが含まれていれば、さらにより的確な認知症の所見を得ることができる。
認知症所見情報60の提示態様としては、第2表示画面75に限らない。認知症所見情報60を紙媒体に印刷出力したり、医師の携帯端末に電子メールの添付ファイルとして認知症所見情報60を送信してもよい。
[第2実施形態]
図21~図23に示す第2実施形態では、集約特徴量群ZAGに加えて、認知症に関わる認知症関連情報131を認知症所見導出モデル132に入力する。
図21~図23に示す第2実施形態では、集約特徴量群ZAGに加えて、認知症に関わる認知症関連情報131を認知症所見導出モデル132に入力する。
一例として図21に示すように、本実施形態の認知症所見導出部130は、集約特徴量群ZAGに加えて、認知症に関わる認知症関連情報131を認知症所見導出モデル132に入力する。そして、認知症所見導出モデル132から認知症所見情報133を出力させる。認知症関連情報131は、認知症の診断を行う患者Pの情報である。なお、認知症関連情報131は、本開示の技術に係る「疾病関連情報」の一例である。
認知症所見導出モデル132は、分位正規化部135および線形判別分析部136を有する。分位正規化部135には、集約特徴量群ZAGと認知症関連情報131が入力される。分位正規化部135は、集約特徴量群ZAGを構成する複数の集約特徴量ZAと、認知症関連情報131の各パラメータとを同列に扱うために、これらを正規分布にしたがうデータに変換する分位正規化(Quantile Normalization)を行う。線形判別分析部136は、分位正規化処理後の集約特徴量ZAおよび認知症関連情報131の各パラメータに対して線形判別分析(Linear Discriminant Analysis)を行い、その結果として認知症所見情報133を出力する。すなわち、認知症所見導出モデル132は、線形判別分析の手法によって構築される。認知症所見情報133は、上記第1実施形態の認知症所見情報60と同様に、現在軽度認知障害の患者Pが2年後も軽度認知障害のまま、あるいは2年後にアルツハイマー病に進行する、のいずれかである。
一例として図22に示すように、認知症関連情報131は、例えば、海馬の体積を含む。また、認知症関連情報131は、長谷川式認知症スケールのスコア、ApoE遺伝子の遺伝子型、アミロイドβ測定値、タウ蛋白質測定値、アポリポ蛋白質測定値、補体蛋白質測定値、トランスサイレチン測定値等を含む。長谷川式認知症スケールのスコア、ApoE遺伝子の遺伝子型、アミロイドβ測定値、タウ蛋白質測定値、アポリポ蛋白質測定値、補体蛋白質測定値、トランスサイレチン測定値等は、図示省略した電子カルテシステムから引用される。
海馬の体積は、例えば、海馬の解剖区域画像56_1の総画素数である。海馬の体積は、本開示の技術に係る「解剖区域の体積」の一例である。なお、海馬の体積に加えて、あるいは代えて、扁桃体等の他の解剖区域の体積を認知症関連情報131に含めてもよい。
長谷川式認知症スケールのスコアは、本開示の技術に係る「認知症テストのスコア」の一例である。なお、長谷川式認知症スケールのスコアに加えて、あるいは代えて、ミニメンタルステート検査(MMSE;Mini-Mental State Examination)のスコア、リバーミード行動記憶検査(RBMT;Rivermead Behavioural Memory Test)のスコア、臨床認知症評価尺度(CDR;Clinical Dementia Rating)、日常生活活動度(ADL;Activities of Daily Living)、および/または、アルツハイマー病の評価尺度(ADAS-Cog;Alzheimer’s Disease Assessment Scale-cognitive subscale)等を認知症関連情報131に含めてもよい。
ApoE遺伝子の遺伝子型は、ε2、ε3、ε4の3種のApoE遺伝子のうちの2種の組み合わせ(ε2とε3、ε3とε4等)である。ε4を全くもたない遺伝子型(ε2とε3、ε3とε3等)に対して、ε4を1つないし2つもつ遺伝子型(ε2とε4、ε4とε4等)のアルツハイマー病の発症リスクは、およそ3倍~12倍とされている。ApoE遺伝子の遺伝子型は、本開示の技術に係る「遺伝子検査の検査結果」の一例である。
アミロイドβ測定値、およびタウ蛋白質測定値は、本開示の技術に係る「髄液検査の検査結果」の一例である。また、アポリポ蛋白質測定値、補体蛋白質測定値、およびトランスサイレチン測定値は、本開示の技術に係る「血液検査の検査結果」の一例である。
認知症所見導出モデル132の学習フェーズにおける処理の概要の一例を示す図23において、認知症所見導出モデル132は、学習データ140を与えられて学習される。学習データ140は、学習用集約特徴量群ZAGLおよび学習用認知症関連情報131Lと、学習用集約特徴量群ZAGLおよび学習用認知症関連情報131Lに対応する正解認知症所見情報133CAとの組である。学習用集約特徴量群ZAGLは、ある頭部MRI画像15のクロッピング画像58を特徴量導出モデル39に入力して得られたものである。学習用認知症関連情報131Lは、学習用集約特徴量群ZAGLを得た頭部MRI画像15の撮影対象の患者Pの情報である。正解認知症所見情報133CAは、学習用集約特徴量群ZAGLを得た頭部MRI画像15に対する認知症の所見を、学習用認知症関連情報131Lも加味して医師が実際に診断した結果である。
学習フェーズにおいて、認知症所見導出モデル132には、学習用集約特徴量群ZAGLおよび学習用認知症関連情報131Lが入力される。認知症所見導出モデル132は、学習用集約特徴量群ZAGLおよび学習用認知症関連情報131Lに対して学習用認知症所見情報133Lを出力する。この学習用認知症所見情報133Lおよび正解認知症所見情報133CAに基づいて、損失関数を用いた認知症所見導出モデル132の損失演算がなされる。そして、損失演算の結果に応じて認知症所見導出モデル132の各種係数の更新設定がなされ、更新設定にしたがって認知症所見導出モデル132が更新される。
認知症所見導出モデル132の学習フェーズにおいては、学習用集約特徴量群ZAGLおよび学習用認知症関連情報131Lの認知症所見導出モデル132への入力、認知症所見導出モデル132からの学習用認知症所見情報133Lの出力、損失演算、更新設定、および認知症所見導出モデル132の更新の上記一連の処理が、学習データ140が交換されつつ繰り返し行われる。上記一連の処理の繰り返しは、正解認知症所見情報133CAに対する学習用認知症所見情報133Lの予測精度が、予め定められた設定レベルまで達した場合に終了される。こうして予測精度が設定レベルまで達した認知症所見導出モデル132が、ストレージ20に記憶されて認知症所見導出部130で用いられる。
このように、第2実施形態では、認知症関連情報131を認知症所見導出モデル132に入力する。認知症関連情報131は、海馬の体積、長谷川式認知症スケールのスコア、ApoE遺伝子の遺伝子型、アミロイドβ測定値、タウ蛋白質測定値、アポリポ蛋白質測定値、補体蛋白質測定値、トランスサイレチン測定値等を含む。認知症関連情報131という認知症の所見の予測に役立つ強力な情報が加わるので、集約特徴量群ZAGだけで認知症の所見を予測する場合と比べて、認知症の所見の予測精度を飛躍的に向上させることができる。
なお、患者Pの性別、年齢、病歴、あるいは患者Pに認知症を発症した親類がいるか否か等を、認知症関連情報131に含めてもよい。
[第3実施形態]
図24~図26に示す第3実施形態では、AE150の圧縮部151を、特徴量導出モデル155として用いる。
図24~図26に示す第3実施形態では、AE150の圧縮部151を、特徴量導出モデル155として用いる。
一例として図24に示すように、AE150は、上記第1実施形態のAE80と同様に、圧縮部151と復元部152とを有する。圧縮部151にはクロッピング画像58が入力される。圧縮部151は、クロッピング画像58を特徴量セット153に変換する。圧縮部151は、特徴量セット153を復元部152に受け渡す。復元部152は、特徴量セット153からクロッピング画像58の復元画像154を生成する。
一例として図25に示すように、AE150は、圧縮部151を特徴量導出モデル155に転用する前の学習フェーズにおいて、学習用クロッピング画像58Lが入力されて学習される。AE150は、学習用クロッピング画像58Lに対して学習用復元画像154Lを出力する。これら学習用クロッピング画像58Lおよび学習用復元画像154Lに基づいて、損失関数を用いたAE150の損失演算がなされる。そして、損失演算の結果に応じてAE150の各種係数の更新設定がなされ、更新設定にしたがってAE150が更新される。
AE150の学習フェーズにおいては、学習用クロッピング画像58LのAE150への入力、AE150からの学習用復元画像154Lの出力、損失演算、更新設定、およびAE150の更新の上記一連の処理が、学習用クロッピング画像58Lが交換されつつ繰り返し行われる。上記一連の処理の繰り返しは、学習用クロッピング画像58Lから学習用復元画像154Lへの復元精度が、予め定められた設定レベルまで達した場合に終了される。こうして復元精度が設定レベルまで達したAE150の圧縮部151が、ストレージ20に記憶されて特徴量導出モデル155として用いられる。このため、本実施形態においては、圧縮部151から出力される特徴量セット153が、本開示の技術に係る「特徴量データ」として扱われる(図26参照)。
一例として図26に示すように、本実施形態の認知症所見導出部160は、特徴量セット群161を認知症所見導出モデル162に入力する。そして、認知症所見導出モデル162から認知症所見情報163を出力させる。特徴量セット群161は、複数のクロッピング画像58毎に特徴量導出モデル155から出力された複数の特徴量セット153で構成される。認知症所見情報163は、上記第1実施形態の認知症所見情報60および上記第2実施形態の認知症所見情報133と同じ内容である。
このように、第3実施形態では、AE150の圧縮部151が、特徴量導出モデル155として用いられる。前述のように、AE150は機械学習の分野において頻繁に用いられるニューラルネットワークモデルの1つであるため、比較的容易に特徴量導出モデル155に転用することができる。
[第4実施形態]
図27および図28に示す第4実施形態では、シングルタスクCNN170の圧縮部171を、特徴量導出モデル175として用いる。
図27および図28に示す第4実施形態では、シングルタスクCNN170の圧縮部171を、特徴量導出モデル175として用いる。
一例として図27に示すように、シングルタスクCNN170は、上記第1実施形態のシングルタスクCNN81と同様に、圧縮部171と出力部172とを有する。圧縮部171にはクロッピング画像58が入力される。圧縮部171は、クロッピング画像58を特徴量セット173に変換する。圧縮部171は、特徴量セット173を出力部172に受け渡す。出力部172は、特徴量セット173に基づいて、1つのクラス174を出力する。図27においては、出力部172は、認知症を発症している、または認知症を発症していない、という判別結果をクラス174として出力する。
一例として図28に示すように、シングルタスクCNN170は、圧縮部171を特徴量導出モデル175に転用する前の学習フェーズにおいて、学習データ180を与えられて学習される。学習データ180は、学習用クロッピング画像58Lと、学習用クロッピング画像58Lに対応する正解クラス174CAとの組である。正解クラス174CAは、学習用クロッピング画像58Lに対して、認知症を発症しているか否かを、医師が実際に判別した結果である。
学習フェーズにおいて、シングルタスクCNN170には、学習用クロッピング画像58Lが入力される。シングルタスクCNN170は、学習用クロッピング画像58Lに対して学習用クラス174Lを出力する。この学習用クラス174Lおよび正解クラス174CAに基づいて、シングルタスクCNN170の損失演算がなされる。そして、損失演算の結果に応じてシングルタスクCNN170の各種係数の更新設定がなされ、更新設定にしたがってシングルタスクCNN170が更新される。
シングルタスクCNN170の学習フェーズにおいては、学習用クロッピング画像58LのシングルタスクCNN170への入力、シングルタスクCNN170からの学習用クラス174Lの出力、損失演算、更新設定、およびシングルタスクCNN170の更新の上記一連の処理が、学習データ180が交換されつつ繰り返し行われる。上記一連の処理の繰り返しは、正解クラス174CAに対する学習用クラス174Lの予測精度が、予め定められた設定レベルまで達した場合に終了される。こうして予測精度が設定レベルまで達したシングルタスクCNN170の圧縮部171が、ストレージ20に記憶されて特徴量導出モデル175として用いられる。なお、上記第3実施形態と同様に、本実施形態においても、圧縮部171から出力される特徴量セット173が、本開示の技術に係る「特徴量データ」として扱われる。
このように、第4実施形態では、シングルタスクCNN170の圧縮部171が、特徴量導出モデル175として用いられる。前述のように、シングルタスクCNN170も、機械学習の分野において頻繁に用いられるニューラルネットワークモデルの1つであるため、比較的容易に特徴量導出モデル175に転用することができる。
なお、クラス174としては、例えば、患者Pの年齢が75歳未満である、または75歳以上である、という内容であってもよいし、60歳代、70歳代等の患者Pの年代であってもよい。
[第5実施形態]
図29および図30に示す第5実施形態では、マルチタスクのクラス判別用CNN(以下、マルチタスクCNNと略す)180の圧縮部181を、特徴量導出モデル186として用いる。
図29および図30に示す第5実施形態では、マルチタスクのクラス判別用CNN(以下、マルチタスクCNNと略す)180の圧縮部181を、特徴量導出モデル186として用いる。
一例として図29に示すように、マルチタスクCNN180は圧縮部181と出力部182とを有する。圧縮部181にはクロッピング画像58が入力される。圧縮部181は、クロッピング画像58を特徴量セット183に変換する。圧縮部181は、特徴量セット183を出力部182に受け渡す。出力部182は、特徴量セット183に基づいて、第1クラス184および第2クラス185の2つのクラスを出力する。図29においては、出力部182は、認知症を発症している、または認知症を発症していない、という判別結果を第1クラス184として出力する。また、図29においては、出力部182は、患者Pの年齢を第2クラス185として出力する。
一例として図30に示すように、マルチタスクCNN180は、圧縮部181を特徴量導出モデル186に転用する前の学習フェーズにおいて、学習データ190を与えられて学習される。学習データ190は、学習用クロッピング画像58Lと、学習用クロッピング画像58Lに対応する正解第1クラス184CAおよび正解第2クラス185CAとの組である。正解第1クラス184CAは、学習用クロッピング画像58Lに対して、認知症を発症しているか否かを、医師が実際に判別した結果である。また、正解第2クラス185CAは、学習用クロッピング画像58Lを得た頭部MRI画像15の撮影対象の患者Pの実際の年齢である。
学習フェーズにおいて、マルチタスクCNN180には、学習用クロッピング画像58Lが入力される。マルチタスクCNN180は、学習用クロッピング画像58Lに対して学習用第1クラス184Lおよび学習用第2クラス185Lを出力する。この学習用第1クラス184Lおよび学習用第2クラス185Lと、正解第1クラス184CAおよび正解第2クラス185CAとに基づいて、マルチタスクCNN180の損失演算がなされる。そして、損失演算の結果に応じてマルチタスクCNN180の各種係数の更新設定がなされ、更新設定にしたがってマルチタスクCNN180が更新される。
マルチタスクCNN180の学習フェーズにおいては、学習用クロッピング画像58LのマルチタスクCNN180への入力、マルチタスクCNN180からの学習用第1クラス184Lおよび学習用第2クラス185Lの出力、損失演算、更新設定、およびマルチタスクCNN180の更新の上記一連の処理が、学習データ190が交換されつつ繰り返し行われる。上記一連の処理の繰り返しは、正解第1クラス184CAおよび正解第2クラス185CAに対する学習用第1クラス184Lおよび学習用第2クラス185Lの予測精度が、予め定められた設定レベルまで達した場合に終了される。こうして予測精度が設定レベルまで達したマルチタスクCNN180の圧縮部181が、ストレージ20に記憶されて特徴量導出モデル186として用いられる。なお、上記第3実施形態および上記第4実施形態と同様に、本実施形態においても、圧縮部181から出力される特徴量セット183が、本開示の技術に係る「特徴量データ」として扱われる。
このように、第5実施形態では、マルチタスクCNN180の圧縮部181が、特徴量導出モデル186として用いられる。マルチタスクCNN180は、AE80および150、あるいはシングルタスクCNN81および170に比べて、複数のクラス(第1クラス184および第2クラス185)を出力する、というより複雑な処理を行う。このため、圧縮部181から出力される特徴量セット183は、クロッピング画像58の特徴をより網羅的に表したものとなる可能性が高い。したがって、結果として、認知症の所見の予測精度をより高めることができる。
なお、第1クラス184としては、例えば5段階レベルの認知症の進行度合いであってもよい。また、第2クラス185としては、患者Pの年代の判別結果でもよい。マルチタスクCNN180は、3以上のクラスを出力するものであってもよい。
上記第1実施形態において、シングルタスクCNN81の代わりに、本実施形態のマルチタスクCNN180を用いてもよい。
[第6実施形態]
図31に示す第6実施形態では、1つのクロッピング画像58を、異なる複数の特徴量導出モデル201~204に入力する。
図31に示す第6実施形態では、1つのクロッピング画像58を、異なる複数の特徴量導出モデル201~204に入力する。
一例として図31に示すように、本実施形態の特徴量導出部200は、1つのクロッピング画像58を、第1特徴量導出モデル201に入力し、第2特徴量導出モデル202に入力し、第3特徴量導出モデル203に入力し、第4特徴量導出モデル204に入力する。これにより特徴量導出部200は、第1特徴量導出モデル201から第1特徴量データ205を出力させ、第2特徴量導出モデル202から第2特徴量データ206を出力させ、第3特徴量導出モデル203から第3特徴量データ207を出力させ、第4特徴量導出モデル204から第4特徴量データ208を出力させる。
第1特徴量導出モデル201は、上記第1実施形態のAE80およびシングルタスクCNN81を合わせたものである。このため、第1特徴量データ205は集約特徴量ZAである。第2特徴量導出モデル202は、上記第3実施形態のAE150の圧縮部151を転用したものである。このため、第2特徴量データ206は特徴量セット153である。第3特徴量導出モデル203は、上記第4実施形態のシングルタスクCNN170の圧縮部171を転用したものである。このため、第3特徴量データ207は特徴量セット173である。第4特徴量導出モデル204は、上記第5実施形態のマルチタスクCNN180の圧縮部181を転用したものである。このため、第4特徴量データ208は特徴量セット183である。
このように、第6実施形態では、特徴量導出部200は、1つのクロッピング画像58を、第1特徴量導出モデル201、第2特徴量導出モデル202、第3特徴量導出モデル203、および第4特徴量導出モデル204に入力する。そして、各モデル201~204から、第1特徴量データ205、第2特徴量データ206、第3特徴量データ207、および第4特徴量データ208を出力させる。このため、1種の特徴量導出モデルを用いる場合と比べて、多種多様な特徴量データを得ることができる。結果として、認知症の所見の予測精度をより高めることができる。
異なる複数の特徴量導出モデルは、例えば、AE150の圧縮部151を転用した第2特徴量導出モデル202と、シングルタスクCNN170の圧縮部171を転用した第3特徴量導出モデル203との組み合わせでもよい。あるいは、シングルタスクCNN170の圧縮部171を転用した第3特徴量導出モデル203と、マルチタスクCNN180の圧縮部181を転用した第4特徴量導出モデル204との組み合わせでもよい。さらには、認知症を発症しているか否かをクラス174として出力するシングルタスクCNN170の圧縮部171を転用した第3特徴量導出モデル203と、患者Pの年代をクラス174として出力するシングルタスクCNN170の圧縮部171を転用した第3特徴量導出モデル203との組み合わせでもよい。
なお、認知症所見情報は、図9等で例示した内容に限らない。例えば図32に示す認知症所見情報215のように、正常(NC;Normal Control)、軽度認知障害(MCI)、およびアルツハイマー病(AD)のいずれかであってもよい。また、例えば図33に示す認知症所見情報217のように、患者Pの1年後の認知症の進行度合いが早いか遅いかであってもよい。あるいは図34に示す認知症所見情報220のように、アルツハイマー病、レビー小体型認知症、および血管性認知症のいずれであるかといった認知症の種類でもよい。
図17で示したAE80およびシングルタスクCNN81の学習、図19および図23で示した認知症所見導出モデル41および132の学習、図25で示したAE150の学習、図28で示したシングルタスクCNN170の学習、および図30で示したマルチタスクCNN180の学習等は、診断支援装置12において行ってもよいし、診断支援装置12以外の装置で行ってもよい。また、これらの学習は、診断支援装置12のストレージ20に各モデルを記憶した後に継続して行ってもよい。
PACSサーバ11が診断支援装置12として機能してもよい。
医用画像は、例示の頭部MRI画像15に限らない。PET(Positron Emission Tomography)画像、SPECT(Single Photon Emission Computed Tomography)画像、CT(Computed Tomography)画像、内視鏡画像、超音波画像等でもよい。
臓器は例示の脳に限らず、心臓、肺、肝臓等でもよい。肺の場合は、右肺S1、S2、左肺S1、S2等を解剖区域として抽出する。肝臓の場合は、右葉、左葉、胆嚢等を解剖区域として抽出する。また、疾病も例示の認知症に限らず、心臓病、間質性肺炎といったびまん性肺疾患、肝硬変といった肝機能障害等でもよい。
上記各実施形態において、例えば、RW制御部45、正規化部46、抽出部47、クロッピング画像生成部48、特徴量導出部49および200、認知症所見導出部50、130、および160、並びに表示制御部51といった各種の処理を実行する処理部(Processing Unit)のハードウェア的な構造としては、次に示す各種のプロセッサ(Processor)を用いることができる。各種のプロセッサには、上述したように、ソフトウェア(作動プログラム30)を実行して各種の処理部として機能する汎用的なプロセッサであるCPU22に加えて、FPGA(Field Programmable Gate Array)等の製造後に回路構成を変更可能なプロセッサであるプログラマブルロジックデバイス(Programmable Logic Device:PLD)、ASIC(Application Specific Integrated Circuit)等の特定の処理を実行させるために専用に設計された回路構成を有するプロセッサである専用電気回路等が含まれる。
1つの処理部は、これらの各種のプロセッサのうちの1つで構成されてもよいし、同種または異種の2つ以上のプロセッサの組み合わせ(例えば、複数のFPGAの組み合わせ、および/または、CPUとFPGAとの組み合わせ)で構成されてもよい。また、複数の処理部を1つのプロセッサで構成してもよい。
複数の処理部を1つのプロセッサで構成する例としては、第1に、クライアントおよびサーバ等のコンピュータに代表されるように、1つ以上のCPUとソフトウェアの組み合わせで1つのプロセッサを構成し、このプロセッサが複数の処理部として機能する形態がある。第2に、システムオンチップ(System On Chip:SoC)等に代表されるように、複数の処理部を含むシステム全体の機能を1つのIC(Integrated Circuit)チップで実現するプロセッサを使用する形態がある。このように、各種の処理部は、ハードウェア的な構造として、上記各種のプロセッサの1つ以上を用いて構成される。
さらに、これらの各種のプロセッサのハードウェア的な構造としては、より具体的には、半導体素子等の回路素子を組み合わせた電気回路(circuitry)を用いることができる。
本開示の技術は、上述の種々の実施形態および/または種々の変形例を適宜組み合わせることも可能である。また、上記各実施形態に限らず、要旨を逸脱しない限り種々の構成を採用し得ることはもちろんである。さらに、本開示の技術は、プログラムに加えて、プログラムを非一時的に記憶する記憶媒体にもおよぶ。
以上に示した記載内容および図示内容は、本開示の技術に係る部分についての詳細な説明であり、本開示の技術の一例に過ぎない。例えば、上記の構成、機能、作用、および効果に関する説明は、本開示の技術に係る部分の構成、機能、作用、および効果の一例に関する説明である。よって、本開示の技術の主旨を逸脱しない範囲内において、以上に示した記載内容および図示内容に対して、不要な部分を削除したり、新たな要素を追加したり、置き換えたりしてもよいことはいうまでもない。また、錯綜を回避し、本開示の技術に係る部分の理解を容易にするために、以上に示した記載内容および図示内容では、本開示の技術の実施を可能にする上で特に説明を要しない技術常識等に関する説明は省略されている。
本明細書において、「Aおよび/またはB」は、「AおよびBのうちの少なくとも1つ」と同義である。つまり、「Aおよび/またはB」は、Aだけであってもよいし、Bだけであってもよいし、AおよびBの組み合わせであってもよい、という意味である。また、本明細書において、3つ以上の事柄を「および/または」で結び付けて表現する場合も、「Aおよび/またはB」と同様の考え方が適用される。
本明細書に記載された全ての文献、特許出願および技術規格は、個々の文献、特許出願および技術規格が参照により取り込まれることが具体的かつ個々に記された場合と同程度に、本明細書中に参照により取り込まれる。
Claims (11)
- プロセッサと、
前記プロセッサに接続または内蔵されたメモリと、を備え、
前記プロセッサは、
医用画像を取得し、
前記医用画像から臓器の解剖区域を抽出し、
異なる位置および/またはサイズにて、前記解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成し、
複数の前記クロッピング画像を、複数の前記クロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、前記特徴量導出モデルから前記クロッピング画像に対応する特徴量データを出力させ、
複数の前記クロッピング画像毎に出力された前記特徴量データを疾病所見導出モデルに入力し、前記疾病所見導出モデルから前記臓器に関わる疾病の所見を出力させる、
診断支援装置。 - 前記プロセッサは、
前記解剖区域を複数抽出し、
複数の前記解剖区域毎に複数の前記クロッピング画像を生成する請求項1に記載の診断支援装置。 - 前記特徴量導出モデルは、オートエンコーダ、シングルタスクのクラス判別用畳み込みニューラルネットワーク、およびマルチタスクのクラス判別用畳み込みニューラルネットワークのうちの少なくともいずれか1つを含む請求項1または請求項2に記載の診断支援装置。
- 前記プロセッサは、
1つの前記クロッピング画像を、異なる複数の前記特徴量導出モデルに入力し、複数の前記特徴量導出モデルの各々から前記特徴量データを出力させる請求項1から請求項3のいずれか1項に記載の診断支援装置。 - 前記疾病所見導出モデルは、ニューラルネットワーク、サポートベクターマシン、ブースティング、および線形判別分析のうちのいずれかの手法によって構築される請求項1から請求項4のいずれか1項に記載の診断支援装置。
- 前記プロセッサは、
複数の前記特徴量データに加えて、前記疾病に関わる疾病関連情報を前記疾病所見導出モデルに入力する請求項1から請求項5のいずれか1項に記載の診断支援装置。 - 前記臓器は脳であり、
前記疾病は認知症である請求項1から請求項6のいずれか1項に記載の診断支援装置。 - 前記複数の解剖区域は、海馬および前側頭葉のうちの少なくともいずれか1つを含む請求項7に記載の診断支援装置。
- 請求項6を引用する請求項7または請求項8に記載の診断支援装置において、
前記疾病関連情報は、前記解剖区域の体積、認知症テストのスコア、遺伝子検査の検査結果、髄液検査の検査結果、および血液検査の検査結果のうちの少なくともいずれか1つを含む診断支援装置。 - 医用画像を取得すること、
前記医用画像から臓器の解剖区域を抽出すること、
異なる位置および/またはサイズにて、前記解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成すること、
複数の前記クロッピング画像を、複数の前記クロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、前記特徴量導出モデルから前記クロッピング画像に対応する特徴量データを出力させること、および、
複数の前記クロッピング画像毎に出力された前記特徴量データを疾病所見導出モデルに入力し、前記疾病所見導出モデルから前記臓器に関わる疾病の所見を出力させること、
を含む診断支援装置の作動方法。 - 医用画像を取得すること、
前記医用画像から臓器の解剖区域を抽出すること、
異なる位置および/またはサイズにて、前記解剖区域の少なくとも一部を包含する領域をクロッピングすることで複数のクロッピング画像を生成すること、
複数の前記クロッピング画像を、複数の前記クロッピング画像の各々に対応して用意された特徴量導出モデルに入力し、前記特徴量導出モデルから前記クロッピング画像に対応する特徴量データを出力させること、および、
複数の前記クロッピング画像毎に出力された前記特徴量データを疾病所見導出モデルに入力し、前記疾病所見導出モデルから前記臓器に関わる疾病の所見を出力させること、
を含む処理をコンピュータに実行させるための診断支援装置の作動プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022571713A JPWO2022138960A1 (ja) | 2020-12-25 | 2021-12-24 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020217838 | 2020-12-25 | ||
| JP2020-217838 | 2020-12-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022138960A1 true WO2022138960A1 (ja) | 2022-06-30 |
Family
ID=82158244
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/048386 WO2022138960A1 (ja) | 2020-12-25 | 2021-12-24 | 診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2022138960A1 (ja) |
| WO (1) | WO2022138960A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI807972B (zh) * | 2022-08-24 | 2023-07-01 | 臺北醫學大學 | 產生預測腦影像之方法及裝置 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018509216A (ja) * | 2015-03-31 | 2018-04-05 | ソニー株式会社 | T1 mriからの自動3dセグメンテーション及び皮質表面再構築 |
| JP2020171841A (ja) * | 2018-09-12 | 2020-10-22 | 株式会社Splink | 診断支援システムおよび方法 |
| JP2020192068A (ja) * | 2019-05-28 | 2020-12-03 | 株式会社日立製作所 | 画像診断支援装置、画像診断支援プログラム、および、医用画像取得装置 |
-
2021
- 2021-12-24 JP JP2022571713A patent/JPWO2022138960A1/ja active Pending
- 2021-12-24 WO PCT/JP2021/048386 patent/WO2022138960A1/ja active Application Filing
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018509216A (ja) * | 2015-03-31 | 2018-04-05 | ソニー株式会社 | T1 mriからの自動3dセグメンテーション及び皮質表面再構築 |
| JP2020171841A (ja) * | 2018-09-12 | 2020-10-22 | 株式会社Splink | 診断支援システムおよび方法 |
| JP2020192068A (ja) * | 2019-05-28 | 2020-12-03 | 株式会社日立製作所 | 画像診断支援装置、画像診断支援プログラム、および、医用画像取得装置 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI807972B (zh) * | 2022-08-24 | 2023-07-01 | 臺北醫學大學 | 產生預測腦影像之方法及裝置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022138960A1 (ja) | 2022-06-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10818048B2 (en) | Advanced medical image processing wizard | |
| JP2005169120A (ja) | 検査対象の結果画像の作成方法および画像処理システム | |
| US11229377B2 (en) | System and method for next-generation MRI spine evaluation | |
| US10165987B2 (en) | Method for displaying medical images | |
| WO2022138960A1 (ja) | 診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラム | |
| Hachaj et al. | Visualization of perfusion abnormalities with GPU-based volume rendering | |
| JP3989896B2 (ja) | 医用画像処理装置、関心領域抽出方法、ならびに、プログラム | |
| US20230260629A1 (en) | Diagnosis support device, operation method of diagnosis support device, operation program of diagnosis support device, dementia diagnosis support method, and trained dementia opinion derivation model | |
| US20230260630A1 (en) | Diagnosis support device, operation method of diagnosis support device, operation program of diagnosis support device, and dementia diagnosis support method | |
| JP6843785B2 (ja) | 診断支援システム、診断支援方法、及びプログラム | |
| JP6882216B2 (ja) | 診断支援システム、診断支援方法、及びプログラム | |
| WO2022138961A1 (ja) | 情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラム | |
| JP2005511177A (ja) | 体の構造の孤立した視覚化されたものを形成する方法及び装置 | |
| JP7083427B2 (ja) | 修正指示領域表示装置、方法およびプログラム | |
| Kao et al. | Demystifying T1-MRI to FDG^ 18 18-PET Image Translation via Representational Similarity | |
| JP7288070B2 (ja) | 画像処理装置、方法およびプログラム | |
| JP7048760B2 (ja) | 領域修正装置、方法およびプログラム | |
| WO2022071160A1 (ja) | 診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラム、並びに認知症診断支援方法 | |
| WO2022065062A1 (ja) | 診断支援装置、診断支援装置の作動方法、診断支援装置の作動プログラム | |
| US20230143966A1 (en) | Image processing apparatus and non-transitory computer readable medium | |
| US20230222656A1 (en) | Image processing apparatus, operation method of image processing apparatus, and operation program of image processing apparatus | |
| CN116490132A (zh) | 诊断辅助装置、诊断辅助装置的工作方法、诊断辅助装置的工作程序、痴呆症诊断辅助方法、以及学习完毕痴呆症诊断意见导出模型 | |
| JP2024018562A (ja) | 画像処理装置、方法およびプログラム | |
| JP2023551421A (ja) | 医用画像内の標識要素の抑制 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21911097 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022571713 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21911097 Country of ref document: EP Kind code of ref document: A1 |