WO2022130648A1 - 情報処理プログラム、情報処理方法および情報処理装置 - Google Patents
情報処理プログラム、情報処理方法および情報処理装置 Download PDFInfo
- Publication number
- WO2022130648A1 WO2022130648A1 PCT/JP2020/047562 JP2020047562W WO2022130648A1 WO 2022130648 A1 WO2022130648 A1 WO 2022130648A1 JP 2020047562 W JP2020047562 W JP 2020047562W WO 2022130648 A1 WO2022130648 A1 WO 2022130648A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- vector
- compound
- target compound
- sub
- reagent
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/10—Analysis or design of chemical reactions, syntheses or processes
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/70—Machine learning, data mining or chemometrics
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02P—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN THE PRODUCTION OR PROCESSING OF GOODS
- Y02P90/00—Enabling technologies with a potential contribution to greenhouse gas [GHG] emissions mitigation
- Y02P90/30—Computing systems specially adapted for manufacturing
Definitions
- the present invention relates to an information processing program or the like.
- Natural organic compounds that exist in nature are very promising candidates for drug discovery, but they are rare, and it is difficult to manufacture various products using such natural organic compounds as they are. For this reason, organic compounds corresponding to rare natural organic compounds are produced by using highly versatile conversion reactions based on inexpensive and easily available raw materials and reagents.
- an organic compound corresponding to a natural organic compound is referred to as a "target compound”.
- a retrosynthetic analysis on a natural organic compound by performing a retrosynthetic analysis on a natural organic compound, a combination of multiple reagents (or raw materials) to be converted and reacted to produce the target compound, a synthetic route showing the order of synthesis, etc. are designed.
- the target compound is synthesized and produced by sequentially reacting the reagents based on the synthetic route designed by the prior art.
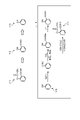
- FIG. 22 is a diagram for explaining an example of retrosynthetic analysis and synthetic pathway.
- the functional groups of acetylsalicylic acid 1-1 are esters and carboxyl groups. Since the ester is obtained from carboxylic acid and alcohol, the precursor before acetylsalicylic acid 1-1 is salicylic acid 1-2 and the reagent used is acetic anhydride. Since salicylic acid 1-2 is obtained from the Kolbe-Schmitt reaction in which carbon dioxide is reacted with an inexpensive sodium salt of phenol at high pressure, the precursor of salicylic acid is phenol 1-3. Based on the result of such reverse synthesis, a synthetic pathway 1-4 is designed, and acetylsalicylic acid 1-1 is synthesized from phenol 1-3.
- the present invention provides an information processing program, an information processing method, and an information processing apparatus capable of detecting a reagent similar to the reagent obtained by retrosynthetic analysis of a target compound and specifying the conversion reaction thereof.
- the purpose is to do.
- the first plan is to have the computer perform the following processing.
- the computer trains the learning model based on the training data that defines the relationship between the vector corresponding to the target compound and the vector corresponding to each of the multiple subcompounds contained in the synthetic pathway for producing the target compound.
- the computer accepts the target compound to be analyzed, the computer inputs the vector of the target compound to be analyzed into the learning model to calculate the vectors of a plurality of sub-compounds corresponding to the target compound to be analyzed.
- Reagents similar to the reagent of the target compound can be detected.
- FIG. 1 is a diagram for explaining an example of processing in the learning phase of the information processing apparatus according to the first embodiment.
- FIG. 2 is a diagram for explaining an example of processing in the analysis phase of the information processing apparatus according to the first embodiment.
- FIG. 3 is a functional block diagram showing the configuration of the information processing apparatus according to the first embodiment.
- FIG. 4 is a diagram showing an example of the data structure of the chemical structural formula file.
- FIG. 5 is a diagram showing an example of a basic dictionary.
- FIG. 6 is a diagram showing an example of a reagent dictionary.
- FIG. 7A is a diagram showing an example of a sub-compound dictionary.
- FIG. 7B is a diagram showing an example of a target compound dictionary.
- FIG. 7C is a diagram showing an example of a common structure dictionary.
- FIG. 8 is a diagram showing an example of the data structure of the basic vector table.
- FIG. 9 is a diagram showing an example of the data structure of the reagent vector table.
- FIG. 10A is a diagram showing an example of the data structure of the subcompound vector table.
- FIG. 10B is a diagram showing an example of the data structure of the target compound vector table.
- FIG. 10C is a diagram showing an example of the data structure of the common structure vector table.
- FIG. 11 is a diagram showing an example of the data structure of the base inverted index.
- FIG. 12 is a diagram showing an example of the data structure of the reagent inverted index.
- FIG. 13A is a diagram showing an example of the data structure of the subcompound inverted index.
- FIG. 13B is a diagram showing an example of the data structure of the target compound inverted index.
- FIG. 13C is a diagram showing an example of the data structure of the common structure inverted index.
- FIG. 14 is a diagram showing an example of the data structure of the retrosynthetic analysis table.
- FIG. 15 is a flowchart (1) showing a processing procedure of the information processing apparatus according to the first embodiment.
- FIG. 16 is a flowchart (2) showing a processing procedure of the information processing apparatus according to the first embodiment.
- FIG. 17 is a diagram for explaining an example of processing in the learning phase of the information processing apparatus according to the second embodiment.
- FIG. 18 is a diagram for explaining the processing of the information processing apparatus according to the second embodiment.
- FIG. 15 is a flowchart (1) showing a processing procedure of the information processing apparatus according to the first embodiment.
- FIG. 16 is a flowchart (2) showing a processing procedure of the information processing apparatus according to the first embodiment.
- FIG. 17 is a diagram for explaining an example of
- FIG. 19 is a functional block diagram showing the configuration of the information processing apparatus according to the second embodiment.
- FIG. 20 is a flowchart showing a processing procedure of the information processing apparatus according to the second embodiment.
- FIG. 21 is a diagram showing an example of a hardware configuration of a computer that realizes the same functions as the information processing apparatus of the embodiment.
- FIG. 22 is a diagram for explaining an example of retrosynthetic analysis and synthetic pathway.
- the information processing apparatus shall execute a process of calculating a vector of a target compound and a process of calculating a vector of each sub-compound (reagent) corresponding to the target compound by pre-processing. ..
- a synthetic route for producing the target compound is designed, and the target compound and each reagent for synthesizing and producing the target compound and a conversion reaction are performed. The relationship with is identified.
- FIG. 1 is a diagram for explaining an example of processing in the learning phase of the information processing apparatus according to the first embodiment.
- the information processing apparatus uses the learning data 65 to perform learning of the learning model 70.
- the learning model 70 corresponds to CNN (Convolutional Neural Network), RNN (Recurrent Neural Network), and the like.
- the learning data 65 defines the relationship between the vector of the target compound having a track record of retrosynthetic analysis and synthesis and the vector of a plurality of sub-compounds used for retrosynthetic analysis and synthesis of the target compound.
- the vector of the target compound corresponds to the input data
- the vector of a plurality of sub-compounds is the correct value of the output data.
- the information processing device executes learning by error back propagation so that the output when the vector of the target compound is input to the learning model 70 approaches the vector of each sub-compound.
- the information processing apparatus adjusts the parameters of the learning model 70 by repeatedly executing the above processing based on the relationship between the vector of the target compound included in the learning data 65 and the vector of a plurality of sub-compounds (machine). Perform learning).
- FIG. 2 is a diagram for explaining an example of processing in the analysis phase of the information processing apparatus according to the first embodiment.
- the information processing apparatus executes the next process using the learning model 70 learned in the learning phase.
- the information processing apparatus When the information processing apparatus receives the analysis query 80 in which the target compound is specified, the information processing apparatus converts the target compound of the analysis query 80 into the vector Bob 80. By inputting the vector Vob80 into the learning model 70, the information processing apparatus calculates a plurality of vectors (Vsb80-1, Vsb80-2, Vsb80-3, ... Vsb80-n) corresponding to each sub-compound. ..
- the information processing apparatus corresponds to a plurality of vectors (Vr80-1, Vr80-2, Vr80-3, ... Vr80-n) stored in the reagent vector table T2 corresponding to each reagent, and each subcompound. Similar subcompounds and reagents are analyzed by comparing the degree of similarity with a plurality of vectors (Vsb80-1, Vsb80-2, Vsb80-3, ... Vsb80-n). The information processing apparatus associates a vector of a similar sub-compound with a vector of a reagent and registers the vector in the sub-compound / reagent table 85.
- the information processing apparatus is based on the learning data 65 that defines the relationship between the vector of the target compound and the vector of each sub-compound based on the retrosynthetic analysis, and is based on the learning model 70. Perform learning.
- the information processing apparatus inputs the vector of the analysis query into the trained learning model 70, and calculates the vector of each sub-compound corresponding to the target compound of the analysis query.
- the vector of each sub-compound output from the learning model 70 it is possible to easily detect each reagent similar to the sub-compound defined in the synthetic pathway of the target compound.
- FIG. 3 is a functional block diagram showing the configuration of the information processing apparatus according to the first embodiment.
- the information processing apparatus 100 includes a communication unit 110, an input unit 120, a display unit 130, a storage unit 140, and a control unit 150.
- the communication unit 110 is connected to an external device or the like by wire or wirelessly, and transmits / receives information to / from the external device or the like.
- the communication unit 110 is realized by a NIC (Network Interface Card) or the like.
- the communication unit 110 may be connected to a network (not shown).
- the input unit 120 is an input device that inputs various information to the information processing device 100.
- the input unit 120 corresponds to a keyboard, a mouse, a touch panel, and the like.
- the display unit 130 is a display device that displays information output from the control unit 150.
- the display unit 130 corresponds to a liquid crystal display, an organic EL (Electro Luminescence) display, a touch panel, and the like.
- the storage unit 140 has a chemical structural formula file 50, a basic coding file 51, a reagent coding file 52, a sub-compound coding file 53, a target compound coding file 54, and a common structure coding file 55.
- the storage unit 140 has a basic dictionary D1, a reagent dictionary D2, a sub-compound dictionary D3, a target compound dictionary D4, and a common structure dictionary D5.
- the storage unit 140 has a group vector table T1, a reagent vector table T2, a subcompound table T3, a target compound vector table T4, and a common structure vector table T5.
- the storage unit 140 has a basic inverted index In1, a reagent inverted index In2, a subcompound inverted index In3, a target compound index In4, and a common structure index In5.
- the storage unit 140 has a retrosynthetic analysis result table 60, learning data 65, a learning model 70, an analysis query 80, and a subcompound / reagent table 85.
- the storage unit 140 is realized by, for example, a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory (Flash Memory), or a storage device such as a hard disk or an optical disk.
- a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory (Flash Memory)
- flash memory Flash Memory
- storage device such as a hard disk or an optical disk.
- the chemical structural formula file 50 is information including the demonstrative formulas of a plurality of functional groups, and by combining the demonstrative formulas of the smallest unit functional groups, it becomes a demonstrative formula of a primary structure or a secondary structure. do.
- the demonstrative formula of the primary structure corresponds to the "sub-compound” or "reagent”
- the demonstrative formula of the secondary structure is "the target compound (or natural organic substance)”.
- the explanation will be given as corresponding to "Compound)".
- the chemical structural formula file 50 includes a sub-compound (reagent) description area in which a demonstrative formula corresponding to each sub-compound (or reagent) is described, and a target compound description area in which the demonstrative formula corresponding to each target compound is described. It is divided into. Further, the chemical structural formula file 50 may include the information of the retrosynthetic analysis result table 60 described later.
- FIG. 4 is a diagram showing an example of the data structure of the chemical structural formula file.
- the demonstrative formula (chemical structural formula) is a formula showing the arrangement of the elements constituting the compound, and may be described by the SMILES method or the like.
- the functional group basic coding file 51 is a file obtained by compressing the chemical structural formula file 50 in units of groups. As will be described later, the base coding file 51 is created based on the chemical structural formula file 50 and the base dictionary D1.
- the reagent coding file 52 is a file generated based on the reagent compression region of the basic coding file 51, and is a file compressed in units of reagents.
- the compression code of one reagent corresponds to a combination of compression codes of a plurality of groups.
- the reagent coding file 52 is created based on the compression code of the reagent compression region and the reagent dictionary D2.
- the sub-compound coding file 53 is a file generated based on the base coding file 51, and is a file compressed in units of sub-compounds.
- the compression code of one subcompound corresponds to a combination of compression codes of a plurality of groups.
- the sub-compound coding file 53 is created based on the compression code of the sub-compound compression region and the sub-compound dictionary D3.
- the target compound coded file 54 is a file generated based on the target compound compressed region of the base coded file 51, and is a file compressed in units of the target compound.
- the compression code of one target compound corresponds to a combination of compression codes of a plurality of groups.
- the target compound coding file 54 is created based on the compression code of the target compound compression region and the target compound dictionary D4.
- the common structure coding file 55 is a file generated based on the basic coding file 51, and is a file compressed in units of the common structure.
- a compression code of one common structure corresponds to a combination of compression codes of a plurality of groups.
- the common structure coding file 55 is created based on the compression code of the common structure region and the common structure dictionary D5.
- the basic dictionary D1 defines the compression code of the group and the arrangement of the elements constituting the group by a demonstrative formula.
- FIG. 5 is a diagram showing an example of a basic dictionary. As shown in FIG. 5, the basic dictionary D1 associates a compression code with a name and a demonstrative expression.
- the compression code is the compression code assigned to the group.
- the name is an example of the name of the corresponding group.
- the demonstrative formula indicates a sequence that becomes the demonstrative formula of the corresponding group.
- the compression code "D0008000h” is assigned to the "methyl group”.
- the index expression corresponding to the compression code "D0008000h” is "CH3".
- "H” is a symbol indicating that the compression code is a hexadecimal number.
- the reagent dictionary D2 defines the relationship between the compression code of a reagent and the combination of the compression codes of a plurality of groups constituting the reagent.
- FIG. 6 is a diagram showing an example of a reagent dictionary. As shown in FIG. 6, the reagent dictionary D2 associates a compression code with a name and a base code sequence.
- the compression code is the compression code assigned to the reagent.
- the name is an example of the name of the corresponding reagent.
- the base code array is a code array in which compression codes of a plurality of groups are combined.
- the sub-compound dictionary D3 defines the relationship between the compression code of the target compound and the combination of the compression codes of the plurality of groups constituting the target compound.
- FIG. 7A is a diagram showing an example of a sub-compound dictionary. As shown in FIG. 7A, the subcompound dictionary D3 associates a compression code with a name and a base code sequence.
- the compression code is a compression code assigned to the sub-compound.
- the name is an example of the name of the corresponding sub-compound.
- the base code array is a code array in which compression codes of a plurality of groups are combined.
- the target compound dictionary D4 defines the relationship between the compression code of the target compound and the combination of the compression codes of a plurality of groups constituting the target compound.
- FIG. 7B is a diagram showing an example of a target compound dictionary. As shown in FIG. 7B, the target compound dictionary D4 associates a compression code with a name and a base code sequence.
- the compression code is a compression code assigned to the target compound.
- the name is an example of the name of the corresponding target compound.
- the base code array is a code array in which compression codes of a plurality of groups are combined.
- the common structure dictionary D5 is a common structure among the structures included in a plurality of reagents.
- the common structure dictionary D5 defines the relationship between the compression code of the common structure and the combination of the compression codes of a plurality of groups constituting the common structure.
- FIG. 7C is a diagram showing an example of a common structure dictionary. As shown in FIG. 7C, the common structure dictionary D5 associates a compression code with a name and a base code array.
- the compression code is a compression code assigned to the common structure.
- the name is an example of the name of the corresponding common structure.
- the base code array is a code array in which compression codes of a plurality of groups are combined.
- the base vector table T1 is a table that defines the base vector.
- FIG. 8 is a diagram showing an example of the data structure of the basic vector table. As shown in FIG. 8, in the group vector table T1, the compression code of the group is associated with the vector assigned to the compression code of the group. The base vector is calculated by Poincaré embedding.
- the reagent vector table T2 is a table that defines a reagent vector.
- FIG. 9 is a diagram showing an example of the data structure of the reagent vector table. As shown in FIG. 9, in the reagent vector table T2, the compression code of the reagent is associated with the vector assigned to the compression code of the reagent.
- the reagent vector is the sum of the compression code vectors of the groups constituting the reagent.
- the reagent vector table T2 may further associate and retain characteristics such as the name of the reagent and the demonstrative formula of the reagent.
- the sub-compound vector table T3 is a table that defines the vector of the sub-compound.
- FIG. 10A is a diagram showing an example of the data structure of the subcompound vector table.
- the sub-compound vector table T3 is associated with the compression code of the sub-compound and the vector assigned to the compression code of the sub-compound.
- the vector of the sub-compound is the sum of the vectors of the compression codes of the groups constituting the sub-compound.
- the sub-compound vector table T3 may further hold features such as the name of the sub-compound and the demonstrative formula of the sub-compound in association with each other.
- the target compound vector table T4 is a table that defines the vector of the target compound.
- FIG. 10B is a diagram showing an example of the data structure of the target compound vector table. As shown in FIG. 10B, the target compound vector table T3 is associated with the compression code of the target compound and the vector assigned to the compression code of the target compound. The vector of the target compound is the sum of the vectors of the compression codes of the groups constituting the target compound.
- the common structure vector table T5 is a table that defines a vector of a common structure.
- FIG. 10C is a diagram showing an example of the data structure of the common structure vector table. As shown in FIG. 10C, in the common structure vector table T5, the compression code of the common structure and the vector assigned to the compression code of the common structure are associated with each other.
- the vector of the common structure is the sum of the vectors of the compression codes of the groups constituting the common structure.
- the base inverted index In1 indicates the appearance position (offset) of the base coding file 51 with respect to the compression code of the group.
- FIG. 11 is a diagram showing an example of the data structure of the base inverted index. As shown in FIG. 11, the horizontal axis of the base inverted index In1 is the axis corresponding to the offset. The vertical axis of the base inverted index In1 is the axis corresponding to the compression code of the base.
- the base inverted index In1 is indicated by a bitmap of "0" or "1", and all bitmaps are set to "0" in the initial state.
- the offset of the compression code of the base at the beginning of the base coding file 51 is set to "0".
- the column of the offset "1" of the group translocation index In1 and the group compression code "D008000h (methyl group)” are included.
- the bit at the position where the line of "base)" intersects is "1".
- the reagent inverted index In2 indicates the appearance position (offset) of the reagent coding file 52 with respect to the compression code of the reagent.
- FIG. 12 is a diagram showing an example of the data structure of the reagent inverted index. As shown in FIG. 12, the horizontal axis of the reagent inverted index In2 is the axis corresponding to the offset. The vertical axis of the test drug inverted index In2 is the axis corresponding to the compression code of the reagent.
- the reagent inverted index In2 is indicated by a bitmap of "0" or "1", and in the initial state, all bitmaps are set to "0".
- the offset of the compression code of the reagent at the beginning of the reagent coding file 52 is set to "0".
- the column of the offset "8" of the reagent transfer index In2 and the row of the reagent compression code "D0008000h” intersect.
- the bit at the position to be used is "1".
- the sub-compound inverted index In3 indicates the appearance position (offset) of the sub-compound coding file 53 with respect to the compression code of the sub-compound.
- FIG. 13A is a diagram showing an example of the data structure of the subcompound inverted index. As shown in FIG. 13A, the horizontal axis of the subcompound inverted index In3 is the axis corresponding to the offset. The vertical axis of the sub-compound inverted index In3 is the axis corresponding to the compression code of the sub-compound.
- the subcompound inverted index In3 is indicated by a bitmap of "0" or "1", and all bitmaps are initially set to "0".
- the offset of the compression code of the sub-compound at the beginning of the sub-compound coding file 53 is set to "0".
- the subcompound code "D0008000h” is included in the ninth position from the beginning of the subcompound coding file 53, the column of the offset "8" of the subcompound inverted index In3 and the compression code "D0008000h” of the subcompound The bit at the position where the line intersects is "1".
- the target compound inverted index In4 indicates the appearance position (offset) of the target compound coding file 54 with respect to the compression code of the target compound.
- FIG. 13B is a diagram showing an example of the data structure of the target compound inverted index. As shown in FIG. 13B, the horizontal axis of the target compound inverted index In4 is the axis corresponding to the offset. The vertical axis of the target compound drug inverted index In4 is the axis corresponding to the compression code of the target compound.
- the target compound inverted index In4 is indicated by a bitmap of "0" or "1", and all the bitmaps are set to "0" in the initial state.
- the offset of the compression code of the target compound at the beginning of the target compound coding file 54 is set to "0".
- the column of the offset "8" of the target compound inverted index In4 and the compression code "D0008000h” of the target compound The bit at the position where the line intersects is "1".
- the common structure inverted index In5 indicates the appearance position (offset) of the common structure coding file 55 with respect to the compression code of the common structure.
- FIG. 13C is a diagram showing an example of the data structure of the common structure inverted index. As shown in FIG. 13C, the horizontal axis of the common structure inverted index In5 is the axis corresponding to the offset. The vertical axis of the common structure inverted index In5 is the axis corresponding to the compression code of the common structure.
- the common structure inverted index In5 is indicated by a bitmap of "0" or "1", and all the bitmaps are set to "0" in the initial state.
- the offset of the compression code of the common structure at the beginning of the common structure coding file 55 is set to "0".
- the code "D0008000h” of the common structure is included in the ninth position from the beginning of the common structure coding file 55, the column of the offset "8" of the common structure translocation index In4 and the compression code "D0008000h” of the subcompound The bit at the position where the line intersects is "1".
- the retrosynthetic analysis result table 60 holds information (synthetic pathway) obtained by performing a retrosynthetic analysis on a target compound (a natural organic compound corresponding to the target compound).
- FIG. 14 is a diagram showing an example of the data structure of the retrosynthetic analysis result table. As shown in FIG. 14, this retrosynthetic analysis result table 60 associates the name of the target compound with the synthetic route obtained by performing the retrosynthetic analysis on the target compound.
- the total pathway shall include the name of each reagent to be reacted in the middle of the synthetic pathway.
- the present invention is not limited to this, and the target compound and each sub-compound are represented by a demonstrative formula. It may be associated with the name of (reagent). Further, the information in the retrosynthetic analysis result table 60 may be a part of the chemical structural formula file 50.
- the learning data 65 defines the relationship between the vector of the target compound and the vector of a plurality of sub-compounds (reagents) used for producing the target compound.
- the data structure of the training data 65 corresponds to the data structure of the training data described with reference to FIG.
- the learning model 70 is a model corresponding to CNN, RNN, etc., and parameters are set.
- the analysis query 80 contains information on the specific formula of the target compound to be analyzed by the reagent.
- the sub-compound / reagent table 85 is a table that holds a vector of similar sub-compounds and a vector of reagents in association with each other.
- the data structure of the subcompound / reagent table 85 corresponds to the data structure of the subcompound / reagent table described with reference to FIG.
- the control unit 150 includes a preprocessing unit 151, a learning unit 152, a calculation unit 153, and an analysis unit 154.
- the control unit 150 is realized by, for example, a CPU (Central Processing Unit) or an MPU (Micro Processing Unit). Further, the control unit 150 may be executed by an integrated circuit such as an ASIC (Application Specific Integrated Circuit) or an FPGA (Field Programmable Gate Array).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- the pretreatment unit 151 calculates the vector of the target compound, the vector of the sub compound (reagent), and the like by executing the following various treatments.
- the preprocessing unit 151 generates a basic coding file 51, a basic vector table T1, a processing for generating a basic inverted index In1, a reagent coding file 52, a reagent vector table T2, and a reagent transfer index In2. Execute the process.
- the pre-processing unit 151 executes a process of generating the sub-compound coding file 53, the sub-compound vector table T3, and the sub-compound inverted index In3.
- the pretreatment unit 151 executes a process of generating the target compound coding file 54, the target compound vector table T4, and the target compound inverted index In4.
- the preprocessing unit 151 executes a process of generating the learning data 65.
- the preprocessing unit 151 identifies the demonstrative formula of the group contained in the chemical structural formula file 50 based on the chemical structural formula file 50 and the basic dictionary D1, and uses the specified group demonstrative formula as a compression code.
- the basic coded file 51 is generated.
- the basic coding file 51 includes a reagent compression region, a sub-compound compression region, and a target compound compression region.
- the pretreatment unit 151 generates a basic coding sequence of the reagent compression region by executing the above processing for each indicator expression included in the reagent description area of the basic coding file 51.
- the pre-processing unit 151 generates a basic-coded sequence of the sub-compound compression region by executing the above processing for each demonstrative expression included in the sub-compound description region of the basic coding file 51.
- the preprocessing unit 151 generates a basic coded sequence of the target compound compressed region by executing the above processing for each demonstrative formula included in the target compound description region of the basic coded file 51.
- the preprocessing unit 151 executes Poincare embedding when generating the base vector table T1.
- the preprocessing unit 151 calculates the vector of the group (compression code of the group) by embedding the compression code of the group in the Poincare space.
- the process of embedding in the Poincare space and calculating the vector is a technique called Poincare Embeddings.
- Poincare embedding for example, the technique described in the non-patent document "Valentin Khrulkov1 et al.” Hyperbolic Image Embeddings "Cornell University, 2019 April 3" may be used.
- the preprocessing unit 151 embeds the compression code of each group in the Poincare space with reference to the group similarity table in which similar groups are defined, and calculates the vector of the compression code of each group.
- the preprocessing unit 151 may execute Poincare embedding in advance for the compression code of each group defined in the group dictionary D1.
- the preprocessing unit 151 generates the group vector table T1 by associating the group (compression code of the group) with the vector of the group.
- the preprocessing unit 151 generates the base inverted index In1 based on the relationship between the base vector and the position of the base (compression code of the base) in the base coding file 51.
- the pretreatment unit 151 replaces the basic coded sequence corresponding to the reagent with the compressed code of the reagent based on the basic coded sequence of the reagent compressed region included in the basic coded file 51 and the reagent dictionary D2.
- the reagent coding file 52 is generated.
- the pretreatment unit 151 identifies the compression code of each group included in the group coded sequence by comparing the group coded sequence corresponding to the reagent with the group vector table T1, and the compression code of each specified group. By integrating the vectors of, the vector corresponding to the reagent is calculated.
- the pretreatment unit 151 generates the reagent vector table T2 by associating the reagent (compression code of the reagent) with the vector of the reagent.
- the pretreatment unit 151 generates the reagent inverted index In2 based on the relationship between the reagent vector and the position of the reagent (compression code of the reagent) in the reagent coding file 52.
- the preprocessing unit 151 compresses the basic coded sequence corresponding to the subcompound based on the basic coded sequence of the subcompound compression region included in the basic coded file 51 and the subcompound dictionary D3.
- the sub-compound coded file 53 is generated by repeatedly executing the process of replacing with the code.
- the pretreatment unit 151 identifies the compression code of each group included in the basic coded sequence by comparing the basic coded sequence corresponding to the subcompound with the basic vector table T1, and compresses each of the specified groups. By integrating the vector of the code, the vector corresponding to the subcompound is calculated.
- the pretreatment unit 151 generates the sub-compound vector table T3 by associating the sub-compound (compression code of the sub-compound) with the vector of the sub-compound.
- the pretreatment unit 151 generates a subcompound inverted index In3 based on the relationship between the vector of the subcompound and the position of the subcompound (compression code of the subcompound) in the subcompound coding file 53.
- the preprocessing unit 151 compresses the target compound by compressing the group coded sequence corresponding to the target compound based on the group coded sequence of the target compound compression region included in the group coded file 51 and the target compound dictionary D4. By repeatedly executing the process of replacing with the code, the target compound coded file 54 is generated.
- the pretreatment unit 151 identifies the compression code of each group included in the group coded sequence by comparing the group coded sequence corresponding to the target compound with the group vector table T1, and compresses each of the specified groups. By integrating the vector of the code, the vector corresponding to the target compound is calculated.
- the pretreatment unit 151 generates the target compound vector table T4 by associating the target compound (compression code of the target compound) with the vector of the target compound.
- the pretreatment unit 151 generates the target compound inverted index In4 based on the relationship between the vector of the target compound and the position of the target compound (compression code of the target compound) in the target compound coding file 54.
- the preprocessing unit 151 may generate a common structure coding file 55, a common structure vector table T5, and a common structure inverted index In5.
- the preprocessing unit 151 uses the basic coded array of the common structure region included in the basic coded file 51 and the common structure dictionary D5 as a basis for compressing the basic coded array corresponding to the common structure into a compression code of the common structure.
- the common structure coding file 55 is generated by repeatedly executing the process of replacing with.
- the preprocessing unit 151 identifies the compression code of each group included in the basic coded array by comparing the basic coded array corresponding to the common structure with the basic vector table T1, and compresses each of the specified groups. By integrating the code vectors, the vector corresponding to the common structure is calculated.
- the preprocessing unit 151 generates the common structure vector table T5 by associating the common structure (compression code of the common structure) with the vector of the common structure.
- the preprocessing unit 151 generates the common structure index In5 based on the relationship between the vector of the common structure and the position of the common structure (compression code of the common structure) in the common structure coding file 55.
- the preprocessing unit 151 will explain an example of the process of generating the learning data 65.
- the pretreatment unit 151 specifies the relationship between the name of the target compound and the names of a plurality of sub-compounds (reagents) to be reacted in the synthetic route of the target compound based on the retrosynthetic analysis result table 60.
- the pretreatment unit 151 specifies the vector of the target compound based on the name of the target compound and the target compound vector table T4.
- the pretreatment unit 151 specifies the vector of the sub-compound (reagent) based on the name of each sub-compound (reagent) and the reagent vector table T2 (or the sub-compound vector table T3).
- the pretreatment unit 151 identifies the relationship between the vector of the target compound and the vector of each sub-compound (reagent) to be reacted in the synthetic route of the target compound, and registers the vector in the learning data 65.
- the pretreatment unit 151 generates learning data 65 by repeatedly executing the above processing for each record (name of target compound, name of each sub-compound (reagent)) in the retrosynthetic analysis result table 60.
- the learning unit 152 executes learning of the learning model 70 using the learning data 65.
- the process of the learning unit 152 corresponds to the process described with reference to FIG.
- the learning unit 152 acquires a set of a vector of the target compound and a vector of each sub-compound (reagent) corresponding to the vector of the target compound from the learning data 65.
- the learning unit 152 performs learning by error back propagation so that the value of the output of the learning model 70 when the vector of the target compound is input to the learning model 70 approaches the value of the vector of each subcompound (reagent). By executing, the parameters of the learning model 70 are adjusted.
- the learning unit 152 executes the learning of the learning model 70 by repeatedly executing the above processing for the set of the vector of the target compound of the learning data 65 and the vector of each sub-compound (reagent).
- the calculation unit 153 calculates the vector of each sub-compound to be reacted in the synthetic route of the target compound of the analysis query 80 by using the learned learning model 70.
- the processing of the calculation unit 153 corresponds to the processing described with reference to FIG.
- the calculation unit 153 may receive the analysis query 80 from the input unit 120 or from an external device via the communication unit 110.
- the calculation unit 153 acquires the demonstrative formula of the target compound contained in the analysis query 80.
- the calculation unit 153 compares the specific formula of the target compound with the basic dictionary D1, identifies the group contained in the specific formula of the target compound, and compresses the specific formula of the target compound in the unit of the group. Convert to a code.
- the calculation unit 153 compares the converted compression code of each group with the group vector table T1 to specify the vector of the compression code of each group.
- the calculation unit 153 calculates the vector Vob80 corresponding to the target compound contained in the analysis query 80 by integrating the vectors of the compression codes of the specified groups.
- the calculation unit 153 calculates a plurality of vectors corresponding to each sub-compound (reagent) by inputting the vector Vob 80 into the learning model 70.
- the calculation unit 153 outputs the calculated vector of each sub-compound to the analysis unit 154.
- the vector of each sub-compound (reagent) calculated by the calculation unit 153 is referred to as an “analysis vector”.
- the analysis unit 154 searches for information on reagents having a vector similar to the analysis vector based on the analysis vector. Based on the search results, the analysis unit 154 associates the vector of each sub-compound constituting the target compound with the vector of each reagent similar to the vector (similar vector shown below) and registers the vector in the sub-compound / reagent table 85. do.
- the analysis unit 154 calculates the distance between the analysis vector and each vector included in the reagent vector table T2, and specifies a vector whose distance from the analysis vector is less than the threshold value.
- a vector included in the reagent vector table T2 whose distance from the analysis vector is less than the threshold value is a “similar vector”.
- the analysis unit 154 identifies the compression code of the reagent corresponding to the similar vector based on the reagent vector table T2, and the reagent is based on the compression code of the specified reagent, the reagent dictionary D2, and the reagent dictionary D1. Identify the reagent corresponding to the compression code of. Further, the reagent vector table T2 may be associated with the characteristics of the reagent. In this case, the analysis unit 154 acquires the characteristics of the reagent corresponding to the similar vector. By executing such a process, the analysis unit 154 searches for the demonstrative formula of the reagent corresponding to the similar vector and the characteristics of the reagent, and registers the searched result in the sub-compound / reagent table 85.
- the analysis unit 154 searches for the demonstrative formula of the reagent corresponding to the similar vector and the characteristics of the reagent for each analysis vector, and registers them in the subcompound / reagent table 85. You may.
- the analysis unit 154 may output the sub-compound / reagent table 85 to the display unit 130 for display, or may transmit the sub-compound / reagent table 85 to an external device connected to the network.
- FIG. 15 is a flowchart (1) showing a processing procedure of the information processing apparatus according to the first embodiment.
- the preprocessing unit 151 of the information processing apparatus 100 calculates the vector of the compression code of each group by executing Poincare embedding (step S101).
- the preprocessing unit 151 generates a basic coding file 51, a basic vector table T1, and a basic inverted index In1 based on the chemical structural formula file 50 and the basic dictionary D1 (step S102).
- the preprocessing unit 151 generates a sub-compound coding file 53, a sub-compound vector table T3, and a sub-compound inverted index In3 based on the base coding file 51 and the sub-compound dictionary D3 (step S103).
- the pretreatment unit 151 generates the target compound coding file 54, the target compound vector table T4, and the target compound inverted index In4 based on the base coding file 51 and the target compound dictionary (step S104).
- the pretreatment unit 151 identifies the relationship between the vector of the target compound and the vector of each sub-compound (reagent) for producing the target compound based on the retrosynthetic analysis result table 60, and obtains the learning data 65. Generate (step S105).
- the learning unit 152 of the information processing apparatus 100 executes learning of the learning model based on the learning data 65 (step S106).
- FIG. 16 is a flowchart (2) showing a processing procedure of the information processing apparatus according to the first embodiment.
- the calculation unit 153 of the information processing apparatus 100 receives the analysis query 80 (step S201).
- the calculation unit 153 calculates the vector of the target compound based on the demonstrative formula of the target compound contained in the analysis query 80 (step S202).
- the calculation unit 153 calculates the vector of each sub-compound by inputting the calculated vector of the target compound into the trained learning model 70 (step S203).
- the calculation unit 153 outputs the vector of each sub-compound and each sub-compound (step S204).
- the analysis unit 154 searches for the vector of each reagent similar to each subcompound constituting the target compound, and searches for the vector of each subcompound.
- the reagent table 85 is generated (step S205).
- the information processing apparatus 100 executes learning of the learning model 70 based on the learning data 65 that defines the relationship between the vector of the target compound and the vector of each sub-compound (reagent) based on the retrosynthetic analysis. I will do it.
- the information processing apparatus 100 inputs the vector of the analysis query into the trained learning model 70, and calculates the vector of each sub-compound (reagent) corresponding to the target compound of the analysis query. By using the vector of each sub-compound (reagent) output from the learning model 70, it is possible to easily detect a reagent similar to the sub-compound defined in the synthetic pathway of the target compound.
- the target compound which is the secondary structure of the functional group
- the target compound is composed of subcompounds, which are the primary structure of a plurality of functional groups.
- the transition of the vector of each of the plurality of functional groups constituting the sub-compound is gradual, the vector of the functional group at the end of the sub-compound and the vector of the functional group at the beginning of the continuing sub-compound often deviate from each other. .. Retrosynthetic analysis of organic compounds by performing machine learning based on the vector of the secondary structure of the functional group of the target compound and the vector of the primary structure of the functional group of the sub-compound that have been proven and analyzed by retrosynthetic analysis. The accuracy can be improved.
- FIG. 17 is a diagram for explaining an example of processing in the learning phase of the information processing apparatus according to the second embodiment. As shown in FIG. 17, the information processing apparatus executes learning of the learning model 91 using the learning data 90.
- the learning model 91 corresponds to CNN, RNN, and the like.
- the learning data 90 defines the relationship between the vector of a plurality of sub-compounds that synthesize the target compound and the vector of the common structure held in the conversion reaction based on the reagent.
- the vector of the sub-compound corresponds to the input data
- the vector of a plurality of common structures is the correct answer value.
- the information processing device executes learning by error back propagation so that the output when the vector of the subcompound is input to the learning model 91 approaches the vector of each common structure.
- the information processing apparatus adjusts the parameters of the learning model 91 by repeatedly executing the above processing based on the relationship between the vector of the sub-compound included in the learning data 90 and the vector of the common structure (machine learning). Run).
- FIG. 18 is a diagram for explaining the processing of the information processing apparatus according to the second embodiment.
- the information processing apparatus according to the second embodiment may learn the learning model 70 in the same manner as the information processing apparatus 100 of the first embodiment. Further, as described with reference to FIG. 17, the information processing apparatus learns a learning model 91, which is different from the learning model 70.
- the learning model 70 outputs the vector of each sub-compound when the vector of the analysis query (target compound) 80 is input.
- the learning model 90 outputs a vector having a common structure when the vector of the analysis query (sub compound) 92 is input.
- the information processing apparatus When the information processing apparatus receives the analysis query 92 in which the sub-compound is specified, the information processing apparatus converts the sub-compound of the analysis query 92 into the vector Vsb92-1 using the sub-compound vector table T3. The information processing apparatus inputs the vector Vsb92-1 of the sub compound into the learning model 91 to calculate the vector Vcm92-1 corresponding to the common structure.
- the information processing apparatus compares the vector Vsb92-1 of the sub-compound with the vectors of a plurality of reagents included in the reagent vector table T2.
- the reagent vector table T2 corresponds to the reagent vector table T2 described in Example 1.
- the information processing apparatus identifies a vector of similar reagents for the vector Vsb92-1 of the sub-compound. For example, let Vr92-1 be a reagent vector similar to the subcompound vector Vsb92-1. Then, it can be seen that the vector having a common structure common to the sub-compound of the vector Vsb92-1 and the reagent of the vector Vr92-1 becomes the vector Vcm92-1 output from the learning model 91. Further, the result of subtracting the vector Vcm92-1 having a common structure from the vector Vr92-1 of the reagent becomes a vector having a different structure (a vector having a conversion structure) different between the similar reagent and the subcompound.
- the information processing device registers the relationship between the vector of the common structure and the vector of the conversion structure in the common structure / conversion structure table 93.
- the information processing apparatus repeatedly executes the above processing for the vector of each sub-compound to generate the common structure / conversion structure table 93.
- the information processing apparatus inputs the vector of the analysis query 92 into the learned learning model 91, and calculates the vector of each common structure corresponding to the subcompound of the analysis query. Further, by subtracting the vector of the common structure from each vector of the reagent similar to the sub-compound, the vector of the conversion structure different between the similar sub-compound and the reagent is calculated.
- FIG. 19 is a functional block diagram showing the configuration of the information processing apparatus according to the second embodiment.
- the information processing apparatus 200 includes a communication unit 210, an input unit 220, a display unit 230, a storage unit 240, and a control unit 250.
- the description of the communication unit 210, the input unit 220, and the display unit 230 is the same as the description of the communication unit 110, the input unit 120, and the display unit 130 described in the first embodiment.
- the storage unit 240 has a chemical structural formula file 50, a basic coding file 51, a reagent coding file 52, a sub-compound coding file 53, a target compound coding file 54, and a common structure coding file 55.
- the storage unit 240 has a basic dictionary D1, a reagent dictionary D2, a sub-compound dictionary D3, a target compound dictionary D4, and a common structure dictionary D5.
- the storage unit 240 has a group vector table T1, a reagent vector table T2, a subcompound vector table T3, a target compound table T4, and a common structure vector table T5.
- the storage unit 240 has a basic inverted index In1, a reagent inverted index In2, a subcompound inverted index In3, a target compound index In4, and a common structure index In5.
- the storage unit 240 has a retrosynthetic analysis result table 60, learning data 90, a learning model 91, and an analysis query 92.
- the storage unit 240 has a common structure / conversion structure table 93.
- the storage unit 240 is realized by, for example, a semiconductor memory element such as a RAM or a flash memory, or a storage device such as a hard disk or an optical disk.
- the description of the chemical structural formula file 50, the basic coding file 51, the reagent coding file 52, the sub-compound coding file 53, the target compound coding file 54, and the common structure coding file 55 is the same as those described in Example 1. The same is true.
- the description of the basic dictionary D1, the reagent dictionary D2, the sub-compound dictionary D3, the target compound dictionary D4, and the common structure dictionary D5 is the same as that described in Example 1.
- the description of the base vector table T1, the reagent vector table T2, the subcompound vector table T3, the target compound table T4, and the common structure vector table T5 is the same as that described in Example 1.
- the description of the basic inverted index In1, the reagent inverted index In2, the subcompound inverted index In3, the target compound index In4, and the common structure index In5 is the same as that described in Example 1.
- the retrosynthetic analysis result table 60 is the same as the content described in Example 1.
- the learning data 90 is the same as the content described with reference to FIG.
- the description of the learning model 91 and the analysis query 92 is the same as that described in FIG.
- the common structure / conversion structure table 93 contains information on the conversion structure vector for the conversion reaction from the reagent similar to the common structure vector to the sub-compound.
- the common structure / conversion structure table 93 includes a conversion structure vector corresponding to Vcm92-1. The vector obtained by integrating the vector of the common structure and the vector of the transformation structure becomes the vector corresponding to the vector of the reagent.
- the control unit 250 has a preprocessing unit 251, a learning unit 252, a calculation unit 253, and an analysis unit 254.
- the control unit 250 is realized by, for example, a CPU or an MPU. Further, the control unit 250 may be executed by an integrated circuit such as an ASIC or FPGA.
- the description of the pretreatment unit 251 is the same as the description of the processing related to the pretreatment unit 151 described in the first embodiment.
- the preprocessing unit 251 generates a basic coding file 51, a reagent coding file 52, a sub-compound coding file 53, a target compound coding file 54, and a common structure coding file 55.
- the pretreatment unit 251 generates a group vector table T1, a reagent vector table T2, a subcompound vector table T3, a target compound table T4, and a common structure vector table T5.
- the pretreatment section 251 generates a basic inverted index In1, a reagent inverted index In2, a subcompound inverted index In3, a target compound index In4, and a common structure index In5.
- the pre-processing unit 251 may acquire the learning data 90 from an external device, or the pre-processing unit 251 may generate the learning data 90.
- the learning unit 252 executes learning of the learning model 91 using the learning data 90.
- the process of the learning unit 252 corresponds to the process described with reference to FIG.
- the learning unit 252 acquires a set of the vector of the sub-compound and the vector of the common structure corresponding to the vector of the sub-compound from the learning data 90.
- the learning unit 252 executes learning by error back propagation so that the output value of the learning model 91 when the vector of the subcompound is input to the learning model 91 approaches the value of the vector of the common structure. , Adjust the parameters of the learning model 91.
- the calculation unit 253 calculates the vector of each common structure to be converted and reacted by the synthetic route of the sub-compound of the analysis query 92 by using the learned learning model 91.
- the calculation unit 253 outputs the calculated vector of each common structure to the analysis unit 254.
- the vector of each common structure calculated by the calculation unit 253 is referred to as a "common structure vector”.
- the analysis unit 254 generates a common structure / change mechanism table 93 based on the vector of the subcompound of the analysis query 92, the common structure vector, and the reagent vector table T2.
- a common structure / change mechanism table 93 based on the vector of the subcompound of the analysis query 92, the common structure vector, and the reagent vector table T2.
- the analysis unit 254 calculates the distance between the vector of the sub-compound and each vector included in the reagent vector table T2, and identifies the vector whose distance from the vector of the sub-compound is less than the threshold value.
- a vector included in the reagent vector table T2 whose distance from the vector of the sub-compound is less than the threshold value is referred to as a “similar vector”.
- the analysis unit 254 calculates the vector of the conversion structure by subtracting the common structure vector from the similar vector, and specifies the correspondence between the common structure vector and the vector of the conversion structure.
- the analysis unit 254 registers the common structure vector and the conversion structure vector in the common structure / conversion structure table 93.
- the analysis unit 245 repeatedly executes the above process to generate the common structure / conversion structure table 93.
- the analysis unit 245 may output the common structure / conversion structure table 93 to the display unit 230 for display, or may transmit it to an external device connected to the network.
- FIG. 20 is a flowchart showing a processing procedure of the information processing apparatus according to the second embodiment.
- the calculation unit 253 of the information processing apparatus 200 receives the analysis query 92 (step S301).
- the calculation unit 253 converts the sub-compound of the analysis query 92 into a vector based on the sub-compound vector table T3 (step S302).
- the calculation unit 253 calculates the vector of the common structure by inputting the vector of the sub-compound into the trained learning model 91 (step S303).
- the analysis unit 254 of the information processing apparatus 200 identifies a similar reagent vector based on the distance between the vector having the common structure and each vector in the reagent vector table T2 (step S304).
- the analysis unit 254 calculates the vector of the conversion structure by subtracting the vector of the common structure from each vector of the sub compound and the similar reagent (step S305).
- the analysis unit 254 registers the relationship between the vector of the common structure and the vector of the conversion structure in the common structure / conversion structure table (step S306).
- the analysis unit 254 outputs the information of the common structure / conversion structure table (step S307).
- the information processing apparatus 100 inputs the vector of the analysis query 92 into the trained learning model 91, and calculates the vector of each common structure corresponding to the subcompound of the analysis query. Further, by subtracting the vector of the common structure from the vector of the reagent similar to the sub-compound, the vector of the conversion structure different between the similar sub-compound and the reagent is calculated.
- Sub-compounds and reagents have a primary structure composed of multiple functional groups. Further, by using the dispersion vector of the functional group, the functional group adjacent to a certain functional group can be estimated, and it can be applied to the evaluation of the degree of coupling and the stability of each functional group. Regarding the conversion reaction from a reagent to a proven sub-compound, the conversion reaction from the reagent and resynthesis are performed by performing machine learning based on the vectors of multiple functional groups constituting the sub-compound and the primary structure of the reagent. The analysis accuracy of can be improved.
- FIG. 21 is a diagram showing an example of a hardware configuration of a computer that realizes the same functions as the information processing apparatus of the embodiment.
- the computer 300 has a CPU 301 for executing various arithmetic processes, an input device 302 for receiving data input from a user, and a display 303. Further, the computer 300 has a communication device 304 for exchanging data with an external device or the like via a wired or wireless network, and an interface device 305. Further, the computer 300 has a RAM 306 for temporarily storing various information and a hard disk device 307. Then, each of the devices 301 to 307 is connected to the bus 308.
- the hard disk device 307 has a preprocessing program 307a, a learning program 307b, a calculation program 307c, and an analysis program 307d. Further, the CPU 301 reads out each of the programs 307a to 307d and deploys them in the RAM 306.
- the pretreatment program 307a functions as the pretreatment process 306a.
- the learning program 307b functions as a learning process 306b.
- the calculation program 307c functions as the calculation process 306c.
- the analysis program 307d functions as the analysis process 306d.
- the processing of the pretreatment process 306a corresponds to the processing of the pretreatment units 151 and 251.
- the processing of the learning process 306b corresponds to the processing of the learning units 152 and 252.
- the processing of the calculation process 306c corresponds to the processing of the calculation units 153 and 253.
- the processing of the analysis process 306d corresponds to the processing of the analysis units 154 and 254.
- each program 307a to 307d does not necessarily have to be stored in the hard disk device 307 from the beginning.
- each program is stored in a "portable physical medium" such as a flexible disk (FD), a CD-ROM, a DVD, a magneto-optical disk, or an IC card inserted in the computer 300. Then, the computer 300 may read and execute each program 307a to 307d.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Analytical Chemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Crystallography & Structural Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Communication Control (AREA)
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202080107270.6A CN116648753A (zh) | 2020-12-18 | 2020-12-18 | 信息处理程序、信息处理方法和信息处理装置 |
| AU2020481898A AU2020481898A1 (en) | 2020-12-18 | 2020-12-18 | Information processing program, information processing method, and information processing device |
| PCT/JP2020/047562 WO2022130648A1 (ja) | 2020-12-18 | 2020-12-18 | 情報処理プログラム、情報処理方法および情報処理装置 |
| EP20966034.9A EP4266316A4 (en) | 2020-12-18 | 2020-12-18 | INFORMATION PROCESSING PROGRAM, INFORMATION PROCESSING METHOD AND INFORMATION PROCESSING APPARATUS |
| JP2022569687A JP7563485B2 (ja) | 2020-12-18 | 2020-12-18 | 情報処理プログラム、情報処理方法および情報処理装置 |
| US18/134,581 US20230252351A1 (en) | 2020-12-18 | 2023-04-14 | Non-transitory computer-readable recording medium, information processing method, and information processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/047562 WO2022130648A1 (ja) | 2020-12-18 | 2020-12-18 | 情報処理プログラム、情報処理方法および情報処理装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/134,581 Continuation US20230252351A1 (en) | 2020-12-18 | 2023-04-14 | Non-transitory computer-readable recording medium, information processing method, and information processing apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022130648A1 true WO2022130648A1 (ja) | 2022-06-23 |
Family
ID=82059317
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/047562 Ceased WO2022130648A1 (ja) | 2020-12-18 | 2020-12-18 | 情報処理プログラム、情報処理方法および情報処理装置 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20230252351A1 (https=) |
| EP (1) | EP4266316A4 (https=) |
| JP (1) | JP7563485B2 (https=) |
| CN (1) | CN116648753A (https=) |
| AU (1) | AU2020481898A1 (https=) |
| WO (1) | WO2022130648A1 (https=) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001507675A (ja) | 1996-11-04 | 2001-06-12 | 3―ディメンショナル ファーマシューティカルズ インコーポレイテッド | 所望の特性を有する化合物を識別するシステム、方法、コンピュータ・プログラム製品 |
| CN109872780A (zh) * | 2019-03-14 | 2019-06-11 | 北京深度制耀科技有限公司 | 一种化学合成路线的确定方法及装置 |
| US20190286791A1 (en) * | 2018-03-15 | 2019-09-19 | International Business Machines Corporation | Creation of new chemical compounds having desired properties using accumulated chemical data to construct a new chemical structure for synthesis |
| US20190340160A1 (en) * | 2017-03-01 | 2019-11-07 | International Business Machines Corporation | Iterative widening search for designing chemical compounds |
| US20200152295A1 (en) * | 2018-11-13 | 2020-05-14 | Recursion Pharmaceuticals, Inc. | Systems and methods for high throughput compound library creation |
| JP2020154442A (ja) | 2019-03-18 | 2020-09-24 | 株式会社日立製作所 | 生物反応情報処理システムおよび生物反応情報処理方法 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6114728B2 (ja) * | 2014-09-29 | 2017-04-12 | 富士フイルム株式会社 | 投映像表示用部材および投映像表示システム |
| US10679733B2 (en) * | 2016-10-06 | 2020-06-09 | International Business Machines Corporation | Efficient retrosynthesis analysis |
| WO2020023650A1 (en) * | 2018-07-25 | 2020-01-30 | Wuxi Nextcode Genomics Usa, Inc. | Retrosynthesis prediction using deep highway networks and multiscale reaction classification |
| JP7115107B2 (ja) | 2018-07-26 | 2022-08-09 | 株式会社デンソー | 車両のシャッタ装置 |
| US11735292B2 (en) * | 2018-08-07 | 2023-08-22 | International Business Machines Corporation | Intelligent personalized chemical synthesis planning |
-
2020
- 2020-12-18 CN CN202080107270.6A patent/CN116648753A/zh active Pending
- 2020-12-18 JP JP2022569687A patent/JP7563485B2/ja active Active
- 2020-12-18 WO PCT/JP2020/047562 patent/WO2022130648A1/ja not_active Ceased
- 2020-12-18 AU AU2020481898A patent/AU2020481898A1/en not_active Abandoned
- 2020-12-18 EP EP20966034.9A patent/EP4266316A4/en not_active Withdrawn
-
2023
- 2023-04-14 US US18/134,581 patent/US20230252351A1/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001507675A (ja) | 1996-11-04 | 2001-06-12 | 3―ディメンショナル ファーマシューティカルズ インコーポレイテッド | 所望の特性を有する化合物を識別するシステム、方法、コンピュータ・プログラム製品 |
| US20190340160A1 (en) * | 2017-03-01 | 2019-11-07 | International Business Machines Corporation | Iterative widening search for designing chemical compounds |
| US20190286791A1 (en) * | 2018-03-15 | 2019-09-19 | International Business Machines Corporation | Creation of new chemical compounds having desired properties using accumulated chemical data to construct a new chemical structure for synthesis |
| US20200152295A1 (en) * | 2018-11-13 | 2020-05-14 | Recursion Pharmaceuticals, Inc. | Systems and methods for high throughput compound library creation |
| CN109872780A (zh) * | 2019-03-14 | 2019-06-11 | 北京深度制耀科技有限公司 | 一种化学合成路线的确定方法及装置 |
| JP2020154442A (ja) | 2019-03-18 | 2020-09-24 | 株式会社日立製作所 | 生物反応情報処理システムおよび生物反応情報処理方法 |
Non-Patent Citations (2)
| Title |
|---|
| See also references of EP4266316A4 |
| VALENTIN KHRULKOV1 ET AL.: "Hyperbolic Image Embeddings", 3 April 2019, CORNELL UNIVERSITY |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4266316A1 (en) | 2023-10-25 |
| CN116648753A (zh) | 2023-08-25 |
| JPWO2022130648A1 (https=) | 2022-06-23 |
| AU2020481898A1 (en) | 2023-06-15 |
| JP7563485B2 (ja) | 2024-10-08 |
| US20230252351A1 (en) | 2023-08-10 |
| EP4266316A4 (en) | 2024-02-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Popic et al. | Cue: a deep-learning framework for structural variant discovery and genotyping | |
| EP4261831A1 (en) | Prediction of chemical compounds with desired properties | |
| US20090024575A1 (en) | Methods for similarity searching of chemical reactions | |
| CN116363212A (zh) | 一种基于语义匹配知识蒸馏的3d视觉定位方法和系统 | |
| CN117056452A (zh) | 知识点学习路径构建方法、装置、设备以及存储介质 | |
| Huang et al. | Using random forest to classify T-cell epitopes based on amino acid properties and molecular features | |
| CN117788785A (zh) | 一种基于文本和图像的多模态目标检测的MultiFNet架构方法 | |
| CN111259176B (zh) | 融合有监督信息的基于矩阵分解的跨模态哈希检索方法 | |
| Chen et al. | Multi-modal graph aggregation transformer for image captioning | |
| Roy Choudhury et al. | PredβTM: A novel β-transmembrane region prediction algorithm | |
| WO2022130648A1 (ja) | 情報処理プログラム、情報処理方法および情報処理装置 | |
| KR20220109707A (ko) | 염기서열 시퀀싱 데이터 분석 장치 및 그 동작 방법 | |
| Shi et al. | YieldFCP: enhancing reaction yield prediction via fine-grained cross-modal pre-training | |
| CN116468978A (zh) | 一种Transformer多模态数据特征融合方法 | |
| Srinivas et al. | Crossing New Frontiers: Knowledge-Augmented Large Language Model Prompting for Zero-Shot Text-Based De Novo Molecule Design | |
| CN116484935A (zh) | 模型训练方法、舞蹈生成方法、设备及介质 | |
| WO2023223671A1 (ja) | 動画マニュアル生成装置 | |
| JP2023128459A (ja) | 情報処理装置及びプログラム | |
| US20230064163A1 (en) | Labeling system, activity recognition system, and teaching material generating system | |
| CN117688068B (zh) | 一种数据可视化图表的处理方法及装置 | |
| Ganapathy et al. | An Explainable AI Framework with ML Model Stacking for House Price Prediction | |
| CN118898270B (zh) | 一种用于训练生物语言模型的方法及装置 | |
| US20250285773A1 (en) | Retrieval-augmented fusion language models for ai-based protein and drug design | |
| Sakhinana et al. | Crossing new frontiers: Knowledge-augmented large language model prompting for zero-shot text-based de novo molecule design | |
| JP7428252B2 (ja) | 情報処理プログラム、情報処理方法および情報処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20966034 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022569687 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202080107270.6 Country of ref document: CN |
|
| ENP | Entry into the national phase |
Ref document number: 2020481898 Country of ref document: AU Date of ref document: 20201218 Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020966034 Country of ref document: EP Effective date: 20230718 |