WO2022130578A1 - 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 - Google Patents
類似度判定プログラム、類似度判定装置、及び、類似度判定方法 Download PDFInfo
- Publication number
- WO2022130578A1 WO2022130578A1 PCT/JP2020/047218 JP2020047218W WO2022130578A1 WO 2022130578 A1 WO2022130578 A1 WO 2022130578A1 JP 2020047218 W JP2020047218 W JP 2020047218W WO 2022130578 A1 WO2022130578 A1 WO 2022130578A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document
- similarity
- groups
- named entity
- compound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
Definitions
- the present invention relates to a similarity determination program, a similarity determination device, and a similarity determination method.
- one of the objects of the present invention is to improve the accuracy of determining the degree of similarity between partially similar documents.
- the similarity determination program may cause the computer to perform the following processing.
- the process classifies the first named entity based on the position of each of the first named entity contained in the first document and the similarity of each of the first named entity. It may include the process of acquiring the first plurality of groups generated by the above. In addition, the process is based on the position of each of the second named entity included in the second document and the similarity of each of the second named entity. It may include a process of acquiring a second plurality of groups generated by classifying. Further, the process includes a process of determining the degree of similarity between the first document and the second document based on the comparison between the first plurality of groups and the second plurality of groups. good.
- the present invention can improve the accuracy of determining the degree of similarity between partially similar documents.
- HW hardware
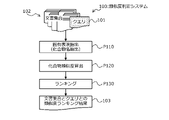
- FIG. 1 is a diagram for explaining the similarity determination system 100 according to a comparative example.
- the similarity determination system 100 uses a query 101 that requests determination of similarity of a query document (input document) and a document set 102 including one or more comparison target documents as a unique expression. Calculate the degree of similarity based on.
- the similarity determination system 100 extracts a compound name as a unique expression from each of a plurality of documents, that is, a query document included in the query 101 and a comparison target document included in the document set 102 (process P110), and documents. Generate a compound list for each.
- the similarity determination system 100 calculates the compound similarity between each of the query document and the comparison target document by comparing the compound list for each document (process P120). Examples of the compound similarity include cosine similarity.
- the similarity determination system 100 performs ranking processing based on the calculated compound similarity (processing P130), and stores the comparison target document having a high similarity with the query document as the ranking result 103 together with the similarity.
- FIG. 2 is a diagram illustrating an example of calculation of compound similarity by the similarity determination system 100 shown in FIG.
- the compound list Cx is generated from the query document and the compound list Cy is generated from the comparison target document for the query document and the comparison target document related to the lithium ion battery.
- compound list C when the compound lists Cx and Cy generated for the set of documents for which the compound similarity is to be determined are not distinguished from each other, they are simply referred to as "compound list C".
- the compound list C may include the compound name and the number of occurrences of the compound name in the document.
- the common compounds common between the compound lists Cx and Cy are shown in bold underline.
- the similarity determination system 100 calculates the cosine similarity as the compound similarity by the calculation of the following formula (1) based on the compound list C.
- i is an index for specifying all the compound names included in the compound list Cx and Cy
- Cx i and Cy i are the i-th compound names in the compound list Cx and Cy.
- the denominator is the sum of the square roots of the sum of squares of the number of occurrences of Cx compounds and the square root of the sum of squares of the number of appearances of Cy compounds, and the molecules are Cx and Cy. It is the sum of the products of the number of appearances of common compounds between.
- the "document” includes a document including a description of a plurality of elements, and, for example, a document such as a patent document or a paper describing a device, a system, a manufacturing method, etc. having a plurality of components.
- a document such as a patent document or a paper describing a device, a system, a manufacturing method, etc. having a plurality of components.
- each of the components of the lithium ion battery such as "positive electrode active material”, “negative electrode active material”, “binder”, “electrolyte”, and “electrolyte solution solvent” is provided.
- Compound names related to the classification (group) of may be mixed and described.
- the comparison target document with other elements in other words, the element not to be investigated.
- the difference in the above may affect the judgment result of the similarity between documents.
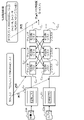
- the similarity determination system 1 classifies each of the plurality of named entity included in the document to generate a plurality of groups, and among the documents. , The degree of similarity between the query document and the comparison target document is determined by comparing the groups.
- FIG. 3 is a diagram for explaining the similarity determination system 1 according to the first embodiment
- FIGS. 4 and 5 are diagrams for explaining an example of processing of the similarity determination system 1.
- the similarity determination system 1 includes a query 11 requesting determination of the similarity of a query document (input document) and one or more comparison target documents to be determined. Based on the document set (document group) 12, the similarity based on the eigenexpression is calculated.
- the similarity determination system 1 extracts a compound name as an example of a named entity from each of a plurality of documents (process P1), and prepares a named entity list, for example, a compound list for each document, as in the comparative example. Generate.
- the similarity determination system 1 extracts the compound name from the query document 11a (denoted as “document X”) included in the query 11 and generates the compound list C X. Further, the similarity determination system 1 extracts a compound name from the comparison target document 12a (denoted as “document Y”) included in the document set 12 to generate a compound list CY .
- the query document 11a is an example of the first document
- the comparison target document 12a is an example of the second document.
- the query document 11a and the comparison target document 12a are documents relating to the lithium ion battery.
- compound list C when the compound lists C X and CY generated for the set of documents for which the compound similarity is to be determined are not distinguished from each other, they are simply referred to as “compound list C”.
- the similarity determination system 1 executes clustering for classifying and grouping named entity based on the named entity list (process P2 in FIG. 3).
- clustering method various existing methods such as the shortest distance method may be used.
- the similarity determination system 1 calculates the named entity similarity for each cluster, for example, the compound similarity (process P3 in FIG. 3). Named entity similarity may be calculated, for example, for each pair of clusters between documents.
- the similarity determination system 1 performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the named entity similarity (process P4 in FIG. 3).
- the result 13 is output.
- the result 13 may include a ranking result.
- the similarity determination system 1 may calculate the similarity score S between named entities included in the named entity list for each pair (set) of named entity based on the named entity list. For example, the similarity determination system 1 calculates a similarity score S for a pair of named entity based on each position of the named entity and the similarity between the named entity.
- the similarity determination system 1 may calculate the similarity score S (x 1 , x 2 ) using the following equation (2). ..
- TC (x 1 , x 2 ) is the Tanimoto coefficient of MACCS Key.
- MACCS Key is one of the expression methods (compound descriptors) of the characteristics of compounds
- Tanimoto coefficient is one of the indexes showing the structural similarity between compounds using MACCS Key
- the named entity is the compound name. This is an example of the degree of similarity between named entities in the case of.
- Distance (x 1 , x 2 ) is, for example, a numerical value obtained by quantifying the proximity of each appearance position of the named entity in a document, and is, for example, a value corresponding to the following conditions.
- the similarity determination system 1 applies the above formula (2) to each combination of compound name pairs (x 1 , x 2 ) for a plurality of compound names included in the compound list C, and applies each pair (x 1 , x 2).
- the similarity score S (x 1 , x 2 ) of x 2 ) may be calculated.
- the similarity determination system 1 classifies a plurality of compound names included in the compound list C by applying a method such as the shortest distance method to a plurality of calculated similarity scores S (x 1 , x 2 ). By grouping them together, the compound names may be clustered.
- the similarity determination system 1 divides the compound names in the compound list C X into clusters (groups) of N (N is an integer of 2 or more) by clustering to the compound list C X. Generate compound lists C X1 to C XN for each compound. Further, the similarity determination system 1 divides the compound names in the compound list CY into clusters (groups) of M (M is an integer of 2 or more) by clustering to the compound list CY , and the compound list for each cluster. Generates CY1 to CYM .
- -Compound list C X1 and CY1 A cluster having an element (characteristic) of "positive electrode active material”.
- -Compound list C X2 and CY2 A cluster having elements (characteristics) of "negative electrode active material”.
- -Compound list C X3 and CY3 A cluster with a "binder" element (characteristic).
- -Compound list C X4 and CY4 A cluster having an element (characteristic) of "electrolyte solvent”.
- the Tanimoto coefficient of MACCS Key is used as the structural similarity, but the description is not limited to this.
- the method for expressing the characteristics of a compound is not limited to MACCS Key, in other words, MACCS fingerprint, and various compound descriptors such as Morgan fingerprint may be adopted.
- the index indicating the structural similarity between the compounds is not limited to the Tanimoto coefficient, and various coefficients such as the Dice coefficient may be used.
- the similarity determination system 1 uses the similarity score S (x 1 , x 2 ) as a numerical value of the proximity of the appearance position in the document of the named entity and the named entity.
- the product with the similarity is calculated, but the product is not limited to this.
- the similarity determination system 1 may calculate the similarity score S (x 1 , x 2 ) using the following equation (3).
- W is a weight.
- W for example, a value such as "0.5" may be appropriately defined and set by the user or the like so that each position of the named entity and the similarity between the named entity are considered evenly.
- W may be set based on a model trained so that the correct answer example is searched higher by machine learning based on the search query and the training data including the correct answer example (correct answer data). ..
- the similarity determination system 1 is based on the position of each of the first plurality of compound names included in the query document 11a and the similarity of each of the first plurality of compound names. By classifying the compound names of, the first cluster group is generated. Further, the similarity determination system 1 is based on the position of each of the second plurality of compound names included in the comparison target document 12a and the similarity of each of the second plurality of compound names. By classifying the names, a second cluster group is generated. The first cluster group is an example of the first plurality of groups, and the second cluster group is an example of the second plurality of groups.
- the similarity determination system 1 has a plurality of first clusters in the first cluster group generated from the query document 11a and a second cluster in the second cluster group generated from the comparison target document 12a. Each of the two plurality of clusters may be compared. Then, in the similarity determination system 1, the compound similarity, for example, cosine similarity, is obtained by the calculation of the following formula (4) for all the cluster pairs between the first plurality of clusters and the second plurality of clusters. The degree may be calculated.
- a is an integer of 1 to N
- b is an integer of 1 to M
- i is an index for specifying all the compound names contained in the compound lists C Xa and CYb
- C Xai and CYbi are the number of occurrences of the i-th compound name in the compound lists C Xa and CYb . Is shown.
- the formula for calculating the cosine similarity is the same as the above formula (1).
- the similarity determination system 1 has the compound lists C X1 , C X2 , C X3 , ... C XN and the compound lists CY1 , CY2 , CY3 . , ...
- the compound similarity may be calculated according to the above formula (4).
- the similarity determination system 1 acquires the document similarity between the query document 11a and each of the plurality of comparison target documents 12a in the ranking process, and determines the similarity with the query document 11a based on the document similarity.
- the ranking of a plurality of comparison target documents 12a corresponding to the corresponding is output.
- the similarity determination system 1 may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (5).
- max is a function that adopts the maximum value among all combinations in parentheses.
- the similarity determination system 1 determines that the pair of the compound lists C X1 and CY 1 , in other words, the clusters of the “positive electrode active material” has the maximum compound similarity, and determines that the compound similarity is the maximum.
- the degree is determined to be the document similarity Sim (X, Y) between the documents X and Y.
- FIGS. 4 and 5 and the above formula (5) show an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a).
- the similarity determination system 1 performs the above processing for each of a plurality of comparison target documents 12a, for example, documents Y 1 to Y L (L is an integer of 2 or more and the number of documents of the comparison target document 12a), and the document similarity Sim. (X, Y 1 ) to Sim (X, Y L ) may be acquired.
- the similarity determination system 1 sorts all the documents Y 1 to Y L to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ), for example.
- the sort result may be output as the result 13.
- the result 13 may include the identification information of the document Y together with the rank (rank), and may include the document similarity Sim (X, Y) of each document Y.
- the identification information of the document Y includes at least one of an identifier such as a document number or a document code, bibliographic information such as a document name, and at least a part of the contents of the document Y such as a summary and a predetermined part. But it may be.
- the similarity determination system 1 identifies information of the document Y having the highest document similarity Sim (X, Y) with the document Y determined to have a specific order, for example, the query document 11a. May be output.
- the similarity between documents is partially determined based on the named entity similarity for each cluster classified by the clustering process. It is possible to improve the determination accuracy of the similarity between the documents.
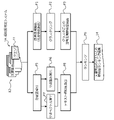
- FIG. 6 is a block diagram showing a functional configuration example of the server 2 in the similarity determination system 1 according to the first embodiment
- FIG. 7 is a diagram showing a screen output example by the server 2. Is.
- the server 2 is an example of a similarity determination device, an information processing device, or a computer.
- the server 2 performs various communications such as reception of the query document 11a and the comparison target document 12a and transmission of the result 13 with a terminal device (not shown), another server, or the like. good.
- the server 2 may provide, for example, a function for enabling access to the terminal device.
- Examples of the function include generation and display control of a screen such as a web page used for access by a terminal device.
- the terminal device sends an access request to the server 2 using an application such as a browser, and accesses the server 2 via a web page displayed on the application based on the screen information received from the server 2. good.
- the server 2 may output the screen information of the query specification screen 210 for designating the query and the determination result output screen 240 for outputting the determination result.
- the server 2 may optionally include a memory unit 21, a document input unit 22, a similarity calculation unit 23, and a similarity output unit 24.
- the memory unit 21, the document input unit 22, the similarity calculation unit 23, and the similarity output unit 24 are examples of control units.
- the memory unit 21 has a storage area for storing various data related to the similarity determination process.
- the memory unit 21 may store information such as the query document 11a shown in FIG. 3, a plurality of comparison target documents 12a, and the result 13. Further, the memory unit 21 uses the compound list C for each document, the similarity score S, the compound list C for each cluster, the compound similarity, and the document similarity Sim as intermediate data in the similarity determination process. Information such as may be stored.
- the document input unit 22 may receive input of the query document 11a and the comparison target document 12a from a computer such as a terminal device (not shown) or another server, and store the query document 11a and the comparison target document 12a in the memory unit 21, for example, as a DB (Database). In this way, the document input unit 22 may be able to construct and refer to the DB of the document.
- a computer such as a terminal device (not shown) or another server
- DB Database
- the document input unit 22 may receive the input of the query document 11a related to the similarity determination request from a computer such as a terminal device (not shown) or another server and store it in the memory unit 21.
- the query document 11a may be included in the query 11, for example.
- the document input unit 22 may accept, for example, as the query 11, not the query document 11a itself, but the identification information of the query document 11a, for example, information such as a document number and a document code.
- the document input unit 22 may specify the query document 11a related to the similarity determination request from, for example, the DB of the memory unit 21 based on the identification information.
- the document input unit 22 may accept the document number set in the input field 211 when the determination button 212 of the query specification screen 210 is pressed.
- the similarity calculation unit 23 calculates the similarity between the query document 11a and the comparison target document 12a. As illustrated in FIG. 6, the similarity calculation unit 23 may include a compound name extraction unit 231, a clustering unit 232, and a document similarity calculation unit 233.
- the compound name extraction unit 231 extracts the compound name from each of the query document 11a and the comparison target document 12a stored in the memory unit 21, and generates the compound lists C X and CY .
- the treatment of the compound name extraction unit 231 is an example of the treatment P1 in FIG.
- the clustering unit 232 calculates the similarity score S for each of the compound names included in the compound lists C X and CY . Further, the clustering unit 232 classifies the compound names into a plurality of clusters based on the similarity score S, and the compound lists C X1 , C X2 , C X3 , ... C XN , and the compound lists CY1 , CY2 , and so on. Generate CY3 , ... CYM .
- the process of the clustering unit 232 is an example of the process P2 of FIG.
- the clustering unit 232 When one or both of the query document 11a and the comparison target document 12a are stored in the memory unit 21 in advance, the clustering unit 232 performs a clustering process for each document in advance and generates a compound list C for each cluster. You may leave it. As an example, the clustering unit 232 may perform a clustering process on each registered document at the timing of registering the document in the memory unit 21.
- the document similarity calculation unit 233 calculates the compound similarity for each cluster based on the compound list for each cluster, and determines the compound similarity of the cluster having the highest compound similarity in the document as the similarity Sim (X) of the document. , Y).
- the document similarity calculation unit 233 calculates the similarity Sim (X, Y 1 ) to Sim (X, Y L ) for each comparison target document 12a. You can do it.
- the document similarity calculation unit 233 may store the calculated similarity Sim (X, Y) in the memory unit 21.
- the similarity output unit 24 outputs the similarity Sim (X, Y) calculated by the similarity calculation unit 23.
- the documents to be compared are compared in descending order of the calculated similarity Sim (X, Y 1 ) to Sim (X, Y L ).
- Information on 12a and the similarity Sim (X, Y) may be output.
- the processing of the document similarity calculation unit 233 and the similarity output unit 24 is an example of the processes P3 and P4 of FIG.
- the output by the similarity output unit 24 may include, for example, transmission to a computer such as a terminal device (not shown), storage in a storage area of a server 2 such as a memory unit 21, and the like.
- the similarity output unit 24 may output the determination result output screen 240.
- the determination result output screen 240 may include a display area 241 of the query document 11a and display areas 245a to 245c of at least one (three in FIG. 7) of the comparison target document 12a.
- the display area 241 may include a display area 242 such as bibliographic information and a summary, and a full-text reference button 243 for transitioning to a screen for displaying the full text of the query document 11a.
- the display areas 245a to 245c may include display areas 246a to 246c for bibliographic information and summaries, full text reference buttons 247a to 247c, and compound lists 248a to 248c of clusters determined to be similar.
- the similarity Sim (X, Y) may be displayed in the display areas 245a to 245c.
- the similarity output unit 24 belongs to the cluster determined to have the highest similarity as a result of the similarity calculation between the query document 11a and the comparison target document 12a by displaying the compound lists 248a to 248c. A list of named entities can be presented to the user.
- FIG. 8 is a flowchart illustrating an operation example of the server 2. As shown in FIG. 8, the server 2 may execute the processing for the query document 11a and the processing for the comparison target document 12a at different timings.
- the document input unit 22 accepts the input of the query document 11a (step S1).
- the compound name extraction unit 231 extracts the compound name from the query document 11a (step S2).
- the clustering unit 232 clusters the extracted compound names (step S3).
- the document input unit 22 accepts the input of the comparison target document 12a (step S4).
- the compound name extraction unit 231 selects an unselected comparison target document 12a (step S5), and extracts a compound name from the selected comparison target document 12a (step S6).
- the clustering unit 232 clusters the extracted compound names (step S7).
- the document similarity calculation unit 233 compares the compound clusters of the query document 11a and the comparison target document 12a, calculates the similarity Sim between the documents (step S8), and stores it in the memory unit 21 (step S9).
- the document similarity calculation unit 233 determines whether or not there is an unselected comparison target document 12a (step S10), and if it is determined to be present (YES in step S10), the process proceeds to step S5.
- step S10 When the document similarity calculation unit 233 determines that there is no unselected document to be compared 12a (NO in step S10), the document to be compared 12a and its similarity Sim (X) are in descending order of similarity Sim (X, Y). , Y) is output (step S11), and the process ends.
- the server 2 may be a virtual server (VM; Virtual Machine) or a physical server. Further, the function of the server 2 may be realized by one computer or may be realized by two or more computers. Further, at least a part of the functions of the server 2 may be realized by using the HW (Hardware) resource and the NW (Network) resource provided by the cloud environment.
- VM Virtual Machine
- HW Hardware
- NW Network
- FIG. 9 is a block diagram showing a hardware (HW) configuration example of the computer 10 that realizes the function of the server 2.
- HW hardware
- the computer 10 has an HW configuration, for example, a processor 10a, a memory 10b, a storage unit 10c, an IF (Interface) unit 10d, an I / O (Input / Output) unit 10e, and a reading unit. It may be provided with 10f.
- a processor 10a for example, a processor 10a, a memory 10b, a storage unit 10c, an IF (Interface) unit 10d, an I / O (Input / Output) unit 10e, and a reading unit. It may be provided with 10f.
- the processor 10a is an example of an arithmetic processing unit that performs various controls and operations.
- the processor 10a may be connected to each block in the computer 10 so as to be communicable with each other by the bus 10i.
- the processor 10a may be a multi-processor including a plurality of processors, a multi-core processor having a plurality of processor cores, or a configuration having a plurality of multi-core processors.
- Examples of the processor 10a include integrated circuits (ICs) such as CPUs, MPUs, GPUs, APUs, DSPs, ASICs, and FPGAs. As the processor 10a, two or more combinations of these integrated circuits may be used.
- ICs integrated circuits
- MPU is an abbreviation for Micro Processing Unit
- GPU is an abbreviation for Graphics Processing Unit
- APU is an abbreviation for Accelerated Processing Unit.
- DSP is an abbreviation for Digital Signal Processor
- ASIC is an abbreviation for Application Specific IC
- FPGA is an abbreviation for Field-Programmable Gate Array.
- the memory 10b is an example of HW that stores information such as various data and programs.
- Examples of the memory 10b include one or both of a volatile memory such as DRAM (Dynamic Random Access Memory) and a non-volatile memory such as PM (Persistent Memory).
- the storage unit 10c is an example of HW that stores information such as various data and programs.
- Examples of the storage unit 10c include a magnetic disk device such as an HDD (Hard Disk Drive), a semiconductor drive device such as an SSD (Solid State Drive), and various storage devices such as a non-volatile memory.
- Examples of the non-volatile memory include flash memory, SCM (Storage Class Memory), ROM (Read Only Memory) and the like.
- the storage unit 10c may store a program 10g (similarity determination program) that realizes all or a part of various functions of the computer 10.
- the processor 10a of the server 2 can realize the function as the server 2 illustrated in FIG. 6 by expanding and executing the program 10g stored in the storage unit 10c in the memory 10b.
- the memory unit 21 shown in FIG. 6 may be realized by a storage area of one or both of the memory unit 10b and the storage unit 10c.
- the IF unit 10d is an example of a communication IF that controls connection and communication with a network.
- the IF unit 10d may include an adapter compliant with LAN (Local Area Network) such as Ethernet (registered trademark) or optical communication such as FC (Fibre Channel).
- the adapter may support one or both wireless and wired communication methods.
- the server 2 may be connected to the terminal device and each of the other servers so as to be able to communicate with each other via the IF unit 10d.
- the program 10g may be downloaded from the network to the computer 10 via the communication IF and stored in the storage unit 10c.
- the I / O unit 10e may include one or both of an input device and an output device.
- Examples of the input device include a keyboard, a mouse, a touch panel, and the like.
- Examples of the output device include a monitor, a projector, a printer and the like.
- the reading unit 10f is an example of a reader that reads data and program information recorded on the recording medium 10h.
- the reading unit 10f may include a connection terminal or device to which the recording medium 10h can be connected or inserted.
- Examples of the reading unit 10f include an adapter compliant with USB (Universal Serial Bus), a drive device for accessing a recording disk, a card reader for accessing a flash memory such as an SD card, and the like.
- the program 10g may be stored in the recording medium 10h, or the reading unit 10f may read the program 10g from the recording medium 10h and store it in the storage unit 10c.
- Examples of the recording medium 10h include non-temporary computer-readable recording media such as magnetic / optical disks and flash memories.
- Examples of the magnetic / optical disk include flexible discs, CDs (Compact Discs), DVDs (Digital Versatile Discs), Blu-ray discs, HVDs (Holographic Versatile Discs), and the like.
- Examples of the flash memory include semiconductor memories such as USB memory and SD card.
- the above-mentioned HW configuration of the computer 10 is an example. Therefore, the increase / decrease of HW (for example, addition or deletion of arbitrary blocks), division, integration in any combination, addition or deletion of buses, etc. may be appropriately performed in the computer 10.
- the server 2 at least one of the I / O unit 10e and the reading unit 10f may be omitted.
- Second Embodiment [2-1] Description of the Second Embodiment Next, the second embodiment will be described.
- a method of determining the similarity between documents by using the similarity based on the meaning vector of the word in addition to the similarity based on the named entity according to the first embodiment will be described.
- FIG. 10 is a diagram for explaining the similarity determination system 1A according to the second embodiment.
- the processes P1 to P3 based on the query 11 and the document set 12 are the same as those in the first embodiment.
- the processes P5 to P8 may be executed in parallel with or before and after the processes P1 to P3 and at least a part of the processes. Further, the process P9 may be executed and the result 14 may be output based on the results of the processes P3 and P8.
- the processes P5 to P9 will be described.
- the similarity determination system 1A extracts words from each of a plurality of documents, for example, a query document 11a and a plurality of comparison target documents 12a, for example, by morphological analysis (process P5).
- the similarity determination system 1A statistically calculates the word weights for each of the plurality of documents based on the words obtained in the process P5 (process P6). For example, the similarity determination system 1A may evaluate the importance of a word in a document as a weight by using an evaluation method such as tf-idf (Term Frequency-Inverse Document Frequency).
- the similarity determination system 1A executes the process P7 in parallel with or before and after the process P6 and at least a part of the processes. For example, the similarity determination system 1A calculates a word vector for each of a plurality of documents based on the words obtained in the process P5 (process P7).
- the word vector may be referred to as a word embedding vector or a meaning vector.
- the similarity determination system 1A may search a vector database in which a vector expressing the meaning of a word is stored and acquire a word vector.
- the similarity determination system 1A may acquire a word vector corresponding to each of the words obtained in the process P5 based on the trained model.
- the similarity determination system 1A calculates the document vector by adding the result of multiplying the word vector acquired in the process P7 and the weight of the word acquired in the process P6 over all the words in the document for each document. do. Then, the similarity determination system 1A calculates the similarity between the document vector (first vector) of the query document 11a and each document vector (second vector) of the comparison target document 12a. In other words, the similarity determination system 1A calculates the text similarity between the query document 11a and the comparison target document 12a based on the meaning vector of the word (process P8).
- the similarity determination system 1A may calculate the text similarity, for example, the cosine similarity between the query document 11a and the comparison target document 12a by the calculation of the following equation (6).
- W X is a dispersion vector of words included in the document X
- W Y is a dispersion vector of words included in the document Y.
- the similarity determination system 1A has the compound lists C X1 , C X2 , C X3 , ... C XN and the compound lists CY1 , CY2 , CY3 . , ...
- the text similarity may be calculated according to the above equation (6).
- the similarity determination system 1A performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the text similarity and the named entity similarity (process P9).
- the result 14 is output.
- the result 14 may include a ranking result.
- the similarity determination system 1A calculates the similarity in which the text similarity and the named entity similarity are integrated in the ranking process, and based on the similarity, a plurality of comparison targets according to the similarity with the query document 11a.
- the ranking of the document 12a is output.
- the similarity determination system 1A may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (7).
- max is a function that adopts the maximum value among all the combinations in parentheses.
- fc and ft are named entity similarity and text similarity, respectively, as shown in the following equations (8) and (9).
- the similarity determination system 1A is based on the named entity similarity calculated by the equation (4) and the text similarity calculated by the equation (6) according to the above equations (7) to (9). And the document similarity Sim (X, Y) between Y may be acquired.
- the above formula (7) shows an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). Similar to the first embodiment, the similarity determination system 1A may acquire document similarity Sims (X, Y 1 ) to Sim (X, Y L ) according to the number of documents Y.
- the similarity determination system 1A for example, as in the first embodiment, all the documents Y to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ). Ranking processing is performed by sorting 1 to Y L (processing P9). Further, the similarity determination system 1A may output the sort result as the result 14. The content and output method of the result 14 are the same as those of the result 13 according to the first embodiment.
- the document similarity Sim (X, Y) is calculated based on the above equation (7), but is not limited thereto.
- the document similarity Sim (X, Y) determines the document similarity Sim (X, Y) between the document X and one comparison target document Y according to the following formula (10). , May be calculated as a weighted sum of eigenexpression similarity and text similarity.
- w is a weight.
- w for example, a value such as “0.5” may be appropriately defined and set by the user or the like so that the named entity similarity and the text similarity are considered equally.
- w may be set based on a model trained so that the correct answer example is searched higher by machine learning based on the search query and the training data including the correct answer example (correct answer data). ..
- the similarity determination system 1A As described above, according to the similarity determination system 1A according to the second embodiment, the same effect as that of the first embodiment can be obtained. Further, according to the similarity determination system 1A, the similarity determination accuracy between documents is further improved by determining the similarity between documents based on the similarity based on the semantic vector in addition to the named entity similarity. Can be made to.
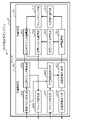
- FIG. 11 is a block diagram showing a functional configuration example of the server 3 in the similarity determination system 1A according to the second embodiment
- FIG. 12 is a diagram showing a screen output example by the server 3. Is.
- the server 3 is an example of a similarity determination device, an information processing device, or a computer.
- the server 3 performs various communications such as reception of the query document 11a and the comparison target document 12a and transmission of the result 14 with a terminal device (not shown), another server, or the like. good.
- the server 3 may provide, for example, a function for enabling access to the terminal device. For example, as shown in FIG. 12, the server 3 may output screen information of a search query specification screen 330 for designating a search query and a search result output screen 340 for outputting search results.
- the above-mentioned similarity determination process by the similarity determination system 1A may be realized by the server 3.
- the server 3 may optionally include a document DB unit 31 and a document retrieval unit 32.
- the document DB unit 31 and the document search unit 32 are examples of control units.
- the server 3 may include the document input unit 22 shown in FIG.
- the document DB unit 31 stores the query document 11a and the comparison target document 12a, and performs a document DB construction process for constructing the document DB.
- the document search unit 32 performs a document search process for searching a comparison target document 12a similar to the query document 11a specified in the query 11 based on the information stored in the document DB unit 31 in response to the acceptance of the query 11.
- the document search process is a process including a similarity determination process, and is an example of use (application example) of the similarity determination process.
- the document DB unit 31 is exemplified by the document storage unit 311, the compound name extraction unit 312, the clustering unit 313, the compound cluster storage unit 314, the document vector calculation unit 315, and the document vector storage unit. 316 may be provided.
- the document storage unit 311 is an example of the memory unit 21 (see FIG. 6) according to the first embodiment, and stores a plurality of documents.
- the document is a document that can be used as either the query document 11a or the comparison target document 12a. Therefore, it can be said that the document storage unit 311 stores the query document 11a and the document set (document group) 12 including the plurality of comparison target documents 12a that are the targets of the query 11.
- the document storage unit 311 may store a plurality of documents in advance before receiving the query 11.
- the document storage unit 311 may store a plurality of documents received by the document input unit 22 according to the first embodiment.
- the compound name extraction unit 312 is an example of the compound name extraction unit 231 shown in FIG. 6, and the compound name as an example of the named entity is extracted from each of the plurality of documents accumulated by the document storage unit 311 for each document. Generate compound lists C X and CY .
- the treatment of the compound name extraction unit 312 is an example of the treatment P1 in FIG.
- the clustering unit 313 is an example of the clustering unit 232 shown in FIG.
- the clustering unit 313 is based on the compound lists C X and CY for each document, and for each document, a plurality of compound clusters of compound names, in other words, a plurality of compound lists C X1 , C X 2 , C X 3 , ... Generate C XN , CY1 , CY2 , CY3 , ... CYM .
- the process of the clustering unit 313 is an example of the process P2 of FIG.
- the compound cluster storage unit 314 is an example of the memory unit 21 shown in FIG. 6, and is a plurality of compound clusters generated by the clustering unit 313, in other words, a plurality of compound lists C X1 , C X2 , C X3 , ... C XN , CY1 , CY2 , CY3 , ... CYM is accumulated.
- the document vector calculation unit 315 extracts a word from each of the plurality of documents accumulated by the document storage unit 311, calculates a word weight and a word vector based on the word, and based on the weight and the word vector, the document vector calculation unit 315 of the plurality of documents. Calculate each document vector.
- the process of the document vector calculation unit 315 is an example of at least a part of the processes P5 to P7 and the process P8 in FIG.
- the document vector storage unit 316 is an example of the memory unit 21 shown in FIG. 6, and stores the document vector calculated by the document vector calculation unit 315.
- the document search unit 32 may optionally include a search query designation unit 321, a document similarity calculation unit 322, a search result generation unit 323, and a search result output unit 324.
- the search query designation unit 321 is an example of the document input unit 22 shown in FIG. 6, and is a query 11 requesting a document search from a computer such as a terminal device (not shown) or another server (hereinafter referred to as “search query 11”). (May be) Accept the input.
- the search query specification unit 321 may accept the document number of the query document 11a set in the input field 331 when the search button 332 of the search query specification screen 330 is pressed. ..
- the document similarity calculation unit 322 is an example of the document similarity calculation unit 233 shown in FIG.
- the document similarity calculation unit 322 includes the query document 11a specified by the search query 11 and other documents based on the compound cluster stored in the compound cluster storage unit 314 and the document vector stored in the document vector storage unit 316.
- the document similarity calculation unit 322 compares the compound clusters corresponding to the query document 11a and the comparison target document 12a among the compound clusters accumulated in the compound cluster storage unit 314, and calculates the compound similarity. You can do it.
- the document similarity calculation unit 322 compares the document vectors corresponding to the query document 11a and the comparison target document 12a among the document vectors stored in the document vector storage unit 316, and calculates the text similarity. You can do it.
- the document similarity calculation unit 322 calculates the document similarity Sim (X, Y) based on the compound similarity and the text similarity, and compares the documents 12a in descending order of the document similarity Sim (X, Y). By sorting, the ranking result 14 may be generated.
- the process of the document similarity calculation unit 322 is an example of the process P3, at least a part of the process P8, and the process P9 in FIG.
- the search result generation unit 323 generates a search result for output based on the result 14.
- the search result generation unit 323 may generate the search result output screen 340 shown in FIG.
- the search result output screen 340 may replace the determination result 244 in the determination result output screen 240 shown in FIG. 7 with the search result 344.
- the search result output screen 340 includes a display area 341 of the query document 11a and display areas 345a to 345c of at least one (three in FIG. 12) of the comparison target document 12a. good.
- the display area 341 may include a display area 342 such as bibliographic information and a summary of the query document 11a, and a full-text reference button 343 of the query document 11a.
- the display areas 345a to 345c include display areas 346a to 346c for bibliographic information and summaries of the comparison target document 12a, full text reference buttons 347a to 347c, and compound lists 348a to 348c of clusters determined to be similar. good.
- the similarity Sim (X, Y) may be displayed in the display areas 345a to 345c.
- the search result output unit 324 outputs the search result output screen 340 to a computer such as a terminal device or another server (not shown).
- FIG. 13 is a flowchart illustrating an operation example of the document DB construction process of the server 3
- FIG. 14 is a flowchart illustrating an operation example of the document retrieval process of the server 3.
- the document storage unit 311 selects an unselected document (step S21) and registers the document in the document DB (step S22).
- the document vector calculation unit 315 calculates the document vector of the text of the document (step S23).
- the document vector storage unit 316 associates the calculated document vector with the document and registers (stores) it in, for example, a document DB or a document vector DB (step S24).
- the compound name extraction unit 312 extracts the compound name from the text of the document (step S25).
- the clustering unit 313 clusters the extracted compound names (step S26).
- the compound cluster storage unit 314 associates the information of the compound cluster with the document and registers (stores) it in, for example, the document DB or the compound cluster DB (step S27).
- the document storage unit 311 determines whether or not there is an unselected document (step S28), and if it determines that there is an unselected document (YES in step S28), the process proceeds to step S21. When the document storage unit 311 determines that there is no unselected document (NO in step S28), the process ends.
- steps S23 and S24 may be interchanged with the processes of steps S25 to S27, or at least a part of these processes may be executed before, after, or in parallel.
- the search query designation unit 321 accepts the designation of the query document 11a from the search query designation screen 330 (step S31).
- the document similarity calculation unit 322 acquires the document vector of the query document 11a from the document vector storage unit 316 (step S32), and acquires the compound cluster of the query document 11a from the compound cluster storage unit 314 (step S33).
- the document similarity calculation unit 322 selects an unselected document (step S34), acquires the document vector of the selected document from the document vector storage unit 316 (step S35), and selects the document from the compound cluster storage unit 314. Acquire a compound cluster (step S36).
- the document similarity calculation unit 322 calculates the document similarity Sim (X, Y) of the query document 11a and the selected document (step S37).
- the document similarity calculation unit 322 determines whether or not there is an unselected document (step S38), and if so (YES in step S38), the process proceeds to step S34.
- the document similarity calculation unit 322 determines that there is no unselected document (NO in step S38)
- the document similarity calculation unit 322 has a predetermined number of documents in descending order of document similarity and a query document for each document.
- the cluster having the highest document similarity with 11a is extracted (step S39).
- the search result generation unit 323 generates a search result based on the extracted data, the search result output unit 324 outputs a search result, for example, a search result output screen 340 (step S40), and the process ends.
- FIG. 15 is a block diagram showing a functional configuration example of the server 4 in the similarity determination system 1B according to the first modification of the second embodiment and the second modification described later, and FIGS. 16 and 17 are the server 4. It is a figure which shows the screen output example by.
- the similarity determination system 1B according to the first modification is selected after presenting the cluster that is the result of clustering of the query document 11a to the user as a list of unique expressions and allowing the user to select the cluster to be used for the similarity calculation.
- the similarity is calculated using the clusters.
- the server 4 may optionally include a document DB unit 31 and a document search unit 42.
- the document DB unit 31 and the document search unit 42 are examples of control units.
- the document DB unit 31 is the same as the document DB unit 31 shown in FIG.
- the document search unit 42 is exemplified by a search query designation unit 421, a document similarity calculation unit 422, a search result generation unit 423, a search result output unit 424, a compound cluster acquisition unit 425, a cluster presentation unit 426, and a cluster designation.
- a unit 427 may be provided.
- the search query specification unit 421, the document similarity calculation unit 422, the search result generation unit 423, and the search result output unit 424 are the search query specification unit 321 shown in FIG. 11, the document similarity calculation unit 322, and the search results. This is the same as the generation unit 323 and the search result output unit 324.
- the compound cluster acquisition unit 425 acquires the compound cluster of the query document 11a received by the search query designation unit 421 from the compound cluster storage unit 314, and notifies the cluster presentation unit 426 together with the query document 11a.
- the cluster presentation unit 426 presents the compound cluster of the query document 11a acquired from the compound cluster acquisition unit 425 to the user. For example, the cluster presentation unit 426 generates the cluster designation screen 440 shown in FIG. 16 and outputs it to a computer such as a terminal device or another server.
- the cluster designation screen 440 may include a display area 441 of the query document 11a and a display area 444 that presents a plurality of compound clusters contained in the query document 11a.
- the display area 441 may include a display area 442 such as bibliographic information and a summary of the query document 11a, and a full-text reference button 443 of the query document 11a.
- a plurality of compound lists 445 corresponding to the plurality of clusters of the query document 11a, a check box 446 for designating the compound clusters to be used for the similarity calculation from the plurality of compound lists 445, and a search are executed. May include a search button 447 for.
- the cluster designation unit 427 notifies the document similarity calculation unit 422 of the information of the compound list 445 in which the check box 446 is selected when the search button 447 of the cluster designation screen 440 is pressed.
- the document similarity calculation unit 422 adds the compound cluster used for calculating the document similarity Sim (X, Y) between the query document 11a and the selected document to the compound list designated by the cluster designation unit 427.
- Limit limit
- the document similarity calculation unit 422 is limited to the specified compound cluster among the plurality of compound clusters of the query document 11a, and compares the compound list of the compound cluster with the plurality of compound lists of the selected document. It's okay.
- the search result generation unit 423 and the search result output unit 424 may generate and output the search result output screen 450 as shown in FIG. 17 based on the result 14 by the document similarity calculation unit 422.
- the cluster designation screen 440 the compound cluster used for the similarity calculation is designated. Therefore, the display of the compound list (see the compound lists 348a to 348c in FIG. 12) may be omitted on the search result output screen 450. As in the example of FIG. 12, the compound list may be displayed on the search result output screen 450.
- the same effect as that of the second embodiment can be obtained, and the compound cluster used for determining the similarity can be limited to an appropriate compound cluster. , It is possible to further improve the determination accuracy of the similarity between documents. Further, since the number of compound clusters used for determining the similarity can be limited, the processing time of the document retrieval process can be shortened.
- FIG. 18 is a flowchart illustrating an operation example of the document retrieval process of the server 4.
- FIG. 14 a process different from the operation example shown in FIG. 14 in the document retrieval process of the server 4 will be described.
- the compound cluster acquisition unit 425 acquires the compound cluster of the query document 11a, in other words, the compound list, from the compound cluster storage unit 314 (step S41).
- the cluster presentation unit 426 generates a cluster designation screen 440 including the compound list acquired by the compound cluster acquisition unit 425 and presents it to the user (step S42).
- the cluster designation unit 427 accepts the designation of the compound cluster on the cluster designation screen 440 (step S43), and the process proceeds to step S34.
- the processes of steps S41 to S43 may be executed before, after, or in parallel with step S32.
- the document similarity calculation unit 422 limits the compound cluster of the selected document to the designated cluster accepted by the cluster designation unit 427.
- the document similarity calculation unit 422 limits the compound list of the query document 11a to the designated cluster, in other words, the designated compound list, and the inter-document similarity between the query document 11a and the selected document. Is calculated (step S44), and the process proceeds to step S38.
- step S45 the document similarity calculation unit 422 extracts a predetermined number of documents in descending order of similarity (step S45), and the process is step S40. Move to.
- FIG. 19 is a diagram showing a screen output example of the server 4 according to the second modification.
- the search query specification unit 421 inputs the document number input field 461 of the query document 11a and one or more keywords (here, the compound name) on the search query specification screen 460. Includes region 462.
- the cluster designation unit 427 calculates the document similarity of the document number of the query document 11a input in the input field 461 and the information of one or more keywords input in the input area 462 when the search button 463 is pressed. Notify section 422.
- the document similarity calculation unit 422 limits the compound cluster of the document to be compared with the designated query document 11a to the cluster including the keyword accepted by the cluster designation unit 427 (for example, including a predetermined number of times or more). Then, the document similarity calculation unit 422 focuses on the cluster including the designated keyword, in other words, the compound list, and calculates the inter-document similarity between the query document 11a and the document.
- the same effect as that of the first modification can be obtained, and the user is not limited to a specific cluster and can flexibly use a cluster including a predetermined keyword. It can be specified as, and it is highly convenient.
- FIG. 20 is a diagram for explaining the similarity determination system 1C according to the third embodiment
- FIGS. 21 and 22 are diagrams for explaining an example of processing of the similarity determination system 1C.
- the similarity determination system 1C replaces the process P8 of the similarity determination system 1B shown in FIG. 10 with the processes P10 and P11, replaces the process P9 with the process P12, and replaces the process P2 with the process P2.
- the processing result of is passed to the processing P10.
- the processes P10 to P12 will be described.
- the similarity determination system 1C acquires a plurality of partial documents (partial texts) by dividing the document for each document in the process P10.
- Sub-documents in other words, document division units include, for example, sentences, paragraphs, chapters, sections, and the like.
- the partial document is a paragraph.
- the similarity determination system 1C divides the document X included in the query 11 to acquire a plurality of paragraphs PX , and divides the document Y included in the document set 12 into a plurality of documents Y. Get the paragraph P Y.
- paragraph P when paragraphs PX and P Y are not distinguished from each other, they are simply referred to as "paragraph P".
- the similarity determination system 1C acquires a partial document cluster by clustering the paragraph P based on the named entity (for example, compound) cluster obtained in the process P2.
- the similarity determination system 1C may cluster the paragraphs P based on the degree of agreement between the named entity included in the named entity cluster and the named entity included in the plurality of paragraphs P.
- the similarity determination system 1C determines the degree of coincidence between each of the compound lists C X1 to C XN for each cluster and each of the plurality of paragraphs PX for the document X according to the following formula (11). Based on this, partial document clusters PX1 to PXN are generated. Further, the similarity determination system 1C has a degree of coincidence cos (CPX,) between each of the compound lists CY1 to CYN for each cluster and each of the plurality of paragraphs P Y for the document Y according to the following formula (12) . Sub-document clusters P Y1 to P YN are generated based on C Xa ).
- C PX is a list of compounds included in paragraph PX
- C P Y is a list of compounds included in paragraph P Y
- C Xa and CYb are compound lists of documents X and Y obtained in treatment P2.
- argmax is a function that extracts the condition (here, cluster) when the element in parentheses is the maximum.
- the cosine similarity between each of the compound names contained in paragraph P and each of the compound names in the compound cluster is the maximum, for example, the number of occurrences is the largest.
- Paragraph P can be assigned to the element (compound cluster).
- paragraphs PX and P Y can be classified into sub-document clusters of the following four elements (characteristics) by such clustering.
- -Partial document clusters PX1 and PY1 A paragraph describing "negative electrode active material”.
- -Partial document clusters PX2 and PY2 A paragraph describing "positive electrode active material”.
- -Partial document clusters PX3 and PY3 A paragraph describing "binder”.
- -Partial document clusters PX4 and PY4 A paragraph describing "electrolyte solvent”.
- the similarity determination system 1C calculates a plurality of subdocument vectors corresponding to each of the plurality of subdocument clusters based on the words included in each of the subdocument clusters. For example, the similarity determination system 1C adds the result of multiplying the word vector acquired in the process P7 and the weight of the word acquired in the process P6 over all the words in the subdocument cluster for each subdocument cluster. By doing so, the partial document vector may be calculated.
- the similarity determination system 1C is a partial document based on the similarity between the partial document vector of the query document 11a and each partial document vector of the comparison target document 12a, in other words, the meaning vector of the word. Calculate the text similarity between clusters.
- the partial document vector of the query document 11a is an example of the first plurality of vectors
- the partial document vector of the comparison target document 12a is an example of the second plurality of vectors.
- the similarity determination system 1C calculates the text similarity, for example, the cosine similarity between the partial document cluster of the query document 11a and the partial document cluster of the comparison target document 12a by the calculation of the following equation (13). good.
- WP Xa is a dispersion vector of words included in paragraph PXa
- WP Yb is a dispersion vector of words included in paragraph P Yb .
- the similarity determination system 1C has partial document clusters PX1 , PX2 , PX3 , ... PXN , and partial document clusters XY1 , PHY2 , CY3 , ... PHYM .
- the text similarity may be calculated according to the above equation (13) for all pairs of and.
- the similarity determination system 1C performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the text similarity and the named entity similarity (process P12). , The result 14 is output.
- the similarity determination system 1C calculates the similarity in which the text similarity and the named entity similarity are integrated in the ranking process, and based on the similarity, a plurality of comparison targets according to the similarity with the query document 11a.
- the ranking of the document 12a is output.
- the similarity determination system 1C may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (14).
- fc is the named entity similarity according to the above equation (8)
- ft is the text similarity according to the above equation (13).
- the above formula (14) shows an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). Similar to the second embodiment, the similarity determination system 1C may acquire document similarity Sims (X, Y 1 ) to Sim (X, Y L ) according to the number of documents Y.
- the similarity determination system 1C for example, as in the second embodiment, all the documents Y to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ). Ranking processing is performed by sorting 1 to Y L. Further, the similarity determination system 1C may output the sort result as the result 14.
- the similarity determination system 1C expresses the document similarity Sim (X, Y) between the document X and one comparison target document Y according to the following equation (15). It may be calculated as a weighted sum of similarity and text similarity.
- the degree of similarity between the documents X and Y is high because the semantic vectors for the “positive electrode active material” are similar. be able to.
- the semantic vector space is shown in two dimensions, but it can actually be a vector of several hundred dimensions. According to the third embodiment, the accuracy of determining the degree of similarity between partially similar documents can be improved by comparing the partial document clusters.
- FIG. 23 is a block diagram showing a functional configuration example of the server 5 in the similarity determination system 1C according to the third embodiment. Unless otherwise specified, the server 5 may be the same as the server 3 shown in FIG. 11 or the server 4 shown in FIG.
- the server 5 may optionally include a document DB unit 51 and a document retrieval unit 52.
- the document DB unit 51 and the document search unit 52 are examples of control units.
- the document DB unit 51 may include a document cluster vector calculation unit 515 and a document cluster vector storage unit 516 in place of the document vector calculation unit 315 and the document vector storage unit 316 shown in FIG. Further, in the document DB unit 51, the compound cluster which is the clustering result may be output from the clustering unit 313 to the document cluster vector calculation unit 515.
- the document retrieval unit 52 may include a document similarity calculation unit 522 instead of the document similarity calculation unit 322 shown in FIG.
- the document cluster vector calculation unit 515 may calculate the document vector for each partial document cluster based on the information of the compound cluster from the clustering unit 313.
- the process of the document cluster vector calculation unit 515 is an example of the process of the process P10 shown in FIG.
- the document cluster vector storage unit 516 stores the document vector for each partial document cluster calculated by the document cluster vector calculation unit 515.
- the document similarity calculation unit 522 calculates the document similarity Sim (X, Y) between the partial document vector of the query document 11a and each partial document vector of the comparison target document 12a, and calculates the document similarity Sim (X, Y). , Y) may generate result 14.
- the process of the document similarity calculation unit 522 is an example of the process P3, the process P11, and the process P12 in FIG.
- document retrieval unit 52 may output the various screens shown in FIGS. 12, 16, 17, 19, 19 and the like.
- FIG. 24 is a flowchart illustrating an operation example of the document DB construction process of the server 5
- FIG. 25 is a flowchart illustrating an operation example of the document retrieval process of the server 5.
- steps S23 and S24 shown in FIG. 13 are deleted, and steps S51 to S54 are added between steps S27 and S28.
- the document cluster vector calculation unit 515 divides the text of the document into predetermined units (step S51), and each division unit (paragraph P) is based on the compound cluster accumulated by the compound cluster storage unit 314. (Step S52).
- the document cluster vector calculation unit 515 calculates the document vector of each partial document cluster (step S53).
- the document cluster vector storage unit 516 stores the document vectors of each partial document cluster (step S54), and the process shifts to step S28.
- steps S32, S35, and S37 shown in FIG. 14 are replaced with steps S61, S62, and S63, respectively.
- step S61 the document similarity calculation unit 522 acquires the document vector of the partial document cluster of the query document 11a from the document cluster vector storage unit 516.
- step S62 the document similarity calculation unit 522 acquires the document vector of the partial document cluster of the document selected from the document cluster vector storage unit 516.
- step S63 the document similarity calculation unit 522 calculates the document similarity Sim (X, Y) based on the document vector acquired in steps S61 and S62, respectively, and the compound cluster.
- the compound name is used as a named entity
- the present invention is limited to this. It is not something that is done.
- the named entity various terms that can be the target of the named entity extraction process in natural language processing, such as a gene sequence (genome), may be used.
- each of the servers 2 to 5 shown in FIGS. 6, 11, 15, and 20 may be merged or divided in any combination.
- the first to third embodiments and the first and second modifications of the second embodiment may be combined as appropriate.
- each of the servers 2 to 5 may generate screen information of any of the screens of FIGS. 7, 12, 16, 17, and 19, and may have a functional configuration according to the screen.
- each of the servers 2 to 5 shown in FIGS. 6, 11, 15, and 20 may be configured to realize each processing function by coordinating a plurality of devices with each other via a network.
- the memory unit 21 is a DB server
- the document DB units 31 and 51 are a combination of an application server and a DB server
- a document input unit 22 a similarity calculation unit 23
- a similarity output unit 24 and a document search unit 32, 42 and 52.
- the computer, the application server, and the DB server may cooperate with each other via the network to realize each processing function as the servers 2 to 5.
- each of the servers 3 to 5 may be provided with the HW configuration of the computer 10 illustrated in FIG.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/047218 WO2022130578A1 (ja) | 2020-12-17 | 2020-12-17 | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 |
| JP2022569434A JP7487797B2 (ja) | 2020-12-17 | 2020-12-17 | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/047218 WO2022130578A1 (ja) | 2020-12-17 | 2020-12-17 | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022130578A1 true WO2022130578A1 (ja) | 2022-06-23 |
Family
ID=82057405
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/047218 Ceased WO2022130578A1 (ja) | 2020-12-17 | 2020-12-17 | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7487797B2 (https=) |
| WO (1) | WO2022130578A1 (https=) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11272680A (ja) * | 1998-03-19 | 1999-10-08 | Fujitsu Ltd | 文書データ提供装置およびそのプログラム記録媒体 |
| JP2000112949A (ja) * | 1998-09-30 | 2000-04-21 | Fuji Xerox Co Ltd | 情報判別支援装置及び類似情報判別支援プログラムを記録した記録媒体 |
| JP2002259411A (ja) * | 2001-03-06 | 2002-09-13 | Nec Corp | 文章情報変換システム、文章情報変換方法および文章情報変換プログラム |
| JP2008009671A (ja) * | 2006-06-29 | 2008-01-17 | National Institute Of Information & Communication Technology | データ表示装置、データ表示方法及びデータ表示プログラム |
| JP2013020431A (ja) * | 2011-07-11 | 2013-01-31 | Nec Corp | 多義語抽出システム、多義語抽出方法、およびプログラム |
| JP2016045552A (ja) * | 2014-08-20 | 2016-04-04 | 富士通株式会社 | 特徴抽出プログラム、特徴抽出方法、および特徴抽出装置 |
-
2020
- 2020-12-17 WO PCT/JP2020/047218 patent/WO2022130578A1/ja not_active Ceased
- 2020-12-17 JP JP2022569434A patent/JP7487797B2/ja active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11272680A (ja) * | 1998-03-19 | 1999-10-08 | Fujitsu Ltd | 文書データ提供装置およびそのプログラム記録媒体 |
| JP2000112949A (ja) * | 1998-09-30 | 2000-04-21 | Fuji Xerox Co Ltd | 情報判別支援装置及び類似情報判別支援プログラムを記録した記録媒体 |
| JP2002259411A (ja) * | 2001-03-06 | 2002-09-13 | Nec Corp | 文章情報変換システム、文章情報変換方法および文章情報変換プログラム |
| JP2008009671A (ja) * | 2006-06-29 | 2008-01-17 | National Institute Of Information & Communication Technology | データ表示装置、データ表示方法及びデータ表示プログラム |
| JP2013020431A (ja) * | 2011-07-11 | 2013-01-31 | Nec Corp | 多義語抽出システム、多義語抽出方法、およびプログラム |
| JP2016045552A (ja) * | 2014-08-20 | 2016-04-04 | 富士通株式会社 | 特徴抽出プログラム、特徴抽出方法、および特徴抽出装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022130578A1 (https=) | 2022-06-23 |
| JP7487797B2 (ja) | 2024-05-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20130311487A1 (en) | Semantic search using a single-source semantic model | |
| KR102402466B1 (ko) | 키워드 클러스터링을 이용한 문서 요약 방법 및 장치 | |
| KR102059743B1 (ko) | 딥러닝 기반의 지식 구조 생성 방법을 활용한 의료 문헌 구절 검색 방법 및 시스템 | |
| KR20180129001A (ko) | 다언어 특질 투영된 개체 공간 기반 개체 요약본 생성 방법 및 시스템 | |
| Xu et al. | Learning to refine expansion terms for biomedical information retrieval using semantic resources | |
| Hare et al. | Imageterrier: an extensible platform for scalable high-performance image retrieval | |
| US20140067853A1 (en) | Data search method, information system, and recording medium storing data search program | |
| WO2022130579A1 (ja) | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 | |
| JP2017151588A (ja) | 画像評価学習装置、画像評価装置、画像検索装置、画像評価学習方法、画像評価方法、画像検索方法、およびプログラム | |
| Oliveira et al. | A distributed system for SearchOnMath based on the Microsoft BizSpark program | |
| Arasu et al. | Experiences with using data cleaning technology for bing services | |
| CN113434654B (zh) | 一种数据处理方法及装置、设备、存储介质 | |
| JP5869948B2 (ja) | パッセージ分割方法、装置、及びプログラム | |
| Sailaja et al. | An overview of pre-processing text clustering methods | |
| CN115206533A (zh) | 基于知识图谱健康管理方法、装置及电子设备 | |
| JP5362807B2 (ja) | ドキュメントランク付け方法および装置 | |
| JP2011248827A (ja) | 言語横断型情報検索方法、言語横断型情報検索システム及び言語横断型情報検索プログラム | |
| WO2022130578A1 (ja) | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 | |
| Ullah et al. | On the analysis and evaluation of information retrieval models for social book search | |
| JP6622921B2 (ja) | 文字列辞書の構築方法、文字列辞書の検索方法、および、文字列辞書の処理システム | |
| US11003647B2 (en) | Multidimensional data management system and multidimensional data management method | |
| CN112712866A (zh) | 一种确定文本信息相似度的方法及装置 | |
| JP7646091B2 (ja) | 情報処理装置、検索方法、及び検索プログラム | |
| Kendea et al. | Graph dbs vs. column-oriented stores: A pure performance comparison | |
| Clementino et al. | Bag-of-attributes representation: A vector space model for electronic health records analysis in omop |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20965965 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022569434 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20965965 Country of ref document: EP Kind code of ref document: A1 |