WO2022130578A1 - Similarity determination program, similarity determination device, and similarity determination method - Google Patents
Similarity determination program, similarity determination device, and similarity determination method Download PDFInfo
- Publication number
- WO2022130578A1 WO2022130578A1 PCT/JP2020/047218 JP2020047218W WO2022130578A1 WO 2022130578 A1 WO2022130578 A1 WO 2022130578A1 JP 2020047218 W JP2020047218 W JP 2020047218W WO 2022130578 A1 WO2022130578 A1 WO 2022130578A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document
- similarity
- groups
- named entity
- compound
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 181
- 150000001875 compounds Chemical class 0.000 claims description 213
- 239000013598 vector Substances 0.000 claims description 106
- 238000012545 processing Methods 0.000 claims description 36
- 230000014509 gene expression Effects 0.000 abstract description 10
- 238000004364 calculation method Methods 0.000 description 82
- 230000015654 memory Effects 0.000 description 38
- 238000010586 diagram Methods 0.000 description 20
- 238000012986 modification Methods 0.000 description 20
- 230000004048 modification Effects 0.000 description 20
- 230000006870 function Effects 0.000 description 19
- 239000000284 extract Substances 0.000 description 12
- 238000000605 extraction Methods 0.000 description 12
- 238000004891 communication Methods 0.000 description 7
- 238000010276 construction Methods 0.000 description 7
- 239000007774 positive electrode material Substances 0.000 description 7
- 230000000052 comparative effect Effects 0.000 description 6
- 238000002902 MACCS key Methods 0.000 description 5
- HBBGRARXTFLTSG-UHFFFAOYSA-N Lithium ion Chemical compound [Li+] HBBGRARXTFLTSG-UHFFFAOYSA-N 0.000 description 4
- 239000006185 dispersion Substances 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 229910001416 lithium ion Inorganic materials 0.000 description 4
- 239000011230 binding agent Substances 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 3
- 239000003792 electrolyte Substances 0.000 description 3
- 239000007773 negative electrode material Substances 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 235000019800 disodium phosphate Nutrition 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 238000010801 machine learning Methods 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 238000012549 training Methods 0.000 description 2
- NAWXUBYGYWOOIX-SFHVURJKSA-N (2s)-2-[[4-[2-(2,4-diaminoquinazolin-6-yl)ethyl]benzoyl]amino]-4-methylidenepentanedioic acid Chemical compound C1=CC2=NC(N)=NC(N)=C2C=C1CCC1=CC=C(C(=O)N[C@@H](CC(=C)C(O)=O)C(O)=O)C=C1 NAWXUBYGYWOOIX-SFHVURJKSA-N 0.000 description 1
- 101100520018 Ceratodon purpureus PHY2 gene Proteins 0.000 description 1
- 229910032387 LiCoO2 Inorganic materials 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 239000008151 electrolyte solution Substances 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 108090000623 proteins and genes Proteins 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
Images




















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
Definitions
- the present invention relates to a similarity determination program, a similarity determination device, and a similarity determination method.
- one of the objects of the present invention is to improve the accuracy of determining the degree of similarity between partially similar documents.
- the similarity determination program may cause the computer to perform the following processing.
- the process classifies the first named entity based on the position of each of the first named entity contained in the first document and the similarity of each of the first named entity. It may include the process of acquiring the first plurality of groups generated by the above. In addition, the process is based on the position of each of the second named entity included in the second document and the similarity of each of the second named entity. It may include a process of acquiring a second plurality of groups generated by classifying. Further, the process includes a process of determining the degree of similarity between the first document and the second document based on the comparison between the first plurality of groups and the second plurality of groups. good.
- the present invention can improve the accuracy of determining the degree of similarity between partially similar documents.
- HW hardware
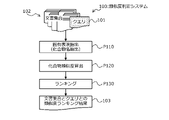
- FIG. 1 is a diagram for explaining the similarity determination system 100 according to a comparative example.
- the similarity determination system 100 uses a query 101 that requests determination of similarity of a query document (input document) and a document set 102 including one or more comparison target documents as a unique expression. Calculate the degree of similarity based on.
- the similarity determination system 100 extracts a compound name as a unique expression from each of a plurality of documents, that is, a query document included in the query 101 and a comparison target document included in the document set 102 (process P110), and documents. Generate a compound list for each.
- the similarity determination system 100 calculates the compound similarity between each of the query document and the comparison target document by comparing the compound list for each document (process P120). Examples of the compound similarity include cosine similarity.
- the similarity determination system 100 performs ranking processing based on the calculated compound similarity (processing P130), and stores the comparison target document having a high similarity with the query document as the ranking result 103 together with the similarity.
- FIG. 2 is a diagram illustrating an example of calculation of compound similarity by the similarity determination system 100 shown in FIG.
- the compound list Cx is generated from the query document and the compound list Cy is generated from the comparison target document for the query document and the comparison target document related to the lithium ion battery.
- compound list C when the compound lists Cx and Cy generated for the set of documents for which the compound similarity is to be determined are not distinguished from each other, they are simply referred to as "compound list C".
- the compound list C may include the compound name and the number of occurrences of the compound name in the document.
- the common compounds common between the compound lists Cx and Cy are shown in bold underline.
- the similarity determination system 100 calculates the cosine similarity as the compound similarity by the calculation of the following formula (1) based on the compound list C.
- i is an index for specifying all the compound names included in the compound list Cx and Cy
- Cx i and Cy i are the i-th compound names in the compound list Cx and Cy.
- the denominator is the sum of the square roots of the sum of squares of the number of occurrences of Cx compounds and the square root of the sum of squares of the number of appearances of Cy compounds, and the molecules are Cx and Cy. It is the sum of the products of the number of appearances of common compounds between.
- the "document” includes a document including a description of a plurality of elements, and, for example, a document such as a patent document or a paper describing a device, a system, a manufacturing method, etc. having a plurality of components.
- a document such as a patent document or a paper describing a device, a system, a manufacturing method, etc. having a plurality of components.
- each of the components of the lithium ion battery such as "positive electrode active material”, “negative electrode active material”, “binder”, “electrolyte”, and “electrolyte solution solvent” is provided.
- Compound names related to the classification (group) of may be mixed and described.
- the comparison target document with other elements in other words, the element not to be investigated.
- the difference in the above may affect the judgment result of the similarity between documents.
- the similarity determination system 1 classifies each of the plurality of named entity included in the document to generate a plurality of groups, and among the documents. , The degree of similarity between the query document and the comparison target document is determined by comparing the groups.
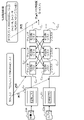
- FIG. 3 is a diagram for explaining the similarity determination system 1 according to the first embodiment
- FIGS. 4 and 5 are diagrams for explaining an example of processing of the similarity determination system 1.
- the similarity determination system 1 includes a query 11 requesting determination of the similarity of a query document (input document) and one or more comparison target documents to be determined. Based on the document set (document group) 12, the similarity based on the eigenexpression is calculated.
- the similarity determination system 1 extracts a compound name as an example of a named entity from each of a plurality of documents (process P1), and prepares a named entity list, for example, a compound list for each document, as in the comparative example. Generate.
- the similarity determination system 1 extracts the compound name from the query document 11a (denoted as “document X”) included in the query 11 and generates the compound list C X. Further, the similarity determination system 1 extracts a compound name from the comparison target document 12a (denoted as “document Y”) included in the document set 12 to generate a compound list CY .
- the query document 11a is an example of the first document
- the comparison target document 12a is an example of the second document.
- the query document 11a and the comparison target document 12a are documents relating to the lithium ion battery.
- compound list C when the compound lists C X and CY generated for the set of documents for which the compound similarity is to be determined are not distinguished from each other, they are simply referred to as “compound list C”.
- the similarity determination system 1 executes clustering for classifying and grouping named entity based on the named entity list (process P2 in FIG. 3).
- clustering method various existing methods such as the shortest distance method may be used.
- the similarity determination system 1 calculates the named entity similarity for each cluster, for example, the compound similarity (process P3 in FIG. 3). Named entity similarity may be calculated, for example, for each pair of clusters between documents.
- the similarity determination system 1 performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the named entity similarity (process P4 in FIG. 3).
- the result 13 is output.
- the result 13 may include a ranking result.
- the similarity determination system 1 may calculate the similarity score S between named entities included in the named entity list for each pair (set) of named entity based on the named entity list. For example, the similarity determination system 1 calculates a similarity score S for a pair of named entity based on each position of the named entity and the similarity between the named entity.
- the similarity determination system 1 may calculate the similarity score S (x 1 , x 2 ) using the following equation (2). ..
- TC (x 1 , x 2 ) is the Tanimoto coefficient of MACCS Key.
- MACCS Key is one of the expression methods (compound descriptors) of the characteristics of compounds
- Tanimoto coefficient is one of the indexes showing the structural similarity between compounds using MACCS Key
- the named entity is the compound name. This is an example of the degree of similarity between named entities in the case of.
- Distance (x 1 , x 2 ) is, for example, a numerical value obtained by quantifying the proximity of each appearance position of the named entity in a document, and is, for example, a value corresponding to the following conditions.
- the similarity determination system 1 applies the above formula (2) to each combination of compound name pairs (x 1 , x 2 ) for a plurality of compound names included in the compound list C, and applies each pair (x 1 , x 2).
- the similarity score S (x 1 , x 2 ) of x 2 ) may be calculated.
- the similarity determination system 1 classifies a plurality of compound names included in the compound list C by applying a method such as the shortest distance method to a plurality of calculated similarity scores S (x 1 , x 2 ). By grouping them together, the compound names may be clustered.
- the similarity determination system 1 divides the compound names in the compound list C X into clusters (groups) of N (N is an integer of 2 or more) by clustering to the compound list C X. Generate compound lists C X1 to C XN for each compound. Further, the similarity determination system 1 divides the compound names in the compound list CY into clusters (groups) of M (M is an integer of 2 or more) by clustering to the compound list CY , and the compound list for each cluster. Generates CY1 to CYM .
- -Compound list C X1 and CY1 A cluster having an element (characteristic) of "positive electrode active material”.
- -Compound list C X2 and CY2 A cluster having elements (characteristics) of "negative electrode active material”.
- -Compound list C X3 and CY3 A cluster with a "binder" element (characteristic).
- -Compound list C X4 and CY4 A cluster having an element (characteristic) of "electrolyte solvent”.
- the Tanimoto coefficient of MACCS Key is used as the structural similarity, but the description is not limited to this.
- the method for expressing the characteristics of a compound is not limited to MACCS Key, in other words, MACCS fingerprint, and various compound descriptors such as Morgan fingerprint may be adopted.
- the index indicating the structural similarity between the compounds is not limited to the Tanimoto coefficient, and various coefficients such as the Dice coefficient may be used.
- the similarity determination system 1 uses the similarity score S (x 1 , x 2 ) as a numerical value of the proximity of the appearance position in the document of the named entity and the named entity.
- the product with the similarity is calculated, but the product is not limited to this.
- the similarity determination system 1 may calculate the similarity score S (x 1 , x 2 ) using the following equation (3).
- W is a weight.
- W for example, a value such as "0.5" may be appropriately defined and set by the user or the like so that each position of the named entity and the similarity between the named entity are considered evenly.
- W may be set based on a model trained so that the correct answer example is searched higher by machine learning based on the search query and the training data including the correct answer example (correct answer data). ..
- the similarity determination system 1 is based on the position of each of the first plurality of compound names included in the query document 11a and the similarity of each of the first plurality of compound names. By classifying the compound names of, the first cluster group is generated. Further, the similarity determination system 1 is based on the position of each of the second plurality of compound names included in the comparison target document 12a and the similarity of each of the second plurality of compound names. By classifying the names, a second cluster group is generated. The first cluster group is an example of the first plurality of groups, and the second cluster group is an example of the second plurality of groups.
- the similarity determination system 1 has a plurality of first clusters in the first cluster group generated from the query document 11a and a second cluster in the second cluster group generated from the comparison target document 12a. Each of the two plurality of clusters may be compared. Then, in the similarity determination system 1, the compound similarity, for example, cosine similarity, is obtained by the calculation of the following formula (4) for all the cluster pairs between the first plurality of clusters and the second plurality of clusters. The degree may be calculated.
- a is an integer of 1 to N
- b is an integer of 1 to M
- i is an index for specifying all the compound names contained in the compound lists C Xa and CYb
- C Xai and CYbi are the number of occurrences of the i-th compound name in the compound lists C Xa and CYb . Is shown.
- the formula for calculating the cosine similarity is the same as the above formula (1).
- the similarity determination system 1 has the compound lists C X1 , C X2 , C X3 , ... C XN and the compound lists CY1 , CY2 , CY3 . , ...
- the compound similarity may be calculated according to the above formula (4).
- the similarity determination system 1 acquires the document similarity between the query document 11a and each of the plurality of comparison target documents 12a in the ranking process, and determines the similarity with the query document 11a based on the document similarity.
- the ranking of a plurality of comparison target documents 12a corresponding to the corresponding is output.
- the similarity determination system 1 may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (5).
- max is a function that adopts the maximum value among all combinations in parentheses.
- the similarity determination system 1 determines that the pair of the compound lists C X1 and CY 1 , in other words, the clusters of the “positive electrode active material” has the maximum compound similarity, and determines that the compound similarity is the maximum.
- the degree is determined to be the document similarity Sim (X, Y) between the documents X and Y.
- FIGS. 4 and 5 and the above formula (5) show an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a).
- the similarity determination system 1 performs the above processing for each of a plurality of comparison target documents 12a, for example, documents Y 1 to Y L (L is an integer of 2 or more and the number of documents of the comparison target document 12a), and the document similarity Sim. (X, Y 1 ) to Sim (X, Y L ) may be acquired.
- the similarity determination system 1 sorts all the documents Y 1 to Y L to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ), for example.
- the sort result may be output as the result 13.
- the result 13 may include the identification information of the document Y together with the rank (rank), and may include the document similarity Sim (X, Y) of each document Y.
- the identification information of the document Y includes at least one of an identifier such as a document number or a document code, bibliographic information such as a document name, and at least a part of the contents of the document Y such as a summary and a predetermined part. But it may be.
- the similarity determination system 1 identifies information of the document Y having the highest document similarity Sim (X, Y) with the document Y determined to have a specific order, for example, the query document 11a. May be output.
- the similarity between documents is partially determined based on the named entity similarity for each cluster classified by the clustering process. It is possible to improve the determination accuracy of the similarity between the documents.
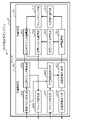
- FIG. 6 is a block diagram showing a functional configuration example of the server 2 in the similarity determination system 1 according to the first embodiment
- FIG. 7 is a diagram showing a screen output example by the server 2. Is.
- the server 2 is an example of a similarity determination device, an information processing device, or a computer.
- the server 2 performs various communications such as reception of the query document 11a and the comparison target document 12a and transmission of the result 13 with a terminal device (not shown), another server, or the like. good.
- the server 2 may provide, for example, a function for enabling access to the terminal device.
- Examples of the function include generation and display control of a screen such as a web page used for access by a terminal device.
- the terminal device sends an access request to the server 2 using an application such as a browser, and accesses the server 2 via a web page displayed on the application based on the screen information received from the server 2. good.
- the server 2 may output the screen information of the query specification screen 210 for designating the query and the determination result output screen 240 for outputting the determination result.
- the server 2 may optionally include a memory unit 21, a document input unit 22, a similarity calculation unit 23, and a similarity output unit 24.
- the memory unit 21, the document input unit 22, the similarity calculation unit 23, and the similarity output unit 24 are examples of control units.
- the memory unit 21 has a storage area for storing various data related to the similarity determination process.
- the memory unit 21 may store information such as the query document 11a shown in FIG. 3, a plurality of comparison target documents 12a, and the result 13. Further, the memory unit 21 uses the compound list C for each document, the similarity score S, the compound list C for each cluster, the compound similarity, and the document similarity Sim as intermediate data in the similarity determination process. Information such as may be stored.
- the document input unit 22 may receive input of the query document 11a and the comparison target document 12a from a computer such as a terminal device (not shown) or another server, and store the query document 11a and the comparison target document 12a in the memory unit 21, for example, as a DB (Database). In this way, the document input unit 22 may be able to construct and refer to the DB of the document.
- a computer such as a terminal device (not shown) or another server
- DB Database
- the document input unit 22 may receive the input of the query document 11a related to the similarity determination request from a computer such as a terminal device (not shown) or another server and store it in the memory unit 21.
- the query document 11a may be included in the query 11, for example.
- the document input unit 22 may accept, for example, as the query 11, not the query document 11a itself, but the identification information of the query document 11a, for example, information such as a document number and a document code.
- the document input unit 22 may specify the query document 11a related to the similarity determination request from, for example, the DB of the memory unit 21 based on the identification information.
- the document input unit 22 may accept the document number set in the input field 211 when the determination button 212 of the query specification screen 210 is pressed.
- the similarity calculation unit 23 calculates the similarity between the query document 11a and the comparison target document 12a. As illustrated in FIG. 6, the similarity calculation unit 23 may include a compound name extraction unit 231, a clustering unit 232, and a document similarity calculation unit 233.
- the compound name extraction unit 231 extracts the compound name from each of the query document 11a and the comparison target document 12a stored in the memory unit 21, and generates the compound lists C X and CY .
- the treatment of the compound name extraction unit 231 is an example of the treatment P1 in FIG.
- the clustering unit 232 calculates the similarity score S for each of the compound names included in the compound lists C X and CY . Further, the clustering unit 232 classifies the compound names into a plurality of clusters based on the similarity score S, and the compound lists C X1 , C X2 , C X3 , ... C XN , and the compound lists CY1 , CY2 , and so on. Generate CY3 , ... CYM .
- the process of the clustering unit 232 is an example of the process P2 of FIG.
- the clustering unit 232 When one or both of the query document 11a and the comparison target document 12a are stored in the memory unit 21 in advance, the clustering unit 232 performs a clustering process for each document in advance and generates a compound list C for each cluster. You may leave it. As an example, the clustering unit 232 may perform a clustering process on each registered document at the timing of registering the document in the memory unit 21.
- the document similarity calculation unit 233 calculates the compound similarity for each cluster based on the compound list for each cluster, and determines the compound similarity of the cluster having the highest compound similarity in the document as the similarity Sim (X) of the document. , Y).
- the document similarity calculation unit 233 calculates the similarity Sim (X, Y 1 ) to Sim (X, Y L ) for each comparison target document 12a. You can do it.
- the document similarity calculation unit 233 may store the calculated similarity Sim (X, Y) in the memory unit 21.
- the similarity output unit 24 outputs the similarity Sim (X, Y) calculated by the similarity calculation unit 23.
- the documents to be compared are compared in descending order of the calculated similarity Sim (X, Y 1 ) to Sim (X, Y L ).
- Information on 12a and the similarity Sim (X, Y) may be output.
- the processing of the document similarity calculation unit 233 and the similarity output unit 24 is an example of the processes P3 and P4 of FIG.
- the output by the similarity output unit 24 may include, for example, transmission to a computer such as a terminal device (not shown), storage in a storage area of a server 2 such as a memory unit 21, and the like.
- the similarity output unit 24 may output the determination result output screen 240.
- the determination result output screen 240 may include a display area 241 of the query document 11a and display areas 245a to 245c of at least one (three in FIG. 7) of the comparison target document 12a.
- the display area 241 may include a display area 242 such as bibliographic information and a summary, and a full-text reference button 243 for transitioning to a screen for displaying the full text of the query document 11a.
- the display areas 245a to 245c may include display areas 246a to 246c for bibliographic information and summaries, full text reference buttons 247a to 247c, and compound lists 248a to 248c of clusters determined to be similar.
- the similarity Sim (X, Y) may be displayed in the display areas 245a to 245c.
- the similarity output unit 24 belongs to the cluster determined to have the highest similarity as a result of the similarity calculation between the query document 11a and the comparison target document 12a by displaying the compound lists 248a to 248c. A list of named entities can be presented to the user.
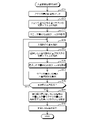
- FIG. 8 is a flowchart illustrating an operation example of the server 2. As shown in FIG. 8, the server 2 may execute the processing for the query document 11a and the processing for the comparison target document 12a at different timings.
- the document input unit 22 accepts the input of the query document 11a (step S1).
- the compound name extraction unit 231 extracts the compound name from the query document 11a (step S2).
- the clustering unit 232 clusters the extracted compound names (step S3).
- the document input unit 22 accepts the input of the comparison target document 12a (step S4).
- the compound name extraction unit 231 selects an unselected comparison target document 12a (step S5), and extracts a compound name from the selected comparison target document 12a (step S6).
- the clustering unit 232 clusters the extracted compound names (step S7).
- the document similarity calculation unit 233 compares the compound clusters of the query document 11a and the comparison target document 12a, calculates the similarity Sim between the documents (step S8), and stores it in the memory unit 21 (step S9).
- the document similarity calculation unit 233 determines whether or not there is an unselected comparison target document 12a (step S10), and if it is determined to be present (YES in step S10), the process proceeds to step S5.
- step S10 When the document similarity calculation unit 233 determines that there is no unselected document to be compared 12a (NO in step S10), the document to be compared 12a and its similarity Sim (X) are in descending order of similarity Sim (X, Y). , Y) is output (step S11), and the process ends.
- the server 2 may be a virtual server (VM; Virtual Machine) or a physical server. Further, the function of the server 2 may be realized by one computer or may be realized by two or more computers. Further, at least a part of the functions of the server 2 may be realized by using the HW (Hardware) resource and the NW (Network) resource provided by the cloud environment.
- VM Virtual Machine
- HW Hardware
- NW Network
- FIG. 9 is a block diagram showing a hardware (HW) configuration example of the computer 10 that realizes the function of the server 2.
- HW hardware
- the computer 10 has an HW configuration, for example, a processor 10a, a memory 10b, a storage unit 10c, an IF (Interface) unit 10d, an I / O (Input / Output) unit 10e, and a reading unit. It may be provided with 10f.
- a processor 10a for example, a processor 10a, a memory 10b, a storage unit 10c, an IF (Interface) unit 10d, an I / O (Input / Output) unit 10e, and a reading unit. It may be provided with 10f.
- the processor 10a is an example of an arithmetic processing unit that performs various controls and operations.
- the processor 10a may be connected to each block in the computer 10 so as to be communicable with each other by the bus 10i.
- the processor 10a may be a multi-processor including a plurality of processors, a multi-core processor having a plurality of processor cores, or a configuration having a plurality of multi-core processors.
- Examples of the processor 10a include integrated circuits (ICs) such as CPUs, MPUs, GPUs, APUs, DSPs, ASICs, and FPGAs. As the processor 10a, two or more combinations of these integrated circuits may be used.
- ICs integrated circuits
- MPU is an abbreviation for Micro Processing Unit
- GPU is an abbreviation for Graphics Processing Unit
- APU is an abbreviation for Accelerated Processing Unit.
- DSP is an abbreviation for Digital Signal Processor
- ASIC is an abbreviation for Application Specific IC
- FPGA is an abbreviation for Field-Programmable Gate Array.
- the memory 10b is an example of HW that stores information such as various data and programs.
- Examples of the memory 10b include one or both of a volatile memory such as DRAM (Dynamic Random Access Memory) and a non-volatile memory such as PM (Persistent Memory).
- the storage unit 10c is an example of HW that stores information such as various data and programs.
- Examples of the storage unit 10c include a magnetic disk device such as an HDD (Hard Disk Drive), a semiconductor drive device such as an SSD (Solid State Drive), and various storage devices such as a non-volatile memory.
- Examples of the non-volatile memory include flash memory, SCM (Storage Class Memory), ROM (Read Only Memory) and the like.
- the storage unit 10c may store a program 10g (similarity determination program) that realizes all or a part of various functions of the computer 10.
- the processor 10a of the server 2 can realize the function as the server 2 illustrated in FIG. 6 by expanding and executing the program 10g stored in the storage unit 10c in the memory 10b.
- the memory unit 21 shown in FIG. 6 may be realized by a storage area of one or both of the memory unit 10b and the storage unit 10c.
- the IF unit 10d is an example of a communication IF that controls connection and communication with a network.
- the IF unit 10d may include an adapter compliant with LAN (Local Area Network) such as Ethernet (registered trademark) or optical communication such as FC (Fibre Channel).
- the adapter may support one or both wireless and wired communication methods.
- the server 2 may be connected to the terminal device and each of the other servers so as to be able to communicate with each other via the IF unit 10d.
- the program 10g may be downloaded from the network to the computer 10 via the communication IF and stored in the storage unit 10c.
- the I / O unit 10e may include one or both of an input device and an output device.
- Examples of the input device include a keyboard, a mouse, a touch panel, and the like.
- Examples of the output device include a monitor, a projector, a printer and the like.
- the reading unit 10f is an example of a reader that reads data and program information recorded on the recording medium 10h.
- the reading unit 10f may include a connection terminal or device to which the recording medium 10h can be connected or inserted.
- Examples of the reading unit 10f include an adapter compliant with USB (Universal Serial Bus), a drive device for accessing a recording disk, a card reader for accessing a flash memory such as an SD card, and the like.
- the program 10g may be stored in the recording medium 10h, or the reading unit 10f may read the program 10g from the recording medium 10h and store it in the storage unit 10c.
- Examples of the recording medium 10h include non-temporary computer-readable recording media such as magnetic / optical disks and flash memories.
- Examples of the magnetic / optical disk include flexible discs, CDs (Compact Discs), DVDs (Digital Versatile Discs), Blu-ray discs, HVDs (Holographic Versatile Discs), and the like.
- Examples of the flash memory include semiconductor memories such as USB memory and SD card.
- the above-mentioned HW configuration of the computer 10 is an example. Therefore, the increase / decrease of HW (for example, addition or deletion of arbitrary blocks), division, integration in any combination, addition or deletion of buses, etc. may be appropriately performed in the computer 10.
- the server 2 at least one of the I / O unit 10e and the reading unit 10f may be omitted.
- Second Embodiment [2-1] Description of the Second Embodiment Next, the second embodiment will be described.
- a method of determining the similarity between documents by using the similarity based on the meaning vector of the word in addition to the similarity based on the named entity according to the first embodiment will be described.
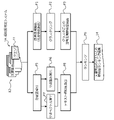
- FIG. 10 is a diagram for explaining the similarity determination system 1A according to the second embodiment.
- the processes P1 to P3 based on the query 11 and the document set 12 are the same as those in the first embodiment.
- the processes P5 to P8 may be executed in parallel with or before and after the processes P1 to P3 and at least a part of the processes. Further, the process P9 may be executed and the result 14 may be output based on the results of the processes P3 and P8.
- the processes P5 to P9 will be described.
- the similarity determination system 1A extracts words from each of a plurality of documents, for example, a query document 11a and a plurality of comparison target documents 12a, for example, by morphological analysis (process P5).
- the similarity determination system 1A statistically calculates the word weights for each of the plurality of documents based on the words obtained in the process P5 (process P6). For example, the similarity determination system 1A may evaluate the importance of a word in a document as a weight by using an evaluation method such as tf-idf (Term Frequency-Inverse Document Frequency).
- the similarity determination system 1A executes the process P7 in parallel with or before and after the process P6 and at least a part of the processes. For example, the similarity determination system 1A calculates a word vector for each of a plurality of documents based on the words obtained in the process P5 (process P7).
- the word vector may be referred to as a word embedding vector or a meaning vector.
- the similarity determination system 1A may search a vector database in which a vector expressing the meaning of a word is stored and acquire a word vector.
- the similarity determination system 1A may acquire a word vector corresponding to each of the words obtained in the process P5 based on the trained model.
- the similarity determination system 1A calculates the document vector by adding the result of multiplying the word vector acquired in the process P7 and the weight of the word acquired in the process P6 over all the words in the document for each document. do. Then, the similarity determination system 1A calculates the similarity between the document vector (first vector) of the query document 11a and each document vector (second vector) of the comparison target document 12a. In other words, the similarity determination system 1A calculates the text similarity between the query document 11a and the comparison target document 12a based on the meaning vector of the word (process P8).
- the similarity determination system 1A may calculate the text similarity, for example, the cosine similarity between the query document 11a and the comparison target document 12a by the calculation of the following equation (6).
- W X is a dispersion vector of words included in the document X
- W Y is a dispersion vector of words included in the document Y.
- the similarity determination system 1A has the compound lists C X1 , C X2 , C X3 , ... C XN and the compound lists CY1 , CY2 , CY3 . , ...
- the text similarity may be calculated according to the above equation (6).
- the similarity determination system 1A performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the text similarity and the named entity similarity (process P9).
- the result 14 is output.
- the result 14 may include a ranking result.
- the similarity determination system 1A calculates the similarity in which the text similarity and the named entity similarity are integrated in the ranking process, and based on the similarity, a plurality of comparison targets according to the similarity with the query document 11a.
- the ranking of the document 12a is output.
- the similarity determination system 1A may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (7).
- max is a function that adopts the maximum value among all the combinations in parentheses.
- fc and ft are named entity similarity and text similarity, respectively, as shown in the following equations (8) and (9).
- the similarity determination system 1A is based on the named entity similarity calculated by the equation (4) and the text similarity calculated by the equation (6) according to the above equations (7) to (9). And the document similarity Sim (X, Y) between Y may be acquired.
- the above formula (7) shows an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). Similar to the first embodiment, the similarity determination system 1A may acquire document similarity Sims (X, Y 1 ) to Sim (X, Y L ) according to the number of documents Y.
- the similarity determination system 1A for example, as in the first embodiment, all the documents Y to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ). Ranking processing is performed by sorting 1 to Y L (processing P9). Further, the similarity determination system 1A may output the sort result as the result 14. The content and output method of the result 14 are the same as those of the result 13 according to the first embodiment.
- the document similarity Sim (X, Y) is calculated based on the above equation (7), but is not limited thereto.
- the document similarity Sim (X, Y) determines the document similarity Sim (X, Y) between the document X and one comparison target document Y according to the following formula (10). , May be calculated as a weighted sum of eigenexpression similarity and text similarity.
- w is a weight.
- w for example, a value such as “0.5” may be appropriately defined and set by the user or the like so that the named entity similarity and the text similarity are considered equally.
- w may be set based on a model trained so that the correct answer example is searched higher by machine learning based on the search query and the training data including the correct answer example (correct answer data). ..
- the similarity determination system 1A As described above, according to the similarity determination system 1A according to the second embodiment, the same effect as that of the first embodiment can be obtained. Further, according to the similarity determination system 1A, the similarity determination accuracy between documents is further improved by determining the similarity between documents based on the similarity based on the semantic vector in addition to the named entity similarity. Can be made to.
- FIG. 11 is a block diagram showing a functional configuration example of the server 3 in the similarity determination system 1A according to the second embodiment
- FIG. 12 is a diagram showing a screen output example by the server 3. Is.
- the server 3 is an example of a similarity determination device, an information processing device, or a computer.
- the server 3 performs various communications such as reception of the query document 11a and the comparison target document 12a and transmission of the result 14 with a terminal device (not shown), another server, or the like. good.
- the server 3 may provide, for example, a function for enabling access to the terminal device. For example, as shown in FIG. 12, the server 3 may output screen information of a search query specification screen 330 for designating a search query and a search result output screen 340 for outputting search results.
- the above-mentioned similarity determination process by the similarity determination system 1A may be realized by the server 3.
- the server 3 may optionally include a document DB unit 31 and a document retrieval unit 32.
- the document DB unit 31 and the document search unit 32 are examples of control units.
- the server 3 may include the document input unit 22 shown in FIG.
- the document DB unit 31 stores the query document 11a and the comparison target document 12a, and performs a document DB construction process for constructing the document DB.
- the document search unit 32 performs a document search process for searching a comparison target document 12a similar to the query document 11a specified in the query 11 based on the information stored in the document DB unit 31 in response to the acceptance of the query 11.
- the document search process is a process including a similarity determination process, and is an example of use (application example) of the similarity determination process.
- the document DB unit 31 is exemplified by the document storage unit 311, the compound name extraction unit 312, the clustering unit 313, the compound cluster storage unit 314, the document vector calculation unit 315, and the document vector storage unit. 316 may be provided.
- the document storage unit 311 is an example of the memory unit 21 (see FIG. 6) according to the first embodiment, and stores a plurality of documents.
- the document is a document that can be used as either the query document 11a or the comparison target document 12a. Therefore, it can be said that the document storage unit 311 stores the query document 11a and the document set (document group) 12 including the plurality of comparison target documents 12a that are the targets of the query 11.
- the document storage unit 311 may store a plurality of documents in advance before receiving the query 11.
- the document storage unit 311 may store a plurality of documents received by the document input unit 22 according to the first embodiment.
- the compound name extraction unit 312 is an example of the compound name extraction unit 231 shown in FIG. 6, and the compound name as an example of the named entity is extracted from each of the plurality of documents accumulated by the document storage unit 311 for each document. Generate compound lists C X and CY .
- the treatment of the compound name extraction unit 312 is an example of the treatment P1 in FIG.
- the clustering unit 313 is an example of the clustering unit 232 shown in FIG.
- the clustering unit 313 is based on the compound lists C X and CY for each document, and for each document, a plurality of compound clusters of compound names, in other words, a plurality of compound lists C X1 , C X 2 , C X 3 , ... Generate C XN , CY1 , CY2 , CY3 , ... CYM .
- the process of the clustering unit 313 is an example of the process P2 of FIG.
- the compound cluster storage unit 314 is an example of the memory unit 21 shown in FIG. 6, and is a plurality of compound clusters generated by the clustering unit 313, in other words, a plurality of compound lists C X1 , C X2 , C X3 , ... C XN , CY1 , CY2 , CY3 , ... CYM is accumulated.
- the document vector calculation unit 315 extracts a word from each of the plurality of documents accumulated by the document storage unit 311, calculates a word weight and a word vector based on the word, and based on the weight and the word vector, the document vector calculation unit 315 of the plurality of documents. Calculate each document vector.
- the process of the document vector calculation unit 315 is an example of at least a part of the processes P5 to P7 and the process P8 in FIG.
- the document vector storage unit 316 is an example of the memory unit 21 shown in FIG. 6, and stores the document vector calculated by the document vector calculation unit 315.
- the document search unit 32 may optionally include a search query designation unit 321, a document similarity calculation unit 322, a search result generation unit 323, and a search result output unit 324.
- the search query designation unit 321 is an example of the document input unit 22 shown in FIG. 6, and is a query 11 requesting a document search from a computer such as a terminal device (not shown) or another server (hereinafter referred to as “search query 11”). (May be) Accept the input.
- the search query specification unit 321 may accept the document number of the query document 11a set in the input field 331 when the search button 332 of the search query specification screen 330 is pressed. ..
- the document similarity calculation unit 322 is an example of the document similarity calculation unit 233 shown in FIG.
- the document similarity calculation unit 322 includes the query document 11a specified by the search query 11 and other documents based on the compound cluster stored in the compound cluster storage unit 314 and the document vector stored in the document vector storage unit 316.
- the document similarity calculation unit 322 compares the compound clusters corresponding to the query document 11a and the comparison target document 12a among the compound clusters accumulated in the compound cluster storage unit 314, and calculates the compound similarity. You can do it.
- the document similarity calculation unit 322 compares the document vectors corresponding to the query document 11a and the comparison target document 12a among the document vectors stored in the document vector storage unit 316, and calculates the text similarity. You can do it.
- the document similarity calculation unit 322 calculates the document similarity Sim (X, Y) based on the compound similarity and the text similarity, and compares the documents 12a in descending order of the document similarity Sim (X, Y). By sorting, the ranking result 14 may be generated.
- the process of the document similarity calculation unit 322 is an example of the process P3, at least a part of the process P8, and the process P9 in FIG.
- the search result generation unit 323 generates a search result for output based on the result 14.
- the search result generation unit 323 may generate the search result output screen 340 shown in FIG.
- the search result output screen 340 may replace the determination result 244 in the determination result output screen 240 shown in FIG. 7 with the search result 344.
- the search result output screen 340 includes a display area 341 of the query document 11a and display areas 345a to 345c of at least one (three in FIG. 12) of the comparison target document 12a. good.
- the display area 341 may include a display area 342 such as bibliographic information and a summary of the query document 11a, and a full-text reference button 343 of the query document 11a.
- the display areas 345a to 345c include display areas 346a to 346c for bibliographic information and summaries of the comparison target document 12a, full text reference buttons 347a to 347c, and compound lists 348a to 348c of clusters determined to be similar. good.
- the similarity Sim (X, Y) may be displayed in the display areas 345a to 345c.
- the search result output unit 324 outputs the search result output screen 340 to a computer such as a terminal device or another server (not shown).
- FIG. 13 is a flowchart illustrating an operation example of the document DB construction process of the server 3
- FIG. 14 is a flowchart illustrating an operation example of the document retrieval process of the server 3.
- the document storage unit 311 selects an unselected document (step S21) and registers the document in the document DB (step S22).
- the document vector calculation unit 315 calculates the document vector of the text of the document (step S23).
- the document vector storage unit 316 associates the calculated document vector with the document and registers (stores) it in, for example, a document DB or a document vector DB (step S24).
- the compound name extraction unit 312 extracts the compound name from the text of the document (step S25).
- the clustering unit 313 clusters the extracted compound names (step S26).
- the compound cluster storage unit 314 associates the information of the compound cluster with the document and registers (stores) it in, for example, the document DB or the compound cluster DB (step S27).
- the document storage unit 311 determines whether or not there is an unselected document (step S28), and if it determines that there is an unselected document (YES in step S28), the process proceeds to step S21. When the document storage unit 311 determines that there is no unselected document (NO in step S28), the process ends.
- steps S23 and S24 may be interchanged with the processes of steps S25 to S27, or at least a part of these processes may be executed before, after, or in parallel.
- the search query designation unit 321 accepts the designation of the query document 11a from the search query designation screen 330 (step S31).
- the document similarity calculation unit 322 acquires the document vector of the query document 11a from the document vector storage unit 316 (step S32), and acquires the compound cluster of the query document 11a from the compound cluster storage unit 314 (step S33).
- the document similarity calculation unit 322 selects an unselected document (step S34), acquires the document vector of the selected document from the document vector storage unit 316 (step S35), and selects the document from the compound cluster storage unit 314. Acquire a compound cluster (step S36).
- the document similarity calculation unit 322 calculates the document similarity Sim (X, Y) of the query document 11a and the selected document (step S37).
- the document similarity calculation unit 322 determines whether or not there is an unselected document (step S38), and if so (YES in step S38), the process proceeds to step S34.
- the document similarity calculation unit 322 determines that there is no unselected document (NO in step S38)
- the document similarity calculation unit 322 has a predetermined number of documents in descending order of document similarity and a query document for each document.
- the cluster having the highest document similarity with 11a is extracted (step S39).
- the search result generation unit 323 generates a search result based on the extracted data, the search result output unit 324 outputs a search result, for example, a search result output screen 340 (step S40), and the process ends.
- FIG. 15 is a block diagram showing a functional configuration example of the server 4 in the similarity determination system 1B according to the first modification of the second embodiment and the second modification described later, and FIGS. 16 and 17 are the server 4. It is a figure which shows the screen output example by.
- the similarity determination system 1B according to the first modification is selected after presenting the cluster that is the result of clustering of the query document 11a to the user as a list of unique expressions and allowing the user to select the cluster to be used for the similarity calculation.
- the similarity is calculated using the clusters.
- the server 4 may optionally include a document DB unit 31 and a document search unit 42.
- the document DB unit 31 and the document search unit 42 are examples of control units.
- the document DB unit 31 is the same as the document DB unit 31 shown in FIG.
- the document search unit 42 is exemplified by a search query designation unit 421, a document similarity calculation unit 422, a search result generation unit 423, a search result output unit 424, a compound cluster acquisition unit 425, a cluster presentation unit 426, and a cluster designation.
- a unit 427 may be provided.
- the search query specification unit 421, the document similarity calculation unit 422, the search result generation unit 423, and the search result output unit 424 are the search query specification unit 321 shown in FIG. 11, the document similarity calculation unit 322, and the search results. This is the same as the generation unit 323 and the search result output unit 324.
- the compound cluster acquisition unit 425 acquires the compound cluster of the query document 11a received by the search query designation unit 421 from the compound cluster storage unit 314, and notifies the cluster presentation unit 426 together with the query document 11a.
- the cluster presentation unit 426 presents the compound cluster of the query document 11a acquired from the compound cluster acquisition unit 425 to the user. For example, the cluster presentation unit 426 generates the cluster designation screen 440 shown in FIG. 16 and outputs it to a computer such as a terminal device or another server.
- the cluster designation screen 440 may include a display area 441 of the query document 11a and a display area 444 that presents a plurality of compound clusters contained in the query document 11a.
- the display area 441 may include a display area 442 such as bibliographic information and a summary of the query document 11a, and a full-text reference button 443 of the query document 11a.
- a plurality of compound lists 445 corresponding to the plurality of clusters of the query document 11a, a check box 446 for designating the compound clusters to be used for the similarity calculation from the plurality of compound lists 445, and a search are executed. May include a search button 447 for.
- the cluster designation unit 427 notifies the document similarity calculation unit 422 of the information of the compound list 445 in which the check box 446 is selected when the search button 447 of the cluster designation screen 440 is pressed.
- the document similarity calculation unit 422 adds the compound cluster used for calculating the document similarity Sim (X, Y) between the query document 11a and the selected document to the compound list designated by the cluster designation unit 427.
- Limit limit
- the document similarity calculation unit 422 is limited to the specified compound cluster among the plurality of compound clusters of the query document 11a, and compares the compound list of the compound cluster with the plurality of compound lists of the selected document. It's okay.
- the search result generation unit 423 and the search result output unit 424 may generate and output the search result output screen 450 as shown in FIG. 17 based on the result 14 by the document similarity calculation unit 422.
- the cluster designation screen 440 the compound cluster used for the similarity calculation is designated. Therefore, the display of the compound list (see the compound lists 348a to 348c in FIG. 12) may be omitted on the search result output screen 450. As in the example of FIG. 12, the compound list may be displayed on the search result output screen 450.
- the same effect as that of the second embodiment can be obtained, and the compound cluster used for determining the similarity can be limited to an appropriate compound cluster. , It is possible to further improve the determination accuracy of the similarity between documents. Further, since the number of compound clusters used for determining the similarity can be limited, the processing time of the document retrieval process can be shortened.
- FIG. 18 is a flowchart illustrating an operation example of the document retrieval process of the server 4.
- FIG. 14 a process different from the operation example shown in FIG. 14 in the document retrieval process of the server 4 will be described.
- the compound cluster acquisition unit 425 acquires the compound cluster of the query document 11a, in other words, the compound list, from the compound cluster storage unit 314 (step S41).
- the cluster presentation unit 426 generates a cluster designation screen 440 including the compound list acquired by the compound cluster acquisition unit 425 and presents it to the user (step S42).
- the cluster designation unit 427 accepts the designation of the compound cluster on the cluster designation screen 440 (step S43), and the process proceeds to step S34.
- the processes of steps S41 to S43 may be executed before, after, or in parallel with step S32.
- the document similarity calculation unit 422 limits the compound cluster of the selected document to the designated cluster accepted by the cluster designation unit 427.
- the document similarity calculation unit 422 limits the compound list of the query document 11a to the designated cluster, in other words, the designated compound list, and the inter-document similarity between the query document 11a and the selected document. Is calculated (step S44), and the process proceeds to step S38.
- step S45 the document similarity calculation unit 422 extracts a predetermined number of documents in descending order of similarity (step S45), and the process is step S40. Move to.
- FIG. 19 is a diagram showing a screen output example of the server 4 according to the second modification.
- the search query specification unit 421 inputs the document number input field 461 of the query document 11a and one or more keywords (here, the compound name) on the search query specification screen 460. Includes region 462.
- the cluster designation unit 427 calculates the document similarity of the document number of the query document 11a input in the input field 461 and the information of one or more keywords input in the input area 462 when the search button 463 is pressed. Notify section 422.
- the document similarity calculation unit 422 limits the compound cluster of the document to be compared with the designated query document 11a to the cluster including the keyword accepted by the cluster designation unit 427 (for example, including a predetermined number of times or more). Then, the document similarity calculation unit 422 focuses on the cluster including the designated keyword, in other words, the compound list, and calculates the inter-document similarity between the query document 11a and the document.
- the same effect as that of the first modification can be obtained, and the user is not limited to a specific cluster and can flexibly use a cluster including a predetermined keyword. It can be specified as, and it is highly convenient.
- FIG. 20 is a diagram for explaining the similarity determination system 1C according to the third embodiment
- FIGS. 21 and 22 are diagrams for explaining an example of processing of the similarity determination system 1C.
- the similarity determination system 1C replaces the process P8 of the similarity determination system 1B shown in FIG. 10 with the processes P10 and P11, replaces the process P9 with the process P12, and replaces the process P2 with the process P2.
- the processing result of is passed to the processing P10.
- the processes P10 to P12 will be described.
- the similarity determination system 1C acquires a plurality of partial documents (partial texts) by dividing the document for each document in the process P10.
- Sub-documents in other words, document division units include, for example, sentences, paragraphs, chapters, sections, and the like.
- the partial document is a paragraph.
- the similarity determination system 1C divides the document X included in the query 11 to acquire a plurality of paragraphs PX , and divides the document Y included in the document set 12 into a plurality of documents Y. Get the paragraph P Y.
- paragraph P when paragraphs PX and P Y are not distinguished from each other, they are simply referred to as "paragraph P".
- the similarity determination system 1C acquires a partial document cluster by clustering the paragraph P based on the named entity (for example, compound) cluster obtained in the process P2.
- the similarity determination system 1C may cluster the paragraphs P based on the degree of agreement between the named entity included in the named entity cluster and the named entity included in the plurality of paragraphs P.
- the similarity determination system 1C determines the degree of coincidence between each of the compound lists C X1 to C XN for each cluster and each of the plurality of paragraphs PX for the document X according to the following formula (11). Based on this, partial document clusters PX1 to PXN are generated. Further, the similarity determination system 1C has a degree of coincidence cos (CPX,) between each of the compound lists CY1 to CYN for each cluster and each of the plurality of paragraphs P Y for the document Y according to the following formula (12) . Sub-document clusters P Y1 to P YN are generated based on C Xa ).
- C PX is a list of compounds included in paragraph PX
- C P Y is a list of compounds included in paragraph P Y
- C Xa and CYb are compound lists of documents X and Y obtained in treatment P2.
- argmax is a function that extracts the condition (here, cluster) when the element in parentheses is the maximum.
- the cosine similarity between each of the compound names contained in paragraph P and each of the compound names in the compound cluster is the maximum, for example, the number of occurrences is the largest.
- Paragraph P can be assigned to the element (compound cluster).
- paragraphs PX and P Y can be classified into sub-document clusters of the following four elements (characteristics) by such clustering.
- -Partial document clusters PX1 and PY1 A paragraph describing "negative electrode active material”.
- -Partial document clusters PX2 and PY2 A paragraph describing "positive electrode active material”.
- -Partial document clusters PX3 and PY3 A paragraph describing "binder”.
- -Partial document clusters PX4 and PY4 A paragraph describing "electrolyte solvent”.
- the similarity determination system 1C calculates a plurality of subdocument vectors corresponding to each of the plurality of subdocument clusters based on the words included in each of the subdocument clusters. For example, the similarity determination system 1C adds the result of multiplying the word vector acquired in the process P7 and the weight of the word acquired in the process P6 over all the words in the subdocument cluster for each subdocument cluster. By doing so, the partial document vector may be calculated.
- the similarity determination system 1C is a partial document based on the similarity between the partial document vector of the query document 11a and each partial document vector of the comparison target document 12a, in other words, the meaning vector of the word. Calculate the text similarity between clusters.
- the partial document vector of the query document 11a is an example of the first plurality of vectors
- the partial document vector of the comparison target document 12a is an example of the second plurality of vectors.
- the similarity determination system 1C calculates the text similarity, for example, the cosine similarity between the partial document cluster of the query document 11a and the partial document cluster of the comparison target document 12a by the calculation of the following equation (13). good.
- WP Xa is a dispersion vector of words included in paragraph PXa
- WP Yb is a dispersion vector of words included in paragraph P Yb .
- the similarity determination system 1C has partial document clusters PX1 , PX2 , PX3 , ... PXN , and partial document clusters XY1 , PHY2 , CY3 , ... PHYM .
- the text similarity may be calculated according to the above equation (13) for all pairs of and.
- the similarity determination system 1C performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the text similarity and the named entity similarity (process P12). , The result 14 is output.
- the similarity determination system 1C calculates the similarity in which the text similarity and the named entity similarity are integrated in the ranking process, and based on the similarity, a plurality of comparison targets according to the similarity with the query document 11a.
- the ranking of the document 12a is output.
- the similarity determination system 1C may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (14).
- fc is the named entity similarity according to the above equation (8)
- ft is the text similarity according to the above equation (13).
- the above formula (14) shows an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). Similar to the second embodiment, the similarity determination system 1C may acquire document similarity Sims (X, Y 1 ) to Sim (X, Y L ) according to the number of documents Y.
- the similarity determination system 1C for example, as in the second embodiment, all the documents Y to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ). Ranking processing is performed by sorting 1 to Y L. Further, the similarity determination system 1C may output the sort result as the result 14.
- the similarity determination system 1C expresses the document similarity Sim (X, Y) between the document X and one comparison target document Y according to the following equation (15). It may be calculated as a weighted sum of similarity and text similarity.
- the degree of similarity between the documents X and Y is high because the semantic vectors for the “positive electrode active material” are similar. be able to.
- the semantic vector space is shown in two dimensions, but it can actually be a vector of several hundred dimensions. According to the third embodiment, the accuracy of determining the degree of similarity between partially similar documents can be improved by comparing the partial document clusters.
- FIG. 23 is a block diagram showing a functional configuration example of the server 5 in the similarity determination system 1C according to the third embodiment. Unless otherwise specified, the server 5 may be the same as the server 3 shown in FIG. 11 or the server 4 shown in FIG.
- the server 5 may optionally include a document DB unit 51 and a document retrieval unit 52.
- the document DB unit 51 and the document search unit 52 are examples of control units.
- the document DB unit 51 may include a document cluster vector calculation unit 515 and a document cluster vector storage unit 516 in place of the document vector calculation unit 315 and the document vector storage unit 316 shown in FIG. Further, in the document DB unit 51, the compound cluster which is the clustering result may be output from the clustering unit 313 to the document cluster vector calculation unit 515.
- the document retrieval unit 52 may include a document similarity calculation unit 522 instead of the document similarity calculation unit 322 shown in FIG.
- the document cluster vector calculation unit 515 may calculate the document vector for each partial document cluster based on the information of the compound cluster from the clustering unit 313.
- the process of the document cluster vector calculation unit 515 is an example of the process of the process P10 shown in FIG.
- the document cluster vector storage unit 516 stores the document vector for each partial document cluster calculated by the document cluster vector calculation unit 515.
- the document similarity calculation unit 522 calculates the document similarity Sim (X, Y) between the partial document vector of the query document 11a and each partial document vector of the comparison target document 12a, and calculates the document similarity Sim (X, Y). , Y) may generate result 14.
- the process of the document similarity calculation unit 522 is an example of the process P3, the process P11, and the process P12 in FIG.
- document retrieval unit 52 may output the various screens shown in FIGS. 12, 16, 17, 19, 19 and the like.
- FIG. 24 is a flowchart illustrating an operation example of the document DB construction process of the server 5
- FIG. 25 is a flowchart illustrating an operation example of the document retrieval process of the server 5.
- steps S23 and S24 shown in FIG. 13 are deleted, and steps S51 to S54 are added between steps S27 and S28.
- the document cluster vector calculation unit 515 divides the text of the document into predetermined units (step S51), and each division unit (paragraph P) is based on the compound cluster accumulated by the compound cluster storage unit 314. (Step S52).
- the document cluster vector calculation unit 515 calculates the document vector of each partial document cluster (step S53).
- the document cluster vector storage unit 516 stores the document vectors of each partial document cluster (step S54), and the process shifts to step S28.
- steps S32, S35, and S37 shown in FIG. 14 are replaced with steps S61, S62, and S63, respectively.
- step S61 the document similarity calculation unit 522 acquires the document vector of the partial document cluster of the query document 11a from the document cluster vector storage unit 516.
- step S62 the document similarity calculation unit 522 acquires the document vector of the partial document cluster of the document selected from the document cluster vector storage unit 516.
- step S63 the document similarity calculation unit 522 calculates the document similarity Sim (X, Y) based on the document vector acquired in steps S61 and S62, respectively, and the compound cluster.
- the compound name is used as a named entity
- the present invention is limited to this. It is not something that is done.
- the named entity various terms that can be the target of the named entity extraction process in natural language processing, such as a gene sequence (genome), may be used.
- each of the servers 2 to 5 shown in FIGS. 6, 11, 15, and 20 may be merged or divided in any combination.
- the first to third embodiments and the first and second modifications of the second embodiment may be combined as appropriate.
- each of the servers 2 to 5 may generate screen information of any of the screens of FIGS. 7, 12, 16, 17, and 19, and may have a functional configuration according to the screen.
- each of the servers 2 to 5 shown in FIGS. 6, 11, 15, and 20 may be configured to realize each processing function by coordinating a plurality of devices with each other via a network.
- the memory unit 21 is a DB server
- the document DB units 31 and 51 are a combination of an application server and a DB server
- a document input unit 22 a similarity calculation unit 23
- a similarity output unit 24 and a document search unit 32, 42 and 52.
- the computer, the application server, and the DB server may cooperate with each other via the network to realize each processing function as the servers 2 to 5.
- each of the servers 3 to 5 may be provided with the HW configuration of the computer 10 illustrated in FIG.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
This similarity determination program causes a computer to execute processes for: acquiring a plurality of first groups (CX1-CXN) generated by classifying a plurality of first unique expressions on the basis of the positions of a plurality of respective first unique expressions included in a first document (X) and similarities of the plurality of respective unique expressions; acquiring a plurality of second groups (CY1-CYM) generated by classifying a plurality of second unique expressions on the basis of the positions of a plurality of respective second unique expressions included in a second document (Y) and similarities of the plurality of respective second unique expressions; and determining a similarity (Sim) between the first document (X) and the second document (Y) on the basis of comparison between the plurality of first groups (CX1-CXN) and the plurality of second groups (CY1-CYM)
Description
本発明は、類似度判定プログラム、類似度判定装置、及び、類似度判定方法に関する。
The present invention relates to a similarity determination program, a similarity determination device, and a similarity determination method.
複数文書を単語に分割し、単語の意味を表現するベクトル、及び、各単語の重みを算出して、ベクトル及び重みに基づき、各文書の文書ベクトルを算出することで、文書間の類似度を判定する手法が知られている。
By dividing multiple documents into words, calculating the vector expressing the meaning of the word, and calculating the weight of each word, and calculating the document vector of each document based on the vector and weight, the similarity between the documents can be calculated. A method for determining is known.
文書内には様々な情報が記載されているため、文書全体を文書ベクトル化して文書間の類似度を判定すると、部分的に類似した文書間であっても類似度が低いと判定される可能性がある。
Since various information is described in the document, if the entire document is vectorized and the similarity between the documents is judged, it is possible to judge that the similarity is low even between partially similar documents. There is sex.
1つの側面では、本発明は、部分的に類似した文書間の類似度の判定精度を向上させることを目的の1つとする。
In one aspect, one of the objects of the present invention is to improve the accuracy of determining the degree of similarity between partially similar documents.
1つの側面では、類似度判定プログラムは、コンピュータに、以下の処理を実行させてよい。前記処理は、第1の文書に含まれる第1の複数の固有表現のそれぞれの位置と前記第1の複数の固有表現のそれぞれの類似度とに基づいて前記第1の複数の固有表現を分類することによって生成された第1の複数のグループを取得する処理を含んでよい。また、前記処理は、第2の文書に含まれる第2の複数の固有表現のそれぞれの位置と前記第2の複数の固有表現のそれぞれの類似度とに基づいて前記第2の複数の固有表現を分類することによって生成された第2の複数のグループを取得する処理を含んでよい。さらに、前記処理は、前記第1の複数のグループと前記第2の複数のグループとの比較に基づいて、前記第1の文書と前記第2の文書との類似度を判定する処理を含んでよい。
In one aspect, the similarity determination program may cause the computer to perform the following processing. The process classifies the first named entity based on the position of each of the first named entity contained in the first document and the similarity of each of the first named entity. It may include the process of acquiring the first plurality of groups generated by the above. In addition, the process is based on the position of each of the second named entity included in the second document and the similarity of each of the second named entity. It may include a process of acquiring a second plurality of groups generated by classifying. Further, the process includes a process of determining the degree of similarity between the first document and the second document based on the comparison between the first plurality of groups and the second plurality of groups. good.
1つの側面では、本発明は、部分的に類似した文書間の類似度の判定精度を向上させることができる。
In one aspect, the present invention can improve the accuracy of determining the degree of similarity between partially similar documents.
以下、図面を参照して本発明の実施の形態を説明する。ただし、以下に説明する実施形態は、あくまでも例示であり、以下に明示しない種々の変形又は技術の適用を排除する意図はない。例えば、本実施形態を、その趣旨を逸脱しない範囲で種々変形して実施することができる。なお、以下の説明で用いる図面において、同一符号を付した部分は、特に断らない限り、同一若しくは同様の部分を表す。
Hereinafter, embodiments of the present invention will be described with reference to the drawings. However, the embodiments described below are merely examples, and there is no intention of excluding the application of various modifications or techniques not specified below. For example, the present embodiment can be variously modified and implemented without departing from the spirit of the present embodiment. In the drawings used in the following description, the parts with the same reference numerals represent the same or similar parts unless otherwise specified.
〔1〕第1実施形態
〔1-1〕比較例
上述したように、文書全体を文書ベクトル化して文書間の類似度を判定すると、部分的に類似した文書間であっても類似度が低いと判定される可能性がある。そこで、比較例として、文書中の固有表現に基づく類似度を判定することで文書間の類似度を判定する場合を説明する。比較例では、文書中の固有表現は、化合物名であるものとし、化合物名を含む化学分野の文書間の類似度を判定する場合を想定する。 [1] First Embodiment [1-1] Comparative Example As described above, when the entire document is vectorized and the similarity between the documents is determined, the similarity is low even between partially similar documents. May be determined. Therefore, as a comparative example, a case where the similarity between documents is determined by determining the similarity based on the named entity in the document will be described. In the comparative example, the named entity in the document is assumed to be a compound name, and it is assumed that the similarity between documents in the field of chemistry including the compound name is determined.
〔1-1〕比較例
上述したように、文書全体を文書ベクトル化して文書間の類似度を判定すると、部分的に類似した文書間であっても類似度が低いと判定される可能性がある。そこで、比較例として、文書中の固有表現に基づく類似度を判定することで文書間の類似度を判定する場合を説明する。比較例では、文書中の固有表現は、化合物名であるものとし、化合物名を含む化学分野の文書間の類似度を判定する場合を想定する。 [1] First Embodiment [1-1] Comparative Example As described above, when the entire document is vectorized and the similarity between the documents is determined, the similarity is low even between partially similar documents. May be determined. Therefore, as a comparative example, a case where the similarity between documents is determined by determining the similarity based on the named entity in the document will be described. In the comparative example, the named entity in the document is assumed to be a compound name, and it is assumed that the similarity between documents in the field of chemistry including the compound name is determined.
図1は、比較例に係る類似度判定システム100を説明するための図である。図1に示すように、類似度判定システム100は、クエリ文書(入力文書)の類似度の判定を要求するクエリ101と、1以上の比較対象文書を含む文書集合102とに基づき、固有表現に基づく類似度を算出する。
FIG. 1 is a diagram for explaining the similarity determination system 100 according to a comparative example. As shown in FIG. 1, the similarity determination system 100 uses a query 101 that requests determination of similarity of a query document (input document) and a document set 102 including one or more comparison target documents as a unique expression. Calculate the degree of similarity based on.
例えば、類似度判定システム100は、複数の文書、すなわち、クエリ101に含まれるクエリ文書及び文書集合102に含まれる比較対象文書のそれぞれから、固有表現として化合物名を抽出し(処理P110)、文書ごとに化合物リストを生成する。
For example, the similarity determination system 100 extracts a compound name as a unique expression from each of a plurality of documents, that is, a query document included in the query 101 and a comparison target document included in the document set 102 (process P110), and documents. Generate a compound list for each.
類似度判定システム100は、文書ごとの化合物リストを比較することで、クエリ文書と比較対象文書の各々との間の化合物類似度を算出する(処理P120)。化合物類似度としては、例えば、コサイン類似度が挙げられる。
The similarity determination system 100 calculates the compound similarity between each of the query document and the comparison target document by comparing the compound list for each document (process P120). Examples of the compound similarity include cosine similarity.
類似度判定システム100は、算出した化合物類似度に基づくランキング処理を行ない(処理P130)、クエリ文書との類似度が高い比較対象文書を類似度とともにランキング結果103として保存する。
The similarity determination system 100 performs ranking processing based on the calculated compound similarity (processing P130), and stores the comparison target document having a high similarity with the query document as the ranking result 103 together with the similarity.
図2は、図1に示す類似度判定システム100による化合物類似度の算出例を説明する図である。図2の例では、処理P110において、リチウムイオン電池に関するクエリ文書及び比較対象文書について、クエリ文書から化合物リストCxが生成され、比較対象文書から化合物リストCyが生成されたものとする。
FIG. 2 is a diagram illustrating an example of calculation of compound similarity by the similarity determination system 100 shown in FIG. In the example of FIG. 2, in the processing P110, it is assumed that the compound list Cx is generated from the query document and the compound list Cy is generated from the comparison target document for the query document and the comparison target document related to the lithium ion battery.
以下、化合物類似度の判定対象の文書の組について生成された化合物リストCx及びCyを互いに区別しない場合には、単に「化合物リストC」と表記する。化合物リストCは、化合物名と、当該化合物名の文書内での出現数とを含んでよい。なお、図2の例において、化合物リストCx及びCy間で共通する共通化合物を下線太字で示す。
Hereinafter, when the compound lists Cx and Cy generated for the set of documents for which the compound similarity is to be determined are not distinguished from each other, they are simply referred to as "compound list C". The compound list C may include the compound name and the number of occurrences of the compound name in the document. In the example of FIG. 2, the common compounds common between the compound lists Cx and Cy are shown in bold underline.
類似度判定システム100は、化合物リストCに基づき、下記式(1)の演算により、化合物類似度としてのコサイン類似度を算出する。

The similarity determination system 100 calculates the cosine similarity as the compound similarity by the calculation of the following formula (1) based on the compound list C.
上記式(1)において、iは、化合物リストCx及びCyに含まれる全ての化合物名を特定するためのインデックスであり、Cxi及びCyiは、化合物リストCx及びCy内のi番目の化合物名の出現数を示す。上記式(1)において、分母は、Cxの化合物の出現数の2乗和の平方根と、Cyの化合物の出現数の2乗和の平方根との和であり、分子は、CxとCyとの間の共通化合物の出現数の積の総和である。
In the above formula (1), i is an index for specifying all the compound names included in the compound list Cx and Cy, and Cx i and Cy i are the i-th compound names in the compound list Cx and Cy. Indicates the number of appearances of. In the above formula (1), the denominator is the sum of the square roots of the sum of squares of the number of occurrences of Cx compounds and the square root of the sum of squares of the number of appearances of Cy compounds, and the molecules are Cx and Cy. It is the sum of the products of the number of appearances of common compounds between.
ところで、「文書」には、複数の要素についての記載を含む文書、一例として、複数の構成要素を備える装置、システム又は製造方法等について記載された特許文献又は論文等の文書がある。例えば、図2に示すリチウムイオン電池に関する文書には、「正極活物質」、「負極活物質」、「バインダー」、「電解質」、「電解液溶媒」等の、リチウムイオン電池の構成要素のそれぞれの区分(グループ)に関する化合物名が混在して記載されることがある。
By the way, the "document" includes a document including a description of a plurality of elements, and, for example, a document such as a patent document or a paper describing a device, a system, a manufacturing method, etc. having a plurality of components. For example, in the document relating to the lithium ion battery shown in FIG. 2, each of the components of the lithium ion battery such as "positive electrode active material", "negative electrode active material", "binder", "electrolyte", and "electrolyte solution solvent" is provided. Compound names related to the classification (group) of may be mixed and described.
このため、クエリ文書に記載された所定の要素に着目して比較対象文書との類似度を判定したい場合であっても、その他の要素、換言すれば調査対象ではない要素についての比較対象文書との差異が、文書間の類似度の判定結果に影響を与える場合がある。
Therefore, even if it is desired to determine the similarity with the comparison target document by focusing on a predetermined element described in the query document, the comparison target document with other elements, in other words, the element not to be investigated. The difference in the above may affect the judgment result of the similarity between documents.
図2の例では、調査対象の要素が「正極活物質」である場合、「LiCoO2」等の「正極活物質」に関する化合物名が文書間で共通して出現する一方、他の要素に関する化合物名が文書間で相違するため、文書間の化合物類似度が低い値として算出される場合がある。
In the example of FIG. 2, when the element to be investigated is "positive electrode active material", the compound name related to "positive electrode active material" such as "LiCoO2" appears in common between documents, while the compound name related to other elements appears. Is different between documents, so the compound similarity between documents may be calculated as a low value.
このように、調査対象の要素が文書間で類似する場合であっても、文書間の類似度が低いと判定される場合がある。
In this way, even if the elements to be investigated are similar between documents, it may be determined that the degree of similarity between documents is low.
〔1-2〕第1実施形態の説明
そこで、第1実施形態に係る類似度判定システム1は、文書に含まれる複数の固有表現のそれぞれを分類して複数のグループを生成し、文書間で、グループどうしの比較を行なうことにより、クエリ文書と比較対象文書との類似度を判定する。 [1-2] Description of the First Embodiment Therefore, thesimilarity determination system 1 according to the first embodiment classifies each of the plurality of named entity included in the document to generate a plurality of groups, and among the documents. , The degree of similarity between the query document and the comparison target document is determined by comparing the groups.
そこで、第1実施形態に係る類似度判定システム1は、文書に含まれる複数の固有表現のそれぞれを分類して複数のグループを生成し、文書間で、グループどうしの比較を行なうことにより、クエリ文書と比較対象文書との類似度を判定する。 [1-2] Description of the First Embodiment Therefore, the
図3は、第1実施形態に係る類似度判定システム1を説明するための図であり、図4及び図5は、類似度判定システム1の処理の一例を説明するための図である。
FIG. 3 is a diagram for explaining the similarity determination system 1 according to the first embodiment, and FIGS. 4 and 5 are diagrams for explaining an example of processing of the similarity determination system 1.
図3に示すように、第1実施形態に係る類似度判定システム1は、クエリ文書(入力文書)の類似度の判定を要求するクエリ11と、判定対象となる1以上の比較対象文書を含む文書集合(文書群)12とに基づき、固有表現に基づく類似度を算出する。
As shown in FIG. 3, the similarity determination system 1 according to the first embodiment includes a query 11 requesting determination of the similarity of a query document (input document) and one or more comparison target documents to be determined. Based on the document set (document group) 12, the similarity based on the eigenexpression is calculated.
例えば、類似度判定システム1は、比較例と同様に、複数の文書のそれぞれから、固有表現の一例としての化合物名を抽出し(処理P1)、文書ごとに、固有表現リスト、例えば化合物リストを生成する。
For example, the similarity determination system 1 extracts a compound name as an example of a named entity from each of a plurality of documents (process P1), and prepares a named entity list, for example, a compound list for each document, as in the comparative example. Generate.
図4及び図5の例では、類似度判定システム1は、クエリ11に含まれるクエリ文書11a(「文書X」と表記)から化合物名を抽出して化合物リストCXを生成する。また、類似度判定システム1は、文書集合12に含まれる比較対象文書12a(「文書Y」と表記)から化合物名を抽出して化合物リストCYを生成する。クエリ文書11aは、第1の文書の一例であり、比較対象文書12aは、第2の文書の一例である。
In the examples of FIGS. 4 and 5, the similarity determination system 1 extracts the compound name from the query document 11a (denoted as “document X”) included in the query 11 and generates the compound list C X. Further, the similarity determination system 1 extracts a compound name from the comparison target document 12a (denoted as “document Y”) included in the document set 12 to generate a compound list CY . The query document 11a is an example of the first document, and the comparison target document 12a is an example of the second document.
第1実施形態では、クエリ文書11a及び比較対象文書12aは、リチウムイオン電池に関する文書であるものとする。以下、化合物類似度の判定対象の文書の組について生成された化合物リストCX及びCYを互いに区別しない場合には、単に「化合物リストC」と表記する。
In the first embodiment, the query document 11a and the comparison target document 12a are documents relating to the lithium ion battery. Hereinafter, when the compound lists C X and CY generated for the set of documents for which the compound similarity is to be determined are not distinguished from each other, they are simply referred to as “compound list C”.
第1実施形態に係る類似度判定システム1は、固有表現リストに基づき、固有表現を分類及びグループ化するクラスタリングを実行する(図3の処理P2)。クラスタリングの手法としては、例えば、最短距離法等の既存の種々の手法が用いられてよい。
The similarity determination system 1 according to the first embodiment executes clustering for classifying and grouping named entity based on the named entity list (process P2 in FIG. 3). As the clustering method, various existing methods such as the shortest distance method may be used.
次いで、類似度判定システム1は、クラスタごとの固有表現類似度、例えば化合物類似度を算出する(図3の処理P3)。固有表現類似度は、例えば、文書間のクラスタのペアごとに算出されてよい。
Next, the similarity determination system 1 calculates the named entity similarity for each cluster, for example, the compound similarity (process P3 in FIG. 3). Named entity similarity may be calculated, for example, for each pair of clusters between documents.
そして、類似度判定システム1は、固有表現類似度に基づき、クエリ文書11aとの類似度に応じて複数の比較対象文書12aの各々をランキング付けするランキング処理を行ない(図3の処理P4)、結果13を出力する。結果13は、ランキング結果を含んでもよい。
Then, the similarity determination system 1 performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the named entity similarity (process P4 in FIG. 3). The result 13 is output. The result 13 may include a ranking result.
以下、クラスタリング処理(処理P2)、固有表現類似度算出処理(処理P3)、及び、ランキング処理(処理P4)のそれぞれの一例を説明する。
Hereinafter, an example of each of the clustering process (process P2), the named entity similarity calculation process (process P3), and the ranking process (process P4) will be described.
(クラスタリング処理の一例)
図3の処理P2において、類似度判定システム1は、固有表現リストに基づき、固有表現リストに含まれる固有表現間の類似度スコアSを、固有表現のペア(組)ごとに算出してよい。例えば、類似度判定システム1は、固有表現のペアについて、固有表現のそれぞれの位置と、固有表現間の類似度とに基づき類似度スコアSを算出する。 (Example of clustering process)
In the process P2 of FIG. 3, thesimilarity determination system 1 may calculate the similarity score S between named entities included in the named entity list for each pair (set) of named entity based on the named entity list. For example, the similarity determination system 1 calculates a similarity score S for a pair of named entity based on each position of the named entity and the similarity between the named entity.
図3の処理P2において、類似度判定システム1は、固有表現リストに基づき、固有表現リストに含まれる固有表現間の類似度スコアSを、固有表現のペア(組)ごとに算出してよい。例えば、類似度判定システム1は、固有表現のペアについて、固有表現のそれぞれの位置と、固有表現間の類似度とに基づき類似度スコアSを算出する。 (Example of clustering process)
In the process P2 of FIG. 3, the
一例として、固有表現のペアを化合物x1及びx2と表記した場合、類似度判定システム1は、下記式(2)を用いて類似度スコアS(x1,x2)を算出してよい。

As an example, when the named entity pair is expressed as compounds x 1 and x 2 , the similarity determination system 1 may calculate the similarity score S (x 1 , x 2 ) using the following equation (2). ..
上記式(2)において、TC(x1,x2)は、MACCS KeyのTanimoto係数である。MACCS Keyは、化合物の特徴の表現手法(化合物記述子)の1つであり、Tanimoto係数は、MACCS Keyを用いて化合物間の構造類似度を示す指標の1つであり、固有表現が化合物名である場合の固有表現間の類似度の一例である。また、Distance(x1,x2)は、例えば、文書内での固有表現のそれぞれの出現位置の近さを数値化した値であり、一例として、以下の条件に応じた値である。
・化合物x1及びx2が同一文に出現し、且つ、並列関係にある場合:“1.0”
・化合物x1及びx2が同一文に出現する場合: “0.8”
・化合物x1及びx2が同一段落に出現する場合: “0.5”
・上記以外の場合: “0.1” In the above equation (2), TC (x 1 , x 2 ) is the Tanimoto coefficient of MACCS Key. MACCS Key is one of the expression methods (compound descriptors) of the characteristics of compounds, Tanimoto coefficient is one of the indexes showing the structural similarity between compounds using MACCS Key, and the named entity is the compound name. This is an example of the degree of similarity between named entities in the case of. Further, Distance (x 1 , x 2 ) is, for example, a numerical value obtained by quantifying the proximity of each appearance position of the named entity in a document, and is, for example, a value corresponding to the following conditions.
-When compounds x1 and x2 appear in the same sentence and are in a parallel relationship: "1.0"
-When compounds x1 and x2 appear in the same sentence: "0.8"
-When compounds x1 and x2 appear in the same paragraph: "0.5"
・ Other than the above: “0.1”
・化合物x1及びx2が同一文に出現し、且つ、並列関係にある場合:“1.0”
・化合物x1及びx2が同一文に出現する場合: “0.8”
・化合物x1及びx2が同一段落に出現する場合: “0.5”
・上記以外の場合: “0.1” In the above equation (2), TC (x 1 , x 2 ) is the Tanimoto coefficient of MACCS Key. MACCS Key is one of the expression methods (compound descriptors) of the characteristics of compounds, Tanimoto coefficient is one of the indexes showing the structural similarity between compounds using MACCS Key, and the named entity is the compound name. This is an example of the degree of similarity between named entities in the case of. Further, Distance (x 1 , x 2 ) is, for example, a numerical value obtained by quantifying the proximity of each appearance position of the named entity in a document, and is, for example, a value corresponding to the following conditions.
-When compounds x1 and x2 appear in the same sentence and are in a parallel relationship: "1.0"
-When compounds x1 and x2 appear in the same sentence: "0.8"
-When compounds x1 and x2 appear in the same paragraph: "0.5"
・ Other than the above: “0.1”
類似度判定システム1は、化合物リストCに含まれる複数の化合物名について、化合物名のペア(x1,x2)の組み合わせごとに上記式(2)を適用して、各ペア(x1,x2)の類似度スコアS(x1,x2)を算出してよい。
The similarity determination system 1 applies the above formula (2) to each combination of compound name pairs (x 1 , x 2 ) for a plurality of compound names included in the compound list C, and applies each pair (x 1 , x 2). The similarity score S (x 1 , x 2 ) of x 2 ) may be calculated.
類似度判定システム1は、算出した複数の類似度スコアS(x1,x2)に対して、例えば最短距離法等の手法を適用して、化合物リストCに含まれる複数の化合物名を分類してグループ化することで、化合物名のクラスタリングを行なってよい。
The similarity determination system 1 classifies a plurality of compound names included in the compound list C by applying a method such as the shortest distance method to a plurality of calculated similarity scores S (x 1 , x 2 ). By grouping them together, the compound names may be clustered.
図4の例では、類似度判定システム1は、化合物リストCXに対するクラスタリングにより、化合物リストCX内の化合物名をN(Nは2以上の整数)個のクラスタ(グループ)に分割し、クラスタごとの化合物リストCX1~CXNを生成する。また、類似度判定システム1は、化合物リストCYに対するクラスタリングにより、化合物リストCY内の化合物名をM(Mは2以上の整数)個のクラスタ(グループ)に分割し、クラスタごとの化合物リストCY1~CYMを生成する。
In the example of FIG. 4, the similarity determination system 1 divides the compound names in the compound list C X into clusters (groups) of N (N is an integer of 2 or more) by clustering to the compound list C X. Generate compound lists C X1 to C XN for each compound. Further, the similarity determination system 1 divides the compound names in the compound list CY into clusters (groups) of M (M is an integer of 2 or more) by clustering to the compound list CY , and the compound list for each cluster. Generates CY1 to CYM .
図5の例では、類似度判定システム1は、化合物リストCX及びCYをそれぞれ4つのクラスタに分類し(N=M=4)、化合物リストCX1~CX4及びCY1~CY4を生成する。このようなクラスタリングにより、結果的に、化合物リストCX及びCYを、以下のような4つの要素(特性)のクラスタに分類することができる。
・化合物リストCX1及びCY1:
「正極活物質」の要素(特性)を有するクラスタ。
・化合物リストCX2及びCY2:
「負極活物質」の要素(特性)を有するクラスタ。
・化合物リストCX3及びCY3:
「バインダー」の要素(特性)を有するクラスタ。
・化合物リストCX4及びCY4:
「電解液溶媒」の要素(特性)を有するクラスタ。 In the example of FIG. 5, thesimilarity determination system 1 classifies the compound lists C X and CY into four clusters (N = M = 4), respectively, and divides the compound lists C X1 to C X4 and CY1 to CY4 . Generate. As a result, the compound lists C X and CY can be classified into clusters of the following four elements (characteristics) by such clustering.
-Compound list C X1 and CY1 :
A cluster having an element (characteristic) of "positive electrode active material".
-Compound list C X2 and CY2 :
A cluster having elements (characteristics) of "negative electrode active material".
-Compound list C X3 and CY3 :
A cluster with a "binder" element (characteristic).
-Compound list C X4 and CY4 :
A cluster having an element (characteristic) of "electrolyte solvent".
・化合物リストCX1及びCY1:
「正極活物質」の要素(特性)を有するクラスタ。
・化合物リストCX2及びCY2:
「負極活物質」の要素(特性)を有するクラスタ。
・化合物リストCX3及びCY3:
「バインダー」の要素(特性)を有するクラスタ。
・化合物リストCX4及びCY4:
「電解液溶媒」の要素(特性)を有するクラスタ。 In the example of FIG. 5, the
-Compound list C X1 and CY1 :
A cluster having an element (characteristic) of "positive electrode active material".
-Compound list C X2 and CY2 :
A cluster having elements (characteristics) of "negative electrode active material".
-Compound list C X3 and CY3 :
A cluster with a "binder" element (characteristic).
-Compound list C X4 and CY4 :
A cluster having an element (characteristic) of "electrolyte solvent".
なお、ここまで、構造類似度としてMACCS KeyのTanimoto係数が用いられるものとして説明したが、これに限定されるものではない。例えば、化合物の特徴の表現手法としては、MACCS Key、換言すればMACCSフィンガープリントに限定されるものではなく、例えば、Morganフィンガープリント等の種々の化合物記述子が採用されてもよい。また、化合物間の構造類似度を示す指標としては、Tanimoto係数に限定されるものではなく、例えば、Dice係数等の種々の係数が用いられてもよい。
Up to this point, the explanation has been made assuming that the Tanimoto coefficient of MACCS Key is used as the structural similarity, but the description is not limited to this. For example, the method for expressing the characteristics of a compound is not limited to MACCS Key, in other words, MACCS fingerprint, and various compound descriptors such as Morgan fingerprint may be adopted. Further, the index indicating the structural similarity between the compounds is not limited to the Tanimoto coefficient, and various coefficients such as the Dice coefficient may be used.
また、上記式(2)では、類似度判定システム1は、類似度スコアS(x1,x2)として、固有表現の文書内の出現位置の近さを数値化した値と、固有表現の類似度との積を算出するものとしたが、これに限定されるものではない。
Further, in the above equation (2), the similarity determination system 1 uses the similarity score S (x 1 , x 2 ) as a numerical value of the proximity of the appearance position in the document of the named entity and the named entity. The product with the similarity is calculated, but the product is not limited to this.
一例として、類似度判定システム1は、下記式(3)を用いて類似度スコアS(x1,x2)を算出してもよい。

As an example, the similarity determination system 1 may calculate the similarity score S (x 1 , x 2 ) using the following equation (3).
上記式(3)において、Wは重みである。Wとしては、例えば、固有表現のそれぞれの位置と、固有表現間の類似度とが均等に考慮されるように“0.5”等の値がユーザ等により適宜定義及び設定されてもよい。或いは、Wは、検索クエリ及び正解例(正解データ)を含む訓練データに基づく機械学習により、正解例が上位に検索されるような値になるように訓練されたモデルに基づき設定されてもよい。
In the above equation (3), W is a weight. As W, for example, a value such as "0.5" may be appropriately defined and set by the user or the like so that each position of the named entity and the similarity between the named entity are considered evenly. Alternatively, W may be set based on a model trained so that the correct answer example is searched higher by machine learning based on the search query and the training data including the correct answer example (correct answer data). ..
例えば、化学構造は類似していないが1つの構成要素で同様に用いられる化合物(同一文で併記される可能性が高い)は、上記式(2)を用いると類似度が過少評価される可能性がある。これに対し、上記式(3)のように、固有表現の文書内の出現位置の近さを数値化した値と、固有表現の類似度との重み付き和に基づき類似度スコアを算出することで、化合物の類似度を正当に評価することができる。
For example, compounds that are not similar in chemical structure but are used in the same way in one component (which is likely to be written together in the same sentence) may be underestimated in similarity when the above formula (2) is used. There is sex. On the other hand, as in the above equation (3), the similarity score is calculated based on the weighted sum of the value obtained by quantifying the proximity of the appearance position of the named entity in the document and the similarity of the named entity. Therefore, the similarity of the compounds can be justified.
以上のように、類似度判定システム1は、クエリ文書11aに含まれる第1の複数の化合物名のそれぞれの位置と第1の複数の化合物名のそれぞれの類似度とに基づいて第1の複数の化合物名を分類することで、第1クラスタ群を生成する。また、類似度判定システム1は、比較対象文書12aに含まれる第2の複数の化合物名のそれぞれの位置と第2の複数の化合物名のそれぞれの類似度とに基づいて第2の複数の化合物名を分類することで、第2クラスタ群を生成する。第1クラスタ群は、第1の複数のグループの一例であり、第2クラスタ群は、第2の複数のグループの一例である。
As described above, the similarity determination system 1 is based on the position of each of the first plurality of compound names included in the query document 11a and the similarity of each of the first plurality of compound names. By classifying the compound names of, the first cluster group is generated. Further, the similarity determination system 1 is based on the position of each of the second plurality of compound names included in the comparison target document 12a and the similarity of each of the second plurality of compound names. By classifying the names, a second cluster group is generated. The first cluster group is an example of the first plurality of groups, and the second cluster group is an example of the second plurality of groups.
(固有表現類似度算出処理の一例)
図3の処理P3において、例えば、類似度判定システム1は、クエリ文書11aから生成した第1クラスタ群内の第1の複数のクラスタと、比較対象文書12aから生成した第2クラスタ群内の第2の複数のクラスタとをそれぞれ比較してよい。そして、類似度判定システム1は、第1の複数のクラスタと第2の複数のクラスタとの間の全てのクラスタのペアについて、下記式(4)の演算により、化合物類似度、一例としてコサイン類似度を算出してよい。

(Example of named entity similarity calculation processing)
In the process P3 of FIG. 3, for example, thesimilarity determination system 1 has a plurality of first clusters in the first cluster group generated from the query document 11a and a second cluster in the second cluster group generated from the comparison target document 12a. Each of the two plurality of clusters may be compared. Then, in the similarity determination system 1, the compound similarity, for example, cosine similarity, is obtained by the calculation of the following formula (4) for all the cluster pairs between the first plurality of clusters and the second plurality of clusters. The degree may be calculated.
図3の処理P3において、例えば、類似度判定システム1は、クエリ文書11aから生成した第1クラスタ群内の第1の複数のクラスタと、比較対象文書12aから生成した第2クラスタ群内の第2の複数のクラスタとをそれぞれ比較してよい。そして、類似度判定システム1は、第1の複数のクラスタと第2の複数のクラスタとの間の全てのクラスタのペアについて、下記式(4)の演算により、化合物類似度、一例としてコサイン類似度を算出してよい。
In the process P3 of FIG. 3, for example, the
上記式(4)において、aは、1~Nの整数であり、bは、1~Mの整数である。iは、化合物リストCXa及びCYbに含まれる全ての化合物名を特定するためのインデックスであり、CXai及びCYbiは、化合物リストCXa及びCYb内のi番目の化合物名の出現数を示す。コサイン類似度の算出式は、上記式(1)と同様である。
In the above equation (4), a is an integer of 1 to N, and b is an integer of 1 to M. i is an index for specifying all the compound names contained in the compound lists C Xa and CYb , and C Xai and CYbi are the number of occurrences of the i-th compound name in the compound lists C Xa and CYb . Is shown. The formula for calculating the cosine similarity is the same as the above formula (1).
図4に示す化合物リストCX及びCYの例では、類似度判定システム1は、化合物リストCX1、CX2、CX3、・・・CXNと、化合物リストCY1、CY2、CY3、・・・CYMとの全てのペア(組み合わせ)について、上記式(4)に従い化合物類似度を算出してよい。
In the example of the compound lists C X and CY shown in FIG. 4, the similarity determination system 1 has the compound lists C X1 , C X2 , C X3 , ... C XN and the compound lists CY1 , CY2 , CY3 . , ... For all pairs (combinations) with CYM , the compound similarity may be calculated according to the above formula (4).
(ランキング処理の一例)
例えば、類似度判定システム1は、ランキング処理において、クエリ文書11aと複数の比較対象文書12aの各々との間の文書類似度を取得し、文書類似度に基づき、クエリ文書11aとの類似度に応じた複数の比較対象文書12aのランキングを出力する。 (Example of ranking processing)
For example, thesimilarity determination system 1 acquires the document similarity between the query document 11a and each of the plurality of comparison target documents 12a in the ranking process, and determines the similarity with the query document 11a based on the document similarity. The ranking of a plurality of comparison target documents 12a corresponding to the corresponding is output.
例えば、類似度判定システム1は、ランキング処理において、クエリ文書11aと複数の比較対象文書12aの各々との間の文書類似度を取得し、文書類似度に基づき、クエリ文書11aとの類似度に応じた複数の比較対象文書12aのランキングを出力する。 (Example of ranking processing)
For example, the
類似度判定システム1は、例えば、下記式(5)に従い、文書Xと1つの比較対象文書Yとの間の文書類似度Sim(X,Y)を算出してよい。

The similarity determination system 1 may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (5).
上記式(5)において、maxは、括弧内の全ての組み合わせのうちの最大の値を採用する関数である。
In the above equation (5), max is a function that adopts the maximum value among all combinations in parentheses.
類似度判定システム1は、上記式(5)に従い、上記式(4)で算出された固有表現類似度のうちの、値が最大となるクラスタのペア(a=1~N、b=1~Mのいずれかの組み合わせ)を、文書X及びY間の文書類似度Sim(X,Y)として採用してよい。
The similarity determination system 1 is a pair of clusters (a = 1 to N, b = 1 to) having the maximum value among the named entity similarity calculated by the above equation (4) according to the above equation (5). Any combination of M) may be adopted as the document similarity Sim (X, Y) between the documents X and Y.
図5の例では、類似度判定システム1は、化合物リストCX1及びCY1のペア、換言すれば、「正極活物質」のクラスタどうしの化合物類似度が最大であると判定し、当該化合物類似度を文書X及びY間の文書類似度Sim(X,Y)に決定する。
In the example of FIG. 5, the similarity determination system 1 determines that the pair of the compound lists C X1 and CY 1 , in other words, the clusters of the “positive electrode active material” has the maximum compound similarity, and determines that the compound similarity is the maximum. The degree is determined to be the document similarity Sim (X, Y) between the documents X and Y.
なお、図4及び図5並びに上記式(5)では、文書X(クエリ文書11a)と、1つの文書Y(比較対象文書12a)との間の文書類似度を算出する例を示す。類似度判定システム1は、複数の比較対象文書12a、例えば文書Y1~YL(Lは2以上の整数であり、比較対象文書12aの文書数)それぞれについて上記処理を行ない、文書類似度Sim(X,Y1)~Sim(X,YL)を取得してよい。
Note that FIGS. 4 and 5 and the above formula (5) show an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). The similarity determination system 1 performs the above processing for each of a plurality of comparison target documents 12a, for example, documents Y 1 to Y L (L is an integer of 2 or more and the number of documents of the comparison target document 12a), and the document similarity Sim. (X, Y 1 ) to Sim (X, Y L ) may be acquired.
そして、類似度判定システム1は、例えば、文書類似度Sim(X,Y1)~Sim(X,YL)が高い文書Yから降順に検索対象の全文書Y1~YLをソートし、ソート結果を結果13として出力してよい。結果13には、ランク(順位)とともに文書Yの識別情報が含まれてよく、各文書Yの文書類似度Sim(X,Y)が含まれてもよい。文書Yの識別情報には、文書番号又は文書コード等の識別子及び文書名等の書誌情報、並びに、要約及び所定の部分等の文書Yの少なくとも一部の内容、のうちの少なくとも1つを含んでもよい。
Then, the similarity determination system 1 sorts all the documents Y 1 to Y L to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ), for example. The sort result may be output as the result 13. The result 13 may include the identification information of the document Y together with the rank (rank), and may include the document similarity Sim (X, Y) of each document Y. The identification information of the document Y includes at least one of an identifier such as a document number or a document code, bibliographic information such as a document name, and at least a part of the contents of the document Y such as a summary and a predetermined part. But it may be.
なお、類似度判定システム1は、結果13として、特定の順位であると判定した文書Y、例えば、クエリ文書11aとの間で最も文書類似度Sim(X,Y)の高い文書Yの識別情報を出力してもよい。
As a result 13, the similarity determination system 1 identifies information of the document Y having the highest document similarity Sim (X, Y) with the document Y determined to have a specific order, for example, the query document 11a. May be output.
以上のように、第1実施形態に係る類似度判定システム1によれば、クラスタリング処理により分類したクラスタごとの固有表現類似度に基づき、文書間の類似度を判定することで、部分的に類似した文書間の類似度の判定精度を向上させることができる。
As described above, according to the similarity determination system 1 according to the first embodiment, the similarity between documents is partially determined based on the named entity similarity for each cluster classified by the clustering process. It is possible to improve the determination accuracy of the similarity between the documents.
〔1-3〕機能構成例
図6は、第1実施形態に係る類似度判定システム1におけるサーバ2の機能構成例を示すブロック図であり、図7は、サーバ2による画面出力例を示す図である。 [1-3] Functional Configuration Example FIG. 6 is a block diagram showing a functional configuration example of theserver 2 in the similarity determination system 1 according to the first embodiment, and FIG. 7 is a diagram showing a screen output example by the server 2. Is.
図6は、第1実施形態に係る類似度判定システム1におけるサーバ2の機能構成例を示すブロック図であり、図7は、サーバ2による画面出力例を示す図である。 [1-3] Functional Configuration Example FIG. 6 is a block diagram showing a functional configuration example of the
サーバ2は、類似度判定装置、情報処理装置、又は、コンピュータの一例である。例えば、サーバ2は、類似度判定システム1において、図示しない端末装置、他のサーバ等との間で、クエリ文書11a及び比較対象文書12aの受信、結果13の送信等の種々の通信を行なってよい。
The server 2 is an example of a similarity determination device, an information processing device, or a computer. For example, in the similarity determination system 1, the server 2 performs various communications such as reception of the query document 11a and the comparison target document 12a and transmission of the result 13 with a terminal device (not shown), another server, or the like. good.
サーバ2は、例えば、端末装置に対して、アクセスを可能とするための機能を提供してよい。当該機能としては、例えば、端末装置によるアクセスに用いられる、ウェブページ等の画面の生成及び表示制御が挙げられる。例えば、端末装置は、ブラウザ等のアプリケーションを用いてサーバ2にアクセス要求を送信し、サーバ2から受信する画面情報に基づきアプリケーションに表示されるウェブページを介して、サーバ2へのアクセスを行なってよい。例えば、サーバ2は、図7に示すように、クエリを指定するためのクエリ指定画面210、及び、判定結果を出力するための判定結果出力画面240の画面情報を出力してよい。
The server 2 may provide, for example, a function for enabling access to the terminal device. Examples of the function include generation and display control of a screen such as a web page used for access by a terminal device. For example, the terminal device sends an access request to the server 2 using an application such as a browser, and accesses the server 2 via a web page displayed on the application based on the screen information received from the server 2. good. For example, as shown in FIG. 7, the server 2 may output the screen information of the query specification screen 210 for designating the query and the determination result output screen 240 for outputting the determination result.
類似度判定システム1による上述した類似度判定処理は、サーバ2により実現されてよい。図6に示すように、サーバ2は、例示的に、メモリ部21、文書入力部22、類似度算出部23、及び、類似度出力部24を備えてよい。メモリ部21、文書入力部22、類似度算出部23、及び、類似度出力部24は、制御部の一例である。
The above-mentioned similarity determination process by the similarity determination system 1 may be realized by the server 2. As shown in FIG. 6, the server 2 may optionally include a memory unit 21, a document input unit 22, a similarity calculation unit 23, and a similarity output unit 24. The memory unit 21, the document input unit 22, the similarity calculation unit 23, and the similarity output unit 24 are examples of control units.
メモリ部21は、類似度判定処理に係る種々のデータを記憶する記憶領域を有する。メモリ部21は、例えば、図3に示すクエリ文書11a、複数の比較対象文書12a、結果13等の情報を記憶してよい。また、メモリ部21は、類似度判定処理における中間データとして、図4及び図5に示す文書ごとの化合物リストC、類似度スコアS、クラスタごとの化合物リストC、化合物類似度、文書類似度Sim等の情報を記憶してもよい。
The memory unit 21 has a storage area for storing various data related to the similarity determination process. The memory unit 21 may store information such as the query document 11a shown in FIG. 3, a plurality of comparison target documents 12a, and the result 13. Further, the memory unit 21 uses the compound list C for each document, the similarity score S, the compound list C for each cluster, the compound similarity, and the document similarity Sim as intermediate data in the similarity determination process. Information such as may be stored.
文書入力部22は、図示しない端末装置又は他のサーバ等のコンピュータから、クエリ文書11a及び比較対象文書12aの入力を受け付け、例えばメモリ部21にDB(Database)として蓄積してもよい。このように、文書入力部22は、文書のDBを構築及び参照可能であってもよい。
The document input unit 22 may receive input of the query document 11a and the comparison target document 12a from a computer such as a terminal device (not shown) or another server, and store the query document 11a and the comparison target document 12a in the memory unit 21, for example, as a DB (Database). In this way, the document input unit 22 may be able to construct and refer to the DB of the document.
また、文書入力部22は、図示しない端末装置又は他のサーバ等のコンピュータから、類似判定要求に係るクエリ文書11aの入力を受け付け、メモリ部21に格納してよい。クエリ文書11aは、例えばクエリ11に含まれてもよい。
Further, the document input unit 22 may receive the input of the query document 11a related to the similarity determination request from a computer such as a terminal device (not shown) or another server and store it in the memory unit 21. The query document 11a may be included in the query 11, for example.
文書入力部22は、例えば、クエリ11として、クエリ文書11aそのものではなく、クエリ文書11aの識別情報、例えば文書番号、文書コード等の情報を受け付けてもよい。この場合、文書入力部22は、識別情報に基づき、例えばメモリ部21のDBから、類似判定要求に係るクエリ文書11aを特定してよい。
The document input unit 22 may accept, for example, as the query 11, not the query document 11a itself, but the identification information of the query document 11a, for example, information such as a document number and a document code. In this case, the document input unit 22 may specify the query document 11a related to the similarity determination request from, for example, the DB of the memory unit 21 based on the identification information.
例えば、図7に示すように、文書入力部22は、クエリ指定画面210の判定ボタン212が押下された際に入力欄211に設定されている文書番号を受け付けてよい。
For example, as shown in FIG. 7, the document input unit 22 may accept the document number set in the input field 211 when the determination button 212 of the query specification screen 210 is pressed.
類似度算出部23は、クエリ文書11a及び比較対象文書12aの類似度を算出する。図6に例示するように、類似度算出部23は、化合物名抽出部231、クラスタリング部232、及び、文書類似度算出部233を備えてよい。
The similarity calculation unit 23 calculates the similarity between the query document 11a and the comparison target document 12a. As illustrated in FIG. 6, the similarity calculation unit 23 may include a compound name extraction unit 231, a clustering unit 232, and a document similarity calculation unit 233.
化合物名抽出部231は、メモリ部21に格納されたクエリ文書11a及び比較対象文書12aのそれぞれから化合物名を抽出し、化合物リストCX及びCYを生成する。化合物名抽出部231の処理は、図3の処理P1の一例である。
The compound name extraction unit 231 extracts the compound name from each of the query document 11a and the comparison target document 12a stored in the memory unit 21, and generates the compound lists C X and CY . The treatment of the compound name extraction unit 231 is an example of the treatment P1 in FIG.
クラスタリング部232は、化合物リストCX及びCYのそれぞれに含まれる化合物名について類似度スコアSを算出する。また、クラスタリング部232は、類似度スコアSに基づき化合物名を複数のクラスタに分類して、化合物リストCX1、CX2、CX3、・・・CXNと、化合物リストCY1、CY2、CY3、・・・CYMとを生成する。クラスタリング部232の処理は、図3の処理P2の一例である。
The clustering unit 232 calculates the similarity score S for each of the compound names included in the compound lists C X and CY . Further, the clustering unit 232 classifies the compound names into a plurality of clusters based on the similarity score S, and the compound lists C X1 , C X2 , C X3 , ... C XN , and the compound lists CY1 , CY2 , and so on. Generate CY3 , ... CYM . The process of the clustering unit 232 is an example of the process P2 of FIG.
なお、クエリ文書11a及び比較対象文書12aの一方又は双方が予めメモリ部21に格納される場合、クラスタリング部232は、各文書について事前にクラスタリング処理を行ない、クラスタごとの化合物リストCを生成しておいてもよい。一例として、クラスタリング部232は、メモリ部21への文書の登録のタイミングで、登録される各文書についてクラスタリング処理を行なってもよい。
When one or both of the query document 11a and the comparison target document 12a are stored in the memory unit 21 in advance, the clustering unit 232 performs a clustering process for each document in advance and generates a compound list C for each cluster. You may leave it. As an example, the clustering unit 232 may perform a clustering process on each registered document at the timing of registering the document in the memory unit 21.
文書類似度算出部233は、クラスタごとの化合物リストに基づき、クラスタごとの化合物類似度を算出し、文書内で最も化合物類似度の高いクラスタの化合物類似度を、当該文書の類似度Sim(X,Y)として算出する。なお、文書類似度算出部233は、比較対象文書12aが複数(例えばL個)存在する場合、比較対象文書12aごとの類似度Sim(X,Y1)~Sim(X,YL)を算出してよい。文書類似度算出部233は、算出した類似度Sim(X,Y)をメモリ部21に格納してよい。
The document similarity calculation unit 233 calculates the compound similarity for each cluster based on the compound list for each cluster, and determines the compound similarity of the cluster having the highest compound similarity in the document as the similarity Sim (X) of the document. , Y). When a plurality of comparison target documents 12a (for example, L) exist, the document similarity calculation unit 233 calculates the similarity Sim (X, Y 1 ) to Sim (X, Y L ) for each comparison target document 12a. You can do it. The document similarity calculation unit 233 may store the calculated similarity Sim (X, Y) in the memory unit 21.
類似度出力部24は、類似度算出部23が算出した類似度Sim(X,Y)を出力する。なお、類似度出力部24は、比較対象文書12aが複数(例えばL個)存在する場合、算出した類似度Sim(X,Y1)~Sim(X,YL)が高い順に、比較対象文書12a及び類似度Sim(X,Y)の情報を出力してもよい。
The similarity output unit 24 outputs the similarity Sim (X, Y) calculated by the similarity calculation unit 23. When there are a plurality (for example, L) of the documents to be compared in the similarity output unit 24, the documents to be compared are compared in descending order of the calculated similarity Sim (X, Y 1 ) to Sim (X, Y L ). Information on 12a and the similarity Sim (X, Y) may be output.
文書類似度算出部233及び類似度出力部24の処理は、図3の処理P3及びP4の一例である。類似度出力部24による出力には、例えば、図示しない端末装置等のコンピュータへの送信、メモリ部21等のサーバ2の記憶領域への格納、等が含まれてよい。
The processing of the document similarity calculation unit 233 and the similarity output unit 24 is an example of the processes P3 and P4 of FIG. The output by the similarity output unit 24 may include, for example, transmission to a computer such as a terminal device (not shown), storage in a storage area of a server 2 such as a memory unit 21, and the like.
例えば、図7に示すように、類似度出力部24は、判定結果出力画面240を出力してもよい。判定結果出力画面240には、クエリ文書11aの表示領域241と、比較対象文書12aの少なくとも1つ(図7では3つ)の表示領域245a~245cとが含まれてよい。表示領域241には、書誌情報及び要約等の表示領域242、及び、クエリ文書11aの全文を表示する画面に遷移するための全文参照ボタン243が含まれてよい。
For example, as shown in FIG. 7, the similarity output unit 24 may output the determination result output screen 240. The determination result output screen 240 may include a display area 241 of the query document 11a and display areas 245a to 245c of at least one (three in FIG. 7) of the comparison target document 12a. The display area 241 may include a display area 242 such as bibliographic information and a summary, and a full-text reference button 243 for transitioning to a screen for displaying the full text of the query document 11a.
表示領域245a~245cには、書誌情報及び要約等の表示領域246a~246c、全文参照ボタン247a~247c、及び、類似すると判定されたクラスタの化合物リスト248a~248cが含まれてよい。なお、表示領域245a~245cには、類似度Sim(X,Y)が表示されてよい。
The display areas 245a to 245c may include display areas 246a to 246c for bibliographic information and summaries, full text reference buttons 247a to 247c, and compound lists 248a to 248c of clusters determined to be similar. The similarity Sim (X, Y) may be displayed in the display areas 245a to 245c.
このように、類似度出力部24は、化合物リスト248a~248cの表示により、クエリ文書11aと比較対象文書12aとの間の類似度計算の結果、最も類似度が高いと判断されたクラスタに属する固有表現のリストをユーザに提示することができる。
As described above, the similarity output unit 24 belongs to the cluster determined to have the highest similarity as a result of the similarity calculation between the query document 11a and the comparison target document 12a by displaying the compound lists 248a to 248c. A list of named entities can be presented to the user.
〔1-4〕動作例
図8は、サーバ2の動作例を説明するフローチャートである。図8に示すように、サーバ2は、クエリ文書11aに対する処理と、比較対象文書12aに対する処理とを互いに異なるタイミングで実施してもよい。 [1-4] Operation Example FIG. 8 is a flowchart illustrating an operation example of theserver 2. As shown in FIG. 8, the server 2 may execute the processing for the query document 11a and the processing for the comparison target document 12a at different timings.
図8は、サーバ2の動作例を説明するフローチャートである。図8に示すように、サーバ2は、クエリ文書11aに対する処理と、比較対象文書12aに対する処理とを互いに異なるタイミングで実施してもよい。 [1-4] Operation Example FIG. 8 is a flowchart illustrating an operation example of the
図8に例示するように、文書入力部22は、クエリ文書11aの入力を受け付ける(ステップS1)。化合物名抽出部231は、クエリ文書11aから化合物名を抽出する(ステップS2)。クラスタリング部232は、抽出した化合物名をクラスタリングする(ステップS3)。
As illustrated in FIG. 8, the document input unit 22 accepts the input of the query document 11a (step S1). The compound name extraction unit 231 extracts the compound name from the query document 11a (step S2). The clustering unit 232 clusters the extracted compound names (step S3).
また、文書入力部22は、比較対象文書12aの入力を受け付ける(ステップS4)。化合物名抽出部231は、未選択の比較対象文書12aを選択し(ステップS5)、選択した比較対象文書12aから化合物名を抽出する(ステップS6)。クラスタリング部232は、抽出した化合物名をクラスタリングする(ステップS7)。
Further, the document input unit 22 accepts the input of the comparison target document 12a (step S4). The compound name extraction unit 231 selects an unselected comparison target document 12a (step S5), and extracts a compound name from the selected comparison target document 12a (step S6). The clustering unit 232 clusters the extracted compound names (step S7).
文書類似度算出部233は、クエリ文書11a及び比較対象文書12aの化合物クラスタを比較し、当該文書間の類似度Simを算出し(ステップS8)、メモリ部21に格納する(ステップS9)。
The document similarity calculation unit 233 compares the compound clusters of the query document 11a and the comparison target document 12a, calculates the similarity Sim between the documents (step S8), and stores it in the memory unit 21 (step S9).
文書類似度算出部233は、未選択の比較対象文書12aがあるか否かを判定し(ステップS10)、あると判定した場合(ステップS10でYES)、処理がステップS5に移行する。
The document similarity calculation unit 233 determines whether or not there is an unselected comparison target document 12a (step S10), and if it is determined to be present (YES in step S10), the process proceeds to step S5.
未選択の比較対象文書12aがないと文書類似度算出部233が判定した場合(ステップS10でNO)、類似度Sim(X,Y)が高い順に、比較対象文書12a及びその類似度Sim(X,Y)を出力し(ステップS11)、処理が終了する。
When the document similarity calculation unit 233 determines that there is no unselected document to be compared 12a (NO in step S10), the document to be compared 12a and its similarity Sim (X) are in descending order of similarity Sim (X, Y). , Y) is output (step S11), and the process ends.
〔1-5〕ハードウェア構成例
サーバ2は、仮想サーバ(VM;Virtual Machine)であってもよいし、物理サーバであってもよい。また、サーバ2の機能は、1台のコンピュータにより実現されてもよいし、2台以上のコンピュータにより実現されてもよい。さらに、サーバ2の機能のうちの少なくとも一部は、クラウド環境により提供されるHW(Hardware)リソース及びNW(Network)リソースを用いて実現されてもよい。 [1-5] Hardware Configuration Example Theserver 2 may be a virtual server (VM; Virtual Machine) or a physical server. Further, the function of the server 2 may be realized by one computer or may be realized by two or more computers. Further, at least a part of the functions of the server 2 may be realized by using the HW (Hardware) resource and the NW (Network) resource provided by the cloud environment.
サーバ2は、仮想サーバ(VM;Virtual Machine)であってもよいし、物理サーバであってもよい。また、サーバ2の機能は、1台のコンピュータにより実現されてもよいし、2台以上のコンピュータにより実現されてもよい。さらに、サーバ2の機能のうちの少なくとも一部は、クラウド環境により提供されるHW(Hardware)リソース及びNW(Network)リソースを用いて実現されてもよい。 [1-5] Hardware Configuration Example The
図9は、サーバ2の機能を実現するコンピュータ10のハードウェア(HW)構成例を示すブロック図である。サーバ2の機能を実現するHWリソースとして、複数のコンピュータが用いられる場合は、各コンピュータが図9に例示するHW構成を備えてよい。
FIG. 9 is a block diagram showing a hardware (HW) configuration example of the computer 10 that realizes the function of the server 2. When a plurality of computers are used as the HW resource that realizes the function of the server 2, each computer may have the HW configuration illustrated in FIG.
図9に示すように、コンピュータ10は、HW構成として、例示的に、プロセッサ10a、メモリ10b、記憶部10c、IF(Interface)部10d、I/O(Input / Output)部10e、及び読取部10fを備えてよい。
As shown in FIG. 9, the computer 10 has an HW configuration, for example, a processor 10a, a memory 10b, a storage unit 10c, an IF (Interface) unit 10d, an I / O (Input / Output) unit 10e, and a reading unit. It may be provided with 10f.
プロセッサ10aは、種々の制御や演算を行なう演算処理装置の一例である。プロセッサ10aは、コンピュータ10内の各ブロックとバス10iで相互に通信可能に接続されてよい。なお、プロセッサ10aは、複数のプロセッサを含むマルチプロセッサであってもよいし、複数のプロセッサコアを有するマルチコアプロセッサであってもよく、或いは、マルチコアプロセッサを複数有する構成であってもよい。
The processor 10a is an example of an arithmetic processing unit that performs various controls and operations. The processor 10a may be connected to each block in the computer 10 so as to be communicable with each other by the bus 10i. The processor 10a may be a multi-processor including a plurality of processors, a multi-core processor having a plurality of processor cores, or a configuration having a plurality of multi-core processors.
プロセッサ10aとしては、例えば、CPU、MPU、GPU、APU、DSP、ASIC、FPGA等の集積回路(IC;Integrated Circuit)が挙げられる。なお、プロセッサ10aとして、これらの集積回路の2以上の組み合わせが用いられてもよい。CPUはCentral Processing Unitの略称であり、MPUはMicro Processing Unitの略称である。GPUはGraphics Processing Unitの略称であり、APUはAccelerated Processing Unitの略称である。DSPはDigital Signal Processorの略称であり、ASICはApplication Specific ICの略称であり、FPGAはField-Programmable Gate Arrayの略称である。
Examples of the processor 10a include integrated circuits (ICs) such as CPUs, MPUs, GPUs, APUs, DSPs, ASICs, and FPGAs. As the processor 10a, two or more combinations of these integrated circuits may be used. CPU is an abbreviation for Central Processing Unit, and MPU is an abbreviation for Micro Processing Unit. GPU is an abbreviation for Graphics Processing Unit, and APU is an abbreviation for Accelerated Processing Unit. DSP is an abbreviation for Digital Signal Processor, ASIC is an abbreviation for Application Specific IC, and FPGA is an abbreviation for Field-Programmable Gate Array.
メモリ10bは、種々のデータやプログラム等の情報を格納するHWの一例である。メモリ10bとしては、例えばDRAM(Dynamic Random Access Memory)等の揮発性メモリ、及び、PM(Persistent Memory)等の不揮発性メモリ、の一方又は双方が挙げられる。
The memory 10b is an example of HW that stores information such as various data and programs. Examples of the memory 10b include one or both of a volatile memory such as DRAM (Dynamic Random Access Memory) and a non-volatile memory such as PM (Persistent Memory).
記憶部10cは、種々のデータやプログラム等の情報を格納するHWの一例である。記憶部10cとしては、HDD(Hard Disk Drive)等の磁気ディスク装置、SSD(Solid State Drive)等の半導体ドライブ装置、不揮発性メモリ等の各種記憶装置が挙げられる。不揮発性メモリとしては、例えば、フラッシュメモリ、SCM(Storage Class Memory)、ROM(Read Only Memory)等が挙げられる。
The storage unit 10c is an example of HW that stores information such as various data and programs. Examples of the storage unit 10c include a magnetic disk device such as an HDD (Hard Disk Drive), a semiconductor drive device such as an SSD (Solid State Drive), and various storage devices such as a non-volatile memory. Examples of the non-volatile memory include flash memory, SCM (Storage Class Memory), ROM (Read Only Memory) and the like.
また、記憶部10cは、コンピュータ10の各種機能の全部若しくは一部を実現するプログラム10g(類似度判定プログラム)を格納してよい。例えば、サーバ2のプロセッサ10aは、記憶部10cに格納されたプログラム10gをメモリ10bに展開して実行することにより、図6に例示するサーバ2としての機能を実現できる。
Further, the storage unit 10c may store a program 10g (similarity determination program) that realizes all or a part of various functions of the computer 10. For example, the processor 10a of the server 2 can realize the function as the server 2 illustrated in FIG. 6 by expanding and executing the program 10g stored in the storage unit 10c in the memory 10b.
図6に示すメモリ部21は、メモリ10b及び記憶部10cの一方又は双方の記憶領域により実現されてよい。
The memory unit 21 shown in FIG. 6 may be realized by a storage area of one or both of the memory unit 10b and the storage unit 10c.
IF部10dは、ネットワークとの間の接続及び通信の制御等を行なう通信IFの一例である。例えば、IF部10dは、イーサネット(登録商標)等のLAN(Local Area Network)、或いは、FC(Fibre Channel)等の光通信等に準拠したアダプタを含んでよい。当該アダプタは、無線及び有線の一方又は双方の通信方式に対応してよい。例えば、サーバ2は、IF部10dを介して、端末装置及び他のサーバのそれぞれと相互に通信可能に接続されてよい。また、例えば、プログラム10gは、当該通信IFを介して、ネットワークからコンピュータ10にダウンロードされ、記憶部10cに格納されてもよい。
The IF unit 10d is an example of a communication IF that controls connection and communication with a network. For example, the IF unit 10d may include an adapter compliant with LAN (Local Area Network) such as Ethernet (registered trademark) or optical communication such as FC (Fibre Channel). The adapter may support one or both wireless and wired communication methods. For example, the server 2 may be connected to the terminal device and each of the other servers so as to be able to communicate with each other via the IF unit 10d. Further, for example, the program 10g may be downloaded from the network to the computer 10 via the communication IF and stored in the storage unit 10c.
I/O部10eは、入力装置、及び、出力装置、の一方又は双方を含んでよい。入力装置としては、例えば、キーボード、マウス、タッチパネル等が挙げられる。出力装置としては、例えば、モニタ、プロジェクタ、プリンタ等が挙げられる。
The I / O unit 10e may include one or both of an input device and an output device. Examples of the input device include a keyboard, a mouse, a touch panel, and the like. Examples of the output device include a monitor, a projector, a printer and the like.
読取部10fは、記録媒体10hに記録されたデータやプログラムの情報を読み出すリーダの一例である。読取部10fは、記録媒体10hを接続可能又は挿入可能な接続端子又は装置を含んでよい。読取部10fとしては、例えば、USB(Universal Serial Bus)等に準拠したアダプタ、記録ディスクへのアクセスを行なうドライブ装置、SDカード等のフラッシュメモリへのアクセスを行なうカードリーダ等が挙げられる。なお、記録媒体10hにはプログラム10gが格納されてもよく、読取部10fが記録媒体10hからプログラム10gを読み出して記憶部10cに格納してもよい。
The reading unit 10f is an example of a reader that reads data and program information recorded on the recording medium 10h. The reading unit 10f may include a connection terminal or device to which the recording medium 10h can be connected or inserted. Examples of the reading unit 10f include an adapter compliant with USB (Universal Serial Bus), a drive device for accessing a recording disk, a card reader for accessing a flash memory such as an SD card, and the like. The program 10g may be stored in the recording medium 10h, or the reading unit 10f may read the program 10g from the recording medium 10h and store it in the storage unit 10c.
記録媒体10hとしては、例示的に、磁気/光ディスクやフラッシュメモリ等の非一時的なコンピュータ読取可能な記録媒体が挙げられる。磁気/光ディスクとしては、例示的に、フレキシブルディスク、CD(Compact Disc)、DVD(Digital Versatile Disc)、ブルーレイディスク、HVD(Holographic Versatile Disc)等が挙げられる。フラッシュメモリとしては、例示的に、USBメモリやSDカード等の半導体メモリが挙げられる。
Examples of the recording medium 10h include non-temporary computer-readable recording media such as magnetic / optical disks and flash memories. Examples of the magnetic / optical disk include flexible discs, CDs (Compact Discs), DVDs (Digital Versatile Discs), Blu-ray discs, HVDs (Holographic Versatile Discs), and the like. Examples of the flash memory include semiconductor memories such as USB memory and SD card.
上述したコンピュータ10のHW構成は例示である。従って、コンピュータ10内でのHWの増減(例えば任意のブロックの追加や削除)、分割、任意の組み合わせでの統合、又は、バスの追加若しくは削除等は適宜行なわれてもよい。例えば、サーバ2において、I/O部10e及び読取部10fの少なくとも一方は、省略されてもよい。
The above-mentioned HW configuration of the computer 10 is an example. Therefore, the increase / decrease of HW (for example, addition or deletion of arbitrary blocks), division, integration in any combination, addition or deletion of buses, etc. may be appropriately performed in the computer 10. For example, in the server 2, at least one of the I / O unit 10e and the reading unit 10f may be omitted.
〔2〕第2実施形態
〔2-1〕第2実施形態の説明
次に、第2実施形態について説明する。第2実施形態では、第1実施形態に係る固有表現に基づく類似度に加えて、単語の意味ベクトルに基づく類似度を用いて、文書間の類似度を判定する手法を説明する。 [2] Second Embodiment [2-1] Description of the Second Embodiment Next, the second embodiment will be described. In the second embodiment, a method of determining the similarity between documents by using the similarity based on the meaning vector of the word in addition to the similarity based on the named entity according to the first embodiment will be described.
〔2-1〕第2実施形態の説明
次に、第2実施形態について説明する。第2実施形態では、第1実施形態に係る固有表現に基づく類似度に加えて、単語の意味ベクトルに基づく類似度を用いて、文書間の類似度を判定する手法を説明する。 [2] Second Embodiment [2-1] Description of the Second Embodiment Next, the second embodiment will be described. In the second embodiment, a method of determining the similarity between documents by using the similarity based on the meaning vector of the word in addition to the similarity based on the named entity according to the first embodiment will be described.
なお、以下の第2実施形態の説明では、特に言及しない構成、処理又は機能は、既述の第1実施形態に係る構成、処理又は機能と同様であるものとする。
In the following description of the second embodiment, the configuration, processing or function not particularly mentioned shall be the same as the configuration, processing or function according to the first embodiment described above.
図10は、第2実施形態に係る類似度判定システム1Aを説明するための図である。図10に示すように、第2実施形態に係る類似度判定システム1Aにおいて、クエリ11及び文書集合12に基づく処理P1~P3については、第1実施形態と同様である。
FIG. 10 is a diagram for explaining the similarity determination system 1A according to the second embodiment. As shown in FIG. 10, in the similarity determination system 1A according to the second embodiment, the processes P1 to P3 based on the query 11 and the document set 12 are the same as those in the first embodiment.
図10に例示するように、類似度判定システム1Aにおいて、処理P1~P3と少なくとも一部の処理が並行又は前後して、処理P5~P8が実行されてよい。また、処理P3及びP8の結果に基づき、処理P9が実行され、結果14が出力されてよい。以下、処理P5~P9について説明する。
As illustrated in FIG. 10, in the similarity determination system 1A, the processes P5 to P8 may be executed in parallel with or before and after the processes P1 to P3 and at least a part of the processes. Further, the process P9 may be executed and the result 14 may be output based on the results of the processes P3 and P8. Hereinafter, the processes P5 to P9 will be described.
例えば、類似度判定システム1Aは、複数の文書、例えばクエリ文書11a及び複数の比較対象文書12aのそれぞれから、例えば形態素解析により単語を抽出する(処理P5)。
For example, the similarity determination system 1A extracts words from each of a plurality of documents, for example, a query document 11a and a plurality of comparison target documents 12a, for example, by morphological analysis (process P5).
類似度判定システム1Aは、処理P5で得られた単語に基づき、複数の文書のそれぞれについて、統計的に単語の重みを算出する(処理P6)。例えば、類似度判定システム1Aは、tf-idf(Term Frequency - Inverse Document Frequency)等の評価手法を用いて、文書内での単語の重要度を重みとして評価してよい。
The similarity determination system 1A statistically calculates the word weights for each of the plurality of documents based on the words obtained in the process P5 (process P6). For example, the similarity determination system 1A may evaluate the importance of a word in a document as a weight by using an evaluation method such as tf-idf (Term Frequency-Inverse Document Frequency).
また、類似度判定システム1Aは、処理P6と少なくとも一部の処理が並行又は前後して、処理P7を実行する。例えば、類似度判定システム1Aは、処理P5で得られた単語に基づき、複数の文書のそれぞれについて、単語ベクトルを算出する(処理P7)。単語ベクトルは、単語埋め込みベクトル又は意味ベクトルと称されてもよい。
Further, the similarity determination system 1A executes the process P7 in parallel with or before and after the process P6 and at least a part of the processes. For example, the similarity determination system 1A calculates a word vector for each of a plurality of documents based on the words obtained in the process P5 (process P7). The word vector may be referred to as a word embedding vector or a meaning vector.
例えば、類似度判定システム1Aは、単語の意味を表現するベクトルが格納されたベクトルデータベースを検索して単語ベクトルを取得してよい。一例として、類似度判定システム1Aは、訓練済みのモデルに基づき、処理P5で得られた単語のそれぞれに対応する単語ベクトルを取得してよい。
For example, the similarity determination system 1A may search a vector database in which a vector expressing the meaning of a word is stored and acquire a word vector. As an example, the similarity determination system 1A may acquire a word vector corresponding to each of the words obtained in the process P5 based on the trained model.
類似度判定システム1Aは、文書ごとに、処理P7で取得した単語ベクトルと、処理P6で取得した単語の重みとを乗じた結果を文書内の全単語に亘って加算することで文書ベクトルを算出する。そして、類似度判定システム1Aは、クエリ文書11aの文書ベクトル(第1のベクトル)と、比較対象文書12aの各々の文書ベクトル(第2のベクトル)との間の類似度を算出する。換言すれば、類似度判定システム1Aは、単語の意味ベクトルに基づく、クエリ文書11aと比較対象文書12aとの間のテキスト類似度を算出する(処理P8)。
The similarity determination system 1A calculates the document vector by adding the result of multiplying the word vector acquired in the process P7 and the weight of the word acquired in the process P6 over all the words in the document for each document. do. Then, the similarity determination system 1A calculates the similarity between the document vector (first vector) of the query document 11a and each document vector (second vector) of the comparison target document 12a. In other words, the similarity determination system 1A calculates the text similarity between the query document 11a and the comparison target document 12a based on the meaning vector of the word (process P8).
例えば、類似度判定システム1Aは、クエリ文書11aと比較対象文書12aとについて、下記式(6)の演算により、テキスト類似度、一例としてコサイン類似度を算出してよい。

For example, the similarity determination system 1A may calculate the text similarity, for example, the cosine similarity between the query document 11a and the comparison target document 12a by the calculation of the following equation (6).
上記式(6)において、WXは、文書Xに含まれる単語の分散ベクトルであり、WYは、文書Yに含まれる単語の分散ベクトルである。
In the above equation (6), W X is a dispersion vector of words included in the document X, and W Y is a dispersion vector of words included in the document Y.
図4に示す化合物リストCX及びCYの例では、類似度判定システム1Aは、化合物リストCX1、CX2、CX3、・・・CXNと、化合物リストCY1、CY2、CY3、・・・CYMとの全てのペアについて、上記式(6)に従いテキスト類似度を算出してよい。
In the example of the compound lists C X and CY shown in FIG. 4, the similarity determination system 1A has the compound lists C X1 , C X2 , C X3 , ... C XN and the compound lists CY1 , CY2 , CY3 . , ... For all pairs with CYM , the text similarity may be calculated according to the above equation (6).
そして、類似度判定システム1Aは、テキスト類似度及び固有表現類似度に基づき、クエリ文書11aとの類似度に応じて複数の比較対象文書12aの各々をランキング付けするランキング処理を行ない(処理P9)、結果14を出力する。結果14は、ランキング結果を含んでもよい。
Then, the similarity determination system 1A performs a ranking process of ranking each of the plurality of comparison target documents 12a according to the similarity with the query document 11a based on the text similarity and the named entity similarity (process P9). , The result 14 is output. The result 14 may include a ranking result.
例えば、類似度判定システム1Aは、ランキング処理において、テキスト類似度と固有表現類似度を統合した類似度を算出し、当該類似度に基づき、クエリ文書11aとの類似度に応じた複数の比較対象文書12aのランキングを出力する。
For example, the similarity determination system 1A calculates the similarity in which the text similarity and the named entity similarity are integrated in the ranking process, and based on the similarity, a plurality of comparison targets according to the similarity with the query document 11a. The ranking of the document 12a is output.
類似度判定システム1Aは、例えば、下記式(7)に従い、文書Xと1つの比較対象文書Yとの間の文書類似度Sim(X,Y)を算出してよい。

The similarity determination system 1A may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (7).
上記式(7)において、maxは、括弧内の全ての組み合わせのうちの最大の値を採用する関数である。fc及びftは、それぞれ、下記式(8)及び(9)に示すように、固有表現類似度及びテキスト類似度である。

In the above equation (7), max is a function that adopts the maximum value among all the combinations in parentheses. fc and ft are named entity similarity and text similarity, respectively, as shown in the following equations (8) and (9).
類似度判定システム1Aは、上記式(7)~(9)に従い、上記式(4)で算出された固有表現類似度と、上記(6)で算出されたテキスト類似度に基づいて、文書X及びY間の文書類似度Sim(X,Y)を取得してよい。
The similarity determination system 1A is based on the named entity similarity calculated by the equation (4) and the text similarity calculated by the equation (6) according to the above equations (7) to (9). And the document similarity Sim (X, Y) between Y may be acquired.
なお、上記式(7)では、文書X(クエリ文書11a)と、1つの文書Y(比較対象文書12a)との間の文書類似度を算出する例を示す。類似度判定システム1Aは、第1実施形態と同様に、文書Yの数に応じた文書類似度Sim(X,Y1)~Sim(X,YL)を取得してよい。
The above formula (7) shows an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). Similar to the first embodiment, the similarity determination system 1A may acquire document similarity Sims (X, Y 1 ) to Sim (X, Y L ) according to the number of documents Y.
そして、類似度判定システム1Aは、例えば、第1実施形態と同様に、文書類似度Sim(X,Y1)~Sim(X,YL)が高い文書Yから降順に検索対象の全文書Y1~YLをソートすることで、ランキング処理を行なう(処理P9)。また、類似度判定システム1Aは、ソート結果を結果14として出力してよい。結果14の内容及び出力手法は、第1実施形態に係る結果13と同様である。
Then, in the similarity determination system 1A, for example, as in the first embodiment, all the documents Y to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ). Ranking processing is performed by sorting 1 to Y L (processing P9). Further, the similarity determination system 1A may output the sort result as the result 14. The content and output method of the result 14 are the same as those of the result 13 according to the first embodiment.
なお、文書類似度Sim(X,Y)は、上記式(7)に基づき算出されるものとしたが、これに限定されるものではない。例えば、類似度判定システム1Aは、文書類似度Sim(X,Y)は、下記式(10)に従い、文書Xと1つの比較対象文書Yとの間の文書類似度Sim(X,Y)を、固有表現似度とテキスト類似度との重み付き和として算出してもよい。

The document similarity Sim (X, Y) is calculated based on the above equation (7), but is not limited thereto. For example, in the similarity determination system 1A, the document similarity Sim (X, Y) determines the document similarity Sim (X, Y) between the document X and one comparison target document Y according to the following formula (10). , May be calculated as a weighted sum of eigenexpression similarity and text similarity.
上記式(10)において、wは重みである。wとしては、例えば、固有表現類似度とテキスト類似度とが均等に考慮されるように“0.5”等の値がユーザ等により適宜定義及び設定されてもよい。或いは、wは、検索クエリ及び正解例(正解データ)を含む訓練データに基づく機械学習により、正解例が上位に検索されるような値になるように訓練されたモデルに基づき設定されてもよい。
In the above equation (10), w is a weight. As w, for example, a value such as “0.5” may be appropriately defined and set by the user or the like so that the named entity similarity and the text similarity are considered equally. Alternatively, w may be set based on a model trained so that the correct answer example is searched higher by machine learning based on the search query and the training data including the correct answer example (correct answer data). ..
以上のように、第2実施形態に係る類似度判定システム1Aによれば、第1実施形態と同様の効果を奏することができる。また、類似度判定システム1Aによれば、固有表現類似度に加えて、意味ベクトルに基づく類似度に基づき、文書間の類似度を判定することで、文書間の類似度の判定精度をより向上させることができる。
As described above, according to the similarity determination system 1A according to the second embodiment, the same effect as that of the first embodiment can be obtained. Further, according to the similarity determination system 1A, the similarity determination accuracy between documents is further improved by determining the similarity between documents based on the similarity based on the semantic vector in addition to the named entity similarity. Can be made to.
〔2-2〕機能構成例
図11は、第2実施形態に係る類似度判定システム1Aにおけるサーバ3の機能構成例を示すブロック図であり、図12は、サーバ3による画面出力例を示す図である。 [2-2] Functional Configuration Example FIG. 11 is a block diagram showing a functional configuration example of theserver 3 in the similarity determination system 1A according to the second embodiment, and FIG. 12 is a diagram showing a screen output example by the server 3. Is.
図11は、第2実施形態に係る類似度判定システム1Aにおけるサーバ3の機能構成例を示すブロック図であり、図12は、サーバ3による画面出力例を示す図である。 [2-2] Functional Configuration Example FIG. 11 is a block diagram showing a functional configuration example of the
サーバ3は、類似度判定装置、情報処理装置、又は、コンピュータの一例である。例えば、サーバ3は、類似度判定システム1Aにおいて、図示しない端末装置、他のサーバ等との間で、クエリ文書11a及び比較対象文書12aの受信、結果14の送信等の種々の通信を行なってよい。
The server 3 is an example of a similarity determination device, an information processing device, or a computer. For example, in the similarity determination system 1A, the server 3 performs various communications such as reception of the query document 11a and the comparison target document 12a and transmission of the result 14 with a terminal device (not shown), another server, or the like. good.
サーバ3は、サーバ2と同様に、例えば、端末装置に対して、アクセスを可能とするための機能を提供してよい。例えば、サーバ3は、図12に示すように、検索クエリを指定するための検索クエリ指定画面330、及び、検索結果を出力するための検索結果出力画面340の画面情報を出力してよい。
Similar to the server 2, the server 3 may provide, for example, a function for enabling access to the terminal device. For example, as shown in FIG. 12, the server 3 may output screen information of a search query specification screen 330 for designating a search query and a search result output screen 340 for outputting search results.
類似度判定システム1Aによる上述した類似度判定処理は、サーバ3により実現されてよい。図11に示すように、サーバ3は、例示的に、文書DB部31、及び、文書検索部32を備えてよい。文書DB部31、及び、文書検索部32は、制御部の一例である。なお、サーバ3は、図6に示す文書入力部22を備えてもよい。
The above-mentioned similarity determination process by the similarity determination system 1A may be realized by the server 3. As shown in FIG. 11, the server 3 may optionally include a document DB unit 31 and a document retrieval unit 32. The document DB unit 31 and the document search unit 32 are examples of control units. The server 3 may include the document input unit 22 shown in FIG.
文書DB部31は、クエリ文書11a及び比較対象文書12aを蓄積し、文書DBを構築する文書DB構築処理を行なう。
The document DB unit 31 stores the query document 11a and the comparison target document 12a, and performs a document DB construction process for constructing the document DB.
文書検索部32は、クエリ11の受け付けに応じて、文書DB部31が記憶する情報に基づき、クエリ11で指定されたクエリ文書11aと類似する比較対象文書12aを検索する文書検索処理を行なう。文書検索処理は、類似度判定処理を含む処理であり、類似判定処理の利用例(応用例)である。
The document search unit 32 performs a document search process for searching a comparison target document 12a similar to the query document 11a specified in the query 11 based on the information stored in the document DB unit 31 in response to the acceptance of the query 11. The document search process is a process including a similarity determination process, and is an example of use (application example) of the similarity determination process.
(文書DB部31の説明)
図11に示すように、文書DB部31は、例示的に、文書蓄積部311、化合物名抽出部312、クラスタリング部313、化合物クラスタ蓄積部314、文書ベクトル算出部315、及び、文書ベクトル蓄積部316を備えてよい。 (Explanation of document DB section 31)
As shown in FIG. 11, thedocument DB unit 31 is exemplified by the document storage unit 311, the compound name extraction unit 312, the clustering unit 313, the compound cluster storage unit 314, the document vector calculation unit 315, and the document vector storage unit. 316 may be provided.
図11に示すように、文書DB部31は、例示的に、文書蓄積部311、化合物名抽出部312、クラスタリング部313、化合物クラスタ蓄積部314、文書ベクトル算出部315、及び、文書ベクトル蓄積部316を備えてよい。 (Explanation of document DB section 31)
As shown in FIG. 11, the
文書蓄積部311は、第1実施形態に係るメモリ部21(図6参照)の一例であり、複数の文書を蓄積する。文書は、クエリ文書11a及び比較対象文書12aのいずれとしても用いられ得る文書である。従って、文書蓄積部311は、クエリ文書11aと、クエリ11の対象となる複数の比較対象文書12aを含む文書集合(文書群)12とを蓄積するといえる。文書蓄積部311は、クエリ11の受付前に、予め複数の文書を蓄積してよい。なお、文書蓄積部311には、第1実施形態に係る文書入力部22が受け付けた複数の文書が格納されてもよい。
The document storage unit 311 is an example of the memory unit 21 (see FIG. 6) according to the first embodiment, and stores a plurality of documents. The document is a document that can be used as either the query document 11a or the comparison target document 12a. Therefore, it can be said that the document storage unit 311 stores the query document 11a and the document set (document group) 12 including the plurality of comparison target documents 12a that are the targets of the query 11. The document storage unit 311 may store a plurality of documents in advance before receiving the query 11. The document storage unit 311 may store a plurality of documents received by the document input unit 22 according to the first embodiment.
化合物名抽出部312は、図6に示す化合物名抽出部231の一例であり、文書蓄積部311が蓄積する複数の文書の各々から、固有表現の一例としての化合物名を抽出し、文書ごとの化合物リストCX及びCYを生成する。化合物名抽出部312の処理は、図10の処理P1の一例である。
The compound name extraction unit 312 is an example of the compound name extraction unit 231 shown in FIG. 6, and the compound name as an example of the named entity is extracted from each of the plurality of documents accumulated by the document storage unit 311 for each document. Generate compound lists C X and CY . The treatment of the compound name extraction unit 312 is an example of the treatment P1 in FIG.
クラスタリング部313は、図6に示すクラスタリング部232の一例である。クラスタリング部313は、文書ごとの化合物リストCX及びCYに基づき、文書ごとに、化合物名の複数の化合物クラスタ、換言すれば、複数の化合物リストCX1、CX2、CX3、・・・CXN、CY1、CY2、CY3、・・・CYMを生成する。クラスタリング部313の処理は、図10の処理P2の一例である。
The clustering unit 313 is an example of the clustering unit 232 shown in FIG. The clustering unit 313 is based on the compound lists C X and CY for each document, and for each document, a plurality of compound clusters of compound names, in other words, a plurality of compound lists C X1 , C X 2 , C X 3 , ... Generate C XN , CY1 , CY2 , CY3 , ... CYM . The process of the clustering unit 313 is an example of the process P2 of FIG.
化合物クラスタ蓄積部314は、図6に示すメモリ部21の一例であり、クラスタリング部313が生成した複数の化合物クラスタ、換言すれば、複数の化合物リストCX1、CX2、CX3、・・・CXN、CY1、CY2、CY3、・・・CYMを蓄積する。
The compound cluster storage unit 314 is an example of the memory unit 21 shown in FIG. 6, and is a plurality of compound clusters generated by the clustering unit 313, in other words, a plurality of compound lists C X1 , C X2 , C X3 , ... C XN , CY1 , CY2 , CY3 , ... CYM is accumulated.
文書ベクトル算出部315は、文書蓄積部311が蓄積する複数の文書の各々から単語を抽出し、単語に基づき単語の重み及び単語ベクトルを算出して、重み及び単語ベクトルに基づき、複数の文書の各々の文書ベクトルを算出する。文書ベクトル算出部315の処理は、図10の処理P5~P7及び処理P8の少なくとも一部の一例である。
The document vector calculation unit 315 extracts a word from each of the plurality of documents accumulated by the document storage unit 311, calculates a word weight and a word vector based on the word, and based on the weight and the word vector, the document vector calculation unit 315 of the plurality of documents. Calculate each document vector. The process of the document vector calculation unit 315 is an example of at least a part of the processes P5 to P7 and the process P8 in FIG.
文書ベクトル蓄積部316は、図6に示すメモリ部21の一例であり、文書ベクトル算出部315が算出した文書ベクトルを蓄積する。
The document vector storage unit 316 is an example of the memory unit 21 shown in FIG. 6, and stores the document vector calculated by the document vector calculation unit 315.
(文書検索部32の説明)
図11に示すように、文書検索部32は、例示的に、検索クエリ指定部321、文書類似度算出部322、検索結果生成部323、及び、検索結果出力部324を備えてよい。 (Explanation of the document search unit 32)
As shown in FIG. 11, thedocument search unit 32 may optionally include a search query designation unit 321, a document similarity calculation unit 322, a search result generation unit 323, and a search result output unit 324.
図11に示すように、文書検索部32は、例示的に、検索クエリ指定部321、文書類似度算出部322、検索結果生成部323、及び、検索結果出力部324を備えてよい。 (Explanation of the document search unit 32)
As shown in FIG. 11, the
検索クエリ指定部321は、図6に示す文書入力部22の一例であり、図示しない端末装置又は他のサーバ等のコンピュータから、文書検索を要求するクエリ11(以下、「検索クエリ11」と表記する場合がある)の入力を受け付ける。
The search query designation unit 321 is an example of the document input unit 22 shown in FIG. 6, and is a query 11 requesting a document search from a computer such as a terminal device (not shown) or another server (hereinafter referred to as “search query 11”). (May be) Accept the input.
例えば、図12に示すように、検索クエリ指定部321は、検索クエリ指定画面330の検索ボタン332が押下された際に入力欄331に設定されている、クエリ文書11aの文書番号を受け付けてよい。
For example, as shown in FIG. 12, the search query specification unit 321 may accept the document number of the query document 11a set in the input field 331 when the search button 332 of the search query specification screen 330 is pressed. ..
文書類似度算出部322は、図6に示す文書類似度算出部233の一例である。文書類似度算出部322は、化合物クラスタ蓄積部314に蓄積された化合物クラスタ、及び、文書ベクトル蓄積部316に蓄積された文書ベクトルに基づき、検索クエリ11で指定されたクエリ文書11aと他の文書との間の文書類似度Sim(X,Y)を算出する。
The document similarity calculation unit 322 is an example of the document similarity calculation unit 233 shown in FIG. The document similarity calculation unit 322 includes the query document 11a specified by the search query 11 and other documents based on the compound cluster stored in the compound cluster storage unit 314 and the document vector stored in the document vector storage unit 316. The document similarity Sim (X, Y) between and is calculated.
例えば、文書類似度算出部322は、化合物クラスタ蓄積部314に蓄積された化合物クラスタのうちの、クエリ文書11a及び比較対象文書12aにそれぞれ対応する化合物クラスタどうしを比較し、化合物類似度を算出してよい。
For example, the document similarity calculation unit 322 compares the compound clusters corresponding to the query document 11a and the comparison target document 12a among the compound clusters accumulated in the compound cluster storage unit 314, and calculates the compound similarity. You can do it.
また、文書類似度算出部322は、文書ベクトル蓄積部316に蓄積された文書ベクトルのうちの、クエリ文書11a及び比較対象文書12aにそれぞれ対応する文書ベクトルどうしを比較し、テキスト類似度を算出してよい。
Further, the document similarity calculation unit 322 compares the document vectors corresponding to the query document 11a and the comparison target document 12a among the document vectors stored in the document vector storage unit 316, and calculates the text similarity. You can do it.
そして、文書類似度算出部322は、化合物類似度及びテキスト類似度に基づき、文書類似度Sim(X,Y)を算出し、文書類似度Sim(X,Y)の大きい順に比較対象文書12aをソートすることで、ランキングの結果14を生成してよい。
Then, the document similarity calculation unit 322 calculates the document similarity Sim (X, Y) based on the compound similarity and the text similarity, and compares the documents 12a in descending order of the document similarity Sim (X, Y). By sorting, the ranking result 14 may be generated.
文書類似度算出部322の処理は、図10の処理P3、処理P8の少なくとも一部、及び、処理P9の一例である。
The process of the document similarity calculation unit 322 is an example of the process P3, at least a part of the process P8, and the process P9 in FIG.
検索結果生成部323は、結果14に基づき、出力するための検索結果を生成する。例えば、検索結果生成部323は、図12に示す検索結果出力画面340を生成してよい。検索結果出力画面340は、図7に示す判定結果出力画面240における判定結果244を検索結果344に置き換えたものであってもよい。
The search result generation unit 323 generates a search result for output based on the result 14. For example, the search result generation unit 323 may generate the search result output screen 340 shown in FIG. The search result output screen 340 may replace the determination result 244 in the determination result output screen 240 shown in FIG. 7 with the search result 344.
図12に示すように、検索結果出力画面340には、クエリ文書11aの表示領域341と、比較対象文書12aの少なくとも1つ(図12では3つ)の表示領域345a~345cとが含まれてよい。表示領域341には、クエリ文書11aの書誌情報及び要約等の表示領域342、及び、クエリ文書11aの全文参照ボタン343が含まれてよい。
As shown in FIG. 12, the search result output screen 340 includes a display area 341 of the query document 11a and display areas 345a to 345c of at least one (three in FIG. 12) of the comparison target document 12a. good. The display area 341 may include a display area 342 such as bibliographic information and a summary of the query document 11a, and a full-text reference button 343 of the query document 11a.
表示領域345a~345cには、比較対象文書12aの書誌情報及び要約等の表示領域346a~346c、全文参照ボタン347a~347c、及び、類似すると判定されたクラスタの化合物リスト348a~348cが含まれてよい。なお、表示領域345a~345cには、類似度Sim(X,Y)が表示されてもよい。
The display areas 345a to 345c include display areas 346a to 346c for bibliographic information and summaries of the comparison target document 12a, full text reference buttons 347a to 347c, and compound lists 348a to 348c of clusters determined to be similar. good. The similarity Sim (X, Y) may be displayed in the display areas 345a to 345c.
検索結果出力部324は、図示しない端末装置又は他のサーバ等のコンピュータに対して、検索結果出力画面340を出力する。
The search result output unit 324 outputs the search result output screen 340 to a computer such as a terminal device or another server (not shown).
〔2-3〕動作例
図13は、サーバ3の文書DB構築処理の動作例を説明するフローチャートであり、図14は、サーバ3の文書検索処理の動作例を説明するフローチャートである。 [2-3] Operation Example FIG. 13 is a flowchart illustrating an operation example of the document DB construction process of theserver 3, and FIG. 14 is a flowchart illustrating an operation example of the document retrieval process of the server 3.
図13は、サーバ3の文書DB構築処理の動作例を説明するフローチャートであり、図14は、サーバ3の文書検索処理の動作例を説明するフローチャートである。 [2-3] Operation Example FIG. 13 is a flowchart illustrating an operation example of the document DB construction process of the
(文書DB構築処理の動作例)
図13に例示するように、文書蓄積部311は、未選択の文書を選択し(ステップS21)、文書DBに文書を登録する(ステップS22)。 (Operation example of document DB construction process)
As illustrated in FIG. 13, thedocument storage unit 311 selects an unselected document (step S21) and registers the document in the document DB (step S22).
図13に例示するように、文書蓄積部311は、未選択の文書を選択し(ステップS21)、文書DBに文書を登録する(ステップS22)。 (Operation example of document DB construction process)
As illustrated in FIG. 13, the
文書ベクトル算出部315は、文書のテキストの文書ベクトルを算出する(ステップS23)。文書ベクトル蓄積部316は、算出した文書ベクトルを文書と対応付けて、例えば文書DB又は文書ベクトルDB等に登録(蓄積)する(ステップS24)。
The document vector calculation unit 315 calculates the document vector of the text of the document (step S23). The document vector storage unit 316 associates the calculated document vector with the document and registers (stores) it in, for example, a document DB or a document vector DB (step S24).
化合物名抽出部312は、文書のテキストから化合物名を抽出する(ステップS25)。クラスタリング部313は、抽出した化合物名をクラスタリングする(ステップS26)。化合物クラスタ蓄積部314は、化合物クラスタの情報を文書と対応付けて、例えば文書DB又は化合物クラスタDB等に登録(蓄積)する(ステップS27)。
The compound name extraction unit 312 extracts the compound name from the text of the document (step S25). The clustering unit 313 clusters the extracted compound names (step S26). The compound cluster storage unit 314 associates the information of the compound cluster with the document and registers (stores) it in, for example, the document DB or the compound cluster DB (step S27).
文書蓄積部311は、未選択の文書があるか否かを判定し(ステップS28)、あると判定した場合(ステップS28でYES)、処理がステップS21に移行する。文書蓄積部311が未選択の文書がないと判定した場合(ステップS28でNO)、処理が終了する。
The document storage unit 311 determines whether or not there is an unselected document (step S28), and if it determines that there is an unselected document (YES in step S28), the process proceeds to step S21. When the document storage unit 311 determines that there is no unselected document (NO in step S28), the process ends.
なお、ステップS23及びS24の処理と、ステップS25~S27の処理とを入れ替えてもよいし、これらの処理の少なくとも一部が前後又は並行して実行されてもよい。
Note that the processes of steps S23 and S24 may be interchanged with the processes of steps S25 to S27, or at least a part of these processes may be executed before, after, or in parallel.
(文書検索処理の動作例)
図14に例示するように、検索クエリ指定部321は、検索クエリ指定画面330からのクエリ文書11aの指定を受け付ける(ステップS31)。 (Operation example of document search processing)
As illustrated in FIG. 14, the searchquery designation unit 321 accepts the designation of the query document 11a from the search query designation screen 330 (step S31).
図14に例示するように、検索クエリ指定部321は、検索クエリ指定画面330からのクエリ文書11aの指定を受け付ける(ステップS31)。 (Operation example of document search processing)
As illustrated in FIG. 14, the search
文書類似度算出部322は、文書ベクトル蓄積部316からクエリ文書11aの文書ベクトルを取得し(ステップS32)、化合物クラスタ蓄積部314からクエリ文書11aの化合物クラスタを取得する(ステップS33)。
The document similarity calculation unit 322 acquires the document vector of the query document 11a from the document vector storage unit 316 (step S32), and acquires the compound cluster of the query document 11a from the compound cluster storage unit 314 (step S33).
文書類似度算出部322は、未選択の文書を選択し(ステップS34)、文書ベクトル蓄積部316から選択した文書の文書ベクトルを取得し(ステップS35)、化合物クラスタ蓄積部314から選択した文書の化合物クラスタを取得する(ステップS36)。
The document similarity calculation unit 322 selects an unselected document (step S34), acquires the document vector of the selected document from the document vector storage unit 316 (step S35), and selects the document from the compound cluster storage unit 314. Acquire a compound cluster (step S36).
文書類似度算出部322は、クエリ文書11a及び選択した文書の文書類似度Sim(X,Y)を算出する(ステップS37)。
The document similarity calculation unit 322 calculates the document similarity Sim (X, Y) of the query document 11a and the selected document (step S37).
文書類似度算出部322は、未選択の文書があるか否かを判定し(ステップS38)、ある場合(ステップS38でYES)、処理がステップS34に移行する。文書類似度算出部322が未選択の文書がないと判定した場合(ステップS38でNO)、文書類似度算出部322は、文書類似度が高い順に所定の個数の文書と、各文書でクエリ文書11aとの文書類似度が最も高いクラスタとを抽出する(ステップS39)。
The document similarity calculation unit 322 determines whether or not there is an unselected document (step S38), and if so (YES in step S38), the process proceeds to step S34. When the document similarity calculation unit 322 determines that there is no unselected document (NO in step S38), the document similarity calculation unit 322 has a predetermined number of documents in descending order of document similarity and a query document for each document. The cluster having the highest document similarity with 11a is extracted (step S39).
検索結果生成部323は、抽出したデータに基づき検索結果を生成し、検索結果出力部324が検索結果、例えば検索結果出力画面340を出力し(ステップS40)、処理が終了する。
The search result generation unit 323 generates a search result based on the extracted data, the search result output unit 324 outputs a search result, for example, a search result output screen 340 (step S40), and the process ends.
〔2-4〕第1変形例
次に、第2実施形態の第1変形例について説明する。 [2-4] First Modification Example Next, a first modification of the second embodiment will be described.
次に、第2実施形態の第1変形例について説明する。 [2-4] First Modification Example Next, a first modification of the second embodiment will be described.
(機能構成例)
図15は、第2実施形態の第1変形例及び後述する第2変形例に係る類似度判定システム1Bにおけるサーバ4の機能構成例を示すブロック図であり、図16及び図17は、サーバ4による画面出力例を示す図である。 (Functional configuration example)
FIG. 15 is a block diagram showing a functional configuration example of theserver 4 in the similarity determination system 1B according to the first modification of the second embodiment and the second modification described later, and FIGS. 16 and 17 are the server 4. It is a figure which shows the screen output example by.
図15は、第2実施形態の第1変形例及び後述する第2変形例に係る類似度判定システム1Bにおけるサーバ4の機能構成例を示すブロック図であり、図16及び図17は、サーバ4による画面出力例を示す図である。 (Functional configuration example)
FIG. 15 is a block diagram showing a functional configuration example of the
第1変形例に係る類似度判定システム1Bは、クエリ文書11aのクラスタリングの結果であるクラスタを固有表現のリストとしてユーザに提示し、類似度計算に用いるクラスタをユーザに選択させた後に、選択されたクラスタを用いて類似度計算を行なう。これにより、クエリ文書11a内の複数の構成要素のうち、ユーザの意図した構成要素による比較対象文書12aの検索を行なうことができ、文書間の類似度の判定精度をより向上させることができる。
The similarity determination system 1B according to the first modification is selected after presenting the cluster that is the result of clustering of the query document 11a to the user as a list of unique expressions and allowing the user to select the cluster to be used for the similarity calculation. The similarity is calculated using the clusters. As a result, among the plurality of components in the query document 11a, the comparison target document 12a can be searched by the component intended by the user, and the accuracy of determining the degree of similarity between the documents can be further improved.
図15に示すように、サーバ4は、例示的に、文書DB部31及び文書検索部42を備えてよい。文書DB部31及び文書検索部42は、制御部の一例である。文書DB部31は、図11に示す文書DB部31と同様である。
As shown in FIG. 15, the server 4 may optionally include a document DB unit 31 and a document search unit 42. The document DB unit 31 and the document search unit 42 are examples of control units. The document DB unit 31 is the same as the document DB unit 31 shown in FIG.
文書検索部42は、例示的に、検索クエリ指定部421、文書類似度算出部422、検索結果生成部423、検索結果出力部424、化合物クラスタ取得部425、クラスタ提示部426、及び、クラスタ指定部427を備えてよい。
The document search unit 42 is exemplified by a search query designation unit 421, a document similarity calculation unit 422, a search result generation unit 423, a search result output unit 424, a compound cluster acquisition unit 425, a cluster presentation unit 426, and a cluster designation. A unit 427 may be provided.
検索クエリ指定部421、文書類似度算出部422、検索結果生成部423及び検索結果出力部424は、特に言及しない場合、図11に示す検索クエリ指定部321、文書類似度算出部322、検索結果生成部323及び検索結果出力部324と同様である。
Unless otherwise specified, the search query specification unit 421, the document similarity calculation unit 422, the search result generation unit 423, and the search result output unit 424 are the search query specification unit 321 shown in FIG. 11, the document similarity calculation unit 322, and the search results. This is the same as the generation unit 323 and the search result output unit 324.
化合物クラスタ取得部425は、検索クエリ指定部421が受け付けたクエリ文書11aの化合物クラスタを化合物クラスタ蓄積部314から取得し、クエリ文書11aとともにクラスタ提示部426に通知する。
The compound cluster acquisition unit 425 acquires the compound cluster of the query document 11a received by the search query designation unit 421 from the compound cluster storage unit 314, and notifies the cluster presentation unit 426 together with the query document 11a.
クラスタ提示部426は、化合物クラスタ取得部425から取得したクエリ文書11aの化合物クラスタをユーザに提示する。例えば、クラスタ提示部426は、図16に示すクラスタ指定画面440を生成し、端末装置又は他のサーバ等のコンピュータに出力する。
The cluster presentation unit 426 presents the compound cluster of the query document 11a acquired from the compound cluster acquisition unit 425 to the user. For example, the cluster presentation unit 426 generates the cluster designation screen 440 shown in FIG. 16 and outputs it to a computer such as a terminal device or another server.
図16に示すように、クラスタ指定画面440は、クエリ文書11aの表示領域441と、当該クエリ文書11aに含まれる複数の化合物クラスタを提示する表示領域444とを含んでよい。表示領域441には、クエリ文書11aの書誌情報及び要約等の表示領域442、及び、クエリ文書11aの全文参照ボタン443が含まれてよい。
As shown in FIG. 16, the cluster designation screen 440 may include a display area 441 of the query document 11a and a display area 444 that presents a plurality of compound clusters contained in the query document 11a. The display area 441 may include a display area 442 such as bibliographic information and a summary of the query document 11a, and a full-text reference button 443 of the query document 11a.
表示領域444には、クエリ文書11aの複数のクラスタに対応する複数の化合物リスト445と、複数の化合物リスト445から類似度計算に用いる化合物クラスタを指定するためのチェックボックス446と、検索を実行するための検索ボタン447とを含んでよい。
In the display area 444, a plurality of compound lists 445 corresponding to the plurality of clusters of the query document 11a, a check box 446 for designating the compound clusters to be used for the similarity calculation from the plurality of compound lists 445, and a search are executed. May include a search button 447 for.
クラスタ指定部427は、クラスタ指定画面440の検索ボタン447が押下された際にチェックボックス446が選択されている化合物リスト445の情報を、文書類似度算出部422に通知する。
The cluster designation unit 427 notifies the document similarity calculation unit 422 of the information of the compound list 445 in which the check box 446 is selected when the search button 447 of the cluster designation screen 440 is pressed.
文書類似度算出部422は、クエリ文書11aと、選択した文書との間の文書類似度Sim(X,Y)の算出の際に用いる化合物クラスタを、クラスタ指定部427から指定された化合物リストに制限(限定)する。例えば、文書類似度算出部422は、クエリ文書11aの複数の化合物クラスタのうちの指定された化合物クラスタに限定し、当該化合物クラスタの化合物リストと、選択した文書の複数の化合物リストとを比較してよい。
The document similarity calculation unit 422 adds the compound cluster used for calculating the document similarity Sim (X, Y) between the query document 11a and the selected document to the compound list designated by the cluster designation unit 427. Limit (limit). For example, the document similarity calculation unit 422 is limited to the specified compound cluster among the plurality of compound clusters of the query document 11a, and compares the compound list of the compound cluster with the plurality of compound lists of the selected document. It's okay.
検索結果生成部423及び検索結果出力部424は、文書類似度算出部422による結果14に基づき、図17に示すような検索結果出力画面450を生成及び出力してよい。ここで、クラスタ指定画面440において、類似度計算に用いる化合物クラスタが指定されている。このため、検索結果出力画面450では、化合物リスト(図12の化合物リスト348a~348c参照)の表示が省略されてよい。なお、図12の例と同様に、検索結果出力画面450に化合物リストが表示されてもよい。
The search result generation unit 423 and the search result output unit 424 may generate and output the search result output screen 450 as shown in FIG. 17 based on the result 14 by the document similarity calculation unit 422. Here, on the cluster designation screen 440, the compound cluster used for the similarity calculation is designated. Therefore, the display of the compound list (see the compound lists 348a to 348c in FIG. 12) may be omitted on the search result output screen 450. As in the example of FIG. 12, the compound list may be displayed on the search result output screen 450.
このように、第1変形例に係るサーバ4によれば、第2実施形態と同様の効果を奏することができるほか、類似度の判定に用いる化合物クラスタを適切な化合物クラスタに限定することができ、文書間の類似度の判定精度をより向上させることができる。また、類似度の判定に用いる化合物クラスタの数を制限できるため、文書検索処理の処理時間を短縮することができる。
As described above, according to the server 4 according to the first modification, the same effect as that of the second embodiment can be obtained, and the compound cluster used for determining the similarity can be limited to an appropriate compound cluster. , It is possible to further improve the determination accuracy of the similarity between documents. Further, since the number of compound clusters used for determining the similarity can be limited, the processing time of the document retrieval process can be shortened.
(文書検索処理の動作例)
図18は、サーバ4の文書検索処理の動作例を説明するフローチャートである。以下、サーバ4の文書検索処理のうちの図14に示す動作例とは異なる処理を説明する。 (Operation example of document search processing)
FIG. 18 is a flowchart illustrating an operation example of the document retrieval process of theserver 4. Hereinafter, a process different from the operation example shown in FIG. 14 in the document retrieval process of the server 4 will be described.
図18は、サーバ4の文書検索処理の動作例を説明するフローチャートである。以下、サーバ4の文書検索処理のうちの図14に示す動作例とは異なる処理を説明する。 (Operation example of document search processing)
FIG. 18 is a flowchart illustrating an operation example of the document retrieval process of the
図18に例示するように、化合物クラスタ取得部425は、化合物クラスタ蓄積部314から、クエリ文書11aの化合物クラスタ、換言すれば化合物リストを取得する(ステップS41)。
As illustrated in FIG. 18, the compound cluster acquisition unit 425 acquires the compound cluster of the query document 11a, in other words, the compound list, from the compound cluster storage unit 314 (step S41).
クラスタ提示部426は、化合物クラスタ取得部425が取得した化合物リストを含むクラスタ指定画面440を生成し、ユーザに提示する(ステップS42)。クラスタ指定部427は、クラスタ指定画面440における化合物クラスタの指定を受け付け(ステップS43)、処理がステップS34に移行する。なお、ステップS41~S43の処理は、ステップS32の前、後、又は、並行して実行されてもよい。
The cluster presentation unit 426 generates a cluster designation screen 440 including the compound list acquired by the compound cluster acquisition unit 425 and presents it to the user (step S42). The cluster designation unit 427 accepts the designation of the compound cluster on the cluster designation screen 440 (step S43), and the process proceeds to step S34. The processes of steps S41 to S43 may be executed before, after, or in parallel with step S32.
文書類似度算出部422は、選択した文書の文書ベクトル及び化合物クラスタの取得後、選択した文書の化合物クラスタを、クラスタ指定部427が受け付けた指定クラスタに限定する。
After acquiring the document vector and compound cluster of the selected document, the document similarity calculation unit 422 limits the compound cluster of the selected document to the designated cluster accepted by the cluster designation unit 427.
そして、文書類似度算出部422は、クエリ文書11aの化合物リストを、指定クラスタ、換言すれば、指定された化合物リストに限定して、クエリ文書11aと選択した文書との間の文書間類似度を算出し(ステップS44)、処理がステップS38に移行する。
Then, the document similarity calculation unit 422 limits the compound list of the query document 11a to the designated cluster, in other words, the designated compound list, and the inter-document similarity between the query document 11a and the selected document. Is calculated (step S44), and the process proceeds to step S38.
文書類似度算出部422は、全ての文書について文書類似度の算出が完了すると(ステップS38でNO)、類似度が高い順に、所定の個数の文書を抽出し(ステップS45)、処理がステップS40に移行する。
When the document similarity calculation unit 422 completes the calculation of the document similarity for all the documents (NO in step S38), the document similarity calculation unit 422 extracts a predetermined number of documents in descending order of similarity (step S45), and the process is step S40. Move to.
〔2-5〕第2変形例
次に、第2実施形態の第2変形例について説明する。 [2-5] Second Modified Example Next, a second modified example of the second embodiment will be described.
次に、第2実施形態の第2変形例について説明する。 [2-5] Second Modified Example Next, a second modified example of the second embodiment will be described.
第2変形例に係る類似度判定システム1Bにおけるサーバ4の機能構成例は、図15に示す第1変形例と同様である。図19は、第2変形例に係るサーバ4の画面出力例を示す図である。図19に示すように、第2変形例では、検索クエリ指定部421が、検索クエリ指定画面460に、クエリ文書11aの文書番号の入力欄461及び1以上のキーワード(ここでは化合物名)の入力領域462を含める。クラスタ指定部427は、検索ボタン463が押下された際に入力欄461に入力されているクエリ文書11aの文書番号及び入力領域462に入力されている1以上のキーワードの情報を、文書類似度算出部422に通知する。
The functional configuration example of the server 4 in the similarity determination system 1B according to the second modification is the same as the first modification shown in FIG. FIG. 19 is a diagram showing a screen output example of the server 4 according to the second modification. As shown in FIG. 19, in the second modification, the search query specification unit 421 inputs the document number input field 461 of the query document 11a and one or more keywords (here, the compound name) on the search query specification screen 460. Includes region 462. The cluster designation unit 427 calculates the document similarity of the document number of the query document 11a input in the input field 461 and the information of one or more keywords input in the input area 462 when the search button 463 is pressed. Notify section 422.
文書類似度算出部422は、指定されたクエリ文書11aと比較する文書の化合物クラスタを、クラスタ指定部427が受け付けたキーワードを含む(例えば所定回数以上含む)クラスタに限定する。そして、文書類似度算出部422は、指定キーワードを含むクラスタ、換言すれば化合物リストに着目して、クエリ文書11aと当該文書との間の文書間類似度を算出する。
The document similarity calculation unit 422 limits the compound cluster of the document to be compared with the designated query document 11a to the cluster including the keyword accepted by the cluster designation unit 427 (for example, including a predetermined number of times or more). Then, the document similarity calculation unit 422 focuses on the cluster including the designated keyword, in other words, the compound list, and calculates the inter-document similarity between the query document 11a and the document.
このように、第2変形例に係るサーバ4によれば、第1変形例と同様の効果を奏することができるほか、ユーザは、特定のクラスタに限定せず、所定のキーワードを含むクラスタを柔軟に指定することができ、利便性が高い。
As described above, according to the server 4 according to the second modification, the same effect as that of the first modification can be obtained, and the user is not limited to a specific cluster and can flexibly use a cluster including a predetermined keyword. It can be specified as, and it is highly convenient.
〔3〕第3実施形態
〔3-1〕第3実施形態の説明
次に、第3実施形態について説明する。第3実施形態では、第2実施形態に係るテキスト類似度の算出処理において、固有表現類似度の算出の過程で得られるクラスタリング結果を利用する手法を説明する。 [3] Third Embodiment [3-1] Description of the Third Embodiment Next, the third embodiment will be described. In the third embodiment, a method of utilizing the clustering result obtained in the process of calculating the named entity similarity in the text similarity calculation process according to the second embodiment will be described.
〔3-1〕第3実施形態の説明
次に、第3実施形態について説明する。第3実施形態では、第2実施形態に係るテキスト類似度の算出処理において、固有表現類似度の算出の過程で得られるクラスタリング結果を利用する手法を説明する。 [3] Third Embodiment [3-1] Description of the Third Embodiment Next, the third embodiment will be described. In the third embodiment, a method of utilizing the clustering result obtained in the process of calculating the named entity similarity in the text similarity calculation process according to the second embodiment will be described.
なお、以下の第3実施形態の説明では、特に言及しない構成、処理又は機能は、既述の第1実施形態及び第2実施形態に係る構成、処理又は機能と同様であるものとする。
In the following description of the third embodiment, the configurations, processes or functions not particularly mentioned are the same as the configurations, processes or functions according to the first embodiment and the second embodiment described above.
図20は、第3実施形態に係る類似度判定システム1Cを説明するための図であり、図21及び図22は、類似度判定システム1Cの処理の一例を説明するための図である。
FIG. 20 is a diagram for explaining the similarity determination system 1C according to the third embodiment, and FIGS. 21 and 22 are diagrams for explaining an example of processing of the similarity determination system 1C.
図20に示すように、第3実施形態に係る類似度判定システム1Cは、図10に示す類似度判定システム1Bの処理P8を処理P10及びP11に置き換え、処理P9を処理P12に置き換え、処理P2の処理結果を処理P10に渡すものである。以下、処理P10~P12について説明する。
As shown in FIG. 20, the similarity determination system 1C according to the third embodiment replaces the process P8 of the similarity determination system 1B shown in FIG. 10 with the processes P10 and P11, replaces the process P9 with the process P12, and replaces the process P2 with the process P2. The processing result of is passed to the processing P10. Hereinafter, the processes P10 to P12 will be described.
(部分文書クラスタリング処理;処理P10)
類似度判定システム1Cは、処理P10において、文書ごとに、文書を分割することによって複数の部分文書(部分テキスト)を取得する。部分文書、換言すれば、文書の分割単位としては、例えば、文、段落、章又は節等が挙げられる。以下、部分文書が段落であるものとする。 (Partial document clustering process; process P10)
The similarity determination system 1C acquires a plurality of partial documents (partial texts) by dividing the document for each document in the process P10. Sub-documents, in other words, document division units include, for example, sentences, paragraphs, chapters, sections, and the like. Hereinafter, it is assumed that the partial document is a paragraph.
類似度判定システム1Cは、処理P10において、文書ごとに、文書を分割することによって複数の部分文書(部分テキスト)を取得する。部分文書、換言すれば、文書の分割単位としては、例えば、文、段落、章又は節等が挙げられる。以下、部分文書が段落であるものとする。 (Partial document clustering process; process P10)
The similarity determination system 1C acquires a plurality of partial documents (partial texts) by dividing the document for each document in the process P10. Sub-documents, in other words, document division units include, for example, sentences, paragraphs, chapters, sections, and the like. Hereinafter, it is assumed that the partial document is a paragraph.
図21及び図22の例では、類似度判定システム1Cは、クエリ11に含まれる文書Xを分割して複数の段落PXを取得し、文書集合12に含まれる文書Yを分割して複数の段落PYを取得する。以下、段落PX及びPYを互いに区別しない場合には、単に「段落P」と表記する。
In the example of FIGS. 21 and 22, the similarity determination system 1C divides the document X included in the query 11 to acquire a plurality of paragraphs PX , and divides the document Y included in the document set 12 into a plurality of documents Y. Get the paragraph P Y. Hereinafter, when paragraphs PX and P Y are not distinguished from each other, they are simply referred to as "paragraph P".
類似度判定システム1Cは、段落Pを、処理P2で得られる固有表現(例えば化合物)クラスタに基づきクラスタリングすることによって、部分文書クラスタを取得する。例えば、類似度判定システム1Cは、固有表現クラスタに含まれる固有表現と、複数の段落Pに含まれる固有表現との間の一致度に基づいて、段落Pをクラスタリングしてよい。
The similarity determination system 1C acquires a partial document cluster by clustering the paragraph P based on the named entity (for example, compound) cluster obtained in the process P2. For example, the similarity determination system 1C may cluster the paragraphs P based on the degree of agreement between the named entity included in the named entity cluster and the named entity included in the plurality of paragraphs P.
図21の例では、類似度判定システム1Cは、文書Xについて、下記式(11)に従い、クラスタごとの化合物リストCX1~CXNのそれぞれと、複数の段落PXのそれぞれとの一致度に基づき、部分文書クラスタPX1~PXNを生成する。また、類似度判定システム1Cは、文書Yについて、下記式(12)に従い、クラスタごとの化合物リストCY1~CYNのそれぞれと、複数の段落PYのそれぞれとの一致度cos(CPX,CXa)に基づき、部分文書クラスタPY1~PYNを生成する。

In the example of FIG. 21, the similarity determination system 1C determines the degree of coincidence between each of the compound lists C X1 to C XN for each cluster and each of the plurality of paragraphs PX for the document X according to the following formula (11). Based on this, partial document clusters PX1 to PXN are generated. Further, the similarity determination system 1C has a degree of coincidence cos (CPX,) between each of the compound lists CY1 to CYN for each cluster and each of the plurality of paragraphs P Y for the document Y according to the following formula (12) . Sub-document clusters P Y1 to P YN are generated based on C Xa ).
上記式(11)及び式(12)において、CPXは、段落PXに含まれる化合物リストであり、CPYは、段落PYに含まれる化合物リストである。CXa及びCYbは、処理P2で得られる文書X及びYの化合物リストである。argmaxは、括弧内の要素が最大となるときの条件(ここではクラスタ)を抽出する関数である。上記式(11)及び式(12)によれば、段落Pに含まれる化合物名の各々と、化合物クラスタ内の化合物名の各々との間のコサイン類似度が最大となる、例えば出現数が最多となる要素(化合物クラスタ)に、段落Pを振り分けることができる。
In the above formulas (11) and (12), C PX is a list of compounds included in paragraph PX , and C P Y is a list of compounds included in paragraph P Y. C Xa and CYb are compound lists of documents X and Y obtained in treatment P2. argmax is a function that extracts the condition (here, cluster) when the element in parentheses is the maximum. According to the above formulas (11) and (12), the cosine similarity between each of the compound names contained in paragraph P and each of the compound names in the compound cluster is the maximum, for example, the number of occurrences is the largest. Paragraph P can be assigned to the element (compound cluster).
図22の例では、類似度判定システム1Cは、段落PX及びPYをそれぞれ4つのクラスタに分類し(N=M=4)、部分文書クラスタPX1~PX4及びPY1~PY4を生成する。このようなクラスタリングにより、結果的に、段落PX及びPYを、以下のような4つの要素(特性)の部分文書クラスタに分類することができる。
・部分文書クラスタPX1及びPY1:
「負極活物質」について記載された段落。
・部分文書クラスタPX2及びPY2:
「正極活物質」について記載された段落。
・部分文書クラスタPX3及びPY3:
「バインダー」について記載された段落。
・部分文書クラスタPX4及びPY4:
「電解液溶媒」について記載された段落。 In the example of FIG. 22, the similarity determination system 1C classifies paragraphs PX and P Y into four clusters (N = M = 4), respectively, and divides the partial document clusters PX1 to PX4 and PY1 to PY4 . Generate. As a result, paragraphs PX and P Y can be classified into sub-document clusters of the following four elements (characteristics) by such clustering.
-Partial document clusters PX1 and PY1 :
A paragraph describing "negative electrode active material".
-Partial document clusters PX2 and PY2 :
A paragraph describing "positive electrode active material".
-Partial document clusters PX3 and PY3 :
A paragraph describing "binder".
-Partial document clusters PX4 and PY4 :
A paragraph describing "electrolyte solvent".
・部分文書クラスタPX1及びPY1:
「負極活物質」について記載された段落。
・部分文書クラスタPX2及びPY2:
「正極活物質」について記載された段落。
・部分文書クラスタPX3及びPY3:
「バインダー」について記載された段落。
・部分文書クラスタPX4及びPY4:
「電解液溶媒」について記載された段落。 In the example of FIG. 22, the similarity determination system 1C classifies paragraphs PX and P Y into four clusters (N = M = 4), respectively, and divides the partial document clusters PX1 to PX4 and PY1 to PY4 . Generate. As a result, paragraphs PX and P Y can be classified into sub-document clusters of the following four elements (characteristics) by such clustering.
-Partial document clusters PX1 and PY1 :
A paragraph describing "negative electrode active material".
-Partial document clusters PX2 and PY2 :
A paragraph describing "positive electrode active material".
-Partial document clusters PX3 and PY3 :
A paragraph describing "binder".
-Partial document clusters PX4 and PY4 :
A paragraph describing "electrolyte solvent".
そして、類似度判定システム1Cは、部分文書クラスタのそれぞれに含まれる単語に基づいて、複数の部分文書クラスタのそれぞれに対応する複数の部分文書ベクトルを算出する。例えば、類似度判定システム1Cは、部分文書クラスタごとに、処理P7で取得した単語ベクトルと、処理P6で取得した単語の重みとを乗じた結果を部分文書クラスタ内の全単語に亘って加算することで、部分文書ベクトルを算出してよい。
Then, the similarity determination system 1C calculates a plurality of subdocument vectors corresponding to each of the plurality of subdocument clusters based on the words included in each of the subdocument clusters. For example, the similarity determination system 1C adds the result of multiplying the word vector acquired in the process P7 and the weight of the word acquired in the process P6 over all the words in the subdocument cluster for each subdocument cluster. By doing so, the partial document vector may be calculated.
(テキスト類似度算出処理;処理P11)
類似度判定システム1Cは、処理P11において、クエリ文書11aの部分文書ベクトルと、比較対象文書12aの各々の部分文書ベクトルとの間の類似度、換言すれば、単語の意味ベクトルに基づく、部分文書クラスタ間のテキスト類似度を算出する。クエリ文書11aの部分文書ベクトルは、第1の複数のベクトルの一例であり、比較対象文書12aの部分文書ベクトルは、第2の複数のベクトルの一例である。 (Text similarity calculation process; process P11)
In the process P11, the similarity determination system 1C is a partial document based on the similarity between the partial document vector of thequery document 11a and each partial document vector of the comparison target document 12a, in other words, the meaning vector of the word. Calculate the text similarity between clusters. The partial document vector of the query document 11a is an example of the first plurality of vectors, and the partial document vector of the comparison target document 12a is an example of the second plurality of vectors.
類似度判定システム1Cは、処理P11において、クエリ文書11aの部分文書ベクトルと、比較対象文書12aの各々の部分文書ベクトルとの間の類似度、換言すれば、単語の意味ベクトルに基づく、部分文書クラスタ間のテキスト類似度を算出する。クエリ文書11aの部分文書ベクトルは、第1の複数のベクトルの一例であり、比較対象文書12aの部分文書ベクトルは、第2の複数のベクトルの一例である。 (Text similarity calculation process; process P11)
In the process P11, the similarity determination system 1C is a partial document based on the similarity between the partial document vector of the
例えば、類似度判定システム1Cは、クエリ文書11aの部分文書クラスタと比較対象文書12aの部分文書クラスタとについて、下記式(13)の演算により、テキスト類似度、一例としてコサイン類似度を算出してよい。

For example, the similarity determination system 1C calculates the text similarity, for example, the cosine similarity between the partial document cluster of the query document 11a and the partial document cluster of the comparison target document 12a by the calculation of the following equation (13). good.
上記式(13)において、WPXaは、段落PXaに含まれる単語の分散ベクトルであり、WPYbは、段落PYbに含まれる単語の分散ベクトルである。
In the above equation (13), WP Xa is a dispersion vector of words included in paragraph PXa , and WP Yb is a dispersion vector of words included in paragraph P Yb .
図21に示す例では、類似度判定システム1Cは、部分文書クラスタPX1、PX2、PX3、・・・PXNと、部分文書クラスタPY1、PY2、PY3、・・・PYMとの全てのペアについて、上記式(13)に従いテキスト類似度を算出してよい。
In the example shown in FIG. 21, the similarity determination system 1C has partial document clusters PX1 , PX2 , PX3 , ... PXN , and partial document clusters XY1 , PHY2 , CY3 , ... PHYM . The text similarity may be calculated according to the above equation (13) for all pairs of and.
(ランキング処理;処理P12)
そして、類似度判定システム1Cは、テキスト類似度及び固有表現類似度に基づき、クエリ文書11aとの類似度に応じて複数の比較対象文書12aの各々をランキング付けするランキング処理を行ない(処理P12)、結果14を出力する。 (Ranking process; process P12)
Then, the similarity determination system 1C performs a ranking process of ranking each of the plurality ofcomparison target documents 12a according to the similarity with the query document 11a based on the text similarity and the named entity similarity (process P12). , The result 14 is output.
そして、類似度判定システム1Cは、テキスト類似度及び固有表現類似度に基づき、クエリ文書11aとの類似度に応じて複数の比較対象文書12aの各々をランキング付けするランキング処理を行ない(処理P12)、結果14を出力する。 (Ranking process; process P12)
Then, the similarity determination system 1C performs a ranking process of ranking each of the plurality of
例えば、類似度判定システム1Cは、ランキング処理において、テキスト類似度と固有表現類似度を統合した類似度を算出し、当該類似度に基づき、クエリ文書11aとの類似度に応じた複数の比較対象文書12aのランキングを出力する。
For example, the similarity determination system 1C calculates the similarity in which the text similarity and the named entity similarity are integrated in the ranking process, and based on the similarity, a plurality of comparison targets according to the similarity with the query document 11a. The ranking of the document 12a is output.
類似度判定システム1Cは、例えば、下記式(14)に従い、文書Xと1つの比較対象文書Yとの間の文書類似度Sim(X,Y)を算出してよい。

The similarity determination system 1C may calculate the document similarity Sim (X, Y) between the document X and one comparison target document Y, for example, according to the following equation (14).
上記式(14)において、fcは前述の(8)式に従った固有表現類似度、ftは上記式(13)に従ったテキスト類似度である。
In the above equation (14), fc is the named entity similarity according to the above equation (8), and ft is the text similarity according to the above equation (13).
なお、上記式(14)では、文書X(クエリ文書11a)と、1つの文書Y(比較対象文書12a)との間の文書類似度を算出する例を示す。類似度判定システム1Cは、第2実施形態と同様に、文書Yの数に応じた文書類似度Sim(X,Y1)~Sim(X,YL)を取得してよい。
The above formula (14) shows an example of calculating the document similarity between the document X (query document 11a) and one document Y (comparison target document 12a). Similar to the second embodiment, the similarity determination system 1C may acquire document similarity Sims (X, Y 1 ) to Sim (X, Y L ) according to the number of documents Y.
そして、類似度判定システム1Cは、例えば、第2実施形態と同様に、文書類似度Sim(X,Y1)~Sim(X,YL)が高い文書Yから降順に検索対象の全文書Y1~YLをソートすることで、ランキング処理を行なう。また、類似度判定システム1Cは、ソート結果を結果14として出力してよい。
Then, in the similarity determination system 1C, for example, as in the second embodiment, all the documents Y to be searched in descending order from the documents Y having the highest document similarity Sim (X, Y 1 ) to Sim (X, Y L ). Ranking processing is performed by sorting 1 to Y L. Further, the similarity determination system 1C may output the sort result as the result 14.
なお、類似度判定システム1Cは、第2実施形態と同様に、下記式(15)に従い、文書Xと1つの比較対象文書Yとの間の文書類似度Sim(X,Y)を、固有表現似度とテキスト類似度との重み付き和として算出してもよい。

As in the second embodiment, the similarity determination system 1C expresses the document similarity Sim (X, Y) between the document X and one comparison target document Y according to the following equation (15). It may be calculated as a weighted sum of similarity and text similarity.
以上のように、第3実施形態に係る類似度判定システム1Cによれば、第1及び第2実施形態と同様の効果を奏することができる。
As described above, according to the similarity determination system 1C according to the third embodiment, the same effects as those of the first and second embodiments can be obtained.
また、図22に示すように、部分文書クラスタどうしの比較を行なうことで、例えば、「正極活物質」についての意味ベクトルが類似しているから文書X及びYの類似度が高い、と判断することができる。図22では、便宜上、意味ベクトル空間を2次元で示すが、実際には数百次元のベクトルとなり得る。第3実施形態によれば、部分文書クラスタどうしの比較により、部分的に類似する文書間の類似度の判定精度を向上させることができる。
Further, as shown in FIG. 22, by comparing the partial document clusters, it is determined that, for example, the degree of similarity between the documents X and Y is high because the semantic vectors for the “positive electrode active material” are similar. be able to. In FIG. 22, for convenience, the semantic vector space is shown in two dimensions, but it can actually be a vector of several hundred dimensions. According to the third embodiment, the accuracy of determining the degree of similarity between partially similar documents can be improved by comparing the partial document clusters.
〔3-2〕機能構成例
図23は、第3実施形態に係る類似度判定システム1Cにおけるサーバ5の機能構成例を示すブロック図である。サーバ5は、特に言及しない場合、図11に示すサーバ3、又は、図15に示すサーバ4と同様であってよい。 [3-2] Functional Configuration Example FIG. 23 is a block diagram showing a functional configuration example of theserver 5 in the similarity determination system 1C according to the third embodiment. Unless otherwise specified, the server 5 may be the same as the server 3 shown in FIG. 11 or the server 4 shown in FIG.
図23は、第3実施形態に係る類似度判定システム1Cにおけるサーバ5の機能構成例を示すブロック図である。サーバ5は、特に言及しない場合、図11に示すサーバ3、又は、図15に示すサーバ4と同様であってよい。 [3-2] Functional Configuration Example FIG. 23 is a block diagram showing a functional configuration example of the
類似度判定システム1Cによる上述した類似度判定処理は、サーバ5により実現されてよい。図23に示すように、サーバ5は、例示的に、文書DB部51及び文書検索部52を備えてよい。文書DB部51及び文書検索部52は、制御部の一例である。
The above-mentioned similarity determination process by the similarity determination system 1C may be realized by the server 5. As shown in FIG. 23, the server 5 may optionally include a document DB unit 51 and a document retrieval unit 52. The document DB unit 51 and the document search unit 52 are examples of control units.
文書DB部51は、図11に示す文書ベクトル算出部315及び文書ベクトル蓄積部316に代えて、文書クラスタベクトル算出部515及び文書クラスタベクトル蓄積部516を備えてよい。また、文書DB部51では、クラスタリング部313から文書クラスタベクトル算出部515に、クラスタリング結果である化合物クラスタが出力されてよい。
The document DB unit 51 may include a document cluster vector calculation unit 515 and a document cluster vector storage unit 516 in place of the document vector calculation unit 315 and the document vector storage unit 316 shown in FIG. Further, in the document DB unit 51, the compound cluster which is the clustering result may be output from the clustering unit 313 to the document cluster vector calculation unit 515.
文書検索部52は、図11に示す文書類似度算出部322に代えて、文書類似度算出部522を備えてよい。
The document retrieval unit 52 may include a document similarity calculation unit 522 instead of the document similarity calculation unit 322 shown in FIG.
(文書DB部51の説明)
例えば、文書クラスタベクトル算出部515は、クラスタリング部313からの化合物クラスタの情報に基づき、部分文書クラスタごとの文書ベクトルを算出してよい。文書クラスタベクトル算出部515の処理は、図20に示す処理P10の処理の一例である。 (Explanation of document DB section 51)
For example, the document clustervector calculation unit 515 may calculate the document vector for each partial document cluster based on the information of the compound cluster from the clustering unit 313. The process of the document cluster vector calculation unit 515 is an example of the process of the process P10 shown in FIG.
例えば、文書クラスタベクトル算出部515は、クラスタリング部313からの化合物クラスタの情報に基づき、部分文書クラスタごとの文書ベクトルを算出してよい。文書クラスタベクトル算出部515の処理は、図20に示す処理P10の処理の一例である。 (Explanation of document DB section 51)
For example, the document cluster
文書クラスタベクトル蓄積部516は、文書クラスタベクトル算出部515が算出した部分文書クラスタごとの文書ベクトルを蓄積する。
The document cluster vector storage unit 516 stores the document vector for each partial document cluster calculated by the document cluster vector calculation unit 515.
(文書検索部52の説明)
文書類似度算出部522は、クエリ文書11aの部分文書ベクトルと、比較対象文書12aの各々の部分文書ベクトルとの間の文書類似度Sim(X,Y)を算出し、文書類似度Sim(X,Y)から結果14を生成してよい。文書類似度算出部522の処理は、図20の処理P3、処理P11、及び、処理P12の一例である。 (Explanation of the document search unit 52)
The documentsimilarity calculation unit 522 calculates the document similarity Sim (X, Y) between the partial document vector of the query document 11a and each partial document vector of the comparison target document 12a, and calculates the document similarity Sim (X, Y). , Y) may generate result 14. The process of the document similarity calculation unit 522 is an example of the process P3, the process P11, and the process P12 in FIG.
文書類似度算出部522は、クエリ文書11aの部分文書ベクトルと、比較対象文書12aの各々の部分文書ベクトルとの間の文書類似度Sim(X,Y)を算出し、文書類似度Sim(X,Y)から結果14を生成してよい。文書類似度算出部522の処理は、図20の処理P3、処理P11、及び、処理P12の一例である。 (Explanation of the document search unit 52)
The document
なお、第3実施形態に係る文書検索部52は、図12、図16、図17、図19等に示す上述した種々の画面を出力してよい。
Note that the document retrieval unit 52 according to the third embodiment may output the various screens shown in FIGS. 12, 16, 17, 19, 19 and the like.
〔3-3〕動作例
図24は、サーバ5の文書DB構築処理の動作例を説明するフローチャートであり、図25は、サーバ5の文書検索処理の動作例を説明するフローチャートである。 [3-3] Operation Example FIG. 24 is a flowchart illustrating an operation example of the document DB construction process of theserver 5, and FIG. 25 is a flowchart illustrating an operation example of the document retrieval process of the server 5.
図24は、サーバ5の文書DB構築処理の動作例を説明するフローチャートであり、図25は、サーバ5の文書検索処理の動作例を説明するフローチャートである。 [3-3] Operation Example FIG. 24 is a flowchart illustrating an operation example of the document DB construction process of the
(文書DB構築処理の動作例)
図24は、図13に示すステップS23及びS24を削除し、ステップS27とS28との間にステップS51~S54を追加したものである。 (Operation example of document DB construction process)
In FIG. 24, steps S23 and S24 shown in FIG. 13 are deleted, and steps S51 to S54 are added between steps S27 and S28.
図24は、図13に示すステップS23及びS24を削除し、ステップS27とS28との間にステップS51~S54を追加したものである。 (Operation example of document DB construction process)
In FIG. 24, steps S23 and S24 shown in FIG. 13 are deleted, and steps S51 to S54 are added between steps S27 and S28.
図24に例示するように、文書クラスタベクトル算出部515は、文書のテキストを所定単位に分割し(ステップS51)、化合物クラスタ蓄積部314が蓄積する化合物クラスタに基づき、各分割単位(段落P)をクラスタリングする(ステップS52)。
As illustrated in FIG. 24, the document cluster vector calculation unit 515 divides the text of the document into predetermined units (step S51), and each division unit (paragraph P) is based on the compound cluster accumulated by the compound cluster storage unit 314. (Step S52).
また、文書クラスタベクトル算出部515は、各部分文書クラスタの文書ベクトルを算出する(ステップS53)。文書クラスタベクトル蓄積部516は、各部分文書クラスタの文書ベクトルを蓄積し(ステップS54)、処理がステップS28に移行する。
Further, the document cluster vector calculation unit 515 calculates the document vector of each partial document cluster (step S53). The document cluster vector storage unit 516 stores the document vectors of each partial document cluster (step S54), and the process shifts to step S28.
(文書検索処理の動作例)
図25は、図14に示すステップS32、S35、S37を、それぞれステップS61、S62、ステップS63に置き換えたものである。 (Operation example of document search processing)
In FIG. 25, steps S32, S35, and S37 shown in FIG. 14 are replaced with steps S61, S62, and S63, respectively.
図25は、図14に示すステップS32、S35、S37を、それぞれステップS61、S62、ステップS63に置き換えたものである。 (Operation example of document search processing)
In FIG. 25, steps S32, S35, and S37 shown in FIG. 14 are replaced with steps S61, S62, and S63, respectively.
文書類似度算出部522は、ステップS61において、文書クラスタベクトル蓄積部516からクエリ文書11aの部分文書クラスタの文書ベクトルを取得する。
In step S61, the document similarity calculation unit 522 acquires the document vector of the partial document cluster of the query document 11a from the document cluster vector storage unit 516.
文書類似度算出部522は、ステップS62において、文書クラスタベクトル蓄積部516から選択した文書の部分文書クラスタの文書ベクトルを取得する。
In step S62, the document similarity calculation unit 522 acquires the document vector of the partial document cluster of the document selected from the document cluster vector storage unit 516.
文書類似度算出部522は、ステップS63において、ステップS61及びS62でそれぞれ取得した文書ベクトルと、化合物クラスタとに基づき、文書類似度Sim(X,Y)を算出する。
In step S63, the document similarity calculation unit 522 calculates the document similarity Sim (X, Y) based on the document vector acquired in steps S61 and S62, respectively, and the compound cluster.
〔4〕その他
上述した第1~第3実施形態、並びに、第2実施形態の第1及び第2変形例に係る技術は、以下のように変形、変更して実施することができる。 [4] Other Techniques according to the first to third embodiments described above and the first and second modifications of the second embodiment can be modified or modified as follows.
上述した第1~第3実施形態、並びに、第2実施形態の第1及び第2変形例に係る技術は、以下のように変形、変更して実施することができる。 [4] Other Techniques according to the first to third embodiments described above and the first and second modifications of the second embodiment can be modified or modified as follows.
例えば、上述した第1~第3実施形態、並びに、第2実施形態の第1及び第2変形例では、固有表現として、化合物名が用いられる場合を例に挙げて説明したが、これに限定されるものではない。固有表現としては、例えば遺伝子配列(ゲノム)等、自然言語処理において固有表現抽出処理の対象となり得る種々の用語が用いられてもよい。
For example, in the above-mentioned first to third embodiments and the first and second modifications of the second embodiment, the case where the compound name is used as a named entity has been described as an example, but the present invention is limited to this. It is not something that is done. As the named entity, various terms that can be the target of the named entity extraction process in natural language processing, such as a gene sequence (genome), may be used.
また、例えば、図6、図11、図15、図20に示すサーバ2~サーバ5のそれぞれが備える機能構成は、任意の組み合わせで併合してもよく、それぞれ分割してもよい。また、第1~第3実施形態、並びに、第2実施形態の第1及び第2変形例を適宜組み合わせて実施してもよい。さらに、サーバ2~サーバ5のそれぞれは、図7、図12、図16、図17、図19のいずれの画面の画面情報を生成してもよく、画面に応じた機能構成を備えてよい。
Further, for example, the functional configurations included in each of the servers 2 to 5 shown in FIGS. 6, 11, 15, and 20 may be merged or divided in any combination. Further, the first to third embodiments and the first and second modifications of the second embodiment may be combined as appropriate. Further, each of the servers 2 to 5 may generate screen information of any of the screens of FIGS. 7, 12, 16, 17, and 19, and may have a functional configuration according to the screen.
さらに、図6、図11、図15、図20に示すサーバ2~サーバ5のそれぞれは、複数の装置がネットワークを介して互いに連携することにより、各処理機能を実現する構成であってもよい。一例として、メモリ部21はDBサーバ、文書DB部31及び51はアプリケーションサーバ及びDBサーバの組み合わせ、文書入力部22、類似度算出部23、類似度出力部24、文書検索部32、42及び52はアプリケーションサーバ及びWebサーバの組み合わせ、等であってもよい。これらの場合、コンピュータ、アプリケーションサーバ及びDBサーバが、ネットワークを介して互いに連携することにより、サーバ2~5としての各処理機能を実現してもよい。
Further, each of the servers 2 to 5 shown in FIGS. 6, 11, 15, and 20 may be configured to realize each processing function by coordinating a plurality of devices with each other via a network. .. As an example, the memory unit 21 is a DB server, the document DB units 31 and 51 are a combination of an application server and a DB server, a document input unit 22, a similarity calculation unit 23, a similarity output unit 24, and a document search unit 32, 42 and 52. May be a combination of an application server and a Web server, and the like. In these cases, the computer, the application server, and the DB server may cooperate with each other via the network to realize each processing function as the servers 2 to 5.
また、サーバ3~5のそれぞれは、図9に例示するコンピュータ10のHW構成を備えてよい。
Further, each of the servers 3 to 5 may be provided with the HW configuration of the computer 10 illustrated in FIG.
1、1A~1C 類似度判定システム
10 コンピュータ
11 クエリ
11a クエリ文書
12 文書集合
12a 比較対象文書
13、14 結果
2~5 サーバ
21 メモリ部
22 文書入力部
23 類似度算出部
24 類似度出力部
231、312 化合物名抽出部
232、313 クラスタリング部
233 文書類似度算出部
31、51 文書DB部
311 文書蓄積部
314 化合物クラスタ蓄積部
315 文書ベクトル算出部
316 文書ベクトル蓄積部
32、42、52 文書検索部
321、421 検索クエリ指定部
322、422、522 文書類似度算出部
323、423 検索結果生成部
324、424 検索結果出力部
425 化合物クラスタ取得部
426 クラスタ提示部
427 クラスタ指定部
515 文書クラスタベクトル算出部
516 文書クラスタベクトル蓄積部 1, 1A ~ 1CSimilarity judgment system 10 Computer 11 Query 11a Query document 12 Document set 12a Comparison target document 13, 14 Result 2 ~ 5 Server 21 Memory part 22 Document input part 23 Similarity calculation part 24 Similarity output part 231 312 Compound name extraction unit 232, 313 Clustering unit 233 Document similarity calculation unit 31, 51 Document DB unit 311 Document storage unit 314 Compound cluster storage unit 315 Document vector calculation unit 316 Document vector storage unit 32, 42, 52 Document search unit 321 , 421 Search query designation part 322, 422, 522 Document similarity calculation part 323, 423 Search result generation part 324, 424 Search result output part 425 Compound cluster acquisition part 426 Cluster presentation part 427 Cluster designation part 515 Document cluster vector calculation part 516 Document cluster vector storage unit
10 コンピュータ
11 クエリ
11a クエリ文書
12 文書集合
12a 比較対象文書
13、14 結果
2~5 サーバ
21 メモリ部
22 文書入力部
23 類似度算出部
24 類似度出力部
231、312 化合物名抽出部
232、313 クラスタリング部
233 文書類似度算出部
31、51 文書DB部
311 文書蓄積部
314 化合物クラスタ蓄積部
315 文書ベクトル算出部
316 文書ベクトル蓄積部
32、42、52 文書検索部
321、421 検索クエリ指定部
322、422、522 文書類似度算出部
323、423 検索結果生成部
324、424 検索結果出力部
425 化合物クラスタ取得部
426 クラスタ提示部
427 クラスタ指定部
515 文書クラスタベクトル算出部
516 文書クラスタベクトル蓄積部 1, 1A ~ 1C
Claims (20)
- 第1の文書に含まれる第1の複数の固有表現のそれぞれの位置と前記第1の複数の固有表現のそれぞれの類似度とに基づいて前記第1の複数の固有表現を分類することによって生成された第1の複数のグループを取得し、
第2の文書に含まれる第2の複数の固有表現のそれぞれの位置と前記第2の複数の固有表現のそれぞれの類似度とに基づいて前記第2の複数の固有表現を分類することによって生成された第2の複数のグループを取得し、
前記第1の複数のグループと前記第2の複数のグループとの比較に基づいて、前記第1の文書と前記第2の文書との類似度を判定する、
処理をコンピュータに実行させる、類似度判定プログラム。 Generated by classifying the first named entity based on the position of each of the first named entities contained in the first document and the similarity of each of the first named entity. Get the first multiple groups that have been
Generated by classifying the second named entity based on the position of each of the second named entity contained in the second document and the similarity of each of the second named entity. Get the second multiple groups that have been
The degree of similarity between the first document and the second document is determined based on the comparison between the first plurality of groups and the second plurality of groups.
A similarity determination program that causes a computer to execute processing. - 前記第1の複数のグループを取得する処理は、前記第1の複数の固有表現の各々の前記第1の文書内の出現位置の近さを数値化した値と、前記第1の複数の固有表現の各々の類似度とを用いたクラスタリング処理を含み、
前記第2の複数のグループを取得する処理は、前記第2の複数の固有表現の各々の前記第2の文書内の出現位置の近さを数値化した値と、前記第2の複数の固有表現の各々の類似度とを用いたクラスタリング処理を含む、
請求項1に記載の類似度判定プログラム。 In the process of acquiring the first plurality of groups, the value obtained by quantifying the proximity of the appearance position in the first document of each of the first plurality of named entity and the first plurality of named entity. Includes clustering with each similarity of representation
In the process of acquiring the second plurality of groups, the value obtained by quantifying the proximity of the appearance position in the second document of each of the second named entity and the second named entity. Includes a clustering process with each similarity of representation.
The similarity determination program according to claim 1. - 前記類似度を判定する処理は、前記第1の複数のグループの各々と前記第2の複数のグループの各々との組み合わせの中で、グループの類似度が最大となる組み合わせの前記グループの類似度を、前記第1の文書と前記第2の文書との類似度と判定する処理を含む、
請求項1又は請求項2に記載の類似度判定プログラム。 The process of determining the similarity is the similarity of the group having the maximum similarity among the combinations of each of the first plurality of groups and each of the second plurality of groups. Is included in the process of determining the degree of similarity between the first document and the second document.
The similarity determination program according to claim 1 or 2. - 前記第2の複数のグループのうちの前記グループの類似度が最大となるグループに属する固有表現のリストを含む画面情報を出力する、
処理を前記コンピュータに実行させる、
請求項3に記載の類似度判定プログラム。 Outputs screen information including a list of named entities belonging to the group having the maximum similarity among the second plurality of groups.
Let the computer perform the process,
The similarity determination program according to claim 3. - 前記第1の文書に含まれる単語に基づいて、前記第1の文書に対応する第1のベクトルを算出し、
前記第2の文書に含まれる単語に基づいて、前記第2の文書に対応する第2のベクトルを算出する、
処理を前記コンピュータに実行させ、
前記類似度を判定する処理は、前記第1の複数のグループと前記第2の複数のグループとの比較と、前記第1のベクトルと前記第2のベクトルとの比較とに基づいて、前記第1の文書と前記第2の文書との前記類似度を判定する処理を含む、
請求項1~請求項4のいずれか1項に記載の類似度判定プログラム。 Based on the words contained in the first document, the first vector corresponding to the first document is calculated.
A second vector corresponding to the second document is calculated based on the words contained in the second document.
Let the computer perform the process
The process for determining the similarity is based on a comparison between the first plurality of groups and the second plurality of groups and a comparison between the first vector and the second vector. The process of determining the similarity between the document 1 and the document 2 is included.
The similarity determination program according to any one of claims 1 to 4. - 前記第1のベクトルを算出する処理は、前記第1の文書を分割することによって得られた第1の複数の部分文書を前記第1の複数のグループに基づいて分類することによって得られた第1の複数の部分文書グループについて、前記第1の複数の部分文書グループのそれぞれに含まれる単語に基づいて、前記第1の複数の部分文書グループのそれぞれに対応する第1の複数のベクトルを算出する処理を含み、
前記第2のベクトルを算出する処理は、前記第2の文書を分割することによって得られた第2の複数の部分文書を前記第2の複数のグループに基づいて分類することによって得られた第2の複数の部分文書グループについて、前記第2の複数の部分文書グループのそれぞれに含まれる単語に基づいて、前記第2の複数の部分文書グループのそれぞれに対応する第2の複数のベクトルを算出する処理を含む、
請求項5に記載の類似度判定プログラム。 The process of calculating the first vector is obtained by classifying the first plurality of partial documents obtained by dividing the first document based on the first plurality of groups. For a plurality of sub-document groups, a first plurality of vectors corresponding to each of the first plurality of sub-document groups are calculated based on words included in each of the first plurality of sub-document groups. Including the processing to do
The process of calculating the second vector is obtained by classifying the second plurality of partial documents obtained by dividing the second document based on the second plurality of groups. For the two plurality of sub-document groups, the second plurality of vectors corresponding to each of the second plurality of sub-document groups are calculated based on the words contained in each of the second plurality of sub-document groups. Including processing to do,
The similarity determination program according to claim 5. - 前記第1の複数のグループの各々の情報を含む画面情報を出力する、
処理を前記コンピュータに実行させ、
前記類似度を判定する処理は、前記画面情報に応じて選択されたグループと、前記第2の複数のグループとの比較に基づいて、前記第1の文書と前記第2の文書との前記類似度を判定する処理を含む、
請求項1~請求項6のいずれか1項に記載の類似度判定プログラム。 Outputs screen information including information of each of the first plurality of groups.
Let the computer perform the process
The process of determining the similarity is the similarity between the first document and the second document based on the comparison between the group selected according to the screen information and the second plurality of groups. Including the process of determining the degree,
The similarity determination program according to any one of claims 1 to 6. - 前記類似度を判定する処理は、前記第1の複数のグループのうちの指定されたキーワードを含むグループと、前記第2の複数のグループとの比較に基づいて、前記第1の文書と前記第2の文書との前記類似度を判定する処理を含む、
請求項1~請求項7のいずれか1項に記載の類似度判定プログラム。 The process of determining the similarity is based on the comparison between the group including the specified keyword among the first plurality of groups and the second plurality of groups, and the first document and the first document. The process of determining the similarity with the document of 2 is included.
The similarity determination program according to any one of claims 1 to 7. - 前記第1の文書が検索クエリで指定された文書であり、
前記第2の文書が前記検索クエリの検索対象となる文書群に含まれる複数の前記第2の文書のうちの1つであり、
前記第1の文書と前記複数の第2の文書の各々との複数の前記類似度に応じて判定した第2の文書の情報を、前記検索クエリの検索結果として出力する、
処理を前記コンピュータに実行させる、
請求項1~請求項8のいずれか1項に記載の類似度判定プログラム。 The first document is the document specified in the search query.
The second document is one of a plurality of the second documents included in the document group to be searched by the search query.
The information of the second document determined according to the plurality of similarities between the first document and each of the plurality of second documents is output as the search result of the search query.
Let the computer perform the process,
The similarity determination program according to any one of claims 1 to 8. - 前記第1の複数の固有表現、及び、前記第2の複数の固有表現の各々は化合物名であり、
前記第1の複数の固有表現のそれぞれの類似度、及び、前記第2の複数の固有表現のそれぞれの類似度の各々は、化合物の構造類似度である、
請求項1~請求項9のいずれか1項に記載の類似度判定プログラム。 Each of the first named entity and the second named entity is a compound name.
Each of the similarity of each of the first named entity and the similarity of each of the second named entity is the structural similarity of the compound.
The similarity determination program according to any one of claims 1 to 9. - 第1の文書に含まれる第1の複数の固有表現のそれぞれの位置と前記第1の複数の固有表現のそれぞれの類似度とに基づいて前記第1の複数の固有表現を分類することによって生成された第1の複数のグループを取得し、
第2の文書に含まれる第2の複数の固有表現のそれぞれの位置と前記第2の複数の固有表現のそれぞれの類似度とに基づいて前記第2の複数の固有表現を分類することによって生成された第2の複数のグループを取得し、
前記第1の複数のグループと前記第2の複数のグループとの比較に基づいて、前記第1の文書と前記第2の文書との類似度を判定する、制御部を備える、
類似度判定装置。 Generated by classifying the first named entity based on the position of each of the first named entities contained in the first document and the similarity of each of the first named entity. Get the first multiple groups that have been
Generated by classifying the second named entity based on the position of each of the second named entity contained in the second document and the similarity of each of the second named entity. Get the second multiple groups that have been
A control unit for determining the degree of similarity between the first document and the second document based on the comparison between the first plurality of groups and the second plurality of groups is provided.
Similarity determination device. - 前記制御部は、
前記第1の複数のグループの取得において、前記第1の複数の固有表現の各々の前記第1の文書内の出現位置の近さを数値化した値と、前記第1の複数の固有表現の各々の類似度とを用いたクラスタリング処理を行ない、
前記第2の複数のグループの取得において、前記第2の複数の固有表現の各々の前記第2の文書内の出現位置の近さを数値化した値と、前記第2の複数の固有表現の各々の類似度とを用いたクラスタリング処理を行なう、
請求項11に記載の類似度判定装置。 The control unit
In the acquisition of the first plurality of groups, the numerical value of the proximity of the appearance position in the first document of each of the first plurality of named entity and the first plurality of named entity. Perform clustering processing using each similarity.
In the acquisition of the second plurality of groups, the numerical value of the proximity of the appearance position in the second document of each of the second plurality of named entity and the second plurality of named entity. Perform clustering processing using each similarity.
The similarity determination device according to claim 11. - 前記制御部は、前記類似度の判定において、前記第1の複数のグループの各々と前記第2の複数のグループの各々との組み合わせの中で、グループの類似度が最大となる組み合わせの前記グループの類似度を、前記第1の文書と前記第2の文書との類似度と判定する
請求項11又は請求項12に記載の類似度判定装置。 In the determination of the similarity, the control unit is the group of the combination in which the similarity of the group is the maximum among the combinations of each of the first plurality of groups and each of the second plurality of groups. The similarity determination device according to claim 11 or 12, wherein the similarity of the first document is determined to be the similarity between the first document and the second document. - 前記制御部は、前記第2の複数のグループのうちの前記グループの類似度が最大となるグループに属する固有表現のリストを含む画面情報を出力する、
請求項13に記載の類似度判定装置。 The control unit outputs screen information including a list of named entities belonging to the group having the maximum similarity among the second plurality of groups.
The similarity determination device according to claim 13. - 前記制御部は、
前記第1の文書に含まれる単語に基づいて、前記第1の文書に対応する第1のベクトルを算出し、
前記第2の文書に含まれる単語に基づいて、前記第2の文書に対応する第2のベクトルを算出し、
前記類似度の判定において、前記第1の複数のグループと前記第2の複数のグループとの比較と、前記第1のベクトルと前記第2のベクトルとの比較とに基づいて、前記第1の文書と前記第2の文書との前記類似度を判定する、
請求項11~請求項14のいずれか1項に記載の類似度判定装置。 The control unit
Based on the words contained in the first document, the first vector corresponding to the first document is calculated.
Based on the words contained in the second document, the second vector corresponding to the second document is calculated.
In the determination of the similarity, the first is based on the comparison between the first plurality of groups and the second plurality of groups and the comparison between the first vector and the second vector. Determining the similarity between the document and the second document,
The similarity determination device according to any one of claims 11 to 14. - 前記制御部は、
前記第1のベクトルを算出する処理において、前記第1の文書を分割することによって得られた第1の複数の部分文書を前記第1の複数のグループに基づいて分類することによって得られた第1の複数の部分文書グループについて、前記第1の複数の部分文書グループのそれぞれに含まれる単語に基づいて、前記第1の複数の部分文書グループのそれぞれに対応する第1の複数のベクトルを算出し、
前記第2のベクトルを算出する処理において、前記第2の文書を分割することによって得られた第2の複数の部分文書を前記第2の複数のグループに基づいて分類することによって得られた第2の複数の部分文書グループについて、前記第2の複数の部分文書グループのそれぞれに含まれる単語に基づいて、前記第2の複数の部分文書グループのそれぞれに対応する第2の複数のベクトルを算出する、
請求項15に記載の類似度判定装置。 The control unit
In the process of calculating the first vector, the first plurality of partial documents obtained by dividing the first document are classified based on the first plurality of groups. For a plurality of sub-document groups, a first plurality of vectors corresponding to each of the first plurality of sub-document groups are calculated based on words included in each of the first plurality of sub-document groups. death,
In the process of calculating the second vector, the second plurality of documents obtained by dividing the second document are classified based on the second plurality of groups. For the two plurality of sub-document groups, the second plurality of vectors corresponding to each of the second plurality of sub-document groups are calculated based on the words contained in each of the second plurality of sub-document groups. do,
The similarity determination device according to claim 15. - 第1の文書に含まれる第1の複数の固有表現のそれぞれの位置と前記第1の複数の固有表現のそれぞれの類似度とに基づいて前記第1の複数の固有表現を分類することによって生成された第1の複数のグループを取得し、
第2の文書に含まれる第2の複数の固有表現のそれぞれの位置と前記第2の複数の固有表現のそれぞれの類似度とに基づいて前記第2の複数の固有表現を分類することによって生成された第2の複数のグループを取得し、
前記第1の複数のグループと前記第2の複数のグループとの比較に基づいて、前記第1の文書と前記第2の文書との類似度を判定する、
処理をコンピュータが実行する、類似度判定方法。 Generated by classifying the first named entity based on the position of each of the first named entities contained in the first document and the similarity of each of the first named entity. Get the first multiple groups that have been
Generated by classifying the second named entity based on the position of each of the second named entity contained in the second document and the similarity of each of the second named entity. Get the second multiple groups that have been
The degree of similarity between the first document and the second document is determined based on the comparison between the first plurality of groups and the second plurality of groups.
A similarity determination method in which a computer executes processing. - 前記第1の複数のグループを取得する処理は、前記第1の複数の固有表現の各々の前記第1の文書内の出現位置の近さを数値化した値と、前記第1の複数の固有表現の各々の類似度とを用いたクラスタリング処理を含み、
前記第2の複数のグループを取得する処理は、前記第2の複数の固有表現の各々の前記第2の文書内の出現位置の近さを数値化した値と、前記第2の複数の固有表現の各々の類似度とを用いたクラスタリング処理を含む、
請求項17に記載の類似度判定方法。 In the process of acquiring the first plurality of groups, the value obtained by quantifying the proximity of the appearance position in the first document of each of the first plurality of named entity and the first plurality of named entity. Includes clustering with each similarity of representation
In the process of acquiring the second plurality of groups, the value obtained by quantifying the proximity of the appearance position in the second document of each of the second named entity and the second named entity. Includes a clustering process with each similarity of representation.
The similarity determination method according to claim 17. - 前記類似度を判定する処理は、前記第1の複数のグループの各々と前記第2の複数のグループの各々との組み合わせの中で、グループの類似度が最大となる組み合わせの前記グループの類似度を、前記第1の文書と前記第2の文書との類似度と判定する処理を含む、
請求項17又は請求項18に記載の類似度判定方法。 The process of determining the similarity is the similarity of the group having the maximum similarity among the combinations of each of the first plurality of groups and each of the second plurality of groups. Is included in the process of determining the degree of similarity between the first document and the second document.
The similarity determination method according to claim 17 or 18. - 前記第2の複数のグループのうちの前記グループの類似度が最大となるグループに属する固有表現のリストを含む画面情報を出力する、
処理を前記コンピュータが実行する、
請求項19に記載の類似度判定方法。 Outputs screen information including a list of named entities belonging to the group having the maximum similarity among the second plurality of groups.
The computer executes the process.
The similarity determination method according to claim 19.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/047218 WO2022130578A1 (en) | 2020-12-17 | 2020-12-17 | Similarity determination program, similarity determination device, and similarity determination method |
| JP2022569434A JP7487797B2 (en) | 2020-12-17 | 2020-12-17 | Similarity determination program, similarity determination device, and similarity determination method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/047218 WO2022130578A1 (en) | 2020-12-17 | 2020-12-17 | Similarity determination program, similarity determination device, and similarity determination method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022130578A1 true WO2022130578A1 (en) | 2022-06-23 |
Family
ID=82057405
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/047218 WO2022130578A1 (en) | 2020-12-17 | 2020-12-17 | Similarity determination program, similarity determination device, and similarity determination method |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7487797B2 (en) |
| WO (1) | WO2022130578A1 (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11272680A (en) * | 1998-03-19 | 1999-10-08 | Fujitsu Ltd | Document data providing device and program recording medium thereof |
| JP2000112949A (en) * | 1998-09-30 | 2000-04-21 | Fuji Xerox Co Ltd | Information discrimination supporting device and record medium recording similar information discrimination supporting program |
| JP2002259411A (en) * | 2001-03-06 | 2002-09-13 | Nec Corp | Text information conversion system, text information conversion method and text information conversion program |
| JP2008009671A (en) * | 2006-06-29 | 2008-01-17 | National Institute Of Information & Communication Technology | Data display device, data display method and data display program |
| JP2013020431A (en) * | 2011-07-11 | 2013-01-31 | Nec Corp | Polysemic word extraction system, polysemic word extraction method and program |
| JP2016045552A (en) * | 2014-08-20 | 2016-04-04 | 富士通株式会社 | Feature extraction program, feature extraction method, and feature extraction device |
-
2020
- 2020-12-17 JP JP2022569434A patent/JP7487797B2/en active Active
- 2020-12-17 WO PCT/JP2020/047218 patent/WO2022130578A1/en active Application Filing
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11272680A (en) * | 1998-03-19 | 1999-10-08 | Fujitsu Ltd | Document data providing device and program recording medium thereof |
| JP2000112949A (en) * | 1998-09-30 | 2000-04-21 | Fuji Xerox Co Ltd | Information discrimination supporting device and record medium recording similar information discrimination supporting program |
| JP2002259411A (en) * | 2001-03-06 | 2002-09-13 | Nec Corp | Text information conversion system, text information conversion method and text information conversion program |
| JP2008009671A (en) * | 2006-06-29 | 2008-01-17 | National Institute Of Information & Communication Technology | Data display device, data display method and data display program |
| JP2013020431A (en) * | 2011-07-11 | 2013-01-31 | Nec Corp | Polysemic word extraction system, polysemic word extraction method and program |
| JP2016045552A (en) * | 2014-08-20 | 2016-04-04 | 富士通株式会社 | Feature extraction program, feature extraction method, and feature extraction device |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022130578A1 (en) | 2022-06-23 |
| JP7487797B2 (en) | 2024-05-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20130311487A1 (en) | Semantic search using a single-source semantic model | |
| KR102059743B1 (en) | Method and system for providing biomedical passage retrieval using deep-learning based knowledge structure construction | |
| WO2022130579A1 (en) | Similarity determination program, similarity determination device, and similarity determination method | |
| KR20180129001A (en) | Method and System for Entity summarization based on multilingual projected entity space | |
| Hare et al. | Imageterrier: an extensible platform for scalable high-performance image retrieval | |
| Xu et al. | Learning to refine expansion terms for biomedical information retrieval using semantic resources | |
| KR20220025540A (en) | Method and apparatus for summarizing document using keyword clustering | |
| CN111143400B (en) | Full stack type retrieval method, system, engine and electronic equipment | |
| CN111373386A (en) | Similarity index value calculation device, similarity search device, and similarity index value calculation program | |
| US20140067853A1 (en) | Data search method, information system, and recording medium storing data search program | |
| Oliveira et al. | A distributed system for SearchOnMath based on the Microsoft BizSpark program | |
| Arasu et al. | Experiences with using data cleaning technology for bing services | |
| JP5869948B2 (en) | Passage dividing method, apparatus, and program | |
| Sailaja et al. | An overview of pre-processing text clustering methods | |
| JP4202287B2 (en) | A system for visually processing an information object composed of sentence text in which information of interest is described using a plurality of terms, and computer software therefor | |
| JP5362807B2 (en) | Document ranking method and apparatus | |
| Ullah et al. | On the analysis and evaluation of information retrieval models for social book search | |
| WO2022130578A1 (en) | Similarity determination program, similarity determination device, and similarity determination method | |
| JP6622921B2 (en) | Character string dictionary construction method, character string dictionary search method, and character string dictionary processing system | |
| CN112417154B (en) | Method and device for determining similarity of documents | |
| US11003647B2 (en) | Multidimensional data management system and multidimensional data management method | |
| TW202111571A (en) | Information processing device, program, and information processing method | |
| CN112712866A (en) | Method and device for determining text information similarity | |
| JP2011248827A (en) | Cross-lingual information searching method, cross-lingual information searching system and cross-lingual information searching program | |
| KR20190136292A (en) | Method and Apparatus for Processing Data Based on Intelligent Data Structure |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20965965 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022569434 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20965965 Country of ref document: EP Kind code of ref document: A1 |