WO2022070256A1 - 情報処理装置、情報処理方法、及び、記録媒体 - Google Patents
情報処理装置、情報処理方法、及び、記録媒体 Download PDFInfo
- Publication number
- WO2022070256A1 WO2022070256A1 PCT/JP2020/036907 JP2020036907W WO2022070256A1 WO 2022070256 A1 WO2022070256 A1 WO 2022070256A1 JP 2020036907 W JP2020036907 W JP 2020036907W WO 2022070256 A1 WO2022070256 A1 WO 2022070256A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- feature
- latent
- distance
- information processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2453—Query optimisation
- G06F16/24534—Query rewriting; Transformation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- the present invention relates to a technical field of an information processing apparatus, an information processing method, and a recording medium capable of calculating information on a factor influencing a distance between two data in a vector space.
- Metric learning (in other words, metric learning) is used as an example of a method for calculating the distance between two data (specifically, the distance between two feature vectors indicating the feature quantities of the two data).
- the method is known (see Patent Document 1).
- Metric learning is a transformation that can transform the feature vector of each data so that the distance between two or more similar data is short and the distance between two or more dissimilar data is long in a vector space. This is a method for generating a model. In this case, two feature vectors indicating the feature quantities of the two data are transformed by the transformation model, and the distance between the transformed two feature vectors is calculated as the distance between the two data.
- the transformation model generated by metric learning is generally a black box model in which the process of transforming feature vectors cannot be understood by the user. As a result, the user cannot understand the factors influencing the distance between the two data. Therefore, from the viewpoint of improving user convenience, it is desirable to calculate information on factors influencing the distance between two data.
- An object of the present invention is to provide an information processing apparatus, an information processing method, and a recording medium capable of solving the above-mentioned technical problems.
- One aspect of the information processing apparatus is to display a plurality of feature vector data indicating the feature quantities of the plurality of sample data groups in the expression space, and to display the feature quantities of the plurality of sample data groups in a latent space different from the representation space.
- the conversion means for converting into the plurality of latent vector data shown respectively and the plurality of latent vector data the distance from the plurality of feature vector data to the desired query data in the latent space is the other feature vector data.
- An extraction means for extracting at least one feature vector data shorter than that of the neighborhood data as neighborhood data, and for each element of the feature quantity of the query data and the neighborhood data in the representation space based on the neighborhood data.
- a generation means for generating a local model that outputs an estimated value of the latent distance, which is the distance between the query data and the neighboring data in the latent space when the difference information regarding the difference is input, and the local.
- a calculation means for calculating an element contribution degree indicating the magnitude of the influence of each element of the feature amount of the neighborhood data on the latent distance based on the model and the difference information is provided.
- One aspect of the information processing method is to display a plurality of feature vector data indicating the feature quantities of the plurality of sample data groups in the expression space, and to display the feature quantities of the plurality of sample data groups in a latent space different from the representation space. Conversion to a plurality of latent vector data shown respectively, and based on the plurality of latent vector data, the distance from the plurality of feature vector data to the desired query data in the latent space is different from that of the other feature vector data. Extracting at least one feature vector data that is shorter in comparison as neighborhood data, and the difference between the feature quantities of the query data and the neighborhood data in the representation space based on the neighborhood data for each element.
- the local model To generate a local model that outputs an estimated value of the latent distance, which is the distance between the query data and the neighboring data in the latent space when the difference information is input, the local model and the difference. It includes calculating the element contribution degree indicating the magnitude of the influence of each element of the feature amount of the neighborhood data on the latent distance based on the information.
- One aspect of the recording medium is to provide a computer with a plurality of feature vector data indicating the feature quantities of the plurality of sample data groups in the representation space, respectively, in a latent space different from the representation space, and the features of the plurality of sample data groups.
- the distance from the plurality of feature vector data to the desired query data in the latent space is the other feature vector based on the conversion into the plurality of latent vector data indicating the quantity respectively and the plurality of latent vector data.
- At least one feature vector data that is shorter than the data is extracted as neighborhood data, and based on the neighborhood data, for each element of the feature quantity of the query data and the neighborhood data in the representation space.
- a computer program that executes an information processing method including calculating an element contribution degree indicating the magnitude of the influence of each element of the feature amount of the neighboring data on the latent distance based on the difference information. It is a recorded recording medium.
- each one of the above-mentioned information processing apparatus, information processing method, and recording medium it is possible to calculate information on factors influencing the distance between two data.
- FIG. 1 is a block diagram showing a configuration of the communication system of the present embodiment.
- FIG. 2 is a block diagram showing the configuration of the information processing apparatus of the present embodiment.
- FIG. 3 is a data structure diagram showing the data structure of the proxy log DB of the present embodiment.
- FIG. 4 is a data structure diagram showing the data structure of the feature data set of the present embodiment.
- FIG. 5 is a flowchart showing the flow of the model generation operation performed by the information processing apparatus.
- FIG. 6 is a data structure diagram showing the data structure of the teacher data set of the present embodiment.
- FIG. 7 is a flowchart showing the flow of the threat detection operation performed by the information processing apparatus.
- FIG. 8 is a flowchart showing the flow of the operation of extracting n neighborhood data.
- FIG. 1 is a block diagram showing a configuration of the communication system of the present embodiment.
- FIG. 2 is a block diagram showing the configuration of the information processing apparatus of the present embodiment.
- FIG. 3 is a data structure diagram
- FIG. 9 is a plan view showing a display example of the element contribution degree.
- FIG. 10 is a table showing the affiliation rate in which the vector component belongs to the feature group.
- FIG. 11 is a plan view showing a display example of the degree of group contribution.
- FIG. 12 is a block diagram showing a configuration of a communication system in the second modification.
- FIG. 13 is a block diagram showing the configuration of the information processing apparatus in the third modification.
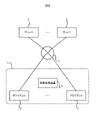
- FIG. 1 is a block diagram showing an overall configuration of the communication system SYS in the present embodiment.
- the communication system SYS includes a proxy server 1, a plurality of clients 2, a plurality of servers 3, and an information processing device 4.
- the communication system SYS may include a single client 2.
- the communication system SYS may include a single server 3.
- the proxy server 1 and each of the plurality of servers 3 can communicate with each other via the network 5.
- the network 5 may include a wired network or may include a wireless network.
- the proxy server 1 is a device that relays communication between the client 2 and the server 3.
- the proxy server 1 may send a request acquired from the client 2 to the server 3 specified by the acquired request via the network 5.
- the request may include, for example, an HTTP (HyperText Transfer Protocol) request.
- HTTP HyperText Transfer Protocol
- the proxy server 1 may send the response acquired from the server 3 via the network 5 to the client 2 specified by the response.
- the response may include, for example, an HTTP response.
- the response is not limited to the HTTP response.
- a system including a proxy server 1 and a plurality of clients 2 may be referred to as a local system L.
- the proxy server 1 is arranged at the boundary between the local system L and the wide area network outside the local system L. It can be said that the proxy server 1 relays the communication between the local system L and the wide area network.
- the client 2 communicates with the server 3 via the proxy server 1.
- the client 2 may send desired data to the server 3 via the proxy server 1.
- the client 2 may receive desired data from the server 3 via the proxy server 1.
- the server 3 communicates with the client 2 via the proxy server 1.
- the server 3 may send desired data to the client 2 via the proxy server 1.
- the server 3 may receive desired data from the client 2 via the proxy server 1.
- the server 3 is, for example, an HTTP server.
- the server 3 may be a server other than the HTTP server.
- the information processing device 4 performs a threat detection operation for detecting a threat that has already invaded the local system L via the network 5.
- a threat detection operation for detecting a threat that has already invaded the local system L via the network 5.
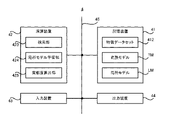
- FIG. 2 is a block diagram showing the configuration of the information processing apparatus 4 according to the present embodiment.
- the information processing device 4 includes a storage device 41 and an arithmetic unit 42. Further, the information processing device 4 may include an input device 43 and an output device 44. However, the information processing device 4 does not have to include at least one of the input device 43 and the output device 44.
- the storage device 41, the arithmetic unit 42, the input device 43, and the output device 44 may be connected via the data bus 45.
- the storage device 41 can store desired data.
- the storage device 41 may temporarily store the computer program executed by the arithmetic unit 42.
- the storage device 41 may temporarily store data temporarily used by the arithmetic unit 42 while the arithmetic unit 42 is executing a computer program.
- the storage device 41 may store data stored in the information processing device 4 for a long period of time.
- the storage device 41 may include at least one of a RAM (Random Access Memory), a ROM (Read Only Memory), a hard disk device, a magneto-optical disk device, an SSD (Solid State Drive), and a disk array device. good. That is, the storage device 41 may include a recording medium that is not temporary.
- the storage device 41 stores the data used by the information processing device 4 to perform the threat detection operation.
- FIG. 1 shows, as an example of data used by the information processing apparatus 4 for performing a threat detection operation, a proxy log DB (Data: database) 411, a feature data set 412, a teacher data set 413, and a conversion model TM.
- the local model LM are described. That is, FIG. 4 shows an example in which the storage device 41 stores the proxy log DB 411, the feature data set 412, the teacher data set 413, the conversion model TM, and the local model LM.
- the proxy log DB 411 stores a plurality of proxy log data 4111 (see FIG. 3).
- the proxy log data 4111 is log data showing a history of communication relayed by the proxy server 1 (that is, communication between the client 2 and the server 3).
- FIG. 3 shows the data structure of the proxy log DB 411 that stores such a plurality of proxy log data 4111.
- the proxy log data 4111 is, for example, (i) log information (client information) indicating the client 2 communicating with the server 3 and (ii) log information indicating the server 3 communicating with the client 2 (ii).
- the log information (reception size information) indicating the size of the server 3 and the log information (transmission size information) indicating the size of the data transmitted by the client 2 to the server 3 may be included.
- the proxy log data 4111 does not have to include at least one of the plurality of log information shown in FIG.
- the proxy log data 4111 may include other log information different from the plurality of log information shown in FIG.
- the proxy log data 4111 may be referred to as sample data. Further, the log information included in the proxy log data 4111 may be referred to as sample
- the feature data set 412, the teacher data set 413, the conversion model TM, and the local model LM will be described in detail later.
- the arithmetic unit 42 includes, for example, at least one of a CPU (Central Processing Unit), a GPU (Graphical Processing Unit), and an FPGA (Field Programmable Gate Array).
- the arithmetic unit 42 reads a computer program.
- the arithmetic unit 42 may read the computer program stored in the storage device 41.
- the arithmetic unit 42 may read a computer program stored in a recording medium that can be read by a computer and is not temporary by using a recording medium reading device (not shown).
- the arithmetic unit 42 may acquire (that is, download) a computer program from a device (not shown) arranged outside the information processing device 4 via an input device 43 capable of functioning as a communication device.
- the arithmetic unit 42 executes the read computer program.
- a logical functional block for executing an operation to be performed by the information processing device 4 (for example, the above-mentioned threat detection operation) is realized in the arithmetic unit 42. That is, the arithmetic unit 42 can function as a controller for realizing a logical functional block for executing an operation to be performed by the information processing unit 4.
- FIG. 2 shows an example of a logical functional block realized in the arithmetic unit 42 to execute a threat detection operation.
- a feature extraction unit 421 in the arithmetic unit 42, a feature extraction unit 421, a metric learning unit 422, a search unit 423 which is a specific example of each of the "conversion means” and the “extraction means", and a “generation” are provided.
- a local model learning unit 424 which is a specific example of the "means”, a contribution calculation unit 425 which is a specific example of the "calculation means”, and an output control unit 426 are realized.
- the feature extraction unit 421 extracts a plurality of (or at least one) proxy log data 4111 classified into the same log data group from the proxy log DB 411 based on a predetermined log classification standard.
- the predetermined log classification standard is a log classification in which a plurality of proxy log data 4111s having the same client information, the same server information, and the communication date / time information satisfying the predetermined date / time standard are classified into the same log data group. Criteria may be included.
- the plurality of proxy log data 4111 satisfying a predetermined date and time reference may include a plurality of proxy log data 4111 in which the communication dates indicated by the communication date and time information are the same.
- the plurality of proxy log data 4111 satisfying a predetermined date and time reference includes a plurality of proxy log data 4111 in which the interval between the communication times (or communication date and time) indicated by the communication date and time information is less than a predetermined value and is continuous. You may go out.
- the proxy log data 4111 classified into the same log data group may be referred to as a sample data group.
- the feature extraction unit 421 is performed from the proxy log DB 411 shown in FIG. 3 between the client 2 corresponding to the identifier C1 and the server 3 corresponding to the identifier S1 on January 1, 2019.
- Each of the three proxy log data 4111 showing the communication history may be extracted as the proxy log data 4111 classified into the first log data group.
- the feature extraction unit 421 is performed from the proxy log DB 411 shown in FIG. 3 between the client 2 corresponding to the identifier C2 and the server 3 corresponding to the identifier S2 on January 1, 2019.
- Each of the three proxy log data 4111 showing the communication history may be extracted as proxy log data 4111 classified into a second log data group different from the first log data group.
- the feature extraction unit 421 further generates a feature vector XV indicating a feature amount of the extracted plurality of proxy log data 4111 (that is, a plurality of proxy log data 4111 classified into the same log data group).
- the feature extraction unit 421 generates one feature vector XV from a plurality of proxy log data 4111 classified in the same log data group. Therefore, the feature extraction unit 421 generates feature vectors XV as many as the number of log data groups.
- the number of log data groups is K (K is a constant indicating an integer of 1 or more), and the feature extraction unit 421 uses K feature vectors XV (hereinafter, K feature vectors XV, respectively).
- the feature extraction unit 421 may generate a feature vector XV by analyzing a plurality of extracted proxy log data 4111.
- the feature extraction unit 421 may generate the feature vector XV, for example, by performing an arithmetic process for calculating the statistics of the plurality of proxy log data 4111.
- the feature vector XV may include, for example, an element (that is, a vector component, the same applies hereinafter) indicating a feature amount related to transmission size information.
- the feature amount related to the transmission size information may include a feature amount related to a transmission size statistic (for example, at least one of a minimum value, a maximum value, an average value, a variance, and an average value) indicated by the transmission size information.
- the feature vector XV may include, for example, an element indicating a feature amount related to reception size information.
- the feature amount related to the received size information may include a feature amount related to a received size statistic (for example, at least one of a minimum value, a maximum value, an average value, a variance, and a total value) indicated by the received size information.
- the feature vector XV may include, for example, an element indicating a feature quantity related to path information.
- the feature amount related to the path information may include a feature amount related to a statistic of the data length of the request path indicated by the path information (for example, at least one such as a minimum value, a maximum value, an average value, and a variance).
- the feature amount related to the path information may include the feature amount related to the frequency of the extension of the request path indicated by the path information (for example, the frequency of the request for each extension).
- the feature vector XV may include, for example, an element indicating a feature quantity related to method information.
- the feature amount related to the method information may include a feature amount related to the frequency of the method indicated by the method information (for example, at least one such as the ratio of the GET method, the ratio of the POST method, and the ratio of other methods).
- the feature vector XV may include, for example, an element indicating a feature quantity relating to the distribution of access times (eg, the percentage of requests sent per unit time (eg, 1 hour)).
- the feature vector XV may include, for example, an element indicating a feature quantity relating to the number of times a request has been transmitted.
- the proxy log data 4111 includes header information
- the feature vector XV may include, for example, an element indicating a feature amount related to the header information.
- the feature vector XV generated by the feature extraction unit 421 is stored by the storage device 41 as at least a part of the feature data set 412.
- An example of the data structure of the feature dataset 412 is shown in FIG.
- the feature extraction unit 421 generates one feature vector XV from a plurality of proxy log data 4111 classified in the same log data group. Therefore, the storage device 41 stores the feature vector XV generated by the feature extraction unit 421 as a feature data DV in which the data identifier for identifying the log data group corresponding to the feature vector XV and the feature vector XV are associated with each other. You may. In this case, as shown in FIG.
- the feature data set 412 contains feature data DV (ie, feature vector XV) as many as the number of log data groups classified according to a predetermined log classification criterion. That is, the feature data set 412 includes K feature data DVs (hereinafter, K feature data DVs are referred to as "feature data DV 1 to DV K " each using a subscript as an index). May be good.
- K feature data DVs are referred to as "feature data DV 1 to DV K " each using a subscript as an index). May be good.
- the feature data DV including the feature vector XV v is referred to as a feature data DV v .
- the predetermined log classification standard includes a log classification standard in which a plurality of proxy log data 4111 having the same client information, server information, and communication date / time information are classified into the same log data group.
- the storage device 41 uses the generated feature vector XV as feature data in which a data identifier uniquely indicating client information, server information, and communication date / time information is associated with the feature vector XV. It may be stored as DV.
- the metric learning unit 422 generates a conversion model TM used for converting the feature vector XV.
- the feature vector XV indicates the feature amount of the proxy log data 4111 in the expression space (that is, the vector space).
- the conversion model TM uses a feature vector XV indicating the feature amount of the proxy log data 4111 in such an expression space, and a latent vector indicating the feature amount of the proxy log data 4111 in a latent space which is a vector space different from the expression space. It is a model to convert to ZV. Since XV K is generated from K feature vectors XV 1 as described above, the conversion model TM changes K feature vectors XV 1 to XV K and K latent vectors ZV 1 to ZV K , respectively.
- the conversion model TM may convert the feature vector XV v into the latent vector ZV v .
- the latent vector ZV may be referred to as latent vector data ZV.
- the conversion model TM generated by the metric learning unit 422 is stored, for example, by the storage device 41. The operation of generating the conversion model TM will be described in detail later with reference to FIG. 5 and the like.
- the number of elements of the vector component of the latent vector ZV (that is, the number of elements of the feature quantity indicated by the latent vector ZV and the number of dimensions of the latent space) is typically the number of elements of the vector component of the feature vector XV (that is, that is). It is the number of elements of the feature amount indicated by the feature vector XV, and is preferably smaller than the number of dimensions of the expression space). Therefore, the latent vector ZV may be referred to as a low-dimensional vector, and the feature vector XV may be referred to as a high-dimensional vector.
- the human threat detection operation is compared with the case where the feature vector XV is not converted into the latent vector ZV.
- the senses are reflected relatively strongly (that is, the threat is detected after the human senses are considered relatively strongly).
- the number of elements of the vector component of the latent vector ZV may be the same as the number of elements of the vector component of the feature vector XV.
- the number of elements of the vector component of the latent vector ZV may be larger than the number of elements of the vector component of the feature vector XV.
- the search unit 423 is based on the query data DQ that specifies the threat to be detected by the threat detection operation (hereinafter referred to as “detection target threat”), and from the feature data set 412, the similarity to the query data DQ is other feature data. Search for at least one feature data DV that is higher than the DV.
- detection target threat the threat to be detected by the threat detection operation
- the distance between the query data DQ and the feature data DV in the latent space is obtained by converting the feature vector XQ (that is, the feature vector indicating the feature amount of the detection target threat) indicated by the query data DQ by the conversion model TM. It means the distance between the obtained latent vector ZQ and the latent vector ZV obtained by converting the feature vector XV indicated by the feature data DV by the conversion model TM. Therefore, in the present embodiment, the search unit 423 searches the feature data set 412 for at least one feature data DV whose distance from the query data DQ in the latent space is shorter than that of the other feature data DV.
- the query data DQ may include a feature vector XQ indicating the feature amount of the detection target threat.
- the number of dimensions of the feature vector XQ of the query data DQ is the same as the number of dimensions of the feature vector XV of the feature data DV. That is, when the number of dimensions of the feature vector XV is F (where F is a constant indicating an integer of 1 or more), it is preferable that the number of dimensions of the feature vector XQ is also F.
- the types of F feature quantities indicated by the F vector components of the feature vector XV are the same as the types of the F feature quantities indicated by the F vector components of the feature vector XQ.
- the feature vector XV includes a vector component indicating a feature amount related to the reception size and a vector component indicating a feature amount related to the transmission size
- the feature vector XQ also includes a vector component indicating the feature amount related to the reception size and transmission. It is preferable to include a vector component indicating a feature amount related to size.
- the search unit 423 has a shorter distance from the feature data set 412 from the query data DQ in the latent space than other feature data DVs (where n is 1 ⁇ n ⁇ feature data DV).
- n is 1 ⁇ n ⁇ feature data DV.
- the search unit 423 refers the searched n feature data DVs to n neighborhood data DNs (hereinafter, n neighborhood data DNs are referred to as “neighborhood data DN 1 to DN n ”, respectively. (Referred to as).
- the neighborhood data DN i (where i is a variable indicating an integer satisfying 1 ⁇ i ⁇ n) corresponds to the data located in the vicinity of the query data DQ in the latent space. That is, the neighborhood data DN i corresponds to the feature data DV indicating the feature amount of the proxy log data 4111 showing the trace of the same or similar threat as the detection target threat specified by the query data DQ. Therefore, when the neighborhood data DN i is detected, it is assumed that a threat similar to or similar to the detected target threat may have already invaded the local system L. Therefore, the extracted neighborhood data DN i (or proxy log data 4111 corresponding to the neighborhood data DN i ) is further analyzed in order to determine whether or not a threat has actually invaded the local system L. May be good.
- the local model learning unit 424 generates a local model LM based on the neighborhood data DN 1 to DN n .
- the local model LM is a distance di i between the query data DQ and the neighborhood data DN i in the latent space when the difference information V i regarding the difference between the query data DQ and the neighborhood data DN i in the representation space is input. It is a model that outputs the estimated value dpi of. The operation of generating the local model LM will be described in detail later with reference to FIG. 7 and the like.
- the difference information V i is, for example, the difference information vi, f indicating the difference between the query data DQ and the neighborhood data DN i for each vector component (that is, for each element (type) of the feature amount corresponding to the vector component). It may be included. That is, the difference information V i may include the difference information v i and f indicating the difference for each vector component between the feature vector XQ of the query data DQ and the feature vector XN i of the neighborhood data DN i .
- the f (where f is a variable indicating an integer satisfying 1 ⁇ f ⁇ F) of the feature vector XN i (that is, the feature amount corresponding to the fth element of the neighborhood data DN i ) is xn.
- the difference information v i and f are values based on the difference between the vector component xn i and f and the vector component xq f .
- the difference information V i is the difference information vi , 1 , the difference information v i, 2 , ..., The difference information. It may include vi, f and ..., Difference information vi , F.
- the contribution calculation unit 425 determines the element contribution c indicating the magnitude of the influence of each vector component of the feature vector of the neighborhood data on the distance between the query data and the neighborhood data in the latent space. calculate. Specifically, the contribution calculation unit 425 is the f-th vector component (that is, the neighborhood data ) of the feature vector XN i with respect to the distance di between the query data DQ and the neighborhood data DN i in the latent space. The element contribution degree c representing the magnitude of the influence of the feature amount corresponding to the f-th element of DN i ) is calculated.
- the element contribution degree c representing the magnitude of the influence of the f-th vector component of the feature vector XN i on the distance di is referred to as “element contribution degree c i , f ”.
- the contribution calculation unit 425 calculates the element contributions c i and f representing the magnitude of the importance of the f-th vector component of the feature vector XN i when calculating the distance di.
- the contribution calculation unit 425 calculates the element contributions ci and f based on the difference information vi and f and the local model LM generated by the local model learning unit 424. The calculation operation of the element contribution degrees ci and f will be described in detail later with reference to FIG. 7 and the like.
- the output control unit 426 may control the output device 44 described later so as to output information regarding at least one of the n neighborhood data DN 1 extracted by the search unit 423.
- the output control unit 426 outputs the element contribution degrees ci and f calculated by the contribution degree calculation unit 425 in addition to or in place of the information regarding at least one of the n neighborhood data DN 1 to DN n .
- the output device 44 described later may be controlled.
- the input device 43 is a device that receives information input to the information processing device 4 from the outside of the information processing device 4.
- the input device 43 may include an operation device (for example, at least one of a keyboard, a mouse, and a touch panel) that can be operated by the user of the information processing device 4.
- the input device 43 may include a receiving device (that is, a communication device) capable of receiving information transmitted as data from the outside of the information processing device 4 to the information processing device 4 via the communication network.
- the output device 44 is a device that outputs information.
- the output device 44 may output information regarding the threat detection operation performed by the information processing device 4 (for example, information regarding the detected threat).
- An example of such an output device 44 is a display (display device) capable of outputting (that is, displaying) information as an image.
- a speaker voice output device
- An example of the output device 44 is a printer capable of outputting a document in which information is printed.
- a transmission device that is, a communication device capable of transmitting information as data via a communication network or a data bus.
- the information processing apparatus 4 performs a threat detection operation for detecting a threat that has already invaded the local system L. Further, the information processing apparatus 4 may perform a model generation operation for generating a conversion model TM used in the threat detection operation before performing the threat detection operation. Therefore, in the following, the model generation operation and the threat detection operation will be described in order.
- FIG. 5 is a flowchart showing the flow of the model generation operation performed by the information processing apparatus 4.
- the metric learning unit 422 acquires at least one teacher data 4131 from the teacher data set 413 (step S11).
- the teacher data set 413 includes a plurality of teacher data 4131.
- the metric learning unit 422 may acquire all of the plurality of teacher data 4131 included in the teacher data set 413. Alternatively, the metric learning unit 422 acquires a part of the plurality of teacher data 4131 contained in the teacher data set 413, but does not acquire another part of the plurality of teacher data 4131 contained in the teacher data set 413. You may.
- Each teacher data 4131 contains data designation information that specifies two of the plurality of feature data DVs (ie, feature data DV 1 to DV K ) contained in the feature data set 412.
- the feature data DV can be uniquely distinguished by the data identifier for identifying the log data group corresponding to the feature vector XV included in the feature data DV. Therefore, as shown in FIG. 6, the data designation information may include the data identifiers of the two feature data DVs.
- Each teacher data 4131 further includes label information indicating whether the two feature data DVs designated by the data designation information correspond to a positive example or a negative example.
- the label information representing "0" indicates that the two feature data DVs designated by the data designation information correspond to a negative example
- the label information representing "1" is the data designation information.
- the two specified feature data DVs correspond to the positive example.
- the two feature data DVs corresponding to the positive example may mean two feature data DVs having similar features.
- the two feature data DVs having similar features may be two feature data DVs in which the distance in the latent space between the two feature data DVs is less than a predetermined first threshold value.
- the two feature data DVs corresponding to the negative example may mean two feature data DVs having dissimilar features.
- the distance in the latent space between the two feature data DVs is larger than a predetermined second threshold value (however, the second threshold value is equal to or higher than the above-mentioned first threshold value). It may be two feature data DVs.
- the metric learning unit 422 generates a conversion model TM based on the teacher data 4131 acquired in step S11 (step S12). Specifically, for example, the metric learning unit 422 may generate the conversion model TM by performing a learning operation for learning the conversion model TM. Therefore, the transformation model TM may be a learnable model.
- the transformation model TM may be a model including a neural network capable of learning parameters (eg, at least one of weights and biases).
- the metric learning unit 422 may generate a conversion model TM by performing metric learning (in other words, metric learning).
- Quantitative learning generally involves relatively short distances between two or more similar data and relatively long distances between two or more dissimilar data in a vector space. It is a learning method for generating a transformation model that can transform the feature vector of each data. Therefore, in the present embodiment, the metric learning unit 422 performs metric learning to perform a distance (that is, two or more similar feature data) in the latent space between two or more similar feature data DVs.
- the distance between two or more latent vectors ZV corresponding to each DV is relatively short, and the distance between two or more dissimilar feature data DVs (that is, two or more dissimilar feature data).
- a conversion model TM capable of converting a plurality of feature vectors XV into a plurality of latent vectors ZV is generated so that the distance between two or more latent vectors ZV corresponding to each DV) becomes relatively long. good.
- the metric learning unit 422 performs metric learning so that the distance in the latent space between two or more similar feature data DVs is within the latent space between two or more dissimilar feature data DVs.
- a conversion model TM that can convert a plurality of feature vectors XV into a plurality of latent vectors Zv may be generated so as to be equal to or greater than the distance in.
- the metric learning unit 422 performs metric learning so that (i) the distance in the latent space between two or more similar feature data DVs is between two or more similar feature data DVs. It is less than or equal to the distance in the representation space (that is, the distance between two or more feature vectors XV corresponding to each of two or more similar feature data DVs), and (ii) two or more dissimilar features.
- the distance in the latent space between the data DVs is the distance in the representation space between the two or more dissimilar feature data DVs (ie, two or more corresponding to each of the two or more dissimilar feature data DVs).
- a conversion model TM capable of converting a plurality of feature vectors XV into a plurality of latent vectors ZV may be generated so as to be equal to or larger than the distance between the feature vectors XV.
- the metric learning unit 422 may perform metric learning using, for example, a neural network used for performing metric learning.
- a neural network used for performing metric learning at least one of a siamese network (Siamese Network) and a triplet network (Triplet Network) can be mentioned.
- the metric learning unit 422 Based on the teacher data 4131, the metric learning unit 422 extracts at least one set of data sets including two feature vector XVs to which label information corresponding to a positive example is added from the feature data set 412. Further, the metric learning unit 422 extracts at least one set of two feature vectors XV to which label information corresponding to a negative example is added from the feature data set 412 based on the teacher data 4131. The metric learning unit 422 acquires two latent vectors ZV corresponding to the two feature vectors XV by inputting the two extracted feature vectors XV into the conversion model TM. After that, the metric learning unit 422 calculates the distance between the two latent vectors ZV.
- the metric learning unit 422 has a relatively short distance between the two latent vectors ZV obtained by converting the two feature vectors XV to which the label information corresponding to the positive example is given, and the negative example. Quantitative learning is performed so that the distance between the two latent vectors ZV obtained by converting the two feature vectors XV to which the label information corresponding to is attached is relatively long. Therefore, the metric learning unit 422 may perform metric learning using a loss function determined based on the distance between two latent vectors ZV in the latent space. For example, as described above, when the metric learning unit 422 performs metric learning using the sham network, the metric learning unit 422 may use a loss function based on the Conductive Loss.
- the storage device 41 stores the conversion model TM generated in step S12 (step S13).
- the conversion model TM stored in the storage device 41 is used in the threat detection operation described later.
- FIG. 7 is a flowchart showing the flow of the threat detection operation performed by the information processing apparatus 4.
- the threat detection operation shown in FIG. 7 may be started by the input of the query data DQ to the information processing apparatus 4.
- a threat detection operation is performed for each query data DQ.
- the threat detection operation and the second query data DQ are performed for the first query data DQ.
- the target threat detection operation is performed.
- the search unit 423 acquires the query data DQ (step S21). For example, the search unit 423 directly or indirectly detects a detection target threat (or feature vector XQ) input to the information processing device 4 via an input device 43 capable of functioning as a user-operable operation device. The information specified in may be acquired as query data DQ. For example, the search unit 423 can directly or indirectly specify a detection target threat (or feature vector XQ) transmitted to the information processing device 4 via an input device 43 capable of functioning as a communication device. The information may be acquired as query data DQ.
- a detection target threat or feature vector XQ
- the search unit 423 extracts DN n from n neighborhood data DN 1 from the feature data set 412 based on the query data DQ acquired in step S21 (step S22).
- the operation of extracting DN n from n neighborhood data DN 1 will be described with reference to FIG.
- FIG. 8 is a flowchart showing a flow of an operation of extracting DN n from n neighborhood data DN 1 .
- the search unit 423 detects the feature vector XQ of the query data DQ acquired in step 21 in the latent space by using the conversion model TM stored in the storage device 41. It is converted into a latent vector ZQ indicating a quantity (step S221).
- the search unit 423 extracts the feature data DV v of one of the plurality of feature data DVs included in the feature data set 412 (step S222). After that, the search unit 423 converts the feature vector XV v of the extracted one feature data DV v into the latent vector ZV v using the conversion model TM (step S222). After that, the search unit 423 calculates the distance (that is, the distance in the latent space) between the latent vector ZQ generated in step S221 and the latent vector ZV v generated in step S222 (step S223).
- the search unit 423 repeats the operations from step S222 to step S223 for a plurality of feature data DVs included in the feature data set 412 (step S224).
- the feature data set 412 contains K feature data DV 1 to DV K. Therefore, the search unit 423 performs the calculation of the K distances between the ZV K and the latent vector ZQ from the K latent vectors ZV 1 corresponding to the K feature data DV 1 to the DV K , respectively, until the calculation is completed.
- One feature data DV v that has not yet been extracted in step S222 is newly extracted from the plurality of feature data DV included in the feature data set 412, and then the operations from step S222 to step S223 are performed. repeat.
- the search unit 423 sets the distance between the latent vector ZV 1 corresponding to the feature data DV 1 and the latent vector ZQ, and the distance between the latent vector ZV 2 corresponding to the feature data DV 2 and the latent vector ZQ.
- the operation from step S222 to step S223 is repeated until the calculation of the distance between the two and the distance between the latent vector ZV K corresponding to the feature data DV K and the latent vector ZQ is completed.
- the search unit 423 transfers n feature data DVs out of the plurality of feature data DVs included in the feature data set 412 from the n neighborhood data DN 1s , respectively, based on the distance calculated in step S223. Extract as DN n (step S225). Specifically, the search unit 423 has n features among the K feature data DVs, which have a shorter distance from the query data DQ in the latent space than the other Kn feature data DVs. The data DV is extracted as DN n from n neighboring data DN 1 respectively. That is, the search unit 423 extracts n feature data DVs from the K feature data DVs in ascending order of the calculated distance, and the extracted n feature data DVs are n neighborhood data DN 1 respectively. To DN n .
- the local model learning unit 424 then generates a local model LM based on the DN n from the n neighborhood data DN 1 extracted in step S22 (step S23).
- the local model LM is a linear regression model
- Equation 1 An example of such a local model LM is shown in Equation 1.
- w f in Equation 1 is a weight multiplied by the difference information vi and f .
- the weight w f (specifically, each of w 1 to w F ) is a weight of 0 or more. That is, the weight w f (specifically, each of w 1 to w F ) is a weight that does not have a negative value.
- the local model LM is a linear regression model specified by a regression equation that does not include a bias term (that is, the bias term becomes zero).
- the local model LM is not limited to the linear regression model shown in Equation 1.
- the local model LM may be a linear regression model specified by a regression equation in which the weight w f (specifically, at least one of w 1 to w F ) is a negative value.
- the local model LM may be a linear regression model specified by a regression equation that includes a bias term (that is, the bias term does not become zero).
- the local model LM is not limited to the linear regression model.
- the local model LM may be a non-linear regression model.
- the local model LM may be any other model.
- or vi , f (xq f -xn i, f ) 2 .
- or vi , f (xq f -xn i, f ) 2 to obtain the difference information Vi. Generate.
- the local model learning unit 424 After that, the local model learning unit 424 generates a local model LM based on the neighborhood data DN 1 to DN n extracted in step S22 and the difference information V 1 to V n calculated in step S23.
- the local model learning unit 424 inputs the difference information V 1 to V n in order for the generated or default local model LM.
- the local model learning unit 424 has the estimated value dp 1 of the distance d 1 between the query data DQ and the neighborhood data DN 1 in the latent space, and the query data DQ and the neighborhood data DN 2 in the latent space.
- the estimated value dp 2 of the distance d 2 between them and the estimated value dp n of the distance d n between the query data DQ and the neighboring data DN n in the latent space are acquired.
- the actual distance di (that is, the actual calculated value of the distance di ) is the latent vector ZQ and the latent vector ZV (that is, the neighborhood data DN i ) in order to extract the neighborhood data DN i in step S223 of FIG. It corresponds to the distance calculated based on the latent vector ZN i ) generated by converting the feature vector XN i of the above by the conversion model TM.
- the loss function Loss may be a loss function that becomes smaller as the error between the actual calculated value of the distance di and the estimated value dpi of the distance di becomes smaller.
- Equation 2 An example of such a loss function Loss is shown in Equation 2.
- the loss function Loss is not limited to the loss function shown in Equation 2.
- the contribution calculation unit 425 determines the f-th vector component of the feature vector XN i (that is, the neighborhood data DN i ) with respect to the distance di between the query data DQ and the neighborhood data DN i in the latent space.
- the element contribution degrees ci and f representing the magnitude of the influence of the feature amount corresponding to the F elements) are calculated (step S24).
- the amount of change in the distance di when the p (where p is a variable indicating an integer satisfying 1 ⁇ p ⁇ F) th vector component of the feature vector XN i changes by a certain amount is r (r (where p) of the feature vector XN i .
- r is a variable indicating an integer satisfying 1 ⁇ r ⁇ F and r ⁇ p).
- the influence of the p-th vector component of the feature vector XN i is larger than the influence of the r-th vector component of the feature vector XN i on the distance di . Therefore, the element contribution degrees c i and p are larger than the element contribution degrees c i and r .
- the contribution degree calculation unit 425 uses the element contribution degree c i, based on the local model LM generated in step S23 and the difference information vi, f . Calculate f .
- the contribution calculation unit 425 may calculate the element contributions ci and f using the mathematical formula 3.
- the mathematical formula 3 is a mathematical formula used to calculate the element contribution degrees ci and f based on the parameters (in this case, the weights w f ) defining the local model LM and the difference information vi and f.
- the contribution calculation unit 425 calculates the element contributions c i and f while changing the variable f between 1 and F and changing the variable i between 1 and n, so that the element contribution c 1 and 1 , c 1, 2 , ..., and c 1, F , element contribution c 2, 1 , c 2 , 2, ..., and c 2, F , ..., and element contribution c n, 1 , c n, 2 , ..., And cn, F are calculated.
- the element contribution degrees c i and f are calculated using the above-mentioned mathematical formula 3
- the sum of the element contribution degrees c i and 1 to ci and F is 1.
- the output control unit 426 may control the output device 44 so as to output information regarding at least one of the n neighborhood data DN 1 extracted by the search unit 423 in step S23 (step). S25).
- the information regarding the neighborhood data DN i may include information regarding the proxy log data 4111 which is the basis for calculating the feature vector XN i of the neighborhood data DN i . That is, the output control unit 426 outputs the output device 44 so as to output the information regarding the proxy log data 4111 corresponding to at least one of the n neighborhood data DN 1 to the DN n extracted by the search unit 423 in step S23. You may control it.
- the output control unit 426 adds or replaces the information regarding at least one of the n neighborhood data DN 1 to DN n from the element contribution degree c 1 , 1 calculated by the contribution degree calculation unit 425 in step S24.
- the output device 44 may be controlled so as to output at least one of cn and F (step S25).
- the output control unit 426 may control the output device 44 so as to output a list of element contribution degrees c 1 , 1 to cn , F as shown in FIG.
- FIG. 9 shows an example of a list of element contribution degrees c 1 , 1 to cn , F output by the output device 44 (that is, displayed by the display device) when the output device 44 is a display device.
- the neighborhood data DN i has a first vector component indicating the feature amount regarding the minimum value of the reception size, a second vector component indicating the feature amount regarding the maximum value of the reception size, and a transmission size.
- the output control unit 426 features element contributions c i and 1 indicating the influence of the feature amount on the minimum value of the reception size on the distance di, and features on the maximum value of the reception size on the distance di .
- Element contribution c i, 2 indicating the effect of the amount
- element contribution c i , 3 indicating the effect of the feature amount on the minimum value of the transmission size on the distance di, and transmission to the distance di .
- Element contribution c i, 4 showing the influence of the feature on the maximum size
- element contribution c i , 5 showing the influence of the feature on the sum of the reception size and the transmission size on the distance di.
- the element contribution degree c i , 6 showing the influence of the feature amount on the method (GET) on the distance di
- the element contribution degree showing the influence of the feature amount on the method (POST) on the distance di .
- the output device 44 may be controlled to output a list of c i, 7 and element contributions c i , 8 indicating the influence of the feature amount on the method (other) on the distance di.
- the element contribution degrees c 1 , 1 to c 1, 4 are relatively large. Therefore, it can be seen that the influence of the feature quantities of the reception size and the transmission size on the distance di between the query data DQ and the neighborhood data DN 1 in the latent space is relatively large. Further, in the example shown in FIG. 9, the element contribution degrees c 2 , 1 to c 2, 1 are relatively large. Therefore, it can be seen that the influence of the feature amount on the reception size on the distance d 2 between the query data DQ and the neighborhood data DN 2 in the latent space is relatively large. Further, in the example shown in FIG. 9, the element contribution degrees c3 , 1 to c3 , 1 are relatively large. Therefore, it can be seen that the feature amount relating to the reception size has a relatively large influence on the distance d 3 between the query data DQ and the neighborhood data DN 3 in the latent space.
- the information processing device 4 of the present embodiment has a relative distance di between the query data DQ and the neighborhood data DN i in the latent space. It is possible to calculate the element contribution degrees c i and f indicating the magnitude of the influence of the feature amount corresponding to the f-th element of the neighborhood data DN i . Therefore, the user of the information processing apparatus 4 has a relatively large influence on the distance di based on the element contribution degrees c i and f (that is, relative to the calculation of the distance di ) . It is possible to grasp the feature amount (which greatly contributes to).
- the information processing apparatus 4 can generate a local model LM and calculate the element contribution degrees ci and f using the generated local model LM (for example, the weight w f that defines the local model LM). Therefore, the information processing apparatus 4 can calculate the element contribution degrees ci and f relatively easily.
- the information processing apparatus 4 can calculate the element contribution degrees c i and f using the weights w f that define the generated local model LM. Therefore, the information processing apparatus 4 calculates the element contribution degrees ci and f using a relatively simple mathematical formula such as the above-mentioned mathematical formula 1 (particularly, a mathematical formula that is easy to handle for a device that performs a matrix operation). Can be done.
- the local model LM is a linear regression model specified by a regression equation that does not include a bias term. If the local model LM is a linear regression model specified by a regression equation including a bias term, the information processing apparatus 4 sets the element contributions ci and f when calculating the local model LM. In the calculation, it is necessary to consider the deviation from the origin caused by the bias term (that is, the amount of offset in the expression space and / or the latent space).
- the information processing apparatus 4 calculates the local model LM and / or performs the matrix operation for calculating the element contribution degrees ci and f , not only the internal product of the matrices but also the offset amount of the matrix component ( That is, it is necessary to consider addition and subtraction).
- the local model LM is a linear regression model specified by a regression equation that does not include a bias term
- the information processing apparatus 4 is used when calculating the local model LM and / or the degree of element contribution.
- the information processing apparatus 4 can calculate the local model LM and / or the element contribution degrees ci and f relatively easily.
- the local model LM is a linear regression model specified by a regression equation in which the weight w f is 0 or more. If the local model LM is a linear regression model specified by a regression equation that allows the weight w f to be less than 0, the element contribution degrees ci and f may be negative values. .. However, for the user of the information processing apparatus 4, the negative element contribution degrees ci and f are assumed to be indicators that are difficult to understand intuitively. On the other hand, in the present embodiment, since the local model LM is a linear regression model specified by a regression equation having a weight w f of 0 or more, the element contribution degrees ci and f do not have negative values. .. Therefore, the information processing apparatus 4 can calculate the element contribution degrees ci and f that are intuitively easy for the user of the information processing apparatus 4.
- the information processing apparatus 4 may specify the factor that the distance di between the query data DQ and the neighborhood data DN i in the latent space is relatively small based on the element contribution degrees c i and f . good. That is, the information processing apparatus 4 may specify the factor that causes the query data DQ and the neighborhood data DN i to be determined to be similar based on the element contribution degrees c i and f . For example, in the example shown in FIG. 9 described above, the element contribution degrees c3 , 1 to c3, 2 are relatively large. In this case, the information processing apparatus 4 may specify that the factor for determining that the query data DQ and the neighborhood data DN 3 are similar is due to the reception size.
- the reason why the query data DQ and the neighborhood data DN 3 are determined to be similar is that the proxy log data 4111 corresponding to the neighborhood data DN 3 is determined to show traces of the same or similar threat as the detection target threat. It can be said that it is equivalent to the factor.
- the information processing apparatus 4 may classify DN n from n neighborhood data DN 1 extracted by the search unit 423 based on the element contribution degrees c i and f . Specifically, the information processing apparatus 4 classifies DN n from n neighborhood data DN 1 so that neighborhood data DN i having similar element contribution degrees c i and f are classified into the same contribution data group. You may. In this case, the information processing apparatus 4 may perform a learning operation for updating the weight w f of the local model LM by using the neighborhood data DN i classified into the same contribution data group.
- the information processing apparatus 4 determines whether or not the search unit 423 has erroneously extracted at least one of the n neighborhood data DN 1 to DN n based on the element contribution degrees c i and f . You may judge. For example, since the n neighborhood data DN 1 to DN n are similar to the query data DQ in the first place, it is usually composed of F element contribution degrees c 1, 1 to c 1 and F corresponding to the neighborhood data DN 1 . Vectors, F element contributions corresponding to the neighborhood data DN 2 , a vector composed of c 2, 1 to c 2, F , ..., F element contributions corresponding to the neighborhood data DN n .
- the search unit 423 erroneously extracts at least one of n neighborhood data DN 1 to DN n based on the element contribution degrees c i and f . It may be determined whether or not it is.
- the information processing apparatus 4 may calculate the group contribution degree e in addition to the element contribution degrees c i and f .
- the group contribution e means that each vector component of the feature vector of a certain neighborhood data (that is, each element of the feature quantity indicated by the neighborhood data) belongs to at least one of a plurality of feature groups (in other words, it is classified). It is an index value calculated under the circumstances.
- the group contribution e represents the magnitude of the influence of each feature group on the distance between a certain query data and a certain neighborhood data in the latent space.
- the group contribution e is classified into at least one vector component belonging to each feature group (that is, one feature group) with respect to the distance between a certain query data and a certain neighborhood data in the latent space. It represents the magnitude of the effect of at least one feature quantity element).
- the plurality of feature groups may be groups corresponding to a plurality of types of log information included in the proxy log data 4111 from which the feature vector XN i is calculated.
- the proxy log data 4111 includes reception size information, transmission size information, and method information as a plurality of types of log information.
- a feature group related to the reception size, a feature group related to the transmission size, and a feature group related to the method may be used. Further, in the above-mentioned example, as shown in FIG.
- the first vector component indicating the feature amount relating to the minimum value of the reception size and the second feature amount indicating the feature amount relating to the maximum value of the reception size are shown.
- the 5th vector component shown, the 6th vector component showing the feature amount related to the method (GET), the 7th vector component showing the feature amount related to the method (POST), and the feature amount related to the method (others) 8 are shown. Includes the second vector component.
- the first vector component indicating the feature amount relating to the minimum value of the reception size, the second vector component indicating the feature amount relating to the maximum value of the reception size, and the feature quantity relating to the sum of the reception size and the transmission size are shown.
- the fifth vector component may belong to a feature group related to reception size.
- the vector component may belong to a feature group related to transmission size.
- the sixth vector component indicating the feature amount related to the method (GET), the seventh vector component indicating the feature amount related to the method (POST), and the eighth vector component indicating the feature amount related to the method (other) are received. You may belong to a feature group related to size.
- the contribution calculation unit 425 may perform the contribution calculation unit 425.
- the group contribution degree e representing the size may be calculated.
- the group contribution e indicating the magnitude of the influence of the g-th feature group on the distance di is referred to as “group contribution e i , g ”.
- the contribution calculation unit 425 calculates the group contribution e i , g while changing the variable g from 1 to G, so that the contribution calculation unit 425 belongs to at least the first feature group with respect to the distance di .
- Group contributions e i, 1 that represent the magnitude of the effect of one vector component
- group contributions that represent the magnitude of the effect of at least one vector component belonging to the second feature group with respect to the distance di are calculated. May be good.
- the contribution calculation unit 425 may calculate the group contribution e i, g based on the element contribution c i, f .
- the contribution calculation unit 425 may be calculated using the mathematical formula 4.
- the group contribution degrees e i and g calculated using the formula 4 are the sum of the element contribution degrees c i and f weighted by the belonging rates b g and f , which will be described later.
- b g and f in Equation 4 indicate the affiliation rate in which the f-th vector component of the neighborhood data DN i belongs to the g-th feature group.
- the belonging rates b g and f are set so that the sum of the belonging rates b g and f of each vector component (that is, b 1, f + b 2, f + ... + b G, f ) is 1.
- the belonging ratios bg and f to which the f-th vector component belongs to the g-th feature group are 1 (that is, 100%). It may be set to.
- the f-th vector component is the g1 (where g1 is a variable indicating an integer satisfying 1 ⁇ g1 ⁇ G) th feature group and g2 (where g2 is 1 ⁇ g2 ⁇ G and g2 ⁇ g).
- the affiliation rates bg and f may be set in advance, or may be set by the information processing apparatus 4 (particularly, the contribution calculation unit 425).
- the output control unit 426 may control the output device 44 so as to output the group contribution degree e i, g .
- the group contribution degrees e i, 1 to e i, G correspond to each of the G feature groups corresponding to the G types of log information included in the proxy log data 4111, respectively. Therefore, the output control unit 426 includes at least a part of the G type log information included in the proxy log data 4111 corresponding to the neighborhood data DN i and at least a G group contribution degree e i, 1 to e i, G.
- the output device 44 may be controlled so as to output the proxy log data 4111 in an output mode in which a part is associated with each other.
- the display mode in which at least a part of the G type log information and at least a part of the group contributions e i, 1 to e i, and G are associated with each other is the g-th log corresponding to the g-th feature group. It may include a display mode in which the information is associated with the group contributions e i and g of the g-th feature group. Specifically, for example, a display mode in which at least a part of G type log information and at least a part of G group contributions e i, 1 to e i, G are associated with each other is (i) reception size.
- the display mode in which the g-th log information and the group contribution degrees e i and g are associated with each other is the display mode of the g-th log information (for example, color, brightness, luminance and high). It may include a display mode in which at least one of the lights) is changed according to the group contribution degree e i, g .
- FIG. 11B shows an example of highlighting log information having a relatively high group contribution degree e i, g .
- the display mode in which the g-th log information is associated with the group contribution e i , g includes a display mode in which whether or not to display the g-th log information is determined according to the group contribution e i, g . You may go out.
- the g-th log information may not be displayed.
- the group contribution degrees e i and g exceed a predetermined display threshold value, the g-th log information may be displayed.
- the information processing apparatus 4 can calculate the group contribution degrees e i and g .
- the group contribution degrees e i and g are, for example, the sum of a plurality of element contribution degrees c i and f corresponding to the same feature group. Therefore, the variation of the group contribution degrees e i and g is smaller than the variation of each element contribution degree c i and f . Therefore, the information processing apparatus 4 can calculate the group contribution degree e i, g which can be regarded as a more stable contribution degree as compared with the element contribution degree c i, f .
- the plurality of feature groups correspond to a plurality of types of log information of the proxy log data 4111, respectively. Therefore, when the information processing apparatus 4 displays the neighborhood data DN i (that is, when displaying the proxy log data 4111 corresponding to the neighborhood data DN i ), the information processing apparatus 4 sets the group contribution degrees e i and g to the neighborhood data DN i.
- the neighborhood data DN i can be displayed relatively easily in the display mode associated with i .
- the communication system SYS includes a proxy server 1.
- the communication system SYS does not have to include the proxy server 1. That is, the client 2 may communicate with the server 3 without going through the proxy server 1.
- the server 3 may communicate with the client 2 without going through the proxy server 1.
- the information processing apparatus 4 may perform the above-mentioned threat detection operation by using the log data indicating the history of communication between the client 2 and the server 3.
- the information processing apparatus 4 includes a feature extraction unit 421.
- the information processing apparatus 4 does not have to include the feature extraction unit 421.
- the storage device 41 may store the feature data set 412 including the feature vector XV generated by an arbitrary method from the proxy log data 4111 included in the proxy log DB 411. In this case, as shown in FIG. 13, the storage device 41 does not have to store the proxy log DB 411.
- the information processing apparatus 4 includes a metric learning unit 422.
- the information processing apparatus 4 does not have to include the metric learning unit 422.
- the storage device 41 may store the conversion model TM generated by a device different from the information processing device 4.
- the storage device 41 does not have to store the teacher data set 413.
- the information processing apparatus 4 includes an output control unit 426.
- the information processing apparatus 4 does not have to include the output control unit 426.
- the operation of outputting the neighborhood data DN 1 to the element contribution degrees ci and f performed by the output control unit 426 may be performed by an external device of the information processing device 4.
- the embodiment of the information processing apparatus, the information processing method, and the recording medium is applied to the communication system SYS that performs the threat detection operation.
- the information processing device, the information processing method, and the embodiment of the recording medium may be applied to any data processing device that handles arbitrary data.
- the data processing device may perform the model generation operation described above as long as the distance between the plurality of data handled by the data processing device can be defined in the vector space.
- the data processing device may perform a data detection operation according to the threat detection operation described above.
- the data detection operation is between the process of detecting the neighborhood data DN i corresponding to the data located in the vicinity of the query data DQ in the latent space and the query data DQ and the neighborhood data DN i in the latent space. It may include at least one of a process of calculating element contribution degrees c i and f representing the magnitude of the influence of each vector component of the feature vector XN i of the neighborhood data DN i on the distance di.
- a process of calculating element contribution degrees c i and f representing the magnitude of the influence of each vector component of the feature vector XN i of the neighborhood data DN i on the distance di.
- the present invention can be appropriately modified within the scope of the claims and within the scope not contrary to the gist or idea of the invention that can be read from the entire specification, and the information processing apparatus, information processing method, and recording medium accompanied by such changes are also included. It is also included in the technical idea of the present invention.
- SYSTEM communication system 1 Proxy server 2 Server 3 Client 4 Information processing device 41 Storage device 411 Proxy log DB 4111 Proxy log data 412 Feature data set 413 Teacher data set 4131 Teacher data 42 Computing device 421 Feature extraction unit 422 Metric learning unit 423 Search unit 424 Local model learning unit 425 Contribution calculation unit TM conversion model LM Local model DQ query data DV Features Data DN Neighborhood data XQ, XV, XN Feature vector ZQ, ZV, ZN Latent vector
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Computational Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Optimization (AREA)
- Mathematical Analysis (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Computing Systems (AREA)
- Algebra (AREA)
- Computational Linguistics (AREA)
- Medical Informatics (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/022,618 US12360994B2 (en) | 2020-09-29 | 2020-09-29 | Information processing apparatus, information processing method, and recording medium |
| PCT/JP2020/036907 WO2022070256A1 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
| JP2022553259A JP7420278B2 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/036907 WO2022070256A1 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022070256A1 true WO2022070256A1 (ja) | 2022-04-07 |
Family
ID=80951528
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/036907 Ceased WO2022070256A1 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12360994B2 (https=) |
| JP (1) | JP7420278B2 (https=) |
| WO (1) | WO2022070256A1 (https=) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230409110A1 (en) * | 2020-11-18 | 2023-12-21 | Sony Group Corporation | Information processing apparatus, information processing method, computer-readable recording medium, and model generating method |
| JP7853879B2 (ja) * | 2022-09-26 | 2026-04-30 | 株式会社Screenホールディングス | マーク検出方法およびコンピュータプログラム |
| CN120687483B (zh) * | 2025-06-26 | 2025-12-12 | 江苏冲浪软件科技有限公司 | 基于房产交易多维度数据的数据查询方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006190191A (ja) * | 2005-01-07 | 2006-07-20 | Sony Corp | 情報処理装置および方法、並びにプログラム |
| US20160180196A1 (en) * | 2014-12-22 | 2016-06-23 | Canon Kabushiki Kaisha | Object re-identification using self-dissimilarity |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2000000951A1 (en) * | 1998-06-29 | 2000-01-06 | Honeywell Inc. | Method of and system for detecting and rendering of graphic elements |
| JP2003141077A (ja) | 2001-11-02 | 2003-05-16 | Cognitive Research Laboratories Inc | 高速データ通信対応の分散処理型ファイアウォールシステム |
| JP3773888B2 (ja) | 2002-10-04 | 2006-05-10 | インターナショナル・ビジネス・マシーンズ・コーポレーション | データ検索システム、データ検索方法、コンピュータに対してデータ検索を実行させるためのプログラム、該プログラムを記憶したコンピュータ可読な記憶媒体、検索されたドキュメントを表示するためのグラフィカル・ユーザ・インタフェイス・システム、グラフィカル・ユーザ・インタフェイスを実現するためのコンピュータ実行可能なプログラムおよび該プログラムを記憶した記憶媒体 |
| JP2007183927A (ja) | 2005-12-05 | 2007-07-19 | Sony Corp | 情報処理装置および方法、並びにプログラム |
| US10445555B2 (en) * | 2009-01-27 | 2019-10-15 | Sciometrics, Llc | Systems and methods for ridge-based fingerprint analysis |
| JP5604249B2 (ja) | 2010-09-29 | 2014-10-08 | Kddi株式会社 | 人体姿勢推定装置、人体姿勢推定方法、およびコンピュータプログラム |
| WO2013129580A1 (ja) | 2012-02-28 | 2013-09-06 | 公立大学法人大阪府立大学 | 近似最近傍探索装置、近似最近傍探索方法およびそのプログラム |
| US9781139B2 (en) * | 2015-07-22 | 2017-10-03 | Cisco Technology, Inc. | Identifying malware communications with DGA generated domains by discriminative learning |
| US10565496B2 (en) | 2016-02-04 | 2020-02-18 | Nec Corporation | Distance metric learning with N-pair loss |
| JP6700831B2 (ja) * | 2016-02-12 | 2020-05-27 | キヤノン株式会社 | 画像処理装置、撮像装置、画像処理方法、及びプログラム |
| JP7000766B2 (ja) | 2017-09-19 | 2022-01-19 | 富士通株式会社 | 学習データ選択プログラム、学習データ選択方法、および、学習データ選択装置 |
| US12045696B2 (en) * | 2020-03-20 | 2024-07-23 | Kpn Innovations, Llc | Artificial intelligence systems and methods for generating educational inquiry responses from biological extractions |
| JP7502211B2 (ja) * | 2021-02-02 | 2024-06-18 | 株式会社東芝 | 情報処理装置、情報処理方法、およびプログラム |
| WO2022225516A1 (en) * | 2021-04-21 | 2022-10-27 | Google Llc | Machine-learned models for implicit object representation |
-
2020
- 2020-09-29 JP JP2022553259A patent/JP7420278B2/ja active Active
- 2020-09-29 US US18/022,618 patent/US12360994B2/en active Active
- 2020-09-29 WO PCT/JP2020/036907 patent/WO2022070256A1/ja not_active Ceased
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006190191A (ja) * | 2005-01-07 | 2006-07-20 | Sony Corp | 情報処理装置および方法、並びにプログラム |
| US20160180196A1 (en) * | 2014-12-22 | 2016-06-23 | Canon Kabushiki Kaisha | Object re-identification using self-dissimilarity |
Also Published As
| Publication number | Publication date |
|---|---|
| US12360994B2 (en) | 2025-07-15 |
| US20240004878A1 (en) | 2024-01-04 |
| JPWO2022070256A1 (https=) | 2022-04-07 |
| JP7420278B2 (ja) | 2024-01-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113609398B (zh) | 一种基于异构图神经网络的社交推荐方法 | |
| Zhang et al. | Attributed network embedding via subspace discovery | |
| CN111063392B (zh) | 基于神经网络的基因突变致病性检测方法、系统及介质 | |
| CN110503531A (zh) | 时序感知的动态社交场景推荐方法 | |
| CN115713270B (zh) | 一种同行互评异常评分检测及修正方法和装置 | |
| WO2022070256A1 (ja) | 情報処理装置、情報処理方法、及び、記録媒体 | |
| CN117349743A (zh) | 一种基于多模态数据的超图神经网络的数据分类方法及系统 | |
| CN113515519A (zh) | 图结构估计模型的训练方法、装置、设备及存储介质 | |
| de Andrade Silva et al. | An experimental study on the use of nearest neighbor-based imputation algorithms for classification tasks | |
| CN114219562A (zh) | 模型的训练方法、企业信用评估方法和装置、设备、介质 | |
| CN113945537A (zh) | 一种高准确度近红外光谱定量模型建立方法 | |
| Ankam et al. | Generalized Dirichlet Regression and other Compositional Models with Application to Market-share Data Mining of Information Technology Companies. | |
| CN107391443B (zh) | 一种稀疏数据异常检测方法及装置 | |
| Lu et al. | MD-MBPLS: A novel explanatory model in computational social science | |
| Mangal et al. | Learning a family of rheological constitutive models using neural operators | |
| Gangwar et al. | An adaptive boosting technique to mitigate popularity bias in recommender system | |
| CN117371511A (zh) | 图像分类模型的训练方法、装置、设备及存储介质 | |
| CN115423120A (zh) | 一种业务模型的训练方法、训练装置和计算设备 | |
| Guo et al. | On consistency of signature using Lasso | |
| CN113010687A (zh) | 一种习题标签预测方法、装置、存储介质以及计算机设备 | |
| Lakshminarayan et al. | Topological data analysis in digital marketing | |
| Kim et al. | Identifying aberrant data in structural equation models with IRLS-ADF | |
| Ma et al. | Fuzzy nodes recognition based on spectral clustering in complex networks | |
| CN116049733A (zh) | 基于神经网络的效能评估方法、系统、设备与存储介质 | |
| US11388187B2 (en) | Method of digital signal feature extraction comprising multiscale analysis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20956186 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022553259 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20956186 Country of ref document: EP Kind code of ref document: A1 |
|
| WWG | Wipo information: grant in national office |
Ref document number: 18022618 Country of ref document: US |