WO2022070256A1 - 情報処理装置、情報処理方法、及び、記録媒体 - Google Patents
情報処理装置、情報処理方法、及び、記録媒体 Download PDFInfo
- Publication number
- WO2022070256A1 WO2022070256A1 PCT/JP2020/036907 JP2020036907W WO2022070256A1 WO 2022070256 A1 WO2022070256 A1 WO 2022070256A1 JP 2020036907 W JP2020036907 W JP 2020036907W WO 2022070256 A1 WO2022070256 A1 WO 2022070256A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- feature
- latent
- distance
- information processing
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 112
- 238000003672 processing method Methods 0.000 title claims description 15
- 239000013598 vector Substances 0.000 claims abstract description 274
- 238000000034 method Methods 0.000 claims description 35
- 238000004364 calculation method Methods 0.000 claims description 33
- 238000006243 chemical reaction Methods 0.000 claims description 32
- 238000000605 extraction Methods 0.000 claims description 19
- 238000012417 linear regression Methods 0.000 claims description 17
- 238000004590 computer program Methods 0.000 claims description 9
- 238000012545 processing Methods 0.000 claims description 9
- 238000004891 communication Methods 0.000 description 37
- 238000001514 detection method Methods 0.000 description 35
- 230000005540 biological transmission Effects 0.000 description 27
- 230000004048 modification Effects 0.000 description 13
- 238000012986 modification Methods 0.000 description 13
- 230000006870 function Effects 0.000 description 10
- 238000010586 diagram Methods 0.000 description 9
- 239000000284 extract Substances 0.000 description 8
- 230000000694 effects Effects 0.000 description 7
- 230000004044 response Effects 0.000 description 6
- 230000009466 transformation Effects 0.000 description 6
- 230000008569 process Effects 0.000 description 4
- 238000013528 artificial neural network Methods 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 238000012546 transfer Methods 0.000 description 2
- 230000001174 ascending effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2453—Query optimisation
- G06F16/24534—Query rewriting; Transformation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- the present invention relates to a technical field of an information processing apparatus, an information processing method, and a recording medium capable of calculating information on a factor influencing a distance between two data in a vector space.
- Metric learning (in other words, metric learning) is used as an example of a method for calculating the distance between two data (specifically, the distance between two feature vectors indicating the feature quantities of the two data).
- the method is known (see Patent Document 1).
- Metric learning is a transformation that can transform the feature vector of each data so that the distance between two or more similar data is short and the distance between two or more dissimilar data is long in a vector space. This is a method for generating a model. In this case, two feature vectors indicating the feature quantities of the two data are transformed by the transformation model, and the distance between the transformed two feature vectors is calculated as the distance between the two data.
- the transformation model generated by metric learning is generally a black box model in which the process of transforming feature vectors cannot be understood by the user. As a result, the user cannot understand the factors influencing the distance between the two data. Therefore, from the viewpoint of improving user convenience, it is desirable to calculate information on factors influencing the distance between two data.
- An object of the present invention is to provide an information processing apparatus, an information processing method, and a recording medium capable of solving the above-mentioned technical problems.
- One aspect of the information processing apparatus is to display a plurality of feature vector data indicating the feature quantities of the plurality of sample data groups in the expression space, and to display the feature quantities of the plurality of sample data groups in a latent space different from the representation space.
- the conversion means for converting into the plurality of latent vector data shown respectively and the plurality of latent vector data the distance from the plurality of feature vector data to the desired query data in the latent space is the other feature vector data.
- An extraction means for extracting at least one feature vector data shorter than that of the neighborhood data as neighborhood data, and for each element of the feature quantity of the query data and the neighborhood data in the representation space based on the neighborhood data.
- a generation means for generating a local model that outputs an estimated value of the latent distance, which is the distance between the query data and the neighboring data in the latent space when the difference information regarding the difference is input, and the local.
- a calculation means for calculating an element contribution degree indicating the magnitude of the influence of each element of the feature amount of the neighborhood data on the latent distance based on the model and the difference information is provided.
- One aspect of the information processing method is to display a plurality of feature vector data indicating the feature quantities of the plurality of sample data groups in the expression space, and to display the feature quantities of the plurality of sample data groups in a latent space different from the representation space. Conversion to a plurality of latent vector data shown respectively, and based on the plurality of latent vector data, the distance from the plurality of feature vector data to the desired query data in the latent space is different from that of the other feature vector data. Extracting at least one feature vector data that is shorter in comparison as neighborhood data, and the difference between the feature quantities of the query data and the neighborhood data in the representation space based on the neighborhood data for each element.
- the local model To generate a local model that outputs an estimated value of the latent distance, which is the distance between the query data and the neighboring data in the latent space when the difference information is input, the local model and the difference. It includes calculating the element contribution degree indicating the magnitude of the influence of each element of the feature amount of the neighborhood data on the latent distance based on the information.
- One aspect of the recording medium is to provide a computer with a plurality of feature vector data indicating the feature quantities of the plurality of sample data groups in the representation space, respectively, in a latent space different from the representation space, and the features of the plurality of sample data groups.
- the distance from the plurality of feature vector data to the desired query data in the latent space is the other feature vector based on the conversion into the plurality of latent vector data indicating the quantity respectively and the plurality of latent vector data.
- At least one feature vector data that is shorter than the data is extracted as neighborhood data, and based on the neighborhood data, for each element of the feature quantity of the query data and the neighborhood data in the representation space.
- a computer program that executes an information processing method including calculating an element contribution degree indicating the magnitude of the influence of each element of the feature amount of the neighboring data on the latent distance based on the difference information. It is a recorded recording medium.
- each one of the above-mentioned information processing apparatus, information processing method, and recording medium it is possible to calculate information on factors influencing the distance between two data.
- FIG. 1 is a block diagram showing a configuration of the communication system of the present embodiment.
- FIG. 2 is a block diagram showing the configuration of the information processing apparatus of the present embodiment.
- FIG. 3 is a data structure diagram showing the data structure of the proxy log DB of the present embodiment.
- FIG. 4 is a data structure diagram showing the data structure of the feature data set of the present embodiment.
- FIG. 5 is a flowchart showing the flow of the model generation operation performed by the information processing apparatus.
- FIG. 6 is a data structure diagram showing the data structure of the teacher data set of the present embodiment.
- FIG. 7 is a flowchart showing the flow of the threat detection operation performed by the information processing apparatus.
- FIG. 8 is a flowchart showing the flow of the operation of extracting n neighborhood data.
- FIG. 1 is a block diagram showing a configuration of the communication system of the present embodiment.
- FIG. 2 is a block diagram showing the configuration of the information processing apparatus of the present embodiment.
- FIG. 3 is a data structure diagram
- FIG. 9 is a plan view showing a display example of the element contribution degree.
- FIG. 10 is a table showing the affiliation rate in which the vector component belongs to the feature group.
- FIG. 11 is a plan view showing a display example of the degree of group contribution.
- FIG. 12 is a block diagram showing a configuration of a communication system in the second modification.
- FIG. 13 is a block diagram showing the configuration of the information processing apparatus in the third modification.
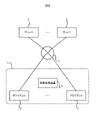
- FIG. 1 is a block diagram showing an overall configuration of the communication system SYS in the present embodiment.
- the communication system SYS includes a proxy server 1, a plurality of clients 2, a plurality of servers 3, and an information processing device 4.
- the communication system SYS may include a single client 2.
- the communication system SYS may include a single server 3.
- the proxy server 1 and each of the plurality of servers 3 can communicate with each other via the network 5.
- the network 5 may include a wired network or may include a wireless network.
- the proxy server 1 is a device that relays communication between the client 2 and the server 3.
- the proxy server 1 may send a request acquired from the client 2 to the server 3 specified by the acquired request via the network 5.
- the request may include, for example, an HTTP (HyperText Transfer Protocol) request.
- HTTP HyperText Transfer Protocol
- the proxy server 1 may send the response acquired from the server 3 via the network 5 to the client 2 specified by the response.
- the response may include, for example, an HTTP response.
- the response is not limited to the HTTP response.
- a system including a proxy server 1 and a plurality of clients 2 may be referred to as a local system L.
- the proxy server 1 is arranged at the boundary between the local system L and the wide area network outside the local system L. It can be said that the proxy server 1 relays the communication between the local system L and the wide area network.
- the client 2 communicates with the server 3 via the proxy server 1.
- the client 2 may send desired data to the server 3 via the proxy server 1.
- the client 2 may receive desired data from the server 3 via the proxy server 1.
- the server 3 communicates with the client 2 via the proxy server 1.
- the server 3 may send desired data to the client 2 via the proxy server 1.
- the server 3 may receive desired data from the client 2 via the proxy server 1.
- the server 3 is, for example, an HTTP server.
- the server 3 may be a server other than the HTTP server.
- the information processing device 4 performs a threat detection operation for detecting a threat that has already invaded the local system L via the network 5.
- a threat detection operation for detecting a threat that has already invaded the local system L via the network 5.
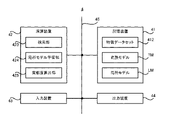
- FIG. 2 is a block diagram showing the configuration of the information processing apparatus 4 according to the present embodiment.
- the information processing device 4 includes a storage device 41 and an arithmetic unit 42. Further, the information processing device 4 may include an input device 43 and an output device 44. However, the information processing device 4 does not have to include at least one of the input device 43 and the output device 44.
- the storage device 41, the arithmetic unit 42, the input device 43, and the output device 44 may be connected via the data bus 45.
- the storage device 41 can store desired data.
- the storage device 41 may temporarily store the computer program executed by the arithmetic unit 42.
- the storage device 41 may temporarily store data temporarily used by the arithmetic unit 42 while the arithmetic unit 42 is executing a computer program.
- the storage device 41 may store data stored in the information processing device 4 for a long period of time.
- the storage device 41 may include at least one of a RAM (Random Access Memory), a ROM (Read Only Memory), a hard disk device, a magneto-optical disk device, an SSD (Solid State Drive), and a disk array device. good. That is, the storage device 41 may include a recording medium that is not temporary.
- the storage device 41 stores the data used by the information processing device 4 to perform the threat detection operation.
- FIG. 1 shows, as an example of data used by the information processing apparatus 4 for performing a threat detection operation, a proxy log DB (Data: database) 411, a feature data set 412, a teacher data set 413, and a conversion model TM.
- the local model LM are described. That is, FIG. 4 shows an example in which the storage device 41 stores the proxy log DB 411, the feature data set 412, the teacher data set 413, the conversion model TM, and the local model LM.
- the proxy log DB 411 stores a plurality of proxy log data 4111 (see FIG. 3).
- the proxy log data 4111 is log data showing a history of communication relayed by the proxy server 1 (that is, communication between the client 2 and the server 3).
- FIG. 3 shows the data structure of the proxy log DB 411 that stores such a plurality of proxy log data 4111.
- the proxy log data 4111 is, for example, (i) log information (client information) indicating the client 2 communicating with the server 3 and (ii) log information indicating the server 3 communicating with the client 2 (ii).
- the log information (reception size information) indicating the size of the server 3 and the log information (transmission size information) indicating the size of the data transmitted by the client 2 to the server 3 may be included.
- the proxy log data 4111 does not have to include at least one of the plurality of log information shown in FIG.
- the proxy log data 4111 may include other log information different from the plurality of log information shown in FIG.
- the proxy log data 4111 may be referred to as sample data. Further, the log information included in the proxy log data 4111 may be referred to as sample
- the feature data set 412, the teacher data set 413, the conversion model TM, and the local model LM will be described in detail later.
- the arithmetic unit 42 includes, for example, at least one of a CPU (Central Processing Unit), a GPU (Graphical Processing Unit), and an FPGA (Field Programmable Gate Array).
- the arithmetic unit 42 reads a computer program.
- the arithmetic unit 42 may read the computer program stored in the storage device 41.
- the arithmetic unit 42 may read a computer program stored in a recording medium that can be read by a computer and is not temporary by using a recording medium reading device (not shown).
- the arithmetic unit 42 may acquire (that is, download) a computer program from a device (not shown) arranged outside the information processing device 4 via an input device 43 capable of functioning as a communication device.
- the arithmetic unit 42 executes the read computer program.
- a logical functional block for executing an operation to be performed by the information processing device 4 (for example, the above-mentioned threat detection operation) is realized in the arithmetic unit 42. That is, the arithmetic unit 42 can function as a controller for realizing a logical functional block for executing an operation to be performed by the information processing unit 4.
- FIG. 2 shows an example of a logical functional block realized in the arithmetic unit 42 to execute a threat detection operation.
- a feature extraction unit 421 in the arithmetic unit 42, a feature extraction unit 421, a metric learning unit 422, a search unit 423 which is a specific example of each of the "conversion means” and the “extraction means", and a “generation” are provided.
- a local model learning unit 424 which is a specific example of the "means”, a contribution calculation unit 425 which is a specific example of the "calculation means”, and an output control unit 426 are realized.
- the feature extraction unit 421 extracts a plurality of (or at least one) proxy log data 4111 classified into the same log data group from the proxy log DB 411 based on a predetermined log classification standard.
- the predetermined log classification standard is a log classification in which a plurality of proxy log data 4111s having the same client information, the same server information, and the communication date / time information satisfying the predetermined date / time standard are classified into the same log data group. Criteria may be included.
- the plurality of proxy log data 4111 satisfying a predetermined date and time reference may include a plurality of proxy log data 4111 in which the communication dates indicated by the communication date and time information are the same.
- the plurality of proxy log data 4111 satisfying a predetermined date and time reference includes a plurality of proxy log data 4111 in which the interval between the communication times (or communication date and time) indicated by the communication date and time information is less than a predetermined value and is continuous. You may go out.
- the proxy log data 4111 classified into the same log data group may be referred to as a sample data group.
- the feature extraction unit 421 is performed from the proxy log DB 411 shown in FIG. 3 between the client 2 corresponding to the identifier C1 and the server 3 corresponding to the identifier S1 on January 1, 2019.
- Each of the three proxy log data 4111 showing the communication history may be extracted as the proxy log data 4111 classified into the first log data group.
- the feature extraction unit 421 is performed from the proxy log DB 411 shown in FIG. 3 between the client 2 corresponding to the identifier C2 and the server 3 corresponding to the identifier S2 on January 1, 2019.
- Each of the three proxy log data 4111 showing the communication history may be extracted as proxy log data 4111 classified into a second log data group different from the first log data group.
- the feature extraction unit 421 further generates a feature vector XV indicating a feature amount of the extracted plurality of proxy log data 4111 (that is, a plurality of proxy log data 4111 classified into the same log data group).
- the feature extraction unit 421 generates one feature vector XV from a plurality of proxy log data 4111 classified in the same log data group. Therefore, the feature extraction unit 421 generates feature vectors XV as many as the number of log data groups.
- the number of log data groups is K (K is a constant indicating an integer of 1 or more), and the feature extraction unit 421 uses K feature vectors XV (hereinafter, K feature vectors XV, respectively).
- the feature extraction unit 421 may generate a feature vector XV by analyzing a plurality of extracted proxy log data 4111.
- the feature extraction unit 421 may generate the feature vector XV, for example, by performing an arithmetic process for calculating the statistics of the plurality of proxy log data 4111.
- the feature vector XV may include, for example, an element (that is, a vector component, the same applies hereinafter) indicating a feature amount related to transmission size information.
- the feature amount related to the transmission size information may include a feature amount related to a transmission size statistic (for example, at least one of a minimum value, a maximum value, an average value, a variance, and an average value) indicated by the transmission size information.
- the feature vector XV may include, for example, an element indicating a feature amount related to reception size information.
- the feature amount related to the received size information may include a feature amount related to a received size statistic (for example, at least one of a minimum value, a maximum value, an average value, a variance, and a total value) indicated by the received size information.
- the feature vector XV may include, for example, an element indicating a feature quantity related to path information.
- the feature amount related to the path information may include a feature amount related to a statistic of the data length of the request path indicated by the path information (for example, at least one such as a minimum value, a maximum value, an average value, and a variance).
- the feature amount related to the path information may include the feature amount related to the frequency of the extension of the request path indicated by the path information (for example, the frequency of the request for each extension).
- the feature vector XV may include, for example, an element indicating a feature quantity related to method information.
- the feature amount related to the method information may include a feature amount related to the frequency of the method indicated by the method information (for example, at least one such as the ratio of the GET method, the ratio of the POST method, and the ratio of other methods).
- the feature vector XV may include, for example, an element indicating a feature quantity relating to the distribution of access times (eg, the percentage of requests sent per unit time (eg, 1 hour)).
- the feature vector XV may include, for example, an element indicating a feature quantity relating to the number of times a request has been transmitted.
- the proxy log data 4111 includes header information
- the feature vector XV may include, for example, an element indicating a feature amount related to the header information.
- the feature vector XV generated by the feature extraction unit 421 is stored by the storage device 41 as at least a part of the feature data set 412.
- An example of the data structure of the feature dataset 412 is shown in FIG.
- the feature extraction unit 421 generates one feature vector XV from a plurality of proxy log data 4111 classified in the same log data group. Therefore, the storage device 41 stores the feature vector XV generated by the feature extraction unit 421 as a feature data DV in which the data identifier for identifying the log data group corresponding to the feature vector XV and the feature vector XV are associated with each other. You may. In this case, as shown in FIG.
- the feature data set 412 contains feature data DV (ie, feature vector XV) as many as the number of log data groups classified according to a predetermined log classification criterion. That is, the feature data set 412 includes K feature data DVs (hereinafter, K feature data DVs are referred to as "feature data DV 1 to DV K " each using a subscript as an index). May be good.
- K feature data DVs are referred to as "feature data DV 1 to DV K " each using a subscript as an index). May be good.
- the feature data DV including the feature vector XV v is referred to as a feature data DV v .
- the predetermined log classification standard includes a log classification standard in which a plurality of proxy log data 4111 having the same client information, server information, and communication date / time information are classified into the same log data group.
- the storage device 41 uses the generated feature vector XV as feature data in which a data identifier uniquely indicating client information, server information, and communication date / time information is associated with the feature vector XV. It may be stored as DV.
- the metric learning unit 422 generates a conversion model TM used for converting the feature vector XV.
- the feature vector XV indicates the feature amount of the proxy log data 4111 in the expression space (that is, the vector space).
- the conversion model TM uses a feature vector XV indicating the feature amount of the proxy log data 4111 in such an expression space, and a latent vector indicating the feature amount of the proxy log data 4111 in a latent space which is a vector space different from the expression space. It is a model to convert to ZV. Since XV K is generated from K feature vectors XV 1 as described above, the conversion model TM changes K feature vectors XV 1 to XV K and K latent vectors ZV 1 to ZV K , respectively.
- the conversion model TM may convert the feature vector XV v into the latent vector ZV v .
- the latent vector ZV may be referred to as latent vector data ZV.
- the conversion model TM generated by the metric learning unit 422 is stored, for example, by the storage device 41. The operation of generating the conversion model TM will be described in detail later with reference to FIG. 5 and the like.
- the number of elements of the vector component of the latent vector ZV (that is, the number of elements of the feature quantity indicated by the latent vector ZV and the number of dimensions of the latent space) is typically the number of elements of the vector component of the feature vector XV (that is, that is). It is the number of elements of the feature amount indicated by the feature vector XV, and is preferably smaller than the number of dimensions of the expression space). Therefore, the latent vector ZV may be referred to as a low-dimensional vector, and the feature vector XV may be referred to as a high-dimensional vector.
- the human threat detection operation is compared with the case where the feature vector XV is not converted into the latent vector ZV.
- the senses are reflected relatively strongly (that is, the threat is detected after the human senses are considered relatively strongly).
- the number of elements of the vector component of the latent vector ZV may be the same as the number of elements of the vector component of the feature vector XV.
- the number of elements of the vector component of the latent vector ZV may be larger than the number of elements of the vector component of the feature vector XV.
- the search unit 423 is based on the query data DQ that specifies the threat to be detected by the threat detection operation (hereinafter referred to as “detection target threat”), and from the feature data set 412, the similarity to the query data DQ is other feature data. Search for at least one feature data DV that is higher than the DV.
- detection target threat the threat to be detected by the threat detection operation
- the distance between the query data DQ and the feature data DV in the latent space is obtained by converting the feature vector XQ (that is, the feature vector indicating the feature amount of the detection target threat) indicated by the query data DQ by the conversion model TM. It means the distance between the obtained latent vector ZQ and the latent vector ZV obtained by converting the feature vector XV indicated by the feature data DV by the conversion model TM. Therefore, in the present embodiment, the search unit 423 searches the feature data set 412 for at least one feature data DV whose distance from the query data DQ in the latent space is shorter than that of the other feature data DV.
- the query data DQ may include a feature vector XQ indicating the feature amount of the detection target threat.
- the number of dimensions of the feature vector XQ of the query data DQ is the same as the number of dimensions of the feature vector XV of the feature data DV. That is, when the number of dimensions of the feature vector XV is F (where F is a constant indicating an integer of 1 or more), it is preferable that the number of dimensions of the feature vector XQ is also F.
- the types of F feature quantities indicated by the F vector components of the feature vector XV are the same as the types of the F feature quantities indicated by the F vector components of the feature vector XQ.
- the feature vector XV includes a vector component indicating a feature amount related to the reception size and a vector component indicating a feature amount related to the transmission size
- the feature vector XQ also includes a vector component indicating the feature amount related to the reception size and transmission. It is preferable to include a vector component indicating a feature amount related to size.
- the search unit 423 has a shorter distance from the feature data set 412 from the query data DQ in the latent space than other feature data DVs (where n is 1 ⁇ n ⁇ feature data DV).
- n is 1 ⁇ n ⁇ feature data DV.
- the search unit 423 refers the searched n feature data DVs to n neighborhood data DNs (hereinafter, n neighborhood data DNs are referred to as “neighborhood data DN 1 to DN n ”, respectively. (Referred to as).
- the neighborhood data DN i (where i is a variable indicating an integer satisfying 1 ⁇ i ⁇ n) corresponds to the data located in the vicinity of the query data DQ in the latent space. That is, the neighborhood data DN i corresponds to the feature data DV indicating the feature amount of the proxy log data 4111 showing the trace of the same or similar threat as the detection target threat specified by the query data DQ. Therefore, when the neighborhood data DN i is detected, it is assumed that a threat similar to or similar to the detected target threat may have already invaded the local system L. Therefore, the extracted neighborhood data DN i (or proxy log data 4111 corresponding to the neighborhood data DN i ) is further analyzed in order to determine whether or not a threat has actually invaded the local system L. May be good.
- the local model learning unit 424 generates a local model LM based on the neighborhood data DN 1 to DN n .
- the local model LM is a distance di i between the query data DQ and the neighborhood data DN i in the latent space when the difference information V i regarding the difference between the query data DQ and the neighborhood data DN i in the representation space is input. It is a model that outputs the estimated value dpi of. The operation of generating the local model LM will be described in detail later with reference to FIG. 7 and the like.
- the difference information V i is, for example, the difference information vi, f indicating the difference between the query data DQ and the neighborhood data DN i for each vector component (that is, for each element (type) of the feature amount corresponding to the vector component). It may be included. That is, the difference information V i may include the difference information v i and f indicating the difference for each vector component between the feature vector XQ of the query data DQ and the feature vector XN i of the neighborhood data DN i .
- the f (where f is a variable indicating an integer satisfying 1 ⁇ f ⁇ F) of the feature vector XN i (that is, the feature amount corresponding to the fth element of the neighborhood data DN i ) is xn.
- the difference information v i and f are values based on the difference between the vector component xn i and f and the vector component xq f .
- the difference information V i is the difference information vi , 1 , the difference information v i, 2 , ..., The difference information. It may include vi, f and ..., Difference information vi , F.
- the contribution calculation unit 425 determines the element contribution c indicating the magnitude of the influence of each vector component of the feature vector of the neighborhood data on the distance between the query data and the neighborhood data in the latent space. calculate. Specifically, the contribution calculation unit 425 is the f-th vector component (that is, the neighborhood data ) of the feature vector XN i with respect to the distance di between the query data DQ and the neighborhood data DN i in the latent space. The element contribution degree c representing the magnitude of the influence of the feature amount corresponding to the f-th element of DN i ) is calculated.
- the element contribution degree c representing the magnitude of the influence of the f-th vector component of the feature vector XN i on the distance di is referred to as “element contribution degree c i , f ”.
- the contribution calculation unit 425 calculates the element contributions c i and f representing the magnitude of the importance of the f-th vector component of the feature vector XN i when calculating the distance di.
- the contribution calculation unit 425 calculates the element contributions ci and f based on the difference information vi and f and the local model LM generated by the local model learning unit 424. The calculation operation of the element contribution degrees ci and f will be described in detail later with reference to FIG. 7 and the like.
- the output control unit 426 may control the output device 44 described later so as to output information regarding at least one of the n neighborhood data DN 1 extracted by the search unit 423.
- the output control unit 426 outputs the element contribution degrees ci and f calculated by the contribution degree calculation unit 425 in addition to or in place of the information regarding at least one of the n neighborhood data DN 1 to DN n .
- the output device 44 described later may be controlled.
- the input device 43 is a device that receives information input to the information processing device 4 from the outside of the information processing device 4.
- the input device 43 may include an operation device (for example, at least one of a keyboard, a mouse, and a touch panel) that can be operated by the user of the information processing device 4.
- the input device 43 may include a receiving device (that is, a communication device) capable of receiving information transmitted as data from the outside of the information processing device 4 to the information processing device 4 via the communication network.
- the output device 44 is a device that outputs information.
- the output device 44 may output information regarding the threat detection operation performed by the information processing device 4 (for example, information regarding the detected threat).
- An example of such an output device 44 is a display (display device) capable of outputting (that is, displaying) information as an image.
- a speaker voice output device
- An example of the output device 44 is a printer capable of outputting a document in which information is printed.
- a transmission device that is, a communication device capable of transmitting information as data via a communication network or a data bus.
- the information processing apparatus 4 performs a threat detection operation for detecting a threat that has already invaded the local system L. Further, the information processing apparatus 4 may perform a model generation operation for generating a conversion model TM used in the threat detection operation before performing the threat detection operation. Therefore, in the following, the model generation operation and the threat detection operation will be described in order.
- FIG. 5 is a flowchart showing the flow of the model generation operation performed by the information processing apparatus 4.
- the metric learning unit 422 acquires at least one teacher data 4131 from the teacher data set 413 (step S11).
- the teacher data set 413 includes a plurality of teacher data 4131.
- the metric learning unit 422 may acquire all of the plurality of teacher data 4131 included in the teacher data set 413. Alternatively, the metric learning unit 422 acquires a part of the plurality of teacher data 4131 contained in the teacher data set 413, but does not acquire another part of the plurality of teacher data 4131 contained in the teacher data set 413. You may.
- Each teacher data 4131 contains data designation information that specifies two of the plurality of feature data DVs (ie, feature data DV 1 to DV K ) contained in the feature data set 412.
- the feature data DV can be uniquely distinguished by the data identifier for identifying the log data group corresponding to the feature vector XV included in the feature data DV. Therefore, as shown in FIG. 6, the data designation information may include the data identifiers of the two feature data DVs.
- Each teacher data 4131 further includes label information indicating whether the two feature data DVs designated by the data designation information correspond to a positive example or a negative example.
- the label information representing "0" indicates that the two feature data DVs designated by the data designation information correspond to a negative example
- the label information representing "1" is the data designation information.
- the two specified feature data DVs correspond to the positive example.
- the two feature data DVs corresponding to the positive example may mean two feature data DVs having similar features.
- the two feature data DVs having similar features may be two feature data DVs in which the distance in the latent space between the two feature data DVs is less than a predetermined first threshold value.
- the two feature data DVs corresponding to the negative example may mean two feature data DVs having dissimilar features.
- the distance in the latent space between the two feature data DVs is larger than a predetermined second threshold value (however, the second threshold value is equal to or higher than the above-mentioned first threshold value). It may be two feature data DVs.
- the metric learning unit 422 generates a conversion model TM based on the teacher data 4131 acquired in step S11 (step S12). Specifically, for example, the metric learning unit 422 may generate the conversion model TM by performing a learning operation for learning the conversion model TM. Therefore, the transformation model TM may be a learnable model.
- the transformation model TM may be a model including a neural network capable of learning parameters (eg, at least one of weights and biases).
- the metric learning unit 422 may generate a conversion model TM by performing metric learning (in other words, metric learning).
- Quantitative learning generally involves relatively short distances between two or more similar data and relatively long distances between two or more dissimilar data in a vector space. It is a learning method for generating a transformation model that can transform the feature vector of each data. Therefore, in the present embodiment, the metric learning unit 422 performs metric learning to perform a distance (that is, two or more similar feature data) in the latent space between two or more similar feature data DVs.
- the distance between two or more latent vectors ZV corresponding to each DV is relatively short, and the distance between two or more dissimilar feature data DVs (that is, two or more dissimilar feature data).
- a conversion model TM capable of converting a plurality of feature vectors XV into a plurality of latent vectors ZV is generated so that the distance between two or more latent vectors ZV corresponding to each DV) becomes relatively long. good.
- the metric learning unit 422 performs metric learning so that the distance in the latent space between two or more similar feature data DVs is within the latent space between two or more dissimilar feature data DVs.
- a conversion model TM that can convert a plurality of feature vectors XV into a plurality of latent vectors Zv may be generated so as to be equal to or greater than the distance in.
- the metric learning unit 422 performs metric learning so that (i) the distance in the latent space between two or more similar feature data DVs is between two or more similar feature data DVs. It is less than or equal to the distance in the representation space (that is, the distance between two or more feature vectors XV corresponding to each of two or more similar feature data DVs), and (ii) two or more dissimilar features.
- the distance in the latent space between the data DVs is the distance in the representation space between the two or more dissimilar feature data DVs (ie, two or more corresponding to each of the two or more dissimilar feature data DVs).
- a conversion model TM capable of converting a plurality of feature vectors XV into a plurality of latent vectors ZV may be generated so as to be equal to or larger than the distance between the feature vectors XV.
- the metric learning unit 422 may perform metric learning using, for example, a neural network used for performing metric learning.
- a neural network used for performing metric learning at least one of a siamese network (Siamese Network) and a triplet network (Triplet Network) can be mentioned.
- the metric learning unit 422 Based on the teacher data 4131, the metric learning unit 422 extracts at least one set of data sets including two feature vector XVs to which label information corresponding to a positive example is added from the feature data set 412. Further, the metric learning unit 422 extracts at least one set of two feature vectors XV to which label information corresponding to a negative example is added from the feature data set 412 based on the teacher data 4131. The metric learning unit 422 acquires two latent vectors ZV corresponding to the two feature vectors XV by inputting the two extracted feature vectors XV into the conversion model TM. After that, the metric learning unit 422 calculates the distance between the two latent vectors ZV.
- the metric learning unit 422 has a relatively short distance between the two latent vectors ZV obtained by converting the two feature vectors XV to which the label information corresponding to the positive example is given, and the negative example. Quantitative learning is performed so that the distance between the two latent vectors ZV obtained by converting the two feature vectors XV to which the label information corresponding to is attached is relatively long. Therefore, the metric learning unit 422 may perform metric learning using a loss function determined based on the distance between two latent vectors ZV in the latent space. For example, as described above, when the metric learning unit 422 performs metric learning using the sham network, the metric learning unit 422 may use a loss function based on the Conductive Loss.
- the storage device 41 stores the conversion model TM generated in step S12 (step S13).
- the conversion model TM stored in the storage device 41 is used in the threat detection operation described later.
- FIG. 7 is a flowchart showing the flow of the threat detection operation performed by the information processing apparatus 4.
- the threat detection operation shown in FIG. 7 may be started by the input of the query data DQ to the information processing apparatus 4.
- a threat detection operation is performed for each query data DQ.
- the threat detection operation and the second query data DQ are performed for the first query data DQ.
- the target threat detection operation is performed.
- the search unit 423 acquires the query data DQ (step S21). For example, the search unit 423 directly or indirectly detects a detection target threat (or feature vector XQ) input to the information processing device 4 via an input device 43 capable of functioning as a user-operable operation device. The information specified in may be acquired as query data DQ. For example, the search unit 423 can directly or indirectly specify a detection target threat (or feature vector XQ) transmitted to the information processing device 4 via an input device 43 capable of functioning as a communication device. The information may be acquired as query data DQ.
- a detection target threat or feature vector XQ
- the search unit 423 extracts DN n from n neighborhood data DN 1 from the feature data set 412 based on the query data DQ acquired in step S21 (step S22).
- the operation of extracting DN n from n neighborhood data DN 1 will be described with reference to FIG.
- FIG. 8 is a flowchart showing a flow of an operation of extracting DN n from n neighborhood data DN 1 .
- the search unit 423 detects the feature vector XQ of the query data DQ acquired in step 21 in the latent space by using the conversion model TM stored in the storage device 41. It is converted into a latent vector ZQ indicating a quantity (step S221).
- the search unit 423 extracts the feature data DV v of one of the plurality of feature data DVs included in the feature data set 412 (step S222). After that, the search unit 423 converts the feature vector XV v of the extracted one feature data DV v into the latent vector ZV v using the conversion model TM (step S222). After that, the search unit 423 calculates the distance (that is, the distance in the latent space) between the latent vector ZQ generated in step S221 and the latent vector ZV v generated in step S222 (step S223).
- the search unit 423 repeats the operations from step S222 to step S223 for a plurality of feature data DVs included in the feature data set 412 (step S224).
- the feature data set 412 contains K feature data DV 1 to DV K. Therefore, the search unit 423 performs the calculation of the K distances between the ZV K and the latent vector ZQ from the K latent vectors ZV 1 corresponding to the K feature data DV 1 to the DV K , respectively, until the calculation is completed.
- One feature data DV v that has not yet been extracted in step S222 is newly extracted from the plurality of feature data DV included in the feature data set 412, and then the operations from step S222 to step S223 are performed. repeat.
- the search unit 423 sets the distance between the latent vector ZV 1 corresponding to the feature data DV 1 and the latent vector ZQ, and the distance between the latent vector ZV 2 corresponding to the feature data DV 2 and the latent vector ZQ.
- the operation from step S222 to step S223 is repeated until the calculation of the distance between the two and the distance between the latent vector ZV K corresponding to the feature data DV K and the latent vector ZQ is completed.
- the search unit 423 transfers n feature data DVs out of the plurality of feature data DVs included in the feature data set 412 from the n neighborhood data DN 1s , respectively, based on the distance calculated in step S223. Extract as DN n (step S225). Specifically, the search unit 423 has n features among the K feature data DVs, which have a shorter distance from the query data DQ in the latent space than the other Kn feature data DVs. The data DV is extracted as DN n from n neighboring data DN 1 respectively. That is, the search unit 423 extracts n feature data DVs from the K feature data DVs in ascending order of the calculated distance, and the extracted n feature data DVs are n neighborhood data DN 1 respectively. To DN n .
- the local model learning unit 424 then generates a local model LM based on the DN n from the n neighborhood data DN 1 extracted in step S22 (step S23).
- the local model LM is a linear regression model
- Equation 1 An example of such a local model LM is shown in Equation 1.
- w f in Equation 1 is a weight multiplied by the difference information vi and f .
- the weight w f (specifically, each of w 1 to w F ) is a weight of 0 or more. That is, the weight w f (specifically, each of w 1 to w F ) is a weight that does not have a negative value.
- the local model LM is a linear regression model specified by a regression equation that does not include a bias term (that is, the bias term becomes zero).
- the local model LM is not limited to the linear regression model shown in Equation 1.
- the local model LM may be a linear regression model specified by a regression equation in which the weight w f (specifically, at least one of w 1 to w F ) is a negative value.
- the local model LM may be a linear regression model specified by a regression equation that includes a bias term (that is, the bias term does not become zero).
- the local model LM is not limited to the linear regression model.
- the local model LM may be a non-linear regression model.
- the local model LM may be any other model.
- or vi , f (xq f -xn i, f ) 2 .
- or vi , f (xq f -xn i, f ) 2 to obtain the difference information Vi. Generate.
- the local model learning unit 424 After that, the local model learning unit 424 generates a local model LM based on the neighborhood data DN 1 to DN n extracted in step S22 and the difference information V 1 to V n calculated in step S23.
- the local model learning unit 424 inputs the difference information V 1 to V n in order for the generated or default local model LM.
- the local model learning unit 424 has the estimated value dp 1 of the distance d 1 between the query data DQ and the neighborhood data DN 1 in the latent space, and the query data DQ and the neighborhood data DN 2 in the latent space.
- the estimated value dp 2 of the distance d 2 between them and the estimated value dp n of the distance d n between the query data DQ and the neighboring data DN n in the latent space are acquired.
- the actual distance di (that is, the actual calculated value of the distance di ) is the latent vector ZQ and the latent vector ZV (that is, the neighborhood data DN i ) in order to extract the neighborhood data DN i in step S223 of FIG. It corresponds to the distance calculated based on the latent vector ZN i ) generated by converting the feature vector XN i of the above by the conversion model TM.
- the loss function Loss may be a loss function that becomes smaller as the error between the actual calculated value of the distance di and the estimated value dpi of the distance di becomes smaller.
- Equation 2 An example of such a loss function Loss is shown in Equation 2.
- the loss function Loss is not limited to the loss function shown in Equation 2.
- the contribution calculation unit 425 determines the f-th vector component of the feature vector XN i (that is, the neighborhood data DN i ) with respect to the distance di between the query data DQ and the neighborhood data DN i in the latent space.
- the element contribution degrees ci and f representing the magnitude of the influence of the feature amount corresponding to the F elements) are calculated (step S24).
- the amount of change in the distance di when the p (where p is a variable indicating an integer satisfying 1 ⁇ p ⁇ F) th vector component of the feature vector XN i changes by a certain amount is r (r (where p) of the feature vector XN i .
- r is a variable indicating an integer satisfying 1 ⁇ r ⁇ F and r ⁇ p).
- the influence of the p-th vector component of the feature vector XN i is larger than the influence of the r-th vector component of the feature vector XN i on the distance di . Therefore, the element contribution degrees c i and p are larger than the element contribution degrees c i and r .
- the contribution degree calculation unit 425 uses the element contribution degree c i, based on the local model LM generated in step S23 and the difference information vi, f . Calculate f .
- the contribution calculation unit 425 may calculate the element contributions ci and f using the mathematical formula 3.
- the mathematical formula 3 is a mathematical formula used to calculate the element contribution degrees ci and f based on the parameters (in this case, the weights w f ) defining the local model LM and the difference information vi and f.
- the contribution calculation unit 425 calculates the element contributions c i and f while changing the variable f between 1 and F and changing the variable i between 1 and n, so that the element contribution c 1 and 1 , c 1, 2 , ..., and c 1, F , element contribution c 2, 1 , c 2 , 2, ..., and c 2, F , ..., and element contribution c n, 1 , c n, 2 , ..., And cn, F are calculated.
- the element contribution degrees c i and f are calculated using the above-mentioned mathematical formula 3
- the sum of the element contribution degrees c i and 1 to ci and F is 1.
- the output control unit 426 may control the output device 44 so as to output information regarding at least one of the n neighborhood data DN 1 extracted by the search unit 423 in step S23 (step). S25).
- the information regarding the neighborhood data DN i may include information regarding the proxy log data 4111 which is the basis for calculating the feature vector XN i of the neighborhood data DN i . That is, the output control unit 426 outputs the output device 44 so as to output the information regarding the proxy log data 4111 corresponding to at least one of the n neighborhood data DN 1 to the DN n extracted by the search unit 423 in step S23. You may control it.
- the output control unit 426 adds or replaces the information regarding at least one of the n neighborhood data DN 1 to DN n from the element contribution degree c 1 , 1 calculated by the contribution degree calculation unit 425 in step S24.
- the output device 44 may be controlled so as to output at least one of cn and F (step S25).
- the output control unit 426 may control the output device 44 so as to output a list of element contribution degrees c 1 , 1 to cn , F as shown in FIG.
- FIG. 9 shows an example of a list of element contribution degrees c 1 , 1 to cn , F output by the output device 44 (that is, displayed by the display device) when the output device 44 is a display device.
- the neighborhood data DN i has a first vector component indicating the feature amount regarding the minimum value of the reception size, a second vector component indicating the feature amount regarding the maximum value of the reception size, and a transmission size.
- the output control unit 426 features element contributions c i and 1 indicating the influence of the feature amount on the minimum value of the reception size on the distance di, and features on the maximum value of the reception size on the distance di .
- Element contribution c i, 2 indicating the effect of the amount
- element contribution c i , 3 indicating the effect of the feature amount on the minimum value of the transmission size on the distance di, and transmission to the distance di .
- Element contribution c i, 4 showing the influence of the feature on the maximum size
- element contribution c i , 5 showing the influence of the feature on the sum of the reception size and the transmission size on the distance di.
- the element contribution degree c i , 6 showing the influence of the feature amount on the method (GET) on the distance di
- the element contribution degree showing the influence of the feature amount on the method (POST) on the distance di .
- the output device 44 may be controlled to output a list of c i, 7 and element contributions c i , 8 indicating the influence of the feature amount on the method (other) on the distance di.
- the element contribution degrees c 1 , 1 to c 1, 4 are relatively large. Therefore, it can be seen that the influence of the feature quantities of the reception size and the transmission size on the distance di between the query data DQ and the neighborhood data DN 1 in the latent space is relatively large. Further, in the example shown in FIG. 9, the element contribution degrees c 2 , 1 to c 2, 1 are relatively large. Therefore, it can be seen that the influence of the feature amount on the reception size on the distance d 2 between the query data DQ and the neighborhood data DN 2 in the latent space is relatively large. Further, in the example shown in FIG. 9, the element contribution degrees c3 , 1 to c3 , 1 are relatively large. Therefore, it can be seen that the feature amount relating to the reception size has a relatively large influence on the distance d 3 between the query data DQ and the neighborhood data DN 3 in the latent space.
- the information processing device 4 of the present embodiment has a relative distance di between the query data DQ and the neighborhood data DN i in the latent space. It is possible to calculate the element contribution degrees c i and f indicating the magnitude of the influence of the feature amount corresponding to the f-th element of the neighborhood data DN i . Therefore, the user of the information processing apparatus 4 has a relatively large influence on the distance di based on the element contribution degrees c i and f (that is, relative to the calculation of the distance di ) . It is possible to grasp the feature amount (which greatly contributes to).
- the information processing apparatus 4 can generate a local model LM and calculate the element contribution degrees ci and f using the generated local model LM (for example, the weight w f that defines the local model LM). Therefore, the information processing apparatus 4 can calculate the element contribution degrees ci and f relatively easily.
- the information processing apparatus 4 can calculate the element contribution degrees c i and f using the weights w f that define the generated local model LM. Therefore, the information processing apparatus 4 calculates the element contribution degrees ci and f using a relatively simple mathematical formula such as the above-mentioned mathematical formula 1 (particularly, a mathematical formula that is easy to handle for a device that performs a matrix operation). Can be done.
- the local model LM is a linear regression model specified by a regression equation that does not include a bias term. If the local model LM is a linear regression model specified by a regression equation including a bias term, the information processing apparatus 4 sets the element contributions ci and f when calculating the local model LM. In the calculation, it is necessary to consider the deviation from the origin caused by the bias term (that is, the amount of offset in the expression space and / or the latent space).
- the information processing apparatus 4 calculates the local model LM and / or performs the matrix operation for calculating the element contribution degrees ci and f , not only the internal product of the matrices but also the offset amount of the matrix component ( That is, it is necessary to consider addition and subtraction).
- the local model LM is a linear regression model specified by a regression equation that does not include a bias term
- the information processing apparatus 4 is used when calculating the local model LM and / or the degree of element contribution.
- the information processing apparatus 4 can calculate the local model LM and / or the element contribution degrees ci and f relatively easily.
- the local model LM is a linear regression model specified by a regression equation in which the weight w f is 0 or more. If the local model LM is a linear regression model specified by a regression equation that allows the weight w f to be less than 0, the element contribution degrees ci and f may be negative values. .. However, for the user of the information processing apparatus 4, the negative element contribution degrees ci and f are assumed to be indicators that are difficult to understand intuitively. On the other hand, in the present embodiment, since the local model LM is a linear regression model specified by a regression equation having a weight w f of 0 or more, the element contribution degrees ci and f do not have negative values. .. Therefore, the information processing apparatus 4 can calculate the element contribution degrees ci and f that are intuitively easy for the user of the information processing apparatus 4.
- the information processing apparatus 4 may specify the factor that the distance di between the query data DQ and the neighborhood data DN i in the latent space is relatively small based on the element contribution degrees c i and f . good. That is, the information processing apparatus 4 may specify the factor that causes the query data DQ and the neighborhood data DN i to be determined to be similar based on the element contribution degrees c i and f . For example, in the example shown in FIG. 9 described above, the element contribution degrees c3 , 1 to c3, 2 are relatively large. In this case, the information processing apparatus 4 may specify that the factor for determining that the query data DQ and the neighborhood data DN 3 are similar is due to the reception size.
- the reason why the query data DQ and the neighborhood data DN 3 are determined to be similar is that the proxy log data 4111 corresponding to the neighborhood data DN 3 is determined to show traces of the same or similar threat as the detection target threat. It can be said that it is equivalent to the factor.
- the information processing apparatus 4 may classify DN n from n neighborhood data DN 1 extracted by the search unit 423 based on the element contribution degrees c i and f . Specifically, the information processing apparatus 4 classifies DN n from n neighborhood data DN 1 so that neighborhood data DN i having similar element contribution degrees c i and f are classified into the same contribution data group. You may. In this case, the information processing apparatus 4 may perform a learning operation for updating the weight w f of the local model LM by using the neighborhood data DN i classified into the same contribution data group.
- the information processing apparatus 4 determines whether or not the search unit 423 has erroneously extracted at least one of the n neighborhood data DN 1 to DN n based on the element contribution degrees c i and f . You may judge. For example, since the n neighborhood data DN 1 to DN n are similar to the query data DQ in the first place, it is usually composed of F element contribution degrees c 1, 1 to c 1 and F corresponding to the neighborhood data DN 1 . Vectors, F element contributions corresponding to the neighborhood data DN 2 , a vector composed of c 2, 1 to c 2, F , ..., F element contributions corresponding to the neighborhood data DN n .
- the search unit 423 erroneously extracts at least one of n neighborhood data DN 1 to DN n based on the element contribution degrees c i and f . It may be determined whether or not it is.
- the information processing apparatus 4 may calculate the group contribution degree e in addition to the element contribution degrees c i and f .
- the group contribution e means that each vector component of the feature vector of a certain neighborhood data (that is, each element of the feature quantity indicated by the neighborhood data) belongs to at least one of a plurality of feature groups (in other words, it is classified). It is an index value calculated under the circumstances.
- the group contribution e represents the magnitude of the influence of each feature group on the distance between a certain query data and a certain neighborhood data in the latent space.
- the group contribution e is classified into at least one vector component belonging to each feature group (that is, one feature group) with respect to the distance between a certain query data and a certain neighborhood data in the latent space. It represents the magnitude of the effect of at least one feature quantity element).
- the plurality of feature groups may be groups corresponding to a plurality of types of log information included in the proxy log data 4111 from which the feature vector XN i is calculated.
- the proxy log data 4111 includes reception size information, transmission size information, and method information as a plurality of types of log information.
- a feature group related to the reception size, a feature group related to the transmission size, and a feature group related to the method may be used. Further, in the above-mentioned example, as shown in FIG.
- the first vector component indicating the feature amount relating to the minimum value of the reception size and the second feature amount indicating the feature amount relating to the maximum value of the reception size are shown.
- the 5th vector component shown, the 6th vector component showing the feature amount related to the method (GET), the 7th vector component showing the feature amount related to the method (POST), and the feature amount related to the method (others) 8 are shown. Includes the second vector component.
- the first vector component indicating the feature amount relating to the minimum value of the reception size, the second vector component indicating the feature amount relating to the maximum value of the reception size, and the feature quantity relating to the sum of the reception size and the transmission size are shown.
- the fifth vector component may belong to a feature group related to reception size.
- the vector component may belong to a feature group related to transmission size.
- the sixth vector component indicating the feature amount related to the method (GET), the seventh vector component indicating the feature amount related to the method (POST), and the eighth vector component indicating the feature amount related to the method (other) are received. You may belong to a feature group related to size.
- the contribution calculation unit 425 may perform the contribution calculation unit 425.
- the group contribution degree e representing the size may be calculated.
- the group contribution e indicating the magnitude of the influence of the g-th feature group on the distance di is referred to as “group contribution e i , g ”.
- the contribution calculation unit 425 calculates the group contribution e i , g while changing the variable g from 1 to G, so that the contribution calculation unit 425 belongs to at least the first feature group with respect to the distance di .
- Group contributions e i, 1 that represent the magnitude of the effect of one vector component
- group contributions that represent the magnitude of the effect of at least one vector component belonging to the second feature group with respect to the distance di are calculated. May be good.
- the contribution calculation unit 425 may calculate the group contribution e i, g based on the element contribution c i, f .
- the contribution calculation unit 425 may be calculated using the mathematical formula 4.
- the group contribution degrees e i and g calculated using the formula 4 are the sum of the element contribution degrees c i and f weighted by the belonging rates b g and f , which will be described later.
- b g and f in Equation 4 indicate the affiliation rate in which the f-th vector component of the neighborhood data DN i belongs to the g-th feature group.
- the belonging rates b g and f are set so that the sum of the belonging rates b g and f of each vector component (that is, b 1, f + b 2, f + ... + b G, f ) is 1.
- the belonging ratios bg and f to which the f-th vector component belongs to the g-th feature group are 1 (that is, 100%). It may be set to.
- the f-th vector component is the g1 (where g1 is a variable indicating an integer satisfying 1 ⁇ g1 ⁇ G) th feature group and g2 (where g2 is 1 ⁇ g2 ⁇ G and g2 ⁇ g).
- the affiliation rates bg and f may be set in advance, or may be set by the information processing apparatus 4 (particularly, the contribution calculation unit 425).
- the output control unit 426 may control the output device 44 so as to output the group contribution degree e i, g .
- the group contribution degrees e i, 1 to e i, G correspond to each of the G feature groups corresponding to the G types of log information included in the proxy log data 4111, respectively. Therefore, the output control unit 426 includes at least a part of the G type log information included in the proxy log data 4111 corresponding to the neighborhood data DN i and at least a G group contribution degree e i, 1 to e i, G.
- the output device 44 may be controlled so as to output the proxy log data 4111 in an output mode in which a part is associated with each other.
- the display mode in which at least a part of the G type log information and at least a part of the group contributions e i, 1 to e i, and G are associated with each other is the g-th log corresponding to the g-th feature group. It may include a display mode in which the information is associated with the group contributions e i and g of the g-th feature group. Specifically, for example, a display mode in which at least a part of G type log information and at least a part of G group contributions e i, 1 to e i, G are associated with each other is (i) reception size.
- the display mode in which the g-th log information and the group contribution degrees e i and g are associated with each other is the display mode of the g-th log information (for example, color, brightness, luminance and high). It may include a display mode in which at least one of the lights) is changed according to the group contribution degree e i, g .
- FIG. 11B shows an example of highlighting log information having a relatively high group contribution degree e i, g .
- the display mode in which the g-th log information is associated with the group contribution e i , g includes a display mode in which whether or not to display the g-th log information is determined according to the group contribution e i, g . You may go out.
- the g-th log information may not be displayed.
- the group contribution degrees e i and g exceed a predetermined display threshold value, the g-th log information may be displayed.
- the information processing apparatus 4 can calculate the group contribution degrees e i and g .
- the group contribution degrees e i and g are, for example, the sum of a plurality of element contribution degrees c i and f corresponding to the same feature group. Therefore, the variation of the group contribution degrees e i and g is smaller than the variation of each element contribution degree c i and f . Therefore, the information processing apparatus 4 can calculate the group contribution degree e i, g which can be regarded as a more stable contribution degree as compared with the element contribution degree c i, f .
- the plurality of feature groups correspond to a plurality of types of log information of the proxy log data 4111, respectively. Therefore, when the information processing apparatus 4 displays the neighborhood data DN i (that is, when displaying the proxy log data 4111 corresponding to the neighborhood data DN i ), the information processing apparatus 4 sets the group contribution degrees e i and g to the neighborhood data DN i.
- the neighborhood data DN i can be displayed relatively easily in the display mode associated with i .
- the communication system SYS includes a proxy server 1.
- the communication system SYS does not have to include the proxy server 1. That is, the client 2 may communicate with the server 3 without going through the proxy server 1.
- the server 3 may communicate with the client 2 without going through the proxy server 1.
- the information processing apparatus 4 may perform the above-mentioned threat detection operation by using the log data indicating the history of communication between the client 2 and the server 3.
- the information processing apparatus 4 includes a feature extraction unit 421.
- the information processing apparatus 4 does not have to include the feature extraction unit 421.
- the storage device 41 may store the feature data set 412 including the feature vector XV generated by an arbitrary method from the proxy log data 4111 included in the proxy log DB 411. In this case, as shown in FIG. 13, the storage device 41 does not have to store the proxy log DB 411.
- the information processing apparatus 4 includes a metric learning unit 422.
- the information processing apparatus 4 does not have to include the metric learning unit 422.
- the storage device 41 may store the conversion model TM generated by a device different from the information processing device 4.
- the storage device 41 does not have to store the teacher data set 413.
- the information processing apparatus 4 includes an output control unit 426.
- the information processing apparatus 4 does not have to include the output control unit 426.
- the operation of outputting the neighborhood data DN 1 to the element contribution degrees ci and f performed by the output control unit 426 may be performed by an external device of the information processing device 4.
- the embodiment of the information processing apparatus, the information processing method, and the recording medium is applied to the communication system SYS that performs the threat detection operation.
- the information processing device, the information processing method, and the embodiment of the recording medium may be applied to any data processing device that handles arbitrary data.
- the data processing device may perform the model generation operation described above as long as the distance between the plurality of data handled by the data processing device can be defined in the vector space.
- the data processing device may perform a data detection operation according to the threat detection operation described above.
- the data detection operation is between the process of detecting the neighborhood data DN i corresponding to the data located in the vicinity of the query data DQ in the latent space and the query data DQ and the neighborhood data DN i in the latent space. It may include at least one of a process of calculating element contribution degrees c i and f representing the magnitude of the influence of each vector component of the feature vector XN i of the neighborhood data DN i on the distance di.
- a process of calculating element contribution degrees c i and f representing the magnitude of the influence of each vector component of the feature vector XN i of the neighborhood data DN i on the distance di.
- the present invention can be appropriately modified within the scope of the claims and within the scope not contrary to the gist or idea of the invention that can be read from the entire specification, and the information processing apparatus, information processing method, and recording medium accompanied by such changes are also included. It is also included in the technical idea of the present invention.
- SYSTEM communication system 1 Proxy server 2 Server 3 Client 4 Information processing device 41 Storage device 411 Proxy log DB 4111 Proxy log data 412 Feature data set 413 Teacher data set 4131 Teacher data 42 Computing device 421 Feature extraction unit 422 Metric learning unit 423 Search unit 424 Local model learning unit 425 Contribution calculation unit TM conversion model LM Local model DQ query data DV Features Data DN Neighborhood data XQ, XV, XN Feature vector ZQ, ZV, ZN Latent vector
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Optimization (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Computing Systems (AREA)
- Algebra (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
情報処理装置4は、表現空間内の複数の特徴ベクトルデータXVを潜在空間内の複数の潜在ベクトルデータZVに変換する変換手段423と、複数の潜在ベクトルデータに基づいて、複数の特徴ベクトルデータから、潜在空間内においてクエリデータDQからの距離が他の特徴ベクトルデータと比較して短い特徴ベクトルデータを、近傍データDNiとして抽出する抽出手段423と、近傍データに基づいて、表現空間内でのクエリデータと近傍データとの特徴量の要素毎の差分に関する差分情報Viが入力された場合に、潜在空間内でのクエリデータと近傍データとの間の距離である潜在距離diの推定値dpiを出力する局所モデルLMを生成する生成手段424と、局所モデルと差分情報とに基づいて、潜在距離に対して近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度ci,fを算出する算出手段425とを備える。
Description
本発明は、ベクトル空間内での二つのデータの間の距離に対して影響を与えている要因に関する情報を算出可能な情報処理装置、情報処理方法及び記録媒体の技術分野に関する。
二つのデータの間の距離(具体的には、二つのデータの特徴量を夫々示す二つの特徴ベクトルの間の距離)を算出する方法の一例として、計量学習(言い換えれば、メトリック学習)を用いる方法が知られている(特許文献1参照)。計量学習は、ベクトル空間内において、類似する二つ以上のデータの間の距離が短くなり且つ類似しない二つ以上のデータの間の距離が長くなるように各データの特徴ベクトルを変換可能な変換モデルを生成するための方法である。この場合、二つのデータの特徴量を夫々示す二つの特徴ベクトルが変換モデルによって変換され、変換された二つの特徴ベクトルの間の距離が、二つのデータの間の距離として算出される。
その他、本願発明に関連する先行技術文献として、特許文献2から特許文献7があげられる。
計量学習によって生成される変換モデルは、一般的には、特徴ベクトルを変換する過程がユーザには理解できないブラックボックスなモデルである。その結果、ユーザは、二つのデータの間の距離に対して影響を与えている要因を理解することができない。このため、ユーザの利便性を向上させるという観点から言えば、二つのデータの間の距離に対して影響を与えている要因に関する情報を算出することが望まれる。
本発明は、上述した技術的問題を解決可能な情報処理装置、情報処理方法、及び、記録媒体を提供することを課題とする。一例として、本発明は、二つのデータの間の距離に対して影響を与えている要因に関する情報を算出可能な情報処理装置、情報処理方法、及び、記録媒体を提供することを課題とする。
情報処理装置の一態様は、複数のサンプルデータ群の特徴量を表現空間内で夫々示す複数の特徴ベクトルデータを、前記表現空間とは異なる潜在空間内で前記複数のサンプルデータ群の特徴量を夫々示す複数の潜在ベクトルデータに変換する変換手段と、前記複数の潜在ベクトルデータに基づいて、前記複数の特徴ベクトルデータから、前記潜在空間内において所望のクエリデータからの距離が他の特徴ベクトルデータと比較して短い少なくとも一つの特徴ベクトルデータを、近傍データとして抽出する抽出手段と、前記近傍データに基づいて、前記表現空間内での前記クエリデータと前記近傍データとの特徴量の要素毎の差分に関する差分情報が入力された場合に、前記潜在空間内での前記クエリデータと前記近傍データとの間の距離である潜在距離の推定値を出力する局所モデルを生成する生成手段と、前記局所モデルと前記差分情報とに基づいて、前記潜在距離に対して前記近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度を算出する算出手段とを備える。
情報処理方法の一態様は、複数のサンプルデータ群の特徴量を表現空間内で夫々示す複数の特徴ベクトルデータを、前記表現空間とは異なる潜在空間内で前記複数のサンプルデータ群の特徴量を夫々示す複数の潜在ベクトルデータに変換することと、前記複数の潜在ベクトルデータに基づいて、前記複数の特徴ベクトルデータから、前記潜在空間内において所望のクエリデータからの距離が他の特徴ベクトルデータと比較して短い少なくとも一つの特徴ベクトルデータを、近傍データとして抽出することと、前記近傍データに基づいて、前記表現空間内での前記クエリデータと前記近傍データとの特徴量の要素毎の差分に関する差分情報が入力された場合に、前記潜在空間内での前記クエリデータと前記近傍データとの間の距離である潜在距離の推定値を出力する局所モデルを生成すること、前記局所モデルと前記差分情報とに基づいて、前記潜在距離に対して前記近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度を算出することとを含む。
記録媒体の一態様は、コンピュータに、複数のサンプルデータ群の特徴量を表現空間内で夫々示す複数の特徴ベクトルデータを、前記表現空間とは異なる潜在空間内で前記複数のサンプルデータ群の特徴量を夫々示す複数の潜在ベクトルデータに変換することと、前記複数の潜在ベクトルデータに基づいて、前記複数の特徴ベクトルデータから、前記潜在空間内において所望のクエリデータからの距離が他の特徴ベクトルデータと比較して短い少なくとも一つの特徴ベクトルデータを、近傍データとして抽出することと、前記近傍データに基づいて、前記表現空間内での前記クエリデータと前記近傍データとの特徴量の要素毎の差分に関する差分情報が入力された場合に、前記潜在空間内での前記クエリデータと前記近傍データとの間の距離である潜在距離の推定値を出力する局所モデルを生成すること、前記局所モデルと前記差分情報とに基づいて、前記潜在距離に対して前記近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度を算出することとを含む情報処理方法を実行させるコンピュータプログラムが記録された記録媒体である。
上述した情報処理装置、情報処理方法、及び、記録媒体のそれぞれの一の態様によれば、二つのデータの間の距離に対して影響を与えている要因に関する情報が算出可能となる。
以下、図面を参照しながら、情報処理装置、情報処理方法、及び、記録媒体の実施形態について説明する。以下では、情報処理装置、情報処理方法、及び、記録媒体の実施形態が適用された通信システムSYSを用いて、情報処理装置、情報処理方法、及び、記録媒体の実施形態について説明する。
(1)通信システムSYSの構成
(1-1)通信システムSYSの全体構成
初めに、図1を参照しながら、本実施形態における通信システムSYSの全体構成について説明する。図1は、本実施形態における通信システムSYSの全体構成を示すブロック図である。
(1-1)通信システムSYSの全体構成
初めに、図1を参照しながら、本実施形態における通信システムSYSの全体構成について説明する。図1は、本実施形態における通信システムSYSの全体構成を示すブロック図である。
図1に示すように、通信システムSYSは、プロキシサーバ1と、複数のクライアント2と、複数のサーバ3と、情報処理装置4とを備えている。但し、通信システムSYSは、単一のクライアント2を備えていてもよい。通信システムSYSは、単一のサーバ3を備えていてもよい。プロキシサーバ1と、複数のサーバ3の夫々とは、ネットワーク5を介して通信可能である。ネットワーク5は、有線のネットワークを含んでいてもよいし、無線のネットワークを含んでいてもよい。
プロキシサーバ1は、クライアント2とサーバ3との通信を中継する装置である。例えば、プロキシサーバ1は、クライアント2から取得したリクエストを、ネットワーク5を介して、取得したリクエストで指定されたサーバ3へと送信してもよい。リクエストは、例えば、HTTP(Hyper Text Transfer Protcol)リクエストを含んでいてもよい。但し、リクエストは、HTTPリクエストに限定されることはない。例えば、プロキシサーバ1は、ネットワーク5を介してサーバ3から取得したレスポンスを、レスポンスで指定されたクライアント2へと送信してもよい。レスポンスは、例えば、HTTPレスポンスを含んでいてもよい。但し、レスポンスは、HTTPレスポンスに限定されることはない。
プロキシサーバ1と複数のクライアント2とを含むシステムは、ローカルシステムLと称されてもよい。この場合、プロキシサーバ1は、ローカルシステムLと、ローカルシステムLの外部の広域ネットワークとの境界に配置されているとも言える。プロキシサーバ1は、ローカルシステムLと広域ネットワークとの間の通信を中継するとも言える。
クライアント2は、プロキシサーバ1を介してサーバ3と通信する。例えば、クライアント2は、プロキシサーバ1を介して、所望のデータをサーバ3に送信してもよい。例えば、クライアント2は、プロキシサーバ1を介して、所望のデータをサーバ3から受信してもよい。
サーバ3は、プロキシサーバ1を介してクライアント2と通信する。例えば、サーバ3は、プロキシサーバ1を介して、所望のデータをクライアント2に送信してもよい。例えば、サーバ3は、プロキシサーバ1を介して、所望のデータをクライアント2から受信してもよい。サーバ3は、例えば、HTTPサーバである。但し、サーバ3は、HTTPサーバ以外のサーバであってもよい。
情報処理装置4は、ネットワーク5を介してローカルシステムLに既に侵入している脅威を検出するための脅威検出動作を行う。以下、このような脅威検出動作を行う情報処理装置4の構成について更に説明する。
(1-2)情報処理装置4の構成
図2を参照しながら、本実施形態における情報処理装置4の構成について説明する。図2は、本実施形態における情報処理装置4の構成を示すブロック図である。
図2を参照しながら、本実施形態における情報処理装置4の構成について説明する。図2は、本実施形態における情報処理装置4の構成を示すブロック図である。
図2に示すように、情報処理装置4は、記憶装置41と、演算装置42とを備えている。更に、情報処理装置4は、入力装置43と、出力装置44とを備えていてもよい。但し、情報処理装置4は、入力装置43及び出力装置44の少なくとも一方を備えていなくてもよい。記憶装置41と、演算装置42と、入力装置43と、出力装置44とは、データバス45を介して接続されていてもよい。
記憶装置41は、所望のデータを記憶可能である。例えば、記憶装置41は、演算装置42が実行するコンピュータプログラムを一時的に記憶していてもよい。記憶装置41は、演算装置42がコンピュータプログラムを実行している際に演算装置42が一時的に使用するデータを一時的に記憶してもよい。記憶装置41は、情報処理装置4が長期的に保存するデータを記憶してもよい。尚、記憶装置41は、RAM(Random Access Memory)、ROM(Read Only Memory)、ハードディスク装置、光磁気ディスク装置、SSD(Solid State Drive)及びディスクアレイ装置のうちの少なくとも一つを含んでいてもよい。つまり、記憶装置41は、一時的でない記録媒体を含んでいてもよい。
本実施形態では、記憶装置41は、脅威検出動作を行うために情報処理装置4が利用するデータを記憶する。図1には、脅威検出動作を行うために情報処理装置4が利用するデータの一例として、プロキシログDB(Database:データベース)411と、特徴データセット412と、教師データセット413と、変換モデルTMと、局所モデルLMとが記載されている。つまり、図4は、記憶装置41がプロキシログDB411と、特徴データセット412と、教師データセット413と、変換モデルTMと、局所モデルLMとを記憶する例を示している。
プロキシログDB411は、複数のプロキシログデータ4111(図3参照)を格納する。プロキシログデータ4111は、プロキシサーバ1が中継した通信(つまり、クライアント2とサーバ3との間の通信)の履歴を示すログデータである。このような複数のプロキシログデータ4111を格納するプロキシログDB411のデータ構造が図3に示されている。図3に示すように、プロキシログデータ4111は、例えば、(i)サーバ3と通信したクライアント2を示すログ情報(クライアント情報)と、(ii)クライアント2と通信したサーバ3を示すログ情報(サーバ情報)と、(iii)クライアント2とサーバ3とが通信した日時を示すログ情報(通信日時情報)と、(iv)クライアント2がサーバ3と通信する際に利用したメソッドを示すログ情報(メソッド情報)と、(v)クライアント2がサーバ3に送信したリクエストで指定されていたパス(リクエストパス)を示すログ情報(リクエストパス情報)と、(vi)クライアント2がサーバ3から受信したデータのサイズを示すログ情報(受信サイズ情報)と、(vii)クライアント2がサーバ3に送信したデータのサイズを示すログ情報(送信サイズ情報)とを含んでいてもよい。但し、プロキシログデータ4111は、図3に示す複数のログ情報のうちの少なくとも一つを含んでいなくてもよい。プロキシログデータ4111は、図3に示す複数のログ情報とは異なる他のログ情報を含んでいてもよい。尚、プロキシログデータ4111は、サンプルデータと称されてもよい。また、プロキシログデータ4111に含まれるログ情報は、サンプル情報と称されてもよい。
尚、特徴データセット412と、教師データセット413と、変換モデルTMと、局所モデルLMとについては、後に詳述する。
再び図2において、演算装置42は、例えば、CPU(Central Proecssing Unit)、GPU(Graphical Processing Unit)及びFPGA(Field Programmable Gate Array)のうちの少なくとも一つを含む。演算装置42は、コンピュータプログラムを読み込む。例えば、演算装置42は、記憶装置41が記憶しているコンピュータプログラムを読み込んでもよい。例えば、演算装置42は、コンピュータで読み取り可能であって且つ一時的でない記録媒体が記憶しているコンピュータプログラムを、図示しない記録媒体読み取り装置を用いて読み込んでもよい。演算装置42は、通信装置として機能可能な入力装置43を介して、情報処理装置4の外部に配置される不図示の装置からコンピュータプログラムを取得してもよい(つまり、ダウンロードしてもよい又は読み込んでもよい)。演算装置42は、読み込んだコンピュータプログラムを実行する。その結果、演算装置42内には、情報処理装置4が行うべき動作(例えば、上述した脅威検出動作)を実行するための論理的な機能ブロックが実現される。つまり、演算装置42は、情報処理装置4が行うべき動作を実行するための論理的な機能ブロックを実現するためのコントローラとして機能可能である。
図2には、脅威検出動作を実行するために演算装置42内に実現される論理的な機能ブロックの一例が示されている。図2に示すように、演算装置42内には、特徴抽出部421と、計量学習部422と、「変換手段」及び「抽出手段」の夫々の一具体例である検索部423と、「生成手段」の一具体例である局所モデル学習部424と、「算出手段」の一具体例である貢献度算出部425と、出力制御部426とが実現される。
特徴抽出部421は、プロキシログDB411から、所定のログ分類基準に基づいて、同一のログデータ群に分類される複数の(或いは、少なくとも一つの)プロキシログデータ4111を抽出する。所定のログ分類基準は、クライアント情報が同一であり、サーバ情報が同一であり且つ通信日時情報が所定の日時基準を満たす複数のプロキシログデータ4111が同一のログデータ群に分類されるというログ分類基準を含んでいてもよい。所定の日時基準を満たす複数のプロキシログデータ4111は、通信日時情報が示す通信日が同一になるという複数のプロキシログデータ4111を含んでいてもよい。所定の日時基準を満たす複数のプロキシログデータ4111は、は、通信日時情報が示す通信時刻(或いは、通信日時)の間の間隔が所定値未満で連続している複数のプロキシログデータ4111を含んでいてもよい。尚、同一のログデータ群に分類されたプロキシログデータ4111は、サンプルデータ群と称されてもよい。この場合、例えば、特徴抽出部421は、図3に示すプロキシログDB411から、C1という識別子に対応するクライアント2とS1という識別子に対応するサーバ3との間で2019年1月1日に行われた通信の履歴を示す三つのプロキシログデータ4111の夫々を、第1のログデータ群に分類されるプロキシログデータ4111として抽出してもよい。同様に、例えば、特徴抽出部421は、図3に示すプロキシログDB411から、C2という識別子に対応するクライアント2とS2という識別子に対応するサーバ3との間で2019年1月1日に行われた通信の履歴を示す三つのプロキシログデータ4111の夫々を、第1のログデータ群とは異なる第2のログデータ群に分類されるプロキシログデータ4111として抽出してもよい。
特徴抽出部421は更に、抽出した複数のプロキシログデータ4111(つまり、同一のログデータ群に分類される複数のプロキシログデータ4111)の特徴量を示す特徴ベクトルXVを生成する。特徴抽出部421は、同一のログデータ群に分類される複数のプロキシログデータ4111から、一つの特徴ベクトルXVを生成する。このため、特徴抽出部421は、特徴ベクトルXVを、ログデータ群の数だけ生成する。以下の説明では、ログデータ群の数がK(Kは、1以上の整数を示す定数)であり、特徴抽出部421がK個の特徴ベクトルXV(以降、K個の特徴ベクトルXVを、夫々、下付き文字を“インデックスとする特徴ベクトルXV1からXVK”と称する)を生成する例について説明する。また、以下の説明では、K個のログデータ群のうちのインデックスがv(vは、1≦v≦Kを満たす変数)となる一のログデータ群から生成される特徴ベクトルXVを、特徴ベクトルXVvと称する。尚、特徴ベクトルXVは、特徴ベクトルデータXVと称されてもよい。特徴抽出部421は、抽出した複数のプロキシログデータ4111を解析することで、特徴ベクトルXVを生成してもよい。特徴抽出部421は、例えば、複数のプロキシログデータ4111の統計量を算出する演算処理を行うことで、特徴ベクトルXVを生成してもよい。
特徴ベクトルXVは、例えば、送信サイズ情報に関する特徴量を示す要素(つまり、ベクトル成分、以下同じ)を含んでいてもよい。送信サイズ情報に関する特徴量は、送信サイズ情報が示す送信サイズの統計量(例えば、最小値、最大値、平均値、分散及び平均値等の少なくとも一つ)に関する特徴量を含んでいてもよい。特徴ベクトルXVは、例えば、受信サイズ情報に関する特徴量を示す要素を含んでいてもよい。受信サイズ情報に関する特徴量は、受信サイズ情報が示す受信サイズの統計量(例えば、最小値、最大値、平均値、分散及び合計値等の少なくとも一つ)に関する特徴量を含んでいてもよい。特徴ベクトルXVは、例えば、パス情報に関する特徴量を示す要素を含んでいてもよい。パス情報に関する特徴量は、パス情報が示すリクエストパスのデータ長の統計量(例えば、最小値、最大値、平均値及び分散等の少なくとも一つ)に関する特徴量を含んでいてもよい。パス情報に関する特徴量は、パス情報が示すリクエストパスの拡張子の頻度(例えば、拡張子毎のリクエストの頻度)に関する特徴量を含んでいてもよい。特徴ベクトルXVは、例えば、メソッド情報に関する特徴量を示す要素を含んでいてもよい。メソッド情報に関する特徴量は、メソッド情報が示すメソッドの頻度(例えば、GETメソッドの割合、POSTメソッドの割合及びその他のメソッドの割合等の少なくとも一つ)に関する特徴量を含んでいてもよい。特徴ベクトルXVは、例えば、アクセス時刻の分布(例えば、単位時間(例えば、1時間)当たりに送信されたリクエストの割合)に関する特徴量を示す要素を含んでいてもよい。特徴ベクトルXVは、例えば、リクエストが送信された回数に関する特徴量を示す要素を含んでいてもよい。尚、プロキシログデータ4111にヘッダ情報が含まれている場合には、特徴ベクトルXVは、例えば、ヘッダ情報に関する特徴量を示す要素を含んでいてもよい。
特徴抽出部421が生成した特徴ベクトルXVは、記憶装置41によって、特徴データセット412の少なくとも一部として記憶される。特徴データセット412のデータ構造の一例が図4に示されている。上述したように、特徴抽出部421は、同一のログデータ群に分類される複数のプロキシログデータ4111から、一つの特徴ベクトルXVを生成する。このため、記憶装置41は、特徴抽出部421が生成した特徴ベクトルXVを、特徴ベクトルXVに対応するログデータ群を識別するためのデータ識別子と特徴ベクトルXVとが関連付けられた特徴データDVとして記憶してもよい。この場合、図4に示すように、特徴データセット412は、特徴データDV(つまり、特徴ベクトルXV)を、所定のログ分類基準によって分類されるログデータ群の数だけ含む。つまり、特徴データセット412は、K個の特徴データDV(以降、K個の特徴データDVを、夫々、下付き文字をインデックスとする“特徴データDV1からDVK”と称する)を含んでいてもよい。尚、以下の説明では、特徴ベクトルXVvを含む特徴データDVを、特徴データDVvと称する。上述した説明では、所定のログ分類基準が、クライアント情報、サーバ情報及び通信日時情報が同一になる複数のプロキシログデータ4111が同一のログデータ群に分類されるというログ分類基準を含んでいる。この場合には、図4に示すように、記憶装置41は、生成した特徴ベクトルXVを、クライアント情報、サーバ情報及び通信日時情報を一意に示すデータ識別子と特徴ベクトルXVとが関連付けられた特徴データDVとして記憶してもよい。
計量学習部422は、特徴ベクトルXVを変換するために用いる変換モデルTMを生成する。特徴ベクトルXVは、表現空間(つまり、ベクトル空間)内で、プロキシログデータ4111の特徴量を示している。変換モデルTMは、このような表現空間内でプロキシログデータ4111の特徴量を示す特徴ベクトルXVを、表現空間とは異なるベクトル空間である潜在空間内でプロキシログデータ4111の特徴量を示す潜在ベクトルZVに変換するモデルである。上述したようにK個の特徴ベクトルXV1からXVKが生成されるため、変換モデルTMは、K個の特徴ベクトルXV1からXVKを、夫々、K個の潜在ベクトルZV1からZVKに変換してもよい。つまり、変換モデルTMは、特徴ベクトルXVvを、潜在ベクトルZVvに変換してもよい。尚、潜在ベクトルZVは、潜在ベクトルデータZVと称されてもよい。計量学習部422が生成した変換モデルTMは、例えば、記憶装置41によって記憶される。尚、変換モデルTMを生成する動作については、図5等を参照しながら後に詳述する。
潜在ベクトルZVのベクトル成分の要素数(つまり、潜在ベクトルZVが示す特徴量の要素数であり、潜在空間の次元数)は、典型的には、特徴ベクトルXVのベクトル成分の要素数(つまり、特徴ベクトルXVが示す特徴量の要素数であり、表現空間の次元数)よりも少なくなることが好ましい。このため、潜在ベクトルZVは、低次元ベクトルと称されてもよいし、特徴ベクトルXVは、高次元ベクトルと称されてもよい。このように特徴ベクトルXVが特徴ベクトルXVよりも低次元の潜在ベクトルZVに変換される場合には、特徴ベクトルXVが潜在ベクトルZVに変換されない場合と比較して、脅威検出動作に対して人の感覚が相対的に強く反映される(つまり、人の感覚が相対的に強く考慮された上で、脅威が検出される)というメリットがある。但し、潜在ベクトルZVのベクトル成分の要素数は、特徴ベクトルXVのベクトル成分の要素数と同一であってもよい。潜在ベクトルZVのベクトル成分の要素数は、特徴ベクトルXVのベクトル成分の要素数よりも多くてもよい。
検索部423は、脅威検出動作によって検出したい脅威(以降、“検出ターゲット脅威”と称する)を指定するクエリデータDQに基づいて、特徴データセット412から、クエリデータDQに対する類似度が他の特徴データDVと比較して高い少なくとも一つの特徴データDVを検索する。本実施形態では、クエリデータDQと特徴データDVとの類似度と示す指標値として、潜在空間におけるクエリデータDQと特徴データDVとの間の距離が用いられる例について説明する。尚、潜在空間におけるクエリデータDQと特徴データDVとの間の距離は、クエリデータDQが示す特徴ベクトルXQ(つまり、検出ターゲット脅威の特徴量を示す特徴ベクトル)を変換モデルTMで変換することで得られる潜在ベクトルZQと、特徴データDVが示す特徴ベクトルXVを変換モデルTMで変換することで得られる潜在ベクトルZVとの間の距離を意味する。このため、本実施形態では、検索部423は、特徴データセット412から、潜在空間におけるクエリデータDQからの距離が他の特徴データDVと比較して短い少なくとも一つの特徴データDVを検索する。
クエリデータDQは、検出ターゲット脅威の特徴量を示す特徴ベクトルXQを含んでいてもよい。この際、クエリデータDQの特徴ベクトルXQの次元数は、特徴データDVの特徴ベクトルXVの次元数と同じであることが好ましい。つまり、特徴ベクトルXVの次元数がF(但し、Fは、1以上の整数を示す定数)である場合には、特徴ベクトルXQの次元数もまたFであることが好ましい。特に、特徴ベクトルXVのF個のベクトル成分が夫々示すF個の特徴量の種類は、特徴ベクトルXQのF個のベクトル成分が夫々示すF個の特徴量の種類と同一であることが好ましい。例えば、特徴ベクトルXVが、受信サイズに関する特徴量を示すベクトル成分と送信サイズに関する特徴量を示すベクトル成分とを含む場合には、特徴ベクトルXQもまた、受信サイズに関する特徴量を示すベクトル成分と送信サイズに関する特徴量を示すベクトル成分とを含むことが好ましい。
本実施形態では、検索部423が、特徴データセット412から、潜在空間におけるクエリデータDQからの距離が他の特徴データDVと比較して短いn(尚、nは、1≦n≦特徴データDVの総数Kを満たす整数を示す定数)個の特徴データDVを検索する例について説明する。この場合、検索部423は、検索されたn個の特徴データDVを、夫々、n個の近傍データDN(以下、n個の近傍データDNを、夫々、“近傍データDN1からDNn”と称する)として抽出する。
近傍データDNi(尚、iは、1≦i≦nを満たす整数を示す変数である)は、潜在空間においてクエリデータDQの近傍に位置するデータに相当する。つまり、近傍データDNiは、クエリデータDQが指定する検出ターゲット脅威と同じ又は類似する脅威の痕跡を示すプロキシログデータ4111の特徴量を示す特徴データDVに相当する。このため、近傍データDNiが検出された場合には、検出ターゲット脅威と同じ又は類似する脅威がローカルシステムLに既に侵入した可能性があると想定される。このため、抽出された近傍データDNi(或いは、近傍データDNiに対応するプロキシログデータ4111)は、ローカルシステムLに実際に脅威が侵入したか否かを判定するために、更に解析されてもよい。
局所モデル学習部424は、近傍データDN1からDNnに基づいて、局所モデルLMを生成する。局所モデルLMは、表現空間におけるクエリデータDQと近傍データDNiとの差分に関する差分情報Viが入力された場合に、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diの推定値dpiを出力するモデルである。尚、局所モデルLMを生成する動作については、図7等を参照しながら後に詳述する。
差分情報Viは、例えば、クエリデータDQと近傍データDNiとのベクトル成分毎の(つまり、ベクトル成分に対応する特徴量の要素(種類)毎の)差分を示す差分情報vi,fを含んでいてもよい。つまり、差分情報Viは、クエリデータDQの特徴ベクトルXQと近傍データDNiの特徴ベクトルXNiとのベクトル成分毎の差分を示す差分情報vi,fを含んでいてもよい。尚、特徴ベクトルXNiのf(但し、fは、1≦f≦Fを満たす整数を示す変数)番目のベクトル成分(つまり、近傍データDNiのf番目の要素に相当する特徴量)がxni,fであり、特徴ベクトルXQのf番目のベクトル成分がxqfである場合には、差分情報vi,fは、ベクトル成分xni,fとベクトル成分xqfとの差分に基づく値であってもよい。例えば、差分情報vi,fとして、ベクトル成分xni,fとベクトル成分xqfとの差分の絶対値(=|xqf-xni,f|)又はベクトル成分xni,fとベクトル成分xqfとの差分の二乗(=(xqf-xni,f)2)が用いられてもよい。上述したように、特徴ベクトルXQ及びXNiの夫々の次元数がFであるため、差分情報Viは、差分情報vi,1と、差分情報vi,2と、・・・、差分情報vi,fと、・・・、差分情報vi,Fとを含んでいてもよい。
貢献度算出部425は、潜在空間内におけるあるクエリデータとある近傍データとの間の距離に対して、当該近傍データの特徴ベクトルの各ベクトル成分が与える影響の大きさを表す要素貢献度cを算出する。具体的には、貢献度算出部425は、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diに対して、特徴ベクトルXNiのf番目のベクトル成分(つまり、近傍データDNiのf番目の要素に相当する特徴量)が与える影響の大きさを表す要素貢献度cを算出する。尚、以下の説明では、距離diに対して特徴ベクトルXNiのf番目のベクトル成分が与える影響の大きさを表す要素貢献度cを、“要素貢献度ci、f”と称する。言い換えれば、貢献度算出部425は、距離diを算出する際の特徴ベクトルXNiのf番目のベクトル成分の重要度の大きさを表す要素貢献度ci、fを算出する。具体的には、貢献度算出部425は、差分情報vi、fと局所モデル学習部424が生成した局所モデルLMとに基づいて、要素貢献度ci、fを算出する。尚、要素貢献度ci、fの算出動作については、図7等を参照しながら後に詳述する。
出力制御部426は、検索部423が抽出したn個の近傍データDN1からDNnの少なくとも一つに関する情報を出力するように、後述する出力装置44を制御してもよい。出力制御部426は、n個の近傍データDN1からDNnの少なくとも一つに関する情報に加えて又は代えて、貢献度算出部425が算出した要素貢献度ci、fを出力するように、後述する出力装置44を制御してもよい。
入力装置43は、情報処理装置4の外部からの情報処理装置4に対する情報の入力を受け付ける装置である。例えば、入力装置43は、情報処理装置4のユーザが操作可能な操作装置(例えば、キーボード、マウス及びタッチパネルのうちの少なくとも一つ)を含んでいてもよい。例えば、入力装置43は、情報処理装置4の外部から通信ネットワークを介して情報処理装置4にデータとして送信される情報を受信可能な受信装置(つまり、通信装置)を含んでいてもよい。
出力装置44は、情報を出力する装置である。例えば、出力装置44は、情報処理装置4が行う脅威検出動作に関する情報(例えば、検出された脅威に関する情報)を出力してもよい。このような出力装置44の一例として、情報を画像として出力可能な(つまり、表示可能な)ディスプレイ(表示装置)があげられる。出力装置44の一例として、情報を音声として出力可能なスピーカ(音声出力装置)があげられる。出力装置44の一例として、情報が印刷された文書を出力可能なプリンタがあげられる。出力装置44の一例として、通信ネットワーク又はデータバスを介して情報をデータとして送信可能な送信装置(つまり、通信装置)があげられる。
(2)情報処理装置4が行う動作
続いて、情報処理装置4が行う動作について説明する。上述したように、情報処理装置4は、ローカルシステムLに既に侵入している脅威を検出するための脅威検出動作を行う。更に、情報処理装置4は、脅威検出動作を行う前に、脅威検出動作で用いる変換モデルTMを生成するためのモデル生成動作を行ってもよい。このため、以下では、モデル生成動作と脅威検出動作とについて順に説明する。
続いて、情報処理装置4が行う動作について説明する。上述したように、情報処理装置4は、ローカルシステムLに既に侵入している脅威を検出するための脅威検出動作を行う。更に、情報処理装置4は、脅威検出動作を行う前に、脅威検出動作で用いる変換モデルTMを生成するためのモデル生成動作を行ってもよい。このため、以下では、モデル生成動作と脅威検出動作とについて順に説明する。
(2-1)モデル生成動作
初めに、図5を参照しながら、情報処理装置4が行うモデル生成動作について説明する。図5は、情報処理装置4が行うモデル生成動作の流れを示すフローチャートである。
初めに、図5を参照しながら、情報処理装置4が行うモデル生成動作について説明する。図5は、情報処理装置4が行うモデル生成動作の流れを示すフローチャートである。
図5に示すように、計量学習部422は、教師データセット413から少なくとも一つの教師データ4131を取得する(ステップS11)。
教師データセット413のデータ構造の一例が、図6に示されている。図6に示すように、教師データセット413は、複数の教師データ4131を含む。計量学習部422は、教師データセット413に含まれる複数の教師データ4131の全てを取得してもよい。或いは、計量学習部422は、教師データセット413に含まれる複数の教師データ4131の一部を取得する一方で、教師データセット413に含まれる複数の教師データ4131の他の一部を取得しなくてもよい。
各教師データ4131は、特徴データセット412に含まれている複数の特徴データDV(つまり、特徴データDV1からDVK)のうちの二つを指定するデータ指定情報を含む。上述したように、特徴データDVは、特徴データDVに含まれる特徴ベクトルXVに対応するログデータ群を識別するためのデータ識別子によって一意に区別可能である。このため、図6に示すように、データ指定情報は、二つの特徴データDVのデータ識別子を含んでいてもよい。
各教師データ4131は更に、データ指定情報が指定する二つの特徴データDVが、正例に相当するのか又は負例に相当するのかを示すラベル情報を含む。図6に示す例では、「0」を表すラベル情報は、データ指定情報が指定する二つの特徴データDVが負例に相当することを示し、「1」を表すラベル情報は、データ指定情報が指定する二つの特徴データDVが正例に相当することを示すものとする。本実施形態では、正例に相当する二つの特徴データDVは、特徴が似ている二つの特徴データDVを意味していてもよい。ここで、特徴が似ている二つの特徴データDVは、二つの特徴データDVの間の潜在空間における距離が所定の第1閾値未満になる二つの特徴データDVであってもよい。一方で、負例に相当する二つの特徴データDVは、特徴が似ていない二つの特徴データDVを意味していてもよい。ここで、特徴が似ていない二つの特徴データDVは、二つの特徴データDVの間の潜在空間における距離が所定の第2閾値(但し、第2閾値は、上述した第1閾値以上)より大きくなる二つの特徴データDVであってもよい。
再び図5において、計量学習部422は、ステップS11で取得した教師データ4131に基づいて、変換モデルTMを生成する(ステップS12)。具体的には、例えば、計量学習部422は、変換モデルTMを学習するための学習動作を行うことで、変換モデルTMを生成してもよい。このため、変換モデルTMは、学習可能なモデルであってもよい。例えば、変換モデルTMは、パラメータ(例えば、重み及びバイアスの少なくとも一つ)を学習可能なニューラルネットワークを含むモデルであってもよい。
本実施形態では、計量学習部422は、計量学習(言い換えれば、メトリック学習)を行うことで、変換モデルTMを生成してもよい。計量学習は、一般的には、ベクトル空間内において、類似する二つ以上のデータの間の距離が相対的に短くなり且つ類似しない二つ以上のデータの間の距離が相対的に長くなるように各データの特徴ベクトルを変換可能な変換モデルを生成するための学習方法である。このため、本実施形態では、計量学習部422は、計量学習を行うことで、類似する二つ以上の特徴データDVの間の潜在空間内での距離(つまり、類似する二つ以上の特徴データDVに夫々対応する二つ以上の潜在ベクトルZVの間の距離)が相対的に短くなり、且つ、類似しない二つ以上の特徴データDVの間の距離(つまり、類似しない二つ以上の特徴データDVに夫々対応する二つ以上の潜在ベクトルZVの間の距離)が相対的に長くなるように、複数の特徴ベクトルXVを夫々複数の潜在ベクトルZVに変換可能な変換モデルTMを生成してもよい。例えば、計量学習部422は、計量学習を行うことで、類似する二つ以上の特徴データDVの間の潜在空間内での距離が、類似しない二つ以上の特徴データDVの間の潜在空間内での距離以上になるように、複数の特徴ベクトルXVを夫々複数の潜在ベクトルZvに変換可能な変換モデルTMを生成してもよい。例えば、計量学習部422は、計量学習を行うことで、(i)類似する二つ以上の特徴データDVの間の潜在空間内での距離が、類似する二つ以上の特徴データDVの間の表現空間内での距離(つまり、類似する二つ以上の特徴データDVに夫々対応する二つ以上の特徴ベクトルXVの間の距離)以下になり、且つ、(ii)類似しない二つ以上の特徴データDVの間の潜在空間内での距離が、類似しない二つ以上の特徴データDVの間の表現空間内での距離(つまり、類似しない二つ以上の特徴データDVに夫々対応する二つ以上の特徴ベクトルXVの間の距離)以上になるように、複数の特徴ベクトルXVを夫々複数の潜在ベクトルZVに変換可能な変換モデルTMを生成してもよい。
計量学習部422は、例えば、計量学習を行うために用いられるニューラルネットワークを用いて、計量学習を行ってもよい。計量学習を行うために用いられるニューラルネットワークの一例として、シャムネットワーク(Siamese Network)及びトリプレットネットワーク(Triplet Network)の少なくとも一つがあげられる。
教師データ4131を用いて行われる計量学習の一例について以下に説明する。計量学習部422は、教師データ4131に基づいて、正例に相当するラベル情報が付与された二つの特徴ベクトルXVを含むデータセットを、特徴データセット412から少なくとも一組抽出する。更に、計量学習部422は、教師データ4131に基づいて、負例に相当するラベル情報が付与された二つの特徴ベクトルXVを、特徴データセット412から少なくとも一組抽出する。計量学習部422は、抽出した二つの特徴ベクトルXVを変換モデルTMに入力することで、二つの特徴ベクトルXVに対応する二つの潜在ベクトルZVを取得する。その後、計量学習部422は、二つの潜在ベクトルZVの間の距離を算出する。計量学習部422は、正例に相当するラベル情報が付与された二つ特徴ベクトルXVを変換することで得られた二つの潜在ベクトルZVの間の距離が相対的に短くなり、且つ、負例に相当するラベル情報が付与された二つ特徴ベクトルXVを変換することで得られた二つの潜在ベクトルZVの間の距離が相対的に長くなるように、計量学習を行う。このため、計量学習部422は、潜在空間内での二つの潜在ベクトルZVの間の距離に基づいて定まる損失関数を用いて、計量学習を行ってもよい。例えば、上述したように、計量学習部422がシャムネットワークを用いて計量学習を行う場合には、計量学習部422は、Contrastive Lossに基づく損失関数を用いてもよい。
その後、記憶装置41は、ステップS12で生成された変換モデルTMを記憶する(ステップS13)。記憶装置41が記憶している変換モデルTMは、後述する脅威検出動作において用いられる。
(2-2)脅威検出動作
続いて、図7を参照しながら、情報処理装置4が行う脅威検出動作について説明する。図7は、情報処理装置4が行う脅威検出動作の流れを示すフローチャートである。尚、図7に示す脅威検出動作は、情報処理装置4に対するクエリデータDQの入力をトリガに開始されてもよい。複数のクエリデータDQが情報処理装置4に入力された場合には、各クエリデータDQを対象に脅威検出動作が行われる。例えば、第1のクエリデータDQと第2のクエリデータDQとが情報処理装置4に入力された場合には、第1のクエリデータDQを対象に脅威検出動作と、第2のクエリデータDQを対象とする脅威検出動作とが行われる。
続いて、図7を参照しながら、情報処理装置4が行う脅威検出動作について説明する。図7は、情報処理装置4が行う脅威検出動作の流れを示すフローチャートである。尚、図7に示す脅威検出動作は、情報処理装置4に対するクエリデータDQの入力をトリガに開始されてもよい。複数のクエリデータDQが情報処理装置4に入力された場合には、各クエリデータDQを対象に脅威検出動作が行われる。例えば、第1のクエリデータDQと第2のクエリデータDQとが情報処理装置4に入力された場合には、第1のクエリデータDQを対象に脅威検出動作と、第2のクエリデータDQを対象とする脅威検出動作とが行われる。
図7に示すように、まず、検索部423は、クエリデータDQを取得する(ステップS21)。例えば、検索部423は、ユーザが操作可能な操作装置として機能可能な入力装置43を介して情報処理装置4に入力される、検出ターゲット脅威(或いは、特徴ベクトルXQ)を直接的に又は間接的に指定する情報を、クエリデータDQとして取得してもよい。例えば、検索部423は、通信装置として機能可能な入力装置43を介して情報処理装置4に送信される、検出ターゲット脅威(或いは、特徴ベクトルXQ)を直接的に又は間接的に指定するための情報を、クエリデータDQとして取得してもよい。
その後、検索部423は、ステップS21で取得したクエリデータDQに基づいて、特徴データセット412から、n個の近傍データDN1からDNnを抽出する(ステップS22)。以下、図8を参照しながら、n個の近傍データDN1からDNnを抽出する動作について説明する。図8は、n個の近傍データDN1からDNnを抽出する動作の流れを示すフローチャートである。
図8に示すように、検索部423は、記憶装置41が記憶している変換モデルTMを用いて、ステップ21で取得したクエリデータDQの特徴ベクトルXQを、潜在空間内で検出ターゲット脅威の特徴量を示す潜在ベクトルZQに変換する(ステップS221)。
ステップS221の動作と並行して又は相前後して、検索部423は、特徴データセット412に含まれる複数の特徴データDVのうちの一の特徴データDVvを抽出する(ステップS222)。その後、検索部423は、変換モデルTMを用いて、抽出した一の特徴データDVvの特徴ベクトルXVvを、潜在ベクトルZVvに変換する(ステップS222)。その後、検索部423は、ステップS221で生成された潜在ベクトルZQとステップS222で生成された潜在ベクトルZVvとの間の距離(つまり、潜在空間での距離)を算出する(ステップS223)。
検索部423は、ステップS222からステップS223までの動作を、特徴データセット412に含まれる複数の特徴データDVを対象に繰り返す(ステップS224)。上述したように、特徴データセット412には、K個の特徴データDV1からDVKが含まれている。このため、検索部423は、K個の特徴データDV1からDVKに夫々対応するK個の潜在ベクトルZV1からZVKと潜在ベクトルZQとの間のK個の距離の算出が完了するまで、特徴データセット412に含まれる複数の特徴データDVの中から、ステップS222において未だ抽出されたことがない一の特徴データDVvを新たに抽出した上で、ステップS222からステップS223までの動作を繰り返す。具体的には、検索部423は、特徴データDV1に対応する潜在ベクトルZV1と潜在ベクトルZQとの間の距離と、特徴データDV2に対応する潜在ベクトルZV2と潜在ベクトルZQとの間の距離と、・・・、特徴データDVKに対応する潜在ベクトルZVKと潜在ベクトルZQとの間の距離との算出が完了するまで、ステップS222からステップS223までの動作を繰り返す。
その後、検索部423は、ステップS223で算出した距離に基づいて、特徴データセット412に含まれる複数の特徴データDVのうちのn個の特徴データDVを、夫々、n個の近傍データDN1からDNnとして抽出する(ステップS225)。具体的には、検索部423は、K個の特徴データDVの中から、他のK-n個の特徴データDVと比較して、潜在空間におけるクエリデータDQからの距離が短いn個の特徴データDVを、夫々、n個の近傍データDN1からDNnとして抽出する。つまり、検索部423は、K個の特徴データDVの中から、算出した距離が短い順にn個の特徴データDVを抽出し、抽出したn個の特徴データDVを夫々n個の近傍データDN1からDNnに設定する。
再び図7において、その後、局所モデル学習部424は、ステップS22において抽出されたn個の近傍データDN1からDNnに基づいて、局所モデルLMを生成する(ステップS23)。
本実施形態では、説明の便宜上、局所モデルLMが線形回帰モデルである例について説明する。上述したように、局所モデルLMは、表現空間におけるクエリデータDQと近傍データDNiとの差分に関する差分情報Vi(=vi,1からvi,F)が入力された場合に、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diの推定値dpiを出力するモデルである。このため、局所モデルLMは、差分情報Vi(=vi,1からvi,F)が説明変数として用いられ、且つ、距離diの推定値dpiが目的変数として用いられる線形回帰モデルであってもよい。このような局所モデルLMの一例が数式1に示されている。尚、数式1におけるwfは、差分情報vi、fに掛け合わせられる重みである。重みwf(具体的には、w1からwFの夫々)は、0以上の重みである。つまり、重みwf(具体的には、w1からwFの夫々)は、負値とならない重みである。また、数式1に示すように、局所モデルLMは、バイアス項を含まない(つまり、バイアス項がゼロになる)回帰式で特定される線形回帰モデルである。

但し、局所モデルLMが、数式1に示す線形回帰モデルに限定されることはない。例えば、局所モデルLMは、重みwf(具体的には、w1からwFの少なくとも一つ)が負値となる回帰式で特定される線形回帰モデルであってもよい。例えば、局所モデルLMは、バイアス項を含む(つまり、バイアス項がゼロにならない)回帰式で特定される線形回帰モデルであってもよい。或いは、局所モデルLMが、線形回帰モデルに限定されることはない。例えば、局所モデルLMは、非線形回帰モデルであってもよい。例えば、局所モデルLMは、その他の任意のモデルであってもよい。
局所モデルLMを生成するために、局所モデル学習部424は、差分情報Vi(=vi,1からvi,F)を生成する。つまり、局所モデル学習部424は、差分情報V1(=v1,1からv1,F)、差分情報V2(=v2,1からv2,F)、・・・、及び、差分情報Vn(=vn,1からvn,F)を生成する。尚、以下の説明では、差分情報vi,fが、vi,f=|xqf-xni,f|又はvi,f=(xqf-xni,f)2という上述した数式で特定される例について説明する。従って、局所モデル学習部424は、vi,f=|xqf-xni,f|又はvi,f=(xqf-xni,f)2という数式を用いて、差分情報Viを生成する。
その後、局所モデル学習部424は、ステップS22で抽出した近傍データDN1からDNnと、ステップS23において算出した差分情報V1からVnとに基づいて、局所モデルLMを生成する。
具体的には、局所モデル学習部424は、生成済みの又はデフォルトの局所モデルLMに対して、差分情報V1からVnを順に入力する。その結果、局所モデル学習部424は、潜在空間内におけるクエリデータDQと近傍データDN1との間の距離d1の推定値dp1と、潜在空間内におけるクエリデータDQと近傍データDN2との間の距離d2の推定値dp2と、・・・、潜在空間内におけるクエリデータDQと近傍データDNnとの間の距離dnの推定値dpnとを取得する。
その後、局所モデル学習部424は、実際の距離diと距離diの推定値dpiとの間の誤差に基づく損失関数Lossを用いて、局所モデルLMを規定する重みwf(=w1からwF)を更新する。尚、実際の距離di(つまり、距離diの実際の算出値)は、図8のステップS223において近傍データDNiを抽出するために潜在ベクトルZQと潜在ベクトルZV(つまり、近傍データDNiの特徴ベクトルXNiを変換モデルTMで変換することで生成される潜在ベクトルZNi)とに基づいて算出された距離に相当する。損失関数Lossは、距離diの実際の算出値と距離diの推定値dpiとの間の誤差が小さくなるほど小さくなる損失関数であってもよい。この場合、局所モデル学習部424は、損失関数Lossが最小になるように、局所モデルLMを規定する重みwf(=w1からwF)を更新してもよい。このような損失関数Lossの一例が、数式2に示されている。但し、損失関数Lossが数式2に示される損失関数に限定されることはない。

その後、貢献度算出部425は、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diに対して、特徴ベクトルXNiのf番目のベクトル成分(つまり、近傍データDNiのF個の要素に相当する特徴量)が与える影響の大きさを表す要素貢献度ci、fを算出する(ステップS24)。特徴ベクトルXNiのp(但し、pは、1≦p≦Fを満たす整数を示す変数)番目のベクトル成分が一定量変化した場合の距離diの変動量が、特徴ベクトルXNiのr(但し、rは、1≦r≦F且つr≠pを満たす整数を示す変数)番目のベクトル成分が同じ一定量変化した場合の距離diの変動量よりも大きい場合には、距離diに対して特徴ベクトルXNiのp番目のベクトル成分が与える影響は、距離diに対して特徴ベクトルXNiのr番目のベクトル成分が与える影響よりも大きい。このため、要素貢献度ci、pは、要素貢献度ci、rよりも大きくなる。
このような要素貢献度ci、fを算出するために、貢献度算出部425は、ステップS23で生成した局所モデルLMと、差分情報vi,fとに基づいて、要素貢献度ci、fを算出する。例えば、貢献度算出部425は、数式3を用いて、要素貢献度ci、fを算出してもよい。数式3は、局所モデルLMを規定するパラメータ(この場合、重みwf)と差分情報vi,fとに基づいて要素貢献度ci、fを算出するために用いられる数式である。
貢献度算出部425は、変数fを1からFの間で変化させ且つ変数iを1からnの間で変化させながら要素貢献度ci、fを算出することで、要素貢献度c1、1、c1、2、・・・、及びc1、F、要素貢献度c2、1、c2、2、・・・、及びc2、F、・・・、並びに、要素貢献度cn、1、cn、2、・・・、及びcn、Fを算出する。尚、上述した数式3を用いて要素貢献度ci、fが算出される場合には、要素貢献度ci、1からci、Fの総和は、1になる。
その後、出力制御部426は、ステップS23で検索部423が抽出したn個の近傍データDN1からDNnの少なくとも一つに関する情報を出力するように、出力装置44を制御してもよい(ステップS25)。尚、近傍データDNiに関する情報は、近傍データDNiの特徴ベクトルXNiを算出する根拠となったプロキシログデータ4111に関する情報を含んでいてもよい。つまり、出力制御部426は、ステップS23で検索部423が抽出したn個の近傍データDN1からDNnの少なくとも一つに対応するプロキシログデータ4111に関する情報を出力するように、出力装置44を制御してもよい。
或いは、出力制御部426は、n個の近傍データDN1からDNnの少なくとも一つに関する情報に加えて又は代えて、ステップS24で貢献度算出部425が算出した要素貢献度c1、1からcn、Fの少なくとも一つを出力するように、出力装置44を制御してもよい(ステップS25)。
一例として、出力制御部426は、図9に示すように、要素貢献度c1、1からcn、Fのリストを出力するように、出力装置44を制御してもよい。尚、図9は、出力装置44が表示装置である場合に出力装置44が出力する(つまり、表示装置が表示する)要素貢献度c1、1からcn、Fのリストの一例を示している。図9に示す例では、近傍データDNiは、受信サイズの最小値に関する特徴量を示す1番目のベクトル成分と、受信サイズの最大値に関する特徴量を示す2番目のベクトル成分と、送信サイズの最小値に関する特徴量を示す3番目のベクトル成分と、送信サイズの最大値に関する特徴量を示す4番目のベクトル成分と、受信サイズと送信サイズとの総和に関する特徴量を示す5番目のベクトル成分と、メソッド(GET)に関する特徴量を示す6番目のベクトル成分と、メソッド(POST)に関する特徴量を示す7番目のベクトル成分と、メソッド(その他)に関する特徴量を示す8番目のベクトル成分とを含む。この場合、出力制御部426は、距離diに対して受信サイズの最小値に関する特徴量が与える影響を示す要素貢献度ci、1と、距離diに対して受信サイズの最大値に関する特徴量が与える影響を示す要素貢献度ci、2と、距離diに対して送信サイズの最小値に関する特徴量が与える影響を示す要素貢献度ci、3と、距離diに対して送信サイズの最大値に関する特徴量が与える影響を示す要素貢献度ci、4と、距離diに対して受信サイズと送信サイズとの総和に関する特徴量が与える影響を示す要素貢献度ci、5と、距離diに対してメソッド(GET)に関する特徴量が与える影響を示す要素貢献度ci、6と、距離diに対してメソッド(POST)に関する特徴量が与える影響を示す要素貢献度ci、7と、距離diに対してメソッド(その他)に関する特徴量が与える影響を示す要素貢献度ci、8とのリストを出力するように、出力装置44を制御してもよい。
図9に示す例では、要素貢献度c1、1からc1、4が相対的に大きい。このため、潜在空間におけるクエリデータDQと近傍データDN1との間の距離diに対して、受信サイズ及び送信サイズの夫々に関する特徴量が与える影響が相対的に大きいことが分かる。また、図9に示す例では、要素貢献度c2、1からc2、1が相対的に大きい。このため、潜在空間におけるクエリデータDQと近傍データDN2との間の距離d2に対して、受信サイズに関する特徴量が与える影響が相対的に大きいことが分かる。また、図9に示す例では、要素貢献度c3、1からc3、1が相対的に大きい。このため、潜在空間におけるクエリデータDQと近傍データDN3との間の距離d3に対して、受信サイズに関する特徴量が与える影響が相対的に大きいことが分かる。
(3)情報処理装置1の技術的効果
以上説明したように、本実施形態の情報処理装置4は、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diに対して、近傍データDNiのf番目の要素に相当する特徴量が与える影響の大きさを表す要素貢献度ci、fを算出することができる。このため、情報処理装置4のユーザは、要素貢献度ci、fに基づいて、距離diに対して相対的に大きな影響を与えている(つまり、距離diの算出に対して相対的に大きく寄与している)特徴量を把握することができる。
以上説明したように、本実施形態の情報処理装置4は、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diに対して、近傍データDNiのf番目の要素に相当する特徴量が与える影響の大きさを表す要素貢献度ci、fを算出することができる。このため、情報処理装置4のユーザは、要素貢献度ci、fに基づいて、距離diに対して相対的に大きな影響を与えている(つまり、距離diの算出に対して相対的に大きく寄与している)特徴量を把握することができる。
また、情報処理装置4は、局所モデルLMを生成し、生成した局所モデルLM(例えば、局所モデルLMを規定する重みwf)を用いて要素貢献度ci、fを算出することができる。このため、情報処理装置4は、比較的容易に要素貢献度ci、fを算出することができる。
また、情報処理装置4は、生成した局所モデルLMを規定する重みwfを用いて要素貢献度ci、fを算出することができる。このため、情報処理装置4は、上述した数式1のような比較的簡易的な数式(特に、行列演算を行う装置にとって扱いやすい数式)を用いて、要素貢献度ci、fを算出することができる。
また、上述した例では、局所モデルLMは、バイアス項を含まない回帰式で特定される線形回帰モデルである。仮に局所モデルLMが、バイアス項を含む回帰式で特定される線形回帰モデルである場合には、情報処理装置4は、局所モデルLMを算出する際に及び/又は要素貢献度ci、fを算出する際に、バイアス項に起因して生ずる原点からのずれ(つまり、表現空間及び/又は潜在空間内でのオフセット量)を考慮する必要がある。つまり、情報処理装置4は、局所モデルLMを算出する及び/又は要素貢献度ci、fを算出するための行列演算を行う際に、行列同士の内積のみならず、行列成分のオフセット量(つまり、加減算)を考慮する必要がある。しかるに、本実施形態では、局所モデルLMが、バイアス項を含まない回帰式で特定される線形回帰モデルであるため、情報処理装置4は、局所モデルLMを算出する際に及び/又は要素貢献度ci、fを算出する際に、バイアス項に起因して生ずる原点からのずれ(つまり、表現空間及び/又は潜在空間内でのオフセット量)を考慮しなくてもよくなる。このため、情報処理装置4は、比較的容易に、局所モデルLMを算出する及び/又は要素貢献度ci、fを算出することができる。
また、上述した例では、局所モデルLMは、重みwfが0以上になる回帰式で特定される線形回帰モデルである。仮に局所モデルLMが、重みwfが0未満となることを許容する回帰式で特定される線形回帰モデルである場合には、要素貢献度ci、fが負の値になる可能性がある。しかしながら、情報処理装置4のユーザにとっては、負の要素貢献度ci、fは、直感的に分かりづらい指標であると想定される。一方で、本実施形態では、局所モデルLMが、重みwfが0以上になる回帰式で特定される線形回帰モデルであるため、要素貢献度ci、fが負の値になることはない。このため、情報処理装置4は、情報処理装置4のユーザにとって直感的に分かりやすい要素貢献度ci、fを算出することができる。
尚、情報処理装置4は、要素貢献度ci、fに基づいて、潜在空間におけるクエリデータDQと近傍データDNiとの間の距離diが相対的に小さくなった要因を特定してもよい。つまり、情報処理装置4は、要素貢献度ci、fに基づいて、クエリデータDQと近傍データDNiとが類似すると判定されることになった要因を特定してもよい。例えば、上述した図9に示す例では、要素貢献度c3、1からc3、2が相対的に大きい。この場合、情報処理装置4は、クエリデータDQと近傍データDN3とが類似すると判定される要因が、受信サイズに起因していると特定してもよい。尚、上述したように、クエリデータDQと近傍データDN3とが類似している場合には、クエリデータDQが指定する検出ターゲット脅威と同じ又は類似する脅威がローカルシステムLに既に侵入した可能性があると想定される。この場合、クエリデータDQと近傍データDN3とが類似すると判定される要因は、近傍データDN3に対応するプロキシログデータ4111が、検出ターゲット脅威と同じ又は類似する脅威の痕跡を示すと判定される要因と等価であるとも言える。
また、情報処理装置4は、要素貢献度ci、fに基づいて、検索部423が抽出したn個の近傍データDN1からDNnを分類してもよい。具体的には、情報処理装置4は、要素貢献度ci、fが類似する近傍データDNiが同じ貢献データ群に分類されるように、n個の近傍データDN1からDNnを分類してもよい。この場合、情報処理装置4は、同じ貢献データ群に分類された近傍データDNiを用いて、局所モデルLMの重みwfを更新するための学習動作を行ってもよい。
また、情報処理装置4は、要素貢献度ci,fに基づいて、検索部423がn個の近傍データDN1からDNnのうちの少なくとも一つを誤って抽出してしまったか否かを判定してもよい。例えば、n個の近傍データDN1からDNnがそもそもクエリデータDQに類似するがゆえに、通常は、近傍データDN1に対応するF個の要素貢献度c1、1からc1、Fから構成されるベクトルと、近傍データDN2に対応するF個の要素貢献度c2、1からc2、Fから構成されるベクトルと、・・・、近傍データDNnに対応するF個の要素貢献度cn,1からcn、Fから構成されるベクトルとが互いに大きく異なるものになる可能性は高くはない。このような状況下で、近傍データDNj(但し、jは、1≦j≦nを満たす整数を示す変数)に対応するF個の要素貢献度cj、fから構成されるベクトルと、近傍データDNj以外の他の近傍データDNに対応するF個の要素貢献度ci、fから構成されるベクトル(つまり、近傍データDN1に対応するF個の要素貢献度c1、fから構成されるベクトル、・・・、近傍データDNj-1に対応するF個の要素貢献度cj-1、fから構成されるベクトル、近傍データDNj+1に対応するF個の要素貢献度cj+1、fから構成されるベクトル、・・・、及び、近傍データDNnに対応するF個の要素貢献度cn、fから構成されるベクトルの夫々)との間の差分が、許容量を超えるほどに大きくなっている場合には、検索部423が、近傍データDNjを、クエリデータDQに類似するデータとして誤って抽出してしまった可能性があると想定される。このような観点から、情報処理装置4は、要素貢献度ci、fに基づいて、検索部423がn個の近傍データDN1からDNnのうちの少なくとも一つを誤って抽出してしまったか否かを判定してもよい。
(4)変形例
続いて、通信システムSYS(特に、情報処理装置4)の変形例について説明する。
続いて、通信システムSYS(特に、情報処理装置4)の変形例について説明する。
(4-1)第1変形例
第1変形例では、情報処理装置4(特に、貢献度算出部425)は、要素貢献度ci,fに加えて、グループ貢献度eを算出してもよい。グループ貢献度eは、ある近傍データの特徴ベクトルの各ベクトル成分(つまり、近傍データが示す特徴量の各要素)が複数の特徴グループの少なくとも一つに所属する(言い換えれば、分類される)という状況下で算出される指標値である。具体的には、グループ貢献度eは、潜在空間内におけるあるクエリデータとある近傍データとの間の距離に対して、各特徴グループが与える影響の大きさを表す。つまり、グループ貢献度eは、潜在空間内におけるあるクエリデータとある近傍データとの間の距離に対して、各特徴グループに所属する少なくとも一つのベクトル成分(つまり、一の特徴グループに分類される少なくとも一つの特徴量の要素)が与える影響の大きさを表す。
一例として、複数の特徴グループは、特徴ベクトルXNiを算出する元となったプロキシログデータ4111が含む複数のログ情報の種類に夫々対応するグループであってもよい。具体的には、上述した例では、プロキシログデータ4111は、複数種類のログ情報として、受信サイズ情報、送信サイズ情報及びメソッド情報を含む。この場合、複数の特徴グループとして、受信サイズに関する特徴グループと、送信サイズに関する特徴グループと、メソッドに関する特徴グループとが用いられてもよい。また、上述した例では、図9に示すように、近傍データDNiは、受信サイズの最小値に関する特徴量を示す1番目のベクトル成分と、受信サイズの最大値に関する特徴量を示す2番目のベクトル成分と、送信サイズの最小値に関する特徴量を示す3番目のベクトル成分と、送信サイズの最大値に関する特徴量を示す4番目のベクトル成分と、受信サイズと送信サイズとの総和に関する特徴量を示す5番目のベクトル成分と、メソッド(GET)に関する特徴量を示す6番目のベクトル成分と、メソッド(POST)に関する特徴量を示す7番目のベクトル成分と、メソッド(その他)に関する特徴量を示す8番目のベクトル成分とを含む。この場合、受信サイズの最小値に関する特徴量を示す1番目のベクトル成分と、受信サイズの最大値に関する特徴量を示す2番目のベクトル成分と、受信サイズと送信サイズとの総和に関する特徴量を示す5番目のベクトル成分とは、受信サイズに関する特徴グループに所属してもよい。送信サイズの最小値に関する特徴量を示す3番目のベクトル成分と、送信サイズの最大値に関する特徴量を示す4番目のベクトル成分と、受信サイズと送信サイズとの総和に関する特徴量を示す5番目のベクトル成分とは、送信サイズに関する特徴グループに所属してもよい。メソッド(GET)に関する特徴量を示す6番目のベクトル成分と、メソッド(POST)に関する特徴量を示す7番目のベクトル成分と、メソッド(その他)に関する特徴量を示す8番目のベクトル成分とは、受信サイズに関する特徴グループに所属してもよい。
近傍データDNiの特徴ベクトルXNiの各ベクトル成分がG(但し、Gは1以上の整数を示す定数)個の特徴グループの少なくとも一つに所属する場合には、貢献度算出部425は、潜在空間内におけるクエリデータDQと近傍データDNiとの間の距離diに対して、g(但し、gは、1≦g≦Gを満たす整数を示す変数)番目の特徴グループが与える影響の大きさを表すグループ貢献度eを算出してもよい。尚、以下の説明では、距離diに対してg番目の特徴グループが与える影響の大きさを表すグループ貢献度eを、“グループ貢献度ei,g”と称する。言い換えれば、貢献度算出部425は、距離diに対して、g番目の特徴グループに所属する少なくとも一つのベクトル成分が与える影響の大きさを表すグループ貢献度ei,gを算出してもよい。この場合、貢献度算出部425は、変数gを1からGの間で変化させながらグループ貢献度ei,gを算出することで、距離diに対して1番目の特徴グループに所属する少なくとも一つのベクトル成分が与える影響の大きさを表すグループ貢献度ei,1と、距離diに対して2番目の特徴グループに所属する少なくとも一つのベクトル成分が与える影響の大きさを表すグループ貢献度ei,2と、・・・、距離diに対してG番目の特徴グループに所属する少なくとも一つのベクトル成分が与える影響の大きさを表すグループ貢献度ei,Gとを算出してもよい。
貢献度算出部425は、要素貢献度ci,fに基づいて、グループ貢献度ei,gを算出してもよい。例えば、貢献度算出部425は、数式4を用いて算出してもよい。数式4を用いて算出されたグループ貢献度ei,gは、後述する所属率bg,fで重み付けされた要素貢献度ci,fの総和となる。

ここで、数式4におけるbg,fは、近傍データDNiのf番目のベクトル成分がg番目の特徴グループに所属する所属率を示す。尚、所属率bg,fは、各ベクトル成分の所属率bg,fの総和(つまり、b1,f+b2,f+・・・+bG,f)が1になるように設定される。例えば、f番目のベクトル成分がg番目の特徴グループにのみ所属する場合には、f番目のベクトル成分がg番目の特徴グループに所属する所属率bg,fは、1(つまり、100%)に設定されていてもよい。一方で、例えば、f番目のベクトル成分がg1(但し、g1は、1≦g1≦Gを満たす整数を示す変数)番目の特徴グループ及びg2(但し、g2は、1≦g2≦G且つg2≠g1を満たす整数を示す変数)番目の特徴グループの双方に所属する場合には、f番目のベクトル成分がg1番目の特徴グループに所属する所属率bg1,fは、1/2(=50%)に設定され、f番目のベクトル成分がg2番目の特徴グループに所属する所属率bg2,fは、1/2(=50%)に設定されていてもよい。つまり、一のベクトル成分がH(但し、Hは2以上の整数を示す定数)個の特徴グループに所属する場合には、一のベクトル成分がH個の特徴グループの夫々に所属する所属率bg,fは、1/N(=100/N%)に設定されていてもよい。尚、所属率bg,fは、予め設定されていてもよいし、情報処理装置4(特に、貢献度算出部425)によって設定されてもよい。
グループ貢献度ei,gが算出された場合には、出力制御部426は、グループ貢献度ei,gを出力するように、出力装置44を制御してもよい。例えば、上述したように、グループ貢献度ei,1からei,Gは、プロキシログデータ4111が含むG種類のログ情報に夫々対応するG個の特徴グループに夫々対応する。このため、出力制御部426は、近傍データDNiに対応するプロキシログデータ4111に含まれるG種類のログ情報の少なくとも一部とG個のグループ貢献度ei,1からei,Gの少なくとも一部とを夫々関連付けた出力態様で、プロキシログデータ4111を出力するように、出力装置44を制御してもよい。
G種類のログ情報の少なくとも一部とG個のグループ貢献度ei,1からei,Gの少なくとも一部とを夫々関連付けた表示態様は、g番目の特徴グループに対応するg番目のログ情報とg番目の特徴グループのグループ貢献度ei,gとを関連付けた表示態様を含んでいてもよい。具体的には、例えば、G種類のログ情報の少なくとも一部とG個のグループ貢献度ei,1からei,Gの少なくとも一部とを夫々関連付けた表示態様は、(i)受信サイズに関するログ情報と受信サイズに関する特徴グループのグループ貢献度ei,gとを関連付けた表示態様、(ii)送信サイズに関するログ情報と送信サイズに関する特徴グループのグループ貢献度ei,gとを関連付けた表示態様、及び、(iii)メソッドに関するログ情報とメソッドに関する特徴グループのグループ貢献度ei,gとを関連付けた表示態様を含んでいてもよい。g番目のログ情報とグループ貢献度ei,gとを関連付けた表示態様は、図11(a)に示すように、g番目のログ情報と共にグループ貢献度ei,gを表示する表示態様を含んでいてもよい。g番目のログ情報とグループ貢献度ei,gとを関連付けた表示態様は、図11(b)に示すように、g番目のログ情報の表示態様(例えば、色、明るさ、輝度及びハイライトの少なくとも一つ)をグループ貢献度ei,gに応じて変更する表示態様を含んでいてもよい。例えば、図11(b)は、グループ貢献度ei,gが相対的に高いログ情報をハイライト表示する例を示している。g番目のログ情報とグループ貢献度ei,gとを関連付けた表示態様は、g番目のログ情報を表示するか否かがグループ貢献度ei,gに応じて決定される表示態様を含んでいてもよい。例えば、グループ貢献度ei,gが所定の表示閾値を下回る場合には、g番目のログ情報は表示されなくてもよい。一方で、例えば、グループ貢献度ei,gが所定の表示閾値を上回る場合には、g番目のログ情報が表示されてもよい。
以上説明した第1変形例によれば、情報処理装置4は、グループ貢献度ei,gを算出することができる。ここで、グループ貢献度ei,gは、例えば、同じ特徴グループに対応する複数の要素貢献度ci,fの総和である。このため、グループ貢献度ei,gのばらつきは、各要素貢献度ci,fのばらつきよりも小さくなる。このため、情報処理装置4は、要素貢献度ci,fと比較して、より安定した貢献度とみなせるグループ貢献度ei,gを算出することができる。
また、複数の特徴グループは、プロキシログデータ4111の複数のログ情報の種類に夫々対応している。このため、情報処理装置4は、近傍データDNiを表示する際に(つまり、近傍データDNiに対応するプロキシログデータ4111を表示する際に)、グループ貢献度ei,gを近傍データDNiに関連付けた表示態様で近傍データDNiを比較的容易に表示することができる。
(4-2)第2変形例
上述した説明では、通信システムSYSは、プロキシサーバ1を備えている。しかしながら、第2変形例では、図12に示すように、通信システムSYSは、プロキシサーバ1を備えていなくてもよい。つまり、クライアント2は、プロキシサーバ1を介することなく、サーバ3と通信してもよい。サーバ3は、プロキシサーバ1を介することなく、クライアント2と通信してもよい。この場合であっても、情報処理装置4は、クライアント2とサーバ3との間の通信の履歴を示すログデータを用いて、上述した脅威検出動作を行ってもよい。
上述した説明では、通信システムSYSは、プロキシサーバ1を備えている。しかしながら、第2変形例では、図12に示すように、通信システムSYSは、プロキシサーバ1を備えていなくてもよい。つまり、クライアント2は、プロキシサーバ1を介することなく、サーバ3と通信してもよい。サーバ3は、プロキシサーバ1を介することなく、クライアント2と通信してもよい。この場合であっても、情報処理装置4は、クライアント2とサーバ3との間の通信の履歴を示すログデータを用いて、上述した脅威検出動作を行ってもよい。
(4-3)第3変形例
上述した説明では、情報処理装置4は、特徴抽出部421を備えている。しかしながら、第3変形例では、図13に示すように、情報処理装置4は、特徴抽出部421を備えていなくてもよい。この場合、記憶装置41は、プロキシログDB411に含まれるプロキシログデータ4111から任意の方法で生成された特徴ベクトルXVを含む特徴データセット412を記憶していてもよい。尚、この場合には、図13に示すように、記憶装置41は、プロキシログDB411を記憶していなくてもよい。
上述した説明では、情報処理装置4は、特徴抽出部421を備えている。しかしながら、第3変形例では、図13に示すように、情報処理装置4は、特徴抽出部421を備えていなくてもよい。この場合、記憶装置41は、プロキシログDB411に含まれるプロキシログデータ4111から任意の方法で生成された特徴ベクトルXVを含む特徴データセット412を記憶していてもよい。尚、この場合には、図13に示すように、記憶装置41は、プロキシログDB411を記憶していなくてもよい。
上述した説明では、情報処理装置4は、計量学習部422を備えている。しかしながら、第3変形例では、図13に示すように、情報処理装置4は、計量学習部422を備えていなくてもよい。この場合、記憶装置41は、情報処理装置4とは異なる装置によって生成された変換モデルTMを記憶していてもよい。尚、この場合には、図13に示すように、記憶装置41は、教師データセット413を記憶していなくてもよい。
上述した説明では、情報処理装置4は、出力制御部426を備えている。しかしながら、第3変形例では、図13に示すように、情報処理装置4は、出力制御部426を備えていなくてもよい。この場合、出力制御部426が行っていた近傍データDN1からDNn及び要素貢献度ci、fを出力する動作は、情報処理装置4の外部の装置によって行われてもよい。
(4-4)第4変形例
上述した説明では、脅威検出動作を行う通信システムSYSに対して、情報処理装置、情報処理方法、及び、記録媒体の実施形態が適用されている。しかしながら、第4変形例では、任意のデータを取り扱う任意のデータ処理装置に対して、情報処理装置、情報処理方法、及び、記録媒体の実施形態が適用されてもよい。この場合であっても、データ処理装置が取り扱う複数のデータの間の距離をベクトル空間内で定義可能である限りは、データ処理装置は、上述したモデル生成動作を行ってもよい。同様に、データ処理装置が取り扱う複数のデータの間の距離をベクトル空間内で定義可能である限りは、データ処理装置は、上述した脅威検出動作に準じたデータ検出動作を行ってもよい。尚、データ検出動作は、潜在空間内でクエリデータDQの近傍に位置するデータに相当する近傍データDNiを検出する処理と、潜在空間内でのクエリデータDQと近傍データDNiとの間の距離diに対して近傍データDNiの特徴ベクトルXNiの各ベクトル成分が与える影響の大きさを表す要素貢献度ci、fを算出する処理との少なくとも一つを含んでいてもよい。このようなデータ処理装置が取り扱うデータの一例として、リスト化可能なデータ、データベース化可能なデータ、及び、テーブル化可能なデータのうちの少なくとも一つがあげられる。
上述した説明では、脅威検出動作を行う通信システムSYSに対して、情報処理装置、情報処理方法、及び、記録媒体の実施形態が適用されている。しかしながら、第4変形例では、任意のデータを取り扱う任意のデータ処理装置に対して、情報処理装置、情報処理方法、及び、記録媒体の実施形態が適用されてもよい。この場合であっても、データ処理装置が取り扱う複数のデータの間の距離をベクトル空間内で定義可能である限りは、データ処理装置は、上述したモデル生成動作を行ってもよい。同様に、データ処理装置が取り扱う複数のデータの間の距離をベクトル空間内で定義可能である限りは、データ処理装置は、上述した脅威検出動作に準じたデータ検出動作を行ってもよい。尚、データ検出動作は、潜在空間内でクエリデータDQの近傍に位置するデータに相当する近傍データDNiを検出する処理と、潜在空間内でのクエリデータDQと近傍データDNiとの間の距離diに対して近傍データDNiの特徴ベクトルXNiの各ベクトル成分が与える影響の大きさを表す要素貢献度ci、fを算出する処理との少なくとも一つを含んでいてもよい。このようなデータ処理装置が取り扱うデータの一例として、リスト化可能なデータ、データベース化可能なデータ、及び、テーブル化可能なデータのうちの少なくとも一つがあげられる。
本発明は、請求の範囲及び明細書全体から読み取るこのできる発明の要旨又は思想に反しない範囲で適宜変更可能であり、そのような変更を伴う情報処理装置、情報処理方法、及び、記録媒体もまた本発明の技術思想に含まれる。
SYS 通信システム
1 プロキシサーバ
2 サーバ
3 クライアント
4 情報処理装置
41 記憶装置
411 プロキシログDB
4111 プロキシログデータ
412 特徴データセット
413 教師データセット
4131 教師データ
42 演算装置
421 特徴抽出部
422 計量学習部
423 検索部
424 局所モデル学習部
425 貢献度算出部
TM 変換モデル
LM 局所モデル
DQ クエリデータ
DV 特徴データ
DN 近傍データ
XQ、XV、XN 特徴ベクトル
ZQ、ZV、ZN 潜在ベクトル
1 プロキシサーバ
2 サーバ
3 クライアント
4 情報処理装置
41 記憶装置
411 プロキシログDB
4111 プロキシログデータ
412 特徴データセット
413 教師データセット
4131 教師データ
42 演算装置
421 特徴抽出部
422 計量学習部
423 検索部
424 局所モデル学習部
425 貢献度算出部
TM 変換モデル
LM 局所モデル
DQ クエリデータ
DV 特徴データ
DN 近傍データ
XQ、XV、XN 特徴ベクトル
ZQ、ZV、ZN 潜在ベクトル
Claims (10)
- 複数のサンプルデータ群の特徴量を表現空間内で夫々示す複数の特徴ベクトルデータを、前記表現空間とは異なる潜在空間内で前記複数のサンプルデータ群の特徴量を夫々示す複数の潜在ベクトルデータに変換する変換手段と、
前記複数の潜在ベクトルデータに基づいて、前記複数の特徴ベクトルデータから、前記潜在空間内において所望のクエリデータからの距離が他の特徴ベクトルデータと比較して短い少なくとも一つの特徴ベクトルデータを、近傍データとして抽出する抽出手段と、
前記近傍データに基づいて、前記表現空間内での前記クエリデータと前記近傍データとの特徴量の要素毎の差分に関する差分情報が入力された場合に、前記潜在空間内での前記クエリデータと前記近傍データとの間の距離である潜在距離の推定値を出力する局所モデルを生成する生成手段と、
前記局所モデルと前記差分情報とに基づいて、前記潜在距離に対して前記近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度を算出する算出手段と
を備える情報処理装置。 - 前記算出手段は、前記局所モデルを規定するパラメータと前記差分情報とに基づいて、前記要素貢献度を算出する
請求項1に記載の情報処理装置。 - 前記局所モデルは、前記差分情報を説明変数として用い、且つ、前記潜在距離を目的変数として用いる線形回帰モデルを含み、
前記パラメータは、前記説明変数に掛け合わせられる重みを含む
請求項2に記載の情報処理装置。 - 前記線形回帰モデルは、バイアス項を含まない
請求項3に記載の情報処理装置。 - 前記重みは、0以上である
請求項3又は4に記載の情報処理装置。 - 前記近傍データ及び前記クエリデータの夫々の特徴量の要素数がF(但し、Fは、1以上の整数を示す定数)であり、前記近傍データの第f(但し、fは、1≦f≦Fを満たす整数を示す変数)番目の要素に相当する特徴量と前記クエリデータの第f番目の要素に相当する特徴量との差分に関する前記差分情報がvi、fであり、前記差分情報vi、fに掛け合わせられる重みがwfであり、前記局所モデルが出力する前記潜在距離の推定値がdpiである場合に、前記生成手段は、数式1で表される前記線形回帰モデルを生成し、
前記潜在距離に対して前記近傍データの第f番目の要素に相当する特徴量が与える影響の大きさを表す前記要素貢献度がci、fである場合に、前記算出手段は、数式2を用いて、前記要素貢献度を算出する


請求項1から5のいずれか一項に記載の情報処理装置。 - 前記特徴ベクトルデータが示す特徴量の各要素は、異なる複数の特徴グループの少なくとも一つに所属可能であり、
前記算出手段は、前記要素貢献度に基づいて、前記潜在距離に対して各特徴グループが与える影響の大きさを示すグループ貢献度を算出する
請求項1から6のいずれか一項に記載の情報処理装置。 - 前記複数の特徴グループは、夫々、前記サンプルデータ群が含む複数のサンプル情報の種類に夫々対応しており、
前記近傍データが特徴量を示す前記サンプルデータ群に含まれる前記複数のサンプル情報の少なくとも一部と前記グループ貢献度と関連付けた表示態様で、前記サンプルデータ群を表示する表示手段を更に備える
請求項7に記載の情報処理装置。 - 複数のサンプルデータ群の特徴量を表現空間内で夫々示す複数の特徴ベクトルデータを、前記表現空間とは異なる潜在空間内で前記複数のサンプルデータ群の特徴量を夫々示す複数の潜在ベクトルデータに変換することと、
前記複数の潜在ベクトルデータに基づいて、前記複数の特徴ベクトルデータから、前記潜在空間内において所望のクエリデータからの距離が他の特徴ベクトルデータと比較して短い少なくとも一つの特徴ベクトルデータを、近傍データとして抽出することと、
前記近傍データに基づいて、前記表現空間内での前記クエリデータと前記近傍データとの特徴量の要素毎の差分に関する差分情報が入力された場合に、前記潜在空間内での前記クエリデータと前記近傍データとの間の距離である潜在距離の推定値を出力する局所モデルを生成すること、
前記局所モデルと前記差分情報とに基づいて、前記潜在距離に対して前記近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度を算出することと
を含む情報処理方法。 - コンピュータに、
複数のサンプルデータ群の特徴量を表現空間内で夫々示す複数の特徴ベクトルデータを、前記表現空間とは異なる潜在空間内で前記複数のサンプルデータ群の特徴量を夫々示す複数の潜在ベクトルデータに変換することと、
前記複数の潜在ベクトルデータに基づいて、前記複数の特徴ベクトルデータから、前記潜在空間内において所望のクエリデータからの距離が他の特徴ベクトルデータと比較して短い少なくとも一つの特徴ベクトルデータを、近傍データとして抽出することと、
前記近傍データに基づいて、前記表現空間内での前記クエリデータと前記近傍データとの特徴量の要素毎の差分に関する差分情報が入力された場合に、前記潜在空間内での前記クエリデータと前記近傍データとの間の距離である潜在距離の推定値を出力する局所モデルを生成すること、
前記局所モデルと前記差分情報とに基づいて、前記潜在距離に対して前記近傍データの特徴量の各要素が与える影響の大きさを表す要素貢献度を算出することと
を含む情報処理方法を実行させるコンピュータプログラムが記録された記録媒体。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/036907 WO2022070256A1 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
| US18/022,618 US20240004878A1 (en) | 2020-09-29 | 2020-09-29 | Information processing apparatus, information processing method, and recording medium |
| JP2022553259A JP7420278B2 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/036907 WO2022070256A1 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022070256A1 true WO2022070256A1 (ja) | 2022-04-07 |
Family
ID=80951528
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/036907 WO2022070256A1 (ja) | 2020-09-29 | 2020-09-29 | 情報処理装置、情報処理方法、及び、記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240004878A1 (ja) |
| JP (1) | JP7420278B2 (ja) |
| WO (1) | WO2022070256A1 (ja) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006190191A (ja) * | 2005-01-07 | 2006-07-20 | Sony Corp | 情報処理装置および方法、並びにプログラム |
| US20160180196A1 (en) * | 2014-12-22 | 2016-06-23 | Canon Kabushiki Kaisha | Object re-identification using self-dissimilarity |
-
2020
- 2020-09-29 US US18/022,618 patent/US20240004878A1/en active Pending
- 2020-09-29 WO PCT/JP2020/036907 patent/WO2022070256A1/ja active Application Filing
- 2020-09-29 JP JP2022553259A patent/JP7420278B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006190191A (ja) * | 2005-01-07 | 2006-07-20 | Sony Corp | 情報処理装置および方法、並びにプログラム |
| US20160180196A1 (en) * | 2014-12-22 | 2016-06-23 | Canon Kabushiki Kaisha | Object re-identification using self-dissimilarity |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240004878A1 (en) | 2024-01-04 |
| JP7420278B2 (ja) | 2024-01-23 |
| JPWO2022070256A1 (ja) | 2022-04-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Talagala et al. | Meta-learning how to forecast time series | |
| Gurumoorthy et al. | Efficient data representation by selecting prototypes with importance weights | |
| Zhang et al. | Attributed network embedding via subspace discovery | |
| CN110245285B (zh) | 一种基于异构信息网络的个性化推荐方法 | |
| CN111797321A (zh) | 一种面向不同场景的个性化知识推荐方法及系统 | |
| US8595155B2 (en) | Kernel regression system, method, and program | |
| CN111063392B (zh) | 基于神经网络的基因突变致病性检测方法、系统及介质 | |
| CN113377964B (zh) | 知识图谱链接预测方法、装置、设备及存储介质 | |
| de Andrade Silva et al. | An experimental study on the use of nearest neighbor-based imputation algorithms for classification tasks | |
| Mao et al. | Improved extreme learning machine and its application in image quality assessment | |
| US11847389B2 (en) | Device and method for optimizing an input parameter in a processing of a semiconductor | |
| Liu et al. | On empirical estimation of mode based on weakly dependent samples | |
| Li et al. | Data-driven ranking and selection: High-dimensional covariates and general dependence | |
| WO2022070256A1 (ja) | 情報処理装置、情報処理方法、及び、記録媒体 | |
| TW202001611A (zh) | 多元流動網路之可靠度計算方法及其系統 | |
| CN113515519A (zh) | 图结构估计模型的训练方法、装置、设备及存储介质 | |
| WO2022249518A1 (ja) | 情報処理装置、情報処理方法、情報処理プログラム、及び学習モデル生成装置 | |
| Dessureault et al. | Explainable global error weighted on feature importance: The xGEWFI metric to evaluate the error of data imputation and data augmentation | |
| CN113010687B (zh) | 一种习题标签预测方法、装置、存储介质以及计算机设备 | |
| US11388187B2 (en) | Method of digital signal feature extraction comprising multiscale analysis | |
| Lakshminarayan et al. | Topological data analysis in digital marketing | |
| Ma et al. | A two-stage causality method for time series prediction based on feature selection and momentary conditional independence | |
| CN113807749B (zh) | 一种对象评分方法和装置 | |
| JP2018151913A (ja) | 情報処理システム、情報処理方法、及びプログラム | |
| Alberg | An interval tree approach to predict forest fires using meteorological data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20956186 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022553259 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20956186 Country of ref document: EP Kind code of ref document: A1 |