WO2022044425A1 - 学習装置、学習方法、プログラム、学習済みモデル、及び内視鏡システム - Google Patents
学習装置、学習方法、プログラム、学習済みモデル、及び内視鏡システム Download PDFInfo
- Publication number
- WO2022044425A1 WO2022044425A1 PCT/JP2021/016004 JP2021016004W WO2022044425A1 WO 2022044425 A1 WO2022044425 A1 WO 2022044425A1 JP 2021016004 W JP2021016004 W JP 2021016004W WO 2022044425 A1 WO2022044425 A1 WO 2022044425A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- feature amount
- input
- layer
- learning
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B1/00—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor
- A61B1/00002—Operational features of endoscopes
- A61B1/00004—Operational features of endoscopes characterised by electronic signal processing
- A61B1/00009—Operational features of endoscopes characterised by electronic signal processing of image signals during a use of endoscope
- A61B1/000096—Operational features of endoscopes characterised by electronic signal processing of image signals during a use of endoscope using artificial intelligence
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B1/00—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor
- A61B1/00002—Operational features of endoscopes
- A61B1/00004—Operational features of endoscopes characterised by electronic signal processing
- A61B1/00009—Operational features of endoscopes characterised by electronic signal processing of image signals during a use of endoscope
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B1/00—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor
- A61B1/00002—Operational features of endoscopes
- A61B1/00043—Operational features of endoscopes provided with output arrangements
- A61B1/00045—Display arrangement
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B1/00—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor
- A61B1/06—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor with illuminating arrangements
- A61B1/0638—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor with illuminating arrangements providing two or more wavelengths
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Definitions
- the present invention relates to a learning device, a learning method, a program, a trained model, and an endoscope system, and in particular, a learning device, a learning method, a program, a trained model, and an endoscope system that perform learning using a hierarchical network. Regarding.
- Hierarchical networks are generally composed of a plurality of layers for feature extraction, recognition, and the like, but there are various aspects in a specific network configuration and learning method.
- Patent Document 1 describes a learning device for the purpose of appropriately learning a first data group and a second data group acquired under different conditions. Specifically, the first data group and the second data group acquired under different conditions are input to the first input layer and the second input layer independently of each other, and the first input layer is input. And a hierarchical network in which a common intermediate layer is provided for the second input layer is described.
- Non-Patent Document 1 a technique for improving the accuracy of a recognizer by normalizing the calculated feature amount is known.
- the present invention has been made in view of such circumstances, and an object thereof is learning that enables efficient learning even when learning is performed using data acquired under different conditions. It is to provide equipment, learning methods, programs, trained models, and endoscopic systems.
- the learning device for achieving the above object is a learning device including a processor constituting a learning model of a recognizer and a learning control unit for learning the learning model.
- a first input layer in which first data selected from a first data group composed of a plurality of data acquired under the first condition is input and a first feature amount is output, and a first input layer. It is a second input layer independent of the input layer, and is composed of a plurality of data acquired under the second condition, which belongs to the same category as the data constituting the first data group and is different from the first condition.
- the second data selected from the second data group is input, and is common to the second input layer that outputs the second feature amount, the first input layer, and the second input layer.
- the first intermediate feature amount When the first feature amount is input, the first intermediate feature amount is output, and when the second feature amount is input, the second intermediate feature amount is output.
- the first intermediate layer, the first normalized layer in which the first intermediate feature amount is input and the first normalized feature amount based on the first intermediate feature amount is output, and the second intermediate feature amount are In the second normalization layer that is input and outputs the second normalized feature amount based on the second intermediate feature amount, and the intermediate layer common to the first normalization layer and the second normalization layer. Therefore, when the first normalized feature amount is input, the third intermediate feature amount is output, and when the second normalized feature amount is input, the fourth intermediate feature amount is output.
- a learning device including a hierarchical network including an output layer that outputs a second recognition result based on the fourth intermediate feature amount when a fourth intermediate feature amount is input.
- the learning control unit trains the learning model based on the first error between the first recognition result and the correct answer of the first data, and the second recognition result and the correct answer of the second data.
- the second training is performed so that the training model is trained based on the second error of.
- the first intermediate layer outputs the first intermediate feature amount when the first feature amount based on the first data is input, and the second intermediate layer outputs the second feature amount based on the second data. Is input, the second intermediate feature amount is output. Then, the first normalization layer inputs the first intermediate feature amount and outputs the first normalized feature amount, and the second normalization layer inputs the second intermediate feature amount and the second normalization. Output the amount.
- the second intermediate layer inputs the first normalized feature quantity and the second normalized feature quantity.
- the first and second data are input to the independent first and second input layers, respectively, and the feature amount is calculated in the first and second input layers, respectively.
- the feature amount calculation in one of the second input layers is not affected by the feature amount calculation in the other input layer.
- the first intermediate feature in the first intermediate layer common to the first and second input layers. Since the amount and the second intermediate feature amount are calculated, the feature amount calculated from the first and second data in the input layer can be reflected in the intermediate feature amount calculation in the first intermediate layer.
- the second intermediate layer is also common to the first normalization layer and the second normalization layer, similarly, the first normal feature amount and the second normalization feature amount are applied to the second intermediate layer. It can be reflected in the calculation of intermediate features.
- the hierarchical network tends to be overfitted because it has many parameters, but overfitting can be avoided by giving a large amount of data.
- the intermediate layer can learn with a large amount of data including the first and second data, so that overfitting is unlikely to occur, while the input layer is independent of the first and second input layers. Since the parameters of each input layer are reduced, overfitting is unlikely to occur even with a small amount of data. According to this aspect, the data belonging to the same category and acquired under different conditions can be appropriately learned in this way.
- the "first and second feature amounts based on the feature amounts output from the first and second input layers” are output from the first and second input layers.
- the feature amount may be input as it is as the first and second feature amounts, or the feature amount obtained by applying some processing to the feature amount output from the first and second input layers may be input as the first and second feature amounts. It may be input as a feature amount.
- “belonging to the same category” means a combination such as image and image, text and text, voice and voice, and "the first condition and the second condition are different” means “under the same condition". It does not include "dividing the acquired data into two".
- the first and second input layers and the intermediate layer may be composed of one layer or may be composed of a plurality of layers. Further, the number of layers constituting the first and second input layers may be the same or different.
- the hierarchical network may include an output layer, a recognition layer, and the like in addition to the first and second input layers and intermediate layers.
- the learning result for example, recognition
- the feature amount output from the first and second input layers can appropriately express the feature of the first and second data. It is preferable to adjust the number of layers of the first and second input layers and the parameters in each layer in consideration of the error between the result and the correct answer data, loss, etc.).
- the intermediate layer it is preferable to adjust the number of layers of the intermediate layer and the parameters in each layer in consideration of the learning result.
- the learning control unit causes the first learning to be performed at least twice, and the second intermediate layer is after the third intermediate feature amount in the first first learning is output, 2
- the fourth intermediate feature amount in the second learning is output in the period before the third intermediate feature amount in the first learning is output.
- the feature amount calculated in the intermediate layer is strongly influenced by the first data, and the learning for the second data (feature amount). Calculation) may not be performed properly (and vice versa). Therefore, in this embodiment, the calculation of the fourth intermediate feature amount is executed in the period from the completion of the calculation of the third intermediate feature amount to the start of the calculation of the other third intermediate feature amount. Therefore, it is possible to prevent the feature amount calculated at the time of calculating the fourth intermediate feature amount from being excessively affected by the first data, and to appropriately learn the first and second data. ..
- the learning control unit causes the first learning to be performed at least twice, and the second intermediate layer outputs the third intermediate feature amount in the first first learning, and the second first learning. After the output of the third intermediate feature amount in the learning is completed, the fourth intermediate feature amount in the second learning is output.
- the feature amount calculated at the time of calculating the third intermediate feature amount is prevented from being excessively affected by the first data, and the first and second data are compared. You can study properly.
- the hierarchical network is a convolutional neural network.
- the first normalization layer calculates the first normalization feature amount by the batch normalization process
- the second normalization layer calculates the second normalization feature amount by the batch normalization process
- the first input layer outputs the first feature amount by an operation including any one of a convolution operation, a pooling process, a batch normalization process, and an activation process.
- the second input layer outputs the second feature amount by an operation including any one of a convolution operation, a pooling process, a batch normalization process, and an activation process.
- the first intermediate layer outputs the first intermediate feature amount or the second intermediate feature amount by an operation including any one of the convolution operation, the pooling process, and the activation process.
- the second intermediate layer outputs the third intermediate feature amount or the fourth intermediate feature amount by an operation including any one of the convolution operation, the pooling process, and the activation process.
- the first input layer inputs the first image data acquired under the first condition as the first data
- the second input layer acquires the first image data under a second condition different from the first condition.
- the generated second image data is input as the second data.
- At least one of the image pickup device, the wavelength balance of the observation light, the resolution, and the image processing applied to the image is different between the first condition and the second condition.
- the imaging device is different
- the modality is the same, but the model, model number, performance, etc. are different.
- the modality of the endoscope device and the CT device is different.
- the wavelength balance of the observed light means that the relative relationship between the wavelength band of the observed light and / or the intensity of each wavelength band in the observed light is different.
- the image processing applied to the image includes, for example, a process of emphasizing or reducing the influence of a specific wavelength component, or a process of emphasizing or making a specific object or region inconspicuous, but is limited to these. It's not something.
- the first input layer inputs the data of the first medical image acquired by the first observation light as the first image data
- the second input layer has a wavelength balance with the first observation light.
- the data of the second medical image acquired by different second observation lights is input as the second image data.
- the "medical image” is also referred to as a "medical image”.
- the first input layer inputs the data of the first medical image acquired with white light as the first observation light as the first image data
- the second input layer uses the narrow band light as the second.
- the data of the second medical image acquired as the observation light of the above is input as the second image data.
- the "narrow band light” may be observation light having a short wavelength such as blue light or purple light, or observation light having a long wavelength such as red light or infrared light.
- the first input layer inputs the data of the first medical image acquired by using the first narrow band light as the first observation light as the first image data
- the second input layer is the first.
- the data of the second medical image acquired by using the second narrow band light different from the narrow band light of the above as the second observation light is input as the second image data.
- an image When acquiring a medical image, an image may be acquired using a plurality of narrow band lights as observation light depending on the purpose of use of the image, but according to this embodiment, appropriate learning can be performed even in such a case. can.
- the "second narrowband light different from the first narrowband light” means that the wavelength band of the observed light and / or the intensity of the observed light differs between the first narrowband light and the second narrowband light. Means that.
- the learning method is a learning method of a learning device including a processor constituting a learning model of a recognizer and a learning control unit for learning the learning model, and the learning model is a first method.
- It is a second input layer independent of the above, and is composed of a plurality of data acquired under the second condition different from the first condition and belonging to the same category as the data constituting the first data group.
- the second data selected from the second data group is input, and an intermediate common to the second input layer that outputs the second feature amount and the first input layer and the second input layer.
- the layer when the first feature amount is input, the first intermediate feature amount is output, and when the second feature amount is input, the second intermediate feature amount is output.
- the intermediate layer and the first intermediate feature amount are input, and the first normalized layer that outputs the first normalized feature amount based on the first intermediate feature amount and the second intermediate feature amount are input.
- a second normalization layer that outputs a second normalization feature amount based on the second intermediate feature amount, and an intermediate layer common to the first normalization layer and the second normalization layer.
- the third intermediate feature amount or the fourth intermediate feature amount are input, and when the third intermediate feature amount is input, the first recognition result based on the third intermediate feature amount is output. It is a learning method of a learning device including a layered network including an output layer that outputs a second recognition result based on the fourth intermediate feature amount when the fourth intermediate feature amount is input.
- the learning control unit trains the learning model based on the first error between the first recognition result and the correct answer of the first data, and the second recognition result and the second data. It includes a second learning step of training a learning model based on a second error from the correct answer.
- the program according to another aspect of the present invention is a program that executes a learning method of a learning device including a processor constituting a learning model of a recognizer and a learning control unit for learning the learning model.
- a first input layer in which first data selected from a first data group composed of a plurality of data acquired under the first condition is input and a first feature amount is output, and a first input layer. It is a second input layer independent of the input layer of, and is a plurality of data acquired under the second condition different from the first condition and belonging to the same category as the data constituting the first data group.
- the second data selected from the configured second data group is input to the second input layer that outputs the second feature amount, and the first input layer and the second input layer.
- the common intermediate layer when the first feature amount is input, the first intermediate feature amount is output, and when the second feature amount is input, the second intermediate feature amount is output.
- a first normalized layer and a second intermediate feature amount to which a first intermediate feature amount is input and a first normalized feature amount based on the first intermediate feature amount is output. Is input, and a second normalization layer that outputs a second normalization feature amount based on the second intermediate feature amount, and an intermediate layer common to the first normalization layer and the second normalization layer.
- the first recognition based on the third intermediate feature amount is performed.
- the first learning step and the second recognition that the learning control unit trains the learning model based on the first error between the first recognition result and the correct answer of the first data.
- a learning method including a second learning step of training a learning model based on a second error between the result and the correct answer of the second data is executed.
- the trained model of the recognizer which is another aspect of the present invention, can be obtained by the above-mentioned learning method.
- the endoscope system which is another aspect of the present invention, is equipped with the trained model of the above-mentioned recognizer.
- At least one of the image pickup device, the wavelength balance of the observation light, the resolution, and the image processing applied to the image is different between the first condition and the second condition.
- efficient learning can be performed even when learning is performed using data acquired under different conditions.
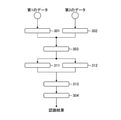
- FIG. 1 is a block diagram showing a configuration of a learning device.
- FIG. 2 is a diagram showing an example of the layer structure of CNN.
- FIG. 3 is a diagram showing input and output data, feature amounts, and the like in each layer of CNN shown in FIG.
- FIG. 4 is a flowchart showing a learning method executed by the learning device.
- FIG. 5 is a diagram illustrating the first learning.
- FIG. 6 is a diagram illustrating the second learning.
- FIG. 7 is a diagram showing how the feature amount to be input to the first intermediate layer is switched.
- FIG. 8 is a diagram showing a state of convolution when a feature amount is input from the first input layer and the second input layer to the first intermediate layer.
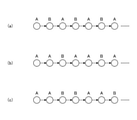
- FIG. 9 is a diagram showing a pattern of the first learning and the second learning.
- FIG. 10 is a diagram showing another pattern of the first learning and the second learning.
- FIG. 1 is a block diagram showing a configuration of a learning device 10 according to the present embodiment.
- the learning device 10 includes a recognizer 100 that performs recognition processing based on an image captured by an endoscope inserted into a subject, and a plurality of endoscope images acquired using normal light (white light) as observation light. It includes a first image database 201 for recording and a second image database 202 for recording a plurality of endoscopic images acquired by using special light (narrow band light) as observation light.
- the image obtained by using normal light (white light) as observation light is referred to as "normal light image” (or “white light image"), and special light (narrow band light) is obtained as observation light.
- the image is called a "special optical image” (or “narrow band optical image”).
- the endoscopic images recorded in the first image database 201 and the second image database 202 are examples of medical images.
- the first image database 201 and the second image database 202 are composed of a recording medium such as a hard disk.
- a plurality of normal light images first data group, first data, first image data, first
- a plurality of special light images second data group, second data, second
- special light images medical images
- the special light is taken as observation light (second observation light) in the second image database 202.
- Image data, second medical image is recorded.
- the plurality of ordinary optical images recorded in the first image database 201 is one aspect of the "plurality of data acquired under the first condition" in the present invention, and is recorded in the second image database 202.
- the plurality of special optical images is an aspect of "a plurality of data acquired under a second condition different from the first condition" in the present invention.
- Special light The special light (narrow band light) for capturing an image can be, for example, blue narrow band light, but may have other wavelengths such as red narrow band light. Further, in the above example, the case where the first and second observation lights are white light and narrow band light is described, but the first and second narrow band lights having different wavelength bands and / or intensities are observed.
- a medical image such as an endoscopic image acquired as light may be used.
- the normal light image acquisition condition (first condition) and the special light image acquisition condition (second condition) differ in the wavelength balance of the observed light, but in addition to this, the normal light image and the special light image
- the image pickup device, the resolution, and the image processing applied to the image may be different. That is, at least one of the image pickup device, the wavelength balance of the observed light, the resolution, and the image processing applied to the image may be different between the first condition and the second condition.
- “Different image pickup devices” includes, but is not limited to, using endoscopes having different optical system characteristics and processor performance.
- the image processing applied to the image is different means that the presence / absence and / or degree of the processing for emphasizing or inconspicuous a specific area such as a region of interest and the processing for emphasizing or reducing the influence of a specific wavelength component are different. Included, but not limited to.
- the first image database 201 and the second image database 202 in addition to the above-mentioned endoscopic image, "correct answer data" for identifying a region of interest (ROI) is stored in association with the image. .. Specifically, the first image database 201 stores a plurality of correct answer data corresponding to a plurality of normal optical images, and the second image database 202 stores a plurality of correct answer data corresponding to a plurality of special optical images.
- the correct answer data is preferably the region of interest designated by the doctor for the endoscopic image and the discrimination result.
- the recognizer 100 includes an image acquisition unit 110, an operation unit 120, a control unit 130, a display unit 140, a recording unit 150, and a processing unit 160.
- the image acquisition unit 110 is composed of an external server, a device that communicates with a database, etc. via a network, and uses endoscopic images and correct answer data for learning and recognition in the first image database 201 and the second image database 202. Get from.
- the image acquisition unit 110 can also acquire an endoscope image from an endoscope system connected to the learning device 10 by a network (not shown), a server in a hospital, or the like.
- the operation unit 120 includes input devices such as a keyboard and a mouse (not shown), and the user can perform operations necessary for processing such as image acquisition, learning, and recognition through these devices.
- the control unit 130 reads various programs recorded in the recording unit 150 and controls the operation of the entire learning device 10 according to a command input from the operation unit 120.
- control unit 130 updates the weight parameter of the CNN 162 by back-propagating the error (loss) calculated by the error calculation unit 164 described later to the CNN 162 (CNN: Convolutional Neural Network, convolutional neural network). That is, the control unit 130 has a function as a learning control unit that causes the CNN 162 to perform learning. Further, CNN 162 is a learning model of the recognizer 100. When the first learning and the second learning described below are performed in the CNN 162, the CNN 162 becomes a trained model of the recognizer 100.
- the display unit 140 includes a monitor 142 (display device) and displays an endoscope image, a learning result, a recognition result, a processing condition setting screen, and the like.
- the recording unit 150 is composed of a ROM (Read Only Memory), a RAM (Random Access Memory), a hard disk, etc., which are not shown, and records the data acquired by the image acquisition unit 110, the learning result, the recognition result, and the like in the processing unit 160. .. Further, the recording unit 150 records a program for learning and recognizing an endoscopic image (medical image) (including a program for causing the learning device 10 to execute the learning method of the present invention).
- the processing unit 160 includes a CNN 162 which is a hierarchical network, and an error calculation unit 164 which calculates a loss (error) based on the output (recognition result) of the CNN 162 and the above-mentioned “correct answer data”.
- the functions of the image acquisition unit 110, the control unit 130, and the processing unit 160 (CNN 162, error calculation unit 164) described above can be realized by using various processors.
- the various processors include, for example, a CPU (Central Processing Unit), which is a general-purpose processor that executes software (program) to realize various functions.
- the various processors described above include programmable logic devices (PLCs) such as GPUs (Graphics Processing Units) and FPGAs (Field Programmable Gate Arrays), which are specialized processors for image processing, whose circuit configurations can be changed after manufacturing. Programmable Logic Device (PLD) is also included.
- the above-mentioned various processors also include a dedicated electric circuit, which is a processor having a circuit configuration specially designed for executing a specific process such as an ASIC (Application Specific Integrated Circuit).
- ASIC Application Specific Integrated Circuit
- each part may be realized by one processor, or may be realized by a plurality of processors of the same type or different types (for example, a plurality of FPGAs, or a combination of a CPU and an FPGA, or a combination of a CPU and a GPU). Further, a plurality of functions may be realized by one processor. As an example of configuring a plurality of functions with one processor, first, as represented by a computer, one processor is configured by a combination of one or more CPUs and software, and this processor is used as a plurality of functions. There is a form to be realized.
- SoC System On Chip
- the hardware-like structure of these various processors is, more specifically, an electric circuit (circuitry) in which circuit elements such as semiconductor elements are combined.
- the processor (computer) readable code of the software to be executed is stored in a non-temporary recording medium such as ROM (Read Only Memory), and the processor.
- the software stored in the non-temporary recording medium includes a program for executing the learning method according to the present invention.
- the code may be recorded on a non-temporary recording medium such as various optical magnetic recording devices or semiconductor memories instead of the ROM.
- RAM RandomAccessMemory
- EEPROM Electrically Erasable and Programmable Read Only Memory
- these ROMs, RAMs, EEPROMs, etc., those provided in the recording unit 150 can be used.
- FIG. 2 is a diagram showing an example of the layer structure of CNN 162.
- FIG. 3 is a diagram showing input and output data, feature amounts, and the like in each layer of CNN 162 shown in FIG.
- the CNN 162 includes a first input layer 301 (first input layer), a second input layer 302 (second input layer), and a first intermediate layer 303 (1st input layer). (Intermediate layer), the first normalization layer 311 (first normalization layer), the second normalization layer 312 (second normalization layer), and the second intermediate layer 313 (second intermediate layer). Layer) and an output layer 304 (output layer).
- the first input layer 301 inputs an image (first data) selected from a normal optical image (first data group) stored in the first image database 201 and inputs a feature amount (first feature amount). ) Is output.
- the second input layer 302 is an input layer independent of the first input layer 301, and is an image (second data group) selected from the special optical image (second data group) stored in the second image database 202. Data) is input and the feature amount (second feature amount) is output.
- the first intermediate layer 303 is an intermediate layer common to the first input layer 301 and the second input layer 302.
- the first intermediate layer 303 outputs the first intermediate feature amount (B1) when the first feature amount (A1) output by the first input layer 301 is input. Further, the first intermediate layer 303 outputs the second intermediate feature amount (B2) when the second feature amount (A2) output by the second input layer 302 is input.
- the switching of the feature amounts output by the first intermediate layer 303 and the second intermediate layer 313 will be described later.
- the first intermediate feature amount (B1) output from the first intermediate layer 303 is input, and the first normalized feature amount (C1) based on the first intermediate feature amount is input. Is output.
- the second intermediate feature amount (B2) output from the first intermediate layer 303 is input, and the second normalized feature amount (C2) based on the second intermediate feature amount is input. Is output.
- the second intermediate layer 313 is an intermediate layer common to the first normalized layer 311 and the second normalized layer 312.
- the second intermediate layer 313 outputs the third intermediate feature amount (D1) when the first normalized feature amount (C1) output from the first normalized layer 311 is input. Further, the second intermediate layer 313 outputs the fourth feature amount (D2) when the second feature amount (C2) output from the second normalized layer 312 is input.
- the output layer 304 outputs the recognition result in the image in which the feature amount is input from the second intermediate layer 313 and is input to the first input layer 301 or the second input layer 302. Specifically, the output layer 304 is the first based on the third feature amount (D1) when the third intermediate feature amount (D1) output from the second intermediate layer 313 is input. The recognition result (E1) is output. Further, when the fourth intermediate feature amount (D2) output from the second intermediate layer 313 is input, the output layer 304 has a second recognition result based on the fourth intermediate feature amount (D2). (E2) is output.
- the first recognition result (E1) is the recognition result of the first data
- the second recognition result (E2) is the recognition result of the second data.
- a plurality of "nodes” are “edges”. It has a connected structure and holds multiple weight parameters. Further, in the second input layer 302, the first intermediate layer 303, the second normalization layer 312, the second intermediate layer 313, and the output layer 304, a plurality of "nodes” are “edges”. It has a structure connected by, and holds multiple weight parameters. Then, the values of these weight parameters change as the learning progresses.
- Each layer of the first input layer 301 and the second input layer 302 outputs a feature amount by an operation including any one of a convolution operation, a pooling process, an activation process, and a batch normalization process.
- Each layer of the first intermediate layer 303 and the second intermediate layer 313 outputs a feature amount by an operation including any one of a convolution operation, a pooling process, and an activation process.
- each layer of the first input layer 301 and the second input layer 302 is a layered combination of a convolution operation, a pooling process, an activation process, and a batch normalization operation, and outputs a feature amount.
- the operations of the convolution operation, the pooling process, and the activation process are combined in a layered manner, and the feature amount is output.
- the convolution operation is a process of acquiring a feature map by a convolution operation using a filter on the input data (for example, an image).
- the convolution operation plays a role of feature extraction such as edge extraction from an image.
- a feature map of one channel one sheet is generated for one filter.
- the size of the feature map is downscaled by convolution and becomes smaller as each layer is convolved.
- the pooling process is a process of reducing (or enlarging) the feature map output by the convolution operation to make a new feature map.
- the pooling process plays a role of imparting robustness so that the extracted features are not affected by translation or the like.
- the activation process performs an operation on the feature map using the activation function.
- the activation function a jigmoid function or ReLU (RectifiedLinerUnit) is used.
- the batch normalization process is a process that normalizes the distribution of data in units of mini-batch when learning, and plays a role of advancing learning quickly, reducing dependence on initial values, suppressing overfitting, and so on.
- the first input layer 301, the second input layer 302, the first intermediate layer 303, and the second intermediate layer 313 can be composed of one or a plurality of layers that perform these processes.
- the layer configuration is not limited to the case where each layer is subjected to the convolution operation, the pooling process, the activation process, and the batch normalization process, and any one of the layers may be included.
- first input layer 301 second input layer 302, first intermediate layer 303, and second intermediate layer 313, lower-order feature extraction (edge extraction, etc.) is performed in the layer closer to the input side. ) Is performed, and higher-order feature extraction (extraction of features related to the shape, structure, etc. of the object) is performed as the output side is approached.
- the first normalization layer 311 and the second normalization layer 312 normalize the input feature amount. Specifically, the first normalization layer 311 and the second normalization layer 312 normalize the input feature amount distribution and output the normalized feature amount.
- the first normalization layer 311 normalizes the first intermediate feature amount (B1) based on the first data
- the second normalization layer 312 is the second intermediate based on the second data. Normalize the feature amount (B2).
- the first normalization layer 311 dedicated to the first intermediate feature amount (B1) and the second normalization layer 312 dedicated to the second intermediate feature amount (B2) are independent. It is provided in.
- the first intermediate feature amount (B1) and the second intermediate feature amount (B2) are normalized under appropriate conditions of individual independence.
- the effect of the normalization process may be reduced.
- the learning of CNN162 does not proceed efficiently by performing the normalization process. This is because when the two feature quantities derived from the first data and the second data acquired under different conditions are normalized, the feature quantities in between are normalized. Therefore, in CNN 162, between the first intermediate layer 303 and the second intermediate layer 313, the first normalized layer 311 and the second intermediate feature amount (B2) dedicated to the first intermediate feature amount (B1).
- the normalization process suitable for each of the first data and the second data is realized. Further, the first normalized layer 311 and the second normalized layer 312 are provided in parallel at positions sandwiched between the first intermediate layer 303 and the second intermediate layer 313. As a result, the first intermediate feature amount (B1) and the second intermediate feature amount (B2) output by the first intermediate layer 303 are normalized, and the normalized feature amount (first normalization) is performed. The feature amount and the second normalized feature amount) can be further output to the second intermediate layer 313.
- the normalization process performed in the first normalization layer 311 and the second normalization layer 312 is, for example, a batch normalization process.
- the distribution of the first intermediate feature amount (B1) is normalized to have an average 0 variance 1 and the distribution of the second intermediate feature amount (B2) has an average 0 variance 1.
- Processing is done.
- the first normalization layer 311 and the second normalization layer 312 are used. Normalization may be performed under different conditions for each color. In this way, by providing the first normalization layer 311 and the second normalization layer 312, the CNN 162 can perform learning using the first data and the second data acquired under different conditions. Even so, normalization can be performed appropriately for each, and efficient learning can be performed.
- the batch normalization process is also performed on the first input layer 301 and the second input layer 302 described above, the first input layer 301 and the second input layer 302 are each of the first data or the second input layer 302. Since only the data of is input, it is a batch normalization process dedicated to the first data or dedicated to the second data.
- the first intermediate layer 303 since the feature quantities derived from the first data and the second data having different properties are input, the branched first normalization layer 311 and the second normalization layer 312 are input. Is set up and normalization is performed correctly.
- the output layer 304 detects the position of the region of interest reflected in the input image (normal light image, special light image) based on the feature amount output from the second intermediate layer 313, and outputs the result. It is a layer.
- the output layer 304 grasps the position of the region of interest in the image at the pixel level by the "feature map" obtained from the second intermediate layer 313. That is, it is possible to detect whether or not each pixel of the endoscope image belongs to the region of interest and output the detection result.
- the output layer 304 may be one that executes discrimination related to lesions and outputs the discrimination result.
- the output layer 304 classifies endoscopic images into three categories of "neoplastic”, “non-neoplastic", and “other”, and as a result of discrimination, "neoplastic", “non-neoplastic", and “other”. May be output as three scores corresponding to "" (the total of the three scores is 100%), or if the three scores can be clearly classified, the classification result may be output.
- the output layer 304 has a fully connected layer as the last one layer or a plurality of layers.
- FIG. 4 is a flowchart showing a learning method executed by the learning device 10.
- control unit 130 of the learning device 10 performs the first learning step (see step S106), and then the second learning step (see step S112).
- the processing unit 160 performs a first feature amount calculation process (step S101) on the first input layer 301.
- the processing unit 160 performs the first intermediate feature amount calculation process (step S102) on the first intermediate layer 303.
- the processing unit 160 performs the first normalization feature amount calculation processing (step S103) in the first normalization layer 311.
- the processing unit 160 performs a third intermediate feature amount calculation process (step S104) on the second intermediate layer 313.
- the processing unit 160 performs the first recognition result output processing (step S105) on the output layer 304.
- the control unit 130 causes the CNN 162 to perform the first learning (step S106).
- the second learning is performed after the first learning described above.
- the processing unit 160 performs a second feature amount calculation process (step S107) on the second input layer 302.
- the processing unit 160 performs a second intermediate feature amount calculation process (step S108) on the first intermediate layer 303.
- the processing unit 160 performs a second normalization feature amount calculation process (step S109) on the second normalization layer 312.
- the processing unit 160 performs a fourth intermediate feature amount calculation process (step S110) on the second intermediate layer 313.
- the processing unit 160 performs a second recognition result output processing (step S111) on the output layer 304.
- the control unit 130 causes the CNN 162 to perform the second learning (step S112).
- FIG. 5 is a diagram illustrating the first learning in CNN 162.
- the downward arrow indicates information transmitted from the first input layer 301 to the output layer 304 via the first intermediate layer 303, the first normalized layer 311 and the second intermediate layer 313. It means that it is done (learning direction), and the upward arrow opposite to the learning direction is from the output layer 304 to the second intermediate layer 313, the first normalized layer 311 and the first intermediate layer 303, the first. It means that information is transmitted to the input layer 301 (error back propagation described later).
- a mini-batch is composed of a plurality of images (first data) selected from a plurality of normal optical images recorded in the first image database 201, and the mini-batch is input to the first input layer 301. .. Then, in the first input layer 301, the first feature amount calculation process (step S101) is performed to calculate the first feature amount.
- the first intermediate layer 303 Since the first input layer 301 and the second input layer 302 are connected to the first intermediate layer 303 as described above, the output of the first input layer 301 and the second input are used during learning. The output of the layer 302 is switched and input. As shown in FIG. 5, the first intermediate layer 303 has a first intermediate feature when the first feature amount output from the first input layer 301 is input to the first intermediate layer 303. The amount is calculated (step S102).
- FIG. 7 is a diagram showing how the feature amount to be input to the first intermediate layer 303 is switched.
- FIG. 7A shows a state in which the first feature amount is input to the first intermediate layer 303 (output from the node 301A constituting the layer included in the first input layer 301 is output from the first intermediate layer 303). (Input to the node 303A to be configured) is shown.
- the feature amount output from the first input layer 301 may be directly input to the first intermediate layer 303 as the first feature amount, or the feature amount multiplied by an appropriate weight may be used as the first feature amount.
- the quantity may be input to the first intermediate layer 303 (see FIG. 8).
- the solid line in the figure indicates a state in which data is output or input from the node by switching the output described above, and the dotted line in the figure indicates a state in which data is not output or input from the node.
- the nodes 301A and 303A are conceptually shown, and the number is not particularly limited. The same applies to FIG. 8 regarding these points.
- FIG. 8 is a diagram showing a state of convolution when a feature amount is input to the first input layer 301 and the second input layer 302 to the first intermediate layer 303.
- the part (a) in FIG. 8 is a state in which the outputs of the nodes X11, X12, and X13 of the first input layer 301 are multiplied by the weight parameters W11, W12, and W13, respectively, and input to the node Y11 of the first intermediate layer 303. (In the state shown in the figure, the input is not input from the node X10 to the node Y11). Although the figure shows the input relationship between the nodes X11, X12, X13 and the node Y11, the same relationship holds for the other nodes Y10, Y12, Y13 of the first intermediate layer 303.
- the processing unit 160 performs the first normalization feature amount calculation processing in the first normalization layer 311. Specifically, the processing unit 160 calculates the first normalized feature amount based on the first intermediate feature amount output from the first intermediate layer 303 (step S103).
- the processing unit 160 performs a third intermediate feature amount calculation process on the second intermediate layer 313 (step S104). Specifically, the processing unit 160 calculates a third intermediate feature amount based on the second normalized feature amount output from the first normalization layer 311. In the second intermediate layer 313, the first normalized feature amount and the second normalized layer 312 output from the first normalized layer 311 are the same as the first intermediate feature amount calculation process described above. The second normalized feature amount output from is switched and input. The detailed description of the third intermediate feature amount calculation process is the same as that of the first intermediate feature amount calculation process, and is therefore omitted.
- the output layer 304 inputs the third intermediate feature amount calculated by the second intermediate layer 313, performs the first recognition result output process, and outputs the first recognition result (step S105).
- the error calculation unit 164 calculates the loss (first error) by comparing the first recognition result output by the output layer 304 with the correct answer for the first data. In the second learning described later, the error calculation unit 164 calculates the loss (second error) by comparing the second recognition result output by the output layer 304 with the correct answer for the second data. .. Then, as shown in FIG. 5, the error calculation unit 164 sets the first input layer 301, the first intermediate layer 303, the first normalization layer 311 and the second intermediate layer so that the calculated loss becomes small. The weight parameters in 313 and the output layer 304 are updated from the output side layer to the input side layer (error back propagation). Updating these parameters is the first learning (step S106).
- FIG. 6 is a diagram illustrating the second learning in CNN 162.
- the downward arrow indicates information transmitted from the second input layer 302 to the output layer 304 via the first intermediate layer 303, the second normalized layer 312, and the second intermediate layer 313. It means that it is done (learning direction), and the upward arrow opposite to the learning direction is from the output layer 304 to the second intermediate layer 313, the second normalized layer 312, the first intermediate layer 303, and the second. It means that information is transmitted to the input layer 302 (error back propagation described later).
- a mini-batch is composed of a plurality of images (second data) selected from a plurality of special optical images recorded in the second image database 202, and the mini-batch is input to the second input layer 302. .
- the second feature amount calculation process (step S107) is performed to calculate the second feature amount.
- the second intermediate feature amount is input to the first intermediate layer 303, and the second intermediate feature amount is calculated by performing the second intermediate feature amount calculation process (step S108). Since the first input layer 301 and the second input layer 302 are connected to the first intermediate layer 303 as described above, the output of the first input layer 301 and the second input are used during learning. The output of the layer 302 is switched and input.
- FIG. 7B shows a state in which the second feature amount is input to the first intermediate layer 303 (the output from the node 302A constituting the second input layer 302 is input to the node constituting the first intermediate layer 303). It is a figure which shows input to 303A).
- the second feature amount based on the feature amount output from the second input layer 302 is input to the first intermediate layer 303, and the second intermediate feature is input to the first intermediate layer 303. Calculate the amount.
- FIG. 7B shows a state in which the second feature amount is input to the first intermediate layer 303.
- FIG. 8B is the first intermediate portion obtained by multiplying the outputs of the nodes X21, X22, and X23 of the second input layer 302 by the weight parameters W21, W22, and W23, respectively, as in the portion (a) of the figure.
- the state of inputting to the node Y11 of the layer 303 is shown (in the state shown in the figure, it is not input to the node Y11 from the node X20).
- the figure shows the input relationship between the nodes X21, X22, X23 and the node Y11, the same relationship holds for the other nodes Y10, Y12, Y13 of the first intermediate layer 303.
- step S109 second normalized feature amount calculation process
- step S110 fourth intermediate feature amount calculation process
- step S111 second recognition result output process
- step S112 is the “first normalized feature amount calculation process (step S103)", “third intermediate feature amount calculation process (step S104)", and “first” in the first learning. Since the same processing as “recognition result output processing (step S105)” and “first learning (step S106)” is performed, the description thereof will be omitted.
- Example of learning pattern> In the description of the learning method described above, an example in which the first learning and the second learning are performed once is described, but the learning method performed by the learning device 10 is not limited to this. It suffices that the first learning and the second learning are performed at least once each, and various aspects are adopted. Hereinafter, an example of the number of times and the order of processing will be described.
- the second intermediate layer 313 is after the third intermediate feature amount in the first first learning is output, and the third intermediate feature in the second first learning. In the period before the quantity is output, the fourth intermediate feature quantity in the second learning is output.
- the second intermediate layer 313 completes the output of the third intermediate feature amount in the first first learning and the output of the third intermediate feature amount in the second first learning. After that, the fourth intermediate feature amount in the second learning is output.
- the process is repeated in the order shown in FIG. 9 (b).
- the terms "A” and “B” in FIG. 9B have the same meaning as the portion (a) in the figure. In this case, "B" may be performed twice in succession as shown in FIG. 9 (c).
- the learning device 10 performs the first learning a plurality of times in succession, and then performs the second learning a plurality of times in succession.
- the learning device 10 performs learning in the order shown in FIG.
- the "first" and “second” in FIG. 10 are “first learning” and “second learning", respectively.
- the patterns shown in FIGS. 9 and 10 are examples, and various other patterns can be used for learning.
- the learning device 10 outputs the first intermediate feature amount when the first feature amount based on the first data is input, and the first intermediate layer 303 outputs the first intermediate feature amount, and the second intermediate layer 303 is based on the second data.
- the second intermediate feature amount is output.
- the first normalized layer 311 inputs the first intermediate feature amount and outputs the first normalized feature amount
- the second normalized layer 312 inputs the second intermediate feature amount and the second.
- the second intermediate layer 313 inputs the first normalized feature quantity and the second normalized feature quantity.
- the first and second data are input to the independent first and second input layers, respectively, and the feature amount is calculated in the first and second input layers, respectively.
- the feature amount calculation in one of the second input layers is not affected by the feature amount calculation in the other input layer.
- a first intermediate layer 303 common to the first and second input layers is further used. Since the intermediate feature amount of 1 and the second intermediate feature amount are calculated, the feature amount calculated from the first and second data in the input layer should be reflected in the intermediate feature amount calculation in the first intermediate layer 303. Can be done.
- the second intermediate layer 313 is also common to the first normalization layer 311 and the second normalization layer 312, similarly, the first normal feature amount and the second normalization feature amount are used as the second normalization feature amount. It can be reflected in the calculation of the intermediate feature amount in the intermediate layer 313.
- the hierarchical network tends to be overfitted because it has many parameters, but overfitting can be avoided by giving a large amount of data.
- the intermediate layer can be learned with a large amount of data including the first and second data, so that overfitting is unlikely to occur, while the input layer is independent of the first and second input layers. Since the parameters of each input layer are reduced, overfitting is unlikely to occur even with a small amount of data.
- the learning device 10 the data belonging to the same category and acquired under different conditions can be appropriately learned in this way.
- the feature amount is calculated separately for each mini-batch for the first and second data, but one of the first and second mini-batch is set immediately before the input to the first intermediate layer 303. It may be synthesized into a mini-batch. Specifically, a mini-batch (first mini-batch) is composed of a plurality of images (first data) selected from a plurality of normal optical images recorded in the first image database 201, and a first input is made. The feature amount is calculated by inputting to the layer 301.
- a mini-batch (second mini-batch) is composed of a plurality of images (second data) selected from a plurality of special optical images recorded in the second image database 202, and the second input layer 302 is formed. Input and calculate the feature amount. Immediately before inputting these feature quantities to the first intermediate layer 303, the first and second mini-batch may be combined into one mini-batch and input to the first intermediate layer 303.
- the CNN 162 of the recognizer 100 becomes a trained model.
- the recognition (inference) process using the trained model CNN 162 the first input layer 301 or the second input layer 302 may be removed for recognition.
- recognition can be performed on the first data in a state where the second input layer 302 is removed and only the first input layer 301 is connected.
- recognition can be performed on the second data in a state where the first input layer 301 is removed and only the second input layer 302 is connected.
- the first input layer 301 inputs the data of the first medical image acquired by using the first narrow band light as the first observation light as the first image data
- the second input layer 302 is the first.
- the data of the second medical image acquired by using the second narrow band light different from the narrow band light as the second observation light may be input as the second image data.
- a combination of the narrow band light a plurality of blue narrow band light, a blue narrow band light and a purple narrow band light, a plurality of red narrow band light, and the like can be used.
- ⁇ Learning using other data> learning using endoscopic images acquired with different observation lights has been described, but in the learning device and learning method according to the present invention, a CT device (Computed Tomography), an MRI (Magnetic Resonance Imaging) device, etc. Even when using a medical image other than the endoscopic image of the above, the same learning can be performed. Further, even when an image other than the medical image (for example, another image such as a person, an animal, a landscape, etc.) is used, the learning can be performed in the same manner. Further, when the input data is not an image but a sentence, a voice, or the like, it can be learned in the same manner.
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Theoretical Computer Science (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Surgery (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Radiology & Medical Imaging (AREA)
- Pathology (AREA)
- Heart & Thoracic Surgery (AREA)
- Optics & Photonics (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Signal Processing (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Image Analysis (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022545299A JP7648638B2 (ja) | 2020-08-28 | 2021-04-20 | 学習装置、学習方法、プログラム、学習済みモデル、及び内視鏡システム |
| US18/165,934 US12357149B2 (en) | 2020-08-28 | 2023-02-08 | Learning apparatus, learning method, program, trained model, and endoscope system |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-144568 | 2020-08-28 | ||
| JP2020144568 | 2020-08-28 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/165,934 Continuation US12357149B2 (en) | 2020-08-28 | 2023-02-08 | Learning apparatus, learning method, program, trained model, and endoscope system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022044425A1 true WO2022044425A1 (ja) | 2022-03-03 |
Family
ID=80354949
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/016004 Ceased WO2022044425A1 (ja) | 2020-08-28 | 2021-04-20 | 学習装置、学習方法、プログラム、学習済みモデル、及び内視鏡システム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12357149B2 (https=) |
| JP (1) | JP7648638B2 (https=) |
| WO (1) | WO2022044425A1 (https=) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023139227A (ja) * | 2022-07-27 | 2023-10-03 | 浙江極▲け▼智能科技有限公司 | 電池健康状態予測方法、装置、電子機器及び可読記憶媒体 |
| WO2024185045A1 (ja) * | 2023-03-07 | 2024-09-12 | 日本電気株式会社 | データ生成装置、データ生成方法および記録媒体 |
| JP2025087996A (ja) * | 2023-11-30 | 2025-06-11 | MedBank株式会社 | 医用画像の自動選別方法、装置、コンピュータ可読記憶媒体及びプログラム |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015102806A (ja) * | 2013-11-27 | 2015-06-04 | 国立研究開発法人情報通信研究機構 | 統計的音響モデルの適応方法、統計的音響モデルの適応に適した音響モデルの学習方法、ディープ・ニューラル・ネットワークを構築するためのパラメータを記憶した記憶媒体、及び統計的音響モデルの適応を行なうためのコンピュータプログラム |
| WO2020022027A1 (ja) * | 2018-07-26 | 2020-01-30 | 富士フイルム株式会社 | 学習装置及び学習方法 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6236296B2 (ja) | 2013-11-14 | 2017-11-22 | 株式会社デンソーアイティーラボラトリ | 学習装置、学習プログラム、及び学習方法 |
| JP6196598B2 (ja) | 2014-09-30 | 2017-09-13 | 富士フイルム株式会社 | 内視鏡システム、プロセッサ装置、内視鏡システムの作動方法、及びプロセッサ装置の作動方法 |
| US11144785B2 (en) | 2016-03-17 | 2021-10-12 | Imagia Cybernetics Inc. | Method and system for processing a task with robustness to missing input information |
| JP6656357B2 (ja) | 2016-04-04 | 2020-03-04 | オリンパス株式会社 | 学習方法、画像認識装置およびプログラム |
| JP6151404B1 (ja) | 2016-04-26 | 2017-06-21 | ヤフー株式会社 | 学習装置、学習方法および学習プログラム |
| RU2016138608A (ru) | 2016-09-29 | 2018-03-30 | Мэджик Лип, Инк. | Нейронная сеть для сегментации изображения глаза и оценки качества изображения |
| WO2018184192A1 (en) * | 2017-04-07 | 2018-10-11 | Intel Corporation | Methods and systems using camera devices for deep channel and convolutional neural network images and formats |
| US11094029B2 (en) * | 2017-04-10 | 2021-08-17 | Intel Corporation | Abstraction layers for scalable distributed machine learning |
| US11017291B2 (en) * | 2017-04-28 | 2021-05-25 | Intel Corporation | Training with adaptive runtime and precision profiling |
| US11373266B2 (en) * | 2017-05-05 | 2022-06-28 | Intel Corporation | Data parallelism and halo exchange for distributed machine learning |
| US12154028B2 (en) * | 2017-05-05 | 2024-11-26 | Intel Corporation | Fine-grain compute communication execution for deep learning frameworks via hardware accelerated point-to-point primitives |
| JP2020525258A (ja) * | 2017-06-30 | 2020-08-27 | プロマトン・ホールディング・ベー・フェー | 深層学習法を使用する3d歯顎顔面構造の分類および3dモデリング |
| KR102589303B1 (ko) * | 2017-11-02 | 2023-10-24 | 삼성전자주식회사 | 고정 소수점 타입의 뉴럴 네트워크를 생성하는 방법 및 장치 |
| US11449759B2 (en) * | 2018-01-03 | 2022-09-20 | Siemens Heathcare Gmbh | Medical imaging diffeomorphic registration based on machine learning |
| US11769042B2 (en) | 2018-02-08 | 2023-09-26 | Western Digital Technologies, Inc. | Reconfigurable systolic neural network engine |
| JP7098498B2 (ja) * | 2018-10-01 | 2022-07-11 | 富士フイルム株式会社 | 疾患領域を判別する判別器の学習装置、方法及びプログラム、疾患領域を判別する判別器、並びに疾患領域判別装置及びプログラム |
| WO2021010225A1 (ja) * | 2019-07-18 | 2021-01-21 | Hoya株式会社 | コンピュータプログラム、情報処理方法、及び内視鏡用プロセッサ |
| US12530820B2 (en) * | 2019-09-30 | 2026-01-20 | Nvidia Corporation | Image generation using one or more neural networks |
| US11238650B2 (en) * | 2020-03-13 | 2022-02-01 | Nvidia Corporation | Self-supervised single-view 3D reconstruction via semantic consistency |
-
2021
- 2021-04-20 JP JP2022545299A patent/JP7648638B2/ja active Active
- 2021-04-20 WO PCT/JP2021/016004 patent/WO2022044425A1/ja not_active Ceased
-
2023
- 2023-02-08 US US18/165,934 patent/US12357149B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015102806A (ja) * | 2013-11-27 | 2015-06-04 | 国立研究開発法人情報通信研究機構 | 統計的音響モデルの適応方法、統計的音響モデルの適応に適した音響モデルの学習方法、ディープ・ニューラル・ネットワークを構築するためのパラメータを記憶した記憶媒体、及び統計的音響モデルの適応を行なうためのコンピュータプログラム |
| WO2020022027A1 (ja) * | 2018-07-26 | 2020-01-30 | 富士フイルム株式会社 | 学習装置及び学習方法 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023139227A (ja) * | 2022-07-27 | 2023-10-03 | 浙江極▲け▼智能科技有限公司 | 電池健康状態予測方法、装置、電子機器及び可読記憶媒体 |
| WO2024185045A1 (ja) * | 2023-03-07 | 2024-09-12 | 日本電気株式会社 | データ生成装置、データ生成方法および記録媒体 |
| JP2025087996A (ja) * | 2023-11-30 | 2025-06-11 | MedBank株式会社 | 医用画像の自動選別方法、装置、コンピュータ可読記憶媒体及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US12357149B2 (en) | 2025-07-15 |
| JPWO2022044425A1 (https=) | 2022-03-03 |
| US20230180999A1 (en) | 2023-06-15 |
| JP7648638B2 (ja) | 2025-03-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7019815B2 (ja) | 学習装置 | |
| Sharma et al. | Deep learning applications for disease diagnosis | |
| Zhang et al. | Context-guided fully convolutional networks for joint craniomaxillofacial bone segmentation and landmark digitization | |
| Chan et al. | Texture-map-based branch-collaborative network for oral cancer detection | |
| Cao et al. | Efficient multi-kernel multi-instance learning using weakly supervised and imbalanced data for diabetic retinopathy diagnosis | |
| EP2357612A2 (en) | Method for quantifying and imaging features of a tumor | |
| US12357149B2 (en) | Learning apparatus, learning method, program, trained model, and endoscope system | |
| CN113450305B (zh) | 医疗图像的处理方法、系统、设备及可读存储介质 | |
| JP7187557B2 (ja) | 医療画像学習装置、方法及びプログラム | |
| CN116258732B (zh) | 一种基于pet/ct图像跨模态特征融合的食管癌肿瘤靶区分割方法 | |
| Chen et al. | Detection of various dental conditions on dental panoramic radiography using faster R-CNN | |
| CN115004222A (zh) | Oct数据的神经网络处理以生成对地图状萎缩生长率的预测 | |
| CN117274270A (zh) | 基于人工智能的消化内镜实时辅助系统及方法 | |
| Singh et al. | Preprocessing of medical images using deep learning: A comprehensive review | |
| US20200372650A1 (en) | Identifying device, learning device, method, and storage medium | |
| Rao et al. | OTONet: Deep neural network for precise otoscopy image classification | |
| CN114155190B (zh) | 基于病灶注意条件生成对抗网络的视网膜图像合成方法 | |
| Soomro et al. | The state of retinal image analysis: Deep learning advances and applications | |
| CN120600323B (zh) | 一种基于神经网络的半月板损伤预测方法及系统 | |
| KR102809111B1 (ko) | 합성곱 신경망의 계층 연관성 전파를 이용한 퇴행성 뇌질환 이미지 분류 장치 및 방법 | |
| CN118799624A (zh) | 一种基于深度学习的眼底图像病灶识别方法及相关设备 | |
| CN118822957A (zh) | 基于多模态医学图像的病灶时间演化方法、介质及设备 | |
| Nayagi et al. | Detection and classification of neonatal jaundice using color card techniques-a study | |
| Wang et al. | Auto-context fully convolutional network for levator hiatus segmentation in ultrasoudn images | |
| Chandra et al. | Deep learning-powered corneal endothelium image segmentation with attention u-net |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21860857 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022545299 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21860857 Country of ref document: EP Kind code of ref document: A1 |