WO2022038785A1 - 訓練データ生成プログラム、訓練データ生成方法および訓練データ生成装置 - Google Patents
訓練データ生成プログラム、訓練データ生成方法および訓練データ生成装置 Download PDFInfo
- Publication number
- WO2022038785A1 WO2022038785A1 PCT/JP2020/031713 JP2020031713W WO2022038785A1 WO 2022038785 A1 WO2022038785 A1 WO 2022038785A1 JP 2020031713 W JP2020031713 W JP 2020031713W WO 2022038785 A1 WO2022038785 A1 WO 2022038785A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- training data
- data
- value
- generated
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
Definitions
- An embodiment of the present invention relates to a training data generation program, a training data generation method, and a training data generation device.
- the training data for retraining includes old training data
- the retraining effect is reduced.
- the meaning (translated word) of the same word changes, it is difficult to train the translation of the term well if the retraining data is retrained with the old meaning case and the new meaning case coexisting. Will be. Therefore, it is required to remove training cases in which the effect of retraining is reduced from the training data for retraining.
- a quality score is calculated using a forward-trained model for a training pair consisting of input and output of a discrete series that may contain an error in the correspondence, and it is natural.
- a learning quality estimation device that can remove erroneous data in training data used for machine learning such as language processing is known.
- One aspect is to provide a training data generation program, a training data generation method, and a training data generation device that can support the improvement of the effect of machine learning.
- the training data generation program causes a computer to execute a process of acquiring a first value, a process of acquiring a second value, a process of comparison, and a process of generating.
- the process of acquiring the first value is to input the first data included in the first plurality of training data into the first model generated by machine learning based on the first plurality of training data. To get the first value.
- the process of acquiring the second value the first data and the second data are added to the second model generated by machine learning based on the first plurality of training data and the second plurality of training data.
- the second value is acquired by inputting the second data included in the plurality of training data.
- the process of comparison the first value and the second value are compared.
- the process to generate is based on the first plurality of training data and the second plurality of training data, depending on the result of the comparison, and the third plurality of training data not including at least a part of the first data. To generate.
- FIG. 1 is an explanatory diagram illustrating an outline of an embodiment.
- FIG. 2 is a block diagram showing a functional configuration example of the information processing apparatus according to the first embodiment.
- FIG. 3 is a flowchart showing an operation example of the information processing apparatus according to the first embodiment.
- FIG. 4 is an explanatory diagram illustrating an outline of processing of the information processing apparatus according to the first embodiment.
- FIG. 5 is an explanatory diagram illustrating an example of score calculation.
- FIG. 6A is an explanatory diagram illustrating an outline of processing of the information processing apparatus according to the first embodiment.
- FIG. 6B is an explanatory diagram illustrating an outline of processing of the information processing apparatus according to the first embodiment.
- FIG. 7 is a flowchart showing an operation example of the information processing apparatus according to the second embodiment.
- FIG. 8 is an explanatory diagram illustrating an outline of processing of the information processing apparatus according to the second embodiment.
- FIG. 9 is a block diagram showing a functional configuration example of the information processing apparatus according to the third embodiment.
- FIG. 10 is a flowchart showing an operation example of the information processing apparatus according to the third embodiment.
- FIG. 11 is an explanatory diagram illustrating an example of the second training data.
- FIG. 12 is a block diagram showing a functional configuration example of the information processing apparatus according to the fourth embodiment.
- FIG. 13 is a flowchart showing an operation example of the information processing apparatus according to the fourth embodiment.
- FIG. 14 is a flowchart showing an operation example of the information processing apparatus according to the fifth embodiment.
- FIG. 15 is an explanatory diagram illustrating an outline of processing of the information processing apparatus according to the fifth embodiment.
- FIG. 16 is a block diagram showing a functional configuration example of the information processing apparatus according to the sixth embodiment.
- FIG. 17 is a flowchart showing an operation example of the information processing apparatus according to the sixth embodiment.
- FIG. 18 is a block diagram showing a functional configuration example of the information processing apparatus according to the seventh embodiment.
- FIG. 19 is a flowchart showing an operation example of the information processing apparatus according to the seventh embodiment.
- FIG. 20 is a block diagram showing an example of a computer configuration.
- the training data generation program, the training data generation method, and the training data generation device according to the embodiment will be described with reference to the drawings. Configurations having the same function in the embodiment are designated by the same reference numerals, and duplicate description will be omitted.
- the training data generation program, the training data generation method, and the training data generation device described in the following embodiments are merely examples, and the embodiments are not limited. In addition, the following embodiments may be appropriately combined within a consistent range.
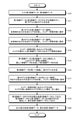
- FIG. 1 is an explanatory diagram illustrating an outline of an embodiment. As shown in FIG. 1, this embodiment corresponds to concept drift and the like, and generates data for retraining a model by machine learning in order to maintain the quality of output, and the effect of retraining is reduced. The final result is to generate training data for retraining.
- model for retraining a model used for conversion processing from a discrete series (original language) to another discrete series (translation destination language) is exemplified.
- the model to which this embodiment is applied may be any model that is retrained in response to changes, and is not limited to the model used for such natural language processing.
- it may be applied to model retraining in a recommendation system using a model that inputs a customer's feature amount and outputs a recommended product (product category) to the customer.
- the first training data D1 is training data relating to the old case before the change.
- the second training data D2 is training data on new cases (changes in the meaning and wording of words, new words (unregistered words such as new product names)) after changes due to concept drift and the like.
- Each case includes an input to the model and a correct output.
- the input is “I like AAAA (fruit name)! And the output is "AAAA is my favorite.”
- Case 001 and the input is "I love BBBB (company name)! And the output includes Case 002 of "I am a BBBBB believer.”
- the input is "I like AAAA (company name)! And the output is "I have no eyes on AAAA products” 003, and the input is "I love CCCC (new product)”. Name)! ”And case 004 with output“ I love CCCC! ”Is included.
- Case 003 is a case showing a change in meaning with respect to Case 001 (“AAAA (fruit) ⁇ “ AAAA (company name) ”). That is, both inputs are “I like AAAA”, but the output is "AAAA is my favorite” in case 001, while case 003 is "I have no eyes on AAAA products”. There is.
- Case 004 is a case showing a newly appearing word (unregistered word) "CCCC (new product name)”.
- Case 001 and Case 003 have different outputs for the same (or almost the same) input, and therefore, when they are mixed, they are contradictory cases. Therefore, when Case 001 and Case 003 coexist, both cannot be trained. That is, when Case 001 and Case 003 coexist, the retraining effect is reduced.
- the first model M1 is generated by machine learning with the first training data D1 (S1).
- the first training data D1 is input to the generated first model M1, and the generated scores of case 001 and case 002 in the first training data D1 (scores related to the output of the first model M1) are calculated. (S2).
- the second model M2 is generated by machine learning with the first training data D1 and the second training data D2 (S3).
- the first training data D1 and the second training data D2 are input to the generated second model M2, and the generated scores of Cases 001 to 004 (scores related to the output of the second model M2) are obtained. Calculate (S4).
- the generated score regarding the output of the contradictory case becomes low.
- the generated score for the output of consistent cases can be maintained at a high level.
- the generated score of S2 and the generated score of S4 are compared, and the old of the first training data D1 is based on the training data obtained by adding the second training data D2 to the first training data D1.
- the generated scores of Cases 002 and 004 in S4 are high, and the generated scores of Case 001 are lower than S2, so that Case 001 in the old cases is determined to be inconsistent (S5). ..
- training data that does not include the case 001 in the old cases is generated.
- the case 001 in order to confirm that the deleted case 001 is a case (noise) that deteriorates the output quality, the case 001 is obtained from the training data obtained by adding the second training data D2 to the first training data D1. It is deleted and machine learning is performed to generate a third model M3 (S6).
- cases 002, 003, 004 are input to the generated third model M3, and the generated scores of cases 002, 003, 004 (scores relating to the output of the third model M3) are calculated (S7).
- the generated scores of non-contradictory cases are almost unchanged, and even if there are fluctuations, they are slightly reduced (the effect of the decrease in the training data scale).
- the deleted Case 001 is the output quality. Confirm that it is a case (noise) that reduces. Based on this confirmation, it is determined that Case 001 should be deleted in the present embodiment (S8).
- the retraining data in which the case 001 is deleted in the training data obtained by adding the second training data D2 to the first training data D1 is confirmed (cases 002, 003, 004).
- the case (noise) that deteriorates the output quality is accurately removed, and the training data expected to improve the retraining effect.
- the generated score of the third model M3 it is possible to generate training data for retraining after ascertaining that the case of removal is a case of deteriorating the quality of output.
- FIG. 2 is a block diagram showing a functional configuration example of the information processing apparatus according to the first embodiment.
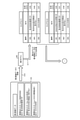
- the information processing apparatus 1 includes a processing control unit 10, a model learning unit 11, a score calculation unit 12, a score evaluation calculation unit 13, a score temporary storage unit 14, and a training data generation unit 15.
- a PC Personal Computer
- the like can be applied to the information processing apparatus 1.
- the processing control unit 10 is a processing unit that controls the execution of processing for generating retraining data.
- the model learning unit 11 is a processing unit that generates a model by performing processing related to known machine learning. Specifically, the model learning unit 11 performs machine learning (optimization of parameters) of the model so that the output sequence can be generated from the input sequence of the training data in which the input and the output are paired.
- the model learning unit 11 generates the first model M1 by performing training using the first training data D1. Further, the model learning unit 11 generates the second model M2 by performing training using the second training data D2 including the first training data D1. Further, the model learning unit 11 generates the third model M3 by performing training using the third training data D3.
- the input (for example, the original language) and the output (for example, the translation destination language) of the discrete series of the natural language are paired, and a model for translation operated by the automatic translation system is generated.
- This is training data.
- the second training data D2 is training data including, in addition to the first training data D1, a new case after the change due to concept drift or the like.
- the third training data D3 is training data newly created as training data that does not include the case determined to be inconsistent among the old cases based on the first training data D1 and the second training data D2. ..
- the score calculation unit 12 is a processing unit that calculates a score related to the output when the model generated by machine learning is applied to each input of training data and the corresponding output is generated. For the calculation of this score, a known calculation method such as JP-A-2019-149030 is used. The score calculation unit 12 stores the calculated score in the score temporary storage unit 14 after adding identification information (for example, ID) to each training data (case).
- identification information for example, ID
- the score calculation unit 12 inputs the first training data D1 to the first model M1, calculates the generated score of each input case, and stores it in the score temporary storage unit 14. Further, the score calculation unit 12 inputs the second training data D2 to the second model M2, calculates the generated score of each input case, and stores it in the score temporary storage unit 14. Further, the score calculation unit 12 inputs the third training data D3 to the third model M3, calculates the generated score of each input case, and stores it in the score temporary storage unit 14.
- the score evaluation calculation unit 13 is a processing unit that compares the generated scores stored in the temporary score storage unit 14 to evaluate changes in the generated scores, and detects cases of deletion from the training data. For example, the score evaluation calculation unit 13 compares the generated score of the second model M2 with the generated score of the first model M1 and detects a contradictory case among the old cases.
- the score temporary storage unit 14 is a processing unit that temporarily stores the generated score calculated by the score calculation unit 12 in a memory or the like. Specifically, the score temporary storage unit 14 stores the generated score in association with the model of the generation source and the training data (case).
- the training data generation unit 15 deletes a case designated as a case to be deleted based on the detection result of the score evaluation calculation unit 13 in the training data of the second training data D2 including the first training data D1.
- the modified second training data D21 is the output of the confirmed third training data D3 as a processing result.
- the modified first training data D11 is obtained by extracting only the training data included in the first training data D1 from the third training data D3.
- FIG. 3 is a flowchart showing an operation example of the information processing apparatus 1 according to the first embodiment.
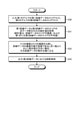
- the processing control unit 10 accepts the inputs of the first training data D1 and the second training data D2 (S10).
- the model learning unit 11 trains with the first training data D1 and the second training data D2, respectively, and generates the first model M1 and the second model M2 (S11). Specifically, the model learning unit 11 generates the first model M1 by performing training using the first training data D1. Further, the model learning unit 11 generates the second model M2 by performing training using the second training data D2.
- the score calculation unit 12 applies the first model M1 to the first training data D1, calculates the generated score of the output of each case included in the first training data D1, and stores it in the score temporary storage unit 14 ( S12).
- FIG. 4 is an explanatory diagram illustrating an outline of processing of the information processing apparatus according to the first embodiment.
- the score calculation unit 12 calculates the generated score of each case included in the first training data D1 in the first model M1 in S12. As a result, for example, for Case 001 of No. 001, a generation score of 0.99 is obtained. Further, for the case 002 of the number 002, a generation score of 0.96 is obtained.
- the score calculation unit 12 applies the second model M2 to the second training data D2, calculates the generated score of the output of each case included in the second training data D2, and stores it in the score temporary storage unit 14 ( S13).
- the generation score of each case (case 001 to case 004) included in the second training data D2 is obtained.
- a generation score of 0.60 is obtained.
- a generation score of 0.91 is obtained.
- a generation score of 0.56 is obtained.
- a generation score of 0.88 is obtained for the case 004 of the number 004.
- FIG. 5 is an explanatory diagram illustrating an example of score calculation.
- the score for the result (output) of each case input to the first model M1, the second model M2, the third model M3, etc. is used as it is. You may.
- N the total number of possible outputs
- the calculation is performed based on the overall order of the correct answer output. May be good.
- the score evaluation calculation unit 13 compares the generated scores of S12 and S13 in the score temporary storage unit 14, and the input / output pair of the first training data D1 whose score is reduced in S13 (example). ) Is detected (S14). As a result, as shown in FIG. 4, the score evaluation calculation unit 13 detects that the generated score of case 001 in the first training data D1 has deteriorated from 0.89 to 0.60 (S14).
- the training data generation unit 15 deletes the input / output pair (case) detected in S14 from the first training data D1 and the second training data D2, synthesizes the deleted new training data, and synthesizes the deleted new training data D3. Is generated (S15). Specifically, as shown in FIG. 4, the training data generation unit 15 creates the third training data D3 by deleting the case 001 in which the deterioration of the generated score is detected in S14 from the second training data D2. That is, the third training data D3 is obtained by deleting the case 001 from the second training data D2.
- the model learning unit 11 generates the third model M3 by performing training using the third training data D3 (S16).
- 6A and 6B are explanatory views illustrating an outline of processing of the information processing apparatus according to the first embodiment. As shown in FIG. 6A, the model learning unit 11 generates the third model M3 in S16 by machine learning using the cases 002 to 004 included in the third training data D3.
- the score calculation unit 12 applies the third model M3 to each input of the third training data D3, calculates the generated score of each output corresponding to the input, and stores it in the score temporary storage unit 14 (S17). Specifically, as shown in FIG. 6A, the score calculation unit 12 calculates the generated score of each case (cases 002 to 004) included in the third training data D3 in the third model M3 in S17. As a result, for example, for the case 002 of the number 002, a generation score of 0.89 is obtained. Further, for the case 003 of the number 003, a generation score of 0.82 is obtained. Also. For case 004 of number 004, a generation score of 0.87 is obtained.
- the score evaluation calculation unit 13 compares the generated scores of S17 and S13 in the score temporary storage unit 14, and if the score of the case where the generated score is low in S13 is improved in S17, the process proceeds to the next S19 ( S18).
- the score evaluation calculation unit 13 compares the generated scores of S17 and S13 in S18, and verifies the appropriateness of whether or not the generated score is deteriorated in the result of S17. ..
- the training data generation unit 15 outputs the third training data D3 as it is as the second training data D21, extracts only the part in the first training data D1 from the third training data D3, and corrects the third training data D3. 1 Output as training data D11.
- the training data generation unit 15 outputs the modified second training data D21 and the modified first training data D11 as the final result of the training data for retraining (S20), and ends the process.
- Case 001 is determined to be deleted. Based on this determination result, the training data generation unit 15 outputs the modified second training data D21 and the modified first training data D11 from which the case 001 is deleted (S19a).
- the score evaluation calculation unit 13 determines that the deletion of case 001 is canceled due to the deterioration of S17. Based on this determination result, the training data generation unit 15 outputs the modified first training data D11 and the modified second training data D21 returned to the same first training data D1 and second training data D2 as at the time of input. Output (S19b).
- training data (third training data D3) that is expected to improve the retraining effect can be generated.
- the training data for retraining (corrected first training data D11, D21) is determined after determining that the case of removing the third training data D3 is a case of deteriorating the output quality. ) Can be generated.
- the generated scores of S12 and S13 in the score temporary storage unit 14 are compared with statistics (deviation of scores, average value) to obtain training data (case) to be deleted. It is different from the embodiment of 1.
- FIG. 7 is a flowchart showing an operation example of the information processing apparatus 1 according to the second embodiment.
- the score evaluation calculation unit 13 includes the generated score of the first training data D1 in the first model M1 and (S12), and the second training data in the second model M2.
- the generated score of D2 and the input of (S13) are accepted (S30).
- the score evaluation calculation unit 13 acquires statistics of only the old training data portion (the portion excluding the new training data) of the generated scores of the first training data D1 and the second training data D2 (S31).
- the statistic acquired here is a deviation (difference between the generated score and the average value) between the average value of the generated scores of the first training data D1 or the second training data D2 and the generated scores of each training data.
- the score evaluation calculation unit 13 deletes the training data satisfying such a condition because the difference in the deviation becomes a negative number when the generated score deteriorates. Specifically, the score evaluation calculation unit 13 compares the deviation of S13 with the deviation of S12, and when the absolute value is larger than the specific threshold value in which the difference of the deviation of the training data (case) is a negative number, The training data (case) is targeted for deletion (S32). Next, the score evaluation calculation unit 13 outputs the case to be deleted in the second training data D2 to the training data generation unit 15 (S33). As a result, the training data generation unit 15 deletes the case from the second training data D2 based on the output from the score evaluation calculation unit 13, and generates the third training data D3.
- FIG. 8 is an explanatory diagram illustrating an outline of processing of the information processing apparatus 1 according to the second embodiment.
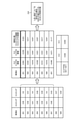
- the case IDs 001 to 007 correspond to the old training data (first training data D1).
- the case IDs 008 and 009 correspond to the new training data (additional part to the first training data D1 in the second training data D2).
- the score evaluation calculation unit 13 has a statistic (score deviation, score average) for the old training data portion (case IDs 001 to 007) of the generated scores of the first training data D1 and the second training data D2. To get. Next, the score evaluation calculation unit 13 compares the difference in deviation with the threshold value (for example, ⁇ 0.1) which is a negative number, and determines that the case ID 001 satisfying the condition is to be deleted.
- the threshold value for example, ⁇ 0.1
- the threshold value may be automatically set by a negative value of the standard deviation of the score of S13 or a negative value of the average of S13 and the score difference of S12.
- the second embodiment by comparing the generated scores using the statistics, it is possible to robustly determine the case to be deleted with respect to the noise included in the generated scores.
- FIG. 9 is a block diagram showing a functional configuration example of the information processing apparatus according to the third embodiment. As shown in FIG. 9, the information processing device 1a is different from the above-mentioned information processing device 1 in that it has a statistical information acquisition unit 16.
- the statistical information acquisition unit 16 is a processing unit that acquires statistical information (statistical information of words in this embodiment) of a plurality of cases included in the first training data D1 and a plurality of cases included in the second training data D2. be. Specifically, the statistical information acquisition unit 16 acquires the appearance frequency of cases and the co-occurrence frequency at which each case occurs for each case (word) included in the first training data D1 and the second training data D2.
- the score evaluation calculation unit 13 excludes training data corresponding to a case (old case included in the first training data D1) in which the statistical information satisfies a specific condition based on the statistical information acquired by the statistical information acquisition unit 16. (Deleted) Determined as a target. In this way, a case such as a change in language (concept drift) may be specified based on the statistical information and may be deleted.
- the score evaluation calculation unit 13 excludes the case of training data including the word as if there is a change in the word (concept drift). set to target.
- the score evaluation calculation unit 13 excludes the case including the word as if there is a change in the word (concept drift). set to target.
- FIG. 10 is a flowchart showing an operation example of the information processing apparatus 1a according to the third embodiment.
- the statistical information acquisition unit 16 accepts the input of the second training data D2 (S40).
- the statistical information acquisition unit 16 acquires statistical information (word appearance frequency, word co-occurrence frequency) of the second training data D2 for each of the new and old training data (S41).
- the score evaluation calculation unit 13 selects a deletion case in the second training data D2 that meets the above-mentioned conditions based on the statistical information acquired by the statistical information acquisition unit 16 (S42).
- the score evaluation calculation unit 13 also selects a deletion case that also exists in the first training data D1.
- the score evaluation calculation unit 13 outputs the deletion example in the second training data D2 to the training data generation unit 15 (S43).
- the training data generation unit 15 deletes the case from the second training data D2 based on the output from the score evaluation calculation unit 13, and generates the third training data D3.
- FIG. 11 is an explanatory diagram illustrating an example of the second training data D2.
- the frequency of co-occurrence between the input "AAAA (fruit name)” and the output "favorite food” is high, but in the new data, "AAAA (company name)” and "favorite food”.
- the frequency of co-occurrence with "" is low. Therefore, the case of ID001 in the old data is a deletion case.
- the change in co-occurrence frequency is determined, for example, by comparison with a preset co-occurrence frequency threshold value (SD).
- SD co-occurrence frequency threshold value
- FIG. 12 is a block diagram showing a functional configuration example of the information processing apparatus according to the fourth embodiment. As shown in FIG. 12, the information processing apparatus 1b is different from the above-mentioned information processing apparatus 1 in that it has a similarity calculation unit 17.
- the similarity calculation unit 17 is a processing unit that compares a plurality of cases (input or output) included in the second training data D2 and acquires the similarity. For this similarity, known methods such as the method of calculating the similarity of the structural tree of data (sentence) and the method of calculating the similarity of sentences by vector synthesis of the constituent words of the sentence, which is an extension of word2vec, are applied. And get it.
- the score evaluation calculation unit 13 excludes training data corresponding to a case (old case included in the first training data D1) in which the similarity satisfies a specific condition based on the similarity acquired by the similarity calculation unit 17. (Deleted) Determined as a target. For example, the score evaluation calculation unit 13 determines a case (old case included in the first training data D1) in which the inputs (or outputs) are similar (more than a specific degree of similarity) but the outputs (or inputs) are not similar. Judged as a deletion case. In this way, a case where there is a change in language (concept drift) may be specified based on the degree of similarity and may be deleted.
- FIG. 13 is a flowchart showing an operation example of the information processing apparatus 1b according to the fourth embodiment.
- the similarity calculation unit 17 accepts the input of the second training data D2 (S50).
- the similarity calculation unit 17 calculates the similarity between the new (old) inputs according to the old and new data of the second training data D2. Further, the similarity calculation unit 17 calculates the similarity between the old and new outputs (S51).
- the score evaluation calculation unit 13 selects a deletion case in the second training data D2 that meets the above-mentioned conditions based on the similarity information calculated by the similarity calculation unit 17 (S52).
- the score evaluation calculation unit 13 also selects a deletion case that also exists in the first training data D1.
- the score evaluation calculation unit 13 outputs the deletion example in the second training data D2 to the training data generation unit 15 (S53).
- the training data generation unit 15 deletes the case from the second training data D2 based on the output from the score evaluation calculation unit 13, and generates the third training data D3.
- the input of the case of ID001 in the old data and the case of ID003 in the new data are both "I like AAAA", so that the similarity of the inputs is specified. It becomes more than the value.
- the output of the case of ID001 is "AAAA is my favorite”
- the output of the case of ID003 is "I have no eyes on AAAA's products”
- the similarity of the outputs is It becomes low (below a specific value). Therefore, the case of ID001 is the target of deletion.
- the degree of similarity is determined by comparing with a preset threshold value. For example, when the similarity between the input and output is equal to or higher than the similarity threshold value (SS) and the other similarity degree is equal to or lower than the difference threshold value (SI), the deletion example is used.
- SS similarity threshold value
- SI difference threshold value
- the generated scores of S13 and S17 in the score temporary storage unit 14 are compared with statistics (deviation of scores, average value) to confirm the suitability of the third training data D3. It is different from the first embodiment.
- FIG. 14 is a flowchart showing an operation example of the information processing apparatus 1 according to the fifth embodiment.
- the score evaluation calculation unit 13 includes the generated score of the second training data D2 in the second model M2 and (S13), and the third training data in the third model M3.
- the input of the generated score of D3 and (S17) is accepted (S60).
- the score evaluation calculation unit 13 acquires the statistic of the score only for the data existing in both the second training data D2 and the third training data D3 (S61).
- the statistic acquired here is a deviation (difference between the generated score and the average value) between the average value of the generated scores of the second training data D2 or the third training data D3 and the generated scores of each training data.
- the score evaluation calculation unit 13 determines that the training data satisfying such a condition does not exist in the third training data D3 because the difference in the deviation becomes a negative number when the generated score deteriorates. Recognize the suitability of D3. Specifically, the score evaluation calculation unit 13 compares the deviation of S17 with the deviation of S13, and the data whose absolute value is larger than the specific threshold value in which the difference of the deviation of the training data (case) is a negative number is obtained. If it does not exist, the suitability of the third training data D3 is recognized (S62).
- the score evaluation calculation unit 13 outputs the aptitude determination result of the third training data D3 to the training data generation unit 15 (S63).
- the training data generation unit 15 outputs the modified first training data D11 and the modified second training data D21 based on the third training data D3 recognized as having aptitude. If there is no aptitude, the training data generation unit 15 outputs the modified first training data D11 and the modified second training data D21, which are the same as the inputs.
- FIG. 15 is an explanatory diagram illustrating an outline of processing of the information processing apparatus 1 according to the fifth embodiment.
- the case IDs 002 to 009 correspond to the data existing in both the second training data D2 and the third training data D3.
- the score evaluation calculation unit 13 acquires the statistics (score deviation, score average) of the case IDs 002 to 009 existing in both the second training data D2 and the third training data D3. do. Next, the score evaluation calculation unit 13 compares the difference in deviation with the threshold value (for example, ⁇ 0.1) which is a negative number, and confirms whether or not there is a case that satisfies the condition. In the illustrated example, since there is no data (case) exceeding the threshold value of ⁇ 0.1, the suitability of the data of S17 (third training data D3) is confirmed.
- the threshold value for example, ⁇ 0.1
- the fifth embodiment by comparing the generated scores using the statistics, it is possible to robustly determine the suitability of the third training data D3 for the noise included in the generated scores. ..
- FIG. 16 is a block diagram showing a functional configuration example of the information processing apparatus according to the sixth embodiment. As shown in FIG. 16, the information processing apparatus 1c is different from the above-mentioned information processing apparatus 1 in that it has a re-execution processing unit 18.
- the re-execution processing unit 18 uses the modified first training data D11 generated by the training data generation unit 15 as the first training data D1 and the modified second training data D21 as the second training data D2, and after modification again. This is a processing unit that re-executes the generation of the first training data D11 and the modified second training data D21.
- FIG. 17 is a flowchart showing an operation example of the information processing apparatus 1c according to the sixth embodiment.
- the processing control unit 10 accepts the inputs of the first training data D1 and the second training data D2 (S70).
- the processing control unit 10 executes the above-mentioned processes S11 to S19 based on the received first training data D1 and second training data D2 (S71).
- the processing control unit 10 obtains the output of the modified second training data D21 and the modified first training data D11 (S72).
- the re-execution processing unit 18 outputs the modified second training data D21 and the modified first training data D11, and are both data the same as the first training data D1 and the second training data D2? It is determined whether or not (S73).
- the re-execution processing unit 18 converts the modified second training data D21 into the second training data D2 and the modified first training data D2.
- the training data D11 is replaced with the first training data D1 (S74), and the processing is returned to S70.
- the re-execution processing unit 18 ends the processing.
- the modified first training data D11 generated by the training data generation unit 15 is not the same as the first training data D1, and the modified second training data D21 is the second training data D2. If not the same, the modified first training data D11 is replaced with the first training data D1, and the modified second training data D21 is replaced with the second training data D2. Then, based on the replaced first training data D1 and second training data D2, the generation of the modified first training data D11 and the modified second training data D21 is re-executed. By repeating the generation of the modified first training data D11 and the modified second training data D21 in this way, it is possible to obtain training data for retraining that has converged accurately.
- FIG. 18 is a block diagram showing a functional configuration example of the information processing apparatus according to the seventh embodiment.
- the information processing apparatus 1d has the AI system re-learning control unit 20, the second training data generation unit 21, the AI system execution unit 22, and the AI system execution for the information processing apparatus 1 described above. It differs from the model 23 in that it has.
- the AI system re-learning control unit 20 is a processing unit that controls re-learning of an AI system such as an automatic translation system. Specifically, the AI system re-learning control unit 20 inputs the first training data D1 and the second training data D2 to the processing control unit 10 at a specific timing (preset system update timing). The modified second training data D21 and the modified first training data D11 are obtained. Next, the AI system re-learning control unit 20 retrains the AI system execution model 23 using the obtained modified second training data D21.
- the second training data generation unit 21 is a processing unit that generates the second training data D2. Specifically, the second training data generation unit 21 collects input / output data during operation of the AI system, and obtains newly collected data (new case) in comparison with the first training data D1. Next, the second training data generation unit 21 synthesizes the newly collected data (input / output) into the first training data D1 to generate the second training data D2.
- the AI system execution unit 22 is an operation unit of the AI system, applies the data input to the AI system to the AI system execution model 23, and provides the output obtained from the AI system execution model 23.
- the AI system execution model 23 is a machine learning model based on machine learning technology for providing an output for an input of an AI system.
- FIG. 19 is a flowchart showing an operation example of the information processing apparatus according to the seventh embodiment. As shown in FIG. 19, when the process is started, the new data accumulated / acquired by the second training data generation unit 21 is joined to the first training data D1 to generate the second training data D2 (S80). ..
- the AI system re-learning control unit 20 inputs the generated second training data D2 together with the first training data D1 to the processing control unit 10, and causes the processing of S10 to S20 to be performed (S81).
- the AI system re-learning control unit 20 performs machine learning using the modified second training data D21 obtained by the processing of S81, and arranges the generated model in the AI system execution model 23 (S82).
- the model in the automatic translation system can be automatically updated to the model corresponding to the change of language (concept drift).
- each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of them may be functionally or physically distributed / physically in any unit according to various loads and usage conditions. Can be integrated and configured.
- various processes of the model learning unit 11, the score calculation unit 12, the score evaluation calculation unit 13, the score temporary storage unit 14, the training data generation unit 15, and the statistical information acquisition unit 16 performed by the processing control unit 10 of the information processing unit 1.
- the function may be executed on the CPU (or a micro computer such as an MPU or MCU (Micro Controller Unit)) in whole or in any part thereof.
- various processing functions may be executed in whole or in any part on a program analyzed and executed by a CPU (or a microcomputer such as an MPU or MCU) or on hardware by wired logic. Needless to say, it's good.
- various processing functions performed by the information processing apparatus 1 may be executed by a plurality of computers in cooperation by cloud computing.
- FIG. 20 is a block diagram showing an example of a computer configuration.
- the computer 200 has a CPU 201 that executes various arithmetic processes, an input device 202 that accepts data input, a monitor 203, and a speaker 204. Further, the computer 200 has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting to various devices, and a communication device 207 for communicating with an external device by wire or wirelessly. Further, the information processing device 1 has a RAM 208 for temporarily storing various information and a hard disk device 209. Further, each part (201 to 209) in the computer 200 is connected to the bus 210.
- the hard disk device 209 has a functional configuration described in the above embodiment (for example, a processing control unit 10, a model learning unit 11, a score calculation unit 12, a score evaluation calculation unit 13, a score temporary storage unit 14, a training data generation unit 15, and the like.
- 211 is stored. Further, various data 212 referred to by the program 211 are stored in the hard disk device 209.
- the input device 202 receives, for example, an input of operation information from an operator.
- the monitor 203 displays, for example, various screens operated by the operator. For example, a printing device or the like is connected to the interface device 206.
- the communication device 207 is connected to a communication network such as a LAN (Local Area Network), and exchanges various information with an external device via the communication network.
- LAN Local
- the CPU 201 reads out the program 211 stored in the hard disk device 209, expands it into the RAM 208, and executes it to execute the above-mentioned functional configuration (for example, processing control unit 10, model learning unit 11, score calculation unit 12, score evaluation calculation). Unit 13, score temporary storage unit 14, training data generation unit 15, statistical information acquisition unit 16, similarity calculation unit 17, re-execution processing unit 18, AI system re-learning control unit 20, second training data generation unit 21 and AI. Performs various processes related to the system execution unit 22). That is, the CPU 201 is an example of a control unit.
- the program 211 may not be stored in the hard disk device 209.
- the computer 200 may read and execute the program 211 stored in a readable storage medium.
- the storage medium that can be read by the computer 200 is, for example, a CD-ROM, a DVD disk, a portable recording medium such as a USB (Universal Serial Bus) memory, a semiconductor memory such as a flash memory, a hard disk drive, or the like.
- the program 211 may be stored in a device connected to a public line, the Internet, a LAN, or the like, and the computer 200 may read the program 211 from these and execute the program 211.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Mathematical Physics (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Complex Calculations (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/031713 WO2022038785A1 (ja) | 2020-08-21 | 2020-08-21 | 訓練データ生成プログラム、訓練データ生成方法および訓練データ生成装置 |
| EP20950350.7A EP4202798A4 (en) | 2020-08-21 | 2020-08-21 | TRAINING DATA GENERATION PROGRAM, TRAINING DATA GENERATION METHOD AND TRAINING DATA GENERATION DEVICE |
| CN202080103196.0A CN115956248A (zh) | 2020-08-21 | 2020-08-21 | 训练数据生成程序、训练数据生成方法以及训练数据生成装置 |
| JP2022543256A JP7444265B2 (ja) | 2020-08-21 | 2020-08-21 | 訓練データ生成プログラム、訓練データ生成方法および訓練データ生成装置 |
| US18/165,478 US20230186176A1 (en) | 2020-08-21 | 2023-02-07 | Training data generation program, training data generation method, and training data generation device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/031713 WO2022038785A1 (ja) | 2020-08-21 | 2020-08-21 | 訓練データ生成プログラム、訓練データ生成方法および訓練データ生成装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/165,478 Continuation US20230186176A1 (en) | 2020-08-21 | 2023-02-07 | Training data generation program, training data generation method, and training data generation device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022038785A1 true WO2022038785A1 (ja) | 2022-02-24 |
Family
ID=80322887
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/031713 Ceased WO2022038785A1 (ja) | 2020-08-21 | 2020-08-21 | 訓練データ生成プログラム、訓練データ生成方法および訓練データ生成装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20230186176A1 (https=) |
| EP (1) | EP4202798A4 (https=) |
| JP (1) | JP7444265B2 (https=) |
| CN (1) | CN115956248A (https=) |
| WO (1) | WO2022038785A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025158625A1 (ja) * | 2024-01-25 | 2025-07-31 | 日本電気株式会社 | 情報処理装置、情報処理方法、プログラム |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20250265421A1 (en) * | 2024-02-19 | 2025-08-21 | International Business Machines Corporation | Identification of symbol drift in written discourse |
| WO2025234001A1 (ja) * | 2024-05-07 | 2025-11-13 | Ntt株式会社 | 学習装置及び学習方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6513314B1 (ja) * | 2018-07-30 | 2019-05-15 | 楽天株式会社 | 判定システム、判定方法及びプログラム |
| JP2019149030A (ja) | 2018-02-27 | 2019-09-05 | 日本電信電話株式会社 | 学習品質推定装置、方法、及びプログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109327421A (zh) * | 2017-08-01 | 2019-02-12 | 阿里巴巴集团控股有限公司 | 数据加密、机器学习模型训练方法、装置及电子设备 |
| CN109472318B (zh) * | 2018-11-27 | 2021-06-04 | 创新先进技术有限公司 | 为构建的机器学习模型选取特征的方法及装置 |
-
2020
- 2020-08-21 CN CN202080103196.0A patent/CN115956248A/zh active Pending
- 2020-08-21 WO PCT/JP2020/031713 patent/WO2022038785A1/ja not_active Ceased
- 2020-08-21 EP EP20950350.7A patent/EP4202798A4/en not_active Withdrawn
- 2020-08-21 JP JP2022543256A patent/JP7444265B2/ja active Active
-
2023
- 2023-02-07 US US18/165,478 patent/US20230186176A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019149030A (ja) | 2018-02-27 | 2019-09-05 | 日本電信電話株式会社 | 学習品質推定装置、方法、及びプログラム |
| JP6513314B1 (ja) * | 2018-07-30 | 2019-05-15 | 楽天株式会社 | 判定システム、判定方法及びプログラム |
Non-Patent Citations (2)
| Title |
|---|
| ANONYMOUS: "Impact of Concept Drift on Machine Learning Tasks ", KIYOSHI'S PROPOSITION, 28 May 2020 (2020-05-28), XP055909305, Retrieved from the Internet <URL:https://yolo-kiyoshi.com/2020/05/28/post-1850/> [retrieved on 20220405] * |
| See also references of EP4202798A4 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025158625A1 (ja) * | 2024-01-25 | 2025-07-31 | 日本電気株式会社 | 情報処理装置、情報処理方法、プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230186176A1 (en) | 2023-06-15 |
| EP4202798A4 (en) | 2023-08-30 |
| JPWO2022038785A1 (https=) | 2022-02-24 |
| CN115956248A (zh) | 2023-04-11 |
| EP4202798A1 (en) | 2023-06-28 |
| JP7444265B2 (ja) | 2024-03-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230186176A1 (en) | Training data generation program, training data generation method, and training data generation device | |
| CN101996232B (zh) | 信息处理装置和用于处理信息的方法 | |
| KR101813683B1 (ko) | 커널 rdr을 이용한 태깅 말뭉치 오류 자동수정방법 | |
| US20100010803A1 (en) | Text paraphrasing method and program, conversion rule computing method and program, and text paraphrasing system | |
| US20230037894A1 (en) | Automated learning based executable chatbot | |
| CN107577689A (zh) | 决策树生成装置、决策树生成方法、非暂时性记录介质以及提问系统 | |
| CN114841164A (zh) | 一种实体链接方法、装置、设备及存储介质 | |
| WO2018168193A1 (ja) | 業務改善支援装置および業務改善支援方法 | |
| US20180137435A1 (en) | Information extraction support device, information extraction support method and computer program product | |
| US10460240B2 (en) | Apparatus and method for tag mapping with industrial machines | |
| JP2020034704A (ja) | テキスト生成装置、テキスト生成プログラムおよびテキスト生成方法 | |
| JP6824795B2 (ja) | 修正装置、修正方法および修正プログラム | |
| JP2010146222A (ja) | 文書分類装置、文書分類方法およびプログラム | |
| WO2023044632A1 (zh) | 工业设备维护策略生成方法、装置、电子设备和存储介质 | |
| EP4242889A1 (en) | Identity verification method and system | |
| KR20190024148A (ko) | 음성 인식 장치 및 음성 인식 방법 | |
| US20190354533A1 (en) | Information processing device, information processing method, and non-transitory computer-readable recording medium | |
| CN110674276A (zh) | 机器人自学习方法、机器人终端、装置及可读存储介质 | |
| JP2022185799A (ja) | 情報処理プログラム、情報処理方法および情報処理装置 | |
| CN112163415A (zh) | 针对反馈内容的用户意图识别方法、装置及电子设备 | |
| CN117435489A (zh) | 基于需求文档自动分析软件功能点方法及系统 | |
| JP4479745B2 (ja) | 文書の類似度補正方法、プログラムおよびコンピュータ | |
| JPH08202388A (ja) | 音声認識装置及び音声認識方法 | |
| US20200193329A1 (en) | Learning method and learning apparatus | |
| JP4176691B2 (ja) | 問題作成プログラムおよび問題作成装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20950350 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022543256 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020950350 Country of ref document: EP Effective date: 20230321 |