WO2021157124A1 - 解析装置、解析方法及び解析プログラム - Google Patents
解析装置、解析方法及び解析プログラム Download PDFInfo
- Publication number
- WO2021157124A1 WO2021157124A1 PCT/JP2020/036328 JP2020036328W WO2021157124A1 WO 2021157124 A1 WO2021157124 A1 WO 2021157124A1 JP 2020036328 W JP2020036328 W JP 2020036328W WO 2021157124 A1 WO2021157124 A1 WO 2021157124A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- algorithms
- algorithm
- model
- learning model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0985—Hyperparameter optimisation; Meta-learning; Learning-to-learn
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/04—Inference or reasoning models
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N10/00—Quantum computing, i.e. information processing based on quantum-mechanical phenomena
- G06N10/20—Models of quantum computing, e.g. quantum circuits or universal quantum computers
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N10/00—Quantum computing, i.e. information processing based on quantum-mechanical phenomena
- G06N10/60—Quantum algorithms, e.g. based on quantum optimisation, quantum Fourier or Hadamard transforms
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/004—Artificial life, i.e. computing arrangements simulating life
- G06N3/006—Artificial life, i.e. computing arrangements simulating life based on simulated virtual individual or collective life forms, e.g. social simulations or particle swarm optimisation [PSO]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
Definitions
- the present invention relates to an analysis device, an analysis method, and an analysis program.
- Patent Document 1 describes a model selection device intended to be used for solving problems in various realistic events.
- a plurality of algorithms for performing the learning process of the learning model are known, and the performance of the learning model may not be sufficiently brought out unless the algorithm of the learning process is appropriately selected according to the problem.
- a predetermined algorithm is used for a predetermined problem based on the empirical rule of the person who sets the learning model, and a means for evaluating the performance of whether or not the selected algorithm is appropriate is provided. There wasn't.
- the present invention provides an analysis device, an analysis method, and an analysis program for predicting the performance of a learning model when learning processing is performed by a plurality of algorithms.
- the analyzer includes a learning unit that performs machine learning of a predetermined learning model so as to reduce the value of the first loss function set for a predetermined problem by using a plurality of algorithms. Based on machine learning, a new calculation unit that calculates the first shape information representing the global shape of the first loss function and the performance of the learning model for each algorithm, and at least one of a plurality of algorithms are used. Machine learning that reduces the value of the second loss function set for a problem is executed by the learning unit, and the second shape information representing the global shape of the second loss function calculated by the calculation unit is acquired.
- an analysis device an analysis method, and an analysis program that predict the performance of a learning model when learning processing is performed by a plurality of algorithms.
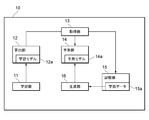
- FIG. 1 is a diagram showing an example of a functional block of the analysis device 10 according to the first embodiment of the present invention.
- the analysis device 10 includes a learning unit 11, a calculation unit 12, an acquisition unit 13, a prediction unit 14, a storage unit 15, and a generation unit 16.
- the analysis device 10 may be composed of a general-purpose computer.
- the learning unit 11 uses a plurality of algorithms to perform machine learning of a predetermined learning model so as to reduce the value of the first loss function set for the predetermined problem.
- a predetermined problem includes, for example, a problem of performing at least one of classification, generation, and optimization for at least one of image data, series data, and text data.
- the image data includes still image data and moving image data.
- Series data includes voice data and stock price data.
- the predetermined learning model includes an image recognition model, a series data analysis model, a robot control model, an enhanced learning model, a voice recognition model, a voice generation model, an image generation model, a natural language processing model, and the like.
- the training model also includes a model obtained by pruning, quantizing, distilling or transferring an existing trained model. It should be noted that these are only examples, and the learning unit 11 may perform machine learning of the learning model for problems other than these.
- the plurality of algorithms are algorithms that perform machine learning of the learning model 12a, and when the learning model 12a includes a neural network, it may be an algorithm that updates and optimizes the parameters of the neural network by the error backpropagation method. .. Multiple algorithms include stochastic gradient descent (SGD), momentum SGD, AdaGrad, RMSProp, AdaDelta, ADAM and the like. Further, the plurality of algorithms include an algorithm for updating the parameters of the learning model 12a by a quantum computer of a quantum gate method or a quantum annealing method. For example, when the learning model 12a is constructed by one strong learner that combines multiple weak learners, Hartmut Neven, Vasil S. Denchev, Geordie Rose, William G.
- the plurality of algorithms include the "adaptive bulk search” algorithm described in Reference 1 below.
- Reference 1 "New solution of combinatorial optimization problem that maximizes the computing power of GPU-Adaptive bulk search exceeding 1 trillion search / sec", [online], [Reiwa 2 August 25 Search], ⁇ https://www.hiroshima-u.ac.jp/news/59579>
- the plurality of algorithms may include algorithms other than these.
- a quantum computer a qubit is composed of a superconducting line, a qubit is composed of an ion trap, a qubit is composed of a quantum dot, or a quantum is formed by an optical circuit. It may constitute a bit, and the hardware configuration is arbitrary.
- the plurality of algorithms may include an algorithm in which the parameters of the learning model 12a are updated by a hybrid computer of a quantum computer and a classical computer.
- the calculation unit 12 calculates the first shape information representing the global shape of the first loss function and the performance of the learning model 12a for each algorithm.
- the first loss function set for a predetermined problem may be a square error function related to the output of the learning model 12a and the label data, or may be a cross entropy function.
- the first loss function can be expressed as a function L ( ⁇ ) relating to the plurality of parameters ⁇ .
- the value of the function L ( ⁇ ) is referred to as the first shape information representing the global shape of the first loss function.
- the calculation unit 12 records the value of the function L ( ⁇ ) with respect to the parameter ⁇ based on the machine learning of the learning model 12a, and the first shape information L ( ⁇ ) representing the global shape of the first loss function. Is calculated.
- the performance of the learning model 12a may be expressed by, for example, an F value, an F value / (calculation time of learning processing), or a value of the first loss function.
- the F value is a value calculated by 2PR / (P + R) when the precision is represented by P and the recall is represented by R.
- the performance of the learning model 12a is, for example, ME (mean error), MAE (mean absolute error), RMSE (mean square error), MPE (mean error rate), MAPE (mean absolute error rate), RMSPE (mean). Square square error rate), ROC (Receiver Operating Characteristic) curve and AUC (Area Under the Curve), Gini Norm, Kolmogorov-Smirnov, Precision / Recall, etc. may be used.
- the calculation unit 12 calculates the performance of the learning model 12a represented by an F value or the like based on the machine learning of the learning model 12a.
- the learning unit 11 sets a plurality of initial values for the parameters of the learning model 12a, and individually executes machine learning of a predetermined learning model 12a so as to reduce the value of the first loss function by using a plurality of algorithms. It may be executed in parallel. In the case of parallel execution, the calculation unit 12 calculates the first shape information and the performance of the learning model 12a in parallel for each algorithm based on machine learning.
- the reason for setting a plurality of initial values for the parameters of the learning model 12a is that by executing machine learning of the learning model 12a using the plurality of initial values, the parameters corresponding to the minimum values of the loss function may be selected. This is because it can be reduced. This makes it possible to increase the probability that the parameter corresponding to the minimum value of the globally optimal loss function can be selected. Further, when the machine learning of the learning model 12a is executed in parallel for each of a plurality of initial values, the global optimum solution can be obtained at higher speed.
- the acquisition unit 13 machine learning that reduces the value of the second loss function set for the new problem by using at least one of the plurality of algorithms is executed by the learning unit 11, and is calculated by the calculation unit 12.
- the second shape information representing the global shape of the second loss function is acquired.
- the new problem includes a problem of performing at least one of classification, generation, and optimization for at least one of image data, series data, and text data.
- the second loss function may be a square error function related to the output of the learning model 12a and the label data, or a cross entropy function
- the second shape information is the second loss related to a plurality of parameters ⁇ . It may be the function form L ( ⁇ ) of the function.
- the prediction unit 14 uses the prediction model 14a generated by supervised learning using the first shape information and the performance of the learning model 12a as learning data. Further, the prediction unit 14 uses the prediction model 14a to perform machine learning of the learning model 12a so as to reduce the value of the second loss function based on the second shape information. Is predicted for each of the plurality of algorithms. For example, the prediction unit 14 inputs the second shape information of a predetermined algorithm into the prediction model 14a to obtain the performance of the learning model 12a when machine learning is executed for each of a plurality of algorithms including other algorithms. Output.
- the machine learning of the learning model 12a is executed by using at least one of the plurality of algorithms, and the machine learning of the learning model 12a is executed by using the other algorithms.
- the performance of the learning model 12a obtained in this case can be predicted. Therefore, when a new problem is given, it is possible to quickly determine which algorithm should be used, and the performance of the learning model 12a can be appropriately derived.
- the learning unit 11 uses a plurality of algorithms including one or a plurality of hyperparameters to reduce the value of the first loss function, optimizes one or a plurality of hyperparameters using a plurality of optimization algorithms, and determines.
- the machine learning of the learning model 12a of the above may be performed respectively.
- the calculation unit 12 calculates the first shape information representing the global shape of the first loss function and the performance of the learning model 12a for each of the plurality of optimization algorithms based on machine learning.
- the hyperparameter includes a learning coefficient, for example, when the algorithm is SGD.
- hyperparameters such as learning coefficient and momentum coefficient are set for other algorithms.
- the plurality of optimization algorithms include, for example, random search, Basian optimization, CMA-ES, coordinate descent method, Nelder-Mead method, particle swarm optimization and genetic algorithm.
- the learning unit 11 predicts the performance of the learning model 12a when the machine learning of the learning model 12a is executed when the optimization algorithm that optimizes one or a plurality of hyperparameters with respect to the plurality of algorithms is used. This not only predicts which of the multiple algorithms should be selected, but also predicts what hyperparameter optimization method should be used, reducing the time required for hyperparameter tuning. Can be done.
- the storage unit 15 stores the learning data 15a including the first shape information and the performance of the learning model 12a.
- the learning data 15a includes first shape information representing the global shape of the loss function when machine learning of the learning model 12a is executed by a certain algorithm, and the performance of the learning model 12a obtained as a result of the machine learning.
- the generation unit 16 generates a prediction model 14a by supervised learning using the learning data 15a.
- the prediction model 14a may be composed of, for example, a neural network, and uses a plurality of algorithms as input to the second shape information representing the global shape of the second loss function set for the new problem, and describes the new problem. This is a model that predicts the performance of the learning model 12a when machine learning of the learning model 12a is executed so as to reduce the value of the set second loss function.
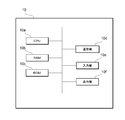
- FIG. 2 is a diagram showing an example of the physical configuration of the analysis device 10 according to the present embodiment.
- the analysis device 10 includes a CPU (Central Processing Unit) 10a corresponding to a calculation unit, a RAM (Random Access Memory) 10b corresponding to a storage unit, a ROM (Read only Memory) 10c corresponding to a storage unit, and a communication unit 10d. And an input unit 10e and a display unit 10f.
- Each of these configurations is connected to each other via a bus so that data can be transmitted and received.
- the analysis device 10 is composed of one computer will be described, but the analysis device 10 may be realized by combining a plurality of computers or a plurality of arithmetic units.
- the configuration shown in FIG. 2 is an example, and the analysis device 10 may have configurations other than these, or may not have a part of these configurations.
- the CPU 10a is a control unit that controls execution of a program stored in the RAM 10b or ROM 10c, calculates data, and processes data.
- the CPU 10a predicts the performance of the learning model when the machine learning of the learning model is executed so as to reduce the value of the second loss function set for the new problem by using the plurality of algorithms for each of the plurality of algorithms. It is an arithmetic unit that executes a program (analysis program) to be executed.
- the CPU 10a receives various data from the input unit 10e and the communication unit 10d, displays the calculation result of the data on the display unit 10f, and stores the data in the RAM 10b.
- the RAM 10b is a storage unit in which data can be rewritten, and may be composed of, for example, a semiconductor storage element.
- the RAM 10b may store data such as a program executed by the CPU 10a, learning data including the global shape of the loss function set for a predetermined problem and the performance of the learning model. It should be noted that these are examples, and data other than these may be stored in the RAM 10b, or a part of these may not be stored.
- the ROM 10c is a storage unit capable of reading data, and may be composed of, for example, a semiconductor storage element.
- the ROM 10c may store, for example, an analysis program or data that is not rewritten.
- the communication unit 10d is an interface for connecting the analysis device 10 to another device.
- the communication unit 10d may be connected to a communication network such as the Internet.
- the input unit 10e receives data input from the user, and may include, for example, a keyboard and a touch panel.
- the display unit 10f visually displays the calculation result by the CPU 10a, and may be configured by, for example, an LCD (Liquid Crystal Display). Displaying the calculation result by the display unit 10f can contribute to XAI (eXplainable AI).
- the display unit 10f may display, for example, the global shape of the loss function.
- the analysis program may be stored in a storage medium readable by a computer such as RAM 10b or ROM 10c and provided, or may be provided via a communication network connected by the communication unit 10d.
- the CPU 10a executes the analysis program to realize various operations described with reference to FIG. It should be noted that these physical configurations are examples and do not necessarily have to be independent configurations.
- the analysis device 10 may include an LSI (Large-Scale Integration) in which the CPU 10a and the RAM 10b or ROM 10c are integrated.
- the analysis device 10 may include a GPU (Graphical Processing Unit) or an ASIC (Application Specific Integrated Circuit).
- FIG. 3 is a diagram showing an example of the performance of the learning model in which the learning process is performed by the analysis device 10 according to the present embodiment.
- algorithms such as SGD, Momentum SGD (Momentum SGD), AdaGrad, RMSProp, AdaDelta, ADAM, quantum gate method and quantum annealing method are used, respectively, and random search (Random Search) and Bayesian Optimization (Bayesian Optimization), respectively.
- It shows the performance of the training model when one or more hyperparameters are optimized by CMA-ES, coordinate descent method (Coordinate Search) and Nelder-Mead method.
- a1 to a5 are the performance of the training model when one or more hyperparameters are optimized by random search, Bayesian optimization, CMA-ES, coordinate descent method or Nelder-Mead method using SGD as an algorithm. It is a numerical value representing. Note that b1 to b5, c1 to c5, d1 to d5, e1 to e5, f1 to f5, g1 to g5, and h1 to h5 are numerical values that similarly represent the performance of the learning model.
- FIG. 4 is a diagram showing an example of shape information calculated by the analysis device 10 according to the present embodiment.
- ⁇ 1 and ⁇ 2 are shown as parameters of the learning model, and the value L ( ⁇ ) of the loss function is shown.
- the global shape of the loss function includes a plurality of minimum points, and it may be difficult to search for the minimum point.
- the analysis device 10 according to the present embodiment regards such a global shape of the loss function as a feature quantity of the learning model and the learning algorithm, and learns the learning model from the global shape of the loss function by using a plurality of algorithms. Predict the performance of the learning model when processing is performed.
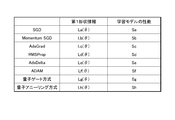
- FIG. 5 is a diagram showing an example of learning data calculated by the analysis device 10 according to the present embodiment.
- the figure shows the performance of the first shape information and the learning model for the algorithms of SGD, Momentum SGD (Momentum SGD), AdaGrad, RMSProp, AdaDelta, ADAM, quantum gate method and quantum annealing method.
- La ( ⁇ ) represents the first shape information when SGD is used as the algorithm
- Sa is a numerical value representing the performance of the learning model when SGD is used as the algorithm.
- Lb ( ⁇ ), Lc ( ⁇ ), Ld ( ⁇ ), Le ( ⁇ ), Lf ( ⁇ ), Lg ( ⁇ ) and Lh ( ⁇ ) are algorithms such as AdaGrad, RMSProp, AdaDelta, ADAM, and quantum. It represents the first shape information when the gate method or the quantum annealing method is used.
- Sb, Sc, Sd, Se, Sf, Sg and Sh are numerical values representing the performance of the learning model when the AdaGrad, RMSProp, AdaDelta, ADAM, quantum gate method or quantum annealing method is used as the algorithm. As shown in FIG. 3, the performance of the learning model may be calculated for each hyperparameter optimization algorithm and used as training data.
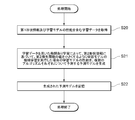
- FIG. 6 is a flowchart showing an example of the prediction process executed by the analysis device 10 according to the present embodiment.
- the analysis device 10 receives a predetermined problem and a predetermined learning model designation from another information processing device (S10).
- the designation of a predetermined problem and a predetermined learning model may be input by the user.
- the analyzer 10 sets a plurality of initial values for the parameters of the learning model (S11), reduces the value of the first loss function by using a plurality of algorithms including one or a plurality of hyperparameters, and 1 Alternatively, a plurality of hyperparameters are optimized by using a plurality of optimization algorithms, and machine learning of a predetermined learning model is executed in parallel (S12).
- the analysis device 10 calculates the first shape information representing the global shape of the first loss function and the performance of the learning model in parallel for each algorithm based on machine learning (S13). Then, the analysis device 10 stores the first shape information and the performance of the learning model in the storage unit 15 as learning data (S14).
- the analysis device 10 receives the designation of a new problem from another information processing device (S15).
- the specification of the new problem may be entered by the user.
- machine learning is executed by the learning unit 11 so as to reduce the value of the second loss function set for the new problem by using at least one of the plurality of algorithms, and the calculation unit 12 calculates.
- the second shape information representing the global shape of the second loss function is acquired (S16).
- the analysis device 10 determines the performance of the learning model when the machine learning of the learning model is executed so as to reduce the value of the second loss function based on the second shape information using the prediction model. Predict for each algorithm (S17).
- FIG. 7 is a flowchart showing an example of the prediction model generation process executed by the analysis device 10 according to the present embodiment.
- the analysis device 10 acquires learning data including the first shape information and the performance of the learning model (S20).
- the learning data may be acquired from an external storage device via a communication network such as the Internet.
- the analysis device 10 performs machine learning of the learning model based on the second shape information by supervised learning using the learning data so as to reduce the value of the second loss function. Is generated for each of the plurality of algorithms (S21). Then, the analysis device 10 stores the generated prediction model.
- FIG. 8 is a diagram showing the performance of the learning model subjected to the learning process by the analysis device 10 according to the present embodiment.
- training data is classified using unsupervised learning such as hierarchical clustering, non-hierarchical clustering, topic model, self-organizing map, association analysis, cooperative filtering, canonical correlation analysis, quantum gate method, and quantum annealing method.
- preprocessing algorithm according to the classification, random search (Random Search), Bayesian Optimization (Bayesian Optimization), CMA-ES, coordinate descent method (Coordinate Search) and Nelder-Mead method (Nelder-), respectively. It shows the performance of the learning model when one or more hyperparameters are optimized by Mead).
- G1 to G5 use hierarchical clustering as unsupervised learning to select one or more hyperparameters included in hierarchical clustering by random search, Basian optimization, CMA-ES, coordinate descent or Nelder-Mead method. It is a numerical value representing the performance of the learning model when optimized. In addition, G6 to G45 are numerical values representing the performance of the learning model in the same manner.
- the learning unit 11 preprocesses the learning data used for machine learning by using a plurality of preprocessing algorithms including one or a plurality of hyperparameters, and reduces the value of the first loss function by using the plurality of algorithms.
- One or a plurality of hyperparameters are optimized by using a plurality of optimization algorithms, and machine learning using preprocessed learning data is performed on a predetermined learning model.
- the calculation unit 12 obtains the first shape information representing the global shape of the first loss function and the performance of the learning model for each of the plurality of preprocessing algorithms based on machine learning using the preprocessed learning data. Calculate to.
- Multiple preprocessing algorithms may include missing value processing, outlier correspondence, continuous value discretization, data manipulation, dimensionality reduction, one-hot vectorization, data expansion, feature engineering and bin partitioning.
- the plurality of preprocessing algorithms include an algorithm that classifies training data using unsupervised learning and performs preprocessing according to the classification. That is, multiple preprocessing algorithms use unsupervised learning such as hierarchical clustering, non-hierarchical clustering, topic models, self-organizing maps, association analysis, co-filtering, canonical correlation analysis, quantum gate method and quantum annealing method. It includes an algorithm that classifies training data according to the classification and performs at least one of missing value processing, narrowing down explanatory variables, one-hot vectorization, and bin partitioning.
- FIG. 9 is a diagram showing a hyperparameter adjustment screen displayed by the analysis device 10 according to the present embodiment.
- the slide bar for adjusting the hyperparameters of the learning algorithm the slide bar for adjusting the hyperparameters of the preprocessing algorithm
- the vertical axis represents the type of learning algorithm numerically
- the horizontal axis represents the preprocessing.
- the type of algorithm is expressed numerically
- the heat map of the value of (L-loss function) is displayed.
- L is the maximum value of the loss function.
- the value of (L-loss function) is an example of a value indicating the performance of the learning model
- the analyzer 10 replaces the heat map of the value of the loss function with an F value or F indicating the performance of the learning model.
- a heat map of value / (calculation time of learning process) may be displayed.
- the analysis device 10 tunably displays one or a plurality of hyperparameters included in the plurality of algorithms and one or a plurality of hyperparameters included in the plurality of preprocessing algorithms, and displays the performance of the learning model by the plurality of algorithms. And display for each of the multiple preprocessing algorithms.
- the user of the analyzer 10 adjusts the hyperparameters of the learning algorithm and the hyperparameters of the preprocessing algorithm, and confirms the point where the value of the loss function is the smallest (most likely point) indicated by the heat map, and at that point. By selecting the corresponding learning algorithm and preprocessing algorithm, the optimum algorithm can be efficiently selected from the plurality of learning algorithms and the plurality of preprocessing algorithms.
- FIG. 10 is a flowchart of the prediction process executed by the analysis device 10 according to the present embodiment.
- the analysis device 10 accepts the hyperparameter designation of the learning algorithm and the hyperparameter designation of the preprocessing algorithm (S30).
- the analysis device 10 classifies the learning data using unsupervised learning (S31). Then, the analyzer 10 preprocesses the learning data used for machine learning by using a plurality of preprocessing algorithms including one or a plurality of hyperparameters, and uses the plurality of algorithms to obtain the value of the first loss function. It is made smaller, one or a plurality of hyperparameters are optimized by using a plurality of optimization algorithms, and machine learning using the preprocessed learning data is executed for a predetermined learning model (S32).
- the analysis device 10 calculates the first shape information representing the global shape of the first loss function and the performance of the learning model for each of the plurality of preprocessing algorithms based on machine learning using the preprocessed learning data. (S33). Then, the analysis device 10 stores the first shape information and the performance of the learning model as learning data (S34).
- the analysis device 10 accepts the designation of a new problem (S35). Then, in the analysis device 10, machine learning is executed by the learning unit so as to reduce the value of the second loss function set for the new problem by using at least one of the plurality of preprocessing algorithms, and the calculation unit The second shape information representing the global shape of the second loss function calculated by (S36) is acquired.
- the analysis device 10 determines the performance of the learning model when the machine learning of the learning model is executed so as to reduce the value of the second loss function based on the second shape information using the prediction model. For each of the preprocessing algorithms of (S37).
- FIG. 11 is a diagram showing a functional block of the analysis device 20 according to the second embodiment.
- the analysis device 20 according to the second embodiment includes a learning unit 21, a calculation unit 22, an acquisition unit 23, an estimation unit 24, a storage unit 25, and an estimation model generation unit 26.
- the analysis device 20 according to the second embodiment includes an estimation unit 24 instead of the prediction unit 14 included in the analysis device 10 according to the first embodiment, and an estimation model generation unit instead of the generation unit 16 according to the first embodiment. It has 26.
- the functions of the learning unit 21, the calculation unit 22, the acquisition unit 23, and the storage unit 25 included in the analysis device 20 according to the second embodiment are at least the functions of the corresponding functional units included in the analysis device 10 according to the first embodiment. May have.
- the algorithm according to the second embodiment is, for example, a reinforcement learning algorithm.
- the learning unit 21 optimizes one or a plurality of hyperparameters included in each of the plurality of reinforcement learning algorithms by using a plurality of optimization algorithms, and a plurality of reinforcement learning algorithms including the optimized one or a plurality of hyperparameters. Each machine learning of a predetermined learning model is performed using.
- the learning unit 21 uses a plurality of reinforcement learning algorithms to perform machine learning of a predetermined learning model based on training data set for a predetermined problem.
- the learning unit 21 uses, for example, stock price movement data as training data, and performs machine learning of the learning model so as to maximize the reward obtained by the agent.
- various news and social data for example, information on the reputation of a brand
- the action of the agent in reinforcement learning is, for example, a stock trading (specifically, stock purchase, sale, hold, etc.), and the reward is the profit from the stock trading, and the reward is Maximizing is equivalent to maximizing yield.
- the learning unit 21 may perform machine learning of the learning model in units of predetermined time, for example, in units of 1 ⁇ sec.
- the calculation unit 22 calculates the performance of the learning model using the test data set for a predetermined problem.
- the test data may include, for example, stock price movement data.
- the performance may be, for example, the yield obtained when the learning model is evaluated using the training data.
- the storage unit 25 stores data used for machine learning (training data, test data, etc., for example, price movement data), reinforcement learning algorithm, optimization algorithm, and the like. Further, the storage unit 25 stores the training data 25a including the training data and the combination of the reinforcement learning algorithm and the optimization algorithm.
- the estimation model generation unit 26 generates an estimation model that estimates a combination of reinforcement learning algorithms and optimization algorithms according to a new problem by supervised learning using learning data. Specifically, the estimation model generation unit 26 solves a new problem by performing supervised learning using the training data and the combination of the algorithm and the optimization algorithm selected based on the performance of the learning model as the learning data. Generate an estimation model for estimating the combination of the corresponding algorithm and the optimization algorithm.
- the combination of the algorithm used as the training data and the optimization algorithm (hereinafter, also referred to as “enhancement strategy”) may be selected based on the performance of the training model. For example, the optimal strengthening strategy for the set problem may be selected by the estimation model generation unit 26 as training data.
- the estimation unit 24 uses the estimation model 24a to estimate a combination of the reinforcement learning algorithm and the optimization algorithm according to the new problem based on the setting data set for the new problem.
- the setting data set for the new problem may be, for example, new stock price movement data that is not used for machine learning.
- the analysis device 20 according to the second embodiment has substantially the same physical configuration as the physical configuration shown in FIG. 2 included in the analysis device 10 according to the first embodiment.
- the difference between the physical configuration included in the analysis device 20 according to the second embodiment and the physical configuration included in the analysis device 10 according to the first embodiment will be briefly described.
- the CPU 10a optimizes one or a plurality of hyperparameters included in each of the plurality of algorithms by using a plurality of optimization algorithms, and uses the plurality of algorithms to perform machine learning of a predetermined learning model. It is a calculation unit that executes each of them and executes a program (analysis program) that calculates the performance of the learning model for each algorithm and the optimization algorithm.
- the RAM 10b according to the second embodiment may store data such as a program executed by the CPU 10a, training data, test data, a combination of reinforcement learning algorithms and optimization algorithms. It should be noted that these are examples, and data other than these may be stored in the RAM 10b, or a part of these may not be stored.
- the display unit 10f according to the second embodiment may display, for example, the estimation result by the estimation model.
- FIG. 12 is a diagram showing price movement data of stock prices in a predetermined brand used for machine learning of a learning model in the present embodiment.
- the price movement data is, for example, data on stock prices that fluctuate on a daily basis, and is assumed to be data from January to December 2019.
- a holdout method or the like is used, and the price movement data is divided into training data and test data.
- the price movement data from the beginning of January to the end of June 2019 may be used as training data
- the price movement data from the beginning of July to the end of December 2019 may be used as test data.
- FIG. 13 is a diagram showing a reinforcement learning algorithm and an optimization algorithm used in machine learning by the analysis device 20 according to the present embodiment.
- Turtle Trading agent Moving Average agent, Signal Rolling agent, Policy Gradient agent, Q-learning agent, Evolution Strategy agent, Double Q-learning agent, Recurrent Q-learning agent, Double.
- Recurrent Q-learning agent Duel Q-learning agent, Double Duel Q-learning agent, Duel Recurrent Q-learning agent, Double Duel Recurrent Q-learning agent, Double Duel Recurrent Q-learning agent, Actor-critic agent, Actor-critic Duel agent, Actor-critic Recurrent agent , Actor-critic Duel Recurrent agent, Curiosity Q-learning agent, Recurrent Curiosity Q-learning agent, Duel Curiosity Q-learning agent, Neuro-evolution agent, Neuro-evolution with Novelty search agent, ABCD strategy agent, Deep Use a learning algorithm.
- random search Random Search
- Bayesian Optimization Bayesian Optimization
- CMA-ES coordinate descent method
- Nelder-Mead method Nelder-Mead method
- G1 to G120 shown in FIG. 13 are numbers that specify a combination of the reinforcement learning algorithm and the optimization algorithm.
- the performance is calculated by the calculation unit 22 for each of the learning models constructed by the strengthening strategies of G1 to G120.
- the calculation of performance may be an evaluation based on test data (for example, the yield obtained). This makes it possible to select the optimal strengthening strategy, that is, the strengthening strategy that can build the most highly evaluated learning model.
- the analysis device 20 identifies the optimum strengthening strategy for each of the plurality of price movement data of different brands, and corresponds to each of the plurality of identification numbers with information on the price movement data and the optimum strengthening strategy. You may attach it and memorize it.
- the data associated with each of the plurality of identification numbers includes, for example, price movement data, brand (for example, A Co., Ltd.), price movement data period (for example, January 1st to April 30th), and training data period (for example, January 1st to April 30th). For example, January 1st-February 28th), optimal enhancement strategy (eg G1), test data period (eg March 1st-April 30th) and yield (eg 12%). You can.
- the yield is a yield obtained when the optimum strengthening strategy is evaluated using test data, and may be an IRR (internal rate of return).
- the training data extracted based on the information associated with each of the plurality of identification numbers and the optimum strengthening strategy become the learning data for generating the estimation model described later.
- FIG. 14 is a diagram showing an example of an estimation model generated by the estimation model generation unit 26.
- the estimation model is composed of a neural network including an input layer 31, a hidden layer 32, and an output layer 33.
- the estimation model generation unit 26 performs supervised learning using the training data and the optimum strengthening strategy as learning data, and generates an estimation model. Specifically, the estimation model generation unit 26 inputs the training data to the input layer 31, and learns the weighting parameters so that the optimum enhancement strategy is output from the output layer 33.
- the estimation model generation unit 26 may input various data (for example, a brand or the like) related to price movement data into the input layer 31 as incidental information in addition to the training data.
- the output layer 33 outputs the strengthening strategy according to the new problem.
- the strengthening strategy of G11 shown in FIG. 13 can be output as the optimum strengthening strategy for a new problem.
- the analysis device 20 uses the softmax function to display the 120 combinations shown in FIG. 12 in the order (for example, yield order) according to the performance (for example, yield) on the display unit included in the analysis device 20. It may be displayed. This makes it possible to build a learning model with a good yield by selecting an appropriate strengthening strategy according to, for example, a brand.
- FIG. 15 is a flowchart showing an example of estimation processing executed by the analysis device 20 according to the present embodiment.
- the analysis device 20 receives the designation of a predetermined problem and a predetermined learning model from another information processing device (S40).
- the designation of a predetermined problem and a predetermined learning model may be input by the user.
- the analysis device 20 sets a plurality of initial values for the parameters of the learning model (S41).
- the analyzer 20 optimizes one or a plurality of hyperparameters included in each of the plurality of reinforcement learning algorithms by using the plurality of optimization algorithms, and optimizes them based on the training data set for a predetermined problem.
- Machine learning of the learning model is individually executed or executed in parallel using a plurality of reinforcement learning algorithms including one or a plurality of hyperparameters (S42).
- the analysis device 20 calculates the performance of the learning model individually or in parallel for each reinforcement learning algorithm and optimization algorithm based on machine learning (S43). Then, the analysis device 20 stores the training data set for a predetermined problem and the combination of the reinforcement learning algorithm and the optimization algorithm in the storage unit 25 as learning data (S44).
- the analysis device 20 receives the designation of a new problem from another information processing device (S45).
- the specification of the new problem may be entered by the user.
- the analysis device 20 acquires the setting data set for the new problem (S46).
- the analysis device 20 uses the estimation model generated by the estimation model generation process described later, and based on the setting data set for the new problem, the reinforcement learning algorithm and the optimization algorithm corresponding to the new problem Estimate the combination (S47).
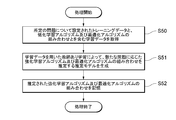
- FIG. 16 is a flowchart showing an example of the estimation model generation process executed by the analysis device 20 according to the present embodiment.
- the analysis device 20 acquires training data including training data set for a predetermined problem and a combination of a reinforcement learning algorithm and an optimization algorithm (S50).
- the learning data may be acquired from an external storage device via a communication network such as the Internet.
- the analysis device 20 After that, the analysis device 20 generates an estimation model that estimates the combination of the reinforcement learning algorithm and the optimization algorithm according to the new problem by supervised learning using the learning data (S51). Then, the analysis device 20 stores the generated estimation model (S52).
- the algorithm has been described as being a reinforcement learning algorithm, but the algorithm is not limited to this, and is an algorithm used for various machine learning such as supervised learning and unsupervised learning. It may be there. That is, according to the technique of the present disclosure, it is possible to calculate the performance of the learning model for each of various algorithms and optimization algorithms.
- various configurations described in the first embodiment can be applied.
- the pretreatment described in the first embodiment may be performed.
- various processes such as preprocessing, reinforcement learning, and hyperparameter optimization are automatically executed, and stock trading transactions can be executed by the algorithm of the present disclosure.
- the reinforcement learning agent may be an autonomous vehicle that travels by autonomous driving.
- the score of (MAD + FDE) / 2 may be used as an index, and the smaller the score, the more reward the agent may be set to obtain.
- the algorithm may include, for example, Social LSTM, Social GAN, MX-LSTM, Social Force, SR-LSTM, RED, Ind-TF, AMENet and the like. These algorithms are described in the following documents. (Social LSTM) A.
- the optimization algorithm includes, for example, random search, Bayesian optimization, CMA-ES, coordinate descent method, Nelder-Mead method, and the like.
- the index of reinforcement learning is not limited to (MAD + FDE) / 2, and may be MAD, FDE, or the like.
- the calculation unit 22 may calculate the performance of the learning model. The agent can determine which combination of algorithms and optimization algorithms is optimal based on the performance of the learning model generated by LSTM or the like.
- Reference 2 below attempts to solve the above problems by using deep learning and computer vision. Specifically, Reference 2 discloses a deep neural network architecture that learns how to predict future link-brockage from observed RGB image sequences and beamforming vectors. ..
- the hyperparameter optimization algorithm shown in Reference 2 is ADAM and the batch size is 1000. Under this precondition, the prediction accuracy of link blockage is about 86%.
- a combination of an algorithm and an optimization algorithm capable of automatically optimizing hyperparameters and constructing an appropriate learning model is selected. It is considered that the prediction accuracy can be improved by doing so.
- (Reference 2) G. Charan, M. Alrabeiah, and A. Alkhateeb, Vision-Aided Dynamic Blockage Prediction for 6G Wireless Communication Networks, arXiv preprint arXiv: 2006.09902 (2020).
- Reference 3 describes a technique for guessing a person who can be seen through a curved mirror from an autonomous mobile robot.
- a network based on FCN-8s at-once is adopted.
- This network consists of two networks, one of which is a classification network that performs semantic segmentation and the other network is a recurrent network that performs depth image prediction.
- Both the classification network and the regression network initialize the weights using up to the fc7 layer of the pre-trained VGG16 model. In particular, up to the 5th layer of pool is treated as a feature extractor.
- the input of the recurrent network is a 6-channel image in which the 3-channel color image Real and the 3-channel depth image Dcolor converted from the depth image Real acquired from the sensor are connected to each other, only the convl_1 layer is weighted. It is duplicated to support 6 channels.
- Reference 3 Yuto Utsumi, Shingo Kitagawa, Iori Yanokura, Kei Okada, Masayuki Inaba: Object perception of blind spots using mirrors based on depth prediction by CNN, Proceedings of the Japanese Society for Artificial Intelligence National Convention, 33rd National Convention (2019).
- a learning model is generated by performing preprocessing of learning data using the above-mentioned preprocessing algorithm, optimization of hyperparameters using the optimization algorithm, and machine learning using the reinforcement learning algorithm. It's okay.
- the combination of the preprocessing algorithm, the optimization algorithm, and the reinforcement learning algorithm is also simply referred to as a combination of algorithms.
- the analyzer may calculate the performance of each combination of algorithms using, for example, training data, as described in the second embodiment.
- the analysis device may apply the various methods described in the second embodiment to the combination of algorithms to generate an estimation model for estimating the combination of algorithms according to a new problem. At this time, an estimation model may be generated using the training data, the combination of algorithms, and the performance as training data.
- the analysis device acquires data from, for example, an external device connected to a network, adds or updates training data (for example, stock price movement data, etc.) in the first hour unit, and first Actions (for example, stock trading, etc.) may be performed in a predetermined learning model in fixed time units.
- the analysis device can execute the inference process in the second hour unit and further execute the full search process in the third hour unit.
- the first hour may be shorter than the second hour
- the second hour may be shorter than the third hour.
- the first hour, the second hour, and the third hour are not particularly limited, but in the fourth application example, examples of 1 ⁇ s, 1 minute, 1 hour, and the like will be described.
- a learning model is generated by machine learning based on the acquired training data using each of the algorithm combinations, the performance of each algorithm combination is evaluated, and each algorithm combination and performance are evaluated. This is the process of updating the associated actual data.
- Inference processing is performed by inputting, for example, stock price movement data into an estimation model, acquiring a combination of algorithms according to the input data, and using a learning model generated based on the acquired algorithm to acquire a learning model for trading stocks. This is the process of switching.
- the analysis device inputs 6 million data into the estimation model, acquires a combination of algorithms, and switches to a learning model generated by the combination of the acquired algorithms.
- the analysis device can perform actions in units of the first hour using the learning model.
- the analysis device trades stocks every short time, such as every first hour, it is strong in executing transactions, specifically, in a sudden upward or downward trend of stock prices, the Great Depression, bubbles, and the like. At this time, if all combinations of algorithms are not searched, there is always a risk of opportunity loss or simple loss even if a transaction based on an appropriate learning model is performed.
- the analysis device is strong in instructing the transaction method, and specifically, using newly acquired learning data (for example, stock price movement data acquired one hour ago), the analysis device is used every second hour. You can switch to the appropriate combination of algorithms. That is, it is possible to trade stocks while changing the combination of algorithms for trading stocks inside the analysis device at any time. This reduces the risk of opportunity loss and simple loss. Further, since the combination of algorithms used is dispersed, the possibility of loss due to the above-mentioned contrarian attack or the like can be reduced.
- the analysis device can update the actual data of the combination of algorithms every 3rd hour, is strong in measuring transactions, and specifically, can find the optimum solution for the price movement of stock prices with extremely high accuracy. .. Although it takes time to process the data due to the nature of the processing, it is possible to generate training data of a very excellent estimation model.
- the analysis device will be able to perform more appropriate processing while repeating transactions, inference processing, and total search processing using the learning model.
- the algorithm for preprocessing the preprocessing is, for example, Reference 4, which first mentions the CASH problem, Reference 5, which is related to AutoML (Automated Machine Learning) written in Python, and Reference which introduces meta-learning. 6 and the algorithm described in Reference 7, which describes the generation of a flexible pipeline by a genetic algorithm, and the like may be used.
- the analyzer executes preprocessing algorithms, optimization algorithms, and algorithms based on training data in these references to perform preprocessing algorithms for the preprocessing described in these references.
- a training model may be generated using a combination of a preprocessing algorithm, an optimization algorithm, and an algorithm based on the data generated by the previous algorithm. Further, the analyzer may calculate the performance for each combination of these algorithms.
- AGI Artificial
- AGI Advanced
- General Intelligence which is a more versatile AI, is performed by performing preprocessing on the preprocessed training data, optimizing hyperparameters, and generating a learning model using an algorithm. It is expected that General Intelligence) can be generated. That is, it can be expected to realize AI using all kinds of learning data such as brain wave data or image data.
- 10, 20 ... Analytical device 10a ... CPU, 10b ... RAM, 10c ... ROM, 10d ... Communication unit, 10e ... Input unit, 10f ... Display unit, 11,21 ... Learning unit, 12, 22 ... Calculation unit, 12a, 22a ... learning model, 13, 23 ... acquisition unit, 14 ... prediction unit, 14a ... prediction model, 24 ... estimation unit, 24a ... estimation model, 15, 25 ... storage unit, 15a, 25a ... learning data, 16 ... generation unit , 26 ... Estimated model generator
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computational Linguistics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Condensed Matter Physics & Semiconductors (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Operations Research (AREA)
- Probability & Statistics with Applications (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/608,978 US11568264B2 (en) | 2020-02-03 | 2020-09-25 | Using shape information and loss functions for predictive modelling |
| EP20918102.3A EP4102418A4 (en) | 2020-02-03 | 2020-09-25 | ANALYSIS DEVICE, ANALYSIS METHOD AND ANALYSIS PROGRAM |
| CN202210750874.3A CN115271091A (zh) | 2020-02-03 | 2020-09-25 | 信息处理装置、信息处理方法以及计算机可读的存储介质 |
| CN202080005675.9A CN113490956B (zh) | 2020-02-03 | 2020-09-25 | 解析装置、解析方法以及解析程序 |
| US17/665,424 US20220156647A1 (en) | 2020-02-03 | 2022-02-04 | Analysis device, analysis method, and analysis program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-016010 | 2020-02-03 | ||
| JP2020016010A JP6774129B1 (ja) | 2020-02-03 | 2020-02-03 | 解析装置、解析方法及び解析プログラム |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/608,978 A-371-Of-International US11568264B2 (en) | 2020-02-03 | 2020-09-25 | Using shape information and loss functions for predictive modelling |
| US17/665,424 Division US20220156647A1 (en) | 2020-02-03 | 2022-02-04 | Analysis device, analysis method, and analysis program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021157124A1 true WO2021157124A1 (ja) | 2021-08-12 |
Family
ID=72829627
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/036328 Ceased WO2021157124A1 (ja) | 2020-02-03 | 2020-09-25 | 解析装置、解析方法及び解析プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (2) | US11568264B2 (enExample) |
| EP (1) | EP4102418A4 (enExample) |
| JP (2) | JP6774129B1 (enExample) |
| CN (1) | CN113490956B (enExample) |
| WO (1) | WO2021157124A1 (enExample) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240227829A1 (en) * | 2023-01-11 | 2024-07-11 | GM Global Technology Operations LLC | System and method of adaptively tuning parameters in action planning for automated driving |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11922314B1 (en) * | 2018-11-30 | 2024-03-05 | Ansys, Inc. | Systems and methods for building dynamic reduced order physical models |
| JP7613962B2 (ja) * | 2021-03-18 | 2025-01-15 | 株式会社奥村組 | シールド掘進機の掘進予測モデル |
| JP7688251B2 (ja) * | 2021-04-19 | 2025-06-04 | 日新電機株式会社 | モデル生成装置、情報処理装置、モデル生成方法、および情報処理装置の制御方法 |
| US11972052B2 (en) * | 2021-05-05 | 2024-04-30 | University Of Southern California | Interactive human preference driven virtual texture generation and search, and haptic feedback systems and methods |
| WO2022271998A1 (en) * | 2021-06-23 | 2022-12-29 | Zapata Computing, Inc. | Application benchmark using empirical hardness models |
| JP7752380B2 (ja) * | 2021-09-29 | 2025-10-10 | 株式会社アダコテック | ハイパーパラメータ探索システムおよびそのプログラム |
| US20230353648A1 (en) * | 2022-04-27 | 2023-11-02 | Cisco Technology, Inc. | Data tracking for data owners |
| CN118607676B (zh) * | 2024-08-09 | 2025-01-14 | 中交路桥科技有限公司 | 基于机器学习的滑坡灾害预警方法、设备及存储介质 |
| CN120440226A (zh) * | 2025-07-08 | 2025-08-08 | 集美大学 | 基于Stacking和SHAP的船舶主机能耗预测及可解释性方法及装置 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0561848A (ja) * | 1991-09-02 | 1993-03-12 | Hitachi Ltd | 最適アルゴリズムの選定及び実行のための装置及び方法 |
| JPH05298277A (ja) * | 1992-04-24 | 1993-11-12 | Hitachi Ltd | ニュ−ラルネット学習装置及び学習方法 |
| JP2005135287A (ja) * | 2003-10-31 | 2005-05-26 | National Agriculture & Bio-Oriented Research Organization | 予測装置、予測方法および予測プログラム |
| JP2018066136A (ja) * | 2016-10-18 | 2018-04-26 | 北海道瓦斯株式会社 | 融雪制御装置、ニューラルネットワークの学習方法、融雪制御方法及び融雪制御用プログラム |
| JP2019159769A (ja) * | 2018-03-13 | 2019-09-19 | 富士通株式会社 | 探索プログラム、探索方法および探索装置 |
| JP2019220063A (ja) | 2018-06-22 | 2019-12-26 | 国立研究開発法人情報通信研究機構 | モデル選択装置、及びモデル選択方法 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9330362B2 (en) | 2013-05-15 | 2016-05-03 | Microsoft Technology Licensing, Llc | Tuning hyper-parameters of a computer-executable learning algorithm |
| US11120361B1 (en) * | 2017-02-24 | 2021-09-14 | Amazon Technologies, Inc. | Training data routing and prediction ensembling at time series prediction system |
| JP6849915B2 (ja) | 2017-03-31 | 2021-03-31 | 富士通株式会社 | 比較プログラム、比較方法および比較装置 |
| US11232369B1 (en) * | 2017-09-08 | 2022-01-25 | Facebook, Inc. | Training data quality for spam classification |
| EP3740910B1 (en) * | 2018-01-18 | 2025-03-05 | Google LLC | Classification using quantum neural networks |
| US11704567B2 (en) * | 2018-07-13 | 2023-07-18 | Intel Corporation | Systems and methods for an accelerated tuning of hyperparameters of a model using a machine learning-based tuning service |
| CN109447277B (zh) * | 2018-10-19 | 2023-11-10 | 厦门渊亭信息科技有限公司 | 一种通用的机器学习超参黑盒优化方法及系统 |
| US11429762B2 (en) * | 2018-11-27 | 2022-08-30 | Amazon Technologies, Inc. | Simulation orchestration for training reinforcement learning models |
| JP7059166B2 (ja) * | 2018-11-29 | 2022-04-25 | 株式会社東芝 | 情報処理装置、情報処理方法およびプログラム |
| JP7213948B2 (ja) * | 2019-02-28 | 2023-01-27 | 旭化成株式会社 | 学習装置および判断装置 |
| CN109887284B (zh) * | 2019-03-13 | 2020-08-21 | 银江股份有限公司 | 一种智慧城市交通信号控制推荐方法、系统及装置 |
| US12292944B2 (en) * | 2019-09-19 | 2025-05-06 | Cognizant Technology Solutions U.S. Corp. | Loss function optimization using Taylor series expansion |
| CN114556359B (zh) * | 2019-10-09 | 2025-06-13 | 瑞典爱立信有限公司 | 数据流中的事件检测 |
-
2020
- 2020-02-03 JP JP2020016010A patent/JP6774129B1/ja active Active
- 2020-08-21 JP JP2020140108A patent/JP7437763B2/ja active Active
- 2020-09-25 CN CN202080005675.9A patent/CN113490956B/zh active Active
- 2020-09-25 EP EP20918102.3A patent/EP4102418A4/en active Pending
- 2020-09-25 US US17/608,978 patent/US11568264B2/en active Active
- 2020-09-25 WO PCT/JP2020/036328 patent/WO2021157124A1/ja not_active Ceased
-
2022
- 2022-02-04 US US17/665,424 patent/US20220156647A1/en not_active Abandoned
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0561848A (ja) * | 1991-09-02 | 1993-03-12 | Hitachi Ltd | 最適アルゴリズムの選定及び実行のための装置及び方法 |
| JPH05298277A (ja) * | 1992-04-24 | 1993-11-12 | Hitachi Ltd | ニュ−ラルネット学習装置及び学習方法 |
| JP2005135287A (ja) * | 2003-10-31 | 2005-05-26 | National Agriculture & Bio-Oriented Research Organization | 予測装置、予測方法および予測プログラム |
| JP2018066136A (ja) * | 2016-10-18 | 2018-04-26 | 北海道瓦斯株式会社 | 融雪制御装置、ニューラルネットワークの学習方法、融雪制御方法及び融雪制御用プログラム |
| JP2019159769A (ja) * | 2018-03-13 | 2019-09-19 | 富士通株式会社 | 探索プログラム、探索方法および探索装置 |
| JP2019220063A (ja) | 2018-06-22 | 2019-12-26 | 国立研究開発法人情報通信研究機構 | モデル選択装置、及びモデル選択方法 |
Non-Patent Citations (15)
| Title |
|---|
| A. ALAHIK. GOELV. RAMANATHANA. ROBICQUETL. FEI-FEIS. SAVARESE: "Social Istm: Human trajectory prediction in crowded spaces", IN PROCEEDINGS OF CVPR, 2016, pages 961 - 971, XP033021272, DOI: 10.1109/CVPR.2016.110 |
| A. GUPTAJ. JOHNSONL. FEI-FEIS. SAVARESEA. ALAHI: "Social gan: Socially acceptable trajectories with generative adversarial networks", IN PROCEEDINGS OF CVPR, 2018, pages 2255 - 2264 |
| B. KOMERJ. BERGSTRAC. ELIASMITH: "Hyperopt-Sklearn: Automatic Hyperparameter Configuration for Scikit-Learn", PROC. OF THE 13TH PYTHON IN SCIENCE CONF., 2014, pages 34 - 40 |
| C. THORNTONF. HUTTERH. H. HOOSK. L. BROWN: "Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms", ARXIV PREPRINT ARXIV, vol. 1208, 2013, pages 3719 |
| D. HELBINGP. MOLNAR: "Social force model for pedestrian dynamics", PHYSICAL REVIEW E, vol. 51, no. 5, 1995, pages 4282 |
| G. CHARANM. ALRABEIAHA. ALKHATEEB: "Vision-Aided Dynamic Blockage Prediction for 6G Wireless Communication Networks, arXiv preprint", ARXIV, vol. 2006, 2020, pages 09902 |
| HARTMUT NEVENVASIL S. DENCHEVGEORDIE ROSEWILLIAM G. MACREADY: "QBoost: Large Scale Classifier Training with Adiabatic Quantum Optimization", PROCEEDINGS OF THE ASIAN CONFERENCE ON MACHINE LEARNING, PMLR, vol. 25, 2012, pages 333 - 348, XP055344107 |
| I. HASANF. SETTIT. TSESMELISA. DEL BUEF. GALASSOM. CRISTANI: "Mxlstm: mixing tracklets and vislets to jointly forecast trajectories and head poses", IN PROCEEDINGS OF CVPR, 2018, pages 6067 - 6076 |
| JACOB BIAMONTEPETER WITTEKNICOLA PANCOTTIPATRICK REBENTROSTNATHAN WIEBESETH LLOYD: "Quantum Machine Learning", NATURE, vol. 549, 2017, pages 195 - 202 |
| KUJIRAHIKOUZUKE, YOICHI SUGIYAMA, SHUNSUKE ENDO: "2.5 Find the best algorithms and parameters", HOW TO CREATE AI, MACHINE LEARNING, AND DEEP LEARNING APPLICATIONS USING PYTHON, 20 February 2019 (2019-02-20), JP, pages 107 - 115, XP009538952, ISBN: 978-4-8026-1164-0 * |
| M. FEURERA. KLEINK. EGGENSPERGERJ. SPRINGENBERGM. BLUMF. HUTTER: "Efficient and Robust Automated Machine Learning", NIPS, 2015 |
| P. ZHANGW. OUYANGP. ZHANGJ. XUEN. ZHENG: "Sr-Istm: State refinement for Istm towards pedestrian trajectory prediction", IN PROCEEDINGS OF CVPR, 2019, pages 12085 - 12094 |
| R. S. OLSONN. BARTLEYR. J. URBANOWICZJ. H. MOORE: "Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science", ARXIV PREPRINT ARXIV, vol. 1603, 2016, pages 06212 |
| See also references of EP4102418A4 |
| YUTO UCHIMISHINGO KITAGAWALORI YANOKURAKEI OKADAMASAYUKI INABA: "Object Perception in the Blind Spots with Mirror Based on Depth Prediction Using CNN, Proceedings of the Annual Conference of the Japanese Society for Artificial Intelligence", 33RD ANNUAL CONFERENCE, 2019 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240227829A1 (en) * | 2023-01-11 | 2024-07-11 | GM Global Technology Operations LLC | System and method of adaptively tuning parameters in action planning for automated driving |
| US12454276B2 (en) * | 2023-01-11 | 2025-10-28 | GM Global Technology Operations LLC | System and method of adaptively tuning parameters in action planning for automated driving |
Also Published As
| Publication number | Publication date |
|---|---|
| US11568264B2 (en) | 2023-01-31 |
| EP4102418A1 (en) | 2022-12-14 |
| JP7437763B2 (ja) | 2024-02-26 |
| US20220156647A1 (en) | 2022-05-19 |
| CN113490956B (zh) | 2022-05-31 |
| JP2021124805A (ja) | 2021-08-30 |
| JP2021125210A (ja) | 2021-08-30 |
| US20220147829A1 (en) | 2022-05-12 |
| EP4102418A4 (en) | 2024-03-06 |
| CN113490956A (zh) | 2021-10-08 |
| JP6774129B1 (ja) | 2020-10-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021157124A1 (ja) | 解析装置、解析方法及び解析プログラム | |
| Das et al. | A hybridized ELM-Jaya forecasting model for currency exchange prediction | |
| Dixon | Sequence classification of the limit order book using recurrent neural networks | |
| Liang et al. | Adversarial deep reinforcement learning in portfolio management | |
| Bisoi et al. | A hybrid evolutionary dynamic neural network for stock market trend analysis and prediction using unscented Kalman filter | |
| Khan et al. | A study of forecasting stocks price by using deep Reinforcement Learning | |
| Ebadati et al. | An efficient hybrid machine learning method for time series stock market forecasting. | |
| Ding et al. | Futures volatility forecasting based on big data analytics with incorporating an order imbalance effect | |
| Li et al. | An empirical research on the investment strategy of stock market based on deep reinforcement learning model | |
| Babaei et al. | GPT classifications, with application to credit lending | |
| CN112101516A (zh) | 一种目标变量预测模型的生成方法、系统及装置 | |
| Srivastava et al. | Stock market prediction using RNN LSTM | |
| US20240289882A1 (en) | Method, electronic device and system for trading signal generation of financial instruments using transformer graph convolved dynamic mode decomposition | |
| He | A hybrid model based on multi-LSTM and ARIMA for time series forcasting | |
| Nigam | Forecasting time series using convolutional neural network with multiplicative neuron | |
| Mozafari et al. | A cellular learning automata model of investment behavior in the stock market | |
| TATANE et al. | From Time Series to Images: Revolutionizing Stock Market Predictions with Convolutional Deep Neural Networks. | |
| Zouaghia et al. | Hybrid machine learning model for predicting NASDAQ composite index | |
| HK40054517A (en) | Analysis device, analysis method, and analysis program | |
| HK40054783A (en) | Analysis device, analysis method, and analysis program | |
| HK40054783B (en) | Analysis device, analysis method, and analysis program | |
| CN113469368A (zh) | 解析装置、解析方法以及解析程序 | |
| Kishore et al. | An Effective Stock Market Prediction using an Advanced Machine Learning Algorithm and Emotional Analysis | |
| Sher | Evolving chart pattern sensitive neural network based forex trading agents | |
| Nagdiya et al. | Hybrid Deep Learning Architecture Combining Attention Mechanisms and Recurrent Neural Networks for Enhanced Time Series Analysis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20918102 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020918102 Country of ref document: EP Effective date: 20220905 |