WO2021144938A1 - 学習支援プログラム、学習支援方法及び学習支援装置 - Google Patents
学習支援プログラム、学習支援方法及び学習支援装置 Download PDFInfo
- Publication number
- WO2021144938A1 WO2021144938A1 PCT/JP2020/001382 JP2020001382W WO2021144938A1 WO 2021144938 A1 WO2021144938 A1 WO 2021144938A1 JP 2020001382 W JP2020001382 W JP 2020001382W WO 2021144938 A1 WO2021144938 A1 WO 2021144938A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- cluster
- clusters
- distance
- learning
- pair
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/211—Selection of the most significant subset of features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0499—Feedforward networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0895—Weakly supervised learning, e.g. semi-supervised or self-supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/04—Inference or reasoning models
- G06N5/045—Explanation of inference; Explainable artificial intelligence [XAI]; Interpretable artificial intelligence
Definitions
- the present invention relates to a learning support program, a learning support method, and a learning support device.
- Mahalanobis distance learning and deep metric learning using deep learning technology have been proposed.
- the label set between the data of the training sample may adversely affect the model after re-learning.
- the first embedded vector is calculated by inputting a sample representing the cluster into the first distance measurement model for each cluster in which the samples included in the training data are clustered.
- a second distance measurement model is learned from the first distance measurement model based on the label set for the pair of samples included in the training data, and for each cluster, a sample representing the cluster is obtained as the second.
- a second embedded vector is calculated by inputting to the distance metric model, and when training the second distance metric model based on the first embedded vector of each cluster and the second embedded vector of each cluster. Detects cluster pairs that can be integrated when training is performed with more epochs than the number of epochs, and outputs the cluster pairs that do not have similar labels among the cluster pairs. Let it run.
- FIG. 1 is a diagram showing a configuration example of the system according to the first embodiment.
- FIG. 2 is a diagram showing an example of a multi-class classification model.
- FIG. 3 is a diagram showing an example of the structure of Siamese Network.
- FIG. 4 is a diagram showing an example of a metric space.
- FIG. 5 is a diagram showing an example of a metric space.
- FIG. 6 is a diagram showing an example of document data.
- FIG. 7 is a diagram showing an example of the extraction result of the word string.
- FIG. 8 is a diagram showing an example of a label setting screen.
- FIG. 9 is a diagram showing an example of an embedded vector.
- FIG. 10 is a diagram showing an example of an embedded vector.
- FIG. 11 is a diagram showing an example of the inquiry screen.
- FIG. 12 is a diagram showing an example of a label setting screen.
- FIG. 13 is a flowchart showing the procedure of the learning support process according to the first embodiment.
- FIG. 1 is a diagram showing a configuration example of the system according to the first embodiment.
- the system 1 shown in FIG. 1 provides a function corresponding to an arbitrary machine learning task, for example, classification, as only one aspect.
- the system 1 may include a server device 10 and a client terminal 30.
- the server device 10 and the client terminal 30 are communicably connected via the network NW.
- the network NW may be any kind of communication network such as the Internet or LAN (Local Area Network) regardless of whether it is wired or wireless.
- FIG. 1 shows an example in which one client terminal 30 is connected to one server device 10, but this is merely a schematic diagram, and a plurality of client terminals 30 are connected to one server device 10. Does not prevent it from being done.
- the server device 10 is an example of a computer that executes the above classification.
- the server device 10 may correspond to a learning support device.
- the server device 10 can be implemented by installing a classification program that realizes the functions corresponding to the above classification on an arbitrary computer.
- the server device 10 can be implemented as a server that provides the above-mentioned functions related to classification on-premises.
- the server device 10 may be implemented as a SaaS (Software as a Service) type application to provide a function corresponding to the above classification as a cloud service.
- SaaS Software as a Service
- the client terminal 30 corresponds to an example of a computer that receives a function corresponding to the above classification.
- the client terminal 30 corresponds to a desktop computer such as a personal computer.
- the client terminal 30 may be any computer such as a laptop computer, a mobile terminal device, or a wearable terminal.
- An example of a function in which the above classification task can be implemented is a similarity determination function between documents that determines similarity or dissimilarity between two documents.
- the above-mentioned similarity discrimination function between documents is a failure isolation graph in which similar case samples are associated between trouble events and trouble causes from past case collections related to operation management of IT (Information Technology) services, etc. Allows construction.
- the failure isolation graph constructed in this way can realize a function of outputting a recommendation of the cause of the trouble corresponding to the trouble event when dealing with the trouble, as an example.
- the classification includes a method of selecting a feature based on the importance of the feature and a method of learning the feature space. Technology may be incorporated.
- Mahalanobis distance learning represented by Mahalanobis distance learning is known as an example of a method for learning feature space.
- distance metric learning a transformation is learned in which the similarity between samples in the input space corresponds to the distance in the feature space. That is, in the distance metric learning, the original space is distorted so that the distances between the samples belonging to the same class are short and the distances between the samples belonging to different classes are long.
- feature space may be called a metric space or an embedded space.
- the Mahalanobis distance d M (x, x') shown in the following equation (1) is defined, and learning is performed using the component of M as a design variable.
- Such an optimization problem of M is equivalent to learning a transformation L that makes the Euclidean distance between samples correspond to the similarity between samples. From this, the transformation L can be learned by solving the problem of minimizing the loss function of the following equation (2).
- ⁇ pull (L) is represented by the following equation (3)
- ⁇ push (L) is represented by the following equation (4).
- J (arrow symbol) i” in the following equation (3) and the following equation (4) means that x j is in the vicinity of x i.
- ⁇ pull (L) and ⁇ push (L) k-nearest neighbors j of the instance i based on the k-nearest neighbor method are used.
- ⁇ pull (L) shown in the above equation (3) a penalty is given when the distance between instances having the same label is large.
- ⁇ push (L) shown in the above equation (4) a penalty is given when the distance between instances having different labels is small.
- a method using a decision tree is known as a method for determining the importance of the feature amount.
- a decision tree is generated by repeating the selection of features that divide a node.
- the importance is calculated for each feature amount.
- the importance FI (f j ) of the j-th feature amount f j can be calculated by calculating the sum of the information gains I at all the nodes as shown in the following equation (5).
- the “information gain I" in the above equation (5) refers to the amount of information obtained when dividing from a parent node to a child node.
- the "parent node” referred to here refers to the node before being divided by the branch of the feature amount, and the “child node” refers to the node after being divided by the branch of the feature amount.
- the amount of information I (D p , f) obtained when the feature amount is divided by the branching of the feature amount in the decision tree can be expressed by the following equation (6).
- f refers to the feature quantity selected for the branch.
- D p refers to the parent node.
- D left refers to the child node on the left side after branching
- Dlight refers to the child node on the right side after branching.
- N p refers to the number of samples in the parent node.
- N left refers to the number of samples of the child node on the left side
- Dright refers to the number of samples of the child node on the right side.
- a feature amount that maximizes such an amount of information is selected for the branch of the decision tree.
- the Gini coefficient, entropy, and the like can be used as the above amount of information.
- Gini coefficient I G (t) can be calculated by the following equation (7).
- the entropy I H (t) can be calculated by the following formula (8).
- the clustering distance learning device performs the following processing instead of the algorithm described in Non-Patent Document 3 that performs iterative calculation until the Mahalanobis distance matrix A converges. That is, in the clustering distance learning system, Mahalanobis distance estimation algorithm matrix A described in Non-Patent Document 3, the Mahalanobis distance function of the matrix A and the cluster center mu k under the constraint condition for limiting the magnitude of the matrix A It is formulated into a problem that minimizes J.
- the Mahalanobis distance matrix A is calculated according to the following equation (9) obtained by such a formulation.
- the above distance metric learning is not limited to the example of learning the linear transformation to the feature space as in the above Mahalanobis distance learning, but by applying a neural network to the distance definition part of the classification model, the features You can also learn non-linear transformations into quantitative space.
- FIG. 2 is a diagram showing an example of a multi-class classification model.
- FIG. 2 shows an example of a multiclass classification model 2 that predicts the label of the class to which an instance of input data belongs.
- the hidden vector input to any hidden layer of the trained multi-class classification model is the label of the class to which the input data belongs. It can be considered that the position in the metric space corresponding to is converted. From this, the hidden vector input to any hidden layer can be used as an embedded vector.
- Siamese Network As an example of deep metric learning, Siamese Network is known. In Siamese Network, a function that maps input data onto an appropriate metric space while performing non-linear and dimensional contraction based on similar or dissimilar pairs is learned.
- FIG. 3 is a diagram showing an example of the structure of Siamese Network.
- Siamese Network a pair of two samples with similar or dissimilar labels is input to two neural networks NN1 and NN2.
- parameters and layer structures are shared between neural networks NN1 and NN2 in which two sample pairs are input.
- the distance between the samples obtained from the embedded vector output by the neural network NN1 and the embedded vector output by the neural network NN2 is output as the degree of similarity.
- the parameters of the neural networks NN1 and NN2 that bring the distances of the similar pairs closer based on the similar or dissimilar labels while keeping the distances of the dissimilar pairs farther are learned.
- a model in which distance measurement is performed that is, a model in which distance measurement is performed, for example, a neural network NN1 or NN2 of Siamese Network, may be described as a “distance measurement model”.
- One aspect of the challenge For example, from the aspect of adapting the trained model to a new task, a fine-tune or the like in which the trained distance measurement model is retrained using new data may be performed. In this case, there is an aspect that the label set between the data of the training sample at the time of retraining the distance measurement model mentioned above may adversely affect the model after retraining.
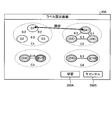
- FIG. 4 is a diagram showing an example of a metric space.
- the distance space S1 embedded by the distance metric model before re-learning and the distance space S2 embedded by the distance metric model after re-learning are shown side by side in order from the left.
- the clustering result in which each sample of the training data used for the re-learning is clustered based on the embedding vector before or after the re-learning is shown. ..
- the distance space S1 before relearning includes six clusters, clusters C1 to C6.
- the embedding in the metric space S2 is re-learned. .. That is, in the metric space S2, the distance between the clusters C1 and the cluster C2 is closer than that in the metric space S1 due to the relearning based on the similar labels set in the pair of the cluster C1 and the cluster C2.
- the distance between the clusters C3 and the cluster C4 is also closer than that in the metric space S1.
- the integration of clusters C3 and C4 is not always intended by the model designer, and unexpected models may be retrained.
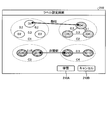
- FIG. 5 is a diagram showing an example of a metric space.
- a metric space S11 embedded by the distance metric model before relearning a metric space S12 embedded by the distance metric model in the relearning process, and a metric space S13 embedded by the distance metric model after relearning are shown. They are shown side by side from the left.
- each sample of the learning data used for the re-learning is clustered based on the embedding vector before, during the re-learning process, or after the re-learning. The clustering results are shown.
- the distance space S11 before relearning includes six clusters, clusters C1 to C6.
- the above-mentioned learning support function is set with a label similar to the pair of cluster C1 and cluster C2 among the above-mentioned six clusters. Re-learn in this state.
- the above-mentioned learning support function has a required number of epochs, for example, the number of epochs in which the value of the loss function converges or the number of epochs in the re-learning process in which the accuracy rate of the test data reaches a certain value, for example, one epoch. Relearn.
- the embedding in the metric space S12 is learned in the re-learning process.
- the above-mentioned learning support function sets a pair of clusters that are close to each other and do not have similar labels set based on the embedded vector output by the distance measurement model before relearning and at each time in the relearning process.
- the embedded vector EV of the cluster representative is obtained for each of the clusters C1 to C6.
- the average of the embedded vectors obtained by inputting the sample belonging to the cluster into the distance metric model before or during the re-learning process can be used.
- the above learning support function calculates the moving direction of the cluster.
- the moving direction of the cluster can be obtained by subtracting the embedding vector of the cluster representative before relearning from the embedding vector of the cluster representative in the relearning process.
- the above-mentioned learning support function extracts a pair of clusters existing on a straight line in which the moving directions of the two clusters are substantially the same according to the following equation (10).
- "delta_EV_cluster1" refers to the moving direction of the cluster C1.
- delta_EV_cluster2 indicates the moving direction of the cluster C2.
- ⁇ 1 indicates a threshold value.
- a pair of clusters satisfying the formula (10) is extracted.
- the above-mentioned learning support function calculates the distance between clusters before re-learning and at each time point in the re-learning process.
- the distance between clusters can be obtained by calculating the Euclidean distance and cosine distance of the embedded vector of the cluster representative for each pair of clusters.
- the above-mentioned learning support function calculates the amount of change in the distance between clusters before re-learning and during the re-learning process.
- the amount of change before relearning and during the relearning process can be obtained by dividing the distance between clusters in the relearning process by the distance between clusters before relearning. In this way, a pair of clusters in which the amount of change calculated before relearning and during the relearning process is less than a predetermined threshold value, for example, ⁇ 2, is extracted.
- a predetermined threshold value for example, ⁇ 2
- the cluster pairs extracted using these ⁇ 1 and ⁇ 2 are detected as query targets that can be integrated after re-learning.
- an arbitrary output destination such as the client terminal 30, it is possible to accept the integration suitability of the cluster pair.
- the pair of cluster C1 and cluster C2 and the pair of cluster C3 and cluster C4 are narrowed down using ⁇ 1 and ⁇ 2.
- the pair of cluster C1 and cluster C2 to which a similar label is set is excluded from the query target.
- the pair of cluster C3 and cluster C4 to which a similar label is not set is detected as a query target.
- Such a pair of cluster C3 and cluster C4 is output to the client terminal 30 or the like to accept whether or not the cluster pair is integrated, for example, canceling re-learning or resetting the label. For example, it accepts a request to stop re-learning. This can prevent cluster consolidation that is not intended by the model designer.
- dissimilar labels are set for the pairs of clusters C3 and C4, and similar labels are set for the pairs of clusters C5 and C6. This makes it possible to adjust the environment for re-learning while suppressing unintended cluster integration by the model designer.
- the above learning support function relearns the required number of epochs based on the reset label. For example, re-learning is performed with a similar label set for the pair of cluster C1 and cluster C2, a dissimilar label set for cluster C3 and cluster C4, and a similar label set for cluster C5 and cluster C6. Will be done.
- the distance metric model before re-learning may be used for the distance metric learning such as Siamese Network, or the distance metric model in the re-learning process may be used.
- the learning support function according to the present embodiment it is possible to suppress the unintended integration of cluster pairs by the model designer, and thus it is possible to suppress the adverse effect of the distance measurement model after re-learning. become.
- FIG. 1 shows an example of the functional configuration of the server device 10 according to the first embodiment.
- the server device 10 includes a communication interface 11, a storage unit 13, and a control unit 15.
- FIG. 1 shows a solid line showing the relationship between data transfer, only the minimum part is shown for convenience of explanation. That is, the input / output of data relating to each processing unit is not limited to the illustrated example, and the input / output of data other than those shown in the drawing, for example, between the processing unit and the processing unit, between the processing unit and the data, and between the processing unit and the outside. Data may be input and output between the devices.
- the communication interface 11 is an interface that controls communication with another device, for example, the client terminal 30.
- a network interface card such as a LAN card can be adopted as the communication interface 11.
- the communication interface 11 receives a label setting, a relearning execution instruction, a relearning stop instruction, and the like from the client terminal 30.
- the communication interface 11 transmits a pair of clusters to be inquired about for integration to the client terminal 30.
- the storage unit 13 is a functional unit that stores data used in various programs, including an OS (Operating System) executed by the control unit 15.
- OS Operating System
- the above program may be supported by a learning support program in which the above learning support function is modularized, packaged software in which the learning support program is packaged in the above classification program, and the like.
- the storage unit 13 can correspond to the auxiliary storage device in the server device 10.
- HDD Hard Disk Drive
- optical disk SSD (Solid State Drive), etc.
- flash memory such as EPROM (Erasable Programmable Read Only Memory) can also be used as an auxiliary storage device.
- the storage unit 13 stores the first model data 13M1 and the learning data 14 as an example of the data used in the program executed by the control unit 15.
- data referred to by the learning support program for example, re-learning conditions such as the required number of epochs and the number of epochs in the re-learning process are stored in the storage unit 13. It may be that.
- the first model data 13M1 is the data of the distance measurement model before re-learning.
- the "distance metric model before re-learning" referred to here can correspond to a distance metric model that has been trained using learning data different from the learning data used for re-learning, as an example.
- the layer structure of the model such as neurons and synapses of each layer of the input layer, the hidden layer and the output layer forming the Siamese Network, and the model parameters such as the weight and bias of each layer are stored in the storage unit. It is stored in 13.
- the training data 14 is data used for re-learning the distance measurement model.
- the training data 14 may include document data 14A and label data 14B.
- Document data 14A is document data.
- the "document” referred to here can correspond to an example of a sample input to the distance measurement model.
- FIG. 6 is a diagram showing an example of document data 14A.
- ten documents of the document D1 to the document D10 are illustrated as an example.
- the cluster C1 includes documents D1 to D3.
- cluster C2 includes documents D4 to D6.
- cluster C3 includes documents D7 and D8.
- cluster C4 includes documents D9 and D10.
- FIG. 6 shows text data as an example of the document data 14A, but the text data is converted into a numerical expression that can be input to the distance measurement model, for example, a vector expression, as a preprocessing for inputting to the distance measurement model. Will be converted.
- Bag of words and the like can be used as an example for such conversion of numerical expressions. Specifically, the following processing is performed for each of the documents D1 to D10.
- the word string of the content word is extracted from the word string of the sentence obtained by applying the morphological analysis to the text of the natural language.
- FIG. 7 is a diagram showing an example of the extraction result of the word string.
- FIG. 7 shows the extraction result of the word string for each of the documents D1 to D10 shown in FIG.
- function words are excluded from the word strings corresponding to the sentences of documents D1 to D10, and specific expressions such as date and time are excluded as stop words, resulting in content words.
- Word string is extracted.
- a dictionary of all the documents of the documents D1 to D10 is generated from the word strings of the content words of the documents D1 to D10. For example, a dictionary containing words such as “monitoring”, “AP server”, “DB server”, “failure”, “error”, “occurrence”, “VEO000481436” and “VEO000481437” is generated.
- vectors such as ⁇ monitoring: 1, AP server: 1, DB server: 0, failure: 0, error: 1, occurrence: 1, VEO000481436: 1, VEO000481437: 0 ⁇ can be obtained. ..
- a vector such as ⁇ monitoring: 1, AP server: 0, DB server: 1, failure: 1, error: 1, occurrence: 1, VEO000481436: 1, VEO000481437: 0 ⁇ Is obtained.
- vectors such as ⁇ monitoring: 1, AP server: 0, DB server: 1, failure: 0, error: 1, occurrence: 1, VEO000481436: 1, VEO000481437: 0 ⁇ can be obtained. ..
- a vector such as ⁇ monitoring: 1, AP server: 1, DB server: 0, failure: 1, error: 1, occurrence: 1, VEO000481436: 0, VEO000481437: 1 ⁇ Is obtained.
- the 8-dimensional vectors of documents D1 to D10 obtained by such preprocessing can be input to the distance measurement model.
- the vectors of the document D1 to the document D10 may be described as "document vector”.
- Label data 14B is data related to labels set in a cluster pair.
- the label data 14B can be generated by accepting the label setting from the client terminal 30.
- the label setting can be accepted via the label setting screen 200 shown in FIG.
- FIG. 8 is a diagram showing an example of the label setting screen 200.
- the clustering result of the embedded vector obtained by inputting the vectors of the documents D1 to D10 into the distance measurement model before re-learning is displayed on the label setting screen 200.
- clusters C1 to C4 are displayed on the label setting screen 200.
- cluster C1 includes documents D1 to D3.
- cluster C2 includes documents D4 to D6.
- cluster C3 includes documents D7 and D8.
- cluster C4 includes documents D9 and D10.
- the label setting screen 200 displays the distance of the embedded vector between the documents in the cluster.
- the operation of assigning a similar label to a pair of clusters is accepted on such a label setting screen 200.
- a label similar to a document pair can be set by a drag-and-drop operation.
- the label setting screen 200 by dragging the document D1 belonging to the cluster C1 and dropping it on the document D4 belonging to the cluster C2, the label setting screen 200 is similar to the pair of the cluster C1 and the cluster C2.
- An example where the label is set is shown.
- the label set in the cluster pair in this way is saved as the label data 14B.
- the specified document pair is regarded as a cluster pair and the label is set, but it is not always necessary to consider the specified document pair as a cluster pair, and the document pair may be labeled. can.
- the label setting an example of accepting the setting of a similar label is given, but as a matter of course, the setting of a dissimilar label can also be accepted.
- an example of accepting the label setting by user operation is given, but if the label setting can be acquired via the network NW, the label setting can be acquired from the internal or external storage including the removable disk or the like. It doesn't matter what you do.
- the control unit 15 is a functional unit that controls the entire server device 10.
- control unit 15 can be implemented by a hardware processor such as a CPU (Central Processing Unit) or an MPU (Micro Processing Unit).
- a CPU and an MPU are illustrated as an example of a processor, but it can be implemented by any processor regardless of a general-purpose type or a specialized type.
- control unit 15 may be realized by hard-wired logic such as ASIC (Application Specific Integrated Circuit) or FPGA (Field Programmable Gate Array).
- the control unit 15 By executing the above learning support program, the control unit 15 virtually places the processing unit shown in FIG. 1 on the work area of a RAM such as a DRAM (Dynamic Random Access Memory) mounted as a main storage device (not shown). Realize.
- a learning support program in which the above learning support function is modularized is executed is given, but the program running on the server device 10 is not limited to this.
- packaged software in which a learning support program is packaged in the above classification program may be executed.
- control unit 15 includes a reception unit 15A, a first calculation unit 15B, a learning unit 15C, a second calculation unit 15D, a third calculation unit 15E, and a detection unit 15F.
- reception unit 15A a reception unit 15A
- first calculation unit 15B a learning unit 15C
- second calculation unit 15D a second calculation unit 15D
- third calculation unit 15E a detection unit 15F.
- the reception unit 15A is a processing unit that accepts requests for re-learning.
- the reception unit 15A receives a press operation of the re-learning button 200A arranged on the label setting screen 200 shown in FIG. 8 from the client terminal 30 to request re-learning such as fine-tune. accept. Then, when the request for re-learning is received, the reception unit 15A reads out the first model data 13M1 and the learning data 14 from the storage unit 13.
- the first calculation unit 15B is a processing unit that calculates an embedded vector before re-learning.
- the first calculation unit 15B performs the first distance measurement process for calculating the embedding vector of the representative of each cluster of the training data 14 using the distance measurement model before re-learning. For example, the first calculation unit 15B transfers each sample of the training data 14 to the distance measurement model before re-learning developed on the work area of the memory (not shown) according to the first model data 13M1 read from the storage unit 13. Enter the vector. As a result, the embedded vector is output from the distance metric model before re-learning.
- a document vector which is a sample representing the cluster
- the input layer of the distance measurement model is the number of words "8" of the documents D1 to D10
- the output layer is 2.
- each of the representative samples of the clusters C1 to C4 of the training data is referred to as document D1, document D4, document D7, and document D9.
- the vector of document D1 ⁇ monitoring: 1, AP server: 1, DB server: 0, failure: 1, error: 1, occurrence: 1, VEO000481436: 1, VEO000481437: 0 ⁇ is before relearning.
- the output layer of the distance measurement model before re-learning outputs the embedding vector [-5, -5] before re-learning of the document D1.
- the embedded vector [-5, 5] before the re-learning of the document D4 is obtained.
- the embedded vector [5, 3] before the re-learning of the document D7 is obtained.
- the embedded vector [5, -3] before the re-learning of the document D4 is obtained.
- the input and output in the above first distance measurement process are as follows.
- FIG. 9 is a diagram showing an example of an embedded vector.
- the embedded vectors of the documents D1, the document D4, the document D7, and the document D9 which are representative of the clusters C1 to C4 embedded by the distance measurement model before re-learning, are mapped.
- the document D1 representing the cluster C1 is embedded in [-5, -5]
- the document D4 representing the cluster C2 is embedded in [-5, 5].
- the document D7 representing the cluster C3 is embedded in [5,3]
- the document D9 representing the cluster C4 is embedded in [5, -3].
- the learning unit 15C is a processing unit that relearns the learned distance measurement model.
- the learning unit 15C uses the learning data 14 to perform distance measurement learning, that is, re-learning of the distance measurement model defined by the first model data 13M1. For example, the learning unit 15C performs the following processing for each pair of documents obtained by combining two of the documents D1 to D10. That is, the learning unit 15C relearns the parameters of Siamese Network that reduce the distance of the dissimilar pair while reducing the distance of the similar pair based on the similar or dissimilar label set for the pair of documents.
- the learning unit 15C uses a similar label set for the pair of cluster C1 and cluster C2 to update the parameters of Siamese Network.
- the above combination may include a pair of documents D1 and D4, a pair of documents D1 and D5, and a pair of documents D1 and D6. Further, the above combination may include a pair of document D2 and document D4, a pair of document D2 and document D5, and a pair of document D2 and document D6. Further, the above combination may include a pair of document D3 and document D4, a pair of document D3 and document D5, and a pair of document D3 and document D6.
- the learning unit 15C does not always repeat the re-learning using the learning data 14 until the required number of epochs, for example, the number of epochs at which the value of the loss function converges and the number of epochs at which the accuracy rate of the test data reaches a certain value. .. That is, the learning unit 15C relearns the number of epochs in the relearning process, for example, one epoch, which is smaller than the required number of epochs.
- the input and output in the above distance measurement learning process are as follows.
- Learned Siamese Network Number of epochs 1 Learning data: Similar pairs: (D1, D4), (D1, D5), (D1, D6), (D2, D4), (D2, D5), (D2, D6), (D3, D4), (D3, D5) , (D3, D6)
- the parameters of the distance measurement model of the re-learning process obtained by the re-learning of the learning unit 15C in this way are stored as the second model data 13M2 in the work area of the memory referred to by the control unit 15.
- the second model data 13M2 is stored in the memory referenced by the control unit 15 is given, but as a matter of course, it is stored in an arbitrary storage, for example, a storage area possessed by the storage unit 13. It doesn't matter.
- the second calculation unit 15D is a processing unit that calculates the embedded vector in the re-learning process.
- the second calculation unit 15D performs the second distance measurement process for calculating the embedding vector of the representative of each cluster of the learning data 14 using the distance measurement model of the re-learning process. For example, the second calculation unit 15D inputs the vector of each sample of the training data 14 into the distance measurement model of the re-learning process developed on the work area of the memory (not shown) according to the second model data 13M2 described above. As a result, the embedded vector is output from the distance metric model in the re-learning process.
- a document vector which is a sample representing the cluster, is input to the input layer of the distance measurement model in the re-learning process.
- the parameters of the distance measurement model are different but the layer structure is common between the pre-learning process and the re-learning process.
- the vector of document D1 ⁇ monitoring: 1, AP server: 1, DB server: 0, failure: 1, error: 1, occurrence: 1, VEO000481436: 1, VEO000481437: 0 ⁇ is the relearning process. Is input to the input layer of the distance measurement model.
- the output layer of the distance measurement model of the re-learning process outputs the embedding vector [-5, -4] of the re-learning process of the document D1.
- the embedded vector [-5, 4] of the re-learning process of the document D4 is obtained.
- the embedded vector [5, 2] of the re-learning process of the document D7 is obtained.
- the embedded vector [5, -2] of the re-learning process of the document D4 is obtained.
- the input and output in the above second distance measurement process are as follows.
- D1_process_of_fine_tune [-5, -4]
- D4_process_of_fine_tune [-5, 4]
- D7_process_of_fine_tune [5, 2]
- D9_process_of_fine_tune [5, -2]
- FIG. 10 is a diagram showing an example of an embedded vector.
- the embedded vectors of the documents D1, the document D4, the document D7, and the document D9 which are representative of the clusters C1 to C4 embedded by the distance measurement model before re-learning, are mapped by black circles.
- the embedded vectors of the documents D1, the document D4, the document D7, and the document D9 which are representative of the clusters C1 to C4 embedded by the distance measurement model of the re-learning process, are mapped by white circles.
- the document D1 represented by the cluster C1 is embedded in [-5, -5] before relearning, while it is embedded in [-5, -4] in the relearning process. It has been.
- the document D4 represented by the cluster C2 is embedded in [-5,5] before the relearning, while it is embedded in [-5,4] in the relearning process.
- the document D7 represented by the cluster C3 is embedded in [5,3] before the relearning, while it is embedded in [5,2] in the relearning process.
- the document D9 represented by the cluster C4 is embedded in [5, -3] before the re-learning, while it is embedded in [5, -2] in the re-learning process.
- the third calculation unit 15E is a processing unit that calculates movement parameters between clusters before relearning and during the relearning process.
- the third calculation unit 15E calculates the moving direction of the cluster by subtracting the embedded vector of the cluster representative before relearning from the embedded vector of the cluster representative in the relearning process.
- the input and output when calculating the moving direction of the cluster in this way are as follows.
- D1_before_fine_tune [-5, -5]
- D4_before_fine_tune [-5,5]
- D7_before_fine_tune [5, 3]
- D9_before_fine_tune [5, -3]
- D1_process_of_fine_tune [-5, -4]
- D4_process_of_fine_tune [-5, 4]
- D7_process_of_fine_tune [5, 2]
- D9_process_of_fine_tune [5, -2]
- D1_delta [0,1]
- D4_delta [0, -1]
- D7_delta [0, -1]
- D9_delta [0,1]
- the third calculation unit 15E calculates the magnitude of the traveling angle between the clusters.
- the input and output when calculating the traveling angle between clusters in this way are as follows.
- D1_delta [0,1]
- D4_delta [0, -1]
- D7_delta [0, -1]
- D9_delta [0,1]
- the third calculation unit 15E calculates the amount of change in the distance between clusters based on the embedding vector of the cluster representative in the relearning process and the embedding vector of the cluster representative before relearning.
- the amount of change before relearning and during the relearning process can be obtained by dividing the distance between clusters in the relearning process by the distance between clusters before relearning.
- the input and output when calculating the amount of change in the distance between clusters in this way are as follows.
- D1_before_fine_tune [-5, -5]
- D4_before_fine_tune [-5,5]
- D7_before_fine_tune [5, 3]
- D9_before_fine_tune [5, -3]
- D1_process_of_fine_tune [-5, -4]
- D4_process_of_fine_tune [-5, 4]
- D7_process_of_fine_tune [5, 2]
- D9_process_of_fine_tune [5, -2]
- After_distance (D1, D7) / before_distance (D1, D7) ⁇ 136 / ⁇ 164 ⁇ 0.91 for the pair of the document D1 representing the cluster C1 and the document D7 representing the cluster C3.
- After_distance (D4, D9) / before_distance (D4, D9) ⁇ 136 / ⁇ 164 ⁇ 0.91 for the pair of the document D4 representing the cluster C2 and the document D9 representing the cluster C4.
- After_distance (D7, D9) / before_distance (D7, D9) 4/6 ⁇ 0.67 for the pair of the document D7 representing the cluster C3 and the document D9 representing the cluster C4.
- before_distance refers to the distance between clusters in the relearning process
- after_distance refers to the distance between clusters in the relearning process.
- the detection unit 15F is a processing unit that detects a pair of clusters that can be integrated after relearning.
- a pair of clusters that can be integrated after re-learning may be referred to as an "integrated cluster pair".
- the detection unit 15F can correspond to an example of the output unit.
- the detection unit 15F is at least one of the magnitude of the traveling angle between clusters calculated by the third calculation unit 15E and the amount of change in the distance between clusters calculated by the third calculation unit 15E. Discover integrated cluster pairs based on the combination.
- the detection unit 15F can detect an integrated cluster pair under the AND condition of the magnitude of the traveling angle between clusters and the amount of change in the distance between clusters. For example, the detection unit 15F detects a pair of clusters in which the magnitude of the traveling angle between clusters is less than a predetermined threshold value ⁇ 1 and the amount of change in the distance between clusters is less than a predetermined threshold value ⁇ 2 as an integrated cluster pair. ..
- ⁇ 1 0.01 and ⁇ 2 is 0.9
- the cluster C1 and cluster C2 pairs and the cluster C3 and cluster C4 pairs are detected as integrated cluster pairs.
- cluster C1 and cluster C2 pair, cluster C1 and cluster C3 pair, cluster C2 and cluster C4 pair, and cluster C3 and cluster C4 pair Is detected as an integrated cluster pair.
- the detection unit 15F excludes the pair of clusters to be integrated as intended by the model designer, and among the pairs of clusters detected as the integrated cluster pair, the pair of clusters with a similar label is set. Is excluded from the query. For example, in the example of the label setting screen 200 shown in FIG. 8, since the label data 14B has a label similar to the pair of cluster C1 and cluster C2, the cluster C1 and the cluster C2 pair are excluded. A pair of cluster C3 and cluster C4 is extracted.
- FIG. 11 is a diagram showing an example of the inquiry screen.
- FIG. 11 shows an example in which the inquiry screen 400 including the integrated cluster pair detected as the inquiry target is popped up in front of the label setting screen 200 as an example.
- a message warning that the pair of cluster C3 and cluster C4 may be integrated after re-learning is displayed, and the continuation button 400A and the suspend button 400B are displayed. Is displayed.
- the re-learning is continued by the learning unit 15C with the above label data 14B set up to the required number of epochs without interrupting the re-learning in the re-learning process.
- the re-learning can be interrupted in the re-learning process. In addition to such interruption, the label can be reset on the label setting screen.
- FIG. 12 is a diagram showing an example of a label setting screen.
- FIG. 12 shows a label setting screen 210 displayed after the interrupt button 400B of the inquiry screen 400 shown in FIG. 11 is operated.
- Resetting of similar or dissimilar labels can be accepted through the operation of associating a pair of documents on the label setting screen 210 shown in FIG.
- FIG. 12 shows a label setting screen 210 displayed after the interrupt button 400B of the inquiry screen 400 shown in FIG. 11 is operated.
- Resetting of similar or dissimilar labels can be accepted through the operation of associating a pair of documents on the label setting screen 210 shown in FIG.
- FIG. 12 shows a label setting screen 210 displayed after the interrupt button 400B of the inquiry screen 400 shown in FIG. 11 is operated.
- Resetting of similar or dissimilar labels can be accepted through the operation of associating a pair of documents on the label setting screen 210 shown in FIG.
- FIG. 12 shows a label setting screen 210 displayed after the interrupt button 400B of the inquiry screen 400 shown in FIG. 11
- the following behavior can be expected by outputting an integrated cluster pair that does not have a similar label set.
- the label setting screen 200 shown in FIG. 8 shows an example in which a similar label is set for the pair of cluster C1 and cluster C2 with the intention of integrating cluster C1 and cluster C2.
- Such label setting diminishes the importance of the words “AP server” appearing in the documents D1 to D3 and the words “DB server” appearing in the documents D4 to D6 in forming a cluster.
- the importance of "VEO000481436” and "VEO000481437” will increase in embedding in the metric space. From these facts, it is highly possible that the pair setting of the cluster C1 and the cluster C2 causes the integration of the pair of the cluster C1 and the cluster C2.
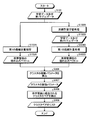
- FIG. 13 is a flowchart showing the procedure of the learning support process according to the first embodiment. This process is started as an example only when a request for re-learning is received. As shown in FIG. 4, the reception unit 15A reads the first model data 13M1 and the learning data 14 from the storage unit 13 (step S101).
- the first calculation unit 15B performs the first distance measurement process for calculating the embedding vector of the representative of each cluster of the training data 14 using the distance measurement model before re-learning defined in the first model data 13M1.
- the embedded vector of the cluster representative before relearning calculated in step S102A is output from the first calculation unit 15B to the third calculation unit 15E (step S103A).
- step S102B the learning unit 15C uses the learning data 14 to perform distance measurement learning, that is, re-learning of the distance measurement model defined by the first model data 13M1.
- distance measurement learning that is, re-learning of the distance measurement model defined by the first model data 13M1.
- the number of epochs in the relearning process which is smaller than the required number of epochs, is applied.
- the parameters of the distance measurement model in the re-learning process are output as the second model data 13M2 from the learning unit 15C to the second calculation unit 15D (step S103B).
- the second calculation unit 15D performs a second distance measurement process for calculating the embedding vector of the representative of each cluster of the training data 14 using the distance measurement model of the relearning process defined in the second model data 13M2.
- Step S104B The embedded vector of the cluster representative in the relearning process calculated in step S104B is output from the second calculation unit 15D to the third calculation unit 15E (step S105B).
- the third calculation unit 15E determines the movement parameters between clusters based on the embedded vector of the cluster representative before relearning and the embedded vector of the cluster representative in the relearning process, for example, the magnitude of the traveling angle between clusters and the distance between clusters.
- the amount of change in is calculated (step S106).
- the movement parameters between clusters calculated in step S106 are output from the third calculation unit 15E to the detection unit 15F (step S107).
- the detection unit 15F detects a pair of clusters that can be integrated after relearning based on at least one or a combination of the magnitude of the traveling angle between the clusters and the amount of change in the distance between the clusters (step S108).
- the cluster pairs detected in step S108 the cluster pairs for which similar labels are not set are output to a predetermined output destination, for example, the client terminal 30 (step S109).
- the server devices 10 according to the present embodiment are close to each other based on the embedded vector output by the distance measurement model before re-learning and at each time in the re-learning process, and similar labels are set. It provides a learning support function that detects pairs of clusters that are not present. Therefore, according to the server device 10 according to the present embodiment, the integration of the cluster pair unintentionally performed by the model designer is suppressed, so that it is possible to suppress the adverse effect of the distance measurement model after re-learning. Is.
- each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of the device is functionally or physically distributed / physically in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
- the reception unit 15A, the first calculation unit 15B, the learning unit 15C, the second calculation unit 15D, the third calculation unit 15E, or the detection unit 15F may be connected via a network as an external device of the server device 10.
- another device has a reception unit 15A, a first calculation unit 15B, a learning unit 15C, a second calculation unit 15D, a third calculation unit 15E, or a detection unit 15F, respectively, and is connected to a network to cooperate with each other.
- the function of the server device 10 may be realized.
- FIG. 14 is a diagram showing an example of a computer hardware configuration.
- the computer 100 includes an operation unit 110a, a speaker 110b, a camera 110c, a display 120, and a communication unit 130. Further, the computer 100 has a CPU 150, a ROM 160, an HDD 170, and a RAM 180. Each of these 110 to 180 parts is connected via the bus 140.
- the HDD 170 is the same as the reception unit 15A, the first calculation unit 15B, the learning unit 15C, the second calculation unit 15D, the third calculation unit 15E, and the detection unit 15F shown in the first embodiment.
- the learning support program 170a that exerts the function of is stored.
- the learning support program 170a is integrated or integrated like the components of the reception unit 15A, the first calculation unit 15B, the learning unit 15C, the second calculation unit 15D, the third calculation unit 15E, and the detection unit 15F shown in FIG. It may be separated. That is, not all the data shown in the first embodiment may be stored in the HDD 170, and the data used for processing may be stored in the HDD 170.
- the CPU 150 reads the learning support program 170a from the HDD 170 and then deploys it to the RAM 180.
- the learning support program 170a functions as the learning support process 180a, as shown in FIG.
- the learning support process 180a develops various data read from the HDD 170 in the area allocated to the learning support process 180a in the storage area of the RAM 180, and executes various processes using the developed various data.
- the process shown in FIG. 13 is included.
- the CPU 150 not all the processing units shown in the first embodiment need to operate, and the processing units corresponding to the processes to be executed may be virtually realized.
- each program is stored in a "portable physical medium" such as a flexible disk inserted into the computer 100, a so-called FD, CD-ROM, DVD disk, magneto-optical disk, or IC card. Then, the computer 100 may acquire and execute each program from these portable physical media. Further, each program is stored in another computer or server device connected to the computer 100 via a public line, the Internet, LAN, WAN, etc., so that the computer 100 acquires and executes each program from these. You may do it.
- System 10 Server device 11 Communication interface 13 Storage unit 13M1 1st model data 14 Learning data 14A Document data 14B Label data 15 Control unit 15A Reception unit 15B 1st calculation unit 15C Learning unit 15D 2nd calculation unit 15E 3rd calculation unit 15F detector 30 client terminal
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computational Linguistics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Biology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/001382 WO2021144938A1 (ja) | 2020-01-16 | 2020-01-16 | 学習支援プログラム、学習支援方法及び学習支援装置 |
| JP2021570583A JP7287505B2 (ja) | 2020-01-16 | 2020-01-16 | 学習支援プログラム、学習支援方法及び学習支援装置 |
| US17/863,511 US20220374648A1 (en) | 2020-01-16 | 2022-07-13 | Computer-readable recording medium storing learning support program, learning support method, and learning support device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/001382 WO2021144938A1 (ja) | 2020-01-16 | 2020-01-16 | 学習支援プログラム、学習支援方法及び学習支援装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/863,511 Continuation US20220374648A1 (en) | 2020-01-16 | 2022-07-13 | Computer-readable recording medium storing learning support program, learning support method, and learning support device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021144938A1 true WO2021144938A1 (ja) | 2021-07-22 |
Family
ID=76864067
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/001382 Ceased WO2021144938A1 (ja) | 2020-01-16 | 2020-01-16 | 学習支援プログラム、学習支援方法及び学習支援装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220374648A1 (https=) |
| JP (1) | JP7287505B2 (https=) |
| WO (1) | WO2021144938A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7314331B1 (ja) | 2022-01-28 | 2023-07-25 | 俊二 有賀 | Aiを用いた類似デザイン判定システム |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB202017510D0 (en) * | 2020-09-29 | 2020-12-23 | Univ Oxford Innovation Ltd | Method of training a machine learning model, method of assessing ultrasound measurement data, method of determining information about an anatomical featur |
| EP4379671B1 (en) * | 2022-12-01 | 2026-03-18 | Siemens Mobility GmbH | Assessment of input-output datasets using local complexity values and associated data structure |
| US20240211796A1 (en) * | 2022-12-22 | 2024-06-27 | Microsoft Technology Licensing, Llc | Explanation of emergent semantics in embedding spaces via analogy |
| CN116361679B (zh) * | 2023-06-02 | 2023-08-11 | 青岛豪迈电缆集团有限公司 | 基于数据驱动的电缆寿命智能预测方法及系统 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013161295A (ja) * | 2012-02-06 | 2013-08-19 | Canon Inc | ラベル付加装置、ラベル付加方法及びプログラム |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11024424B2 (en) * | 2017-10-27 | 2021-06-01 | Nuance Communications, Inc. | Computer assisted coding systems and methods |
-
2020
- 2020-01-16 WO PCT/JP2020/001382 patent/WO2021144938A1/ja not_active Ceased
- 2020-01-16 JP JP2021570583A patent/JP7287505B2/ja active Active
-
2022
- 2022-07-13 US US17/863,511 patent/US20220374648A1/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013161295A (ja) * | 2012-02-06 | 2013-08-19 | Canon Inc | ラベル付加装置、ラベル付加方法及びプログラム |
Non-Patent Citations (1)
| Title |
|---|
| OKADA, SHOGO ET AL.: "Image Classification System based on Interaction with Human", PROCEEDINGS OF THE 24TH ANNUAL CONFERENCE OF THE JAPANESE SOCIETY FOR ARTIFICIAL INTELLIGENCE, 2010, 11 June 2010 (2010-06-11), pages 1 - 4, ISSN: 1347-9881, Retrieved from the Internet <URL:https://www.jstage.jst.go.jp/article/pjsai/JSAI2010/0/JSAI2010_2G20S96/_article/-char/ja> DOI: 10. 11517/pjsai.JSAI2010.0_2G20S96 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7314331B1 (ja) | 2022-01-28 | 2023-07-25 | 俊二 有賀 | Aiを用いた類似デザイン判定システム |
| JP2023110126A (ja) * | 2022-01-28 | 2023-08-09 | 俊二 有賀 | Aiを用いた類似デザイン判定システム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021144938A1 (https=) | 2021-07-22 |
| JP7287505B2 (ja) | 2023-06-06 |
| US20220374648A1 (en) | 2022-11-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7287505B2 (ja) | 学習支援プログラム、学習支援方法及び学習支援装置 | |
| JP2022524662A (ja) | 蒸留を用いたそれぞれのターゲット・クラスを有するモデルの統合 | |
| Debnath et al. | A decision based one-against-one method for multi-class support vector machine | |
| Punyakanok et al. | Learning and inference over constrained output | |
| Chen et al. | Fedmax: Mitigating activation divergence for accurate and communication-efficient federated learning | |
| JP6879433B2 (ja) | 回帰装置、回帰方法、及びプログラム | |
| Babu et al. | Three-stage multi-objective feature selection with distributed ensemble machine and deep learning for processing of complex and large datasets | |
| US11758010B1 (en) | Transforming an application into a microservice architecture | |
| Li et al. | Aligning model outputs for class imbalanced non-IID federated learning | |
| Murugesan et al. | Some measures to impact on the performance of Kohonen self-organizing map | |
| EP4116841A1 (en) | Machine learning program, machine learning method, and machine learning device | |
| Johnny et al. | Sign language translator using Machine Learning | |
| Saha et al. | Recal: Reuse of established cnn classifier apropos unsupervised learning paradigm | |
| Song et al. | An accelerator for support vector machines based on the local geometrical information and data partition | |
| US12536447B2 (en) | Feature selection in vertical federated learning | |
| US20240176784A1 (en) | Adaptively generating outlier scores using histograms | |
| Shetty et al. | Comparative analysis of different classification techniques | |
| Fu et al. | A supervised method to enhance distance-based neural network clustering performance by discovering perfect representative neurons | |
| Figuera et al. | Probability Density Function for Clustering Validation | |
| Zang et al. | Kernel extreme learning machine with discriminative transfer feature and instance selection for unsupervised domain adaptation | |
| Pal et al. | Random partition based adaptive distributed kernelized SVM for big data | |
| Simen et al. | Evolutionary-enhanced quantum supervised learning model: A. Simen et al. | |
| Steponavičė et al. | Dynamic algorithm selection for pareto optimal set approximation | |
| Khim et al. | Multiclass classification via class-weighted nearest neighbors | |
| US20240095515A1 (en) | Bilevel Optimization Based Decentralized Framework for Personalized Client Learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20913838 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021570583 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20913838 Country of ref document: EP Kind code of ref document: A1 |