WO2021095211A1 - 出力方法、出力プログラム、および出力装置 - Google Patents
出力方法、出力プログラム、および出力装置 Download PDFInfo
- Publication number
- WO2021095211A1 WO2021095211A1 PCT/JP2019/044769 JP2019044769W WO2021095211A1 WO 2021095211 A1 WO2021095211 A1 WO 2021095211A1 JP 2019044769 W JP2019044769 W JP 2019044769W WO 2021095211 A1 WO2021095211 A1 WO 2021095211A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- vector
- modal
- information
- output device
- corrected
- Prior art date
Links
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/15—Correlation function computation including computation of convolution operations
- G06F17/153—Multidimensional correlation or convolution
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Definitions
- the present invention relates to an output method, an output program, and an output device.
- the modal is a concept indicating the style and type of information, and specific examples thereof include images, documents (texts), and sounds.
- Machine learning using multiple modals is called multimodal learning.
- ViLBERT Vision-and-Language Bidirectional Encoder Representations from Transformers.
- ViLBERT is a modal image-related vector that is corrected based on a modal information-based vector for a document and a modal information-based vector for a document. It is a technique to solve a problem by referring to an information-based vector.
- the accuracy of the solution when solving the problem using a plurality of modal information may be poor.
- ViLBERT when solving the problem of judging the situation based on an image and a document, it is only necessary to refer directly to the vector based on the modal information on the corrected document and the vector based on the modal information on the corrected image. , The accuracy of the solution when solving the problem is poor.
- the present invention aims to improve the accuracy of a solution when solving a problem using a plurality of modal information.
- the information of the first modal is based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal different from the first modal. Corrects the vector based on, and corrects the vector based on the information of the second modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- a first vector is generated based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the first modal, and from the vector based on the information of the second modal after correction.
- a second vector is generated, and a predetermined vector, the generated first vector, and the generated second vector are combined from a coupling vector.
- An output method that generates a third vector that aggregates the first vector and the second vector based on the obtained correlation between the two different types of vectors, and outputs the generated third vector. , Output programs, and output devices are proposed.
- FIG. 1 is an explanatory diagram showing an embodiment of an output method according to an embodiment.
- FIG. 2 is an explanatory diagram showing an example of the information processing system 200.
- FIG. 3 is a block diagram showing a hardware configuration example of the output device 100.
- FIG. 4 is a block diagram showing a functional configuration example of the output device 100.
- FIG. 5 is an explanatory diagram showing a specific example of the Co-Attention Network 500.
- FIG. 6 is an explanatory diagram showing a specific example of the SA layer 600 and a specific example of the TA layer 610.
- FIG. 7 is an explanatory diagram showing an example of operation using CAN500.
- FIG. 8 is an explanatory diagram (No. 1) showing usage example 1 of the output device 100.
- FIG. 9 is an explanatory diagram (No.
- FIG. 10 is an explanatory diagram (No. 1) showing usage example 2 of the output device 100.
- FIG. 11 is an explanatory diagram (No. 2) showing usage example 2 of the output device 100.
- FIG. 12 is a flowchart showing an example of the learning processing procedure.
- FIG. 13 is a flowchart showing an example of the estimation processing procedure.
- FIG. 1 is an explanatory diagram showing an embodiment of an output method according to an embodiment.
- the output device 100 is a computer for improving the accuracy of a solution when the problem is solved by making it easy to obtain information useful for solving the problem by using a plurality of modal information.
- BERT Bidirectional Encoder Representations from Transformers
- the BERT is formed by stacking the Encoder portions of the Transformer.
- the following non-patent document 2 and the following non-patent document 3 can be referred to.
- BERT is supposed to be applied to a situation where a problem is solved using modal information about a document, and cannot be applied to a situation where a problem is solved using a plurality of modal information. ..
- Non-Patent Document 2 Devlin, Jacob et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” NAACL-HLT (2019).
- Non-Patent Document 3 Vaswani, Ashish, et al. "Attention is all you need.” Advances in neural information processing systems. 2017.
- VideoBERT As a method for solving a problem, for example, there is a method called VideoBERT.
- the VideoBERT is specifically an extension of the BERT that can be applied to situations where a problem is solved using modal information about a document and modal information about an image.
- VideoBERT for example, the following Non-Patent Document 4 can be referred to.
- the VideoBERT handles modal information about a document and modal information about an image without explicitly distinguishing them when solving a problem, the accuracy of the solution when solving the problem may be poor.
- Non-Patent Document 4 Sun, Chen, et al. "Video: A joint model for video and language learning learning.”
- MCAN Modular Co-Attention Network
- the MCAN solves the problem by referring to the modal information about the document and the modal information about the image corrected by the modal information about the document.
- MCAN for example, the following Non-Patent Document 5 can be referred to.
- the modal information about the document is not corrected by the modal information about the image and is referred to as it is, so that the accuracy of the solution when solving the problem may be poor.
- Non-Patent Document 5 Yu, Zhou, et al. "Deep Modular Co-Attention Network for Visual Question Answering.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2019.
- ViLBERT as a method for solving a problem, for example, there is a method called ViLBERT.
- ViLBERT only refers to the modal information about the document corrected by the modal information about the image and the modal information about the image corrected by the modal information about the document as it is, when the problem is solved.
- the accuracy of the solution may be poor.
- the output device 100 acquires a vector based on the information of the first modal and a vector based on the information of the second modal.
- Modal means a form of information.
- the first modal and the second modal are different modals.
- the first modal is, for example, an image modal.
- the information of the first modal is, for example, an image represented according to the first modal.
- the second modal is, for example, a modal for documents.
- the information of the second modal is, for example, a document expressed according to the second modal.
- the vector based on the information of the first modal is, for example, a vector generated based on the information of the first modal expressed according to the first modal.
- the first modal information-based vector is specifically an image-based vector.
- the vector based on the information of the second modal is, for example, a vector generated based on the information of the second modal expressed according to the second modal.
- the second modal information-based vector is specifically a document-based vector.
- the output device 100 corrects the vector based on the information of the first modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- the output device 100 corrects the vector based on the information of the first modal by using, for example, the first correction model 111.
- the first correction model 111 is, for example, a target attention layer for the first modal.
- the output device 100 corrects the vector based on the information of the second modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- the output device 100 corrects the vector based on the information of the second modal by using, for example, the second correction model 112.
- the second correction model 112 is, for example, a target attention layer for the second modal.
- the output device 100 generates the first vector based on the correlation between two vectors of different types obtained from the vector based on the corrected first modal information.
- the two different types of vectors are, for example, a query vector and a key vector.
- the output device 100 generates the first vector by using, for example, the first generation model 121.
- the first generative model 121 is, for example, a self-attention layer for the first modal.
- the output device 100 generates a second vector based on the correlation between two vectors of different types obtained from the vector based on the corrected second modal information.
- the two different types of vectors are, for example, a query vector and a key vector.
- the output device 100 generates a second vector using, for example, the second generation model 122.
- the second generative model 122 is, for example, a self-attention layer for a second modal.
- the output device 100 generates a coupling vector including a predetermined vector, the generated first vector, and the generated second vector.
- the predetermined vector is set in advance by the user, for example.
- the predetermined vector is an aggregation vector for aggregating the first vector and the second vector.
- the predetermined vector is, for example, a vector in which elements are randomly set.
- the predetermined vector is, for example, a vector whose elements are default values set by the user.
- the connection vector is obtained, for example, by combining a predetermined vector, a first vector, and a second vector in order.
- the output device 100 generates a third vector based on the correlation between two different types of vectors obtained from the combined vector.
- the two different types of vectors are, for example, a query vector and a key vector.
- the third vector is a vector that aggregates the first vector and the second vector.
- the output device 100 uses the third generation model 130 to generate a third vector.
- the third generative model 130 is, for example, a self-attention layer.
- the output device 100 correlates the portion included in the key vector based on the first vector and the second vector with the portion included in the query vector based on the predetermined vector.
- a predetermined vector can be corrected based on.
- the output device 100 can correct a predetermined vector by, for example, a portion of a vector having a value based on the first vector and the second vector based on the correlation. Therefore, the output device 100 can perform processing such that the first vector and the second vector are aggregated with respect to the predetermined vector, and the third vector can be obtained.
- the output device 100 outputs the generated third vector.
- the output format is, for example, display on a display, print output to a printer, transmission to another computer, or storage in a storage area.
- the output device 100 aggregates the first vector and the second vector, and is useful for solving the problem among the vector based on the information of the first modal and the vector based on the information of the second modal.
- a third vector that tends to reflect information can be generated and made available.
- the output device 100 can use, for example, a third vector that accurately expresses the features of a real-world image or document that are useful for solving a problem on a computer.
- the output device 100 uses, for example, the third vector, the first correction model 111, the second correction model 112, the first generation model 121, the second generation model 122, and the third.
- the generation model 130 and the like can be updated. Therefore, the output device 100 can easily reflect information useful for solving the problem among the vector based on the information of the first modal and the vector based on the information of the second modal in the third vector. it can. As a result, the output device 100 can improve the accuracy of the subsequent solution when the problem is solved.
- the output device 100 When solving a problem, for example, the output device 100 tends to reflect information useful for solving the problem, which is a vector based on the information of the first modal and a vector based on the information of the second modal.
- the vector of can be used, and the accuracy of the solution when solving the problem can be improved.
- the output device 100 can accurately determine the target situation in solving the problem of determining the target situation based on the image and the document.
- the problem of determining the situation of the subject is, for example, the problem of determining whether the situation of the subject is a positive situation or a negative situation.
- FIG. 2 is an explanatory diagram showing an example of the information processing system 200.
- the information processing system 200 includes an output device 100, a client device 201, and a terminal device 202.
- the output device 100 and the client device 201 are connected via a wired or wireless network 210.
- the network 210 is, for example, a LAN (Local Area Network), a WAN (Wide Area Network), the Internet, or the like. Further, in the information processing system 200, the output device 100 and the terminal device 202 are connected via a wired or wireless network 210.
- the output device 100 has a Co-Attention Network that generates a third vector based on a vector based on the information of the first modal and a vector based on the information of the second modal.
- the first modal is, for example, an image modal.
- the second modal is, for example, a modal for documents.
- the Co-Attention Network is, for example, the first correction model 111, the second correction model 112, the first generation model 121, the second generation model 122, and the third generation shown in FIG. Corresponds to the whole with model 130.
- the output device 100 updates the Co-Attention Network based on the teacher data.
- the teacher data is, for example, a source for generating a vector based on the information of the first modal as a sample and a vector based on the information of the second modal as a sample. Correspondence information in which the second modal information and the correct answer data are associated with each other.
- the teacher data is input to the output device 100 by the user of the output device 100, for example.
- the correct answer data shows, for example, the correct answer when the problem is solved based on the third vector. For example, if the first modal is a modal about an image, then the information in the first modal from which the vector based on the information in the first modal is generated is the image. For example, if the second modal is a modal about a document, the information in the second modal from which the vector based on the information in the second modal is generated is the document.
- the output device 100 acquires, for example, by generating a vector based on the information of the first modal from the image which is the information of the first modal of the teacher data, and obtains the information of the second modal of the teacher data. Is obtained by generating a vector based on the information of the second modal from the document. Then, the output device 100 uses an error back propagation or the like based on the vector based on the acquired first modal information, the vector based on the acquired second modal information, and the correct answer data of the teacher data, and causes Co. -Update the Attention Network. The output device 100 may update the Co-Attention Network by a learning method other than error back propagation.
- the output device 100 acquires a vector based on the information of the first modal and a vector based on the information of the second modal. Then, the output device 100 uses Co-Attention Network to generate a third vector based on the vector based on the acquired first modal information and the vector based on the acquired second modal information. Then, based on the generated third vector, solve the problem. After that, the output device 100 transmits the result of solving the problem to the client device 201.
- the output device 100 acquires, for example, a vector based on the first modal information input to the output device 100 by the user of the output device 100. Further, the output device 100 may acquire a vector based on the first modal information by receiving the vector from the client device 201 or the terminal device 202. Further, the output device 100 may acquire, for example, the information of the first modal which is the source for generating the vector based on the information of the first modal by receiving the information of the first modal from the client device 201 or the terminal device 202. For example, if the first modal is a modal about an image, then the information in the first modal from which the vector based on the information in the first modal is generated is the image.
- the output device 100 acquires, for example, a vector based on the second modal information input to the output device 100 by the user of the output device 100. Further, the output device 100 may acquire a vector based on the second modal information by receiving the vector from the client device 201 or the terminal device 202. Further, the output device 100 may acquire, for example, the information of the second modal which is the source for generating the vector based on the information of the second modal by receiving the information of the second modal from the client device 201 or the terminal device 202. For example, if the second modal is a modal about a document, the information in the second modal from which the vector based on the information in the second modal is generated is the document.
- the output device 100 uses Co-Attention Network to generate a third vector based on the vector based on the acquired first modal information and the vector based on the acquired second modal information. Then, based on the generated third vector, solve the problem. After that, the output device 100 transmits the result of solving the problem to the client device 201.
- the output device 100 is, for example, a server, a PC (Personal Computer), or the like.
- the client device 201 is a computer capable of communicating with the output device 100.
- the client device 201 may transmit, for example, a vector based on the information of the first modal to the output device 100. Further, the client device 201 may transmit, for example, the information of the first modal which is the source for generating the vector based on the information of the first modal to the output device 100.
- the client device 201 may transmit, for example, a vector based on the second modal information to the output device 100. Further, the client device 201 may transmit, for example, the information of the second modal, which is the source of generating the vector based on the information of the second modal, to the output device 100.
- the client device 201 receives and outputs the result of solving the problem by the output device 100.
- the output format is, for example, display on a display, print output to a printer, transmission to another computer, or storage in a storage area.
- the client device 201 is, for example, a PC, a tablet terminal, a smartphone, or the like.
- the terminal device 202 is a computer capable of communicating with the output device 100.
- the terminal device 202 may transmit, for example, a vector based on the information of the first modal to the output device 100. Further, the terminal device 202 may transmit, for example, the information of the first modal which is the source for generating the vector based on the information of the first modal to the output device 100.
- the terminal device 202 may transmit, for example, a vector based on the information of the second modal to the output device 100. Further, the terminal device 202 may transmit, for example, the information of the second modal, which is the source of generating the vector based on the information of the second modal, to the output device 100.
- the terminal device 202 is, for example, a PC, a tablet terminal, a smartphone, an electronic device, an IoT device, a sensor device, or the like. Specifically, the terminal device 202 may be a surveillance camera.
- the output device 100 updates the Co-Attention Network and solves the problem by using the Co-Attention Network
- another computer may update the Co-Attention Network, and the output device 100 may solve the problem using the Co-Attention Network received from the other computer.
- the output device 100 may update the Co-Attention Network and provide it to another computer, and the other computer may solve the problem by using the Co-Attention Network.
- the teacher data is the source that generates the information of the first modal that is the source for generating the vector based on the information of the first modal that is the sample, and the source that generates the vector based on the information of the second modal that is the sample.
- the case where the second modal information is associated with the correct answer data has been described, but the present invention is not limited to this.
- the teacher data is correspondence information in which the vector based on the information of the first modal as a sample, the vector based on the information of the second modal as a sample, and the correct answer data are associated with each other. Good.
- the output device 100 is a device different from the client device 201 and the terminal device 202 has been described, but the present invention is not limited to this.
- the output device 100 may be integrated with the client device 201.
- the output device 100 may be integrated with the terminal device 202.
- the output device 100 realizes the Co-Attention Network in terms of software has been described, but the present invention is not limited to this.
- the output device 100 may realize the Co-Attention Network electronically.
- the output device 100 stores an image and a document that serves as a question about the image.
- the question text is, for example, "what is cut in the image”. Then, the output device 100 solves the problem of estimating the answer sentence to the question sentence based on the image and the document.
- the output device 100 estimates, for example, an answer sentence to a question sentence about what is cut in the image based on the image and the document, and transmits the answer sentence to the client device 201.
- the terminal device 202 is a surveillance camera, and an image of the target is transmitted to the output device 100.
- the object is specifically the appearance of the fitting room.
- the output device 100 stores a document that serves as an explanatory text about the target.
- the explanation is an explanation that the curtain of the fitting room tends to be closed while the person is using the fitting room.
- the output device 100 solves the problem of determining the degree of risk based on the image and the document.
- the degree of risk is, for example, an index value indicating the high possibility that a person who has not completed evacuation remains in the fitting room.
- the output device 100 determines, for example, the degree of risk indicating the high possibility that a person who has not completed evacuation remains in the fitting room in the event of a disaster.
- the output device 100 stores an image forming a moving image and a document serving as an explanatory text about the image.
- the moving image is, for example, a moving image showing the state of cooking.
- the explanation is specifically an explanation about the cooking procedure.
- the output device 100 solves the problem of determining the degree of risk based on the image and the document.
- the degree of risk is, for example, an index value indicating the high degree of risk during cooking.
- the output device 100 determines, for example, a degree of risk indicating a high degree of risk during cooking.
- FIG. 3 is a block diagram showing a hardware configuration example of the output device 100.
- the output device 100 includes a CPU (Central Processing Unit) 301, a memory 302, a network I / F (Interface) 303, a recording medium I / F 304, and a recording medium 305. Further, each component is connected by a bus 300.
- the CPU 301 controls the entire output device 100.
- the memory 302 includes, for example, a ROM (Read Only Memory), a RAM (Random Access Memory), a flash ROM, and the like. Specifically, for example, a flash ROM or ROM stores various programs, and RAM is used as a work area of CPU 301. The program stored in the memory 302 is loaded into the CPU 301 to cause the CPU 301 to execute the coded process.
- the network I / F 303 is connected to the network 210 through a communication line, and is connected to another computer via the network 210. Then, the network I / F 303 controls the internal interface with the network 210 and controls the input / output of data from another computer.
- the network I / F 303 is, for example, a modem or a LAN adapter.
- the recording medium I / F 304 controls data read / write to the recording medium 305 according to the control of the CPU 301.
- the recording medium I / F 304 is, for example, a disk drive, an SSD (Solid State Drive), a USB (Universal Serial Bus) port, or the like.
- the recording medium 305 is a non-volatile memory that stores data written under the control of the recording medium I / F 304.
- the recording medium 305 is, for example, a disk, a semiconductor memory, a USB memory, or the like.
- the recording medium 305 may be detachable from the output device 100.
- the output device 100 may include, for example, a keyboard, a mouse, a display, a printer, a scanner, a microphone, a speaker, and the like, in addition to the above-described components. Further, the output device 100 may have a plurality of recording media I / F 304 and recording media 305. Further, the output device 100 does not have to have the recording medium I / F 304 or the recording medium 305.
- the hardware configuration example of the client device 201 is specifically the same as the hardware configuration example of the output device 100 shown in FIG. 3, and thus the description thereof will be omitted.
- the hardware configuration example of the terminal device 202 is specifically the same as the hardware configuration example of the output device 100 shown in FIG. 3, and thus the description thereof will be omitted.
- FIG. 4 is a block diagram showing a functional configuration example of the output device 100.
- the output device 100 includes a storage unit 400, an acquisition unit 401, a first correction unit 402, a first generation unit 403, a second correction unit 404, a second generation unit 405, and a third. It includes a generation unit 406, an analysis unit 407, and an output unit 408.
- the storage unit 400 is realized by, for example, a storage area such as the memory 302 or the recording medium 305 shown in FIG.
- a storage area such as the memory 302 or the recording medium 305 shown in FIG.
- the storage unit 400 may be included in a device different from the output device 100, and the stored contents of the storage unit 400 may be referred to by the output device 100.
- the acquisition unit 401 to the output unit 408 function as an example of the control unit.
- the acquisition unit 401 to the output unit 408 may be, for example, by causing the CPU 301 to execute a program stored in a storage area such as the memory 302 or the recording medium 305 shown in FIG. 3, or the network I / F 303. To realize the function.
- the processing result of each functional unit is stored in a storage area such as the memory 302 or the recording medium 305 shown in FIG. 3, for example.
- the storage unit 400 stores various information referred to or updated in the processing of each functional unit.
- the storage unit 400 stores the Co-Attention Network.
- the Co-Attention Network is a model that generates a third vector based on a vector based on the information of the first modal and a vector based on the information of the second modal.
- the Co-Attention Network covers the first target attention layer, the second target attention layer, the first self-attention layer, the second self-attention layer, and the third self-attention layer, which will be described later. Correspond.
- the first target attention layer is related to, for example, the first modal.
- the first target attention layer is a model that corrects the vector based on the information of the first modal.
- the first self-attention layer relates to, for example, the first modal.
- the first self-attention layer is a model that further corrects the corrected vector based on the information of the first modal to generate the first vector.
- the second target attention layer relates to, for example, a second modal.
- the second target attention layer is a model that corrects the vector based on the information of the second modal.
- the second self-attention layer relates to, for example, a second modal.
- the second self-attention layer is a model that further corrects the corrected vector based on the information of the second modal to generate the second vector.
- the third self-attention layer is a model that generates a third vector based on the first vector and the second vector.
- the first modal is a modal related to images
- the second modal is a modal related to documents.
- the first modal is an image modal
- the second modal is an audio modal.
- the first modal is a modal for a document in a first language
- the second modal is a modal for a document in a second language.
- the Co-Attention Network is updated by the analysis unit 407 or used when solving a problem by the analysis unit 407.
- the storage unit 400 stores, for example, the parameters of the Co-Attention Network. Specifically, the storage unit 400 includes a first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third self-attention layer.
- the parameters are described in detail below.
- the storage unit 400 may store teacher data.
- the teacher data is, for example, a source for generating a vector based on the information of the first modal as a sample and a vector based on the information of the second modal as a sample. Correspondence information in which the second modal information and the correct answer data are associated with each other.
- the teacher data is input by the user, for example.
- the correct answer data shows, for example, the correct answer when the problem is solved based on the third vector.
- the information of the first modal that is the source of generating a vector based on the information of the first modal is an image.
- the second modal is a modal about a document
- the information in the second modal from which the vector based on the information in the second modal is generated is the document.
- the teacher data may be correspondence information in which the vector based on the information of the first modal as a sample, the vector based on the information of the second modal as a sample, and the correct answer data are associated with each other.
- the acquisition unit 401 acquires various information used for processing of each functional unit.
- the acquisition unit 401 stores various acquired information in the storage unit 400 or outputs it to each function unit. Further, the acquisition unit 401 may output various information stored in the storage unit 400 to each function unit.
- the acquisition unit 401 acquires various information based on, for example, a user's operation input.
- the acquisition unit 401 may receive various information from a device different from the output device 100, for example.
- the acquisition unit 401 acquires a vector based on the information of the first modal and a vector based on the information of the second modal.
- the acquisition unit 401 acquires teacher data, and based on the teacher data, acquires a vector based on the information of the first modal and a vector based on the information of the second modal. To do.
- the acquisition unit 401 accepts the input of teacher data by the user, and from the teacher data, the information of the first modal that is the source of generating the vector based on the information of the first modal, and the information of the second modal. Get the information of the second modal from which the information-based vector is generated. Then, the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on the various acquired information.
- the acquisition unit 401 acquires an image included in the teacher data and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 specifically acquires the document included in the teacher data and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 receives the teacher data from the client device 201 or the terminal device 202, and from the received teacher data, the acquisition unit 401 of the first modal that is the source of generating a vector based on the information of the first modal.
- the information and the information of the second modal from which the vector based on the information of the second modal is generated may be acquired.
- the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on the acquired information.
- the acquisition unit 401 acquires an image included in the teacher data and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 specifically acquires the document included in the teacher data and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 accepts the input of teacher data by the user, and may acquire the vector based on the first modal information and the vector based on the second modal information as they are from the teacher data. Good.
- the acquisition unit 401 receives the teacher data from the client device 201 or the terminal device 202, and from the received teacher data, a vector based on the first modal information and a vector based on the second modal information. And may be acquired as it is.
- the acquisition unit 401 uses the Co-Attention Network to acquire a vector based on the information of the first modal and a vector based on the information of the second modal when solving the problem.
- the acquisition unit 401 for example, is a second modal information source for generating a vector based on the first modal information by the user and a second modal source for generating a vector based on the second modal information. Accepts input with modal information. Then, the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on various input information.
- the acquisition unit 401 acquires an image and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 specifically acquires a document and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 of the first modal information that is the source of generating the vector based on the information of the first modal and the second modal that is the source of generating the vector based on the information of the second modal.
- Information may be received from the client device 201 or the terminal device 202. Then, the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on the various acquired information.
- the acquisition unit 401 acquires an image and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 acquires a document and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 may accept, for example, input by the user of a vector based on the information of the first modal and a vector based on the information of the second modal.
- the acquisition unit 401 may receive, for example, a vector based on the information of the first modal and a vector based on the information of the second modal from the client device 201 or the terminal device 202.
- the acquisition unit 401 may accept a start trigger to start processing of any of the functional units.
- the start trigger is, for example, that there is a predetermined operation input by the user.
- the start trigger may be, for example, the receipt of predetermined information from another computer.
- the start trigger may be, for example, that any functional unit outputs predetermined information.
- the acquisition unit 401 receives, for example, the acquisition of the vector based on the information of the first modal and the vector based on the information of the second modal as a start trigger for starting the processing of each functional unit.
- the first correction unit 402 corrects the vector based on the information of the first modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal. Correlation is expressed, for example, by the degree of similarity between a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal.
- the vector obtained from the vector based on the information of the first modal is, for example, a query.
- the vector obtained from the vector based on the information of the second modal is, for example, a key.
- the similarity is expressed by, for example, the inner product.
- the degree of similarity may be expressed by, for example, the sum of squares of differences.
- the first correction unit 402 uses, for example, the first target attention layer to obtain a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal. Correct the informed vector of the first modal based on the inner product.
- the first correction unit 402 uses the first target attention layer to obtain a query obtained from a vector based on the information of the first modal and a vector based on the information of the second modal. Correct the informed vector of the first modal based on the inner product with the key.
- an example of correcting a vector based on the first modal information is shown in, for example, an operation example described later with reference to FIG.
- the first correction unit 402 uses the vector based on the information of the first modal as the component that is relatively closely related to the vector based on the information of the first modal among the vectors based on the information of the second modal.
- the vector based on the information of the first modal can be corrected so that it is strongly reflected in.
- the first generation unit 403 generates the first vector based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the first modal. Correlation is represented, for example, by the similarity of two different types of vectors obtained from a vector based on the corrected first modal information. Two different types of vectors are, for example, a query and a key. The similarity is expressed by, for example, the inner product. The degree of similarity may be expressed by, for example, the sum of squares of differences.
- the first generation unit 403 for example, using the first self-attention layer, is corrected based on the inner product of two different types of vectors obtained from the corrected first modal information-based vector.
- the vector based on the information of the first modal is further corrected to generate the first vector.
- the first generation unit 403 uses the first self-attention layer and is corrected based on the inner product of the query and the key obtained from the vector based on the information of the first modal after correction.
- the vector based on the information of the first modal of is further corrected to generate the first vector.
- an example of generating the first vector is shown in, for example, an operation example described later with reference to FIG.
- the first generation unit 403 further increases the vector based on the corrected first modal information so that the more useful component of the vector based on the corrected first modal information becomes larger. It can be corrected.
- the second correction unit 404 corrects the vector based on the second modal information based on the correlation between the vector based on the first modal information and the vector based on the second modal information. Correlation is expressed, for example, by the degree of similarity between a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal.
- the vector obtained from the vector based on the information of the first modal is, for example, a key.
- the vector obtained from the vector based on the information of the second modal is, for example, a query.
- the similarity is expressed by, for example, the inner product.
- the degree of similarity may be expressed by, for example, the sum of squares of differences.
- the second correction unit 404 uses, for example, a second target attention layer to obtain a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal. Correct the informed vector of the second modal based on the inner product.
- the second correction unit 404 is obtained from the key obtained from the vector based on the information of the first modal and the vector based on the information of the second modal by using the second target attention layer. Correct the informed vector of the second modal based on the inner product with the query.
- an example of correcting a vector based on the second modal information is shown in, for example, an operation example described later with reference to FIG.
- the second correction unit 404 uses the vector based on the information of the second modal as the component that is relatively closely related to the vector based on the information of the second modal among the vectors based on the information of the first modal.
- the vector based on the information of the second modal can be corrected so that it is strongly reflected in.
- the second generation unit 405 generates a second vector based on the correlation between two different types of vectors obtained from the corrected vector based on the information of the second modal. Correlation is represented, for example, by the similarity of two different types of vectors obtained from a vector based on the corrected second modal information.
- Two different types of vectors are, for example, a query and a key.
- the similarity is expressed by, for example, the inner product.
- the degree of similarity may be expressed by, for example, the sum of squares of differences.
- the second generator 405 uses a second self-attention layer and is based on the inner product of two different types of vectors obtained from the corrected second modal information-based vector.
- the vector based on the information of the second modal is further corrected to generate the second vector.
- the second generation unit 405 uses the second self-attention layer and is corrected based on the inner product of the query and the key obtained from the vector based on the corrected second modal information.
- the vector based on the information of the second modal of is further corrected to generate the second vector.
- an example of generating the second vector is shown in, for example, an operation example described later with reference to FIG.
- the second generation unit 405 further increases the vector based on the corrected second modal information so that the more useful component of the corrected vector based on the second modal information becomes larger. It can be corrected.
- the output device 100 may repeat the operations of the first correction unit 402 to the second generation unit 405 once or more. For example, when the output device 100 repeats the operations of the first correction unit 402 to the second generation unit 405, the output device 100 sets the generated first vector to a vector based on new first modal information. , Set the generated second vector to a vector based on the new second modal information. As a result, the output device 100 can further improve the accuracy of the solution when the problem is solved.
- the output device 100 can generate a third vector in a more useful state, for example, from the viewpoint of improving the accuracy of the solution when solving the problem.
- the third generation unit 406 generates a coupling vector.
- the coupling vector includes a predetermined vector, a generated first vector, and a generated second vector.
- the third generation unit 406 generates, for example, a coupling vector in which a predetermined vector, the first vector, and the second vector are combined.
- the third generation unit 406 was generated last with a predetermined vector, the first vector generated last, and the first vector generated last, for example, after repeating the operations of the first correction unit 402 to the second generation unit 405. Generate a combined vector by combining with the second vector.
- the third generation unit 406 generates a third vector that aggregates the first vector and the second vector based on the correlation between two different types of vectors obtained from the coupling vector. Correlation is represented, for example, by the similarity of two different types of vectors obtained from the combined vector. Two different types of vectors are, for example, a query and a key. The similarity is expressed by, for example, the inner product. The degree of similarity may be expressed by, for example, the sum of squares of differences.
- the third generation unit 406 corrects the coupling vector and generates the third vector, for example, using the third self-attention layer, based on the inner product of two different types of vectors obtained from the coupling vector. ..
- the third vector is, for example, a partial vector included in a position corresponding to a predetermined vector among the corrected coupling vectors.
- the third generator 406 uses the third self-attention layer to correct the join vector based on the inner product of the query and the key obtained from the join vector, thereby correcting the third vector. Generate a corrected coupling vector containing.
- an example of generating the third vector is shown in, for example, an operation example described later with reference to FIG.
- the third generation unit 406 can generate a third vector useful from the viewpoint of improving the accuracy of the solution when solving the problem and make it referenceable.
- the analysis unit 407 updates the Co-Attention Network based on the generated third vector.
- the analysis unit 407 for example, based on the third vector, has a first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third. Update with the self-attention layer. The update is performed, for example, by error backpropagation.
- the analysis unit 407 solves the problem on a trial basis using the generated third vector and compares it with the correct answer data.
- One example of the problem is, for example, the problem of determining whether the situation relating to the first modal and the second modal is a positive situation or a negative situation.
- One example of the problem is, specifically, the problem of determining whether the situation suggested by the image is a situation in which humans can be harmed or a situation in which humans are not harmed.
- the analysis unit 407 includes a first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third self. Update with the attention layer.
- the analysis unit 407 can update various attention layers so that the third vector can be generated in a more useful state, and can improve the accuracy of the solution when the problem is solved.
- the analysis unit 407 solves the actual problem using the generated third vector.
- One example of the problem is, for example, the problem of determining whether the situation relating to the first modal and the second modal is a positive situation or a negative situation.
- One example of the problem is, specifically, the problem of determining whether the situation suggested by the image is a situation in which humans can be harmed or a situation in which humans are not harmed. As a result, the analysis unit 407 can improve the accuracy of the solution when the problem is solved.
- the output unit 408 outputs the processing result of any of the functional units.
- the output format is, for example, display on a display, print output to a printer, transmission to an external device by the network I / F 303, or storage in a storage area such as a memory 302 or a recording medium 305.
- the output unit 408 can notify the user of the processing result of each functional unit, and the convenience of the output device 100 can be improved.
- the output unit 408 outputs, for example, the updated Co-Attention Network.
- the output unit 408 includes an updated first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third self-attention. Output layers.
- the output unit 408 can refer to the updated Co-Attention Network. Therefore, the output unit 408 can improve the accuracy of the solution when the problem is solved by using the updated Co-Attention Network, for example, on another computer.
- the output unit 408 outputs, for example, the generated third vector.
- the output unit 408 can refer to the third vector, make the Co-Attention Network updatable, or improve the accuracy of the solution when solving the problem.
- the output unit 408 outputs, for example, the third vector in association with the result of solving the actual problem. Specifically, the output unit 408 outputs the third vector in association with the determined situation. As a result, the output unit 408 can make the result of solving the problem visible to the user or the like.
- the output unit 408 may output the result of solving the actual problem without outputting the third vector, for example. Specifically, the output unit 408 outputs the determined situation without outputting the third vector. As a result, the output unit 408 can make the result of solving the problem visible to the user or the like.
- FIG. 5 is an explanatory diagram showing a specific example of Co-Attention Network 500.
- Co-Attention Network 500 may be referred to as "CAN500”.
- the target attention may be expressed as "TA”.
- SA self-attention
- the CAN 500 has an image TA layer 501, an image SA layer 502, a document TA layer 503, a document SA layer 504, a binding layer 505, and an integrated SA layer 506.
- the CAN 500 outputs the vector Z T in response to the input of the feature amount vector L related to the document and the feature amount vector I related to the image.
- the feature quantity vector L related to the document is, for example, an arrangement of M feature quantity vectors related to the document.
- the M feature vector is, for example, a feature vector indicating M words included in the document.
- the feature amount vector I related to the image is, for example, an arrangement of N feature amount vectors related to the image.
- the N feature vector is, for example, a feature vector indicating N objects in the image.
- the image TA layer 501 accepts inputs of the feature amount vector I related to the image and the feature amount vector L related to the document.
- the image TA layer 501 corrects the feature vector I for the image based on the query obtained from the feature vector I for the image and the keys and values obtained from the feature vector L for the document.
- the image TA layer 501 outputs the feature amount vector I related to the corrected image to the image SA layer 502. Specific examples of the image TA layer 501 will be described later with reference to, for example, FIG.
- the image SA layer 502 accepts the input of the feature amount vector I related to the corrected image.
- the image SA layer 502 further corrects the feature vector I related to the corrected image based on the query, key, and value obtained from the feature vector I related to the corrected image, and generates a new feature vector Z I. And output to the bond layer 505.
- a specific example of the image SA layer 502 will be described later with reference to, for example, FIG.
- the document TA layer 503 accepts inputs of the feature amount vector L related to the document and the feature amount vector I related to the image.
- the document TA layer 503 corrects the feature vector L related to the document based on the query obtained from the feature vector L related to the document and the keys and values obtained from the feature vector I related to the image.
- the document TA layer 503 outputs the feature amount vector L related to the corrected document to the document SA layer 504.
- a specific example of the document TA layer 503 will be described later with reference to, for example, FIG.
- the document SA layer 504 accepts the input of the feature amount vector L related to the corrected document.
- the document SA layer 504 further corrects the feature vector L related to the corrected document based on the query, key, and value obtained from the feature vector L related to the corrected document, and generates a new feature vector Z L. And output. Specific examples of the document SA layer 504 will be described later with reference to, for example, FIG.
- the coupling layer 505 receives inputs of the aggregation vector H, the feature amount vector Z I, and the feature amount vector Z L.
- the coupling layer 505 combines the aggregation vector H, the feature quantity vector Z I, and the feature quantity vector Z L to generate the coupling vector C, and outputs the coupling vector C to the integrated SA layer 506.
- the integrated SA layer 506 accepts the input of the coupling vector C.
- the integrated SA layer 506 corrects the coupling vector C based on the query, key, and value obtained from the coupling vector C, and generates and outputs the feature vector Z T.
- the feature vector Z T includes an aggregate vector Z H , an integrated feature vector Z 1 to Z M related to the document, and an integrated feature vector Z M + 1 to Z M + N related to the image.
- the output device 100 can generate a feature vector Z T including an aggregate vector Z H , which is useful from the viewpoint of improving the accuracy of the solution when the problem is solved, and make it referenceable. Therefore, the output device 100 can improve the accuracy of the solution when the problem is solved.
- the output device 100 can further improve the accuracy of the solution when the problem is solved.
- the SA layer 600 such as the image SA layer 502 forming the CAN 500, the document SA layer 504, and the integrated SA layer 506 will be described.
- the TA layer 610 such as the image TA layer 501 and the document TA layer 503 forming the CAN 500 will be described.
- FIG. 6 is an explanatory diagram showing a specific example of the SA layer 600 and a specific example of the TA layer 610.
- Multi-Head Attention may be referred to as "MHA”.
- Add & Norm may be referred to as "A & N”.
- Feed Forward may be described as "FF”.
- the SA layer 600 has an MHA layer 601, an A & N layer 602, an FF layer 603, and an A & N layer 604.
- the MHA layer 601 generates a correction vector R that corrects the input vector X based on the query Q, the key K, and the value V obtained from the input vector X, and outputs the correction vector R to the A & N layer 602.
- the MHA layer 601 divides the input vector X into Head vectors for processing. Head is a natural number of 1 or more.
- the A & N layer 602 is normalized after adding the input vector X and the correction vector R, and the normalized vector is output to the FF layer 603 and the A & N layer 604.
- the FF layer 603 compresses the normalized vector and outputs the compressed vector to the A & N layer 604.
- the A & N layer 604 adds the normalized vector and the compressed vector, normalizes the vector, generates an output vector Z, and outputs the output vector Z.
- the TA layer 610 has an MHA layer 611, an A & N layer 612, an FF layer 613, and an A & N layer 614.
- the MHA layer 611 generates a correction vector R that corrects the input vector X based on the query Q obtained from the input vector X and the key K and the value V obtained from the input vector Y, and outputs the correction vector R to the A & N layer 612. .
- the A & N layer 612 adds the input vector X and the correction vector R and normalizes them, and outputs the normalized vector to the FF layer 613 and the A & N layer 614.
- the FF layer 613 compresses the normalized vector and outputs the compressed vector to the A & N layer 614.
- the A & N layer 614 adds and normalizes the normalized vector and the compressed vector, generates an output vector Z, and outputs the output vector Z.
- the above-mentioned MHA layer 601 and MHA layer 611 are formed by Head Attention layers 620.
- the Attention layer 620 has a MatMul layer 621, a Scale layer 622, a Mask layer 623, a SoftMax layer 624, and a MatMul layer 625.
- MatMul layer 621 calculates the inner product of query Q and key K and sets it in Score.
- the Scale layer 622 divides the entire Score by a constant a and updates it.
- the Mask layer 623 may mask the updated Score.
- the SoftMax layer 624 normalizes the updated Score and sets it to Att.
- the MatMul layer 625 calculates the inner product of Att and the value V and sets it in the correction vector R.
- the input vector X is the feature amount vector X related to the image represented by the following equation (1).
- x 1 , x 2 , and x 3 are d-dimensional vectors.
- x 1 , x 2 , and x 3 correspond to the objects in the image, respectively.
- the query Q is calculated by the following equation (2).
- W Q is a transformation matrix and is set by learning.
- the key K is calculated by the following formula (3).
- W K is a transformation matrix and is set by learning.
- the value V is calculated by the following formula (4).
- W V is a transformation matrix and is set by learning.
- the query Q, the key K, and the value V have the same dimensions as the input vector X.
- the MatMul layer 621 calculates the inner product of the query Q and the key K as shown in the following equation (5), and sets it in Score.
- the Scale layer 622 is updated by dividing the entire Score by the constant a, as shown in the following equation (6).
- the Mask layer 623 omits the masking process.
- the SoftMax layer 624 normalizes the updated Score and sets it to Att.
- the MatMul layer 625 calculates the inner product of Att and the value V and sets it in the correction vector R.
- the MHA layer 601 generates the correction vector R as described above.
- the A & N layer 602 adds and normalizes the input vector X and the correction vector R, and updates the input vector X.
- ⁇ is defined by the following equation (11).
- ⁇ is defined by the following equation (12).
- the FF layer 603 converts the updated input vector X and sets the conversion vector X'.
- f is an activation function.
- the A & N layer 604 adds and normalizes the updated input vector X and the set conversion vector X', and generates an output vector Z.
- the input vector X is the feature amount vector X related to the image represented by the above equation (1).
- x 1 , x 2 , and x 3 are d-dimensional vectors.
- x 1 , x 2 , and x 3 correspond to the objects in the image, respectively.
- the input vector Y is a feature vector Y related to the document represented by the following equation (14).
- y 1 , y 2 , and y 3 are d-dimensional vectors.
- y 1 , y 2 , and y 3 correspond to the words contained in the document, respectively.
- the query Q is calculated by the following equation (15).
- W Q is a transformation matrix and is set by learning.
- the key K is calculated by the following formula (16).
- W K is a transformation matrix and is set by learning.
- the value V is calculated by the following formula (17).
- W V is a transformation matrix and is set by learning.
- the query Q has the same dimensions as the input vector X.
- the key K and the value V have the same dimensions as the input vector Y.
- the MatMul layer 621 calculates the inner product of the query Q and the key K as shown in the above equation (5), and sets it in Score. As shown in the above equation (6), the Scale layer 622 divides the entire Score by the constant a and updates it. Here, the Mask layer 623 omits the masking process. As shown in the above equation (7), the SoftMax layer 624 normalizes the updated Score and sets it to Att. As shown in the above equation (8), the MatMul layer 625 calculates the inner product of Att and the value V and sets it in the correction vector R.
- the MHA layer 601 generates the correction vector R as described above.
- the A & N layer 602 adds and normalizes the input vector X and the correction vector R, and updates the input vector X.
- the FF layer 603 converts the updated input vector X and sets the conversion vector X'.
- the A & N layer 604 adds and normalizes the updated input vector X and the set conversion vector X', and generates an output vector Z.
- FIG. 7 is an explanatory diagram showing an example of operation using CAN500.
- the output device 100 acquires the document 700 and the image 710.
- the output device 100 tokenizes the document 700, vectorizes the token set 701, generates a feature amount vector 702 related to the document 700, and inputs the feature amount vector 702 to the CAN 500.
- the output device 100 detects an object from the image 710, vectorizes a set of partial images 711 for each object, generates a feature amount vector 712 related to the image 710, and inputs the feature amount vector 712 to the CAN 500.
- the output device 100 acquires the feature amount vector Z T from the CAN 500, and inputs the aggregate vector Z H included in the feature amount vector Z T to the risk estimator 720.
- the output device 100 acquires the estimation result No. from the risk estimator 720.
- the output device 100 can be made to estimate by the risk estimator 720 by using the aggregate vector Z H in which the features of the image and the document are reflected, and can be estimated with high accuracy.
- the output device 100 performs a learning phase and learns the CAN 500.
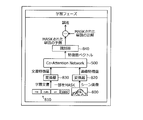
- the output device 100 acquires, for example, an image 800 in which some scene is captured and a document 810 as subtitles corresponding to the image 800.
- Image 800 captures, for example, a scene of cutting an apple.
- the output device 100 converts the image 800 into a feature amount vector by the converter 820 and inputs the image 800 to the CAN 500. Further, the output device 100 masks the word apple of the document 810, converts it into a feature amount vector by the converter 830, and inputs it to the CAN 500.
- the output device 100 inputs the feature amount vector generated by the CAN 500 into the classifier 840, acquires the result of predicting the masked word, and calculates the error from the correct answer "apple" of the masked word.
- the output device 100 learns the CAN 500 by error back propagation based on the calculated error. Further, the output device 100 may learn the converters 820 and 830 and the classifier 840 by backpropagation of errors. Thereby, the output device 100 updates the CAN 500, and the converters 820, 830 and the classifier 840 so as to be useful from the viewpoint of estimating the word in consideration of the image 800 and the context of the document 810 which is the subtitle. Can be done. Next, the description shifts to FIG.
- the output device 100 carries out the test phase, and uses the learned converters 820 and 830 and the learned CAN500 to generate and output an answer.
- the output device 100 acquires, for example, an image 900 in which some scene is captured and a document 910 as a question sentence corresponding to the image 900.
- Image 900 captures, for example, a scene of cutting an apple.
- the output device 100 converts the image 900 into a feature amount vector by the converter 820 and inputs it to the CAN 500. Further, the output device 100 converts the document 910 into a feature amount vector by the converter 830 and inputs the document 910 to the CAN 500. The output device 100 inputs the feature amount vector generated by the CAN 500 into the answer generator 920, acquires a word to be an answer, and outputs it. As a result, the output device 100 can accurately estimate the word to be answered in consideration of the image 900 and the context of the document 910 which is a question sentence.
- the output device 100 performs a learning phase and learns the CAN 500.
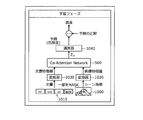
- the output device 100 acquires, for example, an image 1000 in which some scene is captured and a document 1010 as a subtitle corresponding to the image 1000.
- Image 1000 captures, for example, a scene of cutting an apple.
- the output device 100 converts the image 1000 into a feature amount vector by the converter 1020 and inputs it to the CAN 500. Further, the output device 100 masks the word apple of the document 1010, converts it into a feature amount vector by the converter 1030, and inputs it to the CAN 500.
- the output device 100 inputs the feature amount vector generated by the CAN 500 into the classifier 1040, acquires the result of predicting the risk level of the scene shown in the image, and calculates the error from the correct answer of the risk level.
- the output device 100 learns the CAN 500 by error back propagation based on the calculated error. Further, the output device 100 learns the converters 1020 and 1030 and the classifier 1040 by backpropagation of errors. As a result, the output device 100 updates the CAN 500, the converters 1020, 1030, and the classifier 1040 so as to be useful from the viewpoint of predicting the degree of risk in consideration of the context of the image 1000 and the document 1010 which is the subtitle. be able to. Next, the description shifts to FIG.
- the output device 100 carries out a test phase, predicts the degree of risk and outputs using the learned converters 1020 and 1030 and the classifier 1040 and the learned CAN500.
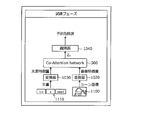
- the output device 100 acquires, for example, an image 1100 in which some scene is captured and a document 1110 as an explanatory text corresponding to the image.
- Image 1100 captures, for example, a scene of cutting a thigh.
- the output device 100 converts the image 1100 into a feature amount vector by the converter 1020 and inputs it to the CAN 500. Further, the output device 100 converts the document 1110 into a feature amount vector by the converter 1030 and inputs it to the CAN 500. The output device 100 inputs the feature quantity vector generated by the CAN 500 into the classifier 1040, acquires the degree of risk, and outputs the vector. As a result, the output device 100 can accurately predict the degree of risk in consideration of the context of the image 1100 and the document 1110 which is the explanatory text.
- the learning process is realized, for example, by the CPU 301 shown in FIG. 3, a storage area such as a memory 302 or a recording medium 305, and a network I / F 303.
- FIG. 12 is a flowchart showing an example of the learning processing procedure.
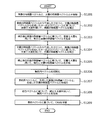
- the output device 100 acquires the feature amount vector of the image and the feature amount vector of the document (step S1201).
- the output device 100 uses the image TA layer 501 based on the query generated from the acquired image feature vector and the keys and values generated from the acquired document feature vector to image features.
- the quantity vector is corrected (step S1202).
- the output device 100 further corrects the feature amount vector of the corrected image by using the image SA layer 502 based on the feature amount vector of the corrected image, and newly generates the feature amount vector of the image. (Step S1203).
- the output device 100 uses the document TA layer 503 based on the query generated from the acquired document feature vector and the keys and values generated from the acquired image feature vector, to use the document features.
- the quantity vector is corrected (step S1204).
- the output device 100 further corrects the feature amount vector of the corrected document by using the document SA layer 504 based on the feature amount vector of the corrected document, and newly generates the feature amount vector of the document. (Step S1205).
- the output device 100 initializes the aggregation vector (step S1206). Then, the output device 100 combines the aggregation vector, the feature amount vector of the generated image, and the feature amount vector of the generated document to generate a combined vector (step S1207).
- the output device 100 corrects the coupling vector using the integrated SA layer 506 based on the coupling vector and generates an aggregate vector (step S1208). Then, the output device 100 learns the CAN 500 based on the aggregation vector (step S1209).
- the output device 100 ends the learning process.
- the output device 100 can update the parameters of the CAN 500 so that the accuracy of the solution when the problem is solved is improved.
- the output device 100 may execute the processing in the partial steps of FIG. 12 in a different order.
- the order of the processes of steps S1202 and S1203 and the processes of steps S1204 and S1205 can be exchanged.
- the output device 100 may repeatedly execute the processes of steps S1202 to S1205.
- Estimatiation processing procedure Next, an example of the estimation processing procedure executed by the output device 100 will be described with reference to FIG.
- the estimation process is realized, for example, by the CPU 301 shown in FIG. 3, a storage area such as a memory 302 or a recording medium 305, and a network I / F 303.
- FIG. 13 is a flowchart showing an example of the estimation processing procedure.
- the output device 100 acquires the feature amount vector of the image and the feature amount vector of the document (step S1301).
- the output device 100 uses the image TA layer 501 based on the query generated from the acquired image feature vector and the keys and values generated from the acquired document feature vector to image features.
- the quantity vector is corrected (step S1302).
- the output device 100 further corrects the feature amount vector of the corrected image by using the image SA layer 502 based on the feature amount vector of the corrected image, and newly generates the feature amount vector of the image. (Step S1303).
- the output device 100 uses the document TA layer 503 based on the query generated from the acquired document feature vector and the keys and values generated from the acquired image feature vector, to use the document features.
- the quantity vector is corrected (step S1304).
- the output device 100 further corrects the feature amount vector of the corrected document by using the document SA layer 504 based on the feature amount vector of the corrected document, and newly generates the feature amount vector of the document. (Step S1305).
- the output device 100 initializes the aggregation vector (step S1306). Then, the output device 100 combines the aggregation vector, the feature amount vector of the generated image, and the feature amount vector of the generated document to generate a combined vector (step S1307).
- the output device 100 corrects the coupling vector using the integrated SA layer 506 based on the coupling vector and generates an aggregate vector (step S1308). Then, the output device 100 estimates the situation using the discriminative model based on the aggregation vector (step S1309).
- the output device 100 outputs the estimated situation (step S1310). Then, the output device 100 ends the estimation process. As a result, the output device 100 can improve the accuracy of the solution when the problem is solved by using the CAN 500.
- the output device 100 may be executed by changing the order of processing of some steps in FIG. For example, the order of the processes of steps S1302 and S1303 and the processes of steps S1304 and S1305 can be exchanged. Further, the output device 100 may repeatedly execute the processes of steps S1302 to S1305.
- a vector based on the information of the first modal is obtained based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal. It can be corrected.
- the vector based on the information of the second modal can be corrected based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- the first vector can be generated based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the first modal.
- the second vector can be generated based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the second modal.
- the first vector is based on the correlation of two different types of vectors obtained from a predetermined vector, a combined vector including the generated first vector and the generated second vector.
- the second vector can be aggregated to generate a third vector.
- the generated third vector can be output.
- the output device 100 aggregates the first vector and the second vector, and is useful for solving the problem among the vector based on the information of the first modal and the vector based on the information of the second modal.
- a third vector that tends to reflect information can be generated and made available. Therefore, the output device 100 can improve the accuracy of the solution when solving the problem by using the third vector.
- the first target attention layer is used and is based on the inner product of the vector obtained from the vector based on the information of the first modal and the vector obtained from the vector based on the information of the second modal. Therefore, the vector based on the information of the first modal can be corrected.
- the second target attention layer is used based on the inner product of the vector obtained from the vector based on the information of the first modal and the vector obtained from the vector based on the information of the second modal. Therefore, the vector based on the information of the second modal can be corrected.
- the corrected first is based on the inner product of two different types of vectors obtained from the corrected first modal information-based vector using the first self-attention layer.
- the vector based on the modal information can be further corrected to generate the first vector.
- the corrected second is based on the inner product of two different types of vectors obtained from the corrected second modal information-based vector using the second self-attention layer.
- a vector based on modal information can be further corrected to generate a second vector.
- a third self-attention layer is used, based on the inner product of two different types of vectors obtained from a combined vector that combines a predetermined vector, the first vector, and the second vector. , A third vector can be generated.
- the output device 100 can easily realize the process of generating the third vector by using various attention layers.
- the situation regarding the first modal and the second modal can be determined and output based on the generated third vector.
- the output device 100 can be made applicable when solving the problem of determining the situation, and the result of solving the problem can be referred to.
- the generated first vector can be set as a vector based on the new first modal information.
- the generated second vector can be set as a vector based on the new second modal information.
- the vector based on the set first modal information is corrected, the vector based on the set second modal information is corrected, the first vector is generated, and the second vector is generated.
- the generated process can be repeated one or more times.
- the first vector is based on the correlation of two different types of vectors obtained from a predetermined vector, a combined vector including the generated first vector and the generated second vector.
- the second vector can be aggregated to generate a third vector.
- the output device 100 can correct various vectors in multiple stages and further improve the accuracy of the solution when the problem is solved.
- a modal related to an image can be adopted as the first modal.
- a document-related modal can be adopted as the second modal.
- the output device 100 can be made applicable when solving a problem based on an image and a document.
- a modal related to an image can be adopted as the first modal.
- a modal related to voice can be adopted as the second modal.
- the output device 100 can be made applicable when solving a problem based on an image and a sound.
- the output device 100 as the first modal, the modal related to the document in the first language can be adopted.
- the output device 100 as the second modal, a modal relating to a document in a second language can be adopted. This makes the output device 100 applicable when solving a problem based on two documents in different languages.
- the output device 100 it is possible to determine and output a positive situation or a negative situation based on the generated third vector. As a result, the output device 100 can be made applicable when solving a problem for determining a positive situation or a negative situation, and the result of solving the problem can be referred to.
- the output device 100 based on the generated third vector, the first target attention layer, the second target attention layer, the first self-attention layer, the second self-attention layer, and the second It is possible to update with three self-attention layers. As a result, the output device 100 can update various attention layers so that the third vector can be generated in a more useful state, and can improve the accuracy of the solution when the problem is solved.
- the output method described in this embodiment can be realized by executing a program prepared in advance on a computer such as a PC or a workstation.
- the output program described in this embodiment is recorded on a computer-readable recording medium and executed by being read from the recording medium by the computer.
- the recording medium is a hard disk, a flexible disk, a CD (Compact Disc) -ROM, an MO, a DVD (Digital Any Disc), or the like.
- the output program described in this embodiment may be distributed via a network such as the Internet.
- Output device 111,112 Correction model 121,122,130 Generation model 200 Information processing system 201 Client device 202 Terminal device 210 Network 300 Bus 301 CPU 302 Memory 303 Network I / F 304 Recording medium I / F 305 Recording medium 400 Storage unit 401 Acquisition unit 402 First correction unit 403 First generation unit 404 Second correction unit 405 Second generation unit 406 Third generation unit 407 Analysis unit 408 Output unit 500 Co-Attention Network 501 Image TA layer 502 Image SA layer 503 Document TA layer 504 Document SA layer 505 Bonding layer 506 Integrated SA layer 510 Group 600 SA layer 601,611 MHA layer 602,604,612,614 A & N layer 603,613 FF layer 610 TA layer 620 Attention layer 621,625 MatMul layer 622 Scale layer 623 Mask layer 624 SoftMax layer 700,810,910,1010,1110 Document 701 Token set 702,712 Feature vector 710,800,900,1000,1100 Image 7 Degree estimator 820, 8
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Mathematical Optimization (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Pure & Applied Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Databases & Information Systems (AREA)
- Algebra (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
出力装置(100)は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第一のモーダルの情報に基づくベクトルを補正する。出力装置(100)は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第二のモーダルの情報に基づくベクトルを補正する。出力装置(100)は、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成する。出力装置(100)は、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成する。出力装置(100)は、所定のベクトルと、第一のベクトルと、第二のベクトルとを含む結合ベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第三のベクトルを生成して出力する。
Description
本発明は、出力方法、出力プログラム、および出力装置に関する。
従来、複数のモーダルの情報を用いて問題を解く技術がある。この技術は、例えば、文書翻訳や質疑応答、物体検出、状況判断などの問題を解く際に利用される。ここで、モーダルとは、情報の様式や種類を示す概念であり、具体例としては、画像、文書(テキスト)、音声などを挙げることができる。複数のモーダルを用いた機械学習はマルチモーダル学習と呼ばれる。
先行技術としては、例えば、ViLBERT(Vision-and-Language Bidirectional Encoder Representations from Transformers)と呼ばれるものがある。具体的には、ViLBERTは、画像に関するモーダルの情報に基づくベクトルに基づいて補正した、文書に関するモーダルの情報に基づくベクトルと、文書に関するモーダルの情報に基づくベクトルに基づいて補正した、画像に関するモーダルの情報に基づくベクトルとを参照し、問題を解く技術である。
Lu, Jiasen, et al. "vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks." arXiv preprint arXiv:1908.02265 (2019).
しかしながら、従来技術では、複数のモーダルの情報を用いて問題を解いた際の解の精度が悪い場合がある。例えば、ViLBERTにおいて、画像と文書とを基に状況を判断する問題を解くにあたり、補正した文書に関するモーダルの情報に基づくベクトルと、補正した画像に関するモーダルの情報に基づくベクトルとをそのまま参照するだけでは、問題を解いた際の解の精度が悪い。
1つの側面では、本発明は、複数のモーダルの情報を用いて問題を解いた際の解の精度の向上を図ることを目的とする。
1つの実施態様によれば、第一のモーダルの情報に基づくベクトルと、前記第一のモーダルとは異なる第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第一のモーダルの情報に基づくベクトルを補正し、前記第一のモーダルの情報に基づくベクトルと、前記第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第二のモーダルの情報に基づくベクトルを補正し、補正後の前記第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成し、補正後の前記第二のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成し、所定のベクトルと、生成した前記第一のベクトルと、生成した前記第二のベクトルとを含む結合ベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第一のベクトルと前記第二のベクトルとを集約した第三のベクトルを生成し、生成した前記第三のベクトルを出力する出力方法、出力プログラム、および出力装置が提案される。
一態様によれば、複数のモーダルの情報を用いて問題を解いた際の解の精度の向上を図ることが可能になる。
以下に、図面を参照して、本発明にかかる出力方法、出力プログラム、および出力装置の実施の形態を詳細に説明する。
(実施の形態にかかる出力方法の一実施例)
図1は、実施の形態にかかる出力方法の一実施例を示す説明図である。出力装置100は、複数のモーダルの情報を用いて、問題の解決に有用な情報を得やすくすることにより、問題を解いた際の解の精度の向上を図るためのコンピュータである。
図1は、実施の形態にかかる出力方法の一実施例を示す説明図である。出力装置100は、複数のモーダルの情報を用いて、問題の解決に有用な情報を得やすくすることにより、問題を解いた際の解の精度の向上を図るためのコンピュータである。
従来、問題を解くための手法として、例えば、BERT(Bidirectional Encoder Representations from Transformers)と呼ばれるものがある。BERTは、具体的には、TransformerのEncoder部を積み重ねて形成される。BERTについては、例えば、下記非特許文献2や下記非特許文献3を参照することができる。ここで、BERTは、文書に関するモーダルの情報を用いて問題を解くような状況に適用することが想定されており、複数のモーダルの情報を用いて問題を解くような状況に適用することができない。
非特許文献2 : Devlin, Jacob et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” NAACL-HLT (2019).
非特許文献3 : Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
また、問題を解くための手法として、例えば、VideoBERTと呼ばれるものがある。VideoBERTは、具体的には、BERTを、文書に関するモーダルの情報と、画像に関するモーダルの情報とを用いて問題を解くような状況に適用可能に拡張したものである。VideoBERTについては、例えば、下記非特許文献4を参照することができる。ここで、VideoBERTは、問題を解くにあたり、文書に関するモーダルの情報と、画像に関するモーダルの情報とを明示的に区別せずに扱うため、問題を解いた際の解の精度が悪い場合がある。
非特許文献4 : Sun, Chen, et al. “Videobert: A joint model for video and language representation learning.” arXiv preprint arXiv:1904.01766 (2019).
また、問題を解くための手法として、例えば、MCAN(Modular Co-Attention Network)と呼ばれるものがある。MCANは、文書に関するモーダルの情報と、文書に関するモーダルの情報で補正した画像に関するモーダルの情報とを参照し、問題を解くものである。MCANについては、例えば、下記非特許文献5を参照することができる。ここで、MCANは、問題を解くにあたり、文書に関するモーダルの情報を、画像に関するモーダルの情報で補正せず、そのまま参照するため、問題を解いた際の解の精度が悪い場合がある。
非特許文献5 : Yu, Zhou, et al. “Deep Modular Co-Attention Networks for Visual Question Answering.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
また、上述した通り、問題を解くための手法として、例えば、ViLBERTと呼ばれるものがある。しかしながら、ViLBERTは、画像に関するモーダルの情報で補正した文書に関するモーダルの情報と、文書に関するモーダルの情報で補正した、画像に関するモーダルの情報とをそのまま参照するだけであるため、問題を解いた際の解の精度が悪い場合がある。
そこで、本実施の形態では、複数のモーダルの情報が集約された集約ベクトルを生成することにより、複数のモーダルの情報を用いて問題を解くような状況に適用可能であり、問題を解いた際の解の精度を向上可能にすることができる出力方法について説明する。
図1において、出力装置100は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを取得する。モーダルは、情報の様式を意味する。第一のモーダルと、第二のモーダルとは、それぞれ異なるモーダルである。第一のモーダルは、例えば、画像に関するモーダルである。第一のモーダルの情報は、例えば、第一のモーダルに従って表現された、画像である。第二のモーダルは、例えば、文書に関するモーダルである。第二のモーダルの情報は、例えば、第二のモーダルに従って表現された、文書である。
第一のモーダルの情報に基づくベクトルは、例えば、第一のモーダルに従って表現された、第一のモーダルの情報に基づいて生成されたベクトルである。第一のモーダルの情報に基づくベクトルは、具体的には、画像に基づいて生成されたベクトルである。第二のモーダルの情報に基づくベクトルは、例えば、第二のモーダルに従って表現された、第二のモーダルの情報に基づいて生成されたベクトルである。第二のモーダルの情報に基づくベクトルは、具体的には、文書に基づいて生成されたベクトルである。
(1-1)出力装置100は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第一のモーダルの情報に基づくベクトルを補正する。出力装置100は、例えば、第一の補正モデル111を用いて、第一のモーダルの情報に基づくベクトルを補正する。第一の補正モデル111は、例えば、第一のモーダルに関するターゲットアテンション層である。
(1-2)出力装置100は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第二のモーダルの情報に基づくベクトルを補正する。出力装置100は、例えば、第二の補正モデル112を用いて、第二のモーダルの情報に基づくベクトルを補正する。第二の補正モデル112は、例えば、第二のモーダルに関するターゲットアテンション層である。
(1-3)出力装置100は、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成する。異なる種類の2つのベクトルは、例えば、クエリとなるベクトルと、キーとなるベクトルとである。出力装置100は、例えば、第一の生成モデル121を用いて、第一のベクトルを生成する。第一の生成モデル121は、例えば、第一のモーダルに関するセルフアテンション層である。
(1-4)出力装置100は、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成する。異なる種類の2つのベクトルは、例えば、クエリとなるベクトルと、キーとなるベクトルとである。出力装置100は、例えば、第二の生成モデル122を用いて、第二のベクトルを生成する。第二の生成モデル122は、例えば、第二のモーダルに関するセルフアテンション層である。
(1-5)出力装置100は、所定のベクトルと、生成した第一のベクトルと、生成した第二のベクトルとを含む結合ベクトルを生成する。所定のベクトルは、例えば、予めユーザによって設定される。所定のベクトルは、第一のベクトルと、第二のベクトルとを集約するための集約用ベクトルである。所定のベクトルは、例えば、要素がランダムに設定されたベクトルである。所定のベクトルは、例えば、要素が、ユーザによって設定された既定値のベクトルである。結合ベクトルは、例えば、所定のベクトルと、第一のベクトルと、第二のベクトルとを順に結合することにより得られる。
そして、出力装置100は、結合ベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第三のベクトルを生成する。異なる種類の2つのベクトルは、例えば、クエリとなるベクトルと、キーとなるベクトルとである。第三のベクトルは、第一のベクトルと第二のベクトルとを集約したベクトルである。出力装置100は、第三の生成モデル130を用いて、第三のベクトルを生成する。第三の生成モデル130は、例えば、セルフアテンション層である。
これによれば、出力装置100は、第一のベクトルと第二のベクトルとに基づく、キーとなるベクトルに含まれる部分と、所定のベクトルに基づく、クエリとなるベクトルに含まれる部分との相関に基づいて、所定のベクトルを補正することができる。出力装置100は、例えば、当該相関に基づいて、第一のベクトルと第二のベクトルとに基づく、バリューとなるベクトルの部分により、所定のベクトルを補正することができる。このため、出力装置100は、所定のベクトルに対し、第一のベクトルと第二のベクトルとが集約されるような処理を行うことができ、第三のベクトルを得ることができる。
(1-6)出力装置100は、生成した第三のベクトルを出力する。出力形式は、例えば、ディスプレイへの表示、プリンタへの印刷出力、他のコンピュータへの送信、または、記憶領域への記憶などである。これにより、出力装置100は、第一のベクトルと第二のベクトルとが集約され、第一のモーダルの情報に基づくベクトルと第二のモーダルの情報に基づくベクトルとのうち問題の解決に有用な情報が反映される傾向がある第三のベクトルを生成し、利用可能にすることができる。出力装置100は、例えば、実世界の画像や文書の特徴のうち、問題の解決に有用な特徴を、コンピュータ上で精度よく表現した第三のベクトルを利用可能にすることができる。
出力装置100は、例えば、第三のベクトルを利用し、第一の補正モデル111と、第二の補正モデル112と、第一の生成モデル121と、第二の生成モデル122と、第三の生成モデル130となどを更新することができる。このため、出力装置100は、第一のモーダルの情報に基づくベクトルと第二のモーダルの情報に基づくベクトルとのうち問題の解決に有用な情報が、第三のベクトルに反映されやすくすることができる。結果として、出力装置100は、以降の、問題を解いた際の解の精度の向上を図ることができる。
出力装置100は、例えば、問題を解くにあたり、第一のモーダルの情報に基づくベクトルと第二のモーダルの情報に基づくベクトルとのうち問題の解決に有用な情報が反映される傾向がある第三のベクトルを利用することができ、問題を解いた際の解の精度を向上させることができる。出力装置100は、具体的には、画像と文書とを基に、対象の状況を判断する問題を解くにあたり、正確に対象の状況を判断することができる。対象の状況を判断する問題は、例えば、対象の状況が、ポジティブな状況であるか、またはネガティブな状況であるかを判断する問題である。
(情報処理システム200の一例)
次に、図2を用いて、図1に示した出力装置100を適用した、情報処理システム200の一例について説明する。
次に、図2を用いて、図1に示した出力装置100を適用した、情報処理システム200の一例について説明する。
図2は、情報処理システム200の一例を示す説明図である。図2において、情報処理システム200は、出力装置100と、クライアント装置201と、端末装置202とを含む。
情報処理システム200において、出力装置100とクライアント装置201とは、有線または無線のネットワーク210を介して接続される。ネットワーク210は、例えば、LAN(Local Area Network)、WAN(Wide Area Network)、インターネットなどである。また、情報処理システム200において、出力装置100と端末装置202とは、有線または無線のネットワーク210を介して接続される。
出力装置100は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとに基づいて、第三のベクトルを生成するCo-Attention Networkを有する。第一のモーダルは、例えば、画像に関するモーダルである。第二のモーダルは、例えば、文書に関するモーダルである。Co-Attention Networkは、例えば、図1に示した、第一の補正モデル111と、第二の補正モデル112と、第一の生成モデル121と、第二の生成モデル122と、第三の生成モデル130との全体に対応する。
出力装置100は、教師データに基づいて、Co-Attention Networkを更新する。教師データは、例えば、標本となる第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、標本となる第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報と、正解データとを対応付けた対応情報である。教師データは、例えば、出力装置100のユーザにより出力装置100に入力される。正解データは、例えば、第三のベクトルに基づいて、問題を解いた場合についての正解を示す。例えば、第一のモーダルが、画像に関するモーダルであれば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報は、画像である。例えば、第二のモーダルが、文書に関するモーダルであれば、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報は、文書である。
出力装置100は、例えば、教師データのうち第一のモーダルの情報となる画像から、第一のモーダルの情報に基づくベクトルを生成することにより取得し、教師データのうち第二のモーダルの情報となる文書から、第二のモーダルの情報に基づくベクトルを生成することにより取得する。そして、出力装置100は、取得した第一のモーダルの情報に基づくベクトルと、取得した第二のモーダルの情報に基づくベクトルと、教師データの正解データとに基づいて、誤差逆伝搬などにより、Co-Attention Networkを更新する。出力装置100は、誤差逆伝搬以外の学習方法により、Co-Attention Networkを更新してもよい。
出力装置100は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを取得する。そして、出力装置100は、Co-Attention Networkを用いて、取得した第一のモーダルの情報に基づくベクトルと、取得した第二のモーダルの情報に基づくベクトルとに基づいて、第三のベクトルを生成し、生成した第三のベクトルに基づいて、問題を解く。その後、出力装置100は、問題を解いた結果を、クライアント装置201に送信する。
出力装置100は、例えば、出力装置100のユーザにより出力装置100に入力された第一のモーダルの情報に基づくベクトルを取得する。また、出力装置100は、第一のモーダルの情報に基づくベクトルを、クライアント装置201または端末装置202から受信することにより取得してもよい。また、出力装置100は、例えば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報を、クライアント装置201または端末装置202から受信することにより取得してもよい。例えば、第一のモーダルが、画像に関するモーダルであれば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報は、画像である。
出力装置100は、例えば、出力装置100のユーザにより出力装置100に入力された第二のモーダルの情報に基づくベクトルを取得する。また、出力装置100は、第二のモーダルの情報に基づくベクトルを、クライアント装置201または端末装置202から受信することにより取得してもよい。また、出力装置100は、例えば、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報を、クライアント装置201または端末装置202から受信することにより取得してもよい。例えば、第二のモーダルが、文書に関するモーダルであれば、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報は、文書である。
そして、出力装置100は、Co-Attention Networkを用いて、取得した第一のモーダルの情報に基づくベクトルと、取得した第二のモーダルの情報に基づくベクトルとに基づいて、第三のベクトルを生成し、生成した第三のベクトルに基づいて、問題を解く。その後、出力装置100は、問題を解いた結果を、クライアント装置201に送信する。出力装置100は、例えば、サーバやPC(Personal Computer)などである。
クライアント装置201は、出力装置100と通信可能なコンピュータである。クライアント装置201は、例えば、第一のモーダルの情報に基づくベクトルを、出力装置100に送信してもよい。また、クライアント装置201は、例えば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報を、出力装置100に送信してもよい。クライアント装置201は、例えば、第二のモーダルの情報に基づくベクトルを、出力装置100に送信してもよい。また、クライアント装置201は、例えば、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報を、出力装置100に送信してもよい。
クライアント装置201は、出力装置100が問題を解いた結果を受信して出力する。出力形式は、例えば、ディスプレイへの表示、プリンタへの印刷出力、他のコンピュータへの送信、または、記憶領域への記憶などである。クライアント装置201は、例えば、PC、タブレット端末、またはスマートフォンなどである。
端末装置202は、出力装置100と通信可能なコンピュータである。端末装置202は、例えば、第一のモーダルの情報に基づくベクトルを、出力装置100に送信してもよい。また、端末装置202は、例えば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報を、出力装置100に送信してもよい。端末装置202は、例えば、第二のモーダルの情報に基づくベクトルを、出力装置100に送信してもよい。また、端末装置202は、例えば、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報を、出力装置100に送信してもよい。端末装置202は、例えば、PC、タブレット端末、スマートフォン、電子機器、IoT機器、またはセンサ装置などである。端末装置202は、具体的には、監視カメラであってもよい。
ここでは、出力装置100が、Co-Attention Networkを更新し、かつ、Co-Attention Networkを用いて、問題を解く場合について説明したが、これに限らない。例えば、他のコンピュータが、Co-Attention Networkを更新し、出力装置100が、他のコンピュータから受信したCo-Attention Networkを用いて、問題を解く場合があってもよい。また、例えば、出力装置100が、Co-Attention Networkを更新し、他のコンピュータに提供し、他のコンピュータで、Co-Attention Networkを用いて、問題を解く場合があってもよい。
ここでは、教師データが、標本となる第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、標本となる第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報と、正解データとを対応付けた対応情報である場合について説明したが、これに限らない。例えば、教師データが、標本となる第一のモーダルの情報に基づくベクトルと、標本となる第二のモーダルの情報に基づくベクトルと、正解データとを対応付けた対応情報である場合があってもよい。
ここでは、出力装置100が、クライアント装置201や端末装置202とは異なる装置である場合について説明したが、これに限らない。例えば、出力装置100が、クライアント装置201と一体である場合があってもよい。また、例えば、出力装置100が、端末装置202と一体である場合があってもよい。
ここでは、出力装置100が、ソフトウェア的に、Co-Attention Networkを実現する場合について説明したが、これに限らない。例えば、出力装置100が、Co-Attention Networkを、電子回路的に実現する場合があってもよい。
(情報処理システム200の適用例1)
適用例1において、出力装置100は、画像と、画像についての質問文となる文書とを記憶する。質問文は、例えば、「画像内で何を切っているか」である。そして、出力装置100は、画像と文書とに基づいて、質問文に対する回答文を推定する問題を解く。出力装置100は、例えば、画像と文書とに基づいて、画像内で何を切っているかの質問文に対する回答文を推定し、クライアント装置201に送信する。
適用例1において、出力装置100は、画像と、画像についての質問文となる文書とを記憶する。質問文は、例えば、「画像内で何を切っているか」である。そして、出力装置100は、画像と文書とに基づいて、質問文に対する回答文を推定する問題を解く。出力装置100は、例えば、画像と文書とに基づいて、画像内で何を切っているかの質問文に対する回答文を推定し、クライアント装置201に送信する。
(情報処理システム200の適用例2)
適用例2において、端末装置202は、監視カメラであり、対象を撮像した画像を、出力装置100に送信する。対象は、具体的には、試着室の外観である。また、出力装置100は、対象についての説明文となる文書を記憶している。説明文は、具体的には、人間が試着室を利用中は、試着室のカーテンが閉まっている傾向があることの説明文である。そして、出力装置100は、画像と文書とに基づいて、危険度を判断する問題を解く。危険度は、例えば、試着室に避難が未完了の人間が残っている可能性の高さを示す指標値である。出力装置100は、例えば、災害時に、試着室に避難が未完了の人間が残っている可能性の高さを示す危険度を判断する。
適用例2において、端末装置202は、監視カメラであり、対象を撮像した画像を、出力装置100に送信する。対象は、具体的には、試着室の外観である。また、出力装置100は、対象についての説明文となる文書を記憶している。説明文は、具体的には、人間が試着室を利用中は、試着室のカーテンが閉まっている傾向があることの説明文である。そして、出力装置100は、画像と文書とに基づいて、危険度を判断する問題を解く。危険度は、例えば、試着室に避難が未完了の人間が残っている可能性の高さを示す指標値である。出力装置100は、例えば、災害時に、試着室に避難が未完了の人間が残っている可能性の高さを示す危険度を判断する。
(情報処理システム200の適用例3)
適用例3において、出力装置100は、動画を形成する画像と、画像についての説明文となる文書を記憶している。動画は、例えば、料理の様子を写した動画である。説明文は、具体的には、料理の手順についての説明文である。そして、出力装置100は、画像と文書とに基づいて、危険度を判断する問題を解く。危険度は、例えば、料理中の危険性の高さを示す指標値である。出力装置100は、例えば、料理中の危険性の高さを示す危険度を判断する。
適用例3において、出力装置100は、動画を形成する画像と、画像についての説明文となる文書を記憶している。動画は、例えば、料理の様子を写した動画である。説明文は、具体的には、料理の手順についての説明文である。そして、出力装置100は、画像と文書とに基づいて、危険度を判断する問題を解く。危険度は、例えば、料理中の危険性の高さを示す指標値である。出力装置100は、例えば、料理中の危険性の高さを示す危険度を判断する。
(出力装置100のハードウェア構成例)
次に、図3を用いて、出力装置100のハードウェア構成例について説明する。
次に、図3を用いて、出力装置100のハードウェア構成例について説明する。
図3は、出力装置100のハードウェア構成例を示すブロック図である。図3において、出力装置100は、CPU(Central Processing Unit)301と、メモリ302と、ネットワークI/F(Interface)303と、記録媒体I/F304と、記録媒体305とを有する。また、各構成部は、バス300によってそれぞれ接続される。
ここで、CPU301は、出力装置100の全体の制御を司る。メモリ302は、例えば、ROM(Read Only Memory)、RAM(Random Access Memory)およびフラッシュROMなどを有する。具体的には、例えば、フラッシュROMやROMが各種プログラムを記憶し、RAMがCPU301のワークエリアとして使用される。メモリ302に記憶されるプログラムは、CPU301にロードされることで、コーディングされている処理をCPU301に実行させる。
ネットワークI/F303は、通信回線を通じてネットワーク210に接続され、ネットワーク210を介して他のコンピュータに接続される。そして、ネットワークI/F303は、ネットワーク210と内部のインターフェースを司り、他のコンピュータからのデータの入出力を制御する。ネットワークI/F303は、例えば、モデムやLANアダプタなどである。
記録媒体I/F304は、CPU301の制御に従って記録媒体305に対するデータのリード/ライトを制御する。記録媒体I/F304は、例えば、ディスクドライブ、SSD(Solid State Drive)、USB(Universal Serial Bus)ポートなどである。記録媒体305は、記録媒体I/F304の制御で書き込まれたデータを記憶する不揮発メモリである。記録媒体305は、例えば、ディスク、半導体メモリ、USBメモリなどである。記録媒体305は、出力装置100から着脱可能であってもよい。
出力装置100は、上述した構成部のほか、例えば、キーボード、マウス、ディスプレイ、プリンタ、スキャナ、マイク、スピーカーなどを有してもよい。また、出力装置100は、記録媒体I/F304や記録媒体305を複数有していてもよい。また、出力装置100は、記録媒体I/F304や記録媒体305を有していなくてもよい。
(クライアント装置201のハードウェア構成例)
クライアント装置201のハードウェア構成例は、具体的には、図3に示した出力装置100のハードウェア構成例と同様であるため、説明を省略する。
クライアント装置201のハードウェア構成例は、具体的には、図3に示した出力装置100のハードウェア構成例と同様であるため、説明を省略する。
(端末装置202のハードウェア構成例)
端末装置202のハードウェア構成例は、具体的には、図3に示した出力装置100のハードウェア構成例と同様であるため、説明を省略する。
端末装置202のハードウェア構成例は、具体的には、図3に示した出力装置100のハードウェア構成例と同様であるため、説明を省略する。
(出力装置100の機能的構成例)
次に、図4を用いて、出力装置100の機能的構成例について説明する。
次に、図4を用いて、出力装置100の機能的構成例について説明する。
図4は、出力装置100の機能的構成例を示すブロック図である。出力装置100は、記憶部400と、取得部401と、第一の補正部402と、第一の生成部403と、第二の補正部404と、第二の生成部405と、第三の生成部406と、解析部407と、出力部408とを含む。
記憶部400は、例えば、図3に示したメモリ302や記録媒体305などの記憶領域によって実現される。以下では、記憶部400が、出力装置100に含まれる場合について説明するが、これに限らない。例えば、記憶部400が、出力装置100とは異なる装置に含まれ、記憶部400の記憶内容が出力装置100から参照可能である場合があってもよい。
取得部401~出力部408は、制御部の一例として機能する。取得部401~出力部408は、具体的には、例えば、図3に示したメモリ302や記録媒体305などの記憶領域に記憶されたプログラムをCPU301に実行させることにより、または、ネットワークI/F303により、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302や記録媒体305などの記憶領域に記憶される。
記憶部400は、各機能部の処理において参照され、または更新される各種情報を記憶する。記憶部400は、Co-Attention Networkを記憶する。Co-Attention Networkは、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとに基づいて、第三のベクトルを生成するモデルである。Co-Attention Networkは、後述する第一のターゲットアテンション層と、第二のターゲットアテンション層と、第一のセルフアテンション層と、第二のセルフアテンション層と、第三のセルフアテンション層との全体に対応する。
第一のターゲットアテンション層は、例えば、第一のモーダルに関する。第一のターゲットアテンション層は、第一のモーダルの情報に基づくベクトルを補正するモデルである。第一のセルフアテンション層は、例えば、第一のモーダルに関する。第一のセルフアテンション層は、補正後の第一のモーダルの情報に基づくベクトルをさらに補正し、第一のベクトルを生成するモデルである。第二のターゲットアテンション層は、例えば、第二のモーダルに関する。第二のターゲットアテンション層は、第二のモーダルの情報に基づくベクトルを補正するモデルである。第二のセルフアテンション層は、例えば、第二のモーダルに関する。第二のセルフアテンション層は、補正後の第二のモーダルの情報に基づくベクトルをさらに補正し、第二のベクトルを生成するモデルである。第三のセルフアテンション層は、第一のベクトルと、第二のベクトルとに基づいて、第三のベクトルを生成するモデルである。
例えば、第一のモーダルは、画像に関するモーダルであり、第二のモーダルは、文書に関するモーダルである。例えば、第一のモーダルは、画像に関するモーダルであり、第二のモーダルは、音声に関するモーダルである。例えば、第一のモーダルは、第一の言語の文書に関するモーダルであり、第二のモーダルは、第二の言語の文書に関するモーダルである。Co-Attention Networkは、解析部407によって更新され、または解析部407によって問題を解く際に利用される。
記憶部400は、例えば、Co-Attention Networkのパラメータを記憶する。記憶部400は、具体的には、第一のターゲットアテンション層と、第二のターゲットアテンション層と、第一のセルフアテンション層と、第二のセルフアテンション層と、第三のセルフアテンション層とのパラメータを記憶する。
記憶部400は、教師データを記憶してもよい。教師データは、例えば、標本となる第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、標本となる第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報と、正解データとを対応付けた対応情報である。教師データは、例えば、ユーザにより入力される。正解データは、例えば、第三のベクトルに基づいて、問題を解いた場合についての正解を示す。
例えば、第一のモーダルが、画像に関するモーダルであれば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報は、画像である。例えば、第二のモーダルが、文書に関するモーダルであれば、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報は、文書である。教師データは、標本となる第一のモーダルの情報に基づくベクトルと、標本となる第二のモーダルの情報に基づくベクトルと、正解データとを対応付けた対応情報であってもよい。
取得部401は、各機能部の処理に用いられる各種情報を取得する。取得部401は、取得した各種情報を、記憶部400に記憶し、または、各機能部に出力する。また、取得部401は、記憶部400に記憶しておいた各種情報を、各機能部に出力してもよい。取得部401は、例えば、ユーザの操作入力に基づき、各種情報を取得する。取得部401は、例えば、出力装置100とは異なる装置から、各種情報を受信してもよい。
取得部401は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを取得する。取得部401は、Co-Attention Networkを更新する際に、教師データを取得し、教師データに基づいて、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを取得する。
取得部401は、例えば、ユーザによる教師データの入力を受け付け、教師データの中から、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報とを取得する。そして、取得部401は、取得した各種情報に基づいて、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを生成する。
取得部401は、具体的には、教師データに含まれる画像を取得し、第一のモーダルの情報に基づくベクトルとして、取得した画像に関する特徴量ベクトルを生成する。画像に関する特徴量ベクトルは、例えば、画像に写る物体ごとの特徴量ベクトルを並べたものである。また、取得部401は、具体的には、教師データに含まれる文書を取得し、第二のモーダルの情報に基づくベクトルとして、取得した文書に関する特徴量ベクトルを生成する。文書に関する特徴量ベクトルは、例えば、文書に含まれる単語ごとの特徴量ベクトルを並べたものである。
取得部401は、例えば、教師データを、クライアント装置201または端末装置202から受信し、受信した教師データの中から、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報とを取得してもよい。そして、取得部401は、取得した情報に基づいて、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを生成する。
取得部401は、具体的には、教師データに含まれる画像を取得し、第一のモーダルの情報に基づくベクトルとして、取得した画像に関する特徴量ベクトルを生成する。画像に関する特徴量ベクトルは、例えば、画像に写る物体ごとの特徴量ベクトルを並べたものである。また、取得部401は、具体的には、教師データに含まれる文書を取得し、第二のモーダルの情報に基づくベクトルとして、取得した文書に関する特徴量ベクトルを生成する。文書に関する特徴量ベクトルは、例えば、文書に含まれる単語ごとの特徴量ベクトルを並べたものである。
取得部401は、例えば、ユーザによる教師データの入力を受け付け、教師データの中から、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを、そのまま取得してもよい。取得部401は、例えば、教師データを、クライアント装置201または端末装置202から受信し、受信した教師データの中から、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを、そのまま取得してもよい。
取得部401は、Co-Attention Networkを利用し、問題を解く際に、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを取得する。取得部401は、例えば、ユーザによる、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報との入力を受け付ける。そして、取得部401は、入力された各種情報に基づいて、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを生成する。
取得部401は、具体的には、画像を取得し、第一のモーダルの情報に基づくベクトルとして、取得した画像に関する特徴量ベクトルを生成する。画像に関する特徴量ベクトルは、例えば、画像に写る物体ごとの特徴量ベクトルを並べたものである。また、取得部401は、具体的には、文書を取得し、第二のモーダルの情報に基づくベクトルとして、取得した文書に関する特徴量ベクトルを生成する。文書に関する特徴量ベクトルは、例えば、文書に含まれる単語ごとの特徴量ベクトルを並べたものである。
取得部401は、例えば、第一のモーダルの情報に基づくベクトルを生成する元となる第一のモーダルの情報と、第二のモーダルの情報に基づくベクトルを生成する元となる第二のモーダルの情報とを、クライアント装置201または端末装置202から受信してもよい。そして、取得部401は、取得した各種情報に基づいて、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを生成する。
取得部401は、具体的には、画像を取得し、第一のモーダルの情報に基づくベクトルとして、取得した画像に関する特徴量ベクトルを生成する。画像に関する特徴量ベクトルは、例えば、画像に写る物体ごとの特徴量ベクトルを並べたものである。取得部401は、具体的には、文書を取得し、第二のモーダルの情報に基づくベクトルとして、取得した文書に関する特徴量ベクトルを生成する。文書に関する特徴量ベクトルは、例えば、文書に含まれる単語ごとの特徴量ベクトルを並べたものである。
取得部401は、例えば、ユーザによる、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの入力を受け付けてもよい。取得部401は、例えば、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを、クライアント装置201または端末装置202から受信してもよい。
取得部401は、いずれかの機能部の処理を開始する開始トリガーを受け付けてもよい。開始トリガーは、例えば、ユーザによる所定の操作入力があったことである。開始トリガーは、例えば、他のコンピュータから、所定の情報を受信したことであってもよい。開始トリガーは、例えば、いずれかの機能部が所定の情報を出力したことであってもよい。取得部401は、例えば、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとを取得したことを、各機能部の処理を開始する開始トリガーとして受け付ける。
第一の補正部402は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第一のモーダルの情報に基づくベクトルを補正する。相関は、例えば、第一のモーダルの情報に基づくベクトルから得たベクトルと、第二のモーダルの情報に基づくベクトルから得たベクトルとの類似度によって表現される。第一のモーダルの情報に基づくベクトルから得たベクトルは、例えば、クエリである。第二のモーダルの情報に基づくベクトルから得たベクトルは、例えば、キーである。類似度は、例えば、内積によって表現される。類似度は、例えば、差分の二乗和などによって表現されてもよい。
第一の補正部402は、例えば、第一のターゲットアテンション層を用いて、第一のモーダルの情報に基づくベクトルから得たベクトルと、第二のモーダルの情報に基づくベクトルから得たベクトルとの内積に基づいて、第一のモーダルの情報に基づくベクトルを補正する。
第一の補正部402は、具体的には、第一のターゲットアテンション層を用いて、第一のモーダルの情報に基づくベクトルから得たクエリと、第二のモーダルの情報に基づくベクトルから得たキーとの内積に基づいて、第一のモーダルの情報に基づくベクトルを補正する。ここで、第一のモーダルの情報に基づくベクトルを補正する一例は、例えば、図5を用いて後述する動作例に示す。これにより、第一の補正部402は、第二のモーダルの情報に基づくベクトルのうち、第一のモーダルの情報に基づくベクトルと相対的に関連深い成分ほど、第一のモーダルの情報に基づくベクトルに強く反映されるように、第一のモーダルの情報に基づくベクトルを補正することができる。
第一の生成部403は、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成する。相関は、例えば、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの類似度によって表現される。異なる種類の2つのベクトルは、例えば、クエリとキーとである。類似度は、例えば、内積によって表現される。類似度は、例えば、差分の二乗和などによって表現されてもよい。
第一の生成部403は、例えば、第一のセルフアテンション層を用いて、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの内積に基づいて、補正後の第一のモーダルの情報に基づくベクトルをさらに補正し、第一のベクトルを生成する。
第一の生成部403は、具体的には、第一のセルフアテンション層を用いて、補正後の第一のモーダルの情報に基づくベクトルから得たクエリとキーとの内積に基づいて、補正後の第一のモーダルの情報に基づくベクトルをさらに補正し、第一のベクトルを生成する。ここで、第一のベクトルを生成する一例は、例えば、図5を用いて後述する動作例に示す。これにより、第一の生成部403は、補正後の第一のモーダルの情報に基づくベクトルのうち、より有用な成分ほど大きくなるように、補正後の第一のモーダルの情報に基づくベクトルをさらに補正することができる。
第二の補正部404は、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第二のモーダルの情報に基づくベクトルを補正する。相関は、例えば、第一のモーダルの情報に基づくベクトルから得たベクトルと、第二のモーダルの情報に基づくベクトルから得たベクトルとの類似度によって表現される。第一のモーダルの情報に基づくベクトルから得たベクトルは、例えば、キーである。第二のモーダルの情報に基づくベクトルから得たベクトルは、例えば、クエリである。類似度は、例えば、内積によって表現される。類似度は、例えば、差分の二乗和などによって表現されてもよい。
第二の補正部404は、例えば、第二のターゲットアテンション層を用いて、第一のモーダルの情報に基づくベクトルから得たベクトルと、第二のモーダルの情報に基づくベクトルから得たベクトルとの内積に基づいて、第二のモーダルの情報に基づくベクトルを補正する。
第二の補正部404は、具体的には、第二のターゲットアテンション層を用いて、第一のモーダルの情報に基づくベクトルから得たキーと、第二のモーダルの情報に基づくベクトルから得たクエリとの内積に基づいて、第二のモーダルの情報に基づくベクトルを補正する。ここで、第二のモーダルの情報に基づくベクトルを補正する一例は、例えば、図5を用いて後述する動作例に示す。これにより、第二の補正部404は、第一のモーダルの情報に基づくベクトルのうち、第二のモーダルの情報に基づくベクトルと相対的に関連深い成分ほど、第二のモーダルの情報に基づくベクトルに強く反映されるように、第二のモーダルの情報に基づくベクトルを補正することができる。
第二の生成部405は、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成する。相関は、例えば、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの類似度によって表現される。異なる種類の2つのベクトルは、例えば、クエリとキーとである。類似度は、例えば、内積によって表現される。類似度は、例えば、差分の二乗和などによって表現されてもよい。
第二の生成部405は、例えば、第二のセルフアテンション層を用いて、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの内積に基づいて、補正後の第二のモーダルの情報に基づくベクトルをさらに補正し、第二のベクトルを生成する。
第二の生成部405は、具体的には、第二のセルフアテンション層を用いて、補正後の第二のモーダルの情報に基づくベクトルから得たクエリとキーとの内積に基づいて、補正後の第二のモーダルの情報に基づくベクトルをさらに補正し、第二のベクトルを生成する。ここで、第二のベクトルを生成する一例は、例えば、図5を用いて後述する動作例に示す。これにより、第二の生成部405は、補正後の第二のモーダルの情報に基づくベクトルのうち、より有用な成分ほど大きくなるように、補正後の第二のモーダルの情報に基づくベクトルをさらに補正することができる。
ここで、出力装置100は、第一の補正部402~第二の生成部405の動作を、1回以上繰り返してもよい。出力装置100は、例えば、第一の補正部402~第二の生成部405の動作を繰り返す際には、生成した第一のベクトルを、新たな第一のモーダルの情報に基づくベクトルに設定し、生成した第二のベクトルを、新たな第二のモーダルの情報に基づくベクトルに設定する。これにより、出力装置100は、問題を解いた際の解の精度をさらに向上可能にすることができる。出力装置100は、例えば、問題を解いた際の解の精度を向上させる観点で、第三のベクトルをより有用な状態で生成可能にすることができる。
第三の生成部406は、結合ベクトルを生成する。結合ベクトルは、所定のベクトルと、生成した第一のベクトルと、生成した第二のベクトルとを含む。第三の生成部406は、例えば、所定のベクトルと第一のベクトルと第二のベクトルとを結合した結合ベクトルを生成する。第三の生成部406は、例えば、第一の補正部402~第二の生成部405の動作を繰り返した後であれば、所定のベクトルと最後に生成した第一のベクトルと最後に生成した第二のベクトルとを結合した結合ベクトルを生成する。
第三の生成部406は、結合ベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルと第二のベクトルとを集約した第三のベクトルを生成する。相関は、例えば、結合ベクトルから得た異なる種類の2つのベクトルの類似度によって表現される。異なる種類の2つのベクトルは、例えば、クエリとキーとである。類似度は、例えば、内積によって表現される。類似度は、例えば、差分の二乗和などによって表現されてもよい。
第三の生成部406は、例えば、第三のセルフアテンション層を用いて、結合ベクトルから得た異なる種類の2つのベクトルの内積に基づいて、結合ベクトルを補正し、第三のベクトルを生成する。第三のベクトルは、例えば、補正後の結合ベクトルのうち、所定のベクトルに対応する位置に含まれる部分的なベクトルである。
第三の生成部406は、具体的には、第三のセルフアテンション層を用いて、結合ベクトルから得たクエリとキーとの内積に基づいて、結合ベクトルを補正することにより、第三のベクトルを含む補正後の結合ベクトルを生成する。ここで、第三のベクトルを生成する一例は、例えば、図5を用いて後述する動作例に示す。これにより、第三の生成部406は、問題を解いた際の解の精度を向上させる観点で有用な第三のベクトルを生成し、参照可能にすることができる。
解析部407は、生成した第三のベクトルに基づいて、Co-Attention Networkを更新する。解析部407は、例えば、第三のベクトルに基づいて、第一のターゲットアテンション層と、第二のターゲットアテンション層と、第一のセルフアテンション層と、第二のセルフアテンション層と、第三のセルフアテンション層とを更新する。更新は、例えば、誤差逆伝搬によって実施される。
解析部407は、具体的には、生成した第三のベクトルを用いて、試験的に問題を解き、正解データと比較する。問題の一例は、例えば、第一のモーダルと第二のモーダルとに関する状況が、ポジティブな状況であるか、または、ネガティブな状況であるかを判断する問題である。問題の一例は、具体的には、画像が示唆する状況が、人間に危害が及び得る状況であるか、または、人間に危害が及ばない状況であるかを判断する問題である。
そして、解析部407は、比較した結果に基づいて、第一のターゲットアテンション層と、第二のターゲットアテンション層と、第一のセルフアテンション層と、第二のセルフアテンション層と、第三のセルフアテンション層とを更新する。これにより、解析部407は、第三のベクトルをより有用な状態で生成可能に、各種アテンション層を更新し、問題を解いた際の解の精度を向上可能にすることができる。
解析部407は、生成した第三のベクトルを用いて、実際の問題を解く。問題の一例は、例えば、第一のモーダルと第二のモーダルとに関する状況が、ポジティブな状況であるか、または、ネガティブな状況であるかを判断する問題である。問題の一例は、具体的には、画像が示唆する状況が、人間に危害が及び得る状況であるか、または、人間に危害が及ばない状況であるかを判断する問題である。これにより、解析部407は、問題を解いた際の解の精度を向上させることができる。
出力部408は、いずれかの機能部の処理結果を出力する。出力形式は、例えば、ディスプレイへの表示、プリンタへの印刷出力、ネットワークI/F303による外部装置への送信、または、メモリ302や記録媒体305などの記憶領域への記憶である。これにより、出力部408は、各機能部の処理結果をユーザに通知可能にし、出力装置100の利便性の向上を図ることができる。
出力部408は、例えば、更新済みのCo-Attention Networkを出力する。出力部408は、具体的には、更新済みの第一のターゲットアテンション層と、第二のターゲットアテンション層と、第一のセルフアテンション層と、第二のセルフアテンション層と、第三のセルフアテンション層とを出力する。これにより、出力部408は、更新済みのCo-Attention Networkを参照可能にすることができる。このため、出力部408は、例えば、他のコンピュータで、更新済みのCo-Attention Networkを用いて、問題を解いた際の解の精度を向上可能にすることができる。
出力部408は、例えば、生成した第三のベクトルを出力する。これにより、出力部408は、第三のベクトルを参照可能にし、Co-Attention Networkを更新可能にしたり、または、問題を解いた際の解の精度を向上可能にすることができる。
出力部408は、例えば、第三のベクトルを、実際の問題を解いた結果に対応付けて出力する。出力部408は、具体的には、第三のベクトルを、判断した状況に対応付けて出力する。これにより、出力部408は、問題を解いた結果を、ユーザなどに参照可能にすることができる。
出力部408は、例えば、第三のベクトルを出力せずに、実際の問題を解いた結果を出力してもよい。出力部408は、具体的には、第三のベクトルを出力せずに、判断した状況を出力する。これにより、出力部408は、問題を解いた結果を、ユーザなどに参照可能にすることができる。
(出力装置100の動作例)
次に、図5~図7を用いて、出力装置100の動作例について説明する。まず、図5を用いて、出力装置100によって用いられるCo-Attention Network500の具体例について説明する。
次に、図5~図7を用いて、出力装置100の動作例について説明する。まず、図5を用いて、出力装置100によって用いられるCo-Attention Network500の具体例について説明する。
図5は、Co-Attention Network500の具体例を示す説明図である。以下の説明では、Co-Attention Network500を「CAN500」と表記する場合がある。また、ターゲットアテンションを「TA」と表記する場合がある。また、セルフアテンションを「SA」と表記する場合がある。
図5に示すように、CAN500は、画像TA層501と、画像SA層502と、文書TA層503と、文書SA層504と、結合層505と、統合SA層506とを有する。
図5において、CAN500は、文書に関する特徴量ベクトルLと画像に関する特徴量ベクトルIとが入力されたことに応じて、ベクトルZTを出力する。文書に関する特徴量ベクトルLは、例えば、文書に関するM個の特徴量ベクトルを並べたものである。M個の特徴量ベクトルは、例えば、文書に含まれるM個の単語を示す特徴量ベクトルである。画像に関する特徴量ベクトルIは、例えば、画像に関するN個の特徴量ベクトルを並べたものである。N個の特徴量ベクトルは、例えば、画像に写ったN個の物体を示す特徴量ベクトルである。
具体的には、画像TA層501は、画像に関する特徴量ベクトルIと、文書に関する特徴量ベクトルLとの入力を受け付ける。画像TA層501は、画像に関する特徴量ベクトルIから得たクエリと、文書に関する特徴量ベクトルLから得たキーおよびバリューとに基づいて、画像に関する特徴量ベクトルIを補正する。画像TA層501は、補正後の画像に関する特徴量ベクトルIを、画像SA層502に出力する。画像TA層501の具体例については、例えば、図6を用いて後述する。
また、画像SA層502は、補正後の画像に関する特徴量ベクトルIの入力を受け付ける。画像SA層502は、補正後の画像に関する特徴量ベクトルIから得たクエリ、キーおよびバリューに基づいて、補正後の画像に関する特徴量ベクトルIをさらに補正し、新たな特徴量ベクトルZIを生成し、結合層505に出力する。画像SA層502の具体例については、例えば、図6を用いて後述する。
また、文書TA層503は、文書に関する特徴量ベクトルLと、画像に関する特徴量ベクトルIとの入力を受け付ける。文書TA層503は、文書に関する特徴量ベクトルLから得たクエリと、画像に関する特徴量ベクトルIから得たキーおよびバリューとに基づいて、文書に関する特徴量ベクトルLを補正する。文書TA層503は、補正後の文書に関する特徴量ベクトルLを、文書SA層504に出力する。文書TA層503の具体例については、例えば、図6を用いて後述する。
また、文書SA層504は、補正後の文書に関する特徴量ベクトルLの入力を受け付ける。文書SA層504は、補正後の文書に関する特徴量ベクトルLから得たクエリ、キーおよびバリューに基づいて、補正後の文書に関する特徴量ベクトルLをさらに補正し、新たな特徴量ベクトルZLを生成して出力する。文書SA層504の具体例については、例えば、図6を用いて後述する。
また、結合層505は、集約用ベクトルHと、特徴量ベクトルZIと、特徴量ベクトルZLとの入力を受け付ける。結合層505は、集約用ベクトルHと、特徴量ベクトルZIと、特徴量ベクトルZLとを結合し、結合ベクトルCを生成し、統合SA層506に出力する。
また、統合SA層506は、結合ベクトルCの入力を受け付ける。統合SA層506は、結合ベクトルCから得たクエリ、キーおよびバリューに基づいて、結合ベクトルCを補正し、特徴量ベクトルZTを生成して出力する。特徴量ベクトルZTは、集約ベクトルZHと、文書に関する統合特徴量ベクトルZ1~ZMと、画像に関する統合特徴量ベクトルZM+1~ZM+Nとを含む。これにより、出力装置100は、問題を解いた際の解の精度を向上させる観点で有用な集約ベクトルZHを含む特徴量ベクトルZTを生成し、参照可能にすることができる。このため、出力装置100は、問題を解いた際の解の精度を向上可能にすることができる。
ここでは、説明の簡略化のため、画像TA層501と、画像SA層502と、文書TA層503と、文書SA層504とのグループ510が、1段である場合について説明したが、これに限らない。例えば、画像TA層501と、画像SA層502と、文書TA層503と、文書SA層504とのグループ510が、複数段存在する場合があってもよい。これによれば、出力装置100は、問題を解いた際の解の精度のさらなる向上を図ることができる。
次に、図6の説明に移行し、CAN500を形成する画像SA層502と文書SA層504と統合SA層506となどのようなSA層600の具体例について説明する。また、CAN500を形成する画像TA層501と文書TA層503となどのようなTA層610の具体例について説明する。
図6は、SA層600の具体例と、TA層610の具体例とを示す説明図である。以下の説明では、Multi-Head Attentionを「MHA」と表記する場合がある。また、Add&Normを「A&N」と表記する場合がある。また、Feed Forwardを「FF」と表記する場合がある。
図6に示すように、SA層600は、MHA層601と、A&N層602と、FF層603と、A&N層604とを有する。MHA層601は、入力ベクトルXから得たクエリQとキーKとバリューVとに基づいて、入力ベクトルXを補正する補正ベクトルRを生成し、A&N層602に出力する。MHA層601は、具体的には、入力ベクトルXを、Head個のベクトルに分割して処理する。Headは、1以上の自然数である。
A&N層602は、入力ベクトルXと補正ベクトルRとを加算した上で正規化し、正規化後のベクトルを、FF層603とA&N層604とに出力する。FF層603は、正規化後のベクトルを圧縮し、圧縮後のベクトルを、A&N層604に出力する。A&N層604は、正規化後のベクトルと、圧縮後のベクトルとを加算した上で正規化し、出力ベクトルZを生成して出力する。
また、TA層610は、MHA層611と、A&N層612と、FF層613と、A&N層614とを有する。MHA層611は、入力ベクトルXから得たクエリQと、入力ベクトルYから得たキーKとバリューVとに基づいて、入力ベクトルXを補正する補正ベクトルRを生成し、A&N層612に出力する。A&N層612は、入力ベクトルXと補正ベクトルRとを加算した上で正規化し、正規化後のベクトルを、FF層613とA&N層614とに出力する。FF層613は、正規化後のベクトルを圧縮し、圧縮後のベクトルを、A&N層614に出力する。A&N層614は、正規化後のベクトルと、圧縮後のベクトルとを加算した上で正規化し、出力ベクトルZを生成して出力する。
上述したMHA層601やMHA層611は、より具体的には、Head個のAttention層620により形成される。Attention層620は、MatMul層621と、Scale層622と、Mask層623と、SoftMax層624と、MatMul層625とを有する。
MatMul層621は、クエリQとキーKとの内積を算出し、Scoreに設定する。Scale層622は、Score全体を定数aで除算し、更新する。Mask層623は、更新後のScoreをマスク処理してもよい。SoftMax層624は、更新後のScoreを、正規化し、Attに設定する。MatMul層625は、AttとバリューVとの内積を算出し、補正ベクトルRに設定する。
ここで、SA層600の計算例について説明する。具体的には、SA層600の計算例の一つとして、SA層600で画像SA層502を実現する場合における計算例を示す。また、説明の簡略化のため、Head=1であるとする。
ここで、入力ベクトルXは、下記式(1)により表現される画像に関する特徴量ベクトルXであるとする。x1,x2,x3は、d次元のベクトルである。x1,x2,x3は、それぞれ、画像に写った物体に対応する。

クエリQは、下記式(2)により算出される。WQは、変換行列であり、学習により設定される。キーKは、下記式(3)により算出される。WKは、変換行列であり、学習により設定される。バリューVは、下記式(4)により算出される。WVは、変換行列であり、学習により設定される。クエリQと、キーKと、バリューVとは、入力ベクトルXと同じ次元である。



MatMul層621は、下記式(5)に示すように、クエリQとキーKとの内積を算出し、Scoreに設定する。Scale層622は、下記式(6)に示すように、Score全体を定数aで除算し、更新する。ここでは、Mask層623は、マスク処理を省略する。SoftMax層624は、下記式(7)に示すように、更新後のScoreを、正規化し、Attに設定する。MatMul層625は、下記式(8)に示すように、AttとバリューVとの内積を算出し、補正ベクトルRに設定する。


MHA層601は、上述したように、補正ベクトルRを生成する。A&N層602は、下記式(9)および下記式(10)に示すように、入力ベクトルXと補正ベクトルRとを加算した上で正規化し、入力ベクトルXを更新する。μは、下記式(11)により定義される。σは、下記式(12)により定義される。FF層603は、下記式(13)に示すように、更新後の入力ベクトルXを変換し、変換ベクトルX’を設定する。fは、活性化関数である。A&N層604は、更新後の入力ベクトルXと、設定した変換ベクトルX’とを加算した上で正規化し、出力ベクトルZを生成する。


次に、TA層610の計算例について説明する。具体的には、TA層610の計算例の一つとして、TA層610で画像TA層501を実現する場合における計算例を示す。また、説明の簡略化のため、Head=1であるとする。
ここで、入力ベクトルXは、上記式(1)により表現される画像に関する特徴量ベクトルXであるとする。x1,x2,x3は、d次元のベクトルである。x1,x2,x3は、それぞれ、画像に写った物体に対応する。入力ベクトルYは、下記式(14)により表現される文書に関する特徴量ベクトルYであるとする。y1,y2,y3は、d次元のベクトルである。y1,y2,y3は、それぞれ、文書に含まれる単語に対応する。

クエリQは、下記式(15)により算出される。WQは、変換行列であり、学習により設定される。キーKは、下記式(16)により算出される。WKは、変換行列であり、学習により設定される。バリューVは、下記式(17)により算出される。WVは、変換行列であり、学習により設定される。クエリQは、入力ベクトルXと同じ次元である。キーKと、バリューVとは、入力ベクトルYと同じ次元である。



MatMul層621は、上記式(5)に示すように、クエリQとキーKとの内積を算出し、Scoreに設定する。Scale層622は、上記式(6)に示すように、Score全体を定数aで除算し、更新する。ここでは、Mask層623は、マスク処理を省略する。SoftMax層624は、上記式(7)に示すように、更新後のScoreを、正規化し、Attに設定する。MatMul層625は、上記式(8)に示すように、AttとバリューVとの内積を算出し、補正ベクトルRに設定する。
MHA層601は、上述したように、補正ベクトルRを生成する。A&N層602は、上記式(9)および上記式(10)に示すように、入力ベクトルXと補正ベクトルRとを加算した上で正規化し、入力ベクトルXを更新する。FF層603は、上記式(13)に示すように、更新後の入力ベクトルXを変換し、変換ベクトルX’を設定する。A&N層604は、更新後の入力ベクトルXと、設定した変換ベクトルX’とを加算した上で正規化し、出力ベクトルZを生成する。次に、図7を用いて、出力装置100による、CAN500を用いた動作の一例について説明する。
図7は、CAN500を用いた動作の一例を示す説明図である。出力装置100は、文書700を取得し、画像710を取得する。出力装置100は、文書700をトークン化し、トークン集合701をベクトル化し、文書700に関する特徴量ベクトル702を生成し、CAN500に入力する。また、出力装置100は、画像710から物体を検出し、物体ごとの部分画像の集合711をベクトル化し、画像710に関する特徴量ベクトル712を生成し、CAN500に入力する。
出力装置100は、CAN500から、特徴量ベクトルZTを取得し、特徴量ベクトルZTに含まれる集約ベクトルZHを、危険度推定器720に入力する。出力装置100は、危険度推定器720から推定結果Noを取得する。これにより、出力装置100は、画像と文書との特徴が反映された集約ベクトルZHを用いて、危険度推定器720に推定させることができ、精度よく推定可能にすることができる。危険度推定器720は、例えば、銃を持った人物が写っている画像710があるが、ミュージアムの展示物であることを示す文書もあるため、推定結果No=危険ではないと推定することができる。
(出力装置100の利用例)
次に、図8~図11を用いて、出力装置100の利用例について説明する。
次に、図8~図11を用いて、出力装置100の利用例について説明する。
図8および図9は、出力装置100の利用例1を示す説明図である。図8において、出力装置100は、学習フェーズを実施し、CAN500を学習する。出力装置100は、例えば、何らかのシーンを写した画像800と、画像800に対応する字幕となる文書810とを取得する。画像800は、例えば、りんごを切るシーンを写す。出力装置100は、画像800を変換器820により特徴量ベクトルに変換し、CAN500に入力する。また、出力装置100は、文書810の単語appleをマスクした上で、変換器830により特徴量ベクトルに変換し、CAN500に入力する。
出力装置100は、CAN500により生成された特徴量ベクトルを、識別器840に入力し、マスクされた単語を予測した結果を取得し、マスクされた単語の正解「apple」との誤差を算出する。出力装置100は、算出した誤差に基づいて、誤差逆伝搬によりCAN500を学習する。さらに、出力装置100は、誤差逆伝搬により、変換器820,830や識別器840を学習してもよい。これにより、出力装置100は、画像800と字幕となる文書810の文脈とを考慮して単語を推定する観点で有用なように、CAN500、および変換器820,830や識別器840を更新することができる。次に、図9の説明に移行する。
図9において、出力装置100は、試験フェーズを実施し、学習した変換器820,830と、学習したCAN500とを用いて、回答を生成して出力する。出力装置100は、例えば、何らかのシーンを写した画像900と、画像900に対応する質問文となる文書910とを取得する。画像900は、例えば、りんごを切るシーンを写す。
出力装置100は、画像900を変換器820により特徴量ベクトルに変換し、CAN500に入力する。また、出力装置100は、文書910を変換器830により特徴量ベクトルに変換し、CAN500に入力する。出力装置100は、CAN500により生成された特徴量ベクトルを、回答生成器920に入力し、回答となる単語を取得して出力する。これにより、出力装置100は、画像900と質問文となる文書910の文脈とを考慮して、精度よく回答となる単語を推定することができる。
図10および図11は、出力装置100の利用例2を示す説明図である。図10において、出力装置100は、学習フェーズを実施し、CAN500を学習する。出力装置100は、例えば、何らかのシーンを写した画像1000と、画像1000に対応する字幕となる文書1010とを取得する。画像1000は、例えば、りんごを切るシーンを写す。出力装置100は、画像1000を変換器1020により特徴量ベクトルに変換し、CAN500に入力する。また、出力装置100は、文書1010の単語appleをマスクした上で、変換器1030により特徴量ベクトルに変換し、CAN500に入力する。
出力装置100は、CAN500により生成された特徴量ベクトルを、識別器1040に入力し、画像に写ったシーンの危険度を予測した結果を取得し、危険度の正解との誤差を算出する。出力装置100は、算出した誤差に基づいて、誤差逆伝搬によりCAN500を学習する。また、出力装置100は、誤差逆伝搬により、変換器1020,1030や識別器1040を学習する。これにより、出力装置100は、画像1000と字幕となる文書1010の文脈とを考慮して危険度を予測する観点で有用なように、CAN500、および変換器1020,1030や識別器1040を更新することができる。次に、図11の説明に移行する。
図11において、出力装置100は、試験フェーズを実施し、学習した変換器1020,1030や識別器1040と、学習したCAN500とを用いて、危険度を予測して出力する。出力装置100は、例えば、何らかのシーンを写した画像1100と、画像に対応する説明文となる文書1110とを取得する。画像1100は、例えば、ももを切るシーンを写す。
出力装置100は、画像1100を変換器1020により特徴量ベクトルに変換し、CAN500に入力する。また、出力装置100は、文書1110を変換器1030により特徴量ベクトルに変換し、CAN500に入力する。出力装置100は、CAN500により生成された特徴量ベクトルを、識別器1040に入力し、危険度を取得して出力する。これにより、出力装置100は、画像1100と説明文となる文書1110の文脈とを考慮して、精度よく危険度を予測することができる。
(学習処理手順)
次に、図12を用いて、出力装置100が実行する、学習処理手順の一例について説明する。学習処理は、例えば、図3に示したCPU301と、メモリ302や記録媒体305などの記憶領域と、ネットワークI/F303とによって実現される。
次に、図12を用いて、出力装置100が実行する、学習処理手順の一例について説明する。学習処理は、例えば、図3に示したCPU301と、メモリ302や記録媒体305などの記憶領域と、ネットワークI/F303とによって実現される。
図12は、学習処理手順の一例を示すフローチャートである。図12において、出力装置100は、画像の特徴量ベクトルと、文書の特徴量ベクトルとを取得する(ステップS1201)。
次に、出力装置100は、取得した画像の特徴量ベクトルから生成したクエリと、取得した文書の特徴量ベクトルから生成したキーおよびバリューとに基づいて、画像TA層501を用いて、画像の特徴量ベクトルを補正する(ステップS1202)。
そして、出力装置100は、補正後の画像の特徴量ベクトルに基づいて、画像SA層502を用いて、補正後の画像の特徴量ベクトルをさらに補正し、新たに画像の特徴量ベクトルを生成する(ステップS1203)。
次に、出力装置100は、取得した文書の特徴量ベクトルから生成したクエリと、取得した画像の特徴量ベクトルから生成したキーおよびバリューとに基づいて、文書TA層503を用いて、文書の特徴量ベクトルを補正する(ステップS1204)。
そして、出力装置100は、補正後の文書の特徴量ベクトルに基づいて、文書SA層504を用いて、補正後の文書の特徴量ベクトルをさらに補正し、新たに文書の特徴量ベクトルを生成する(ステップS1205)。
次に、出力装置100は、集約用ベクトルを初期化する(ステップS1206)。そして、出力装置100は、集約用ベクトルと、生成した画像の特徴量ベクトルと、生成した文書の特徴量ベクトルとを結合し、結合ベクトルを生成する(ステップS1207)。
次に、出力装置100は、結合ベクトルに基づいて、統合SA層506を用いて、結合ベクトルを補正し、集約ベクトルを生成する(ステップS1208)。そして、出力装置100は、集約ベクトルに基づいて、CAN500を学習する(ステップS1209)。
その後、出力装置100は、学習処理を終了する。これにより、出力装置100は、CAN500を用いて問題を解くにあたり、問題を解いた際の解の精度が向上するように、CAN500のパラメータを更新することができる。
ここで、出力装置100は、図12の一部ステップの処理の順序を入れ替えて実行してもよい。例えば、ステップS1202,S1203の処理と、ステップS1204,S1205の処理との順序は入れ替え可能である。また、出力装置100は、ステップS1202~S1205の処理を繰り返し実行してもよい。
(推定処理手順)
次に、図13を用いて、出力装置100が実行する、推定処理手順の一例について説明する。推定処理は、例えば、図3に示したCPU301と、メモリ302や記録媒体305などの記憶領域と、ネットワークI/F303とによって実現される。
次に、図13を用いて、出力装置100が実行する、推定処理手順の一例について説明する。推定処理は、例えば、図3に示したCPU301と、メモリ302や記録媒体305などの記憶領域と、ネットワークI/F303とによって実現される。
図13は、推定処理手順の一例を示すフローチャートである。図13において、出力装置100は、画像の特徴量ベクトルと、文書の特徴量ベクトルとを取得する(ステップS1301)。
次に、出力装置100は、取得した画像の特徴量ベクトルから生成したクエリと、取得した文書の特徴量ベクトルから生成したキーおよびバリューとに基づいて、画像TA層501を用いて、画像の特徴量ベクトルを補正する(ステップS1302)。
そして、出力装置100は、補正後の画像の特徴量ベクトルに基づいて、画像SA層502を用いて、補正後の画像の特徴量ベクトルをさらに補正し、新たに画像の特徴量ベクトルを生成する(ステップS1303)。
次に、出力装置100は、取得した文書の特徴量ベクトルから生成したクエリと、取得した画像の特徴量ベクトルから生成したキーおよびバリューとに基づいて、文書TA層503を用いて、文書の特徴量ベクトルを補正する(ステップS1304)。
そして、出力装置100は、補正後の文書の特徴量ベクトルに基づいて、文書SA層504を用いて、補正後の文書の特徴量ベクトルをさらに補正し、新たに文書の特徴量ベクトルを生成する(ステップS1305)。
次に、出力装置100は、集約用ベクトルを初期化する(ステップS1306)。そして、出力装置100は、集約用ベクトルと、生成した画像の特徴量ベクトルと、生成した文書の特徴量ベクトルとを結合し、結合ベクトルを生成する(ステップS1307)。
次に、出力装置100は、結合ベクトルに基づいて、統合SA層506を用いて、結合ベクトルを補正し、集約ベクトルを生成する(ステップS1308)。そして、出力装置100は、集約ベクトルに基づいて、識別モデルを用いて、状況を推定する(ステップS1309)。
次に、出力装置100は、推定した状況を出力する(ステップS1310)。そして、出力装置100は、推定処理を終了する。これにより、出力装置100は、CAN500を用いて、問題を解いた際の解の精度を向上させることができる。
ここで、出力装置100は、図13の一部ステップの処理の順序を入れ替えて実行してもよい。例えば、ステップS1302,S1303の処理と、ステップS1304,S1305の処理との順序は入れ替え可能である。また、出力装置100は、ステップS1302~S1305の処理を繰り返し実行してもよい。
以上説明したように、出力装置100によれば、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第一のモーダルの情報に基づくベクトルを補正することができる。出力装置100によれば、第一のモーダルの情報に基づくベクトルと、第二のモーダルの情報に基づくベクトルとの相関に基づいて、第二のモーダルの情報に基づくベクトルを補正することができる。出力装置100によれば、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成することができる。出力装置100によれば、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成することができる。出力装置100によれば、所定のベクトルと、生成した第一のベクトルと、生成した第二のベクトルとを含む結合ベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルと第二のベクトルとを集約した第三のベクトルを生成することができる。出力装置100によれば、生成した第三のベクトルを出力することができる。これにより、出力装置100は、第一のベクトルと第二のベクトルとが集約され、第一のモーダルの情報に基づくベクトルと第二のモーダルの情報に基づくベクトルとのうち問題の解決に有用な情報が反映される傾向がある第三のベクトルを生成し、利用可能にすることができる。このため、出力装置100は、第三のベクトルを利用し、問題を解いた際の解の精度を向上可能にすることができる。
出力装置100によれば、第一のターゲットアテンション層を用いて、第一のモーダルの情報に基づくベクトルから得たベクトルと、第二のモーダルの情報に基づくベクトルから得たベクトルとの内積に基づいて、第一のモーダルの情報に基づくベクトルを補正することができる。出力装置100によれば、第二のターゲットアテンション層を用いて、第一のモーダルの情報に基づくベクトルから得たベクトルと、第二のモーダルの情報に基づくベクトルから得たベクトルとの内積に基づいて、第二のモーダルの情報に基づくベクトルを補正することができる。出力装置100によれば、第一のセルフアテンション層を用いて、補正後の第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの内積に基づいて、補正後の第一のモーダルの情報に基づくベクトルをさらに補正し、第一のベクトルを生成することができる。出力装置100によれば、第二のセルフアテンション層を用いて、補正後の第二のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの内積に基づいて、補正後の第二のモーダルの情報に基づくベクトルをさらに補正し、第二のベクトルを生成することができる。出力装置100によれば、第三のセルフアテンション層を用いて、所定のベクトルと第一のベクトルと第二のベクトルとを結合した結合ベクトルから得た異なる種類の2つのベクトルの内積に基づいて、第三のベクトルを生成することができる。これにより、出力装置100は、各種アテンション層を用いて、第三のベクトルを生成する処理を、容易に実現することができる。
出力装置100によれば、生成した第三のベクトルに基づいて、第一のモーダルと第二のモーダルとに関する状況を判断して出力することができる。これにより、出力装置100は、状況を判別する問題を解く場合に適用可能にすることができ、問題を解いた結果を参照可能にすることができる。
出力装置100によれば、生成した第一のベクトルを、新たな第一のモーダルの情報に基づくベクトルに設定することができる。出力装置100によれば、生成した第二のベクトルを、新たな第二のモーダルの情報に基づくベクトルに設定することができる。出力装置100によれば、設定した第一のモーダルの情報に基づくベクトルを補正し、設定した第二のモーダルの情報に基づくベクトルを補正し、第一のベクトルを生成し、第二のベクトルを生成する、処理を1回以上繰り返すことができる。出力装置100によれば、所定のベクトルと、生成した第一のベクトルと、生成した第二のベクトルとを含む結合ベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルと第二のベクトルとを集約した第三のベクトルを生成することができる。これにより、出力装置100は、各種ベクトルを多段階に補正し、問題を解いた際の解の精度をさらに向上可能にすることができる。
出力装置100によれば、第一のモーダルとして、画像に関するモーダルを採用することができる。出力装置100によれば、第二のモーダルとして、文書に関するモーダルを採用することができる。これにより、出力装置100は、画像と文書とに基づいて問題を解く場合に適用可能にすることができる。
出力装置100によれば、第一のモーダルとして、画像に関するモーダルを採用することができる。出力装置100によれば、第二のモーダルとして、音声に関するモーダルを採用することができる。これにより、出力装置100は、画像と音声とに基づいて問題を解く場合に適用可能にすることができる。
出力装置100によれば、第一のモーダルとして、第一の言語の文書に関するモーダルを採用することができる。出力装置100によれば、第二のモーダルとして、第二の言語の文書に関するモーダルを採用することができる。これにより、出力装置100は、異なる言語の2つの文書に基づいて問題を解く場合に適用可能にすることができる。
出力装置100によれば、生成した第三のベクトルに基づいて、ポジティブな状況、または、ネガティブな状況を判断して出力することができる。これにより、出力装置100は、ポジティブな状況、または、ネガティブな状況を判別する問題を解く場合に適用可能にすることができ、問題を解いた結果を参照可能にすることができる。
出力装置100によれば、生成した第三のベクトルに基づいて、第一のターゲットアテンション層と、第二のターゲットアテンション層と、第一のセルフアテンション層と、第二のセルフアテンション層と、第三のセルフアテンション層とを更新することができる。これにより、出力装置100は、第三のベクトルをより有用な状態で生成可能に、各種アテンション層を更新し、問題を解いた際の解の精度を向上可能にすることができる。
なお、本実施の形態で説明した出力方法は、予め用意されたプログラムをPCやワークステーションなどのコンピュータで実行することにより実現することができる。本実施の形態で説明した出力プログラムは、コンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。記録媒体は、ハードディスク、フレキシブルディスク、CD(Compact Disc)-ROM、MO、DVD(Digital Versatile Disc)などである。また、本実施の形態で説明した出力プログラムは、インターネットなどのネットワークを介して配布してもよい。
100 出力装置
111,112 補正モデル
121,122,130 生成モデル
200 情報処理システム
201 クライアント装置
202 端末装置
210 ネットワーク
300 バス
301 CPU
302 メモリ
303 ネットワークI/F
304 記録媒体I/F
305 記録媒体
400 記憶部
401 取得部
402 第一の補正部
403 第一の生成部
404 第二の補正部
405 第二の生成部
406 第三の生成部
407 解析部
408 出力部
500 Co-Attention Network
501 画像TA層
502 画像SA層
503 文書TA層
504 文書SA層
505 結合層
506 統合SA層
510 グループ
600 SA層
601,611 MHA層
602,604,612,614 A&N層
603,613 FF層
610 TA層
620 Attention層
621,625 MatMul層
622 Scale層
623 Mask層
624 SoftMax層
700,810,910,1010,1110 文書
701 トークン集合
702,712 特徴量ベクトル
710,800,900,1000,1100 画像
711 集合
720 危険度推定器
820,830,1020,1030 変換器
840,1040 識別器
920 回答生成器
111,112 補正モデル
121,122,130 生成モデル
200 情報処理システム
201 クライアント装置
202 端末装置
210 ネットワーク
300 バス
301 CPU
302 メモリ
303 ネットワークI/F
304 記録媒体I/F
305 記録媒体
400 記憶部
401 取得部
402 第一の補正部
403 第一の生成部
404 第二の補正部
405 第二の生成部
406 第三の生成部
407 解析部
408 出力部
500 Co-Attention Network
501 画像TA層
502 画像SA層
503 文書TA層
504 文書SA層
505 結合層
506 統合SA層
510 グループ
600 SA層
601,611 MHA層
602,604,612,614 A&N層
603,613 FF層
610 TA層
620 Attention層
621,625 MatMul層
622 Scale層
623 Mask層
624 SoftMax層
700,810,910,1010,1110 文書
701 トークン集合
702,712 特徴量ベクトル
710,800,900,1000,1100 画像
711 集合
720 危険度推定器
820,830,1020,1030 変換器
840,1040 識別器
920 回答生成器
Claims (9)
- 第一のモーダルの情報に基づくベクトルと、前記第一のモーダルとは異なる第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第一のモーダルの情報に基づくベクトルを補正し、
前記第一のモーダルの情報に基づくベクトルと、前記第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第二のモーダルの情報に基づくベクトルを補正し、
補正後の前記第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成し、
補正後の前記第二のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成し、
所定のベクトルと、生成した前記第一のベクトルと、生成した前記第二のベクトルとを含む結合ベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第一のベクトルと前記第二のベクトルとを集約した第三のベクトルを生成し、
生成した前記第三のベクトルを出力する、
処理をコンピュータが実行することを特徴とする出力方法。 - 前記第一のモーダルの情報に基づくベクトルを補正する処理は、
前記第一のモーダルに関する第一のターゲットアテンション層を用いて、前記第一のモーダルの情報に基づくベクトルから得たベクトルと、前記第二のモーダルの情報に基づくベクトルから得たベクトルとの内積に基づいて、前記第一のモーダルの情報に基づくベクトルを補正し、
前記第二のモーダルの情報に基づくベクトルを補正する処理は、
前記第二のモーダルに関する第二のターゲットアテンション層を用いて、前記第一のモーダルの情報に基づくベクトルから得たベクトルと、前記第二のモーダルの情報に基づくベクトルから得たベクトルとの内積に基づいて、前記第二のモーダルの情報に基づくベクトルを補正し、
前記第一のベクトルを生成する処理は、
前記第一のモーダルに関する第一のセルフアテンション層を用いて、補正後の前記第一のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの内積に基づいて、補正後の前記第一のモーダルの情報に基づくベクトルをさらに補正し、前記第一のベクトルを生成し、
前記第二のベクトルを生成する処理は、
前記第二のモーダルに関する第二のセルフアテンション層を用いて、補正後の前記第二のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの内積に基づいて、補正後の前記第二のモーダルの情報に基づくベクトルをさらに補正し、前記第二のベクトルを生成し、
前記第三のベクトルを生成する処理は、
第三のセルフアテンション層を用いて、前記所定のベクトルと前記第一のベクトルと前記第二のベクトルとを結合した結合ベクトルから得た前記異なる種類の2つのベクトルの内積に基づいて、前記結合ベクトルを補正し、前記第三のベクトルを生成する、ことを特徴とする請求項1に記載の出力方法。 - 生成した前記第三のベクトルに基づいて、前記第一のモーダルと前記第二のモーダルとに関する状況を判断して出力する、
処理を前記コンピュータが実行することを特徴とする請求項1または2に記載の出力方法。 - 生成した前記第一のベクトルを、新たな前記第一のモーダルの情報に基づくベクトルに設定し、
生成した前記第二のベクトルを、新たな前記第二のモーダルの情報に基づくベクトルに設定し、
設定した前記第一のモーダルの情報に基づくベクトルと、設定した前記第二のモーダルの情報に基づくベクトルとの相関に基づいて、設定した前記第一のモーダルの情報に基づくベクトルを補正し、
設定した前記第一のモーダルの情報に基づくベクトルと、設定した前記第二のモーダルの情報に基づくベクトルとの相関に基づいて、設定した前記第二のモーダルの情報に基づくベクトルを補正し、
補正後の前記第一のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第一のベクトルを生成し、
補正後の前記第二のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第二のベクトルを生成する、
処理を前記コンピュータが1回以上繰り返し、
前記第三のベクトルを生成する処理は、
前記所定のベクトルと、生成した前記第一のベクトルと、生成した前記第二のベクトルとを含む結合ベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第一のベクトルと前記第二のベクトルとを集約した第三のベクトルを生成する、ことを特徴とする請求項1~3のいずれか一つに記載の出力方法。 - 前記第一のモーダルと前記第二のモーダルとの組は、画像に関するモーダルと文書に関するモーダルとの組、画像に関するモーダルと音声に関するモーダルとの組、第一の言語の文書に関するモーダルと第二の言語の文書に関するモーダルとの組のうちいずれかの組である、ことを特徴とする請求項1~4のいずれか一つに記載の出力方法。
- 前記状況は、ポジティブな状況、または、ネガティブな状況である、ことを特徴とする請求項3に記載の出力方法。
- 生成した前記第三のベクトルに基づいて、前記第一のターゲットアテンション層と、前記第二のターゲットアテンション層と、前記第一のセルフアテンション層と、前記第二のセルフアテンション層と、前記第三のセルフアテンション層とを更新する、
処理を前記コンピュータが実行することを特徴とする請求項2に記載の出力方法。 - 第一のモーダルの情報に基づくベクトルと、前記第一のモーダルとは異なる第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第一のモーダルの情報に基づくベクトルを補正し、
前記第一のモーダルの情報に基づくベクトルと、前記第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第二のモーダルの情報に基づくベクトルを補正し、
補正後の前記第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成し、
補正後の前記第二のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成し、
所定のベクトルと、生成した前記第一のベクトルと、生成した前記第二のベクトルとを含む結合ベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第一のベクトルと前記第二のベクトルとを集約した第三のベクトルを生成し、
生成した前記第三のベクトルを出力する、
処理をコンピュータに実行させることを特徴とする出力プログラム。 - 第一のモーダルの情報に基づくベクトルと、前記第一のモーダルとは異なる第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第一のモーダルの情報に基づくベクトルを補正し、
前記第一のモーダルの情報に基づくベクトルと、前記第二のモーダルの情報に基づくベクトルとの相関に基づいて、前記第二のモーダルの情報に基づくベクトルを補正し、
補正後の前記第一のモーダルの情報に基づくベクトルから得た異なる種類の2つのベクトルの相関に基づいて、第一のベクトルを生成し、
補正後の前記第二のモーダルの情報に基づくベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、第二のベクトルを生成し、
所定のベクトルと、生成した前記第一のベクトルと、生成した前記第二のベクトルとを含む結合ベクトルから得た前記異なる種類の2つのベクトルの相関に基づいて、前記第一のベクトルと前記第二のベクトルとを集約した第三のベクトルを生成し、
生成した前記第三のベクトルを出力する、
制御部を有することを特徴とする出力装置。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/044769 WO2021095211A1 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
| JP2021555728A JP7205646B2 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
| US17/719,438 US20220237263A1 (en) | 2019-11-14 | 2022-04-13 | Method for outputting, computer-readable recording medium storing output program, and output device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/044769 WO2021095211A1 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/719,438 Continuation US20220237263A1 (en) | 2019-11-14 | 2022-04-13 | Method for outputting, computer-readable recording medium storing output program, and output device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021095211A1 true WO2021095211A1 (ja) | 2021-05-20 |
Family
ID=75912592
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/044769 WO2021095211A1 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220237263A1 (ja) |
| JP (1) | JP7205646B2 (ja) |
| WO (1) | WO2021095211A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11921711B2 (en) * | 2020-03-06 | 2024-03-05 | Alibaba Group Holding Limited | Trained sequence-to-sequence conversion of database queries |
| US11699275B2 (en) * | 2020-06-17 | 2023-07-11 | Tata Consultancy Services Limited | Method and system for visio-linguistic understanding using contextual language model reasoners |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005199403A (ja) | 2004-01-16 | 2005-07-28 | Sony Corp | 情動認識装置及び方法、ロボット装置の情動認識方法、ロボット装置の学習方法、並びにロボット装置 |
| US10417498B2 (en) | 2016-12-30 | 2019-09-17 | Mitsubishi Electric Research Laboratories, Inc. | Method and system for multi-modal fusion model |
| US10916135B2 (en) | 2018-01-13 | 2021-02-09 | Toyota Jidosha Kabushiki Kaisha | Similarity learning and association between observations of multiple connected vehicles |
| JP2019169147A (ja) | 2018-03-20 | 2019-10-03 | 国立大学法人電気通信大学 | 情報処理装置及び情報処理システム |
-
2019
- 2019-11-14 WO PCT/JP2019/044769 patent/WO2021095211A1/ja active Application Filing
- 2019-11-14 JP JP2021555728A patent/JP7205646B2/ja active Active
-
2022
- 2022-04-13 US US17/719,438 patent/US20220237263A1/en active Pending
Non-Patent Citations (3)
| Title |
|---|
| LU, JIASEN ET AL.: "ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks", ARXIV.ORG, 6 August 2019 (2019-08-06), pages 1 - 11, XP081456681, Retrieved from the Internet <URL:https://arxiv.org/pdf/1908.02265vl.pdf> [retrieved on 20191213] * |
| NGUYEN, DUY-KIEN ET AL., IMPROVED FUSION OF VISUAL AND LANGUAGE REPRESENTATIONS BY DENSE SYMMETRIC CO-ATTENTION FOR VISUAL QUESTION ANSWERING, 2018, pages 6087 - 6096, XP033473524, Retrieved from the Internet <URL:http://openaccess.thecvf.com/content_cvpr_2018/html/Nguyen_Improved_Fusion_of_CVPR_2018_paper.html> [retrieved on 20191213] * |
| YU, JIANFEI ET AL., ADAPTING BERT FOR TARGET-ORIENTED MULTIMODAL SENTIMENT CLASSIFICATION, August 2019 (2019-08-01), pages 5408 - 5414, XP055823561, Retrieved from the Internet <URL:https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=5444&context=sis_research> [retrieved on 20191213] * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021095211A1 (ja) | 2021-05-20 |
| JP7205646B2 (ja) | 2023-01-17 |
| US20220237263A1 (en) | 2022-07-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020258668A1 (zh) | 基于对抗网络模型的人脸图像生成方法及装置、非易失性可读存储介质、计算机设备 | |
| US11521110B2 (en) | Learning apparatus, learning method, and non-transitory computer readable storage medium | |
| US20220237263A1 (en) | Method for outputting, computer-readable recording medium storing output program, and output device | |
| KR102196199B1 (ko) | 음성인식 기반의 사진 공유 방법, 장치 및 시스템 | |
| KR102274581B1 (ko) | 개인화된 hrtf 생성 방법 | |
| JP4511135B2 (ja) | データ分布を表現する方法、データ要素を表現する方法、データ要素の記述子、照会データ要素を照合または分類する方法、その方法を実行するように設定した装置、コンピュータプログラム並びにコンピュータ読み取り可能な記憶媒体 | |
| JPWO2021095211A5 (ja) | ||
| WO2022227765A1 (zh) | 生成图像修复模型的方法、设备、介质及程序产品 | |
| JP2021521704A (ja) | 遠隔会議システム、遠隔会議のための方法、およびコンピュータ・プログラム | |
| US10923106B2 (en) | Method for audio synthesis adapted to video characteristics | |
| WO2024160178A1 (zh) | 图像翻译模型的训练、图像翻译方法、设备及存储介质 | |
| US20220237421A1 (en) | Method for outputting, computer-readable recording medium storing output program, and output device | |
| KR102562386B1 (ko) | 이미지 합성 시스템의 학습 방법 | |
| WO2021095213A1 (ja) | 学習方法、学習プログラム、および学習装置 | |
| JP6843409B1 (ja) | 学習方法、コンテンツ再生装置、及びコンテンツ再生システム | |
| KR102504722B1 (ko) | 감정 표현 영상 생성을 위한 학습 장치 및 방법과 감정 표현 영상 생성 장치 및 방법 | |
| JPWO2021095212A5 (ja) | ||
| US20230196739A1 (en) | Machine learning device and far-infrared image capturing device | |
| JP4816874B2 (ja) | パラメータ学習装置、パラメータ学習方法、およびプログラム | |
| US20240104180A1 (en) | User authentication based on three-dimensional face modeling using partial face images | |
| JP2021018477A (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| WO2020044630A1 (ja) | 検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム | |
| KR102563522B1 (ko) | 사용자의 얼굴을 인식하는 장치, 방법 및 컴퓨터 프로그램 | |
| CN113807251A (zh) | 一种基于外观的视线估计方法 | |
| CN115428013A (zh) | 信息处理装置和程序 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19952179 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021555728 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19952179 Country of ref document: EP Kind code of ref document: A1 |