WO2020044630A1 - 検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム - Google Patents
検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム Download PDFInfo
- Publication number
- WO2020044630A1 WO2020044630A1 PCT/JP2019/010187 JP2019010187W WO2020044630A1 WO 2020044630 A1 WO2020044630 A1 WO 2020044630A1 JP 2019010187 W JP2019010187 W JP 2019010187W WO 2020044630 A1 WO2020044630 A1 WO 2020044630A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- detector
- face image
- learning data
- data sets
- learning
- Prior art date
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
Definitions
- the present invention relates to a detector generation device, a monitoring device, a detector generation method, and a detector generation program.
- an organ of the driver's face is detected from an image obtained by photographing the driver.
- the state of the driver can be estimated based on the positional relationship between the detected organs. For example, if each eye is detected from the face image and the position of each eye can be specified, the gaze direction of the driver can be estimated based on the specified positional relationship of each eye.
- Patent Literature 1 proposes an apparatus for detecting a facial organ by using a convolutional neural network (Convolutional Neural Network). Specifically, the apparatus extracts a feature point candidate related to a facial organ from face image data using a convolutional neural network, and performs a geometric correction process on each extracted candidate. By doing so, the position of each feature point is determined. Thus, the device can recognize the target person based on the determined positions of the feature points.
- Convolutional Neural Network Convolutional Neural Network
- a detector constituted by a learning model such as a neural network may be employed.
- This detector can detect the position of the facial organ from the input face image by machine learning.
- a face image in which the face appears and position information indicating the positions of the facial organs are prepared.
- the parameters of the detector are adjusted so as to output an output value corresponding to the position information.
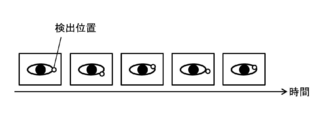
- FIG. 1 schematically illustrates an example of a scene in which the position of a facial organ is detected by a conventional method.
- FIG. 1 illustrates a scene in which an eye (specifically, an outer corner of the eye) is detected as an example of a facial organ.
- the detector has the ability to output the same output value for the same face image, in other words, the ability to answer the same position to the same face image as the detection position of the target organ. To win. Therefore, if the driver does not move the facial organ, the detection position of the organ that is answered by the detector should be constant.
- a plurality of continuously acquired images such as moving images may randomly include noise according to the performance of the imaging device, the imaging environment, and the like. Due to the effects of this random noise, it is difficult to obtain completely identical images, and each image may be slightly different. Due to the subtle differences between the images, the detected positions of the organs answered by the detector are blurred even though the driver does not move the facial organs. That is, as shown in FIG. 1, the detection position of the organ varies between face images due to the influence of noise included in each face image even though the organ (the outer corner of the eye) is not moved. The present inventors have found that can occur.
- the estimation result of the gaze direction of the driver fluctuates because the detection position of each eye is blurred even though the driver has not changed his / her gaze. Will be. This may result in the system erroneously recognizing the driver's state, for example, recognizing that the driver is looking aside while the driver is gazing ahead. Occurs.
- this problem is not a scene for detecting the facial organ of the driver as described above, but, for example, a scene for detecting a facial organ of a target person other than the driver, an object other than the facial organ of the target person.
- This can occur in any scene where an object is detected, such as a scene where the object is detected.
- a method using a conventional detector uses a method using a plurality of images even when the object is not moving. There may be a problem that the detection position of the object is blurred.
- the present invention in one aspect, has been made in view of such circumstances, and a purpose thereof is to provide a technique for generating a detector that is robust to the influence of noise and that can detect an object with higher accuracy. It is to provide.
- the present invention employs the following configuration in order to solve the above-described problems.
- the detector generation device uses a combination of a first face image in which the face of a subject driving a vehicle is captured and position information indicating the position of the facial organ in the first face image.
- a learning data acquisition unit that acquires a plurality of learning data sets configured respectively, and a learning processing unit that performs machine learning of a detector using the plurality of learning data sets. Then, performing the machine learning of the detector includes inputting the first face image of each of the learning data sets to the detector to generate a first output of each of the learning data sets for the first face image.
- the detector generation device acquires a plurality of learning data sets each configured by a combination of the first face image and the position information, and uses the acquired plurality of learning data sets to perform machine learning of the detector. Is carried out.
- the first face image corresponds to training data (input data)
- the position information corresponds to correct answer data (teacher data).
- the detector is configured to receive an input of a face image and output an output value corresponding to a result of detecting the position of a facial organ (for example, a coordinate value of the organ) in the input facial image.
- the detector generation device obtains a first output value by inputting a first face image to the detector in a process of machine learning, and obtains an organ specified based on the obtained first output value.
- a total value of a first error between the first detection position and the position indicated by the position information is calculated.
- the total value of the first error corresponds to a loss between the result of detecting the organ from the first face image by the detector and the correct answer of the position of the organ specified by the position information. Therefore, the detector generation device according to the above configuration trains the detector so that the total value of the first errors becomes small.
- a detector that has acquired the ability to detect an organ from the first face image is constructed so as to match the correct answer indicated by the position information.
- the detector generation device generates a second face image by adding noise to the first face image, and inputs the generated second face image to the detector to generate a second output value. To get. Then, the detector generation device according to the above configuration calculates a total value of a second error between the first detection position and the second detection position of the organ specified based on the acquired second output value.
- the total value of the second error is a blur of the detection result of the organ by the detector, and corresponds to a loss of the blur caused by the presence or absence of the noise. Therefore, the detector generation device according to the above configuration trains the detector such that the total value of the second error is reduced together with the total value of the first error. Thereby, it is possible to construct a detector in which the detection result of the organ is hardly affected by the noise.
- the detector generating apparatus having the above configuration, the organ is detected from the first face image so as to coincide with the correct answer indicated by the position information, and the detection result is hardly affected by noise.
- a constructed detector can be constructed. Therefore, it is possible to generate a detector that is robust against the influence of noise and that can detect an object (a facial organ in the above-described aspect) with higher accuracy.
- the detector is composed of a learning model that can execute machine learning.
- a detector may be constituted by a neural network, for example.
- the type of organ detected from the face image is not particularly limited as long as it is some part included in the face, and may be appropriately selected according to the embodiment.
- the organ to be detected may be selected from, for example, eyes, nose, mouth, eyebrows, chin, and combinations thereof.
- the organ to be detected may include the contour of the face.
- performing the machine learning of the detector includes applying a predetermined geometric transformation to the first face image of each of the learning data sets, so that each of the learning data sets Generating a third face image for the first face image, and inputting each of the third face images to the detector to obtain a third output value for each of the third face images.
- the first detection position specified based on the first output value obtained for the first face image of each of the learning data sets and the first detection position generated for the first face image Calculating a total value of a third error between the organ and a third detection position specified based on the third output value obtained for the third face image.
- the learning Management unit the sum of the first error may be trained sum and the detector so that the total value of the third error is smaller in the second error.
- the present inventors have found that, in addition to the influence of random noise generated in the image, the problem that the detection position of the organ fluctuates due to the following reasons. That is, the position information used as the correct answer data of the machine learning may include noise. That is, the position information has an instability that the position of the target organ is not always accurately indicated according to a certain reference. For example, when the position information is input by a human, if the person who inputs the position information is different, the position specified as the position where the organ exists may be different. Even if the same person inputs the position information, it is difficult to specify a position that completely matches the same face image a plurality of times.
- the input position information always indicates the position of the target organ in accordance with a certain standard. Is not always shown exactly. That is, the position at which the organ indicated by the position information exists may vary.
- position information including such noise is used as correct data for machine learning
- the detector learns not only to reproduce the position of a given organ with respect to the face image but also to reproduce this noise. .
- the detected position of the organ that is answered by the learned detector is blurred. That is, as illustrated in FIG. 1 above, even though the organ (the outer corner of the eye) is not moved, the effect of learning the noise included in the position information used for the machine learning can be reduced between the face images. There may be a problem that the detection position fluctuates.
- the detector generation device generates a third face image by applying a predetermined geometric transformation to the first face image, and inputs the generated third face image to the detector. Obtains the third output value. Then, the detector generation device according to the configuration calculates a total value of a third error between the first detection position and the third detection position of the organ specified based on the acquired third output value.
- the detector constructed can capture some characteristic of the target organ corresponding to a certain criterion and accurately detect the position of the target organ. Therefore, the detector can also accurately detect the position of the target organ based on the characteristics of the third face image generated by performing the geometric transformation on the first face image.
- the detector constructed by machine learning based on the first error can accurately detect the above features. Cannot detect it, and the position where the target organ is detected is blurred. Therefore, there is a high possibility that this detector cannot accurately detect the position of the target organ with respect to the third face image generated by geometrically transforming the first face image.
- the position information given to each first face image does not indicate the position of the target organ according to a certain standard is, for example, in spite of the fact that the position of the face is shifted in each first face image. In this case, position information indicating a fixed position for each face image is added to each first face image.
- the total value of the third error is a blur of the detection result of the organ by the detector, and corresponds to a loss of the blur caused by the influence of the geometric noise in the face image. Therefore, the detector generation device according to the configuration trains the detector so that the total value of the third error is reduced together with the total value of the first error and the second error. This makes it possible to construct a detector that is robust against the influence of image noise and geometric noise included in position information.
- the predetermined geometric transformation may be, for example, translation, rotation, inversion, enlargement, reduction, or a combination thereof.
- the predetermined geometric transformation may be a transformation involving translation and rotation. This makes it possible to construct a detector that is robust to the effects of the parallel movement and the rotational movement.
- the position information of each of the learning data sets is obtained by inputting the first face image combined with the position information to another detector on which machine learning has been performed. May be provided based on output values obtained from the other detectors. According to this configuration, since the detection result of the other detector is used as the position information, it is possible to prevent the artificial noise from being included in the position information. This makes it possible to construct a detector that is robust to the influence of noise that may be included in the position information.
- the other detector may be a temporary detector generated in the process of obtaining a final detector by machine learning. That is, the detector generation device may alternately and repeatedly execute a process of constructing a detector by machine learning using a learning data set and a process of updating position information by the constructed detector. In order to construct a detector that is robust to the influence of the artificial noise, only a part that alternately executes a process of constructing the detector and a process of updating the position information is extracted, and according to a new mode.
- a detector generation device may be configured.
- the detector generation device is configured by a combination of a face image showing a face of a subject driving a vehicle and first position information indicating a position of the facial organ shown in the face image.
- a learning data acquisition unit that acquires a plurality of first learning data sets to be performed, and machine learning of a first detector using the plurality of first learning data sets, thereby obtaining each of the first learning data sets.
- a learning processing unit configured to construct a first detector that outputs an output value corresponding to the first position information combined with the input face image when the set of face images is input. Then, the learning data obtaining unit inputs the face image of each of the first learning data sets and the face image to the constructed first detector, thereby obtaining an output value obtained from the first detector.
- the learning processing unit performs machine learning of a second detector using the plurality of second learning data sets, so that the face image of each of the second learning data sets is input. And constructing a second detector that outputs an output value corresponding to the second position information combined with the input face image.
- the first detector is an example of the above “other detector”, that is, a temporary detector.
- the second detector constructed in one step is used as the first detector in the next step.
- the second detector constructed last is an example of the above “detector”, that is, an example of a final detector.
- the monitoring device has already performed machine learning by a data acquisition unit that acquires a face image of a face of a driver driving a vehicle and a detector generation device according to any one of the above embodiments.
- a detection unit that obtains from the detector an output value corresponding to a result of detecting the facial organ of the driver, and a detector of the driver's face.
- An output unit that outputs information on a result of detecting the organ.
- the detector generation device and the monitoring device according to each of the above-described embodiments are not only used to detect a facial organ of a driver of a vehicle, but also to detect a facial organ of a worker of a production line.
- the present invention may be applied to any scene where a facial organ of a subject other than the subject is detected.
- the detector generation device and the monitoring device according to each of the above-described embodiments detect not only a scene for detecting a facial organ of a subject, but also, for example, a position of some characteristic (for example, a scratch) of a product flowing on a production line.
- the present invention may be applied to any scene, such as a scene, in which the position of an object other than a person is detected from an image of the object.
- the detector generation device is configured by a combination of a first face image in which a face of a subject is captured and position information indicating a position of the face organ in the first face image.
- a learning data acquisition unit that acquires a plurality of learning data sets; and a learning processing unit that performs machine learning of the detector using the plurality of learning data sets. Then, performing the machine learning of the detector includes inputting the first face image of each of the learning data sets to the detector to generate a first output of each of the learning data sets for the first face image.
- the detector generation device includes a plurality of images each of which is configured by a combination of a first image in which an object is captured and position information indicating a position of the object in the first image.
- a learning data acquisition unit that acquires a learning data set; and a learning processing unit that implements machine learning of a detector using the plurality of learning data sets. Then, performing the machine learning of the detector includes inputting the first image of each of the learning data sets to the detector, thereby obtaining a first output value of each of the learning data sets for the first image. Acquiring from the detector, a first detection position of the target object specified based on the first output value obtained for the first image of each of the learning data sets, and the first image.
- the detector generation device includes a plurality of face images each including a face image of a subject's face and first position information indicating a position of the facial organ in the face image.
- a learning data acquisition unit for acquiring a first learning data set; and machine learning of a first detector using the plurality of first learning data sets, thereby obtaining the face of each of the first learning data sets.
- a learning processing unit configured to construct a first detector that outputs an output value corresponding to the first position information combined with the input face image when an image is input. Then, the learning data obtaining unit inputs the face image of each of the first learning data sets and the face image to the constructed first detector, thereby obtaining an output value obtained from the first detector.
- the learning processing unit performs machine learning of a second detector using the plurality of second learning data sets, so that the face image of each of the second learning data sets is input. And constructing a second detector that outputs an output value corresponding to the second position information combined with the input face image.
- the detector generation device may include a plurality of first detectors each configured by a combination of an image of an object and first position information indicating a position of the object in the image.
- a learning data acquisition unit that acquires a learning data set; and machine learning of a first detector using the plurality of first learning data sets, whereby the image of each of the first learning data sets is input.
- a learning processing unit configured to construct a first detector that outputs an output value corresponding to the first position information combined with the input image. Then, the learning data acquisition unit is configured to input the image of each of the first learning data sets and the image to the constructed first detector, and to output the image based on an output value obtained from the first detector.
- a plurality of second learning data sets each constituted by a combination of the second position information given by the second learning unit. Further, the learning processing unit performs machine learning of a second detector using the plurality of second learning data sets, and when the image of each of the second learning data sets is input, A second detector is further configured to output an output value corresponding to the second position information combined with the input image.
- Training the detector is to adjust the parameters of the detector.
- the parameters of the detector are used in an arithmetic process for detecting (obtaining an output value) any object from an image.
- the parameters are, for example, the weight of the connection between each neuron, the threshold value of each neuron, and the like.
- the type of the target object is not particularly limited as long as it can be captured in an image, and may be appropriately selected according to the embodiment.
- the target object When an image of a person is acquired as the first image, the target object may be, for example, a facial organ, a face itself, or a body part other than the face.
- the target object When an image of a product produced on the production line is obtained as the first image, the target object may be, for example, the product itself, or some feature (for example, a scratch) included in the product.
- Each detection position is a position at which the detector detects an object for each image.
- the second error corresponds to a difference between the detection position of the target with respect to the noise image (the second face image and the second image) and the detection position of the target with respect to the original image (the first face image and the first image).
- the third error is a relative difference between the detection position of the target with respect to the geometrically transformed image (the third face image and the third image) and the detection position of the target with respect to the original image (the first face image and the first image). Is equivalent to The third error may be derived by calculating a difference between a position obtained by applying the inverse transform of the geometric transformation to the position detected from the geometrically transformed image and a position detected from the original image.
- the third error may be derived by calculating a difference between a position detected from the geometrically transformed image and a position obtained by applying the geometric transformation to the position detected from the original image.
- calculating “the third error between the first detection position of the organ specified based on the first output value and the third detection position of the organ specified based on the third output value” is equivalent to performing the geometric transformation. Calculating the difference between the position obtained by applying the inverse transformation of the geometric transformation to the position detected from the image and the position detected from the original image, and detecting from the position detected from the geometrically transformed image and the original image And calculating a difference from the position obtained by applying the geometric transformation to the set position.
- the detector may be referred to as a “learner”.
- the detector after machine learning may be referred to as a “learned learning device”.
- the format of the position information need not be particularly limited, and may be appropriately determined according to the embodiment.
- the position information may be constituted by, for example, coordinate values of the object, or may be constituted by information indicating an area of the object.
- one aspect of the present invention may be an information processing method or a program for realizing each of the above configurations.
- a computer-readable storage medium storing such a program may be used.
- a storage medium readable by a computer or the like is a medium that stores information such as a program by electrical, magnetic, optical, mechanical, or chemical action.
- a detection system according to one aspect of the present invention may be configured by the detector generation device and the monitoring device according to any one of the above-described embodiments.
- the computer may include a first face image in which a face of a subject driving a vehicle is captured, and position information indicating a position of the face organ in the first face image.
- Detector Acquiring, the first detection position specified based on the first output value obtained for the first face image of each of the learning data sets, and the first detection position specified for the first face image. Calculating a total value of a second error between the second detection position of the organ specified based on the second output value obtained for the second face image, and a total value of the first error Training the detector such that the sum of the second errors is small.
- the detector generation program indicates to a computer a first face image in which a face of a subject driving a vehicle is captured, and a position of an organ of the face in the first face image.
- the step of performing machine learning of the detector includes inputting the first face image of each of the learning data sets to the detector, thereby outputting a first output of each of the learning data sets for the first face image.
- Detector Acquiring, the first detection position specified based on the first output value obtained for the first face image of each of the learning data sets, and the first detection position specified for the first face image. Calculating a total value of a second error between the second detection position of the organ specified based on the second output value obtained for the second face image, and a total value of the first error Training the detector such that the sum of the second errors is small.
- the present invention it is possible to generate a detector that is robust to the influence of noise and that can detect an object with higher accuracy.
- FIG. 1 is a diagram for explaining a problem that occurs in a conventional detector.
- FIG. 2 schematically illustrates an example of a scene to which the present invention is applied.
- FIG. 3 schematically illustrates an example of a hardware configuration of the detector generation device according to the embodiment.
- FIG. 4 schematically illustrates an example of a hardware configuration of the monitoring device according to the embodiment.
- FIG. 5 schematically illustrates an example of a software configuration of the detector generation device according to the embodiment.
- FIG. 6 schematically illustrates an example of a software configuration of the monitoring device according to the embodiment.
- FIG. 7 illustrates an example of a processing procedure of the detector generation device according to the embodiment.
- FIG. 8A illustrates an example of a processing procedure of machine learning according to the embodiment.
- FIG. 8A illustrates an example of a processing procedure of machine learning according to the embodiment.
- FIG. 8B illustrates an example of a processing procedure of machine learning according to the embodiment.
- FIG. 9 schematically illustrates an example of a scene in which machine learning is repeatedly performed.
- FIG. 10 illustrates an example of a processing procedure of the monitoring device according to the embodiment.
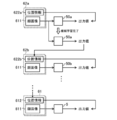
- FIG. 11 schematically illustrates an example of a software configuration of a detector generation device according to a modification.
- FIG. 12 schematically illustrates another example of a scene to which the present invention is applied.
- FIG. 13 schematically illustrates another example of a scene to which the present invention is applied.
- FIG. 14 schematically illustrates an example of a software configuration of a detector generation device according to a modification.
- FIG. 15 schematically illustrates an example of a software configuration of a detector generation device according to a modification.
- the present embodiment will be described with reference to the drawings.
- the present embodiment described below is merely an example of the present invention in every respect. It goes without saying that various improvements and modifications can be made without departing from the scope of the invention. That is, in implementing the present invention, a specific configuration according to the embodiment may be appropriately adopted.
- the data appearing in the present embodiment is described in a natural language, more specifically, it is specified in a pseudo language, a command, a parameter, a machine language, and the like that can be recognized by a computer.
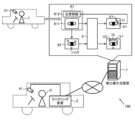
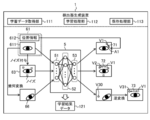
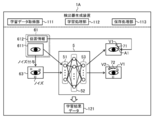
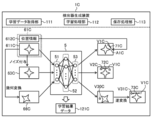
- FIG. 2 schematically illustrates an example of an application scene of the detection system 100 according to the present embodiment.
- a face of a driver driving a vehicle is photographed, and a facial organ is detected from an obtained face image.
- the face image is an example of the “image” of the present invention
- the facial organ is an example of the “object” of the present invention.
- the application target of the present invention is not limited to such an example, and is applicable to any scene in which an object is detected from an image.
- the detection system 100 includes a detector generation device 1 and a monitoring device 2 connected to each other via a network, and includes a detector for detecting a facial organ.
- the generated and configured detector is configured to detect a facial organ of the driver.
- the type of network between the detector generation device 1 and the monitoring device 2 may be appropriately selected from, for example, the Internet, a wireless communication network, a mobile communication network, a telephone network, a dedicated network, and the like.
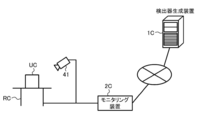
- the detector generation device 1 is a computer configured to construct a detector 5 for detecting a facial organ from a face image by performing machine learning. Specifically, the detector generation device 1 uses a combination of a first face image 611 showing the face of the subject T driving the vehicle and position information 612 indicating the position A1 of the facial organ shown in the first face image 611. A plurality of learning data sets 61 configured respectively are acquired.
- the first face image 611 is obtained, for example, by the camera 31 installed at a position in the vehicle where the face of the subject T can be photographed.
- the first face image 611 corresponds to training data (input data) in machine learning
- the position information 612 corresponds to correct answer data (teacher data).
- the detector generation device 1 performs machine learning of the detector 5 using such a plurality of learning data sets 61.
- the detector generation device 1 first inputs the first face image 611 of each learning data set 61 to the detector 5 so that the first face image of each learning data set 61
- the first output value for 611 is obtained from the detector 5.
- the detector 5 is configured to receive an input of a face image and output an output value corresponding to a result of detecting a position of a facial organ appearing in the input face image. That is, the first output value corresponds to the result of the detector 5 detecting the position of the facial organ of the subject T appearing in the first face image 611.
- Such a detector 5 is configured by a learning model capable of performing machine learning.
- the detector 5 is configured by a neural network described later.
- the detector generation device 1 determines the first detection position V1 of the organ specified based on the first output value obtained for the first face image 611 of each learning data set 61 and the first face image
- the total value of the first error 71 from the position A1 indicated by the position information 612 combined with 611 is calculated. That is, for each learning data set 61, the detector generation device 1 calculates the difference between the first detection position V1 obtained for the first face image 611 and the position A1 indicated by the corresponding position information 612 as the first error.
- the total value of the first errors 71 is calculated by adding the calculated first errors 71 to each other.
- the detector generation device 1 generates a second face image 63 for the first face image 611 of each learning data set 61 by adding noise to the first face image 611 of each learning data set 61. . Subsequently, the detector generation device 1 acquires the second output value for each second face image 63 from the detector 5 by inputting each generated second face image 63 to the detector 5. Further, the detector generation device 1 determines the first detection position V1 specified based on the first output value obtained for the first face image 611 of each of the learning data sets 61 and the first detection image V11. A total value of the second error 72 between the second detection position V2 of the specified organ and the second specified position is calculated based on the second output value obtained for the second face image 63 generated as described above.
- the detector generation device 1 obtains the first detection position V1 obtained for the first face image 611 and the second detection position V1 obtained for the corresponding second face image 63.
- the difference between the positions V2 is calculated as the second errors 72, and the calculated second errors 72 are added to calculate the total value of the second errors 72.
- the detector generation device 1 trains the detector 5 so that the total value of the first error 71 and the total value of the second error 72 become small.
- Training the detector 5 is, in particular, adjusting the parameters of the detector 5.
- the parameters of the detector 5 are used for arithmetic processing for detecting (obtaining an output value) any object from an image.
- the detector 5 is configured by a neural network described later. Therefore, this parameter is, for example, the weight of the connection between each neuron, the threshold value of each neuron, and the like.
- a known learning algorithm such as an error back propagation method may be used.
- the total value of the first errors 71 corresponds to the loss between the result of detecting the organ from the first face image 611 by the detector 5 and the correct answer of the position of the organ specified by the position information 612.
- the total value of the second errors 72 is the blur of the detection result of the organ by the detector 5, and corresponds to the blur loss caused by the presence or absence of noise in the first face image 611. Therefore, by the machine learning, the detector generation device 1 detects the organ from the first face image 611 so as to match the correct answer indicated by the position information 612, and the detection result is less likely to be affected by noise.
- the trained (learned) detector 5 can be constructed (generated).
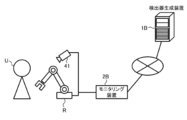
- the monitoring device 2 uses the learned detector 5 constructed by the detector generation device 1 to detect the facial organ of the driver D driving the vehicle from the face image.
- the monitoring device 2 acquires a face image in which the face of the driver D driving the vehicle is captured.
- the face image is obtained, for example, by the camera 41 installed at a position in the vehicle where the driver D can photograph the face.
- the monitoring device 2 inputs the acquired face image to the detector 5 on which the machine learning has been performed by the detector generation device 1 and outputs an output value corresponding to the result of detecting the facial organ of the driver D. From the detector 5. Then, the monitoring device 2 outputs information on the result of detecting the facial organ of the driver D. For example, the monitoring device 2 can estimate the state of the driver D such as the line of sight based on the detected position of the facial organ. Therefore, the monitoring device 2 may output, as information on the detection result, a result of estimating the state of the driver D based on the detection result. Thereby, the monitoring device 2 can monitor the state of the driver D.
- the detector 5 is built robustly to the effects of noise. Therefore, the monitoring device 2 can detect the facial organ of the driver D with high accuracy by using the detector 5. Therefore, the monitoring device 2 can accurately estimate, for example, the state of the driver D's line of sight during the driving operation.
- the detector generation device 1 and the monitoring device 2 are separate computers.
- the configuration of the detection system 100 need not be limited to such an example.
- the detector generation device 1 and the monitoring device 2 may be configured by an integrated computer. Further, the detector generation device 1 and the monitoring device 2 may each be configured by a plurality of computers. Further, the detector generation device 1 and the monitoring device 2 need not be connected to a network. In this case, data exchange between the detector generation device 1 and the monitoring device 2 may be performed via a storage medium such as a nonvolatile memory.
- FIG. 2 illustrates an eye (specifically, an outer corner of the eye) as an example of a facial organ to be detected.
- the facial organs to be detected need not be limited to the eyes.
- the facial organ to be detected may be selected from, for example, eyes, nose, mouth, eyebrows, chin, and combinations thereof.
- the organ to be detected may include the contour of the face. The same applies to FIGS. 5 and 11 described later.
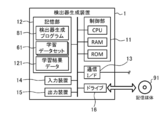
- FIG. 3 schematically illustrates an example of hardware of the detector generation device 1 according to the present embodiment.
- the detector generation device 1 includes a computer in which a control unit 11, a storage unit 12, a communication interface 13, an input device 14, an output device 15, and a drive 16 are electrically connected. It is.
- the communication interface is described as “communication I / F”.
- the control unit 11 includes a CPU (Central Processing Unit) as a hardware processor, a RAM (Random Access Memory), a ROM (Read Only Memory), and the like, and is configured to execute information processing based on programs and various data.
- the storage unit 12 is an example of a memory, and includes, for example, a hard disk drive, a solid state drive, and the like. In the present embodiment, the storage unit 12 stores various information such as a detector generation program 81, a plurality of learning data sets 61, learning result data 121, and the like.
- the detector generation program 81 is a program for causing the detector generation device 1 to execute machine learning information processing (FIGS. 7, 8A, and 8B) to be described later to construct the learned detector 5.
- the detector generation program 81 includes a series of instructions for this information processing.
- Each learning data set 61 includes the first face image 611 and position information 612.
- the learning result data 121 is data for setting the learned detector 5 constructed by machine learning using each learning data set 61.
- the learning result data 121 is generated as an execution result of the detector generation program 81. Details will be described later.
- the communication interface 13 is, for example, a wired LAN (Local Area Network) module, a wireless LAN module, or the like, and is an interface for performing wired or wireless communication via a network.
- the detector generation device 1 can perform data communication via the network with another information processing device (for example, the monitoring device 2) by using the communication interface 13.
- the input device 14 is a device for inputting, for example, a mouse and a keyboard.
- the output device 15 is a device for outputting, for example, a display, a speaker, and the like. The operator can operate the detector generation device 1 by using the input device 14 and the output device 15.
- the drive 16 is, for example, a CD drive, a DVD drive, or the like, and is a drive device for reading a program stored in the storage medium 91.
- the type of the drive 16 may be appropriately selected according to the type of the storage medium 91.
- At least one of the detector generation program 81 and the plurality of learning data sets 61 may be stored in the storage medium 91.
- the storage medium 91 stores information such as a program by an electrical, magnetic, optical, mechanical, or chemical action so that a computer or other device or machine can read the information such as a recorded program. It is a medium for storing.
- the detector generation device 1 may acquire at least one of the detector generation program 81 and the plurality of learning data sets 61 from the storage medium 91.
- FIG. 3 illustrates a disk-type storage medium such as a CD or a DVD as an example of the storage medium 91.
- the type of the storage medium 91 is not limited to the disk type, and may be other than the disk type.
- Examples of the storage medium other than the disk type include a semiconductor memory such as a flash memory.
- the control unit 11 may include a plurality of hardware processors.
- the hardware processor may include a microprocessor, a field-programmable gate array (FPGA), a digital signal processor (DSP), and the like.
- the storage unit 12 may be configured by a RAM and a ROM included in the control unit 11. At least one of the communication interface 13, the input device 14, the output device 15, and the drive 16 may be omitted.
- the detector generation device 1 may further include an external interface for connecting to the camera 31. This external interface may be configured similarly to an external interface 24 of the monitoring device 2 described below.
- the detector generation device 1 may be composed of a plurality of computers. In this case, the hardware configuration of each computer may or may not match.
- the detector generation device 1 may be a general-purpose server device, a personal computer (PC), or the like, in addition to an information processing device designed specifically for a provided service.
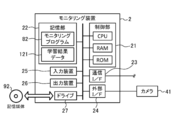
- FIG. 4 schematically illustrates an example of a hardware configuration of the monitoring device 2 according to the present embodiment.
- the monitoring device 2 includes a control unit 21, a storage unit 22, a communication interface 23, an external interface 24, an input device 25, an output device 26, and a drive 27, which are electrically connected.
- Computer In FIG. 4, the communication interface and the external interface are described as “communication I / F” and “external I / F”, respectively.
- the control unit 21 to the communication interface 23 and the input device 25 to the drive 27 of the monitoring device 2 may be configured similarly to the control unit 11 to the drive 16 of the detector generation device 1, respectively. That is, the control unit 21 includes a hardware processor such as a CPU, a RAM, a ROM, and the like, and is configured to execute various types of information processing based on programs and data.
- the storage unit 22 includes, for example, a hard disk drive, a solid state drive, and the like. The storage unit 22 stores various information such as the monitoring program 82 and the learning result data 121.
- the monitoring program 82 is a program for causing the monitoring device 2 to execute information processing (FIG. 10) described below for monitoring the state of the driver D using the learned detector 5.
- the monitoring program 82 includes a series of instructions for this information processing. Details will be described later.
- the communication interface 23 is, for example, a wired LAN module, a wireless LAN module, or the like, and is an interface for performing wired or wireless communication via a network.
- the monitoring device 2 can perform data communication via a network with another information processing device (for example, the detector generation device 1) by using the communication interface 23.
- the external interface 24 is, for example, a USB (Universal Serial Bus) port, a dedicated port, or the like, and is an interface for connecting to an external device.
- the type and number of external interfaces 24 may be appropriately selected according to the type and number of external devices to be connected.
- the monitoring device 2 is connected to the camera 41 via the external interface 24.
- the camera 41 is used to obtain a face image by photographing the face of the driver D.
- the type and location of the camera 41 need not be particularly limited, and may be appropriately determined according to the embodiment.
- a known camera such as a digital camera and a video camera may be used.
- the camera 41 may be arranged, for example, above and in front of the driver's seat such that at least the upper body of the driver D is set as a shooting range.
- the monitoring device 2 may be connected to the camera 41 via the communication interface 23 instead of the external interface 24.
- the input device 25 is a device for inputting, for example, a mouse and a keyboard.
- the output device 26 is, for example, a device for outputting a display, a speaker, or the like.
- the operator such as the driver D can operate the monitoring device 2 by using the input device 25 and the output device 26.
- the drive 27 is, for example, a CD drive, a DVD drive, or the like, and is a drive device for reading a program stored in the storage medium 92. At least one of the monitoring program 82 and the learning result data 121 may be stored in the storage medium 92. In addition, the monitoring device 2 may acquire at least one of the monitoring program 82 and the learning result data 121 from the storage medium 92.
- the control unit 21 may include a plurality of hardware processors.
- the hardware processor may be constituted by a microprocessor, an FPGA, a DSP, or the like.
- the storage unit 22 may be configured by a RAM and a ROM included in the control unit 21. At least one of the communication interface 23, the external interface 24, the input device 25, the output device 26, and the drive 27 may be omitted.
- the monitoring device 2 may be composed of a plurality of computers. In this case, the hardware configuration of each computer may or may not match.
- a general-purpose server device a general-purpose desktop PC, a notebook PC, a tablet PC, a mobile phone including a smartphone, or the like may be used in addition to the information processing device designed exclusively for the provided service.
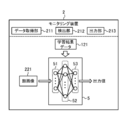
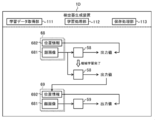
- FIG. 5 schematically illustrates an example of a software configuration of the detector generation device 1 according to the present embodiment.
- the control unit 11 of the detector generation device 1 expands the detector generation program 81 stored in the storage unit 12 in the RAM. Then, the control unit 11 controls the components by interpreting and executing the detector generation program 81 expanded in the RAM by the CPU.
- the detector generation device 1 operates as a computer including the learning data acquisition unit 111, the learning processing unit 112, and the storage processing unit 113 as software modules. That is, in the present embodiment, each software module of the detector generation device 1 is realized by the control unit 11 (CPU).
- the learning data acquisition unit 111 includes a plurality of sets each including a combination of a first face image 611 in which the face of the subject T driving the vehicle is captured and position information 612 indicating a position of a facial organ in the first face image 611.
- the learning data set 61 is obtained.
- the target organ may be selected from, for example, eyes, nose, mouth, eyebrows, chin, and combinations thereof. Further, the target organ may include a face outline.
- the learning processing unit 112 performs machine learning of the detector 5 using the plurality of learning data sets 61. Specifically, as a process of machine learning, the learning processing unit 112 first inputs the first face image 611 of each learning data set 61 to the detector 5 so that the first face image of each learning data set 61 The first output value for 611 is obtained from the detector 5. Subsequently, the learning processing unit 112 determines the first detection position V1 of the organ specified based on the first output value obtained for the first face image 611 of each learning data set 61 and the first face image 611 Is calculated with respect to the position A1 indicated by the position information 612 combined with the first error 71.
- the learning processing unit 112 generates a second face image 63 for the first face image 611 of each learning data set 61 by adding noise to the first face image 611 of each learning data set 61. Subsequently, the learning processing unit 112 acquires the second output value for each second face image 63 from the detector 5 by inputting each of the generated second face images 63 to the detector 5. Then, the learning processing unit 112 determines the first detection position V1 specified based on the first output value obtained for the first face image 611 of each learning data set 61 and the first face image 611. Based on the second output value obtained for the generated second face image 63, the total value of the second error 72 with the second detection position V2 of the specified organ is calculated.
- the learning processing unit 112 applies a predetermined geometric transformation to the first face image 611 of each of the learning data sets 61 to thereby perform the first face image 611 of each of the learning data sets 61 on the first face image 611.
- a three-face image 66 is generated.
- the predetermined geometric transformation may be, for example, translation, rotation, inversion, enlargement, reduction, or a combination thereof.
- the predetermined geometric transformation may be a transformation involving translation and rotation. In the example of FIG. 5, a scene in which a transformation involving translation and rotation is applied to the first face image 611 is illustrated.
- the learning processing unit 112 acquires a third output value for each third face image 66 from the detector 5 by inputting each generated third face image 66 to the detector 5. Then, the learning processing unit 112 generates a first detection position specified based on the first output value obtained for the first face image 611 of each learning data set 61 and generates the first detection position for the first face image 611. Based on the third output value obtained for the obtained third face image 66, the total value of the third error 73 with the third detection position of the specified organ is calculated.
- the learning processing unit 112 sets the coordinate axes of the first face image 611 and the coordinate axes of the third face image 66. And performs a conversion process to match.
- the learning processing unit 112 specifies the third detection position V30 of the organ on the coordinate axis of the third face image 66 based on the third output value acquired from the detector 5.
- the learning processing unit 112 applies an inverse transformation of a predetermined geometric transformation to the specified detection position V30, matches the coordinate axis of the third face image 66 with the coordinate axis of the first face image 611, and The third detection position V31 on the coordinate axis 611 is specified.
- the learning processing unit 112 calculates the difference between the third detection position V31 and the first detection position V1 as a third error 73, and adds the third error 73 for each learning data set 61 to obtain the third error.
- the total value of the errors 73 is calculated.
- the method of calculating the total value of the third errors between the first detection position and the third detection position is not limited to such an example.
- the learning processing unit 112 applies a predetermined inverse transformation to the first detection position V1 on the coordinate axis of the first face image 611, so that the coordinate axis of the first face image 611 matches the coordinate axis of the third face image 66. Good. Then, the learning processing unit 112 may calculate the difference between the first detection position and the third detection position V30 on the coordinate axis of the third face image 66 as the third error 73.
- the learning processing unit 112 trains the detector 5 so that the total value of the first error 71, the total value of the second error 72, and the total value of the third error 73 become small. Accordingly, the learning processing unit 112 constructs the learned detector 5 for detecting the facial organ of the driver.
- the detector 5 is configured by a neural network.
- the detector 5 is configured by a multilayered neural network used for so-called deep learning, and includes an input layer 51, an intermediate layer (hidden layer) 52, and an output layer 53.
- the neural network constituting the detector 5 includes one intermediate layer 52, the output of the input layer 51 is input to the intermediate layer 52, and the output of the intermediate layer 52 is output to the output layer. 53 has been input.
- the configuration of the detector 5 need not be limited to such an example.
- the number of the intermediate layers 52 may not be limited to one layer.
- the detector 5 may include two or more intermediate layers 52.
- Each of the layers 51 to 53 has one or more neurons.
- the number of neurons in the input layer 51 may be set according to the number of pixels of the first face image 611.
- the number of neurons in the intermediate layer 52 may be appropriately set according to the embodiment.
- the number of neurons in the output layer 53 may be set according to the number of organs to be detected, the position expression, and the like.
- each neuron in adjacent layers is appropriately connected to each other, and a weight (connection weight) is set for each connection.
- connection weight is set for each connection.
- each neuron is connected to all neurons in an adjacent layer.
- the connection of the neurons is not limited to such an example, and may be appropriately set according to the embodiment.
- a threshold is set for each neuron, and basically, the output of each neuron is determined by whether or not the sum of the product of each input and each weight exceeds the threshold. That is, the weight of the connection between these neurons and the threshold value of each neuron are examples of the parameters of the detector 5 used for the arithmetic processing.
- the learning processing unit 112 inputs each face image (611, 63, 66) to the input layer 51, and executes the arithmetic processing of the detector 5 using these parameters.
- the learning processing unit 112 acquires each output value from the output layer 53 as a detection result of an organ for each face image (611, 63, 66). Subsequently, the learning processing unit 112 calculates the total value of the errors 71 to 73 based on the obtained output values as described above. Then, the learning processing unit 112 adjusts the parameters of the detector 5 so as to reduce the total value of the errors 71 to 73 as the training process. Thereby, the learned detector 5 for detecting the facial organ of the driver is constructed.
- the storage processing unit 113 includes a configuration of the constructed learned detector 5 (for example, the number of layers of the neural network, the number of neurons in each layer, a connection relationship between neurons, a transfer function of each neuron), and an operation parameter (for example, , Information indicating the weight of the connection between each neuron and the threshold value of each neuron) is stored in the storage unit 12 as the learning result data 121.
- the constructed learned detector 5 for example, the number of layers of the neural network, the number of neurons in each layer, a connection relationship between neurons, a transfer function of each neuron
- an operation parameter for example, Information indicating the weight of the connection between each neuron and the threshold value of each neuron
- FIG. 6 schematically illustrates an example of a software configuration of the monitoring device 2 according to the present embodiment.
- the control unit 21 of the monitoring device 2 loads the monitoring program 82 stored in the storage unit 22 into the RAM. Then, the control unit 21 interprets and executes the monitoring program 82 loaded on the RAM by the CPU, and controls each component. Accordingly, as illustrated in FIG. 6, the monitoring device 2 according to the present embodiment operates as a computer including the data acquisition unit 211, the detection unit 212, and the output unit 213 as software modules. That is, in the present embodiment, each software module of the monitoring device 2 is also realized by the control unit 21 (CPU), similarly to the detector generation device 1.
- the data acquisition unit 211 acquires a face image 221 that shows the face of the driver D who drives the vehicle. For example, the data acquisition unit 211 acquires the face image 221 by photographing the face of the driver D using the camera 41.
- the detection unit 212 includes the learned detector 5 by holding the learning result data 121. Specifically, the detection unit 212 sets the learned detector 5 with reference to the learning result data 121. Then, by inputting the acquired face image 221 to the detector 5, the detection unit 212 acquires from the detector 5 an output value corresponding to a result of detecting the facial organ of the driver D from the face image 221. .
- the output unit 213 outputs information on the result of detecting the facial organ of the driver D.
- each software module of the detector generation device 1 and the monitoring device 2 will be described in detail in an operation example described later.
- an example is described in which each software module of the detector generation device 1 and the monitoring device 2 is realized by a general-purpose CPU.
- some or all of the above software modules may be implemented by one or more dedicated processors.
- the omission, replacement, and addition of software modules may be performed as appropriate according to the embodiment.
- FIG. 7 is a flowchart illustrating an example of a processing procedure of the detector generation device 1 according to the present embodiment.
- the processing procedure described below is an example of the “detector generation method” of the present invention.
- the processing procedure described below is merely an example, and each processing may be changed as much as possible. Further, in the processing procedure described below, steps can be omitted, replaced, and added as appropriate according to the embodiment.
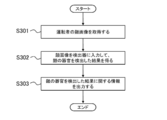
- Step S101 the control unit 11 operates as the learning data acquisition unit 111, and acquires a plurality of learning data sets 61 each configured by a combination of the first face image 611 and the position information 612.
- the method of acquiring the plurality of learning data sets 61 is not particularly limited and may be appropriately selected according to the embodiment.
- a plurality of first face images 611 including the face of the subject T are obtained by preparing a vehicle equipped with the camera 31 and the subject T and photographing the subject T driving the vehicle under various conditions using the camera. Can be.
- the number of vehicles and the number of subjects T to be prepared may be appropriately determined according to the embodiment.
- the learning data sets 61 can be generated by combining the obtained first face images 611 with the position information 612 indicating the position of the target organ shown in each first face image 611.
- the organ of interest may be selected from, for example, eyes, nose, mouth, eyebrows, jaws, and combinations thereof.
- the target organ may include a face outline.
- Each of the learning data sets 61 may be automatically generated or manually generated. Further, generation of each learning data set 61 may be performed by the detector generation device 1 or may be performed by a computer other than the detector generation device 1.
- the control unit 11 acquires each first face image 611 from the camera 31 via an external interface, a network, a storage medium 91, and the like. Next, the control unit 11 generates position information 612 to be given to each first face image 611.
- the control unit 11 accepts designation of the position of the organ via the input device 14 by the operator. Subsequently, the control unit 11 generates position information 612 indicating the position of the designated organ according to the operation of the input device 14 by the operator.
- the control unit 11 detects the position of the target organ from each first face image 611.
- control unit 11 For this detection, a known image processing method such as edge detection and pattern matching may be used, or a tentatively generated detector described later may be used. Subsequently, the control unit 11 generates position information 612 indicating the position of the detected organ. Then, the control unit 11 generates each learning data set 61 by combining the generated position information 612 with the first face image 611. Thereby, the control unit 11 may acquire a plurality of learning data sets 61.
- each learning data set 61 is generated by another computer
- the control unit 11 transmits a plurality of learning data sets 61 generated by another computer via a network, a storage medium 91, or the like. May be obtained.
- each learning data set 61 may be generated in the same manner as in the detector generation device 1.
- the data formats of the first face image 611 and the position information 612 may be appropriately selected according to the embodiment.
- the position information 612 may indicate the position of the organ by a point using coordinate values or the like, or may indicate the position of the organ by an area.
- the number of learning data sets 61 to be acquired is not particularly limited, and may be appropriately determined to the extent that machine learning of the detector 5 can be performed.
- the control unit 11 proceeds to the next step S102.
- Step S102 the control unit 11 operates as the learning processing unit 112, and performs machine learning of the detector 5 using the plurality of learning data sets 61 acquired in step S101.
- the processing procedure of machine learning will be described later.
- the control unit 11 proceeds to the next step S103.
- Step S103 the control unit 11 operates as the storage processing unit 113, and generates information indicating the configuration and the operation parameters of the detector 5 constructed by machine learning as learning result data 121. Then, the control unit 11 stores the generated learning result data 121 in the storage unit 12. Thus, the control unit 11 ends the process according to the operation example.
- the storage destination of the learning result data 121 is not limited to the storage unit 12.
- the control unit 11 may store the learning result data 121 in a data server such as a NAS (Network Attached Storage). After constructing the learned detector 5, the control unit 11 may transfer the generated learning result data 121 to the monitoring device 2 at an arbitrary timing.
- a data server such as a NAS (Network Attached Storage).
- the monitoring device 2 may acquire the learning result data 121 by accepting the transfer from the detector generation device 1, or may acquire the learning result data 121 by accessing the detector generation device 1 or the data server. Good.
- the learning result data 121 may be incorporated in the monitoring device 2 in advance.
- step S102 is a flowcharts illustrating an example of a processing procedure of machine learning by the detector generation device 1 according to the present embodiment.
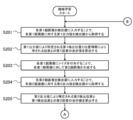
- the process of step S102 according to the present embodiment includes the following processes of steps S201 to S210.
- the processing procedure described below is merely an example, and each processing may be changed as much as possible. Further, in the processing procedure described below, steps can be omitted, replaced, and added as appropriate according to the embodiment.
- the control unit 11 Before starting the process of step S201, the control unit 11 prepares a neural network (the detector 5 before learning) to be subjected to machine learning.
- the configuration of the neural network to be prepared and each parameter may be provided by a template or may be provided by an operator input.
- the control unit 11 may prepare a neural network based on the learning result data 121 to be re-learned.
- the control unit 11 starts the process of step S201.
- step S201 the control unit 11 inputs the first face image 611 of each learning data set 61 to the detector 5, and executes a calculation process of the detector 5. Specifically, the control unit 11 inputs each of the first face images 611 to the input layer 51 of the detector 5 and determines firing of each neuron included in each of the layers 51 to 53 in order from the input side. Thereby, the control unit 11 acquires the first output value for each first face image 611 from the output layer 53. Each first output value corresponds to a result of detection of the position of an organ from each first face image 611 by the detector 5 at the current stage. When acquiring the first output values, the control unit 11 proceeds to the next step S202.
- the output value of the detector 5 is not particularly limited as long as the output value of the detector 5 can indicate the position at which the organ is detected, and is appropriately selected according to the embodiment. May be.
- the output value of the detector 5 may directly indicate the position of the organ, such as a coordinate value.
- the output value of the detector 5 may indirectly indicate the position of the organ, and information indicating the position of the organ may be obtained by applying some arithmetic processing to the output value of the detector 5. Regardless of the format, the output value of the detector 5 can be handled similarly. Therefore, in the following, for convenience of explanation, the output value of the detector 5 will be treated as directly indicating the position of the organ.
- step S202 the control unit 11 calculates a total value of the first errors 71 between the first detection position V1 of the organ specified based on each first output value and the position A1 indicated by the corresponding position information 612. . Specifically, for each learning data set 61, the control unit 11 calculates the difference between the first detection position V1 obtained for each first face image 611 and the position A1 indicated by the corresponding position information 612. It is calculated as one error 71. Then, the control unit 11 calculates the total value of the first errors 71 by adding the calculated first errors 71.
- the difference between the first detection position V1 and the position A1 may be appropriately calculated according to a format for specifying the position of the organ. For example, when the position of the organ is designated by a point, the control unit 11 may calculate the distance (norm) between the first detection position V1 and the position A1 as a difference. Further, for example, when the position of the organ is specified by the region, the control unit 11 may calculate the difference between the first detection position V1 and the position A1 using an index such as IoU (Intersection Over Union). Good. After calculating the total value of the first errors 71, the control unit 11 proceeds to the next step S203.
- IoU Intersection Over Union
- Step S203 the control unit 11 generates each second face image 63 by adding noise to the first face image 611 of each learning data set 61.
- the type of noise given to each first face image 611 is not particularly limited and may be appropriately selected according to the embodiment.
- the noise for example, Gaussian noise, Poisson noise, noise based on uniform random numbers, or the like may be used.
- the control unit 11 may add random Gaussian noise to each first face image 611.
- the control unit 11 may apply noise to each first face image 611 by applying a filter such as a local average filter to each first face image 611.
- the type of noise given to each first face image 611 may be the same or different.
- control unit 11 may add noise to a position where the detection by the detector 5 is likely to change so as to form a hostile example (Adversarial example). Whether or not the detection is likely to change can be determined, for example, based on a comparison between the amount of change in the detection position due to the addition of noise and a threshold. After generating each second face image 63, the control unit 11 proceeds to the next step S204.
- Step S204 the control unit 11 inputs each of the generated second face images 63 to the detector 5, and executes the arithmetic processing of the detector 5.
- the calculation process of the detector 5 may be the same as that in step S201.
- the control unit 11 obtains the second output value for each second face image 63 from the output layer 53 of the detector 5.
- Each second output value corresponds to the result of detection of the position of an organ from each second face image 63 by the detector 5 at this stage.
- the control unit 11 proceeds to the next step S205.
- Step S205 the control unit 11 is specified based on the second output value obtained for the second face image 63 corresponding to the first detection position V1 of the organ specified based on each first output value. Then, the total value of the second errors 72 between the second detection position V2 and the second detection position V2 is calculated. Specifically, for each learning data set 61, the control unit 11 calculates the second detection result V1 obtained for each first face image 611 and the second detection result V1 obtained for the second face image 63 corresponding to the first detection image V1. The difference from the detection position V2 is calculated as a second error 72. The method of calculating this difference may be the same as in step S202. Then, the control unit 11 calculates the total value of the second errors 72 by adding the calculated second errors 72. After calculating the total value of the second errors 72, the control unit 11 proceeds to the next step S206.
- Step S206 the control unit 11 generates each third face image 66 by applying a predetermined geometric transformation to the first face image 611 of each learning data set 61.
- the geometric transformation applied to each first face image 611 may be, for example, translation, rotation, inversion, enlargement, reduction, or a combination thereof.
- the geometric transformation applied to each first face image 611 may be a transformation involving translation and rotation.
- the geometric transformation applied to each third face image 66 may be the same or different.
- the control unit 11 may generate each of the third face images 66 while randomly changing the parameters of the geometric transformation.
- the parameters of the geometric transformation are, for example, each transformation amount (parallel movement amount, rotation amount, etc.).
- Step S207 the control unit 11 inputs each of the generated third face images 66 to the detector 5, and executes the arithmetic processing of the detector 5.
- the calculation process of the detector 5 may be the same as that in step S201.
- the control unit 11 acquires the third output value for each third face image 66 from the output layer 53 of the detector 5.
- Each third output value corresponds to the result of detection of the position of an organ from each third face image 66 by the detector 5 at the present stage.
- the control unit 11 proceeds to the next step S208.
- step S208 the control unit 11 is specified based on the third output value obtained for the third face image 66 corresponding to the first detection position of the organ specified based on each first output value.
- the total value of the third error 73 from the third detection position of the organ is calculated.
- the control unit 11 applies the inverse transformation of the geometric transformation to the third detection position V30 derived from the third output value obtained for each first face image 611, and performs the third detection position V31 is calculated.
- the control unit 11 sets the third detection position V31 obtained for the third face image 66 corresponding to the first detection position V1 obtained for each first face image 611. Is calculated as a third error 73.
- control unit 11 may calculate the difference between the position derived by applying the geometric transformation to the first detection position V1 and the third detection position V30 as the third error 73. Then, the control unit 11 calculates the total value of the third errors 73 by adding the calculated third errors 73. After calculating the total value of the third errors 73, the control unit 11 proceeds to the next step S209.
- Step S209 the control unit 11 determines whether or not the sum of the calculated errors 71 to 73 is equal to or smaller than a threshold.
- the threshold value is a criterion for determining whether or not the detector 5 has been sufficiently trained to appropriately detect the organ from the face image. This threshold may be set as appropriate.
- the control unit 11 ends the machine learning process according to the present operation example (that is, completes the process of step S102). The process proceeds to step S103.
- the control unit 11 proceeds to the next step S210.
- Step S210 the control unit 11 performs training of the detector 5 so that the total value of the errors 71 to 73 becomes small. Specifically, the control unit 11 adjusts the parameters of the detector 5 so that the total value of the errors 71 to 73 decreases.
- a known method such as an error back propagation method may be used for adjusting the parameter. That is, the control unit 11 calculates the error of each parameter such as the weight of connection between each neuron and the threshold value of each neuron in order from the output layer 53 using the total value of each error 71 to 73. Then, the control unit 11 updates the value of each parameter based on the calculated error.
- the learning rate that determines the update width of each parameter may be set as appropriate.
- the control unit 11 repeats the processing from step S201.
- the control unit 11 optimizes the parameters of the detector 5 by repeating the processes of steps S201 to S210 such that the total value of the errors 71 to 73 is sufficiently small.
- a known method such as a stochastic gradient descent method may be used for optimizing the parameter.
- the detector 5 is trained so that the sum of the errors 71 to 73 becomes small. That is, in step S209, it is determined that the total value of the errors 71 to 73 is equal to or smaller than the threshold, and the machine learning process according to this operation example is completed.
- step S202 is executed after step S201
- step S204 is executed after step S203
- the process of step S205 is executed after steps S201 and S204
- the process of step S207 is executed after step S206. If the process of step S208 is performed after steps S201 and S207, the order of the processes of steps S201 to S208 may be appropriately changed.
- the detector generation device 1 may repeat the processes of steps S101 to S103. In the course of this repetition, the position information 612 included in each of the learning data sets 61 may be updated using the provisionally generated detector 5. That is, in step S102, the detector generation device 1 generates the learned detector 5 using each learning data set 61, and then adds each first face image 611 to the generated learned detector 5. The position of an organ may be detected from each of the first face images 611 by input. Then, the detector generation device 1 indicates the position detected by the learned detector 5 from the original position (that is, the position indicated by the position information 612 when generating the learned detector 5). As described above, the position information 612 of each learning data set 61 may be updated.
- FIG. 9 schematically illustrates an example of a scene in which machine learning is repeatedly performed.
- the control unit 11 when performing steps S101 to S103 for the first time, in step S101, the control unit 11 obtains a plurality of learning data sets 62a each including the first face image 611 and the position information 622a. Assume that you have done.
- the position information 622a may be given by an operator's designation, may be given by a known image processing method, or may be given based on an output value obtained from another detector. .
- the control unit 11 executes the machine learning process of step S102 by using the obtained learning data sets 62a. Accordingly, given each learning data set 62a, the control unit 11 learns a trained detector trained to detect an organ from the first face image 611 so as to match the correct answer indicated by the position information 622a. 50a is provisionally generated. The control unit 11 may store the provisionally generated learning result data of the learned detector 50a in a predetermined storage area by executing the process of step S103. The generation of the learned detector 50a ends the first learning process.
- the control unit 11 updates the position information 622a of each learning data set 62a using the provisionally generated learned detector 50a. That is, the control unit 11 inputs each of the first face images 611 to the learned detector 50a generated in the first learning process, and executes the arithmetic processing of the detector 50a. Thereby, the control unit 11 acquires an output value corresponding to the result of detecting the position of the organ from each first face image 611 from the learned detector 50a.
- the control unit 11 specifies the position where the target organ is detected from each first face image 611 by the learned detector 50a based on the obtained output values. Then, the control unit 11 generates position information 622b indicating the specified detection position for each learning data set 62a, and replaces the generated position information 622b with the position information 622a. Accordingly, in step S101, the control unit 11 acquires each new learning data set 62b configured by a combination of the first face image 611 and the position information 622b.
- the position information 622b is obtained by inputting the first face image 611 combined with the position information 622b to the detector 50a that has already performed the machine learning, thereby obtaining an output obtained from the detector 50a.
- the learned detector 50a is an example of the “other detector” and the “first detector” of the present invention.
- Each learning data set 62a is an example of a “first learning data set”.
- Each learning data set 62b is an example of a “second learning data set”.
- the control unit 11 executes the machine learning process of step S102 using each of the learning data sets 62b.
- the control unit 11 learns a trained detector trained to detect an organ from the first face image 611 so as to match the correct answer indicated by the position information 622b. Generate 50b.
- the control unit 11 may store the generated learning result data of the learned detector 50b in a predetermined storage area by executing the process of step S103. The generation of the learned detector 50b ends the second learning process.
- the detector generation device 1 performs processing for generating a learned detector by machine learning using each learning data set, and updates position information using the generated learned detector.
- the processing may be repeatedly executed alternately.
- each learning data set finally obtained corresponds to each of the learning data sets 61
- the learned detector that is automatically generated corresponds to the learned detector 5 described above.
- the position information 612 is given based on an output value obtained from the learned detector by inputting the first face image 611 to the learned detector generated by the last previous learning process. .
- FIG. 9 illustrates a case where the machine learning process is repeated three times or more.
- the number of times of repeating the machine learning process is not limited to such an example, and may be appropriately selected according to the embodiment. The number of repetitions may be two.
- FIG. 10 is a flowchart illustrating an example of a processing procedure of the monitoring device 2 according to the present embodiment.
- the processing procedure described below is merely an example, and each processing may be changed as much as possible. Further, in the processing procedure described below, steps can be omitted, replaced, and added as appropriate according to the embodiment.
- Step S301 the control unit 21 operates as the data acquisition unit 211, and acquires a face image 221 in which the face of the driver D driving the vehicle is captured.
- the monitoring device 2 is connected to the camera 41 via the external interface 24. Therefore, the control unit 21 acquires the face image 221 from the camera 41.
- the face image 221 may be moving image data or still image data.
- the control unit 21 proceeds to the next step S302.
- the path for acquiring the face image 221 is not limited to such an example, and may be appropriately selected according to the embodiment.
- another computer different from the monitoring device 2 may be connected to the camera 41.
- the control unit 21 may acquire the face image 221 by receiving the transmission of the face image 221 from another computer.
- Step S302 the control unit 21 operates as the detection unit 212 and sets the learned detector 5 with reference to the learning result data 121. Subsequently, the control unit 21 inputs the acquired face image 221 to the learned detector 5 and executes the arithmetic processing of the detector 5.
- the calculation process of the detector 5 may be the same as that in step S201. Thereby, the control unit 21 acquires from the detector 5 an output value corresponding to a result of detecting the facial organ of the driver D from the face image 221. After acquiring the output value, the control unit 21 proceeds to the next step S303.
- Step S303 the control unit 21 operates as the output unit 213, and outputs information on the result of detecting the facial organ of the driver D.
- the output destination and the content of the information to be output may be appropriately determined according to the embodiment.
- the control unit 21 may output the result of detecting the facial organ of the driver D from the face image 221 in step S302 via the output device 26 as it is.
- control unit 21 may execute some information processing such as estimating the state of the driver D based on the result of detecting the facial organ of the driver D from the face image 221. Then, the control unit 21 may output a result of executing the information processing.
- the control unit 21 may estimate the gaze direction of the driver D based on the detected positional relationship of each eye. Then, the control unit 21 may output information related to the result of estimating the line-of-sight direction. For example, when the line of sight does not face the front of the vehicle, the control unit 21 may output a warning via the output device 26 to prompt the user to turn the line of sight to the front.
- control unit 21 may estimate the facial expression of the driver D based on the detected positional relationship between the organs. Then, the control unit 21 may output information related to the result of estimating the facial expression. For example, when the expression of the driver D is tired, the control unit 21 may output, via the output device 26, a message urging the driver to stop.
- the control unit 21 ends the processing according to this operation example.
- the control unit 21 may continuously and repeatedly execute the series of processes of steps S301 to S303.
- the monitoring device 2 can monitor the state of the driver D via detecting the position of the facial organ of the driver D from the face image.
- the detector generation device 1 trains the detector 5 so that the total value of the respective errors 71 to 73 is reduced by the processes of steps S201 to S210.
- the total value of the first errors 71 among the errors 71 to 73 is calculated as the loss between the result of detecting the organ from the first face image 611 by the detector 5 and the correct answer of the position of the organ specified by the position information 612. Equivalent to.
- the total value of the second errors 72 is the blur of the detection result of the organ by the detector 5, and corresponds to the blur loss caused by the presence or absence of noise in the first face image 611.
- the detector generation device 1 detects the organ from the first face image 611 so as to match the correct answer indicated by the position information 612 by the machine learning processing in steps S201 to S210, and the detection result is noise.
- a trained (learned) detector 5 that is less susceptible to influence can be constructed (generated).
- the total value of the third errors 73 is the blur of the detection result of the organ by the detector 5, and corresponds to the loss of the blur caused by the influence of the geometric noise included in the position information 612.
- the detector generation device 1 can construct the detector 5 further trained so as to be hardly affected by the geometric noise included in the position information by the machine learning processing in steps S201 to S210. it can.
- the neural network constituting the detector 5 is a fully connected neural network.
- the structure and type of the neural network constituting the detector 5 need not be limited to such an example, and may be appropriately selected according to the embodiment.
- a convolutional neural network, a recursive neural network, or the like may be used for the detector 5.
- the detector 5 is configured by a neural network.
- the type of the learning model constituting the detector 5 is not limited to the neural network, and may be appropriately selected according to the embodiment.
- the method of machine learning may be appropriately selected depending on a learning model to be used.
- the detector 5 may be trained so that an initial value of the position of the organ to be detected is given and the position is updated so that the position of the organ appearing in the target face image can be appropriately detected.
- the average value of the correct answer data given to the learning face image can be used as the initial value of the position of the organ.
- the update of the position can be performed by using the feature amount.
- the feature amount for example, a Haar-like feature amount, a luminance difference, or the like may be used.
- learning model for example, a support vector machine, a linear regression model, a random forest, or the like may be used.
- the parameters of the detector 5 are, for example, a weight vector, a conversion vector, a threshold value of each branch, and the like.
- the learning result data 121 includes information indicating the configuration of the learned neural network (detector 5).
- the configuration of the learning result data 121 is not limited to such an example, and may be appropriately determined according to the embodiment as long as it can be used for setting the learned detector 5.
- the learning result data 121 may not include information indicating the learned configuration of the neural network.
- the detector generation device 1 adjusts the parameters of the detector 5 by machine learning in step S102 such that the total value of the errors 71 to 73 becomes smaller.
- the process of machine learning need not be limited to such an example.
- the third error 73 among the errors 71 to 73 may be omitted.
- FIG. 11 schematically illustrates an example of a software configuration of the detector generation device 1A according to the present modification.
- the hardware configuration of the detector generation device 1A is the same as that of the detector generation device 1 according to the above embodiment.
- the software configuration of the detector generation device 1A is the same as that of the detector generation device 1 according to the above embodiment.
- the detector generation device 1A operates in the same manner as the detector generation device 1 according to the above embodiment, except that the process of deriving the third error 73 is omitted. That is, the control unit of the detector generation device 1A executes the processing of steps S101 and S103, similarly to the detector generation device 1. Further, the control unit operates as the learning processing unit 112, and executes the process of step S102. In this modified example, in the machine learning process of step S102, the control unit omits the processes of steps S206 to S208. In other words, the control unit executes the processing of steps S201 to S205 and then executes the processing of step S209, as in the case of the detector generation device 1. Then, in step S209, the control unit determines whether the total value of the first error 71 and the total value of the second error 72 are equal to or smaller than a threshold.
- step S210 the control unit performs training of the detector 5 so that the total value of the errors 71 to 72 becomes small.
- the training of the detector 5, ie, the method of adjusting the parameters of the detector 5, may be the same as in the above embodiment.
- the detector generation device 1A detects the organ from the first face image 611 so as to match the correct answer indicated by the position information 612, and the detection result is similar to the above-described embodiment.
- a trained (learned) detector 5 that is less susceptible to noise can be constructed (generated).
- the present invention is applied to a scene in which the face of a driver driving a vehicle is photographed and the position of a facial organ is detected from an obtained face image.
- the applicable range of the present invention is not limited to the case where the position of the organ is detected from the face image of the driver.
- INDUSTRIAL APPLICABILITY The present invention is widely applicable to scenes in which a facial organ of a subject other than a driver is detected from a face image.
- FIG. 12 schematically illustrates an example of another scene to which the present invention is applied.
- FIG. 12 shows an example in which the present invention is applied to a scene where an operator U who works at a production site is photographed and the facial organ of the operator U is detected from the obtained face image.
- the hardware configuration and software configuration of the detector generation device 1B according to the present modification are the same as those of the detector generation device 1 according to the above embodiment.
- the hardware configuration and software configuration of the monitoring device 2B according to the present modification are the same as those of the monitoring device 2 according to the above embodiment.
- the detector generation device 1B and the monitoring device 2B according to the present modified example operate in the same manner as the detector generation device 1 and the monitoring device 2 according to the above-described embodiment, except that a face image of a subject other than the driver is handled. I do.
- step S101 the control unit of the detector generation device 1B operates as a learning data acquisition unit, and outputs the first face image in which the subject's face is captured and the position information indicating the position of the face organ in the first face image.
- a plurality of learning data sets each constituted by a combination are acquired.
- the process of step S101 according to the present modification is the same as in the above embodiment.
- the control unit operates as a learning processing unit, and implements machine learning of the detector using the plurality of acquired learning data sets.
- the process of step S102 according to the present modification may be the same as the above-described embodiment, or may be the same as the above ⁇ 4.4>.
- the control unit operates as a storage processing unit, and stores information indicating the configuration and operation parameters of the detector constructed by machine learning as learning result data.
- the detector generation device 1B can generate a detector that has acquired the ability to detect the position of an organ from a face image in which the face of a target person other than the driver appears.
- the monitoring device 2B uses the detector constructed by the detector generation device 1B to photograph the worker U working with the robot device R on the production line using the camera 41, and the monitoring device 2B is obtained for the worker U.
- the position of a facial organ is detected from the face image.
- the control unit of the monitoring device 2B operates as a data acquisition unit, and acquires, from the camera 41, a face image showing the face of the worker U working with the robot device R.
- the control unit operates as a detection unit, and inputs the face image obtained to the learned detector constructed by the detector generation device 1B, thereby recognizing the facial organ of the worker U. An output value corresponding to the result detected from the face image is obtained from the detector.
- the control unit outputs information on the result of detecting the facial organ of the worker U.
- the content of the information to be output may be appropriately determined according to the embodiment, as in the above embodiment.
- the control unit estimates the gaze direction of the worker U based on the detected positional relationship of each eye, and outputs information related to the estimation result of the gaze direction. You may.
- the control unit may output a warning prompting the gaze direction to be directed to a direction related to the work. Good.
- the control unit may output to the robot device R an instruction to perform an operation that matches the line of sight of the worker U.
- the monitoring device 2B uses the detector generated by the detector generation device 1B to extract the position of the facial organ from the face image obtained by photographing the face of the worker U. Can be detected.
- FIG. 13 schematically illustrates an example of another scene to which the present invention is applied. Specifically, FIG. 13 illustrates an example in which the present invention is applied to a case where a product UC flowing through a production line RC is photographed, and a defect is present in the product UC, and the position of the defect in the product UC is detected from an obtained image. Is shown.
- FIG. 14 schematically illustrates an example of a software configuration of a detector generation device 1C according to the present modification.
- the defect of the product UC according to the present modification is an example of the “object” of the present invention.
- the “target” does not have to be limited to such a defect of the product, and may be appropriately selected according to the embodiment.
- the “target” may be, for example, the face itself, a body part other than the face, or the like, in addition to the facial organ (the above embodiment).
- the “object” may be, for example, the product itself, or some feature included in the product.
- the hardware configuration of the detector generation device 1C according to this modification is the same as that of the detector generation device 1 according to the above embodiment.
- the software configuration of the detector generation device 1C according to the present modification is the same as that of the detector generation device 1 according to the above embodiment.
- the hardware configuration and the software configuration of the monitoring device 2C according to the present modification are the same as those of the monitoring device 2 according to the above embodiment.
- the detector generation device 1C and the monitoring device 2C according to the present modification operate in the same manner as the detector generation device 1 and the monitoring device 2 according to the above-described embodiment, except that they handle images in which products are captured.
- step S101 the control unit of the detector generation device 1C operates as the learning data acquisition unit 111, and outputs the first image 611C in which the product including the defect appears, and the position information indicating the position of the defect in the first image 611C.
- a plurality of learning data sets 61C constituted by combinations of 612C are acquired.
- the processing in step S101 according to this modified example is the same as that in the above-described embodiment, except that the object to be photographed is different.
- control unit operates as the learning processing unit 112, and performs machine learning of the detector 5 using the acquired plurality of learning data sets 61C.
- step S201 the control unit inputs the first image 611C of each learning data set 61C to the detector 5, and executes a calculation process of the detector 5. Thereby, the control unit acquires the first output value for each first image from the detector 5.
- step S202 the control unit compares the first detection position V1C of the defect of the product specified based on the first output value obtained for each first image with the position A1C indicated by the corresponding position information 612C. The total value of the first errors 71C is calculated.
- step S203 the control unit generates a second image 63C for each first image 611C by adding noise to each first image 611C.
- step S204 the control unit inputs each of the generated second images 63C to the detector 5, and executes the arithmetic processing of the detector 5. Thereby, the control unit acquires the second output value for each second image 63C from the detector 5.
- step S205 the control unit performs the second detection specified based on the second output value obtained for the second image 63C corresponding to the first detection position V1C specified based on each first output value. The total value of the second error 72C from the position V2C is calculated.
- step S206 the control unit generates a third image 66C for each first image 611C by applying a predetermined geometric transformation to each first image 611C.
- step S207 the control unit inputs each of the generated third images 66C to the detector 5, and executes the arithmetic processing of the detector 5. Thereby, the control unit obtains the third output value for each third image 66C from the detector 5.
- step S208 the control unit determines the third detection position specified based on the third output value obtained for the third image 66C corresponding to the first detection position specified based on each first output value. Is calculated as the third error 73C.
- step S208 the control unit is derived for the third image 66C corresponding to the first detection position V1C obtained for each first image 611C, as in the above embodiment.
- the difference from the third detection position V31C may be calculated as the third error 73C.
- the control unit calculates a difference between a position derived by applying a predetermined geometric transformation to the first detection position V1C obtained for each first image 611C and the third detection position V30C as a third error 73C. May be calculated as
- step S209 the control unit determines whether or not the sum of the calculated errors 71C to 73C is equal to or smaller than a threshold. When determining that the total value of the errors 71C to 73C is equal to or less than the threshold, the control unit ends the machine learning process and proceeds to the next step S103. On the other hand, if it is determined that the total value of the errors 71C to 73C exceeds the threshold, the control unit proceeds to the next step S210. In step S210, the control unit performs training of the detector 5 so that the total value of the errors 71C to 73C becomes small. When the update of the parameter values of each layer 51 to 53 of the detector 5 is completed, the control unit repeats the processing from step S201.
- step S102 according to the present modified example is the same as in the above embodiment.
- the processing procedure of step S102 according to the present modification need not be limited to such an example, and may be, for example, the same as the above ⁇ 4.4>.
- the processing of steps S206 to S208 may be omitted.
- step S209 the control unit may determine whether or not the total value of the calculated errors 71C to 72C is equal to or smaller than a threshold. When determining that the total value of the errors 71C to 72C is equal to or less than the threshold, the control unit may proceed to the next step S103.
- control unit may proceed to the next step S210.
- the control unit may train the detector 5 so that the total value of the errors 71C to 72C becomes smaller.
- step S103 the control unit operates as the storage processing unit 113, and stores information indicating the configuration and operation parameters of the detector 5 constructed by machine learning as learning result data 121C.
- the detector generation device 1C can generate the detector 5 that has acquired the ability to detect the position of a defect (object) from an image of a product.
- the monitoring device 2C takes an image of the product UC flowing through the production line RC by using the detector 5 constructed by the detector generation device 1C and, when the product UC has a defect, obtains a product from the obtained image. The position of the UC defect is detected.
- the control unit of the monitoring device 2C operates as a data acquisition unit, and acquires an image of the product UC flowing through the production line RC from the camera 41.
- the control unit operates as a detection unit and sets the learned detector 5 with reference to the learning result data 121C. Subsequently, the control unit obtains an output value corresponding to a result of detecting a defect of the product UC from the image by inputting the obtained image to the learned detector 5.
- the control unit outputs information on the result of detecting a defect of the product UC.
- the content of the information to be output may be appropriately determined according to the embodiment, as in the above embodiment.
- the control unit may output information indicating the position of the detected defect.
- the control unit may output an instruction to flow the product UC in which the defect is detected to another line to the production line RC.
- the monitoring device 2C uses the detector 5 generated by the detector generation device 1C to detect a defect from an image of the product UC, thereby detecting the defect of the product UC flowing through the production line RC. Can be monitored.
- the detector generation device 1 alternately repeats a process of generating a detector and a process of updating position information, thereby causing an artificial noise included in the position information. It is possible to construct a detector that is robust to the influence and capable of detecting the facial organ of the subject from the facial image. From the viewpoint of constructing a detector that is robust against the influence of artificial noise, only the part that alternately executes the process of generating the detector and the process of updating the position information is extracted, and the detection according to the new form is performed.
- An apparatus generator may be configured.
- FIG. 15 schematically illustrates an example of a software configuration of the detector generation device 1D according to the present modification.
- the hardware configuration of a detector generation device 1D according to the present modification is the same as that of the detector generation device 1 according to the above embodiment.
- the software configuration of a detector generation device 1D according to the present modification is also the same as that of the detector generation device 1 according to the above embodiment.
- the detector generation device 1D operates basically in the same manner as the detector generation device 1 according to the above embodiment, except that the process of deriving the second error 72 and the third error 73 is omitted. That is, in step S101 of the first learning process, the control unit of the detector generation device 1D operates as the learning data acquisition unit 111, and appears in the face image 681 and the face image 681 of the face of the subject driving the vehicle.
- a plurality of first learning data sets 68 each composed of a combination of the first position information 682 indicating the position of the facial organ are acquired.
- the first position information 682 may be given by an operator.
- step S ⁇ b> 102 the control unit operates as the learning processing unit 112, and implements the machine learning of the first detector 58 using the plurality of acquired first learning data sets 68.
- steps S203 to S208 are omitted.
- step S201 the control unit inputs each face image 681 to the first detector 58, and executes a calculation process of the first detector 58.
- step S202 the control unit obtains the output value for each face image 681 from the first detector 58, the control unit determines whether the detection value is specified based on the output value obtained for each face image 681. The total value of the error between the position and the position indicated by the first position information 682 corresponding to the position is calculated.
- step S209 the control unit determines whether the calculated total value of the errors is equal to or smaller than a threshold. When it is determined that the total value of the errors is equal to or smaller than the threshold, the control unit ends the machine learning process, and proceeds to step S103. On the other hand, when determining that the total value of the errors exceeds the threshold, the control unit proceeds to the next step S210.
- step S210 the control unit performs training of the first detector 58 so that the total value of the errors becomes small.
- the method of adjusting the parameters of the first detector 58 may be the same as in the above embodiment. Accordingly, when each face image 681 is input, the control unit constructs the detector 5 trained to output an output value corresponding to the corresponding first position information 682.
- step S103 the control unit operates as the storage processing unit 113, and stores information indicating the configuration and operation parameters of the first detector 58 constructed by machine learning as learning result data. In the first learning process, the process of step S103 may be omitted.
- the detector generation device 1D alternately repeats a series of processing of such machine learning and a processing of updating position information using a provisionally generated detector.
- step S101 of the second learning process the control unit inputs the face image 681 to the face image 681 and the constructed first detector 58, thereby converting the output value obtained from the first detector 58 into the output value.
- a plurality of second learning data sets 69 each constituted by a combination of the second position information 692 given based on the acquired information are acquired.
- the control unit performs machine learning of the second detector 59 using the plurality of second learning data sets 69. This machine learning process is the same as the first learning process.
- the control unit constructs the second detector 59 trained to output an output value corresponding to the corresponding second position information 692. Accordingly, the detector generation device 1D according to the present modification can generate a detector (second detector 59) that is robust to the influence of artificial noise. Note that the generated second detector 59 may be used in the same manner as the detector 5 described above.
- FIG. 15 illustrates a case where the machine learning process is repeated twice.
- the number of times of repeating the machine learning process is not limited to such an example, and may be appropriately selected according to the embodiment.
- the number of repetitions may be three or more.
- this modification is widely applicable to scenes in which a facial organ of a subject other than the driver is detected from a face image. Therefore, the face image 681 may be replaced with a face image that shows the face of a subject other than the driver. This makes it possible to construct a detector that has acquired the ability to detect the position of an organ from a face image in which the face of a target person other than the driver appears.
- the present modified example can be widely applied to any scene where the position of any object is detected from an image. Therefore, the face image 681 may be replaced with an image in which some target object appears. Each position information (682, 692) may be replaced with position information indicating the position of the object. This makes it possible to construct a detector that has acquired the ability to detect the position of an object from an image.
- each learning data set was prepared under the following conditions.
- a learning network including a convolutional neural network and a fully connected neural network was used as the detector.
- the output of the convolutional neural network was connected to the input of a fully connected neural network.
- a detector generator general-purpose personal computer
- the prepared detector generator was used to execute each process according to the above-described embodiment using each prepared learning data set.
- a learned detector according to the first example was obtained.
- the learned detector according to the first embodiment uses the learned detector according to the first embodiment to detect the position of the outer corner of the eye from the face image of each learning data set used in the first embodiment, and the position information is updated based on the detection result. Each learning data set was obtained. Then, using the obtained learning data sets, the detector generation device was caused to execute the machine learning processing according to the above embodiment. Thus, a learned detector according to the second embodiment was obtained. That is, the learned detector according to the second example corresponds to a learned detector generated by repeating the machine learning process according to the above-described embodiment twice.
- the position of the outer corner of the eye is detected from the face image of each learning data set used in the second embodiment, and the position information is updated based on the detection result.
- Each learning data set was obtained.
- the detector generation device was caused to execute the machine learning processing according to the above embodiment.
- a learned detector according to the third example was obtained. That is, the learned detector according to the third example corresponds to a learned detector generated by repeating the machine learning process according to the above-described embodiment three times.
- the detector according to the comparative example was obtained by omitting the calculation of the second error 72 and the third error 73. That is, in the comparative example, the processing of steps S203 to S208 in the processing procedure according to the above embodiment is omitted. Then, in steps S209 and S210, each of the errors 71 to 73 was replaced with the first error 71.
- the detection accuracy of the detectors according to the first to third examples and the comparative example was evaluated by the following method. That is, the face of the subject was photographed by a camera, and 5000 face images (64 ⁇ 64 pixels) for evaluation were prepared in the same manner as the face images for learning. Each face image for evaluation was input to each detector, and a first detection result of the position of the outer corner of the eye with respect to each face image was obtained from each detector. Further, a transformed image was generated by geometrically transforming (translating and rotating) each face image for evaluation. Each generated converted image was input to each detector, and a second detection result of the position of the outer corner of the eye with respect to each converted image was obtained from each detector.
- the detection error of the detector according to the first to third embodiments for implementing the learning of the second error 72 and the third error 73 depends on the learning of the second error 72 and the third error 73 It was smaller than the comparative example without performing. From this, it was found that according to the above-described embodiment, it is possible to generate a detector with less fluctuation in the detection result than in the case where only the first error 71 is learned. In addition, as the third embodiment is changed from the first embodiment, the blur of the detection of the outer corner of the eye by the detector is reduced. From this, it was found that by alternately repeating the process of generating the detector and the process of updating the position information, it is possible to suppress the fluctuation of the detection of the detector. Therefore, according to the above-described embodiment, it has been found that a detector capable of detecting a target with higher accuracy can be generated.
- Detector generator 11 control unit, 12: storage unit, 13: communication interface, 14 input device, 15 output device, 16 drive 111: learning data acquisition unit, 112: learning processing unit, 113: storage processing unit, 121: learning result data, 81: detector generation program, 91: storage medium, 2 ... Monitoring device, 21: control unit, 22: storage unit, 23: communication interface, 24 ... External interface, 25 input device, 26 output device, 27 drive 211: data acquisition unit, 212: detection unit, 213 ... output unit, 221 ... face image, 82: monitoring program, 92: storage medium, 31 ... camera, 41 ...
Landscapes
- Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Image Analysis (AREA)
- Image Processing (AREA)
Abstract
ノイズの影響にロバストで、対象物をより高精度に検出可能な検出器を生成するための技術を提供する。本発明の一側面に係る検出器生成装置は、第1顔画像及び顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得し、取得した複数の学習データセットを利用して、検出器の機械学習を実施する。機械学習を実施することは、検出器を利用して各第1顔画像において特定される第1検出位置と位置情報により示される位置との第1誤差の合計値を算出すること、各第1顔画像にノイズを付与することで各第2顔画像を生成すること、検出器を利用して各第2顔画像において特定される第2検出位置と各第1検出位置との第2誤差の合計値を算出すること、及び各誤差の合計値が小さくなるように検出器を訓練することを含む。
Description
本発明は、検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラムに関する。
近年、脇見等に起因する自動車の交通事故を防止するために、運転者の状態を監視する技術の開発が進んでいる。また、自動車の自動運転の実現に向けた動きが加速している。自動運転は、システムにより自動車の操舵を制御するものであるが、システムに代わって運転者が運転しなければならない場面もあり得ることから、自動運転中であっても、運転者が運転操作を行える状態にあるか否かを監視する必要性があるとされている。この自動運転中に運転者の状態を監視する必要性があることは、国連欧州経済委員会(UN-ECE)の政府間会合(WP29)においても確認されている。この点からも、運転者の状態を監視する技術の開発が進められている。
運転者の状態を監視する技術の一つとして、視線方向等の運転者の顔の状態を推定するために、運転者を撮影することで得られた画像から運転者の顔の器官を検出する技術がある。顔の器官を検出することができれば、検出した器官の位置関係に基づいて、運転者の状態を推定することができる。例えば、顔画像から各目を検出し、各目の位置を特定することができれば、特定した各目の位置関係に基づいて、運転者の視線方向を推定することができる。
人物の器官を検出する技術として、例えば、特許文献1では、畳み込みニューラルネットワーク(Convolutional Neural Networks)を利用して、顔の器官を検出するための装置が提案されている。具体的には、この装置は、畳み込みニューラルネットワークを使用して、顔の器官に関連する特徴点の候補を顔画像データから抽出し、抽出した各候補に対して幾何学的な補正処理を実行することで、各特徴点の位置を決定する。これにより、当該装置は、決定した各特徴点の位置に基づいて、対象人物を認識することができる。
従来、特許文献1で例示されるように、顔の器官の位置を検出するために、ニューラルネットワーク等の学習モデルにより構成された検出器を採用することがある。この検出器は、機械学習により、入力された顔画像から顔の器官の位置を検出することができるようになる。検出器の機械学習を実施するためには、顔の写る顔画像及び顔の器官の位置を示す位置情報が用意される。機械学習では、用意した顔画像が入力されると、位置情報に対応する出力値を出力するように検出器のパラメータが調整される。この機械学習により、顔画像から顔の器官の位置を検出する能力を獲得した学習済みの検出器が生成される。
本件発明者らは、このような学習済みの検出器を用いる従来の方法では、図1に示すような問題点が生じることを見出した。図1は、従来の方法により顔の器官の位置を検出する場面の一例を模式的に例示する。図1では、顔の器官の一例として目(具体的には、目尻)を検出する場面を例示する。機械学習により、検出器は、同一の顔画像に対して同一の出力値を出力するように、換言すると、同一の顔画像に対して同一の位置を対象の器官の検出位置として回答する能力を獲得する。したがって、運転者が顔の器官を動かさなければ、本来、検出器から回答される器官の検出位置は一定のはずである。
しかしながら、動画像等の連続的に取得される複数の画像には、撮影装置の性能、撮影環境等に応じたノイズがランダムに含まれ得る。このランダムなノイズの影響によって、完全に同一の画像を得ることは難しく、各画像は微妙に異なり得る。この各画像の微妙な相違に起因して、運転者が顔の器官を動かしていないにも関わらず、検出器から回答される器官の検出位置にぶれが生じてしまう。すなわち、図1の示すように、器官(目尻)を動かしていないにも関わらず、各顔画像に含まれるノイズの影響によって、各顔画像間で器官の検出位置が変動してしまうという問題点が生じ得ることを本件発明者らは見出した。
運転者が顔の器官を動かしていないにも関わらず、検出器による器官の検出位置にぶれが生じてしまうと、この検出結果の変動に起因して、運転者の状態を推定する精度が低くなってしまう。例えば、上記の視線方向を推定する例では、運転者が視線を変えていないにも関わらず、各目の検出位置がぶれてしまうことにより、運転者の視線方向の推定結果が変動してしまうことになる。これにより、例えば、運転者が前方を注視しているにも関わらず運転者が脇見をしていると認識してしまう等のように、システムが運転者の状態を誤認識してしまう可能性が生じる。
なお、この課題は、上記のような運転者の顔の器官を検出する場面ではなく、例えば、運転者以外の対象者の顔の器官を検出する場面、対象者の顔の器官以外の対象物を検出する場面等の、対象物を検出するあらゆる場面で生じ得る。例えば、生産ラインを流れる製品、製品に形成された傷等の対象物を検出する場合に、従来の検出器を用いた方法では、対象物が動いていないにも関わらず、複数の画像間で対象物の検出位置がぶれてしまうという問題点が生じ得る。
本発明は、一側面では、このような実情を鑑みてなされたものであり、その目的は、ノイズの影響にロバストで、対象物をより高精度に検出可能な検出器を生成するための技術を提供することである。
本発明は、上述した課題を解決するために、以下の構成を採用する。
すなわち、本発明の一側面に係る検出器生成装置は、車両を運転する被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する学習データ取得部と、前記複数の学習データセットを利用して、検出器の機械学習を実施する学習処理部と、を備える。そして、前記検出器の機械学習を実施することは、前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記器官の第1検出位置と当該第1顔画像に組み合わせられた前記位置情報により示される前記位置との第1誤差の合計値を算出するステップと、前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記第1検出位置と当該第1顔画像に対して生成された前記第2顔画像に対して得られた前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、を含む。
上記構成に係る検出器生成装置は、第1顔画像及び位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得し、取得した複数の学習データセットを利用して、検出器の機械学習を実施する。第1顔画像は訓練データ(入力データ)に対応し、位置情報は正解データ(教師データ)に対応する。検出器は、顔画像の入力を受け付け、入力された顔画像に写る顔の器官の位置を検出した結果(例えば、器官の座標値)に対応する出力値を出力するように構成される。
上記構成に係る検出器生成装置は、機械学習の過程において、第1顔画像を検出器に入力することで第1出力値を取得し、取得した第1出力値に基づいて特定される器官の第1検出位置と位置情報により示される位置との第1誤差の合計値を算出する。この第1誤差の合計値は、検出器により第1顔画像から器官を検出した結果と位置情報により指定される器官の位置の正解との間の損失に相当する。そこで、上記構成に係る検出器生成装置は、この第1誤差の合計値が小さくなるように検出器を訓練する。これにより、位置情報により示される正解と一致するように、第1顔画像から器官を検出する能力を習得した検出器が構築される。
加えて、上記構成に係る検出器生成装置は、第1顔画像にノイズを付与することで第2顔画像を生成し、生成した第2顔画像を検出器に入力することで第2出力値を取得する。そして、上記構成に係る検出器生成装置は、上記第1検出位置と取得した第2出力値に基づいて特定される器官の第2検出位置との第2誤差の合計値を算出する。この第2誤差の合計値は、検出器による器官の検出結果のブレであって、ノイズの有無によって生じるブレの損失に相当する。そこで、上記構成に係る検出器生成装置は、上記第1誤差の合計値と共に、第2誤差の合計値が小さくなるように検出器を訓練する。これにより、器官の検出結果がノイズによる影響を受け難い検出器を構築することができる。
したがって、上記構成に係る検出器生成装置によれば、位置情報により示される正解と一致するように第1顔画像から器官を検出し、かつその検出結果がノイズによる影響を受け難い、ように訓練された検出器を構築することができる。よって、ノイズの影響にロバストで、対象物(上記一側面では、顔の器官)をより高精度に検出可能な検出器を生成することができる。
なお、検出器は、機械学習を実施可能な学習モデルにより構成される。このような検出器は、例えば、ニューラルネットワークにより構成されてよい。顔画像から検出される器官の種類は、顔に含まれる何らかの部位であれば特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。検出の対象となる器官は、例えば、目、鼻、口、眉、顎及びこれらの組み合わせから選択されてよい。また、検出の対象となる器官には、顔の輪郭が含まれてもよい。
上記一側面に係る検出器生成装置において、前記検出器の機械学習を実施することは、前記各学習データセットの前記第1顔画像に所定の幾何変換を適用することで、前記各学習データセットの前記第1顔画像に対して第3顔画像を生成するステップと、前記各第3顔画像を前記検出器に入力することで、前記各第3顔画像に対する第3出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記第1検出位置と当該第1顔画像に対して生成された前記第3顔画像に対して得られた前記第3出力値に基づいて特定される前記器官の第3検出位置との第3誤差の合計値を算出するステップと、を更に含んでもよく、前記訓練するステップでは、前記学習処理部は、前記第1誤差の合計値、前記第2誤差の合計値及び前記第3誤差の合計値が小さくなるように前記検出器を訓練してもよい。
本件発明者らは、上記画像に生じるランダムなノイズの影響の他、次のような理由によっても、器官の検出位置が変動してしまうという問題点が生じ得ることを見出した。すなわち、機械学習の正解データとして利用される位置情報にはノイズが含まれ得る。つまり、位置情報は、常に一定の基準に従って対象の器官の位置を正確に示すとは限らないという不安定性を有している。例えば、位置情報が人間により入力される場合に、位置情報を入力する人物が異なれば、器官の存在する位置として指定される位置は異なり得る。また、同一の人物が位置情報を入力したとしても、同一の顔画像に対して完全に一致する位置を複数回指定するのは困難である。
具体例として、上記図1に例示される目尻の位置を位置情報として入力する場面を想定する。この場面において、複数の異なる人物が顔画像に対して目尻の位置を指定する場合に、各人物の間には、目尻の位置の定義に対する解釈に微妙な差が存在し得る。そのため、同一の顔画像に対して各人物が目尻の位置を指定したとしても、各人物により指定される目尻の位置は微妙に相違し得る。また、同一の人物により目尻の位置を指定したとしても、完全に一致する位置を複数回指定するのは困難である。そのため、同一の顔画像に対して同一の人物が目尻の位置を指定したとしても、各回に指定される目尻の位置は微妙に相違し得る。
したがって、複数の異なる人物が位置情報を入力する場合は勿論のこと、同一の人物が位置情報を入力する場合であっても、入力された位置情報は、常に一定の基準に従って対象の器官の位置を正確に示すとは限らない。すなわち、位置情報により示される器官の存在する位置は変動し得る。このようなノイズを含む位置情報を機械学習の正解データとして利用した場合、検出器は、顔画像に対して与えられた器官の位置だけではなく、このノイズをも再現するように学習してしまう。これに起因して、運転者が顔の器官を動かしていないにも関わらず、学習済みの検出器から回答される器官の検出位置にぶれが生じてしまう。すなわち、上記図1に例示されるように、器官(目尻)を動かしていないにも関わらず、機械学習に利用した位置情報に含まれるノイズを学習した影響によっても、各顔画像間で器官の検出位置が変動してしまうという問題点が生じ得る。
これに対して、当該構成に係る検出器生成装置は、第1顔画像に所定の幾何変換を適用することで第3顔画像を生成し、生成した第3顔画像を検出器に入力することで第3出力値を取得する。そして、当該構成に係る検出器生成装置は、上記第1検出位置と取得した第3出力値に基づいて特定される器官の第3検出位置との第3誤差の合計値を算出する。
各第1顔画像に付与される位置情報が、常に一定の基準に従って対象の器官(図1の例では、目尻)の位置を正確に示していた場合には、第1誤差に基づく機械学習により構築される検出器は、一定の基準に対応する対象の器官の何らかの特徴を捉えて、当該対象の器官の位置を正確に検出することができるようになる。そのため、この検出器は、第1顔画像を幾何変換することで生成された第3顔画像に対しても、その特徴に基づいて、対象の器官の位置を正確に検出することができる。
一方、各第1顔画像に付与される位置情報が一定の基準に従って対象の器官の位置を示すものではない場合、第1誤差に基づく機械学習により構築される検出器は、上記の特徴を正確には捉えることができず、対象の器官の検出する位置がぶれてしまう。そのため、この検出器は、第1顔画像を幾何変換することで生成された第3顔画像に対して、対象の器官の位置を正確に検出することができない可能性が高い。なお、各第1顔画像に付与される位置情報が一定の基準に従って対象の器官の位置を示すものではないケースとは、例えば、各第1顔画像において顔の位置がずれているにも関わらず、各顔画像に対して一定の位置を示す位置情報が各第1顔画像に付与されるケースである。
上記第3誤差の合計値は、検出器による器官の検出結果のブレであって、このような顔画像における幾何的なノイズの影響によって生じるブレの損失に相当する。そこで、当該構成に係る検出器生成装置は、上記第1誤差及び第2誤差それぞれの合計値と共に、第3誤差の合計値が小さくなるように検出器を訓練する。これにより、画像ノイズ及び位置情報に含まれる幾何的なノイズによる影響にロバストな検出器を構築することができる。
なお、所定の幾何変換(幾何学的な変換)は、例えば、平行移動、回転移動、反転、拡大、縮小又はこれらの組み合わせであってよい。具体例として、所定の幾何変換は、平行移動及び回転移動を伴う変換であってよい。これにより、平行移動及び回転移動による影響にロバストな検出器を構築することができる。
上記一側面に係る検出器生成装置において、前記各学習データセットの前記位置情報は、当該位置情報に組み合わせられる前記第1顔画像を、機械学習を実施済みの他の検出器に入力することで、当該他の検出器から得られる出力値に基づいて与えられてよい。当該構成によれば、他の検出器による検出結果を位置情報として利用するため、上記人為的なノイズが位置情報に含まれるのを防止することができる。これにより、位置情報に含まれ得るノイズによる影響にロバストな検出器を構築することができる。
なお、他の検出器は、機械学習により最終的な検出器を得る過程で生成される暫定的な検出器であってよい。つまり、検出器生成装置は、学習データセットを利用した機械学習による検出器の構築する処理と、構築された検出器により位置情報を更新する処理とを交互に繰り返し実行してもよい。上記人為的なノイズによる影響にロバストな検出器を構築するために、この検出器を構築する処理と位置情報を更新する処理とを交互に実行する部分のみを抽出して、新たな形態に係る検出器生成装置が構成されてもよい。
例えば、本発明の一側面に係る検出器生成装置は、車両を運転する被験者の顔の写る顔画像、及び前記顔画像に写る前記顔の器官の位置を示す第1位置情報の組み合わせによりそれぞれ構成される複数の第1学習データセットを取得する学習データ取得部と、前記複数の第1学習データセットを利用して、第1検出器の機械学習を実施することで、前記各第1学習データセットの前記顔画像が入力されると、入力された前記顔画像に組み合わせられた前記第1位置情報に対応する出力値を出力する第1検出器を構築する学習処理部と、を備える。そして、前記学習データ取得部は、前記各第1学習データセットの前記顔画像、及び構築された前記第1検出器に当該顔画像を入力することで、当該第1検出器から得られる出力値に基づいて与えられる第2位置情報の組み合わせによりそれぞれ構成される複数の第2学習データセットを更に取得する。また、前記学習処理部は、前記複数の第2学習データセットを利用して、第2検出器の機械学習を実施することで、前記各第2学習データセットの前記顔画像が入力されると、入力された前記顔画像に組み合わせられた前記第2位置情報に対応する出力値を出力する第2検出器を更に構築する。なお、第1検出器は、上記「他の検出器」、すなわち、暫定的な検出器の一例である。また、第2学習データセットの取得及び第2検出器の構築を繰り返す場合、あるステップで構築される第2検出器が、次のステップの第1検出器と利用される。そして、最後に構築される第2検出器が、上記「検出器」、すなわち、最終的な検出器の一例である。
また、本発明の一側面に係るモニタリング装置は、車両を運転する運転者の顔の写る顔画像を取得するデータ取得部と、上記いずれかの形態に係る検出器生成装置による機械学習を実施済みの前記検出器に取得した前記顔画像を入力することで、前記運転者の前記顔の器官を検出した結果に対応する出力値を前記検出器から取得する検出部と、前記運転者の顔の器官を検出した結果に関する情報を出力する出力部と、を備える。当該構成に係るモニタリング装置によれば、ノイズの影響にロバストな検出器により、運転者の顔の器官を高精度に検出することができる。したがって、例えば、運転操作中における運転者の状態等を精度よく認識することができる。
また、上記各形態に係る検出器生成装置及びモニタリング装置は、車両の運転者の顔の器官を検出する場面だけではなく、例えば、生産ラインの作業者の顔の器官を検出する場面等、運転者以外の対象者の顔の器官を検出するあらゆる場面に適用されてよい。更に、上記各形態に係る検出器生成装置及びモニタリング装置は、対象者の顔の器官を検出する場面だけではなく、例えば、生産ラインを流れる製品の何らかの特徴(例えば、傷)の位置を検出する場面等、人物以外の対象物の写る画像から当該対象物の位置を検出するあらゆる場面に適用されてよい。
例えば、本発明の一側面に係る検出器生成装置は、被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する学習データ取得部と、前記複数の学習データセットを利用して、検出器の機械学習を実施する学習処理部と、を備える。そして、前記検出器の機械学習を実施することは、前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記器官の第1検出位置と当該第1顔画像に組み合わせられた前記位置情報により示される前記位置との第1誤差の合計値を算出するステップと、前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記第1検出位置と当該第1顔画像に対して生成された前記第2顔画像に対して得られた前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、を含む。
また、例えば、本発明の一側面に係る検出器生成装置は、対象物の写る第1画像、及び前記第1画像に写る前記対象物の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する学習データ取得部と、前記複数の学習データセットを利用して、検出器の機械学習を実施する学習処理部と、を備える。そして、前記検出器の機械学習を実施することは、前記各学習データセットの前記第1画像を前記検出器に入力することで、前記各学習データセットの前記第1画像に対する第1出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1画像に対して得られた前記第1出力値に基づいて特定される前記対象物の第1検出位置と当該第1画像に組み合わせられた前記位置情報により示される前記位置との第1誤差の合計値を算出するステップと、前記各学習データセットの前記第1画像にノイズを付与することで、前記各学習データセットの前記第1画像に対して第2画像を生成するステップと、前記各第2画像を前記検出器に入力することで、前記各第2画像に対する第2出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1画像に対して得られた前記第1出力値に基づいて特定される前記第1検出位置と当該第1画像に対して生成された前記第2画像に対して得られた前記第2出力値に基づいて特定される前記対象物の第2検出位置との第2誤差の合計値を算出するステップと、前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、を含む。
例えば、本発明の一側面に係る検出器生成装置は、被験者の顔の写る顔画像、及び前記顔画像に写る前記顔の器官の位置を示す第1位置情報の組み合わせによりそれぞれ構成される複数の第1学習データセットを取得する学習データ取得部と、前記複数の第1学習データセットを利用して、第1検出器の機械学習を実施することで、前記各第1学習データセットの前記顔画像が入力されると、入力された前記顔画像に組み合わせられた前記第1位置情報に対応する出力値を出力する第1検出器を構築する学習処理部と、を備える。そして、前記学習データ取得部は、前記各第1学習データセットの前記顔画像、及び構築された前記第1検出器に当該顔画像を入力することで、当該第1検出器から得られる出力値に基づいて与えられる第2位置情報の組み合わせによりそれぞれ構成される複数の第2学習データセットを更に取得する。また、前記学習処理部は、前記複数の第2学習データセットを利用して、第2検出器の機械学習を実施することで、前記各第2学習データセットの前記顔画像が入力されると、入力された前記顔画像に組み合わせられた前記第2位置情報に対応する出力値を出力する第2検出器を更に構築する。
また、例えば、本発明の一側面に係る検出器生成装置は、対象物の写る画像、及び前記画像に写る前記対象物の位置を示す第1位置情報の組み合わせによりそれぞれ構成される複数の第1学習データセットを取得する学習データ取得部と、前記複数の第1学習データセットを利用して、第1検出器の機械学習を実施することで、前記各第1学習データセットの前記画像が入力されると、入力された前記画像に組み合わせられた前記第1位置情報に対応する出力値を出力する第1検出器を構築する学習処理部と、を備える。そして、前記学習データ取得部は、前記各第1学習データセットの前記画像、及び構築された前記第1検出器に当該画像を入力することで、当該第1検出器から得られる出力値に基づいて与えられる第2位置情報の組み合わせによりそれぞれ構成される複数の第2学習データセットを更に取得する。また、前記学習処理部は、前記複数の第2学習データセットを利用して、第2検出器の機械学習を実施することで、前記各第2学習データセットの前記画像が入力されると、入力された前記画像に組み合わせられた前記第2位置情報に対応する出力値を出力する第2検出器を更に構築する。
なお、検出器を訓練することは、検出器のパラメータを調節することである。検出器のパラメータは、何らかの対象物を画像から検出する(出力値を得る)ための演算処理に利用される。検出器がニューラルネットワークにより構成される場合、パラメータは、例えば、各ニューロン間の結合の重み、各ニューロンの閾値等である。
対象物の種類は、画像に写り得るものであれば特に限定されなくてよく、実施の形態に応じて適宜選択されてよい。人間の写る画像が第1画像として取得される場合、対象物は、例えば、顔の器官、顔そのもの、顔以外の身体部位等であってよい。また、生産ラインで生産される製品の写る画像が第1画像として取得される場合、対象物は、例えば、製品そのもの、製品に含まれる何らかの特徴(例えば、傷)等であってよい。
各検出位置は、各画像に対して検出器が対象物を検出した位置である。第2誤差は、ノイズ画像(第2顔画像、第2画像)に対する対象物の検出位置と元の画像(第1顔画像、第1画像)に対する対象物の検出位置との差分に相当する。第3誤差は、幾何変換画像(第3顔画像、第3画像)に対する対象物の検出位置と元の画像(第1顔画像、第1画像)に対する対象物の検出位置との相対的な差分に相当する。この第3誤差は、幾何変換画像から検出した位置に幾何変換の逆変換を適用することで得られた位置と元の画像から検出した位置との差分を算出することで導出されてよい。あるいは、第3誤差は、幾何変換画像から検出した位置と元の画像から検出した位置に幾何変換を適用することで得られた位置との差分を算出することで導出されてもよい。つまり、「第1出力値に基づいて特定される器官の第1検出位置と第3出力値に基づいて特定される器官の第3検出位置との第3誤差」を計算することは、幾何変換画像から検出した位置に幾何変換の逆変換を適用することで得られた位置と元の画像から検出した位置との差分を算出すること、及び幾何変換画像から検出した位置と元の画像から検出した位置に幾何変換を適用することで得られた位置との差分を算出することを含んでよい。検出器は、「学習器」と称されてもよい。また、機械学習後の検出器は、「学習済みの学習器」と称されてもよい。位置情報の形式は、特に限定されなくてもよく、実施の形態に応じて適宜決定されてよい。位置情報は、例えば、対象物の座標値により構成されてもよいし、対象物の領域を示す情報により構成されてもよい。
上記各形態に係る検出器生成装置及びモニタリング装置それぞれの別の態様として、本発明の一側面は、以上の各構成を実現する情報処理方法であってもよいし、プログラムであってもよいし、このようなプログラムを記憶した、コンピュータ等が読み取り可能な記憶媒体であってもよい。ここで、コンピュータ等が読み取り可能な記憶媒体とは、プログラム等の情報を、電気的、磁気的、光学的、機械的、又は、化学的作用によって蓄積する媒体である。また、本発明の一側面に係る検出システムは、上記いずれかの形態に係る検出器生成装置及びモニタリング装置により構成されてもよい。
例えば、本発明の一側面に係る検出器生成方法は、コンピュータが、車両を運転する被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得するステップと、前記複数の学習データセットを利用して、検出器の機械学習を実施するステップと、を実行する、情報処理方法である。そして、前記検出器の機械学習を実施するステップは、前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記器官の第1検出位置と当該第1顔画像に組み合わせられた前記位置情報により示される前記位置との第1誤差の合計値を算出するステップと、前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記第1検出位置と当該第1顔画像に対して生成された前記第2顔画像に対して得られた前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、を含む。
また、例えば、本発明の一側面に係る検出器生成プログラムは、コンピュータに、車両を運転する被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得するステップと、前記複数の学習データセットを利用して、検出器の機械学習を実施するステップと、を実行させるためのプログラムである。そして、前記検出器の機械学習を実施するステップは、前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記器官の第1検出位置と当該第1顔画像に組み合わせられた前記位置情報により示される前記位置との第1誤差の合計値を算出するステップと、前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、前記各学習データセットの前記第1顔画像に対して得られた前記第1出力値に基づいて特定される前記第1検出位置と当該第1顔画像に対して生成された前記第2顔画像に対して得られた前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、を含む。
本発明によれば、ノイズの影響にロバストで、対象物をより高精度に検出可能な検出器を生成することができる。
以下、本発明の一側面に係る実施の形態(以下、「本実施形態」とも表記する)を、図面に基づいて説明する。ただし、以下で説明する本実施形態は、あらゆる点において本発明の例示に過ぎない。本発明の範囲を逸脱することなく種々の改良や変形を行うことができることは言うまでもない。つまり、本発明の実施にあたって、実施形態に応じた具体的構成が適宜採用されてもよい。なお、本実施形態において登場するデータを自然言語により説明しているが、より具体的には、コンピュータが認識可能な疑似言語、コマンド、パラメータ、マシン語等で指定される。
§1 適用例
まず、図2を用いて、本発明が適用される場面の一例について説明する。図2は、本実施形態に係る検出システム100の適用場面の一例を模式的に例示する。図2の例では、車両を運転する運転者の顔を撮影し、得られる顔画像から顔の器官を検出する場面を想定している。顔画像は、本発明の「画像」の一例であり、顔の器官は、本発明の「対象物」の一例である。しかしながら、本発明の適用対象は、このような例に限定されなくてもよく、何らかの対象物を画像から検出するあらゆる場面に適用可能である。
まず、図2を用いて、本発明が適用される場面の一例について説明する。図2は、本実施形態に係る検出システム100の適用場面の一例を模式的に例示する。図2の例では、車両を運転する運転者の顔を撮影し、得られる顔画像から顔の器官を検出する場面を想定している。顔画像は、本発明の「画像」の一例であり、顔の器官は、本発明の「対象物」の一例である。しかしながら、本発明の適用対象は、このような例に限定されなくてもよく、何らかの対象物を画像から検出するあらゆる場面に適用可能である。
図2に示されるとおり、本実施形態に係る検出システム100は、ネットワークを介して互いに接続される検出器生成装置1及びモニタリング装置2を備えており、顔の器官を検出するための検出器を生成し、生成した検出器により運転者の顔の器官を検出するように構成される。検出器生成装置1及びモニタリング装置2の間のネットワークの種類は、例えば、インターネット、無線通信網、移動通信網、電話網、専用網等から適宜選択されてよい。
本実施形態に係る検出器生成装置1は、機械学習を実施することにより、顔画像から顔の器官を検出するための検出器5を構築するように構成されたコンピュータである。具体的には、検出器生成装置1は、車両を運転する被験者Tの顔の写る第1顔画像611、及び第1顔画像611に写る顔の器官の位置A1を示す位置情報612の組み合わせによりそれぞれ構成される複数の学習データセット61を取得する。第1顔画像611は、例えば、被験者Tの顔を撮影可能な車両内の位置に設置されたカメラ31により得られる。第1顔画像611は、機械学習における訓練データ(入力データ)に対応し、位置情報612は、正解データ(教師データ)に対応する。検出器生成装置1は、このような複数の学習データセット61を利用して、検出器5の機械学習を実施する。
具体的に、機械学習の処理として、検出器生成装置1は、まず、各学習データセット61の第1顔画像611を検出器5に入力することで、各学習データセット61の第1顔画像611に対する第1出力値を検出器5から取得する。検出器5は、顔画像の入力を受け付け、入力された顔画像に写る顔の器官の位置を検出した結果に対応する出力値を出力するように構成される。つまり、第1出力値は、第1顔画像611に写る被験者Tの顔の器官の位置を検出器5が検出した結果に対応する。このような検出器5は、機械学習を実施可能な学習モデルにより構成される。本実施形態では、検出器5は、後述するニューラルネットワークにより構成される。
次に、検出器生成装置1は、各学習データセット61の第1顔画像611に対して得られた第1出力値に基づいて特定される器官の第1検出位置V1と当該第1顔画像611に組み合わせられた位置情報612により示される位置A1との第1誤差71の合計値を算出する。つまり、検出器生成装置1は、各学習データセット61について、第1顔画像611に対して得られた第1検出位置V1、及び対応する位置情報612により示される位置A1の差分を第1誤差71として算出し、算出した各第1誤差71を足し合わせることで、第1誤差71の合計値を算出する。
また、検出器生成装置1は、各学習データセット61の第1顔画像611にノイズを付与することで、各学習データセット61の第1顔画像611に対して第2顔画像63を生成する。続いて、検出器生成装置1は、生成した各第2顔画像63を検出器5に入力することで、各第2顔画像63に対する第2出力値を検出器5から取得する。更に、検出器生成装置1は、各学習データセット61の第1顔画像611に対して得られた第1出力値に基づいて特定される第1検出位置V1と当該第1顔画像611に対して生成された第2顔画像63に対して得られた第2出力値に基づいて特定される器官の第2検出位置V2との第2誤差72の合計値を算出する。つまり、検出器生成装置1は、各学習データセット61について、第1顔画像611に対して得られた第1検出位置V1、及び対応する第2顔画像63に対して得られた第2検出位置V2の差分を第2誤差72として算出し、算出した各第2誤差72を足し合わせることで、第2誤差72の合計値を算出する。
そして、検出器生成装置1は、第1誤差71の合計値及び第2誤差72の合計値が小さくなるように検出器5を訓練する。検出器5を訓練することは、詳細には、検出器5のパラメータを調整することである。検出器5のパラメータは、何らかの対象物を画像から検出する(出力値を得る)ための演算処理に利用されるものである。本実施形態では、検出器5は後述するニューラルネットワークにより構成される。そのため、このパラメータは、例えば、各ニューロン間の結合の重み、各ニューロンの閾値等である。この検出器5のパラメータの調整には、例えば、誤差逆伝播法等の公知の学習アルゴリズムが用いられてよい。
第1誤差71の合計値は、検出器5により第1顔画像611から器官を検出した結果と位置情報612により指定される器官の位置の正解との間の損失に相当する。また、第2誤差72の合計値は、検出器5による器官の検出結果のブレであって、第1顔画像611におけるノイズの有無によって生じるブレの損失に相当する。そのため、上記機械学習により、検出器生成装置1は、位置情報612により示される正解と一致するように第1顔画像611から器官を検出し、かつその検出結果がノイズによる影響を受け難い、ように訓練された(学習済みの)検出器5を構築(生成)することができる。
一方、本実施形態に係るモニタリング装置2は、検出器生成装置1により構築された学習済みの検出器5を利用して、車両を運転する運転者Dの顔の器官を顔画像から検出するように構成されたコンピュータである。具体的には、モニタリング装置2は、車両を運転する運転者Dの顔の写る顔画像を取得する。顔画像は、例えば、運転者Dの顔を撮影可能な車両内の位置に設置されたカメラ41により得られる。
続いて、モニタリング装置2は、検出器生成装置1による機械学習を実施済みの検出器5に取得した顔画像を入力することで、運転者Dの顔の器官を検出した結果に対応する出力値を検出器5から取得する。そして、モニタリング装置2は、運転者Dの顔の器官を検出した結果に関する情報を出力する。例えば、モニタリング装置2は、検出した顔の器官の位置に基づいて、視線方向等の運転者Dの状態を推定することができる。そこで、モニタリング装置2は、検出結果に関する情報として、検出結果に基づいて運転者Dの状態を推定した結果を出力してもよい。これにより、モニタリング装置2は、運転者Dの状態を監視することができる。
上記のとおり、検出器5は、ノイズの影響にロバストに構築される。そのため、モニタリング装置2は、この検出器5を利用することで、運転者Dの顔の器官を高精度に検出することができる。したがって、モニタリング装置2は、例えば、運転操作中における運転者Dの視線方向等の状態を精度よく推定することができる。
なお、図2の例では、検出器生成装置1及びモニタリング装置2は別個のコンピュータである。しかしながら、検出システム100の構成は、このような例に限定されなくてもよい。検出器生成装置1及びモニタリング装置2は一体のコンピュータで構成されてもよい。また、検出器生成装置1及びモニタリング装置2はそれぞれ複数台のコンピュータにより構成されてもよい。更に、検出器生成装置1及びモニタリング装置2はネットワークに接続されていなくてもよい。この場合、検出器生成装置1及びモニタリング装置2の間のデータのやりとりは、不揮発メモリ等の記憶媒体を介して行われてもよい。
また、説明の便宜のため、図2では、検出の対象となる顔の器官の一例として、目(詳細には、目尻)を例示している。しかしながら、検出の対象となる顔の器官は、目に限定されなくてもよい。検出の対象となる顔の器官は、例えば、目、鼻、口、眉、顎及びこれらの組み合わせから選択されてよい。また、検出の対象となる器官には、顔の輪郭が含まれてもよい。後述する図5及び図11においても同様である。
§2 構成例
[ハードウェア構成]
<検出器生成装置>
次に、図3を用いて、本実施形態に係る検出器生成装置1のハードウェア構成の一例について説明する。図3は、本実施形態に係る検出器生成装置1のハードウェアの一例を模式的に例示する。
[ハードウェア構成]
<検出器生成装置>
次に、図3を用いて、本実施形態に係る検出器生成装置1のハードウェア構成の一例について説明する。図3は、本実施形態に係る検出器生成装置1のハードウェアの一例を模式的に例示する。
図3に示されるとおり、本実施形態に係る検出器生成装置1は、制御部11、記憶部12、通信インタフェース13、入力装置14、出力装置15、及びドライブ16が電気的に接続されたコンピュータである。なお、図3では、通信インタフェースを「通信I/F」と記載している。
制御部11は、ハードウェアプロセッサであるCPU(Central Processing Unit)、RAM(Random Access Memory)、ROM(Read Only Memory)等を含み、プログラム及び各種データに基づいて情報処理を実行するように構成される。記憶部12は、メモリの一例であり、例えば、ハードディスクドライブ、ソリッドステートドライブ等で構成される。本実施形態では、記憶部12は、検出器生成プログラム81、複数の学習データセット61、学習結果データ121等の各種情報を記憶する。
検出器生成プログラム81は、検出器生成装置1に、後述する機械学習の情報処理(図7、図8A、図8B)を実行させ、学習済みの検出器5を構築させるためのプログラムである。検出器生成プログラム81は、この情報処理の一連の命令を含む。各学習データセット61は、上記第1顔画像611及び位置情報612により構成される。学習結果データ121は、各学習データセット61を利用した機械学習により構築された学習済みの検出器5の設定を行うためのデータである。学習結果データ121は、検出器生成プログラム81の実行結果として生成される。詳細は後述する。
通信インタフェース13は、例えば、有線LAN(Local Area Network)モジュール、無線LANモジュール等であり、ネットワークを介した有線又は無線通信を行うためのインタフェースである。検出器生成装置1は、この通信インタフェース13を利用することで、ネットワークを介したデータ通信を他の情報処理装置(例えば、モニタリング装置2)と行うことができる。
入力装置14は、例えば、マウス、キーボード等の入力を行うための装置である。また、出力装置15は、例えば、ディスプレイ、スピーカ等の出力を行うための装置である。オペレータは、入力装置14及び出力装置15を利用することで、検出器生成装置1を操作することができる。
ドライブ16は、例えば、CDドライブ、DVDドライブ等であり、記憶媒体91に記憶されたプログラムを読み込むためのドライブ装置である。ドライブ16の種類は、記憶媒体91の種類に応じて適宜選択されてよい。上記検出器生成プログラム81及び複数の学習データセット61の少なくともいずれかは、この記憶媒体91に記憶されていてもよい。
記憶媒体91は、コンピュータその他装置、機械等が、記録されたプログラム等の情報を読み取り可能なように、当該プログラム等の情報を、電気的、磁気的、光学的、機械的又は化学的作用によって蓄積する媒体である。検出器生成装置1は、この記憶媒体91から、上記検出器生成プログラム81及び複数の学習データセット61の少なくともいずれかを取得してもよい。
ここで、図3では、記憶媒体91の一例として、CD、DVD等のディスク型の記憶媒体を例示している。しかしながら、記憶媒体91の種類は、ディスク型に限定される訳ではなく、ディスク型以外であってもよい。ディスク型以外の記憶媒体として、例えば、フラッシュメモリ等の半導体メモリを挙げることができる。
なお、検出器生成装置1の具体的なハードウェア構成に関して、実施形態に応じて、適宜、構成要素の省略、置換及び追加が可能である。例えば、制御部11は、複数のハードウェアプロセッサを含んでもよい。ハードウェアプロセッサは、マイクロプロセッサ、FPGA(field-programmable gate array)、DSP(digital signal processor)等で構成されてよい。記憶部12は、制御部11に含まれるRAM及びROMにより構成されてもよい。通信インタフェース13、入力装置14、出力装置15及びドライブ16の少なくともいずれかは省略されてもよい。検出器生成装置1は、カメラ31と接続するための外部インタフェースを更に備えてもよい。この外部インタフェースは、モニタリング装置2の後述する外部インタフェース24と同様に構成されてよい。検出器生成装置1は、複数台のコンピュータで構成されてもよい。この場合、各コンピュータのハードウェア構成は、一致していてもよいし、一致していなくてもよい。また、検出器生成装置1は、提供されるサービス専用に設計された情報処理装置の他、汎用のサーバ装置、PC(Personal Computer)等であってもよい。
<モニタリング装置>
次に、図4を用いて、本実施形態に係るモニタリング装置2のハードウェア構成の一例について説明する。図4は、本実施形態に係るモニタリング装置2のハードウェア構成の一例を模式的に例示する。
次に、図4を用いて、本実施形態に係るモニタリング装置2のハードウェア構成の一例について説明する。図4は、本実施形態に係るモニタリング装置2のハードウェア構成の一例を模式的に例示する。
図4に示されるとおり、本実施形態に係るモニタリング装置2は、制御部21、記憶部22、通信インタフェース23、外部インタフェース24、入力装置25、出力装置26、及びドライブ27が電気的に接続されたコンピュータである。なお、図4では、通信インタフェース及び外部インタフェースをそれぞれ「通信I/F」及び「外部I/F」と記載している。
モニタリング装置2の制御部21~通信インタフェース23及び入力装置25~ドライブ27はそれぞれ、上記検出器生成装置1の制御部11~ドライブ16それぞれと同様に構成されてよい。すなわち、制御部21は、ハードウェアプロセッサであるCPU、RAM、ROM等を含み、プログラム及びデータに基づいて各種情報処理を実行するように構成される。記憶部22は、例えば、ハードディスクドライブ、ソリッドステートドライブ等で構成される。記憶部22は、モニタリングプログラム82、学習結果データ121等の各種情報を記憶する。
モニタリングプログラム82は、学習済みの検出器5を利用して、運転者Dの状態を監視する後述の情報処理(図10)をモニタリング装置2に実行させるためのプログラムである。モニタリングプログラム82は、この情報処理の一連の命令を含む。詳細は後述する。
通信インタフェース23は、例えば、有線LANモジュール、無線LANモジュール等であり、ネットワークを介した有線又は無線通信を行うためのインタフェースである。モニタリング装置2は、この通信インタフェース23を利用することで、ネットワークを介したデータ通信を他の情報処理装置(例えば、検出器生成装置1)と行うことができる。
外部インタフェース24は、例えば、USB(Universal Serial Bus)ポート、専用ポート等であり、外部装置と接続するためのインタフェースである。外部インタフェース24の種類及び数は、接続される外部装置の種類及び数に応じて適宜選択されてよい。本実施形態では、モニタリング装置2は、外部インタフェース24を介して、カメラ41に接続される。
カメラ41は、運転者Dの顔を撮影することで、顔画像を取得するのに利用される。カメラ41の種類及び配置場所は、特に限定されなくてもよく、実施の形態に応じて適宜決定されてよい。カメラ41には、例えば、デジタルカメラ、ビデオカメラ等の公知のカメラが利用されてよい。また、カメラ41は、例えば、少なくとも運転者Dの上半身を撮影範囲とするように、運転席の前方上方に配置されてよい。なお、カメラ41が通信インタフェースを備える場合、モニタリング装置2は、外部インタフェース24ではなく、通信インタフェース23を介して、カメラ41に接続されてもよい。
入力装置25は、例えば、マウス、キーボード等の入力を行うための装置である。また、出力装置26は、例えば、ディスプレイ、スピーカ等の出力を行うための装置である。運転者D等のオペレータは、入力装置25及び出力装置26を利用することで、モニタリング装置2を操作することができる。
ドライブ27は、例えば、CDドライブ、DVDドライブ等であり、記憶媒体92に記憶されたプログラムを読み込むためのドライブ装置である。上記モニタリングプログラム82及び学習結果データ121のうちの少なくともいずれかは、記憶媒体92に記憶されていてもよい。また、モニタリング装置2は、記憶媒体92から、上記モニタリングプログラム82及び学習結果データ121のうちの少なくともいずれかを取得してもよい。
なお、モニタリング装置2の具体的なハードウェア構成に関して、上記検出器生成装置1と同様に、実施の形態に応じて、適宜、構成要素の省略、置換及び追加が可能である。例えば、制御部21は、複数のハードウェアプロセッサを含んでもよい。ハードウェアプロセッサは、マイクロプロセッサ、FPGA、DSP等で構成されてよい。記憶部22は、制御部21に含まれるRAM及びROMにより構成されてもよい。通信インタフェース23、外部インタフェース24、入力装置25、出力装置26及びドライブ27の少なくともいずれかは省略されてもよい。モニタリング装置2は、複数台のコンピュータで構成されてもよい。この場合、各コンピュータのハードウェア構成は、一致していてもよいし、一致していなくてもよい。また、モニタリング装置2は、提供されるサービス専用に設計された情報処理装置の他、汎用のサーバ装置、汎用のデスクトップPC、ノートPC、タブレットPC、スマートフォンを含む携帯電話等が用いられてよい。
[ソフトウェア構成]
<検出器生成装置>
次に、図5を用いて、本実施形態に係る検出器生成装置1のソフトウェア構成の一例について説明する。図5は、本実施形態に係る検出器生成装置1のソフトウェア構成の一例を模式的に例示する。
<検出器生成装置>
次に、図5を用いて、本実施形態に係る検出器生成装置1のソフトウェア構成の一例について説明する。図5は、本実施形態に係る検出器生成装置1のソフトウェア構成の一例を模式的に例示する。
検出器生成装置1の制御部11は、記憶部12に記憶された検出器生成プログラム81をRAMに展開する。そして、制御部11は、RAMに展開された検出器生成プログラム81をCPUにより解釈及び実行して、各構成要素を制御する。これによって、図5に示されるとおり、本実施形態に係る検出器生成装置1は、学習データ取得部111、学習処理部112、及び保存処理部113をソフトウェアモジュールとして備えるコンピュータとして動作する。すなわち、本実施形態では、検出器生成装置1の各ソフトウェアモジュールは、制御部11(CPU)により実現される。
学習データ取得部111は、車両を運転する被験者Tの顔の写る第1顔画像611、及び第1顔画像611に写る顔の器官の位置を示す位置情報612の組み合わせによりそれぞれ構成された複数の学習データセット61を取得する。対象となる器官は、例えば、目、鼻、口、眉、顎及びこれらの組み合わせから選択されてよい。また、対象となる器官には、顔の輪郭が含まれてもよい。
学習処理部112は、複数の学習データセット61を利用して、検出器5の機械学習を実施する。具体的には、機械学習の処理として、学習処理部112は、まず、各学習データセット61の第1顔画像611を検出器5に入力することで、各学習データセット61の第1顔画像611に対する第1出力値を検出器5から取得する。続いて、学習処理部112は、各学習データセット61の第1顔画像611に対して得られた第1出力値に基づいて特定される器官の第1検出位置V1と当該第1顔画像611に組み合わせられた位置情報612により示される位置A1との第1誤差71の合計値を算出する。
また、学習処理部112は、各学習データセット61の第1顔画像611にノイズを付与することで、各学習データセット61の第1顔画像611に対して第2顔画像63を生成する。続いて、学習処理部112は、生成した各第2顔画像63を検出器5に入力することで、各第2顔画像63に対する第2出力値を検出器5から取得する。そして、学習処理部112は、各学習データセット61の第1顔画像611に対して得られた第1出力値に基づいて特定される第1検出位置V1と当該第1顔画像611に対して生成された第2顔画像63に対して得られた第2出力値に基づいて特定される器官の第2検出位置V2との第2誤差72の合計値を算出する。
更に、本実施形態では、学習処理部112は、各学習データセット61の第1顔画像611に所定の幾何変換を適用することで、各学習データセット61の第1顔画像611に対して第3顔画像66を生成する。所定の幾何変換(幾何的な変換)は、例えば、平行移動、回転移動、反転、拡大、縮小又はこれらの組み合わせであってよい。具体例として、所定の幾何変換は、平行移動及び回転移動を伴う変換であってよい。図5の例では、平行移動及び回転移動を伴う変換を第1顔画像611に適用した場面を例示している。続いて、学習処理部112は、生成した各第3顔画像66を検出器5に入力することで、各第3顔画像66に対する第3出力値を検出器5から取得する。そして、学習処理部112は、各学習データセット61の第1顔画像611に対して得られた第1出力値に基づいて特定される第1検出位置と当該第1顔画像611に対して生成された第3顔画像66に対して得られた第3出力値に基づいて特定される器官の第3検出位置との第3誤差73の合計値を算出する。
ここで、第3顔画像66は、第1顔画像611に幾何変換を適用することで得られるため、第3顔画像66の座標軸と第1顔画像611の座標軸とは幾何変換の分だけずれている。そのため、第1顔画像611に対する器官の検出結果と第3顔画像66に対する器官の検出結果とを比較するため、学習処理部112は、第1顔画像611の座標軸と第3顔画像66の座標軸とを一致させる変換処理を実行する。
図5の例では、まず、学習処理部112は、検出器5から取得した第3出力値に基づいて、第3顔画像66の座標軸における器官の第3検出位置V30を特定する。次に、学習処理部112は、特定した検出位置V30に所定の幾何変換の逆変換を適用し、第3顔画像66の座標軸を第1顔画像611の座標軸に一致させて、第1顔画像611の座標軸における第3検出位置V31を特定する。そして、学習処理部112は、第3検出位置V31と第1検出位置V1との差分を第3誤差73として算出し、各学習データセット61についての第3誤差73を足し合わせることで、第3誤差73の合計値を算出する。
しかしながら、第1検出位置と第3検出位置との第3誤差の合計値を算出する方法は、このような例に限定されなくてもよい。学習処理部112は、第1顔画像611の座標軸における第1検出位置V1に所定の逆変換を適用することで、第1顔画像611の座標軸を第3顔画像66の座標軸に一致させてもよい。そして、学習処理部112は、第3顔画像66の座標軸における第1検出位置と第3検出位置V30とを差分を第3誤差73として算出してもよい。
以上の各処理によって、第1誤差71、第2誤差72、及び第3誤差73それぞれの合計値が算出される。学習処理部112は、第1誤差71の合計値、第2誤差72の合計値、及び第3誤差73の合計値が小さくなるように検出器5を訓練する。これにより、学習処理部112は、運転者の顔の器官を検出するための学習済みの検出器5を構築する。
(検出器)
次に、検出器5の構成の一例について説明する。図5に示されるとおり、本実施形態に係る検出器5は、ニューラルネットワークにより構成されている。具体的には、検出器5は、いわゆる深層学習に用いられる多層構造のニューラルネットワークにより構成されており、入力層51、中間層(隠れ層)52、及び出力層53を備えている。
次に、検出器5の構成の一例について説明する。図5に示されるとおり、本実施形態に係る検出器5は、ニューラルネットワークにより構成されている。具体的には、検出器5は、いわゆる深層学習に用いられる多層構造のニューラルネットワークにより構成されており、入力層51、中間層(隠れ層)52、及び出力層53を備えている。
なお、図5の例では、検出器5を構成するニューラルネットワークは、1層の中間層52を備えており、入力層51の出力が中間層52に入力され、中間層52の出力が出力層53に入力されている。ただし、検出器5の構成は、このような例に限定されなくてもよい。中間層52の数は、1層に限られなくてもよい。検出器5は、2層以上の中間層52を備えてもよい。
各層51~53は、1又は複数のニューロンを備えている。例えば、入力層51のニューロンの数は、第1顔画像611の画素数に応じて設定されてよい。中間層52のニューロンの数は、実施の形態に応じて適宜設定されてよい。また、出力層53のニューロンの数は、検出する器官の数、位置表現等に応じて設定されてよい。
隣接する層のニューロン同士は適宜結合され、各結合には重み(結合荷重)が設定されている。図5の例では、各ニューロンは、隣接する層の全てのニューロンと結合されている。しかしながら、ニューロンの結合は、このような例に限定されなくてもよく、実施の形態に応じて適宜設定されてよい。
各ニューロンには閾値が設定されており、基本的には、各入力と各重みとの積の和が閾値を超えているか否かによって各ニューロンの出力が決定される。つまり、これらの各ニューロン間の結合の重み及び各ニューロンの閾値は、演算処理に利用される検出器5のパラメータの一例である。学習処理部112は、各顔画像(611、63、66)を入力層51に入力し、これらのパラメータを利用して、検出器5の演算処理を実行する。
この演算処理の結果、学習処理部112は、各顔画像(611、63、66)に対する器官の検出結果として、出力層53から各出力値を取得する。続いて、学習処理部112は、上記のとおり、取得した各出力値に基づいて、各誤差71~73の合計値を算出する。そして、学習処理部112は、上記訓練処理として、各誤差71~73の合計値が小さくなるように、検出器5のパラメータを調節する。これにより、運転者の顔の器官を検出するための学習済みの検出器5が構築される。
保存処理部113は、構築された学習済みの検出器5の構成(例えば、ニューラルネットワークの層数、各層におけるニューロンの個数、ニューロン同士の結合関係、各ニューロンの伝達関数)、及び演算パラメータ(例えば、各ニューロン間の結合の重み、各ニューロンの閾値)を示す情報を学習結果データ121として記憶部12に保存する。
<モニタリング装置>
次に、図6を用いて、本実施形態に係るモニタリング装置2のソフトウェア構成の一例について説明する。図6は、本実施形態に係るモニタリング装置2のソフトウェア構成の一例を模式的に例示する。
次に、図6を用いて、本実施形態に係るモニタリング装置2のソフトウェア構成の一例について説明する。図6は、本実施形態に係るモニタリング装置2のソフトウェア構成の一例を模式的に例示する。
モニタリング装置2の制御部21は、記憶部22に記憶されたモニタリングプログラム82をRAMに展開する。そして、制御部21は、RAMに展開されたモニタリングプログラム82をCPUにより解釈及び実行して、各構成要素を制御する。これによって、図6に示されるとおり、本実施形態に係るモニタリング装置2は、データ取得部211、検出部212、及び出力部213をソフトウェアモジュールとして備えるコンピュータとして動作する。すなわち、本実施形態では、モニタリング装置2の各ソフトウェアモジュールも、上記検出器生成装置1と同様に、制御部21(CPU)により実現される。
データ取得部211は、車両を運転する運転者Dの顔の写る顔画像221を取得する。例えば、データ取得部211は、カメラ41により運転者Dの顔を撮影することで、顔画像221を取得する。検出部212は、学習結果データ121を保持することで、学習済みの検出器5を含んでいる。具体的には、検出部212は、学習結果データ121を参照し、学習済みの検出器5の設定を行う。そして、検出部212は、取得された顔画像221を検出器5に入力することで、運転者Dの顔の器官を顔画像221より検出した結果に対応する出力値を検出器5から取得する。出力部213は、運転者Dの顔の器官を検出した結果に関する情報を出力する。
<その他>
検出器生成装置1及びモニタリング装置2の各ソフトウェアモジュールに関しては後述する動作例で詳細に説明する。なお、本実施形態では、検出器生成装置1及びモニタリング装置2の各ソフトウェアモジュールがいずれも汎用のCPUによって実現される例について説明している。しかしながら、以上のソフトウェアモジュールの一部又は全部が、1又は複数の専用のプロセッサにより実現されてもよい。また、検出器生成装置1及びモニタリング装置2それぞれのソフトウェア構成に関して、実施形態に応じて、適宜、ソフトウェアモジュールの省略、置換及び追加が行われてもよい。
検出器生成装置1及びモニタリング装置2の各ソフトウェアモジュールに関しては後述する動作例で詳細に説明する。なお、本実施形態では、検出器生成装置1及びモニタリング装置2の各ソフトウェアモジュールがいずれも汎用のCPUによって実現される例について説明している。しかしながら、以上のソフトウェアモジュールの一部又は全部が、1又は複数の専用のプロセッサにより実現されてもよい。また、検出器生成装置1及びモニタリング装置2それぞれのソフトウェア構成に関して、実施形態に応じて、適宜、ソフトウェアモジュールの省略、置換及び追加が行われてもよい。
§3 動作例
[検出器生成装置]
次に、図7を用いて、検出器生成装置1の動作例について説明する。図7は、本実施形態に係る検出器生成装置1の処理手順の一例を示すフローチャートである。以下で説明する処理手順は、本発明の「検出器生成方法」の一例である。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である
。
[検出器生成装置]
次に、図7を用いて、検出器生成装置1の動作例について説明する。図7は、本実施形態に係る検出器生成装置1の処理手順の一例を示すフローチャートである。以下で説明する処理手順は、本発明の「検出器生成方法」の一例である。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である
。
(ステップS101)
ステップS101では、制御部11は、学習データ取得部111として動作し、第1顔画像611及び位置情報612の組み合わせによりそれぞれ構成された複数の学習データセット61を取得する。
ステップS101では、制御部11は、学習データ取得部111として動作し、第1顔画像611及び位置情報612の組み合わせによりそれぞれ構成された複数の学習データセット61を取得する。
複数件の学習データセット61を取得する方法は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、カメラ31を搭載した車両及び被験者Tを用意し、車両を運転する被験者Tをカメラにより様々な条件で撮影することで、被験者Tの顔の写る複数の第1顔画像611を取得することができる。用意する車両及び被験者Tの数は、実施の形態に応じて適宜決定されてよい。そして、得られた各第1顔画像611に対して、各第1顔画像611に写る対象の器官の位置を示す位置情報612を組み合わせることで、各学習データセット61を生成することができる。対象の器官は、例えば、目、鼻、口、眉、顎及びこれらの組み合わせから選択されてよい。また、対象の器官には、顔の輪郭が含まれてもよい。
この各学習データセット61は、自動的に生成されてもよいし、手動的に生成されてもよい。また、各学習データセット61の生成は、検出器生成装置1により行われてもよいし、検出器生成装置1以外の他のコンピュータにより行われてもよい。
各学習データセット61が検出器生成装置1により生成される場合、制御部11は、外部インタフェース、ネットワーク、記憶媒体91等を介して、各第1顔画像611をカメラ31から取得する。次に、制御部11は、各第1顔画像611に付与する位置情報612を生成する。位置情報612を手動的に生成する場合、制御部11は、オペレータによる入力装置14を介する器官の位置の指定を受け付ける。続いて、制御部11は、オペレータによる入力装置14の操作に応じて、指定された器官の位置を示す位置情報612を生成する。他方、位置情報612を自動的に生成する場合、制御部11は、各第1顔画像611から対象の器官の位置を検出する。この検出には、エッジ検出、パターンマッチング等の公知の画像処理方法が用いられてもよいし、後述する暫定的に生成された検出器が用いられてもよい。続いて、制御部11は、検出された器官の位置を示す位置情報612を生成する。そして、制御部11は、生成した位置情報612を第1顔画像611に組み合わせることで、各学習データセット61を生成する。これにより、制御部11は、複数の学習データセット61を取得してもよい。
一方、各学習データセット61が他のコンピュータにより生成される場合、本ステップS101では、制御部11は、ネットワーク、記憶媒体91等を介して、他のコンピュータにより生成された複数の学習データセット61を取得してもよい。他のコンピュータでは、上記検出器生成装置1と同様の方法で、各学習データセット61が生成されてよい。
なお、第1顔画像611及び位置情報612のデータ形式は、実施の形態に応じて適宜選択されてよい。位置情報612は、座標値等により器官の位置を点で示してもよいし、器官の位置を領域で示してもよい。また、取得する学習データセット61の件数は、特に限定されなくてもよく、検出器5の機械学習を実施可能な程度に適宜決定されてよい。複数の学習データセット61を取得すると、制御部11は、次のステップS102に処理を進める。
(ステップS102)
ステップS102では、制御部11は、学習処理部112として動作し、ステップS101により取得した複数の学習データセット61を利用して、検出器5の機械学習を実施する。機械学習の処理手順は後述する。これにより、学習済みの検出器5を構築すると、制御部11は、次のステップS103に処理を進める。
ステップS102では、制御部11は、学習処理部112として動作し、ステップS101により取得した複数の学習データセット61を利用して、検出器5の機械学習を実施する。機械学習の処理手順は後述する。これにより、学習済みの検出器5を構築すると、制御部11は、次のステップS103に処理を進める。
(ステップS103)
ステップS103では、制御部11は、保存処理部113として動作し、機械学習により構築された検出器5の構成及び演算パラメータを示す情報を学習結果データ121として生成する。そして、制御部11は、生成した学習結果データ121を記憶部12に保存する。これにより、制御部11は、本動作例に係る処理を終了する。
ステップS103では、制御部11は、保存処理部113として動作し、機械学習により構築された検出器5の構成及び演算パラメータを示す情報を学習結果データ121として生成する。そして、制御部11は、生成した学習結果データ121を記憶部12に保存する。これにより、制御部11は、本動作例に係る処理を終了する。
なお、学習結果データ121の保存先は、記憶部12に限られなくてもよい。制御部11は、例えば、NAS(Network Attached Storage)等のデータサーバに学習結果データ121を格納してもよい。また、学習済みの検出器5を構築した後、制御部11は、生成した学習結果データ121を任意のタイミングでモニタリング装置2に転送してもよい。
モニタリング装置2は、検出器生成装置1から転送を受け付けることで学習結果データ121を取得してもよいし、検出器生成装置1又はデータサーバにアクセスすることで学習結果データ121を取得してもよい。また、学習結果データ121は、モニタリング装置2に予め組み込まれてもよい。
<機械学習の処理>
次に、図8A及び図8Bを用いて、上記ステップS102の処理の一例を詳細に説明する。図8A及び図8Bは、本実施形態に係る検出器生成装置1による機械学習の処理手順の一例を示すフローチャートである。本実施形態に係るステップS102の処理は、以下のステップS201~S210の処理を含む。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
次に、図8A及び図8Bを用いて、上記ステップS102の処理の一例を詳細に説明する。図8A及び図8Bは、本実施形態に係る検出器生成装置1による機械学習の処理手順の一例を示すフローチャートである。本実施形態に係るステップS102の処理は、以下のステップS201~S210の処理を含む。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
ステップS201の処理を開始する前に、制御部11は、機械学習を実施する対象となるニューラルネットワーク(学習前の検出器5)を用意する。用意するニューラルネットワークの構成及び各パラメータは、テンプレートにより与えられてもよいし、オペレータの入力により与えられてもよい。また、再学習を実施する場合には、制御部11は、再学習の対象となる学習結果データ121に基づいて、ニューラルネットワークを用意してもよい。これにより、学習前の検出器5の用意が完了すると、制御部11は、ステップS201の処理を開始する。
(ステップS201)
ステップS201では、制御部11は、各学習データセット61の第1顔画像611を検出器5に入力し、検出器5の演算処理を実行する。具体的には、制御部11は、各第1顔画像611を検出器5の入力層51に入力し、入力側から順に各層51~53に含まれる各ニューロンの発火判定を行う。これにより、制御部11は、各第1顔画像611に対する第1出力値を出力層53から取得する。各第1出力値は、現段階における検出器5が各第1顔画像611から器官の位置を検出した結果に対応する。各第1出力値を取得すると、制御部11は、次のステップS202に処理を進める。
ステップS201では、制御部11は、各学習データセット61の第1顔画像611を検出器5に入力し、検出器5の演算処理を実行する。具体的には、制御部11は、各第1顔画像611を検出器5の入力層51に入力し、入力側から順に各層51~53に含まれる各ニューロンの発火判定を行う。これにより、制御部11は、各第1顔画像611に対する第1出力値を出力層53から取得する。各第1出力値は、現段階における検出器5が各第1顔画像611から器官の位置を検出した結果に対応する。各第1出力値を取得すると、制御部11は、次のステップS202に処理を進める。
なお、検出器5の出力値は、器官を検出した位置を示し得るものであれば、検出器5の出力値の形式は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、検出器5の出力値は、座標値等のように、器官の位置を直接的に示すものであってもよい。また、例えば、検出器5の出力値は器官の位置を間接的に示し、検出器5の出力値に何らかの演算処理を適用することにより、器官の位置を示す情報が得られてもよい。いずれの形式であっても、検出器5の出力値は同様に取り扱うことができる。そのため、以下では、説明の便宜上、検出器5の出力値は、器官の位置を直接示すものとして取り扱うことにする。
(ステップS202)
ステップS202では、制御部11は、各第1出力値に基づいて特定される器官の第1検出位置V1と対応する位置情報612により示される位置A1との第1誤差71の合計値を算出する。具体的には、制御部11は、各学習データセット61について、各第1顔画像611に対して得られた第1検出位置V1と対応する位置情報612により示される位置A1との差分を第1誤差71として算出する。そして、制御部11は、算出した各第1誤差71を足し合わせることで、第1誤差71の合計値を算出する。
ステップS202では、制御部11は、各第1出力値に基づいて特定される器官の第1検出位置V1と対応する位置情報612により示される位置A1との第1誤差71の合計値を算出する。具体的には、制御部11は、各学習データセット61について、各第1顔画像611に対して得られた第1検出位置V1と対応する位置情報612により示される位置A1との差分を第1誤差71として算出する。そして、制御部11は、算出した各第1誤差71を足し合わせることで、第1誤差71の合計値を算出する。
なお、第1検出位置V1と位置A1との差分は、器官の位置を指定する形式に応じて適宜算出されてよい。例えば、器官の位置が点で指定される場合、制御部11は、第1検出位置V1と位置A1との間の距離(ノルム)を差分として算出してもよい。また、例えば、器官の位置が領域で指定される場合、制御部11は、IoU(Intersection Over Union)等の指標を利用して、第1検出位置V1と位置A1との差分を算出してもよい。第1誤差71の合計値を算出すると、制御部11は、次のステップS203に処理を進める。
(ステップS203)
ステップS203では、制御部11は、各学習データセット61の第1顔画像611にノイズを付与することで、各第2顔画像63を生成する。各第1顔画像611に付与するノイズの種類は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。ノイズには、例えば、ガウシアンノイズ、ポアソンノイズ、一様乱数によるノイズ等が用いられてよい。例えば、制御部11は、ランダムなガウシアンノイズを各第1顔画像611に付与してもよい。また、例えば、制御部11は、局所平均フィルタ等のフィルタを各第1顔画像611に適用することで、各第1顔画像611にノイズを付与してもよい。各第1顔画像611に付与するノイズの種類は、同じであってもよいし、異なっていてもよい。また、例えば、制御部11は、敵対的な例(Adversarial example)を形成するように、検出器5による検出が変化しやすい位置にノイズを付与してもよい。検出が変化しやすいか否かは、例えば、ノイズを付与したことによる検出位置の変化量と閾値との比較に基づいて判定することができる。各第2顔画像63を生成すると、制御部11は、次のステップS204に処理を進める。
ステップS203では、制御部11は、各学習データセット61の第1顔画像611にノイズを付与することで、各第2顔画像63を生成する。各第1顔画像611に付与するノイズの種類は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。ノイズには、例えば、ガウシアンノイズ、ポアソンノイズ、一様乱数によるノイズ等が用いられてよい。例えば、制御部11は、ランダムなガウシアンノイズを各第1顔画像611に付与してもよい。また、例えば、制御部11は、局所平均フィルタ等のフィルタを各第1顔画像611に適用することで、各第1顔画像611にノイズを付与してもよい。各第1顔画像611に付与するノイズの種類は、同じであってもよいし、異なっていてもよい。また、例えば、制御部11は、敵対的な例(Adversarial example)を形成するように、検出器5による検出が変化しやすい位置にノイズを付与してもよい。検出が変化しやすいか否かは、例えば、ノイズを付与したことによる検出位置の変化量と閾値との比較に基づいて判定することができる。各第2顔画像63を生成すると、制御部11は、次のステップS204に処理を進める。
(ステップS204)
ステップS204では、制御部11は、生成した各第2顔画像63を検出器5に入力し、検出器5の演算処理を実行する。この検出器5の演算処理は、上記ステップS201と同様であってよい。これにより、制御部11は、各第2顔画像63に対する第2出力値を検出器5の出力層53から取得する。各第2出力値は、現段階における検出器5が各第2顔画像63から器官の位置を検出した結果に対応する。各第2出力値を取得すると、制御部11は、次のステップS205に処理を進める。
ステップS204では、制御部11は、生成した各第2顔画像63を検出器5に入力し、検出器5の演算処理を実行する。この検出器5の演算処理は、上記ステップS201と同様であってよい。これにより、制御部11は、各第2顔画像63に対する第2出力値を検出器5の出力層53から取得する。各第2出力値は、現段階における検出器5が各第2顔画像63から器官の位置を検出した結果に対応する。各第2出力値を取得すると、制御部11は、次のステップS205に処理を進める。
(ステップS205)
ステップS205では、制御部11は、各第1出力値に基づいて特定される器官の第1検出位置V1と対応する第2顔画像63に対して得られた第2出力値に基づいて特定される器官の第2検出位置V2との第2誤差72の合計値を算出する。具体的には、制御部11は、各学習データセット61について、各第1顔画像611に対して得られた第1検出位置V1と対応する第2顔画像63に対して得られた第2検出位置V2との差分を第2誤差72として算出する。この差分を算出する方法は、上記ステップS202と同様であってよい。そして、制御部11は、算出した各第2誤差72を足し合わせることで、第2誤差72の合計値を算出する。第2誤差72の合計値を算出すると、制御部11は、次のステップS206に処理を進める。
ステップS205では、制御部11は、各第1出力値に基づいて特定される器官の第1検出位置V1と対応する第2顔画像63に対して得られた第2出力値に基づいて特定される器官の第2検出位置V2との第2誤差72の合計値を算出する。具体的には、制御部11は、各学習データセット61について、各第1顔画像611に対して得られた第1検出位置V1と対応する第2顔画像63に対して得られた第2検出位置V2との差分を第2誤差72として算出する。この差分を算出する方法は、上記ステップS202と同様であってよい。そして、制御部11は、算出した各第2誤差72を足し合わせることで、第2誤差72の合計値を算出する。第2誤差72の合計値を算出すると、制御部11は、次のステップS206に処理を進める。
(ステップS206)
ステップS206では、制御部11は、各学習データセット61の第1顔画像611に所定の幾何変換を適用することで、各第3顔画像66を生成する。各第1顔画像611に適用する幾何変換は、例えば、平行移動、回転移動、反転、拡大、縮小又はこれらの組み合わせであってよい。具体例として、各第1顔画像611に適用する幾何変換は、平行移動及び回転移動を伴う変換であってよい。各第3顔画像66に適用する幾何変換は、同じであってもよいし、異なっていてもよい。制御部11は、幾何変換のパラメータをランダムに変更しながら、各第3顔画像66を生成してもよい。幾何変換のパラメータは、例えば、各変換量(平行移動量、回転量等)である。各第3顔画像66を生成すると、制御部11は、次のステップS207に処理を進める。
ステップS206では、制御部11は、各学習データセット61の第1顔画像611に所定の幾何変換を適用することで、各第3顔画像66を生成する。各第1顔画像611に適用する幾何変換は、例えば、平行移動、回転移動、反転、拡大、縮小又はこれらの組み合わせであってよい。具体例として、各第1顔画像611に適用する幾何変換は、平行移動及び回転移動を伴う変換であってよい。各第3顔画像66に適用する幾何変換は、同じであってもよいし、異なっていてもよい。制御部11は、幾何変換のパラメータをランダムに変更しながら、各第3顔画像66を生成してもよい。幾何変換のパラメータは、例えば、各変換量(平行移動量、回転量等)である。各第3顔画像66を生成すると、制御部11は、次のステップS207に処理を進める。
(ステップS207)
ステップS207では、制御部11は、生成した各第3顔画像66を検出器5に入力し、検出器5の演算処理を実行する。この検出器5の演算処理は、上記ステップS201と同様であってよい。これにより、制御部11は、各第3顔画像66に対する第3出力値を検出器5の出力層53から取得する。各第3出力値は、現段階における検出器5が各第3顔画像66から器官の位置を検出した結果に対応する。各第3出力値を取得すると、制御部11は、次のステップS208に処理を進める。
ステップS207では、制御部11は、生成した各第3顔画像66を検出器5に入力し、検出器5の演算処理を実行する。この検出器5の演算処理は、上記ステップS201と同様であってよい。これにより、制御部11は、各第3顔画像66に対する第3出力値を検出器5の出力層53から取得する。各第3出力値は、現段階における検出器5が各第3顔画像66から器官の位置を検出した結果に対応する。各第3出力値を取得すると、制御部11は、次のステップS208に処理を進める。
(ステップS208)
ステップS208では、制御部11は、各第1出力値に基づいて特定される器官の第1検出位置と対応する第3顔画像66に対して得られた第3出力値に基づいて特定される器官の第3検出位置との第3誤差73の合計値を算出する。具体的には、制御部11は、各第1顔画像611に対して得られた第3出力値から導出される第3検出位置V30に幾何変換の逆変換を適用して、第3検出位置V31を算出する。そして、制御部11は、各学習データセット61について、各第1顔画像611に対して得られた第1検出位置V1と対応する第3顔画像66に対して得られた第3検出位置V31との差分を第3誤差73として算出する。この差分を算出する方法は、上記ステップS202と同様であってよい。また、上記のとおり、制御部11は、第1検出位置V1に幾何変換を適用することで導出される位置と第3検出位置V30との差分を第3誤差73として算出してもよい。そして、制御部11は、算出した各第3誤差73を足し合わせることで、第3誤差73の合計値を算出する。第3誤差73の合計値を算出すると、制御部11は、次のステップS209に処理を進める。
ステップS208では、制御部11は、各第1出力値に基づいて特定される器官の第1検出位置と対応する第3顔画像66に対して得られた第3出力値に基づいて特定される器官の第3検出位置との第3誤差73の合計値を算出する。具体的には、制御部11は、各第1顔画像611に対して得られた第3出力値から導出される第3検出位置V30に幾何変換の逆変換を適用して、第3検出位置V31を算出する。そして、制御部11は、各学習データセット61について、各第1顔画像611に対して得られた第1検出位置V1と対応する第3顔画像66に対して得られた第3検出位置V31との差分を第3誤差73として算出する。この差分を算出する方法は、上記ステップS202と同様であってよい。また、上記のとおり、制御部11は、第1検出位置V1に幾何変換を適用することで導出される位置と第3検出位置V30との差分を第3誤差73として算出してもよい。そして、制御部11は、算出した各第3誤差73を足し合わせることで、第3誤差73の合計値を算出する。第3誤差73の合計値を算出すると、制御部11は、次のステップS209に処理を進める。
(ステップS209)
ステップS209では、制御部11は、算出した各誤差71~73の合計値が閾値以下であるか否かを判定する。閾値は、顔画像から器官を適切に検出するように検出器5が十分に訓練されたか否かを判定するための基準となる。この閾値は、適宜設定されてよい。
ステップS209では、制御部11は、算出した各誤差71~73の合計値が閾値以下であるか否かを判定する。閾値は、顔画像から器官を適切に検出するように検出器5が十分に訓練されたか否かを判定するための基準となる。この閾値は、適宜設定されてよい。
各誤差71~73の合計値が閾値以下であることは、換言すると、各誤差71~73の合計値が十分に小さいことは、顔画像から器官を適切に検出可能に検出器5が十分に訓練されたことを示す。そのため、各誤差71~73の合計値が閾値以下であると判定した場合には、制御部11は、本動作例に係る機械学習の処理を終了し(すなわち、ステップS102の処理を完了し)、上記ステップS103に処理を進める。
一方、各誤差71~73の合計値が閾値を超えていることは、換言すると、各誤差71~73の合計値が大きいことは、検出器5がまだ十分には訓練されていないことを示す。そのため、各誤差71~73の合計値が閾値を超えていると判定した場合には、制御部11は、次のステップS210に処理を進める。
(ステップS210)
ステップS210では、制御部11は、各誤差71~73の合計値が小さくなるように検出器5の訓練を行う。具体的には、制御部11は、各誤差71~73の合計値が小さくなるように、検出器5のパラメータを調整する。このパラメータの調整には、誤差逆伝播法等の公知の方法が採用されてよい。すなわち、制御部11は、各誤差71~73の合計値を利用して、出力層53側から順に、各ニューロン間の結合の重み、各ニューロンの閾値等の各パラメータの誤差を算出する。そして、制御部11は、算出した誤差に基づいて、各パラメータの値を更新する。各パラメータの更新幅を定める学習率は、適宜設定されてよい。
ステップS210では、制御部11は、各誤差71~73の合計値が小さくなるように検出器5の訓練を行う。具体的には、制御部11は、各誤差71~73の合計値が小さくなるように、検出器5のパラメータを調整する。このパラメータの調整には、誤差逆伝播法等の公知の方法が採用されてよい。すなわち、制御部11は、各誤差71~73の合計値を利用して、出力層53側から順に、各ニューロン間の結合の重み、各ニューロンの閾値等の各パラメータの誤差を算出する。そして、制御部11は、算出した誤差に基づいて、各パラメータの値を更新する。各パラメータの更新幅を定める学習率は、適宜設定されてよい。
各層51~53のパラメータの値の更新が完了すると、制御部11は、ステップS201から処理を繰り返す。制御部11は、ステップS201~S210の処理を繰り返すことで、各誤差71~73の合計値が十分に小さくなるように、検出器5のパラメータを最適化する。なお、学習時間を短縮化するために、このパラメータの最適化には、確率的勾配降下法等の公知の方法が採用されてもよい。これにより、検出器5は、各誤差71~73の合計値が小さくなるように訓練される。すなわち、ステップS209において、各誤差71~73の合計値が閾値以下であると判定されるようになり、本動作例に係る機械学習の処理が完了する。
なお、上記処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。例えば、ステップS202の処理がステップS201の後に実行され、ステップS204の処理がステップS203の後に実行され、ステップS205の処理がステップS201及びS204の後に実行され、ステップS207の処理がステップS206の後に実行され、ステップS208の処理がステップS201及びS207の後に実行されるのであれば、ステップS201~S208の処理の順序は適宜入れ替えられてよい。
<繰り返し学習>
検出器生成装置1は、上記ステップS101~S103の処理を繰り返してもよい。この繰り返しの過程で、暫定的に生成される検出器5を利用して、各学習データセット61に含まれる位置情報612を更新してもよい。すなわち、検出器生成装置1は、ステップS102により、各学習データセット61を利用して学習済みの検出器5を生成した後、生成された学習済みの検出器5に各第1顔画像611を入力し、各第1顔画像611から器官の位置を検出してもよい。そして、検出器生成装置1は、元の位置(すなわち、学習済みの検出器5を生成する際に位置情報612により示されていた位置)から学習済みの検出器5により検出された位置を示すように、各学習データセット61の位置情報612を更新してもよい。
検出器生成装置1は、上記ステップS101~S103の処理を繰り返してもよい。この繰り返しの過程で、暫定的に生成される検出器5を利用して、各学習データセット61に含まれる位置情報612を更新してもよい。すなわち、検出器生成装置1は、ステップS102により、各学習データセット61を利用して学習済みの検出器5を生成した後、生成された学習済みの検出器5に各第1顔画像611を入力し、各第1顔画像611から器官の位置を検出してもよい。そして、検出器生成装置1は、元の位置(すなわち、学習済みの検出器5を生成する際に位置情報612により示されていた位置)から学習済みの検出器5により検出された位置を示すように、各学習データセット61の位置情報612を更新してもよい。
図9を用いて、この繰り返し学習について詳細に説明する。図9は、機械学習を繰り返し実施する場面の一例を模式的に例示する。図9に示されるとおり、ステップS101~S103を最初に実施する際に、ステップS101により、制御部11は、第1顔画像611及び位置情報622aによりそれぞれ構成された複数の学習データセット62aを取得したと想定する。位置情報622aは、上記のとおり、オペレータの指定により与えられてもよいし、公知の画像処理方法により与えられてもよいし、他の検出器から得られる出力値に基づいて与えられてもよい。
1回目の学習処理では、制御部11は、得られた各学習データセット62aを利用して、ステップS102の機械学習の処理を実行する。これにより、制御部11は、各学習データセット62aを与えられると、位置情報622aにより示される正解と一致するように第1顔画像611から器官を検出するように訓練された学習済みの検出器50aを暫定的に生成する。制御部11は、ステップS103の処理を実行することで、この暫定的に生成した学習済みの検出器50aの学習結果データを所定の記憶領域に保存してもよい。学習済みの検出器50aが生成されることで、1回目の学習処理は終了である。
2回目の学習処理では、制御部11は、暫定的に生成された学習済みの検出器50aを利用して、各学習データセット62aの位置情報622aを更新する。すなわち、制御部11は、1回目の学習処理で生成された学習済みの検出器50aに各第1顔画像611を入力し、検出器50aの演算処理を実行する。これにより、制御部11は、各第1顔画像611より器官の位置を検出した結果に対応する出力値を学習済みの検出器50aから取得する。
制御部11は、得られた各出力値に基づいて、学習済みの検出器50aによって各第1顔画像611から対象の器官を検出した位置を特定する。そして、制御部11は、各学習データセット62aについて、特定した検出位置を示す位置情報622bを生成し、生成した位置情報622bに位置情報622aを置き換える。これにより、ステップS101では、制御部11は、第1顔画像611及び位置情報622bの組み合わせにより構成された新たな各学習データセット62bを取得する。
つまり、2回目の学習処理では、位置情報622bは、位置情報622bに組み合わせられる第1顔画像611を、機械学習を実施済みの検出器50aに入力することで、当該検出器50aから得られる出力値に基づいて与えられる。この2回目の学習処理の場面では、学習済みの検出器50aは、本発明の「他の検出器」及び「第1検出器」の一例である。各学習データセット62aは、「第1学習データセット」の一例である。各学習データセット62bは、「第2学習データセット」の一例である。
2回目の学習処理では、制御部11は、この各学習データセット62bを利用して、ステップS102の機械学習の処理を実行する。これにより、制御部11は、各学習データセット62bを与えられると、位置情報622bにより示される正解と一致するように第1顔画像611から器官を検出するように訓練された学習済みの検出器50bを生成する。1回目の学習処理と同様に、制御部11は、ステップS103の処理を実行することで、この生成した学習済みの検出器50bの学習結果データを所定の記憶領域に保存してもよい。学習済みの検出器50bが生成されることで、2回目の学習処理は終了する。
以上のように、検出器生成装置1は、各学習データセットを利用した機械学習により学習済みの検出器を生成する処理、及び生成された学習済みの検出器を利用して位置情報を更新する処理を交互に繰り返し実行してもよい。検出器生成装置1が、検出器を生成する処理及び位置情報を更新する処理を交互に繰り返し実行した場合、最終的に取得される各学習データセットが上記各学習データセット61に対応し、最終的に生成される学習済みの検出器が上記学習済みの検出器5に対応する。位置情報612は、最終の1回前の学習処理により生成された学習済みの検出器に第1顔画像611を入力することで、当該学習済みの検出器から得られる出力値に基づいて与えられる。
この検出器の生成処理及び位置情報の更新処理の繰り返しにより、暫定的に生成された検出器による検出結果を位置情報612として利用するため、人為的なノイズが位置情報612に含まれるのを防止することができる。また、初期段階における位置情報622aが、オペレータの入力により与えられることで人為的なノイズを含んでいたとしても、この繰り返しの過程において、暫定的に生成された検出器を利用した位置情報の更新により、位置情報に含まれる人為的なノイズを低減することができる。そのため、位置情報622aに含まれ得る人為的なノイズによる影響にロバストで、対象者の顔の器官を顔画像から検出可能な検出器5を構築することができる。なお、図9では、機械学習の処理を3回以上繰り返す場面を例示している。しかしながら、機械学習の処理を繰り返す回数は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。繰り返しの回数は、2回であってもよい。
[モニタリング装置]
次に、図10を用いて、モニタリング装置2の動作例について説明する。図10は、本実施形態に係るモニタリング装置2の処理手順の一例を示すフローチャートである。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
次に、図10を用いて、モニタリング装置2の動作例について説明する。図10は、本実施形態に係るモニタリング装置2の処理手順の一例を示すフローチャートである。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
(ステップS301)
ステップS301では、制御部21は、データ取得部211として動作し、車両を運転する運転者Dの顔の写る顔画像221を取得する。本実施形態では、モニタリング装置2は、外部インタフェース24を介してカメラ41に接続されている。そのため、制御部21は、カメラ41から顔画像221を取得する。この顔画像221は、動画像データであってもよいし、静止画像データであってもよい。顔画像221を取得すると、制御部21は、次のステップS302に処理を進める。
ステップS301では、制御部21は、データ取得部211として動作し、車両を運転する運転者Dの顔の写る顔画像221を取得する。本実施形態では、モニタリング装置2は、外部インタフェース24を介してカメラ41に接続されている。そのため、制御部21は、カメラ41から顔画像221を取得する。この顔画像221は、動画像データであってもよいし、静止画像データであってもよい。顔画像221を取得すると、制御部21は、次のステップS302に処理を進める。
ただし、顔画像221を取得する経路は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、モニタリング装置2とは異なる他のコンピュータが、カメラ41に接続されていてもよい。この場合、制御部21は、他のコンピュータから顔画像221の送信を受け付けることで、顔画像221を取得してもよい。
(ステップS302)
ステップS302では、制御部21は、検出部212として動作し、学習結果データ121を参照して、学習済みの検出器5の設定を行う。続いて、制御部21は、取得した顔画像221を学習済みの検出器5に入力し、検出器5の演算処理を実行する。この検出器5の演算処理は、上記ステップS201と同様であってよい。これにより、制御部21は、運転者Dの顔の器官を顔画像221より検出した結果に対応する出力値を検出器5から取得する。出力値を取得すると、制御部21は、次のステップS303に処理を進める。
ステップS302では、制御部21は、検出部212として動作し、学習結果データ121を参照して、学習済みの検出器5の設定を行う。続いて、制御部21は、取得した顔画像221を学習済みの検出器5に入力し、検出器5の演算処理を実行する。この検出器5の演算処理は、上記ステップS201と同様であってよい。これにより、制御部21は、運転者Dの顔の器官を顔画像221より検出した結果に対応する出力値を検出器5から取得する。出力値を取得すると、制御部21は、次のステップS303に処理を進める。
(ステップS303)
ステップS303では、制御部21は、出力部213として動作し、運転者Dの顔の器官を検出した結果に関する情報を出力する。出力先及び出力する情報の内容はそれぞれ、実施の形態に応じて適宜決定されてよい。例えば、制御部21は、ステップS302により運転者Dの顔の器官を顔画像221から検出した結果をそのまま出力装置26を介して出力してもよい。
ステップS303では、制御部21は、出力部213として動作し、運転者Dの顔の器官を検出した結果に関する情報を出力する。出力先及び出力する情報の内容はそれぞれ、実施の形態に応じて適宜決定されてよい。例えば、制御部21は、ステップS302により運転者Dの顔の器官を顔画像221から検出した結果をそのまま出力装置26を介して出力してもよい。
また、例えば、制御部21は、運転者Dの顔の器官を顔画像221から検出した結果に基づいて、運転者Dの状態を推定する等の何らかの情報処理を実行してもよい。そして、制御部21は、その情報処理を実行した結果を出力してもよい。顔の器官として目を検出した場合、情報処理の一例として、制御部21は、検出した各目の位置関係に基づいて、運転者Dの視線方向を推定してもよい。そして、制御部21は、視線方向を推定した結果に関連する情報を出力してもよい。例えば、視線方向が車両の前方を向いていない場合に、制御部21は、出力装置26を介して、視線方向を前方に向けるように促す警告を出力してもよい。また、情報処理の他の例として、制御部21は、検出した各器官の位置関係に基づいて、運転者Dの表情を推定してもよい。そして、制御部21は、表情を推定した結果に関連する情報を出力してもよい。例えば、運転者Dの表情が疲れている場合に、制御部21は、出力装置26を介して、停車を促すメッセージを出力してもよい。
情報の出力が完了すると、制御部21は、本動作例に係る処理を終了する。なお、運転者Dが車両の運転操作を行っている間、制御部21は、ステップS301~S303の一連の処理を継続的に繰り返し実行してもよい。これにより、モニタリング装置2は、運転者Dの顔の器官の位置を顔画像から検出することを介して、当該運転者Dの状態を監視することができる。
[特徴]
以上のように、本実施形態に係る検出器生成装置1は、上記ステップS201~S210の処理により、各誤差71~73の合計値が小さくなるように検出器5を訓練する。各誤差71~73のうち第1誤差71の合計値は、検出器5により第1顔画像611から器官を検出した結果と位置情報612により指定される器官の位置の正解との間の損失に相当する。また、第2誤差72の合計値は、検出器5による器官の検出結果のブレであって、第1顔画像611におけるノイズの有無によって生じるブレの損失に相当する。そのため、検出器生成装置1は、上記ステップS201~S210の機械学習の処理により、位置情報612により示される正解と一致するように第1顔画像611から器官を検出し、かつその検出結果がノイズによる影響を受け難い、ように訓練された(学習済みの)検出器5を構築(生成)することができる。
以上のように、本実施形態に係る検出器生成装置1は、上記ステップS201~S210の処理により、各誤差71~73の合計値が小さくなるように検出器5を訓練する。各誤差71~73のうち第1誤差71の合計値は、検出器5により第1顔画像611から器官を検出した結果と位置情報612により指定される器官の位置の正解との間の損失に相当する。また、第2誤差72の合計値は、検出器5による器官の検出結果のブレであって、第1顔画像611におけるノイズの有無によって生じるブレの損失に相当する。そのため、検出器生成装置1は、上記ステップS201~S210の機械学習の処理により、位置情報612により示される正解と一致するように第1顔画像611から器官を検出し、かつその検出結果がノイズによる影響を受け難い、ように訓練された(学習済みの)検出器5を構築(生成)することができる。
加えて、第3誤差73の合計値は、検出器5による器官の検出結果のブレであって、位置情報612に含まれる幾何学的なノイズの影響によって生じるブレの損失に相当する。そのため、検出器生成装置1は、上記ステップS201~S210の機械学習の処理により、位置情報に含まれる幾何的なノイズによる影響を受け難い、ように更に訓練された検出器5を構築することができる。
§4 変形例
以上、本発明の実施の形態を詳細に説明してきたが、前述までの説明はあらゆる点において本発明の例示に過ぎない。本発明の範囲を逸脱することなく種々の改良や変形を行うことができることは言うまでもない。例えば、以下のような変更が可能である。なお、以下では、上記実施形態と同様の構成要素に関しては同様の符号を用い、上記実施形態と同様の点については、適宜説明を省略した。以下の変形例は適宜組み合わせ可能である。
以上、本発明の実施の形態を詳細に説明してきたが、前述までの説明はあらゆる点において本発明の例示に過ぎない。本発明の範囲を逸脱することなく種々の改良や変形を行うことができることは言うまでもない。例えば、以下のような変更が可能である。なお、以下では、上記実施形態と同様の構成要素に関しては同様の符号を用い、上記実施形態と同様の点については、適宜説明を省略した。以下の変形例は適宜組み合わせ可能である。
<4.1>
上記実施形態では、検出器5を構成するニューラルネットワークは、全結合ニューラルネットワークである。しかしながら、検出器5を構成するニューラルネットワークの構造及び種類は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、検出器5には、畳み込みニューラルネットワーク、再帰型ニューラルネットワーク等が利用されてよい。
上記実施形態では、検出器5を構成するニューラルネットワークは、全結合ニューラルネットワークである。しかしながら、検出器5を構成するニューラルネットワークの構造及び種類は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、検出器5には、畳み込みニューラルネットワーク、再帰型ニューラルネットワーク等が利用されてよい。
<4.2>
上記実施形態では、検出器5は、ニューラルネットワークにより構成されている。しかしながら、画像を入力として利用可能であれば、検出器5を構成する学習モデルの種類は、ニューラルネットワークに限られなくてよく、実施の形態に応じて適宜選択されてよい。また、機械学習の方法は、利用する学習モデルによって適宜選択されてよい。例えば、検出する器官の位置の初期値を与え、その位置を更新することで対象の顔画像に写る器官の位置を適切に検出できるように検出器5を訓練してもよい。学習用の顔画像に与えられた正解データの平均値を器官の位置の初期値として利用することができる。また、位置の更新は、特徴量を用いて行うことができる。この特徴量には、例えば、Haar-like特徴量、輝度差等が用いられてよい。学習モデルには、例えば、サポートベクタマシン、線形回帰モデル、ランダムフォレスト等が用いられてもよい。この場合、検出器5のパラメータは、例えば、重みベクトル、変換ベクトル、各分岐の閾値等である。
上記実施形態では、検出器5は、ニューラルネットワークにより構成されている。しかしながら、画像を入力として利用可能であれば、検出器5を構成する学習モデルの種類は、ニューラルネットワークに限られなくてよく、実施の形態に応じて適宜選択されてよい。また、機械学習の方法は、利用する学習モデルによって適宜選択されてよい。例えば、検出する器官の位置の初期値を与え、その位置を更新することで対象の顔画像に写る器官の位置を適切に検出できるように検出器5を訓練してもよい。学習用の顔画像に与えられた正解データの平均値を器官の位置の初期値として利用することができる。また、位置の更新は、特徴量を用いて行うことができる。この特徴量には、例えば、Haar-like特徴量、輝度差等が用いられてよい。学習モデルには、例えば、サポートベクタマシン、線形回帰モデル、ランダムフォレスト等が用いられてもよい。この場合、検出器5のパラメータは、例えば、重みベクトル、変換ベクトル、各分岐の閾値等である。
<4.3>
上記実施形態では、学習結果データ121は、学習済みのニューラルネットワーク(検出器5)の構成を示す情報を含んでいる。しかしながら、学習結果データ121の構成は、このような例に限定されなくてもよく、学習済みの検出器5の設定に利用可能であれば、実施の形態に応じて適宜決定されてよい。例えば、利用するニューラルネットワークの構成が各装置で共通化されている場合、学習結果データ121は、学習済みのニューラルネットワークの構成を示す情報を含んでいなくてもよい。
上記実施形態では、学習結果データ121は、学習済みのニューラルネットワーク(検出器5)の構成を示す情報を含んでいる。しかしながら、学習結果データ121の構成は、このような例に限定されなくてもよく、学習済みの検出器5の設定に利用可能であれば、実施の形態に応じて適宜決定されてよい。例えば、利用するニューラルネットワークの構成が各装置で共通化されている場合、学習結果データ121は、学習済みのニューラルネットワークの構成を示す情報を含んでいなくてもよい。
<4.4>
上記実施形態では、検出器生成装置1は、ステップS102の機械学習により、各誤差71~73の合計値が小さくなるように、検出器5のパラメータを調整している。しかしながら、機械学習の処理は、このような例に限定されなくてもよい。例えば、各誤差71~73のうち第3誤差73は省略されてもよい。
上記実施形態では、検出器生成装置1は、ステップS102の機械学習により、各誤差71~73の合計値が小さくなるように、検出器5のパラメータを調整している。しかしながら、機械学習の処理は、このような例に限定されなくてもよい。例えば、各誤差71~73のうち第3誤差73は省略されてもよい。
図11は、本変形例に係る検出器生成装置1Aのソフトウェア構成の一例を模式的に例示する。検出器生成装置1Aのハードウェア構成は、上記実施形態に係る検出器生成装置1と同様である。また、図11に示されるとおり、検出器生成装置1Aのソフトウェア構成も、上記実施形態に係る検出器生成装置1と同様である。
検出器生成装置1Aは、第3誤差73を導出する処理を省略する点を除き、上記実施形態に係る検出器生成装置1と同様に動作する。すなわち、検出器生成装置1Aの制御部は、上記検出器生成装置1と同様に、ステップS101及びS103の処理を実行する。また、制御部は、学習処理部112として動作し、ステップS102の処理を実行する。本変形例では、このステップS102の機械学習の処理において、制御部は、上記ステップS206~S208の処理を省略する。つまり、制御部は、上記検出器生成装置1と同様に、上記ステップS201~S205の処理を実行した後に、ステップS209の処理を実行する。そして、ステップS209では、制御部は、第1誤差71の合計値及び第2誤差72の合計値が閾値以下であるか否かを判定する。
第1誤差71の合計値及び第2誤差72の合計値が閾値以下であると判定した場合には、制御部は、機械学習の処理を終了し、上記ステップS103に処理を進める。一方、第1誤差71の合計値及び第2誤差72の合計値が閾値を超えていると判定した場合には、制御部は、次のステップS210に処理を進める。ステップS210では、制御部は、各誤差71~72の合計値が小さくなるように検出器5の訓練を行う。検出器5の訓練、すなわち、検出器5のパラメータを調整する方法は、上記実施形態と同様であってよい。これにより、本変形例に係る検出器生成装置1Aは、上記実施形態と同様に、位置情報612により示される正解と一致するように第1顔画像611から器官を検出し、かつその検出結果がノイズによる影響を受け難い、ように訓練された(学習済みの)検出器5を構築(生成)することができる。
<4.5>
上記実施形態では、車両を運転する運転者の顔を撮影し、得られる顔画像から顔の器官の位置を検出する場面に本発明を適用した例を示している。しかしながら、本発明の適用可能な範囲は、このような運転者の顔画像から器官の位置を検出する場面に限られなくてもよい。本発明は、運転者以外の対象者の顔の器官を顔画像から検出する場面に広く適用可能である。
上記実施形態では、車両を運転する運転者の顔を撮影し、得られる顔画像から顔の器官の位置を検出する場面に本発明を適用した例を示している。しかしながら、本発明の適用可能な範囲は、このような運転者の顔画像から器官の位置を検出する場面に限られなくてもよい。本発明は、運転者以外の対象者の顔の器官を顔画像から検出する場面に広く適用可能である。
図12は、本発明が適用される他の場面の一例を模式的に例示する。具体的に、図12は、生産現場で作業する作業者Uを撮影し、得られる顔画像から作業者Uの顔の器官を検出する場面に本発明を適用した例を示している。本変形例に係る検出器生成装置1Bのハードウェア構成及びソフトウェア構成は、上記実施形態に係る検出器生成装置1と同様である。本変形例に係るモニタリング装置2Bのハードウェア構成及びソフトウェア構成は、上記実施形態に係るモニタリング装置2と同様である。本変形例に係る検出器生成装置1B及びモニタリング装置2Bは、運転者以外の対象者の顔画像を取り扱う点を除いて、上記実施形態に係る検出器生成装置1及びモニタリング装置2と同様に動作する。
すなわち、ステップS101では、検出器生成装置1Bの制御部は、学習データ取得部として動作し、被験者の顔の写る第1顔画像及び第1顔画像に写る顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する。被験者の属性が異なる点を除き、本変形例に係るステップS101の処理は、上記実施形態と同様である。次のステップS102では、制御部は、学習処理部として動作し、取得した複数の学習データセットを利用して、検出器の機械学習を実施する。本変形例に係るステップS102の処理は、上記実施形態と同様であってもよいし、上記<4.4>と同様であってもよい。次のステップS103では、制御部は、保存処理部として動作し、機械学習により構築された検出器の構成及び演算パラメータを示す情報を学習結果データとして保存する。これにより、本変形例に係る検出器生成装置1Bは、運転者以外の対象者の顔の写る顔画像から器官の位置を検出する能力を習得した検出器を生成することができる
。
。
一方、モニタリング装置2Bは、検出器生成装置1Bにより構築された検出器を利用して、生産ラインでロボット装置Rと共に作業を行う作業者Uをカメラ41により撮影し、作業者Uについて得られた顔画像から顔の器官の位置を検出する。ステップS301では、モニタリング装置2Bの制御部は、データ取得部として動作し、ロボット装置Rと共に作業を行う作業者Uの顔の写る顔画像をカメラ41から取得する。次のステップS302では、制御部は、検出部として動作し、検出器生成装置1Bにより構築された学習済みの検出器に得られた顔画像を入力することで、作業者Uの顔の器官を顔画像より検出した結果に対応する出力値を検出器から取得する。次のステップS303では、制御部は、作業者Uの顔の器官を検出した結果に関する情報を出力する。
本変形例に係るステップS303において、出力する情報の内容は、上記実施形態と同様に、実施の形態に応じて適宜決定されてよい。例えば、顔の器官として目を検出した場合、制御部は、検出した各目の位置関係に基づいて、作業者Uの視線方向を推定し、視線方向を推定した結果に関連する情報を出力してもよい。この情報の一例として、ロボット装置Rとの作業に無関係な方向を視線方向が向いている場合に、制御部は、視線方向を作業に関係のある方向に向けるように促す警告を出力してもよい。また、制御部は、作業者Uの視線方向に適合する動作を実施する指示をロボット装置Rに出力してもよい。これにより、本変形例に係るモニタリング装置2Bは、検出器生成装置1Bにより生成された検出器を利用して、作業者Uの顔を撮影することで得られた顔画像から顔の器官の位置を検出することができる。
<4.6>
上記実施形態及び変形例では、顔の器官の位置を顔画像から検出する場面に適用した例を示している。しかしながら、本発明の適用範囲は、このような顔の器官の位置を顔画像から検出する場面に限られなくてもよい。本発明は、何らかの対象物の位置を画像から検出するあらゆる場面に広く適用可能である。
上記実施形態及び変形例では、顔の器官の位置を顔画像から検出する場面に適用した例を示している。しかしながら、本発明の適用範囲は、このような顔の器官の位置を顔画像から検出する場面に限られなくてもよい。本発明は、何らかの対象物の位置を画像から検出するあらゆる場面に広く適用可能である。
図13は、本発明が適用される他の場面の一例を模式的に例示する。具体的に、図13は、生産ラインRCを流れる製品UCを撮影し、製品UCに欠陥が存在する場合に、得られる画像から製品UCの欠陥の位置を検出する場面に本発明を適用した例を示している。図14は、本変形例に係る検出器生成装置1Cのソフトウェア構成の一例を模式的に例示する。
本変形例に係る製品UCの欠陥は、本発明の「対象物」の一例である。なお、「対象物」は、このような製品の欠陥に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。人間の写る画像が得られる場合、「対象物」は、顔の器官(上記実施形態)の他、例えば、顔そのもの、顔以外の身体部位等であってよい。また、本変形例と同様に製品の写る画像が得られる場合、「対象物」は、例えば、製品そのもの、製品に含まれる何らかの特徴等であってよい。
本変形例に係る検出器生成装置1Cのハードウェア構成は、上記実施形態に係る検出器生成装置1と同様である。図14に示されるとおり、本変形例に係る検出器生成装置1Cのソフトウェア構成も、上記実施形態に係る検出器生成装置1と同様である。また、本変形例に係るモニタリング装置2Cのハードウェア構成及びソフトウェア構成も、上記実施形態に係るモニタリング装置2と同様である。本変形例に係る検出器生成装置1C及びモニタリング装置2Cは、製品の写る画像を取り扱う点を除いて、上記実施形態に係る検出器生成装置1及びモニタリング装置2と同様に動作する。
すなわち、ステップS101では、検出器生成装置1Cの制御部は、学習データ取得部111として動作し、欠陥を含む製品の写る第1画像611C、及び第1画像611Cに写る欠陥の位置を示す位置情報612Cの組み合わせによりそれぞれ構成される複数の学習データセット61Cを取得する。撮影の対象が異なる点を除き、本変形例に係るステップS101の処理は、上記実施形態と同様である。
次のステップS102では、制御部は、学習処理部112として動作し、取得した複数の学習データセット61Cを利用して、検出器5の機械学習を実施する。
ステップS201では、制御部は、各学習データセット61Cの第1画像611Cを検出器5に入力し、検出器5の演算処理を実行する。これにより、制御部は、各第1画像に対する第1出力値を検出器5から取得する。ステップS202では、制御部は、各第1画像に対して得られた第1出力値に基づいて特定される製品の欠陥の第1検出位置V1Cと対応する位置情報612Cにより示される位置A1Cとの第1誤差71Cの合計値を算出する。
ステップS203では、制御部は、各第1画像611Cにノイズを付与することで、各第1画像611Cに対して第2画像63Cを生成する。ステップS204では、制御部は、生成した各第2画像63Cを検出器5に入力し、検出器5の演算処理を実行する。これにより、制御部は、各第2画像63Cに対する第2出力値を検出器5から取得する。ステップS205では、制御部は、各第1出力値に基づいて特定される第1検出位置V1Cと対応する第2画像63Cに対して得られた第2出力値に基づいて特定される第2検出位置V2Cとの第2誤差72Cの合計値を算出する。
ステップS206では、制御部は、各第1画像611Cに所定の幾何変換を適用することで、各第1画像611Cに対して第3画像66Cを生成する。ステップS207では、制御部は、生成した各第3画像66Cを検出器5に入力し、検出器5の演算処理を実行する。これにより、制御部は、各第3画像66Cに対する第3出力値を検出器5から取得する。ステップS208では、制御部は、各第1出力値に基づいて特定される第1検出位置と対応する第3画像66Cに対して得られた第3出力値に基づいて特定される第3検出位置との第3誤差73Cの合計値を算出する。
なお、本変形例に係るステップS208では、上記実施形態と同様に、制御部は、各第1画像611Cに対して得られた第1検出位置V1Cと対応する第3画像66Cに対して導出された第3検出位置V31Cとの差分を第3誤差73Cとして算出してもよい。また、制御部は、各第1画像611Cに対して得られた第1検出位置V1Cに所定の幾何変換を適用することで導出される位置と第3検出位置V30Cとの差分を第3誤差73Cとして算出してもよい。
ステップS209では、制御部は、算出した各誤差71C~73Cの合計値が閾値以下であるか否かを判定する。各誤差71C~73Cの合計値が閾値以下であると判定した場合、制御部は、機械学習の処理を終了し、次のステップS103に処理を進める。一方、各誤差71C~73Cの合計値が閾値を超えていると判定した場合、制御部は、次のステップS210に処理を進める。ステップS210では、制御部は、各誤差71C~73Cの合計値が小さくなるように検出器5の訓練を行う。検出器5の各層51~53のパラメータの値の更新が完了すると、制御部は、ステップS201から処理を繰り返す。
なお、上記本変形例に係るステップS102の処理手順は、上記実施形態と同様である。しかしながら、本変形例に係るステップS102の処理手順は、このような例に限定されなくてもよく、例えば、上記<4.4>と同様であってもよい。この場合、本変形例に係るステップS102の処理において、上記ステップS206~S208の処理は省略されてよい。ステップS209では、制御部は、算出した各誤差71C~72Cの合計値が閾値以下であるか否かを判定してもよい。各誤差71C~72Cの合計値が閾値以下であると判定した場合に、制御部は、次のステップS103に処理を進めてもよい。一方、各誤差71C~72Cの合計値が閾値を超えていると判定した場合、制御部は、次のステップS210に処理を進めてもよい。ステップS210では、制御部は、各誤差71C~72Cの合計値が小さくなるように検出器5の訓練を行ってもよい。
ステップS103では、制御部は、保存処理部113として動作し、機械学習により構築された検出器5の構成及び演算パラメータを示す情報を学習結果データ121Cとして保存する。これにより、本変形例に係る検出器生成装置1Cは、製品の写る画像から欠陥(対象物)の位置を検出する能力を習得した検出器5を生成することができる。
一方、モニタリング装置2Cは、検出器生成装置1Cにより構築された検出器5を利用して、生産ラインRCを流れる製品UCを撮影し、製品UCに欠陥が存在する場合に、得られる画像から製品UCの欠陥の位置を検出する。ステップS301では、モニタリング装置2Cの制御部は、データ取得部として動作し、生産ラインRCを流れる製品UCの写る画像をカメラ41から取得する。次のステップS302では、制御部は、検出部として動作し、学習結果データ121Cを参照して、学習済みの検出器5の設定を行う。続いて、制御部は、学習済みの検出器5に得られた画像を入力することで、製品UCの欠陥を画像より検出した結果に対応する出力値を検出器から取得する。次のステップS303では、制御部は、製品UCの欠陥を検出した結果に関する情報を出力する。
本変形例に係るステップS303において、出力する情報の内容は、上記実施形態と同様に、実施の形態に応じて適宜決定されてよい。例えば、製品UCに欠陥が存在する場合、制御部は、検出した欠陥の位置を示す情報を出力してもよい。また、例えば、制御部は、欠陥が検出された製品UCを別のラインに流す指示を生産ラインRCに出力してもよい。これにより、本変形例に係るモニタリング装置2Cは、検出器生成装置1Cにより生成された検出器5を利用して、製品UCの写る画像から欠陥を検出することで、生産ラインRCを流れる製品UCの状態を監視することができる。
<4.7>
図9に示されるとおり、上記実施形態に係る検出器生成装置1は、検出器を生成する処理及び位置情報を更新する処理を交互に繰り返すことで、位置情報に含まれ得る人為的なノイズによる影響にロバストで、対象者の顔の器官を顔画像から検出可能な検出器を構築することができる。人為的なノイズによる影響にロバストな検出器を構築するという観点から、この検出器を生成する処理及び位置情報を更新する処理を交互に実行する部分のみを抽出して、新たな形態に係る検出器生成装置が構成されてもよい。
図9に示されるとおり、上記実施形態に係る検出器生成装置1は、検出器を生成する処理及び位置情報を更新する処理を交互に繰り返すことで、位置情報に含まれ得る人為的なノイズによる影響にロバストで、対象者の顔の器官を顔画像から検出可能な検出器を構築することができる。人為的なノイズによる影響にロバストな検出器を構築するという観点から、この検出器を生成する処理及び位置情報を更新する処理を交互に実行する部分のみを抽出して、新たな形態に係る検出器生成装置が構成されてもよい。
図15は、本変形例に係る検出器生成装置1Dのソフトウェア構成の一例を模式的に例示する。本変形例に係る検出器生成装置1Dのハードウェア構成は、上記実施形態に係る検出器生成装置1と同様である。また、図15に示されるとおり、本変形例に係る検出器生成装置1Dのソフトウェア構成も、上記実施形態に係る検出器生成装置1と同様である。
検出器生成装置1Dは、第2誤差72及び第3誤差73を導出する処理を省略する点を除き、上記実施形態に係る検出器生成装置1と基本的には同様に動作する。すなわち、第1回目の学習処理のステップS101では、検出器生成装置1Dの制御部は、学習データ取得部111として動作し、車両を運転する被験者の顔の写る顔画像681及び顔画像681に写る顔の器官の位置を示す第1位置情報682の組み合わせによりそれぞれ構成される複数の第1学習データセット68を取得する。第1位置情報682は、オペレータの指定により与えられてもよい。
ステップS102では、制御部は、学習処理部112として動作し、取得した複数の第1学習データセット68を利用して、第1検出器58の機械学習を実施する。本変形例に係るステップS102では、ステップS203~S208が省略される。ステップS201では、制御部は、各顔画像681を第1検出器58に入力し、第1検出器58の演算処理を実行する。これにより、制御部は、各顔画像681に対する出力値を第1検出器58から取得するステップS202では、制御部は、各顔画像681に対して得られた出力値に基づいて特定される検出位置と対応する第1位置情報682により示される位置との誤差の合計値を算出する。
ステップS209では、制御部は、算出された誤差の合計値が閾値以下であるか否かを判定する。誤差の合計値が閾値以下であると判定した場合に、制御部は、機械学習の処理を終了し、ステップS103に処理を進める。一方、誤差の合計値が閾値を超えていると判定した場合には、制御部は、次のステップS210に処理を進める。ステップS210では、制御部は、誤差の合計値が小さくなるように第1検出器58の訓練を行う。第1検出器58のパラメータを調整する方法は、上記実施形態と同様であってよい。これにより、制御部は、各顔画像681が入力されると、対応する第1位置情報682に対応する出力値を出力するように訓練された検出器5を構築する。ステップS103では、制御部は、保存処理部113として動作し、機械学習により構築された第1検出器58の構成及び演算パラメータを示す情報を学習結果データとして保存する。なお、第1回目の学習処理では、このステップS103の処理は省略されてもよい。
本変形例に係る検出器生成装置1Dは、このような機械学習の一連の処理と暫定的に生成された検出器を利用して位置情報を更新する処理とを交互に繰り返す。第2回目の学習処理のステップS101では、制御部は、顔画像681、及び構築された第1検出器58に顔画像681を入力することで当該第1検出器58から得られた出力値に基づいて与えられる第2位置情報692の組み合わせによりそれぞれ構成された複数の第2学習データセット69を取得する。そして、ステップS102では、制御部は、複数の第2学習データセット69を利用して、第2検出器59の機械学習を実施する。この機械学習の処理は、第1回目の学習処理と同様である。これにより、制御部は、各顔画像681が入力されると、対応する第2位置情報692に対応する出力値を出力するように訓練された第2検出器59を構築する。これにより、本変形例に係る検出器生成装置1Dは、人為的なノイズによる影響にロバストな検出器(第2検出器59)を生成することができる。なお、生成された第2検出器59は、上記検出器5と同様に利用されてよい。
なお、図15では、機械学習の処理を2回繰り返す場面を例示している。しかしながら、機械学習の処理を繰り返す回数は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。繰り返しの回数は、3回以上であってもよい。
また、上記<4.5>で記載のとおり、本変形例は、運転者以外の対象者の顔の器官を顔画像から検出する場面に広く適用可能である。そのため、顔画像681は、運転者以外の被験者の顔の写る顔画像に置き換えられてよい。これにより、運転者以外の対象者の顔の写る顔画像から器官の位置を検出する能力を習得した検出器を構築することができる。
更に、上記<4.6>で記載のとおり、本変形例は、何らかの対象物の位置を画像から検出するあらゆる場面に広く適用可能である。そのため、顔画像681は、何らかの対象物の写る画像に置き換えられてよい。各位置情報(682、692)は、対象物の位置を示す位置情報に置き換えられてよい。これにより、対象物の位置を画像から検出する能力を習得した検出器を構築することができる。
§5 実施例
以下、本発明の実施例について説明する。ただし、本発明は、これらの実施例に限定されるものではない。
以下、本発明の実施例について説明する。ただし、本発明は、これらの実施例に限定されるものではない。
[第1実施例]
まず、第1実施例では、目尻を検出するための検出器を生成するために、各学習データセットを以下の条件で用意した。検出器には、畳み込みニューラルネットワーク及び全結合ニューラルネットワークを含む学習ネットワークを用いた。学習ネットワークでは、畳み込みニューラルネットワークの出力を全結合ニューラルネットワークの入力に接続した。そして、検出器生成装置(汎用のパーソナルコンピュータ)を用意し、用意した各学習データセットを利用して、用意した検出器生成装置に上記実施形態に係る各処理を実行させた。これにより、第1実施例に係る学習済みの検出器を得た。
まず、第1実施例では、目尻を検出するための検出器を生成するために、各学習データセットを以下の条件で用意した。検出器には、畳み込みニューラルネットワーク及び全結合ニューラルネットワークを含む学習ネットワークを用いた。学習ネットワークでは、畳み込みニューラルネットワークの出力を全結合ニューラルネットワークの入力に接続した。そして、検出器生成装置(汎用のパーソナルコンピュータ)を用意し、用意した各学習データセットを利用して、用意した検出器生成装置に上記実施形態に係る各処理を実行させた。これにより、第1実施例に係る学習済みの検出器を得た。
<学習データセットの条件>
・件数:3000枚
・顔画像:64×64ピクセルの画像(目の写る部分のみ抽出)
・抽出方法:オペレータの指定した目頭及び目尻の位置に基づいて目の写る部分を抽出
・顔画像の取得条件:近赤外線カメラにより被験者の顔を撮影
・位置情報:目尻の位置を示す
・位置情報の取得条件:オペレータの入力(オペレータにマウスを操作させて、顔画像内で目尻の位置を指定させた)
・件数:3000枚
・顔画像:64×64ピクセルの画像(目の写る部分のみ抽出)
・抽出方法:オペレータの指定した目頭及び目尻の位置に基づいて目の写る部分を抽出
・顔画像の取得条件:近赤外線カメラにより被験者の顔を撮影
・位置情報:目尻の位置を示す
・位置情報の取得条件:オペレータの入力(オペレータにマウスを操作させて、顔画像内で目尻の位置を指定させた)
[第2実施例]
第1実施例に係る学習済みの検出器を利用して、第1実施例で利用した各学習データセットの顔画像から目尻の位置を検出し、検出結果により位置情報を更新することで、新たな各学習データセットを得た。そして、得られた各学習データセットを利用して、検出器生成装置に上記実施形態に係る機械学習の処理を実行させた。これにより、第2実施例に係る学習済みの検出器を得た。つまり、第2実施例に係る学習済みの検出器は、上記実施形態に係る機械学習の処理を2回繰り返すことで生成された学習済みの検出器に相当する。
第1実施例に係る学習済みの検出器を利用して、第1実施例で利用した各学習データセットの顔画像から目尻の位置を検出し、検出結果により位置情報を更新することで、新たな各学習データセットを得た。そして、得られた各学習データセットを利用して、検出器生成装置に上記実施形態に係る機械学習の処理を実行させた。これにより、第2実施例に係る学習済みの検出器を得た。つまり、第2実施例に係る学習済みの検出器は、上記実施形態に係る機械学習の処理を2回繰り返すことで生成された学習済みの検出器に相当する。
[第3実施例]
第2実施例に係る学習済みの検出器を利用して、第2実施例で利用した各学習データセットの顔画像から目尻の位置を検出し、検出結果により位置情報を更新することで、新たな各学習データセットを得た。そして、得られた各学習データセットを利用して、検出器生成装置に上記実施形態に係る機械学習の処理を実行させた。これにより、第3実施例に係る学習済みの検出器を得た。つまり、第3実施例に係る学習済みの検出器は、上記実施形態に係る機械学習の処理を3回繰り返すことで生成された学習済みの検出器に相当する。
第2実施例に係る学習済みの検出器を利用して、第2実施例で利用した各学習データセットの顔画像から目尻の位置を検出し、検出結果により位置情報を更新することで、新たな各学習データセットを得た。そして、得られた各学習データセットを利用して、検出器生成装置に上記実施形態に係る機械学習の処理を実行させた。これにより、第3実施例に係る学習済みの検出器を得た。つまり、第3実施例に係る学習済みの検出器は、上記実施形態に係る機械学習の処理を3回繰り返すことで生成された学習済みの検出器に相当する。
[比較例]
上記第1実施例において、第2誤差72及び第3誤差73の計算を省略することで、比較例に係る検出器を得た。すなわち、比較例では、上記実施形態に係る処理手順のうち、ステップS203~S208の処理を省略した。そして、ステップS209及びS210では、各誤差71~73を第1誤差71に置き換えた。
上記第1実施例において、第2誤差72及び第3誤差73の計算を省略することで、比較例に係る検出器を得た。すなわち、比較例では、上記実施形態に係る処理手順のうち、ステップS203~S208の処理を省略した。そして、ステップS209及びS210では、各誤差71~73を第1誤差71に置き換えた。
<評価方法>
次に、第1~第3実施例及び比較例に係る検出器の検出精度を次の方法で評価した。すなわち、カメラにより対象者の顔を撮影し、学習用の顔画像と同様に、評価用の5000枚の顔画像(64×64ピクセル)を用意した。評価用の各顔画像を各検出器に入力し、各顔画像に対する目尻の位置の第1検出結果を各検出器から得た。また、評価用の各顔画像を幾何変換(平行移動+回転移動)することで変換画像を生成した。生成した各変換画像を各検出器に入力し、各変換画像に対する目尻の位置の第2検出結果を各検出器から得た。続いて、各検出器の第1検出結果の示す位置と第2検出結果の示す位置に上記幾何変換の逆変換を適用することで得られた位置との差分(ずれ)をピクセル単位で算出した。そして、得られた差分の平均及び標準偏差を算出した。差分の平均及び標準偏差の算出結果は、以下の表1のとおりである。
次に、第1~第3実施例及び比較例に係る検出器の検出精度を次の方法で評価した。すなわち、カメラにより対象者の顔を撮影し、学習用の顔画像と同様に、評価用の5000枚の顔画像(64×64ピクセル)を用意した。評価用の各顔画像を各検出器に入力し、各顔画像に対する目尻の位置の第1検出結果を各検出器から得た。また、評価用の各顔画像を幾何変換(平行移動+回転移動)することで変換画像を生成した。生成した各変換画像を各検出器に入力し、各変換画像に対する目尻の位置の第2検出結果を各検出器から得た。続いて、各検出器の第1検出結果の示す位置と第2検出結果の示す位置に上記幾何変換の逆変換を適用することで得られた位置との差分(ずれ)をピクセル単位で算出した。そして、得られた差分の平均及び標準偏差を算出した。差分の平均及び標準偏差の算出結果は、以下の表1のとおりである。

表1に示されるとおり、第2誤差72及び第3誤差73の学習を実施する第1~第3実施例に係る検出器の検出のブレは、第2誤差72及び第3誤差73の学習を実施しない比較例よりも小さかった。このことから、上記実施形態によれば、第1誤差71のみの学習を実施するケースよりも検出結果のブレの少ない検出器を生成可能であることが分かった。また、第1実施例から第3実施例になるにつれ、検出器による目尻の検出のブレが低減した。このことから、検出器を生成する処理と位置情報を更新する処理とを交互に繰り返すことで、検出器の検出のブレを抑えることができることが分かった。したがって、上記実施形態によれば、対象物をより高精度に検出可能な検出器を生成可能であることが分かった。
1…検出器生成装置、
11…制御部、12…記憶部、13…通信インタフェース、
14…入力装置、15…出力装置、16…ドライブ、
111…学習データ取得部、112…学習処理部、
113…保存処理部、
121…学習結果データ、
81…検出器生成プログラム、91…記憶媒体、
2…モニタリング装置、
21…制御部、22…記憶部、23…通信インタフェース、
24…外部インタフェース、
25…入力装置、26…出力装置、27…ドライブ、
211…データ取得部、212…検出部、
213…出力部、
221…顔画像、
82…モニタリングプログラム、92…記憶媒体、
31…カメラ、41…カメラ、
5…検出器、
51…入力層、52…中間層(隠れ層)、53…出力層、
61…学習データセット、
611…顔画像(第1顔画像)、612…位置情報、
63…顔画像(第2顔画像)、66…顔画像(第3顔画像)、
71…誤差(第1誤差)、72…誤差(第2誤差)、
73…誤差(第3誤差)、
A1…位置、
V1…検出位置(第1検出位置)、V2…検出位置(第2検出位置)、
V30・V31…検出位置(第3検出位置)、
T…被験者、D…運転者(対象者)
11…制御部、12…記憶部、13…通信インタフェース、
14…入力装置、15…出力装置、16…ドライブ、
111…学習データ取得部、112…学習処理部、
113…保存処理部、
121…学習結果データ、
81…検出器生成プログラム、91…記憶媒体、
2…モニタリング装置、
21…制御部、22…記憶部、23…通信インタフェース、
24…外部インタフェース、
25…入力装置、26…出力装置、27…ドライブ、
211…データ取得部、212…検出部、
213…出力部、
221…顔画像、
82…モニタリングプログラム、92…記憶媒体、
31…カメラ、41…カメラ、
5…検出器、
51…入力層、52…中間層(隠れ層)、53…出力層、
61…学習データセット、
611…顔画像(第1顔画像)、612…位置情報、
63…顔画像(第2顔画像)、66…顔画像(第3顔画像)、
71…誤差(第1誤差)、72…誤差(第2誤差)、
73…誤差(第3誤差)、
A1…位置、
V1…検出位置(第1検出位置)、V2…検出位置(第2検出位置)、
V30・V31…検出位置(第3検出位置)、
T…被験者、D…運転者(対象者)
Claims (11)
- 車両を運転する被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する学習データ取得部と、
前記複数の学習データセットを利用して、検出器の機械学習を実施する学習処理部と、
を備え、
前記検出器の機械学習を実施することは、
前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1出力値に基づいて特定される前記器官の第1検出位置と前記位置情報により示される位置との第1誤差の合計値を算出するステップと、
前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、
前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1検出位置と前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、
前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、
を含む、
検出器生成装置。 - 前記検出器の機械学習を実施することは、
前記各学習データセットの前記第1顔画像に所定の幾何変換を適用することで、前記各学習データセットの前記第1顔画像に対して第3顔画像を生成するステップと、
前記各第3顔画像を前記検出器に入力することで、前記各第3顔画像に対する第3出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1検出位置と前記第3出力値に基づいて特定される前記器官の第3検出位置との第3誤差の合計値を算出するステップと、
を更に含み、
前記訓練するステップでは、前記学習処理部は、前記第1誤差の合計値、前記第2誤差の合計値及び前記第3誤差の合計値が小さくなるように前記検出器を訓練する、
請求項1に記載の検出器生成装置。 - 前記所定の幾何変換は、平行移動及び回転移動を伴う変換である、
請求項2に記載の検出器生成装置。 - 前記各学習データセットの前記位置情報は、当該位置情報に組み合わせられる前記第1顔画像を、機械学習を実施済みの他の検出器に入力することで、当該他の検出器から得られる出力値に基づいて与えられる、
請求項1から3のいずれか1項に記載の検出器生成装置。 - 前記器官は、目、鼻、口、眉、顎及びこれらの組み合わせから選択される、
請求項1から4のいずれか1項に記載の検出器生成装置。 - 前記検出器は、ニューラルネットワークにより構成される、
請求項1から5のいずれか1項に検出器生成装置。 - 車両を運転する運転者の顔の写る顔画像を取得するデータ取得部と、
請求項1から6のいずれか1項の検出器生成装置による機械学習を実施済みの前記検出器に取得した前記顔画像を入力することで、前記運転者の前記顔の器官を検出した結果に対応する出力値を前記検出器から取得する検出部と、
前記運転者の顔の器官を検出した結果に関する情報を出力する出力部と、
を備える、
モニタリング装置。 - コンピュータが、
車両を運転する被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得するステップと、
前記複数の学習データセットを利用して、検出器の機械学習を実施するステップと、
を実行し、
前記検出器の機械学習を実施するステップは、
前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1出力値に基づいて特定される前記器官の第1検出位置と前記位置情報により示される位置との第1誤差の合計値を算出するステップと、
前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、
前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1検出位置と前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、
前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、
を含む、
検出器生成方法。 - コンピュータに、
車両を運転する被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得するステップと、
前記複数の学習データセットを利用して、検出器の機械学習を実施するステップと、
を実行させるための検出器生成プログラムであって、
前記検出器の機械学習を実施するステップは、
前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1出力値に基づいて特定される前記器官の第1検出位置と前記位置情報により示される位置との第1誤差の合計値を算出するステップと、
前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、
前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1検出位置と前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、
前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、
を含む、
検出器生成プログラム。 - 被験者の顔の写る第1顔画像、及び前記第1顔画像に写る前記顔の器官の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する学習データ取得部と、
前記複数の学習データセットを利用して、検出器の機械学習を実施する学習処理部と、
を備え、
前記検出器の機械学習を実施することは、
前記各学習データセットの前記第1顔画像を前記検出器に入力することで、前記各学習データセットの前記第1顔画像に対する第1出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1出力値に基づいて特定される前記器官の第1検出位置と前記位置情報により示される位置との第1誤差の合計値を算出するステップと、
前記各学習データセットの前記第1顔画像にノイズを付与することで、前記各学習データセットの前記第1顔画像に対して第2顔画像を生成するステップと、
前記各第2顔画像を前記検出器に入力することで、前記各第2顔画像に対する第2出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1検出位置と前記第2出力値に基づいて特定される前記器官の第2検出位置との第2誤差の合計値を算出するステップと、
前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、
を含む、
検出器生成装置。 - 対象物の写る第1画像、及び前記第1画像に写る前記対象物の位置を示す位置情報の組み合わせによりそれぞれ構成される複数の学習データセットを取得する学習データ取得部と、
前記複数の学習データセットを利用して、検出器の機械学習を実施する学習処理部と、
を備え、
前記検出器の機械学習を実施することは、
前記各学習データセットの前記第1画像を前記検出器に入力することで、前記各学習データセットの前記第1画像に対する第1出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1出力値に基づいて特定される前記対象物の第1検出位置と前記位置情報により示される位置との第1誤差の合計値を算出するステップと、
前記各学習データセットの前記第1画像にノイズを付与することで、前記各学習データセットの前記第1画像に対して第2画像を生成するステップと、
前記各第2画像を前記検出器に入力することで、前記各第2画像に対する第2出力値を前記検出器から取得するステップと、
前記各学習データセットについて、前記第1検出位置と前記第2出力値に基づいて特定される前記対象物の第2検出位置との第2誤差の合計値を算出するステップと、
前記第1誤差の合計値及び前記第2誤差の合計値が小さくなるように前記検出器を訓練するステップと、
を含む、
検出器生成装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018-162683 | 2018-08-31 | ||
| JP2018162683A JP6996455B2 (ja) | 2018-08-31 | 2018-08-31 | 検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020044630A1 true WO2020044630A1 (ja) | 2020-03-05 |
Family
ID=69644087
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/010187 WO2020044630A1 (ja) | 2018-08-31 | 2019-03-13 | 検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP6996455B2 (ja) |
| WO (1) | WO2020044630A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7458857B2 (ja) | 2020-04-01 | 2024-04-01 | キヤノン株式会社 | 画像処理装置、画像処理方法及びプログラム |
| WO2022097195A1 (ja) * | 2020-11-04 | 2022-05-12 | 日本電信電話株式会社 | 学習方法、学習装置及びプログラム |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008536211A (ja) * | 2005-03-31 | 2008-09-04 | フランス テレコム | ニューラルネットワークを実現するオブジェクトイメージにおいて興味のあるポイントを位置決めするシステム及び方法 |
-
2018
- 2018-08-31 JP JP2018162683A patent/JP6996455B2/ja active Active
-
2019
- 2019-03-13 WO PCT/JP2019/010187 patent/WO2020044630A1/ja active Application Filing
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008536211A (ja) * | 2005-03-31 | 2008-09-04 | フランス テレコム | ニューラルネットワークを実現するオブジェクトイメージにおいて興味のあるポイントを位置決めするシステム及び方法 |
Non-Patent Citations (2)
| Title |
|---|
| YAMASHITA, TAKAYOSHI ET AL.: "Optimal Mini-Batch Generation Method for Facial Feature Point Detection Using Deep Convolutional Neural Network", PROCEEDINGS OF THE 21ST SYMPOSIUM ON SENSING VIA IMAGE INFORMATION, 10 June 2015 (2015-06-10) * |
| YAMASHITA, TAKAYOSHI: "An Illustrated Guide to Deep Learning", 22 February 2016, article YAMASHITA, TAKAYOSHI, pages: 70 - 73 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020035290A (ja) | 2020-03-05 |
| JP6996455B2 (ja) | 2022-01-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6946831B2 (ja) | 人物の視線方向を推定するための情報処理装置及び推定方法、並びに学習装置及び学習方法 | |
| CN108921782B (zh) | 一种图像处理方法、装置及存储介质 | |
| WO2021135827A1 (zh) | 视线方向确定方法、装置、电子设备及存储介质 | |
| US8615135B2 (en) | Feature point positioning apparatus, image recognition apparatus, processing method thereof and computer-readable storage medium | |
| CN111696196B (zh) | 一种三维人脸模型重建方法及装置 | |
| WO2015089436A1 (en) | Efficient facial landmark tracking using online shape regression method | |
| KR20160053612A (ko) | 영상 학습 모델을 이용한 영상 생성 방법 및 장치 | |
| CN112200057B (zh) | 人脸活体检测方法、装置、电子设备及存储介质 | |
| US11328418B2 (en) | Method for vein recognition, and apparatus, device and storage medium thereof | |
| US9165213B2 (en) | Information processing apparatus, information processing method, and program | |
| CN112488067B (zh) | 人脸姿态估计方法、装置、电子设备和存储介质 | |
| WO2020044630A1 (ja) | 検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム | |
| JP6283124B2 (ja) | 画像特性推定方法およびデバイス | |
| JP2019148980A (ja) | 画像変換装置及び画像変換方法 | |
| KR20210018114A (ko) | 교차 도메인 메트릭 학습 시스템 및 방법 | |
| WO2020044629A1 (ja) | 検出器生成装置、モニタリング装置、検出器生成方法及び検出器生成プログラム | |
| JP2024516016A (ja) | 入力画像の処理方法、入力画像の処理装置及びプログラム | |
| WO2019228195A1 (zh) | 空间环境的感知方法及装置 | |
| US11393069B2 (en) | Image processing apparatus, image processing method, and computer readable recording medium | |
| KR20210048622A (ko) | 딥러닝 기반 이미지 복원을 이용한 성별 인식 장치 및 방법 | |
| KR102420924B1 (ko) | 딥러닝 기반 3d 시선 예측 방법 및 그 장치 | |
| JP7310931B2 (ja) | 視線推定装置、視線推定方法、モデル生成装置、及びモデル生成方法 | |
| CN113642415B (zh) | 人脸特征表达方法及人脸识别方法 | |
| Klingner et al. | Modeling human movements with self-organizing maps using adaptive metrics | |
| WO2024166536A1 (ja) | 推定プログラム、機械学習方法、推定装置、及び非一時的記憶媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19854080 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19854080 Country of ref document: EP Kind code of ref document: A1 |