WO2021095211A1 - 出力方法、出力プログラム、および出力装置 - Google Patents
出力方法、出力プログラム、および出力装置 Download PDFInfo
- Publication number
- WO2021095211A1 WO2021095211A1 PCT/JP2019/044769 JP2019044769W WO2021095211A1 WO 2021095211 A1 WO2021095211 A1 WO 2021095211A1 JP 2019044769 W JP2019044769 W JP 2019044769W WO 2021095211 A1 WO2021095211 A1 WO 2021095211A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- vector
- modal
- information
- output device
- corrected
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/15—Correlation function computation including computation of convolution operations
- G06F17/153—Multidimensional correlation or convolution
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0499—Feedforward networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
Definitions
- the present invention relates to an output method, an output program, and an output device.
- the modal is a concept indicating the style and type of information, and specific examples thereof include images, documents (texts), and sounds.
- Machine learning using multiple modals is called multimodal learning.
- ViLBERT Vision-and-Language Bidirectional Encoder Representations from Transformers.
- ViLBERT is a modal image-related vector that is corrected based on a modal information-based vector for a document and a modal information-based vector for a document. It is a technique to solve a problem by referring to an information-based vector.
- the accuracy of the solution when solving the problem using a plurality of modal information may be poor.
- ViLBERT when solving the problem of judging the situation based on an image and a document, it is only necessary to refer directly to the vector based on the modal information on the corrected document and the vector based on the modal information on the corrected image. , The accuracy of the solution when solving the problem is poor.
- the present invention aims to improve the accuracy of a solution when solving a problem using a plurality of modal information.
- the information of the first modal is based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal different from the first modal. Corrects the vector based on, and corrects the vector based on the information of the second modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- a first vector is generated based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the first modal, and from the vector based on the information of the second modal after correction.
- a second vector is generated, and a predetermined vector, the generated first vector, and the generated second vector are combined from a coupling vector.
- An output method that generates a third vector that aggregates the first vector and the second vector based on the obtained correlation between the two different types of vectors, and outputs the generated third vector. , Output programs, and output devices are proposed.
- FIG. 1 is an explanatory diagram showing an embodiment of an output method according to an embodiment.
- FIG. 2 is an explanatory diagram showing an example of the information processing system 200.
- FIG. 3 is a block diagram showing a hardware configuration example of the output device 100.
- FIG. 4 is a block diagram showing a functional configuration example of the output device 100.
- FIG. 5 is an explanatory diagram showing a specific example of the Co-Attention Network 500.
- FIG. 6 is an explanatory diagram showing a specific example of the SA layer 600 and a specific example of the TA layer 610.
- FIG. 7 is an explanatory diagram showing an example of operation using CAN500.
- FIG. 8 is an explanatory diagram (No. 1) showing usage example 1 of the output device 100.
- FIG. 9 is an explanatory diagram (No.
- FIG. 10 is an explanatory diagram (No. 1) showing usage example 2 of the output device 100.
- FIG. 11 is an explanatory diagram (No. 2) showing usage example 2 of the output device 100.
- FIG. 12 is a flowchart showing an example of the learning processing procedure.
- FIG. 13 is a flowchart showing an example of the estimation processing procedure.
- FIG. 1 is an explanatory diagram showing an embodiment of an output method according to an embodiment.
- the output device 100 is a computer for improving the accuracy of a solution when the problem is solved by making it easy to obtain information useful for solving the problem by using a plurality of modal information.
- BERT Bidirectional Encoder Representations from Transformers
- the BERT is formed by stacking the Encoder portions of the Transformer.
- the following non-patent document 2 and the following non-patent document 3 can be referred to.
- BERT is supposed to be applied to a situation where a problem is solved using modal information about a document, and cannot be applied to a situation where a problem is solved using a plurality of modal information. ..
- Non-Patent Document 2 Devlin, Jacob et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” NAACL-HLT (2019).
- Non-Patent Document 3 Vaswani, Ashish, et al. "Attention is all you need.” Advances in neural information processing systems. 2017.
- VideoBERT As a method for solving a problem, for example, there is a method called VideoBERT.
- the VideoBERT is specifically an extension of the BERT that can be applied to situations where a problem is solved using modal information about a document and modal information about an image.
- VideoBERT for example, the following Non-Patent Document 4 can be referred to.
- the VideoBERT handles modal information about a document and modal information about an image without explicitly distinguishing them when solving a problem, the accuracy of the solution when solving the problem may be poor.
- Non-Patent Document 4 Sun, Chen, et al. "Video: A joint model for video and language learning learning.”
- MCAN Modular Co-Attention Network
- the MCAN solves the problem by referring to the modal information about the document and the modal information about the image corrected by the modal information about the document.
- MCAN for example, the following Non-Patent Document 5 can be referred to.
- the modal information about the document is not corrected by the modal information about the image and is referred to as it is, so that the accuracy of the solution when solving the problem may be poor.
- Non-Patent Document 5 Yu, Zhou, et al. "Deep Modular Co-Attention Network for Visual Question Answering.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2019.
- ViLBERT as a method for solving a problem, for example, there is a method called ViLBERT.
- ViLBERT only refers to the modal information about the document corrected by the modal information about the image and the modal information about the image corrected by the modal information about the document as it is, when the problem is solved.
- the accuracy of the solution may be poor.
- the output device 100 acquires a vector based on the information of the first modal and a vector based on the information of the second modal.
- Modal means a form of information.
- the first modal and the second modal are different modals.
- the first modal is, for example, an image modal.
- the information of the first modal is, for example, an image represented according to the first modal.
- the second modal is, for example, a modal for documents.
- the information of the second modal is, for example, a document expressed according to the second modal.
- the vector based on the information of the first modal is, for example, a vector generated based on the information of the first modal expressed according to the first modal.
- the first modal information-based vector is specifically an image-based vector.
- the vector based on the information of the second modal is, for example, a vector generated based on the information of the second modal expressed according to the second modal.
- the second modal information-based vector is specifically a document-based vector.
- the output device 100 corrects the vector based on the information of the first modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- the output device 100 corrects the vector based on the information of the first modal by using, for example, the first correction model 111.
- the first correction model 111 is, for example, a target attention layer for the first modal.
- the output device 100 corrects the vector based on the information of the second modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- the output device 100 corrects the vector based on the information of the second modal by using, for example, the second correction model 112.
- the second correction model 112 is, for example, a target attention layer for the second modal.
- the output device 100 generates the first vector based on the correlation between two vectors of different types obtained from the vector based on the corrected first modal information.
- the two different types of vectors are, for example, a query vector and a key vector.
- the output device 100 generates the first vector by using, for example, the first generation model 121.
- the first generative model 121 is, for example, a self-attention layer for the first modal.
- the output device 100 generates a second vector based on the correlation between two vectors of different types obtained from the vector based on the corrected second modal information.
- the two different types of vectors are, for example, a query vector and a key vector.
- the output device 100 generates a second vector using, for example, the second generation model 122.
- the second generative model 122 is, for example, a self-attention layer for a second modal.
- the output device 100 generates a coupling vector including a predetermined vector, the generated first vector, and the generated second vector.
- the predetermined vector is set in advance by the user, for example.
- the predetermined vector is an aggregation vector for aggregating the first vector and the second vector.
- the predetermined vector is, for example, a vector in which elements are randomly set.
- the predetermined vector is, for example, a vector whose elements are default values set by the user.
- the connection vector is obtained, for example, by combining a predetermined vector, a first vector, and a second vector in order.
- the output device 100 generates a third vector based on the correlation between two different types of vectors obtained from the combined vector.
- the two different types of vectors are, for example, a query vector and a key vector.
- the third vector is a vector that aggregates the first vector and the second vector.
- the output device 100 uses the third generation model 130 to generate a third vector.
- the third generative model 130 is, for example, a self-attention layer.
- the output device 100 correlates the portion included in the key vector based on the first vector and the second vector with the portion included in the query vector based on the predetermined vector.
- a predetermined vector can be corrected based on.
- the output device 100 can correct a predetermined vector by, for example, a portion of a vector having a value based on the first vector and the second vector based on the correlation. Therefore, the output device 100 can perform processing such that the first vector and the second vector are aggregated with respect to the predetermined vector, and the third vector can be obtained.
- the output device 100 outputs the generated third vector.
- the output format is, for example, display on a display, print output to a printer, transmission to another computer, or storage in a storage area.
- the output device 100 aggregates the first vector and the second vector, and is useful for solving the problem among the vector based on the information of the first modal and the vector based on the information of the second modal.
- a third vector that tends to reflect information can be generated and made available.
- the output device 100 can use, for example, a third vector that accurately expresses the features of a real-world image or document that are useful for solving a problem on a computer.
- the output device 100 uses, for example, the third vector, the first correction model 111, the second correction model 112, the first generation model 121, the second generation model 122, and the third.
- the generation model 130 and the like can be updated. Therefore, the output device 100 can easily reflect information useful for solving the problem among the vector based on the information of the first modal and the vector based on the information of the second modal in the third vector. it can. As a result, the output device 100 can improve the accuracy of the subsequent solution when the problem is solved.
- the output device 100 When solving a problem, for example, the output device 100 tends to reflect information useful for solving the problem, which is a vector based on the information of the first modal and a vector based on the information of the second modal.
- the vector of can be used, and the accuracy of the solution when solving the problem can be improved.
- the output device 100 can accurately determine the target situation in solving the problem of determining the target situation based on the image and the document.
- the problem of determining the situation of the subject is, for example, the problem of determining whether the situation of the subject is a positive situation or a negative situation.
- FIG. 2 is an explanatory diagram showing an example of the information processing system 200.
- the information processing system 200 includes an output device 100, a client device 201, and a terminal device 202.
- the output device 100 and the client device 201 are connected via a wired or wireless network 210.
- the network 210 is, for example, a LAN (Local Area Network), a WAN (Wide Area Network), the Internet, or the like. Further, in the information processing system 200, the output device 100 and the terminal device 202 are connected via a wired or wireless network 210.
- the output device 100 has a Co-Attention Network that generates a third vector based on a vector based on the information of the first modal and a vector based on the information of the second modal.
- the first modal is, for example, an image modal.
- the second modal is, for example, a modal for documents.
- the Co-Attention Network is, for example, the first correction model 111, the second correction model 112, the first generation model 121, the second generation model 122, and the third generation shown in FIG. Corresponds to the whole with model 130.
- the output device 100 updates the Co-Attention Network based on the teacher data.
- the teacher data is, for example, a source for generating a vector based on the information of the first modal as a sample and a vector based on the information of the second modal as a sample. Correspondence information in which the second modal information and the correct answer data are associated with each other.
- the teacher data is input to the output device 100 by the user of the output device 100, for example.
- the correct answer data shows, for example, the correct answer when the problem is solved based on the third vector. For example, if the first modal is a modal about an image, then the information in the first modal from which the vector based on the information in the first modal is generated is the image. For example, if the second modal is a modal about a document, the information in the second modal from which the vector based on the information in the second modal is generated is the document.
- the output device 100 acquires, for example, by generating a vector based on the information of the first modal from the image which is the information of the first modal of the teacher data, and obtains the information of the second modal of the teacher data. Is obtained by generating a vector based on the information of the second modal from the document. Then, the output device 100 uses an error back propagation or the like based on the vector based on the acquired first modal information, the vector based on the acquired second modal information, and the correct answer data of the teacher data, and causes Co. -Update the Attention Network. The output device 100 may update the Co-Attention Network by a learning method other than error back propagation.
- the output device 100 acquires a vector based on the information of the first modal and a vector based on the information of the second modal. Then, the output device 100 uses Co-Attention Network to generate a third vector based on the vector based on the acquired first modal information and the vector based on the acquired second modal information. Then, based on the generated third vector, solve the problem. After that, the output device 100 transmits the result of solving the problem to the client device 201.
- the output device 100 acquires, for example, a vector based on the first modal information input to the output device 100 by the user of the output device 100. Further, the output device 100 may acquire a vector based on the first modal information by receiving the vector from the client device 201 or the terminal device 202. Further, the output device 100 may acquire, for example, the information of the first modal which is the source for generating the vector based on the information of the first modal by receiving the information of the first modal from the client device 201 or the terminal device 202. For example, if the first modal is a modal about an image, then the information in the first modal from which the vector based on the information in the first modal is generated is the image.
- the output device 100 acquires, for example, a vector based on the second modal information input to the output device 100 by the user of the output device 100. Further, the output device 100 may acquire a vector based on the second modal information by receiving the vector from the client device 201 or the terminal device 202. Further, the output device 100 may acquire, for example, the information of the second modal which is the source for generating the vector based on the information of the second modal by receiving the information of the second modal from the client device 201 or the terminal device 202. For example, if the second modal is a modal about a document, the information in the second modal from which the vector based on the information in the second modal is generated is the document.
- the output device 100 uses Co-Attention Network to generate a third vector based on the vector based on the acquired first modal information and the vector based on the acquired second modal information. Then, based on the generated third vector, solve the problem. After that, the output device 100 transmits the result of solving the problem to the client device 201.
- the output device 100 is, for example, a server, a PC (Personal Computer), or the like.
- the client device 201 is a computer capable of communicating with the output device 100.
- the client device 201 may transmit, for example, a vector based on the information of the first modal to the output device 100. Further, the client device 201 may transmit, for example, the information of the first modal which is the source for generating the vector based on the information of the first modal to the output device 100.
- the client device 201 may transmit, for example, a vector based on the second modal information to the output device 100. Further, the client device 201 may transmit, for example, the information of the second modal, which is the source of generating the vector based on the information of the second modal, to the output device 100.
- the client device 201 receives and outputs the result of solving the problem by the output device 100.
- the output format is, for example, display on a display, print output to a printer, transmission to another computer, or storage in a storage area.
- the client device 201 is, for example, a PC, a tablet terminal, a smartphone, or the like.
- the terminal device 202 is a computer capable of communicating with the output device 100.
- the terminal device 202 may transmit, for example, a vector based on the information of the first modal to the output device 100. Further, the terminal device 202 may transmit, for example, the information of the first modal which is the source for generating the vector based on the information of the first modal to the output device 100.
- the terminal device 202 may transmit, for example, a vector based on the information of the second modal to the output device 100. Further, the terminal device 202 may transmit, for example, the information of the second modal, which is the source of generating the vector based on the information of the second modal, to the output device 100.
- the terminal device 202 is, for example, a PC, a tablet terminal, a smartphone, an electronic device, an IoT device, a sensor device, or the like. Specifically, the terminal device 202 may be a surveillance camera.
- the output device 100 updates the Co-Attention Network and solves the problem by using the Co-Attention Network
- another computer may update the Co-Attention Network, and the output device 100 may solve the problem using the Co-Attention Network received from the other computer.
- the output device 100 may update the Co-Attention Network and provide it to another computer, and the other computer may solve the problem by using the Co-Attention Network.
- the teacher data is the source that generates the information of the first modal that is the source for generating the vector based on the information of the first modal that is the sample, and the source that generates the vector based on the information of the second modal that is the sample.
- the case where the second modal information is associated with the correct answer data has been described, but the present invention is not limited to this.
- the teacher data is correspondence information in which the vector based on the information of the first modal as a sample, the vector based on the information of the second modal as a sample, and the correct answer data are associated with each other. Good.
- the output device 100 is a device different from the client device 201 and the terminal device 202 has been described, but the present invention is not limited to this.
- the output device 100 may be integrated with the client device 201.
- the output device 100 may be integrated with the terminal device 202.
- the output device 100 realizes the Co-Attention Network in terms of software has been described, but the present invention is not limited to this.
- the output device 100 may realize the Co-Attention Network electronically.
- the output device 100 stores an image and a document that serves as a question about the image.
- the question text is, for example, "what is cut in the image”. Then, the output device 100 solves the problem of estimating the answer sentence to the question sentence based on the image and the document.
- the output device 100 estimates, for example, an answer sentence to a question sentence about what is cut in the image based on the image and the document, and transmits the answer sentence to the client device 201.
- the terminal device 202 is a surveillance camera, and an image of the target is transmitted to the output device 100.
- the object is specifically the appearance of the fitting room.
- the output device 100 stores a document that serves as an explanatory text about the target.
- the explanation is an explanation that the curtain of the fitting room tends to be closed while the person is using the fitting room.
- the output device 100 solves the problem of determining the degree of risk based on the image and the document.
- the degree of risk is, for example, an index value indicating the high possibility that a person who has not completed evacuation remains in the fitting room.
- the output device 100 determines, for example, the degree of risk indicating the high possibility that a person who has not completed evacuation remains in the fitting room in the event of a disaster.
- the output device 100 stores an image forming a moving image and a document serving as an explanatory text about the image.
- the moving image is, for example, a moving image showing the state of cooking.
- the explanation is specifically an explanation about the cooking procedure.
- the output device 100 solves the problem of determining the degree of risk based on the image and the document.
- the degree of risk is, for example, an index value indicating the high degree of risk during cooking.
- the output device 100 determines, for example, a degree of risk indicating a high degree of risk during cooking.
- FIG. 3 is a block diagram showing a hardware configuration example of the output device 100.
- the output device 100 includes a CPU (Central Processing Unit) 301, a memory 302, a network I / F (Interface) 303, a recording medium I / F 304, and a recording medium 305. Further, each component is connected by a bus 300.
- the CPU 301 controls the entire output device 100.
- the memory 302 includes, for example, a ROM (Read Only Memory), a RAM (Random Access Memory), a flash ROM, and the like. Specifically, for example, a flash ROM or ROM stores various programs, and RAM is used as a work area of CPU 301. The program stored in the memory 302 is loaded into the CPU 301 to cause the CPU 301 to execute the coded process.
- the network I / F 303 is connected to the network 210 through a communication line, and is connected to another computer via the network 210. Then, the network I / F 303 controls the internal interface with the network 210 and controls the input / output of data from another computer.
- the network I / F 303 is, for example, a modem or a LAN adapter.
- the recording medium I / F 304 controls data read / write to the recording medium 305 according to the control of the CPU 301.
- the recording medium I / F 304 is, for example, a disk drive, an SSD (Solid State Drive), a USB (Universal Serial Bus) port, or the like.
- the recording medium 305 is a non-volatile memory that stores data written under the control of the recording medium I / F 304.
- the recording medium 305 is, for example, a disk, a semiconductor memory, a USB memory, or the like.
- the recording medium 305 may be detachable from the output device 100.
- the output device 100 may include, for example, a keyboard, a mouse, a display, a printer, a scanner, a microphone, a speaker, and the like, in addition to the above-described components. Further, the output device 100 may have a plurality of recording media I / F 304 and recording media 305. Further, the output device 100 does not have to have the recording medium I / F 304 or the recording medium 305.
- the hardware configuration example of the client device 201 is specifically the same as the hardware configuration example of the output device 100 shown in FIG. 3, and thus the description thereof will be omitted.
- the hardware configuration example of the terminal device 202 is specifically the same as the hardware configuration example of the output device 100 shown in FIG. 3, and thus the description thereof will be omitted.
- FIG. 4 is a block diagram showing a functional configuration example of the output device 100.
- the output device 100 includes a storage unit 400, an acquisition unit 401, a first correction unit 402, a first generation unit 403, a second correction unit 404, a second generation unit 405, and a third. It includes a generation unit 406, an analysis unit 407, and an output unit 408.
- the storage unit 400 is realized by, for example, a storage area such as the memory 302 or the recording medium 305 shown in FIG.
- a storage area such as the memory 302 or the recording medium 305 shown in FIG.
- the storage unit 400 may be included in a device different from the output device 100, and the stored contents of the storage unit 400 may be referred to by the output device 100.
- the acquisition unit 401 to the output unit 408 function as an example of the control unit.
- the acquisition unit 401 to the output unit 408 may be, for example, by causing the CPU 301 to execute a program stored in a storage area such as the memory 302 or the recording medium 305 shown in FIG. 3, or the network I / F 303. To realize the function.
- the processing result of each functional unit is stored in a storage area such as the memory 302 or the recording medium 305 shown in FIG. 3, for example.
- the storage unit 400 stores various information referred to or updated in the processing of each functional unit.
- the storage unit 400 stores the Co-Attention Network.
- the Co-Attention Network is a model that generates a third vector based on a vector based on the information of the first modal and a vector based on the information of the second modal.
- the Co-Attention Network covers the first target attention layer, the second target attention layer, the first self-attention layer, the second self-attention layer, and the third self-attention layer, which will be described later. Correspond.
- the first target attention layer is related to, for example, the first modal.
- the first target attention layer is a model that corrects the vector based on the information of the first modal.
- the first self-attention layer relates to, for example, the first modal.
- the first self-attention layer is a model that further corrects the corrected vector based on the information of the first modal to generate the first vector.
- the second target attention layer relates to, for example, a second modal.
- the second target attention layer is a model that corrects the vector based on the information of the second modal.
- the second self-attention layer relates to, for example, a second modal.
- the second self-attention layer is a model that further corrects the corrected vector based on the information of the second modal to generate the second vector.
- the third self-attention layer is a model that generates a third vector based on the first vector and the second vector.
- the first modal is a modal related to images
- the second modal is a modal related to documents.
- the first modal is an image modal
- the second modal is an audio modal.
- the first modal is a modal for a document in a first language
- the second modal is a modal for a document in a second language.
- the Co-Attention Network is updated by the analysis unit 407 or used when solving a problem by the analysis unit 407.
- the storage unit 400 stores, for example, the parameters of the Co-Attention Network. Specifically, the storage unit 400 includes a first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third self-attention layer.
- the parameters are described in detail below.
- the storage unit 400 may store teacher data.
- the teacher data is, for example, a source for generating a vector based on the information of the first modal as a sample and a vector based on the information of the second modal as a sample. Correspondence information in which the second modal information and the correct answer data are associated with each other.
- the teacher data is input by the user, for example.
- the correct answer data shows, for example, the correct answer when the problem is solved based on the third vector.
- the information of the first modal that is the source of generating a vector based on the information of the first modal is an image.
- the second modal is a modal about a document
- the information in the second modal from which the vector based on the information in the second modal is generated is the document.
- the teacher data may be correspondence information in which the vector based on the information of the first modal as a sample, the vector based on the information of the second modal as a sample, and the correct answer data are associated with each other.
- the acquisition unit 401 acquires various information used for processing of each functional unit.
- the acquisition unit 401 stores various acquired information in the storage unit 400 or outputs it to each function unit. Further, the acquisition unit 401 may output various information stored in the storage unit 400 to each function unit.
- the acquisition unit 401 acquires various information based on, for example, a user's operation input.
- the acquisition unit 401 may receive various information from a device different from the output device 100, for example.
- the acquisition unit 401 acquires a vector based on the information of the first modal and a vector based on the information of the second modal.
- the acquisition unit 401 acquires teacher data, and based on the teacher data, acquires a vector based on the information of the first modal and a vector based on the information of the second modal. To do.
- the acquisition unit 401 accepts the input of teacher data by the user, and from the teacher data, the information of the first modal that is the source of generating the vector based on the information of the first modal, and the information of the second modal. Get the information of the second modal from which the information-based vector is generated. Then, the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on the various acquired information.
- the acquisition unit 401 acquires an image included in the teacher data and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 specifically acquires the document included in the teacher data and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 receives the teacher data from the client device 201 or the terminal device 202, and from the received teacher data, the acquisition unit 401 of the first modal that is the source of generating a vector based on the information of the first modal.
- the information and the information of the second modal from which the vector based on the information of the second modal is generated may be acquired.
- the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on the acquired information.
- the acquisition unit 401 acquires an image included in the teacher data and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 specifically acquires the document included in the teacher data and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 accepts the input of teacher data by the user, and may acquire the vector based on the first modal information and the vector based on the second modal information as they are from the teacher data. Good.
- the acquisition unit 401 receives the teacher data from the client device 201 or the terminal device 202, and from the received teacher data, a vector based on the first modal information and a vector based on the second modal information. And may be acquired as it is.
- the acquisition unit 401 uses the Co-Attention Network to acquire a vector based on the information of the first modal and a vector based on the information of the second modal when solving the problem.
- the acquisition unit 401 for example, is a second modal information source for generating a vector based on the first modal information by the user and a second modal source for generating a vector based on the second modal information. Accepts input with modal information. Then, the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on various input information.
- the acquisition unit 401 acquires an image and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 specifically acquires a document and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 of the first modal information that is the source of generating the vector based on the information of the first modal and the second modal that is the source of generating the vector based on the information of the second modal.
- Information may be received from the client device 201 or the terminal device 202. Then, the acquisition unit 401 generates a vector based on the information of the first modal and a vector based on the information of the second modal based on the various acquired information.
- the acquisition unit 401 acquires an image and generates a feature amount vector related to the acquired image as a vector based on the first modal information.
- the feature amount vector related to the image is, for example, an arrangement of the feature amount vectors for each object appearing in the image.
- the acquisition unit 401 acquires a document and generates a feature quantity vector related to the acquired document as a vector based on the second modal information.
- the feature vector related to the document is, for example, an arrangement of the feature vectors for each word included in the document.
- the acquisition unit 401 may accept, for example, input by the user of a vector based on the information of the first modal and a vector based on the information of the second modal.
- the acquisition unit 401 may receive, for example, a vector based on the information of the first modal and a vector based on the information of the second modal from the client device 201 or the terminal device 202.
- the acquisition unit 401 may accept a start trigger to start processing of any of the functional units.
- the start trigger is, for example, that there is a predetermined operation input by the user.
- the start trigger may be, for example, the receipt of predetermined information from another computer.
- the start trigger may be, for example, that any functional unit outputs predetermined information.
- the acquisition unit 401 receives, for example, the acquisition of the vector based on the information of the first modal and the vector based on the information of the second modal as a start trigger for starting the processing of each functional unit.
- the first correction unit 402 corrects the vector based on the information of the first modal based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal. Correlation is expressed, for example, by the degree of similarity between a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal.
- the vector obtained from the vector based on the information of the first modal is, for example, a query.
- the vector obtained from the vector based on the information of the second modal is, for example, a key.
- the similarity is expressed by, for example, the inner product.
- the degree of similarity may be expressed by, for example, the sum of squares of differences.
- the first correction unit 402 uses, for example, the first target attention layer to obtain a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal. Correct the informed vector of the first modal based on the inner product.
- the first correction unit 402 uses the first target attention layer to obtain a query obtained from a vector based on the information of the first modal and a vector based on the information of the second modal. Correct the informed vector of the first modal based on the inner product with the key.
- an example of correcting a vector based on the first modal information is shown in, for example, an operation example described later with reference to FIG.
- the first correction unit 402 uses the vector based on the information of the first modal as the component that is relatively closely related to the vector based on the information of the first modal among the vectors based on the information of the second modal.
- the vector based on the information of the first modal can be corrected so that it is strongly reflected in.
- the first generation unit 403 generates the first vector based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the first modal. Correlation is represented, for example, by the similarity of two different types of vectors obtained from a vector based on the corrected first modal information. Two different types of vectors are, for example, a query and a key. The similarity is expressed by, for example, the inner product. The degree of similarity may be expressed by, for example, the sum of squares of differences.
- the first generation unit 403 for example, using the first self-attention layer, is corrected based on the inner product of two different types of vectors obtained from the corrected first modal information-based vector.
- the vector based on the information of the first modal is further corrected to generate the first vector.
- the first generation unit 403 uses the first self-attention layer and is corrected based on the inner product of the query and the key obtained from the vector based on the information of the first modal after correction.
- the vector based on the information of the first modal of is further corrected to generate the first vector.
- an example of generating the first vector is shown in, for example, an operation example described later with reference to FIG.
- the first generation unit 403 further increases the vector based on the corrected first modal information so that the more useful component of the vector based on the corrected first modal information becomes larger. It can be corrected.
- the second correction unit 404 corrects the vector based on the second modal information based on the correlation between the vector based on the first modal information and the vector based on the second modal information. Correlation is expressed, for example, by the degree of similarity between a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal.
- the vector obtained from the vector based on the information of the first modal is, for example, a key.
- the vector obtained from the vector based on the information of the second modal is, for example, a query.
- the similarity is expressed by, for example, the inner product.
- the degree of similarity may be expressed by, for example, the sum of squares of differences.
- the second correction unit 404 uses, for example, a second target attention layer to obtain a vector obtained from a vector based on the information of the first modal and a vector obtained from a vector based on the information of the second modal. Correct the informed vector of the second modal based on the inner product.
- the second correction unit 404 is obtained from the key obtained from the vector based on the information of the first modal and the vector based on the information of the second modal by using the second target attention layer. Correct the informed vector of the second modal based on the inner product with the query.
- an example of correcting a vector based on the second modal information is shown in, for example, an operation example described later with reference to FIG.
- the second correction unit 404 uses the vector based on the information of the second modal as the component that is relatively closely related to the vector based on the information of the second modal among the vectors based on the information of the first modal.
- the vector based on the information of the second modal can be corrected so that it is strongly reflected in.
- the second generation unit 405 generates a second vector based on the correlation between two different types of vectors obtained from the corrected vector based on the information of the second modal. Correlation is represented, for example, by the similarity of two different types of vectors obtained from a vector based on the corrected second modal information.
- Two different types of vectors are, for example, a query and a key.
- the similarity is expressed by, for example, the inner product.
- the degree of similarity may be expressed by, for example, the sum of squares of differences.
- the second generator 405 uses a second self-attention layer and is based on the inner product of two different types of vectors obtained from the corrected second modal information-based vector.
- the vector based on the information of the second modal is further corrected to generate the second vector.
- the second generation unit 405 uses the second self-attention layer and is corrected based on the inner product of the query and the key obtained from the vector based on the corrected second modal information.
- the vector based on the information of the second modal of is further corrected to generate the second vector.
- an example of generating the second vector is shown in, for example, an operation example described later with reference to FIG.
- the second generation unit 405 further increases the vector based on the corrected second modal information so that the more useful component of the corrected vector based on the second modal information becomes larger. It can be corrected.
- the output device 100 may repeat the operations of the first correction unit 402 to the second generation unit 405 once or more. For example, when the output device 100 repeats the operations of the first correction unit 402 to the second generation unit 405, the output device 100 sets the generated first vector to a vector based on new first modal information. , Set the generated second vector to a vector based on the new second modal information. As a result, the output device 100 can further improve the accuracy of the solution when the problem is solved.
- the output device 100 can generate a third vector in a more useful state, for example, from the viewpoint of improving the accuracy of the solution when solving the problem.
- the third generation unit 406 generates a coupling vector.
- the coupling vector includes a predetermined vector, a generated first vector, and a generated second vector.
- the third generation unit 406 generates, for example, a coupling vector in which a predetermined vector, the first vector, and the second vector are combined.
- the third generation unit 406 was generated last with a predetermined vector, the first vector generated last, and the first vector generated last, for example, after repeating the operations of the first correction unit 402 to the second generation unit 405. Generate a combined vector by combining with the second vector.
- the third generation unit 406 generates a third vector that aggregates the first vector and the second vector based on the correlation between two different types of vectors obtained from the coupling vector. Correlation is represented, for example, by the similarity of two different types of vectors obtained from the combined vector. Two different types of vectors are, for example, a query and a key. The similarity is expressed by, for example, the inner product. The degree of similarity may be expressed by, for example, the sum of squares of differences.
- the third generation unit 406 corrects the coupling vector and generates the third vector, for example, using the third self-attention layer, based on the inner product of two different types of vectors obtained from the coupling vector. ..
- the third vector is, for example, a partial vector included in a position corresponding to a predetermined vector among the corrected coupling vectors.
- the third generator 406 uses the third self-attention layer to correct the join vector based on the inner product of the query and the key obtained from the join vector, thereby correcting the third vector. Generate a corrected coupling vector containing.
- an example of generating the third vector is shown in, for example, an operation example described later with reference to FIG.
- the third generation unit 406 can generate a third vector useful from the viewpoint of improving the accuracy of the solution when solving the problem and make it referenceable.
- the analysis unit 407 updates the Co-Attention Network based on the generated third vector.
- the analysis unit 407 for example, based on the third vector, has a first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third. Update with the self-attention layer. The update is performed, for example, by error backpropagation.
- the analysis unit 407 solves the problem on a trial basis using the generated third vector and compares it with the correct answer data.
- One example of the problem is, for example, the problem of determining whether the situation relating to the first modal and the second modal is a positive situation or a negative situation.
- One example of the problem is, specifically, the problem of determining whether the situation suggested by the image is a situation in which humans can be harmed or a situation in which humans are not harmed.
- the analysis unit 407 includes a first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third self. Update with the attention layer.
- the analysis unit 407 can update various attention layers so that the third vector can be generated in a more useful state, and can improve the accuracy of the solution when the problem is solved.
- the analysis unit 407 solves the actual problem using the generated third vector.
- One example of the problem is, for example, the problem of determining whether the situation relating to the first modal and the second modal is a positive situation or a negative situation.
- One example of the problem is, specifically, the problem of determining whether the situation suggested by the image is a situation in which humans can be harmed or a situation in which humans are not harmed. As a result, the analysis unit 407 can improve the accuracy of the solution when the problem is solved.
- the output unit 408 outputs the processing result of any of the functional units.
- the output format is, for example, display on a display, print output to a printer, transmission to an external device by the network I / F 303, or storage in a storage area such as a memory 302 or a recording medium 305.
- the output unit 408 can notify the user of the processing result of each functional unit, and the convenience of the output device 100 can be improved.
- the output unit 408 outputs, for example, the updated Co-Attention Network.
- the output unit 408 includes an updated first target attention layer, a second target attention layer, a first self-attention layer, a second self-attention layer, and a third self-attention. Output layers.
- the output unit 408 can refer to the updated Co-Attention Network. Therefore, the output unit 408 can improve the accuracy of the solution when the problem is solved by using the updated Co-Attention Network, for example, on another computer.
- the output unit 408 outputs, for example, the generated third vector.
- the output unit 408 can refer to the third vector, make the Co-Attention Network updatable, or improve the accuracy of the solution when solving the problem.
- the output unit 408 outputs, for example, the third vector in association with the result of solving the actual problem. Specifically, the output unit 408 outputs the third vector in association with the determined situation. As a result, the output unit 408 can make the result of solving the problem visible to the user or the like.
- the output unit 408 may output the result of solving the actual problem without outputting the third vector, for example. Specifically, the output unit 408 outputs the determined situation without outputting the third vector. As a result, the output unit 408 can make the result of solving the problem visible to the user or the like.
- FIG. 5 is an explanatory diagram showing a specific example of Co-Attention Network 500.
- Co-Attention Network 500 may be referred to as "CAN500”.
- the target attention may be expressed as "TA”.
- SA self-attention
- the CAN 500 has an image TA layer 501, an image SA layer 502, a document TA layer 503, a document SA layer 504, a binding layer 505, and an integrated SA layer 506.
- the CAN 500 outputs the vector Z T in response to the input of the feature amount vector L related to the document and the feature amount vector I related to the image.
- the feature quantity vector L related to the document is, for example, an arrangement of M feature quantity vectors related to the document.
- the M feature vector is, for example, a feature vector indicating M words included in the document.
- the feature amount vector I related to the image is, for example, an arrangement of N feature amount vectors related to the image.
- the N feature vector is, for example, a feature vector indicating N objects in the image.
- the image TA layer 501 accepts inputs of the feature amount vector I related to the image and the feature amount vector L related to the document.
- the image TA layer 501 corrects the feature vector I for the image based on the query obtained from the feature vector I for the image and the keys and values obtained from the feature vector L for the document.
- the image TA layer 501 outputs the feature amount vector I related to the corrected image to the image SA layer 502. Specific examples of the image TA layer 501 will be described later with reference to, for example, FIG.
- the image SA layer 502 accepts the input of the feature amount vector I related to the corrected image.
- the image SA layer 502 further corrects the feature vector I related to the corrected image based on the query, key, and value obtained from the feature vector I related to the corrected image, and generates a new feature vector Z I. And output to the bond layer 505.
- a specific example of the image SA layer 502 will be described later with reference to, for example, FIG.
- the document TA layer 503 accepts inputs of the feature amount vector L related to the document and the feature amount vector I related to the image.
- the document TA layer 503 corrects the feature vector L related to the document based on the query obtained from the feature vector L related to the document and the keys and values obtained from the feature vector I related to the image.
- the document TA layer 503 outputs the feature amount vector L related to the corrected document to the document SA layer 504.
- a specific example of the document TA layer 503 will be described later with reference to, for example, FIG.
- the document SA layer 504 accepts the input of the feature amount vector L related to the corrected document.
- the document SA layer 504 further corrects the feature vector L related to the corrected document based on the query, key, and value obtained from the feature vector L related to the corrected document, and generates a new feature vector Z L. And output. Specific examples of the document SA layer 504 will be described later with reference to, for example, FIG.
- the coupling layer 505 receives inputs of the aggregation vector H, the feature amount vector Z I, and the feature amount vector Z L.
- the coupling layer 505 combines the aggregation vector H, the feature quantity vector Z I, and the feature quantity vector Z L to generate the coupling vector C, and outputs the coupling vector C to the integrated SA layer 506.
- the integrated SA layer 506 accepts the input of the coupling vector C.
- the integrated SA layer 506 corrects the coupling vector C based on the query, key, and value obtained from the coupling vector C, and generates and outputs the feature vector Z T.
- the feature vector Z T includes an aggregate vector Z H , an integrated feature vector Z 1 to Z M related to the document, and an integrated feature vector Z M + 1 to Z M + N related to the image.
- the output device 100 can generate a feature vector Z T including an aggregate vector Z H , which is useful from the viewpoint of improving the accuracy of the solution when the problem is solved, and make it referenceable. Therefore, the output device 100 can improve the accuracy of the solution when the problem is solved.
- the output device 100 can further improve the accuracy of the solution when the problem is solved.
- the SA layer 600 such as the image SA layer 502 forming the CAN 500, the document SA layer 504, and the integrated SA layer 506 will be described.
- the TA layer 610 such as the image TA layer 501 and the document TA layer 503 forming the CAN 500 will be described.
- FIG. 6 is an explanatory diagram showing a specific example of the SA layer 600 and a specific example of the TA layer 610.
- Multi-Head Attention may be referred to as "MHA”.
- Add & Norm may be referred to as "A & N”.
- Feed Forward may be described as "FF”.
- the SA layer 600 has an MHA layer 601, an A & N layer 602, an FF layer 603, and an A & N layer 604.
- the MHA layer 601 generates a correction vector R that corrects the input vector X based on the query Q, the key K, and the value V obtained from the input vector X, and outputs the correction vector R to the A & N layer 602.
- the MHA layer 601 divides the input vector X into Head vectors for processing. Head is a natural number of 1 or more.
- the A & N layer 602 is normalized after adding the input vector X and the correction vector R, and the normalized vector is output to the FF layer 603 and the A & N layer 604.
- the FF layer 603 compresses the normalized vector and outputs the compressed vector to the A & N layer 604.
- the A & N layer 604 adds the normalized vector and the compressed vector, normalizes the vector, generates an output vector Z, and outputs the output vector Z.
- the TA layer 610 has an MHA layer 611, an A & N layer 612, an FF layer 613, and an A & N layer 614.
- the MHA layer 611 generates a correction vector R that corrects the input vector X based on the query Q obtained from the input vector X and the key K and the value V obtained from the input vector Y, and outputs the correction vector R to the A & N layer 612. .
- the A & N layer 612 adds the input vector X and the correction vector R and normalizes them, and outputs the normalized vector to the FF layer 613 and the A & N layer 614.
- the FF layer 613 compresses the normalized vector and outputs the compressed vector to the A & N layer 614.
- the A & N layer 614 adds and normalizes the normalized vector and the compressed vector, generates an output vector Z, and outputs the output vector Z.
- the above-mentioned MHA layer 601 and MHA layer 611 are formed by Head Attention layers 620.
- the Attention layer 620 has a MatMul layer 621, a Scale layer 622, a Mask layer 623, a SoftMax layer 624, and a MatMul layer 625.
- MatMul layer 621 calculates the inner product of query Q and key K and sets it in Score.
- the Scale layer 622 divides the entire Score by a constant a and updates it.
- the Mask layer 623 may mask the updated Score.
- the SoftMax layer 624 normalizes the updated Score and sets it to Att.
- the MatMul layer 625 calculates the inner product of Att and the value V and sets it in the correction vector R.
- the input vector X is the feature amount vector X related to the image represented by the following equation (1).
- x 1 , x 2 , and x 3 are d-dimensional vectors.
- x 1 , x 2 , and x 3 correspond to the objects in the image, respectively.
- the query Q is calculated by the following equation (2).
- W Q is a transformation matrix and is set by learning.
- the key K is calculated by the following formula (3).
- W K is a transformation matrix and is set by learning.
- the value V is calculated by the following formula (4).
- W V is a transformation matrix and is set by learning.
- the query Q, the key K, and the value V have the same dimensions as the input vector X.
- the MatMul layer 621 calculates the inner product of the query Q and the key K as shown in the following equation (5), and sets it in Score.
- the Scale layer 622 is updated by dividing the entire Score by the constant a, as shown in the following equation (6).
- the Mask layer 623 omits the masking process.
- the SoftMax layer 624 normalizes the updated Score and sets it to Att.
- the MatMul layer 625 calculates the inner product of Att and the value V and sets it in the correction vector R.
- the MHA layer 601 generates the correction vector R as described above.
- the A & N layer 602 adds and normalizes the input vector X and the correction vector R, and updates the input vector X.
- ⁇ is defined by the following equation (11).
- ⁇ is defined by the following equation (12).
- the FF layer 603 converts the updated input vector X and sets the conversion vector X'.
- f is an activation function.
- the A & N layer 604 adds and normalizes the updated input vector X and the set conversion vector X', and generates an output vector Z.
- the input vector X is the feature amount vector X related to the image represented by the above equation (1).
- x 1 , x 2 , and x 3 are d-dimensional vectors.
- x 1 , x 2 , and x 3 correspond to the objects in the image, respectively.
- the input vector Y is a feature vector Y related to the document represented by the following equation (14).
- y 1 , y 2 , and y 3 are d-dimensional vectors.
- y 1 , y 2 , and y 3 correspond to the words contained in the document, respectively.
- the query Q is calculated by the following equation (15).
- W Q is a transformation matrix and is set by learning.
- the key K is calculated by the following formula (16).
- W K is a transformation matrix and is set by learning.
- the value V is calculated by the following formula (17).
- W V is a transformation matrix and is set by learning.
- the query Q has the same dimensions as the input vector X.
- the key K and the value V have the same dimensions as the input vector Y.
- the MatMul layer 621 calculates the inner product of the query Q and the key K as shown in the above equation (5), and sets it in Score. As shown in the above equation (6), the Scale layer 622 divides the entire Score by the constant a and updates it. Here, the Mask layer 623 omits the masking process. As shown in the above equation (7), the SoftMax layer 624 normalizes the updated Score and sets it to Att. As shown in the above equation (8), the MatMul layer 625 calculates the inner product of Att and the value V and sets it in the correction vector R.
- the MHA layer 601 generates the correction vector R as described above.
- the A & N layer 602 adds and normalizes the input vector X and the correction vector R, and updates the input vector X.
- the FF layer 603 converts the updated input vector X and sets the conversion vector X'.
- the A & N layer 604 adds and normalizes the updated input vector X and the set conversion vector X', and generates an output vector Z.
- FIG. 7 is an explanatory diagram showing an example of operation using CAN500.
- the output device 100 acquires the document 700 and the image 710.
- the output device 100 tokenizes the document 700, vectorizes the token set 701, generates a feature amount vector 702 related to the document 700, and inputs the feature amount vector 702 to the CAN 500.
- the output device 100 detects an object from the image 710, vectorizes a set of partial images 711 for each object, generates a feature amount vector 712 related to the image 710, and inputs the feature amount vector 712 to the CAN 500.
- the output device 100 acquires the feature amount vector Z T from the CAN 500, and inputs the aggregate vector Z H included in the feature amount vector Z T to the risk estimator 720.
- the output device 100 acquires the estimation result No. from the risk estimator 720.
- the output device 100 can be made to estimate by the risk estimator 720 by using the aggregate vector Z H in which the features of the image and the document are reflected, and can be estimated with high accuracy.
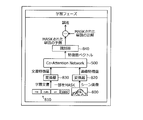
- the output device 100 performs a learning phase and learns the CAN 500.
- the output device 100 acquires, for example, an image 800 in which some scene is captured and a document 810 as subtitles corresponding to the image 800.
- Image 800 captures, for example, a scene of cutting an apple.
- the output device 100 converts the image 800 into a feature amount vector by the converter 820 and inputs the image 800 to the CAN 500. Further, the output device 100 masks the word apple of the document 810, converts it into a feature amount vector by the converter 830, and inputs it to the CAN 500.
- the output device 100 inputs the feature amount vector generated by the CAN 500 into the classifier 840, acquires the result of predicting the masked word, and calculates the error from the correct answer "apple" of the masked word.
- the output device 100 learns the CAN 500 by error back propagation based on the calculated error. Further, the output device 100 may learn the converters 820 and 830 and the classifier 840 by backpropagation of errors. Thereby, the output device 100 updates the CAN 500, and the converters 820, 830 and the classifier 840 so as to be useful from the viewpoint of estimating the word in consideration of the image 800 and the context of the document 810 which is the subtitle. Can be done. Next, the description shifts to FIG.
- the output device 100 carries out the test phase, and uses the learned converters 820 and 830 and the learned CAN500 to generate and output an answer.
- the output device 100 acquires, for example, an image 900 in which some scene is captured and a document 910 as a question sentence corresponding to the image 900.
- Image 900 captures, for example, a scene of cutting an apple.
- the output device 100 converts the image 900 into a feature amount vector by the converter 820 and inputs it to the CAN 500. Further, the output device 100 converts the document 910 into a feature amount vector by the converter 830 and inputs the document 910 to the CAN 500. The output device 100 inputs the feature amount vector generated by the CAN 500 into the answer generator 920, acquires a word to be an answer, and outputs it. As a result, the output device 100 can accurately estimate the word to be answered in consideration of the image 900 and the context of the document 910 which is a question sentence.
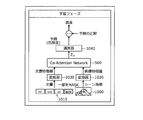
- the output device 100 performs a learning phase and learns the CAN 500.
- the output device 100 acquires, for example, an image 1000 in which some scene is captured and a document 1010 as a subtitle corresponding to the image 1000.
- Image 1000 captures, for example, a scene of cutting an apple.
- the output device 100 converts the image 1000 into a feature amount vector by the converter 1020 and inputs it to the CAN 500. Further, the output device 100 masks the word apple of the document 1010, converts it into a feature amount vector by the converter 1030, and inputs it to the CAN 500.
- the output device 100 inputs the feature amount vector generated by the CAN 500 into the classifier 1040, acquires the result of predicting the risk level of the scene shown in the image, and calculates the error from the correct answer of the risk level.
- the output device 100 learns the CAN 500 by error back propagation based on the calculated error. Further, the output device 100 learns the converters 1020 and 1030 and the classifier 1040 by backpropagation of errors. As a result, the output device 100 updates the CAN 500, the converters 1020, 1030, and the classifier 1040 so as to be useful from the viewpoint of predicting the degree of risk in consideration of the context of the image 1000 and the document 1010 which is the subtitle. be able to. Next, the description shifts to FIG.
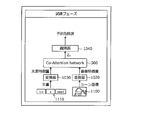
- the output device 100 carries out a test phase, predicts the degree of risk and outputs using the learned converters 1020 and 1030 and the classifier 1040 and the learned CAN500.
- the output device 100 acquires, for example, an image 1100 in which some scene is captured and a document 1110 as an explanatory text corresponding to the image.
- Image 1100 captures, for example, a scene of cutting a thigh.
- the output device 100 converts the image 1100 into a feature amount vector by the converter 1020 and inputs it to the CAN 500. Further, the output device 100 converts the document 1110 into a feature amount vector by the converter 1030 and inputs it to the CAN 500. The output device 100 inputs the feature quantity vector generated by the CAN 500 into the classifier 1040, acquires the degree of risk, and outputs the vector. As a result, the output device 100 can accurately predict the degree of risk in consideration of the context of the image 1100 and the document 1110 which is the explanatory text.
- the learning process is realized, for example, by the CPU 301 shown in FIG. 3, a storage area such as a memory 302 or a recording medium 305, and a network I / F 303.
- FIG. 12 is a flowchart showing an example of the learning processing procedure.
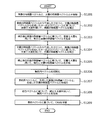
- the output device 100 acquires the feature amount vector of the image and the feature amount vector of the document (step S1201).
- the output device 100 uses the image TA layer 501 based on the query generated from the acquired image feature vector and the keys and values generated from the acquired document feature vector to image features.
- the quantity vector is corrected (step S1202).
- the output device 100 further corrects the feature amount vector of the corrected image by using the image SA layer 502 based on the feature amount vector of the corrected image, and newly generates the feature amount vector of the image. (Step S1203).
- the output device 100 uses the document TA layer 503 based on the query generated from the acquired document feature vector and the keys and values generated from the acquired image feature vector, to use the document features.
- the quantity vector is corrected (step S1204).
- the output device 100 further corrects the feature amount vector of the corrected document by using the document SA layer 504 based on the feature amount vector of the corrected document, and newly generates the feature amount vector of the document. (Step S1205).
- the output device 100 initializes the aggregation vector (step S1206). Then, the output device 100 combines the aggregation vector, the feature amount vector of the generated image, and the feature amount vector of the generated document to generate a combined vector (step S1207).
- the output device 100 corrects the coupling vector using the integrated SA layer 506 based on the coupling vector and generates an aggregate vector (step S1208). Then, the output device 100 learns the CAN 500 based on the aggregation vector (step S1209).
- the output device 100 ends the learning process.
- the output device 100 can update the parameters of the CAN 500 so that the accuracy of the solution when the problem is solved is improved.
- the output device 100 may execute the processing in the partial steps of FIG. 12 in a different order.
- the order of the processes of steps S1202 and S1203 and the processes of steps S1204 and S1205 can be exchanged.
- the output device 100 may repeatedly execute the processes of steps S1202 to S1205.
- Estimatiation processing procedure Next, an example of the estimation processing procedure executed by the output device 100 will be described with reference to FIG.
- the estimation process is realized, for example, by the CPU 301 shown in FIG. 3, a storage area such as a memory 302 or a recording medium 305, and a network I / F 303.
- FIG. 13 is a flowchart showing an example of the estimation processing procedure.
- the output device 100 acquires the feature amount vector of the image and the feature amount vector of the document (step S1301).
- the output device 100 uses the image TA layer 501 based on the query generated from the acquired image feature vector and the keys and values generated from the acquired document feature vector to image features.
- the quantity vector is corrected (step S1302).
- the output device 100 further corrects the feature amount vector of the corrected image by using the image SA layer 502 based on the feature amount vector of the corrected image, and newly generates the feature amount vector of the image. (Step S1303).
- the output device 100 uses the document TA layer 503 based on the query generated from the acquired document feature vector and the keys and values generated from the acquired image feature vector, to use the document features.
- the quantity vector is corrected (step S1304).
- the output device 100 further corrects the feature amount vector of the corrected document by using the document SA layer 504 based on the feature amount vector of the corrected document, and newly generates the feature amount vector of the document. (Step S1305).
- the output device 100 initializes the aggregation vector (step S1306). Then, the output device 100 combines the aggregation vector, the feature amount vector of the generated image, and the feature amount vector of the generated document to generate a combined vector (step S1307).
- the output device 100 corrects the coupling vector using the integrated SA layer 506 based on the coupling vector and generates an aggregate vector (step S1308). Then, the output device 100 estimates the situation using the discriminative model based on the aggregation vector (step S1309).
- the output device 100 outputs the estimated situation (step S1310). Then, the output device 100 ends the estimation process. As a result, the output device 100 can improve the accuracy of the solution when the problem is solved by using the CAN 500.
- the output device 100 may be executed by changing the order of processing of some steps in FIG. For example, the order of the processes of steps S1302 and S1303 and the processes of steps S1304 and S1305 can be exchanged. Further, the output device 100 may repeatedly execute the processes of steps S1302 to S1305.
- a vector based on the information of the first modal is obtained based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal. It can be corrected.
- the vector based on the information of the second modal can be corrected based on the correlation between the vector based on the information of the first modal and the vector based on the information of the second modal.
- the first vector can be generated based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the first modal.
- the second vector can be generated based on the correlation of two different types of vectors obtained from the corrected vector based on the information of the second modal.
- the first vector is based on the correlation of two different types of vectors obtained from a predetermined vector, a combined vector including the generated first vector and the generated second vector.
- the second vector can be aggregated to generate a third vector.
- the generated third vector can be output.
- the output device 100 aggregates the first vector and the second vector, and is useful for solving the problem among the vector based on the information of the first modal and the vector based on the information of the second modal.
- a third vector that tends to reflect information can be generated and made available. Therefore, the output device 100 can improve the accuracy of the solution when solving the problem by using the third vector.
- the first target attention layer is used and is based on the inner product of the vector obtained from the vector based on the information of the first modal and the vector obtained from the vector based on the information of the second modal. Therefore, the vector based on the information of the first modal can be corrected.
- the second target attention layer is used based on the inner product of the vector obtained from the vector based on the information of the first modal and the vector obtained from the vector based on the information of the second modal. Therefore, the vector based on the information of the second modal can be corrected.
- the corrected first is based on the inner product of two different types of vectors obtained from the corrected first modal information-based vector using the first self-attention layer.
- the vector based on the modal information can be further corrected to generate the first vector.
- the corrected second is based on the inner product of two different types of vectors obtained from the corrected second modal information-based vector using the second self-attention layer.
- a vector based on modal information can be further corrected to generate a second vector.
- a third self-attention layer is used, based on the inner product of two different types of vectors obtained from a combined vector that combines a predetermined vector, the first vector, and the second vector. , A third vector can be generated.
- the output device 100 can easily realize the process of generating the third vector by using various attention layers.
- the situation regarding the first modal and the second modal can be determined and output based on the generated third vector.
- the output device 100 can be made applicable when solving the problem of determining the situation, and the result of solving the problem can be referred to.
- the generated first vector can be set as a vector based on the new first modal information.
- the generated second vector can be set as a vector based on the new second modal information.
- the vector based on the set first modal information is corrected, the vector based on the set second modal information is corrected, the first vector is generated, and the second vector is generated.
- the generated process can be repeated one or more times.
- the first vector is based on the correlation of two different types of vectors obtained from a predetermined vector, a combined vector including the generated first vector and the generated second vector.
- the second vector can be aggregated to generate a third vector.
- the output device 100 can correct various vectors in multiple stages and further improve the accuracy of the solution when the problem is solved.
- a modal related to an image can be adopted as the first modal.
- a document-related modal can be adopted as the second modal.
- the output device 100 can be made applicable when solving a problem based on an image and a document.
- a modal related to an image can be adopted as the first modal.
- a modal related to voice can be adopted as the second modal.
- the output device 100 can be made applicable when solving a problem based on an image and a sound.
- the output device 100 as the first modal, the modal related to the document in the first language can be adopted.
- the output device 100 as the second modal, a modal relating to a document in a second language can be adopted. This makes the output device 100 applicable when solving a problem based on two documents in different languages.
- the output device 100 it is possible to determine and output a positive situation or a negative situation based on the generated third vector. As a result, the output device 100 can be made applicable when solving a problem for determining a positive situation or a negative situation, and the result of solving the problem can be referred to.
- the output device 100 based on the generated third vector, the first target attention layer, the second target attention layer, the first self-attention layer, the second self-attention layer, and the second It is possible to update with three self-attention layers. As a result, the output device 100 can update various attention layers so that the third vector can be generated in a more useful state, and can improve the accuracy of the solution when the problem is solved.
- the output method described in this embodiment can be realized by executing a program prepared in advance on a computer such as a PC or a workstation.
- the output program described in this embodiment is recorded on a computer-readable recording medium and executed by being read from the recording medium by the computer.
- the recording medium is a hard disk, a flexible disk, a CD (Compact Disc) -ROM, an MO, a DVD (Digital Any Disc), or the like.
- the output program described in this embodiment may be distributed via a network such as the Internet.
- Output device 111,112 Correction model 121,122,130 Generation model 200 Information processing system 201 Client device 202 Terminal device 210 Network 300 Bus 301 CPU 302 Memory 303 Network I / F 304 Recording medium I / F 305 Recording medium 400 Storage unit 401 Acquisition unit 402 First correction unit 403 First generation unit 404 Second correction unit 405 Second generation unit 406 Third generation unit 407 Analysis unit 408 Output unit 500 Co-Attention Network 501 Image TA layer 502 Image SA layer 503 Document TA layer 504 Document SA layer 505 Bonding layer 506 Integrated SA layer 510 Group 600 SA layer 601,611 MHA layer 602,604,612,614 A & N layer 603,613 FF layer 610 TA layer 620 Attention layer 621,625 MatMul layer 622 Scale layer 623 Mask layer 624 SoftMax layer 700,810,910,1010,1110 Document 701 Token set 702,712 Feature vector 710,800,900,1000,1100 Image 7 Degree estimator 820, 8
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021555728A JP7205646B2 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
| PCT/JP2019/044769 WO2021095211A1 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
| US17/719,438 US20220237263A1 (en) | 2019-11-14 | 2022-04-13 | Method for outputting, computer-readable recording medium storing output program, and output device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/044769 WO2021095211A1 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/719,438 Continuation US20220237263A1 (en) | 2019-11-14 | 2022-04-13 | Method for outputting, computer-readable recording medium storing output program, and output device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021095211A1 true WO2021095211A1 (ja) | 2021-05-20 |
Family
ID=75912592
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/044769 Ceased WO2021095211A1 (ja) | 2019-11-14 | 2019-11-14 | 出力方法、出力プログラム、および出力装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220237263A1 (https=) |
| JP (1) | JP7205646B2 (https=) |
| WO (1) | WO2021095211A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240420446A1 (en) * | 2023-06-14 | 2024-12-19 | Fujitsu Limited | Computer-readable recording medium storing machine learning program, computer-readable recording medium storing determination program, and machine learning device |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11921711B2 (en) * | 2020-03-06 | 2024-03-05 | Alibaba Group Holding Limited | Trained sequence-to-sequence conversion of database queries |
| US11699275B2 (en) * | 2020-06-17 | 2023-07-11 | Tata Consultancy Services Limited | Method and system for visio-linguistic understanding using contextual language model reasoners |
| CN115062782B (zh) * | 2022-07-06 | 2025-02-14 | 支付宝(杭州)信息技术有限公司 | 编码装置、数据处理方法及装置 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005199403A (ja) * | 2004-01-16 | 2005-07-28 | Sony Corp | 情動認識装置及び方法、ロボット装置の情動認識方法、ロボット装置の学習方法、並びにロボット装置 |
| US10417498B2 (en) * | 2016-12-30 | 2019-09-17 | Mitsubishi Electric Research Laboratories, Inc. | Method and system for multi-modal fusion model |
| US10916135B2 (en) * | 2018-01-13 | 2021-02-09 | Toyota Jidosha Kabushiki Kaisha | Similarity learning and association between observations of multiple connected vehicles |
| JP2019169147A (ja) * | 2018-03-20 | 2019-10-03 | 国立大学法人電気通信大学 | 情報処理装置及び情報処理システム |
| US20240119713A1 (en) * | 2022-09-27 | 2024-04-11 | Google Llc | Channel Fusion for Vision-Language Representation Learning |
-
2019
- 2019-11-14 WO PCT/JP2019/044769 patent/WO2021095211A1/ja not_active Ceased
- 2019-11-14 JP JP2021555728A patent/JP7205646B2/ja active Active
-
2022
- 2022-04-13 US US17/719,438 patent/US20220237263A1/en active Pending
Non-Patent Citations (3)
| Title |
|---|
| LU, JIASEN ET AL.: "ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks", ARXIV.ORG, 6 August 2019 (2019-08-06), pages 1 - 11, XP081456681, Retrieved from the Internet <URL:https://arxiv.org/pdf/1908.02265vl.pdf> [retrieved on 20191213] * |
| NGUYEN, DUY-KIEN ET AL., IMPROVED FUSION OF VISUAL AND LANGUAGE REPRESENTATIONS BY DENSE SYMMETRIC CO-ATTENTION FOR VISUAL QUESTION ANSWERING, 2018, pages 6087 - 6096, XP033473524, Retrieved from the Internet <URL:http://openaccess.thecvf.com/content_cvpr_2018/html/Nguyen_Improved_Fusion_of_CVPR_2018_paper.html> [retrieved on 20191213] * |
| YU, JIANFEI ET AL., ADAPTING BERT FOR TARGET-ORIENTED MULTIMODAL SENTIMENT CLASSIFICATION, August 2019 (2019-08-01), pages 5408 - 5414, XP055823561, Retrieved from the Internet <URL:https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=5444&context=sis_research> [retrieved on 20191213] * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240420446A1 (en) * | 2023-06-14 | 2024-12-19 | Fujitsu Limited | Computer-readable recording medium storing machine learning program, computer-readable recording medium storing determination program, and machine learning device |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021095211A1 (https=) | 2021-05-20 |
| US20220237263A1 (en) | 2022-07-28 |
| JP7205646B2 (ja) | 2023-01-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220237263A1 (en) | Method for outputting, computer-readable recording medium storing output program, and output device | |
| CN112889108B (zh) | 使用视听数据进行说话分类 | |
| JPWO2021095211A5 (https=) | ||
| CN114239717B (zh) | 模型训练方法、图像处理方法及装置、电子设备、介质 | |
| WO2021077140A2 (en) | Systems and methods for prior knowledge transfer for image inpainting | |
| CN106778867A (zh) | 目标检测方法和装置、神经网络训练方法和装置 | |
| CN118737121B (zh) | 伴随音频生成方法、相关装置和介质 | |
| KR102045575B1 (ko) | 스마트 미러 디스플레이 장치 | |
| Jaumard-Hakoun et al. | An articulatory-based singing voice synthesis using tongue and lips imaging | |
| KR102274581B1 (ko) | 개인화된 hrtf 생성 방법 | |
| TWI868522B (zh) | 人臉影像增益方法與系統 | |
| US20240104180A1 (en) | User authentication based on three-dimensional face modeling using partial face images | |
| US12423955B2 (en) | Machine learning device and far-infrared image capturing device | |
| CN113850714A (zh) | 图像风格转换模型的训练、图像风格转换方法及相关装置 | |
| JP4511135B2 (ja) | データ分布を表現する方法、データ要素を表現する方法、データ要素の記述子、照会データ要素を照合または分類する方法、その方法を実行するように設定した装置、コンピュータプログラム並びにコンピュータ読み取り可能な記憶媒体 | |
| JP2021018477A (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP2021521704A (ja) | 遠隔会議システム、遠隔会議のための方法、およびコンピュータ・プログラム | |
| KR102003221B1 (ko) | 필기 이미지 데이터 생성 시스템 및 이를 이용한 필기 이미지 데이터 생성 방법 | |
| US20200043465A1 (en) | Method for audio synthesis adapted to video characteristics | |
| JP6843409B1 (ja) | 学習方法、コンテンツ再生装置、及びコンテンツ再生システム | |
| WO2021095213A1 (ja) | 学習方法、学習プログラム、および学習装置 | |
| CN113763232A (zh) | 图像处理方法、装置、设备及计算机可读存储介质 | |
| US20220237421A1 (en) | Method for outputting, computer-readable recording medium storing output program, and output device | |
| CN111797897A (zh) | 一种基于深度学习的音频生成人脸图像方法 | |
| JPWO2021095212A5 (https=) |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19952179 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021555728 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19952179 Country of ref document: EP Kind code of ref document: A1 |