WO2021064771A1 - システム、方法及び制御装置 - Google Patents
システム、方法及び制御装置 Download PDFInfo
- Publication number
- WO2021064771A1 WO2021064771A1 PCT/JP2019/038459 JP2019038459W WO2021064771A1 WO 2021064771 A1 WO2021064771 A1 WO 2021064771A1 JP 2019038459 W JP2019038459 W JP 2019038459W WO 2021064771 A1 WO2021064771 A1 WO 2021064771A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- parameter
- reinforcement learning
- network
- adjusting means
- adjusting
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/16—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks using machine learning or artificial intelligence
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/0813—Configuration setting characterised by the conditions triggering a change of settings
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/0823—Configuration setting characterised by the purposes of a change of settings, e.g. optimising configuration for enhancing reliability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/08—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters
- H04L43/0876—Network utilisation, e.g. volume of load or congestion level
Definitions
- This disclosure relates to systems, methods and control devices.
- Machine learning is expected as a method for automatically setting the control parameters.
- Reinforcement learning is known as a type of machine learning.
- Patent Document 1 describes a technique for performing control using reinforcement learning.
- Reinforcement learning can be used to adjust parameters for controlling communication in a communication network.
- the parameter deviates significantly from the optimum value for the state of the communication network, it may take a long time to bring the parameter closer to the optimum value by reinforcement learning accompanied by search. Therefore, for a long time, the control of communication in the communication network may not match the state of the communication network. That is, it may be difficult for the communication control to follow the communication environment.
- An object of the present invention is to provide a system, a method and a control device that enable communication control to quickly follow a communication environment.
- the system according to one aspect of the present disclosure is enhanced after the first adjusting means for adjusting the parameters for controlling communication in the communication network using the parameter determining method and the adjusting of the parameters using the parameter determining method. It includes a second adjusting means for adjusting the above parameters using learning.
- a method uses a parameter determination method to adjust parameters for controlling communication in a communication network, and after adjusting the parameters using the parameter determination method, reinforcement learning is used. To adjust the above parameters.
- the control device includes a first adjusting means for adjusting parameters for controlling communication in a communication network using a parameter determining method, and after adjusting the parameters using the parameter determining method.
- a second adjusting means for adjusting the above parameters using reinforcement learning is provided.
- FIG. 1 is a diagram for explaining the outline of reinforcement learning.
- the agent 81 observes the state of the environment 83 and selects an action from the observed state.
- the agent 81 receives a reward from the environment 83 by selecting the action under the environment.
- the agent 81 can learn what kind of action brings the greatest reward depending on the state of the environment 83. That is, the agent 81 can learn the action to be selected according to the environment in order to maximize the reward.
- Q-learning is an example of reinforcement learning.
- Q-learning for example, a Q-table showing how much each action is worth for each state of the environment 83 is used.
- the agent 81 uses the Q table to select an action according to the state of the environment 83. Further, the agent 81 updates the Q table based on the reward obtained according to the selection of the action.
- FIG. 2 is a diagram for explaining an example of the Q table.
- the state of the environment 83 includes the state A (State A) and the state B (State B), and the actions of the agent 81 include the action A (Action A) and the action B (Action B).
- the Q table shows the value when each action is taken in each state. For example, the value of taking action A in state A is q AA , and the value of taking action B in state A is q AB .
- the value of taking action A in state B is q BA , and the value of taking action B in state B is q BB .
- the agent 81 takes the action with the highest value in each state.
- the agent 81 takes action A in state A.
- the values in the Q table (q AA , q AB , q BA and q BB ) are updated based on the rewards obtained according to the action selection.
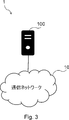
- FIG. 3 shows an example of a schematic configuration of the system 1 according to the first embodiment.
- system 1 includes a communication network 10 and a control device 100.
- the communication network 10 transfers data.
- the communication network 10 includes a network device (for example, a proxy server, a gateway, a router and / or a switch, etc.) and a line, and each of the network devices transfers data via the line.
- a network device for example, a proxy server, a gateway, a router and / or a switch, etc.
- the communication network 10 may be a wired network or a wireless network.
- the communication network 10 may include both a wired network and a wireless network.
- the wireless network may be, for example, a mobile communication network using a communication line standard such as LTE (Long Term Evolution) or 5G (5th Generation), or a wireless LAN (Local Area Network) or local 5G. It may be a network used in a specific area.
- the wired network may be, for example, a LAN (Local Area Network), a WAN (Wide Area Network), the Internet, or the like.
- Control device 100 The control device 100 controls for the communication network 10.
- control device 100 adjusts parameters for controlling communication in the communication network 10.
- control device 100 is a network device (for example, a proxy server, a gateway, a router, and / or a switch, etc.) that transfers data within the communication network 10.
- a network device for example, a proxy server, a gateway, a router, and / or a switch, etc.
- the control device 100 according to the first embodiment is not limited to the network device that transfers data within the communication network 10. This point will be described in detail later as a fifth modification of the first embodiment.
- FIG. 4 is a block diagram showing an example of a schematic functional configuration of the control device 100 according to the first embodiment.
- the control device 100 includes a first adjusting means 110, a second adjusting means 120, and a communication processing means 130.
- the operations of the first adjusting means 110, the second adjusting means 120, and the communication processing means 130 will be described later.
- FIG. 5 is a block diagram showing an example of a schematic hardware configuration of the control device 100 according to the first embodiment.
- the control device 100 includes a processor 210, a main memory 220, a storage 230, a communication interface 240, and an input / output interface 250.
- the processor 210, the main memory 220, the storage 230, the communication interface 240, and the input / output interface 250 are connected to each other via the bus 260.
- the processor 210 executes a program read from the main memory 220.
- the processor 210 is a CPU (Central Processing Unit).
- the main memory 220 stores programs and various data.
- the main memory 220 is a RAM (Random Access Memory).
- the storage 230 stores programs and various data.
- the storage 230 includes an SSD (Solid State Drive) and / or an HDD (Hard Disk Drive).
- the communication interface 240 is an interface for communication with other devices.
- the communication interface 240 is a network adapter or a network interface card.
- the input / output interface 250 is an interface for connecting to an input device such as a keyboard and an output device such as a display.
- Each of the first adjusting means 110, the second adjusting means 120 and the communication processing means 130 may be implemented by the processor 210 and the main memory 220, or may be implemented by the processor 210, the main memory 220 and the communication interface 240. Good.
- control device 100 is not limited to this example.
- the control device 100 may be implemented by other hardware configurations.
- control device 100 may be virtualized. That is, the control device 100 may be implemented as a virtual machine.
- the control device 100 may operate as a virtual machine on a physical machine (hardware) including a processor, a memory, and the like and a hypervisor.
- the control device 100 may be distributed and operated in a plurality of physical machines.
- the control device 100 may include a memory (main memory 220) for storing a program (instruction) and one or more processors (processor 210) capable of executing the program (instruction).
- the one or more processors may execute the above program to operate the first adjusting means 110, the second adjusting means 120, and / or the communication processing means 130.
- the program may be a program for causing the processor to execute the operations of the first adjusting means 110, the second adjusting means 120, and / or the communication processing means 130.
- the control device 100 (first adjusting means 110) adjusts a parameter for controlling communication in the communication network 10 (hereinafter, referred to as “network control parameter”) by using a parameter determining method.
- the control device 100 (second adjusting means 120) adjusts the network control parameters by using reinforcement learning.
- control device 100 (second adjusting means 120) adjusts the network control parameter using the reinforcement learning after adjusting the parameter using the parameter determining method.
- the control device 100 is a network device (for example, a proxy server, a gateway, a router, and / or a switch) that transfers data within the communication network 10.
- the network control parameter is, for example, a parameter set in the control device 100, and the control device 100 (communication processing means 130) transfers data (for example, a packet) according to the network control parameter.
- the network control parameter is, for example, a parameter for controlling a specific flow in the communication network 10. That is, the network control parameters are parameters for each flow.
- the specific flow may be a specific flow for video traffic.
- the flow corresponding to the packet is identified from, for example, the transmission address, the reception address, and the port number of the packet.
- the above network control parameter is the upper limit of throughput.
- the network control parameters according to the first embodiment are not limited to the above-mentioned example. This point will be described in detail later as a first modification of the first embodiment.
- control device 100 (second adjusting means 120) adjusts the network control parameters by using reinforcement learning.
- control device 100 uses the reinforcement learning to control the network based on the state of the communication network 10 (hereinafter referred to as "network state"). Adjust the parameters.
- the control device 100 applies the network state as the state of the environment in the reinforcement learning, and applies the change of the network control parameter as the action selected according to the state of the environment.
- the network control parameters are adjusted using the reinforcement learning. That is, the control device 100 (second adjusting means 120) controls the network by selecting the change (that is, the action) of the network control parameter from the network state (that is, the state) by using the reinforcement learning. Adjust the parameters.
- the network control parameter is, for example, a parameter for controlling a specific flow in the communication network 10.
- the network state is, for example, the state of the communication network 10 for the specific flow.
- the specific flow may be a specific flow for video traffic.
- the network control parameter is the upper limit of throughput.
- the above network state is the QoE (Quality of Experience) of the moving image.
- the QoE may be the bit rate of the moving image or the resolution of the moving image.
- the network state according to the first embodiment is not limited to the above-mentioned example. This point will be described in detail later as a first modification of the first embodiment.
- the reward in the above reinforcement learning is the QoE of the video as in the above network state.
- the reward according to the first embodiment is not limited to this example.
- the network state is the state of the communication network 10, but the network state can also be said to be the state of communication in the communication network 10.
- the control device 100 selects a random change of the network control parameter as a search, and uses the network from the viewpoint of the learning result.
- the network control parameters are adjusted by selecting the optimum change of the control parameters.
- the control device 100 selects a random change of the network control parameter with a probability ⁇ , and has a probability 1- ⁇ with the network control parameter from the viewpoint of the learning result. Select the best change for.
- the control device 100 selects the change of the network control parameters from the network state by using the reinforcement learning. Then, the control device 100 (second adjusting means 120) sets the changed value of the network control parameter. The control device 100 (second adjusting means 120) adjusts the network control parameters, for example, by repeating such selection and setting.
- control device 100 (first adjusting means 110) adjusts the network control parameter by using the parameter determination method.
- the control device 100 selects a random change of the network control parameter as a search in the reinforcement learning.
- the control device 100 adjusts the network control parameter in the parameter determining method without randomly determining the network control parameter.
- the above parameter determination method is a gradient method.
- the control device 100 (first adjusting means 110) adjusts the network control parameters by iteratively determining the network control parameters using the gradient method.
- control device 100 uses a gradient method to find the value of the network control parameter that minimizes the difference between the target value of the reward for determining the network control parameter and the actual value.
- the above network control parameters are iteratively determined using. As a result, the control device 100 (first adjusting means 110) adjusts the network control parameters.
- the above reward is the same as the reward in the above reinforcement learning, for example.
- the reward is a moving image QoE (eg, bit rate, resolution, etc.).
- the network control parameters are determined and set, and as a result, the actual value of the reward is obtained. Then, the difference between the target value of the reward and the actual value is calculated. Further, the gradient of the difference with respect to the network control parameter (that is, the ratio of the increase amount of the difference to the increase amount of the network control parameter) is calculated. Next, based on the gradient, the network control parameters are increased or decreased so that the difference is smaller. In this way, the network control parameters are determined and set again. The above operation is repeated, and the network control parameter transitions so as to approach a value that minimizes the difference. The increase or decrease of the network control parameters is performed based on the gradient, and is not performed randomly.
- the amount of increase or decrease of the network control parameter may be a predetermined amount, or an amount corresponding to the gradient (for example, if the gradient is larger, the amount is larger, and if the gradient is smaller, the amount is larger. , Lesser amount).
- the value of the network control parameter may be represented as x
- the difference between the target value of the reward and the actual value eg, target QoE-actual QoE
- the difference y can be considered as a function of x. It can be expressed, for example, as f (x).
- x i (i-th x) is determined, it is set such that the value of the implementation of the compensation is obtained. Then, y i (i-th y), which is the difference between the target QoE and the actual QoE, is calculated. Further, the gradient ai of y (that is, f (x)) with respect to x is calculated. Since the content of f (x) is unknown, the gradient ai may be simply calculated by, for example, (y i- y i-1 ) / (x i- x i-1).
- x i + 1 is obtained by adding or subtracting b (positive value) to x i so that y i + 1 (i + 1th y) becomes smaller based on the gradient a i.
- the control device 100 determines the network control parameters by using the parameter determination method. Then, the control device 100 (first adjusting means 110) sets the determined values of the network control parameters. The control device 100 (second adjusting means 120) adjusts the network control parameters, for example, by repeating such determination and setting.
- the network control parameter using the parameter determination method is used. Finish the adjustment of. This makes it possible, for example, to avoid unnecessary iterations of parameter determination.
- control device 100 uses the parameter determination method when the number of determinations of the network control parameters reaches a predetermined number even if the difference does not become less than a predetermined threshold value. Finish adjusting network control parameters. This allows, for example, the avoidance of many iterations of parameter determination.
- control device 100 (second adjusting means 120) finishes adjusting the network control parameters using the parameter determination method, the control device 100 adjusts the network control parameters using the reinforcement learning.
- the network control parameter can be set to the optimum value. You can get closer quickly. Therefore, the communication control can quickly follow the communication environment.
- the control device 100 uses the parameter determining method to set the network control parameter. adjust. Then, the control device 100 (second adjusting means 120) adjusts the network control parameter by using the reinforcement learning after adjusting the network control parameter by using the parameter determining method.
- the above state of the communication network 10 is a network state applied as an environment state in the above reinforcement learning.
- the network state is the QoE (eg, bit rate or resolution) of the moving image.
- the predetermined condition for the change in the network state is that the amount of change in the network state within a certain period exceeds a predetermined threshold value. That is, when the amount of change in the network state within a certain period exceeds the predetermined threshold value, the network control parameter is adjusted by using the parameter determination method, and then the network control parameter is adjusted by using reinforcement learning. It will be adjusted.
- the above parameter determination method is used to raise the upper limit of the throughput for the flow. It will be adjusted. Then, using the reinforcement learning, the upper limit of the throughput for the flow is further adjusted.
- the network control parameters are adjusted using the parameter determination method, and then the network control parameters are adjusted using the reinforcement learning.
- the network control parameter can be quickly brought closer to the optimum value.
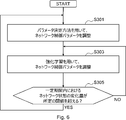
- FIG. 6 is a flowchart for explaining an example of a schematic flow of the parameter adjustment process according to the first embodiment.
- the control device 100 (first adjusting means 110) adjusts the network control parameters by using the parameter determining method (that is, the gradient method) (S301).
- the parameter determining method that is, the gradient method
- the control device 100 (second adjusting means 120) adjusts the network control parameters using reinforcement learning (S303).
- the control device 100 uses the above parameter determination method (that is, the gradient method). Adjust the network control parameters (S301).
- control device 100 When the amount of change does not exceed the predetermined threshold value (S305-NO), the control device 100 (first adjusting means 110) subsequently adjusts the network control parameter using the reinforcement learning (S303). ..
- the network control parameter is, for example, a parameter for controlling a specific flow in the communication network 10, and the network state is, for example, the specific flow. This is the state of the communication network 10.
- the specific flow may be a specific flow for video traffic.
- the network control parameter is an upper limit of throughput
- the network state is a moving image QoE (eg, bit rate or resolution).
- the network control parameters and network states according to the first embodiment are not limited to this example.
- the network control parameter does not have to be a parameter for each flow, and the network state does not have to be the network state for each flow.
- the network control parameter may be a parameter for the entire communication that may include a plurality of flows, and the network state may also be a network state for the entire communication.
- the network control parameter does not have to be the upper limit of the throughput, and the network state does not have to be the QoE of the moving image.
- the combination of the network state (NW state) and the network control parameter (NW control parameter) may be as follows.
- Example 1 (Example of TCP (Transmission Control Protocol) flow control)] [NW state] Number of active flows, available bandwidth, and / or IP (Internet Protocol) past buffer size [NW control parameter] Transmission buffer size [Example 2 (Example of robot control)] [NW state] Packet arrival interval and / or packet size statistics (for example, maximum value, minimum value, mean value, standard deviation, etc.) [NW control parameter] Packet transmission interval [Example 3 (Example of video traffic control)] [NW state] Throughput and / or packet arrival interval [NW control parameter] Priority and / or bandwidth
- the control device 100 may adjust a single network control parameter or may adjust a plurality of network control parameters.
- the reward in the reinforcement learning is the same as the network state (that is, the state of the environment in the reinforcement learning)
- the reward and the network state according to the first embodiment are not limited to this example.
- the reward in the reinforcement learning and the network state may be different from each other.
- the reward in the parameter determination method (gradient method) is the same as the reward in the reinforcement learning
- the reward according to the first embodiment is not limited to this example.
- the reward in the parameter determination method and the reward in the reinforcement learning may be different from each other.
- the parameter determination method may be another parameter determination method that does not involve random determination of the network control parameters.
- the parameter determination method iteratively determines the network control parameter in order to find the value of the network control parameter that minimizes the difference between the target value of the reward for the determination of the network control parameter and the actual value.
- Other parameter determination methods may be used.
- the parameter determination method is a method of determining the network control parameter based on the past result of the adjustment of the network control parameter using the reinforcement learning. It may be.
- the parameter determination method is a method of determining the network control parameter so that the network control parameter becomes a statistical value of the network control parameter adjusted by using reinforcement learning. May be good.
- the parameter determination method may be a statistical value of the value of the network control parameter that can be obtained in the reinforcement learning.
- the statistic may be mean, median or mode.
- the network control parameter can approach the optimum value without repeatedly determining the network control parameter.
- the reinforcement learning may be reinforcement learning performed in one of the plurality of reinforcement learning-based controllers, a reinforcement learning-based controller (hereinafter, referred to as a “first reinforcement learning-based controller”).
- the reinforcement learning-based controller actually used for adjusting the network control parameters may be selected from the plurality of reinforcement learning-based controllers according to the congestion state of the communication network 10.
- the plurality of reinforcement learning-based controllers may each support a plurality of congestion levels. That is, one reinforcement learning-based controller may correspond to one congestion level. Since the network control parameters suitable for the network state differ depending on the congestion level, reinforcement learning for each congestion level can be performed by selecting a reinforcement learning-based controller for each congestion level. Therefore, communication control suitable for the communication environment can be performed.
- the reinforcement learning-based controller used for adjusting the network control parameters is another reinforcement learning-based controller among the plurality of reinforcement learning-based controllers (hereinafter, referred to as “second reinforcement learning-based controller”). May be switched to the first reinforcement learning-based controller described above.
- the control device 100 first adjusting means 110
- the control device 100 may adjust the network control parameter by using the parameter determining method.
- the control device 100 may adjust the network control parameter by using the reinforcement learning after adjusting the network control parameter by using the parameter determining method.
- the reinforcement learning-based controller is switched (that is, the reinforcement learning is switched), and as a result, even if the network control parameter deviates significantly from the optimum value for the network state, the above The network control parameters can be quickly brought closer to the optimum value.
- FIG. 7 is a flowchart for explaining an example of a schematic flow of the parameter adjustment processing according to the third modification of the first embodiment.
- the parameter adjustment process is started when the reinforcement learning-based controller used for adjusting the network control parameters is switched from the second reinforcement learning-based controller to the first reinforcement learning-based controller.
- the control device 100 uses a parameter determining method (that is, a method of determining the network control parameter based on the past result of adjusting the network control parameter using reinforcement learning) to control the network. Adjust the parameters (S321).
- a parameter determining method that is, a method of determining the network control parameter based on the past result of adjusting the network control parameter using reinforcement learning
- the control device 100 (second adjusting means 120) adjusts the network control parameters using reinforcement learning (S323).
- the process ends. .. After that, the parameter adjustment process shown in FIG. 7 can also be performed on the third reinforcement learning-based controller.
- the control device 100 (second adjustment means 120) subsequently uses the reinforcement learning to control the network. Adjust the parameters (S323).
- control device 100 selects a parameter determination method from the plurality of parameter determination methods, and the present invention
- the above parameters may be adjusted using a parameter determination method.
- the plurality of parameter determination methods may include a gradient method (that is, the parameter determination method in the main example of the first embodiment). Further, the plurality of parameter determination methods are methods for determining the network control parameters based on the past results of adjustment of the network control parameters using the reinforcement learning (that is, a third modification of the first embodiment). The parameter determination method in the example) may be included.
- the control device 100 (first adjusting means 110) selects a parameter determination method from the plurality of parameter determination methods based on the learning maturity in reinforcement learning. You may.
- control device 100 may select the gradient method.
- the control device 100 may select the method of determining the network control parameter based on the past result.
- the reward when the reward is steady in time series (for example, within a certain range) in the reinforcement learning, it may be determined that the learning is mature in the reinforcement learning. Further or, when the reward reaches near the upper limit in the reinforcement learning (for example, the difference between the reward and the upper limit is less than the threshold value), it is determined that the learning is mature in the reinforcement learning. You may.
- the above upper limit may be obtained from the history of past learning.
- the network control parameters are efficiently adjusted based on the history, and when the learning is not mature, the network control parameters are surely adjusted by the gradient method. Can be adjusted.
- FIG. 8 is a flowchart for explaining an example of a schematic flow of the parameter adjustment processing according to the fourth modification of the first embodiment.
- the parameter adjustment process is started when the reinforcement learning-based controller used for adjusting the network control parameters is switched from the second reinforcement learning-based controller to the first reinforcement learning-based controller.
- the control device 100 (first adjusting means 110) selects a parameter determination method from a plurality of parameter determination methods based on the maturity of learning in reinforcement learning (S341).
- the control device 100 (first adjusting means 110) adjusts the network control parameters using the selected parameter determination method (S343).
- the control device 100 (second adjusting means 120) adjusts the network control parameters using the reinforcement learning (S345).
- the process ends. .. After that, the parameter adjustment process shown in FIG. 8 can also be performed on the third reinforcement learning-based controller.
- the control device 100 (second adjustment means 120) subsequently uses the reinforcement learning to control the network. Adjust the parameters (S345).
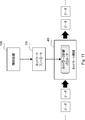
- the control device 100 is a network device (for example, a proxy server, a gateway, a router, and / or a switch) that transfers data within the communication network 10 (FIG. 9). Further, as described above, for example, the control device 100 (communication processing means 130) receives data (for example, the data (for example, the first adjusting means 110 and the second adjusting means 120) according to the network control parameters adjusted by the control device 100 (first adjusting means 110 and second adjusting means 120). Packets) are forwarded (see Figure 9). However, the control device 100 according to the first embodiment is not limited to this example.
- the control device 100 is a network device itself that transfers data in the communication network 10. Instead, it may be a device (for example, a network controller) that controls a network device 30 that transfers data within the communication network 10.
- the network control parameter may be a parameter set in the network device 30, and the control device 100 (first adjusting means 110 and second adjusting means 120) is a network control parameter set in the network device 30. May be adjusted.
- the control device 100 (first adjusting means 110 and second adjusting means 120) provides parameter information for adjusting the network control parameter (for example, a command for instructing a change of the network control parameter). It may be transmitted to the network device 30.
- the network device 30 may set the network control parameter based on the parameter information, or may transfer data (for example, a packet) according to the network control parameter.
- the network state may be a state observed by the network device 30.
- the control device 100 may receive information indicating a state observed by the network device 30 from the network device 30.
- the network controller 50 controls the network device 40 that transfers data in the communication network 10, and the control device 100 controls the network controller 50.
- the control device 100 controls the network controller 50.
- it may be an assisting device.
- the network control parameter may be a parameter set in the network device 40
- the control device 100 (first adjusting means 110 and second adjusting means 120) is a network control parameter set in the network device 40. May be adjusted.
- the control device 100 instructs the change of the first parameter information (for example, the network control parameter) for adjusting the network control parameter.
- a command or support information for instructing a change in network control parameters may be transmitted to the network controller 50.
- the network controller 50 transmits the second parameter information for adjusting the network control parameter (for example, a command for instructing the change of the network control parameter) to the network device 40 based on the first parameter information. You may.
- the network device 40 may set the network control parameter based on the second parameter information, or may transfer data (for example, a packet) according to the network control parameter.
- the network state may be a state observed by the network device 40.
- the control device 100 may receive information indicating a state observed in the network device 40 from the network device 40 or the network controller 50.
- the network controller 70 controls the network device 60 that transfers data in the communication network 10, and the control device 100 controls the network controller 70. It may be a device for
- the network control parameter may be a parameter set in the network controller 70
- the control device 100 (first adjusting means 110 and second adjusting means 120) is a network control parameter set in the network controller 70. May be adjusted.
- the control device 100 (first adjusting means 110 and second adjusting means 120) provides parameter information for adjusting the network control parameter (for example, a command for instructing a change of the network control parameter). It may be transmitted to the network controller 70.
- the network controller 70 may set the network control parameter based on the parameter information and control the network device 60 according to the network control parameter.
- the network device 40 may transfer data (for example, a packet) under the control of the network controller 70.
- the network state may be a state observed by the network device 60.
- the control device 100 may receive information indicating a state observed in the network device 60 from the network device 60 or the network controller 70.
- the control device 100 includes a first adjusting means 110, a second adjusting means 120, and a communication processing means 130.
- the control device 100 according to the first embodiment is not limited to this example.
- the control device 100 includes the first adjusting means 110, but does not include the second adjusting means 120, and the other device includes the second adjusting means 120. But it may be.
- the control device 100 includes the second adjusting means 120, but does not include the first adjusting means 110, and another device may include the first adjusting means 110.
- the communication processing means 130 for transferring data is not included in the control device 100, but may be included in another device.
- the communication processing means 130 may not be included in the control device 100 but may be included in the network device.
- FIG. 13 shows an example of a schematic configuration of the system 2 according to the second embodiment.
- the system 2 includes a first adjusting means 400 and a second adjusting means 500.
- FIG. 14 is a flowchart for explaining an example of a schematic flow of the parameter adjustment process according to the second embodiment.
- the first adjusting means 400 adjusts the parameters for controlling the communication in the communication network by using the parameter determining method (S601).
- the second adjusting means 500 adjusts the above parameters using reinforcement learning (S603).
- the description of the above parameters (that is, network control parameters), the above reinforcement learning, the above parameter determination method, and the operation conditions is the same as the description of these in the first embodiment, for example. Further, the description of the modified example of the second embodiment is the same as the description of the modified example of the first embodiment except for the difference in reference numerals. Therefore, a duplicate description will be omitted here.
- the above parameters are adjusted. This makes it possible, for example, to quickly make the communication control follow the communication environment.
- the steps in the processing described in the present specification do not necessarily have to be executed in chronological order in the order described in the flowchart.
- the steps in the process may be executed in an order different from the order described in the flowchart, or may be executed in parallel.
- some of the steps in the process may be deleted, and additional steps may be added to the process.
- a method including processing of a component of a system or a control device described in the present specification may be provided, and a program for causing a processor to execute the processing of the component may be provided.
- a non-transitory computer readable recording medium may be provided that can be read by the computer on which the program is recorded.
- Appendix 2 The system according to Appendix 1, wherein the second adjusting means adjusts the parameters based on the state of the communication network by using the reinforcement learning.
- the second adjusting means applies the state of the communication network as the state of the environment, and applies the change of the parameter as the action selected according to the state of the environment.
- the second adjusting means adjusts the parameter by selecting a random change of the parameter as a search, and selects the optimum change of the parameter from the viewpoint of the learning result as a utilization.
- the first adjusting means adjusts the parameter in the parameter determining method without randomly determining the parameter.
- the first adjusting means iteratively determines the parameter using the parameter determining method in order to find the value of the parameter that minimizes the difference between the target value of the reward for determining the parameter and the actual value.
- the system according to any one of Supplementary note 1 to 5, wherein the parameter is adjusted by the above method.
- Appendix 7 The system according to Appendix 6, wherein the reward is the same as the reward in the reinforcement learning.
- Appendix 11 The system according to Appendix 10, wherein the parameter determination method is a method of determining the parameter so that the parameter becomes a statistical value of the parameter adjusted by using the reinforcement learning.
- Appendix 13 The system according to Appendix 12, wherein the first adjusting means selects the parameter determining method from the plurality of parameter determining methods based on the maturity of learning in the reinforcement learning.
- the parameter determination method is the gradient method when the learning is not mature in the reinforcement learning, and the parameters are determined based on the past results when the learning is mature in the reinforcement learning.
- the first adjusting means adjusts the parameter by using the parameter determining method
- the second adjusting means adjusts the parameter determining method.
- Appendix 17 The system according to Appendix 16, wherein the predetermined condition is that the amount of change in the state of the communication network exceeds a predetermined threshold value within a certain period of time.
- the reinforcement learning is reinforcement learning performed in one of a plurality of reinforcement learning-based controllers selectively used for adjusting the parameters.
- the reinforcement learning-based controller used for adjusting the parameters is switched from the other reinforcement learning-based controller among the plurality of reinforcement learning-based controllers to the one reinforcement learning-based controller in which the reinforcement learning is performed. If so, the first adjusting means adjusts the parameter using the parameter determining method, and the second adjusting means uses the reinforcement learning after adjusting the parameter using the parameter determining method. Adjust the parameters, The system according to any one of Appendix 1 to 17.
- Appendix 20 19. The method of Appendix 19, wherein the parameters are adjusted based on the state of the communication network using the reinforcement learning.
- the parameter is adjusted by selecting a random change of the parameter as a search, and the parameter is adjusted by selecting the optimum change of the parameter from the viewpoint of the learning result as a use. Being done In the parameter determination method, the parameter is adjusted without randomly determining the parameter. The method according to Appendix 21.
- Appendix 23 The method according to any one of Appendix 19 to 22, wherein the parameter determination method is a gradient method.
- the parameter is determined by iteratively determining the parameter using the parameter determination method in order to find the value of the parameter that minimizes the difference between the target value of the reward and the actual value for the determination of the parameter.
- the method according to any one of Appendix 19 to 23, which is adjusted.
- Appendix 25 The method according to Appendix 24, wherein the reward is the same as the reward in the reinforcement learning.
- Appendix 28 The method according to any one of Appendix 19 to 22, wherein the parameter determination method is a method of determining the parameter based on the past result of the adjustment of the parameter using the reinforcement learning.
- Appendix 29 The method according to Appendix 28, wherein the parameter determination method is a method of determining the parameter so that the parameter becomes a statistical value of the parameter adjusted by using the reinforcement learning.
- Appendix 30 The method according to any one of Appendix 19 to 22, further comprising selecting the parameter determination method from a plurality of parameter determination methods.
- Appendix 31 The method according to Appendix 30, wherein the parameter determination method is selected from the plurality of parameter determination methods based on the maturity of learning in the reinforcement learning.
- Appendix 32 The plurality of parameter determination methods are described. Gradient method and A method of determining the parameter based on the past result of adjusting the parameter using the reinforcement learning, and including, The method according to Appendix 30 or 31.
- the parameter determination method is the gradient method when learning is not mature in the reinforcement learning, and determines the parameters based on the past results when learning is mature in the reinforcement learning.
- the method according to Appendix 32 which is the method described above.
- Appendix 35 The method according to Appendix 34, wherein the predetermined condition is that the amount of change in the state of the communication network exceeds a predetermined threshold within a certain period of time.
- the reinforcement learning is reinforcement learning performed in one of a plurality of reinforcement learning-based controllers selectively used for adjusting the parameters.
- the reinforcement learning-based controller used for adjusting the parameters is switched from the other reinforcement learning-based controller among the plurality of reinforcement learning-based controllers to the one reinforcement learning-based controller in which the reinforcement learning is performed. If so, the parameter is adjusted using the parameter determination method, and after the parameter is adjusted using the parameter determination method, the parameter is adjusted using reinforcement learning.
- the method according to any one of Supplementary Notes 19 to 35.
- Appendix 38 The control device according to Appendix 37, wherein the second adjusting means adjusts the parameters based on the state of the communication network by using the reinforcement learning.
- the second adjusting means applies the state of the communication network as the state of the environment, and applies the change of the parameter as the action selected according to the state of the environment.
- the second adjusting means adjusts the parameter by selecting a random change of the parameter as a search, and selects the optimum change of the parameter from the viewpoint of the learning result as a utilization.
- the first adjusting means adjusts the parameter in the parameter determining method without randomly determining the parameter.
- Appendix 41 The control device according to any one of Appendix 37 to 40, wherein the parameter determination method is a gradient method.
- the first adjusting means iteratively determines the parameter using the parameter determining method in order to find the value of the parameter that minimizes the difference between the target value of the reward for determining the parameter and the actual value.
- the control device according to any one of Supplementary note 37 to 41, wherein the parameter is adjusted by the above.
- Appendix 43 The control device according to Appendix 42, wherein the reward is the same as the reward in the reinforcement learning.
- Appendix 47 The control device according to Appendix 46, wherein the parameter determination method is a method of determining the parameter so that the parameter becomes a statistical value of the parameter adjusted by using the reinforcement learning.
- Appendix 49 The control device according to Appendix 48, wherein the first adjusting means selects the parameter determining method from the plurality of parameter determining methods based on the maturity of learning in the reinforcement learning.
- Appendix 50 The plurality of parameter determination methods are described. Gradient method and A method of determining the parameter based on the past result of adjusting the parameter using the reinforcement learning, and including, The control device according to Appendix 48 or 49.
- the parameter determination method is the gradient method when learning is not mature in the reinforcement learning, and determines the parameters based on the past results when learning is mature in the reinforcement learning.
- the control device according to Appendix 50 which is the method described above.
- the first adjusting means adjusts the parameter by using the parameter determining method
- the second adjusting means adjusts the parameter determining method.
- the control device according to any one of Supplementary note 37 to 45, wherein after adjusting the parameters used, the parameters are adjusted by using the reinforcement learning.
- Appendix 53 The control device according to Appendix 52, wherein the predetermined condition is that the amount of change in the state of the communication network exceeds a predetermined threshold value within a certain period of time.
- the reinforcement learning is reinforcement learning performed in one of a plurality of reinforcement learning-based controllers selectively used for adjusting the parameters.
- the reinforcement learning-based controller used for adjusting the parameters is switched from the other reinforcement learning-based controller among the plurality of reinforcement learning-based controllers to the one reinforcement learning-based controller in which the reinforcement learning is performed. If so, the first adjusting means adjusts the parameter using the parameter determining method, and the second adjusting means uses the reinforcement learning after adjusting the parameter using the parameter determining method. Adjust the parameters, The control device according to any one of Appendix 37 to 53.
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/038459 WO2021064771A1 (ja) | 2019-09-30 | 2019-09-30 | システム、方法及び制御装置 |
| JP2021550736A JP7347525B2 (ja) | 2019-09-30 | 2019-09-30 | システム、方法及び制御装置 |
| US17/641,178 US20220345376A1 (en) | 2019-09-30 | 2019-09-30 | System, method, and control apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/038459 WO2021064771A1 (ja) | 2019-09-30 | 2019-09-30 | システム、方法及び制御装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021064771A1 true WO2021064771A1 (ja) | 2021-04-08 |
Family
ID=75337014
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/038459 Ceased WO2021064771A1 (ja) | 2019-09-30 | 2019-09-30 | システム、方法及び制御装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220345376A1 (https=) |
| JP (1) | JP7347525B2 (https=) |
| WO (1) | WO2021064771A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024514611A (ja) * | 2021-04-15 | 2024-04-02 | エヌイーシー ラボラトリーズ アメリカ インク | 動的マイクロサービス相互通信構成 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11616736B2 (en) * | 2020-12-17 | 2023-03-28 | Nokia Solutions And Networks Oy | Dynamic resource allocation aided by reinforcement learning |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013026980A (ja) * | 2011-07-25 | 2013-02-04 | Fujitsu Ltd | パラメータ設定装置、コンピュータプログラム及びパラメータ設定方法 |
| JP2017064830A (ja) * | 2015-09-29 | 2017-04-06 | ファナック株式会社 | 移動軸異常負荷警告機能を有するワイヤ放電加工機 |
| JP2017200172A (ja) * | 2016-04-27 | 2017-11-02 | 株式会社東芝 | 無線アクセスネットワークにおける無線リソーススライシング |
| JP2018126799A (ja) * | 2017-02-06 | 2018-08-16 | セイコーエプソン株式会社 | 制御装置、ロボットおよびロボットシステム |
| US10396919B1 (en) * | 2017-05-12 | 2019-08-27 | Virginia Tech Intellectual Properties, Inc. | Processing of communications signals using machine learning |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5733166B2 (ja) * | 2011-11-14 | 2015-06-10 | 富士通株式会社 | パラメータ設定装置、コンピュータプログラム及びパラメータ設定方法 |
| JP6275423B2 (ja) * | 2013-09-06 | 2018-02-07 | 株式会社Nttドコモ | 無線基地局、無線通信システム及び無線通信方法 |
| US20170347279A1 (en) * | 2016-05-27 | 2017-11-30 | Alcatel-Lucent Usa Inc. | MONITORING AND MANAGEMENT OF eMBMS SYSTEMS |
| US10375585B2 (en) * | 2017-07-06 | 2019-08-06 | Futurwei Technologies, Inc. | System and method for deep learning and wireless network optimization using deep learning |
| US11360757B1 (en) * | 2019-06-21 | 2022-06-14 | Amazon Technologies, Inc. | Request distribution and oversight for robotic devices |
-
2019
- 2019-09-30 US US17/641,178 patent/US20220345376A1/en not_active Abandoned
- 2019-09-30 JP JP2021550736A patent/JP7347525B2/ja active Active
- 2019-09-30 WO PCT/JP2019/038459 patent/WO2021064771A1/ja not_active Ceased
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013026980A (ja) * | 2011-07-25 | 2013-02-04 | Fujitsu Ltd | パラメータ設定装置、コンピュータプログラム及びパラメータ設定方法 |
| JP2017064830A (ja) * | 2015-09-29 | 2017-04-06 | ファナック株式会社 | 移動軸異常負荷警告機能を有するワイヤ放電加工機 |
| JP2017200172A (ja) * | 2016-04-27 | 2017-11-02 | 株式会社東芝 | 無線アクセスネットワークにおける無線リソーススライシング |
| JP2018126799A (ja) * | 2017-02-06 | 2018-08-16 | セイコーエプソン株式会社 | 制御装置、ロボットおよびロボットシステム |
| US10396919B1 (en) * | 2017-05-12 | 2019-08-27 | Virginia Tech Intellectual Properties, Inc. | Processing of communications signals using machine learning |
Non-Patent Citations (1)
| Title |
|---|
| NAKANOYA, MANABU: "Reinforcement Learning based Automated Process Generation for Virtual Network Update", IEICE TECHNICAL REPORT, vol. 117, no. 305, 9 November 2017 (2017-11-09), pages 63 - 68 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024514611A (ja) * | 2021-04-15 | 2024-04-02 | エヌイーシー ラボラトリーズ アメリカ インク | 動的マイクロサービス相互通信構成 |
| JP7734208B2 (ja) | 2021-04-15 | 2025-09-04 | エヌイーシー ラボラトリーズ アメリカ インク | 動的マイクロサービス相互通信構成 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021064771A1 (https=) | 2021-04-08 |
| JP7347525B2 (ja) | 2023-09-20 |
| US20220345376A1 (en) | 2022-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Zhang et al. | A multi-agent reinforcement learning approach for efficient client selection in federated learning | |
| US10505818B1 (en) | Methods for analyzing and load balancing based on server health and devices thereof | |
| CN113966596B (zh) | 用于数据流量路由的方法和设备 | |
| CN110855737B (zh) | 一种一致性级别可控的自适应数据同步方法和系统 | |
| CN105122772A (zh) | 通过头部交换服务器状态和客户端信息以用于请求管理和负载平衡 | |
| CN114616810A (zh) | 网络路径重定向 | |
| WO2021064771A1 (ja) | システム、方法及び制御装置 | |
| JP7251647B2 (ja) | 制御装置、制御方法及びシステム | |
| WO2024255470A1 (zh) | 路由震荡的定位方法及装置、非易失性可读存储介质及电子设备 | |
| CN110971451B (zh) | Nfv资源分配方法 | |
| CN117544565A (zh) | 分布式模型训练的网络拥塞控制方法、装置、设备和介质 | |
| CN110598871A (zh) | 一种微服务架构下的业务流柔性控制的方法及系统 | |
| WO2022271189A1 (en) | Remote access session management | |
| JP7251646B2 (ja) | 制御装置、方法及びシステム | |
| CN114090218A (zh) | 边缘计算环境下动态任务复制方法、设备和系统 | |
| JP7259978B2 (ja) | 制御装置、方法及びシステム | |
| JP7231049B2 (ja) | システム、方法及び制御装置 | |
| JP7188609B2 (ja) | システム、方法及び制御装置 | |
| CN114365460B (zh) | 用于媒体会话的基于模型的参数预测和选择 | |
| JP2017034307A (ja) | 情報収集管理装置、方法、及び情報収集システム | |
| Luo et al. | A novel Congestion Control algorithm based on inverse reinforcement learning with parallel training | |
| CN119544522A (zh) | 集合通信方法、装置、计算机设备、可读存储介质和程序产品 | |
| US20210067539A1 (en) | Software defined network whitebox infection detection and isolation | |
| JP6816824B2 (ja) | 分散システム、データ管理装置、データ管理方法、及びプログラム | |
| US20220019871A1 (en) | Method for Adapting a Software Application Executed in a Gateway |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19947782 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021550736 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19947782 Country of ref document: EP Kind code of ref document: A1 |