WO2021038887A1 - 類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 - Google Patents
類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 Download PDFInfo
- Publication number
- WO2021038887A1 WO2021038887A1 PCT/JP2019/034306 JP2019034306W WO2021038887A1 WO 2021038887 A1 WO2021038887 A1 WO 2021038887A1 JP 2019034306 W JP2019034306 W JP 2019034306W WO 2021038887 A1 WO2021038887 A1 WO 2021038887A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document
- word
- search target
- hash function
- words
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/38—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/383—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
Definitions
- An embodiment of the present invention relates to a similar document search method, a similar document search program, a similar document search device, an index information creation method, an index information creation program, and an index information creation device.
- a search process for searching a document similar to an input document from the documents stored in a database. For example, a sample inquiry document and a response document corresponding to the sample are registered in the database. Then, it is conceivable to construct a dialogue interface such as a chatbot that searches for a sample similar to the input inquiry document and outputs a response document corresponding to the similar sample.
- a dialogue interface such as a chatbot that searches for a sample similar to the input inquiry document and outputs a response document corresponding to the similar sample.
- a plurality of hash functions (sometimes called Min-hash functions) that calculate one hash value from a word set included in a certain document are defined.
- Each hash function has a correspondence relationship in which different values are associated with different words, and outputs the smallest value among the values corresponding to the words included in a certain word set as a hash value.
- a vector enumerating a plurality of hash values calculated by using the plurality of hash functions is generated in advance. Then, a vector is similarly calculated from the word set included in the input document and the above-mentioned plurality of hash functions, and a vector similar to the sample vector registered in the database is searched for.
- a computer executes a process of generating, a process of calculating, and a process of searching.
- the process of generating is based on the set of words included in the search target document and the inter-word information indicating the closeness of the meanings of the words, and for each word included in the set of words, the corresponding word is used as a reference.
- Generate a hash function that assigns values to words in order of closeness.
- the summary information of each of the plurality of search target documents is calculated based on the generated hash function, and the summary information of the input document is calculated based on the generated hash function.
- the search process searches for a document similar to the input document from a plurality of search target documents based on the comparison between the calculated summary information of the search target document and the summary information of the input document.
- FIG. 1 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment.
- FIG. 2 is an explanatory diagram showing an example of a processing flow of the information processing apparatus according to the embodiment.
- FIG. 3 is a flowchart showing an example of the hash function generation process.
- FIG. 4 is an explanatory diagram illustrating a hash function.
- FIG. 5 is an explanatory diagram illustrating the degree of similarity between words.
- FIG. 6 is an explanatory diagram illustrating a hash value by Min hash.
- FIG. 7 is an explanatory diagram illustrating an outline of the operation of the information processing apparatus according to the embodiment.
- FIG. 8 is an explanatory diagram for explaining the narrowing down of the search target documents.
- FIG. 9 is an explanatory diagram showing a display example of the operation screen.
- FIG. 10 is a diagram showing an example of a computer that executes a program.
- the similar document search method, the similar document search program, the similar document search device, the index information creation method, the index information creation program, and the index information creation device according to the embodiment will be described with reference to the drawings. Configurations having the same function in the embodiment are designated by the same reference numerals, and duplicate description will be omitted.
- the similar document search method, the similar document search program, the similar document search device, the index information creation method, the index information creation program, and the index information creation device described in the following embodiments are merely examples. It is not limited.
- the following embodiments may be appropriately combined within a consistent range.
- an information processing device that searches for a document similar to an input document (hereinafter, also referred to as an inquiry document) from a sample (hereinafter, also referred to as a search target document) registered in a database is illustrated.
- first pre-processing is performed, and then search processing is performed.
- a hash value is calculated for each search target document using a hash function, and an index structure (for example, a search tree) such as a tree structure for searching the search target document is created from the calculated hash value.
- the hash value of the inquiry document is calculated using the hash function.
- the information processing apparatus compares the hash value of the inquiry document with the hash value of each search target document, and searches for the closest hash value of each search target document indicated by the index structure.
- the information processing apparatus sets a search target document having a hash value close to the hash value of the inquiry document as a search result of a similar document.
- a plurality of hash functions for calculating the hash value are defined based on the set of words obtained by extracting the words included in the search target document registered in the database.
- the information processing device has a hash function in which W is a set of words and h is a set of all injective functions (plural hash functions) from W to ⁇ 0,1, ...,
- the information processing device performs the following processing on the search target document and the inquiry document to obtain a vector with a plurality of hash values and obtain summary information summarizing the search target document and the inquiry document by a hash function.
- a hash function from h.
- -The smallest integer obtained from each word by the selected h is used as the hash value.
- -Multiple hash values are obtained by randomly selecting a function multiple times.
- Jakar coefficient For the selection of the hash function from h, the probability that the hash values match matches the Jakar coefficient. Therefore, in comparing the hash values of documents when finding similar documents, the Jakar coefficient can be calculated probabilistically from the matching ratio of each element of the vector, and the humming distance of the hash values (for example, the number of mismatches) is between documents. It reflects the closeness (similarity) of.
- n the number of search target documents
- m the number of words (average value) for each search target document
- k the number of hash functions. Then, the amount of calculation for calculating the vector of the search target document becomes O (kmn).
- the amount of calculation for calculating the vector of one inquiry document is O (km), and the calculation cost of the neighborhood search using this vector is O (log (n)).
- K hash functions are randomly generated in advance. When k is O (log (n)), the collision probability that the same hash value is calculated from different search target documents can be sufficiently reduced.
- the information processing device generates a hash function that assigns values in the order of close word meanings based on a predetermined word, based on the word-to-word distance information indicating the closeness of word meanings between words. Specifically, the information processing device extracts words included in the search target document, sets the words, and randomly selects a reference word. Next, the information processing device sorts the words included in the set of words in the order of their meanings closer to the reference word based on the inter-word distance information, and sets a unique value in the sort order (for example, an arrangement that increases in the sort order). Numerical value) is assigned. The information processing device generates a plurality of hash functions by repeating the above processing.
- the information processing device sorts the words in order of closeness based on ⁇ cat ⁇ .
- ⁇ cat, cat, ... rice, food ⁇ can be obtained.
- the hash value generated by the hash function in this way is a value corresponding to the distance between words (also called between words) with respect to a predetermined word. Therefore, it is possible to verify not only the Hamming distance between hash values but also the similarity by the Euclidean distance. Therefore, even if there is no common word and the hash values do not match (when the elements do not match), the similarity can be verified by the Euclidean distance, and the accuracy of the similarity search can be improved.
- FIG. 1 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment.
- the information processing device 100 is a device that performs a process of obtaining a similar similar document 102 from the search target documents stored in the search target document database 121 for the input inquiry document 101.
- the information processing device 100 for example, a personal computer or the like can be applied.
- the information processing device 100 includes an index generation module 111 that performs preprocessing to create an index structure, a search module 112 that performs search processing, and a storage unit (search target document database 121, inter-word distance information) that stores various data related to the processing. It has a storage unit 122, a hash function storage unit 123, and an index storage unit 124). That is, the information processing device 100 is an example of a similar document retrieval device and an index information creating device.
- the search target document database 121 is a database in which search target documents to be searched are registered for the inquiry document 101.
- the search target document in the search target document database 121 may be registered in advance, may be added through a dialogue in a dialogue interface such as a chatbot with a user who uses the information processing device 100, or may be automatically added from the network. May be collected in.
- the inter-word distance information storage unit 122 stores inter-word distance information indicating the closeness (interval between words) of the meaning of each word to other words.
- the inter-word distance information includes a function d (d, w) that represents the distance (interval between words) between each word (v) and another word (w). That is, the inter-word distance information is an example of inter-word information indicating the closeness of word meanings.
- the hash function storage unit 123 stores a plurality of different hash functions generated by the index generation module 111.
- Each hash function has a correspondence relationship in which a unique integer (in order of close meaning to a predetermined word) is associated with each word that can appear in the search target document, accepts a word set, and outputs one hash value. To do. Also, different hash functions have different correspondences.
- the index storage unit 124 stores an index structure for searching a search target document similar to the inquiry document 101.
- the index structure is generated by the index generation unit 132 based on the vector (summary information) calculated from the search target document using a plurality of hash functions, and is the index information for searching the summary information of each search target document. This is an example.
- a search tree can be applied.
- the search tree contains a plurality of nodes (a leaf node and each node leading to the leaf node) connected to the tree structure.
- the search Konoha node points to the document to be searched.
- the leaf node contains a vector of the search target document and identification information (for example, a document ID) that identifies the search target document.
- the leaf node does not have to contain the vector.
- Two child nodes are connected to each node other than the leaf node.
- Each node, except the leaf node has a threshold for a particular dimension in the vector. If the hash value of a specific dimension in the input vector is greater than or equal to the threshold value, the process proceeds to the right child node, and if the hash value of the specific dimension is less than the threshold value, the process proceeds to the left child node. In this way, by tracing the search tree from the root node to the leaf node, it is possible to efficiently search for a search target document close to a predetermined vector.
- the index generation module 111 has a hash function generation unit 131 and an index generation unit 132.
- the hash function generation unit 131 generates a plurality of hash functions based on the search target document stored in the hash function generation unit 131 and the inter-word distance information stored in the inquiry receiving unit 133, and a plurality of generated hash functions.
- the hash function is stored in the hash function storage unit 123.
- the hash function generation unit 131 extracts words included in the search target document, sets the words, and randomly selects a reference word. Next, the hash function generation unit 131 refers to the inter-word distance information of the inter-word distance information storage unit 122, and arranges (sorts) the words included in the word set in the order of the word meaning closer to the reference word. Next, the hash function generation unit 131 generates a hash function by assigning a unique value (for example, an integer value that increases in the sort order) to the words included in the word set in the sort order. The hash function generation unit 131 generates a plurality of hash functions by repeating the process of generating the hash function.
- a function d (d, w) representing the distance (interval between words) between each word (v) and another word (w) is given as inter-word distance information.
- This function d (d, w) can be created in advance by referring to the similarity between words and the vector representation of words.
- the hash function generator 131 randomly selects w from W, and sorts all v ⁇ W in ascending order of d (v, w). Next, the hash function generation unit 131 assigns integers 0, 1, 2, ... To the sorted words w, v 1 , v 2 ... Note that the hash function generation unit 131 may use the value of d (v, w) as it is instead of assigning an integer (assuming that there is no duplication).
- the index generation unit 132 generates an index structure based on the search target document stored in the search target document database 121 and the hash function stored in the hash function storage unit 123, and the generated index structure is stored in the index storage unit 124. Store.
- the index generation unit 132 extracts a word set for each search target document, inputs the extracted word set to each of a plurality of hash functions, and inputs a vector of hash values, that is, summary information of the search target document. calculate.
- the index generation unit 132 generates an index structure so that a plurality of vectors corresponding to the plurality of search target documents can be efficiently searched. For example, the index generation unit 132 pays attention to one dimension in the vector and repeatedly determines the threshold value of the hash value of the dimension so that the set of vectors is divided into two to generate a search tree. .. At this time, the index generation unit 132 generates an intermediate node so that a single vector is associated with the leaf node of the search tree as much as possible.
- the search module 112 includes an inquiry receiving unit 133, a hash value calculation unit 134, a search unit 135, and an output unit 136.
- the inquiry receiving unit 133 receives the inquiry document 101.
- the inquiry receiving unit 133 may receive the inquiry document 101 input as a character string from the user, or may convert the voice signal of the inquiry utterance uttered by the user into a character string.
- the inquiry receiving unit 133 may receive a character string or an audio signal from another information processing device.
- the hash value calculation unit 134 generates a vector corresponding to the inquiry document 101, that is, summary information of the inquiry document 101, based on a plurality of hash functions stored in the hash function storage unit 123. Specifically, the hash value calculation unit 134 extracts a word set from the inquiry document 101, inputs the extracted word set into each of the plurality of hash functions, and calculates a hash value vector.
- the search unit 135 searches for the search target document most similar to the inquiry document 101 by neighborhood search based on the index structure stored in the index storage unit 124 and the vector of the inquiry document 101. Specifically, the search target document most similar to the inquiry document 101 has the largest number of dimensions in which the hash values match when the vectors are compared.
- the search unit 135 traces the search tree stored in the index storage unit 124 from the root node to the leaf node while comparing the hash value of a specific dimension in the vector of the inquiry document 101 with the threshold value. Reach a specific leaf node. The search unit 135 selects the search target document corresponding to the reached leaf node.
- the search unit 135 compares the hash values with each other to obtain the Euclidean distance. Next, the search unit 135 sets the document having the closer Euclidean distance as the most similar search target document.
- the output unit 136 outputs the searched search target document as a similar document 102.
- the output unit 136 may display the character string of the similar document 102 on a display or the like, or may convert the similar document 102 into a voice signal and reproduce the voice by the speaker. Further, the output unit 136 may transmit a character string or an audio signal of the similar document 102 to another information processing device.
- the output unit 136 may perform a process associated with the searched search target document in advance in the search target document database 121. Specifically, it is assumed that predetermined processes (for example, schedule registration and e-mail transmission) are registered in the search target document database 121 for each search target document. The output unit 136 can perform the process corresponding to the inquiry document 101 by reading the process associated with the searched search target document from the search target document database 121 and executing the process.
- predetermined processes for example, schedule registration and e-mail transmission
- FIG. 2 is an explanatory diagram showing an example of a processing flow of the information processing apparatus according to the embodiment.
- the information processing apparatus 100 performs a pre-processing (S1) for creating an index structure and a search process (S2) for searching and outputting a similar document 102 for the inquiry document 101.
- S1 pre-processing
- S2 search process
- the pre-processing (S1) will be described.
- the search target document is first read from the search target document database 121 and input to the hash function generation unit 131 (S11).
- the hash function generation unit 131 receives input of the distance between words from the inquiry receiving unit 133 (S13), and generates a plurality of hash functions 123a based on the input search target document and the distance between words (S12). ).
- FIG. 3 is a flowchart showing an example of the hash function generation process.
- the hash function generation unit 131 accepts the input of the search target document (S31) and extracts the words (appearing words) included in the search target document (S32) to set the words (words). Set) (S33).
- the hash function generation unit 131 generates a plurality of hash functions 123a by repeating k times, which is the number of hash functions that generate the processes of S34 to S39.
- the hash function generation unit 131 randomly selects one word from the word set (S35), accepts input of inter-word distance information indicating the distance between words (S36), and selects the selected word. The distance between the word and another word is referred to from the inter-word distance information (S37).
- the hash function generation unit 131 sorts the words in the word set in order of proximity to the selected word (S38), and assigns an integer value that increases in the order of arrangement to each arranged word as a hash value (S39). ..
- the hash function generation unit 131 outputs a plurality of hash functions 123a obtained by repeating the processes of S34 to S39 k times and stores them in the index generation unit 132 (S40).
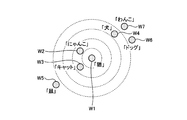
- FIG. 4 is an explanatory diagram illustrating the hash function 123a. As shown in FIG. 4, h 1 , h 2 , ... h 2, ... In the hash function 123a is one hash function.
- h 1 uses (cat) as a reference word, and an integer value corresponding to the distance between words with respect to (cat) is assigned to each word in the word set.
- h 2 uses (rice) as a reference word, and an integer value corresponding to the distance between words for (rice) is assigned to each word in the word set.
- h 3 uses (Nyanko) as a reference word, and an integer value corresponding to the distance between words for (Nyanko) is assigned to each word in the word set.
- h 4 uses (food) as a reference word, and an integer value corresponding to the distance between words with respect to (food) is assigned to each word in the word set.
- h 5 is assigned an integer value corresponding to the distance between the word for (flowers) and a reference word, and for each word in the word set (flowers). Further, h 6 uses (water) as a reference word, and an integer value corresponding to the distance between words with respect to (water) is assigned to each word in the word set.
- the word set of document A is ⁇ cat, rice ⁇
- the word set of document B is ⁇ nyanko, food ⁇
- the index generation unit 132 generates an index structure 124a based on the input search target document and the generated hash function 123a (S14), and stores the generated index structure 124a as an index. It is stored in the unit 124.
- the inquiry document 101 received by the inquiry receiving unit 133 is input to the hash value calculating unit 134 (S21).
- the hash value calculation unit 134 generates a plurality of hash values of the input inquiry document 101 based on the plurality of hash functions stored in the hash function storage unit 123 (S22), and obtains a vector corresponding to the inquiry document 101. ..
- the search unit 135 collates the hash value of each vector of the search target document in the index structure stored in the index storage unit 124 with the hash value of the vector of the inquiry document 101 (S23), and the search target most similar to the inquiry document 101. Search for documents.
- the output unit 136 outputs the similar document 102 searched by the search unit 135 (S24).
- FIG. 5 is an explanatory diagram for explaining the degree of similarity between words.
- FIG. 5 is a bird's-eye view of the arrangement of words W1 to W6 in a high-dimensional space showing the degree of similarity between words.
- Each of the words W1 to W6 in FIG. 5 indicates a word contained in the document.
- the words W1 to W3 are similar to words such as "cat” and form clusters shown by dotted lines.
- the words W4 to W6 are similar for words such as "dog” and form a cluster separate from the words W1 to W3.
- the projection based on the distance from the reference word is used.
- FIG. 6 is an explanatory diagram for explaining the hash value by Min hash.
- the word W1 is "cat”
- the word W2 is "nyanko”
- the word W3 is “cat”
- the word W4 is "dog”
- the word W5 is “mouse”
- the word W6 is "dog”
- the word W7 is “dog”. It shall be. Further, it is assumed that the reference point is the word W1.
- Min hash the minimum value among the hash values of the word set.
- FIG. 7 is an explanatory diagram illustrating an outline of the operation of the information processing apparatus 100 according to the embodiment.
- the information processing apparatus 100 uses the words included in each of the search target documents 121a of the search target document database 121 based on the similarity between words based on the inter-word distance information. For a set of, generate a plurality of hash functions that assign values close to each other in order of close meaning based on a predetermined word.
- the information processing apparatus 100 converts each of the search target documents 121a by Min Hash using the generated plurality of hash functions, generates an index structure for searching the calculated vector, and stores the index storage unit 124. Store.
- the information processing apparatus 100 converts the input inquiry document 101 by Min Hash using the same plurality of hash functions generated in S1. Next, the information processing apparatus 100 compares the hash value vector calculated from the inquiry document 101 with the hash value vector stored in the index storage unit 124, so that the search target document 121a most similar to the inquiry document 101 To search for.
- the output unit 136 may output one similar document 102 that is most similar to the searched search target document, or a plurality of documents whose similarity obtained by the Hamming distance and the Euclidean distance is equal to or higher than a predetermined threshold value. You may output the similar document 102 of.
- FIG. 8 is an explanatory diagram for explaining the narrowing down of the search target documents. Specifically, FIG. 8 is a graph showing an example of the relationship between the threshold value of similarity and the number of hits of the search target document 121a.
- Graph 10 shows the relationship between the threshold value of the similarity between the inquiry document 101 and the search target document 121a and the number (hits) of the search target document 121a whose similarity is greater than the threshold value.
- the similarity is the number of dimensions in which the hash values match between the vector of the inquiry utterance and the vector of the search target utterance, and the Euclidean distance between the hash values.
- the similarity between the inquiry document 101 and each search target document 121a takes into account the Euclidean distance. Therefore, the relationship between the similarity threshold and the number of hits is continuous as shown in curve 13. As a result, the search target document 121a similar to the inquiry document 101 can be efficiently narrowed down.
- FIG. 9 is an explanatory diagram showing a display example of the operation screen.
- the operation screen 20 is a screen that accepts various operations from the user by presenting it to the user of the information processing apparatus 100 in a dialogue interface such as a chatbot.
- the display area 21 is an area for displaying a processing result or the like
- the input area 22 is an area for inputting a document or the like.
- the information processing apparatus 100 searches for a similar document 102 with respect to the inquiry document 101 input to the input area 22, and outputs an output according to the search result to the display area 21.
- the information processing apparatus 100 searches for a similar document 102 using the input document 21a that "wants to adjust the schedule” as the inquiry document 101, and displays the search result 21b in the display area 21. Specifically, for the inquiry document 101 that "wants to adjust the schedule", the schedule registration process corresponding to the "schedule adjustment" obtained as the similar document 102 from the search target document 121a is executed.
- the information processing apparatus 100 even when the inquiry document 101 is mainly a spoken language and one sentence is short and the expressions are diverse, as in the interactive interface such as the chatbot in the example of FIG. 9, a similar document is appropriately used. 102 searches can be performed.
- the information processing apparatus 100 includes a hash function generation unit 131, an index generation unit 132, a hash value calculation unit 134, and a search unit 135.
- the hash function generation unit 131 determines a predetermined word for each word included in the word set based on the set of words included in the search target document 121a and the inter-word distance information indicating the closeness of the word meanings of the words. Generates a hash function that assigns values that are closer to each other in order of increasing meaning based on.
- the index generation unit 132 calculates the summary information of each of the plurality of search target documents 121a based on the generated hash function.
- the hash value calculation unit 134 calculates the summary information of the input document (inquiry document 101) based on the generated hash function.
- the search unit 135 searches a plurality of search target documents 121a for documents similar to the input document based on the comparison between the calculated summary information of the search target document 121a and the summary information of the inquiry document 101.
- the hash value included in the summary information of the search target document 121a calculated based on the generated hash function and the summary information of the inquiry document 101 depends on the distance of the meaning of the word to the predetermined word. Value. Therefore, in the information processing apparatus 100, in the comparison between the summary information of the search target document 121a and the summary information of the inquiry document 101, for example, the similarity using not only the Hamming distance between the summary information but also the Euclidean distance is used. The degree can be verified, and the search accuracy of similar documents can be improved.
- each of the index generation unit 132 and the hash value calculation unit 134 sets the minimum value among the values assigned to each of the words in the set of words included in the search target document 121a or the inquiry document 101 in the generated hash function. Calculated as a hash value. In this way, the information processing apparatus 100 can calculate the summary information of the search target document 121a or the inquiry document 101 by the Min-hash function.
- the hash function generation unit 131 generates a plurality of hash functions by repeating the process of reselecting a predetermined word and generating the hash function. Then, each of the index generation unit 132 and the hash value calculation unit 134 summarizes a vector containing a plurality of hash values calculated from a set of words included in the search target document 121a or the inquiry document 101 by the generated hash functions. Calculated as information.
- the information processing apparatus 100 in the comparison between the summary information of the search target document 121a and the summary information of the inquiry document 101, by comparing the vectors listing a plurality of hash values, for example, the Hamming distance, the Euclidean distance, etc. Can be obtained to verify the degree of similarity.
- the index generation unit 132 of the information processing apparatus 100 generates index information in which the calculated summary information of each of the plurality of search target documents 121a is associated with the search target document 121a.
- the search unit 135 compares the summary information of the inquiry document 101 with the summary information associated with the search target document 121a in the index information. By generating index information, the information processing apparatus 100 can quickly search for a document similar to the inquiry document 101 from among a plurality of search target documents 121a.
- each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of the device is functionally or physically distributed / physically in arbitrary units according to various loads and usage conditions. It can be integrated and configured.
- the information processing device 100 having the index generation module 111 and the search module 112 is illustrated, but even if the index generation module 111 and the search module 112 have different information processing devices, respectively. Good. That is, the pre-processing (S1) and the search processing (S2) may be performed by different information processing devices.
- the various processing functions performed by the information processing apparatus 100 may execute all or any part thereof on the CPU (or a microcomputer such as an MPU or an MCU (Micro Controller Unit)). Further, various processing functions may be executed in whole or in any part on a program analyzed and executed by a CPU (or a microcomputer such as an MPU or MCU) or on hardware by wired logic. Needless to say, it's good. Further, various processing functions performed by the information processing apparatus 100 may be executed by a plurality of computers in cooperation by cloud computing.
- FIG. 10 is a diagram showing an example of a computer that executes a program.
- the computer 1 has a CPU 201 that executes various arithmetic processes, an input device 202 that receives data input, a monitor 203, and a speaker 204. Further, the computer 1 has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting to various devices, and a communication device 207 for communicating with an external device by wire or wirelessly. Further, the computer 1 has a RAM 208 for temporarily storing various information and a hard disk device 209. Further, each part (201 to 209) in the computer 1 is connected to the bus 210.
- the hard disk device 209 stores a program 211 for executing various processes described in the above embodiment. Further, the hard disk device 209 stores various data 212 (for example, information of the inter-word distance information storage unit 122, the search target document database 121, the hash function storage unit 123, and the index storage unit 124) referred to by the program 211.
- the input device 202 receives, for example, input of operation information from the operator of the computer 1.
- the monitor 203 displays, for example, various screens operated by the operator. For example, a printing device or the like is connected to the interface device 206.
- the communication device 207 is connected to a communication network such as a LAN (Local Area Network), and exchanges various information with an external device via the communication network.
- LAN Local Area Network
- the CPU 201 reads the program 211 stored in the hard disk device 209, expands it into the RAM 208, and executes it, thereby executing the hash function generation unit 131, the index generation unit 132, the inquiry reception unit 133, the hash value calculation unit 134, and the search unit. Various processes related to 135 and the output unit 136 are performed.
- the program 211 may not be stored in the hard disk device 209.
- the computer 1 may read and execute the program 211 stored in the storage medium that can be read by the computer 1.
- the storage medium that can be read by the computer 1 corresponds to, for example, a CD-ROM, a DVD disk, a portable recording medium such as a USB (Universal Serial Bus) memory, a semiconductor memory such as a flash memory, a hard disk drive, or the like.
- the program 211 may be stored in a device connected to a public line, the Internet, a LAN, or the like, and the computer 1 may read the program from these and execute the program.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Library & Information Science (AREA)
- Software Systems (AREA)
- Business, Economics & Management (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/034306 WO2021038887A1 (ja) | 2019-08-30 | 2019-08-30 | 類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 |
| JP2021541969A JP7193000B2 (ja) | 2019-08-30 | 2019-08-30 | 類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/034306 WO2021038887A1 (ja) | 2019-08-30 | 2019-08-30 | 類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021038887A1 true WO2021038887A1 (ja) | 2021-03-04 |
Family
ID=74683387
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/034306 Ceased WO2021038887A1 (ja) | 2019-08-30 | 2019-08-30 | 類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7193000B2 (https=) |
| WO (1) | WO2021038887A1 (https=) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022239174A1 (ja) * | 2021-05-13 | 2022-11-17 | 日本電気株式会社 | 類似度導出システムおよび類似度導出方法 |
| CN116302074A (zh) * | 2023-05-12 | 2023-06-23 | 卓望数码技术(深圳)有限公司 | 第三方组件识别方法、装置、设备及存储介质 |
| WO2024089910A1 (ja) * | 2022-10-26 | 2024-05-02 | 株式会社LegalOn Technologies | 情報処理方法、情報処理プログラム、情報処理システム |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010267108A (ja) * | 2009-05-15 | 2010-11-25 | Nippon Telegr & Teleph Corp <Ntt> | 類似文書を検出するための文書署名生成装置、文書署名生成方法、文書署名生成プログラム |
| US20110087669A1 (en) * | 2009-10-09 | 2011-04-14 | Stratify, Inc. | Composite locality sensitive hash based processing of documents |
| JP2015201042A (ja) * | 2014-04-08 | 2015-11-12 | 日本電信電話株式会社 | ハッシュ関数生成方法、ハッシュ値生成方法、装置、及びプログラム |
| CN106156154A (zh) * | 2015-04-14 | 2016-11-23 | 阿里巴巴集团控股有限公司 | 相似文本的检索方法及其装置 |
| CN107784110A (zh) * | 2017-11-03 | 2018-03-09 | 北京锐安科技有限公司 | 一种索引建立方法及装置 |
-
2019
- 2019-08-30 WO PCT/JP2019/034306 patent/WO2021038887A1/ja not_active Ceased
- 2019-08-30 JP JP2021541969A patent/JP7193000B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010267108A (ja) * | 2009-05-15 | 2010-11-25 | Nippon Telegr & Teleph Corp <Ntt> | 類似文書を検出するための文書署名生成装置、文書署名生成方法、文書署名生成プログラム |
| US20110087669A1 (en) * | 2009-10-09 | 2011-04-14 | Stratify, Inc. | Composite locality sensitive hash based processing of documents |
| JP2015201042A (ja) * | 2014-04-08 | 2015-11-12 | 日本電信電話株式会社 | ハッシュ関数生成方法、ハッシュ値生成方法、装置、及びプログラム |
| CN106156154A (zh) * | 2015-04-14 | 2016-11-23 | 阿里巴巴集团控股有限公司 | 相似文本的检索方法及其装置 |
| CN107784110A (zh) * | 2017-11-03 | 2018-03-09 | 北京锐安科技有限公司 | 一种索引建立方法及装置 |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022239174A1 (ja) * | 2021-05-13 | 2022-11-17 | 日本電気株式会社 | 類似度導出システムおよび類似度導出方法 |
| JPWO2022239174A1 (https=) * | 2021-05-13 | 2022-11-17 | ||
| JP7464193B2 (ja) | 2021-05-13 | 2024-04-09 | 日本電気株式会社 | 類似度導出システムおよび類似度導出方法 |
| US12413413B2 (en) | 2021-05-13 | 2025-09-09 | Nec Corporation | Similarity degree derivation system and similarity degree derivation method |
| WO2024089910A1 (ja) * | 2022-10-26 | 2024-05-02 | 株式会社LegalOn Technologies | 情報処理方法、情報処理プログラム、情報処理システム |
| CN116302074A (zh) * | 2023-05-12 | 2023-06-23 | 卓望数码技术(深圳)有限公司 | 第三方组件识别方法、装置、设备及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021038887A1 (https=) | 2021-03-04 |
| JP7193000B2 (ja) | 2022-12-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN116932730B (zh) | 基于多叉树和大规模语言模型的文档问答方法及相关设备 | |
| US20230259761A1 (en) | Transfer learning system and method for deep neural network | |
| JP6019604B2 (ja) | 音声認識装置、音声認識方法、及びプログラム | |
| US20230177089A1 (en) | Identifying similar content in a multi-item embedding space | |
| WO2019102533A1 (ja) | 文献分類装置 | |
| KR102011099B1 (ko) | 이미지 기반 음원 선택 방법, 장치 및 컴퓨터 프로그램 | |
| JP7193000B2 (ja) | 類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置 | |
| CN114021541A (zh) | 演示文稿生成方法、装置、设备及存储介质 | |
| JP2019184852A (ja) | データ分析サーバ、データ分析システム、及びデータ分析方法 | |
| JP6004015B2 (ja) | 学習方法、情報処理装置および学習プログラム | |
| JP2022185799A (ja) | 情報処理プログラム、情報処理方法および情報処理装置 | |
| CN116127066A (zh) | 文本聚类方法、文本聚类装置、电子设备及存储介质 | |
| JP2018180459A (ja) | 音声合成システム、音声合成方法、及び音声合成プログラム | |
| US20240070726A1 (en) | Automated generation of creative parameters based on approval feedback | |
| WO2008062822A1 (en) | Text mining device, text mining method and text mining program | |
| US6944329B2 (en) | Information processing method and apparatus | |
| CN113302601B (zh) | 含义关系学习装置、含义关系学习方法及记录了含义关系学习程序的记录介质 | |
| JP6973733B2 (ja) | 特許情報処理装置、特許情報処理方法およびプログラム | |
| JP6976178B2 (ja) | 抽出装置、抽出方法、及び抽出プログラム | |
| KR102313549B1 (ko) | 음원 생성 방법 및 음원 생성 시스템 | |
| CN116012072B (zh) | 一种基于用户消费数据的精准营销方法、装置及设备 | |
| JP7032650B2 (ja) | 類似テキスト検索方法、類似テキスト検索装置および類似テキスト検索プログラム | |
| CN110892401B (zh) | 生成用于k个不匹配搜索的过滤器的系统和方法 | |
| JP2018045657A (ja) | 学習装置、プログラムパラメータおよび学習方法 | |
| KR102072238B1 (ko) | 신뢰도 기반 질의응답 시스템 및 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19943706 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021541969 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19943706 Country of ref document: EP Kind code of ref document: A1 |