WO2021038887A1 - Similar document retrieval method, similar document retrieval program, similar document retrieval device, index information creation method, index information creation program, and index information creation device - Google Patents
Similar document retrieval method, similar document retrieval program, similar document retrieval device, index information creation method, index information creation program, and index information creation device Download PDFInfo
- Publication number
- WO2021038887A1 WO2021038887A1 PCT/JP2019/034306 JP2019034306W WO2021038887A1 WO 2021038887 A1 WO2021038887 A1 WO 2021038887A1 JP 2019034306 W JP2019034306 W JP 2019034306W WO 2021038887 A1 WO2021038887 A1 WO 2021038887A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document
- word
- search target
- hash function
- words
- Prior art date
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/38—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/383—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
Definitions
- An embodiment of the present invention relates to a similar document search method, a similar document search program, a similar document search device, an index information creation method, an index information creation program, and an index information creation device.
- a search process for searching a document similar to an input document from the documents stored in a database. For example, a sample inquiry document and a response document corresponding to the sample are registered in the database. Then, it is conceivable to construct a dialogue interface such as a chatbot that searches for a sample similar to the input inquiry document and outputs a response document corresponding to the similar sample.
- a dialogue interface such as a chatbot that searches for a sample similar to the input inquiry document and outputs a response document corresponding to the similar sample.
- a plurality of hash functions (sometimes called Min-hash functions) that calculate one hash value from a word set included in a certain document are defined.
- Each hash function has a correspondence relationship in which different values are associated with different words, and outputs the smallest value among the values corresponding to the words included in a certain word set as a hash value.
- a vector enumerating a plurality of hash values calculated by using the plurality of hash functions is generated in advance. Then, a vector is similarly calculated from the word set included in the input document and the above-mentioned plurality of hash functions, and a vector similar to the sample vector registered in the database is searched for.
- a computer executes a process of generating, a process of calculating, and a process of searching.
- the process of generating is based on the set of words included in the search target document and the inter-word information indicating the closeness of the meanings of the words, and for each word included in the set of words, the corresponding word is used as a reference.
- Generate a hash function that assigns values to words in order of closeness.
- the summary information of each of the plurality of search target documents is calculated based on the generated hash function, and the summary information of the input document is calculated based on the generated hash function.
- the search process searches for a document similar to the input document from a plurality of search target documents based on the comparison between the calculated summary information of the search target document and the summary information of the input document.
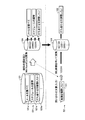
- FIG. 1 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment.
- FIG. 2 is an explanatory diagram showing an example of a processing flow of the information processing apparatus according to the embodiment.
- FIG. 3 is a flowchart showing an example of the hash function generation process.
- FIG. 4 is an explanatory diagram illustrating a hash function.
- FIG. 5 is an explanatory diagram illustrating the degree of similarity between words.
- FIG. 6 is an explanatory diagram illustrating a hash value by Min hash.
- FIG. 7 is an explanatory diagram illustrating an outline of the operation of the information processing apparatus according to the embodiment.
- FIG. 8 is an explanatory diagram for explaining the narrowing down of the search target documents.
- FIG. 9 is an explanatory diagram showing a display example of the operation screen.
- FIG. 10 is a diagram showing an example of a computer that executes a program.
- the similar document search method, the similar document search program, the similar document search device, the index information creation method, the index information creation program, and the index information creation device according to the embodiment will be described with reference to the drawings. Configurations having the same function in the embodiment are designated by the same reference numerals, and duplicate description will be omitted.
- the similar document search method, the similar document search program, the similar document search device, the index information creation method, the index information creation program, and the index information creation device described in the following embodiments are merely examples. It is not limited.
- the following embodiments may be appropriately combined within a consistent range.
- an information processing device that searches for a document similar to an input document (hereinafter, also referred to as an inquiry document) from a sample (hereinafter, also referred to as a search target document) registered in a database is illustrated.
- first pre-processing is performed, and then search processing is performed.
- a hash value is calculated for each search target document using a hash function, and an index structure (for example, a search tree) such as a tree structure for searching the search target document is created from the calculated hash value.
- the hash value of the inquiry document is calculated using the hash function.
- the information processing apparatus compares the hash value of the inquiry document with the hash value of each search target document, and searches for the closest hash value of each search target document indicated by the index structure.
- the information processing apparatus sets a search target document having a hash value close to the hash value of the inquiry document as a search result of a similar document.
- a plurality of hash functions for calculating the hash value are defined based on the set of words obtained by extracting the words included in the search target document registered in the database.
- the information processing device has a hash function in which W is a set of words and h is a set of all injective functions (plural hash functions) from W to ⁇ 0,1, ...,
- the information processing device performs the following processing on the search target document and the inquiry document to obtain a vector with a plurality of hash values and obtain summary information summarizing the search target document and the inquiry document by a hash function.
- a hash function from h.
- -The smallest integer obtained from each word by the selected h is used as the hash value.
- -Multiple hash values are obtained by randomly selecting a function multiple times.
- Jakar coefficient For the selection of the hash function from h, the probability that the hash values match matches the Jakar coefficient. Therefore, in comparing the hash values of documents when finding similar documents, the Jakar coefficient can be calculated probabilistically from the matching ratio of each element of the vector, and the humming distance of the hash values (for example, the number of mismatches) is between documents. It reflects the closeness (similarity) of.
- n the number of search target documents
- m the number of words (average value) for each search target document
- k the number of hash functions. Then, the amount of calculation for calculating the vector of the search target document becomes O (kmn).
- the amount of calculation for calculating the vector of one inquiry document is O (km), and the calculation cost of the neighborhood search using this vector is O (log (n)).
- K hash functions are randomly generated in advance. When k is O (log (n)), the collision probability that the same hash value is calculated from different search target documents can be sufficiently reduced.
- the information processing device generates a hash function that assigns values in the order of close word meanings based on a predetermined word, based on the word-to-word distance information indicating the closeness of word meanings between words. Specifically, the information processing device extracts words included in the search target document, sets the words, and randomly selects a reference word. Next, the information processing device sorts the words included in the set of words in the order of their meanings closer to the reference word based on the inter-word distance information, and sets a unique value in the sort order (for example, an arrangement that increases in the sort order). Numerical value) is assigned. The information processing device generates a plurality of hash functions by repeating the above processing.
- the information processing device sorts the words in order of closeness based on ⁇ cat ⁇ .
- ⁇ cat, cat, ... rice, food ⁇ can be obtained.
- the hash value generated by the hash function in this way is a value corresponding to the distance between words (also called between words) with respect to a predetermined word. Therefore, it is possible to verify not only the Hamming distance between hash values but also the similarity by the Euclidean distance. Therefore, even if there is no common word and the hash values do not match (when the elements do not match), the similarity can be verified by the Euclidean distance, and the accuracy of the similarity search can be improved.
- FIG. 1 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment.
- the information processing device 100 is a device that performs a process of obtaining a similar similar document 102 from the search target documents stored in the search target document database 121 for the input inquiry document 101.
- the information processing device 100 for example, a personal computer or the like can be applied.
- the information processing device 100 includes an index generation module 111 that performs preprocessing to create an index structure, a search module 112 that performs search processing, and a storage unit (search target document database 121, inter-word distance information) that stores various data related to the processing. It has a storage unit 122, a hash function storage unit 123, and an index storage unit 124). That is, the information processing device 100 is an example of a similar document retrieval device and an index information creating device.
- the search target document database 121 is a database in which search target documents to be searched are registered for the inquiry document 101.
- the search target document in the search target document database 121 may be registered in advance, may be added through a dialogue in a dialogue interface such as a chatbot with a user who uses the information processing device 100, or may be automatically added from the network. May be collected in.
- the inter-word distance information storage unit 122 stores inter-word distance information indicating the closeness (interval between words) of the meaning of each word to other words.
- the inter-word distance information includes a function d (d, w) that represents the distance (interval between words) between each word (v) and another word (w). That is, the inter-word distance information is an example of inter-word information indicating the closeness of word meanings.
- the hash function storage unit 123 stores a plurality of different hash functions generated by the index generation module 111.
- Each hash function has a correspondence relationship in which a unique integer (in order of close meaning to a predetermined word) is associated with each word that can appear in the search target document, accepts a word set, and outputs one hash value. To do. Also, different hash functions have different correspondences.
- the index storage unit 124 stores an index structure for searching a search target document similar to the inquiry document 101.
- the index structure is generated by the index generation unit 132 based on the vector (summary information) calculated from the search target document using a plurality of hash functions, and is the index information for searching the summary information of each search target document. This is an example.
- a search tree can be applied.
- the search tree contains a plurality of nodes (a leaf node and each node leading to the leaf node) connected to the tree structure.
- the search Konoha node points to the document to be searched.
- the leaf node contains a vector of the search target document and identification information (for example, a document ID) that identifies the search target document.
- the leaf node does not have to contain the vector.
- Two child nodes are connected to each node other than the leaf node.
- Each node, except the leaf node has a threshold for a particular dimension in the vector. If the hash value of a specific dimension in the input vector is greater than or equal to the threshold value, the process proceeds to the right child node, and if the hash value of the specific dimension is less than the threshold value, the process proceeds to the left child node. In this way, by tracing the search tree from the root node to the leaf node, it is possible to efficiently search for a search target document close to a predetermined vector.
- the index generation module 111 has a hash function generation unit 131 and an index generation unit 132.
- the hash function generation unit 131 generates a plurality of hash functions based on the search target document stored in the hash function generation unit 131 and the inter-word distance information stored in the inquiry receiving unit 133, and a plurality of generated hash functions.
- the hash function is stored in the hash function storage unit 123.
- the hash function generation unit 131 extracts words included in the search target document, sets the words, and randomly selects a reference word. Next, the hash function generation unit 131 refers to the inter-word distance information of the inter-word distance information storage unit 122, and arranges (sorts) the words included in the word set in the order of the word meaning closer to the reference word. Next, the hash function generation unit 131 generates a hash function by assigning a unique value (for example, an integer value that increases in the sort order) to the words included in the word set in the sort order. The hash function generation unit 131 generates a plurality of hash functions by repeating the process of generating the hash function.
- a function d (d, w) representing the distance (interval between words) between each word (v) and another word (w) is given as inter-word distance information.
- This function d (d, w) can be created in advance by referring to the similarity between words and the vector representation of words.
- the hash function generator 131 randomly selects w from W, and sorts all v ⁇ W in ascending order of d (v, w). Next, the hash function generation unit 131 assigns integers 0, 1, 2, ... To the sorted words w, v 1 , v 2 ... Note that the hash function generation unit 131 may use the value of d (v, w) as it is instead of assigning an integer (assuming that there is no duplication).
- the index generation unit 132 generates an index structure based on the search target document stored in the search target document database 121 and the hash function stored in the hash function storage unit 123, and the generated index structure is stored in the index storage unit 124. Store.
- the index generation unit 132 extracts a word set for each search target document, inputs the extracted word set to each of a plurality of hash functions, and inputs a vector of hash values, that is, summary information of the search target document. calculate.
- the index generation unit 132 generates an index structure so that a plurality of vectors corresponding to the plurality of search target documents can be efficiently searched. For example, the index generation unit 132 pays attention to one dimension in the vector and repeatedly determines the threshold value of the hash value of the dimension so that the set of vectors is divided into two to generate a search tree. .. At this time, the index generation unit 132 generates an intermediate node so that a single vector is associated with the leaf node of the search tree as much as possible.
- the search module 112 includes an inquiry receiving unit 133, a hash value calculation unit 134, a search unit 135, and an output unit 136.
- the inquiry receiving unit 133 receives the inquiry document 101.
- the inquiry receiving unit 133 may receive the inquiry document 101 input as a character string from the user, or may convert the voice signal of the inquiry utterance uttered by the user into a character string.
- the inquiry receiving unit 133 may receive a character string or an audio signal from another information processing device.
- the hash value calculation unit 134 generates a vector corresponding to the inquiry document 101, that is, summary information of the inquiry document 101, based on a plurality of hash functions stored in the hash function storage unit 123. Specifically, the hash value calculation unit 134 extracts a word set from the inquiry document 101, inputs the extracted word set into each of the plurality of hash functions, and calculates a hash value vector.
- the search unit 135 searches for the search target document most similar to the inquiry document 101 by neighborhood search based on the index structure stored in the index storage unit 124 and the vector of the inquiry document 101. Specifically, the search target document most similar to the inquiry document 101 has the largest number of dimensions in which the hash values match when the vectors are compared.
- the search unit 135 traces the search tree stored in the index storage unit 124 from the root node to the leaf node while comparing the hash value of a specific dimension in the vector of the inquiry document 101 with the threshold value. Reach a specific leaf node. The search unit 135 selects the search target document corresponding to the reached leaf node.
- the search unit 135 compares the hash values with each other to obtain the Euclidean distance. Next, the search unit 135 sets the document having the closer Euclidean distance as the most similar search target document.
- the output unit 136 outputs the searched search target document as a similar document 102.
- the output unit 136 may display the character string of the similar document 102 on a display or the like, or may convert the similar document 102 into a voice signal and reproduce the voice by the speaker. Further, the output unit 136 may transmit a character string or an audio signal of the similar document 102 to another information processing device.
- the output unit 136 may perform a process associated with the searched search target document in advance in the search target document database 121. Specifically, it is assumed that predetermined processes (for example, schedule registration and e-mail transmission) are registered in the search target document database 121 for each search target document. The output unit 136 can perform the process corresponding to the inquiry document 101 by reading the process associated with the searched search target document from the search target document database 121 and executing the process.
- predetermined processes for example, schedule registration and e-mail transmission
- FIG. 2 is an explanatory diagram showing an example of a processing flow of the information processing apparatus according to the embodiment.
- the information processing apparatus 100 performs a pre-processing (S1) for creating an index structure and a search process (S2) for searching and outputting a similar document 102 for the inquiry document 101.
- S1 pre-processing
- S2 search process
- the pre-processing (S1) will be described.
- the search target document is first read from the search target document database 121 and input to the hash function generation unit 131 (S11).
- the hash function generation unit 131 receives input of the distance between words from the inquiry receiving unit 133 (S13), and generates a plurality of hash functions 123a based on the input search target document and the distance between words (S12). ).
- FIG. 3 is a flowchart showing an example of the hash function generation process.
- the hash function generation unit 131 accepts the input of the search target document (S31) and extracts the words (appearing words) included in the search target document (S32) to set the words (words). Set) (S33).
- the hash function generation unit 131 generates a plurality of hash functions 123a by repeating k times, which is the number of hash functions that generate the processes of S34 to S39.
- the hash function generation unit 131 randomly selects one word from the word set (S35), accepts input of inter-word distance information indicating the distance between words (S36), and selects the selected word. The distance between the word and another word is referred to from the inter-word distance information (S37).
- the hash function generation unit 131 sorts the words in the word set in order of proximity to the selected word (S38), and assigns an integer value that increases in the order of arrangement to each arranged word as a hash value (S39). ..
- the hash function generation unit 131 outputs a plurality of hash functions 123a obtained by repeating the processes of S34 to S39 k times and stores them in the index generation unit 132 (S40).
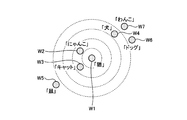
- FIG. 4 is an explanatory diagram illustrating the hash function 123a. As shown in FIG. 4, h 1 , h 2 , ... h 2, ... In the hash function 123a is one hash function.
- h 1 uses (cat) as a reference word, and an integer value corresponding to the distance between words with respect to (cat) is assigned to each word in the word set.
- h 2 uses (rice) as a reference word, and an integer value corresponding to the distance between words for (rice) is assigned to each word in the word set.
- h 3 uses (Nyanko) as a reference word, and an integer value corresponding to the distance between words for (Nyanko) is assigned to each word in the word set.
- h 4 uses (food) as a reference word, and an integer value corresponding to the distance between words with respect to (food) is assigned to each word in the word set.
- h 5 is assigned an integer value corresponding to the distance between the word for (flowers) and a reference word, and for each word in the word set (flowers). Further, h 6 uses (water) as a reference word, and an integer value corresponding to the distance between words with respect to (water) is assigned to each word in the word set.
- the word set of document A is ⁇ cat, rice ⁇
- the word set of document B is ⁇ nyanko, food ⁇
- the index generation unit 132 generates an index structure 124a based on the input search target document and the generated hash function 123a (S14), and stores the generated index structure 124a as an index. It is stored in the unit 124.
- the inquiry document 101 received by the inquiry receiving unit 133 is input to the hash value calculating unit 134 (S21).
- the hash value calculation unit 134 generates a plurality of hash values of the input inquiry document 101 based on the plurality of hash functions stored in the hash function storage unit 123 (S22), and obtains a vector corresponding to the inquiry document 101. ..
- the search unit 135 collates the hash value of each vector of the search target document in the index structure stored in the index storage unit 124 with the hash value of the vector of the inquiry document 101 (S23), and the search target most similar to the inquiry document 101. Search for documents.
- the output unit 136 outputs the similar document 102 searched by the search unit 135 (S24).
- FIG. 5 is an explanatory diagram for explaining the degree of similarity between words.
- FIG. 5 is a bird's-eye view of the arrangement of words W1 to W6 in a high-dimensional space showing the degree of similarity between words.
- Each of the words W1 to W6 in FIG. 5 indicates a word contained in the document.
- the words W1 to W3 are similar to words such as "cat” and form clusters shown by dotted lines.
- the words W4 to W6 are similar for words such as "dog” and form a cluster separate from the words W1 to W3.
- the projection based on the distance from the reference word is used.
- FIG. 6 is an explanatory diagram for explaining the hash value by Min hash.
- the word W1 is "cat”
- the word W2 is "nyanko”
- the word W3 is “cat”
- the word W4 is "dog”
- the word W5 is “mouse”
- the word W6 is "dog”
- the word W7 is “dog”. It shall be. Further, it is assumed that the reference point is the word W1.
- Min hash the minimum value among the hash values of the word set.
- FIG. 7 is an explanatory diagram illustrating an outline of the operation of the information processing apparatus 100 according to the embodiment.
- the information processing apparatus 100 uses the words included in each of the search target documents 121a of the search target document database 121 based on the similarity between words based on the inter-word distance information. For a set of, generate a plurality of hash functions that assign values close to each other in order of close meaning based on a predetermined word.
- the information processing apparatus 100 converts each of the search target documents 121a by Min Hash using the generated plurality of hash functions, generates an index structure for searching the calculated vector, and stores the index storage unit 124. Store.
- the information processing apparatus 100 converts the input inquiry document 101 by Min Hash using the same plurality of hash functions generated in S1. Next, the information processing apparatus 100 compares the hash value vector calculated from the inquiry document 101 with the hash value vector stored in the index storage unit 124, so that the search target document 121a most similar to the inquiry document 101 To search for.
- the output unit 136 may output one similar document 102 that is most similar to the searched search target document, or a plurality of documents whose similarity obtained by the Hamming distance and the Euclidean distance is equal to or higher than a predetermined threshold value. You may output the similar document 102 of.
- FIG. 8 is an explanatory diagram for explaining the narrowing down of the search target documents. Specifically, FIG. 8 is a graph showing an example of the relationship between the threshold value of similarity and the number of hits of the search target document 121a.
- Graph 10 shows the relationship between the threshold value of the similarity between the inquiry document 101 and the search target document 121a and the number (hits) of the search target document 121a whose similarity is greater than the threshold value.
- the similarity is the number of dimensions in which the hash values match between the vector of the inquiry utterance and the vector of the search target utterance, and the Euclidean distance between the hash values.
- the similarity between the inquiry document 101 and each search target document 121a takes into account the Euclidean distance. Therefore, the relationship between the similarity threshold and the number of hits is continuous as shown in curve 13. As a result, the search target document 121a similar to the inquiry document 101 can be efficiently narrowed down.
- FIG. 9 is an explanatory diagram showing a display example of the operation screen.
- the operation screen 20 is a screen that accepts various operations from the user by presenting it to the user of the information processing apparatus 100 in a dialogue interface such as a chatbot.
- the display area 21 is an area for displaying a processing result or the like
- the input area 22 is an area for inputting a document or the like.
- the information processing apparatus 100 searches for a similar document 102 with respect to the inquiry document 101 input to the input area 22, and outputs an output according to the search result to the display area 21.
- the information processing apparatus 100 searches for a similar document 102 using the input document 21a that "wants to adjust the schedule” as the inquiry document 101, and displays the search result 21b in the display area 21. Specifically, for the inquiry document 101 that "wants to adjust the schedule", the schedule registration process corresponding to the "schedule adjustment" obtained as the similar document 102 from the search target document 121a is executed.
- the information processing apparatus 100 even when the inquiry document 101 is mainly a spoken language and one sentence is short and the expressions are diverse, as in the interactive interface such as the chatbot in the example of FIG. 9, a similar document is appropriately used. 102 searches can be performed.
- the information processing apparatus 100 includes a hash function generation unit 131, an index generation unit 132, a hash value calculation unit 134, and a search unit 135.
- the hash function generation unit 131 determines a predetermined word for each word included in the word set based on the set of words included in the search target document 121a and the inter-word distance information indicating the closeness of the word meanings of the words. Generates a hash function that assigns values that are closer to each other in order of increasing meaning based on.
- the index generation unit 132 calculates the summary information of each of the plurality of search target documents 121a based on the generated hash function.
- the hash value calculation unit 134 calculates the summary information of the input document (inquiry document 101) based on the generated hash function.
- the search unit 135 searches a plurality of search target documents 121a for documents similar to the input document based on the comparison between the calculated summary information of the search target document 121a and the summary information of the inquiry document 101.
- the hash value included in the summary information of the search target document 121a calculated based on the generated hash function and the summary information of the inquiry document 101 depends on the distance of the meaning of the word to the predetermined word. Value. Therefore, in the information processing apparatus 100, in the comparison between the summary information of the search target document 121a and the summary information of the inquiry document 101, for example, the similarity using not only the Hamming distance between the summary information but also the Euclidean distance is used. The degree can be verified, and the search accuracy of similar documents can be improved.
- each of the index generation unit 132 and the hash value calculation unit 134 sets the minimum value among the values assigned to each of the words in the set of words included in the search target document 121a or the inquiry document 101 in the generated hash function. Calculated as a hash value. In this way, the information processing apparatus 100 can calculate the summary information of the search target document 121a or the inquiry document 101 by the Min-hash function.
- the hash function generation unit 131 generates a plurality of hash functions by repeating the process of reselecting a predetermined word and generating the hash function. Then, each of the index generation unit 132 and the hash value calculation unit 134 summarizes a vector containing a plurality of hash values calculated from a set of words included in the search target document 121a or the inquiry document 101 by the generated hash functions. Calculated as information.
- the information processing apparatus 100 in the comparison between the summary information of the search target document 121a and the summary information of the inquiry document 101, by comparing the vectors listing a plurality of hash values, for example, the Hamming distance, the Euclidean distance, etc. Can be obtained to verify the degree of similarity.
- the index generation unit 132 of the information processing apparatus 100 generates index information in which the calculated summary information of each of the plurality of search target documents 121a is associated with the search target document 121a.
- the search unit 135 compares the summary information of the inquiry document 101 with the summary information associated with the search target document 121a in the index information. By generating index information, the information processing apparatus 100 can quickly search for a document similar to the inquiry document 101 from among a plurality of search target documents 121a.
- each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of the device is functionally or physically distributed / physically in arbitrary units according to various loads and usage conditions. It can be integrated and configured.
- the information processing device 100 having the index generation module 111 and the search module 112 is illustrated, but even if the index generation module 111 and the search module 112 have different information processing devices, respectively. Good. That is, the pre-processing (S1) and the search processing (S2) may be performed by different information processing devices.
- the various processing functions performed by the information processing apparatus 100 may execute all or any part thereof on the CPU (or a microcomputer such as an MPU or an MCU (Micro Controller Unit)). Further, various processing functions may be executed in whole or in any part on a program analyzed and executed by a CPU (or a microcomputer such as an MPU or MCU) or on hardware by wired logic. Needless to say, it's good. Further, various processing functions performed by the information processing apparatus 100 may be executed by a plurality of computers in cooperation by cloud computing.
- FIG. 10 is a diagram showing an example of a computer that executes a program.
- the computer 1 has a CPU 201 that executes various arithmetic processes, an input device 202 that receives data input, a monitor 203, and a speaker 204. Further, the computer 1 has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting to various devices, and a communication device 207 for communicating with an external device by wire or wirelessly. Further, the computer 1 has a RAM 208 for temporarily storing various information and a hard disk device 209. Further, each part (201 to 209) in the computer 1 is connected to the bus 210.
- the hard disk device 209 stores a program 211 for executing various processes described in the above embodiment. Further, the hard disk device 209 stores various data 212 (for example, information of the inter-word distance information storage unit 122, the search target document database 121, the hash function storage unit 123, and the index storage unit 124) referred to by the program 211.
- the input device 202 receives, for example, input of operation information from the operator of the computer 1.
- the monitor 203 displays, for example, various screens operated by the operator. For example, a printing device or the like is connected to the interface device 206.
- the communication device 207 is connected to a communication network such as a LAN (Local Area Network), and exchanges various information with an external device via the communication network.
- LAN Local Area Network
- the CPU 201 reads the program 211 stored in the hard disk device 209, expands it into the RAM 208, and executes it, thereby executing the hash function generation unit 131, the index generation unit 132, the inquiry reception unit 133, the hash value calculation unit 134, and the search unit. Various processes related to 135 and the output unit 136 are performed.
- the program 211 may not be stored in the hard disk device 209.
- the computer 1 may read and execute the program 211 stored in the storage medium that can be read by the computer 1.
- the storage medium that can be read by the computer 1 corresponds to, for example, a CD-ROM, a DVD disk, a portable recording medium such as a USB (Universal Serial Bus) memory, a semiconductor memory such as a flash memory, a hard disk drive, or the like.
- the program 211 may be stored in a device connected to a public line, the Internet, a LAN, or the like, and the computer 1 may read the program from these and execute the program.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Library & Information Science (AREA)
- Business, Economics & Management (AREA)
- General Business, Economics & Management (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
In a similar document retrieval method according to an embodiment, a computer executes a generation process, a computation process, and a retrieval process. The generation process generates a hash function for allocating a value to each word included in a set of words in a retrievable document on the basis of the set of words and word interval information indicating word meaning closeness, said hash function allocating a closer value with reference to a specific word in the order of closeness to said word. The computation process computes summary information for each of a plurality of retrievable documents on the basis of the generated hash function and computes summary information for an inputted document on the basis of the generated hash function. The retrieval process retrieves a document similar to the inputted document among the plurality of retrievable documents on the basis of a comparison between the computed summary information for the retrievable documents and the computed summary information for the inputted document.
Description
本発明の実施形態は、類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置に関する。
An embodiment of the present invention relates to a similar document search method, a similar document search program, a similar document search device, an index information creation method, an index information creation program, and an index information creation device.
従来、コンピュータによる自然言語処理の一つとして、データベースに記憶された文書の中から入力文書に類似する文書を検索する検索処理がある。例えば、問い合わせ文書のサンプルと当該サンプルに対応する返答文書とをデータベースに登録しておく。そして、入力された問い合わせ文書に類似するサンプルを検索し、当該類似するサンプルに対応する返答文書を出力するチャットボット等の対話インタフェースを構築することが考えられる。
Conventionally, as one of the natural language processes by a computer, there is a search process for searching a document similar to an input document from the documents stored in a database. For example, a sample inquiry document and a response document corresponding to the sample are registered in the database. Then, it is conceivable to construct a dialogue interface such as a chatbot that searches for a sample similar to the input inquiry document and outputs a response document corresponding to the similar sample.
データベースに登録されたサンプルの中から入力文書に類似するサンプルを検索する方法としては、2つの文書の間で出現する単語の共通度を評価する方法がある。例えば、以下のような検索方法が考えられる。ある文書に含まれる単語集合から1つのハッシュ値を算出するハッシュ関数(Min-hash関数と言うことがある)を複数個定義しておく。各ハッシュ関数は、異なる単語に対して異なる値を対応付けた対応関係をもち、ある単語集合に含まれる単語に対応する値のうち最小の値をハッシュ値として出力する。データベースに登録されたサンプルに対して、この複数のハッシュ関数を用いて算出された複数のハッシュ値を列挙したベクトルを予め生成しておく。そして、入力文書に含まれる単語集合と上記の複数のハッシュ関数から同様にベクトルを算出し、データベースに登録されたサンプルのベクトルと近似するものを検索する。
As a method of searching for a sample similar to the input document from the samples registered in the database, there is a method of evaluating the commonality of words appearing between the two documents. For example, the following search methods can be considered. A plurality of hash functions (sometimes called Min-hash functions) that calculate one hash value from a word set included in a certain document are defined. Each hash function has a correspondence relationship in which different values are associated with different words, and outputs the smallest value among the values corresponding to the words included in a certain word set as a hash value. For the sample registered in the database, a vector enumerating a plurality of hash values calculated by using the plurality of hash functions is generated in advance. Then, a vector is similarly calculated from the word set included in the input document and the above-mentioned plurality of hash functions, and a vector similar to the sample vector registered in the database is searched for.
しかしながら、上記の従来技術では、入力文書が短い、文書に用いられる表現が多様でサンプルと一致する表現が少ないなどの場合に、単語の共通度が低く評価され、検索精度が低下するという問題がある。例えば、チャットボットの入力文書は、主に話し言葉であり、1文が短く表現も多様であることから、入力文書と、サンプルとの間で共通の単語が出現する確率が全体的に低くなる。この結果、入力文書に対するサンプルの検索精度が低くなりやすい。
However, in the above-mentioned prior art, there is a problem that the commonality of words is evaluated low and the search accuracy is lowered when the input document is short, the expressions used in the document are diverse, and there are few expressions that match the sample. is there. For example, the input document of a chatbot is mainly spoken language, and since one sentence is short and the expressions are diverse, the probability that a common word appears between the input document and the sample is generally low. As a result, the accuracy of the sample search for the input document tends to be low.
1つの側面では、類似する文書の検索精度を向上させる類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置を提供することを目的とする。
In one aspect, it is an object of the present invention to provide a similar document search method, a similar document search program, a similar document search device, an index information creation method, an index information creation program, and an index information creation device that improve the search accuracy of similar documents. To do.
1つの案では、類似文書検索方法は、生成する処理と、算出する処理と、検索する処理とをコンピュータが実行する。生成する処理は、検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成する。算出する処理は、生成したハッシュ関数に基づいて複数の検索対象文書それぞれの要約情報を算出し、生成したハッシュ関数に基づいて入力文書の要約情報を算出する。検索する処理は、算出した検索対象文書の要約情報と、入力文書の要約情報との間の比較に基づいて、複数の検索対象文書の中から入力文書に類似する文書を検索する。
In one plan, in the similar document search method, a computer executes a process of generating, a process of calculating, and a process of searching. The process of generating is based on the set of words included in the search target document and the inter-word information indicating the closeness of the meanings of the words, and for each word included in the set of words, the corresponding word is used as a reference. Generate a hash function that assigns values to words in order of closeness. In the calculation process, the summary information of each of the plurality of search target documents is calculated based on the generated hash function, and the summary information of the input document is calculated based on the generated hash function. The search process searches for a document similar to the input document from a plurality of search target documents based on the comparison between the calculated summary information of the search target document and the summary information of the input document.
1つの側面では、類似する文書の検索精度が向上する。
On one side, the search accuracy of similar documents is improved.
以下、図面を参照して、実施形態にかかる類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置を説明する。実施形態において同一の機能を有する構成には同一の符号を付し、重複する説明は省略する。なお、以下の実施形態で説明する類似文書検索方法、類似文書検索プログラム、類似文書検索装置、索引情報作成方法、索引情報作成プログラムおよび索引情報作成装置は、一例を示すに過ぎず、実施形態を限定するものではない。また、以下の各実施形態は、矛盾しない範囲内で適宜組みあわせてもよい。
Hereinafter, the similar document search method, the similar document search program, the similar document search device, the index information creation method, the index information creation program, and the index information creation device according to the embodiment will be described with reference to the drawings. Configurations having the same function in the embodiment are designated by the same reference numerals, and duplicate description will be omitted. The similar document search method, the similar document search program, the similar document search device, the index information creation method, the index information creation program, and the index information creation device described in the following embodiments are merely examples. It is not limited. In addition, the following embodiments may be appropriately combined within a consistent range.
[概要]
本実施形態では、データベースに登録されたサンプル(以下、検索対象文書とも呼ぶ)の中から入力文書(以下、問い合わせ文書とも呼ぶ)に類似する文書を検索する情報処理装置を例示する。 [Overview]
In the present embodiment, an information processing device that searches for a document similar to an input document (hereinafter, also referred to as an inquiry document) from a sample (hereinafter, also referred to as a search target document) registered in a database is illustrated.
本実施形態では、データベースに登録されたサンプル(以下、検索対象文書とも呼ぶ)の中から入力文書(以下、問い合わせ文書とも呼ぶ)に類似する文書を検索する情報処理装置を例示する。 [Overview]
In the present embodiment, an information processing device that searches for a document similar to an input document (hereinafter, also referred to as an inquiry document) from a sample (hereinafter, also referred to as a search target document) registered in a database is illustrated.
この情報処理装置では、先ず事前処理を行い、次いで検索処理を行う。事前処理では、ハッシュ関数を用いて検索対象文書それぞれについてハッシュ値を算出し、算出したハッシュ値より検索対象文書を検索するための木構造などの索引構造(例えば探索木)を作る。
In this information processing device, first pre-processing is performed, and then search processing is performed. In the preprocessing, a hash value is calculated for each search target document using a hash function, and an index structure (for example, a search tree) such as a tree structure for searching the search target document is created from the calculated hash value.
検索処理では、ハッシュ関数を用いて問い合わせ文書のハッシュ値を算出する。次いで、情報処理装置は、問い合わせ文書のハッシュ値と、検索対象文書それぞれのハッシュ値とを比較し、索引構造で示された検索対象文書それぞれのハッシュ値の中から近いものを探す。次いで、情報処理装置は、問い合わせ文書のハッシュ値と近いハッシュ値の検索対象文書を類似する文書の検索結果とする。
In the search process, the hash value of the inquiry document is calculated using the hash function. Next, the information processing apparatus compares the hash value of the inquiry document with the hash value of each search target document, and searches for the closest hash value of each search target document indicated by the index structure. Next, the information processing apparatus sets a search target document having a hash value close to the hash value of the inquiry document as a search result of a similar document.
ハッシュ値を算出するハッシュ関数については、データベースに登録された検索対象文書に含まれる単語を抽出して得られた単語の集合をもとに、複数個定義しておく。具体的には、情報処理装置は、Wを単語の集合、hをWから{0,1,…,|W|-1}へのすべての単射の集合(複数のハッシュ関数)としてハッシュ関数を複数生成しておく。
A plurality of hash functions for calculating the hash value are defined based on the set of words obtained by extracting the words included in the search target document registered in the database. Specifically, the information processing device has a hash function in which W is a set of words and h is a set of all injective functions (plural hash functions) from W to {0,1, ..., | W | -1}. Generate multiple.
情報処理装置は、検索対象文書および問い合わせ文書について次の処理を行うことで、複数のハッシュ値によるベクトルを求めて検索対象文書および問い合わせ文書をハッシュ関数で要約した要約情報を得る。
・hからハッシュ関数をランダムに選択する。
・検索対象文書に含まれる単語を抽出して単語の集合を取得する。
・選択したhにより各単語から得る整数の中で最小のものをハッシュ値とする。
・関数のランダムな選択を複数回行うことで複数のハッシュ値を得る。 The information processing device performs the following processing on the search target document and the inquiry document to obtain a vector with a plurality of hash values and obtain summary information summarizing the search target document and the inquiry document by a hash function.
-Randomly select a hash function from h.
-Extract the words included in the search target document and obtain a set of words.
-The smallest integer obtained from each word by the selected h is used as the hash value.
-Multiple hash values are obtained by randomly selecting a function multiple times.
・hからハッシュ関数をランダムに選択する。
・検索対象文書に含まれる単語を抽出して単語の集合を取得する。
・選択したhにより各単語から得る整数の中で最小のものをハッシュ値とする。
・関数のランダムな選択を複数回行うことで複数のハッシュ値を得る。 The information processing device performs the following processing on the search target document and the inquiry document to obtain a vector with a plurality of hash values and obtain summary information summarizing the search target document and the inquiry document by a hash function.
-Randomly select a hash function from h.
-Extract the words included in the search target document and obtain a set of words.
-The smallest integer obtained from each word by the selected h is used as the hash value.
-Multiple hash values are obtained by randomly selecting a function multiple times.
互いに類似する文書同士は、共通語の出現割合(ジャカール係数)が高くなる。hからのハッシュ関数の選択について、ハッシュ値が一致する確率はジャカール係数に一致する。よって、類似する文書を求める際の文書のハッシュ値同士の比較において、ベクトルの各要素の一致の割合からジャカール係数を確率的に計算でき、ハッシュ値のハミング距離(例えば不一致の数)が文書間の近さ(類似度)を反映している。
Documents that are similar to each other have a high rate of appearance of common words (Jacquard coefficient). For the selection of the hash function from h, the probability that the hash values match matches the Jakar coefficient. Therefore, in comparing the hash values of documents when finding similar documents, the Jakar coefficient can be calculated probabilistically from the matching ratio of each element of the vector, and the humming distance of the hash values (for example, the number of mismatches) is between documents. It reflects the closeness (similarity) of.
また、nを検索対象文書の数、mを検索対象文書ごとの単語数(平均値)、kをハッシュ関数の数とする。すると、検索対象文書のベクトルを計算する計算量はO(kmn)となる。1つの問い合わせ文書のベクトルを計算する計算量はO(km)となり、このベクトルを用いた近傍探索の計算コストはO(log(n))となる。ハッシュ関数は予めランダムにk個生成される。kをO(log(n))とすると、異なる検索対象文書から同一のハッシュ値が算出される衝突確率を十分に小さくすることができる。
Also, let n be the number of search target documents, m be the number of words (average value) for each search target document, and k be the number of hash functions. Then, the amount of calculation for calculating the vector of the search target document becomes O (kmn). The amount of calculation for calculating the vector of one inquiry document is O (km), and the calculation cost of the neighborhood search using this vector is O (log (n)). K hash functions are randomly generated in advance. When k is O (log (n)), the collision probability that the same hash value is calculated from different search target documents can be sufficiently reduced.
しかしながら、ハミング距離による類似度の検証では、ベクトルの各要素の差に意味はなく、要素が不一致の場合(共通語の出現がない場合)、類似度は0となる。このため、共通語の出現が少ない場合、類似検索の精度が低くなりやすい。
However, in the verification of similarity by Hamming distance, the difference between each element of the vector is meaningless, and if the elements do not match (when there is no common word), the similarity is 0. Therefore, when the appearance of common words is small, the accuracy of similar search tends to be low.
そこで、本実施形態では、情報処理装置は、単語間の語意の近さを示す語間距離情報をもとに、所定の単語を基準として語意の近い順に近い値を割り当てるハッシュ関数を生成する。具体的には、情報処理装置は、検索対象文書に含まれる単語を抽出して単語の集合し、ランダムに基準とする単語を選択する。次いで、情報処理装置は、語間距離情報をもとに、基準とする単語に対して語意の近い順に単語の集合に含まれる単語をソートし、ソート順に一意な値(例えばソート順に大きくなる整数値)の割り当てを行う。情報処理装置は、上記の処理を繰り返すことで、複数のハッシュ関数を生成する。
Therefore, in the present embodiment, the information processing device generates a hash function that assigns values in the order of close word meanings based on a predetermined word, based on the word-to-word distance information indicating the closeness of word meanings between words. Specifically, the information processing device extracts words included in the search target document, sets the words, and randomly selects a reference word. Next, the information processing device sorts the words included in the set of words in the order of their meanings closer to the reference word based on the inter-word distance information, and sets a unique value in the sort order (for example, an arrangement that increases in the sort order). Numerical value) is assigned. The information processing device generates a plurality of hash functions by repeating the above processing.
例えば、単語の集合が{猫、ご飯、…にゃんこ、えさ}であり、基準とする単語を{猫}とする場合、情報処理装置は、{猫}を基準として語意の近い順にソートする。これにより、{猫、にゃんこ、…ご飯、えさ}が得られる。このようにソートした単語の集合について、情報処理装置は、{猫=0、にゃんこ=1、…ご飯=5、えさ=6}などのように、ソート順に整数値を割り当てる。
For example, when the set of words is {cat, rice, ... Nyanko, food} and the reference word is {cat}, the information processing device sorts the words in order of closeness based on {cat}. As a result, {cat, cat, ... rice, food} can be obtained. For the set of words sorted in this way, the information processing device assigns integer values in the sort order, such as {cat = 0, cat = 1, ... rice = 5, food = 6}.
このようにして生成されたハッシュ関数によるハッシュ値は、所定の単語に対する語意の距離(語間とも呼ぶ)に応じた値となる。このため、ハッシュ値間のハミング距離だけでなく、ユークリッド距離による類似度の検証が可能となる。したがって、共通語の出現がなく、ハッシュ値が不一致(要素が不一致の場合)であっても、ユークリッド距離により類似度を検証することができ、類似検索の精度を向上させることができる。
The hash value generated by the hash function in this way is a value corresponding to the distance between words (also called between words) with respect to a predetermined word. Therefore, it is possible to verify not only the Hamming distance between hash values but also the similarity by the Euclidean distance. Therefore, even if there is no common word and the hash values do not match (when the elements do not match), the similarity can be verified by the Euclidean distance, and the accuracy of the similarity search can be improved.
[構成例]
図1は、実施形態にかかる情報処理装置の機能構成例を示すブロック図である。図1に示すように、情報処理装置100は、入力された問い合わせ文書101について、検索対象文書データベース121に格納された検索対象文書の中から類似する類似文書102を求める処理を行う装置である。情報処理装置100としては、例えばパーソナルコンピュータ等を適用できる。 [Configuration example]
FIG. 1 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment. As shown in FIG. 1, theinformation processing device 100 is a device that performs a process of obtaining a similar similar document 102 from the search target documents stored in the search target document database 121 for the input inquiry document 101. As the information processing device 100, for example, a personal computer or the like can be applied.
図1は、実施形態にかかる情報処理装置の機能構成例を示すブロック図である。図1に示すように、情報処理装置100は、入力された問い合わせ文書101について、検索対象文書データベース121に格納された検索対象文書の中から類似する類似文書102を求める処理を行う装置である。情報処理装置100としては、例えばパーソナルコンピュータ等を適用できる。 [Configuration example]
FIG. 1 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment. As shown in FIG. 1, the
情報処理装置100は、索引構造を作成する事前処理を行うインデックス生成モジュール111と、検索処理を行う検索モジュール112と、処理に関する各種データを格納する記憶部(検索対象文書データベース121、語間距離情報記憶部122、ハッシュ関数記憶部123およびインデックス記憶部124)とを有する。すなわち、情報処理装置100は、類似文書検索装置および索引情報作成装置の一例である。
The information processing device 100 includes an index generation module 111 that performs preprocessing to create an index structure, a search module 112 that performs search processing, and a storage unit (search target document database 121, inter-word distance information) that stores various data related to the processing. It has a storage unit 122, a hash function storage unit 123, and an index storage unit 124). That is, the information processing device 100 is an example of a similar document retrieval device and an index information creating device.
検索対象文書データベース121は、問い合わせ文書101に対して検索対象となる検索対象文書が登録されたデータベースである。検索対象文書データベース121における検索対象文書は、事前に登録されていてもよいし、情報処理装置100を使用するユーザとのチャットボット等の対話インタフェースにおける対話を通じて追加されてもよし、ネットワークから自動的に収集されてもよい。
The search target document database 121 is a database in which search target documents to be searched are registered for the inquiry document 101. The search target document in the search target document database 121 may be registered in advance, may be added through a dialogue in a dialogue interface such as a chatbot with a user who uses the information processing device 100, or may be automatically added from the network. May be collected in.
語間距離情報記憶部122は、単語それぞれについて、他の単語との語意の近さ(語間)を表す語間距離情報を格納する。具体的には、語間距離情報としては、単語それぞれ(v)と、他の単語(w)との語意の距離(語間)を表す関数d(d,w)などがある。すなわち、語間距離情報は、単語の語意の近さを示す語間情報の一例である。
The inter-word distance information storage unit 122 stores inter-word distance information indicating the closeness (interval between words) of the meaning of each word to other words. Specifically, the inter-word distance information includes a function d (d, w) that represents the distance (interval between words) between each word (v) and another word (w). That is, the inter-word distance information is an example of inter-word information indicating the closeness of word meanings.
ハッシュ関数記憶部123は、インデックス生成モジュール111が生成した異なる複数のハッシュ関数を記憶する。各ハッシュ関数は、検索対象文書に出現し得る単語それぞれに対して一意な整数(所定の単語に対して語意の近い順)を対応付ける対応関係をもち、単語集合を受け付けて1つのハッシュ値を出力する。また、異なるハッシュ関数は異なる対応関係をもつ。
The hash function storage unit 123 stores a plurality of different hash functions generated by the index generation module 111. Each hash function has a correspondence relationship in which a unique integer (in order of close meaning to a predetermined word) is associated with each word that can appear in the search target document, accepts a word set, and outputs one hash value. To do. Also, different hash functions have different correspondences.
インデックス記憶部124は、問い合わせ文書101に類似する検索対象文書を検索するための索引構造を記憶する。索引構造は、複数のハッシュ関数を用いて検索対象文書から算出されたベクトル(要約情報)に基づいてインデックス生成部132が生成したものであり、検索対象文書それぞれの要約情報を探索する索引情報の一例である。
The index storage unit 124 stores an index structure for searching a search target document similar to the inquiry document 101. The index structure is generated by the index generation unit 132 based on the vector (summary information) calculated from the search target document using a plurality of hash functions, and is the index information for searching the summary information of each search target document. This is an example.
索引構造としては、例えば探索木を適用できる。探索木は、木構造に接続された複数のノード(葉ノードと、葉ノードに至る各ノード)を含む。探索木の葉ノードは、検索対象文書を指し示す。例えば、葉ノードは、検索対象文書のベクトルと当該検索対象文書を識別する識別情報(例えば文書ID)とを含む。ただし、葉ノードがベクトルを含まなくてもよい。
As the index structure, for example, a search tree can be applied. The search tree contains a plurality of nodes (a leaf node and each node leading to the leaf node) connected to the tree structure. The search Konoha node points to the document to be searched. For example, the leaf node contains a vector of the search target document and identification information (for example, a document ID) that identifies the search target document. However, the leaf node does not have to contain the vector.
葉ノード以外の各ノードには2つの子ノードが接続されている。葉ノード以外の各ノードは、ベクトルの中の特定の次元に対する閾値をもつ。入力されたベクトルの中の特定の次元のハッシュ値が閾値以上である場合は右子ノードに進み、特定の次元のハッシュ値が閾値未満である場合は左子ノードに進む。このようにして、探索木をルートノードから葉ノードに向かって辿ることで、所定のベクトルに近い検索対象文書を効率的に検索することができる。
Two child nodes are connected to each node other than the leaf node. Each node, except the leaf node, has a threshold for a particular dimension in the vector. If the hash value of a specific dimension in the input vector is greater than or equal to the threshold value, the process proceeds to the right child node, and if the hash value of the specific dimension is less than the threshold value, the process proceeds to the left child node. In this way, by tracing the search tree from the root node to the leaf node, it is possible to efficiently search for a search target document close to a predetermined vector.
インデックス生成モジュール111は、ハッシュ関数生成部131と、インデックス生成部132とを有する。
The index generation module 111 has a hash function generation unit 131 and an index generation unit 132.
ハッシュ関数生成部131は、ハッシュ関数生成部131に記憶された検索対象文書と、問い合わせ受信部133に記憶された語間距離情報とに基づいて、複数のハッシュ関数を生成し、生成した複数のハッシュ関数をハッシュ関数記憶部123に格納する。
The hash function generation unit 131 generates a plurality of hash functions based on the search target document stored in the hash function generation unit 131 and the inter-word distance information stored in the inquiry receiving unit 133, and a plurality of generated hash functions. The hash function is stored in the hash function storage unit 123.
具体的には、ハッシュ関数生成部131は、検索対象文書に含まれる単語を抽出して単語の集合し、ランダムに基準とする単語を選択する。次いで、ハッシュ関数生成部131は、語間距離情報記憶部122の語間距離情報を参照し、基準とする単語に対して語意の近い順に単語の集合に含まれる単語を整列(ソート)する。次いで、ハッシュ関数生成部131は、単語の集合に含まれる単語について、整列順に一意な値(例えばソート順に大きくなる整数値)を割り当ててハッシュ関数を生成する。ハッシュ関数生成部131は、上記のハッシュ関数を生成する処理を繰り返すことで、複数のハッシュ関数を生成する。
Specifically, the hash function generation unit 131 extracts words included in the search target document, sets the words, and randomly selects a reference word. Next, the hash function generation unit 131 refers to the inter-word distance information of the inter-word distance information storage unit 122, and arranges (sorts) the words included in the word set in the order of the word meaning closer to the reference word. Next, the hash function generation unit 131 generates a hash function by assigning a unique value (for example, an integer value that increases in the sort order) to the words included in the word set in the sort order. The hash function generation unit 131 generates a plurality of hash functions by repeating the process of generating the hash function.
例えば、語間距離情報として単語それぞれ(v)と、他の単語(w)との語意の距離(語間)を表す関数d(d,w)が与えられているものとする。この関数d(d,w)については、語間の類似度や単語のベクトル表現などを参照して予め作成することができる。また、関数d(d,w)は、次のとおりである。
・任意のv,w∈Wについて、0≦d(v,w)である。
・任意のw∈Wについて、d(w,w)=0である。 For example, it is assumed that a function d (d, w) representing the distance (interval between words) between each word (v) and another word (w) is given as inter-word distance information. This function d (d, w) can be created in advance by referring to the similarity between words and the vector representation of words. The function d (d, w) is as follows.
• For any v, w ∈ W, 0 ≦ d (v, w).
• For any w ∈ W, d (w, w) = 0.
・任意のv,w∈Wについて、0≦d(v,w)である。
・任意のw∈Wについて、d(w,w)=0である。 For example, it is assumed that a function d (d, w) representing the distance (interval between words) between each word (v) and another word (w) is given as inter-word distance information. This function d (d, w) can be created in advance by referring to the similarity between words and the vector representation of words. The function d (d, w) is as follows.
• For any v, w ∈ W, 0 ≦ d (v, w).
• For any w ∈ W, d (w, w) = 0.
また、ハッシュ関数については、任意のu、v∈Wについて、h(u)>h(v)⇔d(u,w)>d(v,w)となるw∈Wがあるものとする。
Regarding the hash function, it is assumed that there is w ∈ W such that h (u)> h (v) ⇔ d (u, w)> d (v, w) for any u, v ∈ W.
ハッシュ関数生成部131は、Wからwをランダムに選択し、すべてのv∈Wをd(v,w)の小さい順にソートする。次いで、ハッシュ関数生成部131は、ソートされた語w,v1,v2…に整数0,1,2,…を割り当てる。なお、ハッシュ関数生成部131は、整数を割り当てる代わりにd(v,w)の値をそのまま使ってもよい(重複がないものとする)。
The hash function generator 131 randomly selects w from W, and sorts all v ∈ W in ascending order of d (v, w). Next, the hash function generation unit 131 assigns integers 0, 1, 2, ... To the sorted words w, v 1 , v 2 ... Note that the hash function generation unit 131 may use the value of d (v, w) as it is instead of assigning an integer (assuming that there is no duplication).
インデックス生成部132は、検索対象文書データベース121に記憶された検索対象文書とハッシュ関数記憶部123に記憶されたハッシュ関数に基づいて、索引構造を生成し、生成した索引構造をインデックス記憶部124に格納する。
The index generation unit 132 generates an index structure based on the search target document stored in the search target document database 121 and the hash function stored in the hash function storage unit 123, and the generated index structure is stored in the index storage unit 124. Store.
具体的には、インデックス生成部132は、検索対象文書ごとに単語集合を抽出し、抽出した単語集合を複数のハッシュ関数それぞれに入力して、ハッシュ値のベクトル、すなわち検索対象文書の要約情報を算出する。次いで、インデックス生成部132は、複数の検索対象文書に対応する複数のベクトルを効率的に検索できるように、索引構造を生成する。例えば、インデックス生成部132は、ベクトルの中の1つの次元に着目し、ベクトルの集合が二分割されるように当該次元のハッシュ値の閾値を決定することを繰り返すことで、探索木を生成する。このとき、インデックス生成部132は、探索木の葉ノードにはできる限り単一のベクトルが対応付けられるように中間ノードを生成する。
Specifically, the index generation unit 132 extracts a word set for each search target document, inputs the extracted word set to each of a plurality of hash functions, and inputs a vector of hash values, that is, summary information of the search target document. calculate. Next, the index generation unit 132 generates an index structure so that a plurality of vectors corresponding to the plurality of search target documents can be efficiently searched. For example, the index generation unit 132 pays attention to one dimension in the vector and repeatedly determines the threshold value of the hash value of the dimension so that the set of vectors is divided into two to generate a search tree. .. At this time, the index generation unit 132 generates an intermediate node so that a single vector is associated with the leaf node of the search tree as much as possible.
検索モジュール112は、問い合わせ受信部133と、ハッシュ値算出部134と、検索部135と、出力部136とを有する。
The search module 112 includes an inquiry receiving unit 133, a hash value calculation unit 134, a search unit 135, and an output unit 136.
問い合わせ受信部133は、問い合わせ文書101を受信する。問い合わせ受信部133は、ユーザから文字列として入力された問い合わせ文書101を受信してもよいし、ユーザが口頭で発した問い合わせ発話の音声信号を文字列に変換してもよい。また、問い合わせ受信部133は、他の情報処理装置から文字列または音声信号を受信してもよい。
The inquiry receiving unit 133 receives the inquiry document 101. The inquiry receiving unit 133 may receive the inquiry document 101 input as a character string from the user, or may convert the voice signal of the inquiry utterance uttered by the user into a character string. In addition, the inquiry receiving unit 133 may receive a character string or an audio signal from another information processing device.
ハッシュ値算出部134は、ハッシュ関数記憶部123に記憶された複数のハッシュ関数に基づいて、問い合わせ文書101に対応するベクトル、すなわち問い合わせ文書101の要約情報を生成する。具体的には、ハッシュ値算出部134は、問い合わせ文書101から単語集合を抽出し、抽出した単語集合を複数のハッシュ関数それぞれに入力して、ハッシュ値のベクトルを算出する。
The hash value calculation unit 134 generates a vector corresponding to the inquiry document 101, that is, summary information of the inquiry document 101, based on a plurality of hash functions stored in the hash function storage unit 123. Specifically, the hash value calculation unit 134 extracts a word set from the inquiry document 101, inputs the extracted word set into each of the plurality of hash functions, and calculates a hash value vector.
検索部135は、インデックス記憶部124に記憶された索引構造と問い合わせ文書101のベクトルに基づいて、近傍探索により問い合わせ文書101に最も類似する検索対象文書を検索する。具体的には、問い合わせ文書101に最も類似する検索対象文書は、ベクトル同士を比較したときにハッシュ値が一致する次元が最も多いものである。
The search unit 135 searches for the search target document most similar to the inquiry document 101 by neighborhood search based on the index structure stored in the index storage unit 124 and the vector of the inquiry document 101. Specifically, the search target document most similar to the inquiry document 101 has the largest number of dimensions in which the hash values match when the vectors are compared.
例えば、検索部135は、問い合わせ文書101のベクトルの中の特定の次元のハッシュ値と閾値とを比較しながら、インデックス記憶部124に記憶された探索木をルートノードから葉ノードに向かって辿り、特定の葉ノードに到達する。検索部135は、到達した葉ノードに対応する検索対象文書を選択する。
For example, the search unit 135 traces the search tree stored in the index storage unit 124 from the root node to the leaf node while comparing the hash value of a specific dimension in the vector of the inquiry document 101 with the threshold value. Reach a specific leaf node. The search unit 135 selects the search target document corresponding to the reached leaf node.
なお、到達した葉ノードに2以上の検索対象文書が対応付けられている場合、すなわち、ハッシュ値が一致する次元数が同じであり、探索木では検索対象文書を1つに絞り込めない場合、検索部135は、ハッシュ値同士を比較してユークリッド距離を求める。次いで、検索部135は、ユークリッド距離がより近いものを最も類似する検索対象文書とする。
When two or more search target documents are associated with the reached leaf node, that is, when the number of dimensions in which the hash values match is the same and the search tree cannot narrow down the search target documents to one. The search unit 135 compares the hash values with each other to obtain the Euclidean distance. Next, the search unit 135 sets the document having the closer Euclidean distance as the most similar search target document.
出力部136は、検索された検索対象文書を類似文書102として出力する。例えば、出力部136は、類似文書102の文字列をディスプレイ等に表示してもよいし、類似文書102を音声信号に変換してスピーカにより音声を再生してもよい。また、出力部136は、他の情報処理装置に類似文書102の文字列または音声信号を送信してもよい。
The output unit 136 outputs the searched search target document as a similar document 102. For example, the output unit 136 may display the character string of the similar document 102 on a display or the like, or may convert the similar document 102 into a voice signal and reproduce the voice by the speaker. Further, the output unit 136 may transmit a character string or an audio signal of the similar document 102 to another information processing device.
また、出力部136は、類似文書102を出力する代わりに、検索された検索対象文書に対して検索対象文書データベース121において予め紐付けられた処理を実施してもよい。具体的には、検索対象文書データベース121には、検索対象文書ごとに、所定の処理(例えばスケジュール登録、メール送信)が登録されているものとする。出力部136は、検索された検索対象文書に紐付けられた処理を検索対象文書データベース121より読み出して実行することで、問い合わせ文書101に対応した処理を行うことが可能となる。
Further, instead of outputting the similar document 102, the output unit 136 may perform a process associated with the searched search target document in advance in the search target document database 121. Specifically, it is assumed that predetermined processes (for example, schedule registration and e-mail transmission) are registered in the search target document database 121 for each search target document. The output unit 136 can perform the process corresponding to the inquiry document 101 by reading the process associated with the searched search target document from the search target document database 121 and executing the process.
[動作例]
図2は、実施形態にかかる情報処理装置の処理フローの一例を示す説明図である。図2に示すように、情報処理装置100は、索引構造を作成する事前処理(S1)と、問い合わせ文書101に対する類似文書102を検索して出力する検索処理(S2)とを行う。 [Operation example]
FIG. 2 is an explanatory diagram showing an example of a processing flow of the information processing apparatus according to the embodiment. As shown in FIG. 2, theinformation processing apparatus 100 performs a pre-processing (S1) for creating an index structure and a search process (S2) for searching and outputting a similar document 102 for the inquiry document 101.
図2は、実施形態にかかる情報処理装置の処理フローの一例を示す説明図である。図2に示すように、情報処理装置100は、索引構造を作成する事前処理(S1)と、問い合わせ文書101に対する類似文書102を検索して出力する検索処理(S2)とを行う。 [Operation example]
FIG. 2 is an explanatory diagram showing an example of a processing flow of the information processing apparatus according to the embodiment. As shown in FIG. 2, the
先ず、事前処理(S1)について説明する。事前処理(S1)では、先ず検索対象文書データベース121より検索対象文書が読み出され、ハッシュ関数生成部131に入力される(S11)。
First, the pre-processing (S1) will be described. In the pre-processing (S1), the search target document is first read from the search target document database 121 and input to the hash function generation unit 131 (S11).
ハッシュ関数生成部131では、問い合わせ受信部133より語間の距離の入力を受け付け(S13)、入力された検索対象文書と、語間の距離とに基づき、複数のハッシュ関数123aを生成する(S12)。
The hash function generation unit 131 receives input of the distance between words from the inquiry receiving unit 133 (S13), and generates a plurality of hash functions 123a based on the input search target document and the distance between words (S12). ).
図3は、ハッシュ関数の生成処理の一例を示すフローチャートである。図3に示すように、ハッシュ関数生成部131は、検索対象文書の入力を受け付け(S31)、検索対象文書に含まれる単語(出現語)を抽出することで(S32)、単語の集合(語集合)を取得する(S33)。
FIG. 3 is a flowchart showing an example of the hash function generation process. As shown in FIG. 3, the hash function generation unit 131 accepts the input of the search target document (S31) and extracts the words (appearing words) included in the search target document (S32) to set the words (words). Set) (S33).
次いで、ハッシュ関数生成部131は、S34~S39の処理を生成するハッシュ関数の数であるk回繰り返すことで、複数のハッシュ関数123aを生成する。
Next, the hash function generation unit 131 generates a plurality of hash functions 123a by repeating k times, which is the number of hash functions that generate the processes of S34 to S39.
具体的には、ハッシュ関数生成部131は、語集合の中からランダムに1つの単語を選択し(S35)、語間の距離を示す語間距離情報の入力を受け付け(S36)、選択した単語と他の単語との距離を語間距離情報より参照する(S37)。次いで、ハッシュ関数生成部131は、選択した単語との距離の近い順に語集合の単語をソートし(S38)、整列した各単語に整列順に大きくなるような整数値をハッシュ値として割り当てる(S39)。
Specifically, the hash function generation unit 131 randomly selects one word from the word set (S35), accepts input of inter-word distance information indicating the distance between words (S36), and selects the selected word. The distance between the word and another word is referred to from the inter-word distance information (S37). Next, the hash function generation unit 131 sorts the words in the word set in order of proximity to the selected word (S38), and assigns an integer value that increases in the order of arrangement to each arranged word as a hash value (S39). ..
次いで、ハッシュ関数生成部131は、S34~S39の処理をk回繰り返して得られた複数のハッシュ関数123aを出力し、インデックス生成部132に格納する(S40)。
Next, the hash function generation unit 131 outputs a plurality of hash functions 123a obtained by repeating the processes of S34 to S39 k times and stores them in the index generation unit 132 (S40).
図4は、ハッシュ関数123aを説明する説明図である。図4に示すように、ハッシュ関数123aにおけるh1,h2,…h2,…が1つのハッシュ関数である。
FIG. 4 is an explanatory diagram illustrating the hash function 123a. As shown in FIG. 4, h 1 , h 2 , ... h 2, ... In the hash function 123a is one hash function.
例えば、h1は、(猫)を基準の単語としており、語集合における各単語について(猫)に対する語間の距離に応じた整数値が割り当てられている。また、h2は、(ごはん)を基準の単語としており、語集合における各単語について(ごはん)に対する語間の距離に応じた整数値が割り当てられている。また、h3は、(にゃんこ)を基準の単語としており、語集合における各単語について(にゃんこ)に対する語間の距離に応じた整数値が割り当てられている。また、h4は、(えさ)を基準の単語としており、語集合における各単語について(えさ)に対する語間の距離に応じた整数値が割り当てられている。また、h5は、(花)を基準の単語としており、語集合における各単語について(花)に対する語間の距離に応じた整数値が割り当てられている。また、h6は、(水)を基準の単語としており、語集合における各単語について(水)に対する語間の距離に応じた整数値が割り当てられている。
For example, h 1 uses (cat) as a reference word, and an integer value corresponding to the distance between words with respect to (cat) is assigned to each word in the word set. Further, h 2 uses (rice) as a reference word, and an integer value corresponding to the distance between words for (rice) is assigned to each word in the word set. Further, h 3 uses (Nyanko) as a reference word, and an integer value corresponding to the distance between words for (Nyanko) is assigned to each word in the word set. Further, h 4 uses (food) as a reference word, and an integer value corresponding to the distance between words with respect to (food) is assigned to each word in the word set. Also, h 5 is assigned an integer value corresponding to the distance between the word for (flowers) and a reference word, and for each word in the word set (flowers). Further, h 6 uses (water) as a reference word, and an integer value corresponding to the distance between words with respect to (water) is assigned to each word in the word set.
ここで、図4に例示したハッシュ関数123aにより次の文書A~文書Cのハッシュ値を求める場合を例示する。
文書A:「猫にごはんをやる」
文書B:「にゃんこにえさをやる」
文書C:「花に水をやる」 Here, a case where the hash values of the following documents A to C are obtained by thehash function 123a illustrated in FIG. 4 is illustrated.
Document A: "Give cats food"
Document B: "Feed Nyanko"
Document C: "Watering flowers"
文書A:「猫にごはんをやる」
文書B:「にゃんこにえさをやる」
文書C:「花に水をやる」 Here, a case where the hash values of the following documents A to C are obtained by the
Document A: "Give cats food"
Document B: "Feed Nyanko"
Document C: "Watering flowers"
文書Aの語集合は{猫、ご飯}、文書Bの語集合は{にゃんこ、えさ}、文書Cの語集合は{花、水}である。よって、図4に例示したハッシュ関数123aによる文書Aのハッシュ値HAは、HA=001133となる。同様に、文書Bのハッシュ値HBは、HB=110022となる。また、文書Cのハッシュ値HCは、HC=424200となる。
The word set of document A is {cat, rice}, the word set of document B is {nyanko, food}, and the word set of document C is {flower, water}. Therefore, the hash value H A of document A by a hash function 123a illustrated in Figure 4, the H A = 001 133. Similarly, the hash value H B of the document B is H B = 110022. Further, the hash value H C of document C becomes H C = 424 200.
ここで、文書A~Cのハッシュ値を比較してハミング距離を計算すると、HA,HB:6、HA,HC:6、HB,HC:6となる。また、文書A~Cのハッシュ値を比較してユークリッド距離を計算すると、HA,HB:1、HA,HC:6.9、HB,HC:6.2となる。このように、ハミング距離では類似度の検証が困難な場合(共通語が含まれていない場合)でも、ユークリッド距離により互いに類似する文書(図示例では文書A、B)を検証することができる。
Here, when calculating the Hamming distance by comparing the hash value of the document A ~ C, H A, H B: 6, H A, H C: 6, H B, H C: a 6. Further, when the Euclidean distance is calculated by comparing the hash values of the documents A to C, it becomes HA , H B : 1, H A , H C : 6.9, H B , H C : 6.2. In this way, even when it is difficult to verify the similarity with the Hamming distance (when the common language is not included), documents similar to each other (documents A and B in the illustrated example) can be verified with the Euclidean distance.
図2に戻り、S12に次いで、インデックス生成部132は、入力された検索対象文書と、生成したハッシュ関数123aに基づいて、索引構造124aを生成し(S14)、生成した索引構造124aをインデックス記憶部124に格納する。
Returning to FIG. 2, following S12, the index generation unit 132 generates an index structure 124a based on the input search target document and the generated hash function 123a (S14), and stores the generated index structure 124a as an index. It is stored in the unit 124.
検索処理(S2)では、問い合わせ受信部133が受信した問い合わせ文書101がハッシュ値算出部134に入力される(S21)。ハッシュ値算出部134は、ハッシュ関数記憶部123に記憶された複数のハッシュ関数に基づいて、入力された問い合わせ文書101のハッシュ値を複数生成し(S22)、問い合わせ文書101に対応するベクトルを得る。
In the search process (S2), the inquiry document 101 received by the inquiry receiving unit 133 is input to the hash value calculating unit 134 (S21). The hash value calculation unit 134 generates a plurality of hash values of the input inquiry document 101 based on the plurality of hash functions stored in the hash function storage unit 123 (S22), and obtains a vector corresponding to the inquiry document 101. ..
次いで、検索部135は、インデックス記憶部124に記憶された索引構造における検索対象文書それぞれのベクトルと、問い合わせ文書101のベクトルのハッシュ値を照合し(S23)、問い合わせ文書101に最も類似する検索対象文書を検索する。出力部136は、検索部135が検索した類似文書102を出力する(S24)。
Next, the search unit 135 collates the hash value of each vector of the search target document in the index structure stored in the index storage unit 124 with the hash value of the vector of the inquiry document 101 (S23), and the search target most similar to the inquiry document 101. Search for documents. The output unit 136 outputs the similar document 102 searched by the search unit 135 (S24).
図5は、語間の類似度を説明する説明図である。具体的には、図5は、語間の類似度を示す高次元の空間における語W1~W6それぞれの配置を俯瞰した図である。図5の語W1~W6それぞれは、文書に含まれる単語を示す。ここで、語W1~W3は、例えば「猫」などの単語について類似するものであり、点線で示すクラスターを形成している。同様に、語W4~W6は、例えば「犬」などの単語について類似するものであり、語W1~W3とは別のクラスターを形成している。
FIG. 5 is an explanatory diagram for explaining the degree of similarity between words. Specifically, FIG. 5 is a bird's-eye view of the arrangement of words W1 to W6 in a high-dimensional space showing the degree of similarity between words. Each of the words W1 to W6 in FIG. 5 indicates a word contained in the document. Here, the words W1 to W3 are similar to words such as "cat" and form clusters shown by dotted lines. Similarly, the words W4 to W6 are similar for words such as "dog" and form a cluster separate from the words W1 to W3.
図5に示すように、語間の類似度を示す高次元の空間において、単純な射影では、類似度をうまく評価することは困難である。例えば、軸A1への直交射影では、類似する単語(語W1~W3または語W4~W6)の値が近くなる。しかしながら、軸A1とは異なる軸A2への直交射影では、互いに類似しない単語(例えば語W1と語W4)が互いに類似する単語(例えば語W1と語W3)よりも近くなる場合がある。
As shown in FIG. 5, in a high-dimensional space showing the similarity between words, it is difficult to evaluate the similarity well with a simple projection. For example, in orthogonal projection on the axis A1, the values of similar words (words W1 to W3 or words W4 to W6) are close to each other. However, in orthogonal projection onto an axis A2 that is different from the axis A1, words that are not similar to each other (eg, words W1 and W4) may be closer than words that are similar to each other (eg, words W1 and W3).
本実施形態では、ランダムに基準とする単語を選択し、Min hashによるハッシュ値を用いることから、基準とする単語(基準点)からの距離による射影を用いている。
In this embodiment, since the reference word is randomly selected and the hash value by Min hash is used, the projection based on the distance from the reference word (reference point) is used.
図6は、Min hashによるハッシュ値を説明する説明図である。ここで、語W1は「猫」、語W2は「にゃんこ」、語W3は「キャット」、語W4は「犬」、語W5は「鼠」、語W6は「ドッグ」、語W7は「わんこ」であるものとする。また、基準点は語W1であるものとする。
FIG. 6 is an explanatory diagram for explaining the hash value by Min hash. Here, the word W1 is "cat", the word W2 is "nyanko", the word W3 is "cat", the word W4 is "dog", the word W5 is "mouse", the word W6 is "dog", and the word W7 is "dog". It shall be. Further, it is assumed that the reference point is the word W1.
図6に示すように、基準点である語W1をもとに、ハッシュ関数123aでは、1:「猫」、2:「にゃんこ」、3:「キャット」、4:「犬」、5:「鼠」、6:「ドッグ」、7:「わんこ」の値が割り当てられる。ここで、基準点からの距離ならば、基準点に近いほど類似度の大小関係が保たれている(例えば1:「猫」、2:「にゃんこ」、3:「キャット」など)。しかしながら、基準点からの距離が遠いところでは(例えば5:「鼠」、6:「ドッグ」)、類似しない語の値が近くなる場合がある。
As shown in FIG. 6, based on the word W1 which is the reference point, in the hash function 123a, 1: "cat", 2: "cat", 3: "cat", 4: "dog", 5: " Values of "mouse", 6: "dog", and 7: "dog" are assigned. Here, as far as the distance from the reference point is concerned, the closer to the reference point, the more the degree of similarity is maintained (for example, 1: "cat", 2: "nyanko", 3: "cat", etc.). However, when the distance from the reference point is long (for example, 5: "mouse", 6: "dog"), the values of dissimilar words may be close to each other.
本実施形態では、語集合のハッシュ値の中の最小値を用いる(Min hash)ので、類似度の大小関係が保たれた、語の類似度を表現できる射影として適切なものとなっている。
In this embodiment, since the minimum value among the hash values of the word set is used (Min hash), it is appropriate as a projection capable of expressing the similarity of words while maintaining the magnitude relationship of the similarity.
図7は、実施形態にかかる情報処理装置100の動作の概要を説明する説明図である。図7に示すように、事前処理(S1)において、情報処理装置100は、語間距離情報による語間の類似度をもとに、検索対象文書データベース121の検索対象文書121aそれぞれに含まれる単語の集合について、所定の単語を基準として語意の近い順に近い値を割り当てるハッシュ関数を複数生成する。次いで、情報処理装置100は、生成した複数のハッシュ関数を用いて検索対象文書121aそれぞれをMin Hashによる変換を行い、算出されたベクトルを検索するための索引構造を生成してインデックス記憶部124に格納する。
FIG. 7 is an explanatory diagram illustrating an outline of the operation of the information processing apparatus 100 according to the embodiment. As shown in FIG. 7, in the pre-processing (S1), the information processing apparatus 100 uses the words included in each of the search target documents 121a of the search target document database 121 based on the similarity between words based on the inter-word distance information. For a set of, generate a plurality of hash functions that assign values close to each other in order of close meaning based on a predetermined word. Next, the information processing apparatus 100 converts each of the search target documents 121a by Min Hash using the generated plurality of hash functions, generates an index structure for searching the calculated vector, and stores the index storage unit 124. Store.
検索処理(S2)において、情報処理装置100は、入力された問い合わせ文書101について、S1で生成した同じ複数のハッシュ関数を用いてMin Hashによる変換を行う。次いで、情報処理装置100は、問い合わせ文書101より算出したハッシュ値のベクトルと、インデックス記憶部124に格納されたハッシュ値のベクトルとを比較することで、問い合わせ文書101に最も類似する検索対象文書121aを検索する。
In the search process (S2), the information processing apparatus 100 converts the input inquiry document 101 by Min Hash using the same plurality of hash functions generated in S1. Next, the information processing apparatus 100 compares the hash value vector calculated from the inquiry document 101 with the hash value vector stored in the index storage unit 124, so that the search target document 121a most similar to the inquiry document 101 To search for.
図示例では、「会議を調整したい」とする問い合わせ文書101に対し、検索対象文書121aの中で「スケジュールの調整」と、「打ち合わせの調整」とが「調整」という単語においてハッシュ値が一致することから、ハミング距離が近いものとなる。ここで、問い合わせ文書101に含まれる「会議」に対し、「スケジュール」よりも「会議」の方がより語意が近く、ユークリッド距離が近いものとなる。したがって、「会議を調整したい」とする問い合わせ文書101に対しては、「打ち合わせを調整したい」とする類似文書102が得られることとなる。
In the illustrated example, for the inquiry document 101 that "wants to adjust the meeting", the hash values of "schedule adjustment" and "meeting adjustment" in the search target document 121a match in the word "adjustment". Therefore, the Hamming distance is short. Here, the meaning of the word "meeting" is closer to that of the "meeting" included in the inquiry document 101 than the "schedule", and the Euclidean distance is closer. Therefore, for the inquiry document 101 that "wants to coordinate the meeting", a similar document 102 that "wants to coordinate the meeting" is obtained.
なお、出力部136は、検索された検索対象文書について、最も類似する1つの類似文書102を出力してもよいし、ハミング距離およびユークリッド距離により得られた類似度が所定の閾値以上である複数の類似文書102を出力してもよい。
Note that the output unit 136 may output one similar document 102 that is most similar to the searched search target document, or a plurality of documents whose similarity obtained by the Hamming distance and the Euclidean distance is equal to or higher than a predetermined threshold value. You may output the similar document 102 of.
図8は、検索対象文書の絞り込みを説明する説明図である。具体的には、図8は、類似度の閾値と検索対象文書121aのヒット数との関係例を示すグラフである。
FIG. 8 is an explanatory diagram for explaining the narrowing down of the search target documents. Specifically, FIG. 8 is a graph showing an example of the relationship between the threshold value of similarity and the number of hits of the search target document 121a.
グラフ10は、問い合わせ文書101と検索対象文書121aの類似度の閾値と、類似度が閾値より大きい検索対象文書121aの数(ヒット数)との間の関係を示す。類似度は、問い合わせ発話のベクトルと検索対象発話のベクトルの間でハッシュ値が一致する次元の数に、ハッシュ値同士のユークリッド距離を合わせたものである。
Graph 10 shows the relationship between the threshold value of the similarity between the inquiry document 101 and the search target document 121a and the number (hits) of the search target document 121a whose similarity is greater than the threshold value. The similarity is the number of dimensions in which the hash values match between the vector of the inquiry utterance and the vector of the search target utterance, and the Euclidean distance between the hash values.
(A)関連語を考慮せずにベクトルを算出する方法では、問い合わせ文書101と各検索対象文書121aの類似度が全体として低く算出される。よって、類似度の閾値とヒット数との間の関係は曲線11のようになる。すなわち、類似度の閾値を低く設定してもヒット数が少なくなり、類似する検索対象文書121aの検索漏れが多くなる。
(A) In the method of calculating the vector without considering the related words, the similarity between the inquiry document 101 and each search target document 121a is calculated to be low as a whole. Therefore, the relationship between the similarity threshold and the number of hits is as shown in curve 11. That is, even if the threshold value of the similarity is set low, the number of hits is small, and the search omission of the similar search target document 121a is large.
(B)関連語を同一視してベクトルを算出する方法では、問い合わせ文書101と各検索対象文書121aの類似度が全体として高く算出される。よって、類似度の閾値とヒット数との間の関係は曲線12のようになる。すなわち、類似度の閾値を高く設定してもヒット数が多くなり、類似する検索対象文書121aを効率的に絞り込むことが難しい。
(B) In the method of equating related words and calculating the vector, the degree of similarity between the inquiry document 101 and each search target document 121a is calculated to be high as a whole. Therefore, the relationship between the similarity threshold and the number of hits is as shown in curve 12. That is, even if the threshold value of the similarity is set high, the number of hits increases, and it is difficult to efficiently narrow down similar search target documents 121a.
(C)本実施形態の方法では、問い合わせ文書101と各検索対象文書121aの類似度がユークリッド距離を加味したものとなる。よって、類似度の閾値とヒット数との間の関係は曲線13のように連続的なものとなる。その結果、問い合わせ文書101に類似する検索対象文書121aを効率的に絞り込むことができる。
(C) In the method of the present embodiment, the similarity between the inquiry document 101 and each search target document 121a takes into account the Euclidean distance. Therefore, the relationship between the similarity threshold and the number of hits is continuous as shown in curve 13. As a result, the search target document 121a similar to the inquiry document 101 can be efficiently narrowed down.
図9は、操作画面の表示例を示す説明図である。操作画面20は、例えばチャットボット等の対話インタフェースにおいて情報処理装置100のユーザに提示することでユーザからの各種操作を受け付ける画面である。操作画面20において、表示領域21は処理結果などを表示する領域であり、入力領域22は文書などの入力を行う領域である。例えば、情報処理装置100は、入力領域22に入力された問い合わせ文書101に対して類似文書102の検索を行い、検索結果に応じた出力を表示領域21に行う。
FIG. 9 is an explanatory diagram showing a display example of the operation screen. The operation screen 20 is a screen that accepts various operations from the user by presenting it to the user of the information processing apparatus 100 in a dialogue interface such as a chatbot. On the operation screen 20, the display area 21 is an area for displaying a processing result or the like, and the input area 22 is an area for inputting a document or the like. For example, the information processing apparatus 100 searches for a similar document 102 with respect to the inquiry document 101 input to the input area 22, and outputs an output according to the search result to the display area 21.
例えば、情報処理装置100は、「スケジュール調整したい」とする入力文書21aを問い合わせ文書101として類似文書102の検索を行い、検索結果21bを表示領域21に表示する。具体的には、「スケジュール調整したい」とする問い合わせ文書101に対し、検索対象文書121aの中から類似文書102として得られた「スケジュールの調整」に対応するスケジュール登録の処理が実行される。
For example, the information processing apparatus 100 searches for a similar document 102 using the input document 21a that "wants to adjust the schedule" as the inquiry document 101, and displays the search result 21b in the display area 21. Specifically, for the inquiry document 101 that "wants to adjust the schedule", the schedule registration process corresponding to the "schedule adjustment" obtained as the similar document 102 from the search target document 121a is executed.
情報処理装置100では、図9の例におけるチャットボット等の対話インタフェースのように、問い合わせ文書101が主に話し言葉であり、1文が短く表現も多様である場合であっても、適切に類似文書102の検索を行うことができる。
In the information processing apparatus 100, even when the inquiry document 101 is mainly a spoken language and one sentence is short and the expressions are diverse, as in the interactive interface such as the chatbot in the example of FIG. 9, a similar document is appropriately used. 102 searches can be performed.
[効果]
以上のように、情報処理装置100は、ハッシュ関数生成部131と、インデックス生成部132と、ハッシュ値算出部134と、検索部135とを有する。ハッシュ関数生成部131は、検索対象文書121aに含まれる単語の集合と、単語の語意の近さを示す語間距離情報とに基づき、単語の集合に含まれる単語それぞれに対して、所定の単語を基準として語意の近い順に近い値を割り当てるハッシュ関数を生成する。インデックス生成部132は、生成したハッシュ関数に基づいて複数の検索対象文書121aそれぞれの要約情報を算出する。ハッシュ値算出部134は、生成したハッシュ関数に基づいて入力文書(問い合わせ文書101)の要約情報を算出する。検索部135は、算出した検索対象文書121aの要約情報と、問い合わせ文書101の要約情報との間の比較に基づいて、複数の検索対象文書121aの中から入力文書に類似する文書を検索する。 [effect]
As described above, theinformation processing apparatus 100 includes a hash function generation unit 131, an index generation unit 132, a hash value calculation unit 134, and a search unit 135. The hash function generation unit 131 determines a predetermined word for each word included in the word set based on the set of words included in the search target document 121a and the inter-word distance information indicating the closeness of the word meanings of the words. Generates a hash function that assigns values that are closer to each other in order of increasing meaning based on. The index generation unit 132 calculates the summary information of each of the plurality of search target documents 121a based on the generated hash function. The hash value calculation unit 134 calculates the summary information of the input document (inquiry document 101) based on the generated hash function. The search unit 135 searches a plurality of search target documents 121a for documents similar to the input document based on the comparison between the calculated summary information of the search target document 121a and the summary information of the inquiry document 101.
以上のように、情報処理装置100は、ハッシュ関数生成部131と、インデックス生成部132と、ハッシュ値算出部134と、検索部135とを有する。ハッシュ関数生成部131は、検索対象文書121aに含まれる単語の集合と、単語の語意の近さを示す語間距離情報とに基づき、単語の集合に含まれる単語それぞれに対して、所定の単語を基準として語意の近い順に近い値を割り当てるハッシュ関数を生成する。インデックス生成部132は、生成したハッシュ関数に基づいて複数の検索対象文書121aそれぞれの要約情報を算出する。ハッシュ値算出部134は、生成したハッシュ関数に基づいて入力文書(問い合わせ文書101)の要約情報を算出する。検索部135は、算出した検索対象文書121aの要約情報と、問い合わせ文書101の要約情報との間の比較に基づいて、複数の検索対象文書121aの中から入力文書に類似する文書を検索する。 [effect]
As described above, the
このため、情報処理装置100において、生成したハッシュ関数に基づいて算出した検索対象文書121aの要約情報と、問い合わせ文書101の要約情報とに含まれるハッシュ値は、所定の単語に対する語意の距離に応じた値となる。したがって、情報処理装置100では、検索対象文書121aの要約情報と、問い合わせ文書101の要約情報との間の比較において、例えば互いの要約情報の間におけるハミング距離だけでなく、ユークリッド距離を用いた類似度合いの検証を行うことができ、類似する文書の検索精度を向上させることができる。
Therefore, in the information processing apparatus 100, the hash value included in the summary information of the search target document 121a calculated based on the generated hash function and the summary information of the inquiry document 101 depends on the distance of the meaning of the word to the predetermined word. Value. Therefore, in the information processing apparatus 100, in the comparison between the summary information of the search target document 121a and the summary information of the inquiry document 101, for example, the similarity using not only the Hamming distance between the summary information but also the Euclidean distance is used. The degree can be verified, and the search accuracy of similar documents can be improved.
また、インデックス生成部132およびハッシュ値算出部134のそれぞれは、生成したハッシュ関数において検索対象文書121aまたは問い合わせ文書101に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する。このように、情報処理装置100では、Min-hash関数により検索対象文書121aまたは問い合わせ文書101の要約情報を算出できる。
Further, each of the index generation unit 132 and the hash value calculation unit 134 sets the minimum value among the values assigned to each of the words in the set of words included in the search target document 121a or the inquiry document 101 in the generated hash function. Calculated as a hash value. In this way, the information processing apparatus 100 can calculate the summary information of the search target document 121a or the inquiry document 101 by the Min-hash function.
また、ハッシュ関数生成部131は、所定の単語を選び直してハッシュ関数を生成する処理を繰り返すことでハッシュ関数を複数生成する。そして、インデックス生成部132およびハッシュ値算出部134のそれぞれは、生成した複数のハッシュ関数によって検索対象文書121aまたは問い合わせ文書101に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する。これにより、情報処理装置100では、検索対象文書121aの要約情報と、問い合わせ文書101の要約情報との間の比較において、複数のハッシュ値を列挙したベクトルの比較により、例えばハミング距離、ユークリッド距離などを求めて類似度合いを検証することができる。
Further, the hash function generation unit 131 generates a plurality of hash functions by repeating the process of reselecting a predetermined word and generating the hash function. Then, each of the index generation unit 132 and the hash value calculation unit 134 summarizes a vector containing a plurality of hash values calculated from a set of words included in the search target document 121a or the inquiry document 101 by the generated hash functions. Calculated as information. As a result, in the information processing apparatus 100, in the comparison between the summary information of the search target document 121a and the summary information of the inquiry document 101, by comparing the vectors listing a plurality of hash values, for example, the Hamming distance, the Euclidean distance, etc. Can be obtained to verify the degree of similarity.
また、情報処理装置100のインデックス生成部132は、算出した複数の検索対象文書121aそれぞれの要約情報と、検索対象文書121aとを対応付けた索引情報を生成する。検索部135は、問い合わせ文書101の要約情報と、索引情報において検索対象文書121aと対応付けられた要約情報との間の比較を行う。情報処理装置100では、索引情報を生成しておくことで、複数の検索対象文書121aの中から問い合わせ文書101に類似する文書の検索を高速に行うことができる。
Further, the index generation unit 132 of the information processing apparatus 100 generates index information in which the calculated summary information of each of the plurality of search target documents 121a is associated with the search target document 121a. The search unit 135 compares the summary information of the inquiry document 101 with the summary information associated with the search target document 121a in the index information. By generating index information, the information processing apparatus 100 can quickly search for a document similar to the inquiry document 101 from among a plurality of search target documents 121a.
[その他]
なお、図示した各装置の各構成要素は、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。 [Other]
It should be noted that each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of the device is functionally or physically distributed / physically in arbitrary units according to various loads and usage conditions. It can be integrated and configured.
なお、図示した各装置の各構成要素は、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。 [Other]
It should be noted that each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of the device is functionally or physically distributed / physically in arbitrary units according to various loads and usage conditions. It can be integrated and configured.
例えば、本実施形態では、インデックス生成モジュール111と、検索モジュール112とを有する情報処理装置100を例示したが、インデックス生成モジュール111と、検索モジュール112とはそれぞれ異なる情報処理装置が有していてもよい。すなわち、事前処理(S1)と、検索処理(S2)とは、それぞれ異なる情報処理装置で実施してもよい。
For example, in the present embodiment, the information processing device 100 having the index generation module 111 and the search module 112 is illustrated, but even if the index generation module 111 and the search module 112 have different information processing devices, respectively. Good. That is, the pre-processing (S1) and the search processing (S2) may be performed by different information processing devices.
また、情報処理装置100で行われる各種処理機能は、CPU(またはMPU、MCU(Micro Controller Unit)等のマイクロ・コンピュータ)上で、その全部または任意の一部を実行するようにしてもよい。また、各種処理機能は、CPU(またはMPU、MCU等のマイクロ・コンピュータ)で解析実行されるプログラム上、またはワイヤードロジックによるハードウエア上で、その全部または任意の一部を実行するようにしてもよいことは言うまでもない。また、情報処理装置100で行われる各種処理機能は、クラウドコンピューティングにより、複数のコンピュータが協働して実行してもよい。
Further, the various processing functions performed by the information processing apparatus 100 may execute all or any part thereof on the CPU (or a microcomputer such as an MPU or an MCU (Micro Controller Unit)). Further, various processing functions may be executed in whole or in any part on a program analyzed and executed by a CPU (or a microcomputer such as an MPU or MCU) or on hardware by wired logic. Needless to say, it's good. Further, various processing functions performed by the information processing apparatus 100 may be executed by a plurality of computers in cooperation by cloud computing.
ところで、上記の実施形態で説明した各種の処理は、予め用意されたプログラムをコンピュータで実行することで実現できる。そこで、以下では、上記の実施例と同様の機能を有するプログラムを実行するコンピュータ(ハードウエア)の一例を説明する。図10は、プログラムを実行するコンピュータの一例を示す図である。
By the way, various processes described in the above embodiment can be realized by executing a program prepared in advance on a computer. Therefore, an example of a computer (hardware) that executes a program having the same function as that of the above embodiment will be described below. FIG. 10 is a diagram showing an example of a computer that executes a program.
図10に示すように、コンピュータ1は、各種演算処理を実行するCPU201と、データ入力を受け付ける入力装置202と、モニタ203と、スピーカ204とを有する。また、コンピュータ1は、記憶媒体からプログラム等を読み取る媒体読取装置205と、各種装置と接続するためのインタフェース装置206と、有線または無線により外部機器と通信接続するための通信装置207とを有する。また、コンピュータ1は、各種情報を一時記憶するRAM208と、ハードディスク装置209とを有する。また、コンピュータ1内の各部(201~209)は、バス210に接続される。
As shown in FIG. 10, the computer 1 has a CPU 201 that executes various arithmetic processes, an input device 202 that receives data input, a monitor 203, and a speaker 204. Further, the computer 1 has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting to various devices, and a communication device 207 for communicating with an external device by wire or wirelessly. Further, the computer 1 has a RAM 208 for temporarily storing various information and a hard disk device 209. Further, each part (201 to 209) in the computer 1 is connected to the bus 210.
ハードディスク装置209には、上記の実施形態で説明した各種の処理を実行するためのプログラム211が記憶される。また、ハードディスク装置209には、プログラム211が参照する各種データ212(例えば語間距離情報記憶部122、検索対象文書データベース121、ハッシュ関数記憶部123およびインデックス記憶部124の情報)が記憶される。入力装置202は、例えば、コンピュータ1の操作者から操作情報の入力を受け付ける。モニタ203は、例えば、操作者が操作する各種画面を表示する。インタフェース装置206は、例えば印刷装置等が接続される。通信装置207は、LAN(Local Area Network)等の通信ネットワークと接続され、通信ネットワークを介した外部機器との間で各種情報をやりとりする。
The hard disk device 209 stores a program 211 for executing various processes described in the above embodiment. Further, the hard disk device 209 stores various data 212 (for example, information of the inter-word distance information storage unit 122, the search target document database 121, the hash function storage unit 123, and the index storage unit 124) referred to by the program 211. The input device 202 receives, for example, input of operation information from the operator of the computer 1. The monitor 203 displays, for example, various screens operated by the operator. For example, a printing device or the like is connected to the interface device 206. The communication device 207 is connected to a communication network such as a LAN (Local Area Network), and exchanges various information with an external device via the communication network.
CPU201は、ハードディスク装置209に記憶されたプログラム211を読み出して、RAM208に展開して実行することで、ハッシュ関数生成部131、インデックス生成部132、問い合わせ受信部133、ハッシュ値算出部134、検索部135および出力部136に関する各種の処理を行う。なお、プログラム211は、ハードディスク装置209に記憶されていなくてもよい。例えば、コンピュータ1が読み取り可能な記憶媒体に記憶されたプログラム211を、コンピュータ1が読み出して実行するようにしてもよい。コンピュータ1が読み取り可能な記憶媒体は、例えば、CD-ROMやDVDディスク、USB(Universal Serial Bus)メモリ等の可搬型記録媒体、フラッシュメモリ等の半導体メモリ、ハードディスクドライブ等が対応する。また、公衆回線、インターネット、LAN等に接続された装置にこのプログラム211を記憶させておき、コンピュータ1がこれらからプログラムを読み出して実行するようにしてもよい。
The CPU 201 reads the program 211 stored in the hard disk device 209, expands it into the RAM 208, and executes it, thereby executing the hash function generation unit 131, the index generation unit 132, the inquiry reception unit 133, the hash value calculation unit 134, and the search unit. Various processes related to 135 and the output unit 136 are performed. The program 211 may not be stored in the hard disk device 209. For example, the computer 1 may read and execute the program 211 stored in the storage medium that can be read by the computer 1. The storage medium that can be read by the computer 1 corresponds to, for example, a CD-ROM, a DVD disk, a portable recording medium such as a USB (Universal Serial Bus) memory, a semiconductor memory such as a flash memory, a hard disk drive, or the like. Further, the program 211 may be stored in a device connected to a public line, the Internet, a LAN, or the like, and the computer 1 may read the program from these and execute the program.
1…コンピュータ
10…グラフ
11~13…曲線
20…操作画面
21…表示領域
21a…入力文書
21b…検索結果
22…入力領域
100…情報処理装置
101…問い合わせ文書
102…類似文書
111…インデックス生成モジュール
112…検索モジュール
121…検索対象文書データベース
121a…検索対象文書
122…語間距離情報記憶部
123…ハッシュ関数記憶部
123a…ハッシュ関数
124…インデックス記憶部
124a…索引構造
131…ハッシュ関数生成部
132…インデックス生成部
133…問い合わせ受信部
134…ハッシュ値算出部
135…検索部
136…出力部
201…CPU
202…入力装置
203…モニタ
204…スピーカ
205…媒体読取装置
206…インタフェース装置
207…通信装置
208…RAM
209…ハードディスク装置
210…バス
211…プログラム
212…各種データ
A1~A2…軸
W1~W7…語 1 ...Computer 10 ... Graphs 11 to 13 ... Curve 20 ... Operation screen 21 ... Display area 21a ... Input document 21b ... Search result 22 ... Input area 100 ... Information processing device 101 ... Inquiry document 102 ... Similar document 111 ... Index generation module 112 ... Search module 121 ... Search target document database 121a ... Search target document 122 ... Inter-word distance information storage unit 123 ... Hash function storage unit 123a ... Hash function 124 ... Index storage unit 124a ... Index structure 131 ... Hash function generation unit 132 ... Index Generation unit 133 ... Inquiry receiving unit 134 ... Hash value calculation unit 135 ... Search unit 136 ... Output unit 201 ... CPU
202 ...Input device 203 ... Monitor 204 ... Speaker 205 ... Media reader 206 ... Interface device 207 ... Communication device 208 ... RAM
209 ...Hard disk device 210 ... Bus 211 ... Program 212 ... Various data A1 to A2 ... Axis W1 to W7 ... Words
10…グラフ
11~13…曲線
20…操作画面
21…表示領域
21a…入力文書
21b…検索結果
22…入力領域
100…情報処理装置
101…問い合わせ文書
102…類似文書
111…インデックス生成モジュール
112…検索モジュール
121…検索対象文書データベース
121a…検索対象文書
122…語間距離情報記憶部
123…ハッシュ関数記憶部
123a…ハッシュ関数
124…インデックス記憶部
124a…索引構造
131…ハッシュ関数生成部
132…インデックス生成部
133…問い合わせ受信部
134…ハッシュ値算出部
135…検索部
136…出力部
201…CPU
202…入力装置
203…モニタ
204…スピーカ
205…媒体読取装置
206…インタフェース装置
207…通信装置
208…RAM
209…ハードディスク装置
210…バス
211…プログラム
212…各種データ
A1~A2…軸
W1~W7…語 1 ...
202 ...
209 ...
Claims (21)
- 検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、前記単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成し、
生成した前記ハッシュ関数に基づいて複数の前記検索対象文書それぞれの要約情報を算出し、
生成した前記ハッシュ関数に基づいて入力文書の要約情報を算出し、
算出した前記検索対象文書の要約情報と、前記入力文書の要約情報との間の比較に基づいて、複数の前記検索対象文書の中から前記入力文書に類似する文書を検索する、
処理をコンピュータが実行することを特徴とする類似文書検索方法。 Based on the set of words included in the search target document and the inter-word information indicating the closeness of the word meanings of the words, for each word included in the set of words, with respect to the predetermined word as a reference. Generate a hash function that assigns values closest to each other in order of word meaning,
Based on the generated hash function, the summary information of each of the plurality of search target documents is calculated.
The summary information of the input document is calculated based on the generated hash function.
Based on the comparison between the calculated summary information of the search target document and the summary information of the input document, a document similar to the input document is searched from among the plurality of search target documents.
A similar document retrieval method characterized by a computer performing processing. - 前記算出する処理のそれぞれは、生成した前記ハッシュ関数において前記検索対象文書または前記入力文書に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する、
ことを特徴とする請求項1に記載の類似文書検索方法。 In each of the calculation processes, the smallest value among the values assigned to each word of the set of words included in the search target document or the input document in the generated hash function is calculated as the hash value.
The similar document retrieval method according to claim 1, wherein the similar document is searched for. - 前記生成する処理は、前記所定の単語を選び直して前記ハッシュ関数を生成する処理を繰り返すことで前記ハッシュ関数を複数生成し、
前記算出する処理のそれぞれは、生成した複数の前記ハッシュ関数によって前記検索対象文書または前記入力文書に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する、
ことを特徴とする請求項2に記載の類似文書検索方法。 In the process of generating, a plurality of the hash functions are generated by repeating the process of reselecting the predetermined word and generating the hash function.
Each of the calculation processes calculates as summary information a vector including a plurality of hash values calculated from a set of words included in the search target document or the input document by the generated hash functions.
The similar document retrieval method according to claim 2, wherein the similar document is searched for. - 算出した複数の前記検索対象文書それぞれの要約情報と、前記検索対象文書とを対応付けた索引情報を生成する処理をさらにコンピュータが実行し、
前記検索する処理は、前記入力文書の要約情報と、前記索引情報において前記検索対象文書と対応付けられた要約情報との間の比較を行う、
ことを特徴とする請求項1に記載の類似文書検索方法。 The computer further executes a process of generating index information in which the calculated summary information of each of the plurality of search target documents is associated with the search target documents.
The search process compares the summary information of the input document with the summary information associated with the search target document in the index information.
The similar document retrieval method according to claim 1, wherein the similar document is searched for. - 検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、前記単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成し、
生成した前記ハッシュ関数に基づいて複数の前記検索対象文書それぞれの要約情報を算出し、
生成した前記ハッシュ関数に基づいて入力文書の要約情報を算出し、
算出した前記検索対象文書の要約情報と、前記入力文書の要約情報との間の比較に基づいて、複数の前記検索対象文書の中から前記入力文書に類似する文書を検索する、
処理をコンピュータに実行させることを特徴とする類似文書検索プログラム。 Based on the set of words included in the search target document and the inter-word information indicating the closeness of the word meanings of the words, for each word included in the set of words, for the word based on a predetermined word. Generate a hash function that assigns values closest to each other in order of word meaning,
Based on the generated hash function, the summary information of each of the plurality of search target documents is calculated.
The summary information of the input document is calculated based on the generated hash function.
Based on the comparison between the calculated summary information of the search target document and the summary information of the input document, a document similar to the input document is searched from among the plurality of search target documents.
A similar document retrieval program characterized by having a computer perform processing. - 前記算出する処理のそれぞれは、生成した前記ハッシュ関数において前記検索対象文書または前記入力文書に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する、
ことを特徴とする請求項5に記載の類似文書検索プログラム。 In each of the calculation processes, the smallest value among the values assigned to each word of the set of words included in the search target document or the input document in the generated hash function is calculated as the hash value.
The similar document retrieval program according to claim 5. - 前記生成する処理は、前記所定の単語を選び直して前記ハッシュ関数を生成する処理を繰り返すことで前記ハッシュ関数を複数生成し、
前記算出する処理のそれぞれは、生成した複数の前記ハッシュ関数によって前記検索対象文書または前記入力文書に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する、
ことを特徴とする請求項6に記載の類似文書検索プログラム。 In the process of generating, a plurality of the hash functions are generated by repeating the process of reselecting the predetermined word and generating the hash function.
Each of the calculation processes calculates as summary information a vector including a plurality of hash values calculated from a set of words included in the search target document or the input document by the generated hash functions.
The similar document search program according to claim 6. - 算出した複数の前記検索対象文書それぞれの要約情報と、前記検索対象文書とを対応付けた索引情報を生成する処理をさらにコンピュータが実行し、
前記検索する処理は、前記入力文書の要約情報と、前記索引情報において前記検索対象文書と対応付けられた要約情報との間の比較を行う、
ことを特徴とする請求項5に記載の類似文書検索プログラム。 The computer further executes a process of generating index information in which the calculated summary information of each of the plurality of search target documents is associated with the search target documents.
The search process compares the summary information of the input document with the summary information associated with the search target document in the index information.
The similar document retrieval program according to claim 5. - 検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、前記単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成するハッシュ関数生成部と、
生成した前記ハッシュ関数に基づいて複数の前記検索対象文書それぞれの要約情報を算出する第1の算出部と、
生成した前記ハッシュ関数に基づいて入力文書の要約情報を算出する第2の算出部と、
算出した前記検索対象文書の要約情報と、前記入力文書の要約情報との間の比較に基づいて、複数の前記検索対象文書の中から前記入力文書に類似する文書を検索する検索部と、
を有することを特徴とする類似文書検索装置。 Based on the set of words included in the search target document and the inter-word information indicating the closeness of the word meanings of the words, for each word included in the set of words, for the word based on a predetermined word. A hash function generator that generates a hash function that assigns values that are closer to each other in order of word meaning,
A first calculation unit that calculates summary information for each of the plurality of search target documents based on the generated hash function, and
A second calculation unit that calculates the summary information of the input document based on the generated hash function,
A search unit that searches for a document similar to the input document from a plurality of the search target documents based on a comparison between the calculated summary information of the search target document and the summary information of the input document.
A similar document retrieval device characterized by having. - 前記第1の算出部および前記第2の算出部のそれぞれは、生成した前記ハッシュ関数において前記検索対象文書または前記入力文書に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する、
ことを特徴とする請求項9に記載の類似文書検索装置。 Each of the first calculation unit and the second calculation unit is the smallest value assigned to each word in the set of words included in the search target document or the input document in the generated hash function. Calculate the value as a hash value,
The similar document retrieval device according to claim 9. - 前記ハッシュ関数生成部は、前記所定の単語を選び直して前記ハッシュ関数を生成する処理を繰り返すことで前記ハッシュ関数を複数生成し、
前記第1の算出部および前記第2の算出部のそれぞれは、生成した複数の前記ハッシュ関数によって前記検索対象文書または前記入力文書に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する、
ことを特徴とする請求項10に記載の類似文書検索装置。 The hash function generation unit generates a plurality of the hash functions by repeating the process of reselecting the predetermined word and generating the hash function.
Each of the first calculation unit and the second calculation unit is a vector containing a plurality of hash values calculated from a set of words included in the search target document or the input document by the generated hash functions. Is calculated as summary information,
The similar document retrieval device according to claim 10. - 算出した複数の前記検索対象文書それぞれの要約情報と、前記検索対象文書とを対応付けた索引情報を生成する索引情報生成部をさらに有し、
前記検索部は、前記入力文書の要約情報と、前記索引情報において前記検索対象文書と対応付けられた要約情報との間の比較を行う、
ことを特徴とする請求項9に記載の類似文書検索装置。 It further has an index information generation unit that generates index information in which the calculated summary information of each of the plurality of search target documents is associated with the search target documents.
The search unit compares the summary information of the input document with the summary information associated with the search target document in the index information.
The similar document retrieval device according to claim 9. - 検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、前記単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成し、
生成した前記ハッシュ関数に基づいて複数の前記検索対象文書それぞれの要約情報を算出し、
算出した複数の前記検索対象文書それぞれの要約情報を探索する索引情報を生成する、
処理をコンピュータが実行することを特徴とする索引情報作成方法。 Based on the set of words included in the search target document and the inter-word information indicating the closeness of the word meanings of the words, for each word included in the set of words, for the word based on a predetermined word. Generate a hash function that assigns values closest to each other in order of word meaning,
Based on the generated hash function, the summary information of each of the plurality of search target documents is calculated.
Generate index information for searching the summary information of each of the plurality of calculated search target documents.
A method of creating index information, characterized in that the processing is performed by a computer. - 前記算出する処理は、生成した前記ハッシュ関数において前記検索対象文書に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する、
ことを特徴とする請求項13に記載の索引情報作成方法。 In the calculation process, the smallest value among the values assigned to each word in the set of words included in the search target document in the generated hash function is calculated as the hash value.
The index information creation method according to claim 13, wherein the index information is created. - 前記生成する処理は、前記所定の単語を選び直して前記ハッシュ関数を生成する処理を繰り返すことで前記ハッシュ関数を複数生成し、
前記算出する処理は、生成した複数の前記ハッシュ関数によって前記検索対象文書に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する、
ことを特徴とする請求項14に記載の索引情報作成方法。 In the process of generating, a plurality of the hash functions are generated by repeating the process of reselecting the predetermined word and generating the hash function.
In the calculation process, a vector including a plurality of hash values calculated from a set of words included in the search target document by the generated plurality of hash functions is calculated as summary information.
The index information creation method according to claim 14, wherein the index information is created. - 検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、前記単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成し、
生成した前記ハッシュ関数に基づいて複数の前記検索対象文書それぞれの要約情報を算出し、
算出した複数の前記検索対象文書それぞれの要約情報を探索する索引情報を生成する、
処理をコンピュータに実行させることを特徴とする索引情報作成プログラム。 Based on the set of words included in the search target document and the inter-word information indicating the closeness of the word meanings of the words, for each word included in the set of words, for the word based on a predetermined word. Generate a hash function that assigns values closest to each other in order of word meaning,
Based on the generated hash function, the summary information of each of the plurality of search target documents is calculated.
Generate index information for searching the summary information of each of the plurality of calculated search target documents.
An index information creation program characterized by having a computer execute processing. - 前記算出する処理は、生成した前記ハッシュ関数において前記検索対象文書に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する、
ことを特徴とする請求項16に記載の索引情報作成プログラム。 In the calculation process, the smallest value among the values assigned to each word in the set of words included in the search target document in the generated hash function is calculated as the hash value.
16. The index information creation program according to claim 16. - 前記生成する処理は、前記所定の単語を選び直して前記ハッシュ関数を生成する処理を繰り返すことで前記ハッシュ関数を複数生成し、
前記算出する処理は、生成した複数の前記ハッシュ関数によって前記検索対象文書に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する、
ことを特徴とする請求項17に記載の索引情報作成プログラム。 In the process of generating, a plurality of the hash functions are generated by repeating the process of reselecting the predetermined word and generating the hash function.
In the calculation process, a vector including a plurality of hash values calculated from a set of words included in the search target document by the generated plurality of hash functions is calculated as summary information.
The index information creation program according to claim 17, wherein the index information is created. - 検索対象文書に含まれる単語の集合と、単語の語意の近さを示す語間情報とに基づき、前記単語の集合に含まれる単語それぞれに対して、所定の単語を基準として当該単語に対して語意の近い順に近い値を割り当てるハッシュ関数を生成するハッシュ関数生成部と、
生成した前記ハッシュ関数に基づいて複数の前記検索対象文書それぞれの要約情報を算出する算出部と、
算出した複数の前記検索対象文書それぞれの要約情報を探索する索引情報を生成する索引情報生成部と、
を有することを特徴とする索引情報作成装置。 Based on the set of words included in the search target document and the inter-word information indicating the closeness of the word meanings of the words, for each word included in the set of words, for the word based on a predetermined word. A hash function generator that generates a hash function that assigns values that are closer to each other in order of word meaning,
A calculation unit that calculates summary information for each of the plurality of search target documents based on the generated hash function.
An index information generation unit that generates index information for searching summary information of each of the plurality of calculated search target documents, and an index information generation unit.
An index information creation device characterized by having. - 前記算出部は、生成した前記ハッシュ関数において前記検索対象文書に含まれる単語の集合の単語それぞれに割り当てられた値の中で最小の値をハッシュ値として算出する、
ことを特徴とする請求項19に記載の索引情報作成装置。 The calculation unit calculates, as a hash value, the smallest value among the values assigned to each word in the set of words included in the search target document in the generated hash function.
The index information creating apparatus according to claim 19. - 前記ハッシュ関数生成部は、前記所定の単語を選び直して前記ハッシュ関数を生成する処理を繰り返すことで前記ハッシュ関数を複数生成し、
前記算出部は、生成した複数の前記ハッシュ関数によって前記検索対象文書に含まれる単語の集合から算出される複数のハッシュ値を含むベクトルを要約情報として算出する、
ことを特徴とする請求項20に記載の索引情報作成装置。 The hash function generation unit generates a plurality of the hash functions by repeating the process of reselecting the predetermined word and generating the hash function.
The calculation unit calculates as summary information a vector including a plurality of hash values calculated from a set of words included in the search target document by the plurality of generated hash functions.
The index information creating apparatus according to claim 20.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/034306 WO2021038887A1 (en) | 2019-08-30 | 2019-08-30 | Similar document retrieval method, similar document retrieval program, similar document retrieval device, index information creation method, index information creation program, and index information creation device |
| JP2021541969A JP7193000B2 (en) | 2019-08-30 | 2019-08-30 | Similar document search method, similar document search program, similar document search device, index information creation method, index information creation program, and index information creation device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/034306 WO2021038887A1 (en) | 2019-08-30 | 2019-08-30 | Similar document retrieval method, similar document retrieval program, similar document retrieval device, index information creation method, index information creation program, and index information creation device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021038887A1 true WO2021038887A1 (en) | 2021-03-04 |
Family
ID=74683387
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/034306 WO2021038887A1 (en) | 2019-08-30 | 2019-08-30 | Similar document retrieval method, similar document retrieval program, similar document retrieval device, index information creation method, index information creation program, and index information creation device |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7193000B2 (en) |
| WO (1) | WO2021038887A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022239174A1 (en) * | 2021-05-13 | 2022-11-17 | 日本電気株式会社 | Similarity degree derivation system and similarity degree derivation method |
| CN116302074A (en) * | 2023-05-12 | 2023-06-23 | 卓望数码技术(深圳)有限公司 | Third party component identification method, device, equipment and storage medium |
| WO2024089910A1 (en) * | 2022-10-26 | 2024-05-02 | 株式会社LegalOn Technologies | Information processing method, information processing program, information processing system |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010267108A (en) * | 2009-05-15 | 2010-11-25 | Nippon Telegr & Teleph Corp <Ntt> | Device, method and program for generating document signature for detecting similar document |
| US20110087669A1 (en) * | 2009-10-09 | 2011-04-14 | Stratify, Inc. | Composite locality sensitive hash based processing of documents |
| JP2015201042A (en) * | 2014-04-08 | 2015-11-12 | 日本電信電話株式会社 | Hash function generation method, hash value generation method, device, and program |
| CN106156154A (en) * | 2015-04-14 | 2016-11-23 | 阿里巴巴集团控股有限公司 | The search method of Similar Text and device thereof |
| CN107784110A (en) * | 2017-11-03 | 2018-03-09 | 北京锐安科技有限公司 | A kind of index establishing method and device |
-
2019
- 2019-08-30 WO PCT/JP2019/034306 patent/WO2021038887A1/en active Application Filing
- 2019-08-30 JP JP2021541969A patent/JP7193000B2/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010267108A (en) * | 2009-05-15 | 2010-11-25 | Nippon Telegr & Teleph Corp <Ntt> | Device, method and program for generating document signature for detecting similar document |
| US20110087669A1 (en) * | 2009-10-09 | 2011-04-14 | Stratify, Inc. | Composite locality sensitive hash based processing of documents |
| JP2015201042A (en) * | 2014-04-08 | 2015-11-12 | 日本電信電話株式会社 | Hash function generation method, hash value generation method, device, and program |
| CN106156154A (en) * | 2015-04-14 | 2016-11-23 | 阿里巴巴集团控股有限公司 | The search method of Similar Text and device thereof |
| CN107784110A (en) * | 2017-11-03 | 2018-03-09 | 北京锐安科技有限公司 | A kind of index establishing method and device |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022239174A1 (en) * | 2021-05-13 | 2022-11-17 | 日本電気株式会社 | Similarity degree derivation system and similarity degree derivation method |
| JP7464193B2 (en) | 2021-05-13 | 2024-04-09 | 日本電気株式会社 | Similarity derivation system and similarity derivation method |
| WO2024089910A1 (en) * | 2022-10-26 | 2024-05-02 | 株式会社LegalOn Technologies | Information processing method, information processing program, information processing system |
| CN116302074A (en) * | 2023-05-12 | 2023-06-23 | 卓望数码技术(深圳)有限公司 | Third party component identification method, device, equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7193000B2 (en) | 2022-12-20 |
| JPWO2021038887A1 (en) | 2021-03-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021038887A1 (en) | Similar document retrieval method, similar document retrieval program, similar document retrieval device, index information creation method, index information creation program, and index information creation device | |
| CN1139911C (en) | Dynamically configurable acoustic model for speech recognition systems | |
| US11521110B2 (en) | Learning apparatus, learning method, and non-transitory computer readable storage medium | |
| JP6019604B2 (en) | Speech recognition apparatus, speech recognition method, and program | |
| US8204837B2 (en) | Information processing apparatus and method, and program for providing information suitable for a predetermined mood of a user | |
| CN1331467A (en) | Method and device for producing acoustics model | |
| JP6004015B2 (en) | Learning method, information processing apparatus, and learning program | |
| JP7058574B2 (en) | Information processing equipment, information processing methods, and programs | |
| US20190354533A1 (en) | Information processing device, information processing method, and non-transitory computer-readable recording medium | |
| WO2008062822A1 (en) | Text mining device, text mining method and text mining program | |
| US20240070726A1 (en) | Automated generation of creative parameters based on approval feedback | |
| US6944329B2 (en) | Information processing method and apparatus | |
| US20230259761A1 (en) | Transfer learning system and method for deep neural network | |
| JP2018180459A (en) | Speech synthesis system, speech synthesis method, and speech synthesis program | |
| KR102072238B1 (en) | question answering system and method based on reliability | |
| JP6976178B2 (en) | Extractor, extraction method, and extraction program | |
| JP2018045657A (en) | Learning device, program parameter and learning method | |
| KR102011099B1 (en) | Method, apparatus, and computer program for selecting music based on image | |
| US7240050B2 (en) | Methods and apparatus for generating automated graphics using stored graphics examples | |
| JP2022185799A (en) | Information processing program, information processing method and information processing device | |
| JPWO2018066083A1 (en) | Learning program, information processing apparatus and learning method | |
| KR20220041336A (en) | Graph generation system of recommending significant keywords and extracting core documents and method thereof | |
| CN116049414B (en) | Topic description-based text clustering method, electronic equipment and storage medium | |
| JP4705430B2 (en) | Language processing device based on the concept of distance | |
| JP2001265788A (en) | Method and device for sorting document and recording medium storing document sorting program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19943706 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021541969 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19943706 Country of ref document: EP Kind code of ref document: A1 |