WO2021010276A1 - 識別支援システム、識別支援クライアント、識別支援サーバ、及び識別支援方法 - Google Patents
識別支援システム、識別支援クライアント、識別支援サーバ、及び識別支援方法 Download PDFInfo
- Publication number
- WO2021010276A1 WO2021010276A1 PCT/JP2020/026849 JP2020026849W WO2021010276A1 WO 2021010276 A1 WO2021010276 A1 WO 2021010276A1 JP 2020026849 W JP2020026849 W JP 2020026849W WO 2021010276 A1 WO2021010276 A1 WO 2021010276A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- drug
- text
- identification
- unit
- image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images









Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61J—CONTAINERS SPECIALLY ADAPTED FOR MEDICAL OR PHARMACEUTICAL PURPOSES; DEVICES OR METHODS SPECIALLY ADAPTED FOR BRINGING PHARMACEUTICAL PRODUCTS INTO PARTICULAR PHYSICAL OR ADMINISTERING FORMS; DEVICES FOR ADMINISTERING FOOD OR MEDICINES ORALLY; BABY COMFORTERS; DEVICES FOR RECEIVING SPITTLE
- A61J3/00—Devices or methods specially adapted for bringing pharmaceutical products into particular physical or administering forms
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/10—Image acquisition
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/768—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using context analysis, e.g. recognition aided by known co-occurring patterns
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/98—Detection or correction of errors, e.g. by rescanning the pattern or by human intervention; Evaluation of the quality of the acquired patterns
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/192—Recognition using electronic means using simultaneous comparisons or correlations of the image signals with a plurality of references
- G06V30/194—References adjustable by an adaptive method, e.g. learning
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/10—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to drugs or medications, e.g. for ensuring correct administration to patients
Definitions
- the present invention relates to a drug identification support system, an identification support client, an identification support server, and an identification support method.
- Patent Document 1 describes an image processing device that performs character recognition.
- One embodiment of the present invention provides an identification support system, an identification support client, and an identification support method capable of accurately identifying a drug by a user.
- the present invention also provides an identification support server that can be used to identify drugs.
- the identification support system presents an image acquisition unit that acquires an image of a drug and a character string that is extracted for each character.
- a text-forming section that generates the first text
- a text-correcting section that modifies the first text based on the expression used to identify the drug and generates a second text
- the code and / or name of the drug are stored as texts in the drug master
- the second text is collated with the drug master to be a candidate for the drug indicated by the second text. It includes a collation unit that acquires identification information about the candidate drug, and an output unit that outputs identification information about the candidate drug.
- the character string included in the image is extracted character by character, the extracted text is corrected based on the expression used for identifying the drug, and the corrected text is collated with the drug master.
- the user can accurately identify the drug.
- the components of the system may be housed in one housing, or may be stored in a plurality of housings separately. Further, a plurality of devices may be connected via a network to satisfy the configuration requirements of the first aspect as a whole.
- the text conversion unit extracts a character string using a learned model configured by machine learning.
- the trained model may be a trained model using a neural network.
- the identification support system further includes an emphasis processing unit that emphasizes a character string included in the image to generate a character string emphasis image, and the text conversion unit enhances the character string. Generate the first text from the image. According to the third aspect, the recognition accuracy when extracting the character string from the image can be improved.
- the collation unit calculates the similarity between the second text and the character information, and the candidate drug is based on the similarity. Select. In the fourth aspect, the collation unit may consider the distance between character strings in calculating the similarity.
- the drug master has layout information for character information, and the collation unit performs collation based on the layout information.
- the layout information may include information such as the number of columns (2 columns, 3 columns, etc.) and arrangement (from upper left to upper right, then to lower left, further to lower right, etc.). The recognition accuracy can be improved by collating the collation unit based on the layout information.
- the identification support system stores the identification information and the image of the drug in association with each other, and the output unit stores the identification information and the image of the candidate drug. Is associated with and displayed on the display device. According to the sixth aspect, the user can easily visually determine whether or not the collation result is appropriate.
- the image of the drug may be an image of the packaging of the drug (PTP sheet or the like) instead of the drug itself.
- the identification support client presents an image acquisition unit that acquires an image of a drug and a character string that is extracted for each character.
- a text conversion unit that generates the first text
- a text correction unit that modifies the first text based on the expression used to identify the drug to generate the second text, and information indicating the second text.
- a client-side transmitter that transmits to the identification support server, and a client-side receiver that receives identification information including the drug code and / or name of the candidate drug that is a drug candidate indicated by the second text from the identification support server.
- An output unit that outputs identification information about a candidate drug.
- the user can accurately identify the drug.
- the identification support client according to the seventh aspect may have the configurations according to the second to sixth aspects.
- the identification support server contains, as text, identification information indicating a drug code and / or name and character information indicating characters attached to the drug.
- Identification information about the stored drug master the server-side receiver that receives the text information about the drug from the identification support client, and the candidate drug that is the candidate drug indicated by the text information by collating the text information with the drug master. It is provided with a collation unit for acquiring the information and a server-side transmission unit for transmitting the acquired identification information to the identification support client.
- the identification support server according to the eighth aspect can be used for drug identification support.
- the identification support client according to the eighth aspect may have the configurations according to the second to sixth aspects. Further, the identification support client according to the seventh aspect and the identification support server according to the eighth aspect can form an identification support system similar to the identification support system according to the first aspect.
- the identification support method includes an image acquisition step of acquiring an image of a drug, and a character string included in the image is extracted for each character to indicate the character string.
- the text modification step of generating the first text the text modification step of modifying the first text based on the expression used to identify the drug to generate the second text, and the code and / or name of the drug.
- the identification information shown and the character information indicating the characters attached to the drug are collated with the drug master stored as a text and the second text, and the candidate drug that is a candidate for the drug indicated by the second text It has a collation step of acquiring the identification information of the candidate drug and an output step of outputting the identification information of the candidate drug.
- the user can accurately identify the drug.
- the identification support method according to the ninth aspect may have the same configuration as the second to sixth aspects.
- a program that causes an identification support system or a computer to execute the identification support method of these aspects, and a non-temporary recording medium that records a computer-readable code of such a program can also be mentioned as an aspect of the present invention.
- the identification support system, identification support client, identification support server, and identification support method of the above-described aspects can be used for drug discrimination support and / or audit support.
- the identification support system As described above, according to the identification support system, the identification support client, and the identification support method of the present invention, the user can accurately identify the drug.
- the identification support server of the present invention can be used for drug identification.
- FIG. 1 is a diagram showing a configuration of an identification support system according to the first embodiment.
- FIG. 2 is a functional block diagram of the processing unit.
- FIG. 3 is a diagram showing information stored in the storage unit.
- FIG. 4 is a flowchart showing the processing of the identification support method according to the first embodiment.
- FIG. 5 is a flowchart showing the collation process.
- FIG. 6 is a diagram showing an example of a stamp or the like attached to the drug.
- FIG. 7 is a diagram showing a configuration of the identification support system according to the second embodiment.
- FIG. 8 is a functional block diagram of the client processing unit.
- FIG. 9 is a diagram showing information stored in the client storage unit.
- FIG. 10 is a functional block diagram of the server processing unit.
- FIG. 11 is a diagram showing information stored in the server storage unit.
- FIG. 12 is a flowchart showing the processing of the identification support method according to the second embodiment.
- FIG. 13 is another flowchart showing the processing of
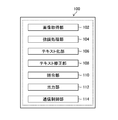
- FIG. 1 is a block diagram showing a configuration of the identification support system 10 (identification support system) according to the first embodiment.
- the identification support system 10 is a system that supports the identification of drugs, and can be realized by using a computer. As shown in FIG. 1, the identification support system 10 includes a processing unit 100, a lighting unit 120, a photographing unit 130, a storage unit 200, a display unit 300, and an operation unit 400, and is connected to each other to transmit and receive necessary information. ..
- the illumination unit 120 includes a light source for illuminating the drug, and the photographing unit 130 includes a camera for acquiring an image of the drug.
- the identification support system 10 is connected to an external server (not shown), an external database, etc. via a communication control unit 114 (see FIG. 2) and a network (not shown), and information (drug identification information, images, etc.) is required. ) Can be obtained.
- the identification support system 10 can be applied to support for discrimination of drugs brought by patients and support for auditing drugs provided to patients.
- FIG. 2 is a diagram showing the configuration of the processing unit 100.
- the processing unit 100 includes an image acquisition unit 102 (image acquisition unit), an emphasis processing unit 104 (emphasis processing unit), a text conversion unit 106 (text conversion unit), a text correction unit 108 (text correction unit), and a collation unit 110 (collation unit). ), An output unit 112 (output unit), and a communication control unit 114.
- the processing unit 100 further includes a CPU (CPU: Central Processing Unit), a ROM (ROM: Read Only Memory), and a RAM (RAM: Random Access Memory) (not shown). The processing by each of these parts is performed under the control of the CPU.
- CPU Central Processing Unit
- ROM Read Only Memory
- RAM Random Access Memory
- the functions of each part of the processing unit 100 described above can be realized by using various processors.
- the various processors include, for example, a CPU, which is a general-purpose processor that executes software (program) to realize various functions.
- the various processors described above include programmable logic devices (programmable logic devices), which are processors whose circuit configurations can be changed after manufacturing, such as GPU (Graphics Processing Unit) and FPGA (Field Programmable Gate Array), which are processors specialized in image processing. Programmable Logic Device (PLD) is also included.
- the above-mentioned various processors include a dedicated electric circuit, which is a processor having a circuit configuration specially designed for executing a specific process such as an ASIC (Application Specific Integrated Circuit).
- ASIC Application Specific Integrated Circuit
- each part may be realized by one processor, or may be realized by a plurality of processors of the same type or different types (for example, a plurality of FPGAs, or a combination of a CPU and an FPGA, or a combination of a CPU and a GPU). Further, one processor may realize a plurality of functions. As an example of configuring a plurality of functions with one processor, first, as represented by a computer such as a client and a server, one processor is configured by a combination of one or more CPUs and software, and this processor is configured. Is realized as a plurality of functions.
- SoC System On Chip
- a code readable by a computer of the software to be executed for example, various processors and electric circuits constituting the processing unit 100, and / or a combination thereof.
- the software stored in the non-temporary recording medium includes a program (identification support program) for executing the identification support method according to the present invention.
- the program code may be recorded on a non-temporary recording medium such as various optical magnetic recording devices or semiconductor memories instead of the ROM.
- RAM is used as a temporary storage area, and for example, data stored in an EEPROM (Electronically Erasable and Programmable Read Only Memory) (not shown) can be referred to.
- EEPROM Electrically Erasable and Programmable Read Only Memory
- the storage unit 200 is composed of a non-temporary recording medium such as a DVD (Digital Versatile Disk), a hard disk (Hard Disk), various semiconductor memories, and a control unit thereof, and as shown in FIG. 3, a drug master 202 (drug master) and a drug.
- Image 204 image of the drug
- collation result 206 collation result 206
- additional learning data 208 are stored.
- a drug collation dictionary (described later) in which expressions used for identifying drugs may be stored may be stored.
- the drug collation dictionary is a dictionary in which numbers, alphabets, company names and their abbreviations are registered as conversion candidates, for example, and it is possible to increase the possibility that an intended word is input as a search keyword.
- identification information including a drug code and / or name and character information indicating characters attached to the drug are stored as text information in association with each other.
- the "code” is, for example, a YJ code (an individual drug code composed of 12 alphanumeric characters), and the name may include the capacity of the active ingredient.
- "text information” includes marking information and / or printing information of the drug. For engraving and printing, it is preferable to store information on the front surface and the back surface of the drug.
- the drug master 202 may store the general name of the drug and the information of each product, or the information of the original drug and the information of the generic drug in association with each other.
- the storage unit 200 stores the drug image 204 in association with the drug master 202.
- the drug image 204 is also preferably stored for each of the front and back surfaces of the drug.
- the storage unit 200 can store the photographed image and the character string-weighted image as the drug image 204.
- the display unit 300 includes a monitor 310 (display device), and can display information stored in the storage unit 200, the result of processing by the processing unit 100, and the like.
- the operation unit 400 includes a keyboard 410 and a mouse 420 as input devices or pointing devices, and the user performs operations necessary for executing the identification support method according to the present invention through the screens of these devices and the monitor 310. Can be done (see below).
- the monitor 310 may be configured with a touch panel so that the user can operate through the touch panel.
- the image acquisition unit 102 controls the lighting unit 120 and the photographing unit 130 to acquire an image of the drug (step S100: image acquisition step).
- the image acquisition unit 102 captures a plurality of images of the drug while switching the illumination direction, and the enhancement processing unit 104 emphasizes the character strings (engraving, printing, etc.) included in the captured images to generate a character string emphasis image. May be good.
- the image acquisition unit 102 and the communication control unit 114 may acquire an image from a device connected via a network. In order to improve the accuracy of identification, it is preferable to acquire images of the drug on both sides. Further, the image to be taken may be an image of the packaging of the drug (PTP or the like).
- the text conversion unit 106 extracts a character string included in the captured image or the character string emphasized image for each character, and generates a first text indicating the character string (step S110: text conversion step).
- the method of text conversion is not particularly limited, but a trained model such as a neural network constructed by machine learning, for example, Mask-RCNN (RCNN: Regions with Convolutional Neural Networks) can be used.
- Mask-RCNN a fixed-size feature map obtained by convolving an input image is branched into a fully connected layer and a convolutional layer for region division, and a mask region is estimated in the convolutional layer.
- the text conversion unit 106 may directly estimate the center of the character by machine learning and then specify the individual character range.
- the text conversion unit 106 detects the layout of the character string included in the image (for example, “from the upper left to the upper right, the lower left, the lower right", “two columns”, “free layout”, etc.).
- the drug master 202 also has layout information about the character string (layout information about the character information) (described later).
- the text correction unit 108 modifies the first text based on the expression used for identifying the drug to generate the second text (step S120: text correction step). Specifically, the text correction unit 108 corrects the text (generates a second text) using a trained model trained by pairing a character string (text) containing an error and a correct character string (text). )can do.
- a trained model should be constructed by a neural network using RNN (Recurrent Neural Network) or LSTM (Long Short Term Memory) such as seq2seq (sequence to sequence) based on an algorithm of natural language processing.
- seq2seq is a model that learns a rule that inputs a "word sequence” (in the present invention, a character string containing an error) and outputs (replaces) another "word sequence” (correct character string). Yes, it is used for machine translation, etc.
- the RNN has an input layer, a hidden layer, and an output layer, and the hidden layer has a first hidden layer indicating a state at the current time (time t) and a second hidden layer indicating a state at a past time (time t-1). It differs from other neural networks (convolutional neural networks, etc.) in that it has a hidden layer.
- the trained model by RNN holds the state of the hidden layer at time t-1 and uses it for inputting the next time t, so that the past history (characters) of the information input in time series like natural language And the context of words) can be used for estimation.
- LSTM is a kind of RNN, and can be realized by replacing the unit in the intermediate layer of RNN with a "block having a memory and three gates" called “LSTM block".
- LSTM it is possible to learn long-term dependencies (relationships of distant letters and words) that are difficult to learn with ordinary RNNs.
- step S110 determines by natural language processing that "the number before and after the" day "is a number or an error in the alphabet", and sets the "day” to "8” or "B". It is conceivable to correct it.
- the text correction unit 108 may accept corrections to the first and second texts, and may execute additional learning in the above-mentioned trained model or drug collation dictionary (described later) based on the received corrections.
- the collation unit 110 collates the second text with the drug master 202 to acquire identification information about the candidate drug that is a candidate for the drug indicated by the second text (step S130: collation step).
- the collation unit 110 calculates the similarity between the second text and the character information (third text) of the drug master 202 (step S132 in FIG. 5), and selects a candidate drug based on the similarity.
- the Levenshtein distance, the Damerau-Levenshtein distance, the Hamming distance, the Jaro-Winkler distance, and the like can be used.
- the collation unit 110 may normalize the second text to generate a normalized text, and collate using the normalized text (collation step, normalization step).
- the collation unit 110 can perform, for example, uppercase to lowercase letters, full-width to half-width, kanji and / or hiragana to katakana (or the reverse of these conversions) as "normalization", thereby expressing the text. Can be unified to improve search accuracy. It is preferable that the collation unit 110 performs conversion according to the expression format of the identification information in the drug master 202 (whether uppercase or lowercase letters are used, etc.).
- FIG. 6 is a diagram showing an example of a character string attached to the drug.
- the part (a) in FIG. 6 is an example in which the character string is composed of an identification code of about 1 to 4 characters in English characters and an identification code of about 2 to 4 digits in numbers.
- the character length is short and the amount of information is short as text, so it is required that the character string sequence be extracted accurately.
- the text conversion unit 106 composes a character string from each recognized character based on the layout of the character string included in the image.
- the case of only numbers (or only letters) as in the part (b) of FIG. 6 is the same as the case of the part (a) of the same figure.
- Part (c) in FIG. 6 is an example in which a mark (in this case, a star) and a number are attached to the drug. Since the mark is not text, in this case it is preferable to define a rule for expressing the mark with a special character string in advance. For example, a star can be expressed as " ⁇ S" using the escape character " ⁇ ”, and " ⁇ S" can be treated as one character in the same way as a normal character.
- Part (d) and part (e) of FIG. 6 are examples in which the character string is composed of a plurality of columns and the amount of information is abundant. In such a case, since the number of characters is large, it is effective to count the characters by character type even if the text sequence is extracted differently from the original one. For example, when the character string extracted from the image is extracted as "Kasataa OD Na 10FF" in the example shown in the part (e) of the figure, the collation unit 110 ignores the order of the character strings and displays "ka”. One, one "sa”, one "ta”, one "a”, one "O”, one "D”, one "na", one "1” One, "0” is counted as one, and "F” is counted as two. Similarly, the collation unit 110 also examines the character information of the drug master 202 by ignoring the order of the character strings and checking the consistency between the two.
- the characters may be undecidable and cannot be used for collation, or the character string may be shortened due to division of tablets or packaging (PTP sheet, etc.).
- the short drug name has a relatively higher degree of similarity to the keyword than the long drug name, and there is a possibility that appropriate search results cannot be obtained. Therefore, in the identification support system 10, the similarity can be calculated in consideration of the number of characters of the keyword as follows. Specifically, when the "number of characters of the corrected text (second text)" is less than the "number of characters of the text information (third text) stored in the drug master 202", the collation unit 110 is the first.
- a character string having the same length as the second text is extracted from the text of 3, the similarity between the extracted character string and the second text is calculated, and the value when the similarity is maximum is used (step S130: Collation process).
- the collation unit 110 calculates the similarity without extracting the character string (step S130: Collation process). In this way, by calculating the degree of similarity in consideration of the number of characters of the keyword, it becomes easy to obtain an accurate search result.
- FIG. 5 is a flowchart showing the narrowing down of candidate drugs (part of step S130 in the flowchart of FIG. 4: collation step).
- the collation unit 110 calculates the similarity (step S132) and selects a drug having a similarity equal to or higher than the threshold value as a candidate drug (step S133). Then, the collation unit 110 determines whether or not a plurality of candidate drugs exist (step S134) and whether or not to narrow down when a plurality of candidate drugs exist (step S136).
- the collation unit 110 can narrow down by template matching between the captured image (or the character string emphasized image) and the master image of the drug master 202 (step S138), but the collation unit 110 may be narrowed down by another method.
- the collation unit 110 can determine whether or not to narrow down according to the user's operation via the operation unit 400. Further, the collation unit 110 may select all the drugs having a similarity equal to or higher than the threshold value as candidate drugs without narrowing down (if NO in step S136, go to step S139). The collation unit 110 acquires identification information and an image of the final candidate drug (step S139).
- the output unit 112 displays (outputs) the collation result (identification information and image) of the candidate drug on the monitor 310 (display device) (step S140 in FIG. 4: output step).
- the identification information drug code and / or name
- the user can easily grasp whether or not the candidate drug is appropriate (whether or not the collation is appropriate).
- the identification support system 10 (collation unit 110) determines that "the candidate drug is not appropriate” (NO in step S150) and "the collation of all drugs has not been completed” (in step S160). NO) returns to step S100 and repeats the process.
- the identification support system 10 can make these determinations based on the user's operation via the operation unit 400.
- the text correction unit 108 (text correction unit) accepts corrections to the first and second texts, and additionally learns the trained model for generating the first and second texts described above based on the received corrections. May be executed. In addition, the text correction unit 108 may update the drug collation dictionary described later.
- the text correction unit 108 accepts corrections to the first and second texts, it generates additional learning data 208 according to the contents of the received corrections (step S170: data generation step).
- the text correction unit 108 may perform additional learning each time additional learning data is generated, or may be performed periodically or at any time according to a user's instruction via the operation unit 400. By such additional learning, the accuracy of generating the first and second texts can be improved.
- the text correction unit 108 may modify the first text to generate the second text by referring to the drug collation dictionary trained with the expressions used for identifying the drug (text correction step).
- the drug collation dictionary is a conversion dictionary in which words used for drug identification are registered as conversion candidates, and for example, numbers, alphabets, drug names, pharmaceutical company names and their store names and abbreviations are registered.
- This information may be attached to the drug by engraving and / or printing, printing on the packaging, attaching a label, etc., and by registering in the drug collation dictionary, enter the intended word as a collation (search) keyword. Accurate collation (search) can be performed.
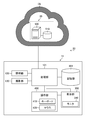
- FIG. 7 is a diagram showing a configuration of an identification support system 20 (identification support system) according to a second embodiment of the present invention.
- the identification support system 20 has the same functions as the identification support system 10 according to the first embodiment as a whole, but the system includes an identification support client 11 (identification support client) and an identification support server 30 (identification support server). It differs from the first embodiment in that it is composed of.
- the same reference reference numerals are given to the configurations common to the identification support system 10 according to the first embodiment, and detailed description thereof will be omitted.
- the identification support client 11 includes a processing unit 101, a lighting unit 120, a photographing unit 130, a storage unit 201, a display unit 300, and an operation unit 400, and character recognition (text conversion) for a drug image is performed as described later. Data transmission / reception, result display, etc. with the identification support server 30 are performed.
- the identification support client 11 can be realized by using a computer such as a personal computer or a mobile terminal such as a smartphone, and the display unit 300 and the operation unit 400 may be integrally configured by using a touch panel type monitor.
- FIG. 8 is a diagram showing a functional configuration of the processing unit 101.
- the processing unit 101 outputs the image acquisition unit 102 (image acquisition unit), the emphasis processing unit 104 (emphasis processing unit), the text conversion unit 106 (text conversion unit), the text correction unit 108 (text correction unit), and the output.
- a unit 112 output unit
- a client-side transmitting unit 116 client-side transmitting unit
- a client-side receiving unit 118 client-side transmitting unit
- Each of these parts can be realized by using various processors and electric circuits as described above for the processing unit 100, and when the processor or electric circuit executes software (program), ROM, RAM, etc. are used. Be done.
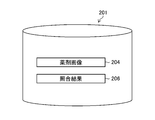
- FIG. 9 is a diagram showing the configuration of the storage unit 201.
- the storage unit 201 stores the drug image 204 (photographed image, character string emphasized image, image of the candidate drug acquired from the server (described later), etc.) and the collation result 206.
- the storage unit 201 may store the collation result 206 in association with the first and second texts.
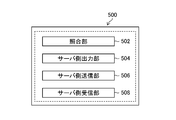
- the identification support server 30 is a server on the cloud CL (see FIG. 7), and has a server main body 500 and a storage unit 510.
- the server main body 500 includes a collation unit 502 (collation unit), a server side output unit 504 (server side output unit), a server side transmission unit 506 (server side transmission unit), and a server side reception unit. 508 (server side receiving unit) and.
- the storage unit 510 stores the drug master 512 (similar to the drug master 202 in FIG. 3) and the drug image 514 (similar to the drug image 204 in FIG. 3).
- ⁇ Processing of identification support method> 12 to 13 are flowcharts showing the processing of the identification support method according to the second embodiment.
- the left side of these figures shows the processing in the identification support client 11, and the right side shows the processing in the identification support server 30.
- the image acquisition unit 102 and the text correction unit 108 of the identification support client 11 perform the processes of steps S200 to S220 (acquisition of drug image, first text by character recognition) in the same manner as in steps S100 to S120 described above for the first embodiment.
- Generation of the second text by text correction; image acquisition step, text conversion step, text correction step) is executed.
- the text conversion unit 106 and the text correction unit 108 can generate and modify text using the trained model as in the first embodiment, but a conversion dictionary may be used.
- the client-side transmission unit 116 transmits text information (collation text; second text) about the drug to the identification support server 30 (step S230), and the server-side reception unit 508 (server-side reception unit) of the identification support server 30. Receives the text information (step S400).
- text information collation text; second text
- server-side reception unit 508 server-side reception unit
- the collation unit 502 collates the received text information (second text) with the text information of the drug master 512 to acquire identification information and an image of the candidate drug (step). S410; collation step).
- the server-side transmission unit 506 transmits the collation result (identification information and image of the candidate drug) to the identification support client 11 (step S420), the client-side reception unit 118 receives the collation result (step S240), and the output unit 112. Displays identification information and an image of the candidate drug on the monitor 310 (display device) (step S250: output step).
- the identification support client 11 repeats the processes of steps S200 to S250 until the processes for all the drugs are completed (until YES in step S270), similarly to steps S150 to S160 described above.
- the identification support server 30 transmits an image of the candidate drug to the identification support client 11
- another configuration may be adopted for transmitting and receiving the image.
- the identification support server 30 transmits a URL (Uniform Resource Locator) indicating the storage destination of the image to the identification support client 11, and the output unit 112 of the identification support client 11 downloads the image from the specified URL.
- the storage destination of the image may be the storage unit 510 or another storage device.
- the output unit 112 can store the acquired image in the storage unit 200.
- the storage unit 510 of the identification support server 30 holds (stores) the image of the drug (drug image 514) is described, but the processing capacity of the identification support client 11 is sufficient. In that case, the storage unit 201 of the identification support client 11 may hold (store) an image of the drug.
- the text correction unit 108 of the identification support client 11 generates additional learning data in the same manner as in step S170 described above (step S280).
- the user accurately identifies the drug as in the first embodiment. Can be done.
- Identification support system 11 Identification support client 20 Identification support system 30 Identification support server 100 Processing unit 101 Processing unit 102 Image acquisition unit 104 Emphasis processing unit 106 Text conversion unit 108 Text correction unit 110 Verification unit 112 Output unit 114 Communication control unit 116 Client Side transmitter 118 Client side receiver 120 Lighting unit 130 Imaging unit 200 Storage unit 201 Storage unit 202 Drug master 204 Drug image 206 Matching result 208 Additional learning data 300 Display unit 310 Monitor 400 Operation unit 410 Keyboard 420 Mouse 500 Server body 502 Matching unit 504 Server side output unit 506 Server side transmitting unit 508 Server side receiving unit 510 Storage unit 512 Drug master 514 Drug image CL Cloud S100 to S420 Each step of the identification support method
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Medicinal Chemistry (AREA)
- Evolutionary Computation (AREA)
- Quality & Reliability (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Chemical & Material Sciences (AREA)
- Artificial Intelligence (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Epidemiology (AREA)
- Primary Health Care (AREA)
- Medical Treatment And Welfare Office Work (AREA)
- Character Discrimination (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021533014A JP7343585B2 (ja) | 2019-07-17 | 2020-07-09 | 識別支援システム、識別支援クライアント、識別支援サーバ、及び識別支援方法 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019132074 | 2019-07-17 | ||
| JP2019-132074 | 2019-07-17 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021010276A1 true WO2021010276A1 (ja) | 2021-01-21 |
Family
ID=74210776
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/026849 Ceased WO2021010276A1 (ja) | 2019-07-17 | 2020-07-09 | 識別支援システム、識別支援クライアント、識別支援サーバ、及び識別支援方法 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7343585B2 (https=) |
| WO (1) | WO2021010276A1 (https=) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023005928A (ja) * | 2021-06-30 | 2023-01-18 | 株式会社コンテック | 薬剤識別システムおよび薬剤識別方法 |
| JP2023136771A (ja) * | 2022-03-17 | 2023-09-29 | 日本放送協会 | 文書分類用学習装置、文書分類装置及びプログラム |
| JPWO2023238566A1 (https=) * | 2022-06-10 | 2023-12-14 | ||
| JP7519649B1 (ja) * | 2024-02-02 | 2024-07-22 | ファーストアカウンティング株式会社 | 情報処理装置、情報処理方法及びプログラム |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH025937B2 (https=) * | 1985-03-07 | 1990-02-06 | Tokai Rubber Ind Ltd | |
| JP2009098867A (ja) * | 2007-10-16 | 2009-05-07 | Canon Inc | 文字列認識方法、コンピュータプログラム、記憶媒体 |
| WO2016047569A1 (ja) * | 2014-09-25 | 2016-03-31 | 株式会社湯山製作所 | 鑑査支援システム、錠剤分包装置 |
| WO2017002713A1 (ja) * | 2015-06-29 | 2017-01-05 | 株式会社湯山製作所 | 薬剤払出装置 |
| WO2018190394A1 (ja) * | 2017-04-14 | 2018-10-18 | 株式会社湯山製作所 | 薬剤仕分装置、仕分容器、及び薬剤返却方法 |
| WO2019039302A1 (ja) * | 2017-08-25 | 2019-02-28 | 富士フイルム株式会社 | 薬剤検査支援装置、画像処理装置、画像処理方法及びプログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6611346B2 (ja) * | 2016-06-01 | 2019-11-27 | 日本電信電話株式会社 | 文字列認識装置、方法、及びプログラム |
| JP6505937B1 (ja) * | 2018-11-26 | 2019-04-24 | フューチャー株式会社 | 照合システム、照合方法及び照合プログラム |
-
2020
- 2020-07-09 JP JP2021533014A patent/JP7343585B2/ja active Active
- 2020-07-09 WO PCT/JP2020/026849 patent/WO2021010276A1/ja not_active Ceased
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH025937B2 (https=) * | 1985-03-07 | 1990-02-06 | Tokai Rubber Ind Ltd | |
| JP2009098867A (ja) * | 2007-10-16 | 2009-05-07 | Canon Inc | 文字列認識方法、コンピュータプログラム、記憶媒体 |
| WO2016047569A1 (ja) * | 2014-09-25 | 2016-03-31 | 株式会社湯山製作所 | 鑑査支援システム、錠剤分包装置 |
| WO2017002713A1 (ja) * | 2015-06-29 | 2017-01-05 | 株式会社湯山製作所 | 薬剤払出装置 |
| WO2018190394A1 (ja) * | 2017-04-14 | 2018-10-18 | 株式会社湯山製作所 | 薬剤仕分装置、仕分容器、及び薬剤返却方法 |
| WO2019039302A1 (ja) * | 2017-08-25 | 2019-02-28 | 富士フイルム株式会社 | 薬剤検査支援装置、画像処理装置、画像処理方法及びプログラム |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023005928A (ja) * | 2021-06-30 | 2023-01-18 | 株式会社コンテック | 薬剤識別システムおよび薬剤識別方法 |
| JP7274529B2 (ja) | 2021-06-30 | 2023-05-16 | 株式会社コンテック | 薬剤識別システムおよび薬剤識別方法 |
| JP2023136771A (ja) * | 2022-03-17 | 2023-09-29 | 日本放送協会 | 文書分類用学習装置、文書分類装置及びプログラム |
| JP7808988B2 (ja) | 2022-03-17 | 2026-01-30 | 日本放送協会 | 文書分類用学習装置、文書分類装置及びプログラム |
| JPWO2023238566A1 (https=) * | 2022-06-10 | 2023-12-14 | ||
| WO2023238566A1 (ja) * | 2022-06-10 | 2023-12-14 | 富士フイルム富山化学株式会社 | 医薬品情報遠隔共有システム及び医薬品情報遠隔共有方法 |
| JP7827849B2 (ja) | 2022-06-10 | 2026-03-10 | 富士フイルムメディカル株式会社 | 医薬品情報遠隔共有システム及び医薬品情報遠隔共有方法 |
| JP7519649B1 (ja) * | 2024-02-02 | 2024-07-22 | ファーストアカウンティング株式会社 | 情報処理装置、情報処理方法及びプログラム |
| WO2025163880A1 (ja) * | 2024-02-02 | 2025-08-07 | ファーストアカウンティング株式会社 | 情報処理装置、情報処理方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7343585B2 (ja) | 2023-09-12 |
| JPWO2021010276A1 (https=) | 2021-01-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7343585B2 (ja) | 識別支援システム、識別支援クライアント、識別支援サーバ、及び識別支援方法 | |
| CN112329964B (zh) | 用于推送信息的方法、装置、设备以及存储介质 | |
| US11256918B2 (en) | Object detection in images | |
| US12032906B2 (en) | Method, apparatus and device for quality control and storage medium | |
| US11157816B2 (en) | Systems and methods for selecting and generating log parsers using neural networks | |
| CN113707300A (zh) | 基于人工智能的搜索意图识别方法、装置、设备及介质 | |
| US11416531B2 (en) | Systems and methods for parsing log files using classification and a plurality of neural networks | |
| CN111626048A (zh) | 文本纠错方法、装置、设备及存储介质 | |
| JP7260315B2 (ja) | 服薬指導支援装置および服薬指導支援システム | |
| US11847411B2 (en) | Obtaining supported decision trees from text for medical health applications | |
| US20210312173A1 (en) | Method, apparatus and device for recognizing bill and storage medium | |
| CN113889074A (zh) | 语音生成方法、装置、设备及介质 | |
| US10755028B2 (en) | Analysis method and analysis device | |
| TWI851259B (zh) | 一種語意分析商標類別推薦系統及其方法 | |
| CN111275110B (zh) | 图像描述的方法、装置、电子设备及存储介质 | |
| US11321529B2 (en) | Date and date-range extractor | |
| US20230123711A1 (en) | Extracting key value pairs using positional coordinates | |
| US20250378070A1 (en) | Answer generation using machine reading comprehension and supported decision trees | |
| US9881004B2 (en) | Gender and name translation from a first to a second language | |
| CN116882496A (zh) | 一种多级逻辑推理的医学知识库构建方法 | |
| US20260004076A1 (en) | Methods and systems for preparing unstructured data for statistical analysis using electronic characters | |
| CN114399001B (zh) | 模型的训练方法、数据处理方法和装置、设备、介质 | |
| CN110134920A (zh) | 绘文字兼容显示方法、装置、终端及计算机可读存储介质 | |
| CN117435106A (zh) | 一种页面生成方法、装置、电子设备及存储介质 | |
| JP7225402B2 (ja) | 識別支援システム、識別支援サーバ、及び識別支援方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20840732 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021533014 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20840732 Country of ref document: EP Kind code of ref document: A1 |